- OCR
- OCR 介绍
- OCR 历史
- OCR 应用
- OCR 识别技术
- OCR 数据集
- OCR 模型
- OCR工具
- 大模型
- 验证码识别
- 结束
OCR
OCR 介绍
光学字符识别(OCR,Optical Character Recognition)
- 对文本资料进行扫描,对图像文件分析处理,获取文字及版面信息的过程。
- 将印刷体或手写文字转化为可编辑文本的技术。即将图像中的文字进行识别,并以文本形式返回。
OCR技术非常专业,一般多是印刷、打印行业的从业人员使用,可快速将纸质资料转换为电子资料。

参考
OCR 历史
OCR技术发展历程分为几类:
- 概念提出:
- 1929年由德国科学家Tausheck最早提出OCR概念,后来美国科学家Handel也提出利用技术对文字进行识别想法。最先对印刷体汉字识别进行研究的是IBM公司,于1966年发表第一篇关于汉字识别的文章,采用模板匹配法识别印刷体汉字。
- 发展研究:
- 早在60、70年代,世界各国就开始有OCR研究,而初期以文字识别方法研究为主,且识别的文字仅为0至9的数字。
- 以日本为例,1960年左右开始研究OCR的基本识别理论,初期以数字为对象,直至1965至1970年之间开始有一些简单的产品,如印刷文字的邮政编码识别系统。
- 形成产品:
- 70年代,中国开始对数字、英文字母及符号识别进行研究,1986年,我国提出“863”高新科技研究计划,汉字识别的研究进入一个实质性阶段,相继推出中文OCR产品。早期OCR软件,因为识别率、硬件设备成本高及产品化等多方面的因素,未能达到实际要求。
- 百花齐放:
- 进入20世纪90年代之后,随着信息自动化普及,大大推进了OCR技术的进一步发展,使OCR的识别正确率和速度满足广大用户需求。随着人工智能技术不断发展,OCR软件产品已趋于成熟,可以识别各类语言、各类场景下识别,代表有全能扫描王、天若OCR等。
作者:GoAI
发展历史
- 1929年:德国科学家Tausheck首次提出OCR概念,设想利用机器来读取字符和数字
- 20世纪60年代:世界各国开始对OCR进行正式研究,研究人员将OCR技术理论运用到实际应用中,诞生了第一批OCR系统,但基本只支持数字和英文字母识别,典型案例就是邮政编码自动识别系统。
- 20世纪70年代末:我国开始开始进行汉字识别研究,直到1986年研究才进入实际性阶段(863计划),相继推出各种OCR产品。
- 20世纪80年代:随着计算机技术的发展、扫描设备的逐渐提升以及计算机视觉的不断成熟,开始出现基于图像处理(二值化、投影分析等)和统计机器学习的OCR技术,识别准确度进一步提升。
- 21世纪:OCR场景逐渐复杂以及识别精度的要求不断提升,传统OCR逐渐不能满足已有需求,基于深度学习技术让OCR识别效果更近一步。
OCR 应用
OCR 应用广泛,涵盖各个领域,如
- OCR识别车辆牌照实现快速通行和行车计费
- 识别票据快速录入信息
- 识别试卷辅助计算分数等
应用场景
按照识别场景划分,可分为:
- 文档文字识别:可以将图书馆、报社、博物馆、档案馆等的纸质版图书、报纸、杂志、历史文献档案资料等进行电子化管理,实现精准地保存文献资料。
- 自然场景文字识别:识别自然场景图像中的文字信息如车牌、广告干词、路牌等信息。对车辆进行识别可以实现停车场收费管理、交通流量控制指标测量、车辆定位、防盗、高速公路超速自动化监管等功能。
- 票据文字识别:可以对增值税发票、报销单、车票等不同格式的票据进行文字识别,可以避免财务人员手动输入大量票据信息,如今已广泛应用于财务管理、银行、金融等众多领域。。
- 证件识别:可以快速识别身份证、银行卡、驾驶证等卡证类信息,将证件文字信息直接转换为可编辑文本,可以大大提高工作效率、减少人工成本、还可以实时进行相关人员的身份核验,以便安全管理。
按照文字形成方式划分,可分为:
- 标准印刷体文字的识别(包括印刷体数字、汉字、英文);
- 手写文字的识别(包括手写数字、汉字、英文);
- 即存在印刷体又存在手写体的文字识别;
- 艺术体、合成文字等复杂字体识别;
主要指标有:
拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等
OCR 识别技术
技术历史
OCR 技术变迁
- CNN:
- CNN 特征提取 关键特征(边缘、线条、曲线等),经过几层卷积,逐层抽象
- RNN+LSTM:
- OCR 不只是单个字符识别, 还要考虑字符顺序
- RNN 擅长处理序列数据,LSTM 解决了 RNN 的遗忘问题
- Attention:
- 注意力机制
- 识别效率、准确度飞跃
- CRNN+CTC: 顶级算法组合拳
- CRNN(卷积神经网络)+CTC(连接时序分类)
- Transformer: 新宠
- ViT 比 CRNN 还厉害
传统OCR技术原理
(1) 数字图像处理
传统OCR基于图像处理(二值化、连通域分析、投影分析等)和统计机器学习(Adaboot、SVM),提取图片上的文本内容;
流程
主要流程
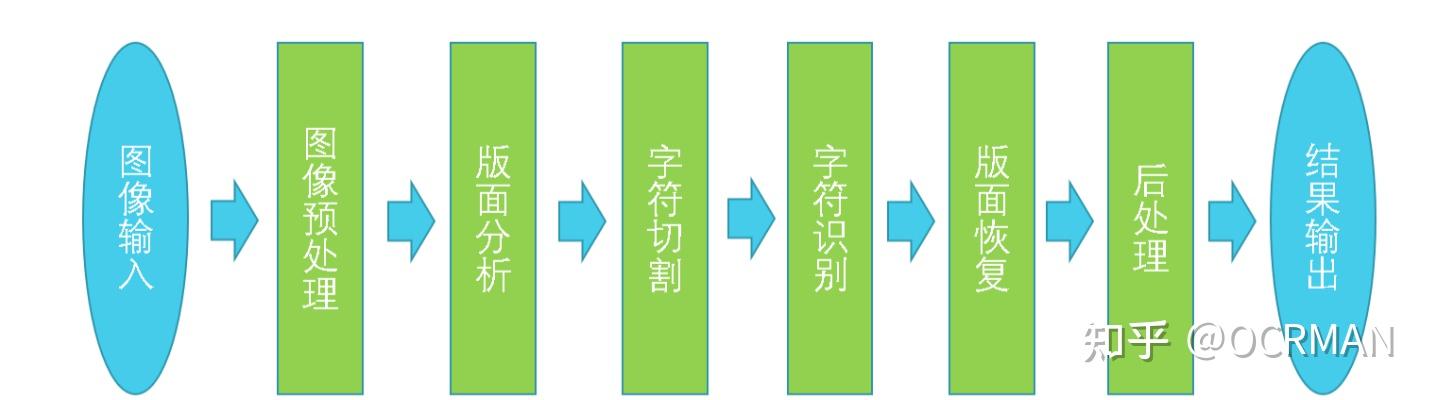
- 图像预处理: 图像增强,便于分离文本和背景,提高识别准确率
- 方法: 灰度化(去掉颜色信息)、二值化、去噪(各种滤波器)、倾斜检测与矫正(霍夫直线检测)、透视矫正等
- 透视矫正: 边缘检测→最大轮廓检测、拟合四边形、角点检测、透视矫正
- 版面分析: 识别文本区域、非文本区域、结构信息,如 行、列、块、标题、段落、表格等
- 方法: 连通域检测、MSER检测文本
- 字符切割: 识别字符比识别单词更容易
- 方法: 连通域轮廓切割、垂直投影切割
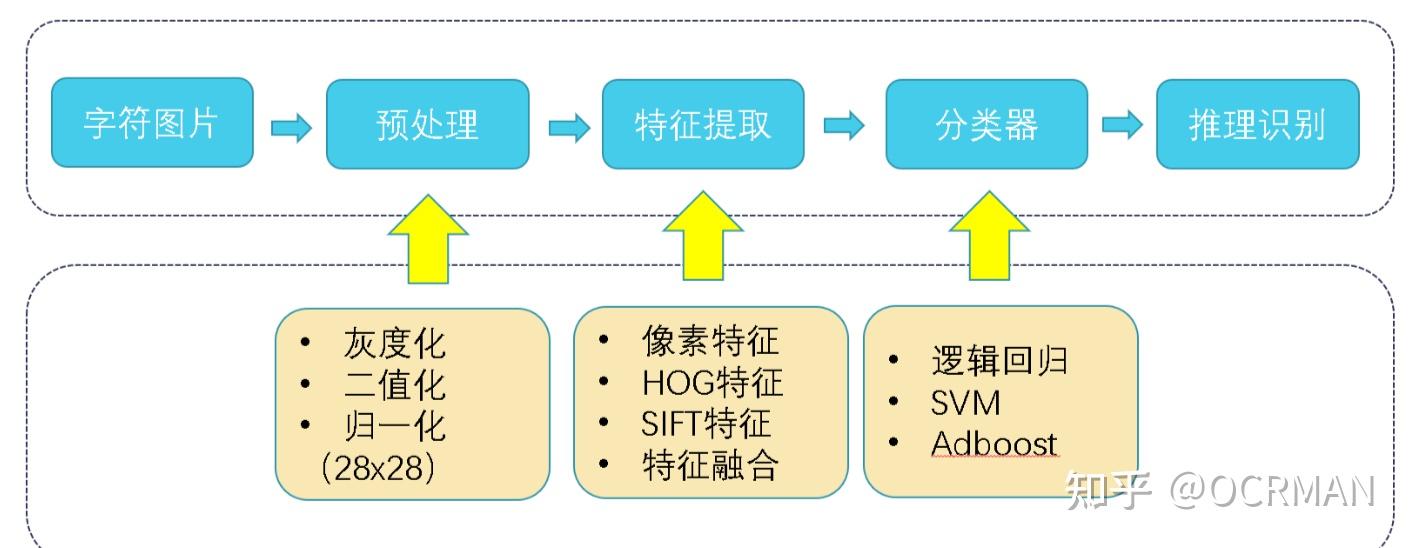
- 字符识别: 多分类问题, 中文有5800个类目,包含常见汉字、标点符号、特殊符号等
- 原理: 切片归一化 → 提取特征(HoG/SIFT) → 分类(svm/lr/dt) → 预测
- 特征: 像素特征、HoG特征、SIFT特征
- 版面恢复: 与版面分析对应, 将识别后的文字按原文档方式排列,如 段落、位置、顺序等
- 后处理: 文本纠错、文本结构化
工具
计算机视觉算法库
- 主要有 OpenCV、Halcon、VisionPro等
- 出于开源、多语言支持和方便易用的考虑,通常采用OpenCV 开发
问题
局限性:
- 对清晰度和质量的高要求:传统的OCR技术高度依赖图像的质量。如果输入的图像质量较差(例如,图像模糊、对比度低、光照不均、存在噪声等),则OCR的准确度可能会大大降低。
- 对字体和布局的依赖性:传统的OCR技术通常基于特定的字体和布局进行训练。因此,如果输入的文本使用了训练数据中未包含的字体或者不同的布局,那么识别精度可能会受到影响。
- 复杂背景下识别效果差:如果文本字符与背景紧密相连或者文本在复杂的背景上,传统的OCR系统可能会难以准确地分割和识别字符。类似地,如果字符被装饰或者以艺术字形式呈现,传统的OCR系统可能也无法准确地识别出这些字符。
- 手写识别效果差:对于手写文字的识别,传统的OCR系统通常会遇到更大的挑战,因为手写文字的形状、大小和倾斜度变化非常大,且往往缺乏清晰的边界。
- 无法处理多语言和特殊字符:传统的OCR系统通常针对单一或者少数几种语言进行优化,对于其他语言或者特殊字符,例如数学符号、音乐符号等,可能无法提供满意的识别效果。
- 缺乏上下文理解:传统的OCR技术通常将字符识别作为一个独立的任务进行,而没有考虑字符的上下文信息。因此,如果一个字符在图像中模糊不清,OCR系统可能无法准确地识别出这个字符。
(2) 深度学习OCR
传统OCR技术在处理复杂图像和不规则形状的文本时,效果并不理想。
深度学习时代,机器可以“学习”处理复杂任务,并且对数据具有很好的适应性。通过结合深度学习,建立更为强大和灵活的OCR模型,它能够处理各种类型的文本,并且提高字符识别的准确率。
典型OCR技术路线:图像预处理 → 文本检测 → 文本识别
两种方法
- 第一种分为:
文字检测和文字识别两个阶段;- 文本检测: 基于回归、基于分割的方法
- 文字识别: 基于CTC、基于attention
- 第二种端对端模型一次性完成文字的检测和识别。
OCR技术流程
OCR技术流程进行介绍。典型的OCR技术pipline如下图所示:
- 输入 → 图像预处理 → 文字检测 → 文本识别 → 输出
其中,文本检测和识别是OCR技术的两个重要核心技术。
1 图像预处理
图像预处理是OCR流程的第一步,用于提高字符识别的准确性。常见的预处理操作包括灰度化、二值化和去噪。
- 灰度化将彩色图像转换为灰度图像,将每个像素的RGB值转换为相应的灰度值。在灰度图像中每个像素只有一个灰度值,简化后续的处理步骤。
- 二值化将灰度图像转换为二值图像,将灰度值高于某个阈值的像素设为白色,低于阈值的像素设为黑色。这将图像转换为黑白二值图像,方便后续的文本定位和字符分割。
- 去噪是为了减少图像中的噪声和干扰,以提高后续处理的准确性。常用的去噪方法包括中值滤波、高斯滤波和形态学操作。
此外,针对不规则文本识别,在预处理阶段可以先进行校正操作再进行识别。
2 文字检测
文本检测的任务是定位出输入图像中的文字区域。
近年来,使用深度学习进行文本检测成为主流技术,一类方法将文本检测视为目标检测中的一个特定场景,基于通用目标检测算法进行改进适配,如TextBoxes 基于一阶段目标检测器SSD 算法,调整目标框使之适合极端长宽比的文本行,CTPN则是基于Faster RCNN架构改进而来。但是文本检测与目标检测在目标信息以及任务本身上仍存在一些区别,如文本一般长宽比较大,往往呈“条状”,文本行之间可能比较密集,弯曲文本等,因此又衍生了很多专用于文本检测的算法,如EAST、PSENet、DBNet 等等。
3 文字识别
文本识别的任务是识别出图像中的文字内容。
文本识别一般输入来自于文本检测得到的文本框截取出的图像文字区域。文本识别一般可以根据待识别文本形状分为规则文本识别和不规则文本识别两大类。不规则文本场景具有很大的挑战性,也是目前文本识别领域的主要研究方向。
- 规则文本主要指印刷字体、扫描文本等,文本大致处在水平线位置,如下图左半部分;
- 不规则文本往往不在水平位置,存在弯曲、遮挡、模糊等问题,如下图右半部分。
识别难点
自然场景:
自然场景下的文本通常出现在复杂的背景中,且文本的字体、颜色、大小和方向都可能不同。例如路标、广告牌和商品包装等。 不同于传统的扫描图像文本,自然场景文本因表现形式丰富,图像背景复杂,以及图像拍摄引入的干扰因素等的影响,其识别的难点包括但不限于以下几个方面:
- 图片背景多变: 经常面临低亮度、低对比度、光照不均、透视变形和残缺遮挡等问题,还可能会受到噪声的影响,例如风沙、雨雪等天气条件,以及拍摄设备本身的噪声等,使得对其的分析与处理难度远高于传统的扫描文档图像。
- 文字弯曲: 文本的布局可能存在扭曲、褶皱、换向等问题,其中的文字也可能字体多样、字号字重颜色不一的问题。
- 文本格式: 自然场景中的文字数量较多,且分布较为分散,这使得算法的训练难度加大。针对长文本,需要处理文本行之间的连续性和上下文关系。针对多行文本,需要进行有效的文本区域分割和识别。
- 数据规模与资源 为训练和优化深度学习OCR模型,需要大规模的数据集和充足的计算资源。然而,自然场景OCR数据集往往比较难以获取和标注,同时深度学习模型的训练也需要较大的计算开销。
文档文字:
尽管普通文档识别相较于场景文本识别来说通常难度较小,但在特定领域中仍存在许多挑战。例如,针对票据扫描的目标检测,由于扫描仪分辨率低、纸张和油墨质量差等因素的影响,导致所扫描的票据质量低下。此外,字体过小以及干扰文本也是需要考虑的问题。
此外,针对复杂场景(复杂版面、数学公式、表格、结构化符号/图形等)的识别效果仍存在一定提升空间。
识别难点解决办法:
关于上述不同场景OCR技术面临许多挑战,需要更强大算法来应对文本的多样性和背景的复杂性。那么我们从那些角度入手解决上述问题呢?
以下为作者简单列出几点通用的解决方法,:
- 数据增强: 通过对训练数据进行增强,如随机旋转、缩放、裁剪、变换和加噪声等,可以使OCR模型更好地适应不同的图像条件和多样性。
- 多尺度检测: 设计多尺度的检测模型可以在不同大小和分辨率的文本实例中进行检测,从而提高对不同文本大小和形状的适应性。
- 背景抑制: 采用背景抑制技术,通过将注意力集中在文本区域,忽略或减弱背景干扰,从而提高文本检测的准确性。
- 多任务学习: 将文本检测和识别任务结合起来进行多任务学习,可以更好地处理复杂场景中的文本实例,并提高整体性能。
- 引入先验知识: 利用先验知识,如字符形状、文本的统计信息等,对文本进行建模,可以提高对复杂文本实例的理解和识别。
- 迁移学习/强化学习: 使用迁移学习或强化学习技术来优化OCR模型,使其能够在不同场景下进行更好的适应和调整。
OCR 数据集
规则数据集
规则数据集
- IIIT5K-Words (IIIT) 2000 for Train; 3000 for Test
- Street View Text (SVT) 257 for Train; 647 for Test
- ICDAR 2003(IC03) 、ICDAR2013 (IC13)
- 由500张左右英文标注的自然场景图片构成,标注形式为两点水平标注,坐标格式为左上角,和右下角
不规则数据集
不规则数据集
- ICDAR2015 (IC15) 4468 for Train; 2077 for Test;
- 1500张(训练1000,测试500)英文标注的自然场景图片构成,标注形式为四点标注,坐标格式依次为为左上角,右上角,右下角和左下角
- SVT Perspective (SP) 645 for Test
- CUTE80 (CT) 288 for Test
合成数据集
SynthText(ST) 5.5million个图像
中文场景数据集
中文场景数据集
- Chinese Text in the Wild (CTW):
CTW数据集是一个针对中文场景文本的数据集,用于文本检测和识别任务。CTW数据集包含了超过40,000张高分辨率的中文场景图像,这些图像从不同来源和环境中获取,具有广泛的多样性。
OCR 模型
总结
OCR识别模型
- 评价指标为准确率
| Regular Dataset | Irregular dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | Year | IIIT | SVT | IC13(857) | IC13(1015) | IC15(1811) | IC15(2077) | SVTP | CUTE | |
| CRNN | 2015 | 78.2 | 80.8 | - | 86.7 | - | - | - | - | |
| ASTER(L2R) | 2015 | 92.67 | 91.16 | - | 90.74 | 76.1 | - | 78.76 | 76.39 | |
| CombBest | 2019 | 87.9 | 87.5 | 93.6 | 92.3 | 77.6 | 71.8 | 79.2 | 74 | |
| ESIR | 2019 | 93.3 | 90.2 | - | 91.3 | - | 76.9 | 79.6 | 83.3 | |
| SE-ASTER | 2020 | 93.8 | 89.6 | - | 92.8 | 80 | 81.4 | 83.6 | ||
| DAN | 2020 | 94.3 | 89.2 | - | 93.9 | - | 74.5 | 80 | 84.4 | |
| RobustScanner | 2020 | 95.3 | 88.1 | - | 94.8 | - | 77.1 | 79.5 | 90.3 | |
| AutoSTR | 2020 | 94.7 | 90.9 | - | 94.2 | 81.8 | - | 81.7 | - | |
| Yang et al. | 2020 | 94.7 | 88.9 | - | 93.2 | 79.5 | 77.1 | 80.9 | 85.4 | |
| SATRN | 2020 | 92.8 | 91.3 | - | 94.1 | - | 79 | 86.5 | 87.8 | |
| SRN | 2020 | 94.8 | 91.5 | 95.5 | - | 82.7 | - | 85.1 | 87.8 | |
| GA-SPIN | 2021 | 95.2 | 90.9 | - | 94.8 | 82.8 | 79.5 | 83.2 | 87.5 | |
| PREN2D | 2021 | 95.6 | 94 | 96.4 | - | 83 | - | 87.6 | 91.7 | |
| Bhunia et al. | 2021 | 95.2 | 92.2 | - | 95.5 | - | 84 | 85.7 | 89.7 | |
| Luo et al. | 2021 | 95.6 | 90.6 | - | 96.0 | 83.9 | 81.4 | 85.1 | 91.3 | |
| VisionLAN | 2021 | 95.8 | 91.7 | 95.7 | - | 83.7 | - | 86 | 88.5 | |
| ABINet | 2021 | 96.2 | 93.5 | 97.4 | - | 86.0 | - | 89.3 | 89.2 | |
| MATRN | 2021 | 96.7 | 94.9 | 97.9 | 95.8 | 86.6 | 82.9 | 90.5 | 94.1 |
分析
传统OCR算法训练需要准备大量数据,迭代更新效果差的问题,不过速度确实快。
OCR工具
主流OCR识别应用平台
pdf 文件解析
总结
- 非扫描件无OCR要求,直接使用
pymupdf(fitz)即可,能正确保留双列布局的文本顺序,同时能提取表格和图片,而且表格是以List格式保留。 - 其余几个传统PDF解析库倾向于对pdf进行编辑,比如添加水印,增加或者删除页面等。
llama-parse中文文档效果不好,而且还是通过API使用,但是每天有固定的免费额度,可以用于处理扫描件。deepdoc和MinerU是近期开源项目中比较强大的RAG解析工具。- deepdoc 优点: 表格效果较好,亲测无边框的表格有大多数效果仍可圈可点,并且保留为html格式,因此允许合并单元格;
- MinerU 优势: 识别的文本带有markdown格式,因此用于RAG切分文档中可以省去不少功夫。
参考
| 名称(含链接) | 类型 | OCR | 提取表格内容 | 保留文本顺序 | 提取图片 | 保存成md格式 | 其他特性 |
|---|---|---|---|---|---|---|---|
| pymupdf | 传统PDF解析库 | ❌ | ✔️ | ✔️ | ✔️ | ❌ | 表格提取、自定义字体 |
| pdfminer | 传统PDF解析库 | ❌ | ❌ | ✔️ | ❌ | ❌ | 版面分析 |
| pdfplumber | 传统PDF解析库 | ❌ | ✔️ | ❌ | ❌ | ❌ | 表格提取,但存在丢失列的问题 |
| pypdf2 | 传统PDF解析库 | ❌ | ❌ | ✔️ | ❌ | ❌ | pdf合并与拆分、添加水印 |
| llama-parse | 基于模型的PDF解析一体库 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | 付费API每天有免费额度 |
| open-parse | 基于模型的PDF解析一体库 | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | 文本支持保存markdown和html格式、内置表格模型,可自由选择、表格带markdown格式 |
| deepdoc | 基于模型的PDF解析一体库 | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | 支持版面分析、表格带html格式 |
| MinerU | 基于模型的PDF解析一体库 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | 文本带markdown格式、解析保留中间过程,可用于二次调优、表格提取非常慢,目前效果一般 |
简易工具
- 【2021-7-26】免费在线OCR工具 ocrmaker
- UU Tool:截图黏贴图片到网站,提取文本;text转语音
- 城华OCR,将图片转成各种文档格式,限制次数
- 白描:提取图片中的文字、数学公式等
- Chrome插件
- Copyfish Free OCR, 中文支持不佳,手工设置语言后,依然乱码
- 【2024-2-8】一键读图(OCR),可识别中文
工具
对比总结
【2022-1-25】kaggle笔记:各类OCR方法对比:Keras-OCR vs EasyOCR vs PYTESSERACT

CONCLUSIONS 对比结论
- Keras-OCR is image specific OCR tool. If text is inside the image and their fonts and colors are unorganized, Keras-ocr consumes time if used on CPU
- EasyOCR is lightweight model which is giving a good performance for receipt or PDF conversion. It is giving more accurate results with organized texts like pdf files, receipts, bills. EasyOCR also performs well on noisy images 适合发票、pdf格式、噪声图片
- Pytesseract is performing well for high-resolution images. Certain morphological operations such as dilation, erosion, OTSU binarization can help increase pytesseract performance. It also provides better results on handwritten text as compared to EasyOCR 适合高分辨率图、手写字体
- All these results can be further improved by performing specific image operations.
| 解决方案 | 优点 | 缺点 |
|---|---|---|
PaddleOCR+ 规则匹配 |
快、准 | 很多场景如姓名、地址这些自然语言类型的关键词提取不了 |
PaddleOCR+ 命名实体识别+规则匹配 |
快、准 | 泛化能力差,加一个识别的字段可能就需要重新训练 |
PaddleOCR+ 大模型做命名实体识别 |
相对上面两种方案,更加准确,泛化能力更好,能识别的关键信息更多 | 慢 |
私有化多模态大模型如Qwen-VL-Plus |
较快、准、泛化能力强 | 以Qwen为例,需要2-4GB显存,并发低。 |
| 多模态大模型API调用 | 较快、准、泛化能力强,资源消耗低 | 图片需要上传到云端服务商如阿里那里。 |
显存开销
- PaddleOCR 显存大概需要 6GB 左右
- P40显卡8GB显存,可运行 Paddle Serving OCR 2个定位进程,1个识别进程,并发10+没问题
- RexUniNLU 模型大概需要 2G 显存
- Qwen-VL-Plus 需要24GB 显存
- API Qwen-VL-Plus
根据自己的情况选择解决方案。
EasyOCR
【2020-8-7】一个超好用的开源OCR:EasyOCR,目前能够支持80种语言,其中有中文(简体和繁体)、日语、泰语、韩语等
EasyOCR 是由 Jaided AI 公司创建
- EasyOCR 模型主要分为两个,基于CRAFT的文字检测模型和基于ResNet+LSTM+CTC的识别模型
- 官方体验地址: EasyOCR
- 第三方基于easyOCR提供了几个demo地址,大家可以试试自己的数据看看效果:
功能
OCR 框架
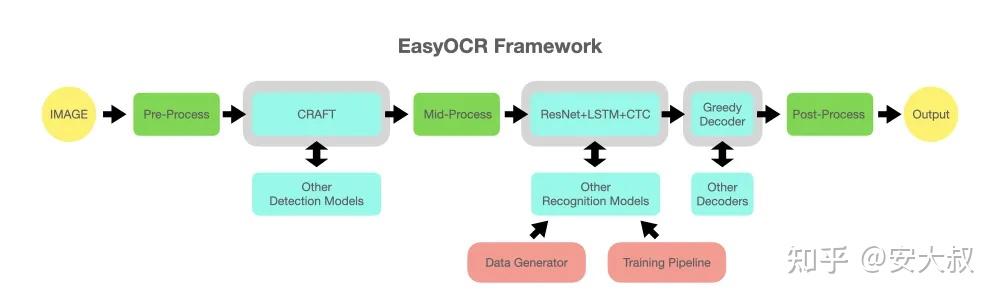

EasyOCR 允许用户训练和使用自定义识别模型,以适应特定场景的需求。
EasyOCR 默认使用GPU进行计算加速。
- 没有GPU或GPU内存不足的用户,可设置为CPU模式。
限制:
- 对于复杂背景或低质量图像,识别准确率可能下降
- 处理大量图像时,可能需要较长时间
- 某些特殊字体或手写体可能识别效果不佳
手写体识别目前不支持!等后面功能升级
输入数据
EasyOCR支持80多种语言,包括但不限于:
- 中文(简体和繁体)
- 英语
- 日语
- 韩语
- 阿拉伯语
- 俄语
- 德语
- 法语
- 西班牙语
各语种对应符号
- 南非荷兰语 (af)、阿塞拜疆语 (az)、波斯尼亚语 (bs)、捷克语 (cs)、威尔士语 (cy)、丹麦语 (da)、德语 (de)、英语 (en)、西班牙语 (es)、爱沙尼亚语 (et)、法语 (fr)、爱尔兰语 (ga)、克罗地亚语 (hr)、匈牙利语 (hu)、印度尼西亚语 (id)、冰岛语 (is)、意大利语 (it)、日语 (ja)、韩语 (ko)、库尔德语 (ku)、拉丁语 (la)、立陶宛语 (lt)、拉脱维亚语 (lv)、毛利语 (mi)、马来语 (ms)、马耳他语 (mt)、荷兰语 (nl)、挪威语 (no)、波兰语 (pl)、葡萄牙语 (pt)、罗马尼亚语 (ro)、斯洛伐克语 (sk)、斯洛文尼亚语 (sl)、阿尔巴尼亚语 (sq)、瑞典语 (sv)、斯瓦希里语 (sw)、泰语 (th)、他加禄语 (tl)、土耳其语 (tr)、乌兹别克语 (uz)、越南语 (vi)、中文 (zh)
多种语言可以同时使用,只要它们的文字系统兼容。
EasyOCR支持多种输入格式:
- 图片文件路径
- OpenCV图像对象(numpy数组)
- 图像字节数据
- 图片URL
输出格式
EasyOCR 提供多种输出选项:
- 详细模式: 返回文本框坐标、识别文本和置信度
- 简单模式: 只返回识别文本
- 段落模式: 尝试将识别结果组合成易读的段落
import easyocr
reader = easyocr.Reader(['ch_sim','en']) # 只需要运行一次就可以将模型加载到内存中
reader = easyocr.Reader(['ch_sim','en'], gpu=False) # cpu 模式
IMAGE_PATH = 'a.jpg'
result = reader.readtext('chinese.jpg')
# result = reader.readtext(IMAGE_PATH, detail=0) # 精简模式
# result = reader.readtext(IMAGE_PATH, paragraph="False") # 易读模式
result 输出内容
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路', 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西', 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东', 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], '315', 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], '309', 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], 'Yuyuan Rd.', 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], 'W', 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], 'E', 0.8405593633651733)]
输出格式:
- 多个元素组成的list
- 每个元素(tuple)包含: bounding box、text 和 得分
目标检测中 bounding box 几种表示形式
- xyxy型(x_min,y_min,x_max,y_max):
VOC边框表示法, 包含 左上角(x1,y1)、右下角(x2,y2)两个坐标 - tlwh型(x_min,y_min,width,height):
coco边框表示法, 包含 左上角(x,y)、宽(w)、高(h) - xywh型(x_center,y_center,width,height):
yolo边框表示法, 包含 中心点(x,y)、宽(w)、高(h)
图像 bounding box 参数说明
- 左上角是原点 (0,0),右下角逐渐增大
- box 里的4个坐标从左上角开始,顺时针旋转
示例
([[86, 80], [134, 80], [134, 128], [86, 128]], '西', 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东', 0.9989598989486694),
图解
- x 是列: 86 -> 134
- y 是行: 80 -> 128
(x1,y1) → (x2,y1)
↑ ↓
(x1,y2) ← (x2,y2)
使用
官方文档
将 OpenCV图像对象(numpy数组)或图像文件作为字节传递,而不是文件路径 chinese.jpg
- 【2024-12-5】不能并行支持多语种,只有英文可以与其他语种并存
- 【2023-9-15】不支持中国银行卡,以国外为主
# coding:utf-8
# pip install easyocr
import easyocr
test_file = 'e:\\code_new\\ocr\\data\\a.png' # 中文
#test_file = 'e:\\code_new\\ocr\\data\\b.jpg' # 英文
# 语种模型加载,只下载、加载一次,到内存里
reader = easyocr.Reader(['ch_sim','en']) # this needs to run only once to load the model into memory
# reader = easyocr.Reader(['ch_sim','en'],gpu = False)# cpu 环境
# 多语种问题: ch_sim 只能跟英文并存
# ValueError: Chinese_sim is only compatible with English, try lang_list=["ch_sim","en"]
# reader = easyocr.Reader(['ch_sim','en', 'de', 'fr', 'ja', 'ru'])
# -------------- 输入文件 --------------
# ① 本地文件
result = reader.readtext(test_file) # 直接读本地文件
# ② 读 二进制格式 / numpy array
# 二进制 格式
with open("chinese_tra.jpg", "rb") as f:
img = f.read()
# numpy array 格式
img = cv2.imread('chinese_tra.jpg')
result = reader.readtext(img)
# ③ 读 URL 文件
result = reader.readtext('https://www.somewebsite.com/chinese_tra.jpg')
# --------- 输出格式 ----------
# 返回 list 结构,包含解析内容及对应的box区域、置信度
# ([[86, 80], [134, 80], [134, 128], [86, 128]], '西', 0.40452659130096436)
# 输入数字图像
# result = reader.readtext(Image.open(test_file)) # 输入数字图像矩阵
# result = reader.readtext(test_file, detail=0) # list 结构, 只显示解析出的文本内容
reader.readtext('chinese_tra.jpg', detail = 0, paragraph=True)
print(f'OCR结果: {test_file=}')
# 逐行输出
for res in result:
print(f'{res}')
reader
(1) easyocr.Reader() 生成对象 reader
参数:
lang_list(list) - 识别的语言代码列表,例如 [‘ch_sim’,’en’]gpu(bool, string, default = True) - 启用 GPUmodel_storage_directory(string, default = None) - 模型数据目录的路径。- 如果未指定,将从环境变量 EASYOCR_MODULE_PATH(首选)、MODULE_PATH(如果已定义)或
~/.EasyOCR/定义的目录中读取模型。
- 如果未指定,将从环境变量 EASYOCR_MODULE_PATH(首选)、MODULE_PATH(如果已定义)或
download_enabled(bool, default = True) - 如果 EasyOCR 无法找到模型文件,则启用下载;user_network_directory(bool, default = None) - 用户模型存储的路径。如果未指定,将从 MODULE_PATH + ‘/user_network’ (~/.EasyOCR/user_network) 读取模型;recog_network(string, default = ‘standard’) - 用户模型、模块和配置文件的名称;detector(bool, default = True) - 将检测模型加载到内存中recognizer(bool, default = True) - 将识别模型加载到内存中
属性:
lang_char- 显示当前模型中的所有可用字符
readtext
(2) reader.readtext( )
- Reader对象主要方法。
- 有 4 组参数:
General、Contrast、Text Detection和Bounding Box Merging。
参数1:General
image(string, numpy array, byte) - 输入图像;decoder(string, default = ‘greedy’)- 选项有 ‘greedy’、’beamsearch’ 和 ‘wordbeamsearch’;beamWidth(int, default = 5) - 当解码器 = ‘beamsearch’ 或 ‘wordbeamsearch’ 时要保留多少光束;batch_size(int, default = 1) - batch_size>1 将使 EasyOCR 更快但使用更多内存;worker(int, default = 0) - 数据加载器中使用的编号线程;allowlist(string) - 强制 EasyOCR 只识别字符的子集。对特定问题有用(例如车牌等);blocklist(string) - 字符的块子集。如果给定了允许列表,则此参数将被忽略。detail(int, default = 1) - 将此设置为 0 以进行简单输出;paragraph(bool, default = False) - 将结果合并到段落中;min_size(int, default = 10) - 过滤文本框小于最小值(以像素为单位);rotation_info(list, default = None) - 允许 EasyOCR 旋转每个文本框并返回具有最佳置信度分数的文本框。符合条件的值为 90、180 和 270。例如,对所有可能的文本方向尝试 [90, 180 ,270]。
参数2:Contrast 对比度
contrast_ths(float, default = 0.1) - 对比度低于此值的文本框将被传入模型 2 次。首先是原始图像,其次是对比度调整为“adjust_contrast”值。结果将返回具有更高置信度的那个;adjust_contrast(float, default = 0.5) - 低对比度文本框的目标对比度级别。
参数3:Text Detection 文本检测(来自CRAFT)
text_threshold(float, default = 0.7) - 文本置信度阈值low_text(float, default = 0.4) - 文本下限分数link_threshold(float, default = 0.4) - 链接置信度阈值canvas_size(int, default = 2560) - 最大图像尺寸。大于此值的图像将被缩小。mag_ratio(float, default = 1) - 图像放大率
参数4:Bounding Box Merging 边界框合并
- 控制相邻边界框何时相互合并。除了 ‘slope_ths’ 之外的所有参数都以盒子高度为单位。
slope_ths(float, default = 0.1) - 考虑合并的最大斜率 (delta y/delta x)。低值意味着不会合并平铺框。ycenter_ths(float, default = 0.5) - y 方向的最大偏移。不应该合并不同级别的框。height_ths(float, default = 0.5) - 盒子高度的最大差异。不应合并文本大小非常不同的框。width_ths(float, default = 0.5) - 合并框的最大水平距离。add_margin(float, default = 0.1) - 将边界框向所有方向扩展某个值。这对于具有复杂脚本的语言(例如泰语)很重要。x_ths(float, default = 1.0) - 当段落=True 时合并文本框的最大水平距离。y_ths(float, default = 0.5) - 当段落 = True 时合并文本框的最大垂直距离。
返回:结果列表
detect
detect() 参数
image(string, numpy array, byte) -输入图像min_size(int,默认= 10)-筛选小于最小像素值的文本框text_threshold(float, default = 0.7)—文本可信度阈值low_text(float,默认= 0.4)-文本下限得分link_threshold(float, default = 0.4)—链路可信度阈值canvas_size(int,默认= 2560)-最大图像大小。大于此值的图像将向下调整大小。mag_ratio(浮动,默认= 1)-图像放大比slope_ths(float,默认= 0.1)-考虑合并的最大斜率(y/ x)。低值意味着平铺的盒子不会合并。ycenter_ths(float,默认= 0.5)- y方向的最大位移。不同级别的盒子不能合并。height_ths(浮动,默认= 0.5)-框高度的最大差异。文本大小非常不同的框不应该合并。width_ths(浮动,默认= 0.5)-合并框的最大水平距离。add_margin(浮动,默认= 0.1)-向所有方向扩展边界框。这对于具有复杂文字的语言(如泰国语)是很重要的。optimal_num_chars(int,默认= None) -如果指定,则首先返回接近该值的估计字符数的边界框。- 返回horizontal_list, free_list - horizontal_list是一个矩形文本框的列表。格式为
[x_min, x_max, y_min, y_max]。Free_list是一个自由格式文本框的列表。格式为[[x1,y1],[x2,y2],[x3,y3],[x4,y4]]。
- 返回horizontal_list, free_list - horizontal_list是一个矩形文本框的列表。格式为
recognize
recognize() 参数
image(string, numpy array, byte) -输入图像horizontal_list(list, default=None) -查看检测方法输出的格式free_list(list, default=None) -查看检测方法输出的格式decoder(string, default = ‘greedy’) -选项为’greedy’, ‘beamsearch’和’wordbeamsearch’。docoder = ‘beamsearch’或’wordbeamsearch’时,保留多少光束beamWidth(int, default = 5) - 当解码器= ‘beamsearch’或’wordbeamsearch’时,保留多少光束?batch_size(int,默认= 1)- batch_size > 1 将使EasyOCR更快,但会占用更多内存workers(int,默认= 0)-在数据加载器中使用的线程数allowlist(string) -强制EasyOCR只识别字符的子集。适用于特定问题(如车牌等)blocklist(string)—字符的块子集。如果给出allowlist,则该参数将被忽略。detail(int, default = 1) -为简单输出设置为0paragraph(bool, default = False) -将结果合并到段落中contrast_ths(float, default = 0.1) - 对比度低于此值的文本框将被传递到模型2次。第一个是原始图像,第二个是对比度调整为’adjust_contrast’值。结果为置信度高的那个会被返回。- adjust_contrast(浮动,默认= 0.5)-低对比度文本框的目标对比度级别
返回结果列表
详见文档
windows
安装
- 前置依赖: torch, torchvision
- 注意选择对应的 torch 版本, 如果不用 gpu, 设置
CUDA = None
- 注意选择对应的 torch 版本, 如果不用 gpu, 设置
- 终端 power shell
命令行方式
easyocr -f chinese.jpg # 指定图片
easyocr -l ch_sim en -f chinese.jpg # 指定语种
easyocr -l ch_sim en -f chinese.jpg --detail=0 # 精简输出
easyocr -l ch_sim en -f chinese.jpg --detail=1 # 完整输出(默认)
easyocr -l ch_sim en -f chinese.jpg --gpu=True # 使用 GPU
Tesseract
介绍
Tesseract 由HP实验室开发由Google维护。
Tesseract OCR 引擎最先由HP实验室于1985年开始研发的开源OCR(Optical Character Recognition , 光学字符识别)引擎,至1995年时已经成为OCR业内最准确的三款识别引擎之一。
- 目前公认最优秀、最精确的开源OCR系统,用于识别图片中的文字并将其转换为可编辑的文本。
- Tesseract 能将印刷体文字图像转换成可编辑文本,支持多种语言,并且在许多平台上都可使用,包括Windows、Mac OS和Linux。
- Tesseract可以处理各种图像文件格式,如 JPEG、PNG、TIFF等。
- Tesseract 主要功能是识别图像中的文字,并将其转换成机器可读的文本内容。它采用了一系列图像处理、特征提取和机器学习技术来实现文字识别的过程。
- Tesseract 支持 unicode(UTF-8),可以“开箱即用” 识别100多种语言。
训练数据文件
- deu - 德语
- eng - 英语
- fin - 芬兰语
- fra - 法语
- osd - 文字和方向
- por - 葡萄牙语
- rus - 俄语
- spa - 西班牙语
- jpn - 日语
Tesseract算法基础
- 使用训练好的模型来识别字符,并通过上下文和语言模型来提高识别准确性。
Tesseract 目前已作为开源项目, 发布在Google Project,其最新版本3.0已经支持中文OCR,并提供了一个命令行工具。
- 官方文档: tesseract-ocr
- GitHub地址:tesseract
- 第三方UI
安装
客户端安装
① 源码安装 Source Code
Tesseract 5.x.x source code is available in the main branch of the repository. The main branch is using 5.0.0 semver versioning because C++ code modernization caused API incompatibility with 4.x release.
② 二进制文件 Binaries
Binaries are available from:
Mac
Mac 安装方式
# 查看
brew info tesseract
# 安装
brew install tesseract
# 标准包中语言只包括几种语言数据。如果想要更多支持语言,需要输入:
brew install tesseract-lang
tesseract -h
linux
linux 安装:
- 安装客户端
- 安装Python 工具包
pip install pytesseract
windows
【2024-11-30】windows exe 下载地址
- 滑到尾部, 安装 win64版本: tesseract-ocr-w64-setup-v5.3.0.20221214.exe
- 安装正常, 但执行出错, libpng 版本不对
- 错误信息:
libpng warning: Application built with libpng-1.4.3 but running with 1.5.14
改进:更换版本即可
- 安装官方文档上的windows版本: Windows - Tesseract at UB Mannheim
- 配置环境变量:
# PATH 添加安装目录
E:\program_file\Tesseract-OCR
# 设置 变量
TESSDATA_PREFIX = E:\program_file\Tesseract-OCR\tessdata
保存后,启动 power shell
# 版本信息
tesseract -v
# 显示支持的语种
tesseract --list-langs
# 默认英语
tesseract .\data\b.jpg out_b
# 指定语种
tesseract -l chi_sim .\data\a.png out_a
执行完后,当前目录下生成 文件 out_a.txt, out_b.txt, 包含生成的文件内容
使用
使用方式:命令行+程序调用
命令行模式
# 命令模式
tesseract imagename outputbase [-l lang] [--oem ocrenginemode] [--psm pagesegmode] [configfiles...]
tesseract imagename outputbase # 极简模式
tesseract --tessdata-dir /usr/share imagename outputbase -l eng --psm 3 # 等效表达
# 指定语种
tesseract images/eurotext.png - -l eng
tesseract images/eurotext.png - -l eng+deu # 多语种
tesseract images/bilingual.png - -l eng+hin # 顺序有关,排在前面表示主要语种
tesseract images/bilingual.png - -l script/Devanagari # Devanagari和eng并存
tesseract images/bilingual.png - -l script/Devanagari quiet # 不显示分辨率信息
# 输出格式
tesseract testing/eurotext.png testing/eurotext-eng -l eng pdf # 输出 pdf, 保留原图及可搜索的文本层(未直接显示)
tesseract images/eurotext.png - -l eng hocr # xml 格式, 显示每个字符的详细信息
tesseract images/eurotext.png - -l eng tsv # tsv 格式, 表格形式显示每个字符的详细信息
# 版面格式
tesseract images/toc.png - --psm 6 # 水平对齐的文本块, 手写体效果好些
tesseract images/toc.png - --psm 6 -c preserve_interword_spaces=1 # toc 格式,保留中间空格
tesseract images/toc.png images/toc -l eng –psm 11 pdf # pdf 转文本,保留原格式
OCR选项:
--tessdata-dir PATH
--user-words PATH
--user-patterns PATH
--dpi VALUE
-l LANG[+LANG] # 语种, 默认 英语 eng
--psm NUM # 分割模式, 默认 3
--oem NUM
-c VAR=VALUE # 附加参数
# 默认输出文本
命令行方式
- 详见官方解读
tesseract --list-langs # 显示支持的语种
img_file="..\data\联合国宣言\法语.jpg"
# 输出到终端
tesseract $img_file stdout -l chi_sim # 仅中文
# 输出到文件 out.txt
tesseract $img_file out.txt -l eng+deu # 英语+德语
# 多种语言一起指定
tesseract $img_file stdout -l chi_sim+eng+deu+rus+fra+jpn
# lstm 模型
tesseract input.tiff output --oem 1 -l eng
PSM
图片分割模式(PSM)
tesseract有13种图片分割模式(page segmentation mode,psm):
- 0 — Orientation and script detection (OSD) only. 方向及语言检测(Orientation and script detection,OSD)
- 1 — Automatic page segmentation with OSD. 自动图片分割
- 2 — Automatic page segmentation, but no OSD, or OCR. 自动图片分割,没有OSD和OCR
- 3 — Fully automatic page segmentation, but no OSD. (Default) 完全的自动图片分割,没有OSD
- 4 — Assume a single column of text of variable sizes. 不同大小的文本
- 5 — Assume a single uniform block of vertically aligned text. 垂直对齐的文本块
- 6 — Assume a single uniform block of text. 水平对齐的文本块
- 7 — Treat the image as a single text line. 图片为单行文本
- 8 — Treat the image as a single word. 图片为单词
- 9 — Treat the image as a single word in a circle. 图片为圆形单词
- 10 — Treat the image as a single character. 图片为单个字符
- 11 — Sparse text. Find as much text as possible in no particular order.稀疏文本。查找尽可能多的文本,没有特定的顺序。
- 12 — Sparse text with OSD. OSD 稀疏文本
- 13 — Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific. 原始行。将图像视为单个文本行。
OEM
OCR引擎模式(OEM)
有4种OCR引擎模式:
- 0 — Legacy engine only.
- 1 — Neural nets LSTM engine only.
- 2 — Legacy + LSTM engines.
- 3 — Default, based on what is available.
Python 调用
调用代码
- 先确保已安装 tesseract 工具包
常见方法
image_to_string()识别文本内容image_to_boxes()识别字符及字符边框信息。image_to_data()单词及单词位置信息。
import pytesseract
# 列出支持的语言
print(pytesseract.get_languages(config=''))
img = Image.open('test.png')
print(pytesseract.image_to_string(img, lang='chi_sim+eng'))
print(pytesseract.image_to_boxes(img, output_type=Output.STRING, lang='chi_sim'))
# 生 63 211 80 227 0
# 存 81 209 118 227 0
# 是 122 211 139 226 0
print(pytesseract.image_to_data(img, output_type=Output.STRING, lang='chi_sim'))
# level page_num block_num par_num line_num word_num left top width height conf text
# 1 1 0 0 0 0 0 0 566 279 -1
# 2 1 1 0 0 0 63 52 203 18 -1
# 3 1 1 1 0 0 63 52 203 18 -1
image_to_data 内容解析
import numpy as np
import pytesseract
from pytesseract import Output
import cv2
try:
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
except ImportError:
import Image
img = cv2.imread('testimg2.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
width_list = []
for c in cnts:
_, _, w, _ = cv2.boundingRect(c)
width_list.append(w)
wm = np.median(width_list)
tess_text = pytesseract.image_to_data(img, output_type=Output.DICT, lang='chi_sim')
for i in range(len(tess_text['text'])):
word_len = len(tess_text['text'][i])
if word_len > 1:
world_w = int(wm * word_len)
(x, y, w, h) = (tess_text['left'][i], tess_text['top'][i], tess_text['width'][i], tess_text['height'][i])
cv2.rectangle(img, (x, y), (x + world_w, y + h), (255, 0, 0), 1)
im = Image.fromarray(img)
draw = ImageDraw.Draw(im)
font = ImageFont.truetype(font="simsun.ttc", size=18, encoding="utf-8")
draw.text((x, y - 20), tess_text['text'][i], (255, 0, 0), font=font)
img = cv2.cvtColor(np.array(im), cv2.COLOR_RGB2BGR)
cv2.imshow("TextBoundingBoxes", img)
cv2.waitKey(0)

其中
ImageFont.truetype(font="simsun.ttc", size=18, encoding="utf-8")用于设置字体及编码格式,原因是draw.text()默认使用ISO-8859-1(latin-1)编码,中文需要使用UTF-8编码。- Windows中字体存放路径一般为
C:\Windows\Fonts,已经添加到了环境变量,直接写字体名称就可以了,simsun.ttc表示宋体。 - 如果不知道字体对应名称, 可进注册表查看:
- 运行窗口或者命令行窗口输入
regedit打开注册表 - 进入如下路径:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Fonts,可以查看对应字体文件名称。
- 运行窗口或者命令行窗口输入
多语言识别
图片中可能包含了多种语言,比如同时包含了中文和英文
lang='chi_sim+eng'表示识别简体中文和英文。
img = Image.open('test.png')
tess_text = pytesseract.image_to_string(img, lang='chi_sim+eng')
config = r'-l chi_sim+eng --psm 6'
print(pytesseract.image_to_string(img, config=config))
多语言识别中使用了 -l 和 --psm 选项
# coding:utf-8
# pip install opencv-python
import cv2 # OpenCV: Computer vision and image manipulation package
import pytesseract # python Tesseract: OCR in python
import matplotlib.pyplot as plt # plotting
import numpy as np # Numpy for arrays
from PIL import Image # Pillow: helps us read remote images
import requests # Requests: to fetch remote URLs
from io import BytesIO # Helps read remote images
def get_image(url):
response = requests.get(url)
img = Image.open(BytesIO(response.content))
return img
img = get_image('https://github.com/jalammar/jalammar.github.io/raw/master/notebooks/cv/label.png')
# OCR结果
print(pytesseract.image_to_string(img))
方向及语种
方向及语言检测OSD
- Tesseract支持方向及语言检测(Orientation and script detection,OSD)
- 识别 图片中文字方向、语种
- 比如检测下面的图片:
osd = pytesseract.image_to_osd('osd-example.png',config='--psm 0 -c min_characters_to_try=5')
# min_characters_to_try 表示设置最小字符数,默认为50。
print(osd)
执行结果:
Page number: 0
Orientation in degrees: 90
Rotate: 270
Orientation confidence: 0.74
Script: Han
Script confidence: 0.83
结果
- 旋转了270度,语言为中文Han。
只提取数字
只提取图片数字
img = Image.open('number-example.png')
config = r'--oem 3 --psm 6 outputbase digits'
osd = pytesseract.image_to_string(img, config=config)
print(osd)
白/黑名单
字符白名单
- 只检测特定的字符:只检测数字
img = Image.open('number-example.png')
config = r'-c tessedit_char_whitelist=0123456789 --psm 6'
print(pytesseract.image_to_string(img, config=config))
执行结果:
- 识别精度比 outputbase digits 方法更加准确。
字符黑名单
- 不检测数字
img = Image.open('number-example.png')
config = r'-c tessedit_char_blacklist=0123456789 --psm 6'
print(pytesseract.image_to_string(img, config=config, lang='chi_sim'))
格式转换
pdf = pytesseract.image_to_pdf_or_hocr('testimg2.png', extension='pdf')
# 图片转pdf
with open('test.pdf', 'w+b') as f:
f.write(pdf)
hocr = pytesseract.image_to_pdf_or_hocr('testimg2.png', extension='hocr')
xml = pytesseract.image_to_alto_xml('testimg2.png')
手写体
tesseract 中文语言包“chi_sim”对中文手写字体(或环境比较复杂的情况)识别正确率不高
- 示例: 书法作品 “长花短草 贴合而立”, 只能识别3个字
需要针对特定情况用自己的样本进行训练,提高识别率。
pdf 识别
PaddleOCR 支持 pdf 识别
注意
- 【2024-12-12】识别 pdf 文件时, 需要提前准备 fitz 包 ,否则报错!即便没有显示 import fitz
- 执行
pip install PyMuPDF
官方文档
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
PAGE_NUM = 10 # 将识别页码前置作为全局,防止后续打开pdf的参数和前文识别参数不一致 / Set the recognition page number
pdf_path = 'default.pdf'
ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=PAGE_NUM) # need to run only once to download and load model into memory
# ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=PAGE_NUM,use_gpu=0) # 如果需要使用GPU,请取消此行的注释 并注释上一行 / To Use GPU,uncomment this line and comment the above one.
result = ocr.ocr(pdf_path, cls=True)
for idx in range(len(result)):
res = result[idx] # 获取当页内容
if res == None: # 识别到空页就跳过,防止程序报错 / Skip when empty result detected to avoid TypeError:NoneType
print(f"[DEBUG] Empty page {idx+1} detected, skip it.")
continue
for line in res:
print(line)
# 显示结果
import fitz # pip install PyMuPDF
from PIL import Image
import cv2
import numpy as np
imgs = []
with fitz.open(pdf_path) as pdf:
for pg in range(0, PAGE_NUM):
page = pdf[pg]
mat = fitz.Matrix(2, 2)
pm = page.get_pixmap(matrix=mat, alpha=False)
# if width or height > 2000 pixels, don't enlarge the image
if pm.width > 2000 or pm.height > 2000:
pm = page.get_pixmap(matrix=fitz.Matrix(1, 1), alpha=False)
img = Image.frombytes("RGB", [pm.width, pm.height], pm.samples)
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
imgs.append(img)
for idx in range(len(result)):
res = result[idx]
if res == None:
continue
image = imgs[idx]
boxes = [line[0] for line in res]
txts = [line[1][0] for line in res]
scores = [line[1][1] for line in res]
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result_page_{}.jpg'.format(idx))
另一种方法: pdf 批量转换成 image, 然后 调用 paddleocr 逐页识别, 版面分析
PaddleOCR
开源OCR工具中,精度及代码开源是否彻底,首屈一指是 PaddleOCR
- 开源中英文离线 OCR,使用 PaddleOCR 实现,提供了简单的 Web 页面及接口
效果


功能
特点
- 支持多种OCR任务:PaddleOCR 支持多种OCR任务,包括: 文字检测、文字方向检测、多语种OCR、手写体OCR等,可以满足不同场景下的OCR需求。
- 识别精度高:PaddleOCR 深度学习模型经过大量的训练和优化,可以在各种复杂场景下实现高精度的OCR识别,具有较高的识别准确率。可准确识别不同字体、字号、字形的文字图像,实现超越人眼识别率的准确率。
- 易于使用:PaddleOCR 提供了丰富的预训练模型和模型优化技术,可快速部署和使用OCR功能,同时也提供了简单易用的API接口和开发文档,方便用户进行二次开发和定制化。
- 开源免费:PaddleOCR 开源免费,用户可以免费获取源代码和训练数据,自由使用和修改,方便用户进行二次开发和定制化。
PaddleOCR是一个高效、精准、易用、开源免费的OCR工具
功能
- 支持多种 OCR 相关前沿算法,在此基础上打造产业级特色模型
PP-OCR、PP-Structure和PP-ChatOCR,并打通数据生产、模型训练、压缩、预测部署全流程。 
近期优化
- 2024.10.1 添加OCR领域低代码全流程开发能力:
- 飞桨低代码开发工具PaddleX,依托于PaddleOCR的先进技术,支持了OCR领域的低代码全流程开发能力:
- 🎨 模型丰富一键调用:将文本图像智能分析、通用OCR、通用版面解析、通用表格识别、公式识别、印章文本识别涉及的17个模型整合为6条模型产线,通过极简的Python API一键调用,快速体验模型效果。此外,同一套API,也支持图像分类、目标检测、图像分割、时序预测等共计200+模型,形成20+单功能模块,方便开发者进行模型组合使用。
- 🚀提高效率降低门槛:提供基于统一命令和图形界面两种方式,实现模型简洁高效的使用、组合与定制。支持高性能推理、服务化部署和端侧部署等多种部署方式。此外,对于各种主流硬件如英伟达GPU、昆仑芯、昇腾、寒武纪和海光等,进行模型开发时,都可以无缝切换。
- 支持文档场景信息抽取v3PP-ChatOCRv3-doc、基于RT-DETR的高精度版面区域检测模型和PicoDet的高效率版面区域检测模型、高精度表格结构识别模型SLANet_Plus、文本图像矫正模型UVDoc、公式识别模型LatexOCR、基于PP-LCNet的文档图像方向分类模型
- 🔥2024.7 添加 PaddleOCR 算法模型挑战赛冠军方案:
- 赛题一:OCR 端到端识别任务冠军方案——场景文本识别算法-SVTRv2;
- 赛题二:通用表格识别任务冠军方案——表格识别算法-SLANet-LCNetV2。
PP-Structure 文档分析: 版面分析+表格识别
语种
目前提供的模型共支持10个类别, 80种语言的检测和识别:
- 英文模型支持大小写字母和常见标点的检测识别,并优化了空格字符的识别
- 小语种模型覆盖了拉丁语系、阿拉伯语系、中文繁体、韩语、日语等等:
10个类别
- 0: 阿拉伯语(arabic);
- 1: 中文繁体(chinese_cht);
- 2: 斯拉夫语(cyrillic);西里尔文, 如 俄文
- 3: 梵文(devanagari);
- 4: 日语(japan);
- 5: 卡纳达文(ka);
- 6: 韩语(korean);
- 7: 泰米尔文(ta);
- 8: 泰卢固文(te);
- 9: 拉丁语(latin)。
罗曼语族(英文:Romance Languages),又称拉丁语族,属于印欧语系,主要包括法语、意大利语、西班牙语、葡萄牙语、加泰罗尼亚语 、加里西亚语 、罗马尼亚语 、罗曼什语 等
- 语种: Chinese, English, French, German, Korean and Japanese, 各语种对应缩写见官方文档
- 注: 不能组合!已提交 issue
# 语种选择:
['ch', 'en', 'korean', 'japan', 'chinese_cht', 'ta', 'te', 'ka', 'latin', 'arabic', 'cyrillic', 'devanagari']
多语种解法
现在不支持多语言联合识别
- 逐个检测、选最佳
- 语种自动检测
- 切换 tesseract
- 自己训练
自动检测
语种自动检测
import paddleclas
file_name = r"E:\ocr\data\hand\3.jpg"
lang_model = paddleclas.PaddleClas(model_name="language_classification")
result = lang_model.predict(input_data=file_name)
result = list(result)
lang_type = result[0][0]['label_names'][0]
print('语言类型为:',lang_type)
报错
RuntimeError: (NotFound) Cannot open file C:\Users\wqw/.paddleclas/inference_model\PULC\language_classification, please confirm whether the file is normal.
[Hint: Expected static_cast<bool>(fin.is_open()) == true, but received static_cast<bool>(fin.is_open()):0 != true:1.] (at ..\paddle\fluid\inference\api\analysis_predictor.cc:2577)
解决
- PULC 找不到模型文件 windows 下路径分隔符导致
- 【2024-12-10】官方反馈, 修改两处源码即可, 详见 PaddleClas/pull/3313
改动点
# 找到 site-package 的 paddleclas 目录
# (1)文件 paddleclas.py 第 49 行
# BASE_DIR = os.path.expanduser("~/.paddleclas/") # 旧
BASE_DIR = os.path.expanduser(os.path.join("~", ".paddleclas"))
# (2)文件 deploy/utils/predictor.py 第 58-62 行
# pd_version = 0
# for v in paddle.__version__.split(".")[:3]:
# pd_version = 10 * pd_version + eval(v)
# if pd_version == 0 or pd_version >= 260:
major_v, minor_v, _ = paddle.__version__.split(".")[:3]
major_v, minor_v = int(major_v), int(minor_v)
if (major_v == 0 and minor_v == 0) or (major_v >= 3):
验证无误, 但 识别准确率很低,不到 20%
- 反馈给官方 语种检测准确率很差
都检测选最佳
文档包含多种语言且语种未知,可以逐步尝试不同语言模型,结合检测结果的置信度来判断最佳语言。
# 多种返回结果: 空、一个识别结果、多个识别结果
# [null]
# [[
# [[[1931.0, 1453.0], [1990.0, 1453.0], [1990.0, 1487.0], [1931.0, 1487.0]], ["191t", 0.7493318915367126]]
# ]]
# [[
# [[[297.0, 157.0], [1755.0, 124.0], [1760.0, 337.0], [301.0, 370.0]], ["很多人不需要再见!", 0.9498765468597412]],
# [[[351.0, 493.0], [1773.0, 468.0], [1776.0, 657.0], [354.0, 683.0]], ["因为只是路过而已.", 0.8729634881019592]],
# [[[334.0, 833.0], [1755.0, 842.0], [1753.0, 1049.0], [333.0, 1039.0]], ["遗忘就是我给你", 0.9973150491714478]],
# [[[404.0, 1153.0], [1457.0, 1182.0], [1450.0, 1434.0], [397.0, 1404.0]], ["最好的纪念。", 0.951411783695221]],
# [[[1935.0, 1460.0], [1988.0, 1460.0], [1988.0, 1485.0], [1935.0, 1485.0]], ["19楼", 0.9435752034187317]]
# ]]
串行
from paddleocr import PaddleOCR
languages = ['ch', 'japan', 'en'] # 需要支持的语言列表
results = []
result_info = {}
max_lang = ['-', 0]
stop = False
MIN_VAL = 0.85
for lang in languages:
ocr = PaddleOCR(use_angle_cls=True, lang=lang)
result = ocr.ocr(file_name)
if not result[0]:
result_info[lang] = result
continue
# 计算平均得分
score_list = [i[1][1] for i in result[0]]
score_avg = sum(score_list)/len(score_list)
print(f'[Note] {lang=}: \t{score_avg}\t{json.dumps([i[1][0] for i in result[0]], ensure_ascii=False)}')
if score_avg > max_lang[1]:
max_lang = [lang, score_avg]
result_info[lang] = result[0]
if score_avg > MIN_VAL:
# 置信度较高, 终止检测
stop = True
print(f'[Note] 置信度较高 {score_avg:.2f}>{MIN_VAL}, 提前终止 ... 已检测语种: {result_info.keys()}')
break
print(f'语种: {max_lang[0]}, 得分: {max_lang[1]}, 结果: {result_info[lang]}')
多进程并行
import logging
from queue import Queue
import os
import sys
import threading
import json
from paddleocr import PaddleOCR
# file_name = "E:\ocr\data\联合国宣言\中英.jpg"
file_name = r"E:\ocr\data\hand\1.jpg"
# file_name = r"E:\ocr\data\多国语言-1205\日文\1.jpeg"
languages = ['ch', 'en', 'japan', 'fr', 'de'] # 需要支持的语言列表
# 模型初始化
api_info = {}
for lang in languages:
api_info[lang] = PaddleOCR(use_angle_cls=True, lang=lang, show_log=False)
def log(msg):
pid = os.getpid()
tid = threading.current_thread().ident
logging.info(f"进程[{pid}]-线程[{tid}]: {msg}")
def getResult(lock, lang, q):
"""
单次 OCR 请求
"""
log('开始请求OCR服务')
# 开始请求OCR服务
result = api_info[lang].ocr(file_name)
lock.acquire()
score_avg = 0
if not result[0]:
pass
else:
# 计算平均得分
score_list = [i[1][1] for i in result[0]]
score_avg = sum(score_list)/len(score_list)
print(f'[Note] {lang=}: \t{score_avg}\t{json.dumps([i[1][0] for i in result[0]], ensure_ascii=False)}')
lock.release()
q.put([lang, score_avg, result[0]])
log('请求完毕')
if __name__ == '__main__':
thread_lock = threading.Lock()
job_list = []
q = Queue() # 存储结果
for lang in languages:
job = threading.Thread(target=getResult, args=(thread_lock, lang, q), name=f'job_{lang}')
job.start()
job_list.append(job)
# 阻塞在主进程前面
for thread in job_list:
thread.join()
results = []
for _ in languages:
# [lang, score_avg, result[0]]
results.append(q.get())
# # 根据置信度选择最佳结果
best_result = max(results, key=lambda x: x[1])
print(f"最佳语言: {best_result[0]}, 得分: {best_result[1]}, 结果: {best_result[2]}")
text = '\n'.join([i[1][0] for i in best_result[2]])
print('Result: ', json.dumps(text, ensure_ascii=False))
运行结果
# python .\paddleocr_multi.py
[Note] lang='japan': 0.7367656826972961 ["看全世的美景", "又似最妹子"]
[Note] lang='fr': 0.6428748369216919 ["BO", "XXT"]
[Note] lang='de': 0.6428748369216919 ["BO", "XXT"]
[Note] lang='ch': 0.9849963188171387 ["看过全世界的美景,", "然后写给你看。", "汉仪晨妹子"]
最佳语言: ch, 得分: 0.9849963188171387, 结果: [[[[94.0, 100.0], [530.0, 103.0], [530.0, 153.0], [94.0, 150.0]], ('看过全世界的美景,', 0.9754508137702942)], [[[89.0, 183.0], [432.0, 186.0], [431.0, 233.0], [89.0, 230.0]], ('然后写给你看。', 0.9876102209091187)], [[[97.0, 336.0], [197.0, 336.0], [197.0, 356.0], [97.0, 356.0]], ('汉仪晨妹子', 0.9919279217720032)]]
Result: "看过全世界的美景,\n然后写给你看。\n汉仪晨妹子"
安装
paddlepaddle 官方版本选择
Python 工具包
pip install paddlepaddle
# pip install paddlepaddle-gpu # gpu 环境
# 最新版 paddlepaddle
# cpu 版本
python -m pip install paddlepaddle==3.0.0b2 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
# gpu 版本, cuda 11.8
python -m pip install paddlepaddle-gpu -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# paddleocr
# pip install paddleocr
python3 -m pip install paddleocr
# 安装 图像方向分类依赖包paddleclas(如不需要图像方向分类功能,可跳过)
python3 -m pip install paddleclas
问题: ImportError: DLL load failed while importing libpaddle: 找不到指定的模块问题 官方issue
- 分析: ImportError: DLL load failed while importing libpaddle: 找不到指定的模块问题
- 【2024-12-16】操作系统旧了,缺乏vc库,导致paddlepaddle安装失败,
import paddle无法执行,找不到libpaddle - 错误:
Error: Can not import avx core while this file exists - 解法:
- ① 安装vc_redist.x64
- ② 官方 issue: 升级 paddlepaddle
使用
案例
- 用PaddleOCR与PyQT实现多语言文字识别 客户端软件,支持截图、识别结果可视化
命令行
paddleocr -h
# 仅文本检测
paddleocr --image_dir PaddleOCR/doc/imgs_en/img_12.jpg --rec false
# 仅识别
paddleocr --image_dir PaddleOCR/doc/imgs_words_en/word_10.png --det false --lang en
# 仅方向识别
paddleocr --image_dir PaddleOCR/doc/imgs_words_en/word_10.png --use_angle_cls true --det false --rec false
# 所有
paddleocr --image_dir PaddleOCR/doc/imgs_en/img_12.jpg --use_angle_cls true --lang en
输出示例:
[[[442.0, 173.0], [1169.0, 173.0], [1169.0, 225.0], [442.0, 225.0]], ['ACKNOWLEDGEMENTS', 0.99283075]]
[[[393.0, 340.0], [1207.0, 342.0], [1207.0, 389.0], [393.0, 387.0]], ['We would like to thank all the designers and', 0.9357758]]
[[[399.0, 398.0], [1204.0, 398.0], [1204.0, 433.0], [399.0, 433.0]], ['contributors whohave been involved in the', 0.9592447]]
......
还支持 pdf文件,可用page_num参数推断前几页,默认值为0,这意味着识别全部页面
paddleocr --image_dir ./xxx.pdf --use_angle_cls true --use_gpu false --page_num 2
更加详细的文档,请移步:PaddleOCR快速开始
Python 代码
paddleocr whl包自动下载ppocr轻量级模型作为默认模型
- 服务初始化函数定义: C:\Users\wqw\AppData\Roaming\Python\Python311\site-packages\paddleocr\paddleocr.py
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr supports Chinese, English, French, German, Korean and Japanese
# You can set the parameter `lang` as `ch`, `en`, `french`, `german`, `korean`, `japan`
# to switch the language model in order
ocr = PaddleOCR(use_angle_cls=True, lang='en') # need to run only once to download and load model into memory
ocr = PaddleOCR(use_angle_cls=True, lang='en', show_log=False) # 关闭调试日志
ocr = PaddleOCR(use_angle_cls=True, lang='ch', use_gpu=False, det=True, rec=True, cls=True)
img_path = 'PaddleOCR/doc/imgs_en/img_12.jpg'
result = ocr.ocr(img_path, cls=True)
# 逐页解析
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# draw result
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
PP-Structure
PP-Structure 是 PaddleOCR 团队自研的智能文档分析系统,旨在帮助开发者更好的完成版面分析、表格识别等文档理解相关任务。
PP-StructureV2 系统流程图如下
- 文档图像先经过图像矫正模块,判断整图方向并完成转正,随后可以完成版面信息分析与关键信息抽取2类任务。
- 版面分析任务中,图像首先经过版面分析模型,将图像划分为文本、表格、图像等不同区域,随后对这些区域分别进行识别,如,将表格区域送入表格识别模块进行结构化识别,将文本区域送入OCR引擎进行文字识别,最后使用版面恢复模块将其恢复为与原始图像布局一致的word或者pdf格式的文件;
- 关键信息抽取任务中,首先使用OCR引擎提取文本内容,然后由语义实体识别模块获取图像中的语义实体,最后经关系抽取模块获取语义实体之间的对应关系,从而提取需要的关键信息。
PP-StructureV2 主要特性:
- 支持对图片/pdf形式的文档进行版面分析,可以划分文字、标题、表格、图片、公式等区域;
- 支持通用的中英文表格检测任务;
- 支持表格区域进行结构化识别,最终结果输出Excel文件;
- 支持基于多模态的关键信息抽取(Key Information Extraction,KIE)任务-语义实体识别(Semantic Entity Recognition,SER)和关系-抽取(Relation Extraction,RE);
- 支持版面复原,即恢复为与原始图像布局一致的word或者pdf格式的文件;
- 支持自定义训练及python whl包调用等多种推理部署方式,简单易用;
- 与半自动数据标注工具PPOCRLabel打通,支持版面分析、表格识别、SER三种任务的标注。
PP-StructureV2 支持各个模块独立使用或灵活搭配,如,可以单独使用版面分析,或单独使用表格识别
命令
# 图像方向分类+版面分析+表格识别
# 暂时关闭新 IR 功能
export FLAGS_enable_pir_api=0
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure --image_orientation=true
# 版面分析+表格识别
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure
# 版面分析
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure --table=false --ocr=false
# 表格识别
paddleocr --image_dir=ppstructure/docs/table/table.jpg --type=structure --layout=false
版面恢复
# 中文测试图
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure --recovery=true
# 英文测试图
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure --recovery=true --lang='en'
# pdf测试文件
paddleocr --image_dir=ppstructure/docs/recovery/UnrealText.pdf --type=structure --recovery=true --lang='en'
# 不使用 LaTeXOCR 模型进行公式识别:
paddleocr --image_dir=ppstructure/docs/recovery/UnrealText.pdf --type=structure --recovery=true --recovery_to_markdown=true --lang='en'
# 使用 LaTeXOCR 模型进行公式识别,其中必须使用中文layout模型:
paddleocr --image_dir=ppstructure/docs/recovery/UnrealText.pdf --type=structure --recovery=true --formula=true --recovery_to_markdown=true --lang='ch'
训练
训练代码
# 下载预训练模型
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/french_mobile_v2.0_rec_train.tar
tar -xf french_mobile_v2.0_rec_train.tar
#加载预训练模型 单卡训练
python3 tools/train.py -c configs/rec/rec_french_lite_train.yml -o Global.pretrained_model=french_mobile_v2.0_rec_train/best_accuracy
#加载预训练模型 多卡训练,通过--gpus参数指定卡号
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_french_lite_train.yml -o Global.pretrained_model=french_mobile_v2.0_rec_train/best_accuracy
服务部署
将 paddleocr 封装到 flask web 服务中,同时用 pyinstaller 打包
报错:
解法:
pyinstaller.exe -D .\main.py --collect-all paddleocr --collect-all pyclipper --collect-all imghdr --collect-all skimage --collect-all imgaug --collect-all scipy.io --collect-all lmdb
新版 PaddleOCR-VL【sota】
2025年10月16日晚,百度发布并开源自研多模态文档解析模型 PaddleOCR-VL 。
- 开源地址:PaddleOCR
- 技术报告地址:PaddleOCR-VL_Technical_Report.pdf
- 体验Demo地址
全球权威文档解析评测榜单 OmniBenchDoc V1.5中,PaddleOCR-VL 以92.56分取得综合性能全球第一成绩
- 超越 DeepSeek-OCR 86.46,约6分,综合性能继续位居全球第一。
- 在OCR核心四项任务上(文本、公式、表格、结构理解),PaddleOCR-VL均超越DeepSeek-OCR,为当前SOTA方案
四大核心能力(文本、表格、公式、阅读顺序)全线SOTA,超越 GPT-4o、Gemini-2.5 Pro、Qwen2.5-VL-72B 等主流多模态大模型,以及 MonkeyOCR-Pro-3B、MinerU2.5、dots.ocr 等OCR专业模型,刷新全球OCR VL模型性能天花板。
PaddleOCR 由PP-DocLayoutV2和PaddleOCR-VL-0.9B两部分组成,
- PP-DocLayoutV2 是用于识别文档的结构信息,过滤图片中无效视觉部分,如空白,这本身也算是一种“压缩”吧。
- PaddleOCR-VL-0.9B 接受batch块图像进行识别,最终输出结构化输出。
PaddleOCR-VL-0.9B 依旧是经典三结构,图像编码器采用NaViT,MLP映射器,文本解码器采用ERNIE4.5-0.3B模型
安装 PaddleOCR-VL
- 最低配:4核CPU+8GB内存;
- 流畅运行建议:NVIDIA显卡(4GB+显存)+16GB内存。
- 纯CPU可运行但较慢,具体部署细节参考PaddlePaddle官方文档。
PaddleOCR-VL 核心模型参数仅0.9B,轻量高效,能够在极低计算开销下,精准识别文本、手写汉字、表格、公式、图表等复杂元素,支持109 种语言,覆盖中文、英语、法语、日语、俄语、阿拉伯语、西班牙语等多语场景,广泛适用于政企文档管理、知识检索、档案数字化、科研信息抽取等文档智能任务。
OpenOCR
OCR工具、基准和新模型
- GitHub: OpenOCR。
- 超过 PaddleOCR 识别系统,达到SOTA效果
特性:
- 1、兼具精度与效率:OCR竞赛排行榜上精度超过PaddleOCR基线4.5%,在GPU上速度可比。
- 2、具有通用性:支持自然场景、文档、手写等文本识别,支持中文和英文识别。
- 3、支持国产框架 PaddlePaddle 和 Pytorch训练和推理。
作者:topduke
QuickStart、Demo、模型、大规模真实数据集、训练评估脚本已开源
- GitHub: OpenOCR。
效果对比
- 超过 PaddleOCR 识别系统,达到SOTA效果

安装
pip 包安装
pip install openocr-python
代码库源码安装
git clone https://github.com/Topdu/OpenOCR.git
cd OpenOCR
pip install -r requirements.txt
wget https://github.com/Topdu/OpenOCR/releases/download/develop0.0.1/openocr_det_repvit_ch.pth
wget https://github.com/Topdu/OpenOCR/releases/download/develop0.0.1/openocr_repsvtr_ch.pth
# 漏掉的文件 bpe_simple_vocab_16e6
# Rec Server model
# wget https://github.com/Topdu/OpenOCR/releases/download/develop0.0.1/openocr_svtrv2_ch.pth
补充
- 漏掉的文件,从 Google Drive 下载, 文件不存在,提交issue
使用
- cli 命令行
- Python 代码
# OpenOCR system: Det + Rec model
python tools/infer_e2e.py --img_path=/path/img_fold or /path/img_file
# Det model
python tools/infer_det.py --c ./configs/det/dbnet/repvit_db.yml --o Global.infer_img=/path/img_fold or /path/img_file
# Rec model
python tools/infer_rec.py --c ./configs/rec/svtrv2/repsvtr_ch.yml --o Global.infer_img=/path/img_fold or /path/img_file
Python 代码
from openocr import OpenOCR
engine = OpenOCR()
img_path = '/path/img_path or /path/img_file'
result, elapse = engine(img_path)
# Server mode
# engine = OpenOCR(mode='server')
本地安装
pip install gradio==4.20.0
wget https://github.com/Topdu/OpenOCR/releases/download/develop0.0.1/OCR_e2e_img.tar
tar xf OCR_e2e_img.tar
# start demo
python demo_gradio.py
特殊格式
Pix2Text 数学公式
【2022-9-21】Pix2Text: 替代 Mathpix 的免费 Python 开源工具
- Pix2Text 期望成为 Mathpix 的免费开源 Python 替代工具,完成与 Mathpix 类似的功能。当前 Pix2Text 可识别截屏图片中的数学公式、英文、或者中文文字。
Pix2Text首先利用图片分类模型来判断图片类型,然后基于不同的图片类型,把图片交由不同的识别系统进行文字识别:
- 如果图片类型为 formula ,表示图片为数学公式,此时调用 LaTeX-OCR 识别图片中的数学公式,返回其Latex表示;
- 如果图片类型为 english,表示图片中包含的是英文文字,此时使用 CnOCR (https://github.com/breezedeus/cnocr) 中的英文模型识别其中的英文文字;英文模型对于纯英文的文字截图,识别效果比通用模型好;
- 如果图片类型为 general,表示图片中包含的是常见文字,此时使用 CnOCR 中的通用模型识别其中的中或英文文字。
#pip install pix2text -i https://pypi.doubanio.com/simple
from pix2text import Pix2Text
img_fp = './docs/examples/formula.jpg'
p2t = Pix2Text()
out_text = p2t(img_fp) # 也可以使用 `p2t.recognize(img_fp)` 获得相同的结果
print(out_text)
latex ocr
latex ocr:
表格
Surya sota
【2024-12-18】 开源 OCR工具 Surya,性能炸裂,更新了 表格识别功能,不仅能识别表格的行、列、单元格,还能识别旋转的表格和复杂布局,而且支持90多种语言,简直无敌。
Surya 通过先进架构,尤其是在表格识别方面,性能优于当前的SoTA开源模型 Table Transformer。
Surya 不仅仅是一款OCR工具,还具备了处理复杂表格、图片和文本布局的能力,特别是它在表格识别上的表现,远超当前的主流开源工具
目前GitHub上收藏人数超过1万(10K),不仅免费开源,还能应用于商业场景。
核心功能
- 1、表格识别
- Surya 的新版本特别强化了 表格识别,能清晰地识别出表格中的行、列和单元格,同时还能识别出具体的字符内容。
- 这个功能对于需要处理大量表格数据的同学来说无疑是一大福音。
- 2、复杂布局识别
- 它不仅限于表格,还可以识别文档中的复杂布局,比如标题、图片,甚至是旋转的表格。这意味着无论你的文档是多复杂,Surya 都能准确提取出你需要的信息。
- 3、支持90多种语言
- 支持全球超过90种语言的OCR识别,包括中文、日文、韩文、阿拉伯文等。
- 这个多语言支持,使它能够轻松应对各种不同语言的文档,无论是国际业务的文件处理,还是本地化项目的内容转换,Surya 都能游刃有余。
- 4、高效的文本识别与阅读顺序确定
- 除了表格,Surya 还擅长文本的行级检测,并能正确识别文本的阅读顺序,避免文档信息混乱,确保文本内容能够按正确的顺序输出。
- 5、本地运行和API支持
- Surya 能在本地运行,方便开发者离线处理敏感信息,或者大规模处理文档。同时,Surya 还提供了API接口,开发者可以很轻松地将其集成到自己的应用中,进行批量自动化处理。
Surya 优势
- • 性能:相比于市面上其他OCR工具,Surya 使用了新的模型架构,大幅提升了识别精度和速度,尤其在表格识别方面,表现远超目前的 SoTA(State of the Art)模型。无论是文字还是表格的处理,性能都非常出色。
- • 可商用:完全开源且允许商业用途的。这意味着你不仅可以在个人项目中使用,还可以将其集成到商业应用中,充分发挥它的潜力。
- • 跨平台支持:无论你使用的是 Windows、Mac 还是 Linux 系统,Surya 都能完美运行,而且支持本地部署,非常适合需要离线处理文档的企业或个人。
- • 社区支持与活跃开发:Surya 的开发者团队非常活跃,更新频繁,而且还有一个活跃的社区支持。如果你在使用过程中遇到问题,可以通过 Discord 社区及时与开发者交流。
Surya vs Tesseract
| 工具 | 每页耗时 | 平均相似度 |
|---|---|---|
| surya | .62 | 0.97 |
| tesseract | .45 | 0.88 |
文本检测指标
| Model | Time (s) | Time per page (s) | precision | recall |
|---|---|---|---|---|
| surya | 50.2099 | 0.196133 | 0.821061 | 0.956556 |
| tesseract | 74.4546 | 0.290838 | 0.631498 | 0.997694 |
表格识别
| Model | Row Intersection | Col Intersection | Time Per Image |
|---|---|---|---|
| Surya | 0.97 | 0.93 | 0.03 |
| Table transformer | 0.72 | 0.84 | 0.02 |
安装
- Python 3.10+ and PyTorch
- CPU/GPU都行
# Mac OS Homebrew 轻松安装:
brew install surya
# pip 安装
pip install surya-ocr
# 源码安装
git clone https://github.com/VikParuchuri/surya.git
cd surya
make build
# 本地web
pip install streamlit
surya_gui
使用方法
surya_ocr $data_path # 文件(图像/pdf),目录
surya_detect $data_path # 检测框写入json文件
surya_layout $data_path # 文字布局
surya_table $data_path # 表格识别
可选参数
--langs指定语种, 支持90+种, 多语种用逗号分隔,语种代号, 详见 代码surya/languages.py--lang_file多文件时,指定各个文件语种, json 格式, 如{"file1.pdf": ["en", "hi"], "file2.pdf": ["en"]}--images保存图片和检测出来的文本--results_dir指定结果保存目录--max指定最大处理页数--start_page指定开始处理页码
输出 results.json 文件, 字段格式
text_lines检测出来的文本、边界框text文本confidence置信度polygon坐标点数组(从左上角开始顺时针)bbox方框数组 (左上角坐标),(右下角坐标)
languages语种page页码image_bbox指定图片识别区域
Python 代码
from PIL import Image
from surya.ocr import run_ocr
from surya.model.detection.model import load_model as load_det_model, load_processor as load_det_processor
from surya.model.recognition.model import load_model as load_rec_model
from surya.model.recognition.processor import load_processor as load_rec_processor
file_name = r"E:\ocr\data\hand\1.jpg"
image = Image.open(file_name)
langs = ["en", 'zh'] # Replace with your languages - optional but recommended
# 加载模型 huggingface, 保存到 C:\Users\wqw\.cache\huggingface\hub, 1G
det_processor, det_model = load_det_processor(), load_det_model()
rec_model, rec_processor = load_rec_model(), load_rec_processor()
predictions = run_ocr([image], [langs], det_model, det_processor, rec_model, rec_processor)
print(predictions)
# ------------ 批量 -----------
from PIL import Image
from surya.detection import batch_text_detection
from surya.model.detection.model import load_model, load_processor
image = Image.open(file_name)
model, processor = load_model(), load_processor()
# predictions is a list of dicts, one per image
predictions = batch_text_detection([image], model, processor)
print(predictions)
中文OCR比赛第一
【2022-1-25】第一次比赛,拿了世界人工智能大赛 Top1 !,“世界人工智能创新大赛”——手写体 OCR 识别竞赛(任务一),取得了Top1的成绩
- 赛题地址
- 背景:银行日常业务中涉及到各类凭证的识别录入,例如身份证录入、支票录入、对账单录入等。以往的录入方式主要是以人工录入为主,效率较低,人力成本较高。近几年来,OCR相关技术以其自动执行、人为干预较少等特点正逐步替代传统的人工录入方式。但OCR技术在实际应用中也存在一些问题,在各类凭证字段的识别中,手写体由于其字体差异性大、字数不固定、语义关联性较低、凭证背景干扰等原因,导致OCR识别率准确率不高,需要大量人工校正,对日常的银行录入业务造成了一定的影响
- 数据集:原始手写体图像共分为三类,分别涉及银行名称、年月日、金额三大类,分别示意如下:
- 相应图片切片中可能混杂有一定量的干扰信息


OCR比赛最常用的模型是 CRNN + CTC,选择代码:Attention_ocr.pytorch-master.zip
模型改进:crnn的卷积部分类似VGG,我对模型的改进主要有一下几个方面:
- 1、加入激活函数Swish。
- 2、加入BatchNorm。
- 3、加入SE注意力机制。
- 4、适当加深模型。
self.cnn = nn.Sequential(
nn.Conv2d(nc, 64, 3, 1, 1), Swish(), nn.BatchNorm2d(64),
nn.MaxPool2d(2, 2), # 64x16x50
nn.Conv2d(64, 128, 3, 1, 1), Swish(), nn.BatchNorm2d(128),
nn.MaxPool2d(2, 2), # 128x8x25
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), Swish(), # 256x8x25
nn.Conv2d(256, 256, 3, 1, 1), nn.BatchNorm2d(256), Swish(), # 256x8x25
SELayer(256, 16),
nn.MaxPool2d((2, 2), (2, 1), (0, 1)), # 256x4x25
nn.Conv2d(256, 512, 3, 1, 1), nn.BatchNorm2d(512), Swish(), # 512x4x25
nn.Conv2d(512, 512, 1), nn.BatchNorm2d(512), Swish(),
nn.Conv2d(512, 512, 3, 1, 1), nn.BatchNorm2d(512), Swish(), # 512x4x25
SELayer(512, 16),
nn.MaxPool2d((2, 2), (2, 1), (0, 1)), # 512x2x25
nn.Conv2d(512, 512, 2, 1, 0), nn.BatchNorm2d(512), Swish()
) # 512x1x25
# SE和Swish
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=True),
nn.LeakyReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=True),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class Swish(nn.Module):
def forward(self, x):
return x * torch.sigmoid(x)
META Nougat
【2023-8-30】Meta推出OCR神器,PDF、数学公式都能转Nougat
存储在 PDF 等文件中的信息很难转成其他格式,尤其对数学公式更是显得无能为力,因为转换过程中很大程度上会丢失信息。
Nougat 基于 Transformer 模型构建而成,可以轻松的将 PDF 文档转换为 MultiMarkdown,扫描版的 PDF 也能转换,让人头疼的数学公式也不在话下。
2 个 Swin Transformer ,一个参数量为 350M,可处理的序列长度为 4096,另一参数量为 250M,序列长度为 3584。在推理过程中,使用贪婪解码生成文本。
大模型
大模型 OCR
【2025-2-25】 多模态大模型超越上一代 OCR 模型,更准、更快
- 传统OCR适合规范格式:书籍、论文、标准表格
- VLMs 适合处理复杂格式: 表/图/手写等
- OmniAI 91.7%、
Gemini 2.0 Flash86.1% 和 Azure 85.1%。 - OmniAI 每 1000 页 10 美元,
Gemini 2.0 Flash1.12 美元和 Azure 10 美元
OmniAI 传统付费方案
- 图见原帖 x
OCR 实时榜单
- AlphAxiv: State of the Art/OCR
传统OCR问题
传统 OCR 技术方案问题
- 以流水线方式组织模块,错误传递
- 模块: 元素选择、区域裁剪、字符识别
- 泛化性能不佳: 各模块为子任务设计
OCR任务最突出的特点: 要高分辨率输入
- 越大的图片越清晰,能包含的字符也越多。
- 而且OCR任务属于感知任务,不要求有太多reasoning,但需要准确识别每个字符,需要的Visual token也很多。
- 所以动态分辨率几乎是标准配置了。而且对应的需要各种visual token 压缩方案。
作者:同屿Firmirin
ollama-ocr
【2024-12-8】Ollama-OCR 只需几行代码,轻松实现高质量文字识别
Llama 3.2-Vision 是一种多模态大型语言模型,有 11B 和 90B 两种大小,能够处理文本和图像输入,生成文本输出。
该模型在视觉识别、图像推理、图像描述和回答图像相关问题方面表现出色,在多个行业基准测试中均优于现有的开源和闭源多模态模型。
开源的 ollama-ocr 工具,默认使用本地运行的 Llama 3.2-Vision 视觉模型,可准确识别图像中的文字,同时保留原始格式。
- 类似的, 还有 ollama-using-ocr, 使用 streamlit web demo
pip install streamlit ollama opencv-python
streamlit run d:/seeker_algo/upwork/llama-ocr/app.py
Ollama-OCR 特点
- 使用 Llama 3.2-Vision 模型进行高精度文本识别 保留原始文本格式和结构
- 支持多种图像格式:JPG、JPEG、PNG
- 可定制的识别提示和模型
- Markdown 输出格式选项
安装
# 安装 Ollama
# 安装 Llama 3.2-Vision 11B
ollama run llama3.2-vision
# 安装 ollama-ocr
npm install ollama-ocr
# or using pnpm
pnpm add ollama-ocr
UI
import { ollamaOCR, DEFAULT_OCR_SYSTEM_PROMPT } from "ollama-ocr";
async function runOCR() {
const text = await ollamaOCR({
filePath: "./handwriting.jpg",
systemPrompt: DEFAULT_OCR_SYSTEM_PROMPT,
});
console.log(text);
}
以上脚本怎么运行?
python 代码
import base64
import requests
from PIL import Image
SYSTEM_PROMPT = """作为OCR助手。分析提供的图像并:
1. 尽可能准确地识别图像中所有可见的文本。
2. 保持文本的原始结构和格式。
3. 如果任何单词或短语不清晰,请在转录中用[unclear]表示。
仅提供转录,不要有任何额外的评论。"""
def encode_image_to_base64(image_path):
"""将图像文件转换为base64编码的字符串。"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def perform_ocr(image_path):
"""使用Llama 3.2-Vision对给定图像执行OCR。"""
base64_image = encode_image_to_base64(image_path)
response = requests.post(
"http://localhost:8080/chat", # 确保此URL与你的Ollama服务端点匹配
json={
"model": "llama3.2-vision",
"messages": [
{
"role": "user",
"content": SYSTEM_PROMPT,
"images": [base64_image],
},
],
}
)
if response.status_code == 200:
return response.json().get("message", {}).get("content", "")
else:
print("错误:", response.status_code, response.text)
return None
if __name__ == "__main__":
image_path = "path/to/your/image.jpg" # 替换为你的图像路径
result = perform_ocr(image_path)
if result:
print("OCR识别结果:")
print(result)
豆包
【2024-11-30】豆包APP中输入图片,输出内容及格式,一次到位
- 以markdown格式展示文本段落
- 以latex显示公式、表格
智谱
小号 GLM 模型
GOT 介绍
【2024-9-17】GOT有望成为视觉大模型第一个杀手级应用?
大型视觉语言模型 (LVLM) 具备了卓越的文本识别能力,针对 OCR 特定功能进行优化,提升诸如高密度文本或特殊字符的识别成为可能。
通用MLLM重点在于推理reasoning,而非感知perception
- 为了获取来自LLM的收益,经常是将image token对齐到text。
- 但对于OCR这样感知为主的场景,特别是文字密度较大时,只能通过增加image token来提升OCR能力。
- 而且过去工作以7b为主,而当需要增加一种语言,或场景的时候往往要重新预训练,这样成本就太高了,所以还要把模型参数量降下来。
针对以上需求,作者提出模型要做的端到端、轻量、且泛用。
- 用很小的vision encoder(80M),但支持1024*1024的图像输入,每个输入图像将被压缩为 256×1024 维 tokens。
- LLM选用Qwen-2 0.5b,支持 8K 最大长度tokens。
阶跃星辰、旷视科技、中科院大学和清华的研究人员提出 GOT?(General?OCR?Theory) 的新型 通用OCR模型。
GOT 旨在统一框架内解决所有 OCR 需求,提供更通用和高效的系统,用于识别各种格式,包括:纯文本、数学、分子式、表格、图表、乐谱,甚至几何形状。
多种模式
- 纯文本 OCR & 格式文本 OCR:plain texts OCR & format texts OCR:, 图像级 OCR 。
- 纯多裁剪 OCR & 格式多裁剪 OCR:plain multi-crop OCR & format multi-crop OCR, 内容更复杂的图像,获得更高质量的结果。
- 纯细粒度 OCR & 格式细粒度 OCR:plain fine-grained OCR & format fine-grained OCR: 图像上指定细粒度区域,OCR。细粒度区域可以是框的坐标,红色,蓝色或绿色。
功能
- 通用,能端到端解决各种场景的OCR,可以通过简单的提示生成普通或格式化的结果(markdown/tikz/smiles/kern);
- 支持交互式OCR特征,即由坐标或高亮颜色引导的region级识别;
- 支持动态分辨率和多页OCR;
- 轻量化,使用Qwen-0.5B作为解码器,整个模型只有580M,使用80M大小的vision encoder。纯OCR模型,没有什么推理能力。
突出特点:
- OCR 2.0 端到端方式解决OCR问题
- 训练、推理成本低
- 用 Markdown,LaTeX Tikz 矢量图, Smiles 简化分子语言等生成格式化输出,对处理科学论文和数学内容特别有用。
- 模型支持交互式 OCR 基于区域的识别。
GOT 在各种 OCR 任务中展现出强大的性能:
- OCR F1分数 - 英文文档0.952 , 中文文档0.961;
- 场景文本 OCR 准确率 - 英文 0.926,中文 0.934,具备跨语言的广泛适用性。
模型在复杂字符(例如乐谱或几何形状中的字符)识别,数学和分子公式的渲染等任务中都表现良好。
研究人员还将动态分辨率策略和多页 OCR 技术整合到模型中,从而在高分辨率图像或多页文档常见的实际场景中更加实用。
考虑到现实场景中,线下的、存量的各种财务、医疗、供应链单据亟待完成线上化、数字化,因而笔者判断更智能、更通用、更高效的OCR应用具备杀手潜力。
GOT 架构
GOT 模型架构:
- 一个高压缩编码器和一个具有 5.8 亿参数的长上下文解码器。
编码器将输入图像压缩为 256 个“词元”,每个词元 1024 维,而解码器配备8000 个词元,用来生成相应的 OCR 输出。
使用
# plain texts OCR:
python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type ocr
# format texts OCR:
python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type format
# fine-grained OCR:
python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type format/ocr --box [x1,y1,x2,y2]
python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type format/ocr --color red/green/blue
# multi-crop OCR:
python3 GOT/demo/run_ocr_2.0_crop.py --model-name /GOT_weights/ --image-file /an/image/file.png
# Note: This feature is not batch inference!! It works on the token level. Please read the paper and then correct use multi-page OCR (the image path contains multiple .png files):
python3 GOT/demo/run_ocr_2.0_crop.py --model-name /GOT_weights/ --image-file /images/path/ --multi-page
# render the formatted OCR results:
python3 GOT/demo/run_ocr_2.0.py --model-name /GOT_weights/ --image-file /an/image/file.png --type format --render
训练
huggingface 使用
前置条件
- GPU
依赖
torch==2.0.1
torchvision==0.15.2
transformers==4.37.2
tiktoken==0.6.0
verovio==4.3.1
accelerate==0.28.0
代码
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('ucaslcl/GOT-OCR2_0', trust_remote_code=True)
model = AutoModel.from_pretrained('ucaslcl/GOT-OCR2_0', trust_remote_code=True, low_cpu_mem_usage=True, device_map='cuda', use_safetensors=True, pad_token_id=tokenizer.eos_token_id)
model = model.eval().cuda()
# input your test image
image_file = 'xxx.jpg'
# plain texts OCR
res = model.chat(tokenizer, image_file, ocr_type='ocr')
# format texts OCR:
# res = model.chat(tokenizer, image_file, ocr_type='format')
# fine-grained OCR:
# res = model.chat(tokenizer, image_file, ocr_type='ocr', ocr_box='')
# res = model.chat(tokenizer, image_file, ocr_type='format', ocr_box='')
# res = model.chat(tokenizer, image_file, ocr_type='ocr', ocr_color='')
# res = model.chat(tokenizer, image_file, ocr_type='format', ocr_color='')
# multi-crop OCR:
# res = model.chat_crop(tokenizer, image_file, ocr_type='ocr')
# res = model.chat_crop(tokenizer, image_file, ocr_type='format')
# render the formatted OCR results:
# res = model.chat(tokenizer, image_file, ocr_type='format', render=True, save_render_file = './demo.html')
print(res)
训练
- Stage 1: Pre-training Vision encoder, opt-125m
- Stage 2: Joint-training Encoder-decoder, Qwen-0.5b
- Stage 3: Post-training Lanuage decoder, Qwen-0.5b
deepspeed /GOT-OCR-2.0-master/GOT/train/train_GOT.py \
--deepspeed /GOT-OCR-2.0-master/zero_config/zero2.json --model_name_or_path /GOT_weights/ \
--use_im_start_end True \
--bf16 True \
--gradient_accumulation_steps 2 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 200 \
--save_total_limit 1 \
--weight_decay 0. \
--warmup_ratio 0.001 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length 8192 \
--gradient_checkpointing True \
--dataloader_num_workers 8 \
--report_to none \
--per_device_train_batch_size 2 \
--num_train_epochs 1 \
--learning_rate 2e-5 \
--datasets pdf-ocr+scence \
--output_dir /your/output/path
TextHarmony
【2024-10-16】华东师范+字节跳动推出首个OCR领域大一统多模态文字理解与生成大模型,即 TextHarmony
- TextHarmony 不仅精通视觉文本的感知(文字检测识别等)、理解(KIE、VQA等)和生成(视觉文字生成、编辑、抹除等),而且在单一模型中实现了视觉与语言模态生成的和谐统一
- NeurIPS 2024 录用论文:“Harmonizing Visual Text Comprehension and Generation”。
- 代码开源: TextHarmony
如何让机器像人类一样感知、理解、编辑和生成图像中的文字,一直是人工智能领域的热点问题。
当前视觉文字领域的大模型研究专注于单模型生成任务
- 单模态生成的大模型虽然统一了某些任务,但无法做到OCR领域中大部分任务的大一统
- Monkey 等VLM只能处理文字检测、识别、VQA等文本模态生成的任务,无法胜任文字图像生成、抹除、编辑等图像模态生成任务
- 基于Diffusion Model 图像生成模型, 如 AnyText 则相反
- OCR领域中的多模态生成统一大模型仍然是一个空白。
多模态生成大模型中,视觉与语言模态之间的固有不一致性,往往导致性能的显著下降。
- 最近的工作依赖于特定模态的监督微调,从而产生文字生成和图片生成两个不同的模型权重。
这种做法违背了统一视觉理解与生成的初衷。作者提出了一种创新的多模态生成模型——TextHarmony。
TextHarmony 核心贡献: 统一视觉文本的理解和生成。
- 之前, 理解与生成任务由不同模型分别处理。
- 一些模型专注于从图像中检测和识别文字,而另一些模型则致力于根据文字描述生成、编辑图像。
- TextHarmony 整合这两大类生成模型,使得模型能够同时进行视觉文字理解和视觉文字生成,从而统一了OCR领域中的大部分任务。
视觉理解和视觉生成之间具有较大的差异,直接整合在一个模型,会产生严重的模态不一致问题。
- 多模态生成模型在文本生成(视觉感知、理解)和图像生成上,相比单模态生成模型(视觉理解模型或者图像生成模型)效果有比较明显劣化。
- 文本生成任务上,多模态生成模型相比单模态生成模型效果降低5%
- 在图像生成上效果则最高降低了8%。
TextHarmony 基于 ViT+MLLM+Diffusion Model 结构
- ViT 负责将图像压缩为视觉Token序列。
- MLLM 输入视觉Token与文本Token的交叉序列,其输出Token分为两种:
- (1)文本Token将会被送入一个文本解码器,解码为文本输出;
- (2)视觉token将会和文本Token拼接,一起作为Diffusion Model的Condition(条件),引导Diffusion Model生成目标图像。
通过结合多模态大语言模型和扩散模型,TextHarmony实现了多模态内容的理解与生成。
为了缓解训练过程中的模态不一致问题,研究者提出Slide-LoRA,通过动态聚合模态特定的和模态无关的LoRA(Low-Rank Adaptation)专家,来实现在单一模型中部分解耦图像和文本的生成空间。
TextHarmony的训练分为两阶段
- 一阶段使用 MARIO-LAION 和 DocStruct4M 等图文对来预训练模型的对齐模块(Perceiver Resampler)和图像解码器,使得模型具备初步的文本生成与图像生成能力
- 二阶段使用视觉文本的生成、编辑、理解、感知四个类别的数据来做统一微调,这个阶段ViT、对齐模块、图像解码器和Slide-LoRA都被放开,从而学习到统一的多模态理解与生成能力。
TextHarmony 做了四个方面的对比实验:理解、感知、生成与编辑。
- 视觉文本理解:TextHarmony大幅度超过了多模态生成模型,并且接近Monkey等文字理解专家模型。
- 视觉文本感知:TextHarmony在OCR定位任务上超过了TGDoc、DocOwl1.5等模型。
- 视觉文本编辑与生成:TextHarmony大幅度超过了所有的多模态理解模型,并且接近TextDiffuser2等专家模型。
TextHarmony 是首个OCR领域多模态生成模型,统一了视觉文本理解和生成任务。针对多模态生成模型的模态不一致问题,研究者提出Slide-LoRA模块,在单一模型中实现了视觉与语言模态的和谐统一。
TextHarmony展现出了优秀的视觉文字感知、理解、生成和编辑能力,为依赖于视觉文本理解和生成的复杂交互任务提供了革命性的前景。
MinerU
介绍
MinerU 上海AI实验室出品,诞生于 InterLM 预训练时期
- 【2024-9-27】MinerU: An Open-Source Solution for Precise Document Content Extraction
- 客户端安装
- MinerU 代码
- 在线体验: 官方, MinerU 选项多,带示例
A high-quality tool for convert PDF to Markdown and JSON.一站式开源高质量数据提取工具,将PDF转换成Markdown和JSON格式。

原理
当前文档内容抽取的主流方案
- (1)
基于OCR的文本抽取(OCR-based Text Extraction): 使用 OCR 模型从文档中抽取文本内容,容易受图/表/公式等元素影响 - (2)
基于工具包的文本解析(Library-based Text Parsing): 使用 Python 工具包(如PyMuPDF)直接读取文档内容,快速有效,但同样受图/表/公式等元素影响 - (3)
多模块文档解析(Multi-Module Document Parsing):分步骤进行- 布局检测模块识别版面信息,图/表/标题等要素
- 各功能模块针对性识别,如:文本标题、公式、表格等
- 问题:理论上识别效果好,但实际表现不佳,书籍、论文、研究报告、报纸
- (4)
端到端多模态文档解析(End-to-End MLLM Document Parsing):- 案例: Donut, Nougat, Kosmos-2.5, Vary, Vary-toy, mPLUG-DocOwl-1.5, mPLUGDocOwl2, Fox, GOT
- 问题: 多样性数据上表现不足,推理成本高
一站式文档解析工具 MinerU 基于(3)多模块文档解析策略,融合 PDF-Extract-Kit
MinerU 工作流
- 文档预处理 Document Preprocessing: 使用 PyMuPDF 工具读取 pdf 文件, 过滤 加密文件,抽取 pdf 元数据、语种、文档维度
- ✓ Language?
- ✓ Width/Height?
- ✓ Page number?
- ✓ Is encrypted?
- ✓ Need password?
- ✓ Is scanned?
- 内容解析 Content Parsing: 使用 高质量内容抽取算法库 PDF-Extract-Kit 工具提取关键内容,如 版面分析、公式检测,然后,分别使用 OCR/公式识别/表格检测
- ✓ Layout Detection
- ✓ Formula Detection
- ✓ Formula Recognition
- ✓ Table Recognition
- ✓ OCR
- 内容后处理 Content Post-Processing:根据版面情况,删除无效内容,拼接,形成新版的识别结果
- ✓ Deal with overlap bbox
- ✓ Crop image and table
- ✓ Delete header/footer/…
- ✓ Reading order
- 格式转换 Format Conversion:输出不同类型格式
- ✓ Middle Json
- ✓ Markdown
- ✓ Final Json
论文对比:
- 布局检测: DocXchain, Surya 和 360LayoutAnalysis, 自研 LayoutLMv3-Finetined 效果最佳
- 公式抽取: 自研 YOLO-Finetuned 超过 Pix2Text-MFD
- 公式识别: 自研 UniMERNet 超过 Pix2tex, Texify 和 Mathpix
模型
布局、语言识别、表格、公式分别用不同模型
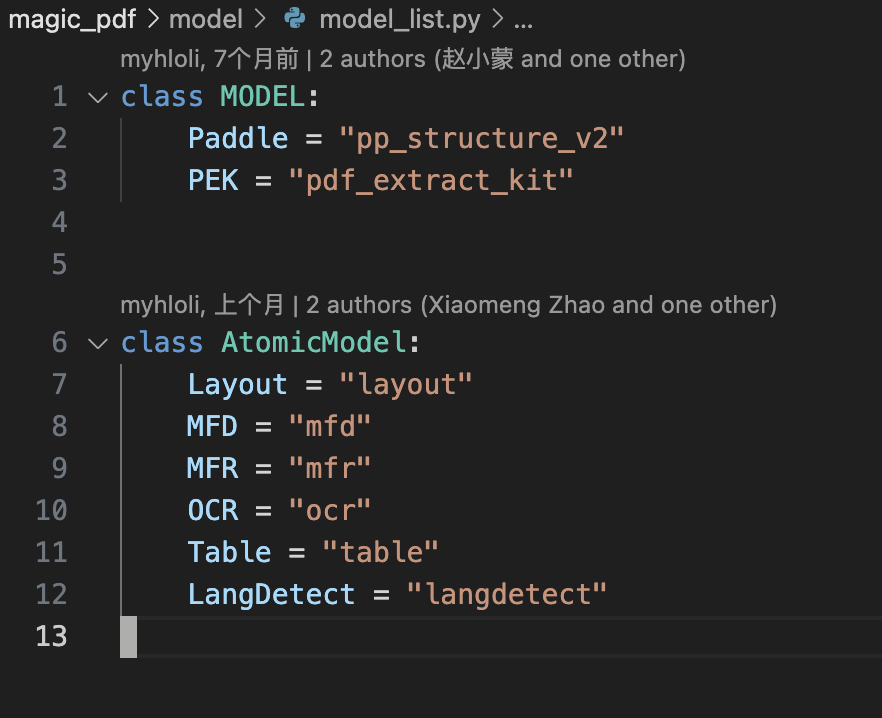
代码
class MODEL:
Paddle ="pp structure v2'
PEK ="pdf extract kit'
class AtomicModel:
Layout ='layout'
MFD ='mfd'
MFR ='mfr'
0CR = "ocr"
Table ='table'
LangDetect ="langdetect"
MinerU 模型目录: PDF-Extract-Kit-1.0
布局检测模型:
- LayoutLMV3 开源微调
- 预训练具有统一文本和图像masked的文档人工智能的多模态transformer
- LayoutLMv3是文档AI中第一个不依赖预训练的CNN或Faster R-CNN主干来提取视觉特征的多模态模型,这大大节省了参数并消除了区域标注。
- LayoutLMv3 通过统一的离散token重构目标MLM和MIM缓解了文本和图像多模态表示学习之间的差异。我们进一步提出了一个单词-碎片对齐(WPA)目标,以促进跨模态对齐学习。
- LayoutLMv3 是通用模型,适用于以文本为中心和以图像为中心的文档人工智能任务。我们首次展示了多模态transformer在文档人工智能视觉任务中的通用性。
- LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking 解读
- YOLOV10_ft 开源微调 YOLO V10
- YOLOv10: Real-Time End-to-End Object Detection - NeurIPS 2024
- doclayout_yolo_ft 开源微调
- 【2024-10-16】上海AI Lab 论文 DocLayout-YOLO: Enhancing Document Layout Analysis through Diverse Synthetic Data and Global-to-Local Adaptive Perception
- 基于 YOLO-v10,通过多样性文档预训练及适配文档检测的模型结构优化,可针对多样性文档进行实时鲁棒的检测
- 数据集 DocSynth300K, 示例, 模型 文件
- 训练方法 数据准备 & 预训练
- DocLayout-YOLO 适用于多样性文档布局检测,包括但不局限于论文、教科书、试卷、幻灯片等多种文档类型。
- 方法解读
微调:
- 在论文、教科书、研究报告、财务报告、模糊和水印方面微调。
公式检测模型:
- yolo_v8_ft 开源微调
微调: 对高级公式检测模型进行了微调。
公式识别模型:
- UniMERNet 开源, 数学表达式图像转换为 LaTeX
- UniMERNet: A Universal Network for Real-World Mathematical Expression Recognition
- UniMERNet: 一个用于真实世界数学表达式识别的通用网络
- 数据集: UniMER-Dataset 2GB, 106万(1,061,791) LaTeX-图像对
表格识别:
- StructEqTable 开源, 采用 InternVL2-1B 基础模型
- TableMaster + PPOCRV4 开源
- PaddleOCR 提供了表格图像中文本的精确识别
- 而 TableMaster 负责识别和重建表格的结构。
文字识别:
- PP-OCRv4 开源
开源工具汇总
| 模型 | 功能 | 介绍 | MinerU 微调 | 分析 |
|---|---|---|---|---|
| LayoutLMV3 | 布局检测 | 统一文本和图像masked的多模态transformer | 论文、教科书、研究报告、财务报告、模糊和水印方面微调 | |
| YOLOV10_ft | 布局检测 | YOLOv10: Real-Time End-to-End Object Detection - NeurIPS 2024 | 同上 | |
| doclayout_yolo_ft | 布局检测 | 官方文档: 预训练使用8卡以上,指令数据集DocSynth300K有113G | 同上 | |
| yolo_v8_ft | 公式检测 | - | ||
| UniMERNet | 公式识别 | 数据集: UniMER-Dataset 2GB, 106万(1,061,791) LaTeX-图像对 | ||
| StructEqTable | 表格识别 | 采用InternVL2-1B基础模型 | ||
| PPOCRV4 | 表格识别 | 表格图像中文本的精确识别 | ||
| TableMaster | 表格识别 | 识别和重建表格的结构 | ||
| PPOCRV4 | 文字识别 | 文本识别 | ||
功能
大模型时代的文档提取/转换神器
- 支持 PDF、Word、PPT等多种文档的智能解析,可用于机器学习、大模型语料生产、RAG等场景
功能介绍
- 多类型转换
- 多语言识别
- 多元素解析
- 高质量提取
主要功能
- 删除页眉、页脚、脚注、页码等元素,确保语义连贯
- 输出符合人类阅读顺序的文本,适用于单栏、多栏及复杂排版
- 保留原文档结构,包括标题、段落、列表等
- 提取图像、图片描述、表格、表格标题及脚注
- 自动识别并转换文档中的公式为LaTeX格式
- 自动识别并转换文档中的表格为HTML格式
- 自动检测扫描版PDF和乱码PDF,并启用OCR功能
- OCR支持84种语言的检测与识别
- 支持多种输出格式,如多模态与NLP的Markdown、按阅读顺序排序的JSON、含有丰富信息的中间格式等
- 支持多种可视化结果,包括layout可视化、span可视化等,便于高效确认输出效果与质检
- 支持纯CPU环境运行,并支持 GPU(CUDA)/NPU(CANN)/MPS 加速
- 兼容Windows、Linux和Mac平台

安装
工具包部署
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com
# 下载模型权重
pip install huggingface_hub
wget https://github.com/opendatalab/MinerU/raw/master/scripts/download_models_hf.py -O download_models_hf.py
python download_models_hf.py
使用
命令行
使用命令
- 官方文档 command_line.html
magic-pdf --help
Usage: magic-pdf [OPTIONS]
Options:
-v, --version # 版本 display the version and exit
-p, --path PATH # 待识别文件路径 local filepath or directory. support PDF, PPT, PPTX, DOC, DOCX, PNG, JPG files [required]
-o, --output-dir PATH # 输出目录 output local directory [required]
-m, --method [ocr|txt|auto] # 抽取方法类型 the method for parsing pdf.
# ocr: using ocr technique to extract information from pdf.
# txt: suitable for the text-based pdf only and outperform ocr.
# auto: automatically choose the best method for parsing pdf from ocr and txt. without method specified, auto will be used by default.
-l, --lang TEXT # 指定语种 Input the languages in the pdf (if known) to improve OCR accuracy. Optional.
# You should input "Abbreviation" with language form url: https://paddlepaddle.github.io/PaddleOCR/en/ppocr /blog/multi_languages.html#5-support-languages-and-abbreviations
-d, --debug BOOLEAN # 调试开关 Enables detailed debugging information during the execution of the CLI commands.
-s, --start INTEGER # 起始页 The starting page for PDF parsing, beginning from 0.
-e, --end INTEGER # 终止页 The ending page for PDF parsing, beginning from 0.
--help # 帮助 Show this message and exit.
## show version
magic-pdf -v
## command line example
magic-pdf -p {some_pdf} -o {some_output_dir} -m auto
# pdf
magic-pdf -p a.pdf -o output -m auto
# 图片
magic-pdf -p a.png -o output -m auto
# 文档 replace with real ms-office file, we support MS-DOC, MS-DOCX, MS-PPT, MS-PPTX now
magic-pdf -p a.doc -o output -m auto
-p 支持的文件格式
- 目录: 包含多个pdf
- 文件: .pdf .png .jpg .ppt .pptx .doc .docx
输出文件
├── some_pdf.md # markdown file
├── images # directory for storing images
├── some_pdf_layout.pdf # layout diagram
├── some_pdf_middle.json # MinerU intermediate processing result
├── some_pdf_model.json # model inference result
├── some_pdf_origin.pdf # original PDF file
├── some_pdf_spans.pdf # smallest granularity bbox position information diagram
└── some_pdf_content_list.json # Rich text JSON arranged in reading order
使用
命令行
# make sure the file have correct suffix
magic-pdf -p a.pdf -o output -m auto
代码调用
import os
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.data.dataset import PymuDocDataset
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.config.enums import SupportedPdfParseMethod
# args
pdf_file_name = "abc.pdf" # replace with the real pdf path
name_without_suff = pdf_file_name.split(".")[0]
# prepare env
local_image_dir, local_md_dir = "output/images", "output"
image_dir = str(os.path.basename(local_image_dir))
os.makedirs(local_image_dir, exist_ok=True)
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(
local_md_dir
)
# read bytes
reader1 = FileBasedDataReader("")
pdf_bytes = reader1.read(pdf_file_name) # read the pdf content
# proc
## Create Dataset Instance
ds = PymuDocDataset(pdf_bytes)
## inference
if ds.classify() == SupportedPdfParseMethod.OCR:
infer_result = ds.apply(doc_analyze, ocr=True)
## pipeline
pipe_result = infer_result.pipe_ocr_mode(image_writer)
else:
infer_result = ds.apply(doc_analyze, ocr=False)
## pipeline
pipe_result = infer_result.pipe_txt_mode(image_writer)
### draw model result on each page
infer_result.draw_model(os.path.join(local_md_dir, f"{name_without_suff}_model.pdf"))
### get model inference result
model_inference_result = infer_result.get_infer_res()
### draw layout result on each page
pipe_result.draw_layout(os.path.join(local_md_dir, f"{name_without_suff}_layout.pdf"))
### draw spans result on each page
pipe_result.draw_span(os.path.join(local_md_dir, f"{name_without_suff}_spans.pdf"))
### get markdown content
md_content = pipe_result.get_markdown(image_dir)
### dump markdown
pipe_result.dump_md(md_writer, f"{name_without_suff}.md", image_dir)
### get content list content
content_list_content = pipe_result.get_content_list(image_dir)
### dump content list
pipe_result.dump_content_list(md_writer, f"{name_without_suff}_content_list.json", image_dir)
### get middle json
middle_json_content = pipe_result.get_middle_json()
### dump middle json
pipe_result.dump_middle_json(md_writer, f'{name_without_suff}_middle.json')
文档
文档
- ppt, pptx, doc, docx
命令行
# replace with real ms-office file, we support MS-DOC, MS-DOCX, MS-PPT, MS-PPTX now
magic-pdf -p a.doc -o output -m auto
代码
import os
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.data.read_api import read_local_office
# prepare env
local_image_dir, local_md_dir = "output/images", "output"
image_dir = str(os.path.basename(local_image_dir))
os.makedirs(local_image_dir, exist_ok=True)
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(
local_md_dir
)
# proc
## Create Dataset Instance
input_file = "some_ppt.ppt" # replace with real ms-office file
input_file_name = input_file.split(".")[0]
ds = read_local_office(input_file)[0]
ds.apply(doc_analyze, ocr=True).pipe_txt_mode(image_writer).dump_md(
md_writer, f"{input_file_name}.md", image_dir
)
图片
命令行
# make sure the file have correct suffix
magic-pdf -p a.png -o output -m auto
单个图片识别
import os
from magic_pdf.data.data_reader_writer import FileBasedDataWriter
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.data.read_api import read_local_images
# prepare env
local_image_dir, local_md_dir = "output/images", "output"
image_dir = str(os.path.basename(local_image_dir))
os.makedirs(local_image_dir, exist_ok=True)
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(
local_md_dir
)
# proc
## Create Dataset Instance
input_file = "some_image.jpg" # replace with real image file
input_file_name = input_file.split(".")[0]
ds = read_local_images(input_file)[0]
ds.apply(doc_analyze, ocr=True).pipe_ocr_mode(image_writer).dump_md(
md_writer, f"{input_file_name}.md", image_dir
)
批量调用
目录使用
import os
from magic_pdf.data.data_reader_writer import FileBasedDataWriter
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.data.read_api import read_local_images
# prepare env
local_image_dir, local_md_dir = "output/images", "output"
image_dir = str(os.path.basename(local_image_dir))
os.makedirs(local_image_dir, exist_ok=True)
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(
local_md_dir
)
# proc
## Create Dataset Instance
input_directory = "some_image_dir/" # replace with real directory that contains images
dss = read_local_images(input_directory, suffixes=['.png', '.jpg'])
count = 0
for ds in dss:
ds.apply(doc_analyze, ocr=True).pipe_ocr_mode(image_writer).dump_md(
md_writer, f"{count}.md", image_dir
)
count += 1
微调
【2025-2-19】 MinerU 官方暂不支持模型微调
- 提交 issue
表格识别使用第三方开源项目 RapidTable 获得支持
Markify
【2025-3-10】 Markify: 融合微软 markitdown 和 MinerU 优势的工具。
MinerU 开源且功能强大的文档数据提取工具,专注于将 PDF 等复杂文档转换为机器可读的格式,非常适用于学术研究、技术写作和大模型训练等场景。
然而, AGPL v3 授权具有传染性,直接集成会迫使项目整体开源,这在商业项目中往往难以接受。
功能
Markify 不仅能将 PDF、Word、PPT、Excel、图片、音频、网页、CSV、JSON、XML 甚至 ZIP 压缩包等多种文件统一转换为 Markdown 格式,还借助 MinerU 实现了高效准确的 PDF 解析,并通过开发 HTTP 服务巧妙绕开 AGPL 传染问题,从而无缝集成于各类项目中。
三种模式以满足不同场景的需求:
- 快速模式(simple) 基于 pdfminer(
markitdown内置的 pdf 解析器),专注于高效文本提取,适合对文本要求较低的场景。 - 高级模式(advanced) 结合 MinerU 的深度解析,不仅能精准提取文本,还能识别并转换复杂表格和图像,还将图像自动转换为 Markdown 中的网络引用形式,例如:

- 云端模式(cloud) 研发中,未来将为用户提供更多云端解析能力。
效果
效果
- Markify 能准确识别复杂表格(三线表)并转换为 Markdown 表格

- 图像转换: Markify 将图像上传至服务器并嵌入 Markdown 中,使得图文混排效果更为直观美观
- 整体版面: Markify 对文本内容提取精准,整体排版清晰易读

安装
安装方法
git clone https://github.com/KylinMountain/markify
启动时,Markify 会自动从 ModelScope 下载 MinerU 的模型文件(若下载较慢,可设置环境变量 MINERU_USE_MODELSCOPE=false 切换至 HuggingFace 下载):
uvicorn main:app --reload --port 20926
启动后,通过浏览器访问 http://localhost:20926/docs 查看 API 文档,支持上传文档、查询任务状态和下载文件。
olmOCR
- 【2025-2-25】olmOCR:PDF文档转换为文本,支持表格、公式和手写内容的识别
- 【2025-2-28】olmOCR端到端解析万亿级PDF
olmOCR 是 Allen Institute for Artificial Intelligence (AI2) 的 AllenNLP 团队开发的一款开源工具
- 将 PDF 文件转换为线性化文本,特别适合用于大规模语言模型 (LLM) 的数据集准备与训练。
- 支持从复杂 PDF 文档中提取文本,保持自然阅读顺序,并能处理表格、公式甚至手写内容。
- 工具设计高效,可在本地 GPU 上运行,或通过 AWS S3 实现多节点并行处理,显著降低处理成本。
- 据官方数据,其处理速度可达每秒 3000+ 令牌,成本仅为 GPT-4o 的 1/32,非常适合需要处理大量 PDF 的研究人员和开发者。
- olmOCR 采用 Apache 2.0 许可,代码、模型权重和数据完全开源,鼓励社区参与改进。
资料
- 技术报告
- 在线体验 olmocr
- 数据集 olmOCR-mix-0225
- 模型下载 olmOCR-7B-0225-preview
- olmocr
使用
命令
conda create -n olmocr python=3.11
conda activate olmocr
git clone https://github.com/allenai/olmocr.git
cd olmocr
pip install -e .[gpu] --find-links https://flashinfer.ai/whl/cu124/torch2.4/flashinfer/
本地部署
- 前置依赖: GPU, SGLang
# Convert a Single PDF:
python -m olmocr.pipeline ./localworkspace --pdfs tests/gnarly_pdfs/horribleocr.pdf
# Convert Multiple PDFs:
python -m olmocr.pipeline ./localworkspace --pdfs tests/gnarly_pdfs/*.pdf
# 多节点处理
python -m olmocr.pipeline s3://my_s3_bucket/pdfworkspaces/exampleworkspace --pdfs s3://my_s3_bucket/jakep/gnarly_pdfs/*.pdf --beaker --beaker_gpus 4
# Results will be stored as JSON in ./localworkspace.
cat localworkspace/results/output_*.jsonl # 输出室内内容
# 组合对比显示: 原pdf+提取内容
python -m olmocr.viewer.dolmaviewer localworkspace/results/output_*.jsonl
浏览器 打开文件 ./dolma_previews/tests_gnarly_pdfs_horribleocr_pdf.html

参数说明
python -m olmocr.pipeline --help
usage: pipeline.py [-h] [--pdfs PDFS] [--workspace_profile WORKSPACE_PROFILE] [--pdf_profile PDF_PROFILE] [--pages_per_group PAGES_PER_GROUP]
[--max_page_retries MAX_PAGE_RETRIES] [--max_page_error_rate MAX_PAGE_ERROR_RATE] [--workers WORKERS] [--apply_filter] [--stats] [--model MODEL]
[--model_max_context MODEL_MAX_CONTEXT] [--model_chat_template MODEL_CHAT_TEMPLATE] [--target_longest_image_dim TARGET_LONGEST_IMAGE_DIM]
[--target_anchor_text_len TARGET_ANCHOR_TEXT_LEN] [--beaker] [--beaker_workspace BEAKER_WORKSPACE] [--beaker_cluster BEAKER_CLUSTER]
[--beaker_gpus BEAKER_GPUS] [--beaker_priority BEAKER_PRIORITY]
workspace
Manager for running millions of PDFs through a batch inference pipeline
positional arguments:
workspace The filesystem path where work will be stored, can be a local folder, or an s3 path if coordinating work with many workers, s3://bucket/prefix/
options:
-h, --help show this help message and exit
--pdfs PDFS Path to add pdfs stored in s3 to the workspace, can be a glob path s3://bucket/prefix/*.pdf or path to file containing list of pdf paths
--workspace_profile WORKSPACE_PROFILE
S3 configuration profile for accessing the workspace
--pdf_profile PDF_PROFILE
S3 configuration profile for accessing the raw pdf documents
--pages_per_group PAGES_PER_GROUP
Aiming for this many pdf pages per work item group
--max_page_retries MAX_PAGE_RETRIES
Max number of times we will retry rendering a page
--max_page_error_rate MAX_PAGE_ERROR_RATE
Rate of allowable failed pages in a document, 1/250 by default
--workers WORKERS Number of workers to run at a time
--apply_filter Apply basic filtering to English pdfs which are not forms, and not likely seo spam
--stats Instead of running any job, reports some statistics about the current workspace
--model MODEL List of paths where you can find the model to convert this pdf. You can specify several different paths here, and the script will try to use the
one which is fastest to access
--model_max_context MODEL_MAX_CONTEXT
Maximum context length that the model was fine tuned under
--model_chat_template MODEL_CHAT_TEMPLATE
Chat template to pass to sglang server
--target_longest_image_dim TARGET_LONGEST_IMAGE_DIM
Dimension on longest side to use for rendering the pdf pages
--target_anchor_text_len TARGET_ANCHOR_TEXT_LEN
Maximum amount of anchor text to use (characters)
--beaker Submit this job to beaker instead of running locally
--beaker_workspace BEAKER_WORKSPACE
Beaker workspace to submit to
--beaker_cluster BEAKER_CLUSTER
Beaker clusters you want to run on
--beaker_gpus BEAKER_GPUS
Number of gpu replicas to run
--beaker_priority BEAKER_PRIORITY
Beaker priority level for the job
效果对比
总结
- 比
GOTOCR、MINERU、Marker都要强
| Model Pair | Wins | Win Rate (%) |
|---|---|---|
OLMOCR vs. MARKER |
49/31 | 61.3 |
OLMOCR vs. GOTOCR |
41/29 | 58.6 |
OLMOCR vs. MINERU |
55/22 | 71.4 |
MARKER vs. MINERU |
53/26 | 67.1 |
MARKER vs. GOTOCR |
45/26 | 63.4 |
GOTOCR vs. MINERU |
38/37 | 50.7 |
| Total | 452 | - |
功能
功能列表
- PDF 文本提取与线性化: 将 PDF 文件转换为 Dolma 风格的 JSONL 格式文本,保留阅读顺序。
- GPU 加速推理: 利用本地 GPU 和 sglang 技术,实现高效文档处理。
- 多节点并行处理: 支持通过 AWS S3 协调多节点任务,适合处理数百万 PDF。
- 复杂内容识别: 处理表格、数学公式和手写文本,输出结构化结果。
- 灵活的工作区管理: 支持本地或云端工作区,存储处理结果和中间数据。
- 开源生态支持: 提供完整代码和文档,方便二次开发与定制。
技术点三个方向:
- 文档锚定技术:olmOCR通过pypdf库提取PDF文档中的文本块和图像的位置信息,并将其与栅格化图像一起输入到VLM模型中。这些位置信息作为“锚点”,帮助模型更好地理解页面的结构和内容。
- VLM模型:olmOCR使用了一个7B参数的VLM模型,该模型在大规模数据集上进行了微调。通过文档锚定技术提供的额外信息,模型能够更准确地提取文本内容,并保持自然阅读顺序。
- 推理管道:olmOCR的推理管道基于SGLang和vLLM框架,能够高效地处理大规模数据。该管道将文档批量处理为工作项,并在多个GPU上并行处理,从而显著提高了处理效率。
OLMOCR 训练过程
数据集构建
- 数据来源:olmOCR的数据集由260,000页PDF文档组成,这些文档从互联网上爬取,并涵盖了多种类型(如学术论文、宣传册、法律文件等)。此外,olmOCR还从互联网档案馆中获取了16,803页的扫描书籍,用于进一步训练模型。
- 数据标注:为了生成训练数据,olmOCR使用GPT-4o模型对PDF页面进行标注,生成结构化的JSON输出。这些标注数据用于微调VLM模型。
模型训练
- 微调过程:olmOCR的VLM模型基于Qwen2-VL-7B-Instruct模型进行微调。训练过程中,使用了AdamW优化器和余弦退火学习率调度器,训练了10,000步(约1.2个epoch)。训练数据的提示文本经过简化,以适应模型的输入格式。
- 验证过程:在训练过程中,olmOCR通过验证损失来跟踪模型的性能。验证结果显示,全微调模型的性能优于LoRA微调模型。
推理管道优化
- 批处理:olmOCR的推理管道将文档批量处理为工作项,并在多个GPU上并行处理。每个工作项包含约500页文档,这些文档同时排队进行推理处理。
- 成本优化:olmOCR通过优化硬件利用和推理效率,显著降低了处理成本。例如,在处理百万页PDF文档时,olmOCR的成本仅为190美元,而GPT-4o的成本为6,240美元。
鲁棒性增强
- 重试机制:在推理过程中,olmOCR通过增加生成温度和重试机制来处理输出退化问题。如果模型输出重复或超出最大上下文长度,olmOCR会重新处理页面,直到成功为止。
- 旋转校正:olmOCR的输出JSON模式包括旋转校正字段,用于处理页面旋转问题。如果页面方向不正确,olmOCR会根据旋转校正值重新处理页面。
问题
【2025-3-18】 推理速度太慢, 3张3090上部署olmOCR,SGLang推理。识别速度很慢,一页pdf文件需要好几分钟
- Issue: Any solution to speed it up ?
- SGLang 加速 sglang or vllm api interface
# 常规命令
python -m olmocr.pipeline /.localworkspace --pdfs tests/gnarly_pdfs/horribleocr.pdf
# 启动 sglang
python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3.1-8B-Instruct --host 0.0.0.0
或 Python 代码
from sglang.test.test_utils import is_in_ci
from sglang.utils import wait_for_server, print_highlight, terminate_process
if is_in_ci():
from patch import launch_server_cmd
else:
from sglang.utils import launch_server_cmd
mistral-ocr
【2025-3-6】复杂表格超96%:mistral-ocr登顶最强OCR
功能
- 支持 media, text, tables 表格, equations 公式
- sota
- 非开源
效果
| Model | Overall | Math | Multilingual | Scanned | Tables |
|---|---|---|---|---|---|
| Google Document AI | 83.42 | 80.29 | 86.42 | 92.77 | 78.16 |
| Azure OCR | 89.52 | 85.72 | 87.52 | 94.65 | 89.52 |
| Gemini-1.5-Flash-002 | 90.23 | 89.11 | 86.76 | 94.87 | 90.48 |
| Gemini-1.5-Pro-002 | 89.92 | 88.48 | 86.33 | 96.15 | 89.71 |
| Gemini-2.0-Flash-001 | 88.69 | 84.18 | 85.80 | 95.11 | 91.46 |
| GPT-4o-2024-11-20 | 89.77 | 87.55 | 86.00 | 94.58 | 91.70 |
| Mistral OCR 2503 | 94.89 | 94.29 | 89.55 | 98.96 | 96.12 |
LAYRA
【2025-4-12】 忘掉OCR吧,LAYRA用“看”的方式理解文档-最新视觉RAG项目 LAYRA 开源了
RAG领域老问题:OCR导致的结构损失和语义错乱
传统文档问答系统将PDF、扫描件等文档“硬转成文本”,不仅破坏了原始排版信息,还对图表、流程图等非文本内容束手无策。
问题:
- ❌ 结构丢失:OCR常常搞不清多栏排版、表格、标题层级
- ❌ 图表失真:图、图例、流程图等非文字信息完全忽略
- ❌ 语义割裂:跨块的逻辑难以拼接,导致问答效果差
基于 colpali 的启发,LAYRA 作者决定另辟蹊径,做一个纯视觉、无OCR的RAG系统 —— LAYRA
LAYRA 开源前后端分离、UI简约的企业级的视觉优先的RAG(Retrieval-Augmented Generation)系统。
- 打破传统 OCR + 文本抽取 方式,直接以文档图片为输入,通过colpali系列最新的 colqwen2.5-v0.2 模型进行向量化理解,实现保留排版结构、图表信息的智能问答体验。
- github layra
一句话总结:
- LAYRA 用“看”的方式理解文档,而不是“读”出来再乱拼。
| 能力 | 描述 |
|---|---|
| 纯视觉Embedding | 直接处理PDF转图片,无需OCR、无需切片 |
| 保留文档结构 | 保留标题层级、段落、列表、多栏、表格 |
| 支持图表推理 | 能“看到”图表并参与问答 |
| 灵活大模型对接 | 当前使用Qwen2.5-VL,并支持openai兼容的接口,未来将支持更多模型 |
| 异步高性能后端 | FastAPI+Kafka+Redis+Mysql+Mongo+Minio全异步处理 |
| 现代化前端 | Next.js15 + Typescript + TailwindCSS4.0 + Zustand |
| 开箱即用 | 文档上传即可体验问答 |
测试版本,支持PDF上传和问答:
- 支持 PDF 批量上传、图像化解析
- 提问即可获得结构感知的答案
- 模型使用 ColQwen2.5-v0.2 作为Embedding基础
- 数据存入 Milvus、MongoDB、MinIO,实现全链路可查询与可复用
核心流程:
- 查询流程(Query Flow)
- 用户提问 → Milvus 检索 → VLLM 生成回答
- 文档上传
- PDF 转图片 → 每页用 ColQwen2.5 向量化 → 存入 Milvus、Mongo 和 MinIO
Nanonets-OCR-s
大多数公开的图像转文本模型主要侧重于从图像中提取纯文本,然而无法区分常规内容和水印、签名或页码等元素。
图像等视觉元素经常被忽略,表格、复选框和公式等复杂结构也无法有效处理,这使得这些模型不太适合下游任务。
与仅提取纯文本的传统 OCR 系统不同,Nanonets-OCR-s 能够理解文档结构和内容上下文(如表格、方程式、图像、图表、水印、复选框等),从而提供智能格式的 markdown 输出,可供大型语言模型进行下游处理。
功能
- LaTeX 公式识别
- 智能图像描述
- 签名检测与隔离
- 水印提取
- 智能复选框处理
- 复杂表格提取
【2025-06-12】Nanonets 团队开源了 Nanonets-OCR-s,该模型基于Qwen2.5-VL-3B微调,9G显存就能跑。
Nanonets-OCR-s是一款强大的模型,能够通过智能内容识别和语义标记,将杂乱的文档转换为现代人工智能应用所需的干净、结构化且上下文丰富的 Markdown 格式。它的功能远超传统的文本提取,是目前图像转 Markdown 领域的SoTA模型。
Nanonets-OCR-s 核心:强大的文档结构理解能力。
基于 Qwen2.5-VL-3B-instruct 大模型,拥有37.5亿参数,使其能够理解扫描文档中的复杂结构和内容上下文,例如表格、公式、图像、图表、水印和复选框等。
这种结构化理解能力远超传统的OCR引擎,后者通常只能提取文本,而无法理解文本之间的关系。
想象一下,需要将一份包含大量表格的财务报表输入LLM进行分析。传统的OCR引擎可能会将表格中的数据提取出来,但无法保留表格的行列结构。这意味着LLM需要进行大量的后处理才能理解数据之间的关系。
而Nanonets-OCR-s可以将表格完整地转换为Markdown格式,LLM可以直接读取并理解表格数据,从而大大提高分析效率。
此外,Nanonets-OCR-s能够识别图像和图表,并将其转换为Markdown格式的链接或描述。这意味着LLM不仅可以读取文本数据,还可以理解图像和图表中的信息,从而进行更全面的分析和推理。
例如,它可以识别一张包含柱状图的报告,并将柱状图转换为Markdown格式的图片链接和简要描述
参考链接
Nanonets-OCR-s 和 PaddleOCR 优缺点:
| 特性 | Nanonets-OCR-s | PaddleOCR |
| ———- | —————————————— | ————————————— |
| 主要优势 | 结构化文档理解、输出Markdown格式、适用于LLM | 手写识别、易于使用 |
| 主要劣势 | 手写识别能力较弱 | 结构化文档理解能力相对较弱 |
| 适用场景 | 包含表格、公式、图像等复杂结构的扫描文档,需要与LLM集成进行分析的应用 | 手写笔记、手写信件、手写表格等手写文档的处理 |
| 输出格式 | Markdown | 可配置,通常是文本或JSON |
| 模型大小 | 37.5亿参数 | 多种模型可选,大小不一 |
Dolphin
OCR 技术虽然在提取原始文本方面表现出色,但忽略了对文档真正理解至关重要的结构关系。
现在,Agentic 文档提取技术应运而生,不仅保留了视觉和空间上下文,还能精确地指向PDF中支持AI生成答案的确切区域,我们称之为“视觉定位”。
无论是分析财务报告、学术论文、医疗表格还是法律合同,这种方法都能确保可验证的参考,并显著减少幻觉现象。
【2025-5-*】Dolphin 字节抖音集团出品, Dolphin 智能解析PDF与图片,提取文字、公式(LaTeX)和表格(HTML)的轻量高效文档处理工具。
Dolphin 模型以仅322M的轻量级参数,在多个基准测试中全面超越了GPT-4V、Claude等大模型
- 第一阶段:页面级布局分析,生成按阅读顺序排列的结构化布局元素序列
- 第二阶段:基于异构锚点提示的并行元素内容解析
核心组件
Dolphin 核心组件包括 Swin Transformer 编码器和 mBART 解码器。
Swin Transformer (编码器)
- 层级视觉 Transformer: 以逐步增大的窗口处理图像。
- 高效且可扩展: 窗口大小为 7,层配置为 [2, 2, 14, 2],它捕获精细的细节和全局文档布局。
- 嵌入维度: 将每个patch转换为 512D 或 1024D 向量,编码其上下文丰富的特征。
Swin Transformer 是一种先进的视觉 Transformer 模型,它通过分层的方式处理图像,能够有效地捕捉不同尺度的视觉信息。在 Dolphin 中,Swin Transformer 的作用是将文档图像转换为一系列具有丰富上下文信息的向量,这些向量包含了文档的布局、内容和结构信息。例如,Swin Transformer 能够识别出文档中的标题、段落、图片和表格等元素,并了解它们之间的关系。
mBART (解码器)
- 一种多语言、序列到序列的 Transformer。
- 在两个阶段中使用,以解码布局序列或元素内容。
- 基于来自编码的视觉特征的交叉注意力,自回归地生成输出。
mBART 是一种强大的视觉语言模型,擅长于生成自然语言文本。
在 Dolphin 中,mBART 作用是将 Swin Transformer 编码的视觉信息转换为人类可读的文本。例如,在页面级布局分析阶段,mBART 会根据 Swin Transformer 提供的视觉信息,生成描述文档布局的文本序列,例如“标题-段落-图片-表格”。在元素级内容解析阶段,mBART 会根据 Swin Transformer 提供的视觉信息,生成每个元素的具体内容,例如提取表格中的数据。
参考
dots.ocr
【2025-8-2】dots.ocr 是小红书 hi lab 开源的多语言文档布局解析模型。 1.7B参数超强OCR大模型dots.ocr,超越GPT-4o和olmOCR
模型基于 17 亿参数的视觉语言模型(VLM),能统一进行布局检测和内容识别,保持良好的阅读顺序。
- 模型规模虽小,但性能达到业界领先水平(SOTA),在 OmniDocBench 等基准测试中表现优异,公式识别效果能与Doubao-1.5和 gemini2.5-pro 等更大规模模型相媲美,在小语种解析方面优势显著。
- dots.ocr 提供简洁高效的架构,任务切换仅需更改输入提示词,推理速度快,适用多种文档解析场景。
核心创新:
- 单模型多任务:通过调整输入提示词(Prompt),同一模型可无缝切换布局检测、文本识别等任务,无需多模型协作,减少传统OCR流水线的误差传递。
- 多语言全覆盖:支持 100+ 种语言,包括藏语、卡纳达语等低资源语言,错误率比竞品低50%。
- 结构化输出:输出结果包含JSON、Markdown、HTML 格式,保留表格边界、公式区域(LaTeX格式)及阅读顺序。
dots.ocr 主要功能
- 多语言文档解析:支持多种语言的文档解析,涵盖文本、表格、公式和图片等元素。
- 布局检测与内容识别:在单一视觉语言模型中统一布局检测和内容识别,保持良好的阅读顺序。
- 高效推理:基于17亿参数的视觉语言模型,推理速度快,适合大规模文档处理。
- 任务切换灵活:通过更改输入提示词,能轻松切换不同任务,如布局检测、内容识别等。
- 输出格式多样化:支持JSON、Markdown等多种输出格式,并提供布局可视化图像。
dots.ocr的技术原理
- 视觉语言模型(VLM):dots.ocr 基于17亿参数的视觉语言模型,模型结合视觉编码器和语言模型的优势。视觉编码器负责提取文档图像中的视觉特征,语言模型用于理解和生成文本内容。
- 三阶段训练过程:
- 视觉编码器预训练:从零开始训练一个12亿参数的视觉编码器,使用大规模图文对数据集。
- 视觉编码器持续预训练:加入高分辨率输入支持,与语言模型对齐,进一步提升视觉特征提取能力。
- VLM训练:用纯OCR数据集进行训练,优化模型在文档解析任务上的表现。
- 监督微调(SFT):用多样化的数据集进行监督微调,包括人工标注数据、合成数据和开源数据集。基于迭代式数据飞轮机制,不断优化模型性能,提升数据质量和多样性。基于“大模型排序+规则后验”的方法修正阅读顺序,确保布局元素的顺序符合人类阅读习惯。
- 任务切换机制:用输入提示词(prompt)指定模型的任务,例如布局检测、内容识别、公式解析等。提示词引导模型生成相应的输出,使模型能灵活应对不同的文档解析需求。
【2025-10-20】DeepSeek-OCR
【2025-10-20】DeepSeek 在GitHub上开源其最新成果——DeepSeek-OCR模型
- 项目地址: DeepSeek-OCR
- Hugging Face: DeepSeek-OCR
Transformer 注意力机制是 N^2 复杂度,输入 token 数量从 1 万增加到 10 万,计算量就会暴涨 100 倍。
哪怕用稀疏注意力、滑动窗口、外部记忆等技巧,成本下降仍然有限,且往往伴随对齐/召回的不确定性。
实际应用中,最拖后腿的恰恰是“混排文档”:合规 PDF、法务合同、工艺/维保手册、SaaS 仪表盘、研发规范、PPT……
今天的常态是“先 OCR+结构化→再喂 LLM”,这一步步的串接又贵又脆。如果输入侧直接统一成视觉,省掉一层中间件与信息损耗;
若再叠加“渐进式分辨率衰减”,老上下文以更低成本“影子驻留”,新上下文以高分辨率强化——这对 RAG/会话长期记忆/代码库理解都是实打实的系统性优化。
社区口径里甚至出现了诸如“A100 单卡日处理 ~20 万页”的粗算(显然依赖具体分辨率/排版/批量参数),虽然属于工程经验值,但方向大体明确:视觉压缩在吞吐/延迟/成本的三角里打开了新空间。
DeepSeek-OCR 是多模态 OCR 模型,把图片、PDF、扫描件里的文字、表格、公式完整识别出来,并且保留排版结构。
和传统 OCR 工具相比,显著优势:
- 复杂排版支持:图文混排、表格、数学公式都能准确还原。
- 多语言识别:不仅支持中文,还能处理英文、日文等多种语言。
- 结构化输出:可以直接生成 Markdown、JSON 等格式,方便后续处理。
- 开源可用:在 Hugging Face 上就能下载,部署简单。
原理
当前主流视觉编码器方案:
| 视觉编码器类型 | 代表模型 | 优势 | 缺点 |
|---|---|---|---|
| 双塔架构(Dual-Tower) | Vary | 1. 视觉词汇参数可控,便于调整模型复杂度; 2. 激活内存消耗可控,降低基础资源压力。 |
1. 需对图像进行双重预处理,增加部署复杂度; 2. 训练阶段编码器流水线并行难度高,影响训练效率。 |
| 基于分块(Tile-Based) | InternVL2.0 | 1. 通过图像分块实现并行计算,高分辨率场景下激活内存消耗低; 2. 支持处理极高分辨率图像。 |
1. 原生编码器分辨率低(通常低于512×512); 2. 大尺寸图像会被过度分割,生成大量视觉 tokens,增加计算负担。 |
| 自适应分辨率编码(Adaptive Resolution) | Qwen2-VL | 1. 采用 NaViT范式,通过基于 patch 的分割直接处理全图,无需分块并行; 2. 可灵活适配不同分辨率图像,兼容性强。 |
1. 处理大尺寸图像时激活内存消耗极高,易导致 GPU 内存溢出; 2. 训练阶段序列打包需极长序列长度,推理阶段的预填充和生成速度会因长视觉 tokens 变慢。 |
端到端OCR实现
- Nougat 首次将端到端框架应用于 arXiv 平台的学术论文 OCR 任务,证明了模型在处理密集感知任务上的潜力。
- GOT-OCR2.0 将 OCR2.0 应用范围扩展到合成图像解析任务,并设计出性能与效率平衡的 OCR 模型。
- Qwen-VL 系列、InternVL 系列等通用视觉模型及其众多衍生模型,也在不断提升自身文档 OCR 能力,以探索密集视觉感知的边界。
然而,当前模型尚未解决关键问题:
- 对于一份包含 1000 个文字文档,解码时至少需要多少个视觉 token(视觉令牌)?
- 这对于 “一图胜千言” 原理的相关研究具有重要意义。
DeepSeek-OCR 设计思路:通过多分辨率的视觉编码机制,实现极高的信息压缩效率。
多个分辨率选项:
- 最低的 512×512 图像仅需 64 个 token,而 1024×1024 则对应 256 个 token。
- 对于复杂版面,会组合多种分辨率——整页用多个 1024×1024 的块进行全局编码,重点区域再以 640×640 的高分辨率单独处理。
这套路线的底层逻辑:
- 把文本先渲染成图片,再用视觉编码器把它压成更少的视觉 token。
- 传统做法是“按字/词切片—> 变成一长串文本 token—> 塞给 LLM”,而 DeepSeek 的思路是“把一页文字变成若干张多尺度图块—> 视觉编码—> 少量视觉 token”。
从工程权衡的角度看,这有三层直接收益:
- 信息密度:排版、层级结构、表格网格、图文对齐,这些在“文本化”过程中会损失,而在“视觉化”里天然携带。
- 计算复杂度:Transformer 注意力是 N2N^2N2——token 越多越爆炸。视觉压缩若能把 10 万 token 的文档“折叠”到几百个视觉 token,延迟、显存、花费都会是数量级改善。
- 输入一致性:现实世界里大量输入本就是截图、PDF、PPT、仪表盘、网页混排。以视觉为统一“底层表示”,有利于做一体化的上下文管理。
DeepSeek 在工程上还给了多分辨率的“粗到细”路径:整页用较粗分辨率覆盖,重点区域再用更高分辨率补洞,既保全结构又兼顾要点密度。
这听上去眼熟?没错,与多尺度生成/理解中的“金字塔”范式一脉相承。
极具想象力的假设:“人脑之所以能记忆长久,是因为它会忘记;那模型也可以通过分辨率的降低来实现遗忘。”
架构
DeepSeek-OCR架构图
该模型通过创新的光学二维映射压缩技术,在长文本识别场景中实现97%的识别精度,为OCR领域树立新的技术标杆。
该模型采用双模块架构,由 DeepEncoder 视觉编码器与 DeepSeek3B-MoE-A570M 混合专家解码器构成。
- 其中,DeepEncoder 处理高分辨率图像时自动维持低激活状态,通过动态压缩生成最优数量的视觉特征令牌(visual tokens),较传统方法减少60%的计算冗余。
专门为 OCR(文字识别)微调的 6.6GB 模型,主要贡献
- 首次量化 “视觉-文本 token 压缩比”,验证 10× 近无损压缩、20× 仍保有 60% 精度的可行性;
- 提出 DeepEncoder,解决现有编码器 “高分辨率-低内存-少token” 不可兼得的问题;
- 开发 DeepSeek-OCR,在实用场景达 SOTA 且 token 消耗最少,兼具科研价值与产业落地能力。
模型结构
- 模块1:视觉感知(窗口注意力主导) 采用SAM-base(Segment Anything Model,80M参数),输入图像被分割为16×16的patch(如1024×1024图像生成4096个patch token)。这个在vary和got中均使用。 作用:通过窗口注意力(局部注意力)捕捉图像细节(如文本位置、字体),避免全局注意力的高内存消耗。
- 模块2:16×卷积压缩器 位于SAM和CLIP之间,由2层卷积构成(核大小3×3,步长2,通道数从256→1024),实现视觉token的16倍下采样。 作用:将SAM输出的4096个token压缩为256个(1024×1024输入场景),大幅减少后续全局注意力模块的计算量,控制激活内存。
- 模块3:视觉知识(全局注意力主导) 采用CLIP-large(300M参数),作用:通过全局注意力整合压缩后的token,提炼图像全局语义(如文档布局、文本逻辑),为解码提供结构化视觉知识。
效果
实验表明
- 当视觉令牌与文本令牌的比例控制在 1:10 时,模型识别准确率达97%; 即便将压缩率提升至1:20,准确率仍保持60%以上,显著优于同类模型在极端压缩条件下的表现。
这项突破性成果源于对光学二维映射压缩技术的深度探索。通过将图像特征转化为离散令牌序列,模型成功解决了长文本场景中视觉信息与语义输出的匹配难题。
该技术路径不仅为OCR系统的小型化提供可行方案,更对大语言模型的记忆管理机制研究具有重要启示——其动态压缩策略可类比为人工智能的选择性遗忘能力,为构建更高效的持续学习系统奠定基础。
PaddleOCR-VL vs DeepSeek-OCR
【2025-10-22】再谈DeepSeek-OCR的信息压缩论!附DeepSeek-OCR与PaddleOCR实测对比
测试链接:
注意:DeepSeek-OCR 选择精度均为Large
评测
- 机打纯文:纯看模型OCR能力,是否能将内容还原,最朴素的需求。
- 手写文本: 考察模型对手写内容的识别准确率,能否直接处理压缩手写内容
- 形近字:考察模型是否可以准确识别形近字
- 数学公式:考察模型对数学公式解析的能力,是否可以将公式还原
- 表格识别:考察模型的表格解析能力,能否将文本内容和表格结构均识别正确。
- 竖版内容识别:考察模型对竖版内容理解的能力,是否知道图像为竖版内容,排序是否准确
- PaddleOCR-VL效果:存在识别错误,但整体字符准确率要比DeepSeek-OCR高
| 模型 | 机打纯文 | 手写文本 | 更难的手写体 | 形近字 | 数学公式 | 表格识别(跨行) | 竖版内容 |
|---|---|---|---|---|---|---|---|
| PaddleOCR-VL | 正确 | 正确 | 少量错误 | 正确 | 正确 | 正确 | 正确 |
| DeepSeekOCR | 正确 | 错1个字 | 更多错误 | 错1个字 | 错了1点 | 结构错误 | 多一句 |
两个模型不同路子,各有各的优势。
- DeepSeek-OCR 视觉压缩创新,解决大模型处理长文档时的算力爆炸问题。
- PaddleOCR-VL 走技术落地,关注点在当下用户最需要的高精度、轻量化识别需求。
打工人日常办公处理表格、手写笔记、多语言文档,显然 PaddleOCR-VL 更符合需求。
图像二维压缩是个好方向,但也确实存在一些问题,OCR上,PaddleOCR 确实是鼻祖级别
使用
DeepSeek-OCR 测试脚本
from transformers import AutoModel, AutoTokenizer
import torch
import os
import time
import psutil
import GPUtil
from pathlib import Path
from PIL import Image
import fitz # PyMuPDF
# ============ 配置区 ============
# 1. 模型路径
model_name = 'deepseek-ai/DeepSeek-OCR' # 从 HuggingFace 下载
# 2. 设置图片/PDF路径
IMAGE_PATH = 'images/2024数学练习.pdf'
# 3. 设置输出目录
OUTPUT_DIR = './output'
# 4. 设置任务类型:'markdown' 或 'ocr'
TASK = 'markdown'
# 5. GPU 设备
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
# =================================
def main():
print("=" * 70)
print("加载模型...")
# 记录初始状态
process = psutil.Process()
initial_memory = process.memory_info().rss / 1024 / 1024 # MB
# 加载模型
load_start = time.time()
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True,
local_files_only=True # 只使用本地缓存,不联网检查更新
)
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
local_files_only=True # 只使用本地缓存,不联网检查更新
)
model = model.eval().cuda().to(torch.bfloat16)
load_time = time.time() - load_start
# 记录加载后状态
after_load_memory = process.memory_info().rss / 1024 / 1024 # MB
gpu = GPUtil.getGPUs()[0] if GPUtil.getGPUs() else None
print(f"✓ 模型加载完成 (耗时: {load_time:.2f}秒)")
print(f"内存占用: {after_load_memory - initial_memory:.2f} MB")
if gpu:
print(f"显存占用: {gpu.memoryUsed:.2f} MB / {gpu.memoryTotal:.2f} MB")
print("=" * 70)
# 设置提示词
if TASK == 'markdown':
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
else:
prompt = "<image>\n<|grounding|>Free OCR. "
# 检查文件类型并转换PDF
file_path = Path(IMAGE_PATH)
if file_path.suffix.lower() == '.pdf':
print(f"\n检测到PDF文件: {IMAGE_PATH}")
print("正在转换PDF为图片...")
# 打开PDF
pdf_doc = fitz.open(IMAGE_PATH)
total_pages = len(pdf_doc)
print(f"PDF共 {total_pages} 页")
os.makedirs(OUTPUT_DIR, exist_ok=True)
all_results = []
total_infer_time = 0
# 逐页处理
for page_num in range(total_pages):
print(f"\n{'='*70}")
print(f"处理第 {page_num + 1}/{total_pages} 页")
print("-" * 70)
# 转换当前页为图片
page = pdf_doc[page_num]
pix = page.get_pixmap(matrix=fitz.Matrix(2, 2))
# 保存临时图片
temp_image_path = f'{OUTPUT_DIR}/temp_page_{page_num + 1}.png'
pix.save(temp_image_path)
# 记录推理前状态
infer_start = time.time()
cpu_percent_start = psutil.cpu_percent(interval=0.1)
gpu_util_start = gpu.load * 100 if gpu else 0
# 执行OCR
page_output_dir = f'{OUTPUT_DIR}/page_{page_num + 1}'
result = model.infer(
tokenizer,
prompt=prompt,
image_file=temp_image_path,
output_path=page_output_dir,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True
)
# 记录推理后状态
infer_time = time.time() - infer_start
total_infer_time += infer_time
# 读取保存的结果文件
result_file = f'{page_output_dir}/result.mmd'
if os.path.exists(result_file):
with open(result_file, 'r', encoding='utf-8') as f:
page_result = f.read()
# 复制该页的images目录到output/images下
page_images_dir = f'{page_output_dir}/images'
if os.path.exists(page_images_dir):
output_images_dir = f'{OUTPUT_DIR}/images'
os.makedirs(output_images_dir, exist_ok=True)
# 复制图片并重命名(添加页码前缀)
import shutil
for img_file in os.listdir(page_images_dir):
src = os.path.join(page_images_dir, img_file)
dst = os.path.join(output_images_dir, f'page{page_num + 1}_{img_file}')
shutil.copy2(src, dst)
# 更新结果中的图片路径
page_result = page_result.replace('](images/', f'](images/page{page_num + 1}_')
all_results.append(f"\n\n# 第 {page_num + 1} 页\n\n{page_result}")
print(f"✓ 第 {page_num + 1} 页识别完成 (耗时: {infer_time:.2f}秒)")
else:
print(f"✗ 第 {page_num + 1} 页识别失败")
pdf_doc.close()
# 合并所有页结果
result = "\n".join(all_results)
# 保存完整结果
with open(f'{OUTPUT_DIR}/full_result.md', 'w', encoding='utf-8') as f:
f.write(result)
print(f"\n{'='*70}")
print("PDF处理完成")
print("=" * 70)
print(f"总页数: {total_pages}")
print(f"总耗时: {total_infer_time:.2f} 秒")
print(f"平均每页: {total_infer_time/total_pages:.2f} 秒")
# 获取最终状态
final_memory = process.memory_info().rss / 1024 / 1024
cpu_percent_end = psutil.cpu_percent(interval=0.1)
if gpu:
gpu = GPUtil.getGPUs()[0]
gpu_util_end = gpu.load * 100
else:
gpu_util_end = 0
print(f"内存使用: {final_memory:.2f} MB")
if gpu:
print(f"显存占用: {gpu.memoryUsed:.2f} MB / {gpu.memoryTotal:.2f} MB")
print("=" * 70)
else:
# 处理单个图片
process_path = IMAGE_PATH
print(f"\n处理文件: {IMAGE_PATH}")
print("-" * 70)
# 记录推理前状态
infer_start = time.time()
cpu_percent_start = psutil.cpu_percent(interval=0.1)
gpu_util_start = gpu.load * 100 if gpu else 0
result = model.infer(
tokenizer,
prompt=prompt,
image_file=process_path,
output_path=OUTPUT_DIR,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True
)
# 记录推理后状态
infer_time = time.time() - infer_start
cpu_percent_end = psutil.cpu_percent(interval=0.1)
final_memory = process.memory_info().rss / 1024 / 1024
if gpu:
gpu = GPUtil.getGPUs()[0]
gpu_util_end = gpu.load * 100
else:
gpu_util_end = 0
# 输出性能统计
print("-" * 70)
print("\n性能统计:")
print("=" * 70)
print(f"推理耗时: {infer_time:.2f} 秒")
print(f"CPU 使用率: {cpu_percent_end:.1f}%")
print(f"内存使用: {final_memory:.2f} MB (推理增加: {final_memory - after_load_memory:.2f} MB)")
if gpu:
print(f"GPU 使用率: {gpu_util_end:.1f}%")
print(f"显存占用: {gpu.memoryUsed:.2f} MB / {gpu.memoryTotal:.2f} MB ({gpu.memoryUsed/gpu.memoryTotal*100:.1f}%)")
print("=" * 70)
# 显示结果预览
print(f"\n识别结果预览:")
print("-" * 70)
if result:
preview = result[:300] if len(result) > 300 else result
print(preview)
if len(result) > 300:
print(f"\n... (共 {len(result)} 字符)")
else:
print("未获取到结果")
print("-" * 70)
print(f"\n✓ 完整结果已保存到: {OUTPUT_DIR}/full_result.md" if file_path.suffix.lower() == '.pdf' else f"\n✓ 完整结果已保存到: {OUTPUT_DIR}")
if __name__ == '__main__':
main()
观点
(1)Pleiasfr 联合创始人 Alexander Doria 更是直言:
- “DeepSeek-OCR 是一个里程碑式的工程成就,代表了轻量高效 OCR 模型的最佳范例。这不是终点,但可能是未来所有 OCR 系统的起点。”
VLM/OCR 模型其实可以小得多。
多模态视觉语言模型(VLM)出现之前,业界领先的 Google Cloud OCR 模型规模其实也不过一亿参数左右。
最近,一些参数相对较小的开源模型已经能与闭源产品正面竞争,其中最令人惊讶的是 dots.ocr ——在其内部和公开的多个基准测试中, 17 亿参数模型在准确率上普遍超过了 OpenAI、Anthropic,甚至在某些任务上优于 Gemini,而成本仅为后者的一小部分。
这背后的原因:
- OCR 本质上是一种“模式识别”任务,不需要太多推理或长程记忆,因此模型架构可以相对轻量。
- 这也解释了为什么 DeepSeek-OCR 采用了仅 12 层的精简架构。
DeepSeek-OCR 在两个方面进一步创新:
- 进入了一个新兴的“小型专家混合(Mixture of Experts)”范式——虽然模型总规模较大,但每次推理时只有 5 亿个参数被激活,这让它能在一批次中处理大量数据;
- 采用了激进的编码策略(aggressive encoding),并结合了语义池化(semantic pooling)。DeepSeek-OCR 的编码器在输入阶段就做了大量“信号压缩”的工作,把低层视觉信号聚合成更高层的语义单元,再加上一些性能优化手段,这显著提升了处理速度。
DeepSeek-OCR 意义在于成为真正“基础型”的 OCR 模型:几乎已经提前找到了推理效率与模型性能的最佳平衡点,奠定了工程基础,但若要在大规模真实业务中应用,还需要针对特定领域进行数据标注和定制化流程设计。
(2)Karpathy 直言:“我很喜欢这篇新的 DeepSeek-OCR 论文。” 最让我感兴趣的部分:
- 更根本的问题 —— 对大语言模型(LLM)来说,像素是否比文本更好的输入形式?文本 token 会不会其实是一种“浪费而糟糕”的输入方式?
逻辑上讲,所有输入都应该是图像。
- 即使原始内容是纯文本,也可以先渲染成图像再输入。为什么这么做有意义?
- 信息压缩更高效:图像输入能在更短的上下文窗口中包含更多信息,推理效率更高。
- 信息流更丰富:不仅能表示文字,还能自然包含加粗、颜色、格式、甚至任意插图等视觉要素。
输入可以天然地使用双向注意力(bidirectional attention),而不是像语言模型那样必须自回归(autoregressive)地逐步处理,这在结构表达上更强大。
最关键的一点:彻底摆脱 tokenizer(输入端)!
我早就对 tokenizer 深恶痛绝, 既丑陋又割裂,让整个模型不再是端到端的流程;
- 继承了 Unicode、字节编码等一大堆历史包袱,还引入了安全和越狱风险(比如续字节攻击);
- 让两个看起来一模一样的字符在内部被编码成完全不同的 token;
- 让一个笑脸表情符号在模型眼里变成一个怪异的 token,而不是一个真实的“笑脸”
- 模型也因此失去了像素级迁移学习所带来的自然语义。
Tokenizer 必须被淘汰。
- OCR 只是视觉 → 文本任务中的一个典型代表。
- 实际上,许多文本 → 文本任务完全可以被重构为视觉 → 文本任务,但反过来却行不通。
- 所以,也许未来用户的输入都是图像,而模型的输出(即助手的回应)仍然是文本。
- 当然,要让模型生成像素级的输出仍然不太现实——或者说,暂时我们也没那么需要。
(3)马斯克
马斯克进一步把这个逻辑推到了物理层的极限:“最终一切输入输出都是光子。”
两人思路一致:语言是人类造的接口,而光是宇宙本身的接口。
他所说的“Nothing else scales”, 并不仅仅指算力的瓶颈,而是信息传输与感知的物理极限。
无论是图像、视频、传感器还是显示屏,所有的信息流本质上都是光子流。
换句话说,语言、文字、符号这些“输入方式”,只是光的低维投影。当模型足够强大时,它们都将被还原为光的形式——即以视觉为基础的直接感知与生成。
语言回归像素
“让语言回归像素”并不是凭空诞生的想法。
- 2022 年,哥本哈根大学论文《Language Modelling with Pixels》中提出了 PIXEL 模型:它通过把文本渲染成图像,并以像素重建代替分词预测,从而绕过传统分词器带来的语言隔阂。PIXEL 实验显示,这种方式在跨语言、异体字、以及正字法攻击(如字符扰动)场景下表现更稳健。
此后,学界陆续出现了多篇沿着这一思路发展的论文:
- 2023 年 CVPR 论文 CLIPPO提出 “Pixels Only” 框架,将图像与语言的对齐完全基于视觉 token;
- 2024 年多篇论文探索如何利用视觉 token 处理长文本上下文;
- 2025 年的 NeurIPS 再度出现类似方向的研究,强化了“视觉编码是长上下文问题解法”的共识。
DeepSeek-OCR 正是在这一脉络下登场。将多篇分散研究成果整合成一条完整工程链路:把视觉编码、上下文压缩、多分辨率建模融合为统一框架。
DeepSeek 多分辨率机制与去年的 NeurIPS Best Paper《Visual Autoregressive Modeling》高度相似。
- 那篇由字节跳动实习生
Tian Keyu领衔的工作,采用“由粗到细”的多尺度预测方式——先低分辨率生成,再逐步提升清晰度。 - 同时,豆包团队也在论文中展示了相同的数据压缩路径:512×512 图像可编码为 64 个 token,256×256 甚至能压到 32 个 token。
久痕科技创始人汪源所评价:
- DeepSeek OCR 性能和思路不算很大的突破,但产品化的贡献值得肯定。
同行
大家都想到一块去了,用视觉特征来压缩LLM的长上下文是个好思路。
DeepSeek OCR 同期工作
- 【2025-10-21】南京理工、中南大学 See the Text: From Tokenization to Visual Readin
- 【2025-10-20】清华:Glyph —— Scaling Context Windows via Visual-Text Compression
- 【2025-10-22】EMNLP 2025 Findings,Text or Pixels? It Takes Half: On the Token Efficiency of Visual Text Inputs in Multimodal LLMs
【2026-1-27】DeepSeek-OCR 2
【2026-1-27】DeepSeek-OCR 2发布:识别性能提升3.73%,让AI“读懂”复杂文档
DeepSeek 发布最新一代文档识别模型 DeepSeek-OCR 2。DeepSeek-OCR 基础上升级而来,核心变化集中在视觉编码器设计上。
研究团队提出名为 DeepEncoder V2 新型编码器结构,根据图像语义动态调整视觉信息的处理顺序,使模型在进行文字识别前先对视觉内容进行智能排序。
这项技术突破源于对传统视觉语言模型处理方式的重新思考,旨在让机器更贴近人类的视觉阅读逻辑。
传统视觉语言模型中,图像通常会被切分为若干视觉 token,并按照从左上到右下的固定栅格顺序送入模型处理。这种方式虽然实现简单,但与人类在阅读文档、表格或公式时基于语义和逻辑关系进行跳跃式浏览的方式并不一致。
DeepSeek 论文指出,尤其在版式复杂的文档场景中,视觉元素之间往往存在明确的逻辑先后关系,仅依赖空间顺序可能限制模型对内容结构的理解能力。
DeepSeek-OCR 2 改进重点在于引入“视觉因果流”的概念。在 DeepEncoder V2 中,研究团队用一种类语言模型结构替代了原先基于 CLIP 的视觉编码模块,并在编码器内部引入可学习的“因果流查询 token”。这些查询 token 通过定制化的注意力机制,在保留视觉 token 全局双向注意力的同时,自身采用因果注意力,只能访问已有信息,从而在编码阶段对视觉 token 的顺序进行动态重排。最终,只有经过因果重排后的查询 token 会被送入后续的语言模型解码器,用于生成识别结果。
DeepSeek-OCR 2在多项关键指标上展现出显著优势。
OmniDocBench v1.5基准测试中,该模型取得了91.09%的成绩,相较于前代DeepSeek-OCR提升了3.73%。
【2026-1-20】LightOnOCR-2-1B
【2026-1-21】LightOnOCR-2-1B:1B小模型吊打9倍大模型,速度快3倍还开源了
LightOn 公司推出 LightOnOCR-1B,介绍: lightonocr
- 【2026-1-20】论文 LightOnOCR: A 1B End-to-End Multilingual Vision-Language Model for State-of-the-Art OCR
- 模型地址:LightOnOCR-2-1B
- 数据集链接:LightOnOCR-bbox-mix-0126
- 在线演示: LightOnOCR-2-1B-Demo
LightOnOCR-2延续了第一代的端到端架构设计理念,但在多个关键方面进行了优化。模型采用原生分辨率的视觉Transformer(ViT)处理图像输入,配合精简的语言模型主干网络。通过多模态投影层将视觉特征与语言特征对齐,实现PDF页面到Markdown文本的直接转换。
相比传统的多阶段OCR流水线,这种端到端设计带来了几个关键优势:
- 训练简化: 整个模型完全可微分,可以端到端优化,无需协调多个独立组件的训练。
- 推理高效: 每页只需一次前向传播,无需多次模型调用和中间处理步骤。
- 适配灵活: 针对新领域或新语言的微调变得简单直接,只需在目标数据上继续训练即可。
LightOnOCR-2发布了一整个模型家族,而不是单一的检查点:
主力模型系列:
- LightOnOCR-2-1B(默认推荐): 纯OCR模型,转录质量最佳
- LightOnOCR-2-1B-bbox: 支持图像边界框定位的版本,可输出文档中嵌入图片的位置信息
- LightOnOCR-2-1B-ocr-soup: 平衡版本,兼顾OCR和bbox能力
基础模型系列:
- LightOnOCR-2-1B-base: 纯OCR基础检查点,用于微调和模型融合
- LightOnOCR-2-1B-bbox-base: 支持bbox的基础检查点,可用于RLVR训练
- LightOnOCR-2-1B-bbox-soup: bbox变体的融合版本,在OCR质量和图像定位之间取得平衡
LightOnOCR-2-1B 在OlmOCR-Bench测试中取得了83.2±0.9的总分,成为目前该基准测试的最强模型。相比第一代版本和其他竞品,这次升级在各个类别上都实现了显著提升,特别是在ArXiv论文、含数学公式的旧文档扫描件以及表格识别方面表现尤为出色。
这些进步主要得益于:
- 更大规模、更高质量的训练数据集
- 增强的科学文献覆盖
- 更高分辨率的训练策略
仅10亿参数的端到端视觉语言模型,在OCR领域的表现令人惊艳:
- 不仅在OlmOCR基准测试中超越了90亿参数的Chandra模型1.5个百分点,速度还快了3.3倍,模型体积却只有后者的九分之一。
- 更重要的是,整个模型家族都以Apache 2.0协议开源,为文档处理领域带来了全新的可能性。
LightOnOCR-2-1B在单张H100 GPU上的处理速度达到了:
- 比Chandra OCR快1.93倍
- 比OlmOCR快2-3倍
- 比dots.ocr快1倍
- 比PaddleOCR-VL-0.9B快2.43倍
- 比DeepSeekOCR快2.68倍
【2025-12-24】UNIREC-0.1B
【2026-1-5】多模态文档解析模型进展:UNIREC-0.1B
起因
- 2025年已发布的模型: DeepSeekOCR,QwenVL,HunyuanOCR,PaddleVL-OCR,Monkey-OCR,MinerU,Dolphin等作品。虽然都取得不错效果,但在一些业务场景中想落地还是有一段距离,比如说性能。
【2025-12-24】复旦+字节提出 UNIREC-0.1B ,公式+文本识别
- 论文UniRec-0.1B: Unified Text and Formula Recognition with 0.1B Parameters
- 代码 Codebase and Dataset-OpenOCR
主要贡献:
- 构建了UniRec40M,其中包含4000万条中英文多层级文本-公式样本,填补了统一文本与公式识别领域的数据空白。
- 提出UniRec-0.1B,一个轻量级的统一识别模型。该模型通过引入分层监督训练和语义解耦分词器,解决了细粒度与模态混合带来的挑战。
大量评估表明
- UniRec-0.1B在各种文本和公式识别任务中的准确率优于或持平于领先的大型视觉语言模型,同时实现了2-9倍的推理速度提升。
模型结构: 主流方案 encoder-decoder 结构
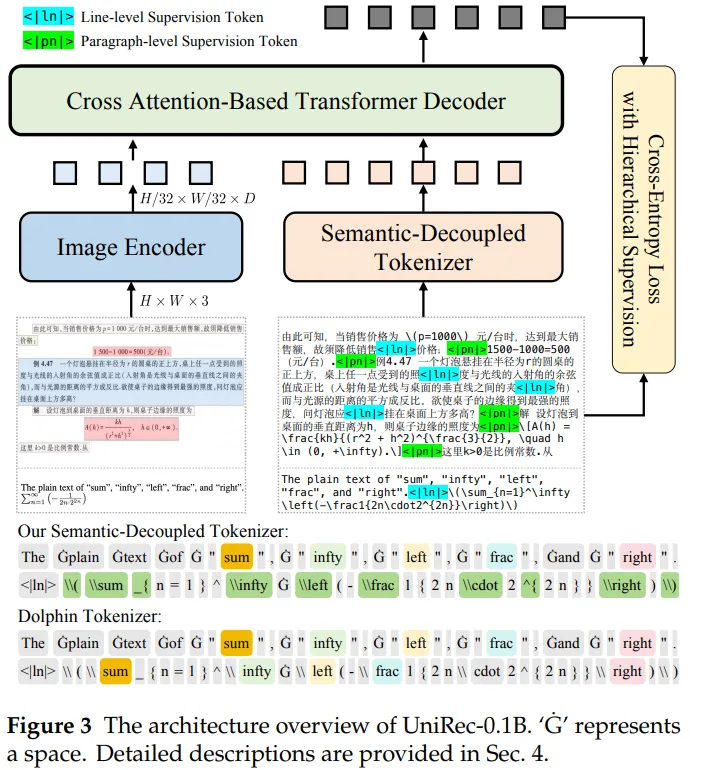
【2026-3-23】MinerU-Diffusion
【2026-3-23】OpenDataLab推出文档OCR领域的最新成果——MinerU-Diffusion
- 论文 MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding OCR 真的应该“逐字生成”吗?过去十年里,文档OCR几乎都默认一个范式:👉 从左到右,一个 token 一个 token 生成 但文档不是语言,它是结构 OCR本质不是“写句子”,而是:👉 把二维文档结构,还原成一维符号序列
💡 MinerU-Diffusion:用“扩散”,而不是“生成” 把OCR从“序列生成”改写为:文本结构的逆向渲染(Inverse Rendering)
- 🔧 核心方法:离散扩散解码(Diffusion Decoding)
- 📊 实验结果:在保证精度的前提下:
- ⚡ 最高可达 5.1× 推理加速
- ⚡ 常规配置下 2–3× 性能提升 在挑战性场景(Semantic Shuffle)中:
- ❌ 自回归模型:性能显著下降(依赖语言先验)
- ✅ 扩散模型:性能基本稳定(依赖视觉信号)
- 👉 这表明:MinerU-Diffusion更直接建模视觉与结构,而非“猜文本”
验证码识别
- 验证码是一种区分用户是计算机还是人的公共全自动程序。可以防止:恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上用验证码是现在很多网站通行的方式。由于验证码可以由计算机生成并评判,但是必须只有人类才能解答,所以回答出问题的用户就可以被认为是人类。
目前验证码通常的种类及特点如下:
- (1)最基础的英文验证码:纯粹的英文与数字组合,白色背景,这是最容易实现OCR识别的验证码。
- (2)字体变形的英文验证码:可以通过简单的机器学习实现对英文与数字的识别,准确率较高。
- (3)加上扰乱背景线条的验证码:可以通过程序去除干扰线,准确率较高。
- (4)中文验证码:中文由于字体多样,形状多变,数量组合众多,实现起来难度较大,准确率不高。
- (5)中文字体变形验证码:准确率更低。
- (6)中英文混合验证码:非常考验OCR程序的判断能力,基本上识别起来非常有难度。
- (7)提问式验证码:这是需要OCR结合人工智能才能实现,目前基本上无法识别。
- (8)GIF动态图验证码:由于GIF图片是动态图,无法定位哪一帧是验证码,所以难度很大。
- (9)划动式验证码:虽然程序可以模拟人的操作,但是具体拖动到哪个位置很难处理。
- (10)视频验证码:目前OCR识别还未实现。
- (11)手机验证码:手机验证码实现自动化是很容易的,但是手机号码不那么容易获得。
- (12)印象验证码:目前无解。

- 附录:
- 「Happy Captcha」,一款易于使用的 Java 验证码软件包,旨在花最短的时间,最少的代码量,实现 Web 站点的验证码功能。
- Captcha缩写含义:Completely Automated Public Turing test to tell Computers and Humans Apart
- 效果图

GAN 方法
【2018-12-14】基于GAN的验证码识别工具,0.5秒宣告验证码死刑!
- 中英两国研究人员联合开发了一套基于GAN的验证码AI识别系统,能在0.5秒之内识别出验证码,从 实际测试结果看,可以说宣布了对验证码的“死刑判决”。
- 该系统已在不同的33个验证码系统中进行了成功测试,其中11个来自世界上最受欢迎的一些网站,包括eBay和维基百科等。
- 这种方法的新颖之处在于:使用生成对抗网络(GAN)来创建训练数据。不需要收集和标记数以百万计的验证码文本数据,只需要500组数据就可以成功学习。而且可以使用这些数据,来生成数百万甚至数十亿的合成训练数据,建立高性能的图像分类器。
- 结果显示,该系统比迄今为止所见的任何验证码识别器系统的识别精度都高。
扩散模型
详见:图像生成专题
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
