课程学习
【2021-4-9】一篇综述带你全面了解课程学习(Curriculum Learning)
- 2021,清华朱文武 A Survey on Curriculum Learning TPAMI,解读
概要
问题:
- (1)课程学习如何定义?
- (2)为何课程学习有效,以及为何要用课程学习?
- (3)如何设计一个课程?
- (4)课程学习与其他机器学习概念的关系?
- (5)课程学习可能的未来发展方向?
课程学习介绍
2009年,Bengio 首先提出课程学习(Curriculum learning,CL)概念,一种训练策略,模仿人类的学习过程,主张让模型先从容易样本开始学习,并逐渐进阶到复杂样本和知识。
- Curriculum learning . ACM, 2009
训练分布和测试分布之间存在着由噪声/错误标注的训练数据引起的偏差。训练分布和目标(测试)分布有一个共同的大密度高置信度标注区域,这对应于CL中比较容易的样本。
传统机器学习算法往往采用随机训练数据,忽略了样本难度与模型当前状态。
课程学习希望从 “设计一个更好的训练课程” 的角度,改进机器学习的训练策略。
CL策略在计算机视觉和自然语言处理等多种场景下,在提高各种模型的泛化能力和收敛率方面表现出了强大的能力。
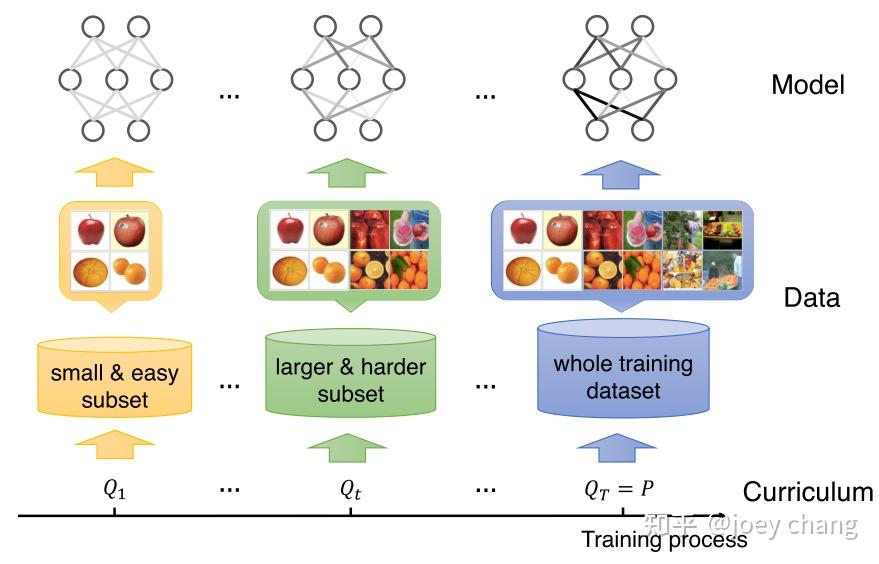
以图像分类为例
- 训练初始阶段,课程学习算法在简单(清晰、典型、易识别)数据子集上训练模型;
- 随着训练的进行,算法逐渐加入了更多更困难(较复杂、难识别)的图像样本到当前训练集中,这就好比人类课程里学习材料难度的增加;
- 最后,算法在完整的原始训练集上进行训练。
好的课程学习算法可以带来更佳的模型表现,以及更快的收敛速度。
一个课程指在 T 步机器学习训练过程中的系列训练标准:C=,其中每个标准 Q_t 是训练分布 P(z)的一个重新加权,即 Q_t(z)∝W_t(z)P(z),z=(x,y)是训练集 D 中的任一样本,且 Qt 满足以下三个条件:
- (1)当前训练集的熵会不断增加,即 H(Q_t)<H(Q_(t+1));
- (2)任意一个样本的权重会不断增加,即:W_t(z)≤W_(t+1)(z);
- (3)Q_T(z)=P(z)。
分析
- 条件(1)意味着当前训练集的多样性和信息量在增加,也即训练后期的时候Q_t会增大采样更困难样本的权重;
- 条件(2)说明训练集中的样本数在不断增加;
- 条件(3)说明最终算法将在完整训练集里均匀采样用于训练。
三个约束条件(1)(2)(3)有时会被舍弃,得到数据级别广义课程学习的定义:训练分布 P(z)的一个重新加权序列。事实上涵盖了样本选择与重新加权,即在每轮训练中动态调整训练样本的采样策略或样本权重。
课程学习即使用这样的课程训练机器学习模型的一种训练策略。
课程学习理论分析
- 从优化角度,课程学习是连续法(continuation method)的一个特例,它在初始阶段松弛了优化目标并逐渐收紧,这有利于模型逃离较差的局部最优点。
- 从数据分布角度,课程学习是一种去噪的策略,这是由于在大数据场景中,困难样本往往包含更多噪声,因此由易到难的策略可以缓解模型在初始学习阶段受到的噪声干扰。
CL 是一种特殊的 continuation 方法,首先优化比较平滑的问题,然后逐渐优化到不够平滑的问题。
如下图所示,continuation 方法提供了一个优化目标序列,从一个比较平滑的目标开始,很容易找到全局最小值,并在整个训练过程中跟踪局部最小值。
另外,从更容易的目标中学习到的局部最小值具有更好的泛化能力,更有可能近似于全局最小值。
课程学习的核心问题:得到一个ranking function
- 对每条数据/每个任务,给出 learning priority (学习优先程度),由
难度测量器(Difficulty Measurer)实现。 - 什么时候把 Hard data 输入训练 以及 每次放多少呢? 这个则由
训练调度器(Training Scheduler)决定。
因此,目前大多数CL都是基于”难度测量器+训练调度器 “的框架设计。
“课程” 的两个关键模块:
- (1)难度评分器,用于决定什么样本更简单(或者什么样本更适合当前的采样);
- (2)训练调度器,用于决定何时增加多少更困难的样本到当前训练集。
课程学习分类
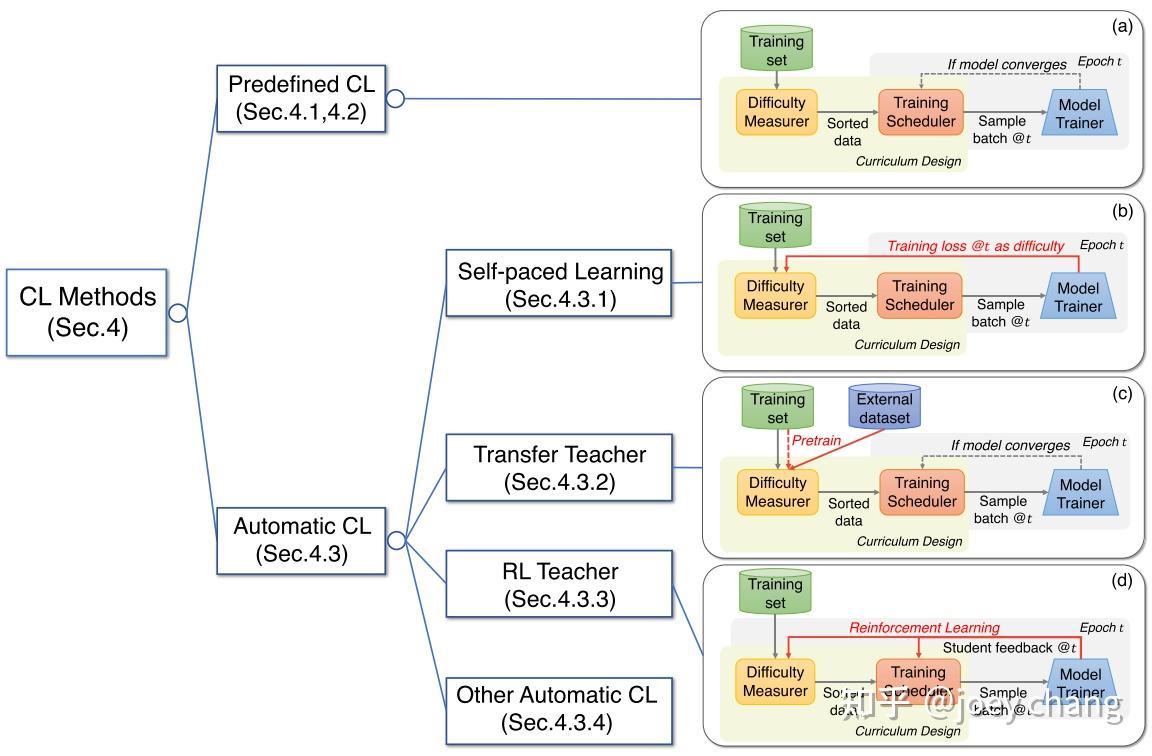
主流的课程学习方法四类:
- 预定义的课程学习
- 自步学习
- 基于迁移教师的课程学习
- 基于强化教师的课程学习(以及一些其他的自动课程学习方法)
根据这两个是否自动设计可以将CL分成两个大类即 Predefined CL 和 Automatic CL。
- (1)Predifined CL (预定义的难度测量器): 难度测量器和训练调度器都用人类先验先验知识,人类专家去设计;
- 完全由人类专家的先验设计得到,而不采用任何数据驱动的算法和模型来决定课程的两个模块,也不动态调整
- 训练调度器可以分为离散调度器和连续调度器。两者的区别在于:离散型调度器是在每一个固定的次数(>1)后调整训练数据子集,或者在当前数据子集上收敛,而连续型调度器则是在每一个epoch调整训练数据子集。
- (2)Automatic CL: 至少其中一个是以数据驱动的方式自动设计。
- 自动课程学习,即采用了数据驱动的算法和模型来决定难度评分器、训练调度器中的任何一个的设计
- 自动CL方法论分为四类,即Self-paced Learning、Transfer Teacher、RL Teacher 和 其他自动CL。
Predifined CL 难度如何定义?
预定义难度评分器主要从复杂度、多样性、噪声估计等角度,利用特定领域的知识来评判样本的难度。
- 从单个样本的复杂度角度,机器翻译中更长的句子对常被认为是更困难的训练样本,而图像语义分割任务中物体数目更多的图片会更困难;
- 从一组数据的分布多样性角度,机器翻译中含有更多更生僻的单词的句子会被认为更困难;
- 从样本的噪声估计角度,语音识别中的信噪比越低的样本会被认为更困难。
- 也有文献利用其它领域知识(如医学等)来预定义难度评分器
预定义的课程学习存在许多局限性,最主要的局限性包括:
- (1)忽略了模型的状态和反馈,导致算法不够灵活,无法根据数据和模型动态调整以达到更好的效果;
- (2)需要人为决定样本难度,不仅耗时、不在更广的领域普适,且人工认定的难度并不一定有利于模型的学习。
为弥补这些局限性,学者们提出了多种自动课程学习方法。
Automatic CL 详情
- 1 Self-paced Learning
- Self-paced Learning 让学生自己充当老师,根据其对实例的损失来衡量训练实例的难度。这种策略类似于学生自学:根据自己的现状决定自己的学习进度。
- 2 Transfer Teacher
- Transfer Teacher 则通过1个强势的教师模型来充当教师,根据教师对实例的表现来衡量训练实例的难度。教师模型经过预训练,并将其知识转移到测量学生模型训练的例子难度上。
- 3 RL Teacher
- RL Teacher 采用强化学习(RL)模式,教师根据学生的反馈,实现数据动态选择。这种策略是人类教育中最理想的场景,教师和学生通过良性互动共同提高:学生根据教师选择的量身定做的学习材料取得最大的进步,而教师也有效地调整自己的教学策略,更好地进行教学。
- 4 其他自动 CL
- 除上述方法外,其他自动CL方法包括各种自动CL策略。如采取不同的优化技术来自动寻找模型训练的最佳课程,包括贝叶斯优化、元学习、hypernetworks等。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
