训练可视化
总结
【2026-6-29】工具选型速记 💡
- 只看训练loss、本地单机调试 → TensorBoard
- 海外团队、大量超参搜索、云端协作 → WandB
- 国内大模型训练、国产框架、需要手机远程看训练 → SwanLab
- 单独解析GGUF/ONNX模型结构、核对权重算子 → Netron(和其他工具互补,不替代)
- 企业生产、完整机器学习流水线、模型归档部署 → MLFlow
| 对比维度 | TensorBoard | Weights & Biases(WandB) | SwanLab | Netron | MLFlow |
|---|---|---|---|---|---|
| 核心定位 | 本地训练指标可视化,TF/PyTorch原生配套 | 云端MLOps全流程实验管理平台 | 国产轻量化云端/本地双模式训练监控工具 | 独立模型结构可视化器(仅查看网络权重/层结构) | 企业级ML全生命周期管理(训练+部署+模型版本) |
| 部署模式 | 纯本地离线,日志文件存储 | 公有云为主,支持私有部署 | 本地离线 + 国内云端,支持私有化部署 | 纯本地桌面程序/命令行 | 本地文件、服务端、私有集群部署 |
| 网络依赖 | 完全不需要联网 | 默认云端同步,离线模式功能受限 | 离线可完整运行,联网同步云端 | 无网络需求 | 离线/云端双支持 |
| 数据隐私 | 本地文件,数据不外流 | 公有云会上传日志,私有部署可控 | 本地日志留存,云端数据国内存储 | 仅本地读取模型文件 | 数据完全自托管,无第三方上传 |
| 训练指标监控(loss/acc/梯度) | ✅ 完整支持标量、直方图、图像、文本、嵌入降维 | ✅ 功能最强,多实验批量对比、自定义仪表盘、实时告警 | ✅ 原生适配LLaMA Factory、XTuner等国产大模型框架,支持NPU/昇腾硬件监控 | ❌ 不支持训练过程监控,仅静态模型解析 | ✅ 基础指标可视化,图表自定义能力弱于前三者 |
| 模型结构可视化 | ✅ 支持计算图可视化,TF原生适配,PyTorch需trace导出 | ✅ 支持,自动记录模型Graph | ✅ 支持模型结构、权重分布记录 | ⭐ 核心强项,支持ONNX/TensorRT/PyTorch/TensorFlow/GGUF等几乎所有模型格式,逐层查看参数、维度、算子 | ❌ 仅基础网络结构展示,无细粒度算子解析 |
| 实验管理/超参对比 | ❌ 无原生实验分组,多实验对比繁琐 | ⭐ 内置Sweeps超参调优,批量实验筛选、表格过滤、结果排序 | ✅ 一体化实验表格,超参筛选、多曲线叠加对比 | ❌ 无实验跟踪能力 | ⭐ 强版本管理,参数、代码、数据集、模型绑定归档 |
| 团队协作能力 | ❌ 无原生分享、评论、权限管理 | ✅ 完善团队空间、实验链接分享、评论、成员权限 | ✅ 国内团队空间、一键分享链接、手机端查看 | ❌ 无协作功能 | ✅ 企业级用户权限、流水线共享、模型仓库 |
| 大模型适配 | 基础适配,无国产框架专属优化 | 通用适配,海外主流框架友好 | 深度适配国产大模型训练框架(ModelScope、LLaMA Factory、Swift),支持GPU/NPU硬件监控 | 完美适配GGUF、AWQ、GPTQ量化大模型文件 | 通用适配,侧重模型导出与部署流水线 |
| 开源/授权 | 完全开源免费 | 开源SDK,公有云免费额度+企业付费 | 核心开源,云端免费版+企业私有化付费 | 完全开源免费 | 完全开源,Apache2.0协议 |
| 上手门槛 | 极低,框架内置,零配置启动 | 中等,需注册账号、配置API Key | 极低,一行命令登录,中文文档 | 极低,打开模型文件即用 | 偏高,需理解Experiment/Run/Model Registry概念 |
| 核心短板 | 仅本地、无协作、大规模实验性能差、无版本管理 | 公有云境外服务器,数据出境风险,基础功能依赖网络 | 高级MLOps流水线、超参搜索功能不完善 | 仅静态模型解析,无法监控训练动态曲线 | 可视化图表交互简陋,UI现代化程度低 |
| 最佳适用场景 | 单人本地快速调试、隐私敏感、无外网环境 | 海外科研团队、多设备分布式训练、大规模超参调优 | 国内大模型研发、高校/初创团队、需要云端远程监控、国产硬件(NPU)训练 | 模型算子调试、量化后权重校验、离线查看GGUF/ONNX网络结构 | 企业生产流水线、模型版本管控、自动化部署交付 |
TensorBoard
TensorFlow 自带的一个强大的可视化工具
查看模型训练过程中各个参数的变化情况(例如损失函数 loss 的值)。虽然可以通过命令行输出来查看,但有时显得不够直观。而 TensorBoard 就是一个能够帮助我们将训练过程可视化的工具。 原理
- 在运行过程中,记录结构化的数据
- 运行一个本地服务器,监听6006端口
- 请求时,分析记录的数据,绘制
TensorBoard Tensorflow
操作方法
- 每运行一次
tf.summary.scalar(),记录器就会向记录文件中写入一条记录。除了最简单的标量(scalar)以外,TensorBoard 还可以对其他类型的数据(如图像,音频等)进行可视化 - 代码目录打开终端:
tensorboard --logdir=./tensorboard - 默认情况下,TensorBoard 每 30 秒更新一次数据。不过也可以点击右上角的刷新按钮手动刷新。
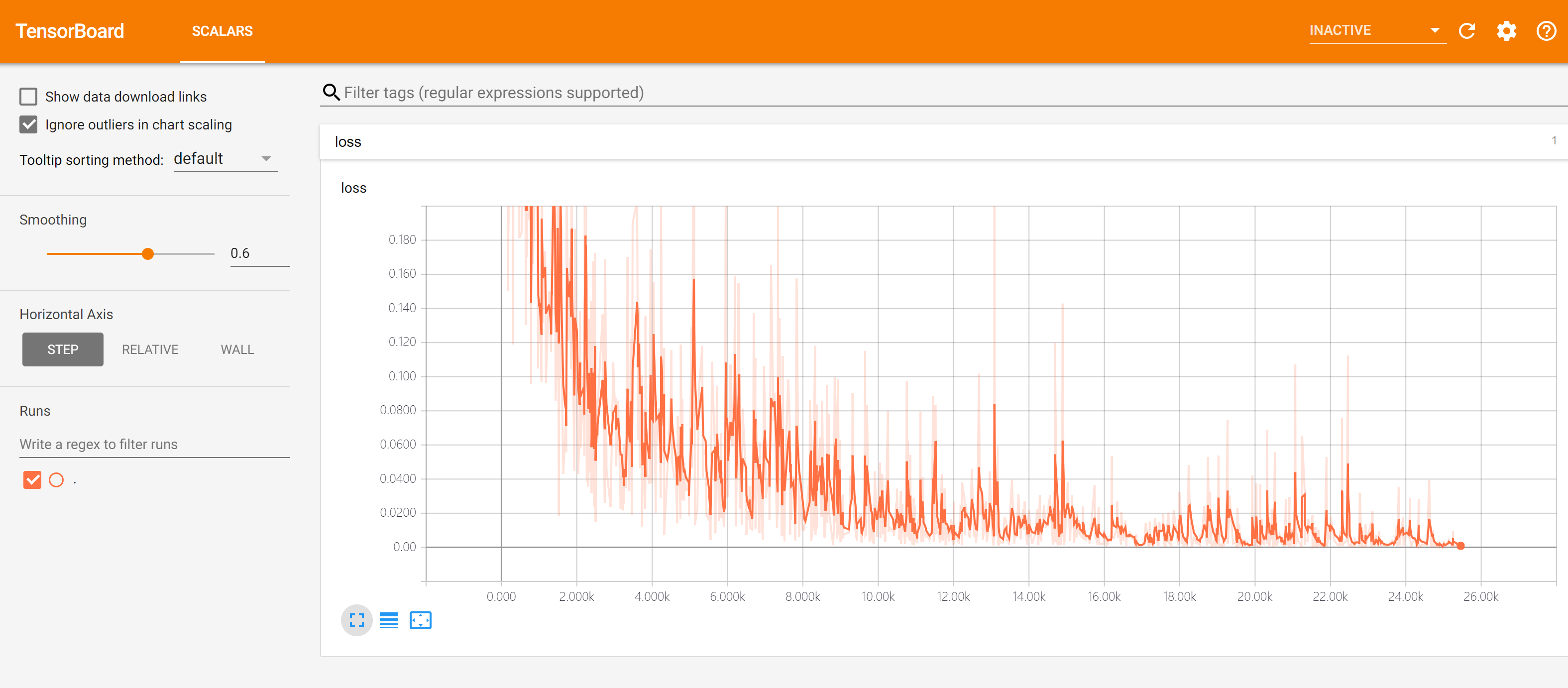
TensorFlow 在MNIST实验数据上得到Tensorboard结果
- Event: 展示训练过程中的统计数据(最值,均值等)变化情况
- Image: 展示训练过程中记录的图像
- Audio: 展示训练过程中记录的音频
- Histogram: 展示训练过程中记录的数据的分布图
注意事项:
- 如果需要重新训练,需要删除掉记录文件夹内的信息并重启 TensorBoard(或者建立一个新的记录文件夹并开启 TensorBoard, –logdir 参数设置为新建立的文件夹);
- 记录文件夹目录保持全英文。
import tensorflow as tf
from zh.model.mnist.mlp import MLP
from zh.model.utils import MNISTLoader
num_batches = 1000
batch_size = 50
learning_rate = 0.001
log_dir = 'tensorboard' # 记录文件所保存的目录
model = MLP()
data_loader = MNISTLoader()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
summary_writer = tf.summary.create_file_writer(log_dir) # 实例化记录器
#tf.summary.trace_on(profiler=True) # 开启Trace(可选)
tf.summary.trace_on(graph=True, profiler=True) # 开启Trace,可以记录图结构和profile信息;如果使用了 tf.function 建立了计算图,也可以点击 “Graphs” 查看图结构。
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
with summary_writer.as_default(): # 指定记录器
tf.summary.scalar("loss", loss, step=batch_index) # 将当前损失函数的值写入记录器
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
with summary_writer.as_default():
tf.summary.trace_export(name="model_trace", step=0, profiler_outdir=log_dir) # 保存Trace信息到文件(可选)
Tensorboard 使用
- 理解训练过程、调试和优化TensorFlow程序,TensorFlow团队开发了一套名为TensorBoard的可视化工具,它是一套可以通过浏览器运行的Web应用程序。TensorBoard可用于可视化TensorFlow计算图,绘制有关计算图运行结果的量化指标,并显示其他数据(如通过它的图像)
-
- 5个步骤
# (1) From TF graph, decide which tensors you want to log
w2_hist = tf.summary.histogram("weights2", W2)
cost_summ = tf.summary.scalar("cost", cost)
# (2) Merge all summaries
summary = tf.summary.merge_all()
# Create writer and add graph
# (3) Create summary writer
writer = tf.summary.FileWriter(‘./logs’)
writer.add_graph(sess.graph)
# (4) Run summary merge and add_summary
s, _ = sess.run([summary, optimizer], feed_dict=feed_dict)
writer.add_summary(s, global_step=global_step)
# (5) Launch TensorBoard
tensorboard --logdir=./logs
# 端口映射,远程server调用本地日志
#ssh -L local_port:127.0.0.1:remote_port username@server.com
ssh -L 7007:121.0.0.0:6006 hunkim@server.com # local
tensorboard —logdir=./logs/xor_logs # server
# 访问:http://127.0.0.1:7007
- TensorBoard 常用API
- tensorboard可视化: 通过 TensorFlow 程序运行过程中输出的日志文件可视化 TenorFlow 程序的运行状态d
Tensorboard PyTorch
安装
win 11 下安装经验
pip install tensorboard
pip show tensorboard # 显示安装路径
确保python目录权限充足,否则报错,需要管理员权限
启动 tensorboard
- ① 工具:确保 Python 工具包里有
tensorboard.exe文件,且路径添加到系统变量中tensorboard --logdir runs
- ② 代码:
python E:\program_file\python\Lib\site-packages\tensorboard\main.py "E:\game\Tetris-DQN-NEAT\runs"
# tensorboard.exe 路径默认是 C:\Users\zhn19\AppData\Roaming\Python\Python39\Scripts
# 如果更换 Python 安装路径,就没有 tensorboard.exe 文件
# 直接使用 main.py , 有效
python E:\program_file\python\Lib\site-packages\tensorboard\main.py --logdir .\DQN\training_logs\
python -m tensorboard.main --logdir .\runs # 简洁版
问题1
找不到 tensorboard.exe
- 信息: ‘tensorboard’ 不是内部或外部命令,也不是可运行的程序 或批处理文件”解决方法
解法:
- 自己设置快捷指令
- windows: 新建 bat 文件,放到 Python根目录
- linux:
echo "alias tensorboard='python3 -m tensorboard.main'" >> ~/.bash_profile
- 使用: tensorboard.bat .\runs
# win: tensorboard.bat
python c:\Users\bernhard.hiller\AppData\Roaming\Python\Python37\site-packages\tensorboard\main.py --logdir="%1"
# linux
echo "alias tensorboard='python3 -m tensorboard.main'" >> ~/.bash_profile
【2025-4-19】更新
win 11上,自定义安装目录到 e 盘,出现问题:
- tensorboard 安装后,没有 tensorboard.exe 文件
原因
- 默认将 tensorboard.exe 编译到
Lib\site-packages\bin中,而此目录已存在(如提前安装了别的库 uv),导致生成失败
解法:
- 安装命令加参数: pip install uv –upgrade
- 此时会覆盖 bin 目录,将新生成的 uv.exe 放进去
- 手工将 uv.exe 复制到 Scripts 目录下
问题2
使用 ①,系统报错
- TensorFlow installation not found - running with reduced feature set
改用 ②,指定 main.py 文件
示例
PyTorch创建了一个名为SummaryWriter的实用程序类。
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("runs")
for i in range(100):
writer.add_scalar("y=2x", i*2, i)
writer.close()
生成日志目录 runs
- 以 events.out.tfevents. 开头的文件
启动 web 服务
- TensorBoard UI: http://localhost:6006
tensorboard --logdir=runs
tensorboard --logdir=runs --port 16006
# 远程绑定
ssh -L 16006:127.0.0.1:16006 username@ip
使用方法
代码示例
import torch
import torch.nn as nn
import numpy as np
from torch.utils.tensorboard import SummaryWriter
# 定义模型
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1) # 输入和输出都是1维
def forward(self, x):
return self.linear(x)
# 准备数据
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167],
[7.042], [10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221],
[2.827], [3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
x_train = torch.from_numpy(x_train)
y_train = torch.from_numpy(y_train)
# 初始化模型
model = LinearRegressionModel()
# 损失和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 初始化 SummaryWriter
writer = SummaryWriter('runs/linear_regression_experiment')
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
# 转换为tensor
inputs = x_train
targets = y_train
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录损失
writer.add_scalar('Loss/train', loss.item(), epoch)
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# 关闭SummaryWriter
writer.close()
问题
【2025-4-18】Win 11, pytorch, python 3.13 上报错
- tensorboard : 无法将“tensorboard”项识别为 cmdlet、函数、脚本文件或可运行程序的名称
PyTorch 可视化
总结
tensorflow的模型结构可视化方法:参考文章
- (1)使用自带的tensorboard(不直观)
- (2)使用netron工具打开(.pd 或者是.meta文件)
- (3)第三方库CNNGraph( https://github.com/huachao1001/CNNGraph)
- (4)tensorspace.js (这个比较高级,没用过)
- (5)高层API中keras的可视化
pytorch的模型结构可视化方法:
- (1)使用tensorboardX(不太直观)
- (2)使用graphviz加上torchviz (依赖于graphviz和GitHub第三方库torchviz)
- (3)使用微软的tensorwatch (只能在jupyter notebook中使用,个人最喜欢这种方式)
- (4)使用netron可视化工具(.pt 或者是 .pth 文件)
网络示例
示例代码
import torch
import torch.nn as nn
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 16, 3, 1, 1),
nn.ReLU(),
nn.AvgPool2d(2, 2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(32 * 7 * 7, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU()
)
self.out = nn.Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
output = self.out(x)
return output
# 输出网络结构
MyConvNet = ConvNet()
print(MyConvNet)
有了基本的神经网络后,分别通过HiddenLayer和PyTorchViz库来可视化上述的卷积层神经网络。
网络结构可视化
HiddenLayer 可视化
安装库
pip install hiddenlayer
可视化
import hiddenlayer as h
vis_graph = h.build_graph(MyConvNet, torch.zeros([1 ,1, 28, 28])) # 获取绘制图像的对象
vis_graph.theme = h.graph.THEMES["blue"].copy() # 指定主题颜色
vis_graph.save("./demo1.png") # 保存图像的路径
可视化训练过程
- HiddenLayer 适用于小网络可视化,其它建议使用更复杂的 tensorboardX
- 不同于tensorboard,hiddenlayer会在程序运行的过程中动态生成图像,而不是模型训练完后
import hiddenlayer as hl
import time
# 记录训练过程的指标
history = hl.History()
# 使用canvas进行可视化
canvas = hl.Canvas()
# 获取优化器和损失函数
optimizer = torch.optim.Adam(MyConvNet.parameters(), lr=3e-4)
loss_func = nn.CrossEntropyLoss()
log_step_interval = 100 # 记录的步数间隔
for epoch in range(5):
print("epoch:", epoch)
# 每一轮都遍历一遍数据加载器
for step, (x, y) in enumerate(train_loader):
# 前向计算->计算损失函数->(从损失函数)反向传播->更新网络
predict = MyConvNet(x)
loss = loss_func(predict, y)
optimizer.zero_grad() # 清空梯度(可以不写)
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新网络
global_iter_num = epoch * len(train_loader) + step + 1 # 计算当前是从训练开始时的第几步(全迭代次数)
if global_iter_num % log_step_interval == 0:
# 控制台输出一下
print("global_step:{}, loss:{:.2}".format(global_iter_num, loss.item()))
# 在测试集上预测并计算正确率
test_predict = MyConvNet(test_data_x)
_, predict_idx = torch.max(test_predict, 1) # 计算softmax后的最大值的索引,即预测结果
acc = accuracy_score(test_data_y, predict_idx)
# 以epoch和step为索引,创建日志字典
history.log((epoch, step),
train_loss=loss,
test_acc=acc,
hidden_weight=MyConvNet.fc[2].weight)
# 可视化
with canvas:
canvas.draw_plot(history["train_loss"])
canvas.draw_plot(history["test_acc"])
canvas.draw_image(history["hidden_weight"])
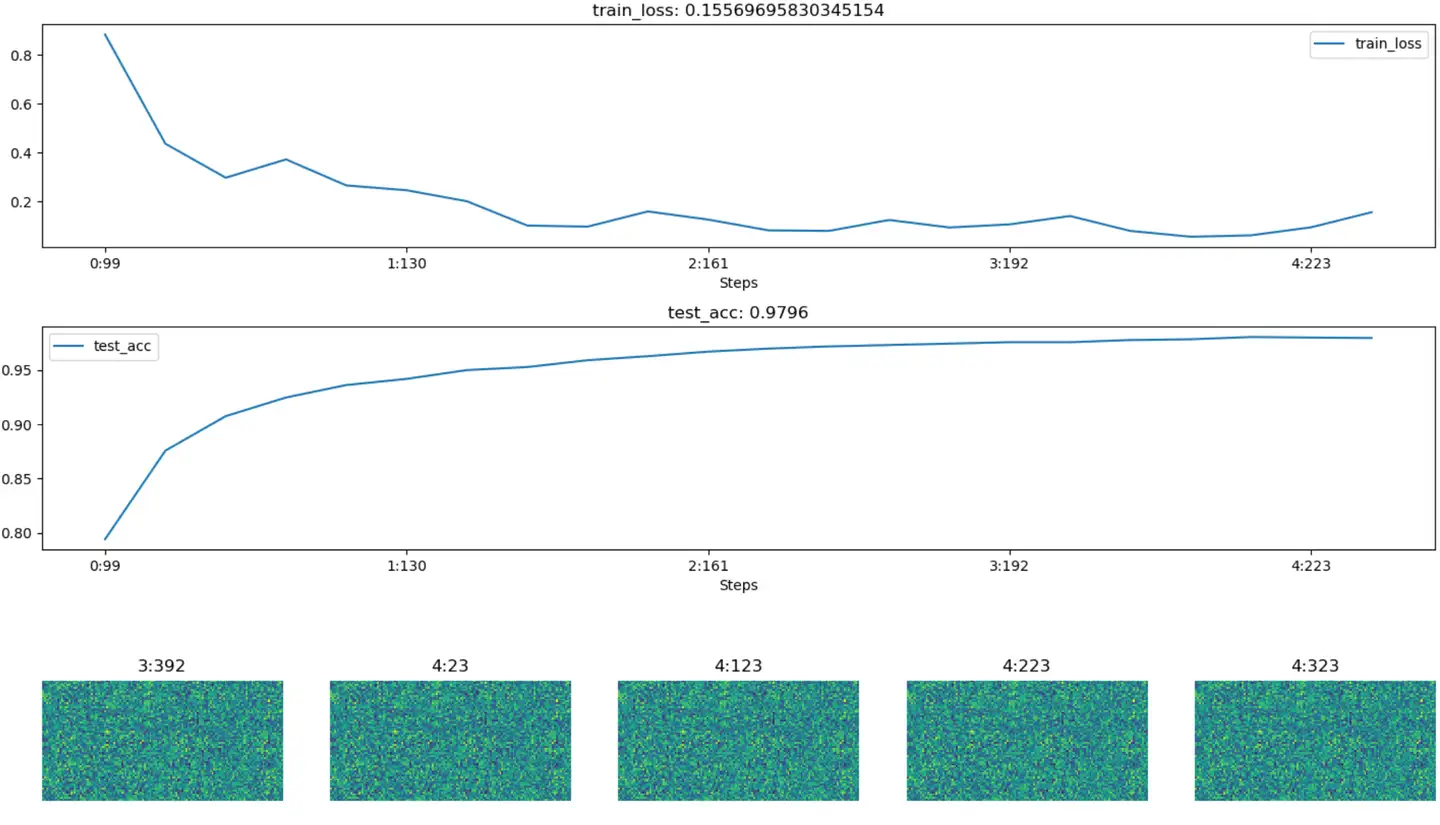
效果

PyTorchViz 可视化
安装
pip install torchviz
只使用可视化函数make_dot()来获取绘图对象,基本使用和HiddenLayer差不多,不同的地方在于PyTorch绘图之前可以指定一个网络的输入值和预测值。
from torchviz import make_dot
x = torch.randn(1, 1, 28, 28).requires_grad_(True) # 定义一个网络的输入值
y = MyConvNet(x) # 获取网络的预测值
MyConvNetVis = make_dot(y, params=dict(list(MyConvNet.named_parameters()) + [('x', x)]))
MyConvNetVis.format = "png"
# 指定文件生成的文件夹
MyConvNetVis.directory = "data"
# 生成文件
MyConvNetVis.view()
打开与上述代码相同根目录下的data文件夹,里面会有一个.gv文件和一个.png文件,其中的.gv文件是Graphviz工具生成图片的脚本代码,.png是.gv文件编译生成的图片,直接打开.png文件就行。
- 默认情况下,上述程序运行后会自动打开.png文件
Zetane Engine
2021年,加拿大蒙特利尔一家公司开发了 3D可视化工具 Zetane Engine, 透视“AI黑箱”过程
只需要上传一个模型,Zetane Engine 就可以巡视整个神经网络,并且还可以放大网络中的任何一层,显示特征图,看清流水线上的每一步
注意
- 只能对 ONNX, Keras(.h5 ) 以及 ZTN 模型进行可视化。
- 如果是 .pth 模型,可以考虑模型转换
训练过程可视化
tensorboardX 可视化
数据集准备
import torchvision
import torch.utils.data as Data
# 准备训练用的MNIST数据集
train_data = torchvision.datasets.MNIST(
root = "./data/MNIST", # 提取数据的路径
train=True, # 使用MNIST内的训练数据
transform=torchvision.transforms.ToTensor(), # 转换成torch.tensor
download=False # 如果是第一次运行的话,置为True,表示下载数据集到root目录
)
# 定义loader
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=128,
shuffle=True,
num_workers=0
)
test_data = torchvision.datasets.MNIST(
root="./data/MNIST",
train=False, # 使用测试数据
download=False
)
# 将测试数据压缩到0-1
test_data_x = test_data.data.type(torch.FloatTensor) / 255.0
test_data_x = torch.unsqueeze(test_data_x, dim=1)
test_data_y = test_data.targets
# 打印一下测试数据和训练数据的shape
print("test_data_x.shape:", test_data_x.shape)
print("test_data_y.shape:", test_data_y.shape)
for x, y in train_loader:
print(x.shape)
print(y.shape)
break
tensorboardX可视化训练过程
tensorboard是谷歌开发的深度学习框架tensorflow的一套深度学习可视化神器,pytorch团队开发出了tensorboardX来让pytorch的玩家也能享受tensorboard的福利。
先安装相关的库:
pip install tensorboardX
pip install tensorboard
并将tensorboard.exe所在的文件夹路径加入环境变量path中
tensorboardX的使用过程。
- 基本使用为,先通过tensorboardX下的SummaryWriter类获取一个日志编写器对象。
- 然后通过这个对象的一组方法往日志中添加事件,即生成相应的图片,最后启动前端服务器,在localhost中就可以看到最终的结果了。
from tensorboardX import SummaryWriter
logger = SummaryWriter(log_dir="data/log")
# 获取优化器和损失函数
optimizer = torch.optim.Adam(MyConvNet.parameters(), lr=3e-4)
loss_func = nn.CrossEntropyLoss()
log_step_interval = 100 # 记录的步数间隔
for epoch in range(5):
print("epoch:", epoch)
# 每一轮都遍历一遍数据加载器
for step, (x, y) in enumerate(train_loader):
# 前向计算->计算损失函数->(从损失函数)反向传播->更新网络
predict = MyConvNet(x)
loss = loss_func(predict, y)
optimizer.zero_grad() # 清空梯度(可以不写)
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新网络
global_iter_num = epoch * len(train_loader) + step + 1 # 计算当前是从训练开始时的第几步(全迭代次数)
if global_iter_num % log_step_interval == 0:
# 控制台输出一下
print("global_step:{}, loss:{:.2}".format(global_iter_num, loss.item()))
# 添加的第一条日志:损失函数-全局迭代次数
logger.add_scalar("train loss", loss.item() ,global_step=global_iter_num)
# 在测试集上预测并计算正确率
test_predict = MyConvNet(test_data_x)
_, predict_idx = torch.max(test_predict, 1) # 计算softmax后的最大值的索引,即预测结果
acc = accuracy_score(test_data_y, predict_idx)
# 添加第二条日志:正确率-全局迭代次数
logger.add_scalar("test accuary", acc.item(), global_step=global_iter_num)
# 添加第三条日志:这个batch下的128张图像
img = vutils.make_grid(x, nrow=12)
logger.add_image("train image sample", img, global_step=global_iter_num)
# 添加第三条日志:网络中的参数分布直方图
for name, param in MyConvNet.named_parameters():
logger.add_histogram(name, param.data.numpy(), global_step=global_iter_num)
代码同一级的目录,输入指令,启动服务器
- tensorboard –logdir=”./data/log”
- 浏览器中访问红框框中的url,便可得到可视化界面,点击上面的页面控件
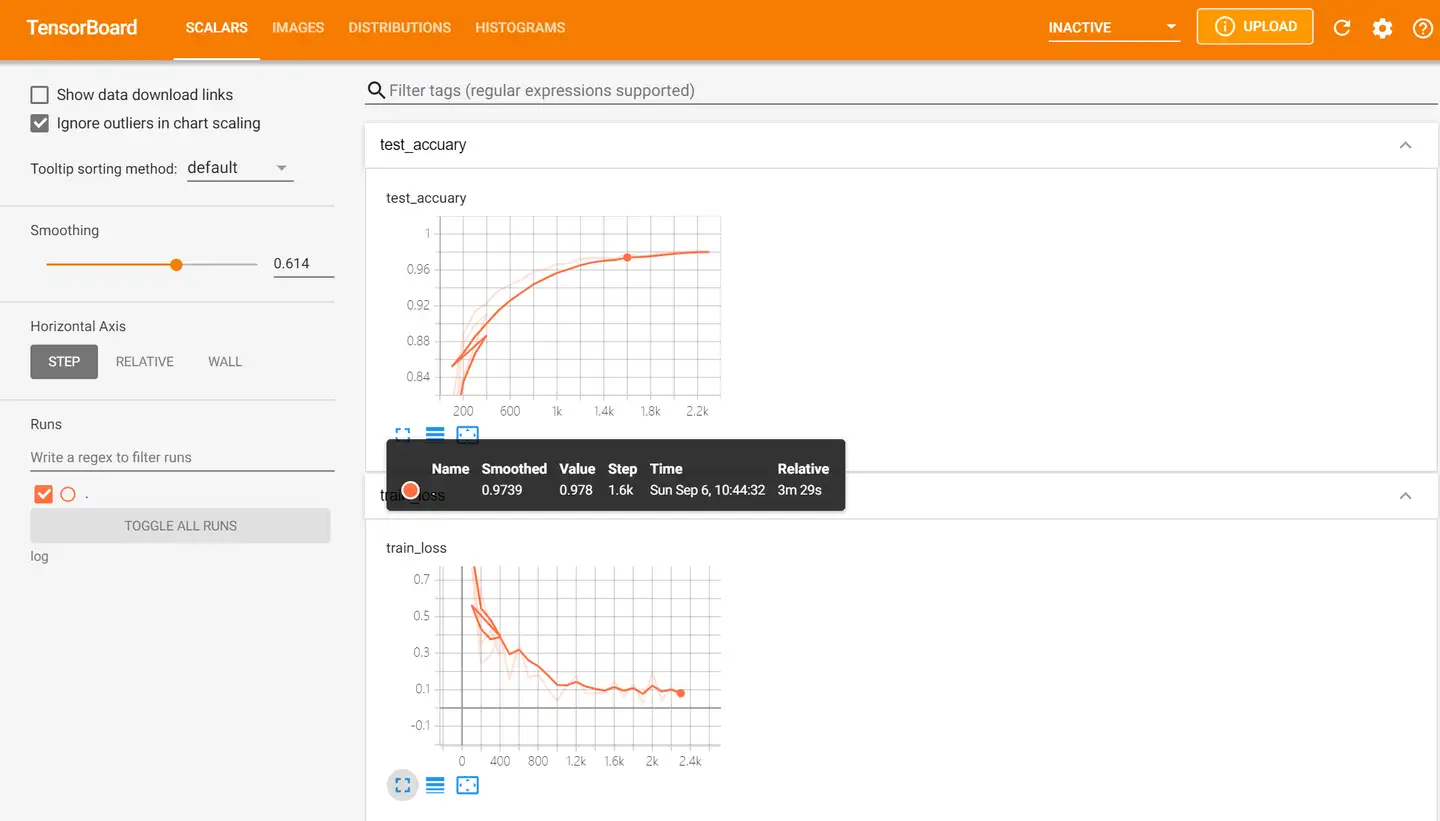
HiddenLayer
tensorboard的图像很华丽,但是使用过程相较于其他的工具包较为繁琐,所以小网络一般没必要使用tensorboard。
- 不同于tensorboard,hiddenlayer会在程序运行的过程中动态生成图像,而不是模型训练完后
import hiddenlayer as hl
import time
# 记录训练过程的指标
history = hl.History()
# 使用canvas进行可视化
canvas = hl.Canvas()
# 获取优化器和损失函数
optimizer = torch.optim.Adam(MyConvNet.parameters(), lr=3e-4)
loss_func = nn.CrossEntropyLoss()
log_step_interval = 100 # 记录的步数间隔
for epoch in range(5):
print("epoch:", epoch)
# 每一轮都遍历一遍数据加载器
for step, (x, y) in enumerate(train_loader):
# 前向计算->计算损失函数->(从损失函数)反向传播->更新网络
predict = MyConvNet(x)
loss = loss_func(predict, y)
optimizer.zero_grad() # 清空梯度(可以不写)
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新网络
global_iter_num = epoch * len(train_loader) + step + 1 # 计算当前是从训练开始时的第几步(全局迭代次数)
if global_iter_num % log_step_interval == 0:
# 控制台输出一下
print("global_step:{}, loss:{:.2}".format(global_iter_num, loss.item()))
# 在测试集上预测并计算正确率
test_predict = MyConvNet(test_data_x)
_, predict_idx = torch.max(test_predict, 1) # 计算softmax后的最大值的索引,即预测结果
acc = accuracy_score(test_data_y, predict_idx)
# 以epoch和step为索引,创建日志字典
history.log((epoch, step),
train_loss=loss,
test_acc=acc,
hidden_weight=MyConvNet.fc[2].weight)
# 可视化
with canvas:
canvas.draw_plot(history["train_loss"])
canvas.draw_plot(history["test_acc"])
canvas.draw_image(history["hidden_weight"])
Visdom进行可视化
Visdom是Facebook为pytorch开发的一块可视化工具。类似于tensorboard,visdom也是通过在本地启动前端服务器来实现可视化的,而在具体操作上,visdom又类似于matplotlib.pyplot。所以使用起来很灵活。
from visdom import Visdom
from sklearn.datasets import load_iris
import torch
import numpy as np
from PIL import Image
# 绘制图像需要的数据
iris_x, iris_y = load_iris(return_X_y=True)
# 获取绘图对象,相当于plt
vis = Visdom()
# ===== 添加折线图 =======
x = torch.linspace(-6, 6, 100).view([-1, 1])
sigmoid = torch.nn.Sigmoid()
sigmoid_y = sigmoid(x)
tanh = torch.nn.Tanh()
tanh_y = tanh(x)
relu = torch.nn.ReLU()
relu_y = relu(x)
# 连接三个张量
plot_x = torch.cat([x, x, x], dim=1)
plot_y = torch.cat([sigmoid_y, tanh_y, relu_y], dim=1)
# 绘制线性图
vis.line(X=plot_x, Y=plot_y, win="line plot", env="main",
opts={
"dash" : np.array(["solid", "dash", "dashdot"]),
"legend" : ["Sigmoid", "Tanh", "ReLU"]
})
# ====== 绘制2D和3D散点图 ========
# 参数Y用来指定点的分布,win指定图像的窗口名称,env指定图像所在的环境,opts通过字典来指定一些样式
vis.scatter(iris_x[ : , 0 : 2], Y=iris_y+1, win="windows1", env="main")
vis.scatter(iris_x[ : , 0 : 3], Y=iris_y+1, win="3D scatter", env="main",
opts={
"markersize" : 4, # 点的大小
"xlabel" : "特征1",
"ylabel" : "特征2"
})
# ==== 添加茎叶图 ======
x = torch.linspace(-6, 6, 100).view([-1, 1])
y1 = torch.sin(x)
y2 = torch.cos(x)
# 连接张量
plot_x = torch.cat([x, x], dim=1)
plot_y = torch.cat([y1, y2], dim=1)
# 绘制茎叶图
vis.stem(X=plot_x, Y=plot_y, win="stem plot", env="main",
opts={
"legend" : ["sin", "cos"],
"title" : "茎叶图"
})
# 计算鸢尾花数据集特征向量的相关系数矩阵
iris_corr = torch.from_numpy(np.corrcoef(iris_x, rowvar=False))
# ==== 绘制热力图 =====
vis.heatmap(iris_corr, win="heatmap", env="main",
opts={
"rownames" : ["x1", "x2", "x3", "x4"],
"columnnames" : ["x1", "x2", "x3", "x4"],
"title" : "热力图"
})
# ==== 可视化图片 =====
img_Image = Image.open("./example.jpg")
img_array = np.array(img_Image.convert("L"), dtype=np.float32)
img_tensor = torch.from_numpy(img_array)
print(img_tensor.shape)
# 这次env自定义
vis.image(img_tensor, win="one image", env="MyPlotEnv",
opts={
"title" : "一张图像"
})
# ==== 可视化文本 =====
text = "hello world"
vis.text(text=text, win="text plot", env="MyPlotEnv",
opts={
"title" : "可视化文本"
})
运行上述代码,再
- 在终端中启动服务器
- python3 -m visdom.server
- 然后根据终端返回的URL,在谷歌浏览器中访问这个URL,就可以看到图像了
- 在Environment中输入不同的env参数可以看到我们在不同环境下绘制的图片。对于分类图集特别有用

注意:
- 如果前端服务器停掉了,那么所有的图片都会丢失,因为此时的图像的数据都是驻留在内存中,而并没有dump到本地磁盘。
- 那么如何保存当前visdom中的可视化结果,并在将来复用呢?点击Manage Views → 点击fork->save
wandb
【2023-4-10】wandb使用教程(一):基础用法
wandb是一个免费、用于记录实验数据的工具。
- wandb相比于tensorboard之类的工具,有更加丰富的用户管理,团队管理功能,更加方便团队协作。
wandb 是 Weight & Bias 缩写,与 Tensorboard 类似的参数可视化平台。
Weights & Biases 是强大的实验跟踪工具,支持 PyTorch、TensorFlow 等多种深度学习框架。它不仅可以可视化训练过程,还可以记录超参数、模型权重等信息。
- 全面的实验跟踪:记录训练过程中的所有关键信息,包括超参数、损失、准确率等。
- 协作功能:支持团队协作,可以共享实验数据和结果。
- 云端存储:所有实验数据都可以存储在云端,方便随时查看和分析
相比 TensorBoard,Wandb 更强大:
- 复现模型:Wandb更有利于复现模型。Wandb 不仅记录指标,还会记录超参数和代码版本。
- 自动上传云端:
- 把项目交给同事或者要去度假,Wandb可以便捷地查看所有模型,不必花费大量时间来重新运行旧实验。
- 快速、灵活的集成:
- 只需5分钟即可把Wandb加到项目。
- 下载Wandb免费的开源Python包,然后在代码中插入几行,以后每次运行模型都会得到记录完备的指标和记录。
- 集中式指示板:
- Wandb提供同样的集中式指示板。不管在哪里训练模型,不管是在本地机器、实验室集群还是在云端实例;不必花时间从别的机器上复制TensorBoard文件。
- 强大的表格:
- 对不同模型的结果进行搜索、筛选、分类和分组。
- 轻而易举地查看成千上万个模型版本,并找到不同任务的最佳模型。
使用wandb,首先要在网站上创建team,然后在team下创建project,然后project下会记录每个实验的详细数据。
wandb 安装
wandb Python库,可通过pip安装:
pip install wandb
# 公司内
pip install -U byted-wandb -i https://bytedpypi.byted.org/simple
# 【024-7-23】Python 3.12版本安装出错,3.11以下才行
No module named 'imp'
然后,在wandb官网注册一个账号,然后获取该账号的私钥。然后在命令行执行:
wandb login
根据提示输入私钥即可。
以本教程中的代码为例,我们创建一个叫做tmarl的team,然后创建了一个叫做wandb_usage的project:
- wandb界面展示
然后在代码里面只要指定该team和project,便可以把数据传输到对应的project下:
import wandb
config = dict (
learning_rate = 0.01,
momentum = 0.2,
architecture = "CNN",
dataset_id = "peds-0192",
infra = "AWS",
)
test = wandb.init(
project='wqw', # 项目名称wqw,运行时会创建 wqw 目录
entity=your_team_name,
notes=socket.gethostname(),
name='test', # 任务名,不设置时,系统会自动拼接两个单词作为名称,如 green-wood-250
# name 取值规则: 支持 - 和 _ 连接, 这类符号报错([]:,)
dir=run_dir,
job_type="training",
reinit=True,
resume="allow", # 是否可恢复, 防止意外中断, 默认None
config=config # 实验参数配置, 保存训练配置,这些配置包含超参数、数据集名称或模型类型等输入设置
)
# 运行中途可以更新config信息
wandb.config.update({'a':10})
test.config.update(dict(epoch=args.epochs, lr=args.lr, batch_size=args.batch_size))
# 补充观测数据
wandb.log({'loss': loss, 'epoch': epoch, 'learning rate': cur_lr,
'images': wandb.Image(images.float()),
'masks': {'true': wandb.Image(targets.float()),
'pred': wandb.Image(pred.float())}
})
wandb.Image() # 用于图像的显示,numpy格式的数组或者PIL实例转化为PNG,从而在网页上直接显示出来。
示例
单机
【2023-11-24】实践通过
专属api key启动
wandb login 666efa48cc...
执行训练脚本
import wandb
import random
# start a new wandb run to track this script
wandb.init(
# set the wandb project where this run will be logged
project="test",
# track hyperparameters and run metadata
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
}
)
# simulate training
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# log metrics to wandb
wandb.log({"acc": acc, "loss": loss})
# [optional] finish the wandb run, necessary in notebooks
wandb.finish()
【2024-3-20】wandb 报错
wandb.sdk.lib.config_util.ConfigError: Attempted to change value of key "batch_size" from 32 to 256
If you really want to do this, pass allow_val_change=True to config.update()
改进
import wandb
wandb.init() # allow_val_change=True 放 init 不管用
wandb.config.update({"allow_val_change":True})
分布式
分布式环境
- 一定要在 主节点(0) 上做日志操作(初始化init, 上传信息log)
- 否则, 造成分布式训练nccl通讯超时失败: 每个节点都初始化、上传,导致通讯混乱
- 加 try except 捕获异常
- name 取值中不能有这些字符:
[],- 否则, 随机初始化name
wandb_enable = True
if args.global_rank == 0:
try:
# exp_str 取值不能直接赋值给 name
exp_str = f'{args.model_name}gpu:{world_size},max:{args.max_seq_len},epochs:{args.num_train_epochs},bs:{args.per_device_train_batch_size},accum:{args.gradient_accumulation_steps},lr:{args.learning_rate}'
# 改进: exp_name 只用-和_连接
exp_name = f'{args.model_name}_gpu_{world_size}_epochs_{args.num_train_epochs}_bs_{args.per_device_train_batch_size}_accum_{args.gradient_accumulation_steps}_lr_{args.learning_rate}'
wandb.init(project=f'{args.project_name}_exp', name=f'{exp_name}', entity='flow-aipaas-wqw', resume='allow', config=vars(args)
)
print_rank_0(f"[Info] wandb 初始化成功, ... {exp_str}", args.global_rank)
except Exception as err:
wandb_enable = False
print_rank_0(f"[Error] wandb 初始化失败, 跳过... {err}", args.global_rank)
使用方法
wandb的基础功能就是跟踪训练过程,然后在wandb网站上查看训练数据。
wandb通过通用的log()函数,可以展示丰富的数据类型,包括训练曲线,图片,视频,表格,html,matplotlib图像等。
详细教程见:wandb使用教程(一):基础用法,本地部署
- 展示训练曲线示例: test_curves.sh
- 展示图片示例: test_images.sh
- 展示视频示例: test_videos.sh
- 展示matplotlib画图示例:test_matplot.sh
- 展示表格示例: test_tables.sh
- 展示多进程group示例: test_multi_process.sh
- 展示html示例: test_html.sh
- PyTorch集成示例: test_pytorch.sh
问题
【2024-3-19】执行
import wandb
# 不设置 project 时,会默认创建 wandb 目录
wandb.init()
# 设置 project
wandb.init(project="wqw")
报错:
分析
- 本地有
wandb目录(包含__init__.py)、wandb.py文件
My guess is that you have either:
- wandb directory that contains an
__init__.py, orwandb.pyfile in your working directory.
实情
- 公司内定制了wandb包,将默认包做了修改
解决方法
- 卸载
SwanLab
【2026-6-29】SwanLab 是AI训练分析与指标观测平台,面向模型训练团队,提供训练可视化、自动日志记录、超参数记录、实验对比、多人协同等功能,帮助团队快速发现训练问题,加速模型迭代。
研究者能基于直观的可视化图表发现训练问题,对比多个实验找到研究灵感,并通过在线网页的分享与基于组织的多人协同训练,打破团队沟通的壁垒,提高组织训练效率。
SwanLab 使用顶尖的 MLOps工具,改进AI开发团队模型训练流程
- 官方文档 guide_cloud
- GitHub SwanLab
特性
- 实验指标与超参数跟踪: 极简的代码嵌入您的机器学习 pipeline,跟踪记录训练关键指标
- ⚡️ 全面的框架集成: PyTorch、🤗HuggingFace Transformers、PyTorch Lightning、🦙LLaMA Factory、MMDetection、Ultralytics、PaddleDetetion、LightGBM、XGBoost、Keras、Tensorboard、Weights&Biases、Swift、XTuner、Stable Baseline3、Hydra 在内的 30+ 框架
- 💻 硬件监控: 支持实时记录与监控CPU、NPU(昇腾Ascend)、GPU(英伟达Nvidia)、AMD(AMD ROCm)、MLU(寒武纪Cambricon)、XLU(昆仑芯Kunlunxin)、DCU(海光DCU)、MetaX GPU(沐曦XPU)、Moore Threads GPU(摩尔线程)、Iluvatar GPU(天数智芯)、内存的系统级硬件指标
- 📦 实验管理: 通过专为训练场景设计的集中式仪表板,通过整体视图速览全局,快速管理多个项目与实验
- 🆚 比较结果: 通过在线表格与对比图表比较不同实验的超参数和结果,挖掘迭代灵感
- 👥 在线协作: 您可以与团队进行协作式训练,支持将实验实时同步在一个项目下,您可以在线查看团队的训练记录,基于结果发表看法与建议
- ✉️ 分享结果: 复制和发送持久的 URL 来共享每个实验,方便地发送给伙伴,或嵌入到在线笔记中
- 💻 支持自托管: 支持离线环境使用,自托管的社区版同样可以查看仪表盘与管理实验,使用攻略
- 🔌 插件拓展: 支持通过插件拓展SwanLab的使用场景,比如 飞书通知、Slack通知、CSV记录器等
开箱即用,轻松集成主流AI训练框架
- 只需 6 行代码即可开始实验跟踪、版本管理和可视化
- 支持 30+ 种主流训练框架集成
- 实时监控 CPU 和 GPU 使用情况
安装
pip install swanlab
pip install 'swanlab[dashboard]' # 离线看板
# 国内源
pip install swanlab -i https://mirrors.cernet.edu.cn/pypi/web/simple
# 登录
swanlab login
swanlab login -k your-api-key
代码
import swanlab
# 登录
swanlab.login(api_key="你的API Key", save=True)
# 1. 创建1个新项目
run = swanlab.init(
project="Qwen3",
experiment_name="qwen3-dpo",
config={
"learning_rate": 1e-4,
"epoch": 20,
},
)
# 2. 跟踪与可视化指标
for i in range(20):
swanlab.log({"loss": 20-i, "acc": i/20})
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
