GPT-2 入门理解
GPT的训练数据、模型大、计算量,不适合个人训练、微调,怎么办?
【2023-1-10】速揽2500星,Andrej Karpathy重写了一份minGPT库
GPT 从诞生之初的 GPT 1.17 亿参数,一路狂飙到 GPT-3 1750 亿参数,出尽风头。
- 随着 GPT-3 的发布,OpenAI 向社区开放了商业 API,鼓励大家使用 GPT-3 尝试更多的实验。
- 然而,API 的使用需要申请,而且申请很有可能石沉大海。
【2023-2-16】GPT3 finetune 其实还好,几个g数据就行,如果几个g都没有 选个好底座 10万条左右就有效果
GPT 组件
GPT(Generative Pre-trained Transformer) 基于Transformer解码器自回归地预测下一个Token,从而进行了语言模型的建模。
- 只要能足够好地预测下一个Token,语言模型便可能有足够潜力实现真正的智能
输入
输入是一些由整数表示的文本序列
- 每个整数都与文本中的token对应。
- 分词器将文本分割为不可分割的词元单位,实现文本的高效表示,且方便模型学习文本的结构和语义。
- 分词器对应一个词汇表,我们可用词汇表将token映射为整数:
# token, 即词元,是文本的子片段,使用某种分词器生成。
text = "robot must obey orders"
tokens = ["robot", "must", "obey", "orders"]
inputs = [1, 0, 2, 4]
# 词汇表中的token索引表示该token的整数ID
# 例如,"robot"的整数ID为1,因为vocab[1] = "robot"
vocab = ["must", "robot", "obey", "the", "orders", "."]
# 一个根据空格进行分词的分词器tokenizer
tokenizer = WhitespaceTokenizer(vocab)
# encode()方法将str字符串转换为list[int]
ids = tokenizer.encode("robot must obey orders") # ids = [1, 0, 2, 4]
# 通过词汇表映射,可以看到实际的token是什么
tokens = [tokenizer.vocab[i] for i in ids] # tokens = ["robot", "must", "obey", "orders"]
# decode()方法将list[int] 转换回str
text = tokenizer.decode(ids) # text = "robot must obey orders"
- 通过语料数据集和分词器tokenizer, 构造一个包含文本中的所有token的词汇表 vocab。
- 用tokenizer将文本text分割为token序列,再使用词汇表vocab将token映射为token id整数,得到输入文本token序列。
- 通过vocab将token id序列再转换回文本。
输出
output 是一个二维数组,其中output[i][j]表示文本序列的第i个位置的token(inputs[i])是词汇表的第j个token(vocab[j])的概率(实际为未归一化的logits得分)。例如:
inputs = [1, 0, 2, 4] # "robot" "must" "obey" "orders"
vocab = ["must", "robot", "obey", "the", "orders", "."]
output = gpt(inputs)
# output[0] = [0.75, 0.1, 0.15, 0.0, 0.0, 0.0]
# 给定 "robot",模型预测 "must" 的概率最高
# output[1] = [0.0, 0.0, 0.8, 0.1, 0.0, 0.1]
# 给定序列 ["robot", "must"],模型预测 "obey" 的概率最高
# output[-1] = [0.0, 0.0, 0.1, 0.0, 0.85, 0.05]
# 给定整个序列["robot", "must", "obey"],模型预测 "orders" 的概率最高
next_token_id = np.argmax(output[-1]) # next_token_id = 4
next_token = vocab[next_token_id] # next_token = "orders"
输入序列为 ["robot", "must", "obey"],GPT模型根据输入预测序列的下一个token是”orderst”,因为 output[-1][4]的值为0.85,是词表中最高的一个。
output[0]表示给定输入 token “robot”,模型预测下一个token可能性最高的是”must”,为0.75。output[-1]表示给定整个输入序列["robot", "must", "obey"],模型预测下一个token是”orders”的可能性最高,为0.85。
为预测序列的下一个token,只需在output的最后一个位置中选择可能性最高的token。那么,通过迭代地将上一轮的输出拼接到输入,并送入模型,从而持续地生成token。
这种生成方式称为贪心采样。实际可以对类别分布用温度系数T进行蒸馏(放大或减小分布的不确定性),并截断类别分布的按top-k,再进行类别分布采样。
结构
GPT架构分为2个主要部分:
嵌入表示层:文本词元嵌入(token embeddings) + 位置嵌入(positional embeddings)- transformer
解码器层:多个transformer decoder block堆叠 最后,在预测下一个Token时,将输出投影回词汇表(projection to vocab)即可
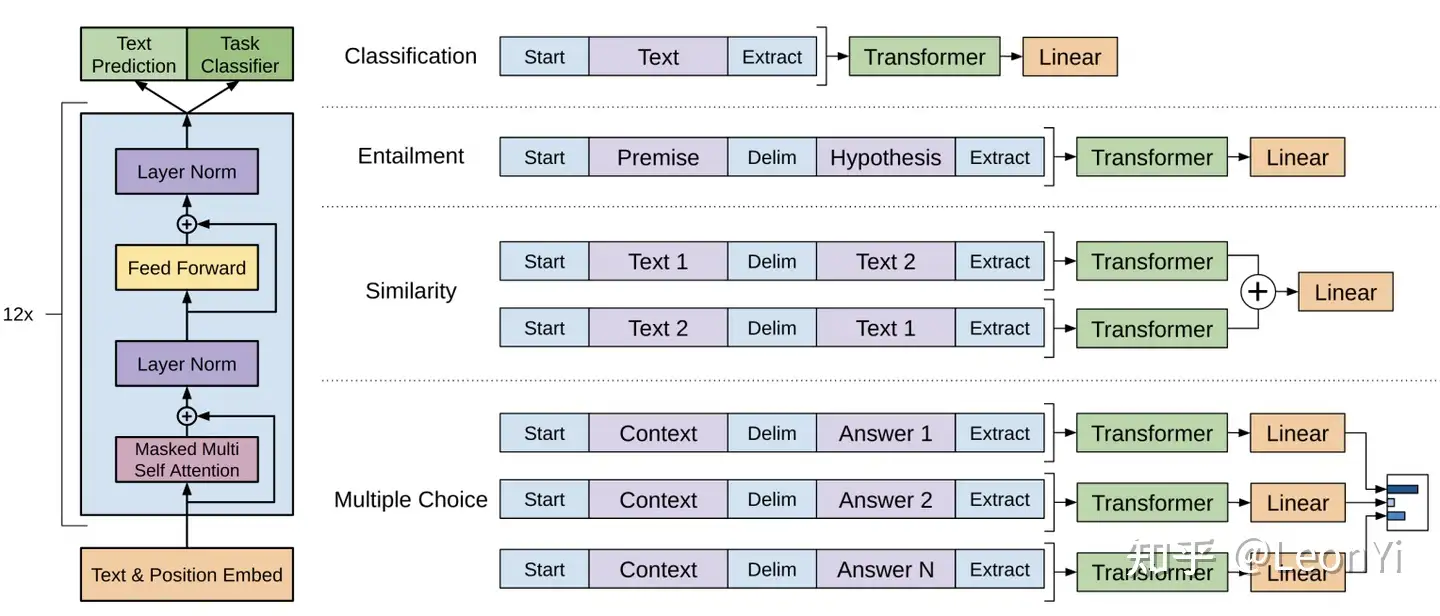
def gpt2(inputs, wte, wpe, blocks, ln_f, n_head):
""" GPT2模型实现
输入输出tensor形状: [n_seq] -> [n_seq, n_vocab]
n_vocab, 词表大小
n_seq, 输入token序列长度
n_layer, 自注意力编码器的层数
n_embd, 词表的词元嵌入大小
n_ctx, 输入最大序列长度(位置编码支持的长度,可用ROPE旋转位置编码提升外推长度)
params:
inputs: List[int], token ids, 输入token ids
wte: np.ndarray[n_vocab, n_embd], token嵌入矩阵 (与输出分类器共享参数)
wpe: np.ndarray[n_ctx, n_embd], 位置编码嵌入矩阵
blocks:object, n_layer层因果自注意力编码器
ln_f:tuple[float], 层归一化参数
n_head:int, 注意力头数
"""
# 1、在词元嵌入中添加位置编码信息:token + positional embeddings
x = wte[inputs] + wpe[range(len(inputs))] # [n_seq] -> [n_seq, n_embd]
# 2、前向传播n_layer层Transformer blocks
for block in blocks:
x = transformer_block(x, **block, n_head=n_head) # [n_seq, n_embd] -> [n_seq, n_embd]
# 3、Transformer编码器块的输出投影到词汇表概率分布上
# 预测下个词在词表上的概率分布[ 输出语言模型的建模的条件概率分布p(x_t|x_t-1 ... x_1) ]
x = layer_norm(x, **ln_f) # [n_seq, n_embd] -> [n_seq, n_embd]
# 就是和嵌入矩阵进行内积(编码器块的输出相当于预测值,内积相当于求相似度最大的词汇)
return x @ wte.T # [n_seq, n_embd] -> [n_seq, n_vocab]
多头注意力
多头因果自注意力
分别解释“多头因果自注意力”的每个词,来一步步理解“多头因果自注意力”:
- 注意力(Attention)
- 自(Self)
- 因果(Causal): 防止序列建模时出现信息泄露,需要修改注意力矩阵(增加Mask)以隐藏或屏蔽输入,从而避免模型在训练阶段直接看到后续的文本序列(信息泄露)进而无法得到有效地训练。
- 多头(Multi-Head)
def attention_raw(q, k, v):
""" 原始缩放点积注意力实现
输入输出tensor形状: [n_q, d_k], [n_k, d_k], [n_k, d_v] -> [n_q, d_v]
params:
q: np.ndarray[n_seq, n_embd], 查询向量
k: np.ndarray[n_seq, n_embd], 键向量
v: np.ndarray[n_seq, n_embd], 值向量
"""
return softmax(q @ k.T / np.sqrt(q.shape[-1])) @ v
# 以通过对q、k、v进行投影变换来增强自注意效果
def self_attention_raw(x, w_k, w_q, w_v, w_proj):
""" 自注意力原始实现
输入输出tensor形状: [n_seq, n_embd] -> [n_seq, n_embd]
params:
x: np.ndarray[n_seq, n_embd], 输入token嵌入序列
w_k: np.ndarray[n_embd, n_embd], 查询向量投影层参数
w_q: np.ndarray[n_embd, n_embd], 键向量投影层参数
w_v: np.ndarray[n_embd, n_embd], 值向量投影层参数
w_proj: np.ndarray[n_embd, n_embd], 自注意力输出投影层参数
"""
# qkv projections
q = x @ w_k # [n_seq, n_embd] @ [n_embd, n_embd] -> [n_seq, n_embd]
k = x @ w_q # [n_seq, n_embd] @ [n_embd, n_embd] -> [n_seq, n_embd]
v = x @ w_v # [n_seq, n_embd] @ [n_embd, n_embd] -> [n_seq, n_embd]
# perform self attention
x = attention(q, k, v) # [n_seq, n_embd] -> [n_seq, n_embd]
# out projection
x = x @ w_proj # [n_seq, n_embd] @ [n_embd, n_embd] -> [n_seq, n_embd]
return x
def self_attention(x, c_attn, c_proj):
""" 自注意力优化后实现(w_q 、w_k 、w_v合并成一个矩阵w_fc进行投影,再拆分结果)
同时GPT-2的实现:加入偏置项参数(所以使用线性层,进行仿射变换)
输入输出tensor形状: [n_seq, n_embd] -> [n_seq, n_embd]
params:
x: np.ndarray[n_seq, n_embd], 输入token嵌入序列
w_fc: np.ndarray[n_embd, 3*n_embd], 查询向量投影层参数
w_proj: np.ndarray[n_embd, n_embd], 自注意力输出投影层参数
"""
# qkv projections
x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# split into qkv
q, k, v = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> 3 of [n_seq, n_embd]
# perform self attention
x = attention(q, k, v) # [n_seq, n_embd] -> [n_seq, n_embd]
# out projection
x = linear(x, **c_proj) # [n_seq, n_embd] @ [n_embd, n_embd] = [n_seq, n_embd]
return x
# 加入掩码矩阵的注意力实现:
def attention(q, k, v, mask):
""" 缩放点积注意力实现
输入输出tensor形状: [n_q, d_k], [n_k, d_k], [n_k, d_v] -> [n_q, d_v]
params:
q: np.ndarray[n_seq, n_embd], 查询向量
k: np.ndarray[n_seq, n_embd], 键向量
v: np.ndarray[n_seq, n_embd], 值向量
mask: np.ndarray[n_seq, n_seq], 注意力掩码矩阵
"""
return softmax(q @ k.T / np.sqrt(q.shape[-1]) + mask) @ v
def causal_self_attention(x, c_attn, c_proj):
""" 因果自注意力优化后实现(w_q 、w_k 、w_v合并成一个矩阵w_fc进行投影,再拆分结果)
同时GPT-2的实现:加入偏置项参数(所以使用线性层,进行仿射变换)
输入输出tensor形状: [n_seq, n_embd] -> [n_seq, n_embd]
params:
x: np.ndarray[n_seq, n_embd], 输入token嵌入序列
c_attn: np.ndarray[n_embd, 3*n_embd], 查询向量投影层参数
c_proj: np.ndarray[n_embd, n_embd], 自注意力输出投影层参数
"""
# qkv projections
x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# split into qkv
q, k, v = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> 3 of [n_seq, n_embd]
# causal mask to hide future inputs from being attended to
causal_mask = (1 - np.tri(x.shape[0], dtype=x.dtype)) * -1e10 # [n_seq, n_seq]
# perform causal self attention
x = attention(q, k, v, causal_mask) # [n_seq, n_embd] -> [n_seq, n_embd]
# out projection
x = linear(x, **c_proj) # [n_seq, n_embd] @ [n_embd, n_embd] = [n_seq, n_embd]
return x
# 多头自注意力
# 将Q、K、V切分为n_head个,分别计算后(适合并行计算),再合并结果
def mha(x, c_attn, c_proj, n_head):
""" 多头自注意力实现
输入输出tensor形状: [n_seq, n_embd] -> [n_seq, n_embd]
每个注意力计算的维度从n_embd降低到 n_embd/n_head。
通过降低维度,模型利用多个子空间进行建模
params:
x: np.ndarray[n_seq, n_embd], 输入token嵌入序列
c_attn: np.ndarray[n_embd, 3*n_embd], 查询向量投影层参数
c_proj: np.ndarray[n_embd, n_embd], 自注意力输出投影层参数
"""
# qkv投影变换
x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# 划分为qkv
qkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> [3, n_seq, n_embd]
# 将n_embd继续划分为_head个注意力头
qkv_heads = list(map(lambda x: np.split(x, n_head, axis=-1), qkv)) # [3, n_seq, n_embd] -> [3, n_head, n_seq, n_embd/n_head]
# 构造causal mask矩阵
causal_mask = (1 - np.tri(x.shape[0], dtype=x.dtype))* -1e10 # [n_seq, n_seq]
# 单独执行每个头的因果自注意力(可多核多线程并行执行)
out_heads = [attention(q, k, v, causal_mask) for q, k, v in zip(*qkv_heads)] # [3, n_head, n_seq, n_embd/n_head] -> [n_head, n_seq, n_embd/n_head]
# 合并多个heads的结果
x = np.hstack(out_heads) # [n_head, n_seq, n_embd/n_head] -> [n_seq, n_embd]
# 多头因果自注意力输出projection
x = linear(x, **c_proj) # [n_seq, n_embd] -> [n_seq, n_embd]
return x
decoder 解码器
def transformer_block(x, mlp, attn, ln_1, ln_2, n_head):
""" 解码器模块 (只实现逻辑,各个子模块参数需传入)
输入输出tensor形状: [n_seq, n_embd] -> [n_seq, n_embd]
n_seq, 输入token序列长度
n_embd, 词表的词元嵌入大小
params:
x: np.ndarray[n_seq, n_embd], 输入token嵌入序列
mlp: object, 前馈神经网络
attn: object, 注意力编码器层
ln1: object, 线性层1
ln2: object, 线性层2
n_head:int, 注意力头数
"""
# Multi-head Causal Self-Attention (层归一化 + 多头自注意力 + 残差连接 )
# Self-Attention中的层规一化和残差连接用于提升训练的稳定性
x = x + mha(layer_norm(x, **ln_1), **attn, n_head=n_head) # [n_seq, n_embd] -> [n_seq, n_embd]
# Position-wise Feed Forward Network
x = x + ffn(layer_norm(x, **ln_2), **mlp) # [n_seq, n_embd] -> [n_seq, n_embd]
return x
def ffn(x, c_fc, c_proj):
""" 2层前馈神经网络实现 (只实现逻辑,各个子模块参数需传入)
输入输出tensor形状: [n_seq, n_embd] -> [n_seq, n_embd]
n_seq, 输入token序列长度
n_embd, 词表的词元嵌入大小
n_hid, 隐藏维度
params:
x: np.ndarray[n_seq, n_embd], 输入token嵌入序列
c_fc: np.ndarray[n_embd, n_hid], 升维投影层参数, 默认:4*n_embd
c_proj: np.ndarray[n_hid, n_embd], 降维投影层参数
"""
# project up:将n_embd投影到一个更高的维度 4*n_embd
a = gelu(linear(x, **c_fc)) # [n_seq, n_embd] -> [n_seq, 4*n_embd]
# project back down:投影回n_embd
x = linear(a, **c_proj) # [n_seq, 4*n_embd] -> [n_seq, n_embd]
return x
generation 生成
自回归预测过程
- 每次迭代中,将上一轮预测出的token, 添加到输入末尾,然后预测下一个位置的值,如此往复
def gpt(inputs: list[int]) -> list[list[float]]:
""" GPT代码,实现预测下一个token
inputs:List[int], shape为[n_seq],输入文本序列的token id的列表
output:List[List[int]], shape为[n_seq, n_vocab],预测输出的logits列表
"""
output = # 需要实现的GPT内部计算逻辑
return output
def generate(inputs, n_tokens_to_generate):
""" GPT生成原始代码
inputs: list[int], 输入文本的token ids列表
n_tokens_to_generate:int, 需要生成的token数量
"""
# 自回归式解码循环
for _ in range(n_tokens_to_generate):
output = gpt(inputs) # 模型前向推理,输出预测词表大小的logits列表
next_id = np.argmax(output[-1]) # 贪心采样
inputs.append(int(next_id)) # 将预测添加回输入
return inputs[len(inputs) - n_tokens_to_generate :] # 只返回生成的ids
# 改进: 引入一个特殊的句子结束token EOS。
# 预训练期间,输入末尾附加 EOS token(比如,tokens = ["not", "all", "heroes", "wear", "capes", ".", "<|EOS|>"])。生成过程中,只需要在遇到EOS token时停止(或者达到最大序列长度):
def generate(inputs, eos_id, max_seq_len):
"""
改进版: 加 token 数、结束标记限制
"""
prompt_len = len(inputs)
while inputs[-1] != eos_id and len(inputs) < max_seq_len:
output = gpt(inputs)
next_id = np.argmax(output[-1])
inputs.append(int(next_id))
return inputs[prompt_len:]
# 随便举例
input_ids = [1, 0, 2] # ["robot", "must", "obey"]
output_ids = generate(input_ids, 1) # output_ids = [1, 0, 2, 4]
output_tokens = [vocab[i] for i in output_ids] # ["robot", "must", "obey", "orders"]
无条件生成
- 模型在没有任何输入时生成文本。
- 用于演示GPT能力
通过在预训练期间在输入开头加上一个特殊的句子开头token (BOS)来实现
- 例如
tokens = ["<|BOS|>", "not", "all", "heroes", "wear", "capes", "."]) - 要进行无条件文本生成,仅需输入一个包含BOS token的列表:
def generate_unconditioned(bos_id, n_tokens_to_generate):
inputs = [bos_id]
for _ in range(n_tokens_to_generate):
output = gpt(inputs)
next_id = np.argmax(output[-1])
inputs.append(int(next_id))
return inputs[1:]
GPT 实现
babyGPT
【2023-4-13】Baby GPT:训练一个极简GPT
- tocken只有0,1两种数字的极简二分类GPT,训练成本不到1块钱(电费),初衷是让人体验GPT背后的技术原理,进行思考。
极简二分类GPT如下所示
[0,1,0] —> GPT —> [P(0) = 20%, P(1) = 80%]
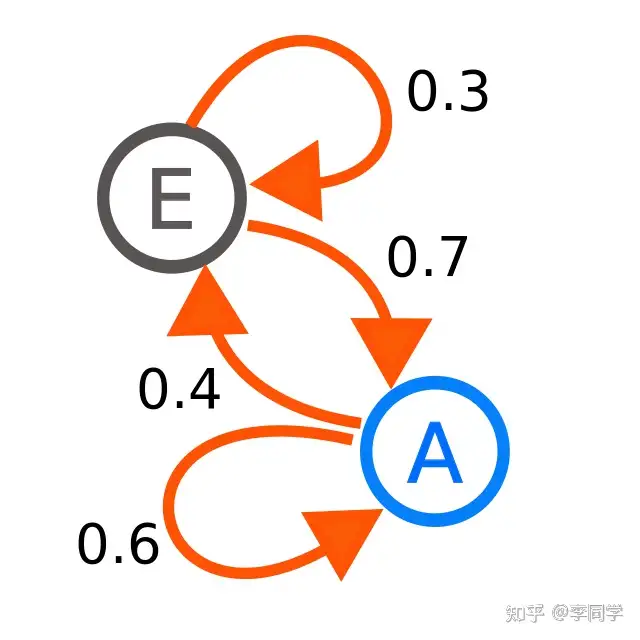
【2023-5-30】GPT 是如何工作的:200 行 Python 代码实现一个极简 GPT,博客解读
2023 年 Andrej Karpathy 的 twitter 和一篇文章: GPT as a finite-state markov chain。
- GPT 是一个神经网络,根据输入的 token sequence(例如,1234567) 来预测下一个 token 出现的概率。
- 极简 GPT,只有 2 个 token 0 和 1,上下文长度为 3;
- GPT 是一个有限状态马尔可夫链(FSMC)。将用 token sequence 111101111011110 作为输入对这个极简 GPT 训练 50 次, 得到的状态转移概率符合预期。
minGPT
【2020-8-18】一天star量破千,300行代码,特斯拉AI总监Karpathy写了个GPT的Pytorch训练库
为了让资源有限的研究者也能体验一把玩大模型的乐趣,前特斯拉 AI 负责人 Andrej Karpathy 基于 PyTorch,仅用 300 行左右的代码就写出了一个小型 GPT 训练库,并将其命名为 minGPT。这个 minGPT 能够进行加法运算和字符级的语言建模,而且准确率还不错。
Karpathy 介绍称:
由于现有可用的 GPT 实现库略显杂乱,于是他在创建 minGPT 的过程中, 力图遵循小巧、简洁、可解释、具有教育意义等原则。
GPT 并非一个复杂的模型,minGPT 实现只有大约 300 行代码,包括样板文件和一个完全不必要的自定义因果自注意力模块。
- Karpathy 将索引序列变成了一个 transformer 块序列,如此一来,下一个索引的概率分布就出现了。剩下的复杂部分就是巧妙地处理 batching,使训练更加高效。
核心的 minGPT 库包含两个文档:mingpt/model.py 和 mingpt/trainer.py。
- mingpt/model.py: 实际的 Transformer 模型定义
- mingpt/trainer.py: 一个与 GPT 无关的 PyTorch 样板文件,可用于训练该模型。
相关的 Jupyter notebook 展示了如何使用该库训练序列模型:
- play_math.ipynb 训练一个专注于加法的 GPT;
- play_char.ipynb 将 GPT 训练成一个可基于任意文本使用字符级语言模型,类似于之前的 char-rnn,但用 transformer 代替了 RNN;
- play_words.ipynb 是
BPE(Byte-Pair Encoding)版本,目前尚未完成。
使用 BPE 编码器、分布式训练 和 fp16,这一实现有可能复现 GPT-1/GPT-2 的结果,不过 Karpathy 还没有尝试。
- 至于 GPT-3,minGPT 可能无法复现,因为 GPT-3 可能不适合 GPU 内存,而且需要更精细的模型并行化处理。
nanoGPT
【2023-1-6】时隔两年,minGPT 迎来更新,Karpathy 又上线新版本,并命名为 NanoGPT,该库用于训练和微调中型大小的 GPT。上线短短几天,狂揽 2.5K 星。
nanoGPT: The simplest, fastest repository for training/finetuning medium-sized GPTs
- NanoGPT 是用于训练和微调中型尺度 GPT 最简单、最快的库。是对 minGPT 的重写,因为 minGPT 太复杂。
- NanoGPT 还在开发当中,当前致力于在 OpenWebText 数据集上重现 GPT-2。
- NanoGPT 代码设计目标:简单易读,其中
- train.py 是一个约 300 行的代码;
- model.py 是一个约 300 行的 GPT 模型定义,可以选择从 OpenAI 加载 GPT-2 权重。
- notebook
使用
先将一些文档 tokenize 为一个简单的 1D 索引数组。
- cd data/openwebtext
- python prepare.py
- 生成两个文件:train.bin 和 val.bin,每个文件都包含一个代表 GPT-2 BPE token id 的 uint16 字节原始序列。
该训练脚本试图复制 OpenAI 提供的最小的 GPT-2 版本,即 124M 版本。
python train.py
# 用 PyTorch 分布式数据并行(DDP)进行训练
torchrun --standalone --nproc_per_node=4 train.py
# 从模型中进行取样
python sample.py
# 微调
python train.py config/finetune_shakespeare.py
训练代价
- 1 个 A100 40GB GPU 上一晚上的训练损失约为 3.74
- 4 个 GPU 上训练损失约为 3.60
- 8 x A100 40GB node 上进行 400,000 次迭代(约 1 天)atm 的训练降至 3.1。
如何在新文本上微调 GPT?
- data/shakespeare 并查看 prepare.py。
- 与 OpenWebText 不同,这将在几秒钟内运行。
微调只需要很少的时间,例如在单个 GPU 上只需要几分钟。
【2023-2-1】andrej kaparthy 亲自讲解 nanoGPT
- We build a Generatively Pretrained Transformer (
GPT), following the paper “Attention is All You Need” and OpenAI’s GPT-2 / GPT-3. We talk about connections to ChatGPT, which has taken the world by storm. We watch GitHub Copilot, itself a GPT, help us write a GPT (meta :D!) . I recommend people watch the earlier makemore videos to get comfortable with the autoregressive language modeling framework and basics of tensors and PyTorch nn, which we take for granted in this video. - Let’s build GPT: from scratch, in code, spelled out.
PicoGPT
【2023-2-19】60行代码就能构建GPT
- 前特斯拉前AI总监的minGPT和nanoGPT也都还要300行代码。
- 这个60行代码的GPT也有名字,博主命名为PicoGPT。
项目主要文件:
- encoder.py 包含了OpenAI的BPE分词器的代码,直接从gpt-2仓库拿过来
- utils.py 包含下载并加载GPT-2模型的权重,分词器和超参数
- gpt2.py 包含了实际GPT模型和生成的代码,可以作为脚本运行
- gpt2_pico.py GPT模型的紧凑实现(核心实现仅40行,代码读起来略费劲)
GPT的架构总结成了三大部分:
- 文本 + 位置嵌入
- 变压器解码器堆栈
- 下一个token预测头
git clone https://github.com/jaymody/picoGPT
cd picoGPT
# Dependencies
pip install -r requirements.txt
# Tested on Python 3.9.10.
每个文件的简要说明:
encoder.py包含了 OpenAI 的 BPE Tokenizer 的代码,直接从gpt-2 仓库中获取。utils.py包含了下载和加载 GPT-2 模型权重、分词器和超参数的代码。gpt2.py包含了实际的 GPT 模型和生成代码,可将其作为 Python 脚本运行。gpt2_pico.py和gpt2.py一样,但代码更简洁。
picoGPT的models/124M下,有如下文件:
- checkpoint
- hparams.json 超参文件
- vocab.bpe 词表
- encoder.json
- model.ckpt.data-00000-of-00001
- model.ckpt.meta
- model.ckpt.index
超参
// hparams
{
"n_vocab": 50257, # number of tokens in our vocabulary
"n_ctx": 1024, # maximum possible sequence length of the input
"n_embd": 768, # embedding dimension (determines the "width" of the network)
"n_head": 12, # number of attention heads (n_embd must be divisible by n_head)
"n_layer": 12 # number of layers (determines the "depth" of the network)
}
Usage
python gpt2.py "Alan Turing theorized that computers would one day become"
# Which generates: the most powerful machines on the planet.
# The computer is a machine that can perform complex calculations, and it can perform these calculations in a way that is very similar to the human brain.
# 参数配置限制token数目
# You can also control the number of tokens to generate, the model size (one of ["124M", "355M", "774M", "1558M"]), and the directory to save the models:
python gpt2.py \
"Alan Turing theorized that computers would one day become" \
--n_tokens_to_generate 40 \
--model_size "124M" \
--models_dir "models"
讲解
字符转换原理:
vocab(词汇表),将字符串token映射为整数索引encode方法可以使 str ->list[int]decode方法可以使list[int]->str[2]
生成过程 : 预测序列中下一个合乎逻辑的单词的任务被称为语言建模。
- 依次拿前i-1个字符生成第i个字符,再添加进去作为输入,循环往复
- 整个序列进行下一个token的预测,我们只需在
output[-1]中选择概率最高的token - 输出一个二维数组,其中
output[i][j]是模型预测的概率,表示inputs[i]的下一个是vocab[j]的概率。
numpy.random.choice(a, size=None, replace=True, p=None)
# 从a(只要是ndarray都可以,但必须是一维)中随机抽取数字,并组成指定大小(size)的数组
# replace:True 表示可以取相同数字,False表示不可以取相同数字
# 数组p:与数组a相对应,表示取数组a中每个元素的概率,默认为选取每个元素的概率相同。
# ------ 自然语言转换id -------
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
# a pretend tokenizer that tokenizes on whitespace
tokenizer = WhitespaceTokenizer(vocab)
# the encode() method converts a str -> list[int]
ids = tokenizer.encode("not all heroes wear") # 【编码】ids = [1, 0, 2, 4]
# we can see what the actual tokens are via our vocab mapping
tokens = [tokenizer.vocab[i] for i in ids] # tokens = ["not", "all", "heroes", "wear"]
# the decode() method converts back a list[int] -> str
text = tokenizer.decode(ids) # 【解码】text = "not all heroes wear"
# ------ GPT 生成过程 ------
def generate(inputs, n_tokens_to_generate):
for _ in range(n_tokens_to_generate): # auto-regressive decode loop
output = gpt(inputs) # model forward pass
# 解码策略
next_id = np.argmax(output[-1]) # greedy sampling 贪心解码; 贪婪解码(greedy decoding)或贪婪采样(greedy sampling)
next_id = np.random.choice(np.arange(vocab_size), p=output[-1]) # 概率分布中采样,增加随机性(stochasticity);结果可能是 capes
inputs.append(int(next_id)) # append prediction to input
return inputs[len(inputs) - n_tokens_to_generate :] # only return generated ids
input_ids = [1, 0] # 输入示例: "not" "all"
# 连续生成3个词
output_ids = generate(input_ids, 3) # output_ids = [2, 4, 6]
# 解码成自然语言
output_tokens = [vocab[i] for i in output_ids] # "heroes" "wear" "capes"
与top-k、top-p和temperature等技术结合使用时,这些技术会修改采样前的分布,从而大大提高我们输出的质量。这些技术还引入了一些超参数,我们可以通过调整它们来获得不同的生成行为(例如,增加temperature会使我们的模型更加冒险,从而更具“创造力”)。
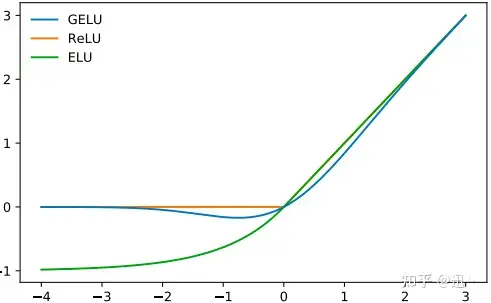
要点
- GPT-2选择的非线性激活函数(activation function)是
GELU(高斯误差线性单元),是ReLU的一种替代方法: - Softmax 将一组实数(介于 −∞ 和 ∞ 之间)转换为概率(介于0和1之间,且所有数字之和为1)
- Layer normalization将值标准化为均值为0,方差为1
- $\text { LayerNorm }(x)=\gamma \cdot \frac{x-\mu}{\sqrt{\sigma^{2}}}+\beta$
- Layer normalization 确保每个层的输入始终在一个一致范围内,有助于加快和稳定训练过程。
- 与Batch Normalization类似,归一化后的输出通过两个可学习的向量 β 和 γ 进行缩放和偏移。分母中的小epsilon项用于避免除以零的错误。
- Transformer中使用层归一化(Layer norm)而不是批归一化(Batch norm)有各种原因。
- Linear 标准矩阵乘法 + 偏置:
- 线性层通常被称为
投影(projections)(因为从一个向量空间投影到另一个向量空间)
- 线性层通常被称为
def gelu(x):
return 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))
gelu(np.array([[1, 2], [-2, 0.5]])) # 逐元素处理
# softmax
def softmax(x): # max(x) 技巧来保持数值稳定性
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
x = softmax(np.array([[2, 100], [-5, 0]])) # 逐行处理
def layer_norm(x, g, b, eps: float = 1e-5):
mean = np.mean(x, axis=-1, keepdims=True)
variance = np.var(x, axis=-1, keepdims=True)
x = (x - mean) / np.sqrt(variance + eps) # normalize x to have mean=0 and var=1 over last axis
return g * x + b # scale and offset with gamma/beta params
x = layer_norm(x, g=np.ones(x.shape[-1]), b=np.zeros(x.shape[-1]))
def linear(x, w, b): # [m, in], [in, out], [out] -> [m, out]
return x @ w + b
linear(x, w, b)
训练
- 数据:仅用原始文本本身生成输入/标签对,这被称为
自监督学习。- 自监督能够大规模扩展训练数据,只需尽可能多地获取原始文本并提供给模型。例如,GPT-3是通过互联网和图书中的3000亿个文本token进行训练
- 自监督训练步骤被称为
预训练(pre-training),因为可以重复使用“预训练”模型的权重来进一步训练模型,用于下游任务,比如判断一条推文是否有害。预训练模型有时也被称为基础模型(foundation models)。 - 下游任务上对模型进行训练被称为
微调(fine-tuning),因为模型权重已经经过预训练来理解语言,现在只是对特定任务进行微调。 - “通用任务上进行预训练,然后在特定任务上进行微调”的策略被称为
迁移学习(transfer learning)。
- 用
梯度下降法(gradient descent)优化某个损失函数(loss function)。GPT 采用语言建模任务(language modeling task)上的交叉熵损失函数
def lm_loss(inputs: list[int], params) -> float:
# the labels y are just the input shifted 1 to the left
# inputs = [not, all, heros, wear, capes]
# x = [not, all, heroes, wear]
# y = [all, heroes, wear, capes]
# of course, we don't have a label for inputs[-1], so we exclude it from x
# as such, for N inputs, we have N - 1 langauge modeling example pairs
x, y = inputs[:-1], inputs[1:] # 样本: 输入、输出
# 前向传播 forward pass
# all the predicted next token probability distributions at each position
output = gpt(x, params)
# 损失函数 cross entropy loss
# we take the average over all N-1 examples
loss = np.mean(-np.log(output[y]))
return loss
def train(texts: list[list[str]], params) -> float:
for text in texts:
inputs = tokenizer.encode(text) # 字符id化
loss = lm_loss(inputs, params) # 计算损失
gradients = compute_gradients_via_backpropagation(loss, params) # 反向传播
params = gradient_descent_update_step(gradients, params) # 梯度更新
return params
GPT架构基于tansformer,encoder-decoder结构,但注意
- 摒弃了编码器,中间的“交叉注意力”层也被移除了。
从高层次来看,GPT架构分为三个部分:
- 文本 + 位置嵌入(embeddings)
- 一个transformer解码器堆栈(decoder stack)
- 一个投影到词汇(projection to vocab)步骤
def gpt2(inputs, wte, wpe, blocks, ln_f, n_head): # [n_seq] -> [n_seq, n_vocab]
# token + positional embeddings
x = wte[inputs] + wpe[range(len(inputs))] # [n_seq] -> [n_seq, n_embd]
# forward pass through n_layer transformer blocks
for block in blocks:
x = transformer_block(x, **block, n_head=n_head) # [n_seq, n_embd] -> [n_seq, n_embd]
# projection to vocab
x = layer_norm(x, **ln_f) # [n_seq, n_embd] -> [n_seq, n_embd]
return x @ wte.T # [n_seq, n_embd] -> [n_seq, n_vocab]
C版 GPT-2 llm.c
【2024-4-9】纯C语言手搓GPT-2,前OpenAI、特斯拉高管新项目
前特斯拉 Autopilot 负责人、OpenAI 科学家 Andrej Karpathy 发布了一个仅用 1000 行代码即可在 CPU/fp32 上实现 GPT-2 训练的项目「llm.c」。
- GitHub 链接:llm.c
- 原始训练的实现:train_gpt2.c
llm.c 旨在让大模型(LM)训练变得简单
- 纯 C 语言 / CUDA,不需要 245MB 的 PyTorch 或 107MB 的 cPython。
- 例如,训练 GPT-2(CPU、fp32)仅需要单个文件中的大约 1000 行干净代码(clean code),可以立即编译运行,并且完全可以媲美 PyTorch 参考实现。
Karpathy 表示,GPT-2 是 LLM 的鼻祖,是大语言模型体系首次以现代形式组合在一起,并且有可用的模型权重。
llm.c 下一步目标:
- 直接的 CUDA 实现,让速度更快,并且可能接近 PyTorch;
- 使用 SIMD 指令、x86 上的 AVX2 / ARM 上的 NEON(例如苹果 M 系列芯片的电脑)来加速 CPU 版本;
- 更多新型架构,例如 Llama2、Gemma 等。
步骤
- Mac 下实践通过
git clone https://github.com/karpathy/llm.c.git
cd llm.c
# 准备数据集
python prepro_tinyshakespeare.py
# 准备权重
python train_gpt2.py
# 编译
make train_gpt2
OMP_NUM_THREADS=8 ./train_gpt2
# test
make test_gpt2
./test_gpt2
中文GPT
【2023-1-12】GPT中文版:GPT2-Chinese,Chinese version of GPT2 training code, using BERT tokenizer.
- 中文的GPT2训练代码,使用BERT的Tokenizer或Sentencepiece的BPE model。
- 可以写诗,新闻,小说,或是训练通用语言模型。支持
字为单位、分词模式、BPE模式。支持大语料训练。
GPT-2 源码解读
更多GPT内容见站内GPT专题
GPT-2 资料
Paper:
Code:
- openai/gpt-2: Code
- minimaxir/gpt-2-simple: Python package to easily retrain OpenAI’s GPT-2 text-generating model on new texts
GPT-2 原理
核心思想:基于 Transformer 的更加 General 的语言模型。多领域文本建模,以实现在不同任务上的迁移。
- 对单域数据集进行单任务训练,是造成当前系统缺乏普遍性的主要原因。
- 目前最好的方法是: 预训练模型 + 下游任务的监督训练。
- 所以,GPT-2 将二者结合起来,提供更加 general 的迁移方法, 使下游任务能够在 zero-shot 下实施,不需要参数或架构调整。证明了语言模型有在 zero-shot 下执行一系列任务的潜力。
- 核心点有两个:
- 基础:更加 general 的预训练模型
- 应用:zero-shot 实施的多下游任务
model :p(output | input, task)
基于 Transformer,对 GPT-1 的改进:
- Layer normalization 移动到每个 sub-block 的 input
- 最后一个 self-attention block 后面加 layer normalization
- 在初始化时按 1/√N 的比例缩放残差层的权重,其中 N 是残差层的数量
- Vocabulary 扩展到 50,257
- 上下文 token 数从 512 调整到 1024
- 更大的 batch size(512)
对底层不理解时,顶层东西看似懂了, 其实都没懂,又称 “司机的知识”
GPT-3 是一种基于 Transformer 模型的巨型语言模型,其训练需要大量的计算资源和数据。
- 由 OpenAI 开发和拥有的,因此其训练代码和模型参数并不公开。
- 但是,如果想在自己的数据集上训练类似的模型,可以考虑使用一些现有的代码库,例如 Hugging Face Transformers,它提供了一个开源的 Transformer 模型库,其中包括一些预训练的语言模型,例如 GPT-2 和 RoBERTa。
GPT-2 Demo
gradio 提供的UI Demo, 默认是文本续写
import gradio as gr
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
def generate(text):
result = generator(text, max_length=30, num_return_sequences=1)
return result[0]["generated_text"]
examples = [
["The Moon's orbit around Earth has"],
["The smooth Borealis basin in the Northern Hemisphere covers 40%"],
]
demo = gr.Interface(
fn=generate,
inputs=gr.inputs.Textbox(lines=5, label="Input Text"),
outputs=gr.outputs.Textbox(label="Generated Text"),
examples=examples
)
demo.launch()
GPT-2 tensorflow 代码【官方】
openai/gpt-2: Code
代码架构
download_model.py # 模型下载
requirements.txt
src/ # 源码
encoder.py # 编码
model.py # 模型定义
sample.py # 采样
generate_unconditional_samples.py
interactive_conditional_samples.py
GPT-2 源码解读
【2023-6-28】官方源码:TensorFlow版本 174行
download_model.py
- 默认模型 124M
import os
import sys
import requests
from tqdm import tqdm
if len(sys.argv) != 2:
print('You must enter the model name as a parameter, e.g.: download_model.py 124M')
sys.exit(1)
model = sys.argv[1]
# 本地创建目录 models
subdir = os.path.join('models', model)
if not os.path.exists(subdir):
os.makedirs(subdir)
subdir = subdir.replace('\\','/') # needed for Windows
# 这个下载文件
for filename in ['checkpoint','encoder.json','hparams.json','model.ckpt.data-00000-of-00001', 'model.ckpt.index', 'model.ckpt.meta', 'vocab.bpe']:
r = requests.get("https://openaipublic.blob.core.windows.net/gpt-2/" + subdir + "/" + filename, stream=True)
with open(os.path.join(subdir, filename), 'wb') as f:
file_size = int(r.headers["content-length"])
chunk_size = 1000
with tqdm(ncols=100, desc="Fetching " + filename, total=file_size, unit_scale=True) as pbar:
# 1k for chunk_size, since Ethernet packet size is around 1500 bytes
for chunk in r.iter_content(chunk_size=chunk_size):
f.write(chunk)
pbar.update(chunk_size)
下载完成后文件信息
4.0K checkpoint
1.0M encoder.json
4.0K hparams.json
480M model.ckpt.data-00000-of-00001
8.0K model.ckpt.index
524K model.ckpt.meta
460K vocab.bpe
encoder.py
"""Byte pair encoding utilities"""
import os
import json
import regex as re
from functools import lru_cache
@lru_cache()
def bytes_to_unicode():
"""
Returns list of utf-8 byte and a corresponding list of unicode strings.
The reversible bpe codes work on unicode strings.
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
This is a signficant percentage of your normal, say, 32K bpe vocab.
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
And avoids mapping to whitespace/control characters the bpe code barfs on.
"""
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
cs = bs[:]
n = 0
for b in range(2**8):
if b not in bs:
bs.append(b)
cs.append(2**8+n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
def get_pairs(word):
"""Return set of symbol pairs in a word.
Word is represented as tuple of symbols (symbols being variable-length strings).
"""
pairs = set()
prev_char = word[0]
for char in word[1:]:
pairs.add((prev_char, char))
prev_char = char
return pairs
class Encoder:
def __init__(self, encoder, bpe_merges, errors='replace'):
self.encoder = encoder
self.decoder = {v:k for k,v in self.encoder.items()}
self.errors = errors # how to handle errors in decoding
self.byte_encoder = bytes_to_unicode()
self.byte_decoder = {v:k for k, v in self.byte_encoder.items()}
self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
self.cache = {}
# Should haved added re.IGNORECASE so BPE merges can happen for capitalized versions of contractions
self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
def bpe(self, token):
if token in self.cache:
return self.cache[token]
word = tuple(token)
pairs = get_pairs(word)
if not pairs:
return token
while True:
bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float('inf')))
if bigram not in self.bpe_ranks:
break
first, second = bigram
new_word = []
i = 0
while i < len(word):
try:
j = word.index(first, i)
new_word.extend(word[i:j])
i = j
except:
new_word.extend(word[i:])
break
if word[i] == first and i < len(word)-1 and word[i+1] == second:
new_word.append(first+second)
i += 2
else:
new_word.append(word[i])
i += 1
new_word = tuple(new_word)
word = new_word
if len(word) == 1:
break
else:
pairs = get_pairs(word)
word = ' '.join(word)
self.cache[token] = word
return word
def encode(self, text):
bpe_tokens = []
for token in re.findall(self.pat, text):
token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
return bpe_tokens
def decode(self, tokens):
text = ''.join([self.decoder[token] for token in tokens])
text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors=self.errors)
return text
def get_encoder(model_name, models_dir):
with open(os.path.join(models_dir, model_name, 'encoder.json'), 'r') as f:
encoder = json.load(f)
with open(os.path.join(models_dir, model_name, 'vocab.bpe'), 'r', encoding="utf-8") as f:
bpe_data = f.read()
bpe_merges = [tuple(merge_str.split()) for merge_str in bpe_data.split('\n')[1:-1]]
return Encoder(
encoder=encoder,
bpe_merges=bpe_merges,
)
model.py
模型定义文件: model.py
import numpy as np
import tensorflow as tf
from tensorflow.contrib.training import HParams
def default_hparams():
return HParams(
n_vocab=0, # 词库大小
n_ctx=1024, # context窗口
n_embd=768, # embedding维度
n_head=12, # 多头注意力,数目
n_layer=12, # 层数
)
def shape_list(x):
"""Deal with dynamic shape in tensorflow cleanly."""
static = x.shape.as_list()
dynamic = tf.shape(x)
return [dynamic[i] if s is None else s for i, s in enumerate(static)]
def softmax(x, axis=-1):
x = x - tf.reduce_max(x, axis=axis, keepdims=True)
ex = tf.exp(x)
return ex / tf.reduce_sum(ex, axis=axis, keepdims=True)
def gelu(x):
return 0.5*x*(1+tf.tanh(np.sqrt(2/np.pi)*(x+0.044715*tf.pow(x, 3))))
def norm(x, scope, *, axis=-1, epsilon=1e-5):
"""
Normalize to mean = 0, std = 1, then do a diagonal affine transform.
"""
with tf.variable_scope(scope):
n_state = x.shape[-1].value
g = tf.get_variable('g', [n_state], initializer=tf.constant_initializer(1))
b = tf.get_variable('b', [n_state], initializer=tf.constant_initializer(0))
u = tf.reduce_mean(x, axis=axis, keepdims=True)
s = tf.reduce_mean(tf.square(x-u), axis=axis, keepdims=True)
x = (x - u) * tf.rsqrt(s + epsilon)
x = x*g + b
return x
def split_states(x, n):
"""
Reshape the last dimension of x into [n, x.shape[-1]/n].
"""
*start, m = shape_list(x)
return tf.reshape(x, start + [n, m//n])
def merge_states(x):
"""Smash the last two dimensions of x into a single dimension."""
*start, a, b = shape_list(x)
return tf.reshape(x, start + [a*b])
def conv1d(x, scope, nf, *, w_init_stdev=0.02):
with tf.variable_scope(scope):
*start, nx = shape_list(x)
w = tf.get_variable('w', [1, nx, nf], initializer=tf.random_normal_initializer(stddev=w_init_stdev))
b = tf.get_variable('b', [nf], initializer=tf.constant_initializer(0))
c = tf.reshape(tf.matmul(tf.reshape(x, [-1, nx]), tf.reshape(w, [-1, nf]))+b, start+[nf])
return c
def attention_mask(nd, ns, *, dtype):
"""
masked attention 掩码注意力
1's in the lower triangle, counting from the lower right corner.
Same as tf.matrix_band_part(tf.ones([nd, ns]), -1, ns-nd), but doesn't produce garbage on TPUs.
"""
i = tf.range(nd)[:,None]
j = tf.range(ns)
m = i >= j - ns + nd
return tf.cast(m, dtype)
def attn(x, scope, n_state, *, past, hparams):
"""
注意力
"""
assert x.shape.ndims == 3 # Should be [batch, sequence, features]
assert n_state % hparams.n_head == 0
if past is not None:
assert past.shape.ndims == 5 # Should be [batch, 2, heads, sequence, features], where 2 is [k, v]
def split_heads(x): # 多头切割
# From [batch, sequence, features] to [batch, heads, sequence, features]
return tf.transpose(split_states(x, hparams.n_head), [0, 2, 1, 3])
def merge_heads(x): # 多头合并
# Reverse of split_heads
return merge_states(tf.transpose(x, [0, 2, 1, 3]))
def mask_attn_weights(w):
# w has shape [batch, heads, dst_sequence, src_sequence], where information flows from src to dst.
_, _, nd, ns = shape_list(w)
b = attention_mask(nd, ns, dtype=w.dtype)
b = tf.reshape(b, [1, 1, nd, ns])
w = w*b - tf.cast(1e10, w.dtype)*(1-b)
return w
def multihead_attn(q, k, v): # 多头注意力
# q, k, v have shape [batch, heads, sequence, features]
w = tf.matmul(q, k, transpose_b=True)
w = w * tf.rsqrt(tf.cast(v.shape[-1].value, w.dtype))
w = mask_attn_weights(w)
w = softmax(w)
a = tf.matmul(w, v)
return a
with tf.variable_scope(scope):
# 注意力结构定义
c = conv1d(x, 'c_attn', n_state*3)
q, k, v = map(split_heads, tf.split(c, 3, axis=2))
present = tf.stack([k, v], axis=1)
if past is not None:
pk, pv = tf.unstack(past, axis=1)
k = tf.concat([pk, k], axis=-2)
v = tf.concat([pv, v], axis=-2)
a = multihead_attn(q, k, v)
a = merge_heads(a)
a = conv1d(a, 'c_proj', n_state)
return a, present
def mlp(x, scope, n_state, *, hparams):
with tf.variable_scope(scope):
nx = x.shape[-1].value
h = gelu(conv1d(x, 'c_fc', n_state))
h2 = conv1d(h, 'c_proj', nx)
return h2
def block(x, scope, *, past, hparams):
with tf.variable_scope(scope):
nx = x.shape[-1].value
a, present = attn(norm(x, 'ln_1'), 'attn', nx, past=past, hparams=hparams)
x = x + a
m = mlp(norm(x, 'ln_2'), 'mlp', nx*4, hparams=hparams)
x = x + m
return x, present
def past_shape(*, hparams, batch_size=None, sequence=None):
return [batch_size, hparams.n_layer, 2, hparams.n_head, sequence, hparams.n_embd // hparams.n_head]
def expand_tile(value, size):
"""Add a new axis of given size."""
value = tf.convert_to_tensor(value, name='value')
ndims = value.shape.ndims
return tf.tile(tf.expand_dims(value, axis=0), [size] + [1]*ndims)
def positions_for(tokens, past_length):
batch_size = tf.shape(tokens)[0]
nsteps = tf.shape(tokens)[1]
return expand_tile(past_length + tf.range(nsteps), batch_size)
def model(hparams, X, past=None, scope='model', reuse=False):
with tf.variable_scope(scope, reuse=reuse):
results = {}
batch, sequence = shape_list(X)
wpe = tf.get_variable('wpe', [hparams.n_ctx, hparams.n_embd],
initializer=tf.random_normal_initializer(stddev=0.01))
wte = tf.get_variable('wte', [hparams.n_vocab, hparams.n_embd],
initializer=tf.random_normal_initializer(stddev=0.02))
past_length = 0 if past is None else tf.shape(past)[-2]
h = tf.gather(wte, X) + tf.gather(wpe, positions_for(X, past_length))
# Transformer
presents = []
pasts = tf.unstack(past, axis=1) if past is not None else [None] * hparams.n_layer
assert len(pasts) == hparams.n_layer
for layer, past in enumerate(pasts):
h, present = block(h, 'h%d' % layer, past=past, hparams=hparams)
presents.append(present)
results['present'] = tf.stack(presents, axis=1)
h = norm(h, 'ln_f')
# Language model loss. Do tokens <n predict token n?
h_flat = tf.reshape(h, [batch*sequence, hparams.n_embd])
logits = tf.matmul(h_flat, wte, transpose_b=True)
logits = tf.reshape(logits, [batch, sequence, hparams.n_vocab])
results['logits'] = logits
return results
sample.py
import tensorflow as tf
import model
def top_k_logits(logits, k):
if k == 0:
# no truncation
return logits
def _top_k():
values, _ = tf.nn.top_k(logits, k=k)
min_values = values[:, -1, tf.newaxis]
return tf.where(
logits < min_values,
tf.ones_like(logits, dtype=logits.dtype) * -1e10,
logits,
)
return tf.cond(
tf.equal(k, 0),
lambda: logits,
lambda: _top_k(),
)
def top_p_logits(logits, p):
"""Nucleus sampling"""
batch, _ = logits.shape.as_list()
sorted_logits = tf.sort(logits, direction='DESCENDING', axis=-1)
cumulative_probs = tf.cumsum(tf.nn.softmax(sorted_logits, axis=-1), axis=-1)
indices = tf.stack([
tf.range(0, batch),
# number of indices to include
tf.maximum(tf.reduce_sum(tf.cast(cumulative_probs <= p, tf.int32), axis=-1) - 1, 0),
], axis=-1)
min_values = tf.gather_nd(sorted_logits, indices)
return tf.where(
logits < min_values,
tf.ones_like(logits) * -1e10,
logits,
)
def sample_sequence(*, hparams, length, start_token=None, batch_size=None, context=None, temperature=1, top_k=0, top_p=1):
if start_token is None:
assert context is not None, 'Specify exactly one of start_token and context!'
else:
assert context is None, 'Specify exactly one of start_token and context!'
context = tf.fill([batch_size, 1], start_token)
def step(hparams, tokens, past=None):
lm_output = model.model(hparams=hparams, X=tokens, past=past, reuse=tf.AUTO_REUSE)
logits = lm_output['logits'][:, :, :hparams.n_vocab]
presents = lm_output['present']
presents.set_shape(model.past_shape(hparams=hparams, batch_size=batch_size))
return {
'logits': logits,
'presents': presents,
}
with tf.name_scope('sample_sequence'):
def body(past, prev, output):
next_outputs = step(hparams, prev, past=past)
logits = next_outputs['logits'][:, -1, :] / tf.to_float(temperature)
logits = top_k_logits(logits, k=top_k)
logits = top_p_logits(logits, p=top_p)
samples = tf.multinomial(logits, num_samples=1, output_dtype=tf.int32)
return [
next_outputs['presents'] if past is None else tf.concat([past, next_outputs['presents']], axis=-2),
samples,
tf.concat([output, samples], axis=1)
]
past, prev, output = body(None, context, context)
def cond(*args):
return True
_, _, tokens = tf.while_loop(
cond=cond, body=body,
maximum_iterations=length - 1,
loop_vars=[
past,
prev,
output
],
shape_invariants=[
tf.TensorShape(model.past_shape(hparams=hparams, batch_size=batch_size)),
tf.TensorShape([batch_size, None]),
tf.TensorShape([batch_size, None]),
],
back_prop=False,
)
return tokens
src/interactive_conditional_samples.py
src/interactive_conditional_samples.py
#!/usr/bin/env python3
import fire
import json
import os
import numpy as np
import tensorflow as tf
import model, sample, encoder
def interact_model(
model_name='124M',
seed=None,
nsamples=1,
batch_size=1,
length=None,
temperature=1,
top_k=0,
top_p=1,
models_dir='models',
):
"""
Interactively run the model
:model_name=124M : String, which model to use
:seed=None : Integer seed for random number generators, fix seed to reproduce
results
:nsamples=1 : Number of samples to return total
:batch_size=1 : Number of batches (only affects speed/memory). Must divide nsamples.
:length=None : Number of tokens in generated text, if None (default), is
determined by model hyperparameters
:temperature=1 : Float value controlling randomness in boltzmann
distribution. Lower temperature results in less random completions. As the
temperature approaches zero, the model will become deterministic and
repetitive. Higher temperature results in more random completions.
:top_k=0 : Integer value controlling diversity. 1 means only 1 word is
considered for each step (token), resulting in deterministic completions,
while 40 means 40 words are considered at each step. 0 (default) is a
special setting meaning no restrictions. 40 generally is a good value.
:models_dir : path to parent folder containing model subfolders
(i.e. contains the <model_name> folder)
"""
models_dir = os.path.expanduser(os.path.expandvars(models_dir))
if batch_size is None:
batch_size = 1
assert nsamples % batch_size == 0
enc = encoder.get_encoder(model_name, models_dir)
hparams = model.default_hparams()
with open(os.path.join(models_dir, model_name, 'hparams.json')) as f:
hparams.override_from_dict(json.load(f))
if length is None:
length = hparams.n_ctx // 2
elif length > hparams.n_ctx:
raise ValueError("Can't get samples longer than window size: %s" % hparams.n_ctx)
with tf.Session(graph=tf.Graph()) as sess:
context = tf.placeholder(tf.int32, [batch_size, None])
np.random.seed(seed)
tf.set_random_seed(seed)
output = sample.sample_sequence(
hparams=hparams, length=length,
context=context,
batch_size=batch_size,
temperature=temperature, top_k=top_k, top_p=top_p
)
saver = tf.train.Saver()
ckpt = tf.train.latest_checkpoint(os.path.join(models_dir, model_name))
saver.restore(sess, ckpt)
while True:
raw_text = input("Model prompt >>> ")
while not raw_text:
print('Prompt should not be empty!')
raw_text = input("Model prompt >>> ")
context_tokens = enc.encode(raw_text)
generated = 0
for _ in range(nsamples // batch_size):
out = sess.run(output, feed_dict={
context: [context_tokens for _ in range(batch_size)]
})[:, len(context_tokens):]
for i in range(batch_size):
generated += 1
text = enc.decode(out[i])
print("=" * 40 + " SAMPLE " + str(generated) + " " + "=" * 40)
print(text)
print("=" * 80)
if __name__ == '__main__':
fire.Fire(interact_model)
generate_unconditional_samples.py
src/generate_unconditional_samples.py
#!/usr/bin/env python3
import fire
import json
import os
import numpy as np
import tensorflow as tf
import model, sample, encoder
def sample_model(
model_name='124M',
seed=None,
nsamples=0,
batch_size=1,
length=None,
temperature=1,
top_k=0,
top_p=1,
models_dir='models',
):
"""
Run the sample_model
:model_name=124M : String, which model to use
:seed=None : Integer seed for random number generators, fix seed to
reproduce results
:nsamples=0 : Number of samples to return, if 0, continues to
generate samples indefinately.
:batch_size=1 : Number of batches (only affects speed/memory).
:length=None : Number of tokens in generated text, if None (default), is
determined by model hyperparameters
:temperature=1 : Float value controlling randomness in boltzmann
distribution. Lower temperature results in less random completions. As the
temperature approaches zero, the model will become deterministic and
repetitive. Higher temperature results in more random completions.
:top_k=0 : Integer value controlling diversity. 1 means only 1 word is
considered for each step (token), resulting in deterministic completions,
while 40 means 40 words are considered at each step. 0 (default) is a
special setting meaning no restrictions. 40 generally is a good value.
:models_dir : path to parent folder containing model subfolders
(i.e. contains the <model_name> folder)
"""
models_dir = os.path.expanduser(os.path.expandvars(models_dir))
enc = encoder.get_encoder(model_name, models_dir)
hparams = model.default_hparams()
with open(os.path.join(models_dir, model_name, 'hparams.json')) as f:
hparams.override_from_dict(json.load(f))
if length is None:
length = hparams.n_ctx
elif length > hparams.n_ctx:
raise ValueError("Can't get samples longer than window size: %s" % hparams.n_ctx)
with tf.Session(graph=tf.Graph()) as sess:
np.random.seed(seed)
tf.set_random_seed(seed)
output = sample.sample_sequence(
hparams=hparams, length=length,
start_token=enc.encoder['<|endoftext|>'],
batch_size=batch_size,
temperature=temperature, top_k=top_k, top_p=top_p
)[:, 1:]
saver = tf.train.Saver()
ckpt = tf.train.latest_checkpoint(os.path.join(models_dir, model_name))
saver.restore(sess, ckpt)
generated = 0
while nsamples == 0 or generated < nsamples:
out = sess.run(output)
for i in range(batch_size):
generated += batch_size
text = enc.decode(out[i])
print("=" * 40 + " SAMPLE " + str(generated) + " " + "=" * 40)
print(text)
if __name__ == '__main__':
fire.Fire(sample_model)
GPT-2 pytorch
【2019】
- gpt-2-Pytorch GPT2-Pytorch with Text-Generator, Colab
- gpt-2-Chinese, 中文版
部署
$ git clone https://github.com/graykode/gpt-2-Pytorch && cd gpt-2-Pytorch
# download huggingface's pytorch model
$ curl --output gpt2-pytorch_model.bin https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-pytorch_model.bin
# setup requirements, if using mac os, then run additional setup as descibed below
$ pip install -r requirements.txt
执行
- 【2024-3-7】Mac os上实践通过
参数
- –text : sentence to begin with.
- –quiet : not print all of the extraneous stuff like the “================”
- –nsamples : number of sample sampled in batch when multinomial function use
- –unconditional : If true, unconditional generation.
- –batch_size : number of batch size
- –length : sentence length (< number of context)
- –temperature: the thermodynamic temperature in distribution (default 0.7)
- –top_k : Returns the top k largest elements of the given input tensor along a given dimension. (default 40)
python main.py --text "It was a bright cold day in April, and the clocks were striking thirteen. Winston Smith, his chin nuzzled into his breast in an effort to escape the vile wind, slipped quickly through the glass doors of Victory Mansions, though not quickly enough to prevent a swirl of gritty dust from entering along with him."
源码
import copy
import torch
import math
import torch.nn as nn
from torch.nn.parameter import Parameter
def gelu(x):
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
class LayerNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-12):
"""Construct a layernorm module in the TF style (epsilon inside the square root).
"""
super(LayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.bias = nn.Parameter(torch.zeros(hidden_size))
self.variance_epsilon = eps
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
return self.weight * x + self.bias
class Conv1D(nn.Module):
def __init__(self, nf, nx):
super(Conv1D, self).__init__()
self.nf = nf
w = torch.empty(nx, nf)
nn.init.normal_(w, std=0.02)
self.weight = Parameter(w)
self.bias = Parameter(torch.zeros(nf))
def forward(self, x):
size_out = x.size()[:-1] + (self.nf,)
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
x = x.view(*size_out)
return x
class Attention(nn.Module):
def __init__(self, nx, n_ctx, config, scale=False):
super(Attention, self).__init__()
n_state = nx # in Attention: n_state=768 (nx=n_embd)
# [switch nx => n_state from Block to Attention to keep identical to TF implem]
assert n_state % config.n_head == 0
self.register_buffer("bias", torch.tril(torch.ones(n_ctx, n_ctx)).view(1, 1, n_ctx, n_ctx))
self.n_head = config.n_head
self.split_size = n_state
self.scale = scale
self.c_attn = Conv1D(n_state * 3, nx)
self.c_proj = Conv1D(n_state, nx)
def _attn(self, q, k, v):
w = torch.matmul(q, k)
if self.scale:
w = w / math.sqrt(v.size(-1))
nd, ns = w.size(-2), w.size(-1)
b = self.bias[:, :, ns-nd:ns, :ns]
w = w * b - 1e10 * (1 - b)
w = nn.Softmax(dim=-1)(w)
return torch.matmul(w, v)
def merge_heads(self, x):
x = x.permute(0, 2, 1, 3).contiguous()
new_x_shape = x.size()[:-2] + (x.size(-2) * x.size(-1),)
return x.view(*new_x_shape) # in Tensorflow implem: fct merge_states
def split_heads(self, x, k=False):
new_x_shape = x.size()[:-1] + (self.n_head, x.size(-1) // self.n_head)
x = x.view(*new_x_shape) # in Tensorflow implem: fct split_states
if k:
return x.permute(0, 2, 3, 1) # (batch, head, head_features, seq_length)
else:
return x.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
def forward(self, x, layer_past=None):
x = self.c_attn(x)
query, key, value = x.split(self.split_size, dim=2)
query = self.split_heads(query)
key = self.split_heads(key, k=True)
value = self.split_heads(value)
if layer_past is not None:
past_key, past_value = layer_past[0].transpose(-2, -1), layer_past[1] # transpose back cf below
key = torch.cat((past_key, key), dim=-1)
value = torch.cat((past_value, value), dim=-2)
present = torch.stack((key.transpose(-2, -1), value)) # transpose to have same shapes for stacking
a = self._attn(query, key, value)
a = self.merge_heads(a)
a = self.c_proj(a)
return a, present
class MLP(nn.Module):
def __init__(self, n_state, config): # in MLP: n_state=3072 (4 * n_embd)
super(MLP, self).__init__()
nx = config.n_embd
self.c_fc = Conv1D(n_state, nx)
self.c_proj = Conv1D(nx, n_state)
self.act = gelu
def forward(self, x):
h = self.act(self.c_fc(x))
h2 = self.c_proj(h)
return h2
class Block(nn.Module):
def __init__(self, n_ctx, config, scale=False):
super(Block, self).__init__()
nx = config.n_embd
self.ln_1 = LayerNorm(nx, eps=config.layer_norm_epsilon)
self.attn = Attention(nx, n_ctx, config, scale)
self.ln_2 = LayerNorm(nx, eps=config.layer_norm_epsilon)
self.mlp = MLP(4 * nx, config)
def forward(self, x, layer_past=None):
a, present = self.attn(self.ln_1(x), layer_past=layer_past)
x = x + a
m = self.mlp(self.ln_2(x))
x = x + m
return x, present
class GPT2Model(nn.Module):
def __init__(self, config):
super(GPT2Model, self).__init__()
self.n_layer = config.n_layer
self.n_embd = config.n_embd
self.n_vocab = config.vocab_size
self.wte = nn.Embedding(config.vocab_size, config.n_embd)
self.wpe = nn.Embedding(config.n_positions, config.n_embd)
block = Block(config.n_ctx, config, scale=True)
self.h = nn.ModuleList([copy.deepcopy(block) for _ in range(config.n_layer)])
self.ln_f = LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
def set_embeddings_weights(self, model_embeddings_weights):
embed_shape = model_embeddings_weights.shape
self.decoder = nn.Linear(embed_shape[1], embed_shape[0], bias=False)
self.decoder.weight = model_embeddings_weights # Tied weights
def forward(self, input_ids, position_ids=None, token_type_ids=None, past=None):
if past is None:
past_length = 0
past = [None] * len(self.h)
else:
past_length = past[0][0].size(-2)
if position_ids is None:
position_ids = torch.arange(past_length, input_ids.size(-1) + past_length, dtype=torch.long,
device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_ids.size(-1))
position_ids = position_ids.view(-1, position_ids.size(-1))
inputs_embeds = self.wte(input_ids)
position_embeds = self.wpe(position_ids)
if token_type_ids is not None:
token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1))
token_type_embeds = self.wte(token_type_ids)
else:
token_type_embeds = 0
hidden_states = inputs_embeds + position_embeds + token_type_embeds
presents = []
for block, layer_past in zip(self.h, past):
hidden_states, present = block(hidden_states, layer_past)
presents.append(present)
hidden_states = self.ln_f(hidden_states)
output_shape = input_shape + (hidden_states.size(-1),)
return hidden_states.view(*output_shape), presents
class GPT2LMHead(nn.Module):
def __init__(self, model_embeddings_weights, config):
super(GPT2LMHead, self).__init__()
self.n_embd = config.n_embd
self.set_embeddings_weights(model_embeddings_weights)
def set_embeddings_weights(self, model_embeddings_weights):
embed_shape = model_embeddings_weights.shape
self.decoder = nn.Linear(embed_shape[1], embed_shape[0], bias=False)
self.decoder.weight = model_embeddings_weights # Tied weights
def forward(self, hidden_state):
# Truncated Language modeling logits (we remove the last token)
# h_trunc = h[:, :-1].contiguous().view(-1, self.n_embd)
lm_logits = self.decoder(hidden_state)
return lm_logits
class GPT2LMHeadModel(nn.Module):
def __init__(self, config):
super(GPT2LMHeadModel, self).__init__()
self.transformer = GPT2Model(config)
self.lm_head = GPT2LMHead(self.transformer.wte.weight, config)
def set_tied(self):
""" Make sure we are sharing the embeddings
"""
self.lm_head.set_embeddings_weights(self.transformer.wte.weight)
def forward(self, input_ids, position_ids=None, token_type_ids=None, lm_labels=None, past=None):
hidden_states, presents = self.transformer(input_ids, position_ids, token_type_ids, past)
lm_logits = self.lm_head(hidden_states)
if lm_labels is not None:
loss_fct = nn.CrossEntropyLoss(ignore_index=-1)
loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), lm_labels.view(-1))
return loss
return lm_logits, presents
GPT-2 Huggingface
huggingface 代码
from transformers import GPT2LMHeadModel, GPT2Tokenizer, TextDataset, DataCollatorForLanguageModeling, Trainer, TrainingArguments
# 使用 GPT2LMHeadModel 类 加载 GPT-2 模型
# Load the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# Load the dataset
dataset = TextDataset(
tokenizer=tokenizer,
file_path='path/to/text/file',
block_size=128
)
# Data collator for language modeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=False
)
# Training arguments
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=1, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
save_steps=10_000, # number of steps between model checkpoints
save_total_limit=2, # limit the total amount of checkpoints
prediction_loss_only=True,
)
# Trainer
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
)
# Train the model
trainer.train()
GPT-2 调用
Hugging Face Transformers 库中的 GPT-2 模型的代码示例,用于生成一个包含给定文本的聊天响应:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载 GPT-2 模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 设置模型的运行环境
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
# 生成响应函数
def generate_response(prompt, length=20, temperature=0.7):
encoded_prompt = tokenizer.encode(prompt, add_special_tokens=False, return_tensors='pt').to(device)
output_sequence = model.generate(
input_ids=encoded_prompt,
max_length=len(encoded_prompt[0]) + length,
temperature=temperature,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
generated_sequence = output_sequence[0, len(encoded_prompt[0]):].tolist()
text = tokenizer.decode(generated_sequence, clean_up_tokenization_spaces=True)
return text
【2023-2-12】ChatGPT简单训练源码
训练
import transformers
import torch
import os
import json
import random
import numpy as np
import argparse
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
from tqdm import tqdm
from torch.nn import DataParallel
from tokenizations.bpe_tokenizer import get_encoder
def build_files(data_path, tokenized_data_path, num_pieces, full_tokenizer, min_length):
with open(data_path, 'r', encoding='utf8') as f:
print('reading lines')
lines = json.load(f)
lines = [line.replace('\n', ' [SEP] ') for line in lines] # 用[SEP]表示换行, 段落之间使用SEP表示段落结束
all_len = len(lines)
if not os.path.exists(tokenized_data_path):
os.mkdir(tokenized_data_path)
for i in tqdm(range(num_pieces)):
sublines = lines[all_len // num_pieces * i: all_len // num_pieces * (i + 1)]
if i == num_pieces - 1:
sublines.extend(lines[all_len // num_pieces * (i + 1):]) # 把尾部例子添加到最后一个piece
sublines = [full_tokenizer.tokenize(line) for line in sublines if
len(line) > min_length] # 只考虑长度超过min_length的句子
sublines = [full_tokenizer.convert_tokens_to_ids(line) for line in sublines]
full_line = []
for subline in sublines:
full_line.append(full_tokenizer.convert_tokens_to_ids('[MASK]')) # 文章开头添加MASK表示文章开始
full_line.extend(subline)
full_line.append(full_tokenizer.convert_tokens_to_ids('[CLS]')) # 文章之间添加CLS表示文章结束
with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'w') as f:
for id in full_line:
f.write(str(id) + ' ')
print('finish')
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='0,1,2,3', type=str, required=False, help='设置使用哪些显卡')
parser.add_argument('--model_config', default='config/model_config_small.json', type=str, required=False,
help='选择模型参数')
parser.add_argument('--tokenizer_path', default='cache/vocab_small.txt', type=str, required=False, help='选择词库')
parser.add_argument('--raw_data_path', default='data/train.json', type=str, required=False, help='原始训练语料')
parser.add_argument('--tokenized_data_path', default='data/tokenized/', type=str, required=False,
help='tokenized语料存放位置')
parser.add_argument('--raw', action='store_true', help='是否先做tokenize')
parser.add_argument('--epochs', default=5, type=int, required=False, help='训练循环')
parser.add_argument('--batch_size', default=8, type=int, required=False, help='训练batch size')
parser.add_argument('--lr', default=1.5e-4, type=float, required=False, help='学习率')
parser.add_argument('--warmup_steps', default=2000, type=int, required=False, help='warm up步数')
parser.add_argument('--log_step', default=1, type=int, required=False, help='多少步汇报一次loss,设置为gradient accumulation的整数倍')
parser.add_argument('--stride', default=768, type=int, required=False, help='训练时取训练数据的窗口步长')
parser.add_argument('--gradient_accumulation', default=1, type=int, required=False, help='梯度积累')
parser.add_argument('--fp16', action='store_true', help='混合精度')
parser.add_argument('--fp16_opt_level', default='O1', type=str, required=False)
parser.add_argument('--max_grad_norm', default=1.0, type=float, required=False)
parser.add_argument('--num_pieces', default=100, type=int, required=False, help='将训练语料分成多少份')
parser.add_argument('--min_length', default=128, type=int, required=False, help='最短收录文章长度')
parser.add_argument('--output_dir', default='model/', type=str, required=False, help='模型输出路径')
parser.add_argument('--pretrained_model', default='', type=str, required=False, help='模型训练起点路径')
parser.add_argument('--writer_dir', default='tensorboard_summary/', type=str, required=False, help='Tensorboard路径')
parser.add_argument('--segment', action='store_true', help='中文以词为单位')
parser.add_argument('--bpe_token', action='store_true', help='subword')
parser.add_argument('--encoder_json', default="tokenizations/encoder.json", type=str, help="encoder.json")
parser.add_argument('--vocab_bpe', default="tokenizations/vocab.bpe", type=str, help="vocab.bpe")
args = parser.parse_args()
print('args:\n' + args.__repr__())
if args.segment:
from tokenizations import tokenization_bert_word_level as tokenization_bert
else:
from tokenizations import tokenization_bert
os.environ["CUDA_VISIBLE_DEVICES"] = args.device # 此处设置程序使用哪些显卡
model_config = transformers.modeling_gpt2.GPT2Config.from_json_file(args.model_config)
print('config:\n' + model_config.to_json_string())
n_ctx = model_config.n_ctx
if args.bpe_token:
full_tokenizer = get_encoder(args.encoder_json, args.vocab_bpe)
else:
full_tokenizer = tokenization_bert.BertTokenizer(vocab_file=args.tokenizer_path)
full_tokenizer.max_len = 999999
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('using device:', device)
raw_data_path = args.raw_data_path
tokenized_data_path = args.tokenized_data_path
raw = args.raw # 选择是否从零开始构建数据集
epochs = args.epochs
batch_size = args.batch_size
lr = args.lr
warmup_steps = args.warmup_steps
log_step = args.log_step
stride = args.stride
gradient_accumulation = args.gradient_accumulation
fp16 = args.fp16 # 不支持半精度的显卡请勿打开
fp16_opt_level = args.fp16_opt_level
max_grad_norm = args.max_grad_norm
num_pieces = args.num_pieces
min_length = args.min_length
output_dir = args.output_dir
tb_writer = SummaryWriter(log_dir=args.writer_dir)
assert log_step % gradient_accumulation == 0
if not os.path.exists(output_dir):
os.mkdir(output_dir)
if raw:
print('building files')
build_files(data_path=raw_data_path, tokenized_data_path=tokenized_data_path, num_pieces=num_pieces,
full_tokenizer=full_tokenizer, min_length=min_length)
print('files built')
if not args.pretrained_model:
model = transformers.modeling_gpt2.GPT2LMHeadModel(config=model_config)
else:
model = transformers.modeling_gpt2.GPT2LMHeadModel.from_pretrained(args.pretrained_model)
model.train()
model.to(device)
num_parameters = 0
parameters = model.parameters()
for parameter in parameters:
num_parameters += parameter.numel()
print('number of parameters: {}'.format(num_parameters))
multi_gpu = False
full_len = 0
print('calculating total steps')
for i in tqdm(range(num_pieces)):
with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'r') as f:
full_len += len([int(item) for item in f.read().strip().split()])
total_steps = int(full_len / stride * epochs / batch_size / gradient_accumulation)
print('total steps = {}'.format(total_steps))
optimizer = transformers.AdamW(model.parameters(), lr=lr, correct_bias=True)
scheduler = transformers.WarmupLinearSchedule(optimizer, warmup_steps=warmup_steps,
t_total=total_steps)
if fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=fp16_opt_level)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = DataParallel(model, device_ids=[int(i) for i in args.device.split(',')])
multi_gpu = True
print('starting training')
overall_step = 0
running_loss = 0
for epoch in range(epochs):
print('epoch {}'.format(epoch + 1))
now = datetime.now()
print('time: {}'.format(now))
x = np.linspace(0, num_pieces - 1, num_pieces, dtype=np.int32)
random.shuffle(x)
piece_num = 0
for i in x:
with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'r') as f:
line = f.read().strip()
tokens = line.split()
tokens = [int(token) for token in tokens]
start_point = 0
samples = []
while start_point < len(tokens) - n_ctx:
samples.append(tokens[start_point: start_point + n_ctx])
start_point += stride
if start_point < len(tokens):
samples.append(tokens[len(tokens)-n_ctx:])
random.shuffle(samples)
for step in range(len(samples) // batch_size): # drop last
# prepare data
batch = samples[step * batch_size: (step + 1) * batch_size]
batch_inputs = []
for ids in batch:
int_ids = [int(x) for x in ids]
batch_inputs.append(int_ids)
batch_inputs = torch.tensor(batch_inputs).long().to(device)
# forward pass
outputs = model.forward(input_ids=batch_inputs, labels=batch_inputs)
loss, logits = outputs[:2]
# get loss
if multi_gpu:
loss = loss.mean()
if gradient_accumulation > 1:
loss = loss / gradient_accumulation
# loss backward
if fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), max_grad_norm)
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
# optimizer step
if (overall_step + 1) % gradient_accumulation == 0:
running_loss += loss.item()
optimizer.step()
optimizer.zero_grad()
scheduler.step()
if (overall_step + 1) % log_step == 0:
tb_writer.add_scalar('loss', loss.item() * gradient_accumulation, overall_step)
print('now time: {}:{}. Step {} of piece {} of epoch {}, loss {}'.format(
datetime.now().hour,
datetime.now().minute,
step + 1,
piece_num,
epoch + 1,
running_loss * gradient_accumulation / (log_step / gradient_accumulation)))
running_loss = 0
overall_step += 1
piece_num += 1
print('saving model for epoch {}'.format(epoch + 1))
if not os.path.exists(output_dir + 'model_epoch{}'.format(epoch + 1)):
os.mkdir(output_dir + 'model_epoch{}'.format(epoch + 1))
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(output_dir + 'model_epoch{}'.format(epoch + 1))
# torch.save(scheduler.state_dict(), output_dir + 'model_epoch{}/scheduler.pt'.format(epoch + 1))
# torch.save(optimizer.state_dict(), output_dir + 'model_epoch{}/optimizer.pt'.format(epoch + 1))
print('epoch {} finished'.format(epoch + 1))
then = datetime.now()
print('time: {}'.format(then))
print('time for one epoch: {}'.format(then - now))
print('training finished')
if not os.path.exists(output_dir + 'final_model'):
os.mkdir(output_dir + 'final_model')
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(output_dir + 'final_model')
# torch.save(scheduler.state_dict(), output_dir + 'final_model/scheduler.pt')
# torch.save(optimizer.state_dict(), output_dir + 'final_model/optimizer.pt')
if __name__ == '__main__':
main()
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
