推理加速

英伟达最新季度财报中,180亿美元数据中心收入,AI推理已占四成。
推理逐渐成为大模型进程,尤其是落地进程中的主旋律。
LLM 部署
gpu
LLM 部署离不开GPU,对于gpu型号有一定要求
cpu
GPU及专用加速芯片一统AI训练天下时,CPU在推理,包括大模型推理这件事上似乎辟出了一条“蹊径”
大模型训练阶段用GPU,但推理阶段,果断把CPU加到菜单上
Hugging Face 官方优化教程中,数篇文章剑指: 如何用CPU高效推理大模型?
- CPU inference 上,提供
- BetterTransformer 推理加速,pytorch代码转torchscript
- Intel CPU: 使用 pytorch intel扩展里的 graph-optimization
- Optimum: ONNX Runtime/OpenVINO 上 cpu 推理
- CPU加速推理方法,涵盖的不只是大语言模型,还涉及图像、音频等形式的多模态大模型
主流框架和库,例如TensorFlow和PyTorch等,也一直在不断优化,提供针对CPU的优化、高效推理版本。
英特尔CEO帕特·基辛格2023年底:
- “从经济学角度看推理应用,我不会打造一个需要花费四万美元的全是
H100的后台环境,因为它耗电太多,并且需要构建新的管理和安全模型,以及新的IT基础设施。”- “如果我能在标准版的英特尔芯片上运行这些模型,就不会出现这些问题。”
京东云推出搭载第五代英特尔® 至强® 可扩展处理器的新一代服务器
- 与相同内置AI加速技术(AMX,高级矩阵扩展)的前一代(第四代至强® 可扩展处理器)相比,深度学习实时推理性能提升高达42%;
- 与内置上一代AI加速技术(DL-Boost,深度学习加速)、隔辈儿(第三代至强® 可扩展处理器)相比,AI推理性能更是最高提升至14倍。
英特尔® 至强® 内置AI加速器经历的两个阶段
- 矢量运算优化
- 2017年第一代至强® 可扩展处理器引入高级矢量扩展 512(英特尔® AVX-512)指令集开始,让矢量运算利用单条CPU指令就能执行多个数据运算。
- 再到第二、三代的矢量神经网络指令 (VNNI,是DL-Boost的核心),进一步把乘积累加运算的三条单独指令合并,进一步提升计算资源的利用率,同时更好地利用高速缓存,避免了潜在的带宽瓶颈。
- 矩阵运算优化
- 第四代至强® 可扩展处理器开始,内置AI加速技术的主角换成了英特尔® 高级矩阵扩展(英特尔® AMX)。它特别针对深度学习模型最常见的矩阵乘法运算优化,支持BF16(训练/推理)和INT8(推理)等常见数据类型。

英特尔也深入与主流大模型如Llama 2、Baichuan、Qwen等深度合作,以英特尔® Extension for Transformer工具包为例,它就能让大模型推理性能加速达40倍。
京东与英特尔联合定制优化的第五代英特尔® 至强® 可扩展处理器的Llama2-13B推理性能(Token 生成速度)提升了 51%,足以满足问答、客服和文档总结等多种AI场景的需求场景。
- CPU内置AI加速器发展到现在,用于推理已能保证在性能上足够应对实战需求了。
- CPU做AI推理,也存在CPU与生俱来的优势,例如成本,还有更为重要的——部署和实践的效率。
【2024-3-27】拿CPU搞AI推理,谁给你的底气?
部署框架
【2024-11-16】如何选择 LLM 部署框架
LLM 推理部署的生态有很多开源框架,例如: vLLM、LMDeploy、TGI
选择依据
- 模型是否支持:优先从已支持的框架中选择
- 现在的模型结构相对统一,所以如果想要在某个框架中支持,难度也不会特别大。
- 框架生态的活跃度:例如 vLLM、LMDeploy 的生态就很活跃,框架一直持续添加新功能以及支持新的模型
- 框架的服务稳定性:基础要求,即模型部署好之后,能否稳定地处理用户的请求,而不会时常报错,例如 OOM、Segmentation fault 等
- 框架性能的评价指标:例如首 token 延迟(Time to First Token, TTFT)、每秒处理的 token 数(Tokens Per Second, TPS)等
评价指标
评价框架性能的常用指标:
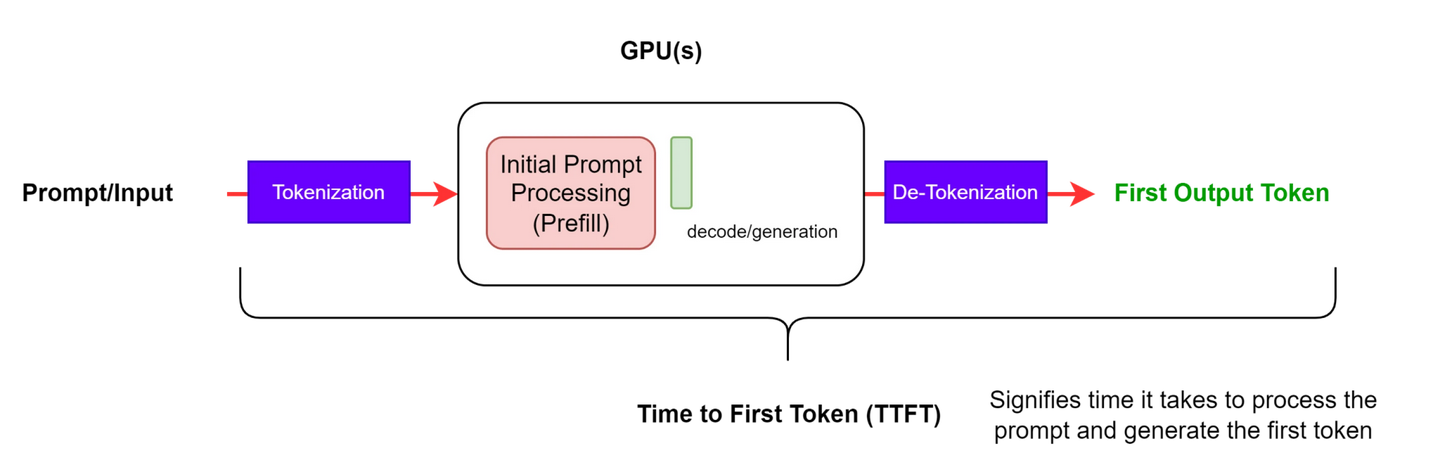
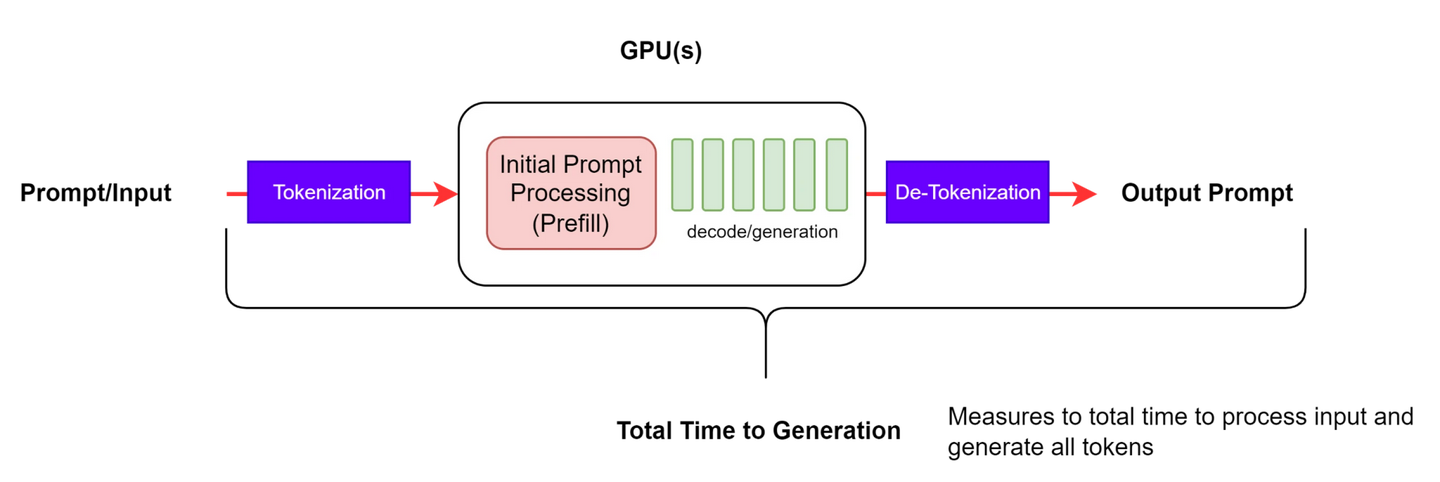
TTFT(Time to First Token):首 token 延迟,即用户发出请求后看到第一个 token 被输出的时间,如图 1 所示:E2EL(End-to-End Request Latency):用户发出请求并得到完整回复的延迟,如图 2 所示:ITL(Inter-token Latency):非首 token 延迟,也称为 TPOT (Time Per Output Token),如图 3 所示: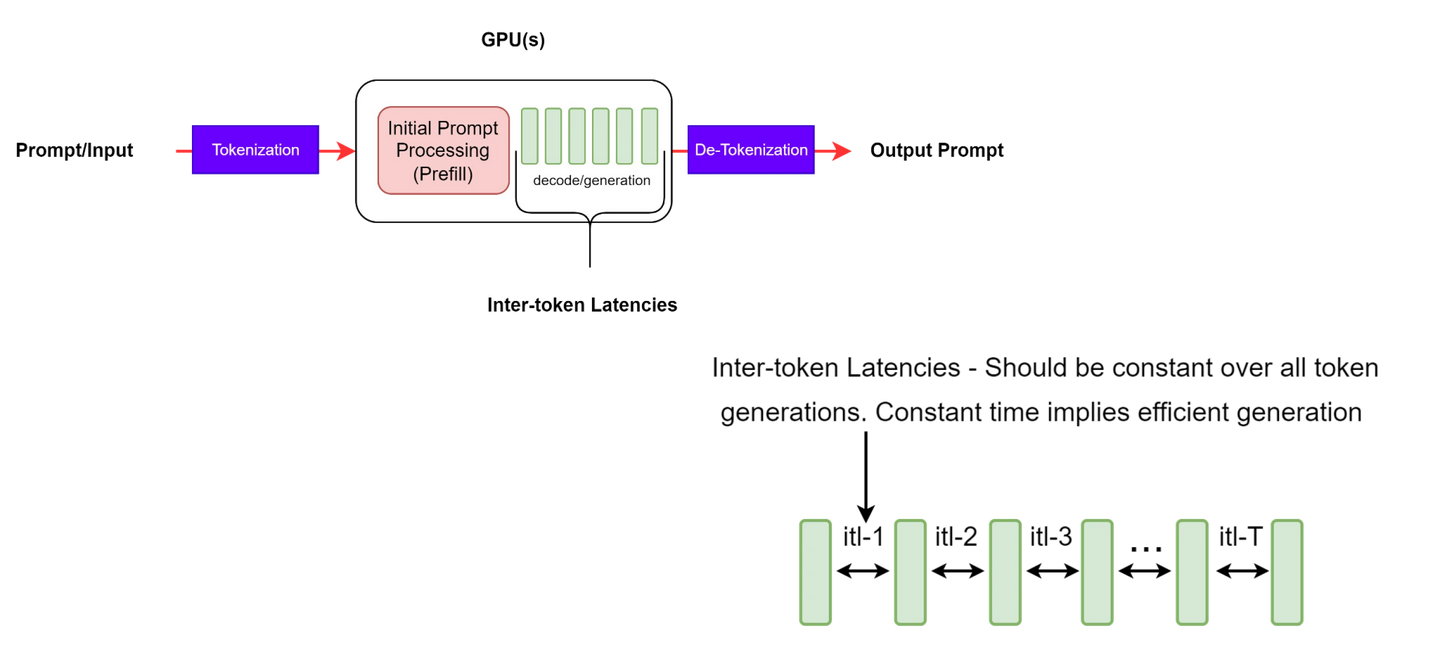
- 计算公式是
- 注意: 实际评测时,ITL 和 TPOT 的计算方式会有些许差别。
TPS(Tokens Per Second):每秒处理 token 数。在介绍如何计算 TPS 前,先简单介绍计算涉及的参数,如图 4 所示:
- T_start 表示 benchmark 开始的时间,T_end 表示 benchmark 结束的时间,Tx 表示第一个请求发出的时间,Ty 表示最后一个请求处理结束的时间,Li 表示第 i 个请求的 e2e_latency。
- 定义好参数后,TPS 的计算公式是
RPS(Requests Per Second):每秒处理请求数。计算公式是
评测指南
- 见原文 如何选择 LLM 部署框架
ONNX
- 【2022-5-17】ONNX 和 Azure 机器学习:创建和加速 ML 模型
- 【2022-6-9】ONNX推理加速技术文档
- 【2022-2-23】贝壳,onnxruntime优化过后的bert模型,cpu推理延迟能从300ms降到100ms以内
推理或模型评分是将部署的模型用于预测(通常针对生产数据)的阶段,ONNX 来帮助优化机器学习模型的推理
pytorch 怎么使用c++调用部署模型?参考
- PyTorch模型 –>
ONNX格式–> C++推理框架
onnx 介绍
开放神经网络交换(Open Neural Network Exchange) ONNX 是微软和Facebook提出,用来表示深度学习模型的开放格式。
- ONNX定义了一组和环境平台均无关的标准格式,来增强各种AI模型的可交互性。
- 优化用于推理(或模型评分)的机器学习模型非常困难,因为需要调整模型和推理库,充分利用硬件功能。 在不同类型的平台(云/Edge、CPU/GPU 等)上获得最佳性能,异常困难,因为每个平台都有不同的功能和特性。 如果模型来自需要在各种平台上运行的多种框架,会极大增加复杂性。 优化框架和硬件的所有不同组合非常耗时。
ONNX就是解决方法,在首选框架中训练一次后能在云或 Edge 上的任意位置运行。
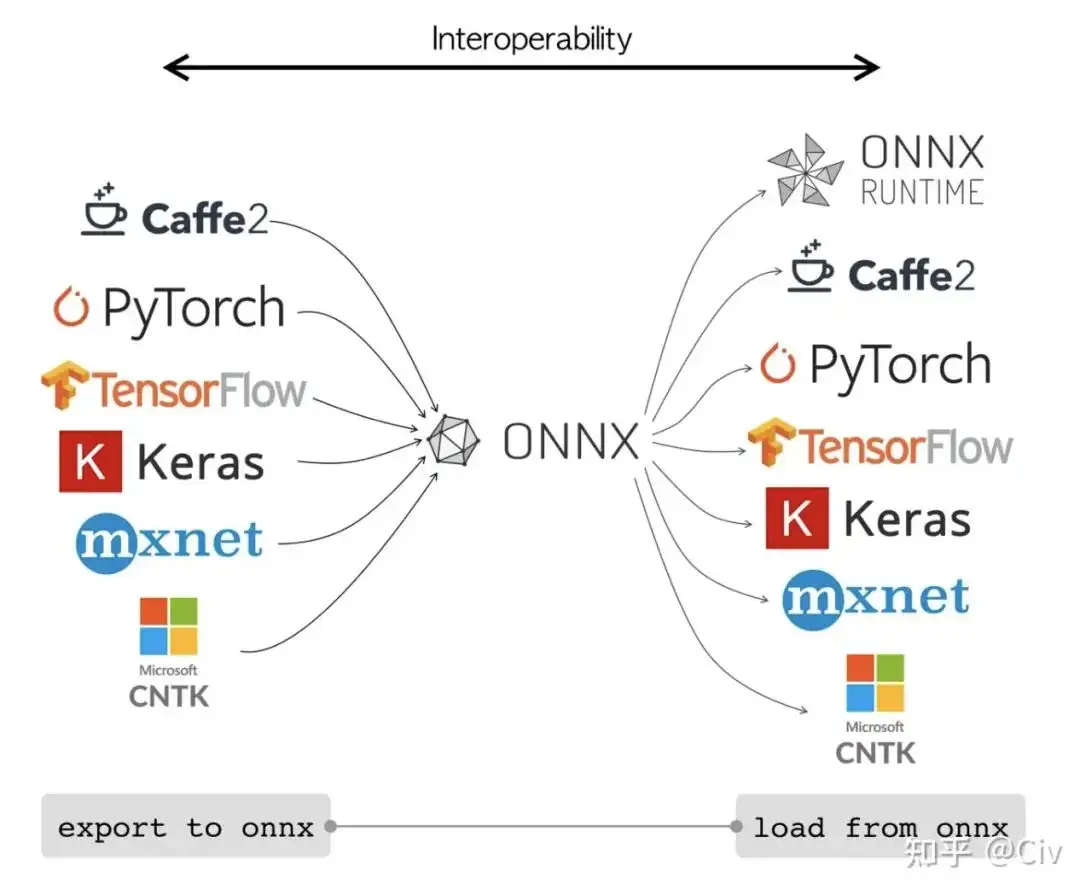
许多框架中的模型都可以导出或转换为标准 ONNX 格式。 模型采用 ONNX 格式后,可在各种平台和设备上运行。
- 各种平台包括 TensorFlow、PyTorch、SciKit-Learn、Keras、Chainer、MXNet、MATLAB 和 SparkML ONNX 运行时是一种用于将 ONNX 模型部署到生产环境的高性能推理引擎。 它针对云和 Edge 进行了优化,适用于 Linux、Windows 和 Mac。
- ONNX文件不仅仅存储了神经网络模型的权重(Protobuf格式),同时也存储了模型的结构信息以及网络中每一层的输入输出和一些其它的辅助信息。
- 用 C++ 编写,还包含 C、Python、C#、Java 和 JavaScript (Node.js) API,可在各种环境中使用。
- ONNX 运行时同时支持 DNN 和传统 ML 模型,并与不同硬件上的加速器(例如,NVidia GPU 上的
TensorRT、Intel 处理器上的OpenVINO、Windows 上的DirectML等)集成。 通过使用 ONNX 运行时,可以从大量的生产级优化、测试和不断改进中受益。 
onnx 可视化
netron
netron 库 可视化导出的静态模型和动态模型
- netron online 在线体验
- 源码 server.py
yolov3-tiny的onnx模型,Netron可视化
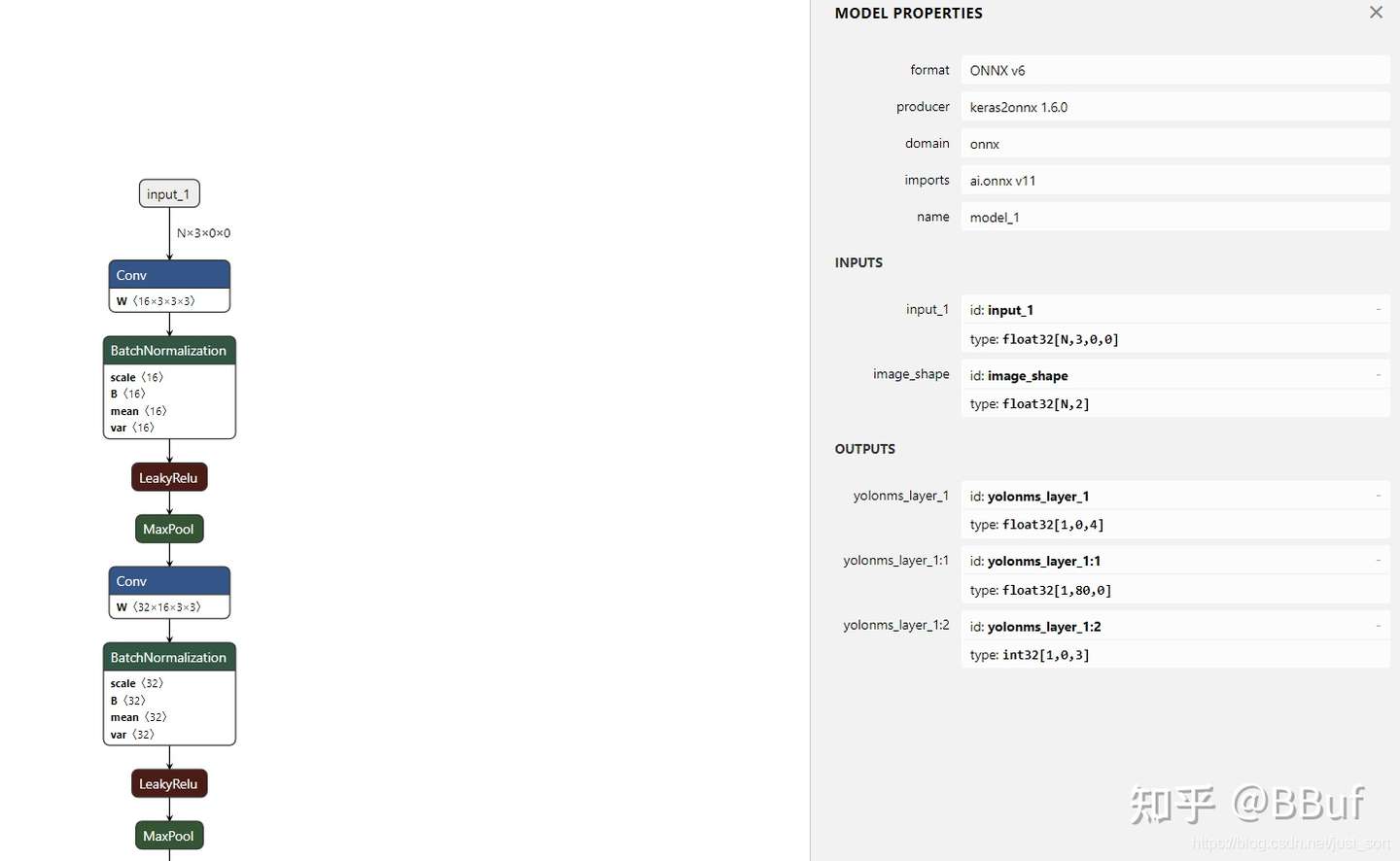
更多使用方法见: ONNX学习笔记
代码如下:
import netron
model_name = './Dynamics_InputNet.onnx'
netron.start(model_name)
netron.start(model_name, browse=False, host='0.0.0.0', port=9000)
onnx 直接推理
onnx文件可直接进行推理,这时的代码就已经与框架无关,可与训练阶段解耦。
但是,为了推理的顺利进行,依然需要为onnx选择一个后端,以TensorFlow为例。
onnx tensorflow
import onnx
import tensorflow as tf
from onnx_tf.backend import prepare
import onnx_tf...# 包装一个TF后端
predictor = onnx.load(onnx_path)
onnx.checker.check_model(predictor)
onnx.helper.printable_graph(predictor.graph)
tf_rep = prepare(predictor, device="CUDA:0") # default CPU
# 使用TF进行预测
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.7) # defalut 0.5
tfconfig = tf.ConfigProto(allow_soft_placement=True, gpu_options=gpu_options)...
with tf.Session(config=tfconfig) as persisted_sess:
persisted_sess.graph.as_default()
tf.import_graph_def(tf_rep.graph.as_graph_def(), name='')
tf_input = persisted_sess.graph.get_tensor_by_name(
tf_rep.tensor_dict[tf_rep.inputs[0]].name
)
tf_scores = persisted_sess.graph.get_tensor_by_name(
tf_rep.tensor_dict[tf_rep.outputs[0]].name
)
tf_boxes = persisted_sess.graph.get_tensor_by_name(
tf_rep.tensor_dict[tf_rep.outputs[1]].name
)
for file_path in listdir:
...
confidences, boxes = persisted_sess.run([tf_scores, tf_boxes], {tf_input: image})
...
onnxruntime 加速推理
如何更高效地使用onnx?
onnxruntime 介绍
ONNX Runtime 针对 ONNX 模型,以性能为中心的引擎,多个平台和硬件高效地进行推理。
- Windows,Linux 和 Mac 以及 CPU 和 GPU 上
- ONNX Runtime 可大大提高多个模型性能。
onnxruntime 对 onnx 模型提供推理加速,支持CPU、GPU加速
- GPU加速版本为
onnxruntime-gpu - 默认版本为CPU加速。
人脸检测 ULFD 模型上
- 未用 onnxruntime 加速,对于320x240分辨率的图片,在CPU上需要跑要50~60ms;
- 使用 onnxruntime 加速,在CPU需要 8~11ms.
安装
安装:
pip install onnxruntime # CPU
pip install onnxruntime-gpu # GPU
加载 onnx
加载 ONNX 格式
- 通过 onnxruntime 的
InferenceSession加载模型; - 通过
session.run()的调用运行 会话 session; - ONNX 模型通过 session 定义和调用运行。
代码示例:
import onnx
import onnxruntime
# 加载ONNX文件
onnx_model = onnx.load("model.onnx")
# 将ONNX文件转化为ORT格式
ort_session = onnxruntime.InferenceSession("model.onnx")
# 输入数据
input_data = np.random.random(size=(1, 3)).astype(np.float32)
# 运行模型
outputs = ort_session.run(None, {"input": input_data})
# 输出结果
print(outputs)
注意
- 要安装
onnx和onnxruntime两个Python包。 - 此外,还要用
numpy等其他常用的科学计算库
使用
使用 onnxruntime 对 onnx 模型加速只需要几行代码
import onnxruntime as ort
class NLFDOnnxCpuInferBase:
"""only support in CPU and accelerate with onnxruntime."""
__metaclass__ = ABCMeta
...
def __init__(self, onnx_path=ONNX_PATH):
"""
pytorch和onnx可以很好地结合
:param onnx_path: .onnx文件路径
"""
self._onnx_path = onnx_path
# 使用onnx模型初始化ort的session
self._ort_session = ort.InferenceSession(self._onnx_path)
self._input_img = self._ort_session.get_inputs()[0].name
...
# 使用run推理
def _detect_img_utils(self, img: np.ndarray):
"""batch is ok."""
feed_dict = {self._input_img: img}
scores_before_nms, rois_before_nms = self._ort_session.run(None,input_feed=feed_dict)
return rois_before_nms, scores_before_nms
onnxruntime 自动检查onnx中无关节点, 并删除,也利用了一些加速库优化推理图,从而加速推理。
python3 inference/ulfd/onnx_cpu_infer.py
# 2020-01-16 12:03:49.259044 [W:onnxruntime:, graph.cc:2412 CleanUnusedInitializers] Removing initializer 'base_net.9.4.num_batches_tracked'. It is not used by any node and should be removed from the model.
# 2020-01-16 12:03:49.259478 [W:onnxruntime:, graph.cc:2412 CleanUnusedInitializers] Removing initializer 'base_net.9.1.num_batches_tracked'. It is not used by any node and should be removed from the model.
# 2020-01-16 12:03:49.259492 [W:onnxruntime:, graph.cc:2412 CleanUnusedInitializers] Removing initializer 'base_net.8.4.num_batches_tracked'. It is not used by any node and should be removed from the model.
# 2020-01-16 12:03:49.259501 [W:onnxruntime:, graph.cc:2412 CleanUnusedInitializers] Removing initializer 'base_net.8.1.num_batches_tracked'. It is not used by any node and should be removed from the model.
完整示例
import numpy as np
import onnx
import onnxruntime
if __name__ == "__main__":
input_data1 = np.random.rand(4, 3, 256, 256).astype(np.float32)
input_data2 = np.random.rand(8, 3, 512, 512).astype(np.float32)
# 导入 Onnx 模型
Onnx_file = "./Dynamics_InputNet.onnx"
Model = onnx.load(Onnx_file)
onnx.checker.check_model(Model) # 验证 Onnx 模型是否准确
# 使用 onnxruntime 推理
model = onnxruntime.InferenceSession(Onnx_file, providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'])
input_name = model.get_inputs()[0].name
output_name = model.get_outputs()[0].name
output1 = model.run([output_name], {input_name:input_data1})
output2 = model.run([output_name], {input_name:input_data2})
print('output1.shape: ', np.squeeze(np.array(output1), 0).shape)
print('output2.shape: ', np.squeeze(np.array(output2), 0).shape)
实践案例
from transformers import AutoTokenizer
from onnxruntime import GraphOptimizationLevel, InferenceSession, SessionOptions, get_available_providers
import onnxruntime as ort
import numpy as np
def create_model_for_provider(model_path: str, provider: str) -> InferenceSession:
# assert provider in get_available_providers(), f"provider {provider} not found, {get_available_providers()}"
# Few properties that might have an impact on performances (provided by MS)
options = SessionOptions()
logging.info("provider is " + str(provider))
# options.intra_op_num_threads = intra_op_num_threads
options.intra_op_num_threads = 1
options.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL
options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
options.enable_profiling = False # 如果是True,则会打印输出
# options.enable_cpu_mem_arena = False
# options.enable_mem_pattern = False
# Load the model as a graph and prepare the CPU backend
session = InferenceSession(model_path, options, providers=[provider])
session.set_providers(['CUDAExecutionProvider'])
# session.disable_fallback()
return session
class Classifier(object):
"""
加载分类模型
"""
def __init__(self):
self.model = None
self.tokenizer = None
def model_init(self):
self.model = create_model_for_provider(config.model_path, "CUDAExecutionProvider")
self.tokenizer = AutoTokenizer.from_pretrained(config.model_dir)
self.tokenizer.truncation_side = "right"
self.tokenizer.padding_side = "right"
# 预热 warm model
model_inputs = self.tokenizer(['这是一条测试文本'], padding=True, return_tensors="pt")
inputs_onnx = {k: v.cpu().detach().numpy() for k, v in model_inputs.items() if k != "token_type_ids"}
self.model.run(None, inputs_onnx)
logging.info("model load finish and test data run success!")
问题
Module onnx is not installed
【2024-7-30】 报错
torch.onnx.errors.OnnxExporterError: Module onnx is not installed!
原因
- 未安装 onnx
解法
pip install onnx
ONNXRuntimeError Load model from …
【2024-8-1】onnxruntime 加载 onnx 模型时报错
onnxruntime.capi.onnxruntime_pybind11_state.Fail: [ONNXRuntimeError] : 1 : FAIL : Load model from /mnt/bn/flow-algo-intl/wangqiwen/change_query_service/model/bert.onnx failed:/onnxruntime_src/onnxruntime/core/graph/model_load_utils.h:47 void onnxruntime::model_load_utils::ValidateOpsetForDomain(const std::unordered_map<std::basic_string<char>, int>&, const onnxruntime::logging::Logger&, bool, const string&, int) ONNX Runtime only *guarantees* support for models stamped with official released onnx opset versions. Opset 17 is under development and support for this is limited. The operator schemas and or other functionality may change before next ONNX release and in this case ONNX Runtime will not guarantee backward compatibility. Current official support for domain ai.onnx is till opset 15.
onnx 模型不匹配
- 可能是转换 gpu, 但是推理 cpu
- 也可能版本不兼容导致
因此
- 卸载cpu版本,重新安装gpu版本 或者 升级gpu版本
pip uninstall onnxruntime-gpu
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnxruntime-gpu
onnxruntime: cannot import name GraphOptimizationLevel
【2024-8-1】 踩坑: gpu 上生成 onnx 模型, 在 gpu 上推理
错误
CUDAExecutionProvider
ImportError: cannot import name 'GraphOptimizationLevel' from 'onnxruntime' (unknown location)
ONNXRuntime 与 CUDA版本对应
- cuda 12.2 版本对应 1.17
#pip install onnxruntime-gpu==1.18.0
pip install onnxruntime-gpu==1.17.0
模型文件转换
ONNX的目的是“通用”,所以难免出现算子不兼容的情况。
- 当把某个框架(例如PyTorch)的模型转成ONNX后,再将ONNX转成另一框架模型(例如ncnn)时,可能会报错(xxx算子不支持)。
解决方法:
- 使用 ONNXSIM 对 ONNX模型 进行精简,非常有效。
- 建议:只要使用了ONNX,都用ONNXSIM对ONNX模型进行处理一次。Github地址。使用非常方便,使用“pip install onnxsim”安装,然后使用命令“onnxsim input_onnx_model_path output_onnx_model_path”即可。代码中调用也很简单,参考Git地址里的示例。
- 避免依赖于中间变量的尺寸来进行运算。
- 在一些Image to Image的任务中,可能会根据中间tensor的尺寸来对另一些tensor进行resize。这时我们的做法是先去获取中间tensor的尺寸H、W,然后将它们作为参数送给其它方法。当遇到这种运算时,ONNX似乎会创建两个与H、W相关的变量,但它们的值会绑定为用dummy_input去forward一次时得到的H、W。这个值一旦绑定就不会改变。所以后续当使用不同尺寸输入时极大概率会报错(这点没有仔细验证过,但看中间结果很像是这种情况)。
- 另外, 强烈建议使用一些网络可视化工具。当遇到模型转换报错时可以用来方便定位出错的位置。个人比较喜欢的是netron
1.1 pth文件(Pytorch)转onnx
pytorch 集成了 onnx模块,属于官方支持,onnx 也覆盖了pytorch框架中的大部分算子。
因此将pth模型文件转换为onnx文件简单。
import torch
# 指定输入尺寸,ONNX需要这个信息来确定输入大小
# 参数对应于 (batch_size, channels, H, W)
dummy_input = torch.randn(1, 3, 224, 224, device="cuda")
# model为模型自身
# dummy_input根据自己的需求更改其尺寸
# "model.onnx"为输出文件,更改为自己的路径即可
torch.onnx.export(model, dummy_input, "model.onnx")
注意
- 转换前,要对pth模型的输入size进行冻结。
batch_size = 1
dummy_input = torch.randn(batch_size, 3, 240, 320).to(device)
输入一旦冻结后,就只会有固定的batch_size,在使用转换后的onnx文件进行模型推理时,推理时输入的batch_size必须和冻结时保持一致。对于这个示例,你只能batch_size=1进行推理。如果你需要在推理时采用不同的batch_size,比如10,你只能在保存onnx模型之前修改冻结的输入节点,代码如下:
batch_size = 10
dummy_input = torch.randn(batch_size, 3, 240, 320).to(device)
这样就拥有了一个bacth_size=10的onnx模型。
导出onnx文件,只需要使用torch.onnx.export()函数,代码如下:
model_name = model_path.split("/")[-1].split(".")[0]
model_path = f"inference/ulfd/onnx/{model_name}-batch-{batch_size}.onnx"
dummy_input = torch.randn(batch_size, 3, 240, 320).to(device)
# dummy_input = torch.randn(1, 3, 480, 640).to("cuda") #if input size is 640*480
torch.onnx.export(net, dummy_input, model_path,
verbose=False, input_names=['input'],
output_names=['scores', 'boxes'])
完整转换代码:
# -*- coding: utf-8 -*-
"""This code is used to convert the pytorch model into an onnx format model."""
import argparse
import sys
import torch.onnx
from models.ulfd.lib.ssd.config.fd_config import define_img_size
input_img_size = 320 # define input size ,default optional(128/160/320/480/640/1280)
define_img_size(input_img_size)
from models.ulfd.lib.ssd.mb_tiny_RFB_fd import create_Mb_Tiny_RFB_fd
from models.ulfd.lib.ssd.mb_tiny_fd import create_mb_tiny_fd
def get_args():
parser = argparse.ArgumentParser(description='convert model to onnx')
parser.add_argument("--net", dest='net_type', default="RFB",
type=str, help='net type.')
parser.add_argument('--batch', dest='batch_size', default=1,
type=int, help='batch size for input.')
args_ = parser.parse_args()
return args_if __name__ == '__main__':
# net_type = "slim" # inference faster,lower precision
args = get_args()
net_type = args.net_type # inference lower,higher precision
batch_size = args.batch_size
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
label_path = "models/ulfd/voc-model-labels.txt"
class_names = [name.strip() for name in open(label_path).readlines()]
num_classes = len(class_names)
if net_type == 'slim':
model_path = "baseline/ulfd/version-slim-320.pth"
# model_path = "models/pretrained/version-slim-640.pth"
net = create_mb_tiny_fd(len(class_names), is_test=True, device=device)
elif net_type == 'RFB':
model_path = "baseline/ulfd/version-RFB-320.pth"
# model_path = "models/pretrained/version-RFB-640.pth"
net = create_Mb_Tiny_RFB_fd(len(class_names), is_test=True, device=device)
else:
print("unsupport network type.")
sys.exit(1)
net.load(model_path)
net.eval()
net.to(device)
model_name = model_path.split("/")[-1].split(".")[0]
model_path = f"inference/ulfd/onnx/{model_name}-batch-{batch_size}.onnx"
dummy_input = torch.randn(batch_size, 3, 240, 320).to(device)
# dummy_input = torch.randn(1, 3, 480, 640).to("cuda") #if input size is 640*480
torch.onnx.export(net, dummy_input, model_path,
verbose=False, input_names=['input'],
output_names=['scores', 'boxes'])
print('onnx model saved ', model_path)
""" PYTHONPATH=. python3 inference/ulfd/pth_to_onnx.py --net RFB --batch 16 PYTHONPATH=. python inference/ulfd/pth_to_onnx.py --net RFB --batch 3 """
静态+动态
Pytorch 将网络导出为 Onnx 模型格式时,可导出为动态输入和静态输入两种方式。
- 动态输入: 模型输入数据的部分维度是动态的,可由用户使用模型时自主设定;
- 静态输入: 模型输入数据的维度是静态的,不能够改变,当用户使用模型时只能输入指定维度的数据进行推理。
显然,动态输入的通用性比静态输入更强。
转化方法如下:
import torch
import torch.onnx
# 将模型保存为.bin文件
model = torch.nn.Linear(3, 1)
torch.save(model.state_dict(), "model.bin")
# torch.save(model.state_dict(), "model.pt")
# torch.save(model.state_dict(), "model.pth")
# 将.bin文件转化为ONNX格式
model = torch.nn.Linear(3, 1)
model.load_state_dict(torch.load("model.bin"))
# model.load_state_dict(torch.load("model.pt"))
# model.load_state_dict(torch.load("model.pth"))
example_input = torch.randn(1, 3)
torch.onnx.export(model, example_input, "model.onnx", input_names=["input"], output_name
通过 torch.onnx.export() 的 dynamic_axes 参数来指定动态输入和静态输入, dynamic_axes 默认值为 None,即默认为静态输入。
通过定义 dynamic_axes 参数设置动态导出输入。
- dynamic_axes 中的 0、2、3 表示相应维度设置为动态值;
# 导出为动态输入
input_name = 'input'
output_name = 'output'
torch.onnx.export(model,
input_data,
"Dynamics_InputNet.onnx",
opset_version=11,
input_names=[input_name],
output_names=[output_name],
dynamic_axes={
input_name: {0: 'batch_size', 2: 'input_height', 3: 'input_width'},
output_name: {0: 'batch_size', 2: 'output_height', 3: 'output_width'}
}
)
完整代码示例
import torch
import torch.nn as nn
class Model_Net(nn.Module):
def __init__(self):
super(Model_Net, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
)
def forward(self, data):
data = self.layer1(data)
return data
if __name__ == "__main__":
# 设置输入参数
Batch_size = 8
Channel = 3
Height = 256
Width = 256
input_data = torch.rand((Batch_size, Channel, Height, Width))
# 实例化模型
model = Model_Net()
# 导出为静态输入
input_name = 'input'
output_name = 'output'
torch.onnx.export(model,
input_data,
"Static_InputNet.onnx",
verbose=True,
input_names=[input_name],
output_names=[output_name])
# 导出为动态输入
torch.onnx.export(model,
input_data,
"Dynamics_InputNet.onnx",
opset_version=11,
input_names=[input_name],
output_names=[output_name],
dynamic_axes={
input_name: {0: 'batch_size', 2: 'input_height', 3: 'input_width'},
output_name: {0: 'batch_size', 2: 'output_height', 3: 'output_width'}})
1.2 pb文件(TensorFlow)转onnx
pb文件转onnx可以使用tf2onnx库,但必须说明的是,TensorFlow并没有官方支持onnx,tf2onnx是一个第三方库。格式转化onnx格式文件将tensorflow的pb文件转化为onnx格式的文件 安装tf2onnx。
- 参考:tensorrt-cubelab-docs tf2onnx安装
pip install tf2onnx
格式转化指令:
python -m tf2onnx.convert --input ./checkpoints/new_model.pb --inputs intent_network/inputs:0,intent_network/seq_len:0 --outputs logits:0 --output ./pb_models/model.onnx --fold_const # SAVE_MODEL保存为save_model
from tensorflow.python.compiler.tensorrt import trt_convert as trt
converter = trt.TrtGraphConverter(input_saved_model_dir=input_saved_model_dir)
converter.convert()
converter.save(output_saved_model_dir)
python -m tf2onnx.convert --saved_model saved_model_dir --output model.onnx # .pb 文件
python -m tf2onnx.convert --input frozen_graph.pb --inputs X:0,X1:0 --outputs output:0 --output model.onnx --fold_const # .ckpt 文件
python -m tf2onnx.convert --checkpoint checkpoint.meta --inputs X:0 --outputs output:0 --output model.onnx --fold_const
1.3 onnx转pb文件(TensorFlow)
有时候,我们需要对模型进行跨框架的转换,比如用pytorch训练了一个模型,但需要集成到TensorFlow中以便和其他的模型保持一致,方便部署。
此时就可以通过将pth转换成onnx,然后再将onnx转换成pb文件,如果转换成功,那么就可以在TensorFlow使用pb文件进行推理了。之所以强调如果,是因为TensorFlow并没有官方支持onnx,有可能会因为一些算子不兼容的问题导致转换后的pb文件在TF推理时出问题。 将onnx转换pb文件可以使用onnx-tf库,安装
pip install onnx-tf
完整的转换代码:
# -*- coding: utf-8 -*-
"""
@File : onnx_to_pb.py@Author: qiuyanjun@Date : 2020-01-10 19:22@Desc :
"""
import cv2
import numpy as np
import onnx
import tensorflow as tf
from onnx_tf.backend import prepare
import onnx_tf
model = onnx.load('models/onnx/version-RFB-320.onnx')
tf_rep = prepare(model)
img = cv2.imread('imgs/1.jpg')
image = cv2.resize(img, (320, 240))# 测试是否能推理
image_mean = np.array([127, 127, 127])
image = (image - image_mean) / 128
image = np.transpose(image, [2, 0, 1])
image = np.expand_dims(image, axis=0)
image = image.astype(np.float32)
output = tf_rep.run(image)
print("output mat: \\n", output)
print("output type ", type(output))# 建立Session并获取输入输出节点信息
with tf.Session() as persisted_sess:
print("load graph")
persisted_sess.graph.as_default()
tf.import_graph_def(tf_rep.graph.as_graph_def(), name='')
inp = persisted_sess.graph.get_tensor_by_name(
tf_rep.tensor_dict[tf_rep.inputs[0]].name
)
print('input_name: ', tf_rep.tensor_dict[tf_rep.inputs[0]].name)
print('input_names: ', tf_rep.inputs)
out = persisted_sess.graph.get_tensor_by_name(
tf_rep.tensor_dict[tf_rep.outputs[0]].name
)
print('output_name_0: ', tf_rep.tensor_dict[tf_rep.outputs[0]].name)
print('output_name_1: ', tf_rep.tensor_dict[tf_rep.outputs[1]].name)
print('output_names: ', tf_rep.outputs)
res = persisted_sess.run(out, {inp: image})
print(res)
print("result is ", res)# 保存成pb文件
tf_rep.export_graph('version-RFB-320.pb')
print('onnx to pb done.')
"""cmd
PYTHONPATH=. python3 onnx_to_pb.py
"""
1.4 ONNX转ncnn
ncnn是腾讯开源的轻量级推理框架, 简单易用, 但当功耗、时耗是主要考虑点的时候,需要多尝试其它框架,如TensorFlow Lite。
TensorRT
- 【2021-5-21】TensorRT入门指北 显卡算力查看
什么是TensorRT
- TensorRT是由Nvidia推出的C++语言开发的高性能神经网络推理库,是一个用于生产部署的优化器和运行时引擎。其高性能计算能力依赖于Nvidia的图形处理单元。它专注于推理任务,与常用的神经网络学习框架形成互补,包括TensorFlow、Caffe、PyTorch、MXNet等。可以直接载入这些框架的已训练模型文件,也提供了API接口通过编程自行构建模型。
- TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。我们利用Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。速度提升的比例是比较可观的。
- TensorRT是由C++、CUDA、python三种语言编写成的一个库,其中核心代码为C++和CUDA,Python端作为前端与用户交互。当然,TensorRT也是支持C++前端的,如果我们追求高性能,C++前端调用TensorRT是必不可少的。
- TensorRT是半开源的,除了核心部分其余的基本都开源了。
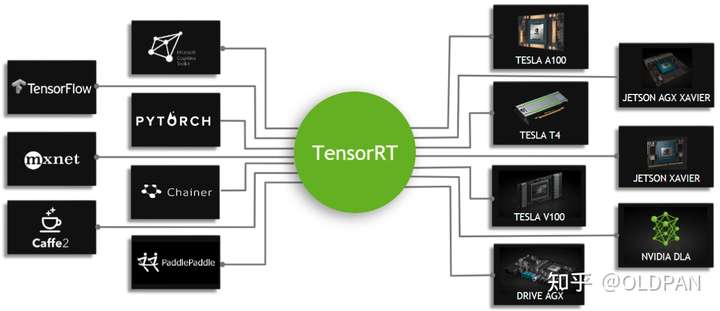

TensorRT的使用场景
TensorRT的使用场景很多。服务端、嵌入式端、家用电脑端都是我们的使用场景。
- 服务端对应的显卡型号为A100、T4、V100等
- 嵌入式端对应的显卡为AGX Xavier、TX2、Nano等
- 家用电脑端对应的显卡为3080、2080TI、1080TI等
当然这不是固定的,只要我们显卡满足TensorRT的先决条件,用就对了。
TensorRT安装
安装TensorRT的方式有很多,官方提供了多种方式:Debian or RPM packages, a pip wheel file, a tar file, or a zip file.
- 如下载TensorRT-7.2.3.4.Ubuntu-18.04.x86_64-gnu.cuda-11.1.cudnn8.1.tar.gz
- TensorRT的版本与CUDA还有CUDNN版本是密切相关的,不匹配版本的cuda以及cudnn是无法和TensorRT一起使用的
- 查看本机驱动:nvidia-smi
- 下载好后,tar -zxvf解压即可。
- 解压之后我们需要添加环境变量,以便让我们的程序能够找到TensorRT的libs
vim ~/.bashrc
# 添加以下内容
export LD_LIBRARY_PATH=/path/to/TensorRT-7.2.3.4/lib:$LD_LIBRARY_PATH
export LIBRARY_PATH=/path/to/TensorRT-7.2.3.4/lib::$LIBRARY_PATH
TensorRT 工作流
工作流主要分为两个阶段:建造阶段(build phase)和执行阶段(compile phase)。
- 在建造阶段,TensorRT 接收外部提供的网络定义(也可包含权值 weights)和超参数,根据当前编译的设备进行网络运行的优化(optimization), 并生成推理引擎 inference engine(可以以 PLAN 形式存在在硬盘上);
- 在执行阶段,通过运行推理引擎调用 GPU 计算资源——整个流程如图 原文链接

TensorRT 接口
必备接口流程图 ,那么TensorRT的优化力度就没有那么夸张了。
为了更充分利用GPU的优势,我们在设计模型的时候,可以更加偏向于模型的并行性,因为同样的计算量,“大而整”的GPU运算效率远超“小而碎”的运算。
工业界更喜欢简单直接的模型和backbone。2020年的RepVGG,就是为GPU和专用硬件设计的高效模型,追求高速度、省内存,较少关注参数量和理论计算量。相比resnet系列,更加适合充当一些检测模型或者识别模型的backbone。
在实际应用中,老潘也简单总结了下TensorRT的加速效果:
- SSD检测模型,加速3倍(Caffe)
- CenterNet检测模型,加速3-5倍(Pytorch)
- LSTM、Transformer(细op),加速0.5倍-1倍(TensorFlow)
- resnet系列的分类模型,加速3倍左右(Keras)
- GAN、分割模型系列比较大的模型,加速7-20倍左右(Pytorch)
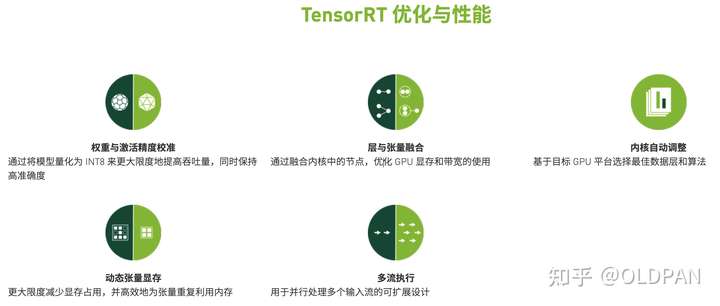
TensorRT有哪些黑科技
为什么TensorRT能够提升我们模型在英伟达GPU上运行的速度,当然是做了很多对提速有增益的优化:
- 算子融合(层与张量融合):简单来说就是通过融合一些计算op或者去掉一些多余op来减少数据流通次数以及显存的频繁使用来提速 量化:量化即IN8量化或者FP16以及TF32等不同于常规FP32精度的使用,这些精度可以显著提升模型执行速度并且不会保持原先模型的精度
- 内核自动调整:根据不同的显卡构架、SM数量、内核频率等(例如1080TI和2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式
- 动态张量显存:我们都知道,显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间
- 多流执行:使用CUDA中的stream技术,最大化实现并行操作 TensorRT的这些优化策略代码虽然是闭源的,但是大部分的优化策略我们或许也可以猜到一些,也包括TensorRT官方公布出来的一些优化策略:
什么模型可以转换为TensorRT
TensorRT官方支持Caffe、Tensorflow、Pytorch、ONNX等模型的转换(不过Caffe和Tensorflow的转换器Caffe-Parser和UFF-Parser已经有些落后了),也提供了三种转换模型的方式:
- 使用TF-TRT,将TensorRT集成在TensorFlow中
- 使用ONNX2TensorRT,即ONNX转换trt的工具
- 手动构造模型结构,然后手动将权重信息挪过去,非常灵活但是时间成本略高,有大佬已经尝试过了:tensorrtx
不过目前TensorRT对ONNX的支持最好,TensorRT-8最新版ONNX转换器又支持了更多的op操作。而深度学习框架中,TensorRT对Pytorch的支持更为友好,除了Pytorch->ONNX->TensorRT这条路,还有:
- torch2trt
- torch2trt_dynamic
- TRTorch
总而言之,理论上95%的模型都可以转换为TensorRT,条条大路通罗马嘛。只不过有些模型可能转换的难度比较大。如果遇到一个无法转换的模型,先不要绝望,再想想,再想想,看看能不能通过其他方式绕过去。
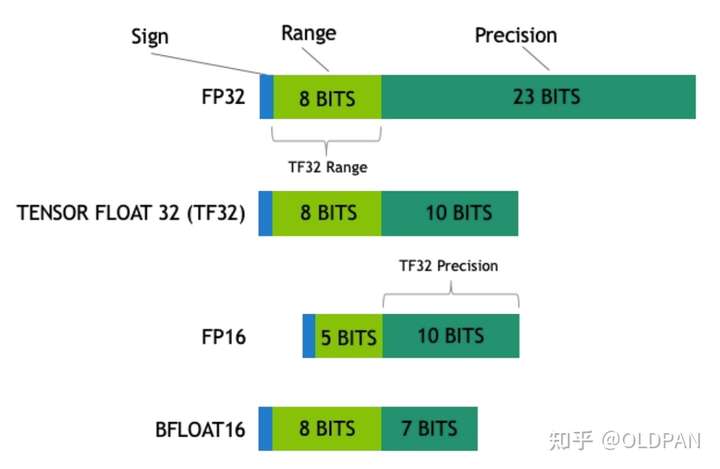
TensorRT支持哪几种权重精度
支持FP32、FP16、INT8、TF32等,这几种类型都比较常用。
- FP32:单精度浮点型,没什么好说的,深度学习中最常见的数据格式,训练推理都会用到;
- FP16:半精度浮点型,相比FP32占用内存减少一半,有相应的指令值,速度比FP32要快很多;
- TF32:第三代Tensor Core支持的一种数据类型,是一种截短的 Float32 数据格式,将FP32中23个尾数位截短为10bits,而指数位仍为8bits,总长度为19(=1+8 +10)。保持了与FP16同样的精度(尾数位都是 10 位),同时还保持了FP32的动态范围指数位都是8位);
- INT8:整型,相比FP16占用内存减小一半,有相应的指令集,模型量化后可以利用INT8进行加速。
简单展示下各种精度的区别:
ZeRO – 突破显存限制
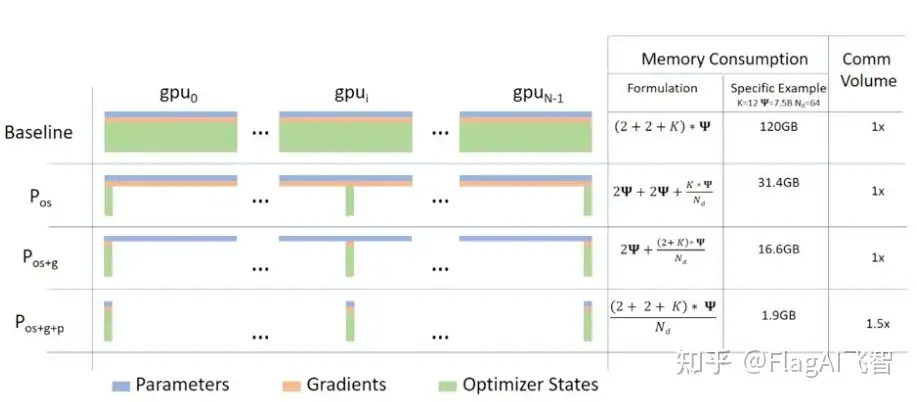
ZeRO 三个优化阶段,对应优化器状态、梯度和参数划分。
- a. Pos:减少4倍内存,通信量与数据并行相同
- b. Pos+g:减少8倍内存,通信量与数据并行相同
- c. Pos+g+p:内存减少与数据并行度Nd呈线性关系。
- 例如,在64个GPU(Nd=64)之间进行拆分将产生64倍的内存缩减。通信量有50%的适度增长。
ZeRO消除了内存冗余,使集群全部聚合内存容量可用。启用所有三个阶段的情况下,ZeRO在1024个NVIDIA GPU上训练万亿参数模型。
- 像Adam这样具有16位精度的优化器的万亿参数模型需要大约16 TB的内存来保存优化器的状态、梯度和参数。16TB除以1024是16GB,这对于GPU来说是在合理的范围内的。
- ZeRO2扩展了ZeRO-1,包括减少梯度内存占用,同时还添加了针对激活内存和碎片内存的优化。
- 与ZeRO-1相比,ZeRO-2将DeepSpeed可以训练的模型大小增加了一倍,同时显著提高了训练效率。
- 使用ZeRO-2,1000亿参数模型的训练速度可以比仅基于模型并行性的现有技术快10倍。
ZeRO: 去除冗余
目前最流行的方法是 ZeRO(即零冗余优化器)。针对模型状态的存储优化(去除冗余),ZeRO使用的方法是分片,即每张卡只存 1/N 的模型状态量,这样系统内只维护一份模型状态。
ZeRO有三个不同级别,对模型状态进行不同程度的分片:
- ZeRO-1: 对优化器状态分片(Optimizer States Sharding)
- ZeRO-2: 对优化器状态和梯度分片(Optimizer States & Gradients Sharding)
- ZeRO-3: 对优化器状态、梯度分片以及模型权重参数分片(Optimizer States & Gradients & Parameters Sharding)
Zero包括3种方案,逐步递进:
zero1:将adam参数分割成N份,一个GPU上只能保存一份adam参数:这对于forward没啥影响,gradient需要进行一次all-reduce,但是只能更新一部分参数,所以W需要进行一次all-gather,通信量为3Nsita,存储为 12sita/N + 4*sitazero2: 将adamw/gradient都分割成N份,梯度就不需要all-gather了,只需要scatter了,w需要all-gather,通讯量为2N*sitazero3: 将参数/adam/gradient都分割,forward的时候,需要将w all-gather,backfoward时,还需要把w all-gather回来,计算梯度,丢掉不属于自己的w,然后对梯度做reduce scatter,更新w,通讯量为3N*sita。
deepspeed 采用stage3:用1.5倍的通讯开销,换回近120倍的显存
ZeRO-Offload 基于Zero2,将adam和gradient放到内存中,在cpu内起了N个线程计算。
- 一条主线是gradient总是需要scatter的,感觉这个数据并行标志。
- 注意:不管是forward 还是backward都要有完整的w的。
- 另外有了gradient,以及adamW的参数,才能更新W。
ZeRO(Zero Redundancy Optimizer)由NVIDIA开发的分布式深度学习训练技术,解决在大规模模型上训练时由于显存限制而导致的性能瓶颈问题。
传统分布式训练中,每个工作节点都必须存储完整的模型参数副本,使用大型模型时,每个工作节点需要拥有足够的显存才能存储这些参数。
而ZeRO技术通过将模型参数分成多个分片,让每个工作节点只需要存储部分参数,从而显著减少了显存占用量。
具体而言,ZeRO技术通过以下三个主要组件实现:
- ZeRO-Stage:将模型参数划分为更小的分片,每个工作节点只需存储自己所负责的参数分片。
- ZeRO-Offload:将一部分模型参数存储在CPU内存中,从而释放显存空间。
通过使用ZeRO技术,可以大幅度提高分布式深度学习训练的效率和规模。同时,由于减少了显存占用量,还可以使用更大的批量大小,从而加速训练过程。
除了ZeRO 外还有 Megatron,Gpip 和 Mesh-TensorFlow 等分布式深度计算方式
另外FlagAI也集成了ZeRO的使用方式,具体实现方式使用的是利用Deepspeed实现ZeRO1和ZeRO2,利用bmtrain实现了ZeRO3。
FlagAI 由北京智源人工智能研究院于 2022 年 5 月开源,是大模型算法、模型及各种优化工具的一站式、高质量开源项目,旨在集成全球各种主流大模型算法技术,以及多种大模型并行处理和训练加速技术,支持高效训练和微调,降低大模型开发和应用的门槛,提高大模型的开发效率。项目地址:https://github.com/FlagAI-Open/FlagAI
【2023-4-5】参考:模型并行下利用ZeRO进行显存优化
ZeRO-Stage
zero_stage
- 论文: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- 核心目的:怎么优化训练方式和(GPU, TPU, CPU)硬件使用效率,让用户训练transformers类的大模型更加高效。
ZeRO将模型训练阶段,每张卡中显存内容分为两类:
- 模型状态(model states): 模型参数(fp16)、模型梯度(fp16)和Adam状态(fp32的模型参数备份,fp32的momentum和fp32的variance)。假设模型参数量 Φ ,则共需要 2Φ+2Φ+(4Φ+4Φ+4Φ)=4Φ+12Φ=16Φ 字节存储,可以看到,Adam状态占比 75% 。
- 剩余状态(residual states): 除了模型状态之外的显存占用,包括激活值(activation)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)。
针对模型状态的存储优化(去除冗余),ZeRO使用的方法是分片(partition),即每张卡只存 1/N 的模型状态量,这样系统内只维护一份模型状态。
- 首先进行分片操作的是模型状态中的Adam,也就是图5中的 Pos ,这里os指的是optimizer states。模型参数(parameters)和梯度(gradients)仍旧是每张卡保持一份,此时,每张卡的模型状态所需显存是 4Φ+12Φ/N 字节,当 N 比较大时,趋向于 4ΦB ,也就是原来 16ΦB 的 1/4 。
- 如果继续对模型梯度进行分片,也就是图5中的 Pos+g ,模型参数仍旧是每张卡保持一份,此时,每张卡的模型状态所需显存是 2Φ+(2Φ+12Φ)/N 字节,当 N 比较大时,趋向于 2ΦB ,也即是原来 16ΦB 的 1/8 。
- 如果继续对模型参数进行分片,也就是图5中的 Pos+g+p ,此时每张卡的模型状态所需显存是 16Φ/N 字节,当 N 比较大时,趋向于 0 。
分析下通信数据量,先说结论:
- Pos 和 Pos+g 的通信量和传统数据并行相同,Pos+g+p 会增加通信量。
传统数据数据并行在每一步(step/iteration)计算梯度后,需要进行一次AllReduce操作来计算梯度均值,目前常用的是Ring AllReduce,分为ReduceScatter和AllGather两步,每张卡的通信数据量(发送+接收)近似为 2Φ ([2])。
直接分析 Pos+g ,每张卡只存储 1N 的优化器状态和梯度,对于 gpu0 来说,为了计算它这 1N 梯度的均值,需要进行一次Reduce操作,通信数据量是 1/N⋅Φ⋅N=Φ ,然后其余显卡则不需要保存这部分梯度值了。实现中使用了bucket策略,保证 1N 的梯度每张卡只发送一次。
当 gpu0 计算好梯度均值后,就可以更新局部的优化器状态(包括 1/N⋅Φ 的参数),当反向传播过程结束,进行一次Gather操作,更新 (1−1/N)Φ 的模型参数,通信数据量是 1/N⋅Φ⋅N=Φ 。
从全局来看,相当于用Reduce-Scatter和AllGather两步,和数据并行一致,使得每张卡只存了 1/N 的参数,不管是在前向计算还是反向传播,都涉及一次Broadcast操作。
解决了模型状态,再来看剩余状态,也就是激活值(activation)、临时缓冲区(buffer)以及显存碎片(fragmentation)。
- 激活值同样使用分片方法,并且配合checkpointing
- 模型训练过程中经常会创建一些大小不等的临时缓冲区,比如对梯度进行AllReduce啥的,解决办法就是预先创建一个固定的缓冲区,训练过程中不再动态创建,如果要传输的数据较小,则多组数据bucket后再一次性传输,提高效率
- 显存出现碎片的一大原因是时候gradient checkpointing后,不断地创建和销毁那些不保存的激活值,解决方法是预先分配一块连续的显存,将常驻显存的模型状态和checkpointed activation存在里面,剩余显存用于动态创建和销毁discarded activation
ZeRO-Offload
ZeRO-Offload 使 GPU 单卡能够训练 10 倍大的模型
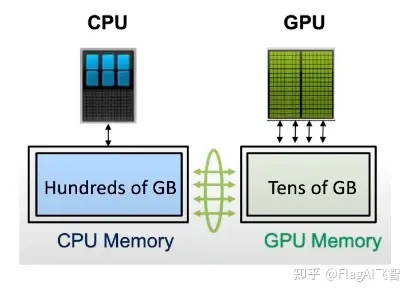
ZeRO-Offload 是 ZeRO(Zero Redundancy Optimizer)技术扩展,用显存作为模型参数存储和通信的中间介质,以减少模型并行化训练中的通信和同步开销。
- 2021年 UC Merced的 Jie Ren 发表 于ATC, ZeRO-Offload: Democratizing Billion-Scale Model Training,博士期间的研究方向是 Memory Management on Heterogeneous Memory Systems for Machine Learning and HPC
ZeRO-Offload让人人训练得起大模型
ZeRO-Offload 技术用显存缓存将模型参数存储在显存中,这可以减少网络带宽的使用,同时还可以加速参数访问和更新。为了最大限度地减少显存的使用,ZeRO-Offload技术使用了一种称为“按需加载”的策略。这种策略只在需要使用参数时才将其从磁盘或网络加载到显存中,而不是一次性将所有参数都加载到显存中。
Offload策略
ZeRO-Offload技术的核心是使用显存缓存和显存内通信来降低通信开销。为了最大程度地利用显存并减少网络带宽的使用,ZeRO-Offload技术采用了一种称为“Offload策略”的技术。下面是ZeRO-Offload技术的Offload策略的几个关键点:
- 按需加载
- ZeRO-Offload技术使用“按需加载”策略,只在需要使用参数时才将其从磁盘或网络加载到显存中,而不是一次性将所有参数都加载到显存中。这种策略可以最大限度地减少显存的使用,并减少网络带宽的使用。
- 数据流水线
- ZeRO-Offload技术使用“数据流水线”策略,将数据流分成多个阶段,每个阶段都使用不同的计算资源进行处理。在模型训练期间,ZeRO-Offload技术将数据分为多个块,并将这些块分配给不同的GPU进行计算。每个GPU只对其分配的数据块进行计算,并将计算结果传递给下一个阶段的GPU,直到所有阶段都完成为止。
- 显存原语
- ZeRO-Offload技术使用一种称为“显存原语”的通信协议,在显存中直接进行通信和同步操作,而不需要通过网络或主机内存。这种协议可以显著减少通信延迟和数据传输时间,从而提高训练效率。
- 数据切片
- ZeRO-Offload技术使用“数据切片”策略来划分模型参数,并通过显存内通信来实现不同GPU上参数的同步。具体来说,ZeRO-Offload技术将模型参数划分为多个小块,并在每个GPU上存储一部分参数块。在训练过程中,每个GPU只对其分配的参数块进行计算,并通过显存内通信将参数块传输到其他GPU上进行同步。
总的来说,ZeRO-Offload技术的Offload策略通过按需加载、数据流水线、显存原语和数据切片等技术手段来最大化地利用显存,并降低通信开销,从而提高深度学习模型训练的效率和可扩展性。
为了找到最优的offload策略,ZeRO作者将模型训练过程看作数据流图(data-flow graph)。
- 圆形节点表示模型状态,比如参数、梯度和优化器状态
- 矩形节点表示计算操作,比如前向计算、后向计算和参数更新
- 边表示数据流向
下图是某一层的一次迭代过程(iteration/step),使用了混合精读训练,前向计算(FWD)需要用到上一次的激活值(activation)和本层的参数(parameter),反向传播(BWD)也需要用到激活值和参数计算梯度,
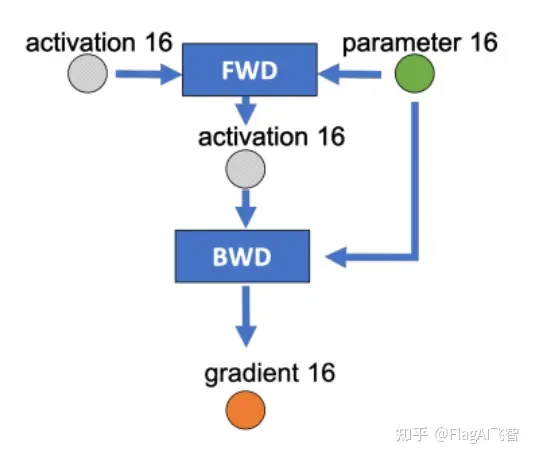
如果用Adam优化器进行参数更新(Param update),流程如下:
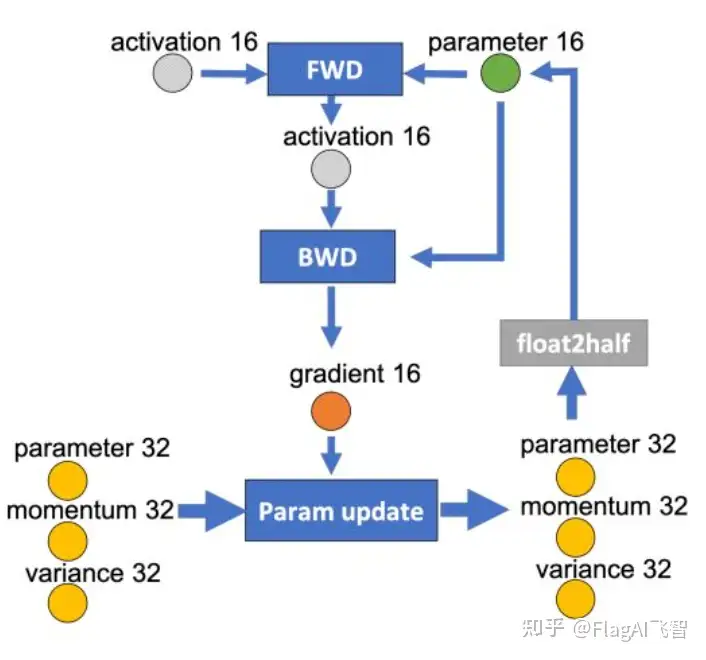
为边添加权重,物理含义是数据量大小(单位是字节),假设模型参数量是 M ,在混合精度训练的前提下,边的权重要么是2M(fp16),要么是4M(fp32)。
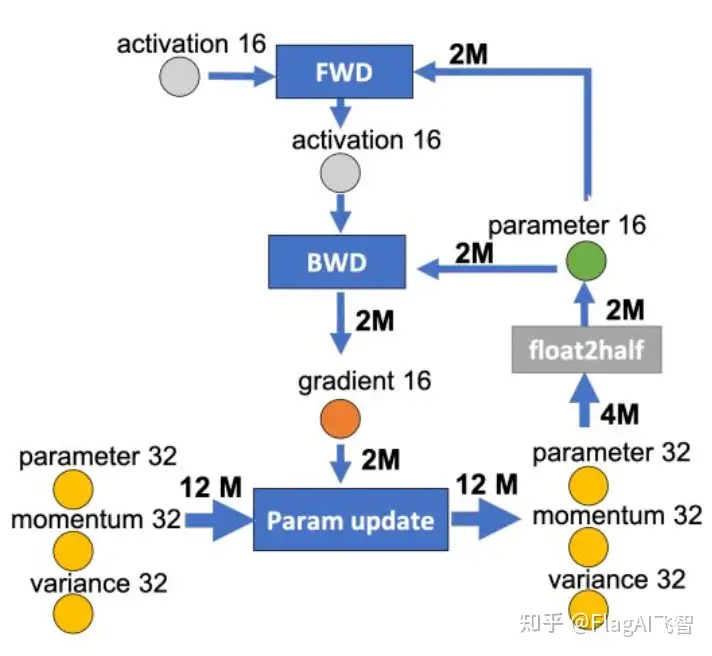
现在要做的就是沿着边把数据流图切分为两部分,分布对应GPU和CPU,计算节点(矩形节点)落在哪个设备,哪个设备就执行计算,数据节点(圆形)落在哪个设备,哪个设备就负责存储,将被切分的边权重加起来,就是CPU和GPU的通信数据量。
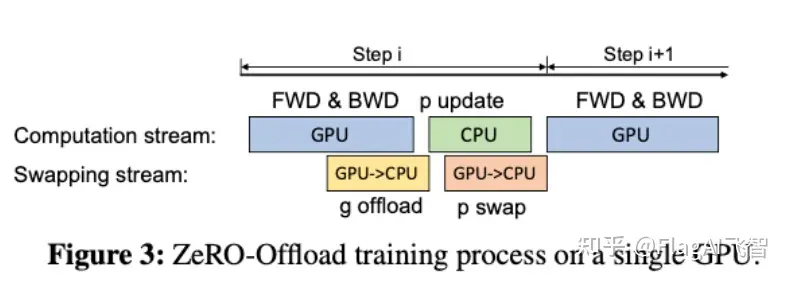
ZeRO-Offload的切分思路如图 10 所示:

图10中有四个计算类节点:FWD、BWD、Param update和float2half,前两个计算复杂度大致是 O(MB) , B 是batch size,后两个计算复杂度是 O(M) 。为了不降低计算效率,将前两个节点放在GPU,后两个节点不但计算量小还需要和Adam状态打交道,所以放在CPU上,Adam状态自然也放在内存中,为了简化数据图,将前两个节点融合成一个节点FWD-BWD Super Node,将后两个节点融合成一个节点Update Super Node。
所以,现在的计算流程是,在GPU上面进行前向和后向计算,将梯度传给CPU,进行参数更新,再将更新后的参数传给GPU。为了提高效率,可以将计算和通信并行起来,GPU在反向传播阶段,可以待梯度值填满bucket后,一遍计算新的梯度一遍将bucket传输给CPU,当反向传播结束,CPU基本上已经有最新的梯度值了,同样的,CPU在参数更新时也同步将已经计算好的参数传给GPU,如下图所示:
ZeRO-Infinity
ZeRO-Infinity: 利用NVMe打破GPU显存墙
- 2021年发表于SC, ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
- 同样是进行 offload,ZeRO-Offload 更侧重单卡场景,而
ZeRO-Infinity则是典型的工业界风格,奔着极大规模训练去了。
ZeRO 问题
【2023-7-6】DeepSpeed-ZeRO++ 技术简介
ZeRO 是一种数据并行策略,将模型权重、梯度以及优化器状态分别切分到各GPU上,从而可在有限的显存上训练更大的模型。
- 模型前向计算和反向计算都需要提前聚合当前层对应的全量参数,这个聚合过程是通过调用通信原语
All-Gather来完成的; - 之后便需要对计算好的梯度平均,把平均后的梯度值传播到各 GPU 上,用于各 GPU 更新自己负责的那一部分模型权重,这个平均以及传播的过程通过调用通信原语
Reduce-Scatter完成。
至此完成一步迭代, ZeRO 通信量以及通信频率都大幅增长
- 普通数据并行只需要对最后计算出的梯度做一次 All-Reduce 通信,而ZeRO需要两次 All-Gather 通信 + 一次 Reduce-Scatter 通信。
- 如果机器集群节点间的网络带宽再拉跨一些,那么 ZeRO 的训练效率简直不堪入目。
因此,很多大模型都基于张量并行和流水并行对模型进行精细切分,让一些频繁通信的操作(张量并行)尽量限制在节点内部,同时把通信压力小的操作放在节点间完成,比如流水并行。
ZeRO++
【2023-7-6】DeepSpeed-ZeRO++ 技术简介
ZeRO 为了打一个翻身仗,不得不优化自己的短板,减少跨机通信,进而提升训练效率,具体优化策略也就是本文将要介绍的 ZeRO++。
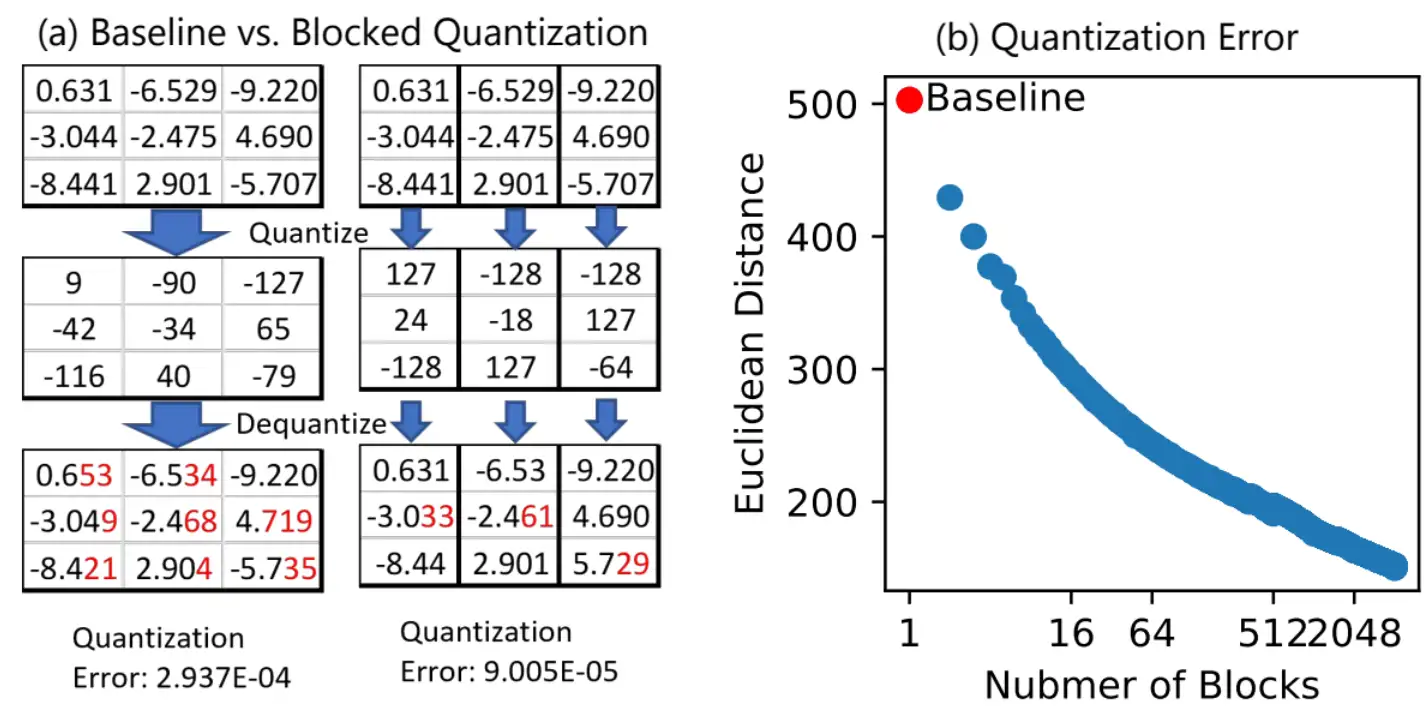
量化权重(qwZ):前向计算时,在 All-Gather 通信之前,首先把 FP16(两字节) 权重量化成 INT8(单字节),这样一来通信数据量就下降了一半;Al-Gather 通信之后,再通过反量化将 INT8 反量化成 FP16。为了取得更好的量化效果,也就是尽量减小量化损失,ZeRO+ 使用 Blocked Quantization 代替朴素的量化策略,如下图(a)是两种量化策略的对比,Blocked Quantization 相比于 Baseline 具有更小的量化误差;下图(b)说明 Block 切得越多,欧式距离越小,量化损失也就越小,但是也会带来额外的开销(scale 和 zero);分层切片(hpZ):由于 ZeRO 把整个模型权重切分到所有的 GPU 上,所以反向计算梯度时需要所有 GPU 参与通信,把权重分片聚拢起来,但是节点间的网络带宽远远小于节点内部,导致节点间通信成为瓶颈。为了缓解这个问题,ZeRO++ 采用分层切片的策略尽量减少反向计算时的跨节点通信。具体过程如下:已知前向计算时会把所有权重 All-Gather 起来,之后便对权重进行切片,切成多少片可以根据集群配置进行调节,一般情况下会把权重切片尽量限制在单个节点内部,也就是一个节点有多少张卡,就切成多少片,这样一来每个节点都拥有完整的权重,在反向计算梯度时只需要在节点内部执行 All-Gather 通信,完全避免了跨节点的通信。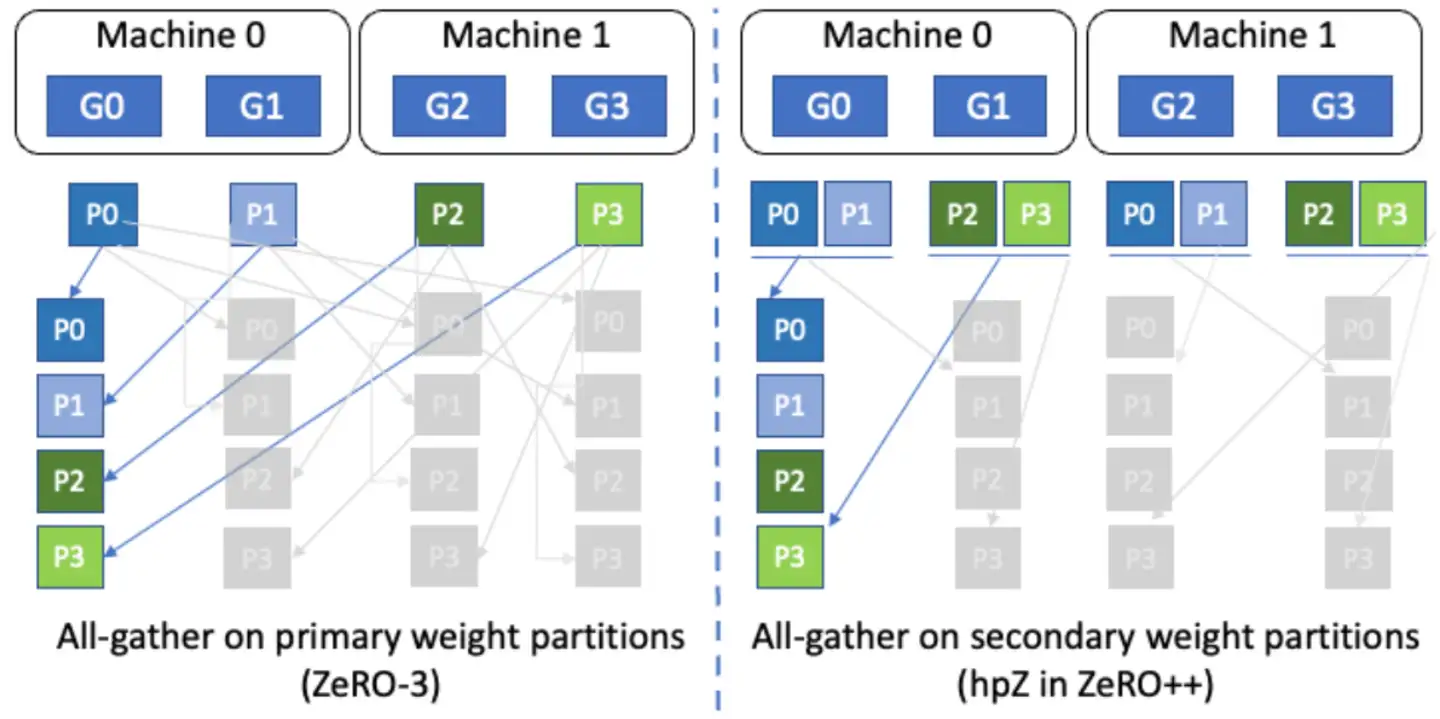
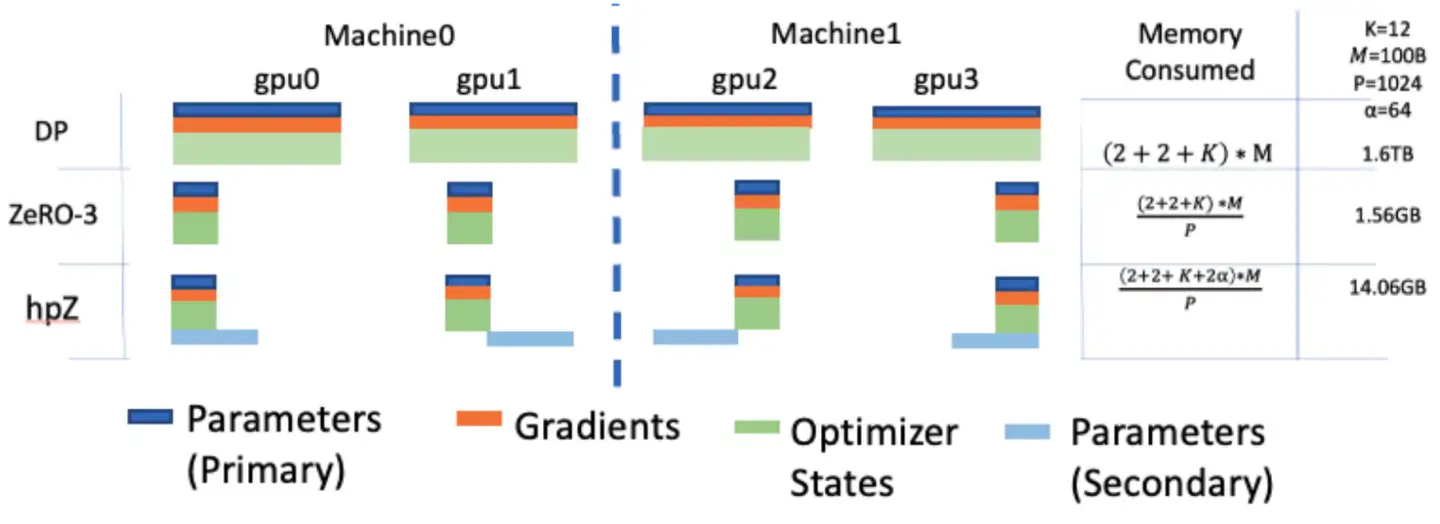
- 额外开销便是每张卡不仅要保存 ZeRO 的权重切片(Primary Parameters),还需要额外保存 ZeRO++ 所需的权重切片(Secondary Parameters),如下图所示:
量化梯度(qgZ):ZeRO 在反向计算完成之后需要一次 Reduce-Scatter 通信,如果直接将量化策略应用到 Reduce-Scatter 通信原语,会造引发一系列的量化和反量化(量化和反量化的次数为所有 GPU 的个数),这不可避免地会引入巨大的量化误差,如下图左所示:
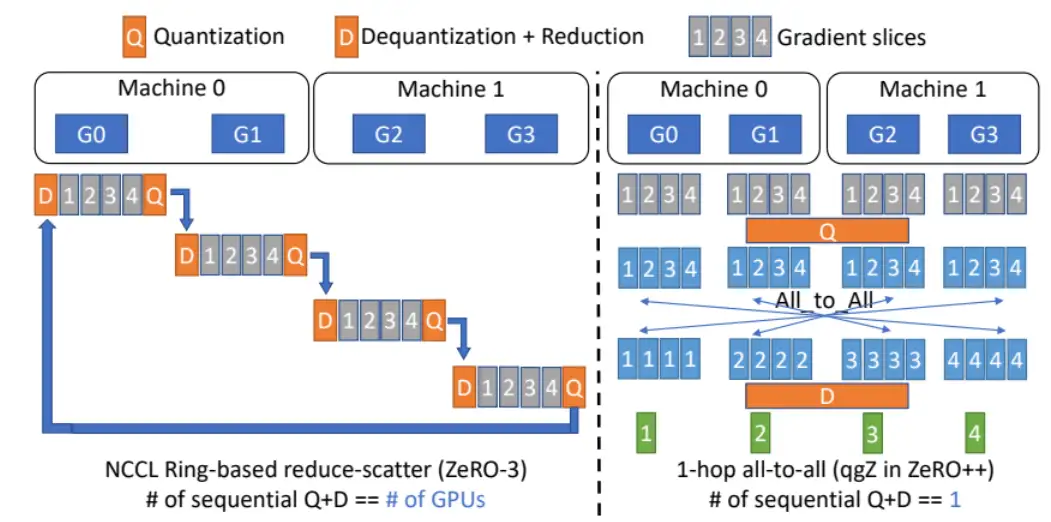
为了减少量化和反量化的次数(Q+D),可如上图右所示,首先对全部梯度量化,然后所有 GPU 进行一次 All-to-All 通信,最后执行反量化操作。这个过程只需一次量化和反量化操作,因此也被称作 1-hop all-to all。下面分析一下这两种方法的通信量:
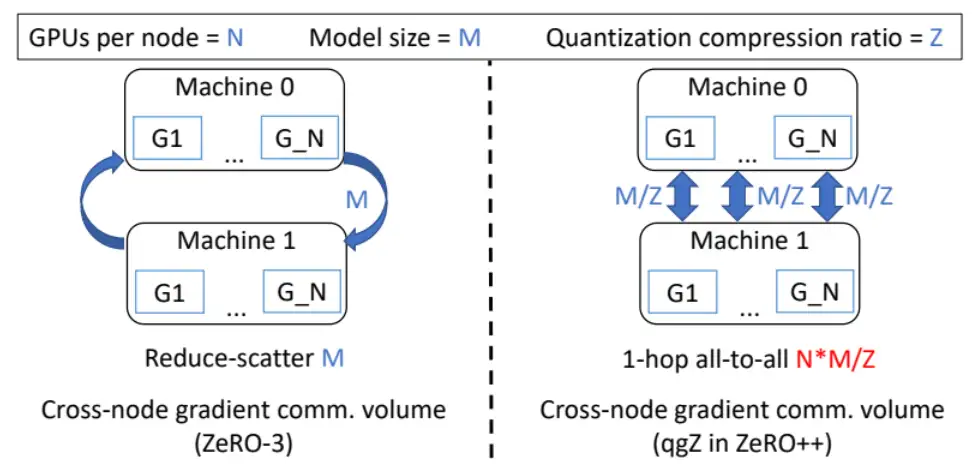
从上图可以看出,基于 Reduce-Scatter 的 ZeRO3 跨机通信量为 M,而基于 1-hop all-to-all 的算法跨机通信量为 N * M / Z(其中 Z 为压缩比率,比如 FP16 量化为 INT8,也就是从 2 个字节压缩成 1 个字节,因此压缩比率为 2;由于每张卡都要发送压缩后的数据,所以需要对压缩后的数据乘上 N)。相比于 Reduce-Scatter,1-hop all-to-all 的跨机通信总量大幅增加,因此需要进一步优化以减少跨机通信数据量。ZeRO++ 提出基于分层策略的 2-hop all-to-all 算法:
- Step1: Tensor Slice Reordering(张量切片重排),重排的原因稍后解释,重排后进行量化(Quantizaiton),然后在节点内执行 All-to-All 通信:
- Step2:在各个节点内部首先执行反量化(Dequantization),然后把反量化的结果相加(Reducetion),减小精度损失:
- Step3:执行 Reduction 之后,再次对张量进行量化(Quantization),然后对量化后的结果执行第二次 All-to-All 通信,只不过这一次是节点间(以下图为例:Machine 0 的 G2 和 Machine 1 的 G2,Machine 0 的 G3 和 Machine 1 的 G3):
- Step4:节点间 All-to-All 通信之后,首先进行反量化(Dequantization),然后执行 Reduction 操作,这时每张卡上都拿到了权重(Primary Parameters)对应的、平均后的梯度:
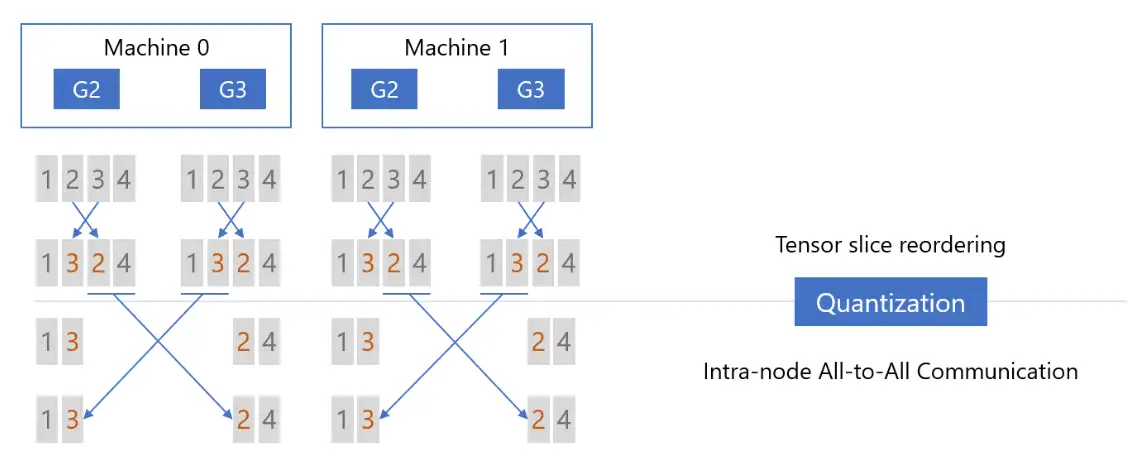
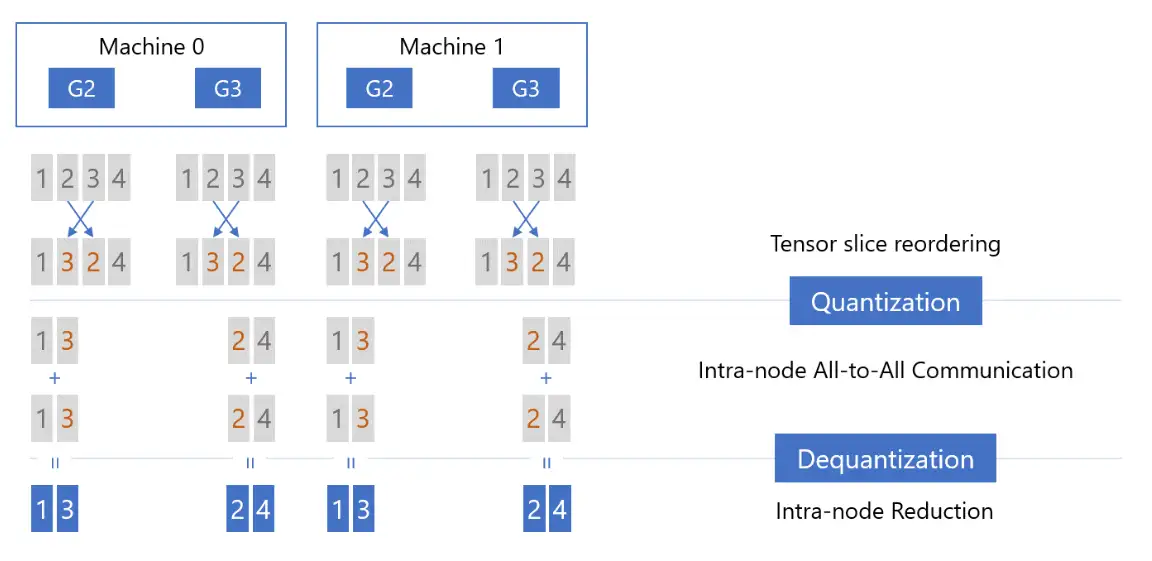
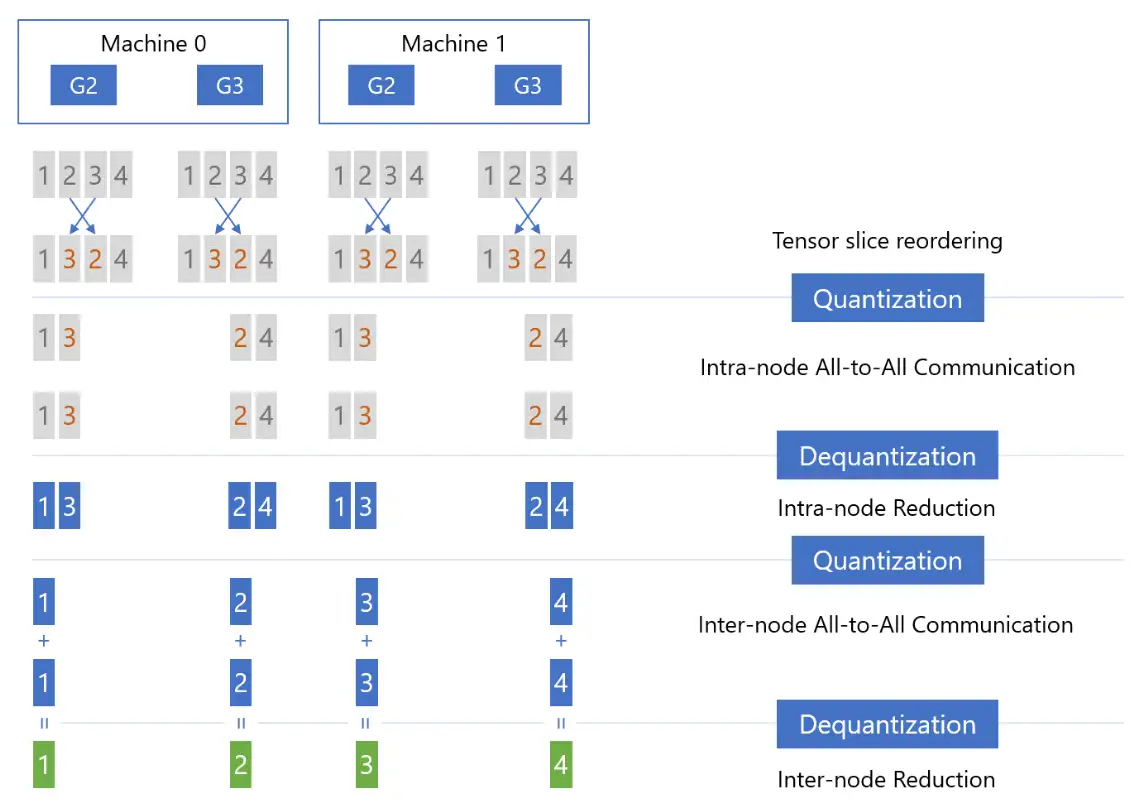
至此,qgZ 通过使用节点内和节点间的 All-to-All 通信,同时搭配 Tensor Slice Reordering,来模拟实现了 Reduce-Scatter 通信,这个过程共执行两次量化和反量化,因此也被称为 2-hop all-to-all。
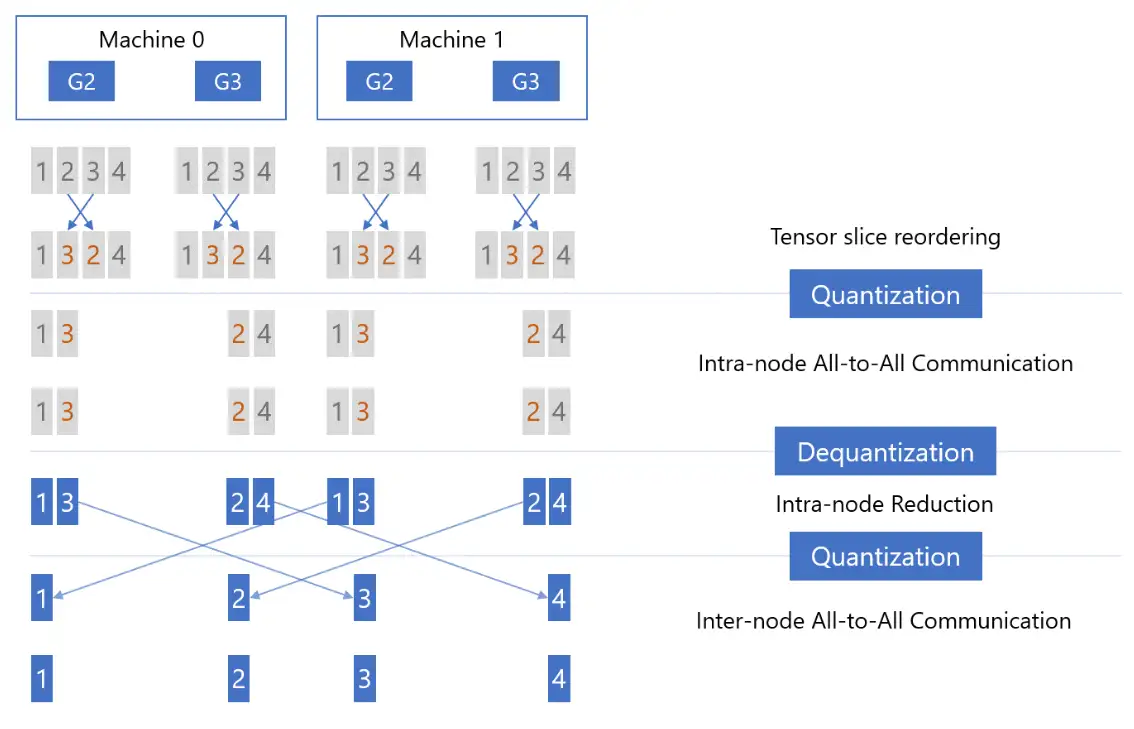
现在解释最开始对张量切片进行重排的原因:
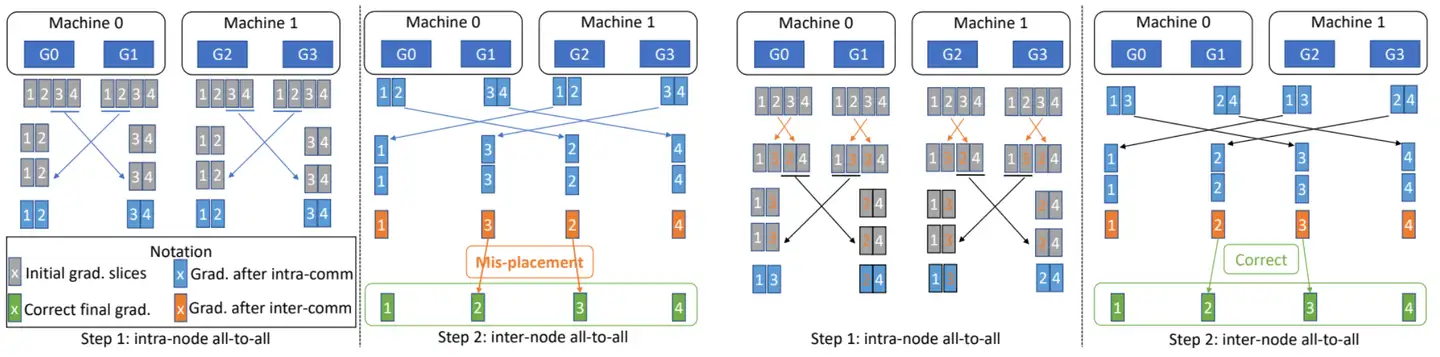
- 左面两图(Step1 & Step2)没有使用张量切片重排,两次 ALL-to-ALL 通信之后,每张卡上的张量切片无法与正确的切片顺序对齐。为了避免这一问题,应该首先对张量切片进行重排,再进行 All-to-All 通信。
至此,已经完整介绍前向通信优化(qwZ),反向通信优化(hpZ),以及梯度通信优化(qgZ)。节点间通信量如下图:
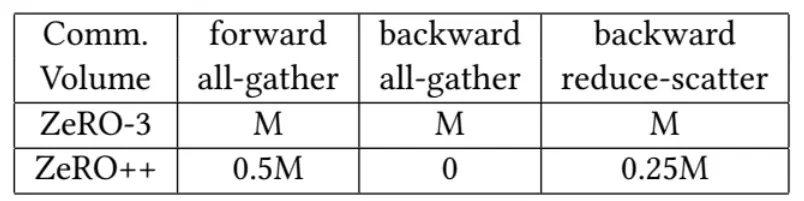
相比于 ZeRO,ZeRO++在前向时量化权重节省了一半的跨机通信量(PF16 -> INT8),后向时由于权重都已经存在本地节点,所以跨机通信量为 0,最后的梯度同步可减少 3/4 跨机通信量:
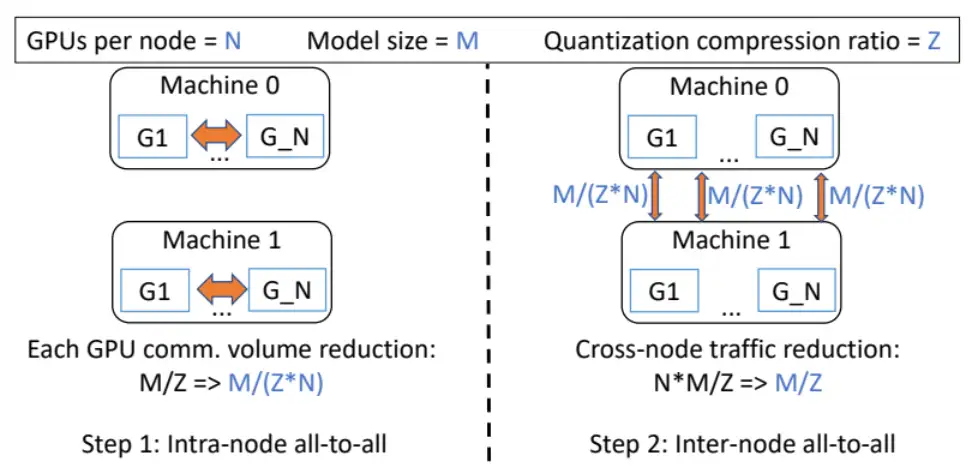
第一次 All-to-All 通信之后,总参数量从 M/Z 降到 M / (Z * N),其中 N 为每个节点的 GPU 个数;第二次 All-to-All 通信每张卡发送的数据量为 M / ( Z * N),那么每台机器的跨机通信量就是 M / (Z * N) * N),也就是 M / Z(FP16 -> INT4,所以是 0.25M)。
最后再讲一下论文里面提到的实现优化,这一步对于效率影响很大,共涉及两个优化点:
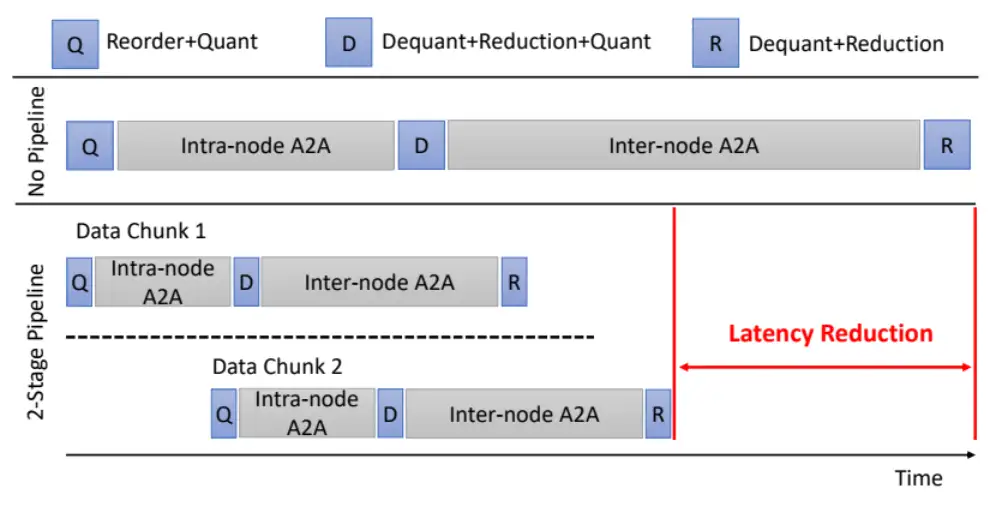
- (1)通信和计算隐藏:针对 All-Gather,当前层在聚拢权重(通信)时,同时对下一层的权重进行量化(计算);针对 2-hop all-to-all,首先对张量分块,再分别执行通信,可实现不同块之间的通信计算隐藏,如下图所示:
- (2)融合算子:优化目标有两个:最大化带宽利用率和最小化内存读写。
大模型推理加速
模型推理优化三个层面:参考
- 算法层面:蒸馏、量化
- 软件层面:计算图优化、模型编译
- 硬件层面:FP8(NVIDIA H系列GPU开始支持FP8,兼有fp16的稳定性和int8的速度)
加速框架
推理加速框架:
FasterTransformer:英伟达推出的FasterTransformer不修改模型架构而是在计算加速层面优化 Transformer 的 encoder 和 decoder 模块。具体包括如下:- 尽可能多地融合除了 GEMM 以外的操作
- 支持 FP16、INT8、FP8
- 移除 encoder 输入中无用的 padding 来减少计算开销
TurboTransformers:腾讯推出的 TurboTransformers 由 computation runtime 及 serving framework 组成。加速推理框架适用于 CPU 和 GPU,最重要的是,它可以无需预处理便可处理变长的输入序列。具体包括如下:- 与 FasterTransformer 类似,它融合了除 GEMM 之外的操作以减少计算量
- smart batching,对于一个 batch 内不同长度的序列,它也最小化了 zero-padding 开销
- 对 LayerNorm 和 Softmax 进行批处理,使它们更适合并行计算
- 引入了模型感知分配器,以确保在可变长度请求服务期间内存占用较小
GPU 与神经网络
如何让神经网络的深度学习更快、更省电?
重点关注一个名为GEMM的函数。
- BLAS(基本线性代数子程序)库的一部分,该库最早创建于1979年
使用Alex Krizhevsky的Imagenet架构进行图像识别的典型深度卷积神经网络的时间。

-
所有以
fc(即:全连接层)或conv(即:卷积层)开头的层都是使用GEMM实现的,几乎所有的时间(95%的GPU版本,89%的CPU版本)都花在这些层上。 - 为什么GEMM是深度学习的核心
- Why GEMM is at the heart of deep learning
GPU 加速核心GEMM
GPU主要加速gemm,论文
- gemm在深度学习中的耗时占比达到80%以上。
- fc可以展开为gemm
- cnn可以通过im2col展开为gemm
cuda框架中,cuBLAS主要是对gemm类算法进行优化,其他cuFFT,cuRAND, cuSPARSE各自针对不同的算法进行优化。
cuDNN则是完全针对DL中的batchNormalization这类神经网络层的计算进行优化。
作者:Huisheng Xu
什么是GEMM?
GEMM 代表 GEneral Matrix to Matrix Multiplication (通用矩阵到矩阵乘法)
- 本质上完全按照tin上所说的做,将两个输入矩阵相乘,得到一个输出矩阵。
- 与3D图形世界中的矩阵运算的不同之处在于,处理矩阵通常非常大。
例如,典型网络中的单个网络层可能需要将256行1152列的矩阵乘以1152行192列的矩阵,以产生256行192列的结果。
- 天真地说,这需要5700万(256x1152x192)次浮点运算,而且在现代网络结构中可能有几十个这样的网络层,所以经常看到一个往往需要几十亿次浮点运算来计算单个图像帧。
FC 全连接层
全连接层是已经存在了几十年的经典神经网络层。
- FC层的每个输出值都可以看到输入的每个值,将输入乘以该输入对应的权重,然后对结果求和以获得其输出。
- 有“k”个输入值,“n”个神经元,每个神经元都有自己的学习权重集。对应的图中有“n”个输出值,每个神经元对应其中一个,该输出值利用对其权重和输入值进行点积运算计算得到。
Conv 卷积层
conv层将其输入视为二维图像,每个像素具有多个通道,非常类似于具有宽度、高度和深度的经典图像。不过,与我以前处理的图像不同,通道的数量可以达到数百个,而不仅仅是RGB或RGBA
为什么要用GEMM矩阵乘法
- Fortran世界的科学程序员花了几十年时间优化代码,以执行大型的矩阵乘法(large matrix to matrix multiplications),而且非常规则的内存访问模式带来的好处超过了浪费的存储成本。
- Nvidia的论文介绍了一些不同方法,描述了为什么最终以修改版的GEMM作为最喜欢的方法。
- cuDNN: Efficient Primitives for Deep Learning
- 同时对1个卷积核批处理大量输入图像也有很多优点,Caffe con TROL 使用了这些方法,取得了很好的效果
- GEMM方法的主要竞争对手是使用傅里叶变换在频率空间中进行运算,但在卷积中使用stride使其难以达到同样的效率。
GEMM是如何应用于卷积层的?
- 卷积似乎是一个相当专业的运算。
- 包含多次乘法计算和最后的求和计算,比如完全连接层,但不清楚如何将其转化为GEMM矩阵乘法。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
