- NLP新范式:Prompt
- 结束
NLP新范式:Prompt
Prompt与ICL,CoT关系
- ICL(上下文学习), 一种特殊的 prompt 形式, GPT-3 首次提出的,它已经成为利用 LLMs 的一种典型方法。
- 思维链(CoT)是一种改进的 prompt 策略,可以提高 LLM 在复杂推理任务中的表现,如算术推理、常识推理和符号推理。CoT 不是像 ICL 那样简单地用 输入-输出 对来构建 prompt,而是将能够导致最终输出的中间推理步骤纳入 prompt。
【2023-4-3】LLMs演进图解, paper
【2023-7-2】五万字综述!Prompt-Tuning:深度解读一种新的微调范式
知识点:
- 什么是预训练语言模型?
- 什么是prompt?为什么要引入prompt?相比传统fine-tuning有什么优势?
- 自20年底开始,prompt的发展历程,哪些经典的代表方法?
- 面向不同种类NLP任务,prompt如何选择和设计?
- 面向超大规模模型,如何借助prompt进行参数有效性训练?
- 面向GPT3,什么是In-Context Learning?什么是Chain-Of-Thought?
- 面向黑盒模型,如何使用prompt?
- ChatGPT里有哪些prompt技术?
- 未来prompt的发展与研究前景
Prompt的由浅入深的理解:
- 1级:Prompt是一种任务指令;
- 2级:Prompt是一种对预训练目标的复用;
- 3级:Prompt本质是参数有效性训练;
Prompt-Tuning技术发展历程
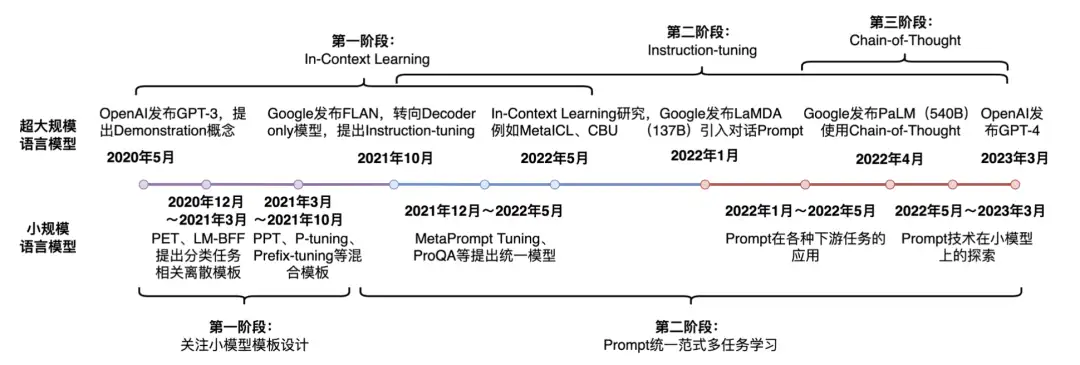
Prompt-Tuning 自从GPT-3被提出以来,从传统的离散、连续的Prompt的构建、走向面向超大规模模型的 In-Context Learning、Instruction-tuning 和 Chain-of-Thought。
自从GPT、EMLO、BERT的相继提出,以 Pre-training + Fine-tuning 模式在诸多自然语言处理(NLP)任务中被广泛使用
- 先在 Pre-training阶段, 通过一个模型在大规模无监督语料上预先训练一个 预训练语言模型(Pre-trained Language Model,PLM)
- 然后在Fine-tuning阶段, 基于训练好的语言模型在具体的下游任务上再次进行 微调(Fine-tuning) ,以获得适应下游任务的模型。
这种模式在诸多任务的表现上超越了传统的监督学习方法,不论在工业生产、科研创新还是竞赛中均作为新的主流方式。然而,这套模式也存在着一些问题。
- 例如,在大多数的下游任务微调时, 下游任务的目标与预训练的目标差距过大, 导致提升效果不明显, 微调过程中依赖大量的监督语料 等。
至此,以GPT-3、PET为首提出一种基于预训练语言模型的新的微调范式——Prompt-Tuning ,其旨在通过添加模板的方法来避免引入额外的参数,从而让语言模型可以在小样本(Few-shot)或零样本(Zero-shot)场景下达到理想的效果。
Prompt-Tuning又可以称为 Prompt、Prompting、Prompt-based Fine-tuning等。
最新进展
Prompt tuning是之前其他论文提出的一种方法,通过冻结语言模型仅去调整连续的prompts,在参数量超过10B的模型上,效果追上了fine-tune,但是在normal-sized模型上表现不好,并且无法解决序列标注任务。针对这两个问题,作者提出了P-tuning v2。
【2023-3-22】一文带你概览Prompt工作新进展
Prompt Learning(提示学习)已经成为现在NLP研究的第四范式,现在已经成为NLP领域一大热点。
刘鹏飞博士在7月的综述更是将Prompt系统性地进行了总结,让更多人所熟知。- 自8月以来,粗略统计,约为109篇关于Prompt的论文发表在EMNLP 2021、arXiv或投稿ICLR 2022、ARR(ACL 2022所采用的每月滚动评审机制)。笔者从中挑选了13行解读。
根据论文的创新点分成 Prompt Engineering,Answer Engineering和Multi-Prompt Learning来进行整理讨论,每个类别里根据论文出现的时间进行排序。
Prompt Engineering
(1) PPT: Pre-trained Prompt Tuning for Few-shot Learning – 9.9 ARR Oct.
超大模型的预训练的Soft Prompt,在NLU任务中进行了小样本实验。首先作者通过先导实验得出了4个结论:
- ① Verbalizer的选择对结果有很大影响;
- ② 将Soft Prompt初始化为具体单词的Embedding并不能提升性能;
- ③ 使用Hard和Soft的混合Prompt有帮助;
- ④ Google提出的Prompt Tuning并不能在小样本场景下取得和微调一样的效果。因此引出了Soft Prompt预训练的想法。
Prompt框架是,基于Hard和Soft的混合完形填空式Prompt,人工设计的Answer,以T5-XXL(英文)为框架,只微调Soft Prompt。论文提出将NLU任务划分为三种:单句分类(情感分类)、句子对分类(NLI)、多选分类(阅读理解),同时这三种任务也可以统一为多选分类任务。然后,在大规模无标注语料上设计针对三种任务的自监督任务,依次达到预训练Soft Prompt的目的。
(2) P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks – 10.14 arXiv
- 聚焦于通用NLU任务的提示方法。Prompt架构类似于Prefix-Tuning,在Transformer的每一层前加上连续型Prompt,利用[CLS]进行预测(没有Verbalizer),模型尝试了BERT-Large,RoBERTa-Large等,仅微调Prompt参数。笔者认为论文的想法和写作一般,但是进行了大量实验,有一些结论值得借鉴。例如进行了Prompt长度、层数、重参数方法、多任务、Verbalizer探究,并在一些序列标注任务上进行了实验。
(3) Towards Unified Prompt Tuning for Few-shot Learning (UPT) – 11.15 ARR Nov.
- 聚焦小样本的NLU任务。想法有点类似于PPT,通过额外的自监督任务来使得预训练模型适应Prompt。具体地
- 论文设计了统一的Prompt-Answer-Verbalizer框架,即
[INPUT] Is it [x1] or [x2]? It is [MASK]; - 然后设计了自监督任务,在无标注[INPUT]上mask形容词(与大部分NLU任务一致)
- 然后将其作为[x1],再挑选意思相反的形容词作为[x2],最后让模型去预测结果。
模型骨架是RoBERTa-Large,微调模型参数。
Answer Engineering
(1) Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification (KPT) – 8.4 ARR Sept.
- 聚集于文本(主题、情感)分类。Prompt是人工设计的完形填空式;论文的重点是在Answer的映射段,首先使用KB查询Label的相关词作为候选集,然后提出了3种方法对候选集进行去噪(即删去一些候选词),最后采用平均或者加权平均候选集的方法得到标签;最后模型使用RoBERTa-Large,微调所有参数,在零样本和小样本场景有了一定提升。
(2) Prompt-Learning for Fine-Grained Entity Typing (PLET) - 8.24 arXiv
- 聚焦于细粒度实体分类问题。在有监督场景下,该论文方案比较常规,Prompt是完形填空式,尝试了人工提示、连续型提示两种方法;在Answer映射时与该Label相关的词都加入候选集;论文使用了BERT-Base作为骨架,训练时微调所有参数,该方案在小样本场景相比传统微调有大幅提升。论文有意思的地方是在零样本场景,认为不同句子的同一个实体在候选集上的预测分布应该越相似越好(虽然笔者不是非常认同这个观点),因此采用了对比学习的办法基于少量的标注数据和大量的无标注数据进行自监督学习。
(3) Prototypical Verbalizer for Prompt-based Few-shot Tuning – 11.15 ARR Nov.
- 聚焦于小样本场景下的文本分类任务。与WARP的Soft Verbalizer思想有点类似,本文使用对比学习更加显示地来学习每个Soft Label。具体地,Prompt是人工设计的完形填空式,在训练时,可以得到每个[MASK]的表示,然后我们希望同一个Label下的[MASK]表示尽可能接近,并由此学习一个Label的Soft Prompt;模型基于RoBERTa-Large,微调所有参数。但是本论文的结果并不能比过精心设计的Verbalizer,只是在搜索式、连续式中有提升。
Multi-Prompt Learning
(1) Finetuned Language Models Are Zero-Shot Learners (FLAN) – 9.3 ICLR 2022
- 提出了基于超大模型的零样本学习方法,该论文正接受ICLR 2022评审,获得4个8分的高分。本文针对62个数据集,每个精心设计了10组人工Prompt和Answer(文中所提的Instruction),然后利用一个预训练的137B的Decoder-only的模型(不是GPT-3,是作者自己利用无标注数据预训练的)结合精心设计的Instruction在60多组数据上进行全参数微调,最后零样本迁移到其他的任务中去。结果表明在大部分数据集上FLAN优于GPT-3,甚至优于GPT-3的小样本学习(专指Demonstration Learning),特别地,FLAN在容易表示成Instruction的任务(NLI,QA)中非常有效,在补全句子(语言建模)这类任务(常识推理,共指消解)中并不是很有效。
(2) SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer – 10.15 arXiv
- 本文聚集于小模型的Soft Prompt学习(可以看做一种预训练)。Prompt Tuning[2]证明了在模型足够大的时候,仅微调Prompt可以媲美微调模型,但是在小模型上还不足以。因此本文提出了Soft Prompt的迁移学习,先在源任务集上学习自己的Prompt,然后将其作为目标任务的Prompt初始化。本文基于Prompt Tuning的Prompt架构,仅在输入前拼上Soft Prompt,然后基于各种尺度的T5,训练微调时仅学习Soft Prompt。论文尝试了几组源任务,发现以GLUE作为源任务,迁移到GLUE和SuperGLUE上效果最佳。但是,笔者发现不同的源任务选择对结果影响较大,有的源任务甚至会低于Prompt Tuning,作者并未提出较优的选择源任务的方法,主要是启发式的人工尝试。
(3) Multitask Prompted Training Enables Zero-Shot Task Generalization (T0) – 10.15 ICLR 2022
- 本文和FLAN思想相似,该论文正接受ICLR 2022评审,获得了8863的得分。本文与FLAN的区别是,基于11B的T5+LM-XXL(Prompt Tuning论文中使用)在171个数据集上使用了近2000个精心设计的Prompt和Answer进行多任务学习。该论文还开发了Prompt模版协作平台,Prompt更加贴合任务特点。最终结果超过GPT-3,与FLAN可比,并且Prompt鲁棒性更好。
(4) Exploring Low-dimensional Intrinsic Task Subspace via Prompt Tuning (IPT) – 10.15 ARR Nov.
- 本文是一篇分析性工作,主要利用Prompt Tuning聚焦小样本场景下预训练模型中低维度内在任务子空间。IPT基于的Prompt架构,在输入前加上Soft Prompt,以BART作为骨架。论文的核心内容是,先在多任务场景下训练一个Prompt的Auto-encoder,即通过一个Encoder将Soft Prompt编码成任务特定的低维子空间,再通过一个Decoder将其恢复成Soft Prompt;之后在迁移到新任务时,我们固定Decoder,只需要训练一个低维的任务特征向量。作者实验发现,在多任务学习阶段,将Prompt到低维空间再恢复相比Prompt Tuning有所提升,说明了低维的任务子空间的确存在;同时只需要学习一个5~100维的任务特征向量,对于一个新的数据集可以达到Prompt Tuning效果的80%,对于新的任务可以达到60%。但是,该发现还值得进一步研究,使重构子空间可以获得更好的表现和泛化性。
(5) On Transferability of Prompt Tuning for Natural Language Understanding (TPT) – 11.12 arXiv
- 本文聚焦于跨任务、跨模型的Soft Prompt学习。论文的Prompt框架、想法与SPoT一致,模型骨架是RoBERTa-Base。在跨任务迁移中,论文发现相似任务的Soft Prompt可以进行零样本学习,并在全量数据下提升效果,并且加快收敛速度(缓解Prompt Tuning收敛慢的问题);同时,论文发现Soft Prompt对Transformer的FFN中的激活神经元的重合度,相比于Soft Prompt本身的矩阵相似度,可以更好地度量两个任务的相似度,以此更好地选择源任务Prompt。但在跨模型迁移中,用一个模型的Soft Prompt映射到另一个模型的方法,并不能取得提升。
(6) TransPrompt: Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification – 11.6 EMNLP 2021
- 本文聚集于小样本NLU任务。该论文的Prompt框架基于P-Tuning,在输入两端加上连续型Prompt,并用BiLSTM进行编码,最后进行完形填空式预测,模型用RoBERTa-large作为骨架,微调所有参数。论文的核心想法是每一个任务使用一个Prompt,外加一个Universal的Prompt学习通用知识(考虑任务间迁移性),然后进行多任务训练。同时还提出了针对小样本场景提出了Prototype-based和Entropy-based两种去偏方法。最终模型在小样本和全量数据场景下都超越了基线模型。
(7) Contrastive Demonstration Tuning for Pre-trained Language Models (Demo-Tuning) – 11.15 ARR Nov.
- 本文聚集于NLU的Demonstration Learning(GPT-3中的In-context Learning)。作者借鉴了Soft Prompt的思想,提出了Soft Demonstration(笔者命名)想法,缓解了Hard Demonstration采样偏差大、长度受限的问题。论文使用对比学习,训练时交替保留正负例的Hard Demonstration,学习另一个的Soft Demonstration。模型骨架是RoBERTa-Large,微调所有的参数。
资料
- 【2023-2-26】Prompt Engineering Guide, Motivated by the high interest in developing with LLMs, we have created this new prompt engineering guide that contains all the latest papers, learning guides, lectures, references, and tools related to prompt engineering.
- 【2023-2-16】清华开源的 OpenPrompt:An Open-Source Framework for Prompt-learning. 包含prompt各个算法、模块的代码及示例
- PromptPapers
- CMU的Neubig老师的Advanced NLP课程
- 【2021-8-3】Fine-tune之后的NLP新范式:Prompt越来越火,CMU华人博士后出了篇综述文章,CMU 博士后研究员刘鹏飞:近代自然语言处理技术发展的第四范式可能是预训练语言模型加持下的 Prompt Learning。
- 从 BERT 开始,预训练+finetune 已经成为了整个领域的常规范式。但是从 GPT-3 开始,一种新范式开始引起大家的关注并越来越流行:prompting。
- 论文地址,更多研究见:清华大学开源的论文列表 thunlp/PromptPapers

prompt讲解
NLP 范式
全监督学习在 NLP 领域也非常重要。但是全监督的数据集对于学习高质量的模型来说是不充足的,早期的 NLP 模型严重依赖特征工程。
- 随着用于 NLP 任务的神经网络出现,使得特征学习与模型训练相结合,研究者将研究重点转向了架构工程,即通过设计一个网络架构能够学习数据特征。
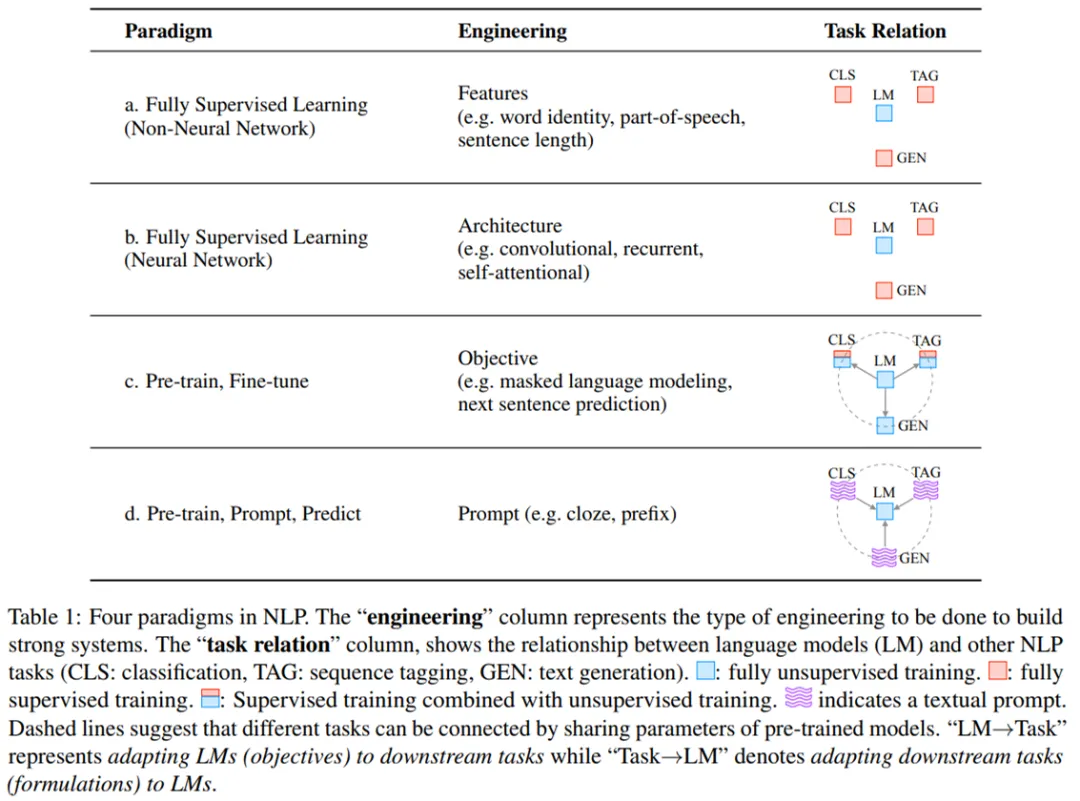
各种模式的对比如下:
| 模式paradigm | 工程重心engineering | 示例 | 任务关系task relation |
|---|---|---|---|
| ① 全监督(非神经网络) | 特征 | 如单词,词性,句子长度等 | 分类、序列标注、语言模型(无监督)、生成 |
| ② 全监督(神经网络) | 结构 | 如卷积、循环、自注意力 | 同上 |
| ③ pre-train与fine-tune | 目标 | 掩码语言模型、NSP下一句预测 | 以语言模型为中心,含无监督训练 |
| ④ pre-train、prompt与predict | 提示 | 完形填空、前缀 | 语言模型为中心,含文本提示 |
- 传统的监督学习(不需要神经网络)
- 神经网络-监督学习:不同NLP任务需要单独训练
pre-train+fine-tune:目前流行的范式,可以适应不同的场景任务pre-train+prompt+predict: 模板prompt范式,可以适应不同的场景任务
【2023-2-12】【NLP】Prompt Learning 超强入门教程, 刘鹏飞在北京智源大会上关于 Prompt 的分享
【2023-2-9】
- 【NLP】Prompt Learning 超强入门教程
- 论文 Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
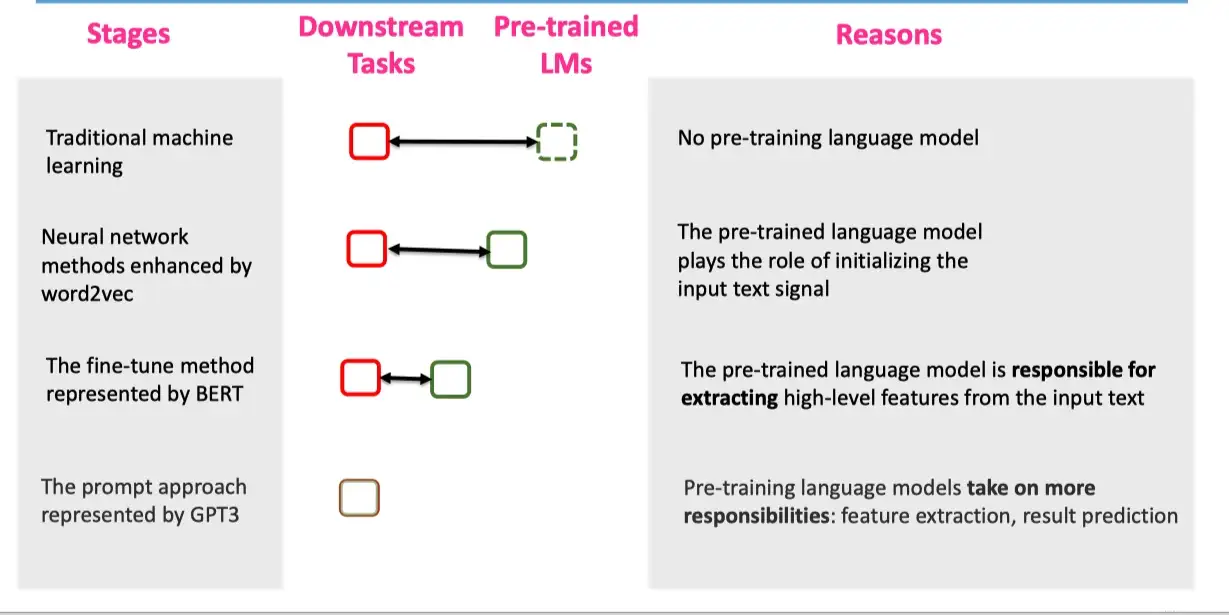
很长一段时间内,NLP任务采用的都是 Pretrain + Fine-tuning(Model Tuning)的解决方案,需要对于每个任务都重新 fine-tune 一个新的模型,且不能共用。
- 但是对于一个预训练的大语言模型来说,这就仿佛对于每个任务都进行了定制化,十分不高效。
- 是否存在一种方式,可以将预训练语言模型作为电源,不同的任务当作电器,仅需要根据不同的电器(任务),选择不同的插座,对于模型来说,即插入不同的任务特定的参数,就可以使得模型适配该下游任务。
Prompt Learning就是这个适配器,它能高效得进行预训练语言模型的使用。
这种方式大大地提升了预训练模型的使用效率,如下图:

- 左边是传统的
Model Tuning的范式:对于不同的任务,都需要将整个预训练语言模型进行精调,每个任务都有自己的一整套参数。 - 右边是
Prompt Tuning,对于不同任务,仅需要插入不同的 prompt参数,每个任务都单独训练 Prompt 参数,不训练预训练语言模型,这样子可以大大缩短训练时间,也极大的提升了模型的使用率。
NLP四大范式
NLP四大范式
- 第一范式:非神经网络时代的完全监督学习(
特征工程)。该阶段需要大量任务相关的训练数据,通过特征工程和算法,比较有代表的算法是朴素贝叶斯Naïve Bayes、支持向量机SVM、逻辑回归LR等; - 第二范式:基于神经网络的完全监督学习(
架构工程)。该阶段也需要大量任务相关的训练数据,通过深度学习方法,自动获取特征(表示学习)进行端到端分类学习; - 第三范式:预训练,精调范式(
目标工程):该阶段是当前使用比较多的预训练+微调范式,通过预训练的方式(比如掩码语言模型Masked Language Model)来学习海量的语言学知识,然后下游使用少量的任务相关的数据对预训练模型进行微调即可完成相关任务; - 第四范式:预训练,提示,预测范式(
Prompt工程):当前进入了Prompt Learning提示学习的新范式,使用Few shot或者Zero shot即可完成下游任务。 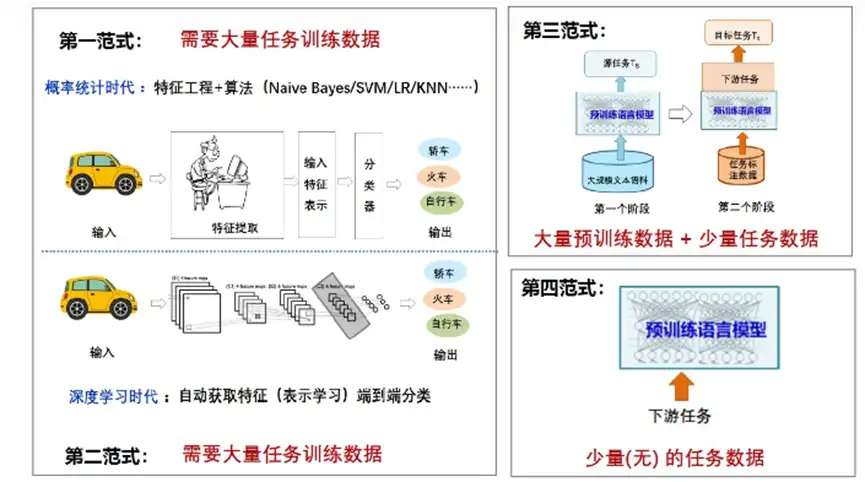
预训练+微调和Prompt Learning流程对比
NLP 范式发展历史
| 年份 | NLP模型范式变化 |
|---|---|
| 2017年以前 | 传统机器学习模型、神经网络 |
| 2017-2019 | 预训练 + 微调(pre-train + fine-tune) |
| 2019-至今 | ”预训练,prompt和预测“(pre-train,prompt and predict)范式 |
NLP发展历史上的三种范式(时间顺序)
- 很久以前发展起来的
全监督学习Fully Supervised Learning - Fully Supervised Learning,即仅在目标任务的输入输出样本数据集上训练特定任务模型,长期以来在许多机器学习任务中发挥着核心作用,同样的,全监督学习在 NLP 领域也非常重要。
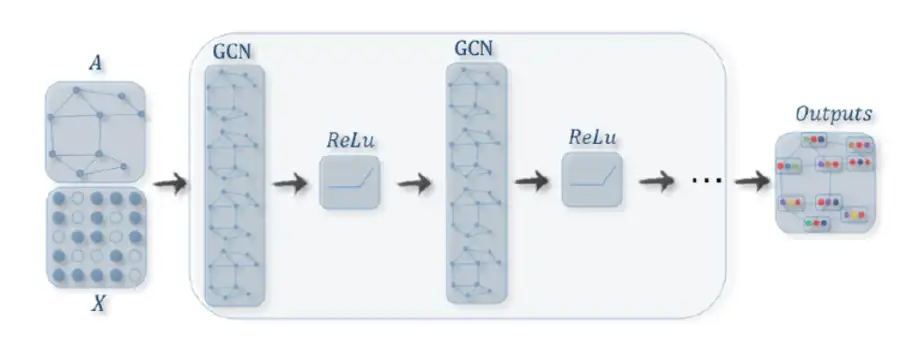
- 但是全监督数据集对于学习高质量的模型来说是不充足的,早期的 NLP 模型严重依赖特征工程。随着用于 NLP 任务的神经网络出现,使得特征学习与模型训练相结合,研究者将研究重点转向了架构工程,即通过设计一个网络架构能够学习数据特征。
- 前三年火爆的
预训练+微调Pre-train, Fine-tune - 然而,从 2017-2019 年开始,NLP 模型发生了翻天覆地的变化,这种
全监督范式发挥的作用越来越小。具体而言,研究重点开始转向预训练、Fine-tuning范式。一个具有固定架构的模型通过预训练作为语言模型(LM),用来预测观测到的文本数据的概率。 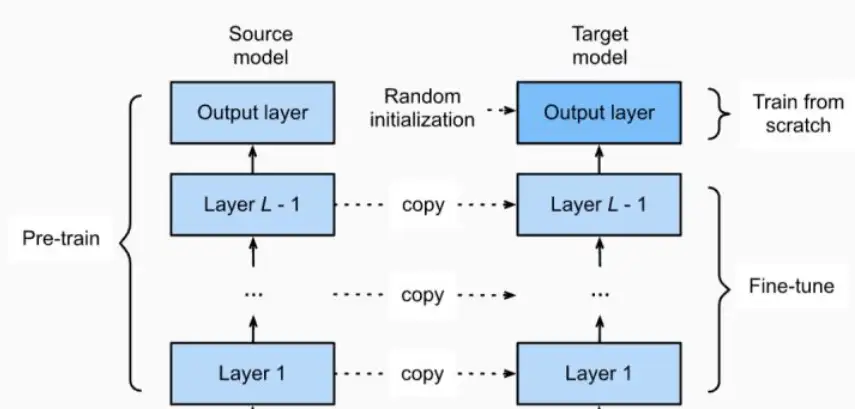
- 最新的
预训练+提示+预测Pre-train, Prompt, Predict - 当前正处于第二次巨变中,「预训练、Fine-tuning」过程被「预训练、prompt 和预测」过程所取代。
- 在这种范式中,不是通过目标工程使预训练的语言模型(LM)适应下游任务,而是重新形式化(Reformulate)下游任务,使其看起来更像是在文本 prompt 的帮助下在原始 LM 训练期间解决的任务。
- 通过这种方式,选择适当的 prompt,该方法可以操纵模型的行为,以便预训练的 LM 本身可以用于预测所需的输出,有时甚至无需任何额外的特定任务训练。
- 优点是给定一组合适的 prompt,以完全无监督方式训练的单个 LM 就能够用于解决大量任务。
- 然而该方法也存在一个问题 —— 这种方法引入了 prompt 挖掘工程的必要性,即需要找出最合适的 prompt 来让 LM 解决面临的问题
Prompt刚刚出现时,还没有被叫做Prompt,是研究者们为了下游任务设计出来的一种输入形式或模板,它能够帮助PLM“回忆”起自己在预训练时“学习”到的东西,因此后来慢慢地被叫做Prompt了。
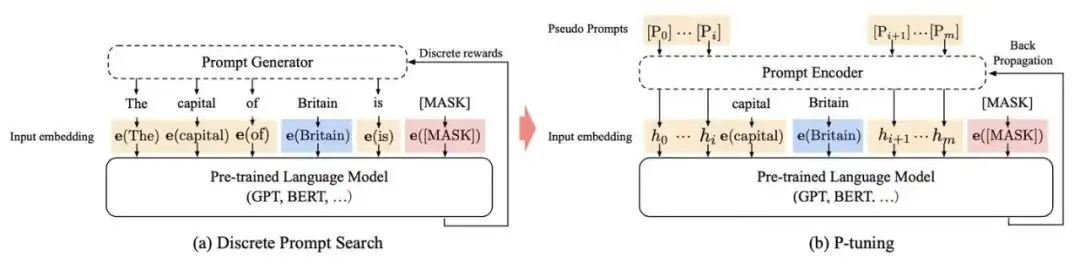
不同于fine-tuning方法,prompt 范式需要给出一个定义好的模板,这个模板可以是离散的或者是连续的,来提醒模型在预训练的时候学习的知识。这是因为预训练的任务和下游任务往往差别较大,模型可能会存在特定性遗忘。
prompt 介绍
什么是 Prompt, Prompt 就是 提示:
- 有人忘记了某个事情,给予特定提示,他就可以想起来
- 白日依山尽, 大家自然而然地会想起来下一句诗:黄河入海流。
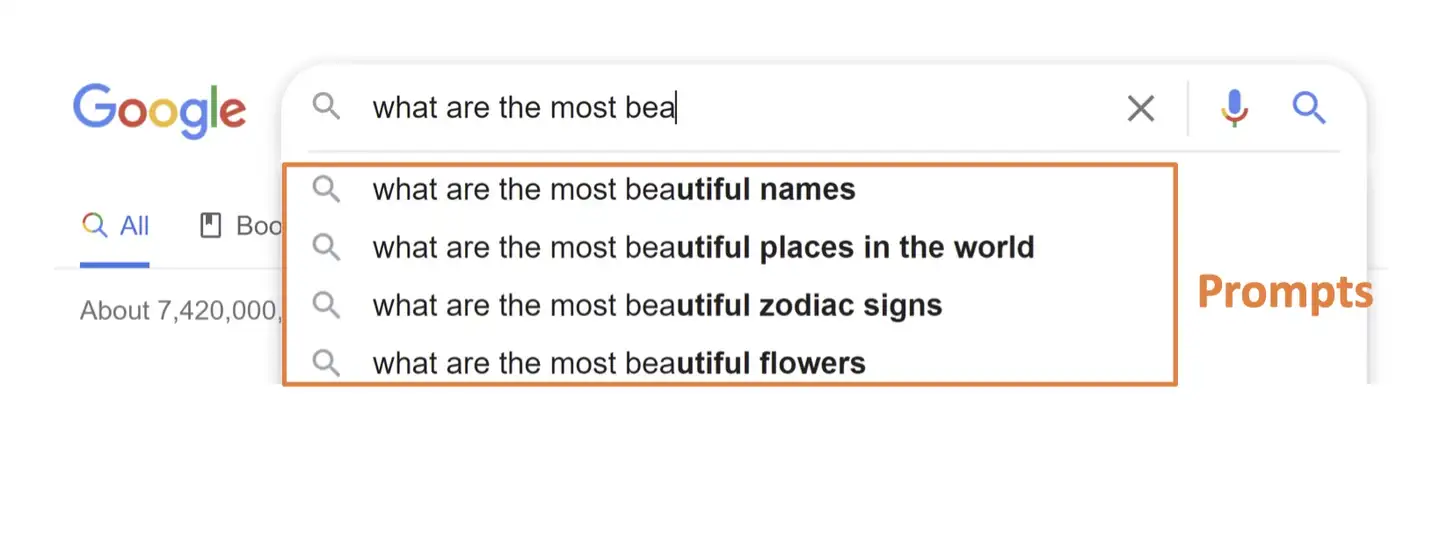
- 搜索引擎,可以根据输入,进行输出提示:
文本情感分类:
- “I missed the bus today.” 句子后紧跟着给出这样一个prompt:“I felt so _____”
- “English: I missed the bus today. French: __”
PLM将自动补充单词sad,或使用法语来进行填空。
prompt演变过程
【2023-2-16】一个小白如何学好prompt tuning?
任务:
- 对描述的商品类型进行分类
- 第一句需要被分类到「水果」类别中;
- 第二句则需要分类到「电脑」类别中。
标注数据集:
什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃! 1
这破笔记本速度太慢了,卡的不要不要的。 0
(1)早期分类方法
直觉上分类方式:
- 将该问题建模成一个传统文本分类任务,通过人工标注,为每一个类别设置一个id,例如:
{
'电脑': 0,
'水果': 1,
....
}
这种方法可行,但需要「较多的标注数据」才能取得不错的效果。
(2)BERT 预训练+分类
由于大多数预训练模型(如BRET)在 pretrain 的时候都使用了 [MASK] token 做 MLM 任务,而实际下游任务中不会使用到 [MASK] 这个 token,这就意味着今天训练下游任务时需要较多的数据集去抹平上下游任务不一致的 gap。
(3)Prompt
如果没有足够多的训练数据呢?
- prompt learning 就是为了解决这一问题,它将 [MASK] 的 token 引入到了下游任务中,将下游任务构造成类似MLM 的任务。
上述评论改写为:
这是一条[MASK][MASK]评论:这破笔记本速度太慢了,卡的不要不要的。
然后让模型去预测两个 [MASK] token 的真实值是什么,那模型根据上下文能推测出被掩码住的词应该为「电脑」。由于下游任务中也使用了和预训练任务中同样的 MLM 任务,这样就可以使用更少的训练数据来进行微调了。
(4)p-tuning
构建句子最关键的部分是在于 prompt生成,即:
# (prompt) (content)
「这是一条[MASK][MASK]评论:」 + 这破笔记本速度太慢了,卡的不要不要的。
被括号括起来的前缀(prompt)的生成非常重要,不同 prompt 会极大影响模型对 [MASK] 预测的正确率。
这个 prompt 怎么生成?
- 当然可以通过人工去设计很多不同类型的前缀 prompt,即
prompt pattern,例如:
这是一条[MASK][MASK]评论:
下面是一条描述[MASK][MASK]的评论:
[MASK][MASK]:
...
但是人工列 prompt pattern 非常麻烦,不同数据集所需要的 prompt pattern 也不同,可复用性很低。能不能通过机器自己去学习 prompt pattern 呢?可以,P-tuning。
作者:何枝
图解
什么是 prompt?
NLP中 Prompt 代表的是什么呢?
- prompt 就是给 预训练语言模型 的一个线索/提示,更好的理解 人类的问题。
下图的 BERT/BART/ERNIE 均为预训练语言模型,对于人类提出的问题以及线索,预训练语言模型可以给出正确的答案。

- 根据提示,BERT能回答,JDK 是 Oracle 研发的
- 根据
TL;DR:的提示,BART知道人类想要问的是文章的摘要 - 根据提示,ERNIE 知道人类想要问鸟类的能力–飞行
Prompt 更严谨的定义如下:
- Prompt is the technique of making better use of the knowledge from the pre-trained model by adding additional texts to the input.
- Prompt 是一种为了更好的使用预训练语言模型的知识,采用在输入段添加额外文本的技术。
- 目的:更好挖掘预训练语言模型的能力
- 手段:在输入端添加文本,即重新定义任务(task reformulation)
Prompting, 又称in-context learning ICL,指“预训练-Prompt“这一NLP最新的范式,也属于Parameter Efficient(参数高效)学习方法的一种,但是把Prompting仅仅理解为Parameter Efficient学习方法, 格局小了
- 之前的范式产生的模型从本质上决定了无法在任务级别拥有泛化能力,而Prompting在任务级别具有泛化能力,对之前的NLP范式降维打击。
- 预训练+微调的范式可以大幅超越只使用特定任务数据训练的模型。
- 预训练模型的性能和模型的大小有关, 模型越大效果越好。
问题:
- 传统微调需要更新所有模型参数,由于特定任务的那点数据跟预训练数据相比,少得可怜,从而导致训练效果并不好。
- 此外,微调好的模型用到线上时,每个任务甚至每个领域都需要单独部署一个微调好的模型,很不经济实惠。
研究人员提出了部分参数微调/冻结部分参数的方法:
- 采用关于模型参数分布的先验知识—模型的某些部分有特定的功能(偏向特定的功能)。
- Transformer模型用在机器翻译时,Encoder部分负责将源语言编码成高维向量,Decoder部分负责生成目标语种中的对应意思的句子。
- 假设之后,在微调模型参数时,利用这些先验知识,只更新和目标任务最相关的那部分。
好处:
- (1)训练更快、更有针对性、效果也往往更好
- (2)部署的时候可以多个任务/领域共用一个背景预训练模型,只需针对每个任务/领域替换被更新的部分参数即可。
在上述”部分参数微调“方法的基础之上,研究人员提出了Adapter方法。通过添加一个灵活的即插即用的可训练适配模块(Adaper Module),改变模型某一层(或某几层)的数据分布,从而让模型可以适用于各种各样的任务和领域。
- 典型的做法: 每一任务或者每一领域对应了一个Adapter Module,训练时只更新对应任务Adapter的参数,推理的时候激活对应任务/领域的Adapter,其它任务/领域的Adapter直接忽视。
和”部分参数微调“方法相比,Adapter方法的优势有
- (1)更轻量级
- (2)同样比例的参数效果更好。
以上方法都是基于”预训练-微调“的范式的方法,无论多么轻量级,每个任务都还是有一套特定的参数(即使大部分参数可以共享)。
大多数人其实并没有意识到,致命缺点正是:任务本身需要人为进行定义。
- 但是现实生活中的知识,并不是完全地按照任务进行分类的,现实中大多数任务会涉及到多个任务的能力: 比如一个中国人阅读了一篇英文的文章,最后用中文写了个总结 — 这就涉及到 翻译+总结 两个任务。
而Prompting可以做到模糊任务的界限—不需要人为对任务进行划分,相反,任务的描述会作为输入的一部分直接输入预训练模型。
这就是为什么Prompting范式是”通往真正大一统语言模型的关键一步。
- 两种prompt范式对比:
预训练-微调范式,预训练-Prompting范式
Prompting方法最初在2020年和GPT-3一同提出来。
- Prompt范式认为预训练模型本身就可以完成很多任务,只需要在输入的时候对模型进行引导(又称:提供context)即可
怎么引导呢?
- 最开始的Prompt版本只需要用自然语言将任务本身进行描述,将任务变为”填空”(针对双向模型BERT)或者”生成”(针对自回归模型GPT)的任务即可。
示例
- 文本情绪分类任务:任务目的是任意输入一段文本,预测对应的情绪(正面、负面、中性)。
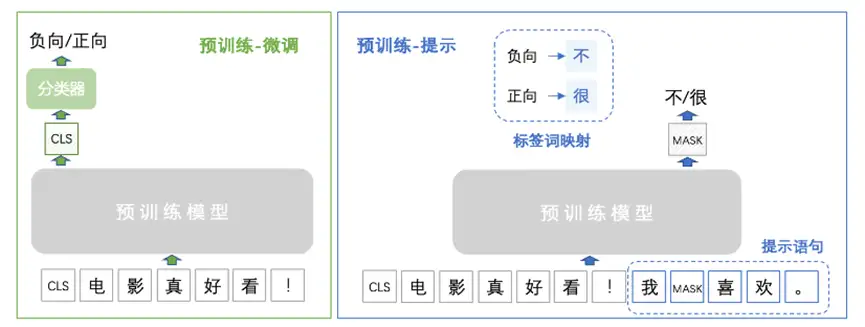
- 经典的预训练-微调范式:将在预训练模型的基础上增加分类器模块,使用特定任务数据进行微调分类器模块。在遇到输入“今天天气很好”时,模型输出“正面”。
- 而在Prompt范式下,将如下文字直接输入没有经过微调的模型: “今天天气很好,我的心情是[MASK]的” ==> [MASK]预测值是”开心”,再将“开心”映射为”正面”就很容易了。
- 机器翻译任务:任务本身的目的是输入一种语言的一段文本,模型生成另一种语言的同义句。
- 在Prompt范式下,将如下文字输入模型:“翻译成英语:今天天气真好” ==> 模型输出“This is a good day.”
Prompt范式特点:
- 无需特定领域的数据进行训练就可以用于各项NLP任务,并且无需在模型参数上做任何调整。
Prompt的成功证明了在模型和训练数据量大到一定程度时,模型本身就更接近“百科全书”,而Prompt就是将“百科全书”里的知识金矿挖掘出来的各种钥匙。

- 短短5年从GPT-1到GPT3.5,模型变大了3000倍,未来的GPT-4更是拥有100Trillion参数
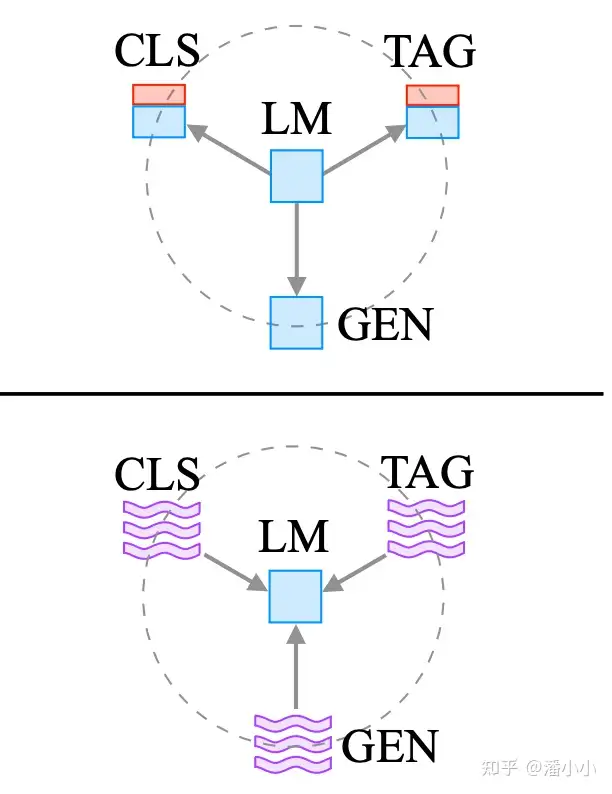
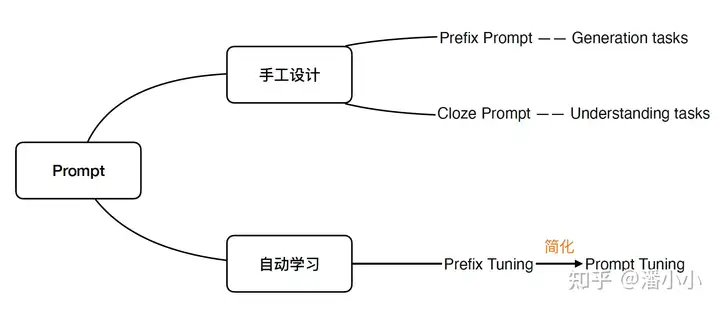
Prompting方法分为
- (1) 手工Prompt
- 对任务进行自然语言描述”的方法。
- 主要分为“
Prefix Prompt“和”Cloze Prompt,其中”Prefix Prompt“一般针对生成式NLP任务(NLG),而Cloze Prompt针对理解式NLP任务(NLU)
- (2) 参数化Prompt: 也叫”自动Prompt”,主要分为
离散Prompt和连续Prompt。- “离散”指候选的Prompts依然是自然语言的词;
- “连续”指Prompts本身不需要是自然语言的序列,而可以是词表中的token的任意组合,甚至可以引入不在原来词表中的token。其中比较出名的就是
Prefix Tuning:在input层添加一串连续的向量(拥有独立embedding的新token)前缀,同时在每个hidden layer对应添加相同长度的前缀(这一步不引入额外参数,但是略微修改了模型结构)。训练时对每个独立的任务做分别的参数更新。需要注意的是,在下游任务上进行训练时,只有Prefix对应的Embedding参数进行更新。
Prompt Tuning 在Prefix Tuning的基础上进一步做了简化,每个hidden layer不再需要对应添加相同长度的前缀,因此模型结构完全没有改变,只是多了prefix token对应的embedding参数(大概占模型总参数的0.1%)。Prompt Tuning也因此更加灵活。
Prompt范式效果怎么样?又有哪些重要结论呢?
- 预训练-Prompt能达到和预训练-微调相当的效果,即使可训练参数缩减了1000倍
- 模型的规模是决定性因素:模型越大,prompting的模型效果越好
- 对任务有泛化能力,即 few-shot / zero-shot能力强
Prompt 概要
该综述研究试图通过提供 prompting 方法的概述和形式化定义,以及使用这些 prompt 的预训练语言模型的概述,来梳理这一迅速发展领域的当前知识状态。然后该论文对 prompt 方法进行了深入的讨论,包括 prompt工程、answer工程等基础和多prompt学习方法、prompt相关的训练方法等更高级的概念。
然后,该研究列出了已有的基于 prompt 学习方法的多种应用,并探讨了不同应用场景中如何选择合适的训练方法。最后,该研究尝试在研究生态系统中定位 prompt 方法的当前状态,并与其他研究领域建立联系。此外,该研究提出一些可能适合进一步研究的挑战性问题,并针对当前研究趋势进行了分析。
基于 Prompt 的学习方法试图通过学习LM来规避这一问题,该 LM 对文本 x 本身的概率 P(x;θ) 进行建模并使用该概率来预测 y,从而减少或消除了训练模型对大型监督数据集的需求。
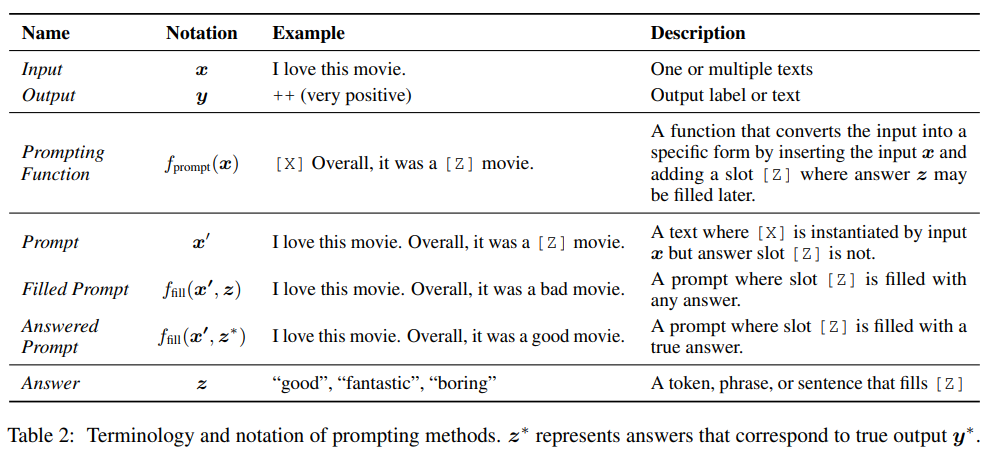
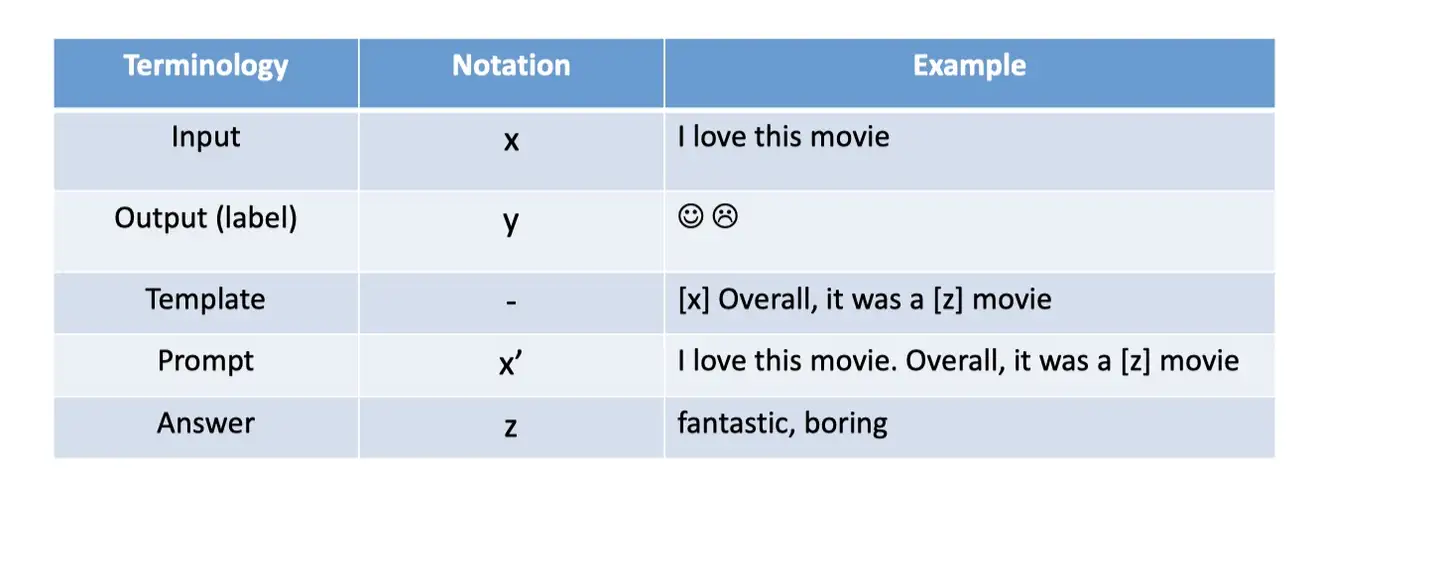
最基本的 Prompt 形式的数学描述,包含许多有关 Prompt 的工作,并且可以扩展到其他内容。
基础 Prompt 分三步预测得分最高的 ^y,即:prompt 添加、answer 搜索和 answer 映射。prompting 方法的术语和符号。
 不同任务的输入、模板和 answer 示例:
不同任务的输入、模板和 answer 示例: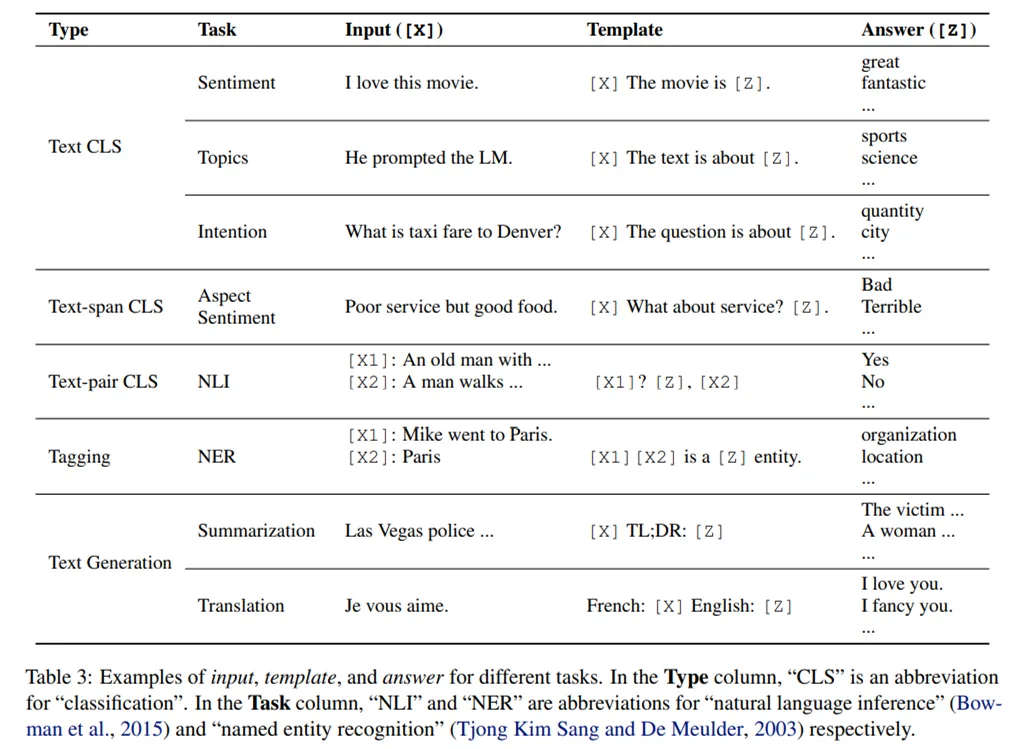
Prompt设计思路
Prompting 设计考虑:
- 预训练模型选择:有许多预训练 LM 可以用来计算 P(x; θ)。在第 3 章中,研究者对预训练 LM 进行了初步的介绍;
- Prompt 工程:如果 prompt 指定了任务,那么选择正确的 prompt 不仅对准确率影响很大,而且对模型首先执行的任务也有很大影响。在第 4 章中,研究者讨论了应该选择哪个 prompt 作为 f_prompt(x) 方法;
- Answer 工程:根据任务的不同,会有不同的方式设计 Z (Answer),可能会和映射函数一起使用。在第 5 章中,详细介绍了不同的设计方式;
- 扩展范式:如上所述, 上面的公式仅仅代表了各种底层框架中最简单的一种,这些框架已经被提议用于执行各种 prompting。在 第 6 章中,研究者讨论了扩展这种基本范式以进一步提高结果或适用性的方法;
- 基于 Prompt 的训练策略:在第 7 章中,研究者总结了不同的训练策略并详细说明它们的相对优势
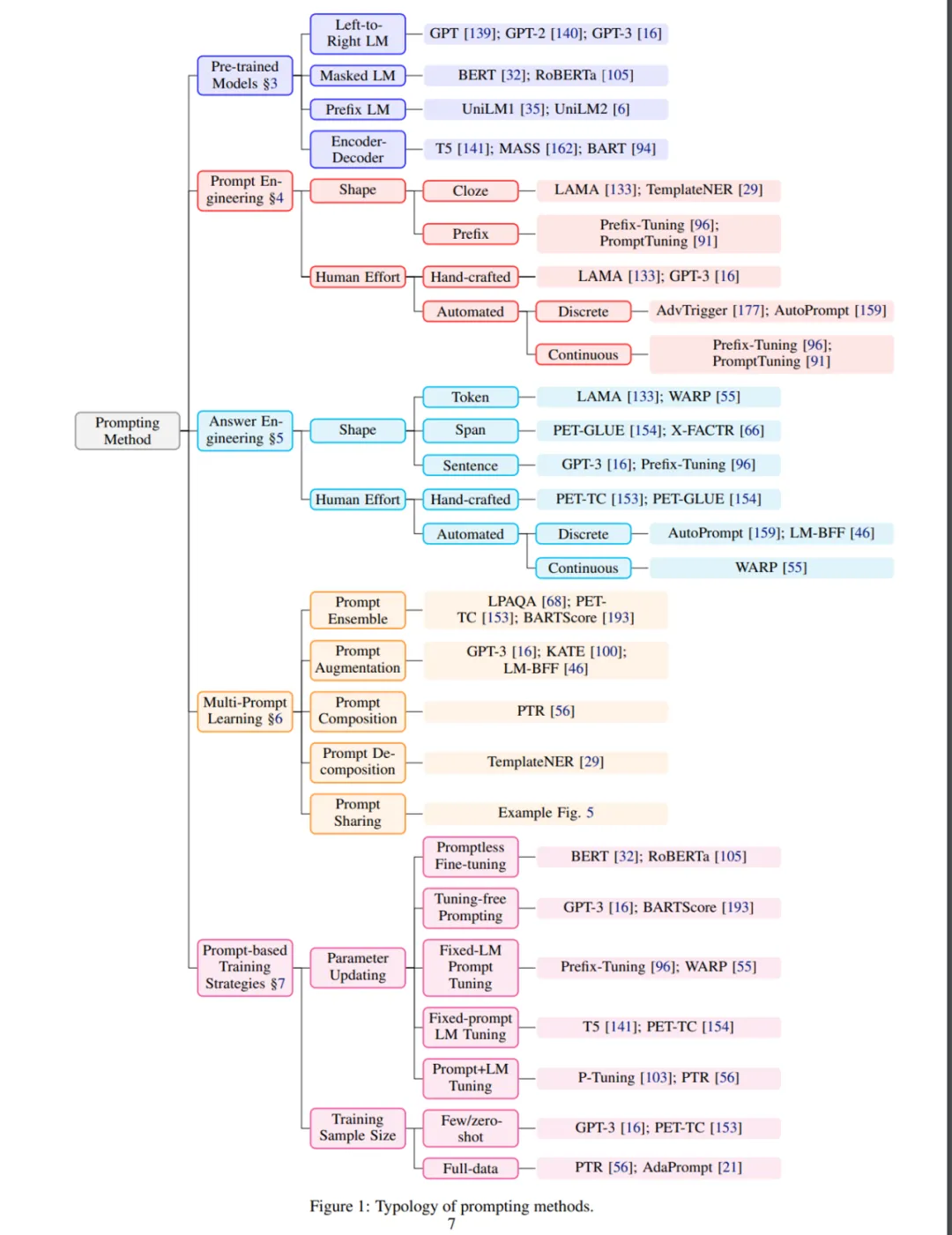
Prompt 工作流
清华:OpenPrompt
Prompt 的工作流包含以下4部分:
- Prompt 模版(Template)构造*
- Prompt 答案空间映射(Verbalizer)的构造
- 文本代入template,并且使用预训练语言模型进行预测
- 将预测结果映射回label。
具体的步骤如下图,拆解分析。
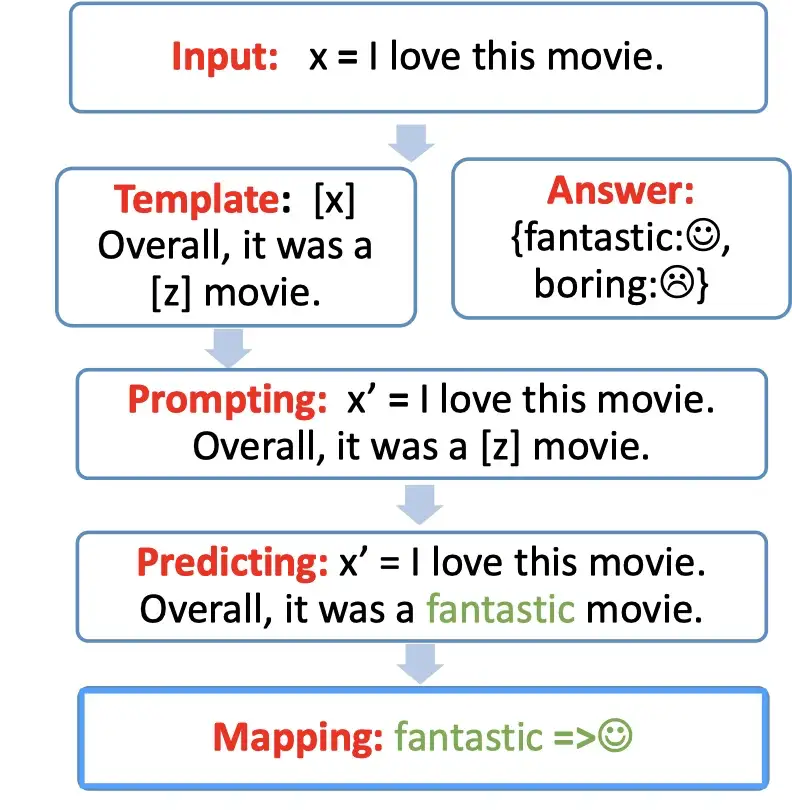
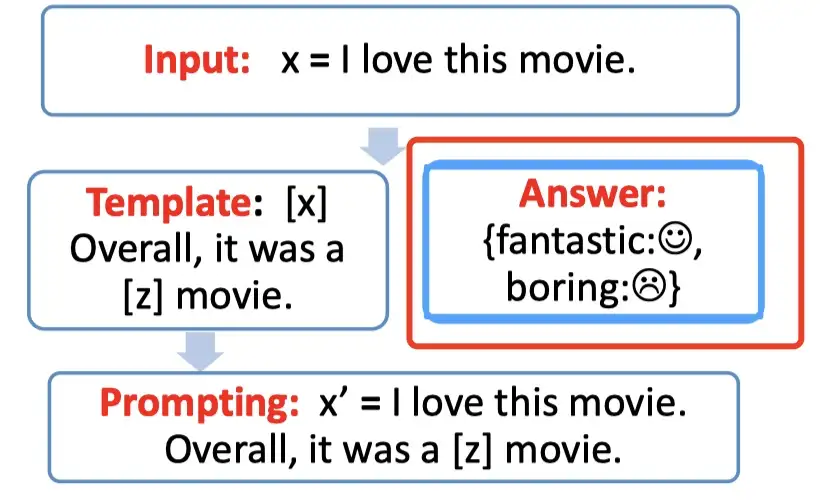
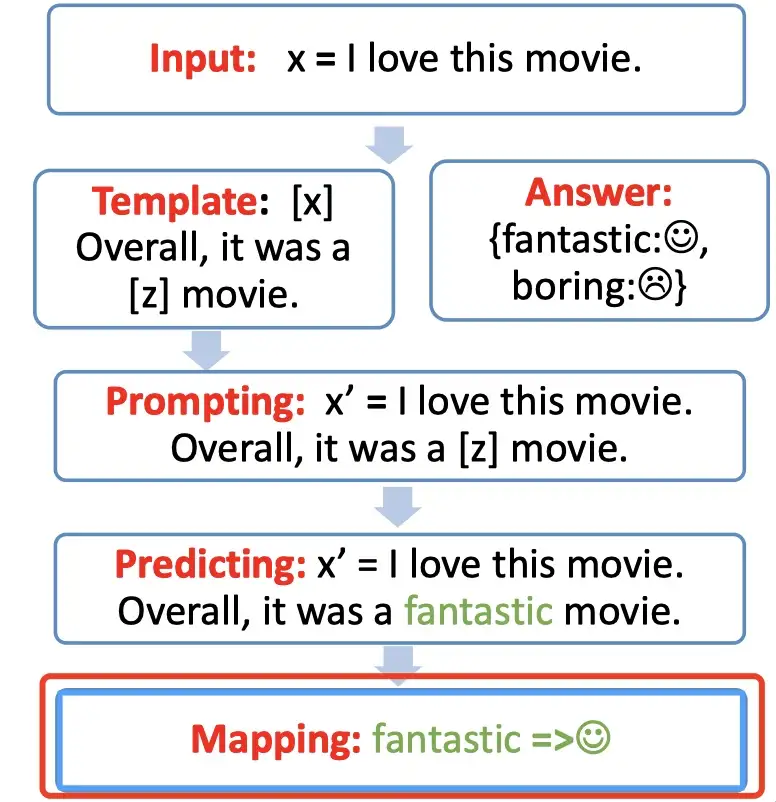
Step 1: prompt construction【Template】
首先构建一个模版Template,作用是将输入和输出进行重新构造,变成一个新的带有mask slots的文本,具体如下:
- 定义一个模版,包含了2处代填入的slots:[x] 和 [z]
- 将[x] 用输入文本代入
例如:
- 输入:x = 我喜欢这个电影。
- 模版:[x]总而言之,它是一个[z]电影。
- 代入(prompting):我喜欢这个电影。总而言之,它是一个[z]电影。

Step 2: answer construction【Verbalizer】
对于构造的prompt,要知道预测词和label 之间的关系,并且不可能运行z(任意词),就需要一个映射函数(mapping function)将输出的词与label进行映射。
- 输出的label 有两个,一个是 😄,一个是 😭,可以限定,如果预测词是
fantastic则对应 😄,如果是boring则对应 😭. 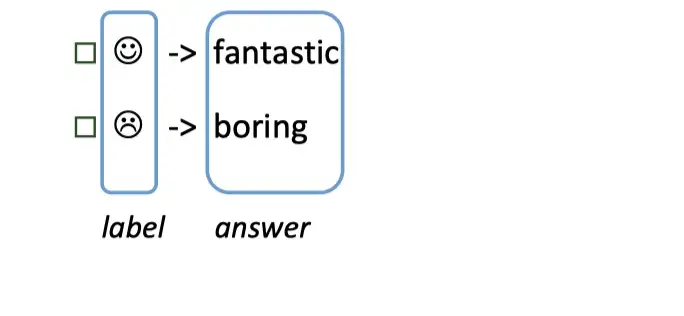
Step 3: answer prediction【Prediction】
只需要选择合适的预训练语言模型,然后进行 mask slots [z] 的预测。例如下图,得到了结果 fantastic, 将其代入[z] 中。

Step 4: answer-label mapping【Mapping】
第四步骤,对于得到的 answer,用 Verbalizer 将其映射回原本的label。
- 例如:fantastic 映射回 label:
总结
Prompt-based 方法的工程选择问题
在知乎中有个提问:
现代的deep learning 就是为了规避 feature engineering,可是prompt 这边选择了 template 和 answer 不还是 feature engineering吗?
确实, 如果使用 BERT 的 fine-tuning 范式(下图左),不需要使用任何的人工特征构造,而使用 prompt-based 的方法的话,需要人工参与的部分包含了以下部分:
- template 构造
- answer 构造
- 预训练模型选择
- prompt 的组合问题选择
- 以及训练策略的选择等
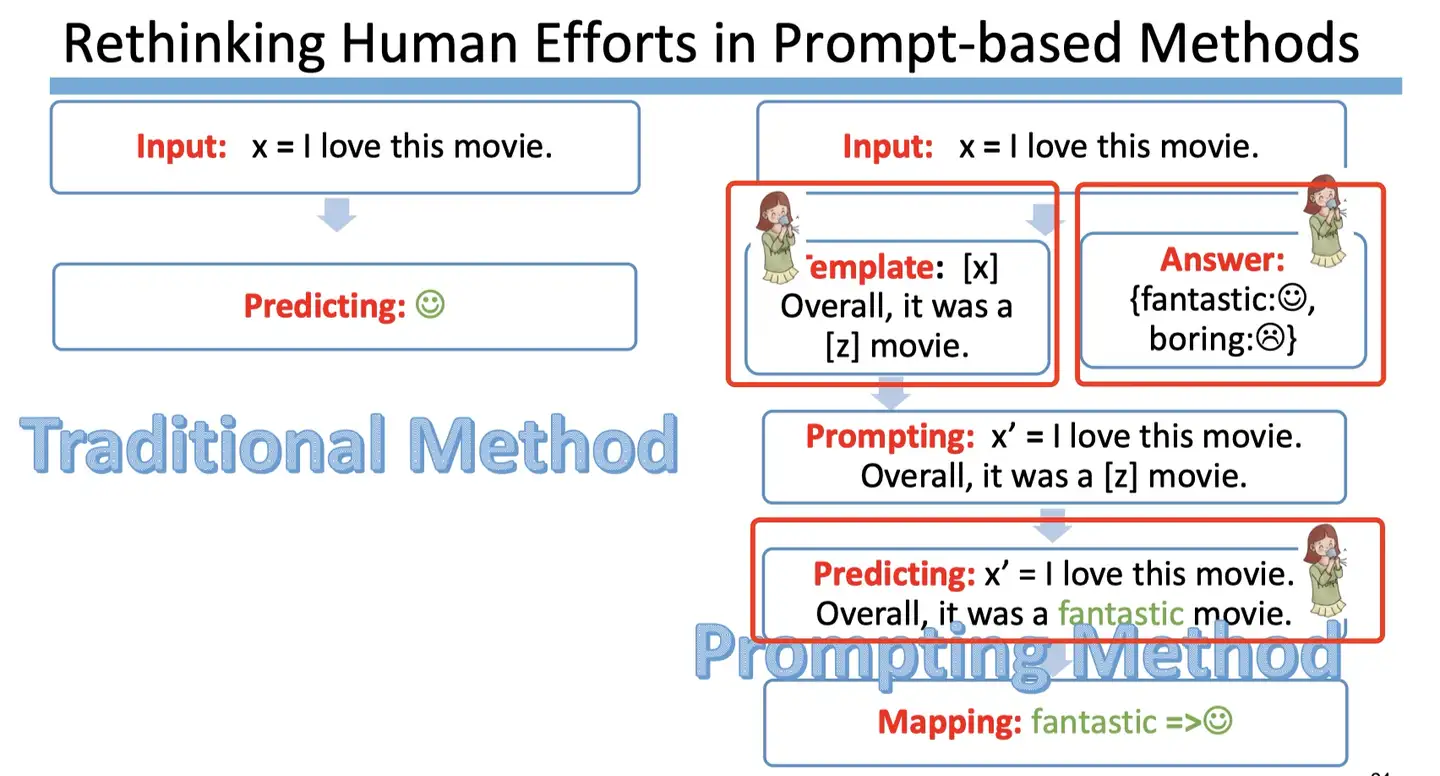
会先进行每个需要人工engineering 的部分进行详细讲解,然后再分析为什么我们还需要prompt 这种范式。
Prompt Template Engineering(Prompt模版工程)
如何构造合适的Prompt 模版?对于同一个任务,不同的人可能构造不同的Template。
且每个模版都具有合理性。Tempalte的选择,对于Prompt任务起到了很重大的作用,就算一个word的区别,也坑导致10几个点的效果差别,论文GPT Understands, Too 给出了如下的结果:

对于不同的template,可以从以下两种角度进行区分:
- 根据slot 的形状/位置区分
- 1.1
完形填空(Cloze)的模式,即未知的slot在template的中间等不定的位置 - 1.2
前缀模式(Prefix),未知的slot在template的开头
- 1.1
- 根据是否由人指定的来区分
- 2.1
人工指定template - 2.2
自动搜索template - 2.3
Discrete离散Template,即搜索的空间是离散的,为预训练语言模型的字典里的字符。 - 2.4
Continuous连续Template,即搜索的空间是连续的,因为所有新增的这些prompt的参数主要是为了让机器更好地服务于任务,所以其参数的取值空间不需要限定在特定的取值范围内,可以是连续的空间。
- 2.1
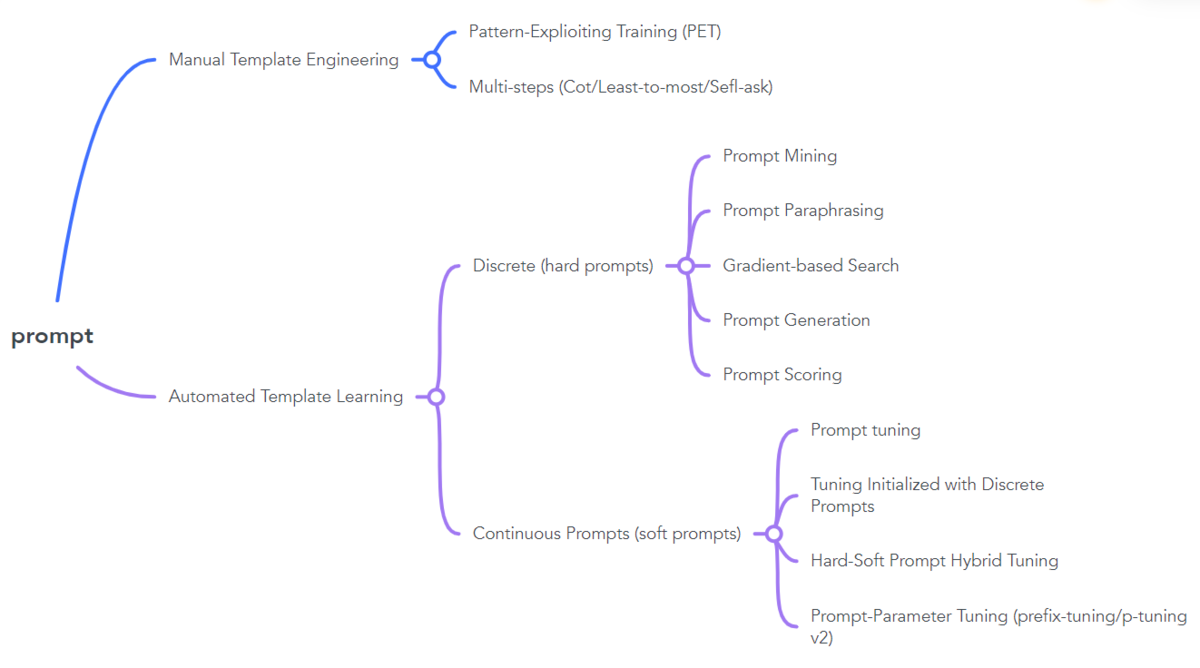
具体的思维导图如下:

P-Tuning 自动生成模板
自动学习模板可以分为离散(Discrete Prompts)和连续(Continuous Prompts)两大类。
离散主要包括 Prompt Mining, Prompt Paraphrasing, Gradient-based Search, Prompt Generation 和 Prompt Scoring;连续则主要包括Prefix Tuning, Tuning Initialized with Discrete Prompts 和 Hard-Soft Prompt Hybrid Tuning
作者:何枝
人工构建模板对人类来讲是合理的,但是在机器眼中,prompt pattern 长成什么样真的关键吗?
- 机器对自然语言的理解和人类对理解大不相同,曾经有做一个 model attention 和人类对语言重要性的理解的对比实验,发现机器对语言的理解和人类是存在一定的偏差的。
那是不是不用特意为模型去设定一堆我们觉得「合理」的 prompt pattern,而是让模型自己去找「合理」的prompt pattern 呢?
p-tuning
- 论文:GPT Understands, Too
- 代码:p-tuning
P-Tuning 的训练一共分为:prompt token(s) 生成、mask label 生成、mlm loss 计算 三个步骤。
- (1)prompt token(s) 生成
- (2)mask label 生成
- (3)mlm loss 计算
(1)prompt token(s) 生成
随便生成一个模板扔给模型
- 选用中文 BERT 作为 backbone 模型,选用 vocab.txt 中的 [unused] token 作为构成 prompt 模板的元素。
- [unused] 是 BERT 词表里预留出来的未使用的 token,本身没有什么含义,随意组合也不会产生很大的语义影响,这也是使用它来构建 prompt 模板的原因。
那么,构建出来的 prompt pattern 就长这样:
[unused1][unused2][unused3][unused4][unused5][unused6]
(2)mask label 生成
完成 prompt 模板构建后,还需要把 mask label 给加到句子中,好让模型完成标签预测任务。
设定 label 的长度为2(’水果’、’电脑’,都是 2 个字的长度),并将 label 塞到句子的开头位置:
[CLS][MASK][MASK]这破笔记本速度太慢了,卡的不要不要的。[SEP]
其中 [MASK] token 就是需要模型预测的标签 token,现在把两个部分拼起来:
[unused1][unused2][unused3][unused4][unused5][unused6][CLS][MASK][MASK]这破笔记本速度太慢了,卡的不要不要的。[SEP]
这就是最终输入给模型的样本。
(3)mlm loss 计算
开始进行模型微调,喂给模型这样的数据:
[unused1][unused2][unused3][unused4][unused5][unused6][CLS][MASK][MASK]这破笔记本速度太慢了,卡的不要不要的。[SEP]
并获得模型预测 [MASK] token 的预测结果,并计算和真实标签之间的 CrossEntropy Loss。
P-Tuning 中标签数据长这样:
水果 什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃!
电脑 这破笔记本速度太慢了,卡的不要不要的。
...
也就是说,需要计算的是模型对 [MASK] token 的输出与「电脑」这两个标签 token 之间的 CrossEntropy Loss,以教会模型在这样的上下文中,被 [MASK] 住的标签应该被还原成「物品类别」。
实验
选用 63 条评论(8 个类别)的评论作为训练数据,在 417 条评论上作分类测试,模型 F1 能收敛在 76%。
- 通过实验结果我们可以看到,基于 prompt 的方式即使在训练样本数较小的情况下模型也能取得较为不错的效果。
- 相比于传统的分类方式,P-Tuning 能够更好的缓解模型在小样本数据下的过拟合,从而拥有更好的鲁棒性。
Answer Engineering(答案工程)
在给定一个任务或者Prompt,如何对 label 空间 和 answer 空间进行映射?
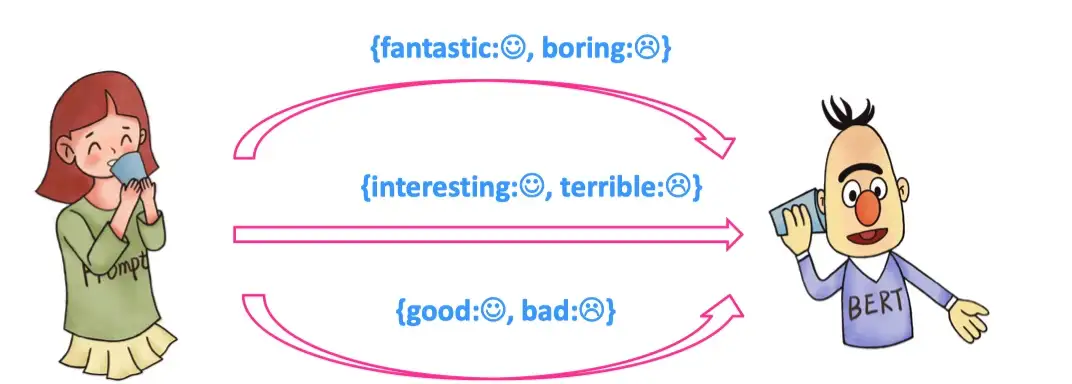
在上图,label 空间 Y 是: Positive, Negative, 答案空间 Z 可以是表示positive或者negative 的词,例如: Interesting/Fantastic/Happy/Boring/1-Star/Bad,具体的答案空间 Z 的选择范围可以由我们指定。可以指定一个 y 对应1-N个字符/词。
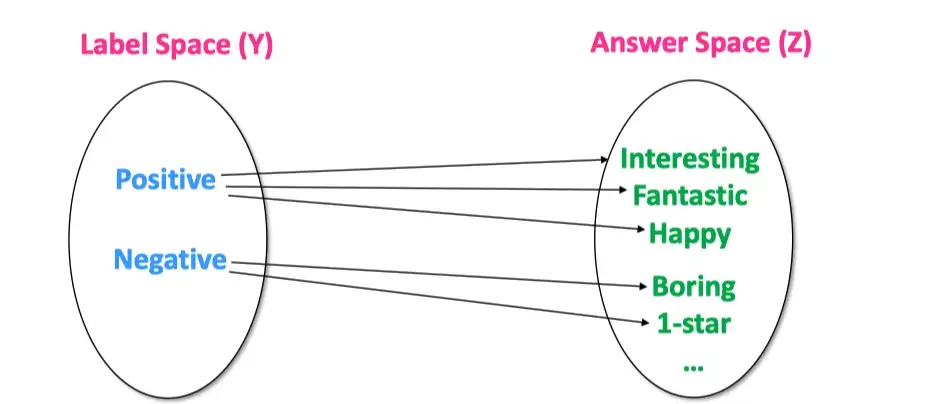
具体的答案空间的选择可以有以下三个分类标注:
- 根据形状
- 1.1 Token 类型
- 1.2 Span 类型
- 1.3 Sentence 类型
- 是否有界
- 2.1 有界
- 2.2 无界
- 是否人工选择
- 3.1 人工选择
- 3.2 自动搜素
- 3.2.1 离散空间
- 3.2.2 连续空间
具体的思维导图如下:
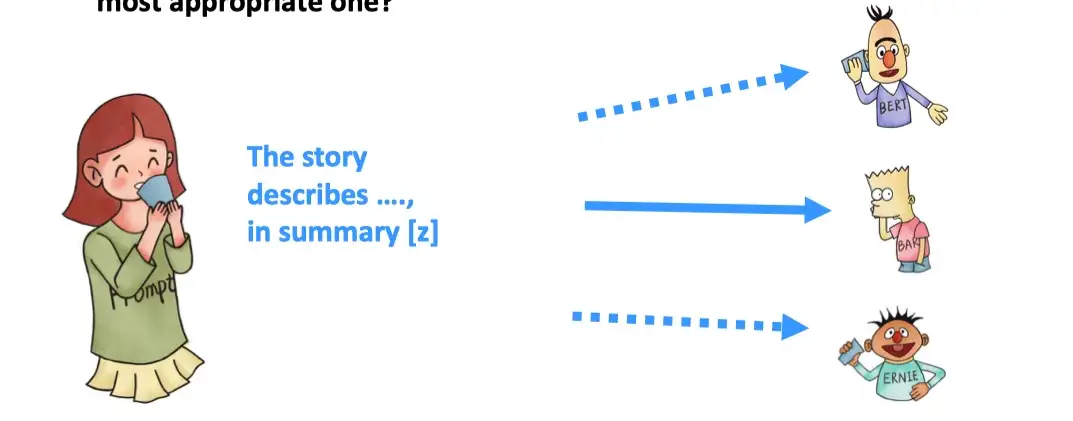
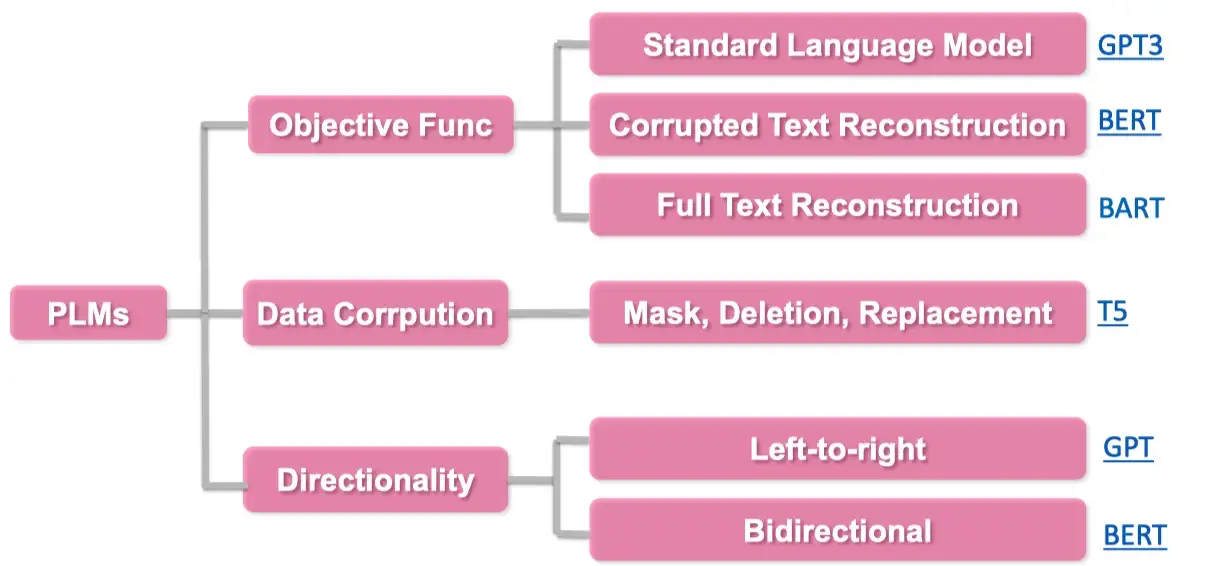
Pre-trained Model Choice(预训练模型选择)
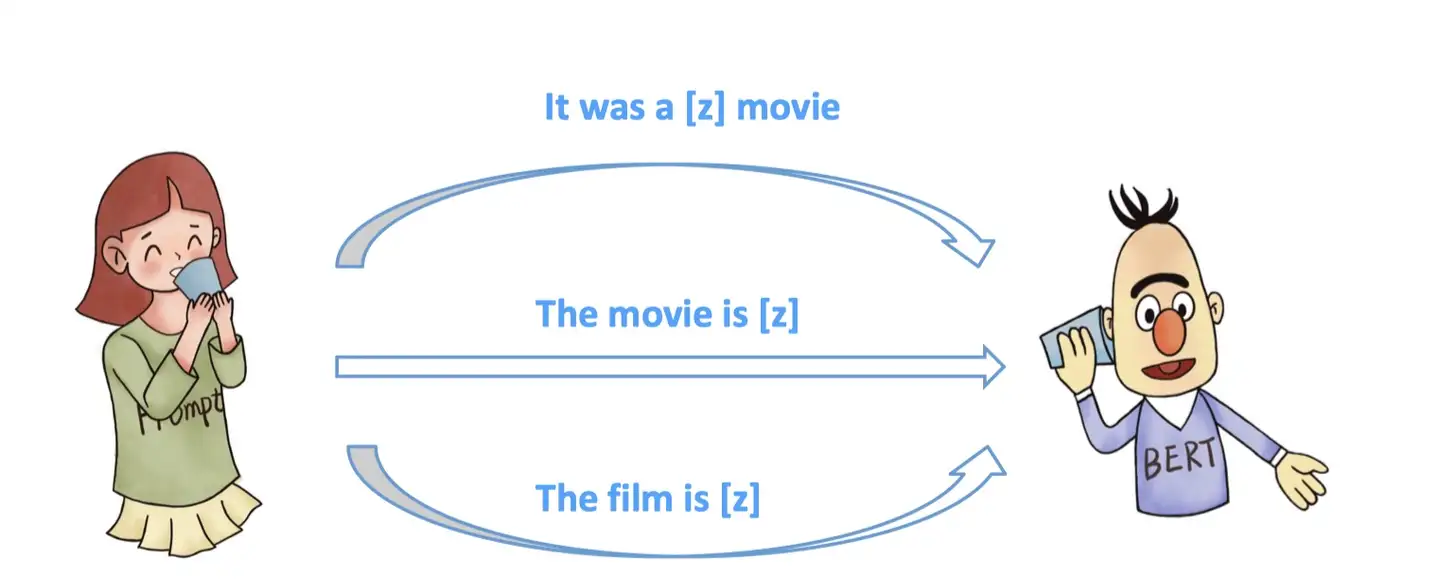
在定义完模版以及答案空间后,选择合适的预训练语言模型对 prompt 进行预测,如何选择一个合适的预训练语言模型需要人工经验判别的。
具体的预训练语言模型可以分为如下5类,具体参考:Huggingface Summary of the models
- autoregressive-models:
自回归模型,主要代表有GPT,主要用于生成任务 - autoencoding-models:
自编码模型,主要代表有BERT,主要用于NLU任务 - seq-to-seq-models:
序列到序列任务,包含了an encoder 和 a decoder,主要代表有BART,主要用于基于条件的生成任务,例如翻译,summary等 - multimodal-models:
多模态模型 - retrieval-based-models:
基于召回的模型,主要用于开放域问答
基于此,例如下图想要做summary 任务,我们可以选择更合适的 BART 模型。
其他分类标准也可参考:

Expanding the Paradigm(范式拓展)
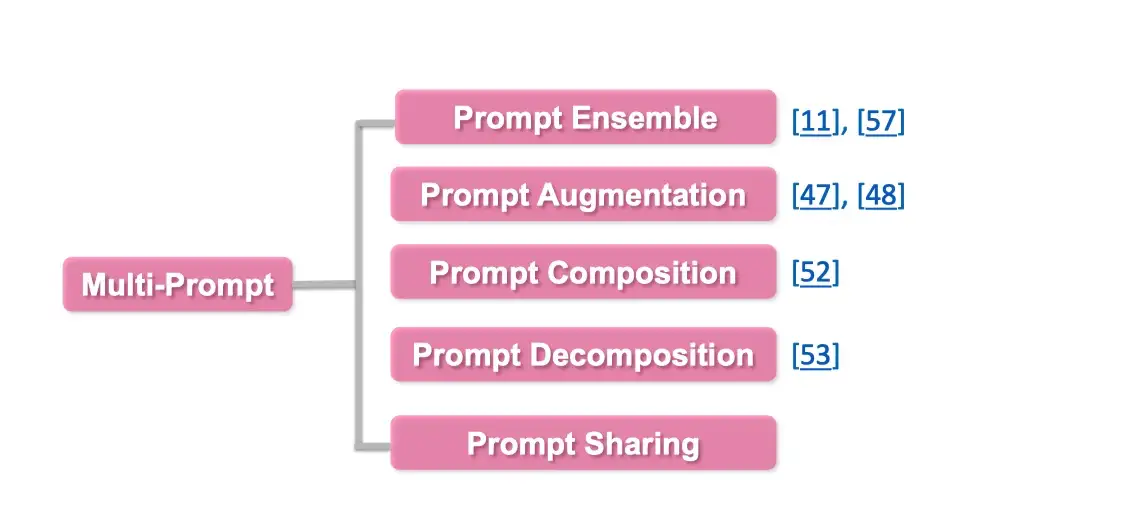
如何对已有的 Prompt 进行任务增强以及拓展,具体可以从以下几个方面进行探讨:
- Prompt Ensemble:Prompt 集成,采用多种方式询问同一个问题

- Prompt Augmentation:Prompt 增强,采用类似的 prompt 提示进行增强

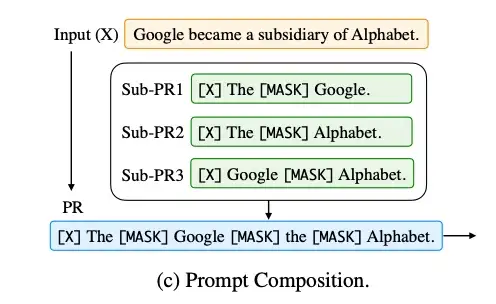
- Prompt Composition:Prompt 组合,例如将一个任务,拆成多个任务的组合,比如判别两个实体之间是否是父子关系,首先对于每个实体,先用Prompt 判别是人物,再进行实体关系的预测。
- Prompt Decomposition:
- 将一个prompt 拆分成多个prompt

具体的思维导图如下:
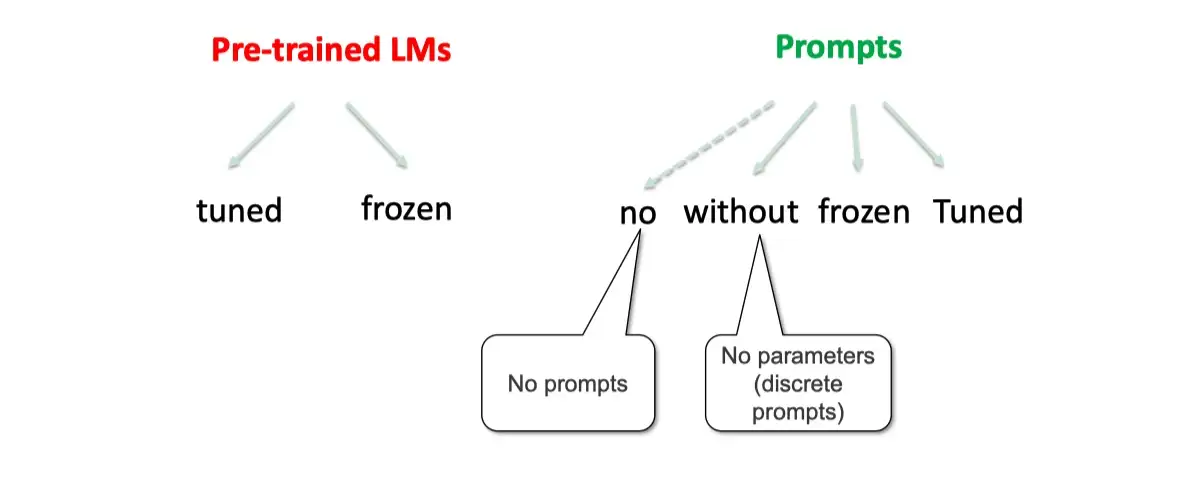
Prompt-based Training Strategies(训练策略选择)
Prompt-based 模型在训练中,有多种训练策略,可以选择哪些模型部分训练,哪些不训练。
可以根据训练数据的多少分为:
Zero-shot: 对于下游任务,没有任何训练数据Few-shot: 对于下游任务只有很少的训练数据,例如100条Full-data: 有很多的训练数据,例如1万多条数据
也可以根据不同的参数更新的部分,对于prompt-based 的模型,主要分为两大块
- 一个是预训练模型,一个是 Prompts 参数。
这两个部分,都可以独立选择参数训练选择。
对于
- 预训练语言模型,可以选择精调,或者不训练
- 对于prompts:
- 可以是没有prompts
- 固定的离散字符 prompts。(无参数)
- 使用训练好的 prompts参数,不再训练。
- 继续训练 prompts参数
这些训练策略均可以两两组合,下面举例说明:
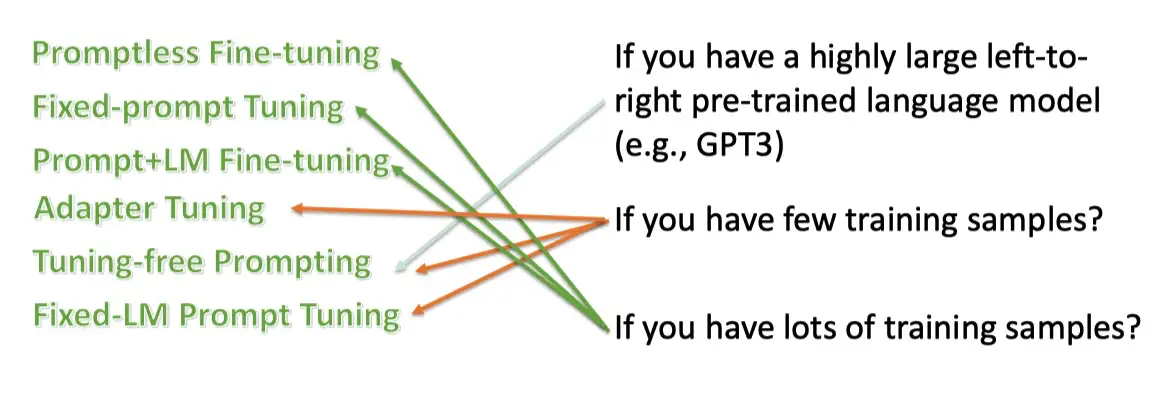
策略分类
- Promptless Fine-tuning
- 如果只有预训练语言模型,没有prompts,然后fine-tuning,即是bert 的常规使用。

- Fixed-Prompt Tuning
- 如果使用精调预训练语言模型+离散的固定prompts,就是 BERT + Discrete Prompt for text classification
- 如果使用精调预训练语言模型+连续训练好的固定prompts,就是 BERT + Transferred Continuous Prompt for text classification

- Prompt+LM Fine-tuning
- 如果使用精调预训练语言模型+可训练的prompts,就是 BERT + Continuous Prompt for text classification
- Adapter Tuning
- 如果使用固定预训练语言模型无prompt,只是插入task-specific模块到预训练语言模型中,就是BERT + Adapter for text classification
- Tuning-free Prompting
- 如果使用固定预训练语言模型和离散固定的prompt,就是GPT3 + Discrete Prompts for Machine Translation

- 如果使用固定预训练语言模型和连续固定的prompt,就是 GPT3 + Continuous Prompts for Machine Translation

- Fixed-LM Prompt Tuning
- 如果使用固定预训练语言模型和可训练的prompt,就是 BART + Continuous Prompts for Machine Translation
策略选择
对于不同的策略,需要进行不同的选择,我们往往需要考虑以下两点:
- 我们的数据量级是多少
- 我们的是否有个超大的 Left-to-right 的语言模型
通常如果只有很少的数据的时候,希望不要去 fine-tune 预训练语言模型,而是使用LM的超强能力,只是去调prompt 参数。而让数据量足够多的时候,我们可以精调语言模型。
而只有像GPT-3 这种超大的语言模型的时候,我们才能直接使用,不需要任何的fine-tuning.
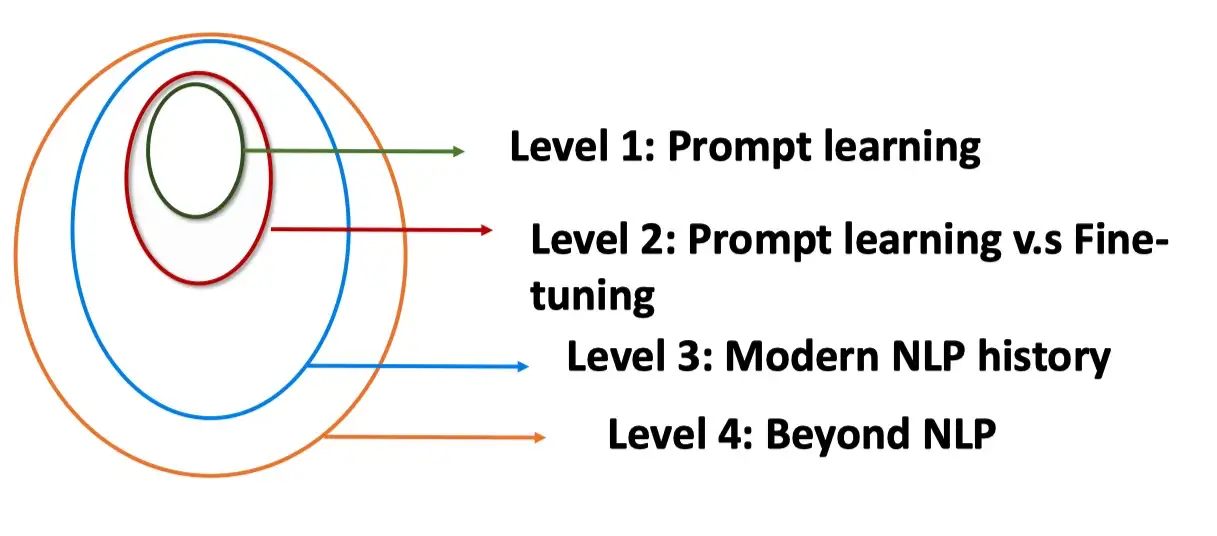
Prompt 的优势是什么
Prompt Learning 的优势有哪些呢?从四个角度进行分析。
- Level 1. Prompt Learning 角度
- Level 2. Prompt Learning 和 Fine-tuning 的区别
- Level 3. 现代 NLP 历史
- Level 4. 超越NLP
Level 1. Prompt Learning 使得所有的NLP任务成为一个语言模型的问题
- Prompt Learning 可以将所有的任务归一化预训练语言模型的任务
- 避免了预训练和fine-tuning 之间的gap,几乎所有 NLP 任务都可以直接使用,不需要训练数据。
- 在少样本的数据集上,能取得超过fine-tuning的效果。
- 使得所有的任务在方法上变得一致

Level 2. Prompt Learning 和 Fine-tuning 的范式区别
- Fine-tuning 是使得预训练语言模型适配下游任务
- Prompting 是将下游任务进行任务重定义,使得其利用预训练语言模型的能力,即适配语言模型

Level 3. 现代 NLP 第四范式
Prompting 方法是现在NLP的第四范式。其中现在NLP的发展史包含
- Feature Engineering:即使用文本特征,例如词性,长度等,在使用机器学习的方法进行模型训练。(无预训练语言模型)
- Architecture Engineering:在W2V基础上,利用深度模型,加上固定的embedding。(有固定预训练embedding,但与下游任务无直接关系)
- Objective Engineering:在bert 的基础上,使用动态的embedding,在加上fine-tuning。(有预训练语言模型,但与下游任务有gap)
- Prompt Engineering:直接利用与训练语言模型辅以特定的prompt。(有预训练语言模型,但与下游任务无gap)
在四个范式中,预训练语言模型,和下游任务之间的距离,变得越来越近,直到最后Prompt Learning是直接完全利用LM的能力。
Level 4. 超越NLP的角度
Prompt 可以作为连接多模态的一个契机,例如 CLIP 模型,连接了文本和图片。相信在未来,可以连接声音和视频,这是一个广大的待探索的领域。

Prompt engineering
zero-shot/few-shot 这种设定确实给 NLP 社区带来了新思路,但是175B 的模型实在是太大了,即不好训练又不好微调也不好部署上线,如何在小模型上应用呢?此外,不同的 pattern(prompt)下同一个task 的效果差距也非常大,如何找到效果最好的prompt 呢?
于是大家就开始花式探索 prompt, NLPer 也变成了 prompt-engineer (误).
- PS:prompt 的语义目前即可以指模型的输入,也可以指输入的一部分。
Prompt tuning是之前的一种方法,通过冻结语言模型仅去调整连续prompts,在参数量超过10B的模型上,效果追上了fine-tune,但是在normal-sized模型上表现不好,并且无法解决序列标注任务。于是,P-tuning v2 诞生。
PET
PET(Pattern-Exploiting Training) 是第一个在小模型上 few-shot 设定下成功应用的工作。
PET 的主要思路:
- 用通顺语言为task 构造一个 pattern(prompt), 如: “下面是{label}新闻。{x}”;
- 将 label 映射为文字。如: “0->体育 ,1-> 财经, 2->科技”;
- 将样本按照 pattern 重构,冻结模型主体,只更新 label 对应的 token(embedding),继续 LM (MLM) 训练;
- 预测时,将 label 对应位置的 token 再映射回label。
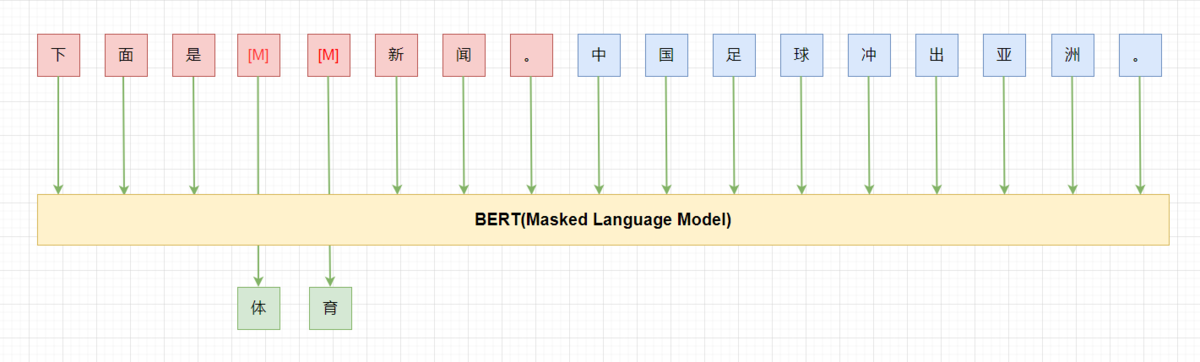
PET 在few-shot 的设定下,利用 BERT-base 就能获得比 GPT-3 175B 更好的结果。不过pattern 是需要人来构造的,pattern 的“好坏” 直接影响最终的效果。
思考:
- PET中的fine-tuning 是与其 pretrain 的形式是一致的,而 pretrain 与 fine-tuning 形式一致能够work 才是一种“自然”的事情,pretrain + fine-tuning 这种下游任务与预训练形式不一致能work 其实不是一个自然的事情,为什么pretrain + fine-tuning 能work 值得思考。
Automated Discrete Prompt
人来写prompt还是需要大量的时间和经验,即使一个经验丰富的人,写出的prompt 也可能是次优的。一种解法是“自动”寻找最优的prompt。
Prompt Mining: 该方法是在语料上统计输入X 与输出Y 之间的中间词或者依赖路径,选取最频繁的作为prompt,即:{X} {middle words} {Y}.Prompt Paraphrasing: 该方法是基于语义的,首先构造种子prompts,然后将其转述成语义相近的表达作为候选prompts,通过在任务上进行验证,最终选择效果最优的。Gradient-based Search: 通过梯度下降搜索的方式来寻找、组合词构成最优prompt。Prompt Generation: 用NLG 的方式,直接生成模型的prompts。Prompt Scoring: 构造模型对不同的prompt 进行打分,选择分数最高的prompt 作为最优prompt。
Automated Continuous Prompt
虽然PET最初在构造prompt 时认为prompt需要是通顺流畅的自然语言。而随着各种自动化方法构造出了很多虽然句子不通顺但是效果更好的prompt,大家也发现:
- 通顺流畅的自然语言或者是自然语言的要求, 只是为了更好的实现预训练与下游任务的“一致性”,但是这并非必须
- 其实并不关心这个pattern 具体长什么样,真正关心的是由哪些token 组成,都插入在什么位置,输出空间是什么,以及最重要的在下游任务上表现有多好。
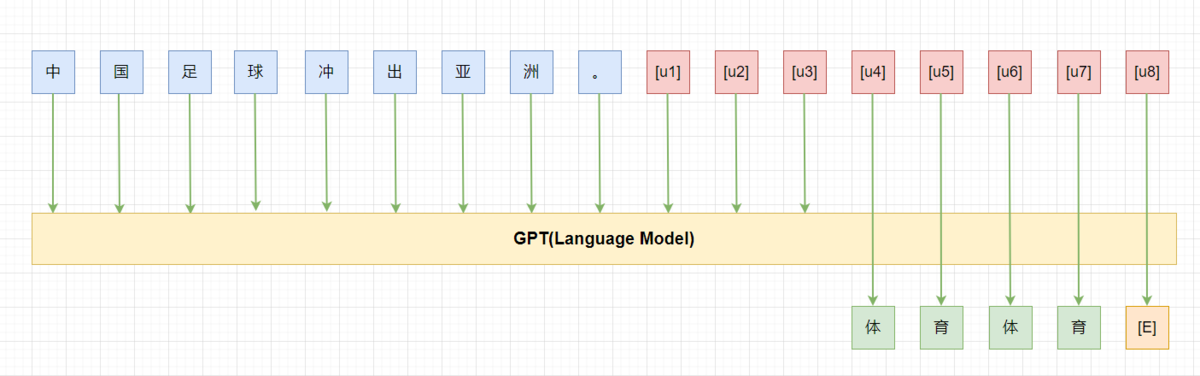
[u*] 为unused token, tuning 时依然冻结模型的参数,只微调[u1-u8] 8个token。
prompt tuning: 利用N 个unused token/new token 构造prompt, 然后微调这N 个token。其中N 是个超参数。Tuning initialized with Discrete prompts:用手工构造的prompt 或者自动搜索的离散prompt 初始化需要微调的token,然后进行prompt tuning,有利于提高准去率。Hard-Soft Prompt Hybrid Tuning: 这类方法将手动设计和自动学习相结合,增强prompt token 之间的相关性。如p-tuning 首先通过一个LSTM 训练手工设计的prompt中插入的可学习的token 来增强prompt 之间的相关性,让prompt token 更接近“自然语言”。Prompt-parameter Tuning: 仅仅训练prompt token 效果不够好,将其与fine-tuning 结合。如prefix-tuning,在输入前增加可学习的prompt token 的同时,在模型每层都增加一部分可学习参数。
Prefix tuning
Prefix tuning是做NLG任务的,具体做法:为不同的任务,添加不同的prefix。
- 训练时 freeze 预训练语言模型,只微调 task-specific 的 prompt,并且prompt不止加在一开始的嵌入层上,每一层都加入可微调的参数,并在最后加了一个MLP。
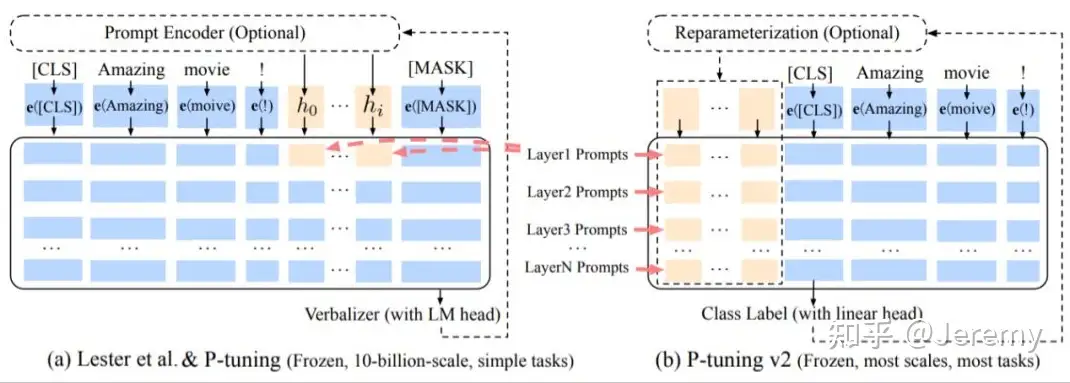
- P-Tuning v2 论文笔记
P-tuning v1
出发点是让GPT这种生成模型也具备NLU能力。主要结构是利用了一个prompt encoder(BiLSTM+MLP),将一些pseudo prompt先encode再与input embedding进行拼接,并且pseudo token的位置不一定是前缀,也可以是中间位置。
Prompt tuning
在原有序列的输入词向量的基础上增加可训练的连续embedings,并通过特殊的初始化方法,在模型参数达到10B时,效果达到了与fine-tune持平,仅需微调0.01%的参数量。P-tuning v2也是延续这个文章的思路,解决了一些他存在的问题。
- 其实 P-tuning做法 和 Prefix tuning更类似,是优化后的 prefix-tuning
对比: P-tuning v1 与 P-tuning v2
Multi-Step Reasong(三步走)
虽然大模型在很多task 都证明了其有效性,但是这些task 都是System 1 thinking,而System 2 thinking 任务需要更多的数学、逻辑以及常识推理。大模型对这类任务还做不好目前,如数学推理、符号推理等。
- GPT-3 175B 在 GSM8K 上直接fine-tuning 也只能得到 33%的准确率
- 通过在fine-tuned model 上进行采样,再标注答案是否正确,然后训练一个verifier 来判断生成的答案是否正确,最终也只能得到55%
- 而一个9-12 岁的孩子平均能得到60%。
所以,OpenAI 的研究员认为,如果想达到 80% 以上,可能需要把模型扩大到 $10^{16}$(175T)。
然而,Gopher 却给这个思路泼了盆冷水:
- 即使继续放大模型,模型在这种推理任务上的表现也不会显著提升。也许语言模型就不能做推理这种 system 2 thinking task。
直至思维链(CoT)出现,这类困局才得以解决。详见Prompt专题
提升效果
提升 prompting 效果的方法
- prompt ensembling
- 把多个prompt通过某种加权方法组合到一起
- prompt augmentation
- 启发式学习
- prompt composition
- 将复合的prompt句子,拆解成多个小段prompt,最后再组合在一起训练
- prompt decomposition
- 由于一些任务的mask工作使用句子数量有限(比如词性标注任务),于是就只能通过decomposition将一个句子拆分成多个部分后,再对每个部分做prompt单独训练
【2023-3-22】Context-faithful Prompting for Large Language Models
prompt 应用
prompt的应用
- 知识探索(事实探索和语言学探索)
- 分类任务(文本分类和自然语言推理)
- 信息提取(关系提取、语义分析和命名实体识别)
- NLP 中的推理(常识推理和数学推理)
- 问答
- 文本生成
- 文本生成的自动评估
- 多模态学习
- 元应用(域自适应、除偏和数据集创建)
prompt 实践
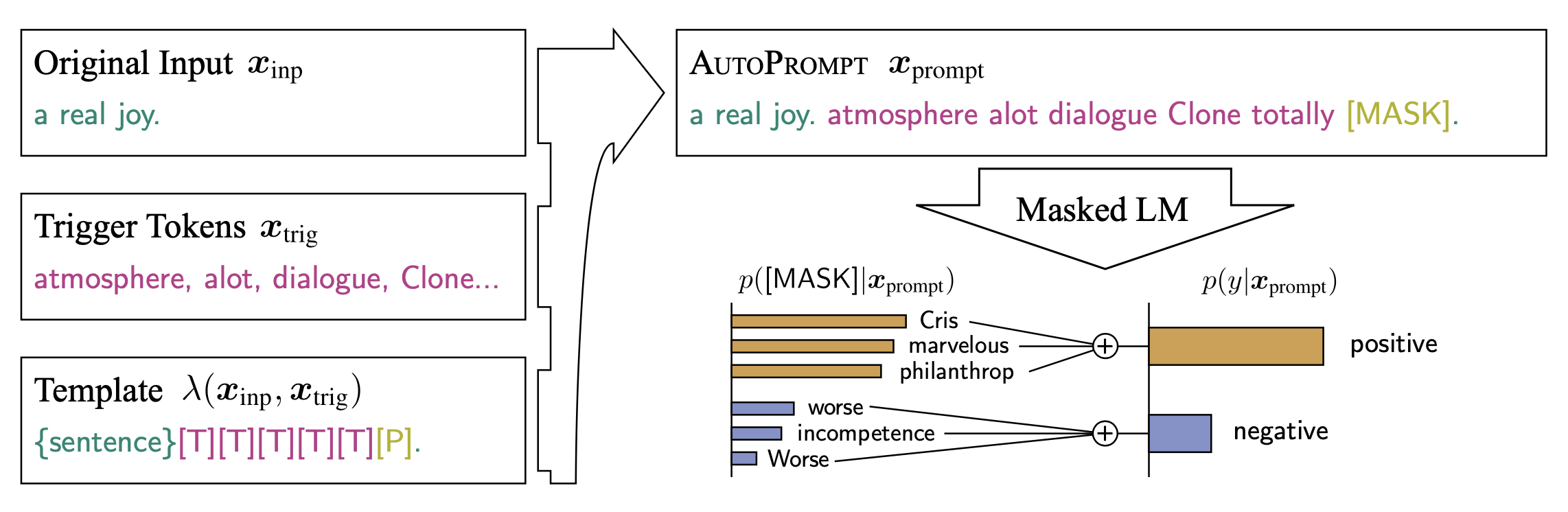
AutoPrompt
AutoPrompt (Shin et al., 2020) is a method to automatically create prompts for various tasks via gradient-based search.
清华 OpenPrompt
- 【2023-2-16】清华开源的 OpenPrompt:An Open-Source Framework for Prompt-learning. 包含prompt各个算法、模块的代码及示例
- 源自:翁丽莲的博客
Define a task
from openprompt.data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative",
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly made.",
),
]
Define a Pre-trained Language Models (PLMs) as backbone.
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased")
定义模板
from openprompt.prompts import ManualTemplate
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)
Define a Verbalizer
from openprompt.prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"negative": ["bad"],
"positive": ["good", "wonderful", "great"],
},
tokenizer = tokenizer,
)
Combine them into a PromptModel
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)
Define a DataLoader
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset = dataset,
tokenizer = tokenizer,
template = promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)
Train and inference
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim = -1)
print(classes[preds])
# predictions would be 1, 0 for classes 'positive', 'negative'
等等组件
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
