分词
参考
- 【2023-8-31】大模型基础组件 - Tokenizer
- 【2023-5-18】NLP三大Subword模型详解:BPE、WordPiece、ULM
- 【20236-22】Current Best Practices for Training LLMs from Scratch
分句
中文分句实现
import re
def cut_sent(para):
para = re.sub('([。!?\\?])([^”’])', r"\1\n\2", para) # 单字符断句符
para = re.sub('(\\.{6})([^”’])', r"\1\n\2", para) # 英文省略号
para = re.sub('(\\…{2})([^”’])', r"\1\n\2", para) # 中文省略号
para = re.sub('([。!?\\?][”’])([^,。!?\\?])', r'\1\n\2', para) # 双引号内的句子
para = para.rstrip() # 去掉段尾多余的换行符
return para.split("\n")
# 示例文本
text = "生活对我们任何人来说都不容易!我们必须努力,最重要的是我们必须相信自己。我们必须相信,我们每个人都能够做得很好,而且,当我们发现这是什么时,我们必须努力工作,直到我们成功。"
sentences = cut_sent(text)
for sentence in sentences:
print(sentence)
什么是分词
分词
分词是将一串文本转换成模型可识别的token的过程
Tokenization is the process of encoding a string of text into transformer-readable token ID integers.
- Most state-of-the-art LLMs use subword-based tokenizers like byte-pair encoding (
BPE) as opposed to word-based approaches. - We’ll present the strengths and weaknesses of various techniques below, with special attention to subword strategies as they’re currently the most popular versus their counterparts.
示意图
- 为什么我还是无法理解transformer? - ketchum的回答
- 输入文本分词生成token -> token 向量化 -> attention
- 含义相近的token 在向量空间“距离比较近”

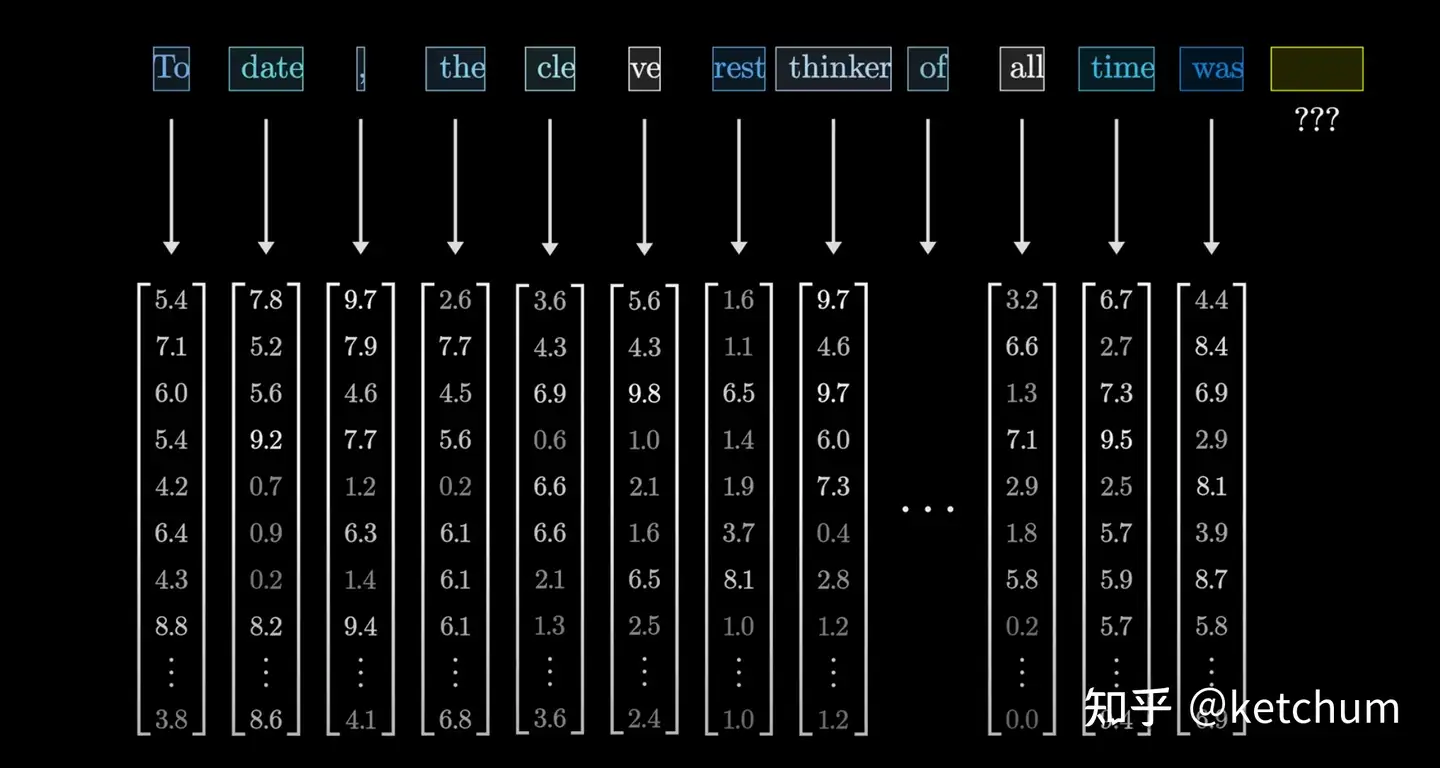
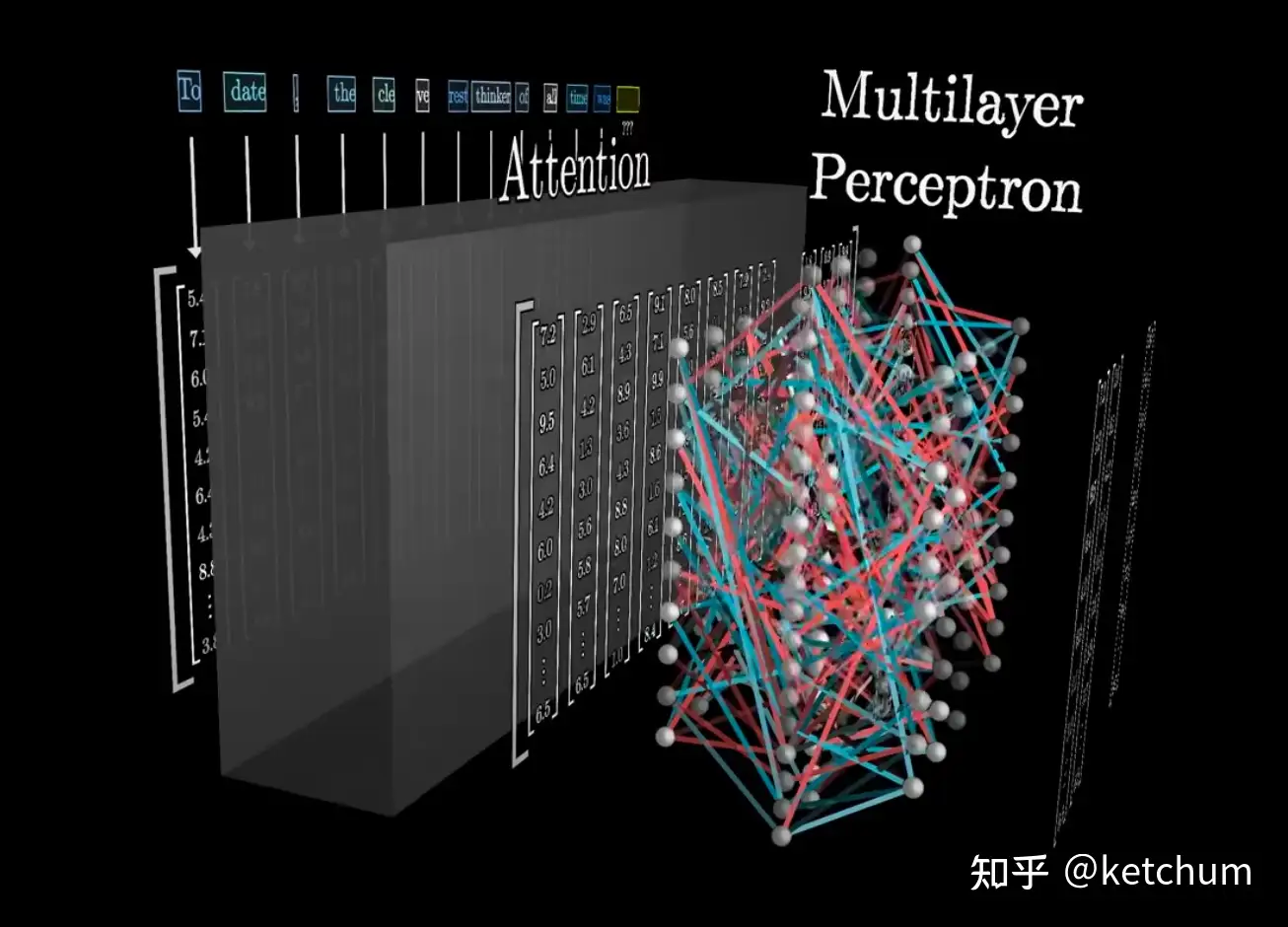
中英文分词
MIT《计算语言学》期刊(2025)研究
- 中文字符的token与部首错位”系统性地破坏了”GPT-4、GPT-4o和Llama3+模型中的中文表示。
- 中文场景下Token级别路由的精确性要求更高,稍有不慎就会损失重要信息。
英文分词与中文分词是两个世界
| 语种 | 方法 | 优点 | 不足 |
|---|---|---|---|
| 英文 | 按照空格划分 | 空格天然划分,BPE处理顺畅 | |
| 中文 | 除了标点符号还有语义分词 | 表达简洁,语义密度远高于英文 | 组合爆炸 |
参考 知乎
分词级别
Tokenization Methods
单词级别分词 Word-Level Tokenization :- Rule-based : 基于规则
- Space-based : 基于空格
- Punctualization-based : 基于拼写
字符级别分词 Character-Level Tokenization :次词分词 Subword Tokenization :- SentencePiece
- WordPiece
- Unigram
- Byte-Pair Encoder(BPE)
给定文本:我们相信AI可以让世界变得更美好。
- 按字Token化:我/们/相/信/A/I/可/以/让/世/界/变/得/更/美/好/。
- 按词Token化:我们/相信/AI/可以/让/世界/变得/更/美好/。
- 按Bi-Gram Token化:我们/们相/相信/信A/AI/I可/可以/以让/让世/世界/界变/变得/得更/更美/美好/好。

分词流程
完整的分词流程包括4个步骤:
- 文本归一化(Normalization) -> 预切分(Pre-tokenization) -> 基于分词模型的切分(Model) -> 后处理(Postprecessor)

1. 归一化 Normalization
最基础的文本清洗,包括:
- 删除多余的换行和空格
- 转小写
- 移除音调等。
例如:
input: Héllò hôw are ü?
normalization: hello how are u?
HuggingFace tokenizer的实现
2. 预分词 Pre-tokenization
预分词阶段会把句子切分成更小的“词”单元。可以基于空格或者标点进行切分。
不同的tokenizer的实现细节不一样。
英语: 简单方式是以单词为单位进行划分。细分出多种划分方式
- BERT 直接基于空格和标点进行切分。
- GPT2 也基于空格和标签,但是空格会保留成特殊字符“
Ġ”。 - T5 则只基于空格进行切分,标点不会切分。并且空格会保留成特殊字符”
▁“,并且句子开头也会添加特殊字符”▁“。
例如:
input: Hello, how are you?
pre-tokenize:
[BERT]: [('Hello', (0, 5)), (',', (5, 6)), ('how', (7, 10)), ('are', (11, 14)), ('you', (16, 19)), ('?', (19, 20))]
[GPT2]: [('Hello', (0, 5)), (',', (5, 6)), ('Ġhow', (6, 10)), ('Ġare', (10, 14)), ('Ġ', (14, 15)), ('Ġyou', (15, 19)), ('?', (19, 20))]
[t5]: [('▁Hello,', (0, 6)), ('▁how', (7, 10)), ('▁are', (11, 14)), ('▁you?', (16, 20))]
代码
model_name = "bert-base-uncased"
model_name = "gpt-2"
model_name = "t5-smal"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
3. 基于分词模型的切分 Model
不同分词模型具体的切分方式。
分词模型包括三种:
- BPE,WordPiece 和 Unigram
HuggingFace tokenizer的实现
4. 后处理 Postprecessor
后处理阶段包括一些特殊的分词逻辑,例如:
- 添加 sepcial token:[CLS],[SEP]等。
HuggingFace tokenizer的实现
方法总览
基于词的切分会造成:
- 词表规模过大
- 一定会存在UNK,造成信息丢失
- 不能学习到词缀之间的关系,例如:dog与dogs,happy与unhappy
基于字的切分,会造成:
- 每个token的信息密度低
- 序列过长,解码效率很低
所以基于词和字的切分方式是两个极端,其优缺点也是互补的。而折中的subword就是一种相对平衡的方案。
subword(次词)的基本切分原则是:
- 高频词依旧切分成完整的整词
- 低频词被切分成有意义的子词,例如 dogs => [dog, ##s]
基于subword的切分可以实现:
- 词表规模适中,解码效率较高
- 不存在UNK,信息不丢失
- 能学习到词缀之间的关系
各种分词算法演进图
词(传统)
传统词表构造方法:
- 先对各个句子进行分词,统计并选出频数最高的前N个词组成词表
- 以英语为例,总单词数量在17万到100万左右。
- 考虑到计算效率,通常N的选取无法包含训练集中的所有词。
问题
- OOV: 实际应用中,模型预测的词汇开放,对于未在词表中出现的词(Out Of Vocabulary,
OOV),模型将无法处理及生成; - 低频/稀疏:词表中的低频词/稀疏词在模型训练过程中无法得到充分训练,进而模型不能充分理解这些词的语义;
- 近义词:一个单词因为不同形态会产生不同的词,如由”look”衍生出的”looks”, “looking”, “looked”,显然这些词具有相近的意思,但是在词表中这些词会被当作不同的词处理,一方面增加了训练冗余,另一方面也造成了大词汇量问题。
字符(改进:解决OOV)
解法
- 用字符粒度来表示词表,解决OOV问题
但单词被拆分成字符后
- 丢失了词的语义信息
- 模型输入会变得很长,这使得模型的训练更加复杂难以收敛。
次词(改进)
Subword(子词)模型方法横空出世。
划分粒度介于词与字符之间,比如
- 将”looking”划分为”look”和”ing”两个子词
- 而划分出来的”look”,”ing”又能够用来构造其它词,如”look”和”ed”子词可组成单词”looked”
Subword方法能够大大降低词典大小,同时对相近词能更好地处理。
次词算法
基于subword的切分包括 BPE,WordPiece 和 Unigram 三种分词模型:
- Byte Pair Encoding (
BPE):2015年,简单有效,最流行 - WordPiece
- Unigram Language Model
| 分词方法 | 典型模型 |
|---|---|
BPE |
GPT, GPT-2, GPT-J, GPT-Neo, RoBERTa, BART, LLaMA, ChatGLM-6B, Baichuan |
WordPiece |
BERT, DistilBERT,MobileBERT |
Unigram |
AlBERT, T5, mBART, XLNet |
BPE最早是一种数据压缩算法,由Sennrich等人于2015年引入到NLP领域并很快得到推广。
- GPT-2和RoBERTa使用的Subword算法都是BPE。
Byte Pair Encoding (BPE) – 最流行
BPE(字节对) 是一种能够解决未登录词问题,并减小词典大小的方法。综合利用了单词层面编码和字符层面编码的优势
Byte-Pair Encoding(BPE)是最广泛采用的subword分词器。
- 训练方法:从字符级的小词表出发,训练产生合并规则以及一个词表
- 编码方法:将文本切分成字符,再应用训练阶段获得的合并规则
- 经典模型:GPT, GPT-2, RoBERTa, BART, LLaMA, ChatGLM等
BPE获得Subword的步骤如下:
- (1) 准备足够大的训练语料,并确定期望的Subword词表大小;
- (2) 将
单词拆分为成最小单元。比如英文中26个字母加上各种符号,这些作为初始词表;- 拆分单词成
最小单元(字符),并初始化词表。 - 单词序列后加上”<\/w>”来表示中止符。在子词解码时,中止符可以区分单词边界。

- 拆分单词成
- (3) 在语料上统计单词内相邻单元对的频数,选取频数最高的单元对, 合并成新的Subword单元;
- 最高频连续子词对”e”和”s”出现了6+3=9次,将其合并成”es”
- 由于语料中不存在’s’子词了,因此将其从词表中删除。同时加入新的子词’es’。一增一减,词表大小保持不变。

- (4) 重复第3步直到达到第1步设定的Subword词表大小或下一个最高频数为1.
- 最高频连续子词对”es”和”t”出现了6+3=9次, 将其合并成”est”
- 最高频连续子词对为”est”和”<\/w>”

示例:语料集经过统计后表示为
- 其中数字代表的是对应单词在语料中的频数
{'low':5,'lower':2,'newest':6,'widest':3}
每次合并后词表大小可能出现3种变化:
- +1: 新子词,原来的2个子词还保留(2个字词分开出现在语料中)。
- +0: 新子词,原来的2个子词中一个保留,一个被消解(一个子词完全随着另一个子词的出现而紧跟着出现)。
- -1: 新子词,原来的2个子词都被消解(2个字词同时连续出现)。
随着合并的次数增加,词表大小通常先增加后减小。
得到Subword词表后,针对每一个单词,可以采用如下的方式来进行编码:
- 将词典中的所有子词按照长度由大到小进行排序;
- 对于单词w,依次遍历排好序的词典。查看当前子词是否是该单词的子字符串,如果是,则输出当前子词,并对剩余单词字符串继续匹配。
- 如果遍历完字典后,仍然有子字符串没有匹配,则将剩余字符串替换为特殊符号输出,如”
”。 - 单词的表示即为上述所有输出子词。
- 解码过程比较简单,如果相邻子词间没有中止符,则将两子词直接拼接,否则两子词之间添加分隔符。
tiktoken
实现
- OpenAI的BPE实现:tiktoken github, demo
- 词库有3个版本
Legacy GPT-3: 更小的词库GPT-3.5 and GPT-4: 更大词库
| Encoding name | OpenAI models |
|---|---|
cl100k_base |
gpt-4, gpt-3.5-turbo, text-embedding-ada-002, text-embedding-3-small, text-embedding-3-large |
p50k_base |
Codex models, text-davinci-002, text-davinci-003 |
r50k_base (or gpt2) |
GPT-3 models like davinci |
详见 OpenAI Cookbook 的 notebook笔记:How to count tokens with tiktoken
# pip install tiktoken
import tiktoken
# 初始化词库
enc = tiktoken.get_encoding("cl100k_base")
# 字符编码、解码验证
assert enc.decode(enc.encode("hello world")) == "hello world"
# 使用特定模型的分词器
# To get the tokeniser corresponding to a specific model in the OpenAI API:
enc = tiktoken.encoding_for_model("gpt-4")
enc.encode('你是谁, my name') # 返回: [57668, 21043, 39013, 223, 11, 856, 836]
notebook 可视化展示, 用于教学演示
- 颜色区分分词效果
from tiktoken._educational import *
# Train a BPE tokeniser on a small amount of text
enc = train_simple_encoding()
# Visualise how the GPT-4 encoder encodes text
enc = SimpleBytePairEncoding.from_tiktoken("cl100k_base")
enc.encode("hello world aaaaaaaaaaaa")
分词扩展
- 指定特殊字符: special_tokens 参数明确特殊字符
cl100k_base = tiktoken.get_encoding("cl100k_base")
# In production, load the arguments directly instead of accessing private attributes
# See openai_public.py for examples of arguments for specific encodings
enc = tiktoken.Encoding(
# If you're changing the set of special tokens, make sure to use a different name
# It should be clear from the name what behaviour to expect.
name="cl100k_im",
pat_str=cl100k_base._pat_str,
mergeable_ranks=cl100k_base._mergeable_ranks,
special_tokens={
**cl100k_base._special_tokens,
"<|im_start|>": 100264,
"<|im_end|>": 100265,
}
)
huggingface transformers 版本
语料
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
预切分处理。采用gpt2的预切分逻辑。具体会按照空格和标点进行切分,并且空格会保留成特殊的字符“Ġ”。
from transformers import AutoTokenizer
# init pre tokenize function
gpt2_tokenizer = AutoTokenizer.from_pretrained("gpt2")
pre_tokenize_function = gpt2_tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str
# pre tokenize
pre_tokenized_corpus = [pre_tokenize_str(text) for text in corpus]
获得的pre_tokenized_corpus如下,每个单元分别为 [word, (start_index, end_index)]
[
[('This', (0, 4)), ('Ġis', (4, 7)), ('Ġthe', (7, 11)), ('ĠHugging', (11, 19)), ('ĠFace', (19, 24)), ('ĠCourse', (24, 31)), ('.', (31, 32))],
[('This', (0, 4)), ('Ġchapter', (4, 12)), ('Ġis', (12, 15)), ('Ġabout', (15, 21)), ('Ġtokenization', (21, 34)), ('.', (34, 35))],
[('This', (0, 4)), ('Ġsection', (4, 12)), ('Ġshows', (12, 18)), ('Ġseveral', (18, 26)), ('Ġtokenizer', (26, 36)), ('Ġalgorithms', (36, 47)), ('.', (47, 48))],
[('Hopefully', (0, 9)), (',', (9, 10)), ('Ġyou', (10, 14)), ('Ġwill', (14, 19)), ('Ġbe', (19, 22)), ('Ġable', (22, 27)), ('Ġto', (27, 30)), ('Ġunderstand', (30, 41)), ('Ġhow', (41, 45)), ('Ġthey', (45, 50)), ('Ġare', (50, 54)), ('Ġtrained', (54, 62)), ('Ġand', (62, 66)), ('Ġgenerate', (66, 75)), ('Ġtokens', (75, 82)), ('.', (82, 83))]
]
进一步统计每个整词的词频
word2count = defaultdict(int)
for split_text in pre_tokenized_corpus:
for word, _ in split_text:
word2count[word] += 1
获得word2count如下
defaultdict(<class 'int'>, {'This': 3, 'Ġis': 2, 'Ġthe': 1, 'ĠHugging': 1, 'ĠFace': 1, 'ĠCourse': 1, '.': 4, 'Ġchapter': 1, 'Ġabout': 1, 'Ġtokenization': 1, 'Ġsection': 1, 'Ġshows': 1, 'Ġseveral': 1, 'Ġtokenizer': 1, 'Ġalgorithms': 1, 'Hopefully': 1, ',': 1, 'Ġyou': 1, 'Ġwill': 1, 'Ġbe': 1, 'Ġable': 1, 'Ġto': 1, 'Ġunderstand': 1, 'Ġhow': 1, 'Ġthey': 1, 'Ġare': 1, 'Ġtrained': 1, 'Ġand': 1, 'Ġgenerate': 1, 'Ġtokens': 1})
因为BPE是从字符级别的小词表,逐步合并成大词表,所以需要先获得字符级别的小词表。
vocab_set = set()
for word in word2count:
vocab_set.update(list(word))
vocabs = list(vocab_set)
获得的初始小词表vocabs如下:
['i', 't', 'p', 'o', 'r', 'm', 'e', ',', 'y', 'v', 'Ġ', 'F', 'a', 'C', 'H', '.', 'f', 'l', 'u', 'c', 'T', 'k', 'h', 'z', 'd', 'g', 'w', 'n', 's', 'b']
基于小词表就可以对每个整词进行切分
word2splits = {word: [c for c in word] for word in word2count}
'This': ['T', 'h', 'i', 's'],
'Ġis': ['Ġ', 'i', 's'],
'Ġthe': ['Ġ', 't', 'h', 'e'],
...
'Ġand': ['Ġ', 'a', 'n', 'd'],
'Ġgenerate': ['Ġ', 'g', 'e', 'n', 'e', 'r', 'a', 't', 'e'],
'Ġtokens': ['Ġ', 't', 'o', 'k', 'e', 'n', 's']
基于word2splits统计vocabs中相邻两个pair的词频pair2count
def _compute_pair2score(word2splits, word2count):
pair2count = defaultdict(int)
for word, word_count in word2count.items():
split = word2splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair2count[pair] += word_count
return pair2count
获得pair2count如下:
defaultdict(<class 'int'>, {('T', 'h'): 3, ('h', 'i'): 3, ('i', 's'): 5, ('Ġ', 'i'): 2, ('Ġ', 't'): 7, ('t', 'h'): 3, ..., ('n', 's'): 1})
统计当前频率最高的相邻pair
def _compute_most_score_pair(pair2count):
best_pair = None
max_freq = None
for pair, freq in pair2count.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
return best_pair
经过统计,当前频率最高的pair为: (‘Ġ’, ‘t’), 频率为7次。 将(‘Ġ’, ‘t’)合并成一个词并添加到词表中。同时在合并规则中添加(‘Ġ’, ‘t’)这条合并规则。
merge_rules = []
best_pair = self._compute_most_score_pair(pair2score)
vocabs.append(best_pair[0] + best_pair[1])
merge_rules.append(best_pair)
此时的vocab词表更新成:
['i', 't', 'p', 'o', 'r', 'm', 'e', ',', 'y', 'v', 'Ġ', 'F', 'a', 'C', 'H', '.', 'f', 'l', 'u', 'c', 'T', 'k', 'h', 'z', 'd', 'g', 'w', 'n', 's', 'b',
'Ġt']
根据更新后的vocab重新对word2count进行切分。具体实现上,可以直接在旧的word2split上应用新的合并规则(‘Ġ’, ‘t’)
def _merge_pair(a, b, word2splits):
new_word2splits = dict()
for word, split in word2splits.items():
if len(split) == 1:
new_word2splits[word] = split
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2:]
else:
i += 1
new_word2splits[word] = split
return new_word2splits
从而获得新的word2split
{'This': ['T', 'h', 'i', 's'],
'Ġis': ['Ġ', 'i', 's'],
'Ġthe': ['Ġt', 'h', 'e'],
'ĠHugging': ['Ġ', 'H', 'u', 'g', 'g', 'i', 'n', 'g'],
...
'Ġtokens': ['Ġt', 'o', 'k', 'e', 'n', 's']}
可以看到新的word2split中已经包含了新的词”Ġt”。
重复上述循环直到整个词表的大小达到预先设定的词表大小。
while len(vocabs) < vocab_size:
pair2score = self._compute_pair2score(word2splits, word2count)
best_pair = self._compute_most_score_pair(pair2score)
vocabs.append(best_pair[0] + best_pair[1])
merge_rules.append(best_pair)
word2splits = self._merge_pair(best_pair[0], best_pair[1], word2splits)
假定最终词表的大小为50,经过上述迭代后我们获得的词表和合并规则如下:
vocabs = ['i', 't', 'p', 'o', 'r', 'm', 'e', ',', 'y', 'v', 'Ġ', 'F', 'a', 'C', 'H', '.', 'f', 'l', 'u', 'c', 'T', 'k', 'h', 'z', 'd', 'g', 'w', 'n', 's', 'b', 'Ġt', 'is', 'er', 'Ġa', 'Ġto', 'en', 'Th', 'This', 'ou', 'se', 'Ġtok', 'Ġtoken', 'nd', 'Ġis', 'Ġth', 'Ġthe', 'in', 'Ġab', 'Ġtokeni', 'Ġtokeniz']
merge_rules = [('Ġ', 't'), ('i', 's'), ('e', 'r'), ('Ġ', 'a'), ('Ġt', 'o'), ('e', 'n'), ('T', 'h'), ('Th', 'is'), ('o', 'u'), ('s', 'e'), ('Ġto', 'k'), ('Ġtok', 'en'), ('n', 'd'), ('Ġ', 'is'), ('Ġt', 'h'), ('Ġth', 'e'), ('i', 'n'), ('Ġa', 'b'), ('Ġtoken', 'i'), ('Ġtokeni', 'z')]
至此根据给定的语料完成了BPE分词器的训练。
推理阶段
- 给定一个句子,将其切分成一个token的序列。
具体实现
- 先对句子进行预分词并切分成字符级别的序列,然后根据合并规则进行合并。
def tokenize(self, text: str) -> List[str]:
# pre tokenize
words = [word for word, _ in self.pre_tokenize_str(text)]
# split into char level
splits = [[c for c in word] for word in words]
# apply merge rules
for merge_rule in self.merge_rules:
for index, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == merge_rule[0] and split[i + 1] == merge_rule[1]:
split = split[:i] + ["".join(merge_rule)] + split[i + 2:]
else:
i += 1
splits[index] = split
return sum(splits, [])
例如
tokenize("This is not a token.")
# ['This', 'Ġis', 'Ġ', 'n', 'o', 't', 'Ġa', 'Ġtoken', '.']
BBPE – 升级
2019年提出的 Byte-level BPE (BBPE)算法是上面BPE算法的进一步升级。
核心思想
- 用byte来构建最基础的词表而不是字符。
- 首先将文本按照UTF-8进行编码,每个字符在UTF-8的表示中占据1-4个byte。
- 在byte序列上再使用BPE算法,进行byte level的相邻合并。
编码形式如下图所示:

这种方式更好的处理跨语言和不常见字符的特殊问题(例如,颜文字),相比传统的BPE更节省词表空间(同等词表大小效果更好),每个token也能获得更充分的训练。
但解码阶段,一个byte序列可能解码后不是一个合法的字符序列,这里需要采用动态规划的算法进行解码,使其能解码出尽可能多的合法字符。
WordPiece – 特殊的 BPE
WordPiece 分词与BPE非常类似,只是在训练阶段合并pair的策略不是pair的频率而是互信息
- pair的频率很高,但是其中pair的一部分的频率更高,这时候不一定需要进行该pair的合并。 而如果一个pair的频率很高,并且这个pair的两个部分都是只出现在这个pair中,就说明这个pair很值得合并。
分析
- 训练方法:从字符级的小词表出发,训练产生合并规则以及一个词表
- 编码方法:将文本切分成词,对每个词在词表中进行最大前向匹配
- 经典模型:BERT及其系列DistilBERT,MobileBERT等
Google的Bert模型分词时使用的是WordPiece算法。
与BPE算法类似,WordPiece算法也是每次从词表中选出两个子词合并成新子词。
最大区别: 如何选择两个子词进行合并
- BPE选择频数最高的相邻子词合并
- 而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
WordPiece每次选择合并的两个子词,他们具有最大的互信息值,即两子词在语言模型上具有较强的关联性,经常在语料中以相邻方式同时出现。
训练阶段
在训练环节,给定语料,通过训练算法,生成最终的词表。 WordPiece算法也是从一个字符级别的词表为基础,逐步扩充成大词表。合并规则为选择相邻pair互信息最大的进行合并。
假定训练的语料(已归一化处理)为
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
首先进行预切分处理。这里采用BERT的预切分逻辑。具体会按照空格和标点进行切分。
from transformers import AutoTokenizer
# init pre tokenize function
bert_tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
pre_tokenize_function = bert_tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str
# pre tokenize
pre_tokenized_corpus = [pre_tokenize_str(text) for text in corpus]
获得的pre_tokenized_corpus如下,每个单元分别为[word, (start_index, end_index)]
[
[('This', (0, 4)), ('is', (5, 7)), ('the', (8, 11)), ('Hugging', (12, 19)), ('Face', (20, 24)), ('Course', (25, 31)), ('.', (31, 32))],
[('This', (0, 4)), ('chapter', (5, 12)), ('is', (13, 15)), ('about', (16, 21)), ('tokenization', (22, 34)), ('.', (34, 35))],
[('This', (0, 4)), ('section', (5, 12)), ('shows', (13, 18)), ('several', (19, 26)), ('tokenizer', (27, 36)), ('algorithms', (37, 47)), ('.', (47, 48))],
[('Hopefully', (0, 9)), (',', (9, 10)), ('you', (11, 14)), ('will', (15, 19)), ('be', (20, 22)), ('able', (23, 27)), ('to', (28, 30)), ('understand', (31, 41)), ('how', (42, 45)), ('they', (46, 50)), ('are', (51, 54)), ('trained', (55, 62)), ('and', (63, 66)), ('generate', (67, 75)), ('tokens', (76, 82)), ('.', (82, 83))]
]
进一步统计词频
word2count = defaultdict(int)
for split_text in pre_tokenized_corpus:
for word, _ in split_text:
word2count[word] += 1
获得word2count如下
defaultdict(<class 'int'>, {'This': 3, 'is': 2, 'the': 1, 'Hugging': 1, 'Face': 1, 'Course': 1, '.': 4, 'chapter': 1, 'about': 1, 'tokenization': 1, 'section': 1, 'shows': 1, 'several': 1, 'tokenizer': 1, 'algorithms': 1, 'Hopefully': 1, ',': 1, 'you': 1, 'will': 1, 'be': 1, 'able': 1, 'to': 1, 'understand': 1, 'how': 1, 'they': 1, 'are': 1, 'trained': 1, 'and': 1, 'generate': 1, 'tokens': 1})
因为WordPiece同样是从字符级别的小词表,逐步合并成大词表,所以先获得字符级别的小词表。注意这里如果字符不是不一个词的开始,需要添加上特殊字符”##”。
vocab_set = set()
for word in word2count:
vocab_set.add(word[0])
vocab_set.update(['##' + c for c in word[1:]])
vocabs = list(vocab_set)
获得的初始小词表vocabs如下:
['##a', '##b', '##c', '##d', '##e', '##f', '##g', '##h', '##i', '##k', '##l', '##m', '##n', '##o', '##p', '##r', '##s', '##t', '##u', '##v', '##w', '##y', '##z', ',', '.', 'C', 'F', 'H', 'T', 'a', 'b', 'c', 'g', 'h', 'i', 's', 't', 'u', 'w', 'y']
基于小词表对每个词进行切分
word2splits = {word: [word[0]] + ['##' + c for c in word[1:]] for word in word2count}
{'This': ['T', '##h', '##i', '##s'],
'is': ['i', '##s'],
'the': ['t', '##h', '##e'],
'Hugging': ['H', '##u', '##g', '##g', '##i', '##n', '##g'],
...
'generate': ['g', '##e', '##n', '##e', '##r', '##a', '##t', '##e'],
'tokens': ['t', '##o', '##k', '##e', '##n', '##s']}
进一步统计vocabs中相邻两个pair的互信息
def _compute_pair2score(word2splits, word2count):
"""
计算每个pair的分数
score=(freq_of_pair)/(freq_of_first_element×freq_of_second_element)
:return:
"""
vocab2count = defaultdict(int)
pair2count = defaultdict(int)
for word, word_count in word2count.items():
splits = word2splits[word]
if len(splits) == 1:
vocab2count[splits[0]] += word_count
continue
for i in range(len(splits) - 1):
pair = (splits[i], splits[i + 1])
vocab2count[splits[i]] += word_count
pair2count[pair] += word_count
vocab2count[splits[-1]] += word_count
scores = {
pair: freq / (vocab2count[pair[0]] * vocab2count[pair[1]])
for pair, freq in pair2count.items()
}
return scores
获得每个pair的互信息如下:
{('T', '##h'): 0.125,
('##h', '##i'): 0.03409090909090909,
('##i', '##s'): 0.02727272727272727,
('a', '##b'): 0.2,
...
('##n', '##s'): 0.00909090909090909}
统计出互信息最高的相邻pair
def _compute_most_score_pair(pair2score):
best_pair = None
max_score = None
for pair, score in pair2score.items():
if max_score is None or max_score < score:
best_pair = pair
max_score = score
return best_pair
此时互信息最高的pair为: (‘a’, ‘##b’) 将(‘a’, ‘##b’)合并成一个词’ab’并添加到词表中
best_pair = self._compute_most_score_pair(pair2score)
vocabs.append(best_pair[0] + best_pair[1])
这样vocab词表更新成:
['##a', '##b', '##c', '##d', '##e', '##f', '##g', '##h', '##i', '##k', '##l', '##m', '##n', '##o', '##p', '##r', '##s', '##t', '##u', '##v', '##w', '##y', '##z', ',', '.', 'C', 'F', 'H', 'T', 'a', 'b', 'c', 'g', 'h', 'i', 's', 't', 'u', 'w', 'y',
'ab']
根据更新的vocab重新对word2count进行切分。
def _merge_pair(a, b, word2splits):
new_word2splits = dict()
for word, split in word2splits.items():
if len(split) == 1:
new_word2splits[word] = split
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
merge = a + b[2:] if b.startswith("##") else a + b
split = split[:i] + [merge] + split[i + 2:]
else:
i += 1
new_word2splits[word] = split
return new_word2splits
获得新的word2split
{'This': ['T', '##h', '##i', '##s'],
'is': ['i', '##s'], 'the': ['t', '##h', '##e'],
'Hugging': ['H', '##u', '##g', '##g', '##i', '##n', '##g'],
'about': ['ab', '##o', '##u', '##t'],
'tokens': ['t', '##o', '##k', '##e', '##n', '##s']}
可以看到新的word2split中已经包含了新的词”ab”。
重复上述步骤,直到整个词表的大小达到预先设定的词表大小。
while len(vocabs) < vocab_size:
pair2score = self._compute_pair2score(word2splits, word2count)
best_pair = self._compute_most_score_pair(pair2score)
word2splits = self._merge_pair(best_pair[0], best_pair[1], word2splits)
new_token = best_pair[0] + best_pair[1][2:] if best_pair[1].startswith('##') else best_pair[1]
vocabs.append(new_token)
假定最终词表的大小为70,经过上述迭代后我们获得的词表如下:
vocabs = ['##a', '##b', '##c', '##ct', '##d', '##e', '##f', '##fu', '##ful', '##full', '##fully', '##g', '##h', '##hm', '##i', '##k', '##l', '##m', '##n', '##o', '##p', '##r', '##s', '##t', '##thm', '##thms', '##u', '##ut', '##v', '##w', '##y', '##z', '##za', '##zat', ',', '.', 'C', 'F', 'Fa', 'Fac', 'H', 'Hu', 'Hug', 'Hugg', 'T', 'Th', 'a', 'ab', 'b', 'c', 'ch', 'cha', 'chap', 'chapt', 'g', 'h', 'i', 'is', 's', 'sh', 't', 'th', 'u', 'w', 'y', '[CLS]', '[MASK]', '[PAD]', '[SEP]', '[UNK]']
注意词表中添加了特殊的token:[CLS], [MASK], [PAD], [SEP], [UNK] 至此我们就根据给定的语料完成了WordPiece分词器的训练。
推理阶段
在推理阶段,给定一个句子,需要将其切分成一个token的序列。 具体实现上需要先对句子进行预分词,然后对每个词进行在词表中进行最大前向的匹配。如果词表中不存在则为UNK。
def _encode_word(self, word):
tokens = []
while len(word) > 0:
i = len(word)
while i > 0 and word[:i] not in self.vocabs:
i -= 1
if i == 0:
return ["[UNK]"]
tokens.append(word[:i])
word = word[i:]
if len(word) > 0:
word = f"##{word}"
return tokens
def tokenize(self, text):
words = [word for word, _ in self.pre_tokenize_str(text)]
encoded_words = [self._encode_word(word) for word in words]
return sum(encoded_words, [])
例如
tokenize("This is the Hugging Face course!")
['Th', '##i', '##s', 'is', 'th', '##e', 'Hugg', '##i', '##n', '##g', 'Fac', '##e', 'c', '##o', '##u', '##r', '##s', '##e', '[UNK]']
Unigram Language Model (ULM)
Unigram 分词与 BPE 和 WordPiece 不同,基于一个大词表逐步裁剪成一个小词表。 通过Unigram语言模型计算删除不同subword造成的损失来衡量subword的重要性,保留重要性较高的子词。
- 训练方法:从包含字符和全部子词的大词表出发,通过训练逐步裁剪出一个小词表,并且每个词都有自己的分数。
- 编码方法:将文本切分成词,对每个词基于Viterbi算法求解出最佳解码路径。
- 经典模型:AlBERT, T5, mBART, Big Bird, XLNet
与 WordPiece 一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。
不同之处
BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。- 而
Unigram Language Model则是减量法, 即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。
ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
ULM算法采用不断迭代的方法来构造词表以及求解分词概率:
- 初始时,建立一个足够大的词表。一般,可用语料中的所有字符加上常见的子字符串初始化词表,也可以通过BPE算法初始化。
- 针对当前词表,用EM算法求解每个子词在语料上的概率。
- 对于每个子词,计算当该子词被从词表中移除时,总的loss降低了多少,记为该子词的loss。
- 将子词按照loss大小进行排序,丢弃一定比例loss最小的子词(比如20%),保留下来的子词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV情况。
- 重复步骤2到4,直到词表大小减少到设定范围。
ULM会保留那些以较高频率出现在很多句子的分词结果中的子词,因为这些子词如果被丢弃,其损失会很大。
训练阶段
在训练环节,目标是给定语料,通过训练算法,生成最终的词表,并且每个词有自己的概率值。 Unigram算法是从大词表为基础,逐步裁剪成小词表。裁剪规则是根据Unigram语言模型的打分依次裁剪重要度相对较低的词。
假定训练的语料(已归一化处理)为
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
首先进行预切分处理。这里采用xlnet的预切分逻辑。具体会按照空格进行切分,标点不会切分。并且空格会保留成特殊字符”▁”,句子开头也会添加特殊字符”▁”。
from transformers import AutoTokenizer
# init pre tokenize function
xlnet_tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
pre_tokenize_function = xlnet_tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str
# pre tokenize
pre_tokenized_corpus = [pre_tokenize_str(text) for text in corpus]
获得的pre_tokenized_corpus如下,每个单元分别为[word, (start_index, end_index)]
[
[('▁This', (0, 4)), ('▁is', (5, 7)), ('▁the', (8, 11)), ('▁Hugging', (12, 19)), ('▁Face', (20, 24)), ('▁Course.', (25, 32))],
[('▁This', (0, 4)), ('▁chapter', (5, 12)), ('▁is', (13, 15)), ('▁about', (16, 21)), ('▁tokenization.', (22, 35))],
[('▁This', (0, 4)), ('▁section', (5, 12)), ('▁shows', (13, 18)), ('▁several', (19, 26)), ('▁tokenizer', (27, 36)), ('▁algorithms.', (37, 48))],
[('▁Hopefully,', (0, 10)), ('▁you', (11, 14)), ('▁will', (15, 19)), ('▁be', (20, 22)), ('▁able', (23, 27)), ('▁to', (28, 30)), ('▁understand', (31, 41)), ('▁how', (42, 45)), ('▁they', (46, 50)), ('▁are', (51, 54)), ('▁trained', (55, 62)), ('▁and', (63, 66)), ('▁generate', (67, 75)), ('▁tokens.', (76, 83))]
]
进一步统计词频
word2count = defaultdict(int)
for split_text in pre_tokenized_corpus:
for word, _ in split_text:
word2count[word] += 1
获得word2count如下
defaultdict(<class 'int'>, {'▁This': 3, '▁is': 2, '▁the': 1, '▁Hugging': 1, '▁Face': 1, '▁Course.': 1, '▁chapter': 1, '▁about': 1, '▁tokenization.': 1, '▁section': 1, '▁shows': 1, '▁several': 1, '▁tokenizer': 1, '▁algorithms.': 1, '▁Hopefully,': 1, '▁you': 1, '▁will': 1, '▁be': 1, '▁able': 1, '▁to': 1, '▁understand': 1, '▁how': 1, '▁they': 1, '▁are': 1, '▁trained': 1, '▁and': 1, '▁generate': 1, '▁tokens.': 1})
统计词表的全部子词,并统计词频。取前300个词,构成最初的大词表。为了避免OOV,char级别的词均需要保留。
char2count = defaultdict(int)
sub_word2count = defaultdict(int)
for word, count in word2count.items():
for i in range(len(word)):
char2count[word[i]] += count
for j in range(i + 2, len(word) + 1):
sub_word2count[word[i:j]] += count
sorted_sub_words = sorted(sub_word2count.items(), key=lambda x: x[1], reverse=True)
# init a large vocab with 300
tokens = list(char2count.items()) + sorted_sub_words[: 300 - len(char2count)]
获得的初始小词表vocabs如下:
[('▁', 31), ('T', 3), ('h', 9), ('i', 13), ('s', 13), ..., ('several', 1)]
进一步统计每个子词的概率,并转换成Unigram里的loss贡献
token2count = {token: count for token, count in tokens}
total_count = sum([count for token, count in token2count.items()])
model = {token: -log(count / total_count) for token, count in token2count.items()}
model = {
'▁': 2.952892114877499,
'T': 5.288267030694535,
'h': 4.189654742026425,
...,
'sever': 6.386879319362645,
'severa': 6.386879319362645,
'several': 6.386879319362645
}
基于每个子词的loss以及Viterbi算法就可以求解出,输入的一个词的最佳分词路径。即整体语言模型的loss最小。词的长度为N,解码的时间复杂度为O(N^2)。
def _encode_word(word, model):
best_segmentations = [{"start": 0, "score": 1}] + [{"start": None, "score": None} for _ in range(len(word))]
for start_idx in range(len(word)):
# This should be properly filled by the previous steps of the loop
best_score_at_start = best_segmentations[start_idx]["score"]
for end_idx in range(start_idx + 1, len(word) + 1):
token = word[start_idx:end_idx]
if token in model and best_score_at_start is not None:
score = model[token] + best_score_at_start
# If we have found a better segmentation (lower score) ending at end_idx
if (
best_segmentations[end_idx]["score"] is None
or best_segmentations[end_idx]["score"] > score
):
best_segmentations[end_idx] = {"start": start_idx, "score": score}
segmentation = best_segmentations[-1]
if segmentation["score"] is None:
# We did not find a tokenization of the word -> unknown
return ["<unk>"], None
score = segmentation["score"]
start = segmentation["start"]
end = len(word)
tokens = []
while start != 0:
tokens.insert(0, word[start:end])
next_start = best_segmentations[start]["start"]
end = start
start = next_start
tokens.insert(0, word[start:end])
return tokens, score
例如:
tokenize("This") # (['This'], 6.288267030694535)
tokenize("this") # (['t', 'his'], 10.03608902044192)
基于上述的函数,可以获得任一个词的分词路径,以及loss。这样就可以计算整个语料上的loss。
def _compute_loss(self, model, word2count):
loss = 0
for word, freq in word2count.items():
_, word_loss = self._encode_word(word, model)
loss += freq * word_loss
return loss
尝试移除model中的一个子词,并计算移除后新的model在全部语料上的loss,从而获得这个子词的score,即删除这个子词使得loss新增的量。
def _compute_scores(self, model, word2count):
scores = {}
model_loss = self._compute_loss(model, word2count)
for token, score in model.items():
# We always keep tokens of length 1
if len(token) == 1:
continue
model_without_token = copy.deepcopy(model)
_ = model_without_token.pop(token)
scores[token] = self._compute_loss(model_without_token, word2count) - model_loss
return scores
scores = self._compute_scores(model, word2count)
为了提升迭代效率,批量删除前10%的结果,即让整体loss增量最小的前10%的词。(删除这些词对整体loss的影响不大。)
sorted_scores = sorted(scores.items(), key=lambda x: x[1])
# Remove percent_to_remove tokens with the lowest scores.
for i in range(int(len(model) * 0.1)):
_ = token2count.pop(sorted_scores[i][0])
获得新的词表后,重新计算每个词的概率,获得新的模型。并重复以上步骤,直到裁剪到词表大小符合要求。
while len(model) > vocab_size:
scores = self._compute_scores(model, word2count)
sorted_scores = sorted(scores.items(), key=lambda x: x[1])
# Remove percent_to_remove tokens with the lowest scores.
for i in range(int(len(model) * percent_to_remove)):
_ = token2count.pop(sorted_scores[i][0])
total_count = sum([freq for token, freq in token2count.items()])
model = {token: -log(count / total_count) for token, count in token2count.items()}
假定预设的词表的大小为100,经过上述迭代后我们获得词表如下:
model = {
'▁': 2.318585434340487,
'T': 4.653960350157523,
'h': 3.5553480614894135,
'i': 3.1876232813640963,
...
'seve': 5.752572638825633,
'sever': 5.752572638825633,
'severa': 5.752572638825633,
'several': 5.752572638825633
}
推理阶段
在推理阶段,给定一个句子,需要将其切分成一个token的序列。 具体实现上先对句子进行预分词,然后对每个词基于Viterbi算法进行解码。
def tokenize(self, text):
words = [word for word, _ in self.pre_tokenize_str(text)]
encoded_words = [self._encode_word(word, self.model)[0] for word in words]
return sum(encoded_words, [])
例如
tokenize("This is the Hugging Face course!")
['▁This', '▁is', '▁the', '▁Hugging', '▁Face', '▁', 'c', 'ou', 'r', 's', 'e', '.']
基于Viterbi的切分获得的是最佳切分,基于unigram可以实现一个句子的多种切分方式,并且可以获得每种切分路径的打分。
思考
就不能不分词吗?
【2024-3-11】不依赖token,字节级模型来了!直接处理二进制数据
微软亚研院等发布 bGPT,仍旧基于Transformer,但模型预测下一个字节(byte)。
- 直接处理原生二进制数据,bGPT 将所有输入内容都视为字节序列,不受限于任何特定的格式或任务。
- 字节粒度非常细,处理的字节序列通常较长,这对基于Transformer的传统模型来说是一个挑战。由于自注意机制的复杂度是二次方的,处理长序列的效率和可扩展性受到了限制。
- 论文:Beyond Language Models: Byte Models are Digital World Simulators
- 代码:bgpt
- 模型:bgpt
- 项目主页:byte-gpt
分词工具包
BPE
OpenAI的BPE实现:tiktoken
- Web 体验: tokenizer
可以实时查看 输入文本在不同模型(GPT-3~4)的分词结果
# 输入
你是谁
# 分词 (GPT 3.5~4)
[57668, 21043, 39013, 223] # 3个字符对应4个Token, 最后一个字(谁)占2个
[19526, 254, 42468, 164, 108, 223] # 换 GPT-3 的结果
# 展示结果
你是�� # 最后是乱码,因为: 中文一般对应1-4个token, (谁)字多个,显示为乱码
��是��� # 换 GPT-3的显示结果
页面提示
Note: Your input contained one or more unicode characters that map to multiple tokens. The output visualization may display the bytes in each token in a non-standard way.
The Tokenizer Playground
【2024-3-25】Huggingface The Tokenizer Playground, 可本地浏览器部署,测试各种LLM的分词功能
Tiktokenizer Demo
可视化展示不同分词结果
- Tiktokenizer, 鼠标滑动,显示对应的id
同样用 “你是谁” 测试
# 输入
你是谁
# 预处理:多轮会话格式,包含上文 system
# GPT-3.5 加工结果
<|im_start|>system
You are a helpful assistant<|im_end|>
<|im_start|>user
你是谁<|im_end|>
<|im_start|>assistant
# GPT-4-32K 加工结果
<|im_start|>system<|im_sep|>You are a helpful assistant<|im_end|><|im_start|>user<|im_sep|>你是谁<|im_end|><|im_start|>assistant<|im_sep|>
# 分词 (GPT-3.5)
[100264, 9125, 198, 2675, 527, 264, 11190, 18328, 100265, 198, 100264, 882, 198, 57668, 21043, 39013, 223, 100265, 198, 100264, 78191, 198] # (GPT-3.5):中间文本部分(57668, 21043, 39013, 223)同上
[100264, 9125, 100266, 2675, 527, 264, 11190, 18328, 100265, 100264, 882, 100266, 57668, 21043, 39013, 223, 100265, 100264, 78191, 100266] # GPT-4-32K
minbpe
自己实现分词
【2024-2-23】Karpathy 又在网上开课:「从头开始构建GPT分词器」,先实现 分词
- GitHub 代码: minbpe
训练数据(莎士比亚)开始,只是Python中的一个大字符串:
First Citizen: Before we proceed any further, hear me speak.
All: Speak, speak.
First Citizen: You are all resolved rather to die than to famish?
All: Resolved. resolved.
First Citizen: First, you know Caius Marcius is chief enemy to the people.
All: We know't, we know't.
读取所有语料,得到所有可能字符集
# here are all the unique characters that occur in this text
chars = sorted(list(set(text)))
vocab_size = len(chars)
print(''.join(chars)) # !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
print(vocab_size) # 65
根据词汇表,创建单个字符和整数转换的查找表。
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
# encoder: take a string, output a list of integers
encode = lambda s: [stoi[c] for c in s]
# decoder: take a list of integers, output a string
decode = lambda l: ''.join([itos[i] for i in l])
print(encode("hii there")) # [46, 47, 47, 1, 58, 46, 43, 56, 43]
print(decode(encode("hii there"))) # hii there
id化: 字符串 → 整数序列
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
def forward(self, idx, targets=None):
tok_emb = self.token_embedding_table(idx) # (B,T,C)
字符分词 → 字符块
- 2019年,GPT-2使用BPE算法进行「字符块」分词
- 相比 GPT-1,词汇量扩大到50257个。将上下文大小从512增加到1024个token,并使用512更大batchsize
分词是很多怪异问题的源头,很多看似神经网络架构的问题,实际上都与分词有关。
分词机制导致的Bad Case:
- 为什么LLM不会拼写单词?—— 可以拼写
- 为什么LLM不能执行超简单的字符串处理任务,比如反转字符串?—— 可以翻转
- 为什么LLM在非英语语言(比如日语)任务中更差?—— 受限于词库
- 为什么LLM不擅长简单算术?—— 分词
- 为什么 GPT-2 用Python编码时遇到了更多问题?——分词
- 为什么LLM在看到字符串
<|endoftext|>时突然停止?—— 分词 - 关于「trailing whitespace」的奇怪警告是什么?—— 分词
- 如果问LLM关于「SolidGoldMagikarp」问题,为什么崩溃?——分词
- 为什么应该用
YAML而不是JSON与LLM交互?—— 分词 - 为什么LLM不是真正的端到端语言建模?—— 分词
【2024-3-26】GPT 3.5 测试
| 案例 | 问题 | 回答 | 分析 |
|---|---|---|---|
| 单词拼写 | spell this word who are you | The word “who are you” spelled out is: W-H-O space A-R-E space Y-O-U. | 有效 |
| 单词翻转 | turn around this word at | The word “at” turned around is “ta”. | 有效 |
| 特殊分隔符 | <|endoftext|> who are you |
“tell your name” | 无效 |
SentencePiece
如何使用上述子词算法?一种简便的方法是使用 SentencePiece
- 谷歌推出的子词开源工具包,其中集成了
BPE、ULM子词算法。 - 除此之外,SentencePiece还能支持
字符和词级别的分词。 - 为了能够处理多语言问题,sentencePiece将句子视为Unicode编码序列,从而子词算法不用依赖于语言的表示。
SentencePiece是Google出的一个分词工具:
- 内置BPE,Unigram,char和word的分词方法
- 无需预分词,以unicode方式直接编码整个句子,空格会被特殊编码为▁
- 相比传统实现进行优化,分词速度速度更快
当前主流大模型都是基于sentencepiece实现,例如:ChatGLM的tokenizer。
class TextTokenizer:
def __init__(self, model_path):
self.sp = spm.SentencePieceProcessor()
self.sp.Load(model_path)
self.num_tokens = self.sp.vocab_size()
def encode(self, text):
return self.sp.EncodeAsIds(text)
def decode(self, ids: List[int]):
return self.sp.DecodeIds(ids)
https://huggingface.co/THUDM/ch
当SentencePiece在训练BPE的时开启--byte_fallback, 在效果上类似BBPE,遇到UNK会继续按照byte进行进一步的切分。参见 具体实现上是将 <0x00> … <0xFF> 这256个token添加到词表中。
分析ChatGLM的模型,可以发现ChatGLM就是开启了--byte_fallback
from sentencepiece import sentencepiece_model_pb2
m = sentencepiece_model_pb2.ModelProto()
with open('chatglm-6b/ice_text.model', 'rb') as f:
m.ParseFromString(f.read())
print('ChatGLM tokenizer\n\n'+str(m.trainer_spec))
output:
ChatGLM tokenizer
input: "/root/train_cn_en.json"
model_prefix: "new_ice_unigram"
vocab_size: 130000
character_coverage: 0.9998999834060669
split_digits: true
user_defined_symbols: "<n>"
byte_fallback: true
pad_id: 3
train_extremely_large_corpus: true
可以看到byte_fallback: true
同样的方法,可以验证LLaMA, ChatGLM-6B, Baichuan这些大模型都是基于sentencepiece实现的BPE的分词算法,并且采用byte回退。
NLP 分词
NLP的底层任务由易到难大致可以分为词法分析、句法分析和语义分析。分词是词法分析(还包括词性标注和命名实体识别)中最基本的任务,可以说既简单又复杂。说简单是因为分词的算法研究已经很成熟了,大部分的准确率都可以达到95%以上,说复杂是因为剩下的5%很难有突破,主要因为三点:
- 粒度,不同应用对粒度的要求不一样,比如“苹果手机”可以是一个词也可以是两个词
- 歧义,比如“下雨天留人天留我不留”
- 未登录词,比如“skrrr”、“打call”等新兴词语
然而,在真实的应用中往往会因为以上的难点造成分词效果欠佳,进而影响之后的任务。对于追求算法表现的童鞋来说,不仅要会调分词包,也要对这些基础技术有一定的了解,在做真正的工业级应用时有能力对分词器进行调整。这篇文章不是着重介绍某个SOTA成果,而是对常用的分词算法(不仅是机器学习或神经网络,还包括动态规划等)以及其核心思想进行介绍。
总结
分词作为NLP底层任务之一,既简单又重要,很多时候上层算法的错误都是由分词结果导致的。因此,对于底层实现的算法工程师,不仅需要深入理解分词算法,更需要懂得如何高效地实现。而对于上层应用的算法工程师,在实际分词时,需要根据业务场景有选择地应用上述算法,比如在搜索引擎对大规模网页进行内容解析时,对分词对速度要求大于精度,而在智能问答中由于句子较短,对分词的精度要求大于速度。
分词算法
分词算法根据其核心思想主要分为两种
- 第一种是基于字典的分词,先把句子按照字典切分成词,再寻找词的最佳组合方式;
- 第二种是基于字的分词,即由字构词,先把句子分成一个个字,再将字组合成词,寻找最优的切分策略,同时也可以转化成序列标注问题。 归根结底,上述两种方法都可以归结为在图或者概率图上寻找最短路径的问题。接下来以“他说的确实在理”这句话为例,讲解各个不同的分词算法核心思想。
基于词典的分词
最大匹配分词算法
最大匹配分词寻找最优组合的方式是将匹配到的最长词组合在一起。主要的思路是先将词典构造成一棵Trie树,也称为字典树,如下图:
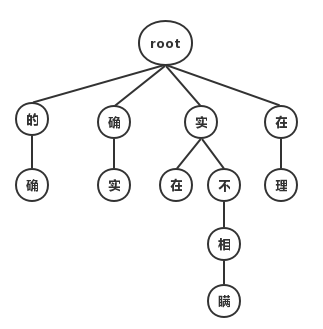
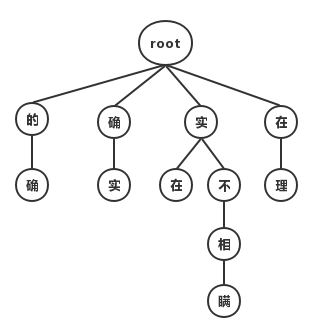
Trie树由词的公共前缀构成节点,降低了存储空间的同时提升查找效率。最大匹配分词将句子与Trie树进行匹配,在匹配到根结点时由下一个字重新开始进行查找。比如正向(从左至右)匹配“他说的确实在理”,得出的结果为“他/说/的确/实在/理”。如果进行反向最大匹配,则为“他/说/的/确实/在理”。
可见,词典分词虽然可以在O(n)时间对句子进行分词,但是效果很差,在实际情况中基本不使用此种方法。
最短路径分词算法
最短路径分词算法首先将一句话中的所有词匹配出来,构成词图(有向无环图DAG),之后寻找从起始点到终点的最短路径作为最佳组合方式,引用《统计自然语言处理》中的图:
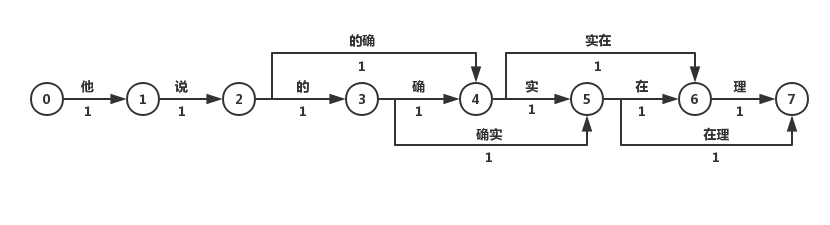
我们认为图中每个词的权重都是相等的,因此每条边的权重都为1。
在求解DAG图的最短路径问题时,总是要利用到一种性质:即两点之间的最短路径也包含了路径上其他顶点间的最短路径。比如S->A->B->E为S到E到最短路径,那S->A->B一定是S到B到最短路径,否则会存在一点C使得d(S->C->B)<d(S->A->B),那S到E的最短路径也会变为S->C->B->E,这就与假设矛盾了。利用上述的最优子结构性质,可以利用贪心算法或动态规划两种求解算法:
最短路径分词算法
基于Dijkstra算法求解最短路径。该算法适用于所有带权有向图,求解源节点到其他所有节点的最短路径,并可以求得全局最优解。Dijkstra本质为贪心算法,在每一步走到当前路径最短的节点,递推地更新原节点到其他节点的距离。针对当前问题,Dijkstra算法的计算结果为:“他/说/的/确实/在理“。可见最短路径分词算法可以满足部分分词要求。但当存在多条距离相同的最短路径时,Dijkstra只保存一条,对其他路径不公平,也缺乏理论依据。
N-最短路径分词算法
N-最短路径分词是对Dijkstra算法的扩展,在每一步保存最短的N条路径,并记录这些路径上当前节点的前驱,在最后求得最优解时回溯得到最短路径。该方法的准确率优于Dijkstra算法,但在时间和空间复杂度上都更大。
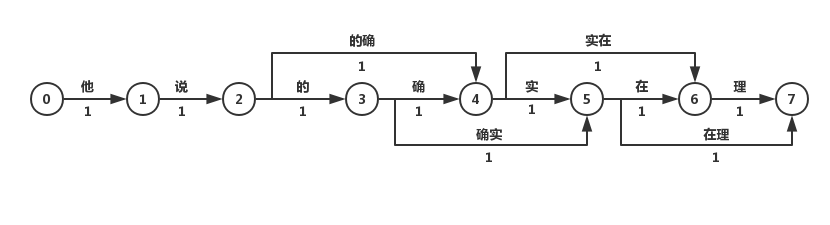
基于n-gram model的分词算法
在前文的词图中,边的权重都为1。而现实中却不一样,常用词的出现频率/概率肯定比罕见词要大。因此可以将求解词图最短路径的问题转化为求解最大概率路径的问题,即分词结果为“最有可能的词的组合“。计算词出现的概率,仅有词典是不够的,还需要有充足的语料。因此分词任务已经从单纯的“算法”上升到了“建模”,即利用统计学方法结合大数据挖掘,对“语言”进行建模。
语言模型的目的是构建一句话出现的概率p(s),根据条件概率公式我们知道:
而要真正计算“他说的确实在理”出现的概率,就必须计算出上述所有形如 n=1,…,6 的概率,计算量太过庞大,因此我们近似地认为:
其中 ,
为字或单词。我们将上述模型成为二元语言模型(2-gram model)。类似的,如果只对词频进行统计,则为一元语言模型。由于计算量的限制,在实际应用中n一般取3。
将基于词的语言模型所统计出的概率分布应用到词图中,可以得到词的概率图:
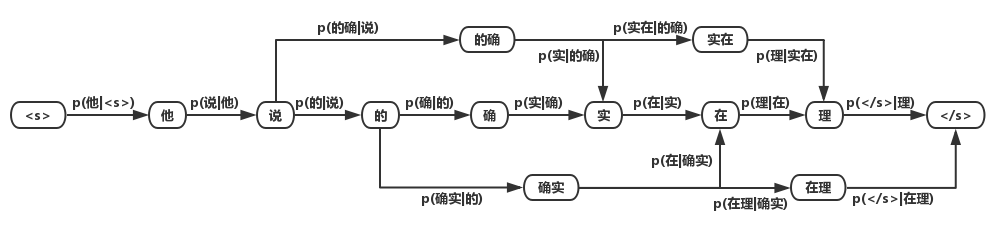
对该词图用2.1.2中的算法求解最大概率的路径,即可得到分词结果。
基于字的分词
与基于词典的分词不同的是,基于字的分词事先不对句子进行词的匹配,而是将分词看成序列标注问题,把一个字标记成B(Begin), I(Inside), O(Outside), E(End), S(Single)。因此也可以看成是每个字的分类问题,输入为每个字及其前后字所构成的特征,输出为分类标记。对于分类问题,可以用统计机器学习或神经网络的方法求解。
统计机器学习方法通过一系列算法对问题进行抽象,进而得到模型,再用得到的模型去解决相似的问题。也可以将模型看成一个函数,输入X,得到f(X)=Y。另外,机器学习中一般将模型分为两类:生成式模型和判别式模型,两者的本质区别在于X和Y的生成关系。生成式模型以“输出Y按照一定的规律生成输入X”为假设对P(X,Y)联合概率进行建模;判别式模型认为Y由X决定,直接对后验概率P(Y|X)进行建模。两者各有利弊,生成模型对变量的关系描述更加清晰,而判别式模型容易建立和学习。下面对几种序列标注方法做简要介绍。
生成式模型分词算法
生成式模型主要有n-gram模型、HMM隐马尔可夫模型、朴素贝叶斯分类等。在分词中应用比较多的是n-gram模型和HMM模型。如果将2.1.3中的节点由词改成字,则可基于字的n-gram模型进行分词,不过这种方法的效果没有基于词的效果要好。
HMM模型认为在解决序列标注问题时存在两种序列,一种是观测序列,即人们显性观察到的句子,而序列标签是隐状态序列,即观测序列为X,隐状态序列是Y,因果关系为Y->X。因此要得到标注结果Y,必须对X的概率、Y的概率、P(X|Y)进行计算,即建立P(X,Y)的概率分布模型。例句的隐马尔科夫序列如下图:
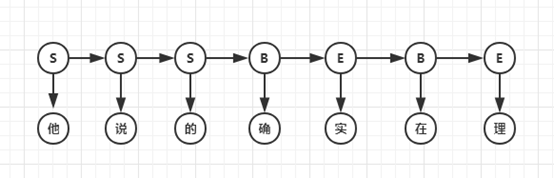
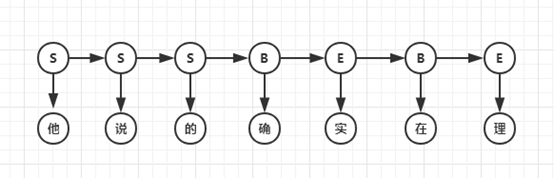
HMM模型是常用的分词模型,基于Python的jieba分词器和基于Java的HanLP分词器都使用了HMM。要注意的是,该模型创建的概率图与上文中的DAG图并不同,因为节点具有观测概率,所以不能再用上文中的算法求解,而应该使用Viterbi算法求解最大概率的路径。
判别式模型分词算法
判别式模型主要有感知机、SVM支持向量机、CRF条件随机场、最大熵模型等。在分词中常用的有感知机模型和CRF模型:
平均感知机分词算法
感知机是一种简单的二分类线性模型,通过构造超平面,将特征空间(输入空间)中的样本分为正负两类。通过组合,感知机也可以处理多分类问题。但由于每次迭代都会更新模型的所有权重,被误分类的样本会造成很大影响,因此采用平均的方法,在处理完一部分样本后对更新的权重进行平均。
CRF分词算法
CRF可以看作一个无向图模型,对于给定的标注序列Y和观测序列X,对条件概率P(Y|X)进行定义,而不是对联合概率建模。CRF可以说是目前最常用的分词、词性标注和实体识别算法,它对未登陆词有很好的识别能力,但开销较大。
神经网络分词算法
在NLP中,最常用的神经网络为循环神经网络(RNN,Recurrent Neural Network),它在处理变长输入和序列输入问题中有着巨大的优势。LSTM为RNN变种的一种,在一定程度上解决了RNN在训练过程中梯度消失和梯度爆炸的问题。双向(Bidirectional)循环神经网络分别从句子的开头和结尾开始对输入进行处理,将上下文信息进行编码,提升预测效果。
目前对于序列标注任务,公认效果最好的模型是BiLSTM+CRF。结构如图:
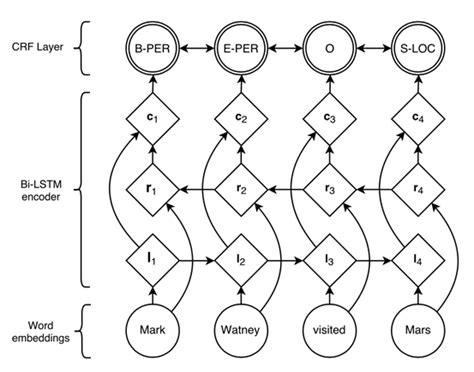
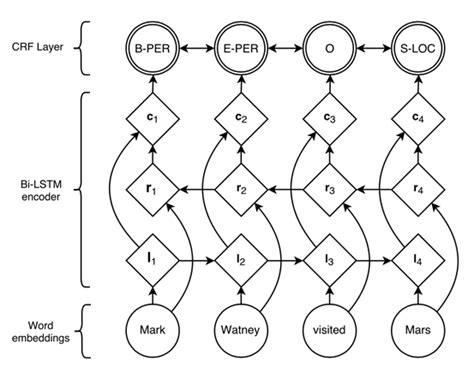
利用双向循环神经网络BiLSTM,相比于上述其它模型,可以更好的编码当前字等上下文信息,并在最终增加CRF层,核心是用Viterbi算法进行解码,以得到全局最优解,避免B,S,E这种标记结果的出现。
分词算法中的数据结构
前文主要讲了分词任务中所用到的算法和模型,但在实际的工业级应用中,仅仅有算法是不够的,还需要高效的数据结构进行辅助。
词典
中文有7000多个常用字,56000多个常用词,要将这些数据加载到内存虽然容易,但进行高并发毫秒级运算是困难的,这就需要设计巧妙的数据结构和存储方式。前文提到的Trie树只可以在O(n)时间完成单模式匹配,识别出“的确”后到达Trie树对也节点,句子指针接着指向“实”,再识别“实在”,而无法识别“确实”这个词。如果要在O(n)时间完成多模式匹配,构建词图,就需要用到Aho-Corasick算法将模式串预处理为有限状态自动机,如模式串是he/she/his/hers,文本为“ushers”。构建的自动机如图:
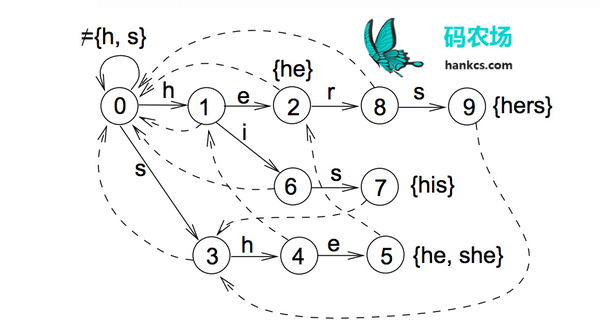
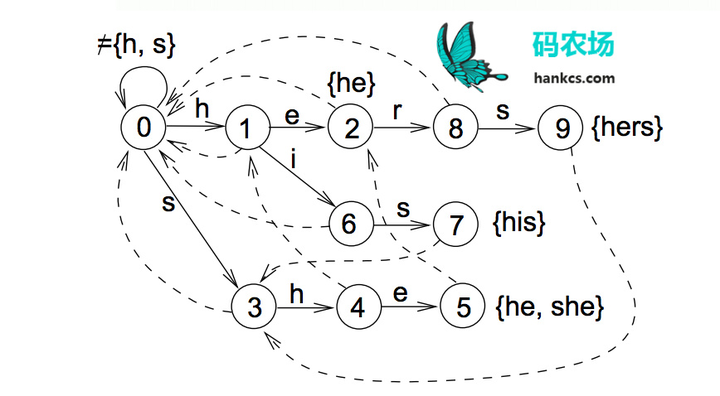
这样,在第一次到叶节点5时,下一步的匹配可以直接从节点2开始,一次遍历就可以识别出所有的模式串。
对于数据结构的存储,一般可以用链表或者数组,两者在查找、插入和删除操作的复杂度上各有千秋。在基于Java的高性能分词器HanLP中,作者使用双数组完成了Trie树和自动机的存储。
词图
图作为一种常见的数据结构,其存储方式一般有两种:
邻接矩阵
邻接矩阵用数组下标代表节点,值代表边的权重,即d[i][j]=v代表节点i和节点j间的边权重为v。如下图:
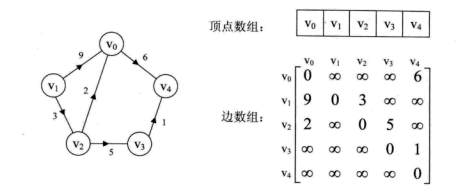
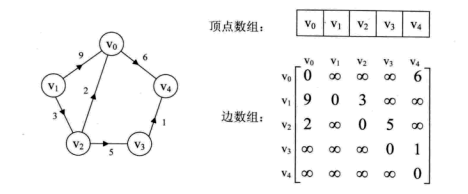
用矩阵存储图的空间复杂度较高,在存储稀疏图时不建议使用。
邻接表
邻接表对图中的每个节点建立一个单链表,对于稀疏图可以极大地节省存储空间。第i个单链表中的节点表示依附于顶点i的边,如下图:
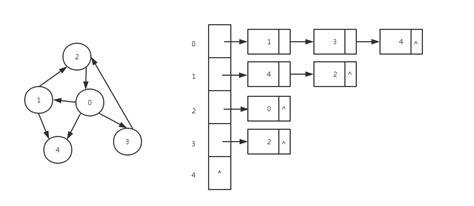
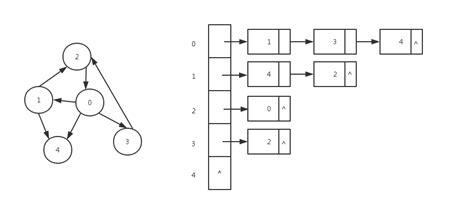
在实际应用中,尤其是用Viterbi算法求解最优路径时,由于是按照广度优先的策略对图进行遍历,最好是使用邻接表对图进行存储,便于访问某个节点下的所有节点。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
