- 总结
- NLP简介
- 算法理论
- 应用
- 结束
总结
- 清华nlp实验室的github主页thunlp,包含刘知远的开源代码
- CCDM 2018 ppt
- 深度学习语义表示,深度学习 = 数据表示 + 网络框架 +学习优化
- 【2021-9-21】NLP为什么难系列
- 【2020-6-11】阿里员工开发的论文知识图谱
- 【2020-8-9】NLP 中的各种不正确打开方式(反向模式 Anti-Pattern),总结的真好。原文,也推荐作者的博客
- 【2021-1-3】Google 的AI团队在2020年底出品的《高性能自然语言处理》,综述了NLP的基础技术、核心技术、案例实践。
- 【2021-1-23】Python Autocomplete:基于Transformer和LSTM的Python代码自动补全】’Python Autocomplete - Use Transformers and LSTMs to learn Python source code’ by LabML
- 【2021-1-23】拼写纠错工具autocorrect,基于seq2seq的文本纠错实现deep-text-corrector
能力总结
- 【2021-2-27】中文NLP实话实话:中文自然语言处理,目前在AI泡沫之下,真假难辨,实战技术与PPT技术往往存在着很大的差异。目前关于AI或者自然语言处理,做的人与讲的人往往是两回事。
- 深度学习在自然语言处理当中,除了在分类问题上能够取得较好效果外(如单选问题:情感分类、文本分类、正确答案分类问题等),在信息抽取上,尤其是在元组抽取上基本上是一塌糊涂,在工业场景下很难达到实用水准。
- 目前各种评测集大多是人为标注的,人为标注的大多为干净环境下的较为规范的文本,而且省略了真实生产环节中的多个环节。在评测环节中达到的诸多state-of-art方法,在真实应用场景下泛化能力很差,大多仅仅是为了刷榜而刷榜。
- 目前关于知识图谱的构建环节中,数据大多数都还是来自于结构化数据,半结构化信息抽取次之,非结构化数据抽取最少。半结构化信息抽取,即表格信息抽取最为危险,一个单元格错误很有可能导致所有数据都出现错误。非结构化抽取中,实体识别和实体关系识别难度相当大。
- 工业场景下命名实体识别,标配的BILSTM+CRF实际上只是辅助手段,工业界还是以领域实体字典匹配为主,大厂中往往在后者有很大的用户日志,这种日志包括大量的实体信息。因此,生产环节中的实体识别工作中,基础性词性的构建和扩展工作显得尤为重要。
-
目前关于知识图谱推理问题,严格意义上不属于推理的范畴,最多只能相当于是知识补全问题,如评测中的知识推理任务,是三元组补全问题。
- Bert本质上仅仅是个编码器,是word2vec的升级版而已,不是无所不能,仅仅是编码能力强,向量表示上语义更为丰富,然而大多人都装糊涂。
- 学界和业界最大的区别在于
- 学术界以探索前沿为目的,提新概念,然后搭个草图就结束,目光并不长远,打完这一战就不知道下一战打什么,下一战该去哪里打,什么时候打,或者打一枪换个阵地再打。
- 而工业界,往往面临着生存问题,需要考虑实际问题,还是以解决实际问题为主,因此没必要把学界的那一套理念融入到生产环节中,要根据实际情况制定自己的方法。
- 利用结构化数据,尤其是百科类infobox数据,采集下来,存入到Neo4j图数据库中,就称自己建立了知识图谱的做法是伪知识图谱做法。基于这类知识图谱,再搞个简单的问答系统,就标榜自己是基于知识图谱的智能问答,实际上很肤浅。
- 知识图谱不是结构化知识的可视化(不是两个点几条边)那么简单,那叫知识的可视化,不是知识图谱。知识图谱的核心在于知识的图谱化,特点在于知识的表示方法和图谱存储结构,前者决定了知识的抽象表示维度,后者决定了知识运行的可行性,图算法(图遍历、联通图、最短路径)。基于图谱存储结构,进行知识的游走,进行知识表征和未知知识的预测。
- 物以稀为贵,大家都能获取到的知识,往往价值都很低。知识图谱也是这样,只有做专门性的具有数据壁垒的知识图谱,才能带来商业价值。
- 目前智能问答,大多都是人工智障,通用型的闲聊型问答大多是个智障,多轮对话缺失,答非所问等问题层出不穷。垂直性的问答才是出路,但真正用心做的太少,大多都是处于demo级别。
- 大多数微信自然语言处理软文实际上都不可不看,纯属浪费时间。尤其是在对内容的分析上,大多是抓语料,调包统计词频,提取关键词,调包情感分析,做柱状图,做折线图,做主题词云,分析方法上千篇一律。应该从根本上去做方法上的创新,这样才能有营养,从根本上来说才能有营养可言。文本分析应该从浅层分析走向深层分析,更好地挖掘文本的语义信息。
- 目前百科类知识图谱的构建工作有很多,重复性的工作不少。基于开放类百科知识图谱的数据获取接口有复旦等开放出来,可以应用到基本的概念下实体查询,实体属性查询等,但目前仅仅只能做到一度。
- 基于知识图谱的问答目前的难点在于两个方面
- 1)多度也称为多跳问题,如姚明的老婆是谁,可以走14条回答,但姚明的老婆的女儿是谁则回答不出来,这种本质上是实体与属性以及实体与实体关系的分类问题。
- 2)多轮问答问题。多轮分成两种,一种是指代补全问答, 如前一句问北京的天气,后者省略“的天气”这一词,而只说“北京”,这个需要进行意图判定并准确加载相应的问答槽。另一种是追问式多轮问答,典型的在天气查询或者酒店预订等垂直性问答任务上。大家要抓住这两个方面去做。
- 关系挖掘是信息抽取的重要里程碑,理解了实体与实体、实体与属性、属性与属性、实体与事件、事件与事件的关系是解决真正语义理解的基础,但目前,这方面,在工业界实际运用中,特定领域中模板的性能要比深度学习多得多,学界大多采用端到端模型进行实验,在这方面还难以超越模版性能。
NLP难点
NLU信心调研
【2022-10-1】自然语言理解要凉?62%从业者认为30年内寒冬将至,调查主页 原版报告
- 来自华盛顿大学、纽约大学和约翰霍普金斯大学的组成的研究团队,就 NLP 领域的一些争议性问题征求了广大研究者的意见,包括研究者在大模型、AGI(通用人工智能)、语言理解、未来方向等多个方面的看法。
- 从调查结果来看,受访者对于这些问题的看法几乎都是对半开,这意味着自然语言理解(NLP)从业者的想法,与整个领域的现状之间,出现了巨大的分歧。
| 专题 | 问题 | 认可比例 | 调研分析 |
|---|---|---|---|
| NLP 领域现状 | (1)私营公司的影响力过大? | 77% | |
| NLP 领域现状 | (2)工业界将会产出最被广泛引用的研究成果? | 86% | 未来十年被广泛引用的论文更有可能来自工业界而非学术界 |
| NLP 领域现状 | (3)NLP会在十年内进入寒冬? | 30% | 认同仅占7%,其余都是稍微认同 |
| NLP 领域现状 | (4)NLP会在三十年内进入寒冬? | 62% | 寒冬将在未来 30 年内到来,长期来看,NLP 领域可能会退烧甚至变冷 |
| NLP 领域现状 | (5)大部分NLP领域发表的相关工作在科学价值上都值得怀疑(dubious)? | 67% | 大多数 NLP 工作在科学意义上是可疑的 |
| NLP 领域现状 | (6)作者匿名评审很重要? | 63% | 评审期间作者的匿名是有价值的,可以保证限制预印本的传播 |
| 规模化、归纳偏差和来自临近领域的启发 | (1)规模化可以解决几乎所有的关键问题? | 17% | 如果用上21世纪内所有的计算资源和数据资源,用现有技术的规模化实施将足以实际解决任何重要的现实世界问题或NLP应用。 |
| 规模化、归纳偏差和来自临近领域的启发 | (2)引入语言学结构是必要的? | 50% | 以语言学理论为基础的语言结构的离散的通用表征(例如,涉及词义、句法或语义图)对于实际解决NLP中的一些重要的现实世界的问题或应用是必要的。 |
| 规模化、归纳偏差和来自临近领域的启发 | (3)专家的归纳偏见是必要的? | 51% | 专家设计的强归纳偏见(如通用语法、符号系统或认知启发的计算基元)对于实际解决NLP中一些重要的现实世界问题或应用是必要的。 |
| 规模化、归纳偏差和来自临近领域的启发 | (4)Ling/CogSci将对引用最多的模型作出贡献? | 61% | 2030年被引用最多的五个系统中,很可能至少有一个会从过去50年的语言学或认知科学研究中的具体的、非微不足道的成果中获得明确的灵感。 |
| AGI和主要风险 | (1)AGI是一个重要的关注点? | 58% | 了解人工通用智能(AGI)的潜在发展以及与之相关的利益/风险,应该是NLP研究人员的一个重要优先事项 |
| AGI和主要风险 | (2)最近的进展正在使我们走向AGI? | 57% | 大规模ML建模的最新发展(如语言建模和强化学习)是朝着AGI发展的重要步骤。 |
| AGI和主要风险 | (3)人工智能可能很快导致革命性的社会变革? | 73% | 本世纪,由人工智能/ML的进步引起的劳动自动化可能会导致经济重组和社会变革,其规模至少是工业革命时期的规模。 |
| AGI和主要风险 | (4)人工智能的决策可能导致核弹级别的灾难? | 36% | 人工智能或机器学习系统做出的决策可能会在本世纪造成至少与全面核战争一样严重的灾难。 |
| 语言理解 | (1)语言模型能理解(understand)语言? | 51% | 一些只对文本进行训练的生成模型,如果有足够的数据和计算资源,就可以在某种意义上理解自然语言 |
| 语言理解 | (2)多模态模型能理解语言? | 67% | 对于多模态生成模型而言,比如一个经过训练可以访问图像、传感器和驱动器actuator数据等的模型,只要有足够的数据和计算资源,就可以理解自然语言。 |
| 语言理解 | (3)纯文本评价可以衡量模型的语言理解能力? | 36% | 原则上,可以通过跟踪一个模型在纯文本分类或语言生成基准上的表现来评估其理解自然语言的程度。 |
| NLP未来的研究方向 | (1)从业者太过于关注语言模型的规模? | 72% | 目前,该领域过多地关注机器学习模型的大规模化 |
| NLP未来的研究方向 | (2)过于关注基准数据集? | 88% | 目前NLP模型过多地关注在基准上优化性能 |
| NLP未来的研究方向 | (3)模型架构走错了方向? | 37% | 过去5年发表的大部分关于模型架构的研究都走在了错误的道路上。 |
| NLP未来的研究方向 | (4)语言生成走错了方向? | 41% | 过去5年中发表的关于开放式语言生成任务的大部分研究都走在了错误的道路上。 |
| NLP未来的研究方向 | (5)可解释模型的研究走错了方向? | 50% | 过去5年中发表的大多数关于建立可解释模型的研究都走在了错误的道路上 |
| NLP未来的研究方向 | (6)黑盒的可解释性走错了方向? | 42% | 过去5年中发表的关于解释黑箱模型的大部分研究都走在了错误的道路上。 |
| NLP未来的研究方向 | (7)我们应该做更多的工作来吸收跨学科的见解? | 82% | 与目前的状况相比,NLP研究人员应该更优先考虑纳入相关领域科学(如社会语言学、认知科学、人机交互)的见解和方法。 |
(1)NLP研究领域
尽管 30%不是一个大数字,但这也反映了这一部分 NLP 研究者的一种信念,即 NLP 研究将在不久的将来发生重大变化(至少在谁提供资金以及提供多少资金方面)。
为什么他们的态度会相对悲观?背后有许多可能原因。
- 比如由于工业界影响力过大而导致的创新停滞,工业界将凭借少量资源充足的实验室来垄断行业,NLP 和其他 AI 子领域之间的界限将消失等等。
67% 的受访者认同,他们认为,大多数 NLP 工作在科学意义上是可疑的。
- 受访者对“可疑”的定义可能是多样的,包括根本不具有完整性的工作、所研究问题不恰当、研究结果无意义,或者研究发现并不重要、不可靠等等。
(2)规模化、归纳偏差和来自临近领域的启发
(3)AGI和主要风险
(4)语言理解
(5)NLP未来的研究方向
NLP ≠ NLU
【2021-8-21】NLP≠NLU,机器学习无法理解人类语言,详情见机器之心的不同于NLP,数据驱动方法与机器学习无法攻克NLU,原因有三点:英文原文
- 长期以来,我们一直在与机器沟通:编写代码–创建程序–执行任务。然而,这些程序并非是用人类“自然语言“编写的,像Java、Python、C和C ++语言,始终考虑的是”机器能够轻松理解和处理吗?”
- “自然语言处理”(Natural Language Processing,NLP)的目的与此相反,它不是以人类顺应机器的方式学习与它们沟通,而是让机器具备智力,学习人类的交流方式。
- 自然语言处理,实际上是人工智能和语言学的交叉领域,但多年来,仅在语音转录、语音命令执行、语音关键词提取的工作上兢兢业业,规规矩矩,应用到人机交互,就显得十分吃力。NLP的核心步骤:分词→词干提取→词形还原→词性标注→命名实体识别→分块
- 因为在语料预处理阶段,NLP通常直接给出“断句”,比如 “订一张明天从北京到杭州的机票,国航头等舱”,经过NLP模型处理后,机器给出的输出出发地、目的地等信息,准确率高但这背后,我们并不知道机器理解了什么。由于足够好用,人们也就不多问了。在更加复杂的任务中,比如机器翻译,基于深度学习的编码、解码架构会将原句子转换成我们根本不熟悉的样子,也就是在无穷维空间中的点。研究人员试图向神经网络添加参数以提高它们在语言任务上的表现,然而,语言理解的根本问题是“理解词语和句子下隐藏的含义“
- 伦斯勒理工学院的两位科学家撰写了一本名为《人工智能时代语言学》的书,探讨了目前的人工智能学习方法在自然语言理解(Natural Language Understanding,NLU)中的瓶颈,并尝试探索更先进的智能体的途径。
- (1)AI必须从“处理”自然语言到“理解”自然语言
- 机器“记录”了数据并不意味着“理解”了数据。近几十年来,机器学习算法一直尝试完成从NLP 到 NLU 的转型,机器学习曾长期承载着转型使命的荣光。机器学习模型是一种知识精益系统,它试图通过统计词语映射来回答上下文关系。在这些模型中,上下文是由词语序列之间的统计关系形成的,而非词语背后的含义。因而数据集越大、示例越多样化,机器对上下文关系的理解越精确。
- 机器学习终将失宠,因为它们需要太多的算力和数据来自动设计特征、创建词汇结构和本体,以及开发将所有这些部分结合在一起的软件系统,而且机器人也不知道自己在做什么,以及为什么这样做。它们解决问题的方法不依赖与世界、语言或自身的互动(人类)。因此,它们无法理解两个人长时间对话中对同一件事情的描述越来越简短的情景,也就是文本缺失现象。巨大人工成本使机器学习陷入瓶颈,并迫使人们寻求其他方法来处理自然语言, 并导致了自然语言处理中经验主义范式(认为语言理解起源于感觉)的出现。
- 具有“感觉”的人工智能,或许会在自然语言处理上有三个突破:
- 通过语言交流激活感觉模型,并以此承载记忆,从而可以应对人类之间交流时的文本缺失现象,实现“默契”(正确)的解码;
- 理解语言的上下文相关含义,并从单词和句子的歧义中找到合适的理解,以及从感觉世界中寻找更强的约束和限制;
- 向它们的人类合作者解释它们的想法、行动和决策;
- 机器也需要在世界互动时保持终身学习。而机器学习由于将可压缩性和可学习性对等起来,并且限于表面的符号统计关系理解,以及不可解释性等原因,不可避免丢失背景信息,而做不到上述层次的理解。总之,机器要理解自然语言,感觉经验是必不可少的。
- 书中指出:“ 语言理解不能与整体的认知过程区分开来,启发机器人理解语言也要运用其他感知(例如视觉、触觉)。”正如在现实世界中,人类也是利用他们丰富的体态动作来填补语言表达的空白。
- NLP 中广泛使用数据驱动的经验方法有以下原因:符号和逻辑方法未能产生可扩展的 NLP 系统,导致 NLP (
EMNLP,指数据驱动、基于语料库的短语,统计和机器学习方法)中所谓的经验方法的兴起。EMNLP的先驱之一肯尼思·丘奇(Kenneth Church)所解释的,NLP数据驱动和统计方法的拥护者对解决简单的语言任务感兴趣,其动机从来不是暗示语言就是这样运作的,而是”做简单的事情总比什么都不做好”。这种转变的动机被严重误解,他们以为这个“可能大致正确的”( Probably Approximately Correct ,PAC)范式将扩展到完全自然的语言理解。 - 是时候重新思考NLU方法了,对 NLU 的”大数据”方法不仅在心理上、认知上甚至计算上都是难以操作的,而且这种盲目的数据驱动 NLU 方法在理论和技术上也有缺陷。
- “新一代和当代的NLP研究人员在语言学和NLP的理解上有差别,因此,这种被误导的趋势导致了一种不幸的状况:坚持使用”大语言模型”(LLM)构建NLP系统,这需要巨大的计算能力,并试图通过记住海量数据来接近自然语言。
- 这几乎是徒劳的尝试。我们认为,这种伪科学方法不仅浪费时间和资源,而且引诱新一代年轻科学家认为语言只是数据。更糟糕的是,这种方法会阻碍自然语言理解(NLU)的任何真正进展。
- 为什么NLP与NLU不同?
- 语言理解不承认任何程度的误差,它们要充分理解一个话语或一个问题。
- 常见的”下游 NLP”任务:综述–主题提取–命名实体识别(NER)–(语义)搜索–自动标记–聚类
- 上述所有任务都符合所有机器学习方法的基础可能大致正确(PAC) 范式。
- 对普通口语的真正理解与单纯的文本(或语言)处理是完全不同的问题。在文本(或语言)处理中,我们可以接受近似正确的结果。
NLU为什么难
【2022-5-31】思考:人类发明语言是为了高效传达信息,潜在要点:
- 忽略共同背景信息:故意省略一些常识信息(都知道的知识)、场景信息(当前时间地点情景)
- 压缩:尽量使用简短语言传达最重要的信息
- 解压缩:对方接收到压缩的信息后,根据常识、场景推断背后的传达的意思
然而,机器远没有人那么聪明,现在没法完成人一样的解压缩工作
- 当前的数据驱动+机器学习方法与NLU关系不大
- 机器学习将大量数据概括为单一函数(模式、范式)
- 统计无法捕捉(甚至不能近似)语义
为什么 NLU 很困难:
- (1)文本容易丢失:”缺失文本现象”(MTP)自然语言理解中所有挑战的核心。
- 场景:演讲者将思想“编码”为某种自然语言中的话语,然后听众将话语“解码”为演讲者打算/希望传达的思想。”解码”过程是NLU中的”U”–即理解话语背后的思想。
- MTP:媒体传输协议,Media Transfer Protocol
- (2)”解码”过程中需要没有任何误差,才能从说话者的话语中,找出唯一一种意在传达的含义。这正是NLU困难的原因。
- 两种优化通信的方案:
- 1.说话者可以压缩(和最小化)在思想编码中发送的信息量,并且听者做一些额外的工作解码(解压缩)话语;
- 2.演讲者多做一部分工作,把所有想要传达的思想信息告诉听者,减少听者的工作量;
- 两种优化通信的方案:
- NLU的问题所在:机器不知道我们遗漏了什么,它们不知道我们都知道什么。如果它们不能以某种方式”整理”我们话语的所有的含义,那么软件程序将永远不能完全理解我们话语背后的想法。
- 为了有效地沟通,人们在交流中通常不会说对方知道的信息。这也正是为什么都倾向于忽略相同的信息——因为都了解每个人都知道的,而这正是所谓的共同背景知识。人类在大约 20 万年的进化过程中,发展出的这一天才优化过程非常有效。
- NLU的挑战,并不是解析,阻止,POS标记,命名实体识别等, 而是解释或揭示那些缺失的信息。并隐含地假定为共享和共同的背景知识。
- 在此背景下,整理了三个原因,说明为什么机器学习和数据驱动的方法不会为自然语言理解提供解决方案。
- 1、ML 方法甚至与 NLU 无关:ML 是压缩的,语言理解需要解压缩:
- 机器的自然语言理解由于MTP而变得困难,因为日常口语被高度压缩,因此”理解”的挑战在于未压缩(或发现)缺失的文本。
- MTP 现象正是为什么数据驱动和机器学习方法虽然在某些 NLP 任务中可能很有用,但与 NLU 甚至不相关的原因。
- 机器可学习性(ML) 和可压缩性(COMP)之间的等价性已在数学上建立。即已经确定,只有在数据高度可压缩(未压缩的数据有大量冗余)时,才能从数据集中学习,反之亦然。
- 机器学习是关于发现将大量数据概括为单一函数。另一方面,由于MTP,自然语言理解需要智能的”不压缩”技术,可以发现所有缺失和隐含的假定文本。因此,机器学习和语言理解是不兼容的——事实上,它们是矛盾的。
- 2、ML 方法甚至与 NLU 无关:统计上的无意义
- ML 本质上是一种基于在数据中找到一些模式(相关性)的范式。因此,该范式的希望是在捕捉自然语言中的各种现象时,发现它们存在统计上的显着差异。
- 但是当”小”和”大”(或”打开”和”关闭”等)等反义词/反义词以相同的概率出现在相同的上下文中,统计分析不能建模(甚至不能近似)语义——就这么简单!
- 有人说,收集足够的例子,一个系统可以确立统计学意义。但是,需要多少个示例来”学习”如何解决结构中的引用呢?机器学习/数据驱动系统需要看到上述 40000000 个变体,以学习如何解决句子中的引用。如果有的话,这在计算上是不可信的。正如Fodor和Pylyshyn曾经引用著名的认知科学家乔治.米勒( George Miller),为了捕捉 NLU 系统所需的所有句法和语义变化,神经网络可能需要的特征数量超过宇宙中的原子数量!这里的寓意是:统计无法捕捉(甚至不能近似)语义。
- 3、ML 方法甚至与 NLU 无关:意图
- 逻辑学家们长期以来一直在研究一种语义概念,试图用语义三角形(符号、概念和语义)解释什么是”内涵”。
- 一个符号用来指代一个概念,概念可能有实际的对象作为实例,但有些概念没有实例,例如,神话中的独角兽只是一个概念,没有实际的实例独角兽。类似地,”被取消的旅行”是对实际未发生的事件的引用,或从未存在的事件等。
- 每个”事物”(或认知的每一个对象)都有三个部分:
- 一个符号,符号所指的概念以及概念具有的具体实例。
- 一个概念(通常由某个符号/标签所指)是由一组属性和属性定义,也许还有额外的公理和既定事实等。
- 然而,概念与实际(不完美)实例不同,在数学世界中也是如此。
- 1、ML 方法甚至与 NLU 无关:ML 是压缩的,语言理解需要解压缩:
- 内涵决定外延,但外延本身并不能完全代表概念。
- 自然语言充斥着内涵现象,因为语言具有不可忽视的内涵。但是机器学习/数据驱动方法的所有变体都纯粹是延伸的——它们以物体的数字(矢量/紧张)表示来运作,而不是它们的象征性和结构特性,因此在这个范式中,我们不能用自然语言来模拟各种内涵。顺便说一句,神经网络纯粹是延伸的,因此不能表示内涵,这是它们总是容易受到对抗性攻击的真正原因
人类在传达自己的想法时,其实是在传递高度压缩的语言表达,需要用大脑来解释和”揭示”所有缺失但隐含假设的背景信息。 语言是承载思想的人工制品,因此,在构建越来越大的语言模型时,机器学习和数据驱动方法试图在尝试找到数据中甚至不存在的东西时,徒劳地追逐无穷大。
【2021-8-21】NLP≠NLU,机器学习无法理解人类语言:英文原文
示例
示例:
- cover me ! → 让盖外套,还是 掩护 ?
【2023-6-4】中文博大精深
- 公交车场景:视频
一直关注刘群老师的微博,常常看见他分享的一些好玩的#自然语言处理太难了#。 遂整理了NLP实在是太难了系列语句,大家一笑无妨。这里列举了一些关于分词、实体识别、知识图谱相关的语句,按照难度从低到高排列,最高难度的放在了最后(需要强大的知识图谱哦,欢迎大家把答案开在评论里,也欢迎添加新的or搞笑的例子,O(∩_∩)O谢谢!)。
- 难度:※※ 两颗星
- 来到杨过曾经生活过的地方,小龙女动情地说:“我也想过过过儿过过的生活。”
- 来到儿子等校车的地方,邓超对孙俪说:“我也想等等等等等过的那辆车。”
- 赵敏说:我也想控忌忌己不想无忌。
- 你也想犯范范范玮琪犯过的错吗
- 对叙打击是一次性行为?
- 《绿林俊杰》–林俊杰做错了什么?为什么要绿他
- 难度:※※※ 三颗星
- 写给卖豆芽的对联: 长长长长长长长,长长长长长长长。(solution: changzhangchangzhangchangchangzhang zhangchangzhangchangzhangzhangchang,zhangchangchangzhangchangzhangchang,zhangchangzhangchangzhangchangchang)
- 季姬寂,集鸡,鸡即棘鸡。棘鸡饥叽,季姬及箕稷济鸡。鸡既济,跻姬笈,季姬忌,急咭鸡,鸡急,继圾几,季姬急,即籍箕击鸡,箕疾击几伎,伎即齑,鸡叽集几基,季姬急极屐击鸡,鸡既殛,季姬激,即记《季姬击鸡记》。
- 石室诗士施氏,嗜狮,誓食十狮。氏时时适市视狮。十时,适十狮适市。是时,适施氏适市。施氏视是十狮,恃矢势,使是十狮逝世。氏拾是十狮尸,适石室。石室湿,氏使侍拭石室。石室拭,氏始试食是十狮尸。食时,始识是十狮尸,实十石狮尸。试释是事。《施氏食狮史》
- 去商店买东西一算账1001块,小王对老板说:“一块钱算了。” 老板说好的。于是小王放下一块钱就走了,老板死命追了小王五条街又要小王付了1000,小王感慨:#自然语言理解太难了#
- “碳碳键键能能否否定定律一”
- 书《无线电法国别研究》
- 要去见投资人,出门时,发现车钥匙下面压了一张员工的小字条,写着“老板,加油!”,瞬间感觉好有温度,当时心理就泪奔了。心里默默发誓:我一定会努力的! 车开了15分钟后,没油了。。。
- 他快抱不起儿子了,因为他太胖了
- 中文里面“大胜”和“大败”意思相同,刚发现英文里面也有类似的现象:valuable和invaluable都是表示非常有价值的意思
- How can I help you? 我能帮您什么?我怎么可以帮你!米国某酒店前台翻译机
- 一家名为“宝鸡有一群怀揣着梦想的少年相信在牛大叔的带领下会创造生命的奇迹网络科技有限公司”走红网络,该公司全名长达39个字,还是一句主谓宾齐全的句子。宝鸡工商部门表示,该公司属合法注册,但名字太长不利于刻公章开发票
- “一位友好的哥谭市民” “一位友好/的哥/谭市民”
- 难度:※※※※ 四颗星
- 宝宝的经纪人睡了宝宝的宝宝,宝宝不知道宝宝的宝宝是不是宝宝的亲生的宝宝,宝宝的宝宝为什么要这样对待宝宝!宝宝真的很难过!宝宝现在最担心的是宝宝的宝宝是不是宝宝的宝宝,如果宝宝的宝宝不是宝宝的宝宝那真是吓死宝宝了。
- 中不不建交是受印度的影响,中不建交不受印度的影响。
- 难度:※※※※※ 五颗星
- NLP同学接招。这玩意非得配合超强知识图谱才能解决,非单纯NLP技术搞的定

- 人工智障:“明天早上六点半的时候,叫我起床” —— 好的,明天早上六点半的时候,我称呼你为“起床”
- 同学会标语:从小便相识,大便情更浓
- 一些easy的作为结尾
- 校长说衣服上除了校徽别别别的
- 过几天天天天气不好
- 看见西门吹雪点上了灯,叶孤城冷笑着说:“我也想吹吹吹雪吹过的灯”,然后就吹灭了灯。
- 今天多得谢逊出手相救,在这里我想真心感谢“谢谢谢逊大侠出手”
- 灭霸把美队按在地上一边摩擦一边给他洗脑,被打残的钢铁侠说:灭霸爸爸叭叭叭叭儿的在那叭叭啥呢
- 姑姑你估估我鼓鼓的口袋里有多少谷和菇!!
- “你看到王刚了吗”“王刚刚刚刚走”
- 张杰陪俩女儿跳格子:俏俏我们不要跳跳跳跳过的格子啦
- 骑车出门差点摔跤,还好我一把把把把住了
- 我朋友问父亲:我大大大(大大爷)和我姑姑谁年龄大?朋友爸爸说:你大大大大!
- 我背有点驼,麻麻说“你的背得背背背背佳
- 南京市长江大桥
男人的一生,分四个阶段:中文:
- 喜欢上一个人 Like someone
- 喜欢上一个人 Like to fuck someone
- 喜欢上一个人 Like the last one
- 喜欢上一个人 Like to be alone
翻译这段话:”人要是行,干一行行一行,一行行行行行。行行行干哪行都行。要是不行,干一行不行一行,一行不行行行不行,行行不行,干哪行都不行。要想行行,首先一行行。成为行业内的内行,行行成内行。行行行,你说我说得行不行。”
Translate this passage: “If a person is capable, they can excel in any profession they choose. If they’re not capable, they won’t succeed in any profession, no matter which one they choose. If you want to be successful, you must first become proficient in one field. Become an expert in your industry, and you’ll achieve success. Is what I’m saying reasonable?”
如何处理OOV
NLP 研究主流目前如何处理 out of vocabulary words?
解决OOV问题的集中方法
- 更换更复杂的字符级模型,字符有限,以单词为单位为导致组合爆炸
- OOV单词较少时,可以直接替换成< UNK>标签来忽略OOV的问题,尽管实际应用时候并不想这样————总不能给用户输出一个< UNK>吧?
如果OOV单词占比较多(如30%),改怎么办?对数据的处理可操作性更强效果也是特别直观地好。
- Mixed Word/Character Model 字符模型
- 即把所有的OOV词,拆成字符。比如 Jessica,变成< B>_J,< M>_e,< M>s,< M>s,< M>i,< M>c,< E>a。其中< B>< M>< E>是Begin,Middle,End的标记。这样处理的好处就是消灭了全部的OOV。坏处就是文本序列变得非常长,对于性能敏感的系统,这是难以接受的维度增长。
- Wordpiece Model(WPM) 拆成子词
- 和上面一样,同样要进行拆词。不同的是,非OOV的词也要拆,并且非字符粒度,而是sub-word 子词。还是 Jessica,变成< B>Je,< M>ssi,< E>ca。这类方法最早应用于Google的语音识别系统,现在已经在NLP中遍地开花了。拆词规则可以从语料中自动统计学习到,常用的是
BPE(Byte Pair Encode)编码,出处在《Neural Machine Translation of Rare Words with Subword Units》。 - 和第一种方法相比,虽然序列的长度控制住了,但是在有限词表的情况下,OOV仍然存在。
- 另外,sub-word的OOV有一种麻烦,对于Jessica的例子,即使只有
ssi是OOV,Je和 ca都在词表内,整个Jessica的**单词仍然无法正确表示**。
- 和上面一样,同样要进行拆词。不同的是,非OOV的词也要拆,并且非字符粒度,而是sub-word 子词。还是 Jessica,变成< B>Je,< M>ssi,< E>ca。这类方法最早应用于Google的语音识别系统,现在已经在NLP中遍地开花了。拆词规则可以从语料中自动统计学习到,常用的是
- UNK处理
- 在训练数据充足的情况下,RNN模型可以轻松支持30k-80k的词表。在大多数情况下,扩大词表都是首选的方案。经过WPM处理后,配合词表加大,剩下的OOV都是冷门的长尾词。如果不关注这部分性能,可以直接扔掉OOV词,删掉包含OOV的数据。对于分类型任务,就全部替换成
标签。对于生成型任务,有不同的细节处理方案,可以看下经典的[《Addressing the Rare Word Problem in Neural Machine Translation》](https://arxiv.org/abs/1410.8206),里面介绍了Copyable、PosALL和PosUNK三种替换策略。这类策略对于实体类NER的词,有比较好的效果。
- 在训练数据充足的情况下,RNN模型可以轻松支持30k-80k的词表。在大多数情况下,扩大词表都是首选的方案。经过WPM处理后,配合词表加大,剩下的OOV都是冷门的长尾词。如果不关注这部分性能,可以直接扔掉OOV词,删掉包含OOV的数据。对于分类型任务,就全部替换成
- 中文的处理
- 英文中包含的姓名、复合词、同源词和外来词,使得WPM的方法效果拔群。
- 在处理中文时,WPM可以有效帮助解决混入的英文词和阿拉伯数字等。对于纯中文的句子,分割成子词的意义不大。
- 这时候,扩大词表仍然是首选。
- 扩大词表
- 终极解决办法。通常情况不使用大词表,一方面是因为训练数据的多样性有限,另一方面是softmax的计算速度受限。对于第一种情况,扩大语料范围。对于第二种情况,相关的加速策略可以将词表扩大10倍而GPU上的预测速度只降低一半(从5W词到50W词)。比如《On Using Very Large Target Vocabulary for Neural Machine Translation》。tensorflow中有对应的实现 tf.nn.sampled_softmax_loss
- 模型
- 构建一个固定词表的同时,维护一个动态的词表。这种机制一般称为Copy/Pointer Mechanism。这个动态的词表,事实上就是source input里面的词copy过来的。动态词表里面一般是一些罕见词,而固定的词表是你基于某种规则构建你的词表(比如:出现频数大于5)。这样的方法在十分优雅,两个不同词表的合作,就像GPU的缓存和内存之间的合作。
NLP简介
《集智俱乐部》NLP介绍专题:北大李嫣然
- ① 【入门】NLP哪里跑: 什么是自然语言处理
- NLP哪里跑: 开篇及一些碎碎念
- NLP哪里跑: 什么是自然语言处理 · ZMonster’s Blog
- NLP哪里跑: Unicode相关的一些小知识和工具 · ZMonster’s Blog
- NLP哪里跑: 文本分类工具一览 · ZMonster’s Blog
- ② 【进阶】自然语言处理与深度学习: 集智俱乐部活动笔记
NLP 就是人类和机器之间沟通的桥梁
自然语言就是大家平时在生活中常用的表达方式,大家平时说的「讲人话」就是这个意思。
- 自然语言:我背有点驼(非自然语言:我的背部呈弯曲状)
- 自然语言:宝宝的经纪人睡了宝宝的宝宝(微博上这种段子一大把)
什么是NLP
自然语言处理研究在人与人交际中以及在人与计算机交际中的语言问题的一门学科。自然语言处理要研制表示语言能力和语言应用的模型,建立计算框架来实现这样的语言模型,提出相应的方法来不断完善这样的语言模型,根据这样的语言模型设计各种实用系统,并探讨这些实用系统的评测技术。
NLP 诞生
1948年,香农提出信息熵的概念。此时尚未有NLP,但由于熵也是NLP的基石之一,在此也算作是NLP的发展历程。
按照维基百科的说法,NLP发源于1950年。图灵于该年提出“图灵测试”,用以检验计算机是否真正拥有智能。
NLP可以追溯到20世纪50年代计算机程序员开始尝试简单的语言输入。NLU在20世纪60年代开始发展,希望让计算机能够理解更复杂的语言输入。NLU被认为是NLP的一个子方向,主要侧重于机器阅读理解:让计算机理解文本的真正含义
自然语言处理,即 Natural Language Processing,简称 NLP ,是一门旨在利用计算机技术来理解并运用自然语言的学科。在不同的场景下,有时候也称之为计算语言学(Computational Linguistics, CL)或者自然语言理解(Natural Language Understanding, NLU)。
- NLP 主要通过计算机技术来进行:通过计算机技术承载、运用
- NLP 要理解和运用的是自然语言:英语、法语等自然演变而来的语言,而非C/Java等人类创造出来的程序设计语言
- NLP 试图理解自然语言,但何谓「理解」其实并没有一个确定的标准
- 脑科学尚未研究清楚人类使用语言时大脑如何运作,还没有一个系统的、全面的认识;现有的技术框架下,用计算机做到完全理解自然语言,是不可能的
- 在特定场景中,机器能对自然语言表达的语句进行正确响应,就算是理解了自然语言
自然语言处理本质上属于认知智能任务。众所周知,认知智能是人类与动物对主要区别之一,与许多动物也具有低级的感知智能不同,认知智能需要更强的抽象和推理能力。自然语言处理本身有很多特性,包括歧义性、抽象性、组合性、进化性、非规范性、主观性、知识性、难迁移性等。这些特性提升了自然语言处理的难度,自然语言处理也成为制约人工智能取得更大突破和更广泛应用的瓶颈。包括多位图灵奖得主在内的多位知名科学家都认为自然语言处理是下一个人工智能需要重点攻克的方向
自然语言处理的核心困难,在于自然语言的形式与语义之间存在多对多的映射。为了解决这个困难,我们通常利用“知识”来进行约束。因此,如何获取和利用“知识”成为了一个关键科学问题。
“知识”(广义)的来源:
- (1)广义的“知识”包括狭义的知识、算法以及数据。其中,狭义的知识指可以人工定义的、显性的知识,包括语言知识、常识知识和世界知识。语言知识通常可以通过词典、规则库等来获取;世界知识也可以从文本中挖到,如知识图谱;而常识知识往往很难从文本中直接获取,现在一般通过人工的方式,将人类的常识知识结构化地存储下来(如CYC项目)。
- (2)算法在本质上也是一种知识,但它是一种动态的知识。在深度学习出现之前,主流的算法是浅层学习,通过人工提取解决问题的关键特征,再对特征进行线性加权,而所谓的“知识”就体现在对“特征”的定义和提取之中。后来,随着深度学习的发展,深层神经网络越来越多地取代人工进行特征的归纳和提取,端到端的学习使得任务可以自动实现。另外,如CKY,MST等NLP算法,也与语言知识密切相关。
- (3)数据也是一种自动的、隐性的知识。数据包括有标注和无标注两种类型。有标注的数据往往规模有限,蕴含的知识也有限;为了扩大数据的规模,最好使用无标注的数据,如大量传统的文本数据,然后通过设计自监督任务来预训练一个语言模型,这也就是目前整个人工智能领域最火的预训练语言模型方向。
NLP分类
自然语言处理主要包括两个方面:一是对文本符号本身的理解,二是自然语言的生成。
NLU与NLP
与NLP类似,NLU使用算法将人类语音转化为结构化本体。 然后使用AI算法检测意图,时间,位置和情绪等
自然语言理解是许多过程的第一步,例如分类文本,收集新闻,归档单个文本,以及更大规模地分析内容。NLU的实际例子包括从基于理解文本发布短命令到小程度的小任务,例如基于基本语法和适当大小的词典将电子邮件重新发送到合适的人。更为复杂的行为可能是完全理解诗歌或小说中的新闻文章或隐含意义。
- 总而言之, NLU是实现NLP的第一步:在机器处理语言之前,必须首先理解它。
NLU是NLP的组成部分,负责人类理解某个文本所呈现的含义。与NLP最大的区别之一是NLU超越了解单词,因为它试图解释和处理常见的人类错误,如错误发音或字母或单词的颠倒。
推动NLP的理论是 Noam Chomsky 在1957年的“句法结构”中所设定的假设:“语言L的语言分析的基本目标是将L的句子的语法序列与不符合语法的序列分开。 这不是研究语言L的句子,而是研究语法序列的结构。”
句法分析确实用于多个任务,通过将语法规则应用于一组单词并通过多种技术从中获得意义来评估语言如何与语法规则保持一致:
- 词形还原:将单词的变形形式简化为单一形式,以便于分析。
- 词干:将变形的词语切割成它们的根形式。
- 形态分割:将单词划分为语素。
- 分词:将连续文本分成不同的单元。
- 解析:句子的语法分析。
- 词性标注:识别每个单词的词性。
- 句子破坏:将句子边界放在连续文本上。
发展历史
微软亚洲研究院成立20周年时表示:NLP将迎来黄金十年。
- 比尔·盖茨曾说过,“语言理解是人工智能皇冠上的明珠”。自然语言处理(NLP,Natural Language Processing)的进步将会推动人工智能整体进展。 NLP的历史几乎跟计算机和人工智能(AI)的历史一样长。回顾基于深度学习的NLP技术的重大进展,从时间轴来看主要包括:
- 2003年,NNLM
- 2013年,Word Embeddings
- 2014年,Seq2Seq
- 2015年,Attention
- 2015年,Memory-based networks
- 2017年,Transformer
- 2018年,BERT
- 2019年,XLNet
【2022-4-24】哈工大教授车万翔:自然语言处理中的伪数据, 报告回放
自然语言处理技术已经经历了四次范式变迁:
- 1950-1990,小规模专家知识
- 1990-2010,浅层学习模型
- 2010-2017,深度学习模型
- 2018年至今,大规模预训练模型 数据越来越重要,目前主要是通过“预训练+精调”的范式来处理大规模数据,但预训练与精调之间的任务往往差距较大,这限制了进一步提高下游任务的准确率。
自然语言处理被誉为“人工智能皇冠上的明珠”,而语言的理解需要“知识”——狭义知识、算法和数据的约束。数据的作用越来越重要,但是目前的预训练方式,预训练任务与目标任务之间的差距较大,本文提出的伪数据方法,正是为了弥补这种差距。同时,伪数据也是融合规则知识的一种手段。
预训练语言模型发展历史
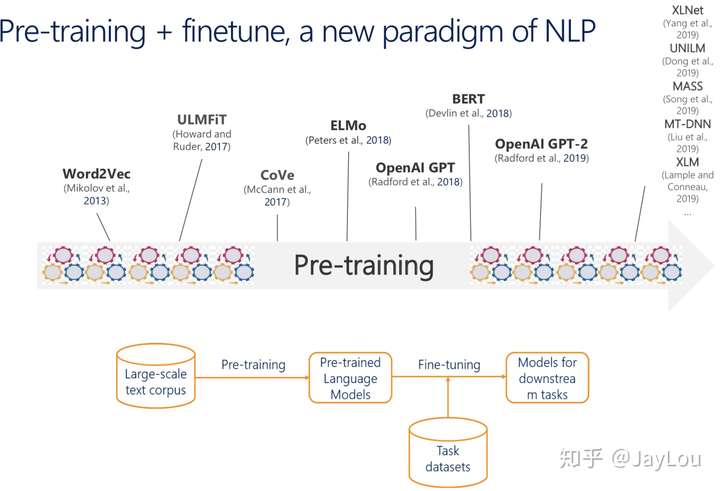
【2021-1-17】Impressive progress of deep learning on unsupervised text corpora,A Review of the Neural History of Natural Language Processing
- 2001 : Neural language models
神经语言模型,完成了n-gram到神经网络的转变- Bengio 等人于 2001 年提出第一个神经语言模型,前馈神经网络(feed-forward neuralnetwork)
- 根据出现前N个词语预测下一个单词,得到副产物,词向量,即后来熟知的词嵌入(word embeddings)
- 语言模型的建立是一种无监督学习(unsupervised learning),Yann LeCun 也将其称之为预测学习(predictive learning),是获得世界如何运作常识的先决条件。
- 接着,前馈神经网络已经被循环神经网络(RNNs)和长短期记忆神经网络(LSTMs)取代
- 2008 : Multi-task learning
多任务学习- 1993 年由 Rich Caruana 首次提出多任务学习思想,并应用于道路追踪和肺炎预测。
- 2008 年Collobert 和 Weston 等人首次在自然语言处理领域将多任务学习应用于神经网络,多任务学习是在多个任务下训练的模型之间共享参数的方法,在神经网络中可以通过捆绑不同层的权重轻松实现;共享的词嵌入矩阵使模型可以相互协作,共享矩阵中的低层级信息,而词嵌入矩阵往往构成了模型中需要训练的绝大部分参数。Collobert 和 Weston 发表于 2008 年的论文,影响远远超过了它在多任务学习中的应用。它开创的诸如预训练词嵌入和使用卷积神经网络处理文本的方法,在接下来的几年被广泛应用。他们也因此获得了 2018 年机器学习国际会议(ICML)的 test-of-time 奖。
- 2013 : Word embeddings,
词嵌入→ Neural networks for NLP开启- 长久以来,NP领域一直通过稀疏向量对文本进行表示的词袋模型
- 2001年首次出现用稠密的向量对词语进行描述,即词嵌入
- 2013年Mikolov等人工作的主要创新之处在于,通过去除隐藏层和近似计算目标使词嵌入模型的训练更为高效。尽管这些改变在本质上是十分简单的,但它们与高效的 word2vec(word to vector,用来产生词向量的相关模型)组合在一起,使得大规模的词嵌入模型训练成为可能。Word2vec 有两种不同的实现方法:CBOW(continuous bag-of-words)和 skip-gram
- 虽然 word2vec 捕捉到的关系具有直观且几乎不可思议的特性,但后来的研究表明,word2vec 本身并没有什么特殊之处:词嵌入也可以通过矩阵分解来学习,经过适当的调试,经典的矩阵分解方法 SVD 和 LSA 都可以获得相似的结果。
- Word2vec 的应用范围也超出了词语级别:带有负采样的 skip-gram——一个基于上下文学习词嵌入的方便目标,已经被用于学习句子的表征。它甚至超越了自然语言处理的范围,被应用于网络和生物序列等领域。
- 2013年 和 2014 年是自然语言处理领域神经网络时代的开始。其中三种类型的神经网络应用最为广泛:
循环神经网络(recurrent neural networks):Vanilla 循环神经网络 → 经典的长短期记忆网络(解决梯度消失和梯度爆炸问题)→ 双向的长短期记忆记忆网络卷积神经网络(convolutionalneural networks):优点是具有更好的并行性。因为卷积操作中每个时间步的状态只依赖于局部上下文,而不是循环神经网络中那样依赖于所有过去的状态结构递归神经网络(recursive neural networks):自下而上构建序列的表示,与从左至右或从右至左对序列进行处理的循环神经网络形成鲜明的对比。树中的每个节点是通过子节点的表征计算得到的。一个树也可以视为在循环神经网络上施加不同的处理顺序,所以长短期记忆网络则可以很容易地被扩展为一棵树。
- 2014 : Sequence-to-sequence models
序列到序列模型- 2014 年,Sutskever 等人提出了序列到序列学习,即使用神经网络将一个序列映射到另一个序列的一般化框架。
- 2016 年,谷歌宣布他们将用神经机器翻译模型取代基于短语的整句机器翻译模型。谷歌大脑负责人 Jeff Dean 表示,这意味着用 500 行神经网络模型代码取代 50 万行基于短语的机器翻译代码。
- 代码解析
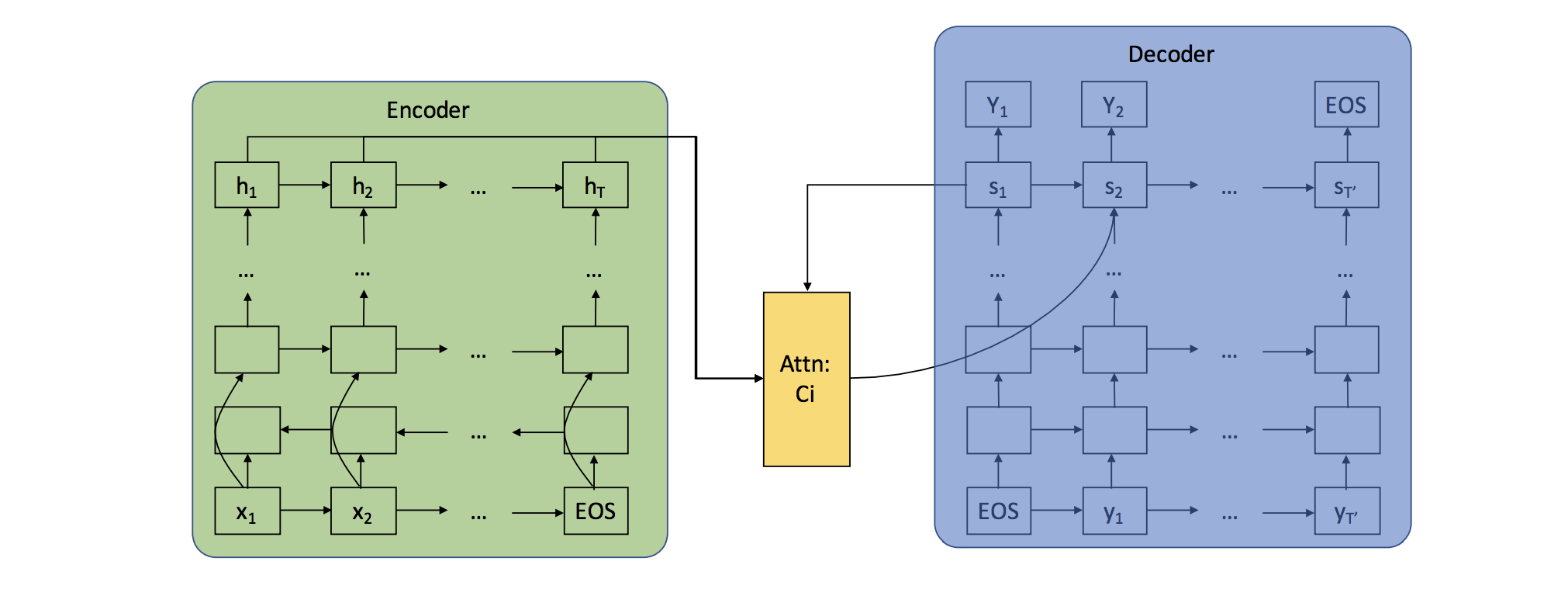
- 2015 : Attention及Memory-based networks
注意力机制- 序列到序列学习的主要瓶颈是,需要将源序列的全部内容压缩为固定大小的向量。注意力机制通过让解码器回顾源序列的隐藏状态,以此为解码器提供加权平均值的输入来缓解这一问题
- 注意力机制是神经网络机器翻译 (NMT) 的核心创新之一,也是使神经网络机器翻译优于经典的基于短语的机器翻译的关键
- 注意力机制一个有用的附带作用是它通过注意力权重来检测输入的哪一部分与特定的输出相关,从而提供了一种罕见的虽然还是比较浅层次的,对模型内部运作机制的窥探
- 自注意力机制 可以用来观察句子或文档中周围的单词,获得包含更多上下文信息的词语表示。多层的自注意力机制是神经机器翻译前沿模型 Transformer 的核心。
- 注意力机制可以视为模糊记忆的一种形式,其记忆的内容包括模型之前的隐藏状态,由模型选择从记忆中检索哪些内容。与此同时,更多具有明确记忆单元的模型被提出。他们有很多不同的变化形式,比如神经图灵机(Neural Turing Machines)、记忆网络(Memory Network)、端到端的记忆网络(End-to-end Memory Newtorks)、动态记忆网络(DynamicMemory Networks)、神经可微计算机(Neural Differentiable Computer)、循环实体网络(RecurrentEntity Network)。
- 记忆的存取通常与注意力机制相似,基于与当前状态且可以读取和写入。这些模型之间的差异体现在它们如何实现和利用存储模块。
- 2016年,谷歌发布了 Google Neural Machine Translation (GNMT),即谷歌神经机器翻译,一个 sequence-to-sequence (“seq2seq”) 的模型。现在,它已经用于谷歌翻译的产品系统。资讯
- 2018 : Pretrained language models,BERT系列
预训练语言模型- 预训练的语言模型于 2015 年被首次提出,但直到最近它才被证明在大量不同类型的任务中均十分有效。
- 其它里程碑:一些其他进展虽不如上面提到的那样流行,但仍产生了广泛的影响。
- 基于字符的描述(Character-based representations)
- 在字符层级上使用卷积神经网络和长短期记忆网络,以获得一个基于字符的词语描述,目前已经相当常见了,特别是对于那些语言形态丰富的语种或那些形态信息十分重要、包含许多未知单词的任务。据目前所知,基于字符的描述最初用于序列标注,现在,基于字符的描述方法,减轻了必须以增加计算成本为代价建立固定词汇表的问题,并使完全基于字符的机器翻译的应用成为可能。
- 对抗学习(Adversarial learning)
- 对抗学习的方法在机器学习领域已经取得了广泛应用,在自然语言处理领域也被应用于不同的任务中。对抗样例的应用也日益广泛,他们不仅仅是探测模型弱点的工具,更能使模型更具鲁棒性(robust)。(虚拟的)对抗性训练,也就是最坏情况的扰动,和域对抗性损失(domain-adversariallosses)都是可以使模型更具鲁棒性的有效正则化方式。生成对抗网络 (GANs) 目前在自然语言生成任务上还不太有效,但在匹配分布上十分有用。
- 强化学习(Reinforcement learning)
- 强化学习已经在具有时间依赖性的任务上证明了它的能力,比如在训练期间选择数据和对话建模。在机器翻译和概括任务中,强化学习可以有效地直接优化”红色”和”蓝色”这样不可微的度量,而不必去优化像交叉熵这样的代理损失函数。同样,逆向强化学习(inverse reinforcement learning)在类似视频故事描述这样的奖励机制非常复杂且难以具体化的任务中,也非常有用。
- 基于字符的描述(Character-based representations)
资料
- 15年来,自然语言处理发展史上的8大里程碑
- 【2022-3-21】自然语言处理专题
发展趋势:
- 规则时代 → 统计时代 → 深度学习时代
NLP 规则时代
1950-1970年,模拟人类学习语言的习惯,以语法规则为主流。除了参照乔姆斯基文法规则定义的上下文无关文法规则外,NLP领域几乎毫无建树。
NLP 统计时代
- 20世纪70年代开始统计学派盛行,NLP转向统计方法,此时的核心是以具有马尔科夫性质的模型(包括语言模型,隐马尔可夫模型等)。
- 2001年,神经语言模型,将神经网络和语言模型相结合,应该是历史上第一次用神经网络得到词嵌入矩阵,是后来所有神经网络词嵌入技术的实践基础。也证明了神经网络建模语言模型的可能性。
- 2001年,条件随机场CRF,从提出开始就一直是序列标注问题的利器,即便是深度学习的现在也常加在神经网络的上面,用以修正输出序列。
- 2003年,LDA模型提出,概率图模型大放异彩,NLP从此进入“主题”时代。Topic模型变种极多,参数模型LDA,非参数模型HDP,有监督的LabelLDA,PLDA等。
- 2008年,分布式假设理论提出,为词嵌入技术的理论基础。
在统计时代,NLP专注于数据分布,如何从文本的分布中设计更多更好的特征模式是这时期的主流。在这期间,还有其他许多经典的NLP传统算法诞生,包括tf-idf、BM25、PageRank、LSI、向量空间与余弦距离等。
- 20世纪80、90年代,卷积神经网络、循环神经网络等就已经被提出,但受限于计算能力,NLP的神经网络方向不适于部署训练,多停留于理论阶段。
NLP 深度时代
- 2013年,word2vec提出,NLP的里程碑式技术。
- 2013年,CNNs/RNNs/Recursive NN,随着算力的发展,神经网络可以越做越深,之前受限的神经网络不再停留在理论阶段。在图像领域证明过实力后,Text CNN问世;同时,RNNs也开始崛起。在如今的NLP技术上,一般都能看见CNN/LSTM的影子。
- 本世纪算力的提升,使神经网络的计算不再受限。有了深度神经网络,加上嵌入技术,人们发现虽然神经网络是个黑盒子,但能省去好多设计特征的精力。至此,NLP深度学习时代开启。
- 2014年,seq2seq提出,在机器翻译领域,神经网络碾压基于统计的SMT模型。
- 2015年,attention提出,可以说是NLP另一里程碑式的存在。带attention的seq2seq,碾压上一年的原始seq2seq。记得好像17年年初看过一张图,调侃当时学术界都是attention的现象,也证明了attention神一般的效果。
- 2017年末,Transformer提出。似乎是为了应对Facebook纯用CNN来做seq2seq的“挑衅”,google就纯用attention,并发表著名的《Attention is All You Need》。初看时以为其工程意义大于学术意义,直到BERT的提出才知道自己还是too young。
- 2018年末,BERT提出,横扫11项NLP任务,奠定了预训练模型方法的地位,NLP又一里程碑诞生。光就SQuAD2.0上前6名都用了BERT技术就知道BERT的可怕。
深度学习时代,神经网络能够自动从数据中挖掘特征,人们从复杂的特征中脱离出来,得以更专注于模型算法本身的创新以及理论的突破。并且深度学习从一开始的机器翻译领域逐渐扩散到NLP其他领域,传统的经典算法地位大不如前。但神经网络似乎一直是个黑箱,可解释性一直是个痛点,且由于其复杂度更高,在工业界经典算法似乎还是占据主流。
NLP入门
1. 什么是语言?
语言是指生物同类之间由于沟通需要而制定的指令系统,语言与逻辑相关,目前只有人类才能使用体系完整的语言进行沟通和思想交流。
2. 什么是自然语言?
自然语言通常会自然地随文化发生演化,英语、汉语、日语都是具体种类的自然语言,这些自然语言履行着语言最原始的作用:人们进行交互和思想交流的媒介性工具。
- 语音:与发音有关的学问,主要在语音技术中发挥作用。
- 音韵:由语音组合起来的读音,即汉语拼音和四声调。
- 词态:封装了可用于自然语言理解的有用信息,其中信息量的大小取决于具体的语言种类。中文没有太多的词态变换,仅存在不同的偏旁,导致出现词的性别转换的情况。
- 句法:主要研究词语如何组成合乎语法的句子,句法提供单词组成句子的约束条件,为语义的合成提供框架。
- 语义和语用:自然语言所包含和表达的意思。
3. 什么是自然语言处理?
自然语言处理(Natural Language Processing,NLP):计算机科学,人工智能和语言学的交叉领域。目标是让计算机处理或“理解”自然语言,以执行语言翻译和问题回答等任务。
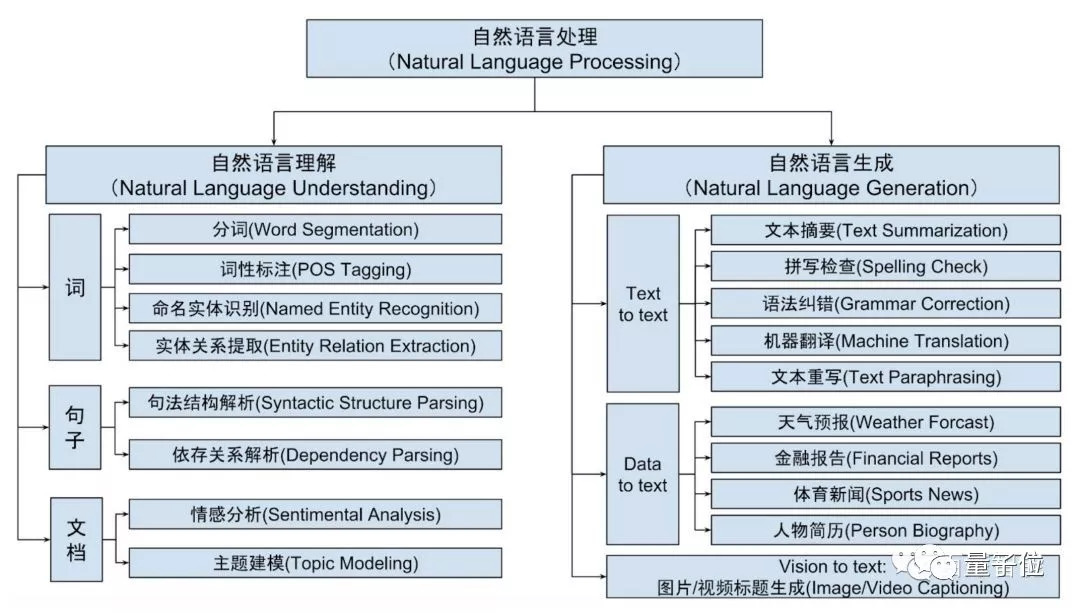
NLP包含自然语言理解(Natural Language Understanding,NLU) 和自然语言生成(Natural Language Generation, NLG)两个重要方向,如下图所示。
- 自然语言理解NLU: 将人的语言形式转化为机器可理解的、结构化的、完整的语义表示,通俗来讲就是让计算机能够理解和生成人类语言。
- 自然语言生成NLG: 让机器根据确定的结构化数据、文本、音视频等生成人类可以理解的自然语言形式的文本。
| 场景 | 小明 | 小红 | |
|---|---|---|---|
| 一 | 非自然语言 | 汪汪汪汪喵喵喵 | (说人话,不然滚犊子) |
| 二 | 自然语言但无法理解 | 苟利国家生死已,岂因祸福避趋之,小红你有没有一种钦定的感觉? | (这个人在说什么……) |
| 三 | 自然语言,理解并回复 | 小明,下午放学后你把教室的窗户玻璃擦一擦吧! | 我擦,我不擦! |
场景一: 接收到非自然语言
- —— 小明: 汪汪汪汪喵喵喵
- —— 小红: (说人话,不然滚犊子)
场景二: 接收到自然语言,但不能理解
- —— 小明: 苟利国家生死已,岂因祸福避趋之,小红你有没有一种钦定的感觉?
- —— 小红: (这个人在说什么……)
场景三: 接收到自然语言,理解并回复
- —— 小红: 小明,下午放学后你把教室的窗户玻璃擦一擦吧!
- —— 小明: 我擦,我不擦!
NLP主要的研究或应用方向有三部分
感知Perceive:理解Understand:沟通Communicate:
4. 自然语言处理的难度
- 自然语言千变万化,没有固定格式。同样的意思可以使用多种句式来表达,同样的句子调整一个字、调整语调或者调整语序,表达的意思可能相差很多。
- 不断有新的词汇出现,计算机需要不断学习新的词汇。
- 受语音识别准确率的影响。
- 自然语言所表达的语义本身存在一定的不确定性,同一句话在不同场景/语境下的语义可能完全不同。
- 人类讲话时往往出现不流畅、错误、重复等现象,而对机器来说,在它理解一句话时,这句话整体所表达的意思比其中每个词的确切含义更加重要。
自然语言理解的5个难点:
- 语言的多样性
- 语言的歧义性
- 语言的鲁棒性
- 语言的知识依赖
- 语言的上下文
NLP难点
- 没有规律:语言是没有规律的,或者说规律是错综复杂的。
- 自由组合:语言是可以自由组合的,可以组合复杂的语言表达。
- 开放集合:语言是一个开放集合,我们可以任意的发明创造一些新的表达方式。
- 知识依赖:语言需要联系到实践知识,有一定的知识依赖。
- 上下文:语言的使用要基于环境和上下文。
【2022-3-21】自然语言处理专题
NLP难点
- 中文分词,这条是专门针对中文说的。众所周知汉语博大精深,老外学汉语尚且虐心,更别提计算机了。同一个任务,同一个模型在英文语料的表现上一般要比中文语料好。无论是基于统计的还是基于深度学习的NLP方法,分词都是第一步。分词表现不好的话,后面的模型最多也只能尽力纠偏
- 梁启超生前住在这里
- 武汉市长江大桥
- 词义消歧:很多单词不只有一个意思,但这个在今年BERT推出后应该不成问题,可以通过上下文学到不同的意思。另一个较难的是指代消歧,即句子中的指代词还原,如“小明受到了老师的表扬,他很高兴”,这个“他”是指“小明”还是指“老师”。
词语(最小单元)级别歧义:- The box is in the pen —— 盒子在笔中 or 盒子在围栏里 ?时至今日,google翻译依然无法解决
- 依赖于文本之外的、海量的「常识」:盒子比笔大
- 多义词:你这个人真有意思,你到底几个意思
- 同义词:缩写、专名的别名、网络用语、方言、口语、书面语等 —— 搜索引擎用查询改写(query rewrite)、知识图谱用实体链接
- 目前 NLP 领域并没有一劳永逸的解决办法,有靠人工构建的小规模高质量知识库如 WordNet、HowNet、同义词词林,也有靠机器学习方法从大量语料中学习到词语的向量表示来隐式地反映词义 —— 量大但并不足够精确。前者往往质量很好但只能覆盖人们实际语言中很小的一部分,后者依赖于语料的数量、质量和领域,对于语料中较少出现的一些词往往就会得到莫名其妙的结果。
- The box is in the pen —— 盒子在笔中 or 盒子在围栏里 ?时至今日,google翻译依然无法解决
句子级别(或段落/篇章)歧义:结构性歧义- 喜欢乡下的孩子
- 放弃美丽的女人让人心碎
- 二义性:有些句子,往往有多种理解方式,其中以两种理解方式的最为常见,称二义性。
- OOV问题:随着词嵌入技术大热后,使用预训练的词向量似乎成为了一个主流。但有个问题,数据中的词很可能不在预训练好的词表里面,此即 OOV(out of vocabulary)。主流方法是要么当做UNK处理,要么生成随机向量或零向量处理,当然都存在一定的弊端。
- 文本相似度计算:文本相似度计算依旧算是难点之一。不过与其说难点,主要是至今没有一种方法能够从理论证明。主流认可的是用余弦相似度。但看论文就会发现,除了余弦相似度外,有人用欧式距离,有人用曼哈顿距离,有人直接向量內积,且效果还都不错。
- 文本生成的评价指标:文本生成的评价指标多用 BLEU 或者 ROUGE ,但尴尬的是,这两个指标都是基于n-gram的,也就是说会判断生成的句子与标签句子词粒度上的相似度。然而由于自然语言的特性(同一个意思可以有多种不同的表达),会出现生成的句子尽管被人为判定有意义,在BLEU或ROUGE上仍可能会得到很低的分数的情况。这两个指标用在机翻领域倒是没多大问题(本身就是机翻的评价指标),但用在文本摘要和对话生成就明显不合适了。
5. 技术概述
自然语言理解技术概述
基于规则的方法
指利用规则定义如何如何从文本中提取语义。大致思路是人工定义很多语法规则,它们是表达某种特定语义的具体方式,然后自然语言理解模块根据这些规则解析输入该模块的文本。
- 优点:灵活,可以定义各种各样的规则,而且不依赖训练数据;
- 缺点:需要大量的、覆盖不同场景的规则,且随着规则数量的增长,对规则进行人工维护的难度也会增加。
- 结论:只适合用在相对简单的场景,其优势在于可以快速实现一个简单可用的语义理解模块。
基于统计的方法
通常使用大量的数据训练模型,并使用训练所得的模型执行各种上层语义任务。
- 优点:数据驱动且健壮性较好;
- 缺点:训练数据难以获得且模型难以解释和调参; 通常使用数据驱动的方法解决分类和序列标注方法。
在具体实践中,通常将这两种方法结合起来使用
- 没有数据及数据较少时先采取基于规则的方法,当数据积累到一定规模时转为使用基于统计的方法。
- 在一些基于统计的方法可以覆盖绝大多数场景,在一些其覆盖不到的场景中使用基于规则的方法兜底,以此来保证自然语言理解的效果。
基于深度学习的方法
2019年,BERT 和 GPT-2 的表现震惊了业界,他们都是用了 Transformer,下面将重点介绍 Transformer,因为他是目前「最先进」的方法。
Transformer 和 CNN / RNN 的比较
- (1)语义特征提取能力:Transformer » 原生CNN = 原生RNN
- 目前实验结论:Transformer在这方面的能力非常显著地超过RNN和CNN(在考察语义类能力的任务WSD中,Transformer超过RNN和CNN大约4-8个绝对百分点),RNN和CNN两者能力差不太多。
- (2)长距离特征捕获能力:Transformer > 原生CNN > 原生RNN
- 原生CNN特征抽取器在这方面极为显著地弱于RNN和Transformer,Transformer微弱优于RNN模型(尤其在主语谓语距离小于13时),能力由强到弱排序为Transformer>RNN»CNN; 但在比较远的距离上(主语谓语距离大于13),RNN微弱优于Transformer,所以综合看,可以认为Transformer和RNN在这方面能力差不太多,而CNN则显著弱于前两者。
- (3)任务综合特征抽取能力:Transformer » 原生CNN = 原生RNN
- Transformer综合能力要明显强于RNN和CNN(你要知道,技术发展到现在阶段,BLEU绝对值提升1个点是很难的事情),而RNN和CNN看上去表现基本相当,貌似CNN表现略好一些。
- (4)并行计算能力及运算效率:Transformer > 原生CNN > 原生RNN
- Transformer Base最快,CNN次之,再次Transformer Big,最慢的是RNN。RNN比前两者慢了3倍到几十倍之间。
一文看懂自然语言理解-NLU(基本概念+实际应用+3种实现方式)
NLP基础任务
追求创建一个能够以人类方式与人类互动的聊天机器人的目标 - 并最终通过图灵测试,企业和学术界正在研发更多的NLP和NLU技术。他们想到产品实现的目标应该轻松,无监督学习,并能够以适当的方式直接与人们互动。
为实现这一目标,该研究分三个层次进行:
- 语法:理解文本的语法
- 语义:理解文本的字面意义
- 语用:理解文本试图表达的意思
不幸的是,理解和处理自然语言并不是提供足够大的词汇量和训练机器那么简单。 如果要取得成功,NLP必须融合来自各个领域的技术:语言,语言学,认知科学,数据科学,计算机科学等。 只有结合所有可能的观点,我们才能揭开人类语言的神秘面纱
NLP 有2个核心的任务:NLU和NLG
- 自然语言理解 – NLU/NLI
- 希望机器像人一样,具备正常人的语言理解能力,由于自然语言在理解上有很多难点(下面详细说明),所以 NLU 是至今还远不如人类的表现。
- 自然语言生成 – NLG
- NLG 是为了跨越人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式,如文章、报告等。
NLG 的6个步骤:
- 内容确定 – Content Determination
- 文本结构 – Text Structuring
- 句子聚合 – Sentence Aggregation
- 语法化 – Lexicalisation
- 参考表达式生成 – Referring Expression Generation, REG
- 语言实现 – Linguistic Realisation
《一文看懂自然语言生成 - NLG(6个实现步骤+3个典型应用)》
英文NLP过程:文章
- 分词 – Tokenization
- 词干提取 – Stemming
- 词形还原 – Lemmatization
- 词性标注 – Parts of Speech
- 命名实体识别 – NER
- 分块 – Chunking 中文NLP过程:
- 中文分词 – Chinese Word Segmentation
- 词性标注 – Parts of Speech
- 命名实体识别 – NER
- 去除停用词
【2020-11-08】邱锡鹏,自然语言处理中的预训练模型
语言表示学习
词短语- 组合语义模型
句子- 连续词袋模型
- 序列模型
- 递归组合模型
- 卷积模型
篇章- 层次模型
自然语言处理任务类型划分为:
- 序列到类别
- 文本分类
- 情感分析
- 同步的序列到序列
- 中文分词
- 词性标注
- 语义角色标注
- 异步的序列到序列
- 机器翻译
- 自动摘要
- 对话系统
- 类别(对象)到序列
- 文本生成
- 图像描述生成
常见任务
词法分析(Lexical Analysis):对自然语言进行词汇层面的分析,是NLP基础性工作- 分词(Word Segmentation/Tokenization):对没有明显边界的文本进行切分,得到词序列
- 新词发现(New Words Identification):找出文本中具有新形势、新意义或是新用法的词
- 形态分析(Morphological Analysis):分析单词的形态组成,包括词干(Sterms)、词根(Roots)、词缀(Prefixes and Suffixes)等
- 词性标注(Part-of-speech Tagging):确定文本中每个词的词性。词性包括动词(Verb)、名词(Noun)、代词(pronoun)等
- 拼写校正(Spelling Correction):找出拼写错误的词并进行纠正
句子分析(Sentence Analysis):对自然语言进行句子层面的分析,包括句法分析和其他句子级别的分析任务- 组块分析(Chunking):标出句子中的短语块,例如名词短语(NP),动词短语(VP)等
- 超级标签标注(Super Tagging):给每个句子中的每个词标注上超级标签,超级标签是句法树中与该词相关的树形结构
- 成分句法分析(Constituency Parsing):分析句子的成分,给出一棵树由终结符和非终结符构成的句法树
- 依存句法分析(Dependency Parsing):分析句子中词与词之间的依存关系,给一棵由词语依存关系构成的依存句法树
- 语言模型(Language Modeling):对给定的一个句子进行打分,该分数代表句子合理性(流畅度)的程度
- 语种识别(Language Identification):给定一段文本,确定该文本属于哪个语种
- 句子边界检测(Sentence Boundary Detection):给没有明显句子边界的文本加边界
语义分析(Semantic Analysis):对给定文本进行分析和理解,形成能勾够表达语义的形式化表示或分布式表示- 词义消歧(Word Sense Disambiguation):对有歧义的词,确定其准确的词义
- 语义角色标注(Semantic Role Labeling):标注句子中的语义角色类标,语义角色,语义角色包括施事、受事、影响等
- 抽象语义表示分析(Abstract Meaning Representation Parsing):AMR是一种抽象语义表示形式,AMR parser把句子解析成AMR结构
- 一阶谓词逻辑演算(First Order Predicate Calculus):使用一阶谓词逻辑系统表达语义
- 框架语义分析(Frame Semantic Parsing):根据框架语义学的观点,对句子进行语义分析
- 词汇/句子/段落的向量化表示(Word/Sentence/Paragraph Vector):研究词汇、句子、段落的向量化方法,向量的性质和应用
信息抽取(Information Extraction):从无结构文本中抽取结构化的信息- 命名实体识别(Named Entity Recognition):从文本中识别出命名实体,实体一般包括人名、地名、机构名、时间、日期、货币、百分比等
- 实体消歧(Entity Disambiguation):确定实体指代的现实世界中的对象
- 术语抽取(Terminology/Giossary Extraction):从文本中确定术语
- 共指消解(Coreference Resolution):确定不同实体的等价描述,包括代词消解和名词消解
- 关系抽取(Relationship Extraction):确定文本中两个实体之间的关系类型
- 事件抽取(Event Extraction):从无结构的文本中抽取结构化事件
- 情感分析(Sentiment Analysis):对文本的主观性情绪进行提取
- 意图识别(Intent Detection):对话系统中的一个重要模块,对用户给定的对话内容进行分析,识别用户意图
- 槽位填充(Slot Filling):对话系统中的一个重要模块,从对话内容中分析出于用户意图相关的有效信息
顶层任务(High-level Tasks):直接面向普通用户,提供自然语言处理产品服务的系统级任务,会用到多个层面的自然语言处理技术- 机器翻译(Machine Translation):通过计算机自动化的把一种语言翻译成另外一种语言
- 文本摘要(Text summarization/Simplication):对较长文本进行内容梗概的提取
- 问答系统(Question-Answering Systerm):针对用户提出的问题,系统给出相应的答案
- 对话系统(Dialogue Systerm):能够与用户进行聊天对话,从对话中捕获用户的意图,并分析执行
- 阅读理解(Reading Comprehension):机器阅读完一篇文章后,给定一些文章相关问题,机器能够回答
- 自动文章分级(Automatic Essay Grading):给定一篇文章,对文章的质量进行打分或分级
参考:
上手案例
- 【2021-8-20】常见30种NLP任务的练手项目,类似论文实现那样的demo级的,也不是传统的工程实现,用的方法一般比工业界的高端,非常适合练手用。涉及:
- 分词 Word Segmentation: chqiwang/convseg ,基于CNN做中文分词,提供数据和代码。对应的论文Convolutional Neural Network with Word Embeddings for Chinese Word Segmentation IJCNLP2017.
- 词预测 Word Prediction: Kyubyong/word_prediction ,基于CNN做词预测,提供数据和代码。
- 文本蕴涵 Textual Entailment: Steven-Hewitt/Entailment-with-Tensorflow,基于Tensorflow做文本蕴涵,提供数据和代码。
- 词性标注(POS)、 命名实体识别(NER)、 句法分析(parser)、 语义角色标注(SRL) 等。
- HIT-SCIR/ltp, 包括代码、模型、数据,还有详细的文档,而且效果还很好
- 词干 Word Stemming: snowballstem/snowball, 实现的词干效果还不错。
- 机器翻译 Machine Translation: OpenNMT/OpenNMT-py, 基于PyTorch的神经机器翻译,很适合练手。
- 复述生成 Paraphrase Generation: vsuthichai/paraphraser,基于Tensorflow的句子级复述生成,适合练手。
- 关系抽取 Relationship Extraction: ankitp94/relationship-extraction,基于核方法的关系抽取。
- 句子边界消歧 Sentence Boundary Disambiguation: Orekhov/SentenceBreaking
- 事件抽取 Event Extraction: liuhuanyong/ComplexEventExtraction, 中文复合事件抽取,包括条件事件、因果事件、顺承事件、反转事件等事件抽取,并形成事理图谱。
- 词义消歧 Word Sense Disambiguation: alvations/pywsd
- 命名实体消歧 Named Entity Disambiguation: dice-group/AGDISTIS
- 实体链接 Entity Linking: hasibi/EntityLinkingRetrieval-ELR
- 指代消歧 Coreference Resolution: huggingface/neuralcoref
- 复述检测 Paraphrase Detection 和 问答 Question Answering: Paraphrase-Driven Learning for Open Question Answering, 基于复述驱动学习的开放域问答。
- 自动摘要 Automatic Summarisation: PKULCWM/PKUSUMSUM,北大万小军老师团队的自动摘要方法汇总,包含了他们大量paper的实现,支持单文档摘要、多文档摘要、topic-focused多文档摘要。
- 文本纠错 Text Correct: atpaino/deep-text-corrector,基于深度学习做文本纠错,提供数据和代码。
- 音汉互译 Pinyin-To-Chinese: Kyubyong/neural_chinese_transliterator,基于CNN做音汉互译
- 字音转换 Grapheme to Phoneme: cmusphinx/g2p-seq2seq,基于网红transformer做, 提供数据和代码。
- 语言识别 Language Identification: saffsd/langid.py,语言识别比较好的开源工具
- 语音识别 Automatic Speech Recognition: buriburisuri/speech-to-text-wavenet,基于DeepMind WaveNet和Tensorflow做句子级语音识别。
- 手语识别 Sign Language Recognition: Home-SignAll, 该项目在手语识别做的非常成熟
工具汇总
- 【2020-8-27】NLP模型可视化工具LIT,为什么模型做出这样的预测?什么时候性能不佳?在输入变化可控的情况下会发生什么?LIT 将局部解释、聚合分析和反事实生成集成到一个流线型的、基于浏览器的界面中,以实现快速探索和错误分析。
- 谷歌开源NLP模型可视化工具LIT,模型训练不再「黑箱」
- 支持多种自然语言处理任务,包括探索情感分析的反事实、度量共指系统中的性别偏见,以及探索文本生成中的局部行为。
- 此外 LIT 还支持多种模型,包括分类、seq2seq 和结构化预测模型。并且它具备高度可扩展性,可通过声明式、框架无关的 API 进行扩展。
- 论文地址
- 项目地址,模块操作细节
- 【2021-7-26】5个流行的自然语言处理库及入门用法
- Hugging Face Datasets: Hugging Face 的 Datasets 库本质上是一个对公开可用的 NLP 数据集的打包集合,带有一组通用的 API 和数据格式,以及一些辅助功能。Datasets 提供了两大特性:用于许多公共数据集的单行数据加载器,以及高效的数据预处理。安装:pip install datasets
- TextHero:在其 GitHub 存储库中的介绍很简单:文本预处理、表示和可视化,助你从零迈向大师。安装:pip install texthero
- spaCy: 专门设计的,其宗旨是成为一个用于实现生产就绪系统的有用库。
- Hugging Face Transformers:Hugging Face 的 Transformers 库已成为 NLP 实践不可或缺的一部分,Transformers 提供了数千个预训练模型,可以对 100 多种语言的文本执行分类、信息提取、问答、摘要、翻译、文本生成等任务。它的目标是让所有人都更容易使用尖端的 NLP 技术。Transformers由两个最流行的深度学习库 PyTorch 和 TensorFlow 提供支持,它们之间无缝集成,允许你使用一个模型来训练你的模型,然后加载它来推理另一个。
# pip install texthero
def text_texthero():
import texthero as hero
import pandas as pd
df = pd.read_csv("https://github.com/jbesomi/texthero/raw/master/dataset/bbcsport.csv")
df['pca'] = (
df['text']
.pipe(hero.clean)
.pipe(hero.tfidf)
.pipe(hero.pca)
)
hero.scatterplot(df, 'pca', color='topic', title="PCA BBC Sport news")
# pip install spacy
# python -m spacy download en # 加载语言模型
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
nlp = spacy.load('en')
doc = nlp(sample)
print("Tokens:\n=======)
for token in doc:
print(token)
print("Stop words:\n===========")
for word in doc:
if word.is_stop == True:
print(word)
print("POS tagging:\n============")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
print("Named entities:\n===============")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
# pip install transformers
from transformers import pipeline
# Allocate a pipeline for sentiment-analysis
classifier = pipeline('sentiment-analysis')
# Classify text
print(classifier('I am a fan of KDnuggets, its useful content, and its helpful editors!'))
# [{'label': 'POSITIVE', 'score': 0.9954679012298584}]
# Allocate a pipeline for question-answering
question_answerer = pipeline('question-answering')
# Ask a question
answer = question_answerer({
'question': 'Where is KDnuggets headquartered?',
'context': 'KDnuggets was founded in February of 1997 by Gregory Piatetsky in Brookline, Massachusetts.'
})
# Print the answer
print(answer)
# {'score': 0.9153624176979065, 'start': 66, 'end': 90, 'answer': 'Brookline, Massachusetts'}
算法理论
词库构建
详见站内分词专题
分类
根据NLP的终极目标,大致可以分为自然语言理解(NLU)和自然语言生成(NLG)两种。
- NLU侧重于如何理解文本,包括文本分类、命名实体识别、指代消歧、句法分析、机器阅读理解等。
- NLG则侧重于理解文本后如何生成自然文本,包括自动摘要、机器翻译、问答系统、对话机器人等。 两者间不存在有明显的界限,如机器阅读理解实际属于问答系统的一个子领域。
自然语言理解基本技术分为:词法分析、句法分析、语义分析三类。
词法分析
词法分析包括分词和词性标注。
分词 word segmentation
- 含义:中文不同于英文,其没有自然分隔符(明显的空格标记),因此汉语自然语言处理的首要工作就是将输入的字串切分为单独的词语。
分词方法:
- A、基于词表匹配的方法:会逐字对字符串进行扫描,发现字符串的子串和词表中的词相同就算匹配。
- 常见方法:有正向最大匹配法、逆向最大匹配法、双向扫描法和逐词遍历法。
- 常见的基于词表的分词工具:IKAnalyzer、庖丁解牛等。
- B、基于统计模型的方法:根据人工标注的词性和统计特征对中文进行建模,通过模型计算各种分词出现的概率,将概率最大的分词结果作为最终结果。
- 常见算法:HMM、CRF
- 常见的基于统计模型的分词工具:ICTCLAS、Stanford word segmenter等。深度学习兴起后,长短期记忆网络LSTM结合CRF的方法得到了快速发展。
词性标注
含义:词性是词语最基础的语法属性之一,因此词性标注Part-Of-Speech Tagging,POS Tagging是词法分析的一部分。
目的:为句子中的每个词赋予一个特定的类别,即为分词结果中的每个单词标注词性。
- 最重要的词性为名词、动词、形容词和副词。
- 模型:最初隐马尔可夫、之后最大熵模型、支持向量机模型
- 两种方法:基于规则的方法、基于统计模型的方法
- 基于规则的词性标注:兼类词搭配关系和上下文语境建造词类消歧规则;
- 基于统计模型的词性标注:通过模型计算各类词性出现的概率,将概率最大的词性作为最终结果。
- 常见方法:结构感知器模型和条件随机场模型。随着深度学习技术的发展,也提出了基于深层神经网络的词性标注方法。
- 工具:standford log-linear part-of-speech tagger、哈工大的LTP工具等。
句法分析
含义:句法分析syntactic parsing的主要任务是对输入的文本句子(字符串)进行分析以得到句子句法结构syntactic structure。
- 原因:一方面是nlu任务自身的需求,另一方面可以为其他nlu任务提供支持。
分类:根据句法结构的不同表示形式,任务分为以下3类:
- 依存句法分析dependency syntactic parsing,主要任务是识别句子中词汇之间的相互依存关系。
- 短语结构句法分析phrase-structure syntactic parsing,也称作为分句法分析constituent syntactic parsing,主要任务是识别句子中短语结构和短语之间的层次句法关系。
- 深层文法句法分析,主要任务是利用深层文法,对句子进行深层的句法及语义分析,这些深层文法包括词汇化树邻接文法、词汇功能文法、组合范畴文法等。
语义分析
语义,指的是自然语言所包含的意义,在计算机科学领域,可以将语义理解为数据对应的现实世界中的事物所代表概念的含义。
语义分析semantic analysis,指运用各种机器学习方法,让机器学习与理解一段文本所表示的语义内容。任何对语言的理解都可以归为语义分析的范畴,涉及语言学、计算语言学、人工智能、机器学习,甚至认知语言。
语义分析的最终目的是理解句子表达的真实含义。
- 语义分析在机器翻译任务中有重要应用。
- 基于语义的搜索一直是搜索追求的目标。
- 语义分析是实现大数据的理解与价值发现的有效手段。
机器翻译
详见站内专题: 机器翻译
分词
详见站内专题: 分词
NER 命名实体识别
详见 NER专题
同义词/近义词
相似度判断
GitHub WordSimilarity, 基于哈工大词林扩展版的单词相似度计算方法的python实现
# pip install WordSimilarity
from word_similarity import WordSimilarity2010
ws_tool = WordSimilarity2010()
b_a = "抄袭"
b_b = "克隆"
sim_b = ws_tool.similarity(b_a, b_b)
print(b_a, b_b, '相似度为', sim_b)
#抄袭 克隆 最终的相似度为 0.585642777645155
w_a = '人民'
sample_list = ["国民", "群众", "党群", "良民", "同志", "成年人", "市民", "亲属", "志愿者", "先锋" ]
for s_a in sample_list:
sim_a = ws_tool.similarity(w_a,s_a)
print(w_a, s_a, '相似度为', sim_a)
# 人民 国民 相似度为 1
# 人民 群众 相似度为 0.9576614882494312
# 人民 党群 相似度为 0.8978076452338418
# 人民 良民 相似度为 0.7182461161870735
# 人民 同志 相似度为 0.6630145969121822
# 人民 成年人 相似度为 0.6306922220793977
# 人民 市民 相似度为 0.5405933332109123
# 人民 亲属 相似度为 0.36039555547394153
# 人民 志愿者 相似度为 0.22524722217121346
# 人民 先锋 相似度为 0.18019777773697077
同义词词库
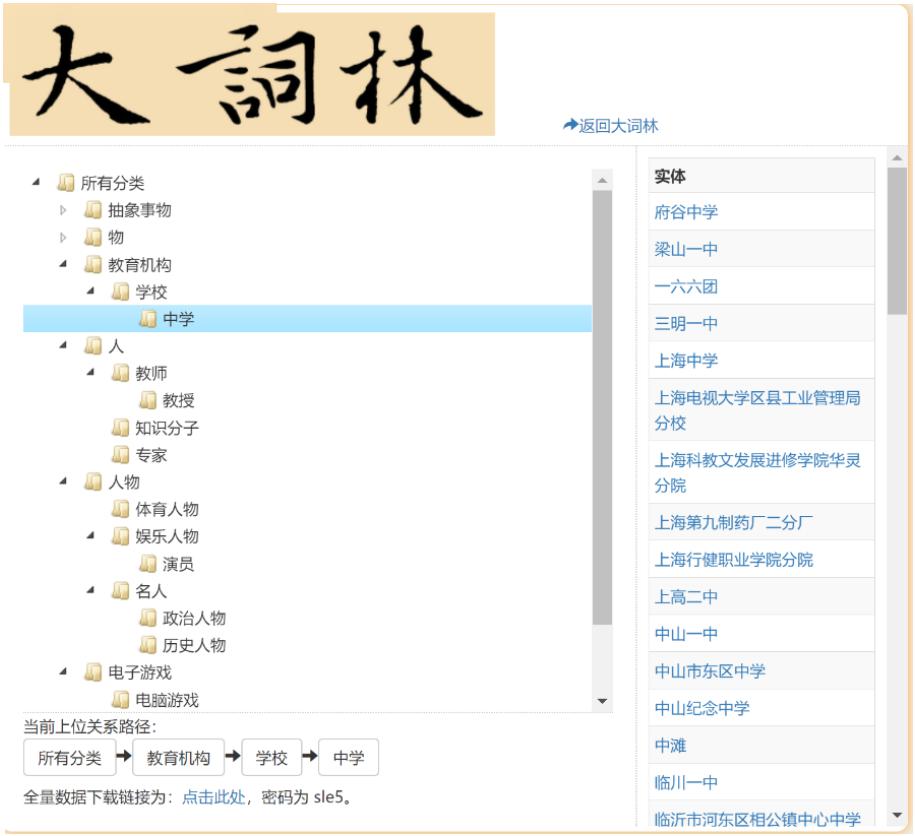
【2023-10-26】哈工大有个大词林,提供了75w同义词信息,Web查询
《大词林》由 哈尔滨工业大学社会计算与信息检索研究中心秦兵教授和刘铭副教授主持研制,一个自动构建的大规模开放域中文知识库。
- 自2014年11月推出《大词林》第一版,第一版的《大词林》包含了自动挖掘的实体和细粒度的上位概念词,类似一个大规模的汉语词典,其特点在于自动构建、自动扩充,细粒度的上下位层次关系。
- 2019年8月推出的第二版《大词林》引入了实体的义项和关系、属性数据,将每一个实体的义项唯一对应到细粒度的上位词概念路径,让《大词林》中实体的含义更加清晰。
相比于传统的开放域实体知识库,《大词林》的特点在于:
- 构建过程不需要领域专家的参与,而是基于多信息源自动获取实体类别并对可能的多个类别进行层次化,从而达到知识库自动构建的效果。
- 其数据规模可以随着互联网中实体词的更新而扩大,很好地解决了以往的人工构建知识库对开放域实体的覆盖程度极为有限的问题。
- 《大词林》是一个树状的网络,每一个实体的义项均能够唯一对应到细粒度的上位词概念路径且具有丰富的实体和关系数据,能够更加清晰明确的展示实体的含义。
《大词林》中的 75万的核心实体词,以及 这些核心实体词对应的细粒度概念词(共 1.8万概念词, 300万实体-概念元组),还有 相关的关系三元组(共 300万)。这75万核心实体列表涵盖了常见的人名、地名、物品名等术语。概念词列表则包含了细粒度的实体概念信息。借助于细粒度的上位概念层次结构和丰富的实体间关系,本次开源的数据能够为人机对话、智能推荐、等应用技术提供数据支持。
下载地址:
- 百度云
- 提取码:mwmj
短语挖掘
关键词提取方案
-
知乎话题:关键词提取都有哪些方案
- 刘知远的博士论文:基于文档主题结构的关键词抽取方法研究
- 关键词挖掘的方法:(2014年,作者:zibuyu9)
-
- TFIDF是很强的baseline,具有较强的普适性,如果没有太多经验的话,可以实现该算法基本能应付大部分关键词抽取的场景了。
-
- 对于中文而言,中文分词和词性标注的性能对关键词抽取的效果至关重要。
-
- 较复杂的算法各自有些问题,如Topic Model,它的主要问题是抽取的关键词一般过于宽泛,不能较好反映文章主题。这在我的博士论文中有专门实验和论述;TextRank实际应用效果并不比TFIDF有明显优势,而且由于涉及网络构建和随机游走的迭代算法,效率极低。这些复杂算法集中想要解决的问题,是如何利用更丰富的文档外部和内部信息进行抽取。如果有兴趣尝试更复杂的算法,我认为我们提出的基于SMT(统计机器翻译)的模型,可以较好地兼顾效率和效果。
- TextRank源于page-rank,page-rank是谷歌提出的对网页按照影响力进行排序的算法。同样的,text-rank认为文档或句子中相邻的词语重要性是相互影响的,所以text-rank引入了词语的顺序信息。
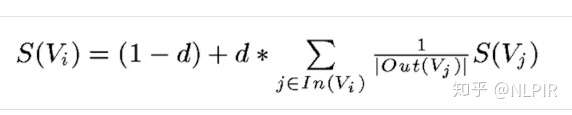
- 较复杂的算法各自有些问题,如Topic Model,它的主要问题是抽取的关键词一般过于宽泛,不能较好反映文章主题。这在我的博士论文中有专门实验和论述;TextRank实际应用效果并不比TFIDF有明显优势,而且由于涉及网络构建和随机游走的迭代算法,效率极低。这些复杂算法集中想要解决的问题,是如何利用更丰富的文档外部和内部信息进行抽取。如果有兴趣尝试更复杂的算法,我认为我们提出的基于SMT(统计机器翻译)的模型,可以较好地兼顾效率和效果。
-
- 以上都是无监督算法,即没有事先标注好的数据集合。而如果我们有事先标注好的数据集合的话,就可以将关键词抽取问题转换为有监督的分类问题。这在我博士论文中的相关工作介绍中均有提到。
- 从性能上来讲,利用有监督模型的效果普遍要优于无监督模型,对关键词抽取来讲亦是如此。在Web 2.0时代的社会标签推荐问题,就是典型的有监督的关键词推荐问题,也是典型的多分类、多标签的分类问题,有很多高效算法可以使用。
-
- 作者:小Fan
- 分两步走:
候选词匹配:基于关键词词库的多模式匹配得到候选,这里最重要的工作是词库构建,往往会融合多种方法:垂直站点专有名词,百科词条,输入法细胞词库,广告主购买词,基于大规模语料库的自动词库挖掘(推荐韩家炜团队的 shangjingbo1226/SegPhrase ,shangjingbo1226/AutoPhrase 方法)等。这里会涉及大量的数据清洗工作,甚至还可以有一个质量分类器决定哪些词条可以进入词库。候选词相关性排序:包括无监督和有监督方法,如下:无监督方法:常见的有 TFIDF(需要统计 phrase 级别的 DF), textrank(优势不明显,计算量大,慎用),topic 相似度(参见 baidu/Familia),embedding 相似度(需要训练或计算 keyword 和 doc embedding),TWE 相似度(参见 baidu/Familia)有监督方法:常见的有基于统计机器翻译 SMT 的方法(转换成翻译问题,可以采用 IBM Model 1),基于序列标注模型的方法(转换成核心成分识别问题,类似 NER,状态只有0和1,即是否是核心成分,较适用于短文本),基于排序学习LTR的方法(转换成候选词排序问题,采用 pairwise 方法,或者深度语义匹配方法,如 DSSM),基于传统机器学习分类方法(转换成二元或多元分类问题)。有监督方法依赖一定规模的标注数据,效果通常会显著好于无监督方法。
AutoPhrase
具体工具如下:
TopMine:频率模式挖掘+统计分析SegPhrase:SegPhrase:弱监督、高质量的 Phrase Mining- 论文:Mining Quality Phrases from Massive Text Corpora
- TopMine 的方法完全是无监督的,如果有少量的 Label 数据可能会在很大程度上提高 Topic Model 的结果。
- SegPhrase框架只需要有限的培训,但是生成的短语的质量却接近于人类的判断力。而且,该方法具有可伸缩性:随着语料库大小的增加,计算时间和所需空间都会线性增长。论文在大型文本语料库上的实验证明了该新方法的质量和效率。
- segphrase已有GitHub开源工具
AutoPhrase:自动的 Phrase Mining- 论文:Automated Phrase Mining from Massive Text Corpora
- AutoPhrase支持多种语言(包含简体中文和繁体中文)基本思想是通过分别在训练和解析过程中添加编码/解码层来重用英语实现。在训练阶段,在中文单词片段和英文字母之间创建一个字典,将输入数据编码为英文伪单词。在解析阶段,在识别出编码后的新文档中的优质短语之后,进行解码以恢复可读的中文。
- AutoPhrase已有GitHub开源工具
- 韩家炜团队开源工具
- 【2020-7-3】数据挖掘之父韩家炜团队的自动短语挖掘论文:Automated Phrase Mining from Massive Text Corpora,提出自动挖掘短语的方法:AutoPhrase
- 思路:使用通用知识库(KB)的来构造正样本(应该就是用完全匹配的方式),然后训练一个NER模型(非神经网络的),然后用这个NER模型的预测结果来减少负样本噪声,引入词性信息
- 先从KB里匹配出正样本,其他的词是负样本,然后训练NER/CRF模型,再卡个阈值,筛掉分低的实体,最后出的作为抽取出的短语。
对于自动短语挖掘任务,
- 输入:语料库(特定语言和特定领域的文本单词序列,长度任意)和知识库
- 输出:一个按质量递减排列的短语列表
短语质量 定义为一个单词序列成为一个完整语义单元的概率,满足以下条件:
流行度: 在给定的文档集合中,质量短语应该出现的频率足够高。一致性: 由于偶然因素,令牌在高质量短语中的搭配出现的概率明显高于预期。信息性: 如果一个短语表达了一个特定的主题或概念,那么这个短语就是信息性的。完备性: 长频繁短语及其子序列均满足上述3个条件。当一个短语可以在特定的文档上下文中解释为一个完整的语义单元时,它就被认为是完整的
流程图

-
AutoPhrase会根据正池和负池对短语质量进行两次评估,一次在短语分割前,一次在短语分割后。也就是说,POS-Guided短语分割需要一组初始的短语质量分数;我们预先根据原始频率估计分数;然后,一旦特征值被纠正,我们重新估计分数。
AutoPhrase超越了分段短语,进一步摆脱了额外的手工标注工作,提高了性能。- 主要使用以下两种新技术:
Robust Positive-Only Distant Training(鲁棒正向远程训练)- 即:利用已有的知识库(Wikipedia)做远程监督训练
- 公共知识库(如维基百科)中的高质量短语,免费并且数量很多。在远程训练中,使用一般知识库中高质量短语,可以避免手工标注。
- 具体做法是:
- 从一般知识库中构建积极标签的样本
- 从给定的领域语料库中构建消极标签的样本
- 训练大量的基本分类器
- 将这些分类器的预测聚合在一起
POS-Guided Phrasal Segmentation. (POS-Guided短语分割)- 即:利用词性信息来增加抽取的准确性
- 语言处理器应该权衡:
性能和领域独立能力- 对于领域独立能力,如果没有语言领域知识,准确性会受限制
- 对于准确性,依赖复杂的、训练有素的语言分析器,就会降低领域独立能力
- 解决办法: 在文档集合的语言中加入一个预先训练的词性标记,以进一步提高性能
新词发现 (互信息)
互信息(Pointwise Mutual Information)
- 互信息越大,说明这两个词经常出现在一起,意味着两个词的凝固程度越大,其组成一个新词的可能性也就越大。
举例:
- “电影院”的互信息是 p(电影院)分别除以 p(电) * p(影院) 和 p(电影) * p(院) 所得的商的较小值再取对数
- 这样处理会有更好的效果,因为用最小值来代表这个词的互信息,更能有力的证明该词的成词性。
左右熵(Information Entropy)
- 如果一个文本片段能够算作一个词的话,它应该能够灵活地出现在各种不同的环境中,具有非常丰富的左邻字集合和右邻字集合。
用信息熵来衡量一个文本片段的左邻字集合和右邻字集合有多随机。
- 示例:“吃葡萄不吐葡萄皮不吃葡萄倒吐葡萄皮”
- “葡萄”一词出现了四次,其中左邻字分别为 {吃, 吐, 吃, 吐} ,右邻字分别为 {不, 皮, 倒, 皮} 。
- 根据公式,“葡萄”一词
- 左邻字的信息熵为 – (1/2) * log(1/2) – (1/2) * log(1/2)
- 右邻字的信息熵则为 – (1/2) * log(1/2) – (1/4) * log(1/4) – (1/4) * log(1/4)。
Demo
from word_discovery import NewWords
discover = NewWords()
discover.parse('''中国科兴生物研发的克尔来福是一种灭活疫苗,由已杀灭的病原体制成,主要通过其中的抗原诱导细胞免疫的产生。另外几种疫苗,例如莫德纳和辉瑞的疫苗都属于核糖核酸疫苗,使用的是RNA疫苗原理,抽取病毒内部分核糖核酸编码蛋白制成疫苗。新加坡南洋理工大学感染与免疫副教授罗大海对BBC表示,“克尔来福是用比较传统的方法制成的(灭活)疫苗,灭活疫苗使用广泛而且非常成功,例如狂犬病疫苗。”理论上,科兴疫苗主要的优势在于它能够在常规冰箱温度下(2至8摄氏度)保存,这一点和牛津/阿斯利康研发的病毒载体疫苗有相同优点。莫德纳的疫苗必须存放在摄氏零下20度,而辉瑞疫苗必须存放在摄氏零下70度。这意味着科兴和牛津/阿斯利康这两种疫苗,更能有效地在发展中国家使用,因为那些地方可能没有足够的低温储存设备供疫苗保存。但是,相对于最新加入接种行列的单剂疫苗 — 美国杨森和中国康希诺 — 而言,科兴疫苗仍需注射两针。疫苗谣言的打破:改变DNA、植入微芯片等疫苗阴谋论。新冠疫苗接种在即,你该了解的四大问题。效果如何?科兴疫苗三期临床试验在4个国家展开,各国试验结果相差较大,有效性从50% - 90%不等。从2021年1月以来,至少有7个国家先后批准科兴疫苗紧急使用。不过到目前为止它的三期临床整体有效性数据仍未公布。截止今年3月8日,香港有10多万人接种第一剂科兴疫苗,虽然近期出现三宗接种科兴疫苗后死亡的案例,但港府新冠疫苗临床事件评估专家委员会对三宗案例的调查结果称科兴疫苗与死亡并无直接关系。今年1月13日,科兴董事长在谷物元联防联控机制发布会上给出一组数据:土耳其中期分析结果显示该疫苗保护率91.25%;印尼三期临床试验保护率65.3%;巴西三期临床试验从2020年10月开始,试验结果显示重症保护率达100%,对高危人群总体保护率达50.3%。''')
for k, v in discover.candidates():
print(k, v)
输出:
主要 {'pmi': 10.448116305409464, 'freq': 2, 'entropy': 1.0}
辉瑞 {'pmi': 10.448116305409464, 'freq': 2, 'entropy': 1.0}
NA {'pmi': 10.448116305409464, 'freq': 2, 'entropy': 1.0}
数据 {'pmi': 10.448116305409464, 'freq': 2, 'entropy': 1.0}
死亡 {'pmi': 10.448116305409464, 'freq': 2, 'entropy': 1.0}
莫德纳 {'pmi': 10.448116305409464, 'freq': 2, 'entropy': 1.0}
病毒 {'pmi': 9.448116305409464, 'freq': 2, 'entropy': 1.0}
新加 {'pmi': 9.448116305409464, 'freq': 2, 'entropy': 1.0}
今年 {'pmi': 9.448116305409464, 'freq': 2, 'entropy': 1.0}
案例 {'pmi': 9.448116305409464, 'freq': 2, 'entropy': 1.0}
个国家 {'pmi': 9.448116305409464, 'freq': 2, 'entropy': 1.0}
其中 {'pmi': 9.1261882105221, 'freq': 2, 'entropy': 1.0}
使用 {'pmi': 9.1261882105221, 'freq': 4, 'entropy': 1.5}
试验 {'pmi': 9.1261882105221, 'freq': 5, 'entropy': 1.3709505944546687}
结果 {'pmi': 9.1261882105221, 'freq': 4, 'entropy': 1.5}
制成 {'pmi': 9.03307880613062, 'freq': 3, 'entropy': 1.584962500721156}
例如 {'pmi': 8.863153804688308, 'freq': 2, 'entropy': 1.0}
三宗 {'pmi': 8.863153804688308, 'freq': 2, 'entropy': 1.0}
保护率 {'pmi': 8.863153804688308, 'freq': 4, 'entropy': 1.5}
年1月 {'pmi': 8.863153804688308, 'freq': 2, 'entropy': 1.0}
有效性 {'pmi': 8.64076138335186, 'freq': 2, 'entropy': 1.0}
接种 {'pmi': 8.318833288464496, 'freq': 4, 'entropy': 2.0}
科兴 {'pmi': 8.1261882105221, 'freq': 10, 'entropy': 1.3567796494470397}
下2 {'pmi': 8.055798882630704, 'freq': 2, 'entropy': 1.0}
Reference
句法分析
NLP 任务中,句法分析有两种
- 一种是成分句法分析: 找到一个句子的组成成分
- 另一种是依存句法分析。 句法分析不适用于之前的 NLP 任务分类体系。它的输出形式相对来说会比较不一样。
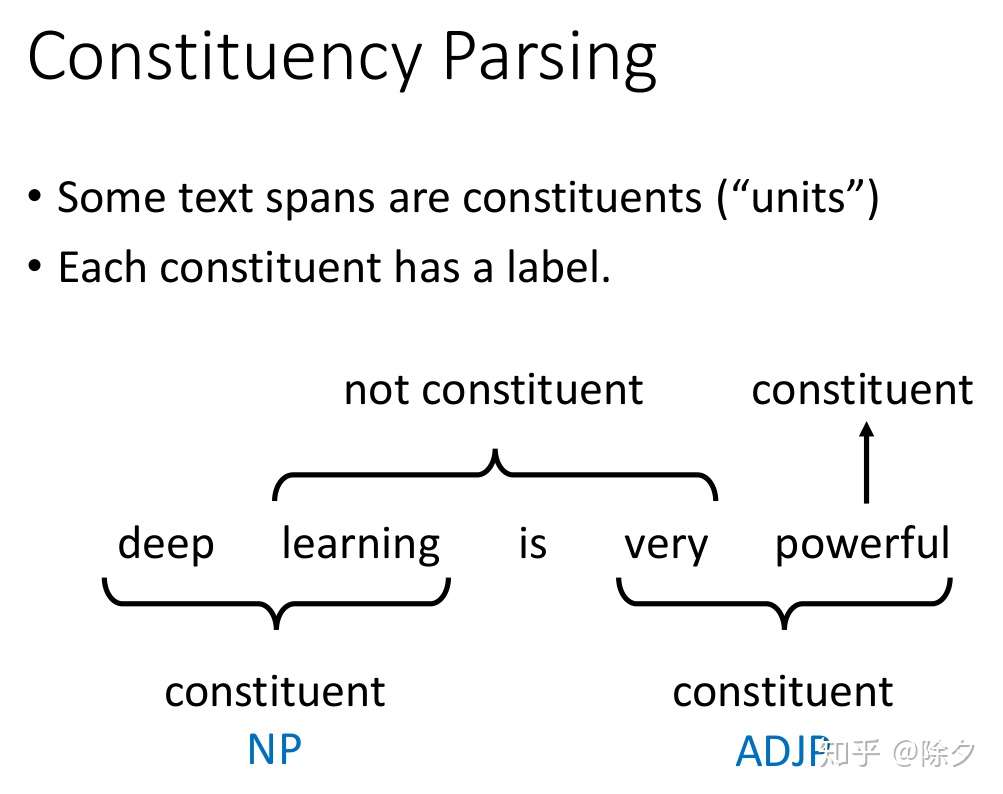
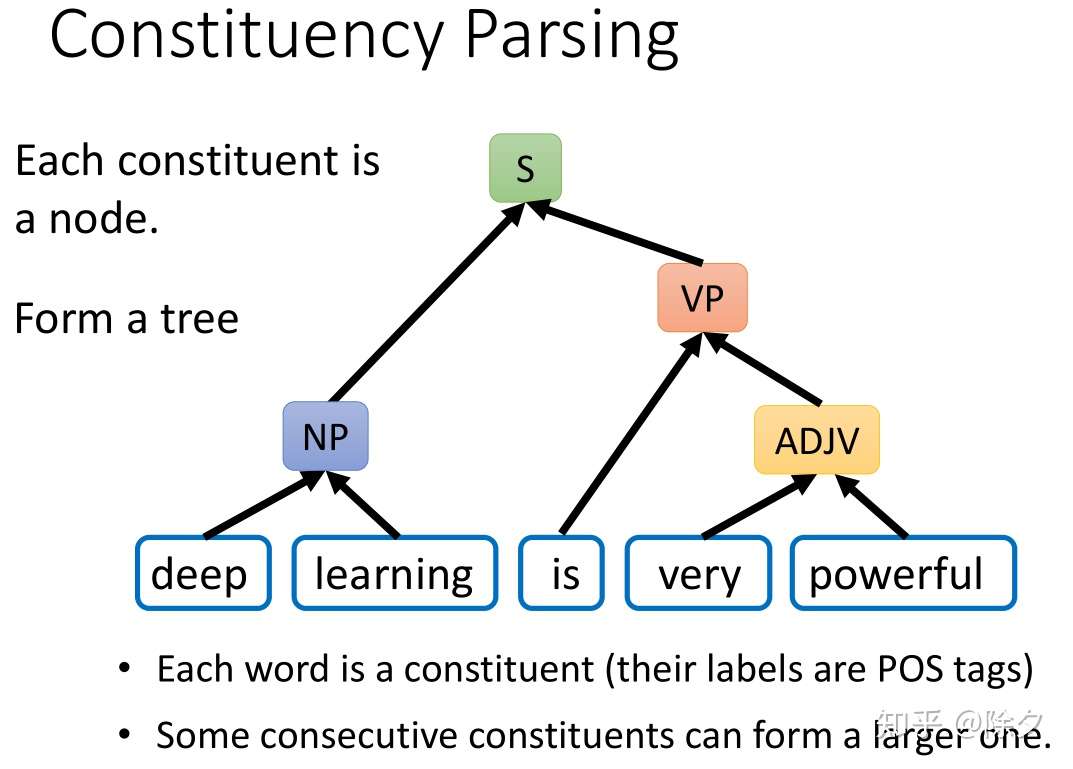
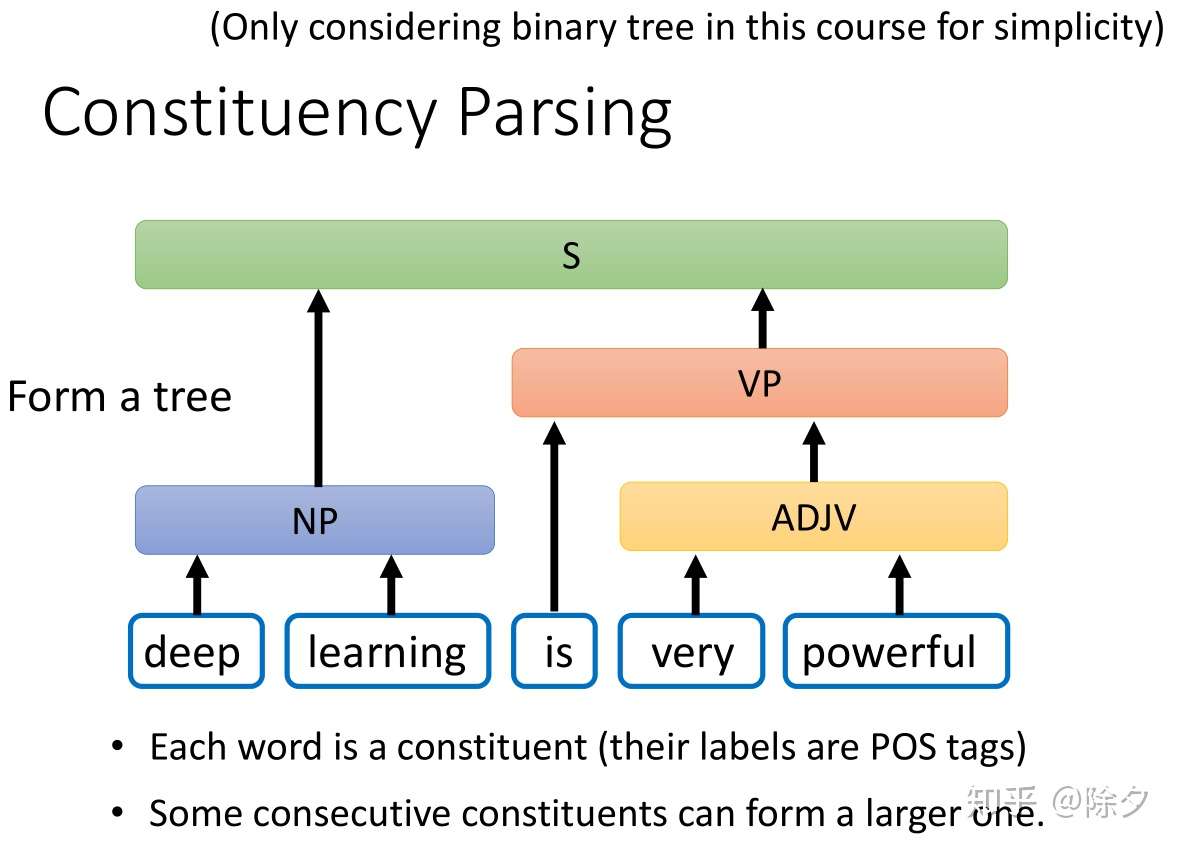
成分句法分析
成分句法分析要做的是给定一个句子,句子中每个词汇都是成分。
- 每一个成分都会有一个标签,比如 deep learning 的标签是 NP,very powerful 的标签是 ADJP。
- 所有词性标注的词项标签也都是可能的标签。
- 相邻的成分可以组合成一个更大的单位。比如 deep 和 learning 可以组合起来成为一个名词短语。最后这个动词短语和名词短语组合起来变成整个句子。

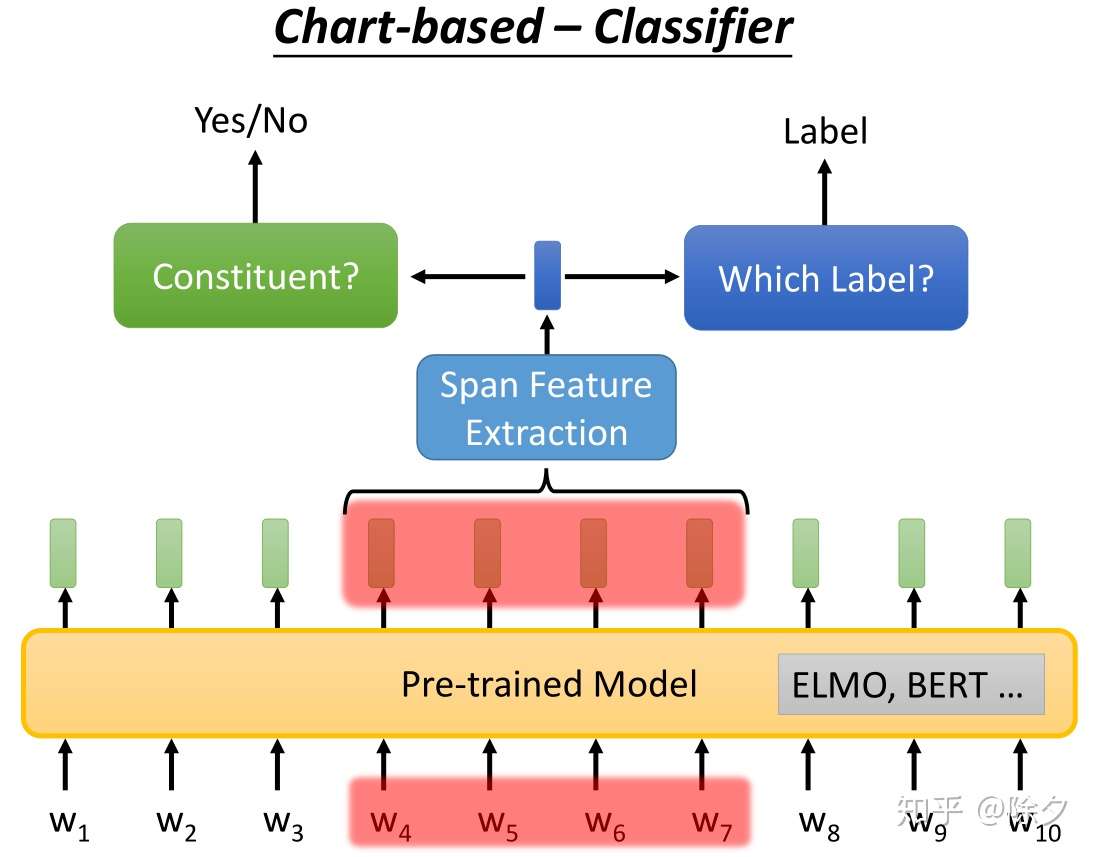
成分句法分析通用的解决方案
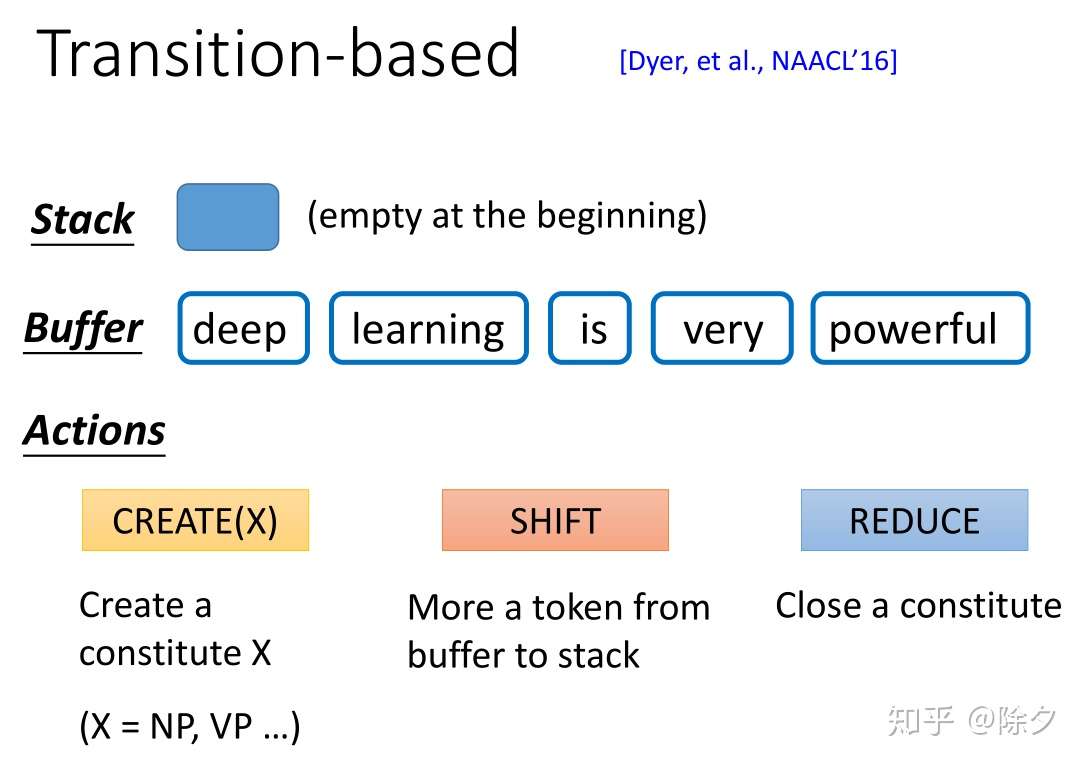
- 一个是 char-based 方案。训练一个分类器,输入是一串 tokens,它决定这个 span 是不是成分。如果确定它是成分,接下来我们要用另一个分类器,对该成分确定它的标签。
- 另一个方法叫作基于转移的方法。它的精神是把产生的句子加入到一个 Buffer 中,加上一连串的操作,就可以做到成分句法解析。
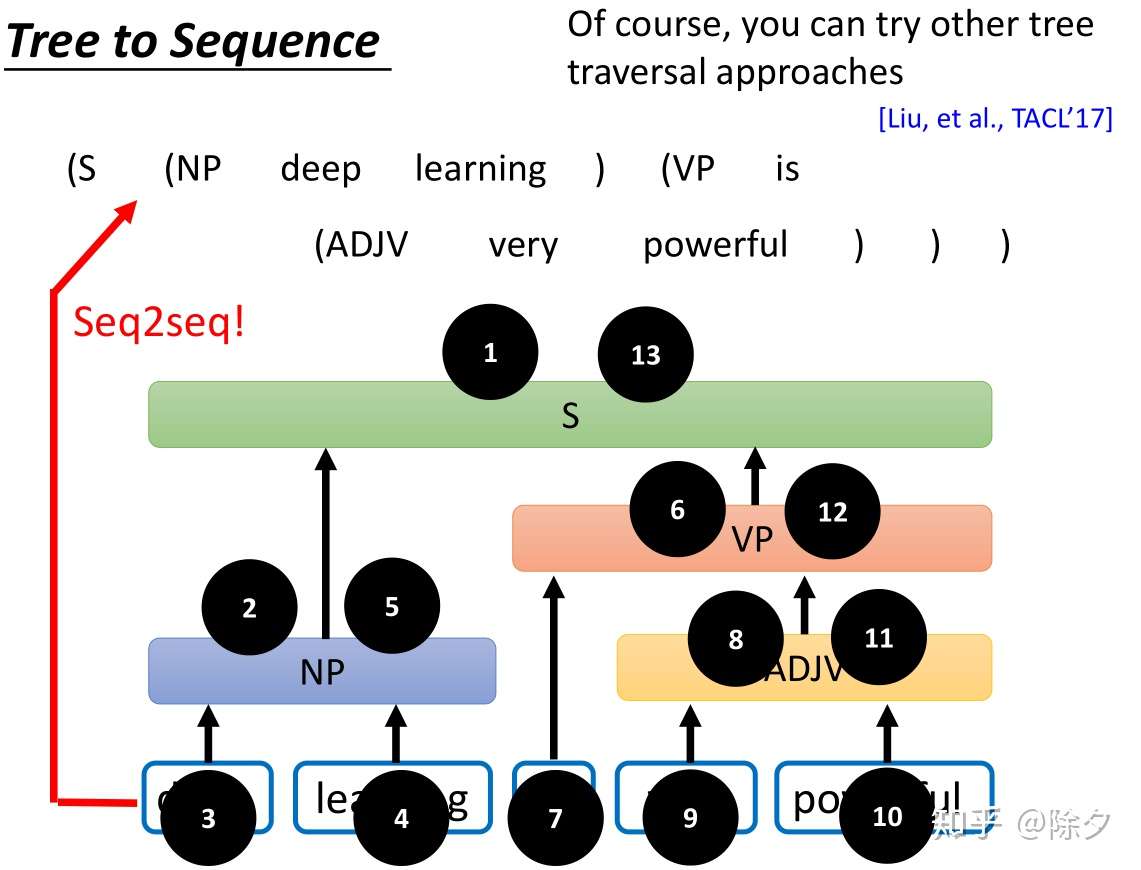
- tree2seq:把树状的结构表示为一个序列,比如用深度优先遍历方法,由上而下,由左到右把每个节点按遍历顺序放在序列中。
资料:成分分析方法综述
依存句法分析
文本分类
见本博客的文本分类专题
文本生成
- 【2021-1-9】现代自然语言生成 黄民烈
综述
- 文本生成被称为NLG,目标是根据输入数据生成自然语言的文本。
- NLP领域使用更多的一般是NLU(Nature Language Understanding 自然语言理解)类任务,如文本分类、命名实体识别等,NLU的目标则是将自然语言文本转化成结构化数据。
- NLU和NLG两者表向上是一对相反的过程,但其实是紧密相连的,甚至目前很多NLU的任务都受到了生成式模型中表示方法的启发,更多只在最终任务上有所区别
- 文本生成,广义上只要输出是自然语言文本的各类任务都属于这个范畴
- 端到端文本生成应用领域

- 端到端文本生成应用领域
技术方案
- 文本生成包含文本表示和文本生成两个关键的部分,既可以独立建模,也可以通过框架完成端到端的训练
文本生成
- (1) seq2seq
- 2014年提出的Seq2Seq Model,是解决这类问题一个非常通用的思路,本质是将输入句子或其中的词Token做Embedding后,输入循环神经网络中作为源句的表示,这一部分称为Encoder;另一部分生成端在每一个位置同样通过循环神经网络,循环输出对应的Token,这一部分称为Decoder。通过两个循环神经网络连接Encoder和Decoder,可以将两个平行表示连接起来。

- (2) attention
- 本质思想是获取两端的某种权重关系,即在Decoder端生成的词和Encoder端的某些信息更相关。它也同样可以处理多模态的问题,比如Image2Text任务,通过CNN等将图片做一个关键特征的向量表示,将这个表示输出到类似的Decoder中去解码输出文本,视频语音等也使用同样的方式

- Encoder-Decoder是一个非常通用的框架,它同样深入应用到了文本生成的三种主流方法,分别是规划式、抽取式和生成式,下面看下这几类方法各自的优劣势:
- 规划式:根据结构化的信息,通过语法规则、树形规则等方式规划生成进文本中,可以抽象为三个阶段。宏观规划解决“说什么内容”,微观规划解决“怎么说”,包括语法句子粒度的规划,以及最后的表层优化对结果进行微调。
- 抽取式:顾名思义,在原文信息中抽取一部分作为输出。可以通过编码端的表征在解码端转化为多种不同的分类任务,来实现端到端的优化。
- 优势: 控制力极强、准确率较高,特别适合新闻播报等模版化场景。控制力极强,对源内容相关性好,改变用户行文较少,也不容易造成体验问题,可以直接在句子级别做端到端优化
- 劣势是很难做到端到端的优化,损失信息上限也不高。
- 在优化评估上,首先标题创意衡量的主观性很强,线上Feeds的标注数据也易受到其他因素的影响,比如推荐排序本身;其次,训练预测数据量差异造成OOV问题非常突出,分类任务叠加噪音效果提升非常困难。对此,我们重点在语义+词级的方向上来对点击/转化率做建模,同时辅以线上E&E选优的机制来持续获取标注对,并提升在线自动纠错的能力。
- 在受限上,抽取式虽然能直接在Seq级别对业务目标做优化,但有时候也须兼顾阅读体验,否则会形成一些“标题党”,亦或造成与原文相关性差的问题。对此,我们抽象了预处理和质量模型,来通用化处理文本创意内容的质控,独立了一个召回模块负责体验保障。并在模型结构上来对原文做独立表示,后又引入了Topic Feature Context来做针对性控制。

- 生成式:通过编码端的表征,在解码端完成序列生成的任务,可以实现完全的端到端优化,可以完成多模态的任务。其在泛化能力上具有压倒性优势,但劣势是控制难度极大,建模复杂度也很高。
- 目前的主流的评估方法主要基于数据和人工评测。基于数据可以从不同角度衡量和训练目标文本的相近程度,如基于N-Gram匹配的BLUE和ROUGE等,基于字符编辑距离(Edit Distance)等,以及基于内容Coverage率的Jarcard距离等。基于数据的评测,在机器翻译等有明确标注的场景下具有很大的意义,这也是机器翻译领域最先有所突破的重要原因。但对于我们创意优化的场景来说,意义并不大,我们更重要的是优化业务目标,多以线上的实际效果为导向,并辅以人工评测。
- 另外,值得一提的是,近两年也逐渐涌现了很多利用GAN(Generative Adversarial Networks,生成对抗网络)的相关方法,来解决文本生成泛化性多样性的问题。有不少思路非常有趣,也值得尝试,只是GAN对于NLP的文本生成这类离散输出任务在效果评测指标层面,与传统的Seq2Seq模型还存在一定的差距,可视为一类具有潜力的技术方向。
文本表示
- 整个2018年有两方面非常重要的工作进展:
- Contextual Embedding:该方向包括一系列工作,如最佳论文Elmo(Embeddings from Language Models),OpenAI的GPT(Generative Pre-Training),以及谷歌大力出奇迹的BERT(Bidirectional Encoder Representations from Transformers)。解决的核心问题,是如何利用大量的没标注的文本数据学到一个预训练的模型,并通过通过这个模型辅助在不同的有标注任务上更好地完成目标。传统NLP任务深度模型,往往并不能通过持续增加深度来获取效果的提升,但是在表示层面增加深度,却往往可以对句子做更好的表征,它的核心思想是利用Embedding来表征上下文的的信息。但是这个想法可以通过很多种方式来实现,比如ELMo,通过双向的LSTM拼接后,可以同时得到含上下文信息的Embedding。而Transformer则在Encoder和Decoder两端,都将Attention机制都应用到了极致,通过序列间全位置的直连,可以高效叠加多层(12层),来完成句子的表征。这类方法可以将不同的终端任务做一个统一的表示,大大简化了建模抽象的复杂度。我们的表示也经历了从RNN到拥抱Attention的过程。

图5 GPT ELMo BERT模型结构
- Tree-Based Embedding:另外一个流派则是通过树形结构进行建模,包括很多方式如传统的语法树,在语法结构上做Tree Base的RNN,用根结点的Embedding即可作为上下文的表征。Tree本身可以通过构造的方式,也可以通过学习的方式(比如强化学习)来进行构建。最终Task效果,既和树的结构(包括深度)有关,也受“表示”学习的能力影响,调优难度比较大。在我们的场景中,人工评测效果并不是很好,仍有很大继续探索的空间。
信息流中的应用
- 【2020-5-26】大众点评信息流基于文本生成的创意优化实践
- 核心目标与推荐问题相似,提升包括点击率、转化率在内的通用指标,同时需要兼顾考量产品的阅读体验包括内容的导向性等
- 信息流中落地重点包括三个方向:
- 文本创意:在文本方面,既包括了面向内容的摘要标题、排版改写等,也包括面向商户的推荐文案及内容化聚合页。它们都广泛地应用了文本表示和文本生成等技术,也是本文的主要方向。
- 图像创意:图像方面涉及到首图或首帧的优选、图像的动态裁剪,以及图像的二次生成等。
- 其他创意:包括多类展示理由(如社交关系等)、元素创意在内的额外补充信息。

- 文本创意优化,在业务和技术上分别面临着不同的挑战。
- 首先业务侧,启动创意优化需要两个基础前提:
- 第一,衔接好创意优化与业务目标,因为并不是所有的创意都能优化,也不是所有创意优化都能带来预期的业务价值,方向不对则易蹚坑。
- 第二,创意优化转化为最优化问题,有一定的Gap。其不同于很多分类排序问题,本身相对主观,所谓“一千个人眼中有一千个哈姆雷特”,创意优化能不能达到预期的业务目标,这个转化非常关键。
- 其次,在技术层面,业界不同的应用都面临不一样的挑战,并且尝试和实践对应的解决方案。对文本创意生成来说,我们面临的最大的挑战包括以下三点:
- 带受限的生成 生成一段流畅的文本并非难事,关键在于根据不同的场景和目标能控制它说什么、怎么说。这是目前挑战相对较大的一类问题,在我们的应用场景中都面临这个挑战。
- 业务导向 生成能够提升业务指标、贴合业务目标的内容。为此,对内容源、内容表示与建模上提出了更高的要求。
- 高效稳定 这里有两层含义,第一层是高效,即模型训练预测的效果和效率;第二层是稳定,线上系统应用,需要具备很高的准确率和一套完善的质量提升方案。
- 首先业务侧,启动创意优化需要两个基础前提:
指针网络
- 【2021-3-24】Pointer-Generator模型,解决了摘要中存在事实性错误的问题。然后作者又向前走了一步,就是加入了Coverage机制来解决重复问题
- Pointer Networks天生具备输出元素来自输入元素这样的特点,于是它非常适合用来实现“复制”这个功能。Pointer Networks其实特别适合用于解决OOV(out of vocabulary)问题
- 演进路线
多轮对话改写
【2021-3-31】指代消解
- 代词是用来代替重复出现的名词
- 例句:
- Ravi is a boy. He often donates money to the poor.
- 先出现主语,后出现代词,所以流动的方向从左到右,这类句子叫回指(Anaphora)
- He was already on his way to airport.Realized Ravi.
- 这种句子表达的方式的逆序的,这类句子叫预指(Cataphora)
- Ravi is a boy. He often donates money to the poor.
- 【2020-6-19】浅谈多轮对话改写
- 2000条日常对话数据进行了简单地统计,发现其中33.5%存在指代,52.7%存在省略的情况
- 人脑具有记忆的能力,能够很好地重建对话历史的重要信息,自动补全或者替换对方当前轮的回复,来理解回复的意思。同样,为了让对话系统具备记忆的能力,通常会通过对话状态跟踪(DST),来存储对话历史中的一些重要信息。
- DST的主要问题有:
- 存储的信息量有限,对于长对话的历史信息无法感知;
- 存储信息不会太丰富,否则会导致冗余信息太多;
- 存储的信息不太便于对话系统中其他模块的任务使用。
- rewrite模型分为Pipeline的方式和End2End的方式
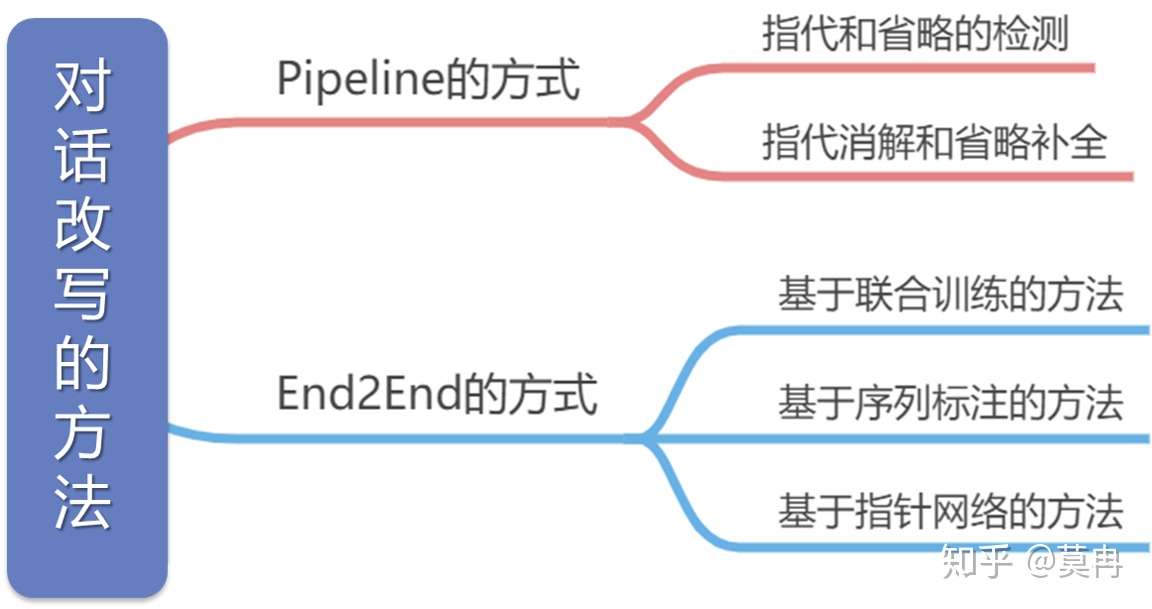
- Pipeline方法将rewrite任务分成两个子任务,即指代和零指代的检测以及指代消解
- 基于模型复杂度和性能的考虑,End2End方法的探索一直没有停止,直到2019年出现了几篇比较优秀的工作,本文将其划分为3种类型:基于联合训练的方法、基于序列标注的方法和基于指针网络的方法。
- ACL 2019 使用表达改写提升多轮对话系统效果
- 代码实现
- 【2020-12-02】优化版,使用transformer,ACL 2019论文复现,多轮对话重写:Improving Multi-turn Dialogue Modelling with Utterance ReWriter
- 作者开源的代码是基于LSTM的,论文中基于Transformer的代码并未公布;
- 论文实验所使用数据与公开的数据不一致,所以给出新的指标以供参考。

- tagger_rewriter
- 模型框架

- 对于任务导向型对话系统和闲聊型对话系统均有效果提升,实现了用更成熟的单轮对话技术解决多轮对话问题。

- Transformer多轮对话改写实践
- 介绍了多轮对话存在指代和信息省略的问题,同时提出了一种新方法-抽取式多轮对话改写,可以更加实用的部署于线上对话系统,并且提升对话效果
- 日常的交流对话中
- 30%的对话会包含指代词。比如“它”用来指代物,“那边”用来指代地址
- 同时有50%以上的对话会有信息省略
- 对话改写的任务有两个:1这句话要不要改写;2 把信息省略和指代识别出来。对于baseline论文放出的数据集,有90%的数据都是简单改写,也就是满足任务2,只有信息省略或者指代词。少数改写语句比较复杂,本文训练集剔除他们,但是验证集保留。

- Transformers结构可以通过attention机制有效提取指代词和上下文中关键信息的配对,最近也有一篇很好的工作专门用Bert来做指代消岐[2]。经过transformer结构提取文本特征后,模型结构及输出如下图。
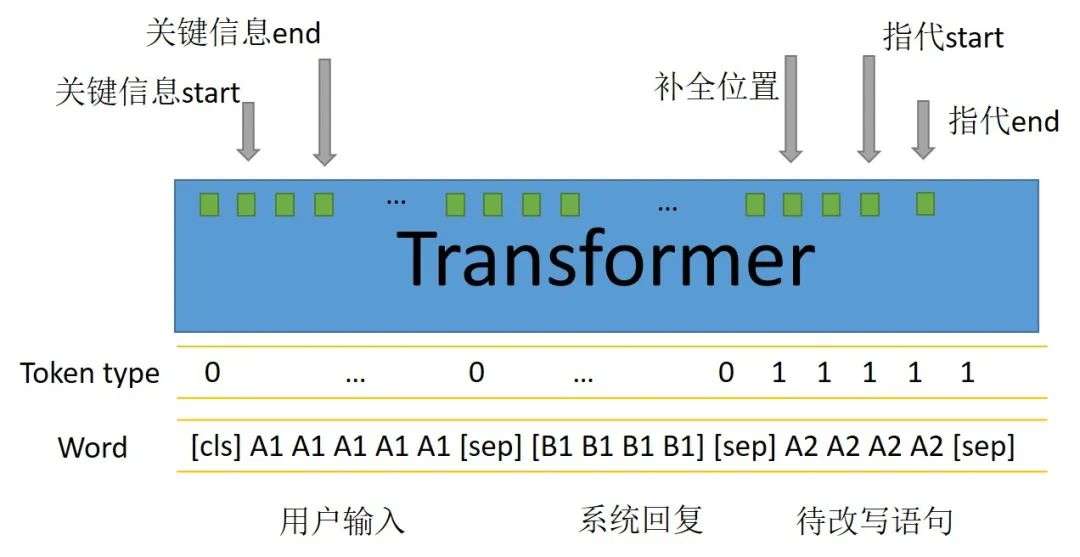
- 输出五个指针中:
- 关键信息的start和end专门用来识别需要为下文做信息补全或者指代的词;
- 补全位置用来预测关键信息(start-end)插入在待改写语句的位置,实验中用插入位置的下一个token来表示;
- 指代start和end用来识别带改写语句出现的指代词。
- 当待改写语句中不存在指代词或者关键信息的补全时,指代的start和end将会指向cls,同理补全位置也这样。如同阅读理解任务中不存在答案一样,这样的操作在做预测任务时,当指代和补全位置的预测最大概率都位于cls时就可以避免改写,从而保证了改写的稳定性。
- 效果评估
- 准确度

- 性能
- 对数据集的依赖

- 对负样本(不需要改写样本)的识别.基于指针抽取的方法对负样本的识别效果会更好。同时根据对长文本的改写效果观察,生成式改写效果较差。

- 准确度
- 示例
| A1 | B1 | A2 | 算法改写结果 | 用户标注label |
|---|---|---|---|---|
| 你知道板泉井水吗 | 知道 | 她是歌手 | 板泉井水是歌手 | 板泉井水是歌手 |
| 乌龙茶 | 乌龙茶好喝吗 | 嗯好喝 | 嗯乌龙茶好喝 | 嗯乌龙茶好喝 |
| 武林外传 | 超爱武林外传的 | 它的导演是谁 | 武林外传的导演是谁 | 武林外传的导演是谁 |
| 李文雯你爱我吗 | 李文雯是哪位啊 | 她是我女朋友 | 李文雯是我女朋友 | 李文雯是我女朋友 |
| 舒马赫 | 舒马赫看球了么 | 看了 | 舒马赫看了 | 舒马赫看球了 |
- 结论
- 抽取式文本改写和生成式改写效果相当
- 抽取式文本改写速度上绝对优于生成式
- 抽取式文本改写对训练数据依赖少
- 抽取式文本改写对负样本识别准确率略高于生成式
- 参考
- 2019.07,ACL,微信AI Lab Improving Multi-turn Dialogue Modelling with Utterance ReWriter
- 2020.12.21,AAAI 2021,Netease Games AI Lab,SARG: A Novel Semi Autoregressive Generator for Multi-turn Incomplete Utterance Restoration,
- 几种模型:
- CopyNet:基于LSTM 的Seq2Seq模型,使用attention 和 copy 机制 (基本的指针网络)
- PAC:首先使用bert fintune 的 H,U 词向量,然后直接喂给标准的指针生成网络
- T-Ptr-λ:就上面讲的那一篇腾讯论文的方法,主要是利用6层-6层 的Transformer Encoder Decoder结构
- Seq2Seq-Uni: 这个baseline 是将Transformer 的各个block 层的输出做了统一结合,然后应用到 seq2seq 结构
- SARG:论文提出的模型,超参数使用 α=3,λ=1
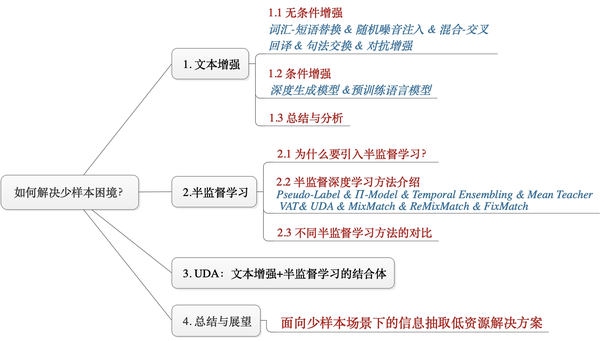
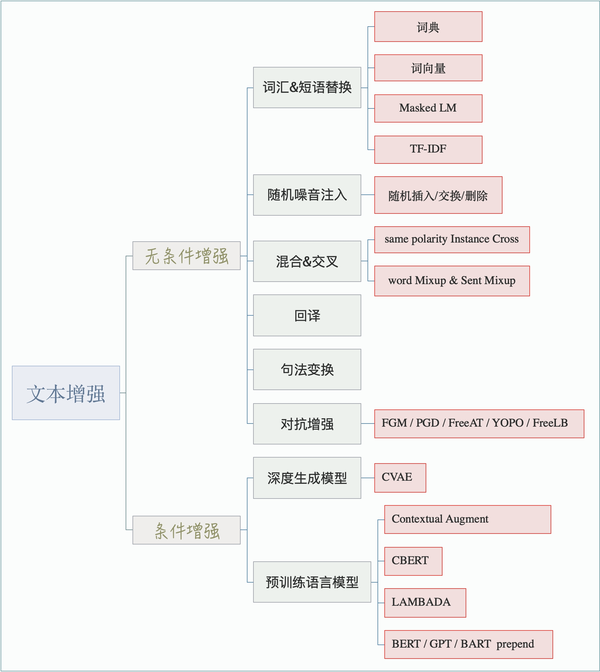
小样本学习
- 从「文本增强」和「半监督学习」这两个角度出发,谈一谈如何解决少样本困境
- NLP中文本增强方法
- 详情参考:
- 标注样本少怎么办?「文本增强+半监督学习」总结(从PseudoLabel到UDA/FixMatch) - JayLou娄杰的文章
- 一文了解NLP中的数据增强方法-简枫的文章
- 【2020-7-7】【一键中文数据增强工具】’NLP Chinese Data Augmentation’ by 425776024 GitHub,支持如下功能:
- 1.随机实体替换
- 2.近义词
- 3.近义近音字替换
- 4.随机字删除(内部细节:数字时间日期片段,内容不会删)
- 5.新增:NER类 BIO 数据增强
- 6.新增 随机置换邻近的字:研表究明,汉字序顺并不定一影响文字的阅读理解«是乱序的
- 7.新增百度中英翻译互转实现的增强
- 8.新增中文等价字替换(1 一 壹 ①,2 二 贰 ②)
- 【2020-7-7】创新奇智有关少样本学习(Few-shot Learning)的研究论文《Prototype Rectification for Few-Shot Learning》被全球计算机视觉顶会ECCV 2020接收为Oral论文,入选率仅2%。参考地址
-
本文提出一种简单有效的少样本学习方法,通过减小类内偏差和跨类偏差进行原型校正,从而显著提高少样本分类结果,并且给出理论推导证明本文所提方法可以提高理论下界,最终通过实验表明本方法在通用数据集中达到了最优结果,论文被ECCV 2020 接收为Oral。
-
【2020-8-19】少样本学习中的深度学习模型综述
- 【2020-11-12】Few-shot Learning最新进展调研
- 【2021-1-20】少样本学习可以使一个模型快速承接各种任务。但是为每个任务更新整个模型的权重是很浪费的。最好进行局部更新,让更改集中在一小部分参数里。有一些方法让这些微调变得更加有效和实用,包括:
- 使用 adapter(Houlsby et al., 2019、Pfeiffer et al., 2020a、Üstün et al., 2020)
- 加入稀疏参数向量(Guo et al., 2020)
- 仅修改偏差值(Ben-Zaken et al., 2020)
- 能够仅基于几个范例就可以让模型学会完成任务的方法,大幅度降低了机器学习、NLP 模型应用的门槛。
- 这让模型可以适应新领域,在数据昂贵的情况下为应用的可能性开辟了道路。
- 对于现实世界的情况,我们可以收集上千个训练样本。模型同样也应该可以在少样本学习和大训练集学习之间无缝切换,不应受到例如文本长度这样的限制。在整个训练集上微调过的模型已经在 SuperGLUE 等很多流行任务中实现了超越人类的性能,但如何增强其少样本学习能力是改进的关键所在。
多模态学习
【2021-8-2】多模态为什么比单模态好?第一份严谨证明来了!:一篇多模态学习理论分析的文章,从数学角度证明了潜表征空间质量直接决定了多模态学习模型的效果。而在充足的训练数据下,模态的种类越丰富,表征空间的估计越精确
- What Makes Multimodal Learning Better than Single (Provably),基于一种经典的多模态学习框架,即无缝进行潜空间学习(Latent Space Learning)与任务层学习(Task-specific Learning)。
- 两个角度回答了这个问题:
- (When)在何种条件下,多模态学习比单模态学习好
- (Why)是什么造成了其效果的提升
- 从真实世界收集的多模态情绪分析的数据集IEMOCAP(Interactive Emotional Dyadic Motion Capture),它包括三种模态:文字(Text)、视频(Video)和音频(Audio)。首先使用离线的特征抽取工具对三种模态信息提取好特征:Audio 100维,Text 100维以及Video 500维。这个数据集的分类有六种,分别是快乐、悲伤、中立、愤怒、兴奋和沮丧。使用了13200条数据做训练,3410条做测试。实验模型上,潜空间的映射使用了一层线性层+Relu,任务层使用了一层Softmax。在对比实验中,如果是单模态模型,则直接进行对应特征映射;如果是多模态模型,则首先进行多模态特征拼接,然后再进行映射。
- 论文使用机器自动生成的方式,构造了不同的模态关联数据用于验证。这里考虑三种情况:
- (1)模态之间完全不共享信息,即每个模态只包含模态特定的信息。
- (2)所有模态之间共享所有信息,没有区分。
- (3)介于两者之间,既共享一部分信息,也保有模态特定信息。
多模态模型
PaLM-E
【2023-3-7】谷歌发布了个多模态模型 PaLM-E,使用传感器数据、自然语言、视觉训练,能直接用人话操作机器人完成任务。
纠错
错误类型
在中文中,常见的错误类型大概有如下几类:
由于字音字形相似导致的错字形式:体脂称—>体脂秤
- 多字错误:iphonee —> iphone
- 少字错误:爱有天意 –> 假如爱有天意
- 顺序错误: 表达难以 –> 难以表达
常见的文本错误可以分为
- (1)字形相似引起的错误
- (2)拼音相似引起的错误 两大类;如:“咳数”->“咳嗽”;“哈蜜”->“哈密”。错别字往往来自于如下的“相似字典”。
- 其他错误还包括方言、口语化、重复输入导致的错误,在ASR中较为常见
现有的NLP技术已经能解决多数文本拼写错误。
- 剩余的纠错难点主要是部分文本拼写错误需要常识背景(world-knowledge)才能识别。
Wrong: "我想去埃及金子塔旅游。"
Right: "我想去埃及金字塔旅游。"
将其中的“金子塔”纠正为“金字塔”需要一定的背景知识。
同时,一些错误需要模型像人一样具备一定的推理和分析能力才能识破。例如:
Wrong: "他的求胜欲很强,为了越狱在挖洞。"
Right: "他的求生欲很强,为了越狱在挖洞。"
“求胜欲”和“求生欲”在自然语言中都是正确的,但是结合上下文语境来分析,显然后者更为合适。
文本纠错技术对于误判率有严格的要求,一般要求低于0.5%。
- 如果纠错方法的误判率很高(将正确的词“纠正”成错误的),会对系统和用户体验有很差的负面效果。
纠错方法
常用方法可以归纳为错别字词典、编辑距离、语言模型等。
- 构建错别字词典人工成本较高,适用于错别字有限的部分垂直领域;
- 编辑距离采用类似字符串模糊匹配的方法,通过对照正确样本可以纠正部分常见错别字和语病,但是通用性不足。
所以,现阶段学术界和工业界研究的重点一般都是基于语言模型的纠错技术。
- 2018年之前,语言模型的方法可以分为传统的 n-gram LM 和 DNN LM,可以以字或词为纠错粒度。
- 其中“字粒度”的语义信息相对较弱,因此误判率会高于“词粒度”的纠错;
- “词粒度”则较依赖于分词模型的准确率。
- 为了降低误判率,往往在模型的输出层加入CRF层校对,通过学习转移概率和全局最优路径避免不合理的错别字输出。
- 2018年之后,预训练语言模型开始流行,研究人员很快把BERT类的模型迁移到了文本纠错中,并取得了新的最优效果。
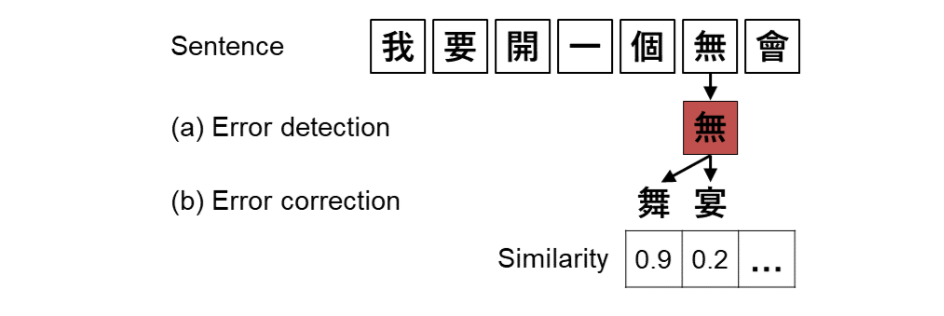
纠错模块
纠错一般分两大模块:
- 错误检测:识别错误发生的位置
- 错误纠正:对疑似的错误词,根据字音字形等对错词进行候选词召回,并且根据语言模型等对纠错后的结果进行排序,选择最优结果。 如下图所示:
拼音纠错
【2021-9-28】语音识别有误,NLU环节如何补救?基于拼音的纠错
from pypinyin import lazy_pinyin,pinyin
print(lazy_pinyin('江西赣州')) #返回拼音
# ['jiang', 'xi', 'gan', 'zhou']
print(lazy_pinyin('江西赣州',1)) #带声调的拼音
# ['jiāng', 'xī', 'gàn', 'zhōu']
print(lazy_pinyin('江西赣州',2)) #另一种拼音风格
# ['jia1ng', 'xi1', 'ga4n', 'zho1u']
print(lazy_pinyin('江西赣州',3)) #只返回拼音首字母
# ['j', 'x', 'g', 'zh']
print(lazy_pinyin('重要',1)) #能够根据词组智能识别多音字
# ['zhòng', 'yào']
print(lazy_pinyin('重阳',1))
# ['chóng', 'yáng']
print(pinyin('江西')) #返回拼音
# [['jiāng'], ['xī']]
print(pinyin('重阳节',heteronym=True)) #返回多音字的所有读音
# [['zhòng', 'chóng', 'tóng'], ['yáng'], ['jié', 'jiē']]
import jieba
x='中英文混合test123456'
print(lazy_pinyin(x)) #自动调用已安装的pypinyin扩展分词功能
# ['zhong', 'ying', 'wen', 'hun', 'he', 'test123456']
print(list(jieba.cut(x))) #自动调用jieba扩展分词功能
# ['中英文', '混合', 'test123456']
x='江西的桃子真好吃'
print(sorted(x,key=lambda ch:lazy_pinyin(ch))) #按拼音对汉字进行排序
# ['吃', '的', '好', '江', '桃', '西', '真', '子']
主流方案
业界纠错主流方案一般包括错误检测→候选召回→候选排序三部分,根据作者调研工作其技术方案主要可分为以下三种:
- ① 基于规则式的通用纠错库pycorrector;
- ② 基于大样本训练深度学习模型的检错算法,以百度纠错系统为代表;
- ③ 基于垂直领域的DCQC纠错框架。
总结
- ① 从百度纠错系统和IJCNLP第一名使用方法来看,当具有充足的标注语料时,将LSTM+CRF这种序列标注方式用来进行错误位置检测是一个比较好的方法,但当标注语料有限时,该种方法难以应用落地;
- ② 基于机器翻译的纠错方法是目前业界及学术界关注的焦点,寿险场景也可以尝试使用NMT的方法来测试效果,然而该技术落地的条件是仍然需要大量的标注数据。 那么在标注资源受限的条件下,如何部署高性能、高效率的纠错系统将成为寿险场景中纠错问题所面临也是急需解决的关键挑战。
Hanlp
HanNLP文本纠错在线Demo
pycorrector
pycorrector 通用纠错模块是github上的开源项目,它提供了一种规则式检错、纠错方案,该方法因逻辑清晰、不依赖大量标注样本从而较容易实现落地,因此为广大研究者提供了良好的借鉴意义。
- pycorrector 支持 kenlm 、 rnn_crf 、 seq2seq 、BERT 等各种模型。
- 结合具体领域的微调和少量规则修正,应该可以满足大部分场景中的文本纠错需求了。
使用人民日报语料微调过的BERT模型,通过pycorrect加载来做基于MLM的文本纠错。识别结果还算可以,甚至“金字塔”这种需要常识的错别字都纠正出来了。
该模块在检错部分利用常用字典、混淆字典与传统语言模型共同判断当前位置是否有错。制订了如下规则:
- ①当切词后的片段不在常用字典中或存在于混淆字典的映射对中时判定有错;
- ②计算传统语言模型概率是否低于门限并判错。 候选召回部分利用同音、同型召回候选字词,打分排序利用句子困惑度来计算候选词权重,从而对候选进行排序。
该方案是面向通用领域开发的,思路简单、易实现,但在保险垂直领域中容易得到较差的表现。
百度纠错系统
百度纠错系统凭借其海量用户点击语料训练了基于深度学习的序列标注模型,方法如下:
- 错误检测:在错误检测部分,它利用10TB的无监督语料预训练Transformer/Lstm + CRF模型,再利用对齐语料(错误句子→正确句子)进行有监督学习该序列标注模型;
- 候选召回:在候选召回部分,利用了对齐语料和对齐模型构建字级别、词级别、音级别的混淆字典,先利用字、音混淆字典初步召回候选,然后再利用词级别混淆字典和语言模型二次筛选候选,从而形成最终候选;
- 候选排序:利用上下文DNN特征和人工提取的形音、词法、语义等特征一起训练GBDT&LR的排序模型。
腾讯基于垂域的DCQC纠错框架
腾讯提出一套针对垂直业务的通用纠错框架——DCQC(Domain Common Query Correction),由召回层和决策层两层组成。该方法可以方便扩展到其他领域[2] 。
- 召回层:每个领域建立属于自己的一个数据库,建立字和拼音两个维度的倒排索引,通过检索排序的方式召回一定量的候选;
- 决策层:人工提取用户特征、拼音特征等5种类型特征训练svm二分类模型用于候选排序。
学术界的进展
学术界近期发表的中文纠错论文主要集中在中文纠错比赛项目上,如:SIGHAN举办的CSC(中文拼写纠错)比赛、IJCNLP举办的CGED(中文语法错误诊断)比赛及NLPCC举办的GGED(中文语法错误诊断)比赛等。
LSTM+CRF序列标注用于错误检测
IJCNLP2017 [3]和2018 [4]的CGED比赛任务中,第一名的方法都用了LSTM+CRF用于错误位置的检测。然而文中,该方法在错误位置检测方面的F1值最高也只有0.39,目前还没有达到工业化使用的要求。
NMT基于神经机器翻译模型纠错方法
基于机器翻译模型的纠错方法的思想是,将纠错任务类比于机器翻译任务,预想利用模型将错误语句翻译为正确语句,利用Seq2seq模型完成端到端的纠正过程。
YUAN等学者在2016首次利用双向RNN编码器+单向RNN解码器+Attention的经典结构对CoNll-2014(英文语料)进行语法纠错,达到当时最好效果,其统计指标F0.5为39.9%;其后,有道团队在NLPCC-2018举办的CGEC比赛中利用Transformer的翻译模型达到比赛最好的结果,其F0.5值 为29.9% [5]。
深度学习纠错
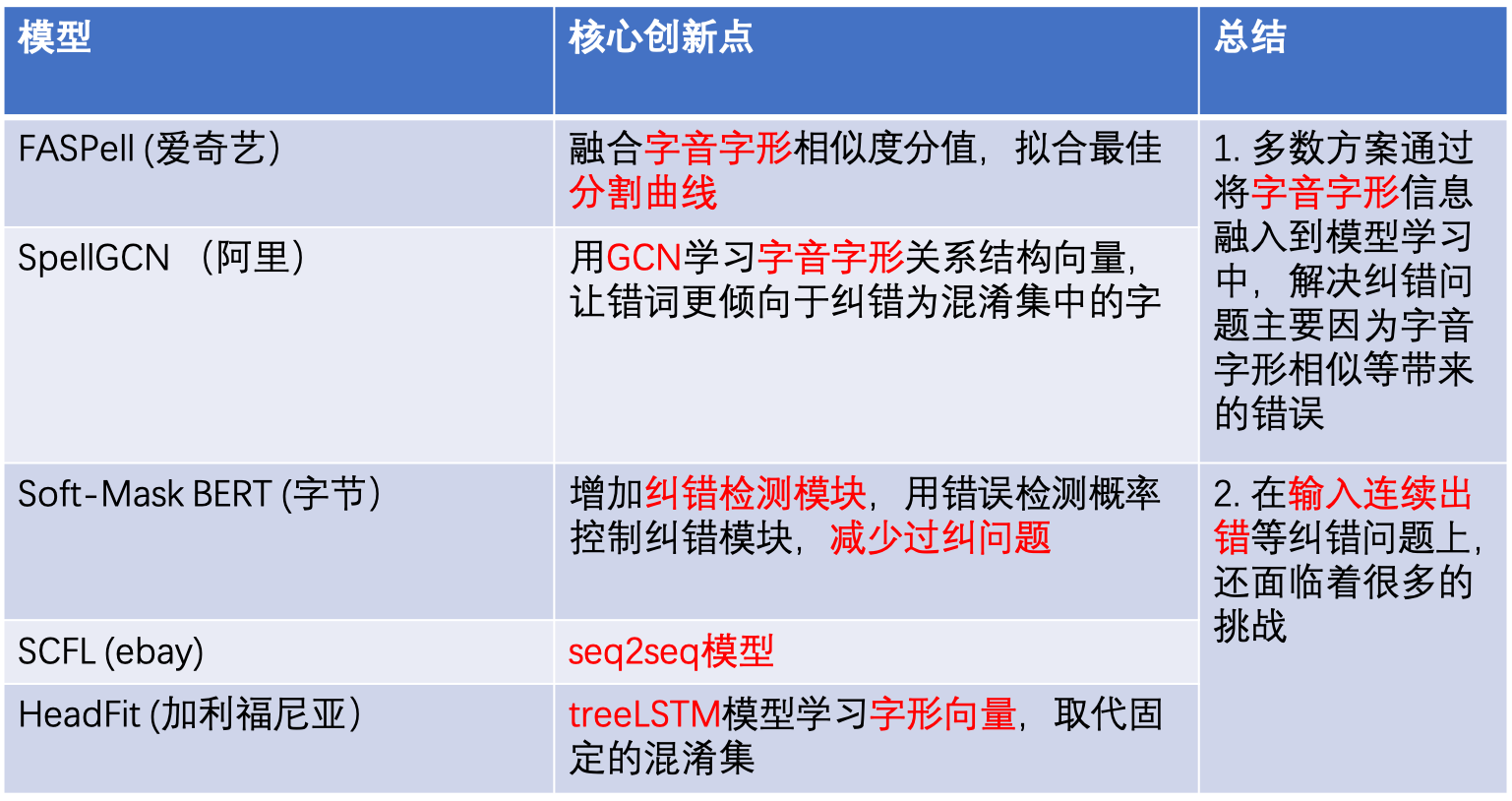
【2021-3-20】中文纠错(Chinese Spelling Correct)最新技术方案总结, 总结:
FASPell(爱奇艺)
- 论文:FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm
- code
爱奇艺团队2019年发表在EMNLP会议上的论文,通过训练一个以BERT为基础的深度降噪编码器(DAE)和以置信度-字音字行相似度为基础的解码器(CSD)进行中文拼写纠错。在DAE阶段,BERT可以动态生成候选集去取代传统的混淆集,而CSD通过计算置信度和字音字形相似度两个维度去取代传统的单一的阈值进行候选集的选择,提高纠错效果,取得了SOTA( state-of-the-art)的一个效果。
模型主要分两大块组成:
- 第一:Masked Language Model (bert)
- 是一个自动编码器(DAE), 基于bert模型,每次获取预测词的top k个候选字。
- 第二:Cofidence-Similarity Decoder
- 该部分是一个解码器,通过编码器输出的置信度confidence分值和中文字音字形的相似度similarity分值两个维度进行候选集的过滤和刷选,选择最佳候选的路径作为输出。
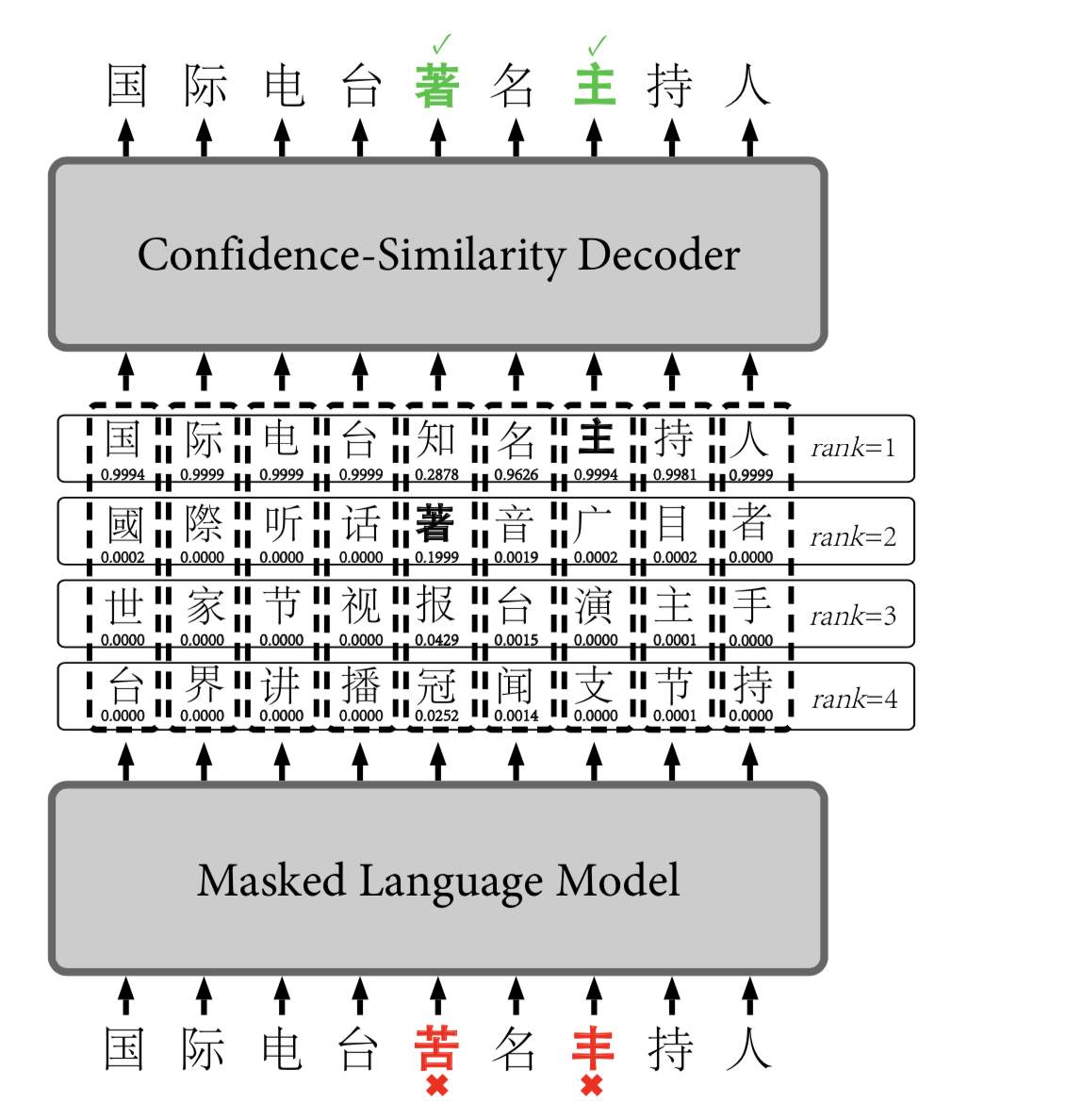
Similarity:包含形体相似(visual similarity) 和字音相似(phonological similarity) ,本论文通过这两种情况进行汉字的相似度计算。
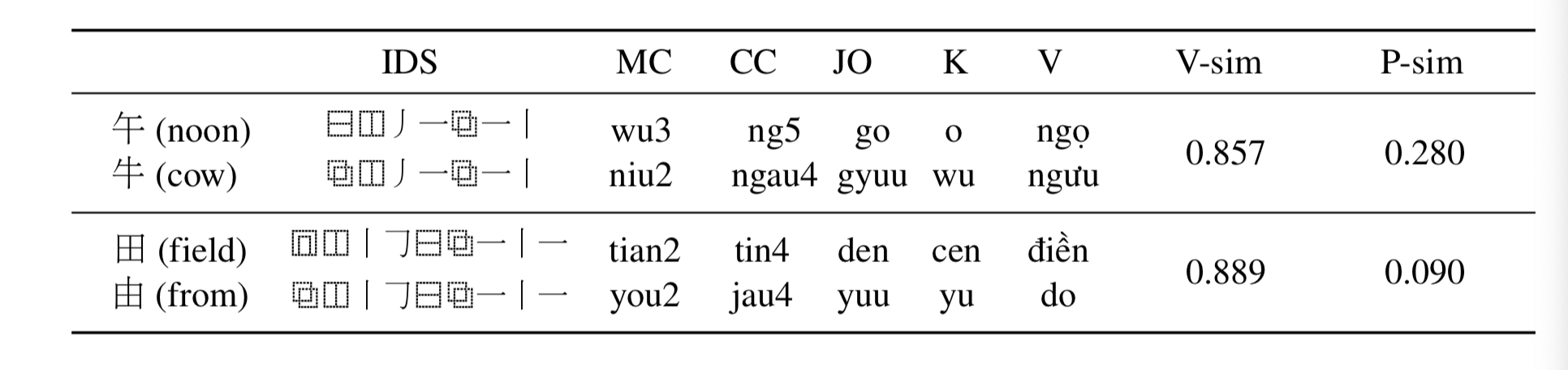
- (1)Visual similarity
- 在字形上采用Unicode标准的Ideographic Description Sequence (IDS)表征。描述汉字更细粒度字体的笔画结构和布局形式(相同的笔画和笔画顺序,例如:“牛”和“午”相似度不为1),比起纯笔画或者五笔编码等计算方式要精细。如下图,展示的是“贫”字的IDS计算,每个字符编码是每个叶子节点从根节点到的搜索路径

- (2)Phonological similarity
- 在字音上,使用了所有的CJK语言中的汉字发音,本文用了普通话(MC),粤语 (CC),日语(JO),韩语(K)和越南语 (V) 中的发音,计算拼音的编辑距离作为相似度分值,最终做一个归一化操作。如下图展示的是字形和字音相似度结果
训练过程
- 预训练MLM部分
- 按照bert原始的mlm方式:对句子15%部分进行置换操作,其中80%替换成[MASK],10%替换成随机的一个词, 10%替换成原始的词
- fine-tune MLM
- 第一部分: 对于没有错词的文本,按照bert原始的mlm方式
- 第二部分: 对于有错词的文本, 两种样本构造:1)用原始错误的词作为mask,正确的词作为target目标词; 2)同时对正确的词也做mask,用原始的词作为mask,目标词为原始词
- 训练CSD
- 训练完encoder,然后根据encoder预测出的confidence分值和字音字形相似度分值,绘制散点图,通过人工观察用直线拟合,确定能够分开正确和错误的点的分界曲线,论文最终给出的曲线为: 0.8 × \times× confidence + 0.2 × \times× similarity >0.8
优点和缺点
- 优点:
- 用MLM预测动态生成候选集,取代了传统的混淆表,整个流程相对简单
- 通过字音字形特征,用多种语言表达的字音特征进行曲线拟合,可解释好
- 缺点
- 不包括少词和多词错误形式纠错
- 训练不是end-to-end的过程,CSD分界曲线靠观察拟合生成
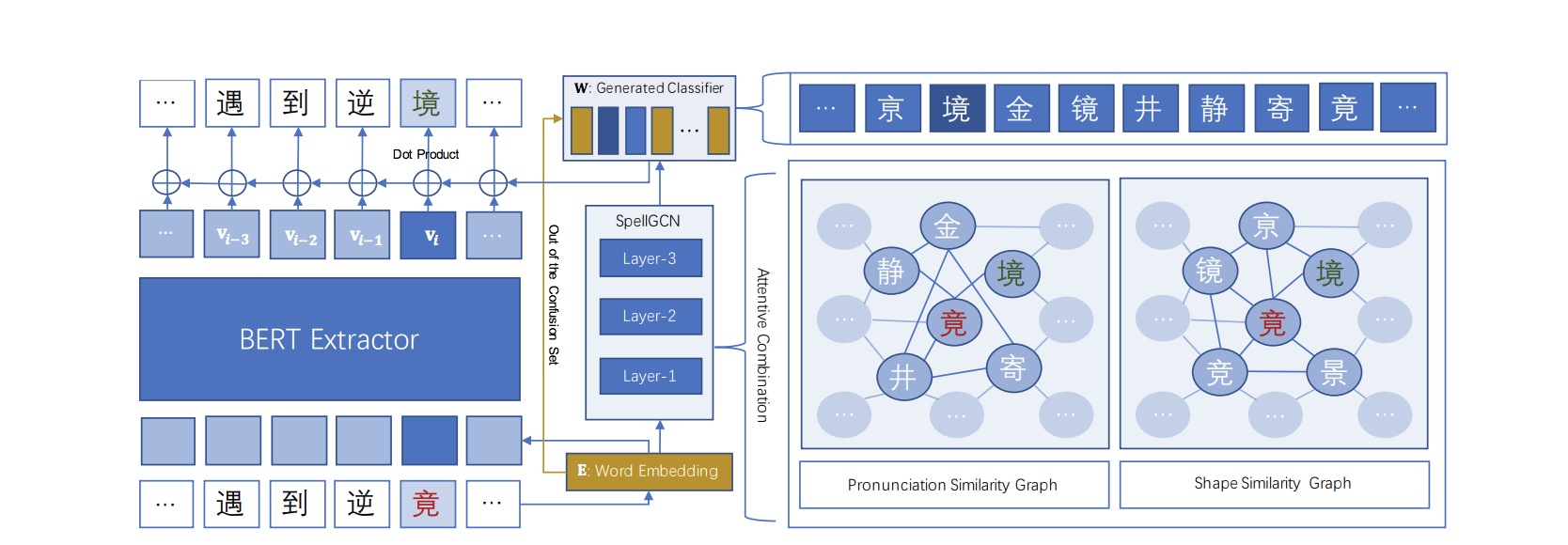
SpellGCN (阿里)
技术方案
- SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
- code
阿里团队于2020年在ACL会议上发表,主要通过graph convolutional network (GCN)对字音和字形结构关系进行学习,并且将这种字音字形的向量融入到字的embedding中,在纠错分类的时候,纠错更倾向于预测为混淆集里的字。模型训练是一个end-to-end的过程,试验显示,在公开的中文纠错数据集上有一个较大的提升
模型也主要分两部分组成:
- 第一部分:特征提取器, 特征提取器基于12层的bert最后一层的输出
- 第二部分:纠错分类模型, 通过GCN学习字音字形相似结构信息,融合字的语义信息和字的结构信息,在分类层提高纠错准确率。
- 优点
- 将字音字形特征通过GCN学习嵌入到语义字向量表征中去,使得错词在纠错的时候能够更倾向于纠正为混淆集中的词,提高纠错准确率
- 缺点
- 不包括少词和多词错误形式纠错
- 混淆集在测试集的覆盖率影响效果评估
Soft-Mask BERT (字节)
技术方案
字节团队于2020年发表在ACL会议,将纠错任务分成两部分:detection network(错误检测)和correction network(错误纠正)。在错误检测部分,通过BiGRU模型对每个输入字符进行错误检测,得到每个输入字符的错误概率值参与计算soft-masked embedding作为纠错部分的输入向量,一定程度减少了bert模型的过纠问题,提高纠错准确率。
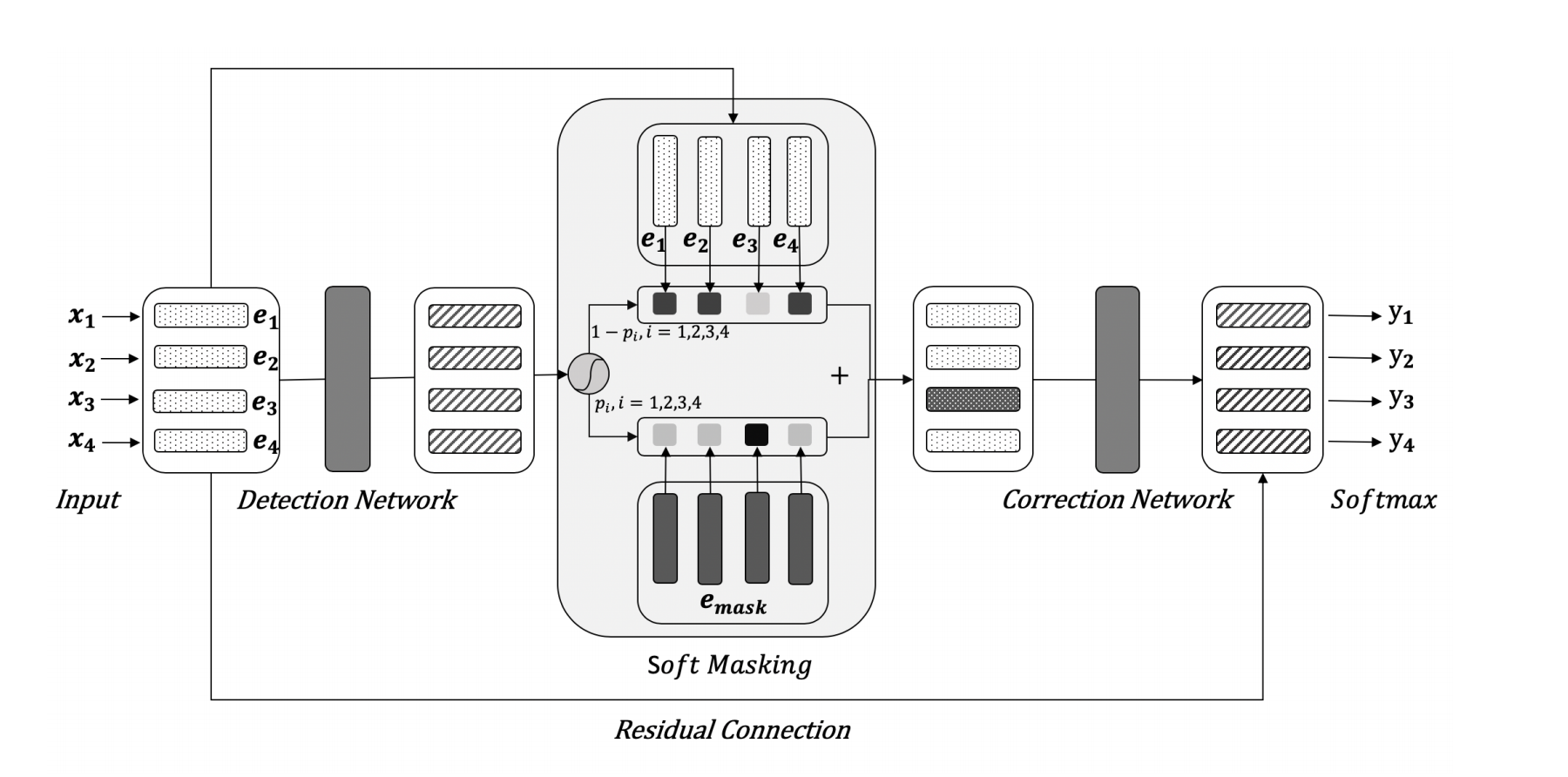
论文首次提出了Soft-Masked BERT模型,主要创新点在于:
- (1)将文本纠错划分为检测网络(Detection)和纠正网络(Correction)两部分,纠正网络的输入来自于检测网络输出。
-
(2)以检测网络的输出作为权重,将 masking-embedding以“soft方式”添加到各个字符特征上,即“Soft-Masked”。
- 优点
- 对中文纠错分成错误检测和错误纠正,并给通过soft-masking技术将两者进行融合,减少bert的过纠问题,提高准确率
- 缺点
- 不包括少词和多词错误形式纠错
- 模型没有引入字音字形相似性约束,虽然引入了错误检测模块,通过soft mask技术减少过纠问题,但是只是依赖bert的语义识别进行纠错,不够鲁棒
Spelling Correction as a Foreign Language (ebay)
技术方案
ebay团队于2019年发表在SIGIR 2019 eCom会议上,将纠错任务当做机器翻译任务,基于encoder-decoder框架。
训练过程
- 训练数据: 主要基于电商平台用户搜索session,通过跟踪用户行为构造样本数据,一个前提假设是,在一个session内,在没有找到满足用户意图商品情况下,用户会主动修改搜索query直到搜索结果符合用户的意图,而基于这样的一个搜索组成的query序列,从中可以挖掘出潜在的错误和正确的query pair对构造训练样本。
- 训练过程: end-to-end训练seq2seq模型。
优点和缺点
- 优点
- 将纠错当做翻译任务去做,可以对不同类型的错误形式:错词,少词,多词等进行纠错
- 缺点
- 模型没有对字音字形相似关系的学习,纠错后的结果不受约束,很容易出现过纠错和误纠问题
HeadFit (加利福尼亚大学)
技术方案
在中文公开纠错数据集上取得了不错的效果。纠错模块分两部分:第一部分是基于bert的base模型,输出可能纠错后的结果,第二部分是一个filter模块,主要基于treeLSTM模型学习出字的hierarchical embedding,通过向量相似度衡量两个字的相似度,取代了预先设定好的混淆集并且可以通过模型的自适应学习,发现字与字之间新的混淆关系能力,通过filter模块,进一步过滤bert模型的过纠等问题,提高准确率。
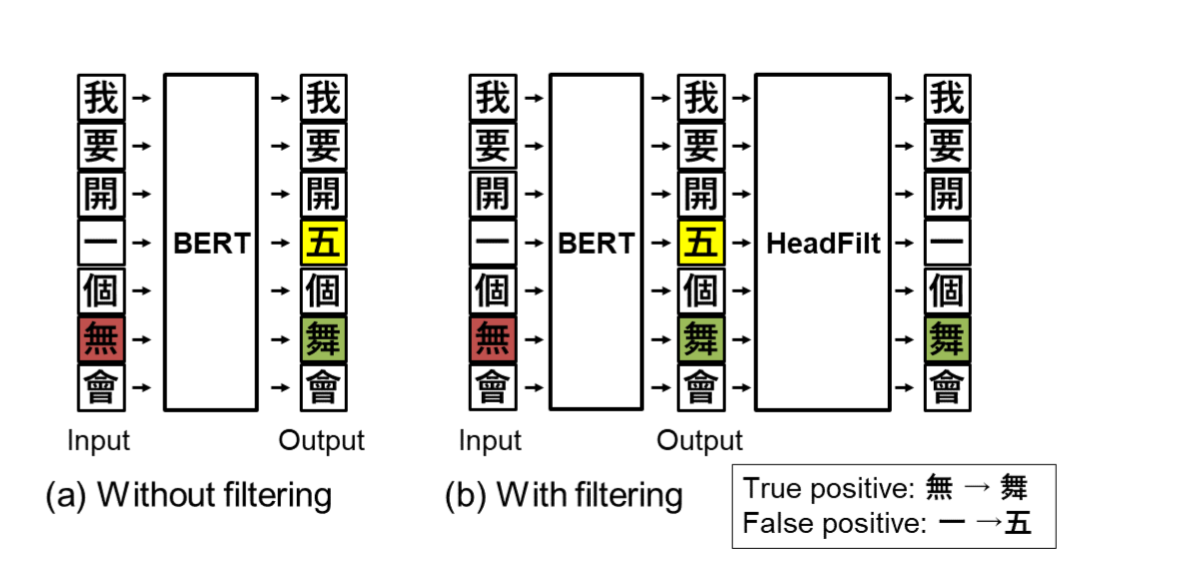
- 优点
- 通过treeLSTM模型学习字的hierarchical向量,不依赖于固定的混淆集,让模型自适应学习字形结构向量特征,通过模型的学习能够扩充混淆关系集,并且对新词和新的领域有较好的适应能力
- 缺点
- 模型学习中没有利用到字与字之间的拼音相似关系
- 模型训练不是一个end-to-end的过程
nlp教程 Curriculum - (Example Purpose)


nlp-tutorial is a tutorial for who is studying NLP(Natural Language Processing) using TensorFlow and Pytorch. Most of the models in NLP were implemented with less than 100 lines of code.(except comments or blank lines)
文本分类 (每个模型内部使用optuna进行调参)
- 2-1. TextCNN
- 2-2. FastText
- 2-3. TextRCNN
- 2-4. TextRNN_Att
- 2-5. DPCNN
- 2-6. XGBoost
- 2-7. Distill_& fine tune Bert
- 2-8. Pattern-Exploiting-Training 利用MLM做文本分类
- 2-9. R-Drop
1. 基础嵌入模型 Basic Embedding Model
词向量
- 1-1. Word2Vec(Skip-gram)
- 1-2. Glove
神经网络语言模型
- 1-1. NNLM(Neural Network Language Model) - Predict Next Word
- Paper - A Neural Probabilistic Language Model(2003)
- Colab - NNLM_Tensor.ipynb, NNLM_Torch.ipynb
- 1-2. Word2Vec(Skip-gram) - Embedding Words and Show Graph
- 1-3. FastText(Application Level) - Sentence Classification
- Paper - Bag of Tricks for Efficient Text Classification(2016)
- Colab - FastText.ipynb
2. CNN(Convolutional Neural Network)
CNN家族在文本分类比较出名的就是Kim的 TextCNN 和kaiming的 DPCN
- 2-1. TextCNN - Binary Sentiment Classification
- Paper - Convolutional Neural Networks for Sentence Classification(2014)
- Colab - TextCNN_Tensor.ipynb, TextCNN_Torch.ipynb
- 工作机制是:卷积窗口沿着长度为n的文本一个个滑动,类似于n-gram机制对文本切词,然后和文本中的每个词进行相似度计算,因为后面接了个Max-pooling,因此只会保留和卷积核最相近的词。这就是TextCNN抓取关键词的机制
- 2-2. DCNN(Dynamic Convolutional Neural Network)
3. RNN(Recurrent Neural Network)
- 3-1. TextRNN - Predict Next Step
- Paper - Finding Structure in Time(1990)
- Colab - TextRNN_Tensor.ipynb, TextRNN_Torch.ipynb
- 3-2. TextLSTM - Autocomplete
- Paper - LONG SHORT-TERM MEMORY(1997)
- Colab - TextLSTM_Tensor.ipynb, TextLSTM_Torch.ipynb
- 3-3. Bi-LSTM - Predict Next Word in Long Sentence
- Colab - Bi_LSTM_Tensor.ipynb, Bi_LSTM_Torch.ipynb
4. 注意力 Attention Mechanism
- 4-1. Seq2Seq - Change Word
- 4-2. Seq2Seq with Attention - Translate
- 4-3. Bi-LSTM with Attention - Binary Sentiment Classification
5. Model based on Transformer
- 5-1. The Transformer - Translate
- 5-2. BERT - Classification Next Sentence & Predict Masked Tokens
| Model | Example | Framework | Lines(torch/tensor) |
|---|---|---|---|
| NNLM | Predict Next Word | Torch, Tensor | 67/83 |
| Word2Vec(Softmax) | Embedding Words and Show Graph | Torch, Tensor | 77/94 |
| TextCNN | Sentence Classification | Torch, Tensor | 94/99 |
| TextRNN | Predict Next Step | Torch, Tensor | 70/88 |
| TextLSTM | Autocomplete | Torch, Tensor | 73/78 |
| Bi-LSTM | Predict Next Word in Long Sentence | Torch, Tensor | 73/78 |
| Seq2Seq | Change Word | Torch, Tensor | 93/111 |
| Seq2Seq with Attention | Translate | Torch, Tensor | 108/118 |
| Bi-LSTM with Attention | Binary Sentiment Classification | Torch, Tensor | 92/104 |
| Transformer | Translate | Torch | 222/0 |
| Greedy Decoder Transformer | Translate | Torch | 246/0 |
| BERT | how to train | Torch | 242/0 |
Dependencies
- Python 3.5+
- Tensorflow 1.12.0+
- Pytorch 0.4.1+
- Plan to add Keras Version
应用
项目实战
- 【2020-6-2】京东AI项目实战课:五个阶段从理论到实践、从项目实战到面试准备的一站式教学,涵盖NLP领域核心技能(特征工程、分类模型、语法树等),前沿技术(BERT、XLNet、Seq2Seq、Transformer、ALBERT、模型蒸馏、模型压缩等);


资料
- 更多Demo地址
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
