- 图像生成
- 文生图
- 图像生成技术演变
- 多模态图像生成
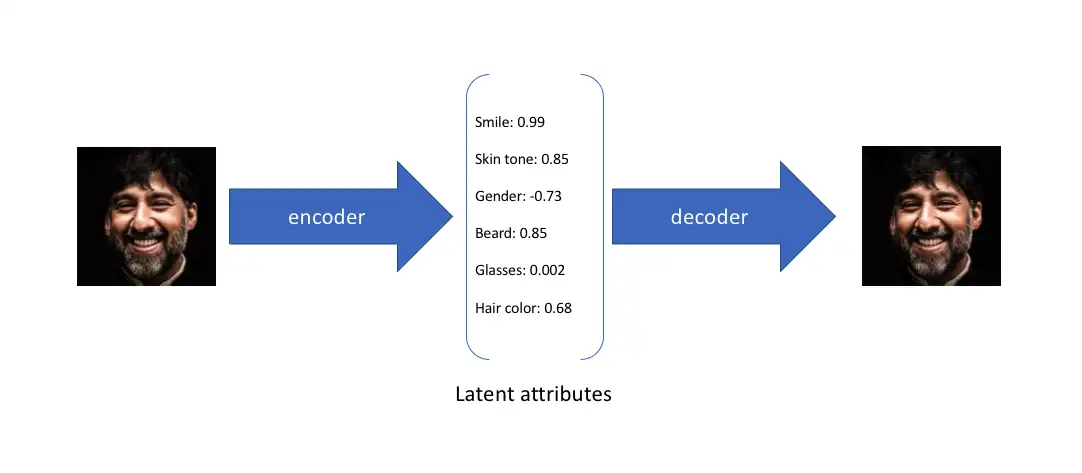
- AE 自编码器
- VAE 变分自编码器 – AE改进
- GAN 对抗生成网络
- Flow-Based
- 扩散模型
- 可控生成
- AI 作画
- 应用
- 结束
图像生成
文生图
任务场景
- 无条件生成
- 有条件生成
无条件生成
生成模型在生成图像时,不受任何额外条件或约束的影响。模型从学习的数据分布中生成图像,而不需要关注输入条件。
无条件适用于不需要额外信息或上下文的场景。
- 针对人脸数据训练,输入随机噪声,然后生成逼真的人脸图像,而不用考虑任何特定属性或描述。
- CelebA-HQ(人脸)、FFHQ(人脸)、LSUN-Churches(教堂) 和 LSUN-Bedrooms(卧室) 都是常见的无条件评估任务。
有条件生成
有条件生成可通过 cross attention 方式引入各式各样的条件控制图像生成。
分类
- 类别条件生成
- 文本条件生成
- 位置条件
- 图像扩充 (Outpainting)
- 图像内编辑 (inpainting)
- 图像内文字生成
- 多种条件生成
类别条件生成
类别条件生成是常见场景
- ImageNet 是最常见的一种,ImageNet 常用于图像分类任务,每个图像都有一个类别标签,总共有 1000 个类别。
- 图像生成领域,可以指定对应的类别标签,然后让模型按照类别生成图像。
文本条件生成
最常见的图像生成范式,输入自然语言描述,模型即可生成相应的图像。
位置条件
有些时候会对图像中物体布局,或主体位置有特殊要求,此时,可以结合上述的类别条件和文本条件来约束模型。
- 左侧图中指定了图片中物体的位置关系(以边界框坐标表示),最终模型按要求生成了对应的图像(图片来自 LDM,模型基于 COCO 数据集训练)
图像扩充 (Outpainting) and 图像内编辑 (inpainting)
给定图像,将其扩展为更大的图片;市面上比较火的应用,如 ai扩图,商品图背景生成,基本上都是基于outpainting 的方式。
inpaint 和 outpaint 模型的训练方式基本相同,都是用文生图模型的权重进行初始化,然后改变 Unet 输入的 channels(5 additional input channels ,4 for the encoded masked-image and 1 for the mask itself),新增的channels zero-initialized。
但是需要注意的是 inpaint 和 outpaint 训练时的mask方式根据推理时mask的特点而有所不同,二者可以混合在一起训练。
图像内文字生成
要图片包含特定的文本内容,以条件形式输入。但是当前大部分文生图的模型直接生成文字效果都不太好 (Dalle3 生成文字比较准确,文字不易变形)
Meta文生图模型Emu 采用 channel数更大的VAE可以改善生成文字畸变的情况。
对于文字概念,需要训练数据中的caption描述更加准确和详细。
多种条件生成
有些场景会包含多种条件,比如:
- 给定图像、文本等多种条件,模型综合考量这些条件才能生成满足要求的图像。
图像生成技术演变
- 【2023-4-4】从VAE到扩散模型:一文解读以文生图新范式
- 【2024-1-19】一文纵览文生图/文生视频技术发展路径与应用场景
图像生成方法除了熟知的生成对抗网络(GAN),主流方法还包括变分自编码器(VAE)和基于流的生成模型(Flow-based models),以及近期颇受关注的扩散模型(Diffusion models)

自2014年生成对抗网络(GAN)诞生以来,图像生成研究成为了深度学习乃至整个人工智能领域的重要前沿课题,现阶段技术发展之强已达到以假乱真的程度。
生成对抗网络(GAN)通过生成器和判别器之间的对抗学习来生成图像变分自编码器(VAE)利用编码器和解码器来学习数据的潜在表示基于流的生成模型(Flow-based models)扩散模型(Diffusion models)通过逐步去除加入数据的噪声来重建图像
文生图的主流技术路径可分为 4 类
- 基于
GAN(Generative Adversarial Network)- 发展阶段:2016 年 -2021 年较火热,后续放缓,不再是主流方向
- 原理 :GAN 由生成器和判别器构成,通过训练生成器和判别器来进行对抗学习,学习数据的分布,并生成新的数据样本。
- 其中生成器试图生成与真实数据相似的样本,而判别器则试图区分生成的样本和真实样本(二分类问题)。
- 生成器和判别器通过博弈论中的对抗过程进行训练,使得生成器不断改进生成的样本,直到判别器无法区分生成的样本和真实样本为止。
- 代表模型: DF-GAN、StackGAN++、GoGAN、AttnGAN
- 基于
VAE(Variational Autoencoder)- 发展阶段:2014 年提出,目前应用广泛,但独立生成图片质量不足,常与 Diffusion Model、自回归模型等架构结合使用
- 原理 :VAE 本质是一个基于梯度的 encoder-decoder 架构,编码器用来学习数据的潜在变量表示(高斯分布的均值和方差);解码器用变分后验来学习生成能力(标准高斯映射到数据样本的能力;而将标准高斯映射到数据样本是自己定义的),生成新的数据样本。
- VAE 通过将数据编码为潜在变量的分布,并使用重新参数化技巧来生成新的样本,VAE 的训练过程可以看作是最小化数据的重构误差和潜在变量的 KL 散度。
- 编码器(Encoder):VAE 首先通过编码器将输入数据(如图像)转换成潜在空间中的表示。这个表示不是单个值,而是概率分布的参数(通常是均值和方差)。
- 潜在空间(Latent Space):潜在空间的数据表示形式更简洁、抽象,可以在捕捉数据的关键特征的同时大幅降低计算成本。
- 重参数化(Reparameterization):为了使模型能够通过梯度下降进行学习,VAE 采用重参数化技巧:从编码器得到的分布中采样,生成可以反向传播的样本。
- 解码器(Decoder):最后,VAE 使用解码器从潜在空间中的样本重建原始数据。
- 代表模型: DF-GAN、StackGAN++、GoGAN、AttnGAN
- 基于 Diffusion Model
- 发展阶段:2022 年至今,受益于开源模式和参数量较少,研究成本相对低,在学术界和工业界的传播和迭代速度快
- 原理:Diffusion Model 通过连续添加高斯噪声来破坏训练数据,然后通过消除噪声来学习如何重建数据
- 代表模型: Stable Diffusion、Midjourney、GLIDE、DALL-E 2、DALL-E 3
- 基于自回归模型(
Auto-regressive Model)- 发展阶段:2020 年至今,囿于闭源模式和参数量较大,研究成本高,迭代速度慢于 Diffusion Model
- 原理:自回归模型 Encoder 将文本转化成 token,经特征融合后,由训练好的模型 Decoder 输出图像
- 代表模型: DALL-E、CogView、CogView2、Parti、CM3leon
Diffusion Model 和 Auto-regressive LLM 两个技术路线并非完全独立,有融合趋势, Diffusion 也不断地吸收和学习语言模型方法,目前主流 Diffusion Model 实际上大量使用 Transformer 模型架构。
- 引入
Latent Diffusion。- 核心思想:把高维数据(如大图像)先降维到一个特征空间(使用 token),然后在这个特征空间上进行扩散过程,然后再把特征空间映射回图像空间。
- Latent Diffusion 研究团队之前主要研究语言模型。借鉴语言模型中的 tokenizer 概念,用于把图像转换为一系列的连续 token,从而使得 Diffusion 模型能更高效地处理复杂数据。
- 把
U-Net替换为Transformer。- 核心思想:Transformer 的处理能力和生成能力更强大,而 U-Net 架构是初期 Diffusion 模型中常用的架构,在处理更复杂任务时存在局限性,例如:
- 冗余太大,由于每个 pixel(像素点)都需要取一个 patch(贴片),那么相邻的两个 pixel 的 patch 相似度是非常高的,导致非常多的冗余,降低网络训练速度。
感受野和定位精度不可兼得,当感受野选取比较大的时候,后面对应的 pooling 层的降维倍数就会增大,这样就会导致定位精度降低,但是如果感受野比较小,那么分类精度就会降低。
| 维度 | GAN | VAE | Diffusion Model(扩散模型) | AR(自回归) | |
|---|---|---|---|---|---|
| 生成质量 | 中(多样性不足) | 中 | 高 | 高 | |
| 生成速度 | 快 | 快 | 中 | 中/慢 | AR受模型规模和推理资源限制 |
| 算力成本 训练/推理 |
低 | 低 | 中 | 高 | |
| 训练数据量 | 高 | 中 | 高 | 非常高 | |
| 训练稳定性 | 不稳定 | 较稳定 | 较稳定 | 较稳定 | |
| 分类 | 两阶段(生成/判别) 多阶段(逐层次/分阶段生成细化) |
- | 早期:pixel diffusion,直接在表示空间进行像素扩散 后期:latent diffusion, 引入transformer/VAE/GAN,形成各种变体 |
- | |
| 图像生成示例 | DF-GAN,Giga GAN,StyleGAN-T | Stack++ GoGAN AttnGAN |
VAE CVAE VQVAE |
早期:DALE 2,Imagen,eDiff-l,DDPM,Improved DDPM,Diffusion Beats GAN 后期:GLIDE,Parti,DALL-E 3,Stable Diffusion,MidJourney,ERNIE-VLG 2 |
DALL-E,CogView系列,Parti,CM3leon |
| 视频生成示例 | VGAN,TGAN,VideoGPT,DVD-GAN | - | Runway Gen-2,Stable Video Diffusion,MagicVideo-v2,WALT | CogVideo,GODIVA,VideoPoet | VideoPoet是基于LLM的Video foundation model |
| 优点 | 计算成本低,生成速度快 | 训练稳定,成本低,速度快 | 训练稳定,图像细节逼真,模型泛化强 | 训练文档,细节逼真,速度快,泛化强 视频生成帧与帧之间更为连贯 |
|
| 缺点 | 训练不稳定,多样性不足,泛化差 | 缺乏细节/清晰度 | 速度慢,资源消耗大,视频采样速度慢 | 参数量大,资源消耗大,数据量大 | |
Diffusion vs Flow
扩散模型和流匹配是同一个概念的两种不同表达方式吗?
- 从表面上看,这两种方法似乎各有侧重:
- 扩散模型专注于通过迭代方式逐步去除噪声,将数据还原成清晰的样本。通过最小化加权均方误差(MSE)损失来完成
- 而流匹配则侧重于构建可逆变换系统,目标是学习如何将简单的基础分布精确地映射到真实数据分布。
- 普遍认知: 样本生成方式上有所不同
- 流匹配采样是确定性的,具有直线路径 —— 实际上,采样轨迹是弯曲
- 而扩散模型采样是随机性的,具有曲线路径。
误解澄清
- 流匹配更新是重参数化采样常微分方程(ODE)的欧拉积分:
从确定性采样中得到的两个重要结论:
- 采样器的等价性:DDIM 与流匹配采样器等价,并且对噪声调度的线性缩放不变。
- 对直线性的误解:流匹配调度仅在模型预测单个点时才是直线。
除了训练考虑和采样器选择之外,扩散和高斯流匹配没有根本区别
扩散模型、流匹配哪个好?
Google DeepMind 研究团队发现,原来扩散模型和流匹配就像一枚硬币的两面,本质上是等价的 (尤其是在流匹配采用高斯分布作为基础分布时),只是不同的模型设定会导致不同的网络输出和采样方案。
这两种框架下的方法可以灵活搭配,发挥组合技了。
- 比如在训练完一个流匹配模型后,不必再局限于传统的确定性采样方法,完全可以引入随机采样策略。
- Diffusion Meets Flow Matching: Two Sides of the Same Coin
详见: 【2024-12-13】扩散模型=流匹配?谷歌DeepMind博客深度详解这种惊人的等价性
多模态图像生成
【2022-9-7】当 AI 邂逅绘画艺术,能迸发出怎样的火花?
多模态图像生成(Multi-Modal Image Generation)旨在利用文本、音频等模态信息作为指导条件,生成具有自然纹理的逼真图像。不像传统的根据噪声生成图像的单模态生成技术,多模态图像生成一直以来就是一件很有挑战的任务,要解决的问题主要包括:
- (1)如何跨越“语义鸿沟”,打破各模态之间固有的隔阂?
- (2)如何生成合乎逻辑的,多样性的,且高分辨率的图像?
近两年,随着 Transformer 在自然语言处理(如 GPT)、计算机视觉(如 ViT)、多模态预训练(如 CLIP)等领域的成功应用,以及以 VAE、GAN 为代表的图像生成技术有逐渐被后起之秀——扩散模型(Diffusion Model)赶超之势,多模态图像生成的发展一发不可收拾。
按照训练方式采用的是 Transformer 自回归还是扩散模型的方式,近两年多模态图像生成重点工作分类如下
- Transformer
自回归:将文本和图像分别转化成 tokens 序列,然后利用生成式的 Transformer 架构从文本序列(和可选图像序列)中预测图像序列,最后使用图像生成技术(VAE、GAN等)对图像序列进行解码,得到最终生成图像。 扩散模型:扩散模型(Diffusion Model)是一种图像生成技术,最近一年发展迅速,被喻为 GAN 的终结者。如图所示,扩散模型分为两阶段:- (1)加噪:沿着扩散的马尔可夫链过程,逐渐向图像中添加随机噪声;
- (2)去噪:学习逆扩散过程恢复图像。常见变体有去噪扩散概率模型(DDPM)等。

采取扩散模型方式的多模态图像生成做法,主要是通过带条件引导的扩散模型学习文本特征到图像特征的映射,并对图像特征进行解码得到最终生成图像
AE 自编码器
自编码器(Auto Encoder,AE)是早期较为简单的生成模型
- 通过一个编码器将输入 X 编码成隐变量 z ,再通过一个解码器将 z 解码成重构样本 X’ 。
- 优化目标: 最小化 X 与 X′ 之间的误差。
自动编码的过程得到一个输入样本 X 的特征 z,也就是隐变量。
神经网络学习到每个输入样本的特征,并根据此特征将输入还原出来。

总结
- 传统自编码器以无监督方式训练一个神经网络,完成将原始输入压缩成中间表示和恢复两个过程,前者通过
编码器(Encoder)将原始高维输入转换为低维隐层编码,后者通过解码器(Decoder)从编码中重建数据。 - 不难看出,自编码器的目标是学习一个恒等函数,用交叉熵(Cross-entropy)或者均方差(Mean Square Error)构建重建损失量化输入和输出的差异。
- AE得到低纬度的隐层编码,捕捉了原始数据的潜在属性,可以用于数据压缩和特征表示。
由于自编码器仅关注隐层编码的重建能力,其隐层空间分布往往是无规律和不均匀的,在连续隐层空间随机采样或者插值得到一组编码, 通常会产生无意义和不可解释的生成结果。
问题
- 固定特征然后还原的实现方式导致 AE 容易过拟合。
- 当模型遇到没有出现过的新样本时,有时得不到有意义的生成结果。
AE 变体
AE:
- 原始图像X通过encoder后,得到较小维度的特征(bottleneck)
- 再从bottleneck开始,经过decoder后得到新的X’
- 希望X‘尽可能重建原始X
AutoEncoder 变种:AE/DAE/VAE/VQ-VAE
DAE:Denoising AutoEncoder
原始图像经过扰乱后得到 Xc(X corrupt),再将Xc传给encoder,后续和AE的步骤一致,目标也是希望X’能够尽可能地重建X(而不是扰乱之后的Xc)
分析
- 优点:训练出来的结果非常稳健,不容易过拟合(原因:图像这边的冗余太高了,参考MAE,masked AutoEncoder,masked 75%)
- 不足
- AE/DAE/MAE 目标都是生成中间的bottleneck,可以用这个embedding做下游的分类任务,但是这里的bottleneck不是一个概率分布,没法对其进行采样,所以无法做生成任务。
VAE 变分自编码器 – AE改进
变分自编码器(Variational Autoencoder)是AE的一种变体
为了构建有规律的隐层空间,使得在不同潜在属性上随机采样和平滑插值,最后通过解码器生成有意义的图像,研究者2014年提出了变分自编码器。
变分自动编码器(Variational Auto Encoder,VAE)在 AE 基础上,对隐变量 z 施加限制,使其符合一个标准正态分布。
- 好处:当隐变量 z 是趋向于一个分布时,对隐变量进行采样,其生成结果与输入样本类似但不完全一样。这样避免了 AE 容易过拟合的问题。
通过变分推断这一数学方法将 p(z) 和 p(z∣X) 后验概率设置为标准高斯分布,同时约束生成的样本尽量与输入样本相似。这样通过神经网络可以学习出解码器,也就是 p(X∣z) 。
通过这样的约束训练后,可以使得隐变量 z 符合标准高斯分布。需要生成新样本时,通过采样隐变量 z 让变分自动编码机生成多样且可用的样本。
整个学习过程中,变分自动编码器都在进行“生成相似度”和“生成多样性”之间的一个 折中 trade off。
- 当隐变量 z 的高斯分布方差变小趋向为 0 时,模型接近 AE。此时模型的生成样本与输入样本相似度较高,但是模型的样本生成采样范围很小,生成新的可用样本的能力不足。
VAE 通常用于数据生成,一个典型的应用场景就是通过修改隐变量,生成整体与原样本相似,但是局部特征不同的新人脸数据。
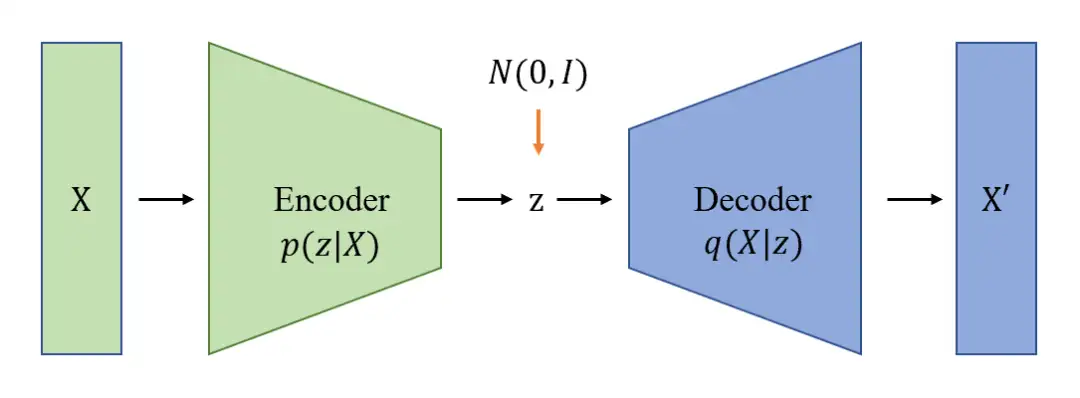
变分自编码器不再将输入映射成隐层空间中的一个固定编码,而是转换成对隐层空间的概率分布估计
- 假设先验分布是一个标准高斯分布。同样的,训练一个概率解码器建模,实现从隐层空间分布到真实数据分布的映射。当给定一个输入,通过后验分布估计出关于分布的参数(多元高斯模型的均值和协方差),并在此分布上采样,可使用重参数化技巧使采样可导(为随机变量),最后通过概率解码器输出关于的分布,如图所示。为了使生成图像尽量真实,需要求解后验分布,目标是最大化真实图像的对数似然。

VQ-VAE
VQ-VAE(Vector Quantization)在 VAE 基础上引入离散、可量化的隐空间表示,有助于模型理解数据中的离散结构和语义信息,同时可避免过拟合。
- VQ-VAE 与 VAE 的结构非常相似,只是中间部分不是学习概率分布,而是换成 VQ 来学习 Codebook。
- codebook:可理解为聚类中心 ,用离散 codebook替代distribution,效果更好(类比分类比回归效果好)
图片通过编码器得到特征图f后,在codebook中找到和特征图最接近的聚类中心,将聚类中心编码记录到Z中,将index对应的特征取出,作为fa,完成后续流程。
额外训练了一个pixel-CNN,当做prior网络,从而利用已经训练好的codebook去做图像的生成。
GAN 对抗生成网络
GAN 左右手互搏,生成器(G)和判别器(D)
- 生成器:给定随机噪声,生成图像X’,希望X’尽可能的接近真实图像。
- 判别器:给定X’和真实图像X,判别图片真假。
目标函数:
通过训练,生成器和判别器不断迭代,最终生成器可以生成比较逼真的图像。
分析
- 优点:生成的图像比较逼真,需要的数据量不那么多,可以在各个场景下使用
- 缺点:训练不稳定,容易模型坍塌。
- 图片真实但是多样性不足。
- 非概率模型,隐式生成图像,在数学上的可解释性不如VAE
GAN 全称 Generative Adversarial Networks,从名称不难读出“对抗(Adversarial)”是其成功之精髓。
- 对抗的思想受博弈论启发,在训练
生成器(Generator)的同时,训练一个判别器(Discriminator)来判断输入是真实图像还是生成图像,两者在一个极小极大游戏中相互博弈不断变强。 - 当从随机噪声生成足以“骗”过的图像时,我们认为较好地拟合出了真实图像的数据分布,通过采样可以生成大量逼真的图像。
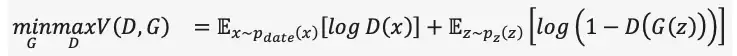
对抗生成网络
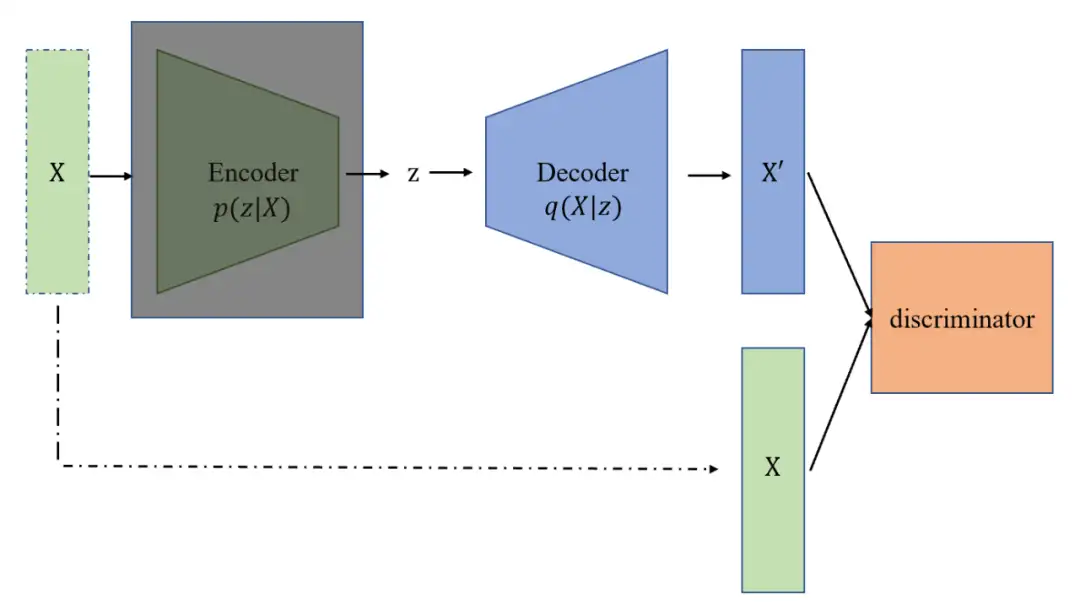
对抗生成网络(GAN)与 VAE 和 AE 的“编码器-解码器”结构不同。GAN 没有 encoder 这一模块, 直接通过生成网络(理解为 decoder)和一个判别网络(discriminator)的对抗博弈,使得生成网络具有较强的样本生成能力。GAN 可以从随机噪声生成样本,随机噪声按照 VAE 中的隐变量理解。
GAN是生成式模型中应用最广泛的技术,在图像、视频、语音和NLP等众多数据合成场景大放异彩。除了直接从随机噪声生成内容外,我们还可以将条件(例如分类标签)作为输入加入生成器和判别器,使得生成结果符合条件输入的属性,让生成内容得以控制。虽然GAN效果出众,但由于博弈机制的存在,其训练稳定性差且容易出现模式崩溃(Mode collapse),如何让模型平稳地达到博弈均衡点,也是GAN的热点研究话题。
VQ-GAN
VQ-GAN vs VQ-VAE
VQ-GAN 相比 VQ-VAE改变:
- 引入 GAN 思想,将 VQ-VAE 当作生成器(Generator),并加入判别器(Discriminator),以对生成图像的质量进行判断、监督,以及加入感知重建损失(不只是约束像素的差异,还约束 feature map 的差异),以此来重建更具有保真度的图片,也就学习了更丰富的 codebook。
- 将 PixelCNN 替换为性能更强大的自回归 GPT2 模型(针对不同的任务可以选择不同的规格)。
- 引入滑动窗口自注意力机制,以降低计算负载,生成更大分辨率的图像。
ViT-VQGAN
ViT-VQGAN 模型结构与 VQGAN 基本一致,主要是将 Encoder 和 Decoder 从 CNN 结构替换为 ViT 模型。
- Encoder:对应 Patch 大小为 8x8,没有重叠,因此 256x256 的图像会生成 32x32=1024 个 Token 序列。推理阶段不再需要。
- Quantization:将 1024 个 Token 序列映射到 Codebook 空间,Codebook 的大小为 8192。
- Decoder:从 1024 个离散 Latent code 中恢复原始图像。
- Autoregressive Transformer:用于生成离散 Latent code。训练中可以直接利用 Encoder 生成好的离线 Latent code 作为 Target,计算交叉熵损失。
Parti
相比原始的 VQ-GAN 和 ViT-VQGAN 中使用 Decoder Only 的 Transformer 来生成离散 latent code,Parti 扩展为 Encoder + Decoder 的 Transformer,这样可以使用 Encoder 来对文本编码,生成文本 embedding,然后文本 embedding 作为条件在 Transformer Decoder 中作为 K 和 V 通过 Cross Attention 与视觉 Token 交叉。
MaskGIT
MaskGIT 采用 VQGAN 模型范式,与 VQGAN 不同的是,VQGAN 中的 Transformer 采用序列生成的方式,在推理阶段其图像 Token 要一个一个预测,性能比较差,而 MaskGIT 中,Transformer 生成模型采用 Masked Visual Token Modeling 方式来训练(采用类似 Bert 的双向 Transformer 模型),也就是随机遮挡部分图像 Token,模型训练的目标是预测这些遮挡的 Token。以此方式训练的 Transformer 可以充分利用并行解码(Parallel Decoding)方式加速生成效率。
Flow-Based
基于流的生成模型(Flow-based models)

- 假设原始数据分布可以通过一系列可逆的转化函数从已知分布获得,即通过雅各布矩阵行列式和变量变化规则,直接估计真实数据的概率密度函数(式(4)),最大化可计算的对数似然。
扩散模型
详见站内专题:扩散模型
可控生成
可控生成是人工智能内容生成(AIGC)的最后一道高墙。
LC-AIGC 介绍
局部可控的图像生成(后续简称LC-AIGC):参考

- 在背景图片(background image)上给定一个边界框(bounding box),提供所需的条件信息(condition),在边界框内生成满足条件信息的前景物体,得到完整的真实自然的图片(generated image)。
- 条件信息包括很多种类型,比如: 文本(text)、轮廓(sketch)、颜色(color)、图片(image)等等。
- 其中和图像合成最相关的是将一张前景物体图片作为条件信息,即在背景图片的边界框内生成该物体,并使其光照、阴影、视角和背景适配。
LC-AIGC 问题
- 边界框的自动生成。某些应用场景(比如数据增广)需要在背景图片上自动产生大量的合理的边界框。该任务叫物体放置(object placement),相关资料。
- 可控性。LC-AIGC虽然能够实现局部可控,但是在图片作为条件信息的情况下控制力度远远不够。总的来说,条件信息提供了前景物体的若干属性。如果条件信息是文本、轮廓、颜色,我们知道了前景物体的某个属性,而其他属性是未知的。LC-AIGC默认已知属性是合理的,然后根据背景信息补充其他未知属性,得到完整的前景物体。
【2024-20-26】深入浅出完整解析ControlNet核心基础知识
由于 Stable Diffusion + LoRA + ControlNet 三巨头的强强联合,形成了一个千变万化的AI绘画“兵器库”
- 传统图像处理技术(Canny、Depth、SoftEdge等)再次得到广泛使用,成功“文艺复兴”;
- 传统深度学习技术(人脸识别、目标检测、人体关键点检测、图像分割、图像分类等)也直接过渡到AIGC时代中,成为AI绘画工作流中的重要辅助工具。
计算机视觉历史中的沉淀与积累,都在AIGC时代有了相应的位置。
Stable Diffusion是AIGC时代的“YOLO”Stable Diffusion XL是AIGC时代的“YOLOv3”LoRA系列模型是AIGC时代的“ResNet”ControlNet系列模型就是AIGC时代的“Transformer”。
ControlNet
文本生成图像只需要用户输入文本(Prompts)就可以实现图像生成,但是由于扩散模型本身特性(多样性较强),生成的图像往往不受控制,不见得能精准满足用户的需求
问题:如何提升生成的可控性?
介绍
【2023-4-4】ControlNet: 给以文生图模型添加条件约束
- Stable Diffusion (SD)模型,添加额外条件(Edge Map, Sketch, Depth Info, Segmentation Map, Human Pose, Normal Maps)做受控图像生成的方法
原理
- 主要思路: 在
SD模型中为添加与UNet结构类似的ControlNet, 学习额外条件信息,映射进参数固定的SD模型中,完成条件生成。 - 【2023-2-10】论文 Adding Conditional Control to Text-to-Image Diffusion Models
- ControlNet代码, model
- diffusers 框架的 ControlNet训练脚本:diffusers/examples/controlnet
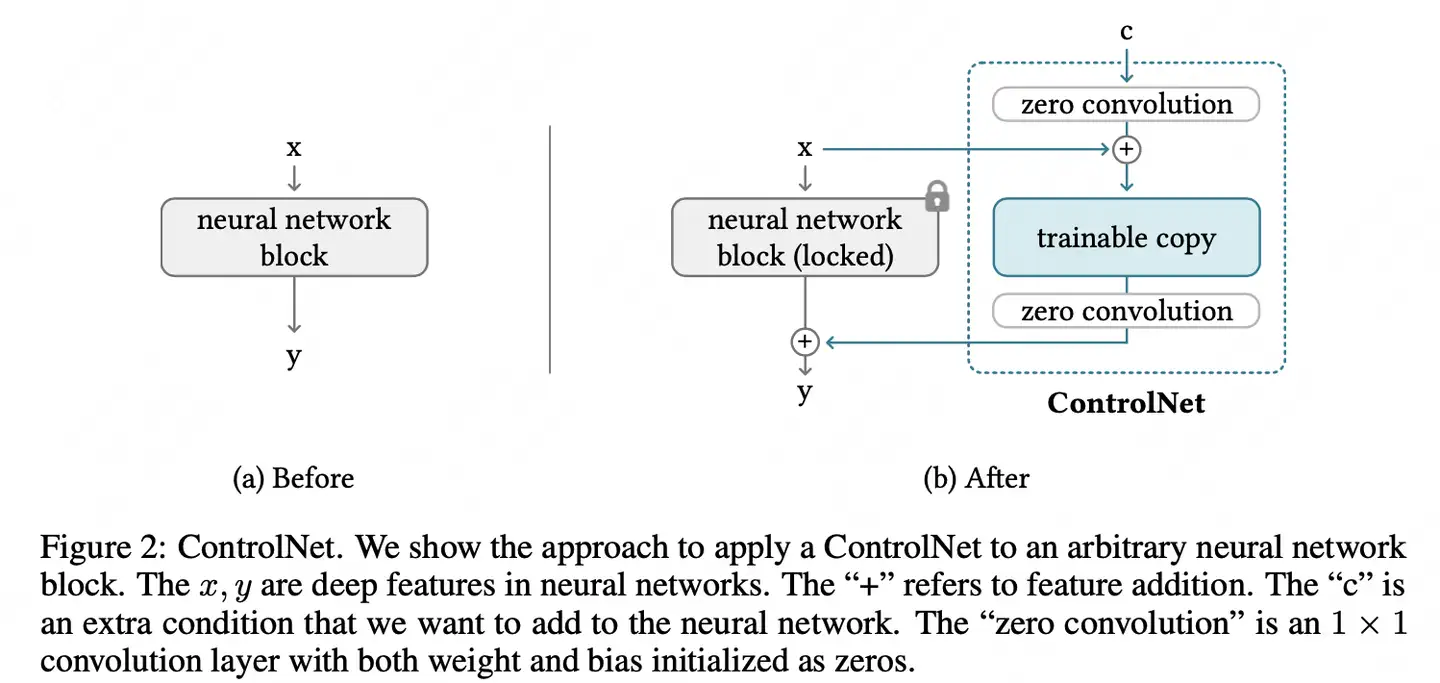
- 固定原始网络参数,复制一个可训练的拷贝网络,对于输入的条件c,通过零卷积(zero convolution),与网络原本的输入x进行特征加和,之后对于拷贝网络的输出,同样通过领卷积处理后与原始网络进行特征加和,输出最终的结果。
- 零卷积(zero convolution): 权重和偏置都是用0初始化的1 x 1卷积。
- 零卷积的好处:训练刚开始,controlNet 输出对原始网络没有影响,之后的任何优化基本上等同于在finetune这个模型,速度会比较快。
ControlNet 模型
- Stable Diffusion 模型的权重被复制出两个相同部分,分别是“锁定”副本(locked)和“可训练”副本。
ControlNet 主要在“可训练”副本上施加控制条件,然后,将施加控制条件之后的结果和原来SD模型的结果相加(add)获得最终的输出结果。
- 其中, “锁定”副本中的权重保持不变,保留了 Stable Diffusion 模型原本的能力;
- 与此同时,使用额外数据对“可训练”副本进行微调,学习想要添加的条件。
- 因为有 Stable Diffusion 模型作为预训练权重,所以使用小批量数据集就能对控制条件进行学习训练,同时不会破坏Stable Diffusion 模型原本的能力。
ControlNet 模型的最小单元结构中有两个 zero convolution (零卷积) 模块,1×1卷积,并且权重和偏置都初始化为零。
- 开始训练ControlNet之前,所有zero convolution模块的输出都为零,使得 ControlNet 完完全全就在原有Stable Diffusion 底模型的能力上进行微调训练,不会产生大的能力偏差。
疑问: 如果 zero convolution 模块的初始权重为零,那么梯度也为零,ControlNet模型将不会学到任何东西。
- 那么为什么“zero convolution模块”有效呢?(AIGC算法面试必考点)
解答
- 假设 controlnet 权重为 y=wx+b, 分别求导, dy/dw=x, dy/dx=w, dy/db=1
- 只要 x≠0, 一次梯度下降迭代将使 w 变成非零值。然后就得到:dy/dx≠0。这样就能让 zero convolution模块逐渐成为具有非零权重的公共卷积层,并不断优化参数权重。
制作副本而不是直接训练原始权重主要是为了避免数据集较小时的过拟合,并保持从数十亿张图像中学习到的大型模型的能力。
controlNet 详细结构
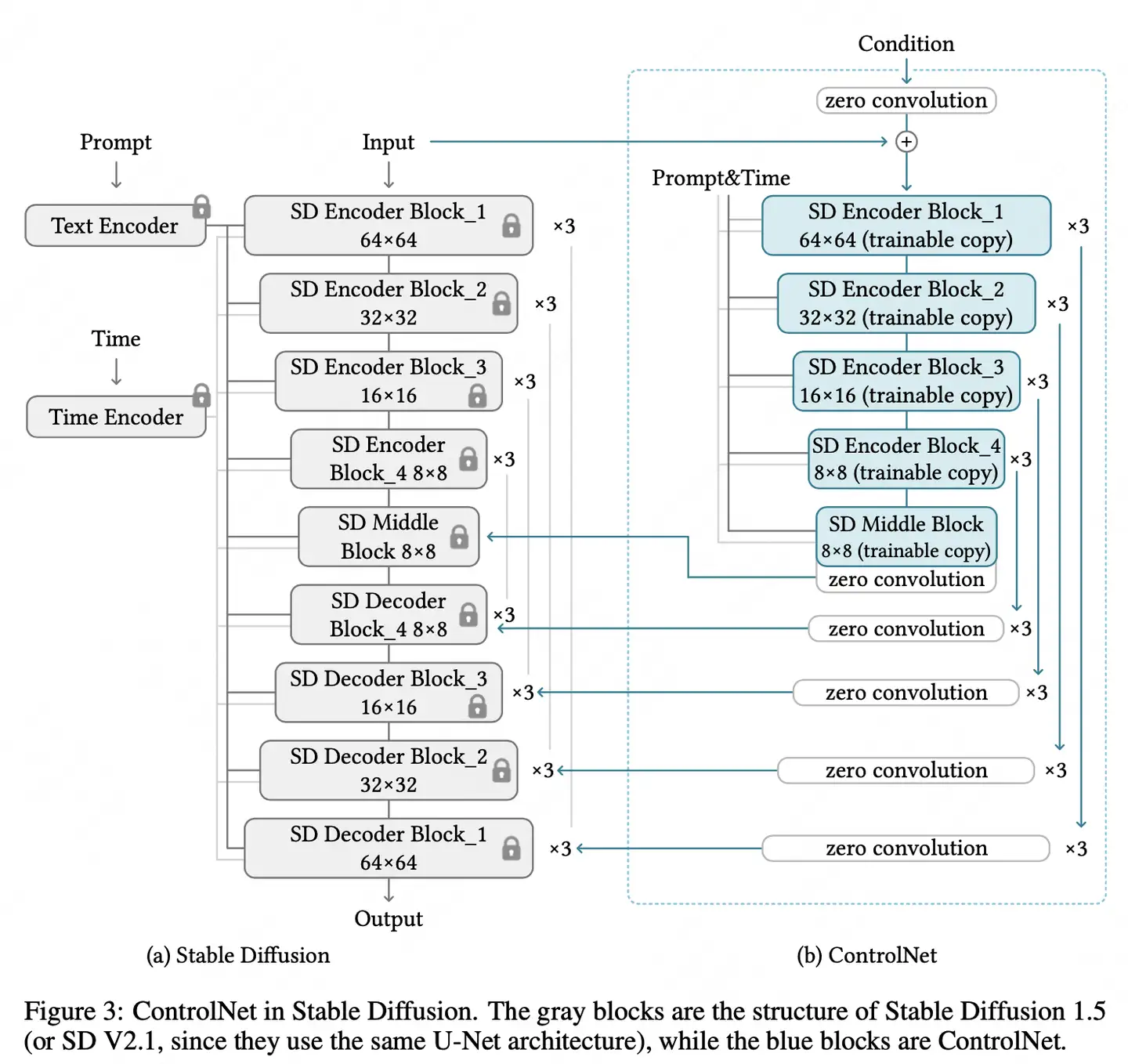
主要在 Stable Diffusion 的 U-Net 中起作用
- ControlNet 主要将 Stable Diffusion U-Net 的 Encoder 部分和 Middle 部分进行复制训练
- 在 Stable Diffusion U-Net 的 Decoder模块中通过 skip connection 加入了zero convolution模块处理后的特征,以实现对最终模型与训练数据的一致性。
由于 ControlNet 训练与使用方法是与原始 Stable Diffusion U-Net 模型进行连接,并且 Stable Diffusion U-Net 模型权重是固定的, 不需要进行梯度计算。
这种设计思想减少了 ControlNet 训练中一半的计算量,在计算上非常高效,能够加速训练过程并减少GPU显存的使用。
- 单个 Nvidia A100 PCIE 40G 环境下,实际应用到Stable Diffusion模型的训练中,ControlNet 仅使得每次迭代所需的GPU显存增加大约23%,时间增加34%左右。
ControlNet 包含了12个编码块和 1个Stable Diffusion U-Net中间块的“可训练”副本。
- 这12个编码块有4种分辨率,分别是64×64、32×32、16×16和8×8,每种分辨率对应3个编码块 。
- ControlNet的输出被添加到Stable Diffusion U-Net的12 个残差结构和1个中间块中。
同时, 由于Stable Diffusion U-Net是经典的U-Net结构,因此 ControlNet架构有很强的兼容性与迁移能力,可以用于其他扩散模型中。
ControlNet 输入包括Latent特征、Time Embedding、Text Embedding以及额外的condition。
- 其中前三个和SD的输入是一致的,而额外的condition是ControlNet独有的输入
- 额外的condition是和输入图片一样大小的图像,比如边缘检测图、深度信息图、轮廓图等。
问题: ControlNet 一开始的输入Condition怎么与SD模型的隐空间特征结合呢?
- ControlNet主要是训练过程中添加了4层卷积层,将图像空间 Condition 转化为隐空间Condition。
- 这些卷积层的卷积核为4×4,步长为2,通道分别为16,32,64,128,初始化为高斯权重,并与整个ControlNet模型进行联合训练。
ControlNet的架构与思想,让其可以对图像的背景、结构、动作、表情等特征进行精准的控制。
ControlNet模型思想使得训练的模型鲁棒性好,能够避免模型过度拟合,并在针对特定问题时具有良好的泛化性,在小规模甚至个人设备上进行训练成为可能。
效果
实验效果
| 受控条件 | 效果 | 备注 |
|---|---|---|
| Canny Edge |  |
|
| Hough Lines |  |
|
| Human Scribbles |  |
|
| HED boundary map |  |
|
| Human Pose |  |
|
| Segmentation Map |  |
|
| Cartoon Line Drawing |  |
ControlNet WebUI
ControlNet 有18种 Control Type,分别是
- Canny,Depth,NormalMap,OpenPose,MLSD,Lineart,SoftEdge,Scribble/Sketch,Segmentation,Shuffle,Tile/Blur,Inpaint,InstructP2P,Reference,Recolor,Revision,T2I-Adapter,IP-Adapter。
- 各种模式使用详解见文章 深入浅出完整解析ControlNet核心基础知识
ControlNet 引领了CV领域的“文艺复兴”,很多传统图像处理时代的算子(Canny,Depth,SoftEdge等)在AIGC时代中再次展现它们的能量。
安装ControlNet插件:
cd stable-diffusion-webui/extensions/
git clone https://github.com/Mikubill/sd-webui-controlnet.git
重启WebUI即可看到ControlNet插件面板:
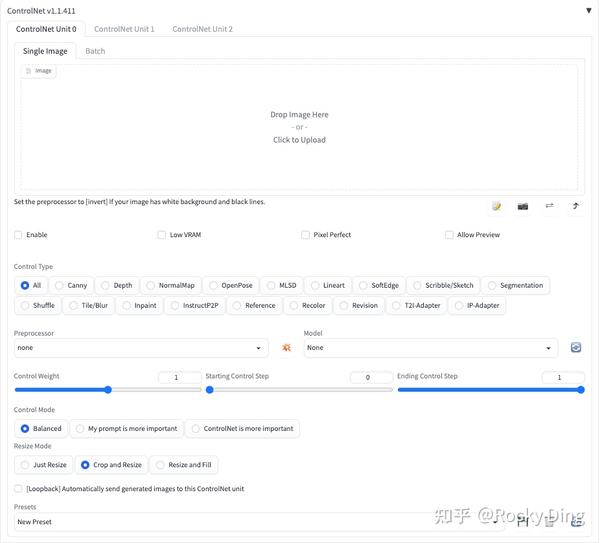
ControlNet插件面板中各个参数的具体作用,大家可以点赞收藏本文,在使用时可以方便的找到:
ControlNet插件面板第一行中的ControlNet Unit 0-3表示默认设置为三个ControlNet选项界面,能够在Stable Diffusion生成过程中使用三个ControNet模型,可以手动增加或减少ControlNet选项界面。
ControlNet 插件面板第二行有Single Image和Batch两个选项卡,表示使用一张图片或一个Batch的图片进行预处理,用于ControlNet过程。
- Enable(启用):点击选择Enable后,点击WebUI中的Generate按钮时,将会加载ControlNet模型辅助控制图像的生成过程。如果不点击选择Enable按钮不生效。
- Low VRAM(低显存模式):如果我们的显卡显存小于4GB,可以开启此选项降低生成图片时ControlNet的显存占用。
- Pixel Perfect(完美像素模式):开启完美像素模式之后,ControlNet 将自动计算选择预处理器分辨率,不再需要我们手动设置分辨率。通过自动进行这些调整,它可以保证最高的图像质量和清晰度。Rocky在这里打一个不太恰当的比喻,ControlNet的Pixel Perfect功能,就如同YOLOv5的自适应anchor一样,自动化为我们的参数调整免去了很多麻烦。
- Allow Preview(预览展示模式):启用后将会把图片经过Preprocessor预处理后的结果展示出来,比如图片的边缘信息,深度信息,关键点信息等。
- Control Type(控制类型):一共有18种控制类型可以选择,选择一个Control Type后,Preprocessor和Model栏里也会限定只能选择与Control Type相匹配的算法和模型,非常方便。
- Preprocessor(预处理器):在Preprocessor栏里我们可以选择需要的预处理器,每个预处理器都有不同的功能。选择的预处理器会先将上传的图片进行预处理,例如Canny会提取图片的边缘特征信息。如果图片不需要进行预处理,设置Preprocessor为none即可。
- Model(模型):Model栏里我们可以选择ControlNet模型,用于SD生成图片时进行控制。
- Control Weight(ControlNet权重):代表使用ControlNet模型辅助控制SD生成图片时的权重。
- Starting Control Step(引导介入时机):表示在图片生成过程中的哪一步开始使用ControlNet进行控制。如果设置为0,就表示从一开始就使用ControlNet控制图片的生成;如果设置为0.5就表示ControlNet从50%的步数时开始进行控制。
- Ending Control Step(引导推出时机):表示在图片生成过程中的哪一步结束ControlNet的控制。和引导介入时机相对应,如果设置为1,表示使用ControlNet进行控制直到完成图片的生成。Ending Control Step默认为1,可调节范围0-1,如果设置为0.8时表示到80%的步数时结束控制。
- Control Mode(控制模式):在使用ControlNet进行控制时,有三种控制模式可以选择,用于确定ControlNet于Prompt之间的配比。我们可以选择平衡二者 (Balanced),或是偏重我们的提示词 (My prompt is more important),亦或者是偏重ControlNet (ControlNet is more important)。
- Resize Mode(缩放模式):用于调整图像大小模式,一共三个选项:Just Resize,Crop and Resize和Resize and Fill。
- 拿512x500的图像为例,使用三个缩放模式生成一个 1024x1024的图像,看看主要经过了哪些过程:
- Just Resize:不考虑宽高比,直接将图像拉伸成1024x1024分辨率。
- Crop and Resize:考虑宽高比,先将图片裁剪至 500x500,然后缩放至1024x1024分辨率,会造成左右两侧的一些数据丢失。
- Resize and Fill:通过添加噪音的方式将图像填充至512x512,然后缩放到1024x1024分辨率。
- Loopbac按钮:
[Loopback]Automatically send generated images to this ControlNet unit。点击开启后,在mov2mov等持续性生成过程中,每一帧的结果都会进行ControlNet控制。 - Presets:用于保存已经配置好的ControlNet参数,以便后续快速加载相关参数。
三种控制模式的原理:
- “Balanced”(平衡):ControlNet的能力在CFG Scale中均衡的使用,一般我们默认可以选择Balanced。
- “My prompt is more important”(提示更重要):ControlNet 能力在CFG Scale中使用,但逐渐减少在SD U-Net模型的注入(
layer_weight *= 0.825^I,其中 0<=I<13,13表示ControlNet注入了SD 13次)。在这种情况下,提示词Prompt在图像的生成过程中占据更大的比重。 - “ControlNet is more important”(ControlNet更重要):ControlNet 仅在CFG Scale的条件控制部分使用。
- 设置的CFG Scale是X,那么ControlNet的控制强度将是X倍(如果我们设置CFG Scale为7,那么ControlNet的强度将是7倍)。
- 注意: X倍强度与“Control Weights”(控制权重)不同,因为ControlNet的权重没有被修改。这种“更强”的效果通常会产生较少的人工痕迹,并且给ControlNet更多空间去猜测我们的提示词中缺少的内容(在之前的版本,这个模式被称为”Guess Mode”)。
效果对比

ControlNet 1.1
ControlNet 1.1 在 ControlNet 1.0 基础上进行了优化,提高了鲁棒性和控制效果,同时添加了几个新的ControlNet模型。
从ControlNet 1.1开始,ControlNet模型开始有标准的命名规则(SCNNR)来命名所有模型,这样使用时也能更加方便。
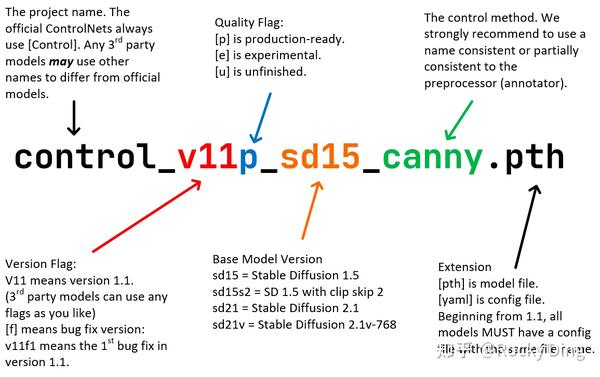
ControlNet 1.1 一共发布了14个模型(11个成品模型和3 个实验模型):
- control_v11p_sd15_canny
- control_v11p_sd15_mlsd
- control_v11f1p_sd15_depth
- control_v11p_sd15_normalbae
- control_v11p_sd15_seg
- control_v11p_sd15_inpaint
- control_v11p_sd15_lineart
- control_v11p_sd15s2_lineart_anime
- control_v11p_sd15_openpose
- control_v11p_sd15_scribble
- control_v11p_sd15_softedge
- control_v11e_sd15_shuffle(实验模型)
- control_v11e_sd15_ip2p(实验模型)
- control_v11f1e_sd15_tile(实验模型)
ControlNet Tile
【2023-5-9】升级版发布:ControlNet Tile,支持:
- 放大
- 修复
- 细节增强
选其一,或其二,或是三者一起组合使用。
Tile模型介绍
图生图(img2img)里使用Tile模型有4个点:
- (1) 参考图不是必须的,如果ControlNet里不填入参考图,tile模型会根据图生图里的参考图来做参考
- (2) 预处理器选择 tile_resample
- (3) 模型选择 control_v11f1e_sd15_tile,这里注意是v11f1e,如果找不到,请按照上面的下载/更新再来一次
- (4) Tile 模型专属参数 Down Sampling Rate,意思是向下缩放取样系数。作用是系数越大,得到的参考图越小,取值细节越小,最终得到的效果图随机细节越多,与原图的关系越小。
一张512512的参考图,在Down Sampling Rate为2的情况下,得到的参考图为256256;值为4的时候,得到128*128。
ControlNet Tile 目前大家都喜欢在图生图(img2img)里使用,那为什么不喜欢在文生图(txt2img)里用?
- 因为Tile模型的性质,修复和细节增强。
文生图(txt2img)里,出图是随机的,也就是我们都不知道出来的图片是什么样子的,如果直接使用细节增强,那么会增加我们的出图时间,减少出图效率,让我们的可控性得不到保障。所以大家不太愿意这样花时间。
图生图(img2img)的重绘强度(Denoising strength)是直接影响Tile模型致输入图和输出图之间变化强度的因子。数值越高,被修改的细节越多,反之则少。
修复,把一张512*512的脸部和手部出现坏了的图片修复
- (1) 第一步,inpaint 修复脸部和手部,重绘强度0.6:
- (2) 第二步,使用图生图(img2img)全图修复,重绘强度0.6:
| 步骤 | 效果 | 备注 |
|---|---|---|
| 原图 | ||
| 遮罩图 | ||
| 第一步 | 脸部和手部得到很好的修复,背景和裤子上的纹理都没有改变。 | |
| 第二步 | 衣服褶皱、裤子纹理、背景清晰度和光线都得到很好的修正 |
正向提示词:
a woman walking int the park, skirt ,shorts,
反向提示词:
kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, blur, poorly drawn, mangled, surreal, text,by <bad-artist-anime:0.8> , by <bad-artist:0.8> , by <bad-hands-5:0.8>, by < bad_prompt_version2:0.8>
Model: deliberate_v2
Steps: 25, Sampler: DPM++ SDE Karras,
CFG scale: 7, Seed: 734068303,Size: 1024x1024
IC-Light
IC-Light V2
【2024-10-28】ControlNet 作者重磅发布IC-Light V2,基于Flux,细节保存能力大大提升!
ControlNet 作者张吕敏重磅发布 IC-Light V2,一系列基于 Flux 的 IC-Light 模型,具有 16ch VAE 和原生高分辨率。
IC-Light V2将包括以下几个版本:
- 前景条件模型,强调保留输入图像细节(此模型)。
- 前景条件模型,强调进行大修改的能力,例如处理低光图像和更改硬阴影(尚未发布)。
- 前景和背景条件模型(尚未发布)。
- 与环境 HDRI 集成(尚未发布)。
得益于16ch VAE、原生高分辨率和更好的训练方法,细节保存能力远高于SD1.5
目前发布的是前景条件模型
- huggingface上体验
- 案例讨论详情见 discussions
与 SD1.5 的另一个重要区别: 处理风格化图像的能力。
- SD15 IC-Light 有时对图像风格进行的修改过大
LuminaBrush
【2024-12-25】 ControlNet作者张吕敏再出新项目LuminaBrush
ControlNet 作者张吕敏发布图像打光新项目LuminaBrush
- LuminaBrush 是一个构建交互式工具的项目,用于在图像上绘制光照效果。
该框架采用两阶段方法:
- 首先将图像转换为均匀光照的外观;
- 然后通过用户的涂鸦生成光照效果。
LuminaBrush也是基于最新的开源SOTA文生图模型Flux构建
- 项目地址:LuminaBrush
- 在线demo:LuminaBrush
LuminaBrush和之前的IC-Light的区别,你可以通过交互式地涂鸦来改变图像主体的光照,IC-Light只是依靠文本描述或者背景图,而LuminaBrush可以通过区域涂鸦更精细地控制光照。
LuminaBrush 架构图,一个两阶段算法。
- 第一阶段:(左侧)将图像转换为均匀光照的外观(例如,由均匀分布的白色环境光源照亮的场景)。
- 第二阶段:(右侧)为这些均匀光照的外观生成光照效果,并通过用户的涂鸦进行引导。 将光照绘制问题分解为两个阶段,使学习过程更加简单和直接——否则(例如,仅使用单阶段),可能需要考虑外部约束或规则(如光传输一致性等)来稳定模型的行为。
应用:装修
【2023-9-3】装修效果美化
效果

| 分割图 |  |
 |
| living room with grey carpet and jukebox in the corner |  |
|
| 线图 |  |
 |
if __name__=='__main__':
prompt = 'living room with grey carpet and modern fireplace'
img_path = 'images/house.jpeg'
control_net_seg = ControlNetSegment(
prompt=prompt,
image_path=img_path)
seg_image = control_net_seg.segment_generation(
save_segmentation_path='images/house_seg.jpeg',
save_gen_path='images/house_seg_gen.jpeg'
)
ControlGPT(微软)– LLM 控制
【2023-6-8】微软提出Control-GPT:用GPT-4实现可控文本到图像生成
扩散模型虽好,但如何保证生成的图像准确高质量?GPT-4或许能帮上忙。
问题
- AI 模型生成的图像在细节上还有很多瑕疵,并且使用自然语言指定对象的确切位置、大小或形状存在一定的困难。
- 为了生成精准、高质量的图像,现有方法通常依赖于广泛的提 prompt 工程或手动创建图像草图。这些方法需要大量的人工工作,因此非常低效。
最近,加州大学伯克利分校(UC 伯克利)和微软研究院的研究者,从编程角度思考了这个问题。
- 当前,用户能够使用大型语言模型较好地控制代码生成,那么也可以编写程序来控制生成图像细节,包括物体的形状、大小、位置等等。
- 该研究提出利用大型语言模型(LLM)生成代码的功能实现可控型文本到图像生成。
资料
简单而有效的框架 Control-GPT, 利用 LLM 的强大功能, 根据文本 prompt 生成草图。原理
- 首先用 GPT-4 生成 TikZ 代码形式的草图。程序草图(programmatic sketch)是按照准确的文本说明绘制的,随后这些草图被输入 Control-GPT。
- Control-GPT 是 Stable Diffusion 的一种变体,它能接受额外的输入,例如参考图像、分割图等等。这些草图会充当扩散模型的参考点,使扩散模型能够更好地理解空间关系和特殊概念,而不是仅仅依赖于文本 prompt。这种方法使得 prompt 工程和草图创建过程不再需要人为干预,并提高了扩散模型的可控性。
对图像生成来说,训练过程的一个较大挑战: 缺乏包含对齐文本和图像的数据集。
该研究将现有实例分割数据集(例如 COCO 和 LVIS)中的实例掩码转换为多边形的表示形式,这与 GPT-4 生成的草图类似。
- 构建了一个包含图像、文本描述和多边形草图的三元数据集
- 并微调了 ControlNet。
这种方法有助于更好地理解 GPT 生成的草图,并且可以帮助模型更好地遵循文本 prompt 指令。
ControlNet 是扩散模型的一种变体,它需要额外的输入条件。该研究使用 ControlNet 作为基础图像生成模型,并通过编程草图和 grounding token 的路径对其进行扩展。
流程
- 首先 GPT-4 会根据文本描述生成 TikZ 代码形式的草图,并输出图像中物体的位置。然后该研究用 LATEX 编译 TikZ 代码,将草图转换为图像格式,再将编程草图、文本描述和物体位置的 grounding token 提供给经过调优的 ControlNet 模型,最终生成符合条件的图像。

阿里 Composer
【2023-4-5】阿里提出composer:AI绘画的可控生成
【2023-5-14】阿里通义文生图,玄恒(黄梁华)分享,composer基于dalle2开发而来…
ControlNet 模型将可控性推上了新的高峰。同一时间,来自阿里巴巴和蚂蚁集团的研究者也在同一领域做出了成果
将图像分解为捕捉图像各个方面的去耦表征,并且描述了该任务中使用的八种表征,这几种表征都是在训练过程中实时提取的。
- 说明(Caption):研究直接使用图像 - 文本训练数据中的标题或描述信息(例如,LAION-5B (Schuhmann et al., 2022))作为图像说明。当注释不可用时,还可以利用预训练好的图像说明模型。研究使用预训练的 CLIP ViT-L /14@336px (Radford et al., 2021) 模型提取的句子和单词嵌入来表征这些标题。
- 语义和风格(Semantics and style):研究使用预先训练的 CLIP ViT-L/14@336px 模型提取的图像嵌入来表征图像的语义和风格,类似于 unCLIP。
- 颜色(Color):研究使用平滑的 CIELab 直方图表征图像的颜色统计。将 CIELab 颜色空间量化为 11 个色调值,5 个饱和度和 5 个光值,使用平滑 sigma 为 10。经验所得,这样设置的效果更好。
- 草图(Sketch):研究应用边缘检测模型,然后使用草图简化算法来提取图像的草图。草图捕捉图像的局部细节,具有较少的语义。
- 实例(Instances):研究使用预训练的 YOLOv5 模型对图像应用实例分割来提取其实例掩码。实例分割掩码反映了视觉对象的类别和形状信息。
- 深度图(Depthmap):研究使用预训练的单目深度估计模型来提取图像的深度图,大致捕捉图像的布局。
- 强度(Intensity):研究引入原始灰度图像作为表征,迫使模型学习处理颜色的解纠缠自由度。为了引入随机性,研究统一从一组预定义的 RGB 通道权重中采样来创建灰度图像。
- 掩码(Masking):研究引入图像掩码,使 Composer 能够将图像生成或操作限制在可编辑的区域。使用 4 通道表征,其中前 3 个通道对应于掩码 RGB 图像,而最后一个通道对应于二进制掩码。
虽然本文使用上述八种条件进行了实验,但用户可以使用 Composer 自由定制条件。
PIXART-δ
【2024-1-12】PIXART-δ:具有潜在一致性模型的快速可控图像生成
将Latent Consistency Model (LCM)和ControlNet集成到高级PIXART-α模型中的文本到图像合成框架。PIXART-α因其能够通过非常高效的训练过程生成1024px分辨率的高质量图像而受到认可。将LCM集成到PIXART-δ中,可以显著加速推理速度,使生产高质量图像只需要2-4步。值得注意的是,PIXART-δ在生成1024×1024像素的图像时只需要0.5秒,比PIXART-α快了7倍。此外,PIXART-δ被设计为在32GB V100 GPU上能够进行高效的训练,并在一天内完成。凭借其8位推理能力(来自Von Platen等人,2023),PIXART-δ可以在8GB GPU内存限制下合成1024px的图像,大大提高了其可用性和可访问性。此外,通过结合ControlNet-like模块,可以对文本到图像的扩散模型进行精细控制。我们引入了一种专门为Transformer设计的ControlNet-Transformer架构,实现了明确的可控制性和高质量的图像生成。作为最先进的开源图像生成模型之一,PIXART-δ为Stable Diffusion系列模型提供了一个有前途的替代方案,为文本到图像的合成做出了重大贡献。
Google Nano Banana
2025年8月,谷歌发布Nano Banana,强大的AI图像生成能力备受粉丝青睐
Nano Banana Pro的核心就在于“Pro”。谷歌称Gemini 3与Nano Banana Pro能以“工作室级别的精度和控制”生成或编辑图像。通俗地说,它基本上会做Nano Banana已经会做的事,但因为使用了Gemini 3,而非常规Nano Banana所采用的Gemini 2.5 Flash Image模型,所以效果更佳。
图片编辑
AnyText
【2023-12-15】阿里通义实验室推出AnyText,一种基于扩散模型的多语言视觉文本生成和编辑模型,能够在图片上生成和编辑任何语言的文字,而且,效果非常逼真和自然。
AnyText 开源了代码和数据集。
outfit-anyone
用户能够在不真实试穿衣物的情况下,尝试不同的时尚款式上传衣服即可试穿。服装电商要好好用上后,让顾客在线体验穿衣搭配
- outfit-anyone demo, github
- paper Outfit Anyone: Ultra-high quality virtual try-on for Any Clothing and Any Person

InstantID
【2024-1-24】InstantID : Zero-shot Identity-Preserving Generation in Seconds
- InstantID is a new state-of-the-art tuning-free method to achieve ID-Preserving generation with only single image, supporting various downstream tasks.
- hf demo
最新免微调的头像生成工具,sota效果

效果对比

# 准备模型
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="InstantX/InstantID", filename="ControlNetModel/config.json", local_dir="./checkpoints")
hf_hub_download(repo_id="InstantX/InstantID", filename="ControlNetModel/diffusion_pytorch_model.safetensors", local_dir="./checkpoints")
hf_hub_download(repo_id="InstantX/InstantID", filename="ip-adapter.bin", local_dir="./checkpoints")
# ===== =====
# !pip install opencv-python transformers accelerate insightface
import diffusers
from diffusers.utils import load_image
from diffusers.models import ControlNetModel
import cv2
import torch
import numpy as np
from PIL import Image
from insightface.app import FaceAnalysis
from pipeline_stable_diffusion_xl_instantid import StableDiffusionXLInstantIDPipeline, draw_kps
# prepare 'antelopev2' under ./models
app = FaceAnalysis(name='antelopev2', root='./', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
# prepare models under ./checkpoints
face_adapter = f'./checkpoints/ip-adapter.bin'
controlnet_path = f'./checkpoints/ControlNetModel'
# load IdentityNet
controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
base_model = 'wangqixun/YamerMIX_v8' # from https://civitai.com/models/84040?modelVersionId=196039
pipe = StableDiffusionXLInstantIDPipeline.from_pretrained(
base_model,
controlnet=controlnet,
torch_dtype=torch.float16
)
pipe.cuda()
# load adapter
pipe.load_ip_adapter_instantid(face_adapter)
# ======= 自定义 ========
# load an image
face_image = load_image("./examples/yann-lecun_resize.jpg")
# prepare face emb
face_info = app.get(cv2.cvtColor(np.array(face_image), cv2.COLOR_RGB2BGR))
face_info = sorted(face_info, key=lambda x:(x['bbox'][2]-x['bbox'][0])*x['bbox'][3]-x['bbox'][1])[-1] # only use the maximum face
face_emb = face_info['embedding']
face_kps = draw_kps(face_image, face_info['kps'])
# prompt
prompt = "film noir style, ink sketch|vector, male man, highly detailed, sharp focus, ultra sharpness, monochrome, high contrast, dramatic shadows, 1940s style, mysterious, cinematic"
negative_prompt = "ugly, deformed, noisy, blurry, low contrast, realism, photorealistic, vibrant, colorful"
# generate image
image = pipe(
prompt,
image_embeds=face_emb,
image=face_kps,
controlnet_conditioning_scale=0.8,
ip_adapter_scale=0.8,
).images[0]
TextHarmony
【2024-10-16】华东师范+字节跳动推出首个OCR领域大一统多模态文字理解与生成大模型,即 TextHarmony
- TextHarmony 不仅精通视觉文本的感知(文字检测识别等)、理解(KIE、VQA等)和生成(视觉文字生成、编辑、抹除等),而且在单一模型中实现了视觉与语言模态生成的和谐统一
- NeurIPS 2024 录用论文:“Harmonizing Visual Text Comprehension and Generation”。
- 代码开源: TextHarmony
详见站内专题: OCR
AI 作画
文本生成图片
【2023-1-31】从ChatGPT说起,AIGC生成模型如何演进
从技术实现突破、到技术提升、再到规模化降低门槛,AI创作能力也不断提升。
- 2022年10月,美国一名男子用AI绘画工具Midjourney,生成了一幅名为《太空歌剧院》的作品,并获得了第一名。这引起了一波不小的争论,也终于形成了一条新赛道。
- 于是,2022年以AI绘画为代表的各种生成式AI工具,如雨后春笋般疯狂冒尖,比如盗梦师、意间AI、6pen、novelAI等等。
汇总
AI作画三巨头
Mid Journey: 地表最强AI,快速生成一组连贯图像,烧会员钱,需联网调用- MJ较SD上手难度低、视觉效果好、界面很流畅、审核门槛高。
Stable Diffusion: 低调神秘慈善家,可本地部署使用;擅长摄影、油画、水彩、概念艺 术等风格都能全面掌握,更具全能性。- SD较MJ推理性更强、可控性更高、模型更多样、内容很开放
Dall-E 2: 甲方终结者Leonardo.ai:使用现有模型或自己训练AI模型来生成各种生产就绪的艺术资产。结合了MJ和SD的优点,但纯属低配版MJ+SDNovelai:几乎只能生成动漫、 手绘、素描、CG风格图片,但在这些风格的人像上出图率更高,是专精型选手。对prompt不敏感;擅长全身夸张二次元整活
Midjourney 的内容限制确实比其他竞争对手(例如 OpenAI 的 DALL-E)更宽松,但目前的管控宽松之王仍然是 Stable Diffusion。
可使用的AI作画平台
- github: awesome-ai-painting
文生图: flux
📪 国外
| Name | Tags | URL |
|---|---|---|
| midjourney | 新用户免费20次 | https://www.midjourney.com/ |
| wombo.art | 免费 | https://app.wombo.art/ |
| Google Colab | 免费 | https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb#scrollTo=yEErJFjlrSWS |
| DALL·E 2 | 排队申请 | https://openai.com/dall-e-2/ |
| artbreeder | 免费 | https://www.artbreeder.com/beta/collage |
| dreamstudio | 200点数 | https://beta.dreamstudio.ai/ |
| nightcafe | - | https://creator.nightcafe.studio/create/text-to-image?algo=stable |
| starryai | - | https://create.starryai.com/my-creations |
| webui | 免费 | https://colab.research.google.com/github/altryne/sd-webui-colab/blob/main/Stable_Diffusion_WebUi_Altryne.ipynb |
| 替换图片 | 免费 | https://colab.research.google.com/drive/1R2HJvufacjy7GNrGCwgSE3LbQBk5qcS3?usp=sharing |
| webui-AUTOMATIC1111版本 | 免费 | https://colab.research.google.com/drive/1Iy-xW9t1-OQWhb0hNxueGij8phCyluOh |
| 生成视频 | 免费 | https://github.com/THUDM/CogVideo |
| PS插件-绘画生成图片 | - | https://www.nvidia.com/en-us/studio/canvas/ |
| 3D模型 | 免费 | https://colab.research.google.com/drive/1u5-zA330gbNGKVfXMW5e3cmllbfafNNB?usp=sharing |
| elbo | - | https://art.elbo.ai/ |
| deepdreamgenerator | - | https://deepdreamgenerator.com/ |
| big-sleep | 免费 | https://github.com/lucidrains/big-sleep/ |
| nightcafe | - | https://nightcafe.studio/ |
| craiyon | - | https://www.craiyon.com/ |
| novelai | - | https://novelai.net/ |
| novelai 免费版 | 免费 | https://github.com/JingShing/novelai-colab-ver |
| Sd-Outpainting | 免费 | https://github.com/lkwq007/stablediffusion-infinity |
| TyPaint | 免费 | https://apps.apple.com/us/app/typaint-you-type-ai-paints/id1624024392 |
| PicSo | 新用户每天免费10次 | https://picso.ai/ |
| sd-outpaing | 免费 | https://github.com/lkwq007/stablediffusion-infinity |
| novelai-colab 版本 | 免费 | https://github.com/acheong08/Diffusion-ColabUI |
| novelai-colab 版本2 | 免费 | https://github.com/JingShing/novelai-colab-ver |
🚴🏻 国内
| Name | 价格 | URL |
|---|---|---|
| 文心大模型 | 暂时免费 | https://wenxin.baidu.com/moduleApi/ernieVilg |
| 文心-一格 | 暂时免费 | https://yige.baidu.com/#/ |
| 6pen | 部分免费 | https://6pen.art/ |
| MewxAI人工智能 | 免费 | 微信小程序 |
| MuseArt | 付费 + 看广告 | 微信小程序搜 MuseArt |
| 大画家Domo | - | https://www.domo.cool/ |
| 盗梦师 | 有免费次数 + 付费 | 微信小程序搜盗梦师 |
| 画几个画 | - | 微信小程序搜画几个画 |
| Niko绘图 | 免费 + 看广告 | 微信小程序搜Niko绘图 |
| 飞链云AI绘画版图 | 免费 | https://ai.feilianyun.cn/ |
| Freehand意绘 | 免费 | https://freehand.yunwooo.com/ |
| 即时AI | 免费 | https://js.design/pluginDetail?id=6322a4ab0eededcff6ba451a |
| 意见AI绘画 | 有免费次数 + 付费 | 微信小程序搜意见AI绘画 |
| PAI | 免费 | https://artpai.xyz/ |
| 爱作画 | 有免费次数 + 付费 | https://aizuohua.com/ |
| 皮卡智能AI | 免费 | https://www.picup.shop/text2image.html#/ |
Prompt技巧
- stable_diffusion_webUI使用教程
- 组合维度:人物,角色,五官,表情,头发,装饰,服装,鞋饰,尾&翅&角,姿势,动作,环境,风格,魔法
| 参数 | 说明 | ||
|---|---|---|---|
| Prompt | 提示词(正向) | ||
| Negative | prompt | 消极的提示词(反向) | |
| Width | & | Height | 要生成的图片尺寸。尺寸越大,越耗性能,耗时越久。 |
| CFG | scale | AI | 对描述参数(Prompt)的倾向程度。值越小生成的图片越偏离你的描述,但越符合逻辑;值越大则生成的图片越符合你的描述,但可能不符合逻辑。 |
| Sampling | method | 采样方法。有很多种,但只是采样算法上有差别,没有好坏之分,选用适合的即可。 | |
| Sampling | steps | 采样步长。太小的话采样的随机性会很高,太大的话采样的效率会很低,拒绝概率高(可以理解为没有采样到,采样的结果被舍弃了)。 | |
| Seed | 随机数种子。生成每张图片时的随机种子,这个种子是用来作为确定扩散初始状态的基础。不懂的话,用随机的即可。 |
注:
- 提示词(Prompt)越多,AI 绘图结果会更加精准
- 目前中文提示词的效果不好,还得使用英文提示词。
【2023-4-14】NovelAI 词图。作画软件:造梦笔,让AI助力你的创作灵感
- 支持txt2img
- 支持img2img
- 支持inpaint
- 支持超分算法
- 更多功能开放中
评测对比
【2023-12-11】四大顶级AI绘画模型直接对比
Meta AI模型和Adobe Firefly 2,Midjourney,DALL-E 3的直接对比
- DALL-E 3语义理解最强,能最符合用户的prompt
- 而 Midjourney 生成图像质量最好。
- 而 Meta的AI模型在语义理解上不如DALL-E 3,在生成质量上也不如Midjourney。
| 主题 | Prompt | 图 | 说明 |
|---|---|---|---|
| 人物 | a closeup candid shot of a happy young woman wearing a blue scarf on a vacation in santorini, white buildings and blue domes |  |
|
| 特写镜头 | extreme closeup shot of an old man with long gray hair and head covered in wrinkles; focused expression looking at the camera | 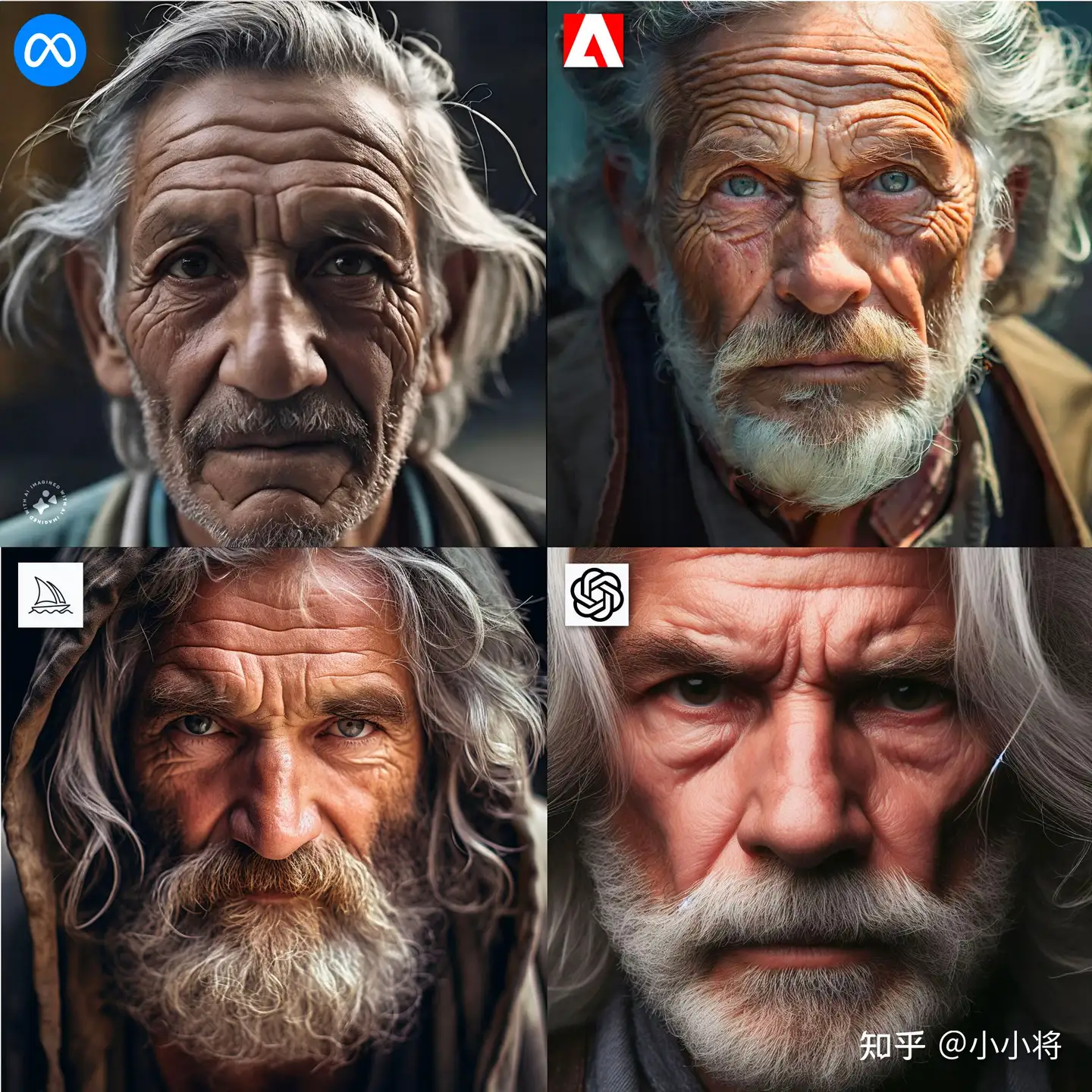 |
|
| 野生动物 | a macro wildlife photo of a green frog in a rainforest pond, highly detailed, eye-level shot |  |
|
| 风景 | an aerial drone shot of the breathtaking landscape of the Bora Bora islands, with sparkling waters under the sun |  |
|
| 广告 | a bottle of perfume on a clean backdrop, surrounded by fragrant white flowers, product photography, minimalistic, natural light |  |
|
| 文字生成 | custom sticker design on an isolated white background with the words “Rachel” written in an elegant font decorated by watercolor butterflies, daisies and soft pastel hues |  |
|
| 矢量图 | simple flat vector illustration of a woman sitting at the desk with her laptop with a puppy, isolated on white background |  |
|
| 像素艺术 | chibi pixel art, game asset for an rpg game on a white background featuring the armor of a dragon sorcerer wielding the power of fire surrounded by a matching item set | 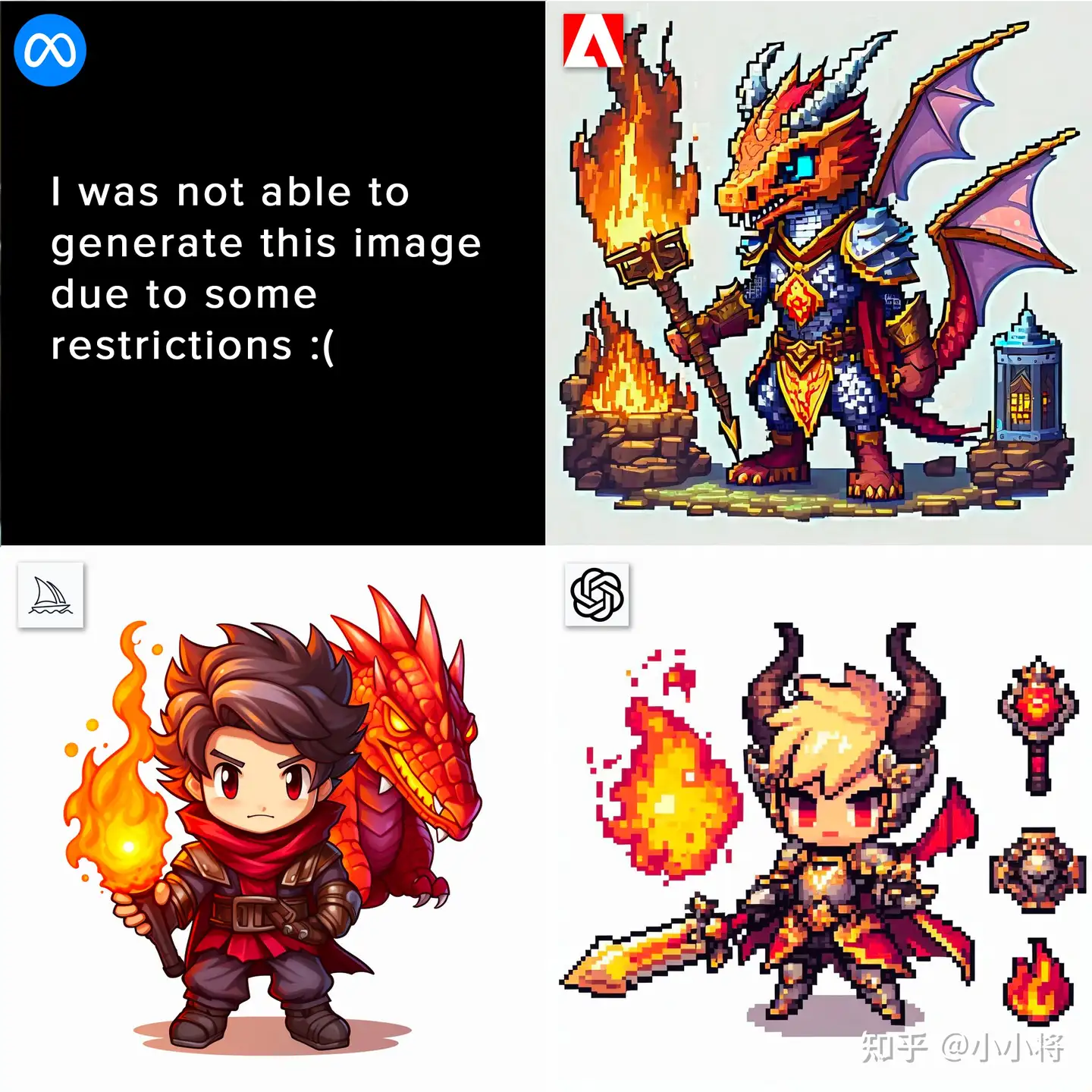 |
|
| 室内设计 | a bedroom with large windows and modern furniture, gray and gold, luxurious, mid century modern style |  |
|
| 着色书 | kid’s coloring book, a happy young girl holding a flower, cartoon, thick lines, black and white, white background |  |
本地部署
Stable Diffusion
-
windows上运行stable-diffusion-webui和模型,需要足够大的显存,最低配置4GB显存,基本配置6GB显存,推荐配置12GB显存。 当然内存也不能太小,最好大于16GB,总之内存越大越好,显卡为NVIDIA GeForce GTX 1060 Ti ( 5GB / NVIDIA ),这个上古显卡跑AI绘画着实比较吃力,但也能将就用。
- 没有 Nvidia 显卡,给 stable-diffusion-webui 指定运行参数
--use-cpu sd,让其使用 CPU 算力运行 - Nvidia 显卡(配置越高,绘图越快)
- A卡不行,CPU 算力跟 GPU 算力相比简直天差地别,虽然可以通过改参来实现,但有条件直接上N卡吧
- 可能 GPU 只需要 10 秒就能绘制完成,而 CPU 却要 10 分钟
- 4G 的显卡加上 –medvram 启动参数
- 2G 的显卡加上 –lowvram 启动参数。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
# 检测 cuda 安装
nvcc --version
OpenAI Consistency Models
【2023-4-13】终结扩散模型:OpenAI开源新模型代码,一步成图,1秒18张
OpenAI 3月偷偷上传了一篇论文《 Consistency Models 》
问题
- 扩散模型依赖于迭代生成过程,这导致此类方法采样速度缓慢,进而限制了它们在实时应用中的潜力。
OpenAI 的这项研究就是为了克服这个限制,提出了 Consistency Models,这是一类新的生成模型,无需对抗训练即可快速获得高质量样本。与此同时,OpenAI 还发布了 Consistency Models 实现以及权重。
- 论文地址:Consistency Models
- 代码地址:consistency_models
Consistency Models 支持快速 one-step 生成,同时仍然允许 few-step 采样,以权衡计算量和样本质量。它们还支持零样本(zero-shot)数据编辑,例如图像修复、着色和超分辨率,而无需针对这些任务进行具体训练。Consistency Models 可以用蒸馏预训练扩散模型的方式进行训练,也可以作为独立的生成模型进行训练。
研究团队通过实验证明 Consistency Models 在 one-step 和 few-step 生成中优于现有的扩散模型蒸馏方法。例如,在 one-step 生成方面,Consistency Models 在 CIFAR-10 上实现了新的 SOTA FID 3.55,在 ImageNet 64 x 64 上为 6.20。当作为独立生成模型进行训练时,Consistency Models 在 CIFAR-10、ImageNet 64 x 64 和 LSUN 256 x 256 等标准基准上的表现也优于 single-step、非对抗生成模型。
Consistency Models 建立在连续时间扩散模型中的概率流 (PF) 常微分方程 (ODE) 之上。如下图 1 所示,给定一个将数据平滑地转换为噪声的 PF ODE,Consistency Models 学会在任何时间步(time step)将任意点映射成轨迹的初始点以进行生成式建模。Consistency Models 一个显著的特性是自洽性(self-consistency):同一轨迹上的点会映射到相同的初始点。这也是模型被命名为 Consistency Models(一致性模型)的原因。
生成速度,3.5 秒生成了 64 张分辨率 256×256 的图片,平均一秒生成 18 张
- Consistency Model 可以根据人类要求生成图像(生成了有床和柜子的卧室)。
- Consistency Model 图像修复功能:左边是经过掩码的图像,中间是 Consistency Model 修复的图像,最右边是参考图像:
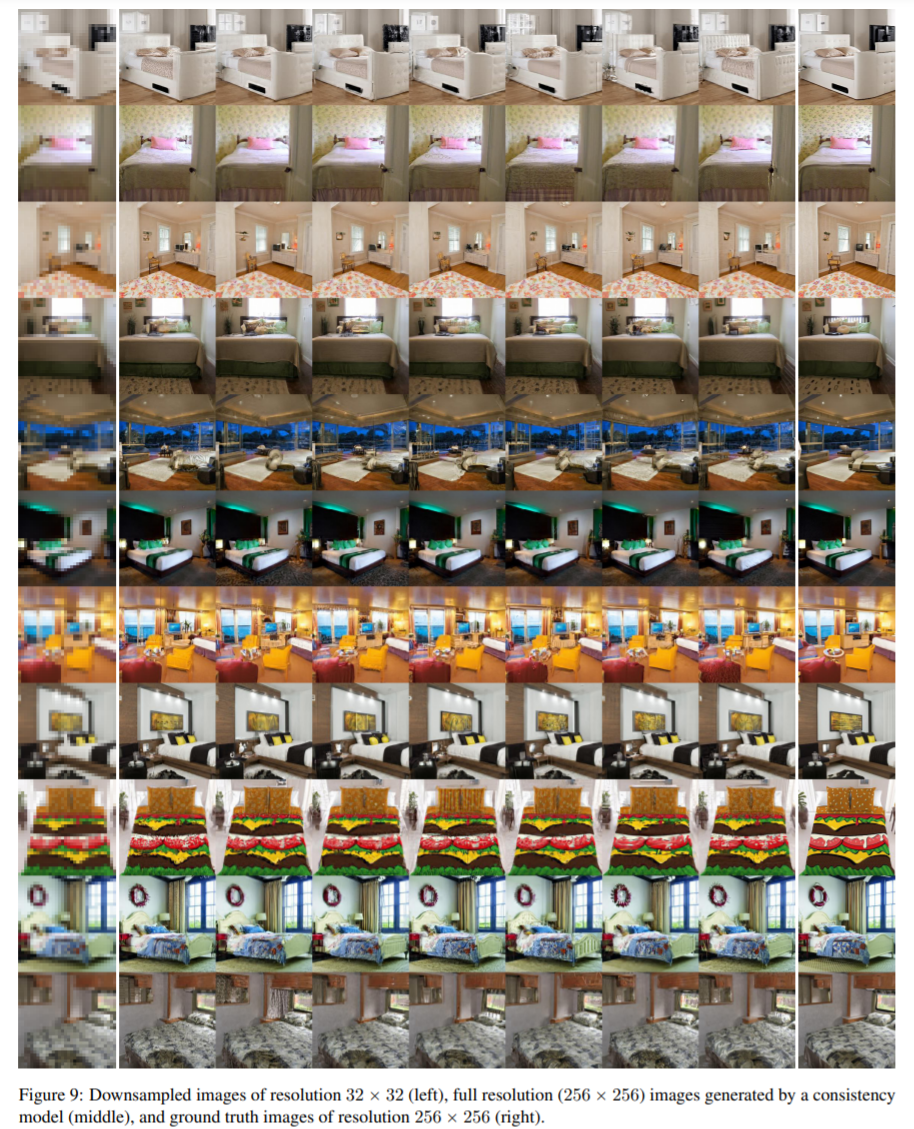
- Consistency Model 生成高分辨率图像:左侧为分辨率 32 x 32 的下采样图像、中间为 Consistency Model 生成的 256 x 256 图像,右边为分辨率为 256x 256 的真值图像。相比于初始图像,Consistency Model 生成的图像更清晰。


Stable Diffusion
Stable Diffusion is a state of the art text-to-image model that generates images from text.
- transformers上的 Stable Diffusion Demo
- For faster generation and forthcoming API access you can try DreamStudio Beta
- stable diffusion v1.5 huggingface, github
【2023-4-3】Kaggle Stable Diffusion赛题 高分思路
【2024-8-22】苹果设备上运行Stable Diffusion模型
介绍
Stable Diffusion 是以文本生成图像的 AI 工具,慕尼黑大学的CompVis小组开发,基于潜在扩散模型打造,也是唯一一款能部署在家用电脑上的 AI 绘图工具,可以在 6GB 显存显卡或无显卡(只依赖 CPU)下运行,并在几秒钟内生成图像,无需预处理和后处理。
- stability ai 公司以此为基础
- Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input, cultivates autonomous freedom to produce incredible imagery, empowers billions of people to create stunning art within seconds.
- demo
支持功能
【2023-12-16】2023年最新Stable Diffusion下载+安装+使用教程(超详细版本)
SD 生态
SD基本概念
- 大模型:用素材+SD低模(如SD1.5/SD1.4/SD2.1),深度学习之后炼制出的大模型,可以直接用来生图。大模型决定了最终出图的大方向,是底料。多为CKPT/SAFETENSORS扩展名。
VAE:类似滤镜,是对大模型的补充,稳定画面的色彩范围。多为CKPT/SAFETENSORS扩展名。LoRA:模型插件,是在基于某个大模型的基础上,深度学习之后炼制出的小模型。需要搭配大模型使用,可以在中小范围内影响出图的风格,或是增加大模型所没有的东西。炼制的时候如果基于SD底模,在不同大模型之间更换使用时的通用性会较好。但如果基于特定的大模型,可能会在和该大模型配合时得到针对性的极佳效果。ControlNet:神级插件,让SD有了眼睛,能够基于现有图片得到诸如线条或景深的信息,再反推用于处理图片。Stable Diffusion Web-UI(SD-WEBUI):开源大神AUTOMATIC1111基于Stability AI算法制作的开源软件,能够展开浏览器,用图形界面操控SD。- 整合包:由于WEBUI本身基于GitHub的特性,绝大多数时候的部署都需要极高的网络需求,以及Python环境的需求。使用整合包,内置了和电脑本身系统隔离的Python环境,以及内置了Git,不需要了解这两个软件就可以运行。可以几乎忽视这样的门槛,让更多人能够享受AI出图。
体验方法
体验方法
- (1)在线工具:Hugging Face 和 DreamStudio。与本地部署相比
- Hugging Face需排队,生成一张图约 5 分钟;
- DreamStudio 可免费生成 200 张图片,之后需要缴费。dreamstudio, stability.ai 出品
- 注意:这类在线工具对图片的调教功能偏弱,无法批量生成图片,只能用于测试体验。
- (2)本地部署:适合大批量使用,参考
- Docker Desktop 将 Stable Diffusion WebUI Docker 部署在 Windows 系统,从而利用 NVIDIA 显卡免费实现 AI 文字绘画,不再被在线工具所限制。Mac 同样适用于该方法,并可省略下方的环境配置步骤。
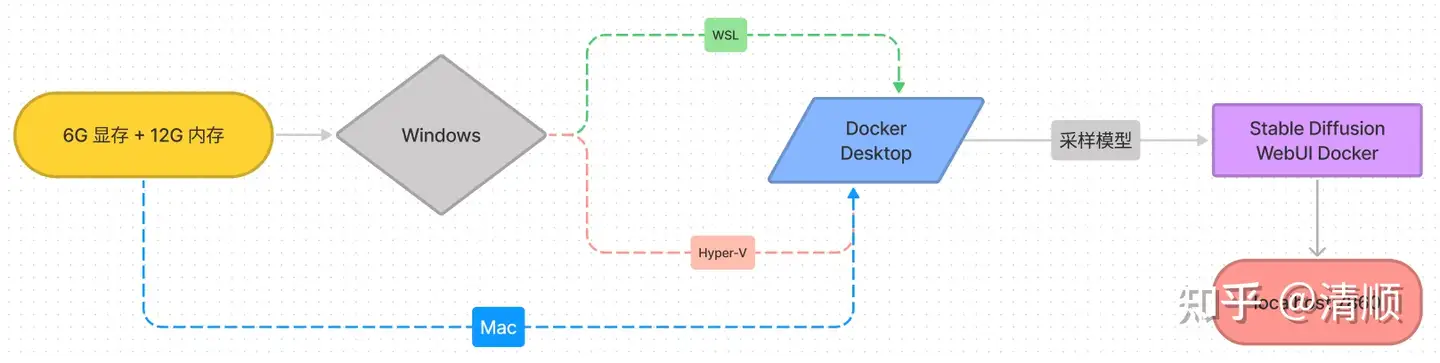
模型下载
【2024-8-22】苹果设备上运行Stable Diffusion模型
Stable Diffusion 模型可在 huggingface 或 Civitai 下载到。
可能会有三种格式
CoreML格式: 模型较少,文件主要以.mlmodelc或.mlmodel为主Diffusers格式: huggingface 渠道的主流格式safetensors格式: Civitai网站下载的大多是这种格式,一个文件,非常方便。
CoreML
CoreML格式
- 这种类别的模型较少,文件主要以
.mlmodelc或.mlmodel为主
Core ML 是 Apple Silicon 芯片产品(包括macOS、iOS、watchOS 和 tvOS)中的机器学习框架,用于执行快速预测或推理,在边缘轻松集成预训练的机器学习模型,从而可以对设备上的实时图像或视频进行实时预测。
Core ML 通过利用 CPU、GPU 和 神经网络引擎 ,同时最大程度地减小内存占用空间和功耗,来优化设备端性能。由于模型严格地在用户设备上,因此无需任何网络连接,这有助于保护用户数据的私密性和 App 的响应速度。
如果模型运行在Silicon芯片的苹果设备上,利用Core ML可以获得更快的性能和更低的内存及能耗。
其文件结构大致为:
├── TextEncoder.mlmodelc
├── TextEncoder2.mlmodelc
├── Unet.mlmodelc
├── VAEDecoder.mlmodelc
├── merges.txt
└── vocab.json
Diffusers格式
在 huggingface 上下载的模型大多是这种类型,其文件结构大致为:
├── model_index.json
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ └── pytorch_model.bin
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet
│ ├── config.json
│ └── diffusion_pytorch_model.bin
└── vae
├── config.json
└── diffusion_pytorch_model.bin
格式转换
下载的模型都转成 CoreML 格式,如果第一步下载的模型已经是 CoreML 格式,那么可以跳过。
Diffusers -> CoreML
Diffusers 格式转 CoreML 格式
- 首先下载该仓库代码:ml-stable-diffusion。查看System Requirements检查自己的设备是否支持。
- 然后安装依赖:
pip install -r requirements.txt
找到 torch2coreml.py 文件,执行以下命令:
python torch2coreml.py \
--bundle-resources-for-swift-cli \
--xl-version \
--convert-unet \
--convert-text-encoder \
--convert-vae-decoder \
--attention-implementation ORIGINAL \
--model-version /your/model/path \
-o /your/model/output/path
注意有个参数–xl-version,如果模型是sdxl类型的,就加上,否则把这行删除。另外如果你的模型支持图生图,你可以加上–convert-vae-encoder参数。
运行完该命令,应该在你指定的目录生成了文件,在Resources目录下的文件就是转换好的CoreML格式。
safetensors -> Diffusers
safetensors 格式转 Diffusers 格式
- 首先下载该仓库代码:Diffusers。
- 然后安装依赖:
pip install --upgrade diffusers
找到 convert_original_stable_diffusion_to_diffusers.py 文件并执行以下命令:
python convert_original_stable_diffusion_to_diffusers.py \
--checkpoint_path /your/model/path \
--dump_path /your/model/output/path \
--from_safetensors \
--half \
--device mps
这里 –half 表示转换时精度为 fp16, –device mps 表示模型使用mps(GPU)进行推理。
运行完该命令,会生成Diffusers格式的模型,再利用Diffusers格式转CoreML格式的步骤,将模型转换为CoreML格式。
训练方法
stable diffusion 常用训练方式:Dreambooth、textual inversion、LORA 和 Hypernetworks
- 1 Dreambooth 2022年谷歌发布,向模型注入自定义主题来 fine-tune diffusion model 的技术。
- 论文: 【2023-3-15】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- 主页: dreambooth
- 仅使用三张图片作为输入,就能在不同的prompt下生成对应的图片
- 2 Textual Inversion
- 3 LORA
- 4 Hypernetworks
Dreambooth
2022年谷歌发布,向模型注入自定义主题来 fine-tune diffusion model 的技术。
- 论文: 【2023-3-15】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- 主页: dreambooth
- 仅使用三张图片作为输入,就能在不同的prompt下生成对应的图片

训练自己数据最直观的方法: 把自己的图片加入模型迭代时一起训练。
但是有两个问题:过拟合,语言漂移(language drift)。
而 Dreambooth 能避免上述两个问题
- 用一个罕见词来代表图片含义,保证新加入的图片对应的词在模型中没有太多的意义
- 为了保留类别的含义,例如图中的“狗”,模型会在狗的类别基础上微调,并保留对应词的语义,例如给这只狗取名为”Devora”, 那么生成的”Devora”就会特指这只狗。
区别于 textual inversion 方法
- Dreambooth 使用罕见词, 而 textual inversion 使用新词。
- Dreambooth 对整个模型做微调,而 textual inversion 只会对text embedding部分调整
训练 dreambooth
数据
- 3-10张图片, 最好是不同角度,且背景有变化的图片
- 独特的标识符(unique identifier)
- 类的名字(class name) 先了解下几个prompt: instance prompt: a photo of [unique identifier] [class name] class prompt: a photo of [class name]
webui 上依次点击”Extensions”->”Available”->”Load from”。会搜索出非常多的插件,选择”Dreambooth”并”Install”
安装完成后依次点击”Extensions”->”Installed”->”Apply and restart UI”
创建一个空的模型,设定好Name和原始的Checkpoint就行

Textual Inversion
【2022-8-2】以色列特拉维夫大学+Nvidia 推出 Textual Inversion
Textual Inversion 是一种在 Stable Diffusion 等文本到图像生成模型中使用的轻量级训练方法。
- 主要目的: 让模型能够学习并生成具有特定风格或对象的新图像,而无需对整个模型进行重新训练。
- 用户可以在原有预训练模型的基础上,仅针对特定概念(如特定的艺术风格、某个物体或者某个人的外观)进行微调。
embedding 是 textual inversion 的结果,因此 textual inversion 也可以称为 embedding。
该方法只需要3-5张图像,通过定义新的关键词,就能生成和训练图像相似的风格。
扩散模型中有很多可以定义模型的方法,例如像 LoRA,Dreambooth,Hypernetworks。但textual inversion方法很不一样的地方在于: 不用改变模型。
工作原理
- 定义一个在现有模型中没有的关键词,新的关键词会和其他的关键词一样,生成Tokenizer(用不同的数字表示);
- 然后, 将其转换为embedding;
- text transformer会映射出对于新给的关键词最好的embedding向量。
- 不用改变模型,可以看作在模型中寻找新的表征来表示新的关键字
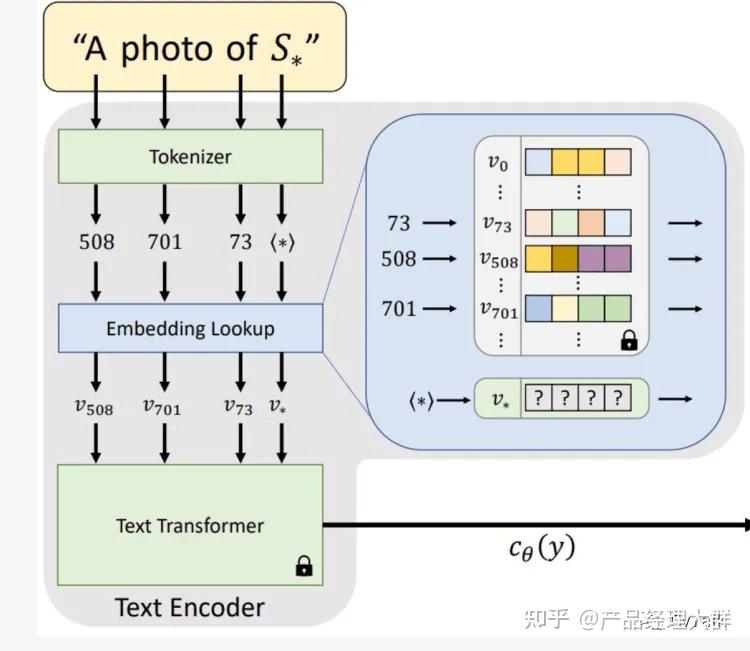
textual inversion可以用来训练新的object,示例是在模型中注入玩具猫

textual inversion 也可以用来训练画风,示例是学习模版图的画风,迁移到其他图片

训练方法
- webui上点击”Train”->”Create embedding”
- “Name”处为需要学习的目标设置一个新的名字;
- “Initialization text”无需更改;
- “Number of vectors per token”表示新建立的”Name”占几个prompt,理论上越大越好,但stable diffusion只支持75个prompt, 会导致可以设置的其他prompt变小,一般设置2-8即可。
- 接着点击创建,则会生成模型文件
- 训练设置:prompt template
- style_filewords.txt: 表示训练画风
- subject_filewords.txt: 表示训练人物或物体
风格的训练和人物的方式基本一样,可以找些比较有特点的画风数据。周末逛一家拼图店看到了一些很有趣的画风,在网上爬了些数据,首先还是将数据缩放成512*512
LoRA
【2021-10-16】微软推出 LoRA, 全称 Low-Rank Adaptation,中文叫”低秩适应”。
LoRA 是一种fine tune扩散模型的训练技术。通过对标准的checkpoint模型做微小的修改,可以比checkpoint模型小10到100倍。区别于Dreambooth和textual inversion技术,Dreambooth训练得到的模型很强大,但模型也很大(2-7GB);而textual inversion生成的模型很小(大约100KB),但模型效果一般。而LoRA则在模型大小(大约200MB)和效果上达到了平衡。
和textual inversion一样,不能直接使用LoRA模型,需要和checkpoint文件一起使用。
工作原理
LoRA通过在checkpoint上做小的修改替换风格,具体而言修改的地方是UNet中的cross-attention层。该层是图像和文本prompt交界的层。LORA的作者们发现微调该部分足以实现良好的性能。
cross attention层的权重是一个矩阵,LoRA fine tune这些权重来微调模型。那么LoRA是怎么做到模型文件如此小?LoRA的做法是将一个权重矩阵分解为两个矩阵存储,能起到的作用可以用下图表示,参数量由(1000* 2000)减少到(1000* 2+2000*2), 大概300多倍
cross-attention是扩散模型中关键的技术之一,在LoRA中通过微调该模块,即可微调生成图片的样式,而在Hypernetwork中使用两个带有dropout和激活函数的全链接层,分别修改cross attention中的key和value,也可以定制想要的生成风格。可见cross attention的重要性。
LoRA 是一种训练技巧,可以和其他的方法结合
- 例如在Dreambooth中,训练的时候可以选择LoRA的方式。
- 在之前Dreambooth的篇章中,介绍了人物的训练,这篇填上风格训练的坑。
- 数据的处理方式和之前的处理一样,训练数据改用特定风格的图片,Concepts中选用Training Wizard (Object/Style)。
Hypernetworks
hypernetworks 是一种fine tune的技术,最开始由novel AI开发。
hypernetworks 是一个附加到stable diffusion model上的小型网络,用于修改扩散模型的风格。
工作原理
既然 Hypernetworks会附加到diffusion model上,那么会附加到哪一部分呢?答案仍然是UNet的cross-attention模块,Lora模型修改的也是这一部分,不过方法略有不同。
hypernetworks 是一个很常见的神经网络结构,具体而言,是一个带有dropout和激活函数的全连接层。通过插入两个网络转换key和query向量,下面的两张图是添加Hypernetworks之前和之后的网络图
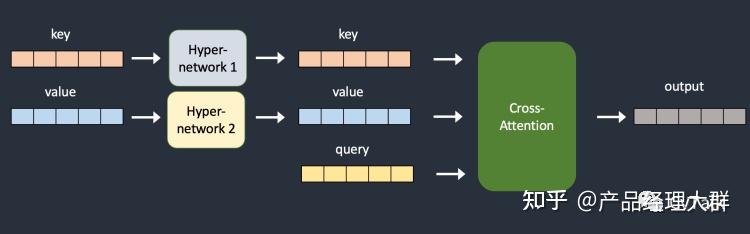
和 embedding(Textual Inversion)比较类似, 训练在同一个tag下,首先第一步需要创建Hypernetworks模型
创建完模型后,就可以开始训练了,训练的参数设置也和Textual Inversion十分相似
设置完后,选择底部的Train Hypernetworks就可以开始训练
ControlNet
ControlNet 可以从提供的参考图中获取布局或者姿势等信息, 并引导 diffusion model 生成和参考图类似的图片。
扩散模型中会需要使用text作为条件引导模型生成, 而ControlNet在引导的时候会增加一个条件实现更加可控的text-to-image生成.
diffusion model进展非常迅速, 针对diffusion model的一些痛点, 作者提出了几个问题和训练扩散模型时的限制, 并着手用ControlNet解决:
- 基于prompt的控制是否能满足我们的需求?
- 在图像处理中, 有许多有明确定义的长期任务, 是否可以用大模型来使这些任务达到新的高度?
- 应该用什么样的框架处理用户想要的各种各样条件?
- 在特定场景, 新提出的框架怎么能继承大模型(diffusion model)的能力.
ControlNet具有以下的特点:
- end2end
- control large im age diffusion model(例如stable diffusion)
- learn task-specific input conditions
三点限制:
- 特定场景的数据量少, 在较少的数据量上很容易出现过拟合
- 大的计算集群很奢侈, (stable diffusion base模型需要15万个A100显卡小时)
- end2end是必要的, 一些特定场景需要将原始的输入转为更高语义的表达, 手工处理的方式不太可行
如何画出好作品?
官方文档描述文字的要素和标准。
样例:
A beautiful painting (画作种类) of a singular lighthouse, shining its light across a tumultuous sea of blood (画面描述) by greg rutkowski and thomas kinkade (画家/画风), Trending on artstation (参考平台), yellow color scheme (配色)。
要素
- 画作种类:ink painting(水墨画),oil painting(油画),comic(漫画),digital painting(数字印刷品),illustration(插画),realistic painting(写实画),portrait photo(肖像照)等等,可叠加多个种类描述。
- 参考平台:Trending on artstation,也可以替换为「Facebook」「Pixiv」「Pixbay」等等。下方提供相同参数下不同参考平台生成的图片风格。
- 画家/画风:成图更接近哪位画家的风格,此处可以输入不止一位画家,如「Van Gogh:3」and「Monet:2」,即作品三分像梵高,两分像莫奈;或直接描述风格种类,如 very coherent symmetrical artwork,将作品结构设为连贯对称的。
- 配色:yellow color scheme 指整个画面的主色调为黄色。
- 画面描述:除了对主题进行描述,还可以添加多个画面元素,如 beautiful background, forest, octane render, night;添加画面质量描述,如 highly detailed, digital painting, Trending on artstation, concept art, smooth, sharp focus, illustration,8k。
作品修复
【2024-6-14】AI绘画Stable Diffusion【手部修复】
本地部署
【2023-12-9】
- 模型比较大,所以必须要有 NVIDIA GPU,至少4GB VRAM,本地磁盘至少有15GB的空间,打包的项目解压后需要11G的磁盘。
在 v100 显卡上实验 stable diffuse 工具:
后台调用
from diffusers import StableDiffusionPipeline
from diffusers import StableDiffusionImg2ImgPipeline
import torch
# --------- 本地模型信息 ----------
model_path = '/mnt/bd/wangqiwen-hl/models/video'
model_id = "runwayml/stable-diffusion-v1-5"
# --------- text2image ---------
#pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, cache_dir=model_path)
pipe = pipe.to("cuda")
prompt = "a man and a woman holding a cat and a dog"
negative_prompt = "distorted faces, low resolution"
images = pipe(prompt, num_images_per_prompt=3, negative_prompt=negative_prompt).images
num = len(images)
print(f"一共生成了{num}张图片, 默认保存第一张")
for i in range(num):
images[i].save(f"output_{i+1}.png")
#image[0].save("output.png")
# --------- image2image ---------
pipeimg = StableDiffusionImg2ImgPipeline.from_pretrained(model_id, torch_dtype=torch.float16, cache_dir=model_path)
pipeimg = pipe.to("cuda")
# 选取一张来进一步修改
from PIL import Image
init_image = Image.open("output_1.png").convert("RGB").resize((768, 512))
prompt = "add another girl"
images = pipe(prompt=prompt, num_images_per_prompt=3, negative_prompt=negative_prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
num = len(images)
for i in range(num):
images[i].save(f"modify_{i+1}.png")
#images[0].save("output_modify.png")
效果
- 中文提示词效果很差,无法理解,猜测是没有中文分词器
- 加负向提示词有利于改进效果
- image2image 并未对已有图片做改进
Web UI
基于Gradio的Web版
- image传参有问题,尚未调通
import gradio as gr
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler, StableDiffusionImg2ImgPipeline
import requests
from PIL import Image
from io import BytesIO
# 本地模型地址、名称
model_path = '/mnt/bd/wangqiwen-hl/models/video'
model_id = "runwayml/stable-diffusion-v1-5"
lms = LMSDiscreteScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear"
)
# 文升图
pipe = StableDiffusionPipeline.from_pretrained(
#"CompVis/stable-diffusion-v1-4",
model_id, cache_dir=model_path,
scheduler=lms,
revision="fp16",
use_auth_token=True
).to("cuda")
# 图生图
pipeimg = StableDiffusionImg2ImgPipeline.from_pretrained(
#"CompVis/stable-diffusion-v1-4",
model_id, cache_dir=model_path,
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
).to("cuda")
# ------ Web UI -------
block = gr.Blocks(css=".container { max-width: 800px; margin: auto; }")
num_samples = 2
def infer(prompt, init_image, strength):
if init_image != None:
init_image = init_image.resize((512, 512))
#init_image = preprocess(init_image)
with autocast("cuda"):
#images = pipeimg([prompt] * num_samples, init_image=init_image, strength=strength, guidance_scale=7.5)["sample"]
images = pipeimg([prompt] * num_samples, init_image=init_image, strength=strength, guidance_scale=7.5)
else:
with autocast("cuda"):
#images = pipe([prompt] * num_samples, guidance_scale=7.5)["sample"]
images = pipe([prompt] * num_samples, guidance_scale=7.5)
return images
with block as demo:
gr.Markdown("<h1><center>Stable Diffusion</center></h1>")
gr.Markdown(
"Stable Diffusion is an AI model that generates images from any prompt you give!"
)
with gr.Group():
with gr.Box():
with gr.Row().style(mobile_collapse=False, equal_height=True):
text = gr.Textbox(
label="Enter your prompt", show_label=False, max_lines=1
).style(
border=(True, False, True, True),
rounded=(True, False, False, True),
container=False,
)
btn = gr.Button("Run").style(
margin=False,
rounded=(False, True, True, False),
)
strength_slider = gr.Slider(
label="Strength",
maximum = 1,
value = 0.75
)
image = gr.Image(
label="Intial Image",
type="pil"
)
gallery = gr.Gallery(label="Generated images", show_label=False).style(
grid=[2], height="auto"
)
text.submit(infer, inputs=[text, image, strength_slider], outputs=gallery)
btn.click(infer, inputs=[text, image, strength_slider], outputs=gallery)
gr.Markdown(
"""___
<p style='text-align: center'>
Created by CompVis and Stability AI
<br/>
</p>"""
)
# 启动时,要先填 huggingface的token,否则报错.
# huggingface-cli login 输入自己的key...
demo.launch(debug=True, share=True)
踩坑
报错:
Failed to import transformers.models.clip.modeling_clip because of the following error (look up to see its traceback): name ‘cuda_setup’ is not defined
原因
- bitsandbytes 工具包版本问题,默认版本是 0.36
# 版本降级 bitsandbytes
pip install bitsandbytes==0.35.0
解决后,出现新的报错:
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
原因 参考
- Pytorch需要安装的四个包,版本没有对应,导致CUDA没法用
解决:
- 去官网找到对应版本的 pytorch、系统(linux),重新安装环境
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
成功!
Mac 版本
【2024-2-25】MochiDiffusion 一款在Macicon上原生运行Stable Diffusion的客户端。
MochiDiffusion 内置 Apple 的 Core ML Stable Diffusion 框架 以实现在搭载 Apple 芯片的 Mac 上用极低的内存占用发挥出最优性能。
功能:
- 极致性能和极低内存占用 (使用神经网络引擎时 ~150MB)
- 在所有搭载 Apple 芯片的 Mac 上充分发挥神经网络引擎的优势
- 生成图像时无需联网
- 图像转图像(Image2Image)
- 使用 ControlNet 生成图像
- 在图像的 EXIF 信息中存储所有的关键词(在访达的“显示简介”窗口中查看)
- 使用 RealESRGAN 放大生成的图像
- 自动保存 & 恢复图像
- 自定义 Stable Diffusion Core ML 模型
- 无需担心损坏的模型
- 使用 macOSicon 原生框架 SwiftUI 开发
Stable Diffusion Web UI
Stable Diffusion Web UI 提供了多种功能,如 txt2img、img2img、inpaint 等,还包含了许多模型融合改进、图片质量修复等附加升级,通过调节不同参数可以生成不同效果,用户可以根据自己的需要和喜好进行创作。
启动界面可以大致分为4个区域【模型】【功能】【参数】【出图】四个区域
- 模型区域:模型区域用于切换我们需要的模型,模型下载后放置相对路径为/modes/Stable-diffusion目录里面,网上下载的safetensors、ckpt、pt模型文件请放置到上面的路径,模型区域的刷新箭头刷新后可以进行选择。
- 功能区域:功能区域主要用于我们切换使用对应的功能和我们安装完对应的插件后重新加载UI界面后将添加对应插件的快捷入口在功能区域,功能区常见的功能描述如下
- txt2img(文生图) — 标准的文字生成图像;
- img2img (图生图)— 根据图像成文范本、结合文字生成图像;
- Extras (更多)— 优化(清晰、扩展)图像;
- PNG Info — 图像基本信息
- Checkpoint Merger — 模型合并
- Textual inversion — 训练模型对于某种图像风格
- Settings — 默认参数修改
- 参数区域:根据您选择的功能模块不同,可能需要调整的参数设置也不一样。例如,在文生图模块您可以指定要使用的迭代次数,掩膜概率和图像尺寸等参数配置
- 出图区域:出图区域是我们看到AI绘图的最终结果,在这个区域我们可以看到绘图使用的相关参数等信息。
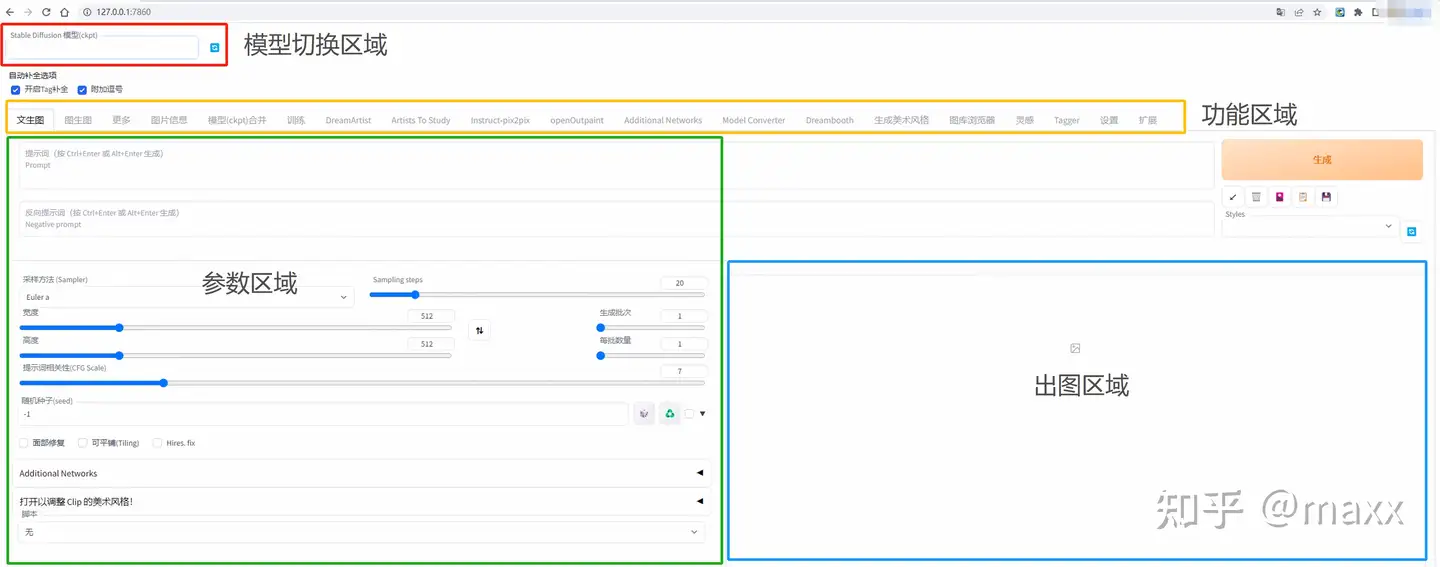
LoRA使用
【2023-3-20】AI作画的lora模型使用体验
- Stable Diffusion有个lora训练功能,可以在6G显存显卡上进行训练风格或者人物的模型,lora模型体积小,所以备受青睐。演示的图是一些lora模型,相互融合所作或者从大模型提取的lora模型而作,诸如人+水墨风格或者动漫风格参考图(扇子)而创作。
SD 进化
VAE Stable Diffusion
VAE Stable Diffusion(稳定扩散)是一种用于生成模型的算法,结合了变分自编码器(Variational Autoencoder,VAE)和扩散生成网络(Diffusion Generative Network)的思想。它通过对变分自编码器进行改进,提高了生成样本的质量和多样性。
VAE Stable Diffusion 核心思想
- 使用扩散生成网络来替代传统的解码器。
扩散生成网络逐步生成样本,每步都通过对噪声进行扩散来生成样本。这种逐步生成的过程可以提高生成样本的质量,并且可以控制生成样本的多样性。
Stable Diffusion 使用 VAE, 能得到颜色更鲜艳、细节更锋利的图像,同时也有助于改善脸和手等部位的图像质量。
如果本身对图像质量没有苛刻要求,其实是不需要额外部署VAE模型
Stability AI 推出 EMA (Exponential Moving Average)和 MSE (Mean Square Error )两个类型的 VAE 模型。
EMA 会更锐利、MSE 会更平滑。
此外,还有两个比较知名的 VAE 模型,主要用在动漫风格的图片生成中:
- WarriorMama777/OrangeMixs
- hakurei/waifu-diffusion-v1-4
有一些模型会自带 VAE 模型,比如最近发布的 SDXL 模型,在项目中,能够看到模型自己的 VAE 模型。
在 Stable Diffusion 的世界,修复人脸主要依赖的是下面两个项目的能力:
- TencentARC/GFPGAN
- sczhou/CodeFormer
Playground v2
【2023-12-11】Playground v2,全面超越 SDXL 了
官方宣传: Playground v2 出图效果各项指标都超越了 SDXL
体验方式
- 下载 Playground v2 模型,在 SD 的 WebUI 或者 ComfyUI 中作为大模型来使用
- 登录 playgroundai 的官网来使用,需要国外vpn
playgroundai 有两种模式,一种就是 board 模式,一种是 Canvas 模式。
- board 模式
- Canvas 模式: 删除图片背景,不需要的元素,拓展图片
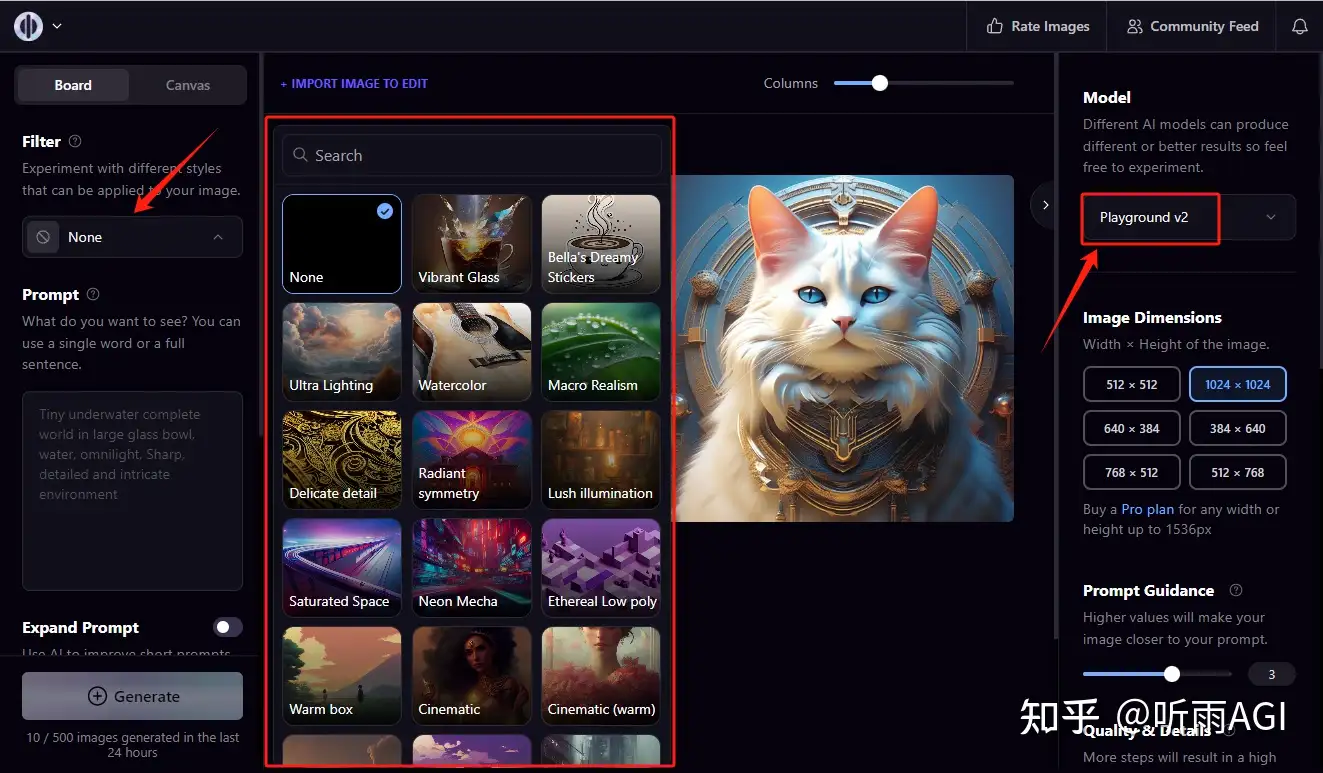
playgroundai 每天可以免费生成 500 张图片

Stable Diffusion 3
【2024-2-22】Stability AI 发布Stable Diffusion 3,号称史上最强大的文生图模型。
【2024-8-16】Stable Diffusion 3 论文及源码概览
新版模型在文本语义理解、色彩饱和度、图像构图、分辨率、类型、质感、对比度等方面都有了显著提升,甚至开始触摸物理世界的奥秘,让生成的图片看起来更加逼真。
- 参数范围在8亿到80亿之间,专为移动设备设计,AI算力消耗更低,推理速度却更快。
Stable Diffusion 3 还具备“多主题生成”和“超高画质”的特点。理解文字描述,甚至能一句话描绘出包含多个主题和多样物品的图像,而且生成的每一张图片都堪称艺术品,无论是在自然写实风景,还是在漫画、海报中,都能精准地捕捉和理解文字描述的每一个细节,将抽象的文字语言转换为具象的画面元素。
技术层面上,Stable Diffusion 3 采用与Sora类似的Diffusion Transformer架构,这种架构在训练过程中通过学习给图片添加和去除噪声,实现了高质量的图像生成。这种创新的架构设计,结合扩散型transformer架构和flow matching,是Stable Diffusion 3取得显著进步的关键。
SD3 中的去噪网络 DiT 模型是怎么一步一步搭起来
除 将去噪网络从 U-Net 改成 DiT 外,SD3 还在模型结构与训练策略上做了很多小改进:
- 改变训练时噪声采样方法
- 将一维位置编码改成二维位置编码
- 提升 VAE 隐空间通道数
- 对注意力 QK 做归一化以确保高分辨率下训练稳定
论文及源码讲解: Stable Diffusion 3 论文及源码概览
Mid-Journey
介绍
Mid 是一款搭载在discord上的人工智能绘画聊天机器人
Midjourney 的工作机制与 Stable Diffusion 和 DALL-E 等图像合成器相近,它使用了经过数百万人造艺术作品训练的 AI 模型,根据称为“提示”的文本描述生成图像。
【2023-3-17】Midjourney 发布了其商用 AI 图像合成服务的第 5 版。该服务可以生成非常逼真的图像,其质量水平极高,一些 AI 艺术爱好者认为这些输出令人毛骨悚然且“过于完美”。Midjourney v5 现在处于 alpha 测试阶段,提供给订阅 Midjourney 服务的客户,该服务可通过 Discord 获取。
【2023-3-30】图像生成器 Midjourney 已叫停免费试用。公司创始人 CEO David Holz 在采访中表示,此举的主要原因是新用户的大量涌入,很多人为了回避付费而注册一次性账户。存在“怪异需求和试用滥用”,可能来自中国的一段操作教学视频,再加上 GPU 临时性短缺,导致付费用户的服务陷入了瘫痪
- 跟 Midjourney 最近生成的一系列病毒式传播图像有关。包括 Trump 被捕和教皇身着时尚夹克的伪造图像,都被部分网民误认为真实存在。
Midjourney 目前是盈利状态,现金流很健康,团队只有 20 多人,没有接受外部融资。
一图总结效果迭代

- 【2024-4-24】 斯坦福AI(大模型)指数2024年度报告
体验方式
一个AI 生成算图工具,只需输入文字就会自动产生图像,Midjourney目前架设在Discord频道上,因此需要有Discord帐号才能使用。
- Discord是一款专为社群设计的免费通讯社交软体,类似于LINE或Slack,但功能更为强大,自带机器人与各种程式功能,能够在上面发开自己工具,有网页版与手机版APP。
使用方法 参考
- #Newbies从侧边栏中选择一个频道
- 使用 /imagine 命令+空格输入关键词
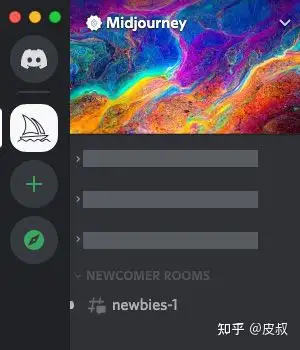
- 等待 MidJourney 机器人处理您的请求。 请求需要一分钟才能根据您的提示生成四个选项。
【2023-5-9】midjourney官方查看自己的作品,仅 5月8日 可用,每月8美金,可以用银联账户
V5
【2023-3-17】Midjourney 发布了其商用 AI 图像合成服务的第 5 版。该服务可以生成非常逼真的图像,其质量水平极高,一些 AI 艺术爱好者认为这些输出令人毛骨悚然且“过于完美”。Midjourney v5 现在处于 alpha 测试阶段,提供给订阅 Midjourney 服务的客户,该服务可通过 Discord 获取。
Midjourney 5 显著提高 了人物图像的描绘质量。例如,以往 AI 生成图像总是处理不好手部形态,这在新版本中已不再是问题。光照和面料质感更加真实,新系统还能生成无数名人和公众人物的形象。
V6
【2023-12-22】Midjourney能生成文字了!V6版5大升级惊艳网友
V6相比于V5来说速度更慢、成本更高(大约每次imagine消耗1gpu/min,每次upscale消耗2gpu/min),但昨天已对V6做了一次更新,速度已提高2.7倍
V6共有5大升级:
- 更精确且更长的提示响应
- 改进了连贯性和模型知识
- 图像生成和混合(remix)得到了优化
- 新增了基础文字绘制功能
- upscale(放大器)功能得到增强,具有’subtle’和’creative’两种模式,分辨率提升两倍
只需给文字加上”引号”,比如”Hello World!”:
Disco Diffusion
Disco Diffsion 存在问题
基于多模态图像生成模型 Disco Diffusion(DD)进行 AI 创作目前存在以下几个问题:
- (1)生成图像质量参差不齐:根据生成任务的难易程度,粗略估算描述内容较难的生成任务良品率 20%~30%,描述内容较容易的生成任务良品率 60%~70%,大多数任务良品率在 30~40% 之间。
- (2)生成速度较慢+内存消耗较大:以迭代 250 steps 生成一张 1280*768 图像为例,需要大约花费 6分钟,以及使用 V100 16G 显存。
- (3)严重依赖专家经验:选取一组合适的描述词需要经过大量文本内容试错及权重设置、画家画风及艺术社区的了解以及文本修饰词的选取等;调整参数需要对 DD 包含的 CLIP 引导次数/饱和度/对比度/噪点/切割次数/内外切/梯度大小/对称/… 等概念深刻了解,同时要有一定的美术功底。众多的参数也意味着需要较强的专家经验才能获得一张还不错的生成图像。
DALL·E
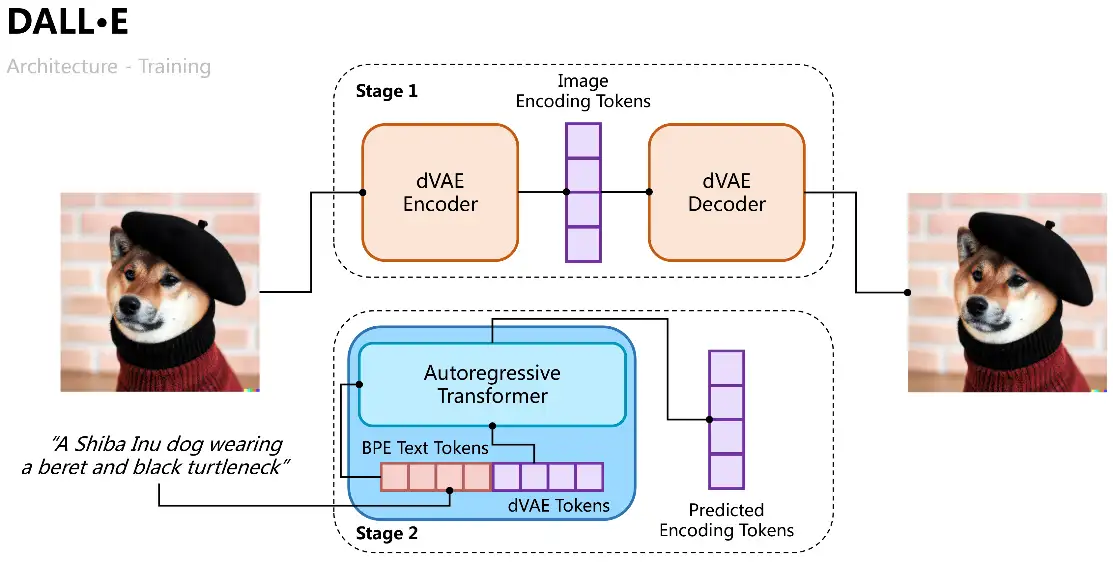
DALL·E由OpenAI在2021年初提出,旨在训练一个输入文本到输出图像的自回归解码器。由CLIP的成功经验可知,文本特征和图像特征可以编码在同一特征空间中,因此我们可以使用Transformer将文本和图像特征自回归建模为单个数据流(“autoregressively models the text and image tokens as a single stream of data”)。
DALL·E的训练过程分成两个阶段,一是训练一个变分自编码器用于图像编解码,二是训练一个文本和图像的自回归解码器用于预测生成图像的Tokens,如图所示。
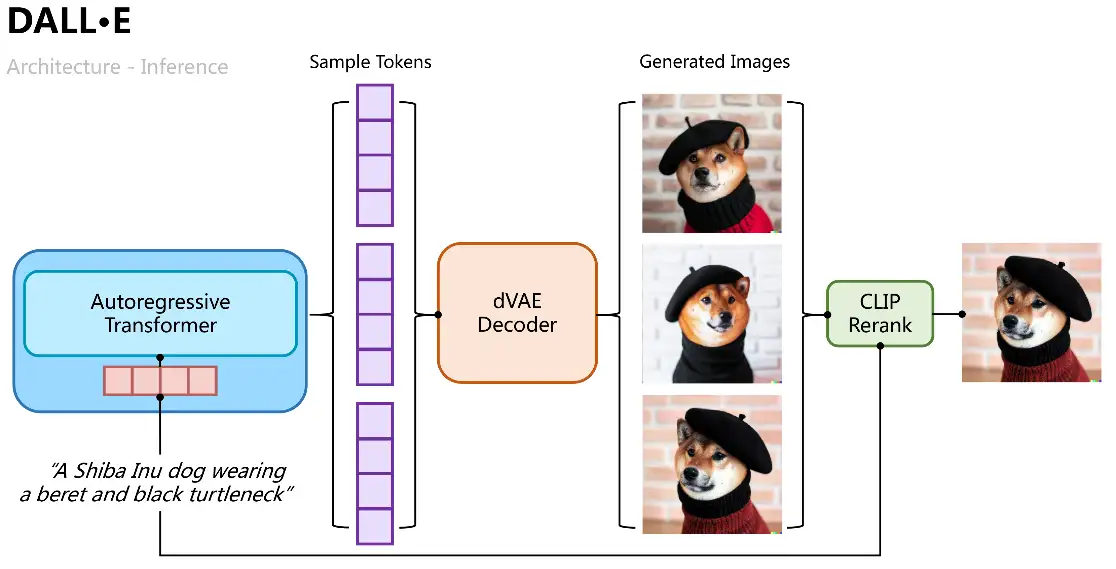
推理过程则比较直观,将文本Tokens用自回归Transformer逐步解码出图像Tokens,解码过程中我们可以通过分类概率采样多组样本,再将多组样本Tokens输入变分自编码中解码出多张生成图像,并通过CLIP相似性计算排序择优
DALL·E 2
为了进一步提升图像生成质量和探求文本-图像特征空间的可解释性,OpenAI结合扩散模型和CLIP在2022年4月提出了DALL·E 2,不仅将生成尺寸增加到了1024*1024,还通过特征空间的插值操作,可视化了文本-图像特征空间的迁移过程。
如图所示,DALL·E 2将CLIP对比学习得到的text embedding、image embedding作为模型输入和预测对象,具体过程是学习一个先验Prior,从text预测对应的image embedding,文章分别用自回归Transformer和扩散模型两种方式训练,后者在各数据集上表现更好;再学习一个扩散模型解码器UnCLIP,可看做是CLIP图像编码器的逆向过程,将Prior预测得到的image embedding作为条件加入中实现控制,text embedding和文本内容作为可选条件,为了提升分辨率UnCLIP还增加了两个上采样解码器(CNN网络)用于逆向生成更大尺寸的图像。
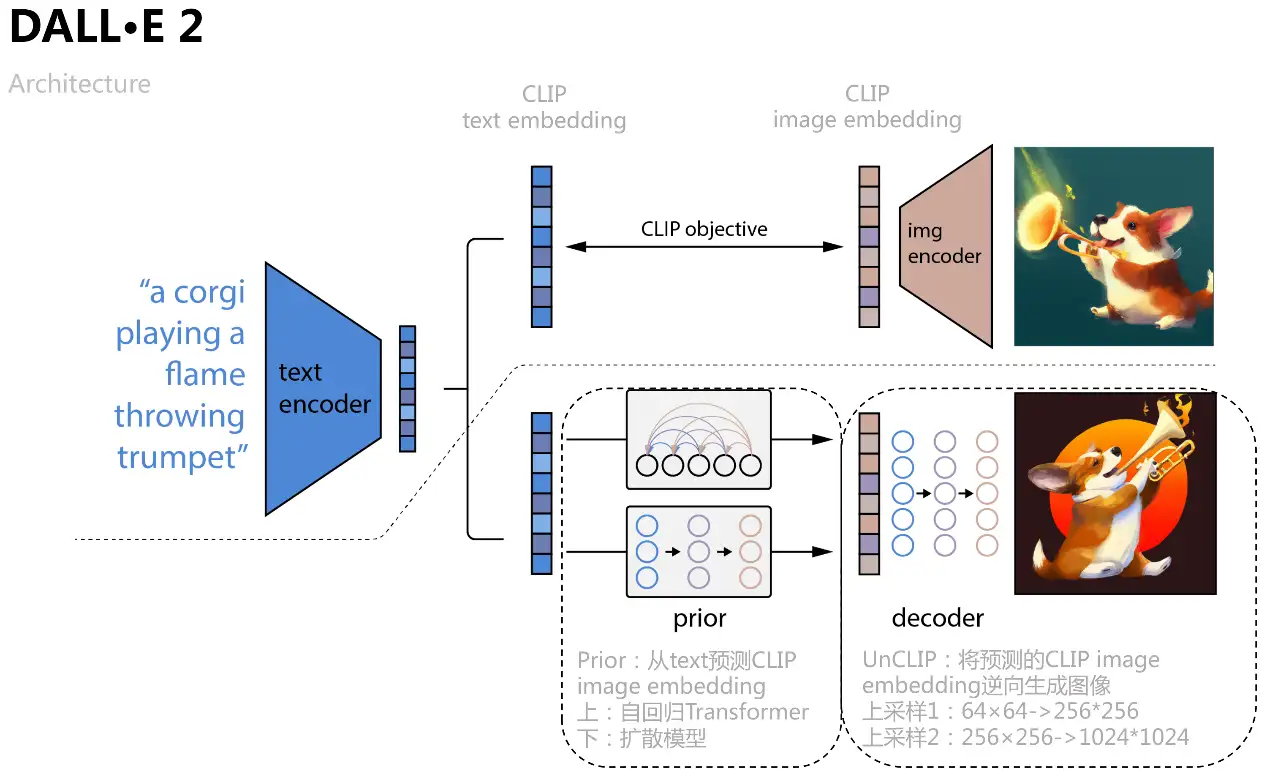
lexica
【2023-3-30】lexica
- 图片搜索:语义搜索
- 图片生成:可控部分除了描述图片的文字,还可以设置负向提示(prompt)
【2023-4-7】类似的,还有 fotor
Tiktok
【2022-8-16】TikTok 乱拳打死老师傅:硅谷大厂还在发论文,它产品已经上线了
- 不少家互联网大厂都在试图测试、开发 AI 文字转图片技术,结果没想到,TikTok 却率先将这项技术应用到了产品里,在 AI 创作潮流中异军突起。
- TikTok 的特效菜单下,最近增加了一个名叫“AI 绿幕” (AI Greenscreen) 的新选项。
- 点击这个选项,然后在屏幕中间的对话框里输入一段文字描述,只用不到5秒的时间,TikTok 就可以根据文字描述生成一张竖版画作,用作短视频的背景:
- 生成结果具有非常强的水彩/油画感觉,风格迁移 (style transfer) 的痕迹明显,而且用的颜色也都鲜亮明快,给人一种耳目一新的感受。
IDEA 太乙
在StabilityAI发布Stable Diffusion模型之后不久,国内的IDEA研究院封神榜团队很快就训练出了名为“太乙”的中文版Stable Diffusion。与原版的Stable Diffusion不同,太乙Stable Diffusion可以更好地理解中文的语言文化环境。
文心一格
- 【2022-8-23】国产AI作画神器火了,更懂中文,竟然还能做周边, “一句话生成画作”这个圈子里,又一个AI工具悄然火起来了,不是你以为的Disco Diffusion、DALL·E,再或者Imagen……而是全圈子都在讲中国话的那种, 文心·一格
- 操作界面上,Disco Diffusion开放的接口不能说很复杂,但确实有点门槛。它直接在谷歌Colab上运行,需要申请账号后使用(图片生成后保存在云盘),图像分辨率、尺寸需要手动输入,此外还有一些模型上的设置。好处是可更改的参数更多,对于高端玩家来说可操作性更强,只是比较适合专门研究AI算法的人群;相比之下,文心·一格的操作只需三个步骤:输入文字,鼠标选择风格&尺寸,点击生成。
- 提示词,Disco Diffusion的设置还要更麻烦一些。除了描述画面的内容以外,包括画作类别和参考的艺术家风格也都得用提示词来设置,通常大伙儿会在其他文档中编辑好,再直接粘过来。相比之下文心·一格倒是没有格式要求,输入150字的句子或词组都可以
- 性能要求上,Disco Diffusion是有GPU使用限制的,每天只能免费跑3小时。抱抱脸(HuggingFace)上部分AI文生图算法的Demo虽然操作简单些,但一旦网速不行,就容易加载不出来; 文心·一格除了使用高峰期以外,基本上都是2分钟就能生成,对使用设备也没有要求。
- 总体来看,同样是文字生成图片AI,实际相比文心·一格的“真·一句话生成图片”,DALL·E和Disco Diffusion的生成过程都不太轻松。
看似“一句话生成图片”不难,其实对AI语义理解和图像生成能力提出了进一步要求。
- 为了能更好地理解文本、提升输出效果,文心·一格还在百度文心的图文生成跨模态模型ERNIE-VilG的基础上,进行了更详细的优化。
- 为了提升图文理解能力,在知识增强的基础上,引入跨模态多视角对比学习;
- 为了降低输入要求同时提升效果,采用基于知识的文本联想能力,让模型学会自己扩展提示词的细节和风格;
- 为了提升图像生成能力,采用渐进式扩散模型训练算法,让模型来选择效果最好的生成网络。
StableDiffusion 图像生成能力一探!Int8量化教程与ONNX导出推理
- CPU下推理StableDiffusion,以及OpenVINO加速的代码,同时,也包含了量化脚本
#git clone https://github.com/luohao123/gaintmodels
git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
git lfs install
cd stable-diffusion-v1-4
git lfs pull
测试StableDiffusion
- 来看看生成的效果,由于模型只能编码英文,我们就以英文作为promopt。
- A green car with appearance of Tesla Model 3 and Porsche 911
- A robot Elon Musk in cyberpunk, driving on a Tesla Model X
【微软】images creator
【2023-3-21】images creator
自定义图片的text2image
【2022-9-7】An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
- github-textual_inversion
- 基于潜在扩散模型(Latent Diffusion Models, LDM),允许用户使用自然语言指导 AI 生成包含特定独特概念的图像。
- 例如我想将心爱的宠物猫咪变成一幅独特的画作——抽象派猫猫,只需要提供3-5张照片,然后通过控制自然语言输入,来得到一个我家猫咪的抽象画作。
- 简单介绍下过程:首先,模型会通过学习这些图片,使用一些单词去表示图片。其次,这些单词可以组合成自然语言句子,通过 prompt 形式指导模型进行个性化创作。好处在于,图像的自然语言表示对用户非常友好。用户可以自由修改 prompt 内容以获取他们想要的风格、主题和独一无二的结果。
- We learn to generate specific concepts, like personal objects or artistic styles, by describing them using new “words” in the embedding space of pre-trained text-to-image models. These can be used in new sentences, just like any other word.
- Our work builds on the publicly available Latent Diffusion Models


商汤秒画
【2023-4-12】【商汤秒画】打造AI画图“模型超市”,心想画成
商汤“日日新SenseNova”大模型体系正式问世,基于该体系的AI内容创作社区平台“商汤秒画SenseMirage”也一并亮相。
商汤科技董事长兼CEO徐立现场演示了“商汤秒画SenseMirage”基于商汤自研AIGC模型的作画能力;
- 秒画平台基于商汤大装置的GPU算力支撑,可帮助用户免除本地化部署流程,既能使用商汤自研作画模型高效地生成高质量内容,也可以将本地模型及其他第三方开源模型一键导入,生成更多样的内容。
相比于Stable Diffusion,商汤作画大模型基于19年开始研发的通用大模型设计体系,采用更先进的大模型结构设计与大batch训练优化算法,模型参数量大小为前者数倍。核心技术包含了自研的 hierarchical inference experts, mixture of token experts, image quality-aware distributed training, texture-guided cross-attention learning等算法,使其具备更优的文本理解泛化性、图像生成风格广度以及图像高质量生成细节。
秒画还提供特异性推理优化服务,开源模型导入后会自动采用秒画底层的模型编译技术进行加速,实测在本地RTX3070显卡需要10秒生成的图片通过秒画加速技术只需要2秒就可以生成。
此外,秒画还支持用户上传本地图像,结合商汤自研作画模型或者开源模型来训练定制化LoRA模型,来高效地生成个性化内容。
清华 LCM – 实时文生图
- 【2023-11-15】实时文生图速度提升5-10倍,清华LCM/LCM-LoRA爆火,浏览超百万、下载超20万
- 【2023-11-23】清华发布LCM:兼容全部SD大模型、LoRA、插件等
起因
Stable Diffusion 等潜在扩散模型(LDM)由于迭代采样过程计算量大,生成速度非常缓慢。
AIGC 时代,包括 Stable Diffusion 和 DALL-E 3 等基于扩散模型的文生图模型受到了广泛关注。扩散模型通过向训练数据添加噪声,然后逆转这一过程来生成高质量图像。然而,扩散模型生成图片需要进行多步采样,这一过程相对较慢,增加了推理成本。缓慢的多步采样问题是部署这类模型时的主要瓶颈。
OpenAI 的宋飏博士在今年提出的一致性模型(Consistency Model,CM)为解决上述问题提供了一个思路。
- 一致性模型被指出在设计上具有单步生成的能力,展现出极大的加速扩散模型的生成的潜力。
- 然而,由于一致性模型局限于无条件图片生成,导致包括文生图、图生图等在内的许多实际应用还难以享受这一模型的潜在优势。
潜在一致性模型(Latent Consistency Model,LCM)就是为解决上述问题而诞生的。
- 潜在一致性模型支持给定条件的图像生成任务,并结合了潜在编码、无分类器引导等诸多在扩散模型中被广泛应用的技术,大大加速了条件去噪过程,为诸多具有实际应用意义的任务打开了一条通路。
【2023-10-6】LCM – 2023 CVPR Best
【2023-10-6】Latent Consistency Models(潜一致性模型)是一个以生成速度为主要亮点的图像生成架构。
- LATENT CONSISTENCY MODELS:SYNTHESIZING HIGH-RESOLUTION IMAGES WITH FEW-STEP INFERENCE
- GitHub,huggingface demo
通过一些创新性的方法,LCM 只用少数的几步推理就能生成高分辨率图像。据统计,LCM 能将主流文生图模型的效率提高 5-10 倍,所以能呈现出实时的效果。

全面兼容 Stable Diffusion生态,LCM模型成功实现5-10倍生成速度的提升,实时AI艺术时代即将到来,所想即所得!
团队现已完全开源 LCM 的代码,并开放了基于 SD-v1.5、SDXL 等预训练模型在内蒸馏得到的模型权重文件和在线 demo
LCM-LoRA
LCM-LORA: 一个通用的 Stable Diffusion 加速模块
和需要多步迭代传统的扩散模型(如Stable Diffusion)不同,LCM 仅用1 - 4步即可达到传统模型30步左右的效果。
由清华大学交叉信息研究院研究生骆思勉和谭亦钦发明,LCM将文生图生成速度提升了5-10倍,世界自此迈入实时生成式AI的时代。
LCM-LoRA出现了:将SD1.5、SSD1B、SDXL蒸馏为LCM的LoRA,将生成5倍加速生成能力带到所有SDXL模型上并兼容所有现存的LoRA,同时牺牲了小部分生成质量; 项目迅速获得了Stable Diffusion生态大量插件、发行版本的支持。
LCM同时也发布了训练脚本,可以支持训练自己的LCM大模型(如LCM-SDXL)或LCM-LoRA,做到兼顾生成质量和速度。只要一次训练,就可以在保持生成质量的前提下提速5倍。
自Stable Diffusion发布至今,生成成本被缓慢优化,而LCM的出现使得图像生成成本直接下降了一个数量级。
LCM至少能在图像生成成本消失、视频生成、实时生成三大方面给产业格局带来重大变化。
- 图像生成成本消失
- C端: 以Midjourney为代表的大量文生图服务选择免费增值作为商业模型
- B端: 减少的生成算力需求会被增长的训练算力需求替代
- 文生视频
- 3分钟快速渲染:AnimateDiff Vid2Vid + LCM
- 实时渲染
- RT-LCM视频渲染, 实时图像编辑, LCM实时空间建模渲染
【2023-11-17】【谷歌】UFOGen
【2023-11-20】打爆LCM!谷歌最新工作UFOGen只需要采样一步生成高质量图像
如何提升扩散模型的生成速度?主要集中在两个方向。
- 一个是设计更高效的数值计算方法,以求能达到利用更少的离散步数求解扩散模型的采样 ODE 的目的。
- 比如清华的朱军团队提出的 DPM 系列数值求解器,被验证在 Stable Diffusion 上非常有效,能显著地把求解步数从 DDIM 默认的 50 步降到 20 步以内。
- 另一个是利用知识蒸馏的方法,将模型的基于 ODE 的采样路径压缩到更小的步数。
- 这个方向的例子是 CVPR2023 最佳论文候选之一的 Guided distillation,以及最近大火的 Latent Consistency Model (LCM)。
- 尤其是 LCM,通过对一致性目标进行蒸馏,能够将采样步数降到只需 4 步,由此催生了不少实时生成的应用。
随着一系列技术(LCM)的提出,从扩散模型中采样所需的步数已经从最初的几百步,到几十步,甚至只需要 4-8 步。
最近,来自谷歌研究团队提出了 UFOGen 模型,一种能极速采样的扩散模型变种。通过论文提出的方法对 Stable Diffusion 进行微调,UFOGen 只需要一步就能生成高质量的图片。与此同时,Stable Diffusion 的下游应用,比如图生图,ControlNet 等能力也能得到保留。
谷歌在 UFOGen 模型中并没有跟随以上大方向,而是另辟蹊径,利用了一年多前提出的扩散模型和 GAN 的混合模型思路。前面提到的基于 ODE 的采样和蒸馏有其根本的局限性,很难将采样步数压缩到极限。
扩散模型和 GAN 的混合模型最早是英伟达的研究团队在 ICLR 2022 上提出的 DDGAN(《Tackling the Generative Learning Trilemma with Denoising Diffusion GANs》)。其灵感来自于普通扩散模型对降噪分布进行高斯假设的根本缺陷。简单来说,扩散模型假设其降噪分布(给定一个加了噪音的样本,对噪音含量更少的样本的条件分布)是一个简单的高斯分布。然而,随机微分方程理论证明这样的假设只在降噪步长趋于 0 的时候成立,因此扩散模型需要大量重复的降噪步数来保证小的降噪步长,导致很慢的生成速度。
DDGAN 提出抛弃降噪分布的高斯假设,而是用一个带条件的 GAN 来模拟这个降噪分布。因为 GAN 具有极强的表示能力,能模拟复杂的分布,所以可以取较大的降噪步长来达到减少步数的目的。然而,DDGAN 将扩散模型稳定的重构训练目标变成了 GAN 的训练目标,很容易造成训练不稳定,从而难以延伸到更复杂的任务。在 NeurIPS 2023 上,和创造 UGOGen 的同样的谷歌研究团队提出了 SIDDM(论文标题 Semi-Implicit Denoising Diffusion Models),将重构目标函数重新引入了 DDGAN 的训练目标,使训练的稳定性和生成质量都相比于 DDGAN 大幅提高。
SIDDM 作为 UFOGen 的前身,只需要 4 步就能在 CIFAR-10, ImageNet 等研究数据集上生成高质量的图片。但是 SIDDM 有两个问题需要解决:首先,它不能做到理想状况的一步生成;其次,将其扩展到更受关注的文生图领域并不简单。为此,谷歌的研究团队提出了 UFOGen,解决这两个问题。
【2023-12-7】【META】 imagine
Meta AI 的 AI 绘图功能,名为“imagine”,可以将文字描述转化为独特的图像。就像一个虚拟画师,根据你的文字指令创作出独一无二的艺术作品。
全新“reimagine”功能:在 Messengericon 和 Instagramicon 上新增的这个功能,群聊中可以与朋友一起创造、修改图像。只需简单的文本提示,Meta AI 就能将原始图像变成全新的作品,让你和朋友们的互动更加有趣。
openart.ai
openart.ai, 需要 国外vpn
One-time 50 trial credits for all the features. Join Discord for additional one-time 100 trial credits
GPT-4o Image Generation
官网
- 【2025-3-25】Introducing 4o Image Generation
OpenAI 发布 GPT-4o原生多模态图像生成功能,支持生成更加逼真的图像。
这是 Deep Research 以来 OpenAI 最有意义的模型更新。
新模型+一句话指令,效果就超过了人类精心设计的工作流。
用户只需在ChatGPT中描述图像(可指定宽高比、色号或透明度等参数),GPT-4o便能在一分钟内生成相应图像。让我们细致看一看:本次更新,突破了以往的哪些边界。
GPT-4o图像生成功能具有以下特点:
- 精准渲染图像内文字,能够制作 logo、菜单、邀请函和信息图等;
- 精确执行复杂指令,甚至在细节丰富的构图中也能做到;
- 基于先前的图像和文本进行扩展,确保多个交互之间的视觉一致性;
- 支持各种艺术风格,从写实照片到插图等。
官方表述
GPT-4o在多个方面相较于过去的模型进行了改进:
- 更好的文本集成:与过去那些难以生成清晰、恰当位置文字的AI模型不同,GPT-4o现在可以准确地将文字嵌入图像中;
- 增强的上下文理解:GPT-4o通过利用聊天历史,允许用户在互动中不断细化图像,并保持多次生成之间的一致性;
- 改进的多对象绑定:过去的模型在正确定位场景中的多个不同物体时存在困难,而GPT-4o现在可以一次处理多达10至20个物体;
- 多样化风格适应:该模型可以生成或将图像转化为多种风格,支持从手绘草图到高清写实风格的转换。
该模型还整合 OpenAI的视频生成平台Sora,进一步扩展了其多模态能力。
新模型即日起将作为ChatGPT的默认图像生成引擎,向ChatGPT Free、Plus、Team及Pro用户开放,取代此前使用的DALL-E 3。企业版、教育版以及API接口也将在不久后支持该功能。
详见站内 Openai进化
字节
Mogao
【2025-5-9】字节发布和GPT-4o类似的图像理解与生成的统一模型 Mogao
- 融合了多项关键架构改进:深度融合设计、双视觉编码器、交错旋转位置编码以及多模态无分类器引导,使其能同时发挥自回归模型在文本生成和扩散模型在高质量图像合成的优势。
- 这些改进使Mogao能高效处理任意交错的图文序列。
- 为充分释放统一模型潜力,这里还基于自建的大规模图文联合生成数据集设计了高效训练策略。
大量实验表明,Mogao不仅在多模态理解和文生图任务上达到最优性能,更能生成高质量、连贯的交错模态内容。其涌现的零样本图像编辑与组合生成能力,标志着 Mogao 已成为实用的全能模态基础模型,为统一多模态系统的未来发展与规模化奠定了基础。
技术报告:05472
BAGEL
【2025-5-20】BAGEL:新的统一多模态基础模型,支持文本、图像、视频的端到端理解与生成
- BAGEL: The Open-Source Unified Multimodal Model
- 论文 Emerging Properties in Unified Multimodal Pretraining
- 代码 BAGEL
- 技术报告和demo BAGEL-Technical-Report.pdf
- 讲解 BAGEL: 更聪明的统一生成理解模型
功能
- 图像编辑 Editing
- 图像导航 Navigation
- 图像推理 Thinking
- 风格迁移 Style Transfer
- 图文聊天 Chat
- 图像生成 Generation
- 图像合成 Composition

在标准基准测试中显著超越现有开源模型,并展现一系列复杂推理能力,包括:自由图像操控、未来帧预测、3D空间操作、世界导航等。
统一模型在增加参数与训练量的过程中,处理不同任务的智能逐渐涌现,从基础的图文理解和文生图,到多样化的editing,再到复杂的manipulation 详细的评测,模型的智能程度不断提升
模型结构
BAGEL adopts a Mixture-of-Transformer-Experts (MoT) architecture to maximize the model’s capacity to learn from richly diverse multimodal information. Following the same principle of capacity maximization, it utilizes two separate encoders to capture pixel-level and semantic-level features of an image. The overall framework follows a Next Group of Token Prediction paradigm, where the model is trained to predict the next group of language or visual tokens as a compression target.
BAGEL scales MoT’s capacity through Pre-training, Continued Training, and Supervised Finetuning on trillions of interleaved multimodal tokens spanning language, image, video, and web data. It surpasses open models on standard understanding and generation benchmarks and demonstrates advanced in-context multimodal abilities like free-form image editing, future frame prediction, 3D manipulation, world navigation, and sequential reasoning.
应用
logo 生成
Logo Diffusion
【2024-5-14】Logo Diffusion 一个几秒钟内设计出令人惊叹的标志和图形的智能设计平台。
Logo Diffusion 是一个智能设计平台,利用定制的生成式AI(人工智能)模型几秒钟内创建精美的标志和图形。
这个平台允许用户通过输入一个提示(比如一段简单的文本描述),让AI将这个想法转化为引人注目的设计。
特色
- 不需要用户进行复杂的提示工程,即可生成令人印象深刻的标志,并且还配备了内置视觉编辑器,用户可以通过它调整输出,指导AI生成完美的标志。
- 完成设计后,用户可以将图像文件导出为透明的PNG或向量文件,以便在线无缝使用。
无论是需要迅速创建标志、寻找设计灵感,还是希望以低成本更新品牌形象的个人和组织,都会发现Logo Diffusion是一个非常有价值的工具。
Lovart
【2025-5-13】Lovart 全球首个设计 Agent,炸裂到起飞
Lovart AI 开放测试
- 全球首个专业设计类Agent,能完成从创意拆解到专业交付的整条视觉流程。
功能
- 把【深度思考】理念引入到了AI图像生成领域
只需描述需求,它会逐步推理和思考,分解任务需求,然后调用合适的模型工具进行创作。
- 一个展开的画布中直接呈现,还能随时修改
- 集成 GPT image-1、Flux Pro、OpenAI-o3、Gemini Imagen 3、Kling AI、Tripo AI、Suno AI 等市面上主流的多模态工具
- 一站式调用,无需来回切换工具和跳来跳去,一个画布内即可完成你的所有图像、视频生成和设计需求。
示例:
- Please help me design a bag. I hope the shape is very avant-garde and fashionable. Refer to the latest design language of brands such as Balenciaga and Jaquemus for our brand Pupu.
- 请帮我设计一款包包。我希望它的造型非常前卫时尚。我们品牌Pupu可以参考Balenciaga、Jaquemus等品牌的最新设计语言。
示例2:
- I am starting a pet treat brands called Billy, please help me design the whole VI system. Let’s start with the logo, I want to use my dog as the logo inspiration, she was a curly hair poodle, please turn her figure into a Playful line art illustration, hand-drawn doodle aesthetic and preserve the brush strokes.
- 我正在创办一个名为Billy的宠物零食品牌,请帮我设计整个VI系统。首先从logo开始,我想用我的狗狗作为logo的灵感,它是一只卷毛贵宾犬。请将她的形象转化为俏皮的线条艺术插画,手绘涂鸦的美感,并保留其笔触
如何鉴别生成图像
【2023-4-7】How to Tell If a Photo Is an AI-Generated Fake
How can skeptical viewers spot images that may have been generated by an artificial intelligence system such as DALL-E, Midjourney or Stable Diffusion?
AI-image-detector
【2023-4-7】AI-image-detector demo
图片PS识别
如何识别图片是否P过?
【2023-5-16】8个图片识别神器
- (1) EXIF/元数据
- 图片生成时是会带有 Exif 等图片信息的, 代表可交换图像文件,用于在JPG 压缩的数码照片中存储信息。
- EXIF 文件中包含的信息包括手机型号、相机信息,如光圈、闪光灯、ISO 编号、曝光、快门速度、镜头、分辨率、白平衡和 GPS 坐标。
- PS 处理过的图片会带有 Photoshop 的软件信息
- ExifData
- 使用:访问 ExifData.com ,上传图像或提交 URL; 点击左侧的“详细”按钮提供更多详细信息,例如文件权限、大小、GPS 坐标(如果可用)等。文件头中找到 “Photoshop”的字样就是PS过的。
- JPEGsnoop 是一款免费的 Windows 应用程序,可检查和解码 JPEG、MotionJPEG AVI 和 Photoshop 文件的内部细节。它还可以用于分析图像的来源以测试其真实性。
- JPEGsnoop 报告了大量信息,包括:量化表矩阵(色度和亮度)、色度子采样、估计 JPEG 质量设置、JPEG 分辨率设置、霍夫曼表、EXIF 元数据、Makernotes、RGB 直方图等。
- (1) 反图像搜索
- 反向图像搜索可用于验证照片、WhatsApp 图像、屏幕截图和 Internet 来源。
- RevEye 是一个 Chrome 插件,可以搜索 Bing、Google、Yandex、TinEye 和百度。使用 RevEye,您只需右键单击图像并直接转到列表中的相应搜索引擎。
- Forensically
- 通过 Exif 鉴别图片是否是原图,的确是行之有效的,但这种方法也有其局限,那就是它只能鉴定图片是否是原图,而不能鉴定图片内容是否保真。
- 用 QQ、微信发送的图片,会被压缩过,图片内容没有被修改,但通过 Exif 鉴别,这仍属于处理过的图片
- 此时,直接鉴别图片的内容更靠谱
- Forensically 是一款基于 Web 的免费图像分析工具,可用于检测克隆、错误级别分析、图像元数据、噪声分析、水平扫描等。错误级别分析或 ELA 用于识别 jpg 图像中不同级别的压缩伪影。
- FotoForensics FotoForensics 使用先进的算法来解码任何可能的 photoshopped 图片和操作;它使用错误级别分析 (ELA) 来识别图像中处于不同压缩级别的区域。
- Ghiro Ghiro 是用于数码照片和数码图像分析的开源软件。取证分析完全自动化,可以从不同角度搜索或汇总报告数据。Ghiro 旨在帮助您和您的团队分析大量图像。
- Amped Authenticate用于揭示图像处理历史的领先取证软件。
- Diff Checker
- Diff Checker 是一个有趣的工具,可以并排或重叠比较两张照片以查看它们之间的差异。此工具可用于捕捉图像的微小变化。在 Diff Checker 的主页上,我们需要上传两张图片进行比较。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
