- 扩散语言模型
- 结束
扩散语言模型
AR vs Diffusion
【2025-6-8】Thinking with Multimodal:开启视觉深度推理与多模态认知的新范式
自回归·AR与扩散·Diffusion做一下梳理:
- 自回归·AR模型:逐步构建认知的“乐高积木”
- 自回归模型通过逐 token 生成,模拟人类逐步构建认知的过程。在“Thinking with Generated Images”中,自回归 LMMs 仍能够在推理过程中动态生成视觉与文本 token,这使其具备了处理长序列多模态思维链的能力。
- 然而,自回归模型问题:其生成过程的顺序性可能导致早期错误累积,影响后续推理结果。 2.扩散·Diffusion模型:从噪声中雕琢认知的“雕塑家”
- 扩散模型则通过逐步去噪过程生成数据,这一特性使其在图像生成任务中表现出色。
- 然而,将其应用于视觉推理时,需要解决如何在去噪过程中保留中间推理信息的问题。
- 尽管如此,扩散模型的并行生成特性为其在多模态推理中的应用提供了新可能,尤其是在需要同时处理多个模态信息的场景中。
- AR与Diffusion的回归与统一 · Latent Space Reasoning
- AR、Diffusion还有更为关键的对于模型内Latent Space Reasoning的完备建模,而AR和Diffusion是对其Latent Space的下游联合概率计算(AR),还是以时间步数为核心的的扩散或流匹配升降噪表征(Diffusion&Flow)也罢的流形分布计算到呈现的不同路径或方式。
- 而transformer或其他诸如Titan或TTT等架构,亦对部分核心Latent Space的未来持续探索起着核心的作用。
ARM 问题
问题:“难道只有自回归范式才能实现LLM的智能吗?”
实践表明,自回归模型虽然有效,但并非完美无缺。
自回归结构的一些局限性:
- 计算效率低:推理时无法并行生成
- 长程依赖于逆向推理难题:缺乏从右向左的推理能力,导致无法反向推理,利用后文
- 上下文限制:未来信息智能纳入隐式表示,无法条件影响后续词;BERT双向,但非生成模型
ARM存在两大固有缺陷:
- 顺序生成瓶颈:逐token生成导致计算效率低下
- 推理速度瓶颈:完全串行机制导致推理延迟高、服务成本居高不下,模型规模越大,问题越严峻
- 推理方向受限:左到右的单向建模难以处理反向任务(如“反转诅咒”现象)—— LLaDA因双向建模特性实现突破
- 局部视野与不可逆生成的双重缺陷:AR模型线性的生成路径不仅带来局部视野局限,难以整体理解化学分子式等结构化知识;更致命的是缺乏自我修正(Self-Correction)能力。
- 每个词元的生成都是一个不可逆的「最终决策」,一旦出错便无法挽回,导致错误累积。
- 这与扩散模型等范式形成了鲜明对比,后者理论上支持迭代优化和全局修正。
DLM 介绍
扩散语言模型(Large Language Diffusion Models, LLaDA)是一种新兴的语言生成模型,通过掩码扩散方法挑战传统自回归模型的局限性,展现出强大的生成能力和上下文学习能力。
别称
- LLaDA:Large Language Diffusion Models
- DLM(Diffusion Large Language Model )

【2025-5-29】DLM(扩散语言模型)会成为2025年的Mamba吗?
- 【2025-2-18】论文 Large Language Diffusion Models
- Demo LLaDA-demo
- 【2025-4-14】What are Diffusion Language Models?
AR vs DLM
两种范式对比
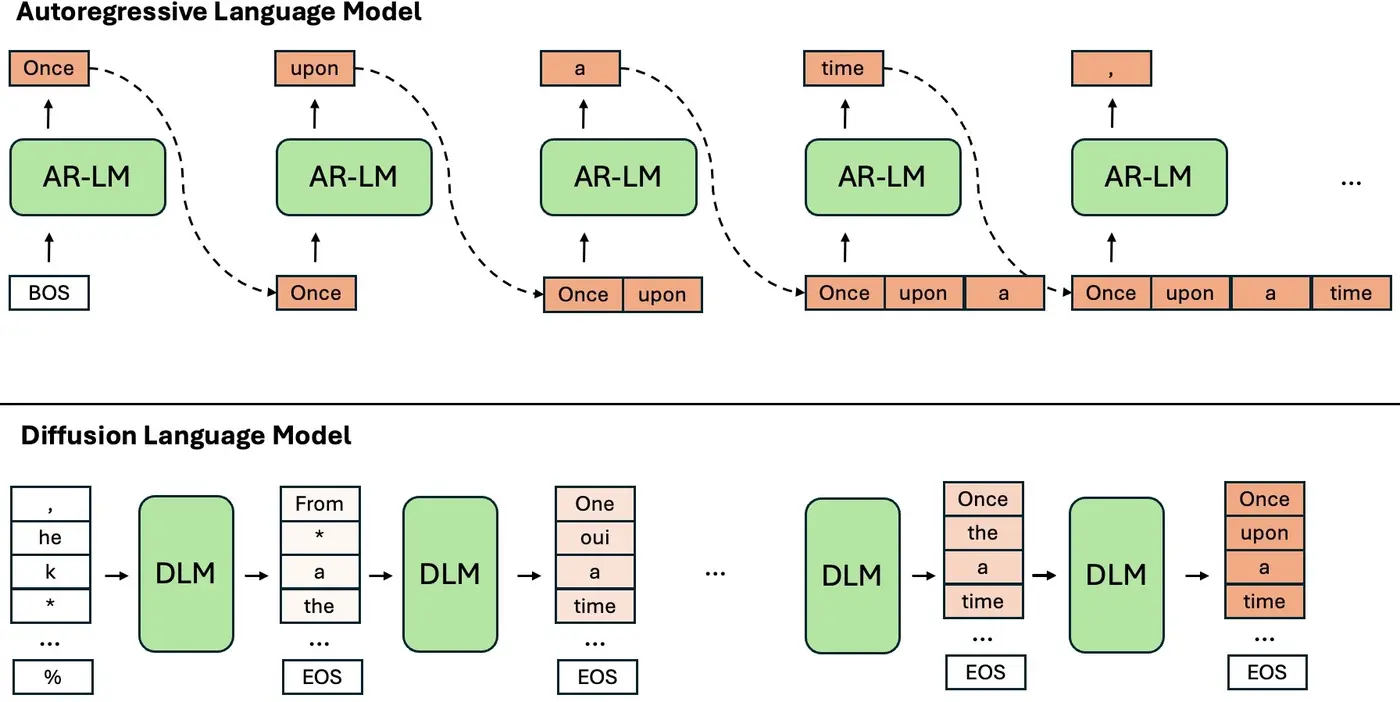
【2025-9-7】火的一塌糊涂的「扩散语言模型」是啥 漫画讲解
- 【2025-8-14】参考论文 A Survey on Diffusion Language Models 包含扩散模型发展进化图
- 自回归模型(AR)像传统厨师,一个字一个词慢慢“下锅”,整个句子串起来才能出锅。
- 扩散语言模型(DLM)不讲究“先放什么”,它把原材料全下锅,通过迭代调整,逐渐生成通顺句子。
总结
- DLM 支持并行预测与修改多个词位,推理速度远超传统AR模型,特别适合“高峰时段”。
- DLM 通过“置信度判断”,留下靠谱的词,不对的就换,直到句子自然流畅。
- DLM 推理速度上领先,但仍在提升稳定性与理解力。就像一个新派厨师,掌握了快手绝技,仍在追求完美味道。
| 模式 | 原理 | 分析 | 图解 |
|---|---|---|---|
ARM |
逐字输出 | 简单,但慢 |  |
DLM |
更符合人类直觉 | 复杂,但快,更容易扩展 | 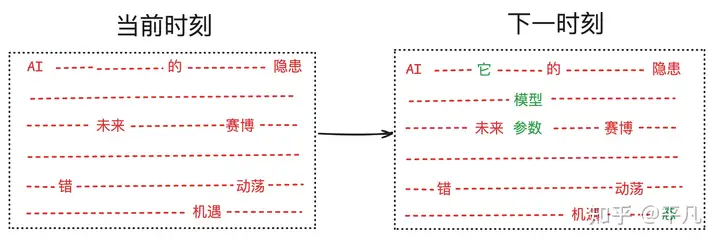 |
【2025-8-27】人大、清华提出 DPT 对偶伪训练器, 基于扩散模型+半监督
- Diffusion Models and Semi-Supervised Learners Benefit Mutually with Few Labels
- 步骤:标注数据训练分类器 → 伪标签训练条件生成模型 → 真假数据再次训练分类器
- 代码 DPT
- 【2025-7-21】Diffusion Beats Autoregressive in Data-Constrained Settings
- Github Diffusion Language Models are Super Data Learners
李宏毅教程
DLM 原理
DLM 工作原理
- 根据问题直接生成一个回答草稿
- 然后一次次的修改和润色草稿,最终输出回答。

DLM(Diffusion Large language model)与ARM差异很大,但更符合人类直觉。
高考作文题要求写一篇不少于800字的议论文: “AI的出现给人类带来了什么改变?”
- 传统LLM: 一个字一个字的往外蹦,即线性生成过程。每个时刻只生成一个字
- 模型: DeepSeek,ChatGPT,Qwen,Gemini等等
- DLM 一轮轮迭代更新,当前时刻可能只确定部分词汇(红色),但下一时刻,可能有更多的内容被确定出来(绿色)。
- 就像油画创作
- 图像、视频生成领域主流,OpenAI的Sora,阿里的Wan通义万相等。
- 文本领域:
- LLaDA,同等模型大小的前提下,在大多数任务上表现并不比其他的模型差多少
- Google Gemini 2.5 推出 扩散语言模型
DLM 只不过是把脱胎于图像生成的技术应用到了文字生成

DLM 核心技术原理很直观,不同于LLM next token prediction,DLM 做 mask predictor。
作者:平凡
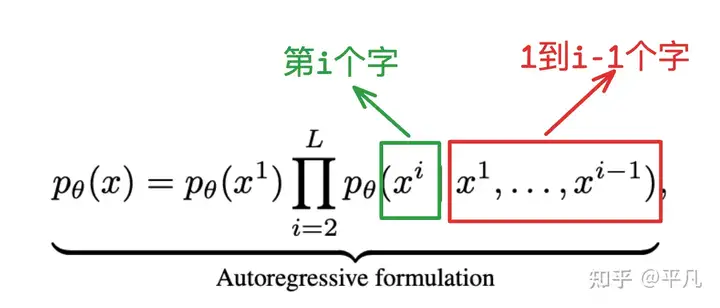
语言模型(自回归) autoregressive modeling (ARM)
核心公式: 根据前面的所有内容预测下个字符。
在图像、音频等连续信号领域,近年兴起的扩散模型 (Diffusion Models)为生成建模提供了新的可能。
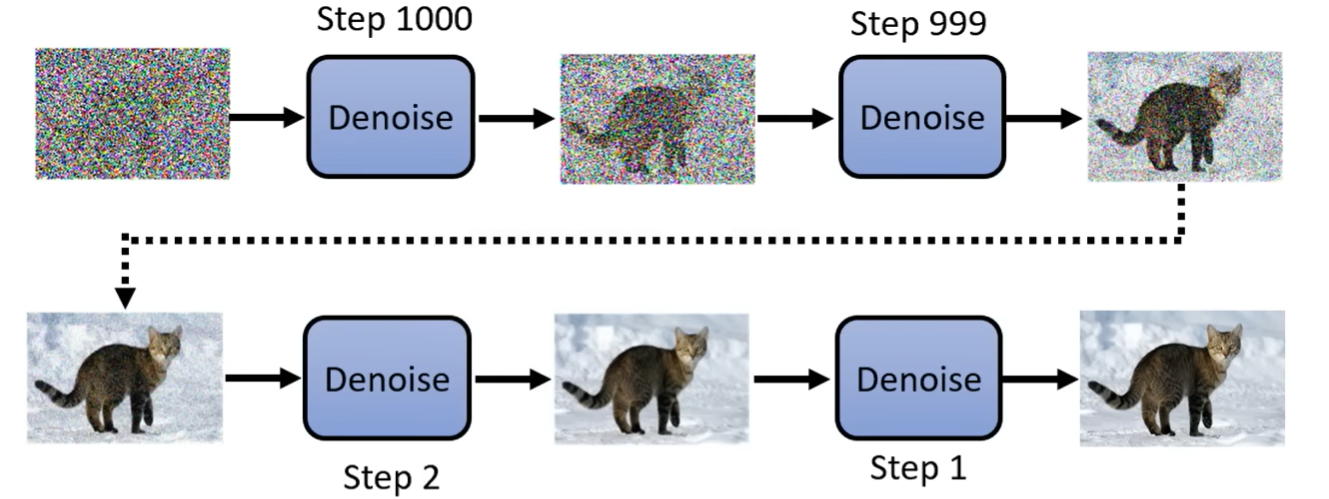
扩散模型通过逐步添加噪声再去噪声的过程来生成数据,在图像生成任务上取得了革命性突破。
- 例如,Ho等人提出的DDPM模型, 在图像生成质量上媲美甚至超越GAN;
- 谷歌的Imagen模型和稳定扩散模型(Stable Diffusion)能够生成高保真、逼真的图像和艺术画作。
- 这些模型的多模态扩展(如文本到图像生成)也非常成功,如OpenAI的DALLE-2和StabilityAI的稳定扩散均采用了扩散技术。
扩散模型已经成为视觉生成AI的主流方法之一
扩散模型成功的关键:将生成过程划分为多步,每一步进行小幅修改,而非一次性生成全部内容。
- 扩散模型包含正向过程(逐步向数据添加噪声,使其趋于随机分布)和反向过程(逐步去除噪声,从纯噪声恢复数据分布)。
- 图像领域,这种逐步生成方式带来了稳定训练和高样本质量的优点。
详见站内专题:扩散模型
例如,基于Transformer的扩散模型也在视觉任务中展现出良好扩展性和性能。
研究表明,用Transformer实现的扩散模型(Diffusion Transformers)在大规模视觉数据上同样可行,并验证了Transformer+扩散的可扩展性
扩散模型的潜力对NLP领域具有启发意义:
- 文本虽然是离散符号序列,但理论上也可以设计类似的逐步“噪声扰动-还原”生成过程。
如果这种思路应用得当,可能在以下方面优于自回归模型:
- 并行生成: 扩散的反向生成可在每个步骤中同时更新多个位置的词元,从而有希望并行化部分生成过程,减少生成时延。
- 双向依赖: 反向去噪过程可以利用全局上下文(部分词元已填充,部分待生成),模型在预测时能够同时参考已生成内容的左侧和右侧。这天然缓解了自回归模型不能利用未来词的缺陷,使模型对顺序倒置的任务更为健壮。
- 新的优化目标: 扩散模型训练基于对数似然的下界(ELBO)优化,这与直接的交叉熵训练不同,可能提供不同的正则效果。理论上,任何符合生成建模基本原理(最大似然)的模型都应具备LLM的通用能力。
因此,用不同于AR的方式来逼近语言分布,也有望学习到相似的能力
AR+DLM比赛
DLM > AR
【2026-2-6】Stable-DiffCoder 超越自回归模型!扩散模型在代码生成取得新突破
DLM 模型能力往往落后于同等规模的强力自回归(AR)模型。
【2026-1-23】华中科技大学和字节跳动联合推出了 Stable-DiffCoder。这不仅仅是一个新的扩散代码模型,更是一次关于 「扩散训练能否提升模型能力上限」 的深度探索。
- 论文标题:Stable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model
- Github 链接: Stable-DiffCoder
- 模型链接: stable-diffcoder
Stable-DiffCoder 完全复用 Seed-Coder 架构、数据的条件下,通过引入 Block Diffusion 持续预训练(CPT)及一系列稳定性优化策略,成功实现了性能反超。
在 多个 Code 主流榜单上(如 MBPP,BigCodeBench 等),它不仅击败了其 AR 原型,更在 8B 规模下超越了 Qwen2.5-Coder ,Qwen3,DeepSeek-Coder 等一众强力开源模型,证明了扩散训练范式本身就是一种强大的数据增强手段。
AR > DLM
视觉任务:AR首次击败DLM
【2023-10-13】资讯, 图像、视频生成上,语言模型首次击败扩散模型,tokenizer是关键
大型语言模型(LLM 或 LM)一开始是用来生成语言的,但随着时间的推移,已经能够生成多模态的内容,并在音频、语音、代码生成、医疗应用、机器人学等领域开始占据主导地位。
当然,LM 也能生成图像和视频。
- 图像像素会被视觉 tokenizer 映射为一系列离散 token。
- 这些 token 被送入 LM transformer,就像词汇一样被用于生成建模。
尽管 LM 在视觉生成方面取得了显著进步,但 LM 的表现仍然不如扩散模型。
- 例如,在图像生成的金标基准 — ImageNet 数据集上进行评估时,最佳语言模型的表现比扩散模型差了 48% 之多(以 256ˆ256 分辨率生成图像时,FID 为 3.41 对 1.79)。
为什么语言模型在视觉生成方面落后于扩散模型?
- 谷歌、CMU 的研究表明: tokenizer 是关键。缺乏一个良好的视觉表示,类似自然语言系统,以有效地建模视觉世界。
- 论文链接:paper
在相同训练数据、可比模型大小和训练预算条件下,利用良好的视觉 tokenizer,掩码语言模型在图像和视频基准的生成保真度和效率方面都超过了 SOTA 扩散模型。这是语言模型在标志性的 ImageNet 基准上击败扩散模型的首个证据。
目的不是断言语言模型是否优于其他模型,而是促进 LLM 视觉 tokenization 方法的探索。
- LLM 与其他模型(如扩散模型)的根本区别: LLM 使用离散潜在格式,即从可视化 tokenizer 获得的 token。
这项研究表明,这些离散的视觉 token 的价值不应该被忽视,因为存在以下优势:
- 1、与 LLM 的兼容性。token 表示的主要优点是与语言 token 共享相同的形式,可直接利用社区多年来为开发 LLM 所做的优化,包括更快的训练和推理速度、模型基础设施的进步、扩展模型的方法以及 GPU/TPU 优化等创新。通过相同的 token 空间统一视觉和语言可以为真正的多模态 LLM 奠定基础,后者可以在我们的视觉环境中理解、生成和推理。
- 2、压缩表示。离散 token 可以为视频压缩提供一个新视角。可视化 token 可以作为一种新的视频压缩格式,以减少数据在互联网传输过程中占用的磁盘存储和带宽。与压缩的 RGB 像素不同,这些 token 可以直接输入生成模型,绕过传统的解压缩和潜在编码步骤。这可以加快生成视频应用的处理速度,在边缘计算情况下尤其有益。
- 3、视觉理解优势。研究表明,离散 token 在自监督表示学习中作为预训练目标是有价值的,如 BEiT 和 BEVT 中所讨论的那样。此外,研究发现,使用 token 作为模型输入提高了鲁棒性和泛化性。
研究者提出了一个名为 MAGVIT-v2 的视频 tokenizer,旨在将视频(和图像)映射为紧凑的离散 token。
该模型建立在 VQ-VAE 框架内的 SOTA 视频 tokenizer——MAGVIT 基础上。基于此,研究者提出了两种新技术:
- 1)一种新颖的无查找(lookup-free)量化方法,使得大量词汇的学习成为可能,以提高语言模型的生成质量;
- 2)通过广泛的实证分析,他们确定了对 MAGVIT 的修改方案,不仅提高了生成质量,而且还允许使用共享词汇表对图像和视频进行 token 化。
实验结果表明,新模型在三个关键领域优于先前表现最好的视频 tokenizer——MAGVIT。
- 首先,新模型显著提高了 MAGVIT 的生成质量,在常见的图像和视频基准上刷新了 SOTA。
- 其次,用户研究表明,其压缩质量超过了 MAGVIT 和当前的视频压缩标准 HEVC。
- 此外,它与下一代视频编解码器 VVC 相当。
- 最后,研究者表明,与 MAGVIT 相比,他们的新 token 在两个设置和三个数据集的视频理解任务中表现更强。
DLM 问题
MDLM(掩码扩散语言模型) 面临两大难题:
- 训练效率低下:其 ELBO 优化目标相比标准 NLL 收敛更慢,导致性能不佳。该工作首次对二者的训练效率进行了公平对比,实验证实,在同等算力下,MDLM 与 AR 模型的性能存在显著差距。
- 推理成本高昂:由于缺乏类似 AR 模型的 KV 缓存机制,MDLM 在推理时每一步都需要处理整个序列,导致计算复杂度高,实际部署依然昂贵。
DLM 适用场景
【2025-7-30】在数据受限场景下,Diffusion优于自回归模型
大语言模型的发展长期依赖自回归(AR)模型,但这类模型在数据重复使用时容易快速饱和甚至过拟合。
随着高质量数据逐渐稀缺(预计2028年耗尽公开人类生成数据),如何高效利用有限数据成为关键。
而扩散模型作为替代方案,虽被认为计算需求高,但在数据受限场景中的优势尚未被充分挖掘。
CMU 团队在数据重复使用的受限场景中,对比了AR模型和掩码扩散模型。
两者共享相同架构和训练参数,核心差异在于:
- AR模型固定从左到右预测序列,扩散模型则通过随机掩码让模型学习多种token排序任务。
- 同时,团队拟合了数据受限下的缩放定律,重点分析了两者对重复数据的利用效率(如有效重复epoch的半衰期)。
核心结论:
- 计算量充足时,扩散模型表现远超AR模型:能从重复数据中持续获益(有效重复epoch达约500次,AR仅约30次),且无过拟合迹象;
- 存在临界计算点,超过该点后扩散模型的验证损失更低,下游任务(如问答、推理)表现更优;
- 临界计算量与数据集大小成幂律关系,为数据稀缺场景提供了明确的模型选择依据。
DLM Agent
【2026-2-10】华为发布业界首个扩散语言模型Agent,部分场景提速8倍
衡量一个Agent够不够强,早已不再看它能不能“答对问题”,而是看它在面对多轮推理、工具调用及复杂协作时,能否用最短的路径、最少的交互预算,稳定地搞定任务。
在这一背景下,一个长期被行业忽视的底层命题浮出水面:
- 当Agent 框架、工具、数据和训练方式都保持一致时,仅仅改变语言模型的生成范式(Autoregressive vs Diffusion),是否会系统性地改变Agent的规划与行为模式?
华为诺亚方舟实验室、华为先进计算与存储实验室、UCL、南洋理工大学、清华大学和北京大学的研究团队,在最新工作中,对这一问题给出了迄今为止最“对照实验式”的回答。
仅仅是把“底座”换成了 扩散式大模型(DLLM),Agent 就像突然开了“上帝视角”,执行速度不仅提升了30%以上,甚至在部分复杂任务中跑出了8倍于传统AR模型的效率。
在完全相同的Agent工作流、训练数据和交互预算下,研究发现:
- 准确率基本持平的前提下,DLLM Agent端到端执行速度平均提升30%以上;
- 成功解题的条件下,DLLM Agent使用更少的交互轮次和工具调用;
- DLLM展现出更强的planner能力:更早收敛到正确轨迹、回溯和冗余更少;
- 这种优势并非仅来自并行解码速度,而是体现在Agent级别的规划与决策行为上。
DLLM为何是天生的“强Planner”?
- 一、Planner Agent:先全局、后细节
- 在任务拆解阶段,DLLM Planner表现出独特的两阶段特征,这与人类先构思大纲再填补内容的思维方式不谋而合
- 二、Information Seeker:先定方向,再填参数
- 三、注意力演化:确定性的迅速锁定
DLM 实现
综述
【2025-7-5】新加坡国立
【2025-7-5】新加坡国立大学 离散扩散语言模型综述
- 论文:Discrete Diffusion in Large Language and Multimodal Models: A Survey
- GitHub 仓库:DLLM-Survey
- 解读 舍弃自回归,离散扩散语言模型如何演化?NUS综述解构技术图谱与应用前沿
自 GPT 引爆大语言模型热潮以来,自回归大语言模型(LLMs)与多模态模型(MLLMs)已成为智能系统的基石。
然而,当人们着眼于更快、更可控、更智能的生成范式时,一条新兴路径悄然浮现:离散扩散(Discrete Diffusion)。
传统大模型采用自回归(Autoregressive, AR)架构,从左至右逐词生成方式虽然自然,但存在显著的性能瓶颈:
- 无法并行解码、难以精确控制输出、局限于对输入的静态感知、对补全和逆向推理的建模能力差。
- 这使其在需要结构化控制与动态感知的复杂场景中表现受限。
离散扩散模型打破了这一范式, 不再逐词预测,而是将生成视为一个「掩码 - 去噪」迭代过程,并行处理所有 Token,并借助全局注意力机制实现动态感知。
这种设计带来了三大核心优势:
- 推理并行性(Parallel Decoding): 并行推理是离散扩散模型最大的特点和优势。并行推理使得离散扩散每次迭代都可以解码出多个 Token,从而带来解码速度上的提升。
- 输出可控性(Controllability)与补全能力(Infilling): 掩码 - 去噪的解码机制,使得每一次回答都可以预设回答的长度、格式、结构,为回答设定一个模板。
- 动态感知能力(Dynamic Perception): 全局注意力机制下模型对左侧 Token 的处理受到右侧 Token 的影响;多轮迭代的解码机制使得对所有 Token 的处理都可以反复多次进行。这使得 dLLM 和 dMLLM 可以对长语料和多模态输入进行多轮、有条件的动态感知,而不是如单向注意力一样仅仅能够感知一次。
自回归模型与典型离散扩散模型的对比
本综述系统梳理了离散扩散方向的研究图谱,呈现了离散扩散语言模型(dLLMs)与离散扩散多模态语言模型(dMLLMs)的理论基础、代表模型、训练与推理技术,以及在推理、视觉、生物等多个领域的应用进展。
离散扩散语言模型(dLLMs)生态,分四类:
- 轻量级模型:早期的离散扩散模型参数量往往不超过 1B,代表作包括 D3PM、DiffusionBERT、RDM、Diffusion-NAT、TESS、SEDD、MDLM、MD4 等。这些模型重点在于探索基础的建模机制与去噪策略,验证离散扩散在文本和多模态生成任务上的可行性。
- 大规模 dLLM:随着技术成熟,多个工作开始将扩散架构拓展至 10 亿以上参数量,构建具备完整语言理解与生成能力的「非自回归大模型」,代表模型包括:LLaDA 系列、DiffuGPT / DiffuLLaMA 和 DREAM 等。这些工作从规模上拓展了扩散语言模型的边界,系统性地探索了其工程可行性。
- 多模态扩展(dMLLM):在语言能力日趋完善之后,研究者开始探索 dLLMs 在多模态任务中的适应性,典型代表有:Dimple、LaViDa 和 LLaDA-V。
- 统一生成模型:离散扩散在图片生成中的可行性很早就被验证了,随着语言生成能力的完善,MMaDA、FUDOKI 和 Muddit 等模型给出了一种统一的架构,使用离散扩散模型在一个神经网络中同时建模文本和视觉的生成。
模型结构
【2025-2-18】 LLaDA
【2025-2-14】LLaDA 提出掩码扩散模型(MDM) 架构,通过双向建模打破ARM的序列依赖
- 论文解读:《Large Language Diffusion Models》(Shen Nie等,2024)
- 项目地址:LLaDA
核心突破:首次证明扩散模型可在8B规模媲美LLaMA3,颠覆“自回归是LLM唯一路径”的固有认知
SFT后,LLaDA展现出多轮对话、多语言翻译、复杂推理能力
效果
同等计算量(2.3T token预训练 + 4.5M pair SFT)下,LLaDA 8B展现出惊人性能,媲美 LLama3
【2025-5-22】Google Gemini Diffusion
【2025-5-22】谷歌在 Google I/O 2025,重磅提出 文本扩散模型 Gemini Diffusion,将扩散模型应用于文本生成的模型。
优势
- 1)更快的响应速度:生成内容的速度甚至比我们迄今为止最快的模型要快得多。
- 2)更连贯的文本:一次生成整个标记块,这意味着它比自回归模型更连贯地响应用户的提示。
- 3)迭代优化:纠正生成过程中的错误以获得更一致的输出。
该模型在保持与 Gemini 2.0 Flash-Lite 相当性能表现的同时,处理速度提升了惊人的5倍。这一创新或将重塑自然语言处理领域的技术路线,扩散模型通过渐进式噪声去除的生成方式,可能为长文本连贯性、多模态融合等Transformer的固有痛点提供新的解决方案。
【2025-7-21】TTD-DR 测试时扩展
【2025-7-21】谷歌:测试时扩散「Deep research agent」
由大语言模型(LLM)驱动的深度研究智能体(Deep research agent)正在迅速发展;
然而,当使用通用测试时扩展算法生成复杂的长篇研究报告时,其性能往往会达到瓶颈。
受人类研究的迭代性(涉及搜索、推理和修订的循环)的启发,谷歌团队提出了“测试时扩散深度研究者”(Test-Time Diffusion Deep Researcher,TTD-DR)。
这一创新框架将研究报告的生成视为一个扩散过程。
TTD-DR Test-Time Diffusion Deep Researcher
- 通过生成可更新的初始草稿启动该过程,该草稿作为不断演进的基础,引导研究方向。
- 随后,草稿通过一个“去噪”过程进行迭代精炼,该过程在每个步骤中动态整合外部信息,由检索机制驱动。
- 核心过程进一步通过应用于 agentic 工作流每个组件的自进化算法得到增强,确保扩散过程生成高质量的上下文。
这种基于草稿的设计使报告撰写过程更加及时和连贯,同时减少了迭代搜索过程中的信息丢失。
TTD-DR 在需要密集搜索和多跳推理的广泛基准测试中实现了 SOTA,显著优于现有 Deep research agent。
【2025-7-28】Seed Diffusion Preview
【2025-7-28】字节 Seed 团队发布实验性扩散语言模型 Seed Diffusion Preview, 标志着在语言模型领域的一次重大技术突破,尤其是在代码生成和推理速度方面的显著提升。
- 项目页面: seed_diffusion
- 体验链接: seed_diffusion
- 技术报告:sdiff_updated.pdf
Seed Diffusion Preview 核心目标: 通过结构化的代码生成实验,验证离散扩散技术作为下一代语言模型基础框架的可行性。
与传统的自回归(AR)模型相比,Seed Diffusion Preview 在推理速度上实现了令人瞩目的进步,达到了每秒2146个tokens,提升幅度高达5.4倍,同时在多个代码生成基准测试中,性能与自回归模型不相上下,甚至在某些任务上表现得更加出色。
自回归模型在推理速度和全局控制方面的局限性。
- 扩散模型在图像和视频合成等连续数据领域取得了显著成功,但将其应用于自然语言等离散领域面临着不少挑战。
- 标准的扩散过程与离散状态空间的不兼容性,曾让这一技术的应用前景蒙上阴影。
将扩散模型迁移到离散的自然语言领域时,会面临重大挑战。主要困难在于标准扩散过程本质上是在连续状态空间中定义的,因此无法直接应用于离散领域如自然语言。
为弥合这一差距,现有方法主要有两类:
- 将离散token投影到连续潜空间,在潜空间应用扩散过程。
- 通过定义显式状态转移矩阵在离散状态空间上直接构建扩散过程。
- 近期的离散状态空间方法已通过先进的架构和训练方案展现出可扩展性和有效性。
但离散扩散模型在语言领域的仍面临两大挑战:
- 顺序建模的归纳偏差:虽然离散扩散模型在理论层面具有强大的优势,以任意顺序建模和生成token,但自然语言本质上遵循顺序性特征。若采用完全随机顺序的学习信号,不仅效率低下,甚至可能对语言建模产生负面影响,导致模型性能下降。
- 推理效率不足:离散扩散模型多步迭代去噪机制会产生严重延迟,这削弱了其相较于自回归模型的速度优势。
原理
Seed Diffusion Preview 通过四项关键技术创新,展示了离散扩散模型在可扩展性和效果上的巨大潜力。
这四项创新包括:两阶段课程学习、约束顺序扩散、同策略学习以及块级并行扩散采样方案。
- 两阶段课程学习策略通过基于掩码和编辑的扩散训练,旨在提升模型的局部上下文补全能力和全局代码合理性评估能力。
- 约束顺序扩散引入代码的结构化先验,引导模型掌握正确的依赖关系
- 而同策略学习则通过优化生成步数来提升推理速度。
- 块级并行扩散采样方案则在保持因果顺序的同时,实现了高效的块级推理。
效果
实验结果表明,Seed Diffusion Preview 在代码推理速度上达到了2146tokens/s的突破性进展,这一速度提升并未以牺牲质量为代价,模型在多个业界基准上的性能与优秀的自回归模型相当,甚至在一些复杂推理任务中表现得更加优异。
推理速度方面,该模型在英伟达H20显卡上实现了2146 tokens/s,相比同等规模自回归模型的提升了5.4倍。
这不仅证明了离散扩散模型在推理加速方面的潜力,更展示了其在复杂推理任务中的应用前景。
这一发布无疑是字节跳动在AI领域的一次大胆尝试,标志着未来语言模型的发展方向。随着技术的不断进步,Seed Diffusion Preview 将为开发者和用户带来更多创新和便利,让我们拭目以待这一技术如何改变我们的编程和交互方式。
【2025-8-1】港中文 DAEDAL
随着 Gemini-Diffusion,Seed-Diffusion 等扩散大语言模型(DLLM)的发布,这一领域成为了工业界和学术界的热门方向。
但是,当前 DLLM 存在问题:
- 推理时必须采用预设固定长度的限制,对于不同任务都需要专门调整才能达到最优效果。
【2025-8-1】香港中文大学 MMLab,上海 AI 实验室等提出 DAEDAL,赋予 DLLM 根据问题情况自主调整回答长度的能力,弥补了 DLLM 与自回归 LLM 的关键差距,为更灵活、高效、强大的扩散大语言模型打下了基石。
- 论文标题:Beyond Fixed: Variable-Length Denoising for Diffusion Large Language Models
- 代码地址:DAEDAL
- 论文解读:扩散LLM推理新范式:打破生成长度限制,实现动态自适应调节
DAEDAL 作为 Training Free 去噪策略,从统一且短的初始长度开始,让模型根据需求在生成中调节长度,动态扩展,达到现有去噪策略在每个评测基准上精心调整生成长度得到的最佳性能相当的表现,有时甚至更胜一筹。
- DAEDAL 使用统一且很短的初始长度,在多个基准上取得了与精心调优的固定长度基线相当甚至更优的性能。
- DAEDAL 能够根据每个问题,在生成过程中自适应地动态调整长度,相比之下,现有方法则对所有问题都只能采用单一的固定长度。
DAEDAL 介绍
扩散大语言模型(DLLM)潜力巨大,但其现有推理流程存在关键问题:需要预定义的,固定的生成长度。
与能够边思考边决定 “说” 多少的人类和自回归模型不同,现有 DLLM 需要预先设定确切的输出长度。
导致了一个两难的困境:
- 设置太短,模型在复杂问题上难以发挥全部实力,可能导致做错;
- 设置太长,则会浪费大量的计算资源,同时,实验中还发现过长的生成长度可能导致性能下降。
这一问题的解决方案就蕴藏在模型自身之中。DLLM 在生成时会不断地全局规划其整体输出,而它的预测置信度正是其内部状态的强大信号。
两种关键信号:
- DLLM 在序列末端生成序列结束符 (EOS) 的意愿直接反映了其对全局预算的规划。当预设长度充足时,模型会自信地在末尾规划出结束区域,从而高置信度地预测 EOS。反之,当长度不足时,模型会试图利用所有可用空间来完成核心内容,因而抑制了在末尾生成 EOS 的置信度。
- 去噪过程中,对某个特定词元的极低预测置信度,则可作为一种局部信号,这不仅代表了模型对该词元的不确定性,更深层次地,它表明当前的局部上下文过于受限,不足以支撑一个复杂的逻辑步骤或细节的展开,或是需要插入空间对过去生成的内容进行补充和修正。
该热力图展示了在对一个长度为 128 的全掩码输入进行首次预测后,于序列末端测得的平均 EOS 词元置信度之差。该差值的计算方式为:用 “长度充足” 问题(在少于 128 长度的 setting 下被正确回答)的平均置信度减去 “长度不足” 问题(仅在长度更长的 setting 才能被正确回答)的平均置信度。图中大面积的绿色(差值 > 0)表明,对于长度充足的问题,结尾 EOS 序列置信度更高,验证了文中的核心发现。
作者提出 DAEDAL,一种无需训练的两阶段推理策略,利用这些内部信号,赋予 DLLM 根据每个问题的具体情况,动态自主调整回答长度的能力。
- 初始长度调整 (Initial Length Adjustment): 在去噪流程开始前,DAEDAL 从一个统一的很短初始长度出发。它会通过检测序列末端的 EOS 序列平均置信度来衡量:“对于这个任务,当前分配的长度是否充足?”。如果置信度很低,即模型规划充分利用全部长度,就表明模型认为长度预算不足。此时,DAEDAL 会通过增加 [MASK] 词元来扩展序列长度,并重复此过程,直到模型确信长度预算充足。这为任务设定了一个合理的全局规划长度。
- 迭代式掩码插入 (Iterative Mask Insertion): 在逐步去噪的过程中,DAEDAL 会持续监控模型的置信度。如果它发现模型对某个 [MASK] 位置极不确定,便会将其标记为 “扩展点”。DAEDAL 通过将这个单个 [MASK] 替换为由多个 [MASK],动态且精准地在模型最需要的地方为序列注入 “思考空间”,以便其在回复中进行补充修补,或是有足够空间去进行更复杂的思考。
通过结合这两个阶段,不需要进行任何训练,DAEDAL 使得 DLLM 能够根据每个问题的具体情况自主调整其回答的长度,展现了强大的效果。
效果
实验结果
DAEDAL 使用统一的短初始长度即可取得强大性能。 实验结果清晰地展示了 DAEDAL 的优越性能。尽管 DAEDAL 默认从一个较短的初始长度开始,但其两阶段的长度调整与扩展机制,不仅使其性能显著优于使用相同短初始长度的基线方法,更能达到与基线方法在所有固定长度中精心调优后的峰值性能相当、甚至在某些情况下超越后者的水平。
这一发现凸显了 DAEDAL 的有效性,并揭示了固定长度范式的内在不便之处,因为基线方法的最佳长度因不同基准而异,这更强调了动态长度适应的必要性。为了直观展示这种动态适应性,图 3 对比了 DAEDAL 所用总生成长度(N_token)的分布与基线方法所用的单一最佳长度。
DAEDAL 能自适应地找到最佳生成长度。 进一步的分析表明,DAEDAL 能智能地预估并生成恰当长度的回答。在多数情况下,DAEDAL 产生的有效词元数(E_token)与基线方法在最佳性能配置下的有效词元数相当。这表明 DAEDAL 能自适应地找到模型内在的、针对特定任务所需词元长度的 “舒适点”。
基线方法的行为也印证了这一点:当设置的长度过长时,即使有效词元数可能继续增加,性能反而可能会下降。DAEDAL 的自适应特性有效避免了这种因过度扩展导致的性能下降。
DAEDAL 能够提升计算资源利用率。在取得优越准确率的同时,DAEDAL 生成的总词元数(N_token)通常低于基线方法在最佳性能 setting 下的总词元数。相近的有效词元数和更低的总词元数带来了更高的有效词元利用率(E_ratio)。这大大地提升了计算资源的利用率。
总结
DAEDAL 通过其初始长度调整(Initial Length Adjustment)和迭代式掩码插入(Iterative Mask Insertion)机制,不仅在多个基准上取得了与精心调优的固定长度基线相当甚至更优的性能,还能为每个任务自适应地分配合适的长度。这使得模型在性能和计算效率上都取得了实质性的提升。DAEDA 弥补了扩散大语言模型与自回归大语言模型在核心能力上的一个关键差距,为更灵活、高效、强大的扩散大语言模型打下了基石。
【2026-5-13】何恺明 ELF
【2026-5-13】何恺明:何恺明团队新作,「嵌入式语言流」ELF来了
2025年 基于「掩码扩散」原理的语言模型 LLaDA 宣称在若干基准测试上能与同规模的自回归大模型(即 GPT 为代表的逐字生成模型)一较高下。扩散语言模型(Diffusion Language Model,DLM)略显小众的研究方向突然进入了更多人的视野。
扩散语言模型两条路:
- 离散扩散语言模型(Discrete DLM):直接在 token 空间里定义扩散过程,比如用 MASK 遮盖 token 再逐步还原(MDLM)、或者把 token 往均匀分布扩散再逐步修正(Duo)。这条路近年来一直是主流,效果更好。
- 连续扩散语言模型(Continuous DLM):先把 token 映射到连续的嵌入向量,在连续空间里做去噪,最后再转回 token。这条路理论上更优雅,但实际效果长期落后于离散派
语言必须是离散的?何恺明选择后者, ELF(Embedded Language Flows,嵌入式语言流)105M参数
- 核心思路:把扩散过程搬进连续的向量空间,只在最后一步才把结果翻译成词。
- “语言是离散的” —— 整个NLP圈默认常识,被何恺明否决了。团队刚发的 ELF,105M参数,只用45B token训练,正面干翻一众500B+的离散扩散模型。
- 把去噪全留在连续embedding空间,直到最后一步才切回token。连续就是连续,离散就是离散,中间不再反复横跳。就这么简单,别人就是没做到底。
- ELF: Embedded Language Flows
- Code: ELF
采样步数砍了多少?从1024步直接砍到32步,困惑度反而压到24。连续派被压了好几年,这回在质量、速度、成本三个维度全赢了
【2026-5-7】Cola DLM
【2026-5-7】Cola DLM(Continuous Latent Diffusion Language Model)是由字节跳动(ByteDance Seed团队)开源的开创性语言模型。
打破了主流大模型“预测下一个Token”的自回归(AR)范式,从“图像/视频生成”中汲取灵感,将语言建模带入连续隐空间。
层级隐扩散语言模型 Cola DLM,依托层级信息拆解逻辑实现文本生成。
模型先通过文本变分自编码器习得稳定的文本 - 隐空间映射关系,再借助块因果扩散变换器在连续隐空间中构建全局语义先验,最终依托条件解码输出文本。
从统一马尔可夫路径视角来看,其扩散过程完成隐空间先验迁移,而非逐词还原观测文本,以此将全局语义架构排布与局部文字细节生成解耦。
该架构具备更灵活的非自回归归纳偏置,可实现连续空间内的语义压缩与先验拟合,还能便捷拓展至其他连续模态任务。
研究围绕四项研究问题、八项基准测试展开实验,采用参数量约 20 亿的自回归模型与 LLaDA 模型作为严格对照基线,算力规模最高达 2000 浮点运算量单位。
实验敲定 Cola DLM 最优整体架构配置,证实其文本生成具备优异的规模扩容性能。
层级连续隐先验建模可作为纯逐词语言建模的合理替代方案。相较于似然概率指标,生成质量与扩容表现更能体现模型真实能力,同时该方案也为离散文本与连续模态的统一建模提供了可行思路。
核心设计与技术亮点
- 分层生成架构:将文本生成解耦为“潜在语义的生成”与“具体文字的还原”两个独立过程。它不直接生成文本,而是先在连续空间内生成表征语义的变量。
- Text VAE:采用文本变分自编码器,将离散的Token压缩并映射到连续的潜在空间(Latent Space)中,提取“语义指纹”。
- DiT 与 Flow Matching:在隐空间中采用基于块因果的扩散变压器(Block-causal DiT)和流匹配(Flow Matching)技术,去拟合、运输潜在变量的分布。
- 任务可诊断性:打破了自回归模型将所有错误混为一谈的黑盒,将训练目标明确拆分为“重建”、“压缩”和“拟合”三个子任务,使模型更易诊断和优化
泛化
【2025-10-13】RND1
【2025-10-13】Qwen3 变身扩散语言模型?不从零训练也能跑,30B参数创纪录
DLM 训练问题,scaling 效率相对低于 AR 模型。
- 直接训练 DLM 需要在有限数据集上更多次迭代,才能超越直接训练的 AR 模型。
- AR 模型还拥有显著的「先发优势」—— 包括成熟的训练基础设施、稳定的训练配方以及广泛的从业者经验积累。
为了克服这些难点, Radical Numerics(AI 初创)研究团队选择另一条路:
- A2D: 现有自回归模型改造成扩散语言模型,具备扩散语言模型的能力。
发布 RND1-Base(Radical Numerics Diffusion,迄今为止规模最大的开源扩散语言模型。
30B 参数稀疏 MoE 模型,其中有 3B 激活参数,由预训练 AR 模型(Qwen3-30BA3B)转换而来,并在持续预训练中累积训练 500B 个 token,以实现完整的扩散行为。
同步开源了模型、训练配方、推理代码以及样例输出。
- 技术报告:Training Diffusion Language Models at Scale using Autoregressive Models
- 代码链接:RND1
- HuggingFace 链接:RND1-Base-0910
主要贡献:
- 系统性研究了大规模 A2D(Autoregressive-to-Diffusion)转换过程中的关键因素,如初始化策略、层级学习率和临界批大小。
- 识别出能够实现可扩展性与稳定性的关键因素,并证明当这些因素与成熟的自回归预训练方法结合时,简单的技术组合也能催生可扩展的 DLM。
- 推出了迄今为止最大的基础扩散语言模型 RND1-30B,展示了将自回归预训练经验科学化转换后可在多项基准测试中取得卓越表现。
在推理(MMLU、ARC-C、RACE、BBH)、STEM(GSM8K)以及代码生成(MBPP)等通用基准测试中测试了 RND1。结果显示,所有评测中均稳定超越现有 Dream-7B 和 LLaDA-8B,同时保持了其自回归基础模型的强大性能
将扩散语言模型规模扩展到 80 亿参数以上不仅可行,而且切实有效。A2D 转换可能是训练 DLM 更优的策略。RND1 也是首个在此规模上成功展示扩散模型训练的开源项目。
加速
分析
- 自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;
- 扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。
【2026-5-23】NVIDIA 光速级别生成速度
【2026-5-23】Nemotron-Labs 扩散语言模型实现光速级文本生成 NVIDIA 在 Hugging Face 发布关于 Nemotron-Labs 扩散语言模型的技术博客。
- 通过扩散语言模型架构大幅提升文本生成速度,目标是逼近“光速级”生成效率。
- 该模型在生成速度上的突破,以及相较于传统自回归模型在延迟和吞吐量方面的性能优势。
Towards Speed-of-Light Text Generation with Nemotron-Labs Diffusion Language Models
3 种生成模式对比

demo 效果

蒸馏
【2025-9-29】普渡 DiDi-Instruct
【2025-10-27】推理效率狂飙60倍:DiDi-Instruct让扩散大模型16步超越千步GPT
自回归模型逐词串行生成的固有瓶颈,使其在长文本生成时面临难以逾越的延迟 “天花板”,即使强大的并行计算硬件也无计可施 。
扩散语言模型( dLLM )将文本生成重塑为从完全噪声(或掩码)序列中迭代去噪、恢复出完整文本的过程 。这一模式天然支持并行化语言段落生成,相较于自回归模型生成速度更快。
然而现有最好的 dLLM 在同等模型尺寸下为了达到与 GPT-2 相当的性能,仍然需要多达上百次模型迭代。
这个困境不禁让人疑惑:
是否存在模型在极端少的迭代次数下(如 8-16 次迭代)下能显著超越 1024 次迭代的 GPT 模型?
【2025-9-29】普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。
- 论文标题:Ultra-Fast Language Generation via Discrete Diffusion Divergence Instruct
- 代码仓库:didi-instruct
- 项目地址:didi-instruct
经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。
DiDi-Instruct 独创概率分布匹配的后训练策略,将原本需要 500 步以上的昂贵的扩散语言 “教师”(diffusion Large Language Model, dLLM)模型,蒸馏成仅需 8-16 步生成整个文本段落的 “学生” 模型。
DiDi-Instruct 是 dLLM 后训练算法。dLLM 通过 DiDi-Instruct 算法训练蒸馏之后,可以将原本的 1024 次推理次数压缩至 8 到 16 步,同时可以显著提升的 dLLM 的建模效果。
DiDi-Instruct 理论源于连续扩散模型中的一个经典单步蒸馏算法:Diff-Instruct。
- DiDi-Instruct 训练算法核心思想: 最小化一个少采样步数的 “学生” 模型与多采样步数的 “教师” dLLM 模型在整个离散 Token 去噪轨迹上分布的积分 KL 散度(Integral Kullback-Leibler Divergence)。
- 该目标把不同时间的 KL 以权重积分汇总,避免只对齐末端样本而训练不稳的问题,从而让学生以一种全局、全过程匹配的方式,高效 “学习” 教师的精髓。一旦积分 KL 散度被优化至收敛(接近 0 值),少步生成的 “学生” 模型便在概率意义上吸收了 “教师 dLLM” 的知识。
在 OpenWebText 标准数据集上,DiDi-Instruct 语言模型既实现了超过 64 倍以上的推理加速,又在性能上同时显著超越了被蒸馏的教师扩散语言模型(dLLM,1024 步生成)和自回归的 GPT2 模型(1024 步生成)。
DiDi-Instruct 算法同时提升了大语言模型的推理效率和推理效果。为极端高效的大语言模型落地提供了新的方案。
并行解码
【2025-9-30】港大 Fast-dLLM
【2025-10-26】NVIDIA港大MIT联合推出Fast-dLLM v2:端到端吞吐量提升2.5倍
【2025-9-30】HKU、NVIDIA、MIT 推出 Fast-dLLM v2
Fast-dLLM v2 给出务实路线:
- 将预训练 AR 模型适配为适配为能并行解码的 Block-dLLM—— 且只需~1B tokens 量级的微调即可达到 “无损” 迁移,不必训练数百 B tokens(如 Dream 需~580B tokens)。
A100/H100 上,它在保持精度的同时,将端到端吞吐显著拉高,最高可达 2.5×。
特点
- 少量数据适配(~1B tokens):已有的 AR 模型(如 Qwen2.5-Instruct 1.5B/7B)用约 1B tokens 的微调就能适配成 Block Diffusion LLM,不必训练数百 B tokens(如 Dream 需~580B tokens)。
- 架构上 “AR 友好”: 设计上 块内双向、块间因果;配合互补掩码与 token-shift,让模型既保留 AR 的语义组织与可变长度能力,又获得块内并行带来的效率增益。迁移过程更自然、数据效率高。
- 层级缓存 + 并行解码:块级 KV Cache + 子块 DualCache,配合置信度阈值的并行解码,端到端最高 2.5× 提速。
- 大模型验证:在 7B 规模上保持与 AR 相当的生成质量下,吞吐对比 Qwen2.5-7B-Instruct 提升 2.54×。
原理与做法:从 AR 到 Block Diffusion
1)块式扩散与 AR - 友好注意力
Fast-dLLM v2 按固定块大小把序列切成若干块:块内双向注意力以并行去噪,块间保持左到右的因果关系,从而既能并行、又能沿用 AR 的语义组织、可变长度和 KV Cache;配合互补掩码(complementary masking)与 token-shift,保证每个 token 都在 “可见 / 被遮” 两种视角下学习,稳定恢复 AR 语义表征。
2)层级缓存(Hierarchical Cache)
- 块级缓存:已解码块的 KV 直接复用,天然支持 KV Cache。
- 子块缓存(DualCache):在部分解码的当前块内部,同时缓存前缀与后缀的 KV 激活,减少迭代去噪揭示 / 复原时的重复计算,贴合并行细化流程。
3)置信度感知的并行解码
延续 v1 的思路:当某位置的预测置信度超过阈值(如 0.9),即可并行确定多个 token,其余不确定位置保留待后续细化。在 GSM8K 上,阈值 0.9 时吞吐从 39.1→101.7 tokens/s,提速约 2.6×,精度影响可忽略。
性能结果
- 端到端加速:综合实验显示,对标准 AR 解码最高 2.5× 提速,同时维持生成质量。
- 7B 规模吞吐与精度:在 A100 上,Fast-dLLM v2(7B)吞吐为 Qwen2.5-7B-Instruct 的 2.54×;同时对比 Fast-dLLM-LLaDA 还有 +5.2% 的准确率提升(GSM8K)。
- Batch / 硬件可扩展性:在 A100/H100 上随 batch 增大,扩散解码的并行优势更明显;A100 上可达~1.5× 吞吐加速,H100 上最高可达~1.8× 加速
【2025-10-7】上海AI Lab SDAR
【2025-11-1】上海AI Lab发布混合扩散语言模型SDAR:首个突破6600 tgs的开源扩散语言模型
混合模型尝试结合二者(自回归于掩码扩散语言模型),块内并行、块间自回归,但其特殊的训练目标函数依赖复杂的注意力掩码,导致训练开销几乎翻倍,令人望而却步。
【2025-10-7】上海人工智能实验室针对该难题提出全新范式 SDAR (Synergistic Diffusion-AutoRegression)。
颠覆性的思路:
为什么要在同一个阶段解决所有问题?SDAR 范式的核心就是「解耦」(Decoupling):
SDAR 范式
- 训练阶段:拥抱高效的 AR 范式。完全沿用成熟、稳定、高效的 AR 模型进行预训练。这确保了模型在一个强大的基础上起步,拥有与顶尖 AR 模型同等水平的知识和能力。
- 推理阶段:轻量级适配,解锁并行解码。在 AR 预训练后,引入一个短暂且成本极低的「适配」阶段,教会模型以「块」为单位进行并行扩散式生成。
通过「训练-推理解耦」的巧妙设计,无缝融合了 AR 模型的高性能与扩散模型的并行推理优势,能以极低成本将任意 AR 模型「改造」为并行解码模型。
- 论文:SDAR: A Synergistic Diffusion-AutoRegression Paradigm for Scalable Sequence Generation
- 代码地址:SDAR
- 推理引擎:lmdeploy
- 模型地址:sdar
SDAR 不仅在多个基准上与原版 AR 模型性能持平甚至超越,还能带来数倍的真实推理加速。更令人惊喜的是,SDAR 在复杂的科学推理任务上展现出巨大潜力。在与采用相同配置训练的 AR 基线模型进行公平对比时,SDAR 在 ChemBench 等基准上最高取得了 12.3 个百分点的性能优势。
该团队已全面开源从 1.7B 到 30B 的全系列 SDAR 模型、高效推理引擎及迄今最强的开源扩散类推理模型 SDAR-30B-A3B-Sci
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
