- 端到端语音交互
- 总结
- 方案
- tts
- 语音克隆
- 实时语音对话
- 语音 Agent 设计
- 评测
- Ichigo
- 全双工 LSLM
- Lepton LLM API
- 【2024-9-3】Mini-Omni
- 【2024-9-24】Westlake-Omni
- 【2024-11-5】Hertz-dev
- 【2024-10-21】ten-agent
- 智谱
- 【2024-7-4】Moshi
- 【2025-1-20】豆包
- 【2025-2-2】SpeechGPT 2.0
- 【2025-2-24】腾讯 全双工 SDS
- 【2025-5-8】Voila
- 阿里
- 阶跃星辰
- 【2025-8-20】AIRI
- 【2025-12-29】OmniAgent
- 【2026-5-12】交互模型
- 【2026-6-2】OpenAI Agentic OS
- 结束
端到端语音交互
端到端实时语音交互 LLM + TTS
总结
端到端的音频模型:
- 1、hertz-dev
- 2、mini-omni2
- 3、GLM-4-Voice
- 4、moshi
- 5、Spiritlm
方案
端到端语音对话的三种方案
- 级联方案:即 ASR + LLM + TTS。
- ASR 将语音转换成文本,文本 LLM 接收文本输入,同时输出文本,TTS将文本转换为语音返回。
- 该方案优点:组件化,相对白盒,“哪里不好调哪里”;
- 缺点:容易造成错误累积,即ASR可能识别错误,同时语音转文本丢失了情绪语气信息
- 半端到端:即 “LLM” + TTS。
- LLM 接收语音输入,输出文本,TTS将文本转换为语音返回。
- 该方案输入语音,因此考虑了情绪语气信息,文本输出,内容相对可控。
- 单独接 TTS 的原因也部分因为拟人化效果更好。
- 端到端:即 “LLM”。
- 这里的 LLM 接收语音输入,输出语音。
【2026-4-1】端到端 ASR 三大方案: CTC、AED (Attention) 和 Transducer
整体来说
- 工业界落地方案以级联方案为主(如 Vapi.ai和云蝠智能),基于RAG 的 LLM 不用微调即可引入客户知识支持不同需求,同时可以采用精细化的方式控制 TTS 参数。
- 半端到端方式:可采用语音理解模型(如 GLM-4-Voice 和Kimi-Audio)做微调。
- 端到端方式:效果依赖于数据质量和数量(如 沐神 BosonAI 开源的基于1000万小时数据的 Higgs Audio 2 模型)。
- 在学术界研究较多(如最近的工作 OpenS2S;Step-Audio-AQAA),同时也有商业接口 (如 OpenAI realtime API)。
如果想搭一个 Voice Agent,可以尝试 Pipecat 和 TEN framework,都是开源的实现框架,支持多种引擎,方便搭建实时对话 Agent。
tts
实时语音聊天上,还可实现低延迟、理解情绪并表达情绪的自然语音交互,而不仅仅是机械的问答
Higgs Audio V2
【2025-7-23】李沐B站更新了!教你手搓语音大模型,代码全开源还能在线试玩
最新研发 Higgs Audio V2 模型,不仅能处理文本,还能同时理解并生成语音。
还具备一些较为罕见的能力,比如
- 生成多种语言的自然多说话人对话
- 旁白过程中的自动韵律调整
- 使用克隆声音进行旋律哼唱以及同时生成语音和背景音乐。
整个过程堪称“大力出奇迹”,直接将1000万小时的语音数据整合到LLM的文本训练,让它能听也能说。
EmergentTTS-Eval基准上,相较于其他模型,性能可以说是遥遥领先,尤其是在“情绪”和“问题”类别中,相比GPT-4o-mini-tts高出了75.7%和55.7%的胜率。
【2025-9-25】清华 多方言 DiaMoe-TTS
【2025-10-15】清华&巨人网络首创MoE多方言TTS框架,数据代码方法全开源
通用 TTS 系统已展现出令人惊叹的能力,但方言 TTS 依然是相关从业者难以触及的「灰色地带」。
现有的工业级模型往往依赖巨量专有数据,这让方言 TTS 从业者和研究者几乎无从下手:
- 缺乏统一的语料构建方法,更缺乏一个可实现多语言的端到端开源框架。
【2025-9-25】巨人网络 AI Lab 与清华大学电子工程系 SATLab 研究团队联合首创 DiaMoe-TTS
- 一定程度上媲美工业级方言 TTS 模型的开源全套解决方案。
- 基于语言学家的专业经验,构建了统一的 IPA 表达体系,并且在仅依赖开源方言 ASR 数据的前提下提出这一方案。
在推出中文方言版本之前,研究团队已在英语、法语、德语、荷兰比尔茨语等多语种场景中进行过验证,确保该方法具备全球范围内多语言的可扩展性与稳健性。
- 论文:DiaMoE-TTS: A Unified IPA-Based Dialect TTS Framework with Mixture-of-Experts and Parameter-Efficient Zero-Shot Adaptation
- 代码与训练推理脚本全面开源:GitHub:
DiaMoE-TTS 不仅仅是一个单点模型,而是一个面向学术界与开源社区的全链路贡献:
- 全开源的数据预处理流程:让研究者能够从原始方言语音数据构建 TTS-ready 方言语音语料;
- 统一的 IPA 标注与对齐方法:解决跨方言建模的一致性问题;
- 完整的训练与推理代码:降低复现与扩展的门槛;
- 方言感知 MoE 架构与低资源适配策略:为研究者提供稳定、灵活且可拓展的建模方法。
DiaMoE-TTS = IPA 前端统一化 + MoE 方言建模 + PEFT 低资源适配
👉 在开放数据驱动下,实现低成本、低门槛、可扩展的多方言语音合成方案。
通俗易懂版本:不用海量数据,也不用复杂流程,DiaMoE-TTS 就能让更多方言在数字世界开口说话。
原理
多方言语音合成中,使用拼音或字符输入常常带来严重的歧义与不一致问题,例如相同字符在不同方言中可能对应完全不同的发音。
(1)国际音标
DiaMoE-TTS 在前端设计中引入了国际音标(IPA) 作为统一的输入体系,将所有方言的语音映射到同一音素空间。
这种方式消除了跨方言间的差异性,使得模型能够在统一的表征体系下进行训练,保证了建模的一致性与泛化能力。
(2)方言感知 Mixture-of-Experts (MoE) 架构
在声学建模部分,DiaMoE-TTS 设计了方言感知的 Mixture-of-Experts (MoE) 架构。传统的单一建模网络在多方言任务下容易出现「风格平均化」,导致各地方言的特色被弱化。MoE 结构通过引入多个专家网络,让不同的专家专注于学习不同方言的特征;同时,动态门控机制会根据输入 IPA 自动选择最合适的专家路由,从而保证了每种方言的音色和韵律特点得以保留。
为了增强门控的区分能力,我们还加入了方言分类辅助损失,使专家网络在训练时能够更有针对性地建模方言特征。
(3)低资源方言适配 (PEFT)
许多方言面临极端的数据稀缺问题,甚至仅有数小时的录音语料。
DiaMoE-TTS 提出了参数高效迁移 (PEFT) 策略,分别在 text embedding 层和 DiT 的注意力层中融入了 Conditioning Adapter 与 LoRA,仅需微调少量参数即可完成方言扩展,主干与 MoE 模块保持冻结,从而避免对已有知识的遗忘。
此外,研究团队还采用了音高扰动与语速扰动等数据增强手段,即便在超低资源条件下,模型也能合成自然、流畅且风格鲜明的方言语音。
(4)多阶段训练方法
DiaMoE-TTS 的训练过程分为多个阶段,以逐步提升模型性能并适应方言多样性:
- IPA 迁移初始化
- 在 F5-TTS 原始 checkpoint 的基础上,引入经过 IPA 音素转换的 Emilia 部分数据,对模型进行预热训练,从而实现输入形式从拼音字符到 IPA 的平滑迁移。
- 多方言联合训练
- 统一 IPA 表达下,利用多个开源方言数据(CommonVoice 和 KeSpeech)进行联合建模,同时激活 MoE 结构,使模型能够学习共享特征并区分不同方言的发音模式。
- 方言专家强化
- 通过动态门控机制与方言分类辅助损失,进一步优化 MoE 的分流效果,让各专家更好地捕捉不同方言的独特特征。
- 低资源快速适配
- 针对仅有数小时语料的新方言,采用 PEFT 策略(LoRA + Conditioning Adapter),结合音高 / 语速扰动等数据增强,实现高效迁移并保持已有知识不被遗忘。
这种多阶段、渐进式训练的方法,使 DiaMoE-TTS 能够在保证稳定性的同时,兼顾跨方言泛化与低资源适配能力。
效果
🌟 生成 demo
- 成都话:祝福大家前程似锦,顺水顺风。
- 郑州话:祝你前途大好,成就非凡!
- 石家庄话:好的开始,等于成功的一半儿。
- 西安话:祝愿大家前程似锦,梦想成真。
- 粤语:我系钟意广州嘅春天。
数据构建方法开源:包含多方言 IPA 对齐语料生成流程,支持可复现的开放式研究。
- Checkpoint Huggingface: DiaMoE_TTS
- Dataset Huggingface: DiaMoE-TTS_IPA_Trainingset
训练数据量较为充足(百小时)的粤语上,DiaMoE-TTS 在 WER、MOS 和 UTMOS 三个指标上均取得了接近工业界语音大模型的表现。而在上海话、成都话、西安话、郑州话、天津话等其他方言(几小时到几十小时不等)的对比实验中,受限于开源方言 ASR 数据在「质量」与「规模」上的不足,模型整体表现略逊于部分工业级大模型。
但值得强调的是,DiaMoE-TTS 支持的方言范围更广,甚至可以扩展到介于语音合成(TTS)与歌声合成之间的特殊类型,如京剧韵白,并能在仅有极少量数据的情况下实现快速建模,这为方言保护与文化传承提供了新的可能性。
【2026-4-6】VoxCPM2
【2026-4-6】面壁智能联合 OpenBMB 开源社区、清华大学人机语音交互实验室开发的2B小模型 VoxCPM 2 ,4月刚刚开源。
VoxCPM2: Tokenizer-Free TTS for Multilingual Speech Generation, Creative Voice Design, and True-to-Life Cloning
VoxCPM2 — 三种语音生成方式:
- 🎨 声音设计(Voice Design)
- 无需参考音频。在 Control Instruction 中描述目标音色特征(性别、年龄、语气、情绪、语速等),VoxCPM2 即可为你从零创造独一无二的声音。
- 🎛️ 可控克隆(Controllable Cloning)
- 上传参考音频,同时可选地使用 Control Instruction 来指定情绪、语速、风格等表达方式,在保留原始音色的基础上灵活控制说话风格。
- 🎙️ 极致克隆(Ultimate Cloning)
- 开启 极致克隆模式 并提供参考音频的文字内容(可自动识别)。模型会将参考音频视为已说出的前文,以音频续写的方式完整还原参考音频中的所有声音细节。注意:该模式与可控克隆模式互斥,将禁用Control Instruction。
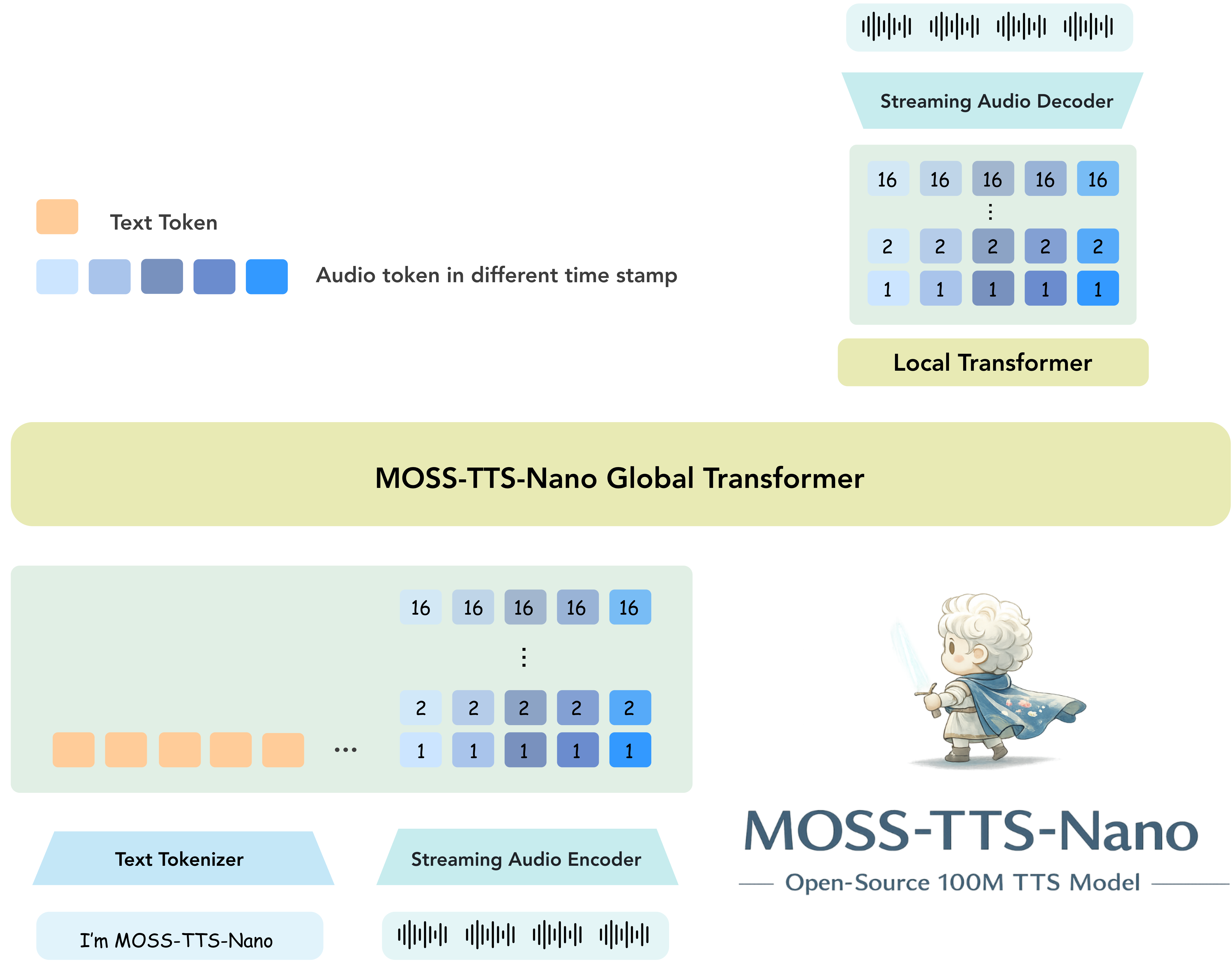
【2026-4-10】MOSS-TTS-Nano
2026-4-10,复旦NLP实验室推出 MOSS-TTS-Nano,0.1b 参数,模型文件压缩后不到300m,纯 CPU 运行,不需要显卡!
- 在线 demo MOSS-TTS-Nano-Demo
支持
- 文本转语音
- 声音克隆
- 实时流式输出
语音克隆
【2024-11-23】两个端到端的语音模型Fish-Speech和GLM-4-Voice
- Fish-Speech 零样本克隆效果达到要求。所以计划数字人的TTS就用它的克隆语音流式播放。
- GLM-4-Voice 生成语音,间隔时间有点长,目前还无法满足我的数字人实时聊天。
Fish-Speech
Fish-Speech 只需3分钟,即可创建属于你的AI数字声音克隆。
- 支持40+种语言,99.9%的还原度。
- 🎯 超高还原度: 采用最新深度学习技术,声音还原度达99.9%,无法与真人声音区分。
- ⚡️ 实时生成: 毫秒级响应,支持实时语音克隆,适用于直播、游戏等场景。
- 🌍 多语言支持: 支持40+种语言,包括中文、英语、日语等,一次训练多语言使用。
Anyvoice
【2025-3-23】Anyvoice 声音克隆
超真实AI声音生成器
- 生成与人类无法区分的AI声音。
- 超真实的文本转语音(TTS)。
- 领先的AI声音生成器,配备即时声音克隆技术。
- 免费无限下载。
AI 声音克隆
- 全球首创:仅需 3 秒!
AnyVoice 支持两种方式进行声音克隆:实时录制音频或者上传音频。
体验突破性的人工智能技术,只需 3 秒音频即可创建超逼真的声音克隆 - 世界上最快、最自然的声音。不再需要冗长的录音!
目前支持以下语言:English/Chinese/Japanese/Korean
实时语音对话
语音 Agent 设计
【2025-6-19】
主动式Agent(Proactive Agent),主要是体现出主动性,能够主动做出决策,根据自主思考的结果驱动目标完成。在语音对话场景下,这种主动性尤为重要,因为用户期望获得即时、自然的交互体验。
语音Agent必须是一个主动式Agent
几个方面:
不被动等待用户输入 传统的语音助手往往在等待用户唤醒或输入后才响应,而主动式Agent会根据场景、上下文或任务进度主动发起对话。例如在检测到用户长时间未说话时,主动询问用户是否需要帮助。
对用户情绪和语速的敏感应答 主动Agent能够实时分析用户的语速、语调和情绪状态。当检测到用户情绪激动或语速过快时,Agent会主动安抚用户,例如说”别急,您慢慢说”,体现出对用户状态的关心和适应。
检测用户是否还在聆听 如果用户长时间没有回应,主动Agent不会一直沉默,而是主动发起确认:”您好,请问您还在吗?”这样可以避免对话中断,提高交互的流畅性。
识别对话对象是否为机器人 主动Agent具备一定的识别能力,能够判断当前对话对象是否为另一个机器人(如小爱同学),从而调整对话策略,避免陷入无意义的机器人互聊。
综上,主动式语音Agent不仅仅是被动响应用户请求,更重要的是能够根据环境、用户状态和对话内容,主动发起、引导和调整对话,提升交互体验和任务完成效率。
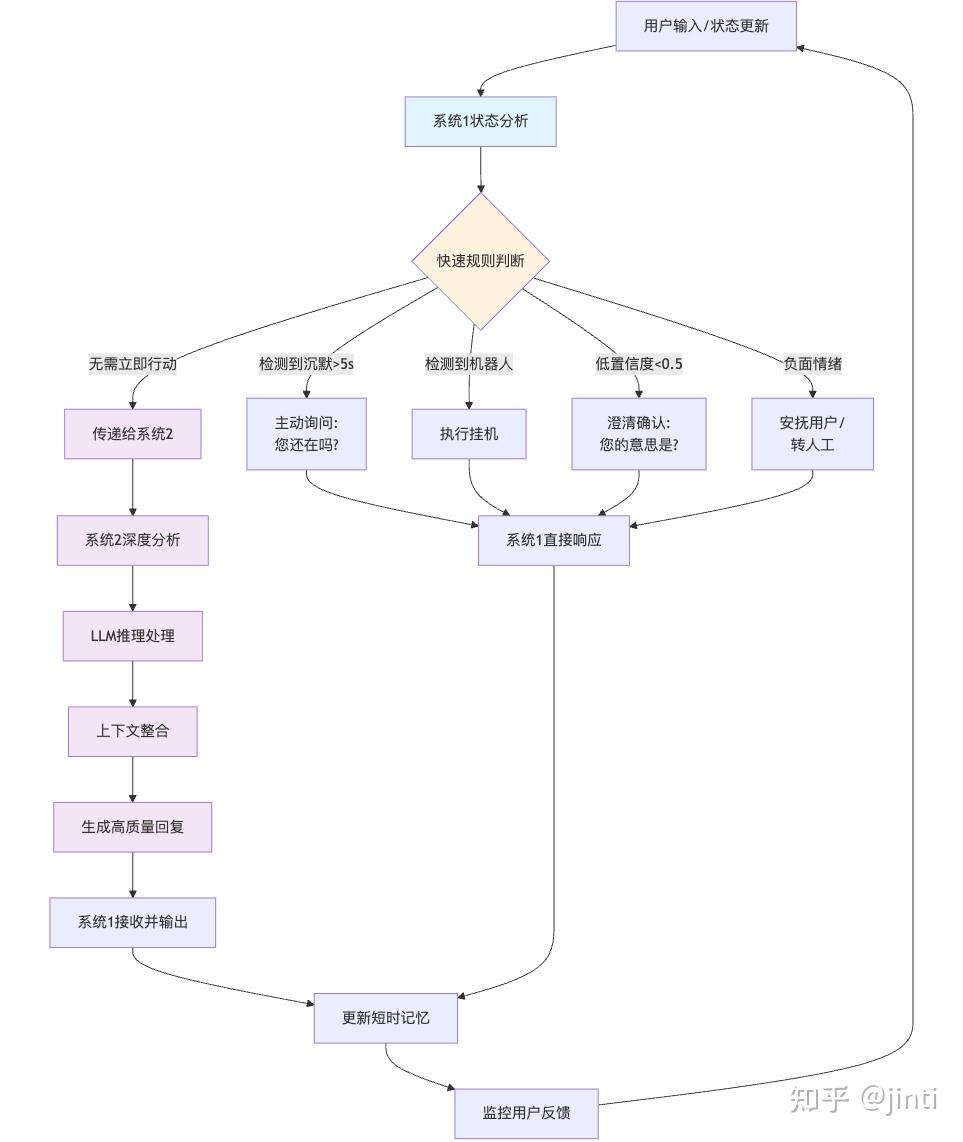
主动式语音Agent的设计中,借鉴《思考快与慢》中的”双系统”理论,将Agent的决策与响应机制分为系统1和系统2。
这种设计特别适合语音对话场景,因为系统1能够提供快速响应,而系统2则负责深度处理。
系统1:快速反应系统(轻量级实现)
系统1是主动式Agent的核心,它通过简单的规则和状态机实现快速响应,无需复杂的工程化实现:
情绪与超时检测 系统1实时分析用户的语音情绪、语速、停顿等信号,快速判断用户是否困惑、焦虑或等待时间过长。例如,检测到长时间无输入时,系统1会主动发起”您好,请问您还在吗?”等确认,或在用户语速过快时安抚用户。
EOU(End of Utterance)判断 能够快速判断用户是否说完,及时给出反馈,避免冷场或误判。
关键行为决策 对于挂机、转接人工等关键行为,系统1可根据规则或短时上下文迅速做出决策,保障对话流畅。
短时记忆机制 系统1维护有限的短时记忆,记录最近的对话状态、用户意图等,避免每次都将全部历史传递给LLM,降低token消耗,提升效率。
无需LLM驱动 系统1以规则、轻量模型或有限状态机为主,不依赖大模型,响应速度快、成本低。 系统2:深度推理系统 系统2在系统1争取到的时间内,负责复杂的推理、规划和生成高质量的回复:
复杂意图理解与任务规划 当用户需求复杂或需要多轮推理时,系统2调用LLM等大模型进行深度理解和生成。
上下文整合与长期记忆 系统2可访问更丰富的上下文和长期记忆,生成更具针对性和个性化的回复。
与系统1协作 系统1在前台快速应答,系统2在后台深度处理,处理结果再由系统1自然地反馈给用户,实现无缝衔接。
双系统协作的优势 提升用户体验:系统1保证对话的流畅和自然,避免冷场和误解;系统2提升Agent的智能和个性化水平。 降低成本:将大部分高频、简单的响应交给系统1处理,减少LLM调用频率,显著降低算力和token消耗。 更真实的主动性:系统1的快速反应和短时记忆让Agent表现得更像真人,能够主动引导和调整对话节奏。
流程图
评测
【2024-12-24】 实时语音交互中文基准12月测评结果出炉,4大维度15项能力8款应用,讯飞星火领跑,国内产品延时、打断和场景应用表现出色
中文原生实时语音交互测评基准(SuperCLUE-Voice)旨在深入评估新一代实时语音交互产品在中文语音交互中的整体表现。
- 该基准不仅全面考察产品在打断、说话风格等语音交互核心能力上的表现,还重点评估其在记忆能力、联网能力等通用能力上的综合水平。
- 同时,测评还特别关注产品在实时翻译、教育辅导等五大实际应用场景中的表现,旨在为语音交互技术的多场景落地提供全面的评判标准。
评测结论
- 1:国内头部产品在实时中文语音综合能力表现上有一定领先性。
- 实时语音产品总体表现差异较大,分层现象明显。国内头部产品在实时中文语音能力上表现领先,
讯飞星火综合表现最强,位居第一,海外产品ChatGPT-4o紧随其后,国内的豆包与海螺AI也表现不俗,展现了各自的优势。
- 实时语音产品总体表现差异较大,分层现象明显。国内头部产品在实时中文语音能力上表现领先,
- 2:语音交互能力上,ChatGPT-4o在说话风格方面有较大的领先性,打断能力和语音自然度方面国内产品表现较好。
- 语音交互方面,ChatGPT-4o在说话风格上保持领先,国内产品在打断能力和语音自然度上占优势,尤其是讯飞星火的语音自然度达到90分以上。
- 3:通用能力方面,国内实时语音产品占有一定的领先优势。
- 国内实时语音产品在通用能力上具有领先优势,文小言在安全和记忆能力方面表现突出,Kimi在推理任务中表现较好,但国内产品在联网能力上普遍较弱,亟待改善。
- 4:在中文场景应用方面,国内实时语音产品依然保持较好的表现。
- 国内语音产品在中文场景应用中仍具优势,通义在场景应用上领先,得分突破70分,其他国内产品得分均超过60分,整体表现较9月有所提升。
排名表格见原文
Ichigo
本地实时语音交互
Ichigo 是一个开放的、持续的研究实验,旨在扩展文本基础的大语言模型,使其具备原生的”听觉”能力。
一个开放数据、开放权重、在设备上运行的 Siri
全双工 LSLM
【2024-8-5】全双工对话:大模型能边说边听了
- 上海交大开发出新模型
LSLM(Listening-while-Speaking Language Model),实现了真正的”全双工对话“。listening-while-speaking language model - 论文 Language Model Can Listen While Speaking
- Demo
传统的AI对话模型都是”你一句我一句”的轮流模式。但LSLM不一样,它可以同时说话和听话。AI一边”嘴巴”不停,一边”耳朵”也没闲着
两个关键技术:
- 基于token的解码器TTS:负责生成语音
- 流式自监督学习编码器:实时处理音频输入
为了让”说”和”听”这两个通道更好地协同工作,探索了三种融合策略:
- 早期融合
- 中期融合
- 晚期融合
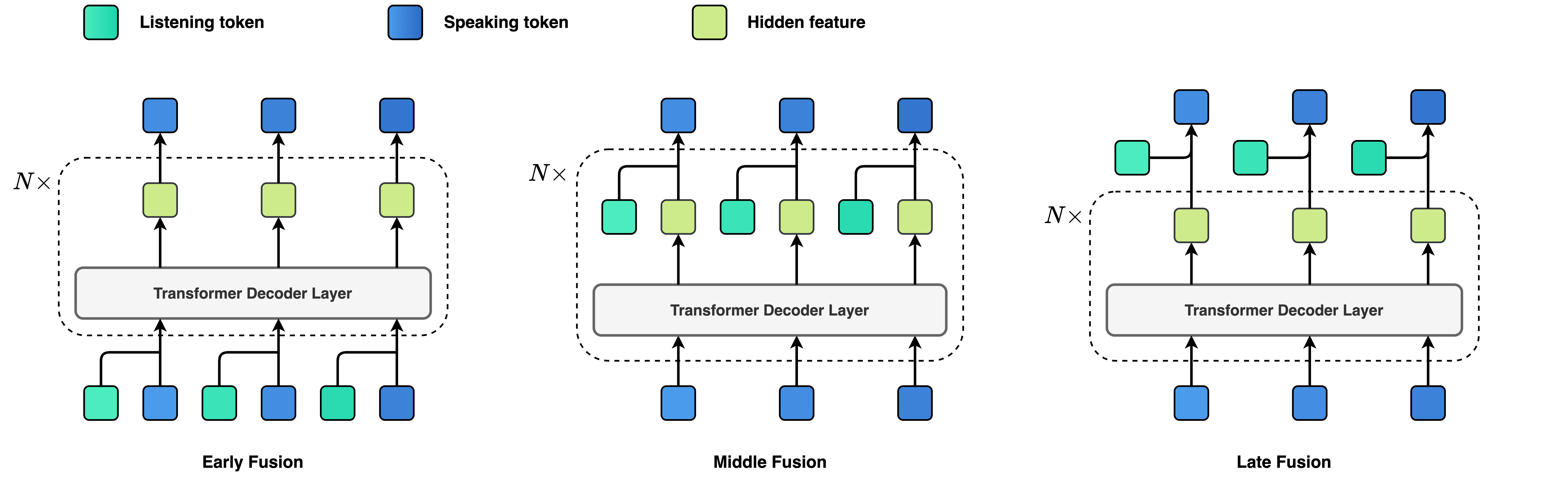
最终,中期融合脱颖而出,在语音生成和实时交互之间取得了最佳平衡。
- “中期融合就像人类大脑处理信息的方式,既不会太早下结论,也不会反应太慢。这可能是未来对话AI的发展方向。”
两种实验场景:
- 基于命令的全双工模式
- 基于语音的全双工模式
结果显示,LSLM不仅能抗噪音,还能对各种指令保持敏感。
Full Duplex Modeling (FDM)
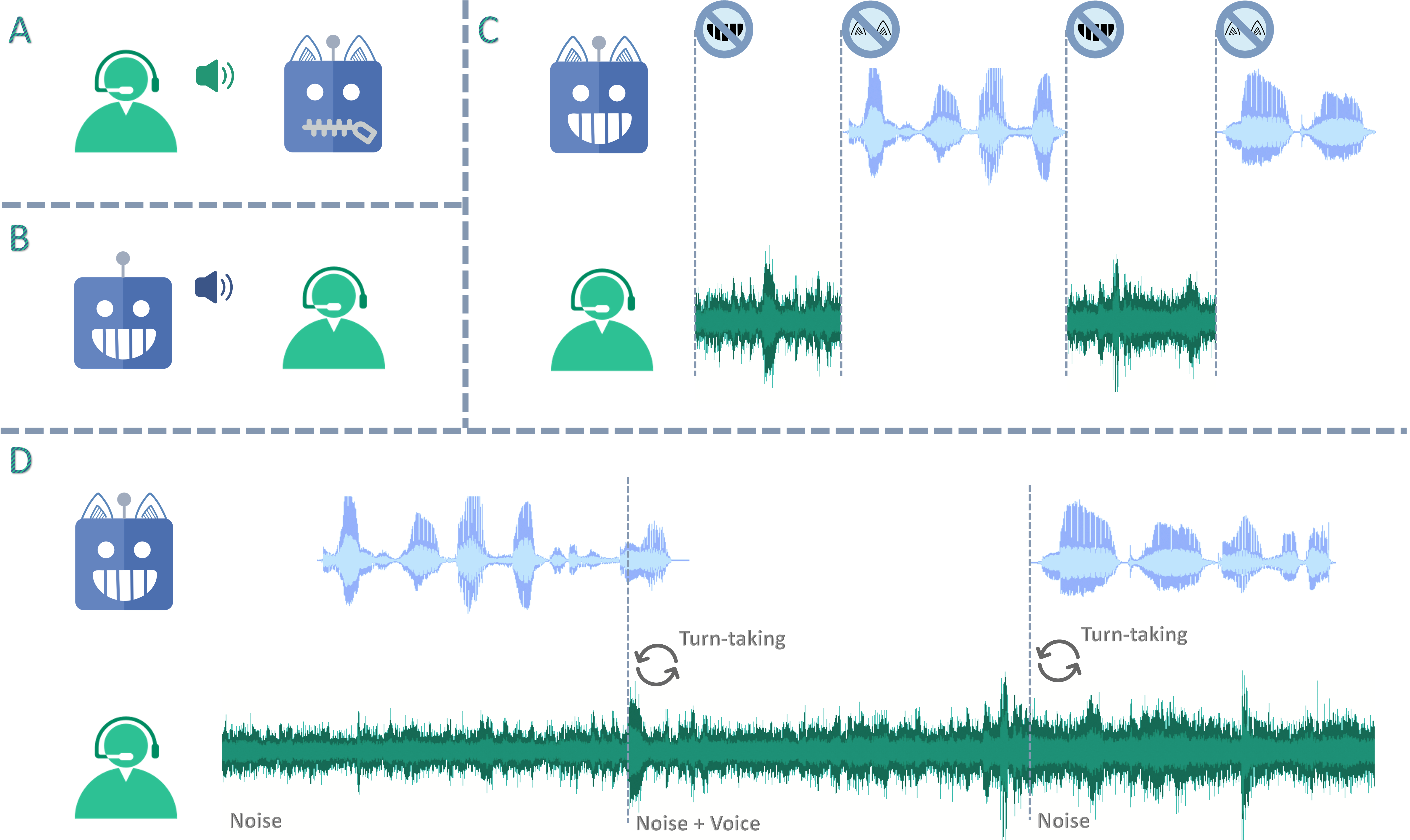
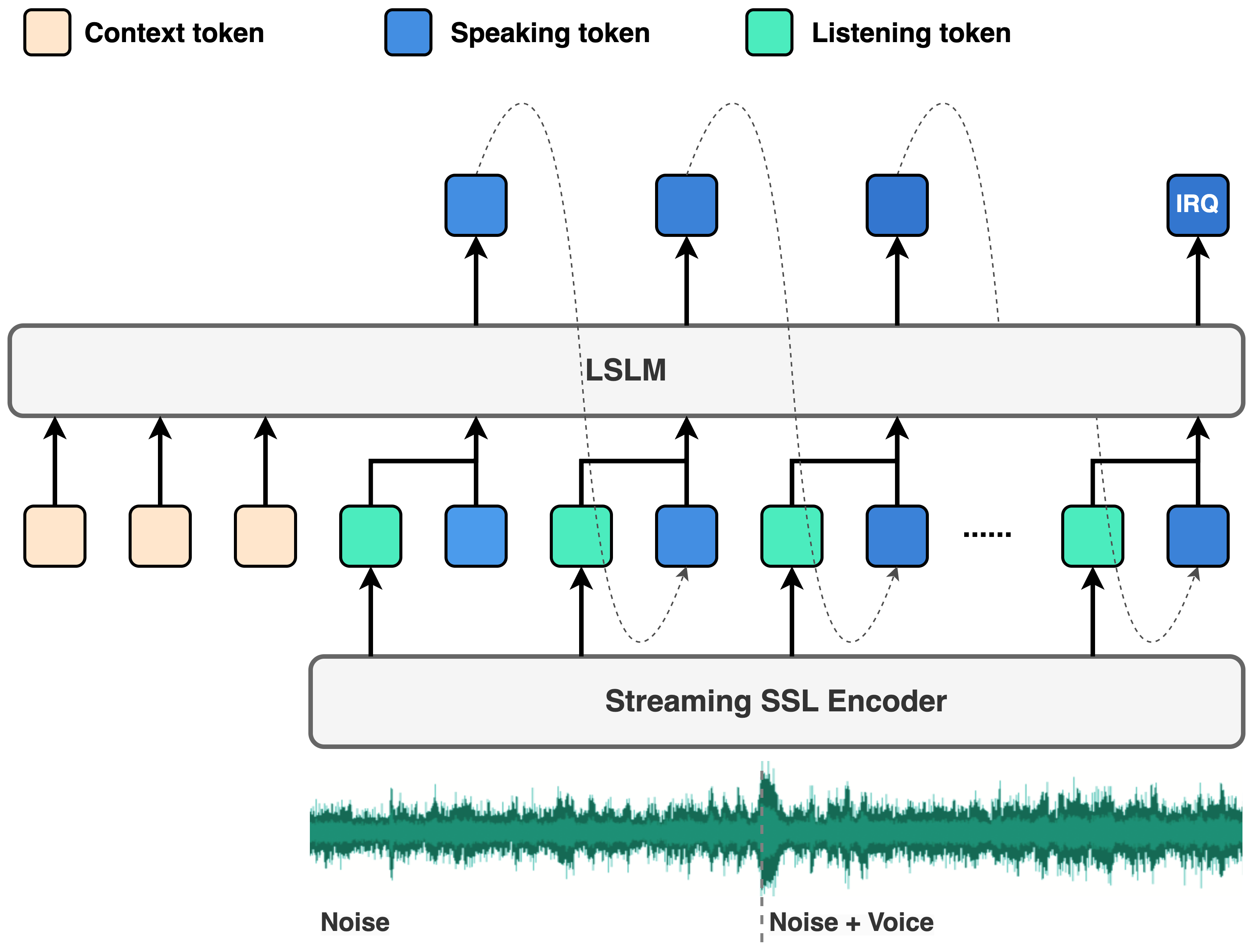
虽然LSLM看起来很厉害,但距离真正的”自然对话”还有一段距离。
不过,这项研究确实为交互式语音对话系统的发展开辟了新路径,让AI在实际应用中更接地气。
Lepton LLM API
【2024-8-8】 告别TTS!贾扬清领衔的 Lepton AI 推出实时语音交互
- 官方 API
AI语音助手传统路子:
- 把问题往LLM(大语言模型)里一丢,等回话,再让TTS(文本转语音)上阵 —— 这一连串动作,听起来挺顺,实则很卡。
- 跟AI聊天还得等它反应,就像给朋友发微信,结果他秒回了个“正在输入……”,急不急人?
- 传统方法每个步骤都得排队,结果就是“首次音频时间”(TTFA) 拖长,对话流畅度直接打折。
- 分块和缓冲 是工程师们的噩梦。
- 为了快那么一点点,系统得把长句子切成小块,到时候再像玩拼图一样拼起来。但这拼图可不是随便拼的,时间差一丁点,不是这边话音未落那边又响起来了,就是句子讲到一半突然卡壳,尴尬得能抠出三室一厅。
- 错误处理也是个大坑。文本和语音本来天生一对,结果被硬生生拆散了。万一哪边出了岔子,找起原因来就像大海捞针,用户体验?先放一边凉快吧。
- 馊主意: 把长句子拆成小段,一个个往TTS里送,想着这样能快点。
- 结果 协调起来比登天还难,同步稍有不慎,音频乱套、停顿尴尬。
说好的流畅对话呢?最后还是让人直呼“带不动”。
手机上 Siri、小爱同学,问它问题需要花费几秒钟去检索
包括GPT4,切换到语音输出模式,还是有不小的延迟。这样一来就显得有些卡顿,等待AI回复的过程像是过了几千年,让人恨不得把脑袋伸进手机里让AI快点。
贾扬清创办的Lepton AI刚刚宣布,Lepton LLM API 已经支持实时语音交互了!
技术原理
Lepton AI 直接把 LLM 和 TTS 合二为一。
- 传统系统里,文本和音频排队等处理;
- 这里文本和语音并行处理,速度嘎嘎快,首次音频时间(TTFA)直接缩水到十分之一,自然无比顺滑。
除了减少延迟外,Lepton AI 还引入用于简化和优化内容处理的高级机制,能根据对话内容动态调整音频片段。这样,对话不仅连贯,还超级自然,停顿、中断?不存在的!用户体验直接拉满!
这技术还超级百搭,跟那些开源的LLM模型都私下里串通好了。
- 比如Llama3.1系列,无论是8B、70B还是405B,都能跟Lepton AI的语音模式无缝对接。
- 开发者们可以随心所欲地挑选心仪的模型,再搭配上 Lepton AI 语音黑科技,创造出既个性又高效的应用,享受“私人订制”服务。
效果
向AI提问题后,AI立即进行回答,几乎是秒回,而且还有不同音色任君选择。
根据测试,他们已经能做到让AI在在300ms内开始回答问题。
贾扬清 Twitter 演示视频
【2024-9-3】Mini-Omni
【2024-9-3】开源版GPT-4o语音来袭,Mini-Omni开启实时语音对话
Mini-Omni, 更强大的实时语音对话AI模型开源
【2024-8-30】清华 gpt-omni 团队开发,语音助手界的一匹黑马,不仅能实现实时语音对话,还能同时生成文本和音频
- 模型下载:mini-omni
- 论文地址:Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
- 代码仓库:mini-omni
Mini-Omni有哪些特性呢?
- 实时语音对话:这意味着你说话的同时,AI就能立即理解并回应,不再有明显的延迟。
- 同时生成文本和音频:这个功能简直太强大了!AI不仅能说,还能同步给出文字版本,对听力不好的朋友来说简直是福音。
- 流式音频输出:这个技术确保了对话的流畅性,让整个交互过程更加自然。
Mini-Omni:语言模型在流式处理中的听、说、思考能力
Mini-Omni 是一个开源的多模态大型语言模型,能够在思考的同时进行听觉和对话。它具备实时的端到端语音输入和流式音频输出对话功能。
- Qwen2 作为 LLM 主干。
- litGPT 用于训练和推理。
- whisper 用于音频编码。
- snac 用于音频解码。
- CosyVoice 用于生成合成语音。
- OpenOrca 和 MOSS 用于对齐。
功能特点
- 实时语音对话功能,无需额外的ASR或TTS模型。
- 边思考边对话,支持同时生成文本和音频。
- 支持流式音频输出。
- 提供“音频转文本”和“音频转音频”的批量推理,进一步提升性能。
模型结构

安装
conda create -n omni python=3.10
conda activate omni
git clone https://github.com/gpt-omni/mini-omni.git
cd mini-omni
pip install -r requirements.txt
使用
# 启动服务器
conda activate omni
cd mini-omni
# 本地测试运行预设的音频样本和问题
python inference.py
# 启动服务
python3 server.py --ip '0.0.0.0' --port 60808
# 运行 Streamlit 演示
# 注意:本地运行 Streamlit 并安装 PyAudio。
pip install PyAudio==0.2.14
API_URL=http://0.0.0.0:60808/chat streamlit run webui/omni_streamlit.py
# 运行 Gradio 演示
API_URL=http://0.0.0.0:60808/chat python3 webui/omni_gradio.py
【2024-9-24】Westlake-Omni
星语智能基于qwen2和fishspeech研发的 Westlake-Omni
- 【2024-10-27】 Westlake-Omni :一款开源的中文情感语音交互大语言模型,可实现更为智能、自然的人机交互体验
Westlake-Omni is an open-source Chinese emotional speech interaction large language model that utilizes discrete representations to achieve unified processing of speech and text modalities. The model supports low-latency generation and high-quality Chinese emotional speech interaction.
西湖心辰团队研发的 Westlake-Omni 模型的开源,为中文情感语音交互领域带来了新的突破与机遇,西湖大学蓝振忠
- 【2024-9-10】AI读懂“话外之音”?杭产大模型实现全国首创,背后是85后博士
- 创始人蓝振忠任教于西湖大学深度学习实验室,是自然语言处理预训练语言模型“ALBERT”第一作者,曾位列《麻省理工科技评论》评选的2021年度亚太地区“35岁以下科技创新35人”。
心辰Lingo 作为国内首个端到端语音大模型,在输入语音后,可以直接分析语音,再回复语音。通过大模型的训练,敏锐捕捉说话者的语气、节奏和情绪。相较于传统的语音交互系统需要将语音转化成文字才能进行文字理解,并再次将生成的回复从文字转换回语音进行最终输出,端到端的语音大模型极大地减少了信息在转换过程中的损失。
心辰Lingo还具有原生的语音理解、多种语音风格表达、语音模态超级压缩三大技术特性。在显著降低计算和存储成本的同时,不仅能提升对话自然度,还能灵活适用于多种应用环境:在常规的对话之外,突发奇想,要听一段相声或是一曲说唱,心辰Lingo也能轻松“安排”。
技术核心与特点
- 1、高质量语音合成
- Westlake-Omni 合成的语音发音准确、流畅,无论是在音色、音调还是语速上,都能够与人类的语音相媲美。用户在与智能系统交互时,能够获得更加舒适、自然的听觉体验。
- 智能客服场景中,清晰、准确的语音回复能够让用户快速理解信息,提高沟通效率;
- 教育领域,高质量的语音合成可以为学生提供生动、有趣的学习内容,增强学习效果。
- 2、强大的情感表达能力——最突出的特点
- Westlake-Omni 根据文本内容和上下文情境,合成带有不同情感状态的语音,如喜悦、悲伤、愤怒、平静等。通过对情感的准确表达,使得智能系统与用户之间的交互更加贴近人类之间的沟通方式,增强了用户的情感共鸣。
- 3、端到端设计
- 端到端的设计理念是 Westlake-Omni 的又一重要优势。从文本输入到语音输出,整个过程无需额外的中间步骤,简化了语音合成的流程,提高了系统的运行效率。这种简洁高效的设计方式,不仅降低了系统的复杂性和出错概率,还为开发者提供了更加便捷的开发环境,使得他们能够更加专注于应用场景的开发和优化。
- 4、离散表示统一文本和语音模态
- Westlake-Omni 使用离散表示法统一了文本和语音模态,这意味着模型能够更好地理解文本和语音之间的内在联系,实现更加精准的语音合成。这种统一的模态表示方式为跨模态的语音交互应用提供了有力的支持,例如语音转文字、文字转语音等场景,能够提高转换的准确性和效率。
【2024-11-5】Hertz-dev
【2024-11-5】Hertz-dev: 首个开源的超低延迟的实时交互语音对话模型
Hertz-dev 在 RTX 4090 上的理论延迟为 65 毫秒,实际平均延迟为 120 毫秒。这比世界上任何公共模型的延迟都低约 2 倍
模型能够以类似人类的方式互动的先决条件,而不是感觉像延迟、断断续续的电话通话。
作者目前正在训练更大、更先进的 Hertz 版本,它将使用缩放的基础模型配方和 RL 调整来大幅提高模型的原始功能和最终一致性。
Hertz-dev 是实时语音交互的一次探索,也是世界上最容易让研究人员进行微调和构建的对话音频模型。
【2024-10-21】ten-agent
【2024-10-21】ten-agent: 又一款王炸级的开源端到端语音模型
首个集成 OpenAI Realtime API和RTC能力的实时多模态AI agent:TEN-Agent,具备
- 天气查询、网络搜索、视觉识别、RAG能力
- 适合智能客服、实时语音助手, 这种实时交互的场景, 能同时看、听、说,处理各种信息,具备超低延迟的音视频交互能力,agent状态实时管理,多模态处理能力
资源
- 代码地址:TEN-Agent
-
体验地址:theten, 在线体验,选模态、点击 connect 按钮开启
- 带有 OpenAI Realtime API 和 RTC 的 TEN 代理
- 将超低延迟的 OpenAI Realtime API 与 RTC 的 AI 噪音抑制相结合,可确保流畅、高质量的交互。除此之外,天气和新闻工具的无缝集成使 TEN Agent 更加通用。
功能
- OpenAI Realtime API 和 RTC 集成:TEN Agent 是集成 OpenAI Realtime API 和 RTC 的世界级多模式 AI 代理。
- 高性能实时多模式交互:为复杂视听AI应用提供高性能、低延迟的解决方案。
- 多语言和多平台支持:支持C++、Go、Python等扩展开发。可在Windows、Mac、Linux和移动设备上运行。
- 边缘云集成:灵活结合边缘和云部署的扩展,平衡隐私、成本和性能。
- 超越模型限制的灵活性:通过简单的拖放编程轻松构建复杂的AI应用程序,集成视听工具,数据库,RAG等。
- 实时代理状态管理:实时管理和调整代理行为以实现动态响应。
智谱
【2024-12-3】GLM-4-Voice
【2024-12-3】智谱开源语音克隆 GLM-4-Voice
- 清华论文: GLM-4-Voice: 通向智能及类似人类的端到端语音会话机器人
- 标题:GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
- 代码:GLM-4-Voice
支持中文和英文对话,能够根据用户指令调整语音的情感、语调、语速和方言,还使用了一种低比特率(175bps)的单码本语音分词器,融入自动语音识别(ASR)模型中,利用向量量化约束作为编码器的一部分,以此产生12.5Hz的帧率。
GLM-4-Voice 能够直接理解和生成中英文语音,进行实时语音对话,并且能够遵循用户的指令要求改变语音的情感、语调、语速、方言等属性。
GLM-4-Voice 由三个部分组成:
GLM-4-Voice-Tokenizer: 通过在 Whisper 的 Encoder 部分增加 Vector Quantization 并在 ASR 数据上有监督训练,将连续的语音输入转化为离散的 token。每秒音频平均只需要用 12.5 个离散 token 表示。GLM-4-Voice-Decoder: 基于 CosyVoice 的 Flow Matching 模型结构训练的支持流式推理的语音解码器,将离散化的语音 token 转化为连续的语音输出。最少只需要 10 个语音 token 即可开始生成,降低端到端对话延迟。GLM-4-Voice-9B: 在 GLM-4-9B 的基础上进行语音模态的预训练和对齐,从而能够理解和生成离散化的语音 token。
预训练方面,为了攻克模型在语音模态下的智商和合成表现力两个难关,将 Speech2Speech 任务解耦合为“根据用户音频做出文本回复”和“根据文本回复和用户语音合成回复语音”两个任务,并设计两种预训练目标,分别基于文本预训练数据和无监督音频数据合成语音-文本交错数据以适配这两种任务形式。GLM-4-Voice-9B 在 GLM-4-9B 的基座模型基础之上,经过了数百万小时音频和数千亿 token 的音频文本交错数据预训练,拥有很强的音频理解和建模能力。
对齐方面,为了支持高质量的语音对话,设计流式思考架构:根据用户语音,GLM-4-Voice 可以流式交替输出文本和语音两个模态的内容,其中语音模态以文本作为参照保证回复内容的高质量,并根据用户的语音指令要求做出相应的声音变化,在最大程度保留语言模型智商的情况下仍然具有端到端建模的能力,同时具备低延迟性,最低只需要输出 20 个 token 便可以合成语音。
【2025-1-18】GLM-Realtime 实时视频
【2025-1-18】 GLM-Realtime 是一款音视频通话模型,能够提供实时的视频通话功能,通话记忆时长长达2分钟,具有跨文本、音频和视频进行实时推理的能力。
GLM-Realtime是智谱推出的低延迟端到端多模态模型,具备:视频理解、语音交互、内容记忆、清唱功能和 Function Call 功能。
它适用于多种实时交互场景,通过 Function Call 功能可以拓展到更广泛的商业应用。开发者可以免费调用该模型,体验其强大的实时交互能力。
功能特性
- 低延迟视频理解与语音交互:实现了低延迟的视频理解与语音交互,特别适合实时应用场景,如视频通话和智能硬件交互。
- 2分钟内容记忆能力:在视频通话中,能够记忆长达2分钟的内容,提供更连贯的交互体验。
- 清唱功能:创新性地实现了清唱功能,让大模型具备在对话中的歌唱能力,增加了互动的趣味性。
- Function Call 功能:支持 Function Call 功能,能够灵活调用外部知识和工具,拓展到更广泛的商业场景。
- 端到端模型:GLM-Realtime 是一个端到端的多模态模型,能够同时处理视频和语音输入,提供更全面的交互体验。
- 高性能与低延迟:优化了模型的性能,确保在实时应用中保持低延迟,提供流畅的交互体验。
GLM-Realtime API已经上线智谱开放平台bigmodel.cn,现阶段可以免费调用。
【2024-7-4】Moshi
【2024-7-4】法国AI实验室发布原生多模态Moshi,现场惊艳演示
8人团队4个月打造
- 模型训练流程和模型架构简单且可扩展性极强,Kyutai这样的8人以上小团队在4个月内就构建了它。合成数据在这里发挥了巨大作用
- 专注于本地设备:Moshi很快就会无处不在。
Kyutai 还开发了一个较小的 Moshi版本,可以在 MacBook 或消费级 GPU 上运行。
开源GPT-4o
【2025-1-20】豆包
上一代流水线语音对话系统(ASR 转成文本, LLM 生成对话文本,最后 TTS),存在多个缺陷,阻碍了真人级别语音对话交互的实现。
- 对用户情绪及语音中各种副语言信息理解有局限
- 模型生成语音情绪存在上限
- 无法遵循语音控制指令
- 无法实现超低延迟等。
介绍
【2025-1-20】豆包实时语音大模型上线即开放
豆包实时语音大模型于正式推出,豆包 APP 全量开放,将豆包 APP 升级至 7.2.0 版本即可体验。
豆包实时语音大模型是一款语音理解和生成一体化的模型,实现了端到端语音对话。
- 相比传统级联模式,在语音表现力、控制力、情绪承接方面表现惊艳,并具备低时延、对话中可随时打断等特性。
面向语音生成和理解进行统一建模,最终实现多模态输入和输出效果。
- 预训练(Pretrain)阶段,对各模态交织数据进行深入训练,精准捕捉并高效压缩海量语音信息,通过 Scaling ,最大程度实现语音与文本能力深度融合和能力涌现。
- 后训练阶段,使用高质量数据与RL算法,进一步提供模型高情商对话能力与安全性,并在“智商”与“情商”之间寻求平衡。
预训练模型具备了丰富多样输入输出的可能性,涵盖 S2S(语音到语音)、S2T(语音到文本)、T2S(文本到语音)、T2T(文本到文本)等多种模式。
该模型的推出具备里程碑式意义,不仅贴合中国用户实际需求,且发布即上线,有能力直接服务亿万用户,而非停留于演示 Demo 层面。
- 技术展示页:realtime_voice
功能
产品功能
- 灵魂歌手
- 百变大咖
- 悄悄说话
- 戏精本精
- 受气小包
- 英语陪练
效果
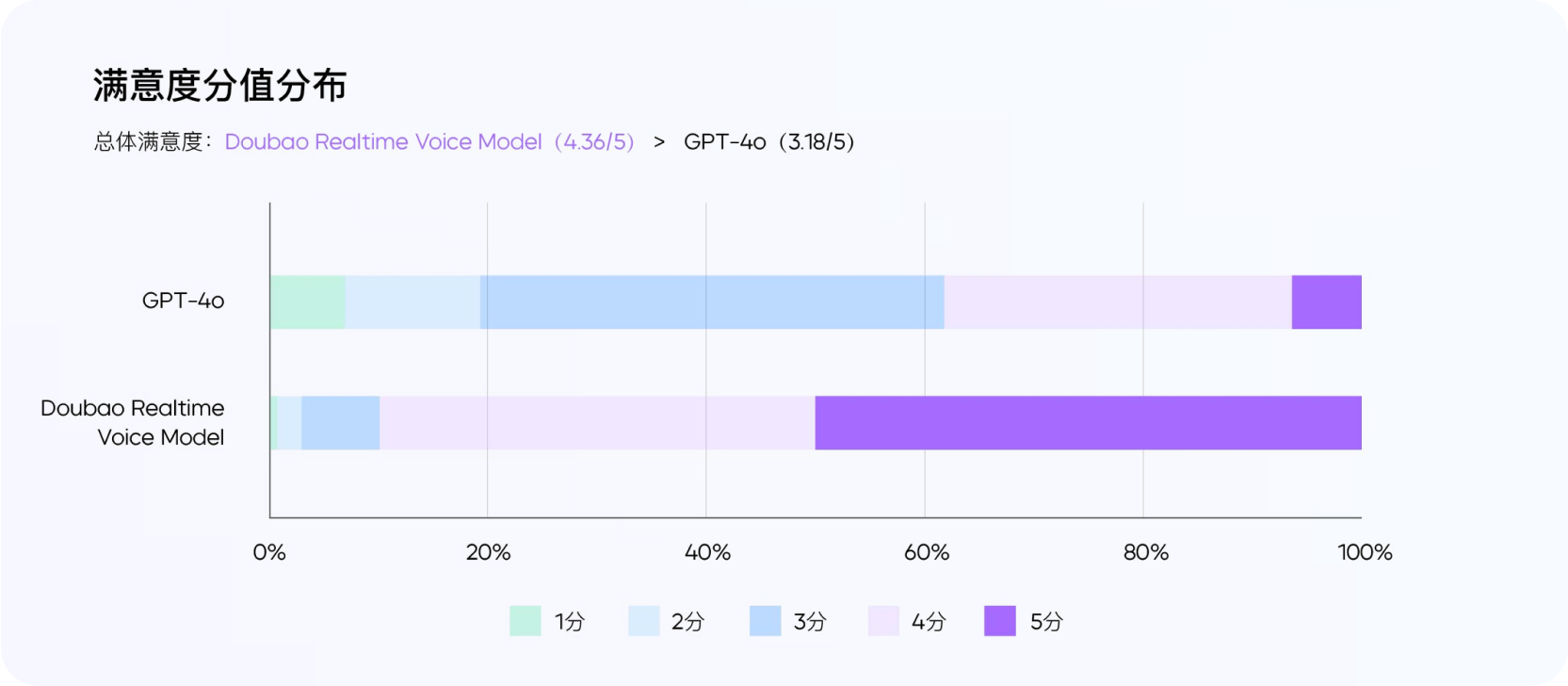
根据外部用户真实反馈,该模型整体满意度较 GPT-4o 有明显优势 ,特别是语音语气自然度和情绪饱满度远高于后者。
测试者来自 10 个城市,其中 9 名男性,女性 18 名,年龄分布为 21-33 岁。
- 11.11% 的测试者从未体验过豆包 APP
- 70.37% 为轻度用户,每周使用 1-2 天,其余粘度较高。
围绕拟人度、有用性、情商、通话稳定性、对话流畅度等多个维度进行考评。
整体满意度(以 5 分为满分)方面,豆包实时语音大模型评分为 4.36,GPT-4o 为 3.18。其中,50% 的测试者对豆包实时语音大模型表现打出满分。
实测
- 中文语境和场景(可进行英语对话,暂不支持多语种)
- 语气更自然
- 情绪更饱满:
- 有感情朗读
- 角色模拟: 模拟宋丹丹小品、小孩儿
- 速度可控:快、慢
- 唱歌
- 方言支持:上海话、四川话、东北话、广东话等
- 男女声切换——不支持
【2025-2-2】SpeechGPT 2.0
【2025-2-2】SpeechGPT 2.0:复旦大学开源端到端 AI 实时语音交互模型,实现 200ms 以内延迟的实时交互
SpeechGPT 2.0 是复旦大学 OpenMOSS 团队推出的拟人化端到端实时语音交互模型,基于百万小时级中文语音数据训练,支持情感控制和低延迟响应。
- Github SpeechGPT-2.0-preview
- Demo
该模型基于百万小时级的中文语音数据进行训练,采用端到端架构,实现了语音与文本模态的高度融合。
具有拟人口语化表达、百毫秒级低延迟响应,支持自然流畅的实时打断交互。
此外,SpeechGPT 2.0 能够精准控制语速、情感、风格和音色,实现智能切换,并具备多种语音才艺,如诗歌朗诵、故事讲述、说方言等。
主要功能
具备拟人口语化表达、多情感控制、实时打断交互和多种语音才艺。
- 情感与风格控制:支持多情感(如虚弱、欢快)、多音色(男女切换)及多风格(诗歌朗诵、方言模仿)的精准控制,角色扮演能力突出。
- 实时打断交互:百毫秒级响应速度支持自然对话中的即时打断与续接。
- 文本能力集成:在语音表现力基础上,保留文本模型的智商,支持工具调用、联网搜索、外挂知识库接入等功能。
- 多任务兼容性:可处理长文档解析、多轮对话等场景,兼容短文本任务的性能未因长上下文能力而降低。

技术原理
采用超低比特率流式语音 Codec 和语义-声学联合建模,实现高效的语音文本混合建模。
- 超低比特率流式语音 Codec:自研的超低比特率流式语音 Codec,能够处理 24khz 的语音输入,将语音压缩至每秒 75 个 token,支持流式输入输出,实现 200ms 以内延迟的实时交互。
- 语义-声学联合建模:通过语义-声学联合建模,直接处理语音输入并生成语音或文本输出,无需传统级联式 ASR(语音识别)和 TTS(语音合成)模块。
- Codec Patchify:通过 Codec Patchify 技术聚合相邻时间步的语音 token 为统一向量,有效减小语音和文本序列之间的模态差异,缓解跨模态建模中的冲突问题。
- 多阶段训练流程:包括模态适应预训练、跨模态指令微调和链式模态微调,兼顾文本能力与语音能力,避免模型在学习语音能力时降低智商。
- 语音文本对齐预训练:通过充分的语音文本对齐预训练,模型可以“涌现”出语音风格的泛化性,例如无需语速调整数据即可控制语速,或模仿未见过的角色语气风格。
使用
git clone https://github.com/OpenMOSS/SpeechGPT-2.0-preview.git
cd SpeechGPT-2.0-preview
# 下载模型权重
# 需要安装 git-lfs
git lfs install
git clone https://huggingface.co/fnlp/SpeechGPT-2.0-preview-Codec
git clone https://huggingface.co/fnlp/SpeechGPT-2.0-preview-7B
# 准备环境
pip3 install -r requirements.txt
pip3 install flash-attn==2.7.3 --no-build-isolation
# 启动网页 demo
python3 demo_gradio.py --codec_ckpt_path SpeechGPT-2.0-preview-Codec/sg2_codec_ckpt.pkl --model_path SpeechGPT-2.0-preview-7B/
【2025-2-24】腾讯 全双工 SDS
腾讯轻量级LLM革新全双工口语对话系统:精准控制轮次,提升交互质量
当前口语对话系统(SDS)虽然靠大语言模型(LLM)变聪明了,但大多还是“半双工”——要么听要么说,没法同时来;就算有“伪全双工”,也因为搞不懂用户状态(比如是不是真说完了、是不是故意打断),聊天很不流畅。
全双工口语对话系统(SDS)核心难题:怎么让系统同时“听、说、思考”还不混乱
想让系统“边听边说”,得先解决三个关键问题:
- 背景干扰:旁边有人说话会搞乱语音识别(ASR)和对话管理,比如系统误启动或乱回复;
- 用户停顿犹豫:不能光靠“没声音”就判断用户说完了——可能人家只是卡壳,早回复或等太久都尴尬;
- 无意打断:用户随口说句“哦对”(搭话)或跟别人聊天,系统要是误以为是打断自己,就会停掉回复,打乱节奏。
已有解法问题:
- 要么把检测、分类拆成多个独立模块,不稳定;
- 要么把对话管理直接塞进大 LLM 里,计算量爆炸。
【2025-2-24】腾讯 AI Labs 论文提出“语义 VAD”当对话管理器(DM),用轻量级 LLM 搞定轮次切换,平衡了交互流畅度和计算效率。
目标很明确:做一个能平衡“聊天质量、稳定性、计算效率”的全双工 SDS。
SDS 有 6 个核心模块,流程很清晰:
- 声学回声消除(AEC):先干掉环境杂音;
- 声学 VAD:靠声音特征隔离“目标用户”,过滤背景说话人;
- 语音识别(ASR):把用户语音转成文字;
- 语义 VAD(重点!也就是对话管理器 DM):用轻量 LLM 判断用户状态,输出控制指令;
- 核心对话引擎(CDE):大 LLM,只在需要生成回复时启动(省算力);
- 语音合成(TTS):把 CDE 的文字回复转成声音
关键是“声学 VAD+语义 VAD”配合:声学 VAD 管“声音层面”的过滤,语义 VAD 管“语义层面”的判断(比如用户是不是真要打断),而且 CDE 不一直工作,只按需激活——既准又省算力。
核心创新:语义 VAD 对话管理器
- 语义 VAD 本质是“微调过的轻量级 LLM(0.5B 参数)”,专门管全双工的轮次切换
- 核心做两件事:判断用户“是不是说完了”(状态检测)和“是不是故意打断”(意图分析),靠四个控制 token 实现。
解决了全双工 SDS 的实际痛点:
- 用语义 VAD 当 DM:靠 0.5B 轻量 LLM,既保留了 LLM 懂语义的优势(比传统 VAD 准),又不会像大 LLM 那样费算力;
- 四个控制 token 精准控轮次:能分清“有意/无意打断”“查询完没完成”,聊天更流畅;
- DM 与 CDE 独立优化:调 DM 不用重训大 CDE,后续改逻辑更灵活,还能按需激活 CDE 省算力;
- 自己造高质量数据:用 Yuanbao 生成带控制 token 的全双工数据,解决了没公开数据的问题,还平衡了场景比例。
【2025-5-8】Voila
【2025-5-5】Maitrix 开源语音大模型 Voila登场: 全双工对话+百万音色克隆,AI语音助手全面爆炸
- 195ms, 超越人类反应速度 —— 全球首个
- 项目主页 Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play
- 论文 Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play
- 视频介绍
- Web demo
高保真、低延迟的实时流式音频处理能力,能直接处理语音输入并生成语音输出,为用户提供流畅且自然的交互体验。
Voila 集成了语音和语言建模能力,支持数百万种预构建和自定义声音,用户可以通过文本指令或音频样本轻松定制说话者的特征和声音。
包含两个主要模型:
- Voila-e2e 用于端到端语音对话
- Voila-autonomous 用于自主互动。
一个模型即可支持多种音频任务,降低了开发和部署成本。
主要功能
- 实时语音交互:Voila能实现低延迟的语音对话,用户可以直接用语音与模型交流,模型会实时处理语音输入生成语音回复,和真人对话一样流畅自然。
- 多轮对话能力:支持多轮语音对话,模型能根据上下文理解用户的意图,做出连贯的回应。
- 预构建声音库:Voila拥有数百万种预构建的声音,涵盖不同性别、年龄、语调等特征的声音类型。用户可以根据自己的喜好选择声音,比如可以选择温柔的女声、低沉的男声或者活泼的卡通声音来与模型交流。
- 自定义声音:用户还可以通过文本指令和音频样本来定制声音。例如,用户可以上传一段自己熟悉的声音样本,并通过指令让模型模仿这种声音进行对话,使交互更加个性化。
- 语音翻译:经过少量适配后,Voila可以用于多语言语音翻译。用户可以用一种语言说话,模型将其翻译成另一种语言并用语音输出,方便不同语言背景的人进行交流。
技术原理
- 高保真、低延迟、实时流式音频处理:Voila实现了高保真、低延迟的实时流式音频处理,能以195毫秒的超低延迟进行全双工对话,超越了人类的平均反应时间。
- 高效集成语音和语言建模能力:Voila将语音和语言建模能力高效集成,结合了大型语言模型(LLMs)的推理能力与强大的声学建模。使模型在理解语音内容和生成语音回复时更加准确和自然,提升了交互的整体质量。
- 层次化的多尺度Transformer架构:Voila采用了层次化的多尺度Transformer架构,将大型语言模型的推理能力与声学建模相结合。能实现自然、角色感知的语音生成,用户可以通过简单的文本指令来定义说话者的身份、语调及其他特征。
- 统一模型设计:Voila被设计为一个统一的模型,适用于多种语音应用,包括自动语音识别(ASR)、文本到语音(TTS),以及经过少量适配的多语言语音翻译。这种统一模型设计降低了开发和部署成本,提高了模型的通用性和灵活性。
- 强大的语音定制能力:Voila支持超过一百万种预构建的声音,能从短至10秒的音频样本中高效定制新的声音。
阿里
【2025-3-28】Qwen2.5-Omni
详见站内专题: 通义千问专题
阶跃星辰
【2025-7-22】Step-Audio 2
【2025-7-22】阶跃星辰端到端语音模型 Step-Audio 2,支持对情绪、副语言、音乐等非文字信号精细理解
Step-Audio 2 是业内首个将语音理解、音频推理与生成统一建模的架构,打通了「听得懂、想得明白、说得自然」的完整交互链路。模型基于千万小时真实语音数据训练,具备实时对话、语音翻译、工具调用等关键能力。在端到端语音模型中首创任意音色切换和深度思考能力,能对情感场景等副语言信息、声音音乐等非语言信息进行精细理解与推理,达到 SOTA 级语音理解与表达水平。
与此同时,我们还发布了 StepEval-Audio-Paralinguistic 和 StepEval-Audio-ToolCall 两项行业新评测基准。分别衡量语音模型在副语言信息理解与工具调用两大能力维度的表现, 填补了领域空白,进一步完善语音模型的评估体系。
Step-Audio 2 主要通过三个技术实现:
- 真端到端多模态架构:Step-Audio 2 的架构「真」端到端,直接处理原始音频,保证对副语言信息和非人声信息的有效理解。
- 一改传统的 ASR + LLM + TTS 三级结构,实现原始音频输入→语音响应输出的直接转换;这样架构更简单,能够有效减少时延。
- 此外,技术上采用了连续输入+离散输出范式,能直接处理原始音频波形,避免特征提取造成的信息损失,还能通过离散音频 token 保证声音合成稳定性。
- 最后,在语言建模层,Step-Audio 2 实现了文本与语音 token 的 固定比例交错排列,确保文本-语音模态高度对齐,显著提升模型的智商上限。
- CoT 推理结合强化学习:团队首创了端到端语音模型中的深度推理能力,能对情绪、副语言、音乐等非文字信号进行精细理解、推理,实现高情商回复。
- 多模态知识检索增强:模型支持调用 web 搜索,有助于模型解决幻觉问题,同时支持音频检索,让模型可以通过任意自然语言描述来无缝切换音色风格,实现百变音色。
效果:
- 超过开源端到端模型(kimi-audio2、Qwen-Omni3) ,sota
Performance comparision of GPT-4o Audio1, Kimi-Audio2, Qwen-Omni3 and Step-Audio 2 and on various benchmarks.
【2025-8-20】AIRI
【2025-8-20】Project AIRI: 一个能陪你打游戏、交谈的开源 AI 伴侣(二次元老婆)
- 开源AI伴侣项目,支持实时语音与游戏交互
- 开源属性(MIT 协议)和可定制性,所有数据都在本地运行,隐私无忧。
- 项目地址:airi
moeru-ai 团队开源 Airi项目
- GitHub星标超3.4k,最新版本功能完整,支持Web、macOS、Windows全平台部署,主打自托管的AI伴侣体验。
- 具备实时语音对话能力,可深度集成 Minecraft、Factorio 等游戏环境,实现AI在游戏中的协同操作,向Neuro-sama级别的虚拟生命体迈进。
- 系统采用模块化架构,包含语音I/O、LLM推理代理、游戏API接口、情感状态管理四大核心组件。
- 支持Ollama、Claude、Gemini等多模型接入,通过插件系统可扩展至更多沙盒环境。
- 适用于AI-Agent开发者、虚拟人研究者、AI娱乐应用探索者,尤其适合希望构建具身智能代理或情感化交互系统的团队参考与二次开发。
- 上手门槛中等,需基础Docker与API配置能力,项目提供Nix Flake与Compose双部署方案,文档齐全,社区活跃。
部署
git clone https://github.com/moeru-ai/airi
cd airi
pnpm i
pnpm dev:web # 启动浏览器版
【2025-12-29】OmniAgent
多模态大模型的问题:看似能“看懂”视频,但一问到需要音视频精确同步的细节问题,就常常“翻车”。
- 比如,视频里的人说了某句话时,旁边牌子上写了什么字?许多模型,要么无法对齐信息,要么干脆忽略其中一个模态。
【2025-12-29】浙江大学、西湖大学和蚂蚁集团共同提出了一种名为 OmniAgent 的新型智能体框架,或许能彻底改变这一现状。
不再是被动地接收和处理信息,而是像一个侦探一样,主动思考、调用工具、并根据线索进行推理,尤其是通过“先听后看”的策略,实现了前所未有的细粒度音视频理解。
技术对比
- (a) 端到端OmniLLMs:这类模型试图将视觉和音频编码器融合进一个统一架构。虽然想法很好,但它们面临着高昂的训练成本、困难的跨模-态对齐问题,导致细粒度推理能力有限。简单来说,模型很难真正“同步”声音和画面。
- (b) 固定工作流Agent:这类方法依赖于预先设定的、僵化的处理流程。它们缺乏灵活性,无法根据具体问题的需求来动态分配注意力,难以进行真正意义上的细粒度分析。
- (c) 基于字幕的Agent:这种方法通过预先生成视频字幕来理解内容,但计算成本高,且对噪声敏感。更重要的是,单独的字幕往往无法捕捉到完整的跨模态上下文信息。
- (d) OmniAgent 采用全新的主动感知推理范式。它在一个迭代的反思循环中,策略性地调用视频和音频理解能力,从而明确地解决了跨模态对齐的难题,实现了细粒度理解。
【2026-5-12】交互模型
【2026-5-12】北大校友Lilian Weng出镜,爆出120亿估值首个交互模型!
前OpenAI CTO Mira Murati 创办的明星公司,在0产品、0论文的情况下,就凭借全明星创始团队完成了高达20亿美元的种子轮融资,由a16z领投,英伟达、AMD、微软等巨头跟投,估值直接冲上120亿美元,刷新了硅谷早期融资纪录。
- 2025年10月, 发布首个开发者平台
Tinker(一个让大模型微调变得像呼吸一样简单的工具)之后,这一次,他们又交出了一份让业界刮目相看的成绩单。 - 2026年5月,发布交互模型
北大校友翁荔首次出镜,介绍 Thinking Machines 又一产品——交互模型(Interaction Models)!
- 200毫秒神同步,能听懂你的犹豫,更能实时感知协作。
- AI不再是冷冰冰的回复机器,更是同频呼吸的灵魂队友。OpenAI前高管天团,终于又有新作亮相了。
示例
- 任务:每听到一次动物的名字,都计数一次。
即使她在喝水或思考而停止说话时,AI也并没有打断。
最后,当她讲完,AI给出正确答案:
- 鹿出现一次,绵羊一次,郊狼一次,卡皮巴拉一次。
注意,这个交互模型可以隐式地追踪她是在思考、让步、自我纠正还是邀请回应,这个过程中,并没有专门内置的对话管理组件!
【2026-6-2】OpenAI Agentic OS
【2026-6-2】推文 OpenAI 语音黑客之夜(OpenAI Voice Hack Night)冠军:语音优先的手机Agentic操作系统, 颠覆性的“代理手机”(agentic phone)Demo, 搭载全新“代理操作系统”
- 核心理念: “UI 即系统”——手机彻底抛弃了传统 APP,所有界面均由端侧模型实时生成,复杂推理则交由云端 GPT 处理。
- 这种“即时生成”的交互方式不仅展现了大众理想中的 AI 助理形态,更对现有的 App Store 商业模式发起了挑战。
- 演示中,开发者全程通过语音指挥手机订票、管理日历、查新闻和发邮件,甚至没有回避中途因“未配置登录”导致发邮件失败的翻车插曲。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
