- 总结
- Tensorflow 介绍
- Tensorflow 1.*
- Tensorflow 2.*
- 结束
总结
- 【2020-8-31】30天吃掉那只TensorFlow2,20天吃掉那只Pytorch
- 入门级解读:小白也能看懂的TensorFlow介绍,日本东京 TensorFlow 聚会联合组织者 Hin Khor 所写的 TensorFlow 系列介绍

深度学习框架
- 2018:TensorFlow 碾压 PyTorch. Jeff Hale 的第一份调研结果发布于 2018 年 9 月。他在那次调研中发现,TensorFlow 是当时的绝对冠军。在 GitHub 活跃度、谷歌搜索量、Medium 文章数、亚马逊书籍和 arXiv 论文等维度上所占的比重都是最大的。此外,TensorFlow 还拥有最多的开发者用户,相关的网上职位描述也是最多的。
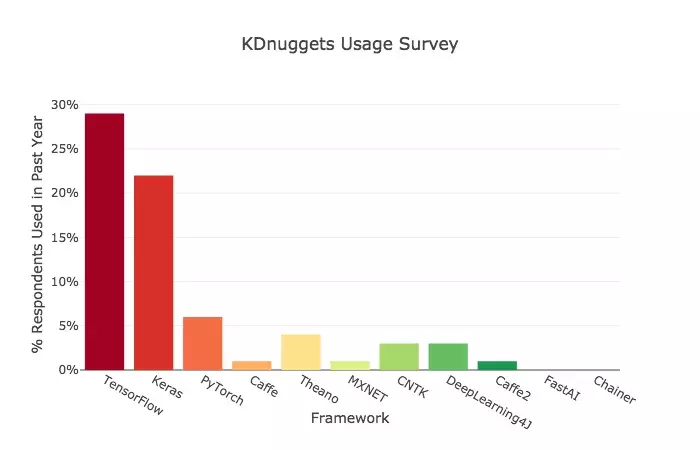
- 2019:PyTorch 火力全开,TensorFlow 增长乏力 2019 年 4 月,Jeff Hale 发布了第二份调查结果。这次,他调研了几个框架在过去 6 个月(此次调研与上次调研之间的时间间隔)里的增长情况。结果发现,TensorFlow 仍然是当时需求量最大、增长最快的框架,但 PyTorch 也不容小觑,在过去的六个月增速超过了原来的第二名 Keras。
- 2020:PyTorch 顶会独领风骚,职场优势追赶 TensorFlow
Tensorflow v.s. Pytorch
结论:
- 如果是工程师,应该优先选TensorFlow2.
- 如果是学生或者研究人员,应该优先选择Pytorch.
- 如果时间足够,最好TensorFlow2和Pytorch都要学习掌握。
- 理由如下:
- 1,在工业界最重要的是模型落地,目前国内的大部分互联网企业只支持TensorFlow模型的在线部署,不支持Pytorch。 并且工业界更加注重的是模型的高可用性,许多时候使用的都是成熟的模型架构,调试需求并不大。
- 2,研究人员最重要的是快速迭代发表文章,需要尝试一些较新的模型架构。而Pytorch在易用性上相比TensorFlow2有一些优势,更加方便调试。 并且在2019年以来在学术界占领了大半壁江山,能够找到的相应最新研究成果更多。
- 3,TensorFlow2和Pytorch实际上整体风格已经非常相似了,学会了其中一个,学习另外一个将比较容易。两种框架都掌握的话,能够参考的开源模型案例更多,并且可以方便地在两种框架之间切换。
- Keras库在2.3.0版本后将不再更新,用户应该使用tf.keras
Tensorflow 介绍
TensorFlow 历史
- 2015年11月9日,Google Research 发布了文章:TensorFlow - Google’s latest machine learning system, open sourced for everyone,正式宣布其新一代机器学习系统开源。
- 2016年4月13日,TensorFlow v0.8发布,提供分布式计算支持。
- 2016年4月29日,开发AlphaGo的DeepMind宣布从Torch7平台转向TensorFlow。
- 2016年4月12日,基于TensorFlow的世界最准确的语法解析器SyntaxNet宣布开源。
- 2016年6月27日,TensorFlow v0.9发布,提高对移动设备的支持。
- 2016年8月30日,TF-Slim——TensorFlow的高层库发布,用户可以更简单快速地定义模型。
- 2017年2月15日,TensorFlow v1.0发布,提高了速度和灵活性,并且承诺提供稳定的Python API。
- 2019年10月1日,TensorFlow在经历七个多月(2019年3月1日-2019年10月1日)的2.0 Alpha 版本的更新迭代后发布 2.0 正式版
TensorFlow 生态
Hub:- TensorFlow Hub 是一个经过训练的机器学习模型库,可以进行微调,让用户只需几行代码就能使用像 BERT 这样的模型。Hub 包含适用于不同用例的 TensorFlow、TensorFlow Lite 和 TensorFlow.js 模型,可用于图像、视频、音频和文本处理。
Model Garden:- 如果现成的预训练模型不适用于用户的应用,那么 TensorFlow 的存储库 Model Garden 可以提供 SOTA 模型的源代码。对于想要深入了解模型工作原理,或根据自己的需要修改模型的用户,Model Garden 将非常有用。
- Model Garden 包含谷歌维护的官方模型、研究人员维护的研究模型和社区维护的精选社区模型。TensorFlow 的长期目标是在 Hub 上提供来自 Model Garden 的模型的预训练版本,并使 Hub 上的预训练模型在 Model Garden 中具有可用的源代码。
Extended(TFX):- TensorFlow Extended 是 TensorFlow 用于模型部署的端到端平台。该平台的功能强大,包括:加载、验证、分析和转换数据;训练和评估模型;使用 Serving 或 Lite 部署模型;跟踪 artifact 及其依赖项。TFX 还可以与 Jupyter 或 Colab 一起使用,并且可以使用 Apache Airflow/Beam 或 Kubernetes 进行编排。TFX 与 Google Cloud 紧密集成,可与 Vertex AI Pipelines 一起使用。
Vertex AI:- Vertex AI 是 Google Cloud 今年刚刚发布的统一机器学习平台,旨在统一 GCP、AI Platform 和 AutoML,成为一个平台。Vertex AI 能够以无服务器方式编排工作流,帮助用户自动化、监控和管理机器学习系统。Vertex AI 还可以存储工作流的 artifact,让用户可以跟踪依赖项和模型的训练数据、超参数和源代码。
Coral:- 尽管有各种各样的 SaaS 公司依赖基于云的人工智能,但许多行业对本地人工智能的需求也在不断增长,Google Coral 就是为了满足这一需求而创建的。Coral 是一个完整的工具包,可以使用本地 AI 构建产品。Coral 于 2020 年发布,解决了部署部分 TFLite 中提到的实现板载 AI 的问题,克服了隐私和效率等方面的困难。
- Coral 提供了一系列用于原型设计、生产和传感的硬件产品,其中一些本质上是增强型的树莓派,专为 AI 应用程序创建,能够利用 Edge TPU 在低功耗设备上进行高性能推理。Coral 还提供用于图像分割、姿态估计、语音识别等任务的预编译模型,为希望创建本地 AI 系统的开发人员提供支持。创建模型的基本步骤如下面的流程图所示。
TensorFlow.js:- TensorFlow.js 是一个用于机器学习的 JavaScript 库,允许用户使用 Node.js 在浏览器和服务器端训练和部署模型。
Cloud:- TensorFlow Cloud 是一个可以将本地环境连接到 Google Cloud 的库,它的 API 旨在弥补本地机器上模型构建和调试与 GCP 上分布式训练和超参数调整之间的差距,而无需使用 Cloud Console。
Colab:- Google Colab 是一个基于云的 notebook 环境,与 Jupyter 非常相似。Colab 易于连接到 Google Cloud 进行 GPU 或 TPU 训练,并且 Colab 还可以和 PyTorch 一起使用。
Playground:- Playground 是一个小而精致的可视化工具,用于帮助用户理解神经网络的基础知识。要户可以更改 Playground 内置神经网络的层数和大小,以实时查看神经网络是如何学习特征的,用户还可以看到改变学习率和正则化强度等超参数如何影响不同数据集的学习过程。Playground 允许实时播放学习过程,以高度直观的方式查看输入在训练过程中是如何转换的。Playground 还提供了一个开源的小型神经网络库,是它自身的构建基础,用户能够查看其源代码的具体细节。
Datasets:- 谷歌研究院的 Datasets 是谷歌定期发布的数据集的整合资源。谷歌还提供了数据集搜索以访问更广泛的数据集资源。当然,PyTorch 用户也可以利用这些数据集。
安装
Mac 环境安装
【2022-8-8】2020年10月后,新版TensorFlow(2以后)支持64位、3.5-3.7的Python!
# 3.7.9
wget https://www.python.org/ftp/python/3.7.9/python-3.7.9-macosx10.9.pkg
As of October 2020:
- Tensorflow only supports the 64-bit version of Python
- Tensorflow only supports Python 3.5 to 3.8
So, if you’re using an out-of-range version of Python (older or newer) or a 32-bit version, then you’ll need to use a different version.
编译安装
- 官网指南:macos下编译安装tensorflow
- 【2022-9-21】macos下编译失败
旧版本安装
【2023-11-17】albert代码需要tensorflow 1.*版本,当前Python 3.10不支持安装旧版TensorFlow
解法
- 新建 Python 3.7环境
- Python 3.10不支持TensorFlow 1版本, 需要 3.5~3.7版本
- TensorFlow各版本与Python对应关系
- tensorflow 历史版本列表
- 找到TensorFlow官方下载地址
- pip源里没有TensorFlow 1版本
# 新建 Python 3.7环境
conda create -n py37_tf1 python==3.7
#conda create -n py37_tf1 python==3.7 tensorflow==1.15.2
conda create -n tf tensorflow-gpu=2.1
# 安装 TensorFlow 1.15
pip install tensorflow==1.15.2
pip install tensorflow-gpu==1.15.2
# 如果pip找不到,就直接通过源文件地址安装, 或编译
# ---- install.sh -----
#export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.11.0-cp27-none-linux_x86_64.whl
export TF_BINARY_URL=https://files.pythonhosted.org/packages/5b/81/84fb7a323f9723f81edfc796d89e89aa95a9446ed7353c144195b3a3a3ba/tensorflow-1.15.2-cp37-cp37m-manylinux2010_x86_64.whl
pip install --ignore-installed --upgrade $TF_BINARY_URL
# ---------
sh install.sh
Tensorflow 1.*
主要的是:
- tf.Variable
- tf.Constant
- tf.Placeholder
- tf.SparseTensor 除了tf.Variable,张量的值是不变的
TensorFlow基础知识
- TensorFlow 是一种采用数据流图(data flow graphs),用于数值计算的开源软件库。
- 其中 Tensor 代表传递的数据为张量(多维数组),Flow 代表使用计算图进行运算。
- 数据流图用「结点」(nodes)和「边」(edges)组成的有向图来描述数学运算。
- 「结点」一般用来表示施加的数学操作,但也可以表示数据输入的起点和输出的终点,或者是读取/写入持久变量(persistent variable)的终点。
- 节点的类型可以分为三种:
- 存储节点:有状态的变量操作,通常用于存储模型参数
- 计算节点:无状态的计算和控制操作,主要负责算法的逻辑或流程的控制
- 数据节点:数据的占位符操作,用于描述图外输入的数据
- 节点的类型可以分为三种:
- 边表示结点之间的输入/输出关系。这些数据边可以传送维度可动态调整的多维数据数组,即张量(tensor)。
- 总结:
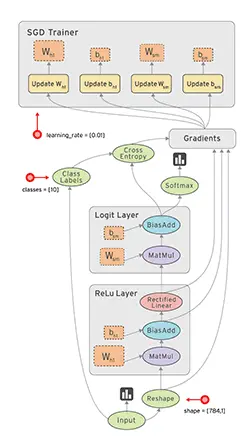
- 「结点」一般用来表示施加的数学操作,但也可以表示数据输入的起点和输出的终点,或者是读取/写入持久变量(persistent variable)的终点。
- 在 Tensorflow 中,所有不同的变量和运算都是储存在计算图。所以构建完模型所需要的图后,还需要打开一个会话(Session)来运行整个计算图。在会话中,我们可以将所有计算分配到可用的 CPU 和 GPU 资源中。
- TensorFlow 中最基本的单位是常量(Constant)、变量(Variable)和占位符(Placeholder)。
- 常量定义后值和维度不可变。tf.constant()
- 变量定义后值可变而维度不可变。tf.Variable()
- 创建方式:
- 每次使用之前,都需要为其进行初始化:tf.global_variables_initializer()
- 在神经网络中,变量一般可作为储存权重和其他信息的矩阵,而常量可作为储存超参数或其他结构信息的变量。
- 占位符并没有初始值,它只会分配必要的内存。在会话中,占位符可以使用 feed_dict 馈送数据。tf.placeholder
- train_filenames = tf.placeholder(tf.string, shape=[None]) # 运行时才能定下来
- feed_dict={train_filenames: training_filenames}
- 稀疏张量:tf.SparseTensor
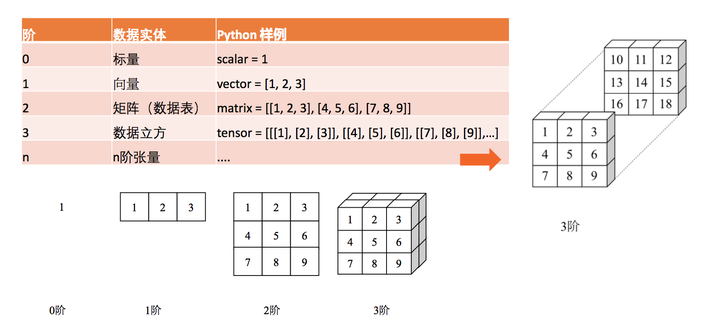
- 张量是计算图执行运算的基本载体

- 零阶张量就是我们熟悉的标量数字,它仅仅只表达了量的大小或性质而没有其它的描述。
- 一阶张量即我们熟悉的向量,它不仅表达了线段量的大小,同时还表达了方向。
- 一般来说二维向量可以表示平面中线段的量和方向,三维向量和表示空间中线段的量和方向。
- 二阶张量即矩阵,可以看作是填满数字的一个表格,矩阵运算即一个表格和另外一个表格进行运算。
- 当然理论上可以产生任意阶的张量,但在实际的机器学习算法运算中,用得最多的还是一阶张量(向量)和二阶张量(矩阵)。
- 一张图巩固以上概念
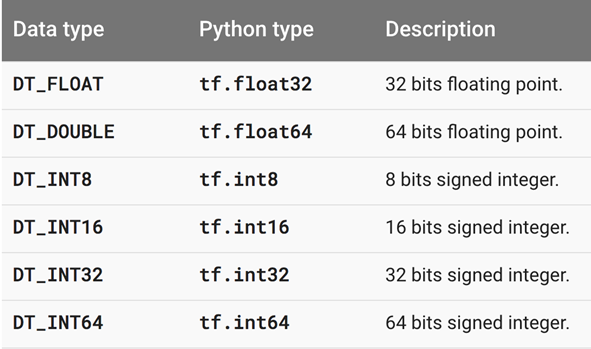
- 张量中每个元素的数据类型有以上几种,即浮点型和整数型,一般在神经网络中比较常用的是 32 位浮点型
- 所有 TensorFlow 机器学习模型所遵循的构建流程,即构建计算图、馈送输入张量、更新权重并返回输出值。


# 1.使用Variable类来创建
# tf.random_normal 方法返回形状为(1,4)的张量。它的4个元素符合均值为100、标准差为0.35的正态分布。
W = tf.Variable(initial_value=tf.random_normal(shape=(1, 4), mean=100, stddev=0.35), name="W")
b = tf.Variable(tf.zeros([4]), name="b")
# 2.使用get_variable的方式来创建
my_int_variable = tf.get_variable("my_int_variable", [1, 2, 3], dtype=tf.int32, initializer=tf.zeros_initializer)
显示张量值
import tensorflow as tf
#定义变量a
a=tf.Variable([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
#定义索引
indics=[[0,0,0],[0,1,1],[0,1,2]]
#把a中索引为indics的值取出
b=tf.gather_nd(a,indics)
#初始化
init=tf.global_variables_initializer()
with tf.Session() as sess:
#执行初始化
sess.run(init)
#打印结果
print(a.eval())
print(b.eval())
tf.Print(a)
基本原理
-
【2017-10-8】香港科技大学TensorFlow课件分享,TensorFlow 三天速成课,Google Drive地址,百度云地址

- 什么是Tensorflow
- 总结
- 使用 张量tensor 表示数据.
- 使用图 (graph) 来表示计算任务.
- 在会话(session)中运行图
- 通过 变量 (Variable) 维护状态.
- TensorFlow 是一个编程系统, 使用图来表示计算任务.
- 图中的节点被称之为 op (operation 的缩写). 一个 op 获得 0 个或多个 Tensor, 执行计算, 产生 0 个或多个 Tensor.
- 每个 Tensor 是一个类型化的多维数组.
Session
- TensorFlow程序通常被组织成一个构建阶段和执行阶段.
- 在构建阶段, op的执行步骤被描述成一个图.
- 注意:有向图,意味着前面执行完了,才是后面
- 在执行阶段, 使用会话执行执行图中的op。
- 在构建阶段, op的执行步骤被描述成一个图.
- 示例程序
import tensorflow as tf
# 创建数据流图:y = W * x + b,其中W和b为存储节点,x为数据节点。
x = tf.placeholder(tf.float32)
W = tf.Variable(1.0)
b = tf.Variable(1.0)
y = W * x + b
# =========如果不使用session来运行,那上面的代码只是一张图。我们通过session运行这张图,得到想要的结果
with tf.Session() as sess:
tf.global_variables_initializer().run() # Operation.run
fetch = y.eval(feed_dict={x: 3.0}) # Tensor.eval
print(fetch) # fetch = 1.0 * 3.0 + 1.0
# 损失函数
logits = tf.matmul(X,W)+b
hypothesis = tf.nn.softmax(logits)
# Cross entropy cost/loss
cost = tf.reduce_mean (-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
# 改进版(数值计算更安全)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=Y))
# 优化器
train = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)
Fetch
- 在session.run的时候传入多个op(tensor),然后返回多个tensor(如果只传入一个tensor的话,那就是返回一个tensor)
eval和run
- tensor.eval()和Operation.run()调用的还是session.run。
- 不同的是session.run可以一次返回多个tensor(通过Fetch)。

特征处理
- 【2021-5-27】推理性能提升一倍,TensorFlow Feature Column 性能优化实践,在 CTR(Click Through Rate) 点击率预估的推荐算法场景,TensorFlow Feature Column 被广泛应用到实践中。这一方面带来了模型特征处理的便利,另一方面也带来了一些线上推理服务的性能问题。

- Feature Column 是 TensorFlow 提供的用于处理结构化数据的工具,是将样本特征映射到用于训练模型特征的桥梁。它提供了多种特征处理方法,让算法人员可以很容易将各种原始特征转换为模型的输入,来进行模型实验。
- 所有 Feature Column 都源自 FeatureColumn 类,并继承了三个子类 CategoricalColumn、DenseColumn 和 SequenceDenseColumn,分别对应稀疏特征、稠密特征、序列稠密特征。算法人员可以按照样本特征的类型找到对应的接口直接适配。

单元测试
- Tensorflow中有一个类tf.test用来做单元测试,它继承于类unittest.TestCase,里面包含了Tensorflow做单元测试相关的方法。
- Tensorflow Unit Test 框架
- tf.test.main
- tf.test.TestCase
import tensorflow as tf
class AlexnetV2Test(tf.test.TestCase):
def testBuild(self):
self.assertEquals(name, 'alexnet_v2/fc8/squeezed')
if __name__ == '__main__':
tf.test.main()
- 模块是对象,并且所有的模块都有一个内置属性 name。一个模块的 name 的值取决于您如何应用模块。如果 import 一个模块,那么模块__name__ 的值通常为模块文件名,不带路径或者文件扩展名。但是您也可以像一个标准的程序样直接运行模块,在这 种情况下, name 的值将是一个特别缺省”main”。
- 在cmd 中直接运行.py文件,则__name__的值是’main’;
import tensorflow as tf
class SquareTest(tf.test.TestCase):
def testSquare(self):
with self.test_session():
# 平方操作
x = tf.square([2, 3])
# 测试x的值是否等于[4,9]
self.assertAllEqual(x.eval(), [4, 9])
if __name__ == "__main__":
tf.test.main()
Tensorflow 2.*
- TF 2.0官方教程
- 高效的TensorFlow 2.0 (tensorflow2官方教程翻译)
- 官方教程导读: ML Study Jam 2020 注意
- 在 TensorFlow 1.X 版本中, 导入TensorFlow库后必须调用 tf.enable_eager_execution() 函数以启用即时执行模式。
- 在 TensorFlow 2 中,即时执行模式将成为默认模式,无需额外调用 tf.enable_eager_execution() 函数(不过若要关闭即时执行模式,则需调用 tf.compat.v1.disable_eager_execution() 函数)。
tf 2 与 tf 1差异
TensorFlow版本差异:
- ① 在TensorFlow1.x中,最常规的是使用”session.run()”方法执行计算图,“session.run()”方法的调用类似于函数调用,指定输入数据和调用的方法,最后返回结果。
- ② TensorFlow2.0将Eager Execcution(动态图机制)作为默认模式。在该模式下用户能够轻松地编写和调试代码,可以使用原生的Python控制语句,大大降低了学习和使用TensorFlow的门槛
- ③ 在TensorFlow2.0中,图(graph)和会话(Session)都会变成底层实现,而不需要用户关心。
- ④ TensorFlow2.0推出了一个新的运行理念,即
AutoGraph。当运行代码时,TensorFlow2.0自动调用Eager模式执行函数,这是内部所完成的。
总结:
- TensorFlow1.x版本之所以要分为两步进行,是因为它无法使用Python支持的常用代码,所以需要将Python代码进行编译为TensorFlow所内置的API和函数才能执行。
- 而2.0版本可以使用”tf.function“来修饰Python函数,以将其标记为即时编译,从而TensorFlow可以将其作为单个图来执行。
基础
将 TensorFlow 视为一个科学计算库(类似于 Python 下的 NumPy)
TensorFlow 使用 张量 (Tensor)作为数据的基本单位。TensorFlow 的张量在概念上等同于多维数组,用它来描述数学中的标量(0 维数组)、向量(1 维数组)、矩阵(2 维数组)等各种量,张量的重要属性是其形状、类型和值。可以通过张量的 shape 、 dtype 属性和 numpy() 方法获得。
- TensorFlow 的大多数 API 函数会根据输入的值自动推断张量中元素的类型(一般默认为 tf.float32 )。不过也可以通过加入 dtype 参数来自行指定类型,例如 zero_vector = tf.zeros(shape=(2), dtype=tf.int32) 将使得张量中的元素类型均为整数。张量的 numpy() 方法是将张量的值转换为一个 NumPy 数组。
- TensorFlow 里有大量的
操作(Operation)
示例如下:
import tensorflow as tf
# 定义一个随机数(标量)
random_float = tf.random.uniform(shape=())
# 定义一个有2个元素的零向量
zero_vector = tf.zeros(shape=(2))
# 定义两个2×2的常量矩阵
A = tf.constant([[1., 2.], [3., 4.]])
B = tf.constant([[5., 6.], [7., 8.]])
# 查看矩阵A的形状、类型和值
print(A.shape) # 输出(2, 2),即矩阵的长和宽均为2
print(A.dtype) # 输出<dtype: 'float32'>
print(A.numpy()) # 输出[[1. 2.]
# [3. 4.]]
# op操作
C = tf.add(A, B) # 计算矩阵A和B的和
D = tf.matmul(A, B) # 计算矩阵A和B的乘积
自动求导机制
TensorFlow 提供了强大的 自动求导机制 来计算导数。
- 在即时执行模式下,TensorFlow 引入了 tf.GradientTape() 这个 “求导记录器” 来实现自动求导。
- 机器学习中,更加常见的是对多元函数求偏导数,以及对向量或矩阵的求导
以下代码展示了如何使用 tf.GradientTape() 计算函数 y(x) = x^2 在 x = 3 时的导数
- x 是一个初始化为 3 的 变量 (Variable),使用 tf.Variable() 声明。与普通张量一样,变量同样具有形状、类型和值三种属性。使用变量需要有一个初始化过程,可以通过在 tf.Variable() 中指定 initial_value 参数来指定初始值。
- 变量与普通张量的一个重要区别: 其默认能够被 TensorFlow 的自动求导机制所求导,因此往往被用于定义机器学习模型的参数。
- tf.GradientTape() 是一个自动求导的记录器。只要进入了 with tf.GradientTape() as tape 的上下文环境,则在该环境中计算步骤都会被自动记录。
- 比如在上面的示例中,计算步骤 y = tf.square(x) 即被自动记录。
- 离开上下文环境后,记录将停止,但记录器 tape 依然可用,因此可以通过 y_grad = tape.gradient(y, x) 求张量 y 对变量 x 的导数。
- 使用 tape.gradient(ys, xs) 自动计算梯度;
- 用 optimizer.apply_gradients(grads_and_vars) 自动更新模型参数
import tensorflow as tf
x = tf.Variable(initial_value=3.)
# ------ 求导 -------
with tf.GradientTape() as tape: # 在 tf.GradientTape() 的上下文内,所有计算步骤都会被记录以用于求导
y = tf.square(x)
y_grad = tape.gradient(y, x) # 计算y关于x的导数
print(y, y_grad)
# ---------偏导数----------
X = tf.constant([[1., 2.], [3., 4.]])
y = tf.constant([[1.], [2.]])
w = tf.Variable(initial_value=[[1.], [2.]])
b = tf.Variable(initial_value=1.)
with tf.GradientTape() as tape:
L = tf.reduce_sum(tf.square(tf.matmul(X, w) + b - y))
w_grad, b_grad = tape.gradient(L, [w, b]) # 计算L(w, b)关于w, b的偏导数
print(L, w_grad, b_grad)
数据
tf.data
若要使用大型数据集或多设备训练,要使用Dateset API ,将tf.data.Dataset实例传递给fit方法:
# 实例化玩具数据集实例:
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
dataset = dataset.batch(32)
dataset = dataset.repeat()
# 在数据集上调用`fit`时,不要忘记指定`steps_per_epoch`
model.fit(dataset, epochs=10, steps_per_epoch=30)
模型建立与训练
基本流程
如何使用 TensorFlow 快速搭建动态模型
- 模型构建: tf.keras.Model 和 tf.keras.layers
- 损失函数: tf.keras.losses
- 优化器: tf.keras.optimizer
-
评估方法: tf.keras.metrics
解释
- 继承 tf.keras.Model 后,同时可以使用父类的若干方法和属性
- 例如在实例化类 model = Model() 后,可以通过 model.
- variables 这一属性直接获得模型中的所有变量,不用一个个显式指定变量的麻烦。
TensorFlow 的模型编写方式,依次进行以下步骤:
- 使用
tf.keras.datasets获得数据集并预处理 - 使用
tf.keras.Model和tf.keras.layers构建模型 - 训练流程,使用
tf.keras.losses计算损失函数,并使用tf.keras.optimizer优化模型 - 评估流程,使用
tf.keras.metrics计算评估指标
模型与层
TensorFlow 中,推荐使用 Keras( tf.keras )构建模型。Keras 是一个广为流行的高级神经网络 API,简单、快速而不失灵活性,现已得到 TensorFlow 的官方内置和全面支持。
Keras 有两个重要的概念: 层(Layer) 和 模型(Model)。
层将各种计算流程和变量进行了封装(例如基本的全连接层,CNN 的卷积层、池化层等)模型则将各种层进行组织和连接,并封装成一个整体,描述了如何将输入数据通过各种层以及运算而得到输出。- 在需要模型调用的时候,使用 y_pred = model(X) 的形式即可。
layer
Keras 在 tf.keras.layers 下内置了深度学习中大量常用的的预定义层,同时也允许自定义层。
tf.keras.layers 一些常见的构造函数参数:
activation:设置层的激活函数。 此参数由内置函数的名称或可调用对象指定。 默认情况下,不使用任何激活。kernel_initializer和bias_initializer:分别指定层的核(原文是Kernel,可以理解为weights)和偏置(bias)的初始化器(initializer)。 参数是名称或可调用对象。 默认为“Glorot uniform”初始化器。kernel_regularizer和bias_regularizer:分别指定层的核(Kernel)和偏置(bias)的正则化方案,例如L1或L2正则化。 默认情况下,不使用正则化。
构造函数参数实例化tf.keras.layers.Dense
# 创建一个sigmoid层:
layers.Dense(64, activation='sigmoid') # 字符串方式
layers.Dense(64, activation=tf.sigmoid) # 对象方式
# 定义一个线性层(linear layer),设置正则化项
layers.Dense(64, kernel_regularizer=tf.keras.regularizers.l1(0.01)) # 核矩阵(kernel matrix)使用一个因子为0.01的L1正则化器
layers.Dense(64, bias_regularizer=tf.keras.regularizers.l2(0.01)) # 偏置向量( bias vector)使用一个因子为0.01的L2正则化器
# 定义了一个线性层,设置初始化项
layers.Dense(64, kernel_initializer='orthogonal') # 核使用的初始化器为orthogonal(核会被初始化为一个随机正交矩阵)
layers.Dense(64, bias_initializer=tf.keras.initializers.constant(2.0)) # 偏置向量的初始化去器为constant(偏置向量的所有元素都会被初始化为2.0)
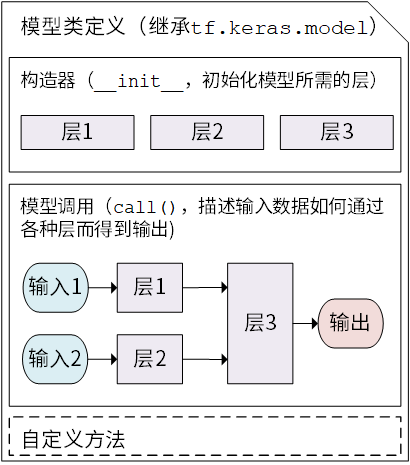
model
Keras 模型以类的形式呈现,可以通过继承 tf.keras.Model 这个 Python 类来定义自己的模型。在继承类中,需要重写 init() (构造函数,初始化)和 call(input) (模型调用)两个方法,同时也可以根据需要增加自定义的方法。
- 继承 tf.keras.Model 后,同时可以使用父类的若干方法和属性
- 例如在实例化类 model = Model() 后,可以通过 model.variables 这一属性直接获得模型中的所有变量,免去我们一个个显式指定变量的麻烦。
class MyModel(tf.keras.Model):
def __init__(self):
super().__init__() # Python 2 下使用 super(MyModel, self).__init__()
# 此处添加初始化代码(包含 call 方法中会用到的层),例如
# layer1 = tf.keras.layers.BuiltInLayer(...)
# layer2 = MyCustomLayer(...)
def call(self, input):
# 此处添加模型调用的代码(处理输入并返回输出),例如
# x = layer1(input)
# output = layer2(x)
return output
# 还可以添加自定义的方法
线性模型 y_pred = a * X + b, 示例代码
import tensorflow as tf
X = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
y = tf.constant([[10.0], [20.0]])
class Linear(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense = tf.keras.layers.Dense(
units=1,
activation=None,
# 问题:为什么权重矩阵的名字是kernel?让人联想到cnn的卷积核
kernel_initializer=tf.zeros_initializer(),
bias_initializer=tf.zeros_initializer()
)
def call(self, input):
output = self.dense(input)
return output
# 以下代码结构与前节类似
model = Linear()
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
for i in range(100):
# ①定义自动求导
with tf.GradientTape() as tape:
y_pred = model(X) # 调用模型 y_pred = model(X) 而不是显式写出 y_pred = a * X + b
loss = tf.reduce_mean(tf.square(y_pred - y))
# ②计算梯度
grads = tape.gradient(loss, model.variables) # 使用 model.variables 这一属性直接获得模型中的所有变量
# ③更新梯度
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
print(model.variables)
没有显式地声明 a 和 b 两个变量并写出 y_pred = a * X + b 这一线性变换,而是建立了一个继承了 tf.keras.Model 的模型类 Linear 。这个类在初始化部分实例化了一个 全连接层 ( tf.keras.layers.Dense ),并在 call 方法中对这个层进行调用,实现了线性变换的计算。
- 如果需要显式地声明自己的变量并使用变量进行自定义运算,或者希望了解 Keras 层的内部原理,请参考 自定义层。
Keras Pipeline
有两种方式建立模型:
- Keras Sequential API:串行结构,单输入单输出
- Keras Functional API:任意结构,多输入多输出
Keras Sequential API 串行
最典型和常用的神经网络结构是将一堆层按特定顺序叠加起来,只需要提供一个层的列表,Keras的 Sequential API就自动首尾相连,形成模型
- 通过向 tf.keras.models.Sequential() 提供一个层的列表,就能快速地建立一个 tf.keras.Model 模型并返回
# Keras Sequential建立串行结构模型
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(), # 展开
tf.keras.layers.Dense(100, activation=tf.nn.relu), # MLP全连接层
tf.keras.layers.Dense(10), # MLP全连接层
tf.keras.layers.Softmax() # # softmax层
])
Keras Functional API 任意
以上层叠结构并不能表示任意神经网络结构。
Keras 提供了 Functional API 来建立更为复杂的模型
- 例如: 多输入/输出或存在参数共享的模型。其使用方法是将层作为可调用的对象并返回张量,并将输入向量和输出向量提供给 tf.keras.Model 的 inputs 和 outputs 参数
Keras Functional 建立任意结构模型
参考:
Keras backend
- Keras是一个模型级的库,提供了快速构建深度学习网络的模块。
- Keras并不处理如张量乘法、卷积等底层操作。这些操作依赖于某种特定的、优化良好的张量操作库。
- Keras依赖于处理张量的库就称为“后端引擎”。
- 将backend字段的值改写为你需要使用的后端:theano或tensorflow或者CNTK,即可完成后端的切换
- 也可以通过定义环境变量KERAS_BACKEND来覆盖上面配置文件中定义的后端:
- KERAS_BACKEND=tensorflow python -c “from keras import backend;”
# 设置backend
KERAS_BACKEND=tensorflow python -c "from keras import backend;"
# 或json方式设置, ~/.keras/keras.json
{
"image_data_format": "channels_last", # "channels_last"或"channels_first",该选项指定了Keras将要使用的维度顺序,可通过keras.backend.image_data_format()来获取当前的维度顺序。对2D数据来说,"channels_last"假定维度顺序为(rows,cols,channels)而"channels_first"假定维度顺序为(channels, rows, cols)。对3D数据而言,"channels_last"假定(conv_dim1, conv_dim2, conv_dim3, channels),"channels_first"则是(channels, conv_dim1, conv_dim2, conv_dim3)
"epsilon": 1e-07, # 防止除0错误的小数字
"floatx": "float32", # float16", "float32", "float64"之一,为浮点数精度
"backend": "tensorflow" # 所使用的后端,为"tensorflow"或"theano"
}
框架无关的代码, 同时在Theano和TensorFlow两个后端上使用
# tf, theano通用
from keras import backend as K
input = K.placeholder(shape=(2, 4, 5))
# also works:
input = K.placeholder(shape=(None, 4, 5))
# also works:
input = K.placeholder(ndim=3)
val = np.random.random((3, 4, 5))
var = K.variable(value=val)
# all-zeros variable:
var = K.zeros(shape=(3, 4, 5))
# all-ones:
var = K.ones(shape=(3, 4, 5))
a = b + c * K.abs(d)
c = K.dot(a, K.transpose(b))
a = K.sum(b, axis=2)
a = K.softmax(b)
a = concatenate([b, c], axis=-1)
模型可视化
pip install pydot graphviz
可视化:

import tensorflow as tf
tf.keras.utils.plot_model(model, './mutilModel.png', show_shapes=True)
多层感知器(Multilayer Perceptron)
- 95% 左右的准确率
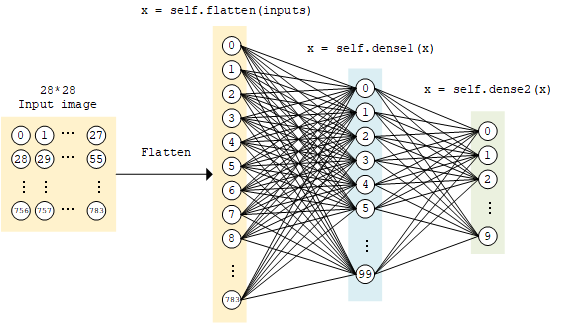
##------ Multilayer Perceptron ------##
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras import backend as K
K.clear_session()
# MLP model
x = Input(shape=(32,))
hidden1 = Dense(10, activation='relu')(x)
hidden2 = Dense(20, activation='relu')(hidden1)
hidden3 = Dense(10, activation='relu')(hidden2)
output = Dense(1, activation='sigmoid')(hidden3)
model = Model(inputs=x, outputs=output)
# summarize layers
model.summary()
# ------- 或者:直接从tf导入 -------
import tensorflow as tf
# Keras Functional 建立任意结构模型
inputs = tf.keras.Input(shape=(28, 28, 1)) # 单独定义inputs
x = tf.keras.layers.Flatten()(inputs)
x = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)(x)
x = tf.keras.layers.Dense(units=10)(x)
outputs = tf.keras.layers.Softmax()(x) # 单独定义outputs
# 通过 Model 组装输入、输出,构建任意结构模型
model = tf.keras.Model(inputs=inputs, outputs=outputs)
卷积神经网络(Convolutional Neural Network)
- 卷积神经网络 (Convolutional Neural Network, CNN)是一种结构类似于人类或动物的 视觉系统 的人工神经网络,包含一个或多个卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully-connected Layer)
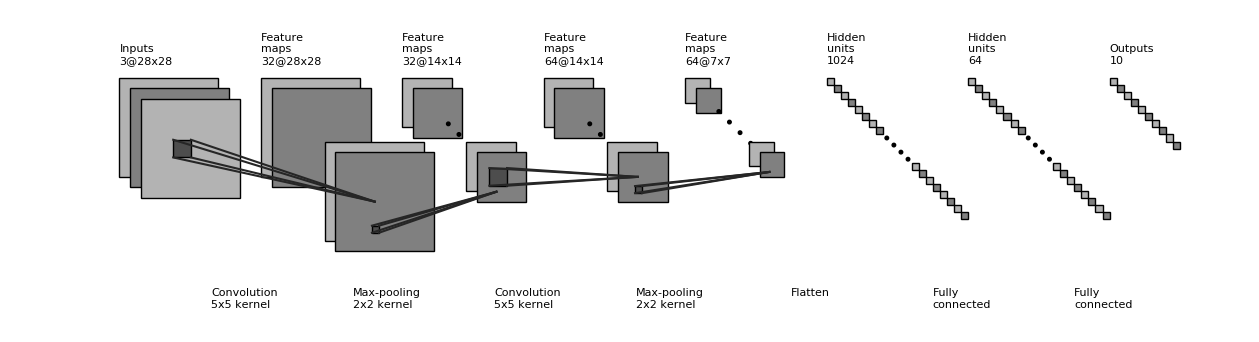
用于图像分类的卷积神经网络。
- 该模型接收3通道的64×64图像作为输入,然后经过两个卷积和池化层的序列作为特征提取器,接着过一个全连接层,最后输出层过softmax激活函数进行10个类别的分类。
##------ Convolutional Neural Network ------##
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import backend as K
K.clear_session()
# CNN model
x = Input(shape=(64,64,3))
conv1 = Conv2D(16, (5,5), activation='relu')(x)
pool1 = MaxPooling2D((2,2))(conv1)
conv2 = Conv2D(32, (3,3), activation='relu')(pool1)
pool2 = MaxPooling2D((2,2))(conv2)
conv3 = Conv2D(32, (3,3), activation='relu')(pool2)
pool3 = MaxPooling2D((2,2))(conv3)
flat = Flatten()(pool3)
hidden1 = Dense(512, activation='relu')(flat)
output = Dense(10, activation='softmax')(hidden1)
model = Model(inputs=x, outputs=output)
# summarize layers
model.summary()
循环神经网络(Recurrent Neural Network)
一个用于文本序列分类的LSTM网络。
- 该模型需要100个时间步长作为输入,然后经过一个Embedding层,每个时间步变成128维特征表示,然后经过一个LSTM层,LSTM输出过一个全连接层,最后输出用sigmoid激活函数用于进行二分类预测。
##------ Recurrent Neural Network ------##
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras import backend as K
K.clear_session()
VOCAB_SIZE = 10000
EMBED_DIM = 128
x = Input(shape=(100,), dtype='int32')
embedding = Embedding(VOCAB_SIZE, EMBED_DIM, mask_zero=True)(x)
hidden1 = LSTM(64)(embedding)
hidden2 = Dense(32, activation='relu')(hidden1)
output = Dense(1, activation='sigmoid')(hidden2)
model = Model(inputs=x, outputs=output)
# summarize layers
model.summary()
双向RNN, 双向循环神经网络,可以用来完成序列标注等任务,相比上面的LSTM网络,多了一个反向的LSTM,其它设置一样
##------ Bidirectional recurrent neural network ------##
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding
from tensorflow.keras.layers import Dense, LSTM, Bidirectional
from tensorflow.keras import backend as K
K.clear_session()
VOCAB_SIZE = 10000
EMBED_DIM = 128
HIDDEN_SIZE = 64
# input layer
x = Input(shape=(100,), dtype='int32')
# embedding layer
embedding = Embedding(VOCAB_SIZE, EMBED_DIM, mask_zero=True)(x)
# BiLSTM layer
hidden = Bidirectional(LSTM(HIDDEN_SIZE, return_sequences=True))(embedding)
# prediction layer
output = Dense(10, activation='softmax')(hidden)
model = Model(inputs=x, outputs=output)
model.summary()
双向LSTM
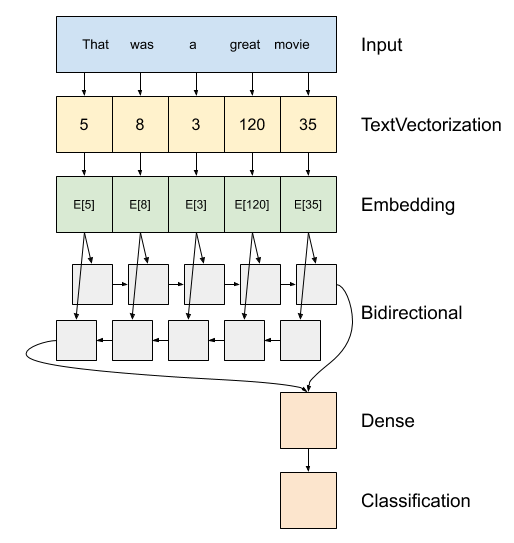
- encoder: 将字符转id,额外准备词表,oov单词统一设置为UNK;字符串 → id列表
- embedding:一个单词一个向量(维数可定义),权重可修改,训练完毕后,相近单词词向量越近 —— 词向量副产物
- rnn层:逐个元素迭代,时间步
- dense层:全连接,对接回归(mse)、分类任务(logit)
Tensorflow实现:
# 序列结构
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()), # 设置词表
output_dim=64, # 嵌入维度
# Use masking to handle the variable sequence lengths
mask_zero=True), # 用0来填充空白位置
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)), # 双向LSTM
tf.keras.layers.Dense(64, activation='relu'), # 全连接层
tf.keras.layers.Dense(1) # 目标值
])
# predict on a sample text without padding.
sample_text = ('The movie was cool. The animation and the graphics '
'were out of this world. I would recommend this movie.')
# 不用padding
predictions = model.predict(np.array([sample_text]))
# 使用padding
padding = "the " * 2000
predictions = model.predict(np.array([sample_text, padding]))
print(predictions[0])
# Compile the Keras model to configure the training process:
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
# Train the model
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
# 评估效果
test_loss, test_acc = model.evaluate(test_dataset)
print('Test Loss:', test_loss)
print('Test Accuracy:', test_acc)
# 绘图
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plot_graphs(history, 'accuracy')
plt.ylim(None, 1)
plt.subplot(1, 2, 2)
plot_graphs(history, 'loss')
plt.ylim(0, None)
共享输入层 (Shared Input Layer Model)
定义了具有不同大小内核的多个卷积层来解释图像输入。
- 该模型采用尺寸为64×64像素的3通道图像。 有两个共享此输入的CNN特征提取子模型; 第一个内核大小为5x5,第二个内核大小为3x3。把提取的特征展平为向量然后拼接成一个长向量,然后过一个全连接层,最后输出层完成10分类。
##------ Shared Input Layer Model ------##
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Concatenate
from tensorflow.keras import backend as K
K.clear_session()
# input layer
x = Input(shape=(64,64,3))
# first feature extractor
conv1 = Conv2D(32, (3,3), activation='relu')(x)
pool1 = MaxPooling2D((2,2))(conv1)
flat1 = Flatten()(pool1)
# second feature extractor
conv2 = Conv2D(16, (5,5), activation='relu')(x)
pool2 = MaxPooling2D((2,2))(conv2)
flat2 = Flatten()(pool2)
# merge feature
merge = Concatenate()([flat1, flat2])
# interpretation layer
hidden1 = Dense(128, activation='relu')(merge)
# prediction layer
output = Dense(10, activation='softmax')(merge)
model = Model(inputs=x, outputs=output)
model.summary()
Shared Feature Extraction Layer
- 定义一个共享特征抽取层的模型,这里共享的是LSTM层的输出
##------ Shared Feature Extraction Layer ------##
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding
from tensorflow.keras.layers import Dense, LSTM, Concatenate
from tensorflow.keras import backend as K
K.clear_session()
# input layer
x = Input(shape=(100,32))
# feature extraction
extract1 = LSTM(64)(x)
# first interpretation model
interp1 = Dense(32, activation='relu')(extract1)
# second interpretation model
interp11 = Dense(64, activation='relu')(extract1)
interp12 = Dense(32, activation='relu')(interp11)
# merge interpretation
merge = Concatenate()([interp1, interp12])
# output layer
output = Dense(10, activation='softmax')(merge)
model = Model(inputs=x, outputs=output)
model.summary()
多输入模型(Multiple Input Model)
定义有两个输入的模型,这里测试的是输入两张图片,一个输入是单通道的64x64,另一个是3通道的32x32,两个经过卷积层、池化层后,展平拼接,最后进行二分类。
##------ Multiple Input Model ------##
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Concatenate
from tensorflow.keras import backend as K
K.clear_session()
# first input model
input1 = Input(shape=(64,64,1))
conv11 = Conv2D(32, (5,5), activation='relu')(input1)
pool11 = MaxPooling2D(pool_size=(2,2))(conv11)
conv12 = Conv2D(16, (3,3), activation='relu')(pool11)
pool12 = MaxPooling2D(pool_size=(2,2))(conv12)
flat1 = Flatten()(pool12)
# second input model
input2 = Input(shape=(32,32,3))
conv21 = Conv2D(32, (5,5), activation='relu')(input2)
pool21 = MaxPooling2D(pool_size=(2,2))(conv21)
conv22 = Conv2D(16, (3,3), activation='relu')(pool21)
pool22 = MaxPooling2D(pool_size=(2,2))(conv22)
flat2 = Flatten()(pool22)
# merge input models
merge = Concatenate()([flat1, flat2])
# interpretation model
hidden1 = Dense(20, activation='relu')(merge)
output = Dense(1, activation='sigmoid')(hidden1)
model = Model(inputs=[input1, input2], outputs=output)
model.summary()
多输出模型(Multiple Output Model)
定义有多个输出的模型,以文本序列输入LSTM网络为例,一个输出是对文本的分类,另外一个输出是对文本进行序列标注。
##------ Multiple Output Model ------ ##
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense, Flatten, TimeDistributed, LSTM
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Concatenate
from tensorflow.keras import backend as K
K.clear_session()
x = Input(shape=(100,1))
extract = LSTM(10, return_sequences=True)(x)
class11 = LSTM(10)(extract)
class12 = Dense(10, activation='relu')(class11)
output1 = Dense(1, activation='sigmoid')(class12)
output2 = TimeDistributed(Dense(1, activation='linear'))(extract)
model = Model(inputs=x, outputs=[output1, output2])
model.summary()
训练
Keras Model 的 compile 、 fit 和 evaluate 方法训练和评估模型
compile 函数
当模型建立完成后,通过 tf.keras.Model 的 compile 方法配置训练过程
tf.keras.Model.compile 有三个重要参数(建议参考下Keras compile document):
optimizer:指定优化器。 从tf.train模块传递优化器实例,例如loss:优化函数。 损失函数由名称或通过从tf.keras.losses模块传递可调用对象来指定。常见的选择包括:- 均方误差(mse)
- categorical_crossentropy
- binary_crossentropy。
metrics:设置训练中评估指标(原文为metrics,指标)组成的列表,如准确率(accuracy)。 指标是来自tf.keras.metrics模块的字符串名称或可调用对象组成的list。
两种传参方式:
- 字符串
- 可调用的对象
# 编译模型,配置相关组件(优化器、损失函数和衡量指标)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), # Adam优化器
loss=tf.keras.losses.sparse_categorical_crossentropy, # 分类损失函数
metrics=[tf.keras.metrics.sparse_categorical_accuracy] # 分类指标
)
# 编译均方误差回归模型(a model for mean-squared error regression)
model.compile(optimizer=tf.train.AdamOptimizer(0.01),
loss='mse', # 最小均方误差(mean squared error)
metrics=['mae']) # 平均绝对误差(mean absolute error)
# 编译一个分类模型(a model for categorical classification)
# 多元分类问题例子,比如手写数字识别
model.compile(optimizer=tf.train.RMSPropOptimizer(0.01),
loss=tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])
# 功能同上,字符串方式
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 二元分类例子
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
fit 函数
tf.keras.Model.fit 接受 5 个重要的参数:
- x :训练数据;
- y :目标数据(数据标签);
- epochs :将训练数据迭代多少遍;
- batch_size :批次的大小;
- validation_data :验证数据,可用于在训练过程中监控模型的性能。
- Keras 支持使用 tf.data.Dataset 进行训练,详见 tf.data
三个重要参数:
epochs:训练多少个epoch。 一个epoch是对整个训练数据集的一次训练(这是以较小的批次完成的)。batch_size:当传递NumPy数据时,模型将数据分成较小的批次(batch),并在训练期间训练这些批次。 此整数指定每个批次的大小。 请注意,如果样本总数不能被批次大小整除,则最后一批可能会更小。validation_data:在对模型进行原型设计时,若要监控其在某些验证数据集上的性能。 传递由(输入,标签)组成的元组, 模型在每个epoch的末尾显示损失和指标。
fit方法函数steps_per_epoch参数: 这是模型在训练集上训练一遍(也就是一个epoch)的训练步数。 由于Dataset生成批次数据,因此此代码段不需要batch_size。
用 tf.keras.Model 的 fit 方法训练模型:
import numpy as np
data = np.random.random((1000, 32))
labels = np.random.random((1000, 10))
val_data = np.random.random((100, 32))
val_labels = np.random.random((100, 10))
# 训练模型
model.fit(data, labels, epochs=10, batch_size=32,
validation_data=(val_data, val_labels))
# model.fit(data_loader.train_data, data_loader.train_label, epochs=num_epochs, batch_size=batch_size)
model.fit(data_loader.train_data, # x
data_loader.train_label, # y
epochs=num_epochs, # 迭代epoch数
batch_size=batch_size) # batch size
# 使用tf.data时,不用设置batch_size,但要指定steps_per_epoch
# 实例化玩具数据集实例:
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
dataset = dataset.batch(32)
dataset = dataset.repeat()
# 在数据集上调用`fit`时,不要忘记指定`steps_per_epoch`
model.fit(dataset, epochs=10, steps_per_epoch=30)
# 使用验证集
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
dataset = dataset.batch(32).repeat()
val_dataset = tf.data.Dataset.from_tensor_slices((val_data, val_labels))
val_dataset = val_dataset.batch(32).repeat()
model.fit(dataset, epochs=10, steps_per_epoch=30,
validation_data=val_dataset,
validation_steps=3)
evaluate 函数
最后,使用 tf.keras.Model.evaluate 评估训练效果,提供测试数据及标签即可:
model.evaluate(data, labels, batch_size=32)
model.evaluate(dataset, steps=30)
# 评估效果
print(model.evaluate(data_loader.test_data, data_loader.test_label))
predict 函数
result = model.predict(data, batch_size=32)
print(result.shape)
自定义
自定义-层
自定义层需要继承 tf.keras.layers.Layer 类,并重写 init 、 build 和 call 三个方法
build:创建图层的权重。 使用add_weight函数来创建。call:定义前向传播。compute_output_shape:计算在给定的输入的shape时,计算出输出的shape。- 可以通过实现
get_config方法和from_config方法来序列化层。不过是可选的。
class MyLayer(layers.Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
shape = tf.TensorShape((input_shape[1], self.output_dim))
# 为此层创建一个可训练的权重
self.kernel = self.add_weight(name='kernel',
shape=shape,
initializer='uniform',
trainable=True)
# 确保在函数结束时调用下面的语句
super(MyLayer, self).build(input_shape)
def call(self, inputs):
# 这里定义了这层要实现的操作,也就是前向传播的操作
return tf.matmul(inputs, self.kernel)
def compute_output_shape(self, input_shape):
# 计算输出tensor的shape
shape = tf.TensorShape(input_shape).as_list()
shape[-1] = self.output_dim
return tf.TensorShape(shape)
def get_config(self):
base_config = super(MyLayer, self).get_config()
base_config['output_dim'] = self.output_dim
return base_config
@classmethod
def from_config(cls, config):
return cls(**config)
调用
model = tf.keras.Sequential([
MyLayer(10),
layers.Activation('softmax')])
model.compile(optimizer=tf.train.RMSPropOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels, batch_size=32, epochs=5)
class MyLayer(tf.keras.layers.Layer):
def __init__(self):
super().__init__()
# 初始化代码
def build(self, input_shape): # input_shape 是一个 TensorShape 类型对象,提供输入的形状
# 在第一次使用该层的时候调用该部分代码,在这里创建变量可以使得变量的形状自适应输入的形状
# 而不需要使用者额外指定变量形状。如果已经可以完全确定变量的形状,也可以在__init__部分创建变量
self.variable_0 = self.add_weight(...) # add_weight()函数中自己定义shape,将他的参数trainable=True
self.variable_1 = self.add_weight(...)
def call(self, inputs):
# 模型调用的代码(处理输入并返回输出)
return output
如果要自己实现一个全连接层( tf.keras.layers.Dense ),可以按如下方式编写。
- 此代码在 build 方法中创建两个变量,并在 call 方法中使用创建的变量进行运算:
class LinearLayer(tf.keras.layers.Layer):
""" 自定义MLP层:重写init、build和call函数 """
def __init__(self, units):
super().__init__()
self.units = units
# 层里涉及的变量
def build(self, input_shape): # input_shape 是第一次运行call()时参数inputs的形状
self.w = self.add_weight(name='w',
shape=[input_shape[-1], self.units], initializer=tf.zeros_initializer())
self.b = self.add_weight(name='b',
shape=[self.units], initializer=tf.zeros_initializer())
# 组装成一层
def call(self, inputs):
y_pred = tf.matmul(inputs, self.w) + self.b
return y_pred
在定义模型的时候,便可以如同 Keras 中的其他层一样,调用自定义的层 LinearLayer:
class LinearModel(tf.keras.Model):
# 调用自定义层
def __init__(self):
super().__init__()
self.layer = LinearLayer(units=1) # 直接调用
def call(self, inputs):
output = self.layer(inputs)
return output
自定义-损失函数
自定义损失函数需要继承 tf.keras.losses.Loss 类,重写 call 方法即可,输入真实值 y_true 和模型预测值 y_pred ,输出模型预测值和真实值之间通过自定义的损失函数计算出的损失值。下面的示例为均方差损失函数:
class MeanSquaredError(tf.keras.losses.Loss):
def call(self, y_true, y_pred):
return tf.reduce_mean(tf.square(y_pred - y_true))
自定义-评估指标
自定义评估指标需要继承 tf.keras.metrics.Metric 类,并重写 init 、 update_state 和 result 三个方法。
- 下面的示例对前面用到的 SparseCategoricalAccuracy 评估指标类做了一个简单的重实现:
class SparseCategoricalAccuracy(tf.keras.metrics.Metric):
def __init__(self):
super().__init__()
self.total = self.add_weight(name='total', dtype=tf.int32, initializer=tf.zeros_initializer())
self.count = self.add_weight(name='count', dtype=tf.int32, initializer=tf.zeros_initializer())
def update_state(self, y_true, y_pred, sample_weight=None):
values = tf.cast(tf.equal(y_true, tf.argmax(y_pred, axis=-1, output_type=tf.int32)), tf.int32)
self.total.assign_add(tf.shape(y_true)[0])
self.count.assign_add(tf.reduce_sum(values))
def result(self):
return self.count / self.total
tf.function :图执行模式(eager模式)
- tf.function 模块,结合 AutoGraph 机制,仅需加一个简单的 @tf.function 修饰符,就能轻松将模型以图执行模式运行。
- @tf.function 使用名为 AutoGraph 的机制将函数中的 Python 控制流语句转换成 TensorFlow 计算图中的对应节点。类似
编译器
- @tf.function 使用名为 AutoGraph 的机制将函数中的 Python 控制流语句转换成 TensorFlow 计算图中的对应节点。类似
- 不是任何函数都可以被 @tf.function 修饰!
- @tf.function 使用静态编译将函数内的代码转换成计算图,因此对函数内可使用的语句有一定限制(仅支持 Python 语言的一个子集),且需要函数内的操作本身能够被构建为计算图
- 建议在函数内只使用 TensorFlow 的原生操作,不要使用过于复杂的 Python 语句,函数参数只包括 TensorFlow 张量或 NumPy 数组
- 直接获得 tf.function 所生成的计算图以进行进一步处理和调试,可以使用被修饰函数的 get_concrete_function 方法
内在原理
使用@tf.function的函数在执行时会生成一个计算图,里面的操作就是计算图的每个节点。下次调用相同的函数,且参数类型相同时,则会直接使用这个计算图计算。若函数名不同或参数类型不同时,则会另外生成一个新的计算图。
注意:建议函数内只使用 TensorFlow 的原生操作,不要使用过于复杂的 Python 语句,函数参数最好只包括 TensorFlow 张量或 NumPy 数组。
- 因为只有tf的原生操作才会在计算图中生产节点。(如python的原生print()函数不会生成节点,而tensorflow的tf.print()会)
- 对于Tensorflow张量或Numpy数组作为参数的函数,只要类型相同便可重用之前的计算图。而对于python原声数据(如原生的整数、浮点数 1,1.5等)必须参数的值一模一样才会重用之前的计算图,否则的话会创建新的计算图。
另外,当模型由较多小操作组成的时候, @tf.function 带来的提升效果较大。而当模型的操作数量较少,但单一操作均很耗时的时候,则 @tf.function 带来的性能提升不会太大。
- 实验结论:不用@tf.function,训练时间大约为3秒。用@tf.function,训练时间仅需要0.5秒。快了很多倍。
示例
import tensorflow as tf
# 函数转计算图
@tf.function
def square_if_positive(x):
# 自动将python函数转成计算图
if x > 0:
x = x * x
else:
x = 0
return x
a = tf.constant(1)
b = tf.constant(-1)
print(square_if_positive(a), square_if_positive(b))
# 动态数组
@tf.function
def array_write_and_read():
# 动态数组TensorArray
arr = tf.TensorArray(dtype=tf.float32, size=3)
arr = arr.write(0, tf.constant(0.0))
arr = arr.write(1, tf.constant(1.0))
arr = arr.write(2, tf.constant(2.0))
arr_0 = arr.read(0)
arr_1 = arr.read(1)
arr_2 = arr.read(2)
return arr_0, arr_1, arr_2
a, b, c = array_write_and_read()
# 使用底层API手工转换
print(tf.autograph.to_code(square_if_positive.python_function))
回调
回调是传递给模型的对象,用于在训练模型期间自定义和扩展其行为。 可以编写自己的自定义回调,或使用以下内置的tf.keras.callbacks:
- tf.keras.callbacks.ModelCheckpoint:定期保存模型的检查点(checkpoint)。
- tf.keras.callbacks.LearningRateScheduler:动态改变学习率。
- tf.keras.callbacks.EarlyStopping:在校验集的性能停止提升时,中断训练。
- tf.keras.callbacks.TensorBoard:使用TensorBoard监控模型的行为。
若要使用tf.keras.callbacks.Callback,请将其传递给模型的_fit_方法:
callbacks = [
# 如果`val_loss`在超过两个epoch都没有提升,那么中断训练
tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'),
# 把TensorBoard的日志写入文件夹`./logs`
tf.keras.callbacks.TensorBoard(log_dir='./logs')
]
model.fit(data, labels, batch_size=32, epochs=5, callbacks=callbacks,
validation_data=(val_data, val_labels))
模型保存
- TensorFlow 提供了SavedModel格式,将整个模型完整导出标准格式的文件,可在不同的平台上部署。
- 与Checkpoint 不同,SavedModel 包含了一个 TensorFlow 程序的完整信息:不仅包含参数的权值,还包含计算的流程(即计算图)。
- 导入时,无须构建源码即可运行,非常适合分享和部署,TensorFlow Serving(服务器端部署模型)、TensorFlow Lite(移动端部署模型)以及 TensorFlow.js 都会用到 Keras 模型均可方便地导出为 SavedModel 格式。
- 注意:SavedModel 基于计算图,所以继承 tf.keras.Model 类建立的 Keras 模型
- 导出到 SavedModel 格式的方法(比如 call )时,都要使用 @tf.function 修饰。
- SavedModel载入后将无法使用 model() 直接进行推断,而需要使用 model.call()
# ----- tf.keras -----
# 把权重保存为TensorFlow Checkpoint文件
model.save_weights('./weights/my_model')
# 载入权重。要求模型和保存权重的模型具有相同的架构
model.load_weights('./weights/my_model')
# 把权重保存为HDF5这种格式的文件
model.save_weights('my_model.h5', save_format='h5')
# 保存模型配置
json_string = model.to_json()
print(json_string)
# 从json字符串恢复模型
fresh_model = tf.keras.models.model_from_json(json_string)
# 模型序列化为YAML格式
yaml_string = model.to_yaml()
print(yaml_string)
# YAML字符串恢复模型: 注意:子类化模型不可序列化,因为它们的体系结构由call函数中的Python代码定义。
fresh_model = tf.keras.models.model_from_yaml(yaml_string)
# 载入权重
model.load_weights('my_model.h5')
# 保存整个模型
# 将整个模型保存到HDF5文件
model.save('my_model.h5')
# 重新创建完全相同的模型,包括权重和优化器。
model = tf.keras.models.load_model('my_model.h5')
# ---- tf -----
tf.saved_model.save(model, "save_dir") # 导出
model = tf.saved_model.load("save_dir") # 导入
TensorFlow 提供了 tf.train.Checkpoint 这一强大的变量保存与恢复类,可以使用其 save() 和 restore() 方法将 TensorFlow 中所有包含 Checkpointable State 的对象进行保存和恢复。具体而言,tf.keras.optimizer 、 tf.Variable 、 tf.keras.Layer 或者 tf.keras.Model 实例都可以被保存。
- tf.train.Checkpoint :变量的保存与恢复
- tf.train.Checkpoint() 接受的初始化参数比较特殊,是一个 **kwargs 。具体而言,是一系列的键值对,键名可以随意取,值为需要保存的对象。
- checkpoint.save(‘./save/model.ckpt’) ,save 目录下发现名为 checkpoint 、 model.ckpt-1.index 、 model.ckpt-1.data-00000-of-00001 的三个文件,这些文件就记录了变量信息。
- checkpoint.save() 方法可以运行多次,每运行一次都会得到一个.index 文件和.data 文件,序号依次累加。
checkpoint = tf.train.Checkpoint(model=model)
# 准备保存模型和优化器
checkpoint = tf.train.Checkpoint(myAwesomeModel=model, myAwesomeOptimizer=optimizer)
# 保存为文件,save_path_with_prefix 是保存文件的目录 + 前缀
checkpoint.save(save_path_with_prefix)
# --------- 中途恢复模型 -----------
model_to_be_restored = MyModel() # 待恢复参数的同一模型
checkpoint = tf.train.Checkpoint(myAwesomeModel=model_to_be_restored) # 键名保持为“myAwesomeModel”
model_name = tf.train.latest_checkpoint('./save') # 返回目录下最近一次 checkpoint 的文件名
save_path_with_prefix_and_index = model_name
# save_path_with_prefix_and_index 是之前保存的文件的目录 + 前缀 + 编号
checkpoint.restore(save_path_with_prefix_and_index)
# -------- train ----------
model = MyModel()
# 实例化Checkpoint,指定保存对象为model(如果需要保存Optimizer的参数也可加入)
checkpoint = tf.train.Checkpoint(myModel=model)
# ...(模型训练代码)
# 模型训练完毕后将参数保存到文件(也可以在模型训练过程中每隔一段时间就保存一次)
checkpoint.save('./save/model.ckpt')
# ------- test -----------
model = MyModel()
checkpoint = tf.train.Checkpoint(myModel=model) # 实例化Checkpoint,指定恢复对象为model
checkpoint.restore(tf.train.latest_checkpoint('./save')) # 从文件恢复模型参数
# -------- manager ------
# CheckpointManager 限制仅保留最后三个 Checkpoint 文件,并使用 batch 的编号作为 Checkpoint 的文件编号。
manager = tf.train.CheckpointManager(checkpoint, directory='./save', checkpoint_name='model.ckpt', max_to_keep=k)
manager.save()
tf.train.Checkpoint 与以前版本常用的 tf.train.Saver 相比,强大之处在于其支持在即时执行模式下 “延迟” 恢复变量。
- 当调用了 checkpoint.restore() ,但模型中的变量还没有被建立的时候,Checkpoint 可以等到变量被建立的时候再进行数值的恢复。
- 即时执行模式下,模型中各个层的初始化和变量的建立是在模型第一次被调用的时候才进行的(好处在于可以根据输入的张量形状而自动确定变量形状,无需手动指定)。这意味着当模型刚刚被实例化的时候,其实里面还一个变量都没有,这时候使用以往的方式去恢复变量数值是一定会报错的。
- 比如,在 train.py 调用 tf.keras.Model 的 save_weight() 方法保存 model 的参数,并在 test.py 中实例化 model 后立即调用 load_weight() 方法,就会出错,只有当调用了一遍 model 之后再运行 load_weight() 方法才能得到正确的结果。
- 可见,tf.train.Checkpoint 在这种情况下可以给我们带来相当大的便利。
- 另外,tf.train.Checkpoint 同时也支持图执行模式。
import tensorflow as tf
import numpy as np
import argparse
from zh.model.mnist.mlp import MLP
from zh.model.utils import MNISTLoader
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('--mode', default='train', help='train or test')
parser.add_argument('--num_epochs', default=1)
parser.add_argument('--batch_size', default=50)
parser.add_argument('--learning_rate', default=0.001)
args = parser.parse_args()
data_loader = MNISTLoader()
def train():
model = MLP()
optimizer = tf.keras.optimizers.Adam(learning_rate=args.learning_rate)
num_batches = int(data_loader.num_train_data // args.batch_size * args.num_epochs)
checkpoint = tf.train.Checkpoint(myAwesomeModel=model) # 实例化Checkpoint,设置保存对象为model
for batch_index in range(1, num_batches+1):
X, y = data_loader.get_batch(args.batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
if batch_index % 100 == 0: # 每隔100个Batch保存一次
path = checkpoint.save('./save/model.ckpt') # 保存模型参数到文件
print("model saved to %s" % path)
def test():
model_to_be_restored = MLP()
# 实例化Checkpoint,设置恢复对象为新建立的模型model_to_be_restored
checkpoint = tf.train.Checkpoint(myAwesomeModel=model_to_be_restored)
checkpoint.restore(tf.train.latest_checkpoint('./save')) # 从文件恢复模型参数
y_pred = np.argmax(model_to_be_restored.predict(data_loader.test_data), axis=-1)
print("test accuracy: %f" % (sum(y_pred == data_loader.test_label) / data_loader.num_test_data))
if __name__ == '__main__':
if args.mode == 'train':
train()
if args.mode == 'test':
test()
在代码目录下建立 save 文件夹并运行代码进行训练后,save 文件夹内将会存放每隔 100 个 batch 保存一次的模型变量数据。
- 在命令行参数中加入 –mode=test 并再次运行代码,将直接使用最后一次保存的变量值恢复模型并在测试集上测试模型性能,可以直接获得 95% 左右的准确率。
manager示例:
import tensorflow as tf
import numpy as np
import argparse
from zh.model.mnist.mlp import MLP
from zh.model.utils import MNISTLoader
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('--mode', default='train', help='train or test')
parser.add_argument('--num_epochs', default=1)
parser.add_argument('--batch_size', default=50)
parser.add_argument('--learning_rate', default=0.001)
args = parser.parse_args()
data_loader = MNISTLoader()
def train():
model = MLP()
optimizer = tf.keras.optimizers.Adam(learning_rate=args.learning_rate)
num_batches = int(data_loader.num_train_data // args.batch_size * args.num_epochs)
checkpoint = tf.train.Checkpoint(myAwesomeModel=model)
# 使用tf.train.CheckpointManager管理Checkpoint
manager = tf.train.CheckpointManager(checkpoint, directory='./save', max_to_keep=3)
for batch_index in range(1, num_batches):
X, y = data_loader.get_batch(args.batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
if batch_index % 100 == 0:
# 使用CheckpointManager保存模型参数到文件并自定义编号
path = manager.save(checkpoint_number=batch_index)
print("model saved to %s" % path)
def test():
model_to_be_restored = MLP()
checkpoint = tf.train.Checkpoint(myAwesomeModel=model_to_be_restored)
checkpoint.restore(tf.train.latest_checkpoint('./save'))
y_pred = np.argmax(model_to_be_restored.predict(data_loader.test_data), axis=-1)
print("test accuracy: %f" % (sum(y_pred == data_loader.test_label) / data_loader.num_test_data))
if __name__ == '__main__':
if args.mode == 'train':
train()
if args.mode == 'test':
test()
Eager execution
Eager execution是一个必要的编程环境,可以立即评估操作。 这对于Keras不是必需的,但是由_tf.keras_支持,对于检查程序和调试很有用。
- 所有_tf.keras_ API都与Eager execution兼容。 虽然可以使用顺序模型和函数式API,但是Eager execution尤其有利于模型子类化和构建自定义层 。
- 有关使用具有自定义训练和tf.GradientTape的Keras模型的示例,请参阅Eager execution 指南。
模型部署 Tensorflow Serving
Flask 等 Python 下的 Web 框架就能非常轻松地实现服务器 API, 不过生产环境就力不从心了。
- TensorFlow Serving 组件能够在生产环境中灵活且高性能地部署机器学习模型
- 可直接读取 SavedModel 格式的模型进行部署
- 支持热更新,多模型,自动选择最大版本号
- 支持以 gRPC 和 RESTful API 调用以 TensorFlow Serving 部署的模型
- Keras模型部署
- Keras Sequential 模式的输入和输出都很固定,因此这种类型的模型很容易部署,无需其他额外操作
- 继承tf.keras.Model 类建立的自定义 Keras模型的自由度相对更高。因此部署时,对导出的 SavedModel 文件也有更多的要求
- 不仅需要使用 @tf.function 修饰,还要在修饰时指定 input_signature 参数,以显式说明输入的形状。该参数传入一个由 tf.TensorSpec 组成的列表,指定每个输入张量的形状和类型
- 用 tf.saved_model.save 导出时,需要通过 signature 参数提供待导出的函数的签名(Signature)
- tensorflow lite导入模型前需要用tflite_convert转换格式
- Quantized 模型在模型大小和运行性能上相对 Float 模型都有非常大的提升,但对模型的识别精度还是有影响的。在边缘设备上资源有限,需要在模型大小、运行速度与识别精度上找到一个权衡
/saved_model_files
/1 # 版本号为1的模型文件
/assets
/variables
saved_model.pb
...
/N # 版本号为N的模型文件
/assets
/variables
saved_model.pb
# 加载SavedModel格式
tensorflow_model_server \
--rest_api_port=端口号(如8501) \
--model_name=模型名 \
--model_base_path="SavedModel格式模型的文件夹绝对地址(不含版本号)"
控制语句
- TensorFlow 提供了几种操作和类用来控制计算图的执行流程和计算条件依赖 计算图控制方法
- tf.identity:和输入的 tensor 大小和数值都一样的 tensor ,类似于 y=x 操作
- tf.tuple:op元组
- tf.group:聚合多个 OP 的 OP
- tf.no_op:什么也不做,只是作为一个控制边界的占位符
- tf.count_up_to:一个计数器,根据计数条件是否满足控制流程;它有两个主要参数,ref,limit,表示每次都在 ref 的基础上递增,直到等于 limit。
- tf.cond:根据条件进行流程控制的函数,它有三个参数,pred, true_fn,false_fn
- tf.case:多分枝流程控制函数
- tf.while_loop:类似于 while 循环的函数,它有三个主要参数,cond, 循环条件,body,循环语句,loop_vars,循环控制变量。
tf.cond
- 用于有条件的执行函数,当pred为True时,执行true_fn函数,否则执行false_fn函数
- 参数说明
- pred:标量决定是否返回 true_fn 或 false_fn 结果。
- true_fn:如果 pred 为 true,则被调用。
- false_fn:如果 pred 为 false,则被调用。
- strict:启用/禁用 “严格”模式的布尔值。
- name:返回的张量的可选名称前缀。
import tensorflow as tf
x = tf.constant(4)
y = tf.constant(3)
z = tf.add(x, y)
print('条件表达语句tf.cond')
result = tf.cond(x < y, lambda: tf.add(x, z), lambda: tf.square(y))
tf.print(result)
print(result.numpy())
tf.while_loop 循环
实现如下循环逻辑
i= 0
n =10
while(i < n):
i = i +1
# tf实现
loop = []
while cond(loop):
loop = body(loop)
- tensorflow内部还是把循环转化为了矩阵运算,所以如果自己能显式的用矩阵运算代替while_loop的话,这样可以避免调入while_loop这么多坑里面
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# tf版本
i = tf.get_variable("i", dtype=tf.int32, shape=[], initializer=tf.ones_initializer())
n = tf.constant(10)
def cond(a, n): # 条件判断
return a< n
def body(a, n): # 主函数体
a = a + 1
return a, n
i, n = tf.while_loop(cond, body, [i, n]) # 执行循环
with tf.Session() as sess:
tf.global_variables_initializer().run()
res = sess.run([i, n])
print(res)
tf.control_dependencies
- 设置op的控制依赖关系
with tf.control_dependencies([a, b]):
#c= tf.no_op(name='train')#tf.no_op;什么也不做
c= tf.group([a, b])
sess.run(c)
常用函数
tf.slice
- tf.slice(inputs, begin, size, name)
- 从列表、数组、张量等对象中抽取一部分数据
- begin和size是两个多维列表,他们共同决定了要抽取的数据的开始和结束位置
- begin表示从inputs的哪几个维度上的哪个元素开始抽取 ,begin基于下标0开始
- size表示在inputs的各个维度上抽取的元素个数
- 若begin[]或size[]中出现-1,表示抽取对应维度上的所有元素
- 注意
- size的大小不能大于切片刀下方表格数据的尺寸,维度数不能大于被切片数据的维度
- 示例:
- 提取原理
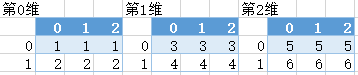
import tensorflow as tf
#这个代码演示测试tf.slice函数
t=tf.constant([[[1,1,1],[2,2,2]],
[[3,3,3],[4,4,4]],
[[5,5,5],[6,6,6]]])
s1=tf.slice(t,[1,0,0],[1,1,3])
#begin=[1,0,0],从第1维的[0,0]开始切片([3,3,3])
#size=[1,1,3]表明切片后是1维,切片的尺寸为1行3列。
s2=tf.slice(t,[0,1,1],[2,1,1])
#begin=[0,1,1],表明从第0维的[1,1]开始切片,也就是从[2,2,2]的第二个2开始
#size=[2,1,1]表明切片后的尺寸为相邻的两张表,数据1行1列。
print(s1)
tf.print(s2)
s1,s2
tf.argmax
import numpy as np
import tensorflow as tf
test = np.array([
[1, 2, 3],
[2, 3, 4],
[5, 4, 3],
[8, 7, 2]])
print('---numpy---')
print(np.argmax(test, 0)) # 列向最大值下标:array([3, 3, 1]
print(np.argmax(test, 1)) # 行向最大值下标:array([2, 2, 0, 0]
print('---tensorflow--')
print(tf.argmax(test).numpy())
print(tf.argmax(test, 1))
tf.equal
- tf.cond
print('--- tf 1.* ---')
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
a = [[1,2,3],[4,5,6]]
b = [[1,0,3],[1,5,1]]
with tf.Session() as sess:
print(sess.run(tf.equal(a,b)))
print('--- tf 2.* ---')
import tensorflow as tf
a = [[1,2,3],[4,5,6]]
b = [[1,0,3],[1,5,1]]
# 张量元素逐个比较
tf.equal(a, b).numpy().tolist()
tf.transpose
- 高维转置,tf.transpose方法讲解
- tf.transpose的第二个参数perm=[0,1,2]
- 0代表三维数组的高(即为二维数组的个数)
- 1代表二维数组的行
- 2代表二维数组的列
- [0, 1, 2]是正常显示,那么交换哪两个数字,就是把对应的输入张量的对应的维度对应交换即可。
- tf.transpose(x, perm=[1,0,2])代表将三位数组的高和行进行转置。
softmax
- 【2020-5-12】logis本身并不是一个概率,所以需要把logist的值变化成“概率模样”。这时Softmax函数该出场了。
- Softmax把一个系列的概率替代物(logits)从[-inf, +inf] 映射到[0,1]。
- 除此之外,Softmax还保证把所有参与映射的值累计之和等于1,变成诸如[0.95, 0.05, 0]的概率向量。
- 这样一来,经过Softmax加工的数据可以当做概率来用.

import tensorflow as tf
#tf.disable_v2_behavior() # tf 1.*的特性
labels = [[0.2,0.3,0.5],
[0.1,0.6,0.3]]
logits = [[4,1,-2],
[0.1,1,3]]
# tensorflow 2.* 直接显示动态图展示,不用加tf.session()
logits_scaled = tf.nn.softmax(logits)
print('-'*10)
print(logits_scaled)
print('-'*10)
tf.print(logits_scaled)
result = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits)
print('-'*10)
print(result)
print('-'*10)
tf.print(result)
#with tf.compat.v1.Session() as sess:
#with tf.Session() as sess:
# print (sess.run(logits_scaled))
# print (sess.run(result))
tf.nn.moments 矩
- 矩:一阶矩对应均值,二阶矩对应方差
- moments函数就是在 [0] 维度上求了个均值和方差
- def moments(x, axes, name=None, keep_dims=False)
- x 可以理解为我们输出的数据,形如 [batchsize, height, width, kernels]
- axes 表示在哪个维度上求解,是个list,例如 [0, 1, 2]
- name 就是个名字,不多解释
- keep_dims 是否保持维度,不多解释
import tensorflow.compat.v1 as tf
img = tf.Variable(tf.random_normal([2, 3]))
axis = list(range(len(img.get_shape()) - 1))
mean, variance = tf.nn.moments(img, axis)
print(mean, variance)
tf.nn.batch_normalization
- 批归一化
- def batch_normalization(x, mean, variance, offset, scale, variance_epsilon, name=None):
-

- BN在神经网络进行training和testing的时候,所用的mean、variance是不一样的!
update_moving_mean = moving_averages.assign_moving_average(moving_mean, mean, BN_DECAY)
update_moving_variance = moving_averages.assign_moving_average(moving_variance, variance, BN_DECAY)
tf.add_to_collection(UPDATE_OPS_COLLECTION, update_moving_mean)
tf.add_to_collection(UPDATE_OPS_COLLECTION, update_moving_variance)
mean, variance = control_flow_ops.cond(['is_training'], lambda: (mean, variance), lambda: (moving_mean, moving_variance))
tf.train.ExponentialMovingAverage
- 采用滑动平均的方法更新参数。这个函数初始化需要提供一个衰减速率(decay),用于控制模型的更新速度。这个函数还会维护一个影子变量(也就是更新参数后的参数值),这个影子变量的初始值就是这个变量的初始值,影子变量值的更新方式如下:
- shadow_variable = decay * shadow_variable + (1-decay) * variable
- shadow_variable是影子变量,variable表示待更新的变量,也就是变量被赋予的值,decay为衰减速率。decay一般设为接近于1的数(0.99,0.999)。- decay越大模型越稳定,因为decay越大,参数更新的速度就越慢,趋于稳定。
v1 = tf.Variable(0, dtype=tf.float32)
step = tf.Variable(tf.constant(0))
ema = tf.train.ExponentialMovingAverage(0.99, step)
maintain_average = ema.apply([v1])
Tensorflow 数据集
内置数据集
import tensorflow_datasets as tfds
dataset = tfds.load("mnist", split=tfds.Split.TRAIN, as_supervised=True)
小数据集用tf.data——内存足够
- tf.data.Dataset 类,提供了对数据集的高层封装,API
- Dataset.map(f) :对数据集中的每个元素应用函数 f ,得到一个新的数据集(这部分往往结合 tf.io 进行读写和解码文件, tf.image 进行图像处理);
- Dataset.shuffle(buffer_size) :将数据集打乱(设定一个固定大小的缓冲区(Buffer),取出前 buffer_size 个元素放入,并从缓冲区中随机采样,采样后的数据用后续数据替换);
- Dataset.batch(batch_size) :将数据集分成批次,即对每 batch_size 个元素,使用 tf.stack() 在第 0 维合并,成为一个元素;
- Dataset.prefetch(): 让数据集对象 Dataset 在训练时预取出若干个元素,使得在 GPU 训练的同时 CPU 可以准备数据,从而提升训练流程的效率
- Dataset.repeat() (重复数据集的元素)
- Dataset.reduce() (与 Map 相对的聚合操作)
- Dataset.take() (截取数据集中的前若干个元素)等
大数据集用tfrecord
- 将数据集处理为 TFRecord 格式,然后使用 tf.data.TFRocrdDataset() 进行载入
- TFRecord 可以理解为一系列序列化的 tf.train.Example 元素所组成的列表文件,而每一个 tf.train.Example 又由若干个 tf.train.Feature 的字典组成。
- tf.train.Feature 支持三种数据格式:
- tf.train.BytesList :字符串或原始 Byte 文件(如图片),通过 bytes_list 参数传入一个由字符串数组初始化的 tf.train.BytesList 对象;
- tf.train.FloatList :浮点数,通过 float_list 参数传入一个由浮点数数组初始化的 tf.train.FloatList 对象;
- tf.train.Int64List :整数,通过 int64_list 参数传入一个由整数数组初始化的 tf.train.Int64List 对象。
示例
异或难题
异或难题
- minsky:异或门是神经网络的命门——诱发神经网络的第一次衰落
问题介绍
)
TensorFlow代码实现
网络结构图(TensorBoard可视化):
- 
#方法二:https://aimatters.wordpress.com/2016/01/16/solving-xor-with-a-neural-network-in-tensorflow/
#There is one thing I did notice in putting this together: it’s quite slow.
#In Octave, I was able to run 10,000 epochs in about 9.5 seconds.
#The Python/NumPy example was able to run in 5.8 seconds.
#The above TensorFlow example runs in about 28 seconds on my laptop.
import tensorflow as tf
import time
x_ = tf.placeholder(tf.float32, shape=[4,2], name = 'x-input')
y_ = tf.placeholder(tf.float32, shape=[4,1], name = 'y-input')
Theta1 = tf.Variable(tf.random_uniform([2,2], -1, 1), name = "Theta1")
Theta2 = tf.Variable(tf.random_uniform([2,1], -1, 1), name = "Theta2")
Bias1 = tf.Variable(tf.zeros([2]), name = "Bias1")
Bias2 = tf.Variable(tf.zeros([1]), name = "Bias2")
with tf.name_scope("layer2") as scope:
A2 = tf.sigmoid(tf.matmul(x_, Theta1) + Bias1)
with tf.name_scope("layer3") as scope:
Hypothesis = tf.sigmoid(tf.matmul(A2, Theta2) + Bias2)
with tf.name_scope("cost") as scope:
cost = tf.reduce_mean(( (y_ * tf.log(Hypothesis)) + ((1 - y_) * tf.log(1.0 - Hypothesis)) ) * -1)
with tf.name_scope("train") as scope:
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
XOR_X = [[0,0],[0,1],[1,0],[1,1]]
XOR_Y = [[0],[1],[1],[0]]
#init = tf.initialize_all_variables()
init = tf.global_variables_initializer()
sess = tf.Session()
writer = tf.summary.FileWriter("./logs/xor_logs", sess.graph_def)
sess.run(init)
t_start = time.clock()
for i in range(100000):
sess.run(train_step, feed_dict={x_: XOR_X, y_: XOR_Y})
if i % 1000 == 0:
print('Epoch ', i)
print('Hypothesis ', sess.run(Hypothesis, feed_dict={x_: XOR_X, y_: XOR_Y}))
print('Theta1 ', sess.run(Theta1))
print('Bias1 ', sess.run(Bias1))
print('Theta2 ', sess.run(Theta2))
print('Bias2 ', sess.run(Bias2))
print('cost ', sess.run(cost, feed_dict={x_: XOR_X, y_: XOR_Y}))
t_end = time.clock()
print('Elapsed time ', t_end - t_start)
线性回归
代码
import tensorflow as tf
#tf.enable_eager_execution()
import numpy as np
X_raw = np.array([2013, 2014, 2015, 2016, 2017, 2018], dtype=np.float32)
y_raw = np.array([12000, 14000, 15000, 16500, 17500, 19000], dtype=np.float32)
X = (X_raw - X_raw.min()) / (X_raw.max() - X_raw.min())
y = (y_raw - y_raw.min()) / (y_raw.max() - y_raw.min())
X = tf.constant(X)
y = tf.constant(y)
a = tf.Variable(initial_value=0.)
b = tf.Variable(initial_value=0.)
variables = [a, b]
num_epoch = 10000
optimizer = tf.keras.optimizers.SGD(learning_rate=5e-4)
for e in range(num_epoch):
if e % 500 == 0:
print('step {}\ta={}\tb={}'.format(e, a.numpy(), b.numpy()))
# 使用tf.GradientTape()记录损失函数的梯度信息
with tf.GradientTape() as tape:
y_pred = a * X + b
loss = tf.reduce_sum(tf.square(y_pred - y))
# TensorFlow自动计算损失函数关于自变量(模型参数)的梯度
grads = tape.gradient(loss, variables)
# TensorFlow自动根据梯度更新参数
optimizer.apply_gradients(grads_and_vars=zip(grads, variables))
print(a, b)
print(a.value().numpy())
print(a.numpy())
print(a.read_value())
TensorFlow 分布式训练
TensorFlow 在 tf.distribute.Strategy 中提供了若干种分布式策略,使得我们能够更高效地训练模型。
单机多卡训练: MirroredStrategy
tf.distribute.MirroredStrategy 是一种简单且高性能的,数据并行的同步式分布式策略,主要支持多个 GPU 在同一台主机上训练。使用这种策略时,我们只需实例化一个 MirroredStrategy 策略:
strategy = tf.distribute.MirroredStrategy()
strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"]) # 指定设备,只使用第 0、1 号 GPU
并将模型构建的代码放入 strategy.scope() 的上下文环境中:
with strategy.scope():
# 模型构建代码
MirroredStrategy 的步骤如下:
- 训练开始前,该策略在所有 N 个计算设备上均各复制一份完整的模型;
- 每次训练传入一个批次的数据时,将数据分成 N 份,分别传入 N 个计算设备(即数据并行);
- N 个计算设备使用本地变量(镜像变量)分别计算自己所获得的部分数据的梯度;
- 使用分布式计算的 All-reduce 操作,在计算设备间高效交换梯度数据并进行求和,使得最终每个设备都有了所有设备的梯度之和;
- 使用梯度求和的结果更新本地变量(镜像变量);
- 当所有设备均更新本地变量后,进行下一轮训练(即该并行策略是同步的)。
- 默认情况下,TensorFlow 中的 MirroredStrategy 策略使用 NVIDIA NCCL 进行 All-reduce 操作。
完整示例
import tensorflow as tf
import tensorflow_datasets as tfds
num_epochs = 5
batch_size_per_replica = 64
learning_rate = 0.001
strategy = tf.distribute.MirroredStrategy()
print('Number of devices: %d' % strategy.num_replicas_in_sync) # 输出设备数量
batch_size = batch_size_per_replica * strategy.num_replicas_in_sync
# 载入数据集并预处理
def resize(image, label):
image = tf.image.resize(image, [224, 224]) / 255.0
return image, label
# 使用 TensorFlow Datasets 载入猫狗分类数据集,详见“TensorFlow Datasets数据集载入”一章
dataset = tfds.load("cats_vs_dogs", split=tfds.Split.TRAIN, as_supervised=True)
dataset = dataset.map(resize).shuffle(1024).batch(batch_size)
with strategy.scope():
model = tf.keras.applications.MobileNetV2(weights=None, classes=2)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
model.fit(dataset, epochs=num_epochs)
用同一台主机上的 4 块 NVIDIA GeForce GTX 1080 Ti 显卡进行单机多卡的模型训练。所有测试的 epoch 数均为 5。
- 使用单机无分布式配置时,虽然机器依然具有 4 块显卡,但程序不使用分布式的设置,直接进行训练,Batch Size 设置为 64。
- 使用单机四卡时,测试总 Batch Size 为 64(分发到单台机器的 Batch Size 为 16)和总 Batch Size 为 256(分发到单台机器的 Batch Size 为 64)两种情况。
| 数据集 | 单机无分布式(Batch Size 为 64) | 单机四卡(总 Batch Size 为 64) | 单机四卡(总 Batch Size 为 256) |
|---|---|---|---|
| cats_vs_dogs | 146s/epoch | 39s/epoch | 29s/epoch |
| tf_flowers | 22s/epoch | 7s/epoch | 5s/epoch |
使用 MirroredStrategy 后,模型训练的速度有了大幅度的提高。在所有显卡性能接近的情况下,训练时长与显卡的数目接近于反比关系。
多机训练: MultiWorkerMirroredStrategy
多机训练的方法和单机多卡类似,将 MirroredStrategy 更换为适合多机训练的 MultiWorkerMirroredStrategy 即可。不过,由于涉及到多台计算机之间的通讯,还需要进行一些额外的设置。具体而言,需要设置环境变量 TF_CONFIG ,示例如下:
os.environ['TF_CONFIG'] = json.dumps({
'cluster': {
'worker': ["localhost:20000", "localhost:20001"]
},
'task': {'type': 'worker', 'index': 0}
})
TF_CONFIG 由 cluster 和 task 两部分组成:
- cluster 说明了整个多机集群的结构和每台机器的网络地址(IP + 端口号)。对于每一台机器,cluster 的值都是相同的;
- task 说明了当前机器的角色。例如, {‘type’: ‘worker’, ‘index’: 0} 说明当前机器是 cluster 中的第 0 个 worker(即 localhost:20000 )。每一台机器的 task 值都需要针对当前主机进行分别的设置。
以上内容设置完成后,在所有的机器上逐个运行训练代码即可。先运行的代码在尚未与其他主机连接时会进入监听状态,待整个集群的连接建立完毕后,所有的机器即会同时开始训练。
- 请在各台机器上均注意防火墙的设置,尤其是需要开放与其他主机通信的端口。如上例的 0 号 worker 需要开放 20000 端口,1 号 worker 需要开放 20001 端口。
示例的训练任务与前节相同,只不过迁移到了多机训练环境。假设我们有两台机器,即首先在两台机器上均部署下面的程序,唯一的区别是 task 部分,第一台机器设置为 {‘type’: ‘worker’, ‘index’: 0} ,第二台机器设置为 {‘type’: ‘worker’, ‘index’: 1} 。接下来,在两台机器上依次运行程序,待通讯成功后,即会自动开始训练流程。
import tensorflow as tf
import tensorflow_datasets as tfds
import os
import json
num_epochs = 5
batch_size_per_replica = 64
learning_rate = 0.001
# ---------
num_workers = 2
os.environ['TF_CONFIG'] = json.dumps({
'cluster': {
'worker': ["localhost:20000", "localhost:20001"]
},
'task': {'type': 'worker', 'index': 0}
})
strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
batch_size = batch_size_per_replica * num_workers
# ---------
def resize(image, label):
image = tf.image.resize(image, [224, 224]) / 255.0
return image, label
dataset = tfds.load("cats_vs_dogs", split=tfds.Split.TRAIN, as_supervised=True)
dataset = dataset.map(resize).shuffle(1024).batch(batch_size)
with strategy.scope():
model = tf.keras.applications.MobileNetV2(weights=None, classes=2)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
model.fit(dataset, epochs=num_epochs)
在 Google Cloud Platform 分别建立两台具有单张 NVIDIA Tesla K80 的虚拟机实例(具体建立方式参见 后文介绍 ),并分别测试在使用一个 GPU 时的训练时长和使用两台虚拟机实例进行分布式训练的训练时长。所有测试的 epoch 数均为 5。
- 使用单机单卡时,Batch Size 设置为 64。使用双机单卡时,测试总 Batch Size 为 64(分发到单台机器的 Batch Size 为 32)和总 Batch Size 为 128(分发到单台机器的 Batch Size 为 64)两种情况。
- 模型训练的速度同样有大幅度的提高。在所有机器性能接近的情况下,训练时长与机器的数目接近于反比关系。
| 数据集 | 单机单卡(Batch Size 为 64) | 双机单卡(总 Batch Size 为 64) | 双机单卡(总 Batch Size 为 128) |
|---|---|---|---|
| cats_vs_dogs | 1622s | 858s | 755s |
| tf_flowers | 301s | 152s | 144s |
使用 TPU 训练 TensorFlow 模型

2017 年 5 月,Alpha Go 在中国乌镇围棋峰会上,与世界第一棋士柯洁比试,并取得了三比零全胜战绩。之后的版本 Alpha Zero 可以通过自我学习 21 天即可以达到胜过中国顶尖棋手柯洁的 Alpha Go Master 的水平。Alpha Go 背后的动力全部由 TPU 提供。
TPU 代表 Tensor Processing Unit (张量处理单元) ,是由谷歌在 2016 年 5 月发布的为机器学习而构建的定制集成电路(ASIC),并为 TensorFlow 量身定制。
早在 2015 年,谷歌大脑团队就成立了第一个 TPU 中心,为 Google Translation,Photos 和 Gmail 等产品提供支持。 为了使所有数据科学家和开发人员能够访问此技术,不久之后就发布了易于使用,可扩展且功能强大的基于云的 TPU,以便在 Google Cloud 上运行 TensorFlow 模型。
TPU 由多个计算核心(Tensor Core)组成,其中包括标量,矢量和矩阵单元(MXU)。TPU(张量处理单元)与 CPU(中央处理单元)和 GPU(图形处理单元)最重要的区别是:TPU 的硬件专为线性代数而设计,线性代数是深度学习的基石。在过去几年中,Google TPU 已经发布了 v1,v2,v3, v2 Pod, v3 Pod, Edge 等多个版本
在 Google Cloud TPU Pod 上可以仅用 8 分钟就能够完成 ResNet-50 模型的训练。TPU 比现代 GPU 和 CPU 快 15~30 倍。同时,TPU 还实现了比传统芯片更好的能耗效率,算力能耗比值提高了 30 倍至 80 倍。
使用TPU
- (1)免费TPU:最方便使用 TPU 的方法,就是使用 Google 的 Colab ,不但通过浏览器访问直接可以用,而且还免费。
- (2)Cloud TPU:在 Google Cloud 上,我们可以购买所需的 TPU 资源,用来按需进行机器学习训练。为了使用 Cloud TPU ,需要在 Google Cloud Engine 中启动 VM 并为 VM 请求 Cloud TPU 资源。请求完成后,VM 就可以直接访问分配给它专属的 Cloud TPU 了
TPU 上进行 TensorFlow 分布式训练的核心 API 是 tf.distribute.TPUStrategy ,可以简单几行代码就实现在 TPU 上的分布式训练,同时也可以很容易的迁移到 GPU 单机多卡、多机多卡的环境。
import os
import tensorflow as tf
if 'COLAB_TPU_ADDR' not in os.environ:
print('ERROR: Not connected to a TPU runtime')
else:
tpu_address = 'grpc://' + os.environ['COLAB_TPU_ADDR']
print ('TPU address is', tpu_address)
# 输出: TPU address is grpc://10.49.237.2:8470
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
Estimators
Estimators API用于分布式环境的训练模型的API。 可以导出模型进行大型数据集的分布式训练,并得到可以商用的模型。
使用tf.keras.estimator.model_to_estimator将模型转换为tf.estimator.Estimator对象,就可以使用tf.estimator API训练tf.keras.Model。 请参阅Creating Estimators from Keras models。
model = tf.keras.Sequential([layers.Dense(10,activation='softmax'),
layers.Dense(10,activation='softmax')])
model.compile(optimizer=tf.train.RMSPropOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# 把模型转换为Estimator
estimator = tf.keras.estimator.model_to_estimator(model)
- 注意:要检查Estimator的输入函数和查看数据时,请启用Eager Execution。
多GPU训练
- _tf.keras_模型可以使用tf.contrib.distribute.DistributionStrategy在多个GPU上训练。 此API在多个GPU上提供分布式训练,几乎不对现有代码进行任何更改。
- 目前,tf.contrib.distribute.MirroredStrategy是唯一受支持的分布式策略。 要将DistributionStrategy与Keras一起使用,请使用tf.keras.estimator.model_to_estimator将_tf.keras.Model_转换为_tf.estimator.Estimator_,然后训练Estimator。
TensorFlow Datasets
TensorFlow Datasets 是一个开箱即用的数据集集合,包含数十种常用的机器学习数据集。通过简单的几行代码即可将数据以 tf.data.Dataset 的格式载入。关于 tf.data.Dataset 的使用可参考 tf.data。
该工具是一个独立的 Python 包,可以通过:
pip install tensorflow-datasets
使用方法
- export HTTPS_PROXY=http://代理服务器IP:端口
tfds.load 方法返回一个 tf.data.Dataset 对象。部分重要的参数如下:
- as_supervised :若为 True,则根据数据集的特性,将数据集中的每行元素整理为有监督的二元组 (input, label) (即 “数据 + 标签”)形式,否则数据集中的每行元素为包含所有特征的字典。
- split:指定返回数据集的特定部分。若不指定,则返回整个数据集。一般有 tfds.Split.TRAIN (训练集)和 tfds.Split.TEST (测试集)选项。
import tensorflow as tf
import tensorflow_datasets as tfds
# MNIST、猫狗分类和 tf_flowers三个图像数据集
# 第一次载入特定数据集时,TensorFlow Datasets 会自动从云端下载数据集到本地,并显示下载进度。
dataset = tfds.load("mnist", split=tfds.Split.TRAIN, as_supervised=True)
dataset = tfds.load("cats_vs_dogs", split=tfds.Split.TRAIN, as_supervised=True)
dataset = tfds.load("tf_flowers", split=tfds.Split.TRAIN, as_supervised=True)
# 使用 TessorFlow Datasets 载入“tf_flowers”数据集
dataset = tfds.load("tf_flowers", split=tfds.Split.TRAIN, as_supervised=True)
# 对 dataset 进行大小调整、打散和分批次操作
dataset = dataset.map(lambda img, label: (tf.image.resize(img, [224, 224]) / 255.0, label)) \
.shuffle(1024) \
.batch(32)
# 迭代数据
for images, labels in dataset:
# 对images和labels进行操作
TF Hub 模型库
TF Hub 目的是为了更好的复用已训练好且经过充分验证的模型,可节省海量的训练时间和计算资源。这些预训练好的模型,可以进行直接部署,也可以进行迁移学习(Transfer Learning)。
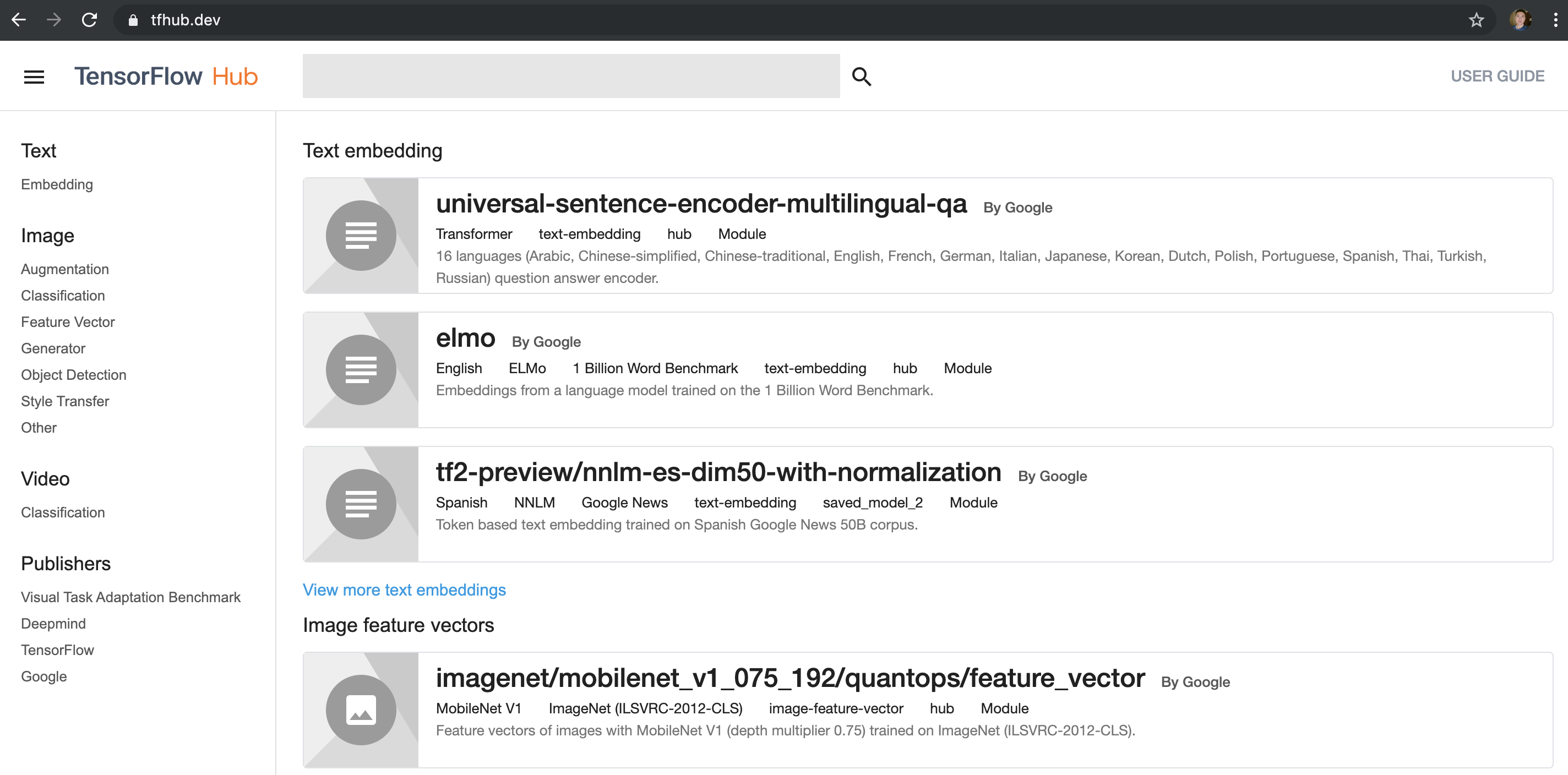
- 左侧有 Text、Image、Video 和 Publishers 等选项,可以选取关注的类别,然后在顶部的搜索框输入关键字可以搜索模型。 注意
- 目前还有很多模型是基于 TF1.0 的,选择的过程中请注意甄别,有些模型会明确写出来是试用哪个版本,或者,检查使用是否是 tfhub 0.5.0 或以上版本的 API hub.load(url) ,在之前版本使用的是 hub.Module(url) 。在 TF2.0 上,必须使用 0.5.0 或以上版本,因为接口有变动
- 如果不能访问 tfhub.dev,请大家转换域名到国内镜像 https://hub.tensorflow.google.cn/ ,模型下载地址也需要相应转换。
TF Hub 是单独的一个库,需要单独安装,安装命令如下:
pip install tensorflow-hub
直接使用模型
import tensorflow_hub as hub
hub_handle = 'https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2'
hub_model = hub.load(hub_handle)
outputs = hub_model(inputs)
图片风格化完整示例
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
def crop_center(image):
"""Returns a cropped square image."""
shape = image.shape
new_shape = min(shape[1], shape[2])
offset_y = max(shape[1] - shape[2], 0) // 2
offset_x = max(shape[2] - shape[1], 0) // 2
image = tf.image.crop_to_bounding_box(image, offset_y, offset_x, new_shape, new_shape)
return image
def load_image_local(image_path, image_size=(512, 512), preserve_aspect_ratio=True):
"""Loads and preprocesses images."""
# Load and convert to float32 numpy array, add batch dimension, and normalize to range [0, 1].
img = plt.imread(image_path).astype(np.float32)[np.newaxis, ...]
if img.max() > 1.0:
img = img / 255.
if len(img.shape) == 3:
img = tf.stack([img, img, img], axis=-1)
img = crop_center(img)
img = tf.image.resize(img, image_size, preserve_aspect_ratio=True)
return img
def show_image(image, title, save=False, fig_dpi=300):
plt.imshow(image, aspect='equal')
plt.axis('off')
if save:
plt.savefig(title + '.png', bbox_inches='tight', dpi=fig_dpi,pad_inches=0.0)
else:
plt.show()
content_image_path = "images/contentimg.jpeg"
style_image_path = "images/styleimg.jpeg"
content_image = load_image_local(content_image_path)
style_image = load_image_local(style_image_path)
show_image(content_image[0], "Content Image")
show_image(style_image[0], "Style Image")
# Load image stylization module. 把 TF Hub 的模型从网络下载和加载进来
hub_module = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2');
# Stylize image. 运行模型
outputs = hub_module(tf.constant(content_image), tf.constant(style_image))
stylized_image = outputs[0]
show_image(stylized_image[0], "Stylized Image", True)
输入的图像是一张笔者拍的风景照片,风格图片是故宫馆藏的《王希孟千里江山图卷》部分截屏。
| 原图 | 风格 | 效果 |
|---|---|---|
 |
 |
 |
- github代码体验
- Google colab代码体验
retrain模型 finetune
预预训练的模型不一定满足开发者的实际诉求,还需要进行二次训练。针对这种情况,TF Hub 提供了很方便的 Keras 接口 hub.KerasLayer(url) ,其可以封装在 Keras 的 Sequential 层状结构中,进而可以针对开发者的需求和数据进行再训练。
以 inception_v3 的模型为例,简单介绍 hub.KerasLayer(url) 使用的方法
import tensorflow as tf
import tensorflow_hub as hub
num_classes = 10
# 使用 hub.KerasLayer 组件待训练模型
new_model = tf.keras.Sequential([
hub.KerasLayer("https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/4", output_shape=[2048], trainable=False),
tf.keras.layers.Dense(num_classes, activation='softmax')
])
new_model.build([None, 299, 299, 3])
# 输出模型结构, keras_layer就是从 TF Hub 上获取的模型
new_model.summary()
# Model: "sequential"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# keras_layer (KerasLayer) multiple 21802784
# _________________________________________________________________
# dense (Dense) multiple 20490
# =================================================================
# Total params: 21,823,274
# Trainable params: 20,490
# Non-trainable params: 21,802,784
# _________________________________________________________________
设备检测
检测是否安装GPU版本:
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
#[name: "/device:CPU:0"
# device_type: "CPU"
# memory_limit: 268435456
# locality {
#}
# incarnation: 1937408177159318398
#]
如果是GPU版本的话,应该会有这样的一段

- 卸载:pip uninstall tensorflow
- 安装:pip install tensorflow-gpu==版本号
代码
import tensorflow as tf
# cpu版tf提示错误:
# 2021-11-18 11:22:03.396212: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: ~/anaconda3/envs/py3/lib:~/anaconda3/lib:~/anaconda3/lib:~/anaconda3/lib:
# 2021-11-18 11:22:03.396264: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
tf.debugging.set_log_device_placement(True) # 设置输出运算所在的设备
cpus = tf.config.list_physical_devices('CPU') # 获取当前设备的 CPU 列表
tf.config.set_visible_devices(cpus) # 设置 TensorFlow 的可见设备范围为 cpu
2021最新:TensorFlow各个GPU版本CUDA和cuDNN对应版本整理(最简洁)
新特性
【2021-3-15】机器学习:TensorFlow 2.0中的10个技巧
- 数据流构建:输入管道的tf.data API和ImageDataGenerator实时生成数据集切片
- tf.image进行数据增强
- TensorFlow数据集工具包:pip install tensorflow-datasets
- 预训练的模型进行迁移学习
- Estimators是TensorFlow完整模型的高级表示,内置的estimators提供了非常高级的模型抽象,其设计目的是易于缩放和异步训练
- 自定义层:神经网络是已知的多层网络,其中的层可以是不同的类型。TensorFlow包含许多预定义层(例如Dense,LSTM等)。但是对于更复杂的架构,层的逻辑可能会复杂得多。TensorFlow允许构建自定义层,这可以通过对tf.keras.layers.Layer类进行子类化来完成
- 定制训练:tf.keras序列和模型API使训练模型更容易。但是,大多数时候在训练复杂模型时会使用自定义损失函数。此外,模型训练也可以不同于缺省值
- 检查点:保存TensorFlow模型可以有两种类型:①SavedModel:保存模型的完整状态以及所有参数。model.save_weights(‘checkpoint’)②检查点(Checkpoints)
- Keras Tuner:TensorFlow中的一个相当新的功能。超参数调优是挑选参数的过程,这些参数定义了机器学习模型的配置,除了HyperBand, BayesianOptimization和RandomSearch也可用于调优。利用最优超参数对模型进行训练
- 分布式训练:如果有多个GPU,并希望通过将训练分散在多个GPU上来优化训练,TensorFlow的各种分布式训练策略能够优化GPU的使用
新旧版兼容
Tensorflow新旧版本兼容
TensorFlow 2 提供了 tf.compat.v1 模块以支持 TensorFlow 1.X 版本的 API。原来静态图代码升级,引入:
- 旧版:import tensorflow as tf
- ① 新版(用工具):TensorFlow 2.0中提供了命令行迁移工具,来自动的把1.x的代码转换为2.0的代码
- tf_upgrade_v2 –infile first-tf.py –outfile first-tf-v2.py
- ② 新版(加代码):适合稳定使用中、并且没有重构意愿的代码
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
- 参考:tensorflow兼容处理 tensorflow.compat.v1
- 注意
- Keras 的模型是同时兼容
即时执行模式和图执行模式的。 - 在图执行模式下, model(input_tensor) 只需运行一次以完成图的建立操作。
- 张量以数组的方式依次存放起来, 可以使用list,但不适用于计算图特性(模型加速/SavedModel模型导出),TensorFlow 提供了 tf.TensorArray ,一种支持计算图特性的 TensorFlow 动态数组
- Keras 的模型是同时兼容
- 问题
- ‘Tensor’ object has no attribute ‘numpy’处理方法
- 开启即时模式
tf.enable_eager_execution(
config=None,
device_policy=None,
execution_mode=None
)
CNN分类
CNN网络
- 卷积神经网络 (Convolutional Neural Network, CNN)是一种结构类似于人类或动物的 视觉系统 的人工神经网络,包含一个或多个卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully-connected Layer)
代码
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs) # [batch_size, 28, 28, 32]
x = self.pool1(x) # [batch_size, 14, 14, 32]
x = self.conv2(x) # [batch_size, 14, 14, 64]
x = self.pool2(x) # [batch_size, 7, 7, 64]
x = self.flatten(x) # [batch_size, 7 * 7 * 64]
x = self.dense1(x) # [batch_size, 1024]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
