- 通义千问
- 结束
通义千问
简介
阿里大模型内部访谈
初期,通义前身为通义千问
- “通义”取自《汉书》中的“天地之常经,古今之通义也”,有“普遍适用的道理与法则”之意;
- “千问”寓意千万次的问,千万的学问,能问出千问的一定是真爱,能回答千问的,也一定是真有学问,以及AI和阿里云一样,都有千万次交互的热情。
- 2024年5月,更名为
通义,意为“通情,达义”,具备全副AI能力,致力于成为人们的工作、学习、生活助手
【2025-10-10】Qwen 命名体系
通义千问技术负责人林俊旸(@JustinLin610)在 2025 年 10 月 3 日发布的一篇推文
Qwen 长期目标:
打造“全能统一模型”,能说、能看、能听、能写的智能体。
但现实是通用智能还没到那一步,于是采用更务实的策略:先分治,再融合。
- 先针对不同任务和场景,维护若干条独立演化的模型路线
- 再在后期逐步汇合。
于是形成了 四大 Qwen 家族 + 两股分支。
- Qwen 四大家族:语言模型 LLM、代码模型 Coder、视觉语言模型 VL、全模态 Omni
- 两个分支:Image和Audio
| 项目 | 命名规则 | 示例 | 解释 | 变体 | 版本号 | 说明 |
|---|---|---|---|---|---|---|
| 家族1:LLM 系列(语言大模型) | Qwen3-xB-AyB-Instruct | Qwen3-235B-A22B-Instruct | xB:总参数量 AyB:激活参数量(MoE 专家模型) |
Instruct:对话 | ||
Thinking:推理 无后缀:混合类型(既能聊,又能想) |
小幅更新时会加时间后缀,如 Qwen3-235B-A22B-Instruct-2507 | Qwen3 起,通义全面切换到 MoE(混合专家)架构,命名多了 AyB。老版本稠密模型没有这段 | ||||
| 家族2:Coder 系列(代码模型) | Qwen3-Coder-xB-AyB-Instruct | 同上,多了”Coder” | 同上 | 针对代码生成、理解与补全优化的版本 | ||
| 家族3:VL 系列(视觉语言模型) | Qwen3-VL-xB-AyB-Instruct | 同上,多了“VL” | 同上 | 多模态理解能力,能看图、能读字 | ||
| 家族4:Omni 系列(全模态模型) | Qwen3-Omni-xB-AyB-Instruct | 整合了文本、图像、语音三种模态能力,是 Qwen 体系中最接近“通用模型”的系列。 | ||||
| 分支1:Image 系列(图像生成模型) | Qwen-Image / Qwen-Image-Edit | 注意: 不带版本号(没有 Qwen3-Image 这种叫法) 基于扩散模型,不走 Transformer 路线 目前只发布了一个主力模型 |
||||
| 分支2:Audio 系列(语音模型) | Qwen3-ASR:语音识别 Qwen3-TTS:文本转语音 |
API 已上线 Qwen3-ASR-Flash,开源版本还在路上 |
API 端的命名思路就简单多了,分为三档:
- Max 拿来干活
- Plus 拿来做产品
- Flash 拿来跑量
| 档位 | 定位 | 示例 |
| Max | 性能最强 | Qwen3-Max |
| Plus | 均衡版本 | Qwen3-Plus |
| Flash | 轻量高效 | Qwen3-Flash |
另外,还有 Next
- 过去一年,Qwen 团队在架构层面做了不少尝试,比如线性注意力、选择性稀疏注意力等。原计划是把新版命名为 “Qwen3.5”,但后来觉得这个小数点命名太“软件味”了,而且容易被误解。
- 于是,他们改名为 Qwen3-Next —— 既保留了“承前启后”的含义,又更符合“面向未来”的气质。
生态
发展历程
- 2023年4月7日,通义千问开始邀请测试。
- 2023年4月11日,阿里云峰会正式发布通义千问
Qwen1(闭源内测版,基座原型)- 阿里所有产品将接入
通义千问大模型,全面改造,包括天猫、钉钉、高德地图、淘宝、优酷、盒马等 ; - 2023年4月,钉钉首次发布基于阿里千问大模型的智能化能力,用户输入斜杠“/”即可唤起10余项AI能力。通义千问 AI 大模型接入天猫精灵,开启相关内测招募。阿里云工程师在实验将千问大模型接入工业机器人,在钉钉对话框输入一句汉字,可远程指挥机器人工作。
- 阿里所有产品将接入
- 2023年08月03日:正式开源首发 Qwen-7B / Qwen-7B-Chat(Qwen1 全系开山, 初代开源,Qwen1.0)
- 同步首发参数梯队:1.8B/7B/14B/72B四款基座 + 对话版
- 2023年08月25日:配套多模态 Qwen-VL(Qwen1 多模态分支) 开源发布
- 2023年9月,通义千问正式向公众开放;淘宝内测应用淘宝问问接入通义千问,基于通义千问的文本理解与文本生成能力实现全新的交互体验以及推荐;
- 2024年02月:Qwen1.5 全系列上线,新增首款 MoE 稀疏模型(14B-A2.7B)、全系列拉满 32K 上下文窗口 (Qwen1 大迭代,首代 MoE)
- 2024年9月25日,阿里云宣布开源通义千问140亿参数模型
Qwen-14B及其对话模型Qwen-14B-Chat,免费可商用; - 2024年10月31日,2023云栖大会现场,阿里大模型家族全面升级发布,
通义千问2.0正式升级发布。通义千问App也随之发布
资讯
阿里通义千问项目(Qwen)负责人林俊旸,突然官宣离职。
2026年3月4日凌晨,林俊旸(Junyang Lin)突然在其X平台上发文称,“我即将离开,再见,我爱的Qwen。”
核心负责人 Binyuan Hui,Qwen3.5/Qwen VL/Qwen Coder 核心贡献者Kaixin Li也在今天宣布辞职。
行业信号:
- 大厂AI团队正普遍从实验室走向业务线,技术负责人话语权让位商业与产品负责人,顶尖AI人才出走将成常态。
- 行业的未来,取决于能否真正平衡商业与技术、短期与长期。
林俊旸
林俊旸,1993年,本科北京大学计算机科学专业,硕士阶段在北京大学外国语学院完成。
2019年毕业后,林俊旸径直加入阿里巴巴达摩院,正式开启职业生涯,担任高级算法工程师,是阿里巴巴最年轻的P10级技术负责人。
硕士毕业后进入达摩院的林俊旸,是阿里巴巴 Qwen 团队的核心成员/技术负责人之一,主要负责Qwen系列大语言模型和多模态模型的研发,是“Qwen宇宙的建造者”之一。其个人是开源精神的坚定倡导者,带领Qwen成为“全球最强开源模型”。
同时,林俊旸在开源社区和中文AI圈知名度很高,经常代表团队发模型更新、回应社区、分享进展,其风格真实、接地气,收获了大量粉丝。
【2025-12-28】Qwen(千问)大模型负责人林俊旸的技术成就
全球下载量第二的开源大模型Qwen,技术负责人既不是计算机博士,也不是硅谷归来的大牛,而是北大语言学硕士。更”反常”的是他的年龄——32岁,已经是阿里P10级别的技术专家,被内部称为”AI技术明星”。
2021年,当大多数中国AI团队还在追赶GPT-3时,这个年轻人尝试更疯狂的事:用512块GPU,在10天内训练一个10万亿参数的模型。
四年后的今天,Qwen系列累计下载量突破3亿次,HuggingFace CEO公开称其为”王者”。
2025年10月,他又宣布组建具身智能团队,带领阿里大模型进军机器人领域
2020年,AI领域存在一道看不见的墙:
- 一边是NLP,GPT-3展示了惊人的文本能力,但它是”盲人”;
- 另一边是CV,视觉模型可以精准识别图像,但它是”哑巴”。
AI无法像人类一样,在”看”和”说”之间自由切换。
M6如何用统一的”语言”描述一切?
林俊旸团队的核心洞察:图像和文本,本质上都可以表示为token序列。既然如此,为什么不用同一个模型来处理它们?
M6 将图像切分成小块,每个小块编码为一个token。这样,图像就变成了与文本形式统一的”token序列”,可以进入同一个Transformer处理。
OFA 发表于ICML 2022,获得700+引用, GPT-4V、Gemini等多模态大模型的设计理念,都可以追溯到OFA开创的”统一生成”范式。
这样同一个模型,既能”看图说话”,也能”读文生图”,还能回答关于图片的问题。一个模型,双向打通,多种任务。
团队提出”Pseudo-to-Real”训练策略,仅用512块GPU在10天内完成了10万亿参数模型的预训练。这证明了中国团队有能力在大模型竞赛中站到最前沿。
M6 证明多模态统一的可行性,但不同任务仍然需要不同的”输出头”——图像分类接分类器,图像描述接解码器,目标检测接边界框预测器。
OFA 突破在于:将所有任务统一为”序列到序列”的生成问题。
这带来了根本性改变:新任务只需设计指令格式,无需修改模型结构;不同任务的知识可以相互迁移;一个模型服务所有场景。
Qwen的技术路线如何差异化选择?
- 第一,激进的开源策略。 大多数公司只开源小模型,Qwen从0.5B-72B 全尺寸覆盖,全部Apache 2.0许可。这种”All-in开源”策略,让Qwen迅速积累了庞大的开发者生态。
- 第二,中文能力的原生优化。 LLaMA 中文是”后天习得”,Qwen从预训练阶段就将中文作为核心语言。结果是:Qwen 中文能力不是”也能用”,而是”非常好用”。
- 第三,多模态的一体化设计。 得益于
M6、OFA的积累,Qwen从一开始就是多模态模型家族:Qwen-VL理解图像,Qwen-Audio理解语音,Qwen-Omni图文声统一处理
Qwen3引入了革命性设计——将”思考模式”和”非思考模式”统一到同一个模型, Qwen3 引入”思考预算”机制:模型自动评估问题复杂度,动态分配计算资源。简单问题直接回答,复杂问题启动深度推理。
这种”元认知”能力通过三阶段训练实现的:推理能力注入、强化学习优化、模式融合统一。
2025年底,Qwen系列全球下载量已突破3亿次,衍生模型超过10万个,正式超越Llama成为全球最受欢迎的开源模型系列。
HuggingFace CEO曾公开表示:”Qwen是王者,中国在全球开源大模型领域处于领导地位。”
模型
截至2024年5月,通义千问提供通义灵码(编码助手)、通义智文(阅读助手)、通义听悟(工作学习)、通义星尘(个性化角色创作平台)、通义点金(投研助手)、通义晓蜜(智能客服)、通义仁心(健康助手)、通义法睿(法律顾问)8大行业模型
总结
四代演进核心脉络
Qwen1→Qwen1.5→Qwen2:稠密架构的成熟期, 如何在有限显存下支持更长上下文?注意力机制的显存优化- Qwen1 采用标准的 MHA(多头注意力),每个 token 的 KV Cache 需要存储所有头的键值对,显存占用随序列长度线性增长。
- Qwen1.5 在 32B 版本首次引入 GQA(分组查询注意力),将 Query 头分组共享 Key/Value 头,显存占用降低 4-8 倍。
- Qwen2 则将 GQA 普及到全系模型,包括 MoE 版本,同时通过 YARN+DCA 技术将上下文从 32K 外推到 128K。
- 这一阶段的标志性成果是GQA 成为行业标配,Qwen 证明了分组查询不影响模型表达能力,却显著降低了部署门槛。
Qwen2→Qwen2.5→Qwen3:MoE 架构的探索期, 上下文从32K扩至128K,数学/代码/结构化能力显著增强,闭源推出MoE版API。Qwen2首次引入MoE架构(57B-A14B,160 专家选 6),但保留了共享专家作为“安全网”;上下文扩至256K,评测全面追赶闭源模型,Thinking能力初步成型。- Qwen3 则进行了大胆实验:移除共享专家,完全依赖 128 个路由专家,并引入全局批次负载均衡替代传统的每层辅助损失。
- 这一阶段的标志性成果是MoE 激活率降至个位数(Qwen3 为 9.4%,Qwen3.5 为 8.5%),证明了极致的稀疏化不会损害模型能力。
Qwen3.5→Qwen3.6:混合注意力的革命期,如何让百万级上下文成为原生能力而非外推技巧?计算复杂度的线性化- MoE专家扩容4倍+共享专家,原生多模态统一预训练,Thinking默认深度思考,评测全面超越GPT-5.2/Claude 4.5,成为开源新标杆。
- Qwen3.5 首次引入 Hybrid Attention(3:1 混合设计):每 4 层中,3 层使用 Gated Delta Networks(线性注意力,复杂度 O(L)),1 层保留全注意力(复杂度 O(L²))捕捉长程依赖。这种设计让整体复杂度从 O(L²) 降至约 O(L),使得 262K 原生上下文成为可能。
- Qwen3.6-Plus 则将这一设计推向极致,原生支持 100 万 token 上下文,无需任何外推技巧。
- 这一阶段的标志性成果是线性注意力层成为长上下文模型的标配,Qwen 证明了混合设计比纯线性注意力更能保持建模能力。
Qwen3.6→Qwen3.7:Agentic 能力的内化期, 如何让模型从“响应指令”变为“自主规划”?智能体能力的架构内生化。- Qwen3.6 系列不再将 Function Calling、Tool Use 视为后训练技巧,而是通过三阶段预训练和四阶段 RL 将其内化为模型本能。
- Qwen3.6-Plus 的 Agentic Coding 能力(自主规划、执行、调试代码)和 Qwen3.6-Max-Preview 的 Preserve Thinking(多轮对话延续推理链)都体现了这一转变。
- 这一阶段的标志性成果是智能体行为从“学来的技巧”变为“架构的本能”,Qwen 开始具备初步的自主性。
参考
- 【2026-3-3】Qwen 三代进化全景对比:从 Qwen2.5 到 Qwen3 再到 Qwen3.5
- 【2026-6-2】Qwen 演进全景:从单一稠密模型到原生智能体生态的四次范式跃迁
Qwen 各系列模型规模分档
| 规模档位 | Qwen 2 | Qwen 2.5 | Qwen 3 | Qwen 3.5 |
|---|---|---|---|---|
| 1B 以下 | 0.5B | 0.5B | 0.6B | 0.8B |
| 1B~2B | 1.8B | 1.5B | 1.7B | 2B |
| 2B~4B | 4B | 3B | 4B | 4B |
| 7B~9B | 7B | 7B | 8B | 9B |
| 10B~14B | 14B | 14B | 14B | — |
| 32B | 32B | 32B | 32B | — |
| 72B | 72B | 72B | — | — |
| MoE 30B 级别 | — | — | 30B-A3B | 35B-A3B |
| MoE 100B 级别 | — | — | — | 122B-A10B |
| MoE 200B 级别 | — | — | 235B-A22B | — |
| MoE 300B 以上 | — | — | — | 397B-A17B |
Qwen 系列四代模型完整参数对比表
| 对比维度 | Qwen2 | Qwen2.5 | Qwen3 | Qwen3.5 |
|---|---|---|---|---|
| 发布时间 | 2024年6月28日 | 2024年9月19日 | 2025年4月29日 | 2026年2月16日 |
| 官方博客 | Qwen2: 开源大模型新标杆 | Qwen2.5-LLM: 扩展大型语言模型的边界 | Qwen3: 思深,行速 | Qwen3.5: Towards Native Multimodal Agents |
| 技术报告 | Qwen2 Technical Report (PDF) | Qwen2.5 Technical Report (PDF) | Qwen3 Technical Report (PDF) | Qwen3.5 Technical Report (PDF) |
| 模型版本 | Dense:0.5B/1.8B/4B/7B/14B/32B/72B; | ① Dense:0.5B/1.5B/3B/7B/14B/32B/72B; ② 专家模型: Qwen2.5-Coder:1.5B/7B/32B,在 5.5T 代码数据上训练 Qwen2.5-Math:1.5B/7B/72B,支持 CoT / PoT / TIR 多种推理方式 ③ API 模型:Qwen2.5-Turbo(快速)、Qwen2.5-Plus(强力) |
Dense:0.6B/1.7B/4B/8B/14B/32B; MoE:30B-A3B/235B-A22B; |
MoE:35B-A3B/122B-A10B/397B-A17B; Dense:0.8B/2B/4B/9B; |
| 评测效果 | MMLU ~75;数学推理一般;代码能力中等 | MMLU ~80;数学/代码显著提升;接近GPT-4基础版 | MMLU-Pro ~82–84;AIME25 81.5;接近Gemini 2.5 Pro | MMLU-Pro 87.8(超GPT-5.2);GPQA 88.4(超Claude 4.5) |
| 架构类型 | Dense | Dense | Dense+MoE | Dense+MoE+混合注意力 |
| 旗舰开源模型 | Qwen2.5-72B | Qwen3-235B-A22B | Qwen3.5-397B-A17B | |
| 模型家族 | “纯稠密+垂直专家”路线,共发布7个通用尺寸+2个专家系列 | 首次引入 MoE 架构,发布6个Dense+2个MoE,共8款模型 | 引入全新Gated DeltaNet混合注意力架构和原生视觉语言融合 | |
| 开源协议 | 混合(部分 Apache 2.0) | 全系列 Apache 2.0 | 全系列 Apache 2.0 | |
| 闭源版本 | Qwen-Plus/Qwen-Turbo(API) | Qwen2.5-Plus/Qwen2.5-Turbo(API) | Qwen3-Max(API) | Qwen3.5-Max/Flash/Plus(API,速度提升8.6–19倍) |
| Thinking能力 | 无原生思考;需手动引导;数学准确率~45% | 基础思考能力;支持指令触发;数学准确率~65% | 思考/非思考双模融合 支持 /think 指令切换;基础推理步骤;数学准确率~61% |
默认深度思考;自动/思考/快速三模式; API参数控制;数学准确率~89% |
| 多模态能力 | 纯文本(VL/Audio 为独立模型) 需独立部署Qwen2-VL(外挂) |
纯文本 独立部署Qwen2.5-VL/Omni(外挂) |
纯文本基座; 独立部署Qwen3-VL(外挂) | 原生多模态 文本+视觉早期融合 支持视频分析、GUI自动化 |
| MoE架构 | 无MoE;纯Dense架构 | 无MoE;纯Dense架构 | 128个专家;无共享专家;激活参数效率一般 | 512个专家;新增1个固定激活共享专家;激活参数效率大幅提升(397B总参仅激活17B) |
| 语种支持 | 29种语言(中/英为主) | 29+种语言;覆盖主流语种 | 82–119种语言 | 201种语言 |
| 预训练数据 | - | 18T | 36T | 远超 36T(未公布) |
| 词表大小 | ~150K | ~150K | ~150K | ~250K |
| 上下文长度 | 原生32K,可扩至64K | 原生128K,可扩至131K | 原生256K,可扩至1M | 原生256K,可扩至1M+;推理速度提升19倍 |
| 注意力机制 | 标准 Transformer | 标准 Transformer | 标准 Transformer | Gated DeltaNet + Full Attention(3:1 混合) |
| Agent能力 | Agent能力弱 | 基础工具调用 | 增强工具调用 + MCP | 原生 Agent 设计 + MCP + UI 操控 |
| 复杂能力 | 基础推理、代码、工具调用; | 推理、代码、结构化理解显著提升; | 基础推理、代码、工具调用; | 推理、代码、Agent、多模态推理全面领先;超越GPT-5.2/Claude 4.5 |
【2025-3-6】QwQ-32b 登顶开源榜单
Qwen 成为全球开源第一
- 32B 挑落
DeepSeek R1 671B, 成为全球最佳开源模型
【2025-3-6】Qwen 推出了 32B 推理模型,击败了除 o1 线推理模型之外的所有模型。
- LiveBench AI 上击败了所有人,包括 DeepSeek、Anthropic、Meta、Google 和 xAI
能分清 3.11 3.9 大小,逻辑清晰。
- Blog: QwQ-32B: 领略强化学习之力
- HF: QwQ-32B
- Qwen Chat
体验
阿里qwq 32b 大失所望
- 语义理解:5分。 远远不如DeepSeekR1,甚至不如之前的72B-VL版本。 大失所望,与RAG和Agent结果效果非常差。
- 代码能力:8分, 一般般正常水平,也比不过DeepSeekR1, 不过胜在回答简洁,直击要害。
主要优点:
- 速度快(32B的优势)
同样的显卡,远不如用清华Ktransformer版本的DeepSeek。
【2025-4-29】Qwen 3
【2025-4-29】
- 官方文章: Qwen3:思深,行速
- 技术报告: Qwen3 Technical Report
Qwen 3 系列模型
- Qwen3-0.6B, Qwen3-1.7B, Qwen3-4B, Qwen3-8B,Qwen3-14B, and Qwen3-32B, and 2 MoE models, Qwen3-30B-A3B and Qwen3-235B-A22B
旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。
此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
两个 MoE 模型的权重:
- Qwen3-235B-A22B,一个拥有 2350 多亿总参数和 220 多亿激活参数的大模型
- Qwen3-30B-A3B,一个拥有约 300 亿总参数和 30 亿激活参数的小型 MoE 模型。
此外,六个 Dense 模型也已开源,包括
- Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B
均在 Apache 2.0 许可下开源。
亮点
- 多种思考模式
- 多语言
- Agent 增强
部署要求
各个版本部署总结
- 参考:Mac上部署对比
注意:
- 内存都是DDR4以上
- 存储 M2 SSD,不建议普通HDD/SSD
| 模型版本 | 参数规模 | CPU核最低要求 | 内存最低要求 | 存储最低要求 | GPU要求 | 纯CPU部署 | 测试环境 | 纯CPU推理速度 | 单套硬件成本(仅硬件) |
|---|---|---|---|---|---|---|---|---|---|
| Qwen-0.6B | 6亿 | 4核 | 16GB | 64GB | 无 | 支持 | i5+8GB内存+2TB M2 SSD | 15 Tokens/秒 | 0.6万左右 |
| Qwen-1.7B | 17亿 | 8核 | 32GB | 256GB | 无 | 支持 | i7+64GB内存+2TB M2 SSD | 20 Tokens/秒 | 0.8万左右 |
| Qwen-4B | 40亿 | 8核 | 32GB | 256GB | 建议8GB GPU(3050、3060等) | 支持 | i7+64GB内存+2TB M2 SSD | 12 Tokens/秒 | 1.5万以上 |
| Qwen-8B | 80亿 | 12核 | 64GB | 512GB | 建议 16GB以上GPU(3090、4080等) | 支持 | i7+64GB内存+2TB M2 SSD | 5 Tokens/秒 | 5万以上 |
| Qwen-14B | 140亿 | 16核 | 96GB | 512GB | A10、A16;建议 A100 | 支持 | i7+64GB内存+2TB M2 SSD | 1 Tokens/秒 | 30万以上 |
| Qwen-32B | 320亿 | 20核 | 128GB | 1TB | A100×2以上、H2等 | 不支持 | 未提及 | 未提及 | 40万以上 |
| Qwen3-235B | 2350亿 | 48核 | 768GB,推荐1.5TB | 2TB | 推荐A100×4(4卡/8卡机),显存≥512GB | 不支持 | 未提及 | 未提及 | 150万以上 |
模型结构
图解 Qwen3
结构图中包含了Attention、MLP、RMSNorm、Trained等模块
训练
预训练方面
Qwen3 的数据集相比 Qwen2.5 有了显著扩展。
- Qwen2.5 在 18 万亿个 token 上进行预训练的
- Qwen3 使用的数据量几乎是其两倍,达到了约 36 万亿个 token,涵盖了 119 种语言和方言。
为了构建这个庞大的数据集,不仅从网络上收集数据,还从 PDF 文档中提取信息。
- 使用 Qwen2.5-VL 从这些文档中提取文本,并用 Qwen2.5 改进提取内容的质量。
- 为了增加数学和代码数据的数量,利用 Qwen2.5-Math 和 Qwen2.5-Coder 这两个数学和代码领域的专家模型合成数据,合成了包括教科书、问答对以及代码片段等多种形式的数据。
预训练过程分为三个阶段。
- 第一阶段(S1),模型在超过 30 万亿个 token 上进行了预训练,上下文长度为 4K token。这一阶段为模型提供了基本的语言技能和通用知识。
- 第二阶段(S2),通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的 5 万亿个 token 上进行了预训练。
- 最后阶段,用高质量的长上下文数据将上下文长度扩展到 32K token,确保模型能够有效地处理更长的输入。
Qwen 3 模型结构与 Qwen 2 相似
- 分词器: BBPE, 151669 个词
- GQA: Grouped Query Attention
- RePE: Rotary Positional Embeddings with pre-normalization
- Qwen3-MoE 架构同 Qwen2.5-MoE,128 total experts with 8 activated experts per token
差异
- 删除 QKV-bias, 替换为 QK-Norm, 保持训练稳定性
- Qwen3-MoE 去掉了共享专家, 采用 global-batch load balancing loss 来鼓励 专家差异化
后训练流程
- 四阶段的训练流程:
- (1)长思维链冷启动: 基本推理能力
- 数学、代码、逻辑推理和 STEM 问题等多种任务和领域
- (2)长思维链强化学习:基于规则的奖励来增强模型的探索和钻研能力。
- (3)思维模式融合:包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。
- 确保了推理和快速响应能力的无缝结合。
- (4)通用强化学习:包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。

【2025-12-8】Qwen3 中的 Thinking 与 Non-Thinking 模式融合和后训练理解
各阶段作用:
| 阶段 | 名称 | 核心目标 | 是否提升推理能力 |
|---|---|---|---|
| Stage 1 | Long-CoT Cold Start | 构建基础推理模式,强调泛化性而非性能 | ✅ 是(基础性) |
| Stage 2 | Reasoning RL | 使用高挑战性任务强化推理能力 | ✅ 强化(关键阶段) |
| Stage 3 | Thinking Mode Fusion | 融合 thinking与non-thinking模式 | ❌ 基本不提升 |
| Stage 4 | General RL | 提升多轮交互、工具调用、对齐等代理能力 | ❌(非纯粹推理) |
(1) 误解:
- Stage 3 会提升模型推理能力。
事实上,核心目标是模式融合,让模型能够根据用户指令(如 /think 或 /no think)自由切换响应模式。
Stage 3 并不以提升推理性能为目标。原因:
- Thinking 数据来源于 Stage 2 模型自身生成:未引入新知识或推理路径,仅用于“固化”已有推理行为;确保生成数据的风格与 Stage 2 一致,避免引入新知识干扰已有推理能力。
- Non-thinking 数据为常规 SFT 数据:不包含推理链,主要用于训练快速、直接的回答能力。采用标准的监督微调(SFT)数据集,包含直接问答、摘要、翻译等无需显式推理的任务。
两种数据均未引入新的推理挑战或反馈信号,因此模型的底层推理能力基本保持稳定。
两种模式的数据通过统一的 prompt 模板结构进行混合训练
模型学会识别何时启动“思考模式”,并在 /think 指令下自动包裹 <think> 标签,实现模式的可编程控制
(2) 推理能力的真正来源:Stage 1 + Stage 2 联合训练:
- Stage 1:通过 Long-CoT 冷启动,构建泛化的推理模式,为后续强化学习打下基础;
- Stage 2:使用 3995 个高难度 query-verifier 对,结合 GRPO(Guided Reinforcement Policy Optimization) 方法,对推理过程进行精细化强化。
Stage 1 和 Stage 2 共同奠定了 reasoning 的“基本盘”,而 Stage 3 和 Stage 4 是在此基础上的功能扩展。
Stage 4 的 RL 训练不再聚焦于“单步推理”,而是针对:
- 多轮交互(multi-turn decision-making)
- 工具调用(tool use)
- 指令遵循与偏好对齐(preference alignment)
其反馈信号也不再依赖 verifier,而是结合 rule-based 与 model-based 的 reward 模型,适用于更广泛的 agent 场景。
(3) 推理长度控制:隐式预算管理
如何限制模型的“思考时间”或“推理步数”?
Qwen3 并未采用显式指令(如“只思考 5 步”),而是通过以下机制实现“thinking budget”控制:
当模型生成的 <think> 内容达到预设长度阈值时,系统自动插入中断语句:
Considering the limited time by the user, I have to give the solution based on the thinking directly now.
</think>
{final answer}
这种方式优点在于:
- 不依赖模型对“步数”的语义理解,降低控制误差;
- 可在推理中途安全中断,避免无限展开;
- 用户可通过调整阈值灵活控制响应延迟与质量的权衡。
使用
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
Qwen3 Coder
【2025-7-22】Qwen3 Coder 一个具备 Agent 能力的代码模型。
-
这个模型在 Agentic Coding、Agentic Browser-Use 和 Agentic Tool-Use 上取得了开源模型的 SOTA。代码和 Agent 能力,可以和 Claude Sonnet4 相媲美。
- 模型总参数量只有 480B,激活参数 35B。
- 模型原生支持 256k 并可通过 yarn 等方式扩展至 1M。
这个模型的推理速度真太快了,特别是习惯了 R1 和 K2 的慢速,感觉瞬间起飞。
Qwen 3.5
【2026-2-14】官方介绍:Qwen3.5:迈向原生多模态智能体
Qwen3.5 在能力、效率与通用性三个维度上推进预训练:
- 能力(Power):在更大规模的视觉-文本语料上训练,并加强中英文、多语言、STEM 与推理数据,采用更严格的过滤,实现跨代持平:Qwen3.5-397B-A17B 与参数量超过 1T 的 Qwen3-Max-Base 表现相当。
- 效率(Efficiency):基于 Qwen3-Next 架构——更高稀疏度的 MoE、Gated DeltaNet + Gated Attention 混合注意力、稳定性优化与多 token 预测。在 32k/256k 上下文长度下,Qwen3.5-397B-A17B 的解码吞吐量分别是 Qwen3-Max 的 8.6 倍/19.0 倍,且性能相当。Qwen3.5-397B-A17B 的解码吞吐量分别是 Qwen3-235B-A22B 的 3.5 倍/7.2 倍。
- 通用性(Versatility):通过早期文本-视觉融合与扩展的视觉/STEM/视频数据实现原生多模态,在相近规模下优于 Qwen3-VL。多语言覆盖从 119 增至 201 种语言/方言;25 万词表(vs. 15 万)在多数语言上带来约 10–60% 的编码/解码效率提升。
Qwen3.5 增强特性:
- 统一视觉语言基础:通过对多模态 Token 早期融合训练,性能上与 Qwen3 跨代对齐,并在推理、代码生成、智能体和视觉理解等基准测试中超越了 Qwen3-VL系列模型。
- 高效混合架构:
门控增量网络(Gated Delta Networks)与稀疏混合专家(sparse Mixture-of-Experts)相结合,高吞吐量推理的同时,将延迟和成本开销降至最低。 - 可扩展强化学习泛化能力:在包含百万智能体的环境中进行强化学习扩展,并逐步增加任务分布的复杂度,从而提升模型在真实世界中的稳健适应能力。
- 全球语言覆盖:支持的语言和方言扩展至 201 种,能够实现更具包容性的全球部署,并具备更精细的文化和区域理解能力。
下一代训练基础设施:多模态训练效率接近纯文本训练水平,同时异步强化学习框架可支持大规模智能体支架和环境编排。
Qwen3.5 模型同时支持非思考模式和思考模式。
- Qwen3.5-2B 默认以非思考模式运行
Qwen 3.5 是原生支持多模态的模型家族,这意味着:
- 视觉理解:可以理解图片内容
- 图像问答:可以回答关于图片的问题
- 文档理解:可以分析截图和图表
- 视频理解:支持视频内容分析
而且是 Early Fusion(早期融合)技术,在多模态 token 上实现了与 Qwen 3 相当的性能,在推理、编码、代理和视觉 理解基准测试中甚至超越了 Qwen 3-VL 模型。
多模态诅咒
【2026-6-3】多模态诅咒: 大模型加入视觉能力后,文本推理能力下降的现象
根源在于四重打击:
- 1)文本高密度vs图像低密度;
- 2)参数容量零和博弈;
- 3)跨模态对齐污染权重;
- 4)视觉token稀释注意力。
行业历经三次突破:
- 2023-2024年通过数据配比(70%+纯文本, ds v2技术报告)和冻结策略”少交税”;
- 2024-2025年采用联合预训练+MOE解耦实现”不互伤”;案例 erin 5.0
- 2025-2026年引入推理模式,将视觉感知转化为深度逻辑推理,实现”互增强”。
前沿模型已突破此难题,但中小团队仍需针对性防御。
实操建议
- 微调 VLM:数据配比是第一道防线,图文占比过高文本必降。
- 中小模型:MOE 解耦是必须的,参数竞争在小模型上很严重。
- 长视频/多图:视觉 Token 压缩策略决定你能走多远。
前沿模型靠“大力+架构创新”,资源有限就得针对性防御。
示例:qwen 3.5文本意图理解效果不如 qwen 3.0
模型结构
双塔→单塔
Qwen3.5 不再是传统“视觉编码器 + 文本解码器”双塔结构,而是采用 端到端单塔融合架构:
- 输入阶段:图像/视频 token 与文本 token 在 embedding 层就拼接融合
- 主干网络:统一的 Transformer 解码器处理多模态序列
- 输出阶段:共享的 LM head 生成文本、坐标、事件等
这种设计显著提升了跨模态对齐能力,支持细粒度视觉问答、视频理解等任务
输入阶段
# 文件: modeling_qwen3_5.py
# 类: Qwen3_5Model
# 方法: forward
if inputs_embeds is None:
inputs_embeds = self.get_input_embeddings()(input_ids) # ← 文本 token 转为 embeddings
# 图像特征注入
if pixel_values is not None:
# 调用视觉编码器,提取图像特征(动态分辨率 ViT)
# pixel_values:原始图像像素值,形状类似 [batch, channels, height, width]。
# image_grid_thw:可能控制特征网格的分辨率。
image_outputs = self.get_image_features(pixel_values, image_grid_thw, ...)
# 处理图像特征
# pooler_output:图像特征的汇总表示(通常是[CLS] token或全局池化后的特征)
# 用 torch.cat处理批次维度,确保与文本embedding的设备、数据类型一致。
image_embeds = torch.cat(image_outputs.pooler_output, dim=0).to(inputs_embeds.device, inputs_embeds.dtype)
# 创建一个布尔掩码,标记文本序列中 <image>占位符的位置。(在构建 input_ids 时,图像特征会扩展为多个连续的 <image> token,其数量等于视觉编码器输出的 token 数。)
image_mask, _ = self.get_placeholder_mask(input_ids, inputs_embeds=inputs_embeds, image_features=image_embeds)
# 关键!用图像特征替换<image>位置的文本embedding
inputs_embeds = inputs_embeds.masked_scatter(image_mask, image_embeds)
# 视频特征注入(同理)
if pixel_values_videos is not None:
...
inputs_embeds = inputs_embeds.masked_scatter(video_mask, video_embeds)
只有一个主干语言模型处理融合后的序列。
- self.language_model 是 Qwen3_5TextModel,即一个 纯文本 Transformer decoder。
- 不知道哪些 token 来自图像、哪些来自文本,只看到一个连续的 token 序列。
- 视觉token数量可变,类似于文本token数量可变。每个视觉token对应文本中的一个”占位符”
- 但 位置编码和 embedding 分布隐式携带了模态信息。
# 继续在 Qwen3_5Model.forward() 中
outputs = self.language_model(
input_ids=None, # ← 不再传 input_ids
position_ids=position_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds, # ← 只传融合后的 embeddings
cache_position=cache_position,
**kwargs,
)
Qwen3.5 是 混合注意力架构(Hybrid Attention):部分层用线性注意力(高效),部分层用标准注意力(强表达力)
class Qwen3_5DecoderLayer:
def __init__(self, config, layer_idx):
if config.layer_types[layer_idx] == "linear_attention":
self.linear_attn = Qwen3_5GatedDeltaNet(config, layer_idx)
elif ... == "full_attention":
self.self_attn = Qwen3_5Attention(...)
Gated DeltaNet(门控 Delta 网络)基于 状态空间模型(SSM)思想 的高效序列建模方法
线性注意力(如 Δ-rule)擅长建模远程依赖,但对局部结构(如 n-gram)较弱。卷积提供局部归纳偏置(因果卷积(Causal Conv1D))
- 线性注意力(Gated DeltaNet):降低 attention 复杂度 O(L²) → O(L) → 支持超长序列(文档、视频)
- MoE(稀疏专家):增大模型容量而不显著增加计算量 → 提升知识覆盖和推理能力
模型总结
Qwen 模型家族
【2026-2-27】Qwen3.5系列
- 第一款模型
Qwen3.5-Plus - 随后阿里云百炼平台上线
Qwen3.5-Flash,基于 Qwen3.5-35B-A3B 增强而来
Qwen3.5-Flash 基于开源 Qwen3.5-35B-A3B增强而来,采用与旗舰版相同的混合架构——线性注意力与稀疏混合专家(MoE)相结合,总参数量35B,每次前向传播仅激活3B参数。作为Qwen3.5家族中面向性价比场景的轻量级成员,它的定位是在有限的参数预算下尽可能逼近大模型的能力上限
【2026-3-2】千问 3.5 家族已开源
- 大尺寸模型:
- Qwen3.5-397B-A17B
- 中尺寸模型:
- Qwen3.5-122-A10B
- Qwen3.5-35B-A3B
- Qwen3.5-27B
- 小尺寸模型:
- Qwen3.5-9B
- Qwen3.5-4B
- Qwen3.5-2B
- Qwen3.5-0.8B
截至2026年3月3日,Qwen 3.5 全系列已发布版本的完整整理:
| 版本 | 发布时间 | 模型规模 | 模型类型(dense/sparse) | 特点 | 下载/访问地址 |
|---|---|---|---|---|---|
| Qwen3.5-397B-A17B | 2026-02-16 | 总397B,激活17B | Sparse (MoE) | 旗舰多模态,原生视觉-语言,256K上下文(可扩1M),201种语言,百万级Agent强化学习 | Hugging Face: Qwen3.5-397B-A17B ModelScope: Qwen3.5-397B-A17B |
| Qwen3.5-122B-A10B | 2026-02-25 | 总122B,激活10B | Sparse (MoE) | 旗舰开源,对标前沿闭源模型,知识密集与视觉任务表现突出 | Hugging Face: Qwen3.5-122B-A10B ModelScope: Qwen3.5-122B-A10B |
| Qwen3.5-35B-A3B | 2026-02-25 | 总35B,激活3B | Sparse (MoE) | 小体积强性能,超越前代Qwen3-235B,24GB显存可运行 | Hugging Face: Qwen3.5-35B-A3B ModelScope: Qwen3.5-35B-A3B |
| Qwen3.5-Flash | 2026-02-25 | 对应35B-A3B | Sparse (MoE) | 生产级托管API,默认1M上下文,低延迟低成本(0.2元/百万Token) | 阿里云百炼API: bailian |
| Qwen3.5-0.8B | 2026-03-02 | 0.8B | Dense | 超轻量,端侧/实时交互场景专用 | Hugging Face: Qwen3.5-0.8B ModelScope: Qwen3.5-0.8B |
| Qwen3.5-2B | 2026-03-02 | 2B | Dense | 极致轻量,推理极快,端侧/边缘设备首选 | Hugging Face: Qwen3.5-2B ModelScope: Qwen3.5-2B |
| Qwen3.5-4B | 2026-03-02 | 4B | Dense | 轻量级Agent基座,多模态能力强,资源与性能平衡 | Hugging Face: Qwen3.5-4B ModelScope: Qwen3.5-4B |
| Qwen3.5-9B | 2026-03-02 | 9B | Dense | 紧凑尺寸,越级性能,媲美GPT-OSS-120B,高性价比服务器部署 | Hugging Face: Qwen3.5-9B ModelScope: Qwen3.5-9B |
| Qwen3.5-27B | 2026-02-25 | 27B | Dense | 全系列唯一稠密架构,编码与指令遵循最强(LiveCodeBench 80.7,IFEval 95.0),复杂Agent场景出色 | Hugging Face: Qwen3.5-27B ModelScope: Qwen3.5-27B |
统一入口
- Hugging Face 合集:https://huggingface.co/collections/Qwen/qwen35
- ModelScope 合集:https://www.modelscope.cn/collections/Qwen/Qwen35
- GitHub:https://github.com/QwenLM/Qwen3.5
效果
- 同样是8B左右,qwen3.5 比 qwen3 在MMMU-Pro(多学科图文理解及推理) 暴涨约14分,从不及格的55.9分 到到70.1
- 8g显卡+32g内存,unsloth q4量化,35B-A3B比27B推理速度快15倍
- 【2026-2-26】参考 deephub
体验
Qwen Chat 上用 Qwen3.5。提供自动(auto)、思考(thinking)与快速(fast)三种模式供用户选择。
- 「自动」模式下用户可使用自适应思考,并调用搜索、代码解释器等工具;
- 「思考」模式下模型会对难题进行深度思考;
- 「快速」模式下模型将直接回答问题,不消耗思考 token。
阿里云百炼调用旗舰模型 Qwen3.5-Plus。
- 若要开启推理、联网搜索与 Code Interpreter 等高级能力,只需传入以下参数:
- enable_thinking:开启推理模式(链式思考)
- enable_search:开启联网搜索与 Code Interpreter
【2026-2-16】Qwen 3.5-Plus
资讯
2026年2月16日除夕,阿里巴巴开源了新一代大模型 Qwen 3.5-Plus,给出不同方向的答案。
- 模型总参数 397B,激活仅 17B
- 以不到 40% 的参数量超越了上一代万亿参数级的 Qwen3-Max,多项基准媲美甚至超越 GPT-5.2 和 Gemini 3 pro:MMLU-Pro 知识推理 87.8 分超越 GPT-5.2,博士级难题 GPQA 拿下 88.4 分超越 Claude 4.5,指令遵循 IFBench 以 76.5 分刷新所有模型纪录。API 价格每百万 Token 低至 0.8 元,仅为 Gemini 3 pro 的 1/18。
继续堆参数,边际收益在递减,部署和推理的成本却在刚性增长。Qwen 3.5 换了一种思路:通过架构创新大幅压缩激活参数,让 397B 总参数中实际参与每次推理的只有 17B。效率的提升体现在具体场景中:32K 常用上下文场景下推理吞吐量提升 8.6 倍,256K 超长上下文场景下最大提升至 19 倍,部署显存占用降低 60%。
Qwen 3.5 完成了从纯文本模型到原生多模态模型的代际跃迁。上一代 Qwen3 的预训练建立在纯文本 Token 上,Qwen 3.5 则在文本和视觉混合 Token 上联合预训练,同时大幅新增 STEM 和推理数据。模型参数规模缩小了,感知世界的维度反而拓宽了。竞争的标准也随之变化:过去比参数量和跑分,现在要比谁能用更少的资源、更统一的架构,覆盖更多的能力维度。
【2026-3-3】Qwen 3.5 Dense
阿里千问正式发布了 Qwen 3.5 系列模型, 8个规格
- 所有规格都支持 256 K 上下文窗口,目前开源模型中最长的上下文之一。
- 支持 201 种语言和方言,真正实现了全球化的部署能力。
创新的混合架构:
- Gated Delta Networks:门控_delta 网络
- 稀疏 MoE:稀疏专家混合模型
- 实现高吞吐量推理,最小化延迟和成本
| 模型规格 | 大小 | 上下文 | 特点 |
|---|---|---|---|
| qwen 3.5:0.8 b | 1.0 GB | 256 K | 极致轻量,笔记本也能跑 |
| qwen 3.5:2b | 2.7 GB | 256 K | 轻量级,性能不错 |
| qwen 3.5:4b | 3.4 GB | 256 K | 平衡之选 |
| qwen 3.5:9b | 6.6 GB | 256 K | 主流选择 |
| qwen 3.5:27b | 17 GB | 256 K | 性能强劲 |
| qwen 3.5:35b | 24 GB | 256 K | 高性能 |
| qwen 3.5:122 b | 81 GB | 256 K | 旗舰级 |
| qwen 3.5:latest | 6.6 GB | 256 K | 默认最新版本 |
Dense 模型结构差异
- 0.8B 和 2B 系列同样是 24 层 Transformer 架构,但 2B 版本的隐藏层维度直接翻倍,视觉层数也变得更深;
- 而到了 4B 和 9B,模型深度扩展到了 32 层,整体表达能力上了一个新台阶。
| 配置项 | Qwen3.5-0.8B | Qwen3.5-2B | Qwen3.5-4B | Qwen3.5-9B |
|---|---|---|---|---|
| 层数 | 24 | 24 | 32 | 32 |
| 隐藏层维度 | 1024 | 2048 | 2560 | 4096 |
| 视觉层数 | 12 | 24 | 24 | 27 |
| 视觉隐维度 | 768 | 1024 | 1024 | 1152 |
| 词表大小 | 248,320 | 248,320 | 248,320 | 248,320 |
| 最大上下文 | 256K | 256K | 256K | 256K |
全系列保持混合注意力机制
- 75% 线性注意力(Linear Attention) + 25% 标准注意力(Full Attention) 的混合设计。
无论是 35B MoE 还是 27B Dense,注意力层都是3 层 Gated DeltaNet + 1 层 Gated Attention
- 只是MoE 差异(27B 保留了传统 FFN,35B则换成了路由专家):
- 网络深度 (Depth):Qwen3.5-35B-A3B只有 40 层;Qwen3.5-27B Dense是 64 层。更深的网络意味着 27B 在前向传播时特征会被进行更多次的非线性变换。
- 理论上27B 在复杂逻辑推理和代码任务上表现更稳健,“思考链路”在物理层面上就更长。
- Qwen3.5-35B-A3B隐藏层维度为 2048;Qwen3.5-27B Dense隐藏层维度高达 5120。
- 27B 的单层宽度是 35B 的两倍半说明着 27B 在单次计算中可以捕捉更密集的特征,35B 虽然总参数量大但它的参数主要是靠 MoE 里那 256 个“专家”堆起来的
并且27B 切分出的注意力头也多于 35B:
- 在 DeltaNet (线性注意力) 部分 27B 有 48 个 V 头;35B 只有 32 个。
- 在 Gated Attention (传统注意力) 部分 27B 有 24 个 Q 头和 4 个 KV 头;35B 只有 16 个 Q 头和 2 个 KV 头。
【2026-2-26】参考 deephub
模型选型
Qwen3.5 不同参数量模型的定位和选型建议
| 模型规格 | 核心定位 | 关键优势 | 主要劣势 | 推荐场景 |
|---|---|---|---|---|
| Qwen3.5-0.8B | 极致轻量,边缘首选 | 体积极小(~533MB)、极速推理,代码生成能力不错 | 复杂推理极弱,常识理解易出错,易陷入思维循环 | 移动端应用、简单机器通信、资源受限的边缘 IoT 设备 |
| Qwen3.5-2B | 平衡之选,日常助手 | 速度与质量的甜点位置,逻辑推理较 0.8B 明显提升 | 难以处理高难度复杂任务 | 日常对话助手、离线文档摘要总结、简单文本问答 |
| Qwen3.5-4B | 主力重装,代码与长文 | 综合能力质变,指令遵循和代码能力显著提升,视觉理解增强 | 端侧运行有内存和算力门槛(推荐 8GB+ RAM) | 本地离线辅助编程(IDE 插件)、垂直领域多模态理解、复杂问答 |
| Qwen3.5-9B | 专业级应用,对标主流 | 接近大模型水平,推理准确度高,多语言支持极佳 | 资源需求极高,峰值内存占用大,推理速度慢 | 专业高精度需求、企业级高阶多模态分析、离线垂类专业客服 |
详见:知乎
代码解析
【2026-2-13】知乎 李先生
Qwen3.5 在transformer 仓库中提交PR,大致了解Qwen3.5 信息
二款模型架构: dense、MOE结构
核心亮点:
- 模型直接支持VL: Qwen 不再单独发布VL模型,这与kimi k2.5一样, 未来模型训练的一个趋势。
模型结构变化
- 1)更大词表,新模型词表大小为 248320(相比Qwen3的151936,差不多增加了10万)
- 2) 采用Qwen3-Next混合注意力机制: Qwen3-next 新注意力机制成为新范式结构
- 3)模型支持多模态(VLM能力)
- Qwen3.5 VL 模块取消了 Qwen3-VL 引入的deepstack操作:收益无法解决后续计算耦合,同时专门针对其优化代价也比较高
- 4)MOE架构,除了路由专家又引入共享专家
ms-swift 训练框架中已经支持 Qwen3.5 dense与MOE模型训练与微调。
本地部署
Qwen 官方发布的是 **HuggingFace 格式&&的权重(safetensors),主要面向 GPU 推理(vLLM、SGLang、Transformers 等框架)。
对于普通玩家,没有高端 GPU,safetensors 不如 GGUF 格式,本地部署更实在。
本地部署方式
- (1)llama.cpp 直接跑(最推荐)
- (2)llama-server 部署为 API 服务
- (3)GPU 玩家(vLLM / SGLang): 独立 GPU(哪怕是 3060 12GB),可直接用 vLLM 或 SGLang 跑原始精度权重,不需要 GGUF 量化
HuggingFace Hub 下载模型:
pip install huggingface_hub hf_transfer
# 下载 9B 的 Q4_K_M 量化版本
huggingface-cli download unsloth/Qwen3.5-9B-GGUF \\
--include "Qwen3.5-9B-Q4_K_M.gguf" \\
--local-dir ./models
注意
- Qwen3.5 小模型系列(0.8B - 9B)默认关闭 Thinking(推理思考)模式,这和大模型(27B+)不一样。
(1)llama.cpp
启动服务
- 默认: Non-Thinking 模式
./build/bin/llama-cli \\
-m ./models/Qwen3.5-9B-Q4_K_M.gguf \\
--ctx-size 16384 \\
-cnv
# --chat-template-kwargs '{"enable_thinking":true}' # 启动推理模式
(2)llama-server
部署代码
- 部署成 OpenAI 兼容的 API 服务(比如给 Claude Code、Cursor 等工具用)
llama-server
# Non-Thinking 模式(默认,推荐日常使用)
./build/bin/llama-server \\
-m ./models/Qwen3.5-9B-Q4_K_M.gguf \\
--ctx-size 16384 \\
--port 8080 \\
--n-gpu-layers 35
# Thinking 模式
./build/bin/llama-server \\
-m ./models/Qwen3.5-9B-Q4_K_M.gguf \\
--ctx-size 16384 \\
--port 8080 \\
--n-gpu-layers 35 \\
--chat-template-kwargs '{"enable_thinking":true}'
(3)vLLM / SGLang
vLLM/SGLang 的优势是:
- 零精度损失
- 推理速度更快(GPU 加速)
- 支持更高并发
- 支持多 GPU 张量并行
代码
# vLLM 部署
vllm serve Qwen/Qwen3.5-9B \\
--port 8000 \\
--tensor-parallel-size 1 \\
--max-model-len 32768 \\
--reasoning-parser qwen3
# SGLang 部署
python -m sglang.launch_server \\
--model-path Qwen/Qwen3.5-9B \\
--port 8000 \\
--tp-size 1 \\
--mem-fraction-static 0.8 \\
--context-length 32768 \\
--reasoning-parser qwen3
超长文本处理(YaRN 扩展到 100万 tokens)
Qwen3.5-9B 原生支持 262,144 tokens 上下文,但如果要处理更长的文本(比如整本书),可通过 YaRN 技术扩展到 1,010,000 tokens。
在 vLLM 中启用:
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3.5-9B \\
--hf-overrides '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' \\
--max-model-len 1010000
9B 模型处理百万 token 上下文!
微调
【2026-3-4】Qwen3.5 0.8B/2B/4B/9B 小模型本地部署指南,微调教程
目前支持 Qwen 3.5 微调的框架
- ms-swift
- Unsloth
Qwen3.5 多模态架构使其能够灵活处理不同模态的训练需求
- 纯文本训练时,视觉组件保持不变,但不会影响训练效果
- pixel_values = None 且 pixel_values_videos = None 时,模型退化为纯文本 LLM
- 训练数据是 混合比例的,包含:高质量 图文对,视频-文本对,大量纯文本语料
- 视觉理解训练必须依赖文本标签,无法单独训练图像
- 多模态模型必须通过文本引导来学习视觉理解。
- Qwen3.5 没有独立的视觉任务头(如分类、检测、分割)。所有视觉输入 必须与文本 prompt 绑定
- 混合模态训练能充分发挥 Qwen3.5 的多模态能力
| 项目 | Qwen3 | Qwen3.5 |
|---|---|---|
| 模态支持 | 仅文本(text-only) | 原生支持文本 + 图像 + 视频(text, image, video) |
| 架构 | 标准 Transformer Decoder(Dense) | 端到端单塔融合架构:文本与视觉 token 在 embedding 层融合,共享同一 Transformer 主干 |
| 输入处理 | 仅 input_ids → embeddings |
input_ids + <image> 占位符 → 动态替换为视觉 token embeddings |
| 位置编码 | 标准 RoPE | mRoPE(multidimensional RoPE):统一编码文本位置、图像高/宽、视频时间维度 |
| 训练数据 | 纯文本语料 | 多模态对齐数据:图文对、视频-文本对、纯文本混合 |
混合模态:同时训练文本+图片
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image>图片中是什么?"}, {"role": "assistant", "content": "这是一只猫。"}], "images": ["/path/to/image.jpg"]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别?"}, {"role": "assistant", "content": "第一张是小猫,第二张是小狗。"}], "images": ["/path/to/cat.jpg", "/path/to/dog.jpg"]}
llama-factory
【2026-3-3】Qwen 3.5 多模态微调
多轮对话数据集,链接:mllm_robot.zip
数据集
- 样本为单轮对话形式,含有 405 条样本
- 每条样本都由一条用户指令和一条模型回答组成,微调过程中模型不断学习样本中的回答风格,从而达到识别机器人的目的。
数据集放到 LlamaFactory/data 下面,并且修改 dataset_info.json 文件, 添加如下内容, 适配 Web UI上 sharegpt格式
"mllm_robot": {
"file_name": "mllm_robot.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
"mllm_robot_en": {
"file_name": "mllm_robot_en.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
启动 Web UI,选择 Qwen3.5-9B 模型,微调方法修改为 lora。
数据集使用 mllm_robot 和 mllm_robot_en,学习率使用 1e-4,Epochs 选择 5
启动微调后需要等待一段时间,待模型下载完毕后可在界面观察到训练进度和损失曲线。在 5090 下模型微调大约需要 30 分钟,显示“训练完毕/Finished”代表微调成功
测试
- 选择「Chat」栏,将检查点路径改为 train_qwen3_5_9B
- 点击「加载模型」即可在 Web UI 中和微调后的模型进行对话。
- 随机上传一张图片,让模型识别图片中的机器人
- 更换原始模型测试,并没有识别出图片中的机器人,说明模型微调有效。
ms-swift
官方代码 qwen3_5
Unsloth
Qwen3.5 小模型系列一发布,Unsloth 团队第一时间放出的 GGUF 量化版
而 Unsloth 是目前开源社区做 GGUF 量化做得最好的团队之一,有套叫 Dynamic 2.0 的量化方案
- 核心思路:把模型中重要的层(如注意力层的关键权重)保留更高精度(8-bit 甚至 16-bit),不重要的层大胆压缩。
- 好处:4-bit 量化下的表现,几乎逼近 FP16 原始精度。
每个模型都提供了从 2-bit 到 8-bit 的多种量化版本
- 0.8B / 2B:几乎任何设备都能跑,3GB 内存就够
- 4B(Q4 量化):7GB 内存,MacBook Air M1 8GB 版就能玩
- 9B(Q4 量化):9GB 内存,MacBook Pro 16GB 或 12GB+ 显存 GPU 轻松搞定
建议:
- 闭眼选 UD-Q4_K_XL 或 Q4_K_M**。
- Unsloth 官方的 KL Divergence 测试显示,UD-Q4_K_XL 在 Pareto 前沿上表现 SOTA(State of the Art),精度损失可以忽略不计。
| 量化版本 | 推荐场景 | 精度损失 |
|---|---|---|
| UD-Q4_K_XL(推荐) | 日常使用首选,精度和体积最佳平衡 | 极小 |
| Q4_K_M | 经典 4-bit 量化,兼容性最好 | 小 |
| UD-Q2_K_XL | 极致省内存,适合内存紧张的设备 | 可接受 |
| Q8_0+ | 追求精度,内存充足时使用 | 几乎无 |
Unsloth 提供完整的 Qwen3.5 微调方案,而且小模型(0.8B / 2B / 4B / 9B)可以直接在 Google Colab 免费 T4 GPU 上完成微调
- 官方:Qwen3.5 微调指南
微调 Qwen3.5 模型系列(0.8B、2B、4B、9B、27B、35B‑A3B、122B‑A10B),使用 Unsloth。
- 支持包括 视觉 和文本微调。
- Qwen3.5‑35B‑A3B - bf16 LoRA 在 74GB 显存上可运行。
- Unsloth 使 Qwen3.5 训练 快 1.5× 并且使用 少 50% 的显存 相比 FA2 配置。
- Qwen3.5 bf16 LoRA 显存使用: 0.8B: 3GB • 2B: 5GB • 4B: 10GB • 9B: 22GB • 27B: 56GB
微调 0.8B, 2B 和 4B 通过 bf16 LoRA 免费 Google Colab 笔记本
Unsloth 安装
pip install --upgrade --force-reinstall --no-cache-dir unsloth unsloth_zoo
SFT(监督微调)脚本:
- 三步:加载模型 → 挂 LoRA → 训练。
- Unsloth 把底层复杂的优化全封装好了。
注意事项
- 想保留推理能力? 训练数据中至少保留 75% 的带 thinking(推理思考)的样本,其余可以是直接回答
- 导出后效果变差? 常见原因是推理时 chat template / EOS token 和训练时不一致。Unsloth 会自动提醒你
- vLLM 版本注意:截至目前 vLLM 0.16.0 尚不支持 Qwen3.5,需要等 0.17.0 或使用 Nightly 版本
from unsloth import FastLanguageModel
import torch
from datasets import load_dataset
from trl import SFTTrainer, SFTConfig
max_seq_length = 2048# 先从小的开始,跑通再加大
# 加载示例数据集(替换成你自己的)
url = "https://huggingface.co/datasets/laion/OIG/resolve/main/unified_chip2.jsonl"
dataset = load_dataset("json", data_files={"train": url}, split="train")
# 加载 Qwen3.5-9B(可以换成 0.8B/2B/4B)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "Qwen/Qwen3.5-9B",
max_seq_length = max_seq_length,
load_in_4bit = True, # 4-bit QLoRA,省显存
full_finetuning = False,
)
# 挂上 LoRA 适配器
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth", # 降低显存 + 支持更长上下文
random_state = 3407,
max_seq_length = max_seq_length,
)
# 开始训练
trainer = SFTTrainer(
model = model,
train_dataset = dataset,
tokenizer = tokenizer,
args = SFTConfig(
max_seq_length = max_seq_length,
per_device_train_batch_size = 1,
gradient_accumulation_steps = 4,
warmup_steps = 10,
max_steps = 100, # 先跑 100 步看看效果
logging_steps = 1,
output_dir = "outputs_qwen35",
optim = "adamw_8bit",
seed = 3407,
),
)
trainer.train()
现存不够?建议:
- 把 per_device_train_batch_size 降到 1
- 减小 max_seq_length(比如从 2048 降到 1024)
- 保持 use_gradient_checkpointing = “unsloth” 开启 —— Unsloth 独家优化,能显著降低显存占用,同时支持更长的上下文
实测 9B 模型用 4-bit QLoRA,在一张 12GB 显卡(比如 3060/4060)上就能跑起来
Qwen3.5 是原生多模态模型, Unsloth 同样支持视觉微调,用图文对数据来训练模型的视觉理解能力:
from unsloth import FastVisionModel
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = True, # 微调视觉层
finetune_language_layers = True, # 微调语言层
finetune_attention_modules = True, # 微调注意力层
finetune_mlp_modules = True, # 微调 MLP 层
r = 16,
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
random_state = 3407,
target_modules = "all-linear",
)
可灵活控制只微调视觉层、只微调语言层、或者全部一起微调,非常灵活。
模型导出
训练完的模型可以导出为多种格式,直接用于本地部署
- 导出为 GGUF (用于 llama.cpp/Ollama/LM Studio/等)或 vLLM
整个工作流:
- Colab 免费训练 → 导出 GGUF → 本地 llama.cpp 跑起来,一分钱不花,完全免费。
# 导出为 GGUF(给 llama.cpp / Ollama / LM Studio 用):
# 导出为 Q4_K_M 量化的 GGUF
model.save_pretrained_gguf("my_model", tokenizer, quantization_method="q4_k_m")
# 或者导出为 Q8 量化
model.save_pretrained_gguf("my_model", tokenizer, quantization_method="q8_0")
# 想上传到 HuggingFace?
model.push_to_hub_gguf("你的用户名/my_model", tokenizer, quantization_method="q4_k_m")
# 导出为 16-bit(给 vLLM 用):
model.save_pretrained_merged("finetuned_model", tokenizer, save_method="merged_16bit")
# 或者上传到 HuggingFace
model.push_to_hub_merged("你的用户名/model", tokenizer, save_method="merged_16bit", token="")
# 只保存 LoRA 适配器(体积小,方便分享):
model.save_pretrained("finetuned_lora")
tokenizer.save_pretrained("finetuned_lora")
Qwen 3.6
【2026-3-30】Qwen 3.6 Plus Preview
【2026-3-30】阿里Qwen在OpenRouter悄然上线 Qwen 3.6 Plus Preview
- 输入输出均为$0,支持100万token上下文。
- 与Claude Opus 4.6的$5/$25和GPT-5.4的$2.5/$15相比,这不是价格竞争,是另一套打法。
没有发布会,没有博客长文,Qwen 3.6 Plus Preview 直接出现在OpenRouter上。免费注册,调用,1M上下文,输入输出$0
【2026-4-2】Qwen3.6-Plus
【2026-4-2】Qwen3.6-Plus:编码智能体能力全面跃升
- 显著提升模型的智能体编程能力。在前端页面生成、代码修复、终端自动化等场景中,Qwen3.6-Plus 表现出更稳定的任务执行能力。
- 同时,模型默认支持 100 万上下文窗口
- 多模态感知与推理能力也同步优化。
要点
- 国内同尺寸模型中,编码智能体能力领先:代码任务端到端成功率显著提升
- Coding Agent 能力升级:代码生成、修复、工具调用更可靠
- 100 万上下文:长文档、多轮对话信息提取更精准
- 多模态能力增强:视觉理解、指令遵循更稳定
- 高性价比:相比K2.5/GLM5尺寸不到1/2,性价比更高
Qwen3.6-Plus 现已通过阿里云百炼的官方 API 正式开放
🔜 Qwen3.6 系列更多版本近期发布,更强性能版本&小尺寸开源模型,敬请期待
【2026-4-22】Qwen 3.6-27b 开源
【2026-4-22】Qwen3.6-27B正式开源
将智能密度压榨到极致,Qwen3.6-27B让本地部署的模型,也能完成以往大尺寸或是MoE模型才能实现的智能体编程任务,有望成为OpenClaw等类龙虾应用或者Hermes Agent最可靠的本地大脑。
Qwen3.6-27B的开源权重已在Hugging Face和ModelScope上提供,支持本地部署;企业和开发者也可通过阿里云百炼API调用;用户也可在Qwen Studio上即时体验。
- 魔搭社区:Qwen3.6-27B
- Hugging Face:Qwen3.6-27B
- Qwen Studio:chat
Qwen3.6-27B 兼容 OpenClaw、适配Qwen Code、Claude Code,可自托管的开源AI编码智能体。将其连接至百炼,即可在终端中获得完整的智能体编码体验。
【2026-5-19】Qwen 3.7
【2026-5-19】Qwen3.7 预览登陆 Arena
- Qwen3.7-Plus-Preview 来了。 阿里云现居 Vision 排名 #5
体验
API
API 支持多种模式
- 文本输入
- 流式输出
- 图像输入
- 视频输入
- 工具调用
- 联网搜索
- 异步调用
- 文档理解
- 文字提取
代码
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
# 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen-plus",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"},
],
# Qwen3模型通过enable_thinking参数控制思考过程(开源版默认True,商业版默认False)
# 使用Qwen3开源版模型时,若未启用流式输出,请将下行取消注释,否则会报错
# extra_body={"enable_thinking": False},
)
print(completion.model_dump_json())
流式输出
输出示例
{"id":"chatcmpl-e30f5ae7-3063-93c4-90fe-beb5f900bd57","choices":[{"delta":{"content":"","function_call":null,"refusal":null,"role":"assistant","tool_calls":null},"finish_reason":null,"index":0,"logprobs":null}],"created":1735113344,"model":"qwen-plus","object":"chat.completion.chunk","service_tier":null,"system_fingerprint":null,"usage":null}
{"id":"chatcmpl-e30f5ae7-3063-93c4-90fe-beb5f900bd57","choices":[{"delta":{"content":"我是","function_call":null,"refusal":null,"role":null,"tool_calls":null},"finish_reason":null,"index":0,"logprobs":null}],"created":1735113344,"model":"qwen-plus","object":"chat.completion.chunk","service_tier":null,"system_fingerprint":null,"usage":null}
...
非流式输出
非流失输出返回格式
{
"choices": [
{
"message": {
"role": "assistant",
"content": "我是阿里云开发的一款超大规模语言模型,我叫通义千问。"
},
"finish_reason": "stop",
"index": 0,
"logprobs": null
}
],
"object": "chat.completion",
"usage": {
"prompt_tokens": 3019,
"completion_tokens": 104,
"total_tokens": 3123,
"prompt_tokens_details": {
"cached_tokens": 2048
}
},
"created": 1735120033,
"system_fingerprint": null,
"model": "qwen-plus",
"id": "chatcmpl-6ada9ed2-7f33-9de2-8bb0-78bd4035025a"
}
阿里百炼
阿里云百炼上通过 UI 启动模型训练
详见站内专题 云平台
多模态
QWen-VL 系列
QWen-VL
模型结构:
- Vision Encoder:ViT-bigG/14
- VL Adapter:a single-layer cross-attention(Q-former的左侧部分)
- LLM:Qwen-7B
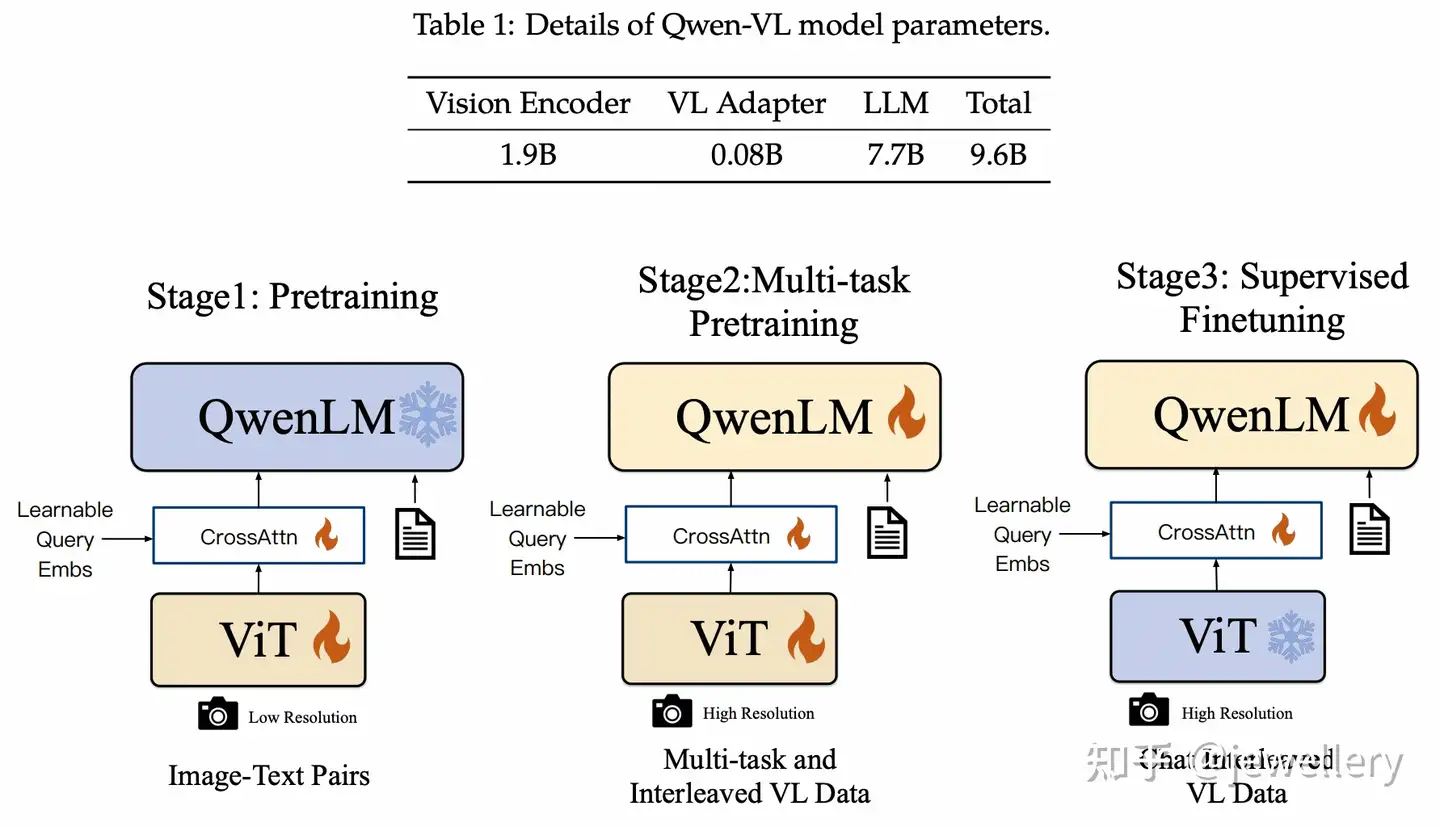
VL Adapter 创建一组可训练 queries向量 和 image features一起做cross-attention,将视觉特征压缩至256的固定长度,同时为了提升细粒度的视觉理解,在cross-attention中也加入图像的2D绝对位置编码。
- Image Input 使用特殊token(
<img>and</img>)分隔 - Bounding Box Input 使用特殊token(
<box>and</box>)分隔 - bounding box 的 content referred使用特殊token(
<ref>and</ref>)分隔。
训练过程:
- Stage 1:预训练,训练Cross-Attention和ViT,冻结QwenLM。
- Stage 2:多任务预训练(7 tasks同时),全参数训练。
- Stage 3:指令微调,训练Cross-Attention和QwenLM,冻结ViT。
训练数据:
- 第一个阶段使用image-text pairs数据,77.3%英文、22.7%中文,一共14亿数据训练,图片size=224*224.
- 第二个阶段使用质量更高的image-text pairs数据,包含7个任务,图像size=448*448. 在同一个任务下构造交错图像文本数据,序列长度为2048. 训练目标与Stage1一致。
- 第三个阶段使用Instruction数据,训练指令遵循和对话能力,通过LLM self-instruction构造,一共350k条。
QWen2-VL
【2024-09-18】QWen-VL 发布
- 论文 Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution
- github:Qwen2
Qwen2-VL 开源了 2B,7B及其量化版本
参考
- 【2024-10-21】多模态大模型Qwen2的深入了解 – Qwen2-VL 部署方法
进一步增强模型对视频中视觉信息的有效感知和理解能力,引入三个关键升级:
- 原始动态分辨率:该功能允许模型处理任意分辨率的图像,而不需要调整模型结构。
- 实现原理: ViT里, 删除原始绝对位置嵌入, 引入 2D-RoPE 捕获图像二维位置信息;推理阶段, 任意分辨率图像包装成单个序列, 长度依赖于GPU内存; ViT 后通过MLP层将 2*2 token 压缩成1个token, 以减少图像的视觉token数
- 多模态旋转位置嵌入 (M-RoPE):该功能通过时间、高度、宽度三个维度来对进行embedding,从而建模了多模态输入的位置信息。
- 传统 1D-RoPE 仅限于编码一维位置信息,M-RoPE 有效地建模了多模态输入的位置信息。
- 这通过将原始旋转嵌入分解为三个组件:时间、高度 和 宽度 来实现。
- 对于文本输入,这些组件使用相同的位移。多模态旋转位置嵌入ID,使 M-RoPE 功能上等同于1D-RoPE。
- 在处理图像时,每个视觉令牌的时间ID保持不变,而高度和宽度组件根据令牌在图像中的位置分配不同的ID。
- 对于视频,这些被当作帧序列来处理的视频,每帧的时间ID递增,而高度和宽度组件遵循与图像相同的ID分配模式。
- M-RoPE不仅增强了对位置信息的建模能力,而且降低了图像和视频中位置ID的价值,使得模型能够在推理期间扩展到更长的序列。
- 统一图像和视频的理解:通过混合训练方法,结合图像和视频数据,确保在图像理解和视频理解方面具有专业水平
- 每秒对每个视频进行两次采样。
- 集成深度为两层的三维卷积来处理视频输入,允许模型处理三维管状结构而不是二维块,从而使其能够处理更多视频帧而无需增加序列长度
- 为了保持一致,每张图片都被视为两张相同的帧。为了平衡长视频处理所需的计算需求与整体训练效率,我们动态调整每个视频帧的分辨率,限制每个视频中的总令牌数量不超过 16384。
- 这种训练方法在模型理解和训练效率之间取得了平衡。
能力更强
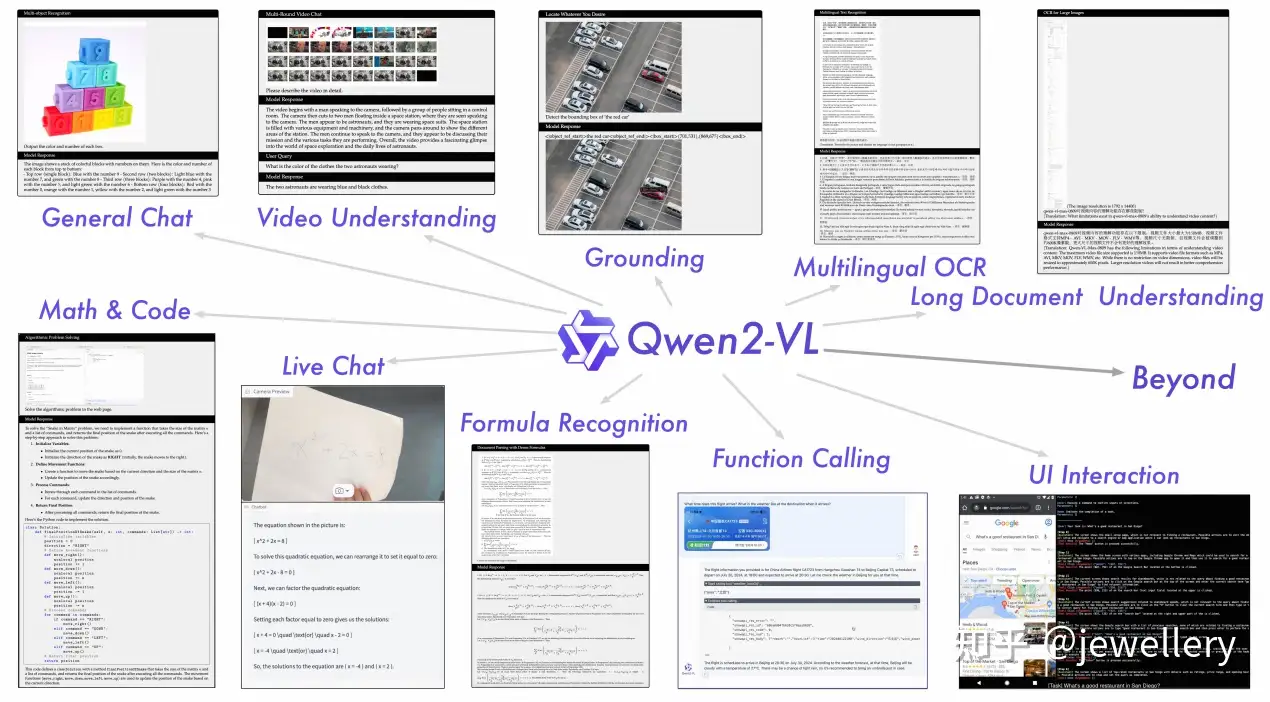
优化亮点:
- 在各种分辨率和比例的图像的理解SoTA:Qwen2-VL 在视觉理解基准上实现了最先进性能,包括 MathVista、DocVQA、RealWorldQA、MTVQA 等。
- 支持理解 20 分钟以上的视频:借助在线流媒体功能,Qwen2-VL 可以通过基于高质量视频的问答、对话、内容创作等方式理解 20 分钟以上的视频。
- 可集成在移动设备上:Qwen2-VL 具有复杂的推理和决策能力,可以与手机、机器人等设备集成,根据视觉环境和文本指令进行自动操作。
- 多语言支持:为了服务全球用户,除了英语和中文,Qwen2-VL 现在还支持理解图像中不同语言的文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
模型结构:
- Vision Encoder:ViT/14
- VL Adapter:Cross-Modal Connector
- LLM:Qwen2-1.5B, Qwen2-7B, Qwen2-72B
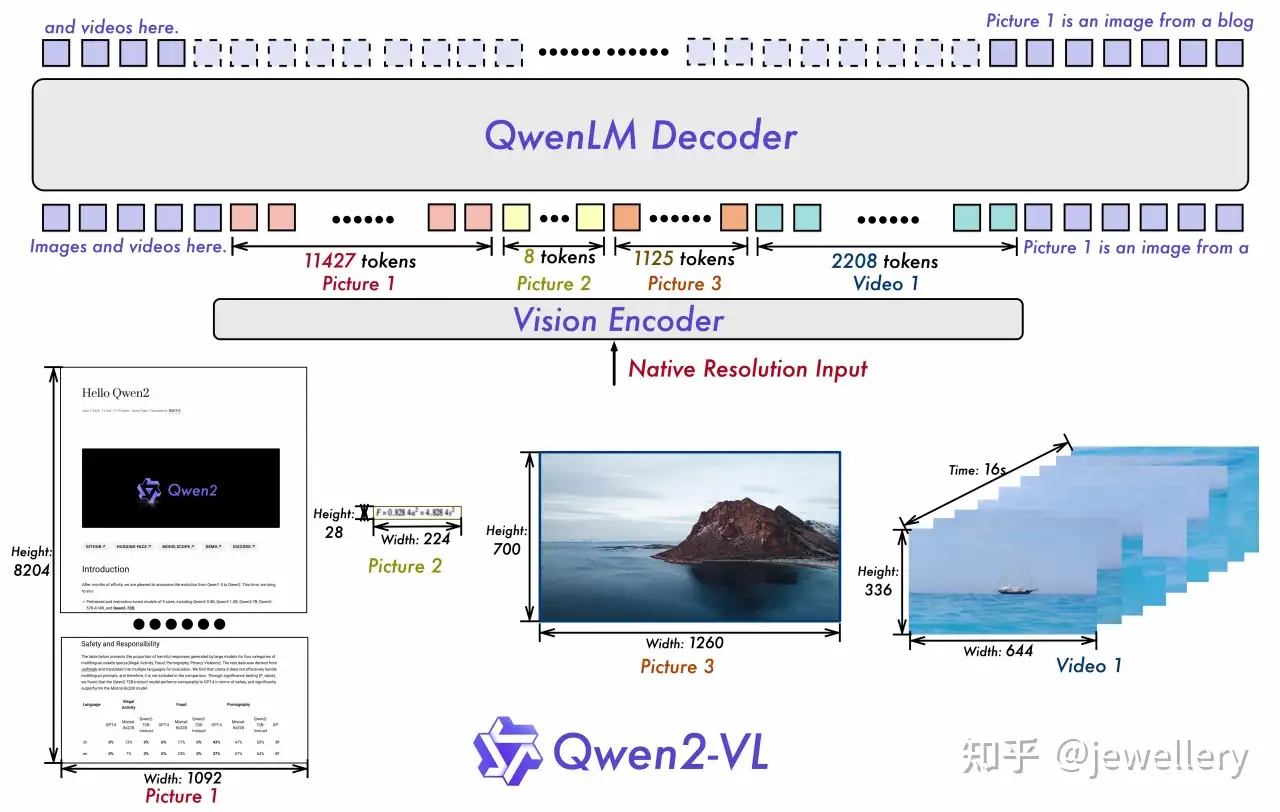
Qwen2-VL 相较于 Qwen-VL 主要改进点(除了VQA等基础能力的提升):
- 1)支持视频理解,支持context上下文长度到128k token(20分钟左右视频)。
- 2)Visual Agent 能力,支持实时视频对话。
- 3)图像位置编码采用 2D-RoPE,一张 224*224 分辨率的图像经过ViT/patch_size=14等一系列转换之后会被压缩至66个token输入到LLM。
Qwen2-VL 模型主要由两个部分组成:视觉编码器 和 语言模型。
- •
视觉编码器(Qwen2VisionTransformerPretrainedModel):- • Patch Embedding:使用 Conv3d 进行图像embedding,切分为多个小块并提取特征。其中卷积核大小为 (2, 14, 14),步幅也为 (2, 14, 14)。
- • Rotary Positional Embedding:如论文所述,进行旋转位置嵌入以增强视觉模型的感知能力。
- • Transformer Blocks:包含 32 个 Qwen2VLVisionBlock,每个块都有两个 Layer Normalization 层和一个 注意力机制,注意力机制采用 Linear 层进行 QKV(查询、键、值)映射。
- • Patch Merger:对提取的特征进行合并,使用 LayerNorm 和 MLP(多层感知机) 处理。
- •
语言模型(Qwen2VLModel):- • Token Embedding:使用 Embedding 层将输入的文本 token 转换为稠密向量,维度为 1536。
- • Decoder Layers:包含 28 个 Qwen2VLDecoderLayer,每层具有自注意力机制和 MLP;自注意力机制(Qwen2VLFlashAttention2)通过 Q、K、V 的线性映射进行注意力计算,采用旋转嵌入增强序列信息。
- • Norm Layer:使用 Qwen2RMSNorm 进行归一化,帮助模型在训练过程中保持稳定性。
- •
输出层(lm_head):- • 最后通过一个线性层将模型的输出映射回词汇表大小(151936),用于生成文本。
训练过程:
- Stage 1:训练ViT,使用大量image-text对。
- Stage 2:全参数微调,使用更多的数据提升模型全面理解的能力。
- Stage 3:指令微调,训练LLM。
下载通义千问2-VL-2B-Instruct模型
# 确保 git lfs 已安装
git lfs install
# 下载模型
git clone https://www.modelscope.cn/Qwen/Qwen2-VL-2B-Instruct.git
安装flash_attention, 加速推理,以减少显存占用
pip install flash-attn
代码
from transformers import Qwen2VLForConditionalGeneration
from transformers import AutoTokenizer
from transformers import AutoProcessor
import torch
from qwen_vl_utils import process_vision_info
# 设置模型路径
model_dir = "Qwen2-VL-2B-Instruct"
# 使用flash-attension加载模型
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto",
)
实践
【2025-7-31】Qwen2-VL模型sft的一些尝试
WWW2025 多模态对话系统意图识别挑战赛, 数据集上做sft的一些经验
- 最终的名次为50左右,分数距离第一名相差0.15个点左右。
- 从最初baseline的0.81提升了接近5个点。
10b 以内的多模态大模型
多模态模型排行榜排名靠前的3个模型如下:
| 模型 | 发布时间/大小 | 备注 |
|---|---|---|
| InternVL2.5-8B-MPO | 2024/12/28发布,大小为8B | 这个是新出的模型,我没有尝试。 |
| InternVL2.5-8B | 2024/12/10发布,大小为8B | 我的机器资源只够预测,不够全量微调,Lora微调掉点较多,这里只使用模型对结果做预测。但可以全量微调Qwenvl-7b。 |
| Qwen2-VL-7B | 2024/09/12发布,大小为8B |
Qwen2-VL-7B-Instruct, sft 框架 Llama-factory
baseline中,尝试了lora微调与全量微调,分数相差近5个点,后续的微调任务全部使用full模式。这里提供下模型full模式的参数。
4卡的A30,全量微调需要使用offload模式,这个模式下会将中间结果保存到内存中,训练过程中的内存占用大概是120G左右。
1000条训练集,优化工作:
- K-Fold训练模型,把预测结果不同的,进行修正。(有轻微提升)
- 模型标注测试集,将测试集的结果加入到训练集里,继续训练。 (有1个点的提升)
原始Prompt为:
<image>
你是一个电商领域识图专家,可以理解消费者上传的软件截图或实物拍摄图。现在,请你对消费者上传的图片进行分类。你只需要回答图片分类结果,不需要其他多余的话。以下是可以参考的分类标签,分类标签:[\"实物拍摄(含售后)\",\"商品分类选项\",\"商品头图\",\"商品详情页截图\",\"下单过程中出现异常(显示购买失败浮窗)\",\"订单详情页面\",\"支付页面\",\"消费者与客服聊天页面\",\"评论区截图页面\",\"物流页面-物流列表页面\",\"物流页面-物流跟踪页面\",\"物流页面-物流异常页面\",\"退款页面\",\"退货页面\",\"换货页面\",\"购物车页面\",\"店铺页面\",\"活动页面\",\"优惠券领取页面\",\"账单/账户页面\",\"个人信息页面\",\"投诉举报页面\",\"平台介入页面\",\"外部APP截图\",\"其他类别图片\"]。
prompt 优化过程
- +1pp: 加入更细致的类别说明
- +1pp: 加入分类原因
- 轻微: 加入Cot
提分最大的3个点是:
- 将模型预测的测试集加入模型训练
- 不止输出类别标签,同时输出原因
- 加入ocr的结果。
- 微调Prompt中的原因部分不能过分相似,我在某一个版本中使用了几乎一致的原因,会导致分数骤降。
- Prompt的长度要适中,太长的Prompt会降低模型对提示词的理解力。
Qwen2.5-Omni
【2025-3-27】阿里巴巴发布Qwen2.5-Omni,全球首个端到端全模态大模型,为多模态信息流实时交互提供了新技术框架。
Qwen2.5-Omni 整合了文本、图像、音频和视频的跨模态理解能力,实现流式文本与自然语音的双向同步生成。
关键技术:
- 1)采用分块处理策略解耦长序列多模态数据,由多模态编码器负责感知、语言模型承担序列建模,通过共享注意力机制强化模态融合;
- 2)提出时间对齐的位置编码方法TMRoPE,通过音视频交错排列实现时间戳同步;
- 3)首创
Thinker-Talker架构,分离文本生成(Thinker语言模型)与语音合成(基于隐藏表征的双轨自回归Talker模型),避免模态间干扰; - 4)引入滑动窗口DiT解码器降低音频流初始延迟。
效果分析:
- Omni-Bench 等多模态基准上达到SOTA,语音指令跟随能力与纯文本输入(MMLU/GSM8K)表现相当,流式语音生成在鲁棒性和自然度上超越主流流式/非流式方案。
【2025-9-21】Qwen3-Omni
【2025-9-21】Qwen3-Omni 模型
Qwen3-Omni 是原生端到端多语言全模态基础模型。它处理文本、图像、音频和视频,并以文本和自然语音形式提供实时流式响应。我们引入了多项架构升级,以提高性能和效率。
- modelscope 地址 Qwen3-Omni-30B-A3B-Instruct
主要特点:
- 跨模态的最先进技术:早期以文本为主的预训练和混合多模态训练提供了原生多模态支持。在实现强大的音频和音视频结果的同时,单模态文本和图像性能没有退化。在36个音频/视频基准测试中的22个上达到SOTA,在36个中的32个上达到开源SOTA;ASR、音频理解和语音对话性能与Gemini 2.5 Pro相当。
- 多语言:支持119种文本语言,19种语音输入语言和10种语音输出语言。
- 语音输入:英语、中文、韩语、日语、德语、俄语、意大利语、法语、西班牙语、葡萄牙语、马来语、荷兰语、印度尼西亚语、土耳其语、越南语、粤语、阿拉伯语、乌尔都语。
- 语音输出:英语、中文、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语。
- 新颖架构:基于MoE的思考者-说话者设计,通过AuT预训练获得强大的通用表示,加上多码本设计,将延迟降至最低。
- 实时音频/视频交互:低延迟流媒体,具有自然的轮流发言和即时文本或语音响应。
- 灵活控制:通过系统提示自定义行为,实现细粒度控制和轻松适应。
- 详细的音频字幕生成器:Qwen3-Omni-30B-A3B-Captioner现已开源:这是一个通用的、高度详细的、低幻觉的音频字幕生成模型,填补了开源社区的一个关键空白。
开源模型:30b 模型占70G,huggingface地址
- Qwen3-Omni-30B-A3B-
Instruct:Qwen3-Omni-30B-A3B 的指令模型,包含思考者和说话者组件,支持音频、视频和文本输入,输出音频和文本。更多信息请阅读 Qwen3-Omni 技术报告。 - Qwen3-Omni-30B-A3B-
Thinking:Qwen3-Omni-30B-A3B 的思考模型,包含思考者组件,具备链式思维推理能力,支持音频、视频和文本输入,输出文本。更多信息请阅读 Qwen3-Omni 技术报告。 - Qwen3-Omni-30B-A3B-
Captioner:从 Qwen3-Omni-30B-A3B-Instruct 微调而来的下游音频细粒度字幕模型,为任意音频输入生成详细且低幻觉的字幕。包含思考者组件,支持音频输入和文本输出。更多信息可以参考该模型的 cookbook。
注:
- moe 稀疏模型与同型号的dense 稠密模型相比,训练、推理时占用的显存相同,但速度不同,moe模型更快,如30B-A3B模型,推理速度接近 3B 全参模型(比30b稠密模型快 5-10 倍)
详见 阿里开源Qwen3-Omni-30B-A3B三剑客——Instruct、Thinking 和 Captioner - 指南
详见站内专题:全模态大模型
【2026-3-30】Qwen3.5-Omni
【2026-3-30】视听全才,言出码随!全模态Qwen3.5-Omni上线
- huggingface demo
- modelscope demo
- 【2026-4-21】技术报告 Qwen3.5-Omni Technical Report
Qwen3.5-Omni 是Qwen最新一代全模态大模型,支持文本,图片,音频,音视频理解。
- 结构上,Qwen3.5-Omni的 Thinker与Talker 均采用 Hybrid-Attention MoE 架构。
Qwen3.5-Omni 延续采用 Thinker-Talker 架构
- Thinker通过Vision Encoder和AuT接受视觉和音频信号输入,音视频信号通过interleave交织搭配TMRoPE编码位置信息。
- Thinker负责处理全模态信号并输出文本,Talker 负责接收来自Thinker的多模态输入以及文本输出,进行contextual 语音生成,语音表征通过Qwen3-Omni提出的RVQ编码,来替代繁重的DiT运算。
- 由于chunk-wise的流式输入设计和流式Talker设计,整个模型可以进行realtime interaction。不同于上一代Qwen3-Omni的双轨Talker输入,Talker在输入的组织方式上采用了ARIA (自适应速率交错对齐,Adaptive Rate Interleave Alignment) 来动态对齐文本与语音单元,然后进行交错排布,来避免由于文本与语音 Token 编码效率差异导致的语音不稳定性,如漏读、误读或数字发音模糊等问题。
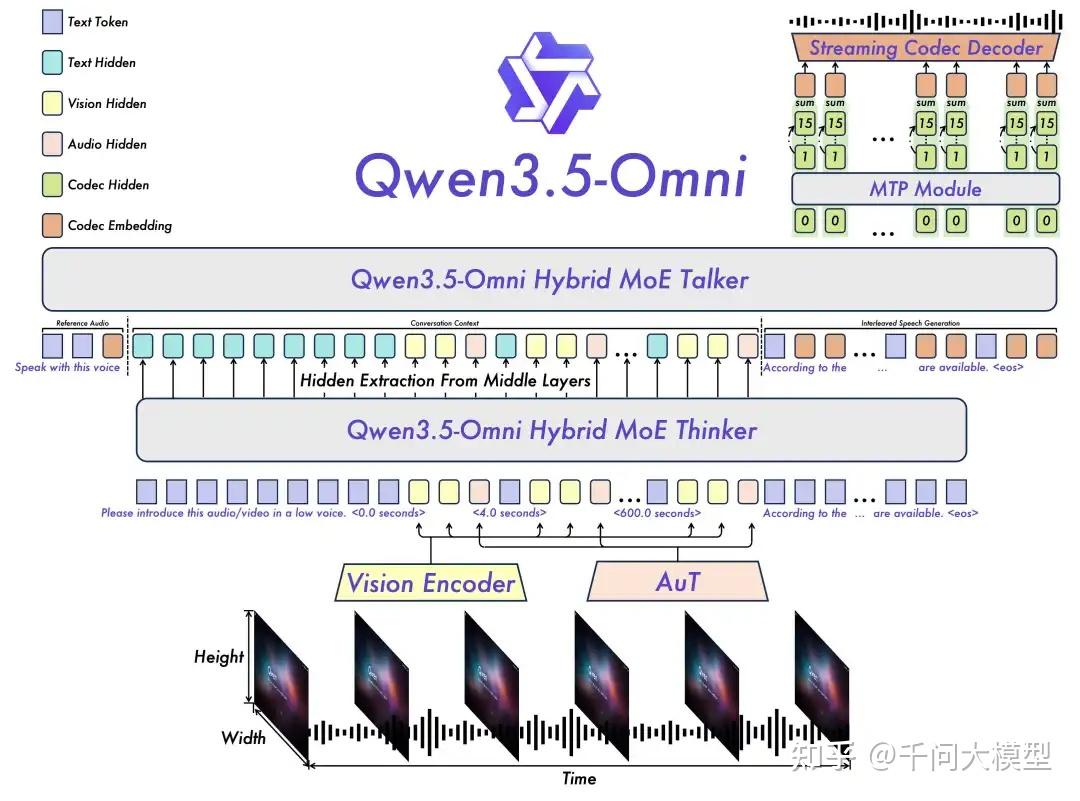
Qwen3.5-Omni vs Qwen3-Omni
| 维度 | Qwen3-Omni | Qwen3.5-Omni |
|---|---|---|
| 主干框架 | MoE | Hybrid-MoE |
| 支持序列 | 32k | 256k 音频:10个小时 音视频 (FPS=1):400秒 |
| Caption能力 | 音频 | 音视频 |
| 智能语义打断 | 无 | 支持 |
| WebSearch/Tool | 无 | 原生API支持 |
| 语音控制 | 无 | 支持 |
| 音色克隆 | 无 | 支持 |
| 开源 | 3款,Qwen3-Omni-30B-A3B-Instruct/Thinking/Captioner | 无 |
| Talker | 双轨自回归 | Interleave |
| Text-Audio Tokenizer Rate | Fixed (1:1) | ARIA (Adaptive Rate Interleaved Alignment) |
| 语音识别 | • 11种多语言:中文、英语、德语、法语、意大利语、泰语、韩语、日语、俄语、西班牙语、葡萄牙语 • 8种方言:四川话、上海话、粤语、闽南语、陕西话、南京话、天津话、北京话 |
• 74种多语言:南非语、阿拉伯语、阿斯图里亚斯语、阿塞拜疆语、巴斯克语、维吾尔语、白俄罗斯语、孟加拉语、波斯尼亚语、保加利亚语、粤语、加泰罗尼亚语、宿务语、中文、克罗地亚语、捷克语、丹麦语、荷兰语、英语、世界语、爱沙尼亚语、菲律宾语、芬兰语、法语、加利西亚语、格鲁吉亚语、德语、希腊语、希伯来语、印地语、匈牙利语、冰岛语、印尼语、国际语、意大利语、日语等 • 39种方言:东北话、贵州话、粤语、河南话、香港粤语、上海话、陕西话、天津话、台湾话、云南话、安徽话、福建话、甘肃话、广东话、湖北话、湖南话、江西话、山东话、山西话、四川话、广西话、海南话、重庆话、长沙话、杭州话、合肥话、银川话、郑州话、沈阳话、温州话、武汉话、昆明话、太原话、南昌话、济南话、兰州话、南京话、客家话、闽南语 |
| 语音合成 | • 29种多语言:中文、英语、德语、意大利语、葡萄牙语、西班牙语、日语、韩语、法语、俄语、泰语、印度尼西亚语、阿拉伯语、越南语、土耳其语、芬兰语、波兰语、印地语、荷兰语、捷克语、乌尔都语、他加禄语、瑞典语、丹麦语、希伯来语、冰岛语、马来语、挪威语、波斯语 • 7种方言:四川话、北京话、天津话、南京话、陕西话、上海话、粤语 |
Qwen3.5-Omni 系列包含 Plus, Flash, Light 三种尺寸的Instruct版本,支持 256k 长上下文,模型支持超过 10 小时的音频输入及超过 400 秒的 720P (1 FPS)音视频输入。
模型在海量文本、视觉以及超过 1 亿小时的音视频数据上进行原生多模态预训练,该模型展现出卓越的全模态感知与生成能力。
- 相比Qwen3-Omni, Qwen3.5-Omni 多语言能力大大增强,能够支持113种语种和方言的语音识别和36种语种和方言的语音生成。
- 目前可通过Offline API和Realtime API进行体验。
问题
当前许多研究表明,使用可验证奖励的RL在提升大语言模型(LLMs)的数学推理能力上取得了显著进展,尤其是Qwen2.5系列模型在MATH-500等数学基准测试中表现优异。
甚至部分研究发现,即使使用随机或错误的奖励信号,Qwen2.5的性能仍能提升,而其他模型(如Llama)则无此现象。
Qwen2.5是在互联网上的大规模网络语料库上预先训练的,包括存储基准问题及其官方解决方案的GitHub存储库,可能会造成数据泄露。
数据污染
s 【2025-7-14】复旦、上海AI Lab团队
- Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination
- 解读 论文阅读
论文揭露 Qwen2.5 数据污染问题
- 用强化学习来训练Qwen2.5系列模型,哪怕给非常弱、甚至是随机的奖励信号,数学推理能力都涨。
- 而且只在Qwen身上灵,换成Llama就不行。由于Llama后来的表现确实拉胯,很多人也没多想,觉得可能是基模太差,RL也救不了。
论文设计了两个钓鱼实验
- 部分提示词精确匹配:只给题目开头,然后看模型能不能把剩下的题干一个字不差地补出来
- 答案匹配准确率:同样用不完整题干,但只看生成内容有没有包含正确答案
实验结果铁证如山
- Qwen2.5-Math-7B 能够准确重现54.6%的MATH-500题目剩余部分,哪怕只看40%开头也能答对53.6%
- Llama3.1-8B 在同样条件下只有3.8%和2.4%,基本是瞎蒙
- 更关键的证据:如果测试发布晚于Qwen2.5的LiveMathBench时,Qwen完成率直接掉到0%,跟Llama差不多
到这里,基本已经能证明,Qwen2.5的训练中确实存在数据污染(Data Contamination)问题。
证明这对强化学习效果有致命影响。构造了RandomCalculation数据集——各种随机算术题,保证Qwen没见过。
结果画风立变:
- 正确奖励信号:Qwen确实能稳步提升
- 随机/错误奖励:训练立刻崩掉
- Llama表现类似,只有正确奖励才管用
说明之前那些“随机奖励也能提升性能”的研究,很可能只是激活了模型去回忆背过的答案,而不是真的激发了潜在的推理能力。
现在最让人觉得可惜的,是之前那些基于Qwen2.5的研究工作。不是说那些工作本身不优秀,方法可能很有创新。但现在由于模型本身有这些问题,必须要怀疑那些工作的意义。
代码
QWen3 from Scratch
《从零实现 Qwen3》,里面包含了 Qwen3 模型(0.6B、1.7B、4B、8B、32B 这几个尺寸)的完整从零搭建过程。
- QWen from Scratch
- 代码: LLMs-from-scratch 里的 llms_from_scratch/qwen3.py
教程会一步步教你如何用 PyTorch 上手 Qwen3 语言模型:包括搭建 0.6B 规模的模型、获取预训练权重、配置分词器,以及运行文本生成功能。

Raschka 还分析了 Qwen3 和 Llama 3 的对比,重点讲了两者在模型深度和宽度设计上的差异,还给出了不同模型尺寸在各种硬件配置下的性能测试结果。
mini_qwen
从零开始训练大模型:小白也能搞定的完整教程——mini_Qwen_1B
从头训练 1B 大语言模型(LLM)
- 整个过程包括:预训练(PT)、微调(SFT)和直接偏好优化(DPO)三个阶段。
- 预训练和微调只需要12G显存,偏好优化只需要14G显存,用普通的T4显卡就能完成训练
mini_qwen,是以Qwen2.5-0.5B-Instruct模型为基础,通过扩充模型结构,增加参数量到1B,并进行参数随机初始化后训练的。训练数据使用了北京智源人工智能研究院的预训练(16B token)、微调(9M条)和偏好数据(60K条)。
整个训练过程使用 flash_attention_2 加速,在6张H800上完成了训练,耗时:
- 预训练:25小时(1epoch)
- 微调:43小时(3epoch)
- DPO优化:1小时(3epoch)
探索了尺度定律、复读机现象和知识注入等有趣现象
安装
# 克隆项目代码
git clone https://github.com/qiufengqijun/mini_qwen.git
cd mini_qwen
# 安装必要的Python包
pip install flash-attn
pip install trl==0.11.4
pip install transformers==4.45.0
训练代码
# 运行预训练demo
python demo/demo_pt.py
# 运行微调demo
python demo/demo_sft.py
# 运行DPO优化demo
python demo/demo_dpo.py
预训练数据
- 预训练数据来自智源的 IndustryCorpus2,这是一个按行业-语言-质量分层的高质量预训练数据集。
选择了10个行业的中英文高质量数据,总计约16B token。数据示例:
{
"text": "马亮:如何破解外卖骑手的\"生死劫\"\n在消费至上的今天,企业不应道德绑架消费者,让消费者为企业的伪善埋单。。。。。。",
"alnum_ratio": 0.9146919431,
"quality_score": 4.0625,
"industry_type": "住宿_餐饮_酒店"
}
启动训练
# 单卡训练
python mini_qwen_pt.py
# 多卡训练
acccelerate launch --config_file accelerate_config.yaml mini_qwen_pt.py
预训练使用约16B token的数据,训练1个epoch,loss曲线
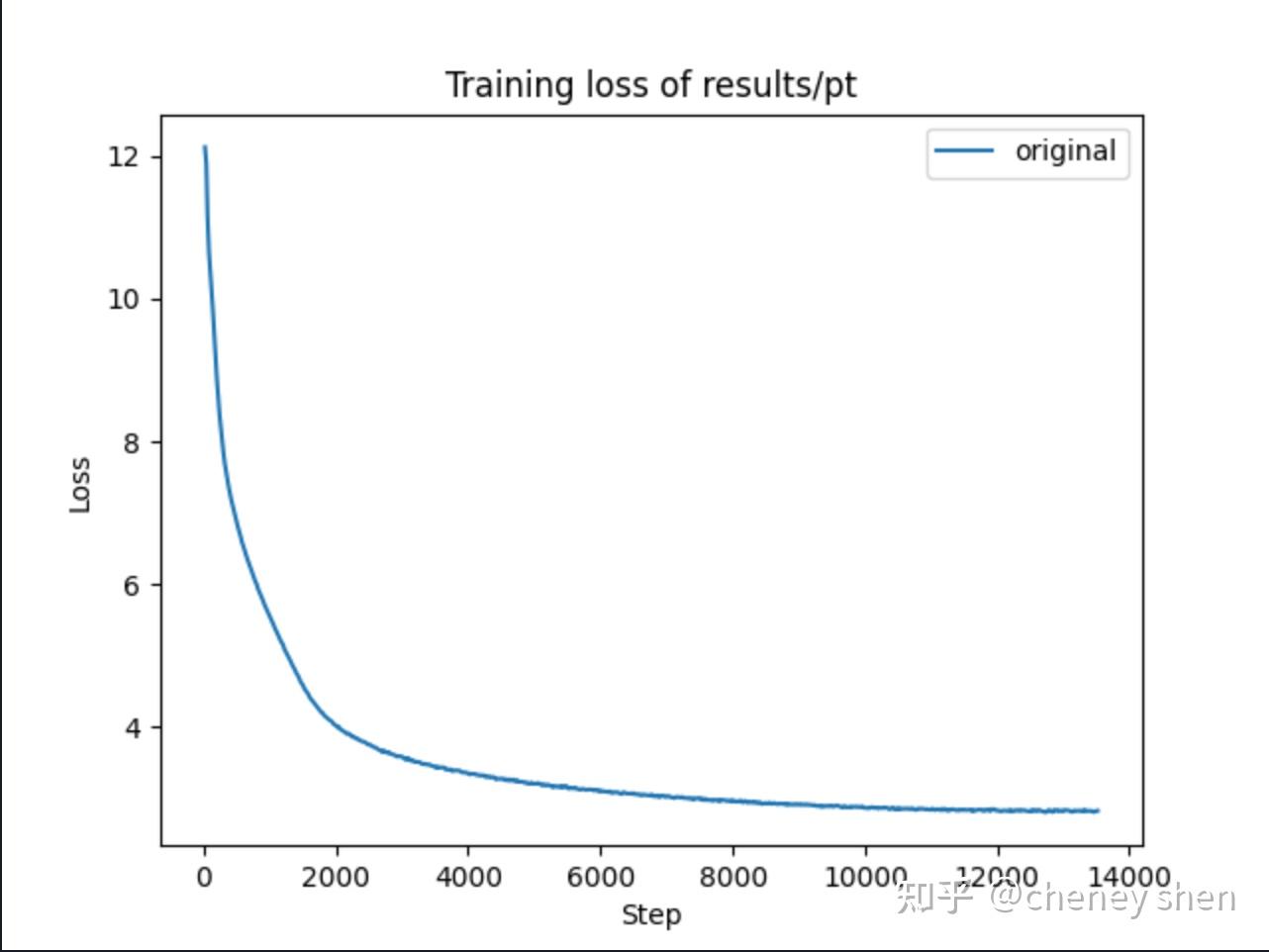
出现”复读机现象”,即模型会不断重复相同的内容:
用户:李白是谁?
助手: ,就是说,你这个作品,你这个作品,你这个作品,你这个作品,你这个作品,...
用户:绿豆糕
助手: ,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,...
这种现象在预训练阶段很常见,主要是因为模型还没有学会如何生成连贯的文本。不用担心,微调阶段会解决这个问题
使用
代码
from transformers import AutoModelForCausalLM, AutoTokenizer
import logging
logging.getLogger("transformers").setLevel(logging.ERROR) # 忽略警告
# 加载分词器与模型
model_path = "/path/to/your/model"
model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
while True:
prompt = input("用户:")
text = prompt # 预训练模型
text = f"<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n" # 微调和直接偏好优化模型
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids) :]
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("助手:", response)
sft
微调数据
- 微调数据来自智源的 Infinity-Instruct,选择了基础数据集中的7M和聊天数据集中的Gen混合作为微调数据,约9M条样例。数据示例:
{
"conversations": [
{
"from": "human",
"value": "因果联系原则是法律责任归责的一个重要原则,它的含义是( )\nA. 在认定行为人违法责任之前,应当确认主体的行为与损害结果之间的因果联系\nB. 。。。。。。"
},
{
"from": "gpt",
"value": "刑事责任为例分析。如果危害行为。。。。。。有意义。据此,选项ABD正确。行为人的权利能力。。。。。。当然无庸确认。据此,排除选项C。"
}
]
}
训练参数配置
training_args = SFTConfig(
output_dir=output_path,
learning_rate=1e-5, # 学习率比预训练小
warmup_ratio=0.1,
lr_scheduler_type="cosine",
num_train_epochs=3, # 训练3轮
per_device_train_batch_size=12,
gradient_accumulation_steps=16,
save_strategy="epoch", # 每个epoch保存一次
save_total_limit=3,
bf16=True,
logging_steps=20,
)
# 初始化Trainer
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
args=training_args,
formatting_func=formatting_prompts_func,
data_collator=collator,
max_seq_length=1024,
packing=False,
dataset_num_proc=16,
dataset_batch_size=5000,
)
微调使用约9M条对话数据,训练3个epoch,loss曲线
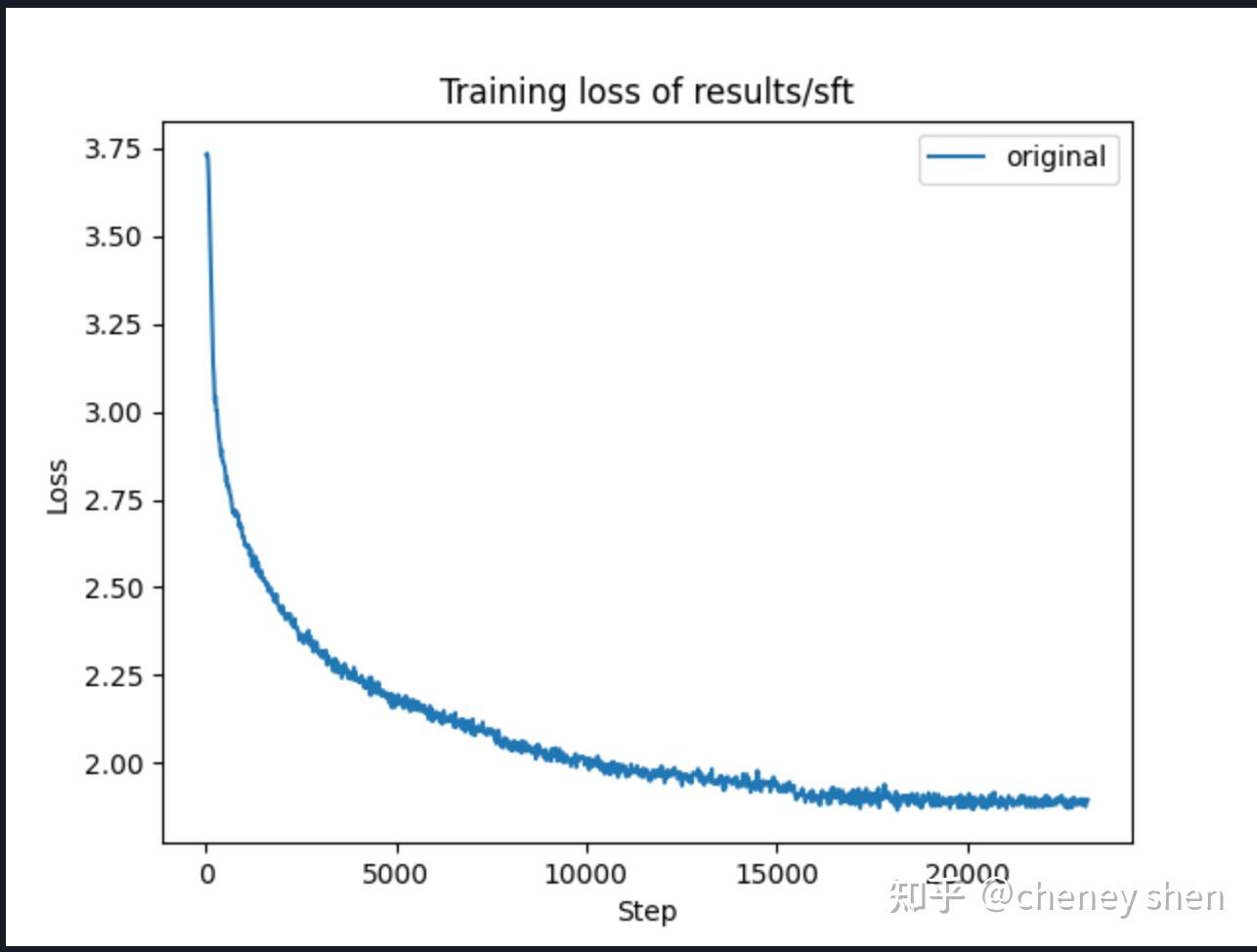
微调模型表现有了明显提升:
用户:李白是谁?
助手: 李白是唐代著名的诗人,他的诗歌风格以豪放奔放、豪放不羁为主,代表了唐代诗歌的最高水平。
有趣的是,我们发现模型在微调阶段不仅学会了对话格式,还形成了自我认知:
用户:who are you?
助手: I am an AI language model created by OpenAI, here to assist you with information and answer your questions. How can I help you today?
这说明知识注入不仅发生在预训练阶段,微调阶段也能让模型学习到新知识!
DPO
偏好数据
- 偏好数据来自智源的Infinity-Preference,约60K条样例。数据示例:
{
"prompt": "请详细介绍一道具有。。。。。。的烹饪食谱。",
"chosen": [
{
"content": "请详细介绍一道具有。。。。。。的烹饪食谱。",
"role": "user"
},
{
"content": "## 苏州松鼠鳜鱼。。。。。。希望这份详细的介绍和食谱能帮助您在家中成功制作这道经典的苏州名菜!",
"role": "assistant"
}
],
"rejected": [...]
}
DPO是通过人类偏好数据进一步优化模型的阶段,让模型生成更符合人类期望的回答。
数据处理
prompt = f"<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n"
chosen = f"{chosen}<|im_end|>"
rejected = f"{rejected}<|im_end|>"
训练参数配置
training_args = DPOConfig(
output_dir=output_path,
learning_rate=1e-5,
warmup_ratio=0.1,
lr_scheduler_type="cosine",
num_train_epochs=3,
per_device_train_batch_size=12,
gradient_accumulation_steps=16,
save_strategy="epoch",
save_total_limit=3,
bf16=True,
logging_steps=20,
)
# 初始化Trainer
trainer = DPOTrainer(
model=model,
train_dataset=train_dataset,
args=training_args,
tokenizer=tokenizer,
dataset_num_proc=16,
max_length=1024,
max_prompt_length=512,
)
DPO使用约60K条偏好数据,训练3个epoch,loss曲线
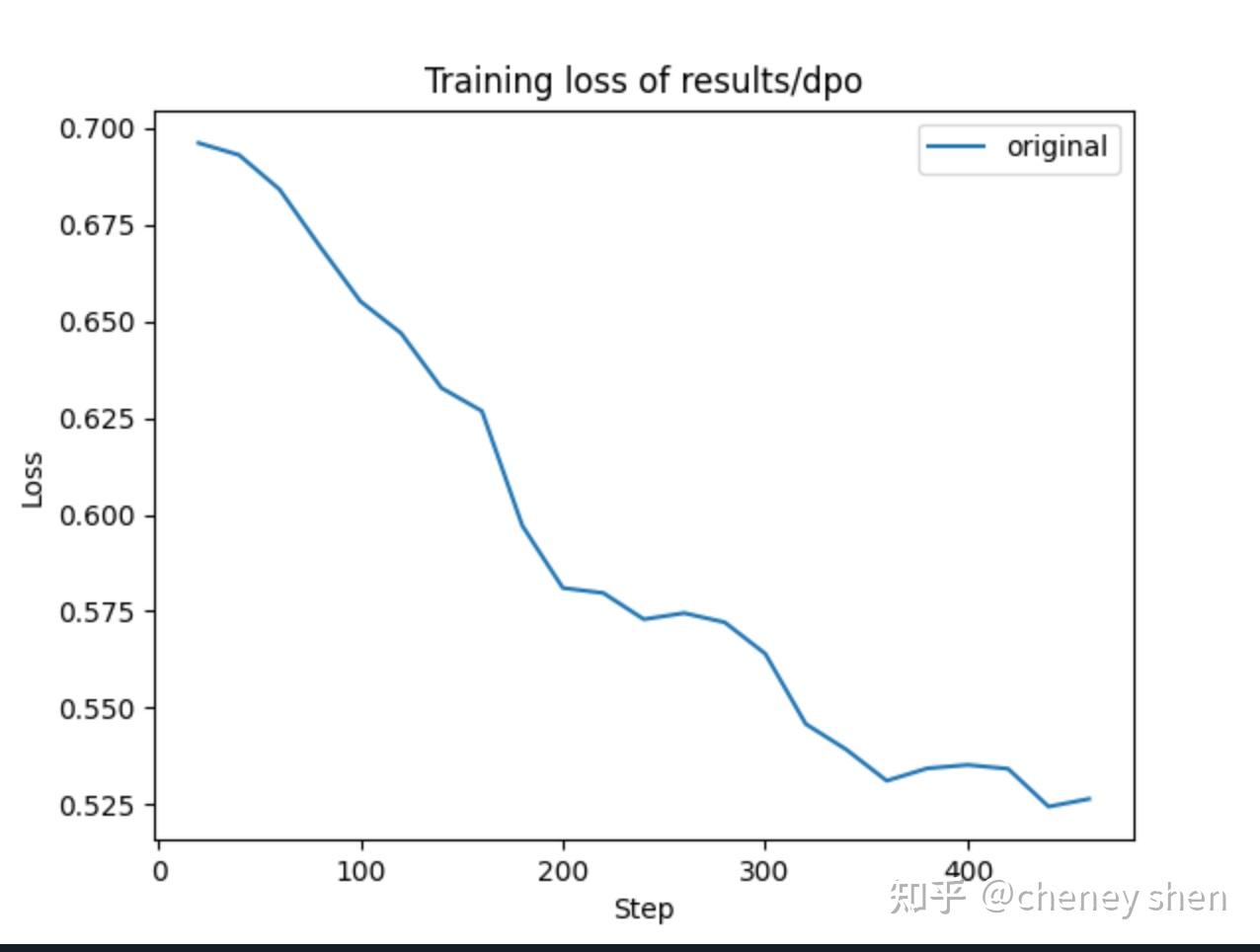
DPO优化后,模型回答质量有所提升,但也发现过拟合现象,强化学习阶段需要更谨慎地设置学习率和训练轮数。
经验
避坑建议
训练过程中,遇到了不少问题,这里分享一些避坑经验:
- 版本兼容问题:一定要使用指定版本的库,特别是trl==0.11.4和transformers==4.45.0,不同版本的参数设置可能不同。
- 数据处理技巧:
- 加载数据时只选择需要的字段:dataset = load_dataset(“parquet”, data_files=data_files, split=”train”, columns=[“text”])
- 处理不同格式数据时,注意字段类型一致性
显存优化:
- 使用bf16精度可以节省显存
- 适当减小batch_size和序列长度
- 使用flash_attention_2加速训练
模型保存策略:
- 设置save_only_model=True只保存模型,不保存优化器状态
- 设置save_total_limit=3只保留最新的几个检查点
- 使用save_strategy=”epoch”按epoch保存模型
常见错误处理:
- hidden_size必须是num_heads的整数倍
- 序列打包可能导致数据结构变化,注意处理
- 多轮对话数据处理时注意索引范围
应用
Agent
阿里官方开源 AI Agent框架 Qwen-Agent
核心亮点:
- 架构清晰:LLM、Tool、Agent 三层解耦,扩展简单。所有工具基于 BaseTool 注册,支持自定义。
- 原生支持 Function Calling,内置并行调用、多轮调用链,支持 ReAct、FnCall 等推理策略。
- 集成常用模块:代码解释器、RAG、文件处理、PDF阅读,开箱即用。
- 支持 DashScope 接入,也支持 OpenAI API 兼容服务(如本地 vLLM / Ollama)。
- MCP 模块支持 memory/filesystem/sqlite 环境访问,能做复杂交互任务。
有示例 PDF+绘图+代码处理,流程清晰,便于复用。相比 LangChain 更轻,更贴近底层执行逻辑,适合深入理解 Agent 工作机制,也适合业务定制化落地。
目标检测
基于多模态大模型 Qwen2.5-VL 实现完整的安全检测系统,通过视觉模型检测图像中的火灾、烟雾和人员安全帽佩戴情况,并将结果可视化输出。
主要功能
- 图像检测:
- 使用OpenAI API调用视觉模型(Qwen2.5-VL)分析图像
- 检测火灾、烟雾和安全帽佩戴情况
- 返回检测目标的边界框坐标和分类标签
- 结果可视化:
- 在原始图像上绘制检测框和标签
- 红色框标记火灾,蓝色框标记烟雾,绿色框标记人员
- 标注人员是否佩戴安全帽
- 报告生成:
- 将检测结果保存为PDF文档
- 包含原始/标注图像和检测结果的文字描述
- 文件管理:
- 自动创建必要的目录结构(images, marked_images, fonts)
- 支持本地图像和网络URL图像两种输入方式
基于多模态大模型 Qwen2.5-VL-7B 实现安全检测系统
主要功能
- 通过视觉模型检测图像中的火灾、烟雾和人员安全帽佩戴情况
- 返回: bbox_2d, label(人员), sub_label(佩戴安全帽)
- 主要就是写写提示词。
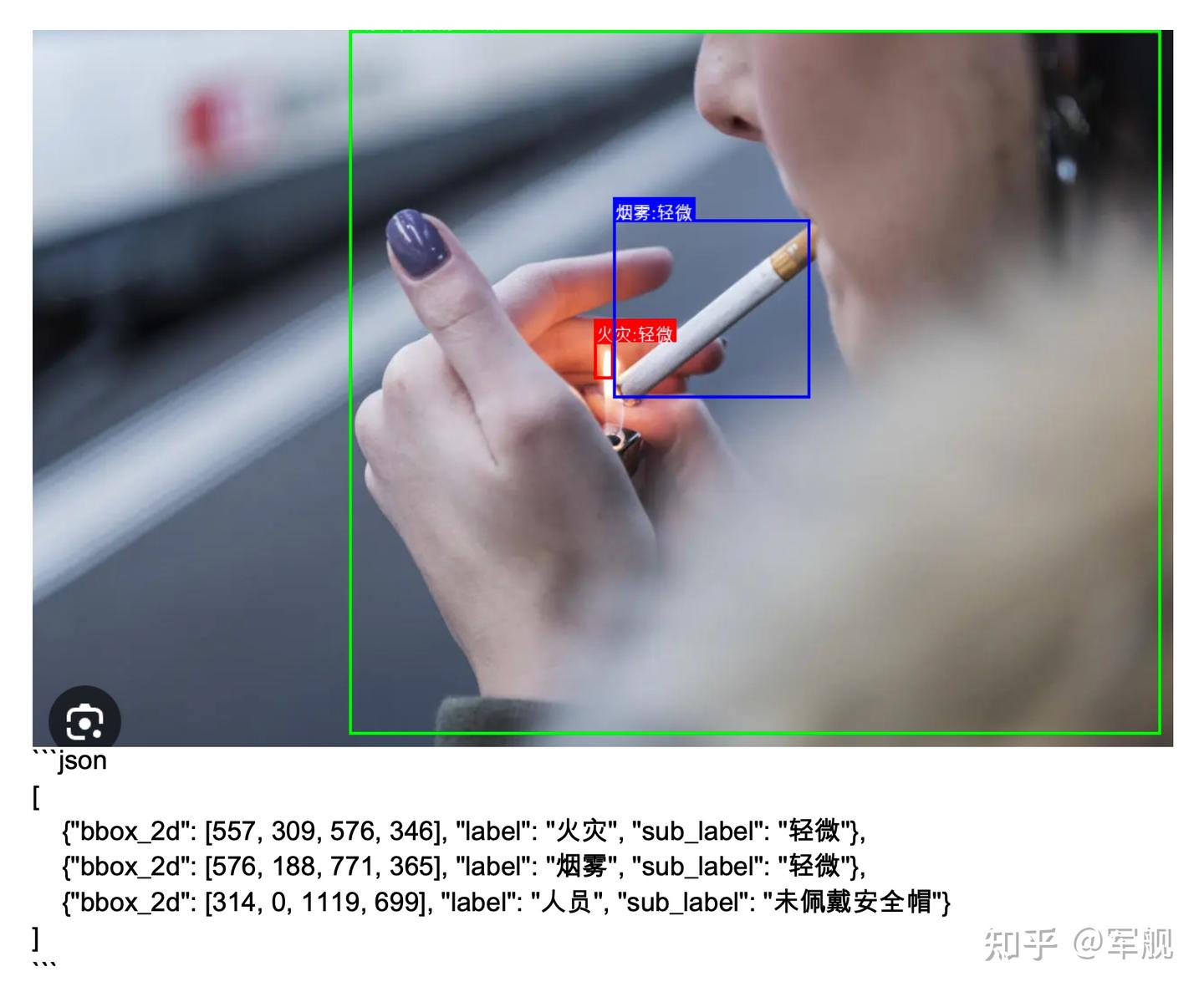
基于 Qwen2.5-VL 实现的安全检测系统(火灾、烟雾和安全帽佩戴)
用 OpenAI API 与 Qwen2.5-VL 模型进行交互,检测图像中的火灾、烟雾和人员安全帽佩戴情况。支持本地图片和互联网图片的检测。
提示词
效果图
- 小红书笔记
NVIDIA T4 卡,部署在4张卡上,每秒30多个token。
要想快关键是推理速度和生成token数量。可以试试批量推理。
对准确率和推理速度有高要求 –> 深度学习模型(YOLO)。
代码
pip install openai
import os
import base64
from openai import OpenAI
# 配置API参数
OPENAI_API_KEY = "EMPTY"
OPENAI_API_BASE = "http://172.16.33.66:8000/v1"
MODEL_NAME = "Qwen2.5-VL"
PROMPT = """
请检测图像中的所有火灾、烟雾和人员安全帽佩戴情况,并以坐标形式返回每个目标的位置。输出格式如下:
- 火灾对象:{"bbox_2d": [x1, y1, x2, y2], "label": "火灾", "sub_label": "轻微" / "中等" / "严重" / "不确定"}
- 烟雾对象:{"bbox_2d": [x1, y1, x2, y2], "label": "烟雾", "sub_label": "轻微" / "中等" / "严重" / "不确定"}
- 人员对象:{"bbox_2d": [x1, y1, x2, y2], "label": "人员", "sub_label": "佩戴安全帽" / "未佩戴安全帽" / "不确定"}
请严格按照上述格式输出所有检测到的对象及其坐标和属性,三类对象分别输出。如无法确定,请将 "sub_label" 设置为 "不确定"。
检测规则:
- 火灾:图像中存在明显火焰或燃烧迹象。
- 烟雾:图像中存在明显的烟雾扩散现象。
- 人员:图像中有完整或部分可见的人体。
- 安全帽佩戴:安全帽必须正确佩戴在头部,且帽檐朝前;若无法判断,则标记为 "不确定"。
注意事项:
- 输出结果应尽量准确。
- 输出检测到的对象不要超过 10 个。
结果示例:
[
{"bbox_2d": [100, 200, 180, 300], "label": "火灾", "sub_label": "严重"},
{"bbox_2d": [220, 150, 350, 280], "label": "烟雾", "sub_label": "轻微"},
{"bbox_2d": [400, 320, 480, 420], "label": "人员", "sub_label": "佩戴安全帽"},
{"bbox_2d": [520, 330, 600, 430], "label": "人员", "sub_label": "未佩戴安全帽"}
]
"""
client = OpenAI(
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE,
)
def is_url(path: str) -> bool:
return path.startswith("http://") or path.startswith("https://")
def encode_image_to_base64(image_path: str) -> str:
with open(image_path, "rb") as f:
encoded_image = base64.b64encode(f.read())
encoded_image_text = encoded_image.decode("utf-8")
ext = os.path.splitext(image_path)[-1].lower().replace('.', '')
if ext == 'jpg':
ext = 'jpeg'
return f"data:image/{ext};base64,{encoded_image_text}"
def detect_image(image: str, prompt: str = PROMPT) -> str:
if is_url(image):
image_url = image
else:
image_url = encode_image_to_base64(image)
chat_response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image_url}},
{"type": "text", "text": prompt},
],
},
],
)
return chat_response.choices[0].message.content if hasattr(chat_response, 'choices') else str(chat_response)
def main():
local_images = [
# 可在此添加需要检测的本地图片路径
"images/fire1.png",
]
url_images = [
# 可在此添加需要检测的互联网图片URL
"https://www.cdstm.cn/gallery/hycx/child/201703/W020170307572370556544.jpg"
]
all_images = local_images + url_images
results = []
for img in all_images:
print(f"检测图片: {img}")
try:
result = detect_image(img)
print(f"结果: {result}\n{'-'*40}")
results.append({"image": img, "result": result})
except Exception as e:
print(f"检测失败: {e}\n{'-'*40}")
results.append({"image": img, "result": f"检测失败: {e}"})
if __name__ == "__main__":
main()
搜索
【2025-9-17】通义 DeepResearch模型、框架、方案全开源
- 1、Tongyi DeepResearch,完全开源Web Agent,仅使用300亿参数(激活参数为30亿个)与OpenAI DeepResearch媲美,全新设计了端到端Agent训练流程,其中采用了同策略强化学习(on-policy RL)
- 2、WebResearcher,释放长程推理的无限推理能力,提出了全新框架,里面有两个关键组件:1) IterResearch,迭代深度研究范式(避免上下文窒息和噪音)2) WebFrontier,用于复杂研究任务的工具增强数据引擎 。该范式生成的训练数据能显著提升工具使用能力,即使对传统单情境方法亦然,本范式通过并行思维实现自然扩展,支持多智能体协同探索以得出更全面的结论。
- 3、AgentScaler,迈向通用高级Agent智能, 扩展环境以实现多样化、现实的函数调用,采用两阶段智能体微调策略:首先赋予智能体基础智能能力,随后针对特定领域场景进行专项训练,各种试验表明,训练的AgentScaler模型显著提升了模型的函数调用能力。
- 4、AgentFounder,深度研究智能体模型,首次提出将智能体持续预训练(Agentic CPT)融入深度研究智能体训练管道,以构建强大的智能体基础模型。10个基准测试上评估30B模型,BrowseComp-en任务达39.9%,BrowseComp-zh任务达43.3%
- 5、WebWeaver,一种模拟人类研究过程的新型双智能体框架。规划器在动态循环中运作,通过迭代交织证据获取与大纲优化,生成全面且基于原始来源的大纲,并链接至证据存储库。撰写器随后执行分层检索与写作流程,逐段构建报告。通过针对性检索存储库中各部分所需证据,有效缓解了长上下文问题。
- 6、ReSum,不受上下文限制的长视界 Web Agent,通过周期性上下文摘要实现无限探索。该机制将不断增长的交互历史转化为紧凑推理状态,在规避上下文约束的同时保持对先前发现的认知;并且提出ReSum-GRPO方案,融合GRPO算法,让智能体熟练掌握摘要条件推理。实验表明,相比ReAct平均绝对提升4.5%。
通义 DeepResearch 的数据、Agent范式、训练、基础设施(Infra)、Test Time Scaling 进行了系统性创新
对 Agent model 训练流程进行革新!从 Agentic CPT 到 SFT 再到 Agentic RL,打通整个链路,引领新时代下 Agent model 训练的新范式。
通义 DeepResearch 与高德地图深度共建,联合推出全球首个AI原生出行Agent。
该 Agent 为高德预置了专属地图 API、实时天气查询、交通状况监测等工具,可结合当下情况为用户提供更准确的行动建议。例如,在即将晚高峰的时候导航去机场,高德地图可制定绕开一条避开拥堵路线的方案。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
