- DeepSeek
- 结束
DeepSeek
资料
- 天津大学, 深度解读deepseek: 原理与效应 [百度云链接]:(https://pan.baidu.com/s/1Ily-BwKw0x5eepcc6d2Shw?pwd=b24w)
- 知乎文字版概要, 含 ppt 截图
- 【2025-2-25】46页PPT,深入了解“DeepSeek”, 精简扼要
资讯
资讯
- 深度求索(DeepSeek)顶尖人才招聘
- 【2025-1-20】杭州科技公司创始人,为何成为总理的“座上宾”?
- 总理座谈会,北京大学经济学院院长
张辉,浙江大学党委书记任少波,中国工商银行党委副书记、行长刘珺,国产大模型企业深度求索(DeepSeek)创始人梁文锋,遨博(北京)智能科技股份有限公司董事长魏洪兴,中国机械工业集团有限公司副总经理、总工程师陈学东,国家图书馆古籍馆馆长陈红彦,中国医学科学院北京协和医院副院长杜斌,国际级运动健将、中国体操运动员邹敬园。
- 总理座谈会,北京大学经济学院院长
杭州六小龙:云深处、宇树科技、深度求索(DeepSeek)、游戏科学、群核科技和强脑科技
云深处的绝影X30成为首个走进海外电力系统的中国机器人,证明了国产机器人在国际市场上的技术成熟度和商业化潜力。宇树科技的B2-W机器狗展示了中国仿生机器人技术的突破,其动态平衡能力与环境适应能力被认为是全球领先。深度求索用不到600万美元的成本,开发出超越当前顶级开源模型的AI大模型DeepSeek-V3,重新定义了AI的性价比。游戏科学凭借《黑神话:悟空》一战成名,将中国文化与全球游戏市场成功连接。群核科技建立了全球最大的3D数据平台,为机器人训练和虚拟现实应用提供了强大支持。强脑科技则在脑机接口技术上与Neuralink比肩,通过高精度、便携化的产品,走在了消费级脑机设备的前沿
作者:元宇宙之家Meta
DeepSeek 登上Nature
【2025-9-18】DeepSeek-R1论文登上Nature封面,通讯作者梁文锋
最新一期 Nature 封面,竟然是 DeepSeek-R1 的研究。
- 2025年1月, DeepSeek 在 arxiv 公布的论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》。这篇Nature论文通讯作者正是梁文锋。
推荐介绍中,Nature 写到:
如果训练出的大模型能够规划解决问题所需的步骤,那么它们往往能够更好地解决问题。这种『推理』与人类处理更复杂问题的方式类似,但这对人工智能有极大挑战,需要人工干预来添加标签和注释。在本周的期刊中,DeepSeek 的研究人员揭示了他们如何能够在极少的人工输入下训练一个模型,并使其进行推理。 DeepSeek-R1 模型采用强化学习进行训练。在这种学习中,模型正确解答数学问题时会获得高分奖励,答错则会受到惩罚。结果,它学会了推理——逐步解决问题并揭示这些步骤——更有可能得出正确答案。这使得 DeepSeek-R1 能够自我验证和自我反思,在给出新问题的答案之前检查其性能,从而提高其在编程和研究生水平科学问题上的表现。
以往的研究主要依赖大量的监督数据来提升模型性能。DeepSeek 的开发团队则开辟了一种全新的思路:即使不用监督微调(SFT)作为冷启动,通过大规模强化学习也能显著提升模型的推理能力。如果再加上少量的冷启动数据,效果会更好。
DeepSeek一举成为首家登上《Nature》封面的中国大模型公司,创始人梁文锋担任通讯作者。纵观全球,之前也只有极少数如DeepMind者,凭借AlphaGo、AlphaFold有过类似殊荣。
Nature版本R1论文不仅首次披露了R1训练成本——仅约29.4万美元(折合人民币约 208 万),还进一步补充了包括模型训练所使用的数据类型及安全性的技术细节。
Nature 还盛赞 DeepSeek-R1 的这种开放模式。
- R1 被认为是首个通过权威学术期刊同行评审的大语言模型。
Hugging Face 机器学习工程师、该论文审稿人之一的 Lewis Tunstall 表示:
- 「这是一个备受欢迎的先例。如果缺乏这种公开分享大部分研发过程的行业规范,我们将很难评估这些系统的潜在风险。」
为回应评审意见,DeepSeek 团队不仅在论文中避免了对模型的拟人化描述,还补充了关于训练数据类型和安全性的技术细节。
俄亥俄州立大学 AI 研究员 Huan Sun 评论道:
「经历严格的同行评审,无疑能有效验证模型的可靠性与实用价值。其他公司也应效仿此举。」
显而易见,当前 AI 行业充斥着发布会上的惊艳演示和不断刷新的排行榜分数。基准测试是可被「操控」, 将模型的设计、方法论和局限性交由独立的外部专家审视,能够有效挤出其中的水分。
同行评审充当了一个公正的「守门人」,它要求 AI 公司从「王婆卖瓜」式的自我宣传,转向用扎实的证据和可复现的流程来支持其声明。
DeepSeek-R1 论文本身固然有其科学价值,但作为首个接受并通过主流期刊同行评审的 LLM,其「程序价值」可能更为深远。
DeepSeek对训练成本、数据及安全性进行了进一步澄清:
💴 训练花费
- R1-Zero和R1都用了512张H800GPU,分别训练了198个小时和80个小时,以H800每GPU小时2美元的租赁价格换算的话,R1的总训练成本为29.4万美元。
- 要知道,R1可是实打实的660B参数的大模型。相比之下,不到30万美元的训练成本,直接让那些动辄烧掉上千万美元的同行们“抬不起头”。
💻 数据来源
- DeepSeek一举打破了拿彼模型之输出当R1之输入的传闻。
- DeepSeek-R1 数据集包含数学、编程、stem、逻辑、通用等5个类型的数据。
- 数学数据集包含2.6万道定量推理题,包括数学考试题和竞赛题;
- 代码数据集包含1.7万道算法竞赛题和8千道代码修复问题;
- STEM数据集包含2.2万道选择题,涵盖物理、化学和生物等学科;
- 逻辑数据集包含真实问题和合成问题等共1.5万道题;
- 通用数据集包含6.6万道题,用于评估模型的有用性,涵盖创意写作、文本编辑、事实问答、角色扮演以及评估无害性等多种类别。
🔐 安全性
虽然开源共享有助于技术在社区中的传播,但同时也可能带来被滥用的潜在风险。
因此DeepSeek又一进步发布了详细的安全评估,涵盖以下几个方面:
- DeepSeek-R1 官方服务的风险控制系统
- 在六个公开安全基准上与其他最先进模型的对比评估
- 基于内部安全测试集的分类学研究
- R1模型的多语言安全性评估
- 模型对越狱攻击的鲁棒性评估。
评估表明,DeepSeek-R1 模型的固有安全水平总体处于中等水平,与GPT-4o相当,通过结合风险控制系统可进一步提高模型的安全水平。
回想年初DeepSeek爆火时,梁文锋“中国AI不可能永远跟随”的豪言壮志令人振奋。如今,DeepSeek影响力获得Nature封面认可。下一个,会是谁?
DeepSeek 介绍
位于杭州的量化投资基金幻方,一家抵达过千亿规模的“顶级基金”
- 2019年,幻方量化成立AI公司,自研深度学习训练平台“
萤火一号”总投资近2亿元,搭载 1100块GPU; - 2021年,“萤火二号”的投入增加到10亿元,搭载了约1万张英伟达A100显卡。幻方在亚太第一个拿到 A100卡,成为全国少数几家囤有上万张 A100 GPU的机构。
- 国内拥有超过1万枚GPU的企业不超过5家。除几家头部大厂,另一家就是幻方。
- 1万枚英伟达A100芯片是做自训大模型的算力门槛: 起步就要5000万美金,训练1次需要上千万美金,非百亿美金公司其实很难持续跟进。
- 成立仅六年的幻方,抵达千亿规模,并被称为“量化四大天王”之一
- 幻方的成长奥秘归结为“选用了一批没有经验但有潜能的人,以及有一个可以让创新发生的组织架构和企业文化”
- 2023年4月11日, 宣布做大模型
- 引用了法国新浪潮导演
特吕弗告诫青年导演的一句话:“务必要疯狂地怀抱雄心,且还要疯狂地真诚。”
- 引用了法国新浪潮导演
- 2023年5月,才把做大模型团队独立出来
- 2023年7月17日,正式成立
深度求索公司,专注于做真正人类级别的人工智能。目标不只是复刻ChatGPT,还要去研究和揭秘通用人工智能(AGI)的更多未知之谜。
deepseek 杭州、北京分工 (源自小红书帖子)
- 北京分部:研发团队的核心成员集中在北京,主要包括算子、推理框架、多模态等领域的研发工程师及深度学习研究人员,约70人。
- 杭州总部:位于杭州市拱墅区环城北路,主要负责前端开发、产品设计及商务运营,研发人员占比相对较少,约30人。
- 团队整体规模约百人,仅为OpenAI员工数的五分之一,但通过高效协作与技术创新实现了多项突破。
自从ChatGPT时刻以来,业界弥漫一股“唯GPU论”的情绪,上万张卡加几亿美元,被认为是做大模型的门槛。
深度求索创立之初就宣布做AGI,会专注在大模型上,先从语言大模型做起,然后再做视觉和多模态等。
- 从2024年初推出首个大型语言模型
DeepSeek LLM,只能对标GPT-3.5 - 直到2024年底推出硬碰
GPT-4o的DeepSeek V3,并且进军多模态、推理模型。
中国7家大模型创业公司中,DeepSeek(深度求索)最不声不响,但又总能以出其不意的方式被人记住。
- 一年前,这种出其不意源自背后的量化私募巨头
幻方,大厂外唯一储备万张A100芯片的公司 - 一年后,则来自引发中国大模型价格战的源头。
幻方量化
【2026-1-13】DeepSeek母公司去年进账50亿,够烧2380个R1
R1横空出世一年后,DeepSeek依然没有新融资。在大模型玩家上市的上市、融资的融资的热闹中,DeepSeek还是那么高冷,并且几乎没有任何商业化的动作。
即便如此,AGI也没有落下——持续产出高水平论文,作者名单也相当稳定,新版R1论文甚至还「回流」了一位。
幻方量化去年赚了50亿。
私募排排网显示,2025年,幻方量化旗下几乎每支基金,收益率都在55%以上。
- 去年是中国量化基金的丰收年:平均收益率为30.5%,是全球竞争对手的两倍多。
即便是如此高涨的势头,依旧难掩幻方量化一骑绝尘的身姿——平均收益率56.6%,在全国百亿级量化基金中位居第二,仅次于收益70%的灵均投资。
幻方量化管理的资产规模超过700亿,这一惊人的收益率,无疑能让公司赚得盆满钵满。
一名上海的私募基金投资总监认为:假设按管理费1%,业绩提成20%来算,幻方量化这棵摇钱树,光去年一年,可能就帮梁文锋赚了超过7亿美元(约50亿人民币)。
CEO 梁文锋
DeepSeek创始人梁文锋 浙江大学电子工程系人工智能方向, 从幻方时代 就在幕后潜心研究技术的80后创始人
-

- 2008年起,
梁文锋就开始带领团队使用机器学习等技术探索全自动量化交易。 - 2015年,幻方量化正式成立
- 2019年,其资金管理规模就突破百亿元。
- 2019年,梁文锋在当年的金牛奖颁奖仪式上,发表主题演讲《一名程序员眼里中国量化投资的未来》,这是他罕有的公开发言。
- 演讲中,梁文锋指出,量化与非量化的判定标准是投资决策过程用数量化方法还是人进行决策。量化公司是没有基金经理的,基金经理就一堆服务器。
- “作为私募,投资人对我们的期望是很高的,如果一年跑赢指数低于25%,投资人是不满意的。” 梁文锋指出,量化投资已经赚了技术面流派原来赚的钱,未来也要抢夺基本面流派原来赚的钱。
- 幻方量化的使命就是提高中国二级市场的有效性。
- 2021年,幻方量化成为国内首家突破千亿规模的的量化私募大厂,被称为国内量化私募“四大天王”之一。不过,由于业绩波动,幻方量化关闭了全部募集通道,并在12月底发布致投资者公开信,致歉称“幻方业绩的回撤达到历史最大值,我们对此深感愧疚”,究其原因,主要是AI投资决策在买卖时点上没有做好,市场风格剧烈切换的时候,AI会倾向于冒更大的风险来博取更多收益,进一步加大了回撤。
在 DeepSeek 时代,依旧延续低调作风,和所有研究员一样,每天 “看论文,写代码,参与小组讨论”。
梁文锋是当下中国AI界非常罕见
- “兼具强大的infra工程能力和模型研究能力,又能调动资源”
- “既可以从高处做精准判断,又可以在细节上强过一线研究员”的人,他拥有“令人恐怖的学习能力”,同时又“完全不像一个老板,而更像一个极客”。
他是少有把“是非观”置于“利害观”之前,并提醒看到时代惯性,把“原创式创新”提上日程的人。
- 【2023-5-24】疯狂的幻方:一家隐形AI巨头的大模型之路
- 【2024-7-17】揭秘DeepSeek:一个更极致的中国技术理想主义故事
- 【2024-11-27】英国程序员西蒙·威利森(Simon Willison)专访: Deepseek: The Quiet Giant Leading China’s AI Race
中国顶级研究者的视野和抱负
- (1)我们做的不是
生成式 AI,而是通用人工智能 AGI。前者只是后者的必经之路,AGI 会在有生之年实现。 - (2)任何 AI 公司(短期内)都没有碾压对手的技术优势
- 因为有 OpenAI 指路,又都基于公开论文和代码,大厂和创业公司都会做出自己的大语言模型。
- (3)在颠覆性技术面前,闭源形成的护城河是短暂的。即使 OpenAI 闭源,也无法阻止被别人赶超。我们把价值沉淀在团队上,同事在这个过程中得到成长,积累很多know-how,形成可以创新的组织和文化,才是护城河。
- (4)我们不会闭源。先有一个强大的技术生态更重要。
- (5)当前是技术创新的爆发期,而不是应用的爆发期。
- 大模型应用门槛会越来越低,创业公司在未来20年任何时候下场,也都有机会。
- (6)很多中国公司习惯别人做技术创新,自己拿过来做应用变现,等着
摩尔定律从天而降,躺在家里18个月就会出来更好的硬件和软件。- 我们的出发点不是趁机赚一笔,而是走到技术前沿,去推动整个生态发展。中国也要逐步成为贡献者,而不是一直搭便车。
- (7)大部分中国公司习惯 跟进,而不是创新。中国创新缺的不是资本,而是缺乏信心,以及不知道怎么组织高密度的人才。
- 我们没有海外回来的人,都是本土制造。前50名顶尖人才可能不在中国,但也许我们能自己打造这样的人。
- (8)我们每个人对于卡和人的调动不设上限。
- 如果有想法,每个人随时可以调用训练集群的卡无需审批。
- 同时因为不存在层级和跨部门,也可以灵活调用所有人,只要对方也有兴趣。
- (9)选人标准一直都是热爱和好奇心,所以很多人会有一些奇特经历,对做研究的渴望远超对钱的在意。
- (10)我们在做最难的事。最吸引顶级人才的是去解决世界上最难的问题。
- 其实,顶尖人才在中国被低估。因为整个社会层面的硬核创新太少了,没有机会被识别出来。
- (11)中国产业结构的调整会更依赖硬核技术创新。很多人发现过去赚快钱很可能来自时代运气,现在赚不到了,就会更愿意俯身去做真正的创新。
- (12)我是八十年代在广东一个五线城市长大的,父亲是小学老师,九十年代,广东赚钱机会很多,当时有不少家长觉得读书没用。
- 但现在回去看,观念都变了。因为钱不好赚了,连开出租车的机会可能都没了。
- 一代人的时间就变了。以后硬核创新会越来越多,因为整个社会群体需要被事实教育。
- 当这个社会让硬核创新的人功成名就,群体性想法就会改变。
- 只是还需要一堆事实和一个过程。
团队
OpenAI前政策主管、Anthropic联合创始人Jack Clark:
- DeepSeek “雇佣了一批高深莫测的奇才”,还认为中国制造的大模型,“将和无人机、电动汽车一样,成为不容忽视的力量。”
团队情况
梁文锋:
- 并没有什么高深莫测的奇才,都是一些Top高校的
应届毕业生、没毕业的博四、博五实习生,还有一些毕业才几年的年轻人。都是本土 —— 达摩院背景的罗福莉参考 罗福莉:天才AI少女“祛魅”记- 保研北大、在顶会顶刊发文章、拿遍大厂offer、进入阿里达摩院、转行跳槽知名私募公司…
- 2019年,一位北大硕士,因在NLP国际顶会 ACL 上发表 8 篇论文(其中2篇一作),曾登上知乎热搜
- 在达摩院,罗福莉主导开发的跨语言预训练模型VECO,成为深度语言模型体系AliceMind八大模型之一,并被顶会ACL2021录用,她也在AliceMind集体开源中挑起大梁。AliceMind 登顶多模态权威榜单VQA Challenge 2021,并在阿里内部数十个核心业务落地,日均调用50亿次,活跃场景超过200个,其中不乏大家熟悉的天猫精灵智能音响等。
招人标准
选人标准: 一直都是热爱和好奇心,所以很多人会有一些奇特的经历。对做研究的渴望远超对钱的在意。
- 对顶级人才吸引最大的,肯定是去解决世界上最难的问题。其实,顶尖人才在中国是被低估的。因为整个社会层面的硬核创新太少了,使得他们没有机会被识别出来。
大模型招人,必卡的条件是什么?
梁文锋:
- 热爱,扎实的基础能力。
- 其他都没那么重要。
投资人说很多适合的人才可能只在OpenAI、FacebookAI Research 等巨头的AI lab里。
你们会去海外挖这类人才吗?
梁文锋:
- 如果追求短期目标,找现成有经验的人是对的。
- 但如果看长远,经验就没那么重要,基础能力、创造性、热爱等更重要。
从这个角度看,国内合适的候选人就不少。
为什么经验没那么重要?
梁文锋:
- 不一定是做过这件事的人才能做这件事。
- 幻方招人有条原则:看能力,而不是看经验。核心技术岗位,基本以应届和毕业一两年的人为主。
创新业务上,经验是阻碍吗?
梁文锋:
- 做一件事,有经验的人会不假思索告诉你,应该这样做
- 但没有经验的人,会反复摸索、很认真去想应该怎么做,然后找到一个符合当前实际情况的解决办法。
- 核心团队,连我自己,一开始都没有量化经验
什么是好奇心?对 AI 能力边界的好奇。
- 对很多行外人来说,ChatGPT 这波浪潮冲击特别大;
- 但对行内人来说
- 2012年 AlexNet 带来的冲击已经引领一个新的时代。AlexNet 的错误率远低于当时其他模型,复苏了沉睡几十年的神经网络研究。
- 虽然具体技术方向一直在变,但模型、数据和算力这三者的组合是不变的
- 特别是当 2020 年 OpenAI 发布 GPT3 后,方向很清楚,需要大量算力;
- 但即便 2021 年,我们投入建设萤火二号时,大部分人还是无法理解。
Attention 架构提出多年来,几乎未被成功改过,更遑论大规模验证;对模型结构进行创新,没有路径可依,要经历很多失败,时间、经济成本都耗费巨大。
而 DeepSeek 成功了,它是 7家中国大模型创业公司中,唯一一家放弃“既要又要”路线,至今专注研究和技术,未做toC应用的公司,也是唯一一家未全面考虑商业化,坚定选择开源路线甚至都没融过资的公司。
- 公司 60 个人, 50 个技术, 10 个工程
DeepSeek 成就
【2024-12-26】2024年,DeepSeek带给硅谷“苦涩的教训”
2024年12月26日,圣诞节刚过,深度求索发布了大模型DeepSeek V3,成为2024年AI界真正的压轴事件。
发布即开源,还很酷:
- 达到开源SOTA,超越
Llama 3.1 405B; - 参数量约为
GPT-4o的1/3,价格仅为Claude 3.5 Sonnet的9%,性能却可以和这两家顶级闭源大模型掰手腕。 - 整个训练过程不到280万个GPU小时,相比之下,
Llama 3 405B训练时长是3080万GPU小时- 注:Llama用的是H100,DeepSeek用的是其缩水版的H800。
- 每秒生成60个token,是其上一个版本的3倍。
- 训练
671BDeepSeek V3的成本仅为557.6万美元,初创公司都负担得起。
DeepSeek V3 推理和训练成本仅为硅谷顶级大模型的十分之一,这让硅谷懵圈儿
- OpenAI 12天连续线上产品发布、中间又有谷歌不停地截胡,刚结束,大家正过圣诞新年假期。
- 深度求索共有139名工程师和研究人员,包括创始人
梁文锋本人,参与了这个项目。 - 而OpenAI有1200名研究人员。Anthropic有500名研究人员。
独角兽AI公司scale.ai创始人Alex感叹这是中国科技带来的苦涩教训:
当美国人休息时,他们在工作,而且以更便宜、更快、更强的产品追上我们。
AI大神卡帕西、Meta科学家田渊栋、QLora发明人Tim Dettmers、OpenAI科学家Sebastian Raschka等点赞好评。
还有各种评论充斥:
- “这对中国来说,可能比第六代战斗机更具‘
斯普特尼克时刻’意义:一款名为DeepSeek v3的中国AI模型在几乎所有方面都与最新的ChatGPT和Claude模型媲美,甚至常常超越它们,而训练成本却极小(仅550万美元),并且开源(意味着任何人都可以使用、修改和改进它)。”- “训练成本如此之低尤为重要,因为彻底改变了谁能参与高级AI开发的游戏规则。在此之前,人们普遍认为训练这样的模型需要数亿甚至数十亿美元,而DeepSeek仅用550万美元就做到了,这笔钱几乎任何地方的初创公司都能负担得起。意味着DeepSeek刚刚证明了严肃的AI开发并不局限于科技巨头。”
2024年收官之时,这对硅谷是一个强烈的提醒:
- 美国对中国科技封锁,包括最严厉的芯片和AI封锁,结果,资源短缺激发了中国科技企业的创新力。
被AI连续轰炸的5月,DeepSeek一跃成名。起因是发布的一款名为DeepSeek V2开源模型,提供了一种史无前例的性价比:
- 推理成本被降到每百万token仅 1块钱,约等于 Llama3 70B 1/7,GPT-4 Turbo 1/70。
DeepSeek 被迅速冠以“AI界拼多多”之称的同时,字节、腾讯、百度、阿里等大厂也按耐不住,纷纷降价。中国大模型价格战由此一触即发。
成见:
- 美国更擅长从0-1的技术创新,而中国更擅长从1-10的应用创新。
很多VC对做研究有顾虑,有退出需求,希望尽快做出产品商业化,而按照优先做研究的思路,很难从VC那里获得融资。但我们有算力和一个工程师团队,相当于有了一半筹码。
“一件激动人心的事,或许不能单纯用钱衡量。”
显卡通常会以20%的速度在折损?
- 电费和维护费用其实是很低的,这些支出每年只占硬件造价的1%左右。
- 人工成本不低,但人工成本也是对未来的投资,是公司最大的资产。
事实:
与很多大厂烧钱补贴不同,DeepSeek 有利润
DeepSeek 对模型架构进行了全方位创新。
- 提出一种崭新的
MLA(一种多头潜在注意力机制)架构,把显存占用降到了过去最常用的MHA架构的5%-13% - 独创
DeepSeekMoESparse结构,把计算量降到极致,所有这些最终促成了成本的下降。
DeepSeek 事件
【2025-2-5】一文带你了解DeepSeek爆火事件的来龙去脉
春节期间, DeepSeek 火遍全球
DeepSeek 以惊人的速度和实力,在全球范围内引发了一场科技“地震”。
- DeepSeek 已经发布 13 个大模型,并且都已开源。
- 自研通用大模型 DeepSeek-V3、推理模型 DeepSeek-R1
这款被誉为“国产AI之光”的应用,不仅在美区 App Store 免费榜上力压 ChatGPT 登顶,也在国内App Store免费榜占据榜首,展现出强大的市场号召力。

【2025-2-13】数据揭露DeepSeek崛起的秘诀
2024年底, 国内大模型产品前三是豆包,Kimi和文心一言
仅仅一个月时间, DeepSeek 全球日活用户数 (DAU) 从34.7万激增至1.19亿。
截止2025年2月8日,DeepSeek 用户
- 国内 APP端 DAU 达到 3494万
- 海外 APP端 DAU 达到 3685万
- 全球 Web端 日活直击 4800万
DeepSeek 以近1.2亿日活数几乎追平ChatGPT,并一举超越豆包、Kimi和文小言。
第二位的豆包,DAU数据大约是2500万,差额也相当大。
用户数从35万到1亿的过程,堪称“奇迹”
而梁文峰因DeepSeek的成功而财富激增,身价或将超过英伟达CEO黄仁勋,问鼎亚洲新科技首富。
彭博社调查显示,DeepSeek 估值在 10亿-1500亿 美元之间,梁文峰持有84%股份,投行看好DeepSeek,认为其估值可达OpenAI一半,即1500亿美元,梁文峰股份价值或达1260亿美元,超过英伟达CEO黄仁勋的1180亿美元。
Xsignal(奇异因子)创始人刘震博士认为:
- DeepSeek‘爆火’ 并非毫无预兆,几个关键时间节点:2024年的4月、10月、12月(
DeepSeek V3),以及2025年1月20日(DeepSeek-R1引爆)
DeepSeek现象和去年豆包/kimi等AI应用的火爆有着根本不同。
- ① 企业推动 和 国家推动 的区别:
豆包流量90%来自短视频,字节跳动天然良好生态的加持;- 而
DeepSeek媒介声量中,新闻、社媒和短视频占比分布均匀。
- ②
DeepSeek和豆包市场定位差异DeepSeek用户量,海外市场几乎贡献了一大半。- 而
豆包主要面向的是国内用户。
DeepSeek 成功关键词:中国,高水平,低成本,新路径,开源。
【2025-2-28】字节跳动内部 deepseek 调研,源自 大厂爆料会
(1) 产品体验
- ① 用户规模:综合多方验证,Deepseek 双端 DAU 在春节前开始快速增长
- 2025年1月底,DAU 达到峰值,Web端 + App Dau 最高触达 4,000万量级,DAU 节后回落
- 截至2025年2月9日,DAU 降至~2,400万,其中App端DAU 1,300万。
- ② 用户体验:目前深度推理DAU渗透率~70%。
- 除了舆论影响外,用户一旦用到深度推理,很难回用到通用模型(“高级感”,缺乏较强深度推理能力是豆包和DS目前最大差距);
(2) 商业模式:
- C端:不盲目追求高目标,不做复杂产品设计,免费模式服务好现有用户。
- B端:舆论、开源、低成本、政府等,极大提升了B端应用落地(医疗、教育、金融均有二次开发);同时,对海外客户具备成本优势;
- 因此B端有收入提升预期。
(3) 算力资源
- 算力:1万
H800+ 1万张A100- 资源分配
- 通用模型 ~4,000张
H800 - 推理模型 ~4,000张
H800 - C端推理集群整体规模合计 ~3,000 - 4,000 张
A100+少量H800,极限仅可支持~500万量级DAU无损使用;
- 通用模型 ~4,000张
- 未来可能和云厂商合作, 而非自己采购硬件扩充集群。
- 资源分配
- 国内芯片适配:
- 训练端:仍深度绑定英伟达,国产卡适配成本较高,内部不希望双线并行分散研发精力,短期内无采购国产卡用于训练的计划。
- 推理端:虽然
华为/寒武纪等厂商在积极推动 DS 开源模型的推理适配和优化且有政策倾斜,但由于DS模型本身infra优化基于英伟达指令集和CUDA体系,在国产卡上运行会导致基于英伟达的infra优化无法发挥作用,导致推理成本提升,比如在华为910上运行DS模型的推理成本是英伟达的 1.5-2 倍。
(4) 模型迭代方向:
- 2025年6月前,推出
DeepSeek V4和 推理模型DeepSeek R2 - 2025年3月,上线目前通用模型V3的优化版本 V3.5;
- V4 和 R2模型采取激进创新方案,核心思路是不在预训练阶段增加更多投入,全力押注后训练RL方向,探索智能上限,且探索MoE多模态架构(目前业内尚未实现)
腾讯元宝全面接入 DeepSeek
- 腾讯元宝(前微信搜索)全面接入 DeepSeek
- 腾讯做AI最大的瓶颈:基座大模型能力不足,公司内部都不看好混元。
- 2024年4月前,所有权威大模型榜单上都看不到混元,此后排名却突然上升,很多人怀疑是刷出来的。
- 腾讯采购的大卡也严重不足,公司内部AI研发申请用卡十分紧张,WXG和IEG都只能依赖自己的显卡小金库。
- 当时部分咨询公司宣称腾讯的大卡采购量位居全国第一甚至比阿里还高,纯属笑话,咨询公司并不靠谱
DeepSeek 2024
中国全部依靠本土人才的AI公司,如何学习和赶超硅谷AI巨头?
2024年, 先后发布8篇论文
- 【2024-1-5】DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
- 深度求索第一个大模型,
DeepSeek LLM包含670亿参数,从零开始在一个包含2万亿token的数据集上训练,数据集涵盖中英文。全部开源 DeepSeek LLM 7B/67B Base和DeepSeek LLM 7B/67B Chat,供研究社区使用。
DeepSeek LLM 67B Base在推理、编码、数学和中文理解等方面超越了Llama2 70B Base。DeepSeek LLM 67B Chat在编码和数学方面表现出色。 - 还展现了显著的泛化能力,在匈牙利国家高中考试中取得了65分的成绩。 - 当然,还精通中文:DeepSeek LLM 67B Chat在中文表现上超越了GPT-3.5。
- 深度求索第一个大模型,
- 【2024-1-25】DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence
DeepSeek Coder由一系列代码语言模型组成,每个模型均从零开始在2万亿token上训练,数据集包含87%的代码和13%的中英文自然语言。代码模型尺寸从1B-33B版本不等。每个模型通过在项目级代码语料库上进行预训练,采用16K的窗口大小和额外的填空任务,以支持项目级代码补全和填充。- DeepSeek Coder 在多种编程语言和各种基准测试中达到了开源代码模型的最先进性能。
- 【2024-2-5】DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath以DeepSeek-Coder-v1.5 7B为基础,继续在从Common Crawl中提取的数学相关token以及自然语言和代码数据上进行预训练,训练规模达 5000亿token。DeepSeekMath 7B在竞赛级MATH基准测试中取得了51.7%的优异成绩,且未依赖外部工具包和投票技术,接近Gemini-Ultra和GPT-4性能水平。
- 【2024-3-11】DeepSeek-VL: Towards Real-World Vision-Language Understanding
DeepSeek-VL是一个开源的视觉-语言(VL)模型,采用了混合视觉编码器,在固定token预算内高效处理高分辨率图像(1024 x 1024),同时保持相对较低的计算开销。- 这一设计确保了模型在各种视觉任务中捕捉关键语义和细节信息的能力。
- DeepSeek-VL 系列(包括1.3B和7B模型)在相同模型尺寸下,在广泛的视觉-语言基准测试中达到了最先进或可竞争的性能。
- 【2024-5-7】DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-V2是一个强大的混合专家(MoE)语言模型,以经济高效的训练和推理为特点。它包含2360亿个总参数,其中每个token激活210亿个参数。- 与
DeepSeek 67B相比,DeepSeek-V2不仅实现了更强的性能,同时还节省了42.5%的训练成本,将KV缓存减少了93.3%,并将最大生成吞吐量提升至5.76倍。在一个包含8.1万亿token的多样化且高质量的语料库上对DeepSeek-V2进行了预训练。在完成全面的预训练后,我们通过监督微调(SFT)和强化学习(RL)进一步释放了模型的潜力。 - 评估结果验证了我们方法的有效性,
DeepSeek-V2在标准基准测试和开放式生成评估中均取得了显著表现。 DeepSeek V2发布,在中国百模大战中掀起了一场价格战,推理成本被降到每百万token仅 1块钱,约等于Llama3 70B的1/7,GPT-4 Turbo的1/70。硅谷惊呆了。- 美国知名半导体和AI咨询公司semianalysis敏锐地感觉到,这家公司会是OpenAI的对手,也有可能碾压其他开源大模型。
- “DeepSeek 推向市场的新颖架构并没有照搬西方公司的做法,而是在
混合专家模型(MoE)、旋转位置编码(RoPE)和注意力机制(Attention)方面带来了全新创新。 - 此外,DeepSeek 还实现了一种新颖的
多头潜在注意力机制(Multi-Head Latent Attention),比其他形式的注意力机制具有更好的扩展性,同时准确性也更高。” - Semianalysis 还为DeepSeek算了笔账,发现其大模型服务的毛利率可达70%以上:“单个由8个H800 GPU组成的节点可以实现超过每秒50,000 解码令牌的峰值吞吐量(或在支持分离预填充的节点中达到 100,000 预填充令牌)。按照其 API 定价仅计算输出令牌,每个节点每小时可产生 50.4 美元的收入。在中国,一个8xH800 GPU节点的成本约为每小时15 美元,因此假设完全利用,DeepSeek 每台服务器每小时可赚取高达 35.4 美元的利润,毛利率可达 70% 以上。” - 这一性价比,无疑具有颠覆性的威胁:“即使假设服务器的利用率从未达到完美,且批量处理规模低于峰值能力,DeepSeek 仍然有足够的空间在碾压其他所有竞争对手的推理经济性的同时实现盈利。Mixtral、Claude 3 Sonnet、Llama 3 和 DBRX 已经在压制 OpenAI 的 GPT-3.5 Turbo,而 DeepSeek 的出现无疑是压垮骆驼的最后一根稻草。” - V2的基础上,DeepSeek迅速推出了Coder-V2和VL2,直到V3。
- 【2024-6-17】DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
DeepSeek-Coder-V2是一个开源的混合专家(MoE)代码语言模型,在代码特定任务中达到了与GPT4-Turbo相当的性能。DeepSeek-Coder-V2是从DeepSeek-V2的一个中间检查点开始,进一步预训练了额外的6万亿token,显著增强了DeepSeek-V2 编码和数学推理能力,同时在通用语言任务中保持了相当的性能。并在代码相关任务、推理能力和通用能力等多个方面都取得了显著进步。此外,DeepSeek-Coder-V2将支持的编程语言从86种扩展到338种,并将上下文长度从16K扩展到128K。- 在标准基准测试中,
DeepSeek-Coder-V2在编码和数学基准测试中表现优异,超越了GPT4-Turbo、Claude 3 Opus和Gemini 1.5 Pro等闭源模型。 - 【2024-11-20】DeepSeek 发布推理模型
R1-Lite预览版, 离OpenAI发布推理模型o1预览版刚过2个月
- 【2024-12-13】DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
- GitHub DeepSeek-VL2
- DeepSeek-VL2 是一个先进的大型混合专家(MoE)视觉-语言模型系列,相较于其前身DeepSeek-VL有了显著改进。
- DeepSeek-VL2 在多种任务中展现了卓越能力,包括但不限于视觉问答、光学字符识别、文档/表格/图表理解以及视觉定位。
- 模型系列由三个变体组成:DeepSeek-VL2-Tiny、DeepSeek-VL2-Small和DeepSeek-VL2,分别具有10亿、28亿和45亿激活参数。与现有的开源密集模型和基于MoE的模型相比,DeepSeek-VL2 在相似或更少的激活参数下实现了具有竞争力或最先进的性能。
- 【2024-12-26】DeepSeek-V3: A Breakthrough in Inference Speed and Performance
- 技术报告: DeepSeek-V3 Technical Report
- DeepSeek-V3 是一个强大的混合专家(MoE)语言模型,总参数为6710亿,每个token激活370亿参数。
- 为了实现高效的推理和经济高效的训练,DeepSeek-V3采用了
多头潜在注意力(MLA)和DeepSeek MoE架构,这些架构在DeepSeek-V2中得到了充分验证。 - 此外,DeepSeek-V3首创无辅助损失的负载均衡策略,并设定了多token预测训练目标以提升性能。团队在14.8万亿个多样化且高质量的token上对DeepSeek-V3进行了预训练,随后通过监督微调和强化学习阶段充分释放其潜力。
- 综合评估表明,DeepSeek-V3超越了其他开源模型,并达到了与领先闭源模型相当的性能。训练过程非常稳定,在整个训练过程中,没有遇到任何不可恢复的损失峰值或进行任何回滚操作。
DeepSeek还于12月10日上线了搜索功能,早于SearchGPT正式上线一周。
如何创新
如何让创新真正发生
“创新往往都是自己产生的,不是刻意安排的,更不是教出来的”
很多家试图模仿你们,却没有成功?
梁文锋:
- 因为仅凭人才这一点,不足以让创新发生。它需要和公司的文化和管理相匹配。
- 第一年他们什么都做不出来,第二年才开始有点成绩。
- 但我们的考核标准和一般公司不一样: 没有 KPI,也没有所谓的任务。
量化领域,别人一般看重客户下单量,我们的销售卖多少和提成不是一开始就算好的,而会更鼓励销售去发展自己的圈子,认识更多人,产生更大影响力。
因为,一个让客户信任的、正直的销售,可能在短时间内做不到让客户来下单,但可以让你觉得他是个靠谱的人。
怎么让新人进入状态?
梁文锋:
- 交给他重要的事,并且不干预他。让他自己想办法,自己发挥。
- 一家公司的基因是很难被模仿的。比如说招没有经验的人,怎么判断他的潜力,招进来之后如何才能让他成长,这些都没法直接模仿。
如何打造一个创新型组织?
梁文锋:
- 创新需要尽可能少的干预和管理,让每个人有自由发挥的空间和试错机会。
- 创新往往都是自己产生的,不是刻意安排的,更不是教出来的。
如何确保一个人做事是有效率?
梁文锋:
- 招人时确保价值观一致,然后通过企业文化来确保步调一致。
- 当然,我们并没有一个成文的企业文化,因为所有成文东西,又会阻碍创新。
- 更多时候,是管理者的以身示范,遇到一件事,你如何做决策,会成为一种准则。
真正的决定力量往往不是一些现成的规则和条件,而是一种适应和调整变化的能力。
很多大公司的组织结构已经不能快速响应和快速做事,而且他们很容易让之前的经验和惯性成为束缚,而这波AI新浪潮之下,一定会有一批新公司诞生。
“创新就是昂贵且低效的,有时候伴随着浪费。”
大模型是一件无休止投入的事,付出的代价顾虑吗?
梁文锋:
- 创新就是昂贵且低效的,有时候伴随着浪费。
- 所以,经济发展到一定程度之后,才能够出现创新。很穷的时候,或者不是创新驱动的行业,成本和效率非常关键。看OpenAI也是烧了很多钱才出来。
思考
DeepSeek 为什么这么火?
高性能+低成本+开源+国产
为什么DeepSeek出来后,国产其他大模型的集体失声了?
【2025-2-12】AI作答
2025年,DeepSeek横空出世后,曾经的喧嚣戛然而止—— 那些高调宣称“技术领先”的玩家们,要么沉默不语,要么匆忙转向,仿佛一夜之间被抽走了底气。
技术与商业逻辑的终极审判:当技术革命撕开营销泡沫,伪强者终将现形。
- 一、技术碾压:从“参数崇拜”到“效率革命”,降维打击的冷酷现实
- 中国大模型赛道曾深陷“参数内卷”的泥潭。动辄万亿参数的宣传,配合“算力军备竞赛”的叙事,成了厂商们彰显实力的核心话术。
- 然而,DeepSeek的崛起却直接掀翻了这张牌桌:参数规模削减至原有1/10,却凭借强化学习(RL)与模型蒸馏技术,在数学推理、代码生成等核心任务上力压GPT-4o,甚至以超低成本实现性能突破。这种“以小博大”的技术路径,彻底颠覆了“模型越大越强”的行业共识。
- DeepSeek 极简奖励设计(仅依赖答案正确性和格式规范)与
GRPO算法,将算力消耗降低30%以上,同时摆脱了对标注数据的依赖。传统厂商引以为傲的“数据壁垒”和“算力霸权”被直接瓦解。
- 二、成本屠夫:烧钱游戏的终结者,商业逻辑的重构者
- 中国AI行业长期存在畸形现象:用资本泡沫掩盖技术短板。无论是月之暗面旗下Kimi的疯狂投流,还是某些厂商依赖政府补贴维持的“假性繁荣”,本质都是“烧钱换市场”的投机策略。
- 然而,DeepSeek的横空出世,直接戳破了这一泡沫。其训练成本仅为行业平均水平的1/5,却通过开源代码和超低价API开放能力,将大模型从“奢侈品”变成了“日用品”。
- 这种“成本杀手”的特质,让依赖高客单价项目的厂商瞬间陷入绝境。例如,某头部厂商曾以“千万元级”标价兜售定制化模型,而DeepSeek的同类方案成本不足其1/10。
- 更讽刺的是,当对手还在为“用户留存率不足1%”焦头烂额时,DeepSeek上线20天日活突破2000万,用户直言“只有DeepSeek卡顿时才用其他产品”。
- 商业世界的残酷在于:当性价比悬殊到一定程度,情怀和营销都会沦为笑话。
- 三、生态颠覆:从“金字塔垄断”到“开源平权”,旧秩序的崩塌
- OpenAI等巨头曾构建了“金字塔式”的AI生态:顶层掌控基础模型,中层企业依赖API调用,底层开发者沦为附庸。这种结构的本质是技术垄断与创新压制——巨头通过“黑箱化”模型维持霸权,中小玩家则陷入“数据空心化”困境。
- DeepSeek却选择了一条截然不同的道路:开源核心模型、开放API定制能力,将技术红利普惠化。直接改写了行业规则。大厂可以转型为“模型超市”,提供垂直领域的小模型;中小厂商则能基于开源代码快速开发专用工具,甚至凭借行业Know-how实现“弯道超车”。例如,一家医疗影像公司只需用普通服务器即可部署DeepSeek优化模型,成本骤降80%。当技术壁垒被打破,那些依赖“封闭生态”收租的厂商,自然失去了话语权。这不是竞争,而是生态逻辑的彻底重构。
- 四、用户觉醒:从“营销幻觉”到“用脚投票”,市场理性的回归
- Kimi堪称行业缩影。2024年爆红,完全依赖B站投流制造的“虚假繁荣”,而非技术突破。用户最初被营销噱头吸引,却在体验后迅速流失——30天后留存率不足1%的惨淡数据,暴露了“重营销、轻技术”路线的致命缺陷。
- 而DeepSeek的爆发,恰恰证明了用户并非盲目:当一款产品能以更低成本提供更优体验时,市场会毫不犹豫地“用脚投票”。
- DeepSeek重新定义了用户预期。其数学推理97.3%的准确率、代码生成的高效性,让用户再也无法忍受其他模型的“平庸表现”。当技术差距变得肉眼可见,任何夸大宣传都会沦为“自欺欺人”。市场的沉默,实则是用户对劣质产品的集体唾弃。
- 五、行业反思:中国AI需要“DeepSeek式颠覆”,而非“Kimi式狂欢”
- DeepSeek的冲击,本质上是对中国AI行业的一次“技术纠偏”。它证明了一点:真正的竞争力来自底层创新,而非资本堆砌或营销炒作。那些沉迷于“融资—烧钱—讲故事”循环的厂商,终将被淘汰。
- 而DeepSeek的开源策略与效率革命,则为行业指明了一条新路:降低技术门槛、赋能实体经济、回归商业本质。
这场沉默的背后,是旧时代的谢幕与新秩序的诞生。当潮水退去,裸泳者终将无处遁形——而DeepSeek,正是那枚照妖镜。中国AI的未来,属于那些敢于撕破泡沫、用技术直面竞争的真实力量。至于沉默者,历史早已写下判词:要么进化,要么消亡。
产品
接入方式
【2024-12-27】DeepSeek 接入体验方式
- Web形式: DeepSeek 免费使用
- 默认版本:
- 联网搜索版本:
- 深度思考版本: R1, 对标 OpenAI o1
- API形式: 收费
- 输入价格: 1 元/百万tokens, 输出价格 2 元/百万tokens
- 新用户赠送10元
注
- 【2024-12-26】全面升级为 DeepSeek V3
API
DeepSeek
- 基于Openai接口规范
- 结合 Langchain
OpenAI SDK
# pip3 install openai
from openai import OpenAI
api_key = 'sk-7284******'
client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
sys_prompt = 'You are a helpful assistant'
sys_prompt = '你是一名数学家'
question = '解此微分方程 xdx+ydy=-xdy+ydx'
response = client.chat.completions.create(
model="deepseek-chat", # DeepSeek-V3
#model="deepseek-reasoner", # DeepSeek-R1
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": question},
],
stream=False
)
print(question)
print(response.choices[0].message.content)
LangChain
LangChain DeepSeek 集成位于 langchain-deepseek 包中
# pip install -qU langchain langchain-deepseek
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# other params...
)
messages = [
(
"system",
"You are a helpful assistant that translates English to French. Translate the user sentence.",
),
("human", "I love programming."),
]
ai_msg = llm.invoke(messages)
ai_msg.content
# ------------------ prompt temmplate ------------------
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate(
[
(
"system",
"You are a helpful assistant that translates {input_language} to {output_language}.",
),
("human", "{input}"),
]
)
chain = prompt | llm
chain.invoke(
{
"input_language": "English",
"output_language": "German",
"input": "I love programming.",
}
)
设置 DEEPSEEK_API_KEY 环境变量
import getpass
import os
if not os.getenv("DEEPSEEK_API_KEY"):
os.environ["DEEPSEEK_API_KEY"] = getpass.getpass("Enter your DeepSeek API key: ")
模型调用的自动追踪,设置 LangSmith API 密钥
# os.environ["LANGSMITH_TRACING"] = "true"
# os.environ["LANGSMITH_API_KEY"] = getpass.getpass("Enter your LangSmith API key: ")
API 问题
【2025-3-18】 用API调用DeepSeek,到底安全不安全 漫画图解
通过API的方式,来调用市面上各种DeepSeek服务,到底安全不安全,会不会造成隐私或者数据泄露?
不安全:
- 无论是API还是网页版,或各种APP客户端,都存在一定的安全风险
- Prompt 信息(输入的文本、问题、指令,提交的图片或者文档等等),都会被传送到公网和云端服务器。
风险
- 1、数据传输风险: 非 https 数据可能会被拦截或窃听
- 2、服务提供商的隐私政策与存储策略: 用户提交到服务器端的数据,在大模型完成推理任务后,这些数据默认会被“短暂保存”,主要用于日志、合规审计、服务优化等目的, 但不排除数据会被长期保存,被用于训练,要看不同服务商的隐私政策。
- 3、大模型服务商自身的安全能力: 即使API服务商“一心向善”,恪守不碰数据的原则。但如果安全能力不足(比如服务器被黑客攻击),数据仍然会面临泄露风险
- 选择有良好声誉、技术实力雄厚、具备强大安全认证(如ISO 27001)的提供商可以降低这种风险。
- 4、本地RAG知识库的数据泄露: 调用API的同时,本地部署知识库做RAG
- 本地知识库在使用过程中,并不会被完整上传到云端。但与用户问题最相关知识片段,会被上传、存储。
- 不仅当前提交的内容有泄露风险,本地知识库也会泄露,知识库中要避免存储敏感信息(隐私数据、商业机密)。
所以,注册使用服务时,要仔细看用户协议和隐私政策,确认数据是否会被存储、如何存储、存储多久,以及数据是否会被使用
- ChatGPT的协议就很霸道。明确会将数据用于训练,不过也给了可选通道,允许用户禁止自己的数据用于训练。商业用户,OpenAI默认不会把他们的数据拿去训练。
建议选择以下方案
- 1、完全本地化部署:一体机、本地化集群、专属云等,牺牲灵活性和成本来换安全。
- 2、云上专属模型部署:选择可靠、有数据安全背书的AI Infra服务商,部署专属模型。
- 3、如必须调用API,则增加数据脱敏措施,避免提交敏感数据,或者在知识库中存放敏感数据。
当然,本地化部署并不一定就比云上安全,这取决于本地的安全防护能力、运维水平和安全意识。
替代方案
总结
【2025-2-19】DeepSeek 满血版方案汇总
| 名称 | 是否支持满血R1 | 使用限制 |
|---|---|---|
| 腾讯元宝 | 支持 | 免费无限制 |
| 秘塔AI | 支持 | 每天免费100次 |
| 纳米搜索 | 支持 | 免费无限制 |
| 硅基流动 | 支持 | 免费无限制 |
| 国家超算中心 | 支持 | 有时速度较慢 |
| 火山引擎 | 支持 | 免费无限制 |
| Monica | 支持 | 每天免费40次 |
| 华为小艺 | 支持 | 免费无限制 |
| Flowith | 支持 | 免费无限制 |
| AskManyAI | 支持 | 免费无限制 |
云端部署
大厂提供的ds访问方式:
- ① “国家队”超算互联网 SCNet 提供两个小号模型服务,免费;
- ② 硅基流动+华为昇腾合作部署了ds满血版服务
- 使用方法:注册硅基流动账户,申请key,安装本地llm工具(如cherry-studio)小红书指南
- 但额度受限,硅基流动新用户有14元额度,速度偏慢,目前是批量输出
本地部署
本地小规模硬件上跑真正的 DeepSeek-R1,被认为基本不可能
- 市面上所谓“本地部署”方案,多为参数量缩水90%的蒸馏版,背后原因是671B参数的MoE架构对显存要求极高——即便用8卡A100也难以负荷
【2025-2-14】KTransformers
清华大学 KVCache.AI 团队与趋境科技合作开源的KTransformers项目,部署 DeepSeek-R1 671B满血版
- 支持 24G显存 本地运行DeepSeek-R1、V3的671B满血版。
- 预处理速度最高达到 286 tokens/s,推理生成速度最高能达到14 tokens/s。
该项目的独特之处:
- 用创新的异构平台设计大大减少了GPU的用量——只需单卡,并让此前在DeepSeek加速中很少显山露水的CPU得以大放光彩。
不少开发者也纷纷用自己的3090显卡和200GB内存进行实测,借助与Unsloth优化的组合,Q2_K_XL模型的推理速度已达到9.1 tokens/s,真正实现了千亿级模型的“家庭化”。
硬件配置要求
- 显卡:单张NVIDIA RTX 4090D(24GB显存)即可满足需求,Q4_K_M量化版仅需14GB显存。
- 内存:标准DDR5-4800服务器内存,推荐382GB以上。
- CPU:支持双路Intel Xeon Gold 6454S(共64核)以发挥NUMA架构优势。
核心技术原理
- 异构计算划分策略:
- 将MoE架构中计算强度低的稀疏路由专家层(Routed Expert)卸载到CPU/DRAM处理,利用llamafile提供高速CPU算子。
- 保留计算强度高的稠密层(MLA注意力机制、共享专家层)在GPU处理,采用Marlin算子加速量化矩阵计算,相比传统方法提速3.87倍。
- 划分依据:通过计算强度(MLA > Shared Expert > Routed Expert)动态分配,直到GPU显存占满。
- KV缓存优化:
- 重构 MLA(Multi-Layered Attention)算子的权重融合技术,将q_proj和out_proj权重直接融合,减少KV缓存体积达70%。
- 采用CUDA Graph加速技术,将多个GPU操作合并为单个内核调用,降低调度开销。
APP
DeepSeek
- 2025年1月20日 DeepSeek R1 模型发布
- 2025年1月28日, 日活跃用户数首次超越豆包
- 2025年2月1日, 突破 3000 万大关,成为史上最快达成这一里程碑的应用。
据 AI 产品榜
- 1 月 DeepSeek 用户增长达 1.25 亿, 含网站(Web)、应用(App)累加不去重。
- 其中,80% 以上用户来自 1 月最后一周,即: DeepSeek 在没有任何广告投放情况下实现了 7 天完成 1 亿用户增长。
全球各互联网产品中用户达 1 亿所用时间排行显示
- ChatGPT 耗时 2 个月仅次于 DeepSeek;
- TikTok 耗时 9 个月位列第三;
- 拼多多耗时 10 个月
- 微信耗时 1 年 2 个月,排名第四和第五。
模型
模型汇总
DeepSeek 已经发布 13 个大模型,并且都已开源。

模型总结
- DeepSeek LLM
- DeepSeek Coder
- DeepSeek Math
- DeepSeek VL
- DeepSeek V2
- DeepSeek Coder V2
- DeepSeek V3
【2025-2-26】

DeepSeek V2
【2024-5-7】DeepSeek-V2 全球最强开源通用MoE模型
- DeepSeek-V2 基于 2 千亿 MoE 模型底座,领先性能,超低价格,越级场景体验,已在对话官网和API全面上线
- 技术报告: 浅读 DeepSeek-V2 技术报告
- 仓库和技术报告地址:DeepSeek-V2
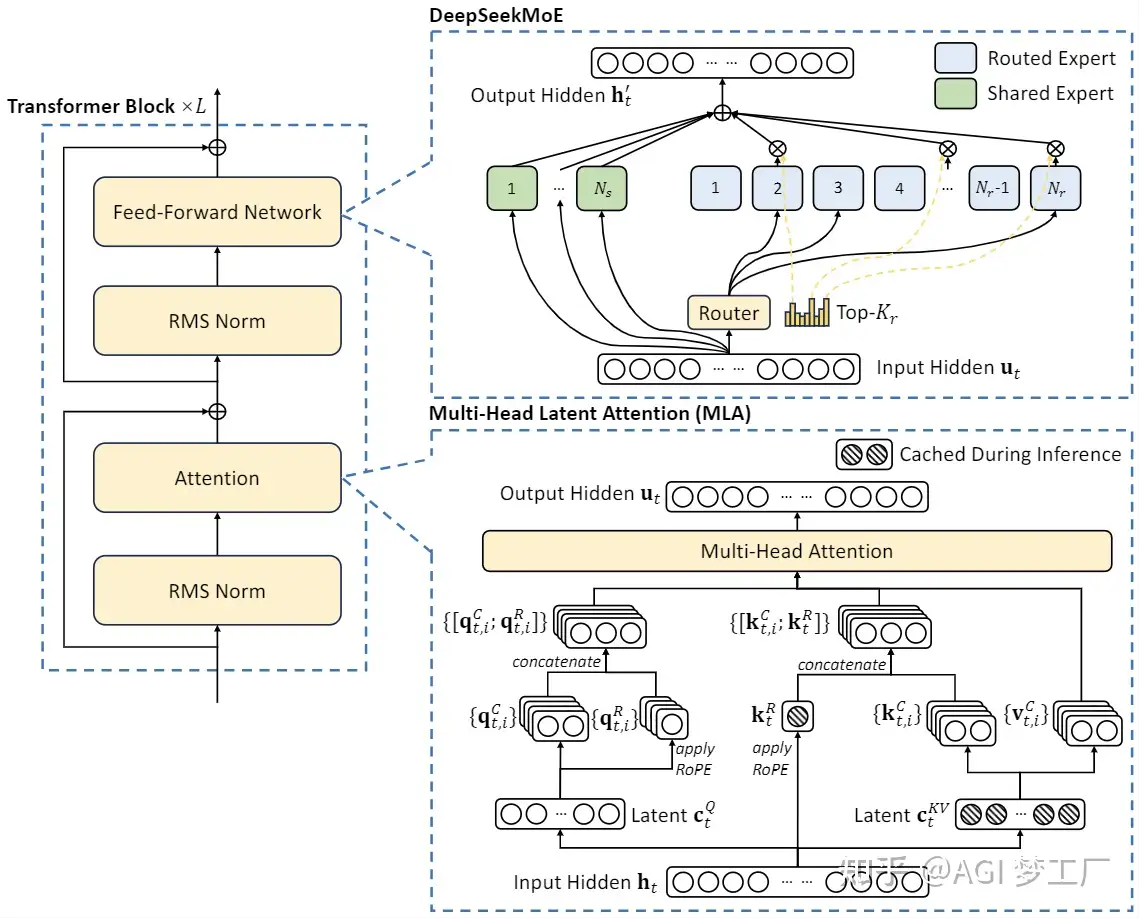
DeepSeek-V2 在 DeepSeek 上改进,但并没有沿用主流的“类LLaMA的Dense结构”和“类Mistral的Sparse结构”,而是对Transformer架构中的自注意力机制进行了全方位创新,提出了MLA(Multi-head Latent Attention)结构,并使用了MoE技术进一步将计算量降低,大幅提高了推理效率。
特点
- 独创 MLA 结构
- 稀疏结构 DeepSeek-MoE
- 推理成本降低近百倍
- LMSYS榜单中,位列开源模型第一
DeepSeek-V2 包含 236B参数,每个Token激活2.1B参数,支持长达 128K 的上下文长度。
- 与DeepSeek 67B相比,DeepSeek-V2 在性能上取得了显著提升,节省了42.5%的训练成本,减少了93.3%的KV缓存,并将最大生成吞吐量提高到了5.76倍。
深度求索将该 DeepSeek-V2 模型已完全上线至平台服务用户,DeepSeek-V2 API也是物美价廉。并且秉持着最开放的开源精神,深度求索将这次的DeepSeek-V2模型和论文也将完全开源,免费商用。
模型结构
模型结构
DeepSeek Coder
2023年11月,DeepSeek Coder V1发布
2024年6月,DeepSeek Coder V2 全球最强代码开源模型
- 全球首个超越 GPT4-Turbo 的开源代码模型
- BigCodeBench 6月榜单中第二
DeepSeek VL
自然语言到多模态初探
DeepSeek R1
DeepSeek R1 详见站内专题: 大模型推理思考-DeepSeek R1
【2024-11-20】DeepSeek R1-Lite
【2024-11-20】DeepSeek 发布推理模型R1-Lite预览版, 离OpenAI发布推理模型o1预览版刚过2个月
【2025-01-20】DeepSeek R1-Zero
【2025-01-20】 正式发布 DeepSeek-R1-Zero 和 改进版 DeepSeek-R1
- 代码 DeepSeek-R1
有技术团队做了对比测试,发现DeepSeek R1存在非常严重的幻觉问题, R1的幻觉率高达14.3%,远超DeepSeek V3(3.9%)。而问题可能出在R1的训练方法上。
【2025-5-28】DeepSeek R1-0528
2025年5月28日,DeepSeek 宣布R1模型的小版本升级(R1-0528)
升级点:
- 1️⃣ 响应质量优化:复杂推理、多步骤计算更准确;长文理解与生成更连贯、逻辑更清晰;数学、编程等专业性输出更可靠。
- 2️⃣ 响应速度小幅提升:在网页端、App、API 接口中响应更敏捷;尤其在处理超长文本输入时,延迟有所降低(约提升 10%~20%)。
- 3️⃣ 对话稳定性增强:上下文记忆更稳定,尤其在超长对话中(支持最多128K上下文);减少偶尔“遗忘设定”或“跑偏”的情况。
- 4️⃣ API 和接口兼容性保持稳定:API 调用方式、参数、返回结构完全不变;用户无需调整现有集成,即可无缝使用新版本。
重点:
- DeepSeek R1-0528 版本对之前被诟病的模型幻觉问题(14.3%,知名推理模型中最高)进行了优化
- 与旧版相比,更新后的模型在改写润色、总结摘要、阅读理解等场景中,幻觉率降低了 45~50% 左右。
实测显示,代码生成、逻辑推理等任务中表现显著提升。
代码测试平台LiveCodeBench中,R1-0528以73.1分排名第四,接近OpenAI的o3-high(75.8分),性能“媲美o3”
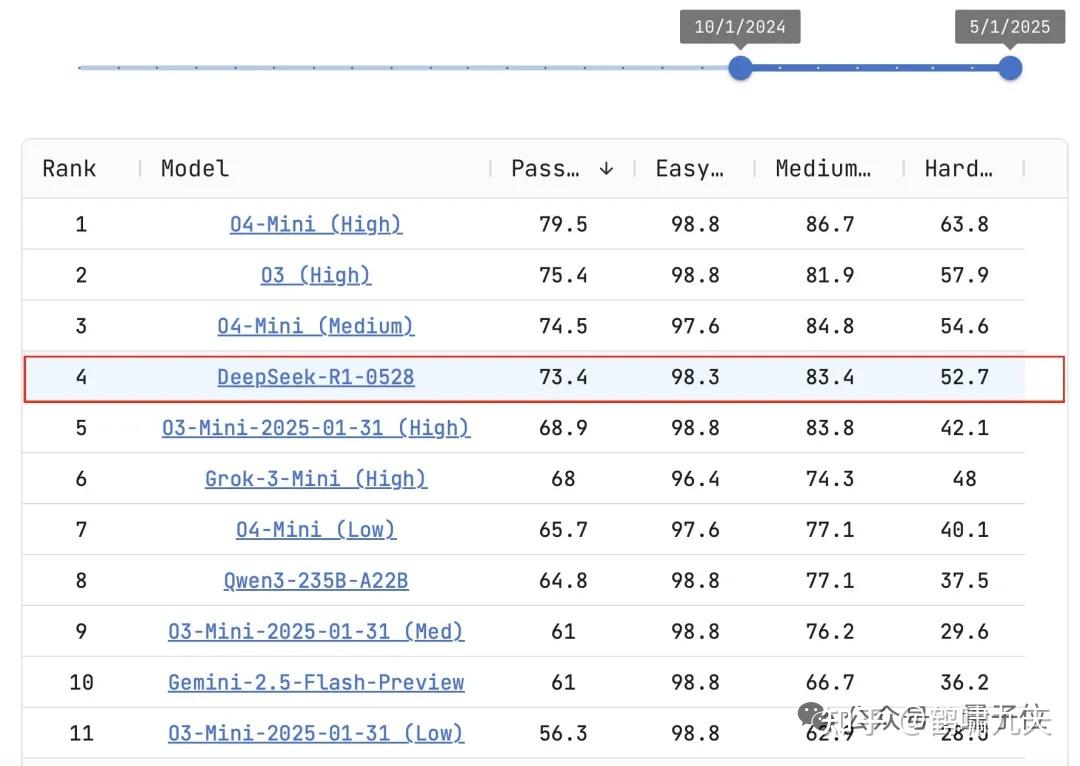
【2024-12-26】DeepSeek V3
DeepSeek V3 发布即完全开源,直接用了53页论文把训练细节和盘托出
- 体验地址:DeepSeek
- 技术报告地址:DeepSeek_V3.pdf
- 抱抱脸开源地址:DeepSeek-V3
- 参考链接:公众号文章
- 【2024-12-26】国产之光DeepSeek把AI大佬全炸出来了!671B大模型训练只需此前算力1/10,细节全公开
DeepSeek V3 是一个参数量为671B的MoE模型,激活37B,在14.8T高质量token上进行了预训练。
DeepSeek V3 整个训练过程仅用了不到280万个GPU小时,相比之下,Llama 3 405B的训练时长是3080万GPU小时(p.s. GPU型号也不同)。
- 训练671B的DeepSeek V3的成本是557.6万美元(约合4070万人民币),而只是训练一个7B的Llama 2,就要花费76万美元(约合555万人民币)。
- 官方2048卡集群上,3.7天就能完成这一训练过程
架构方面,DeepSeek V3采用了创新的负载均衡策略和训练目标。
- DeepSeek-V2架构基础上,提出一种无辅助损失的负载均衡策略,能最大限度减少负载均衡而导致的性能下降。
- 该策略为MoE中的每个专家引入了一个偏置项(bias term),并将其添加到相应的亲和度分数中,以确定top-K路由。
- 多Token预测目标(Multi-Token Prediction,MTP)有利于提高模型性能,可以用于推理加速的推测解码。
预训练方面,DeepSeek V3采用FP8训练。
- 设计一个FP8混合精度训练框架,首次验证了FP8训练在极大规模模型上的可行性和有效性。
跨节点MoE训练中的通信瓶颈问题解决
- 设计DualPipe高效流水线并行算法:在单个前向和后向块对内,重叠计算和通信。
- 这种重叠能确保随着模型的进一步扩大,只要保持恒定的计算和通信比率,就仍然可以跨节点使用细粒度专家,实现接近于0的all-to-all通信开销。
- 高效的跨节点all-to-all通信内核等
后训练方面,DeepSeek V3引入了一种创新方法,将推理能力从长思维链模型(DeepSeek R1)中,蒸馏到标准模型上。这在显著提高推理性能的同时,保持了DeepSeek V3的输出风格和长度控制。
DeepSeek V3的MoE由256个路由专家和1个共享专家组成。在256个路由专家中,每个token会激活8个专家,并确保每个token最多被发送到4个节点。
DeepSeek V3还引入了冗余专家(redundant experts)的部署策略,即复制高负载专家并冗余部署。这主要是为了在推理阶段,实现MoE不同专家之间的负载均衡。
在多项测评上,DeepSeek V3达到了开源SOTA,超越Llama 3.1 405B,能和GPT-4o、Claude 3.5 Sonnet等TOP模型正面掰掰手腕
而其价格比 Claude 3.5 Haiku 还便宜,仅为 Claude 3.5 Sonnet的9%。
OpenAI创始成员Karpathy对此赞道:
- DeepSeek V3让在有限算力预算上进行模型预训练这件事变得容易。
- DeepSeek V3看起来比Llama 3 405B更强,训练消耗的算力却仅为后者的1/11。
贾扬清
- DeepSeek团队的伟大成就在某种程度上植根于多年的专业知识,这些专业知识部分被许多人忽视了
【2024-12-31】 2024年,DeepSeek带给硅谷“苦涩的教训”
深度求索共 139 名工程师和研究人员,包括创始人梁文锋本人也参与了这个项目。
- 而 OpenAI 有1200名研究人员。Anthropic 有500名研究人员。
独角兽AI公司scale.ai创始人 Alex 王 感叹道:
- 中国科技带来的苦涩教训:当美国人休息时,他们在工作,而且以更便宜、更快、更强的产品追上我们。
AI大神卡帕西、Meta科学家田渊栋、QLora发明人Tim Dettmers、OpenAI科学家Sebastian Raschka等点赞好评。
除了硅谷在圣诞假期, 被炸出来的大佬们,还有各种评论充斥:
- “这对中国来说,可能比第六代战斗机更具‘斯普特尼克时刻’意义:一款名为
DeepSeek v3的中国AI模型在几乎所有方面都与最新的ChatGPT和Claude模型媲美,甚至常常超越它们,而训练成本却只是极小的一部分(仅550万美元),并且它是开源的(意味着任何人都可以使用、修改和改进它)。” - “训练成本如此之低尤为重要,因为它彻底改变了谁能参与高级AI开发的游戏规则。在此之前,人们普遍认为训练这样的模型需要数亿甚至数十亿美元,而DeepSeek仅用550万美元就做到了,几乎任何初创公司都能负担得起。意味着DeepSeek刚刚证明了严肃的AI开发并不局限于科技巨头。”
2024年收官之时,这对硅谷是一个强烈的提醒:
美国对中国科技封锁,包括最严厉的芯片和AI封锁,结果,资源短缺激发了中国科技企业的创新力。
【2025-12-1】DeepSeek-V3.2
【2025-12-1】DeepSeek-V3.2 发布 官方doc
【2026-4-24】DeepSeek-V4
2026年4月24日,DeepSeek 开源全新系列模型 DeepSeek-V4 预览版,在Agent能力、世界知识与推理性能三大维度宣称达到国内及开源领域领先水平。体验超越Sonnet 4.5
- deepseek api doc
- 技术报告:DeepSeek-V4: TowardsHighlyEfficientMillion-Token Context Intelligence
DeepSeek-V4 分为 Pro 与 Flash 两个版本,均支持百万(1M)token超长上下文,两个版本均大幅降低了对计算和显存的需求。
| 模型 | 参数 | 激活 | 预训练数据 | 上下文长度 | 开源 | API服务 | 网页端/APP访问方式 |
|---|---|---|---|---|---|---|---|
| deepseek-v4-pro | 1.6T | 49B | 33T | 1M | ✓ | ✓ | 专家模式 |
| deepseek-v4-flash | 284B | 13B | 32T | 1M | ✓ | ✓ | 快速模式 |
API服务同步上线,开发者将 model 参数修改为 deepseek-v4-pro 或 deepseek-v4-flash 即可调用,接口兼容OpenAI ChatCompletions与Anthropic两套标准
解读:DeepSeek V4预览版发布:显存和算力需求大降,Agent能力领跑国内开源,体验超越Sonnet 4.5
Janus
【2025-1-27】Janus-Pro-7B
【2025-1-27】 资讯 DeepSeek 开源 Janus-Pro-7B:多模态AI模型, 图像生成、视觉问答等任务重,性能超越DALL-E 3 和 Stable Diffusion 3,并以“理解-生成双路径”架构和极简部署方案引发AI社区轰动
开源与商业使用
- 免费商用:采用MIT开源协议,允许无限制商业使用
- 极简部署:提供1.5B(需16GB显存)和7B(需24GB显存)版本,普通显卡即可运行
- 一键生成:官方提供Gradio交互界面,输入即可批量出图
- 命令: generate_image(prompt=”夕阳下的雪山”, num_images=4)
相关链接
- GitHub仓库:Janus
- 模型下载:hf
效果
Janus-Pro-7B 虽仅有70亿参数(约为GPT-4的1/25),却在关键测试中碾压对手:
- 文生图质量:在GenEval测试中以80%准确率击败DALL-E 3(67%)和Stable Diffusion 3(74%)
- 复杂指令理解:在DPG-Bench测试中达84.19%准确率,能精准生成如“山脚下有蓝色湖泊的雪山”等复杂场景
- 多模态问答:视觉问答准确率超越
GPT-4V,MMBench测试得分79.2分接近专业分析模型
用户测试
- 1卡,14G以上显存
Janus-Pro-7B- 参考 Deepseek-Janus-Pro-7B 体验
对比
- 文生图: flux
- 多模态理解: Qwen2.5 VL 7B 访问地址

优点
- 将多模态理解和生成任务统一在一个模型中,对视觉任务大一统做出一定的贡献。
待优化:
- 生成任务中,Janus Pro 7B 图片支持尺寸有限384*384,图片较为模糊,图片中生成文字的能力一般;相较主流模型需要进一步的优化。flux尺寸可自定义,当然也需要考虑模型大小的影响。
亮点
技术突破:像“双面神”分工协作
传统模型让同一套视觉编码器既理解图片又生成图片,如同让厨师同时设计菜单和炒菜。
Janus-Pro-7B 创新地将视觉处理拆分为两条独立路径:
- 理解路径:用 SigLIP-L 视觉编码器快速提取图片核心信息(如“这是一只橘猫在沙发上”)
- 生成路径:通过 VQ分词器 将图像分解为像素点阵,像拼乐高一样逐步绘制细节(如毛发纹理、光影效果) 这种“分头行动”的设计解决了传统模型的角色冲突问题,训练时还混合了7200万张合成图像与真实数据,提升生成稳定性。
【2025-2-18】NSA
2025年2月18日,DeepSeek 推出 NSA(Native Sparse Attention),这是一种硬件对齐且原生可训练的稀疏注意力机制,用于超快速长上下文训练与推理。
NSA 核心组件包括: ● 动态分层稀疏策略 ● 粗粒度 token 压缩 ● 细粒度 token 选择
该机制可优化现代硬件设计,加速推理同时降低预训练成本,并且不牺牲性能。在通用基准、长上下文任务和基于指令的推理上,其表现与全注意力模型相当或更加优秀。
论文:paper
【2025-2-24】FlashMLA
【2025-2-24】DeepSeek新技术FlashMLA
FlashMLA核心MLA(Multi-head Latent Attention,多头潜在注意力机制)引入低维潜在向量,将所有头共享键和值压缩到低维空间,尽保留关键信息。
- GitHub地址 FlashMLA
H800 GPU上,FlashMLA 直接突破计算上限,实现 3000GB/s 内存带宽和 580 TFLOPS(每秒执行万亿次浮点运算)的计算性能。
注:
- H100 nvlink带宽900gb/s
- H800 被限制到 400gb/s
这次FlashMLA突破限制,提至7.5倍!
数学证明
【2024-8-15】Prover-V1.5
2024年8月15日,曾发布 DeepSeek-Prover-V1.5,大约 7B 参数模型。
- 论文 DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search
- DeepSeekMath-Base 上微调得到 DeepSeek-Prover-V1, 接着 reinforcement learning from proof assistant feedback (RLPAF) 得到 DeepSeek-Prover-V1.5
- V1.5 结合强化学习和蒙特卡洛树搜索等技术后,在一些标准的数学证明测试(如miniF2F 和 ProofNet)中取得了不错的成果,能够处理从高中到大学本科部分水平的数学问题。
【2025-4-30】Prover-V2
【2025-4-30】 DeepSeek 开源数学证明模型 Prover-V2-671B
- Hugging Face 平台上开源了最新数学定理证明专用模型 DeepSeek-Prover-V2-671B
DeepSeek-Prover-V2-671B 在模型规模上有了巨大飞跃,参数量达到 671B ,比 V1.5 大了近百倍,比其他同类产品如 Llemma-7B/34B、InternLM2-StepProver 等也要大得多。
该模型建立在 DeepSeek-V3 架构之上,因此许多配置与通用的 DeepSeek-V3 模型相似。
采用了混合专家(MoE,Mixture-of-Experts)的设计,每层包含 256 个路由专家(routed experts)和1个共享专家(shared expert),每个专家的中间层大小(moe_intermediate_size)为 2048,在处理每个输入符号(token)时会激活其中的 8 个专家。
此外,该模型支持的最大上下文长度达到了 163,840 个 token。
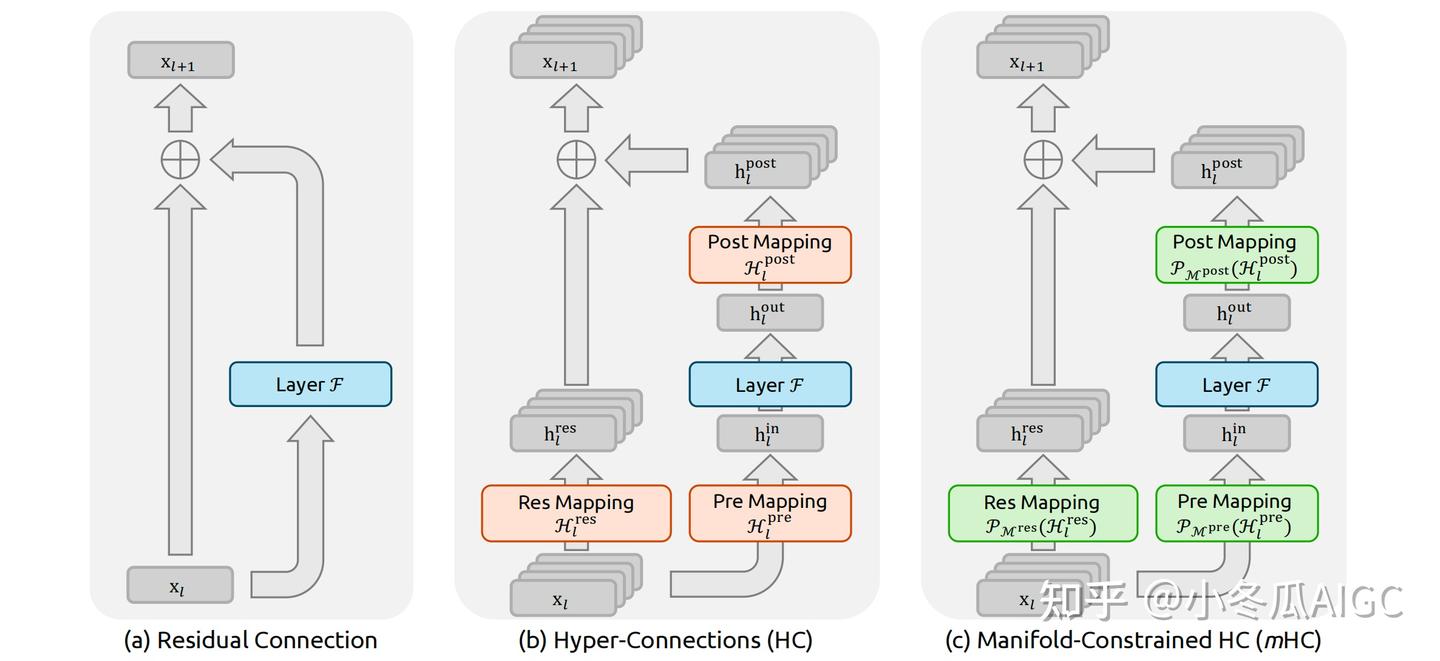
【2026-1-3】mHC
【2026-1-3】详解DeepSeek残差链接mHC进化之路
2016年 ResNet 横空出世,其残差链接成为了深度网络训练的标准组件。
发展历史
- 2016: ResNet 携 Residual Connection 问世;
- 2020: Pre-Normalization 提出,被 Transformer 类的网络广泛运用;
- 2024: ByteDance 提出 HC(Hype-Connection),开启了残差链接扩展(Scaling)的新思路;
- 2026: DeepSeek 在 HC 基础上增加 Mainfold-Constrian, 称为 mHC, 并宣称已在大规模训练中实践;
2026年1月1日,DeepSeek 公布新论文,提出名为 mHC (流形约束超连接)的新架构。根据介绍,该研究旨在解决传统超连接在大规模模型训练中的不稳定性问题,同时保持其显著的性能增益。
DeepSeek 发布 mHC 链接方式,引起热议,mHC 的性能表现,预示着下一个残差链接的范式变革。
【2026-1-16】Engram
【2026-1-16】Engram:把“记忆”从 Transformer 里拆出来
为什么要“解耦推理与知识”?
- 标准 Transformer 里,“推理”和“背知识”用的是同一套计算路径。
对人来说,很多知识检索更像“查表”:看到“李白”,几乎是 O(1) 地回忆出“唐朝/诗人/诗仙”。
而对 Transformer 来说,即使是“李白是诗人”这种静态事实,往往也要靠多层 Attention + FFN 的矩阵乘法把表示“一步步挤出来”。
结果:
- 早期层为了“重建大量静态关系”占用了参数容量与推理算力,真正留给复杂推理(尤其是长程依赖与组合推理)的“有效层数”变少。
总结:
- 用“算法”做“查字典”的工作。
- Engram 试图把这部分工作从主干网络里剥离出来。
Engram 核心想法:
- 若干 Transformer block 内插入一个“确定性 N-gram 记忆检索模块”,把局部、静态、重复出现的依赖关系交给查表,把主干网络的算力更多留给全局建模与推理。
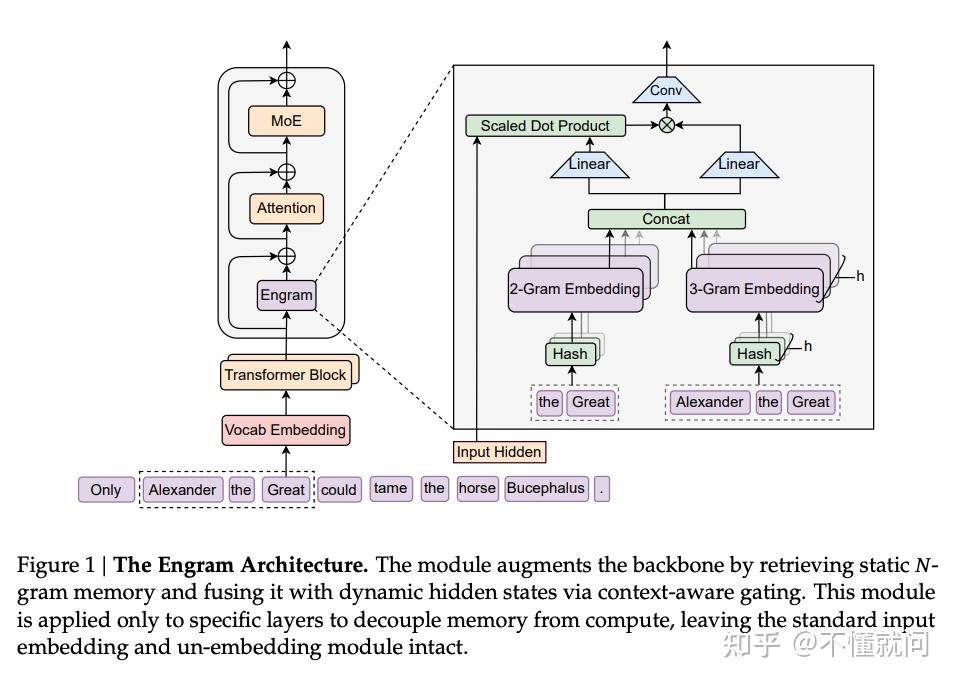
N-gram 为什么能成为“记忆地址”?
N-gram 就是滑动窗口下连续的 N 个 token 子序列。例如句子 “Deep learning is amazing”:
- 1-gram:Deep / learning / is / amazing
- 2-gram:Deep learning / learning is / is amazing
- 3-gram:Deep learning is / learning is amazing
N-gram 价值:
- 抓“局部上下文”。
- 很多语言现象(专有名词、固定搭配、常见短语、局部语法模式)在局部窗口里就足够稳定,因此可以作为检索静态记忆的 key。
Engram 查表是确定性的:输入序列确定后,每层要用哪些 N-gram 就确定了。这带来很实用的系统优化空间:
- 计算与存储解耦:巨大的 embedding 表可以放在 CPU 内存,甚至 SSD,而不必全部常驻 GPU 显存。
- 预取(Prefetching):当 GPU 还在算前几层时,CPU 可以提前把后面若干层会用到的 N-gram 向量查好,经 PCIe 传给 GPU。
- 效果:用“传输时间”去覆盖“计算时间”,把数据搬运尽量藏进流水线,接近“零额外开销”的外挂记忆。
实践
个人微调方式
- 本地: 自备 GPU
- 云平台
- Kaggle
- Colab
DeepSeek R1 复现
【2025-3-12】用PyTorch从零构建 DeepSeek R1:模型架构和分步训练详解
代码库结构
train-deepseek-r1/
├── code.ipynb # Jupyter Notebook 代码实现
├── requirements.txt # 依赖库列表
└── r1_for_dummies.md # 面向非技术受众的 DeepSeek R1 解释
DeepSeek R1 微调
Kaggle lora+医生
【2025-2-12】一步步将DeepSeek R1微调成一个DeepDoctor(资深医生)
- kaggle 地址 DeepSeek R1 FineTune
- LoRA 微调
资源要求
- 电脑微调的话,至少一块 16GB 显存 RTX 3090
- 云 IDE Kaggle 提供免费 GPU 资源。
- 选择两块 T4 GPU。
步骤
- 启动新 Kaggle notebook
- 将 Hugging Face token 和 Weights & Biases token 添加为密钥。
- 安装 unsloth Python 包。
- Unsloth 开源框架,大型语言模型(LLM)的微调速度提高一倍,并且更具内存效率。
核心代码
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
trainer_stats = trainer.train()
Colab lora+算命大师
【2025-2-28】 【DeepSeek微调教程】小白也能学会的DeepSeek微调详细步骤,从零到一,个人低配置笔记本可操作
- trl 框架做 SFT
步骤
创建笔记 create notebook, 选择 T4 GPU
安装依赖包
pip install unsloth
pip install bitsandbytes unsloth_zoo
加载预训练模型
from unsloth import FastLanguageModel # 导入FastLanguageModel类,用来加载和使用模型
import torch # 导入torch工具,用于处理模型的数学运算
max_seq_length = 2048 # 设置模型处理文本的最大长度,相当于给模型设置一个“最大容量”
dtype = None # 设置数据类型,让模型自动选择最适合的精度
load_in_4bit = True # 使用4位量化来节省内存,就像把大箱子压缩成小箱子
# 加载预训练模型,并获取tokenizer工具
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Qwen-7B", # 指定要加载的模型名称
max_seq_length=max_seq_length, # 使用前面设置的最大长度
dtype=dtype, # 使用前面设置的数据类型
load_in_4bit=load_in_4bit, # 使用4位量化
# token="hf...", # 如果需要访问授权模型,可以在这里填入密钥
)
模型测试
prompt_style = """以下是描述任务的指令,以及提供进一步上下文的输入。
请写出一个适当完成请求的回答。
在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。
### 指令:
你是一位精通卜卦、星象和运势预测的算命大师。
请回答以下算命问题。
### 问题:
{}
### 回答:
<think>{}</think>"""
# 定义提示风格的字符串模板,用于格式化问题
question = "1993年七月初九巳时生人,女,想了解爱情运势"
# 定义具体的算命问题
FastLanguageModel.for_inference(model)
# 准备模型以进行推理
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
# 使用 tokenizer 对格式化后的问题进行编码,并移动到 GPU
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
# 使用模型生成回答
response = tokenizer.batch_decode(outputs)
# 解码模型生成的输出为可读文本
print(response[0])
# 打印生成的回答部分
数据集
用 load_dataset 函数可加载数据集
- • 数据集名称:
Conard/fortune-telling - • 使用数据集的前100条数据作为微调数据
split="train[0:100]"
# 定义一个用于格式化提示的多行字符串模板
train_prompt_style = """以下是描述任务的指令,以及提供进一步上下文的输入。
请写出一个适当完成请求的回答。
在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。
### 指令:
你是一位精通八字算命、紫微斗数、风水、易经卦象、塔罗牌占卜、星象、面相手相和运势预测等方面的算命大师。
请回答以下算命问题。
### 问题:
{}
### 回答:
<思考>
{}
</思考>
{}"""
# 定义结束标记 (EOS_TOKEN),用于指示文本的结束
EOS_TOKEN = tokenizer.eos_token # 必须添加结束标记
# 导入数据集加载函数
from datasets import load_dataset
# 加载指定的数据集,选择中文语言和训练集的前500条记录
dataset = load_dataset("Conard/fortune-telling", 'default', split="train[0:100]", trust_remote_code=True)
# 打印数据集的列名,查看数据集中有哪些字段
print(dataset.column_names)
# 定义函数,格式化数据集中每条记录
def formatting_prompts_func(examples):
# 从数据集中提取问题、复杂思考过程和回答
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = [] # 用于存储格式化后的文本
# 遍历每个问题、思考过程和回答,进行格式化
for input, cot, output in zip(inputs, cots, outputs):
# 使用字符串模板插入数据,并加上结束标记
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text) # 将格式化后的文本添加到列表中
return {
"text": texts, # 返回包含所有格式化文本的字典
}
dataset = dataset.map(formatting_prompts_func, batched=True)
dataset["text"][0]
模型微调
FastLanguageModel.for_training(model)
model = FastLanguageModel.get_peft_model(
model, # 传入已经加载好的预训练模型
r=16, # 设置 LoRA 的秩,决定添加的可训练参数数量
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", # 指定模型中需要微调的关键模块
"gate_proj", "up_proj", "down_proj"],
lora_alpha=16, # 设置 LoRA 的超参数,影响可训练参数的训练方式
lora_dropout=0, # 设置防止过拟合的参数,这里设置为 0 表示不丢弃任何参数
bias="none", # 设置是否添加偏置项,这里设置为 "none" 表示不添加
use_gradient_checkpointing="unsloth", # 使用优化技术节省显存并支持更大的批量大小
random_state=3407, # 设置随机种子,确保每次运行代码时模型的初始化方式相同
# use_rsloora=False, # 设置是否使用 Rank Stabilized LoRA 技术,这里设置为 False 表示不使用
loftq_config=None, # 设置是否使用 LoftQ 技术,这里设置为 None 表示不使用
)
from trl import SFTTrainer # 导入 SFTTrainer,用于监督式微调
from transformers import TrainingArguments # 导入 TrainingArguments,用于设置训练参数
from unsloth import is_bfloat16_supported # 导入函数,检查是否支持 bfloat16 数据格式
trainer = SFTTrainer(
model=model, # 传入要微调的模型
tokenizer=tokenizer, # 传入 tokenizer,用于处理文本数据
train_dataset=dataset, # 传入训练数据集
dataset_text_field="text", # 指定数据集中文本字段的名称
max_seq_length=max_seq_length, # 设置最大序列长度
dataset_num_proc=2, # 设置数据处理的并行进程数
packing=False, # 是否启用打包功能(这里设置为 False,打包可以让训练更快,但可能影响效果)
args=TrainingArguments(
per_device_train_batch_size=2, # 每个设备(如 GPU)上的批量大小
gradient_accumulation_steps=4, # 梯度累积步数,用于模拟大批次训练
warmup_steps=5, # 预热步数,训练开始时学习率逐渐增加的步数
max_steps=75, # 最大训练步数
learning_rate=2e-4, # 学习率,模型学习新知识的速度
fp16=not is_bfloat16_supported(), # 是否使用 fp16 格式加速训练(如果环境不支持 bfloat16)
bf16=is_bfloat16_supported(), # 是否使用 bfloat16 格式加速训练(如果环境支持)
logging_steps=1, # 每隔多少步记录一次训练日志
optim="adamw_8bit", # 使用的优化器,用于调整模型参数
weight_decay=0.01, # 权重衰减,防止模型过拟合
lr_scheduler_type="linear", # 学习率调度器类型,控制学习率的变化方式
seed=3407, # 随机种子,确保训练结果可复现
output_dir="outputs", # 训练结果保存的目录
report_to="none", # 是否将训练结果报告到外部工具(如 WandB),这里设置为不报告
),
)
# 启动微调
trainer_stats = trainer.train()
微调效果测试
print(question) # 打印前面的问题
# 将模型切换到推理模式,准备回答问题
FastLanguageModel.for_inference(model)
# 将问题转换成模型能理解的格式,并发送到 GPU 上
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
# 让模型根据问题生成回答,最多生成 1200 个新词
outputs = model.generate(
input_ids=inputs.input_ids, # 输入的数字序列
attention_mask=inputs.attention_mask, # 注意力遮罩,帮助模型理解哪些部分重要
max_new_tokens=1200, # 最多生成 1200 个新词
use_cache=True, # 使用缓存加速生成
)
# 将生成的回答从数字转换回文字
response = tokenizer.batch_decode(outputs)
# 打印回答
print(response[0])
模型保存
- huggingface 申请 token: hugging face的token
- 复制 token 到 colab 密钥中,密钥的名称填:HUGGINGFACE_TOKEN
- 微调模型保存为 gguf 格式, 支持多种量化方法(如 4 位、8 位、16 位量化)
# 导入 Google Colab 的 userdata 模块,用于访问用户数据
from google.colab import userdata
# 从 Google Colab 用户数据中获取 Hugging Face 的 API 令牌
HUGGINGFACE_TOKEN = userdata.get('HUGGINGFACE_TOKEN')
# 将模型保存为 8 位量化格式 (q8_0)
# 这种格式文件小且运行快,适合部署到资源受限的设备
if True: model.save_pretrained_gguf("model", tokenizer,)
# 将模型保存为 16 位量化格式 (f16)
# 16 位量化精度更高,但文件稍大
if False: model.save_pretrained_gguf("model_f16", tokenizer, quantization_method = "f16")
# 将模型保存为 4 位量化格式 (q4_k_m)
# 4 位量化文件最小,但精度可能稍低
if False: model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
# 导入 Hugging Face Hub 的 create_repo 函数,用于创建一个新的模型仓库
from huggingface_hub import create_repo
# ---------------------- 模型上传huggingface ----------------------
# 在 Hugging Face hub 上创建一个新的模型仓库
create_repo("你的Huggingface用户名/微调后模型的名字(自己定)", token=HUGGINGFACE_TOKEN, exist_ok=True)
# 将模型和分词器上传到 Hugging Face Hub 上的仓库
model.push_to_hub_gguf("你的Huggingface用户名/微调后模型的名字(自己定)", tokenizer, token=HUGGINGFACE_TOKEN)
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
