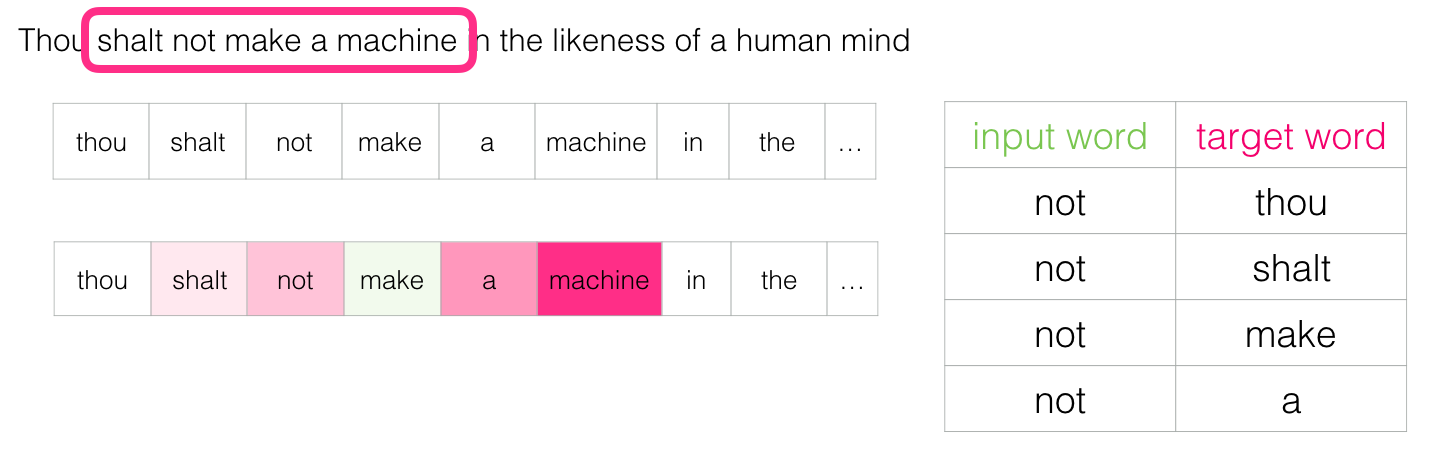
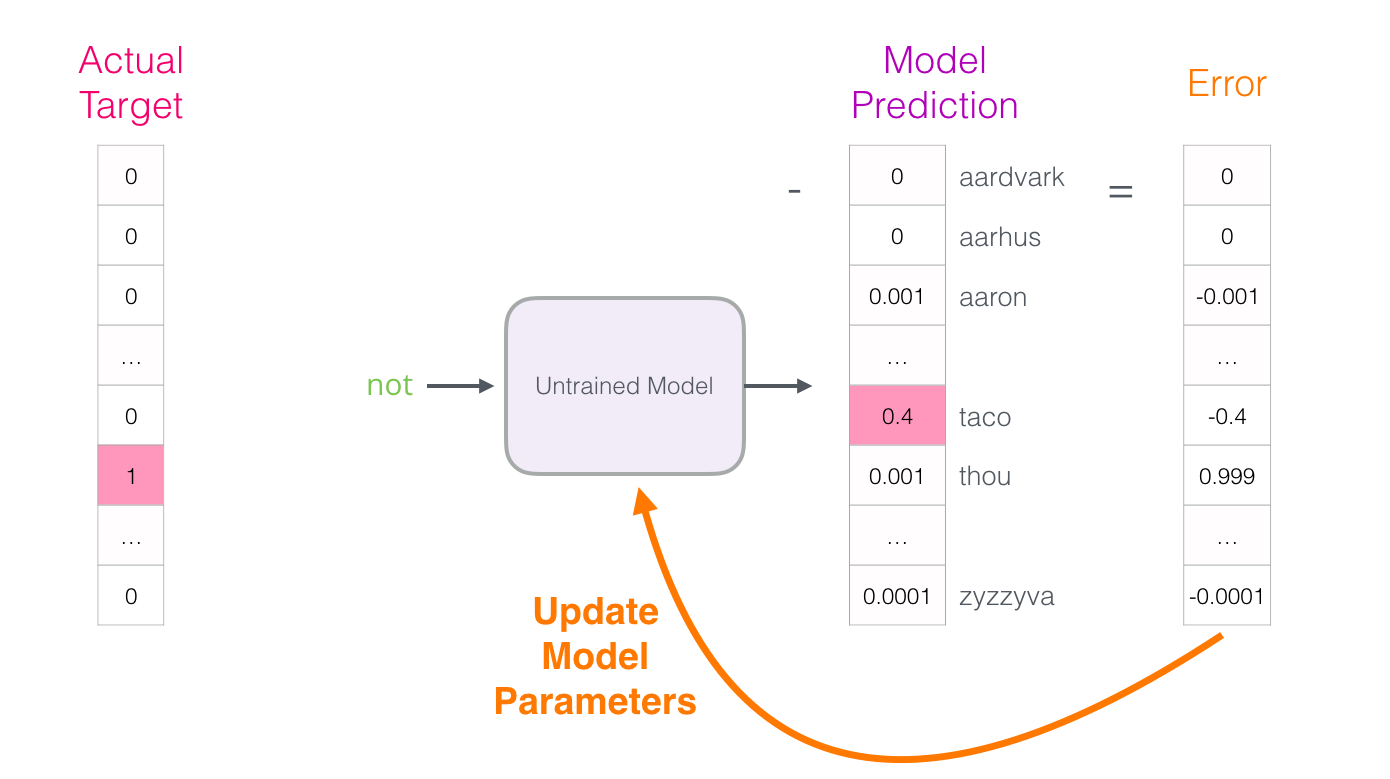
- 自监督表示学习
- 预训练语言模型(PLMs)
- 结束
自监督表示学习
- 【2020-6-19】NLP中的自监督表示学习,英文原文
虽然计算机视觉在自监督学习方面取得了惊人的进展,但在很长一段时间内,自监督学习一直是NLP研究领域的一等公民。语言模型早在90年代就已经存在,甚至在“自我监督学习”这个术语出现之前。2013年的Word2Vec论文推广了这一模式,在许多问题上应用这些自监督的方法,这个领域得到了迅速的发展。
这些自监督方法的核心是一个叫做 “pretext task” 的框架,使用数据本身来生成标签,并使用监督的方法来解决非监督的问题。这些也被称为“auxiliary task”(辅助任务)或“pre-training task“(预训练任务)。通过执行此任务获得的表示可以用作下游监督任务的起点。
下面概述研究人员在没有明确的数据标注的情况下从文本语料库中学习表示的各种pretext tasks。
- 重点是任务的制定,而不是实现它们的架构。
语言模型是对一个语句序列出现概率的建模,它能给出一句话是当前语言地道表述的可能性。
如果一个语句由若干单词序列组成 w1, w2, w3, …, wn,语言模型经过对语料的训练拟合,可以给出概率值 P(w1, w2, w3, …, wn)
- 求解P,需要大量计算量:
P(w1),P(w2|w1),P(w3|w1,w2), …
语言模型演变
长期以来,人类一直梦想着让机器替代人来完成各种工作,包括语言相关工作,如翻译文字,识别语言,检索、生成文字等。完成这些目标的前提是机器能理解语言。
总结
【2024-11-13】大模型时代对话系统(续)
【2024-11-14】NLP应用范式演进史
- 公众号专题文章: NLP范式进化史
语言模型演变过程
【2023-2-20】预训练语言模型的全家福
语法规则→统计语言模型→神经网络语言模型→深度神经网络语言模型
问题:oov/长尾平滑/one-hot维数灾难/无相似性|C1(神经概率语言模型,NPLM):::green C1-->|2010,Tomas Mikolov,RNN记忆|C2(神经网络语言模型,RNNLM):::green C2-->|2013,Tomas Mikolov,层次softmax和负采样,加速训练
首个真正意义上的神经网络语言模型NNLM|C3(神经网络语言模型,Word2Vec):::green C3-->|2018,Google,transformer,两阶段|D(深度神经网络语言模型,双向掩码模型,BERT):::grass D-->|2022,OpenAI,元学习,Prompt|E(深度神经网络语言模型,单向自回归语言模型,GPT-3):::grass
【2023-4-30】国外语言模型演变总结: LLMsPracticalGuide

- 绿色 Encoder-Decoder 、红色 Encoder-only、蓝色 Decoder-only
- ppt, figure_still
【2023-6-9】大模型进化史
- 论文:A Survey of Large Language Models
- 2019 年以来出现的各种大语言模型(百亿参数以上)时间轴,其中标黄的大模型已开源。

【2023-7-2】五万字综述!Prompt-Tuning:深度解读一种新的微调范式
预训练语言模型的发展历程
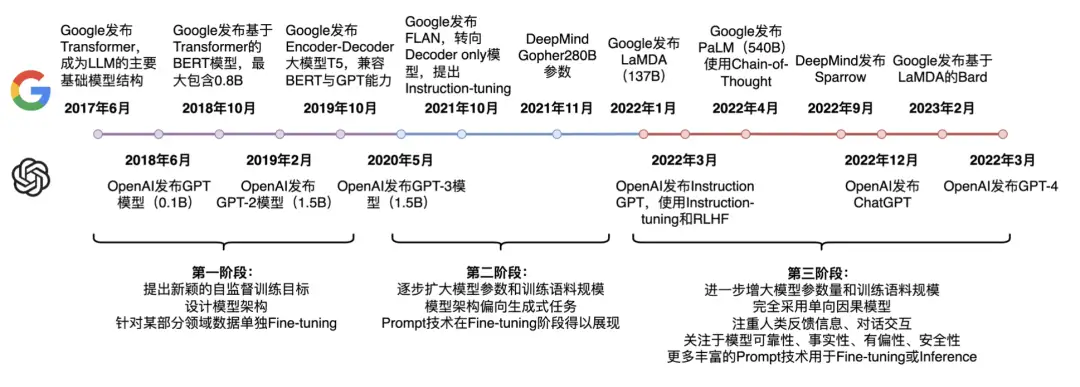
- google 先后推出:
- 2017.6:
Transformer模型 - 2018.10:
BERT(transformer encoder 结构, 0.8b) - 2019.10:
T5(encoder-decoder结构), 兼容 BERT 和 GPT 能力 - 2021.10:
FLAN(Decoder only), 提出 instruction-tuning - 2021.11: Deepmind 退出
Gopher, 280b - 2022.1:
LaMDA137b - 2022.4:
PaLM, 540b, 使用 CoT - 2022.9: Deepmind 发布
Sparrow - 2023.2: 基于 LaMDA 的
Bard模型
- 2017.6:
截止23年3月底,语言模型发展走过了三个阶段:
- 第一阶段 :设计一系列的自监督训练目标(MLM、NSP等),设计新颖的模型架构(Transformer),遵循Pre-training和Fine-tuning范式。典型代表是BERT、GPT、XLNet等;
- 第二阶段 :逐步扩大模型参数和训练语料规模,探索不同类型的架构。典型代表是BART、T5、GPT-3等;
- 第三阶段 :走向AIGC(Artificial Intelligent Generated Content)时代,模型参数规模步入千万亿,模型架构为自回归架构,大模型走向对话式、生成式、多模态时代,更加注重与人类交互进行对齐,实现可靠、安全、无毒的模型。典型代表是InstructionGPT、ChatGPT、Bard、GPT-4等。
语法规则
人们最早想到的办法:让机器模拟人类进行学习,如学习人类通过学习语法规则、词性、构词法、分析语句等学习语言。
乔姆斯基(Noam Chomsky 有史以来最伟大的语言学家)提出 “形式语言” 以后,人们更坚定了利用语法规则的办法进行文字处理的信念。- 遗憾的是,1940-1960,几十年过去了,在计算机处理语言领域,基于这个语法规则的方法几乎毫无突破。
统计语言模型
香农很早就提出了用数学方法来处理自然语言。但是当时用计算机技术无法进行大量的信息处理。
- 不过随着计算机技术的发展,这个思路成了一种可能。
- 首先成功利用数学方法解决自然语言问题的是
贾里尼克(Fred Jelinek) 及他领导的IBM Wason实验室。贾里尼克提出的方法也十分简单:判断一个词序列(短语,句子,文档等)是否合理,就看可能性有多大。- 详见:《数学之美》统计语言模型
- 举个例子:
- 判断 “I have a pen” 翻译为中文 ”我有个笔“是否合理
- 只需要判断 ”I have a pen.我有个笔” 这个序列的可能性有多大。
- 判断一个词序列的可能性需要对这个词序列的概率进行建模,也就是
统计语言模型
马尔科夫假设
- 任意一个词 Wt 出现的概率只同前面的词 Wt-1 有关
如果词由其前面的N−1个词决定,则对应的是N元模型(n-gram), n=2,3,4, (4以上组合爆炸💥,难以计算)
- N-gram/N元语言模型简化P的计算量
马尔科夫假设:当前的单词的出现概率只与之前的n-1个单词有关- 常用:uni-gram, bi-gram, tri-gram等等
- 统计语言模型:基于
VSM(向量空间模型)的语言模型,除了N-Gram,附上典型的LDA、pLSA
统计语言模型初衷是解决语言识别问题。
- 一个语音识别系统,听到一下句子:The apple and 「pear」 salad is delicious.
- 系统它应该如何翻译:The apple and 「pear」 salad is delicious.
- 还是:The apple and 「pair」 salad is delicious.(pear和pair在英文里发音相同)
神经网络语言模型
统计语言模型有很多问题:
- 训练语料中未出现过的词(句子)如何处理(OOV);
- 长尾低频词如何平滑;
- one-hot 向量带来的维度灾难;
- 未考虑词之间的相似性等。
为了解决上述问题,Yoshua Bengio(深度学习三巨头之一)2003年提出用神经网络来建模语言模型,同时学习词的低维度的分布式表征(distributed representation),具体的:
- 不直接对 $P(w^n_1)$ 建模,而是对 $P(w_i|w^{i−1}_1)$ 进行建模;
- 简化求解时,不限制只能是左边的词,也可以含右边的词,即可以是一个上下文窗口(context) 内的所有词;
- 共享网络参数。
当时计算机技术限制,神经网络语言模型的概率结果往往都不好(一层MLP效果肯定好不了),所以当时主要还是用这个形式训练词向量。
- 2013年,word2vec诞生
神经网络语言模型:
- Bengio 在 2003 年提出的
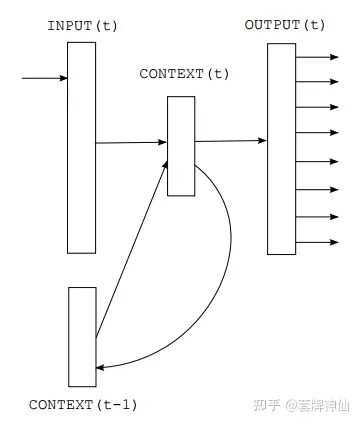
神经概率语言模型(Neural Probabilistic Language Model, NPLM),克服了n-gram模型里词典开销大、需要做平滑的缺点,并提出用 RNN(循环神经网络)做语言模型 VSM升级为词袋模型(CBoW及SG)- 2010年,Tomas Mikolov 提出基于 RNN 的语言模型(Recurrent Neural Network Language Model, RNNLM),RNNLM 根本思想和 NPLM 共通,不同点是词逐个输入到模型,隐藏层有个「记忆功能」单元。
- 2013年,Tomas Mikolov 再接再厉,利用工程经验,引入层次softmax和负采样,解决了RNNLM训练问题,终于诞生了一个真正意义上的神经网络语言模型 Word2vec,主宰了NLP领域预言模型5年多,直至2018年BERT诞生。
神经网络语言模型NNLM。主要有两大类别,基于前馈神经网络的和基于循环神经网络的。
- Feed Forward Based LM
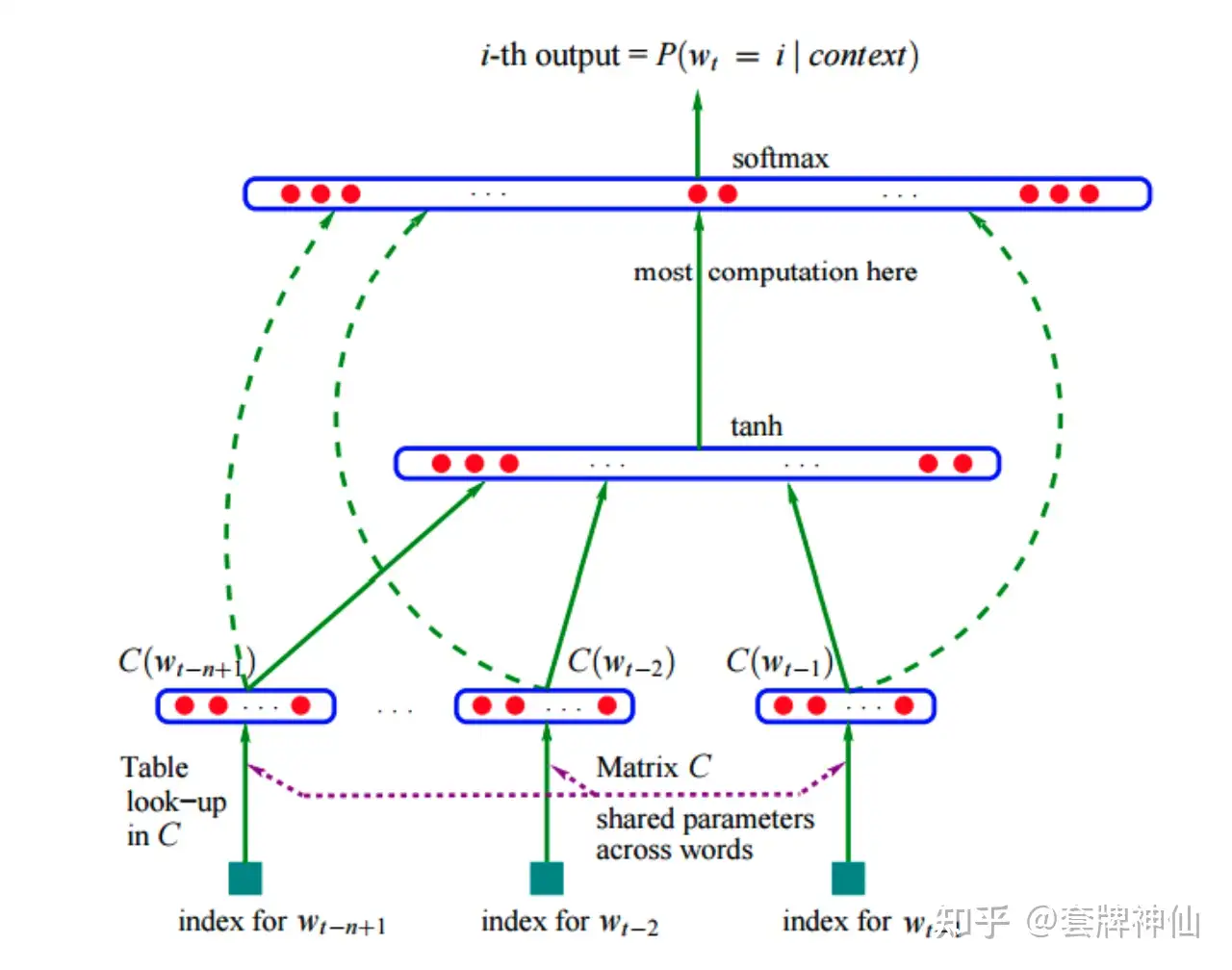
- RNN-Based LM
GPT
随着数据、算力、模型架构、范式等的升级,神经网络语言模型也得到了长足的发展。
- 如模型架构从
mlp到cnn/rnn又到目前的transformer-base ,对应的能力也在不断发展,从之前只对$P(w_i|w_{i−1})$ 建模,通过”“并行”或“串行” 的方式,也可以对 $ P(w^n_i) $ 建模。 - 求解NLP task 从原来的 word2vector + ML 发展为 pretrain + fine-tuning。
- 目前最有代表性的就是
BERT和GPT(1-2)。
随着NLP进入BERT时代后,pretrain + fine tune 这种方式可以解决大量的NLP 任务,但是他依然有很多限制:
- 每个任务都需要大量标注数据,这大大限制了模型的应用。此外,还有大量不好收集标注数据的任务存在;
- 虽然 pretrain 阶段模型吸收了大量知识,但是fine-tuned 后模型又被“缩”到一个很窄的任务相关的分布上,这也导致了一些问题,如在OOD(out-of-distribution) 上表现不好;
- 人类通常不需要在大量的标注数据上学习后才能做任务,而只需要明确告知想让他干嘛(比如:将所给单词翻译为英语:红色->)或者给他几个例子(比如:蓝色->blue,绿色->green,红色->),之后便能处理新的任务了。
GPT 3
终极目标是希望模型能像人一样,灵活的学习如何完成工作。一个可能的方向就是元学习(meta-learning):学习如何学习。
- 而在LM语境下,希望LM 在训练的时候能获得大量的技能和模式识别的能力,而在预测时能快速将技能迁移到新任务或者识别出新任务。
- 为了解决这个问题,一个显现出一定有效性的方法就是”in-context learning”: 用
指令(instruction)或者少量示例(demonstrations)组成预训练语言模型的输入,期望模型生成的内容可以完成对应的任务。 - 根据提供多少个示例,又可以分为
zero-shot,one-shot,few-shot。 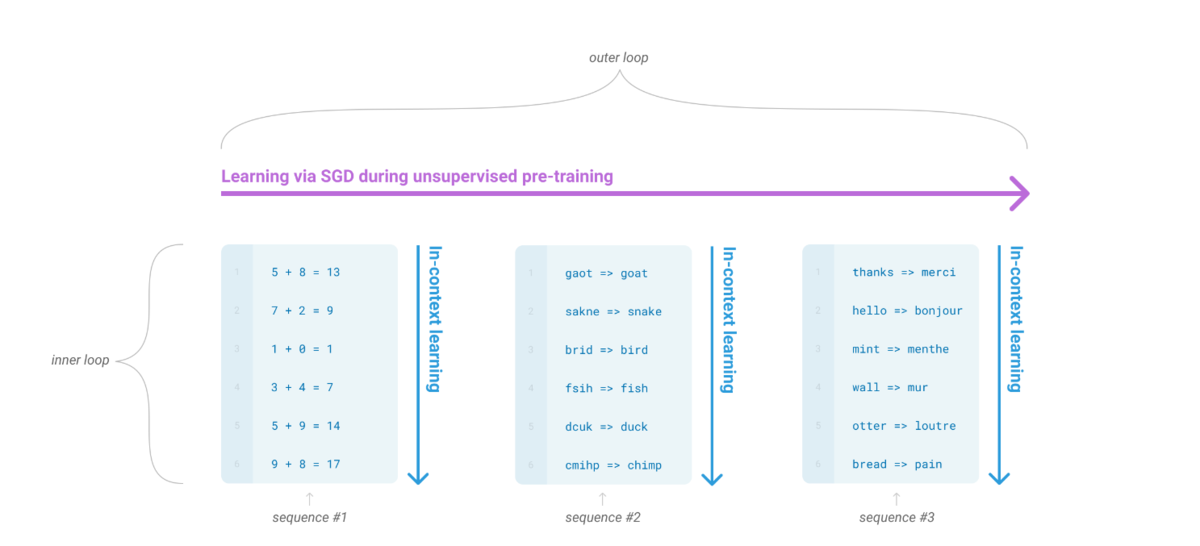

虽然 in-context learning 被证明具有一定的有效性,但是其结果相比 fine-tuing 还有一定的距离。而随着预训练语言模型(PTM)规模的扩大(scaling up), 对应的在下游task 上的表现也在逐步上升,所以OpenAI就猜想:
- PTM的进一步scaling up, 对应的 in-context learning 的能力是不是也会进一步提升?
- 于是他们做了 GPT-3 系列模型,最大的为 GPT-3 175B。
最终模型效果:
- 一些任务上few-shot (zero-shot) 能赶上甚至超过之前 fine-tuned SOTA(如:PIQA)
- 有些任务上还达不到之前的SOTA(如:OpenBookQA);
- 能做一些新task,如3位数算数。
不过他们也发现了模型存在一些问题,并提出了一些可能的解决方案。(所以OpenAI 在2020 年就定下了未来的方向,持续投入至今)
自监督的方案总结
- 【2020-6-21】,英文原文
- 自监督的方法的核心是一个叫做 “pretext task” 的框架,它允许我们使用数据本身来生成标签,并使用监督的方法来解决非监督的问题。这些也被称为“auxiliary task”或“pre-training task“。通过执行此任务获得的表示可以用作我们的下游监督任务的起点。
-
【2020-7-12】刘知远新书:Representation Learning for Natural Language Processing,电子版下载
- 【2020-7-21】自监督学习综述(清华唐杰团队):Self-supervised Learning: Generative or Contrastive
NLP范式
NLP领域技术发展的四个“范式”。
- 非神经网络时代的
完全监督学习(Fully Supervised Learning, Non-Neural Network),此时研究重点关注于特征工程(feature engineering)。 - 基于神经网络的
完全监督学习(Fully Supervised Learning, Neural Network),此时由于神经网络的引入使得特征选取变为了黑盒,研究重点关注于架构工程(architecture engineering)。 预训练-精调范式 (Pre-train, Fine-tune)。NLP领域的第一次重大变化。工作重心又转移到了目标函数工程(objective engineering)上来。预训练-提示-预测范式(Pre-train, Prompt, Predict)。NLP领域的第二次重大变化。但如何选取设计合适的prompt则成了研究热点,即当前的工作重心又转移到了prompt engineering上。
作者:Q同学
自监督任务
总结
总结
- 预测中心词
- 预测邻居词
- 相邻句子的预测
- 自回归语言建模
- 下一个句子预测
- 句子顺序预测
- 句子重排
- 文档旋转
- 表情符号预测
| 任务类型 | 图解 | 示例 |
|---|---|---|
| 预测中心词 | word2vec 里的 CBOW | |
| 预测邻居词 | word2vec 里的 skip-gram | |
| 相邻句子的预测 | Skip-Thought Vectors,句子级别的skip-gram | |
| 自回归语言建模 | n-gram/gpt | |
| 下一个句子预测 | NSP任务,bert使用 | |
| 句子顺序预测 | albert,取代NSP | |
| 句子重排 | bart | |
| 文档旋转 | bart | |
| 表情符号预测 | DeepMoji |
LLM 预训练
【2023-11-29】Jason wei stanford cs330 talk: twitter
6大观点
- (1)NTP(next-word prediction)下一字/词预测 是大规模多任务学习
- I encouraged viewing next-word prediction as massive multi-task learning
- NTP虽然简单,但可以囊括许多下游任务,从简单的语法任务,到复杂的算法推理任务,都能通过LM在预训练阶段学习到
- 示例见博客
- (2)ICL里的
<输入,输出>对学习,可以转化为NTP任务- learning from
<input, output>pairs (in-context learning) can be cast as next-word prediction.
- learning from
- (3)tokens预测任务中信息密度不同,有的很容易,有的很难, LM在推理前需要多花些时间计算(如CoT提示)
- A fundamental observation is that tokens have very different information density;
- easy: “large language ___” is obviously “model”
- hard: answer to a math problem
- A fundamental observation is that tokens have very different information density;
- (4)增加预训练规模有利于降低loss,因为:① LLM 能记忆单词的长尾知识 ② LLM使用复杂启发能尽可能降低loss(优于一阶关联)
- Increasing compute for pre-training is expected to improve loss
- (5)模型规模增加,整体loss平稳下降,而单个任务效果可能突然陡增(涌现能力)
- Although overall loss improves smoothly as you scale, individual tasks might improve suddenly (emergent abilities)
- (6)LLM可以学习ICL中
<输入,输出>对映射关系,有论文证明随机label会降低效果, 最新的研究发现 LLM 能跟随翻转标签和语义无关标签(只存在于一定规模以上的模型)- I argue that large LMs can actually learn at <input, output> relationships in context; our recent work found that language models can follow both flipped labels and semantically-unrelated labels
| Small language model | Large language model |
|---|---|
| Memorization is costly “Parameters are scarce, so I have to decide which facts are worth memorizing” |
More generous with memorizing tail knowledge “I have a lot of parameters so I’ll just memorize all the facts, no worries” |
| First-order correlations “Wow, that token was hard. It was hard enough for me to even get it in the top-10 predictions. Just trying to predict reasonable stuff, I’m not destined for greatness.” |
Complex heuristics “Wow, I got that one wrong. Maybe there’s something complicated going on here, let me try to figure it out. I want to be the GOAT.” |
预训练 vs 后训练
| 维度 | Pre-training | Post-training |
|---|---|---|
| Data quantity | A lot, ~ the internet (trillions of words) | Small, (Millions of examples?) |
| Data quality | Low | High |
| Goal | Most “learning” occurs | Makes model usable by general public |
Emergence in science 涌现科学
General defn. in science
Emergence is a qualitative change that arises from quantitative changes. 量变引起质变
案例
- Given only small molecules such as calcium, you can’t meaningfully encode useful information. Given larger molecules such as DNA, you can encode a genome.
- Popularized by this 1972 piece by Nobel-Prize winning physicist P.W. Anderson.
- With a bit of uranium, nothing special happens. With a large amount of uranium, you get a nuclear reaction.
涌现的问题 Three implications of emergence
- Unpredictable. 难以预测
- Emergence cannot be predicted solely by extrapolating scaling curves from smaller models. 无法通过缩放曲线预测
- Scaling laws don’t apply for downstream tasks! 缩放定律不适用下游任务
- Unintentional.
- Emergent abilities are not explicitly specified by the trainer of the language model (next word prediction “only”).
- In the history of deep learning, has this been true before?
- One model, many-tasks.
- Since scaling has unlocked emergent abilities, further scaling can be expected to elicit more abilities.
- Let’s scale more right? (Any undesirable emergent abilities?)
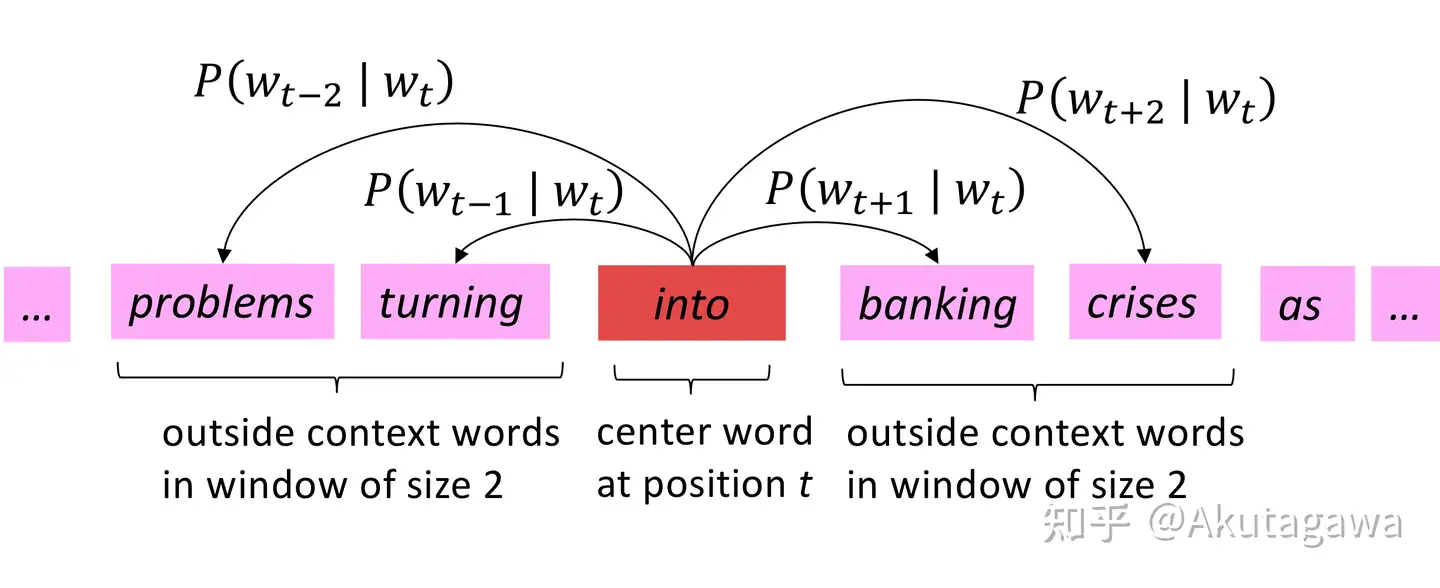
1. 预测中心词(word2vec的CBOW模型)
在这个公式中,取一定窗口大小的一小块文本,我们的目标是根据周围的单词预测中心单词。
- 例如,下图中,有一个大小为1的窗口,在中间单词的两边各有一个单词,用这些相邻的词预测中心词。
这个方案已经在著名的Word2Vec论文的“Continuous Bag of Words”方法中使用过。
2. 预测邻居词(word2vec的skip-gram模型)
在这个公式中,取一定窗口大小的文本张成的空间,目标是在给定中心词的情况下预测周围的词。
这个方案已经在著名的Word2Vec论文的“skip-gram”方法中实现。
3. 相邻句子的预测(Skip-Thought Vectors,句子级别的skip-gram)
在这个公式中,取三个连续的句子,设计一个任务,其中给定中心句,生成前一个句子和下一个句子。它类似于之前的skip-gram方法,但适用于句子而不是单词。
这个方案已经在Skip-Thought Vectors的论文中使用过。
4. 自回归语言建模(n-gram/gpt)
在这个公式中,取大量未标注的文本,并设置一个任务,根据前面的单词预测下一个单词。因为下一个来自语料库的单词已知,所以不需要手工标注。
- 例如,通过预测给定前一个单词的下一个单词来将任务设置为从左到右的语言建模。
- 也可以用这个方案来通给定未来的单词预测之前的单词,方向是从右到左。
这个方案已经使用在许多论文中,从n-gram模型到神经网络模型比如神经概率语言模型 (GPT) 。
5. 掩码语言建模(bert系列)
在这个方案中,文本中的单词是随机掩码的,任务是预测它们。与自回归公式相比,在预测掩码单词时可以同时使用前一个词和下一个词的上下文。
这个方案已经在BERT、RoBERTa和ALBERT的论文中使用过。与自回归相比,在这个任务中,只预测了一小部分掩码词,因此从每句话中学到的东西更少。
6. 下一个句子预测(NSP任务,bert使用)
在这个方案中,我们取文件中出现的两个连续的句子,以及同一文件或不同文件中随机出现的另一个句子。
然后,任务是区分两个句子是否是连贯的。
在BERT的论文中,它被用于提高下游任务的性能,这些任务需要理解句子之间的关系,比如自然语言推理(NLI)和问题回答。然而,后来的研究对其有效性提出了质疑。
7. 句子顺序的预测(albert,取代NSP)
在这个方案中,我们从文档中提取成对的连续句子。然后互换这两个句子的位置,创建出另外一对句子。
目标是对一对句子进行分类,看顺序是否正确。
在ALBERT的论文中,它被用来取代“下一个句子预测”任务。
8. 句子重排(bart)
在这个方案中,从语料库中取出一个连续的文本,并破开的句子。然后,对句子的位置进行随机打乱,任务是恢复句子的原始顺序。
它已经在BART的论文中被用作预训练的任务之一。
9. 文档旋转(bart)
在这个方案中,文档中的一个随机token被选择为旋转点。然后,对文档进行旋转,使得这个token成为开始词。任务是从这个旋转的版本中恢复原来的句子。
它已经在BART的论文中被用作预训练的任务之一。直觉上,这将训练模型开始识别文档。
10. 表情符号预测
这个方案被用在了DeepMoji的论文中,用表情符号来表达推文的情感。如下所示,用推特上的表情符号作为标签,并制定一个监督任务,在给出文本时预测表情符号。
DeepMoji的作者们使用这个概念对一个模型进行了12亿条推文的预训练,然后在情绪分析、仇恨语言检测和侮辱检测等与情绪相关的下游任务上对其进行微调。
表示学习
NLP 应用场景里,做分类、聚类、摘要、机器翻译,首先要将要处理的具体文本转换成模型能够处理的数学形式,并且要求这种表示能够反映文本的独特信息。这就是所谓「Representation」,其实也就是特征提取了。
representation 是 NLP 的核心,在其他机器学习相关的领域,特征表达非常重要,特征设计、特征筛选在以前甚至现在依然是非常重要的一个学术和应用问题。
Embedding(嵌入)2013年在自然语言处理领域频繁出现
- NLP统计学习时代:一般通过one-hot(独热编码)+VSM(向量空间)模型将文本向量化。
- 深度学习时代:广泛使用词嵌入方法来实现文本向量化
【2021-5-6】国立台湾大学陈蕴侬的word embedding,更多课件
从词向量到意义向量——意义向量表征研究
词表示
one-hot 到 embedding
- 顺序编号 → 独热编号 → 词嵌入
(1)顺序编号(离散)
顺序编号:单个字符因为不具有语义,所以一般不对其表示方法作过多探讨(暂不考虑汉语)。
词作为我们认识语言的基本单元,最简单的表示方法是为词进行编号
- 比如有一个包含 1 万个词的词典,第一个词就记为「1」,第二个记为「2」,依次类推。
潜在假设
- 词之间没有任何关系
这种方法一些简单的任务(如文本分类)问题不大,比如可以统计不同 id 的词在两个文本中出现的频次来判断两个文本的相似程度。
- 但问题:id 是一个类别变量值,不能用于比较、计算,词本身是对等的,相互独立,而编号数值无法体现这种特性
- 假想一下要构造一个简单的 NNLM ,某次输入的 N-gram 中包含了 id 为 10000 的词,如果直接输入到模型中,这个巨大的值会导致网络产生严重的偏差。
(2)独热编码(离散)
为了解决顺序编码的问题,独热编码诞生
独热编码:一般用「one-hot representation」来表示一个词
- 每个词都表示为一个向量,其中只有一个维度的值为 1,其他维度的值全为 0,且不同词值为 1 的维度都不同。
比如要处理的语料中一共包含 5 个词,将这 5 个词编号后,可以分别表示为:
- 第一个词: [1 0 0 0 0]
- 第二个词: [0 1 0 0 0]
- 第三个词: [0 0 1 0 0]
- 第四个词: [0 0 0 1 0]
- 第五个词: [0 0 0 0 1]
这就是 one-hot 的含义所在,每个词的向量表示中,只有一个位置是「激活的」(独热)。
- 经过独热编码表示的单词向量相互独立(正交),不能直接比较,满足类别特点
one-hot 表示 应用广泛,但有几个问题:
- 缺乏语义信息,两个词之间无法进行相似性比较
- 假设词之间没有任何关系 —— 显然不符合实际
- 数据稀疏,一个包含 10000 个词的问题,每个词都要表示为长度 10000 的向量,但只有一个位置是有值的,这将会造成很大的存储开销,容易造成
维数灾难- 改进版:
多热编码,一个词向量可以有多个位置激活,舍弃独立假设
- 改进版:
- 【补充】扩展不便:新增一个词就需要改变维数
(3)词嵌入(连续)
鉴于独热编码存在的若干问题(无法表示语义+维数灾难+不易扩展),诞生了词嵌入表示方法
- harris
分布式假说,类似 近朱者赤,近墨者黑
Word Embedding(词嵌入)
- 2003年,Bengio 提出 NPLM 的时候,在模型中去学习每个词的一个连续向量表示
- 2013年,经过 Tomas Mikolov 等人努力,发展出「Word Embedding」这一表示方法。
比如说前面那五个词的表示,用 word embedding 表示:
- 第一个词: [0.2 0.3 0.5]
- 第二个词: [0.7 0.1 0.2]
- 第三个词: [0.1 0.2 0.3]
- 第四个词: [0.2 0.3 0.4]
- 第五个词: [0.3 0.4 0.6]
这样两个词之间就可以比较了, 而且 维数降低(5→3),k 随意指定
- 当然,这种表示下相似值高的两个词,并不一定具有相同语义的,它只能反映两者经常在相近上下文环境中出现。
但无论如何,one-hot 表示的两大问题,word embedding 都给出了一个解决方案。
- word embedding 反映的词与词之间的相似性,可能在语义层面,并不能说是真正的相似(取决于如何定义「相似」了),但「两个 word embedding 接近的词,它们是相关的」这一点是毋庸置疑的。
- word embedding 还能一定程度上反映语言的内在规律 (linguistic regularity)
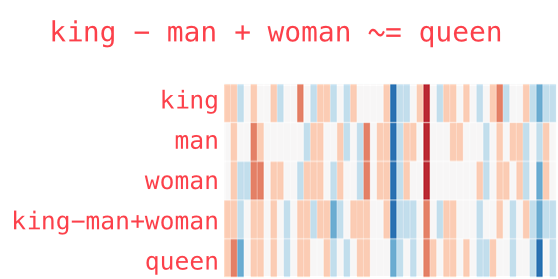
- 比如说 ‘king - man + woman = queen’ 之类的,当然这个特定在实际应用场景里是很少用到的
图解 word2vec
word2vec 是如何训出词向量的?
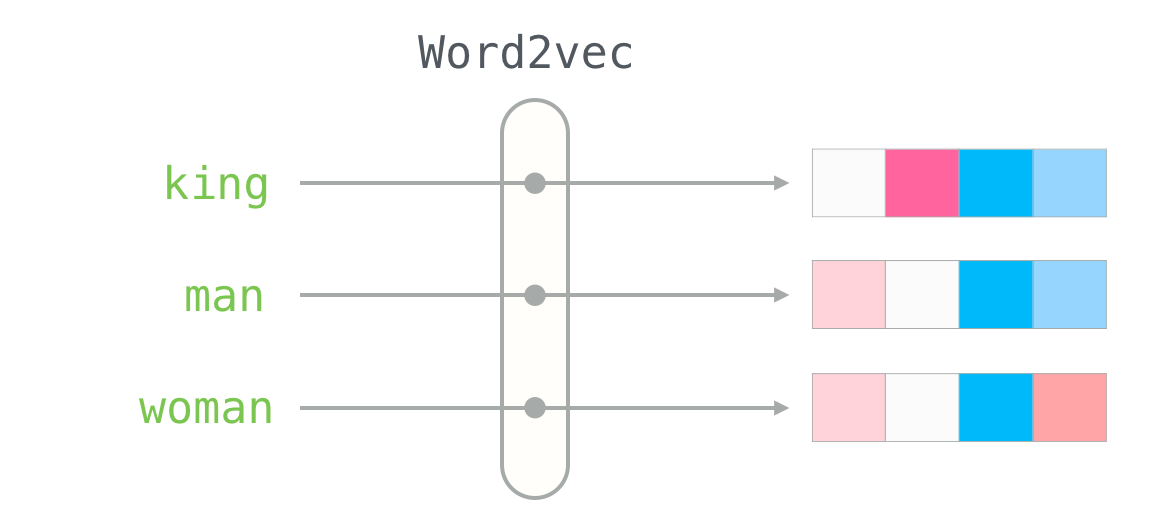
This is a word embedding for the word “king” (GloVe vector trained on Wikipedia):
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
一共50维,取值在0左右波动,范围 [-2,2]

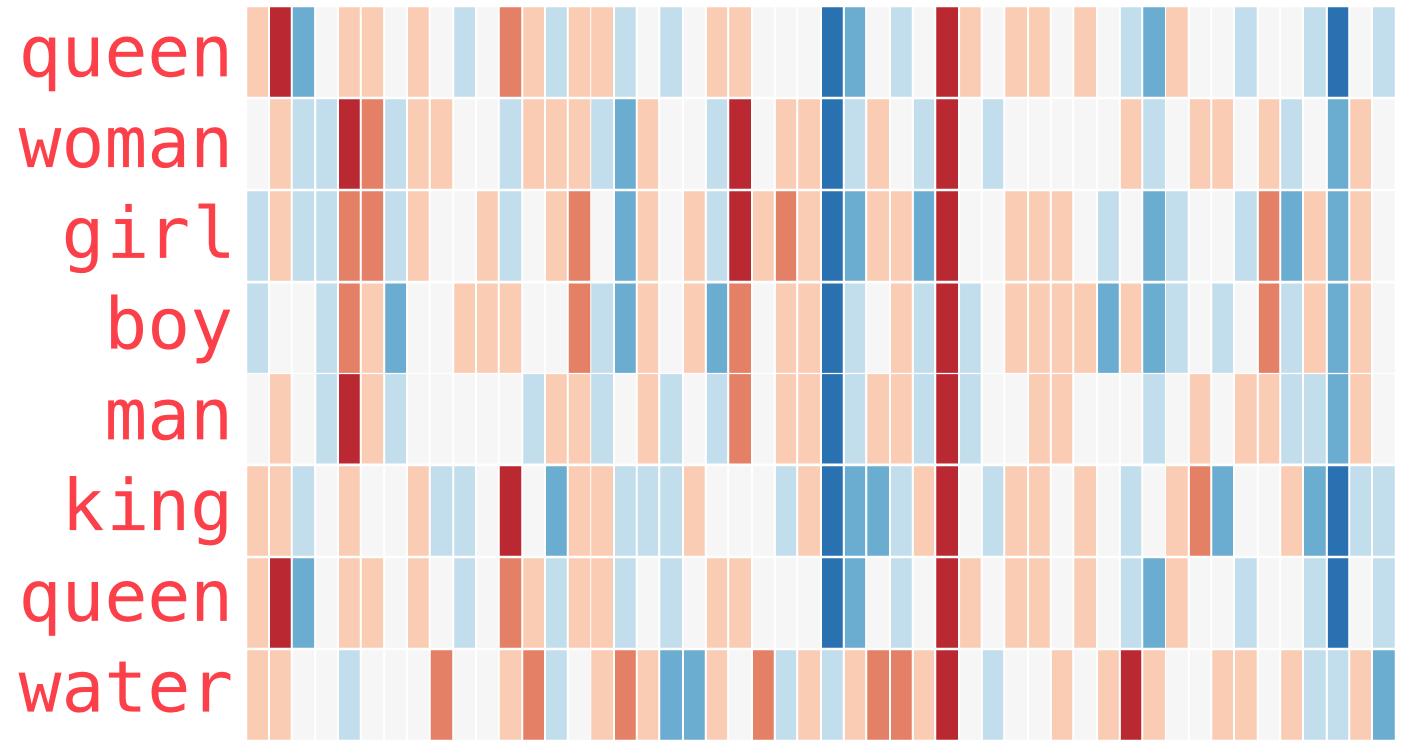
相似度分析:
- “Man” 和 “Woman” 比 “king” 更近(相似),类似的,man 与 boy, girl 与 boy 也近
- “king” - “man” + “woman” -> “queen”
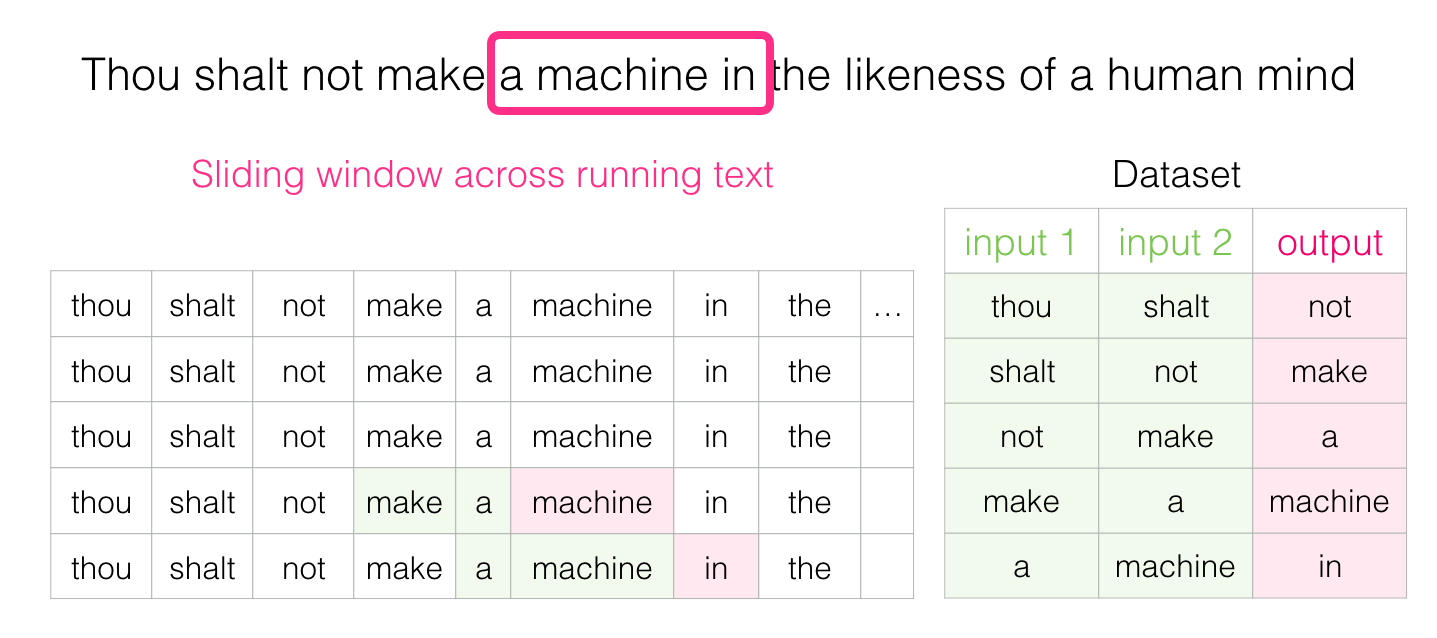
滑动窗口构建训练语料
- CoW
- Skip-Gram
训练方式: 反向传播,得到副产物词向量

句子表示
单词表示有了,句子如何表示?
- 句子及更高层级数据的表示:
VSM和embedding
VSM 与 BoW
在文本分类、文本相似度量等应用场景中,以前常用向量空间模型(Vector Space Model, VSM)来表示一段文本。
- VSM 经常和词袋模型(Bag Of Words, BOW)联系在一起。
- BOW 假设词和词之间是互相独立的,认为词和词之间的位置信息是不重要的,可以算作是 VSM 的一个前提、假设。
BOW 的解释也很形象,假想有一个袋子,每遇到一个词就将其丢进袋子中,直到处理完所有文本。
在此基础上, VSM 要求用一个向量来表示各个文档,这个向量的长度要与词袋中不同词的数量一致。比如说我们有下面两段文本:
- (1) John likes to watch movies. Mary likes movies too.
- (2) John also likes to watch football games.
那么词袋中包含的词就是 $ (John, likes, to, watch, movies, also, football, games, Mary, too)$ 共 10 个词,这样两段文本可以分别表示为:
- (1) [1, 2, 1, 1, 2, 0, 0, 0, 1, 1]
- (2) [1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
不同位置的值为对应的词在文本中的权重,这里使用的是词频。
相似度计算
这样两段文本之间的相似程度可以简单地通过算余弦距离来得到。
TF-IDF
实际上,希望不同维度值是能反映对应的词在文本中的「重要程度」的,而直接使用词频不能达到这个目的,事实上有一些常用的词会在很多的文本里都具有较高的频次,但它们本身并不包含重要的信息。
于是用 TF-IDF(词频-逆文档频率)来作为词的权重
VSM的问题
VSM 的问题
- (1)特征表示往往会很稀疏
- 想象一个包含了 100,000 个不同词汇的文本集合
- 解决方法:将一些文档频率很高的词去除,因为这样的词不能为文本与文本之间的区分性作出贡献,这样的方法能有效地降低向量的维度并保留有效的信息。
- (2)缺乏语义信息。比如说下面两个句子表达的意义是不一样的,但在 VSM 中,两者的表示会一模一样
- Mary loves John
- John loves Mary
n-gram
- 问题(2)的解决办法是使用 N-gram 而非 word 来作为基本单元,比如用 Bigram,上述两句话得到的词袋会是: (Mary loves, loves John, John loves, loves Mary),对应的,两个句子可以表示为:
- [1, 1, 0, 0]
- [0, 0, 1, 1]
神经网络表示
另外一个办法就是使用句子级别的 embedding 表示。
常用的方法有 RNN 和 CNN 两种。
- RNN 比较简单,将句子中的词逐个输入到模型中,结束时取隐藏层的输出即可。
- 因为 RNN 隐藏层的输出是由之前的「记忆」和当前的输入计算得到的,可以认为是「整个句子的记忆」,也就是一个句子的特征表示了
- CNN 是将句子中的词的向量表示拼接成一个矩阵,然后在上面进行卷积,最后得到一个向量表示
CNN 和 RNN 得到的 sentence embedding,同 word embedding 一样,可以进行相似性的对比,语义相近的句子,其向量表示在空间中也会比较接近
段落、篇章表示
既然可以得到 sentence embedding,能不能得到 paragraph embedding 乃至 document embedding 呢?
- 对于前者,Tomas Mikolov 在 2014 年提出了「Paragraph Vector」5,后者的话似乎还没见到过。
- 在 Mikolov 的实验中,paragraph vector 在情感分析上和信息检索两个任务上都取得了比其他模型更好的结果。
- 不过和 word embedding 一样,sentence embedding 和 paragraph embedding 的可解释性仍然存在问题。
预训练语言模型(PLMs)
- The Annotated Transformer,Harvard NLP出品,含pytorch版代码实现
- The Illustrated Transformer
- Transformer模型的PyTorch实现,A PyTorch implementation of the Transformer model in “Attention is All You Need”
【2023-1-31】从ChatGPT说起,AIGC生成模型如何演进
Transformer: 改变了NLP发展困境
- 2017年,Google 发表的著名文章 attention is all you need,提出了transformer模型概念,使得NLP上升了巨大的台阶。Transformer架构的核心是 Self-Attention机制,该机制使得Transformer能够有效提取长序列特征,相较于 CNN能够更好的还原全局。
因为抛弃了传统的RNN模型
- 彻底规避了RNN不能很好并行计算的困扰
- 每一步计算不依赖于上一步的计算结果,因此极大提高了模型并行训练计算的效率。
此外,它能实现自我监督学习。
- 自我监督:不需要标注的样本,使用标准的语料或者图像、模型就能学习了。
随着Transformer的横空出世,根据Decoder/Encoder又可以划分为GPT/BERT模型。
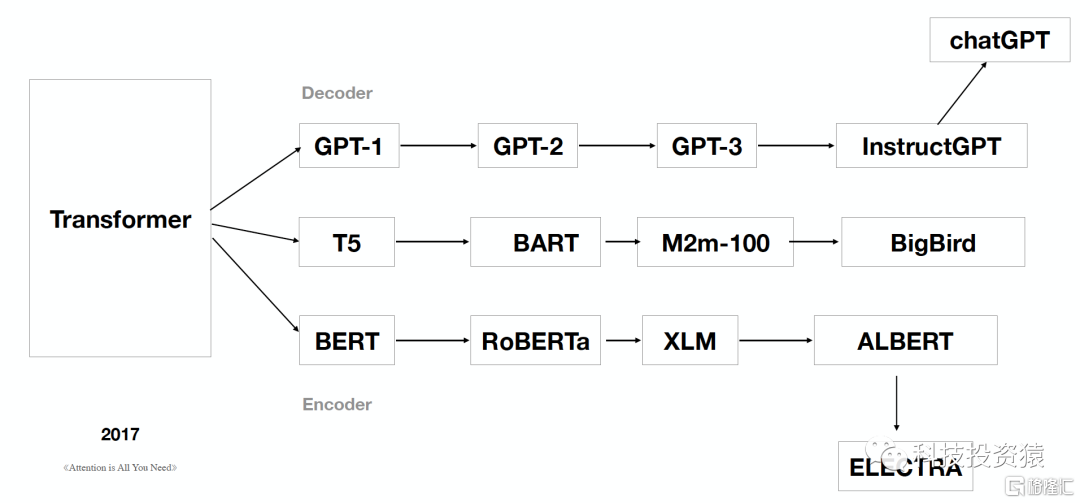
- BERT与GPT分别对应了Transformer的编码器与解码器。其中BERT可以被理解为双向的理解模型,而GPT可以被理解为单向的生成模型。
预训练语言模型
- 【2021-6-7】一文了解预训练语言模型, 配套书籍,预训练语言模型,2021-5出版
- 【2021-6-17】预训练模型最新综述:过去、现在和未来 Pre-Trained Models: Past, Present and Future,全面回顾了 PTM 的最新突破。这些突破是由计算能力的激增和数据可用性增加推动的,朝着四个重要方向发展:设计有效的架构、利用丰富的上下文、提高计算效率以及进行解释和理论分析。
- PTM发展过程 github:清华大学的两位同学——
王晓智和张正彦(在读本科生)整理的一份关于预训练模型的关系图,则可以从功能方面更简单明了的帮我们理解该类模型类别。Pre-Trained Models: Past, Present and Future 论文二作 - 为了解决词汇问题,大规模预训练模型通常采用 subword(深入理解 NLP Subword 算法:BPE、WordPiece、ULM)创建词表。常见的 subword 方式有
BPE(OpenAI GPT-2 与 Facebook RoBERTa),WordPiece(BERT),Unigram Language Model等。 -
采用 Transformer Encoder 架构的 BERT 在预训练时,随机对部分
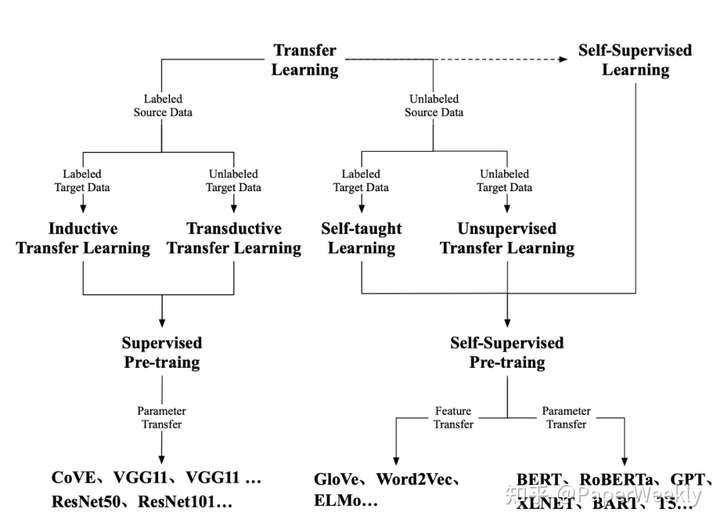
分词(subword)进行了掩码(如 dog, ##ing 变 [MASK] )。对于中文,上述对分词随机掩码的方式存在分割单词、破坏语义的情况,因此 BERT-WWM (Pre-Training with Whole Word Masking for Chinese BERT )提出了 whole word mask 。针对整个 中文单词 进行掩码。 - 迁移学习分类
- 【2020-8-13】打破BERT天花板:11种花式炼丹术刷爆NLP分类SOTA!
- NLP分类模型时间线
- 2020年3月18日,邱锡鹏老师发表了关于NLP预训练模型的综述《Pre-trained Models for Natural Language Processing: A Survey》
- 【2020-9-9】预训练语言模型(PLMs)走的飞快
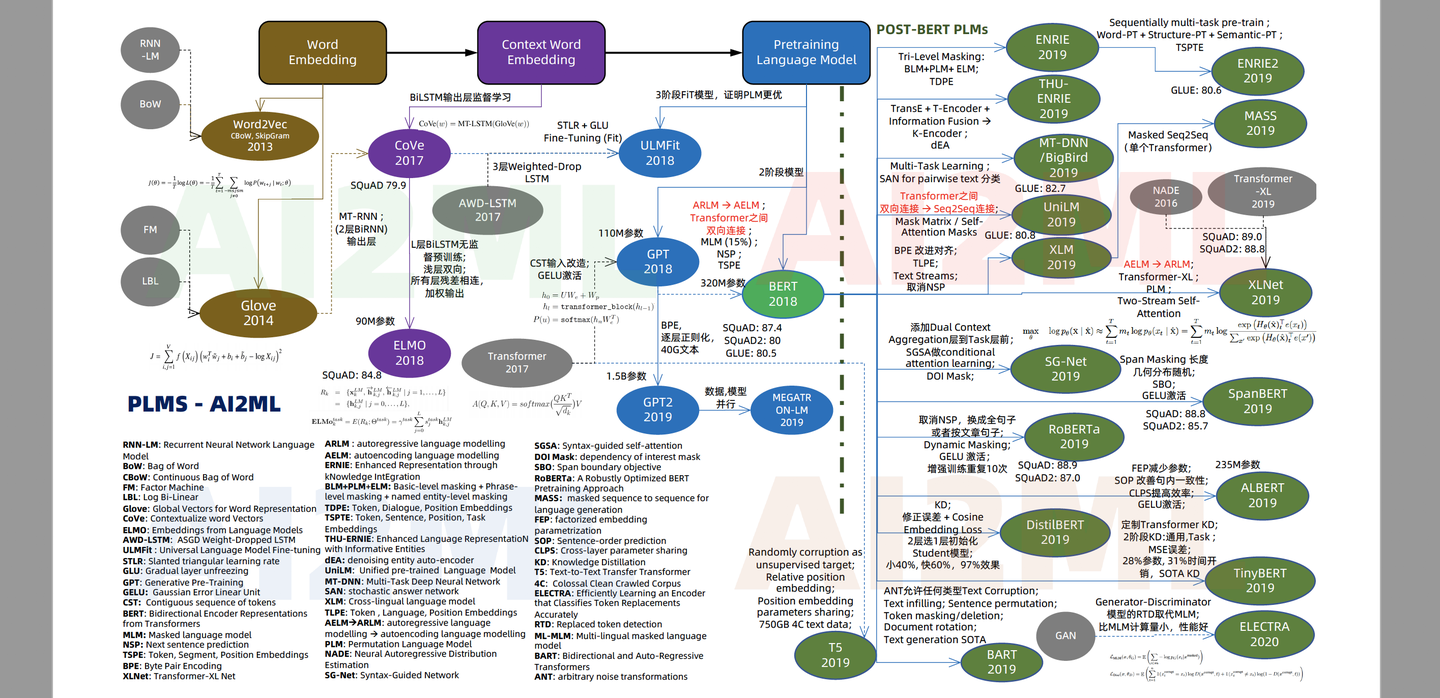
- 预训练模型在经历中4个时代
- 第一个是轰动性的词嵌入(Word Embedding)时代, 杰出代表是Word2Vec和Glove;
- 第二个是上下文嵌入(Context Word Embedding),代表为CoVe和ELMO;
- 第三个时代是预训练模型,代表是GPT和BERT;
- 第四个时代是改进型和领域定制型。
- 改进型代表为ALBERT和XLNet
- 领域定制化(Domain Specific)代表为SciBert (Scientific Bert) 和BioBert(Biomedical Bert)。
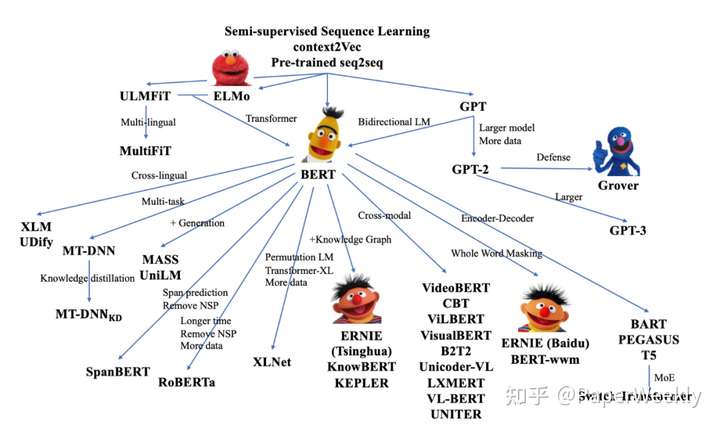
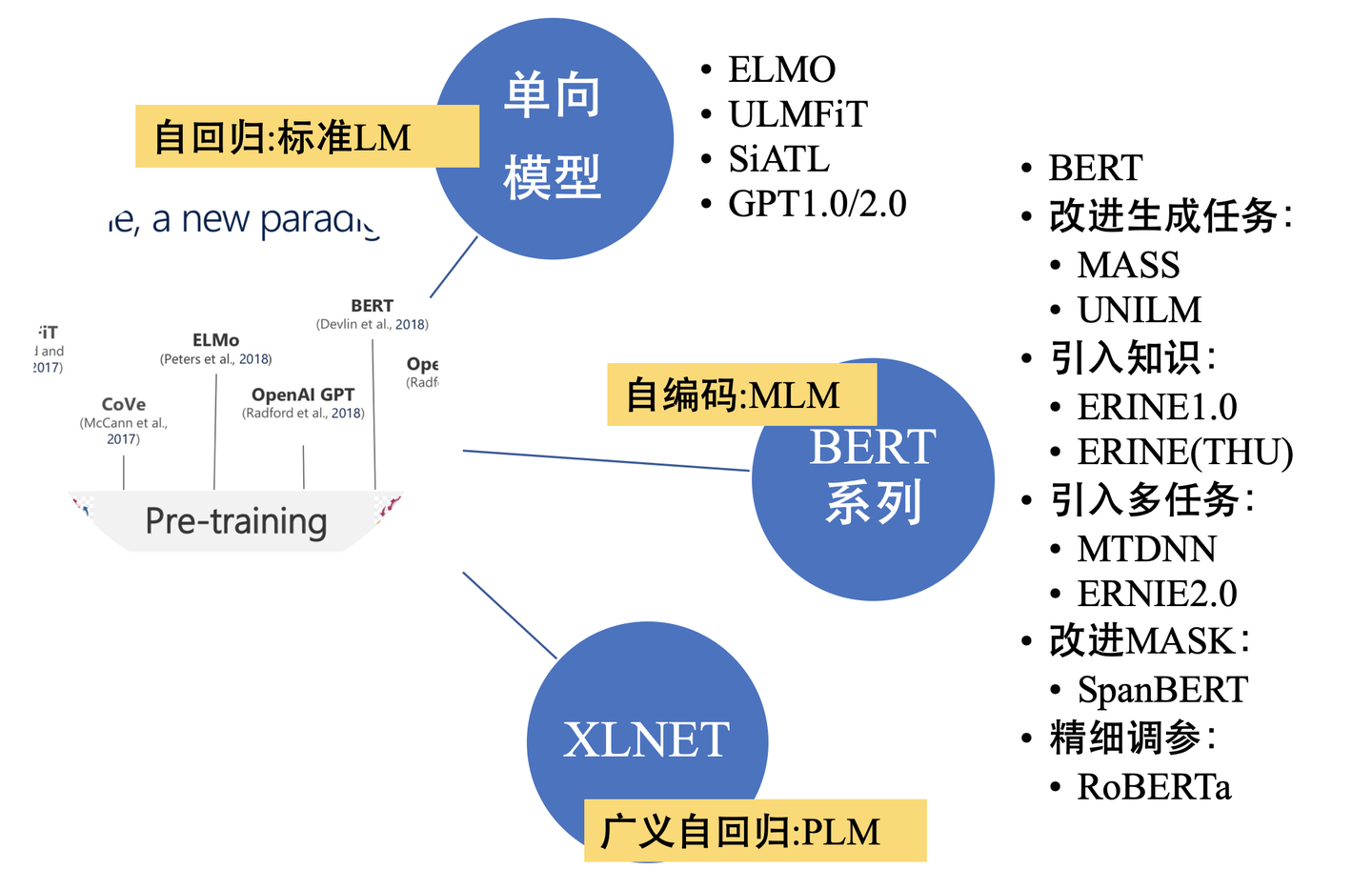
- 【2020-9-30】nlp中的预训练语言模型
- 主要包括3大方面,涉及到的模型有:
- 单向特征表示的自回归预训练语言模型,统称为单向模型:ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0;
- 双向特征表示的自编码预训练语言模型,统称为BERT系列模型:(BERT/MASS/UNILM/ERNIE1.0/ERNIE(THU)/MTDNN/ERNIE2.0/SpanBERT/RoBERTa)
- 双向特征表示的自回归预训练语言模型:XLNet;
- PTMs: Pre-trained-Models in NLP,NLP预训练模型的全面总结(持续更新中)
- 2020年3月18日,邱锡鹏老师发表了关于NLP预训练模型的综述《Pre-trained Models for Natural Language Processing: A Survey》
- 知乎文章1: 全面总结!PTMs:NLP预训练模型,图片下载
- 知乎文章2:nlp中的预训练语言模型总结
- 知乎文章3:nlp中的词向量对比
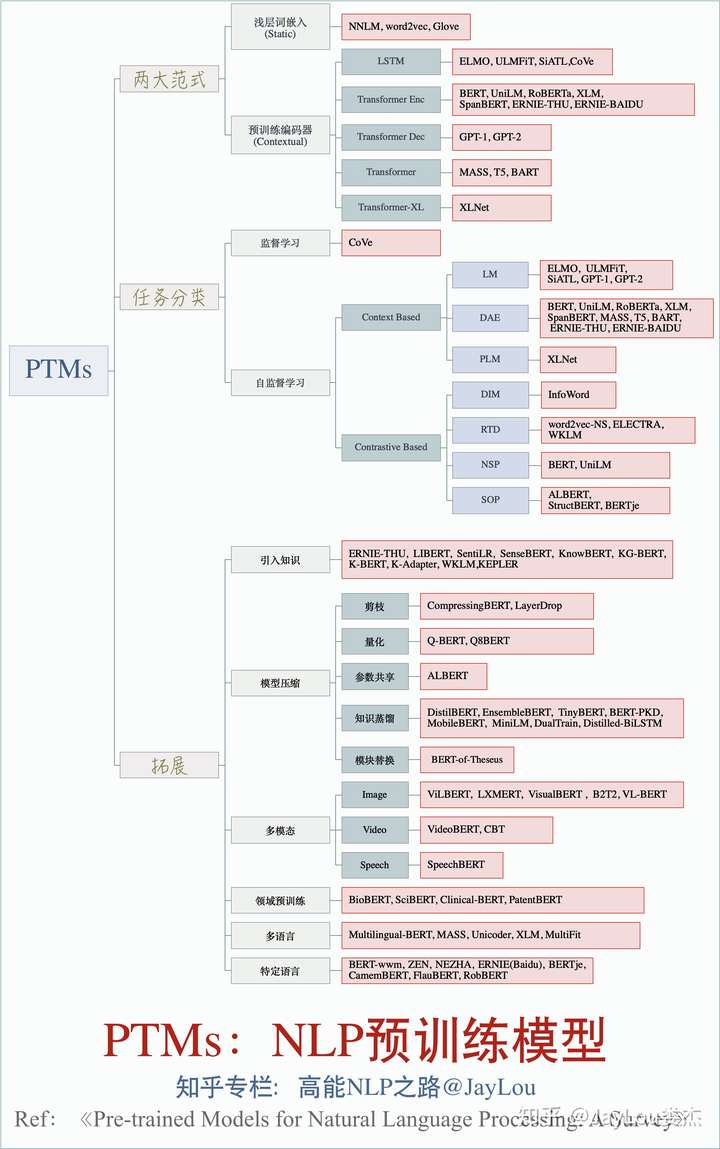
- 对比分析,摘自:论文笔记 - Pre-trained Models for Natural Language Processing,Pre-trained Models for Natural Language Processing: A Survey
LM(Language Modeling)是 NLP 中最常见的无监督任务,通常特指自回归或单向语言建模,BiLM 虽然结合了两个方向的语言模型,但只是两个方向的简单拼接,并不是真正意义上的双向语言模型。MLM(Masked Language Modeling)可以克服传统单向语言模型的缺陷,结合双向的信息,但是 [MASK] 的引入使得预训练和 fine-tune 之间出现 gapPLM(Permuted Language Modeling)则克服了这个问题,实现了双向语言模型和自回归模型的统一。DAE(Denoising Autoencoder)接受部分损坏的输入,并以恢复原始输入为目标。与 MLM 不同,DAE 会给输入额外加一些噪声。CTL(Contrastive Learning) 的原理是在对比中学习,其假设是一些 observed pairs of text 在语义上比随机采样的文本更为接近。CTL 比 LM 计算复杂度更低。
- 综述从四个方面(Representation Types、Architectures、Pre-training Task Types、Extensions)对现有 PTMs (Pre-trained Models) 进行了系统分类,一幅图来概括全文精华:
【2023-3-30】预训练模型综述:将 NLP/CV/GL 领域各个大模型分析的清清楚楚, 应用领域涉及 Speech、Video、Multimodal和Code Generation
【2023-4-3】LLMs演进图解, paper
【2023-6-13】LLM 里程碑论文及各大模型信息, pretrain、instruct对齐、

PTM 模型分类
【2023-3-30】一文详解Prompt学习和微调(Prompt Learning & Prompt Tuning)
- ● Left-to-Right LM: GPT, GPT-2, GPT-3
- ● Masked LM: BERT, RoBERTa
- ● Prefix LM: UniLM1, UniLM2
- ● Encoder-Decoder: T5, MASS, BART
Transformer 开创了继 MLP 、CNN 和 RNN之后的第4大类模型。
基于Transformer结构的模型又可以分为Encoder-only、Decoder-only、Encoder-Decoder这三类。
- 仅
编码器架构(Encoder-only):自编码模型(破坏一个句子,然后让模型去预测或填补),更擅长理解类的任务,例如:文本分类、实体识别、关键信息抽取等。典型代表有:Bert、RoBERTa等。 - 仅
解码器架构(Decoder-only):自回归模型(将解码器自己当前步的输出加入下一步的输入,解码器融合所有已经输入的向量来输出下一个向量,所以越往后的输出考虑了更多输入),更擅长生成类的任务,例如:文本生成。典型代表有:GPT系列、LLaMA、OPT、Bloom等。 编码器-解码器架构(Encoder-Decoder):序列到序列模型(编码器的输出作为解码器的输入),主要用于条件生成任务,例如:翻译,概要等。典型代表有:T5、BART、GLM等。
哈工大分类
【2023-3-6】哈工大资料对PLM的分类
- (1)
编码预训练语言模型(Encoder-only Pre-trained Models):只用transformer里的编码器- 预训练任务:MLM,掩码语言建模任务(Masked Language Modeling)
- 示例:
- BERT: 最经典的编码预训练语言模型,其通过掩码语言建模和下一句预测任务,对 Transformer 模型的参数进行预训练
- ALBERT: 轻量化的 BERT 模型,作者通过分解词向量矩阵和共享 Transformer 层参数来减少模型参数个数
- RoBERTa (更多语料以及动态掩码机制)
- (2)
解码预训练语言模型(Decoder-only Pre-trained Models)- GPT (Generative Pre-trained Transformer) 是由 OpenAI 提出的只有 解码器的预训练模型。
- GPT 系列模型,包括 GPT-1、GPT-2 和 GPT-3
- (3) 基于
编解码架构的预训练语言模型(Encoder-decoder Pre-trained Models)- 基于
编码器的架构得益于双向编码的全局可见性,在语言理解的相关任务上性能卓越,但是因为无法进行可变长度的生成,不能应用于生成任务。 - 基于
解码器的架构采用单向自回归模式,可以完成生成任务,但是信息只能从左到右单向流动,模型只知“上文”而不知“下文”,缺乏双向交互。 - 针对以上问题,一些模型采用序列到序列架构来融合两种结构,使用编码器提取出输入中有用的表示,来辅助并约束解码器的生成。
BART具体结构为一个双向编码器拼接一个单向的自回归解码器,采用的预训练方式为输入含有各种噪声的文本,再由模型进行去噪重构。在解码器部分,BART 每一层对编码器的最后一层的隐藏表示执行交叉 注意力机制以聚合关键信息。BART 在维基百科和 BookCorpus 数据集上训 练,数据量达 160GB。T5BART 为了兼顾不同任务设计了复杂的预训练任务,针对如何在多个 任务中实现优秀的迁移性能这一问题,谷歌研究者提出了一种新的范式:将 所有自然语言处理任务统一成“文本到文本”的生成任务。T5 通过在输入 之前加入提示词,实现了用单个模型解决机器翻译、文本摘要、问答和分类 等多个任务。针对迁移学习需要的巨量、高质量和多样的预训练数据,T5 在 谷歌专门构造的 C4 数据集上进行训练。Switch Transformers随着语言模型的深入研究,参数量的增加可以显著提高模型的性能,但随之而来的就是应用时越来越大的运算量。Swicth-Transformer 将混合专家网络(Mixture-of-Experts,MoE)的条件运算思想引入 Transformer 的全连接层,实现增加模型的尺寸而不增加推理时的运算量
- 基于
huggingface分类
【2023-2-20】预训练语言模型的全家福
PTM指Pre-Trained Language Model,特指遵循两阶段训练模式(预训练+微调)的语言模型。
Huggingface在官网文档中,提供了它目前所支持的预训练模型的全家福。将Transformers目前支持的预训练语言模型分成了五类:
- Autoregressive models -
自回归语言模型 - Autoencoding models -
自编码语言模型 - Sequence-to-sequence models -
序列到序列语言模型 - Multimodal models -
多模态语言模型 - Retrieval-based models -
基于检索的语言模型
其中,多模态语言模型指能够处理输入混合了文本和其它模态的数据,例如图片语音等等的语言模型,适合一些特殊的应用场景。比如像MMBT这个模型,它的输入就组合了文本embedding以及图像经过resnet后最后激活层的embedding数据,并用一层FC变换成适合Transformer结构的尺寸。
基于检索的语言模型也相对小众,它在训练和推理过程中都利用了文档检索的技术,用来解决开放域的问答和推理任务。
| Autoregressive 自回归 | Autoencoding 自编码 | Seq2Seq | Multimodal | Retrieval-based |
|—|—|—|—|—|
| GPT
GPT-2
CTRL
Transformer-XL
Reformer
XLNet | BERT
ALBERT
RoBERTa
DistilBERT
ConvBERT
XLM
XLM-RoBERTa
FlauBERT
ELECTRA
Funnel Transformer
Longformer
| BART
Pegasus
MarianMT
T5
MT5
MBart
ProphetNet
XLM-ProphetNet | MMBT |DPR
RAG |
自回归、自编码、序列到序列语言模型比较
Autoregressive和Autoencoding区分语言模型的概念,由XLNet论文提出。
- Autoregressive/
自回归,这个词来源于时间序列分析,因为在时间轴上,我们无法利用到未来信息。它只对文本进行单向(无论从左到右还是从右到左)处理,即只利用了上文而无法利用下文信息。它的预训练任务是利用概率分布生成第一个词,再根据第一个词生成第二个词,以此类推。从结构上,它类似transformer中的decode部分。虽然它可以经过微调适用于各种类型的下游任务,但最自然的应用场景还是文本生成,典型的模型是GPT系列。 - Autoencoding/
自编码,它可以看成是transformer中的encode部分。它的训练任务把一段被破坏/加噪音/加了Mask的输入文本恢复成完整的样子。预训练的时候,上下文双向信息都可以使用。经过微调,它也可以适用于各种类型的下游任务,但最自然的应用还是句子分类或者是词元分类,典型的模型如BERT。
需要注意的是,所谓自回归和自编码的分类方法,只是针对预训练任务的不同而言。有时候,同样的结构可以胜任多种预训练任务,此时,就以第一次提出它的论文中所述的预训练任务为准。
Seq2Seq/序列到序列任务,它同时使用了encode和decode结构,最典型的应用场景是翻译,当然也可以把其它类型的NLP任务当成是seq2seq任务。原生的transformer,以及预训练模型T5都是这种类型。
CLM vs. MLM vs. PLM vs. TLM
有时候会看到类似CLM,MLM这样的术语。
CLM,即Causal language modeling,对应着传统的自回归训练。MLM,即Masked language modeling,对应着加了Mask噪音文本的去噪复原训练任务。TLM,即Translation language modeling,对应着语言翻译任务。- 有时候
MLM和TLM会结合起来,两种语言的句子对被连接起来并应用了随机遮罩,语言模型在尝试恢复的时候可以同时使用两种语言的信息。
- 有时候
PLM,Permutation language model是XLNet论文中的主要创新。通过BERT模型的发现,它对传统自回归模型的改进效果,很大程度上来自于它可以融合利用双向上下文信息的能力。XLNet虽然算是一种自回归模型,但是它也希望能够学习到这种双向信息,但它又不希望引入MLM中的Mask,因为这会带来预训练和微调阶段的不一致性。XLNet给出了解决方案,虽然从外面看,它的输入仍然是单向有序的,但其内部利用一种Attention Mask技术实现了输入序列的重排,并且不会引入不一致性。重排之后,原本在后面的单词就有可能轮换到前面,从而实现对下文信息的有效利用。
按目标分类
刘鹏飞将预训练语言模型分为了四类:
- 基于特征工程 (feature engineering) 的方法
- 基于特征工程的方法,是为了通过人们的先验知识来定义某些规则,使用这些规则来更好地提取出文本中的特征,以此来对文本进行编码。
词袋模型(Bag-of-words model, BOW) 通过计算词频来对词语进行编码。- TF-IDF
- 基于结构工程 (architecture engineering) 的方法
- 基于目标工程 (objective engineering) 的方法
- 基于提示工程 (prompt engineering) 的方法。
Feature engineering
基于特征工程的方法,是为了通过人们的先验知识来定义某些规则,使用这些规则来更好地提取出文本中的特征,以此来对文本进行编码。
基于特征的方法
- 优点:运行速度快,同时如果特征提取到位可能会取得很好的效果
- 缺点:如何根据先验知识来设计需要提取的特征。
词袋模型(BoW)
三个句子:
- E1: 我 喜欢 小丽
- E2: 小丽 喜欢 小明
- E3: 小明 喜欢 我
对混乱的三角恋关系
- 构建出词与id之间的映射关系:
- {‘我’: 0, ‘喜欢’: 1, ‘小丽’: 2, ‘小明’: 3}
- 接着统计词频,即可获得词编码。
- E1的词编码为 [2, 2, 2, 0];
- E2的词编码为 [0 , 2 , 2 , 2]
- E3的词编码为 [2 , 2 , 0 , 2]
评价
- 优点:
- 比起 one-hot V × V 的内存消耗 (V 为词表大小),BOW 的内存消耗只有 V ;
- 可以提取出词频这个特征。
- 缺点:
- 没有词序特征;
- 不是词频越大的词越重要 (比如“的”)。
词频-逆文档 (TF-IDF)
TF-IDF (Term Frequency-Inverse Document Frequency) 能够有效识别词语在文本中的重要程度。其分为两部分,TF 和 IDF。
TF-IDF 算法不仅考虑了在单一文档中的词频,还考虑了该词语在全局出现频率。
- 如果这个词在少量文章中出现,且词频很高,那么这个词就对这个文章很重要,反之亦然。
评价
- 优点:可以有效识别词语对文档的重要性。
- 缺点:不能够包含词语的上下文信息。
architecture engineering
基于结构工程的方法,无需再用人的先验知识来进行特征工程,而是将人力放在如何设计一个好的模型结构来自动学习文本中的特征。
Architecture engineering 总结
- 优点:采用了深度学习方法来学习词向量,当输入语料很大的时候,可以学习出一个质量很高的词嵌入。
- 缺点:仅仅是训练出词向量,再将词向量放入到下游模型中作为输入,而模型本身并不会用来做下游任务。
Word2Vec
word2vec简单来说就是一个高效的实现word embedding的算法工具。
Word2Vec 的详细信息见博客《Word2Vec原理与公式详细推导》。
- 通过一个线性的全连接层,来预测词语的上下文或者根据词语的上下文来预测该词语。
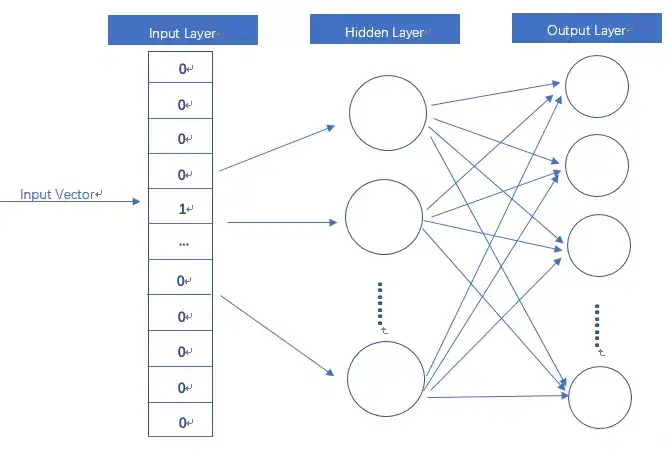
- word2vec模型是一个简单化的神经网络,输入是One-Hot向量,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。
- 模型训练好以后,并不会用这个训练好的模型处理新的任务,真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵。
如何定义数据的输入和输出呢?CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。
CBOW模型: 训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。Skip-Gram模型: 和CBOW的思路是反着,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
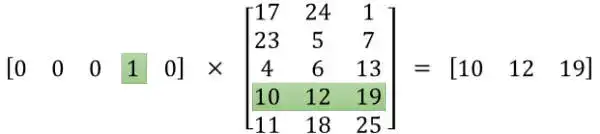
将一个1 x 10000的向量和10000 x 300的矩阵相乘,会消耗相当大的计算资源
- 为了高效计算,隐层权重矩阵看成了一个”查找表“(lookup table),进行矩阵计算时,直接去查输入向量中取值为1的维度下对应的那些权重值。隐层的输出就是每个输入单词的word embedding vector
【2023-6-22】公式推导
似然函数的目标函数 $J(\theta)$, 可以取作(平均)负对数似然
- $J(\theta) = -\frac{1}{T} \log L(\theta) = -\frac{1}{T} \log \prod_{t=1}^{T} \prod_{\substack{-m \leq j \leq m \ j \neq 0}} P(w_{t+j} \mid w_{t};\theta) = -\frac{1}{T} \sum_{t=1}^{T} \sum_{\substack{-m \leq j \leq m \ j \neq 0}} \log P\left(w_{t+j} \mid w_{t} ; \theta\right)$
- 窗口 m, 位置 wj, $\theta$ 为模型权重
- 最小化目标函数 = 最大化似然函数(预测概率/精度),两者等价
- log形式是方便将连乘转化为求和,负号是希望将极大化似然率转化为极小化损失函数的等价问题

- 详见 斯坦福CS224n 第1讲 - NLP介绍与词向量初步
优点:
- W2V 算是掀起了深度学习在NLP领域的热潮,可以为每个词语单独赋予一个独有的词向量,并且词向量中还能够包含上该词语的上下文信息。
缺点:
- 不能包含全局信息;
- 每个词语有且仅有一个词向量,没办法有效区分多义词。
GloVe
GloVe 的详细信息见博客《GloVe原理与公式讲解》。
GloVe 则是通过给定一个目标公式,然后将其反推出来。
评价
- 优点:在 W2V 的基础上,还能够学习到词语的全局信息。
- 缺点:同样没有办法区分多义词。
FastText
FastText 的模型结构与 W2V 类似,只不过 W2V 是做预测上下文或中间词,FastText 是做文本分类。只是输出层不同。而且 FastText 的输入是 char 级的 n-gram,其目的在于许多词的字母都是重复的 (比如 apple 和 people 有 ple 是重复的),采用这种输入方式可以有效降低输入的数量,也可以学习到词语的共性。
- 虽然其目的在于做文本分类,但是也可以学习到字符级的词向量。
评价
- 优点:可以学习字符级的词向量,训练速度快,且性能不弱于很多大模型。
- 缺点:训练出的词向量可以放在下游任务,但是如果要用该模型做下游任务会有困难。
ELMo
EMLo 的详细信息见《BERT学习笔记(4)——小白版ELMo and BERT》。
用一个双向RNN来学习词语 i ii 的上文与下文,通过这些上文信息与下文信息来预测词语 i ii。
评价
- 优点:可以解决一词多义的问题,因为不同的上下文输出的词向量是有区别的。
- 缺点:模型依旧是输出词向量,而模型本身并不能很好的用于下游任务。
objective engineering
基于目标工程的训练方式,不会对模型本身做太多改动 (比如 BERT 家族或者 GPT 家族),而是在损失函数上做改动,以适应输入数据。
- 这类方法也叫做
基于微调(fine-tune) 的预训练语言模型,这类模型不仅可以进行预训练,并且训练好的词向量和模型本身可以直接投放到下游任务中,预训练的参数就是模型在下游任务中的初始点。
常见模型
BERT:- BERT 采用自监督学习的方式,学习模型与词向量。它有两个训练方式,分别为 Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)
RoBERTa:- RoBERTa 该模型并没有对 BERT 本身做什么操作,仅仅是证明了 NSP 并没有什么卵用。同时,在做 MLM 时,为了避免每次都掩盖相同的词语,所以他们重复了十次随机选择的过程,保证每个句子有10种掩盖方式。最后,他们还更改了训练的数据,提出了一个更具有鲁棒性的 BERT
ERNIE:- ERNIE 是清华大学刘知远老师团队的 ERNIE。该模型将知识图谱引入到了 BERT 中,用于做命名实体预测与关系分类任务。在他们的模型中,他们将命名实体的词向量与其知识表示拼接在一起。他们不仅采用了 MLM 与 NSP 的训练目标,还提出了 denoising entity auto-encoder (dEA) 的损失函数。该损失函数实质上就是一个 softmax
SKEP- SKEP 模型是用来做方面级情感分析任务。模型中一共考虑了3类任务:情感词语识别,情感词语极性识别,以及方面级情感词语对及其情感倾向识别。
- 对于每一个任务,有不同的掩盖方式:
- 1) 方面级情感词语对及其情感倾向识别中,对于每个句子随机掩盖至多2个方面情感对;
- 2) 情感词语掩盖,至多掩盖占句子词语总数10%的情感词语,选择的方式依旧是随机选择;
- 3) 普通词语掩盖,如果情感词语占句子词语数不足10%的话,就采用 RoBERTa 的掩盖方式掩盖普通词语至10%。
基于目标工程的模型基本都是基于 Transformer 的,这类方法对模型本身的改动不是特别大,但是会依据输入数据的不同而人工去设计目标函数,使得模型能够更好地学习到我们想要的特征。同时,这类方法可以将训练好的模型直接放在下游任务中,作为起始点来进行训练。
prompt engineering
前三种预训练语言模型都会有人力在里面 (feature engineering 需要人工提取特征,architecture engineering 需要人工设计网络结构,objective engineering 需要人工设计目标函数)。
为什么我们要研究一个新的预训练方式?毕竟 BERT 这一套都一直在刷新 SOTA。
- Prompt Learning激活了很多新的研究场景,比如小样本学习,这显然可以成为那些GPU资源受限研究者的福音。当然,我理解Prompt Learning最重要的一个作用在于给我们prompt(提示)了NLP发展可能的核心动力是什么。
【2023-2-13】什么是 prompt learning?
1、论文汇总:
PTMs-Papers
2. PTMs单模型解读
- 自监督学习:Self-Supervised Learning 入门介绍
- 自监督学习:Self-supervised Learning 再次入门
- 词向量总结:nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
- 词向量总结:从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
- ELMo解读:关于ELMo的若干问题整理记录
- BERT解读: Bert时代的创新:Bert应用模式比较及其它
- XLNET解读:XLNet:运行机制及和Bert的异同比较
- XLNET解读:XLnet:比Bert更强大的预训练模型
- RoBERTa解读:RoBERT: 没错,我就是能更强——更大数据规模和仔细调参下的最优BERT
- 预训练语言模型总结:nlp中的预训练语言模型总结(单向模型、BERT系列模型、XLNet)
- 预训练语言模型总结:8篇论文梳理BERT相关模型进展与反思
- ELECTRA解读: ELECTRA: 超越BERT, 19年最佳NLP预训练模型
- 模型压缩 LayerDrop:结构剪枝:要个4层的BERT有多难?
- 模型压缩 BERT-of-Theseus:bert-of-theseus,一个非常亲民的bert压缩方法
- 模型压缩 TinyBERT:比 Bert 体积更小速度更快的 TinyBERT
- 模型压缩总结:BERT 瘦身之路:Distillation,Quantization,Pruning
中文模型下载
- 2019年,哈工大与讯飞出品:Chinese-BERT-wwm
-
本目录中主要包含base模型,故我们不在模型简称中标注
base字样。对于其他大小的模型会标注对应的标记(例如large)。 BERT-large模型:24-layer, 1024-hidden, 16-heads, 330M parametersBERT-base模型:12-layer, 768-hidden, 12-heads, 110M parameters
| 模型简称 | 语料 | Google下载 | 讯飞云下载 |
|---|---|---|---|
RBTL3, Chinese |
中文维基+ 通用数据[1] |
TensorFlow PyTorch |
TensorFlow(密码vySW) PyTorch(密码rgCs) |
RBT3, Chinese |
中文维基+ 通用数据[1] |
TensorFlow PyTorch |
TensorFlow(密码b9nx) PyTorch(密码Yoep) |
RoBERTa-wwm-ext-large, Chinese |
中文维基+ 通用数据[1] |
TensorFlow PyTorch |
TensorFlow(密码u6gC) PyTorch(密码43eH) |
RoBERTa-wwm-ext, Chinese |
中文维基+ 通用数据[1] |
TensorFlow PyTorch |
TensorFlow(密码Xe1p) PyTorch(密码waV5) |
BERT-wwm-ext, Chinese |
中文维基+ 通用数据[1] |
TensorFlow PyTorch |
TensorFlow(密码4cMG) PyTorch(密码XHu4) |
BERT-wwm, Chinese |
中文维基 | TensorFlow PyTorch |
TensorFlow(密码07Xj) PyTorch(密码hteX) |
BERT-base, ChineseGoogle |
中文维基 | Google Cloud | - |
BERT-base, Multilingual CasedGoogle |
多语种维基 | Google Cloud | - |
BERT-base, Multilingual UncasedGoogle |
多语种维基 | Google Cloud | - |
[1] 通用数据包括:百科、新闻、问答等数据,总词数达5.4B,处理后的文本大小约10G
以上预训练模型以TensorFlow版本的权重为准。中国大陆境内建议使用讯飞云下载点,境外用户建议使用谷歌下载点,base模型文件大小约400M。
对于PyTorch版本,使用的是由Huggingface出品的PyTorch-Transformers 1.0提供的转换脚本。如果使用的是其他版本,请自行进行权重转换。
huggingface项目中语言模型预训练用mask方式如下。仍是按照15%的数据随机mask然后预测自身。如果要做一些高级操作比如whole word masking或者实体预测,可以自行修改transformers.DataCollatorForLanguageModeling。代码
def mask_tokens(self, inputs: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original.
"""
if self.tokenizer.mask_token is None:
raise ValueError(
"This tokenizer does not have a mask token which is necessary for masked language modeling. Remove the --mlm flag if you want to use this tokenizer."
)
labels = inputs.clone()
# We sample a few tokens in each sequence for masked-LM training (with probability args.mlm_probability defaults to 0.15 in Bert/RoBERTa)
probability_matrix = torch.full(labels.shape, self.mlm_probability)
special_tokens_mask = [
self.tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in labels.tolist()
]
probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool), value=0.0)
if self.tokenizer._pad_token is not None:
padding_mask = labels.eq(self.tokenizer.pad_token_id)
probability_matrix.masked_fill_(padding_mask, value=0.0)
masked_indices = torch.bernoulli(probability_matrix).bool()
labels[~masked_indices] = -100 # We only compute loss on masked tokens
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indices
inputs[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
# 10% of the time, we replace masked input tokens with random word
indices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & masked_indices & ~indices_replaced
random_words = torch.randint(len(self.tokenizer), labels.shape, dtype=torch.long)
inputs[indices_random] = random_words[indices_random]
# The rest of the time (10% of the time) we keep the masked input tokens unchanged
return inputs, labels
三个常见的中文bert语言模型:ERNIE > roberta-wwm-ext > bert-base-chinese
- bert-base-chinese:最常见的中文bert语言模型,Google基于中文维基百科相关语料进行预训练。把它作为baseline,在领域内无监督数据进行语言模型预训练很简单。
- roberta-wwm-ext:哈工大讯飞联合实验室发布的预训练语言模型。预训练的方式是采用roberta类似的方法,比如动态mask,更多的训练数据等等。在很多任务中,该模型效果要优于bert-base-chinese。
- ernie
bert-base-chinese
预训练代码:
python run_language_modeling.py \
--output_dir=output \
--model_type=bert \
--model_name_or_path=bert-base-chinese \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--mlm
其中$TRAIN_FILE 代表领域相关中文语料地址。
- 【2021-8-26】中文模型:bert-base-chinese,跑不通!
roberta-wwm-ext
代码:
import torch
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext")
roberta = BertModel.from_pretrained("hfl/chinese-roberta-wwm-ext")
# 切记不可使用官方推荐的以下语句!
tokenizer = AutoTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext")
model = AutoModel.from_pretrained("hfl/chinese-roberta-wwm-ext")
注意:切记不可使用官方推荐的Auto语句!
- 中文roberta类的配置文件比如vocab.txt,都是采用bert的方法设计的。英文roberta模型读取配置文件的格式默认是vocab.json。对于一些英文roberta模型,倒是可以通过AutoModel自动读取。这就解释了huggingface的模型库的中文roberta示例代码为什么跑不通。
如果要基于上面的代码run_language_modeling.py继续预训练roberta。还需要做两个改动。
- 下载roberta-wwm-ext到本地目录hflroberta,在config.json中修改“model_type”:”roberta”为”model_type”:”bert”。
- 对上面的run_language_modeling.py中的AutoModel和AutoTokenizer都进行替换为BertModel和BertTokenizer。
python run_language_modeling_roberta.py \
--output_dir=output \
--model_type=bert \
--model_name_or_path=hflroberta \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--mlm
ernie
ernie是百度发布的基于百度知道贴吧等中文语料结合实体预测等任务生成的预训练模型。这个模型的准确率在某些任务上要优于bert-base-chinese和roberta。如果基于ernie1.0模型做领域数据预训练的话只需要一步修改。
- 下载ernie1.0到本地目录ernie,在config.json中增加字段”model_type”:”bert”。
python run_language_modeling.py \
--output_dir=output \
--model_type=bert \
--model_name_or_path=ernie \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--mlm
向量服务
资料
- 【2022-8-19】腾讯AI Lab开发的近义词查询工具:近邻词汇检索
文本语义化向量化是把文本用Embedding向量来表示,语义相似的文本的embedding向量也相似。语义化向量可以用于文本去重、匹配,在搜索和推荐业务中都有广泛应用。
一般结构: BERT Encoder –> Pooling –> Loss Layer

Pooling Layer
- P1:把encoder的最后一层的[CLS]向量拿出来。
- P2:把Pooler(BERT用来做NSP任务)对应的向量拿出来,跟P1的区别是多了个线性变换层+激活层。
- P3:把encoder的最后一层的所有向量取平均。
- P4:把encoder的第一层与最后一层的所有向量取平均。
- P5:把encoder的最后一层和倒数第二层的所有向量取平均。
相关模型
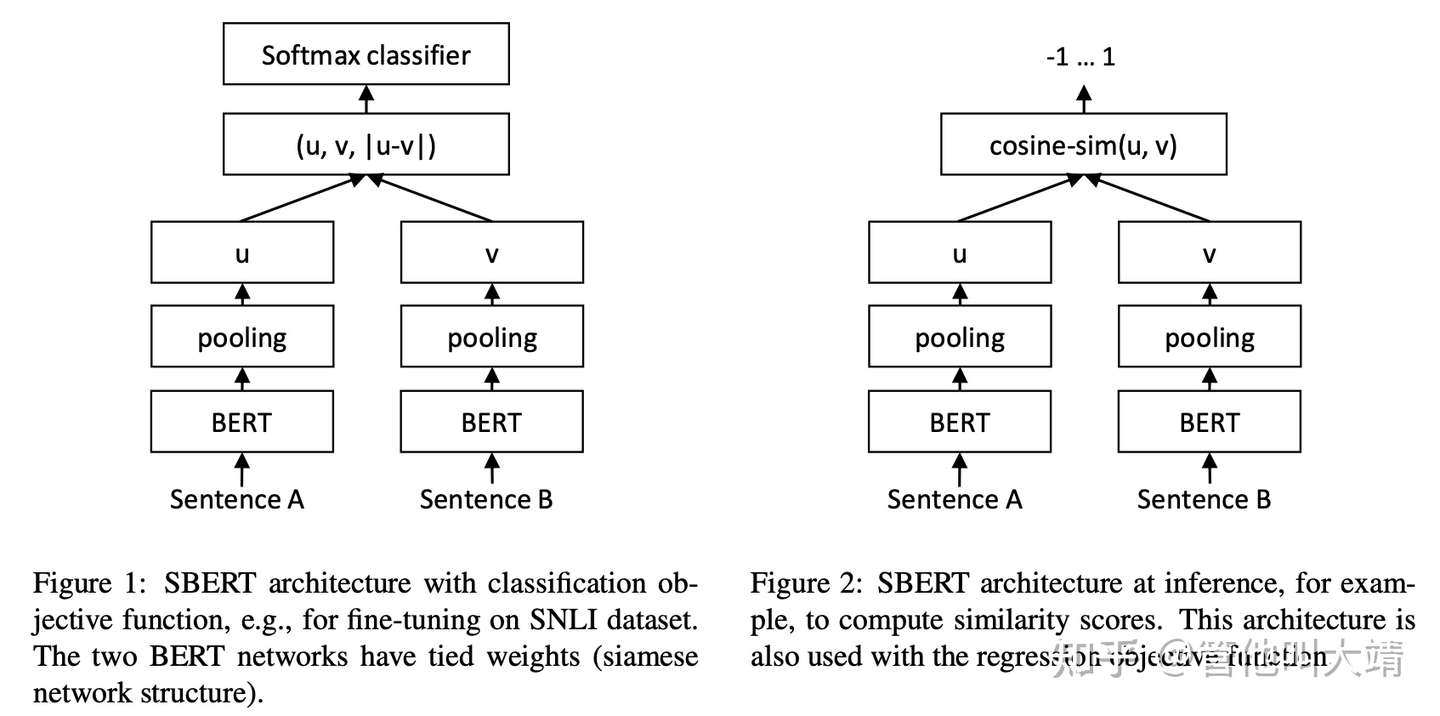
- (1) Sentence-BERT
- Sentence-BERT(SBERT)利用
孪生网络生成具有语义的Sentence embedding,语义相近的句子的embedding向量也相似。 - 将Sentence A和Sentence B经过 BERT+Pooling 后得到向量拼在一起,然后输入softmax分类器,判断A和B的相似性。
- Sentence-BERT(SBERT)利用
- (2) SBERT-WK
- Motivation: BERT不同层的向量具有不同的重要性,同时一句话不同token具有不同的重要性。
- Method:如果一个token在某层的embedding和相邻层的embedding的相关性越大,那么这一层embedding包含的信息越少,权重越小。如果一个token相邻层的相关系数的方差越大,这个token的信息越多,这个token的权重越大。
- (3) BERT-Whitening
- Motivation:用cosin来计算相似度的时候,向量的各个维度应该是各项同性isotropy。因此,可以通过whitening操作来将anisotropy的向量转化为isotropy。
各向同性:指物体的物理、化学等方面的性质不会因方向的不同而有所变化的特性,即某一物体在不同的方向所测得的性能数值完全相同,亦称均质性。在sentence embedding中指各个维度具有相同的重要性。- BERT-whitening的思路很简单,就是在得到每个句子的句向量${x_i}_{i=1}^N$后,对这些矩阵进行一个白化使得每个维度的均值为0、协方差矩阵为单位阵,然后保留 k 个主成分
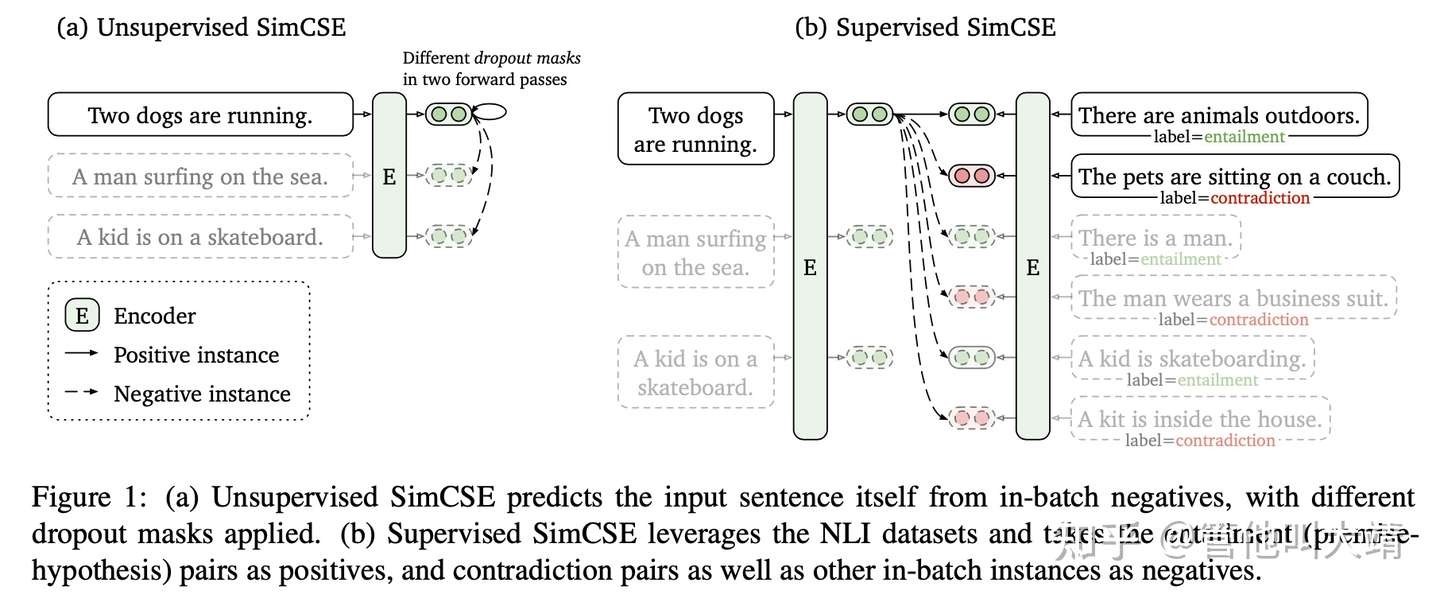
- (4) SimCSE 对比学习
- 通过 contrastive loss 来学习无监督、有监督的语义化向量。通过dropout来产生sentence的不同augmentations。
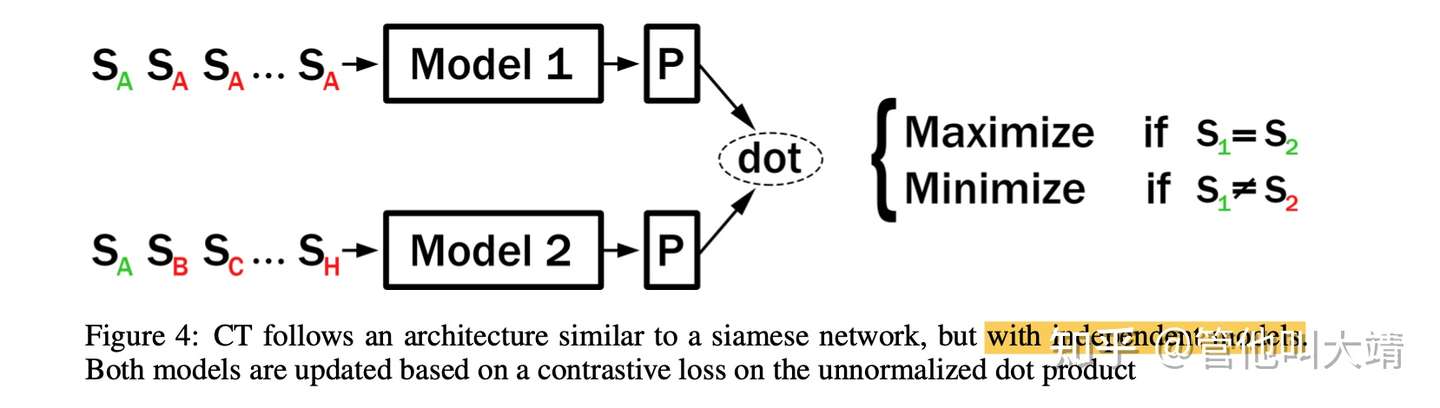
- (5) Contrastive Tension
- Motivation:
- 优化目标:
- 跟 Word2Vec 的skip gram的训练目标很像。
- 训练前:在语义化任务中,低层、中层的向量比顶层的好。原因是预训练模型有task-bias。
- 训练后:顶层的语义化向量效果明显变好。
- Motivation:
- (6) TSDAE
- 用DAE的思路来做语义化编码。同数据集上,无监督语义化向量能达到有监督语义向量的93.1%的效果。

- TSDAE 通过向输入句子添加某种类型的噪声(例如删除或交换单词)来训练Sentence Embedding。将损坏的句子编码为固定大小的向量,然后将向量重建为原始输入。

向量化方法
【2021-4-28】【论文阅读】句向量总结、文本相似度计算
不定长句子用定长向量表示,为NLP下游任务提供服务。
- 对于word embedding,训练完后每个词对应一个向量,可以直观地判断embedding的好坏。
- 但对于sentence embedding,评测没有ground truth。只能将sentence embedding送入下游任务,根据在下游任务的表现来评测其质量。
所以,不存在单独的sentence embedding算法,只有嵌入在NLP系统中的sentence embedding模块。
应用
- 语义搜索:通过句向量相似性,检索语料库中与query最匹配的文本
- 文本聚类:文本转为定长向量,通过聚类模型可无监督聚集相似文本
- 文本分类:表示成句向量,直接用简单分类器即训练文本分类器
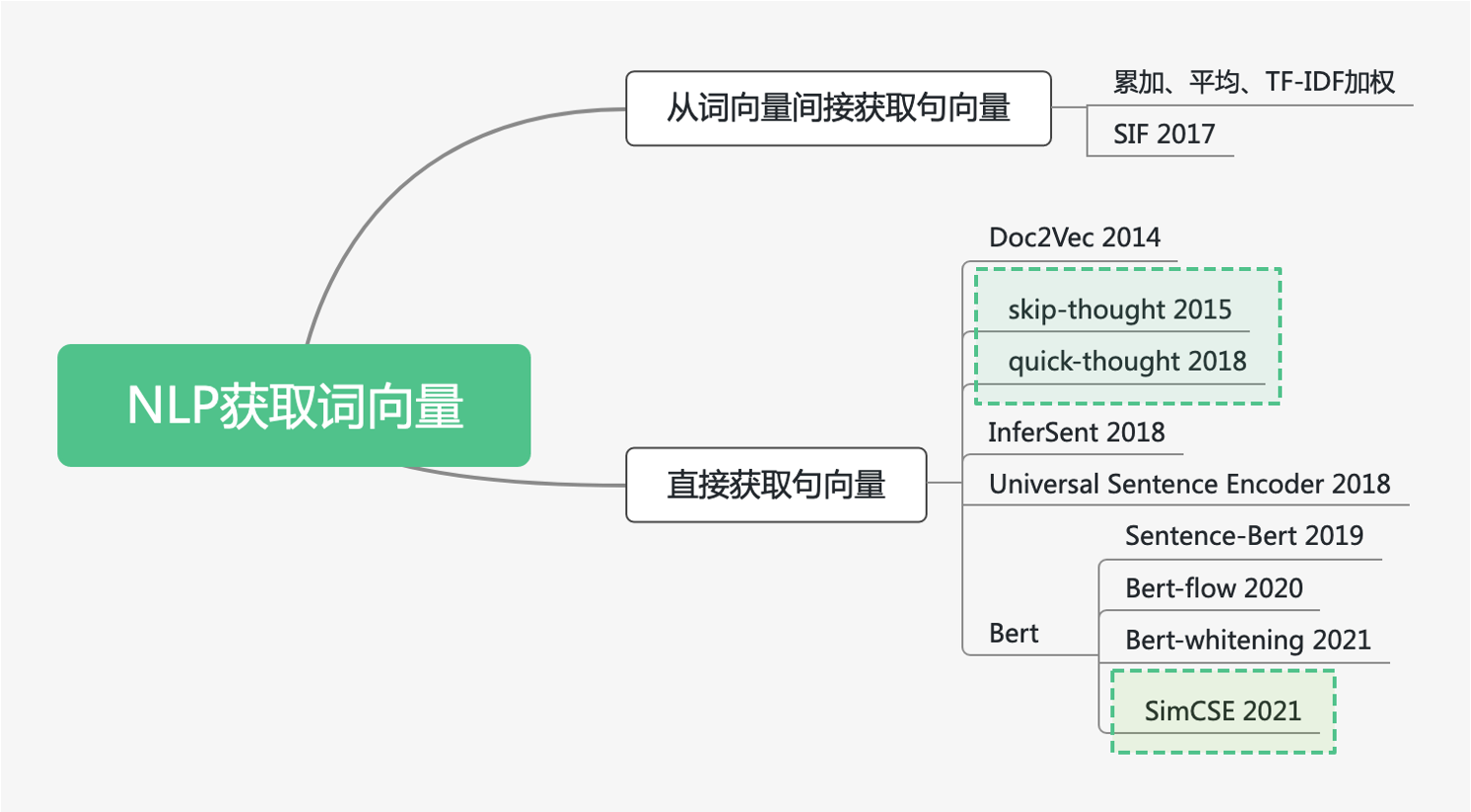
句向量获取方法
- 间接获取:直接从由词向量生成句向量,包含 累加法、平均法、TF-IDF加权平均法以及SIF法。
- 基于统计的词袋模型:早期用one-hot表示
词,使用词袋表示文本,TF-IDF引入了单词的频率。 - 基于词向量获取句向量:2017年,SIF算法提出用平滑倒词频获取所有词的权重,随后抹去共现信息。这个方法计算简便快速,却忽略了词本身的含义、词序对句子的影响。
- SIF(Smooth Inverse Frequency)首先使用平滑倒词频求出所有词的权重。然后移去所有句子向量组成的矩阵的第一个主成分上的投影,抹去句子的共现信息。
- SIF是TF-IDF的改进,在大部分数据集上都比完全平均或直接使用TF-IDF加权平均效果要好。
- 基于统计的词袋模型:早期用one-hot表示
- 直接获取. 图解
- 由词向量获取句向量的方法忽略了词序对句子的影响。
- 直接获取方法:Doc2Vec、skip-thought、quick-thought、InferSent、Universal Sentence Encoder、Bert。
- 2013年,Mikolov提出了
word2vec模型,其中包含CBOW和skip-gram模型,掀开了词向量表达的新篇章。 - 2014年,Mikolov又提出了
Doc2Vec,借鉴word2vec模型的思想,包含PV-DM和PV-DBOW结构。 - 2015年,基于
skip-gram思想的skip-thought模型问世,模型根据输入句,预测其上下文,产生句向量副产物。适合具有连贯性的数据集,但是seq2seq的架构导致训练速度慢。 - 2018年,
quick-thought改进了skip-thought训练慢的问题,将生成任务改为分类任务。- 相比skip-thought,训练速度大大提升,但是适用场景仍然有限。他俩都需要连贯的数据集,不能对单句求embedding。关于他们的跨界应用可以是,利用他们对一段文本提取embedding,然后对embedding进行kmeans聚类,无监督地获取文本摘要。
- 同年,
InferSent将句向量获取定义为有监督任务,模型在自然语言推理数据集上训练,随后将训练好的模型当做特征提取器获得句子向量。-
模型使用siamese结构,两个句子共用一个encoder,分别得到u和v的文本向量表达。然后使用三种计算方式,向量拼接[u,v],向量相乘u*v,向量相减 u-v ,来帮助后面的全连接层提取向量间的交互信息,最后跟一个3-class分类器。
-
- 同样是2018年,谷歌提出
Universal Sentence Encoder,将句向量的获取定义为多任务学习,利用Transformer和DAN提取通用句子表征。 - 2019年,
Sentence-bert提出使用孪生网络学习句向量的表示。- 使用bert获取句向量,我们自然而然想到的是用CLS作为句向量的表达。
- 但是sentence bert论文提到,如果是无监督任务,直接使用CLS甚至还不如用glove对token embedding取平均。
- 2020年,
Bert-flow利用flow模型校正了 bert出来的句向量分布,从而使计算出的cos相似度更为合理。- 根据sentence-bert的实验结果,平均词向量的embedding效果优于CLS对应的embedding,因此bert-flow的实验也都在平均embedding的基础上进行。为了解决bert语义不平滑的问题,将句向量的分布转化为高斯分布。从各向异性变成各向同性。
- 2021年,苏剑林认为bert-flow中的flow是不必要的,介绍了基于简单的线性变换以及降维便能媲美bert-flow的
bert-whitening模型。- 得到句向量后,对矩阵进行PCA白化操作,使得每个维度均值是0,协方差矩阵是单位阵,然后保留k个主成分。
- 没多久,陈丹琦的
SimCSE仅仅使用两次dropout就超越了前人的模型。- 简单对glove求平均,sentence-bert,bert-flow,bert-whitening都是主流办法。陈丹琦的SimCSE-bert模型刷新SOTA。
- 两个变体,分别是无监督和有监督的模型。主要区别就是正负样例的构造上。
- 无监督: 引入dropout给输入加入噪声。正例,用bert对句子编码两次得到两个向量,负例就是随机采样batch里的另一个输入。
- 有监督: 在多种数据集实验后,发现NLI数据最有利于学习句子的表示。对应正例就是NLI数据集中蕴含关系的句子对,负例是NLI数据集中矛盾关系的句子对。
原文链接
ES句向量
- 【2020-9-15】ElasticTransformers
- Elastic Transformers:Jupyter Notebook里的可扩展BERT语义搜索

Faiss
Faiss是Facebook AI团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前最为成熟的近似近邻搜索库。它包含多种搜索任意大小向量集(备注:向量集大小由RAM内存决定)的算法,以及用于算法评估和参数调整的支持代码。Faiss用C++编写,并提供与Numpy完美衔接的Python接口。除此以外,对一些核心算法提供了GPU实现。相关介绍参考《Faiss:Facebook 开源的相似性搜索类库》- Faiss对一些基础的算法提供了非常高效的实现
- 聚类Faiss提供了一个高效的k-means实现
- PCA降维算法
- PQ(ProductQuantizer)编码/解码
- 组件
- Faiss中最常用的是索引Index,而后是PCA降维、PQ乘积量化,这里针对Index和PQ进行说明,PCA降维从流程上都可以理解。
- 以图片搜索为例,所谓相似度搜索,便是在给定的一堆图片中,寻找出我指定的目标最像的K张图片,也简称为KNN(K近邻)问题。
- Faiss流程与原理分析
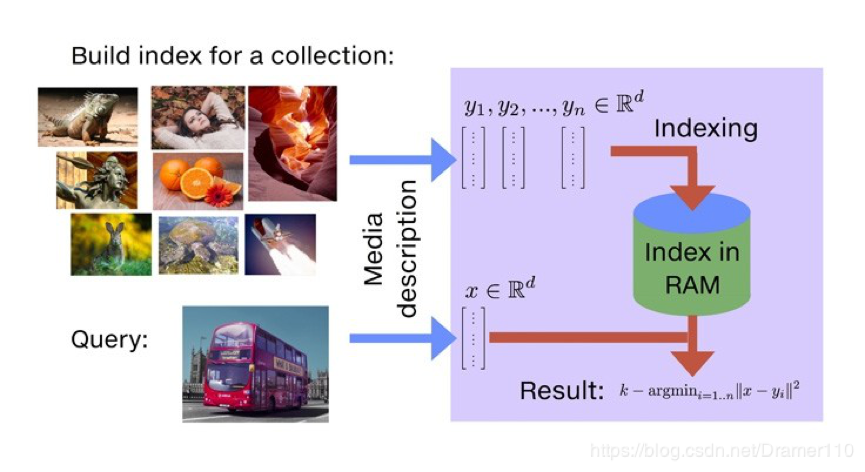
Faiss 使用场景:最常见的人脸比对,指纹比对,基因比对等。
Index使用
Faiss处理固定维数d的向量集合,向量维度d通常为几十到几百。
faiss 三个最基础的 index. 分别是 IndexFlatL2, IndexIVFFlat, IndexIVFPQ,更多参见Guidelines to choose an index
IndexFlatL2:最基础的IndexIndexIVFFlat:更快的搜索,将数据集分割成几部分,加快搜索- d维空间中定义Voronoi单元格,并且每个数据库矢量都落入其中一个单元格中。在搜索时,只有查询x所在单元中包含的数据库向量y与少数几个相邻查询向量进行比较。(划分搜索空间)
- 与数据库向量具有相同分布的任何向量集合上执行训练
- 建索引,即
量化器(quantizer),它将矢量分配给Voronoi单元。每个单元由一个质心定义,找到一个矢量所在的Voronoi单元包括在质心集中找到该矢量的最近邻居。这是另一个索引的任务,通常是索引IndexFlatL2。
- d维空间中定义Voronoi单元格,并且每个数据库矢量都落入其中一个单元格中。在搜索时,只有查询x所在单元中包含的数据库向量y与少数几个相邻查询向量进行比较。(划分搜索空间)
IndexIVFPQ:内存开销更小.- IndexFlatL2和IndexIVFFlat都存储完整的向量,内存开销大
- 基于产品量化器的有损压缩来压缩存储的向量的变体。压缩的方法基于乘积量化(Product Quantizer),矢量没有精确存储,搜索方法返回的距离也是近似值。
IndexIVFFlat Demo 完整代码
# encoding:utf-8
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the BSD+Patents license found in the
# LICENSE file in the root directory of this source tree.
# author : Facebook
# translate : h-j-13
import numpy as np
d = 64 # 向量维度
nb = 100000 # 向量集大小
nq = 10000 # 查询次数
np.random.seed(1234) # 随机种子,使结果可复现
xb = np.random.random((nb, d)).astype('float32')
xb[:, 0] += np.arange(nb) / 1000.
xq = np.random.random((nq, d)).astype('float32')
xq[:, 0] += np.arange(nq) / 1000.
import faiss
nlist = 100
k = 4
quantizer = faiss.IndexFlatL2(d) # the other index
index = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_L2)
# here we specify METRIC_L2, by default it performs inner-product search
assert not index.is_trained
index.train(xb)
assert index.is_trained
index.add(xb) # 添加索引可能会有一点慢
D, I = index.search(xq, k) # 搜索
print(I[-5:]) # 最初五次查询的结果
index.nprobe = 10 # 默认 nprobe 是1 ,可以设置的大一些试试
D, I = index.search(xq, k)
print(I[-5:]) # 最后五次查询的结果
IndexIVFFlat 完整代码
# encoding:utf-8
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the BSD+Patents license found in the
# LICENSE file in the root directory of this source tree.
# author : Facebook
# translate : h-j-13
import numpy as np
d = 64 # 向量维度
nb = 100000 # 向量集大小
nq = 10000 # 查询次数
np.random.seed(1234) # 随机种子,使结果可复现
xb = np.random.random((nb, d)).astype('float32')
xb[:, 0] += np.arange(nb) / 1000.
xq = np.random.random((nq, d)).astype('float32')
xq[:, 0] += np.arange(nq) / 1000.
import faiss
nlist = 100
m = 8
k = 4
quantizer = faiss.IndexFlatL2(d) # 内部的索引方式依然不变
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8)
# 每个向量都被编码为8个字节大小
index.train(xb)
index.add(xb)
D, I = index.search(xb[:5], k) # 测试
print(I)
print(D)
index.nprobe = 10 # 与以前的方法相比
D, I = index.search(xq, k) # 检索
print(I[-5:])
Faiss 索引类型:
- Exact Search for L2 #基于L2距离的确定搜索匹配
- Exact Search for Inner Product #基于内积的确定搜索匹配
- Hierarchical Navigable Small World graph exploration #分层索引
- Inverted file with exact post-verification #倒排索引
- Locality-Sensitive Hashing (binary flat index) #本地敏感hash
- Scalar quantizer (SQ) in flat mode #标量量化索引
- Product quantizer (PQ) in flat mode #笛卡尔乘积索引
- IVF and scalar quantizer #倒排+标量量化索引
- IVFADC (coarse quantizer+PQ on residuals) #倒排+笛卡尔乘积索引
- IVFADC+R (same as IVFADC with re-ranking based on codes) # 倒排+笛卡尔乘积索引 + 基于编码器重排
Faiss 开发资料:
Milvus
【2021-5-31】Milvus 是什么 Milvus 是一款开源的向量数据库,支持针对 TB 级向量的增删改操作和近实时查询,具有高度灵活、稳定可靠以及高速查询等特点。Milvus 集成了 Faiss、NMSLIB、Annoy 等广泛应用的向量索引库,提供了一整套简单直观的 API,让你可以针对不同场景选择不同的索引类型。此外,Milvus 还可以对标量数据进行过滤,进一步提高了召回率,增强了搜索的灵活性。
Milvus 服务器采用主从式架构 (Client-server model)。在服务端,Milvus 由 Milvus Core 和 Meta Store 两部分组成:
- Milvus Core 存储与管理向量和标量数据。
- Meta Store 存储与管理 SQLite 和 MySQL 中的元数据,分别用于测试和生产。 在客户端,Milvus 还提供了基于 Python、Java、Go、C++ 的 SDK 和 RESTful API。
整体架构

Milvus 在全球范围内已被数百家组织和机构所采用,广泛应用于以下场景:
- 图像、视频、音频等音视频搜索领域
- 文本搜索、推荐和交互式问答系统等文本搜索领域
- 新药搜索、基因筛选等生物医药领域
ES里的BERT索引
- 【2020-7-11】ES开始支持embedding的BERT索引,Elasticsearch遇上BERT:使用Elasticsearch和BERT构建搜索引擎
- 【2019-7-5】BERT和TensorFlow构建搜索引擎

BERT结合Faiss的语义表示
【2021-5-31】语义匹配搜索项目使用的 Faiss和BERT的整体架构 image, 参考:基于文本语义的智能问答系统
- 注:深蓝色线为数据导入过程,橘黄色线为用户查询过程。)
- 首先,本文项目使用开源的 bert-serving , BERT做句子编码器,标题数据转化为固定长度为 768 维的特征向量,并导入 Milvus 或者Faiss库。
- 然后,对存入 Milvus/Faiss 库中的特征向量进行存储并建立索引,同时原始数据提供唯一ID编码,将 ID 和对应内容存储在 PostgreSQL 中。
- 最后,用户输入一个标题,BERT 将其转成特征向量。Milvus/Faiss 对特征向量进行相似度检索,得到相似的标题的 ID ,在 知识库(PostgreSQL/MySQL/SQLite。。。) 中找出 ID 对应的详细信息返回
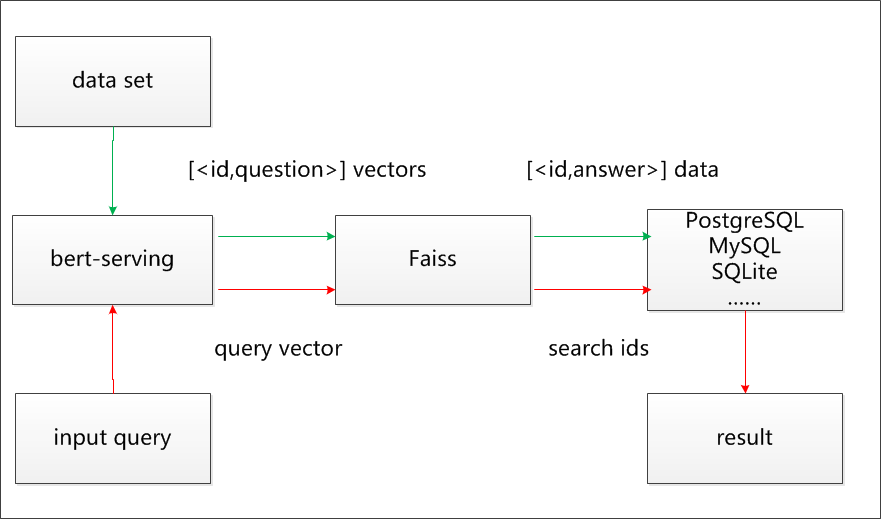
【2021-10-28】FAISS + SBERT实现的十亿级语义相似性搜索,Billion-scale semantic similarity search with FAISS+SBERT
BERT-as-service
-
Google 已经公开了 TensorFlow 版本 BERT 的预训练模型和代码,可以用于生成词向量,但是还有更简单的方法:直接调用封装好的库 bert-as-service 。
- bert-as-service 是腾讯 AI Lab 开源的一个 BERT 服务(肖涵开发),它让用户可以以调用服务的方式使用 BERT 模型而不需要关注 BERT 的实现细节。bert-as-service 分为客户端和服务端,用户可以从 python 代码中调用服务,也可以通过 http 的方式访问。
- 【2020-8-20】以fastapi为基础的NLP as a Service
- Project Insight is designed to create NLP as a service with code base for both front end GUI (streamlit) and backend server (FastApi) the usage of transformers models on various downstream NLP task.
- The downstream NLP tasks covered:
- News Classification
- Entity Recognition
- Sentiment Analysis
- Summarization
- Information Extraction To Do
安装
- 用 pip 命令进行安装,客户端与服务端可以安装在不同的机器上:
pip install bert-serving-server # 服务端
pip install bert-serving-client # 客户端,与服务端互相独立
- 其中,服务端的运行环境为 Python >= 3.5 和 Tensorflow >= 1.10
- 客户端可以运行于 Python 2 或 Python 3
下载预训练模型
- 根据 NLP 任务的类型和规模不同,Google 提供了多种预训练模型供选择:
- BERT-Base, Chinese: 简繁体中文, 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Base, Multilingual Cased: 多语言(104 种), 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Base, Uncased: 英文不区分大小写(全部转为小写), 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Base, Cased: 英文区分大小写, 12-layer, 768-hidden, 12-heads , 110M parameters
- 也可以使用中文效果更好的哈工大版 BERT:Chinese-BERT-wwm
- 解压下载到的 .zip 文件以后,会有 6 个文件:
- TensorFlow 模型文件(bert_model.ckpt) 包含预训练模型的权重,模型文件有三个
- 字典文件(vocab.txt) 记录词条与 id 的映射关系
- 配置文件(bert_config.json ) 记录模型的超参数
启动 BERT 服务
- 使用 bert-serving-start 命令启动服务:
- 其中,-model_dir 是预训练模型的路径,-num_worker 是线程数,表示同时可以处理多少个并发请求
bert-serving-start -model_dir /tmp/english_L-12_H-768_A-12/ -num_worker=2
- 如果启动成功,服务器端会显示:

在客户端获取句向量
- 可以简单的使用以下代码获取语料的向量表示:
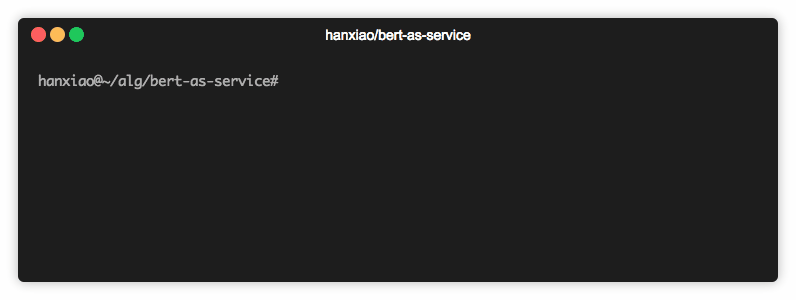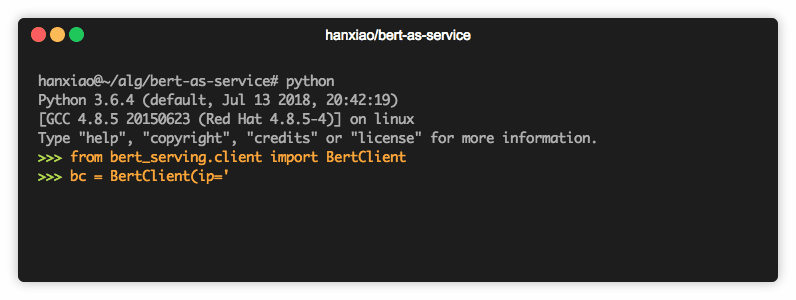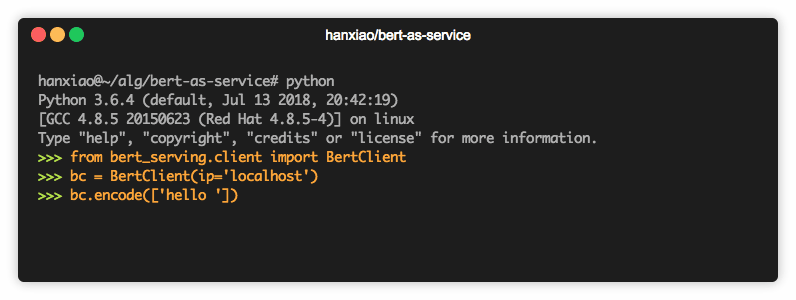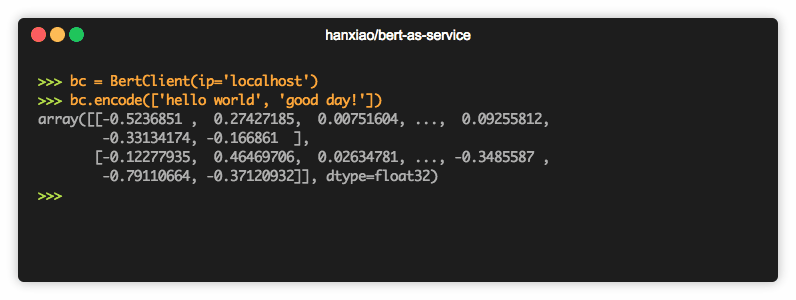
from bert_serving.client import BertClient
bc = BertClient()
doc_vecs = bc.encode(['First do it', 'then do it right', 'then do it better'])
- doc_vecs 是一个 numpy.ndarray ,它的每一行是一个固定长度的句子向量,长度由输入句子的最大长度决定。如果要指定长度,可以在启动服务使用 max_seq_len 参数,过长的句子会被从右端截断。
- BERT 的另一个特性是可以获取一对句子的向量,句子之间使用 ||| 作为分隔,例如:
bc.encode(['First do it ||| then do it right'])
获取词向量
- 启动服务时将参数 pooling_strategy 设置为 None :
# bert服务端
bert-serving-start -pooling_strategy NONE -model_dir /tmp/english_L-12_H-768_A-12/
- 这时的返回是语料中每个 token 对应 embedding 的矩阵
# 客户端
bc = BertClient()
vec = bc.encode(['hey you', 'whats up?'])
vec # [2, 25, 768]
vec[0] # [1, 25, 768], sentence embeddings for `hey you`
vec[0][0] # [1, 1, 768], word embedding for `[CLS]`
vec[0][1] # [1, 1, 768], word embedding for `hey`
vec[0][2] # [1, 1, 768], word embedding for `you`
vec[0][3] # [1, 1, 768], word embedding for `[SEP]`
vec[0][4] # [1, 1, 768], word embedding for padding symbol
vec[0][25] # error, out of index!
远程调用 BERT 服务
- 可以从一台机器上调用另一台机器的 BERT 服务:
# on another CPU machine
from bert_serving.client import BertClient
bc = BertClient(ip='xx.xx.xx.xx') # ip address of the GPU machine
# 一次多输入几个,不要for循环一个个获取!
bc.encode(['First do it', 'then do it right', 'then do it better'])
- 这个例子中,只需要在客户端 pip install -U bert-serving-client
from bert_serving.client import BertClient
import numpy as np
class SimilarModel:
def __init__(self):
# ip默认为本地模式,如果bert服务部署在其他服务器上,修改为对应ip
self.bert_client = BertClient(ip='192.168.x.x')
def close_bert(self):
self.bert_client.close()
def get_sentence_vec(self,sentence):
'''
根据bert获取句子向量
:param sentence:
:return:
'''
return self.bert_client .encode([sentence])[0]
def cos_similar(self,sen_a_vec, sen_b_vec):
'''
计算两个句子的余弦相似度
:param sen_a_vec:
:param sen_b_vec:
:return:
'''
vector_a = np.mat(sen_a_vec)
vector_b = np.mat(sen_b_vec)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
cos = num / denom
return cos
if __name__=='__main__':
# 从候选集condinates 中选出与sentence_a 最相近的句子
condinates = ['为什么天空是蔚蓝色的','太空为什么是黑的?','天空怎么是蓝色的','明天去爬山如何']
sentence_a = '天空为什么是蓝色的'
bert_client = SimilarModel()
max_cos_similar = 0
most_similar_sentence = ''
for sentence_b in condinates:
sentence_a_vec = bert_client.get_sentence_vec(sentence_a)
sentence_b_vec = bert_client.get_sentence_vec(sentence_b)
cos_similar = bert_client.cos_similar(sentence_a_vec,sentence_b_vec)
if cos_similar > max_cos_similar:
max_cos_similar = cos_similar
most_similar_sentence = sentence_b
print('最相似的句子:',most_similar_sentence)
bert_client .close_bert()
# 为什么天空是蔚蓝色的
或者HTTP调用:
curl -X POST http://xx.xx.xx.xx:8125/encode \
-H 'content-type: application/json' \
-d '{"id": 123,"texts": ["hello world"], "is_tokenized": false}'
Bert的输出最终有两个结果可用
- sequence_output:维度【batch_size, seq_length, hidden_size】,这是训练后每个token的词向量。
- pooled_output:维度是【batch_size, hidden_size】,每个sequence第一个位置CLS的向量输出,用于分类任务。
{
"id": 123,
"results": [[768 float-list], [768 float-list]],
"status": 200
}
其他
- 配置要求
- BERT 模型对内存有比较高的要求,如果启动时一直卡在 load graph from model_dir 可以将 num_worker 设置为 1 或者加大机器内存。
- 处理中文是否要提前分词
- 在计算中文向量时,可以直接输入整个句子不需要提前分词。因为 Chinese-BERT 中,语料是以字为单位处理的,因此对于中文语料来说输出的是字向量。
- 举个例子,当用户输入:
bc.encode(['hey you', 'whats up?', '你好么?', '我 还 可以'])
- 实际上,BERT 模型的输入是:
tokens: [CLS] hey you [SEP]
input_ids: 101 13153 8357 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
tokens: [CLS] what ##s up ? [SEP]
input_ids: 101 9100 8118 8644 136 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
tokens: [CLS] 你 好 么 ? [SEP]
input_ids: 101 872 1962 720 8043 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
tokens: [CLS] 我 还 可 以 [SEP]
input_ids: 101 2769 6820 1377 809 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 在英语中词条化后的 ##something 是什么
- 当某个词在不在词典中时,使用最长子序列的方法进行词条化,例如:
input = "unaffable"
tokenizer_output = ["un", "##aff", "##able"]
典型模型
ELMo (改进W2V)
ELMO是“Embedding from Language Models”的简称,名字并没有反应本质思想,
- ELMO的论文题目:“Deep contextualized word representation” 更能体现其精髓,而精髓在哪里?在deep contextualized这个短语,一个是deep,一个是context,其中context更关键。
- 之前的Word Embedding本质上是个静态方式,所谓静态指的是训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的Word Embedding不会跟着上下文场景的变化而改变,
- 比如Bank这个词,它事先学好的Word Embedding中混合了几种语义 ,在应用中来了个新句子,即使从上下文中(比如句子包含money等词)明显可以看出它代表的是“银行”的含义,但是对应的Word Embedding内容也不会变,它还是混合了多种语义。
- 这是为何说它是静态的,问题所在。
- ELMO的本质思想:
- 先用语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过没关系。实际使用Word Embedding的时,单词已经具备了特定的上下文了,这个时候可以根据上下文单词的语义去调整单词的Word Embedding表示,调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。
- 所以ELMO本身是根据当前上下文对Word Embedding动态调整的思路。
ELMO采用了典型的两阶段过程
- 第一个阶段是利用语言模型进行预训练;
- 第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。
ELMO的第一阶段:预训练阶段。

网络结构采用了双层双向LSTM,语言模型训练的任务目标是根据单词的上下文去正确预测单词,
- 之前的单词序列Context-before称为上文
- 之后的单词序列Context-after称为下文
ELMO的预训练过程不仅仅学会单词的Word Embedding,还学会了一个双层双向的LSTM网络结构
训练后如何使用?

- 下游任务的使用过程
- 比如下游任务仍然是QA问题,此时对于问句X,可以先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding,之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。对于图示下游任务QA中的回答句子Y来说也是如此处理。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。至于为何这么做能够达到区分多义词的效果,可以想一想,其实比较容易想明白原因。
静态Word Embedding无法解决多义词的问题,那么ELMO引入上下文动态调整单词的embedding后多义词问题解决了吗?
- 解决了,而且比期待的还要好。

- 对于Glove训练出的Word Embedding来说,多义词比如play,根据它的embedding找出的最接近的其它单词大多数集中在体育领域,这很明显是因为训练数据中包含play的句子中体育领域的数量明显占优导致;而使用ELMO,根据上下文动态调整后的embedding不仅能够找出对应的“演出”的相同语义的句子,而且还可以保证找出的句子中的play对应的词性也是相同的,这是超出期待之处。第一层LSTM编码了很多句法信息,这在这里起到了重要作用。
ELMO经过这般操作,效果如何呢?
- 实验效果,6个NLP任务中性能都有幅度不同的提升,最高的提升达到25%左右,而且这6个任务的覆盖范围比较广,包含句子语义关系判断,分类任务,阅读理解等多个领域,这说明其适用范围是非常广的,普适性强,这是一个非常好的优点。
GPT
- GPT模型,详见专题:GPT
BERT
- BERT模型,详见专题:BERT
T5
【2019年10月】110亿参数的T5
2019年10月,谷歌在论文《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》提出了一个新的预训练模型:T5。该模型涵盖了问题解答,文本分类等方面,参数量达到了110亿,成为全新的NLP SOTA预训练模型。在SuperGlue上,T5也超越了Facebook提出的的RoBERTa,以89.8的得分成为仅次于人类基准的SOTA模型。
T5 是“Transfer Text-to-Text Transformer”的缩写。
T5 作为一个文本到文本的统一框架,可以将同一模型、目标、训练流程和解码过程,直接应用于实验中的每一项任务。研究者可以在这个框架上比较不同迁移学习目标、未标注数据集或者其他因素的有效性,也可以通过扩展模型和数据集来发现 NLP 领域迁移学习的局限。
Flan-T5 通过在超大规模的任务上进行微调,让语言模型具备了极强的泛化性能,做到单个模型就可以在1800多个NLP任务上都能有很好的表现。
微调的目的是让语言模型学习理解指令,不是想让语言模型解决成千上万任务,当然训练方式中是有很多任务,因为不同任务有不同的指令,所以目的还是想让模型理解这些指令,解决各种任务问题。在真实世界中,总会有新任务,模型只要学习新任务的新指令,那么就能解决新任务。指令学习本质是把语言模型的问题用语言讲出来。
一旦模型训练完毕,可以直接在几乎全部的NLP任务上直接使用,实现一个模型解决所有问题(One model for ALL tasks),这就非常有诱惑力!
从创新来看,T5算不上出奇制胜,因为模型没有用到什么新的方法,而是从全面的视角来概述当前 NLP 领域迁移学习的发展现状。简单来说,还是通过大力出奇迹,用110亿参数的大模型,在摘要生成、问答、文本分类等诸多基准测试中都取得了不错的性能。一举超越现有最强模型。
谷歌T5编写的通用知识训练语料库中的片段来自Common Crawl网站,该项目每个月从网络上爬取大约20TB的英文文本。
具体做法分为三步:
- (1) 「任务收集」:收集一系列监督的数据,这里一个任务可以被定义成<数据集,任务类型的形式>,比如“基于SQuAD数据集的问题生成任务”。
- (2) 「形式改写」:因为需要用单个语言模型来完成超过1800+种不同的任务,所以需要将任务都转换成相同的“输入格式”喂给模型训练,同时这些任务的输出也需要是统一的“输出格式”。
- (3) 「训练过程」:采用恒定的学习率以及Adafactor优化器进行训练;同时会将多个训练样本“打包”成一个训练样本,这些训练样本直接会通过一个特殊的“结束token”进行分割。训练时候在每个指定的步数会在“保留任务”上进行模型评估,保存最佳的checkpoint。
尽管微调的任务数量很多,但是相比于语言模型本身的预训练过程,计算量小了非常多,只有0.2%。所以通过这个方案,大公司训练好的语言模型可以被再次有效的利用,应用方只需要做好“微调”即可,不用重复耗费大量计算资源再去训一个语言模型。
从竞赛排行榜看,T5以绝对的优势胜出。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}
{kind=link}
{kind=link}