- LLM 推理优化
- 结束
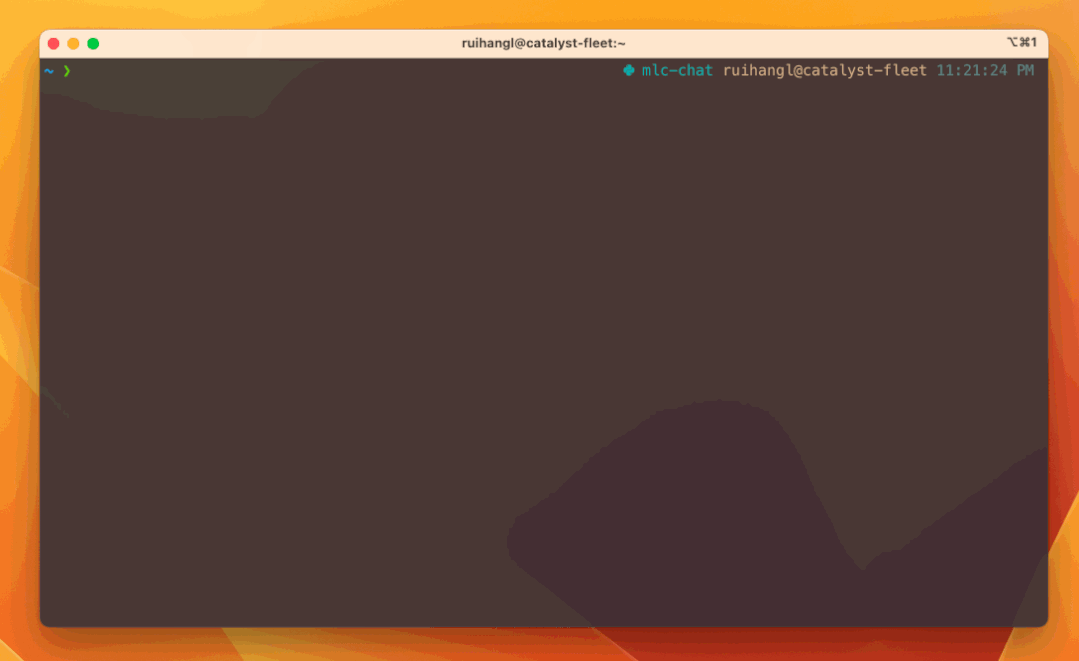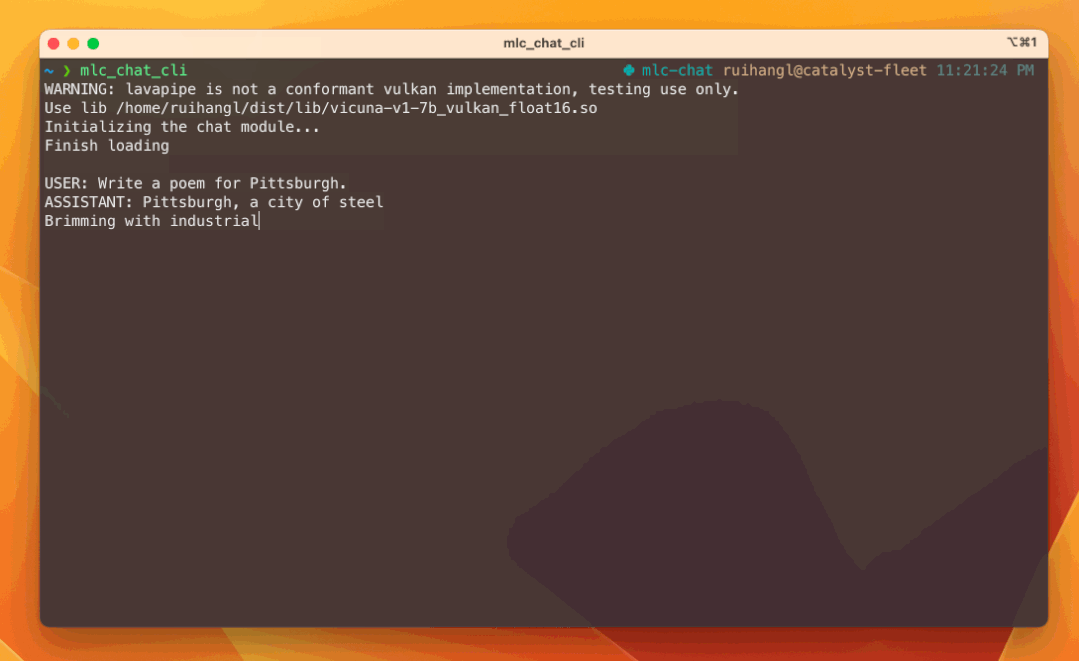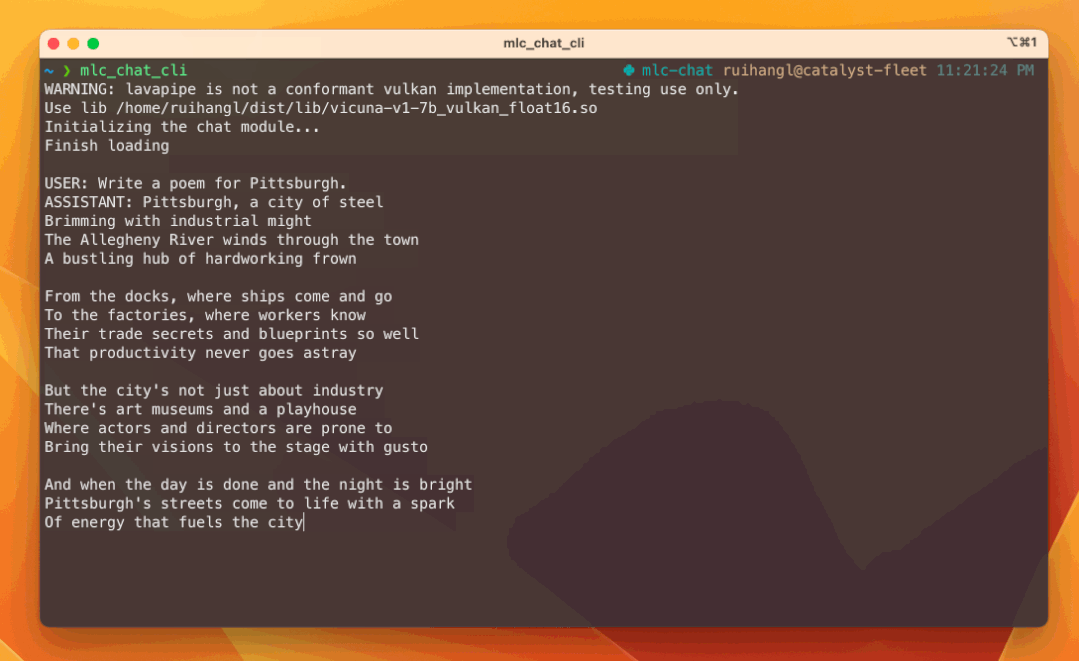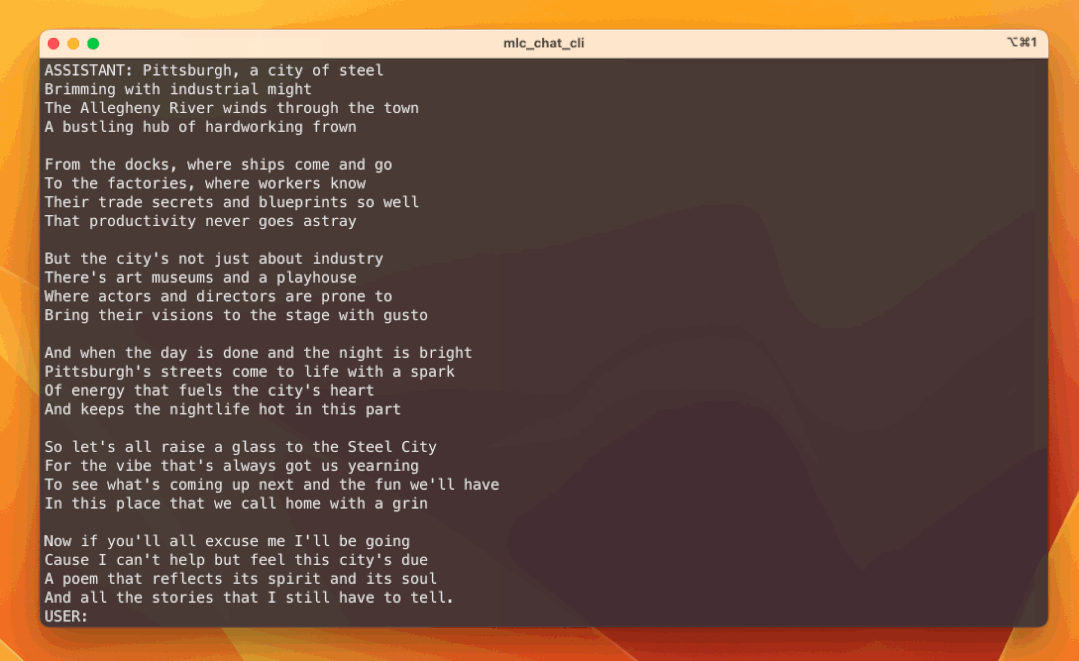
LLM 推理优化
基于 Transformer 架构的大语言模型 (LLM) 在全球范围内引发了深度的技术关注,并取得了令人瞩目的成就。其强大的理解和生成能力,正在深刻改变对人工智能的认知和应用。
然而,大语言模型的推理应用成本过高,高昂的成本,大大阻碍了技术落地。
优化推理性能不仅可以减少硬件成本,还可以提高模型的实时响应速度。它使模型能够更快速地执行自然语言理解、翻译、文本生成等任务,从而改善用户体验,加速科学研究,推动各行业应用的发展。
参考
- 【2023-8-30】LLM七种推理服务框架总结
- 【2023-8-17】LLM 的推理优化技术纵览
LLM 推理
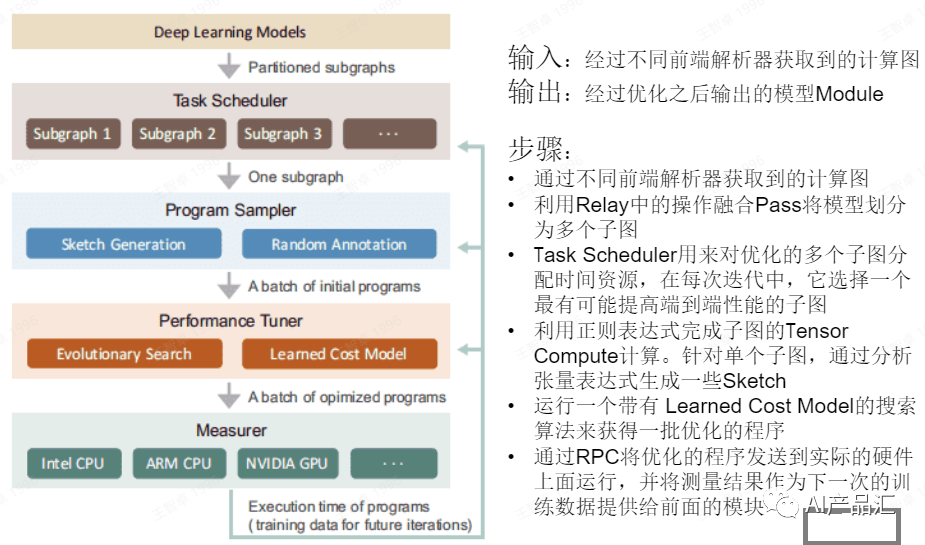
【2024-3-30】图解大模型计算加速系列之:vLLM核心技术PagedAttention原理
LLM 推理过程分两个阶段: prefill 和 decode, 通常用 KV cache 技术加速推理
Prefill: 预填充阶段, 把整段 prompt 喂给模型, 做forward计算。- 如果采用
KV cache技术,会把prompt过 Wk,Wv 后得到的 Xk,Xv 保存在 cache_k 和 cache_v中。对后面的token计算attention时,就不需要对前面的token重复计算,节省推理时间。 - 例如假设prompt中含有3个token,prefill阶段结束后,这三个token相关的KV值都被装进了cache
- 如果采用
Decode: 生成response。根据prompt的prefill结果,逐个token生成response。- 如果采用 KV cache, 则每走完一个decode过程,就把对应response token的KV值存入cache中,以便能加速计算。
- 例如 t4与cache中t0~t3的KV值计算完attention后,就把自己的KV值也装进cache中。对t6也是同理。
为什么不能一个阶段做完?
Prefill与Decode两个阶段的输入特性和计算方式本质不同,拆成两个阶段可以精准优化每步计算路径
- Prefill可用
Flash Attention等并行技术提升性能 - Decode可用
KV Cache、speculative decoding等加速
【2026-1-6】Speculative Decoding: 从Padding 的视角重新理解投机解码
LLM inference 优化两个基本事实:
- 事实一:Decode 阶段是 memory-bandwidth bound
- Prefill 阶段矩阵-矩阵乘(GEMM),计算量大,是 compute-bound;
- 而 decode 阶段每次只生成一个token,做矩阵-向量乘(GEMV),瓶颈在于读取 KV Cache,是 memory-bandwidth bound。
- 事实二:Batch size 和 Context length 对资源的影响方向相反
- Batch size 增大:算力需求增长得比带宽需求快 → 系统往 compute-bound 方向走
- Context length 增大:带宽需求增长得比算力需求快 → 系统往 memory-bound 方向走
小 batch 的时候算力闲着,长 context 的时候带宽不够用.
推理过程里,Prefill和Decode阶段不仅在结构式不同,在性能瓶颈上也大相径庭
由于 Decode 阶段逐一生成token,因此不能像 prefill 阶段那样能做大段prompt的并行计算
所以, LLM推理过程中,Decode阶段的耗时一般是更大的。
用 KV cache 推理时的一些特点:
- 随着prompt数量变多和序列变长,KV cache也变大,对gpu显存造成压力
- 由于输出序列长度无法预先知道,所以很难提前为KV cache量身定制存储空间
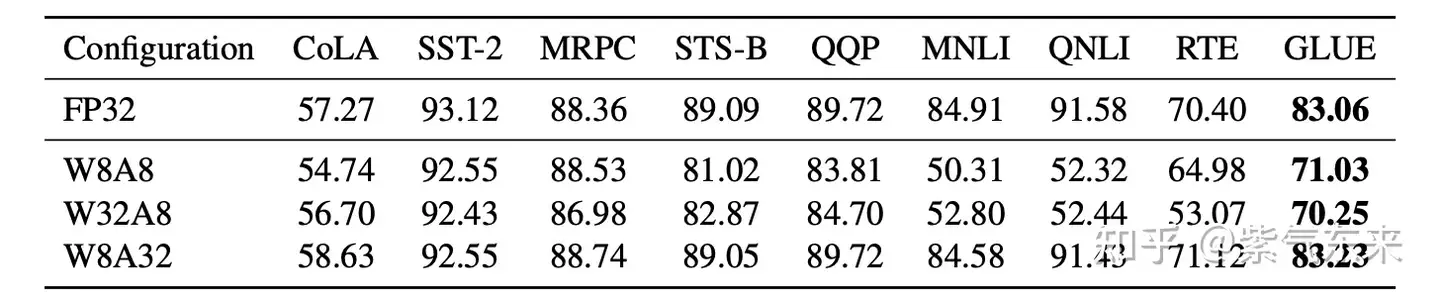
13B模型在A100 40GB gpu 推理时, 显存占用分配
- Parameters 参数 占 26GB, 65%
- KV Cache 占比超过 30%
- 其余是 others, 表示 forward过程中产生的activation 大小,这些activation 转瞬即逝,用完则废,因此占据的显存不大
直观感受到推理中 KV cache 对显存的占用。
因此,如何优化KV cache,节省显存,提高推理吞吐量,就成了LLM推理框架需要解决的重点问题。
训练 vs 推理
AI工程分两个阶段:训练 和 推理
- 训练、推理截断对算力需求完全不同
训练 vs 推理
| 维度 | 第一阶段: 训练 | 第二阶段: 推理 | |
|---|---|---|---|
| 计算能力 | 数据吞吐量大,百亿/千亿参数达数TB-PB | 数据吞吐量小 | |
| 计算能力 | 密集计算 | 持续计算 | |
| 计算时间 | 几天-几周/几月 | 常态,贯穿日常业务 | |
| 时延 | 允许延迟 | 低延迟 |
指标
LLM 推理服务评估指标:
- 首词元(token)时间(Time to First Token):接收提示后多久,才返回第一个词元?
- 生成时延(Generation Latency):接收提示后多久才返回最终词元?
- 吞吐量(Throughput):能够同时通过pipeline传递多少个不同的生成?
- 硬件利用率(Hardware Utilization):在多大程度上有效地利用计算、内存带宽和硬件的其他能力?
重点关注两个指标:吞吐量和时延:
吞吐量:从系统角度来看,即系统在单位时间内能处理的 tokens 数量。计算方法为系统处理完成的 tokens 个数除以对应耗时,其中 tokens 个数一般指输入序列和输出序列长度之和。吞吐量越高,代表 LLM 服务系统的资源利用率越高,对应的系统成本越低。时延:从用户视角看,即用户平均收到每个 token 所需位时间。计算方法为用户从发出请求到收到完整响应所需的时间除以生成序列长度。一般来讲,当时延不大于 50 ms/token 时,用户使用体验会比较流畅。
吞吐量关注系统成本,高吞吐量代表系统单位时间处理的请求大,系统利用率高。时延关注用户使用体验,即返回结果要快。
这两个指标一般相互影响,因此需要权衡。
- 提高
吞吐量的方法一般是提升 batchsize,将用户请求由串行改为并行。 - 但 batchsize 的增大会在一定程度上损害每个用户的
时延,因为以前只计算一个请求,现在合并计算多个请求,每个用户等待的时间变长。
模型小型化关注:模型平均推理时间和功耗
- 平均推理时间: 用
latency或throughput来衡量 - 功耗: 用参考生成token过程中所用到GPU的功耗来近似(因为TP/PP等方法就会引入多个GPU).
这两个指标都与模型参数量紧密相关, 特别是LLMs参数量巨大, 导致部署消耗GPU量大(而且甚至会引起旧GPU, 如:
- 2080ti等消费级卡直接下线离场)及GPU的IO时间长(memory write/read 的cycles是要远大于 operations cycles, 印象中是百倍)
部署过程中如何使得模型变得更小更轻且保持智能尽可能不下降就成了一个重要的研究话题。
总结
LLM 推理性能优化主要以提高吞吐量和降低时延为目的,具体可以划分为如下六部分
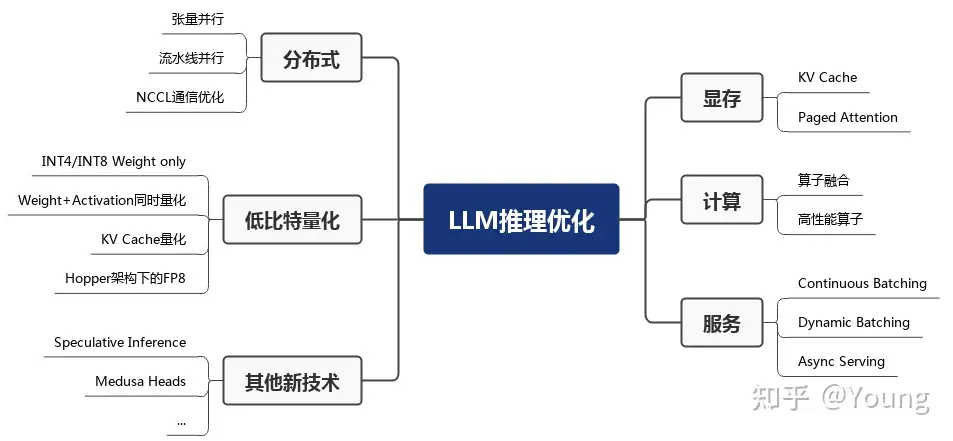
显存优化- KV Cache: 不影响任何计算精度的前提下,通过空间换时间思想,提高推理性能。业界主流 LLM 推理框架均默认支持并开启了该功能。
- Page Attention
- LLM 推理服务的吞吐量指标主要受制于显存限制
- 现有系统由于缺乏精细的显存管理方法而浪费了 60% 至 80% 的显存,浪费的显存主要来自 KV Cache
计算优化- 算子融合:减少计算过程中的访存次数和 Kernel 启动耗时达到提升模型推理性能
- 高性能算子:针对 LLM 推理运行热点函数编写高性能算子,也可以降低推理时延,包含 GEMM 操作优化 和 GEMV 操作优化
服务优化- 服务相关优化主要包括:Continuous Batching、Dynamic Batching 和 异步 Tokenize / Detokenize
- Continuous Batching 和 Dynamic Batching 主要围绕提高可并发的 batchsize 来提高吞吐量
- 异步 Tokenize / Detokenize 则通过多线程方式将 Tokenize / Detokenize 执行与模型推理过程时间交叠,实现降低时延目的。
分布式优化- 模型参数量较大,可能无法存放到单一计算设备中,分布式并行可以有效解决
- 分布式并行中的模型并行和流水线并行已在 LLM 推理中得到应用
低比特量化- 低比特量化可以降低显存占用量和访存量,关键在于节省显存量和访存量以及量化计算的加速远大于反量化带来的额外开销。
- 算法加速
投机采样(Speculative decoding)针对 LLM 推理串行解码特点,通过引入一个近似模型来执行串行解码,原始模型执行并行评估采样,通过近似模型和原始模型的互相配合,在保证精度一致性的同时降低了大模型串行解码的次数,进而降低了推理时延。美杜莎头(Medusa head)则是对投机采样的进一步改进,摒弃了近似模型,原始模型结构上新增了若干解码头,每个解码头可并行预测多个后续 tokens,然后使用基于树状注意力机制并行处理,最后使用典型接收方案筛选出合理的后续 tokens。该方法同样降低了大模型串行解码的次数,最终实现约两倍的时延加速。
生产环境大语言模型优化 – Optimizing your LLM in production
- 部署大规模语言模型(LLM)需要应对计算和内存需求,关键是提高模型在长文本输入下的计算和内存效率。
- 降低参数精度,如8比特或4比特量化,可以减少内存需求,仅轻微影响性能。
- Flash Attention算法可以线性提高内存利用率,并加速计算,是默认自注意力的更高效替代。
- 相对位置Embedding如ALiBi和RoPE可以更好处理长文本输入,并支持长度外推。
- 关键值cache机制可以重复使用先前计算,减少计算量,对会话等任务尤其重要。
- MQA和GQA通过共享键值投影或分组,可以显著减少cache内存需求。
- Falcon、PaLM、LLAMA等新模型设计都采用了这些优化技术,以支持长文本场景。
- 持续研究工作致力于进一步提升大模型计算和内存效率,部署LLM仍面临挑战。选择合适的算法和模型架构十分关键。
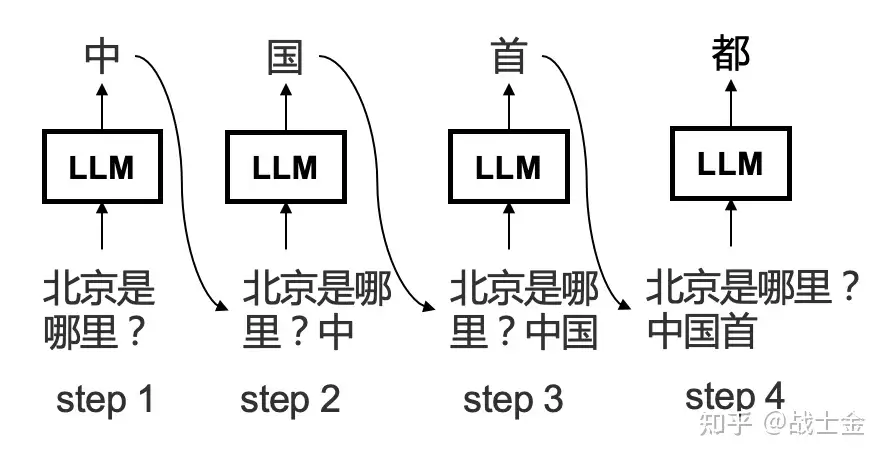
解码原理
大模型推理本质上串行,逐字预测

generate 函数
【2023-12-18】
def generate(prompt: str, tokens_to_generate: int) -> str:
tokens = tokenize(prompt)
for i in range(tokens_to_generate):
next_token = model(tokens)
tokens.append(next_token)
return detokenize(tokens)
generate 函数
- (1) 单次生成: 原版, 一次向模型传递一个序列,并在每个step附加一个词元
- (2) 批次生成: 改为一次向模型传递多个序列,同一前向传递中为每个序列生成一个补全(completion)
- 批处理序列允许模型权重同时用于多个序列,所以将整个序列批次一起运行所需的时间比分别运行每个序列所需的时间少。
- 问题: 整个batch未完成时,已完成的序列还要被迫继续生成随机词元,然后截断,浪费 GPU 资源
- (3) 连续批次生成: 将新序列插入批次来解决这一问题,插入位置是
[end]词元之后,注意力掩码机制来防止该序列受到上一序列中词元的影响
GPT-2 生成下一个词元的情况:
- 20 个词元 x 1 个序列 = 约 70 毫秒
- 20 个词元 x 5 个序列 = 约 220 毫秒(线性扩展约 350 毫秒)
- 20 个词元 x 10 个序列 = 约 400 毫秒(线性扩展约 700 毫秒)
# 单次生成
"Mark is quick. He"
"Mark is quick. He moves"
"Mark is quick. He moves quickly."
"Mark is quick. He moves quickly.[END]"
# 批次生成
"Mark is quick. He moves"
"The Eiffel Tower is"
"I like bananas, because they"
# 1
"Mark is quick. He moves quickly"
"The Eiffel Tower is in"
"I like bananas, because they have"
# 单次生成

详见站内专题: 文本生成之序列解码
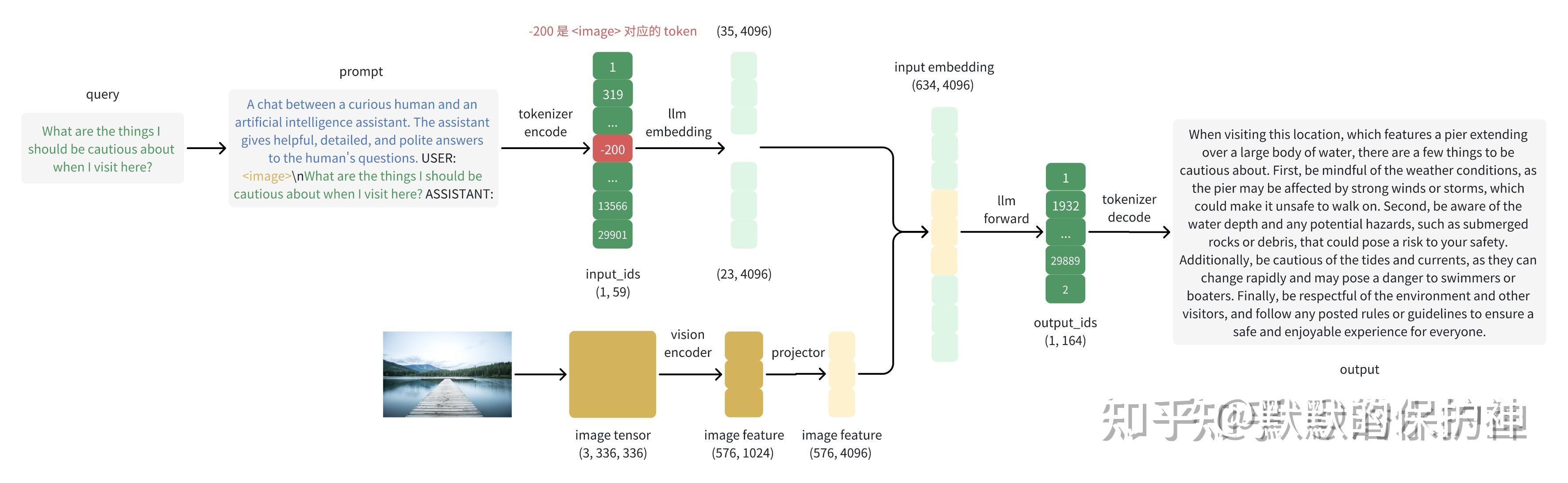
多模态
相较于普通语言模型,多模态模型会
- 输入的 token list里把多模态数据空出来,正常embedding变成token feature
- 同时把原始图像pixel 数据经过 VisionTransformer模型(通常说的VIT模型)转化为image feature
- 最后把 token feature和image feature拼接起来,变成普通的LLM模型输入。
图解
优化
大模型推理优化
- 大模型重复之前计算过的词向量
- mask机制,前边词向量不会受到后边词向量影响。
- 解法: 缓存已计算过的k,v
- 示例: transofrmers(hugging face)库实现了这种推理加速,LlamaAttention类中,通过past_key_value这个变量保存计算过的某个词向量
- 降低模型精度
- 从float32降低到float16,预测效果并不会下降很多,但是推理速度会快两倍
硬件加速
直截了当的方法(尤其有风险投资) :
- 购买更好的硬件, GPU/TPU
- 如果负担不起,就充分利用已有硬件。
cpu 传输
注意:
- CPU和加速器之间存在传输瓶颈
- 如果模型不适应加速器内存,前向传递过程中将被交换出去,显著降低速度。
- 这是苹果M1/M2/M3芯片在推理方面表现突出的原因之一,因为有统一的CPU和GPU内存。
- 无论是CPU还是加速器推理,都要先考虑是否充分利用了硬件
- 经过适当优化的程序可从较差硬件中获得更多收益,而未充分优化的程序尽管使用了最好的硬件,获得的收益可能还不如前者。
kernel 加速
示例
PyTorch 编写注意力
F.softmax(q @ k.T / sqrt(k.size(-1)) + mask) @ v,可以得到正确结果。- 但改用
torch.nn.functional.scaled_dot_product_attention,将在可用时将计算委托给 FlashAttention,从而通过更好地利用缓存的手写kernel实现3倍加速。
编译器
更为通用的是 torch.compile、TinyGrad 和 ONNX 这样的编译器,将简单的Python代码融合成为针对你的硬件进行优化的kernel。
类似 torch.compile 这样的工具是优化代码、提升硬件性能的绝佳选择,而无需使用CUDA以传统方式编写kernel。
加速框架
总结
【2025-5-8】韩国 25种LLM部署框架你知道多少?
- 论文:《A Survey on Inference Engines for Large Language Models: Perspectives on Optimization and Efficiency》
总结了目前市面上的 LLM 的推理框架,总共有 25 个。
技术分类:
- 批处理(动态批、连续批、nano批等)
- 并行策略(数据并行、流水线并行等)
- 模型压缩(量化、剪枝、稀疏优化)
- 缓存机制(KV缓存、Prefix缓存等)
- 注意力机制优化(FlashAttention等)
- 推理采样与结构化输出(Speculative decoding、格式约束)
实践意义:
- 对25种开源及商业推理引擎进行了详尽比较,涵盖如 vLLM、TensorRT-LLM、GroqCloud 等。
- 提供持续更新的公共资源库:Awesome LLM Inference Engine
- 指出未来方向,如更复杂服务支持、多硬件适配、安全性增强等。
总结
- star数:ollama、llama.cpp、vllm(低代码低成本部署还是广受大众喜欢)。
- 综合角度:vllm 遥遥领先。
- 文档完整性:vllm、Deepspeed-fastgen、tensorrt-llm比较完备
- 硬件支持度:Ollama、LLaMA.cpp、MAX、MLC-LLM
- 多级部署:vllm、sglang、lmdeploy
- 优化技巧全面度:vLLM、DeepSpeed-FastGen、SGLang、TensorRT-LLM
决策
- 生产环境,推荐vllm和sglang,支持的模型多,社区活跃,文档也详细。
- 自己玩且资源不够的话,推荐 ollama、llama.cpp、ktransformer。
- 不想自己部署,直接用各大公司的在线版本完事。
推理框架
【2206-1-8】主流大模型推理部署框架:vLLM、SGLang、TensorRT-LLM、ollama、XInference
| 技术工具 | 技术优势 | 适用场景 |
|---|---|---|
| vLLM | 适合动态批处理与多GPU扩展,TTFT表现优异,适合需要快速响应的场景 | 企业级高并发应用 |
| TensorRT-LLM | 在低延迟场景下表现最佳,适合对响应速度要求苛刻的生产级应用 | 企业级高并发应用 |
| SGLang | 在高并发稳定吞吐方面表现突出,适合需要持续高吞吐的场景 | 企业级高并发应用 |
| XInference | 提供分离式部署和分布式能力,适合需要快速验证分布式场景的开发者 | 企业级高并发应用 |
| Ollama | 安装便捷,支持跨平台,冷启动速度快,适合轻量级实验 | 个人开发与本地原型 |
| Llama.cpp | 零硬件门槛,适合无GPU环境下的基础推理,如物联网设备 | 个人开发与本地原型 |
| LightLLM | 轻量级设计,支持边缘设备部署,吞吐表现优异 | 边缘设备部署 |
| LMDepoly | 针对昇腾等国产硬件深度优化,多模态支持能力强,适合视觉语言混合任务 | 国产硬件部署 |
| 昇腾框架 | 支持Qwen2.5-Omni等全模态模型,扩展至3D、视频、传感信号等全模态场景 | 国产硬件部署 |
大模型推理部署框架的选型需综合考量业务场景、硬件条件与长期演进路径。
- 企业级高并发需求下,vLLM与TensorRT-LLM具备最优性能;
- SGLang则在高吞吐与多轮交互场景中优势突出;
- Ollama适用于个人开发与敏捷原型验证;
- XInference和LightLLM在分布式架构与边缘端部署中展现出广阔前景;
- LMDeploy与昇腾框架则在国产化硬件生态适配方面具有不可替代性。
LLM 推理
大模型训好了,如何部署到线上?如何支持多用户高并发调用+快速响应?
方法
- (1)直接上 Hugging Face 的 transformers + FastAPI 写个demo
- 实战时,要实现 batching、kv-cache、流式输出,简陋方案立马崩溃。
- vLLM 和 SGLang,正是为了解决这些痛点而生。
- (2)vLLM
- (3)SGLang
如果 vLLM 是“高性能、低干预”的自动化服务员,那 SGLang 是“懂编程的服务机器人”
选型
- ToC AI 应用开发者,做对话助手、智能客服、内容生成平台之类,SGLang 灵活性省掉不少“拼 prompt、加钩子、加中间件”的麻烦。
- 模型 API 服务、对标 OpenAI SaaS 接口,vLLM 绝对是业内“吞吐率/稳定性”数一数二。
没有最好,只有合适,一切都要以公司业务为主
作者:Trancy Wang
LLM 推理框架
【2024-7-15】本地部署运行私有的开源大型语言模型(LLMs)的方法
- Hugging Face 的
Transformers Llama.cpp基于C++的推理引擎,专为Apple Silicon打造,能够运行Meta的Llama2模型。- 在GPU和CPU上的推理性能均得到优化。
- 优点: 高性能,支持在适度的硬件上运行大型模型(如Llama 7B),并提供绑定,允许您使用其他语言构建AI应用程序。
- 缺点: 模型支持有限,且需要构建工具。
Llamafile- Mozilla开发的C++工具,基于llama.cpp库,为开发人员提供了创建、加载和运行LLM模型所需的各种功能。
- 简化了与LLM的交互,使开发人员能够轻松实现各种复杂的应用场景。
- 优点: 速度与Llama.cpp相当,并且可以构建一个嵌入模型的单个可执行文件。
- 由于项目仍处于早期阶段,不是所有模型都受支持,只限于Llama.cpp支持的模型。
Ollama- Llama.cpp 和 Llamafile的用户友好替代品,Ollama提供了一个可执行文件,可在机器上安装一个服务。
- 安装完成后,只需简单地在终端中运行即可。
- 优点在于易于安装和使用,支持llama和vicuña模型,并且运行速度极快。
- Ollama的模型库有限,需要用户自己管理模型
vLLM- 高吞吐量、内存高效的大型语言模型(LLMs)推理和服务引擎。
- 目标: 为所有人提供简便、快捷、经济的LLM服务。
- vLLM的优点: 高效的服务吞吐量、支持多种模型以及内存高效。
- 然而,为了确保其性能,用户需要确保设备具备GPU、CUDA或RoCm。
TGI(Text Generation Inference)- HuggingFace 推出的大模型推理部署框架,支持主流大模型和量化方案。
- TGI结合Rust和Python,实现服务效率和业务灵活性的平衡。具备许多特性,如简单的启动LLM、快速响应和高效的推理等。
- 通过TGI,用户可以轻松地在本地部署和运行大型语言模型,满足各种业务需求。经过优化处理的TGI和Transformer推理代码在性能上存在差异,这些差异体现在多个层面:
- 并行计算能力:TGI与Transformer均支持并行计算,但TGI更进一步,通过Rust与Python的联合运用,实现了服务效率与业务灵活性的完美平衡。这使得TGI在处理大型语言模型时,能够更高效地运用计算资源,显著提升推理效率。
- 创新优化策略:TGI采纳了一系列先进的优化技术,如Flash Attention、Paged Attention等,这些技术极大地提升了推理的效率和性能。而传统的Transformer模型可能未能融入这些创新优化。
- 模型部署支持:TGI支持GPTQ模型服务的部署,使我们能在单卡上运行启用continuous batching功能的更大规模模型。传统的Transformer模型则可能缺乏此类支持。
- 尽管TGI在某些方面优于传统Transformer推理,但并不意味着应完全放弃Transformer推理。在特定场景下,如任务或数据与TGI优化策略不符,使用传统Transformer推理可能更合适。当前测试表明,TGI的推理速度暂时逊于vLLM。TGI推理支持以容器化方式运行,为用户提供了更为灵活和高效的部署选项。
DeepSpeed- 微软精心打造的开源深度学习优化库,以系统优化和压缩为核心,深度优化硬件设备、操作系统和框架等多个层面,更利用模型和数据压缩技术,极大提升了大规模模型的推理和训练效率。
- DeepSpeed-Inference,作为DeepSpeed在推理领域的扩展,特别针对大语言模型设计。它巧妙运用模型并行、张量并行和流水线并行等技术,显著提升了推理性能并降低了延迟。
如何选择?
- 追求高性能推理:
DeepSpeed。独特的ZeRO(零冗余优化器)、3D并行(数据并行、模型并行和流水线并行的完美融合)以及1比特Adam等技术,都极大提高了大模型训练和推理的效率。 - 易用:
ollama。简洁的命令行界面,让模型运行变得轻松自如。 - 创建嵌入模型的单个可执行文件:
Llamafile。便携性和单文件可执行的特点,让人赞不绝口。 - 多种硬件环境下高效推理:
TGI。其模型并行、张量并行和流水线并行等优化技术,确保了大模型推理的高效运行。 - 复杂的自然语言处理任务,如机器翻译、文本生成等: 基于
Transformer的模型。其强大的表示能力,轻松捕捉文本中的长距离依赖关系。 - 大规模的自然语言处理任务,如文本分类、情感分析等:
vLLM。作为大规模的预训练模型,它在各种NLP任务中都能展现出色的性能。
推理极限
【2024-4-23】大模型推理的极限:理论分析、数学建模与 CPU/GPU 实测
calm 是一个基于 CUDA、完全从头开始编写的轻量级 transformer-based language models 推理实现
- RTX 4090 上 calm 使用 16 位权重时达到 ~15.4 ms/tok,使用 8 位权重时达到 ~7.8 ms/tok, 达到了理论极限的 90%。
- Apple M2 Air 上使用 CPU 推理时,calm 和 llama.cpp 只达到理论 100 GB/s 带宽的 ~65%, 然后带宽就上不去了,这暗示需要尝试 Apple iGPU 了。
- 推导细节 sol.ipynb
推理过程并未充分利用算力(ALU)。 需要重新平衡 FLOP:byte 比例, speculative decoding 等技术试图部分解决这个问题。
GPT-Fast
这几年,有一堆文本生成的开源项目 llama.cpp, vLLM, 和 MLC-LLM. 为了更加使用方便,长城要求模型转成特殊格式、增加新依赖。
纯pytorch框架上的transformer推理能有多快?
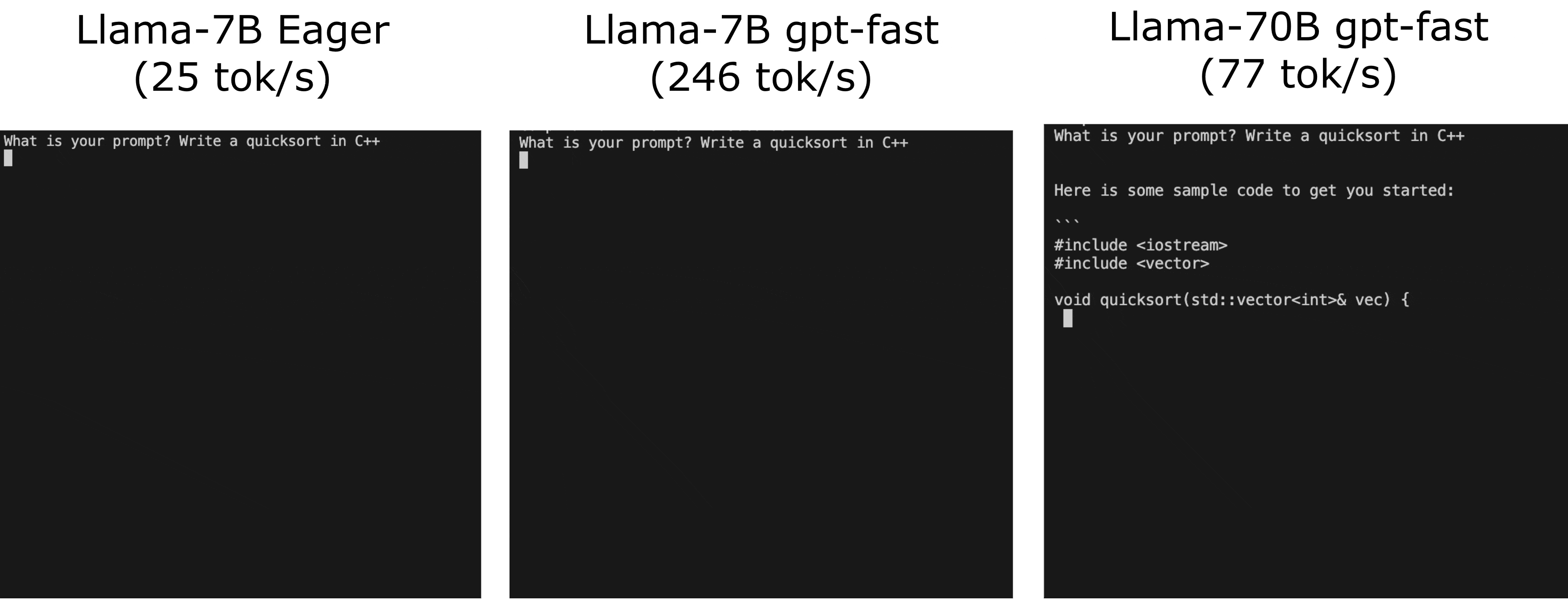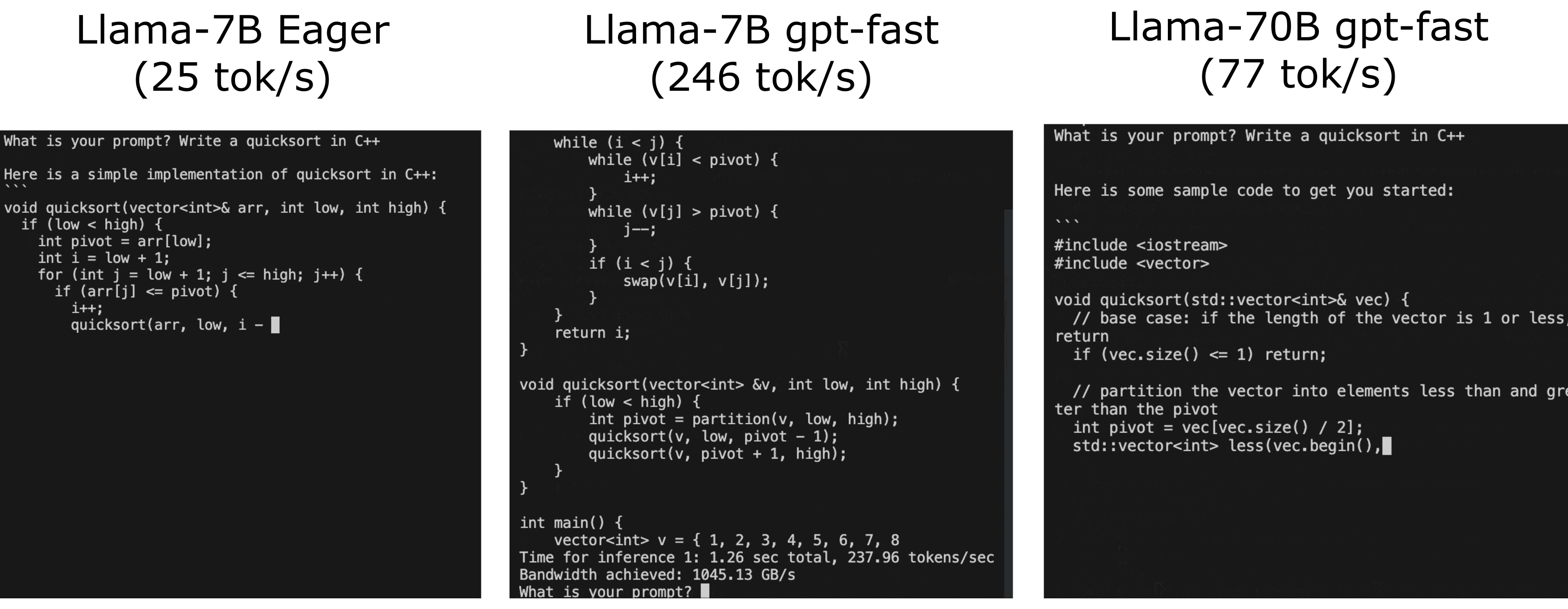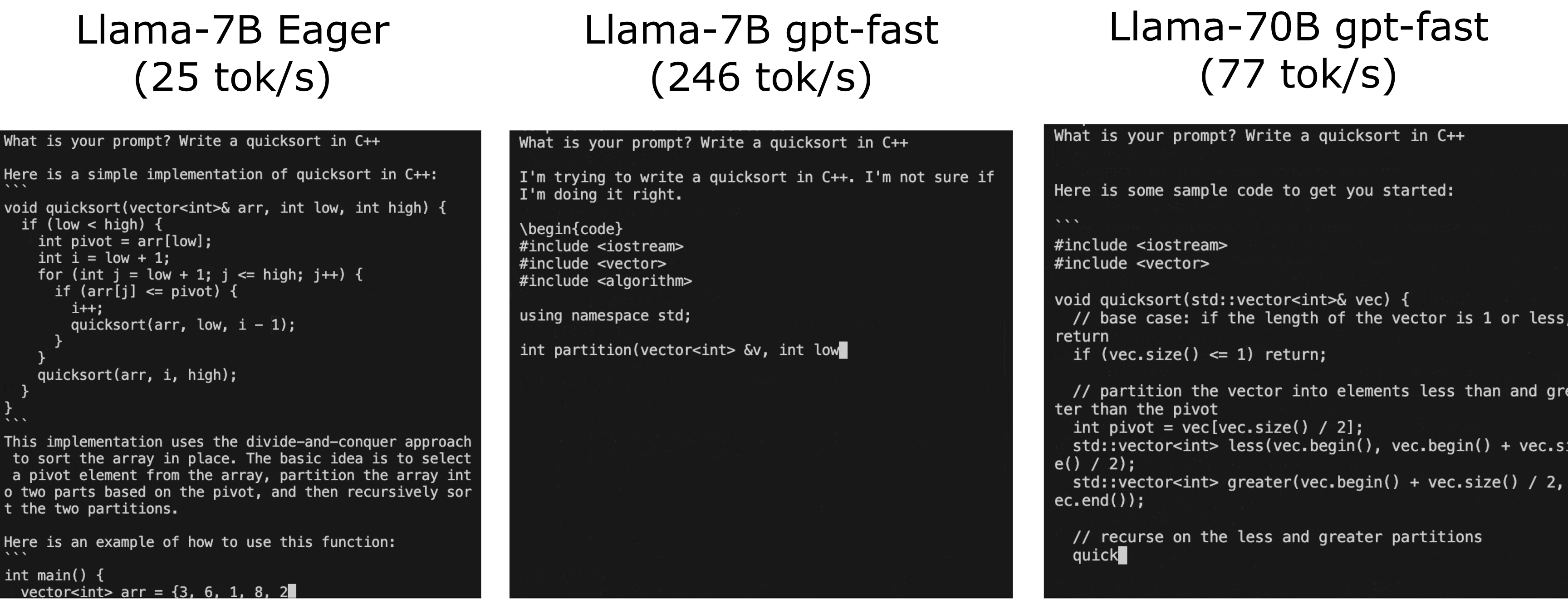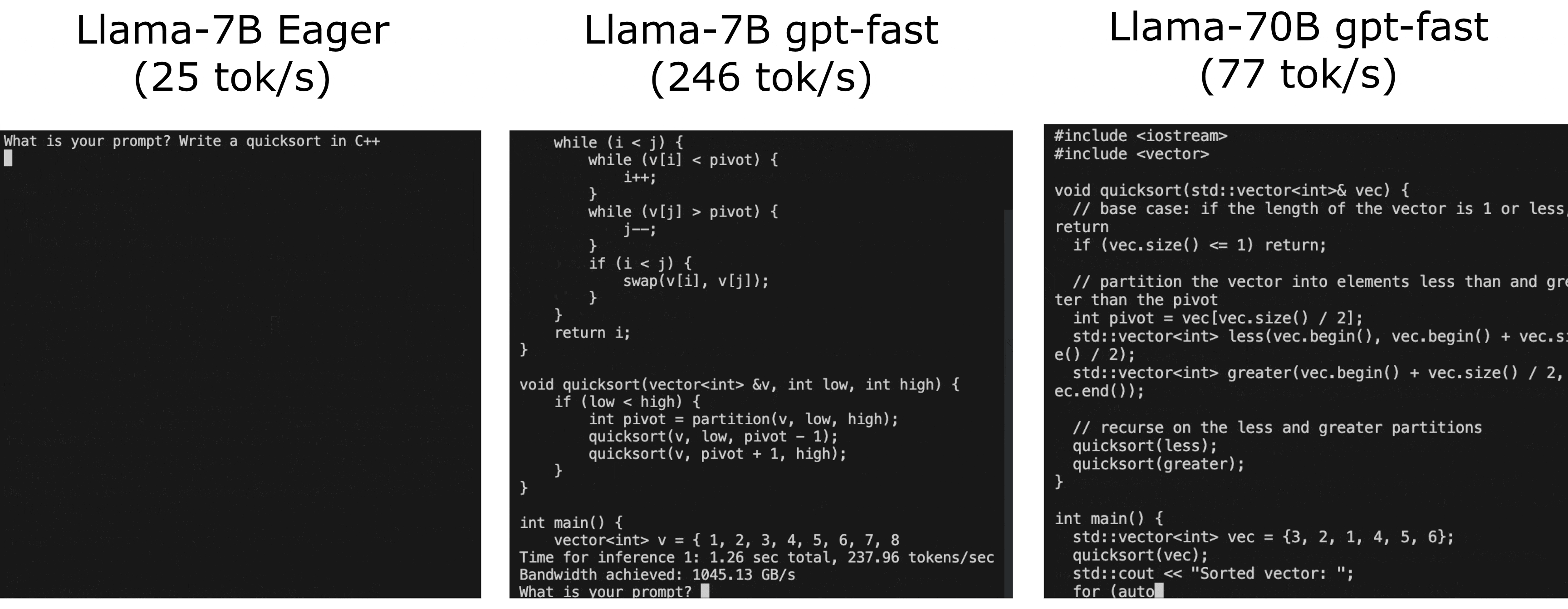
【2023-12-3】PyTorch 团队纯用 Pytorch写个推理框架 GPT-Fast ,极小推理框架,大约1000多行代码,号称性能最高提升10倍。
We leverage a breadth of optimizations including:
Torch.compile: A compiler for PyTorch modelsGPU quantization: Accelerate models with reduced precision operationsSpeculative Decoding: Accelerate LLMs using a small “draft” model to predict large “target” model’s outputTensor Parallelism: Accelerate models by running them across multiple devices.
做法简单:
-
做了个最简版的
kvcache(避免重复计算) +GPTQ量化(减少GPU显存通讯) +PyTorch-Compile(自动对pytorch python代码生成cuda相关的优化代码,可以控制区间,本质就是AI编译器啦) +Tensor Parallelism(多卡计算基本要求) +Speculative Sampling(特别适合打速度排名。。。。因为面对复杂任务这里是逆优化。。。) - Llama-7B Eager版推理速度 25 tokens/s, gpt-fast 版提升到 246 tokens/s
- Llama-70B 77 tokens/s
TensorRT-LLM
【2023-10-17】tensorrt-llm 支持主流大模型加速, github
- TensorRT-LLM 是 TensorRT 和 FastTransformer 的结合体,旨为大模型推理加速而生。
- 除了 FastTransformer 对Transformer做的attention优化、softmax优化、算子融合等方式之外,还引入了众多的大模型推理优化特性
- 支持很多主流大模型
- TensorRT两阶段的调用方式——build+run:
- build:通过配置参数将模型文件序列化为tensorRT的engine文件
- run:加载engine文件,传入数据,进行inference
llama.cpp
详见站内文章: llm_think
vLLM
vLLM(Vectorized Large Language Model Serving System)是加州大学伯克利分校团队推出的开源推理系统,旨在突破大模型部署中显存利用率低与推理吞吐量受限的双重挑战
Meta 前 PyTorch 团队推出 vLLM,最大特色“PagedAttention”。
两项核心机制:PagedAttention(分页注意力)与Continuous Batching(连续批处理),二者均受操作系统内存分页机制启发,重构了注意力计算与请求调度的底层逻辑,从而在不牺牲精度的前提下,大幅优化了显存管理效率与并发推理能力。
PagedAttention:受操作系统分页管理机制启发,将注意力机制中的键值缓存(KV Cache)以非连续方式部署于显存中。相较传统框架为每个请求强制分配连续显存块的模式,vLLM 将 KV Cache 拆分为固定尺寸的“页”,实现显存空间的动态调度与高效复用,从而彻底缓解了显存碎片化、预留冗余与并发容量受限三大核心痛点。该架构使显存利用率由传统方案的 60% 显著跃升至 95% 以上,显著增强系统对高并发请求的承载能力。
PagedAttention:KV 缓存被划分为块;块在内存空间中不需要连续
Continuous Batching:突破传统批量等待机制,支持新请求实时插入处理队列,实现GPU资源的零空闲运行。该机制显著降低高并发场景下的TTFT(首字出词时间),在Llama3.1-170B-FP8单H100环境下,TTFT低至123ms,优于TensorRT-LLM(194ms)与SGLang(340ms)。
多卡并行优化:全面兼容张量并行(Tensor Parallelism)与流水线并行(Pipeline Parallelism),依托NCCL/MPI等高性能通信框架,实现模型参数的精细化切分与高效同步,在降低显存占用的同时,显著增强整体吞吐能力。
量化优化支持:原生集成GPTQ、AWQ等先进量化算法,精准压缩模型参数规模,大幅提升GPU计算密度与推理效率,实现性能与资源消耗的最优平衡。
【2025-12-13】DeepSeek倒逼vLLM升级!芯片内卷、MoE横扫千模,vLLM核心维护者独家回应:如何凭PyTorch坐稳推理“铁王座”
2023 年, 加州大学伯克利分校 Sky Computing Lab 学生与研究员开源核心的 PagedAttention 技术,vLLM
短短一年多, GitHub Star 数突破 4 万,并迅速增长至如今的 6.5 万,如今已成为全球科技公司首选的推理引擎。
2024 年 11 月,红帽正式收购 Neural Magic,并将包括 vLLM 核心维护者 Michael Goin 在内的核心团队纳入旗下。
vLLM(Very Large Language Model)专为大语言模型(LLM)优化的高效推理框架
其核心:PagedAttention、动态批处理pd并行、多LoRA动态加载等
PagedAttention 本质是灵活管理 KV Cache(注意力缓存)的方式。
- 传统 transformer 推理时,每个 token 都带上历史上下文,缓存爆炸。
- vLLM 通过类似虚拟内存分页方式,优化性能。像会打麻将的高效服务员,记牌记得巨快
好处
- API 设计接近 OpenAI 标准接口,部署友好,尤其对做“OpenAI替代”的场景特别合适。
- 高并发时不掉链子,响应速度几乎线性增长。
前提:GPU A100 起步。
vllm 和 sglang
【2025-09-27】vllm:pd并行、多LoRA动态加载
vllm和sglang 部署分别:
- vLLM 在高并发和低延迟场景下表现优异,尤其擅长快速生成第一个词(TTFT低)。
- SGLang 在多轮对话这类前缀复用率高的场景中,吞吐量优势明显,测试显示其在Llama-7B上的吞吐量可比vLLM高5倍。
问题
【2025-2-4】vllm 不支持 embedding的lora功能!
It’s not supported yet according to the compatibility matrix. Let me update the supported models page to avoid this confusion. cc @jeejeelee
框架
核心架构是LLMEngine:包含调度器(Scheduler)和推理工作器(Worker)
- 调度器(Scheduler):
- 调度策略(policy):
- 请求的连续批处理(Continuous Batching)
- 请求队列维护:waiting(待处理)、running(正在处理)、swapped(因显存不足被挂起)
- 空间“调度指挥官”(BlockSpaceManager):负责逻辑资源规划与分配策略;
- 计算kv cache需要的块数量
- 判断是否需要为新token分配新的空间(如需则通知cacheengine)
- 内存共享:例如在并行采样时,多个输出序列可共享同一prompt的KV缓存块
- 调度策略(policy):
- 推理工作器(Worker):
- 模型运行:包括多GPU分布式计算(张量并行、流水线并行)
- 空间“后勤执行者”(CacheEngine):负责物理显存的具体操作与数据存取。
- 性能效果:
- 吞吐:提升高达24倍
- 耗时:提升1.2倍。
多 LoRA 动态加载
- 无延迟切换:单基础模型(如Llama 3-8B)同时挂载多个LoRA适配器(如聊天/函数调用),请求时通过lora_request参数指定,切换延迟低于1ms。
- 资源复用:基础模型参数仅加载一次,适配器共享显存,支持5+适配器并行服务。
与stable diffusion类似,vllm 也支持在请求调用时指定调用某个lora;但有两点差异:
- vllm中的lora是一开始全部就加载进模型的,(sd是请求时才加载)
- vllm中每次请求只能指定一个lora
# 同时加载两个适配器
vllm serve meta-llama/Meta-Llama-3-8B \
--enable-lora \
--lora-modules \
oasst=/path/to/oasst_adapter \ # 名称 oasst
xlam=/path/to/xlam_adapter # 名称 xlam
PagedAttention 动态分页机制
分页注意力机制(PagedAttention)是什么?
- 分页注意力机制借鉴了计算机操作系统中的内存分页管理,通过动态分配和复用显存空间,显著提升大模型推理的效率和吞吐量。
传统大模型推理中,注意力机制(Transformer的自注意力层)为每个请求序列分配连续的显存块,存储以下数据:
- (1)键值缓存(Key-Value Cache,KV Cache):存储历史token的键值对,用于生成后续token。
- (2)中间激活值:计算注意力权重时的中间结果。
vLLM基于PyTorch构建,创新性地引入了PagedAttention技术。借鉴操作系统的虚拟内存分页机制,将注意力键值对(KV Cache)存储在非连续显存空间,显著提高了显存利用率。
PagedAttention 通过分块管理显存、动态按需分配和跨请求共享内存,解决了传统方法中显存碎片化、预留浪费和并发限制三大瓶颈。
特点
- 分块管理KV缓存:将注意力键值(Key-Value Cache)划分为固定大小的块(如4-16 tokens/块),按需动态分配GPU显存,避免传统连续分配导致的碎片问题。
- 显存复用与共享:短序列推理时仅占用必要块,释放空间供其他请求使用;支持跨请求的缓存共享(如相同前缀提示词),显存利用率提升最高达25%。
- 写时复制(Copy-on-Write):共享块标记为只读,修改时创建新副本,减少重复计算
vllm 部署方式
vllm 两种模型部署方式:
- 在线服务形式(Online Serving)
- 在线服务是通过指令来启动一个vllm服务,将模型以服务的形式完成部署,之后可以通过openai格式的api来访问模型
- 离线推理形式 (Offline Inference)
- 离线推理的形式是通过类的方式初始化一个模型,之后传入提示词即可访问模型
vllm 使用
# pip install vllm # 安装vLLM
# 示例代码:生成文本
from vllm import LLM, SamplingParams
prompts = ["什么是vLLM?", "vLLM的优势是什么?"]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="meta-llama/Llama-2-7b-chat-hf") # 可限制最大并发:max_num_seqs=2,使用FP16:dtype="float16"
outputs = llm.generate(prompts, sampling_params) # 批量推理
for output in outputs:
print(f"输入:{output.prompt}\n输出:{output.outputs[0].text}\n"2
服务开启和各参数作用
vllm 服务启动指令如下
vllm serve deepseek-ai/deepseek-vl2-tiny \
--hf_overrides '{"architectures": ["DeepseekVLV2ForCausalLM"]}' \
--dtype float16 --trust_remote_code \
--host 0.0.0.0 --port 8080 \
--chat_template template_deepseek_vl2.jinja \
--gpu-memory-utilization 0.7 \
--limit-mm-per-prompt "image=8"
详见地址
bert 模型
除了生成式任务,但分类任务同样可以通过指定合适的任务类型实现。
【2025-5-1】vLLM项目中部署BERT
关键启动参数包括:
python -m vllm.entrypoints.api_server \
--model path/to/bert_model \
--tensor-parallel-size 1 \
--dtype float16 \
--max-model-len 512 \
--served-model-name bert-cls
注意:
- 最大序列长度应设置为BERT标准配置(通常512)
- 半精度(float16)可显著提升推理速度
- 服务名称用于后续API调用标识
分类任务可以采用以下调用方式:
import openai
client = openai.Client(base_url="http://localhost:8000/v1")
response = client.completions.create(
model="bert-cls",
prompt="这是一条需要分类的文本",
max_tokens=1, # 分类任务通常只需要1个token输出
temperature=0 # 确保确定性输出
)
性能优化建议
- 批处理优化:通过增大
--max-batch-size参数提高吞吐量 - 量化部署:尝试使用
--quantization bitsandbytes进行8bit量化 - 请求合并:客户端实现请求队列合并,减少小包传输
- 监控集成:添加Prometheus监控指标采集
vLLM 分布式
【2025-09-07】利用 vLLM 进行 rollout
vLLM 允许设置 PP 和 DP
llm = LLM(
model=str(model_dir),
dtype='bfloat16',
gpu_memory_utilization=0.4,
tensor_parallel_size=2,
pipeline_parallel_size = 2,
data_parallel_size = 2
)
TP 和 PP 很好理解,而DP 的意思应该是,例如你有4张卡,设置 TP = 2 , PP = 1 ,此时 vLLM 内部会启动“两份模型”, 进行并行的数据处理
vLLM 源码解析
【2024-4-12】图解大模型计算加速系列:vLLM源码解析2,调度器策略(Scheduler)
- 一、入口函数
- 二、SequenceGroup
- 2.1 原生请求输入
- 2.2 SequenceGroup的作用
- 2.3 SequenceGroup的结构
- 三、add_request: 预处理请求
- 四、step:调度器策略
- 4.1 调度器结构
- 4.2 整体调度流程
- 4.3 _passed_delay:waiting队列调度时间阈值判断
- 4.4 can_allocate:能否为seq_group分配物理块(prefill)
- 4.5 can_append_slot: 能否为seq_group分配物理块(decode)
- 4.6 allocate与append_slot:为seq_group实际分配物理块
- 4.7 preempt:抢占策略
- 4.8 调度器整体代码解读
案例
‘qwen-vllm - 通义千问VLLM推理部署DEMO’
- GitHub: qwen-vllm
SGLang
vLLM 虽好,但难以自定义推理逻辑,比如控制 prompt 动态拼接、多轮上下文窗口滚动、token 前缀约束,操作麻烦。
vLLM 设计思想:“底层最优”,更适合请求独立、按 token 走流水线的场景。
SGLang 是伯克利团队打造的另一款大模型推理引擎,致力于优化 LLM 的吞吐性能与响应时延,同时降低编程复杂度。
核心机制: RadixAttention,借助精细化的缓存策略与结构化输出增强,有效支撑高并发服务需求。
SGLang 核心突破: 集成了RadixAttention技术与结构化输出机制
- RadixAttention:通过基数树(Radix Tree)对KV缓存的公共前缀进行高效复用,结合LRU驱逐策略与引用计数机制,显著提升缓存利用率。不同于传统框架在推理结束后即丢弃缓存,SGLang持久化保留提示与生成内容的KV状态于基数树结构中,从而支持快速的前缀匹配、缓存复用、动态插入与智能驱逐。该设计极大增强了系统在多轮交互与序列规划场景下的性能,实测表明,在Llama-7B模型上执行多轮对话任务时,其吞吐量较vLLM提升达5倍。
SkyWork 团队推出 SGLang,最开始为了服务 InternLM 这种国产大模型开发的,但最近社区动静很大。
SGLang 更像“推理框架+推理DSL(领域特定语言)”结合体。鼓励用“Python+模板语言”写法描述推理逻辑,if else 控制输出、循环生成、模板格式化、系统指令,都能 prompt 模板里直接操作
SGLang 把“prompt +推理流程”统一封装成“程序单元”,像写代码那样写推理逻辑,还能自动在多个用户、多个请求之间搞调度优化。
SGLang 是 LMSYS Org 团队于2024年1月推出的 LLM 和 VLM 的通用服务引擎,且完全开源,采用 Apache 2.0 许可授权。
- 纯 Python 编写,核心调度器只用了不到 4K 行代码就实现了
- 已被 LMSYS Chatbot Arena 用于支持部分模型、Databricks、几家初创公司和研究机构,产生了数万亿 token,实现了更快的迭代。
- Paper:SGLang: Efficient Execution of Structured Language Model Programs
- Code:sglang
SGLang 技术结构解析:
- RadixAttention
- Upper-level Scheduling
最新的 SGLang Runtime v0.2 性能更加惊艳。
- 运行 Llama 3.1 405B 时,吞吐量和延迟表现都优于 vLLM 和 TensorRT-LLM,甚至能达到 TensorRT-LLM 的 2.1 倍,vLLm 的 3.8 倍。
- 目前已在 GitHub 上已经收获了超过 4.7k 的 star 量
Lepton AI 联合创始人兼 CEO 贾扬清都评价说:
我一直被我的博士母校加州大学伯克利分校惊艳,因为它不断交付最先进的人工智能和系统协同设计成果。
参考:参考
TensorRT-LLM
TensorRT-LLM 是 NVIDIA 基于 TensorRT 构建的高性能推理引擎,专为大语言模型优化,致力于全面释放 NVIDIA GPU 的算力优势。
核心技术包括:
- 预编译优化:借助TensorRT的端到端优化框架,对模型执行离线编译,生成高度精炼的TensorRT引擎文件。尽管该过程引入一定的冷启动开销,却能大幅增强推理效率与系统吞吐能力。
- 量化支持:兼容FP8、FP4与INT4等多种低精度量化策略,通过精度压缩有效降低显存消耗并加速推理流程。在FP8模式下,TensorRT-LLM可维持近似原生精度的输出质量,同时显存需求下降超40%。
- 内核级优化:对Transformer结构中的核心组件(如自注意力机制、前馈神经网络等)实施底层CUDA内核重构,实现计算密集型操作的极致并行与内存访问优化,从而在NVIDIA GPU平台达成卓越性能表现。
- 张量并行与流水线并行:支持跨多GPU节点的分布式推理,融合张量并行与流水线并行策略,灵活扩展模型参数规模,显著提升单位时间内的请求处理容量。
适用场景与优势局限
适用场景:TensorRT-LLM特别适合对延迟要求极高的企业级应用,如实时客服系统、金融高频交易和需要快速响应的API服务。
Ollama
Ollama是由AI社区开发的轻量级本地推理平台,专注于简化大模型本地部署和运行,特别适合个人开发者和研究者。
Ollama 核心技术特点包括:
- 基于Go语言的封装:Ollama采用Go语言构建,通过模块化架构将模型权重、运行依赖与环境配置统一打包为容器化单元,用户无需配置底层组件,仅需执行单条命令即可启动模型服务。
- llama.cpp集成:Ollama内嵌llama.cpp——这一高效的大语言模型推理引擎,兼容1.5位、2位、3位、4位、5位、6位与8位整数量化方案,实现轻量级推理性能优化。
- 跨平台支持:原生适配macOS、Windows与Linux三大操作系统,对ARM架构设备高度优化,尤其在苹果M系列芯片上表现优异。
- 本地化部署:支持无网络依赖的完全离线运行,全面保障数据不外泄、隐私不泄露,适用于对安全性要求严苛的私有化场景。
- 低硬件门槛:不依赖高性能GPU,可在消费级笔记本、嵌入式终端及边缘计算节点上流畅运行,显著降低大模型落地的硬件成本。
适用场景与优势局限
- 适用场景:Ollama特别适合个人开发者、教育展示和本地隐私要求高的场景,如个人知识库、教育演示和原型验证等。
XInference
XInference:分离式部署的分布式推理框架
XInference 是一个高性能的分布式推理框架,专注于简化AI模型的运行和集成,特别适合企业级大规模部署。
XInference的核心架构:
- API层:采用FastAPI搭建,兼容RESTful规范与OpenAI接口标准,无缝对接现有系统生态。
- Core Service层:依托自研Xoscar框架,高效抽象分布式调度与通信逻辑,原生支持多GPU并行及Kubernetes集群弹性伸缩。
- Actor层:由ModelActor实例构成,承担模型加载与推理执行职责,各实例部署于ActorPool内,实现独立调度与自治管理。
- 分离式部署:将Prefill与Decode阶段分别映射至不同GPU,借助DeepEP通信库实现KVCache低延迟传输,显著增强硬件资源协同效率。
- 算子优化:在Actor层集成FlashMLA与DeepGEMM算子,全面适配海光DCU与NVIDIA Hopper GPU架构,最大化算力吞吐能力。
- 连续批处理:融合vLLM连续批处理机制,动态聚合请求流,优化调度策略,持续提升GPU使用率与吞吐性能。
适用场景与优势局限
- 适用场景:XInference特别适合企业级大规模部署,如智能客服系统、知识库问答和需要分布式扩展的场景。
LightLLM
LightLLM:轻量级高性能推理框架
LightLLM是一个基于Python的LLM推理和服务框架,以轻量级设计、易于扩展和高速性能而闻名。
LightLLM的核心技术包括:
- 三进程异步协作:由独立进程分别承担 tokenization、模型推理与 detokenization 任务,达成异步运行,有效缓解 I/O 瓶颈。
- 动态批处理:依据请求特征与系统负载实时优化批处理策略,在吞吐量与延迟之间实现精准平衡。
- TokenAttention 机制:采用以 token 为粒度的 KV 缓存管理方案,彻底消除内存冗余,兼容 int8 KV Cache,使最大 token 吞吐能力提升近 2 倍。
- 零填充 (nopad-Attention):精准适配输入序列长度的显著差异,规避传统填充策略导致的计算资源冗余。
- FlashAttention 集成:大幅加速注意力运算效率,同步削减 GPU 显存消耗。
- 张量并行技术:协同多 GPU 实现张量级并行计算,显著加快超大规模模型的推理响应速度。
适用场景与优势局限
- 适用场景:LightLLM特别适合需要高吞吐量的场景,如大规模语言模型API服务、多模态模型在线推理和高并发聊天机器人后端等。
昇腾
国产硬件适配框架:昇腾与LMDeploy
针对昇腾等国产硬件的推理框架也日益成熟。昇腾AI处理器和LMDeploy是国产硬件适配的代表。
昇腾AI处理器框架
昇腾AI处理器是华为依托自研达芬奇架构打造的专用AI加速芯片,其推理体系核心包含以下三大组件:
- MindSpore Inference:华为自研的推理引擎,深度适配昇腾达芬奇架构,实现整图下沉至芯片的On-Device执行,融合关键算子(如矩阵乘法与激活函数),并依托静态图优化策略,显著增强推理效率。
- CBQ量化技术:由华为诺亚方舟实验室与中国科学技术大学协同研发的跨块重建后训练量化方案,仅需0.1%的原始训练数据,即可一键将大模型压缩至原体积的1/7,同时保持浮点精度达99%,真正达成“轻量不降智”的目标。
- 昇腾CANN软件栈:构建多层次开发接口体系,通过AscendCL与TBE两大编程接口,赋能各类AI应用在CANN平台上的高效部署与极速运行。
LMDeploy
LMDeploy:视觉语言混合任务专家
LMDeploy是由上海人工智能实验室模型压缩和部署团队开发的部署工具箱,专注于大语言模型和视觉语言模型的部署。
核心技术:
- 国产GPU深度适配,深度优化昇腾等国产硬件架构
- 显存优化,采用动态量化与模型切分技术,显著压缩显存占用
- 多模态融合支持,协同处理视觉与语言跨模态数据流
- TurboMind引擎,实现高效4bit推理的CUDA kernel加速
适用场景:
- 国内企业、政府机构部署,视觉语言混合任务。
MLC-LLM
LLM 推理框架
参考
- 【2023-9-21】大语言模型推理性能优化综述
- 【2024-3-30】图解大模型计算加速系列之:vLLM核心技术PagedAttention原理
LLM 推理过程分两个阶段: prefill 和 decode, 通常用 KV cache 技术加速推理
PagedAttention的设计灵感来自操作系统的虚拟内存分页管理技术
总结
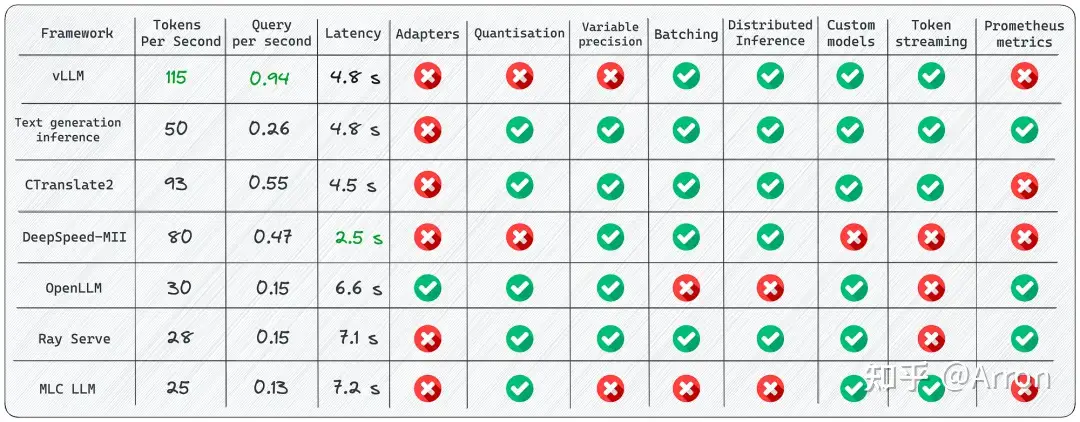
40GB A100 GPU 上,用 LLaMA-1 13b 模型进行7个部署框架的对比
LLM推理有很多框架,各有其特点,七个框架的关键点:
- [1]
vLLM:适用于大批量Prompt输入,并对推理速度要求高的场景;vLLM吞吐量比HuggingFace Transformers(HF)高14x-24倍,比 HuggingFace Text Generation Inference(TGI)高2.2x-2.5倍。
- [2]
Text generation inference:依赖HuggingFace模型,并且不需要为核心模型增加多个adapter的场景; - [3]
CTranslate2:可在CPU上进行推理; - [4]
OpenLLM:为核心模型添加adapter并使用HuggingFace Agents,尤其是不完全依赖PyTorch; - [5]
Ray Serve:稳定的Pipeline和灵活的部署,它最适合更成熟的项目;Ray Serve是一个可扩展的模型服务库,用于构建在线推理API。Serve与框架无关,因此可以使用一个工具包来为深度学习模型的所有内容提供服务。
- [6]
MLC LLM:可在客户端(边缘计算)(例如,在Android或iPhone平台上)本地部署LLM;- LLM的机器学习编译(MLC LLM)是一种通用的部署解决方案,它使LLM能够利用本机硬件加速在消费者设备上高效运行
- [7]
DeepSpeed-MII:使用DeepSpeed库来部署LLM;
一、vLLM
2023年6月,加州大学伯克利分校等机构开源了 vLLM(目前已有 6700 多个 star),其使用了一种新设计的注意力算法 PagedAttention,可让服务提供商轻松、快速且低成本地发布 LLM 服务。
【2023-9-25】vLLM出论文,让每个人都能快速低成本地部署LLM服务

vLLM 吞吐量比 HuggingFace Transformers(HF)高14x-24倍,比HuggingFace Text Generation Inference(TGI)高2.2x-2.5倍。
离线批量推理
# pip install vllm
from vllm import LLM, SamplingParams
prompts = [
"Funniest joke ever:",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.95, top_p=0.95, max_tokens=200)
llm = LLM(model="huggyllama/llama-13b")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
API Server
# Start the server:
python -m vllm.entrypoints.api_server --env MODEL_NAME=huggyllama/llama-13b
# Query the model in shell:
curl http://localhost:8000/generate \
-d '{
"prompt": "Funniest joke ever:",
"n": 1,
"temperature": 0.95,
"max_tokens": 200
}'
功能:
- Continuous batching:有iteration-level的调度机制,每次迭代batch大小都有所变化,因此vLLM在大量查询下仍可以很好的工作。
- PagedAttention:受操作系统中虚拟内存和分页的经典思想启发的注意力算法,这就是模型加速的秘诀。
优点:
- 文本生成的速度:实验多次,发现vLLM的推理速度是最快的;
- 高吞吐量服务:支持各种解码算法,比如parallel sampling, beam search等;
- 与OpenAI API兼容:如果使用OpenAI API,只需要替换端点的URL即可;
缺点:
- 添加自定义模型:虽然可以合并自己的模型,但如果模型没有使用与vLLM中现有模型类似的架构,则过程会变得更加复杂。例如,增加Falcon的支持,这似乎很有挑战性;
- 缺乏对适配器(LoRA、QLoRA等)的支持:当针对特定任务进行微调时,开源LLM具有重要价值。然而,在当前的实现中,没有单独使用模型和适配器权重的选项,这限制了有效利用此类模型的灵活性。
- 缺少权重量化:有时,LLM可能不需要使用GPU内存,这对于减少GPU内存消耗至关重要。
这是LLM推理最快的库。得益于其内部优化,它显著优于竞争对手。尽管如此,它在支持有限范围的模型方面确实存在弱点。
使用vLLM开发路线可以参考:https://github.com/vllm-project/vllm/issues/244**
二、Text generation inference

Text generation inference是用于文本生成推断的Rust、Python和gRPC服务器,在HuggingFace中已有LLM 推理API使用。
使用docker运行web server
mkdir data
docker run --gpus all --shm-size 1g -p 8080:80 \
-v data:/data ghcr.io/huggingface/text-generation-inference:0.9 \
--model-id huggyllama/llama-13b \
--num-shard 1
查询实例
# pip install text-generation
from text_generation import Client
client = Client("http://127.0.0.1:8080")
prompt = "Funniest joke ever:"
print(client.generate(prompt, max_new_tokens=17 temperature=0.95).generated_text)
功能:
- 内置服务评估:可以监控服务器负载并深入了解其性能;
- 使用flash attention(和v2)和Paged attention优化transformer推理代码:并非所有模型都内置了对这些优化的支持,该技术可以对未使用该技术的模型可以进行优化;
优点:
- 所有的依赖项都安装在Docker中:会得到一个现成的环境;
- 支持HuggingFace模型:轻松运行自己的模型或使用任何HuggingFace模型中心;
- 对模型推理的控制:该框架提供了一系列管理模型推理的选项,包括精度调整、量化、张量并行性、重复惩罚等;
缺点:
- 缺乏对适配器的支持:需要注意的是,尽管可以使用适配器部署LLM(可以参考https://www.youtube.com/watch?v=HI3cYN0c9ZU),但目前还没有官方支持或文档;
- 从源代码(Rust+CUDA内核)编译:对于不熟悉Rust的人,将客户化代码纳入库中变得很有挑战性;
- 文档不完整:所有信息都可以在项目的自述文件中找到。尽管它涵盖了基础知识,但必须在问题或源代码中搜索更多细节;
使用Text generation inference的开发路线可以参考
三、CTranslate2

CTranslate2是一个C++和Python库,用于使用Transformer模型进行高效推理。
转换模型
pip install -qqq transformers ctranslate2
# The model should be first converted into the CTranslate2 model format:
ct2-transformers-converter --model huggyllama/llama-13b --output_dir llama-13b-ct2 --force
查询实例
import ctranslate2
import transformers
generator = ctranslate2.Generator("llama-13b-ct2", device="cuda", compute_type="float16")
tokenizer = transformers.AutoTokenizer.from_pretrained("huggyllama/llama-13b")
prompt = "Funniest joke ever:"
tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt))
results = generator.generate_batch(
[tokens],
sampling_topk=1,
max_length=200,
)
tokens = results[0].sequences_ids[0]
output = tokenizer.decode(tokens)
print(output)
功能:
- 在CPU和GPU上快速高效地执行:得益于内置的一系列优化:层融合、填充去除、批量重新排序、原位操作、缓存机制等。推理LLM更快,所需内存更少;
- 动态内存使用率:由于CPU和GPU上都有缓存分配器,内存使用率根据请求大小动态变化,同时仍能满足性能要求;
- 支持多种CPU体系结构:该项目支持x86–64和AArch64/ARM64处理器,并集成了针对这些平台优化的多个后端:英特尔MKL、oneDNN、OpenBLAS、Ruy和Apple Accelerate;
优点:
- 并行和异步执行--可以使用多个GPU或CPU核心并行和异步处理多个批处理;
- Prompt缓存——在静态提示下运行一次模型,缓存模型状态,并在将来使用相同的静态提示进行调用时重用;
- 磁盘上的轻量级--量化可以使模型在磁盘上缩小4倍,而精度损失最小;
缺点:
- 没有内置的REST服务器——尽管仍然可以运行REST服务器,但没有具有日志记录和监控功能的现成服务
- 缺乏对适配器(LoRA、QLoRA等)的支持
四、DeepSpeed-MII

在DeepSpeed支持下,DeepSpeed-MII可以进行低延迟和高通量推理。
运行web服务
# DON'T INSTALL USING pip install deepspeed-mii
# git clone https://github.com/microsoft/DeepSpeed-MII.git
# git reset --hard 60a85dc3da5bac3bcefa8824175f8646a0f12203
# cd DeepSpeed-MII && pip install .
# pip3 install -U deepspeed
# ... and make sure that you have same CUDA versions:
# python -c "import torch;print(torch.version.cuda)" == nvcc --version
import mii
mii_configs = {
"dtype": "fp16",
'max_tokens': 200,
'tensor_parallel': 1,
"enable_load_balancing": False
}
mii.deploy(task="text-generation",
model="huggyllama/llama-13b",
deployment_name="llama_13b_deployment",
mii_config=mii_configs)
查询实例
import mii
generator = mii.mii_query_handle("llama_13b_deployment")
result = generator.query(
{"query": ["Funniest joke ever:"]},
do_sample=True,
max_new_tokens=200
)
print(result)
功能:
- 多个副本上的负载平衡:这是一个非常有用的工具,可用于处理大量用户。负载均衡器在各种副本之间高效地分配传入请求,从而缩短了应用程序的响应时间。
- 非持久部署:目标环境的部署不是永久的,需要经常更新的,这在资源效率、安全性、一致性和易管理性至关重要的情况下,这是非常重要的。
优点:
- 支持不同的模型库:支持多个开源模型库,如Hugging Face、FairSeq、EluetherAI等;
- 量化延迟和降低成本:可以显著降低非常昂贵的语言模型的推理成本;
- Native和Azure集成:微软开发的MII框架提供了与云系统的出色集成;
缺点:
- 支持模型的数量有限:不支持Falcon、LLaMA2和其他语言模型;
- 缺乏对适配器(LoRA、QLoRA等)的支持;
五、OpenLLM

OpenLLM是一个用于在生产中操作大型语言模型(LLM)的开放平台。
运行web服务
pip install openllm scipy
openllm start llama --model-id huggyllama/llama-13b \
--max-new-tokens 200 \
--temperature 0.95 \
--api-workers 1 \
--workers-per-resource 1
查询实例
import openllm
client = openllm.client.HTTPClient('http://localhost:3000')
print(client.query("Funniest joke ever:"))
功能:
- 适配器支持:可以将要部署的LLM连接多个适配器,这样可以只使用一个模型来执行几个特定的任务;
- 支持不同的运行框架:比如Pytorch(pt)、Tensorflow(tf)或Flax(亚麻);
- HuggingFace Agents[11]:连接HuggingFace上不同的模型,并使用LLM和自然语言进行管理;
优点:
- 良好的社区支持:不断开发和添加新功能;
- 集成新模型:可以添加用户自定义模型;
- 量化:OpenLLM支持使用bitsandbytes[12]和GPTQ[13]进行量化;
- LangChain集成:可以使用LangChian与远程OpenLLM服务器进行交互;
缺点:
- 缺乏批处理支持:对于大量查询,这很可能会成为应用程序性能的瓶颈;
- 缺乏内置的分布式推理——如果你想在多个GPU设备上运行大型模型,你需要额外安装OpenLLM的服务组件Yatai[14];
六、Ray Serve

Ray Serve是一个可扩展的模型服务库,用于构建在线推理API。Serve与框架无关,因此可以使用一个工具包来为深度学习模型的所有内容提供服务。
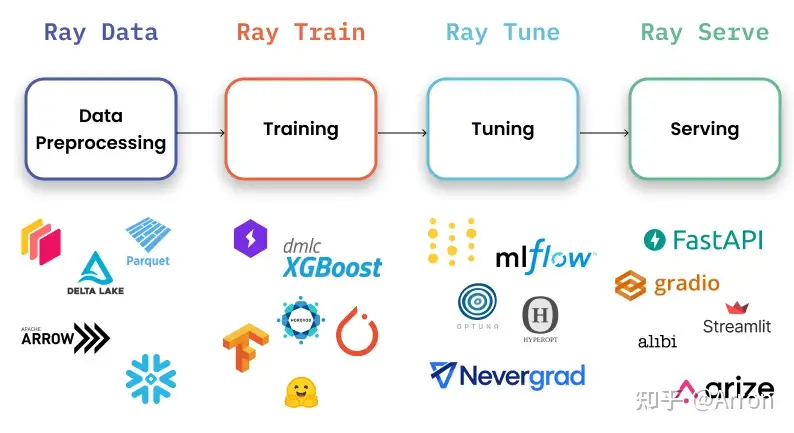
运行web服务
# pip install ray[serve] accelerate>=0.16.0 transformers>=4.26.0 torch starlette pandas
# ray_serve.py
import pandas as pd
import ray
from ray import serve
from starlette.requests import Request
@serve.deployment(ray_actor_options={"num_gpus": 1})
class PredictDeployment:
def __init__(self, model_id: str):
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
self.model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
def generate(self, text: str) -> pd.DataFrame:
input_ids = self.tokenizer(text, return_tensors="pt").input_ids.to(
self.model.device
)
gen_tokens = self.model.generate(
input_ids,
temperature=0.9,
max_length=200,
)
return pd.DataFrame(
self.tokenizer.batch_decode(gen_tokens), columns=["responses"]
)
async def __call__(self, http_request: Request) -> str:
json_request: str = await http_request.json()
return self.generate(prompt["text"])
deployment = PredictDeployment.bind(model_id="huggyllama/llama-13b")
# then run from CLI command:
# serve run ray_serve:deployment
查询实例
import requests
sample_input = {"text": "Funniest joke ever:"}
output = requests.post("http://localhost:8000/", json=[sample_input]).json()
print(output)
功能:
- 监控仪表板和Prometheus度量:可以使用Ray仪表板来获得Ray集群和Ray Serve应用程序状态;
- 跨多个副本自动缩放:Ray通过观察队列大小并做出添加或删除副本的缩放决策来调整流量峰值;
- 动态请求批处理:当模型使用成本很高,为最大限度地利用硬件,可以采用该策略;
优点:
- 文档支持:开发人员几乎为每个用例撰写了许多示例;
- 支持生产环境部署:这是本列表中所有框架中最成熟的;
- 本地LangChain集成:您可以使用LangChian与远程Ray Server进行交互;
缺点:
- 缺乏内置的模型优化:Ray Serve不专注于LLM,它是一个用于部署任何ML模型的更广泛的框架,必须自己进行优化;
- 入门门槛高:该库功能多,提高了初学者进入的门槛;
如果需要最适合生产的解决方案,而不仅仅是深度学习,Ray Serve是一个不错的选择。它最适合于可用性、可扩展性和可观察性非常重要的企业。此外,还可以使用其庞大的生态系统进行数据处理、模型训练、微调和服务。最后,从OpenAI到Shopify和Instacart等公司都在使用它。
七、MLC LLM

LLM的机器学习编译(MLC LLM)是一种通用的部署解决方案,它使LLM能够利用本机硬件加速在消费者设备上高效运行。
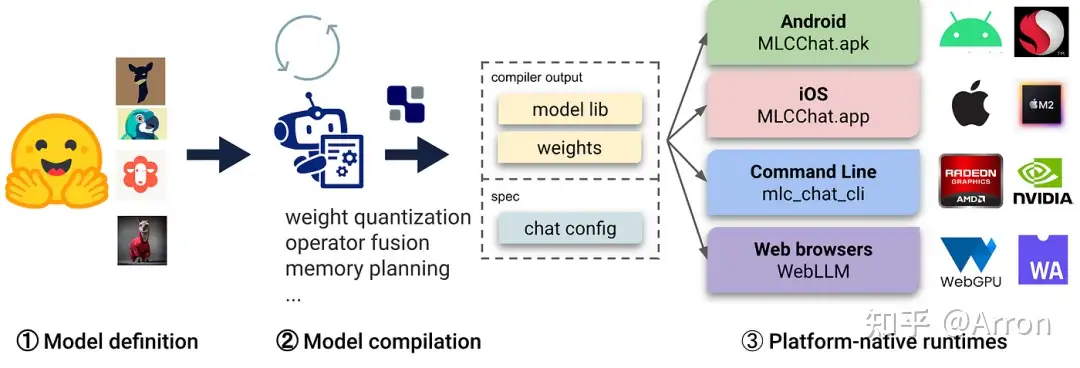
运行web服务
# 1. Make sure that you have python >= 3.9
# 2. You have to run it using conda:
conda create -n mlc-chat-venv -c mlc-ai -c conda-forge mlc-chat-nightly
conda activate mlc-chat-venv
# 3. Then install package:
pip install --pre --force-reinstall mlc-ai-nightly-cu118 \
mlc-chat-nightly-cu118 \
-f https://mlc.ai/wheels
# 4. Download the model weights from HuggingFace and binary libraries:
git lfs install && mkdir -p dist/prebuilt && \
git clone https://github.com/mlc-ai/binary-mlc-llm-libs.git dist/prebuilt/lib && \
cd dist/prebuilt && \
git clone https://huggingface.co/huggyllama/llama-13b dist/ && \
cd ../..
# 5. Run server:
python -m mlc_chat.rest --device-name cuda --artifact-path dist
查询实例
import requests
payload = {
"model": "lama-30b",
"messages": [{"role": "user", "content": "Funniest joke ever:"}],
"stream": False
}
r = requests.post("http://127.0.0.1:8000/v1/chat/completions", json=payload)
print(r.json()['choices'][0]['message']['content'])
功能:
- 平台本机运行时:可以部署在用户设备的本机环境上,这些设备可能没有现成的Python或其他必要的依赖项。应用程序开发人员只需要将MLC编译的LLM集成到他们的项目中即可;
- 内存优化:可以使用不同的技术编译、压缩和优化模型,从而可以部署在不同的设备上;
优点:
- 所有设置均可在JSON配置中完成:在单个配置文件中定义每个编译模型的运行时配置;
- 预置应用程序:可以为不同的平台编译模型,比如C++用于命令行,JavaScript用于web,Swift用于iOS,Java/Kotlin用于Android;
缺点:
- 使用LLM模型的功能有限:不支持适配器,无法更改精度等,该库主要用于编译不同设备的模型;
- 只支持分组量化[15]:这种方法表现良好,但是在社区中更受欢迎的其他量化方法(bitsandbytes和GPTQ)不支持;
- 复杂的安装:安装需要花几个小时,不太适合初学者开发人员;
如果需要在iOS或Android设备上部署应用程序,这个库正是你所需要的。它将允许您快速地以本机方式编译模型并将其部署到设备上。但是,如果需要一个高负载的服务器,不建议选择这个框架。
MLC LLM – 陈天奇
- 【2023-5-2】陈天奇等人新作引爆AI界:手机原生跑大模型,算力不是问题了
- 【2023-6-5】陈天奇官宣新APP,让手机原生跑大模型,应用商店直接下载使用, 陈天奇公布了一个好消息:MLC Chat app 已经在苹果的 App Store 上线了。
【2023-5-2】端侧语言大模型部署时代已经悄悄到来!
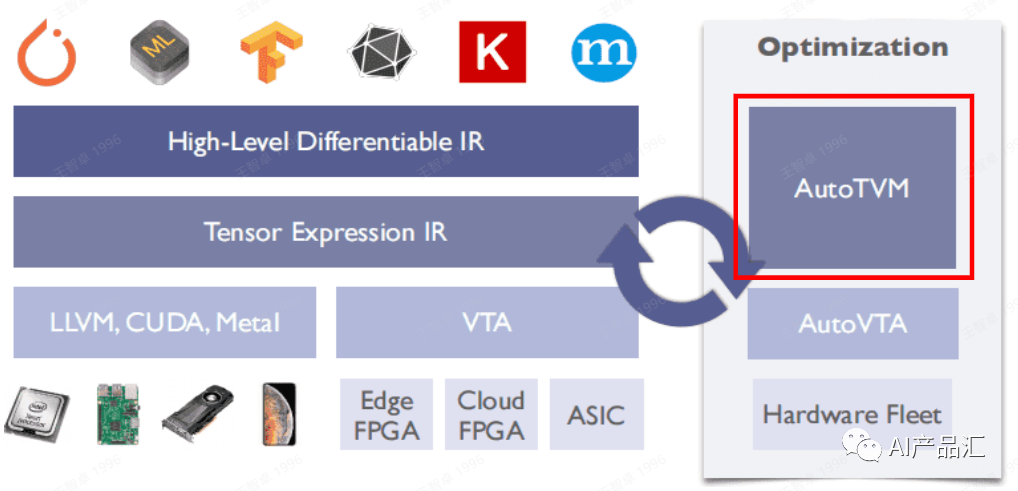
TVM 简介
TVM是一个深度学习编译器,初衷是让各种训练框架训练好的模型能够在不同硬件平台上面快速推理
- 支持Pytorch、AutoML、Tensorflow、Onnx、Kersa、Mxnet等多种前端训练框架;
- 支持ARM CPU、Intel CPU、NVIDIA显卡、FPGA、ASIC等多种硬件设备。
MLC-LLM 底层技术其实就是TVM编译器。
该框架的输入是一些训练框架训练好的模型文件;
- 然后, 利用Relay将其转换成 High-Level Differentiable IR,该阶段会执行一些图优化操作,包括:算子融合、常量折叠、内存重排、模型量化等;
- 接着会利用AutoTVM、Ansor或者Meta Scheduler等自动化优化技术来将这种IR转换为Tensor Expression IR这种更低级的IR表示。
TVM深度学习编译器中的一个亮点工作就是自动优化技术
- 第一代优化技术叫
AutoTVM - 第二代叫
Ansor或者Auto Scheduler - 第三代叫
Meta Scheduler
AutoTVM
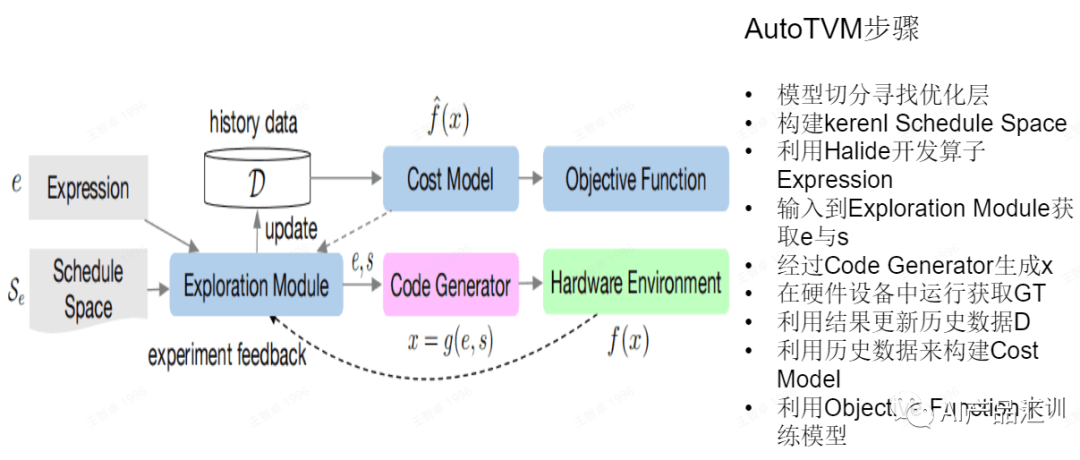
Ansor/Auto Scheduler
MLC LLM 简介
MLC LLM 是一种通用解决方案,允许将任何语言模型本地部署在各种硬件后端和本地应用程序上。
此外还有一个高效框架,供每个人进一步优化自己用例的模型性能。一切都在本地运行,无需服务器支持,并通过手机和笔记本电脑上的本地 GPU 加速。
TVM是一个深度学习编译器,知名编译工具,国内很多大公司都在使用它,国内很多的芯片公司都在使用它构建自己的工具链。
AutoTVM、Ansor是TVM中比较亮眼的工作,思想都是利用ML将算子优化的任务自动化,当前它已经可以很好的支持多种硬件设备。- 语言大模型的轻量化核心是Transformer的加速与优化,TVM社区很早就开始探索Transformer的加速与优化。除此之外,TVM中的图优化技术、自动优化等技术为语言大模型的轻量化打下了坚实的基础。
MLC-LLM只是语言大模型轻量化的开端,语言大模型轻量化方向近期会变得异常火热, 很多大公司陆续都是开源自己的一些工作。
- 随着MIC-LLM等工具出现,端侧大模型部署热潮已经来临。OpenAI一家独大的情况也会慢慢得打缓解,随着语言大模型的赋能,越来越多的智能设备,尤其是机器人的智能程度会更上一层楼!
-
随着端侧语言大模型的部署难题逐步被解决,端侧模型的数据隐私问题可能成为了端侧部署的一个关键问题。不过,这个问题应该相对来说会比较容易一些。期待了端侧语言大模型时代的到来!
- 演示图
- 参考
mlc-llm 部署汇总
- 亲测:华为mate 30下载后,启动即闪退;iOS正常
| 设备 | 地址 | 示例 |
|---|---|---|
| iOS | iOS地址 |  |
| Android | Android地址 |  |
| PC | Windows Linux Mac |  |
| Web | WebLLM |
让大模型变小这条路上,人们做了很多尝试
- 先是 Meta 开源了 LLaMA,让学界和小公司可以训练自己的模型。
- 随后斯坦福研究者启动了 Lamini,为每个开发者提供了从 GPT-3 到 ChatGPT 的快速调优方案。
- 最近 MLC LLM 的项目一步登天,因为它能在任何设备上编译运行大语言模型。
MLC LLM 在各类硬件上原生部署任意大型语言模型提供了解决方案,可将大模型应用于移动端(例如 iPhone)、消费级电脑端(例如 Mac)和 Web 浏览器。
- TVM、MXNET、XGBoost 作者,CMU 助理教授,OctoML CTO 陈天奇等多位研究者共同开发的,参与者来自 CMU、华盛顿大学、上海交通大学、OctoML 等院校机构,同时也获得了开源社区的支持。
- github
- Demo
- MLC课程:机器学习编译
- 知乎专题
曾经开源过XGBoost和TVM 陈天奇大佬已经完成了这件事情,推出了一个叫MLC-LLM 工具,在一些低算力平台上面运行一些语言大模型!只要GPU显存大于6GB,都可以去尝试在本地部署一下属于语言大模型
MLC LLM 旨在让每个人都能在个人设备上本地开发、优化和部署 AI 模型,而无需服务器支持,并通过手机和笔记本电脑上的消费级 GPU 进行加速。具体来说,MLC LLM 支持的平台包括:
- iPhone
- Metal GPU 和英特尔 / ARM MacBook;
- 在 Windows 和 Linux 上支持通过 Vulkan 使用 AMD 和 NVIDIA GPU;
- 在 Windows 和 Linux 上 通过 CUDA 使用 NVIDIA GPU;
- 浏览器上的 WebGPU(借助 MLC LLM 的配套项目 Web LLM)。
为了实现在各类硬件设备上运行 AI 模型的目标,研究团队要解决计算设备和部署环境的多样性问题,主要挑战包括:
- 支持不同型号的 CPU、GPU 以及其他可能的协处理器和加速器;
- 部署在用户设备的本地环境中,这些环境可能没有 python 或其他可用的必要依赖项;
- 通过仔细规划分配和积极压缩模型参数来解决内存限制。
- MLC LLM 提供可重复、系统化和可定制的工作流,使开发人员和 AI 系统研究人员能够以 Python 优先的方法实现模型并进行优化。MLC LLM 可以让研究人员们快速试验新模型、新想法和新的编译器 pass,并进行本地部署。
为了实现原生部署,研究团队以机器学习编译(MLC)技术为基础来高效部署 AI 模型。
- MLC技术
- MLC LLM 借助一些开源生态系统,包括来自 HuggingFace 和 Google 的分词器,以及 LLaMA、Vicuna、Dolly 等开源 LLM。
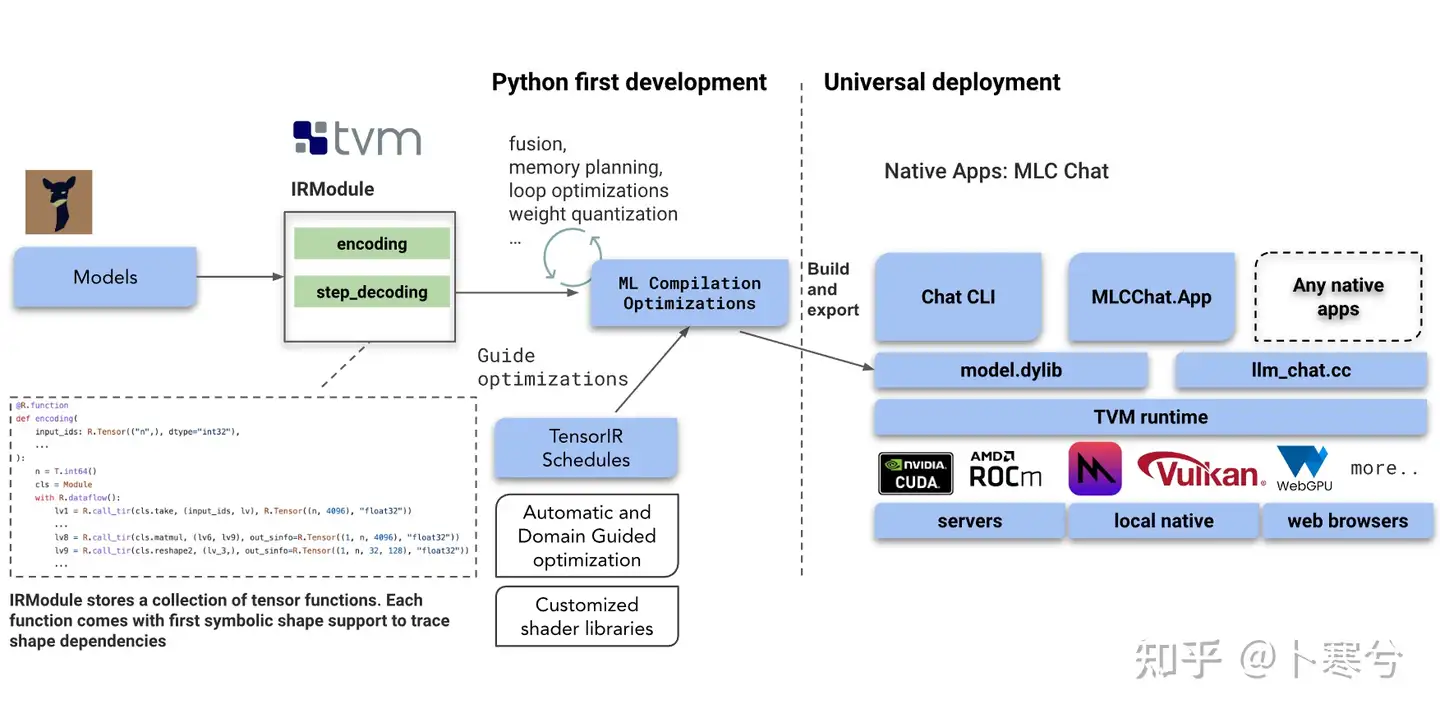
MLC LLM 的主要工作流基于 Apache TVM Unity,通过扩展 TVM 后端使模型编译更加透明和高效。
- Dynamic shape:该研究将语言模型烘焙(bake)为具有原生 Dynamic shape 支持的 TVM IRModule,避免了对最大输入长度进行额外填充的需要,并减少了计算量和内存使用量。
- 可组合的 ML 编译优化:MLC LLM 可以执行许多模型部署优化,例如更好的编译代码转换、融合、内存规划和库卸载(library offloading),并且手动代码优化可以很容易地合并为 TVM 的 IRModule 转换,成为一个 Python API。
- 量化:MLC LLM 利用低位量化来压缩模型权重,并利用 TVM 的 loop-level TensorIR 为不同的压缩编码方案快速定制代码生成。
- 运行时(Runtime):TVM 编译生成的库能够通过 TVM runtime 在设备的原生环境中运行,TVM runtime 支持 CUDA/Vulkan/Metal 等主流 GPU 驱动以及 C、JavaScript 等语言的绑定。
此外,MLC 还为 CUDA、Vulkan 和 Metal 生成了 GPU shader,并通过 LLVM 支持多种 CPU,包括 ARM 和 x86。通过改进 TVM 编译器和运行时,使用者可以添加更多支持,例如 OpenCL、sycl、webgpu-native。
MLC LLM 支持设备
支持的设备类型
-
MLC-LLM工具支持多种设备类型,大到N卡、AMD GPU,小到Android、IOS、WebGPU等。具体测试的设备列表如下所示。建议在设备内存大于等于6GB的设备上面进行推理与测试。
-
iPhone, iPad
| 硬件/GPU | 操作系统 | Tokens/sec | 链接 |
|---|---|---|---|
| iPhone 14 Pro | iOS 16.4.1 | 7.2 | https://github.com/junrushao |
| iPad Pro 11 with M1 | iPadOS 16.1 | 10.6 | https://github.com/mlc-ai/mlc-llm/issues/15#issuecomment-1529377124 |
- Metal GPUs and Intel/ARM MacBooks
| 硬件/GPU | 操作系统 | Tokens/sec | 链接 |
|---|---|---|---|
| UHD Graphics 630 | macOS Ventura | 2.3 | https://github.com/junrushao |
| 2020 MacBook Pro M1 (8G) | macOS | 11.4 | https://github.com/mlc-ai/mlc-llm/issues/15#issuecomment-1529148903 |
| 2021 MacBook Pro M1Pro (16G) | macOS Ventura | 17.1 | https://github.com/mlc-ai/mlcllm/issues/15#issuecomment-1529434801 |
| M1 Max Mac Studio (64G) | 18.6 | https://github.com/mlc-ai/mlcllm/issues/15#issuecomment-1529714864 |
- AMD and NVIDIA GPUs via Vulkan on Windows and Linux
| 硬件/GPU | 操作系统 | Tokens/sec | 链接 |
|---|---|---|---|
| Raden Pro 5300M | macOS Venture | 12.6 | https://github.com/junrushao |
| AMD GPU on Steam Deck | TBD (S macOS Ventura ome Linux) | TBD | https://www.reddit.com/r/LocalLLaMA/comments/132igcy/comment/jia8ux6/ |
| RX 7900 xtx | https://www.reddit.com/r/LocalLLaMA/comments/132igcy/comment/jia691u/ | ||
| RX6800 16G VRAM | macOS Ventura | 22.5 | https://github.com/mlc-ai/mlc-llm/issues/15 |
- NVIDIA GPUs via CUDA on Windows and Linux
| 硬件/GPU | 操作系统 | Tokens/sec | 链接 |
|---|---|---|---|
| GTX 1060 (6GB) | Windows 10 | 16.7 | https://github.com/mlc-ai/mlc-llm/issues/13#issue-1689858446 |
| RTX 3080 | Windows 11 | 26.0 | https://github.com/mlc-ai/mlc-llm/issues/15#issuecomment-1529434801 |
| RTX 3060 | Debian bookworm | 21.3 | https://github.com/mlc-ai/mlc-llm/issues/15#issuecomment-1529572646 |
- WebGPU on browsers
MLC-LLM 核心技术
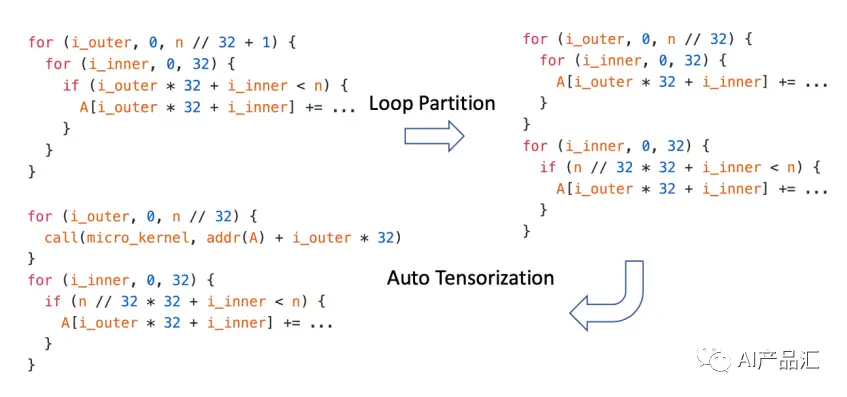
- Dynamic shape: 作者将语言模型转换为具有原生动态形状支持的 TVM IRModule,避免了对最大长度进行额外填充的需要,并减少了计算量和内存使用量。如图所示,为了优化动态形状输入
- 首先应用循环切分技术,即将一个大循环切分成两个小循环操作;
- 然后应用张量自动化技术,即TVM中的Ansor或者Meta Scheduler技术。
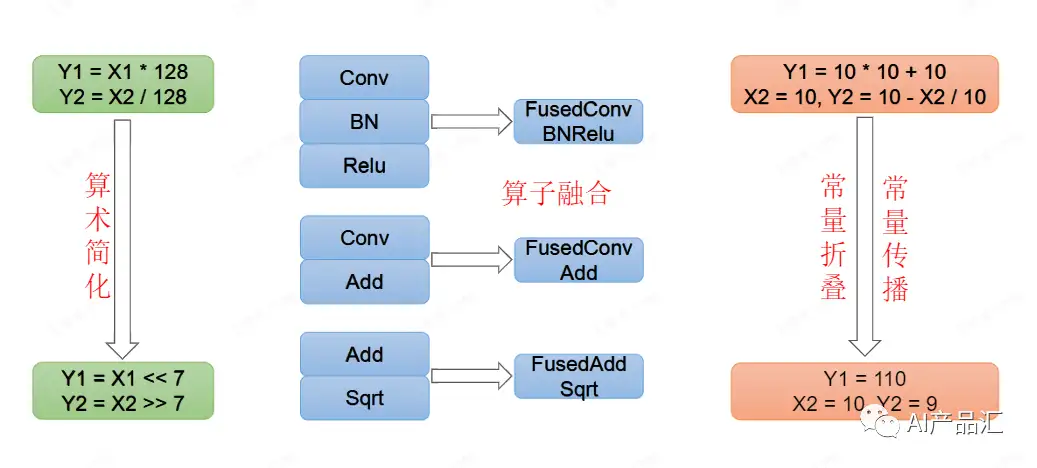
- Composable ML compilation optimizations: 执行了许多模型部署优化,例如更好的编译代码转换、融合、内存规划、库卸载和手动代码优化可以很容易地合并为TVM 的 IRModule 转换,作为 Python API 公开。如上图所示,模型推理工具链中常用的几种优化技术包括:算子简化、算子融合、常量折叠、内存排布等。
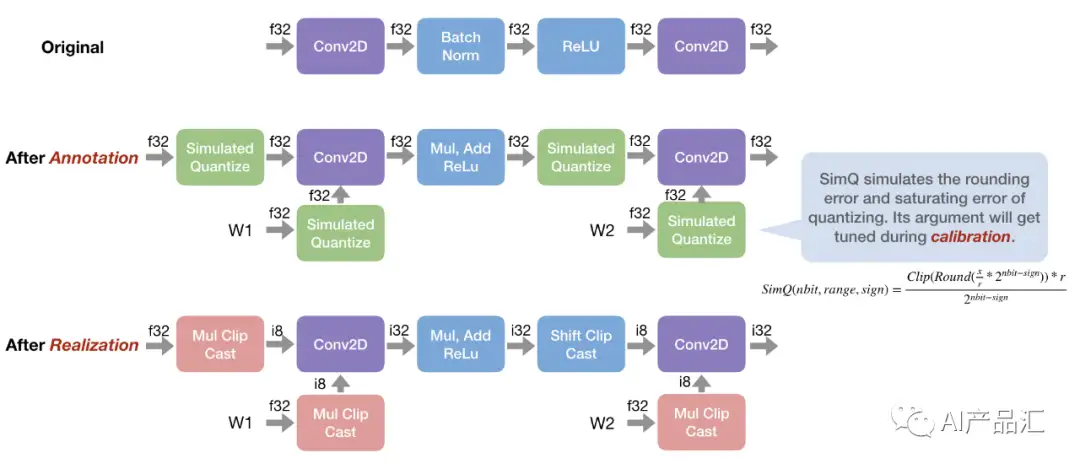
- Quantization: 利用低位量化来压缩模型权重,并利用 TVM 的循环级 TensorIR 为不同的压缩编码方案快速定制代码生成。如图所示,TVM中可以通过两种方式来进行量化:1)通过 relay.quantize 完成浮点模型的量化,该量化包含annotate、calibrate和relize三步;2)通过一种称为 qnn 的 relay方言(http://relay.qnn.xxx) 直接执行已经量化过的模型。
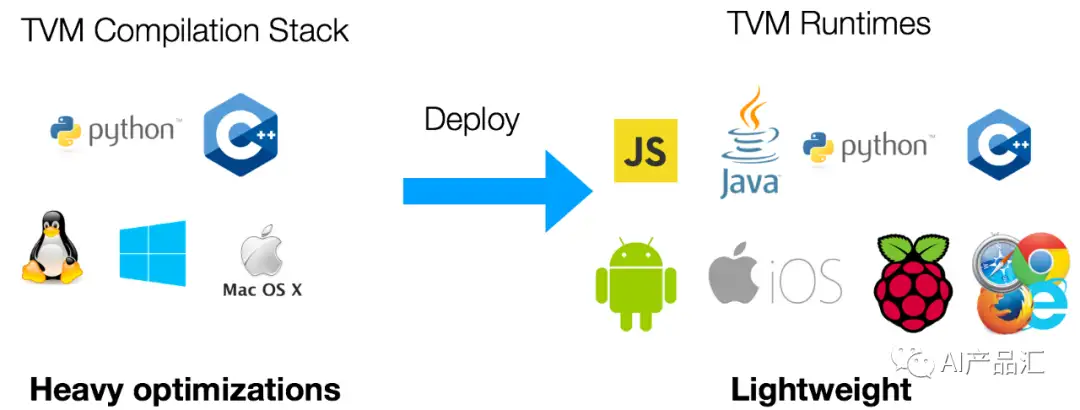
- Runtime: 最终生成的库在原生环境中运行,TVM 运行时具有最小的依赖性,支持各种 GPU 驱动程序 API 和原生语言绑定(C、JavaScript等)。如图所示,TVM支持多种Runtime,包括:JS、Java、Python、C++、Android、IOS、Web等,正是这些Runtime支持,才使得MLC-LLM可以很快的支持很多端侧设备!
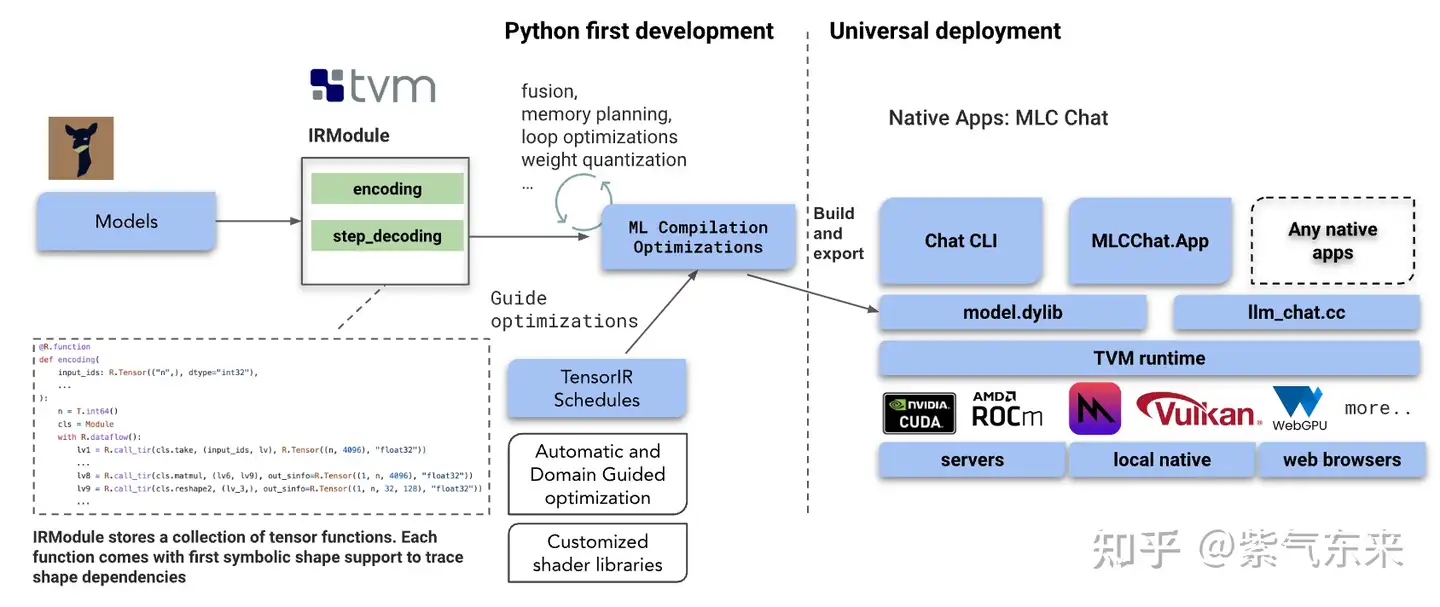
MLC-LLM部署流图
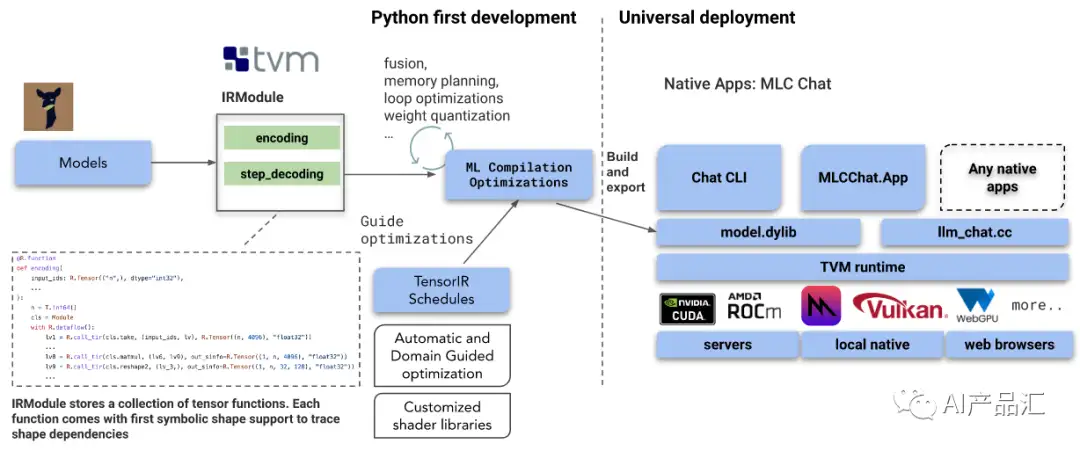
1、Python first development
- IRModule: 如上图所示,该模块存储着一个张量函数集合,每个函数附带首个形状符号,并支持跟踪形状依赖。 该模块包含着Transformer中的关键模块,encoding和step_decoding,前者用来做输入数据的编码操作,后者用来做数据的解码操作。
- ML Compilation Optimization: 该模块主要在计算图上面执行一些优化操作,具体包括:算子融合(降低多次加载的带宽开销)、内存规划(提前在编译阶段分配一些内存,并对内存的排布进行调整)、循环优化(利用常用的tile、reoder、paritation等技术)和权重量化(利用int8、int16等数据类型进行模型压缩)。
- TensorIR Schedules: 该模块主要利用Ansor自动优化或者Meta Scheduler自动优化技术对LLM模型中的算子进行调度优化。这是TVM编译器的一个杀手锏!该技术的核心思想是利用ML的思路来解决循环优化问题。
2、Universal development
- 最底层是硬件驱动层,该层主要完成一些硬件适配与驱动的工作。支持的硬件具体包括:NVIDIA的CUDA、AMD的Rocm、苹果的Vulkan和WebGPU等。
- 第三层是TVM Runtim层,该层主要完成TVM Runtime库的适配与加载任务。用户需要做的是调用TVM的Runtime推理接口完成模型的推理操作。
- 第二层是模型与代码层,该层主要完成模型的优化与业务逻辑码的开发。通过Python First Development可以导出一个model.dylib库,用户需要实现http://llm_chat.cc文件,即语言大模型的业务逻辑代码。
- 第一层是应用层,该层用来开发一些上层应用,具体包括Chat CLI命令行工具、MLCChat.App 安卓或者IOS端的上层应用、基于WebGPU的网页端应用等。
MLC-LLM环境搭建
1、iphone平台
参考页面安装已经编译好的APP。
注意事项:
- 试用此页面(仅限前 9000 名用户)以安装和使用作者为 iPhone 构建的示例 iOS 聊天应用程序。应用程序本身需要大约 4GB的内存才能运行。考虑到 iOS 和其他正在运行的应用程序,我们将需要具有 6GB(或更多)内存的最新 iPhone 来运行该应用程序。作者仅在 iPhone 14 Pro Max 和 iPhone 12 Pro上测试了该应用程序。
2、Windows/Linux/Mac平台
步骤1 - 安装环境依赖
- 安装 Miniconda 或 Miniforge
- windows与linux用户-安装Vulkan驱动;对于Nvidia用户-建议安装Vulkan驱动
步骤2-创建环境
# Create new conda environment and activate the environment.
conda create -n mlc-chat
conda activate mlc-chat
# Install Git and Git-LFS, which is used for downloading the model weights from Hugging Face.
conda install git git-lfs
# Install the chat CLI app from Conda.
conda install -c mlc-ai -c conda-forge mlc-chat-nightly
# Create a directory, download the model weights from HuggingFace, and download the binary libraries from GitHub.
mkdir -p dist
git lfs install
git clone https://huggingface.co/mlc-ai/demo-vicuna-v1-7b-int3 dist/vicuna-v1-7b
git clone https://github.com/mlc-ai/binary-mlc-llm-libs.git dist/lib
# Enter this line and enjoy chatting with the bot running natively on your machine!
mlc_chat_cli
3、Web浏览器平台
步骤
- 安装 Chrome Canary,它是支持使用 WebGPU 的 Chrome 开发者版本。
- 利用下面的命令行发起Chrome Canary
/Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary --enable-dawn-features=disable_robustness
- 在浏览器运行demo
注意事项:
- WebGPU 刚刚发布到 Chrome 并且处于测试阶段。我们在 Chrome Canary 中进行实验。你也可以试试最新的Chrome 113。Chrome版本≤112是不支持的,如果你正在使用它,demo会报错 Find an error initializing the WebGPU device OperationError: Required limit (1073741824) is greater than the 支持的限制 (268435456)。
- 验证 maxBufferSize 时
- 验证所需限制时。已经在 windows 和 mac 上测试过了,你需要一个 6.4G 内存的 gpu。
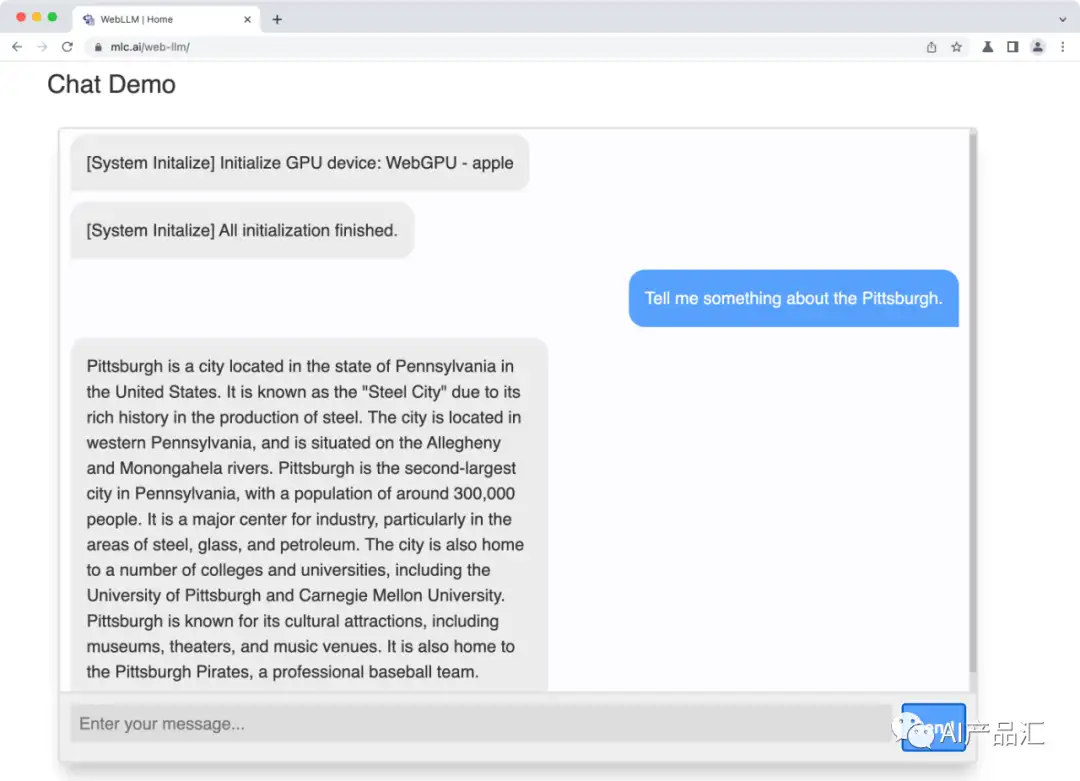
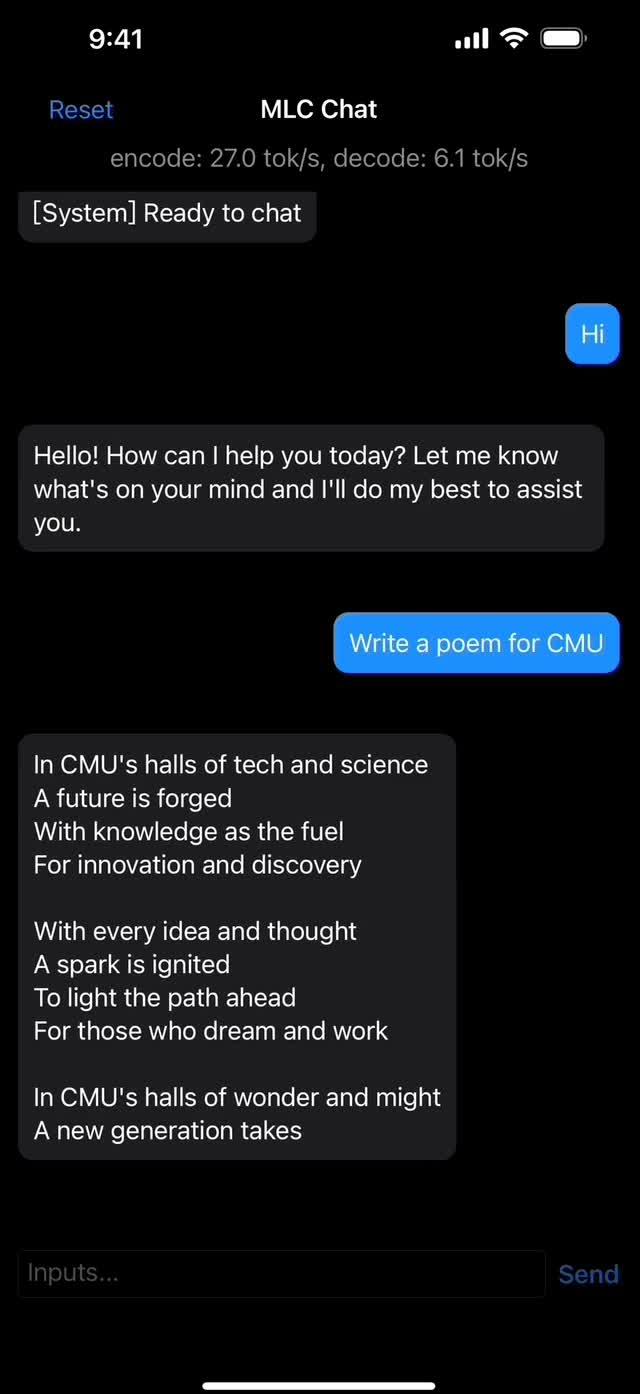
MLC-LLM 效果展示
1、web端Demo
2、IOS端Demo
3、Web Stable Diffusion
优化方法
软件加速
方法
投机采样(Speculative decoding)针对 LLM 推理串行解码特点,通过引入一个近似模型来执行串行解码,原始模型执行并行评估采样,通过近似模型和原始模型的互相配合,在保证精度一致性的同时降低了大模型串行解码的次数,进而降低了推理时延。美杜莎头(Medusa head)则是对投机采样的进一步改进,摒弃了近似模型,原始模型结构上新增了若干解码头,每个解码头可并行预测多个后续 tokens,然后使用基于树状注意力机制并行处理,最后使用典型接收方案筛选出合理的后续 tokens。该方法同样降低了大模型串行解码的次数,最终实现约两倍的时延加速。
对比
- 投机采样和多头美杜莎相对于原始自回归推理带来的提速效果。
- 投机采样在参数规模大的模型中性能提升更高,不过这取决于小模型的选择;
- 多头美杜莎则在不同参数规模的模型中拥有更一致的性能提升
【2022】投机采样
2022年, Google DeepMind 推出大模型推理加速方法: Speculative Decoding,投机采样或推测解码
利用蒸馏学习中小模型近似大模型,不损失生成效果前提下,获得 3x 以上加速比
vllm 框架支持投机采样(Speculative Decoding), 见 spec_decode
核心思想:许多常见的单词和句子都是很容易预测。
因此,大模型只需要在关键部分中指导小模型,就能够带来性能提升。
- 小模型在收到用户提问后会做出单个字的预测,当预测到一定长度后,大模型会判断是否接受小模型预测的多字,这里大模型会一次性处理多字
与传统的自回归推理方法不同,投机采样采用了草稿模型(draft model),通常是规模更小的模型,进行自回归推理。而原始的大模型则会根据小模型推理的结果进行判断,决定是否接受小模型推理出的多字
推测解码是一种推理优化技术,生成当前 Token 时,对未来 Token 进行有根据猜测,这一切都在一次前向传播中完成。
融入了验证机制,以确保这些 Token 正确性,从而保证推测解码的整体输出与普通解码的输出相同。
优化大语言模型(LLMs)的推理成本,是降低成本并提高其应用率的关键因素。
为了实现这一目标,有各种推理优化技术可用,包括自定义内核、输入请求的动态批处理以及大型模型的量化。
推测解码有两种主要方法
- 利用较小模型:例如,将 Llama 7B 用作 Llama 70B 的推测器
- 添加推测头(并对其进行训练):IBM 的 PyTorch 团队实验中,添加推测头的方法在模型质量和延迟改善方面都更为有效。
效率说明:
- 投机者架构:目前方法允许修改头的数量,对应可选择的 token 数量。增加头的数量也会增加所需的额外计算量和训练的复杂性。在实践中,对于语言模型,我们发现 3 - 4 个头在实际应用中效果良好,而代码模型则可以从 6 - 8 个头中获益。
- 计算量:增加头的数量会在两个维度上导致计算量增加,一是单次前向传播的延迟增加,二是处理多个 Token 所需的计算量增加。如果推测器在增加头的数量后准确率不高,就会导致计算资源浪费,增加延迟并降低吞吐量。
- 内存:每次前向传递都需要与高带宽内存(HBM)进行往返通信,增加的计算量由此得到抵消。请注意,如果我们提前正确预测 3 个 Token,那么就节省了三次与 HBM 的往返时间。
不足
GPT4 技术细节泄露后,对于投机采样【Speculative Decoding】策略加速推理的研究比较多,但是问题
- 投机采样依赖一个小而强的模型, 生成对于原始模型来说比较简单的token
- 其次在一个系统中维护2个不同模型,导致架构上的复杂性
- 最后使用投机采样的时候,会带来额外的解码开销,尤其是当使用一个比较高的采样温度值时。
更多见站内专题:投机采样
Google Medusa 美杜莎
投机采样虽好,但某些场景下,小模型选择棘手,如何同时部署大模型和小模型?
【2023-9-18】LLM推理加速-Medusa
- 项目主页: medusa-llm
- Github Medusa
- 论文: Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Medusa: Simple Framework for Accelerating LLM Generation with Multiple Decoding Heads
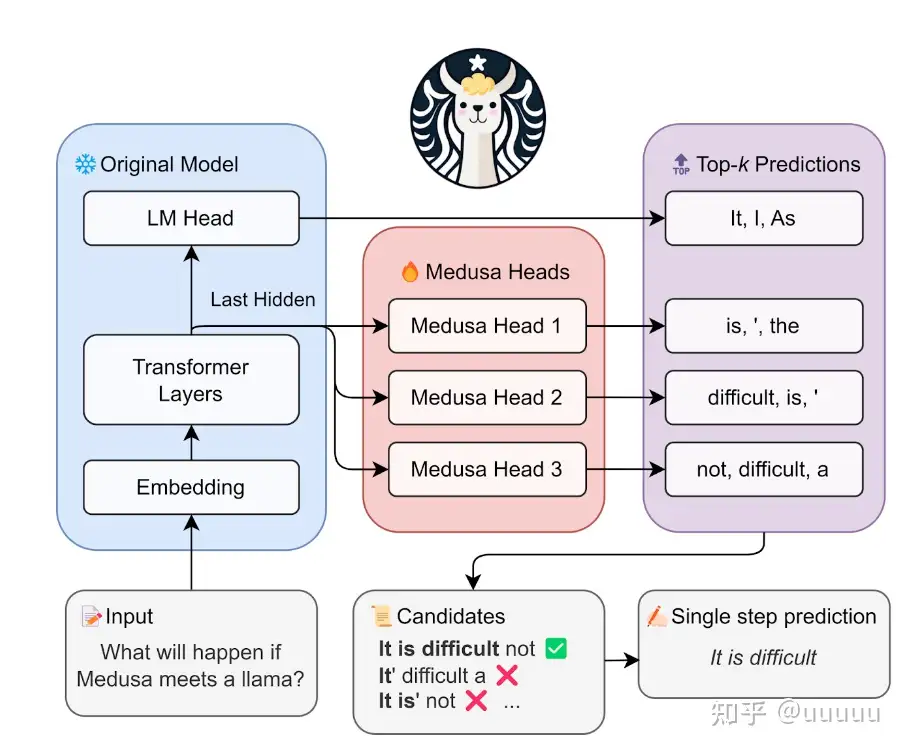
解读
多头美杜莎利用了多个预测头(language model heads)来进行多字预测,这些额外的预测头被称为美杜莎头
正常的LLM 基础上,增加几个解码头,并且每个头预测的偏移量是不同的,比如原始的头预测第i个token,而新增的medusa heads分别为预测第i+1,i+2…个token。如上图,并且每个头可以指定topk个结果,这样可以将所有的topk组装成一个一个的候选结果,最后选择最优的结果
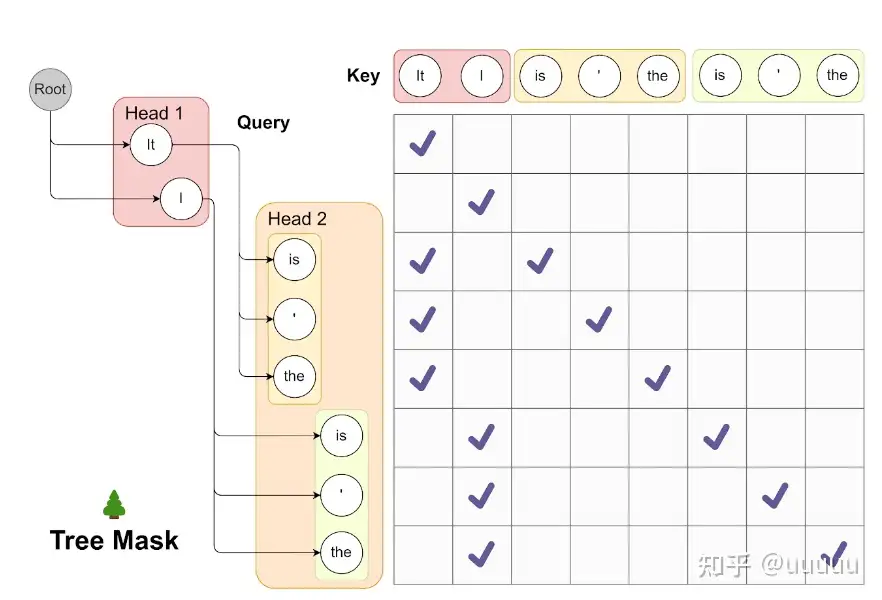
美杜莎(Medusa)推理框架使推测解码流行起来;
- 现有模型上添加一个头,然后对其进行训练以进行推测。
通过使“头”呈分层结构来修改美杜莎架构,其中每个头阶段预测单一 Token,然后将其输入到下一个头阶段。
图解
多头美杜莎的top-1推理(假设每个字都为单个token)。
- 大模型在收到用户提问后会做出多个字的预测,这里大模型会一次性处理多字。具体为主预测头会预测下1个字,第一个和第二个美杜莎头分别会预测第2个和第3个字。更多的美杜莎头也以此类推。
- 美杜莎头为独立模块,可加在现有预训练/微调好的基础模型中(例如Vicuna-13B)
如果直接使用top-1(贪婪)策略来进行推理会很容易掉进局部最优概率组合。
因此,为了提高推理效果,多头美杜莎使用了top-k 方式来进行推理
更多解读见文章
一、子图融合(subgraph fusion)
图融合技术即通过将多个 OP(算子)合并成一个 OP(算子),来减少Kernel的调用。因为每一个基本 OP 都会对应一次 GPU kernel 的调用,和多次显存读写,这些都会增加大量额外的开销。
算子融合
算子融合是深度学习模型推理的一种典型优化技术,旨在通过减少计算过程中的访存次数和 Kernel 启动耗时达到提升模型推理性能的目的,该方法同样适用于 LLM 推理。
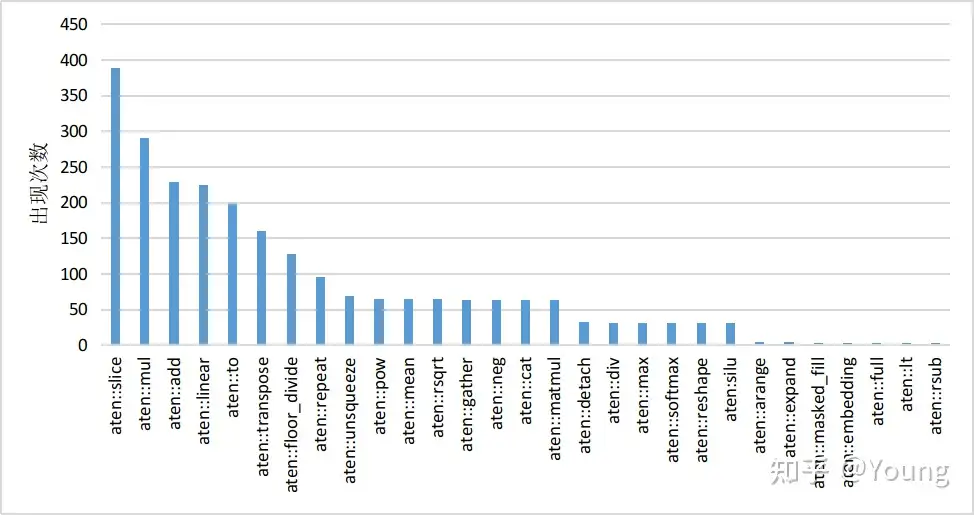
以 HuggingFace Transformers 库推理 LLaMA-7B 模型为例,经分析模型推理时的算子执行分布如下图所示
- 该模型有 30 个类型共计 2436 个算子,其中 aten::slice 算子出现频率为 388 次。
- 大量小算子的执行会降低 GPU 利用率,最终影响推理速度。
目前业界基本都针对 Transformer layer 结构特点,手工实现了算子融合。以 DeepSpeed Inference 为例,算子融合主要分为如下四类:
- 归一化层 和 QKV 横向融合:将三次计算 Query/Key/Value 的操作合并为一个算子,并与前面的归一化算子融合。
- 自注意力计算融合:将自注意力计算涉及到的多个算子融合为一个,业界熟知的 FlashAttention 即是一个成熟的自注意力融合方案。
- 残差连接、归一化层、全连接层和激活层融合:将 MLP 中第一个全连接层上下相关的算子合并为一个。
- 偏置加法和残差连接融合。
- 图 5 Transformer layer中的算子融合示意
由于算子融合一般需要定制化实现算子 CUDA kernel,因此对 GPU 编程能力要求较高。随着编译器技术的引入,涌现出 OpenAI Triton 、TVM 等优秀的框架来实现算子融合的自动化或半自动化,并取得了一定的效果。
高性能算子
针对 LLM 推理运行热点函数编写高性能算子,也可以降低推理时延。
GEMM操作相关优化:在 LLM 推理的预填充阶段,Self-Attention 和 MLP 层均存在多个 GEMM 操作,耗时占据了推理时延的 80% 以上。GEMM 的 GPU 优化是一个相对古老的问题,在此不详细展开描述算法细节。英伟达就该问题已推出 cuBLAS、CUDA、CUTLASS 等不同层级的优化方案。例如,FasterTransformer 框架中存在大量基于 CUTLASS 编写的 GEMM 内核函数。另外,Self-Attention 中存在 GEMM+Softmax+GEMM 结构,因此会结合算子融合联合优化。GEMV操作相关优化:在 LLM 推理的解码阶段,运行热点函数由 GEMM 变为 GEMV。相比 GEMM,GEMV 的计算强度更低,因此优化点主要围绕降低访存开销开展。
高性能算子的实现同样对 GPU 编程能力有较高要求,且算法实现中的若干超参数与特定问题规模相关。因此,编译器相关的技术如自动调优也是业界研究的重点。
1.1 FasterTransformer
FasterTransformer by NVIDIA
FasterTransformer(FT) 是一个用于实现基于Transformer的神经网络推理的加速引擎。FT框架是用C++/CUDA编写的,依赖于高度优化的 cuBLAS、cuBLASLt 和 cuSPARSELt 库,与 NVIDIA TensorRT 等其他编译器相比,FT 的特点是它支持以分布式方式推理 Transformer 大模型。
图融合是FT 的一个重要特征,将多层神经网络组合成一个单一的神经网络,将使用一个单一的内核进行计算。 这种技术减少了数据传输并增加了数学密度,从而加速了推理阶段的计算。 例如, multi-head attention 块中的所有操作都可以合并到一个内核中。
除此之外,FT还对部分大模型分别支持:
INT8低精度量化推理- Ampere 架构的 GPU 硬件部分支持稀疏化
- Hopper 架构支持 FP8 推理
- Tensor 并行
- Pipeline 并行
1.2 DeepSpeed Inference
微软推出的 Transformer 模型的前向推理框架。
- DeepSpeed Inference by Microsoft
- 把模型分散到多块卡(多机)上跑。
- 有 150G+ 显存占用的模型,同时最大卡的显存只有 24G 卡,很多块,那么如果有这种框架随便跑。
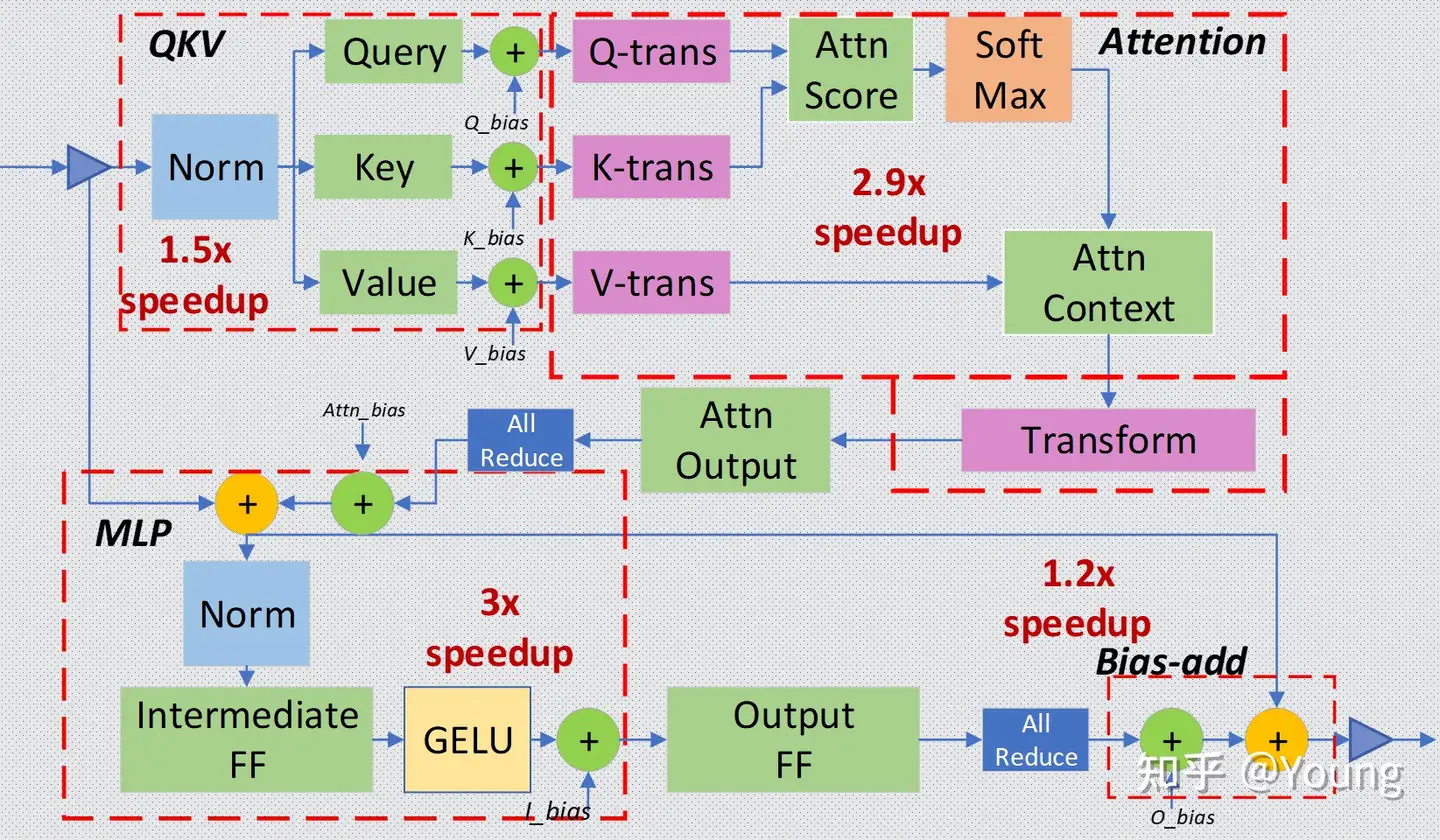
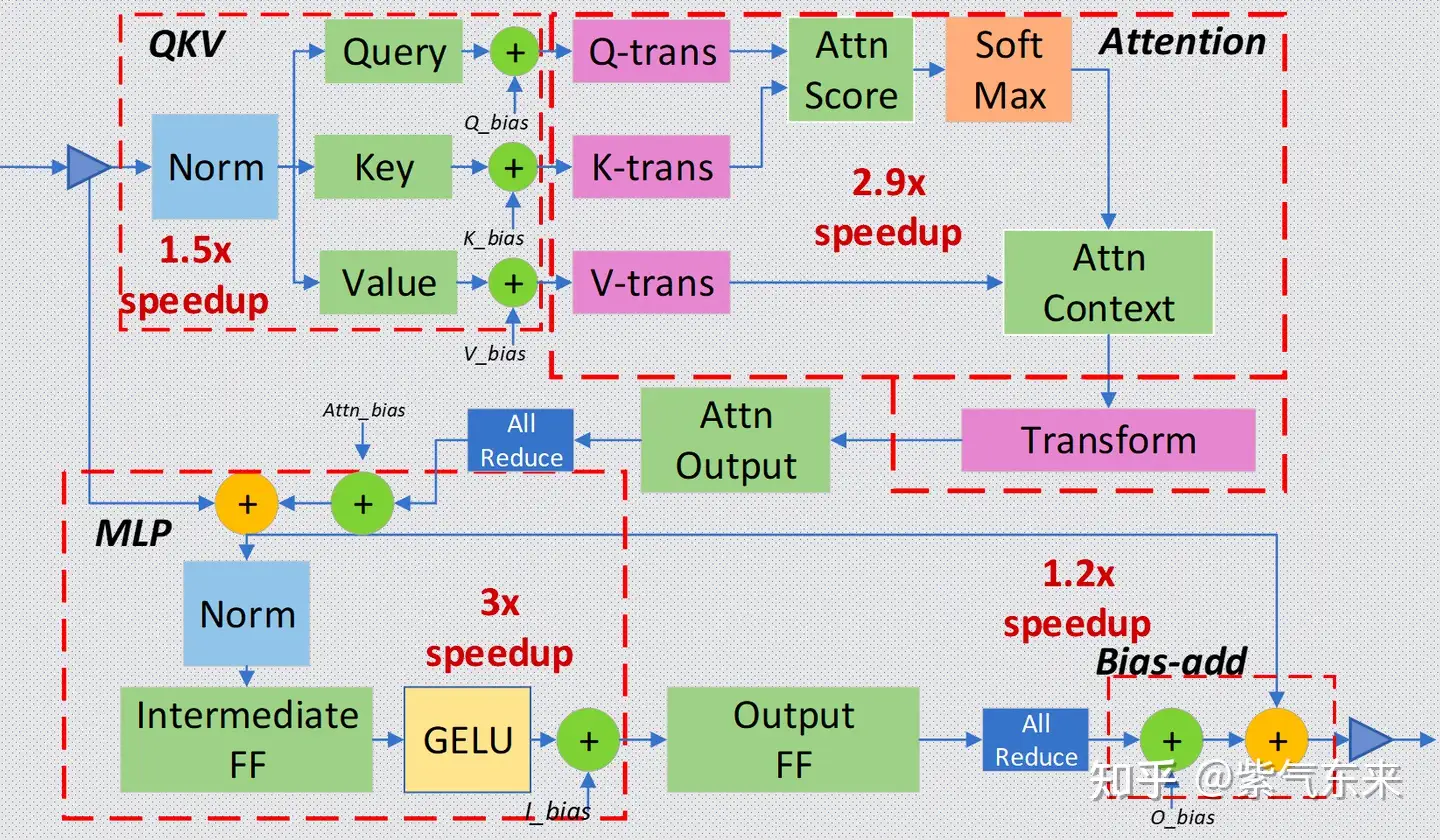
对于 Transformer layer,可分为以下4个主要部分:
- Input Layer-Norm plus Query, Key, and Value GeMMs and their bias adds.
- Transform plus Attention.
- Intermediate FF, Layer-Norm, Bias-add, Residual, and Gaussian Error Linear Unit (GELU).
- Bias-add plus Residual.
如图所示,每一部分可分别进行融合,与未融合相比,以上几个部分的加速比可分别达到 1.5x, 2.9x, 3x, 1.2x 。
除此之外,DeepSpeed Inference 的优化点还有以下几点:
- 多 GPU 的并行优化
- INT8 模型量化
- 推理的 pipeline 方案
DeepSpeed 实现 ZeRO ,为了减少显存使用,跨机器跨节点进行更大模型的训练。一般按层切分模型分别载入参数,像是模型并行。但运行时其实质则是数据并行方式,不同的数据会在不同的卡运行,且同一组数据一般会在一块卡上完成全部前向和后向过程。而被切分的参数和梯度等数据会通过互联结构在运行态共享到不同节点,只是复制出的数据用后即焚删除了,不再占用空间。

安装
- MII 是个壳,主要封装了服务 api。核心并行机制都在 DeepSpeed 里。
pip install deepspeed
pip install deepspeed-mii
测试脚本: example.py
import mii
pipe = mii.pipeline("mistralai/Mistral-7B-v0.1")
response = pipe(["DeepSpeed is", "Seattle is"], max_new_tokens=128)
print(response)
执行
deepspeed --num_gpus 2 mii-example.py
更多详细介绍及实践可参考笔者之前的文章:
1.3 MLC LLM
MLC LLM by TVM
之前介绍的推理方案主要是基于GPU的优化,而 MLC LLM 提供了可应用于移动端(例如 iPhone)、消费级电脑端(例如 Mac)和 Web 浏览器的轻设备解决方案。
MLC LLM 的主要工作流基于 Apache TVM Unity,通过扩展 TVM 后端使模型编译更加透明和高效。其中以编译代码转换、融合、内存规划和库卸载(library offloading)为代表的可组合的 ML 编译优化是其中重要的优化特性。
除此之外,MLC LLM 还具有以下特性:
- Dynamic shape:避免了对最大输入长度进行额外填充的需要,并减少了计算量和内存使用量。
- 量化:MLC LLM 利用低位量化来压缩模型权重,并利用 TVM 的 loop-level TensorIR 为不同的压缩编码方案快速定制代码生成。
- 运行时(Runtime):TVM 编译生成的库能够通过 TVM runtime 在设备的原生环境中运行,TVM runtime 支持 CUDA/Vulkan/Metal 等主流 GPU 驱动以及 C、JavaScript 等语言的绑定。
除了上述3种方案外,其他也支持图融合的方案还包括 NVIDIA TensorRT, Tencent TurboTransformers 等。
二、模型压缩(Model Compression)
模型压缩的基本动机在于当前的模型是冗余的,可以在精度损失很小的情况下实现模型小型化,主要包括3类方法:稀疏(Sparsity)、量化(Quantization)、蒸馏(Distillation)。
2025年11月13日,Compression techniques if you wanted small but smart LLMs.
- 量化 Quantization
- 蒸馏 Distillation
- 地址适配 Low-Rank Adaptation
- 权重分享 Weight Sharing
- 稀疏矩阵 Sparse Matrices
- 层丢弃 Layer Dropping
- 知识迁移 Knowledge Transfer
- 嵌入压缩 Embedding Compression
- 混合稀疏 Mixed Sparsity
- 进度压缩 Progressive Shrinking
- 结构裁剪 Structured Pruning
- 自动压缩 AutoML Compression
2.1 稀疏(Sparsity)
实现稀疏(Sparsity)的一个重要方法是剪枝(Pruning)。剪枝是在保留模型容量的情况下,通过修剪不重要的模型权重或连接来减小模型大小。 它可能需要也可能不需要重新培训。 修剪可以是非结构化的或结构化的。
- 非结构化剪枝允许删除任何权重或连接,因此它不保留原始网络架构。 非结构化剪枝通常不适用于现代硬件,并且不会带来实际的推理加速。
- 结构化剪枝旨在维持某些元素为零的密集矩阵乘法形式。 他们可能需要遵循某些模式限制才能使用硬件内核支持的内容。 当前的主流方法关注结构化剪枝,以实现 Transformer 模型的高稀疏性。
关于剪枝稀疏的基本原理,可参考笔者之前的文章:
除了上文介绍的稀疏方法外,还有其他的稀疏化方法,包括但不限于:
- SparseGPT:该方法的工作原理是将剪枝问题简化为大规模的稀疏回归实例。它基于新的近似稀疏回归求解器,用于解决分层压缩问题,其效率足以在几个小时内使用单个 GPU 在最大的 GPT 模型(175B 参数)上执行。同时,SparseGPT 准确率足够高,不需要任何微调,剪枝后所损耗的准确率也可以忽略不计。
- LLM-Pruner:遵循经典的“重要性估计-剪枝-微调”的策略,能够在有限资源下完成大语言模型的压缩,结果表明即使剪枝 20% 的参数,压缩后的模型保留了 93.6% 的性能。
- Wanda: 该方法由两个简单但必不可少的组件构成——剪枝度量和剪枝粒度。剪枝度量用来评估权重的重要性,然后按照剪枝粒度进行裁剪。该方法在 65B 的模型上只需要 5.6 秒就可以完成剪枝,同时达到SparseGPT相近的效果。
以上主要实现了稀疏的方法,那么对于稀疏后的模型如何加速呢?NVIDIA Ampere 架构对与结构化稀疏做了专门的稀疏加速单元,下图展示了结构化稀疏的物理表示:
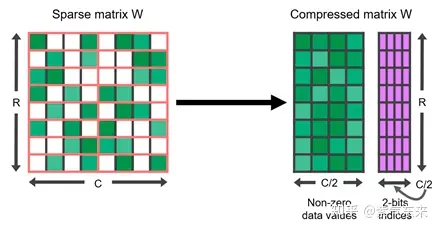
2:4 结构化稀疏表示
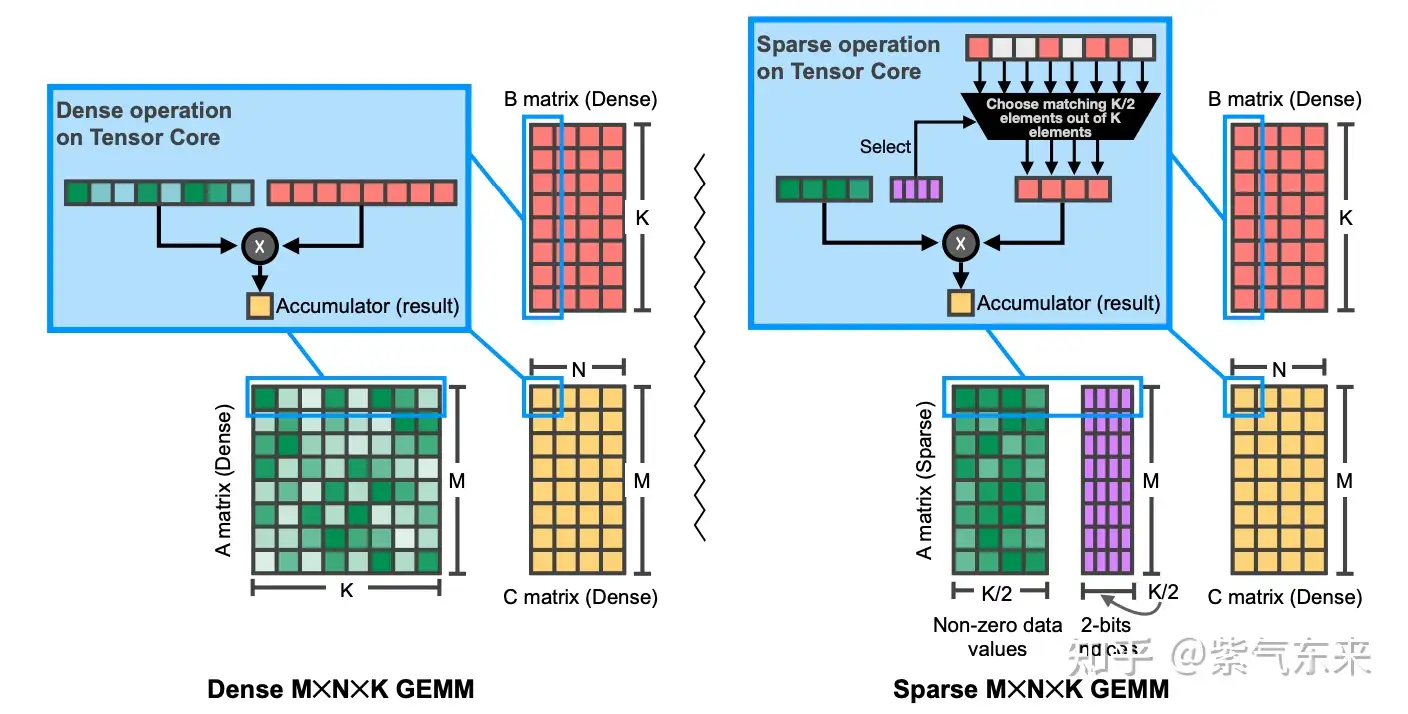
下图展示了稀疏单元GEMM计算与标准GEMM计算的区别(详细解释参见https://arxiv.org/pdf/2104.08378.pdf)
Sparse VS Dense GEMM
2.2 量化(Quantization)
【2023-9-7】
【2024-8-22】 「模型量化技术」可视化指南:A Visual Guide to Quantization, 可视化图解各种模型量化技术的原理和实现方法
目录
- 01 第 1 部分:LLMs 存在的“问题”
- 1.1 参数数值(value)的表示方法
- 1.2 内存限制问题
- 02 第 2 部分:模型量化技术简介
- 2.1 常用的数据类型
- 2.1.1 FP16
- 2.1.2 BF16
- 2.1.3 INT8
- 2.2 对称量化 Symmetric Quantization
- 2.3 非对称量化 asymmetric quantization
- 2.4 取值范围的映射与裁剪
- 2.5 校准过程 Calibration
- 2.5.1 权重(和偏置项) Weights (and Biases)
- 2.5.2 激活值
- 03 第 3 部分:Post-Training Quantization
- 3.1 动态量化(Dynamic Quantization)
- 3.2 静态量化(Static Quantization)
- 3.2 探索 4-bit 量化的极限
- 3.2.1 GPTQ
- 3.2.2 GGUF
- 04 第 4 部分:Quantization Aware Training
- 4.1 1-bit LLM 的时代:BitNet
- 4.2 权重的量化 Weight Quantization
- 4.3 激活值的量化 Activation Quantization
- 4.4 反量化过程 Dequantization
- 4.5 所有 LLMs 实际上均为 1.58-bit
- 4.5.1 The Power of 0
- 4.5.2 Quantization 量化过程
- 05 Conclusion
【2024-8-28】天津大学大模型量化报告 https://blog.csdn.net/2401_85327249/article/details/144079053
量化(Quantization)可以很好地通过将float模型表征为低位宽模型实现减小模型存储空间, 加速模型推理的目标.
量化定义为:
a technique that mapping of a k-bit integer to a float element, which saves space and speedup computation by compressing the digital representation.
LLM 模型推理吞吐量和时延这两个重要的性能指标上:
吞吐量的提升主要受制于显存容量,如果降低推理时显存占用量,就可以运行更大的 batchsize,即可提升吞吐量;- LLM 推理具有 Memory-bound 特点,如果降低访存量,将在
吞吐量和时延两个性能指标上都有收益。
低比特量化技术可以降低显存占用量和访存量,加速关键在于:
- 显存量和访存量的节省以及量化计算的加速远大于反量化带来的额外开销。
浮点数
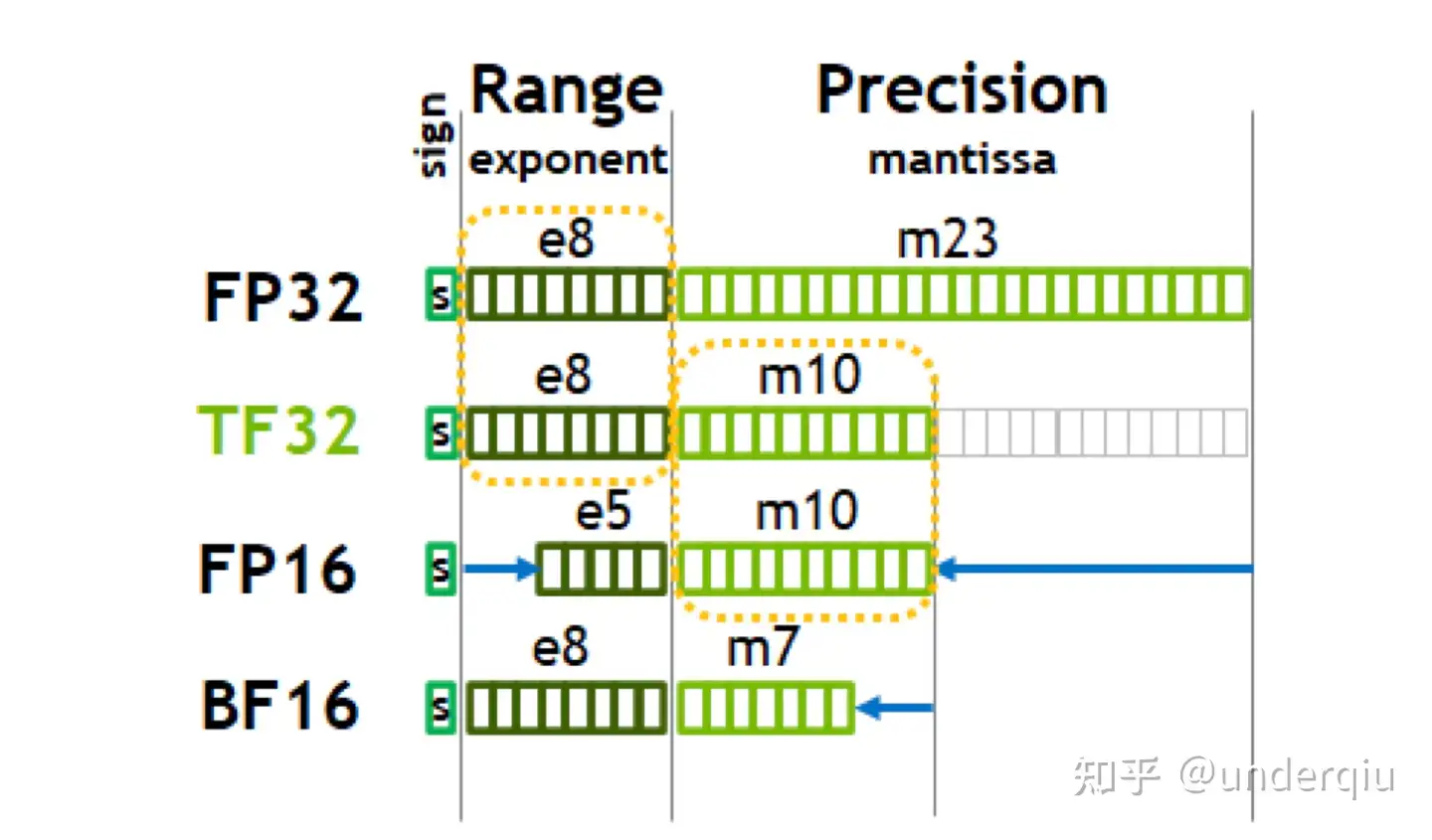
【2024-3-1】一次搞懂FP16、BF16、TF32、FP32
英伟达安培架构白皮书
新数据类型历史
- FP16 最早是在图形学领域写 shader 相关的语言中引入。
- 其与8位或16位整数相比,动态范围高,可以使高对比度图片中更多细节得以保留。
- 与单精度浮点数相比,优点是只需要一半的存储空间和带宽(但是会牺牲精度和数值范围)。
- 之后 FP16 随着 Volta 系列 Tensor Core 推出而广泛引用于深度学习,从而发扬光大。
- 类似的数据类型还有 INT8 INT4 和 binary 1-bit 精度数据在图灵架构推出。
- A100 Tensor Core 增加了 TF32 、BF16 和 FP64 的支持。
这些 Reduced Precision 在算力紧缺的深度学习时代,在精度和性能做了取舍,推动着各种计算任务的发展,而背后真正的不同在于其各自代表的位宽和位模式不一样。
以单精度浮点数为例: 一个浮点数 (Value) 的表示其实可以这样表示(大多数情况) :
- Value = sign X exponent X fraction
浮点数的实际值,等于符号位(sign bit)乘以指数偏移值(exponent bias)再乘以分数值(fraction)。
如 2024.0107 实际表示 工具
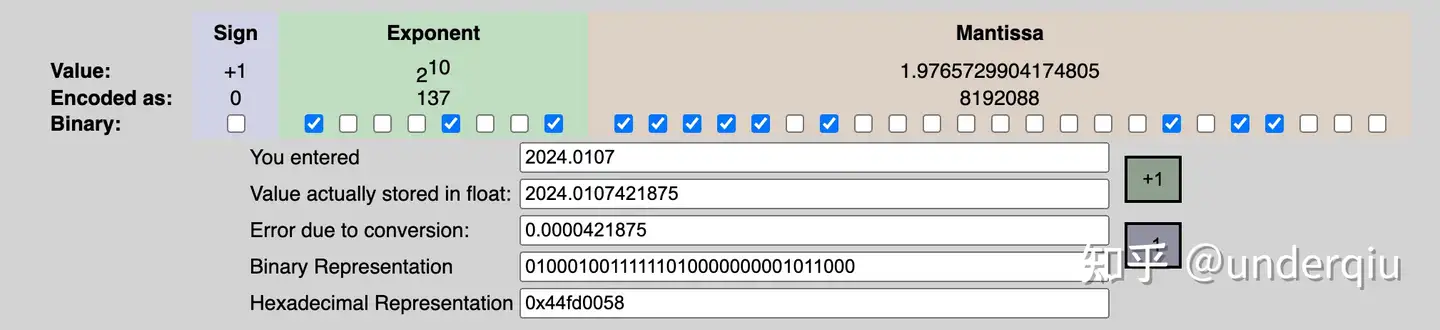
- 不同于定点数,浮点数很多都其实都是近似
- 特殊意义:比如说 nan,inf ,0 之类
(1) FP32 到 BF16 的转换
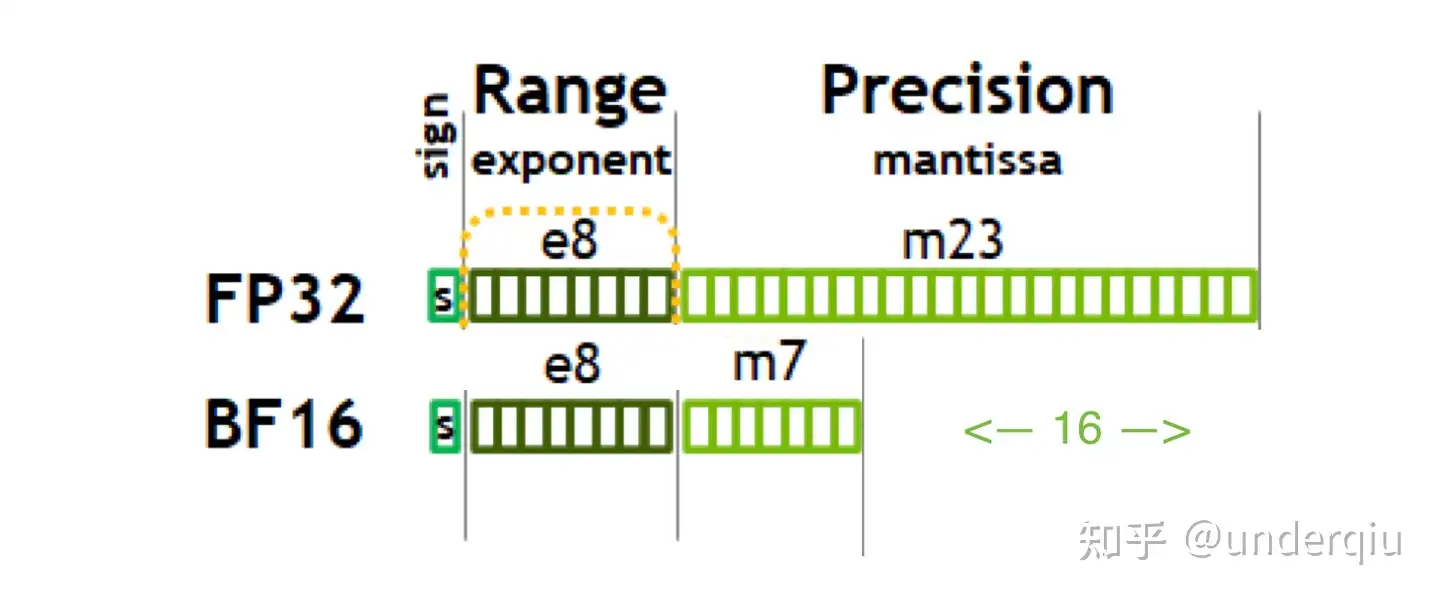
- BF16 组成:1个符号位, 8 个指数位, 举例
0 11110 1111111111 = 65504(max half precision) - 转换: 把 float32 后边多余的位给砍掉
ncnn 代码
// convert float to brain half
NCNN_EXPORT NCNN_FORCEINLINE unsigned short float32_to_bfloat16(float value)
{
// 16 : 16
union
{
unsigned int u;
float f;
} tmp;
tmp.f = value;
return tmp.u >> 16;
}
// convert brain half to float
NCNN_EXPORT NCNN_FORCEINLINE float bfloat16_to_float32(unsigned short value)
{
// 16 : 16
union
{
unsigned int u;
float f;
} tmp;
tmp.u = value << 16;
return tmp.f;
}
(2) FP32 到 FP16 的转换
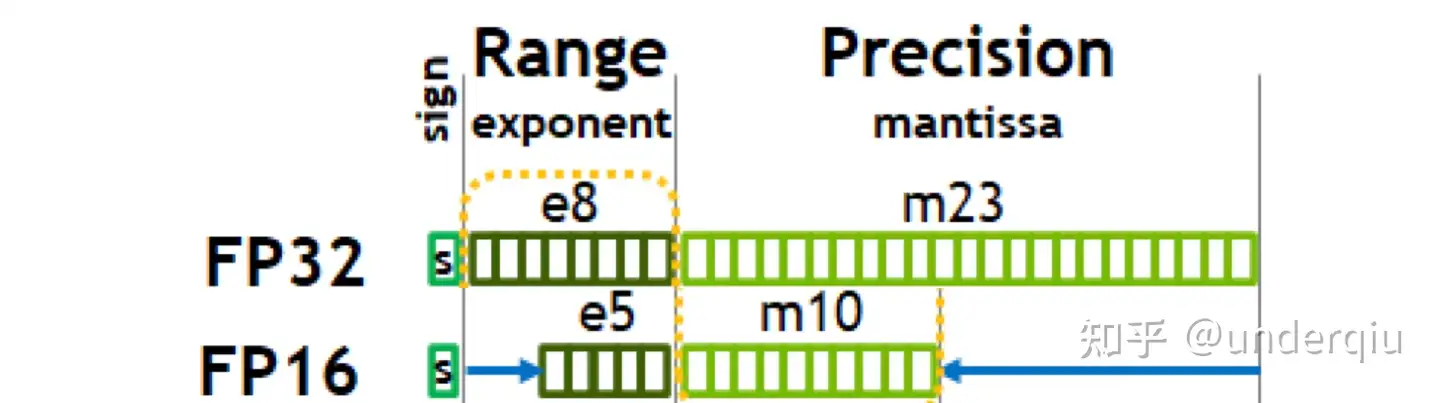
- FP16 和 BF16 位宽一样,但要做起数据类型转换可比 BF16 复杂了不少。
- FP16 是比 BF16 更早得到广泛应用的数据类型
- 组成: 1个符号位5个符号位10个尾数位, 这就和 float32 的位模式只有符号位是相同的了。
转换过程三个映射而已:符号位的对应,指数位的对应,尾数位的对应
// 拆分
unsigned int sign = x & 0x80000000; //sign flag
unsigned int mantissa_f32 = x & 0x007FFFFF; // mantissa
unsigned int exponent_f32 = x & 0x7f800000; // exp
// 映射
// ...
(3) FP32 vs. TF32
TF32 也是深度学习时代诞生的一种新类型。
- 针对 Nvidia Ampere 的 GPU 模式,一般也是 TensorCore 的中间计算类型,默认情况下将启用。
- 由于使用了 TF32,某些 float32 操作在基于 Ampere 架构的 GPU 上以较低的精度运行,包括乘法和卷积。具体来说,这类运算的输入从 23 位精度四舍五入到 10 位。这对于深度学习模型来说,在实践中不太会造成问题。
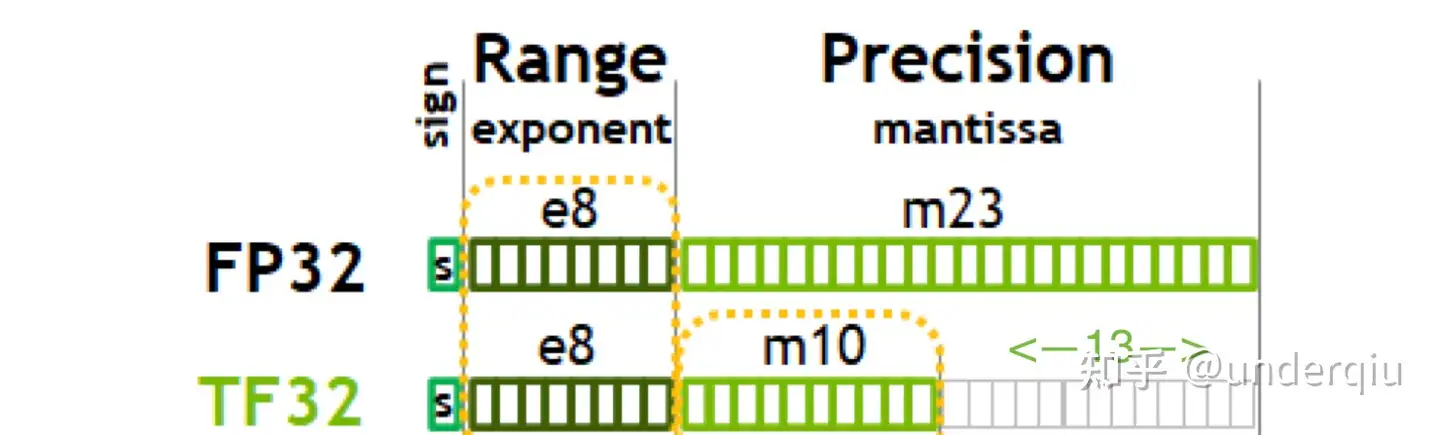
- TF32 保持了 range 和 FP32 一致,减少了小数位,使用和 half 一样的 10bit 小数位,使得总体位数为 19 个 bit,降低了数据精度,但同时也在安培架构上带来了强劲的性能提升
量化分类
量化可以按不同角度对其进行归类:
- 按量化执行阶段 分为训练中量化(
QAT, Quantization-Aware-Training) 和 训练后量化(PTQ, Post-Training-Quantization); - 按量化间隔是否等距 分为
均匀量化和非均匀量化(如图所示). 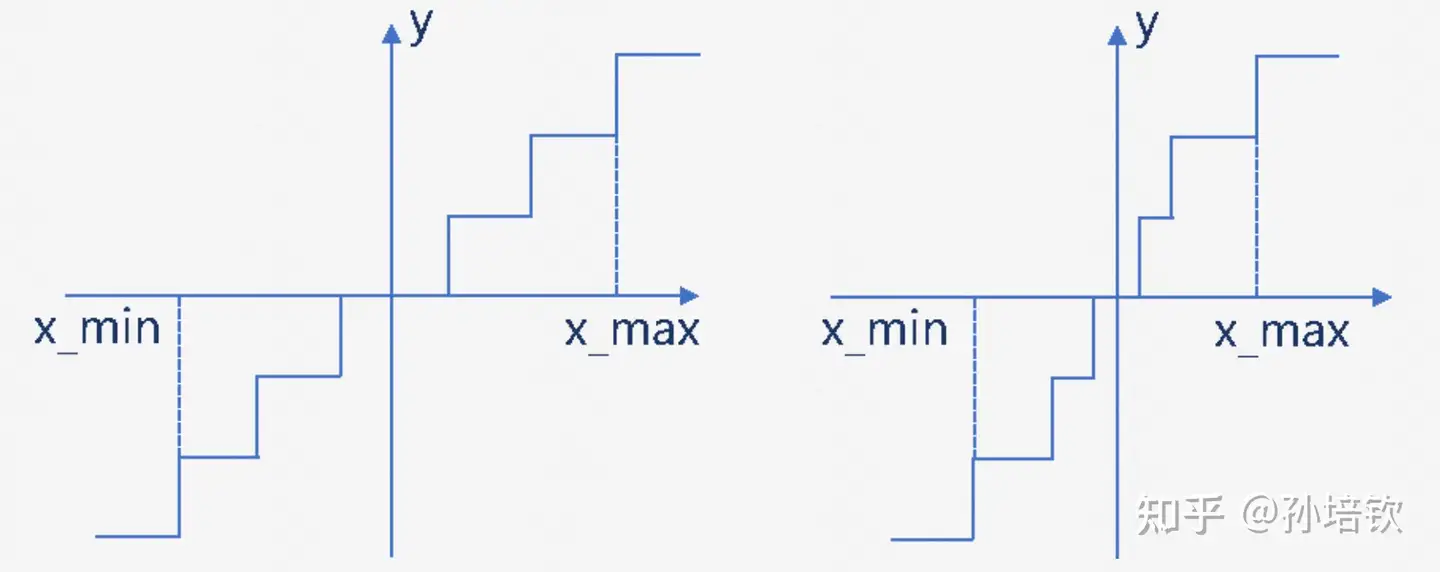
| 划分维度 | 类1 | 类2 |
|---|---|---|
| 执行阶段 | 训练中量化 QAT |
训练后量化 PTQ |
| 间隔是否等距 | 均匀量化 | 非均匀量化 |
这里主要讨论PTQ, 均匀量化. 因为LLMs背景下
QAT目前仍未有机构做出靠谱研究, 主要受限于QAT需要引入模拟量化的操作, 会引起显存&计算量进一步上涨以及梯度mismatch的问题, 从而增加训练成本以及影响Scaling Laws.非均匀量化除非有特殊硬件支持, 否则在GPU上目前多数只能通过 Look-Up-Table 或 移位等方式来实现, 速度和精度没法得到同时保证.
常见量化有两种常见方法:
- 训练后量化(Post-Training Quantization,
PTQ):模型首先经过训练以达到收敛,然后将其权重转换为较低的精度,而无需进行更多训练。 - 与训练相比,实施起来通常相当便宜。
- 量化感知训练(Quantization-Aware Training,
QAT):在预训练或微调期间应用量化。 - QAT 能够获得更好的性能,但需要额外的计算资源和对代表性训练数据的访问。
| 被量化的对象 | 量化方法 | 特点 |
|---|---|---|
| 权重量化 | LLM.int8(), GPTQ | 显存占用减半,但由于计算结果需反量化,时延基本无收益 |
| 权重和激活同时量化 | SmoothQuant | 显存占用减半,时延有收益,精度几乎匹配 FP16 |
| KV Cache量化 | INT8 或 FP8 量化 | 方法简单,吞吐量收益明显 |
| 基于硬件特点的量化:英伟达 Hopper 架构下的 FP8 | 直接利用 TensorCore FP8 计算指令 | 不需要额外的量化/反量化操作,时延收益明显 |
四类量化方法各有特点,业界在低比特量化方向的研究进展也层出不穷,希望探索出一个适用于大语言模型的、能够以较高压缩率压缩模型、加速端到端推理同时保证精度的量化方法。
量化原理
模型大小由其参数量及其精度决定,精度通常为 float32、float16 或 bfloat16
- Float32 (FP32) 。标准的 IEEE 32 位浮点表示,指数 8 位,尾数 23 位,符号 1 位,可以表示大范围的浮点数。大部分硬件都支持 FP32 运算指令。
- Float16 (FP16) 。指数 5 位,尾数 10 位,符号 1 位。FP16 数字的数值范围远低于 FP32,存在上溢 (当用于表示非常大的数时) 和下溢 (当用于表示非常小的数时) 的风险,通过缩放损失 (loss scaling) 来缓解这个问题。
- Bfloat16 (BF16) 。指数 8 位 (与 FP32 相同),尾数 7 位,符号 1 位。这意味着 BF16 可以保留与 FP32 相同的动态范围。但是相对于 FP16,损失了 3 位精度。因此,在使用 BF16 精度时,大数值绝对没有问题,但是精度会比 FP16 差。
- TensorFloat-32(TF32) 。使用 19 位表示,结合了 BF16 的范围和 FP16 的精度,是计算数据类型而不是存储数据类型。目前使用范围较小。
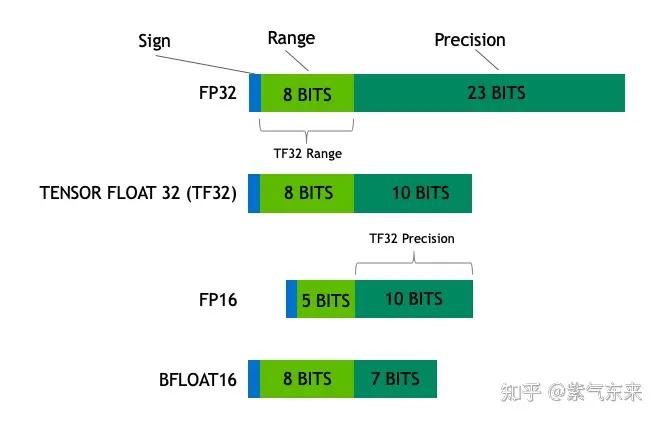
- 浮点数由3部分组成:符号位、指数位和尾数位。
- 指数位越大,可表示的数字范围越大。尾数位越大、数字的精度越高。

量化分类
- 可根据何时量化分为:后训练量化和训练感知量化
- 也可根据量化参数的确定方式分为:静态量化和动态量化。
(1)PTQ 后训练
后训练量化(PTQ, Post-Training Quantization):模型预训练完成后,基于校准数据集(calibration dataset)确定量化参数进而对模型进行量化
① GPTQ(Group-wise Precision Tuning Quantization)是静态的后训练量化技术。
- ”静态”指预训练模型一旦确定,经过量化后量化参数不再更改。
- GPTQ 量化技术将 fp16 精度的模型量化为 4-bit ,在节省了约 75% 的显存的同时大幅提高了推理速度。
- 为了使用GPTQ量化模型,需要指定量化模型名称或路径,例如 model_name_or_path: TechxGenus/Meta-Llama-3-8B-Instruct-GPTQ
② AQLM
AQLM(Additive Quantization of Language Models)作为一种只对模型权重进行量化的PTQ方法,在 2-bit 量化下达到了当时的最佳表现,并且在 3-bit 和 4-bit 量化下也展示了性能的提升。 尽管 AQLM 在模型推理速度方面的提升并不是最显著的,但其在 2-bit 量化下的优异表现意味着您可以以极低的显存占用来部署大模型
(2) QAT 训练阶段
训练感知量化(QAT, Quantization-Aware Training)中,模型在预训练过程中被量化,然后又在训练数据上再次微调,得到最后的量化模型。
AWQ(Activation-Aware Layer Quantization)是静态的后训练量化技术。
思想基于:有很小一部分的权重十分重要,为了保持性能这些权重不会被量化。
AWQ 优势:需要的校准数据集更小,且在指令微调和多模态模型上表现良好。
为了使用 AWQ 量化模型,您需要指定量化模型名称或路径,例如 model_name_or_path: TechxGenus/Meta-Llama-3-8B-Instruct-AWQ
(3)OFTQ 推理阶段
OFTQ(On-the-fly Quantization)是模型无需校准数据集,直接在推理阶段进行量化。OFTQ是一种动态的后训练量化技术. OFTQ在保持性能的同时。 因此,在使用OFTQ量化方法时,您需要指定预训练模型、指定量化方法 quantization_method 和指定量化位数 quantization_bit
① bitsandbytes
区别于 GPTQ, bitsandbytes 是动态的后训练量化技术。
bitsandbytes 使得大于 1B 的语言模型也能在 8-bit 量化后不过多地损失性能。 经过bitsandbytes 8-bit 量化的模型能够在保持性能的情况下节省约50%的显存
② HQQ
依赖校准数据集的方法往往准确度较高,不依赖校准数据集的方法往往速度较快。HQQ(Half-Quadratic Quantization)希望能在准确度和速度之间取得较好的平衡。作为一种动态的后训练量化方法,HQQ无需校准阶段, 但能够取得与需要校准数据集的方法相当的准确度,并且有着极快的推理速度。
③ EETQ
EETQ(Easy and Efficient Quantization for Transformers)是一种只对模型权重进行量化的PTQ方法。具有较快的速度和简单易用的特性。
模型训练
- 训练时为保证精度,主权重始终为
FP32。 - 而推理时,
FP16权重通常能提供与FP32相似的精度
推理时使用 FP16 权重,仅需一半 GPU 显存就能获得相同的结果。那么是否还能进一步减少显存消耗呢?答案是用量化技术,最常见的就是 INT8 量化。
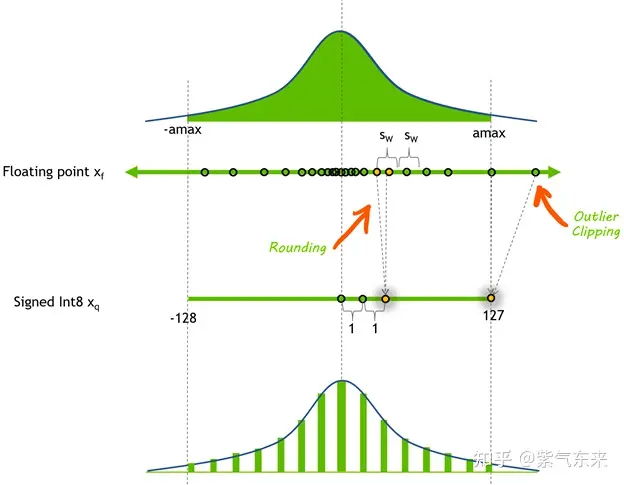
INT8 量化即将浮点数 xf 通过缩放因子 scale 映射到范围在 [-128, 127] 内的 8bit 表示 xq, 即:
- $ x_{q}=\operatorname{Clip}\left(\operatorname{Round}\left(x_{f} / \text { scale }\right)\right) $
-
$ scale = (2*max(\left x_f \right ))/254 $ - Round 表示四舍五入都整数,Clip 表示将离群值(Outlier) 截断到 [-128, 127] 范围内。
量化-反量化例子
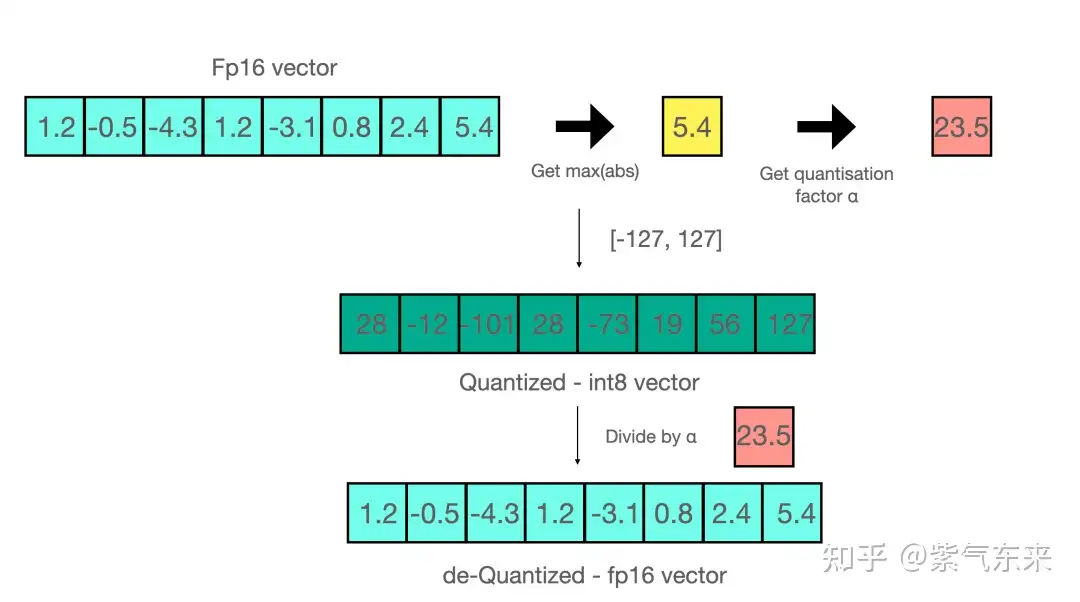
进行矩阵乘法时,可以通过组合各种技巧,例如逐行或逐向量量化,来获取更精确的结果。举个例子,对矩阵乘法,我们不会直接使用常规量化方式,即用整个张量的最大绝对值对张量进行归一化,而会转而使用向量量化方法,找到 A 的每一行和 B 的每一列的最大绝对值,然后逐行或逐列归一化 A 和 B 。最后将 A 与 B 相乘得到 C。最后,我们再计算与 A 和 B 的最大绝对值向量的外积,并将此与 C 求哈达玛积来反量化回 FP16。
由于 GPU 内核缺乏对某些类型的矩阵乘法(例如 INT4 x FP16)的支持,理论最优量化策略与硬件内核支持之间的差距,并非以下所有方法都能加速实际推理。
两个公式
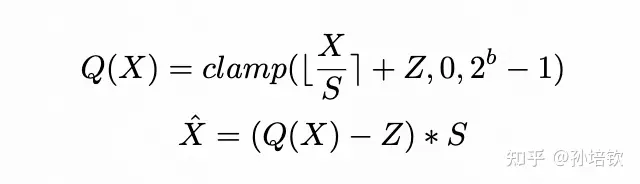
- 1式中,
Q(·)表示量化操作,X代表输入tensor,S即为scale,Z即为zero-point,b为量化位宽。 - 1式称为
quantization, 2式称为de-quantization. S和Z统称为量化参数, 多数的量化算法可以理解为找到更好的S和Z使得量化模型的结果尽可能逼近原模型的结果.
LLMs模型推理大致分为两个stage: context and generation.
- 在context阶段:causal attention 因果注意力, 其行为可以类比训练的前向过程;
- generations阶段:sequence length恒等于1。
这就要求推理框架需要支持两套计算逻辑(在FasterTransformer中可以看出)以适配其不同的特点. 在多数情况下, context阶段是compute bound(这不一定, 需要seqlen大于计算强度), 而generation是IO bound.
很多情况下, generation较context在应用中出现频率更高, 而量化模型由于其低位宽的权重表征, 可以大大缓解IO bound现象. (当然如果在服务时使得batch化技术来加大一次推理的batch的话, 量化的效果可能会退化为节约模型存储(功耗)下降).
关于量化的基本原理和实现细节,可参考笔者之前的文章:
许多关于 Transformer 模型量化的研究都有相同的观察结果:简单的低精度(例如 8 bit)训练后量化会导致性能显着下降,这主要是由于动态的 activation 和静态的 weight 量化策略无法保持一致。
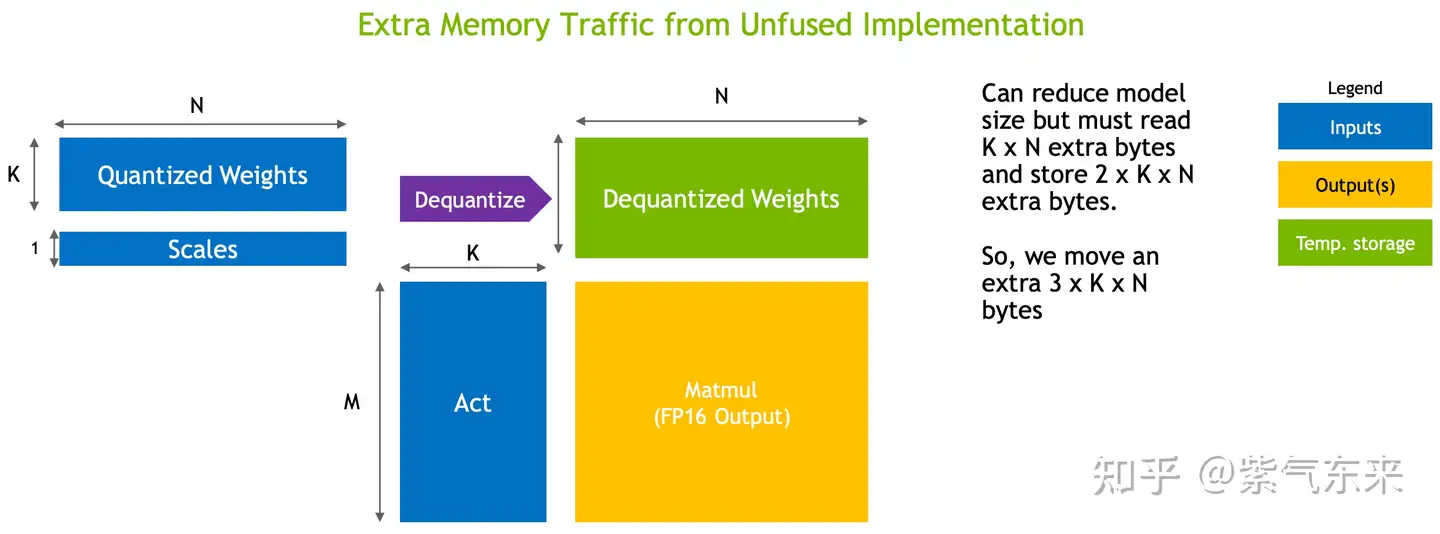
为了不损失精度而提高性能,可以考虑 WeightOnly 量化技术,即只把 Weight 量化成 int8 格式,以降低访存压力。到实际 Kernel 内部再 Dequantize 回 fp16,进行矩阵乘计算。这种方法在 BS 较小是比较有效(因为此时的瓶颈在IO),BS 较大时(因为此时的瓶颈在计算)效果变差。
WeightOnly 量化的典型案例是 AWQ: Activation-aware Weight Quantization,即只对 weight 进行量化以实现压缩和加速的效果。
LLMs 量化方法
常见方法
- LLM.in8
- SmoothQuant
- GPTQ
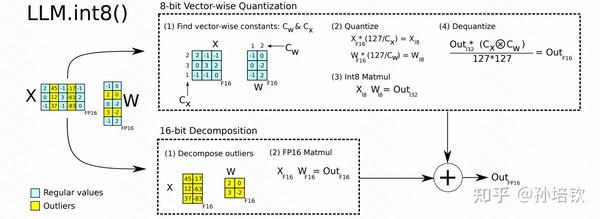
(1) LLM.int8()
由于input的outliers只会固定在几个特定的hidden-dim的特点(LLaMA模型中也有该现象, 且随着模型加深越发严重. RMSNorm引起), 且outliers占据的dims很少(不到1%). 故提出将Linear拆成两部分, 一部分为int8, 一部分为fp16, 分别计算后相加. 该方法得到广泛的应用, 有两个方面
- 一个是因为被huggingface集成
- 另一个是因为其几乎不掉点.
但该方法的缺点也是比较明显:
- 模型量化仅到8bit, 仍是4bit的2倍大;
- Linear的latency大幅上升, 原因在于它拆成两个matmul kernel, 而且后续为了fp16相加引入外积操作等, 即计算流程更为复杂多步.
(2) ZeroQuant系列
首次对采用input token-wise quantization 并结合 weight group-wise quantization; 另外设计LKD(Layerwise Knowledge Distillation, 使用随机生成的数据); 同时, 还做了一些kernel fused的工作, 实现了一个适配于int8的backend. 这系列的工作都比较像technical report, 且适用的模型尺寸比较小, 均在20B以下. 方法的scaling效果较差, 建议follow其量化粒度的设计.
(3) SmoothQuant
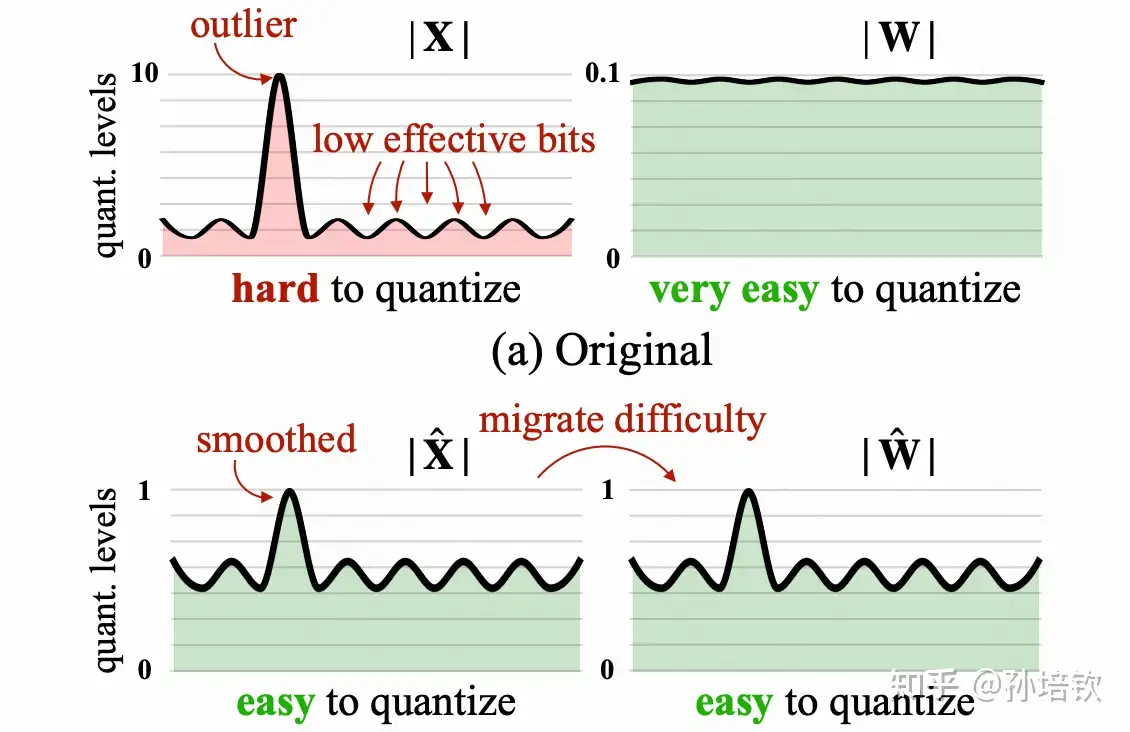
同样是为了解决input outlier的问题, 韩松团队提供将input的动态范围除上scale(该scale > 1即可以实现动态范围减小, 从而改善量化结果), 并将该scale吸到下一层的weight内, 利用weight的细粒度量化来承担该量化困难(因为input往往使用token-wise quantization, 而weight通常使用channel-wise quantization或group-wise quantization). 相较于LLM.int8(), 由于input和weight全都是int8, 并不会出现复杂的计算逻辑, 可以调用CUTLASS默认实现的int8 gemm来加速. 其缺点为: 精度没有LLM.int8()有保证, 且容易受到calibration-set的影响), 同时一旦weight精度调至4bit, 则模型精度下滑严重)
(3) GPTQ
经典之作, 目前几乎是4bit/3bit方案的默认首选, 但也仅限于开源世界的娱乐可用, 离落地认定的靠谱精度还是有比较大的距离. 源于同一团队在nips22的工作(Optimal Brain Compression)延伸, 其同样将方法泛化到剪枝领域(也是大模型剪枝领域的经典, SparseGPT). 该方法的思路大致为: 利用hessian信息作为准则判定每个权重量化后对输出loss(通常定义为MSE)造成的影响, 量化影响最大的权重(即最敏感)挑选出来先进行量化, 然后对其他权重进行更新来补偿该权重量化导致的影响, 如此往复, 直至全部量化结果. 当然, 在GPTQ中作了一些简化, 比如是基于列元素进行量化循环, 来减少算法的运行时间. 该方法的优点: 首次将4bit/3bit权重量化在176B的模型上做work, 同时也提出对应的kernel(但比较糙, 优化空间大, 有不少团队做了优化). 缺点: 4bit/3bit的方案原始kernel由于有unpack操作, 导致gemv操作的计算时间低于fp16), 且精度距离落地有明显距离. 注: 从它开始, 很多人只开始研究4w16f的方案(即weight-only quantization), 因为在batch=1的gemv计算中, 只需要控制权重的读入时间即可, 且input的动态范围过大, 量化掉点过大.
(4) AWQ, Activation-aware Weight Quantization
SmoothQuant的续作, 从源代码来看, 它对SmoothQuant中计算scale时需要的超参alpha, 增加 了一步通过grid search得到每个scale的最优参数, 但论文的故事包装得很好, 同时取得的效果也是十分显著的, 符合大道至简的准则. 该方案是也是4-bit weight-only quantization, 其kernel实现凭借对PTX的深刻理解和应用, 取得了目前这些weight-only quantization的方案的第一. 在此基础上稍加优化即可以得到一个不错的baseline.
(5) SqueezeLLM
通过观察到部分权重决定了最终模型的量化性能, 提出以非均匀量化的方式缩小这些敏感权重的量化误差. 即通过loss的二阶hessian信息来确定量化敏感的权重, 将量化点安置在这些敏感权重附近, 其它点以MSE最小来安置. 该方法以少量的存储空间换来了目前最优的4-bit weight精度, 但其缺点也是极其明显: 由于采用LUT来实现非均匀量化, 导致其kernel在batch > 1(文中的batch我均定义为 batch * seqlen)的情况下, Linear的执行速度急剧下滑。
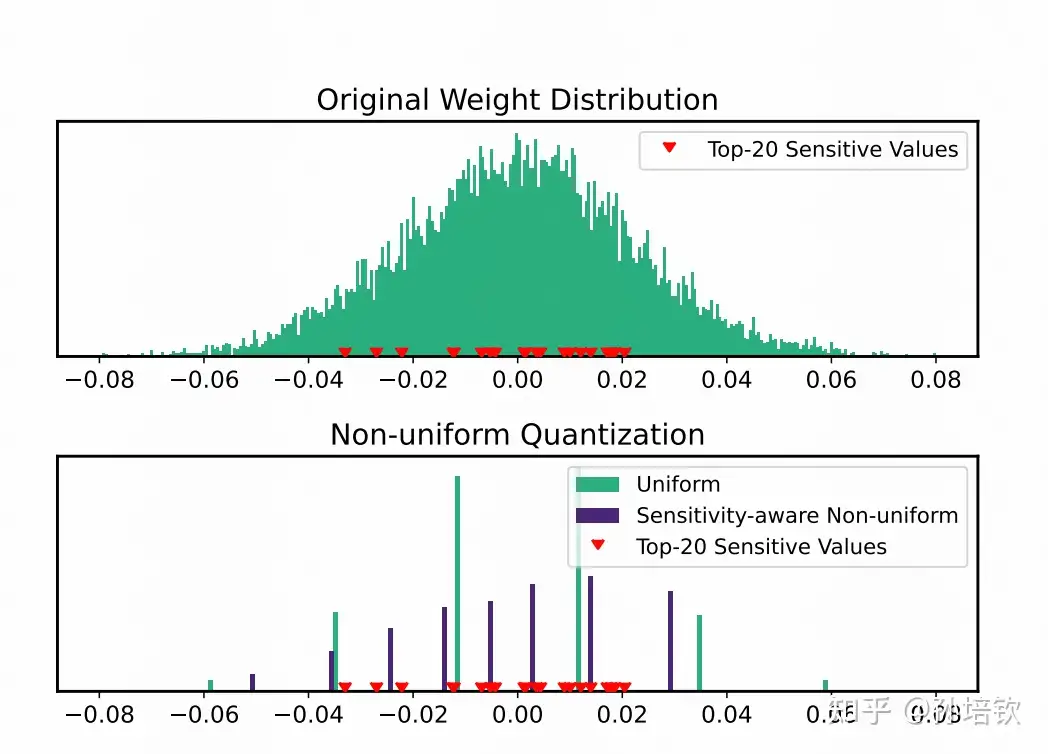
(6) QLoRA
这里顺带简单介绍一下QLoRA. 该方法提出4-bit NormalFloat, 一种新的数制(属于非均匀量化), 从理论角度上证明是4bit最优数制。 利用该方法量化模型的backbone得到4-bit的backbone, 然后基于lora进行SFT, 在只需要4-bit模型权重的情况下完成SFT, 从而使得许多人可以实现在单张消费级卡(i.e. 3080)上玩LLaMA。但当时我跑它的时候, 其缺点就是明显的kernel速度慢, 原因同样是因为它需要通过LUT来实现, 不知道现在情况怎么样了.
Summary & Future
4-bit weight-only quantization是一个相对比较均衡的方案。 在这个setting下, 量化的研究工作应更多集中在模型的精度提升的层面上, 尽可能地减少对模型智能的影响. 但对于如果想进一步得到更轻更快更强的模型, 可以从其他小型化策略入手. 在这些策略中, 蒸馏是一个最值得往前走的方案. 在LLaMA-2的tecnical report中就有多处地方使用了蒸馏, 比如: 在RLHF阶段仅用70B的reject sampling dataset来fine-tuning其他几个小尺寸的模型, 以及很多人都会尝试去用GPT4的SFT数据来fine-tuning自己的模型. 剪枝不太推荐, 因为至少从SparseGPT的复现结果来看, 除了非结构化剪枝精度还算有保证外, 其余方案精度下滑明显, 包括NV的2:4和4:8方案, 距离落地还有些距离, 且和量化结合后并不能进一步拿到50%的压缩收益。最后, 再提几点我认为有可能的方向:
- 更加系统全面地推理优化,包括: 更深度更大粒度的kernel-fusion, 其他部件优化(i.e. long context 下kv-cache的存储和IO时间, attention计算优化), system2的推理路径的优化
- 在模型训练中引入量化友好的策略, 来使得模型的权重和激活可以变得对量化不敏感, 从而实现4w4f
- 尝试引入QAT方案, 达到所见即所得, 拥抱极限 – 但这个有点太激进, 还是需要在模型有足够理解后去尝试.
- 端云推理的协同优化, 即手机端和GPU之间如何交互, 利用手机端训个人SFT, 分配算力等
量化实践
bitsandbytes3
bitsandbytes 基于 LLM.int8() 和 8 比特优化器论文中介绍的方法开发而成。
该库主要专注于大语言模型的 INT8 量化,主要提供对 8 比特矩阵乘法和 8 比特优化器的支持。
- 目前,bitsandbytes 还支持 4 比特的权重量化和混合精度分解方法,包括 NF4(4-bit NormalFloat)和 FP4 数据类型,可以进行加速模型的输出解码以及基于 QLoRA 的轻量化微调。
- 使用上,bitsandbytes 已经集成在 HuggingFace 中,加载模型时直接通过运行参数指定实现对模型权重的量化。
- 例如,可以使用参数 load_in_8bit 和 load_in_4bit 对模型进行 8 比特和 4 比特量化
PyTorch 量化
Quanto:pytorch量化工具包
- quanto是一个灵活的pytorch量化工具包,提供了独特的功能:
- 支持eager模式(可用于非可trace的模型)
- 量化后的模型可在任意设备上运行(包括CUDA和MPS)
- 自动插入量化和反量化代码
- 自动插入量化的函数操作
- 自动插入量化的模块(如QLinear、QConv2d等)
- 提供从动态到静态量化的流程
- 支持量化模型的状态字典序列化
- 不仅支持int8权重,还支持int2和int4
- 不仅支持int8激活,还支持float8
- 典型的量化流程包括:量化、校准、调优和冻结。
- quanto与huggingface transformers库深度集成,可通过QuantoConfig来量化任意模型。
- quanto的实现细节:
- 提供了针对不同量化类型的定制Tensor子类
- 提供了可处理quanto tensor的量化模块,如QLinear、QConv2d等
- 通过pytorch dispatch机制,实现了常见函数的量化版本
- 计划集成各种PTQ优化算法
- quanto的性能:
- 在多个模型上展示了不同量化配置的准确率
- 展示了相比全精度,量化带来的加速比
《Quanto: a pytorch quantization toolkit》
Mixtal GPTQ
huggingface上thebloke,每出一个新模型,就会上传对应的量化模型
- 目前已经有 3181 个量化模型
- Mixtral-8x7B-v0.1-GPTQ
【2024-1-10】智源团队提出首个用于自然语言理解任务的 1bit 轻量化预训练模型 BiPFT。与标准的FP32相比,使用 1bit weight 和 1bit activation,在推理阶段显著节省了56倍的操作数量和28倍的内存。该工作已被 AAAI 2024 收录。
与以往面向特定任务的 1bit Transformer结构的模型相比,BiPFT显著提升了 1bit 神经网络(BNN)的学习和泛化能力,与直接在下游任务上进行二值量化的BERT模型相比,BiPFT 模型在GLUE标准测试集上平均性能超过15.4%。
BitNet – 1 Bit 量化
【2023-10-29】BitNet:用1-bit Transformer训练LLM: 可扩展且稳定的 1-bit Transformer架构来实现大语言模型,称为BitNet。
- 使用BitLinear作为标准nn的替代品。
实验结果
BitNet能够显著减少存储占用和能力消耗,并且与最先进的8-bit量化和FP16Transformer能力相当。- BitNet也表现出了类似于全精度Transformer的scaling law
- 这也表明其有潜力在保持效率和性能的同时,能够更加有效的扩展至更大的语言模型。
模型结构
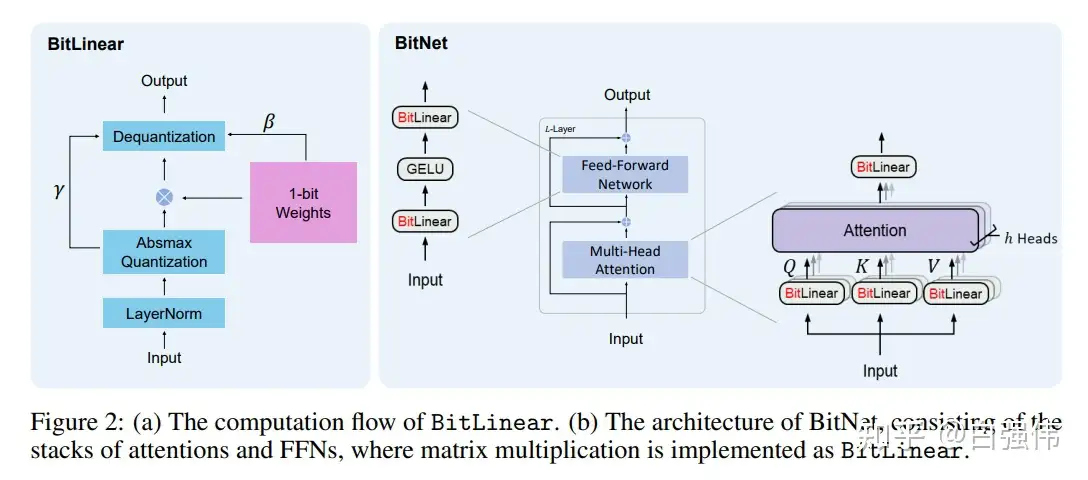
BitNet采用与Transformer相同的布局,但是采用BitLinear而不是标准的矩阵乘法,其他组件仍保持高精度。原因如下:
- (1) 残差连接和Layer Normalization的计算代价对于LLM可以忽略不计;
- (2) 随着模型增大,QKV变换的计算代价远小于投影;
- (3) 保留输入/输出嵌入层的精度,因为语言模型必须使用高精度来执行采样。
【2024-2-28】微软 The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits BitNet b1.58
1 Bit LLM变体,即BitNet b1.58
- LLM的每个参数(或权重)都是三进制
{- 1,0,1}。在困惑度和最终任务性能方面,它与全精度(即FP16或BF16) Transformer LLM相匹配,具有相同的模型大小和训练token,同时在延迟、内存、吞吐量和能耗方面明显更具有成本效益。 - 1.58位LLM定义了新的缩放规律和训练新一代高性能且具有成本效益的LLM的方法。
- 此外,实现了一种新的计算范式,并为设计针对1位llm优化的特定硬件打开了大门。
2.3 蒸馏(Distillation)
知识蒸馏是一种构建更小、更便宜的模型(“student 模型”)的直接方法,通过从预先训练的昂贵模型中转移技能来加速推理(“ teacher 模型”)融入 student。 除了与 teacher 匹配的输出空间以构建适当的学习目标之外,对于如何构建 student 架构没有太多限制。
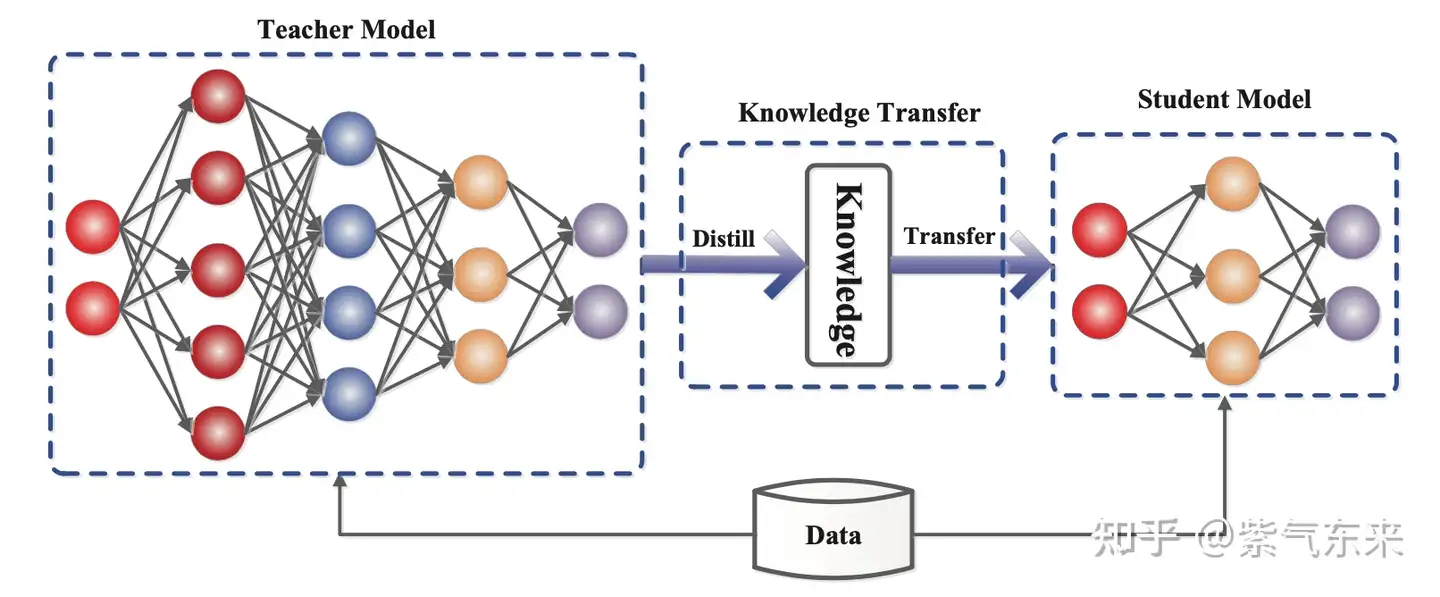
知识蒸馏基本框架
给定数据集,训练 student 模型通过蒸馏损失来模仿 teacher 的输出。 通常神经网络有一个softmax层; 例如,LLM 输出 token 的概率分布。 将 softmax 之前的 logits 层表示为 $\mathbf{z}_t\(\mathbf{z}_t$\\mathbf{z}\_t 和 $\mathbf{z}_s\)\mathbf{z}_s$\mathbf{z}_s , 分别表示 teacher 和 student 模型。 蒸馏损失最小化两个 softmax 输出之间的差异(温度 $T\(T$T )。 当标签 $y\)y$y 已知,可以将其与student 的 logits 之间计算交叉熵,最后将两个损失相加,如下:
$\mathcal{L}{\mathrm{KD}}=\mathcal{L}{\text {distll }}\left(\operatorname{softmax}\left(\mathbf{z}t, T\right), \operatorname{softmax}\left(\mathbf{z}_s, T\right)\right)+\lambda \mathcal{L}{\mathrm{CE}}\left(\mathbf{y}, \mathbf{z}s\right)$$\mathcal{L}{\mathrm{KD}}=\mathcal{L}{\text {distll }}\left(\operatorname{softmax}\left(\mathbf{z}_t, T\right), \operatorname{softmax}\left(\mathbf{z}_s, T\right)\right)+\lambda \mathcal{L}{\mathrm{CE}}\left(\mathbf{y}, \mathbf{z}_s\right)$\mathcal{L}_{\mathrm{KD}}=\mathcal{L}_{\text {distll }}\left(\operatorname{softmax}\left(\mathbf{z}_t, T\right), \operatorname{softmax}\left(\mathbf{z}_s, T\right)\right)+\lambda \mathcal{L}_{\mathrm{CE}}\left(\mathbf{y}, \mathbf{z}_s\right)
在 Transformer 中一个典型案例是DistilBERT,模型参数减少 40%,速度提升71%。在大模型时代,蒸馏可以与量化、剪枝或稀疏化技术相结合,其中 teacher 模型是原始的全精度密集模型,而 student 模型则经过量化、剪枝或修剪以具有更高的稀疏级别,以实现模型的小型化。
三、并行化(Parallelism)
大语言模型参数量较大,可能无法存放到单一计算设备中,分布式并行可以有效解决该问题。
- 分布式并行中的
模型并行和流水线并行已在 LLM 推理中得到应用。
当前的推理的并行化技术主要体现在3个维度上,即 3D Parallelism:
- Data Parallelism(DP)
- Tensor Parallelism(TP)
- Pipeline Parallelism(PP)

3D Parallelism 的3个维度
模型并行
模型并行通过将权重参数拆分到多个计算设备中,实现分布式计算。
模型并行两种常见方式:Column Parallel和Row Parallel
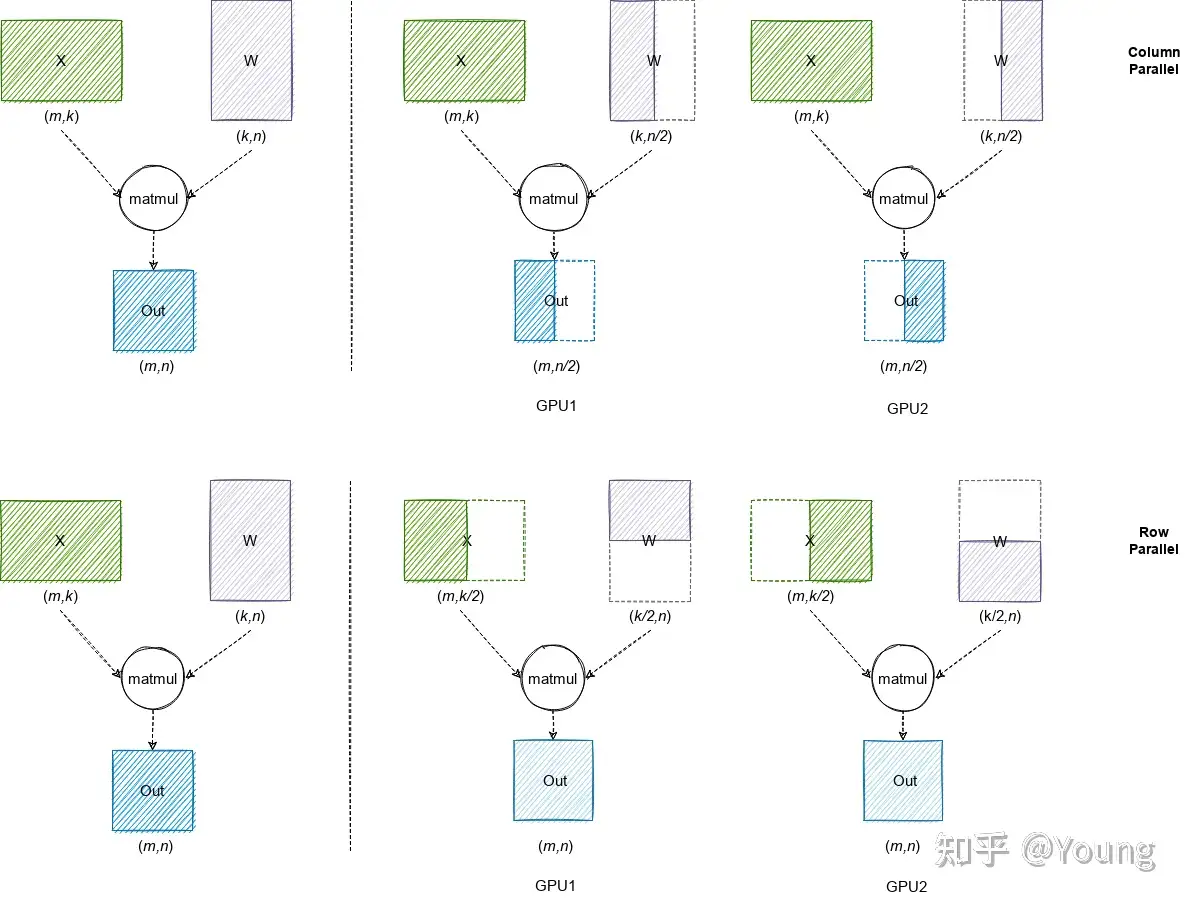
- 第一行代表
Column Parallel,即将权重数据按列拆分到多个 GPU 中,每个 GPU 上的本地计算结果需要在列方向拼接为最终结果; - 第二行代表
Row Parallel,即将权重数据按行拆分到多个 GPU 中,每个 GPU 上的本地计算结果需要 AllReduce 规约为最终结果。
业界最流行的模型并行方案来自 Megatron-LM,其针对 Self-Attention 和 MLP 分别设计了简洁高效的模型并行方案。
MLP: 第一个全连接层为 Column Parallel,第二个全连接层为 Row Parallel,整个 MLP 只需在 Row Parallel 后执行一次 AllReduce 规约操作即可。Self-Attention:在计算 Query、Key 和 Value 向量时执行 Column Parallel(按注意力头个数均分到每个 GPU),在将注意力得分做空间映射时执行 Row Parallel,整个 Self-Attention 只需在 Row Parallel 后执行一次 AllReduce 规约操作即可。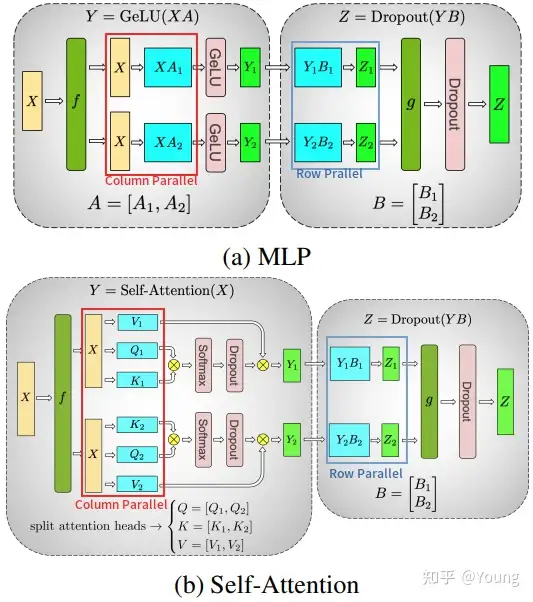
上面分析了 Transformer layer 的模型并行方式。除此之外,LLM 模型中的
- Input Embedding 采用
Row Parallel,Output Embedding 采用Column Parallel; - Dropout / Layer Norm / Residual Connections 等操作都没有做并行拆分。例如 Layer Norm 的权重参数和计算,在每个 GPU 上都是完整的。
| Layers | Model Parallel Method |
|---|---|
| Input Embedding | Row Parallel |
| Self-Attention | Column Parallel + Row Parallel |
| MLP | Column Parallel + Row Parallel |
| Output Embedding | Column Parallel |
以 LLaMA-34B 模型为例进行通信量分析。该模型包含 48 个 Transformer layers,隐藏层大小 8192,每次单 batch 推理共 2*48=96 次 Broadcast 和 2*48=96 次 AllReduce 操作,每次通信传输的数据量均为 16 KB(此处假设数据类型为半精度浮点,8192*2/1024=16 KB)。
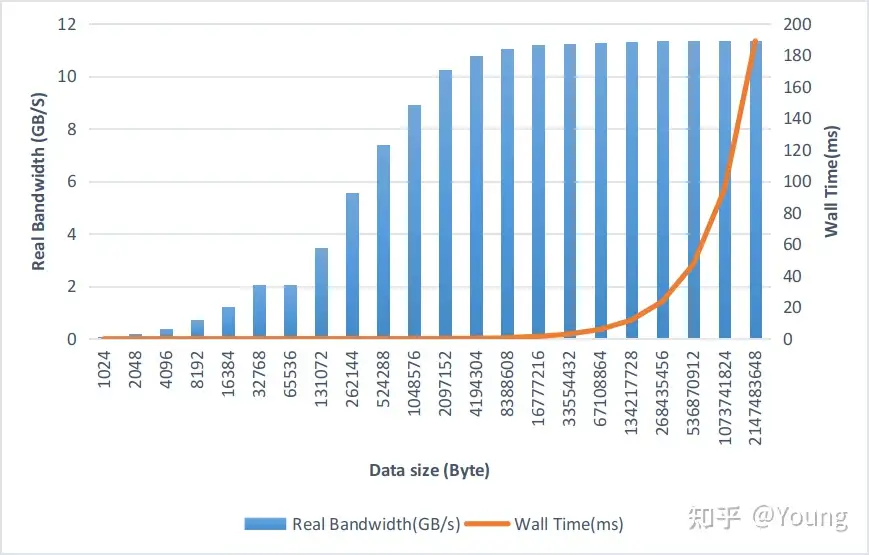
考虑到推理服务一般都是按多 batch 推理执行,假设 batchsize 为 64,每次通信传输的数据量也仅为 1 MB。下图在 A100-PCIE-40GB 机器上测试 NCCL AllReduce 带宽数据,PCIE 理论带宽为 32-64 GB/s 左右,实际推理场景下的通信数据量主要集中在 1 MB 以下,对应的实际带宽约为 1-10 GB/s。NVLink 理论带宽为 400-600 GB/s,但由于每次的通信量很小,实际带宽也远远小于理论带宽。
因此模型参数量越大、batchsize 越大,通信效率越高,使用模型并行获得的收益约明显。
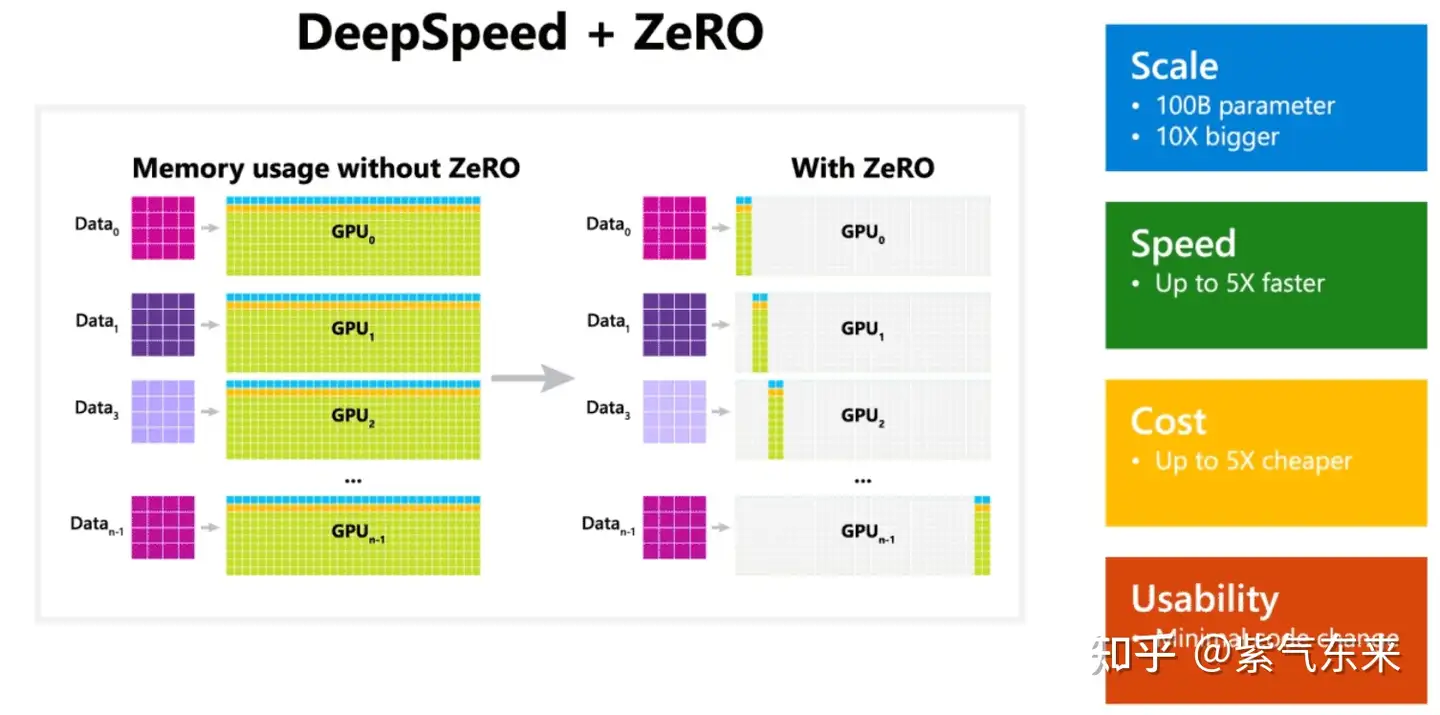
3.1 数据并行 (Data Parallelism, DP)
在推理中,DP 主要是增加设备数来增加系统整体 Throughput,其中最经典的即DeepSpeed的Zero系列
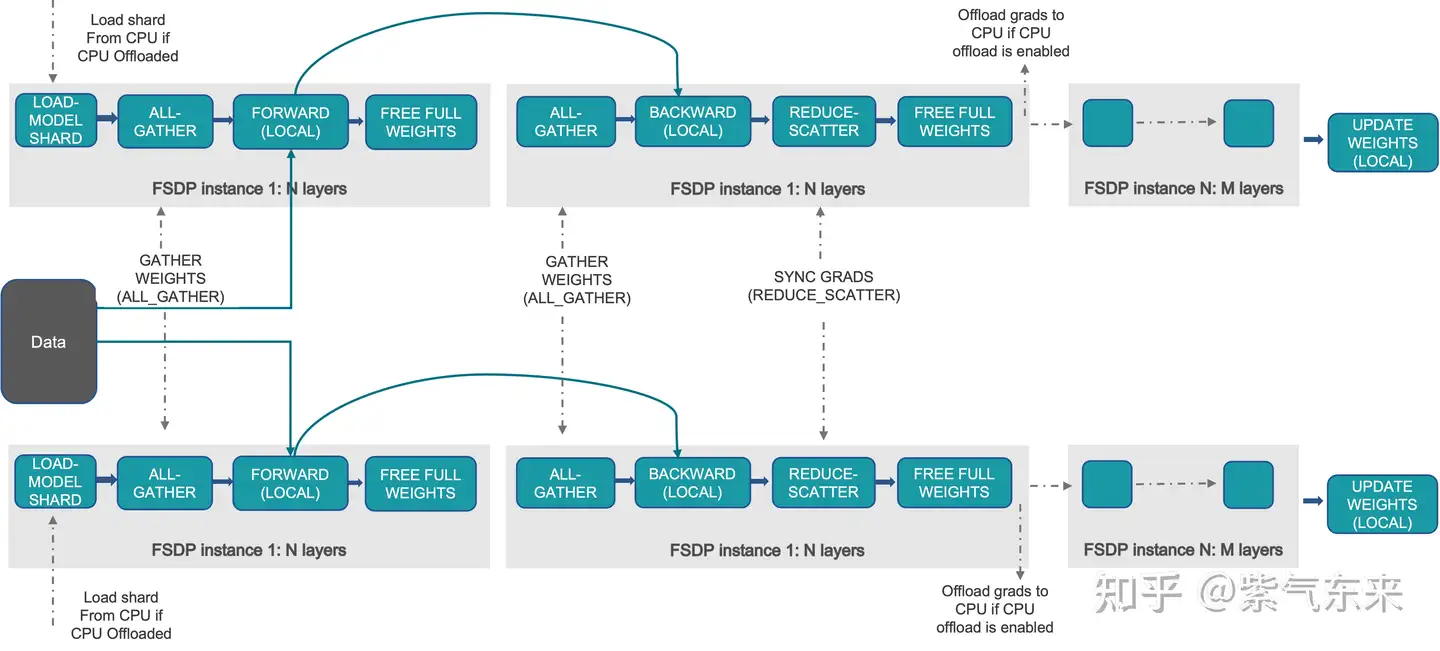
另外 FSDP 也比较高效和易用
3.2 张量并行(Tensor Parallelism, TP)
在推理中,TP 主要是横向增加设备数通过并行计算来减少 latency,其实现原理及细节可参考笔者之前的文章
当前也有一些方便易用的 TP 方案,如 BlackSamorez/tensor_parallel ,使用起来非常简单:
import transformers
import tensor_parallel as tp
tokenizer = transformers.AutoTokenizer.from_pretrained("facebook/opt-13b")
model = transformers.AutoModelForCausalLM.from_pretrained("facebook/opt-13b") # use opt-125m for testing
model = tp.tensor_parallel(model, ["cuda:0", "cuda:1"]) # <- each GPU has half the weights
inputs = tokenizer("A cat sat", return_tensors="pt")["input_ids"].to("cuda:0")
outputs = model.generate(inputs, num_beams=5)
print(tokenizer.decode(outputs[0])) # A cat sat on my lap for a few minutes ...
model(input_ids=inputs, labels=inputs).loss.backward() # training works as usual
当前主流的推理框架都支持 TP 的方式,包括但不限于:
- Megatron-LM
- FasterTransformer
- DeepSpeed Inference
- vLLM
- Text Generation Inference
- ParallelFormers
- ColossalAI
- FlexFlow
- LiBai
- AlpaServe
3.3 流水线并行(Pipeline Parallelism, PP)
在推理中,PP 主要是纵向增加设备数通过并行计算来支持更大模型,同时提高设备利用率。
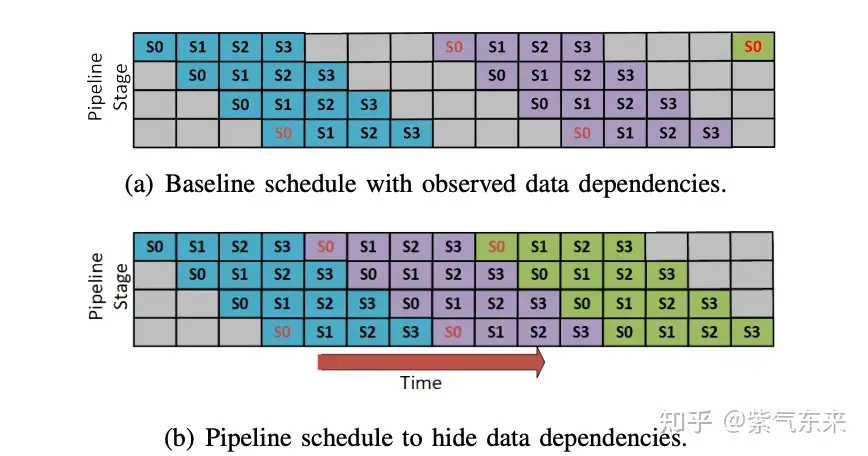
通常来说,PP 需要与 TP 结合以支持更大模型,并实现最佳效果
四、Transformer 结构优化 – 显存优化
该类方法主要通过优化 Transformer 的结构以实现推理性能的提升。
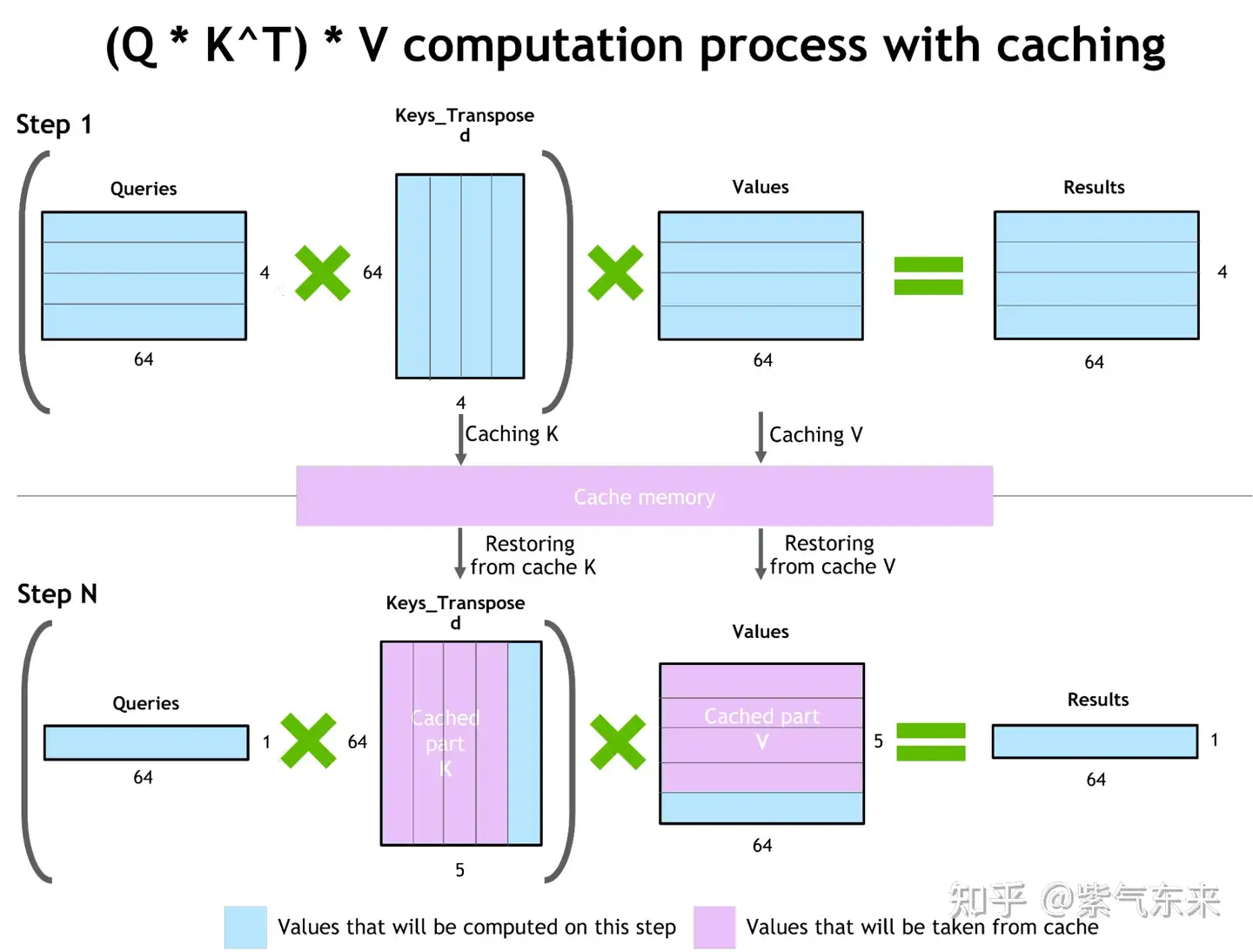
- 【2023-9-12】LLM推理优化技术综述:KVCache、PageAttention、FlashAttention、MQA、GQA
KV Cache
大模型推理性能优化一个最常用技术就是 KV Cache,该技术可以在不影响任何计算精度的前提下,通过空间换时间 提高推理性能。
- 目前业界主流 LLM 推理框架均默认支持并开启了该功能。
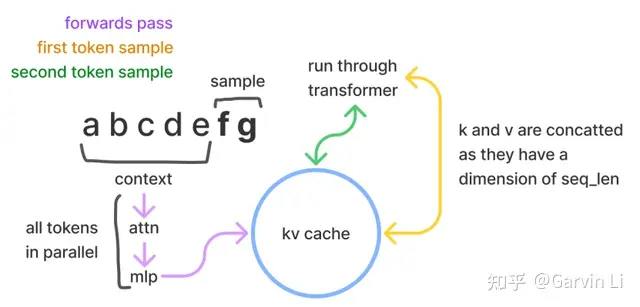
Transformer 模型具有自回归推理的特点
- 每次推理只会预测输出一个 token,当前轮输出token 与历史输入 tokens 拼接,作为下一轮的输入 tokens,反复执行多次。
- 前i次的token会作为第i+1次的预测数据送入模型,拿到第i+1次的推理token
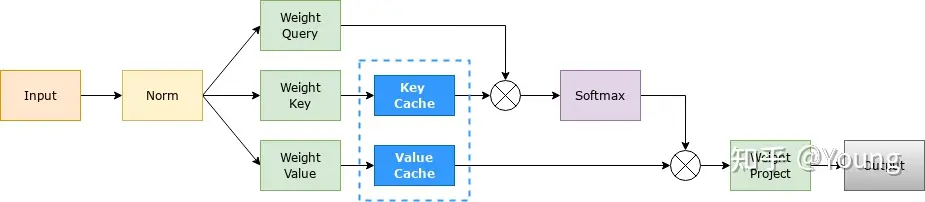
- Transformer会执行自注意力操作,要给当前序列中的每个项目(无论是prompt/context还是生成的token)提取键值(kv)向量
- 这些向量存储在一个矩阵中,通常被称为
kv cache。
- 该过程中,前后两轮的输入只相差一个 token,存在重复计算。
KV Cache 技术实现了将可复用的键值向量结果保存下来,从而避免了重复计算。
利用预先计算好的k值和v值,可以节省大量计算时间,尽管这会占用一定的存储空间。
LLM推理优化方案是尽可能减少推理过程中kv键值对的重复计算,实现kv cache的优化。
KV Cache 技术
- 每次自回归推理过程中,将 Transformer 每层的 Attention 模块中的 $ X_iW_k $ 和 $ X_iW_v $ 结果保存保存在一个数据结构(称为 KV Cache)中(如图)
- 当执行下一次自回归推理时,直接将 $ X_i+1W_k $ 和 $ X_i+1W_v $ 与 KV Cache 拼接在一起,供后续计算使用(如图)。其中,$ X_i $ 代表第 i 步推理的输入,$ W_k $ 和 $ W_v $ 分别代表键值权重矩阵。
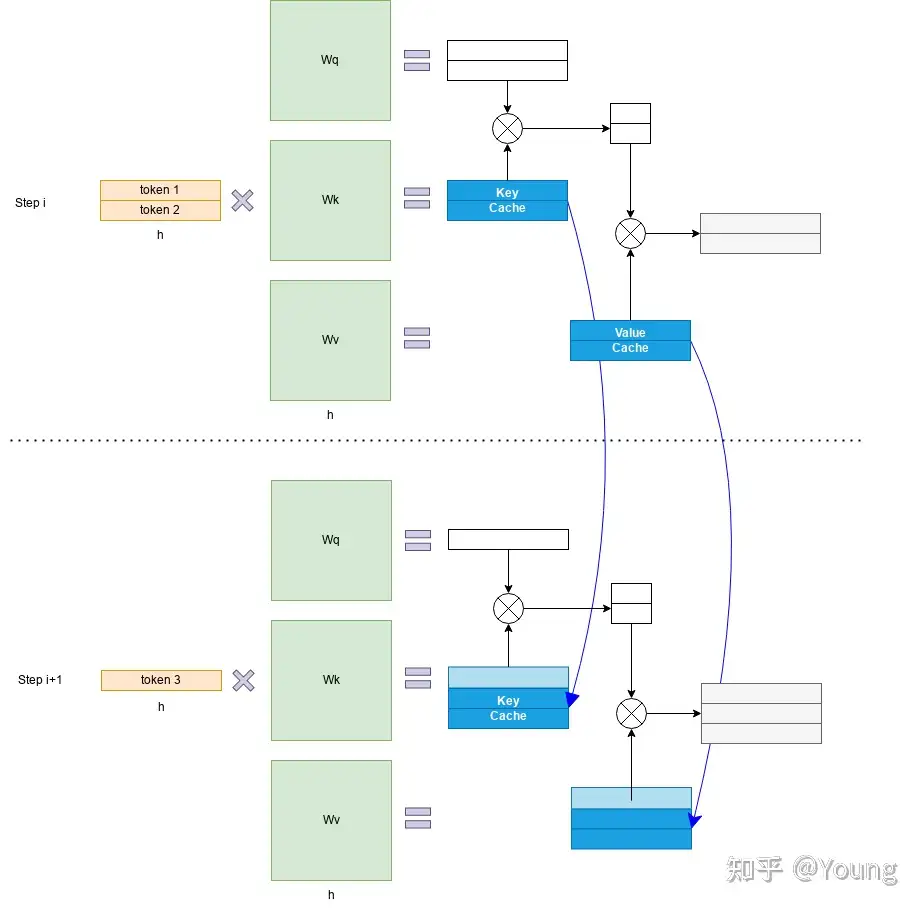
KV Cache 缓存每一轮已计算完毕的键值向量,因此会额外增加显存开销。
- KV Cache 与 batchsize 和序列长度呈线性关系。
KV Cache 的引入也使得推理过程分为如下两个不同阶段,进而影响到后续的其他优化方法。
- 预填充阶段:发生在计算第一个输出 token 过程中,计算时需要为每个 Transformer layer 计算并保存 key cache 和 value cache;FLOPs 同 KV Cache 关闭一致,存在大量 GEMM (GEneral Matrix-Matrix multiply) 操作,属于 Compute-bound 类型计算。
- 解码阶段:发生在计算第二个输出 token 至最后一个 token 过程中,这时 KV Cache 已存有历史键值结果,每轮推理只需读取 Cache,同时将当前轮计算出的新的 Key、Value 追加写入至 Cache;GEMM 变为 GEMV (GEneral Matrix-Vector multiply) 操作,FLOPs 降低,推理速度相对预填充阶段变快,这时属于 Memory-bound 类型计算。
目前减少KV cache的手段有许多,比如: page attention、MQA、MGA等,另外flash attention可以通过硬件内存使用的优化,提升推理性能。
4.1 Flash Attention
Flash attention 推理加速技术利用GPU硬件非均匀的存储器层次结构实现内存节省和推理加速
- 论文: “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”。通过合理的应用GPU显存实现IO的优化,从而提升资源利用率,提高性能。

硬件机制
- 计算速度越快的硬件往往越昂贵且体积越小
Flash attention 核心原理: 尽可能地合理应用SRAM内存计算资源。
A100 GPU有40-80GB的高带宽内存(HBM),带宽为1.5-2.0 TB/s,而每108个流处理器有192KB的SRAM,带宽估计在19TB/s左右。存在一种优化方案是利用SRAM远快于HBM的性能优势,将密集计算尽放在SRAM,减少与HBM的反复通信,实现整体的IO效率最大化。
- 比如可以将矩阵计算过程,softmax函数尽可能在SRAM中处理并保留中间结果,全部计算完成后再写回HBM,这样就可以减少HBM的写入写出频次,从而提升整体的计算性能。
如何有效分割矩阵的计算过程,涉及到flash attention的核心计算逻辑Tiling算法,这部分在论文中也有详细的介绍。
实现细节参考文章
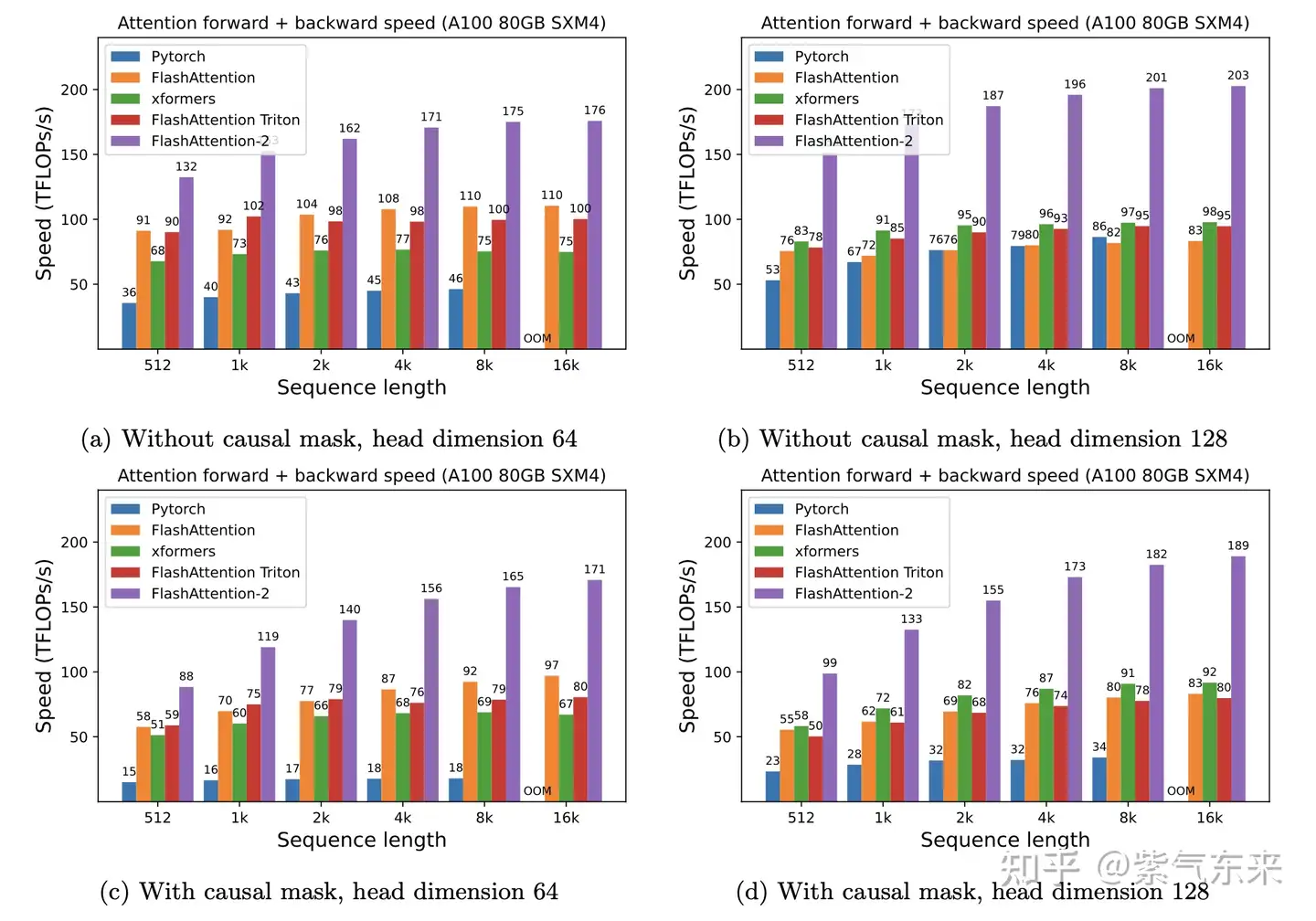
FlashAttention-v2 在原基础上做了改进,使其在算法、并行化和工作分区等方面都有了显著改进,对大模型的适用性也更强。在A100 上性能数据如下:
Flash-Decoding
【2023-10-17】Flash-Decoding方法
斯坦福博士新作:长上下文LLM推理速度提8倍
FlashAttention团队最近推出了Flash-Decoding方法,用于在Transformer架构大模型推理时加速。该方法通过并行计算每个token的注意力值,并在每一步计算过程中使用FlashAttention的优化,从而使长上下文推理变得更快。该方法已经在64k的CodeLlama-34B上得到了验证,并得到了PyTorch官方认可。
4.2 PagedAttention 显存优化, vLLM
LLM 推理服务的吞吐量指标主要受制于显存限制。
- 现有系统由于缺乏精细的显存管理方法而浪费了 60% 至 80% 的显存,浪费的显存主要来自 KV Cache。
因此,有效管理 KV Cache 是一个重大挑战。
Paged Attention 之前,业界主流 LLM 推理框架在 KV Cache 管理方面均存在一定的低效。
- HuggingFace Transformers 库中,KV Cache 是随着执行动态申请显存空间,由于 GPU显存分配耗时一般都高于 CUDA kernel 执行耗时,因此动态申请显存空间会造成极大的时延开销,且会引入显存碎片化。
- FasterTransformer 中,预先为 KV Cache 分配了一个充分长的显存空间,用于存储用户的上下文数据。
- 例如 LLaMA-7B 的上下文长度为 2048,则需要为每个用户预先分配一个可支持 2048 个 tokens 缓存的显存空间。如果用户实际使用的上下文长度低于2048,则会存在显存浪费。
Paged Attention 将传统操作系统中对内存管理的思想引入 LLM,实现了一个高效的显存管理器,通过精细化管理显存,实现了在物理非连续的显存空间中以极低的成本存储、读取、新增和删除键值向量。
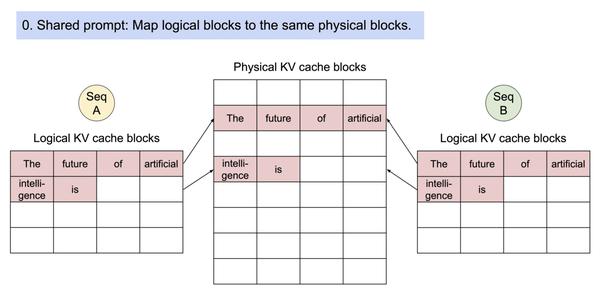
具体来讲,Paged Attention 将每个序列的 KV Cache 分成若干块,每个块包含固定数量token 的键和值。
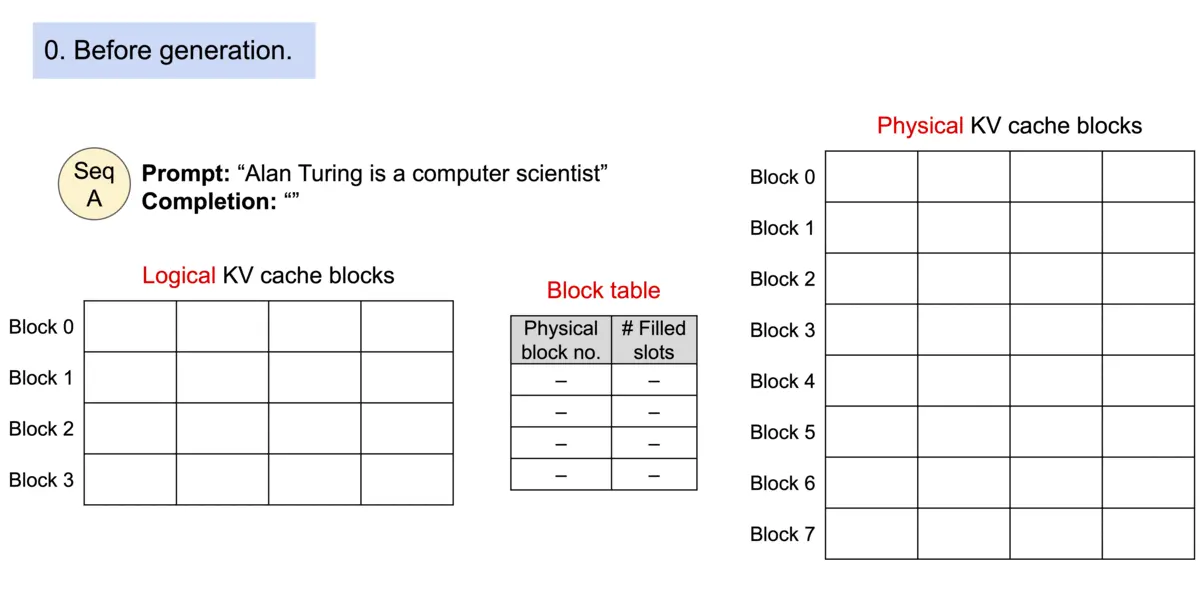
- 首先在推理实际任务前,会根据用户设置的 max_num_batched_tokens 和 gpu_memory_util 预跑一次推理计算,记录峰值显存占用量 peak_memory,然后根上面公式获得当前软硬件环境下 KV Cache 可用的最大空间,并预先申请缓存空间。其中,max_num_batched_tokens 为部署环境的硬件显存一次最多能容纳的 token 总量,gpu_memory_util 为模型推理的最大显存占用比例,total_gpu_memory 为物理显存量, block_size 为块大小(默认设为 16)。
- 实际推理过程中,维护一个逻辑块到物理块的映射表,多个逻辑块可以对应一个物理块,通过引用计数来表示物理块被引用的次数。当引用计数大于一时,代表该物理块被使用,当引用计数等于零时,代表该物理块被释放。通过该方式即可实现将地址不连续的物理块串联在一起统一管理。
Paged Attention 技术开创性地将操作系统中的分页内存管理应用到 KV Cache 的管理中,提高了显存利用效率。另外,通过 token 块粒度的显存管理,系统可以精确计算出剩余显存可容纳的 token 块的个数,配合后文 Dynamic Batching 技术,即可避免系统发生显存溢出的问题。
PageAttention 是目前kv cache优化的重要技术手段,目前最热的大模型推理加速项目vLLM核心就是PageAttention技术。
- 在缓存中 KV cache 都很大,并且大小是动态变化的,难以预测。已有系统中,由于显存碎片和过度预留,浪费了60%-80%的显存。
- PageAttention提供了一种技术手段解决显存碎片化的问题,从而可以减少显存占用,提高KV cache可使用的显存空间,提升推理性能。
首先,PageAttention命名灵感来自OS系统中虚拟内存和分页思想。可以实现在不连续空间存储连续的kv键值
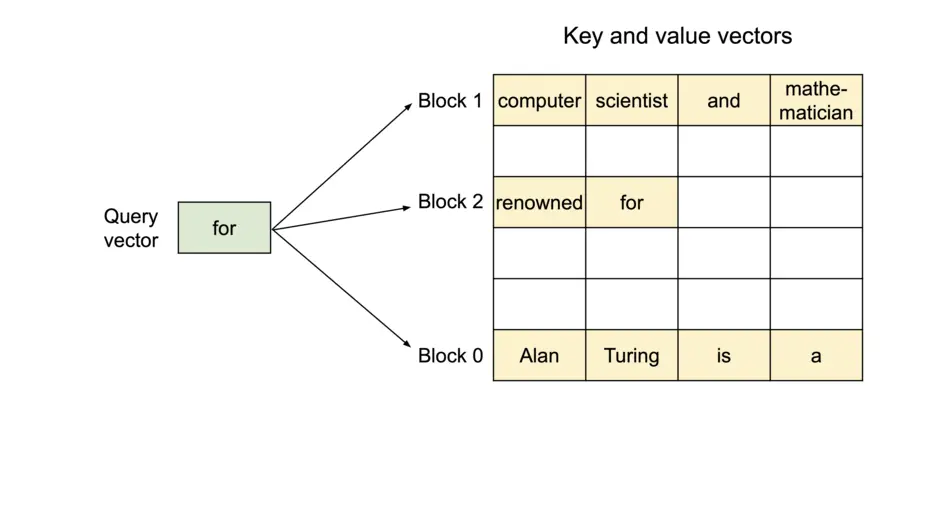
- 所有键值都是分布存储的,需要通过分页管理彼此的关系。序列的连续逻辑块通过 block table 映射到非连续物理块。
- 同一个prompt生成多个输出序列,可以共享计算过程中的attention键值,实现copy-on-write机制,即只有需要修改的时候才会复制,从而大大降低显存占用。
可参考
MHA/GQA/MQA优化技术
LLAMA2的论文提到了相关技术用来做推理优化,目前GQA和MQA也是许多大模型推理研究机构核心探索的方向。
MQA,全称 Multi Query AttentionMQA让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
- 而
GQA则是前段时间 Google 提出的MQA变种,全称 Group-Query Attention。MHA(Multi-head Attention)是标准的多头注意力机制,h个Query、Key 和 Value 矩阵。- GQA 将查询头分成N组,每个组共享一个Key 和 Value 矩阵
GQA以及MQA都可以实现一定程度的Key value的共享,从而可以使模型体积减小,GQA是MQA和MHA的折中方案。
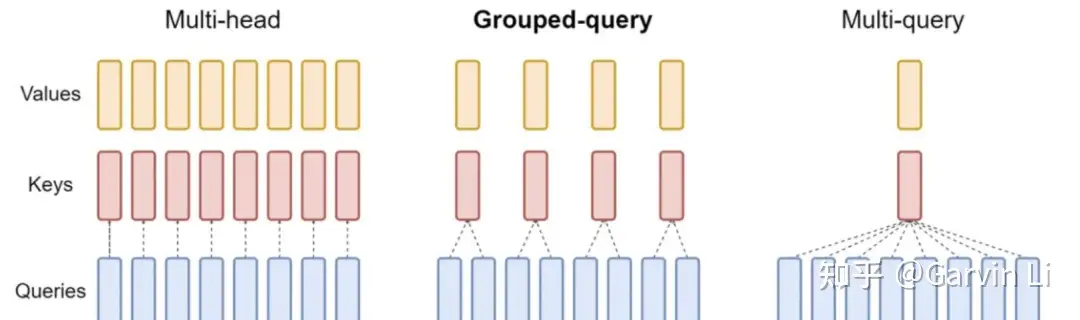
这两种技术的加速原理是
- (1)减少了数据的读取
- (2)减少了推理过程中的KV Cache。
注意:
- GQA和MQA需要在模型训练时开启,按照相应的模式生成模型。
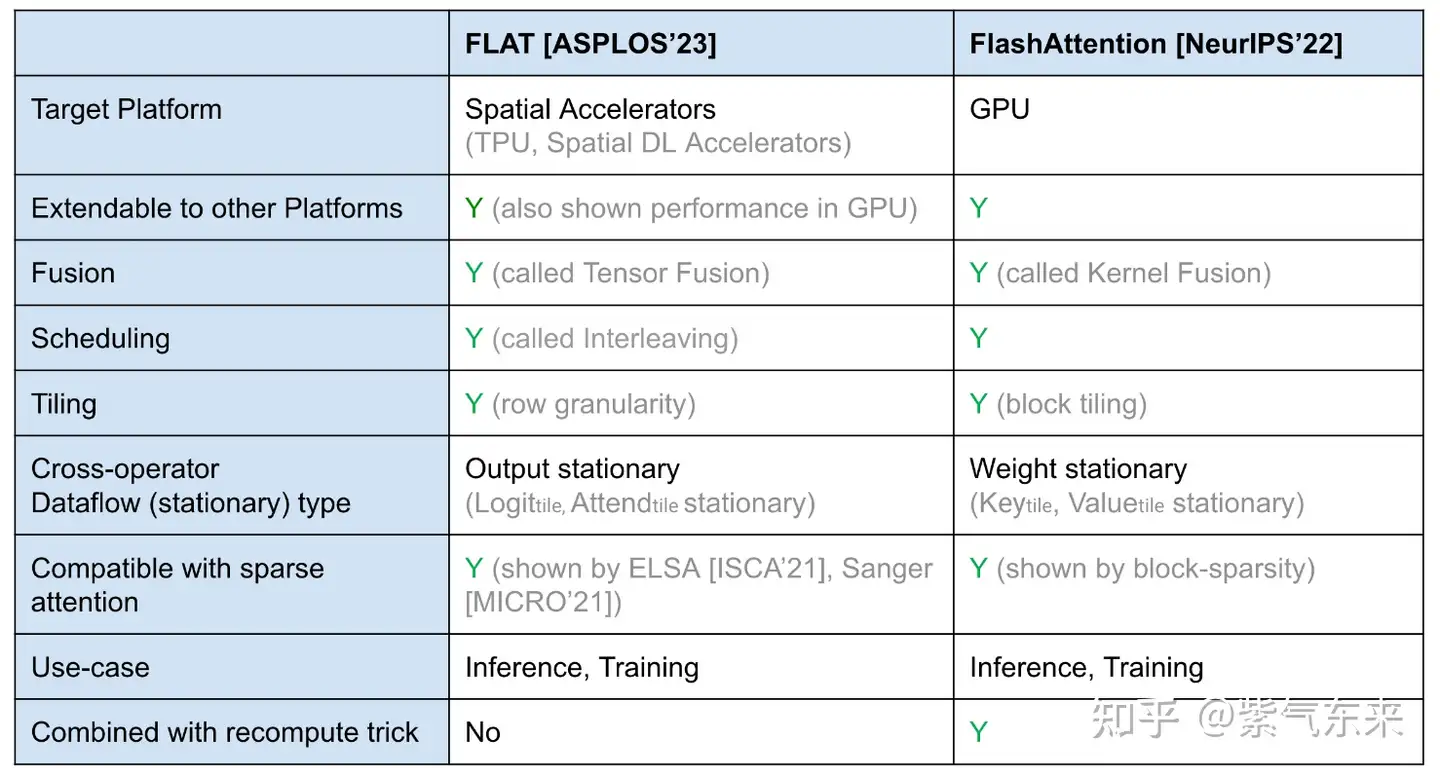
4.3 FLAT Attention
FLAT-Attention 与 FlashAttention 采取不同的路线来解决同一问题。 提出的解决方案有所不同,但关键思想是相同的(tiling 和 scheudling)。下面主要讨论二者不同之处:
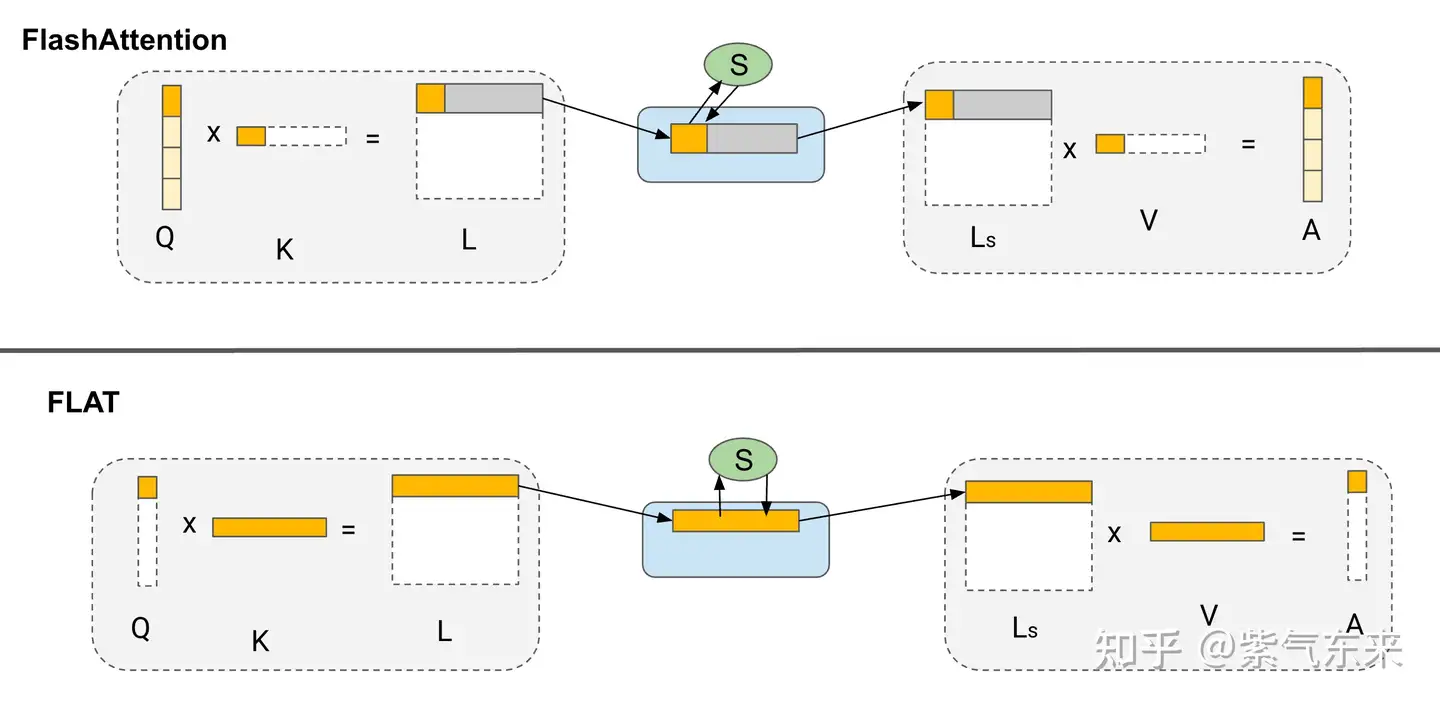
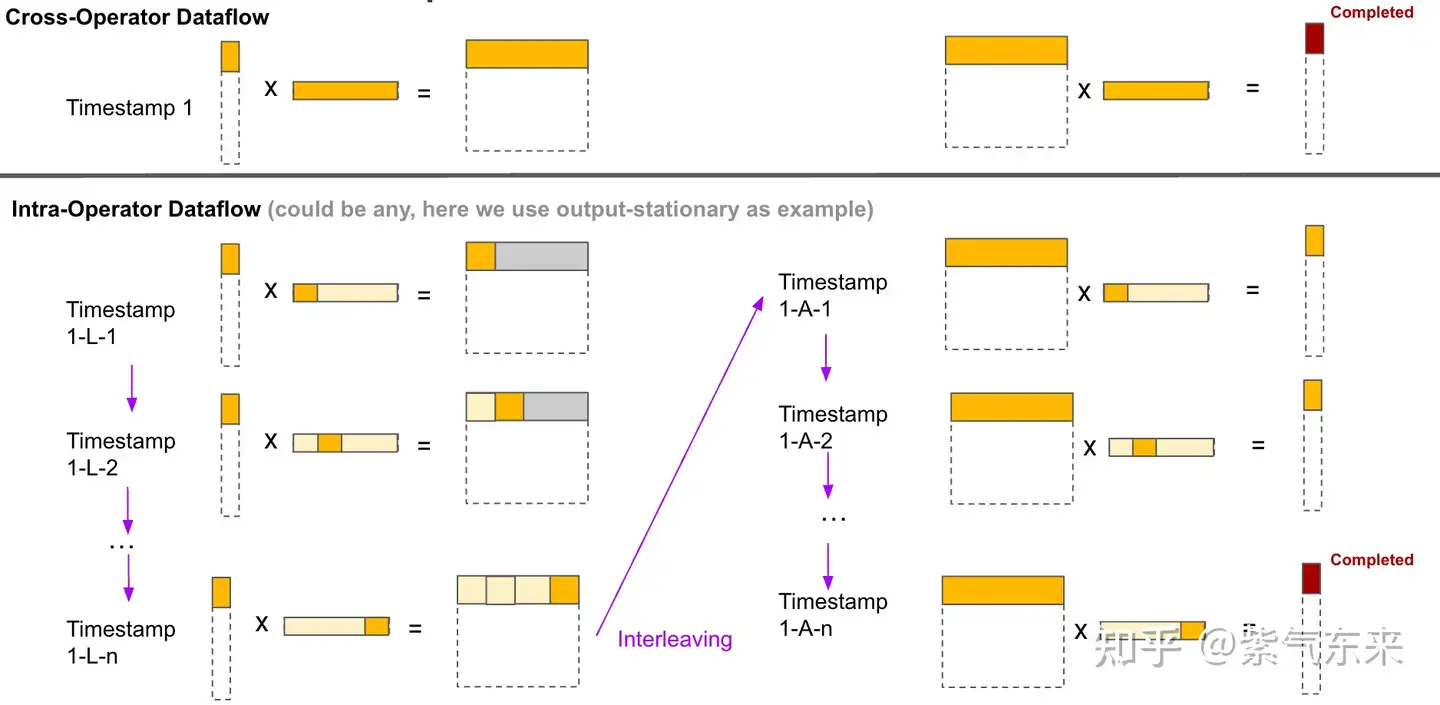
4.3.1 Tiling 策略比较
FlashAttention 使用块平铺和权重固定。 FLAT-Attention 使用行平铺(行粒度)和输出固定。
4.3.2 Scheduling 策略(数据流)比较
FlashAttention 的 Scheduling 过程
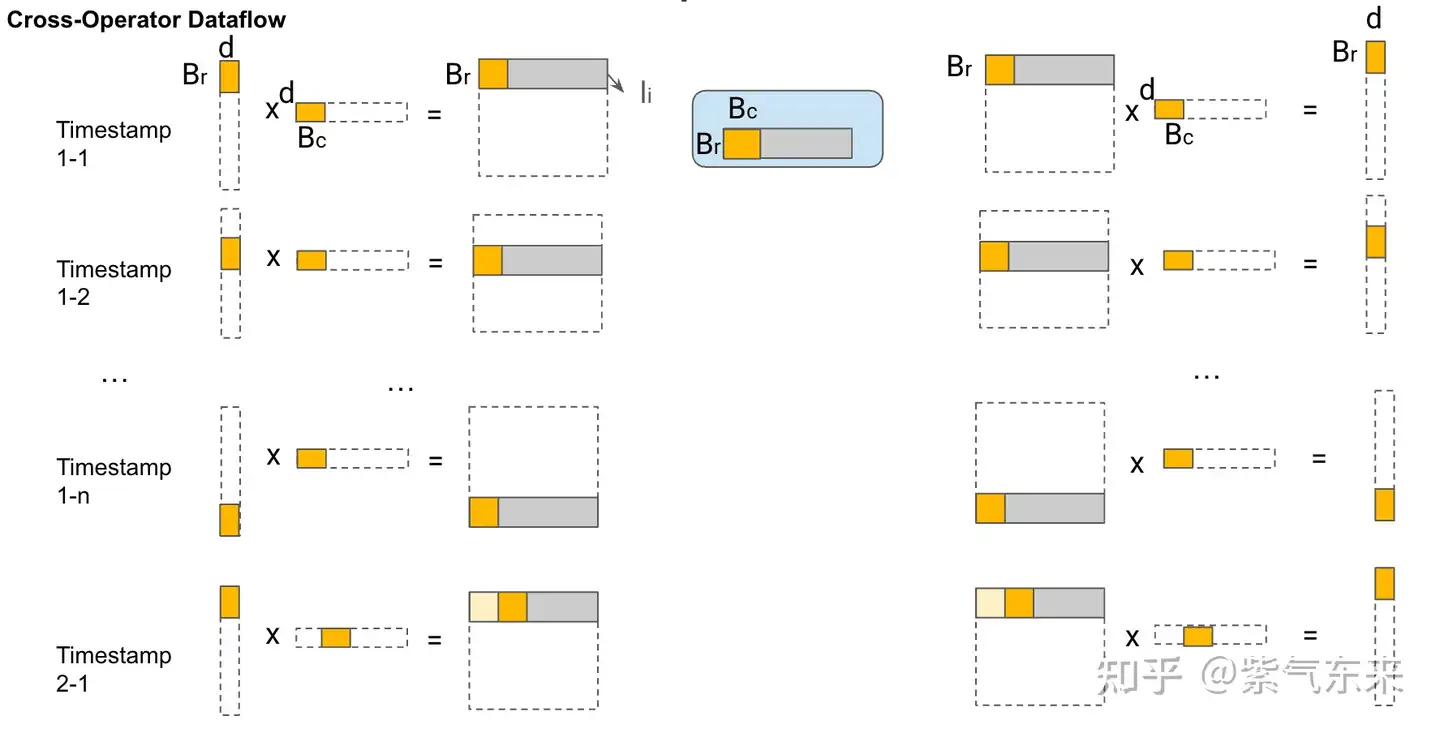
FLAT-Attention 的 Scheduling 过程
【2023-11-20】META S2A
【2023-11-20】System 2 Attention (is something you might need too)
System 2 Attention (S2A) 将 system 2思想引入注意力,改进推理效果
Meta AI 的系统2注意力(S2A),包括提示LLM创建一个上下文,剥离掉可能扭曲推理的不相关信息。
LLM提供了一个上下文(x),并负责生成高质量的输出(y)。S2A通过两步法修改了这个过程。
- 首先,S2A通过删除可能对输出产生负面影响的元素,将给定的上下文(x)重新表述为精炼的版本(x’)。用
x' ~ S2A(x)表示。 - 然后,LLM使用修改后的上下文
(x')生成最终响应(y),而不是用y ~ LLM(x')表示的原始上下文。

Meta AI选择LLaMA-2-70B-chat作为他们的主要评估模型。
【2023-11-6】Stateful API
OpenAI 11月6日 提到的Stateful API 背后用的技术类似于KV Cache,每次NTP下一字预测时,使用缓存,不再重新计算前面的所有字符注意力,空间换时间,提高推理性能
【2023-4-11】GPTCache – query语义缓存
GPTCache将query转换为向量进行相似性搜索,从缓存中检索相关查询,本质上还是语义缓存。
GPTCache是一个开源库,支持OpenAI ChatGPT 接口和 LangChain 接口
- 通过缓存语言模型的response来提高 GPT 应用的效率和速度。
- 支持用户根据自定义缓存规则,包括 embedding 函数、相似性计算方式、存储位置和存储逐出规则等。
三个词来概括:高效(省时间)、节约成本(省钱)、定制化(省劲儿)
GPTCache 工作原理
GPTCache 利用在线服务的数据局部性特点,存储常用数据,降低检索时间,减轻后端服务器负载。
- 与传统缓存系统不同,GPTCache 进行语义缓存,识别并存储相似或相关的查询以提高缓存命中率。
GPTCache 通过 embedding 算法将query转换为向量,并使用向量数据库进行相似性搜索,从缓存中检索相关查询。
GPTCache 采用了模块化的设计,允许用户灵活自定义每个模块。

虽然语义缓存可能会返回假正类(false positive)和负类(negative)结果,但 GPTCache 提供 3 种性能指标来帮助开发人员优化其缓存系统。
通过上述流程,GPTCache 能够从缓存中寻找并召回相似或相关查询,如下图所示。

GPTCache 模块化的架构设计方便用户定制个性化语义缓存。每个模块都提供多种选择,适合各种应用场景。
- 大语言模型适配器(LLM Adapter): 适配器将大语言模型请求转换为缓存协议,并将缓存结果转换为 LLM 响应。适配器方便轻松集成所有大语言模型,并可灵活扩展。GPTCache 支持多种大语言模型,包括:
- OpenAI ChatGPT API
- langchain
- Minigpt4
- Llamacpp
- dolly
- 后续将支持:Hugging Face Hub、Bard、Anthropic 等
- 预处理器(Pre-Processor):预处理器管理、分析请求,并在将请求发送至 LLM 前调整请求格式,具体包括:移除输入种冗余的信息、压缩输入信息、切分长文本、执行其他相关任务等。
- 向量生成器(Embedding Generator): Embedding 生成器将用户查询的问题转化为 embedding 向量,便于后续的向量相似性检索。GPTCache 支持多种模型,包括:
- OpenAI embedding API
- ONNX(GPTCache/paraphrase-albert-onnx 模型)
- Hugging Face embedding API
- Cohere embedding API
- fastText embedding API
- SentenceTransformers embedding API
- Timm 模型库中的图像模型
- 缓存存储(Cache Store): GPTCache 将 LLM 响应存储在各种数据库管理系统中。GPTCache 支持丰富的缓存存储数据库,用户可根据性能、可扩展性需求和成本预算,灵活选择最适合的数据库。GPTCache 支持多个热门数据库,包括:
- SQLite
- PostgreSQL
- MySQL
- MariaDB
- SQL Server
- Oracle
- 向量存储(Vector Store): 向量存储模块会根据输入请求的 embedding 查找 top-K 最相似的请求。简而言之,该模块用于评估请求之间的相似性。GPTCache 的界面十分友好,提供丰富的向量存储数据库。选择不同的向量数据库会影响相似性检索的效率和准确性。GPTCache 支持多个向量数据库,包括:
- Milvus
- Zilliz Cloud
- Milvus Lite
- Hnswlib
- PGVector
- Chroma
- DocArray
- FAISS
- 逐出策略(Eviction Policy) 管理:控制缓存存储和向量存储模块的操作。缓存满了之后,缓存替换机制会决定淘汰哪些数据,为新数据腾出空间。GPTCache 目前支持以下两种标准逐出策略:
- “最近最少使用”逐出策略(Least Recently Used,LRU)
- “先进先出”逐出策略(First In First Out,FIFO)
- 相似性评估器(Similarity Evaluator): GPTCache 中的相似性评估模块从 Cache Storage 和 Vector Store 中收集数据,并使用各种策略来确定输入请求与来自 Vector Store 的请求之间的相似性。该模块用于确定某一请求是否与缓存匹配。GPTCache 提供标准化接口,集成各种相似性计算方式。多样的的相似性计算方式能狗灵活满足不同的需求和应用场景。GPTCache 根据其他用例和需求提供灵活性。
- 后处理器(Post-Processor):后处理器负责在返回响应前处理最终响应。如果没有命中缓存中存储的数据,大语言模型适配器会从 LLM 请求响应并将响应写入缓存存储中。
服务优化
服务相关优化主要包括:Continuous Batching、Dynamic Batching 和 异步 Tokenize / Detokenize。
- Continuous Batching 和 Dynamic Batching 主要围绕提高可并发的 batchsize 来提高
吞吐量 - 异步 Tokenize / Detokenize 则通过多线程方式将 Tokenize / Detokenize 执行与模型推理过程时间交叠,实现降低时延目的。
| 问题分类 | 现象 | 解决方法 | 实现原理 | 特点 |
|---|---|---|---|---|
| 问题一 | 同批次序列推理时,存在“气泡”,导致 GPU 资源利用率低 | Continuous Batching | 由 batch 粒度的调度细化为 step 级别的调度 | 在时间轴方向动态插入新序列 |
| 问题二 | 批次大小固定不变,无法随计算资源负载动态变化,导致 GPU 资源利用率低 | Dynamic Batching | 通过维护一个作业队列实现 | 在 batch 维度动态插入新序列 |
| 问题三 | Tokenize / Detokenize 过程在 CPU 上执行,期间 GPU 处于空闲状态 | 异步 Tokenize / Detokenize | 多线程异步 | 流水线 overlap 实现降低时延 |
大语言模型的输入和输出均是可变长度。对于给定问题,模型在运行前无法预测其输出长度。在实际服务场景下,每个用户的问题长度各不相同,问题对应的答案长度也不相同。传统方法在同批次序列推理过程中,存在“气泡”现象,即必须等同批次内的所有序列完成推理之后,才会执行下一批次序列,这就会引起 GPU 资源的浪费,导致 GPU 利用率偏低。
- 图 6 Static Batching示意图
图中序列 3 率先结束,但由于其他序列尚未结束,因此需要等待直至所有序列计算完毕。理想情况下,同批次的所有序列的输入加输出的长度均相同,这时不存在“气泡”现象;极端情况下则会出现超过 50% 以上的资源浪费。
另一方面,传统方法推理时 batchsize 是固定不变的,无法随计算资源负载动态变化。比如某一段时间内,同批次下的序列长度都偏短,原则上可以增加 batchsize 以充分利用 GPU 计算资源。然而由于固定 batchsize,无法动态调整批次大小。
Continuous Batching 和 Dynamic Batching 最早来自论文 Orca: A Distributed Serving System for Transformer-Based Generative Models。针对问题一,提出 Continuous Batching,原理为将传统 batch 粒度的任务调度细化为 step 级别的调度。首先,调度器会维护两个队列,分别为 Running 队列和 Waiting 队列,队列中的序列状态可以在 Running 和 Waiting 之间转换。在自回归迭代生成每个 token 后,调度器均会检查所有序列的状态。一旦序列结束,调度器就将该序列由 Running 队列移除并标记为已完成,同时从 Waiting 队列中按 FCFS (First Come First Service) 策略取出一个序列添加至 Running 队列。
- 图 7 Continuous Batching示意图
图中,序列 3 率先在 T5 时刻结束,这时调度器会检测到序列 3 已结束,将序列 3 从 Running 队列中移除,并从 Waiting 队列中按 FCFS 策略取出序列 5 添加至 Running 队列并启动该序列的推理。通过该方法,即可最大限度地消除“气泡”现象。
问题一可以理解为在时间轴方向动态插入新序列,问题二则是在 batch 维度动态插入新序列,以尽可能地充分利用显存空间。具体来讲,在自回归迭代生成每个 token 后,调度器通过当前剩余显存量,动态调整 Running 队列的长度,从而实现 Dynamic Batching。例如,当剩余显存量较多时,会尽可能增加 Running 队列长度;当待分配的 KV Cache 超过剩余显存时,调度器会将 Running 队列中低优先级的序列换出至 Waiting 队列,并将换出序列占用的显存释放。
如上两个 batching 相关的优化技术可有效提升推理吞吐量,目前已在 HuggingFace Text-Generation-Interface (TGI)、vLLM、OpenPPL-LLM 等多个框架中实现。
System Prompt Caching
【2024-3-18】LLM推理:首token时延优化与System Prompt Caching
大语言模型(Large Language Model,LLM)推理采用流式输出(streaming)的形式,LLM推理的首token时延就是用户感受到的LLM推理服务的响应时间,直接影响用户体验。
对于在线服务,为了提升用户体验,都希望首token时延要小,一般在一秒左右比较好。
- LLM推理的首token时延(time to first token, TTFT)与模型参数规模、Prompt长度、Batch Size、GPU资源等因素有关。
LLM推理过程中,生成首token是计算密集型任务,生成首token阶段也称为prefill phase或context phase,生成首token的时间与处理输入给大模型的Prompt的计算量有关,与Prompt长度直接相关。例如,在Prompt长度相对较长的情况下(Prompt计算时间显著超过模型参数IO时间),再考虑到FlashAttention2等技术优化,生成首token的时间与输入Prompt的长度近似成线性关系。

个人助理聊天机器人、RAG客服系统等,输入给大模型的Prompt一般包含System Prompt和User Prompt两部分
System Prompt 相对较长,且对LLM的每一次请求都可能带着相同的System Prompt作为输入(作为Prompt的一部分)。这样就导致,对于用户多次请求,LLM推理需要重复计算System Prompt,造成GPU资源浪费,特别是增加了不必要的首token时延。
如果能省去对于System Prompt的重复计算,那将会显著提升首token生成速度。System Prompt Caching方法就是为了避免重复计算System Prompt,从而提高首token生成速度。
System Prompt Caching,也称为 Prefix Sharing,其基本思想是对System Prompt部分进行一次计算,并缓存其对应的Key和Value值(例如,存放在GPU显存中),当LLM推理再次遇到相同的(甚至部分相同的)System Prompt时,直接利用已经缓存的System Prompt对应的Key和Value值,这样就避免了对于System Prompt的重复计算。
System Prompt Caching主要分两种形式。
- Prefix Sharing,适用于 “
Prompt = System Prompt + User Prompt” 场景,其中System Prompt就是Prefix。- 例如,给大模型输入的翻译指令,具有相同的System Prompt (Shared Prefix)。
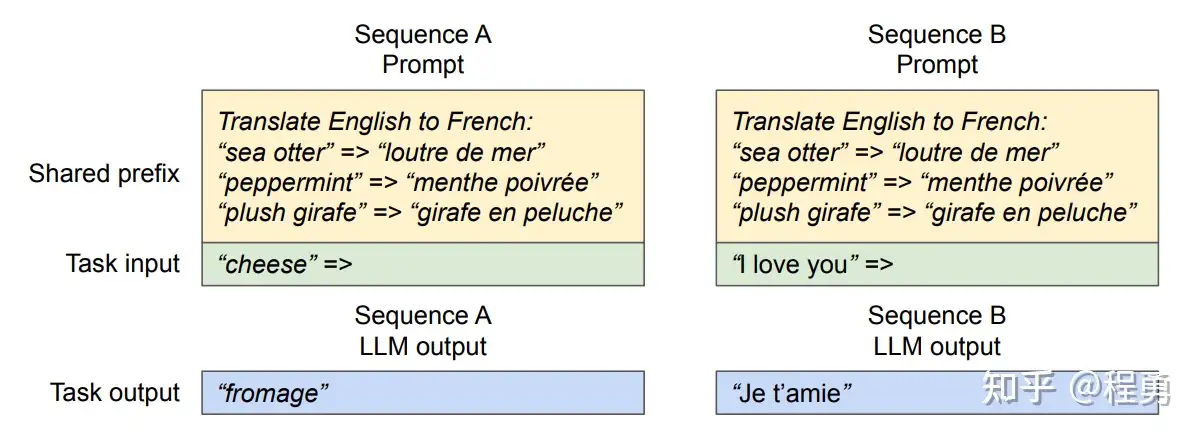
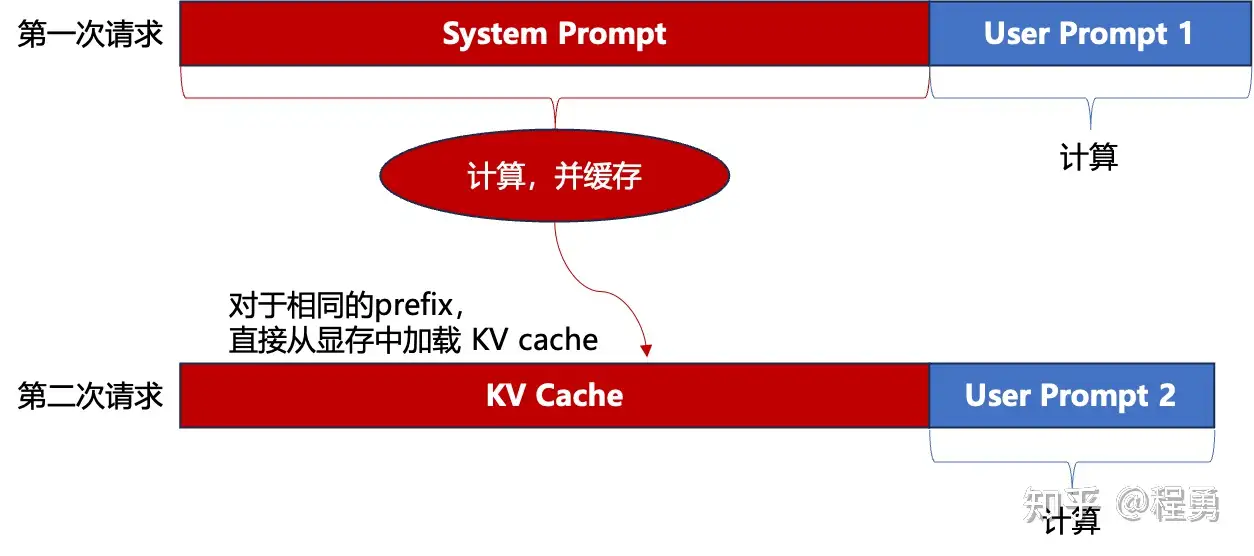
- Prompt Cache,属于相对高级的用法,对整个输入Prompt对应的Key和Value值进行Caching操作,不局限于shared prefix。
- 这种方式需要使用Prompt Cache模板,可以针对Prompt的不同部分分别执行KV Cache。
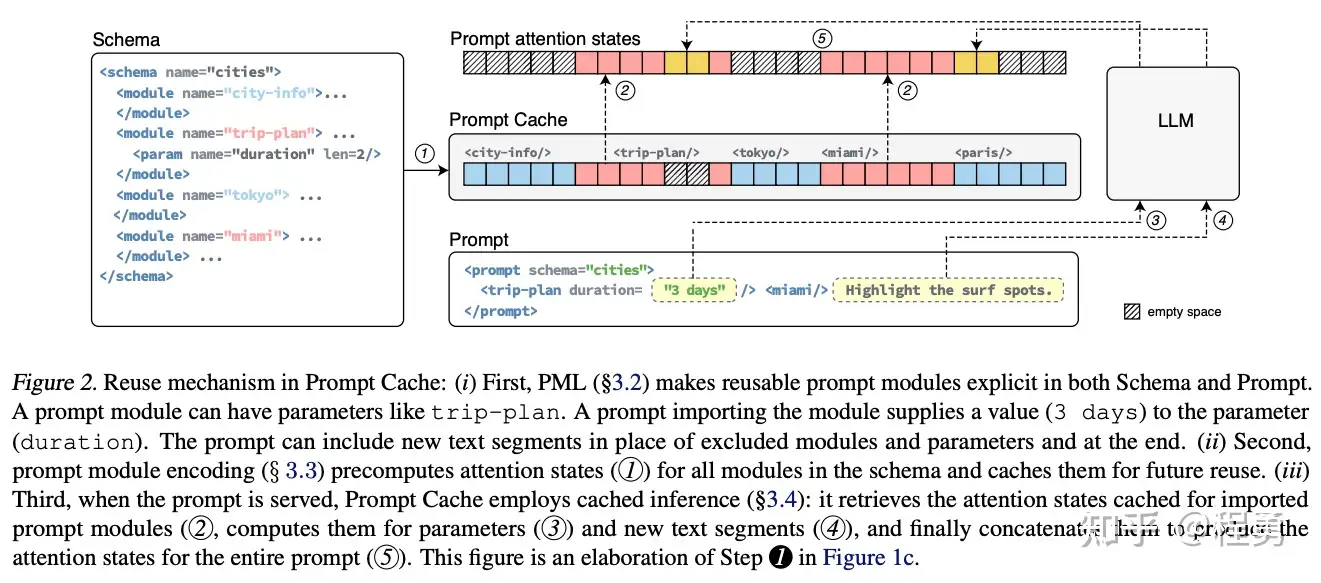
多轮对话场景,第二种方式,即Prompt Cache,可支持Session Prompt Cache。
- 多轮对话session里,输入给LLM的Prompt,会携带多轮对话历史,涉及到很多重复计算。
- 通过 Session Prompt Cache 可以显著减少不必要的重复计算,节省GPU资源,提高对话响应速度和用户体验。
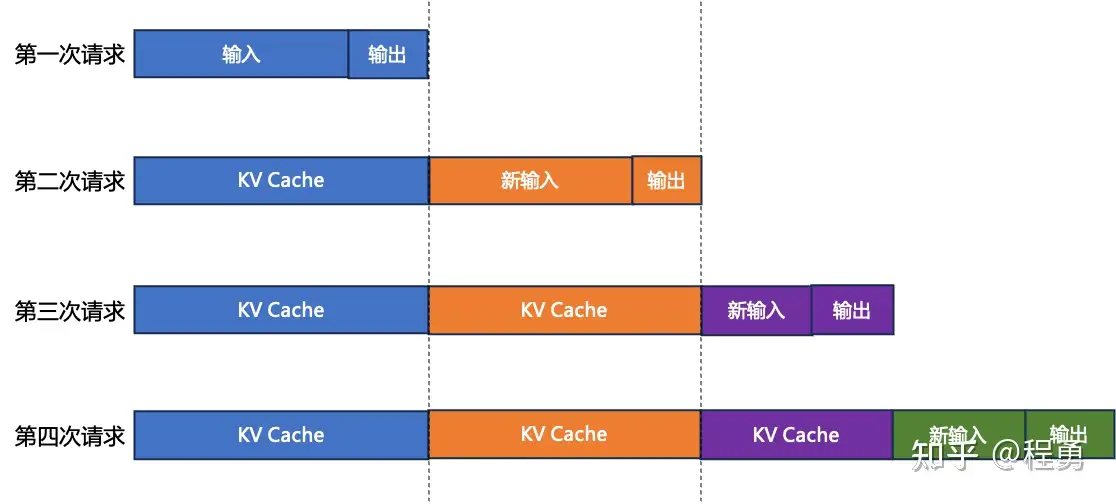
TRT-LLM 实现
- Nvidia 开源的
TensorRT-LLM(TRT-LLM)推理引擎已经支持了System Prompt Caching(Prefix Sharing)功能。 - 实测,当System Prompt在Prompt中占比较大时(即System Prompt比User Prompt长),System Prompt Caching功能可以带来较大的性能提升,可以显著减少生成首token的时延。
不过,TensorRT-LLM里,System Prompt Caching与FP8 KV Cache、INT8 KV Cache并不兼容。期待TensorRT-LLM的下一个版本可以修复这些问题
LLM推理解决方案,推荐 Triton & TRT-LLM。其中,Triton支持RESTFul API流式输出可以通过增加一个HTTP2gRPC模块来实现(过渡方案),可以实现兼容OpenAI接口协议。Triton未来也会直接支持基于RESTFul API的流式输出。
五、动态批处理(Dynamic Batch, Continuous batch)
该类方法主要是针对多 Batch 的场景,通过对 Batch 的时序优化,以达到去除 padding、提高吞吐和设备利用率。传统的 Batch 处理方法是静态的,因为Batch size 的大小在推理完成之前保持不变。
如下图所示,使用静态 Batch 完成四个序列。 在第一次迭代(左)中,每个序列从prompt(黄色)生成一个token(蓝色)。 经过几次迭代(右)后,每个完成的序列都有不同的大小,因为每个序列在不同的迭代中发出其序列结束标记(红色)。 可见序列 3 在两次迭代后就已经结束,但仍然需要等待 Batch 中的最后一个序列完成生成(在本例中,序列 2 在六次迭代后)才能统一输出,这意味着 GPU 未被充分利用。
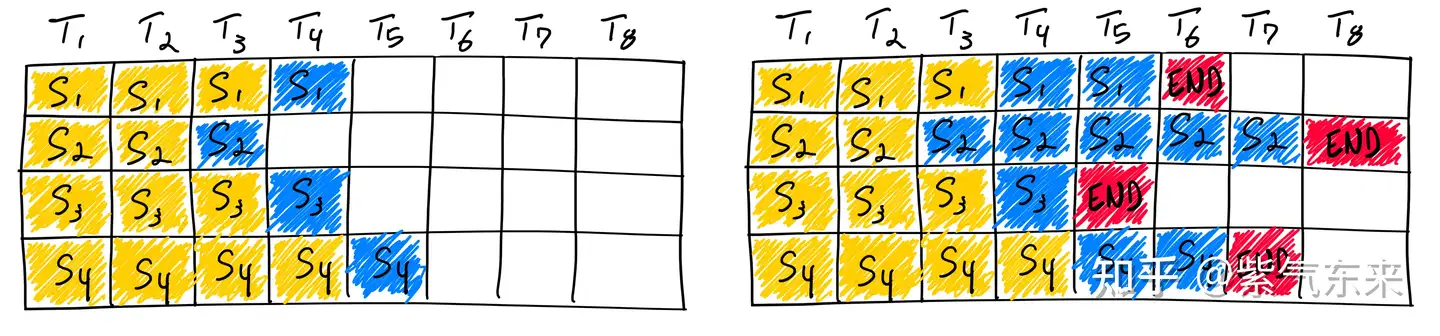
静态 Batch 的推理情况
Dynamic Batch 是如何优化这一过程?
5.1 ORCA
Orca 不是等到 Batch 中的所有序列完成生成,而是实现 iteration 级调度,其中Batch size由每次迭代确定。 结果是,一旦 Batch 中的序列完成生成,就可以在其位置插入新序列,从而比静态 Batch 产生更高的 GPU 利用率。
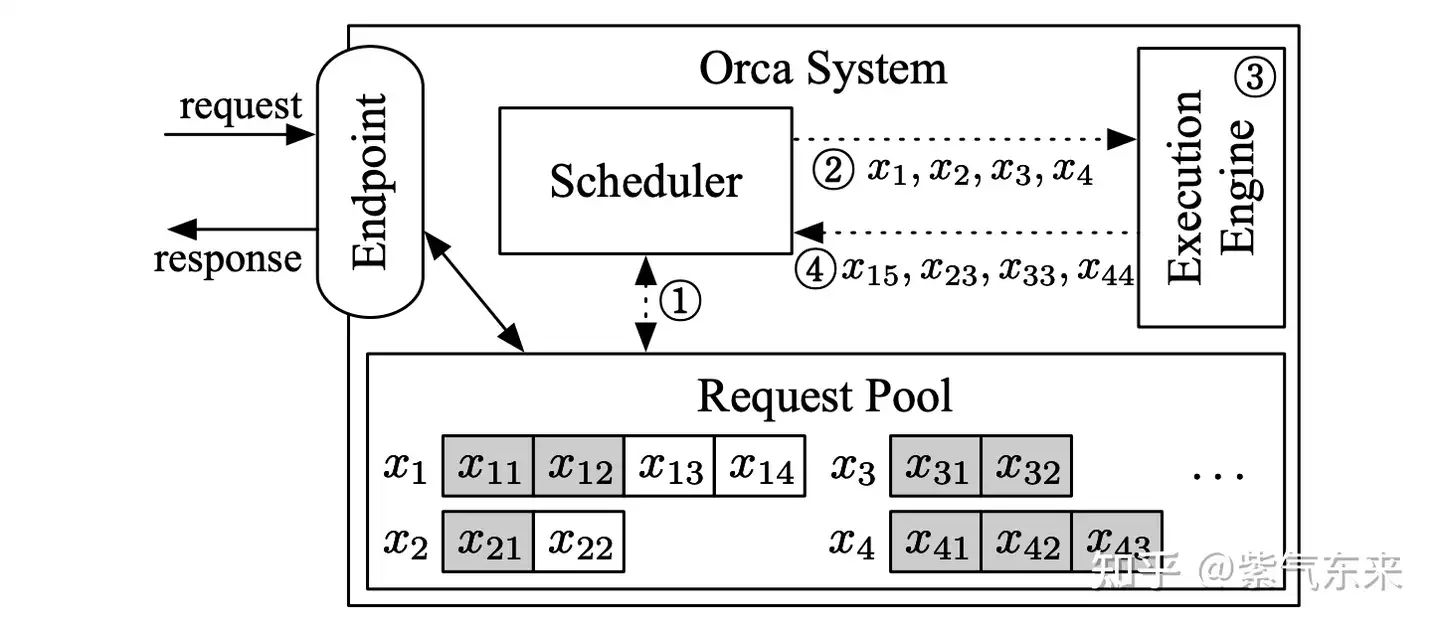
下图展示了使用 Dynamic Batch 完成七个序列的过程。 左侧显示单次迭代后的批次,右侧显示多次迭代后的 Batch 。 一旦序列发出序列结束标记,就在其位置插入一个新序列(即序列 S5、S6 和 S7)。 这样可以实现更高的 GPU 利用率,因为 GPU 不会等待所有序列完成才开始新的序列。
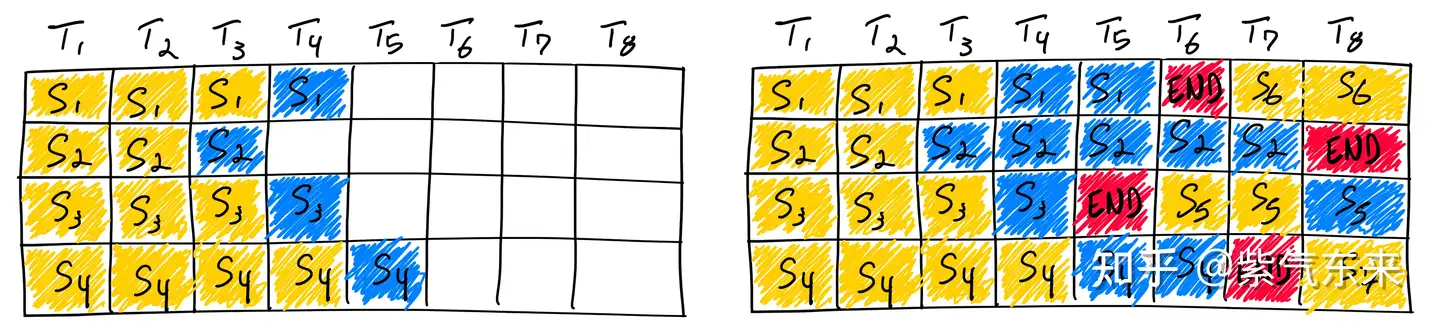
结果显示在延时不变的情况下,其相对于FasterTransformer 可获得 36.9 倍的吞吐提升。

5.2 FastServe
ORCA 使用first-come-first-served (FCFS) 处理推理作业, 计划任务持续运行直至完成。 由于 GPU 内存容量有限以及推理对延时敏感,无法通过任意数量的传入函数来增加处理,由此可能会导致队列阻塞。
FastServe 使用 preemptive scheduling,通过新颖的跳跃连接 Multi-Level Feedback Queue 程序来最小化延时。 基于 LLM 推理的长度无法确定,调度程序利用输入长度信息来分配适当的初始值每个到达作业要加入的队列。 较高优先级队列跳过加入的队列以减少降级。 设计高效的GPU内存管理机制主动下载和上传 GPU 内存和主机内存之间的中间状态,以进行 LLM 推理。
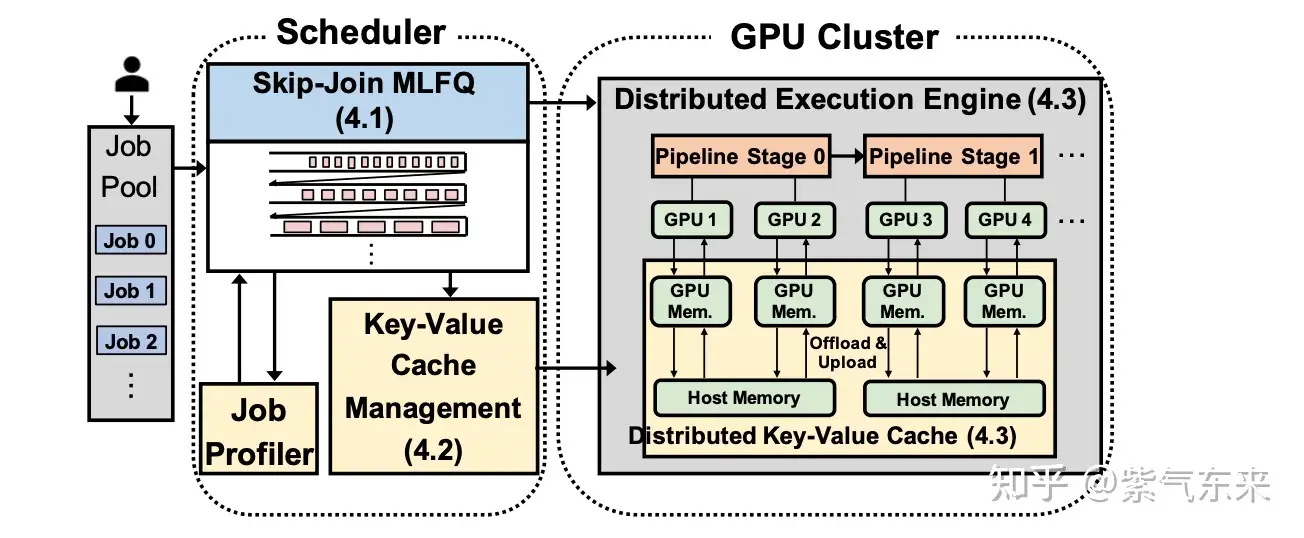
实验表明,该方法比ORCA有明显的性能提升
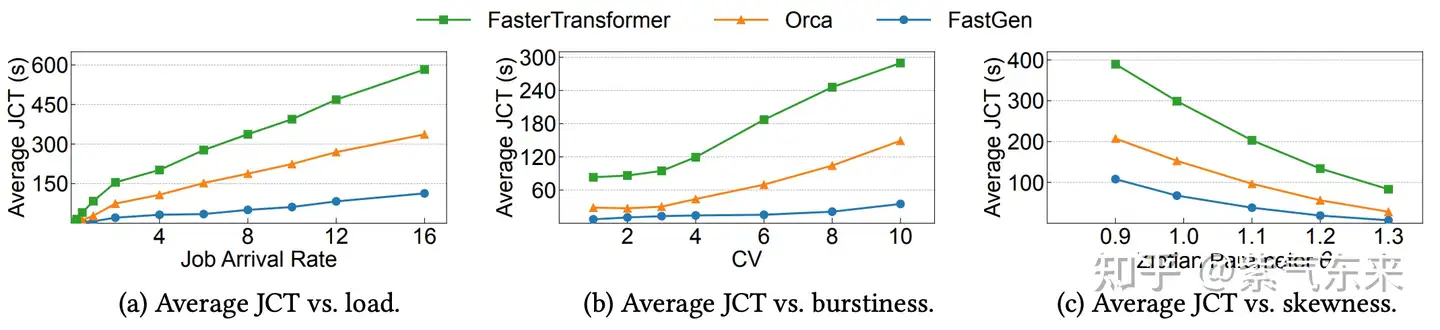
5.3 vLLM
vLLM 的核心是 PagedAttention,其灵感来自传统操作系统概念,例如分页和虚拟内存。 它们通过在固定大小的“页面”或块中分配内存,允许 KV 缓存变得不连续。 然后可以重写 attention 机制以对块对齐的输入进行操作,从而允许在非连续的内存范围上执行 attention 。
这意味着 cache 分配可以 just-in-time,而不是 ahead-of-time:当启动一个新的生成任务时,框架不需要分配大小为 Maximum_context_length 的连续 cache。 每次迭代,调度程序都可以决定特定生成任务是否需要更多空间,并动态分配,而不会降低 PagedAttention 的性能。 这并不能保证内存的完美利用(浪费现在限制在 4% 以下,仅在最后一个块中),但它明显改善了当今业界广泛使用的提前分配方案的浪费 。
总而言之,PagedAttention + vLLM 可节省大量内存,因为大多数序列不会消耗整个上下文窗口。 这些内存节省直接转化为更高的 Batch 大小,这意味着更高的吞吐量和更便宜的服务。
实验表明,该方法相比于静态 Batch 与其他动态 Batch 的方法吞吐性能提升明显。

5.4 Text Generation Inference
TGI 是 HuggingFace 开发的基于 Rust, Python 和 gRPC 的推理服务工具,其基本框架如下:
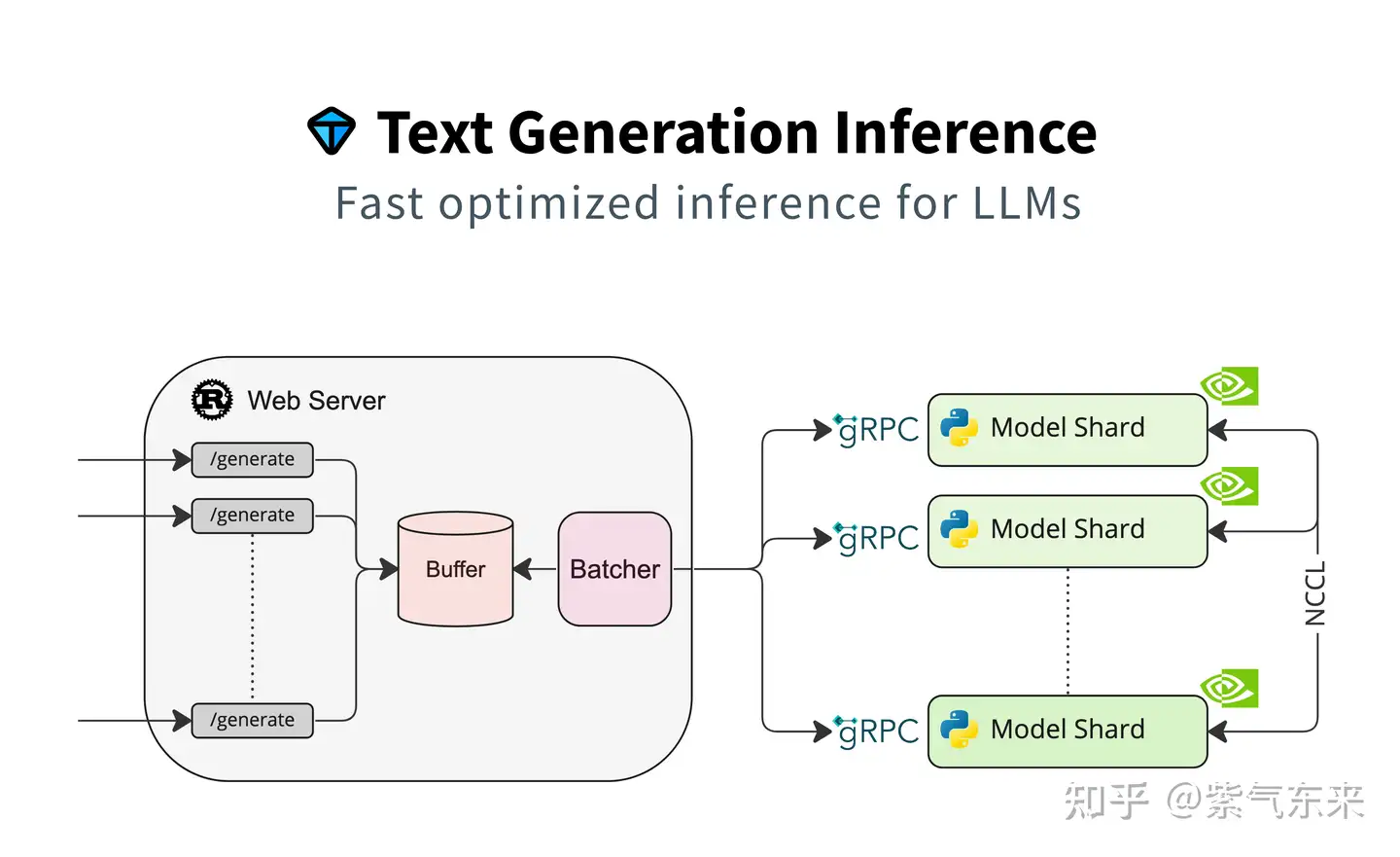
关于 TGI 的用法,可参考笔者的文章,同时对比了和 vLLM 和 FasterTransformer 的性能。
5.5 LMDeploy
LMDeploy 是由 MMRazor 和 MMDeploy 团队开发的用于压缩、部署 LLM 服务的工具包。 它具有以下核心特点:
- TurboMind:基于FasterTransformer 的高效推理引擎。
- 交互推理:通过缓存多轮对话过程中的 k/v,记住对话历史,以避免对历史会话的重复处理。
- 多GPU模型部署和量化
- Dynamic Batch
六、硬件升级
以上主要介绍了在算法和模型层面的优化方法,除此之外,升级硬件系统可以进一步提升整体性能,下面将介绍几种可用于(和潜在的)推理加速的硬件产品。
6.1 NVIDIA H100 PCIe
NVIDIA H100 核心架构与 Ampere 相似,数学运算部分布置在144组CUDA上,最高可拥有18432个FP32(单精度)、9216个FP64(双精度)CUDA核心,辅以576个第四代Tensor核心。H100核心采用台积电的N4工艺制造,内建800亿个晶体管,核心面积仅有814m㎡。其与A100 主要参数对比如下:
在性能方面,H100 较 A100 也有明显提升,其部分数据如下所示。
6.2 AMD MI300
AMD MI300 处理器集成了24个Zen 4架构CPU核心,以及CDNA 3架构GPU核心,周围还有着8颗HBM3高速缓存,容量高达128GB,总计拥有1460亿个晶体管。与上一代 MI250相比,MI300进行AI运算的速度将提高至8倍,能效方面也将提升5倍。
目前未找到公开的在 LLM 方面的推理性能数据。
6.3 Apple M2 Ultra
M2 Ultra 采用第二代 5 纳米工艺制造,并使用 Apple 突破性的 UltraFusion 技术连接两个 M2 Max 芯片的芯片,使性能提高一倍。 M2 Ultra 由 1340 亿个晶体管组成,比 M1 Ultra 多了 200 亿个。 其统一内存架构支持突破性的192GB内存容量,比M1 Ultra多出50%,并具有800GB/s的内存带宽,是M2 Max的两倍。 M2 Ultra 配备更强大的 CPU(比 M1 Ultra 快 20%)、更大的 GPU(快 30%)以及神经引擎(快 40%)。
目前未找到公开的在 LLM 方面的推理性能数据。
6.4 Graphcore IPU
Graphcore C600 IPU处理器PCIe卡是针对机器学习推理应用的高性能加速卡。每个IPU具有1472个处理核心,能够并行运行8832个独立程序线程。每个IPU都有900MB的片上SRAM存储。用户可以在单个机箱中直接连接多达8块卡,通过高带宽的IPU-Links进行桥接。在训练和推理自然语言处理 (NLP) 模型(如 BERT 和 GPT、图神经网络 (GNN)、目标检测、语音等)时表现出色的结果。
目前未找到公开的在 LLM 方面的推理性能数据。
6.5 Biren BR100
BR100是由壁仞科技发布自主研发的首款通用GPU芯片,其16位浮点算力达到1000T以上、8位定点算力达到2000T以上,单芯片峰值算力达到PFlops(1PFlops等于1000万亿次浮点指令/秒)级别。其与 H100 的参数对比如下所示:

目前未找到公开的在 LLM 方面的推理性能数据。
推测解码
【2024-10-6】 LLM推理加速新范式!推测解码(Speculative Decoding)最新综述
推测解码(Speculative Decoding)综述:
- Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding
- Repo: SpeculativeDecodingPapers
推测解码介绍
推测解码定义:
- 推测解码是一种“先推测后验证” (Draft-then-Verify) 的解码算法:
- 每个解码步,该算法首先高效地“推测”target LLM未来多个解码步的结果,然后用target LLM同时进行验证,以加速推理。
所有符合在每个解码步“高效推测->并行验证“模式的推理算法,都可以称为是推测解码(或其变体)。
推测解码实现加速的关键要素,主要在于如下三点:
- 相比于生成单一token,LLM并行计算额外引入的latency很小,甚至可以忽略;
- “推测”的高效性&准确性:如何又快又准地“推测”LLM未来多个解码步的生成结果;
- “验证“策略的选择:如何在确保质量的同时,让尽可能多的“推测”token通过验证,提高解码并行性。
推测解码(Speculative Decoding)是 2023年新兴的LLM推理加速技术
推测解码原理
解决方案:
- 通过增加每个解码步 LLM计算的并行性,减少总解码步数(即减少了LLM参数的反复读写),从而实现推理加速。
每个解码步,推测解码
- 首先 高效地“推测”target LLM(待加速的LLM)未来多个解码步可能生成的token
- 然后 再用target LLM同时验证这些token。通过验证的token作为当前解码步的解码结果。
- 如果“推测”足够准确,推测解码就可以在单个解码步并行生成多个token,从而实现LLM推理加速。
- 并且,使用target LLM的验证过程,在理论上保证解码结果和target LLM自回归解码结果的完全一致。
推测解码在实现对 target LLM 推理加速的同时,不损失LLM的解码质量。
这种优异的性质导致推测解码受到了学界和工业界的广泛关注,从2023年初至今涌现了许多优秀的研究工作和工程项目(如Assisted Generation[7],Medusa[8],Lookahead Decoding[9]等等)。
推测解码方案
推测解码研究思路的演化
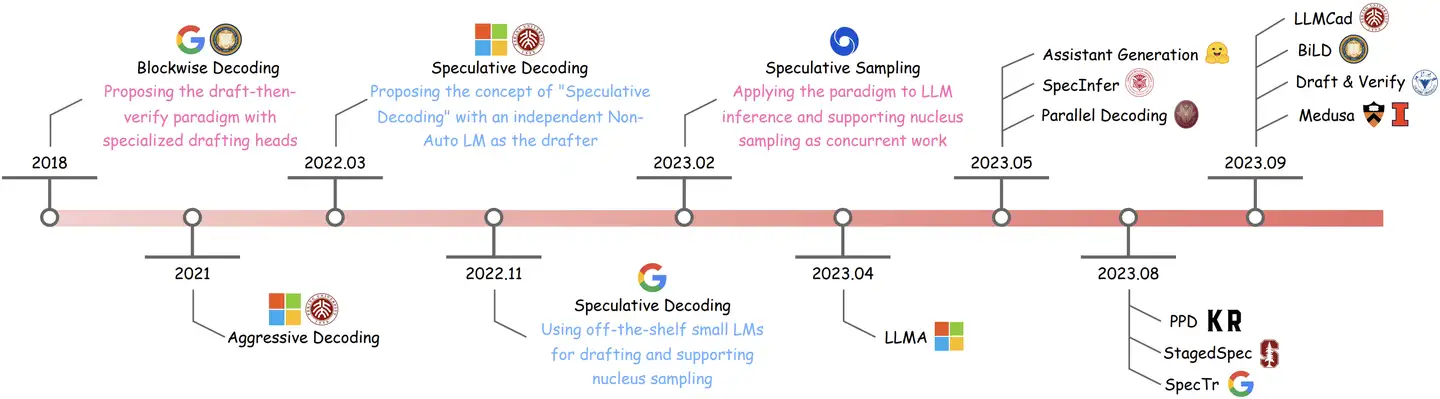
研究总结
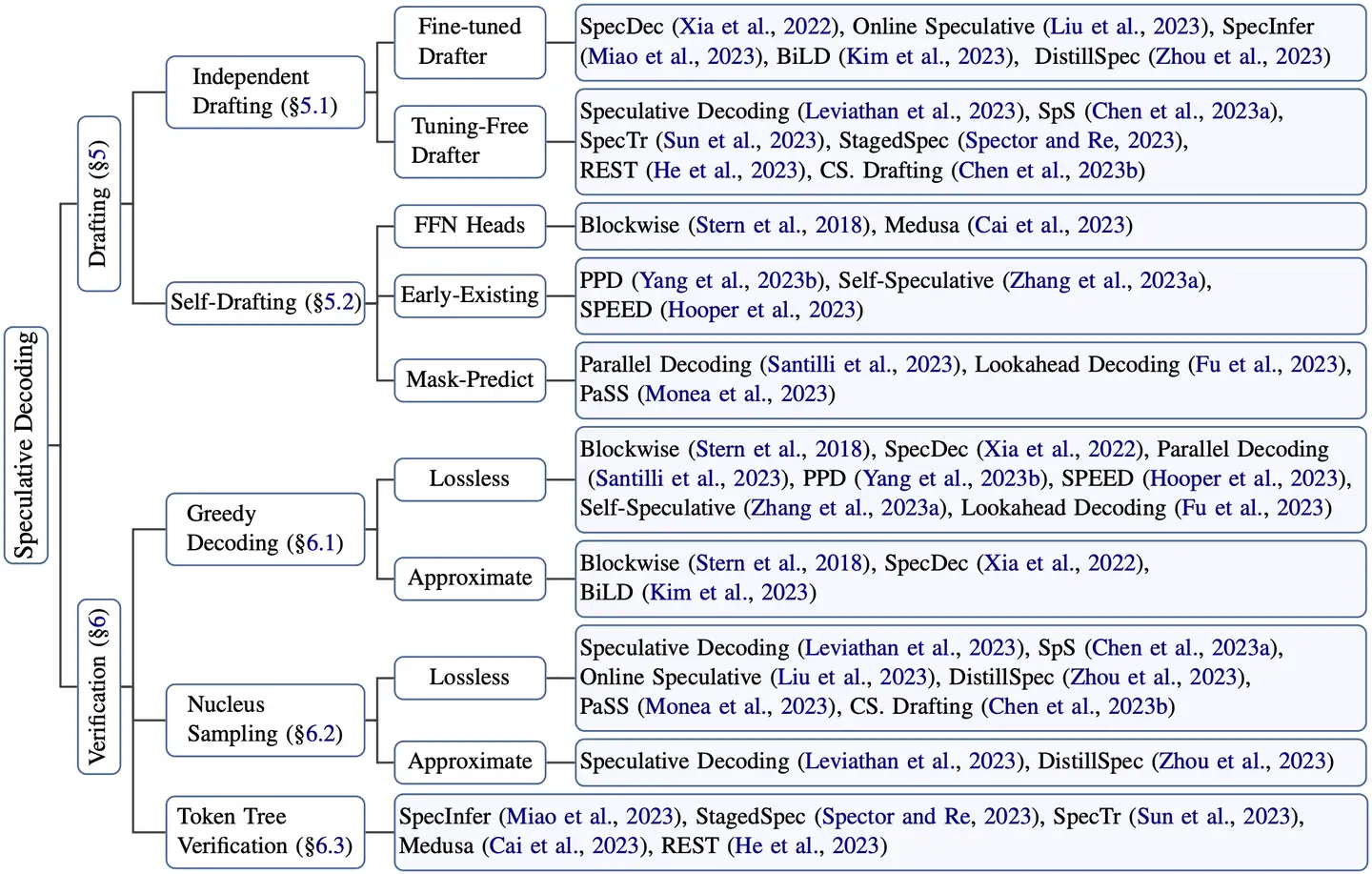
详见介绍
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
