大模型自动评估
标准化评测要解决的核心问题:
- 可量化:把”聪明”变成 72.3% 的准确率,把”差一些”变成具体分数差。
- 可复现:任何人用同样的模型、评测集、参数,跑出来的分数应该一样。科学研究的底线。
- 可对比:A 模型在 MMLU 上 65%,B 模型 58%,这个差距更客观,而不是”我觉得 A 更好”。
大模型评估见站内专题: 大模型评测
LLM-as-a-Judge
思考
LLM-as-a-Judge 真的管用吗?
【2025-8-6】说话人难以识别
大模型从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。
这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。
【2025-8-17】大模型给自己当裁判并不靠谱!上海交通大学新研究揭示LLM-as-a-judge机制缺陷
评判模型是否“入戏”之前,AI裁判能准确识别出对话中到底是谁在说话吗?
【2025-8-6】上海交大王德泉课题组,当前大模型评判能力不足,识别角色任务上,最好的模型(Gemini-2.5-pro)正确率才69%,而人类达到91%
- PersonaEval: Are LLM Evaluators Human Enough to Judge Role-Play?
- github PersonaEval 识别角色,专为LLM裁判打造的“照妖镜”

大模型更关注表层的语言风格(听起来像谁),而人类则首先观察真实的对话意图和上下文(在那个情境下,谁会这么说)
【2025-8-25】LLJ 不管用
【2025-8-25】你的怀疑是对的!LLM作为Judge,既无效又不可靠,终于有论文向LLJ开炮了
LLM Judges 涵盖三大功能:
- 性能评估 (Performance Evaluation):这是最传统的应用,即评估模型生成内容的质量。
- 核心领域:文本摘要、机器翻译、对话生成等。
- 数据构建 (Data Construction):利用AI来自动生成或标注训练数据,以替代部分人力。
- 典型任务:数据标注,尤其是在仇恨言论检测、政治立场分类等主观性强的任务中。
- 模型增强 (Model Enhancement):将“AI裁判”直接整合进模型的训练和对齐流程中,以提升或规范模型行为。
- 关键场景:安全对齐(作为实时安全护栏、自动进行红队演练)、奖励建模、以及实现模型的“自我提升”和“自我对齐”。
“LLM Judges”已经从一个“评估员”,演变成了贯穿数据准备、模型训练、安全部署等环节的“多面手”。
【2025-8-25】加拿大麦吉尔大学论文,对当前热门趋势LLMs as Judges进行了深刻反思和批判。
- 《既无效又不可靠?调查将大型语言模型作为法官的运用》
- Neither Valid nor Reliable? Investigating the Use of LLMs as Judges
对LLJs的应用热情,已经远远超过了对其作为评估工具本身是否科学、可靠、有效的严格审查。
(1) 假设一:AI能完美替代人类?
业界普遍认为,LLMs是人类判断的有效代理 (LLMs as a Proxy for Human Judgment),只要AI裁判的评分和人类专家的评分高度相关,就证明它是有效的。
但研究者们一针见血地指出,这个逻辑链条的起点,所谓“人类判断”这个金标,本身就是摇摇欲坠的。
- 人类评估本身就问题重重:自然语言生成(NLG)领域,人类评估其实非常混乱,缺乏统一标准。
- 比如,对于什么是“连贯性”,不同的研究、不同的标注者可能有完全不同的理解和打分标准,这导致人类评分本身就存在很大的不确定性。
- 用混乱去验证混乱:用一个本身就不太可靠、充满随机误差的“金标准”去验证LLM裁判的可靠性,其说服力自然大打折扣。这就好比用一把刻度模糊的尺子去校准另一把新尺子。
- LLM裁判加剧了问题:目前的LLM裁判实践不仅复制了这些问题,甚至可能因为其内部决策过程不透明而加剧。
- 例如,在使用同一个公开基准(如SummEval)时,不同的研究给LLM的指令、评分量表和评估流程都各不相同,使得结果更难横向比较。
(2) 能力强就等于好裁判?
另一个普遍看法: LLMs是能干的评估者 (LLMs as Capable Evaluators),既然LLM本身能力这么强,当个评估员肯定绰绰有余。
可现实挺骨感的,研究者们发现,作为裁判的LLM存在一系列内在缺陷,严重影响其判断的信度和效度。
- 不听指挥 (Instruction Adherence):研究发现,LLM裁判经常“夹带私货”,并不严格遵循您在指令中给出的评估标准,反而会依赖自己的一些内部偏见,甚至混淆不同的评估维度(比如把“相关性”和“流畅性”搞混)。
- 解释不可信 (Explainability):虽然LLM可以为自己的评分生成解释,但这些解释的“忠实性”值得怀疑。它可能只是为了让结果看起来合理而编造的理由(高“表面效度”),而非其真实的决策逻辑。
- 充满偏见 (Robustness):LLM裁判表现出五花八门的偏见,比如位置偏见(偏爱排在前面的选项)、冗长偏见(喜欢内容更长的回答)、从众偏见(偏爱多数意见)等。
- 极其脆弱 (Robustness):它们对简单的对抗性攻击几乎没有抵抗力。研究表明,通过在文本中加入一些精心设计的、不影响语义的微小扰动,就可以轻易地操纵LLM裁判的评分,甚至让它把100%的有害内容标记为无害。
- 缺乏专业知识 (Expertise):在需要特定领域知识(如事实核查、安全评估)的任务中,LLM本身的能力就存疑,让它来当裁判,其“内容效度”自然无法保证。
(3) 自动化评估能“大力出奇迹”?
大家都爱“大力出奇迹”,LLMs是可扩展的评估者 (LLMs as Scalable Evaluators),觉得用AI裁判可以大规模、自动化地搞定评估和模型对齐,效率直接拉满。
但研究者警告说,这种做法可能正在制造一个巨大的、自我循环的“信息茧房”,最终损害评估的“预测效度”。
- 数据污染与自恋偏见:当您用同一个系列的LLM(比如GPT系列)去生成训练数据、训练模型、最后又用它来做评估时,一个被称为“自恋偏见”或“自我增强偏见”的问题就出现了。模型会不可避免地偏爱与自己同源的模型所生成的输出,导致评分虚高。
- 为刷分而战:自动化排行榜(如Chatbot Arena)的出现,加剧了“应试”现象。各个模型为了在排行榜上获得更高名次,可能会过度优化去迎合裁判模型的偏好,而不是真正提升通用能力,这是一种典型的“过拟合”。
- 肤浅的安全对齐:研究者提到“肤浅对齐假说”,即当前的安全对齐更多是让模型学会了某种“说话风格”(比如礼貌地拒绝回答),而非真正理解了安全概念。过度依赖LLM裁判进行自动化安全评估,可能只会筛选出越来越会“装无辜”的模型,而无法解决深层安全问题。
三家科技巨头“既当运动员又当裁判员”的现状
明确点名Google和OpenAI还有Meta:在讨论“竞争性基准测试”的弊端部分,论文引用研究指出
- 像Chatbot Arena这样的评估平台存在“有利于Google和OpenAI等专有提供商的不平等数据访问”问题。这个事情我记得前几个月在网上还热议过一阵子。
- 以Meta为例:在分析“LLMs作为安全法官”时,论文明确提到了Meta公司的Llama Guard模型作为一个实例。
- 此外,在参考文献中,论文还引用了一篇关于“Meta的Llama 4‘herd’争议与AI污染”的文章,直接将其与数据污染问题联系起来。
(4) AI裁判真的“物美价廉”?
省钱,LLMs是成本效益高的评估者 (LLMs as Cost-Effective Evaluators),这绝对是AI裁判最吸引人的一点。
不过,研究者提醒必须算算那些看不见的“隐形成本”,这些成本关系到评估的“后果效度”,即这项技术应用后带来的长远社会影响。
- 经济与伦理冲击:大规模采用AI裁判,直接冲击的是全球数以万计的数据标注员的生计,这是一个已经很脆弱的群体。这背后是复杂的社会和伦理问题,不能简单地用“效率”二字一笔带过。
- 环境成本:虽然训练模型的环境成本备受关注,但大规模、持续地使用LLM进行评估(这是一种推理任务)所产生的能源消耗和碳排放同样惊人,且随着模型越来越大,这个问题会愈发严重。
- 社会偏见的放大器:LLM会学习并反映训练数据中存在的社会偏见。当一个带有偏见的LLM成为“裁判”时,它可能会在评估中系统性地给某些特定人群(如特定性别、种族)相关的回答打低分,从而在下一代模型的开发中进一步固化甚至放大这些偏见。
怎么办?
三条核心建议
- 放弃“一刀切”的评估方法,强调情境化应用:
- 目前LLJs的应用存在巨大疏忽:无论任务和领域有何不同,部署和设计评估的方式都大同小异。这种做法是危险的,可能导致有害的后果。
- 例子是:使用LLJs来大规模进行“红队演练”(即寻找模型漏洞)可以拓宽评估范围,这是有益的。但如果将同样的方法直接用于模型的安全过滤统,就可能只会训练出“表面上”的安全行为,而非真正的安全理解。
- 因此,评估LLJs的角色必须综合考虑任务性质、应用领域和评估目标等多个关键维度。
- 紧急呼吁改进整个领域的评估实践:
- 减轻LLJs自身的偏见固然重要,但整个领域更迫切需要的是改进评估实践本身。
- 引用近期的争议事件指出,科技公司有操纵现有评估框架的行为,这引发了对数据污染、为跑分而进行的竞争性基准测试以及对基准过度拟合等严重问题的担忧。
- 尽管评估在机器学习发展中至关重要,但从业者之间缺乏严谨、共享的实践方法。大家共享的是基准和指标等“技术产物”,而不是科学的方法论。
- 这篇论文证明,LLJs的采用不仅复制并加剧了NLG评估中长期存在的缺乏标准化和系统化的问题,还带来了新的挑战。
- 倡导评估模式的根本性转变:从自我评估到独立监督:
- 最激进也是最深刻的建议。“也许是时候改变那种依赖有利益关系的公司来提供其旨在推向市场的产品进行透明全面评估的模式了”。
- 应该努力建立适当的机制,以实现透明、有效和可靠的评估。这暗示着需要一个类似于其他高风险行业(如药品、航空)的独立第三方监督体系。
评测工具
总结
【2026-7-6】评测工具
| 工具名称 | 开发者 | 开源协议 | 任务数量 | 中文支持 | 安装复杂度 | 可视化能力 | 社区活跃度 | 适配场景 |
|---|---|---|---|---|---|---|---|---|
| lm-eval-harness | EleutherAI | MIT | 200+ | 有限 | 低 | 无 | 最高 | 快速评测/CI集成 |
| OpenCompass | 上海AI实验室 | Apache 2.0 | 100+ | 强(原生中文) | 中 | 有Web UI | 中等 | 中文模型/学术报告 |
| HELM | Stanford CRFM | Apache 2.0 | 100+ | 有限 | 高 | 有限 | 学术圈活跃 | 学术研究/全面审计 |
选型指南
- 选
lm-eval-harness:想快速验证一个模型,5 分钟出结果- 需要集成到 CI/CD 流水线,每次代码提交自动跑评测- 要对比 HuggingFace Leaderboard 上的模型- 习惯命令行操作,不需要可视化界面
- 选
OpenCompass:评测中文模型(C-Eval、CMMLU 等中文任务原生支持)- 需要生成可视化报告(有 Web UI)
- 做国产模型评测(Baichuan、ChatGLM、DeepSeek 等适配更好)
- 需要主观评测(让 GPT-4 当裁判打分)
- 选
HELM:做学术研究,需要最全面的能力审计- 关注模型的安全性、公平性、偏见(不只是准确率)
- 有足够的 API 预算(全面评测需要大量调用)
- 需要生成标准化的学术报告
【2026-5-13】大模型评测不再拍脑袋:用 lm-evaluation-harness 给模型做”体检”
lm-evaluation-harness
lm-evaluation-harness 是 EleutherAI(开源 AI 研究组织)开发的大模型统一评测框架。”体检中心”
- 把模型送进来,自动跑完 200 多项检查,输出一份详细的”体检报告”。
核心特点:
- 任务最全:支持 200+ 评测任务,覆盖知识、推理、数学、代码、安全等多个维度
- 模型兼容广:HuggingFace 模型、OpenAI API、Claude、Gemini、本地 Ollama 部署的模型,都能接
- 社区标准:HuggingFace Open LLM Leaderboard 的官方评测工具,跑出来的分数可以直接上排行榜对比
- 安装简单:一条 pip 命令搞定
# 创建虚拟环境
python3 -m venv ~/lm-harness-env
source ~/lm-harness-env/bin/activate
# 安装核心框架
pip install lm-eval
# 装本地模型依赖
pip install transformers torch accelerate
启动评测
export OPENAI_API_KEY="你的API密钥"
lm_eval \
--model openai-completions \
--model_args model=gpt-4o-mini \
--tasks mmlu_anatomy \
# --tasks hellaswag,arc_easy,piqa,winogrande # 多任务测评
--limit 10 \
--output_path ./results/gpt4o-mini
# 模型选择
lm_eval \
# hf 上下载模型
--model hf \
--model_args pretrained=Qwen/Qwen2.5-0.5B-Instruct,dtype=float16 \
# 使用本地模型
--model_args pretrained=/path/to/your/model,dtype=float16
--tasks hellaswag \
--limit 20 \
--batch_size 4 \
--output_path ./results/qwen0.5b-hellaswag
原理
- 加载 gpt-4o-mini 模型
- 从 MMLU 解剖学子集抽 10 道题
- 模型答题、自动判卷、输出结果
输出结果
- 10 道解剖学题,GPT-4o-mini 答对了 7 道,准确率 70%
┌─────────────────┬──────────────────┐
│ Task │ Metric │
├─────────────────┼──────────────────┤
│ mmlu_anatomy │ acc,none: 0.7000 │
└─────────────────┴──────────────────┘
ChatEval
会话评估:ChatEval,University of Pennyslvania 宾夕法尼亚大学NLP团队开源,开放领域机器人评估框架,研究人员可以提交自己的模型,ChatEval会自动对比评估效果
- 公开数据集: Neural Conversational Model, Open Subtitles, Cornell Movie Dialogue Corpus …
- 开源,代码:chateval
chatgpt用于NLG评估
- 论文:Is ChatGPT a Good NLG Evaluator? A Preliminary Study
- we regard ChatGPT as a human evaluator and give task-specific (e.g., summarization) and aspect-specific (e.g., relevance) instruction to prompt ChatGPT to score the generation of NLG models. We conduct experiments on three widely-used NLG meta-evaluation datasets (including summarization, story generation and data-to-text tasks).
- Experimental results show that compared with previous automatic metrics, ChatGPT achieves state-of-the-art or competitive correlation with golden human judgments. We hope our preliminary study could prompt the emergence of a general-purposed reliable NLG metric.
复杂会话质量评估:东南大学网络科学与工程学院
- 论文:Evaluation of ChatGPT as a Question Answering System for Answering Complex Questions
- we present a framework that evaluates its ability to answer complex questions. Our approach involves categorizing the potential features of complex questions and describing each test question with multiple labels to identify combinatorial reasoning. Following the black-box testing specifications of CheckList proposed by Ribeiro et.al, we develop an evaluation method to measure the functionality and reliability of ChatGPT in reasoning for answering complex questions.
- We use the proposed framework to evaluate the performance of ChatGPT in question answering on 8 real-world KB-based CQA datasets, including 6 English and 2 multilingual datasets, with a total of approximately 190,000 test cases. We compare the evaluation results of ChatGPT, GPT-3.5, GPT-3, and FLAN-T5 to identify common long-term problems in LLMs.
- The dataset and code are available at Complex-Question-Answering-Evaluation-of-ChatGPT
Question
- In various types of KBQA tasks, complex question answering (KB-based CQA) is a challenging task that requires question answering models to have the ability of compositional reasoning to answer questions that require multi-hop reasoning, attribute comparison, set operations, and other complex reasoning.
- KBQA任务重,回答复杂问题很有挑战性,因为涉及这些问题要求多跳推理、属性对比、集合操作及其他复杂推理
Overview
To evaluate ChatGPT’s ability to answer complex knowledge, we propose an evaluation framework: a feature-driven multi-label annotation method 特征驱动的多标签标注方法
- First, we classify the latent features that constitute complex questions, and describe each question under test with multi-labels for identifying combinatorial reasoning.
- Secondly, following the black-box test specification of CheckList proposed by Microsoft, we design an evaluation method that introduces
CoThints to measure the reasoning function and reliability of large language models in answering complex questions.
Our evaluation uses 8 real complex question answering datasets, including six English datasets and two multilingual datasets, to further analyze the potential impact of language bias. We compared the evaluation results of ChatGPT, GPT3.5, GPT3, and FLAN-T5 to identify persistent historical issues in LLMs. All data and results are available for further analysis.
PandaLM
【2023-4-30】大语言模型对比评估:PandaLM, 本地评测,不用担心数据安全问题


(1)批量多模型对比
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("WeOpenML/PandaLM-7B-v1",use_fast=False)
model = AutoModelForCausalLM.from_pretrained("WeOpenML/PandaLM-7B-v1")
# ----------
from pandalm import EvaluationPipeline
pipeline = EvaluationPipeline(candidate_paths=["huggyllama/llama-7b", "bigscience/bloom-7b1", "facebook/opt-6.7b"], input_data_path="data/pipeline-sanity-check.json")
print(pipeline.evaluate())
(2)本地部署 Web UI
- 启动后,访问链接
cd PandaLM/pandalm/
CUDA_VISIBLE_DEVICES=0 python3 run-gradio.py --base_model=WeOpenML/PandaLM-7B-v1 --server_port=<your-server-port> --server_name=<your-server-name>
LLM-BLENDER
【2023-6-11】Allen AI推出集成主流大语言模型的 LLM-BLENDER 框架
- Allen AI实验室联合南加大和浙江大学的最新研究论文,发表在ACL上。
- 提出了一个集成框架(LLM-BLENDER),通过利用多个开源大型语言模型的不同优势使框架始终保持卓越的性能。
- 鉴于众多LLM有不同的优势和劣势,开发了一种利用其互补潜力的集成方法,从而提高鲁棒性、泛化和准确性。通过结合单个LLM的贡献,可以减轻单个LLM中的偏见、错误和不确定性信息,从而产生更符合人类偏好的输出。
LLM-BLENDER,一个创新的集成框架,通过利用多个开源LLM的不同优势来获得持续卓越的性能。
- LLM-BLENDER通过排名方式来减少单个LLM的弱点,并通过融合生成来整合优势,以提高LLM的能力。
LLM-BLENDER包括两个模块:PAIRRANKER 和 GENFUSER。
- 首先,PAIRRANKER 比较 N个LLM的输出,然后通过 GENFUSER 将它们融合,从排名前K的输出中生成最终输出。
- 现有方法如instructGPT中的reward model能够对输入x的输出Y进行排名,但是当在多个LLM进行组合时其效果并没有那么明显。原因在于,它们都是由复杂的模型产生的,其中一个可能只比另一个好一点。即使对人类来说,在没有直接比较的情况下衡量候选质量也可能是一项挑战。
AlpacaEval 斯坦福 自动评估
【2023-6-15】斯坦福研究人员提出一个基于大语言模型的全新自动评估系统 —— AlpacaEval
- 速度快、成本低,而且还经过了2万个人类标注的验证。
- 资讯
AlpacaEval 结合了 AlpacaFarm 和 Aviary
改善自动评测流程,团队发布了:
- 一个易于定制的流程
- 模型和自动评测器的排行榜
- 分析自动评测器的工具包
- 18K人类标注
- 2K人类交叉标注
AlpacaEval有着拔群的效果:
- 与人类多数票的一致性,高于单个人类标注者
- 胜率与人类标注高度相关(0.94)
- 相比于lmsys评测器,有显著提升(从63%提高到69%)
局限性可以概括为以下三点:
- 指令比较简单
- 评分时可能更偏向于风格而非事实
- 没有衡量模型可能造成的危害
OpenJudge
【2026-1-27】告别盲测,通义AutoRubric自动生成评测标准
做 LLM 评测时,不想花大代价训 Reward Model? 只能让 LLM 当裁判(Judge)!
通义实验室开源首个AI应用评测框架 OpenJudge
- OpenJudge 为 AI 评估提供完整的工作流支持:从收集测试数据 → 定义评估器 → 规模化评估 → 分析弱点 → 快速迭代,让 AI 质量保证更简单、更专业。
这次提出 AutoRubric:
- 把人类偏好背后的“隐性直觉”,变成模型可执行的“显性标准”。不再让模型临场发挥,而是先生成一套结构化的“评分细则”(Rubrics),让它按维度检查。
- AutoRubric 开源在OpenJudge项目,路径:openjudge/generator/iterative_rubric/generator.py
- 项目与论文:OpenJudge
- 论文:OpenJudge: A Unified Framework for Holistic Evaluation and Quality Rewards
😳评测结果往往很“玄学”:
- 凭感觉:说不清为什么 A 比 B 好,理由很泛。
- 位置偏见 (Position Bias):A/B 互换位置,结论竟然变了。
- 大量 Tie:稍微难一点的任务就只会判平局。
AutoRubric “物理外挂”四部曲不用训模型,不用烧大钱,只需 4 步:
- 自动长标准:从少量人类偏好数据里,自动提取“为什么 A 比 B 好”的理由。
- 脱水去重:用数学逻辑(Coding Rate)干掉重复的废话,只留最有信息量的标准。
- 聚合提炼:把散乱的理由变成通用的 Theme-Tips(比如:语气真实度、逻辑连贯性)。
- 权重排序:给标准排座次,重要的先看!
性能提升:
从“玄学”到“工程”在复杂的角色扮演场景下进行了实测,数据提升非常直观:
- AutoRubric较baseline准确率提升14%,位置偏见下降 19%。
- 通过将隐性标准显性化,模型捕捉到了人类标注员更在意的细节,引入 Rubrics 后,模型从“盲目选择”转向“按项核对”,鲁棒性显著增强
如果你也被“Judge 不稳/说不清凭啥选”折磨过,这套方法真的值得去跑一次!你会第一次看清:所谓的“模型好坏”,到底是由哪些具体的标准组成的。
Agent-as-a-Judge
研究团队:AI能否评判AI?META 推出
- 【2024-10-16】Agent-as-a-Judge: Evaluate Agents with Agents
- Dataset: devai-benchmark
- Project: agent-as-a-judge
- 解读 Agent-as-a-Judge:用AI智能体来评估AI智能体,比人类评审更高效?
当大模型日益强大,如何评估表现成了AI领域新难题。
- 传统依靠人工或者自动指标的方式,难以精准、快速地应对复杂、开放式任务。
- 最近,研究团队提出了“
Agent-as-a-Judge(AI代理评审)”的新范式,让AI作为评委来评价其他AI的输出,逐步成为主流趋势。
【2025-12-2】伯克利,生产级别agent评测方法
AI智能体已在多个行业投入使用,但对促成部署成功的技术策略了解有限。
首个针对生产环境中AI智能体的大规模系统性研究,调查了306名从业者,完成了覆盖26个领域的20项深度案例分析。研究聚焦四大核心问题:组织为何构建、如何构建、如何评估,以及主要挑战是什么。
生产环境中的智能体通常采用简单可控的构建方式:68%智能体在需要人工干预前最多执行10个步骤,70%依赖对现成模型的提示工程而非权重微调,74%主要依靠人工评估。
可靠性仍是首要开发挑战,其核心症结在于确保和评估智能体正确性的难度。尽管存在这些挑战,简单却高效的方法已能让智能体在不同行业中创造价值。
本研究记录了当前的实践现状,通过让研究者清晰了解生产环境中的挑战,同时为从业者提供实用参考,搭建起了研究与部署之间的桥梁。
什么是 Agent-as-a-Judge?
一种利用Agent本身推理与视角能力,由AI自动评判其他大模型行为的评测方法。
论文梳理了该概念的起源、如何从单一AI评审进化到多智能体辩论和动态评议小组,并分析了各自的优势与局限。
❓AI评AI有哪些方式?
- 1️⃣ 单模型评审:让一个强力大模型(如GPT-4.1)根据提示,对其他模型输出打分或排序。
- 2️⃣ 多智能体辩论/委员会:多个AI分饰不同专家和批评者角色,像小组讨论一样审议答案,减少单一AI的偏见。
- 3️⃣ Agent-as-a-Judge:AI不只看最终结果,还能像人一样跟踪整个推理和执行过程,逐步给出细致反馈。这对自动化代码生成、复杂推理任务等尤为有效。
效果如何?
多智能体评议明显提升了与人工评价的一致性。
Agent-as-a-Judge 甚至在代码自动化等任务中,几乎与人类专家小组打分一致,且比单一AI评审更细致稳定。
三种主流代码生成智能体(MetaGPT、GPT-Pilot和OpenHands)在DevAI基准上进行了全面测试:
准确性对比:
- Agent-as-a-Judge与人类专家共识的吻合度达90.44%
- 常规LLM-as-a-Judge仅有60.38%
- 单个人类评审员之间的一致性也只有85%左右
效率提升:
- 耗时:118分钟 vs 人类86.5小时(节省97.7%时间)
- 成本:30美元 vs 人类1300美元(节省97.6%费用)
- 深度洞察: 通过PR曲线分析(见图7),Agent-as-a-Judge在识别”部分满足需求”的边界案例时,甚至优于个别人类评审员。
| 评估方式 | 一致率 | 耗时 | 成本 |
|---|---|---|---|
| 人类专家共识 | 100% | 86.5h | $1297 |
| Agent-as-a-Judge | 90.44% | 1.97h | $30.58 |
| LLM-as-a-Judge | 60.38% | 0.18h | $29.63 |
哪些应用场景?
该方法已在医学、法律、金融、教育等领域初步落地。
- 医疗AI评审能模拟不同专家、患者视角;
- 法律AI能像法庭辩论一样多维度评价文本;
- 金融场景下则能关注合规和风险控制。
未来,AI评AI有望推动大模型更加安全、可靠、高效地发展。
LLM 自我诊断
CriticGPT
【2024-6-28】OpenAI前对齐团队「遗作」:RLHF不够用了!用GPT-4训练GPT-4
ChatGPT 错误变得越来越难以察觉,AI训练师难以发现不准确答案,使得驱动 RLHF 的比较任务变得更加艰巨。
- RLHF 的一个根本性限制,随着模型逐渐超越任何提供反馈的人类知识水平,这一局限可能会使得模型的校准变得更加困难。
OpenAI 基于 GPT-4 训练了一个专门找 bug 新模型 —— CriticGPT , 精准地分析 ChatGPT 回答, 并提出建议,帮助人类训练师更准确地评估模型生成的代码,并识别其中的错误或潜在问题
- OpenAI官网: Finding GPT-4’s mistakes with GPT-4
- 论文 LLM Critics Help Catch LLM Bugs
- 作者 Jan Leike 曾共同领导了OpenAI超级对齐团队,致力于开发 InstructGPT、ChatGPT 和 GPT-4 的对齐工作。
- OpenAI 联合创始人、首席科学家 Ilya Sutskever 宣告离职,Jan Leike 也撒手不干了,后转投 Anthropic 麾下。

CriticGPT 在很多情况下比人类专家更擅长发现错误,它们甚至能在一些被认为是「完美无缺」的任务中找出问题,尽管这些任务大多数并不是代码任务,对 CriticGPT 来说有点超纲。
方法
- 用 LLM 来评价 LLM, 采用类似于 InstructGPT 和 ChatGPT 的自回归 Transformer 策略。
- 训练时,研究人员将「问题 - 答案」对作为输入。
- 模型输出的批评将遵循特定格式,在答案中穿插附加评论。
评价标准
- 对于有 bug 的代码,LLM 可能做出多种类型的评价。
- ① 正确地指出代码中的严重错误,但这个批评中也包含一个错误的断言;
- ② 只指出了两个次要问题。
收到这两种批评:
- 有一部分不正确,但可能更有用;
- 另一种未能指出严重问题,但没有明显错误。
哪种来自 LLM 的批评更有效呢?研究团队设置了以下标准请人工训练师做了进一步评价:
- 是否全面,即没有遗漏任何明显和严重的问题(全面性)。
- 是否捕捉到了名为「critique-bug inclusion」(CBI)的预先指定的特定错误。
- 是否包含任何臆想的错误或特别吹毛求疵的小问题。
- 根据回答的风格和有用程度,给 LLM 的批评一个整体的主观评分。
人工训练师将根据 1-7 等级评价LLM审核结果。前两个特征(CBI 和全面性)类似于召回率 —— 模型撰写了包括多个错误点的长篇批评,通常评分会提高。然而,批评变长时更可能包含臆想的问题和吹毛求疵。训练师在总体评分时倾向于给准确、全面、简洁且避免吹毛求疵的批评以高分。
比较批评与 Elo 评分
- 评价过程中,人工训练师将同时看到对同一问题的四个批评,通过比较得出特定属性的偏好率。
- 如果批评 A 在全面性方面得分为 1/7,而批评 B 得分为 2/7,那么 B 比 A 更全面。
为了总结模型之间的成对偏好率,计算 Elo 评分。
- Elo 评分使用 BFGS(强制采样束搜索) 对数据集中用于比较的成对模型进行拟合计算得出。
效果:
- 审查 ChatGPT 代码的准确率提高了 60%
Anthropic 将类似 CriticGPT 的模型整合到 RLHF 流程中
CriticGPT 局限
- 只能处理短答案,但未来需要更厉害的方法,来帮助 AI 训练师理解那些又长又难的任务。
- 仍然会产生幻觉,影响训练师。
- 主要集中在单点错误检测,还不能检测分散在多个部分的错误。
CriticGPT 虽然很有用,但如果任务太难太复杂,即使是专家用了这个模型也可能评估不出来。
AutoDetect
【2024-6-29】AutoDetect:「大模型」检测「大模型」缺陷,从错误中高效学习
如何识别 LLM 缺陷?
现有方法均存在明显不足。
- 人工检查 LLM 的缺陷涉及大量人类专家的参与,需要大量的人力物力,难以规模化扩展;
- 现有自动检查 LLM 缺陷的方式依赖评估基准,但评估基准的构建目的主要是公平地对比一系列模型的表现强弱,无法彻底地、有针对性地发掘特定模型的缺陷,而且评估基准大多存在更新周期长、数据泄漏、区分度较小等问题。
AutoDetect 是第一个在通用任务上系统探索 LLM 缺陷发掘过程的框架,并且在指令遵从、数学、代码等任务上进行了充分的验证。
- 高效搜索模型缺陷,在 GPT-3.5、 Claude-3-sonnet 等多个主流模型上有着高于 30% 的缺陷检测成功率。
-
提升模型性能,通过从自动发掘的缺陷中学习,可以让 LLM 在多个任务上产生 10% 左右的性能提升。
- 论文:AutoDetect: Towards a Unified Framework for Automated Weakness Detection in Large Language Models
- 代码:AutoDetect
框架采用一种类似于教育评估系统的方法,包括创建全面的问题来评估学生,并审查他们的回答,从而识别个性化的薄弱点。
该系统根据具体模型表现进行不断优化和调整,从而提供定制和有效的弱点识别。
框架包含由大模型智能体(agent)实现的三个角色:
主考官(Examiner):负责构建包含多样化测试点的综合分类体系,并根据目标模型的表现动态优化框架,以提供一个完善和定制的评测系统来识别潜在的薄弱点。出题者(Questioner):根据每个测试考点创建有挑战性的问题。通过迭代探索,出题者不断探测模型的薄弱点,并在出现新缺陷时有效地调整问题生成,发现更多薄弱点。评估者(Assessor):需要分析目标模型在测试中的表现,并推测新的个性化的弱点,以将其纳入测试系统中,这对个性化的评估至关重要。
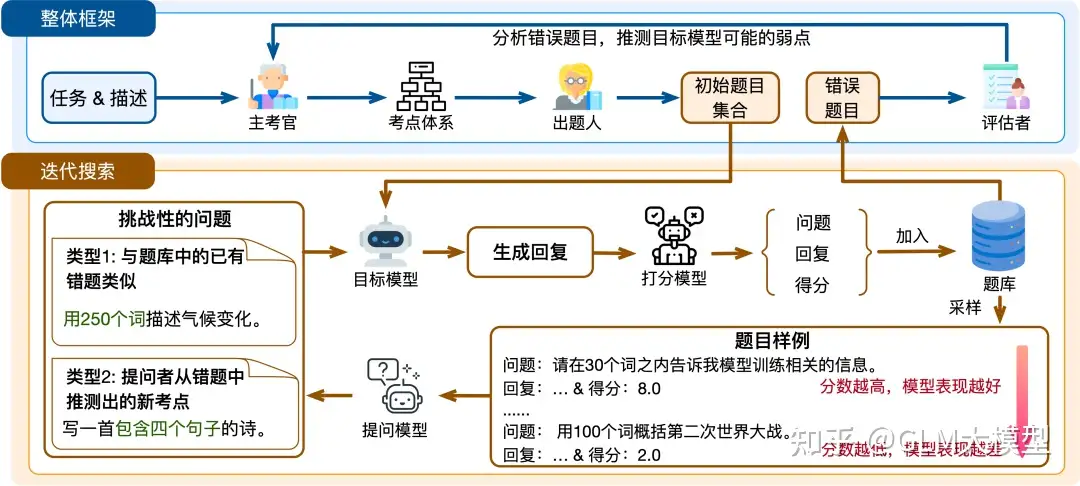
AutoDetect 在指令遵循,数学推理和代码任务上都展现出了出色的效果,在 GPT-3.5 和 Claude-3-Sonnet 上都实现了超过 30% 的弱点检测成功率(ISR)。同时,平均 ISR 的排序也大致符合我们对模型能力的认知,显示了 AutoDetect 发展为动态 benchmark 的潜力。
缺陷:
- LLM 在同一任务中的不同子类上,性能差距非常明显(数学任务中应用题做的不错,但是几何题性能较差);
- LLM 可能在困难的任务中表现出色,但在更简单的任务中失败(可以完成复杂的算法题,但是在基础的概念上可能出错);
- LLM 在复杂指令和多步推理上还存在明显不足。
AutoDetect 可以生成创意性的指令,人工标注员可能由于自身能力限制难以构造。此外,我们发现 AutoDetect 还会自发的结合多种知识点生成问题,比如在指令遵循任务中组合多个知识点。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
