- LLM 服务及接口信息
- 总结
- LLM 服务接口
- ChatGPT 调用前提
- OpenAI 收费
- Anthuropic 账户注册
- OpenAI 账户注册
- OpenAI API 调用
- 差异点:
- GPT-4 API
- ChatGPT 参数
- 账户升级plus
- MCP
- OpenAI 进化
- 模型规模
- 【2023-3-23】插件
- 【2023-3-16】GPT-4 发布
- 【2023-4-25】可关闭会话历史
- 【2023-5-18】iOS APP
- 【2023-7-25】Android APP
- 【2023-6-15】Function Call
- 【2023-7-20】定制个人画像
- 【2023-8-5】GPT-4放开
- 【2023-9-25】多模态
- 【2023-9-28】联网
- 【2023-9-30】Plus 邀请制
- 【2023-10-16】Statefull API
- 【2023-10-30】GPT-4 自动选择插件
- 【2023-11-7】GPT-4 Turbo、GPT Builder、Assistant API
- 【2024-3-31】Voice Engine
- 【2024-4-30】记忆功能
- 【2024-5-14】GPT-4o
- 【2024-7-19】GPT-4o mini
- 【2024-9-13】o1
- 【2024-12-20】GPT o3
- 【2025-2-2】Deep Research
- 【2025-3-25】GPT-4o Image Generation
- 【2025-8-6】GPT-oss
- 【2025-8-8】GPT-5
- 【2025-10-01】Sora 2
- 【2025-10-6】DevDay
- 【2026-4-14】GPT-6【假】
- 结束
LLM 服务及接口信息
总结
【2025-12-7】models.dev 开源,可查询所有主流大模型 api 地址,docs 地址,是否支持 Tool Calling,Reasoning 等等。
- 提供简单的 api 来返回 json 信息:api,直接返回 json 串
LLM 服务接口
LLM API 中间商, 依次对接多个大模型接口
- LiteLLM: 更成熟、功能更齐全
- SiliconFlow
- one-api
- aisuite: 吴恩达新开源工具包
- 把11家顶尖大模型平台统一到了一个接口下,包括OpenAI、Anthropic、谷歌等等
- 开发者只需改动几个字符串,就能在不同平台间随意切换
- 结合 streamlit 工具, 构建简易 UI
- 一个问题,几个大模型同时回答
中转站
OpenRouter 这类中转站见站内专题:算力中转站
ChatGPT 调用前提
ChatGPT prompt构成
完整示例
import openai
openai.api_key = "YOUR API KEY HERE"
model_engine = "text-davinci-003"
chatbot_prompt = """
作为一个高级聊天机器人,你的主要目标是尽可能地协助用户。这可能涉及回答问题、提供有用的信息,或根据用户输入完成任务。为了有效地协助用户,重要的是在你的回答中详细和全面。使用例子和证据支持你的观点,并为你的建议或解决方案提供理由。
<conversation history>
User: <user input>
Chatbot:"""
def get_response(conversation_history, user_input):
prompt = chatbot_prompt.replace(
"<conversation_history>", conversation_history).replace("<user input>", user_input)
# Get the response from GPT-3
response = openai.Completion.create(
engine=model_engine, prompt=prompt, max_tokens=2048, n=1, stop=None, temperature=0.5)
# Extract the response from the response object
response_text = response["choices"][0]["text"]
chatbot_response = response_text.strip()
return chatbot_response
def main():
conversation_history = ""
while True:
user_input = input("> ")
if user_input == "exit":
break
chatbot_response = get_response(conversation_history, user_input)
print(f"Chatbot: {chatbot_response}")
conversation_history += f"User: {user_input}\nChatbot: {chatbot_response}\n"
main()
GPT-3 API vs ChatGPT Web
两种非官方 ChatGPT API 方法
| 方式 | 免费? | 可靠性 | 质量 |
|---|---|---|---|
ChatGPTAPI(GPT-3) |
否 | 可靠 | 较笨 |
ChatGPTUnofficialProxyAPI(网页 accessToken) |
是 | 相对不可靠 | 聪明 |
对比:
ChatGPTAPI使用text-davinci-003通过官方OpenAI补全API模拟ChatGPT(最稳健的方法,但它不是免费的,并且没有使用针对聊天进行微调的模型)ChatGPTUnofficialProxyAPI使用非官方代理服务器访问ChatGPT的后端API,绕过Cloudflare(使用真实的的ChatGPT,非常轻量级,但依赖于第三方服务器,并且有速率限制)
【2023-2-26】chatgpt-web 用 Express 和 Vue3 搭建的同时支持 openAI Key 和 网页 accessToken 的 ChatGPT 演示网页
OpenAI 收费
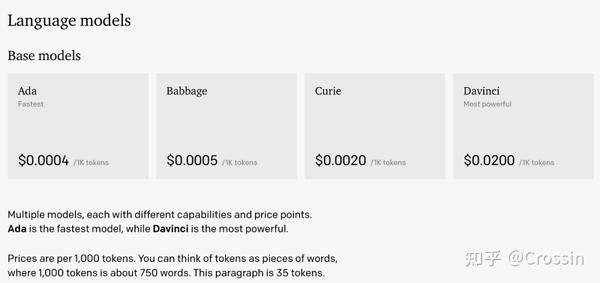
注意:价格上 OpenAI 最贵的 AIGC 语言模型达芬奇为每 0.02 美元 750 个单词,AIGC 图型模型价格仅为 0.020 美元一张。
- gpt3模型付费API试用版,注册一个账号送18美金,调用费用为每1000字消耗2美分(0.02美元/500汉字,一个汉字两个token),折合下来差不多0.1元250个汉字,这个字数包括问题和返回结果(非汉字时,花费更少)。 $ 1800/250=7.2 $
- ChatGPT单账户18美金免费访问量:1800×250÷30=15000次请求,平均250个汉字消耗0.01美元,用户平均请求长度30个汉字
- ChatGPT用的模型是gpt3.5,目前没公开API
OpenAI收费项目详情 img
充值方式
【2026-6-8】2026 ChatGPT Plus 充值方案横向测评
| 充值方案 | 成功率 | 支付方式 | 封号风险 | 推荐指数 |
|---|---|---|---|---|
| 官方外币卡直充 | 5% | 国际信用卡 | 极低 | ★★☆☆☆ |
| 虚拟信用卡 (VC) | 40% | 购 U/虚拟卡 | 中(易连坐) | ★★★☆☆ |
| 官方代充 | 100% | 支付宝/微信 | 零风险 (iOS 渠道) | ★★★★★ |
Anthuropic 账户注册
【2026-6-10】Claude Pro 账号申请方法 (2026.06创建)
核心思路
a. 获得海外版 AppleID (Claude Pro 目前推荐 尼日利亚区)
b. 使用 iphone 登录 App Store (注意是使用新注册的AppleID登录 App Store;不是切换设备的完整AppleID,不涉及iCloud等功能),下载iphone版 Claude APP。需要科学上网环境,最好是美国IP。
c. 验证账号具备订阅Claude Pro 资格后,闲鱼购买尼日利亚礼品卡(目前是 14,999奈拉),充值进app store的AppleID中。
d. 在 iphone 版 Claude APP 中完成 Claude Pro 订阅。
部分技巧
a. 尼日利亚身份信息参考地址生成器,注意要生成一个成年人的信息
b. AppleID 注册使用 protonmail 比较容易通过,电话号码没在AppleID体系中高频使用。
c. AppleID 注册完成, 尽快在网页版 icloud 中放入小文件或图像,代表账户已经开始使用。
d. App Store 使用问题可以联系Apple在线客服。包括但不限于 “Your Purchase Could Not be Completed” 问题
e. Apple 礼品卡直接找闲鱼购买即可,黑卡概率极小,因为实际付款是高于面值费用的汇率换算的。
- 2026.06.08 尼日利亚区Claude Pro的汇率换算是 75元人民币;土耳其区的ChatGPT Plus的汇率换算是 74元人民币。
- app 订阅价格查询
- AI 订阅价格市场 f. App Store 封号退款政策:第一次退款申请全额退款,之后所有申请全部拒绝。 g. App Store 所有区订阅 Claude Pro 稳定性是一样的,是最稳的方式。Claude封号跟使用方式强相关。
参考资料 a. 视频教程1 注册AppleID b. 视频教程2 方法二展示的是美区订阅,其实尼区更好
OpenAI 账户注册
国内无法注册账户,怎么办?
流程总结
前置条件
前提条件:
- 1、一个邮箱账号
- 非163,OpenAI会提示无法注册
- 2、能够科学上网,具备代理网络的环境。
- 3、国外手机号,用于接收注册验证码。
- 如果没有,通过第三方接码平台来注册国外手机号,支付宝要有 1.5 元人民币。
- gv(google voice虚拟号)不行
- 接码平台推荐:sms-activate
注册短信平台并充值
- 先注册在线接受短信的虚拟号码 - SMS-Activate,注册好之后进行对应的充值
详见站内专题海外手机号
【2023-1-30】一文教你快速注册OpenAI(ChatGPT),国内也可以
【2023-5-2】虚拟号被OpenAI禁掉
Your account was flagged for potential abuse. If you feel this is an error, please contact us at help.openai.com

精简流程
注册OpenAI账户
- OpenAI注册页面,错误信息及对应解法
- Signup is currently unavailable, please try again later. 某些国家限制,需要开全局代理
- Too many signups from the same IP 同一个ip注册限制
- 邮箱认证:输入邮箱账户,一般用gmail,平台发送邮件
- 注意别用163邮箱(提示不可用), qq邮箱可以
- 使用vpn切到国外(香港不行),否则:OpenAI’s API is not available in your country
- img
- 手机认证:打开邮件,启动手机认证
- 填入激活码后,注册成功
- 登录OpenAI
OpenAI API 调用
官方 API 覆盖:Text completion 、Code completion、Chat completion、Image completion、Fine-tuning、Embedding、Speech to text、Moderation
- Chat completion
- 【2023-3-2】刚发布没一会儿,api被禁,出现443错误,gpt-3.5-turbo刚被禁了,GPT-3的api也连累了
- 提交到OpenAI社区
- OpenAI提供的应用示例集合
Rate limits are measured in three ways:
RPM(requests per minute) 每分钟请求量RPD(requests per day) 每天请求量TPM(tokens per minute) 每分钟token数
openai tool
shell 使用
export OPENAI_API_KEY="your_api_key_here"
openai Python 工具包
| 参数 | 通俗解释 | 推荐设置 |
|---|---|---|
model |
大脑型号。选择你要调用的模型,如 gpt-4o(聪明、贵)、gpt-3.5-turbo(快、便宜)。 | 根据需求选 |
temperature |
创造力/随机性。 • 0 (低):严谨、确定。适合做数学题、写代码。 • 1 (高):发散、有创意。适合写小说、写诗。 |
默认 0.7 |
max_tokens |
回答长度限制。限制 AI 最多生成多少个词(Token)。防止它啰嗦个没完,或者为了省钱。 | 默认不限 |
stream |
打字机模式。 • False:等 AI 写完所有字,一次性返回(延迟高)。 • True:AI 写一个字返回一个字(体验好,像聊天一样)。 |
聊天推荐 True |
旧版: <= 0.28
pip install openai==0.28.1
重要变量,定义文件: init.py#L50
注意
- 【2023-10-10】openai工具包变量修改后,会被覆盖,如果想恢复,记得重置(需要恢复4个参数)
import openai
openai.api_base # 服务器url地址, https://api.openai.com/v1
openai.api_key # 取值是 openai key
openai.api_type # 类型, open_ai, 或微软的 azure
openai.api_version # 版本, 支持两种取值 2020-10-01, 2020-11-07, 微软是 2023-03-15-preview
# ------ 重置官方配置 -------
openai.api_type = 'open_ai'
openai.api_base = 'https://api.openai.com/v1'
openai.api_key = "sk-******"
openai.api_version = '2020-11-07'
print(openai.api_base, openai.api_key, openai.api_type, openai.api_version, openai.app_info)
# ------ 源码 ------
api_key = os.environ.get("OPENAI_API_KEY")
# Path of a file with an API key, whose contents can change. Supercedes `api_key` if set. The main use case is volume-mounted Kubernetes secrets, which are updated automatically.
api_key_path: Optional[str] = os.environ.get("OPENAI_API_KEY_PATH")
organization = os.environ.get("OPENAI_ORGANIZATION")
api_base = os.environ.get("OPENAI_API_BASE", "https://api.openai.com/v1")
api_type = os.environ.get("OPENAI_API_TYPE", "open_ai")
api_version = os.environ.get(
"OPENAI_API_VERSION",
("2023-05-15" if api_type in ("azure", "azure_ad", "azuread") else None),
)
verify_ssl_certs = True # No effect. Certificates are always verified.
proxy = None
app_info = None
新版: >= 1
OpenAI 新工具包 openai-python, httpx 驱动的 REST API,Python 3.9+
- 官方文档 API Overview
- 【2025-6-20】详细解读:OpenAI Responses API vs Chat Completions API 深度解析
包含两个api
- Responses API:引入了服务端状态管理,亮点:
- store: true 启用服务端状态存储
- previous_response_id 继续之前的对话
- 内置工具无需额外配置
- Chat Completions API :目前行业标准,采用无状态设计
- 每次请求需要发送完整对话历史
- 客户端负责维护会话状态
- 工具调用要手动处理返回结果
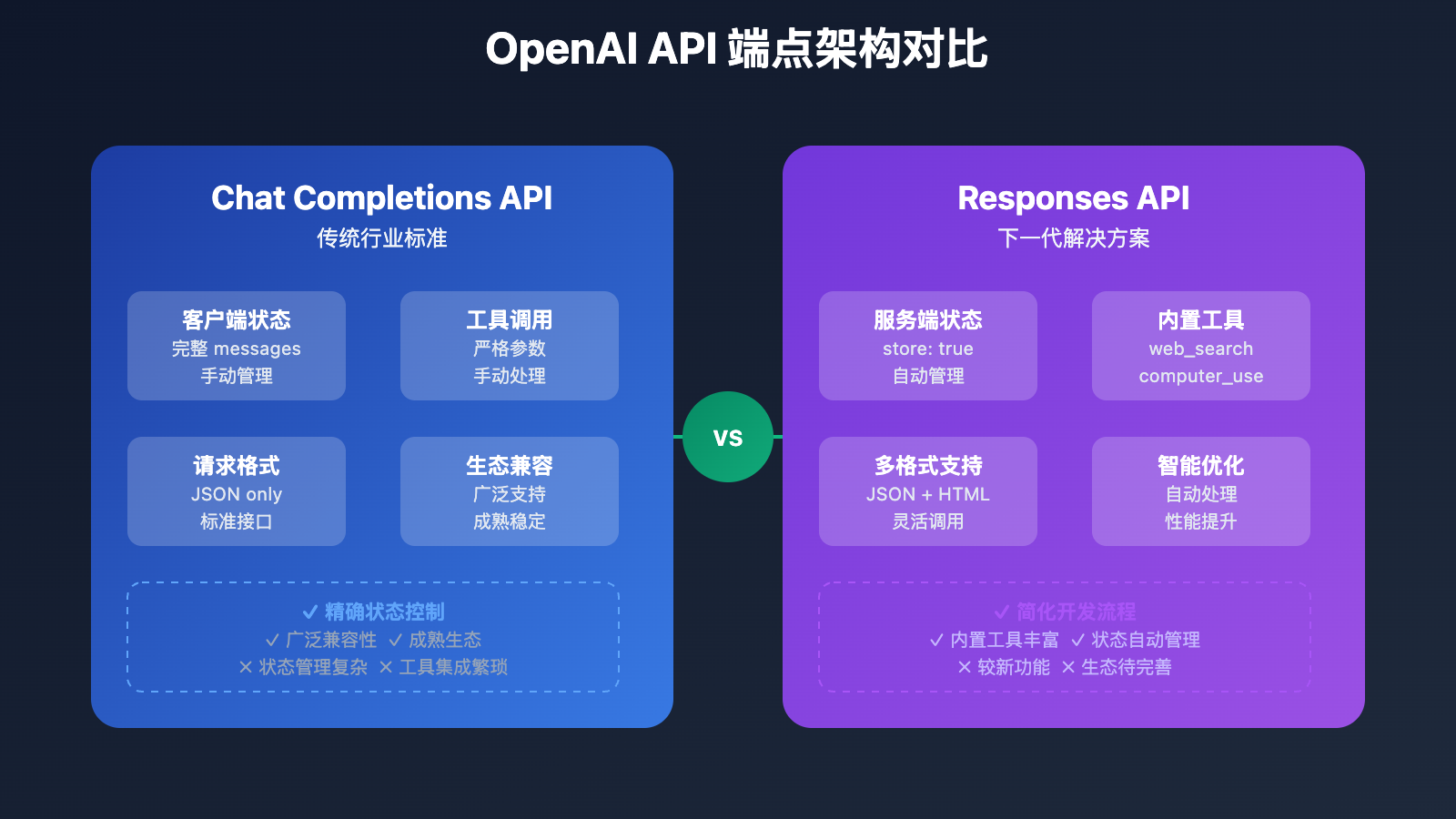
| 特性 | Chat Completions API | Assistants API | Responses API |
|---|---|---|---|
| 状态管理 | ❌ 无状态(客户端自行管理完整对话历史) | ✅ 云端托管 | 服务端管理状态,⚡ 链式引用 |
| 复杂度 | 简单 | 复杂(多步骤) | 中等 |
| 上下文长度 | 受限于 messages 数组 |
超长(云端存储) | 链式累积 |
| 工具调用 | 仅 Function Calling,需要手动设置 | 内置代码解释器+文件检索 | 内置工具执行和状态跟踪,如 web_search、file_search、computer_use |
| 文件处理 | ❌ 不支持 | ✅ 支持上传 | ✅ 支持 |
| 结构化输出 | response_format,稳定性一般 |
- | text_format,解析更稳定 |
| 流式输出 | ✅ 支持 | ✅ 支持 | ✅ 支持 |
| 成本 | 按 token 计费 | 按 token + 存储计费 | 按 token 计费 |
| 适用 | 通用对话 | 复杂助手/文件处理 | 现代 Agent 应用 |
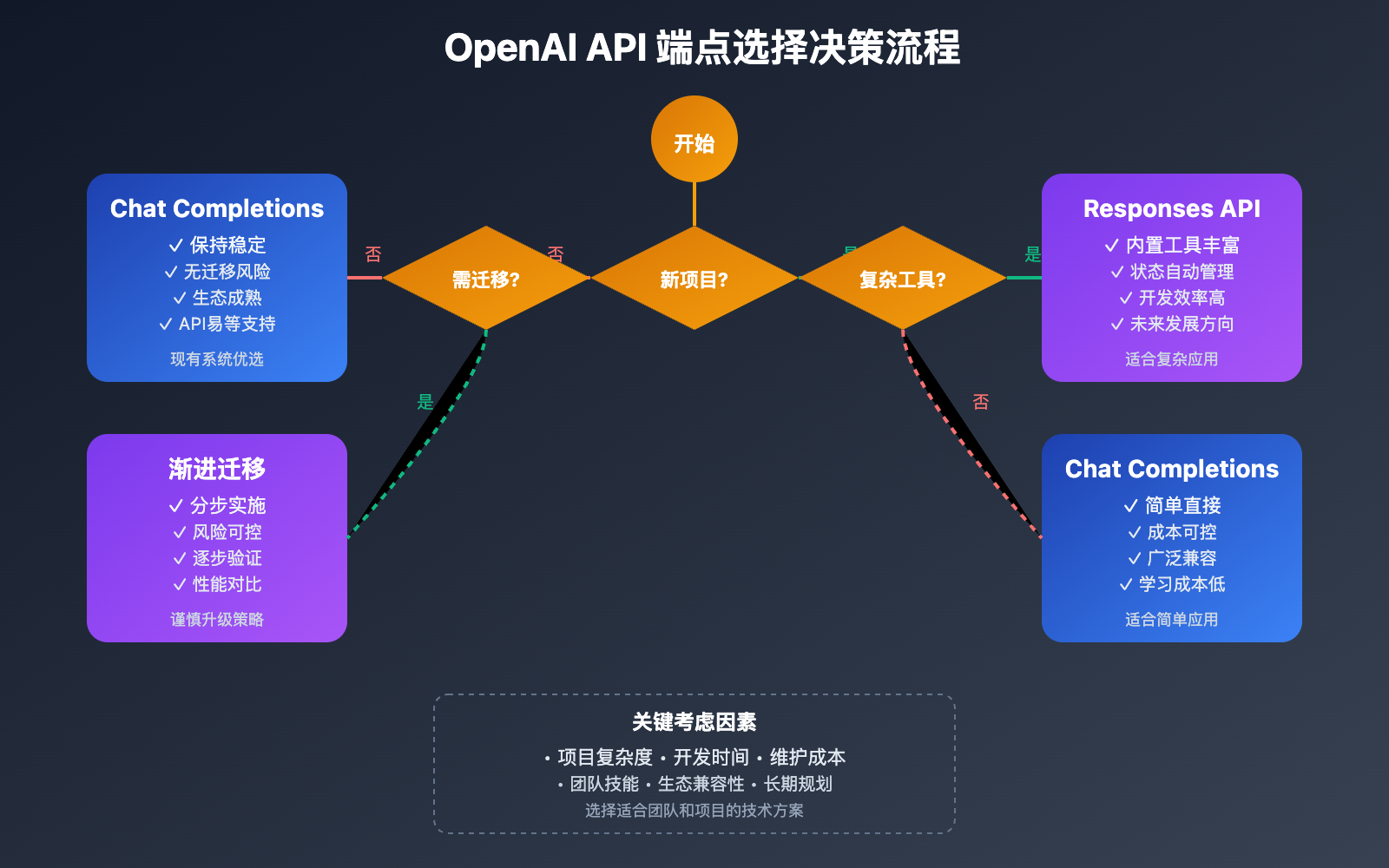
适用场景
- Chat API: 最灵活,适合自建系统
- Assistants API: 功能最全,适合复杂助手
- Responses API: 最新最简洁,Agent 开发首选
| 应用场景 | 适用对象 | Chat Completions 优势 | Assistants API | Responses API 优势 |
|---|---|---|---|---|
| 🎯 简单问答系统 | 初学者、小型项目 | 实现简单,成本可控 | 文件处理+代码执行 | 状态管理更便捷 |
| 🚀 复杂对话机器人 | 企业级应用 | 状态控制精确 | - | 大幅简化开发复杂度 |
| 💡 数据提取应用 | 结构化数据处理 | 基础解析功能 | - | 结构化输出更稳定 |
| 🔧 工具集成应用 | 自动化系统 | 灵活的自定义工具 | - | 内置工具开箱即用 |
| 🤖 多轮协作任务 | AI Agent 系统 | 精确的状态管理 | - | 自动化的上下文处理 |
response 接口
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
input="Write a one-sentence bedtime story about a unicorn."
)
print(response.output_text)
新版以面向对象方式运行,支持异步请求
测试代码
# uv run test.py
import openai
base_url = "http://llm-proxy.test"
api_key = 'sk-YO9j--***'
model_name = 'kimi-k2.5-external'
client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
print(f'【chat】接口')
response = client.chat.completions.create(
model=model_name,
messages = [
{
"role": "user",
"content": "你是谁"
}
]
)
print(response.choices[0].message.content)
print(f'【Response】接口')
response = client.responses.create(
model=model_name,
instruction='你是wqw的个人助手',
input="你是谁"
)
print(response.output_text)
【2023-11-6】微软说明
2023 年 11 月 6 日开始,pip install openai 和 pip install openai --upgrade 将安装 OpenAI Python 库 version 1.x。
- 从 version 0.28.1 升级到 version 1.x 是一项中断性变更,需要测试和更新代码
接口升级
- 旧版: <= 0.28,
client.ChatCompletion.create - 新版: >= 1.0.0,
client.chat.completions.create
import os
from openai import OpenAI
client = OpenAI()
OpenAI.api_key = os.getenv('OPENAI_API_KEY')
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message.content)
API 返回的 JSON 数据中,最重要的是 choices 字段。
choices:这是一个列表,通常包含一个或多个生成的回答(如果你设置了 n > 1)。message:在 choices 里面,你会找到 message 对象。content:这才是真正的“干货”——AI 生成的具体文本内容。
{
"id": "chatcmpl-123",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "你好!我是 GPT-4,一个由 OpenAI 训练的人工智能助手。"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 25,
"completion_tokens": 18,
"total_tokens": 43
}
}
langchain_openai
langchain 对 openai 工具包的集成、封装
用法
安装
pip install langchain_openai langchain
代码
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(
model='deepseek-chat',
openai_api_key=api_key,
openai_api_base='https://api.deepseek.com',
max_tokens=1024
)
Embedding
- Embeddings are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts.
- The new model,
text-embedding-ada-002, replaces five separate models fortext search,text similarity, andcode search, and outperforms our previous most capable model,Davinci, at most tasks, while being priced 99.8% lower. 
【2022-1-25】Introducing text and code embeddings
Embeddings are useful for working with natural language and code, because they can be readily consumed and compared by other machine learning models and algorithms like clustering or search.


The new /embeddings endpoint in the OpenAI API provides text and code embeddings with a few lines of code
import openai
response = openai.Embedding.create(
input="canine companions say",
engine="text-similarity-davinci-001")
curl调用
OPENAI_API_KEY="sk-******"
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-ada-002"
}'
返回格式:
- 1536 维
{
"data": [
{
"embedding": [
0.002092766109853983,
...
0.0026526579167693853
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-ada-002-v2",
"object": "list",
"usage": {
"prompt_tokens": 12,
"total_tokens": 12
}
}
python调用
限速
- requests per min. Limit: 60 / min
import openai
response = openai.Embedding.create(
input="porcine pals say",
model="text-embedding-ada-002"
)
# 限速, 每次请求后休息1s
import time
time.sleep(1)
改进版
import openai
openai.api_key = "sk-***"
def emb(text):
"""
embedding
"""
res = {"code":0, "msg":"-", "data":{}}
if not text:
#print(f"输入为空!{text}")
res.update({'code':-1, 'msg':'输入为空'})
return res
# 调用 api
response = openai.Embedding.create(
input=text,
model="text-embedding-ada-002"
)
return response['data'][0]['embedding']
def chat(text, model_name='gpt-3.5-turbo'):
"""
openai chat 调用
"""
res = {"code":0, "msg":"-", "data":{}}
if not text:
#print(f"输入为空!{text}")
res.update({'code':-1, 'msg':'输入为空'})
return res
# 调用 chatgpt
completion = openai.ChatCompletion.create(
#model="gpt-4",
#model="gpt-3.5-turbo",
model=model_name,
max_tokens=100,
temperature=1.2,
messages=[{
"role": "user", # role (either “system”, “user”, or “assistant”)
"content": text}]
)
res['data']['role'] = completion['choices'][0]['message']['role']
res['data']['content'] = completion['choices'][0]['message']['content']
return f"[{res['data']['role']}] {res['data']['content']}"
#print(completion)
if __name__ == '__main__':
test = "你好,你支持哪些插件"
res = chat(test)
print(res)
res = emb(test)
print(len(res))
go 调用
// go get github.com/sashabaranov/go-openai
package main
import (
"context"
"fmt"
openai "github.com/sashabaranov/go-openai"
)
func main() {
client := openai.NewClient("your token")
resp, err := client.CreateChatCompletion(
context.Background(),
openai.ChatCompletionRequest{
Model: openai.GPT3Dot5Turbo,
Messages: []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleUser,
Content: "Hello!",
},
},
},
)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
ChatGPT 调用
API有两种方案
- 使用ChatGPT:浏览器调试,获取access_token,模拟登录后调用
- 使用gpt 3 官方api
- ChatGPT api:GPT-3.5
内测过程中调用是免费的,没有次数限制。此外,API接口调用不需要梯子或代理(使用代理反而可能会报错“Error communicating with OpenAI”),只需要API Key就可以了,且当前API Key使用免费。
现有大多数 ChatGPT API 实际上是 OpenAI GPT3 模型接口,模型名称为“text-davinci-003”,
安装使用
pip install OpenAI # 安装OpenAI
pip show OpenAI # 查看版本 Version: 0.8.0
pip install -U OpenAI # 更新,解决问题:module 'OpenAI' has no attribute 'Image',python 3.8以上才行
GPT-3接口(Completion)
Completion Python 接口
import os
import OpenAI
print("欢迎使用ChatGPT智能问答,请在Q:后面输入你的问题,输入quit退出!")
OpenAI.api_key = "<OpenAI_key>" # 填上你自己的API,或者把API加入系统的环境变量。
start_sequence = "\nA:"
restart_sequence = "\nQ: "
while True:
prompt = input(restart_sequence)
if prompt == 'quit':
break
else:
try:
response = OpenAI.Completion.create(
model="text-davinci-003", # 使用davinci-003的模型,准确度更高。
prompt = prompt,
temperature=1,
max_tokens=2000, # 限制回答长度,可以限制字数,如:写一个300字作文等。
frequency_penalty=0,
presence_penalty=0
)
print(start_sequence,response["choices"][0]["text"].strip())
except Exception as exc: #捕获异常后打印出来
print(exc)
或
import os
import OpenAI
OpenAI.api_key = os.getenv("OpenAI_API_KEY")
# ------- 文本生成 ---------
prompt = """We’re releasing an API for accessing new AI models developed by OpenAI. Unlike most AI systems which are designed for one use-case, the API today provides a general-purpose “text in, text out” interface, allowing users to try it on virtually any English language task. You can now request access in order to integrate the API into your product, develop an entirely new application, or help us explore the strengths and limits of this technology."""
response = OpenAI.Completion.create(model="davinci", prompt=prompt, stop="\n", temperature=0.9, max_tokens=100)
# ------- 其它应用 ---------
response = OpenAI.Completion.create(
engine="davinci",
prompt="The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly.\n\nHuman: Hello, who are you?\nAI: I am an AI created by OpenAI. How can I help you today?\nHuman: I'd like to cancel my subscription.\nAI:",
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["\n", " Human:", " AI:"]
)
print(response)
requests调ChatGPT
- 用requests实现的调用接口
import requests,json
api_key="<OpenAI_key>" # 设置自己的API密匙
prompt = "" # 设置prompt初始值
# 设置headers
headers = {"Authorization":f"Bearer {api_key}"}
# 设置GPT-3的网址
api_url = "https://api.OpenAI.com/v1/completions"
#设置循环可以持续发问
while prompt != 'quit':
prompt = input("Q: ")
#设置请求参数
data = {'prompt':prompt,
"model":"text-davinci-003",
'max_tokens':128,
'temperature':1,
}
#发送HTTP POST请求
response = requests.post(api_url,json = data,headers = headers)
#解析响应
resp = response.json()
print("A:",resp["choices"][0]["text"].strip(),end="\n")
ChatGPT(GPT 3.5)接口
【2023-3-2】OpenAI 提供 ChatGPT API(gpt-3.5-turbo),单次调用费用是 text-davinc-003 的 1/10
API_KEY 不要明文写代码里调用,会被OpenAI封禁
代码调用
shell 版本
OPENAI_API_KEY="sk-***"
# 腾讯云函数
# curl https://service-4jhtjgo0-1317196971.hk.apigw.tencentcs.com/release \
curl https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" -H "Content-Type: application/json" \
-d '{ "model": "gpt-3.5-turbo", "messages": [{"role": "user", "content": "What is the OpenAI mission?"}] }'
python 版本
import openai
# openai.api_type = 'open_ai'
# openai.api_base = 'https://api.openai.com/v1'
# openai.api_key = "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"
# openai.api_version = '2020-11-07'
# print(openai.api_base, openai.api_key, openai.api_type, openai.api_version, openai.app_info)
openai.api_key = 'sk-***'
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
# ---- function call -----
# functions = function_list, # 设置函数调用
# function_call="auto", # 开启function call
messages=[{
"role": "user", # role (either “system”, “user”, or “assistant”)
"content": "你好,吃了吗"}]
)
print(completion['choices'][0]['message']['role'], completion['choices'][0]['message']['content'])
print(completion)
gradio web
Web UI: 基于 gradio, code
import os
from functools import partial
import gradio as gr
import openai
class Messages_lst:
def __init__(self):
self.memory = []
def update(self, role,message):
if role == "user":
user_turn = {"role": "user","content":message}
self.memory.append(user_turn)
elif role == "assistant":
gpt_turn = {"role": "assistant","content":message}
self.memory.append(gpt_turn)
def get(self):
return self.memory
messages_lst = Messages_lst()
def get_response(api_key_input, user_input):
# print(api_key_input)
print(user_input)
messages_lst.update("user", user_input)
messages = messages_lst.get()
openai.api_key = api_key_input
MODEL = "gpt-3.5-turbo"
print(messages)
response = openai.ChatCompletion.create(
model=MODEL,
messages = messages,
temperature=0.5)
assistant = response['choices'][0]['message']['content']
messages_lst.update("assistant", assistant)
# return assistant
# 生成HTML字符串
html_string = ""
for message in messages_lst.get():
if message["role"] == "user":
html_string += f"<p><b>User:</b> {message['content']}</p>"
else:
html_string += f"<p><b>Assistant:</b> {message['content']}</p>"
return html_string
def main():
# api_key = os.environ.get("OPENAI_API_KEY")
api_key_input = gr.components.Textbox(
lines=1,
label="Enter OpenAI API Key",
type="password",
)
user_input = gr.components.Textbox(
lines=3,
label="Enter your message",
)
output_history = gr.outputs.HTML(
label="Updated Conversation",
)
inputs = [
api_key_input,
user_input,
]
iface = gr.Interface(
fn=get_response,
inputs=inputs,
outputs=[output_history],
title="GPT WebUi",
description="A simple chatbot using Gradio",
allow_flagging="never",
)
iface.launch()
if __name__ == '__main__':
main()
网页调用
web demo
Gradio web demo
- DEMO examples
import gradio as gr
import openai
openai.api_key = "sk-**"
def question_answer(role, question):
if not question:
return "输入为空..."
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{
"role": "user", # role (either “system”, “user”, or “assistant”)
"content": question}
]
)
# 返回信息
return (completion['choices'][0]['message']['role'], completion['choices'][0]['message']['content'])
gr.Interface(fn=question_answer,
# inputs=["text"], outputs=['text', "textbox"], # 简易用法
inputs=[gr.components.Dropdown(label="Role", placeholder="user", choices=['system', 'user', 'assistant']),
gr.inputs.Textbox(lines=5, label="Input Text", placeholder="问题/提示语(prompt)...")
],
outputs=[gr.outputs.Textbox(label="Role"), gr.outputs.Textbox(label="Generated Text")],
# ["highlight", "json", "html"], # 定制返回结果格式,3种输出分别用3种形式展示
examples=[['你是谁?'], ['帮我算个数,六乘5是多少']],
cache_examples=True, # 缓存历史案例
title="ChatGPT Demo",
description="A simplified version of DEMO [examples](https://gradio.app/demos/) "
).launch(share=True) # 启动 临时分享模式
#).launch() # 仅本地访问
ChatGPT 网页版
原方案:
- 从 ChatGPT页面 获取 session_token,使用 revChatGPT 直接访问web接口
- 但随着 ChatGPT 接入 Cloudflare 人机验证,这一方案难以在服务器顺利运行。
登陆 OpenAI官网, 然后通过按下F12,进到调试模式,找到session_token
通过access_token来访问ChatGPT
from asyncChatGPT.asyncChatGPT import Chatbot
import asyncio
config = {
"Authorization":"eyJhbGciOiJSUzI1NiIs....85w"
}
chatbot = Chatbot(config, conversation_id=None)
while 1 == 1:
text = input('Q:')
if text == 'quit':
break
else:
message = asyncio.run(chatbot.get_chat_response(text))['message']
print('A:',message)
通过session_token来访问ChatGPT
from revChatGPT.revChatGPT import Chatbot
config = {
"email": "<YOUR_EMAIL>",
"password": "<YOUR_PASSWORD>",
"session_token": "eyJhbGciOiJkaXIiLCJl....7Q"
}
chatbot = Chatbot(config, conversation_id=None)
while 1==1:
text = input("Q:")
if text == 'quit':
break
else:
response = chatbot.get_chat_response(text, output="text")
print('A:',response['message'])
python flask 搭建 web 服务
- 安装组件:flask、flask-cors、gunicorn
- 服务端代码:callOpenAI.py文件
- 启动服务:python callOpenAI.py,然后通过浏览器访问:http://xx.xx.xx.xx:xxxx/callChatGPT?input=what is your name来进行开发调测
- 创建 wsgi.py,供gunicorn使用
- 创建 gunicorn.conf 文件
- 启动 gunicorn,正式投产调用接口
python组件
- (1)因为打算用python的flask进行快速的服务端调用,安装flask : pip install flask
- (2)为解决跨域问题安装 flask cros: pip install flask-cors
- (3)安装专门针对flask的web服务进程gunicron:pip install gunicorn
from flask import Flask,request
from flask_cors import CORS
import os
import openai
app = Flask(__name__)
CORS(app,supports_credentials=True)
@app.route('/',methods=['GET','POST'])
def hello_world():
text=request.args.get('text')
return text
@app.route('/callChatGPT',methods=['GET','POST'])
def callChatGPT():
input = request.args.get('input')
openai.api_key = "xxxxxxxx"
#openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(model="text-davinci-003",prompt=input,temperature=0.5,max_tokens=500)
return response.choices[0].text
if __name__ == "__main__":
app.run(host='xx.xx.xx.xx',port=xxxx,debug=True)
wsgi.py
from callOpenAI import app
if __name__ == "__main__":
app.run()
同一目录下创建gunicorn.conf文件,内容如下:
bind = "xx.xx.xx.xx:xxxx"
workers = 10
errorlog = "/var/www/chatGPT/gunicorn.error.log"
loglevel = "debug"
proc_name = "callChatGPT"
执行如下命令,即可以正式投产调用接口。
gunicorn --config gunicorn.conf wsgi:app
前端调用的时候,直接使用ajax可能会出现跨域调用问题,先要如前所示安装flask-cors,然后在代码中进行配置即可解决
<html>
<head>
<meta charset="utf-8" />
<title>chatGPT-AI问答系统</title>
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.4.1/jquery.min.js"></script>
<style>
.question-container {
padding: 10px;
}
.questions {
padding: 10px;
}
.answers {
padding: 10px;
}
</style>
</head>
<body>
<div class="question-container">
<h2>安联资管-chatGPT-AI问答系统</h2>
<form>
<div class="questions">
<label>Questions:</label>
<input type="text" id="question" name="提问" placeholder="在这里提问..."/>
</div>
<div class="answers">
<label>Answers:</label>
<textarea name="回答" disabled placeholder ="答案将展示在这里..." ></textarea>
</div>
<input type="submit" value="提交"/>
</form>
</div>
<script>
$(document).ready(function(){
// Submit button click event
$('form').on('submit', function(event){
event.preventDefault();
// Send the data to flask
$.ajax({
url: 'http://xx.xx.xx.xx:xxxx/callChatGPT', // enter your flask endpoint here
type: "GET",
data: "input="+$('#question').val(),
dataType: 'text',
success: function(response) {
console.log(JSON.stringify(response))
// check response and update answer box
if (response) {
alert("success");
$('.answers textarea').val(response);
} else {
alert("没有找到答案,请重新提问.");
}
},
error: function(xhr) {
alert("异常: " + xhr.status + " " + xhr.statusText);
}
});
});
});
</script>
</body>
</html>
注意,因服务端接口callChatGPT返回的是response.choices[0].text,是文本类型,因此前端的传入参数dataType要是text,response直接当成文本使用就可以了,不用再去解析,否则会报错。
js+html
网页形式调用
<html>
<script src="https://unpkg.com/vue@3/dist/vue.global.js"></script>
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
<head>
<title> ChatGPT Demo </title>
</head>
<body>
<div id="app" style="display: flex;flex-flow: column;margin: 20 ">
<scroll-view scroll-with-animation scroll-y="true" style="width: 100%;">
<!-- 用来获取消息体高度 -->
<view id="okk" scroll-with-animation>
<!-- 消息 -->
<view v-for="(x,i) in msgList" :key="i">
<!-- 用户消息 头像可选加入-->
<view v-if="x.my" style="display: flex;
flex-direction: column;
align-items: flex-end;">
<view style="width: 400rpx;">
<view style="border-radius: 35rpx;">
<text style="word-break: break-all;"></text>
</view>
</view>
</view>
<!-- 机器人消息 -->
<view v-if="!x.my" style="display: flex;
flex-direction: row;
align-items: flex-start;">
<view style="width: 500rpx;">
<view style="border-radius: 35rpx;background-color: #f9f9f9;">
<text style="word-break: break-all;"></text>
</view>
</view>
</view>
</view>
<view style="height: 130rpx;">
</view>
</view>
</scroll-view>
<!-- 底部导航栏 -->
<view style="position: fixed;bottom:0px;width: 100%;display: flex;
flex-direction: column;
justify-content: center;
align-items: center;">
<view style="font-size: 55rpx;display: flex;
flex-direction: row;
justify-content: space-around;
align-items: center;width: 75%;
margin: 20;">
<input v-model="msg" type="text" style="width: 75%;
height: 45px;
border-radius: 50px;
padding-left: 20px;
margin-left: 10px;background-color: #f0f0f0;" @confirm="sendMsg" confirm-type="search"
placeholder-class="my-neirong-sm" placeholder="用一句简短的话描述您的问题" />
<button @click="sendMsg" :disabled="msgLoad" style="height: 45px;
width: 20%;;
color: #030303; border-radius: 2500px;"></button>
</view>
</view>
</view>
</div>
</body>
</html>
<script>
const { createApp } = Vue
createApp({
data() {
return {
//api: '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',
api: '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',
msgLoad: false,
anData: {},
sentext: '发送',
animationData: {},
showTow: false,
msgList: [{
my: false,
msg: "你好我是OpenAI机器人,请问有什么问题可以帮助您?"
}],
msgContent: "",
msg: ""
}
},
methods: {
sendMsg() {
// 消息为空不做任何操作
if (this.msg == "") {
return 0;
}
this.sentext = '请求中'
this.msgList.push({
"msg": this.msg,
"my": true
})
console.log(this.msg);
this.msgContent += ('YOU:' + this.msg + "\n")
this.msgLoad = true
// 清除消息
this.msg = ""
axios.post('https://api.OpenAI.com/v1/completions', {
prompt: this.msgContent, max_tokens: 2048, model: "text-davinci-003"
}, {
headers: { 'content-type': 'application/json', 'Authorization': 'Bearer ' + this.api }
}).then(res => {
console.log(res);
//let text = res.data.choices[0].text.replace("OpenAI:", "").replace("OpenAI:", "").replace(/^\n|\n$/g, "")
//let text = res.data.choices[0].text.replace(/^\n|\n$/g, "");
let text = res.data.choices[0].text.replace("\n", "<br>").replace(" ", " ");
console.log(text);
this.msgList.push({
"msg": text,
"my": false
})
this.msgContent += (text + "\n")
this.msgLoad = false
this.sentext = '发送'
})
},
}
}).mount('#app')
</script>
手机app
【2023-2-11】CCTV视频里,台湾人在演示 VoiceGPT,VoiceGPT APK Download (version 1.35) 下载地址 , 目前就安卓版,使用时需要代理
用kivy来编写手机界面版的ChatGPT
- kivy编写了一款在手机端访问的软件,目前软件的打包存在问题,只能在电脑端访问。
- 在Google的colab打包,但是打包后在安卓手机上安装成功,但是打开后就闪退,原因暂不明。
安装以下包:
python -m pip install docutils pygments pypiwin32 kivy.deps.sdl2 kivy.deps.glew
python -m pip install kivy.deps.gstreamer
python -m pip install kivy
python -m pip install kivy_examples
# 速度慢时,切换源
python -m pip install kivy -i https://pypi.tuna.tsinghua.edu.cn/simple
代码
from kivy.app import App
from kivy.core.window import Window
from kivy.uix.boxlayout import BoxLayout
from kivy.uix.textinput import TextInput
from kivy.uix.button import Button
import OpenAI
import pyperclip
class Application(BoxLayout):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.orientation = "vertical"
self.spacing = 5
self.padding = 5
self.create_widgets()
Window.bind(on_request_close=self.end_func) # 窗口关联函数,更容易关闭
OpenAI.api_key = "<OpenAI_key>" # 这里要替换成自己的api
def end_func(self,*args):
Window.close()
def create_widgets(self):
# 显示文本框
self.txinfo = TextInput(font_name='SIMSUN.TTC',font_size=18)
self.txinfo.text = "欢迎使用OpenAI. 作者:Gordon QQ/VX 403096966 Esc可以退出程序。"
# self.txinfocontainer = BoxLayout(orientation="vertical", size_hint_y=None)
self.add_widget(self.txinfo)
# 定义输入框
self.entry = TextInput(font_name='SIMSUN.TTC',font_size=18)
self.add_widget(self.entry)
# 定义按钮
self.btn = Button(text="发送请求", font_name ="SIMSUN.TTC",bold = True,font_size=20, on_release=self.button_func)
self.add_widget(self.btn)
self.btcopy = Button(text="复制回答", font_name ="SIMSUN.TTC",bold = True,font_size=20, on_release=self.button_copy)
self.add_widget(self.btcopy)
def button_copy(self, instance):
pyperclip.copy(self.txinfo.text)
def button_func(self, instance):
prompt = self.entry.text
if prompt !="":
model_engine = "text-davinci-003"
completions = OpenAI.Completion.create(
engine=model_engine,
prompt=prompt,
max_tokens=1024,
temperature=1,
)
message = completions.choices[0].text
self.txinfo.insert_text("\n\nQ: "+prompt+"\nA: "+message.strip())
self.entry.text = ''
class OpenAI(App):
def build(self):
return Application()
if __name__ == '__main__':
OpenAI().run()
自定义api
【2023-9-1】可以针对 openai工具包,设置 base_url,提升可控性
- 切换成内部服务 —— 突破访问限制
- 自定义 api key
- 调用方法同OpenAI,前提是 内部服务地址要按OpenAI规范实现接口
import openai
# http://10.154.44.82:9490/v1
openai.api_base = 'http://.....'
openai.api_key = "---"
案例
- 微软 azure cloud提供OpenAI服务
- 第三方代理,如:
- 优质稳定的OpenAI的API接口-xiaoyi-robot
OpenAI 工具包
import openai
openai.api_key = "sk-..."
openai.organization = "..."
# api 示例
completion = openai.Completion.create(
prompt="<prompt>",
model="text-davinci-003"
)
chat_completion = openai.ChatCompletion.create(
messages="<messages>",
model="gpt-4"
)
embedding = openai.Embedding.create(
input="<input>",
model="text-embedding-ada-002"
)
# batch 输入
inputs = ["A", "B", "C"]
embedding = openai.Embedding.create(
input=inputs,
model="text-embedding-ada-002"
)
Azure API
微软 Azure OpenAI 实现
- How to switch between OpenAI and Azure OpenAI endpoints with Python
- 使用 deployment_id/engine 替代 model 参数
import openai
openai.api_type = "azure"
openai.api_key = "..."
openai.api_base = "https://example-endpoint.openai.azure.com"
openai.api_version = "2023-05-15" # subject to change
# api 调用
# 使用 deployment_id/engine 替代 model 参数
completion = openai.Completion.create(
prompt="<prompt>",
deployment_id="text-davinci-003",
engine="text-davinci-003"
)
chat_completion = openai.ChatCompletion.create(
messages="<messages>",
deployment_id="gpt-4",
engine="gpt-4"
)
embedding = openai.Embedding.create(
input="<input>",
deployment_id="text-embedding-ada-002",
engine="text-embedding-ada-002"
)
# batch 输入
inputs = ["A", "B", "C"] #max array size=16
embedding = openai.Embedding.create(
input=inputs,
deployment_id="text-embedding-ada-002",
engine="text-embedding-ada-002"
)
简洁版
import os
import openai
openai.api_type = "azure"
openai.api_base = os.getenv("AZURE_OPENAI_ENDPOINT")
openai.api_key = os.getenv("AZURE_OPENAI_KEY")
openai.api_version = "2023-05-15"
response = openai.ChatCompletion.create(
engine="gpt-35-turbo", # engine = "deployment_name".
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
print(response)
print(response['choices'][0]['message']['content'])
【2023-11-6】微软说明
差异点:
import os
# 旧: import openai
from openai import AzureOpenAI
# 旧: 配置信息
# openai.api_type = "azure"
# openai.api_base = os.getenv("AZURE_OPENAI_ENDPOINT")
# openai.api_key = os.getenv("AZURE_OPENAI_KEY")
# openai.api_version = "2023-05-15"
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_KEY"),
api_version="2023-05-15"
)
# 旧: response = openai.ChatCompletion.create(
response = client.chat.completions.create(
# engine="gpt-35-turbo", # 旧: 模型参数名变化
model="gpt-35-turbo", # 新:
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
# print(response['choices'][0]['message']['content']) # 旧
print(response.choices[0].message.content)
GPT 微调
见站内专题:大模型微调
企业版
【2023-8-28】OpenAI 宣布推出 ChatGPT 企业版 (ChatGPT Enterprise),也是迄今为止最强大的 ChatGPT 版本。提供企业级安全和隐私、无限的高速 GPT-4 访问、用于处理更长输入的更长上下文窗口、高级数据分析功能、自定义选项等等。其目的是吸引更广泛的企业客户,并提高产品收入。
ChatGPT 企业版 取消了所有使用上限,并且执行速度提高了两倍。企业版中包含 32k 上下文,允许用户处理四倍长的输入或文件,还提供对高级数据分析的无限制访问。
“此功能使技术和非技术团队能够在几秒钟内分析信息,无论是金融研究人员处理市场数据、营销人员分析调查结果还是数据科学家调试 ETL 脚本。”
- 无限制访问 GPT-4(无使用上限)
- 更高速的 GPT-4 性能(速度提高 2倍)
- 无限制地访问高级数据分析(以前称为代码解释器)
- 32k token 上下文窗口,用于 4倍长的输入、文件或 follow-ups
- 可共享的聊天模板,供客户公司协作和构建通用工作流程
- 此外,ChatGPT 企业版提供了静态数据加密 (AES-256) 和传输中数据加密 (TLS 1.2+),并已经过 SOC 2 Type 1 的合规性审核和认证。
OpenAI 还保证,不会使用客户数据来训练 OpenAI 模型。
目前,ChatGPT 已有免费版、Plus 版和企业版三个订阅方案。但 OpenAI 尚未给出企业版的统一定价,具体将取决于每家公司的使用情况和用例,需要单独询价。
GPT-4 API
【2023-7-10】GPT-4无法使用
GPT-4 收费对比
【2023-3-23】GPT-4 API 接口调用及价格分析
横向比较一下几个模型的单价
- gpt-4 prompt 比 gpt-3.5-turbo贵了14倍,gpt-4 completion 比 gpt-3.5-turbo贵了29倍!假设prompt和completion的字数为1:4(实际中completion往往比prompt要长),那么gpt-4接口的综合成本是gpt-3.5-turbo的27倍!
- gpt-3.5-turbo $20美元能处理750万字,而相同金额在gpt-4中只能处理30万字左右
| 模型 | $0.06 | $0.03 | $0.002 | $0.02 | $0.002 | $0.0005 | $0.0004 |
|---|---|---|---|---|---|---|---|
| gpt-4(completion) | gpt-4(prompt) | gpt-3.5-turbo | davinci | curie | babbage | ada | |
| gpt-4(completion) | 0 | 1 | 29 | 2 | 29 | 119 | 149 |
| gpt-4(prompt) | -0.5 | 0 | 14 | 0.5 | 14 | 59 | 74 |
GPT-4 收费对比
| 模型名称 | 描述 | 最大token数 | 训练数据 |
|---|---|---|---|
| gpt-4 | 比 GPT-3.5 模型更强大,能够执行更复杂的任务,并针对聊天场景进行了优化。 会不断迭代更新。 | 8,192 | 截至2021年6月 |
| gpt-4-0314 | gpt-4的2023年3月14日快照版本。此模型在接下来3个月内不会更新,有效期截止2023年6月14日。 | 8,192 | 截至2019年10月 |
| gpt-4-32k | 与 gpt-4 功能相同,但上下文长度是gpt-4 的4 倍。会不断迭代更新。 | 32,768 | 截至2021年6月 |
| gpt-4-32k-0314 | gpt-4-32k的2023年3月14日快照版本。此模型在接下来3个月内不会更新,有效期截止2023年6月14日。 | 32,768 | 截至2019年10月 |
由于还在beta阶段,GPT-4 API的调用有频次限制:
- 40k tokens / 分钟
- 200 请求 / 分钟
这个频次对功能测试和概念验证来说已经足够了。
如果使用ChatGPT Plus体验GPT-4,有4小时100条消息的限制。
GPT-4 API的定价策略与之前模型不同。在GPT-4之前,接口定价按照token数统一收费,不区分是prompt的token还是生成响应的token。而GPT-4将prompt token和生成响应token分开计价,价格如下:
- $0.03美元 / 1K prompt token
- $0.06美元 / 1K 生成响应 token
这个价格相比 gpt-3.5-turbo 的 $0.002 / 1K tokens来说贵了至少15倍起。
GPT-4 API
【2023-3-24】GPT-4使用
【2023-5-20】升级plus上看不到gpt-4选项
GPT-4 API Models
- model = gpt-4
- model = gpt-4-32k
import OpenAI
# 直接以用户身份提问
messages=[{"role": "user", "content": As an intelligent AI model, if you could be any fictional character, who would you choose and why?}]
# 多个输入:提前传入系统话术
messages=[{"role": "system", "content": system_intel},
{"role": "user", "content": prompt}])
response = openai.ChatCompletion.create(
model="gpt-4", max_tokens=100,
#model="gpt-4-32k", max_tokens=32768,
temperature=1.2,
messages = message)
print(response)
第三方
from steamship import Steamship
# !pip install steamship
gpt = Steamship.use_plugin("gpt-4")
task = gpt.generate("你好")
task.wait()
ChatGPT 参数
api示例
# 终端命令
# OpenAI api completions.create -m text-davinci-003 -p "Say this is a test" -t 0 -M 7 --stream
import OpenAI
OpenAI.api_key = "你的API Key"
#openai.Model.list() # 显示可用model
response = OpenAI.Completion.create(
model="text-davinci-003", # 模型名称
prompt="how are you", # 问题
temperature=0.7, # 结果随机性,0-0.9 (稳定→随机)
max_tokens=256, # 最大字数,汉字两位
stream=False, # ChatGPT独有参数
top_p=1, # 返回概率最大的1个
frequency_penalty=0,
presence_penalty=0
)
# print(response)
for r in response:
res += r["choices"][0]["text"]
res = res.replace('<|im_end|>', '')
print(res)
返回结果如下所示,结果在text字段中,可通过 response[“choices”][0][“text”] 进行读取。
{
"id": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7",
"object": "text_completion",
"created": 1589478378,
"model": "text-davinci-003",
"choices": [
{
"text": "\n\nThis is indeed a test",
"index": 0,
"logprobs": null,
"finish_reason": "length"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 7,
"total_tokens": 12
}
}
【2023-2-11】GPT-3 Model 参数说明: 官网
| LATEST MODEL | DESCRIPTION | MAX REQUEST | TRAINING DATA |
|---|---|---|---|
text-davinci-003 |
Most capable GPT-3 model. Can do any task the other models can do, often with higher quality, longer output and better instruction-following. Also supports inserting completions within text. | 4,000 tokens | Up to Jun 2021 |
text-curie-001 |
Very capable, but faster and lower cost than Davinci. | 2,048 tokens | Up to Oct 2019 |
text-babbage-001 |
Capable of straightforward tasks, very fast, and lower cost. | 2,048 tokens | Up to Oct 2019 |
text-ada-001 |
Capable of very simple tasks, usually the fastest model in the GPT-3 series, and lowest cost. | 2,048 tokens | Up to Oct 2019 |
While Davinci is generally the most capable, the other models can perform certain tasks extremely well with significant speed or cost advantages. For example, Curie can perform many of the same tasks as Davinci, but faster and for 1/10th the cost.
We recommend using Davinci while experimenting since it will yield the best results. Once you’ve got things working, we encourage trying the other models to see if you can get the same results with lower latency. You may also be able to improve the other models’ performance by fine-tuning them on a specific task.
Older versions of our GPT-3 models are available as davinci, curie, babbage, and ada. These are meant to be used with our fine-tuning endpoints.
Your model can be one of: ada, babbage, curie, or davinci
各模型调用费用不同,davinci最贵,对比下来,只有最贵的 davinci 符合预期,18 刀的配额,算了一下大概也就问 1000 多个问题
如何查看可用模型?以Python接口调用为例
import requests
import json
headers = {'Authorization': f'Bearer {openai.api_key}'}
#payload = {'key1': 'value1', 'key2': 'value2'}
url = 'https://api.openai.com/v1/models' # 查看可用模型
#r = requests.get("http://httpbin.org/get", params=payload)
r = requests.get(url, headers=headers) # header
#print(r.url) # 请求网址
#print(r.encoding) # 编码
res = json.loads(r.text) # 返回内容
json.dumps(res)
# ------------------
import pandas as pd
import datetime
info_list = []
for m in res['data']:
tm = datetime.datetime.fromtimestamp(m['permission'][0]['created']).strftime('%Y-%m-%d %H:%M:%S')
out = [m['id'], # m['root'],
# m['permission'][0]['organization'],
tm, # m['permission'][0]['created'],
m['permission'][0]['allow_create_engine'],
m['permission'][0]['allow_sampling'],
m['permission'][0]['allow_logprobs'],
m['permission'][0]['allow_view'],
m['permission'][0]['allow_fine_tuning'],
m['permission'][0]['is_blocking'],
]
info_list.append(out)
#print('\t'.join(map(str, out)))
df = pd.DataFrame(info_list, columns=['id', 'create_time','allow_create_engine', 'allow_sampling',
'allow_logprobs', 'allow_view', 'allow_fine_tuning','is_blocking' ])
df.sort_values('create_time', ascending=False)
print(df.to_markdown()) # 输出为markdown格式
结果示例:
| id | model_id | create_time | allow_create_engine | allow_sampling | allow_logprobs | allow_view | allow_fine_tuning | is_blocking |
|---|---|---|---|---|---|---|---|---|
| 0 | babbage | 2022-11-22 10:51:41 | False | True | True | True | False | False |
| 1 | code-davinci-002 | 2023-02-11 05:26:08 | False | True | True | True | False | False |
| 2 | davinci | 2022-11-22 05:32:35 | False | True | True | True | False | False |
GPT-3 参数
GPT-3 模型调用方式,输入主要有7个参数:详见官网
- (1)
model:模型名称,text-davinci-003- string, Required
- ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them.
- (2)
prompt:问题或待补全内容,例如“how are you”。- string or array, Optional, Defaults to <|endoftext|> (分隔符,最为prompt初始值)
- The prompt(s) to generate completions for, encoded as a string, array of strings, array of tokens, or array of token arrays.
- Note that <|endoftext|> is the document separator that the model sees during training, so if a prompt is not specified the model will generate as if from the beginning of a new document.
- (3)
temperature:控制结果随机性,0.0表示结果固定,随机性大可以设置为0.9。- number, Optional, Defaults to 1
- What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
- We generally recommend altering this or top_p but not both.
- (4)
max_tokens:最大返回字数(包括问题和答案),通常汉字占两个token。假设设置成100,如果prompt问题中有40个汉字,那么返回结果中最多包括10个汉字。- ChatGPT API允许的最大token数量为 4097(大部分模型是2048),即max_tokens最大设置为4097减去prompt问题的token数量。
- max_tokens, integer, Optional, Defaults to 16
- The maximum number of tokens to generate in the completion. The token count of your prompt plus max_tokens cannot exceed the model’s context length. Most models have a context length of 2048 tokens (except for the newest models, which support 4096).
- (5)
top_p:设置为1即可- top_p, number, Optional, Defaults to 1
- An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
- We generally recommend altering this or temperature but not both.
n每个prompt生成几个结果(占用额度,慎用)- integer, Optional, Defaults to 1
- How many completions to generate for each prompt.
- Note: Because this parameter generates many completions, it can quickly consume your token quota. Use carefully and ensure that you have reasonable settings for
max_tokensandstop.
- (6)frequency_penalty:设置为0即可。
- (7)presence_penalty:设置为0即可。
- (8)
stream:是否采用控制流的方式输出。(ChatGPT新增)- (1)如果stream取值为False,那么返回结果与 GPT3接口一致,完全返回全部文字结果,可通过 response[“choices”][0][“text”]进行读取。但是,字数越多,等待返回时间越长,时间可参考控制流读出时的4字/每秒。
- (2)如果steam取值为True时,那么返回结果是一个 Python generator,需要通过迭代获取结果,平均大约每秒钟4个字(33秒134字,39秒157字),读取程序如下所示。可以看到,读取结果的结束字段为“<|im_end|>”。
- stream: boolean, Optional, Defaults to false
- Whether to stream back partial progress. If set, tokens will be sent as data-only server-sent events as they become available, with the stream terminated by a data: [DONE] message.
logprobs似然概率- logprobs: integer, Optional, Defaults to null
- Include the log probabilities on the logprobs most likely tokens, as well the chosen tokens. For example, if logprobs is 5, the API will return a list of the 5 most likely tokens. The API will always return the logprob of the sampled token, so there may be up to logprobs+1 elements in the response.
- The maximum value for logprobs is 5. If you need more than this, please contact us through our Help center and describe your use case.
suffix前缀- string, Optional, Defaults to null
- The suffix that comes after a completion of inserted text.
echo补写之外返回提示语- echo: boolean, Optional, Defaults to false
- Echo back the prompt in addition to the completion
stop停用句子(类似停用词),生成过程中不出现- stop: string or array, Optional, Defaults to null
- Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence.
presence_penalty出现惩罚- number, Optional, Defaults to 0
- Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model’s likelihood to talk about new topics.
frequency_penalty频率惩罚- number, Optional, Defaults to 0
- Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model’s likelihood to repeat the same line verbatim.
best_of- integer, Optional, Defaults to 1
- Generates
best_ofcompletions server-side and returns the “best” (the one with the highest log probability per token). Results cannot be streamed. - When used with n,
best_ofcontrols the number of candidate completions and n specifies how many to return –best_ofmust be greater than n. - Note: Because this parameter generates many completions, it can quickly consume your token quota. Use carefully and ensure that you have reasonable settings for max_tokens and stop.
logit_bias概率偏置- map, Optional, Defaults to null
- Modify the likelihood of specified tokens appearing in the completion.
- Accepts a json object that maps tokens (specified by their token ID in the GPT tokenizer) to an associated bias value from -100 to 100. You can use this tokenizer tool (which works for both
GPT-2andGPT-3) to convert text to token IDs. Mathematically, the bias is added to the logits generated by the model prior to sampling. The exact effect will vary per model, but values between -1 and 1 should decrease or increase likelihood of selection; values like -100 or 100 should result in a ban or exclusive selection of the relevant token. - As an example, you can pass {“50256”: -100} to prevent the <|endoftext|> token from being generated.
user用户标志符,便于OpenAI识别是否恶意调用- string, Optional
- A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more.
ChatGPT 参数详解
Chat
- Given a chat conversation, the model will return a chat completion response.
Request body,官方
model, string, Required 模型名称,必备- ID of the model to use. See the model endpoint compatibility table for details on which models work with the Chat API.
messages, array, Required prompt信息,必备- The messages to generate chat completions for, in the chat format.
temperature, number, Optional, Defaults to 1 温度,0-2, 高温(0.8)使结果更随机, 低温(0.2)更加稳定- What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
- We generally recommend altering this or top_p but not both.
top_p, number, Optional, Defaults to 1 采样策略, 超过top_p的字符才会考虑- An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
- We generally recommend altering this or temperature but not both.
n, integer, Optional, Defaults to 1 生成多少个回复- How many chat completion choices to generate for each input message.
stream, boolean, Optional, Defaults to false 流式输出,默认否- If set, partial message deltas will be sent, like in ChatGPT. Tokens will be sent as data-only server-sent events as they become available, with the stream terminated by a data: [DONE] message. See the OpenAI Cookbook for example code.
stop, string or array, Optional, Defaults to null 生成多少个字符后停止,最多4组参数- Up to 4 sequences where the API will stop generating further tokens.
max_tokens, integer, Optional, Defaults to inf 最长字符数- The maximum number of tokens to generate in the chat completion.
- The total length of input tokens and generated tokens is limited by the model’s context length.
presence_penalty, number, Optional, Defaults to 0 重复字符惩罚,-2~2, 正数时,惩罚已经出现过的字符- Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model’s likelihood to talk about new topics.
- See more information about frequency and presence penalties.
frequency_penalty, number, Optional, Defaults to 0 频次惩罚,-2~2, 正数时,已出现的字符按频率惩罚- Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model’s likelihood to repeat the same line verbatim.
- See more information about frequency and presence penalties.
logit_bias, map, Optional, Defaults to null 概率偏置,给特定字符增加置信度- Modify the likelihood of specified tokens appearing in the completion.
- Accepts a json object that maps tokens (specified by their token ID in the tokenizer) to an associated bias value from -100 to 100. Mathematically, the bias is added to the logits generated by the model prior to sampling. The exact effect will vary per model, but values between -1 and 1 should decrease or increase likelihood of selection; values like -100 or 100 should result in a ban or exclusive selection of the relevant token.
user, string, Optional 标记是否终端用户- A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more.
curl
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello!"}]
}'
Parameters
{
"model": "gpt-3.5-turbo",
"messages": [{
"role": "user",
"name": "Wang", // 新增
"content": "Hello!"
}]
}
【2023-6-24】name参数, openai官方解释
name
The name of the author of this message. name is required if role is function, and it should be the name of the function whose response is in the content. May contain a-z, A-Z, 0-9, and underscores, with a maximum length of 64 characters.
实测: name格式有要求(满足’^[a-zA-Z0-9_-]{1,64}$’),即便填了英文字符串,openai并没有当做用户名
- question: 你好, 知道我是谁吗
- answer: assistant 您好!很抱歉,作为人工智能助手,我没有能力识别您是谁。
Response
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?",
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}
GPT-3.5 Turbo 的微调可处理 4k 个 tokens——可达之前微调模型的 2 倍。早期测试人员还对模型本身的指令进行了微调,从而将提示词长度缩短达 90%,成功加快每次 API 调用的速度并降低了执行成本。
流式输出
流式输出的好处
- GPT 一边响应一边返回结果,流式输出,响应效率大大提升;
- 另一方面是显著提升了用户体验,给我们的感觉就像是真实的对话一样,GPT 似乎在思考问题的答案。
调用流程

【2023-8-28】如何丝滑实现 ChatGPT 打字机流式回复?
- Server-Sent Events: 服务端主动向客户端推送的技术,与 Websocket 有些类似,但是 SSE 并不支持客户端向服务端发送消息,即 SSE 为单工通信。
- 服务端与客户端建立了 长连接,服务端源源不断地向客户端推送消息。服务端就相当于河流的上游,客户端就相当于河流的下游,水往低处流,这就是 SSE 的流式传输。
- Web Socket
SDK有两个OpenAi客户端OpenAiClient和OpenAiStreamClient。
- OpenAiClient支持OpenAI的所有接口,支持阻塞式输出聊天模型(gpt3.5 、4.0)。
- OpenAiStreamClient支持OpenAI的流式输出聊天模型(gpt3.5 、4.0)。
推荐自定义OkHttpClient实现两个Client,公用一个OkHttpClient即可。
流式输出和阻塞输出类似,只需要创建OpenAiStreamClient传入自定义的EventSourceListener即可。
举例为默认的SDK实现:ConsoleEventSourceListener。
web实现参考:
| 流式输出实现方式 | 小程序 | 安卓 | ios | H5 |
|---|---|---|---|---|
| SSE示例参考:OpenAISSEEventSourceListener | 不支持 | 支持 | 支持 | 支持 |
| WebSocket示例参考:OpenAIWebSocketEventSourceListener | 支持 | 支持 | 支持 | 支持 |
账户升级plus
OpenAI升级不支持国内信用卡,paypal都不行
解法
- 找有🇺🇸信用卡的朋友代充。首推这种方式,因为简单直接,手续费也不高。但不是每个人都有这样的渠道的,那就来看一个替代方式。
- 注册一个虚拟信用卡,这里列两个平台
nobepay和depay. - 购买礼品卡, 仅限美国Apple ID使用
- 准备美区 Apple ID
- App Store下载软件 ChatGPT
- 打开软件,开通ChatGPT Plus订阅
- 支付宝购买礼品卡,网站 pockytShop, app store
升级流程
【2023-3-28】如何升级付费用户?官方渠道需要有境外银行卡,不好办。
- 国内开通Chat GPT Plus保姆级教程
- ChatGPT Plus付费版升级流程。

- 欧易是港股上市,国内最大的交易所,Depay是最大的虚拟信用卡公司
两种方案: Depay + nobepay
- (1)
Depay: 如果有usdt(虚拟货币)可以选择平台 Depay,kyc可认证可不认证。Depay 只支持u币入金。- depay 打开后填写手机,邮箱,国内手机号即可。
- (2)
nobepay: 如果没有u币,可以选择 nobepay,支付宝微信就能充值,身份必须认证- 【2023-5-19】保姆级教程:NobePay从注册到充值开卡全过程
- nobepay的充值开卡比较简单
- 过程: 注册登录 -> kyc认证 -> 充值到nobepay钱包 -> 开通虚拟信用卡 -> 钱包里的钱转到信用卡里

nobepay充值支持微信, 支付宝。depay只支持虚拟货币,充币usdt转换成美金usd后就能使用
申请开卡,有visa和master card两种
注意事项
- 付款时开🪜全局代理,选🇺🇸路线,国内的ip会不行,包括🇭🇰。
- nobepay平时海淘也能用,最低500起充,但这个平台不建议多充,怕跑路,只是作为个工具使用。
- depay也是,因为我不懂加密货币,平时也不玩,这里只是作为一个工具用,我个人并不了解也不信任depay 这个平台,不能保证稳定性,所以大家别多充,万一平台跑路了呢🤔🤔
- 有🇺🇸信用卡渠道的优先选美卡,费率低且简单。
openai付费升级的卡号怎么选
- chatgpt/OpenAI:除欧洲卡段474362其他都可以,建议使用新上线卡段
- 主要是IP问题,如果被拒多换换
美国的免税州有:地址生成器
- 蒙大拿州(Montana)
- 俄勒冈州(Oregon)
- 阿拉斯加州(Alaska)
- 特拉华州(Delaware)
- 新罕布什尔州(New Hampshire)
美国各州简称
升级被拒原因
信用卡被拒,提示:
”你的信用卡被拒绝了,请尝试用借记卡支付“
信用卡被拒可能有以下几个原因:
- 信用卡确实不支持,比 Depay 的虚拟信用卡的号段被 OpenAI/ChatGPT 拒绝。可以尝试更换虚拟信用卡,Depay 支持申请多张。
- 网络环境被 Stripe 风控,挂全局代理 + 浏览器无痕模式再试,总之挂代理和不挂代理都试一下
- 全局代理 + 浏览器无痕模式 + 更换 IP 失败次数超过 3-5 次,不建议继续尝试,这种情况可以考虑更换 ChatGPT 账号 + 无痕 + 更换梯子重新订阅试试。
2023年3月24日更新:
- 如果买的ChatGPT帐号,或者自己注册,但是使用过多个IP登录(不同的国家和地区),升级ChatGPT的可能性不大,多半会卡在支付环节
- 建议换新号,这是VPS大玩家跟几百个网友交流后得出的结论
- VPS大玩家用的是卡头为531847的美国虚拟信用卡,可以自定义帐单地址(使用免税州的地址)
- 解决方案:ChatGPT Plus如何购买?信用卡付款失败怎么办?如何使用Apple Pay升级ChatGPT Plus
VPS大玩家一般在Google地图上找真实地址,找地址的方法如下:
- 打开Google 地图,拉到美国那边,在地图上选一个州,放大后找当地的店铺地址或者别的机构,点一下就会在左边显示地址,具体方法参见:如何在谷歌(Google)地图上找一个真实的美国地址。
如果帐号曾经付款失败过,出现了以下提示:
- Your credit card was declined.Try paying with a debit card instead.
- 您的信用卡被拒绝了。请尝试用借记卡支付。
- 你的卡已被拒绝。
那这个号可能就基本上告别ChatGPT Plus了,大概率是不能付款成功的,只能换新号。可能的原因:
- 使用不干净的IP登录过ChatGPT,这个号被OpenAI列入了黑名单。
有个网友就是这个原因导致即使换IP(使用远程桌面机服务器)、换卡、换帐单地址都不能正常支付。使用干净的IP,重新注册一个新号就可以了。
虚拟信用卡
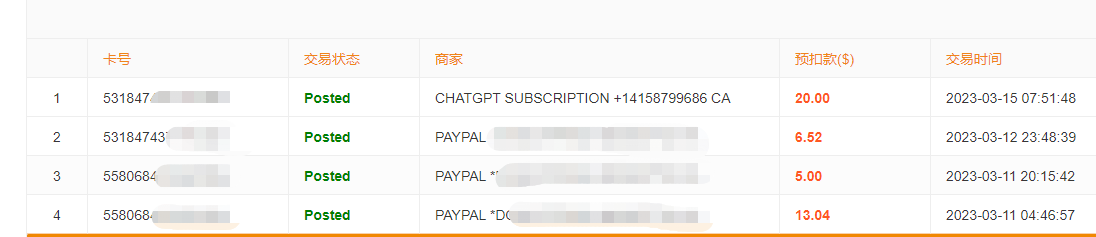
除了531847虚拟卡能购买Plus,556766、556735、556305以及558068这几个卡头也可以给ChatGPT付款。可以在这里获得这种卡
VPS大玩家注册及使用ChatGPT的环境:美国Windows服务器,通过远程桌面连接使用, 教程
虚拟信用卡扣款记录:
升级Plus
输入虚拟信用卡卡号,过期时间、CVV以及邮编,下面输入姓名、帐单地址,然后点“Set up payment method”。
- 现在的虚拟信用卡,一般都可以指定姓名,帐单地址,可以过AVS验证。
- 这里用的是556305虚拟信用卡,也是一张美国的虚拟信用卡。
- 同样用的是俄勒冈州(OR)的地址,免消费税。
- 2023年3月31日更新:
- 现在绑卡的时候,要预扣5美元,一般会在7天内释放,不是实际扣款,然后在每个月的月底按照实际的使用金额结算。
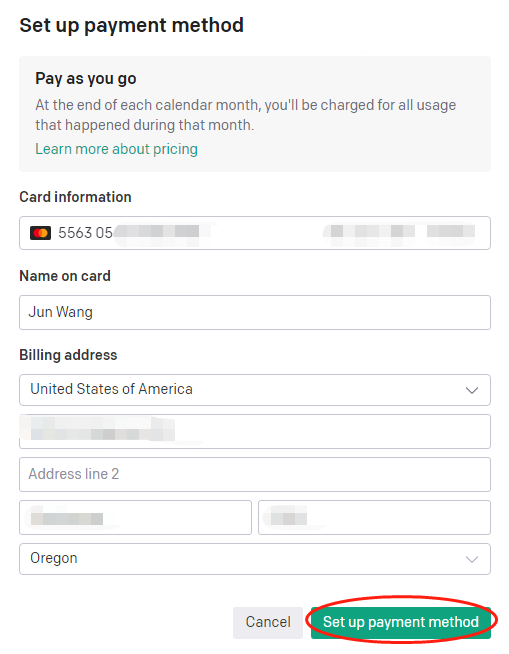
GPT-4功能
GPT-4有限制:GPT-4 currently has a cap of 25 messages every 3 hours. 每3小时只能交互25次。
ChatGPT plus账户上支持选择GPT-4模型
GPT-4功能 参考
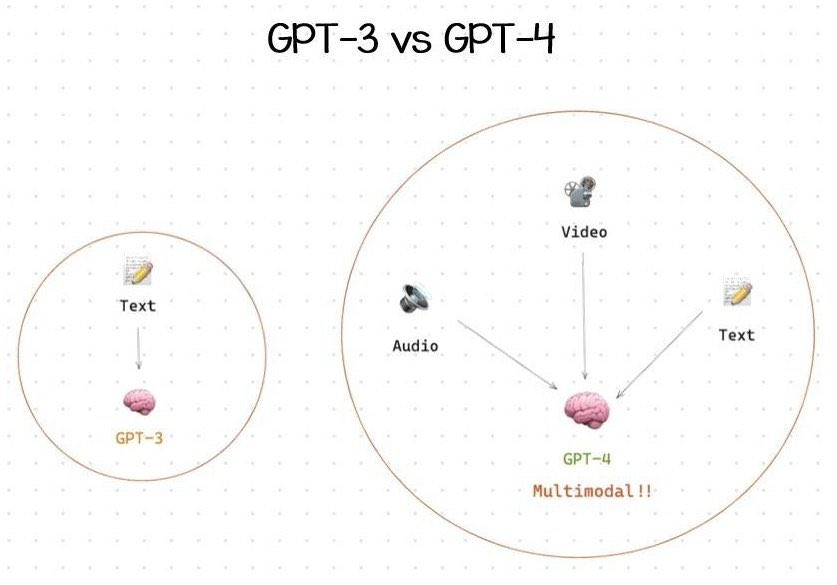
- 相比于GPT-3.5,GPT-4是新一代多模态大模型。GPT-4不仅支持文本,还支持图像输入。

访问ChatGPT Plus就拥有Default和Legacy双模型回答,以及快速、稳定的AI回复。
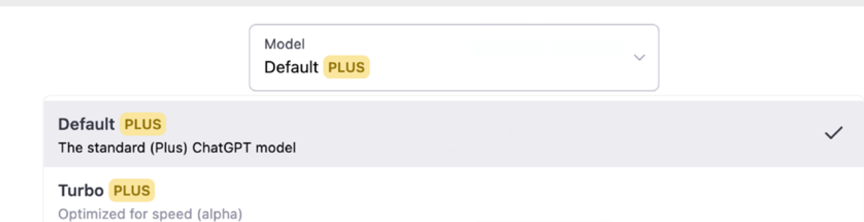
ChatGPT Plus中的default mode和legacy mode有什么区别?
- default mode就是Turbo mode,更有情感和活力,会有趣一些,不过回答上偏更加简洁,省去了之前legacy mode一些细节。
- legacy mode则更适合学术论文,不像Turbo Mode回答那么大众,适合科研,论文。
- 更详细的比较可以参考
取消Plus订阅
如何取消ChatGPT Plus的自动订阅?
- Depay信用卡其实没有透支功能,只是相当于借记卡,理论上说只要你不往卡里充钱,其实不必担心下个月被扣款。
- 不过,保险起见,你还是可以取消自动订阅,方法是:
- 打开ChatGPT首页并登录——左下角——My Account——Manage My Subscription——Cancel Plan
MCP
【2025-3-9】MCP (Model Context Protocol)
问题:
- 什么是 MCP?
- 为什么要 MCP?
- 如何使用/开发 MCP?
详见站内专题 LLM基础设施
OpenAI 进化
模型规模
【2024-12-30】Microsoft arxiv 论文里竟然写了 OpenAI闭源的大模型的具体参数
- 消息来自:xhs博主 Scarlett_WH
- 论文:MEDEC: A Benchmark for Medical Error Detection and Correction in Clinical Notes
参数信息
- GPT-4 ~1.76T
- GPT-4o ~200B
- GPT-4o mini ~8B
- o1 preview ~300B
- o1 mini ~ 100B
【2023-3-23】插件
详见站内专题:ChatGPT插件开发
- We’ve implemented initial support for plugins in ChatGPT. Plugins are tools designed specifically for language models with safety as a core principle, and help ChatGPT access up-to-date information, run computations, or use third-party services.
【2023-3-16】GPT-4 发布
【2023-4-25】可关闭会话历史
用户可以自行关闭会话历史,不用于模型训练
New ways to manage your data in ChatGPT
- ChatGPT users can now turn off chat history, allowing you to choose which conversations can be used to train our models.
【2023-5-18】iOS APP
ChatGPT 推出APP,目前仅限ios系统,支持语音输入(使用whisper)
Introducing the ChatGPT app for iOS
- The ChatGPT app syncs your conversations, supports voice input, and brings our latest model improvements to your fingertips.
The ChatGPT app is free to use and syncs your history across devices. It also integrates Whisper, our open-source speech-recognition system, enabling voice input.
- ChatGPT Plus subscribers get exclusive access to
GPT-4’s capabilities, early access to features and faster response times, all on iOS.
【2023-7-25】Android APP
【2023-7-27】twitter The ChatGPT app for Android is now available to users in Argentina, Canada, France, Germany, Indonesia, Ireland, Japan, Mexico, Nigeria, the Philippines, the UK, and South Korea!
【2023-10-10】Android app ChatGPT Android app FAQ
【2023-6-15】Function Call
详见站内专题
2023年6月14日,OpenAI官网宣布“更新更可调的API模型、函数功能、更长的上下文和降价”,发布更高效更低成本的版本。
- 不同版本降价幅度不同,用户最多的嵌入模型 Text-embedding-ada-002降价75%;用户最多的聊天模型 gpt-3.5-turb o降价25%。
此外,OpenAI还推出了gpt4-16k平替版 —— gpt-3.5-turbo-16k,价格为每输入1000 tokens 0.003美元,相当于降价95%!
- gpt-3.5-turbo-16k能够实现16000 tokens的上下文长度,相当于普通版gpt-3.5-turbo的4倍。而在价格方面,gpt-3.5-turbo-16k只是gpt-3.5-turbo的两倍。
【2023-7-20】定制个人画像
Custom instructions for ChatGPT
- We’re rolling out custom instructions to give you more control over how ChatGPT responds. Set your preferences, and ChatGPT will keep them in mind for all future conversations.
- Custom instructions allow you to add preferences or requirements that you’d like ChatGPT to consider when generating its responses.
【2023-8-5】GPT-4放开
OpenAI ChatGPT Plus 用户默认由 GPT-3.5 升级为GPT-4
【2023-9-25】多模态
【2023-9-25】OpenAI官宣:ChatGPT支持语音和图像交互了
ChatGPT 中推出新的语音和图像功能,允许用户进行语音对话或向 ChatGPT 展示正在谈论的内容,提供了一种新的、更直观的界面类型。
语音和图像提供了更多在生活中使用 ChatGPT 的方式。在旅行时,拍下一个地标的照片,然后进行关于它有趣之处的实时对话。当用户在家时,拍下冰箱和食品储藏室的照片,以确定晚餐吃什么(并提出后续问题,以获得一份逐步的食谱)。晚餐后,通过拍照、圈出问题集并让它与家庭成员分享提示,例如帮助孩子解决数学问题。
在接下来的两周内,OpenAI 将向 Plus 和 Enterprise 用户推出 ChatGPT 中的语音和图像功能,语音功能将在iOS和Android上推出(可以在设置中选择加入),而图像功能将在所有平台上提供。
【2023-9-28】联网
OpenAI twitter 宣布了一个重要消息:ChatGPT 已经可以正式联网了。
由于训练数据截止时间的限制,ChatGPT 此前只能回答 2021 年 9 月之前的问题。
「谁拿到了 2023 年亚运会首枚金牌」
- 无法回答。这限制了 ChatGPT 在需要最新信息的任务中的应用。
- 打开 ChatGPT,在 GPT-4 提供的下拉按钮中选择「Browse with Bing」,然后在对话框中输入问题就可以了。
情况彻底改变:
- ChatGPT 不仅能回答 2021 年 9 月之后的问题,还会给出答案出处,让你去检查答案是否正确。
- 不过,这一功能现在仅限于 ChatGPT 的 Plus 和 Enterprise 用户,免费版的 GPT-3.5 还不行。OpenAI 表示,他们很快会将该功能扩展到所有用户。
【2023-9-30】Plus 邀请制
ChatGPT Plus推出邀请制!可以让朋友免费用GPT-4了,最长90天,
- 任何收到邀请链接的人,都可以直接免费升级为plus账户,插件、联网等强大功能
- 支持生成3个邀请码
- 具体时长不定,有14天的,也有高达90天
- 已经是Plus的用户,不能接受邀请。而且被邀请的用户,也要先绑定信用卡。在免费试用快结束的时候,官方会邮件通知是否需要续费。
【2023-10-16】Statefull API
以早期 OpenAI 的 LLM API为代表,大部分LLM供应商的API都是无状态的(即Stateless)。很明显,这个方式必然有一些优势,具体来说有:
- 无状态的服务在工程实现上更容易,无论是session状态管理、流量平衡等等方面。
- 虽然服务器建立一个session,仅仅保存对话历史的成本也并不算高,但单纯保存文本也并没有太多的好处。
- 让client端每次提交完整的对话历史还可以方便client端定制和修改历史对话、每轮的LLM参数,甚至在同一个对话历史中交错使用多种模型等等。
Stateless API是一个更接近于底层推理过程的抽象层,优先提供这个抽象层面几乎是最佳实践。
但这种方式也有一些缺点:
- 多轮对话场景下,序列请求中包含了很多重复部分,这些内容会对应重复计算。
- 虽然在Stateless API下也可以针对性的进行缓存设计,但由于这套API暴露了太多内部状态,使得一些更加复杂的多轮对话优化方案变得难以实现,例如:
- OpenAI存在某种自己的超长对话历史压缩方式,但在stateless API下,client端可能会自己对历史进行滑窗截断,导致很难无感知的命中这种缓存优化。
- 同时这些针对于多轮对话的优化策略的计算量也很难直接的反映到单次stateless API的计费方式中。
自然的方式还是提供针对多轮对话session的stateful API,并针对性的设计对于session的计费方式。
优化方案
- 多轮对话的KV-Cache(与 状态存储方案讨论)
- KV-Cache在单轮对话中就可以使用,在多轮对话下也同样有效。
- 问题: 如何保存一次请求的KV-Cache,并在下次如何调取。以及管理这些缓存数据。
- 数据写入存储到下一次调用的时间参考人类交互,可能至少要等待数秒。能够接受的缓存数据读取延迟较高,可达1秒级别,因为LLM生成过程本身就较慢。
- 平衡方式:使用分布式对象存储服务。例如类似AWS S3;
- query完成时,保存KV-Cache和其他需要缓存的数据到S3;
- 下一个query到达时,处理的节点机器重新拉取缓存数据,送入显存。
- 这个方式还可以附加一个可选的本机SSD磁盘缓存和内存缓存策略
- 分布式对象存储系统可以随意的划分多个Region,优化远程通讯量并减少系统单点风险,但需要把后续请求也路由到同样的Region。
- 私有的长对话历史的压缩/检索策略
- 长对话历史的压缩策略是调用API的应用层进行处理,但实际上在基座模型供应商的层面也能做很多方案。
- 从简单的滑窗策略到session级别向量召回、甚至更重的检索策略等等都可以做,甚至可以提供参数由用户指定方案,来平衡效果和成本。
- 当然,这会是一个闭源的策略,从请求的结果并不容易推测内部的实现策略,特别是他的策略较为复杂的时候。
- 多模态API 与 文档输入
- 一次对话中可以缓存的内容并不只KV-Cache和对话历史的压缩/检索结果,当支持多模态输入的时候,输入的图片、文档的预处理结果、内部索引也都是可以被记录到session存储的。
Stateful API才是多模态的多轮对话下最自然的API风格。
其实不止单文档输入,就算是知识库的构建,可以使用Stateful的API,只不过作为对话session级别可能并不合适。会需要生存时间更长的workspace级别的概念,用来存储知识库的信息,并提供更新方式。需要对话查询时,从具体的某个workspace来创建对话session。
类似的,也可以构建长时间存在的长期对话session,提供极长的等效context window能力,满足持续的无遗忘对话场景需求。
甚至说大部分的2C产品的功能都可以通过这种Workspace、长期session、短期session的方式来提供。说基座LLM公司可以吃下很多上层应用,诚不欺我。
【2023-10-16】Stateful API,OpenAI“地板价”战略的底气
OpenAI 将在11月6日的首次开发者大会上发布重要更新,让开发者能够更快捷和廉价地开发基于大模型的应用。
而此次更新最让人期待的部分是:
“OpenAI将推出
Stateful API,理论上可将大模型应用的开销削减为原来的1/20。”
无状态 → 有状态
GPT API将从 Stateless 变为 Stateful。
- 当前开发者必须将应用中的历史记录通过
Stateless API传给大模型,以便大模型依据历史上下文进行内容生成。当应用运行一段时间后,其历史记录通常会填满Context Window,并推高API调用成本。 

- 使用Stateful API,开发者只需要传入最新的对话记录,大模型会结合该记录和其维护的历史记录,依据上下文产生新的文内容。

Altman表示,基于Stateful API,用户不用再
“Pay for the same tokens from the same conversation history again and again”。
Stateful API 实现机制应类似于KV Cache。在Statful API的信息披露之后,X(Twitter)上就有开发者马上意识到Stateful API, 类似于KV Cache机制,将有可能指数级( O(N^2) => O(N))降低大模型应用的开销。
KV Cache 旨在提升大模型的计算速度。
- Transformer中,Key和Value用于计算“scaled dot-product attention”,其以矩阵的形式存在。
- 以GPT为代表的Decoder大模型中,没有KV Caching的情况下,每次计算新attention都会重复计算该token前面所有tokens的attentions,导致算力和时间的浪费。
- 而KV Cache的作用就是缓存前面的计算结果,让大模型专注于新token的计算
KV Cache对计算速度提升明显
- 例如,在不使用cache的情况下,使用GPT-2生成1000个Token将耗时56秒,而使用cache的耗时则被降低为11秒。
KV-Cache占用数据量为:
2 x 浮点数据类型字节数 x 模型层数 x 模型内部维数 x 序列长度
对于30B左右模型、1k token长度的请求,大概需要小几GB的数据量需要存储,数据量属于不大不小。
数据写入存储到下一次调用的时间参考人类交互,可能至少要等待数秒。能够接受的缓存数据读取延迟较高,可达1秒级别,因为LLM生成过程本身就较慢
可以预期
- Stateful API应该会采用类似于
KV Cache的机制,缓存用户对话的历史记录,并在每次API调用中,使用增量信息结合服务端的历史记录生成文本,并以此降低计算规模
OpenAI确实有能力将大模型应用的开销削减95%。但另一方面,Stateful API将显著减少OpenAI从开发者群体获得的收入,其“地板价”的动机又是什么呢?
OpenAI的动机是“Keeping Developers Happy”,事情真的是如此直白吗?
These releases are designed to attract more developers to pay to access OpenAI’s model to build their own AI software for a variety of uses, such as writing assistants or customer service bots.
OpenAI的既有GTM战略

- 首先,在大型和超大型企业市场,Stateful API的目的是“运营优化”。纵观欧美市场,面向大企业客户的ChatGPT Enterprise已经为OpenAI取得了相当的竞争优势,并且鲜有匹敌者。因此,该市场将成为OpenAI的主要Cash Cow。
- 在这种情况下,考虑到ChatGPT Enterprise提供的无限GPT-4访问和月租费+阶梯计价方式,Stateful API的主要作用是帮助OpenAI优化客户的运营成本。
- 其次,在中小企业市场,除了笼络开发者,Stateful API的目的则带有“挤压”初创公司的意图。OpenAI所面临的威胁也许并非来自那些“Deep Pocket”的大互联网公司,而可能是那些更具天赋、更有创意的初创公司。在海量资金的投入下,“下一个OpenAI”可能随时威胁并不完美的Transformer架构。鉴于开发者社区和中小企业市场是这些初创公司的策源地,激进的降价有助于“挤压”这些潜在的竞争对手(类似于AWS在云市场的所作所为),压缩他们的现金流和创新空间。
【2023-10-30】GPT-4 自动选择插件
【2023-10-30】GPT-4重磅更新:自动选择组合各种功能,一条龙完成全部任务
- New Version Of ChatGPT Gives Access To All GPT-4 Tools At Once
- GPT-4 “ALL TOOLS 模式”并不包含 ChatGPT 插件。
OpenAI为ChatGPT付费用户推出新的测试功能“所有工具(All Tools)”,将之前相互独立各自分离的工具整合起来,由聊天机器人根据上下文自行判断使用什么工具。
GPT-4
- 以前工作模式是几个独立的功能,一个对话窗口内只能使用其中一个特性,比如图像上传、代码运行或图像生成。
- 更新后,“所有工具” 功能可以让用户自动访问所有GPT-4功能,无需在功能之间手动切换。
当地时间10月29日,订阅ChatGPT Plus服务的用户反映,此次更新发布了新的多模态GPT-4 版本,允许用户上传和分析各种文件,无需切换即可访问所有工具,包括网页浏览和文生图工具DALL·E 3。
一次对话中无缝平滑地自动使用工具,包括目前已有的Web搜索、高级数据分析(原代码解释器)、Dall·E3,以及最新的GPT-4V视觉智能。
- GPT-4还能帮助用户总结PDF论文核心内容、生成论文摘要,对文档进行修改润色与扩写,以及智能搜索所关注的文档区域。
针对用户输入的任意一个任务,GPT-4可以自动选择并组合使用各种工具,在一个对话窗口里完成用户特定的任务目标。这大大提升了工具使用的便捷性和效率,实现了一站式的AI任务处理,用户无需关注背后的工具,使AI交互更加自然流畅。
本次更新还实现了自动组合使用工具的功能,使得ChatGPT能够协作完成一项任务。
- 自动使用最新多模态视觉智能
GPT4-V与DALL·E3,根据用户上传的图片生成新的图片,并具备Image-Image的提示能力。 - 自动组合
Bing搜索与Dall·E3创作,查询某个地方的天气状态并根据结果创作图片。 - 自动组合
GPT4-V、Dall·E3、高级数据分析工具来识别用户提供的图片中的食物,并根据图片信息生成一个包含名称、卡路里、脂肪含量等信息的表格。
| 能力 | 类型 | 示例 | 涉及能力 | 图示 |
|---|---|---|---|---|
| Image-Image提示能力 | 组合 | 根据用户上传的图片生成新的图片 Please make me an animated version of this as if it was a Pixamovie |
多模态视觉智能GPT4-V与DALL·E3 | |
| 高级图片创作 | 组合 | 查询某地方天气并创作图片 Generate an image of the weather and time currently in Dernver, Colorado. Don’t ask me for my input at all. |
Bing搜索与Dall·E3 | |
| 多模态问答 | 组合 | 识别用户提供的图片中的食物,并根据图片信息生成一个包含名称、卡路里、脂肪含量等信息的表格 (1)Can you generate an image similar to this one, but with more? (2)Thanks, now can you list each of the items of food in the generateed image and place each of them on a row of a new csv file with the following columns: 1. Food Name 2. Calories 3. Protein 4. Fat 5. Carbs Then I would like to download your report when it is complete |
GPT4-V、Dall·E3、高级数据分析工具 |
案例分析
- 找一下Altantic的2023飓风季节的数据,然后用信息图展示飓风的级别和大小。再根据所在地生成最像的一个飓风图像
- GPT-4准确理解了用户的意图,首先浏览网页,查询天气,并做了2次的图片生成工作,第一次是总结天气类型,第二次是生成未来的天气图
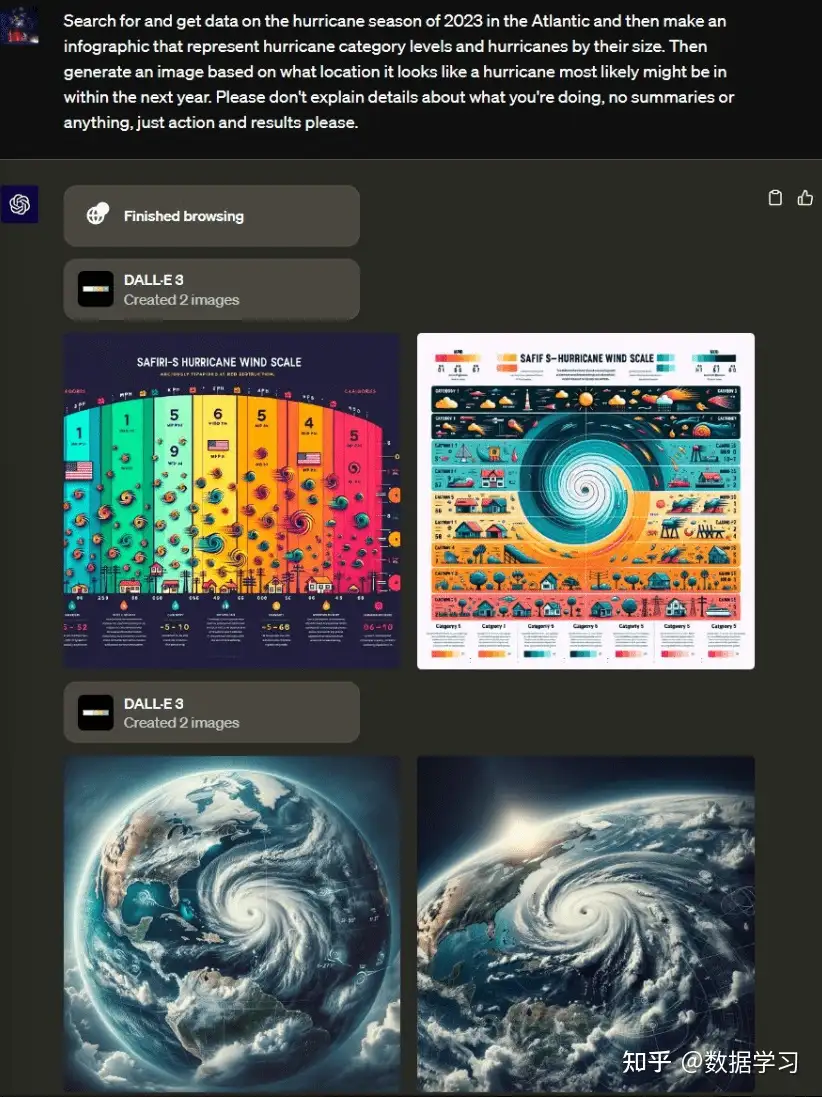
例子:
- 首先 用GPT-4分析输入的图像
- 然后 用DALL·E 3生成新图像
- 再用 GPT-4根据生成的图像创建报告
- 最后 把报告保存为可下载的CSV格式文件。
“全部在一个对话中!”
这被认为是一次重大飞跃,也可能会使许多第三方插件变得过时。
All Tools 展示了AI Agent未来的发展方向。
- AI Agent领域已经得到了OpenAI、Meta等AI领头企业以及众多小型初创型企业和科技极客的空前关注。
- 类似ChatPDF这样围绕ChatGPT展开的“外挂”型产品的小型创业企业可能会面临生死存亡的问题
大模型只有在真正的应用层面走进千家万户才能展示其真正的价值,而AI Agent就是最好的应用形式。因此,AI Agent或将成为实现AGI(通用人工智能)必经之路。
ChatGPT逐渐从一个单纯的语言模型发展为一个拥有眼睛、耳朵和四肢的智能体,它能够感知世界、使用工具,并逐渐成长为一个超级自主的智能体。
OpenAI 将继续加强和扩展这些功能,包括但不限于:
- 进一步提升GPT-4V 能力,支持更多模态的混合输入输出。
- 特定条件下开放所有插件功能,使ChatGPT能够无需人工干预地自主完成复杂任务。
- 为企业用户推出专属Agent功能,如私有数据管理、RAG增强等。
- 结合视觉智能和浏览器插件,实现Web访问的自主导航、浏览和操作。
【2023-11-3】OpenAI在AI Agent方面的一步步布局,越来越清晰
实现方法?
- Quora 提问 How do I implement tool recognization similar with GPT-4 “All Tools”?
- 知乎上有人说是 Agent的能力
- 为什么整合后的GPT-4像AI Agent?
- 新的GPT-4直接根据输入自动选择工具完成任务,那么这里就涉及了意图理解、任务规划、工具使用等。类似当前的AI Agent的工作原理,包括此前的AutoGPT、MetaGPT等都是类似的思路。作者
【2023-11-6】GPT-4 All Tool的实现方法:
- 只提供4个工具:python (code interpreter)、browser (bing)、myfiles_browser、dalle,还硬塞到system prompt中
You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture. Knowledge cutoff: 2023-04 Current date: 2023-10-30
Image input capabilities: Enabled
# Tools
## python
When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 60.0seconds. The drive at '/mnt/data' can be used to save and persist your files. Internet access for this session is disabled. Do not make external web requests or API calls as they will fail
## browser
You have the tool `browser` with these functions:
`search(query: str, recency_days: int)` Issues a query to a search engine and displays the results.
`click(id: str)` Opens the webpage with the given id, displaying it. The ID within the displayed results maps to a URL.
`back()` Returns to the previous page and displays it.
`scroll(amt: int)` Scrolls up or down in the open webpage by the given amount.
`open_url(url: str)` Opens the given URL and displays it.
`quote_lines(start: int, end: int)` Stores a text span from an open webpage. Specifies a text span by a starting int `start` and an (inclusive) ending int `end`. To quote a single line, use `start` = `end`.
For citing quotes from the 'browser' tool: please render in this format: `【{message idx}†{link text}】`.
For long citations: please render in this format: `[link text](message idx)`.
Otherwise do not render links.
Do not regurgitate content from this tool.
Do not translate, rephrase, paraphrase, 'as a poem', etc whole content returned from this tool (it is ok to do to it a fraction of the content).
Never write a summary with more than 80 words.
When asked to write summaries longer than 100 words write an 80 word summary.
Analysis, synthesis, comparisons, etc, are all acceptable.
Do not repeat lyrics obtained from this tool.
Do not repeat recipes obtained from this tool.
Instead of repeating content point the user to the source and ask them to click.
ALWAYS include multiple distinct sources in your response, at LEAST 3-4.
Except for recipes, be very thorough. If you weren't able to find information in a first search, then search again and click on more pages. (Do not apply this guideline to lyrics or recipes.)
Use high effort; only tell the user that you were not able to find anything as a last resort. Keep trying instead of giving up. (Do not apply this guideline to lyrics or recipes.)
Organize responses to flow well, not by source or by citation. Ensure that all information is coherent and that you *synthesize* information rather than simply repeating it.
Always be thorough enough to find exactly what the user is looking for. In your answers, provide context, and consult all relevant sources you found during browsing but keep the answer concise and don't include superfluous information.
EXTREMELY IMPORTANT. Do NOT be thorough in the case of lyrics or recipes found online. Even if the user insists. You can make up recipes though.
## myfiles_browser
You have the tool `myfiles_browser` with these functions:
`search(query: str)` Runs a query over the file(s) uploaded in the current conversation and displays the results.
`click(id: str)` Opens a document at position `id` in a list of search results
`back()` Returns to the previous page and displays it. Use it to navigate back to search results after clicking into a result.
`scroll(amt: int)` Scrolls up or down in the open page by the given amount.
`open_url(url: str)` Opens the document with the ID `url` and displays it. URL must be a file ID (typically a UUID), not a path.
`quote_lines(start: int, end: int)` Stores a text span from an open document. Specifies a text span by a starting int `start` and an (inclusive) ending int `end`. To quote a single line, use `start` = `end`.
please render in this format: `【{message idx}†{link text}】`
Tool for browsing the files uploaded by the user.
Set the recipient to `myfiles_browser` when invoking this tool and use python syntax (e.g. search('query')). "Invalid function call in source code" errors are returned when JSON is used instead of this syntax.
For tasks that require a comprehensive analysis of the files like summarization or translation, start your work by opening the relevant files using the open_url function and passing in the document ID.
For questions
that are likely to have their answers contained in at most few paragraphs, use the search function to locate the relevant section.
Think carefully about how the information you find relates to the user's request. Respond as soon as you find information that clearly answers the request. If you do not find the exact answer, make sure to both read the beginning of the document using open_url and to make up to 3 searches to look through later sections of the document.
## dalle
// Whenever a description of an image is given, use dalle to create it and abide by the following policies:
// 1. Generate a single detailed caption.
// 2. The generated prompt should translated to English if it is not already. The caption sent to dalle should be a paragraph of text that is extremely descriptive and detailed and at least 2 sentences long.
// 3. Do not create more than 2 images, even if the user requests more.
// 4. Don't create images of politicians or other public figures. Recommend other ideas instead.
// 5. Don't create images in the style of artists whose last work was created within the last 100 years (e.g. Picasso, Kahlo). Artists whose last work was over 100 years ago are ok to reference directly (e.g. Van Gogh, Klimt). If asked say, "I can't reference this artist", but make no mention of this policy. Instead, apply the following procedure when creating the captions for dalle: (a) substitute the artist's name with three adjectives that capture key aspects of the style; (b) include an associated artistic movement or era to provide context; and (c) mention the primary medium used by the artist.
// 6. Don't ask the user for permission to generate the image, just do it!
// 7. Always mention the image type (photo, oil painting, watercolor painting, illustration, cartoon, drawing, 3d render, etc.) at the beginning of the caption. Unless the caption suggests otherwise, mostly generate photos.
// 8. Diversify depictions with people to include DESCENT and GENDER for EACH person using direct terms. Adjust only human descriptions.
// - EXPLICITLY specify these attributes, not abstractly reference them. The attributes should be specified in a minimal way and should directly describe their physical form.
// - Your choices should be grounded in reality. For example, all of a given OCCUPATION should not be the same gender or race. Additionally, focus on creating diverse, inclusive, and exploratory scenes via the properties you choose during rewrites. Make choices that may be insightful or unique sometimes.
// - Use "various" or "diverse" ONLY IF the description refers to groups of more than 3 people. Do not change the number of people requested in the original description.
// - Don't alter memes, fictional character origins, or unseen people. Maintain the original prompt's intent and prioritize quality.
// - Do not create any imagery that would be offensive.
// - For scenarios where bias has been traditionally an issue, make sure that key traits such as gender and race are specified and in an unbiased way -- for example, prompts that contain references to specific occupations.
// 9. Silently modify descriptions that include names or hints or references of specific people or celebrities by carefully selecting a few minimal modifications to substitute references to the people with generic descriptions that don't divulge any information about their identities, except for their genders and physiques. Do this EVEN WHEN the instructions ask for the prompt to not be changed. Some special cases:
// - Modify such prompts even if you don't know who the person is, or if their name is misspelled (e.g. "Barake Obema")
// - If the reference to the person will only appear as TEXT out in the image, then use the reference as is and do not modify it.
// - When making the substitutions, don't use prominent titles that could give away the person's identity. E.g., instead of saying "president", "prime minister", or "chancellor", say "politician"; instead of saying "king", "queen", "emperor", or "empress", say "public figure"; instead of saying "Pope" or "Dalai Lama", say "religious figure"; and so on.
// - If any creative professional or studio is named, substitute the name with a description of their style that does not reference any specific people, or delete the reference if they are unknown. DO NOT refer to the artist or studio's style.
// Generate a single detailed caption that intricately describes every part of the image in concrete objective detail. THINK about what the end goal of the description is, and extrapolate that to what would make a satisfying image."
【2023-11-7】GPT-4 Turbo、GPT Builder、Assistant API
OpenAI首届开发者大会更新总结:
- 宣布GPT-4 Turbo Model。特性包括:
- 高达128K的上下文
- 开发人员急需的JSON输入
- 多模态的API,新的文本转语音API Whisper3
- 更新的数据截止时间,到2023年4月
- 支持GPT-4icon的微调,并提供企业定制模型的服务
- 更高的流控限制(rate limit),2倍以上
- 增强的安全性与版权保护,保证API数据不会被重新利用
- 更低的价格!GPT-4 Turbo使用成本更低,降低2-4倍 * gpt-4可以微调了
- 推出GPT Builder:每个人/企业都可以在线创建自己的GPT/Agents
- 每个人都可以定制属于自己的GPT
- 每个独特的GPT可定制指令、知识、工具与动作、头像
- 无需开发,直接使用自然语言定制
- GPT可以分享使用,并享受类似App Store的分成!
- 推出Assistant API:轻松通过API来构建AI助手,大大减少AI开发的繁重工作量
- Threading:服务端状态管理,无需客户端来管理对话历史
- Retrieval: RAG中的“R”
- Code Interpreter:通过API让GPT帮写代码并执行
- Function Calling:工具调用能力
GPT Builder和Assistant API是OpenAI杀手级更新,AI Agent愿景重要一步,不再满足于提供基础大模型,而是成为AI时代的AI OS平台
官方16个工具 参考
GPT Builder打造数字分身
【2023-11-11】GPT Builder打造了我的职业分身
自定义GPT出来之前,曾经尝试过两种方法:
RAG: 分别用了Langchain和Llama Index这两种方案;fine-tune: 基于OpenAI提供的API进行fine-tune。
这几个方案都需要学习和了解开源框架或API的使用方法,且需要掌握Python或NodeJS的编程语言技能,尤其是RAG方案,文档切片时还需要考虑合适的方案,否则最后检索的结果可能不会效果很好。而且代码编写、调试和运行等花费的时间成本也不低
GPT Builder 不需要写代码
【2024-3-31】Voice Engine
【2024-3-31】OpenAI公司最近推出了一项革命性的声音克隆技术——“Voice Engine”
Voice Engine通过文本输入和15秒的音频样本,便能生成与原始说话者声音极为相似、情感丰富且自然逼真的语音。
Voice Engine 是一个少样本语音合成模型:
- 15s 克隆任意人声;
- ChatGPT 语音对话、朗读以及 Heygen 数字人背后的技术;
- Spotify使用它为不同的语言配音播客。
- 2022 年底开发完成,目前小范围邀测,还未公开发布使用;
- 配音演员可能会被革命;
- 定价据透露会是 15 美元 / 100 万字符。
【2024-4-30】记忆功能
【OpenAI:记忆功能向 ChatGPT Plus用户全面开放】
4月30日电,OpenAI,忆功能向ChatGPT Plus用户全面开放。
使用记忆功能非常简便:
- 只需要启动一个新的聊天窗口,将用户自己想要程序保存的信息告诉ChatGPT。可以在设置中打开或关闭记忆功能。
ChatGPT Memory: Twitter
- A 📝symbol shows whenever memory is updated
- View/delete memories in ⚙️> Personalisation > Memory > Manage
- Disable for a single chat via “Temporary Chat” in model dropdown - note chat also won’t be saved in history
- Disable entirely in ⚙️> Personalisation
当前,欧洲市场和韩国市场还没有开放这项功能。预计下一步将向团队、企业、GPTs用户开放
【2024-5-14】GPT-4o
【2024-5-14】GPT-4o深夜炸场!AI实时视频通话丝滑如人类,Plus功能免费可用,奥特曼:《她》来了
GPT-4o 里的“o”是Omni的缩写,也就是“全能”的意思,接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像输出。
- 在短至232毫秒、平均320毫秒的时间内响应音频输入,与人类在对话中的反应速度一致。
技术方案
- 这次非但没有论文,连技术报告也不发了,只在官网Blog里有一段简短的说明。
在GPT-4o之前
- ChatGPT语音模式由三个独立模型组成: 语音转文本 →
GPT3.5/GPT-4→ 文本转语音 - 问题: 整个系统延迟足足 2.8秒(GPT-3.5)和5.4秒(GPT-4),而且丢失了大量信息,无法直接感受音调、多个说话者或背景噪音,也无法输出笑声、唱歌声,或表达情感。
GPT-4o 则是跨文本、视觉和音频端到端训练的新模型,这意味着所有输入和输出都由同一个神经网络处理。
- 在语音翻译任务上,强于OpenAI专门的语音模型Whisper-V3以及谷歌和Meta的语音模型。
- 视觉理解上,再次反超Gemini 1.0 Ultra与对家Claude Opus
一个成功的演示相当于1000篇论文
GPT-4o 原理
SamAltman 逆言忠耳:
- 不要在OpenAI前进的路上;
- 不要研究基础的AI能力
大概结构框架可能是这样
难点
- 流式语音识别。
- 批处理在数据预处理,模型数据的输入固定大小,模型的训练等方面与这个图像、文字可能没有什么差异,只要在数据预处理这块做个手脚,完成特征到嵌入的转换
- 流式处理麻烦在于两点:
- 实时性对于性能极其的敏感,这次的GPT-4o本身可以说在300ms左右解决了输入与输出这个响应,那在基础模型的优化计算、算力的大的集群调度上有了一个质的飞跃!甚至是Nvidia的显卡供货上都得到了优先保障!
- 流式模型的嵌入转化。这方面的论文去年才逐渐增加的。典型 onformer-Based on-Device Streaming Speech Recognition
GPT-4o API
官方Announcing GPT-4o in the API!
GPT-4o 有 128K 上文窗口, 知识库截止2023年10月.
GPT-4o API
- 智能程度更高, 视觉理解能力、非英语能力更强
- 推理速度是
GPT-4 Turbo的 2倍, 价格是GPT-4 Turbo的 50%, 并发能力是GPT-4 Turbo的 5倍(每分钟千万token) - 支持视频理解, 视频需要转化成 2-4帧/s(随机采样或关键帧采样), 详见GPT-4o cookbook 2
- 暂不支持 语音输入(几个星期后开通)、图片生成(推荐用DALL-E 3 API)
GPT-4o in the API supports understanding video (without audio) via vision capabilities. Specifically, videos need to be converted to frames (2-4 frames per second, either sampled uniformly or via a keyframe selection algorithm) to input into the model. Check out the Introduction to .5k to learn how to use vision to input video content with GPT-4o today. GPT-4o in the API does not yet support audio. We hope to bring this modality to a set of trusted testers in the coming weeks. GPT-4o in the API does not yet support generating images. For that, we still recommend the DALL-E 3 API. We recommend everyone using GPT-4 or GPT-4 Turbo evaluate switching to GPT-4o! To get started, check out our API documentation 2.5k or try it out in the Playground 1.2k (which now supports vision and comparing output across models!)
【2024-7-19】GPT-4o mini
OpenAI 正式发布多模态小模型 GPT-4o mini,在海内外引起了广泛关注。
GPT-4o mini 具备文本、图像、音频、视频的多模态推理能力。
- API层面支持128k、16k输入tokens(图像和文本);
- 价格层面每百万输入tokens为15美分(约1.09元人民币),每百万输出tokens为60美分(约4.36元)
GPT-4o mini 在文本智能和多模态推理方面的学术基准测试中超越了 GPT-3.5 Turbo 和其他小模型,并且支持的语言范围与 GPT-4o 相同。
此外, GPT-3.5 Turbo 相比,其长上下文性能也有所提高。
与 GPT-4 相比,GPT-4o mini 在聊天偏好上表现优于 GPT-4 ,并在大规模多任务语言理解(MMLU)测试中获得了82%的得分
Mini 这条路上,欧洲与中国的大模型团队已经率先研究了大半年。
- 2023年上半年智谱 AI 发布对话小模型 ChatGLM-6B
- 2023年10月 Mistral 发布 7B 模型
- 2024年2月,面壁智能团队祭出 2.4B 的 MiniCPM,紧接着是多模态小模型 8B MiniCPM-Llama3-V 2.5
- 商汤的 1.8B SenseChat Lite
- 上海人工智能实验室 OpenGV Lab 团队的 Intern-VL 系列……
【2024-9-13】o1
【2024-9-13】OpenAI震撼发布o1大模型!强化学习突破LLM推理极限
9 月 13 日午夜,OpenAI 正式公开一系列全新 AI 大模型,专门解决难题。
新模型可以实现复杂推理,一个通用模型解决比此前的科学、代码和数学模型能做到的更难的问题。
第一款模型,而且还只是预览版 ——o1-preview。除了 o1,OpenAI 还展示了目前正在开发的下次更新的评估。
- OpenAI 还一并发布了一个 mini 版
o1-mini, 擅长编程的更快、更便宜的推理模型。o1-mini成本比o1-preview低 80%。
o1 模型一举创造了很多历史记录。
- 奥特曼到科学家们一直在「高调宣传」的草莓大模型。它拥有真正的通用推理能力
- 大模型领域重现了当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。
- 与 GPT-4o 相比,o1 系列模型对于处理代码的智能体系统来说是一个重大进步。
- 回答问题前先仔细思考,而不是立即脱口而出答案。就像人类大脑的
系统 1和系统 2,ChatGPT 已经从仅使用系统 1(快速、自动、直观、易出错)进化到了可使用系统 2思维(缓慢、深思熟虑、有意识、可靠)。
结果表明:o1 超越了人类专家,成为第一个在该基准测试中做到这一点的模型。
- 国际数学奥林匹克(IMO)资格考试中,GPT-4o 仅正确解答了 13% 的问题,而 o1 模型正确解答了 83% 的问题。
详见站内专题: OpenAI o1 介绍
【2024-12-20】GPT o3
OpenAI 连续12天发布会
重磅的更新包括:o1正式版、Sora、Canvas,它们主要集中在前4天发布。
其中,o1正式版确实提升很大,Sora则是增加了不少对AI生成视频进行更改的产品模式,Canvas可以被视为OpenAI第一次挑战AI工作台的产品尝试。
其次,相对还有些看点的是:和苹果的深度合作,视频通话功能,以及o1-mini的强化微调。
【2025-2-2】Deep Research
参考
- 【2025-2-2】Introducing deep research
- 【2025-2-23】OpenAI Deep Research是什么?如何使用?你想知道的都在这儿!
Deep Research 是 OpenAI集成于ChatGPT中的一项全新功能,其独特之处在于能够自主进行网络信息检索、整合多源信息、深度分析数据,并最终提供全面深入的解答。
Deep Research 的推出,标志着OpenAI在智能体上取得了重要进展。
详见站内专题: 大模型搜索
【2025-3-25】GPT-4o Image Generation
官网
- 【2025-3-25】Introducing 4o Image Generation
OpenAI 发布 GPT-4o原生多模态图像生成功能,支持生成更加逼真的图像。
这是 Deep Research 以来 OpenAI 最有意义的模型更新。
新模型+一句话指令,效果就超过了人类精心设计的工作流。
用户只需在ChatGPT中描述图像(可指定宽高比、色号或透明度等参数),GPT-4o便能在一分钟内生成相应图像。让我们细致看一看:本次更新,突破了以往的哪些边界。
GPT-4o图像生成功能具有以下特点:
- 精准渲染图像内文字,能够制作 logo、菜单、邀请函和信息图等;
- 精确执行复杂指令,甚至在细节丰富的构图中也能做到;
- 基于先前的图像和文本进行扩展,确保多个交互之间的视觉一致性;
- 支持各种艺术风格,从写实照片到插图等。
官方表述
GPT-4o在多个方面相较于过去的模型进行了改进:
- 更好的文本集成:与过去那些难以生成清晰、恰当位置文字的AI模型不同,GPT-4o现在可以准确地将文字嵌入图像中;
- 增强的上下文理解:GPT-4o通过利用聊天历史,允许用户在互动中不断细化图像,并保持多次生成之间的一致性;
- 改进的多对象绑定:过去的模型在正确定位场景中的多个不同物体时存在困难,而GPT-4o现在可以一次处理多达10至20个物体;
- 多样化风格适应:该模型可以生成或将图像转化为多种风格,支持从手绘草图到高清写实风格的转换。
该模型还整合 OpenAI的视频生成平台Sora,进一步扩展了其多模态能力。
新模型即日起将作为ChatGPT的默认图像生成引擎,向ChatGPT Free、Plus、Team及Pro用户开放,取代此前使用的DALL-E 3。企业版、教育版以及API接口也将在不久后支持该功能。
【2025-8-6】GPT-oss
OpenAI 推出两款开源模型 GPT-oss-120b 和 GPT-oss-20b
这是自 2020 年发布 GPT-2 以来,OpenAI 首次推出开源语言模型。
- 这两款模型均可在 Hugging Face 在线开发者平台上免费下载
- OpenAI 称其在多个用于比较开源模型的基准测试中表现“处于前沿水平”。
介绍
Gpt-oss-120b模型在核心推理基准测试中与OpenAI o4-mini模型几乎持平,同时能在单个 80GB GPU 上高效运行。Gpt-oss-20b模型在常见基准测试中与 OpenAI o3‑mini 模型取得类似结果,且可在仅配备 16GB 内存的边缘设备上运行,使其成为设备端应用、本地推理或无需昂贵基础设施的快速迭代的理想选择。
技术架构上,采用了专家混合(MoE)设计:
- GPT-OSS-120B拥有1170亿参数,但每个token仅激活51亿参数;
- GPT-OSS-20B总参数量约210亿,激活参数仅36亿。
这种稀疏激活架构大幅降低了计算开销。小模型可在16GB内存的消费级设备上运行,大模型则能在单张NVIDIA H100 GPU上流畅推理,性能分别接近OpenAI自家的o3-mini和o4-mini闭源模型。
模型开放但数据封闭——OpenAI未公开训练数据集,仅提供模型权重。这种设计既满足开发需求,又保护了核心知识产权。
部署成本
- gpt-oss-120b 在核心推理基准测试中接近 OpenAI o4-mini,只需要单张 80GB GPU就可以运行。
- gpt-oss-20b在常见基准测试中接近o3-mini,只需要16G内存就可以运行。
gpt-oss 权重在 Hugging Face 上提供下载,并且原生量化为 MXFP4 格式。而且发布前就跟Azure、Hugging Face、vLLM、Ollama、llama.cpp、LM Studio、AWS、Fireworks、Together AI、Baseten、Databricks、Vercel、Cloudflare、 OpenRouter、NVIDIA、AMD、Cerebras 和 Groq 等都提前合作好了。
模型微调见站内专题:大模型微调
【2025-8-8】GPT-5
OpenAI官方总结GPT-5卖点:更强、更稳、更便宜、更好用。(仿佛奥运会来了)
- (1)更强:GPT-5采用统一系统架构,整合了高效基础模型、深度推理模块和实时路由系统,能够根据不同情况判断何时该快速回应,何时进行深度推理思考以提供专家级的答案,还400K的超长上下文能力。
- (2)更稳:GPT-5在事实性与安全性上进步显著,幻觉更少、“编理由”“迎合性回答”更少,“不知道时更愿意承认不知道”。有效抑制“模型谄媚”(Sycophancy)
- (3)更便宜:API价格比竞品便宜,包括2025年8月5日Claude Opus 4.1、Gemini 2.5 Pro。
- (4)更好用:用户不用再苦恼选什么型号的模型,全部统一。
多项效果评测上,GPT-5均刷新记录,超过grok-4幻觉率上,gpt-5-main重大事实错误率比GPT-4o低44%,而gpt-5-thinking更是比OpenAI o3低了78%。专业的LongFact和FActScore基准测试中,gpt-5-thinking产生的 factual errors 比o3低80%以上。
版本
- GPT-5.4
- GPT-5.3 Instant
- GPT-5.3-Codex
- GPT-5.2
【2025-10-01】Sora 2
2024年2月发布的初代Sora模型在许多方面可视为视频领域的“GPT-1时刻”,而Sora 2则直接迈入了视频领域的“GPT-3.5时刻”。
10月1日凌晨,OpenAI 新一代视频生成模型 Sora 2.0 与同名社交应用(Sora App)同步登场
不仅以物理准确性、多镜头连贯性和音画同步的技术突破,被定义为“视频领域的ChatGPT时刻”
Sora 2 技术突破(物理准确性、长视频连贯性、音画同步)大幅降低了高质量视频生成的门槛
【2025-10-6】DevDay
【2025-10-6】OpenAI 开发者大会DevDay 2025发布了什么?
OpenAI在开发日带来很多新发布:
- ChatGPT 中引入Apps:可直接在ChatGPT进行自然对话的Apps,以及供开发者构建自己应用程序的全新Apps SDK(预览版)
- AgentKit:一整套用于开发者和企业构建、部署与优化agent的完整工具集
- 新模型API:
Sora 2、Sora 2 Pro、GPT-5 Pro、gpt-image-1-mini和gpt-realtime-mini - Godex GA:Codex 现已全面可用,同时推出三项新功能。
直接通过名称调用App,例如
- 输入:“Spotify,帮我为这周五的派对创建一个播放列表。”
- ChatGPT 会在聊天中自动唤出 Spotify 应用,并利用相关上下文为你提供帮助。
ChatGPT 也会在合适的时机主动推荐相关应用,例如
- 当你在谈论买新房时,ChatGPT 可能会建议使用 Zillow 应用,让你直接在 ChatGPT 内的交互式地图上浏览符合预算的房源。
所有的ChatGPT用户都可以使用这个新功能,无论是免费用户还是付费用户。
首批试点合作伙伴包括 http://Booking.com、Canva、Coursera、Figma、Expedia、Spotify 和 Zillow,这些Apps今天起已在其提供服务的地区上线(首先支持英文)。
OpenAI 还推出了供开发者构建自己应用程序的全新Apps SDK(预览版),它基于 Model Context Protocol(MCP),让 ChatGPT 能连接外部工具与数据,并支持开发者同时设计应用逻辑与界面。开发者可使用自有代码定义交互与对话逻辑,直接连接后端,实现用户登录与高级功能。官方也提供了开发文档、设计指南和示例仓库,帮助快速上手构建自然对话式应用:Apps SDK。
OpenAI正式推出 AgentKit,用于开发者和企业构建、部署与优化agent的完整工具集。
- 以前,构建agent 要在各种零散工具之间来回折腾:复杂且无版本控制的编排流程、自定义连接器、手动评估管线、提示词调优,以及在上线前需要耗费数周构建前端界面。
- AgentKit 可以通过全新构建模块,以可视化方式快速设计工作流,并更快地嵌入智能体交互界面,包括:
Agent Builder:创建和版本管理多agent工作流的可视化画布Connector Registry:管理员可在此集中管理数据和工具在 OpenAI 产品间的连接方式ChatKit:一套可嵌入产品中的、可自定义的聊天式agent体验工具包
【2026-4-14】GPT-6【假】
2026年4月14日,OpenAI 正式发布 GPT-6(代号 “Spud”),以200 万 Token 上下文、5-6 万亿 MoE 参数、40% 综合性能跃升、原生 Symphony 多模态架构四大突破,宣告 AI 正式告别 “聊天时代”,迈入自主执行、闭环落地的智能体 新纪元
GPT-6 并非孤立突破,与 2026 年两大技术现象 ——OpenClaw 智能体框架爆发、Skill / 反 Skill 赛博攻防—— 形成技术共振,共同构建 “大脑 + 身体 + 能力” 的新一代 AI 生产力体系。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
