总结
- 【2021-4-2】任务型对话方法总结,任务型对话系统简述与细节把捉
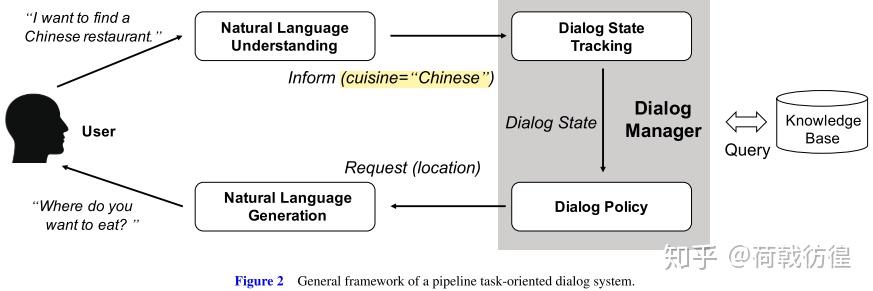
任务型对话简介
DM在对话系统中的位置
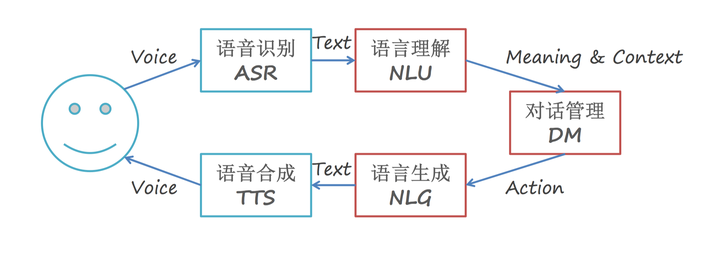
非任务型对话系统,如开放域的闲聊,常见方法:
- ① 基于生成方法,例如序列到序列模型(seq2seq),在对话过程中产生合适的回复,生成型聊天机器人目前是研究界的一个热点,和检索型聊天机器人不同的是,它可以生成一种全新的回复,因此相对更为灵活,但它也有自身的缺点,比如有时候会出现语法错误,或者生成一些没有意义的回复。
-
② 基于检索的方法,从事先定义好的索引中进行搜索,学习从当前对话中选择回复。检索型方法的缺点在于它过于依赖数据质量,如果选用的数据质量欠佳,那就很有可能前功尽弃。
- 任务导向型对话系统旨在通过分析对话内容提取用户任务,并且帮助用户完成实际具体的任务
任务型对话的处理方式有
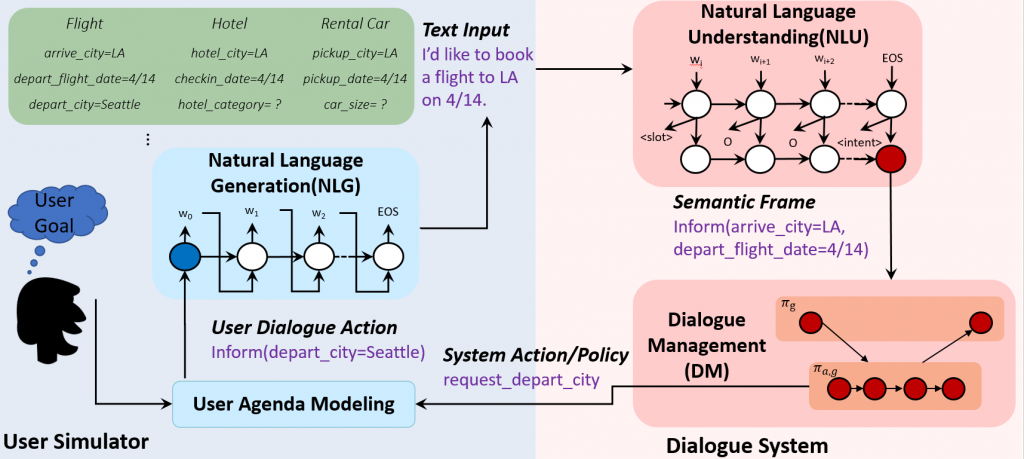
pipeline和端到端两种结构 - pipeline(管道式):定义了数个模块,以一条line的形式串联起来共同完成一个任务,如下图所示。
-
端到端:代表为memory network
- 【2021-1-28】智能对话系统和算法
(1)Pipeline

pipline模块
其核心模块组成是NLU->DM->NLG
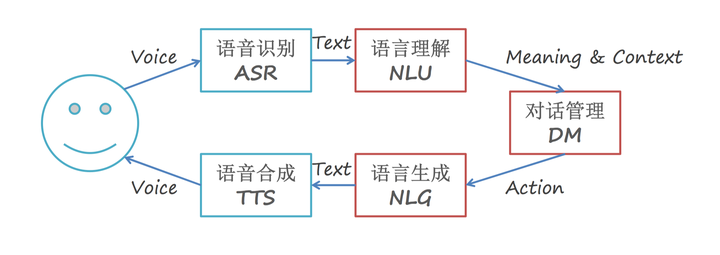
- (1)NLU负责对用户输入进行理解,随后进入DM模块,负责系统状态的追踪以及对话策略的学习,控制系统的下一步动作,而NLG则配合系统将要采取的动作生成合适的对话反馈给用户。
- 其中若用户的输入是语音形式,则在NLU的输入前需再添加一个ASR语音识别模块,负责将语音信号转换为文本信号。
- (2)
DM对话管理器内部又可分为DST(对话状态追踪)和DPL(对话策略学习),DST(对话状态追踪)根据用户每一轮的输入更新当前的系统状态,而DPL则根据当前的系统状态决定下一步采取何种动作。 - (3)
NLG将语言生成后,若用户采用语音交互方式,则还需要TTS(语音合成)模块将文本转换为语音。
pipline工作原理直观理解
ASR:这部分任务比较单一,只负责将语音转换为文本信号。不过,有些论文提起ASR的输入并不是唯一的,因为语音识别可能会存在一定错误,因此一般会输出多个可能的句子,每个句子同时附带一个置信度,表示这个句子正确的概率。这种方式在论文中被称为N-best,及前N个最有可能的句子。NLU:语言理解模块,用户语音转文本后称为用户Utterance,NLU负责对用户Utterance进行领域/意图分类及槽值对填充。- 领域和意图分类是为了让系统明白用户的对话所处领域及意图,方便后续调用相应的model去识别(并不是一个model跑遍所有的领域意图,就好像树一样,根据领域/意图的分类,在树中找到对应的model。当然model结构可能是一样的,不同的是训练采用的数据是对应领域/意图的)。
- 完成一个任务需要去弄清楚一些条件,比如说点一杯咖啡,根据领域/意图分类,系统判断用户的意图是点咖啡,此时系统需要弄明白是什么咖啡,甜度怎么样等等。所以会检索点咖啡所需要的槽值对,这时后台检索发现完成这个任务需要弄明白{咖啡类型=?,甜度=?}(其中咖啡类型和甜度被称为
槽(slot)),系统会反馈回去问用户咖啡类型是什么?甜度是多少?用户反馈后,NLU再对用户Utterance内容进行识别,发现咖啡类型是摩卡,即槽“咖啡类型”的值(value)为“摩卡”,这个过程被称为槽填充。同时这个过程也很容易被人联想到命名实体识别这一方法。考虑到系统的准确率,一般情况下生成的槽值对也会附带一个置信度,也就是说,对于一个slot,可能并不会只输出一个value。 - 【2020-9-7】NLU为什么难?语言的多样性、歧义性、鲁棒性、知识依赖和上下文。源自:自然语言理解-从规则到深度学习
- 意图分类的实现方法:
- 规则:如CFG/JSGF等,CFG最早出现于CMU Phoenix System
- 机器学习:如SVM/ME…
- 深度学习:CNN/RNN/LSTM…
DM对话管理器内部又可分为DST(对话状态追踪)和DPL(对话策略学习)DST:DST(对话状态追踪)归属于DM对话管理器中,负责估计用户的当前轮的目标,它是对话系统中的核心组成部分。在工作过程中维护了一个系统状态(各个槽对应的值以及相应的概率),并根据每一轮对话更新当前的对话状态(各个槽值对)。直观上来看,SLU输出了slot-value,但是不确定,也就是说可能会输出{咖啡类型=摩卡}–0.8, {咖啡类型=拿铁}–0.2,SLU认为这次用户要求的是摩卡的概率是0.8,是拿铁的概率为0.2,并没有输出一个确定值。所以DST需要结合当前的用户输入(即SLU输出的槽值对)、系统上一时刻的动作(询问需要什么类型的咖啡)以及之前多轮对话历史来判断咖啡类型到底是哪个,最后计算得到{咖啡类型=摩卡}–0.9,认为是摩卡的概率为90%,这是DST评估后认为咖啡类型的当前状态。当然还有很多其他的槽,可能甜度还没有问过,所以{甜度=none},等待DPL去询问用户。这些所有的槽值对的状态,被统称为当前的系统状态,每个轮次结束后都会对当前的系统状态做一次更新。- DST主要工作就是更新系统状态,试图捕捉用户的真实意图(意图通过槽值对体现)。
- DST归根结底最终要的还是评估判断当前的用户目标、维护当前系统状态。
- 一般都是对于一个slot建立一个多分类模型,分类数目是slot对应的value数目。常用方法:DNN、RNN、NBT、迁移学习(迁移学习部分还没看,后续会更新到文章末尾)
DPL:对话策略管理是根据DST输出的当前系统状态来判断还有哪些槽需要被问及,去生成下一步的系统动作。- 论文(详见对话系统中的DST)
- 论文一:Deep Neural Network Approach for the Dialog State Tracking Challenge
- 使用n-gram滑动窗口,同时手工构造了12个特征函数来抽取特征,随后将所有特征送入DNN,最后对slot的所有可能value计算概率,概率最高的即为slot对应的value。每一个slot都会有一个对应的model,因此如果该intention内有n个slot需要填充,则系统内有n个该model。
- 论文二:Word-Based Dialog State Tracking with Recurrent Neural Networks
- ASR输出用户Utterance后需要再通过SLU,随后才进行DST。可是ASR可能会出错,SLU也可能会出错,这样会造成一个error传播。因此作者设计的model直接以ASR的输出作为DST的输入,绕过了SLU部分。这种策略目前在paper中也比较常见,一般来说效果也确实比添加SLU模块的要高一些。
- 论文三:Neural Belief Tracker: Data-Driven Dialogue State Tracking
- 将SLU合并到了DST当中。model中可以看到一共有三个输入,System Output(上一时刻系统动作)、User Utterance(用户输入)、Candidate Pairs(候选槽值对)。model要做的就是根据系统之前动作及用户当前输入,判断候选槽值对中那个value才是真正的value。

- 论文一:Deep Neural Network Approach for the Dialog State Tracking Challenge
NLG:DPL生成下一步的系统动作后,生成相应的反馈,是以文本形式的。TTS:若用户是语音交互,则将NLG输出的文本转换为对应语音即可。这部分与ASR差不多,功能相反而已。
(2)端到端
- 基于管道方法的对话系统中有许多特定领域的手工制作,所以它们很难适用于新的领域。近年来,随着端到端神经生成模型的发展,为面向任务的对话系统构建了端到端的可训练框架。与传统的管道模型不同,端到端模型使用一个模块,并与结构化的外部数据库交互。

- 上图的模型是一种基于网络的端到端可训练任务导向型对话系统,将对话系统的学习作为学习从对话历史到系统回复的映射问题,并应用encoder-decoder模型来训练。然而,该系统是在监督的方式下进行训练——不仅需要大量的训练数据,而且由于缺乏对训练数据对话控制的进一步探索,它也可能无法找到一个好的策略。
- 端到端强化学习方法

- 上图的模型首先提出了一种端到端强化学习的方法,在对话管理中联合训练对话状态跟踪和对话策略学习,从而更有力地对系统的动作进行优化。
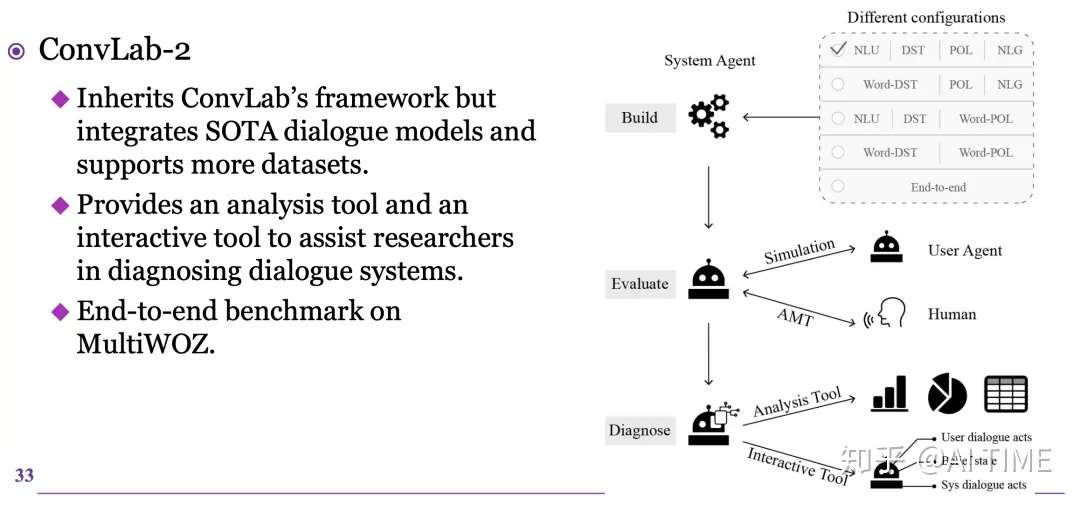
- 【2021-3-2】微软的Jianfeng Gao,ConvLab is an open-source multi-domain end-to-end dialog system platform,aiming to enable researchers to quickly set up experiments with reusable components and compare a large set of different approaches, ranging from conventional pipeline systems to end-to-end neural models, in common environments.
- 开源的ConvLab: Multi-Domain End-to-End Dialog System Platform.
- ACL 2020 demo track, 清华开源的ConvLab-2: An Open-Source Toolkit for Building, Evaluating, and Diagnosing Dialogue Systems,AMiner地址
- ConvLab-2, 端到端模型、评价、诊断,build task-oriented dialogue systems with state-of-the-art models, perform an end-to-end evaluation, and diagnose the weakness of systems. 这篇顶会,助你徒手搭建任务导向对话系统,朱祺的团队用最先进的模型构建面向任务的对话系统,执行端到端评估,并诊断系统缺陷。ConvLab-2继承了ConvLab的框架,但集成了更强大的对话模型并支持更多的数据集。还开发了一个分析工具和一个交互工具来帮助研究人员诊断对话系统。分析工具提供了丰富的统计数据和图表展示,并对模拟数据中的常见错误进行汇总,便于错误分析和系统改进。交互工具提供了一个用户模拟器界面,允许开发人员通过与系统交互并修改系统组件的输出来诊断组装好的对话系统。
- DSTC9 Track 2: Multi-domain Task-oriented Dialog Challenge II
- End-to-end Multi-domain Task Completion Dialog Task
- Cross-lingual Multi-domain Dialog State Tracking Task
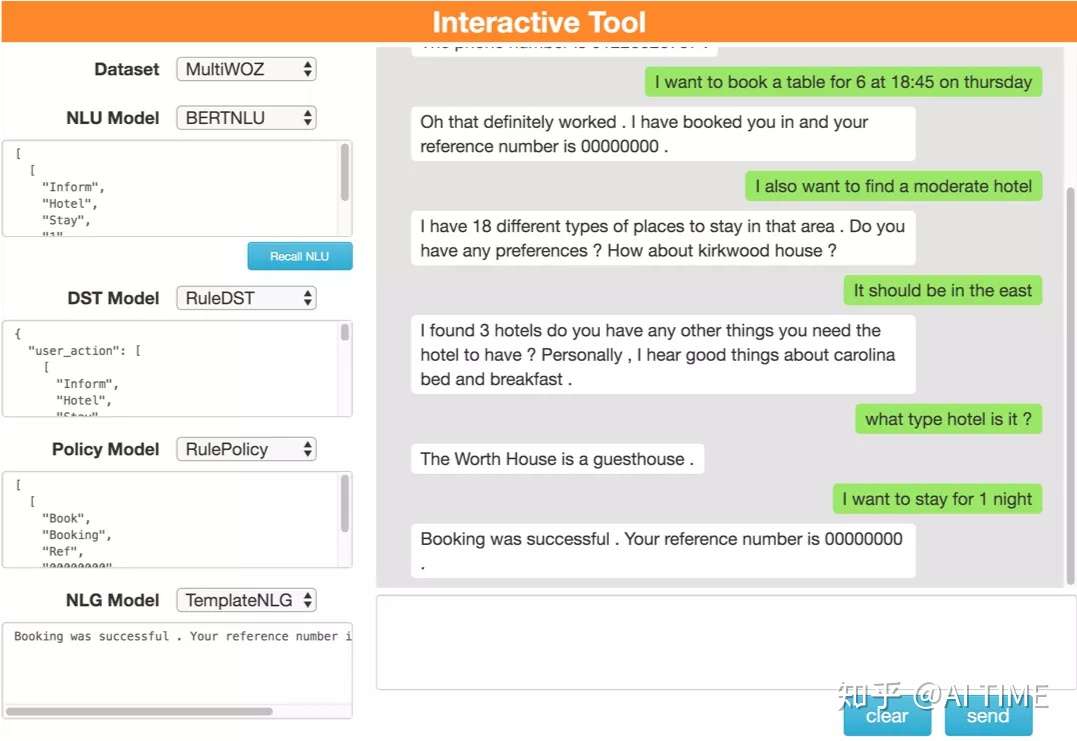
- Deep Reinforcement Learning for Goal-Oriented Dialogues
- 【2021-3-15】百分点智能问答主要流程,图

- 首先进行语音识别,将用户会话识别出来后,经过ASR结果纠错和补全、指代消解、省略恢复等预处理之后,经过敏感词检测,送入中控系统。中控系统是在特定语境下进行意图识别的系统,分为情绪识别、业务意图识别、对话管理、异常处理等四个模块,其中业务意图包括QA问答机器人(QA Bot)、基于知识图谱的问答机器人(KG Bot),NL2SQL机器人(DB Bot),任务型机器人(TASK Bot)。对话管理包括多轮对话的对话历史管理、BOT当前询问、会话状态选取等模块。异常处理包括安全话术(对意图结果的结果进行后处理)、会话日志记录、告警等功能。然后,进入话术/指令生成子系统,这是识别问句意图后的对话结果生成,包括话术生成和指令生成两个模块,在话术生成中,对话系统根据对话历史数据和对话模板生成和拼接产生话术,如果是任务型对话,将生成对应指令。另外,辅助系统通过画像分析、用户分析、问题分析等功能,进一步优化问答系统的效果。
- 智能问答产品典型架构,图

- 智能问答产品主要包括知识库、对话模型、配置中心、多渠道接入以及后台管理。针对不同的任务划分,准备不同的知识库,例如QA BOT需要引入问答知识对,KG BOT需要知识图谱的支持等等。将针对不同任务的对话模型服务,部署接入各个平台接口,譬如小程序、微信、网页等,提供在线问答服务。配置中心主要提供QA对、闲聊语料、同义词库、特征词库等的可视化配置服务,实现知识配置的快速拓展。后台管理针对智能问答系统实施整体监控、日志管理、告警、权限管理等等,另外,它还提供各种维度的统计分析服务。
方法对比
- pipeline
- 问题:错误传递、ASR无法建模知识、汉语重音字(AM和LM);
- 优点:模块化,方法成熟
- end2end问题:
- 优点:同时建模声音和信号;
- 缺点:方法不成熟;end2end依赖ASR好坏;
案例
- 【2020-11-28】怎么让机器人帮我买咖啡(Dialogue System)
这里的对话系统特指 Task-Oriented Dialogue System, 也就是让机器人帮助实现一种特定任务的系统, 有一文献提到的 General Dialogue System 的系统,往往指类似 Chit Chat 的系统。
一般此类对话系统的研究都基于如何让机器人在有限步骤内完成可以完成的任务的系统,并且结果往往定位到一个单一实体。此类系统的一个隐含假设往往是通过电话、文字、语音来进行人机交互,也就是没有什么“点击按钮”,“从多个选项选择”,之类的交互方式。当然在一些类似对话系统演变的工程实践中,是有类似的实现的。
因为这个关于“必须文字交互”的假设,所以实际上有些问题并不适合基于这种假设的对话系统完成。例如你在一些手机软件中搜索餐厅,结果可能会返回多家餐厅(餐厅本身即实体),他们都有名称、地址、电话等等信息(这些也可以称为餐厅这个实体的属性,当然也可以是与餐厅这个实体有关的其他实体)。而你想要通过语音、朗读的文字来获得这个列表,就显得很愚蠢了,不会有人想听机器人读5分钟搜索结果的20家餐厅然后决策吧?所以此类系统往往最后是推荐单一实体,例如结果排名最高的餐厅,如果你需要更换,可以跟系统说换一下餐厅。
一个典型的对话系统的交互过程是这样的:
| 角色 | 类型 | 内容 |
|---|---|---|
| 用户 | User Dialog Act:greeting | 你好 |
| 机器 | Sys Dialog Act:greeting | 你好,我可以帮助你搜索并预订餐厅 |
| 用户 | User Dialog Act:inform(地址=中央公园2.0,口味=意大利) | 我想要找一家在中央公园2.0附近的意大利餐厅 |
| 机器 | Sys Dialog Act:request(价位) | 请问你想要在中央公园2.0附近什么价位的意大利餐厅? |
| 用户 | User Dialog Act:inform(价位=普通) | 普通的就好 |
| 机器 | Sys Dialog Act:inform(名称=柯南家的老意大利料理) | 我知道那里有一家柯南家的老意大利料理餐厅 |
| 用户 | User Dialog Act:alter() | 换一个 |
| 机器 | Sys Dialog Act:inform(名称=意大利油泼面) | 我知道那里有一家意大利油泼面餐厅 |
| 用户 | User Dialog Act:request(价位) | 它家的价格怎么样? |
| 机器 | Sys Dialog Act:inform(价位=普通) | 意大利油泼面的价位是普通 |
| 用户 | User Dialog Act:order() | 就这家吧,帮我预订 |
| 机器 | Sys Dialog Act:request(人数) | 请问有几个人? |
| 用户 | User Dialog Act:inform(人数=1) | 单身狗 |
| 机器 | Sys Dialog Act:confirm(人数=1) | 真的就1个人吗? |
| 用户 | User Dialog Act:confirm() | 是的 |
| 机器 | Sys Dialog Act:order_success() | 已经预定成功 |
| 用户 | User Dialog Act:bye() | 好的,再见 |
| 机器 | Sys Dialog Act:bye() | 再见,欢迎下次使用 |
Dialog Acts 如果是用户发起的(User Dialog Act),那么它是一种处理后的用户意图的抽象表达,是一种形式化的意图描述。
The dialog act expresses an important component of the intention of the speaker (or writer) in saying what they said 系统发起的行为(Sys Dialog Act),是根据用户行为,上下文信息等等综合得出的, 下一步所要进行的操作的抽象表达,这个抽象表达后续会送入NLG部件,生成自然语言。
Asking questions, giving orders, or making informational statements are things that people do in conversation, yet dealing with these kind of actions in dialogue what we will call dialog acts is something that the GUS-style frame-based dialog systems GUS对话系统,是 Genial Understander System 的缩写,可以追溯到1977年的论文(Daniel G. Bobrow, GUS, A Frame-Driven Dialog System, 1977)
常见的不同意图有:
- 用户的greeting:问好
- 用户的inform:用户提供一个信息,例如想要的餐厅的地址
- 用户的request:询问一个信息,例如当前结果餐厅的电话
- 用户的confirm:确认信息正确(例如上一条是机器问你对不对)
-
用户的bye:结束对话
- 机器的greeting:问好,也可以是自我介绍
- 机器的inform:提供机器知道的信息,例如当前结果餐厅的信息
- 机器的request:机器必须有足够的信息才能完成任务,如果欠缺一些必须信息,例如餐厅地址、口味,则会向用户询问
- 机器的confirm:根用户确认信息是否正确
- 机器的bye:结束对话
上文还出现了一些可能的特殊意图,例如:
- 用户的order:确认订餐
- 用户的alter:更换检索结果
- 系统的order_success:反馈订餐成功
整个对话系统,就是为了完成某个特定任务,这个任务所需要的特定条件需需要由用户提供(例如帮助买咖啡需要咖啡品种,热或冷等信息),当信息足够的时候,机器就能完成相应任务。
这个过程总结就是:
- 用户说了什么 =》 分析用户意图 =》 生成系统的对应意图(操作)=》 用户听到了系统的反馈 =》 用户说了什么(第二轮)=》…………
当然根据任务复杂度、和其他系统结合等等问题, 对话系统本身也有各种的不同准确度与实现方式。
DM
对话管理(Dialog Manager,下文简称 DM)一般的定义是,根据用户当前的输入,以及对话上下文,决定系统下一步的最佳响应。对于任务型 DM,其职责是通过一致性的对话交互,完成用户的对话目标。
- 多轮对话之对话管理(Dialog Management)
- 对话管理(Dialog Management, DM)控制着人机对话的过程,DM 根据对话历史信息,决定此刻对用户的反应。最常见的应用还是任务驱动的多轮对话,用户带着明确的目的如订餐、订票等,用户需求比较复杂,有很多限制条件,可能需要分多轮进行陈述,一方面,用户在对话过程中可以不断修改或完善自己的需求,另一方面,当用户的陈述的需求不够具体或明确的时候,机器也可以通过询问、澄清或确认来帮助用户找到满意的结果。
对话管理的任务大致有下面一些:
- 对话状态维护(dialog state tracking,
DST)- 维护 & 更新对话状态
- 生成系统决策(dialog policy)
DP- 根据 DST 中的对话状态(DS),产生系统行为(dialog act),决定下一步做什么dialog act 可以表示观测到的用户输入(用户输入 -> DA,就是 NLU 的过程),以及系统的反馈行为(DA -> 系统反馈,就是 NLG 的过程)
- 作为接口与后端/任务模型进行交互
- 提供语义表达的期望值(expectations for interpretation)interpretation: 用户输入的 internal representation,包括 speech recognition 和 parsing/semantic representation 的结果
对话引擎根据对话按对话由谁主导可以分为三种类型:
- 系统主导
- 系统询问用户信息,用户回答,最终达到目标
- 用户主导
- 用户主动提出问题或者诉求,系统回答问题或者满足用户的诉求
- 混合: 用户和系统在不同时刻交替主导对话过程,最终达到目标。有两种类型
- 一是用户/系统转移任何时候都可以主导权,这种比较困难
- 二是根据 prompt type 来实现主导权的移交
- Prompts 又分为:
- open prompt(如 ‘How may I help you‘ 这种,用户可以回复任何内容 )
- directive prompt(如 ‘Say yes to accept call, or no’ 这种,系统限制了用户的回复选择)
多轮会话
【2023-7-10】复杂多轮对话
多轮对话定义
N阶对话的定义:
- 上下文无关的对话被称为0阶对话
- 简单的多轮对话被称为1阶对话
- 多个多轮对话之间存在上下文依赖关系,称为N阶对话
一阶单论对话结构特点
单轮对话:
- 用户: 你好!
- 用户: 北京今天什么天气?
- 机器人: 北京今天晴天, 气温29度, 注意防晒 // 上下文无关的另一轮对话
单轮对话特点: 轮次之间没有依赖关系, 一次对话即可完成对话目标
单轮对话实现了对用户输入信息的响应.
单轮对话是多轮对话的基石.多轮对话也是由一个个单轮对话构成的, 只是其中任何一个单轮对话节点(Stage), 根据用户的消息, 可以把对话引导到别的节点.- 单轮对话机器人本质上是单轮对话的无限循环, 对话之间缺乏上下文联系与记忆, 例如最常见的闲聊机器人.
一阶多论对话结构特点
一阶多轮对话:
- 用户: 北京今天什么天气?
- 机器人: 北京今天晴天, 气温29度, 注意防晒
- 用户: 后天呢?
- 机器人: 北京后天多云, 气温30度 // 时间改变, 地点没改变, 需要上下文记忆
- 用户: 那上海呢?
- 机器人: 上海后天晴天, 气温28度 // 地点改变, 时间没改变, 需要上下文记忆
一阶多轮对话的特点:
对话主题明确、单一,但是要完成对话目标,需要与用户进行多轮交互收集所依赖的信息
一个线性多轮对话 可能需要 N 轮对话完成一个任务.
与单轮对话相比, 又衍生出额外的技术问题:
- 语义作用域 : 如果单轮对话能响应 100 种用户意图, 每一轮对话都会试图匹配这 100 种意图, 称之为 开放域 匹配. 然而进入到多轮对话时, 机器人需要的就是 “长沙” 这个信息, 那么用户别的意图就应该 拒答 , 于是语义的作用域就变窄了, 变成封闭域.
- 上下文记忆 : 单轮对话不需要记忆. 而多轮对话, 则前几轮用户提供的信息, 例如 “城市” 或者 “日期” 需要带到最后一步. 这就需要至少在本次多轮对话中携带上下文记忆.
- 退出对话 : 由于对话有多个轮次, 用户就可以在某一轮产生退出对话的意愿. 这时机器人就要退出任务并给予反馈 (例如 “好的, 欢迎下次再来”).
现阶段大部分多轮对话机器人, 都做到了实现 1阶多轮对话.
单向多轮对话 (串行)
如果机器人和用户的对话有严格步骤, 这是一个单向多轮对话. 这种多轮对话最为简单常见, 例如:
机器人: 请问您要什么口味的 // stage1
用户: 苹果味的
机器人: 要不要加冰 // stage2
用户: 加
机器人: 是杯装还是碗装? //stage3
用户: 杯子好了
这种有上下文(Context)的多轮对话, 包含:上下文相关记忆, 每一个单轮对话逻辑, 退出规则等
- 也可以多个 stage 组合成管道
只要以下几个参数就能标记多轮对话的当前位置了 :
contextId: 当前对话语境的唯一IDstage: 对话进行到的步骤名称.stacks: 接下来要经过的步骤构成一个栈
许多基于 slot filling (槽填充) 任务型多轮对话实现了一个单向的多轮对话
有分支的多轮对话
既然一个 Stage 可以指定下一个要到达的 Stage, 也可以指定若干个可能前往的 stage,从而出现了分支.
有循环的多轮对话
多轮对话既然有了分支节点, 同理就可以实现循环节点.
中断多轮对话
一个漫长的多轮对话 可能有各种原因让多轮对话中断退出.
常见的中断原因有 :
cancel: 用户或机器人主动取消对话reject: 用户没有权限继续failure: 流程中出现了无法继续下去的故障
中断后的常见策略有:
quit: 结束对话restart: 对话重新开始- 指定一个具体的 stage, 试图通过新的多轮对话流程来修复问题.
对于一个最基础的多轮对话 Context 而言, 中断策略可以定义在某个 Stage 节点, 也可以定义为全局逻辑, 任何一个节点退出都由全局来捕获处理.
分形的多轮对话
由单轮对话构成多轮对话, 再加上分支和循环, 一个初步的复杂多轮对话就成型了. 理论上可以无限轮次.
- 例如用户和机器人围绕各种需求对话了几千轮, 共涉及一千个处理独立功能的单轮对话节点.这么多节点定义在一个 Context 中, 它会不可思议的巨大, 而且无法维护.
所以要像编程语言那样用分形的结构拆分和封装多轮对话. Stage 相当于函数, Context 相当于类, 而要把上万行的代码拆分到几百个相互调用的类与函数中
- 由于 Context1 和 Context2 还可以继续依赖别的 Context, 用这种形式可以实现简单的分形的封装和复用.
依赖关系构成 Thread 栈
上一步实现了多轮对话的分形拆分, 展开来还是同一个有分支和循环的长程多轮对话.
对话过程中很可能出现 Context1 依赖 Context2, Context2 依赖 Context3 … 当被依赖的 Context 完成之后, 会一层层地回调, 从而构成一个栈结构.
最大的特点是依赖关系不仅接受层层回调, 而且共享中断机制. 遇到cancel, failure, reject等事件时, 也会冒泡式地层层回调. 任何一层如果拦截了事件, 可以自己定义重定向的 stage.
非依赖关系构成栈结构
在自然对话中, 很可能出现各种情况, 例如插入一个话题, 使得多轮对话 A 到多轮对话 B 并不是依赖关系的. 多轮对话 B 无论正常结束还是异常结束, 都需要 A 来继续话题.
例如:
机器人: 请问要什么口味的
用户: 苹果的
机器人: 请问是否要加冰
用户: 稍等, 请问有没有会员折扣? // 用户跳到了另一个对话场景
机器人: 我们这里有会员折扣, 需要您...
用户: 算了, 不用了
机器人: 好的. // 对话场景 cancel 掉了
机器人: 请问是否要加冰 // 另一个对话结束后, 回到当前对话
异步任务下的让出与抢占
现有的大多数对话机器人在实现任务时采用同步逻辑. 如果对话机器人要推进到生产领域, 会出现大量的异步逻辑.
简单而言, 一个任务需要经过一段时间之后才会进入下一阶段, 这段时间不需要用户等待, 而是可以先和机器人对话别的事情. 等到任务阶段性完成后, 再抢占当前的多轮对话.
CommuneChatbot 对此有完整的实现机制, 但尚未实装. 简单而言:
- 当前 Thread 让出控制权, 进入yielding状态. 等待服务回调.
- 一个指定的 Thread, 或者 sleeping Thread 获得对话控制权.
- 当 yielding 状态的 Thread 接受到回调后, 移动到 Blocking栈, 按优先级排序.
- 下一轮对话时, 如果 Blocking栈有 Thread, 会将当前 Thread 推到 sleeping 栈中, 然后让 Blocking 的 Thread 抢占控制权.
- Thread 存在优先级, Blocking Thread 优先级低则不能抢占当前对话, 避免多个任务同时回调, 不断抢占.
对话进程
一个多轮对话中可能同时存在若干个 Thread, 分布在不同的位置:
- Current : 当前 Thread, 拥有对话控制权
- Sleeping : 等待被唤醒
- Yielding : 等待回调
- Blocking : 排队要抢占 Current 的位置
完全不在上下文中的 Thread 则会被垃圾回收 (GC), 然后唤醒一个 Sleeping Thread.
这整个数据结构, 构成了一个多轮对话的完整上下文关系
第一反应与场景
- 第一反应指用户与机器人开始对话, 机器人的第一反应. 可能是欢迎语, 或者自我介绍, 或者猜你想问.
对于同一个机器人, 往往用户从不同场景开启对话, 希望对话的内容也不一样. 以瓜子二手车的智能客服为例, 当用户在买车页打开智能客服, 主要想咨询买车事宜. 当用户从卖车页进入, 自然主要想咨询卖车信息.
子对话与多任务调度
每一个 Dialog 对象可以用于管理一个 Process. 一个 Process 对应一个复杂的多轮对话上下文状态.
而在现实对话中, 还可能遇到两种更高阶的对话组织形式.
- 对话嵌套
- 多任务调度
所谓 对话嵌套, 以 CommuneChatbot 的对话游戏 Demo 为例. 用户在玩一个 “大战长坂坡” 的对话游戏, 需要对游戏给出的选项进行选择. 但用户随时说 “菜单”, 会进入到一个 “菜单” 的多轮对话; 而当用户说 “返回游戏”, 又要返回到游戏原来的情景中.
简单来说, 对话的控制权需要被 “菜单对话” 和 “游戏对话” 共享, 又各自保持自己的对话状态.
而所谓 多任务调度 则是指有若干个进行中的对话任务, 都拥有独立的上下文, 而用户可以按需切换, 就像在浏览器上切换不同的窗口一样
比多任务调度更高阶的对话组织形式, 就是多机器人调度了. 这个技术实现更加简单一些. 服务器上实装多个机器人实例, 用户直接面对的机器人起到一个 “中控” 的角色, 负责把消息投递给指定的机器人, 然后返回响应.
这种机制可以通过中间件的方式实现, 直接把一个 SessionPipe 做成路由器. 而其它机器人则变成了它接线的对象, 或者像其它对话机器人那样, 称之为 “技能”.
详见:对话系统生命周期
N阶多轮对话的嵌套结构
现实中的任务往往不是简单的线性结构, 而是分解成若干子任务, 相互嵌套而成.
- 每个子任务都可以分解成一个 1阶的多轮对话.
- 而子任务又可以拆解成新的子任务, 这就形成了1阶多轮对话的嵌套, 产生了像分叉树一样的对话结构:
机器人: 您好, 请问我有什么可以帮您? // 基础对话
用户: 我想买果汁
机器人: 好的, 请问您想要什么口味的? // 开启购物多轮对话
用户: 我想要苹果汁, 常温哈
机器人: 好的, 请问是杯装还是碗装 ?
用户: 杯装就可以.
机器人: 对了, 您办理我家会员可以享受8折优惠哦 // 会员卡导购
用户: 不用了 // 退出导购语境
机器人: 好的, 请付15元. // 回到购物的多轮对话
用户: 这么贵啊? 我不要了
机器人: 好的, 您的订单已取消 // 取消会话
机器人: 您好, 请问还有什么可以帮您? // 回到基础对话
用户: 我想买电影票
...
更多例子:
/*---- 多轮对话 1 : 选择任务 ----*/
用户: 公司的助理机器人, 你好!
机器人: 您好, 请问有什么可以为您做的?
用户: 你能做什么?
机器人: 我能请假, 销假, 报销发票
用户: 我要报销发票
/*---- 多轮对话 1.1 : 获取发票信息 ----*/
机器人: 请问您想报销哪几个月的发票?
用户: 四,五,六 三个月的.
机器人: 好的, 请问您需要报销哪些类型的?
用户: 餐饮, 打⻋的发票.
/*---- 多轮对话 1.1.1 : 获取餐饮发票信息 ----*/
机器人: 好的, 我们先报销餐饮. 请问您要报销多少钱?
用户: 625元.
机器人: 请您提交足额的发票pdf
用户: [发票1], [发票2], [发票3]
/*---- 多轮对话 1.1 : 获取发票信息 ----*/
机器人: 您好, 餐饮和打⻋发票我已收到. 请问还有别的报销需求吗?
用户: 木有了.
/*---- 多轮对话 1 : 选择任务 ----*/
机器人: 好的. 请问您还有别的事情需要我做吗?
用户: 没有了, 拜拜, 公司的助理机器人.
机器人: 好的, 再⻅, 希望下次继续为您服务.
上述对话案例中出现了4个对话任务
- 选择任务
- 提交发票信息
- 提交餐饮发票
- 提交打⻋发票
从该案例中可以到 N阶对话 存在以下特征:
- 对话嵌套 : 一个多轮对话内部, 某个节点可以是另一个多轮对话, 形成嵌套
- 对话分支 : 根据条件不同, 对话会走向不同的子多轮对话分支.
- 对话循环 : 一些多轮对话可以反复循环, 直到用户要求退出.
- 无限轮次 : N阶多轮对话可以无限轮次
- 对任何一个父级的对话,他可以不关心子对话的过程,不关心嵌套了多少级,只需要关心子对话的结果, 专注于自己的流程就可以了
语境关系
N阶多轮对话的复杂性
N 阶多轮对话可以反复分割, 像是分形几何的图形一样. 因为子对话的存在, 于是产生了 分支 和 循环 . 整体看起来像一个树状结构.
如果子对话的结果返回到父对话, 将决定父对话的下一步怎么走, 这就不是树状结构, 而是图状结构了.
这种图状结构并非一阶多轮对话的简单嵌套, 它带来了更多的复杂性.
在 CommuneChatbot 项目中, 总结了以下几个方面:
- 半开放域语境
- 语境的跳转与回归
- 返回上一步
- 逃离语境与拦截
- 有作用域的上下文记忆
- 多任务调度
- 双工状态管理: 让出, 异步 与 抢占
半开放语境定义
对话机器人对话的处理一般分为两个步骤:
- 意图匹配环节: 在对话的任何步骤都可能匹配不一样的意图,还会产生临时中断、调走等各种需求 所以是开放域的。
- 具有明确语境的对话,包括 单轮对话 和 多轮任务型对话
对于每一轮对话,都存在于一个上下文语境,有自己允许匹配的意图,不识别的意图会拒答,所以是封闭域的。
现实世界的对话,是上面两个环节的结合,被称为半开放语境对话。
语境划分
根据语境隔离的原则, 使用如下规则对N阶多轮对话进行建模:
- 将具有一个明确目标的对话段定义为一个Domain。
- 一个或多个在业务逻辑上存在依赖的Domain 组成一个Task,每个Task内的对话具有一个独立语境。
- 每个语境具有一个独立的上下文, 在工程建模上进行独立追踪,就是每个语境有一个独立的Dst。
- 对N阶对话的嵌套结构, 被划分为依赖嵌套 和 非依赖切换,这两种嵌套被触发都导致对话语境的切换。 依赖嵌套的语境切换与恢复 使用一个栈结构进行管理, 对语境进行递归调用和恢复。非依赖切换的语境切换和恢复,使用 优先级选择+hash字典的结构进行管理。
语境关系解释
- 嵌套语境
嵌套语境是指 一个Task A在业务逻辑上依赖另一个Task B,Task A 会根据 Task B 的结果进行对话分支逻辑的跳转。 但是 Task A 在语境上是不关系 Task B 的语境是什么样的, 以及Task B 是如何进行对话流程的。这样保证了语境 的隔离。 这样的嵌套可能会有多层,所以可以使用一个栈结构对这种递归关系进行建模,对语境的切换与回归进行建模。
- 无依赖语境切换
无依赖语境切换是指两个语境间没有明显的业务依赖关系,有用户在对话过程中随机的调用而导致的语境切换。比如用户在进行一个关于出行规划的 对话Task A中, 突然用户想播放一些背景音乐,这样就切换成 影音娱乐的Task B中了。而在TaskB 的进行中可能用户又希望查询歌手的信息,这样又切换到知识图谱或信息搜索的TaskC中. 而一个任务完成后会根据用户的query 来选择恢复哪一个没完成的Task。这个过程可以使用一个 意图相关的优先级规则 和一个 HashMap 结构来对语境进行管理。
多语境中的N阶多轮对话功能分析
N阶对话建模需要解决的问题:
- 上下文记忆问题:在完整的N阶多轮对话树中, 每一个节点的信息都可以被任何一个节点用到 ( 上下文记忆问题 ), 而这些信息可能又是相互隔离的.
- 语境跳转问题:而一个子任务完结后, 会跳转到另一个子任务, 还是返回到父任务, 这也完全取决于上下文
- 语境脱出问题:如果一个子任务因故要终止, 比如用户取消, 用户无权限, 发生错误等; 那它应该退回哪一个任务呢 ? 这同样取决于上下文
复杂多轮对话的核心问题就在于此,如果各种 “语义理解” 算法,解决的是某一句话的 “代数分析问题”, 对话管理模块是要代数的模拟出 “N阶多轮对话嵌套结构” 的问题
在工程上对N阶多轮对话进行建模需要解决以下几个问题:
- N阶对话的递归结构
- 语境隔离
- 语境跳转
- 语境脱出
- 语境导航
- 上下文记忆功能
- 分布一致性
- 语境的挂起和唤醒
- 多任务调度
- 遗留语境唤醒
语境的跳转与回归
既然有了多个半开放域的语境, 就存在语境的跳转以及回归. 回归的形式决定了跳转的形式.
CommuneChatbot 定义了以下三组基本的跳转和回归:
依赖: dependOn & intended, A 语境依赖 B 语境的结果挂起: sleep & fallback, A 语境不依赖 B 语境的结果, 但当 B 结束了会唤醒 A替代: replace, A 将自己替换成 B , 自己从上下文中消失
返回上一步
口误时常常立刻纠正口误信息, 想返回上一步.
让语境返回上一步, 这对于人类很容易做到, 但对于对话机器人而言就不简单了. 因为对话的状态发生了变更, 一些副作用 (计算导致的参数变化) 也发生了. 因此存在三种可能性
- 完全不可回溯
- 对话可回溯, 副作用不可回溯
- 对话可回溯, 副作用也可以消除.
现阶段大多数对话机器人都无法返回上一步. CommuneChatbot 则可以选择保留几个快照(snapshot) , 从而可以返回几步. 但已经发生的副作用难以完全消除. 这种回退的机制很像浏览器的返回.
逃离语境与拦截
在多轮对话流程中, 有种种原因可能导致流程突然中断, 例如:
cancel: 用户主动放弃reject: 用户无权限failure: 服务端发生错误
这些情况发生如果没有处理, 对话就会陷入死循环. 因此是需要 “逃离” 当前语境的. 问题在于流程中断后, 对话应该回归到哪一个节点呢?
- 退回上一步?
- 彻底退出整个对话?
- 退回某一步
退回上一步很可能无法解决问题. 而彻底退出整个对话, 对于长程多轮对话而言极其不友好.
CommuneChatbot 的方案是, A => B => … => N 这样嵌套很多层的语境跳转, 可以根据是否依赖跳转语境的执行结果, 拆分成若干个 Tread :
[thread1 : A => B => C] => [thread2 : D => E ] => [thread n: X => … => N]
每个 Thread 内部的语境是相互依赖的, 而 Thread 之间没有依赖.
这样当 Thread 当前节点发生逃离语境事件时, 整个 Thread 都会被退出. 而返回到另一个 Thread. 当没有上级 Thread 存在时, 整个会话才退出.
进一步的, 当 cancel , reject 这些逃离事件发生时, 它们会像 HTML 的 DOM 树事件那样, 逐层往上冒泡. 每一层都可以定义自己的拦截方法, 终止正常的退出逻辑.
有作用域的上下文记忆
多轮对话管理一定要实现上下文记忆. 然而记忆也会有短程和长程的. 比如 问用户的名字, 就应该永远都记得.
通常的对话机器人项目存在短程和长程记忆. 长程就是无限期存储的; 而短程只在一个 session 的生命周期中生效.
而 CommuneChatbot 中自带的记忆体, 可以自行定义作用域, 类似于局部变量. 只要在作用域一致的情况下, 拿出来永远是同一份记忆.
例如问用户 张三每周三下午两点有什么课程 , 得到的信息可以存储在作用域为 人:张三; 每周:三; 时间:下午两点 这三个维度定义的作用域中. 只要查询的作用域与之相同, 得到的永远是相同的数据.
多任务调度
目前多轮对话机器人很少考虑多任务调度的问题. 在 CommuneChatbot 中定义了 Thread, 定义了 dependOn 和 Sleep 机制, 并且能保证上下文记忆, 因此可以实现多任务调度.
例如官网上的例子:
用户: 我想买水果汁
机器人: 请问您需要什么口味的?
用户: 我想要苹果口味的
机器人: 请问是否要加冰
用户: 长沙明天天气怎么样? // 跳转到另一个任务, 当前任务挂起 (sleep)
机器人: 长沙明天的... 还有其它问题吗?
用户: 没有了
机器人: 请问是否要加冰 // 跳转回到买果汁 (fallback)
这是一个被动匹配, 使用户从 任务A 跳转到 任务B , 又能够调度回来的例子.
在这套机制基础上可以实现多任务调度, 每个任务就是一个 Thread, 用户可以选择让哪一个 Thread 控制当前会话, 而其它 Thread 进入 sleep 状态, 等待未来跳转回来 (fallback), 或者主动唤醒 (wake).
双工下的状态管理: 让出, 异步与抢占
一般的双工指的是通信上的互通. 但对于对话系统而言, 双工不仅是可以主动推送信息给用户, 还意味着上下文语境也可能在机器人方主导下变化:
用户: 帮我搜索一下张三的资料 // 用户发布搜索任务
机器人: 好的, 搜索中
机器人: 稍等, 您有一个电话过来的, 您需要现在接听吗? // 机器人端主动打断流程
用户: 好, 我先接电话 // 用户的回复与上一个任务无关
通常对话的语境切换都是由用户单方面主导. 而双工通信导致了机器人方也能主导语境切换. 两者就必须解决冲突的可能性.
由于机器人一方很可能是从第三方服务接受到信号才主动变更语境的; 因此实现 半双工 还不行, 很可能用户和第三方服务在同一个瞬间发来消息, 导致第三方服务的信息被丢弃.
更重要的是, 用户在对话过程中自己脑海里也会维护一个对话状态; 对话机器人的状态在双工场景中收到其它因素改变, 也必须保证和用户的理解同步, 否则就会进入鸡同鸭讲的死循环中.
CommuneChatbot 为此设计了一整套方案 (目前版本尚未实装). 简单而言, 正常的上下文切换中, Thread 有一个 sleeping栈. sleeping栈 是用户方可以主导的.
而双工场景中, 额外增加 yielding栈 和 blocking 栈. 只能由机器方主导.
- 当一个 Thread 主动让出会话的控制权, 等待异步返回的结果时, 就进入 yielding 栈.
- 当一个 yielding 状态的 Thread 得到异步回调唤醒后, 或者第三方服务唤起了一个新的 Thread, 它们可以进入 sleeping栈, 或者选择进入 blocking栈.
- 进入 blocking栈 的对话, 可以通过双工通道主动向用户推送消息. 但只有在用户下一次回复到达的时候, blocking栈 中的语境才会抢占 控制权, 把当前的会话压入 sleeping栈 等待唤醒.
这种策略对于用户方而言, 自己的话可能因为 抢占 被机器人拒答而引入另一个语境. 而对于第三方服务, 是允许随时回调的.
这套技术方案是否可行, 还需要现实的双工通道和有异步的业务场景共同来验证.
对话平台设计
多轮对话的本质是多轮交互 : 交互就是人与机器之间用各种形式传递信息. 从交互的角度来看, 浏览器, app, 桌面软件, 和多轮对话机器人并没有本质的区别.
用编程语言对多轮对话建模 : 用工程化的方式实现 N阶多轮对话机器人, 本质上就是用编程语言对多轮交互建模.
按这样的思路, 可以对比其它多轮交互应用的 features, 定义出对话交互所需要的 features. 而实现思路也是类似的.
- 一阶多轮对话 : 类似于 function, 是对过程的封装
- 语境的跳转与回归 : 类似于 function 调用另一个 function, 有时依赖 return, 有时不依赖
- 逃离语境与拦截 : 本质上是一个 try … catch … 机制
- 有作用域的上下文记忆 : 相当于编程语言有作用域的局部变量.
- 挂起,异步与抢占 : 可参考协程模式, 非常相似
- 多任务调度 : 参考多线程与 IO
基于上面对N阶对话的分析,设计一套对话开发训练平台,从而实现对半开放域的N阶嵌套型对话一栈是管理开发。整个平台分成前端标注展示部分,和后端 NLU 训练、DM对话管理部分。
(1)前端对话标注平台主要分为:
- NLU 标注 —— 样例语句 意图标注 槽位标注 对话动作标注
- NLG 标注 —- bot回复模板 bot端动作定义 bot动作 包含的对话动作标注
- Task内对话逻辑可视化构建,使用可拖拽式的方式构建对话任务的业务逻辑图。
- 对话标注平台 — 负责对已有对话预料进行标注,方便后端自动生成建议的对话逻辑图,方便使用者对话逻辑抽取。
- 知识库编辑 —- 为bot 提供QA、知识图谱信息的编辑,输入。 QA 和 知识图谱会根据领域封装成独立的Task, 与含有对话逻辑的Task,一起参与对话语境管理。
(2)后端对话标注平台主要分为:
- NLU 交互模块,负责内容:NLU标注内容发送给 NLU 平台进行训练;对话过程中意图信息的识别
- DM部分分为 TaskManger , TaskAgent 两级部分:
- TaskManager:负责多语境切换管理,包含语境的栈切换,全局对话状态追踪;
- TaskAgent:负责独立语境内对话状态追踪以及对话策略管理,内部包含一个独立的状态机用于对语境内Domain间业务跳转逻辑进行建模
- UserSimulator 部分:
- UserTaskAgent:负责对独立语境的用户行为进行模拟, 内部实现是 FSM + Agenda , FSM 用于业务逻辑的模拟, Agenda用于domain内部用户动作模拟
- UserAgentManger:用于模拟用户在多个独立语境间切换,并管理 Agent 之间 约束信息的共享。
DM方法演变
- 【2021-4-1】得助智能丁南的系列文章
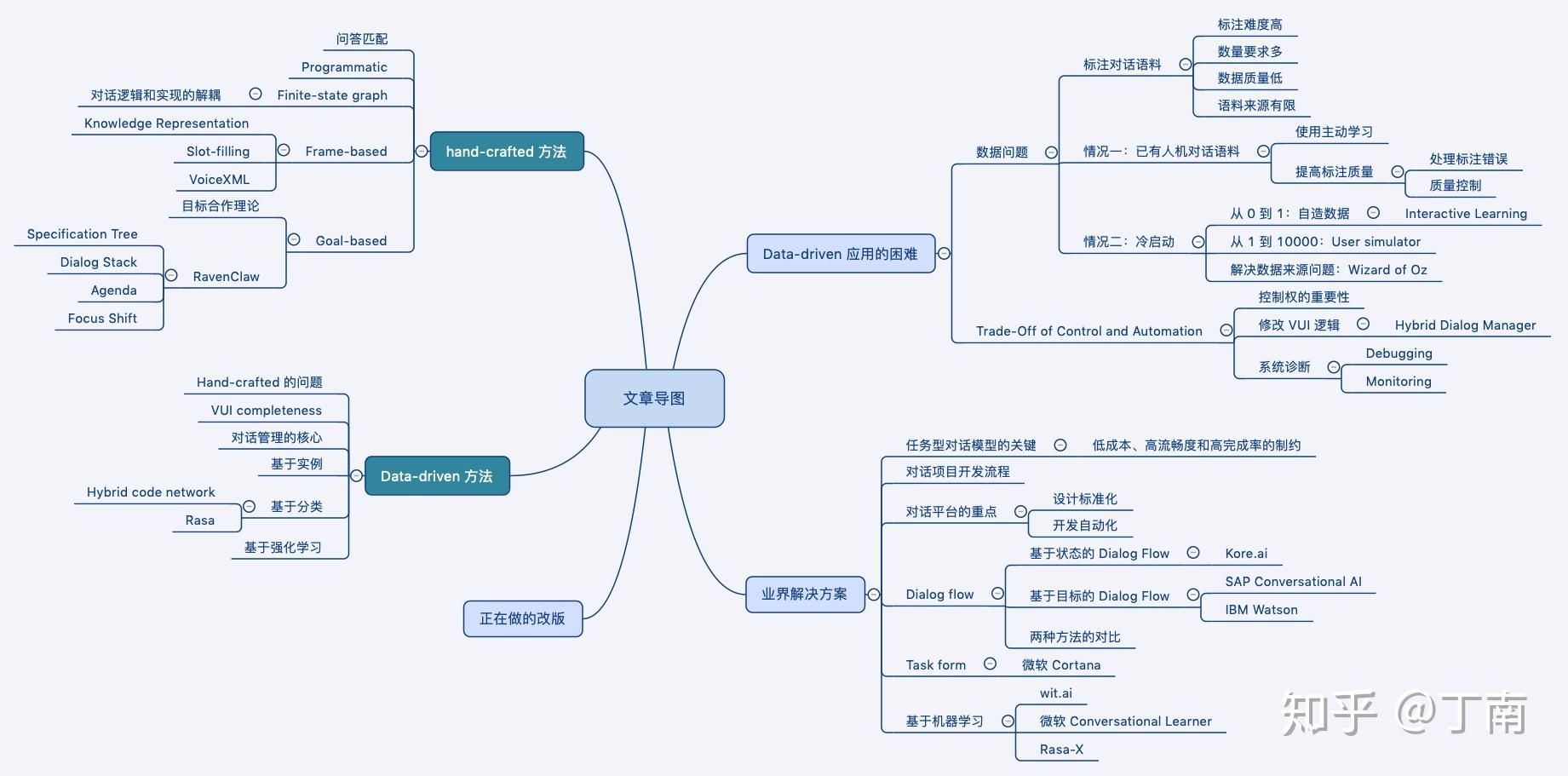
总结
对话管理是对话系统的”中枢神经“,dialogue manager,简称DM
发展至今,DM方法经历了几个阶段
- 问答匹配方法(
点)- 即常见的简单问答模式,单点映射
- 简单易用,但功能受限
- Programmatic方法(规则,
序列)- 将对话控制逻辑(线性→树状→图状)直接用代码写死
- 可控但很不灵活,每次业务逻辑变更都要升级代码
- Finite-state graph方法(
FSM有限状态机,图)- 规则升级版,成功实现了
对话设计与控制执行的 解耦 - 设计与控制解耦,相对灵活
- 但仍然不完美:见下文
- 规则升级版,成功实现了
- 基于Frame的方法(槽填充,
树)- 典型代表:VoiceXML
- 提升泛化能力,不再限制对话路径
- 基于目标的方法(
树+栈+字典)- 跨场景,模仿人类对话,用树实现场景内控制,栈做历史场景记忆,字典存储全局信息
- Data-driven方法(完备性)
- 纯数据驱动,希望用模型从海量数据中学习对话逻辑
- 理想很美好,现实很骨感
方法
对话管理的一些方法,主要有三大类:
- (1)Structure-based Approaches
- Key phrase reactive:本质上就是关键词匹配,通过捕捉用户最后一句话的关键词/关键短语来进行回应,比较知名的两个应用是
ELIZA和AIML。AIML (人工智能标记语言),XML 格式,支持 ELIZA 的规则,并且更加灵活,能支持一定的上下文实现简单的多轮对话(利用 that),支持变量,支持按 topic 组织规则等。 - Tree and FSM:把对话建模为通过树或者有限状态机(图结构)的路径。 相比于 simple reactive approach,这种方法融合了更多的上下文,能用一组有限的信息交换模板来完成对话的建模。这种方法适用于:
- ①系统主导
- ②需要从用户收集特定信息
- ③用户对每个问题的回答在有限集合中
- FSM-based DM 的特点是:
- 人为定义对话流程
- 完全由系统主导,系统问,用户答
- 答非所问的情况直接忽略
- 建模简单,能清晰明了的把交互匹配到模型
- 难以扩展,很容易变得复杂
- 适用于简单任务,对简单信息获取很友好,难以处理复杂的问题
- 缺少灵活性,表达能力有限,输入受限,对话结构/流转路径受限
- 对特定领域要设计 task-specific FSM,简单的任务 FSM 可以比较轻松的搞定,但稍复杂的问题就困难了,毕竟要考虑对话中的各种可能组合,编写和维护都要细节导向,非常耗时。一旦要扩展 FSM,哪怕只是去 handle 一个新的 observation,都要考虑很多问题。实际中,通常会加入其它机制(如变量等)来扩展 FSM 的表达能力。
- …
- Key phrase reactive:本质上就是关键词匹配,通过捕捉用户最后一句话的关键词/关键短语来进行回应,比较知名的两个应用是
- (2)Principle-based Approaches
- Frame:Frame-based approach 通过允许多条路径更灵活的获得信息的方法扩展了基于 FSM 的方法,它将对话建模成一个填槽的过程,槽就是多轮对话过程中将初步用户意图转化为明确用户指令所需要补全的信息。一个槽与任务处理中所需要获取的一种信息相对应。槽直接没有顺序,缺什么槽就向用户询问对应的信息。
- Frame-based DM 包含的一些要素:
- Frame: 是槽位的集合,定义了需要由用户提供什么信息
- 对话状态:记录了哪些槽位已经被填充
- 行为选择:下一步该做什么,填充什么槽位,还是进行何种操作;行为选择可以按槽位填充/槽位加权填充,或者是利用本体选择
- 基于框架/模板的系统本质上是一个生成系统,不同类型的输入激发不同的生成规则,每个生成能够灵活的填入相应的模板。常常用于用户可能采取的行为相对有限、只希望用户在这些行为中进行少许转换的场合。
- 特点
- 用户回答可以包含任何一个片段/全部的槽信息
- 系统来决定下一个行为
- 支持混合主导型系统
- 相对灵活的输入,支持多种输入/多种顺序
- 适用于相对复杂的信息获取
- 难以应对更复杂的情境
- 缺少层次
- Frame-based DM 包含的一些要素:
- Agenda + Frame(CMU Communicator)
- Agenda + Frame(CMU Communicator) 对 frame model 进行了改进,有了层次结构,能应对更复杂的信息获取,支持话题切换、回退、退出。主要要素:
- product:树的结构,能够反映为完成这个任务需要的所有信息的顺序,跟FSM相比,产品树(product tree)的创新在于它是动态的,可以在 session 中对树进行一系列操作比如加一个子树或者挪动子树
- process(含agenda和handler)
- agenda:相当于任务的计划(plan),类似栈的结构(generalization of stack),话题的有序列表(ordered list of topics),handler 的有序列表(list of handlers),handler 有优先级
- handler:产品树上的每个节点对应一个 handler,一个 handler 封装了一个 information item
- 从 product tree 从左到右、深度优先遍历生成 agenda 的顺序。当用户输入时,系统按照 agenda 中的顺序调用每个 handler,每个 handler 尝试解释并回应用户输入。handler 捕获到信息就把信息标记为 consumed,这保证了一个 information item 只能被一个 handler 消费。
- input pass 完成后,如果用户输入不会直接导致特定的 handler 生成问题,那么系统将会进入 output pass,每个 handler 都有机会产生自己的 prompt(例如,departure date handler 可以要求用户出发日期)。
- 可以从 handler 返回代码中确定下一步,选择继续 current pass,还是退出 input pass 切换到 output pass,还是退出 current pass 并等待来自用户输入等。handler 也可以通过返回码声明自己为当前焦点(focus),这样这个 handler 就被提升到 agenda 的顶端。为了保留特定主题的上下文,这里使用 sub-tree promotion 的方法,handler 首先被提升到兄弟节点中最左边的节点,父节点同样以此方式提升
- 论文:AN AGENDA-BASED DIALOG MANAGEMENT ARCHITECTURE FOR SPOKEN LANGUAGE SYSTEMS
- Agenda + Frame(CMU Communicator) 对 frame model 进行了改进,有了层次结构,能应对更复杂的信息获取,支持话题切换、回退、退出。主要要素:
- Information-State
- 背景:①很难去评估各种 DM 系统②理论和实践模型存在很大的 gap,理论型模型有:logic-based, BDI, plan-based, attention/intention,实践中模型大多数是 finite-state 或者 frame-based,即使从理论模型出发,也有很多种实现方法
- Information State Models 作为对话建模的形式化理论,为工程化实现提供了理论指导,也为改进当前对话系统提供了大的方向。Information-state theory 的关键是识别对话中流转信息的 relevant aspects,以及这些成分是怎么被更新的,更新过程又是怎么被控制的。idea 其实比较简单,不过执行很复杂罢了。
- Plan
- 指大名鼎鼎的 BDI (Belief, Desire, Intention) 模型。起源于三篇经典论文
- 基本假设是,一个试图发现信息的行为人,能够利用标准的 plan 找到让听话人告诉说话人该信息的 plan。这就是 Cohen and Perrault 1979 提到的 AI Plan model,Perrault and Allen 1980 和 Allen and Perrault 1980 将 BDI 应用于理解,特别是间接言语语效的理解,本质上是对 Searle 1975 的 speech acts 给出了可计算的形式体系。
- …
- Frame:Frame-based approach 通过允许多条路径更灵活的获得信息的方法扩展了基于 FSM 的方法,它将对话建模成一个填槽的过程,槽就是多轮对话过程中将初步用户意图转化为明确用户指令所需要补全的信息。一个槽与任务处理中所需要获取的一种信息相对应。槽直接没有顺序,缺什么槽就向用户询问对应的信息。
- (3)Statistical Approaches
- 这一类其实和上面两类有交叉…不过重点想提的是:Reinforcement Learning 详情见原文:多轮对话之对话管理(Dialog Management)
1. 问答匹配方法(点)
最简单的DM是被动响应的问答匹配,根据系统内部维护的命令-响应 table,对输入 text 做模式匹配或语义识别,输出匹配命中的响应。
- 优点:简单,可控
- 缺点:只能处理简单命令式任务,类似 unix 命令行工具、或 Mac 上效率神器 Alfred,它没有异常处理机制、无法利用上下文、无法与人进行多轮交互。
2. Programmatic方法(规则,序列)
为了支持多轮的对话交互,早期的商业对话应用(如IVR系统)直接将对话逻辑用 C++ 或 Java 在系统中实现,即 programmatic dialog management 实现起来速度很快,但有一个很大的问题,复用性很差,对话模型和领域逻辑严重耦合,修改对话逻辑必须要修改对话管理的代码,甚至是从头开发,对话变更的成本很高,项目迭代速度很慢。
为了提高系统的复用性,商业公司开发出了很多可以重用的 dialog modules,这些模块封装了对话项目常用的通用组件,例如超时、取消会话、澄清等,甚至是一些常用的对话流程,力争做到只修改部分 dialog modules 就可以通过拼接组件的方式完成对话项目的开发 。
但这种方法对系统的侵入性仍然很大,只有自然语言处理专家和系统专家才能使用和维护。对话系统的使用和推广成本都很高。于是将逻辑设计从系统实现中提出来的需求就非常强烈,这是任务型机器人发展的一个重大改变,即对话逻辑和对话模型的解耦(decoupling dialog specification and dialog engine)。
3. Finite-state graph方法(FSM有限状态机,图)
FSM 总结
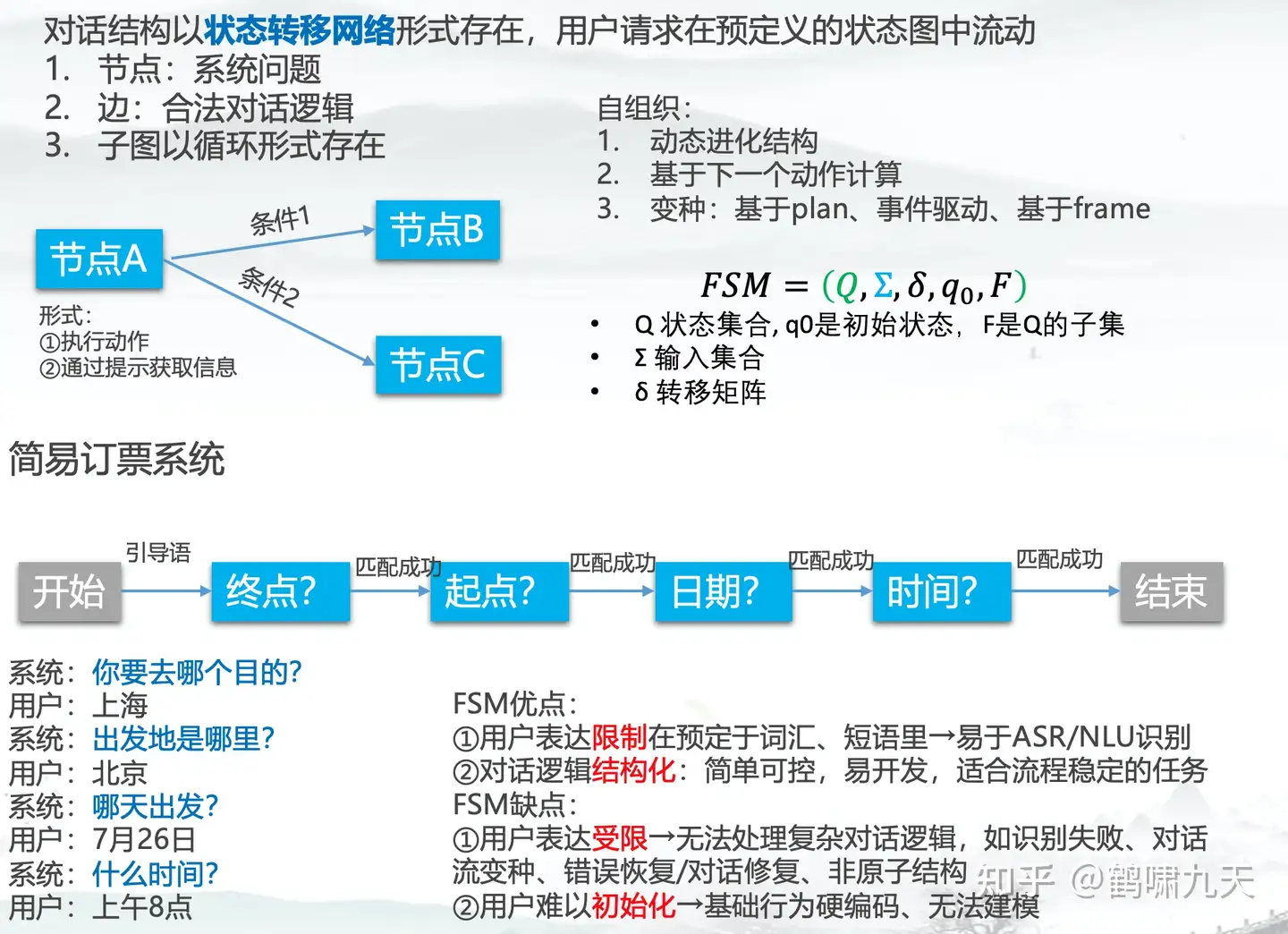
【2023-3-23】AI应用:对话系统之有限状态机(FSM)优缺点
(1)FSM优点
- ① 用户表达限制在预定于词汇、短语里 → 易于ASR/NLU识别
- ② 对话逻辑结构化:简单可控,易开发,适合流程稳定的任务
(2)FSM缺点
- ① 用户表达受限 → 无法处理复杂对话逻辑,如识别失败、对话流变种、错误恢复/对话修复、非原子结构
- ② 用户难以初始化 → 基础行为硬编码、无法建模
(3)FSM适合场景
- 扁平结构、选项少的简单任务
- 订票、天气预报、订餐、银行交易等
(4)不适合
- 路径不确定的子任务
- 需要灵活处理用户请求:纠错、越界
- 对话过程相对确定
- 复杂依赖
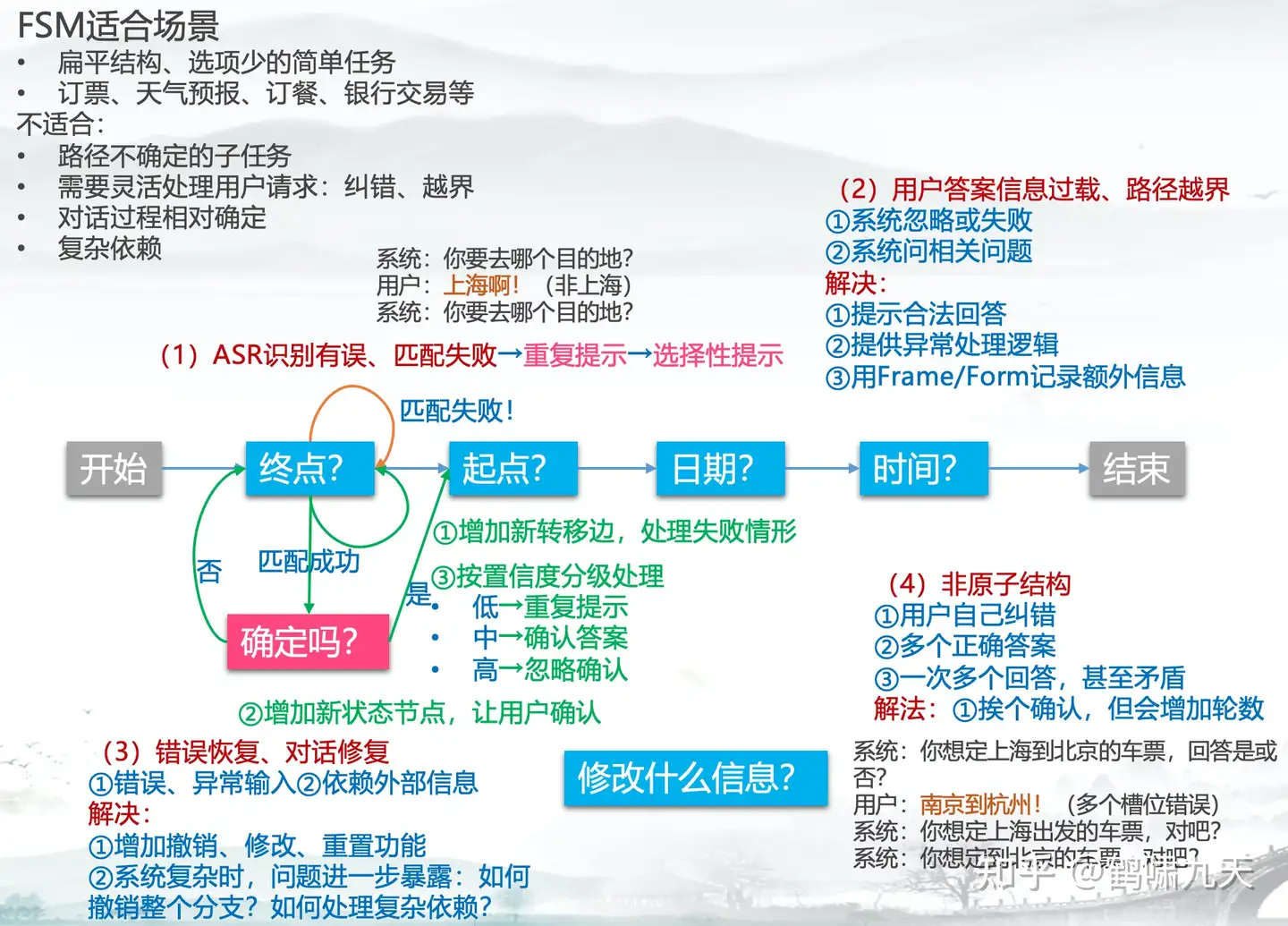
图解
FSM 详解
为了降低开发成本,满足交互设计解耦的需求,基于状态转移的对话系统被开发出来。一些系统将对话设计和对话管理的工作分离,领域逻辑由对话交互设计师完成(称为 VUI designer),对话管理模块在运行时解析对话逻辑。
多轮会话用流程拓扑图来表示,状态节点代表一次对话事件(可以是等待用户输入并给予回复,也可以是一次任意响应),流程图的边代表状态转移条件。设计者用对话流创作工具(一般称为 Authoring Tool)定义好交互逻辑后,创作工具将对话定义转换成一种数据结构或脚本,用来表示整个状态图。对话 run time 阶段,对话管理载入预定义好的流程数据/脚本,根据实际场景,执行流程图的响应或跳转。
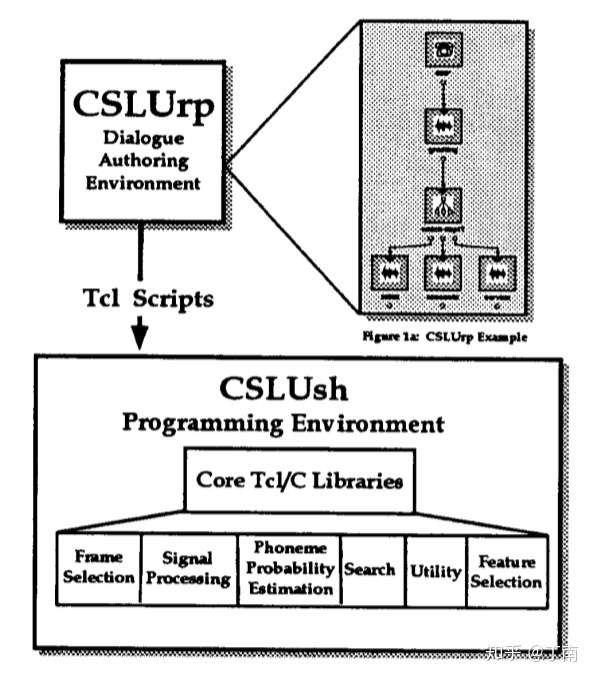
这类对话系统在 90 年代的非常流行,如图俄勒冈州研究所推出的 CSLU toolkit ,类似的方法是后来很多其他对话模型的基础,至今仍有很多公司采用。对话逻辑设计与对话管理系统分离的模式,也一直沿用至今。
 另外 finite-state方法还引入一个额外的好处,一定程度上解决了对话设计 debug 的困难。 对话设计者可以依靠 authoring tool 查看流程图中每个节点的状态,也可以对拓扑图进行覆盖率检查 。这种 debug 模式在现在的商业系统中也比较常见,如百度的 Kitt.ai 就有类似的对话调试器。
另外 finite-state方法还引入一个额外的好处,一定程度上解决了对话设计 debug 的困难。 对话设计者可以依靠 authoring tool 查看流程图中每个节点的状态,也可以对拓扑图进行覆盖率检查 。这种 debug 模式在现在的商业系统中也比较常见,如百度的 Kitt.ai 就有类似的对话调试器。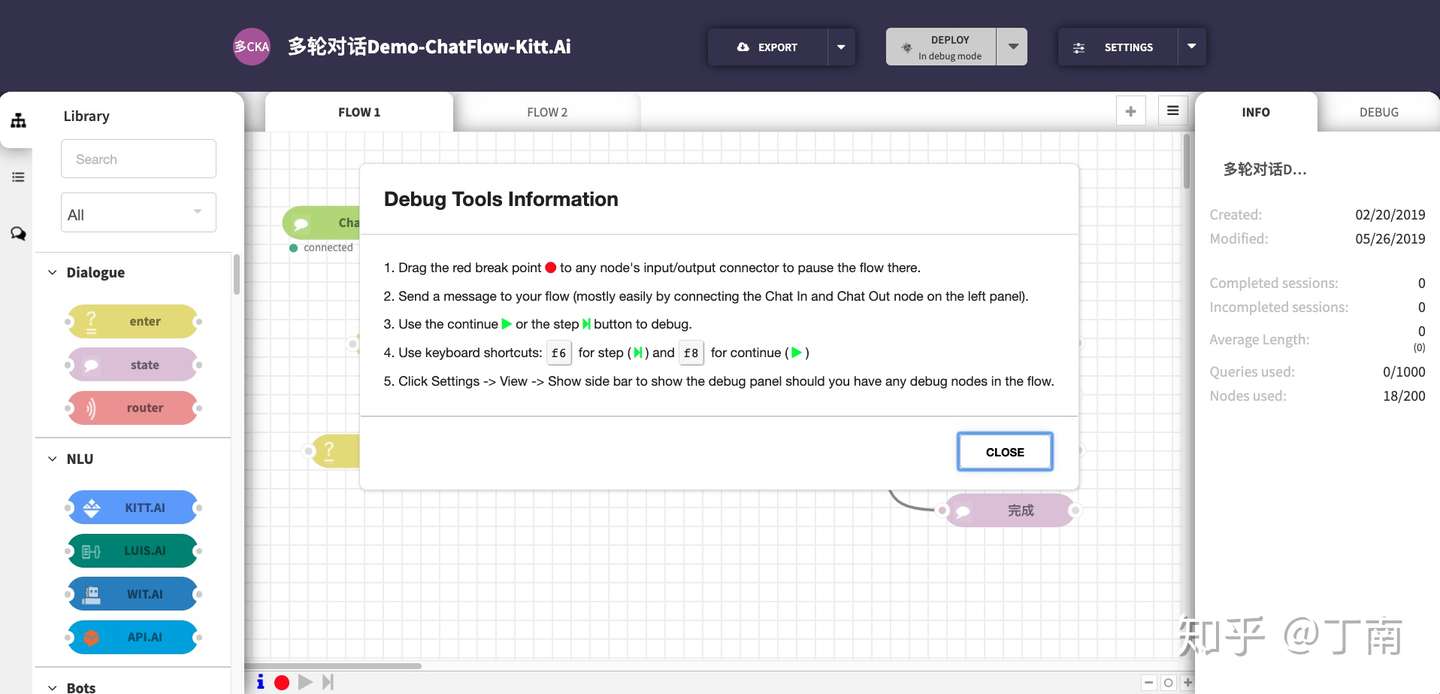 但 finite-state 方法非常不灵活,如果对话任务中有多个待提供的信息时尤为如此。用户可能一并把其他信息也说了,或者用户对已询问的信息做了修改,或者用户并没有按要求回答,也就是说用户可能并没有完全按系统预设的路径走,即用户主导了对话的进行(user initiative)。如果 finite-state 方法需要支持 user initiative,那就需要考虑用户反馈所有可能性,状态跳转的可能路径会非常多,对话流会变得非常复杂,最后变得无法维护 。
但 finite-state 方法非常不灵活,如果对话任务中有多个待提供的信息时尤为如此。用户可能一并把其他信息也说了,或者用户对已询问的信息做了修改,或者用户并没有按要求回答,也就是说用户可能并没有完全按系统预设的路径走,即用户主导了对话的进行(user initiative)。如果 finite-state 方法需要支持 user initiative,那就需要考虑用户反馈所有可能性,状态跳转的可能路径会非常多,对话流会变得非常复杂,最后变得无法维护 。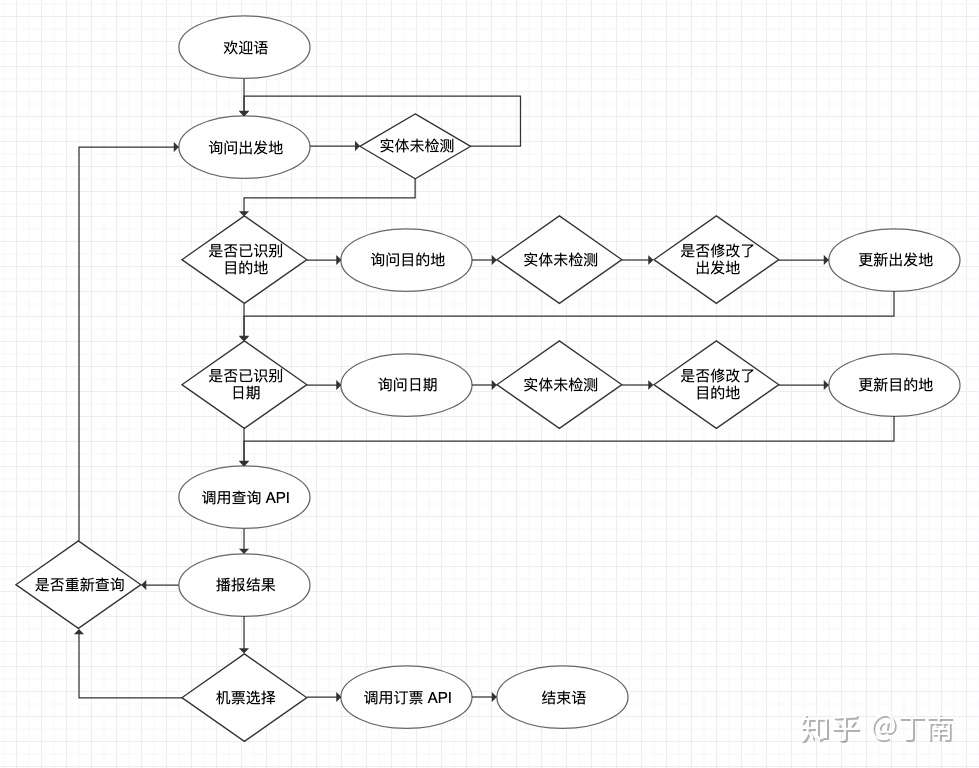
上图是finite-state实现的订机票场景,虽然考虑了部分 user initiative 交互,但仍然存在诸多问题,让用户觉得很不智能
- 第一它并未考虑对话中很多实际情况,系统超时怎么办;
- 第二实现信息的更新很麻烦,需要在图上把信息更新的交互也画出来;
- 第三信息收集的过程用图形式实现很繁琐,对话开发效率很低。
4. 基于Frame的方法(槽填充,树)
一种既能提高灵活性,又能保持低成本的方法是基于Frame方法。
Frame概念在人工智能中的应用可以追溯到马文·明斯基(Marvin Minsky)提出的知识表示框架。Minsky 期望用一种数据结构来表示一类情景/场景(a stereotyped situation),这个数据结构被 Minsky 称为 frame。 这种数据结构用于将知识结构化的数据结构,这种结构能方便解释、处理和预测信息
受到 Minsky 的启发,Daniel 尝试用一种知识表征语言(knowledge representation language)来构建语言理解系统 ,用陈述性的知识表示来描述人类语言。这套知识表示框架后来被 Daniel 等人迁移到了人机对话系统,每一个 frame 代表会话中的一部分信息,Daniel 假设这样就可以用一系列的 frames 来描述并引导人机对话的整个过程。
现在frame-based方法一般被称为槽填充方法,它用一个信息表维护对话任务中没有顺序依赖的信息,信息表包含完成对话任务所必需(或可选)的槽位,该方法的目标是引导用户回答对话信息表当中的槽位,一旦信息表填满后,对话任务所预设的响应将被执行。用户可以以任意次序提供槽位信息,顺序的多样性并不增加对话管理的复杂度。
还拿订机票举例,信息表中的槽位包含必填槽位:出发地、目的地和日期,以及可选槽位:时间(当然对于有的机票任务,时间可能是必填项)。Frame-based 方法将对话开发者从路径跳转设计中解放出来,一个简单的信息表就能代替信息收集的流程图。任务信息表被对话管理的槽填充模块解析,根据解析的数据类型,填写不同的槽位,并且支持对槽位的修改更新。
槽填充的实现方法有很多,常见的方法是用树结构表示一个frame,根节点为frame的名字,叶子节点表示槽位,槽填充通过不断遍历叶节点,执行未填充叶节点的响应(例如一段机器回复),直到一棵树被填充完整为止。
Frame-based方法提出后被应用到很多商用对话系统中,如工业界对话系统的 语音标记语言 VoiceXML。frame之间通过特定跳转逻辑连接,或用一个流程图来连接,一个多任务的对话项目就能快速开发出来。VoiceXML 的对话逻辑用 XML 来定义,frame(在 VoiceXML 中被称为 orm)是 XML 文档的核心组成部分,其 FIA(Form Interpretation Algorithm)算法通过不断遍历 frame 中所有槽位,找到未填充槽位后,将其对应的回复(prompt)输出给 TTS,TTS 生成一段语音给用户,一种 FIA 实现如图。
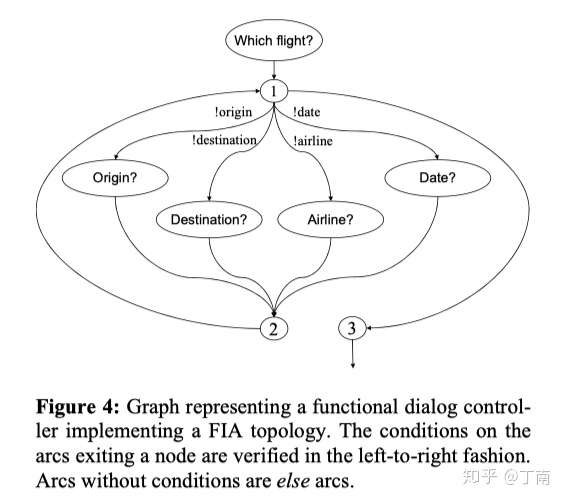 对话交互中的任务被一个个frame表单表示,frame 之间通过特定跳转逻辑连接,或用一个流程图来连接,一个多任务的对话项目就能快速开发出来。现在大多通用 chatbot / 智能对话平台仍然会采用槽填充方法,例如图,IBM Watson 的对话配置界面。现在大多通用chatbot/智能对话平台仍然会采用槽填充方法,如IBM Watson 的对话配置界面
对话交互中的任务被一个个frame表单表示,frame 之间通过特定跳转逻辑连接,或用一个流程图来连接,一个多任务的对话项目就能快速开发出来。现在大多通用 chatbot / 智能对话平台仍然会采用槽填充方法,例如图,IBM Watson 的对话配置界面。现在大多通用chatbot/智能对话平台仍然会采用槽填充方法,如IBM Watson 的对话配置界面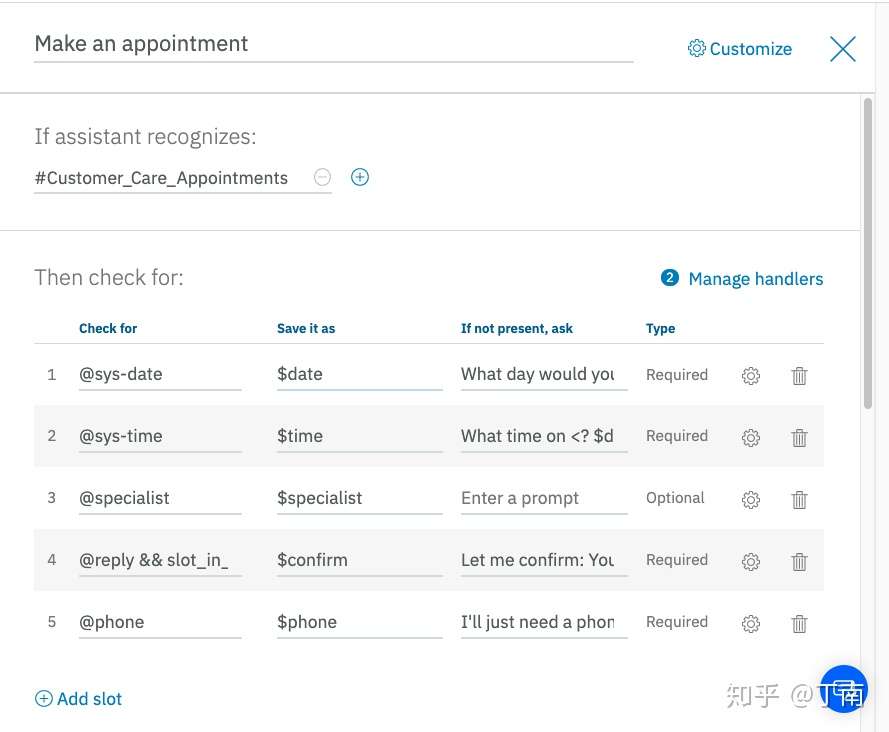
VoiceXML
资料
VoiceXML就是语音网络世界的HTML,一种用于语音应用的开放标准的标记语言。VoiceXML的问世使得为HTML发展起来的web体系也能够轻松地创建和使用语音应用。
什么是VoiceXML
VoiceXML是建立于XML语言规范基础之上,应用于语音浏览的标记语言。如果说HTML是一种用于描述视觉元素,让用户通过键盘鼠标和网络应用交互的标记语言;那么VoiceXML就是一种用于描述听觉元素,让用户通过电话和网络应用交互的标记语言。
它的出现是为了简化AT&T一个名为PML(Phone Markup Language)项目中语音识别程序的开发过程。经过AT&T的重新组织,AT&T,Lucent and Motorola的开发团队继续致力于开发他们的类PML语言。
就像HTML默认需要一个图形化的web浏览器,输入输出装置(通常是键盘,鼠标),VoiceXML也默认需要一个带音频输入输出,以及键盘输入的语音浏览器。语音浏览器中的语音识别部分负责处理语音输入。语音输出可以是录音,也可以是语音浏览器的TTS(Text-To-Speech)合成语音输出。
语音浏览器通常是运行在同时和互联网(Internet)以及公共交换电话网(PSTN)相连的专用语音通道节点上。这种语音通道可以支持数千通话同时进行,可以被当今世界超过15亿电话访问。

VoiceXML是用来创建音频对话的,主要包括语音合成、数字化音频、语音识别、DTMF按键输入识别、录音、通话、混合主动式会话。它的主要作用是把基于网络的开发和信息这两者的优势引入语音应答系统。
发展历史
- 1995年AT&T研究院的Dave Ladd, Chris Ramming, Ken Rehor以及Curt Tuckey在头脑风暴关于互联网会如何改变电话应用的时候,产生了一些新的想法:为什么不设计这样一个系统来运行一种可以解析某种语音标记语言的语音浏览器,用来把互联网的内容和服务提供到千家万户的电话上。于是,AT&T就开始“电话网络项目”(Phone Web Project)。之后,Chris继续留在AT&T,Ken去了朗讯,Dave和Curt去了摩托罗拉。1999年初的时候,他们分别在各自的公司迈出了语音标记语言规范实质性的第一步。因为他们的密友关系,这几家公司合作成立了一个VoiceXML论坛组织,IBM也作为一个创始公司加入了进来。
- 1999年3月至8月,这个论坛的一个小组发布了VoiceXML 0.9版本。
- 2000年3月,VoiceXML 1.0问世。
- 一个月后,VoiceXML论坛把1.0规范提交给了权威的World Wide Web组织(W3C)。
- 2000年5月,W3C接手了这个VoiceXML 1.0规范。
- 2001年10月,VoiceXML 2.0试验版问世。
- 2002年4月,最后一个版本的2.0试验版发布。
- 2003年1月,VoiceXML 2.0正式版发布。
什么是VoiceXML Browser
就像HTML由网页浏览器来将文本标记解释成各种视觉元素一样,VoiceXML也由VoiceXML Browser来处理其中的各种标记,一个VoiceXML Browser至少需要支持以下功能:音频文件的播放、录音、TTS(Text To Speech)、ASR(Automated Speech Recognition)、DTMF检测。通常,支持VoiceXML的媒体服务器(Media Server)、IVR Platform,其核心都是一个VoiceXML Browser,或者说它们就是一个VoiceXML Browser。
VoiceXML能干什么
VoiceXML不是万能的,它不能代替HTML,WebService等其它Web应用,而是它们在语音方面的补充。让我们看一个非常简单的例子,用户拨打一个电话,接通后根据语音提示输入股票代码,听取相应的股票价格。在这个例子中,VoiceXML都做了什么?
- 1、播放语音提示;
- 2、检测用户电话键盘输入;
- 3、通过发送携带着输入的股票代码的HTTP请求来调用查询股票的Web应用;
- 4、利用TTS技术将返回的股票价格转换为语音,播报给用户。
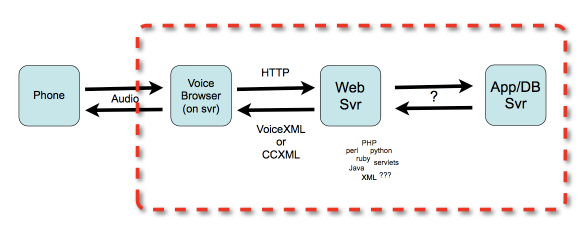
VoiceXML语言
VoiceXML 2.0 是一个用于创建自动语音识别 (ASR) 和互动式语音应答 (IVR) 应用的可扩展标记语言 (XML)。VoiceXML继承了XML的标签风格。一个VoiceXML应用通常由多个文件(document)构成,这些文件均为.vxml后缀,由标记xml以及vxml版本开始。
在vxml标签下,document由多个离散的对话元素组成,称为表单(form)。每个form有各自的名称,且负责执行对话的一个部分。form标签底下含有一系列的用来执行应用的各种任务的元素,大体上可分为两类:field item和control item。
- Field item负责一些识别任务,包括从通话者吸收信息,给变量赋值,也可能包含有一些指令用来告诉通话者应该说些什么,一些语法规则来定义如何解析通话者说的话等等。
- 包含
, , ,
- 包含
- Control item则负责一些非识别的任务。包含
,
看一个VoiceXML文件的小例子:
<?xml version="1.0"?>
<!-- 或 <vxml version="2.0"> -->
<vxml application="tutorial.vxml" version="2.0">
<form id="someName">
<block>
<prompt> Created by tutee
</block>
</form>
</vxml>
- 第一章介绍它的背景、基本概念和用途;
- 第二章介绍form的对话框结构(dialog constructs)、menu、link和它们的解释机制FIA(Form Interpretation Algorithm);
- 第三章介绍用户的DTMF(Dual Tone Multi-Frequency)和语音输入用到的语法;
- 第四章介绍系统输出用到的语音合成和预先录制的音频;
- 第五章介绍对话框(Dialog)流程的控制,包括变量、事件和可执行元素;
- 第六章介绍各种环境特性,例如参数(Parameter)、属性(Property)和资源处理;
附录提供了包括VoiceXML计划、FIA(Form Interpretation Algorithm)、音频文件格式等附加信息。
示例:要求用户选择一种饮料,然后把它提交给服务器端的一个脚本
- field是一个输入域,用户必须给field提供一个值,否则就不可能进行到form中的下一个元素。
<?xml version="1.0" encoding="UTF-8"?>
<vxml xmlns="http://www.w3.org/2001/vxml"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/vxml
http://www.w3.org/TR/voicexml20/vxml.xsd"
version="2.0">
<form>
<field name="drink">
<prompt>Would you like coffee, tea, milk, or nothing?</prompt>
<grammar src="drink.grxml" type="application/srgs+xml"/>
<block>
<submit next="http://www.drink.example.com/drink2.asp"/>
</block>
</field>
</form>
</vxml>
实现效果
C (computer): Would you like coffee, tea, milk, or nothing?
H (human): Orange juice.
C: I did not understand what you said. (a platform-specific default message.)
C: Would you like coffee, tea, milk, or nothing?
H: Tea
C: (continues in document drink2.asp)
5. 基于目标的方法(树+栈+字典)
从上面的三种方法的发展趋势来看,提高对话逻辑的灵活性一直是推动人机对话系统前进的一个重要动力。
- 早期对话描述直接嵌入代码,修改和维护非常不便。
- 后来研究者将其抽象成流程拓扑图,虽然降低了对话开发的耦合度,但由于人类对话的复杂和多样性,流程图难以低成本地覆盖足够多的状态跳转。
- 为了再一次提高对话描述的抽象层次,研究者引入 frame 数据结构来表示固定的对话任务,将特定任务的对话逻辑隐藏在 frame 框架中。
基于frame的方法主要解决了一些固定逻辑的任务,但对话管理不仅处理一个个小的对话任务,还需要考虑对话任务的顺序、任务的层级结构、任务之间的场景切换,以及能动态添加新任务的机制。
在 90 年代研究者提出了一种新的人机对话模式:基于目标的方法,这种方法将人类的沟通模式迁移到了人机对话当中。Charles Rich等人认为人机交互的核心在于交互双方通过不断调整各自的行为,合作完成一个共同目标,并假设当机器遵守人类交流的规则和习惯时,使用者将更容易学习使用这个交互系统 。
对于任务型对话,虽然可以假设user在使用对话系统前就已经有清晰的目标,但对话过程肯定不是一帆风顺,对话多样性太复杂,例如用户并不会按照一个固定的流程进行对话、用户可能想修改之前的一些选择、系统也可能因为误识别而出现信息不对称,对话目标也可能涉及到多个对话任务、对话任务之间的关系可能是多样的,这些都需要交互双方根据实际情况,动态调整交互行为,而这些都无法靠一个静态的流程图和一个个预配置好的frames来实现。
为了在人机对话中实现目标合作理论,Grosz等人将任务型对话结构分成三个部分:
- 表示语言序列的结构(linguistic structure)
- 表示对话意图的结构(intentional structure)
- 表示当前对话焦点的状态(attentional state)
Grosz假设任务型的对话结构可以按意图/目标(purpose)划分成多个相互关联的子段落(segment),每个 segment 表示一个目标,segment 中可以嵌套更小的 segment 表示更小一级的子目标。这样对话就可以看成多层级结构。一个对话对应一个主要目标,其下划分成的多个段落,对应多个子目标。在对话进行的过程中,每一时刻交互双方都会将注意力集中到一个目标。根据实际情况,下一时刻双方可能还在沟通这个目标,也可能聚焦到另外一个目标,对话焦点在对话期间会动态地变化,直到完成对话中所有的子目标,对话沟通就完成了。
简单理解
- linguistic structure 就表示对话的段落(segment)结构
- intentional structure 即表示对话的意图结构
- attentional state 指的就是每一个时刻的对话焦点。
根据基于目标的对话理论框架,研究者们开始考虑如何将其应用到人机对话系统,典型的代表有 Collagen 和 RavenClaw 。要实现基于目标的对话理论,首先需要考虑用什么样的方式来表示这样的对话结构。一般的做法是,用树(tree)表示整个对话的组织结构,用栈(stack)维护对话进行中每一时刻的对话焦点,用字典(dict)存储对话栈中每个对话目标所依赖的信息。
由于一个对话任务的总目标总是可以拆分成多个小目标,所以对话目标可以看成一个层次结构,这就很适合用树形结构表示。
- 示例:简化版的信用卡还款业务如图,目标是信用卡还款,对话被分成了多个小目标(暂且称二级目标),分别是:用户初始化、获取账号信息、询问还款信息、还款操作,以及结束语。为了完成对话的二级目标,继续将目标拆分成三级目标,这样整个对话的多层次树结构就出来了。在 RavenClaw 中,树结构中的节点分成两类
- 一类是叶节点 - 响应节点(灰色部分),代表无法再进行拆分的对话响应,例如调取一个 API、回复用户一段话等等。
- 另一类是非叶节点 - 控制节点(白色节点),它的职责是控制子节点在对话运行时的状态,封装抽象程度更高的对话目标。
- 对话的树形结构包含了整个对话的任务说明(dialog specification),但在对话运行时如何解析这个 specification,就需要另一个数据结构:对话栈(dialog stack)。
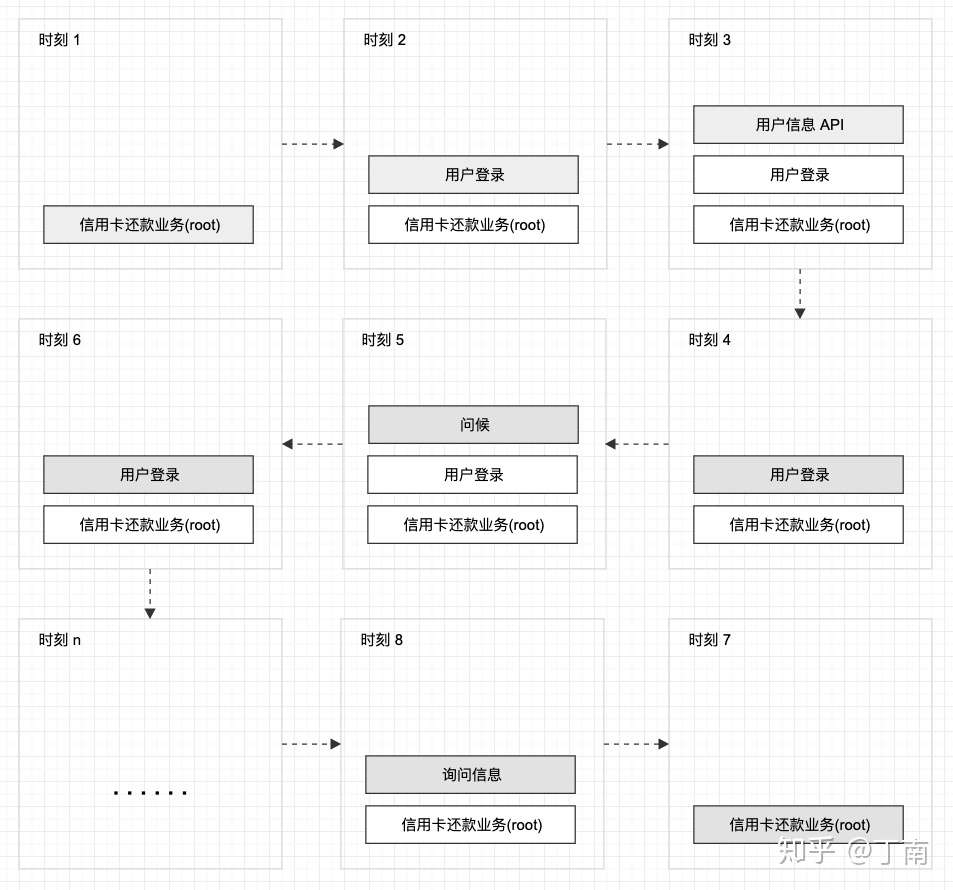
- 为了实现 Grosz 提出的对话焦点的理论,系统从左向右依次遍历整个对话树,每一时刻将一个节点送入 stack,这个节点在该时刻就成了对话焦点(dialog focus)。每一时刻系统将执行栈顶focus节点的响应,当节点的状态为「已完成」时,系统将该节点出栈,下一个节点成为栈顶focus节点,以此系统可将对话树中所有节点的操作执行完。
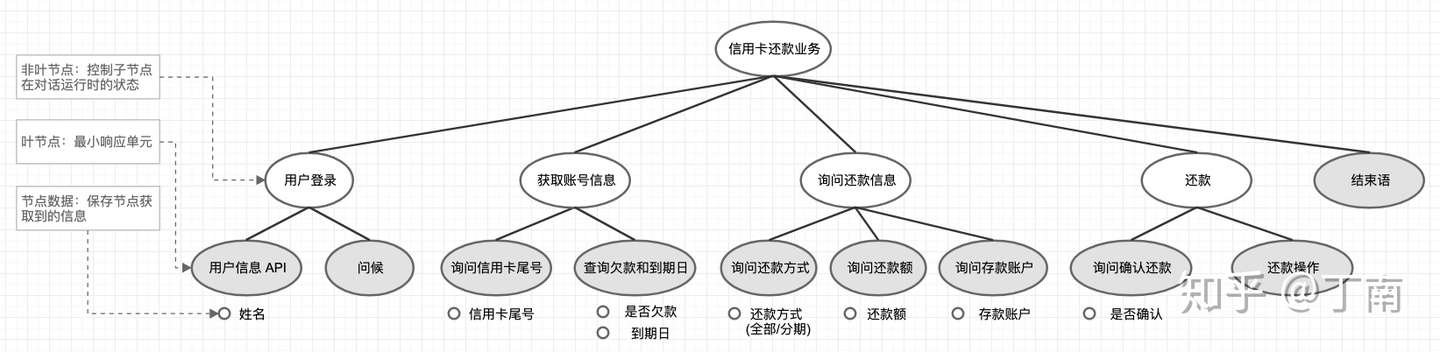
- 信用卡还贷的运行过程:时刻 1 信用卡还款 root 节点入栈,系统执行根节点的操作,注意控制节点(非叶节点)的 action 就是将其子节点从左至右依次送入 stack,所以时刻 2「用户登录」节点入栈。同样的逻辑,时刻 3「用户信息 API」节点入栈,由于该节点为叶节点,响应操作是调用 API,执行完该操作后,「用户信息 API」节点状态被标记为「已完成」,该节点被系统出栈。时刻 4,执行「用户登录」节点,将其未完成的子节点「问候」入栈,系统回复一个问候语后,该节点被标记完成并出栈。下一时刻,由于「用户登录」所有子节点都已完成,则该节点也被标记完成并出栈。就这样,系统依次遍历对话树所有节点,直到所有节点都标记为「已完成」,该任务对话运行结束。
- 除了有对话任务的树结构描述,每个节点的下面可能还有其数据描述,有的系统用基于 frame 方法中的术语,将节点的数据描述称为节点槽位。节点槽位代表节点所依赖的数据,数据的来源可能是 api 接口返回的结果、也可能是一段代码的执行结果,更常见的来源是用户的回复。所有的节点数据都被维护在系统的上下文中(在 RavenClaw 中被称为 concept),上下文的生命周期一般为一个对话任务的整个运行时。
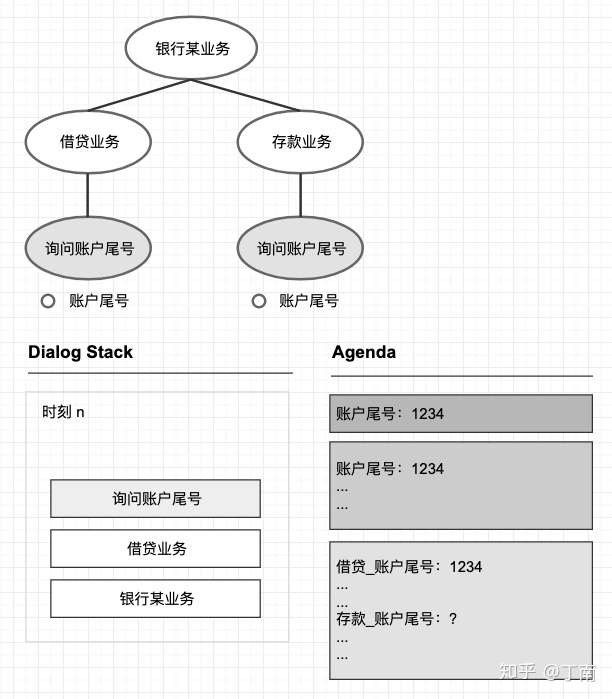
- 上下文数据有了,但需要一个算法能让系统利用上下文信息,基于目标的方法使用一个叫 agenda 的数据结构维护 dialog stack 栈中的节点数据,每个节点有自身的 agenda 信息表维护其所依赖的数据,父节点的 agenda 包含所有其子节点的数据,这样就形成了 agenda 层级结构。
- 下图表示某一时刻对话状态,「询问还款方式」叶节点对应的 agenda 只包含该节点的数据依赖,而其父节点「询问还款信息」不仅维护了还款方式信息,还包含它所有子节点的数据。同样根节点包含了树上所有节点的数据状态,这个就是 agenda 的层级结构。
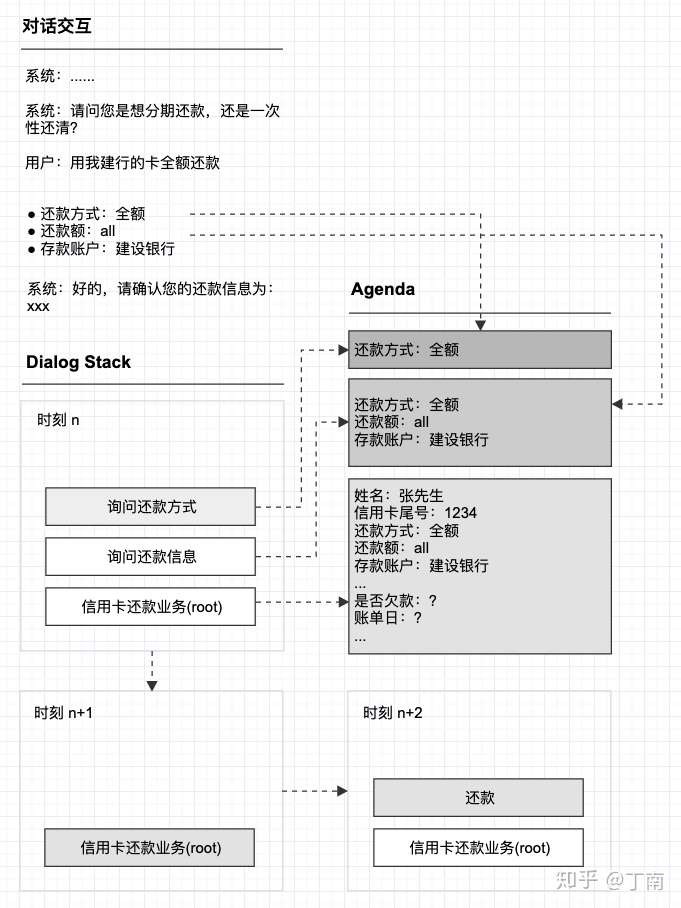
- 对话运行时,系统识别或计算出槽位 value 后(信息处理可能是模式匹配、实体识别、意图识别等多种技术),系统根据 stack 中的节点顺序,自顶向下的遍历 agenda 对应的槽位,依次更新每个 agenda 信息表。
Agenda 算法给对话管理带来了很多特性
- 支持 mixed-initiative 对话交互。类似 frame 槽填充,一个目标节点下的所有槽位填充不依赖于固定对话路径,降低了对话任务设计成本。
- 提高了交互的自然度。Agenda 维护了用户已经提前答复的槽位,每次一个节点入栈之前都会根据其 agenda 中的数据,判断节点的目标是否已完成,若已完成则该节点将被标记并跳过入栈操作。并且系统也会检测 stack 中哪些节点已提前完成,将已完成的节点从 stack 中剔除。例如上图图 9 中由于还款方式和存款账户的槽位已被提前填充,这两个节点就不会入栈,并且「询问还款信息」的目标也提前完成,下一时刻 stack 中只剩下根节点。这样提前跳过已完成的对话节点,用户就不用重复回答已答复的内容,提高了交互的自然度。
- 有利于语义消歧。利用 agenda 的层级结构和 dialog stack,系统能清楚定位到当前的对话焦点,避免了不知道更新哪一个节点槽位的问题。例如下图 10 是银行某业务的部分对话描述,有两个子任务都包含「账户尾号」的槽位填充,需要用到同一类型的实体。利用 stack 结构的对话焦点,系统很清楚当前识别到的实体应该更新哪一个槽位,避免了语义的歧义。
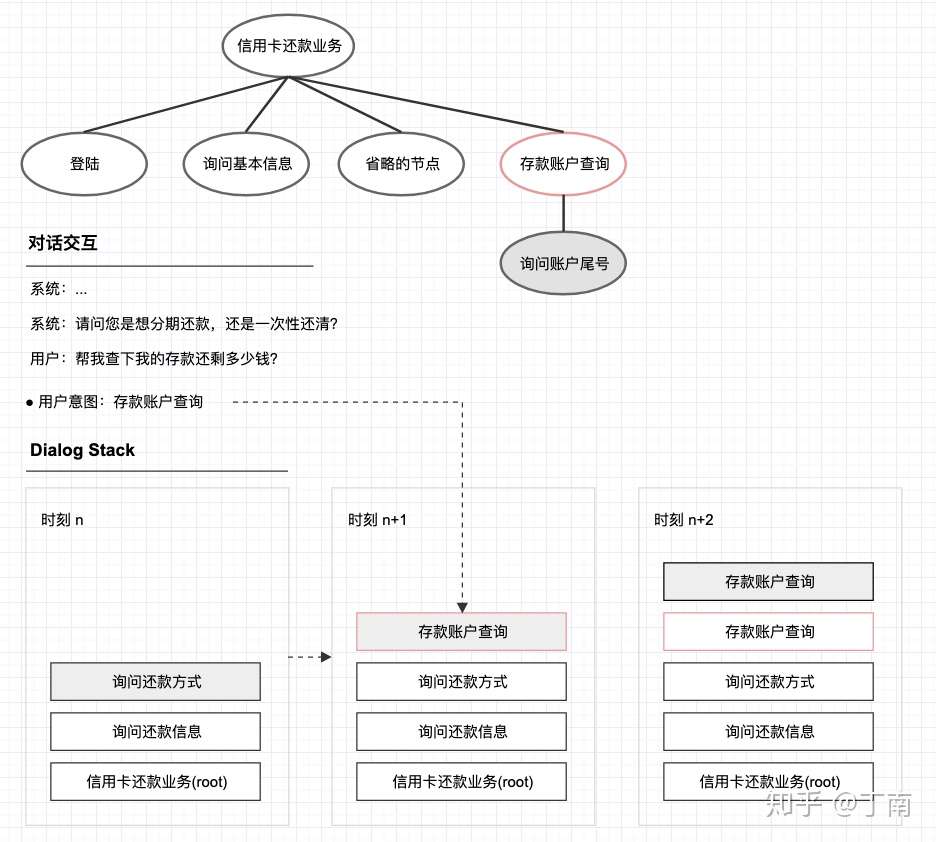
- 基于目标的对话管理还为系统引入了一个非常强大的功能:焦点切换 focus-shift(有的系统可能称为任务切换或场景切换)。基于流程图的方法如果想支持任务切换,需要把切换的流程在拓扑图中表示出来,否则系统无法确定跳转路径。用这种方式任务描述的成本太高,切换的场景太多,很难提高场景覆盖率。 基于目标的对话管理将复杂的任务切换逻辑交给底层引擎,降低了任务描述的复杂度。而基于目标的方法,可以为树结构中的节点设定触发条件(trigger rules),当用户回复或系统事件触发某一个节点,该节点入栈 dialog stack,至此对话从新的节点进行下去,对话交互就完成了任务切换。例如下图 11 是信用卡还款的简化结构,其中多了一个节点「存款账户查询」(因为实际还款中,用户很可能需要知道存款账户是否够还款)。在时刻 n 系统询问还款方式,用户并没有按正常路径回答,而是先问了存款账户的余额,这时触发了「存款账户查询」节点的触发条件,新的节点 push stack,以后系统将先完成「存款账户查询」,再切换回原路径。可以看出这种方法的实现非常简单,将复杂的任务切换逻辑交给底层引擎,降低了任务描述的复杂度。
 由于引入了 focus-shift 算法,一些公共处理策略和可重用的流程就可以从领域相关的对话任务中提取出来,对话管理变成了两层架构,上面一层是领域相关的对话任务描述,由领域专家设计;下面一层是处理领域无关的对话引擎。通用的对话策略和流程做成可插拔式的组件,这样大大降低了不同领域对话设计的成本,提高了对话管理的可扩展性。
由于引入了 focus-shift 算法,一些公共处理策略和可重用的流程就可以从领域相关的对话任务中提取出来,对话管理变成了两层架构,上面一层是领域相关的对话任务描述,由领域专家设计;下面一层是处理领域无关的对话引擎。通用的对话策略和流程做成可插拔式的组件,这样大大降低了不同领域对话设计的成本,提高了对话管理的可扩展性。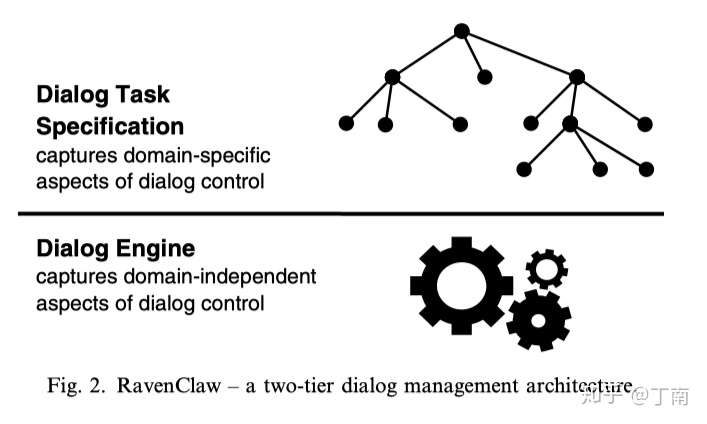
最常见的公共处理策略要属对话中的异常处理了。由于语音识别、意图识别、实体识别等技术肯定达不到 100% 准确,错误被引入对话管理是很常见的,这时就需要一些策略来消除这些不确定性,例如常用的话术澄清策略。这些处理策略在不同领域中大多是相似的,所以最好将其从领域对话描述中解耦出来,提前在系统中预设多个公共对话任务,在对话运行时监测哪些公共任务被触发。如果某公共节点被触发,则将其入栈,实现公共策略的焦点切换。例如下图 13,银行某业务的对话结构(左侧)原本只有两个处理节点,但在借贷业务进行时触发了异常处理,树结构和 dialog stack 中都被动态插入了错误处理节点,系统先处理异常后再返回领域对话。可见这种方法的对话树结构并不是静态的,而是可以根据实际情况动态改变对话逻辑,扩展性和通用性都要优于之前的方法。
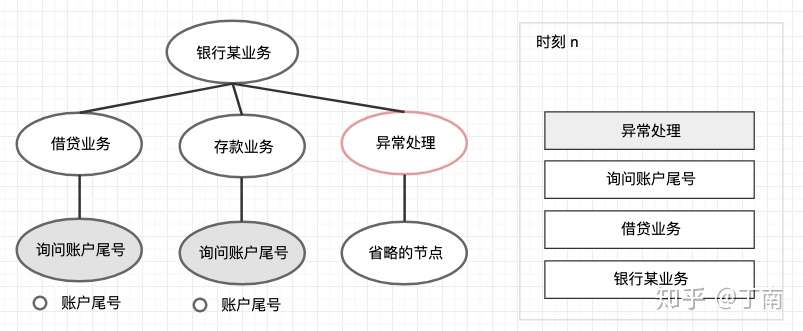
错误处理节点动态插入对话任务
将上面的描述总结起来,RavenClaw 对话管理运行时主要分成两个阶段,系统执行阶段和用户输入阶段。如下图 14 所示,初始时系统先将根节点入栈,然后进入系统执行阶段。首先执行栈顶的节点响应,若是非叶节点(控制节点)则将其一个子节点入栈,若是叶节点则执行其具体的操作。其次判断当前节点是否需要用户回复,若需要则等待用户反馈后,创建节点的 agenda 信息表,并依次进行槽位识别和更新。输入阶段完成后回到执行阶段,系统遍历对话栈,清除中已完成的节点。然后进行公共策略的预处理流程,判断哪些公共节点被触发了,系统将所有被触发的节点依次入栈。最后回到系统执行阶段的第一步,以此循环,直到完成对话任务。
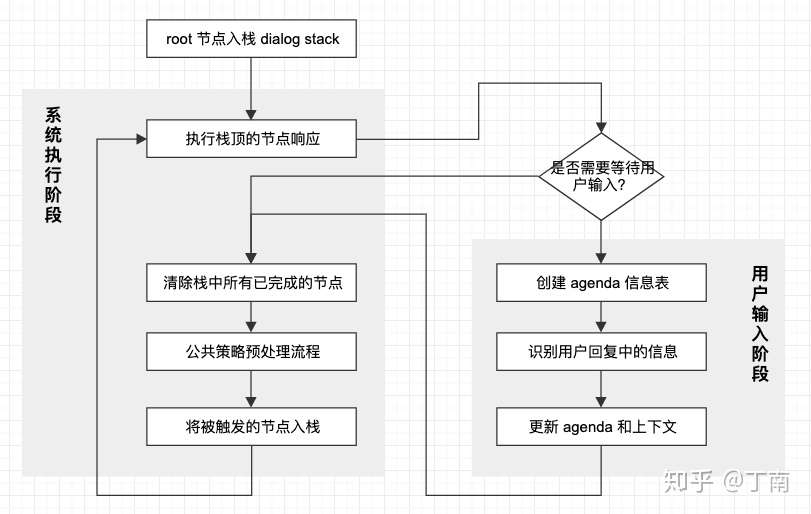 类似 RavenClaw 这种基于目标的对话管理方法虽然很强大,但也有其局限性。上文有提到,可动态变化的任务树结构提高了对话描述的灵活性和可扩展性,不再需要将所有的转移路径显式的画出来,也不需要重复设计常用的公共流程。但这个优势在一些场景也是问题的来源。首先,对话设计者们往往习惯画流程图,因为流程图结构与人机交互运行时的对话结构是相似的,不存在理解门槛。而任务树结构将很多转移路径、对话交互的逻辑隐藏在了其目标结构和运行时的策略中(在论文中称之为 constraint-based task representation),对话设计者需要将对话流映射成任务树结构,这个过程是比较有挑战的。在我们实际工作中也会发现,让非专家理解这套对话模型是比较困难的。另外,在对话项目开发期间,通常需要做对话场景的 debugging。跟踪流程图的跳转路径是最常见的对话调试,而 RavenClaw 并没有采用静态对话流,对话路径并不是完全由系统设计者控制的,对话用例出现错误的原因可能并不容易发现,这样会导致很高的调试成本。这个问题在有的时候可能是致命的,后面我们会讲到,对话管理的「可控性」在实际工程中非常重要,如果一个实现在项目后期才发现不能完全支持某个对话场景,而又不能通过 debugging 快速定位,或需要大规模修改任务树结构才能覆盖测试用例,这将会是对话开发的噩梦。
类似 RavenClaw 这种基于目标的对话管理方法虽然很强大,但也有其局限性。上文有提到,可动态变化的任务树结构提高了对话描述的灵活性和可扩展性,不再需要将所有的转移路径显式的画出来,也不需要重复设计常用的公共流程。但这个优势在一些场景也是问题的来源。首先,对话设计者们往往习惯画流程图,因为流程图结构与人机交互运行时的对话结构是相似的,不存在理解门槛。而任务树结构将很多转移路径、对话交互的逻辑隐藏在了其目标结构和运行时的策略中(在论文中称之为 constraint-based task representation),对话设计者需要将对话流映射成任务树结构,这个过程是比较有挑战的。在我们实际工作中也会发现,让非专家理解这套对话模型是比较困难的。另外,在对话项目开发期间,通常需要做对话场景的 debugging。跟踪流程图的跳转路径是最常见的对话调试,而 RavenClaw 并没有采用静态对话流,对话路径并不是完全由系统设计者控制的,对话用例出现错误的原因可能并不容易发现,这样会导致很高的调试成本。这个问题在有的时候可能是致命的,后面我们会讲到,对话管理的「可控性」在实际工程中非常重要,如果一个实现在项目后期才发现不能完全支持某个对话场景,而又不能通过 debugging 快速定位,或需要大规模修改任务树结构才能覆盖测试用例,这将会是对话开发的噩梦。
6. Data-driven方法(完备性)
以上对话管理方法都基于规则,它能表述的对话场景是被领域专家设计出来的,所能涵盖的对话路径受限于专家设计出的逻辑。
(1)但人类的语言可以算是一种离散组合系统(discrete combinatorial system),有非常庞大的多样性和复杂性,想用一套规则来描述往往并不现实。
- 规则并不仅仅是一个个显式的逻辑条件,凡是领域专家手工(manually)设计和描述的逻辑和结构都可称为规则。例如上文提到的方法,规则可以是代码逻辑(基于 programmatic),规则可以是手工设计的转移矩阵(基于对话流),规则可以内嵌在 form 表中(基于 frame),规则也可以隐含在对话树结构和对话框架中(基于目标方法)。 对话场景的完备性,或称为对话交互的完备性(VUI completeness),是评价一个任务型机器人重要的指标。它指的是系统需要支持用户所有可能的业务对话场景,不存在无法处理的业务对话行为。
- 由于对话组合的复杂性,如果要保证 VUI completeness,基于规则的对话管理会遇到 scalability 的问题,复杂的任务会让 VUI 变得特别复杂,开发者很难进行维护。
(2)除了场景空间很难靠规则覆盖以外,高昂的对话开发成本、多样的用户行为、以及输入信号的不确定性,都是驱动研究者探索规则以外的方法。研究者从不同角度提出很多基于统计的对话模型,我们这里简要讨论三种方法,基于实例(examples-based)方法、基于分类的方法、基于强化学习的方法。
所有的 DM 方法都是围绕着系统根据当前对话的状态选择最合适的操作这个核心展开的,并回答诸如以下问题:
- 如何定义系统的对话状态?
- 如何确定某时刻的对话状态?
- 如何更新下一时刻的对话状态?
- 如何定义「最合适操作」?
- 系统如何做出选择?
基于实例的方法
Lee提出的 Example-based 方法很直接 ,它收集大量的对话语料并提取每一时刻的对话状态,将这些对话状态都当做标准例子索引到数据库。对话运行时系统在数据库中找到与当前对话状态最相似的实例,该实例对应的响应即为当前的系统选择。
这种方法假设数据集中某一个时刻的对话状态能包含会话历史的所有信息,数据库中保存了海量的「历史经验」,只要运行时遇到类似的对话情况,该会话就可以参考数据库中的经验做出「最合适的操作」,所以这种方法也叫做基于情境的方法(situation-based)。
为了让对话状态尽可能涵盖一个时刻的真实状况,Lee 将多种数据源都放到了对话状态的数据结构中,并将之称为一个对话实例。对话实例包括用户的话语、dialog act、用户意图、用户实体、会话历史记录,其中会话历史用会话中所有槽位的 ont-hot 编码表示。
系统响应的决策依据是相似度匹配,相似度算法的选择并不唯一,Lee给出的相似度算法分为三部分:基于编辑距离的词相似度,匹配的word keys占比,以及会话历史的 one-hot 编码余弦距离(由于是 2010 年的 paper,其中并不包括基于深度学习的相似度算法)。

基于分类的方法
这种方法将「系统选择最佳响应」的问题看成一个序列文本的分类问题。
会话历史可用一个状态序列表示,每一时刻的状态 S 是当前时刻多种数据源的总和,例如用户意图、解析出的实体、话语文字本身、上一时刻的系统响应等等,DM 的目标是基于会话历史序列 ,求出条件概率最大的一个系统响应
。
在循环神经网络这类能对文本序列有效建模的模型成熟之前,基于分类的方法一个很大问题是对话状态序列太长,导致特征空间太大。Griol 尝试将历史会话序列的信息都压缩到一个叫 Dialog Register 的数据结构中。与 example-based 方法中的会话历史记录 one-hot 编码类似,dialog register 也是对会话中所有实体、属性等信息的编码,如图 18。Griol 认为,虽然明确的历史会话内容(例如具体的实体值或属性值)是数据库查询等业务 api 处理的关键因素,但并不是 DM 选择下一时刻操作的依据。Griol 假设只要知道对话任务中关键实体和概念是否存在,以及存在的置信度是多少,DM 就足以做出下一时刻的判断。于是系统响应分类的条件概率就简化成:
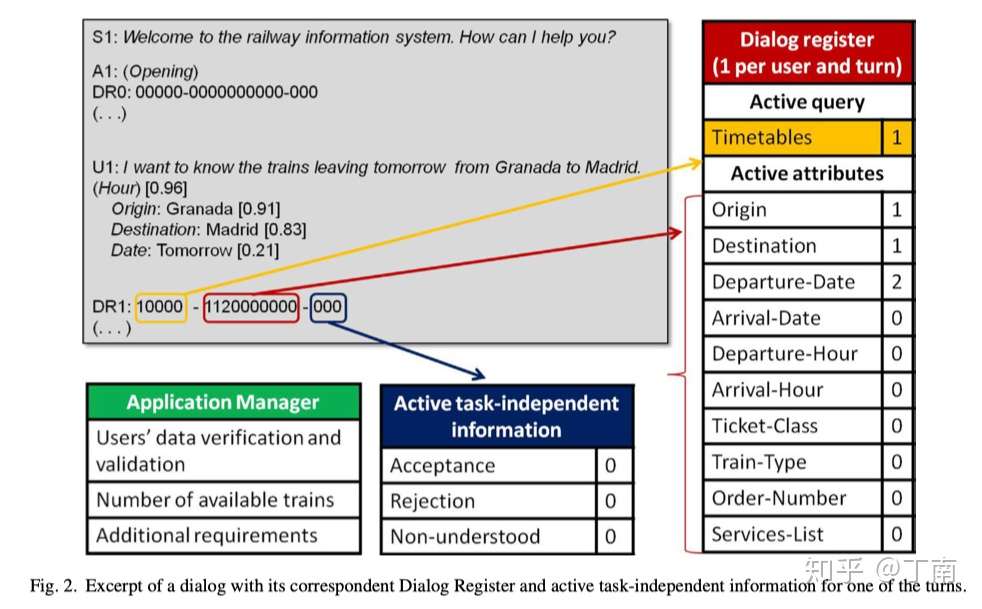
图 18 Dialog register 编码示例图
这几年大家一般用 LSTM 等循环神经网络直接对会话文本序列进行建模,来替换 dialog register 这种人工设计的数据结构。研究者不再对状态序列进行人为编码,而是用每一时刻的多种数据做为特征,隐式的计算出历史会话的表征,避免了一些不可靠的假设。例如图 19 Jason D. Williams 提出的 Hybrid code network用到了会话实体、响应掩码(action mask)、会话 embedding、会话词袋向量、上一时刻 api 结果、上一时刻系统响应来做当前时刻会话的特征,LSTM 模型根据当前特征和上一历史状态隐藏特征计算当前时刻的历史状态表征,然后经过一个全连接网络和 softmax 层,输出的就是系统响应的概率分布。
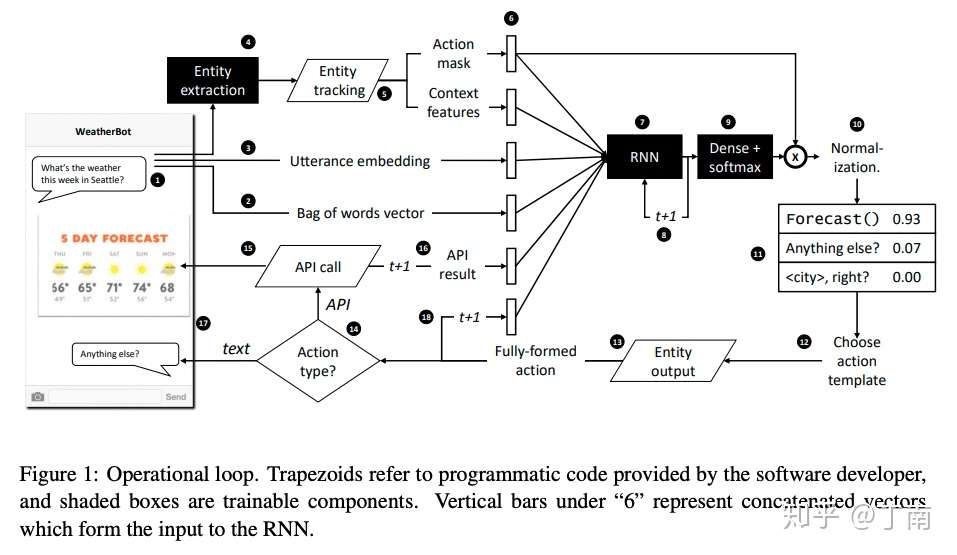
图 19 Hybrid code network 架构图
这两年非常火的开源对话系统框架Rasa 也是用类似的方法 [18]。Rasa 的对话任务用 markdown 语法来描述,这样就形成了可读性非常好的对话数据集。在 Rasa 中对话描述被称为 story,每一个 story 是一个会话序列,Rasa 通过解析 story 形成对话状态序列。每一时刻的对话状态由 3 种特征拼接,上一时刻系统 action、当前用户的意图及实体、和已填充的槽位。所有时刻的对话状态组成的二维向量作为分类模型的输入,把它送到任何一个序列模型(Rasa 默认也用的是 LSTM)来对下一时刻的响应做预测,就可得到响应的概率分布,整个流程如图 20。
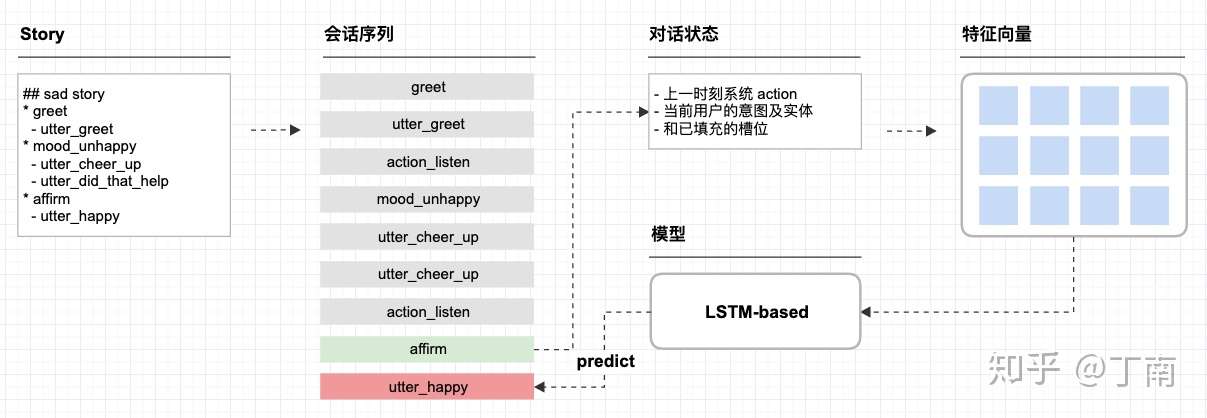
图 20 Rasa 的任务描述,解析过程以及预测流程
Rasa 中一个很好的特性是它支持一问多答的场景(Hybrid code network 也是支持的)。有些基于分类的方法是将用户话语和系统响应当成一组 [16],用户输入和系统响应必须成对出现。模型预测 next action 需要有用户话语做为输入,所以这种系统仅支持一来一回的交互场景,即对于一次用户输入,系统只能给出一次回复动作。但真实的交互场景往往需要系统能响应多个 action,如图 21。为了支持一问多答,Rasa 框架预设了一个响应类型「action_listen」,该响应表示停止预测并等待用户的输入。如上图 20 交互运行时,如果模型给出的预测结果不是 action_listen,模型将输出结果放到输入端,根据最新的序列,继续预测下一时刻响应,直到预测的结果是 action_listen 为止。

图 21 人机对话中一问多答的场景
基于强化学习
目前讨论的所有用人工设计(hand-crafted)和统计学习来做对话管理的方法,都是为了让系统学习合理的对话策略。但如何确定一个策略是一个好策略,这个标准在不同场景和领域下并不统一,甚至不同角色有各自的关注对象。例如对话开发者关注易用性,系统运营方关注对话质量和效率,终端用户关注任务完成率等等。
目前非常流行的一种策略学习是将人机交互看成马尔科夫决策过程(MDP/POMDP),通过强化学习来解决决策过程的优化问题。MDP 用一套离散状态的集合表示人机对话任意时刻的状态,智能体(对话系统)在某个状态下执行动作会有一定概率跳转到一个新的状态,状态的跳转只依赖当前的状态和当前的 action 选择(马尔科夫特性)。每次动作结束后 agent 会得到一个奖惩信号,对话策略的学习目标就是最大化平均累计奖励。
MDP假定对话状态都是可观测的,但在对话系统中并不现实,ASR 和 NLU 给出的都是概率性的结果。为了解决这个问题,MDP 的改进版本 - 部分可观测马尔科夫(POMDP)支持对不确定性的输入进行建模,对话状态不再是确定的离散状态,而是对话状态的概率分布(一般称为 belief states),这样对话管理就包含了两个模型,用于确定对话状态概率分布的 dialog model 和用于确定每一轮系统响应的 policy model,例如图 22。
最近十多年研究者一直在用各种方法解决 POMDP 模型的应用难题,包括减少状态空间、约束响应输出、设计更合理的奖惩函数等等。除了 POMDP 的特征设计,各种 policy 的优化算法也一直是研究热点。
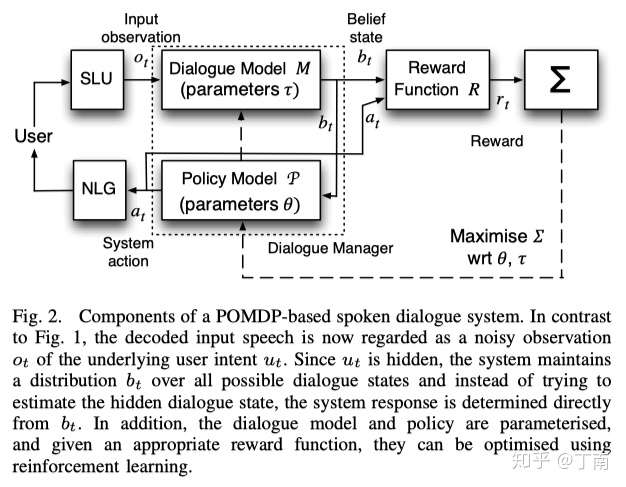
_图 22 POMDP 对话系统框架图 _[20]
这些 data-driven 方法非常有魅力,尤其是强化学习这一套体系,它的「trial-and-error」的思路甚至一度被认为是实现强人工智能的重要方法。但在项目实际应用当中,data-driven 的方法往往很难满足商业对话系统的一些要求,并在实现时会遇到很现实的困难。
对话管理所依赖的语料问题
- 首先,实现「基于数据」的方法前提肯定是需要大量标注数据的,开发者在准备标注语料时通常会面临:标注难度高,数量要求多,数据质量低,以及语料来源有限等问题。
- 跟一般的 NLP 任务的数据标注不同,对话管理所需的语料并不是一段段孤立的文本,而是整个对话序列。标注时需要考虑上下文以及整个对话的目标,以便确定系统的最佳选择,这样的标注工作难度很高。
- 另外,对话场景有多变性和多样性的特点,也就是说样本空间很大,统计学习对数据集规模有很高的要求。通常情况下需要远大于 10000 条的对话语料 [1],这是项目能有效实施一个很大的阻碍。
- 再者,企业并没有那么多专业的领域专家来做语料标注,非专业的数据标注质量也影响着机器学习方法的有效性。通常在开发对话项目的过程中,领域专家设计对话逻辑、完成对话描述、定义用户意图和 dialog act 等信息。项目的 deadline 一般不会允许他/她来做数据标注,这部分工作一般由专门的标注团队来辅助,甚至外包给第三方。但标注团队毕竟不是领域专家,对任务理解不当会导致出现很多标注错误。由于对话系统依赖的语料数量太大,要想快速扩充数据通常会实施多人标注,不同人对项目理解不一致会进一步加重数据质量的问题。
- 最后,开发者在做数据准备时还会遇到数据来源匮乏的问题。这恐怕是最严重的问题,因为真实世界的语料分布几乎决定了机器人上线后的泛化能力。而现实情况是,企业在项目冷启动时往往并没有人机对话数据,手头上可能只有任务描述书,好一点儿的可能会有同领域的人人语料(human-human dialogs),但这些都不足以覆盖整个人机对话真实场景。
情形一:已有人机对话语料
这种情形一般指的是企业已经用上了基于规则对话系统,想通过已有的人机日志来改善系统的鲁棒性和任务的覆盖率。由于已经有了海量的真实对话样本,数量要求和数据来源都已不是问题,重要的是标注难度和标注质量。
业界一般采用先随机选择后主动学习(active learning)的思路来降低标注成本。
大致做法是标注同学先随机抽取人机会话日志,根据每一通对话的上下文和任务目标,顺序检查会话中的所有系统响应。如果响应符合对话目标,该响应保留;如果响应不正确,手工将之修改为正确的系统响应,然后舍弃剩下的对话。这里舍弃的原因,并不是不想处理余下的用户问题,而是用户有可能被错误的系统响应「带偏」,做出了理想对话中不会出现的交互,对话的进展已经不是我们期望的那样,处理这些不正常对话的成本很高,使用价值低,所以一般的处理方式都是直接将其丢弃。跟其他的机器学习任务一样,在有了一批随机选择并标注的语料后,利用主动学习也可以降低 DM 的标注成本(这里主要指的是用监督学习做 DM 的方法)。随机选择标注一段时间后,就可以用这批种子语料来训练一个初始模型,根据该模型的预测结果可得到 DM 输出的「不确定性得分」(有的学者也将「样本代表性」考虑进去,但主动学习的选择策略不是本文的重点,不展开讨论)。最后求出所有会话的平均得分,根据得分进行排序,排序的结果就是对模型提升有价值的一种假设。标注人员优先选择不确定最高的会话进行标注,标注后再迭代模型和下一轮的数据排序。(也有学者是反对 active learning 的,因为这样会生成 biased data,降低标注数据的利用价值,具体讨论可见这个 博客)
解决了项目的数据标注问题,拿到了大批标注语料,本以为模型会立刻起飞、项目会顺利上线、团队会庆祝里程碑 ,但真实情况很可能是 DM 的响应预测并不靠谱,预测正确率和对话完成率都达不到上线要求,这时一种可能的原因是标注质量太差。标注质量问题在机器学习项目中普遍存在,尤其是标注工作外包给非专业的第三方。标注错误的原因大致可分成三类
- 主观理解错误(subjective error),例如不同人员对任务描述的理解可能会不同;
- 数据录入错误(data-entry error),例如将多人标注的结果汇总到一起时的操作错误;
- 关键信息缺失(shortage of information)导致不足以做标注判断。
提高标注质量一般从两个方面入手,处理已标注的错误,和质量控制(quality control)。
(1)比较常见的处理标注错误的方法是数据清洗(data cleansing)。如图 2,根据一种过滤条件,用一类过滤器将标注数据中「最可能出错」的样本剔除,用清洗后的语料训练模型。过滤器可以有很多选择,常见的是 ensemble filtering,根据 model variation 或 data variation 策略训练多个 base classifiers。过滤条件常用的是 majority filtering 或 consensus filtering,majority filtering 指的是如果一半以上的 base classifiers 预测结果都和标注不一致,则该样本为错误样本;Consensus filtering 指的是所有 classifiers 都与标注 label 不一致,才视为错误。可见 consensus 过滤条件更苛刻、更保守,不容易将错误的样本剔除出去;而 majority 过滤条件相对宽松,能更好地识别标注错误,但这是以丢弃正确数据为代价的。在实际项目中,往往不会将标注数据直接丢弃,毕竟是经过真金白银进行了标注工作(通过强渠道可自动打标的项目除外,例如微软的 DSSM 模型)。标注数据是如此宝贵(尤其是项目前期),以致于我们宁愿花人力去审核这些被过滤的样本。
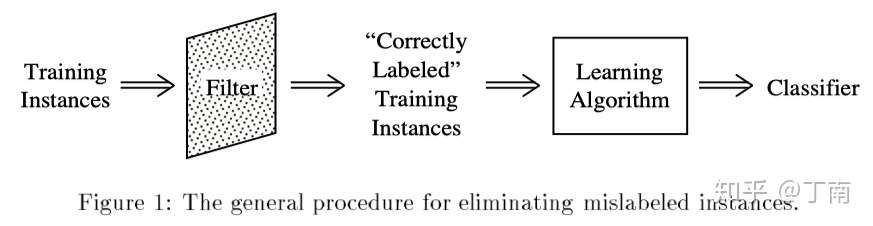
图 2 标注错误 filtering 处理流程 [3]
(2)另一方面,提高标注质量还可以从工具和流程层面入手。一般数据录入(data-entry)错误很多是标注同学的无心之举,毕竟标注任务繁重,不可能 100% 集中注意力,这就对标注工具的产品设计提出了很高的要求。标注工具应尽可能的自动化标注操作,让 annotators 尽可能地只做简单的决策。例如用标签选项代替人工输入,以便排除输入错误的可能性。或者推荐最佳预测标签,annotators 只需做判断题,降低决策成本。数据准备期通常占一个机器学习项目一半以上的时间,优秀的标注工具的重要性是不言而喻的,我们从优秀的产品中学到了很多经验,特别推荐大家使用 Dataturks、LightTag 和 tagtog。
标注质量控制的流程大多用在外包和众包的场景,当公司有独立的标注团队时(比如我们公司),也常用来规范跨团队合作的流程。质量控制一般采取前期任务设计(up-front task design),和事后结果分析(post-hoc result analysis)。在开始标注工作之前,负责人根据手上的任务描述设计标注任务,这时就需要考虑可以通过什么手段来降低标注出错的概率,提高工作的容错率。例如将一个复杂的标注任务拆分成多个简单的子任务,将子任务分派给能力或技能不同的人,最后将子任务的结果再自动化或人工进行合并汇总,这个流程类似分布式系统的 MapReduce,如图 3。它的假设是相比于复杂的任务,普通人更擅长处理简单的任务,如果将任务拆分,整个流程的效率和质量更易控制。而且将一个任务由多人完成,可以更好的利用集体智慧(collective intelligence)。一次标注任务结束后,需要对标注结果进行分析,分析的目的主要有几个,一是让负责人了解这次标注的有效情况,二是有利于标注团队的工作改进,三是方便将无效数据进行过滤或重新审核,四是规避作弊情况(主要针对众包场景)。标注的自动化分析较常用的是结果一致性指标(agreement),通过将一部分相同的语料分给多个 annotators,最后计算这部分标注的一致性结果。这个方法虽然很好操作,但不能 100% 规避作弊问题。类似 Amazon Mechanical Turk 众包平台更常用的是 Golden Answers ,即提前准备一小部分已正确标注的数据,将其作为标注任务的一部分分配给 annotators,这部分的正确率就可以评估标注团队的工作。
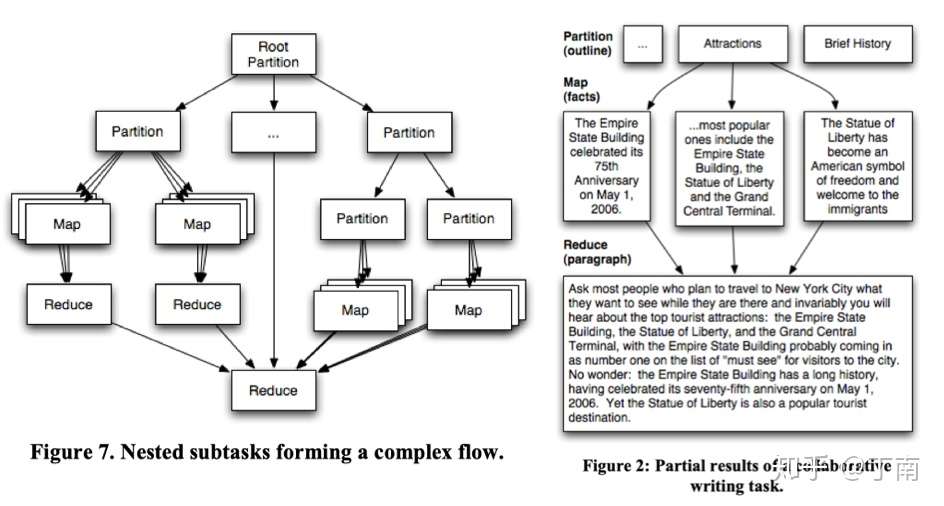
图 3 Partition-Map-Reduce 标注框架及示例 [7]
情形二:冷启动
对于很多企业来说,当开启一个新的对话系统项目时,通常是没有任何语料的,这种情况称为冷启动。这时如果要想实现一个基于统计的对话管理就更困难了,开发者面临的主要问题是:数量要求和语料来源。
在没有任何语料的情况下,大家一般会选择自造数据。得到一份初始种子语料后,快速迭代模型,选择一批种子用户快速得到反馈和新一批测试语料,迭代更新模型,再扩大测试用户,如此滚雪球,将语料和模型慢慢做大。由于对话语料不同于一般 NLP 数据,需要多轮的交互数据才能反映真实的对话场景,Walliams提出用一种 interactive teaching 的方式,让开发者一人分饰两角,模仿用户的问题并同时为系统做对话标注,见图 4 示例。这种方法也应用在了 Rasa 的对话管理开源框架中,Rasa 建议开发者通过 command line 编写领域内的对话,与 command line 交互过程也可以对意图识别、实体识别的结果进行纠错,非常方便。
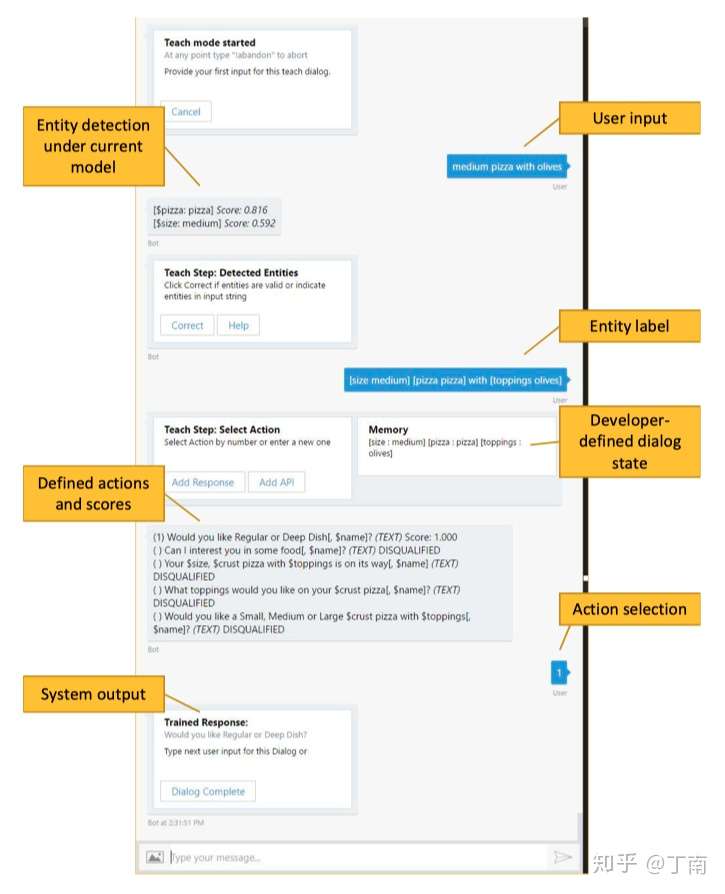
图 4 Dialog interactive learning [10]
自造数据最大的问题是扩展速度太慢,覆盖场景太有限。虽然有种子用户的测试,但测试范围太窄,必须不断迭代扩大种子用户,小心翼翼的反复测试。而如果在场景覆盖不完备的情况下将系统暴露给用户,会立即变成战五渣。所以自造数据往往并不满足统计方法对语料量的要求。
为了解决这个问题,研究者提出可以使用 user simulator模拟人机对话,让机器自动生成对话交互语料。User simulator 是一个很大的话题,也一直是对话系统的研究热点。
- 早期的方法很直接,用 action bi-gram model 根据系统上一个 machine action 预测下一个 user action。这种方法弊端很明显,它仅仅依赖系统的上一个 action,并且也没有考虑诸如 user profile、user goal 等特征,产生的会话一致性会很差。
- 后来 Schatzmann 提出一种很适合任务型对话的 agenda-based user simulator ,这个方法借鉴了类似 goal-based 方法,用一个 stack 结构来维护将要进行的 user action,这个数据结构称为 agenda(图 5)。和机器交互后 simulator 会更新 agenda 中的 future user actions,例如 pop 或 push 新的 user action 到 agenda 中。由于 agenda 隐含了用户目标,会话目的始终是完成对话任务,所以这样生成的对话有很好的一致性。
- 这几年 sequence-to-sequence 方法很火,也有学者将其应用到 user simulator 中,将 machine context 到 user action 看做一个 source-to-target 序列生成问题,由于可控性不高,这种方法应用在任务型的对话系统还不常见。
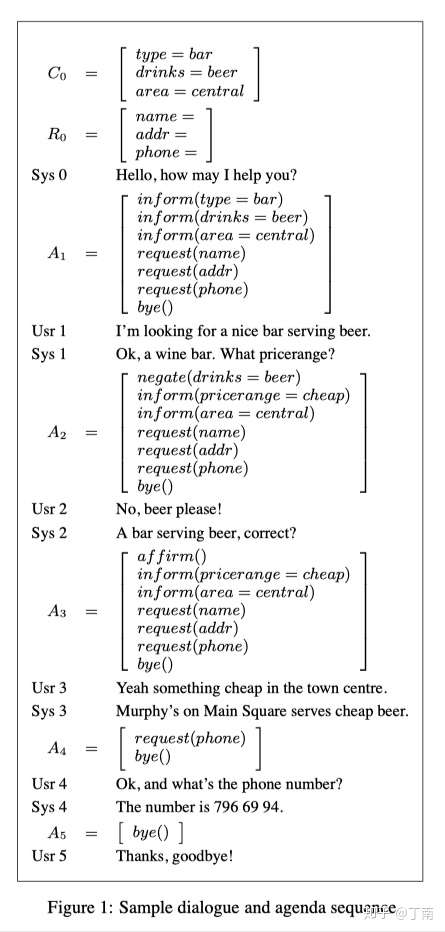
图 5 Sample dialog and agenda sequence [1]
自造语料可以解决数据从 0 到 1 的问题,对话模拟器可以解决从 1 到 10000 的问题,但这两个方式都不能解决数据来源的问题。
企业自造语料时找到的测试用户通常是公司内的同事,他们很可能已经对测试流程和对话场景非常熟悉了,这样产出的语料往往会拟合于已有的对话逻辑。并且种子用户的身份和企业的真实用户可能差距很大,例如理财公司的用户是有真实理财需求的,如果种子用户并没有理财经验,他们无法完全模拟真实用户使用对话系统的情况。
- 一种解决办法是用灰度发布,通过接入小范围的真实用户,检验系统响应质量,收集真实世界的数据。这个方法很普遍也很有效,但有几个限制条件
- 一是企业已经有一个效果还算 ok 的对话系统,例如先做一个基于规则的 DM 跑灰度测试;
- 二是对话任务涉及的业务可以容忍一定程度上的错误率。但如果涉及的业务非常重要,企业需要让对话失败的风险尽可能可控,这样就很难说服业务负责人把未经真实验证的对话系统跑上线,甚至是灰度环境。我们在做一款语音机器人的业务时,就遇到了类似的场景。
- 这时另外一种解决办法可以缓解这个问题,学界一般称为 Wizard of Oz(WOz),一种非常有名的对话数据收集方法。WOz 简单来说是通过让人模拟机器的行为,来服务真实用户,收集真实的用户语料。在对话系统开发中,一般也是采用迭代开发,不同模块的完成时间并不一样,不同模块的研发成熟度也不一样,为了尽快推出一个原型,开发者可以选择将某些模块 mock 掉。但这里的 mock 并不是敏捷开发的 mock,而是用业务专家(wizard)在系统运行时代替这个模块,根据这个模块的输入,wizard 给出模块合理化的输出。值得注意的是,wizard 在模仿模块的行为时不能超出这个模块的设计边界,即不能用他自己的先验知识做超出模块能力范围的行为,否则会导致产生的对话并不符合对话系统的真实场景,拉低数据的可用性 。WOz 的方法能让系统在成熟之前就接触到真实用户,快速收集真实世界的数据分布,降低了上线后泛化的风险。同时也让企业提前检验对话流程的有效性,及时对问题做出调整。
Trade-off of control and automation
从大量语料中自动学习人机对话交互模式,是企业开发对话系统的理想方式。在从事了很多个对话项目之后,我们发现企业对任务型机器人有很多现实的需求,而目前基于数据的方法都很难满足。除了数据获取的困难,data-driven 方法遇到的另一个很大的问题是:自动化和控制权的权衡(control and automation)。自动化的 DM 方法往往是以牺牲对 VUI 逻辑的控制为代价的。机器学习对非专家来说是一个黑盒,虽然知道模型归纳的依据来自于语料,但如何用语料来解释模型的行为、如何通过变更语料来快速修改模型的结果、如何精确的对模型逻辑进行设计,这些能方便控制对话行为的权限是企业开发对话项目时必需的,而基于统计的方法并不能完全支持。
开发者经常要用到的控制权主要包括:快速修改 VUI 逻辑和 debugging/monitoring。
快速增删改 VUI 的逻辑是 hand-crafted 方法非常大的优势。对话的任务描述也是迭代优化的,项目上线后,早期的 VUI 很可能已经不适合业务的发展需要了,企业需要一个手段能快速对 VUI 逻辑进行修改。如果是基于数据的方法,修改的代价可能是巨大的,需要重新收集新的对话语料,并 review 和清洗所有的老数据。就算完成了数据的更新也可能是不够的,数据一旦变化对原有对话策略的影响也需要评估。如果企业只是想对 VUI 做微小的改动,实施这么一套更新流程的成本就太高了。而 hand-crafted 方法就简单的多,只需要修改涉及到的 VUI 即可。从优化机器人策略的角度来看,对话开发者的项目经验,和算法学习到的对话模式,都可以优化对话效果,但这两者的职责并不在一个维度上。由于统计算法仅支持在封闭域中学习,所以它只能在一个有限的候选集中优化它的策略。而对话开发者可以根据需要做更多的修改,例如增加一个新的对话分支、新增或删除一个系统响应、甚至为某些需求做定制的处理。
在实际场景中,只靠data-driven而脱离人工设计并不现实,两个方法的差异性是可以相互补充的,很多研究者开始探索用 hybrid 方式来开发对话管理。例如上文提到的 Hybrid Code Network可以让开发者在 end-to-end RNN 架构中添加领域相关的逻辑,如图 6 论文中的示例,梯形的部分代表领域相关的模块,其中 entity tracking 是开发者集成的领域代码,用于将文本和实体处理成上下文特征(context features),以及响应掩码(action mask)。Context features 由开发者根据实体和自定义逻辑自行设计,action mask 表示某些场景下不可能出现的系统响应。运行时需要 action mask 是由于模型的输出空间是所有 actions 候选集,但在一些实际条件的限制下,有些 actions 在当前 timestamp 是不可能出现的。例如信用卡还款场景,在得到用户信息和账号之前,应禁止进行还款操作。所以为了 100% 规避模型预测的风险,需要 mask 来控制模型的输出。这个方法也曾经被 Walliams 用在了 POMDP 上,为 action selection function 设定限定域,是一种对有风险的 actions 减枝(pruned)操作,可以让 POMDP 优化过程更快、预测结果更可靠 。
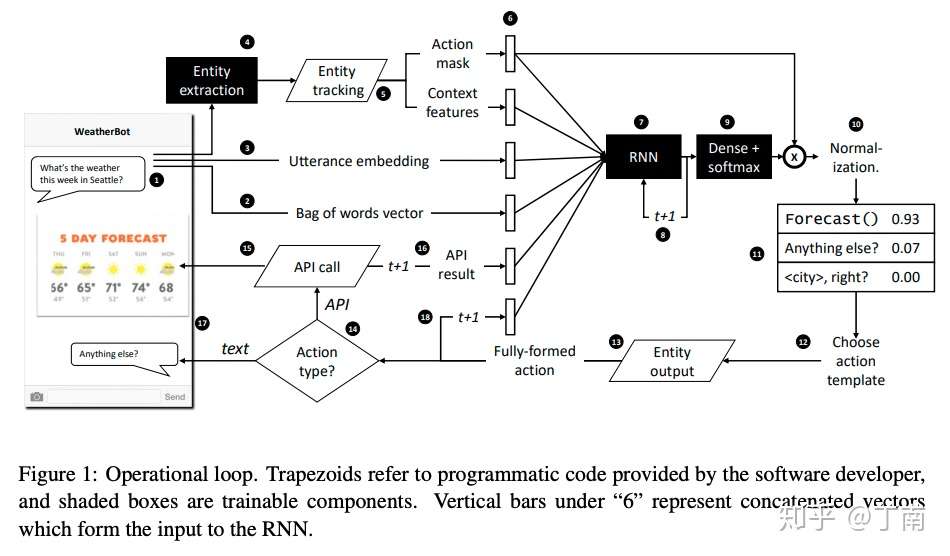
图 6 Hybrid Code Network 系统架构图 [2]
上面介绍了很多关于如何设计对话模型和策略的话题,但此时系统仅是一个开环(open-loop),缺少项目优化所必需的系统诊断方法。对话策略设计仅是对话系统功能的一部分,项目开发时 DS developers 需要对 VUI 进行调试,项目部署前需要对用例进行回归,项目上线后需要对指标进行监控,出现异常时需要对错误进行定位,这些都是企业经常用到的控制权。系统诊断的重点是通过会话分析发现对话策略的不合理之处,为项目优化提供数据上的支撑。现代对话系统平台一般有两种诊断的功能,一个是 debugging,一个是 monitoring。Debugging 指的是,为了验证对话交互是否符合业务目标和项目预期,开发者所需要的对话调试功能。通常包括,实时查看一通对话的状态,定位当前交互节点的位置,查看历史 VUI 日志等等。例如图 7 百度 Kitt.ai 支持对会话进行单步调试,方便开发者分析每个 timestamp 的状态。又如图 8 IBM Watson 对话平台,开发者可以点击模拟器中某一轮对话(红框标记的位置),相应的节点即时在左侧的流程图中显示出来。再如图 9 SAP Conversation AI,开发者可通过模拟器查看一通会话的操作日志,方便问题定位。
图 7 百度 Kitt.ai 对话调试
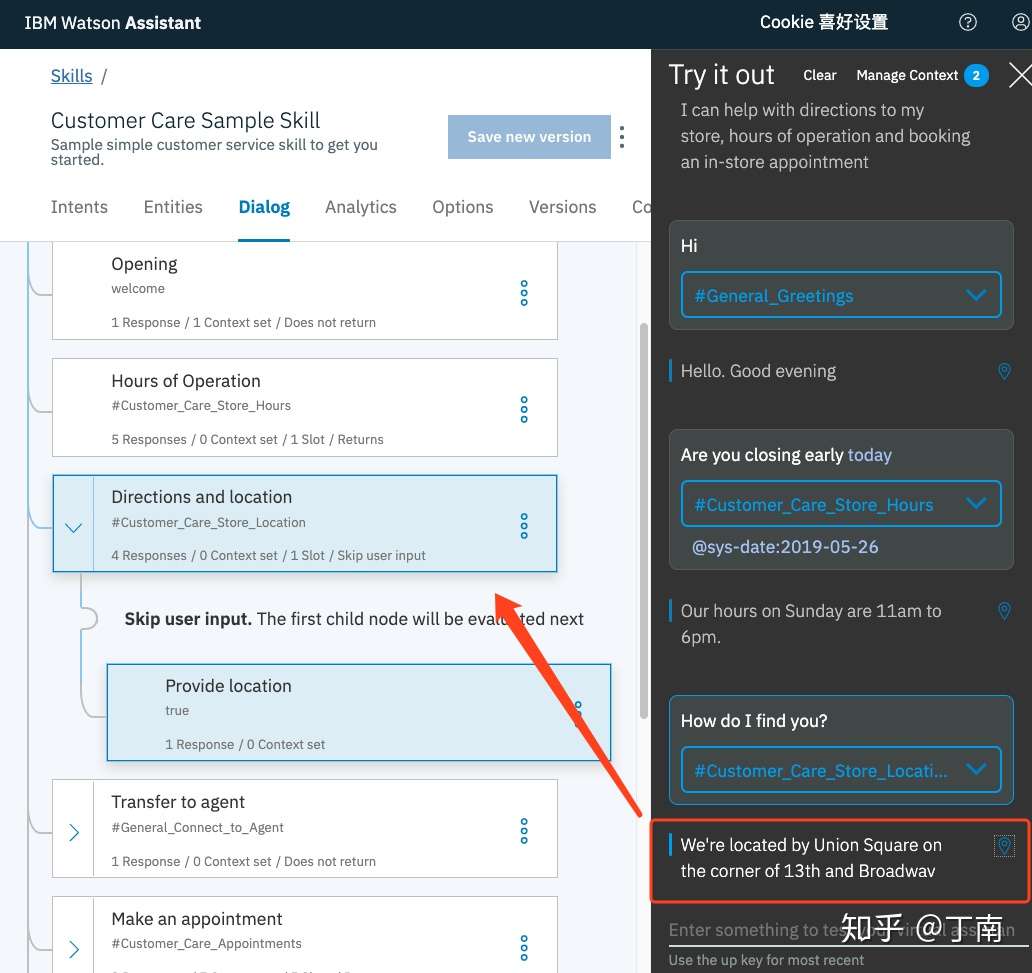
图 8 IBM Watson 对话节点定位
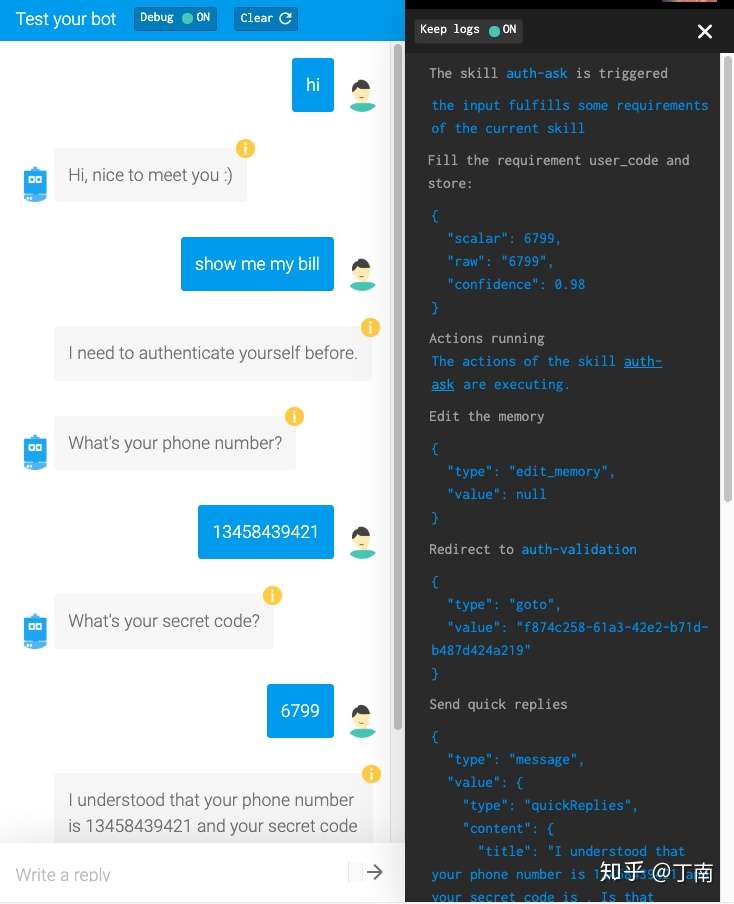
图 9 SAP Conversational AI 对话日志
Monitoring 指的是项目上线后的监控和分析,其意义是通过监控数据指标或 A/B testing,验证对话策略的有效性,持续优化机器人效果。对话策略包括机器人不同的话术、不同的 fallback 方式、不同的 VUI 逻辑、甚至是不同的目标人群等等。Monitor 一般使用业务 KPI 的 summary reports 来监控项目的整体运行情况,以及利用会话日志可视化来宏观调整 VUI 逻辑。对话系统最常用的 KPI 是任务完成率,但任务是否完成并不是那么容易定义。最直接的做法是监控业务数据指标来验证对话目标,例如图 10 Intercom 的每一个对话任务都可以自定义任务指标,对话任务发布后根据这个指标就可以评估对话任务的有效性。Intercom 也支持为同一类客户划分设定不同的对话策略,通过 A/B testing 选择更优的策略。虽然用业务指标来优化策略非常有效,但有时候业务数据并不是即时产生的,甚至有时候对话系统都拿不到敏感的业务数据。这种场景就需要一个间接指标来假设业务目标是否达成,比如通过监控某些节点的完成率来模拟对话目标。可视化整体日志也可以辅助项目分析,例如图 11 Google DialogFlow 的 session flow 功能可将日志的对话流占比可视化出来,方便分析 VUI 有效性。
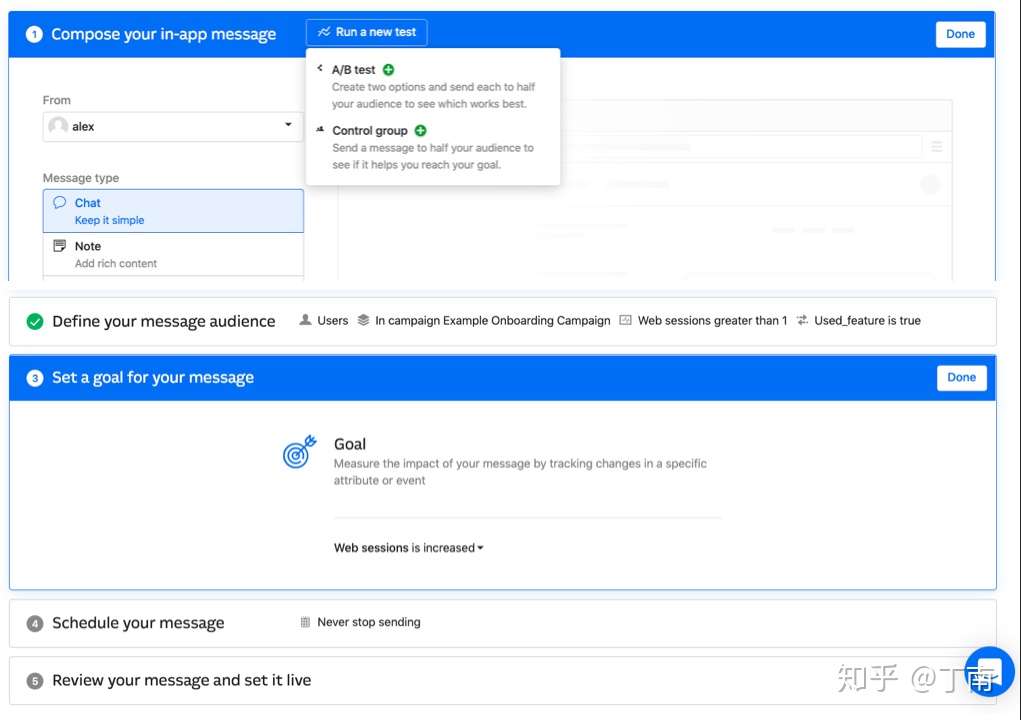
图 10 Intercom 中一个对话任务的监控指标和 A/B testing

图 11 DialogFlow session flow
从上面的论述和实例,可以发现最适合 debugging 和 monitoring 目前还是 hand-crafted 方法,它的 VUI design tools 可以非常方便地发现对话运行时的问题,方便修改对话逻辑,方便 VUI 的快速迭代。不过有的 data-driven 方法也在积极探索这方面的应用,例如图 12 Rasa 框架支持可视化训练数据,可以把对话语料映射成流程图,这样让 DS developers 从宏观角度上审阅目前的数据。这里也可以用类似 Abella 提出的对话轨迹分析方法(dialog trajectory analysis),将运行时产生的实际日志可视化出来,这样训练集和真实日志都以流程图的形式表现出来,之前提到的基于 VUI tools 的功能就可以复用起来了。

图 12 Rasa X 可视化 Story
上面大段的讨论虽然看起来是在聊 data-driven 在实际项目中的不足,其实想强调的是商业对话系统中有很多不可忽略的工作。不论用何种方法,如果这些问题没能有效解决,都将是机器人上线后的重要瓶颈。当然,data-driven dialog manager 的潮流是不可逆的,每年都有大量的研究成果和产品值得我们学习。
工业界解决方案
首先要强调的是,任务型对话系统有两个使用方,对话设计方和对话交互方。对话设计方指的是用系统提供的对话模型来设计任务型对话的开发者,对话交互方指的是任务型对话的目标客户。Pieraccini和 McTear 都曾指出这两个角色对任务型对话有不同的期望。
- 对话交互方(即目标客户)希望系统能自然流畅地进行对话,顺利完成客户的预期目标。
- 对话设计者不仅需要考虑对话理解的识别率、对话任务的完成率,还要预期一个对话项目的投入产出比(ROI)。
如果我们目标是提高系统的交互自然度,就需要让系统支持尽可能多的对话交互场景,不管是增加机器学习方法的语料,还是增加 handcrafted 方法的对话路径,都有大量的工作要做。但项目资源是有限的,如何用尽可能少的成本,实现尽可能流畅的对话,得到尽可能高的任务完成率,是任务型对话模型的关键。
低成本、高流畅度和高完成率三者通常是相互制约的:
- 可用性高(构建成本低)的对话模型大多有较多的设计约束
- 流畅的对话交互需要很高的 VUI 构建成本
- 高完成率的对话往往是限定在一个流畅度受限的场景。 这三个方面是任务型对话管理的 trade-off,也正是由于项目实践要权衡多方面因素,不同的对话系统平台根据其不同的侧重点给出了不同的解决方案。
其实开发一个任务型对话项目的流程在业界这十几年都遵从类似的模式,Pieraccini 在 08 年一篇论文中 [1] 总结了他在SpeechCycle 工作时的开发流程(目前 Pieraccini 在 Google 参与 Google Assistant 的研发),包括我们现在很多做对话系统的公司仍然沿用类似的流程。概括的讲项目开发步骤依次为:
- 确定系统的业务需求(business requirements)
- 定义对话交互的功能说明(functional specification)
- 开发对话任务中用到的语义模型(NLU models)
- 设计和开发对话交互的流程(VUI design)
- 确定对话交互时错误处理策略(error handling)
- 后端系统的集成(backend integration)
- 对话场景模型和 VUI 完备性测试(testing)
- 上线后对效果的监控(monitoring)
顺便提一句,虽然对话系统开发有其特殊性,但与软件开发一样,开发流程的规范化和标准化有利于系统的快速迭代,有利于提高团队协作的效率。在经历过多个项目 POC 和实施后,我们认为规范流程是项目成功的基本保障。所以,一个设计优秀的对话系统平台会在产品上体现出它的开发规范和开发工具,向客户输出它认为的最佳实践。
上面的开发步骤可再概括为 design、develop、test、deploy 和 monitor,后面三个步骤我们在上文或多或少提到过一些,细节可以留到以后的文章,我们这里主要讨论前两个:对话设计和对话开发。在对话系统发展早期,对话设计和开发是割裂的,还没有形成统一的自动化工具,VUI 设计师根据业务需求设计 VUI 规范文档,评审通过后将规范文档提交给开发团队,开发工程师选择一种对话管理模型将 VUI 描述实现出来。这种方式的成本显然是很高的,为了优化这两个步骤,大多数对话系统平台选择了同一个思路:
- 设计标准化:定义一种对话描述语言(dialog description language - DDL),统一对话设计规范
- 开发自动化:用一种对话解析器将 DDL 映射成对话编程模型,解放对话开发工程师
DDL 与其说它是一种对话描述语言,不如说是一种对话编程语言(dialog programming language)。它不仅能用一种方式将对话场景描述出来,而且能利用平台提供的 programming model 控制对话交互的复杂性,例如能力封装、对话继承、层级结构、异常检查等等。这些能力避免了让 VUI 设计师重复造轮子、陷入细节的逻辑交互,规范了对话设计的模式,缩短了从需求描述到设计的时间。用 DDL 将对话交互描述出来后,下一步想到的优化自然就是如何将 DDL 自动转换成代码或对话模型,避免每次由开发工程师去手动实现。之前介绍 programmatic 方法时提到过,虽然开发工程师可以定义很多可复用的 modules 来降低开发成本,但毕竟还是有一些开发工作,理想方案还应该是自动解析 DDL。
上面的开发步骤和思路虽然在绝大多数公司中都是相似的,但每个企业有不同的实现方式和侧重点,给出的解决方案也有较大差异,下面介绍几种常见的方案。
Dialog-Flow
【2022-9-2】快速上手Dialogflow交互机器人
Dialogflow 是Google 提供的一款人机交互平台,通过该平台可以轻松地设计出属于自己的交互机器人,比如常见的网页聊天机器人,电话智能客服等。借助Dialogflow甚至可以用于扫地机器人交互系统或者更高级的使用。
- 马航的订票查票机器人:马来西亚航空公司和 Amadeus 创建了一个聊天机器人,使客户能够搜索、预订和支付航班,从而使航空公司能够满足未来的需求并增加数字渠道的收入。
- 达美乐披萨的订餐机器人
- KLM预定、打包机器人: KLM 于 2016 年开始探索为客户提供体验的方法。他们在测试多个平台后选择了 Dialogflow。
Dialogflow 通过客户输入的语音或者文字甚至情感分析,来识别客户的意图(Intens),结合实体(Entities),来进行相应的回复。
Dialogflow的几个优点:
- 识别准确率高,响应速度快
- 支持 30 多种语言和语言变体
- 上手简单:图形界面配置;官方文档丰富、详细;网络上有案例可供参考
- 有问题易解决:开发者社区超过150万名开发者
常用工具
- 一、内置 Small Talk
- Small Talk 用于为闲聊对话提供响应。 此功能可以解答代理范围之外的常见问题,极大地提升最终用户体验。
- Small Talk 有两种版本:
- 内置 Small Talk:为代理启用 Small Talk 后,它会自动处理闲聊对话,无需向代理添加意图。
- 预建 Small Talk:导入预建 Small Talk 代理时,它会提供处理闲聊对话的意图。
- 二、prebuilt agent
- 由 Dialogflow 提供的一组代理,适用于常见的使用场景。 您可以这些代理为基础,构建涵盖特定场景(如外出就餐、酒店预订和导航)的对话。
如何制作一个自己的天气&新闻语音问答机器人
- 使用了文字输入Dialogflow 的方式, 通过speech-to-text将音频麦克风流到Dialogflow 的文本意图检测API
- 案例使用了以下GCP产品:
- Dialogflow ES & Knowledge Bases
- Speech to Text
- 其它组件:
- Webhook
- Weathers & News API 在这个demo中你可以使用麦克风输入,然后返回新闻或者天气
Dialog flow 是业界最常用的解决方案(这里并不是指 Google 的 DialogFlow),在语音对话系统中(Spoken Dialog System)一般叫做 Call Flow,它用一种对话流程图工具来描述对话逻辑。目前市面上的 bot 平台大部分都采用这个方案,其本质都是状态流程图,是 handcrafted 方法,不同产品之间最主要的区别可能就是状态节点的抽象程度不同。
第一篇介绍对话管理方法的时候介绍过,根据对话描述的灵活程度,可将 handcrafted 方法分成 finite-state、frame-based、goal-based等等。从 VUI 表现层来说,这些方法的对话节点有不同的抽象能力,抽象程度最低的是 finite-state,它每个状态节点只完成一件事,交互逻辑完全表现在状态图中,这会导致 dialog flow 在 VUI 表现层上显得非常复杂。而抽象比较高的是 goal-based,它的对话流程图是 hierarchical 的,一个节点可以代表多个对话交互,复杂的逻辑可以隐藏在一个节点中。
较低抽象程度的 dialog flow 一般会根据状态,将对话节点分成多个类型,例如条件节点、回复节点、API 节点、澄清节点、实体节点等等。每个节点有其特定的功能,是对话交互设计的最小逻辑单元,我们暂且将这种方法称为「基于状态的 dialog flow」。其设计 VUI 的过程是:使用不同类型的节点完成每一时刻的对话逻辑,连接相互依赖的节点完成状态间的跳转,类似 finite-state 方法。例如「条件节点」仅支持当前时刻的对话状态条件判断,根据条件将对话导向不同的分支,跳转后的对话交互由其他节点承担;「API 节点」仅支持 API 接口调用,调用后数据如何使用、对话逻辑如何发展,由后续节点负责;「实体节点」仅用来做槽填充和填槽过程中的交互;「回复节点」仅用来表示回复用户的内容,等等。举个实际例子,Kore.ai 是一款功能非常完善的 chatbot 平台,其多轮对话共有 8 种类型节点,图 2 是 kore 提供的一个航班查询 demo 机器人,每个节点右上角的标签是节点类型。例如 intent/entity 节点表示根据用户意图/实体做状态跳转、webhook/script/message 节点表示 bot 执行相应 action 后做状态跳转。VUI 上每个节点的功能非常清晰,所有对话逻辑都在 graph 上以节点功能和状态跳转的形式呈现。

- 图 2 Kore.ai VUI 示例图
国内的大多数对话系统平台也都是采用类似的方案,比如百度 Kitt.ai、阿里 Dialog Studio(内嵌在钉钉后台)、 竹间智能 、网易七鱼。这里需要澄清一点,虽然我个人将该类型的设计模式理解为「抽象程度较低」,但并不是想表达这种方式不好,基于状态的 dialog flow 有几个非常大的优点。首先它的设计与我们常用的流程图是一致的,很多公司对话交互逻辑的起点都是 visio 流程图,VUI developer 拿到 visio 图后并不需要进行模式转换,很自然地能将设计图映射成 VUI 实现。其次,用这种模式设计出的 VUI 几乎将所有的对话交互逻辑都表现在了流程图上,有利于流程检查和整体 review。还有一个优点,这种模式的节点功能很聚焦,职责很清晰,新增一种节点对原有节点都没有影响,节点依据功能和状态而相互解耦,方便 VUI 增删改查。
另外一类 dialog flow 使用的是较高抽象程度的设计模式,虽然这类也是流程图设计,但它并没有根据功能划分节点类型。相反,其对话节点只有一种类型,节点的设计模式是统一的,一个节点可承载多个对话逻辑。这种方式非常适用于基于目标的对话设计(Goal-based 对话模型可参见第一篇 对话管理基本方法),每个节点完成一个具体对话目标,一个目标所涉及到的对话交互都由这个节点来完成。一个对话任务通常包含多个子目标,子目标的跳转表示相互之间有依赖关系。如此,一个对话任务的 VUI 就可以表示成子目标的流程图,由于很多逻辑细节被隐藏在了目标节点,节点抽象程度很高,VUI 在表现层会显得非常简洁,我们暂且称这类模式为「基于目标的 dialog flow 设计」。
为了理解对话节点如何完成一个具体的目标,我们来看一下基于目标节点的生命周期。这种节点的生命周期通常包括三部分:节点触发、节点依赖和节点动作(trigger、requirements and actions)。首先一个目标通常有其触发条件,用来表示在什么场景下系统需要完成这个目标。例如一个处理超时的节点,其触发条件是超时的信号事件,收到超时信号后,该节点可能会优先触发。接下来,完成一个目标通常需要用户反馈一些信息,以便满足用户的不同需求(例如业务 API 调用需要必备参数),这些信息可称为节点的依赖,通常用槽填充来实现。节点依赖设置中也保存了槽位信息的交互逻辑,例如没有识别到槽位实体时机器人应如何反馈。如果顺利的话,最后机器人将执行一些动作以完成对话目标。对话动作(dialog action)的范围非常宽泛,机器回复、变量保存、API 调用、代码执行、节点跳转等等都称为动作。机器完成节点目标所要求的一系列的动作后,该节点的生命周期即告一段落,节点处于 inactive 状态,等待下一次触发。 图 3 是基于目标的节点描述,这一套设计模式非常统一,灵活的节点配置可以支持任意复杂的交互逻辑。

- 图 3 基于目标的节点设计模式
采用基于目标的 dialog flow 典型的产品有 SAP Conversational AI 和 IBM Watson。SAP Conversation AI 的前身是 Recast.ai,一家非常优秀的创业公司,被 SAP 收购后成了 SAP Conversational AI 的重要产品。如图 4,SAP 的对话节点都是采用同一种设计模式,三个部分 triggers、requirements、actions 和我们上一段讲的非常类似。IBM Watson 虽然借用了大名鼎鼎的 Watson 机器人的名字,但这里指的是 IBM 推出的对话 AI 平台。Watson VUI 与其他 dialog flow 产品有些差异,使用的是 VUI tree 而不是 graph 来描述对话逻辑。类似的,Watson 的对话节点也是统一的,如图 5 每个节点的生命周期包括触发条件、依赖信息、机器响应和节点跳转,对话节点的抽象程度高,能实现复杂的交互逻辑和条件判断。

- 图 4 SAP Conversation AI 多轮对话节点描述

- 图 5 IBM Waston 多轮对话节点描述
相比于基于状态的 dialog flow,基于目标的设计模型有几个很好的特性:较高的抽象程度、统一的节点类型、面向目标的设计理念,但凡事有两面,第一种方法的优点正是这种方法的不足:高抽象的流程图导致 developer 不能在 VUI graph 上直观地审阅所有的对话交互逻辑,设计模式的不同导致 developer 需要花功夫将 visio 流程图「翻译」成新的 VUI 设计。
为了清楚认识两种方法的优劣势以及使用场景,图 6 和图 7 是我用 Kore.ai 和 SAP 两家产品实现的信用卡还款对话任务(仅仅只是 demo,真实的场景会更复杂)。需要说明一点,由于两个产品支持的功能和设计模式都有差异,很难设计出两个完全相同的 VUI 交互场景,不过尽管用户在体验上可能会感觉有细微的差异,但大体的对话任务交互走向都是一致的。图 6 Kore.ai 的实现可以一目了然看到整个交互逻辑,每个状态节点上都清晰显示了对话的逻辑细节。这个 VUI 的缺点也十分明显,这么简单的对话任务,流程图已经显得十分复杂,当任务复杂度显著提高后,流程维护将是一个很大问题。对比图 7 SAP,对话任务被拆分成了 4 个子目标,每个对话节点封装了一个子目标的交互逻辑,实现的 VUI 看起来非常简洁。并且,这种方式很容易能实现对话中的全局节点,每个全局节点就是一个对话目标,可以在不修改主流程的情况下,增加机器人的处理能力。但在 SAP VUI graph 上并不能看出完整的对话交互,需要进入节点中才能进行流程检查,对 VUI 设计师要求会比较高。
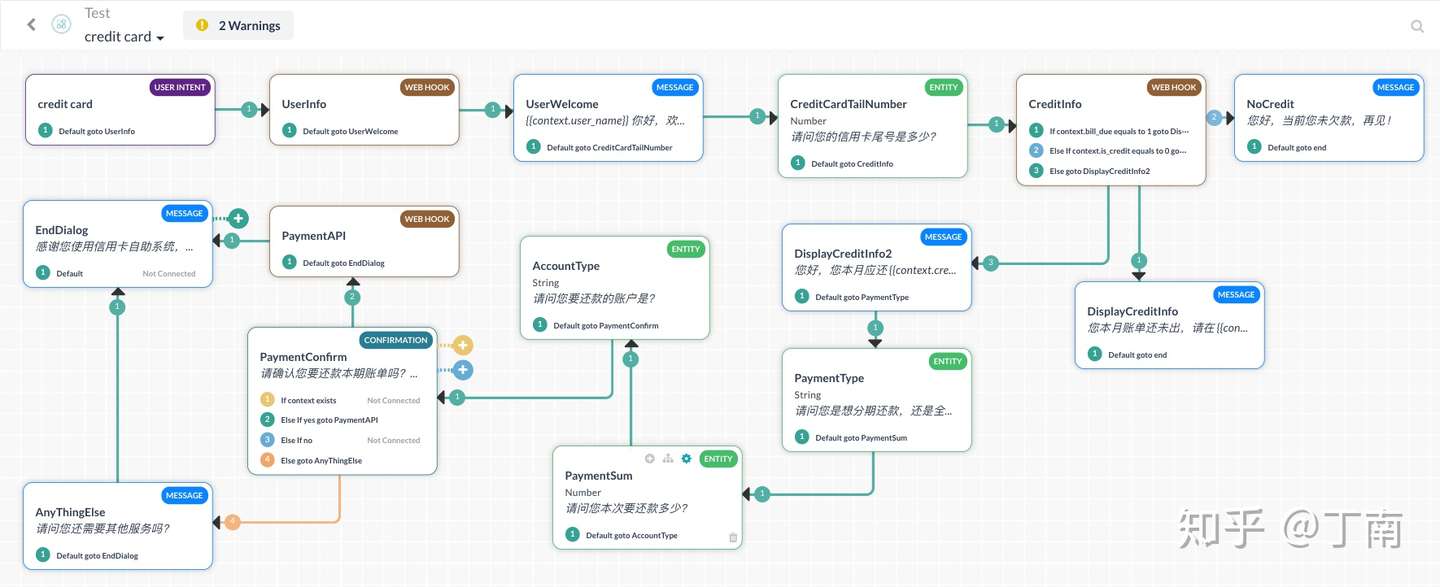
- 图 6 两种产品构建的信用卡流程对比 - Kore.ai
- 图 7 两种产品构建的信用卡流程对比 - SAP Conversational AI
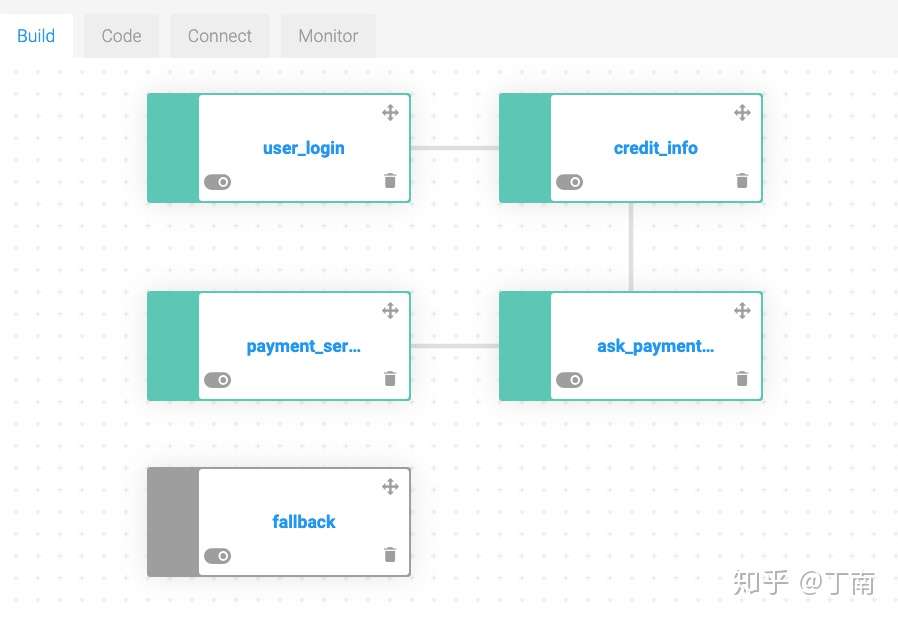
Task form
跟 RavenClaw 的思想一致,为了将对话任务和通用交互策略解耦,微软 Cortana assistant 的 DDL 使用了一种对话任务配置文件(Task form)来描述每一个对话任务。Task form 包含了一个对话任务的所有交互信息,新增对话任务只需要导入一个新的 task form 文件到 Cortana 平台即可,降低对话开发成本。Task form language 与上面讨论的基于目标的设计模式很类似,每一个 form 也由三部分组成:task trigger、task parameter、task action。Task trigger 定义了对话任务的开始条件,parameters 定义了完成对话任务所必须的信息,action 定义了对话任务的最终响应。除了 task action,每个 parameter (槽位)也会绑定一些 dialog acts,表示在填充一个槽位之前可能发生的对话交互,例如当用户话语中没有所需信息时机器人该反馈什么(MissingValue)、当用户提供的信息并没有查询到任何结果时机器人该反馈什么(NoResultsFollowUp)、当识别到的实体概率并不高时机器人做怎样的澄清(Confirmation)等等。个人理解 Cortana 这种方法其实很像基于目标的 dialog flow 中的对话节点,只不过助手类的机器人涉及到的对话任务相对简单,大多是信息查询、命令式的对话,轮数相对较少,用一个 task form 就足以描述大多数场景,并不需要复杂的业务对话流程图。
基于机器学习的方法
在 第一篇 讲对话管理实现方法的时候有提到,可以用机器学习的方法来预测会话中每一时刻的 bot action。这种方式下 conversational interface 不再是流程图设计,而是通过一种方式向对话系统提供 dialog examples,让系统从例子中学习交互模式。 Wit.ai 在 2016 年曾推出过一个类似的功能叫 bot engine,该功能提供了一个 web 交互界面(图 8),用户在上面可以「创作」dialog story(即 examples),bot engine 用机器学习方法训练这些对话序列。由于 wit.ai 没有公布细节,具体哪种算法不得而知。遗憾的是,bot engine 上线一年后被砍掉了 ,据 wit.ai 团队在他们的 博客 上的解释,下线的原因是从使用数据上来看,大部分 wit.ai 用户仅使用了他们 NLU 功能(意图识别、实体识别等),而使用 bot engine 的用户中绝大多数只创建了一轮对话,复杂的多轮场景并不多见,bot engine 在商业上没有体现出应有的价值。虽然 bot engine 被下线了,但在多轮对话产品上却是使用机器学习的一次很好的尝试。
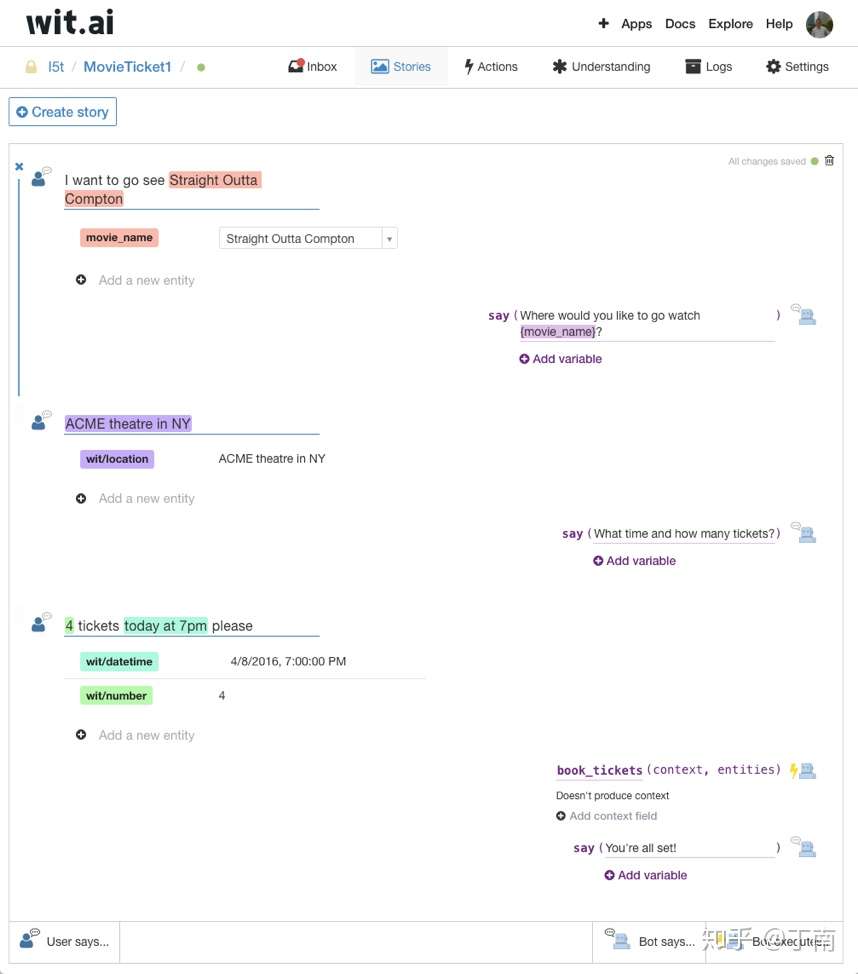
图 8 Wit.ai bot engine web 交互界面截图
另外一个有意思的尝试是微软去年(2018)推出的 Conversational Learner,作为 Microsoft Cognitive Services Labs 下面的一个实验性的项目,Conversational Learner (以下简称 CL)试图探索一种新的任务型 conversational interface 设计模型,让 dialog designers 摆脱对话流程图方法的局限。微软给出的解决方案其实上文反复有介绍过,它是一种结合了机器学习和领域规则的 hybrid 方法,Jason Williams 将之命名为 Hybrid Code Networks(HCNs)。CL 核心是,使用 interactive learning 模式设计 dialog examples,提供 SDK 方便开发者加入领域逻辑,应用端到端 LSTM 模型学习对话响应策略。Interactive learning 是一种方便 designers 编写对话 examples 的方法,上文提到的 Rasa 也是以这个方法收集语料。如图 9 示例,CL 开发的 interactive learning 功能以一种非常自然的方式让 designers 创作对话,左边是对话模拟器,右边是每一轮 bot response。通过为每一轮 bot 选择或添加最合适的 action,designers 即可完成一个对话语料的编写。除了手工增加训练语料「Train Dialog」,CL 也提供了对话日志标注功能「Log Dialog」,交互界面与对话训练一致,designers 对日志进行 review,发现其中不合理的 bot responses,重新选择或添加正确的 bot action,非常方便地就把修改后的日志导入到对话训练集中。
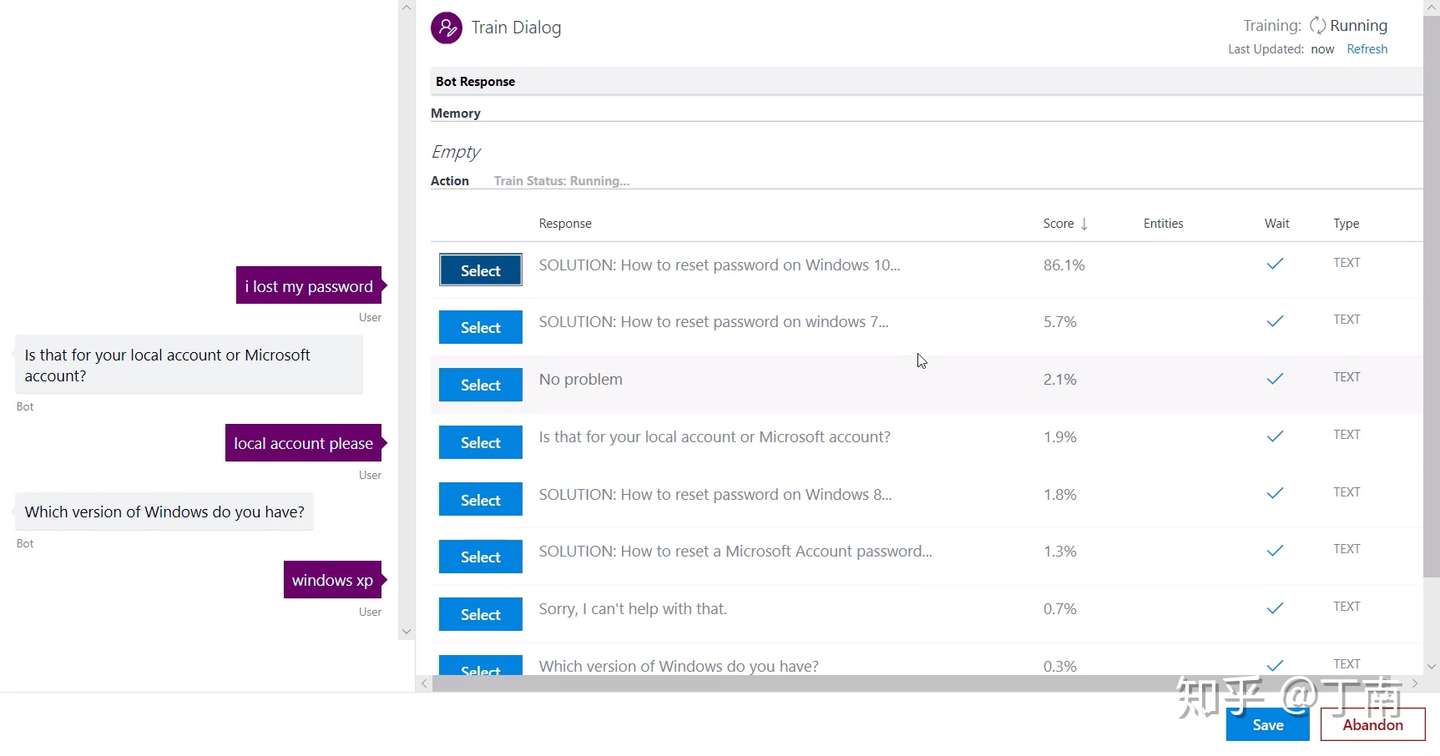
图 9 微软 Conversational Learner - Interactive Learning 交互界面
就像 Walliams(现已不在微软,去了苹果负责 Siri) 在 CL 功能介绍视频中所介绍的,这种方法的哲学非常务实,它并不指望机器学习能解决实际项目中的所有问题,一些领域逻辑仍然需要人工参与。但以前需要流程图设计的对话跳转、对话响应等 control strategies,CL 用端到端的算法来学习。并且由于能方便地加入专家知识,机器学习的难度降低了,原本需要大量数据才能学习到的交互模式,用 CL 只需简单的配置或代码就可实现。举个例子,在手机维修对话中,机器人需要知道可维修的型号范围,如果没有专家知识,designers 需要提供大量语料才能让机器学习到哪些型号在可维修范围,并且一旦可维修的范围更新了,这些语料也需要更新,应用机器学习成本太高。这种场景最合适的是增加简单的领域逻辑,即 Walliams 讲的:code what’s easy to code, and learn what’s esay to learn。
最近(2019 年 5 月) Rasa 发布了一款新的产品 Rasa-X ,提供了一套完整构建对话机器人的前端设计工具,集成了 NLU training、interactive learning、话术模板、版本管理和发布等功能。这套工具降低了之前用 Rasa 开发项目的成本,例如手工创建语料、跑模型、版本发布、收集日志等。任何对话项目都是一个长期的工作,我们很高兴看到 Rasa 越来越重视项目的迭代和维护。由于 Rasa-X 也是用类似微软的 interactive learning 方式,具体功能这里就不再详述。
虽然微软的 Conversational Learner 和 Rasa-X 都还只是实验性的产品,但它所支持的功能比较好的解决了一部分机器学习应用的困难(应用的困难详细讨论请见 文章系列第二篇:interactive learning 降低了企业准备对话语料的成本,hybrid 模式给了企业足够的逻辑控制权,end-to-end 算法让企业有了自动化设计对话的能力。随着 chatbot 在企业级的应用范围越来越广,应用场景越来越深入,这种新的对话设计模式势必会受到越来越多的关注。
正在尝试的优化方案
文章最后简要聊一下我们正在对自家产品做的优化。上文中讨论了很多对话管理的方法,以及具体场景下可能会出现的问题,在我们实际项目中感受很深。为了提高多轮对话的易用性和扩展性,我们主要从两个方面做了优化,一是改用基于目标的对话模型,二是使用机器学习辅助 VUI 设计。
之前我们的多轮对话模型属于基于状态的 dialog flow,状态节点类型包括条件节点、响应节点和两个特殊节点(开始和结束)。产品设计并没有将复杂的交互逻辑进行封装,例如槽填充节点和澄清节点,也不支持流程复用和可插拔式通用策略。VUI 设计的抽象程度很低,复杂对话场景的 VUI 会变得异常复杂,修改和维护多轮对话的成本比较高。虽然这样的模型可以实现任何对话逻辑,但在实际项目中我们发现设计模式的易用性可能直接影响着 VUI 的完成率和完备性。在一些需要多轮交互、需要反馈多个信息、流程有顺序依赖的对话场景,如果仅支持系统引导(system-initiative)的对话,用户体验会大打折扣,一旦用户对 bot 失去信任,对话完成率会受很大影响。另一方面,真实的对话场景所包含的可能性一般远超过项目预期,为了提升 VUI 的覆盖率,我们只好不断增加交互路径的细节,VUI graph 维护性会越来越差。
这些问题让我们转向基于目标的对话模型,希望提高 flow chart 的抽象程度,统一对话任务的设计模式。交互界面上,我们仍然采用 dialog flow 方式,但提高了节点的抽象程度,每一个节点表示一个对话目标,完成一个目标的过程统一成触发条件、依赖信息和对话响应,用这三部分就能完整表示一个目标节点。除了对话节点的改变,我们还支持了流程复用和全局节点,提高 VUI 的可重用性。对话管理的实现上,我们采用类似 RavenClaw 的方案,用 agenda 数据结构来支持槽位共享,用 focus-shift 算法支持场景跳转,同时在引擎底层中预设了很多可插拔的通用对话策略,runtime 时系统会遍历通用策略并将满足条件的策略加入到 dialog stack。
这几年不管是学术界还是工业界,大家都想把所有的业务「机器学习化」,虽然很多场景并不成熟,但试错的工作是值得投入的。需要注意的是,用机器学习来做多轮对话设计目前还不是业界主流,从学习成本、功能灵活性和使用习惯上来看,业界更多采纳的仍然是基于流程图的方法,基于数据的方法更多是以实验性的产品对外的。我们也认为现阶段大部分客户还是倾向于使用 dialog flow,但在项目中我们发现机器学习方法在某些场景下能给 bot 运营带来特别多的补充。
在 第一篇 我们聊过 VUI completeness 的概念,参考 Pieraccini 给出的定义 [1]:企业设计的对话系统应能响应用户所有可能的交互,并且仅支持两种结果,要么完成了对话任务,要么跳转到了 fallback 策略(例如转人工)。这里 VUI 完备性有两个问题,一是使用良好的 fallback 策略总是能处理所有的交互,但用 fallback 来应对合理的用户需求显然是不合理的,所以我们倾向于使用 VUI 业务完备率来代替。二是由于对话的离散组合性,企业是不可能将所有对话路径提前定义好的,VUI 完备性仅仅是现实的一个拟合。这跟机器学习泛化概念一样,在拿到所有数据之前,我们永远不能确切知道总体的真实分布,模型的准确率仅仅是对现实空间的投射。为了不断拟合真实分布,机器的持续迭代是必须的。持续迭代 VUI 常规的做法是不断丰富 VUI graph,这种方法问题很明显,在项目后期 VUI 的修改需要很谨慎,避免对其他交互造成影响,如果 designer/developer 换人了,新负责人需要充分理解 VUI 逻辑才能优化。在这种情况下,用机器学习就非常合适。我们并不指望训练出的模型能有多大的泛化能力,毕竟让客户提供大量对话语料现阶段不太现实。我们希望的是提供给客户一种新的迭代方式,这种方式必须能让客户快速、低成本的更新机器人。所以我们也采用了 interactive learning 方式,让客户能非常方便地添加 dialog examples。不过我们跟微软 Conversational Learner 的侧重点不一样,我们希望用这种方式来弥补 dialog flow 的不足,通过添加对话实例来提高 VUI 覆盖率。这个思路有点儿类似问答系统,用规则/模型的方式保证高频问题的 precision,用检索的方式提高问答的 recall。类比到我们的对话管理就是,用 dialog flow 保证高频对话场景的完成率,用机器学习提高对话场景的召回率。为此,我们统一了两种方法依赖的底层结构,保证对话交互逻辑的等价;实现了 dialog flow 到 examples 的转换,打通 handcrafted 到模型的隔阂;开发了 hybrid design tools,降低开发的使用门槛。努力做到规则和模型的和谐混用,在增强系统能力的同时保证产品的易用性。
以上优化的版本现在正在紧张的开发中,希望产品上线后,新的交互模式能提高客户的使用体验,降低对话开发成本。
结语
对话管理是个非常大的课题,本文所介绍的方法仅仅是一个很小的子集,很多优秀的思路没有提及,例如 information-state 、probabilistic rules、end-to-end等等。本文所涉及的内容也仅仅是对话管理的一部分,其他内容例如多轮对话评价、对话状态跟踪等都是重要的研究课题。本文也仅仅讨论了任务型的对话,问答型和社会化聊天型的对话管理有着不一样的设计思路。本文以一个从业者的视角回顾了对话管理方法,分析了业界的不同解决方案。虽然讨论了很多 data-driven 应用于 DM 的困难,但我们始终对其持有乐观态度。本文想强调一个观点是,在用诸如 end-to-end、reinforcement-learning 等新方法的同时,需要谨慎考虑工业应用时的场景,在不降低易用性和控制权的前提下,持续提高扩展性和自动化的能力。
过去几年我们看到了越来越多的人机对话式的产品,看到了 chatbot 被越来越多的企业接受,只要蛋糕足够大,肯定会有越来越多的探索和实践。不过目前已知的所有方法肯定不是实现通用对话 AI 的路径,我们离人们预期的对话机器人还很远,过分夸大的应用场景只会造成 AI 行业泡沫。希望未来能看到更多的产品落地,通过产品教育的方式慢慢调整消费者的预期。对话式 AI 的想象力很大,但不该只是泡沫。
DM 子模块
DST
【2020-12-23】对话状态追踪(DST)的作用:
- 根据领域(domain)/意图(intention) 、槽值对(slot-value pairs)、之前的状态以及之前系统的Action等来追踪当前状态。
- 输入是
- Un:n时刻的意图和槽值对,也叫用户Action
- An-1:n-1时刻的系统Action
- Sn-1:n-1时刻的状态
- 输出是Sn:n时刻的状态
- 用户Action和系统Action不同,且需要注意
- S = {Gn,Un,Hn}
- Gn是用户目标
- Un同上
- Hn是聊天的历史,Hn= {U0, A0, U1, A1, … , U ?1, A ?1},S =f(S ?1,A ?1,U )。
DST涉及到两方面内容:状态表示、状态追踪。
- DST形象化,图
- DST常见方法
- DST评估方法
- 为了解决领域数据不足的问题,DST还有很多迁移学习(Transfer Learning)方面的工作。比如基于特征的迁移学习、基于模型的迁移学习等。




DST 主要分为三类方法:基于人工规则、基于生成式模型和基于判别模式模型。
- 基于人工规则的方法,如有限状态机(Finite State Machine, FSM)需要人工预先定义好所有的状态和状态转移的条件, 使用分数或概率最高的NLU 模块解析结果进行状态更新。目前,大多数商业应用中的对话系统都使用基于人工规则的状态更新方法来选择最有可能的结果。该方法不需要训练集,且很容易将领域的先验知识编码到规则中,与其对应的是其相关参数需要人工制定且无法自学习, ASR 和 NLU 模块的识别错误没有机会得以纠正。这种限制促进了生成式模型和判别式模型的发展。
- 生成式模型是从训练数据中学习相关联合概率密度分布,计算出所有对话状态的条件概率分布作为预测模型。统计学学习算法将对话过程映射为一个统计模型,并引入强化学习算法来计算对话状态的条件概率分布,例如贝叶斯网络、部分可观测马尔可夫模型(POMDP)等。虽然生成式模型的效果优于基于人工规则的方法,且该方法可以自动进行数据训练,减少了人工成本。但是生成式模型无法从 ASR、 NLU 等模块 挖掘大量潜在信息特征,也无法精确建模特征之间的依赖关系。此外,生成式模型进行了不必要的独立假设,在实际应用中假设往往过于理想。
- 基于判别式模型展现出更为有利的优势,它把 DST 当作分类任务,结合深度学习等方法进行自动特征提取,从而对对话状态进行精准建模。与生成式模型相比,判别式模型善于从 ASR、NLU 等模块提取重要特征,直接学习后验分布从而对模型进行化。

DSTC
- 讲到DST就不得不讲DSTC,DSTC是Dialog System Technology Challenge,主要包括6个Challenge。DSTC对DST的作用就相当于目标函数对机器学习任务的作用,真正起到了评估DST技术以及促进DST技术发展的作用。之所以先说DSTC是因为后面的很多DST的方法是在某个DSTC(大多是DSTC2、DSTC3、DSTC4、DSTC5)上做的。

- 详情参考:任务型对话系统中状态追踪(DST)
- 【2022-1-17】DSTC10开放领域对话评估比赛冠军方法总结,国际竞赛DSTC10开放领域对话评估赛道的冠军方法MME-CRS,该方法设计了多种评估指标,并利用相关性重归一化算法来集成不同指标的打分,为对话评估领域设计更有效的评估指标提供了参考。相关方法已同步发表在AAAI 2022 Workshop上。希望能给从事该技术领域工作的同学一些启发或帮助。
DP
对话策略根据 DST 估计的对话状态St,通过预设的候选动作集,选择系统动作或策略an。DP 性能的优劣决定着人机对话系统的成败。 DP 模型可以通过监督学习、强化学习和模仿学习得到
- 1.监督学习需要专家手工设计对话策略规则,通过上一步生成的动作进行监督学习。由于 DP的性能受特定域的特性、语音识别的鲁棒性、任务的复杂程度等影响,因此手工设计对话策略规则比较困难,而且难以拓展到其他领域。
- 2.强化学习是通过一个马尔可夫决策过程(Markov Decision Process, MDP),寻找最优策略的过程。MDP 可以描述为五元组(S, A, P, R, ):
- 3.模仿学习(Imitation Learning)能够很好的解决多步决策问题。模仿学习的原理是通过给智能体提供先验知识,从而学习、模仿人类行为。 先验知识提供 m 个专家的决策样本${\pi _{1},\pi _{2}…….\pi _{m}}$,每个样本定义为一个状态 s 和动作 a 行动轨迹
总结如下:



【2021-4-2】参考:任务式对话系统总结(1)—自然语言理解
对话管理的一些方法,主要有三大类:
(1)Structure-based Approaches
- Key phrase reactive
- 本质是关键词匹配,通常是通过捕捉用户最后一句话的关键词/关键短语来进行回应,比较知名的两个应用是 ELIZA 和 AIML。
- AIML(人工智能标记语言),代码示例,支持 python3、中文、* 扩展
- 本质是关键词匹配,通常是通过捕捉用户最后一句话的关键词/关键短语来进行回应,比较知名的两个应用是 ELIZA 和 AIML。
- Tree and FSM
- 把对话建模为通过树或有限状态机(图结构)的路径。 相比于 simple reactive approach,这种方法融合了更多的上下文,能用一组有限的信息交换模板来完成对话的建模。
- 这种方法适用于:
- 系统主导
- 需要从用户收集特定信息
- 用户对每个问题的回答在有限集合中
- FSM,把对话看做是在有限状态内跳转的过程,每个状态都有对应的动作和回复,如果能从开始节点顺利的流转到终止节点,任务就完成了。
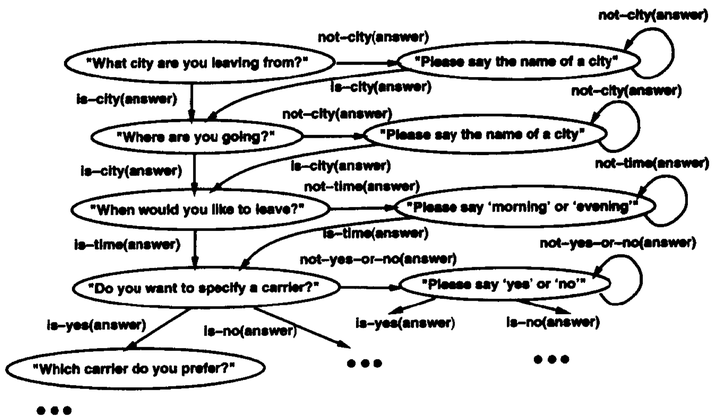
- FSM 的状态对应系统问用户的问题,弧线对应将采取的行为,依赖于用户回答。
- FSM-based DM 的特点是:
- 人为定义对话流程
- 完全由系统主导,系统问,用户答
- 答非所问的情况直接忽略
- 建模简单,能清晰明了的把交互匹配到模型
- 难以扩展,很容易变得复杂
- 适用于简单任务,对简单信息获取很友好,难以处理复杂的问题
- 缺少灵活性,表达能力有限,输入受限,对话结构/流转路径受限
- 对特定领域要设计 task-specific FSM,简单的任务 FSM 可以比较轻松的搞定,但稍复杂的问题就困难了,毕竟要考虑对话中的各种可能组合,编写和维护都要细节导向,非常耗时。一旦要扩展 FSM,哪怕只是去 handle 一个新的 observation,都要考虑很多问题。实际中,通常会加入其它机制(如变量等)来扩展 FSM 的表达能力。
(2)Principle-based Approaches
- Frame-based
- Frame-based approach 通过允许多条路径更灵活的获得信息的方法扩展了基于 FSM 的方法,它将对话建模成一个填槽的过程,槽就是多轮对话过程中将初步用户意图转化为明确用户指令所需要补全的信息。一个槽与任务处理中所需要获取的一种信息相对应。槽直接没有顺序,缺什么槽就向用户询问对应的信息。

- Frame-based DM 包含下面一些要素:
- Frame: 是槽位的集合,定义了需要由用户提供什么信息
- 对话状态:记录了哪些槽位已经被填充
- 行为选择:下一步该做什么,填充什么槽位,还是进行何种操作
- 行为选择可以按槽位填充/槽位加权填充,或者是利用本体选择
- 基于框架/模板的系统本质上是一个生成系统,不同类型的输入激发不同的生成规则,每个生成能够灵活的填入相应的模板。常常用于用户可能采取的行为相对有限、只希望用户在这些行为中进行少许转换的场合。
- Frame-based DM 特点:
- 用户回答可以包含任何一个片段/全部的槽信息
- 系统来决定下一个行为
- 支持混合主导型系统
- 相对灵活的输入,支持多种输入/多种顺序
- 适用于相对复杂的信息获取
- 难以应对更复杂的情境
- 缺少层次
- 槽的更多信息可以参考填槽与多轮对话-AI产品经理需要了解的AI技术概念
- Agenda + Frame
- Agenda + Frame(CMU Communicator) 对 frame model 进行了改进,有了层次结构,能应对更复杂的信息获取,支持话题切换、回退、退出。主要要素如下:
- product
- 树的结构,能够反映为完成这个任务需要的所有信息的顺序
- 相比于普通的 Tree and FSM approach,这里产品树(product tree)的创新在于它是动态的,可以在 session 中对树进行一系列操作比如加一个子树或者挪动子树
- process
- agenda
- 相当于任务的计划(plan)
- 类似栈的结构(generalization of stack)
- 是话题的有序列表(ordered list of topics)
- 是 handler 的有序列表(list of handlers),handler 有优先级
- handler
- 产品树上的每个节点对应一个 handler,一个 handler 封装了一个 information item
- agenda
- product
- 从 product tree 从左到右、深度优先遍历生成 agenda 的顺序。当用户输入时,系统按照 agenda 中的顺序调用每个 handler,每个 handler 尝试解释并回应用户输入。handler 捕获到信息就把信息标记为 consumed,这保证了一个 information item 只能被一个 handler 消费。
- Agenda + Frame(CMU Communicator) 对 frame model 进行了改进,有了层次结构,能应对更复杂的信息获取,支持话题切换、回退、退出。主要要素如下:
- Information-State
- Information State Theories 提出的背景是:
- 很难去评估各种 DM 系统
- 理论和实践模型存在很大的 gap
- 理论型模型有:logic-based, BDI, plan-based, attention/intention
- 实践中模型大多数是 finite-state 或者 frame-based
- 即使从理论模型出发,也有很多种实现方法
- Information State Models 作为对话建模的形式化理论,为工程化实现提供了理论指导,也为改进当前对话系统提供了大的方向。Information-state theory 的关键是识别对话中流转信息的 relevant aspects,以及这些成分是怎么被更新的,更新过程又是怎么被控制的。idea 其实比较简单,不过执行很复杂罢了
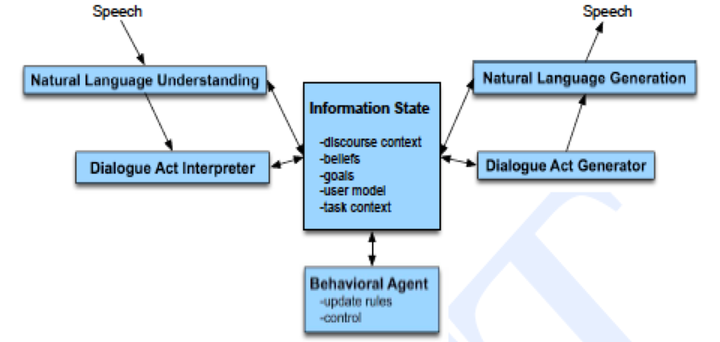
- Information State Theories 提出的背景是:
- Plan
- 一般指大名鼎鼎的 BDI (Belief, Desire, Intention) 模型。起源于三篇经典论文:
- Cohen and Perrault 1979
- Perrault and Allen 1980
- Allen and Perrault 1980
- 基本假设是,一个试图发现信息的行为人,能够利用标准的 plan 找到让听话人告诉说话人该信息的 plan。这就是 Cohen and Perrault 1979 提到的 AI Plan model,Perrault and Allen 1980 和 Allen and Perrault 1980 将 BDI 应用于理解,特别是间接言语语效的理解,本质上是对 Searle 1975 的 speech acts 给出了可计算的形式体系。
- 重要的概念:goals, actions, plan construction, plan inference。
- 理解上有点绕,简单来说就是 agent 会捕捉对 internal state (beliefs) 有益的信息,然后这个 state 与 agent 当前目标(goals/desires)相结合,再然后计划(plan/intention)就会被选择并执行。对于 communicative agents 而言,plan 的行为就是单个的 speech acts。speech acts 可以是复合(composite)或原子(atomic)的,从而允许 agent 按照计划步骤传达复杂或简单的 conceptual utterance。
- 这里简单提一下重要的概念。
- 信念(Belief):基于谓词 KNOW,如果 A 相信 P 为真,那么用 B(A, P) 来表示
- 期望(Desire):基于谓词 WANT,如果 S 希望 P 为真(S 想要实现 P),那么用 WANT(S, P) 来表示,P 可以是一些行为的状态或者实现,W(S, ACT(H)) 表示 S 想让 H 来做 ACT
- Belief 和 WANT 的逻辑都是基于公理。最简单的是基于 action schema。每个 action 都有下面的参数集:
- 前提(precondition):为成功实施该行为必须为真的条件
- 效果(effect):成功实施该行为后变为真的条件
- 体(body):为实施该行为必须达到的部分有序的目标集(partially ordered goal states)
- 一般指大名鼎鼎的 BDI (Belief, Desire, Intention) 模型。起源于三篇经典论文:
- 更多见 Plan-based models of dialogue
(3)Statistical Approaches
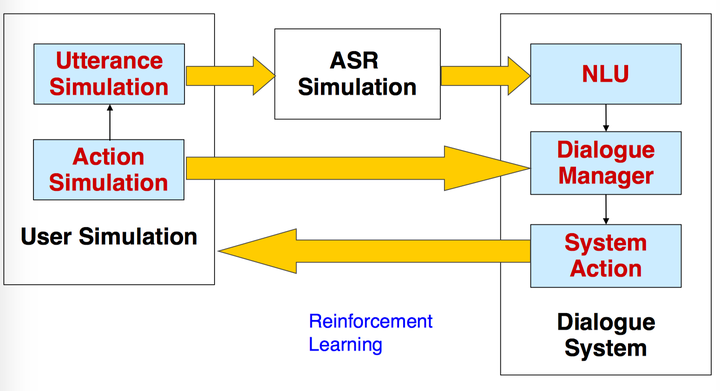
- RL-Based Approaches
- 前面提到的很多方法还是需要人工来定规则的(hand-crafted approaches),然而人很难预测所有可能的场景,这种方法也并不能重用,换个任务就需要从头再来。而一般的基于统计的方法又需要大量的数据。再者,对话系统的评估也需要花费很大的代价。
- 这种情况下,强化学习的优势就凸显出来了。RL-Based DM 能够对系统理解用户输入的不确定性进行建模,让算法来自己学习最好的行为序列。首先利用 simulated user 模拟真实用户产生各种各样的行为(捕捉了真实用户行为的丰富性),然后由系统和 simulated user 进行交互,根据 reward function 奖励好的行为,惩罚坏的行为,优化行为序列。由于 simulated user 只用在少量的人机互动语料中训练,并没有大量数据的需求,不过 user simulation 也是个很难的任务就是了。
有限状态机FSM
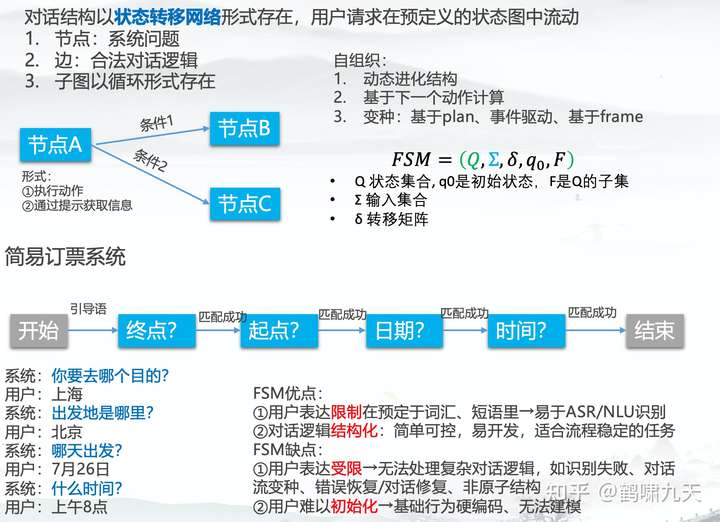
FSM 简介
有限状态机(Finite-state machine,FSM),又称有限状态自动机,简称状态机,表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。- FSM是一种算法思想,简单而言,有限状态机由一组
状态、一个初始状态、输入和根据输入及现有状态转换为下一个状态的转换函数组成。
- FSM是一种算法思想,简单而言,有限状态机由一组
- 描述有限状态机时,
状态、事件、转换和动作是经常会碰到的几个基本概念。状态(State) :对象在其生命周期中的一种状况,处于某个特定状态中的对象必然会满足某些条件、执行某些动作或者是等待某些事件。事件(Event) :在时间和空间上占有一定位置,并且对状态机来讲是有意义的那些事情。事件通常会引起状态的变迁,促使状态机从一种状态切换到另一种状态。转换(Transition):两个状态之间的一种关系,表明对象将在第一个状态中执行一定的动作,并将在某个事件发生同时某个特定条件满足时进入第二个状态。动作(Action):状态机中可以执行的那些原子操作,所谓原子操作指的是它们在运行的过程中不能被其他消息所中断,必须一直执行下去。
生活中有大量有限个状态的系统:钟表系统、电梯系统、交通信号灯系统、通信协议系统、正则表达式、硬件电路系统设计、软件工程,编译器等,有限状态机的概念就是来自于现实世界中的这些有限系统。
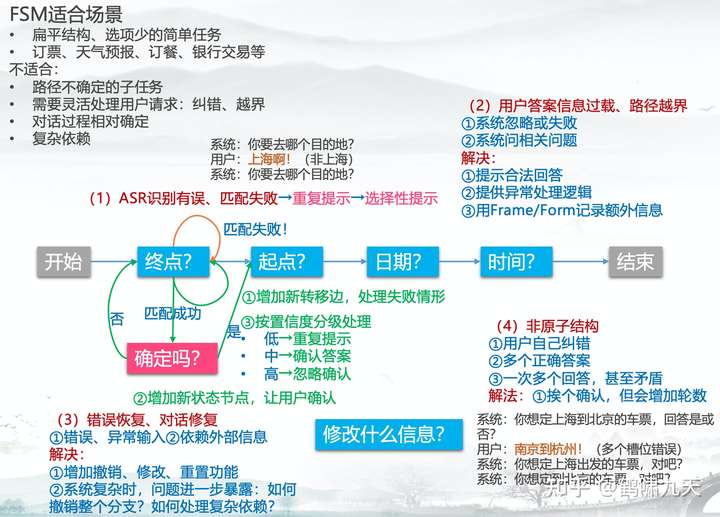
FSM 优缺点
【2022-3-23】AI应用:对话系统之有限状态机(FSM)优缺点
- (1)FSM优点
- ① 用户表达限制在预定于词汇、短语里→易于ASR/NLU识别
- ② 对话逻辑结构化:简单可控,易开发,适合流程稳定的任务
- (2)FSM缺点
- ① 用户表达受限→无法处理复杂对话逻辑,如识别失败、对话流变种、错误恢复/对话修复、非原子结构
- ② 用户难以初始化→基础行为硬编码、无法建模
- (3)FSM适合场景
- 扁平结构、选项少的简单任务
- 订票、天气预报、订餐、银行交易等
- (4)不适合
- 路径不确定的子任务
- 需要灵活处理用户请求:纠错、越界
- 对话过程相对确定
- 复杂依赖
FSM 实现
- FSME 是一个基于Qt的有限状态机工具,它能够让用户通过图形化的方式来对程序中所需要的状态机进行建模,并且还能够自动生成用C++或者Python实现的状态机框架代码。
- 类似的还有QFSM:A graphical tool for designing finite state machines

java版 FSM
Akka fsm,squirrel-foundation
- FSM-Java,项目中共有4中状态机的实现方式。参考:Java有限状态机4种实现对比
- 基于Switch语句实现的有限状态机,代码在master分支
- 基于State模式实现的有限状态机。代码在state-pattern分支
- 基于状态集合实现的有限状态机。代码在collection-state分支
- 基于枚举实现的状态机。代码在enum-state分支
- squirrel
java: 阿里小蜜DM
多轮任务对话管理器状态机:dm代码,含ppt介绍
- 总共6个有效状态节点:意图,回复,判断,服务调用,赋值,填槽
- 意图,判断,服务调用,赋值都是瞬时节点,自我驱动流转状态。
- 回复, 填槽依靠用户输入驱动状态流转。
- 一个虚拟的开始节点,一个虚拟的结束节点
整个节点的设计参考阿里云小蜜的产品设计
Python版:transitions
transitions 是一个由Python实现的轻量级的、面向对象的有限状态机框架。
Python版本
- Transitions, 扩展插件:异步状态机 transitions-anyio, 支持web形式展示、编辑
- Python的Transitions库实现有限状态机(FSM)
- python裸写状态机
- transitions-gui,基于tornado开发的状态机编辑web页面

- 安装方法
conda install transitions graphviz
transitions最基本的用法如下:
- 先自定义一个类Matter
- 定义一系列状态和状态转移
- 初始化状态机
- 获取当前的状态或者进行转化
from transitions import Machine
# 定义类:物质
class Matter(object):
pass
# 实例化
model = Matter()
# 定义状态集合 The states argument defines the name of states
states=['solid', 'liquid', 'gas', 'plasma']
# 转移矩阵 The trigger argument defines the name of the new triggering method
transitions = [
{'trigger': 'melt', 'source': 'solid', 'dest': 'liquid' },
{'trigger': 'evaporate', 'source': 'liquid', 'dest': 'gas'},
{'trigger': 'sublimate', 'source': 'solid', 'dest': 'gas'},
{'trigger': 'ionize', 'source': 'gas', 'dest': 'plasma'}]
# 定义状态机
machine = Machine(model=model, states=states, transitions=transitions, initial='solid')
# 测试 Test
print(model.state) # 当前状态:solid
model.melt() # 动作:融化
print(model.state) # 当前状态:liquid
model.evaporate() # 动作:汽化
print(model.state)
transitions库把一个完整的状态机分为执行器和控制器2部分。
- 执行器:就是在指定状态下分别干什么,各种算法都将装在此处
- 控制器:就是通过外界的动作出发来切换不同的状态。达到想让程序干啥就干啥的目的。状态切换并非状态1->状态2这么简单,还涉及到触发切换后准备阶段、退出旧状态阶段、进入新状态阶段、处于新状态阶段等等
一个状态机控制器最起码应包括几个内容:
- 控制器要控制哪个执行器 model=tracer
- 整个状态机都有哪些状态 states=states_lst
- 状态间切换的触发条件 transitions=transitions_lst
状态机
- state:状态节点
- transition:用于从一个状态节点移动到另一个状态节点
state 可以指定:
- name:状态节点的名字,必须指定。
- on_enter:进入该状态节点会产生的事件(注意,初始节点不会调用,因为已经进入了。见【验证代码】)
- on_exit:退出该状态节点会产生的事件
transition 需要指定三个东西:
- trigger:表示transition的名字(注意,不能和Number类中方法重名了)
- source:原状态节点
- dest:目标转态节点
from transitions import State
zero = '0'
one = State('1')
one = State('1', on_enter=['hello'], on_exit=['hello'])
two = {'name':'2'}
two = {'name':'2', 'on_enter':['hello'], 'on_exit':['hello']}
# ----- 状态 ------
machine.add_states(zero) # 添加一个
machine.add_states([one, two]) # 添加多个
# 一次性定义
states = [
{'name':'0'},
{'name':'1'},
{'name':'2', 'on_enter':['hello'], 'on_exit':['hello']},
]
# ---- 转移条件 -----
machine.add_transition('zero_to_one', source='0', dest='1') # 有效
machine.add_transition('zero_to_one', source='1', dest='2') # 无效
# 一次性定义
# way1
transitions = [
{ 'trigger': 'zero_to_one', 'source': '0', 'dest': '1' },
{ 'trigger': 'zero_to_two', 'source': '0', 'dest': '2' },
{ 'trigger': 'one_to_two', 'source': '1', 'dest': '2' },
{ 'trigger': 'any_to_zero', 'source': '*', 'dest': '0' }, # 任意前状态 '*'
]
# way2
transitions = [
['zero_to_one', '0', '1' ],
['one_to_two', '1', '2' ],
['any_to_zero', '*', '0' ], # 任意前状态 '*'
]
# ----- 定义状态机 -----
from transitions import Machine
class Number(object):
def hello(self):
print('hello')
pass
number = Number()
machine = Machine(model=number, states=states, initial=states[0]['name'], transitions=transitions)
# 得到了两个东西,一个是状态机machine,一个是具体的实体对象number,之后设定状态机是用machine,运行状态机是用具体的实体对象number。
now_state = number.state
print('当前状态:', now_state)
print('判断当前状态:', number.is_0()) # 格式:is_{状态名}
number.to_2() # 强行移动状态 格式:to_{状态名}
machine.get_triggers('0') # 获取到某个状态的transition
# ['to_0', 'to_1', 'to_2', 'zero_to_one', 'any_to_zero']
# 调用transition
number.zero_to_one() # 方法①
number.trigger('zero_to_one') # 方法②
- Machine示例
from transitions import Machine #不嵌套
#from transitions.extensions import HierarchicalMachine as Machine # 嵌套
#from transitions.extensions.nesting import NestedState
# 定义模型 (执行器)
class AModel(object):
def __init__(self):
self.sv = 0 # 当前状态 state variable of the model
self.conditions = { # 状态名 each state
'sA': 0,
'sB': 3,
'sC': 6,
'sD': 0,
}
def poll(self): # 动作切换
if self.sv >= self.conditions[self.state]:
self.next_state() # go to next state
else:
getattr(self, 'to_%s' % self.state)() # enter current state again
def on_enter(self): # 进入状态
print('entered state %s' % self.state)
def on_exit(self): # 退出状态
print('exited state %s' % self.state)
# setup model and state machine
model = AModel()
# 状态集合 init transitions model
list_of_states = ['sA', 'sB', 'sC', 'sD']
# 控制器
machine = Machine(model=model, states=list_of_states, initial='sA',
ordered_transitions=True, before_state_change='on_exit',
after_state_change='on_enter')
# begin main
for i in range(0, 10):
print('iter is: ' + str(i) + " -model state is:" + model.state)
model.sv = i
model.poll() # 用执行器进行切换
- GraphMachine示例,可以画图
from transitions.extensions import GraphMachine
# 定义状态集合
states = ['first', 'second']
# 定义转移集合
transitions = [
['any_trigger', 'first', 'first'],
['anything', '*', 'second'], # * 表示任何位置
]
machine = GraphMachine(states=states, transitions=transitions, initial='first',
auto_transitions=False, show_conditions=True)
# 绘制状态机
machine.get_graph().draw('fsm.png', prog='dot')
from IPython.display import Image
Image('fsm.png')
- 结果
【2022-3-23】案例实践
from transitions.extensions import GraphMachine
# 定义模型
class Matter(object):
def hello(self):
print('\t-->进入')
def bye(self):
print('\t-->退出')
m = Matter()
# 状态定义:简单
states = ['固体', '液体', '气体', '结束']
# 定义方式:复杂
states_new = [
{'name':'固体', 'on_enter':['hello'], 'on_exit':['bye']},
{'name':'液体'},
{'name':'气体', 'on_enter':['hello'], 'on_exit':['bye']},
]
# 定义转移集合
transitions = [
['熔化', '固体', '液体'],
['凝固', '液体', '固体'],
['升华', '固体', '气体'], # * 表示任何位置
['凝华', '气体', '固体'],
['液化', '气体', '液体'],
['汽化', '液体', '气体']
]
# 不用模型
#machine = GraphMachine(states=states, transitions=transitions, initial='固体',
# auto_transitions=False, show_conditions=True)
# 用模型
machine = GraphMachine(m, states=states_new, transitions=transitions, initial='固体',
auto_transitions=False, show_conditions=True)
# 临时新增转移条件
machine.add_transition('静默', source='*', dest='结束') # 有效
print('状态机所有状态:', machine.states)
print('到液体的所有转化条件:', machine.get_triggers('液体')) # 获取到某个状态的transition
print('---- 状态机测试 -----')
print('初始状态:', m.state)
print('当前状态是否固体:', m.is_固体()) # 格式:is_{状态名}
# m.to_液体() # 状态名中文不便调用
# 调用transition
print('动作:升华')
m.升华() # 方法①
print('当前状态:', m.state)
print('动作:液化')
m.trigger('液化') # 方法②
print('当前状态:', m.state)
print('判断当前状态:', m.is_固体()) # 格式:is_{状态名}
print('---- 绘制状态机 -----')
machine.get_graph().draw('fsm-状态机.png', prog='dot')
from IPython.display import Image
Image('fsm-状态机.png')
C++版:DM Kit
FSM实现:
- DM Kit,百度UNIT平台使用,含可视化编辑功能
- DMKit作为UNIT的开源对话管理模块,可以无缝对接UNIT的理解能力,并赋予开发者多状态的复杂对话流程管理能力,还可以低成本对接外部知识库,迅速丰富话术信息量。
- 【C语言】有限状态机FSM
- 一个有限状态机的C++实现,含代码解读
- 用C++11实现的FSM的代码: kuafu
一件事可能会经过多个不同状态的转换, 转换依赖于在不同时间发生的不同事件来触发, 举个例子,比如 TCP的状态转换图, 在实现上就可以用FSM
FSM的实现方案 根据具体的业务需要, 将业务的处理流程定义为一个状态机, 此状态机中存在以下必要元素
- 根据业务拆解抽象出若干个不同状态
State, 并确定此状态机的初始状态; - 抽象出用于触发状态转换的事件
Event; - 为了处理一个Event, 需要定义状态的转换过程
Transition; - 状态机要先判断当前所处的状态是否与当前发生的Event匹配 (注意: 相同的状态可能同时匹配多个Event);

注:
- MachineSet可以同时管理多个Machine;
- 外部触发的Event进入到MachineSet的事件队列;
- 事件队列里的Event被顺序处理, 被Dispatch到match的Machine;
- Machine根据当前的所处的state和Event类型来判断当前Event是否有效;
- 如果上面(4)中的Event有效, 则进行状态转换;
- 状态转换具体来说涉及到三个回调函数: 6.1 当前state离开, 是第一个回调,需要使用者根据实际需要处理; 6.2 trasition这个转换过程, 是第二个回调; 6.3 新state的进入, 是第三个回调;
- 一个简单的状态机,差不多就是上面这些内容, 剩下的就是用程序语言把它实现出来了;
实现简介: 主要就是按上面的思路, 封装了 MachineSet, Machine, Event, Transition, Predicate
对于Event的处理, 提供两种方案:
- 直接使用MachineSet提供的StartBackground, 开启一个work thread, 在这个work thread中不断从存储event的fifo队列中获取event后dispatch到各个machine;
- 不使用MachineSet提供的event fifo, 实现自己的MachineSetHandler, 将其实例注册到MachineSet, 从event的派发;
状态机适用条件
- 状态机问题
- ① 状态机模型的最大缺陷:所有状态都提前预知了才能够规划代码,所以也叫
有限状态机。以有限的状态应对可能比预期更多的状态,一旦遇到新增一个状态,全部状态机代码都得重审一遍,以免遗漏状态切换。 - ② 还有大量的数据一般都是共享的,状态机模型对数据的封闭不利,对一些本来适合在函数参数中传递的变量,适合在private中封闭掉的数据,常常被迫敞开。
- ③ 状态机的架构不太适合多线程模型,有限状态机流行的年代,高效多线程架构还不流行,这方面都是欠缺的。
- ① 状态机模型的最大缺陷:所有状态都提前预知了才能够规划代码,所以也叫
-
最重要的是状态清晰,粒度适中,状态迁移图明确可靠。一般的状态机状态数量4到8个,太少太简单,太多要注意适当切分。
- 【2021-2-24】达摩院Conversational AI研究进展及应用
- 基于状态机的对话管理主要面临两个问题:
- 第一:通过配置的方法,永远无法把整个对话流配置完备,总会有漏掉的配置;
- 第二:基于状态机的对话管理,本质上仍是一个规则化的对话引擎,即使积累再多的日志和数据,也没有办法具备学习能力。
- 基于以上两点,把对话管理从状态机推到深度模型,就是一条必然的路径,但是目前学术界尤其是工业界还没有解决这个问题,这个问题的核心难点是多轮对话数据获取难、标注难。
- (1)标注数据采集
- 达摩院引入了用户模拟器,把用户模拟器和对话系统结合在一起,通过两者之间的Self-Play产生海量的标注数据来解决数据难题。
- 在用户模拟器和对话系统的对偶模型中有两个模块:
- 对话机器人:每一轮中说机器应该说的那句话
- 用户模拟器:模拟用户这个角色应该说的话
- 这样就形成了机器和用户之间的对话过程,产生大量的对话数据,而这些数据最大的优势就是:这些数据是带有标签的。
- (2)深度模型
- 基于以上的基础建模,达摩院实现了对话管理的深度学习模型化,并且在业务场景中进行了大规模的落地应用:

- 整个过程分为以下三部分:
- Step1:利用用户模拟器冷启动对话管理模型,产生大量的模拟训练数据,通过模拟训练数据即可对模型进行训练,得到可直接上线的模型;
- Step2:模型上线之后会产生日志数据,可以利用这些日志数据来进行数据增强,通过模拟器的迭代来提升模型的效果;
- Step3:对于产生的日志数据,也可以通过人力适量标注一部分来进一步提升模型的效果;
- 通过引入用户模拟机器,解决了对话管理的深度学习模型化问题。
- (3)对话管理模型的迁移学习

- 在实际应用的时候还遇到了新的问题:当我们有了一些场景的标注数据以及训练好的模型之后,在面对新的应用场景时,如何将已有的数据和模型复用起来。
- 针对这一新的问题,达摩院考虑使用迁移学习的方法来进行解决。为此对迁移学习在这方面的应用做了一定的研究,最终提出了一个Meta-Dialog Model,对应的工作发表在ACL2020上。主要思想是将MAML(Model-Agnostic Meta-Learning)这种迁移学习的思路引入进来:在已有数据的前提下,利用MAML迁移学习的方法训练出一个比较好的元模型(Meta Model), 当有新的场景时,可以用元模型的参数来进行初始化,这可以使得新场景下的模型有更好的初始化参数和训练起点。基于这种方法,在政务12345热线上进行了实验,得到了4个点的提升。
DAG图
开源社区中DAG-based调度框架也有很多,例如cpp-taskflow。
Airflow
Airflow 是 Airbnb 开源的一个用 Python 编写的调度工具。于 2014 年启动,2015 年春季开源,2016 年加入 Apache 软件基金会的孵化计划。主要包括 Airflow 的服务构成、Airflow 的 Web 界面、DAG 配置、常用配置以及 Airflow DAG Creation Manager Plugin 这一款 Airflow 插件。
一个工作流可以用一个 DAG 来表示,在 DAG 中将完整得记录整个工作流中每个作业之间的依赖关系、条件分支等内容,并可以记录运行状态。通过 DAG,我们可以精准的得到各个作业之间的依赖关系。

- Task: 一旦Operator被实例化,它被称为”任务”。实例化为在调用抽象Operator时定义一些特定值,参数化任务使之成为DAG中的一个节点。
- 任务实例化: 一个任务实例表示任务的一次特定运行,并且被表征为dag,任务和时间点的组合。任务实例也有指示性状态,可能是“运行”,“成功”,“失败”,“跳过”,“重试”等。
Airflow的核心构建块, 概念化:
- (1)DAG:描述工作发生的顺序, 即工作流
- (2)Operator:执行某些工作的模板类,即单个任务
- Operator通常(但不总是)原子性的,这意味着它们可以独立存在,不需要与其他Operator共享资源。DAG将确保Operator按正确的顺序运行; 除了这些依赖之外,Operator通常独立运行。实际上,他们可能会运行在两台完全不同的机器上。
- 注意:如果两个Operator需要共享信息,如文件名或少量数据,则应考虑将它们组合成一个Operator。如果绝对不可避免,Airflow确实有一个名为XCom的Operator可以交叉通信。
- Airflow为Operator提供许多常见任务,包括:
- BashOperator:执行bash命令
- PythonOperator:调用任意的Python函数
- EmailOperator:发送邮件
- HTTPOperator:发送 HTTP 请求
- SqlOperator:执行 SQL 命令
- Sensor:等待一定时间,文件,数据库行,S3键等…
- 还有更多的特定Operator:DockerOperator,HiveOperator,S3FileTransferOperator,PrestoToMysqlOperator,SlackOperator …
- airflow/contrib/目录包含更多由社区建立的Operator。这些Operator并不总是与主包(in the main distribution)中的Operator一样完整或经过很好的测试,但允许用户更轻松地向平台添加新功能。Operators只有在分配给DAG时,才会被Airflow加载。
- (3)Task:Operator的参数化实例
- (4)TaskInstances(任务实例):
- 1)已分配给DAG的任务
- 2)具有DAG特定运行相关的状态 通过组合DAG和Operators来创建TaskInstances,可以构建复杂的工作流。
Operator不需要立即分配给DAG(以前dag是必需的参数)。但是一旦operator分配给DAG, 它就不能transferred或者unassigned. 当一个Operator创建时,通过延迟分配或甚至从其他Operator推断,可以让DAG得到明确的分配
# 默认目录在~/airflow,也可以使用以下命令来指定目录
export AIRFLOW_HOME=~/airflow
pip install apache-airflow
# 初始化数据库
airflow initdb
# 启动web服务,默认端口为8080,也可以通过`-p`来指定
airflow webserver -p 8080
# 启动 scheduler
airflow scheduler
Python版DAG示例:
# coding: utf-8
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
# 定义默认参数
default_args = {
'owner': 'airflow', # 拥有者名称
'start_date': datetime(2018, 6, 6, 20, 00), # 第一次开始执行的时间,为格林威治时间,为了方便测试,一般设置为当前时间减去执行周期
'email': ['shelmingsong@gmail.com'], # 接收通知的email列表
'email_on_failure': True, # 是否在任务执行失败时接收邮件
'email_on_retry': True, # 是否在任务重试时接收邮件
'retries': 3, # 失败重试次数
'retry_delay': timedelta(seconds=5) # 失败重试间隔
}
# 定义DAG
dag = DAG(
dag_id='hello_world', # dag_id
default_args=default_args, # 指定默认参数
# schedule_interval="00, *, *, *, *" # 执行周期,依次是分,时,天,月,年,此处表示每个整点执行
schedule_interval=timedelta(minutes=1) # 执行周期,表示每分钟执行一次
)
# 定义要执行的Python函数1
def hello_world_1():
current_time = str(datetime.today())
with open('/root/tmp/hello_world_1.txt', 'a') as f:
f.write('%s\n' % current_time)
assert 1 == 1 # 可以在函数中使用assert断言来判断执行是否正常,也可以直接抛出异常
# 定义要执行的Python函数2
def hello_world_2():
current_time = str(datetime.today())
with open('/root/tmp/hello_world_2.txt', 'a') as f:
f.write('%s\n' % current_time)
# 定义要执行的Python函数3
def hello_world_3():
current_time = str(datetime.today())
with open('/root/tmp/hello_world_3.txt', 'a') as f:
f.write('%s\n' % current_time)
# 定义要执行的task 1
t1 = PythonOperator(
task_id='hello_world_1', # task_id
python_callable=hello_world_1, # 指定要执行的函数
dag=dag, # 指定归属的dag
retries=2, # 重写失败重试次数,如果不写,则默认使用dag类中指定的default_args中的设置
)
# 定义要执行的task 2
t2 = PythonOperator(
task_id='hello_world_2', # task_id
python_callable=hello_world_2, # 指定要执行的函数
dag=dag, # 指定归属的dag
)
# 定义要执行的task 3
t3 = PythonOperator(
task_id='hello_world_3', # task_id
python_callable=hello_world_3, # 指定要执行的函数
dag=dag, # 指定归属的dag
)
t2.set_upstream(t1)
# 表示t2这个任务只有在t1这个任务执行成功时才执行,
# 等价于 t1.set_downstream(t2)
# 同时等价于 dag.set_dependency('hello_world_1', 'hello_world_2')
t3.set_upstream(t1) # 同理
写完后执行它检查是否有错误,如果命令行没有报错,就表示没问题。
- python $AIRFLOW_HOME/dags/hello_world.py
- 查看生效的dags: airflow list_dags
- 查看hello_world这个dag下面的tasks: airflow list_tasks hello_world
- 查看hello_world这个dag下面tasks的层级关系:airflow list_tasks hello_world –tree
# -*- coding: utf-8 -*-
import airflow
from airflow.operators.bash_operator import BashOperator
from airflow.operators.dummy_operator import DummyOperator
from airflow.models import DAG
from airflow.models import Variable
foo = Variable.get("foo", default_var='a') # 设置当获取不到时使用的默认值
bar = Variable.get("bar", deserialize_json=True) # 对json数据进行反序列化
args = {
'owner': 'airflow',
'start_date': airflow.utils.dates.days_ago(2)
}
dag = DAG(
dag_id='example_bash_operator', default_args=args,
schedule_interval='0 0 * * *')
cmd = 'ls -l'
run_this_last = DummyOperator(task_id='run_this_last', dag=dag)
run_this = BashOperator(
task_id='run_after_loop', bash_command='echo 1', dag=dag)
run_this.set_downstream(run_this_last)
for i in range(3):
i = str(i)
task = BashOperator(
task_id='runme_'+i,
bash_command='echo "" && sleep 1',
dag=dag)
task.set_downstream(run_this)
task = BashOperator(
task_id='also_run_this',
bash_command='echo "run_id= | dag_run="',
dag=dag)
task.set_downstream(run_this_last)
#------------airflow 2.0------------
with DAG('my_dag', start_date=datetime(2016, 1, 1)) as dag:
(
dag
>> DummyOperator(task_id='dummy_1') # 使用位移指定执行顺序,等效于op1.set_downstream(op2)
>> BashOperator(
task_id='bash_1',
bash_command='echo "HELLO!"')
>> PythonOperator(
task_id='python_1',
python_callable=lambda: print("GOODBYE!"))
)
AirFlow使用指南四 DAG Operator Task
Apache Airflow 2.0能否满足当前数据工程需求
Apache Airflow 作为重要的工作流调度组件,社区活跃度非常高,在2020年12月,Airflow正式发布了2.0版本。新UI的主要优点是自动刷新功能,您不再需要不断刷新浏览器来获取工作流程的更新状态,UI会自动刷新,您可以单击以禁用它

2.0版本中,可以利用完整的REST API来创建,读取,更新或删除DagRun,变量,连接或池。本地运行的Airflow,则可以通过以下URL访问Swagger UI: http://localhost:8080/api/v1/ui/
cpp-taskflow
taskflow一个写的比较好的基于task有向无环图(DAG)的并行调度的框架,之所以说写的比较好,有几点原因:
- 是一个兼具学术研究和工业使用的项目,并非一个玩具
- 现代C++开发,风格简洁 (源码要求编译器支持C++17,也比较容易改成C++11)
- 文档全面
- 注释丰富
一个通用的DAG调度框架:
- 拓扑结构的存储和表达: taskflow存储和表达拓扑结构的方式还是比较简单的,用Node类表示DAG中的每个结点,Graph类存储所有的Node对象,Topology类表示一个拓扑结构,后面再详细说。
- 拓扑结构的调度执行: taskflow的调度逻辑中为提高性能做了较多优化:通过WorkStealingQueue提高线程使用率,通过Notifier类(from Eigen库)减少生产者-消费者模式中加锁的频率等。
- 辅助工具或功能: taskflow提供方法可以比较简单的监视每个线程的活动、分析用户程序的性能。
在一个拥有四个任务的调度系统中,cpp-taskflow需要通过下面方式来配置DAG。
auto [A, B, C, D] = taskflow.emplace(
[] () { std::cout << "TaskA\n"; },
[] () { std::cout << "TaskB\n"; },
[] () { std::cout << "TaskC\n"; },
[] () { std::cout << "TaskD\n"; }
);
A.precede(B); // A runs before B
A.precede(C); // A runs before C
B.precede(D); // B runs before D
C.precede(D); // C runs before D
}
生成预期的DAG图需要人工显式定义每两个节点之间的依赖关系,这种方式虽然理解比较直观
gparallel (C++)
几乎所有框架都采用了手工配置的方式生成调度DAG。虽然理解比较直观,但是缺点也非常明显:
- 在有大量任务的时候,人工定义DAG图比较困难并且容易出错。现实中的业务系统一般是多人同时开发,这就需要模块owner对所有的任务节点之间的依赖关系进行人工梳理,可维护性较差。
- 工业环境中很多业务,往往以数据流驱动的方式表达会更加清晰,这就需要花费大量时间来将系统逻辑从数据驱动表示强行转化为任务驱动表示来适配调度系统,耗时耗力。
【2021-10-7】gparallel:一个基于DAG的任务调度框架,gparallel是一个针对具有复杂流程或逻辑的单体式信息检索系统而设计的并行任务调度框架。使用Meta Programming技术根据任务的输入和输出自动推导依赖关系,生成DAG(Directed acyclic graph)并进行并行任务调度。
gparallel是一款基于DAG(Directed acyclic graph)的并且支持自动依赖推导的任务调度框架。
gparallel主要思想有3个:
- 数据划分:将所有数据成员,按照业务逻辑和数据状态划分为不同的集合。
- 依赖推导:将所有的代码逻辑,按照功能划分为不同的task节点,并且自动推导task节点之间的依赖关系,建立DAG。
- 任务调用:通过拓扑排序,将DAG转化为偏序表示,并使用thread或者coroutine对task进行调度。
编译依赖: g++8, boost_log-mt v1.70, gtest v1.10.0

flow-chart
【2022-2-17】网页格式的流程图编辑:flow-chart, 示例
SVG实现流程图绘制,前端页面应用:jquery.js/d3.js/ semantic.css; 功能包括:
- 流程图块生成、拖拽、连线
- 放大缩小功能
- 导入导出json数据
- 产生相应的xml和xpdl
- 保存(还未完成,待更新)
DM案例
AIML
基于关键词的对话管理,比如:ELIZA 和 AIML。
AIML是Artificial Intelligence Markup Language的缩写, 用于描述一类称为AIML对象,同时部分描述了计算机程序处理这些对象时的表现。AIML是XML语言(可扩展标记语言)的衍生。
AIML (人工智能标记语言),XML格式,支持 ELIZA 规则,并且更加灵活,能支持一定的上下文实现简单的多轮对话(利用 that),支持变量,支持按 topic 组织规则等。
AIML语法
AIML对象是由topic和category单元组成的,格式化或未格式化的数据均可。格式化的数据是由字符组成的,其中有的组成符号数据,有的构成AIML元素。AIML元素将应答数据封装在文档中。包含这些元素的字符数据有可能被AIML解释器格式化,也有可能在之后的响应中处理。
aiml中的元素不区分大小写
<?xml version="1.0" encoding="GB2312"?>
<category>
<pattern>MOTHER</pattern>
<template> Tell me more about your family. </template>
</category>
<category>
<pattern>YES</pattern>
<that>DO YOU LIKE MOVIES</that>
<template>What is your favorite movie?</template>
</category>
解释:
- 第一行是所有xml文档都必须申明的,如果是中文这里要申明编码为:GB2312,如果是英文则一般申明为:UTF-8
- category表示一个意图类目,表示一个一问一答匹配和一问多种应答匹配,但不允许多中提问匹配。
- pattern表示匹配模式,表示用户的输入匹配,以上例子,用户一旦输入你好,那机器人就找到这个匹配,然后取出应答“好”;
- template表示应答,这里应答一个“好”字。
有了这几个简单的元素理论上就可以写出任意匹配模式,达到一定智能,但实际应用当中只有这些元素是不够的
语法说明:详见原文AIML元素详细说明
- think元素:将某个信息存储在变量里,简单说,记录信息,不回复
- < get name=””名字/> 即得到name的值。
- < star/>表示*:通配符
- < srai>元素:query改写
- < condition>元素:类似于if-else语句
- < if>元素:判断元素
- < gender>元素:英文性别代名词
- < input>表示用户输入
- < random>随机元素:从候选库中任选一个
- < system> < /system>元素:调用系统函数
- < that>元素:前置问题匹配(上文)
- < Topic name=”film”>元素:设置主题
- < topicstar index=”n”>元素:用来得到先前倒数第n次谈论的主题
安装
目前大部分AIML, PyAIML, 只支持Py2.7版本并且不支持中文, 但有人汉化,AIML汉化版,安装如下:
git clone https://github.com/Shuang0420/aiml.git
cd aiml
python setup.py build
python setup.py install
代码示例:更多示例见example目录
import aiml
import os
# the path where your AIML startup.xml file located
chdir = os.getcwd()
# aiml解释器初始化
k = aiml.Kernel()
# 先下载 "alice" AIML数据集
# for alice
#k.bootstrap(learnFiles="std-startup.xml", commands="load aiml b", chdir=chdir)
# for chinese 中文数据集
k.bootstrap(learnFiles="cn-startup.xml", commands="load aiml cn", chdir=chdir)
# 或者
#k.learn("cn-startup.xml")
# 做出回答
k.respond("load aiml cn")
# Loop forever, reading user input from the command
# line and printing responses.
while True:
if PY3:
print(k.respond(input("> ")))
else:
print(k.respond(raw_input("> ")))
# if python 2
# while True: print(k.respond(raw_input("> ")))
# if python 3
# while True: print(k.respond(input("> ")))
对话效果: example2目录
> 几点了
Sat Sep 18 15:54:47 CST 2021
> 我在案例
你现在在什么地方?
> 上海
真希望我也在上海,陪你.
> 天气咋样
我暂时不会说别的了.
Google Dialogflow
- DialogFlow是基于谷歌的Duplex技术开发,该技术使得客户获得更好的人机交互体验,使得对话聊天更加自然。推出 Dialogflow (https://dialogflow.com),用于替代 API.AI,将 Dialogflow 打造成您构建出色的对话体验的端到端平台
- API.AI 是一家B2D(business to developer)公司,是一个为开发者提供服务的机器人搭建平台,帮助开发者迅速开发一款bot并把发布到各种message平台上。2016年9月被Google收购,是Google基于云的自然语言理解(NLU)解决方案
- Dialogflow 提供了一个网页界面,称为 Dialogflow 控制台(访问文档,打开控制台)

- Dialogflow的工作原理。智能客服技术专栏,解码Dialogflow:构建智能机器人入门
- 1.Dialogflow的输入可以是基于文本或人声的20种不同语言,包括一些本地方言,如英语(美国和英国)或中文(简体和繁体)。文本输入来自消息传递通道,包括SMS,Webchat和电子邮件。谷歌与Slack,Facebook Messenger,Google智能助理,Twitter,微软Skype和Skype for Business,思科Webex Teams,Twilio,Viber,Line,Telegram和Kik建立了Dialogflow集成。来自Amazon和Microsoft的SMS,电子邮件和语音助理需要额外的编码或消息处理才能输入Dialogflow。
- 2.基于文本的消息可以通过可选的拼写检查程序。当人们输入或使用短信时,拼写错误很常见。纠正拼写错误将提高自然语言理解引擎的准确性。
- 3.Dialogflow的语音呼叫通过Google的语音到文本处理器,将用户的语音输入转换为文本流。
- 4.将语音转换为文本或输入文本已更正后,生成的文本流将传递到Dialogflow中的自然语言理解引擎。这实际上是支持智能机器人创建的核心元素。
- Dialogflow首先检查文本流并尝试找出用户的意图。意图是用户想要的–为什么他或她首先与机器人交互。获得正确的意图至关重要。(我们将在后续文章中讨论如何创建Dialogflow意图。)
- 意图的例子可以是“我想知道天气预报”,“我的银行余额是什么”,以及“我想要预订”。
- 意图通常具有与之关联的实体,例如名称,日期和位置。如果你想知道天气,你需要告诉机器人的位置。如果您想知道您的银行余额,那么机器人将需要获取该帐户的名称。一些比如日期,时间,地点和货币都是开箱即用的,并且是作为Google技术堆栈的一部分启用的。
- Dialogflow支持上下文的概念来管理会话状态,流和分支。上下文用于跟踪对话的状态,并且它们会在根据用户之前的回复指导对话时影响匹配的意图。上下文有助于使交互感觉自然而真实。
- Slots是与实体关联的参数。在银行余额意图示例中,实体是该人的姓名。Slot可能是正在寻找余额的人名下的特定帐号。如果您要预订机票,您的座位偏好(窗口或过道)是slot值。
- 使用Dialogflow创建智能机器人需要开发人员考虑机器人应该处理的所有意图以及用户阐明此意图的所有不同方式。然后,对于每个意图,开发人员必须识别与该意图相关联的实体,以及与每个实体相关的任何slots。如果查询中缺少实体(entity)和/或slot,则机器人需要弄清楚如何向用户询问它。
- 5.一旦Dialogflow识别出intent,entities和slot值,它就会将此信息移交给满足意图的软件代码。实现意图可能包括进行数据库检索以查找用户正在查找的信息,或者为后端或基于云的系统调用某种API。例如,如果用户要求提供银行信息,则此代码将与银行应用程序连接。如果意图是用于HR策略信息,则代码触发数据库搜索以检索所请求的信息。
- 6.一旦检索到必要的信息将通过Dialogflow传回并返回给用户。如果交互是基于文本的,则在调用以发送消息的同一渠道中将文本响应发送回用户。如果是语音请求,则将文本转换为语音响应用户。 当Dialogflow通过其中一个联络中心合作伙伴作为CCAI的一部分进行集成时,流程变得有点复杂,但功能更强大。
- 自然语言处理(NLP)算法可以计算两种不同类型的对话内容。
- ①基于意图(Intent-based)的对话:这是当NLP算法使用intents和entities进行对话时,通过识别用户声明中的名词和动词,然后与它的dictionary交叉引用,让bot可以执行有效的操作,这种类型的对话是Dialogflow使用的。
- ②基于流程(Flow-based)的对话:基于流程的对话是智能通信的下一个级别。在这里,我们会给予两个人之间对话的许多不同样本的RNN(循环神经网络),创建的机器人将根据你训练的ML模型进行响应。Wit.ai是在这个领域取得巨大进展的少数网站之一,不用担心,我们不需要做到这个程度。
- Dialogflow 可以与 Google 助理、Slack 和 Facebook Messenger 等许多热门对话平台集成。
- (1)在集成服务中使用 Fulfillment
- (2)通过 API 实现用户互动
- 如果没有使用某个集成选项,则必须编写与最终用户直接交互的代码。必须为每轮对话直接与 Dialogflow 的 API 交互,以发送最终用户表述并接收意图匹配信息。下图展示了使用该 API 进行互动的处理流程。
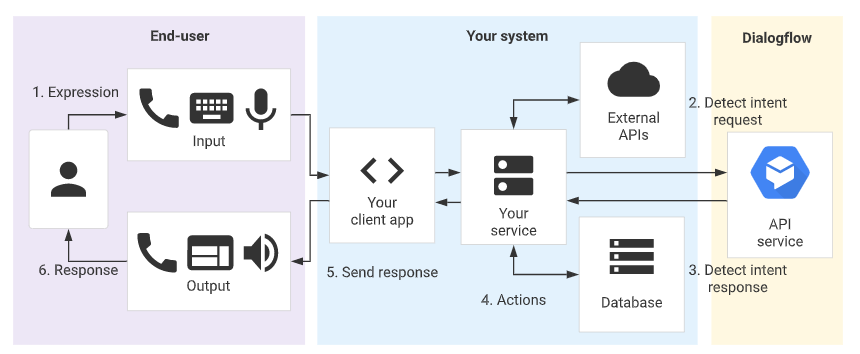
- 参考:
- Dialogueflow基础知识
- Dialogflow ES 基础知识
- 利用Dialogflow构建聊天机器人,当用户在 Google Chat 中提出问题时,启动的聊天机器人会与 Dialogflow 集成,来进行自然的对话,Dialogflow 通过 Cloud Functions 实现与后端数据库或 Sheets集成。含youtube视频介绍,解构聊天机器人系列视频
- 聊天机器人教学:使用Dialogflow (API.AI)开发 iOS Chatbot App,酒店预订示例代码:ChatbotHotel
- 登录自己的Google帐户,可以按照以下步骤登录Dialogflow:https://console.dialogflow.com/api-client/#/login

- 代理agent
- Dialogflow 代理是负责与终端用户对话的虚拟客服人员。它是一种NLU模块,能够理解人类语言的细微差别。Dialogflow 可以在对话过程中将用户输入的文字和音频转换为应用和服务可以理解的结构化数据。您可以设计并构建 Dialogflow 代理来负责您的系统所需的各种对话。
- Dialogflow 代理类似于人类呼叫中心的客服人员。您可以对代理/客服人员进行训练来处理预期的对话场景,您的训练不需要过于明确
- 意图 Intents
- 用户每轮对话的意图进行分类。可以为每个agent定义多个意图,组合意图可以处理一段完整的对话。当终端用户输入文字或说出话语(称为“终端用户表述”时,Dialogflow 会将用户表述与agent中最佳意图进行匹配。匹配意图也又称为“意图分类”。
- 例如,创建一个天气agent,用于识别并响应用户关于天气的问题。您可以为与天气预报有关的问题定义一个意图。如果最终用户说出“What’s the forecast?”,Dialogflow 会将该用户表述与预测意图相匹配。您还可以定义意图,以便从最终用户表述中提取实用信息,例如所需哪个时间或地方的天气预报。提取的数据对于系统为最终用户执行天气查询非常重要。
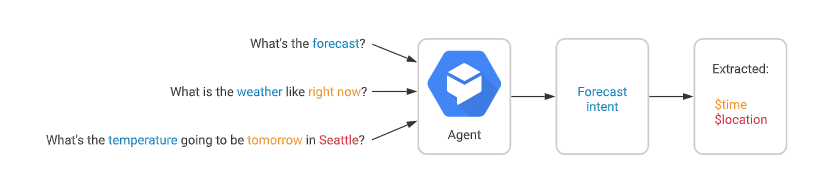
- 基本意图包含以下内容:
- 训练语句:这些是最终用户可能说出的语句示例。 当最终用户的表述与其中某一语句相近时,Dialogflow 会将其视为匹配意图。Dialogflow 的内置机器学习功能会根据您的列表扩展出其他相似的语句,因此您无需定义所有可能出现的示例。
- 操作:您可以为每个意图定义一项操作。 当某个意图匹配时,Dialogflow 会向系统提供该操作,您可以使用该操作触发系统中定义的特定操作。
- 参数:当某个意图在运行时匹配时,Dialogflow 会以“参数”形式提供从最终用户表述中提取的值。 每个参数都有一个类型,称为实体类型,用于明确说明数据的提取方式。 与原始的最终用户输入不同,参数是结构化数据,可以轻松用于执行某些逻辑或生成响应。
- 响应:您可以定义要返回给最终用户的文本、语音或视觉响应。 这些响应可能是为最终用户提供解答、向最终用户询问更多信息或终止对话。
- 下图展示了匹配意图和响应最终用户的基本流程:
- 更复杂的意图还可能包含以下内容:
- 上下文:Dialogflow 上下文类似于自然语言上下文。 如果有人对您说“它们是橙色的”,您需要了解上下文才能理解此人所指的是什么。 同样,为了让 - Dialogflow 处理类似的最终用户表述,您需要为其提供上下文,以便系统正确地匹配意图。
- 事件:借助事件,您可以根据已发生的情况而非最终用户表达的内容来调用意图。
- 实体 Entities
- 上下文
- Dialogflow 上下文类似于自然语言上下文。 如果有人对您说“它们是橙色的”,您需要了解上下文才能理解“它们”指的是什么。 同样,为了让 Dialogflow 顺利处理类似的最终用户表述,您需要为其提供上下文,以便系统正确地匹配意图。
- 您可以使用上下文来控制对话流程。 您可以为意图配置上下文,方法是设置由字符串名称标识的输入和输出上下文。 当某个意图匹配时,为该意图配置的所有输出上下文都将变为活跃状态。 当所有上下文处于活跃状态时,Dialogflow 更可能匹配配置了输入上下文,且该上下文与当前活跃上下文匹配的意图。
- 下图是一个将上下文用于银行代理的示例。
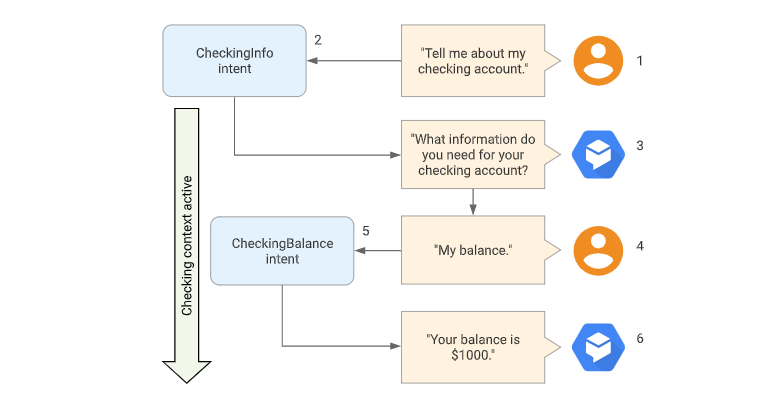
- 用户询问其支票账户的相关信息。
- Dialogflow 将此最终用户表述与 CheckingInfo 意图匹配。此意图具有 checking 输出上下文,因此上下文变为活跃状态。
- 代理询问最终用户他们希望了解支票账户的哪类信息。
- 最终用户回复“my balance”。
- Dialogflow 将此最终用户表述与 CheckingBalance 意图匹配。此意图具有 checking 输入上下文,该上下文需要处于活跃状态才能匹配此意图。当 savings 上下文处于活跃状态时,也可能存在类似的 SavingsBalance 意图来匹配该最终用户表述。
- 系统执行必要的数据库查询后,代理会回复该支票账户的余额。
- 后续意图
- 您可以使用后续意图自动设置意图对的上下文。后续意图是相关父意图下的子意图。创建后续意图时,系统会将输出上下文添加到父意图中,并将同名的输入上下文添加到子意图中。只有父意图在上一轮对话中匹配时,系统才会匹配后续意图。您还可以创建多个级别的嵌套后续意图。
- Dialogflow 提供多个预定义后续意图,旨在处理“是”、“否”或“取消”等常见的最终用户回复。您还可以创建自己的后续意图来处理自定义回复。

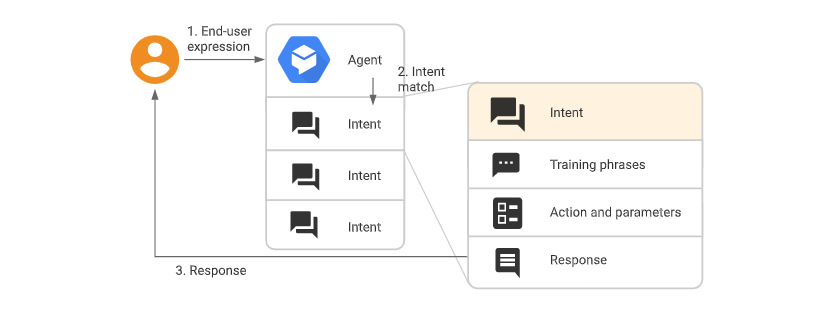
Chatterbot
- 安装
- pip install chatterbot
- 使用
from chatterbot import ChatBot
from chatterbot.trainers import ChatterBotCorpusTrainer
chatbot = ChatBot('Ron Obvious')
# Create a new trainer for the chatbot
trainer = ChatterBotCorpusTrainer(chatbot)
# Train the chatbot based on the english corpus
trainer.train("chatterbot.corpus.english")
# Get a response to an input statement
chatbot.get_response("Hello, how are you today?")
An example of typical input would be something like this:
- user: Good morning! How are you doing?
- bot: I am doing very well, thank you for asking.
- user: You’re welcome.
- bot: Do you like hats?
Rasa
Rasa是一个开源机器学习框架,用于构建上下文AI助手和聊天机器人
为什么用rasa
为什么使用Rasa而不是使用wit、luis、dialogflow这些服务?
- (1)不必把数据交给FaceBook/MSFT/Google;
- 已有的NLU工具,大多是以服务的方式,通过调用远程http的restful API来对目标语句进行解析完成上述两个任务。如Google的API.ai(收购后更名为Dialogueflow), Microsoft的Luis.ai, Facebook的Wit.ai等。刚刚被百度收购的Kitt.ai除了百度拿出来秀的语音唤醒之外,其实也有一大部分工作是在NLU上面,他们很有启发性的的Chatflow就包含了一个自己的NLU引擎。
- 对于数据敏感的用户来说,开源的NLU工具如Rasa.ai提供了另一条路。更加重要的是,可以本地部署,针对实际需求训练和调整模型,据说对一些特定领域的需求效果要比那些通用的在线NLU服务还要好很多。
- Rasa NLU本身是只支持英文和德文的。中文因为其特殊性需要加入特定的tokenizer(如jieba)作为整个流水线的一部分。代码在github上。
- (2)不必每次都做http请求;
- (3)你可以在特殊的场景中调整模型,保证更有效。
rasa示例
示例

rasa项目创建
安装
# 官方安装
python3 -m venv ./venv
source ./venv/bin/activate
pip3 install -U pip
pip3 install rasa
# 或单独安装
pip install rasa_nlu
pip install rasa_core[tensorflow]
rasa是一个聊天机器人框架,所以它有自己的项目结构,就跟Python的Django一样
rasa init # 新建rasa项目,目录结构如下
# .
# ├── actions
# │ ├── actions.py
# │ └── __init__.py
# ├── config.yml
# ├── credentials.yml
# ├── data
# │ ├── nlu.yml
# │ ├── rules.yml
# │ └── stories.yml
# ├── domain.yml
# ├── endpoints.yml
# ├── models
# │ └── 20220225-154216-short-triad.tar.gz
# └── tests
# └── test_stories.yml
rasa shell # 测试对话效果
rasa项目的开发流程
- 聊天机器人本身是一个复杂的系统,一般包含
ASR(自动语音识别)、NLU(自然语音理解)、DM(对话管理)、NLG(自然语言生成)、TTS(文本转语音)五个部分。 - 基于rasa的对话系统可以处理
NLU、DM和NLG三个部分,一般分为rasa nlu和rasa core
用rasa来开发一个聊天机器人大致可以分为如下几步:
- 项目初始化
- 准备NLU训练数据
- 配置NLU所需模型
- 准备story数据
- 定义domain
- 配置core模型
- 训练模型
- 对话测试
- 部署
rasa框架
- Rasa有两个主要模块:
- Rasa NLU (
NLU):用于理解用户消息,包括意图识别和实体识别,它会把用户的输入转换为结构化的数据。使用DIET模型(2020年5月sota)- 支持不同的 Pipeline,其后端实现可支持spaCy、MITIE、MITIE + sklearn 以及 tensorflow,其中 spaCy 是官方推荐的,另外值得注意的是从 0.12 版本后,MITIE 就被列入 Deprecated 了。
- rasa nlu 支持不同的 Pipeline,其后端实现可支持 spaCy、MITIE、MITIE + sklearn 以及 tensorflow,其中 spaCy 是官方推荐的,另外值得注意的是从 0.12 版本后,MITIE 就被列入 Deprecated 了
- 最重要的两个 pipeline 是:
supervised_embeddings和pretrained_embeddings_spacy。- 最大的区别是:pretrained_embeddings_spacy pipeline 是来自 GloVe 或 fastText 的预训练词向量;supervised_embeddings pipeline 不使用任何预先训练的词向量,是为了你的训练集而用的。
- ①
pretrained_embeddings_spacy:优势在于,当你有一个训练示例,比如:“我想买苹果”,并且要求 Rasa 预测“买梨”的意图,那么你的模型已经知道“苹果”和“梨子”这两个词非常相似,如果你没有太多的训练数据,这将很有用。 - ②
supervised_embeddings:优势在于,针对你的 domain 自定义词向量。例如:在英语中单词 “balance” 与 “symmetry” 密切相关,但是与单词 “cash” 有很大不同。在银行领域,”balance” 与 “cash” 密切相关,你希望你的模型能够做到这一点。该 pipeline 不使用特定语言模型,因此它可以与任何你分好词(空格分词或自定义分词)的语言一起使用。该模式支持任何语言。默认情况下,它以空格进行分词 - ③
MITIE:可以在 pipeline 中使用 MITIE 作为词向量的来源,从语料库中训练词向量,使用 MITIE 的特征器和多类分类器。该版本的训练可能很慢,所以不建议用于大型数据集上。- MITIE 后端对于小数据集表现良好,但如果有数百个以上的示例,训练时间可能会花费很长时间。不建议使用,因为在将来的版本中可能不再支持 MITIE。
- 中文语料源:awesome-chinese-nlp中列出的中文wikipedia dump和百度百科语料,MITIE训练耗时,也可以直接使用训练好的文件:中文 wikipedia 和百度百科语料生成的模型文件 total_word_feature_extractor_chi.dat,百度云链接,密码:p4vx
- 仅仅获取语料还不够,因为MITIE模型训练的输入是以词为单位的。所以要先进行分词,如jieba
- MITIE模型训练, 详见:用Rasa NLU构建自己的中文NLU系统
- ④ 自定义 Pipelines:可以选择不使用模板,通过列出要使用的组件名称来自定义自己的 pipeline
- 参考
- 如何选择pipeline?
- 训练数据集<1000: 用语言模型 spaCy,使用
pretraine_embeddings_spacy作为 pipeline, 它用GloVe 或 fastText 的预训练词向量 - 训练数据集≥1000或带有标签的数据:supervised_embeddings 作为 pipeline,它不使用任何预先训练的词向量,只用训练集
- 训练数据集<1000: 用语言模型 spaCy,使用
- 类别不平衡
- 如果存在很大的类别不平衡,例如:有很多针对某些意图的训练数据,但是其他意图的训练数据很少,通常情况下分类算法表现不佳。为了缓解这个问题,rasa 的
supervised_embeddingspipeline 使用了 balanced 批处理策略
- 如果存在很大的类别不平衡,例如:有很多针对某些意图的训练数据,但是其他意图的训练数据很少,通常情况下分类算法表现不佳。为了缓解这个问题,rasa 的
- 多意图
- 将意图拆分为多个标签,比如预测多个意图或者建模分层意图结构,那么只能使用有监督的嵌入 pipeline 来执行此操作。因此,需要使用这些标识:WhitespaceTokenizer:intent_split_symbol:设置分隔符字符串以拆分意图标签,默认 _ 。
- Rasa提供了数据标注平台: rasa-nlu-trainer
- Rasa Core (
DM):对话管理平台,用于举行对话和决定下一步做什么。Rasa Core是用于构建AI助手的对话引擎,是开源Rasa框架的一部分。- 负责协调聊天机器人的各个模块,起到维护人机对话的结构和状态的作用。对话管理模块涉及到的关键技术包括对话行为识别、对话状态识别、对话策略学习以及行为预测、对话奖励等。
- Rasa消息响应过程
- 首先,将用户输入的Message传递到Interpreter(NLU模块),该模块负责识别Message中的”意图(intent)“和提取所有”实体”(entity)数据;
- 其次,Rasa Core会将Interpreter提取到的意图和识别传给Tracker对象,该对象的主要作用是跟踪会话状态(conversation state);
- 第三,利用policy记录Tracker对象的当前状态,并选择执行相应的action,其中,这个action是被记录在Track对象中的;
- 最后,将执行action返回的结果输出即完成一次人机交互。
- Rasa Core包含两个内容: stories 和 domain。
- domain.yml:包括对话系统所适用的领域,包含意图集合,实体集合和相应集合,相当于大脑框架,指定了意图
intents, 实体entities, 插槽slots以及动作actions。- intents和entities与Rasa NLU模型训练样本中标记的一致。slot与标记的entities一致,actions为对话机器人对应用户的请求作出的动作。
- 此外,domain.yml中的templates部分针对utter_类型action定义了模板消息,便于对话机器人对相关动作自动回复。
- story.md:训练数据集合,原始对话在domain中的映射。
- Stories
- stories可以理解为对话的场景流程,需要告诉机器多轮场景是怎样的。Story样本数据就是Rasa Core对话系统要训练的样本,它描述了人机对话过程中可能出现的故事情节,通过对Stories样本和domain的训练得到人机对话系统所需的对话模型。
- Rasa Core中提供了rasa_core.visualize模块可视化故事,有利于掌握设计故事流程。
- Stories
- domain.yml:包括对话系统所适用的领域,包含意图集合,实体集合和相应集合,相当于大脑框架,指定了意图
- Rasa Stack —— 汉化版 Rasa_NLU_Chi
- Rasa Stack 包括 Rasa NLU 和 Rasa Core,前者负责进行语义理解(意图识别和槽值提取),而后者负责会话管理,控制跟踪会话并决定下一步要做什么,两者都使用了机器学习的方法可以从真实的会话数据进行学习;另外他们之间还相互独立,可以单独使用
- Rasa NLU (
- Rasa X(web工具)是一个工具,可帮助您构建、改进和部署由Rasa框架提供支持的AI Assistants。 Rasa X包括用户界面和REST API。
- 基本概念
- intents:意图
- pipeline:
- stories:对话管理(dialogue management)是对话系统或者聊天机器人的核心,在 Rasa 中由 Rasa Core 负责,而这部分的训练数据在Rasa 中由 Stories 提供。Stories可以理解为对话的场景流程,一个 story 是一个用户和AI小助手之间真实的对话,这里面包含了可以反映用户输入(信息)的意图和实体以及小助手在回复中应该采取的 action(行动)
- domain :即知识库,其中定义了意图(intents),动作(actions),以及对应动作所反馈的内容模板(templates),例如它能预测的用户意图,它可以处理的 actions,以及对应 actions 的响应内容。
- rasa train : 模型训练,添加 NLU 或者 Core 数据,或者修改了domain和配置文件,需要重新训练模型
- python -m rasa train –config configs/config.yml –domain configs/domain.yml –data data/
- 测试效果
- 启动rasa服务:python -m rasa run –port 5005 –endpoints configs/endpoints.yml –credentials configs/credentials.yml –debug
- 启动action服务:Python -m rasa run actions –port 5055 –actions actions –debug
- Rasa Server、Action Server和Server.py运行后,在浏览器输入测试:
- http://127.0.0.1:8088/ai?content=询广州明天的天气
- Rasa中文聊天机器人开发指南, github代码示例
- 测试命令
python -m rasa_core.run -d models/chat1 -u models/nlu/model_20190820-105546
- 参数解释;
- -d:modeldir 指定对话模型路径(即Rasa_core训练的模型路径)
- -u:Rasa NLU训练的模型路径
- –port:指定Rasa Core Web应用运行的端口号
- –credentials:指定通道(input channels)属性
- endpoints:用于指定Rasa Core连接其他web server的url地址,比如nlu web
- -o:指定log日志文件输出路径
- –debug:打印调试信息
- 参考:
- Rasa 聊天机器人框架使用
- Rasa官方文档: Build contextual chatbots and AI assistants with Rasa
- github地址:RasaHQ/rasa
百度 DM Kit
【2022-3-23】百度unit平台,支持图谱问答、文档问答; UNIT平台多轮可视化编辑体验
百度开源 DM工具 DMKit
DMKit关注其中的对话管理模块(Dialog Manager),解决对话系统中状态管理、对话逻辑处理等问题。在实际应用中,单个技能下对话逻辑一般都是根据NLU结果中意图与槽位值,结合当前对话状态,确定需要进行处理的子流程。子流程或者返回固定话术结果,或者根据NLU中槽位值与对话状态访问内部或外部知识库获取资源数据并生成话术结果返回,在返回结果的同时也对对话状态进行更新。我们将这部分对话处理逻辑进行抽象,提供一个通过配置快速构建对话流程,可复用的对话管理模块,即Reusable Dialog Manager。
- 针对状态繁多、跳转复杂的垂类,DMKit支持通过可视化编辑工具进行状态跳转流程的编辑设计,并同步转化为对话基础配置供对话管理引擎加载执行。
- 用开源的mxgraph可视化库,对话开发者可在可视化工具上进行图编辑,而该可视化库支持从图转化为xml文件, 官方说明
美团
【2021-10-8】美团智能客服核心技术与实践
- 核心技术: 机器人的能力主要包括问题推荐、问题理解、对话管理以及答案供给。
- 衡量机器人能力好坏的核心输出指标是不满意度和转人工率,分别衡量问题解决的好坏,以及能帮人工处理多少问题。而在人工辅助方面,我们提供了话术推荐和会话摘要等能力,核心指标是ATT和ACW的降低,ATT是人工和用户的平均沟通时长,ACW是人工沟通后的其它处理时长。
- 当2018年底BERT(参见《美团BERT的探索和实践》一文)出现的时候,我们很快全量使用BERT替换原来的DSSM模型。后面,又根据美团客服对话的特点,我们将BERT进行了二次训练及在线学习改造,同时为了避免业务之间的干扰,以及通过增加知识区分性降低噪音的干扰,我们还做了多任务学习(各业务在上层为独立任务)以及多域学习(Query与拓展问匹配,改为与拓展问、标准问和答案的整体匹配),最终我们的模型为Online Learning based Multi-task Multi-Field RoBERTa。经过这样一系列技术迭代,我们的识别准确率也从最初不到80%到现在接近90%的水平。
- 理解了用户意图后,有些问题是可以直接给出答案解决的,而有些问题则需要进一步厘清。比如说“如何申请餐损”这个例子,不是直接告诉申请的方法,而是先厘清是哪一个订单,是否影响食用,进而厘清一些用户的诉求是部分退款还是想安排补送,从而给出不同的解决方案。这样的一个流程是跟业务强相关的,需要由业务的运营团队来进行定义。如右边任务流程树所示,我们首先提供了可视化的TaskFlow编辑工具,并且把外呼、地图以及API等都组件化,然后业务运营人员可以通过拖拽的方式来完成Task流程设计。
- 对话引擎在与用户的真实交互中,要完成Task内各步骤的匹配调度。比如
- 用户如果不是点选”可以但影响就餐了…”这条,而是自己输入“还行,我要部分退款”,怎么办?这个意图也没有提前定义,这就需要对话引擎支持Task内各步骤的模糊匹配。我们基于Bayes Network搭建的TaskFlow Engine恰好能支持规则和概率的结合,这里的模糊匹配算法复用了问题理解模型的语义匹配能力。
- 用户问完“会员能否退订”后,机器人回复的是“无法退回”,虽然回答了这个问题,但这个时候用户很容易不满意,转而去寻找人工服务。如果这个时候除了给出答案外,还去厘清问题背后的真实原因,引导询问用户是“外卖红包无法使用”或者是“因换绑手机导致的问题”,基于顺承关系建模,用户大概率是这些情况,用户很有可能会选择,从而会话可以进一步进行,并给出更加精细的解决方案,也减少了用户直接转人工服务的行为。
- 这个引导任务称为多轮话题引导,具体做法是对会话日志中的事件共现关系以及顺承关系进行建模。原本是要建模句子级之间的引导,考虑到句子稀疏性,我们将其抽象到事件之间的引导,共现关系用的是经典的协同过滤方式建模。另外,考虑到事件之间的方向性,对事件之间的顺承关系进行建模,最终,我们在点击率、不满意度、转人工率层面,都取得了非常正向的收益
构建一个怎么样的对话平台,才能提供期望的没有NLP能力的团队也能拥有很好的对话机器人呢?首先是把对话能力工具化和流程化。如上图所示,系统可分为四层:应用场景层、解决方案层、对话能力层、平台功能层。
- 应用场景层:在售前应用场景,一类需求是商家助手,如图中所列的美团闪购IM助手和到综IM助手,需要辅助商家输入和机器人部分接管高频问题能力;还有一类需求是在没有商家IM的场景需要智能问答来填补咨询空缺,比如图中所列的酒店问一问和景点问答搜索;另外售中、售后以及企业办公场景,各自需求也不尽相同。
- 解决方案层:这就要求我们有几套解决方案,大概可以分为智能机器人、智能问答、商家辅助、座席辅助等。每个解决方案的对话能力要求也有所不同,这些解决方案是需要很方便地对基础对话能力进行组装,对使用方是透明的,可以拿来即用。
- 对话能力层:前面也进行了相应的介绍,六大核心能力包括问题推荐、问题理解、对话管理、答案供给、话术推荐和会话摘要。
- 平台功能层:此外,我们需要提供配套的运营能力,提供给业务方的运营人员来日常维护知识库、数据分析等等。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
