多模态学习笔记
除传统语言以及图像间的交互作用,结合声音、触觉以及动作等多维度信息进行深度学习,从而形成更准确、更具表现力的多模态表示。
- 相比于单模态,多模态模型处理多种数据输入,结构上更复杂,可能涉及使用多个子网络,然后将其输出合并。
- 多模态模型的核心:处理和整合这些不同类型的数据源。这种模型可以捕获跨模态的复杂关系,使机器能够更全面地理解和分析信息,从而在各种任务中表现得更好。
AI模型走向多模态必然性的三大因素:跨模态任务需求+跨模态数据融合+对人类认知能力的模拟。
多模态AI以模态融合为核心技术环节,围绕 “表征-翻译-对齐-融合-联合学习”五大技术环节,解决实际场景下复杂问题的多模态解任务。
多模态应用场景按架构可分为:视频分类、事件检测、情绪分析、视觉问答、情感分析、语音识别、跨模态搜索、图像标注、跨模态嵌入、转移学习、视频解码、图像合成等。
多模态AI实现跨模态任务,应用场景丰富。能够实现基于文本、语音、图片、视频等多模态数据的综合处理应用,完成跨模态领域任务,应用于各种场景。
据布谷实验室统计,当前多模态内容主要应用于商业定制、游戏领域、影视领域、教育领域以及医疗领域五大行业。
多模态思考
多模态与世界模型
【2024-5-20】神经网络在不同数据和模态上以不同目标进行训练,正趋向于在其表示空间中形成一个共享的现实世界统计模型。
这种推测起名为柏拉图表示假说,参考了柏拉图的洞穴寓言以及其关于理想现实本质的观念。
AI系统的表征收敛(Representational Convergence),即不同神经网络模型中的数据点表征方式正变得越来越相似,这种相似性跨不同的模型架构、训练目标乃至数据模态。
什么音速推动了这种收敛?这种趋势会持续下去吗?它的最终归宿在哪里?
经过一系列分析和实验,研究人员推测这种收敛确实有一个终点,并且有一个驱动原则:不同模型都在努力达到对现实的准确表征。
原因:
- 1、任务通用性导致收敛(Convergence via Task Generality)
- 2、模型容量导致收敛(Convergence via Model Capacity)
- 3、简单性偏好导致收敛(Convergence via Simplicity Bias)
深度网络倾向于寻找数据的简单拟合,这种内在的简单性偏差使得大模型在表示上趋于简化,从而导致收敛。
多模态计算
- 虽然人脸、姿态和语音等均能独立地表示一定的情感,但人的相互交流却总是通过信息的综合表现来进行。所以, 只有实现多通道的人机界面,才是人与计算机最为自然的交互方式,它集自然语言、语音、手语、人脸、唇读、头势、体势等多种交流通道为一体,并对这些通道信息进行编码、压缩、集成和融合,集中处理图像、音频、视频、文本等多媒体信息。多模态计算是目前情感计算发展的主流方向。每个模块所传达的人类情感的信息量大小和维度不同。在人机交互中,不同的维度还存在缺失和不完善的问题。因此,人机交互中情感分析应尽可能从多个维度入手,将单一不完善的情感通道补上,最后通过多结果拟合来判断情感倾向。
- 在多模态情感计算研究中,一个很重要的分支就是情感机器人和情感虚拟人的研究。美国麻省理工学院、日本东京科技大学、美国卡内基·梅隆大学均在此领域做出了较好的演示系统。目前中科院自动化所模式识别国家重点实验室已将情感处理融入到了他们已有的语音和人脸的多模态交互平台中,使其结合情感语音合成、人脸建模、视位模型等一系列前沿技术,构筑了栩栩如生的情感虚拟头像,并积极转向嵌入式平台和游戏平台等实际应用。
- 目前, 情感识别和理解的方法上运用了模式识别、人工智能、语音和图像技术的大量研究成果。例如:在情感语音声学分析的基础上,运用线性统计方法和神经网络模型,实现了基于语音的情感识别原型;通过对面部运动区域进行编码,采用 HMM 等不同模型,建立了面部情感特征的识别方法;通过对人姿态和运动的分析,探索肢体运动的情感类别等等。不过,受到情感信息捕获技术的影响, 以及缺乏大规模的情感数据资源,有关多特征融合的情感理解模型研究还有待深入。随着未来的技术进展,还将提出更有效的机器学习机制。
什么是多模态
- 【2023-2-25】多模态学习综述(MultiModal Learning)
- 【2023-6-28】比LLM更重要的多模态学习,含 ppt、视频 资料
模态
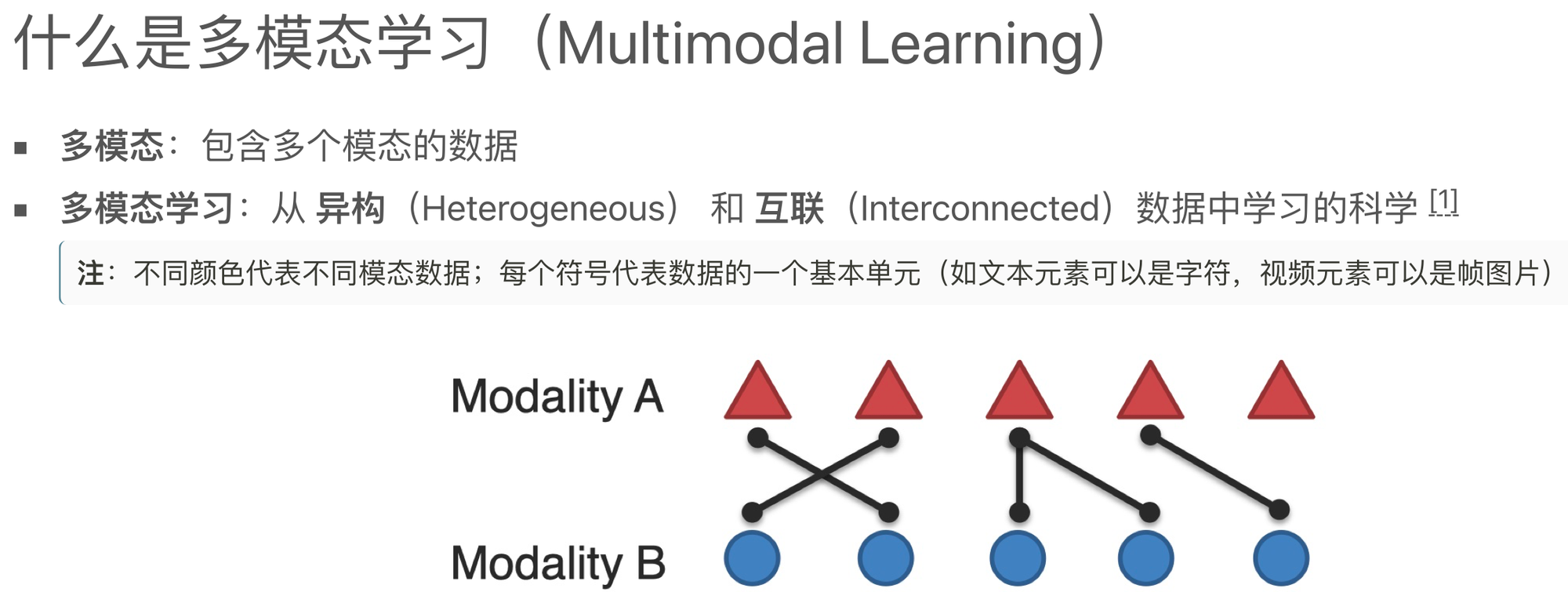
模态(modal)是事情经历和发生的方式,我们生活在一个由多种模态(Multimodal)信息构成的世界,包括视觉信息、听觉信息、文本信息、嗅觉信息等等,当研究的问题或者数据集包含多种这样的模态信息时我们称之为多模态问题,研究多模态问题是推动人工智能更好的了解和认知我们周围世界的关键。
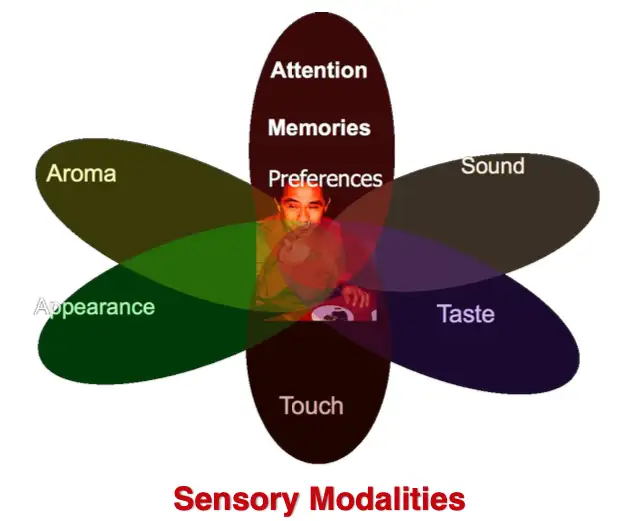
模态是指一些表达或感知事物的方式,每种信息的来源或者形式都可以称为一种模态。例如:
- 人有触觉,听觉,视觉,嗅觉;
- 信息的媒介,有语音、视频、文字等;
- 多种多样的传感器,如雷达、红外、加速度计等。
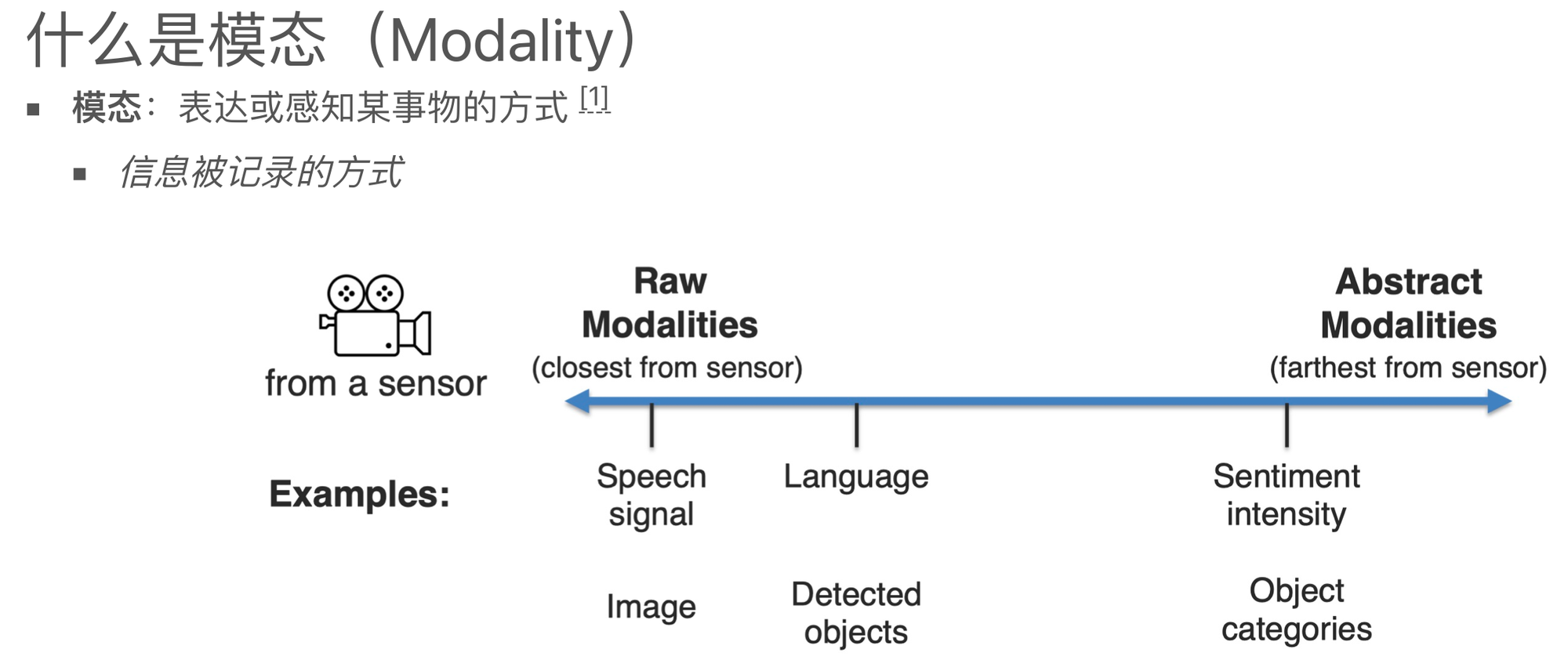
以上的每一种都可以称为一种模态。
相较于图像、语音、文本等多媒体(Multi-media)数据划分形式,“模态”是一个更为细粒度的概念,同一媒介下可存在不同的模态。
- 比如我们可以把两种不同语言当做是两种模态,甚至在两种不同情况下采集到的数据集,亦可认为是两种模态。
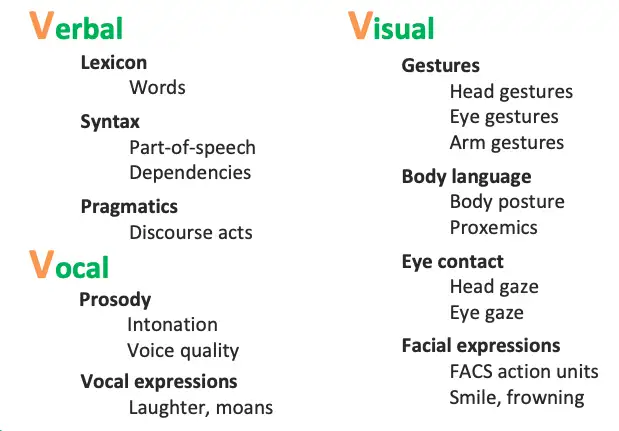
通常主要研究模态包括”3V“:即Verbal(文本)、Vocal(语音)、Visual(视觉)。
多模态
多模态即是从多个模态表达或感知事物。 多模态可归类为同质性的模态,例如从两台相机中分别拍摄的图片,异质性的模态,例如图片与文本语言的关系。
多模态可能有以下三种形式:
- 描述同一对象的多媒体数据。如互联网环境下描述某一特定对象的视频、图片、语音、文本等信息。下图即为典型的多模态信息形式。
- 来自不同传感器的同一类媒体数据。如医学影像学中不同的检查设备所产生的图像数据, 包括B超(B-Scan ultrasonography)、计算机断层扫描(CT)、核磁共振等;物联网背景下不同传感器所检测到的同一对象数据等。
- 具有不同数据结构特点、表示形式的表意符号与信息。如描述同一对象的结构化、非结构化的数据单元;描述同一数学概念的公式、逻辑 符号、函数图及解释性文本;描述同一语义的词向量、词袋、知识图谱以及其它语义符号单元等。

通常主要研究模态包括”3V”:即Verbal(文本)、Vocal(语音)、Visual(视觉)。 人跟人交流时的多模态:
多模态学习
多模态机器学习是从多种模态数据中学习并且提升自身的算法,它不是某一个具体的算法,它是一类算法的总称。
- 从语义感知的角度切入,多模态数据涉及不同的感知通道如视觉、听觉、触觉、嗅觉所接收到的信息;
- 在数据层面理解,多模态数据则可被看作多种数据类型的组合,如图片、数值、文本、符号、音频、时间序列,或者集合、树、图等不同数据结构所组成的复合数据形式,乃至来自不同数据库、不同知识库的各种信息资源的组合。对多源异构数据的挖掘分析可被理解为多模态学习。
与此相对的,就是单模态学习(Unimodal Learning)。
- 在单模态学习中,在单一模态的数据上进行建模,比如文本
多模态机器学习,英文全称 MultiModal Machine Learning (MMML)
- 从异构和互联数据中学习的科学
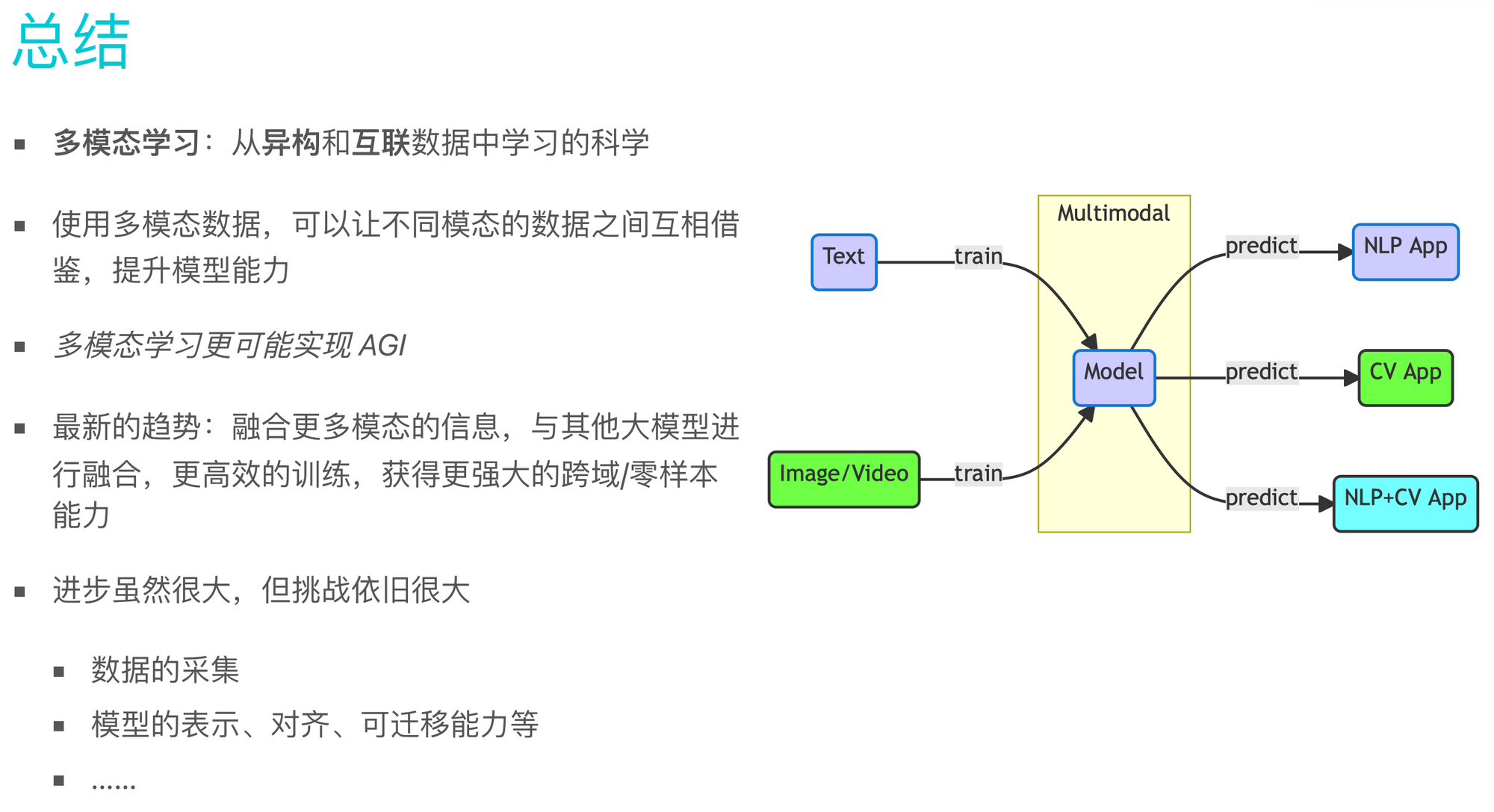
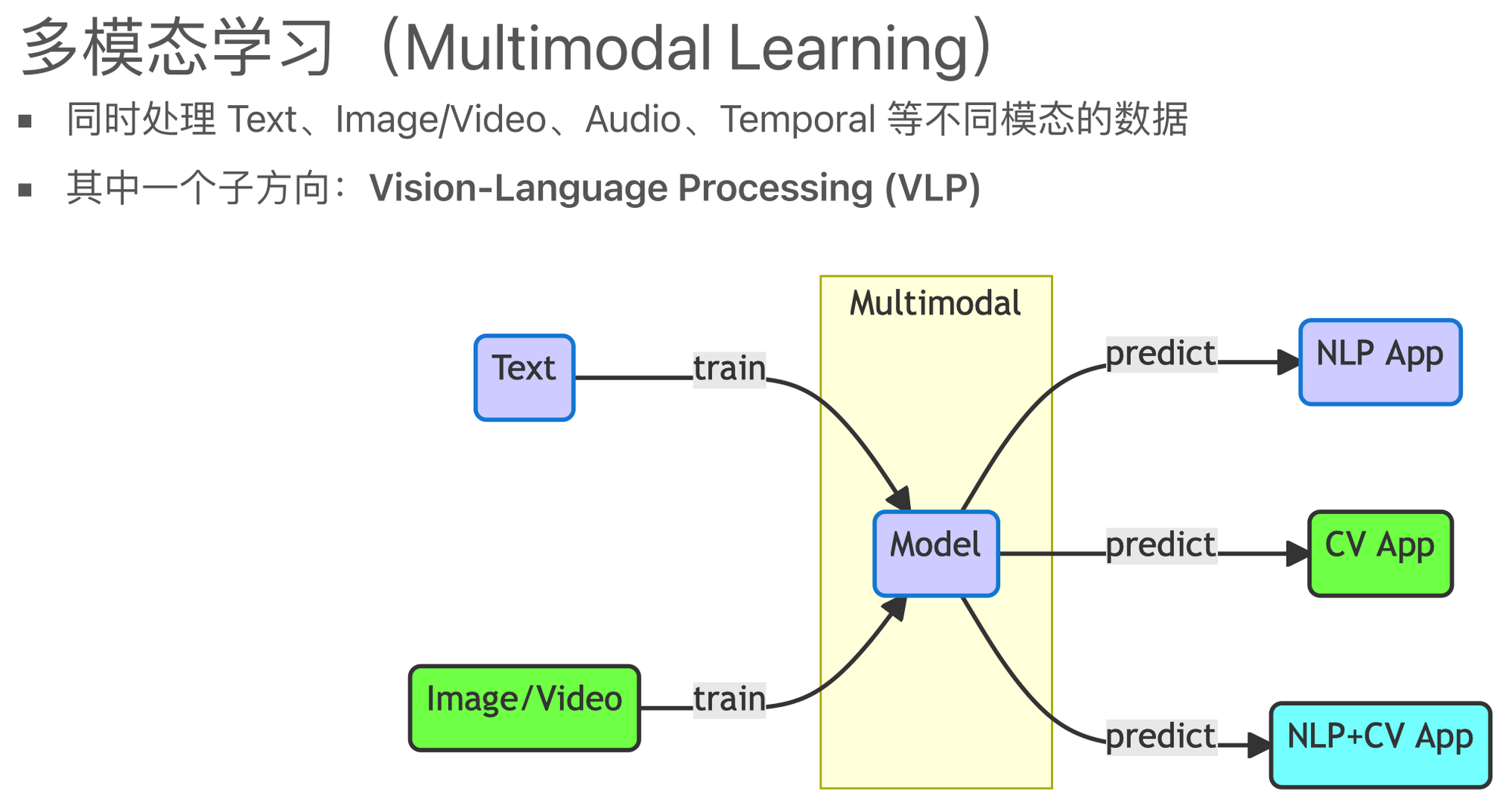
多模态优于单模态
多模态数据可让不同模态的数据之间互相借鉴,提升单模态能⼒
不同模态之间具有以下特性:
- 异构(Heterogeneous):不同的结构、表示⽅法
- 互联(Interconnected):信息相关或共享
- 交互(Interaction):通过交互产⽣新的信息
加⼊视觉信息后,⼩LM模型(1B量级)也能具有CoT 能⼒
使⽤更少的数据量,就可以通过精调获得效果更好的垂域模型
源自ppt
多模态更有可能实现AGI
Yann LeCun
- 单靠语言模型是无法实现AGI的,人类自身是多模态学习的生物,而且很多信息在单纯的语言中难以体现。
- 当 GPT3.5 或 GPT-4 刚出现时,很多人觉得离AGI似乎越来越近了,但现在看来,LLM仍存在很多难以解决的问题。在模型参数达到1000亿级别之后,增加更多的参数只能带来越来越小的收益。
向AGI进军,仅仅依赖LLM是不够的,需要让模型接触到更多的模态数据。
- 这也是为什么像Meta这样的公司在推动多模态学习方面投入了大量的精力,他们不仅在图像处理方面具有传统优势,而且在多模态学习领域也开源了许多模型。
源自ppt
多模态历史
多模态学习不是近几年才火起来,而是近几年因为深度学习使得多模态效果进一步提升。
从1970年代起步,多模态技术经历的4个发展阶段,在2012后迎来 Deep Learning 阶段,在2016年后进入目前真正的多模态阶段。
- 第一阶段为基于
行为的时代(1970s until late 1980s),这一阶段主要从心理学的角度对多模态这一现象进行剖析。 - 第二阶段基于
计算的时代(1980 - 2000),这一阶段主要利用一些浅层的模型对多模态问题进行研究,其中代表性的应用包括视觉语音联合识别,多模态情感计算等等。 - 第三阶段基于
交互的时代,这一阶段主要主要从交互的角度入手,研究多模态识别问题,其中主要的代表作品包括苹果的语音助手Siri等。 - 第四阶段基于
深度学习的时代,促使多模态研究发展的关键促成因素有4个- 1)更大规模的多模态数据集;
- 2)更强大的算力(NPU/GPU/TPU);
- 3)强大的视觉特征抽取能力;
- 4)强大的语言特征抽取能力。
多模态发展的四个时期

行为时代
The “behavioral” era (1970s until late 1980s),这一阶段主要从心理学的角度对多模态这一现象进行剖析。
- Chicago 的McNeill 认为手势是说话人的思考行为,是言语表达的重要组成部分,而不仅仅是补足。
- 1976年的McGurk效应:当语音与唇形不符合时,大脑会脑补出中和的声音MCGURK, H., MACDONALD, J. Hearing lips and seeing voices. Nature 264, 746–748 (1976). The McGurk Effect Video
计算时代
The “computational” era (late 1980s until 2000),这一阶段主要利用一些浅层的模型对多模态问题进行研究,其中代表性的应用包括视觉语音联合识别,多模态情感计算等等。
- 视频音频语音识别(AVSR),在声音的低信噪比下,引入视觉信号能够极大提升识别准确率
- 多模态/多感知接口:情感计算:与情感或其他情感现象有关、源于情感或有意影响情感的计算[Rosalind Picard]
- 多媒体计算:CMU曾有过信息媒体数字视频库项目[1994-2010],
交互时代
The “interaction” era (2000 - 2010),这一阶段主要主要从交互的角度入手,研究多模态识别问题,其中主要的代表作品包括苹果的语音助手Siri等。
拟人类多模态交互过程
- IDIAP实验室的AMI项目[2001-2006],记录会议录音、同步音频视频、转录与注释;
- Alex Waibel的CHIL项目,将计算机置于人类交互圈中,多传感器多模态信号处理,面对面交互
IMI Projet & CHIL Project
- 2003-2008 SRI的学习和组织认知助手,个性化助手,Siri就是这个项目的衍生产品
- 2008-2011 IDIAP的社交信号处理网络,数据库http://sspnet.eu。
CALO Project & SSP Project
深度学习时代
The “deep learning” era (2010s until …),促使多模态研究发展的关键促成因素有4个
- 1)新的大规模多模态数据集
- 2)GPU快速计算
- 3)强大的视觉特征抽取能力
- 4)强大的语言特征抽取能力。
多模态结构
多模态人工智能强调不同模态数据之间的互补性和融合性,通过整合多种模态的数据,利用表征学习、模态融合与对齐等技术,实现跨模态的感知、理解和生成,推动智能应用的全面发展。
三部分:数据采集与表示、数据处理与融合、学习与推理
- 传感器:多模态学习中,传感器用于捕捉不同模态的数据,如摄像头捕捉图像(视觉模态)、麦克风捕捉声音(声音模态)等。
- 传感器是多模态数据采集的起点,它使得机器能够感知并获取来自不同物理世界的信息。
- 模态是指信息的表现形式或感知方式,如文本、图像、声音、视频等
- 多模态是指利用来自多个不同模态的数据进行学习和推理的过程。这些模态可以是文本、图像、声音、视频等的组合。
- 不同模态提供了不同的信息渠道,它们之间可能存在冗余性,但更多的是互补性。多模态模型能够整合来自不同模态的信息,正是利用这些不同模态的信息来增强模型的感知与理解能力。
- 模态融合:将来自不同模态的信息进行有效整合的过程。
- 早期融合:在数据处理的早期阶段就将不同模态的数据合并在一起。
- 晚期融合:在数据处理的后期阶段才将不同模态的信息进行整合。
- 混合融合:结合早期融合和晚期融合的优点,在不同的处理阶段进行多次融合。
- 模态融合能够充分利用不同模态之间的互补性,提高模型的性能和鲁棒性。
- 模态对齐:寻找来自不同模态数据之间的对应关系或一致性。
- 时间维度对齐:如将视频中的动作与音频中的语音进行对齐。
- 空间维度对齐:如将图像中的像素与文本中的单词进行对齐。
- 模态对齐是多模态学习中实现不同模态信息有效融合的重要前提。通过对齐操作,可以确保不同模态的数据在时间和空间上保持一致性,从而进行更有效的融合和推理。
- 多模态学习:利用来自多个不同模态的数据进行学习和推理的过程。
- 它旨在整合不同模态之间的互补信息,以提高模型的感知与理解能力。
- 多模态学习是当前人工智能领域的一个研究热点,它推动了智能应用的边界扩展。通过多模态学习,可以构建更加智能、更加全面的系统来应对复杂多变的现实世界。
多模态机器学习的核心任务主要包括表示学习,模态映射,模态对齐,模态融合,协同学习。
表示学习
表示学习(Representation):主要研究如何将多个模态数据所蕴含的语义信息,数值化为实值向量,简单来说就是特征化。
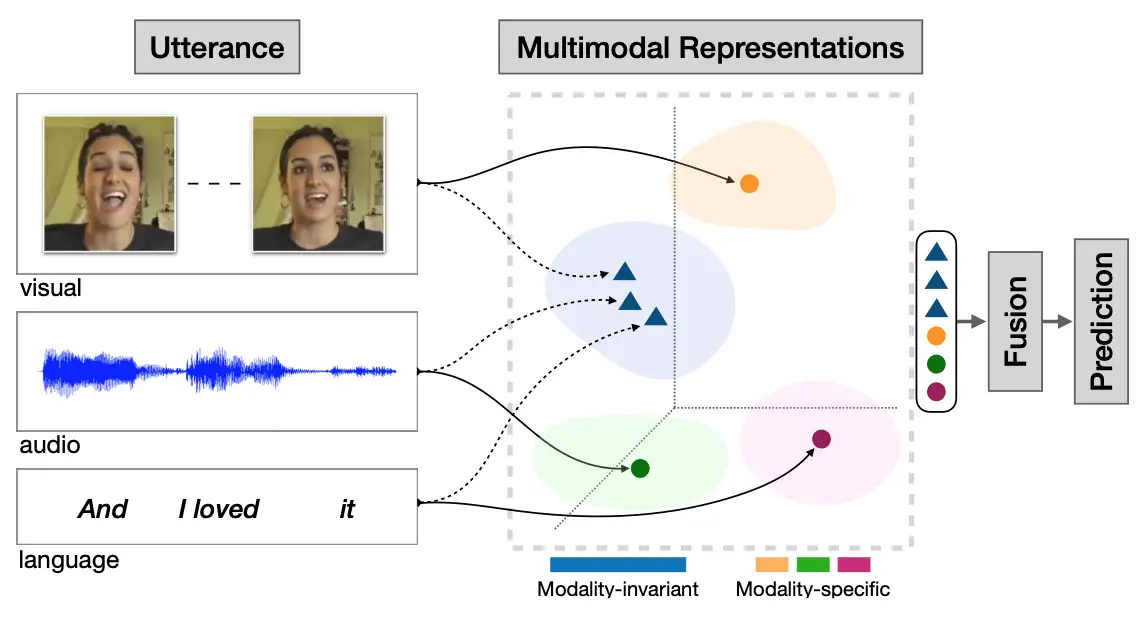
单模态的表示学习负责将信息表示为计算机可以处理的数值向量或者进一步抽象为更高层的特征向量 Feature;- 而多模态表示学习通过利用多模态之间的互补性,剔除模态间的冗余性,从而学习到更好的特征 Feature。
那在表示学习中主要包括两大研究方向:
联合表示(Joint Representations):将多个模态的信息一起映射到一个统一的多模态向量空间。(CLIP 和 DALL·E 使用简单的联合表示,不过效果出奇的赞)。协同表示(Coordinated Representations):将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束(例如线性相关)。
下游任务
接着就是下游任务对特征进行理解(学术上也叫做内容理解),典型的下游任务包括视觉问答、视觉推理、视觉联合推理、图像检索、视频检索。
- 视觉问答(Visual Question Answering,VQA):根据给定的图片提问,从候选中选择出正确的答案,VQA2.0 中从 COCO 图片中筛选了超过100万的问题,训练模型来预测最常见的3129个回答,其本质上可以转化成一个分类问题。

- 视觉推理(Visual Reasoning,VR):视觉推理相对视觉问答更为复杂, 其可以分解为两个子任务视觉问答(Q->A)和选出答案的原因(QA->R), 除了回答的问题需要用自然语言表达具有挑战性的视觉问题外, 模型还需要解释为什么作出这样的回答, 其最开始由华盛顿大学提出, 同时发布的 VCR 数据集包含 11 万的电影场景和 29 万的多项选择问题。

- 检索任务(Index Task):主要包括文本检索图片或者图片检索文本,检索任务应该不用加以过多的解释了,比较好理解,就是以文搜图或者以图搜文。下面图中就是Google 以图搜文的服务,当然包括华为手机里面的截图识字,淘宝拼多多的以文搜图等身边很多诸如此类的服务啦。

跨模态预训练
- 图像/视频与语言预训练。
- 跨任务预训练
ChatGPT 对多模态领域技术发展方向有什么影响?那必然是:卷起来了!
- 2023年3月6日,谷歌发布“通才”模型
PaLM-E,作为一种多模态具身 VLM,它不仅可以理解图像,还能理解、生成语言,执行各种复杂的机器人指令而无需重新训练。还展示出了强大的涌现能力(模型有不可预测的表现)。 - 没隔多久,微软开始拉着OpenAI,N鸣惊人。
- 3月15日,OpenAI携手微软于发布了GPT-4,也是关注多模态的,实验效果要比
PaLM好,并且可以执行非常多的任务,比如,GPT4 在各种职业和学术考试上表现和人类水平相当。- 模拟律师考试,GPT4 取得了前 10% 的好成绩
- 做美国高考 SAT 试题,GPT-4 也在阅读写作中拿下 710 分高分、数学 700 分(满分 800)。
- Bing浏览器立马就把模型用了起来, 推出 New Bing
- 3月17日,微软发布office 全家桶,将通过生成式人工智能(AI)技术来增强 Office 办公套装:Microsoft 365 Copilot,用于 Office 套装中的 Word、Excel 和 PowerPoint 等软件。新工具将帮助商业客户更快地撰写文档,生成艺术画,以及创建图表,帮助企业的数百万员工节省大量时间。
- 微软CEO纳德拉表示,今天是一个里程碑,意味着我们与电脑的交互方式迈入了新的阶段,从此我们的工作方式将永远改变,开启新一轮的生产力大爆发。
- 3月21日,支持 AI画图 Image Creator,背后调用 OpenAI 的 DALL-E
CLIP
OpenAI 推出了 CLIP,在400M的图像-文本对数据上,用最朴素的对比损失训练双塔网络,利用text信息监督视觉任务自训练,对齐了两个模态的特征空间,本质就是将分类任务化成了图文匹配任务,效果可与全监督方法相当。
- 在近 30 个数据集上 zero-shot 达到或超越主流监督学习性能。
- CLIP:《Learning Transferable Visual Models From Natural Language Supervision》
作者:ZOMI酱
CLIP算法原理
- CLIP 不预先定义图像和文本标签类别,直接利用从互联网爬取的 400 million 个image-text pair 进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉分类。
- CLIP 无需利用 ImageNet 的数据和标签进行训练,就可以达到 ResNet50 在 ImageNet数据集上有监督训练的结果,所以叫做 Zero-shot。
CLIP(contrastive language-image pre-training)主要的贡献就是利用无监督的文本信息,作为监督信号来学习视觉特征。CLIP 作者先是回顾了并总结了和上述相关的两条表征学习路线:
- 构建image和text的联系,比如利用已有的image-text pair数据集,从text中学习image的表征;
- 获取更多的数据(不要求高质量,也不要求full labeled)然后做弱监督预训练,就像谷歌使用的JFT-300M数据集进行预训练一样(在JFT数据集中,类别标签是有噪声的)。具体来说,JFT中一共有18291个类别,这能教模型的概念比ImageNet的1000类要多得多,但尽管已经有上万类了,其最后的分类器其实还是静态的、有限的,因为你最后还是得固定到18291个类别上进行分类,那么这样的类别限制还是限制了模型的zero-shot能力。
这两条路线其实都展现了相当的潜力,前者证明 paired image-text 可以用来训练视觉表征,后者证明扩充数据能极大提升性能,即使数据有noise。于是high-level上,CLIP 作者考虑从网上爬取大量的 image-text pair 以扩充数据,同时这样的 pairs 是可以用来训练视觉表征的。作者随即在互联网上采集了4亿个 image-text 对,准备开始训练模型。
CLIP流程有三个阶段:
- Contrastive pre-training:对比预训练阶段,使用image-text对进行对比学习训练。
- Create dataset classifier from label text:提取预测类别文本特征。
- Use for zero-shot prediction:进行 Zero-Shot 推理预测。

PaLM-E
【2023-3-7】谷歌发布了个多模态模型 PaLM-E,使用传感器数据、自然语言、视觉训练,能直接用人话操作机器人完成任务。
Language-Audio
- Text-to-Speech Synthesis: 给定文本,生成一段对应的声音。
- Audio Captioning:给定一段语音,生成一句话总结并描述主要内容。(不是语音识别)
Vision-Audio
- Audio-Visual Speech Recognition(视听语音识别):给定某人的视频及语音进行语音识别。
- Video Sound Separation(视频声源分离):给定视频和声音信号(包含多个声源),进行声源定位与分离。
- Image Generation from Audio: 给定声音,生成与其相关的图像。
- Speech-conditioned Face generation:给定一段话,生成说话人的视频。
- Audio-Driven 3D Facial Animation:给定一段话与3D人脸模版,生成说话的人脸3D动画。
Vision-Language
- Image/Video-Text Retrieval (图(视频)文检索): 图像/视频<–>文本的相互检索。
- Image/Video Captioning(图像/视频描述):给定一个图像/视频,生成文本描述其主要内容。
- Visual Question Answering(视觉问答):给定一个图像/视频与一个问题,预测答案。
- Image/Video Generation from Text:给定文本,生成相应的图像或视频。
- Multimodal Machine Translation:给定一种语言的文本与该文本对应的图像,翻译为另外一种语言。
- Vision-and-Language Navigation(视觉-语言导航): 给定自然语言进行指导,使得智能体根据视觉传感器导航到特定的目标。
- Multimodal Dialog(多模态对话): 给定图像,历史对话,以及与图像相关的问题,预测该问题的回答。
定位相关的任务
- Visual Grounding:给定一个图像与一段文本,定位到文本所描述的物体。
- Temporal Language Localization: 给定一个视频即一段文本,定位到文本所描述的动作(预测起止时间)。
- Video Summarization from text query:给定一段话(query)与一个视频,根据这段话的内容进行视频摘要,预测视频关键帧(或关键片段)组合为一个短的摘要视频。
- Video Segmentation from Natural Language Query: 给定一段话(query)与一个视频,分割得到query所指示的物体。
- Video-Language Inference: 给定视频(包括视频的一些字幕信息),还有一段文本假设(hypothesis),判断二者是否存在语义蕴含(二分类),即判断视频内容是否包含这段文本的语义。
- Object Tracking from Natural Language Query: 给定一段视频和一些文本,追踪视频中文本所描述的对象。
- Language-guided Image/Video Editing: 一句话自动修图。给定一段指令(文本),自动进行图像/视频的编辑。
更多模态
- Affect Computing (情感计算):使用语音、视觉(人脸表情)、文本信息、心电、脑电等模态进行情感识别。
- Medical Image:不同医疗图像模态如CT、MRI、PETRGB-D模态:RGB图与深度图
语料库
多模态情感分析语料库
【2021-8-13】哈工大:多模态情感分析语料库调研
介绍相关子任务和对应数据集以及在数据集上的最新研究工作。主要分为:
- 面向视频评论的情感分析
- 面向视频评论的细粒度情感分析
- 面向视频对话的情绪分析
- 面向视频的反讽识别
- 面向图文的反讽识别
- 面向图文的情感分析
- 面向图文的细粒度情感分析、幽默检测、抑郁检测。
本文分别总结了相关数据集和方法,具体内容见第三部分。
多模态情感分析简述, 任务概览,总结如下:
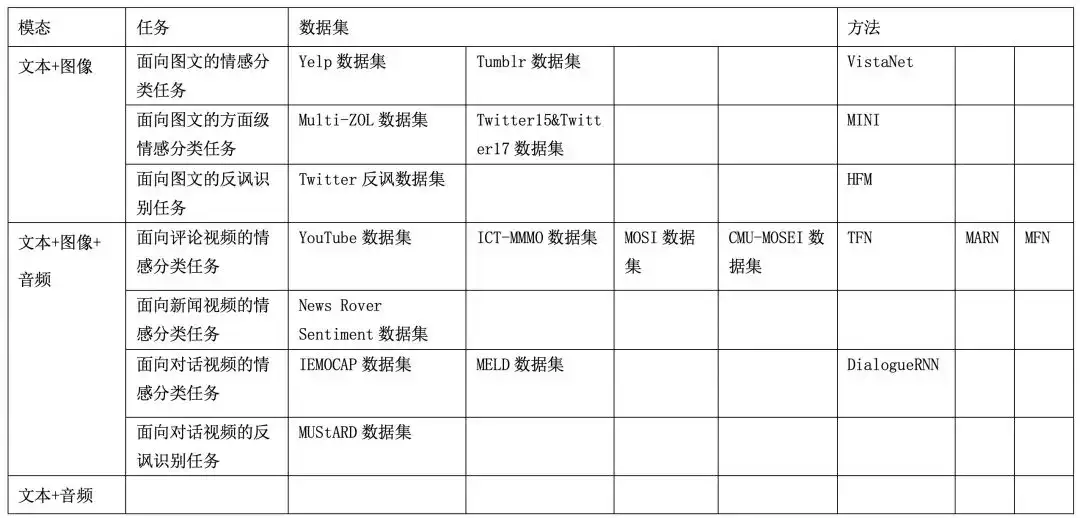
多模态情感分析相关数据集和方法概览
| 模态 | 任务 | 数据集及下载地址 | 方法 |
|---|---|---|---|
| 声图文 | 面向视频评论的情感分析 | Youtube数据集,MOSI数据集,MOSEI数据集 | Self-MM,Mult |
| 声图文 | 面向视频评论的细粒度情感分析 | CH-SIMS数据集 | MTFN |
| 声图文 | 面向视频对话的情绪分析 | IEMOCAP数据集, MELD数据集 | DialogueRNN, MESM |
| 声图文 | 面向视频的反讽识别 | MUStARD数据集 | Early Fusion +SVM |
| 图文 | 面向图文的反讽识别 | Twitter反讽数据集 | D&R net |
| 图文 | 面向图文的情感分析 | Yelp数据集,MVSA数据集 | |
| 图文 | 面向图文的细粒度情感分析 | Multi-ZOL数据集,Twitter-15&17数据集 | TomBert |
| 声图文 | 幽默检测 | UR-FUNNY数据集 | C-MFN |
| 声图文 | 抑郁检测 | DAIC-WOZ数据集 | |
| 图文 | 抑郁检测 | Twitter抑郁检测数据集 | MDL |
详情见原文
多模态模型
多模态模型榜单
【2024-8-2】中文多模态大模型基准8月榜单发布!8大维度30个测评任务,3个模型超过70分
测评要点
- 1:GPT-4o领跑
GPT-4o取得74.36分,领跑多模态基准。其中基础多模态认知能力和应用能力均有70+分的表现,在技术和应用方面均有一定领先优势。
- 2:国内多模态大模型表现不俗
- 国内多模态大模型
hunyuan-vision和InternVL2-40B表现不俗,取得70+分的优异成绩,仅次于GPT-4o。尤其在多模态应用方面领先Claude3.5-Sonnet和Gemini-1.5-Pro,展现出较强的应用优势。
- 国内多模态大模型
- 3:国内大模型基础能力仍需提升
- 在基础能力方面国内大模型较海外模型仍有一定差距,尤其在细粒度视觉认知任务上,国内外最好模型有5分的差距,需要进一步对多模态深度认知能力做优化提升。
GPT-4o > hunyuan-vision > InterVL2-40B > Claude3.5-Sonnet > Gemini-1.5-Pro > Step-1V-8k > GPT-4-Turbo-0409 > GLM-4v > Qwen-VL-Max > ERNIE-4-Turbo > Qwen-VL-Plus > Yi-VL-34B
模型汇总
模型架构5个部分:模态编码器、输入投影器、语言模型骨干、输出投影器和模态生成器。
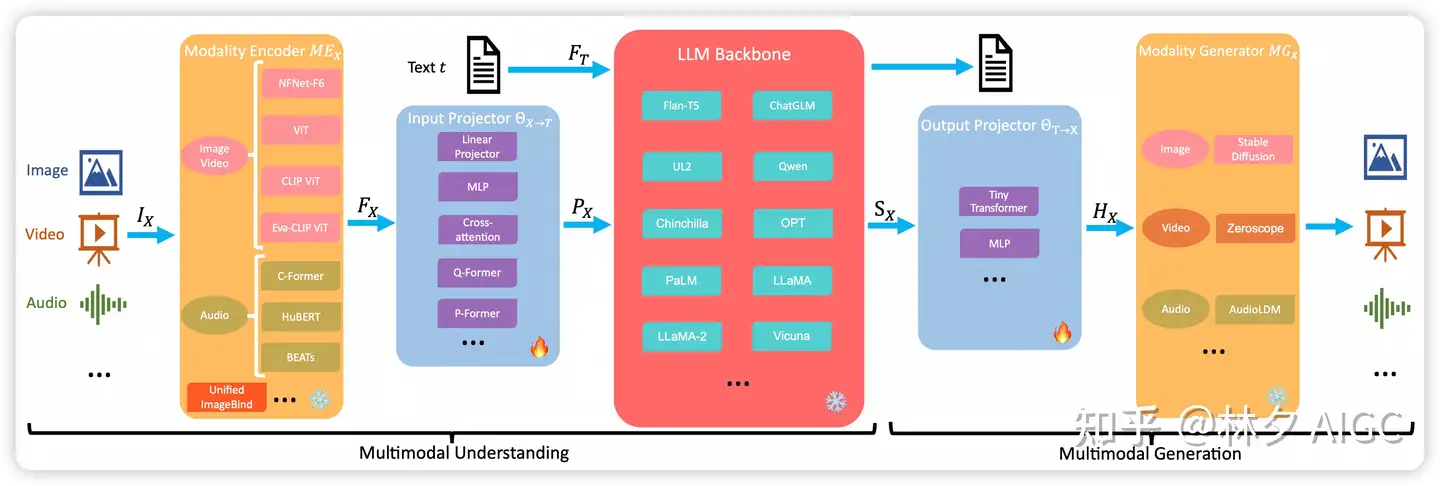
- 多模态理解主要是前三个部分。(模态对齐)训练期间,encoder,LLM Backbone 和 generator 一般保持冻结。
- 主要优化输出和输出的 projector。由于Projector 是轻量级的模块,MM-LLMs 中可以训练的参数比例和总参数相比非常小(2% 左右),模型的总体参数规模取决于LLM 部分。
对比分析
- Vision Encoder 视觉编码器
- VL Adapter 转换器
- Projection Layer 映射层
| 模型 | 时间 | 机构 | 分辨率 | 模型大小 | 视觉编码器 | 转换器 | LLM | 映射层 | 备注 |
|---|---|---|---|---|---|---|---|---|---|
Flamingo |
2022.04 | DeepMind | 480 | 80P | NFNet F6 | Perceiver Resampler | Chinchilla 70B + GATED XATTN-DENSE | 接入LLM的多模态 | |
BLIP-2 |
2023.01 | Saleforce | 224 | 7B | EVA-CLIP ViT-g/14 | Q-Former | Flan-T5/OPT-6.7B | ||
MiniGPT4-v1 |
2023.04 | KAUST | 224 | 13B | EVA-CLIP ViT-g/14 | Q-Former+MLP | Vicuna-13B-v0 | 基于BLIP-2进行改进 | |
InstructBLIP |
2023.05 | Saleforce | 224 | 13B | EVA-CLIP ViT-g/14 | Q-Former | Flan-T5/Vicuna-13B | 对BLIP2进行大规模 | |
VisualGLM-6B |
2023.05 | 智谱 | 224 | 6B | EVA-CLIP ViT-g/14 | Q-Former | ChatGLM-6B | ||
Shikra |
2023.06 | 字节 | 224 | 7B/13B | CLIP ViT-L/14 | 一层MLP | Vicuna-7B/13B(PEFT) | LLaVA结构 | |
Qwen-VL |
2023.08 | 阿里通义 | 448 | 9B | OpenCLIP ViT-G/14 | Cross Attention | Qwen-7B | 只用了一层Cross Attention | |
InternLM-XComposer-VL |
2023.09 | 上海Al Lab | 224 | 7B | EVA-CLIP ViT-g/14 | Q-Former | InternLM-7B | 支持图文混排 | |
mPLUG-Owl |
2023.04 | 达摩院 | 224 | 7B | CLIP ViT-L/14 | Perceiver Resampler | LLaMA-7B | 改装自Flamingo | |
mPLUG-Owl V2 |
2023.11 | 达摩院 | 448 | 7B | CLIP ViT-L/14 | Perceiver Resampler | LLaMA-7B | 添加模态自适应的M | |
ShareGPT4V |
2023.11 | 上海Al Lab | 336 | 7B | CLIP ViT-L/14 | 两层MLP | Vicuna-7B-v1.5 | 使用GPT4V提供了- | |
Sphinx |
2023.11 | 上海Al Lab | 224 | 13B | -ConvNext, DINO-v2, | 两个不同的Projector | LLaMA-2-13B | 将四个不同的encod | |
CogVLM-17B |
2023.11 | 智谱 | 224->496 | 17B | EVA-CLIP ViT-E/14 | 两层Linear | Vicuna-7B-v1.5 +Visual Expert Module | 视觉专家,文本和视 | |
Ferret |
2023.11 | 添加 Spatial Aware | 336 | 7B/13B | CLIP ViT-L/14 | 一层Linear | Vicuna-7B/13B-v1.3 | ||
MiniGPT-V2 |
2023.11.7 | Meta AI, KAUST | 448 | 7B | EVA-CLIP ViT-G/14 | 一层Linear | LLaMA2-chat 7B | ||
Qwen-VL2 |
2024.09 | 阿里通义 | 448 | 9B | ViT/14 | Cross-Modal Connection | Qwen2-1.5B Qwen2-7B Qwen2-72B |
1. ViT 2.全参 3.LLM |
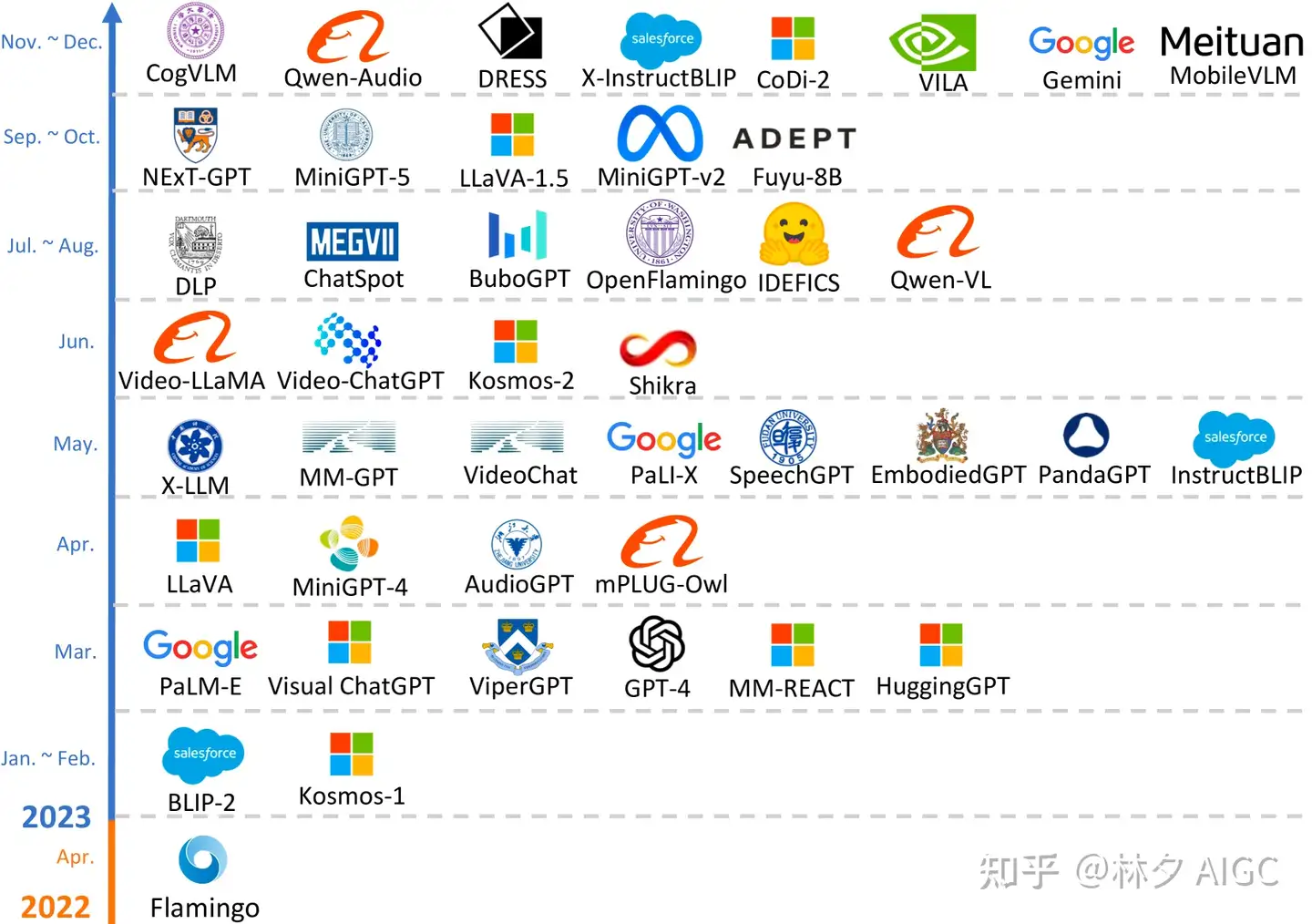
发展历程图解
- 最初集中在多模态的内容理解和文本生成:
- Flamingo,BLIP-2, Kosmos-1,LLaVA/LLaVA-1.5/LLaVA-1.6,MiniGPT-4,MultiModal-GPT,Video-Chat,VIdeo-LLaMA,IDEFICS,Fuyu-8B,Qwen-Audio
- 同时实现多模态的输入和输出工作: MM-LMM,探索特定模态的生成
- 例如 Kosmos-2,Mini-GPT5,以及语音生成的 SpeechGPT
- 将 LLM 和外部工具继承进来,实现“any-to-any”的多模态理解和生成。
- visual-chatgpt,ViperGPT,MM-React,HuggingGPT,AudioGPT
- 减少级联过程中传播误差的工作, 开发任意模式的多模态模型
- NExT-GPT 和 CoDI-2,
改进
【2026-2-25】LaSt-ViT
【2026-5-25】视觉Transformer的「近视眼」手术——LaSt-ViT如何让机器真正「看懂」图像
Vision Transformer (ViT) 已经成为当之无愧的基石模型。无论是图像分类、目标检测还是语义分割,ViT 都展现出了统治级的表现。
然而,ViT 真的“看懂”图片了吗?
场景:
- 给模型看一张“猫坐在沙发上”的照片,模型准确地输出了“猫”。
- 但当用可解释性工具查看模型的注意力(Attention)时,却发现它死死盯着沙发、地毯和背景墙,唯独没有看那只猫。
ViT 过去几年的真实写照。
【2026-2-25】CVPR 2026 上,香港大学和中山大学发表引人深思的论文。不仅揭示了这一反直觉现象的根源,还提出极其优雅的解决方案:LaSt-ViT (LazyStrike ViT)。
问题:
- CLS Token 错误地聚合了背景信息
解决方案:
- 强制 CLS Token 锚定在真正的前景区域上。
LaSt-ViT (LazyStrike ViT) 摒弃标准 CLS Token 提取方式,引入极其巧妙的频域感知选择性聚合机制(Frequency-aware Selective Aggregation)。
LaSt-ViT 的这种“微创手术” 立竿见影,三大监督范式(标签监督、文本监督 CLIP、自监督 DINO)下均表现出强大的通用性:
- 彻底消除伪影:无论是 Patch Score 伪影还是高范数 Token(High-norm token)问题,都被 LaSt-ViT 完美消除,特征对齐变得极其精准。
- 涌现出强大的零样本分割能力:在没有进行任何像素级标注训练的情况下,LaSt-ViT 展现出了惊人的涌现语义分割(Emergent Semantic Segmentation)能力。模型终于知道“猫”到底长在图片的哪个像素位置了。
- 下游任务全面霸榜:在目标发现、语义/实例分割、开放词汇检测(Open-vocabulary detection)等 12 个主流基准测试中,LaSt-ViT 均实现了稳定且一致的性能提升。
LaSt-ViT 不仅给 ViT 增加了一个即插即用的模块,还纠正了对大模型学习机制的认知偏差。
过去认为,只要分类准确率高,模型就一定“理解”了图像。但 LaSt-ViT :高准确率 ≠ 真正的理解,模型可能只是在利用意想不到的捷径。通过深入探究 Patch Score 和频域特征,程石团队找到了真正的病灶,并用最优雅的数学工具(FFT)完成了这台“近视眼手术”。
多模态模块
多模态大模型(MLLMs)5个核心模块
Modality Encoder:模态编码器,将不同模态输入数据(如图片、视频、音频、3D等),编码为可理解的表示(隐层向量)Visual Modality:ViT, transformers 替换 cnn- 图片补丁
image patch encoder: 不用像素, 而是 用视野和步幅较大的卷积核提取图片补丁上的特征 - 图片补丁位置嵌入:
image patch position embedding, 查询表
- 图片补丁
Input Projector:输入映射,将不同模态的向量表示映射到共享表示空间,和LLM语义对齐LLM Backbone:大语言模型基座,LLM基座模型,用于处理文本数据Output Projector:输出映射,将LLM生成的输出,映射回原始模态空间,和各模态对齐Modality Decoder:模态解码器, 或Modality Generator模态生成器 ,将各模态语义解码为对应的模态
注意
- 注重 Comprehension and text generation 的多模态模型,只需要前3个模块
- 预训练阶段,Modality Encoder、LLM Backbone、Modality Decoder 一般都会冻结参数,只优化 Input Projector 和 Output Projector(约占整体参数的2%),因而训练一个多模态模型的成本会小很多。
- SFT阶段,LLM一般也会参与,因而SFT阶段需要更多显存。
模型进化史
多模态技术路线
【2024-7-30】
| 大方向 | 子方向 | 代表工作 |
|---|---|---|
| 内容理解和文本生成 Comprehension and text generation |
image-text understanding | BLIP-2, llaVA, MiniGPT-4, OpenFlamingo |
| 内容理解和文本生成 Comprehension and text generation |
video-text understanding | VideoChat, Video-ChatGPT, LLaMA-VID |
| 内容理解和文本生成 Comprehension and text generation |
audio-text understanding | Qwen-Audio |
| 特定模态 specific modality outputs |
image-text output | GILL, Kosmos-2, Emu, MiniGPT-4 |
| 特定模态 specific modality outputs |
speech/audio-text output | speechGPT, AudioPaLM |
| 任意模态 any-to-any modality outputs |
amalgamate tools | VisualChatGPT, HuggingGPT, AudioGPT |
| 任意模态 any-to-any modality outputs |
end-to-end | NExT-GPT, CoDi-2, ModaVerse |
【2024-5-30】多模态模型的演进和四种主流架构类型
多模态按照架构模式分为四类:A、B、C、D。
- A和B类型在模型内部,深度融合多模态输入,实现细粒度控制模态信息流动,但需要大量训练数据和计算资源;
- C和D类型在输入层,融合多模态输入
- C类型具有模块化设计,可以容易地添加更多模态。
- D类型使用标记化,可训练不同模态,但需要训练通用标记器。
按照不同架构模式,跟踪多模态发展里程碑:
多模态发展里程碑
多模态发展里程碑
1、A型多模态模型
A类模型:基于标准交叉注意力的深度融合(Standard Cross-Attention based Deep Fusion, SCDF)。
1.1 特点
特点
- 内部层深度融合:该架构使用标准的Transformer模型,并在模型的内部层添加了标准的交叉注意力层,以实现输入多模态信息的深度融合。
- 不同模态输入编码:每个输入模态(图像、视频、音频等)都通过对应的编码器进行编码,然后将编码后的多模态特征输入到模型内部层。
- 跨模态特征融合:模型内部层通过标准的交叉注意力层对不同模态的特征进行融合,使模型能够同时处理多个模态的信息。
- 多模态解码器:通常采用只包含解码器的Transformer模型作为多模态解码器,用于生成多模态输出。
- 自回归生成:多模态解码器可以实现多模态输入的自回归生成,即生成多模态输出。
- 训练数据需求:需要大量多模态训练数据,计算资源需求较高。
- 添加模态困难:在模型内部层添加更多模态比较困难。
1.2 优势与不足
A类型多模态模型
- 优势:多模态信息精细控制
- 不足:计算资源需求较高,模型复杂,添加模态困难。
1.3 典型模型开源代码
Flamingo- 官方代码 flamingo
- 基于Transformer 多模态模型,可处理图像和文本数据。
OpenFlamingo- 官方代码:OpenAI flamingo
- 开源Flamingo模型实现,提供了模型的复现。
Otter- 官方代码: 微软 otter-generative
- 基于OpenFlamingo的多模态模型,可处理图像和文本数据。
MultiModal-GPT- 官方代码: multimodal-gpt
- 基于OpenFlamingo的多模态模型,可以处理图像和文本数据。
PaLI-X- 官方代码: 微软 PALI-X
- 多模态模型,可以处理图像、文本和视频数据。
IDEFICS- 官方代码: 谷歌 IDEFICS
- 开源的Flamingo模型的实现,提供了模型的复现。
Dolphins- 官方代码: 微软 Dolphins
- 基于OpenFlamingo的多模态模型,用于自动驾驶场景。
2、B型多模态模型
B类模型
- 基于定制层的深度融合(Custom Layer based Deep Fusion, CLDF),在多模态学习中以其定制化的层和深度融合策略而著称。
2.1 特点
- 使用自定义层进行模态融合:与A类型模型不同,B类型模型不使用标准的Transformer跨注意力层来融合多模态输入,而是采用自定义设计的层来进行模态间的融合。这些自定义层可以是自注意力层、卷积层、线性层等。
- 跨注意力层或自定义层的深度融合:多模态输入通过模态编码器进行处理,然后通过自定义层或跨注意力层与语言模型进行深度融合。这种深度融合有助于模态间的信息交互和共享。
- 解码器端多模态模型为主:通常包含一个预训练的语言模型,用于作为解码器。模态编码器处理不同模态的数据,然后通过自定义层或跨注意力层与解码器层进行融合,从而生成多模态的输出。
- 模态交互和共享机制:通过自定义层或跨注意力层实现模态间的交互和共享。这种机制有助于模型更好地理解多模态数据之间的关联性。
- 支持更多模态类型:自定义层设计可以支持更多类型的模态,包括图像、文本、音频、视频等。通过灵活的自定义层设计,模型可以适应不同的多模态任务需求。
- 训练数据和计算资源需求:训练需要大量的多模态数据和计算资源。自定义层的设计需要大量的实验和调参来优化模型性能。
- 可扩展性:自定义层设计具有一定的可扩展性,可以方便地添加新的模态类型。然而,模型的扩展性仍然有限,需要仔细设计自定义层以支持新的模态类型。
2.2 优势与不足
优势
- 细粒度模态控制:模型可以通过自适应注意力层或自适应模块更好地控制不同模态信息在模型中的流动,实现细粒度的模态融合。
- 灵活的架构设计:自适应注意力层或自适应模块可以根据不同的任务需求进行定制设计,提供更多的灵活性。
- 降低计算复杂度:相比Type-A,B类型模型不需对LLM内部层进行大规模的修改,计算复杂度较低。
- 可扩展性:模型支持增加新的模态,只需要在输入层添加新的自适应模块或注意力层即可。
不足
- 计算资源需求:虽然B类型模型计算复杂度较低,但相比C类型,训练和推理仍然需要较多的计算资源。
- 训练难度:自适应注意力层或自适应模块的设计和训练需要较深的神经网络知识,对研究者有一定挑战。
- 模态融合控制:虽然提供了细粒度的模态控制,但过多控制可能导致模态信息的过度融合或不融合,需要仔细设计。
- 参数数量:添加自适应注意力层或自适应模块会增加模型参数数量,增加计算和存储需求。
- 性能:相比C类型,B类型模型的性能可能略低,因为模型设计更为复杂,需要更多训练数据和计算资源。
2.3 典型B类模型开源代码
LLaMA-Adapter- 官方代码:llama-adapter
- 采用自适应注意力层进行模态融合,适用于文本和图像输入,并输出文本。
LLaMA-Adapter-V2- 官方代码:paper
- 在LLaMA-Adapter基础上增加了视觉指令模型,使用自适应注意力层进行模态融合,适用于文本和图像输入,并输出文本。
CogVLM- 官方代码:微软 cogvlm
- LLM注意力层之前添加了自适应注意力层,用于学习图像特征,适用于图像和文本输入,并输出文本。
mPLUG-Owl2- 官方代码:微软 mplug-owl
- 在LLM的注意力层之前添加了自适应注意力层,称为“模式适应模块”,适用于图像和文本输入,并输出文本。
CogAgent- 官方代码:cogagent
- 在LLM的注意力层之前添加了自适应注意力层,用于学习图像特征,适用于图像和文本输入,并输出文本。
InternVL- 官方代码:微软 internvl
- 包含视觉编码器、重采样器、LLM、特征同步器等,适用于图像和文本输入,并输出文本。
MM-Interleaved- 官方代码:微软 mm-interleaved
- 包含视觉编码器、重采样器、LLM、特征同步器等,适用于图像和文本输入,并输出图像和文本。
CogCoM- 官方代码:微软 cogcom
- 包含视觉编码器、重采样器、LLM、特征同步器等,适用于图像和文本输入,并输出图像和文本。
InternLM-XComposer2- 官方代码:微软 internlm-xcomposer
- 添加了LoRA权重来学习图像模态,适用于图像和文本输入,并输出文本。
MoE-LLaVA- 官方代码:moe-llava
- 在LLaVA的基础上修改了每个解码器层的FFN层,创建了混合专家层,适用于图像和文本输入,并输出文本。
3、C型多模态模型
C类模型
- 非标记化早期融合(NTEF)架构,在多模态学习领域中以其模块化和灵活性而著称。
3.1 特点
- 早期融合:与深度融合模型(A类和B类)不同,C类模型在模型的输入阶段就实现了模态的融合,而不是在模型的内部层中。
- 非标记化输入:直接将不同模态的输入提供给模型,而不需要将输入转换为离散的标记(tokens)。这意味着模型在处理输入时不需要进行复杂的分词处理。
- 模块化设计:具有模块化架构,将不同模态的编码器输出与语言模型(LLM)或变换器模型直接连接起来,无需在模型内部层进行模态融合。可以轻松替换或更新模型的不同部分,如编码器或连接层,而不影响整个系统的其他部分。
- 简化的集成:由于其模块化的特性,可以更容易地集成新的模态或更新现有模态的处理方式。
- 端到端可训练:尽管在输入阶段融合模态,但它们仍然可以端到端地进行训练。
- 资源效率:与其他类型的多模态模型相比,C类模型通常需要较少的训练数据和计算资源。
- 连接器/适配器的使用:使用不同类型的连接器或适配器来链接模态编码器和语言模型(LLM)。这些连接器可以是线性层、多层感知器(MLP)、Q-former、注意力池化层、卷积层、Perceiver resampler或Q-former的变体。
- 训练策略:通常采用预训练、指令调整和对齐调整的三阶段训练策略。预训练阶段主要目的是对齐不同模态并学习多模态世界知识;指令调整用于提高模型对用户指令的理解能力;对齐调整则进一步优化模型以适应人类交互。
- 易于扩展:由于其设计,可以较容易地扩展以包含更多的模态,这使得它们在构建任何到任何的多模态模型时非常有用。
3.2 优势与不足
优势
- 简单高效:不需要在模型内部层进行模态融合,因此其设计较为简单,易于实现和训练。此外,模型的模块化设计也使得其在计算资源需求上相对较低。
- 多模态输入输出:可以接受多种模态(如图像、文本、音频等)作为输入,并生成相应的多模态输出。模型的输入端可以根据需要连接不同的模态编码器,例如图像编码器、文本编码器等。
- 适应性强:模块化设计使得其具有较强的适应性,可以轻松地集成新的模态或修改现有的模态编码器,以满足不同任务的需求。
- 通用性强:通用性较强,可以应用于多种多模态任务,如多模态文本生成、多模态对话、多模态理解等。
不足
- 模态信息处理:C类型模型在模态信息的处理上相对简单,可能无法充分挖掘不同模态之间的潜在联系。
- 性能限制:C类型模型的性能可能略低于Type-A和Type-B,因为模型的设计更为复杂,需要更多训练数据和计算资源。
- 模态编码器设计:C类型模型的性能在很大程度上取决于模态编码器的性能,因此需要设计高效的模态编码器。
- 模态融合控制:C类型模型在模态融合的控制上较为困难,需要仔细设计连接模块,以确保不同模态信息的有效融合。
3.3 典型C类模型开源代码
BLIP-2- 官方代码: BLIP-2 GitHub
- 使用一个名为Q-Former的模块来同时处理图像和文本输入。
MiniGPT-4- 官方代码: MiniGPT-4 GitHub
- 一个大规模的、可微调的多模态语言模型,它通过设计一个连接模块来连接图像编码器输出和语言模型。
LLaVA- 官方代码: LLaVA GitHub
- 一个基于指令微调的、可以处理多模态输入和输出的语言模型。它使用一个线性层来连接图像编码器输出和语言模型。
4、D型多模态模型
D类模型
- Tokenized Early Fusion (TEF),其架构特点主要围绕使用分词器(tokenizer)来处理和融合多模态输入。
4.1 特点
- 输入分词化:使用通用分词器或模态特定的分词器将多模态输入(如图像、视频、音频)转换为离散的标记(tokens)。
- 早期融合:与C类模型类似,D类模型也在输入阶段实现模态融合,但不同之处在于D类模型通过分词化实现这一融合。
- 统一的Transformer架构:通常采用预训练的大型语言模型(LLM)或编码器-解码器(encoder-decoder)风格的Transformer模型来处理分词化后的输入,并生成多模态输出。
- 端到端可训练:D类模型是端到端可训练的,这意味着从输入分词化到输出生成的整个过程可以在一个统一的框架内进行训练。
- 自动回归目标:由于输入和输出都被分词化,可以使用标准的自动回归目标函数来训练模型,这简化了训练过程。
- 处理多种模态:用于处理包括文本在内的多种模态,使其能够生成图像、音频和不同模态的tokens。
- 灵活性和扩展性:通过分词化,可以相对容易地适应新的模态,尽管为新模态训练或调整分词器可能是一项挑战。
- 大规模训练数据需求:通常需要大量的训练数据来训练分词器和主Transformer模型,这可能导致计算资源的大量需求。
- 可训练参数数量大:由于模型需要学习将不同模态的输入映射到统一的标记空间,D类模型往往具有大量的可训练参数。
- 适用于任何到任何的多模态任务:D类模型由于其设计,非常适合构建能够处理任何输入模态到任何输出模态的多模态模型。
4.2 优势与不足
优势
- 标准化训练目标:由于模态都被标记化,模型可以使用标准的自回归目标函数进行训练,这简化了训练过程。
- 模态扩展性:新的模态可以通过训练一个新的标记化器来添加到模型中,这种灵活性使得模型能够扩展到新的模态。
- 模态通用性:标记化的模态表示可以用于多种下游任务,包括文本生成、图像生成、文本到图像的生成等。
不足
- 标记化复杂性:训练一个通用的标记化器或模态特定的标记化器可能是一个挑战。
- 计算资源需求:标记化和去标记化过程增加了计算复杂性,可能需要额外的计算资源。
- 模态信息的损失:标记化可能会丢失一些模态的原始信息,这可能导致模型性能的下降。
- 模态独立性:标记化可能导致模型在学习模态间交互时遇到困难,因为标记化表示可能掩盖了模态间的依赖关系。
4.3 典型D类模型开源代码
Unified-IO- 官方代码: Unified-IO GitHub
- 一个多模态预训练模型,它使用VQ-GAN风格的标记化器来处理不同模态的输入,并使用投影层将非文本模态的输出嵌入映射到文本模态的词汇空间。
Unified-IO-2- 官方代码: Unified-IO-2 GitHub
- Unified-IO的升级版,它包含了更多的模态和更复杂的预训练任务。
4M- 官方代码: 4M GitHub
- 一个可以处理文本、RGB图像、深度、法线和语义分割映射等多模态输入的模型。它使用多模态混合去噪器(Multimodal Mixture of Denoisers)作为预训练目标。
典型模型
传统模型
前 Transformer时代:目标检测+预训练(Faster R-CNN + BERT)
Transformer多模态模型
Transformer(2017): Attention Is All You Need.ViT(2020): 将transformer用于图像任务, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale Transformer.CLIP(2021): 文本和图像混合预训练- Learning Transferable Visual Models From Natuural Language Supervision.
KOSMOS-1(2023): 多模态大规模语言模型- Language Is Not All You Need: AligningPerception with Language Models.
多模态大模型:
- MiniGPT-4:沙特阿拉伯阿卜杜拉国王科技大学的研究团队开源。
- LLaVA:由威斯康星大学麦迪逊分校,微软研究院和哥伦比亚大学共同出品。
- VisualGLM-6B:开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
ViLBERT
ViLBERT的思路是从该模型在BERT模型的基础上,开创性的将视觉特征和文本特征引入单独的处理模块,并使用与单独处理结构相同的结构,以交换部分网络权重的方式结合两个模态的特征信息,最后得出两种不同数据的各自的特征编码。同时引用了能够包括两个模态的预训练任务:MLM、MRM、MRC、ITM
UNITER
UNITER的思路是通过使用单流结构,直接将视觉特征和文本特征融合处理,最后得到一个同时包含视觉语义和文本语义的特征编码。
- 该算法结合了大量的数据集和充足的预训练任务(包括:作者主要设计了4种预训练任务去获得模型的权重参数:基于图像的MRM、基于文本的MLM、图像文本匹配ITM、文本对齐WRA),最终在多个评测任务数据集上获得了当时的SOTA。
新模型
- 【2023-7-27】Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic
- 【2023-9-25】多模态大模型最全综述来了!7位微软研究员大力合作,成文119页
现象:
多模态基础模型已经从专用走向通用。
排行榜
多模态模型排行榜 OpenCampass
详见站内专题:多模态大模型案例
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
