- 对话AI(conversation AI)
- 现状
- 对话任务分类
对话AI(conversation AI)
- 【2022-11-16】直接向一本书提问 Ask My Book
- 【2022-5-11】Google Keynote (Google I/O ‘22) ,Google I/O用多模态唤醒语音设备,不再需要重复说唤醒词,还能识别说话人的表述状态,没说完就继续等待,第33分钟
- Google 将更完善语音和自然语言理解模型放在设备本地,以此提高 Google 助理理解语音指令过程中的语气和停顿,下次还没想好要问啥时,就不用从头再来了。
- 2022 谷歌 I/O 大会来了,我们为你挑了 10 个重点

- 【2020-01-23】哈工大张伟男:任务型对话系统
- 【2021-3-29】开放领域问答梳理系列, 两阶段系统:基于信息检索(information Retrieval, IR)+机器阅读理解(Machine Reading Comprehension, MRC)(retriever-reader)的开放领域问答系统
- 【2021-3-27】【开放域长式问答的进展与挑战】《Progress and Challenges in Long-Form Open-Domain Question Answering-Google AI Blog》,论文 paper:《Hurdles to Progress in Long-form Question Answering》
- 【2021-3-25】对话的囧境?
- 人工智能对话系统一直是让我又爱又恨的存在,爱是因为一想到它的终极NB形态就令人兴奋,觉得自己在从事一门可以改变世界的技术,恨是因为现有的技术与期待相差太远,一旦框架搭起来了就陷入解case的死循环,让我怀疑我是谁我在干什么,我有生之年能看到强人工智能吗???
- 【2020-05-16】如何实现聊天机器人?ChatBot技术栈
- 设计一个机器人时,记住三个创新的核心维度:你的产品必须 desirable(满足客户需求)、viable(满足客户需求)、feasible(技术可行性)
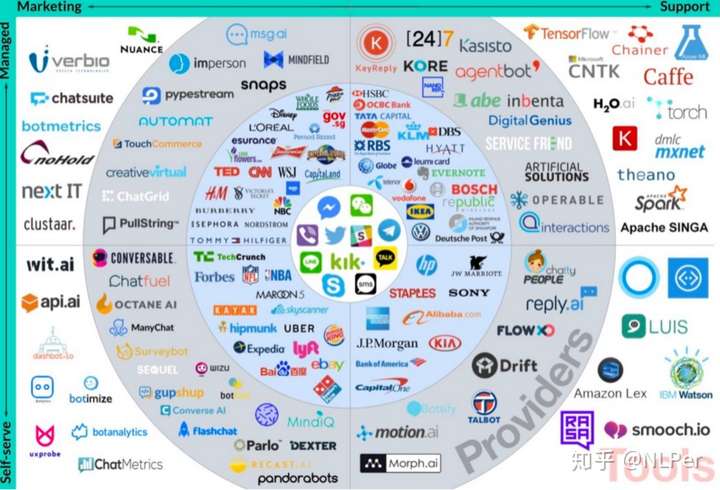
- 怎样解释半智能聊天机器人?
- 用户通过设备在消息平台上进行交互,她的的消息会通过 NLP 进行处理。
- 然后机器人可以启动一个过程,用来自数据库 / API 的实时信息来回应,或者转交人工。
- 接收的消息越多,机器人提升的也就越多:这也就是所谓的机器学习。某些情况下也需要人工来帮助机器人,也就是所谓的监督学习。
- 聊天机器人十大重要问题
- 合适的技术解决方案。举个例子:
- Facebook messenger 可以让你看见在页面管理器中看见所有会话。他们最近宣布了为开发者的转化协议
- Operator,来自 Intercom 的 Operator 似乎被设计成可以让人工插入会话
- Chatfuel 提供按钮来看使「在线聊天会议」, The leading no-code chatbot platform for Facebook, Instagram, and Messenger
- Dashbot 有人工转接功能
- 技术栈:
- 用 API.ai 做 NLP 与监督学习:很不错的讨论小功能,支持法语的最佳平台,漂亮的界面……
- 用 Dashbot 做分析以及人工转接:十分详细的统计,易于集成,报表功能……
- 用 Botpress 做 NodeJS 框架:可以迅速搭建并且十分灵活
- 用 Wechat 做消息接口:10 亿的用户,绝佳的聊天 UX
- 用 MongoDB 做数据库:可以由非技术人群更新
- 还有其他一些取决于项目类型的 API(QQ、Spotify、Youtube、 Google Maps……)
- 【2021-2-22】达摩院Conversational AI研究进展及应用
- 任务型对话引擎Dialog Studio和表格型问答引擎TableQA的核心技术研究进行介绍:
- 语言理解:如何系统解决低资源问题
- 低资源小样本问题
- 冷启动的场景下,统计45个POC机器人的数据,平均每个意图下的训练样本不到6条,是一个典型的小样本学习问题。
- 在脱离了冷启动阶段进入规模化阶段之后,小样本问题依然存在,比如对浙江省11个地市的12345热线机器人数据进行分析,在将近900个意图中,有42%的中长尾意图的训练样本少于10条,这仍然是一个典型的小样本学习问题。
- 解决方案:引入Few-shot Learning系统解决小样本问题;本质是一个迁移学习:迁移学习的方式能够最大化平台方积累数据的优势。即插即用的算法:在应用的时候不需要训练,可以灵活地增添新的数据,这对toB场景非常友好;
- 达摩院Conversational AI团队提出了一个Encoder-Induction-Relation的三层Few-shot learning Framework
- 无论是小孩子还是大人,从小样本中进行学习的时候,主要依靠的是两种强大的能力,归纳能力和记忆能力
- 达摩院提出了Dynamic Memory Induction Networks的动态记忆机制(发表于ACL2020)
- 低资源小样本问题
- 对话管理:如何从状态机到深度模型
- TableQA:Conversational Semantic Parsing的难点和进展
- 语言理解:如何系统解决低资源问题
- 任务型对话引擎Dialog Studio和表格型问答引擎TableQA的核心技术研究进行介绍:
- 【2021-2-25】达摩院基于元学习的对话系统
- 台大对话系统,对话AI的两个分支
- Chit-Chat: seq2seq → 集成上下文 → 集成知识库
- Task-Oriented:single-domain → multi-domain, contextual → end2end learning
- 【2021-2-14】思知机器人,开源中文知识图谱,图谱可视化,Demo体验,包含实时tts;OwnThink开源了史上最大规模(1.4亿)中文知识图谱,地址
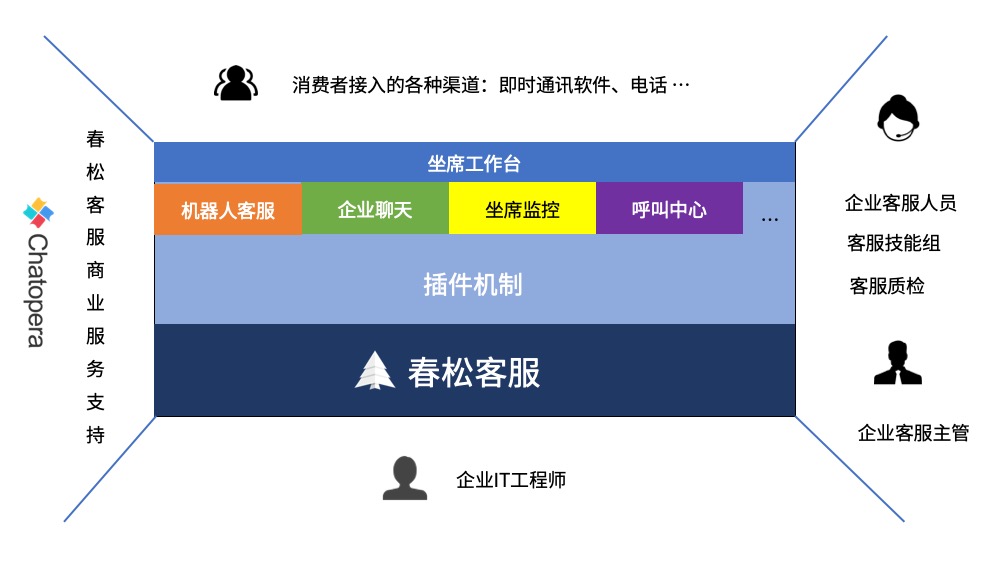
- 【2021-2-28】Chatopera开发的机器人平台使用指南,王海良,Chatopera联合创始人 & CEO,《智能问答与深度学习》作者,腾讯课堂讲解,Chatopera 为企业提供智能对话机器人和智能客服系统解决方案,这些解决方案面向多个行业,支持通用的业务场景,比如客户服务中的多渠道管理、坐席管理、企业知识库和机器人对话管理。同时,Chatopera 面向开发者提供开源软件、云服务、开发者社区和学习资料,帮助开发者掌握智能对话机器人和客服系统的定制化开发技能,进而为企业客户进一步优化软件服务。保险行业语料库,大盛CRM
- 【2021-6-2】百度机器人平台,UNIT,交互式教程
- 【2021-2-4】调停机器人(斡旋)
图灵测试- 现代计算机之父阿兰·图灵1950年在哲学刊物《思维》上发表了“计算机器与智能”一文,提出了经典的图灵测试(the Turing test),在测试者与被测试者(一个人和一台机器)隔开情况下,通过一些装置, 如键盘, 向被测试者随意提问.进行多次测试后,如果有超过30%的测试者不能确定被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能.
- 【2021-7-18】2014年,在英国皇家学会举行的”2014图灵测试”大会上,聊天程序“尤金古斯特曼” (Eugene Goostman)首次通过了图灵测试。在惊呼人工智能进入新时代的同时,人们却仍然认为以AI技术为支撑的聊天机器人还不够”机灵”,无法准确理解人类句意。
- 尤金的开发者很狡猾,他们把它伪装成了不以英语为母语的13岁乌克兰男孩儿。成功地让33%的测试人相信了这一点。正如尤金的创造者弗拉基米尔·维塞罗夫(Vladimir Veselov)所说:“我们的主要想法是,尤金可以号称自己无所不知,但受到年龄的限制,所以他不可能什么都知道。”虽然这从技术上完全讲得通,但从感 性角度来看,却一点都不令人佩服。
- 超级计算机首次通过图灵测试:被当作13岁男孩
- 【2021-2-18】悟空机器人:后台管理端 Demo体验地址 (用户名:wukong;密码:用户名+@2019)
- 模块化。功能插件、语音识别、语音合成、对话机器人都做到了高度模块化,第三方插件单独维护,方便继承和开发自己的插件。
- 中文支持。集成百度、科大讯飞、阿里、腾讯等多家中文语音识别和语音合成技术,且可以继续扩展。
- 对话机器人支持。支持基于 AnyQ 的本地对话机器人,并支持接入图灵机器人、Emotibot 等在线对话机器人。
- 全局监听,离线唤醒。支持 Muse 脑机唤醒,及无接触的离线语音指令唤醒。
- 灵活可配置。支持定制机器人名字,支持选择语音识别和合成的插件。
- 智能家居。支持和 mqtt、HomeAssistant 等智能家居协议联动,支持语音控制智能家电。
- 后台配套支持。提供配套后台,可实现远程操控、修改配置和日志查看等功能。
- 开放API。可利用后端开放的API,实现更丰富的功能。
- 安装简单,支持更多平台。相比 dingdang-robot ,舍弃了 PocketSphinx 的离线唤醒方案,安装变得更加简单,代码量更少,更易于维护并且能在 Mac 以及更多 Linux 系统中运行。
- 【2020-7-30】沈向洋:从深度学习到深度理解
- 现状:NLP需要更多参数,视觉需要更多层网络
- 这三个方面在实现robust AI时大有可为:
- 其一,构建大规模的强机器学习仿真器。不仅是游戏,还有自动驾驶等复杂系统。
- 其二,对于机器学习本质的深度理解。从优化功能开始,思考我们从里面真正学到的是什么。
- 其三,基于神经与符号的混合模型(Hybrid Neural/Symbolic Model for Robust AI)。——今天演讲的重点
- 雷蒙德微软研究院写了一篇论文,题目为《SOLOIST: Few-shot Task-Oriented Dialog with A Single Pre-trainedAuto-regressive Model》,文章中提出了一种新的方法,能够利用迁移学习进行高效地大规模构建面向任务的对话系统。
- 文章有两个亮点
- 其一是有个预训练模型GTG(Grounded Text generator)
- 其二是该方法实现了真正的会话学习。下面我主要讲讲GTG。
- GTG模型与GPT模型对比也有比较大的优势:GPT是学习如何理解和生成自然语言,而GTG是学习预测对话状态,产生grounded responses(真实响应)来完成任务。
- 【2020-8-10】京东副总裁何晓冬:GPT-3后,人机对话与交互何去何从?CCF-GAIR 2020



- 【2020-7-6】台大陈蕴侬,如何让任务型聊天机器人更加鲁棒,课程主页,PPT链接,pdf



- 7/2018: Jianfeng Gao (MSR AI), Lihong Li (Google AI) and I presented a tutorial on Neural Approaches to Conversational AI at SIGIR-18 and ACL-18. Slides: PowerPoint (with animations) and PDF.
- a tutorial on Neural Approaches to Conversational AI paper at ICML-19. Slides: pdf, Powerpoint.
- 【2020-11-28】优质资料,哈工大张伟男:人机对话关键技术及挑战,【2020-11-6】附:前沿动态综述-闲聊型对话-视频版
- 开放域对话系统
- 任务型对话系统
- 【2021-1-20】【基于Unilm模型的夸夸式闲聊机器人项目】’Unilm for Chinese Chitchat Robot - Unilm for Chinese Chitchat Robot.’ by logCong GitHub
- UniLM论文全名为Unified Language Model Pre-training for Natural Language Understanding and Generation,译为自然语言理解与生成的统一预训练语言模型,来自于微软研究院。
- 开源的模型仅使用豆瓣夸夸群数据训练,所以称之为夸夸式闲聊机器人。感兴趣的同学,也可以使用本项目代码对其他对话语料进行训练。 详细介绍见知乎:夸夸式闲聊机器人之Unilm对话生成。
- UniLM模型之所以强大,是因为它既可以应用于自然语言理解(NLU)任务,又可以应用于自然语言生成(NLG)任务。结构与BERT一致,是由一个多层Transformer网络构成,通过修改训练时的Mask矩阵,使模型拥有更多的能力。
- 云问机器人开源出来的模型
- 不足之处
- 本模型最大的问题是,在训练模型时,没有考虑上下文信息,也就是训练是针对单轮对话进行的,因此无法很好地回答上下文相关的问题,并且可能会出现文不对题的情况。
- 示例
#user:工作不开心
chatbot: 你可以的!工作不开心也可以去吃火锅,看个影响自己心情的电视剧
#user:工作不开心
chatbot: 我也是,不过现在开始努力找工作啦!一起加油鸭~
#user:工作不开心
chatbot:那就祝福你,能找到喜欢的工作吧。
#user:工作不开心
chatbot:你也要加油鸭!
#user:工作不开心
chatbot:我也是,不过总有一天就会好起来的
- 【2021-1-23】空妙对话机器人Demo
- 【2021-1-28】AI+HI实现 对话系统 NLU/DM 任务详解
- 在很多场景下,对话用户界面(CUI - Conversational User Interface)比图形用户界面(GUI - Graphical User Interface)更加自然和高效。过去一年中,CUI得到了大量的关注,也取得了迅速的发展。微软提出了对话即平台的战略,Facebook Messenger上出现了各种对话机器人(chatbot),很多和CUI相关的创业公司也应运而生。
- AI+HI表示机器助理和真人助理结合起来,为用户提供优质的体验。为什么要这么做呢?因为当真人能够和机器配合时,能产生一个正反馈:
- 真人纠正机器的错误 -> 更好的用户体验 -> 更多的活跃用户 -> 获取更高质量的数据 -> 训练更好地模型 -> 机器更好地辅助真人。
- HI和AI如何无缝的配合呢?我们通过群聊将用户、AI和HI放在一个群里。由AI根据置信度来判断,什么情况下需要将HI加入群内,将什么样的HI加入群内,以及什么时候HI来干预。AI和HI的配合分为三种:
- 1)AI置信度较高时,无需HI干预,对话系统完全由AI来执行动作;
- 2)AI置信度不高时,AI生成候选动作辅助HI来动作;
- 3)AI不确定性很高时,完全由HI接管来执行动作。图
- 基于AI+HI的对话系统中,HI扮演三种角色:
- 1)为AI提供反馈,如NLU出现错误时,HI可以纠正,然后AI在纠正后的对话状态下继续工作;
- 2)在AI的辅助下执行动作,比如AI生成候选动作但不执行,由HI进行判断最终来执行;
- 3)产生标注数据使AI不断进化,例如HI每一次纠错、执行动作都是一个标注的样本,可以用于训练AI。
- 【2021-1-29】对话系统经典任务核心算法对比
- 摘自:智能对话系统架构及算法
| 任务 | 算法 | 优势 | 劣势 |
|---|---|---|---|
| NLU | Classical Classifier | 实现简单,经典分类算法常用于意图分类、领域分类、对话动作分类等 | 需要特征工程 |
| NLU | CRF | 考虑结合标签的转移概率,适合槽位识别任务 | 只使用了固定窗口尺寸,难以扩展 |
| NLU | RNN | 能够对语言内容长距离建模,适合于上下文相关的多轮意图分类 | 梯度消失或者梯度爆炸问题 |
| NLU | LSTM | 结合“门”机制,能够选择记忆和忘记相关信息 | 需要更多的训练数据 |
| DST | Hidden Information State Model | 理论上能够对任意槽值的依赖进行建模 | 只能够保持top N个状态 |
| DST | Bayesian Update of Dialogue States | 能够对状态的概率进行建模 | 只能对简单的依赖进行表征 |
| DST | Static Classifier | 不需要依赖之前的状态,可对任意的分类器工作 | 没有考虑到状态的转移,使用了人工定义的特征 |
| DST | Sequential Classifier | 考虑到状态的转移概率 | 发生在最后一个状态的错误可能会影响当前状态的估计 |
| DST | Transfer Learning | 能够基于现有槽值信息对新任务或领域进行迁移 | 需要大量的特征设计 |
| DPO | Q-Learning | 经典算法,易于实现 | 不能处理连续的动作空间问题 |
| DPO | Policy Iteration | 能够处理连续动作空间问题 | 优化过程不稳定 |
| DPO | Actor Critic | 能够处理连续动作空间问题,稳定地优化 | 需要严格选择函数的逼近方法 |
| DPO | Transfer Learning | 对于原领域和目标领域的槽值适应性 | 计算复杂度高 |
| 端到端 | End-to-End LSTM Policy Network with Answer Selection | 能够进行对话状态的自动学习 | 仍然有组件需要手工定制 |
| 端到端 | End-to-End Training of Modular Dialogue System | 只需要少量的人工参与 | 槽的数量和槽值信息需要提前定义,DST是分开训练的,需要更多的数据 |
| 端到端 | Memory Network based End-to-End Dialogue System | 对确定槽和槽值信息的依赖性低 | 难以与人类知识集成 |
- 经典任务和数据与评测指标对比
- 摘自:智能对话系统架构及算法
| 任务 | 数据集 | 评价指标 |
|---|---|---|
| NLU | ATIS | Accuracy, F1 |
| NLU | Snips | Accuracy, F1 |
| NLU, NLG | TouristInfo | Accuracy, F1 BLEU |
| NLU | DARPA Communicator | Accuracy, F1 |
| DST | DSTC1~DSTC3 | Joint Goal Accuracy |
| DST | WOZ2, mutli WOZ | Joint Goal Accuracy |
| DST, Policy | TownInfo | Accuracy, Reward, Success Rate |
| DST, Policy | Cambridge Restaurant | Reward, Success Rate BLEU |
人机交互
- 【2021-11-4】人工智能应用技术之人机交互(通识篇)
对话系统分级
【2022-6-30】全球首个《AI对话系统分级定义》发布,这下语音助手有了强弱之分
工业应用领域,AI对话系统已经呈现出了爆炸式增长态势,在智能助理、智能客服、社交机器人、心理咨询、虚拟人和元宇宙等多样化场景中随处可见它的身影,比如以小度、小爱、为代表的智能助理,还有以谷歌对话机器人Meena、Facebook聊天机器人Blender为代表的开放域闲聊产品。
当前AI对话系统标准缺失,造成其在应用中呈现出水平参差不齐、评价体系不一的现状,导致了业界因认知不统一而对人工智能交互水平出现误解,也引起了社会上关于意识、伦理、道德等方面的广泛讨论。
根据系统智能化程度的不同,自动驾驶领域有L0-L5的分级标准。《分级定义》制定时主要参考了这种分级方法,不过这种参考并非生搬硬套,因为对话任务本身自有其特征。
黄民烈教授表示,「考虑到AI对话系统任务繁多、评价维度多样、技术路线丰富,撰写小组在制定《分级定义》时仅关注完全由机器主导的对话系统,人机混合的对话系统不在考虑范围内。」
《分级定义》从自动对话能力、对话质量高低、单一/多个场景、跨场景上下文依赖和自然切换能力、拟人化程度、主动和持续学习能力、多模态感知与表达能力等多个角度出发,将AI对话系统划分为从L0~L5的六个等级,等级越高,AI对话系统水平越高。
对话系统分级定义
| 分级 | 定义 |
|---|---|
L0 |
实际对话由人给出,系统完全没有自动对话能力或者在任意单一场景中,系统均无法给出较高质量的对话 |
L1 |
能完成单一场景的较高质量对话:或虽能完成多个单一场景的较高质量对话,但无法处理场景之间的上下文依赖 |
L2 |
在L1的基础上,能同时完成多个场景的较高质量对话,具有处理跨场景的上下文依赖和自然切换能力,无法完成新场景较高质量的对话 |
L3 |
在L2的基础上,能针对大量场景开展高质量对话,在新场景上具有较高质量对话能力 |
L4 |
在L3的基础上,在新场景上具有高质量对话能力在多轮交互中拟人化(指人设、人格、情感、观点等维度的一致性)程度较高 |
L5 |
在L4的基础上,在多轮交互中拟人化程度高,能在开放场景交互中主动学习和持续学习,具有多模态感知与表达能力 |
概念说明
- 高质量:相关性、信息量、自然度分数达到 8-10分(满分10分)
- 较高质量:相关性、信息量、自然度分数达到 6-8分(满分10分)
- 低质量:相关性、信息量、自然度分数小于 6分(满分10分)
- 相关性:指回复与上文的适配度
- 信息量:指回复是否提供足够必要的信息,而非通用回复
- 自然度:是指与人类回复相比的自然度,包含语法是否通顺、是否包含常识错误等
- 测试方式:通过一定数量的测试者与对话系统进行充分的对话交互,在测试之前测试者被告知系统的能力范围但不告知系统的技术实现方式,最后由测试者从三个维度进行主观的总评分
什么是人机交互
人机交互(Human-Computer Interaction, HCI),也称人机互动,是人与计算机之间为完成某项任务所进行的信息交换过程,是一门研究系统与用户之间的交互关系的学问。
人机交互关注的就是人、机器和交互三个部分。
人机交互涉及到计算机科学的多个学科方向,如图像处理、计算机视觉、编程语言等,以及人文学科的多个方向,如人体工程学、人因工程学、认知心理学等,还涉及相关专业领域知识。
人机交互发展历程
人机交互发展历程:人机交互的发展历史,是从人类通过学习适应机器到机器不断地适应人类的过程,人机交互的发展降低了人类使用机器的学习时间和难度壁垒。
目前,人机交互的技术有基于传统硬件设备的交互技术、基于语音识别的交互技术、基于触控的交互技术、基于动作识别的交互技术、基于眼动追踪的交互技术、基于多通道(多种感觉通道和动作通道,如语音、手写、姿势、视线、表情等输入)的交互技术等
对话系统发展历程

基于传统硬件设备的交互技术
我们常用的鼠标、键盘、游戏手柄等都是常用传统硬件的交互技术,这种交互技术用户操作简单,需要外设支持,但不能为用户提供自然的交互体验。
基于语音识别的交互技术
随着人工智能语音识别技术的发展和商业落地,基于语音识别的交互技术已广泛的应用于现实生活中,如Siri,Cortana等。
基于触控的交互技术
基于触控的交互技术目前已实现从单点触控发展到多点触控,实现了从单一手指点击到多点或多用户的交互的转变,用户可以使用双手进行单点触控,也可以通过识别不同的手势实现单击、双击等操作,如我们最常使用的苹果笔记本的触控区,手机的多点触控等。
基于动作识别的交互技术
基于动作识别的交互技术依赖于动作捕获系统获得的关键部位的位置进行计算、处理,分析出用户的动作行为并将其转化为输入指令,实现用户与计算机之间的交互。如Hololens、Leap Motion、Meta2等。
基于眼动追踪的交互技术
基于眼动追踪的交互技术是利用传感器捕获、提取眼球特征信息,测量眼睛的运动情况,估计视线方向或眼睛注视点位置的技术,通过获取人类眼球的运动信息,从而实现一系列的模拟、操纵功能。最常见使用眼动追踪交互技术的是VR领域。
基于多通道的交互技术
多通道交互涵盖了用户表达意图、执行动作或感知反馈信息的各种通信方法,如言语、眼神、脸部表情、唇动、手动、手势、头动、肢体姿势、触觉、嗅觉或味觉等。目前,使用的多通道交互技术包括手写识别、笔式交互、语音识别、语音合成、数字墨水、视线跟踪技术、触觉通道的力反馈装置、生物特征识别技术和人脸表情识别技术等方面。
CUI
- 【2017-1-19】为什么现在的人工智能助理都像人工智障?
- 最大的几次浪潮基本都伴随着一个规律:核心技术(软硬一堆)的出现和整合,带来全新的人机交互方式 ,在此基础上大量的商业应用应运而生。
- GUI 的核心突破是技术大牛(Xerox)带领的,而其商业应用的发扬光大则是产品经理乔布斯从 Xerox 那儿 “偷来” 的。1973 年,Xerox 推出第一款 GUI 技术个人电脑;在 1983 年,苹果也推出了他们首款 GUI 电脑 Lisa(乔老爷 “完美借鉴” )
- CUI 和 GUI 究竟给用户体验带来什么影响?远远不止现在主流的 “把按钮变成语言操控” 那么简单
- 当移动设备出现的时候,大家对如何在智能手机上开发产品缺乏深入了解。所以当时开发者基本都是从最明显的地方起步,也就是触摸代替键鼠操作。
- 早期的大量应用,都是从 “如何把 web 缩小到手机屏幕” 的思路出发来设计 app 的。—— 这是典型的延续上一代交互的思路。
- 随着开发者不断思考和挖掘移动端的潜力,慢慢有了对移动端真正的核心特质的理解—— 这些 “圣杯属性” 才是真正让移动端产品设计出众的要素。比如 “碎片时间”、“个人身份绑定”、“LBS” 等等,这些特质才是真正让移动产品体现价值的—— 这些是完全颠覆上一代交互的属性。这些属性几乎跟 “触摸” 这个明显的交互行为没有直接关系。
- CUI 出现的时候,产品经理也会面临类似的问题。当前大多数智能助理的设计思路都是 “过去 app 是怎么用的,我现在用语言来代替触摸操作”。好比是用语言来代替手指去触摸屏幕,或者是用说话来代替手指打字。
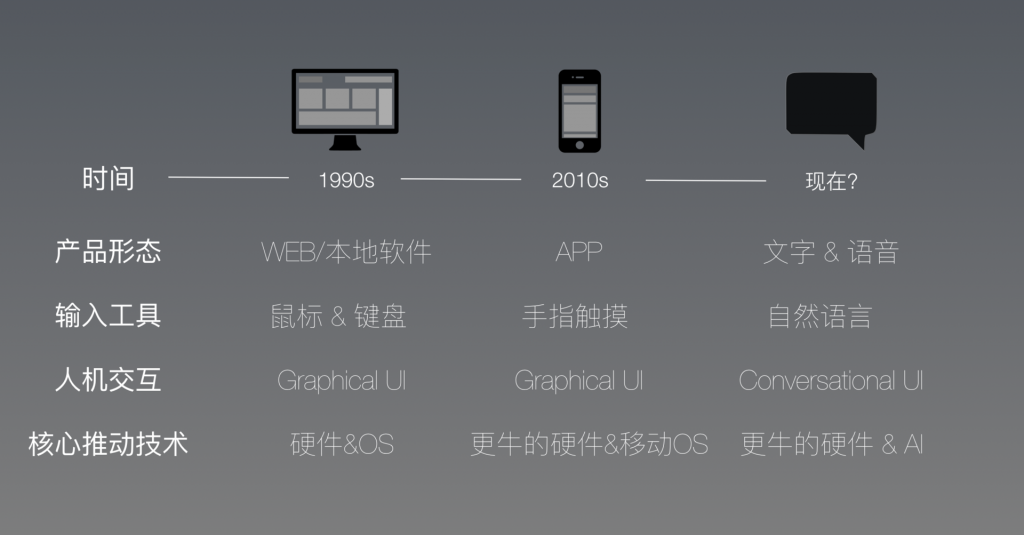
- CUI 的特点:
- 高度个性化。只有 “在外滩附近的” 是之前 GUI 查询范围当中的,其他需求都是过去 GUI 类型当中不存在的维度。但因为 CUI 的开放性,用户很容易给出上面这样高度个性化(非结构化)的需求。
- 使用流程非线性:譬如 GUI 是线性的流程,界面引导用户一步一步走到结果;而 CUI 则可以是完全无视先后顺序的,用户可以在最开始就提出到本来排在最后的条件当中。
- 可避免信息过载:用户打开 GUI 的一个界面,比如点评上找一个餐厅,用户得在一个列表里去找寻自己最想要的选项(典型的案例是,GUI 让用户选择国家的时候那一长排的列表)。而 CUI 则可以规避用户信息过载,直接给出期望结果。这个特点的另一面是,GUI 因此是 informative 的,给不熟悉场景的用户更多提示,或者比较结果的机会。
- 复合动作:“明天后天,晚上最便宜的机票”——从用户的操作和实际体验来看,GUI 无法一次给出结果,只能用户先查一次明天的机票,再查一次后天的机票,然后手动来对比。CUI 完胜——可以直接给出相关条件的检索结果,前提是 AI 足够优秀。
- 高度个性化。只有 “在外滩附近的” 是之前 GUI 查询范围当中的,其他需求都是过去 GUI 类型当中不存在的维度。但因为 CUI 的开放性,用户很容易给出上面这样高度个性化(非结构化)的需求。
- 随着技术的平民化 (democratization),人机交互正不可逆转地向人的方向靠近——不需要学习的人机交互。越来越多的人都能更自然地通过计算设备来获得价值。下一个超级增长点的交互方式,一定是交互更接近人的自然行为,更多人可以使用的。
- 顺为资本:
- 所谓 “做 AI 的” 也有几个类型,底层研发和做应用的是两码事。
- 人工智能的底层交给大公司,小创业公司可以做点小模块。而应用层则有大量的空间给创业公司来实现商业化。
- “这个行业缺 AI 的产品经理,不缺一般意义上的明星,特别牛 x 的算法达人,牛 x 的北京 BAT 出来的人。” 这方面,“人工智能社区是极其开放的,大多数顶级研究者会出版他们的著作/分享他们的想法甚至开源代码。因此,在这个技术开元环境下,数据和人才就是稀缺的资源。”
- CUI 的核心技术是 AI(不只是NLP)。对 CUI 作为新一代颠覆性人机交互的理解,才在产品形态上能发挥底层技术的商业价值。
- 对话式的 Agent 得至少满足以下功能:
- 具备基于上下文的对话能力(contextual conversation)
- 具备理解口语中的逻辑 (logic understanding)
- 所有能理解的需求,都要有能力履行(full-fulfillment)
- 基于上下文的对话能力(contextual conversation)
人机交互研究趋势
借助AMiner平台分析近年来人机交互研究的热点有虚拟现实(Virtual Reality)、增强现实(Augmented Reality)、交互设计(Interaction Design)、视觉缺陷(Visual Impairment)、混合现实(Mixed Reality)、社会计算(Social Computing)、普适计算(Ubiquitous Computing)、眼动追踪(Eye Tracking)、信息可视化(Information Visualization)、众包(Crowdsourcing)。其中,虚拟现实、增强现实是未来的研究热点。
人机交互领域相关顶会有:CSCW,CHI,TOCHI,IJHCS,IWC,IJHCI
【2021-10-21】人机对话的几个层级及发展方向
- 层级

| 层级 | 场景 | 模态 | 对话能力 |
|---|---|---|---|
| L1 | 受限场景 | 单模态 | 预定义对话 |
| L2 | 半开放场景 | 单模态 | 预定义对话 |
| L3 | 半开放场景 | 多模态 | 预定义对话 |
| L4 | 半开放场景 | 多模态 | 终身学习对话 |
| L5 | 完全开放场景 | 多模态 | 终身学习对话 |
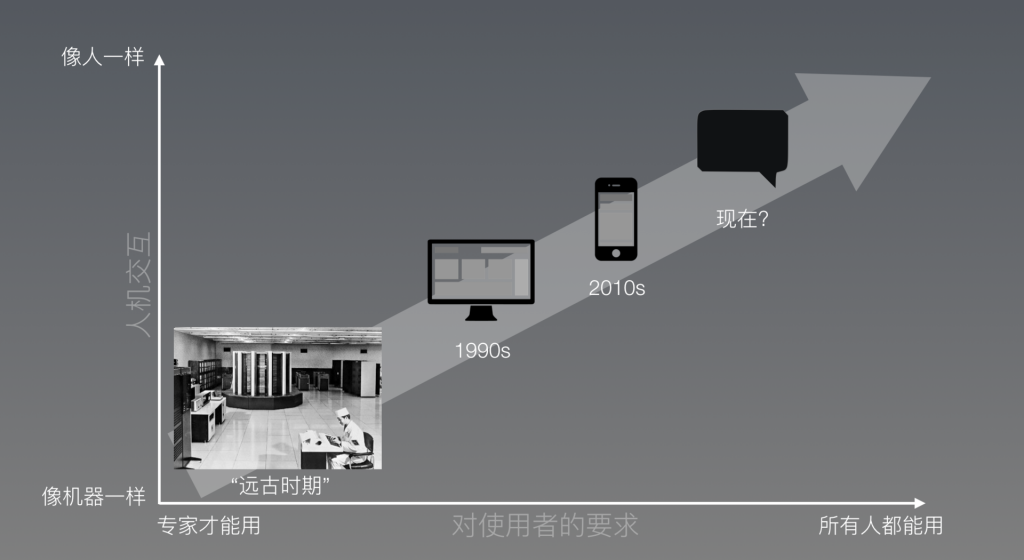
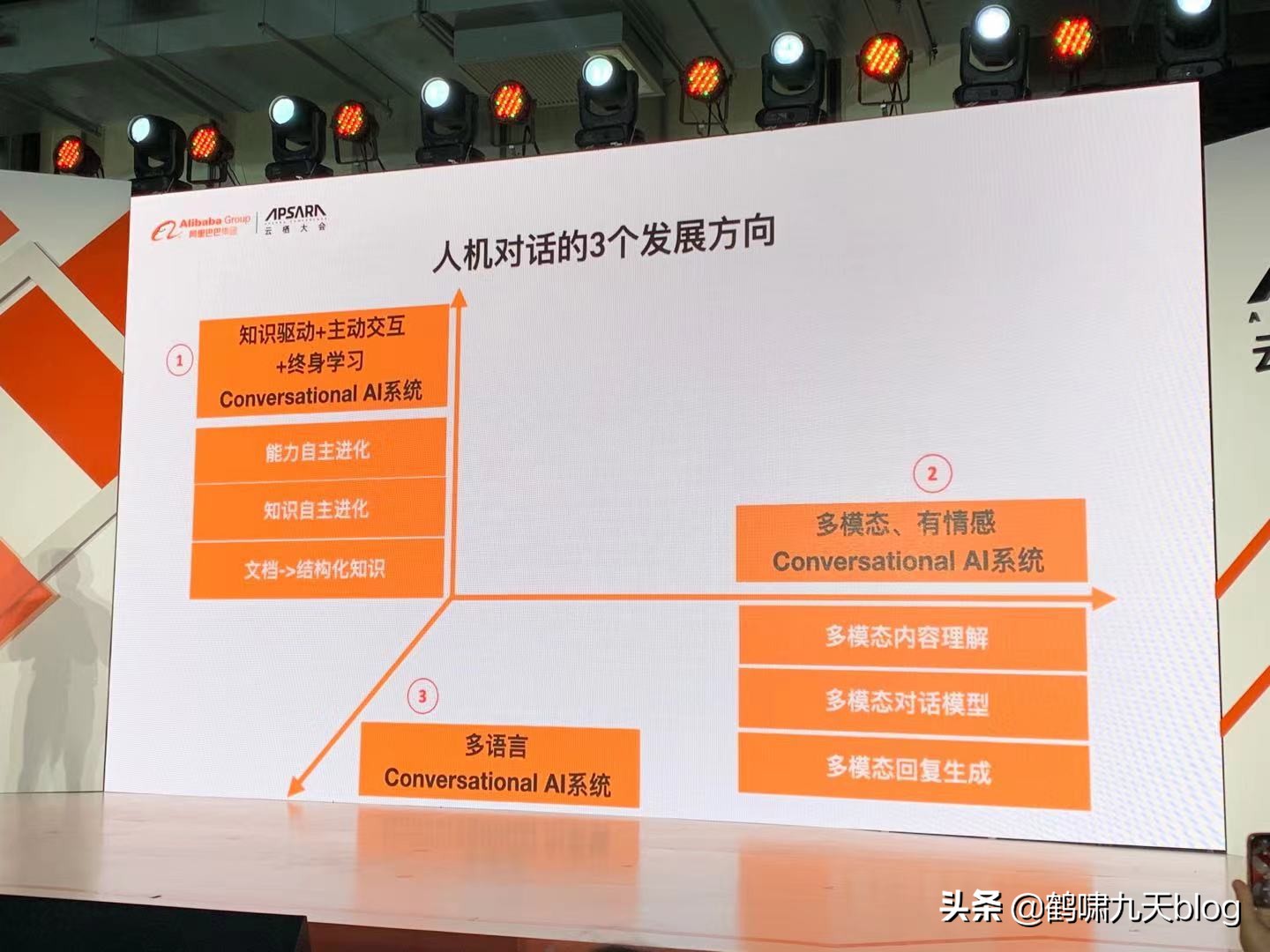
Conversational AI发展方向
- (1)知识驱动+主动交互+终身学习:能力自主进化、知识自主进化、文档→结构化知识
- (2)多模态、有情感:多模态内容理解、对话建模、回复生成
- (3)多语言:
人工智障
对话系统本质:思维
【2019-01-21】【精华】人工智障 2 : 你看到的AI与智能无关
人类对话的本质:思维. 人们用语言来对话,最终的目的是为了让双方对当前场景模型(Situation model)保持同步。
- Toward a neural basis of interactive alignment in conversation
- The interactive-alignment model (based on Pickering and Garrod, 2004)

对话系统领域,不少人认为Context是仅指“对话中的上下文”
-
除此以外,Context还应该包含了对话发生时人们所处的场景。这个场景模型涵盖了对话那一刻,除了明文以外的所有已被感知的信息。 比如对话发生时的天气情况,只要被人感知到了,也会被放入Context中,并影响对话内容的发展。
场景模型是基于某一次对话的,对话不同,场景模型也不同;- 而
世界模型则是基于一个人的,相对而言长期不变。
对世界的感知,包括声音、视觉、嗅觉、触觉等感官反馈,有助于人们对世界建立起一个物理上的认识。对常识的理解,包括各种现象和规律的感知,在帮助人们生成一个更完整的模型:世界模型。
无论精准、或者对错,每一个人的世界模型都不完全一样,有可能是观察到的信息不同,也有可能是推理能力不一样。世界模型影响的是人的思维本身,继而影响思维在低维的投影:对话。
影响人们对话的,仅是信息(还不含推理)至少就有这三部分:明文(含上下文)+ 场景模型(Context)+ 世界模型。
普通人都能毫不费力地完成这个工作。但是深度学习只能处理基于明文的信息。对于场景模型和世界模型的感知、生成、基于模型的推理,深度学习统统无能为力。这就是为什么现在炙手可热的深度学习无法实现真正的智能(AGI)的本质原因:不能进行因果推理。
根据世界模型进行推理的效果,不仅仅体现上在对话上,还能应用在所有现在成为AI的项目上,比如自动驾驶。
人们对话的本质是思维交换,而远不只是明文上的识别和基于识别的回复。而当前的人工智能产品则完全无法实现这个效果。那么当用户带着人类的世界模型和推理能力来跟机器,用自然语言交互时,就很容易看到破绽。
- Sophia是一个技术上的骗局(凡是鼓吹Sophia是真AI的,要么是不懂,要么是忽悠);
- 现在的AI都不会有真正的智能(推理能力什么的不存在的,包括Alpha go在内);
- 只要是深度学习还是主流,就不用担心AI统治人类;
- 对话产品感觉用起来智障,都是因为想跳过思维直接模拟对话(而现在也只能这样);
- “用的越多,数据越多,智能会越强,产品就会越好,使用就会越多”——对于任务类对话产品,这是一个看上去很酷,实际上不靠谱的观点;
- 一个AI agent,能对话多少轮,毫无意义;
- to C 助理产品做不好,是因为解决不了 “如何获得用户的世界模型数据,并加以利用”这个问题;
- to B的对话智能公司为何很难规模化?(因为场景模型是手动生成的)
- 先有智能,后有语言:要做到真正意义上的自然语言对话,至少要实现基于常识和世界模型的推理能力。而这一点如果能实现,那么我们作为人类,就可能真的需要开始担心前文提到的智能了。
- 不要用NLP评价一个对话智能产品:年底了,有些媒体开始出各种AI公司榜单,其中有不少把做对话的公司分在NLP下面。这就好比,不要用触摸屏来衡量一款智能手机。在这儿我不是说触摸屏或者NLP不重要(Essential),反而因为太重要了,这个环节成为了每一家的标配,以至于在这方面基本已经做到头了,差异不过1%。
- 对于一个对话类产品而言,NLU尽管重要,但只应占个整体配件的5-10%左右。更进一步来说,甚至意图识别和实体提取的部分用大厂的,产品间差异也远小于对话管理部分的差距。真正决定产品的是剩下的90%的系统。
对话智能的核心价值:在内容,不在交互
- 我们需要的是对话系统后面的思考能力,解决问题的能力。而对话,只是这个思考能力的交互方式(Conversational User Interface)。如果真能足够聪明的把问题提前解决了,用户甚至连话都不想说。但是对于一个企业而言,客服是只嘴和耳,而专家才是脑,才是内容,才是价值。客服有多不核心?想想大量被外包出去的呼叫中心,就知道了。
对话智能解决重复思考
- 对话智能的产品的核心价值,应该在解决问题的能力上,而不是停留在交互这个表面。
- 工业革命给人类带来的巨大价值在于解决“重复体力劳动”这件事。
- 大量重复的工作不停的演变,从重复的体力,逐步到重复的脑力。
- 对一个场景背后的“思考能力”没有把控的AI产品,会很快被代替掉。首当其冲的,就是典型意义上的智能客服。
- “智能客服” 称为“前台小姐姐”, 他们最重要的技能就是对话,准确点说是用对话来“路由”——了解用户什么需求,把不合适的需求过滤掉,再把需求转给专家去解决。
- 与客服机器人产品对应的是专家机器人。一个专家,必定有识别用户需求的能力,反之不亦然。
- 专业能力是这个机构的核心,而客服不是。
NLP在对话系统里解决的是交互的问题。
- 对话智能类的产品最核心的价值是进一步的代替用户的重复思考。Work on the mind not the mouth. 哪怕已经是在解决脑袋的问题,也尽量去代替用户系统2的工作,而不只是系统1的工作。
对话是思想从高维向低维的投影,用低维方法解决高维问题本身就是极大的挑战,日常对话涉及的环境远不止上文会话历史这么简单,还有时间、地点、教育背景、沟通双方的认知方式等,如果想做成无障碍真人交互级别,单靠深度学习/GPT技术不行,将来也不行…即便是免语言交互的脑机接口也面临沟通障碍,对话相关产品需要降低预期,不可完全对标真人场景交互效果。当前GPT系列的大模型对话也依然只是一个工具,变蛔虫很难,即便是身边的亲朋好友都未必能理解人的真实意图、想法,更何况是机器
2017年10月,一个叫Sophia的机器人,被沙特阿拉伯授予了正式的公民身份。公民身份,这个评价比图灵测试还要牛。
- Sophia in AI for Good Global Summit 2017. Source: ITU

- Sophia经常参加各种会、“发表演讲”、“接受采访”,比如去联合国对话,表现出来非常类似人类的言谈;去和Will Smith拍MV;接受Good morning Britain之类的主流媒体的采访;甚至公司创始人参加Jim Fallon的访谈时一本正经的说Sophia是“basically alive”。

2018 年 11 月,小米 AIoT(人工智能 + 物联网)开发者大会上,「雷布斯」雷军骄傲地展示了新品智能音箱「小爱同学」。

- 雷军:「小爱,你能做什么?」
- 小爱:「人家还小嘛,这个问题太难了……」
- … …
- 雷军:「三个木叫什么?」
- 小爱:「木三分……」
- 雷军:「三个木叫什么?」
- 小爱:「你是电,你是光,你是唯一的神话。」
- 雷军:「三个木头的木叫什么?」
- 小爱:「粘树的木头,感觉你是个乐观……」
- 雷军:「小爱,是不是每次演示的时候你都要出错?」
尴尬的雷军继续问小爱,「125 加 357 加 567 等于多少?」但小爱同学直接「下班」,不再回答,全场哄笑一片。
【2018-12-6】「人工智障」,我们还能忍你多久?
贴心提示:
- 华为用户可以试一下,让小艺给你点个外卖,你会震惊的!
- 三星的的Bixby甚至能玩推理游戏。还会模仿情景声音,能把人吓死。
- 和小爱同学说来一首威风堂堂,你会回来感谢我的。
智障案例
【2023-2-8】知乎专题:你见过哪些“人工智障”?
| AI设备 | 品牌 | 智障特点 | 表现 | 备注 |
|---|---|---|---|---|
| 音箱 | Alex | 诡异 | 无缘无故发出怪笑声:“啊-哈-哈”的声音,听得人毛骨悚然 |  |
| 音箱 | 语义理解不足 | “我是说,明天早上六点半的时候,叫我起床。” “好的,明天早上六点半的时候,我将称呼你为‘起床’。” |
||
| 音箱 | 微软小娜 | 语义理解不足 | “小娜!设置三点钟闹铃“”好的!已设置3:00闹铃!“ 抱歉,我忘记小娜不知道什么是12小时制,我半夜三点被叫醒了! |
|
| 音箱 | 小米小爱 | 语义理解不足 | “小爱同学,播放loveshot” “好的,为你播放拉萨” “小爱同学,播放七月的风” “对不起,只能查询未来十五天天气情况” |
|
| 音箱 | 小米小爱 | 语义理解不足 | 放一首周杰伦的歌 小爱:无反应 放歌! 小爱:放谁的歌儿? |
|
| 音箱 | Google Assistant | 语义理解不足 | 理解不了,什么叫“不要” | 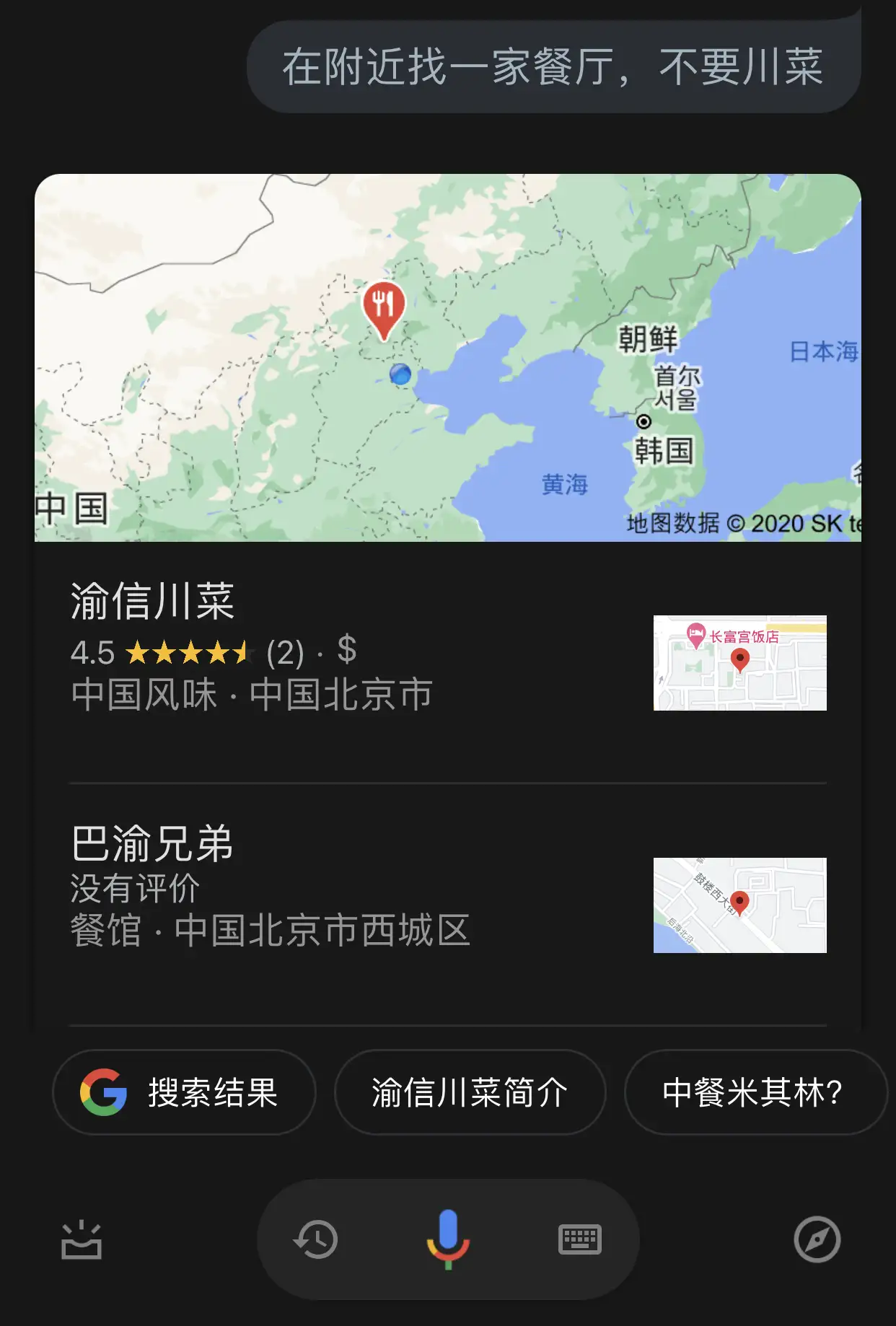 |
| 音箱 | 小米小爱 | 语义理解不足 | “小爱同学,播放loveshot” | |
| 个人助理 | 华为小艺 | 域外意图 | 频繁安全回复、道歉:很抱歉!小艺还在努力学习中,请您换个简单的问法吧 | 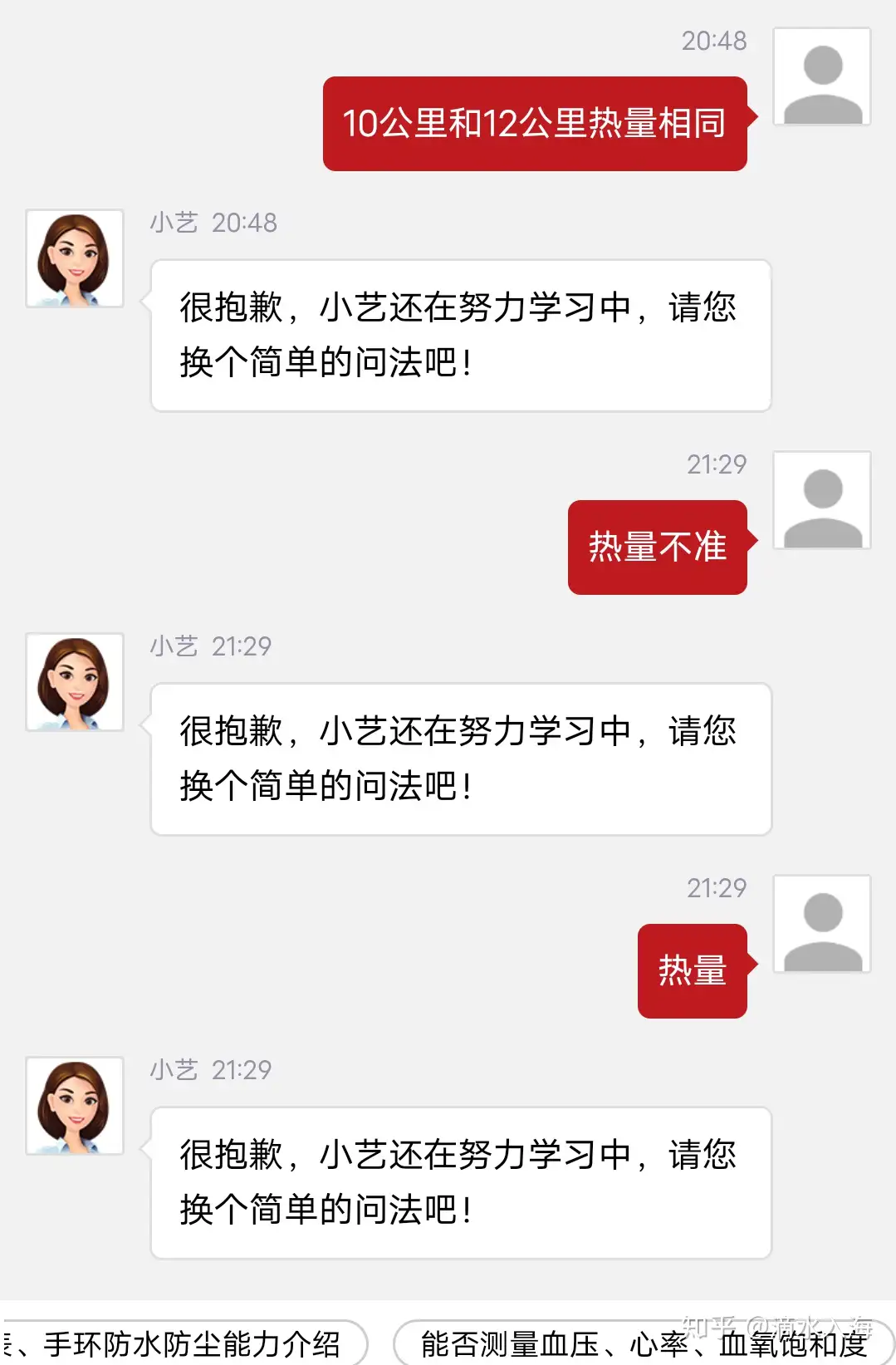 |
| 个人助理 | Apple Siri | 语义理解有误 | 用户:设置一个今早8点的闹钟 Siri:我打开了你6:00的闹钟 |
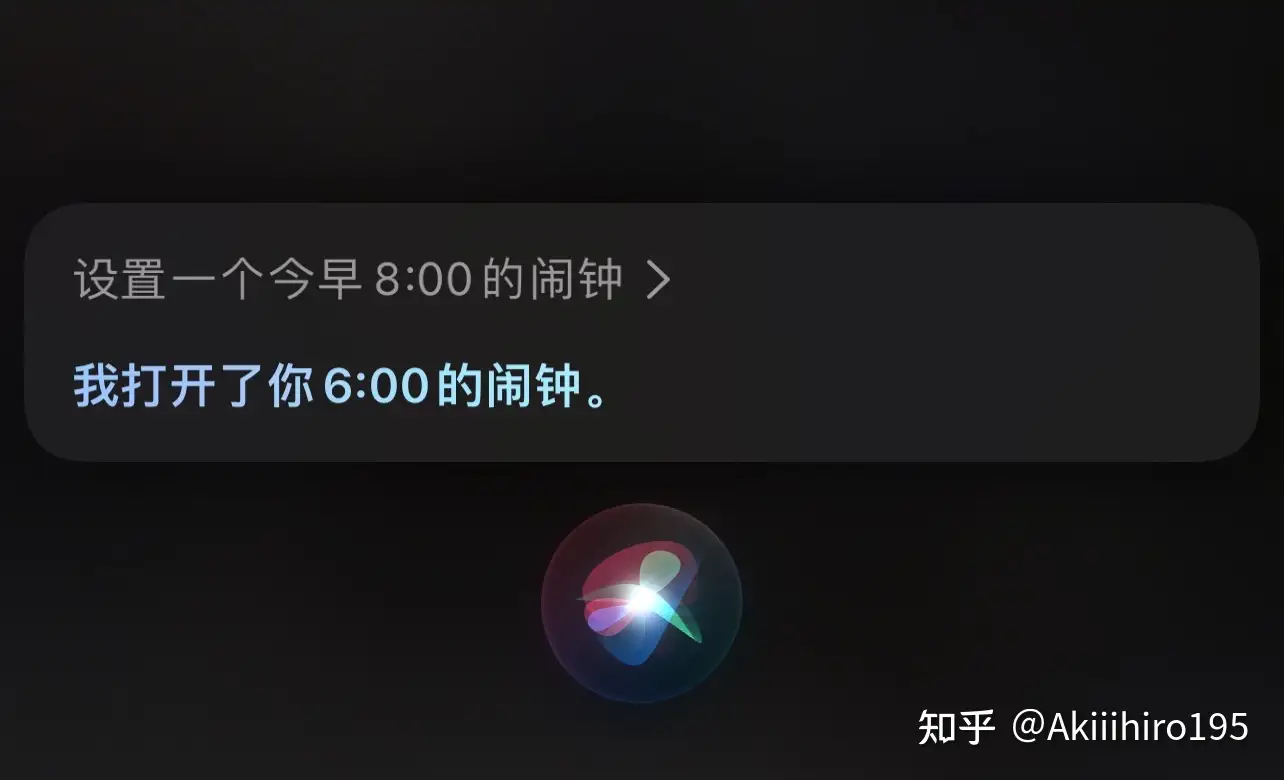 |
| 个人助理 | Apple Siri | 语义理解有误 | 用户:siri,给xx发微信,告诉她我晚点到。 Siri:好的,我将给xx发消息:告诉她我晚点到。 |
|
| 闲聊机器人 | 微软小冰 | 无法理解上文 | 什么? bot: 什么额什么 |
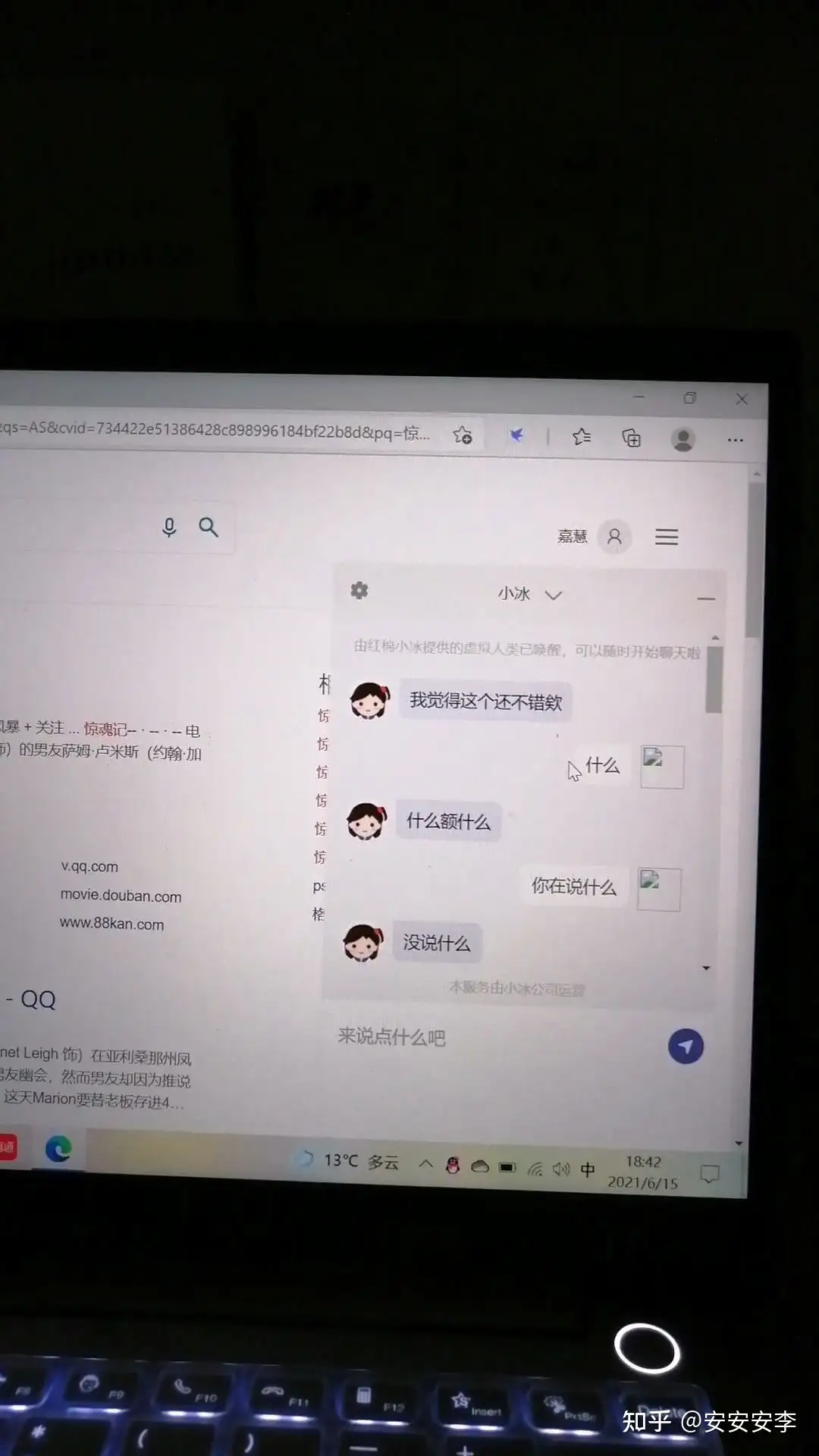 |
| 闲聊机器人 | 微软小冰 | 胡说八道 | 写的诗乱七八糟 |  |
| 智能客服 | 蛋卷 | 语义理解不足 | 客服机器人变复读机 |  |
| 银行大厅机器人 | 快宝 | 人工操作 | 雇佣人工在后台处理 | 视频地址 |
| 图像识别 | 华为P30 | 无法识别域外目标 | 将shit识别成food |  |
| 陪护机器人 | 情绪表达欠缺 | 翻白眼 |  |
|
| 扫地机器人 | 不会充电 |  |
||
| 扫地机器人 | 离家出走 | 生是我的家用电器,死是我家的摆设,休想逃走! |  |
|
| 扫地机器人 | 脾气大 |  |
||
| 奶娃机器人 | 无法精确控制 | 机械臂伤人 | video | |
| 喂食机器人 | 机械控制障碍 | video | ||
| 家政机器人 | 无法感知物体 | 撞门 |  |
|
| 家政机器人 | 无法感知电线 | 自己拔电源 |  |
|
| 陪护机器人 | 行动能力欠缺 | 自己摔倒 | video | |
| 足球机器人 | 行动能力不足 | 无法站立 | video |
手机助手
基本概念
在线对话引擎的基本概念与关系
Bot(机器人): Bot是一个功能合集,包含了很多技能,天猫精灵x1、M1、C1绑定的是同一个Bot,而天猫精灵儿童故事机存在功能范围的差异,绑定的是另一个Bot。Skill(技能): Skill是完整的功能单位,包含了对话理解与对话执行逻辑,独立承接一段对话逻辑。- 一个Bot可以包含多个技能, 例如: 天猫精灵X1的Bot中包含 天气、找手机、掷骰子等skill;
- 一个技能也可以被不同的Bot选用,例如: 天猫精灵X1中存在汇率skill用于查询当前汇率,儿童故事机中就没有。
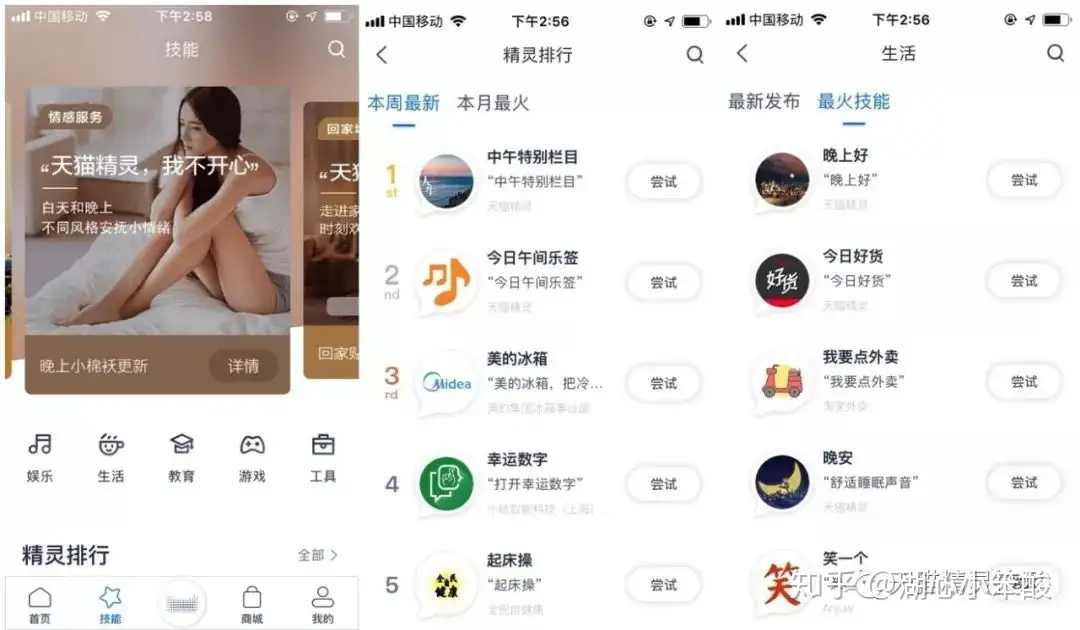
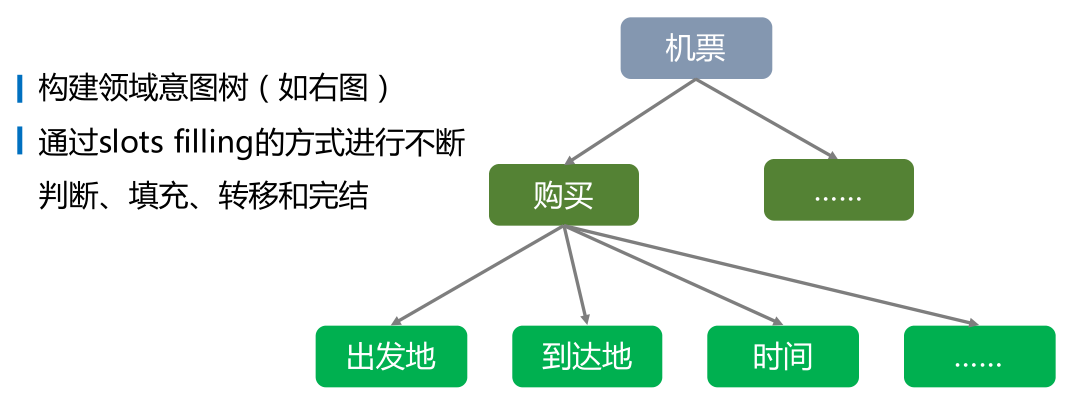
Domain(领域): Domain是一个内部概念,skill包含了对话理解与对话执行两部分。- Domain承载了对话理解NLU部分的数据信息,例如天气是一个领域。
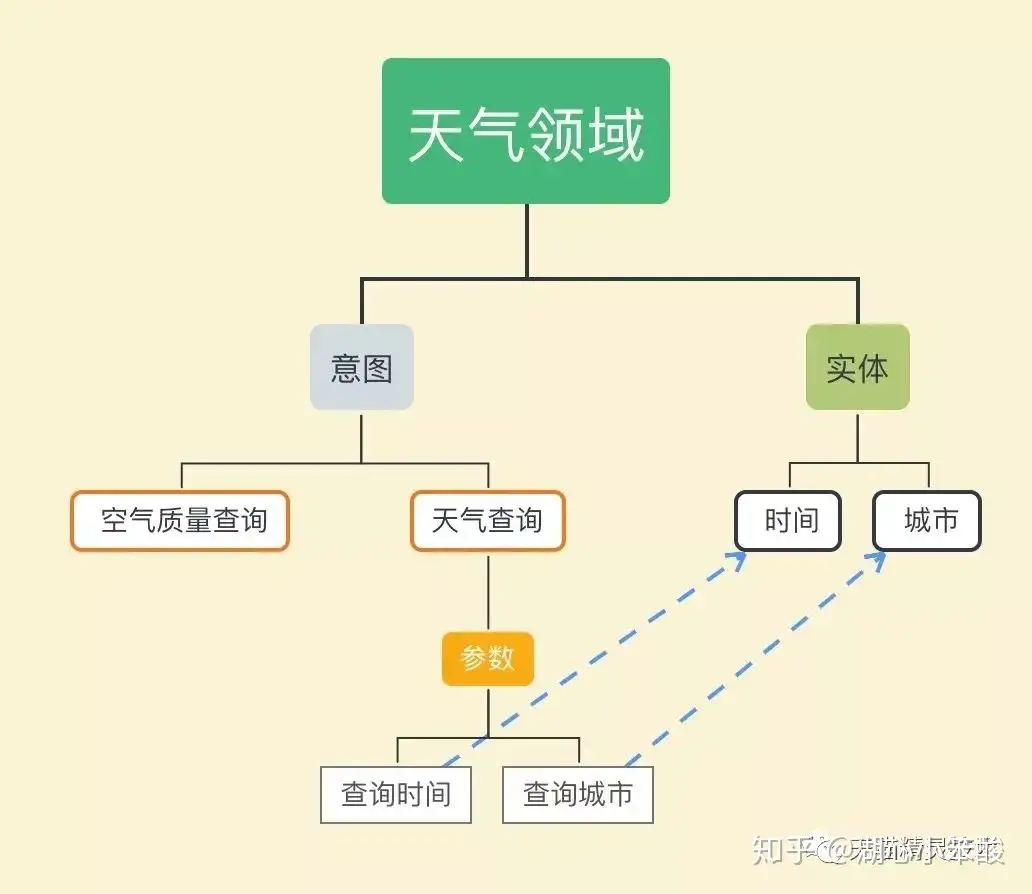
Intent(意图) : 意图是Domain内部细分。天气Domain中,既有普通的天气查询Intent,也存在空气质查询的Intent。Entity(实体): 代表了一种对象类别,例如本体(如明星、电影)、常见的命名实体(时间、地点)以及一些短语集合都可以作为实体。天气领领域就有时间、城市两个实体。Slot(参数/槽位) : 参数是实体的实例化- “帮我订从杭州到北京的机票”,其中“杭州”与“北京”都对应city这个实体,而“杭州”对应参数出发城市startCity,“北京”对应参数endCity。对应到国资委中的天气领域,就有查询时间与查询城市。

对话引擎只包含三个部分:对话总控(DM)、语言理解(NLU)与技能执行(Skill Execute) 。先作简单介绍,下文会有扩展。
- 对话总控: 对话总控是整个对话引擎的控制中心,对话链路的必经之地,也是对话管理的中枢,具体负责对话管理、上下文管理、链路调度等功能。
- 语言理解: 语言理解(NLU)做的事情更为明确,将用户的自然语料输入转换为结构化数据。对话引擎当前采用DIS表示结构,D代表Domain, I代表Intent,S代表Slot,此处的slot对应上文中的IntentParameter。
- 技能执行: 在完成NLU理解之后,对话总控会根据NLU结果以及一定的规则命中相应的skill,并将Intent、Slot等信息以参数形式传递给技能。技能执行根据参数与上下文做技能决策,生成文本回复或者端上可执行指令返回。
天猫精灵内部最主要使用的模型算法方案是: DC + ICSF的两级模型。
- 第一层领域分类模型(DC,Domain Classification),DC模型做第一层的处理,将不同的自然语言输入分类到不同Domain;
- 第二层为领域模型(ICSF, Intent Classification + slot filling),这里采用的一个联合模型,同时完成了意图分类与实体抽取的功能。
对话管理其实分为两部分:
- 1、Bot级全局对话管理
- 2、skill内对话管理
| 对话管理 | 所处环节 | 类比 | session类型 |
|---|---|---|---|
| 全局对话管理 | 对话总控 | 操作系统任务管理 | 全局session |
| skill内对话管理 | 技能执行 | App内页面管理 | skill级session |
多轮对话是基于对话双方完成的,包括用户侧与Bot侧。
- 用户发出指示,到达Bot,Bot命中技能给出回复与本轮回复状态。
Bot侧技能常见的回复状态有两类:
ASK_INF:指追问,如上图天猫精灵首次回复“你想查询哪里的天气”,追问的是city信息。RESULT:指给出回复。如上图,当补充city信息后,回复查询结果,完成当前意图的请求。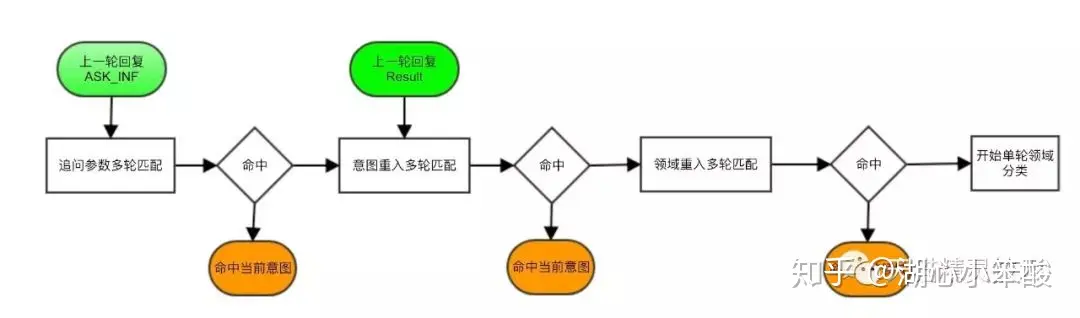
多轮匹配的内容,可简化为以下三类:
- 参数追问:命中用于补全参数的语料,得到意图与上一轮意图相同。例如“我想查询的是杭州”。只有上一轮为ASK_INF时,才会启用。
- 意图重载:命中用意图重入的语料,得到的意图与上一轮意图相同。例如“那上海呢”,在上一轮为空气质量查询时,重入该意图。
- 领域重载:命中重新回到该领域的语料,得到的领域与上一轮的领域相同,例如“有没有下雨?”,上一轮天气领域空气质量查询意图,重新回到该领域,命中是否下雨意图。
天猫精灵设计新功能、开发新技能的时候,往往会遇到这样的尴尬:
- 1、用户查找的东西,纯语音播报难以描述;
- 2、用户查询的东西有多个候选结果,文字量大,不宜语音播报;
- 3、缺少足够的提示引导方式,用户一直只做他摸索成功的几个操作,如果加太多提示引导,又显得音箱很啰嗦。
总而言之,适于交互的语音播报所能传达的信息量还是太少。有时候结合屏幕操作,才能带来更佳操作体验。
带屏语音交互分为两类:1、所说即可见,2、所见即可说。
- 所说即可见: 用户语音命令结果,可在屏幕上以视觉信息展示。
- 例如,用户查询天气,在天猫精灵魔盒的外接电视上可显示如下。

- 所见即可说: 用户可根据屏幕上的信息提示,做相关语音操作。
- 例如,在查询电影的时候,得到如下界面,用户就可以直接说“我选第一个”或者“我要看圆梦巨人”。
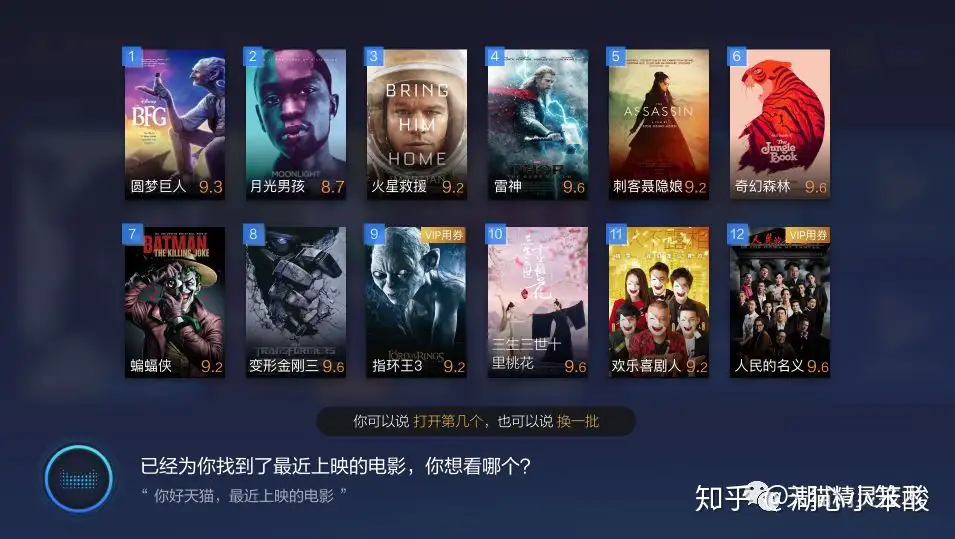
- 所见即可说的原理跟多轮对话类似都参照当前对话的上下文进行NLU的意图决策,只不过多轮对话的上下文主要是前几轮对话记录,而所见即可说的上下文为当前页面信息
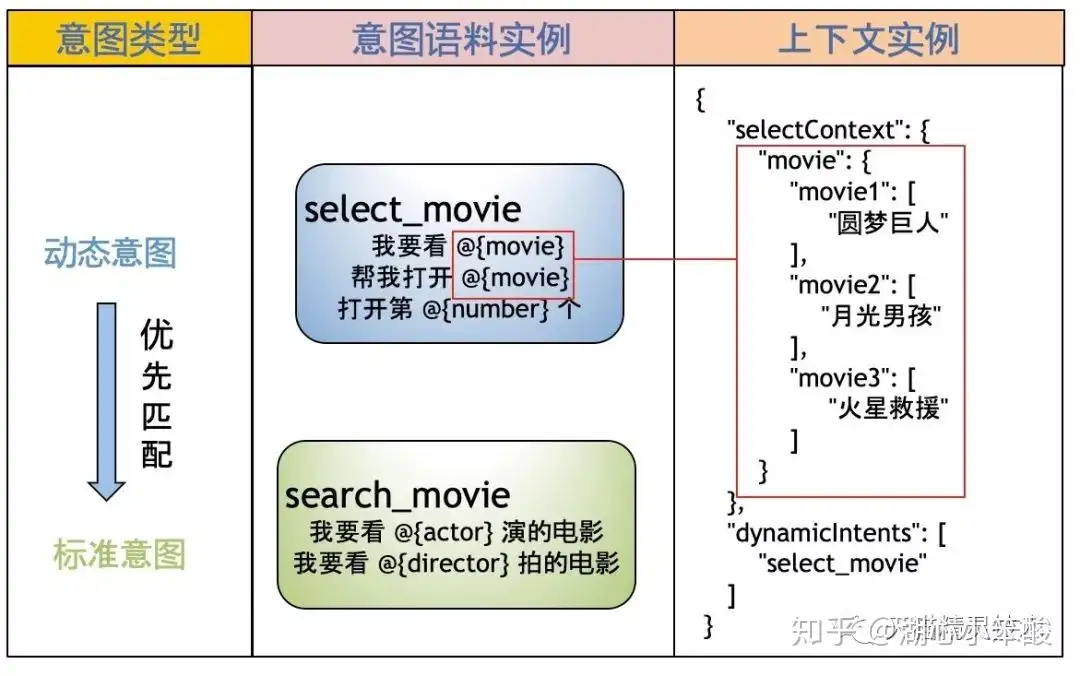
由于带有视觉信息的页面的上下文信息太过复杂,我们做了抽象,传递到对话引擎时,请求会包含两项信息:
- 动态意图列表(dynamic Intents): 动态意图包含了跟当前页面相关的操作的语料。动态意图相较于无页面相关信息的标准意图更优先匹配。不同的页面可以指定不同的动态意图。
- 动态实体信息(slect context):动态实体用于请求时动态指定当前页面的相关词信息,如图中的电影名称。动态实体用于区分同个页面的不同内容。
除了开发者对技能自定义的需求,nlp的一些交互能力上的可复用性依然不足,为此扩展了一系列的公共意图。
- 复用nlu:
sys.yes/sys.nosys.yes代表确认,常见语有“好啊”,“可以”,“行呗”;sys.no代表否认,常见语有”不要了“,”算了“,”不行“。- 大量有多轮能力的技能都需要这样的两类语意表示,为了避免重复的语料配置工作,将其封装成为了公共意图。技能开发者还可以根据各自技能需求自定义扩展语料。
- 复用nlu与技能决策:
sys.nextsys.yes/sys.no做的只是nlu理解部分的复用,而sys.next与播控状态绑定协助完成了技能路由的决策。- 存在有不少内容播放类技能,如”新闻“、”笑话“、”音乐”,都存在”下一首“这种操作的,当用户说”下一首“时,系统会根据技能播控信息以及设备播放状态等信息,找到合适的技能,进行执行。
- 复用nlu与执行交互:
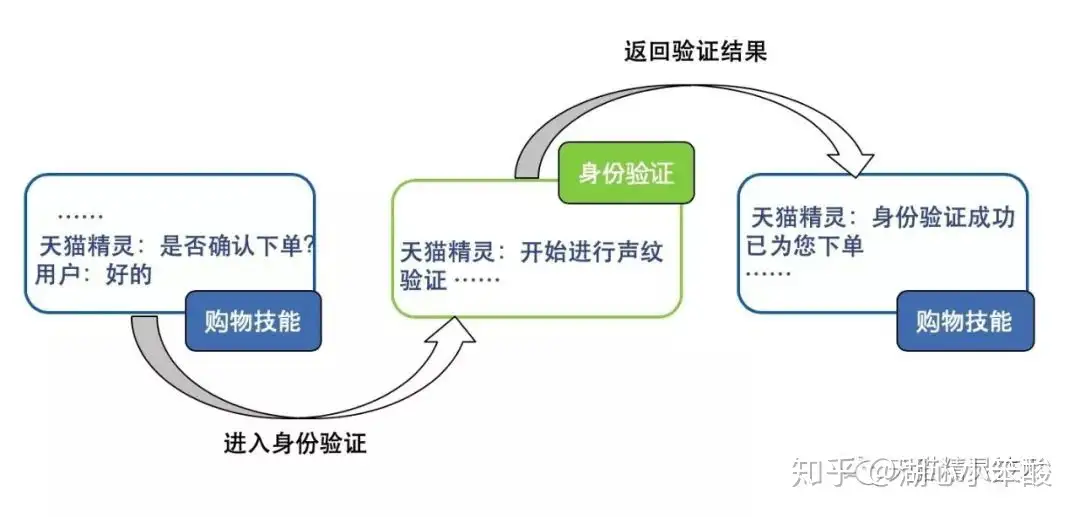
sys.action.verify- sys.action.verify 用于身份验证的公共意图。
- 类似于微博的登录组件,为各个不同技能提供了一套统一的登录方式,而其内部的验证逻辑对于接入的技能来说并不关心,更多关心的是验证结果。语音身份验证同样可以成为一种组件,目前今日好货、淘宝购物、手机充值等技能都已接入了该公共意图。
参考:深度解密天猫精灵对话引擎
案例
小米-小爱
【2023-9-13】NLP 技术在小米语音助手中的应用
语音对话技术的主要流程

NLU例子

意图槽位

智能音箱
- 【2021-11-28】模仿AI音箱声音,网红模仿siri、天猫精灵、小米小爱
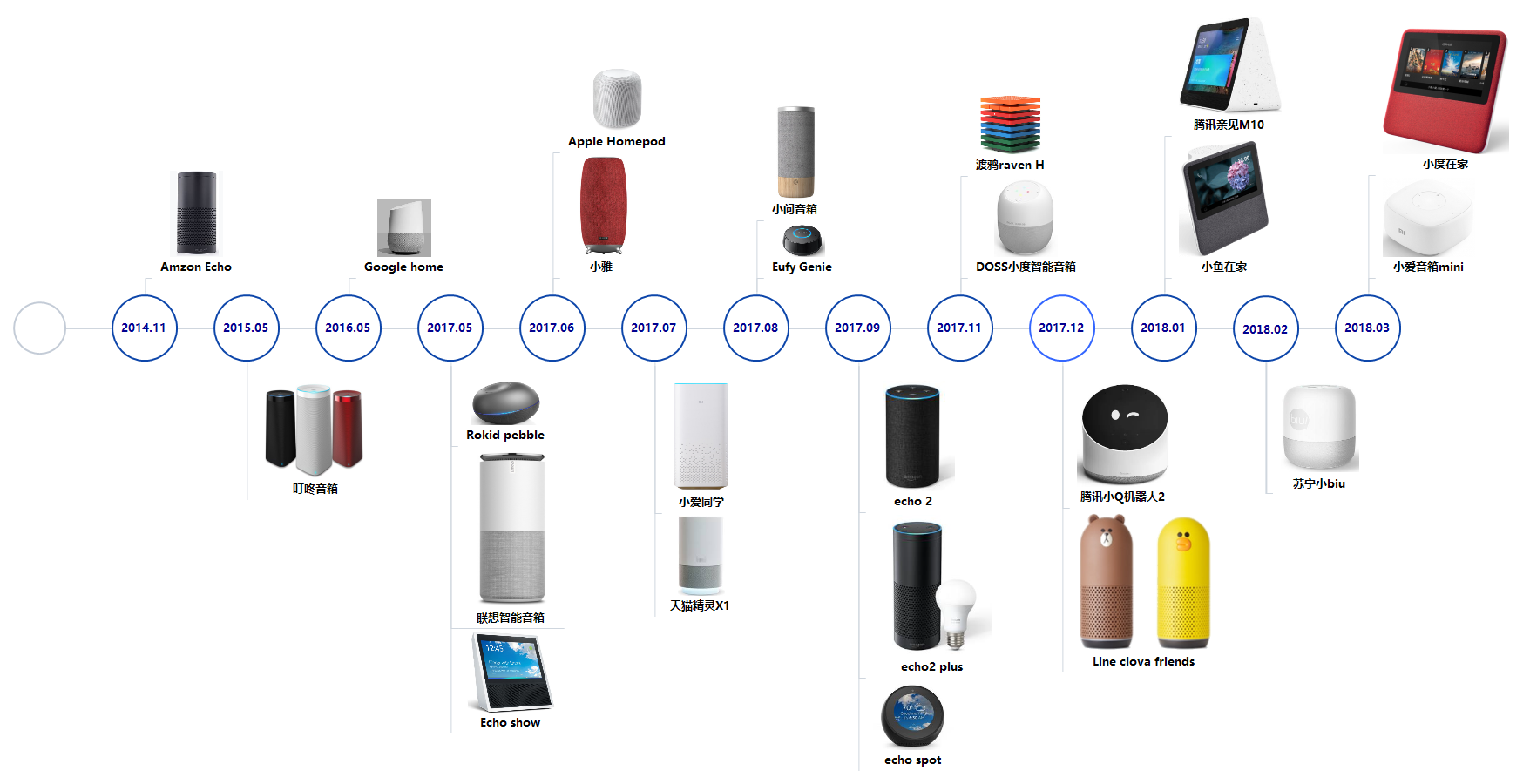
发展历史
- 【2021-3-9】2021年了,对话系统凉透了吗?
- 2011年,世界闻名的人机大战主角——IBM的Wastson,在智力竞猜节目中战胜人类,向全世界宣告了计算机拥有了自然语言理解能力和人机对话能力。
- 2011年,乔布斯收购的Siri担起了苹果向AI领域进军的大旗,作为智能数字助理搭载在iPhone上。
- 2014年,微软在中国区发布会上发布了第一款个人智能助理Cortana(中文名小娜);
- 2014年,亚马逊推出自己的智能语音助理Alexa和智能音箱Echo,凭借新颖性和稳定性迅速占据了全球市场。
- 2016年,谷歌也完成了它的对话产品-谷歌Assistant。
- 2017年,中国本土的对话产品开始觉醒、登场。17年下半年,阿里的天猫精灵、小米的小爱同学正式推出
- 2018年,百度的小度智能音箱,以及华为AI音箱相继跟上,这些头部大厂率先抢占了市场和人心,而后第二梯队的思必驰、出门问问等产品又进一步参与了对话市场的瓜分。
- 2018年5月的时候,Google I/O发布了Duplex的录音Demo,场景是Google Assistant代替用户打电话去订餐厅,和店员沟通,帮助用户预定位子。值得注意,这并不是Live demo。
- 【2022-05-10】人工智障:你看到的AI与智能无关
- 2020年9月30日,百度将旗下智能生活事业群组业务小度科技拆分,完成独立融资。小度也被独立拆分
- 2021年1月,阿里AI Lab解散,天猫精灵凉凉,阿里AI Labs成为国内主要互联网公司里第一个被关闭的人工智能实验室。
- 阿里巴巴人工智能实验室成立于2016年,2017年7月5日首次公开亮相,巅峰的时候阿里AI Labs团队有上千人,旗下孵化出来的最重要的产品就是天猫精灵。
- 2020年9月,阿里AI Lab总经理陈丽娟(浅雪)转入大钉钉事业部;阿里巴巴AI Labs北京研发中心负责人、语音助手首席科学家聂再清,已经于10月加入清华大学任教。
- 聂再清之前曾经在微软亚洲研究院工作过13年,主要负责微软自然语言理解、实体挖掘的研发工作,是微软学术搜索、人立方,以及企业智能助理 EDI 的发起人和负责人。
知名音箱
【2023-2-8】音箱大全:img
语音技术厂商 img

从数据层面,Google Home的表现不算差。
- 在16年Q4季度,在全球智能音箱市场抢下10%的份额。
- 这个份额也在不断扩大,到17年的4月底,Google Home占到全美语音类音箱份额的23.8%
从8:1 到 3:1,背后的竞争格局的变化是致命。商业上,如果市场参与者的份额小于最大竞争者的1/4,是不可能有效地发起竞争攻击。亚马逊如果想保持一家独大的态势,务必把Google Home的份额遏制在20%以下。而现在,显然不行了。

Amazon Echo
说起智能音箱,亚马逊Echo是当之无愧的霸主。
- 早在2011年,亚马逊就在秘密研发Echo。
-
到2016年底,亚马逊已经击败传统音箱巨头Sonos,取得在线音箱份额第一的霸主地位
- (1)Echo的外线防御:对弈模型的三大要素;智能音箱商战博弈模型
- (2)Echo内线帝国:2大场景、6项指令和19类技能应用
- 场景:厨房(51%)、客厅(33%)
- Experianand Creative Strategies 研究机构在2016年美国做过一次用户研究,涉及1300多名Echo用户,研究表明有50.9%的用户在厨房使用Echo,有33.5%的用户在客厅使用。厨房是Echo使用的最高频场景,大概是因为在厨房烹饪的时候,最需要通过语音来解放双手。
- 指令:播放音乐(34%)、控制家居(31%)、连接付费音乐(18%)、设闹钟(24%)、播新闻(17%)、添加购物清单(10%)
- Echo可以做到指令很多,比如播天气、查交通、问百科、定外卖,这些都没有进前六。音乐、家居和计时,是最核心高频的三类指令。
- 技能:一线阵营、二线阵营、边缘阵营
- 亚马逊在15年开放了技能平台,并在17年6月底达到了惊人的1.5万个。邹大湿:技能分析报告;技能类型:播报、指令、互动
- 一线阵营是音乐影视、游戏娱乐、生活和智能家居。这四类技能总数多,消费者关注高。
- 二线阵营是教育、趣玩搞笑、新闻和效率;总量大,但关注度一般。
- 边缘阵营有体育、财经等11类小众技能,体量小,关注度最弱。

- 场景:厨房(51%)、客厅(33%)

Google Home
16年11月,Google Home正式发售。打响了互联网巨头之间智能音箱之战。短短半年,Google Home已经成为Echo一个不可忽视的竞争对手。
Google Home的发展历程,可以划分为两大阶段,以2016年末为节点。
- 第一阶段为单点突破,Google Home攻破了Echo的外线防御,以差异化特性被人们接受;
- 第二阶段是攻城略地,针对Echo的场景技能展开了锋锐的进击。

智能音箱商战对弈的模型。从硬件、软件和商业购买三个角度
- 一级核心要素,分别是音质、技能(含服务)和价格。
- 二级要素: 识别、设计;听音乐、对答;促销、渠道。 而对于亚马逊和谷歌具体而言,Prime会员和Chromecast是两大极其重要的产品协同要素。

2016.5-2016.12:Google Home的外线破局
- 1、一个突破口:避实就虚,绕开海量技能,以智能对答为核心切入;优势彻底、用户感知、付费买单,Google Home 在问答这方面单点突破,成功碾碎了亚马逊的防线。
- 优势彻底:国外专业调研机构Stone Temple 对此做了专业研究,问了5000个常见的问题,谷歌回答了68.1%,是亚马逊 Alexa的3倍。
- 用户感知:谷歌回答的智能,不仅仅是数据上的碾压,而是在用户层面,切切实实可以感受到的。
- 愿意买单:智能回答这个功能点,用户是愿意付费买单的。这个见解在Google Home推出之前,其实就能预料和监测。
- 2、特色:设计优雅和价格亲民
- 一个是优雅的设计外观,配合有不同配色的底座。和纯黑圆柱状的Echo,形成了鲜明的对比。
- 还有一点就是价格,129美金的价格,的确是比Echo 179美金便宜,但却不是最便宜的。设计和价格,都只算是Google Home的特色,还不能算做优势。
现状
- 【2021-6-26】常超:为什么语音助手很难,现状:
- 从 Google、苹果、微软、亚马逊,到国内的 BAT、华为等巨头公司都有做语音助手的团队
- 大多用户眼中,Siri、小度、天猫精灵、小爱同学等语音助手仍然是“人工智障”
- 使用过语音助手的人很多(19年光智能音箱出货7200W台,城镇住房渗透率 20%),但用户活跃度低,使用过的功能也寥寥可数,主要是:听歌、查天气、订闹钟等
- 为什么这么多顶尖的公司,投入了顶尖的资源、顶尖的人才都没做出一款 C 端用户满意的语音助手?为什么在很多用户眼中都是”人工智障“?
- 用户预期与实际助手能力的 gap 过大
- 语音助手的难点又是什么?
- 问题 1:如何让用户知道语音助手能干什么?
- 语音助手背后的技能、内容其实都已小具规模( 在19年,Alexa 集市就已经有了8万多个技能),但很多用户也就只会使用听歌、查天气、订闹钟这么几个技能(有屏音箱里充满了各种引导、推荐,就是试图在解决这个问题),大多用户们不了解语音助手能干什么,本质还是语音助手没有找到一个刚需场景并打透(没有找到刚需场景,或者说没有在一个刚需场景中创造显著的体验差)
- 问题 2:如何让语音助手连接更多的服务、内容?
- 深度方面,单一场景要打通的链路很长,体验闭环难。
- 案例 1:以家庭智能音箱的听歌场景为例,受限于音箱背后的音乐版权,而音箱没有,这会很大的影响体验。比如小爱同学,因为它连接的歌曲资源是QQ音乐,而我就没办法听自己在网易云收藏的歌单了。
- 案例 2:在家庭照明场景,想通过语音助手随意的控制家庭灯光,需要连接整个家庭灯光照明设备,这甚至得打通装修环境,在装修时就考虑。
- 广度方面,用户在跟语音助手交互时,会有非常多的碎片化小需求。
- 案例:在滴滴的司机语音助手中,除了大家可以想到的导航场景,司机还会有各种各样的长尾问题,例如:“网约车考试的题目在哪里?”、“飞机场那边的排队区在哪里”、“帮我查一下我的预约单”等等,这些都是司机自发的问语音助手的碎片化小需求。
- 深度方面,单一场景要打通的链路很长,体验闭环难。
- 问题 3:如何管理用户预期?导致用户预期过高也有两方面的原因:
- 一方面是使用语言交流时,某种程度上人们会不自觉把“语音助手”与真实的人比较,尝试用人脑的思考习惯去理解“语音助手”,这必然会导致很多时候用户会觉得人机对话的结果不符合预期,因为目前的AI的原理和真正的人脑原理差的还很远(根本原因是科学对人脑的了解也还很初级…),再加一些科幻电影,还有媒体对人工智能概念的鼓吹…
- 另一个方面是语音无法设定交互边界,设计GUI交互时,我们可以定义出清晰的交互路径和边界(eg:首页只提供一个按钮),但是语音交互你无法限制用户说什么,就像人与人的对话中,你永远无法避免别人问到你不会的问题。
- 问题 1:如何让用户知道语音助手能干什么?
- 可能的解决路径
- 第一步:找到刚需场景,打造出显著的体验差
- 第二步:规模化复制,带动服务者生态的建立
- 第三步:打造每个属于用户自己的语音助手
评测
- 【2019-12-9】中科院物联网研究发展中心:智能音箱的智能技术解析及其成熟度测评
- 音箱产品
- 无屏音箱:天猫精灵X1、小米AI音箱、腾讯智能听听9420智能音箱TS-T1、小度智能音箱Play。
- 有屏音箱:小米小爱触屏音箱、小度在家1S、天猫精灵CC、腾讯叮当。
- 无屏音箱:天猫精灵X1、小米AI音箱、腾讯智能听听9420智能音箱TS-T1、小度智能音箱Play。
- 结论:以ASR识别率为主要指标的“听清”环节,不论是无屏音箱,还是有屏音箱,四家主要厂商没有明显差距。有屏音箱的ASR识别率整体优于无屏音箱。
- 从无屏音箱维度看,四家主要厂商ASR识别率均达到94%以上,小度音箱识别率98%、天猫精灵为97%、小米小爱为96%、腾讯音箱为94%。
- 从有屏音箱维度看,四家主要厂商ASR识别率均达到96%以上,腾讯叮当、小度在家1S分别以98.6%、98.5%微微领先其他厂商。天猫CC ASR识别率为96.90%,小米有屏ASR识别率则为97.70%。
- 以召回率为主要指标的“听懂”环节,小度系列智能音箱是唯一召回率超过90%的产品,天猫精灵、小米小爱的召回率也达到70%以上。


商业模式
- 2021年了,对话系统凉透了吗?
- C端对话产品成本巨大但盈利空间不明朗,市场竞争激烈
- 在线广告?电商推荐?会员付费?硬件输出?似乎传统的商业模式不易落地
- 长期高额的技术投入却得不到真金白银的反馈,怎么办呢?于是企业将目光投向了B端市场。
- 电信运营商、银行、政务司法、能源电力等各大传统行业都需要部署大量的人工客服,客服就是一个天然的对话场景,如果用对话技术替代掉人工坐席,不仅降低人力成本而且提升服务效率,况且传统企业面临技术更新转型,纷纷想踏上AI这趟快车,所以智能客服的前景一片春天呐。
- 工业界对话系统的核心目的:通过人机对话接口让机器为用户提供服务。
- 这里的服务可以是
- (1)问答型:解答用户一个疑问,基于FAQ、文档、表格、KG等,表面上看是垂类搜索的top1匹配,实际难点重重
- 看起来是刚需,但百度做了20年,知乎做了10年,不就是这个需求吗?
- 问答是什么?就是精准满足用户query,那就可以理解成百度搜索的TOP1搜索结果,或者知乎上的回答最高赞。即做一个 缩小版、精准版、垂直版的搜索引擎 。这就可以理解为什么出道最晚的小度,反而会比天猫精灵和小爱音箱“更聪明”了?
- 垂直行业、细节化的用户query恰恰是对话产品问答需求中的高频问题,而通用搜索对TOP1的准确率要求非常高,面对这种冷门、细节化的query,模型回答不了,可对话产品中几乎注定了是一问一答,如果没有高精准的找到那个TOP1的回答,那只能跟用户说“对不起,我好像不明白”。然后用户就“玛德智障!给我转人工!”
- 学术界对问答对匹配问题研究的挺彻底,但SOTA模型放在业务数据中翻车屡见不鲜,脱离了业务的模型不算好模型。问答对的质量决定了模型效果的上限,更何况随着数据的增加,问题之间的边界模糊和交叉现象会进一步增加匹配的难度。
- 改进:在搜索范式之外,增加针对问答场景设计的辅助模块,来缓解无法精准回答的尴尬局面,如在召回、精排和后处理阶段增加复杂的处理逻辑。但是既要做到垂直而精准,还要试图通用化,用一套模型/系统实现跨场景跨行业的大规模落地变现,现有技术范式几乎不可能。
- 学术界的问答系统的研究重点普遍聚焦在开放域问答和阅读理解问题上,所谓迁移学习、domain adaption、预训练、小样本学习等技术,还不足以经受的住现实的考验,撑不起一个通用和垂直兼备的问答引擎,依然免不了要一个行业一个行业的做,一份数据一份数据的标。用一个模型去精准的覆盖多个场景和行业是非常不现实
- 技术硬伤是打开百亿规模市场的最大障碍。更不必说,这类需求中还存在query描述冗长/超短、FAQ库不完备、甚至ASR解析噪声等问题。
- (2)任务型:帮用户办理一件事
- 问答本质上是一个文本相关性问题,抽象为搜索、匹配问题,而任务型要做query结构化,即意图识别、实体槽位填充,将文本转成系统查询API。
- ①意图识别:智能音箱这种C端对话产品因为是面向所有用户,开放域,难以预料。高频问题可以逐个处理,而长尾问题,就不好办了。不仅难以采集到充分的数据进行标注,甚至难以穷举并定义这些意图,甚至权重还不同,还有论文没提到的,如何在开放域下识别一句话“没有意图”(比如一只猫爬过用户键盘并按下了ENTER)
- ②槽位填充:学术界已经研究烂的技术,而工业界还没做好,为什么?实际业务中的实体不只是机构名/人名/地名这么简单和理想,而是些和业务紧密联系的专有名词,往往是某一家公司所独有的词汇。如“30元每月30G”,没有标注数据,槽位值还会不断变化。所以,还是规则为主,模型为辅
- ③对话管理:工业界的对话管理的第一要义是绝对可控性,所以技术选型上都是pipeline系统,而非端到端系统(尽管学术界2015年就有端到端任务式)。工业界主流做法是有限状态机,优点是可控,缺点是人为提前设置,受限。即使对话流程配置的很精细,也无法应对可能的突发和未知状况。如对话偏离设计时如果回到主流程?一个意图还未结束就开始另一个意图
- 问答本质上是一个文本相关性问题,抽象为搜索、匹配问题,而任务型要做query结构化,即意图识别、实体槽位填充,将文本转成系统查询API。
- (3)闲聊型:单纯的聊天(情感服务) —— 微软小冰的结局是对闲聊需求的证伪,抖音、游戏、陌陌足够
- 闲聊的商业化之所以失败,是因为闲聊技术不够成熟?只要预训练模型足够大,等打败了Google的Meena,Facebook的Blender,微软的DialoGPT,百度的PLATO,我就能像人一样逼真幽默,会聊天了
- 满足情感和娱乐化需求,创造大规模商业价值,那你的对手将会是整个文娱产业。游戏、短视频、网剧、音乐,甚至陌生人社交APP,一个终于做到像人的产品能干掉哪个呢?
- (1)问答型:解答用户一个疑问,基于FAQ、文档、表格、KG等,表面上看是垂类搜索的top1匹配,实际难点重重
- 很多产品都在吹“我们的产品用了A学习,B技术,能做到C效果”,可是,它真的给产品的用户体验带来提升了吗?提升了多少呢?对话的痛点问题又解决了多少
- B端业务订单难啃,难以大规模变现,学术界对话研究热点又似乎跟工业界痛点不合节拍,外界一片看衰。
- 【2021-3-25】对话的囧境:对话的变现能力主要看能不能产品化。
- 产品化是指把能力打包成解决方案,首先要有需求,其次要有量,把一份东西卖给多个人,边际成本递减。
-
ToB不好做
。国内16年开始涌现大批做NLP智能客服的公司,但到现在没有几个能出头的,我认为主要原因就是因为技术发展的限制,无法把FAQ技术产品化,导致换一个客户(换一个封闭域)之后都要从新训模型适配,而模型肯定是不够的,还要针对性的解各种case,这样人力成本就上去了,报价高的话只有大企业买得起,而CEO不一定有大企业的人脉,报价低只能自己倒贴钱吃融资,陷入负循环。
-
ToC似乎是更好的选择
,现在看来的确也是。ToC起码可以做到一份东西卖多份,但切对需求这个点同样重要。
- 国内最早最有名的莫过于小冰,但我个人感觉纯闲聊还是个伪需求,闲聊主要是情感上的交互,除了生理需要外,情感表达是需要信任和反馈的,如果明知道对方是机器,大部分成年人都不会进行深层交流,同时技术也不允许。
- 目前比较成功的语音助理,一方面可以给用户提供信息,比如天气预报、时间,另一方面替用户完成任务,比如打电话、定闹钟、开关灯。国外做得好的有手机助手Google Assitant、Siri,以及亚马逊的智能音箱Echo。国内则有手机微软小娜、小米小爱、百度小度、天猫精灵。手机上的智能助理我有些存疑,但智能音箱我已经把自己说服了。由于巨头前两年的补贴大战,音箱的普及一直在增长,而从使用感受来看,一旦习惯了“命令别人”,就真的很难改掉。比如我现在每天都需要某精灵给我放歌、定闹钟、预报天气,甚至还买了智能插座懒得自己关灯。另外随着国家政策支持(重点发展智慧家庭产品),一些新楼盘的精装交付都会带有智能家居,再加上自动驾驶的发展,大家会越来越习惯AI助理的存在。
-
ToB不好做
- 从大趋势来看,我们已经走过了PC时代、互联网时代、移动互联网时代,接下来自然而然地便是IoT,基础设施的发展会产生更多的软件应用,对话作为人机交互的接口也会有用武之地。
- 产品化是指把能力打包成解决方案,首先要有需求,其次要有量,把一份东西卖给多个人,边际成本递减。
智能客服
详见站内专题:智能客服
智能外呼
- 【2022-06-10】单日流调1500人次 AI“流调员”上岗: 博兴街道为有效加强社区疫情防控工作力量,联合中国电信北京亦庄分公司推出的智能外呼疫情防控解决方案;
- 工作人员打开呼叫中心管理后台,创建任务,导入需要核查信息的居民名单以及“是否去过中高风险区、身体状况是否良好”等配置好的流程话术后,“新员工”AI外呼助手便开始工作了。流调回访、核酸检测通知、疫苗接种通知、购药回访……
- 拨通电话后,AI外呼助手 一 边精准流畅地询问、应答,一边将语音通话内容转化为文字,并将回访结果统一汇总至电子表格,方便工作人员进一步核查处置。对于未接通电话,AI外呼助手会在间隔时间后重新外呼,提升接通率。
- “请问您近期是否到访过XX风险点位”
- “请问您的居住地是否在经开区”
- “您是否存在咳嗽及发热等症状”
- “您最近的一次核酸检测日期是什么时候”……
- 自5月20日使用智能外呼以来,博兴街道共完成了对1785名居民的语音通知,应答率 79.8%。“ 正常时期每天排查50人次,有突发疫情时每日可排查500人次,高峰时期24小时随时待命,每日可排查经开区周边1500人次,基本实现了代替工作人员手动呼叫。节省了人力,跑出了防疫外呼‘加速度’。”博兴街道相关工作人员说,“智能外呼服务基于AI智能语音技术协助社区防疫工作者宣教通知、提醒、回访,解决了我们的外呼难题。”
- 据了解,当前智能外呼系统已全面应用于博兴街道,荣华街道也正在调试过程中。除适用于疫情流调回访、核酸检测通知、疫苗接种通知、购药回访等场景,该系统还可以将流调名单按照街道实际需求批量导入,实现一次导入自动流调,一键外呼批量拨打。科技助力属地疫情防控工作,极大提高了街道回访效率。
- 居民在收到AI外呼助手电话时,首先会收到一条标有“【北京社区(村)防控】您好!社区(村)防控工作人员向您致电,请您放心接听,您近期的行程可能存在涉疫风险,非常感谢您的配合”内容的短信提醒,稍后便会接到“(010)57410515”来电。请及时接听。
- 【2021-5-17】智能外呼机器人,知乎, 行业现状,智能获客机器人
做智能外呼机器人的企业现在已经挺多了,比如各个答案中提到的各家的产品。它的市场认可度也比较高,大家都知道它能用于通知、回访、问卷调查、营销等业务场景。外呼机器人的价值很好衡量,用了外呼机器人后,能给企业赚多少钱,或者能给企业省多少钱,简单地算算收益和成本差异就知道值不值得用了。
总的来说,构建智能外呼机器人的所有产品都是在成本和效果两个坐标上找平衡点。在现有技术水平下,机器人如果功能简单是可以通过机器人平台自主构建的,但如果要求机器人更加智能(比如精准理解用户说的话并提供对应答复),就需要做深度定制。
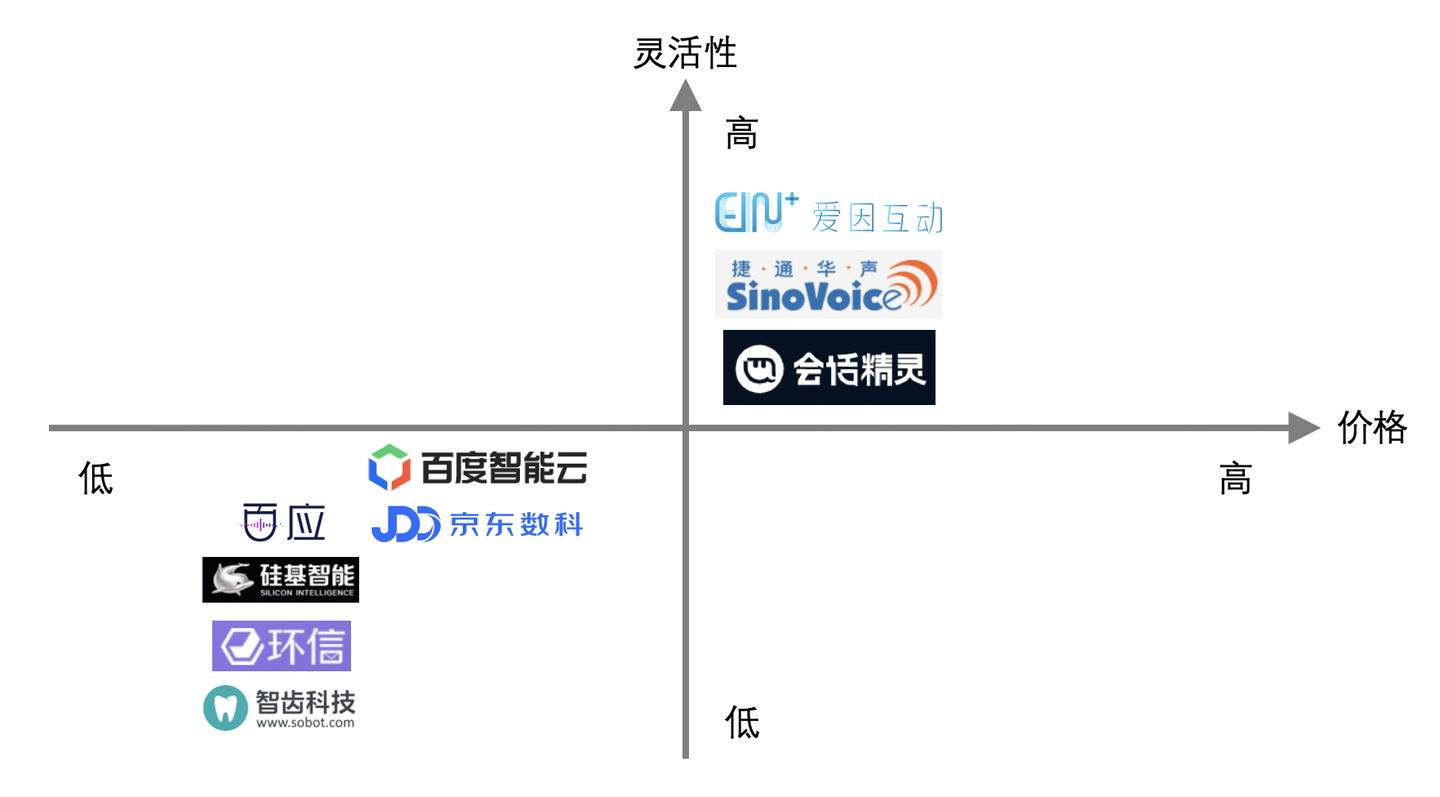
有些产品走的是低价和平台策略,比如百应、硅基、环信、智齿、百度智能云、京东数科,你只要交点钱就可以用他们的平台自己去配置外呼机器人,平台是不怎么负责帮你优化外呼机器人效果的。这样配置出来的机器人,基本只能做简单的通知,不允许用户与机器人有复杂的自主交互。这种产品适用于构建通知类外呼机器人,比如现在很多快递公司都使用机器人打电话通知取快递。
还有另一类外呼产品主打的是机器人的效果,也即平台提供深度定制服务以构建更加智能的外呼机器人。这类产品有:爱因互动、捷通华声、思必驰。这类产品适合业务场景比较复杂,或者(潜在)客户价值较高时的情况。定制开发的机器人能更精准地理解用户说的话,比如对营销产品的意向度、情感倾向,用户画像如性别、年龄、教育程度等。
说说爱因互动做外呼机器人的原因和优势。从算法技术框架上看,智能外呼机器人和文本对话机器人(聊天机器人)差异不大,只是在文本处理逻辑的基础上增加了语音转换的流程:语音转文字(ASR)和文字转语音(TTS),即下图中的红色部分。
相比于大家对文本机器人不切实际的期待(“我们没历史数据,机器人不是会自主学习吗干嘛还要数据训练”,“这两句话虽然没有一个词相同,但它们明明是一个意思机器人怎么识别不了”,“为什么机器人不能跟我闲聊”),外呼机器人的使用场景通常简单单一,且价值容易衡量。这使得外呼机器人中要求的文本处理技术更加简单,在较低成本的定制化后机器人就能达到很高的准确率。作为从文本机器人起家的爱因互动,我们实施过数百个业务定制的复杂文本对话机器人,从中积累了大量快速精准定制的工具和方法论。这些积累都可以直接移植到外呼机器人的研发上。

爱因互动也把文本处理中最新的BERT技术推广到语音处理领域,我们利用自己的数据训练了外呼场景的大规模语音处理模型 audio-BERT。基于audio-BERT技术我们开发了基于语音信号的情绪识别、性别检测、年龄检测等模型。基于我们的语音处理模型和我们在文本处理的积累,我们不仅能精准识别用户意图,在对话中提供灵活打断和答疑等能力,还能为对话打上用户画像的多种标签。


爱因互动的外呼机器人主要包括三大类:
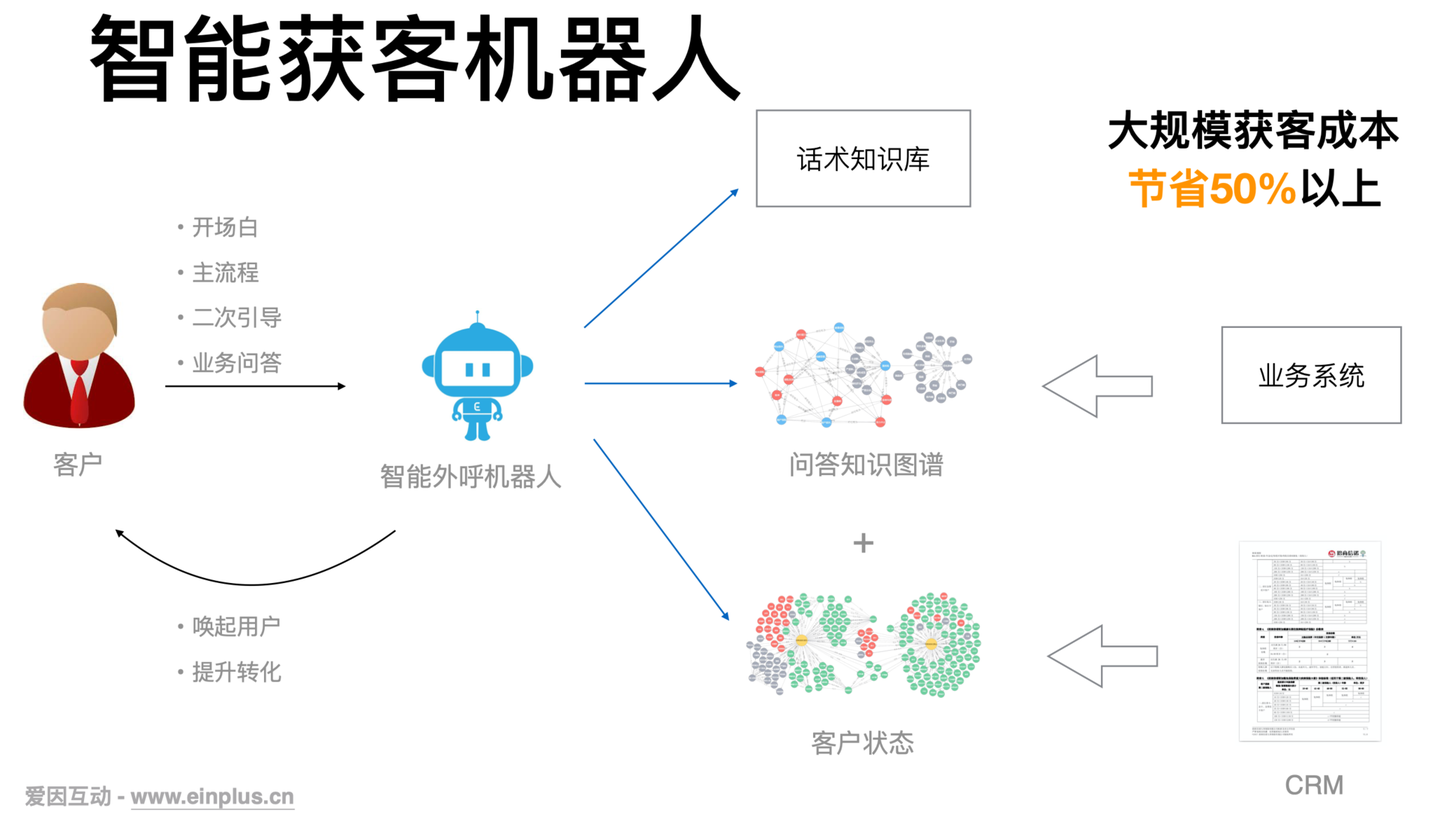

爱因互动也为诸多行业提供了详细的解决方案。比如对于教育行业,我们提供了智能获客的全场景覆盖。

评论
外呼机器人的核心要素:外呼线路,机器人质量,话术制作和外呼名单。
- 外呼线路:目前市面上只有三种线路:中继线(95打头或者固定座机号码显示)、卡线路(置办手机卡插网关,纯本地手机号显)和小号平台(不同归属地的手机+座机显示)。其中中继线的相对接通率最低,卡线路接通率最高,但易封号,且成本相对高。相比较于前两类线路,小号平台 价格适中,接通相对较好,若做本地手机卡报备,也可固定本地手机号显。
- 机器人质量:
- 看其公司工商信息是否有asr tts nlp 等核心技术的软著和行业专利证书,这点可以看出其自研能力和创新性
- 进入机器人后台操作看是否便捷,功能的细节做的如何,有无其他延伸功能,比如在线转人工,手机端推送意向客户,客户管理,人员管理,线路管理,话术管理等,要能满足自身使用需求。有持续迭更功能的系统为佳
- 之后外呼实测一下,看是否可以支持灵活打断,是否可以去非人声干扰。
- 话术制作:
- 是否支持节点的灵活跳转,多轮对话,变量设置,话术内容持续修改,话术学习,字段设置,热词管理等一些重要功能
- 有无足够优质的录音室可供选择和灵活录音,机器人的声音和说的话都是录音室赋予的,所以最终的效果和录音师有很大的关系。
- 外呼名单:名单不精准,用真人外呼也很难出意向客户,所以作为使用方要利用一些方法或者一些渠道获取相对优质的名单。所以只要顺着这个思路去找价廉质优的产品即可,不一定要最好的,要找适合自己的。
最后我补充两点:
- 语音机器人本质是SAAS软件,服务也很重要,建议咱们甲方老板们要找规模相对大,团队稳定特别是有优质的售后团队的公司合作,不要被廉价蒙蔽了双眼。另外再好的公司里也有不称职的员工,找个靠谱的对接人也很重要哦。
- 机器人是工具,工具谁来使用,如何使用也会影响到最终的产出。打出的客户一定要及时跟进,并提炼总结出适合自己的一套跟进思路和方法,不断优化。
【2022-7-21】随着科技的发展,越来越多的企业开始使用智能电销机器人。那么在智能电销机器人工作时,遇到没有人接听的电话,机器人会如何处理呢?
- 现在的智能电销机器人,遇到无人接听的电话,可以根据人为设置的次数,进行重复呼叫。比如,一天同一个号码可以呼叫三次,那么这个号码在第一次没有打通的时候,在24小时内,还会进行两次呼叫。
- 除此之外,智能电销机器人还有很多其他好处,单个电销机器人每天可以拨打1000个电话左右,线路稳定,稳定的拨打量,意向客户自然也会更多,而电销机器人的成本平均下来不到人工的1/10。
- 其次智能电销机器人无间断工作,365天无休息时间,一直保持热情态度。
- 智能电销机器人目前对接了科大讯飞的语音识别器,可以精准识别客户内容,真人语音交互,专业业务解答主动引导销售过程,客户提问、多种语言对答如流,支持客户打断。
- 最后,智能电销机器人还会根据客户的意向将客户自动分为A/B/C/D类客户,再将意向客户主动推送到你的微信上,由业务人员精准跟进。
群聊机器人
群聊功能
核心功能如下:
- 消息即时接收:所有群即时接收消息,支持文字、图片、链接等形式的内容;
- 自动回复
- 任何群员的 @消息,变成群里面的24小时客服,实时在线。
- 关键词回复:群成员一定会有很多问题,但是大部分问题都能归纳总结,我们可以设置相关关键字,用户问题触发关键词,小助手自动回复用户。
- 智能托管:高级形式
- 群新人欢迎功能,新成员加入时,机器人就会马上@那个人,给对方发送一些欢迎信息。
- 群公告:不定期发布消息公告
- 群管理:
- 支持成员签到,投票,查人品等众多娱乐游戏。
- 工单自动生成
群聊产品
群聊机器人功能
如何来高效的管理自己的群组
- (1)个性化管家:自定义小助手昵称、头像,加强品牌效应打造有温度机器;
- (2)入群欢迎语:自定义发送间隔时间,短时间内大量人员入群不刷屏;客户进群后,第一时间发出欢迎通告,让群成员感觉贴切,同时还可以吧群规定等第一时间告知客户,让群成员知道本群可以做什么,不可以做什么
- (3)消息即时接收:所有群即时接收消息,支持文字、图片、链接等形式的内容;
- (4)关键词回复:群成员一定会有很多问题,但是大部分问题都能归纳总结,我们可以设置相关关键字,用户问题触发关键词,小助手自动回复用户。这不仅解放我们的双手,也第一时间回答客户。
- (4)群数据统计:数据实时查看、导出,群成员关系链一目了然让运营者更懂社群;
- (5)无限换群:支持免费无限换群,符合社群的生长周期,让单群性价比更高;
- (6)素材管理:支持自建素材库,文字、链接、图片等,随用随取,消息发送方便;
业界案例
- 智能王二狗,群娱乐机器人
- 群娱乐:二狗的群游戏、点歌、讲笑话等功能,打造欢乐群氛围,增加成员之间互动,不冷场
- 群管理:入群欢迎、定时推送、自定义回复等功能。重复的事情交给二狗,打造智能社群,全天周到服务。
- 智能查询:智慧查询功能,不管天气、星座、快递都是一句话的事。二狗是您群里的贴心小助手。
- 群娱乐:二狗的群游戏、点歌、讲笑话等功能,打造欢乐群氛围,增加成员之间互动,不冷场
- 第一款:小U管家
- 这款微信群聊天机器人是很受欢迎的一款软件,它能够帮助广大群主智能管理微信群,让群主的工作更加便捷、高效。在微信群中引入小U管家,开通社群空间,即可实现群聊内容沉淀、课程资料发送,及10多款娱乐游戏,极大地提升了微信群管理的效率和活跃度,是社群运营的超级利器。
- 第二款:微友助手
- 微友助手是专业的微信群机器人管理专家。拥有群数据分析,新加好友自动应答,自动拉人入群,自动加群用户为好友,入群欢迎语,机器人聊天,消息定时群发,机器人自动回复,群签到,微信群文件、群成员管理等数十项强大功能!帮您持续吸粉提升微信群活跃度及运营效率,为您创造价值。
- 第三款:微群管家
- 微信群管机器人将您的微信号,变成24小时在线客服机器人功能是微信机器人,群内欢迎新人,自定义回复,自动踢人,群邀请统计,定时群发等。还有上百种应用活跃群:签到,抽签,求财神,查人品,投票,群结婚,天气预报,群拍卖,点歌,股票查询,周公解梦,成语接龙,历史上的今天,一站到底,猜图游戏,猜谜,考驾照,星座配对,看美女等等。


聊天机器人 API
目前网络上有许多非常好的智能聊天机器人,这里找了6个目前使用很广泛的:
- 海知智能 功能很强大,不仅仅用于聊天。需申请 key,免费
- 思知对话机器人 注册很简单,调用也很简单,而且完全免费
- 图灵机器人 需要注册账号,可以申请 5 个机器人,未认证账户每个机器人只能回 3 条/天,认证账户每个机器人能用 100 条/天
- 青云客智能机器人 无须申请,无数量限制,但有点智障,分手神器,慎用
- 腾讯闲聊 需要注册和申请,还需要加密处理
- 天行机器人 白嫖用户绑定微信后有 10000 次永久额度,之后 1 元 10000 次
微信
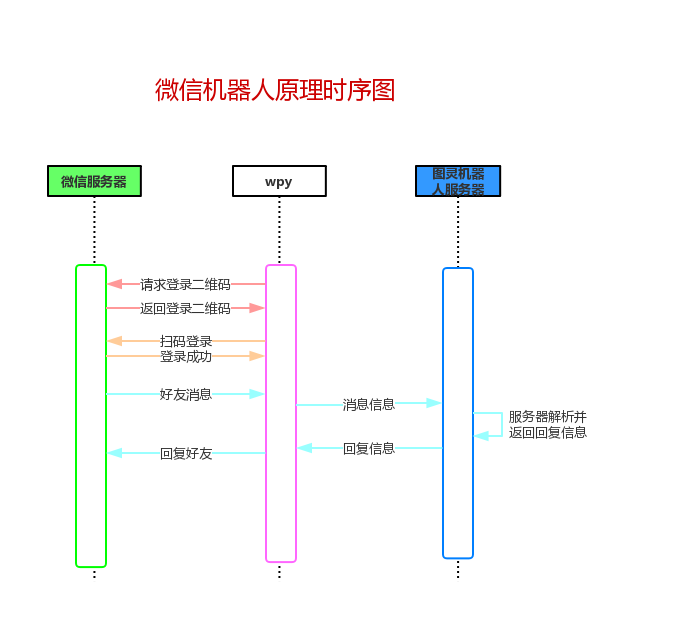
微信机器人开源库调研,GitHub 找到以下 3 个开源作品:
- itchat
- itchat 是一个开源的微信个人号接口,使用
python调用微信,使用不到 30 行的代码,你就可以完成一个能够处理所有信息的微信机器人
- itchat 是一个开源的微信个人号接口,使用
- wechaty
- wechaty 是适用于微信个人号的 Bot SDK ,可以使用 6 行
js创建一个机器人,具有包括 linux,Windows,MacOS 和 Docker 在内的跨平台支持,基于 Node.js
- wechaty 是适用于微信个人号的 Bot SDK ,可以使用 6 行
- vbot
- vbot 是基于微信 web 版的接口,使用 http 协议 以及轮询方式实现, 亮点在于通过匿名函数,能够实现多种有趣的玩法,通过 API,更方便的打造属于自己的网页版微信,基于
PHP
- vbot 是基于微信 web 版的接口,使用 http 协议 以及轮询方式实现, 亮点在于通过匿名函数,能够实现多种有趣的玩法,通过 API,更方便的打造属于自己的网页版微信,基于
python关于开发微信的库主要有 itchat 和 wxpy
- 而wxpy底层是调用的itchat,所以如果你只是要使用的话建议使用wxpy库,它比其他的库都要优雅,更面向对象,而且深度整合了图灵机器人和小i机器人;
- 而itchat扩展性更好,如果你想自己开发一个自己的微信库那建议选itchat。
- wxpy和itchat都是模拟网页版微信来操作的
wxpy: 用 Python 玩微信 模块特色
- 全面对象化接口,调用更优雅
- 默认多线程响应消息,回复更快
- 包含 聊天机器人、共同好友 等 实用组件
- 只需两行代码,在其他项目中用微信接收警告,愉快的探索和调试,无需涂涂改改
- 可混合使用 itchat 的原接口
当然,还覆盖了各类常见基本功能:
- 发送文本、图片、视频、文件
- 通过关键词或用户属性搜索 好友、群聊、群成员等
- 获取好友/群成员的昵称、备注、性别、地区等信息
- 加好友,建群,邀请入群,移出群
代码:
# 安装
# pip install -U wxpy
from wxpy import *
# 初始化机器人,扫码登陆
bot = Bot()
# 搜索名称含有 "游否" 的男性深圳好友
my_friend = bot.friends().search('游否', sex=MALE, city="深圳")[0]
# 发送文本给好友
my_friend.send('Hello WeChat!')
# 发送图片
my_friend.send_image('my_picture.jpg')
# 打印来自其他好友、群聊和公众号的消息
@bot.register()
def print_others(msg):
print(msg)
# 回复 my_friend 的消息 (优先匹配后注册的函数!)
@bot.register(my_friend)
def reply_my_friend(msg):
return 'received: {} ({})'.format(msg.text, msg.type)
# 自动接受新的好友请求
@bot.register(msg_types=FRIENDS)
def auto_accept_friends(msg):
# 接受好友请求
new_friend = msg.card.accept()
# 向新的好友发送消息
new_friend.send('哈哈,我自动接受了你的好友请求')
# 进入 Python 命令行、让程序保持运行
embed()
# 或者仅仅堵塞线程
# bot.join()
企业微信
- 企业微信应用接入
- 【2022-3-3】用企微账号api发消息,只需要access_token就能发消息,这个公司企微管理员应该能看到
- 企业微信接口文档;企业微信提供了好几种发送消息的模式,主要应用支持推送文本、图片、视频、文件、图文等类型;
企业微信官方开发前必读
- 可以将消息发送至对应的用户组,这里需要注意access_token 的有效期7200s,而且接口的请求次数有限制,所以我们需要对返回的token值进行缓存,可以存储在redis或者MySQL,过期以后进行重复获取;
- 开发者需要缓存access_token,用于后续接口的调用(注意:不能频繁调用gettoken接口,否则会受到频率拦截)
# 获取微信access_token
def get_token():
# https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=ID&corpsecret=SECRET
payload_access_token = {'corpid': 'wwfcdce534bxxxxx', 'corpsecret': '-hpCA42o4cm1DzgSfS23XtEZ93ZI3VNwDgcP-xxxxxUd4X6Q'}
token_url = 'https://qyapi.weixin.qq.com/cgi-bin/gettoken'
r = requests.get(token_url, params=payload_access_token)
dict_result = (r.json())
return dict_result['access_token']
def send_message():
url = "https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token=%s" % get_token()
data = {"toparty": 1, "msgtype": "text", "agentid": xxxxx, "text": {"content": "提现成功"}, "safe": 0}
data = json.dumps(data, ensure_ascii=False)
r = requests.post(url=url, data=data.encode("utf-8").decode("latin1"))
return r.json()
if __name__ == '__main__':
send_message()
- 企业微信接入第三方应用(以服务商身份)
- 企业微信接入机器人步骤
- 企微官方文档上列的是机器人主动发消息,目前不支持类似钉钉的 @方式调起机器人
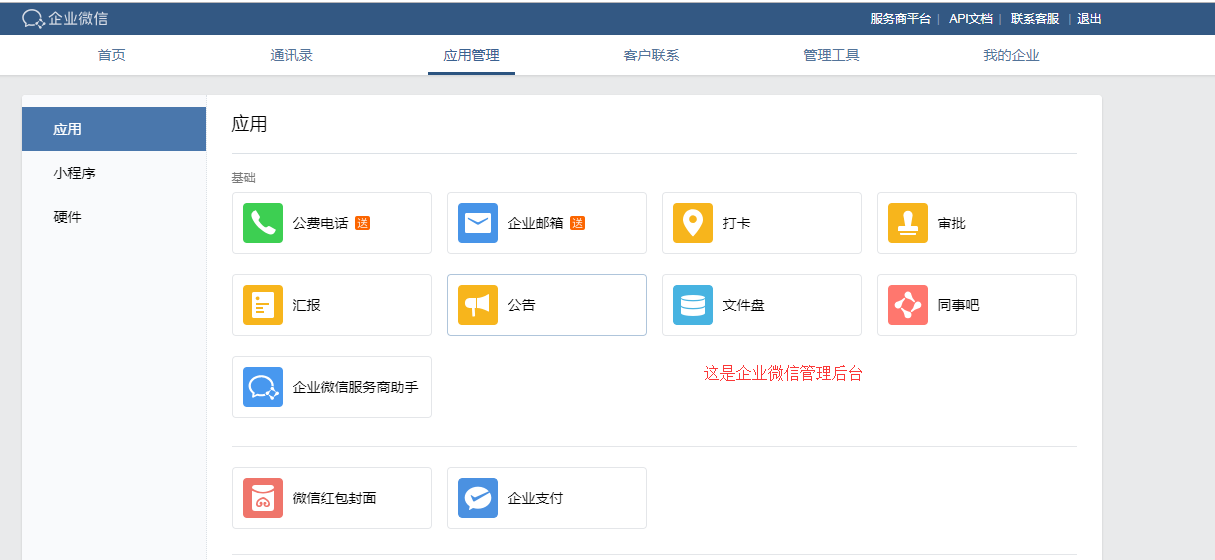
注意:
- 外部群没有机器人接口
- 企微管理后台可以开启自动回复,支持图文、网页、小程序等内容,客户建的群机器人暂无此功能;参考企业微信如何自动回复
- 关键词规则条数支持设置100条,单条回复的字数上线是4000字
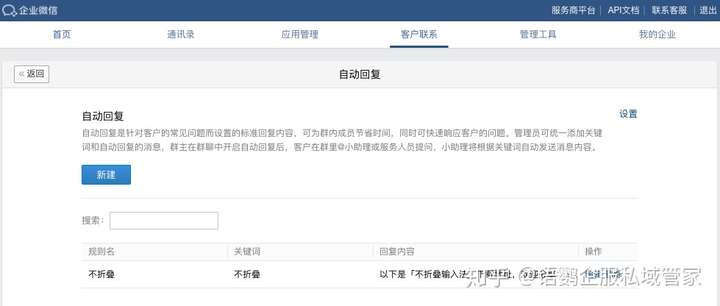
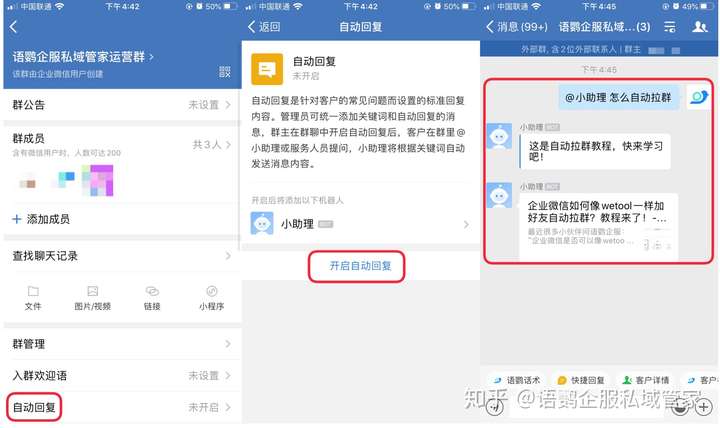
- 企业微信推出3.0.16版本后,新增了群聊关键词自动回复功能,客户在群内@群助理并触发关键词后,即可自动回复相应话术,提升运营人员的运营效率。
- 群主进入群聊,点击右上角的小人头,即可开启自动回复机器人,当群成员在群内@小助理 并触发关键词时,就能实现自动回复了。
- 企业微信机器人支持发送多种数据格式,包括:纯文本、Markdown(部分语法)、图片、新闻卡片、文件
【2021-11-15】企业微信群机器人测试,文档
- 点加号,群管理里点添加机器人按钮,就可以创建一个群机器人了。可以给机器人起个名字,上传个头像,加个简单介绍。系统会自动生成一个Webhook调用地址,关于调用方法在配置说明里有详细说明。
- 企微手机端添加企微机器人,(pc端没有添加入口),记住webhook地址url
- 调用接口发送数据(请求url),传入指定参数
- Windows系统:用VBS创建了一个脚本,然后在windows服务器中加入一个计划任务,在固定时间执行这个脚本,就可以实现一个简单的群里自动提醒功能了。
- 其它系统:shell命令执行


代码:
# --- 企微群机器人 ----
# 文档:https://work.weixin.qq.com/api/doc/90000/90136/91770?version=3.1.0.6189&platform=mac
# 当前自定义机器人支持文本(text)、markdown(markdown)、图片(image)、图文(news)四种消息类型。
# 机器人的text/markdown类型消息支持在content中使用<@userid>扩展语法来@群成员
curl 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=*****' \
-H 'Content-Type: application/json' \
-d '{
"msgtype": "text",
"mentioned_list":["wangqiwen004@ke.com","fanbingbing019@ke.com"],
"mentioned_mobile_list":["1380000000","@all"],
"text": {
"content": "贝壳小冰,你好呀~ @某人 测试"
}
}'
# 更多参数
# "mentioned_mobile_list":["13800001111","@all"]
# -------------
echo "图文格式测试"
curl "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=$key" \
-H 'Content-Type: application/json' \
-d '{
"msgtype": "news",
"news": {
"articles" : [
{
"title" : "图文格式测试:吃饭啦~",
"description" : "吃饭不积极,**有问题",
"url" : "https://bpic.588ku.com/element_origin_min_pic/19/06/28/181fceffd5e9a9782dc2d88345df09d9.jpg",
"picurl" : "http://www.biaoqingb.com/uploads/img1/20200414/96af725485d3cbe70299f59b39ee841c.jpg"
}
]
}
}'
当前自定义机器人支持:文本(text)、markdown(markdown)、图片(image)、图文(news)四种消息类型。可以定制模板卡片
- 亲测markdown格式可用、图片/文件也行,只是需要单独上传图片/文件到腾讯服务器
- 示例:https://qyapi.weixin.qq.com/cgi-bin/webhook/upload_media?key=693a91f6-7xxx-4bc4-97a0-0ec2sifa5aaa&type=file
- type取值:图片(image)、语音(voice)、视频(video),普通文件(file)
- 文件大小在5B~20M之间
- 返回:media_id,媒体文件上传后获取的唯一标识,3天内有效
- @群成员功能无效
- userid的列表,提醒群中的指定成员(@某个成员),@all表示提醒所有人,如果开发者获取不到userid,可以使用mentioned_mobile_list
【2022-3-11】企微机器人发送图片,参考:官方文档,应用案例-python生成折线图并调用企业微信群机器人发送图片消息

# -*- coding: utf-8 -*-
# s = '中文' # 注意这里的 str 是 str 类型的,而不是 unicode
# s.encode('gb2312')
import time
import pymssql
import requests
import matplotlib.pyplot as plt
import hashlib
import os
import base64
# 获取文件的Base64编码
def get_file_base64(filepath):
if not os.path.isfile(filepath):
return
with open(filepath, "rb") as f:
image = f.read()
image_base64 = str(base64.b64encode(image), encoding='utf-8') # 这里要说明编码,否则不成功
return image_base64
# 获取文件md5函数
def get_file_md5(filepath):
# 获取文件的md5
if not os.path.isfile(filepath):
return
myhash = hashlib.md5()
f = open(filepath, "rb")
while True:
b = f.read(8096)
if not b:
break
myhash.update(b)
f.close
# print(myhash.hexdigest())
return myhash.hexdigest()
# 发送消息函数, msgtype定义:text 发送字符串消息,markdown 发送图片消息,image 发送图片消息, news 发送图文消息
def postmsg(url, post_data, msgtype):
# sss = "这是一条用python发送的测试信息,请忽略!"
post_data = '{"msgtype" : "%s", "%s" : %s}' % (msgtype, msgtype, post_data)
# post_data = '{"msgtype": "markdown","markdown": {"content": "%s"}}' % sss
# print(post_data)
if url == '':
print('URL地址为空!')
else:
r = requests.post(url, data=post_data.encode())
rstr = r.json()
if r.status_code == 200 and 'error' not in rstr:
result = '发送成功'
return result
else:
return 'Error'
def querySQL():
# 数据库连接配置
config_dict = {
'user': '***',
'password': '******',
'host': '******',
'database': '******'
}
def conn():
connect = pymssql.connect(**config_dict)
if connect:
print("connect success!!!")
return connect
else:
print("连接失败!请检查配置信息!")
conn = conn()
cursor = conn.cursor()
sql = "select * from [TableName] order by [Fields]" # 编写SQL查询字符串
cursor.execute(sql)
col = cursor.description
resultdata = cursor.fetchall()
return resultdata, col
cursor.close()
conn.close()
if __name__ == '__main__':
url = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=*******-****-****-****-******" # 群机器人地址
resultdata, col = querySQL()
# print(resultdata)
# print(col) 查询到的表的列名
datelist = []
for i in range(len(resultdata)):
datelist.append(resultdata[i][0])
# print(datelist)
saleslist = []
for j in range(len(resultdata)):
saleslist.append(int(resultdata[j][1]))
# print(saleslist) # 销售数据清单
# 刻度和序列值
x_data = datelist
y_data = saleslist
# plt.plot(x_data, y_data)
# 设置画布大小
plt.figure(figsize=(16, 8))
plt.title("The Recent 7 Days Sales")
plt.plot(x_data, y_data, label='金额', linewidth=3, color='black', marker='o', markerfacecolor='r',
markersize=10) # 标记点
# 设置数字标签
for a, b in zip(x_data, y_data):
plt.text(a, b, b, ha='center', va='bottom', fontsize=14)
# 取当前时间为文件名
pic_full_name = './' + time.strftime("%Y%m%d%H%M%S", time.localtime()) + '.jpg'
plt.savefig(pic_full_name)
pic_md5 = get_file_md5(pic_full_name)
pic_base64s = get_file_base64(pic_full_name)
# print(pic_md5)
# print(pic_base64s)
# plt.show() # 显示图表
out_mk_msg = "### 最近七天市场业绩:\n"
for i in range(len(resultdata)):
out_mk_msg = out_mk_msg + r">日期:%s , 业绩:<font color = \"warning\">%d</font> , 店数:%s , 新会员:%s , 老会员:%s " % (
resultdata[i][0], resultdata[i][1], resultdata[i][2], resultdata[i][3], resultdata[i][4]) + "\n"
out_mk_msg = '{"content": "%s"}' % out_mk_msg
# print(out_mk_msg)
# 调用postmsg向接口提交数据,分别提并markdwon格式及图片格式消息
result = postmsg(url, out_mk_msg, "markdown")
# print(result)
out_pic_msg = '{"base64":"%s", "md5":"%s"}' % (pic_base64s, pic_md5)
result = postmsg(url, out_pic_msg, "image")
print(result)
现状
- 参考资料
对话机器人是一个热门话题,大家熟知的应用和产品主要有三种:
- 第一种是
虚拟助手,能对个人输入完成相应的任务或提供相应服务,典型的商业产品包括如siri、cortana、度秘等; - 第二种是
智能音箱,通过语音交互,完成用户任务,也能对智能家居设备进行控制。典型的商业产品包括如echo、天猫精灵、小爱同学等; - 第三种是
闲聊对话,在开放域与用户进行闲聊。典型的商业产品如:微软小冰。

智能助理
- 什么是智能助理
- 【2017-9-27】智能助理的应用场景选择
- 利用AI技术,打造统一的CUI(对话交互界面),一站式的整合信息&服务。
- 真正的智能交互是一种“自由”的交流与交互方式,而不仅仅是与“以自然语言为形式”的交互方式,后者很有可能会沦为自然语言形式的“命令行”。
- 人类的需求是服从正态分布的,例如人类有1万种需求,其中15种的高频需求,覆盖95.4%的用户请求量。但这些高频需求都会被“APP”形式的应用占领(例如淘宝、携程等),因此这些高频需求反而不是CUI需要去覆盖的。
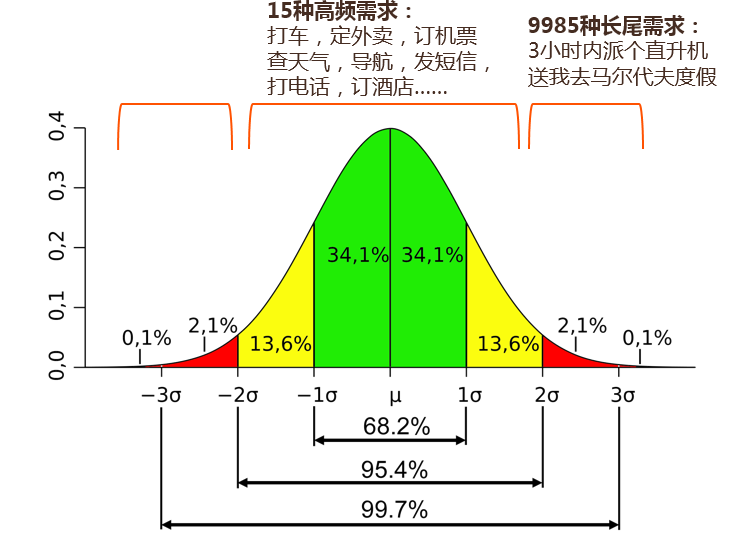
- CUI的重点?
- 人类的需求是服从正态分布的,例如,人类有1万种需求,其中15种的高频需求,覆盖95.4%的用户请求量。但这些高频需求都会被“APP”形式的应用占领(例如淘宝、携程等),因此这些高频需求反而不是CUI需要去覆盖的。
- CUI核心是去覆盖频率只有5%,但数量却有9985种的长尾需求。每个人的长尾需求都不一样,CUI若能很好的满足一些长尾需求,能够使用户和产生依赖,让自己也成为一个“入口”。这是“低频打高频”的畅想。
- 15种高频需求:打车、外卖、订机票、查天气、导航、发短信、打电话、订酒店。。。
- 9985种低频需求:3h内拍个直升机送我去马尔代夫

- 通用领域的长尾困境
- “低频打高频的畅想”实现起来困难重重,即“通用领域的长尾困境”。
- 低频打不过高频:
- 低频通常被定义为:使用频次较低,用户重复选择率较低。
- ×代驾和滴滴打车这两款软件同样是满足有出行需求的用户群,但代驾相对于出租车,属于使用频次较低的功能。当滴滴打车以“出租车”这个高频需求迅速切入市场,培养了大批用户群体后,迅速横向扩展到专车和代驾领域,并且以比单一领域更便捷的方式瓜分市场,自然将代驾产品逼上了绝境。毕竟,用户的手机不会装两款同等效用的产品。
- 创投圈/产品圈都流传着这样一个观点:“高频打低频”,高频的业务(如外卖O2O、日常出行)容易对相对低频的业务(如药品O2O、商务出行)形成竞争优势,高频的业务切入低频业务很容易,低频业务反击高频业务却很难。
- 为什么打不过低频?
- 大部分的解释来自流量模型,即高频业务天然拥有更多流量,即使在用户场景中分流一部分,也能对只做低频业务的独立应用形成流量优势,例如在外卖APP中上线一个送药上门的板块,让高频的外卖业务为低频的送药业务导流。
- 与直接做低频业务相比,从高频业务开始借助样本优势建立的效率差能够给用户带来更多效用差,这就是我认为的“高频打低频”观点的另一个真相
- 摘自:样本优势:“高频打低频”的另一个真相
- 低频打不过高频:
- 主要是由于不同场景下语义可以多种多样,有太多不明确的意图无法确认。
- 为解决此问题,试图限定谈话的领域,从宽度发展变为广度发展。这也就是垂直领域的智能助理。
- “低频打高频的畅想”实现起来困难重重,即“通用领域的长尾困境”。
- 垂直领域智能助理的困境
- (1)推理复杂度
- 机器学习(ML)是计算的逆运算,很多时候从结论反推规则,用数据训练规律。对象的复杂程度直接决定模型的复杂程度。
- 意图理解难推理

- (2)知识复杂度
- (3)数据开放度
- 很多领域,例如医疗领域的数据非常难获取。这也是项目的难题之一。
- (1)推理复杂度
- 解决方案
- 1):面向大众还是专业人士?
- 2)找到“不得不”场景
- Amazon的Echo在2016年出货500万台,2017预计卖1500万台。它的10大应用除了“设闹钟”等需求,还有“读报纸”“新增物品至购物清单”这些适应国外用户的需求。因此我们不仅仅要回答“我有什么好”还要回答“我比原来的方案有什么好”
- 很多用户购买AI是为了满足客户对AI的期望
- 3)认知问题感知化解决
- 穷举在该领域内,用户可能会说的所有query类型
- 完备性 <- 颗粒度 -> 一致性
- 使用对话模板( DIT++等,DIT++对话模板的官网 )

- 使用意图模板

- 4)场景垂直VS领域垂直
- 平时说垂直是说领域的垂直,比如房地产这种行业类的。但是很多时候需要场景的垂直,用很窄的场景就解决一个小问题,并且带来足够多的好处。
- “场景小才能压强大”
- AI是解决简单重复的脑力劳动。在智能助理的产品下,简单重复的脑力劳动就是指“明确目标、有限输入、对话可迅速收敛的任务指令”。
- 平时说垂直是说领域的垂直,比如房地产这种行业类的。但是很多时候需要场景的垂直,用很窄的场景就解决一个小问题,并且带来足够多的好处。
- 5)人机协作系统

- 与其打造高智能的机器系统,不如打造人工和机器一起协作的系统。用人工来保证机器的稳定性。任何一个智能助理的大概的基础架构如上图。当用户输入一句话后,先做NLP部分,再做对话管理部分(决策部分),最后再做业务处理。这三个模块,全部都需要机器去运算,那我们就可以给每个模块加上后台审核人员,对数据做一个标注。这样就能达到数据沉淀的目的。
- 标注数据对AI来说非常重要(很多公司都花了大量的时间和费用去买数据、标注数据),“人机协作”在早期既能保证系统稳定,又能标注大量实时有效的数据,是非常好的一种方式。
- 1):面向大众还是专业人士?
- 技术需要产品化
- AI技术还不够,需要工程化、产品化;
- 行业需要科学家,也需要好的产品经理,好的全栈工程师。
- AI产品的架构比普通的互联网产品多了一个维度——“时间”。
- 这种产品架构,可以生存到未来,并在未来逐步进化,一步步向智能逼近。
- 其他业务实践分享
- 金融科技-智能投顾与AI金融风控-谢成,类似文章:灵智优诺CTO 许可的如何为智能投顾打造对话系统?
- 金融科技的生态是三个相互牵制的部分:公司/银行——监管——资本
- 金融科技发展:
- 20世纪70年代 业务电子化
- 20世纪80年代 前台电子化(ATM机等)
- 20世纪90年代 金融业务互联网化(实现了高效连接)
- 21世纪 金融科技
- 中国金融科技发展
- IT系统 —— 支付 —— 信贷 —— 大金融 —— 生活
- 智能投顾(Robo-advisor):个性投资、私人订制、组合投资、分散风险、智能投顾、自动调节
- 金融建模的业务流程
- (1)收集数据源(信用数据以及非标准数据)
- (2)融和数据加工
- (3)构建模型
- 车载语音助手的实战干货-宏卫
- 做产品,不做AI产品。因为小公司在算法等等技术上很难超过BAT等大公司,所以选择和构成产品每个部分最好的业务技术公司合作,再加上我们对产品的深挖,来做我们的产品
- 车载场景下没有办法直接做to C的软件,因此选择了to B的商业模式。
- 为了启动顺利,做了大量的数据埋点,收集到了颗粒化的数据,甚至是用户每一个问句都做了加密后的信息收集。
- 和大量的内容企业合作,比如QQ音乐、喜马拉雅等等。
- 金融科技-智能投顾与AI金融风控-谢成,类似文章:灵智优诺CTO 许可的如何为智能投顾打造对话系统?



移动端(离线)对话系统
- 【2021-5-8】移动设备不同于服务器,资源受限,离线NLU&DM成为难点
- 腾讯云小微智能助手,车机端无网络或弱网场景下,服务器端功能受限,内存受限以及硬件性能差时,如何提供语义理解与对话管理能力。
- 意图识别模型压缩以及各模块内存优化方案;
- 领域意图识别模型(CNN + Attention -> Albert -> 知识蒸馏模型);
- 离线分布式训练 pipeline 搭建
- 基础 NLP算法,如分词、多模匹配, 分词算法优化(BloomFilter + FMM -> RNN)。
- 领域意图识别(模型分类 + 模板匹配)、实体抽取、槽位填充等语义理解能力;
- 模板匹配引擎支持正则、复杂、黑名单、追问、询参、多意图等各类模板。用于云小微的 NLU 和 KBQA 等任务,线上总模板数量 200w+,服务平均响应耗时 10.6 ms,模板流水处理耗时秒级(模板动态更新可在数秒内生效),在线上有效召回的流量中模板匹配占比 65%+。
- 结果排序,多轮等对话管理能力,如追问、澄清、确认
云小微离线语义全部数据内存占用 < 100M,全领域意图识别准确率86%+,离线优先领域意图准确率90%+,支持单工/双工(单向/双向,主动/被动)两种对话模式、单轮/多轮两种对话状态。接入 50+款不同车机端使用。
语义理解单工模式准确率 95%+,召回率 96%+;双工模式 误识率< 4%,拒识率< 7%。核心技能 F1-score:电台/小说 98%+,车控/导航 95%+。对话能力已输出到家居、出行、教育、文旅、客服等场景。
对话任务分类
【2022-5-9】两万字聊对话系统
按功能划分
整体框架 image
(1)对话机器人按照功能可以分为3-4类:
- 第一类
任务型对话,主要解决如订机票、订酒店等问题。- 用户希望完成特定任务,机器人通过语义执行后台已对接能力,帮用户完成指定任务
- 涉及的技术包括:语义理解、意图识别、状态追踪、对话决策等;
- 第二类
知识型(问答型)对话- 用户希望得到某个问题的答案,机器人回复来自于特定知识库,以特定的回复回答用户
- 在寿险客服的场景里,用户可能会问“你这个保险要交多少钱?”这类问题。
- 涉及的技术包括:文本表示、语义匹配、知识图谱等;
- 问答型聊天机器人需要解决用户对于事实型(Factoid)问答(如 what、which、who、where 和 when)问题的回复,以及非事实型问答(如 how 和 why)的回复
- 第三类
闲聊型对话- 用户可能只想找人聊聊天,对话不涉及到知识或业务,比如说“今天天气真好”。
- 用户没有明确目的,机器人回复也没有标准答案,以趣味性的回复回答用户
- 涉及的技术包括:文本生成模型、文本检索、排序技术等;
- 第四类
推荐式对话,新兴领域- 大多数推荐系统都是以静态的方式工作,于是有了对话推荐系统(Conversational Recommender Systems,CRSs)的出现,打破了传统静态的工作方式,动态地和用户进行交互,获得用户的实时反馈,进而向用户做出心仪的推荐。图

总结:

【2021-8-4】多轮对话体系定义问题的回答——
- 基本定义:什么是多轮对话? (封闭域)多轮对话是一种人机对话中获取必要信息以明确用户指令的方式。多轮对话与一件事情的处理相对应。
- 补充说明1:所谓『必要信息』一定要通过与用户的对话获取吗? 不一定,即便是人与人之间的交流,对话本身所包含的信息也只占总传递信息量的小部分,更多信息来源于说话人的身份、当前的时间/地点等一系列场景信息。所以多轮对话的信息获取方式,也不应当只局限于用户所说的话。
-
补充说明2:多轮对话一定在形式上表现为与用户的多次对话交互吗? 不一定,如果用户的话语中已经提供了充足的信息,或者其它来源的补充信息已足够将用户的初步意图转化为一条明确的用户指令,那就不会存在与用户的多次对话交互。 参考:AI产品经理需要了解的AI技术概念
- 【2021-5-31】问答、任务和闲聊几种类型对话的区别和关系 图
按模式划分
(2)按照模式可以分为检索和生成,混合型
- ① 检索式模型,用预定义的数据库和某种启发式推理来根据输入和上下文选择适当的答复。换句话说就是构建FAQ,存储问题-答案对,之后用检索的方式从该FAQ中返回句子的答案。 这些系统不会产生任何新的文本,他们只是从固定的集合中选择一个响应。
- 这种方法有明显的优点和缺点。 由于使用手工打造的存储库,基于检索的方法不会产生语法错误。 但是,它们可能无法处理没有预定义响应的场景。 出于同样的原因,这些模型不能引用上下文实体信息,如前面提到的名称。
- 知识图谱问答也算检索式;
- 检索式是对话系统主要落地形式,稳定、可控,没什么风险,NLP只需关注理解和匹配,答案内容不用管,整个流程会简单得多。
- 基本流程
- 问答对数据集的清洗
- Embedding(tfidf,word2ec,doc2vec,elmo,bert…)
- 模型训练
- 计算文本相似度
- 在问答库中选出与输入问题相似度最高的问题
- 返回相似度最高的问题所对应的答案
- 检索式对话系统框架 image
- ② 生成式模型,这种方法更难些,它不依赖于预定义的响应,从零开始生成新的响应。
- 生成式通过模型、规则手段生成回复,相对智能。这种方式优点是泛化能力强,不用提前准备所有知识点、答案,但缺点也明显,不可控,缺乏知识的生成可能会一本正经的胡说八道,如:从北京到深圳只需2公里,即便目前最强的GPT也会出现这种问题
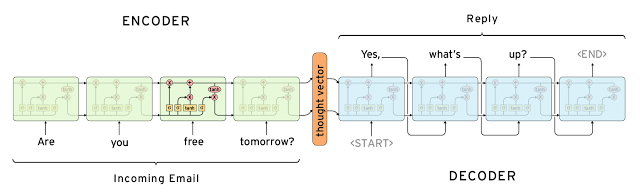
- 生成式模型通常基于机器翻译技术,但不是从一种语言翻译到另一种语言,而是从输入到输出(响应)的“翻译”。图
- 这方法有明显的优点和缺点。它可以引用输入中的实体,给人一种印象,即你正在与人交谈。 然而,这些模型很难训练,而且很可能会有语法错误(特别是在较长的句子上)不可控,并且通常需要大量的训练数据。
- ③ 混合式:检索和生成结果的结合,根据检索式查询到的零散信息,通过生成式将结果拼接成更完整、流畅的回复。
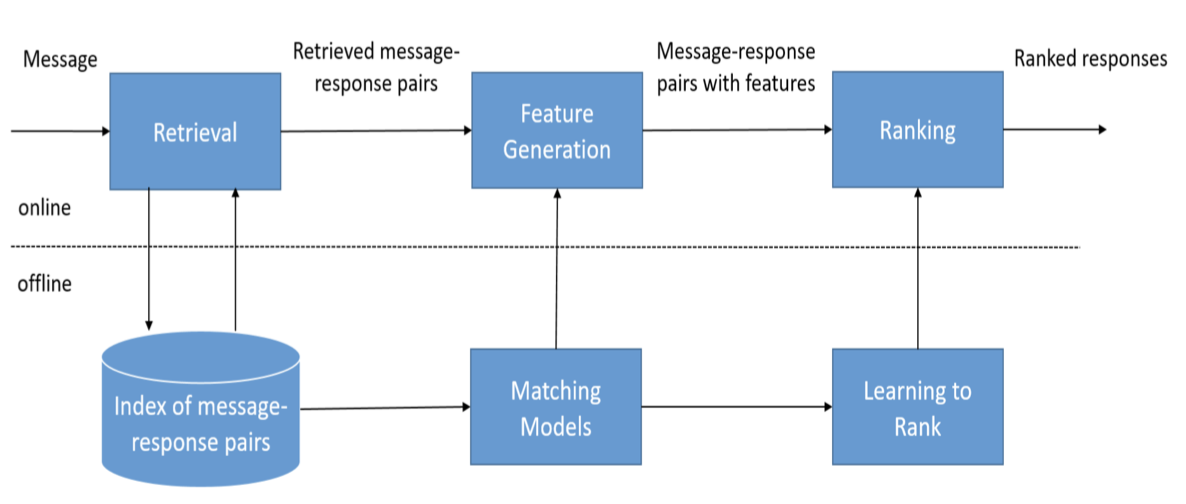
按交互次数
只是回复一次就结束对话,上下文之间不考虑相关性,那就是单轮对话,与之相反就是多轮
- 毫无疑问,多轮对话的难度要大于单轮,单轮对话遇到的问题多轮基本都会有,而多轮因为要考虑上下文,难度可就大很多了。
多轮对话的结构和思路是已经形成了一定的共识,即需要DM模块(dialog management)来管理对话内容
- 无论是对方的还是机器的,都需要维护起来,确保一致,即 DST(dialog state tracking)
- 然后根据对话的进展以及对话管理下的内容进行综合评定给出最终回复,即 DP(dialog policy),或者说是对话策略(dialog strategy)。
按领域划分
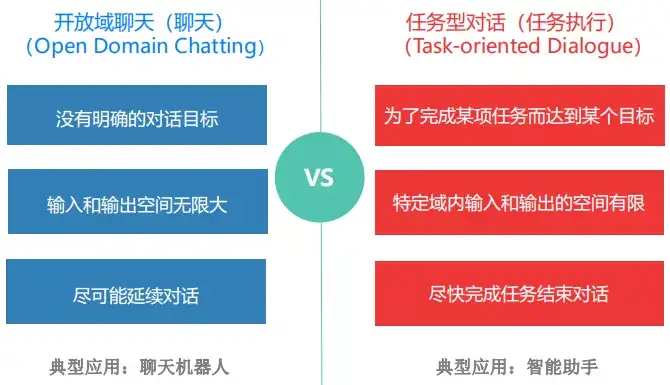
(3)按领域分类可分为:开放领域和封闭领域。
- 开放领域的chatbot更难实现,因为用户 不一定有明确的目标或意图。像Twitter和Reddit这样的社交媒体网站上的对话通常是开放领域的他们可以谈论任何方向的任何话题。 无数的话题和生成合理的反应所需要的知识规模,使得开放领域的聊天机器人实现相当困难。同时这也需要开放域的知识库作为其知识储备,加大了信息检索的难度。
- 封闭领域的chatbot比较容易实现,可能的输入和输出的空间是有限的,因为系统试图实现一个非常特定的目标。 技术支持或购物助理是封闭领域问题的例子。 这些系统不需要谈论政治,只需要尽可能有效地完成具体任务。 当然,用户仍然可以在任何他们想要的地方进行对话,但系统并不需要处理所有这些情况用户也不期望这样做。
按主导方
(4)主导方:系统主导、用户主导
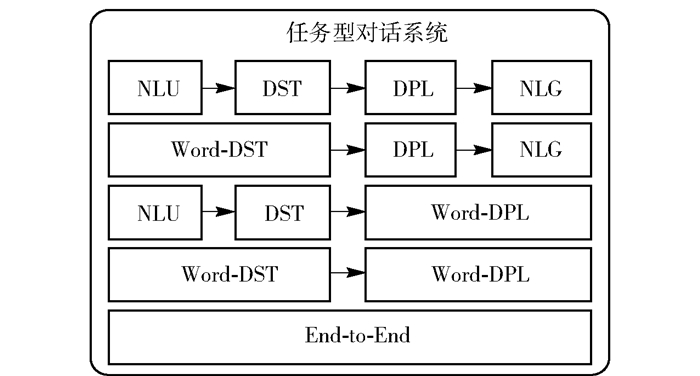
对话系统架构
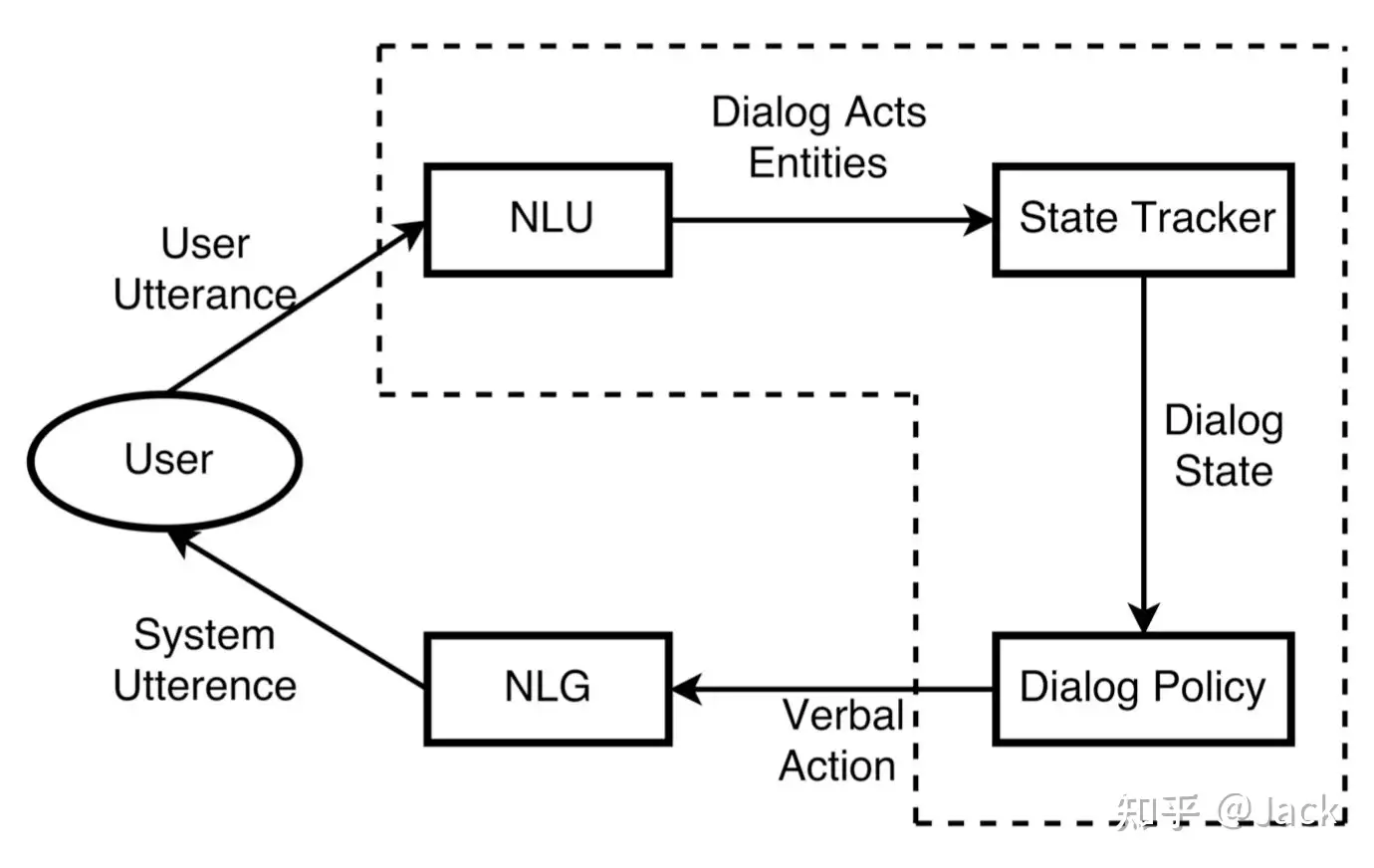
- 按照对话系统的技术架构来分,人机对话系统可以分为任务型对话系统和非任务型对话系统两大类,在实际商业应用中这2种对话方式常常结合在一起使用.
- 任务型对话通过交互的方式帮助用户完成一项或多项特定的任务,系统能够完成的任务通常是一个有限的集合,每个任务有明确的流程、输入和输出,如智能订票系统、账单查询系统等.
- 非任务型对话系统没有明确的任务列表,可以用于同用户闲聊,或者回答用户在某一个或多个领域的问题.
- 摘自:智能对话系统架构及算法
任务型架构
任务型对话的最终目标是完成指定任务,比如小度智能音箱,需要在每一轮对话都采取合适的决策,保证自己执行正确的指令(即识别出用户的正确意图) image
- 多轮对话是一种在人机对话中初步明确用户意图之后,获取必要信息以最终得到明确用户指令的方式。介绍一种对话管理的一种方式:Frame-Based Dialogue Control,预先指定了一张表格 (Frame),聊天机器人的目标就是把这张表格填满。
- 示例
| 角色 | 发言 | 意图 | 槽位 |
|---|---|---|---|
| 我 | 去北京大兴机场多少钱 | 行程花费计算 | 起始地:当前位置;目的地:北京大兴机场;使用货币:??? |
| bot | 您好,请问是使用人民币吗 | ||
| 我 | 是的 | 行程花费计算 | 【起始地:当前位置;目的地:萧山机场;使用货币:人民币】) |
| bot | 『200元』 |
相关技术:image
- 1、意图识别
- 2、填槽、对话管理
- 3、多轮对话

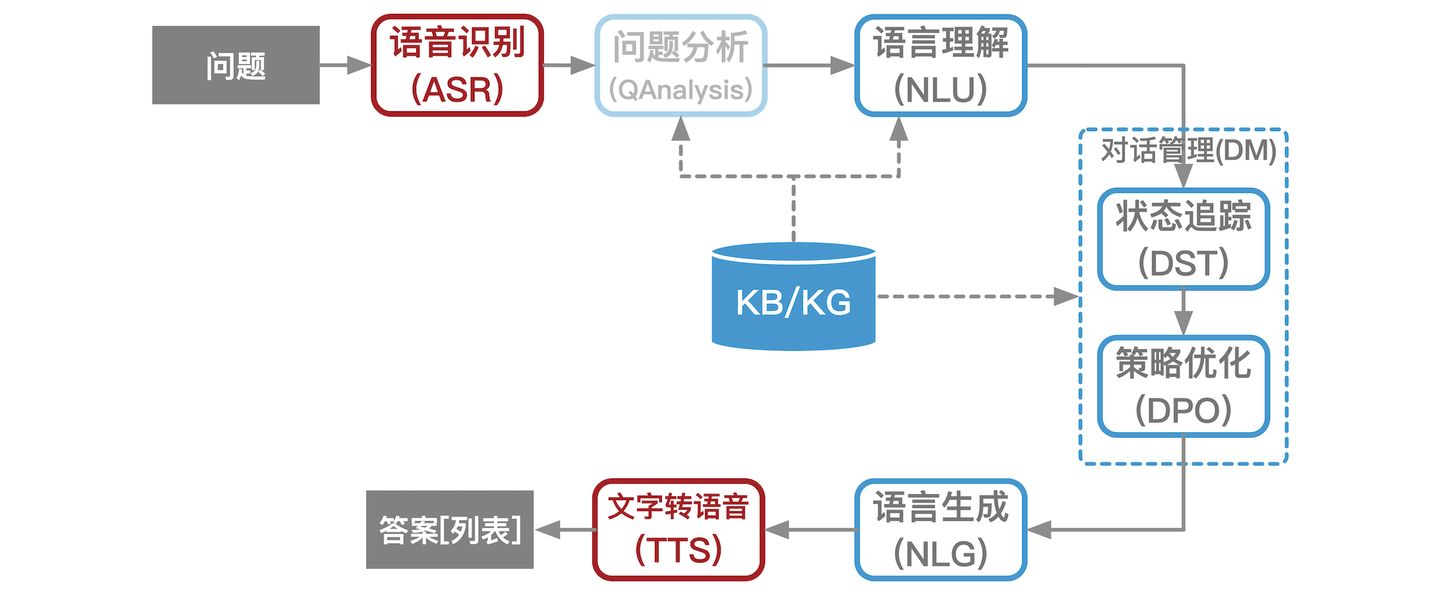
当前任务型对话系统的典型架构主要分为2类:
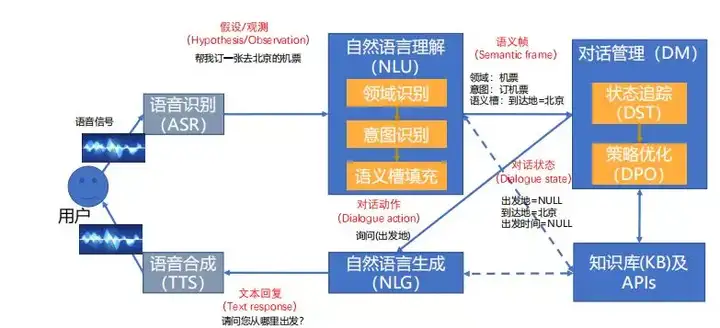
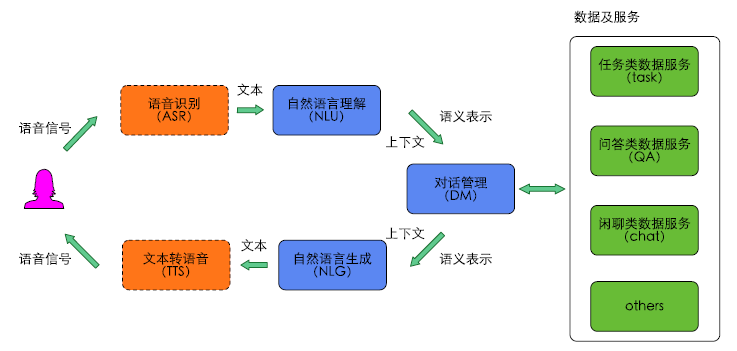
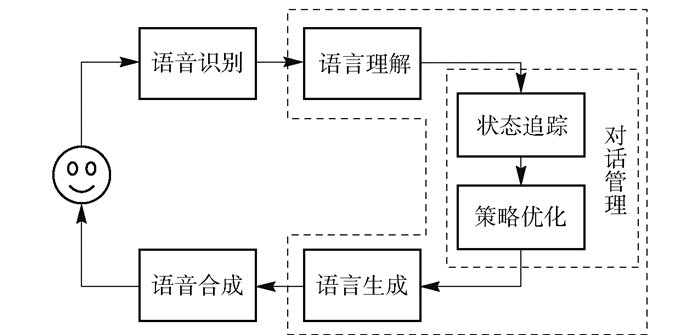
- 管道式架构,(商用典型架构),包含:
- 语音识别(ASR, automatic speech recognition)
- 自然语言理解(NLU, natural language under standing)
- 对话管理器(DM, dialogue manager)
- 语言生成(NLG, natural language generation)
- 语音合成(TTS, text to speech)等组件[5].
- 纯文本的对话不含语音识别NLU和语音合成TTS模块.
- 近几年随着深度学习的发展,一部分对话系统将对话管理器分成对话状态跟踪(DST,dialogue state tracking)及对话策略优化DPO 2个部分,使得对话管理更加依赖统计模型的方法,更加鲁棒.管道式架构中各个模块独立优化,也是目前商用系统的典型架构.
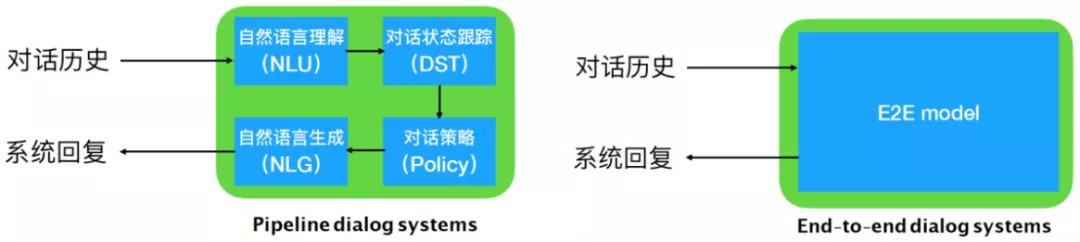
-
尽管模块化的对话系统由于每个部分独立优化,具有更强的可控性,但是端到端的对话系统可以直接利用对话日志进行训练,不需要人工设计特定的语义标签,因此更具备可扩展性,在一些复杂度中低的对话场景中能够快速训练部署使用。
- (1)管道式架构——pipeline
- (2)端到端结构——end2end
- 各个模块彼此依赖,统一优化.目前端到端的人机对话系统随着深度学习等一系列算法技术的进步而迅速发展,逐渐成为当前的研究热点.
- 由于内部独立模块的训练过程,管道式架构往往存在模块之间错误累加的问题.与管道式架构不同,端到端模型根据误差的反向传播共同调整和优化模型内部的网络结构和参数,直到模型收敛或达到预期的效果,中间所有的操作都包含在神经网络内部,不再分成多个独立模块分别处理. 有的方法虽然是端到端的方法,但还是单独设计模型的部件,不同部件解决管道方法中某个或多个模块所承担的任务.
- 端到端对话模型可分为检索式和生成式,检索式模型就是给定对话历史从预定义回复候选集合中选出最佳回复作为当前系统输出,生成式模型则是给定对话历史直接生成回复。两种方式都可以通过和用户多轮交互完成最终的对话任务。图
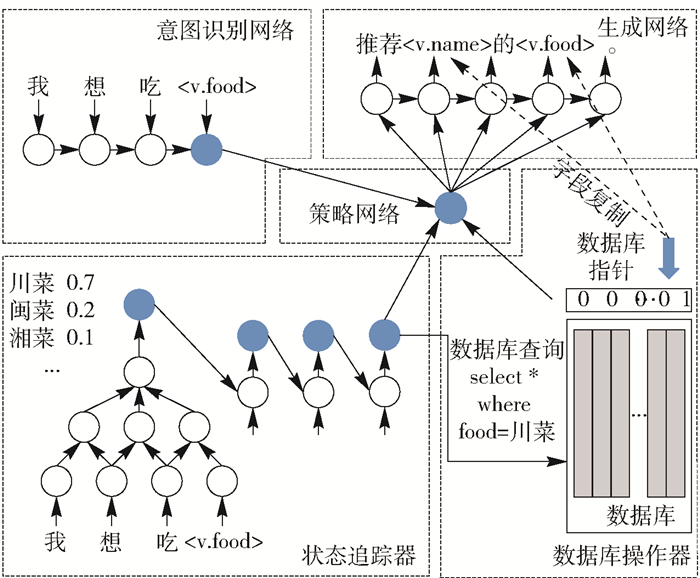
- 将人机对话的过程看作为从对话历史到系统回复的一种映射问题,通常应用编解码模型来进行端到端训练.
- 端到端对话系统是在有监督的方式下进行训练,需要大量人人对话的训练数据,理论上有很多优点,但目前从结果上看仍需要在技术上做大的提升,以确保对话的逻辑性和鲁棒性.
- 总结:任务型对话系统的架构分类,图,源自清华convlab2的论文
非任务型架构
非任务型对话系统架构演进
- 非任务型的对话系统也称为聊天机器人,在开放领域或某一个特定领域与人进行信息沟通,系统没有特定完成任务的列表和槽位列表.
- 典型的非任务型对话系统的回复,一般通过生成方法生成或基于检索的方法抽取
- (1)基于生成模型的架构
- seq2seq对话生成模型将用户这轮对话的问题作为输入,借助神经元网络将用户的问题编码为一个编码矢量,该编码矢量同对话上下文的隐含矢量结合,共同作为一个神经元网络解码器的输入,逐词生成系统回复的句子.
- 1) 编码器和解码器的常用模型包括循环神经网络(RNN, recurrent neural network)、长短时记忆循环神经网络(LSTM, long short-term memory)、门控循环神经元网络、卷积神经网络(CNN, convolutional neural networks)、注意力模型或者组合.
- 2) 对话上下文的编码.研究人员将对话上下文的语义信息有效地用矢量表示,提出了分层的架构,在编码和解码之间加了一层专门对上下文进行建模.
- 3) 对话的实义性和多样性.在当前以序列到序列为基础的对话系统中,一个具有挑战性的问题是,这些系统倾向于产生无关紧要的或不明确的、通用的、没有意义的回复,如“我不知道”、“哈哈”这样的无实际含义的回复.解决这类问题的方法之一是修改目标函数,在生成式对话中加上行列式点过程,使得生成每个词的时候既考虑质量又考虑多样性.另外一个变化是序列到序列模型同对抗神经元网络的结合,以确保生成的答案同人工回复的相似性.
- 4) 主题一致性.为了确保对话过程中内在主题的一致性,对对话主题进行建模,作为额外的输入给对话生成的解码模型.
- 5) 系统人格的一致性.业界典型的做法是将用户的个性化信息用向量来表示,嵌入序列中进行学习,从而确保不同用户的人格和属性特征的一致性.
- 6) 情感.在传统的序列到序列模型的基础上,使用静态的情感向量嵌入表示,动态的情感状态记忆网络和情感词外部记忆的机制,使得新模型可以根据用户的输入以及指定情感分类输出相应情感的回复语句.
- seq2seq对话生成模型将用户这轮对话的问题作为输入,借助神经元网络将用户的问题编码为一个编码矢量,该编码矢量同对话上下文的隐含矢量结合,共同作为一个神经元网络解码器的输入,逐词生成系统回复的句子.
- (2)基于检索的架构
- 基于检索的方法从候选回复中选择回复.检索方法的关键是消息-回复匹配,匹配算法必须克服消息和回复之间的语义鸿沟.基于学习的搜索和排序算法在基于检索的对话系统中起着至关重要的作用,基础算法在近几年取得了非常大的进步,基于检索的对话系统展现出非常客观的性能和准确率.在众多非任务型对话中,基于检索的方法输出的结构也常常作为生成对话模型的输入,或者进行平行组合使用.
- 检索式对话的基本思路就是将输入和候选输出投射到同一个语义空间中,判断两者是否相似.对于是否相似的计算而言,经典方式是基于独热编码或词袋模型,这是比较传统的表达方式.而当深度学习崛起之后,开始使用表示学习,也就是学习出向量嵌入表示,最后是基于抽象表示的匹配相似度计算.
- 近年来,有很多模型被提出,如微软的DSSM、CDSSM及相关系列模型;华为诺亚方舟实验室提出的ARC-Ⅰ和ARC-Ⅱ;斯坦福的Tree-LSTM,IBM的ABCNN,Pang等提出的MatchPyramid,Qian等提出的ESIM等.通常,深度匹配模型可以从大类上分为表示型和交互型2种表示型模型,如DSSM等,侧重对表示层的学习和构建,它会在表示层将输入转换成整体表示向量,利用深度网络进行语义表示的加强.这种模型的问题是容易发生语义偏移,上下文信息的重要性难以显式衡量.交互型模型,如ARC-Ⅱ等,这类模型在输入层就进行词语间的先匹配,并将匹配的结果作为灰度图进行后续的计算和建模,能够更精细地处理句子中的联系.它的优势是可以较好地把握语义焦点,对上下文重要性合理建模.近年来,基于检索的架构在工业界的实践和应用得到了快速的发展.
- 检索知识库的过程中,最重要的是如何找到与输入语义等价的问句,常用的相似度算法包括: 余弦相似度、编辑距离、关键词重合度、BM25等等,实际使用中是有用,但仍然不够,因为可能遇到如下问题:①字面相似的句子语义不等价②字面不相似的句子语义等价,如“什么是新冠肺炎”和“解释下新冠肺炎的定义”是语义等价,但和“什么是支气管肺炎”却不是语义等价的,采用编辑距离之类的算法是无法识别的。图
- 因而,只有基于语义理解的模型才能识别出来,这里包括两类,一是传统机器学习方法,二是深度迁移学习方法。
- 基于BERT和BIMPM的语义等价模型方案,BIMPM本身是十分经典的模型,底层是通过word2vec向量来进行语义匹配计算,这里我们将word2vec词向量全部替换为BERT的最上面若干层的输出,并将原有模型中的BI-LSTM结构,替换为Transformer,以提高其在序列性上的表现,实际测试中,该模型在Quora和SLNI数据集中达到了state-of-the-art的效果,图


NLU
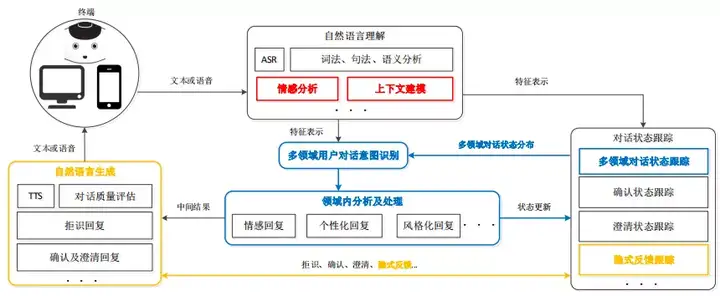
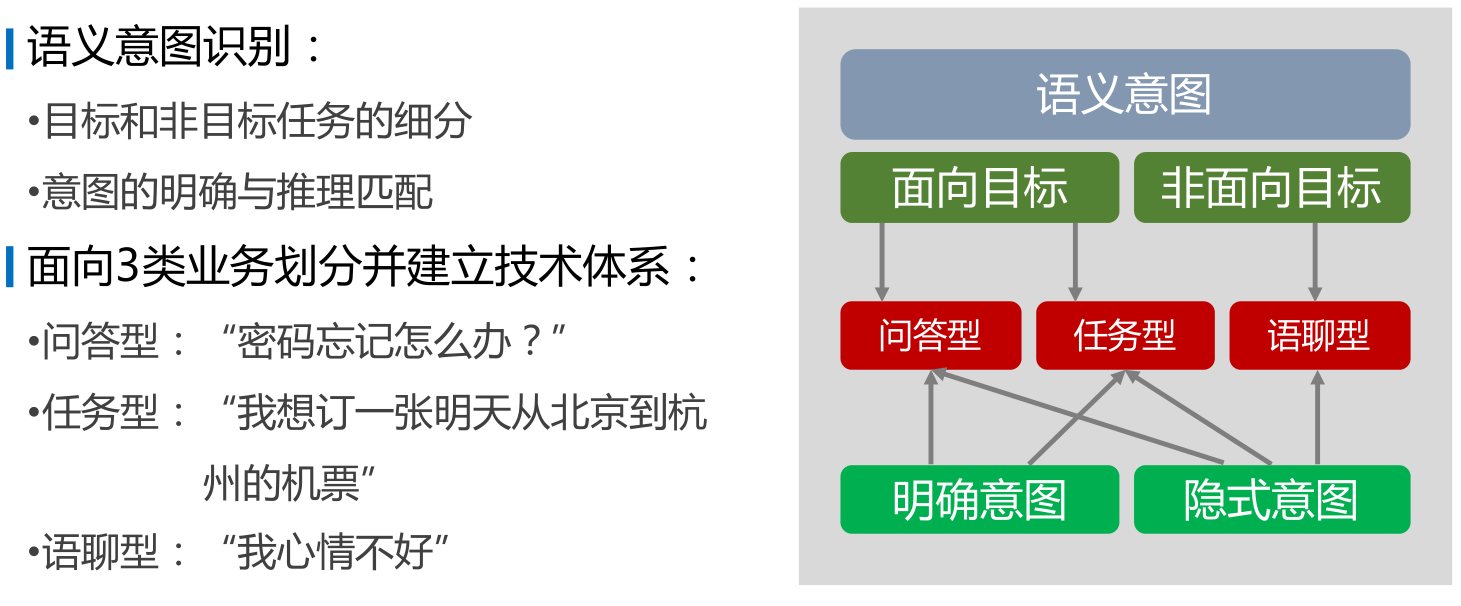
NLU即Natural Language Understanding,负责理解用户的语句输入,一般是做意图识别(intent detection)和槽位抽取(slots filling)。
- 台大陈蕴侬讲解的对话系统,语言理解的pipeline,前两者主要通过Classification实现,第三个是Sequence Labeling
- Domain Identification(分类): Requires Predefined Domain Ontology
- 如:find a good eating place for taiwanese food
- 识别为餐饮领域 2. Intent Detection(分类):Requires Predefined Schema
- 餐饮领域里的找餐馆意图:FIND_RESTAURANT 3. Slot Filling(序列标注):Requires Predefined Schema
- 槽位:rating=“good”,type=“taiwanese”
- Slot Tagging
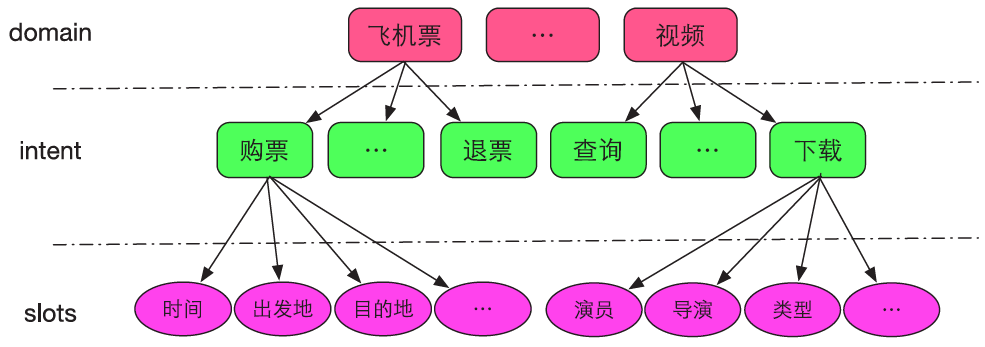
【2021-5-31】自然语言理解的语义表示主要有分布语义表示 (Distributional semantics)、框架语义表示 (Frame semantics) 和模型论语义表示 (Model-theoretic semantics) 三种方式。在智能对话交互中,自然语言理解一般采用的是 frame semantics 表示的一种变形,即采用领域(domain)、意图(intent)和属性槽(slots)来表示语义结果,如图, 摘自:阿里智能对话交互技术实践与创新
开源代码
- Rasa_NLU 英文版、Rasa_NLU_Chi 中文版
意图识别
- 意图识别通过文本分类实现,但是和文本分类有区别,这个区别造就了它更“难一些”,主要难点如下:
- 输入不规范:错别字、堆砌关键词、非标准自然语言;
- 多意图:输入的语句信息量太少造成意图不明确,且有歧义。比如输入仙剑奇侠传,那么是想获得游戏下载、电视剧、电影、音乐还是小说下载呢;
- 意图强度:输入的语句好像即属于A意图,又属于B意图,每个意图的的得分都不高;
- 时效性:用户的意图是有较强时效性的,用户在不同时间节点的相同的query可能是属于不同意图的,比如query为“战狼”,在当前时间节点可能是想在线观看战狼1或者战狼2,而如果是在战狼3开拍的时间节点搜的话,可能很大概率是想了解战狼3的一些相关新闻了。
填槽
【定义】 填槽(Slot filling)定义:
- 一般定义:填槽指的是为了让用户意图转化为用户明确的指令而补全信息的过程。
- 专业定义:从大规模的语料库中抽取给定实体(query)的被明确定义的属性(slot types)的值(slot fillers)——网络文章定义
- 设定闹钟这个行为,需要两个关键信息,一个是行为,一个是时间。这两个信息可以理解为“设闹钟”行为的前置条件,就好像事有个槽空缺在那,需要先补充完整了这个槽,完成这个条件后,触发新的副本,才能继续后续的行为。
【用途】
- ①多用于任务型对话
- 任务型对话系统的语言理解部分,通常使用语义槽来表示用户的需求,如出发地、到达地、出发时间等信息。
- ②作为意图识别的关键字
- ③作为下一步对话的提示信息
- 填槽的意义有两个:作条件分支多轮对话、作信息补全用户意图。填槽不仅是补全用户意图的方式,而且前序槽位的填写还会起到指导后续信息补全走向的作用。图

【基本概念】
- 槽:实体已明确定义的属性,打车中的,出发地点槽,目的地槽,出发时间槽中的属性分别是“出发地点”、“目的地”和“出发时间”
- 槽位:槽是由槽位构成 图
- 槽位的属性
- 接口槽与词槽
- 词槽,通过用户对话的关键词获取信息的填槽方式
- 接口槽,通过其他方式获取信息的填槽方式
- 可默认填写/不可默认填写:有些槽是不可默认填写的,不填没办法继续下去,有些即使不填,有默认值也可。
- 槽位优先级:当有多个槽位的时候,槽该采用那个信息,这时候有个优先级。
- 澄清话术:当槽不可默认填写同时又没有填写的时候,就要进行澄清
- 澄清顺序:当有多个槽需要澄清的时候,就存在先后顺序的问题,所以需要一个澄清顺序,先问什么,再问什么。
- 平级槽或依赖槽,根据槽和槽之间是否独立,后续的槽是否依赖前面槽的结果。可以将槽之间的关系分为
- 平级槽,槽与槽之间没有依赖,例如打车中的三槽
- 依赖槽,后续的槽是否依赖前面槽的结果,例如手机号码槽,不同国家手机号码格式不同(槽的属性不同),所以国家槽会影响选择哪个手机号码槽。
- 接口槽与词槽
- 准入条件:从一个开放域转入到封闭域,或者从一个封闭域转入到另一个封闭域,中间的跳转是需要逻辑判断的,而这个逻辑判断就是准入条件。
- 封闭域对话:封闭域对话是指识别用户意图后,为了明确用户目的(或者称为明确任务细节)而进行的对话
- 澄清话术:当用户的需求中缺乏一些必要条件时,需要对话系统主动发问,把必要条件全部集齐之后再去做最终的满足执行。图

- BIO的解释
- “B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头。
- “I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间位置。
- “O”表示不属于任何类型。
- 注意:
- 没明确意图前的聊天可以看做是开放域的对话,开放域对话中也能填槽。
- 参考:Chatbot中的填槽(Slot Filling)
- 全过程示例解析(参考:大话知识图谱–意图识别和槽位填充)
- 用户:订一张今天下午场次的战狼电影票
- 系统:识别出“订电影票”的意图,于是开始操作订电影票的事了
- 系统:“您好,战狼2在XX影城于下午一点半上映,YY影城将在下午两点半上映;你需要去哪个电影院呢?”
- 用户:“去YY影城”
- 系统:“您好,您可以选择电影票张数和座位号完成预定”
- 针对性的“思考”是全靠槽位填充来实现
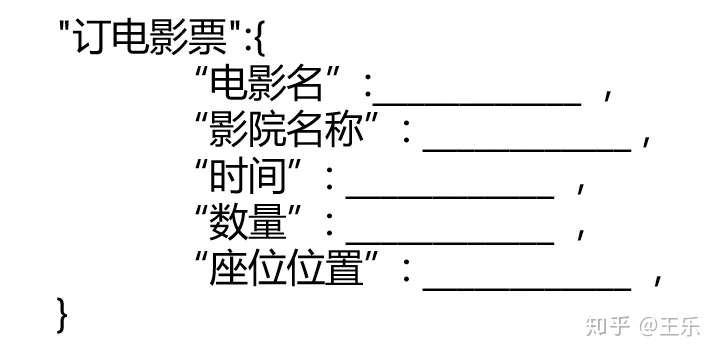
- 需要填的空包含了电影名、影院名称、时间、数量、座位位置等信息
- 系统是如何填空的呢?答案是命名实体识别和槽位预测
- 用户的输入“订一张今天下午场次的战狼电影票”,识别出电影名是“战狼”,时间是“今天下午”;没有识别到影院名称,于是张三根据用户当前的位置,将其预测为XX影院或YY影院,数量和座位位置就没办法预测。针对没办法预测的槽位,张三决定向用户发问或者提供选择来确认“您可以选择电影票张数和座位号完成预定”;对于预测到槽位值不唯一的情况,比如XX影院或YY影院,张三决定让用户自己进行二选一;对于识别到的槽位存在歧义的问题,张三决定进行“澄清”,比如战狼实体不是很明确,需要澄清是战狼1还是战狼2,张三根据现在正上映的是战狼2这一情况来进行自动澄清,但如果此时两部电影都在上映的话,张三就得向用户发问澄清了,比如问“您是想要看战狼1还是战狼2?”。
- 思考过程完全是按照语义槽来进行的,有什么槽位它就思考什么。当语义槽完全填充且消除了歧义之后,也就完成了整个自然语言理解任务,开始利用知识库回答用户问题或者完成某种操作。
- 语义槽到底是怎么来的呢?它是如何和用户进行“发问”交互的?
- 语义槽设计
- 语义槽定义升级:在语义槽的每个槽位加上相对应的“话术”,系统发现哪个槽位没填充或者有歧义就使用该槽位事先预定义好的话术去“发问”

- 实现方法
- 槽位填充包括命名实体识别和槽位预测,其实说命名实体识别不严谨
- 如在“订机票”意图下的语义槽中,应该有“出发地”和“目的地”,虽然他们都是地名,但是有区别,他们的顺序不能变,也就是不能用“地名”来统一代替,而命名实体识别的做法就是将他们都当做“地名”
- 只能称槽位填充是一个序列标注任务,但绝不能说序列标注任务就是命名实体识别,且我们在标注数据的时候也不能一样标注

- ①串行:将意图识别和槽位填充分开,依次进行
- ②并行:将意图识别和槽位填充进行联合训练模型
- 经典方法
- CRF: 条件随机场。通过设置各种特征函数来给序列打分。
- 深度方法
- ①RNN 槽填充
- ②RNN Encoder-Decoder 槽填充
- ③Bi-GRU + CRF
- ——A Joint Model of Intent Determination and Slot Filling for Spoken Language
- ④Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling (比较经典,论文是意图识别和槽填充共同训练)
- ⑤BERT Slot标注:代码
- 槽位填充包括命名实体识别和槽位预测,其实说命名实体识别不严谨

【2021-5-28】意图识别和槽填充是挂钩的吗?
- 二者区别
- 意图识别目的是识别用户对话内容的意图,本质上是一个分类任务.
- 槽位填充是将我们关心的实体识别出来,本质上是一个序列标注任务.
- 当前处理这种具有一定关系任务的两种思想:
- 一种是pipeline思想,先对意图识别,识别完意图之后再提取槽值 —— 简单,直观,普通人的思路
- 另一种是joint思想.两个任务同时做,还能做的更好 —— 大神的思路
- 尤其是在深度学习出现以后,基于joint模型的方法着实火了一把:文本的输入层和中间层保持一致,只需要在输出层加多个输出即可,这样就能共享输入和中间层的特征表示,再输出层进行魔性创新
中文数据集:CQUD
简介
意图识别/意图分类(Intent Classification)和槽位填充 (Slot Filling) 是自然语言理解 (Natural Language Understanding, NLU)领域中的两个比较重要的任务。在聊天机器人、智能语音助手等方面有着广泛的应用。
意图识别可以看作一个分类任务,就是对当前输入的句子进行分类,得到其具体意图,然后完成后续的处理。而槽位填充则是一个序列标注问题,是在得到意图之后,再对句子的每一个词进行标注,标注的格式为BIO格式,将每个元素标注为“B-X”、“I-X”或者“O”。
- “B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头
- “I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间位置
- “O”表示不属于任何类型。
比如tell me the weather report for half moon bay这句话中,它的意图类别为weather/find(查询天气),slot filling的结果为:

对话语料
【2020-9-12】百度王凡:开放域对话系统:现状和未来
- 对话语料,往往充斥着已知和未知的背景信息,使得对话成为一个”一对多“的问题,而神经网络模型解决的是一一映射,最大似然只能学到所有语料的共通点,所有背景、独特语境都可能被模型认为是噪音,最终形成大量安全回复;对话语料中潜藏着很多个人属性、生活常识、知识背景、价值观/态度、对话场景、情绪装填、意图等信息,这些潜藏的信息没有出现在语料,建模它们是十分困难的。
- 百度NLP:做有知识、可控的对话生成方案:围绕多样性对话生成、知识对话生成、自动化评价和对话流控制、大规模和超大规模隐空间对话生成模型4个模块展开。
- 对话生成问题是一个条件非常非常多的条件生成问题(conditional generation)
- 多样性对话生成:
- ① 多映射机制的端到端生成模型:假设每一句回复可能来自于一个独特的映射机制 ( Mapping mechanism ),用M1到M4表示。如果给定某种映射机制,就可确定最终的回复,消除了回复过程中的不确定性。
- ② 类似工作也有很多,不过都存在一些弊端。比如CVAE用了连续的高斯空间,对于对话多样性捕捉能力非常差;而MHAM和MARM没有对先验和后验的分布差异进行有效的建模。如一句上文可能对应4种不同的回复,且都是合理的,而训练时只出现一种,推断时就无法捕捉另外几种映射逻辑。推断和训练时对映射机制的选择是存在差异的,这会导致优化的过程乱掉。
- 创新:一时采用离散的映射机制,二是分离了先验和后验的推断。除了用NLLLoss ( negative log likelihood loss ) 外,还用了一个matching loss,这个loss的目标是为了辅助整个后验选择网络的训练,特别是Response encoder这一块。在推断时模型结构有部分差异,因为在推断时是没有Response的,这时我们就任意选择一个Map来生成回复。图
- 知识对话生成
- 通过知识引入有助于对话”去模糊”、”可控制”. 选择知识库的部分来用,所以常规做法是引入attention来进行知识的选择
- 自动化评价和对话流控制
- ①
自进化对话系统( SEEDS ):监督学习只能考虑当前一轮的回复,当不同Agent在进行交流时会发现很多问题,原因是因为在数据中没有见过这些信息。那能否考虑利用长远的反馈信息来提升对话的控制?多样化生成理论,包含两部分。一部分是Diversified Generation,根据特定知识或隐空间生成回复的过程;另一部分是Dialogue “Controller”,怎么去选择知识或者隐空间而不是仅仅依赖于Prior?我们通过强化学习来提升选择知识或者隐变量的能力。 - ②
自动化的对话评价体系:从连贯性、信息量、逻辑等角度用一系列模型去评价这些对话,使用无监督语料训练出来
- ①
- 大规模和超大规模隐空间对话生成模型
- NLP模型发展趋势
- 使用隐空间的对话模型PLATO,基于前面提到的隐空间的机制,来使得Transformer模型生成的对话丰富度要更丰富。PLATO模型总共由三个模块组成,Generation ( 利用隐变量控制生成 )、Recognition ( 隐变量识别 ) 和Prior ( 隐变量推导 )。而我们6月份提出的PLATO2的一个相对PLATO的改进则是没有使用Prior模块,因为实验发现用一个Retrieval模块来代替Prior模块效果会更好。PLATO2有两个训练阶段:一个叫Coarse-Grained Generation,即先训练一个基础版网络,没有用隐变量。之后基于这个网络我们再进一步训练,叫做Fine-Grained Generation,引入隐变量等信息。训练时用到了三个Loss
未来解决对话问题的要素可以从以下方面入手:
- 语料 & 知识, 这是训练任何模型的基础
- 记忆 & Few-shot Learning, 人类是能够在对话中不断学习的,一个好的对话系统需要具有这种能力
- 虚拟环境 & Self-Play, 当前很多语料不能提供足够背景知识的前提下,虚拟环境能很好地提供这一点
平行语料
- 联合国平行语料
- 爱数智慧提供平行语料: 智能翻译技术训练数据——平行语料
【2022-12-4】什么是平行语料?
平行语料库的定义,一直存在分歧。
- Stig Johansson(1998)认为:平行语料库是收录具有可比关系的两种语言文本的语料库。
- 不过,Mona Baker(1995)则主张:平行语料库收录的文本是A语言文本及其B语言译本。
较之于前者,后者更为学界接受。
- 目前,学界普遍认为:平行语料库是指收录某一源语语言文本及其对应的目的语文本的语料库,不同语言的文本之间构成不同层次的平行对应关系。
- 王克非(2004a)指出:平行语料库是由源语语言文本及其平行对应的译语文本构成的双语语料库。
根据语料所涉及语种的数量,平行语料库可分成双语平行语料库(bilingual parallel corpus)和多语平行语料库(multilingual parallel corpus)。
双语平行语料库由构成翻译或对应关系的两种语言文本组成多语平行语料库则收录一种语言文本和该文本的两种以上语言的译本。
按照语料平行对应的方向,平行语料库可分为单向平行语料库(unidirectional parallel corpus)、双向平行语料库(bidirectional parallel corpus)和多向平行语料库(multidirecitonal parallel corpus)。
单向平行语料库是指所收录语料均为一种语言的源语文本及其译成另一种语言的目的语文本。双向平行语料库所收录的语料由A语言文本和其B语言译本,以及B语言和其A语言译本组成。多向平行语料库收录的语料为一种语言的源语文本和译自该文本的两种或两种以上语言的目的语文本。
NLU 数据集
意图分类和槽位填充任务主要数据集Snips、ATIS和NLU-Benchmark
ATIS
数据集信息:航空旅行领域的语料,上个世纪发布的数据,是对话领域常用的数据集。
-
数据源 ATIS
- 该数据集规模很小,训练集4400+,测试集800+,槽位意图识别难度不大,目前处于被刷爆的程度,intent detection和slot filling任务的F值都已经在95+以上了,唯一可以挑战的是NLU的Acc,也称为Sentence Acc,即输入句子的意图、槽位同时正确才算该样本预测正确。目前的SOTA为Bert,具体可上paper-with-code网站搜索
- 当前的SOTA:
ATIS数据集是一个比较常规的NLU数据集,它是一个标注过的预定机票的样本。分为训练集,开发集和测试集,训练集和开发集包括4,478,500样本,测试集包括893 utterances样本。训练集包含21种意图,79种实体。
SNIPS
SNIPS数据集,该数据集是从Snips个人语音助手收集的。它包含13,784个训练样本和700个测试样本。包含7种意图,39种实体。
NLU-Benchmark
NLU-Benchmark数据集标注了场景,动作和实体。例如:
- ”schedule a call with Lisa on Monday morning“ ,标注的场景是日历calendar, 动作action是设立一个事件event,实体有2个,是事件名字和日期 [event name: a call with Lisa]和 [date: Monday morning], 意图标签是通过拼接场景和动作得到的,例如:calendar set event。
该数据集有25716个utterrances语句,涵盖了多个家庭助理任务,例如播放音乐或日历查询,聊天,以及向机器人发出的命令等。数据集拆分成10 folds, 每个fold有9960个训练样本和1076个测试样本,覆盖了64种意图和54种实体类别。
CQUD
- 无
中文聊天语料
开源中文聊天语料的搜集和系统化整理工作,8个公开闲聊常用语料和短信,白鹭时代问答等语料
- chatterbot
- 豆瓣多轮
- PTT八卦语料
- 青云语料
- 电视剧对白语料
- 贴吧论坛回帖语料
- 微博语料
- 小黄鸡语料
| 语料名称 | 语料数量 | 语料来源说明 | 语料特点 | 语料样例 | 是否已分词 |
|---|---|---|---|---|---|
| chatterbot | 560 | 开源项目 | 按类型分类,质量较高 | Q:你会开心的 A:幸福不是真正的可预测的情绪。 | 否 |
| douban(豆瓣多轮) | 352W | 来自北航和微软的paper, 开源项目 | 噪音相对较少,原本是多轮(平均7.6轮) | Q:烟台 十一 哪 好玩 A:哪 都 好玩 · · · · | 是 |
| ptt(PTT八卦语料) | 77W(v1版本42W) | 开源项目,台湾PTT论坛八卦版 | 繁体,语料较生活化,有噪音 | Q:为什么乡民总是欺负国高中生呢QQ A:如果以为选好科系就会变成比尔盖兹那不如退学吧 | 否 |
| qingyun(青云语料) | 10W | 某聊天机器人交流群 | 相对不错,生活化 | Q:看来你很爱钱 A:噢是吗?那么你也差不多了 | 否 |
| subtitle(电视剧对白语料) | 274W | 开源项目,来自爬取的电影和美剧的字幕 | 有一些噪音,对白不一定是严谨的对话,原本是多轮(平均5.3轮) | Q:京戏里头的人都是不自由的 A:他们让人拿笼子给套起来了了 | 否 |
| tieba(贴吧论坛回帖语料) | 232W | 偶然找到的 | 多轮,有噪音 | Q:前排,鲁迷们都起床了吧 A:标题说助攻,但是看了那球,真是活生生的讽刺了 | 否 |
| weibo(微博语料) | 443W | 来自华为的paper | 仍有一些噪音 | Q:北京的小纯洁们,周日见。#硬汉摆拍清纯照# A:嗷嗷大湿的左手在干嘛,看着小纯洁撸么。 | 否 |
| xiaohuangji(小黄鸡语料) | 45W | 原人人网项目语料 | 有一些不雅对话,少量噪音 | Q:你谈过恋爱么 A:谈过,哎,别提了,伤心..。 | 否 |
CCF
2021年 CCF+中移动 主办的 智能人机交互自然语言理解 智能家居控制 NLU数据集
- 数据集包含用户与音箱等智能设备进行单轮对话文本数据,包含共 11个 意图类别,共计约47个槽位类型。
- train.json 为训练数据,共约 9100条,其文本由ASR语音识别技术转写得到,因此可能需要进一步处理,文本标注包含用户意图、槽位及槽值三个字段
- ccf-2021-iot
交互方式上,“手势交互”,“语音交互”,“AR交互”等新兴交互方式开始出现在公众的视野中,但由于交互效率和人体工学等方面的限制,手势交互等方法短期内较难成为主流的人机交互方式,而搭载了语音交互能力的产品自落地应用起就一直受到极为广泛的关注。在交互手段方面,用户仅需要通过与相关产品对话即可下达命令、完成播放音乐、控制家居等任务,能够真正意义上解放双手,提升生活幸福指数。但在实际应用中,相关产品往往很难满足用户的各类别复杂要求,其根源在于自然语言本身较高的复杂性使得用户意图无法被较好的理解。自然语言理解(NLU ,Natural Language Understanding)任务旨在让计算机具备理解用户语言的能力,从而进行下一步决策或完成交互动作,是具备语音交互能力的产品需要处理的重要任务。
赛题任务:根据用户与系统的单轮对话,识别对话用户意图并进行槽位填充。
除基础的意图识别及槽位填充任务外,本赛题额外包括2个子任务:
- 人机交互-NLU-1(小样本学习任务):根据基础意图类别数据及少量含标注的新意图类别样本,完成新意图类别的识别及槽位填充任务。
- 人机交互-NLU-2(域外意图检测任务):除识别出训练数据中已知的意图类别外,对于未知意图类别数据进行检测。
意图分布
- Alarm-Update 1000
- Audio-Play 50
- Calendar-Query 1000
- FilmTele-Play 1000
- HomeAppliance-Control 1000
- Music-Play 1000
- Radio-Listen 1000
- TVProgram-Play 50
- Travel-Query 1000
- Video-Play 1000
- Weather-Query 1000
意图与槽位信息
{
"FilmTele-Play": ["name", "tag", "artist", "region", "play_setting", "age"],
"Audio-Play": ["language", "artist", "tag", "name", "play_setting"],
"Radio-Listen": ["name", "channel", "frequency", "artist"],
"TVProgram-Play": ["name", "channel", "datetime_date", "datetime_time"],
"Travel-Query": ["query_type", "datetime_date", "departure", "destination", "datetime_time"],
"Music-Play": ["language", "artist", "album", "instrument", "song", "play_mode", "age"],
"HomeAppliance-Control": ["command", "appliance", "details"],
"Calendar-Query": ["datetime_date"],
"Alarm-Update": ["notes", "datetime_date", "datetime_time"],
"Video-Play": ["name", "datetime_date", "region", "datetime_time"],
"Weather-Query": ["datetime_date", "type", "city", "index", "datetime_time"],
"Other": []
}
数据示例
"NLU09095": {
"text": "播放周深的英文歌",
"intent": "Music-Play",
"slots": {
"artist": "周深",
"language": "英语"
}
},
"NLU09096": {
"text": "我想知道开原今天是不是要多加衣物防寒保暖。",
"intent": "Weather-Query",
"slots": {
"city": "开原",
"datetime_date": "今天",
"index": "穿衣指数"
}
}
更多数据分析可视化
获奖方案
Smart Home Assisstant
智能锁视频、图像指令识别
DM 数据集
数据集汇总
检索式对话数据集 —— 相关性
检索式对话数据集,诸如 Ubuntu、Douban,对于给定的多轮对话,需要模型在若干候选回复中,选出最合适的句子作为对话的回复。
然而这些数据集主要关注模型能否选出相关性较好的回复,并不直接考察模型的推理能力。随着 BERT 等预训练模型的涌现,模型在此类数据集上已经达到了很好的效果。
推理式数据集 —— 推理
已有的针对推理的数据集(DROP、CommonsenseQA、ARC、Cosmos等)大多被设计为阅读理解格式。它们需要模型在阅读文章后回答额外问题。由于任务不同,这些现有的推理数据集并不能直接帮助指导训练聊天机器人。
MuTual 微软 —— 高考英语听力
多轮对话推理数据集MuTual发布,聊天机器人常识推理能力大挑战
- 论文, MuTual github,leaderboard
- 在构建聊天机器人时,现有对话模型的回复往往相关性较好,但经常出现常识和逻辑错误。由于现有的大部分检索式对话数据集都没有关注到对话的逻辑问题,导致评价指标也无法直接反映模型对对话逻辑的掌握程度。
- 对此,微软亚洲研究院发布了多轮对话推理数据集 MuTual,针对性地评测模型在多轮对话中的推理能力。
- 相比现有的其他检索式聊天数据集,MuTual 要求对话模型具备常识推理能力;
- 相比阅读理解式的推理数据集,MuTual 的输入输出则完全符合标准检索式聊天机器人的流程。 因此,MuTual 也是目前最具挑战性的对话式数据集。测试过多个基线模型后,RoBERTa-base 表现仅为70分左右。目前已有多个知名院校和企业研究部门进行了提交,最优模型可以达到87分左右,仍与人类表现有一定差距。
MuTual 基于中国高考英语听力题改编。听力考试要求学生根据一段双人多轮对话,回答额外提出的问题(图1左),并通过学生能否正确答对问题衡量学生是否理解了对话内容。为了更自然的模拟开放领域对话,我们进一步将听力题中额外的问题转化为对话中的回复
- 所有的回复都与上下文相关,但其中只有一个是逻辑正确的。一些错误的回复在极端情况下可能是合理的,但正确的回复是最合适的。

MuTual 数据集主要包含聊天机器人需要的六种推理能力:
- 态度推理(13%)
- 数值推理(7%)
- 意图预测(31%)
- 多事实推理(24%)
- 常识等其他推理类型(9%)。
MultiWOZ
【2023-10-21】一文白话跨领域任务型对话系统:MultiWOZ数据集!
MultiWOZ 全称 Multi-domain Wizard-Of-Oz
- MultiWOZ - A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling
- Wizard-Of-Oz(绿野仙踪)是一个过程,允许用户与一个界面互动,这个用户被骗了,认为界面的对面是机器,而事实上在幕后有一个人在进行回复……
- 这个方法是一个比较宏观的建立数据集的思路,能够提升数据集的可信度。
multi-domain 数据集跨越多个领域(domain),MultiWOZ属于任务型对话系统,也就是为了完成一项任务。
MultiWOZ是一个完全标记的人与人之间的书面对话集合。三个关键词:
- 完全标记(每一个round都有标记)
- 人与人(没有任何机器生成的回复,因此属于full-manual dataset)
- 书面(形式比较像一个管家和雇主的对话,而不是随意的聊天,可以自己看下数据集文件,有明确的任务感)。
但是,其实这个数据集最大的亮点是多领域,在这之前的多领域数据集都小的离谱,大的都是单领域的。
MultiWOZ直接提供了三个Benchmark 用来衡量模型的好坏:
- Dialog State Tracking(或者叫做Belief Tracking)
- Act2Text
- Context2Act
这三个benchmark几乎涵盖了多轮会话的所有版块
- NLU+DST:归纳上文,跟踪记录对话状态
- Context2Text:根据上文生成文本
- Act2Text:根据系统推理出的行为生成文本
- 主要目标:旅游城市的信息中心获取旅游者查询的高度自然对话
- Domain:Attraction, Hospital, Police, Hotel, Restaurant, Taxi, Train,其中后四个域属于扩展域,包括子任务Booking。每段对话涉及1-5个领域,因此长度和复杂性差别很大。全部的act和slot如下:

- 数量及分布:10438个对话,其中3406个单领域对话,7032个多领域对话,多领域中,包含最少2-5个领域。70%的对话超过10个回合,其中单领域平均轮数为8.93,多领域为15.39。在数据里,对话的序号前面是SNG就是单轮,MUL就是单轮。
- 数据结构:每个对话包含a goal,multiple user,system utterances,belief state,dialogue acts and slots。
- Belief state:有三个部分,分别是semi、book、booked。其中semi是特定领域里的槽值;book在特定领域的booking slots;booked是book的一个子集,在book这个字典里,是booked entity(一旦预定生成)
DSTC
DSTC大家族(简介):
- DSTC 1 : (人机对话)公交线路查询,目标固定不变。
- 共5个slot(路线,出发点,重点,日期,时间),有些slot(时间和日期)的取值数量不固定。而且DSTC1的用户目标在对话过程中不会发生变化。dialog-state-tracking-challenge
- DSTC 2/3 :(人机对话)餐馆预订,用户查询满足特定条件下的餐馆的某些信息(电话、地址等)。
- 2 用户目标会在对话过程中发生变化
- 例如,一开始用户想订中国餐馆,结果最后改为订印度餐馆,这也从某种程度上增加了对话的复杂度。
- DSTC2 对话状态表示上更加丰富,不仅包含用户目标的槽值对,还包括查找方法以及还有哪些信息用户希望系统可以返回到他。每一轮对话包含三个元素:
informable slot:使用informable slot来对用户目标进行限制,比如用户想要便宜、西边的餐厅等等。requested slot:这个slot是一些信息层面的东西,是用户可以索取索要的,比如说,餐厅地址、电话告诉我等等。search method:用户可以有不同的方法让系统帮忙查询,例如用户有哪些限制,可以在限制内查询;或者用户要求系统更换一个选项;或者用户通过具体的名字直接查询等等。
- 输入/输出:每一轮的输入是SLU的结果,也就是N-BEST的SLU结果的概率分布,输出有三个分布,分别是goal constraints目标限制、requested slot请求槽、search method搜索方法
- 训练数据 1612个,验证集 506个,测试集 1117个
- 3在2的基础上新增了一些slot。而且添加了新领域(旅游信息查询),且只有很少的训练数据,目的就是为了尝试领域迁移。
- dstc
- 2 用户目标会在对话过程中发生变化
- DSTC 4 :(人人对话)旅游信息查询
- DSTC 5 :(人人对话)旅游信息查询,与4的区别在于,训练数据和测试数据用的是不同语言。
- DSTC 6 :由三部分组成,分别是
- End-to-End Goal Oriented Dialog Learning 端到端目标导向对话学习
- End-to-End Conversation Modeling 端到端对话建模
- Dialogue Breakdown Detection 对话终端检测。
- dstc6
- DSTC 7-9 :暂时还没有了解过。
详见:任务型对话系统数据集详解大全(MultiWOZ /DSTC)
模型
- 【2021-8-23】Joint Model (Intent+Slot) 2018年提出的《BERT for Joint Intent Classification and Slot Filling》提出了使用BERT进行文本意图分类和槽位填充的任务,其结果达到了最好的成绩。
| 模型 | 改进点 | 效果 | 其它 |
|---|---|---|---|
| 2018,JointBERT | 联合训练 | snips:98.6(intent),97(slot),92.8(sent); atis:97.5(intent),96.1(slot),88.w(sent); | Joint BERT+CRF不如Joint BERT;github |
| 2018, Slot-Gated | 加gate | 不如Joint BERT | github |
| 双向GRU+CRF | 改进点 | atis:98.32(intent),96.89(slot); | 其它 |
| 2014,RecNN+Viterbi | 语义树构建路径特征 | atis:95.4(intent),93.69(slot); | 其它 |
| 2013,CNN+Tri-CRF | 改进点 | atis:94.14(intent),95.62(slot); | 其它 |
从目前的趋势来看,大体上有两大类方法:
- 多任务学习:按Multi-Task Learning的套路,在学习时最终的loss等于两个任务的loss的weight sum,两者在模型架构上仍然完全独立,或者仅共享特征编码器。
- 交互式模型:将模型中Slot和Intent的隐层表示进行交互,引入更强的归纳偏置,最近的研究显示,这种方法的联合NLU准确率更高。
JointBert——2018年
- JointBERT的pytorch实现:JointBERT
- JointBERT的TensorFlow实现:dialog-nlu
- JointBERT的transformers+TensorFlow实现
参考:Intent Detection and Slot Filling(更新中。。。)
DIET(RASA)——2020年5月
【2021-10-19】DIET模型 rasa 聊天机器人核心模型论文,原文:Introducing DIET: state-of-the-art architecture that outperforms fine-tuning BERT and is 6X faster to train
- With Rasa 1.8, our research team is releasing a new state-of-the-art lightweight, multitask transformer architecture for NLU: Dual Intent and Entity Transformer (DIET).
- 【2023-5】DIET源码开源
DIET模型是Dual Intent and Entity Transformer的简称, 解决了对话理解问题中的2个问题(意图分类和实体识别)。DIET使用纯监督方式,没有任何预训练的情况下,无须大规模预训练是关键,性能好于fine-tuning Bert, 但是训练速度是bert的6倍。
对话建模的2种常用方法:端到端 和 模块化系统
- 模块化系统:如POMDP的对话策略(Williams and Young,2007)和 混合代码网络 (Williams et al., 2017) 会使用独立的自然语言理解(NLU)和生成(NLG)系统。对话策略会从NLU接收输出并选择下一个action,然后NLG生成相应的响应。
- 端到端方法中,用户输入直接喂给对话策略以预测下一个utterance(语句),最新的方法是合并这2种常用方法, Fusion Networks (Mehri et al., 2019)。
对话系统中的自然语言理解的2个任务是意图分类和实体识别, Goo et al认为单独的训练这2个task会导致错误传播,其效果不如2个任务同时使用一个模型,2个任务的效果会相互加强。
最近研究表明大型的预训练模型在自然语言理解上性能很好,但是在训练和微调阶段都需要大量的计算性能。
DIET模型的关键功能是能够将预训练模型的得到的词向量,和可自由组合的稀疏的单词特征和n-gram特征结合起来, 在DIET代码中,这2个是dense-feature 和sparse-feature特征。
(1)通过迁移学习获取dense representations 稠密向量
- 一般使用ELMO,BERT,GPT等模型作为迁移学习的模型,然后使用或不使用fine-tuning获取向量,用于下一个模型,但是这些模型速度慢,训练成本高,不太适合现实的AI对话系统。
- Hen-derson et al. (2019b) 提出了一个更简洁的模型,使用单词和句子级别的encoding进行预训练,比BERT和ELMO效果要好,DIET模型是对此进一步研究。
联合的意图分类和命名实体识别
- Zhang and Wang (2016) 提出了一种由双向门控递归单元(BiGRU)组成的联合架构。每个时间步的隐藏状态用于实体标记,最后时间步的隐藏状态用于意图分类。
- Liuand Lane (2016); Varghese et al. (2020) and Gooet al. (2018) )提出了一种基于注意力的双向长期短期记忆(BiLSTM),用于联合意图分类和NER。
- Haihong et al.(2019) 引入了一个共同关注网络,用于每个任务之间共享信息。
- Chenet al. (2019)提出了联合BERT,该BERT建立在BERT之上,并以端到端的方式进行训练。他们用第一个(CLS)的隐藏状态进行意图分类。使用其他token的最终隐藏状态来预测实体标签。
- Vanzo(2019)提出了一种由BiLSTM单元组成的分层自下而上的体系结构,以捕获语义框架的表示形式。他们从以自下而上的方式堆叠的各个层学习的表示形式,预测对话行为,意图和实体标签。 DIET采用transformer-based 框架,使用的多任务像形式,此外我们还进行了消融测试。
架构图,意图是play_game, 实体是ping pong,FFW是共享权重的。
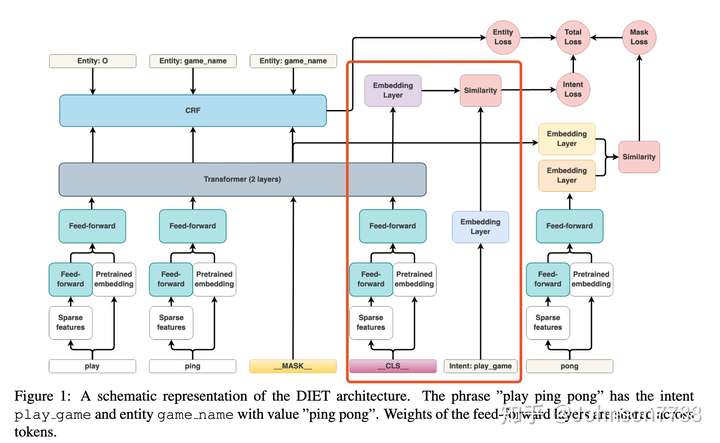
Featurization 特征
输入特征分为2部分,稠密特征 dense features和稀疏特征sparse features。
- 稀疏特征是n-grams(n<=5)的one-hot 或者multi-hot编码,但是稀疏特征包含很多冗余特征,为了避免过拟合,我们对此加入了dropout。
- 稠密特征来自预训练模型, 例如Bert或GloVe。
使用ConveRT作为句子的编码器,ConveRT的_CLS向量作为DIET的初始输入。这就是作为单词信息之外的句子信息特征了。如果使用BERT,我们使用 BERT [ CLS] token, 对于GloVe,我们使用句子所有token的均值作为_CLS_,
稀疏特征通过一个全连接计算,其中全连接的权重是和其它序列的时间步全连接共享的,目的是为了让稀疏特征的维度和稠密特征的维度一致, 然后将稀疏特征的FFW的输出和稠密特征的向量进行concat拼接,因为transformer要求输入的向量维度需要一致,因此我们在拼接后面再接一个FFW,FFW的权重也是共享的。在实验中,这一层的维度是256.
transformer模块,使用2层layer,使用token的相对位置编码。
Intent classification 意图分类
意图分类就是CLS经过transformers的输出,然后后意图标签y向量化后计算相似度, 这里计算损失是用的dot-product loss,点积损失,使得这个相似度和真实意图的相似性最高,使用负采样计算与其它意图的相似性降低。
Named entity recognition 命名实体识别部分
实体识别分类标签y是根据条件随机场Conditional Random Field (CRF) 计算的,是用的transformer的输出的向量,注意根据输出向量可以找到对应的输入token位置。
详见站内专题: diet实现
任务型对话
- 非任务型对话系统,如开放域的闲聊,常见方法:
- ① 基于生成方法,例如序列到序列模型(seq2seq),在对话过程中产生合适的回复,生成型聊天机器人目前是研究界的一个热点,和检索型聊天机器人不同的是,它可以生成一种全新的回复,因此相对更为灵活,但它也有自身的缺点,比如有时候会出现语法错误,或者生成一些没有意义的回复。
- ② 基于检索的方法,从事先定义好的索引中进行搜索,学习从当前对话中选择回复。检索型方法的缺点在于它过于依赖数据质量,如果选用的数据质量欠佳,那就很有可能前功尽弃。
- 任务导向型对话系统旨在通过分析对话内容提取用户任务,并且帮助用户完成实际具体的任务
- 任务型对话的处理方式有
pipeline和端到端两种结构- pipeline(管道式):定义了数个模块,以一条line的形式串联起来共同完成一个任务,如下图所示。
- 端到端:代表为memory network
- 【2021-1-28】智能对话系统和算法
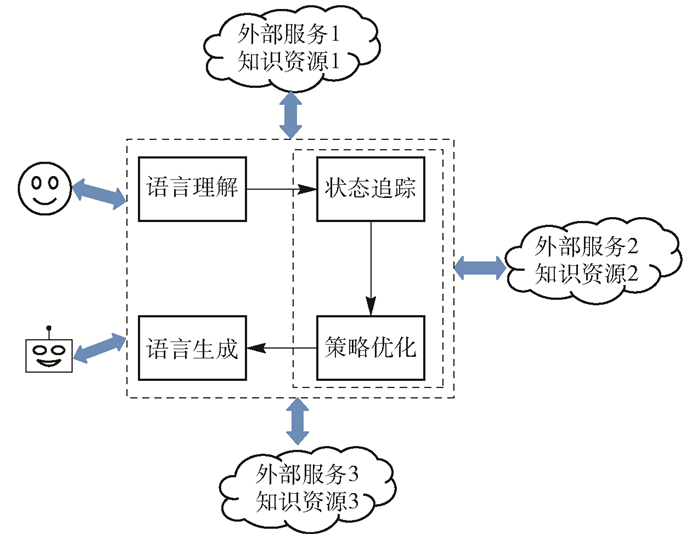
(1)Pipeline

pipline模块
其核心模块组成是NLU->DM->NLG
- (1)NLU负责对用户输入进行理解,随后进入DM模块,负责系统状态的追踪以及对话策略的学习,控制系统的下一步动作,而NLG则配合系统将要采取的动作生成合适的对话反馈给用户。
- 其中若用户的输入是语音形式,则在NLU的输入前需再添加一个ASR语音识别模块,负责将语音信号转换为文本信号。
- (2)
DM对话管理器内部又可分为DST(对话状态追踪)和DPL(对话策略学习),DST(对话状态追踪)根据用户每一轮的输入更新当前的系统状态,而DPL则根据当前的系统状态决定下一步采取何种动作。 - (3)
NLG将语言生成后,若用户采用语音交互方式,则还需要TTS(语音合成)模块将文本转换为语音。
pipline工作原理直观理解
ASR:这部分任务比较单一,只负责将语音转换为文本信号。不过,有些论文提起ASR的输入并不是唯一的,因为语音识别可能会存在一定错误,因此一般会输出多个可能的句子,每个句子同时附带一个置信度,表示这个句子正确的概率。这种方式在论文中被称为N-best,及前N个最有可能的句子。NLU:语言理解模块,用户语音转文本后称为用户Utterance,NLU负责对用户Utterance进行领域/意图分类及槽值对填充。- 领域和意图分类是为了让系统明白用户的对话所处领域及意图,方便后续调用相应的model去识别(并不是一个model跑遍所有的领域意图,就好像树一样,根据领域/意图的分类,在树中找到对应的model。当然model结构可能是一样的,不同的是训练采用的数据是对应领域/意图的)。
- 完成一个任务需要去弄清楚一些条件,比如说点一杯咖啡,根据领域/意图分类,系统判断用户的意图是点咖啡,此时系统需要弄明白是什么咖啡,甜度怎么样等等。所以会检索点咖啡所需要的槽值对,这时后台检索发现完成这个任务需要弄明白{咖啡类型=?,甜度=?}(其中咖啡类型和甜度被称为
槽(slot)),系统会反馈回去问用户咖啡类型是什么?甜度是多少?用户反馈后,NLU再对用户Utterance内容进行识别,发现咖啡类型是摩卡,即槽“咖啡类型”的值(value)为“摩卡”,这个过程被称为槽填充。同时这个过程也很容易被人联想到命名实体识别这一方法。考虑到系统的准确率,一般情况下生成的槽值对也会附带一个置信度,也就是说,对于一个slot,可能并不会只输出一个value。 - 【2020-9-7】NLU为什么难?语言的多样性、歧义性、鲁棒性、知识依赖和上下文。源自:自然语言理解-从规则到深度学习
- 意图分类的实现方法:
- 规则:如CFG/JSGF等,CFG最早出现于CMU Phoenix System
- 机器学习:如SVM/ME…
- 深度学习:CNN/RNN/LSTM…
DM对话管理器内部又可分为DST(对话状态追踪)和DPL(对话策略学习)DST:DST(对话状态追踪)归属于DM对话管理器中,负责估计用户的当前轮的目标,它是对话系统中的核心组成部分。在工作过程中维护了一个系统状态(各个槽对应的值以及相应的概率),并根据每一轮对话更新当前的对话状态(各个槽值对)。直观上来看,SLU输出了slot-value,但是不确定,也就是说可能会输出{咖啡类型=摩卡}–0.8 {咖啡类型=拿铁}–0.2,SLU认为这次用户要求的是摩卡的概率是0.8,是拿铁的概率为0.2,并没有输出一个确定值。所以DST需要结合当前的用户输入(即SLU输出的槽值对)、系统上一时刻的动作(询问需要什么类型的咖啡)以及之前多轮对话历史来判断咖啡类型到底是哪个,最后计算得到{咖啡类型=摩卡}–0.9,认为是摩卡的概率为90%,这是DST评估后认为咖啡类型的当前状态。当然还有很多其他的槽,可能甜度还没有问过,所以{甜度=none},等待DPL去询问用户。这些所有的槽值对的状态,被统称为当前的系统状态,每个轮次结束后都会对当前的系统状态做一次更新。- DST主要工作就是更新系统状态,试图捕捉用户的真实意图(意图通过槽值对体现)。
- DST归根结底最终要的还是评估判断当前的用户目标、维护当前系统状态。
- 一般都是对于一个slot建立一个多分类模型,分类数目是slot对应的value数目。
- 常用方法:DNN、RNN、NBT、迁移学习(迁移学习部分还没看,后续会更新到文章末尾)
DPL:对话策略管理是根据DST输出的当前系统状态来判断还有哪些槽需要被问及,去生成下一步的系统动作。- 论文(详见对话系统中的DST)
- 论文一:Deep Neural Network Approach for the Dialog State Tracking Challenge
- 使用n-gram滑动窗口,同时手工构造了12个特征函数来抽取特征,随后将所有特征送入DNN,最后对slot的所有可能value计算概率,概率最高的即为slot对应的value。每一个slot都会有一个对应的model,因此如果该intention内有n个slot需要填充,则系统内有n个该model。
- 论文二:Word-Based Dialog State Tracking with Recurrent Neural Networks
- ASR输出用户Utterance后需要再通过SLU,随后才进行DST。可是ASR可能会出错,SLU也可能会出错,这样会造成一个error传播。因此作者设计的model直接以ASR的输出作为DST的输入,绕过了SLU部分。这种策略目前在paper中也比较常见,一般来说效果也确实比添加SLU模块的要高一些。
- 论文三:Neural Belief Tracker: Data-Driven Dialogue State Tracking
- 将SLU合并到了DST当中。model中可以看到一共有三个输入,System Output(上一时刻系统动作)、User Utterance(用户输入)、Candidate Pairs(候选槽值对)。model要做的就是根据系统之前动作及用户当前输入,判断候选槽值对中那个value才是真正的value。

- 论文一:Deep Neural Network Approach for the Dialog State Tracking Challenge
NLG:DPL生成下一步的系统动作后,生成相应的反馈,是以文本形式的。TTS:若用户是语音交互,则将NLG输出的文本转换为对应语音即可。这部分与ASR差不多,功能相反而已。
(2)端到端
- 【2020-7-6】端到端聊天技术, 小冰使用这种复杂架构的原因是现在的技术水平只能利用这种方法来平衡系统的智能性和可控性。1月Google的Meena和4月Facebook的Blender验证了端到端这条路真的走得通,足够大的端到端模型可以打败复杂架构的对话系统
- 1月Google的Meena:Towards a Human-like Open-Domain Chatbot,seq2seq模型每层使用的是Evolved Transformer (ET) 块。Encoder端使用了1个ET层(相当于2层 Transformer),Decoder端使用了13个ET层(相当于26层 Transformer)。相比于GPT-2训练使用了40GB的文档数据,Meena训练使用了341GB的对话数据。Meena的模型参数规模达到了2.6B,在GPT-2的基础上又大了不少。Meena的训练样本格式为 (context, response),其中 context 由前几轮(最多7轮)对话拼接而成。训练使用的是标准的MLE。Decoding阶段有两种方法:Beam Search和Sampling方法。定义了一种新的人为评估方法,叫 Sensibleness and Specficity Average (SSA),它是以下两个值的平均值:Sensibleness:回复合理;符合逻辑、保持一致性;Specficity:回复具体,有内容。
- 4月Facebook的Blender:Recipes for building an open-domain chatbot,尝试的三个模型,然后介绍训练使用的数据集,以及各方面的效果评估等,混合版聊天机器人在不断逼近人类的水平(纵坐标是机器聊的比人好的百分比,所以人的聊天水平对应纵坐标50)
- 检索模型、生成模型、检索+生成
- 1月Google的Meena:Towards a Human-like Open-Domain Chatbot,seq2seq模型每层使用的是Evolved Transformer (ET) 块。Encoder端使用了1个ET层(相当于2层 Transformer),Decoder端使用了13个ET层(相当于26层 Transformer)。相比于GPT-2训练使用了40GB的文档数据,Meena训练使用了341GB的对话数据。Meena的模型参数规模达到了2.6B,在GPT-2的基础上又大了不少。Meena的训练样本格式为 (context, response),其中 context 由前几轮(最多7轮)对话拼接而成。训练使用的是标准的MLE。Decoding阶段有两种方法:Beam Search和Sampling方法。定义了一种新的人为评估方法,叫 Sensibleness and Specficity Average (SSA),它是以下两个值的平均值:Sensibleness:回复合理;符合逻辑、保持一致性;Specficity:回复具体,有内容。
- 基于管道方法的对话系统中有许多特定领域的手工制作,所以它们很难适用于新的领域。近年来,随着端到端神经生成模型的发展,为面向任务的对话系统构建了端到端的可训练框架。与传统的管道模型不同,端到端模型使用一个模块,并与结构化的外部数据库交互。

- 上图的模型是一种基于网络的端到端可训练任务导向型对话系统,将对话系统的学习作为学习从对话历史到系统回复的映射问题,并应用encoder-decoder模型来训练。然而,该系统是在监督的方式下进行训练——不仅需要大量的训练数据,而且由于缺乏对训练数据对话控制的进一步探索,它也可能无法找到一个好的策略。
- 端到端强化学习方法

- 上图的模型首先提出了一种端到端强化学习的方法,在对话管理中联合训练对话状态跟踪和对话策略学习,从而更有力地对系统的动作进行优化。
- 【2021-3-2】微软的Jianfeng Gao,ConvLab is an open-source multi-domain end-to-end dialog system platform,aiming to enable researchers to quickly set up experiments with reusable components and compare a large set of different approaches, ranging from conventional pipeline systems to end-to-end neural models, in common environments.
- 开源的ConvLab: Multi-Domain End-to-End Dialog System Platform.
- ACL 2020 demo track, 清华开源的ConvLab-2: An Open-Source Toolkit for Building, Evaluating, and Diagnosing Dialogue Systems,AMiner地址
- ConvLab-2
- 使用指南notebook
- git clone https://github.com/thu-coai/ConvLab-2.git && cd ConvLab-2 && pip install -e .
- Demo部署方法: python ./deploy/run.py, http://0.0.0.0:[port]/dialog, 反应慢,对机器要求高
- 端到端模型、评价、诊断,build task-oriented dialogue systems with state-of-the-art models, perform an end-to-end evaluation, and diagnose the weakness of systems. 这篇顶会,助你徒手搭建任务导向对话系统,朱祺的团队用最先进的模型构建面向任务的对话系统,执行端到端评估,并诊断系统缺陷。ConvLab-2继承了ConvLab的框架,但集成了更强大的对话模型并支持更多的数据集。还开发了一个分析工具和一个交互工具来帮助研究人员诊断对话系统。分析工具提供了丰富的统计数据和图表展示,并对模拟数据中的常见错误进行汇总,便于错误分析和系统改进。交互工具提供了一个用户模拟器界面,允许开发人员通过与系统交互并修改系统组件的输出来诊断组装好的对话系统。
- DSTC9 Track 2: Multi-domain Task-oriented Dialog Challenge II
- End-to-end Multi-domain Task Completion Dialog Task
- Cross-lingual Multi-domain Dialog State Tracking Task
- Deep Reinforcement Learning for Goal-Oriented Dialogues
- 【2021-3-15】百分点智能问答主要流程——源自:百分点认知智能实验室:智能对话技术应用和实践
- 图

- 首先进行语音识别,将用户会话识别出来后,经过ASR结果纠错和补全、指代消解、省略恢复等预处理之后,经过敏感词检测,送入中控系统。中控系统是在特定语境下进行意图识别的系统,分为情绪识别、业务意图识别、对话管理、异常处理等四个模块,其中业务意图包括QA问答机器人(QA Bot)、基于知识图谱的问答机器人(KG Bot),NL2SQL机器人(DB Bot),任务型机器人(TASK Bot)。对话管理包括多轮对话的对话历史管理、BOT当前询问、会话状态选取等模块。异常处理包括安全话术(对意图结果的结果进行后处理)、会话日志记录、告警等功能。然后,进入话术/指令生成子系统,这是识别问句意图后的对话结果生成,包括话术生成和指令生成两个模块,在话术生成中,对话系统根据对话历史数据和对话模板生成和拼接产生话术,如果是任务型对话,将生成对应指令。另外,辅助系统通过画像分析、用户分析、问题分析等功能,进一步优化问答系统的效果。
- 图
- 智能问答产品典型架构
- 图

- 智能问答产品主要包括知识库、对话模型、配置中心、多渠道接入以及后台管理。针对不同的任务划分,准备不同的知识库,例如QA BOT需要引入问答知识对,KG BOT需要知识图谱的支持等等。将针对不同任务的对话模型服务,部署接入各个平台接口,譬如小程序、微信、网页等,提供在线问答服务。配置中心主要提供QA对、闲聊语料、同义词库、特征词库等的可视化配置服务,实现知识配置的快速拓展。后台管理针对智能问答系统实施整体监控、日志管理、告警、权限管理等等,另外,它还提供各种维度的统计分析服务。
- 图


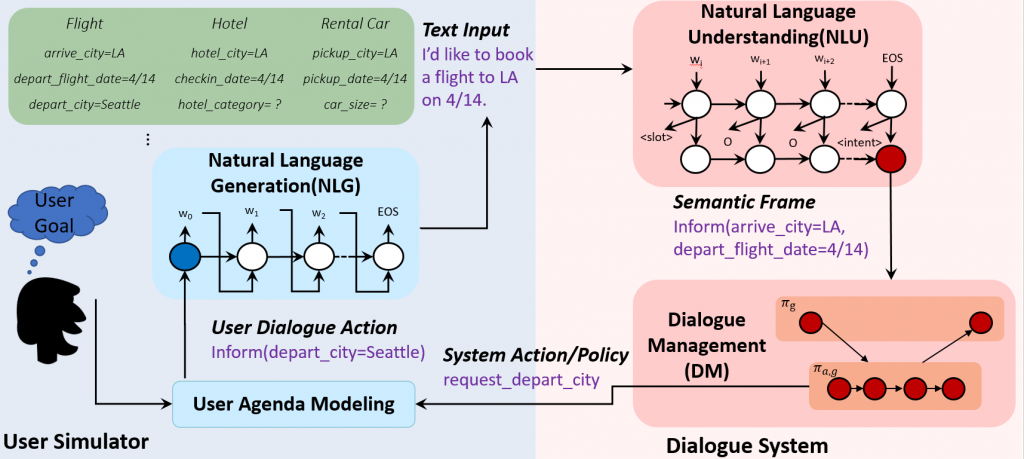
案例
- 【2020-11-28】怎么让机器人帮我买咖啡(Dialogue System)
这里的对话系统特指 Task-Oriented Dialogue System, 也就是让机器人帮助实现一种特定任务的系统, 有一文献提到的 General Dialogue System 的系统,往往指类似 Chit Chat 的系统。
一般此类对话系统的研究都基于如何让机器人在有限步骤内完成可以完成的任务的系统,并且结果往往定位到一个单一实体。此类系统的一个隐含假设往往是通过电话、文字、语音来进行人机交互,也就是没有什么“点击按钮”,“从多个选项选择”,之类的交互方式。当然在一些类似对话系统演变的工程实践中,是有类似的实现的。
因为这个关于“必须文字交互”的假设,所以实际上有些问题并不适合基于这种假设的对话系统完成。例如你在一些手机软件中搜索餐厅,结果可能会返回多家餐厅(餐厅本身即实体),他们都有名称、地址、电话等等信息(这些也可以称为餐厅这个实体的属性,当然也可以是与餐厅这个实体有关的其他实体)。而你想要通过语音、朗读的文字来获得这个列表,就显得很愚蠢了,不会有人想听机器人读5分钟搜索结果的20家餐厅然后决策吧?所以此类系统往往最后是推荐单一实体,例如结果排名最高的餐厅,如果你需要更换,可以跟系统说换一下餐厅。
一个典型的对话系统的交互过程是这样的:
- 用户:你好(User Dialog Act:greeting)
- 机器:你好,我可以帮助你搜索并预订餐厅(Sys Dialog Act:greeting)
- 用户:我想要找一家在中央公园2.0附近的意大利餐厅(User Dialog Act:inform(地址=中央公园2.0,口味=意大利))
- 机器:请问你想要在中央公园2.0附近什么价位的意大利餐厅?(Sys Dialog Act:request(价位))
- 用户:普通的就好(User Dialog Act:inform(价位=普通))
- 机器:我知道那里有一家柯南家的老意大利料理餐厅(Sys Dialog Act:inform(名称=柯南家的老意大利料理))
- 用户:换一个(User Dialog Act:alter())
- 机器:我知道那里有一家意大利油泼面餐厅(Sys Dialog Act:inform(名称=意大利油泼面))
- 用户:它家的价格怎么样?(User Dialog Act:request(价位))
- 机器:意大利油泼面的价位是普通(Sys Dialog Act:inform(价位=普通))
- 用户:就这家吧,帮我预订(User Dialog Act:order())
- 机器:请问有几个人?(Sys Dialog Act:request(人数))
- 用户:单身狗(User Dialog Act:inform(人数=1))
- 机器:真的就1个人吗?(Sys Dialog Act:confirm(人数=1))
- 用户:是的(User Dialog Act:confirm())
- 机器:已经预定成功(Sys Dialog Act:order_success())
- 用户:好的,再见(User Dialog Act:bye())
- 机器:再见,欢迎下次使用(Sys Dialog Act:bye())
Dialog Acts 如果是用户发起的(User Dialog Act),那么它是一种处理后的用户意图的抽象表达,是一种形式化的意图描述。
The dialog act expresses an important component of the intention of the speaker (or writer) in saying what they said 系统发起的行为(Sys Dialog Act),是根据用户行为,上下文信息等等综合得出的, 下一步所要进行的操作的抽象表达,这个抽象表达后续会送入NLG部件,生成自然语言。
Asking questions, giving orders, or making informational statements are things that people do in conversation, yet dealing with these kind of actions in dialogue what we will call dialog acts is something that the GUS-style frame-based dialog systems GUS对话系统,是 Genial Understander System 的缩写,可以追溯到1977年的论文(Daniel G. Bobrow, GUS, A Frame-Driven Dialog System, 1977)
常见的不同意图有:
- 用户的greeting:问好
- 用户的inform:用户提供一个信息,例如想要的餐厅的地址
- 用户的request:询问一个信息,例如当前结果餐厅的电话
- 用户的confirm:确认信息正确(例如上一条是机器问你对不对)
- 用户的bye:结束对话
机器的greeting:问好,也可以是自我介绍
- 机器的inform:提供机器知道的信息,例如当前结果餐厅的信息
- 机器的request:机器必须有足够的信息才能完成任务,如果欠缺一些必须信息,例如餐厅地址、口味,则会向用户询问
- 机器的confirm:根用户确认信息是否正确
- 机器的bye:结束对话
上文还出现了一些可能的特殊意图,例如:
- 用户的order:确认订餐
- 用户的alter:更换检索结果
- 系统的order_success:反馈订餐成功
整个对话系统,就是为了完成某个特定任务,这个任务所需要的特定条件需需要由用户提供(例如帮助买咖啡需要咖啡品种,热或冷等信息),当信息足够的时候,机器就能完成相应任务。
这个过程总结就是:
- 用户说了什么 =》 分析用户意图 =》 生成系统的对应意图(操作)=》 用户听到了系统的反馈 =》 用户说了什么(第二轮)=》…………
当然根据任务复杂度、和其他系统结合等等问题, 对话系统本身也有各种的不同准确度与实现方式。
DM
对话管理(Dialog Manager,下文简称 DM)一般的定义是,根据用户当前的输入,以及对话上下文,决定系统下一步的最佳响应。对于任务型 DM,其职责是通过一致性的对话交互,完成用户的对话目标。
- 多轮对话之对话管理(Dialog Management)
- 对话管理(Dialog Management, DM)控制着人机对话的过程,DM 根据对话历史信息,决定此刻对用户的反应。最常见的应用还是任务驱动的多轮对话,用户带着明确的目的如订餐、订票等,用户需求比较复杂,有很多限制条件,可能需要分多轮进行陈述,一方面,用户在对话过程中可以不断修改或完善自己的需求,另一方面,当用户的陈述的需求不够具体或明确的时候,机器也可以通过询问、澄清或确认来帮助用户找到满意的结果。
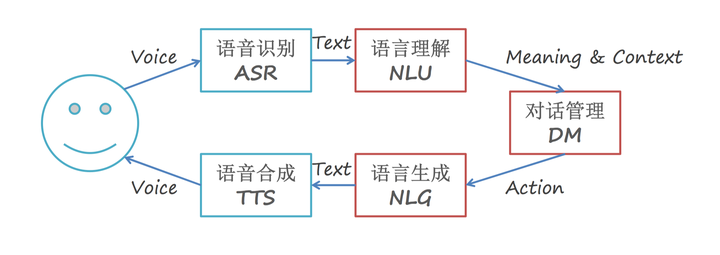
对话管理的任务大致有下面一些:
对话状态维护(DST,dialog state tracking)- 维护 & 更新对话状态
生成系统决策(DP或DPL,dialog policy learning)- 根据 DST 中的对话状态(DS),产生系统行为(dialog act),决定下一步做什么dialog act 可以表示观测到的用户输入(用户输入 -> DA,就是 NLU 的过程),以及系统的反馈行为(DA -> 系统反馈,就是 NLG 的过程)
- 作为接口与后端/任务模型进行交互
- 提供语义表达的期望值(expectations for interpretation)interpretation: 用户输入的 internal representation,包括 speech recognition 和 parsing/semantic representation 的结果
dialogue management的种类(从简单到复杂):
- (1)规则版 Rule Based:基于规则的方法虽然可以较好利用先验知识从而可以较好解决冷启动等问题,但是需要太多人工、非常不灵活、扩展性和移植性很差、不能同时追踪多种状态。
- 优点:准确、可以实现基于配置的可扩展。
- 缺点:难以真正扩展,复杂场景的代码可能非常复杂。
- (2)映射版 Switch statement: 即简单定义一些query模板对应的response。缺点:总是用户拥有主动权,机器不会主动问。也没有使用对话上下文信息。
- (3)有限状态机 Finite state machine:相对强大很多,可以覆盖大部分的对话。缺点:灵活性比较差,必须按照状态机规定的按部就班;相对复杂的对话,有限状态机的构图可能会变得很难维护。
- 简单地考虑点和边表示的内容,可以分成两种:
- 1.点表示数据;边表示操作;
- 2.点表示操作;边表示数据。
- 开源工具:transitions
- 基于状态机的对话管理:Dialogue management using Finite State Models (2002), 详细介绍FSM的演进过程,优缺点。
- 简单地考虑点和边表示的内容,可以分成两种:
- (4)基于目标 Goal based:考虑用户每次对话的最终目标(goal),比如订餐馆、设定导航等。比如当机器人收到用户关于餐馆的问题时,可以设定intent是looking_for_restaurant,goal是finding_restaurant。然后机器人可以知道要完成这个goal,需要用户再提供哪些信息,后续就可以去询问关于这些信息的问题。缺点:构建难度相对较大,开源工具少。
- (5)基于置信度 Belief based:前提是:现实中NLU模块不可能完全正确。因此dm需要考虑把信念(概率分布)加进来。 参考:任务型对话系统综述
对话引擎根据对话按对话由谁主导可以分为三种类型:
- 系统主导
- 系统询问用户信息,用户回答,最终达到目标
- 用户主导
- 用户主动提出问题或者诉求,系统回答问题或者满足用户的诉求
- 混合
- 用户和系统在不同时刻交替主导对话过程,最终达到目标。有两种类型
- 一是用户/系统转移任何时候都可以主导权,这种比较困难
- 二是根据 prompt type 来实现主导权的移交
- Prompts 又分为:
- open prompt(如 ‘How may I help you‘ 这种,用户可以回复任何内容 )
- directive prompt(如 ‘Say yes to accept call, or no’ 这种,系统限制了用户的回复选择)
- 用户和系统在不同时刻交替主导对话过程,最终达到目标。有两种类型
DST
对话状态追踪(Dialogue State Tracker),用于记录和表示当前对话状态。
- 输入:各种可以获取的信息,包括所有的用户utterance、NLU结果、系统动作、以及外部知识库。
- 输出:当前对话的状态评估s。
由于ASR、SLU等组件的识别结果往往会出错,所以常常会输出N-best列表(带置信度概率),这就要求DST拥有比较强的鲁棒性。所以DST往往输出各个状态的概率分布,b(s)。
根据DST对NLU输出信息的保留程度,状态维护又分两种形式:
- 1-Best:只保留NLU结果中置信度最高的槽位,维护对话状态时,只需等同于槽位数量的空间(k)。
- N-Best: 保留每个槽位NLU结果中N-best的结果,还要维护一个槽位组合在一起的整体(overall)置信度。
参考:任务型对话系统综述
状态表示
理论上完整的状态表示,需要维护的状态数是:所有slot的所有可能值的的累乘。因为所有slot搭配都有可能出现。
- 示例:咖啡种类是N1种,即3种,包括Frappuccino(默认是冰的)、Latte、Mocha。温度N2种,即梁两种:Iced、Hot。因此这里需要维护的状态总数是2*3=6。
对话状态数跟意图和槽值对的数成指数关系,维护所有状态的一个分布非常浪费资源,好的状态表示法来减少状态维护的资源开销
以上方法容易形成组合爆炸,简化方法:
(1) 隐藏信息状态模型 Hidden Information State Model (HIS)
- 使用状态分组和状态分割减少跟踪复杂度。其实就是类似于二分查找、剪枝。
- 决策树是对特征空间的切割;HIS是对状态空间的切割。每轮对话,当前空间切分成两个partition。最后需要维护的个数是2的n次方个(切割后空间partition的个数)。处在同一个partition里的状态默认概率相同。
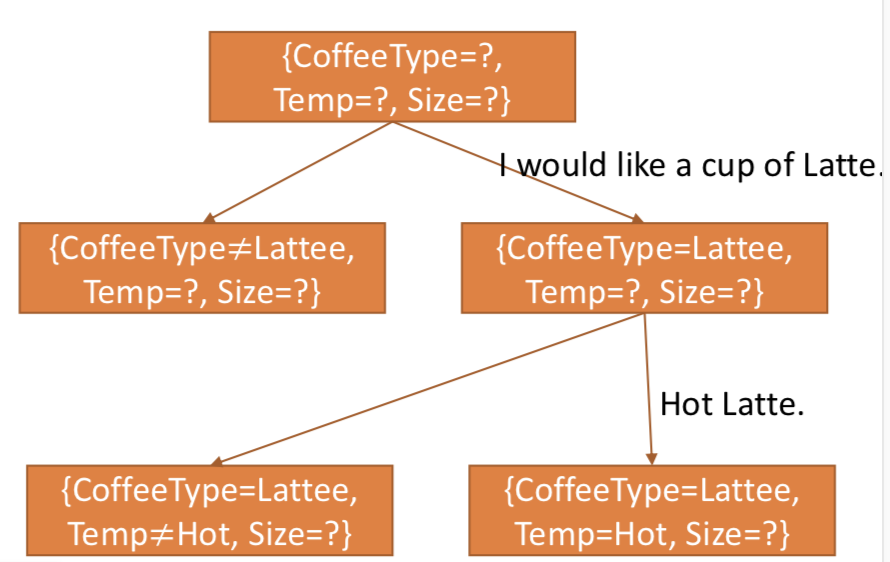
- 示例:第一轮判断类型是Latte的概率很高,所以可以忽略Frappuccino和Mocha的各自分别(这二者合并成一个partition)。最终需要维护的partition数量为2^2=4。
- 评价
- 优点:可以对任何两种状态之间的转换进行建模。
- 缺点:只有前n个状态被追踪。
- 资料:The hidden information state approach to dialog management.
(2) 对话状态的贝叶斯更新 Bayesian Update of Dialogue States (BUDS)
- 假设不同的槽位之间的取值是相互独立的, 或者具有非常简单的依赖关系。这样就将状态数从意图和槽值数的指数减少到了线性。
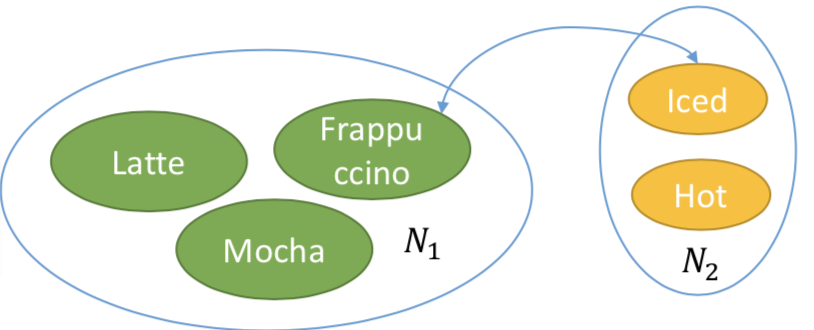
- 举例:需要维护的是N1+N2个状态数,这里即3+2=5种。
- 评价
- 优点:可以追踪所有可能的状态。
- 缺点:不能处理复杂的转换。
- 资料:Bayesian update of dialogue state for robust dialogue systems.
状态跟踪
Hand Crafted
输入上一个状态和当前的最佳(1-best)NLU结果,输出目前状态。
- 优点:不需要训练数据,适合冷启动。
- 缺点:需要人力手动设计规则,不能从实际对话中学习。不能充分挖掘NLU的n-best的结果。
Neural Belief Tracker
- 三个输入:上一次的系统动作+用户输入+候选的slot名-值对
- 输出:是否选用当前的候选slot对。
资料
- Global-Locally Self-Attentive Dialogue State Tracker (2018)
- Neural Belief Tracker: Data-Driven Dialogue State Tracking ,Mrkšić et al., ACL 2017
DPL
对话策略学习(Dialogue Policy Learning),通过当前的状态表示,做出响应动作的选择。常用监督学习+强化学习。
DSTC:Dialog System Technology Challenge
实现方法
- 【2021-4-1】得助智能丁南的系列文章
详见另一篇笔记:对话系统之对话管理器-Dialogue Manager
知识型对话—— Q/A
- 【2021-5-31】业务场景中有三种典型的问答任务
- 一是用户提供 QA-Pairs,一问一答;
- 二是建立结构化的知识图谱,进行基于知识图谱的问答;
- 三是针对非结构化的文本,进行基于阅读理解的问答。
- 资料
- chatbot_with_IR:一个利用搜索引擎构建的简单问答系统,webpy服务
- chatbot_with_IR:一个利用搜索引擎构建的简单问答系统,webpy服务
- 智能问答典型场景

- 闲聊机器人,在拉近距离、建立信任关系、情感陪伴、顺滑对话过程、以及提高用户粘性等方面发挥着作用,一般以关键词触发,模糊匹配回复,知识范围为不深入的开放领域,数据与知识来自于互联网、闲聊交互开发者定期更新的数据。
- 知识型机器人,主要应用于咨询和售后服务的场景,拥有一问一答,智能匹配应答,实现语义归一的能力,在实际使用中代替部分的人工服务,服务于垂直单一行业领域,这部分的数据主要来自于企业自主更新的业务知识库和不断优化的知识体系。
- 任务机器人,在售前,销售,售后均有涉及,可以进行多轮对话,实现深层语义识别,意图识别等任务,主要服务于明确具体的任务场景,数据同样来自于企业自主更新的业务知识库和不断优化的知识体系。
- 另外,知识型机器人和任务型机器人均属于为垂直行业领域服务的业务型机器人。

QA对话技术发展史
Sebastian将QA的研究分为了5个阶段。
- 第一阶段是封闭域手工解析。这些系统的主要模块就是parser,和今天的semantic parsing任务很像,通过人工定义大量的规则,把句子解析成结构化的query后对数据库直接查询。1963年就有学者提出了Baseball系统来解答相关问题,之后是NASA在1972年提出的LUNAR,用于解答月球上岩石和土壤的问题。
- 第二阶段是开放域检索。这个框架也是当今大部分QA系统的解决方案,首先根据问题召回相关文档,再从文档中提取答案。不过考虑到速度与效果,现在的系统会提前把问题-答案对准备好,这就演变成了大部分智能客服使用的FAQ检索式问答。这种方法最早在1999年的TREC测评上被提出,2011年的IBM Watson也基于这个框架提出了更细致的pipeline。
- 第三阶段是阅读理解。研究者们开始把QA简化成阅读理解这样的监督学习问题,也就是给定一个文档和相关query,系统给出答案(也就是span抽取)。但这类数据集的构造基本都是看着答案写问题,直到最近(2019)才开始改成先写问题,再去找文档和答案,演变到了第四阶段的开放域检索+阅读理解。
- 第五阶段是多轮、多跳、多语言、生成、多模态。随着单轮问答的效果提升,简单query都解的很好了,但离人类还有很大差距。目前的学术界就在解答各个细分的复杂问题。
虽然学术界的进展已经很多了,但研究所用的数据集是没法覆盖现实的复杂情况的,同时深度学习模型的鲁棒性也一直是个大问题,因此目前工业界还在封闭域问答挣扎,即使是封闭域也要先对问题进行分类,应对各种长尾case。
问答技术框架
- 【2021-3-29】开放领域问答梳理系列
- 单阶段的系统(比如Phrase Retrieval期望直接通过检索IR找出答案,T5、GPT3这种大规模预训练模型甚至可以期望直接通过MRC生成答案)
- 还有多阶段的系统(比如把二阶段系统中的IR细分到文档检索+文档ranking,MRC细分为answer extraction和answer ranking,或者是迭代式(iterative)问答/多轮问答/multi-hop QA)
- 两阶段系统:基于信息检索(information Retrieval, IR)+ 机器阅读理解(Machine Reading Comprehension, MRC)(retriever-reader)的开放领域问答系统,典型实现如下:
- ① DrQA:Reading Wikipedia to Answer Open-Domain Questions,简称DrQA,是danqi chen(陈丹琦)在2017发表于ACL上的一篇经典文章,业内也经常称该论文是深度学习时代关于开放领域问答的第一篇文章。该文相关代码地址,该文开源代码十分值得入门的同学学习!包括但不限于:自然语言处理任务的文本预处理、TFIDF的高效实现、训练LSTM神经网络用于阅读理解抽取答案、python多线程加速信息检索、文本中的词性标注等作为特征帮助文本理解任务。

- DrQA基本系统改进1: BERTserini
- DrQA基本系统改进2: 训练一个passage ranker
- DrQA基本系统改进3: multi-passage一起处理
- DrQA基本系统改进4: Reader-Ranker互相帮助
- DrQA基本系统改进5:answer re-ranker
- DrQA基本系统改进6: 监督信号的选择
- 【2021-1-25】(美团)智能问答技术框架

- 问题推荐:问题生成、问题排序、问题引导
- 问题理解:领域/意图识别、实体识别/链接、意图澄清、时效识别、句式识别、实体澄清、槽位填充
- 问题解决:KB-QA、DocumentQA、CommunityQA、多答案融合排序、TaskBot、NLG
- (1)Document QA:商户简介、攻略和UGC评论等非结构化文档中包含大量优质信息,从非结构化文档中提取答案,即文档问答 ( Document QA )。近年来基于深度神经网络的机器阅读理解 ( Machine Reading Comprehension,MRC ) 技术得到了快速的发展,逐渐成为问答和对话系统中的关键技术。Document QA借助机器阅读理解 ( MRC ) 技术,从非结构化文档中抽取片段回答用户问题。在问答场景中,当用户输入问题后,问答系统首先采用信息检索方式从商户详情或诸多UGC评论中查找到相关文档,再利用MRC模型从文档中摘取能够确切回答问题的一段文本。
- 文档问答系统的答案预测流程包含三个步骤:
- (a) 文档检索与选择 ( Retriever ):根据Query关键字检索景点等商户下的相关详情和UGC评论,根据相关性排序,筛选出相关的评论用于提取候选答案;
- (b) 候选答案提取 ( Reader ):利用MRC模型在每个相关评论上提取一段文字作为候选答案,同时判断当前评论是否有答案,预测有答案和无答案的概率;
- (c) 答案排序 ( Ranker ):根据候选答案的预测得分排序。这样能够同时处理多篇相关评论,比较并选择最优答案,同时根据无答案概率和阈值判断是否拒绝回答,避免无答案时错误回答。
- 问答框架图
- 文档检索和排序:上图①表示文档检索的过程,首先根据用户询问的商户名定位到具体商户,通过关键字或向量召回该商户下与Query相关评论或详情信息的TopN篇文档。
- 答案片段预测:在答案提取任务中,将每条详情或评论作为一个文档 ( Document ),把用户Query和文档拼接起来,中间加入分割符号[SEP],并在Query前加入特殊分类符号[CLS];把拼接后的序列依次通过②中的模型,在每条评论上提取一段文字作为候选答案,并预测有答案概率 ( HA Score ) 和无答案概率 ( NA Score )。长度分别为N和M的Query和Document,每一个token经过BERT Encoder,分别得到隐层向量表示Ti(i=1,2,…,N) 和 Tj’ (j=1,2,…,M)。将Document的向量表示经过全连接层和Softmax计算后得到每个Token作为答案起始和终止位置的概率Pistart和Pjend,然后找到PistartPjend (i,j=1,2,…,M,i<j) 最大的组合,将位置i和j之间文字作为候选答案,PistartPjend作为有答案概率 ( HA Score )。
- 答案排序:答案重排序部分如③所示,根据前一步的候选答案得分 ( HA Score ) 排序,选择最相关的一个或多个答案输出。
- 无答案判断:在实际使用中还会面临召回文档无答案问题,需要在答案提取的同时加入无答案判断任务。我们的具体做法是联合训练,将BERT模型的[CLS]位置的向量表示C经过额外的全连接层和二分类Softmax,得到无答案概率 ( NA Score ),根据无答案概率 ( NA Score ) 和人为设定的阈值判断是否需要拒绝回答。

- 存在的问题
- ①MRC模型抽取的答案偏短,回答信息不充分,如问”停车方便吗”,答案为”停车方便’,从MRC任务看,这样的回答也很不错,但该答案并没有回答为什么方便,信息不充分,更期望的答案是”停车方便,有免费停车场”。我们通过在构造模型训练数据时选择更完整的句子作为标准答案,在预测时尽量选择完整的句子作为回答等方式来优化解决;
- ②另一个问题是时效性问题,比如”现在需要预约吗?”明确地问当前的情况,如果用经典的阅读理解获取的答案可能是”可以预约”和”不可以预约”。通常情况下,这种信息在我们UGC是大量存在的,不过有一些信息,非常好的答案可能是一个时效性很差的问题,或是很久以前的评论,这种对用户来说帮助不大。所以我们对时效性进行了相应处理,根据时间的关键词,包括现在、今天,也包括一些事件如樱花、桃花等,它们都有一些特定时间点,这些都作为时间词来处理。还有很多场景,比如景点、酒店等领域,通过梳理也能发现有一些意图跟时效性相关,比如说门票、营业状态等,我们对它们也做相应的时效性处理;再就是”是否类”问题缺少直接回答,MRC模型用于答案片段抽取,适合回答事实类的描述性问题。但是真实存在大量的”是不是、是否、能否”等是否类问题,如”酒店提供饮食吗?”,原来的回答是”早上10元一位管吃饱”,但是回答的不够直接,我们希望同时也能更直接地先回答是否。故此我们采用多任务的学习方式,在MRC模型上加入了Yes/No的分类任务,来判断答案的观点是肯定还是否定。改进后的答案为”是的。早上10元一位管吃饱”。
- 改进后的框架
- 文档问答系统的答案预测流程包含三个步骤:
- (2)Community QA
- 社区问答 ( Community Question Answering,CQA ) 和常见问题问答 ( Frequently Asked Questions,FAQ ) 是基于问答对的问答系统的两种方式。
- FAQ通常由人工事先维护好问答知识库,当用户问问题时,根据相似度匹配到最相关的问题,并给出对应的答案。FAQ在限定领域内回答质量较好,但是问答知识库整理成本高。
- 随着社交媒体的发展,CQA可以通过社交平台获得大量用户衍生的问题答案对,为基于问答对的问答系统提供了稳定可靠的问答数据。
- 美团和大众点评APP中,商户详细页中有一个”问大家”模块,其问题和答案都是由用户生成,含有关于当前商户许多用户关心的关键信息,比如景点相关的”是否允许携带宠物”等客观问题,以及”停车是否方便”等主观问题,很大程度上能回答用户对于景点或其他商户的开放域问题。
- CQA问答系统处理框架如上图所示,我们将问题处理分为两个阶段,首先离线阶段通过低质量过滤、答案质量排序等维护一个相对质量较好的问题-答案库,在线阶段,从知识库中检索得到答案并回答用户。
- (3)KB-QA
- 主流的KBQA解决方案包括基于查询图方法 ( Semantic Parser )、基于搜索排序方法 ( Information Retrieval )。查询图方案核心思路就是将自然语言问题经过一些语义分析方式转化成中间的语义表示 ( Logical Forms ),然后再将其转化为可以在 KG 中执行的描述性语言 ( 如 SPARQL 语言 ) 在图谱中查询,这种方式优势就是可解释强,符合知识图谱的显示推理过程。
- 搜索排序方案首先会确定用户Query中的实体提及词 ( Entity Mention ),然后链接到 KG 中的主题实体 ( Topic Entity ),并将与Topic Entity相关的子图 ( Subgraph ) 提取出来作为候选答案集合,通过对Query以及Subgraph进行向量表示并映射到同一向量空间,通过两者相似度排序得到答案。这类方法更偏向于端到端的解决问题,但在扩展性和可解释性上不如查询图方案。在美团场景里我们采用以Semantic Parser方法为主的解决方案。
- 百分点的KB-QA案例
- 将输入问句,转化为SparQL的语句,实现对知识图谱的智能问答,例如武汉大学出了那些科学家,需要识别出武汉大学和科学家的两个查询条件才能得到交集答案,当不能使用常规NER识别出实体的时候,可以将训练语料中的实体词汇导入到ES搜索引擎中,实现对一些难以识别样例的查询.

- (4) NL2QL
- NL2SQL问答不是基于问答对或者知识图谱知识库,它是基于结构化数据表进行智能问答,实现自然语言转SQL查询的功能
- 经典的NL2SQL方案中,基于Seq2Seq的X-SQL模型是十分常见的,该模型的思路是先通过 MT-DNN 对原始问题及字段名称进行编码,再在问题前面人为地添加一个 [CXT] 用于提取全局信息。

- 【2021-3-15】详见:百分点认知智能实验室:智能对话技术应用和实践
- 【2020-8-18】参考:
- 知识库(主要是标准的QA信息)匹配需求是对已经梳理出的大量标准QA对信息进行匹配,找出最符合用户问题的QA对进行回复,拆分主要的处理流程主要为如下两点:
- 标准QA信息入库索引;
- 通过对用户提出的问题进行处理,与索引库中的所有Q进行相似度计算,根据需要返回得分最高的top k个;
- 基于返回的top k问题有平台根据业务需要选择其中的某个问题的答案回复客服。
- 【2021-3-15】百分点认知智能实验室:智能对话技术应用和实践
- 知识库的主要来源包括:历史的问答和咨询数据、业务知识梳理积累、规章制度和流程等内容、辅之以同义词词库等外部数据,在功能上设立新建知识、导出知识、导入知识等。举个例子来说明知识库的格式,例如“北京分为多少区||北京行政区划||北京有四个区吗”,这个个问题都是语义等价的,其一级分类为中国,二级分类为北京,对应的答案是“2015年北京市辖东城、西城、朝阳、丰台、石景山、海淀、门头沟、房山、通州、顺义、昌平、大兴、怀柔、平谷、密云、延庆16个市辖区(合计16个地市级行政区划单位);#n150个街道、143个镇、33个乡、5个民族乡(合计331个乡级行政单位)。||北京一共有16个区;”如果新增问答知识,那么一级分类、二级分类、问题和回答是必须要添加的,以“||”作为分割多个问题和答案的分隔符等。

- 在引擎端处理的主要是前两点,即根据需要对索引入库的Q进行预处理,对用户问题进行同样的预处理,而后计算两者之间的相似度,返回得分最高的前几条。处理流程如下图示:
- NLU意图识别的流程说明
- 基于智能问答的业务流程,所谓的NLU意图识别就是针对已知的训练语料(如语料格式为(x,y)格式的元组列表,其中x为训练语料,y为期望输出类别或者称为意图)采用选定的算法构建一个模型,而后基于构建的模型对未知的文本进行分类。流程梳理如下:
- 准备训练数据,按照固定的格式进行;
- 抽取所需要的特征,形成特征向量;
- 抽取的特征向量与对应的期望输出(也就是目标label)一起输入到机器学习算法中,训练出一个预测模型;
- 对新到的数据采取同样的特征抽取,得到用于预测的特征向量;
- 使用训练好的预测模型,对处特征处理后的新数据进行预测,并返回结果。
- 从流程梳理看,NLU的意图识别从根本上看是有监督的机器学习,即基于给定的人工筛选数据进行特征处理,构建模型用于预测。

- 【2021-1-28】意图识别和槽填充
- 意图识别:分类问题,SVM,adaboost和NN等
- 槽填充:序列标注,CRF,HMM等

基于模板的问答框架
- 【2016-8-11】张俊林:聊天机器人中对话模板的高效匹配方法
- 我是人:你知道王思聪是谁吗
- 我是ChatBot:你问国民老公干嘛,你要跟他借钱吗?
-
看上去回答的够机智吧?难道这还没理解人的意思吗?所以说是错觉吗,其实只要在后台存储这么一个匹配模板就能做到上面的机智回答,而且可以确定的一点是,越是回答的有趣的答案,越可以肯定这是通过模板技术来做的,为啥呢?因为其它技术做不到真正理解人的话,更不要说回答的有趣了。
-
一句交互对话的模板由<Q,A>数据对构成,其中Q代表输入模板
- A代表聊天机器人应该回答什么话,A可能不会是模板,而是就是应答的一句话,也可能是带着标签的模板
- 但是Q往往采用模板,因为这样覆盖率高,当然Q也完全可以是不带模板通配符的完整的一句话,但是一般而言模板居多,否则要穷举所有可能用户的问话基本不可能,通过加入*或者?这种通配符,可以用一个模板匹配更多的用户输入。
当然,模板可以做得更复杂一些,按照复杂度不同,可能有下面几种类型的模板。
- (1)最简单的模板:一句完整的话作为一个模板
- Q:你贵姓?
- A:人家贵性女;
- (2)稍微复杂些的模板:一个模板匹配多种输入
- Q:你喜欢电影是什么
- A:我最喜欢的电影当然是《断背山》了,啥时候咱俩一起去看,帅哥~
- (3)更复杂的,带实体类别标签的模板,把一些常见实体变量抽象出来,适用于经常变化的人名地名日期等的句子模板
- Q:
的生日是 吗? - A:哥,我不敢认识
.Value啊。 - 过程:
- Q:UserA:孙杨的生日是12月32号吗?
- 聊天系统先上实体识别模块,实体变量的值:
.Value=孙杨; .Value=12月32号,把上面这句话转换成: 的生日是 吗? - 对话模板库里面有一个匹配上的模板,于是就可以根据Q对应的A内容,把变量值填充进去
- A:“哥,我不敢认识孙杨啊。”
- Q:
- (4)智能匹配(多模式匹配+倒排索引)
- 如果模板数量巨大,比如几十万上百万,那么一个个暴力匹配不现实,用户还以为你ChatBot休克了呢。有什么高效的会话模板匹配方法吗?
- 测试过查找效率也是非常高的,基本都是几毫秒十几毫秒级别的,和Alice的模板查找速度比性能提升了1到2个数量级,大多数应用场合应该是够用的
- ①对于每个QA进行唯一编号,并对其Q部分,用切割点把Q切割成若干字符串片段,切割点有哪些呢?包括多字符通配符*和单字符通配符?符号,以及事先定义的实体标签(比如
,<Address>, , 等),这里实体标签既是切割点,也是需要记录的字符串片段,一身二用,而通配符只充当切割点。 - 你喜欢电影是什么 → {你,喜欢,电影,是什么}
-
的生日是 吗? → { ,的生日是, ,吗?} - 你贵姓? → {你贵姓?} (无切割点)
- ②将这些被切割的字符串片段相同的合并后,形成了字符串字典:Diction={你,喜欢,电影,是什么, 你贵姓?,
,的生日是, ,吗?} - 根据这个字典构建多模式匹配算法,如Wu_Manber算法,可以从用户输入句子中极快地将字典中包含的字符串片段全部扫描出来;
- ③根据第一步每个Q对应的编号及其被切割成的片段,建立内存倒排索引,Key是字符串片段内容或者其哈希值(因为有时候这个字符串片段可能是完整的一句话),Value是对应的Q编号序列,等价于一般意义搜索引擎的文档ID列表;
- 用户输入NewQ,首先用Wu_Manber算法扫描NewQ,把其中包含的字典中的字符串片段都找出来,比如找出了A,B,C三个片段;使用A,B,C三个片段,从倒排索引中找出同时包含三个片段的模板集合QSet;现在有了用户输入NewQ和一个小的模板集合QSet,可以采用正则表达等传统的方式去进行模式匹配,找出其中某个模式或者一个模式也匹配不上。因为这个QSet相比原先整个模板集合来说,数据量是极小的,绝大多数时候只有一个或者几个,所以这个步骤不会太耗时间。
- 总结:多模式匹配和倒排索引来快速找到一些候选的模板集合,这个模板集合大小相对原先整个模板集合来说相当小,然后在这个小集合上进行常规的模式匹配。

自动Q/A
【2022-8-16】各类QA问答系统的总结与技术实现
从知识的来源、答案类型、交互方式、业务场景及问题类型五个方面对QA任务进行分类
- 回答一个问题需要有依据,人类在回答问题时,会去大脑中搜索相关的内容,然后给出答案;
- 而机器要想实现自动问答,也需要从外部获取知识(或依据)。
- 好比学生上学时学习知识,并把知识存在大脑中;考试时看到考题,会回忆学习过的相关知识,从而给出答案。
机器没有学习知识的过程,我们需要将知识作为结构化或非结构话的数据供其访问,作为其回答问题的依据。
根据知识来源的不同,问答系统可以分为以下三种任务:基于知识库的问答、基于文档的问答、答案选择。
- (1)基于
知识库的问答:- 给定自然语言问题,通过对问题进行语义理解和解析,利用知识库进行查询、推理得出答案。
- 特点是回答的答案是知识库中的实体。
- 如:百度询问 2016年奥斯卡最佳男主角 时,百度会根据知识库进行查询和推理,返回答案 “莱昂纳多”
- 知识库通常由大量的三元组组成,每一条三元组包括:entity - relation - entity,如果我们把实体看作是结点,把实体关系(包括属性,类别等等)看作是一条边,那么包含了大量三元组的知识库就成为了一个庞大的知识图。
- 根据问题的复杂程度,又可以分为两类:
- 简单问句:这种问题只需要一个三元组就能搞定,比较基础的通过LR的方法: Antoine Bordes, Jason Weston, Nicolas Usunier. Open question answering with weakly su-pervised embedding models;或者结合CNN、RNN神经网络的方法:Character-Level Question Answering with Attention
- 复杂问句:需要多个三元组,有时需要进一步的推理或者做一些计算。回答这类问题目前采用下面基于语义解析一类的方法效果较好。贴个微软目前比较新的工作 Wen-tau Yih, Ming-Wei Chang, Xiaodong He, and Jianfeng Gao. 2015. Semantic parsing via staged query graph generation: Question answering with knowledge base.
- (2)基于
文档的问答- 这一类型的任务通常也称为阅读理解问答任务,最有名的是斯坦福基于SQuAD数据集展开的比赛(https://rajpurkar.github.io/SQuAD-explorer/)
- 对于每个问题,会给定几段文本作为参考,这些文本通常根据问题检索得到,每段文本中可能包含有答案,也可能只与问题描述相关,而不含有答案。我们需要从这些文本中抽取出一个词或几个词作为答案。
- (3)Answer Select 答案选择
- Applying Deep Learning To Answer Selection: A Study And An Open Task
- 按答案类型划分
- 事实型问题
- 列举型问题
- 定义型问题
- 交互型问题
- 单轮
- 多轮交互

Document Q/A
这项创新技术,开发者无需梳理意图、词槽,无需进行问题和答案的整理,只需准备文本格式的业务文档,通过平台上传,即可一键获取基于文档的对话技能。无需智能对话技术基础也可以利用该技术,秒变AI达人。
对话式文档问答技能,可以对传统需要人工抽取FAQ或梳理意图的业务文档进行自动学习,通过搜索与语义理解技术,构建了用户输入的问题与业务文档之间的桥梁,使得用户的问题可以由技能自动找到文档中的对应答案片段,使用端到端的多文档阅读理解模型V-NET和自然语言生成技术,技能得以返回更为精准的答案。整个问答技能的构建对开发者来说没有任何技术门槛,且对话式文档问答技能具有自主学习能力,可持续优化,大大提高问答系统的开发人效。
开发者在上传文档后,平台进行模型训练,经过以下几部分处理:
- 基础处理:比如编码处理,冗余字符处理,切分完整语义片段,进行词法分析等,让机器人对用户上传的文档有基础了解;
- 获取文档关键信息并完成倒排索引:此过程采用了TF-IDF及TextRank等多种算法综合片段的重要性,并进行打分;
- 构建基于词向量的KNN分类器:基于大规模语料,使用skip-gram模型,训练并得到词向量,并完成构建KNN分类器。
UNIT 文档对话示例
- 测试模式
- 调优模式
2020年,美团智能问答技术探索与实践
- 从非结构化文档中提取答案,即
文档问答( Document QA )。近年来基于深度神经网络的机器阅读理解( Machine Reading Comprehension,MRC ) 技术得到了快速的发展,逐渐成为问答和对话系统中的关键技术。MRC 模型以问题和文档为输入,通过阅读文档内容预测问题的答案。根据需要预测的答案形式不同,阅读理解任务可以分为填空式( Cloze-style )、多项选择式( Multi-choice )、片段提取式( Span-extraction ) 和自由文本( Free-form )。在实际问答系统中最常使用的是片段提取式阅读理解 ( MRC ),该任务需要从文档中提取连续的一段文字作为答案。最具影响力的片段提取式 MRC 公开数据集有 SQuAD 和 MSMARCO 等,这些数据集的出现促进了 MRC 模型的发展。在模型方面,深度神经网络结构被较早的应用到了机器阅读理解任务中,并采用基于边界预测(boundary-based prediction)方式解决片段提取式阅读理解任务。这些模型采用多层循环神经网络+注意力机制的结构获得问题和文档中每个词的上下文向量表示,在输出层预测答案片段的起始位置和终止位置。近年来预训练语言模型如 BERT,RoBERTa 和 XLNet 等在众多 NLP 任务上取得突破性进展,尤其是在阅读理解任务上。这些工作在编码阶段采用 Transformer 结构获得问题和文档向量表示,在输出层同样采用边界预测方式预测答案在文档中的位置。目前在单文档阅读理解任务 SQuAD 上,深度神经网络模型的预测 EM/F1 指标已经超越了人类标注者的水平,说明了模型在答案预测上的有效性。
文档问答系统的答案预测流程包含三个步骤:
- (1) 文档检索与选择 ( Retriever ):根据 Query 关键字检索景点等商户下的相关详情和 UGC 评论,根据相关性排序,筛选出相关的评论用于提取候选答案;
- (2) 候选答案提取 ( Reader ):利用 MRC 模型在每个相关评论上提取一段文字作为候选答案,同时判断当前评论是否有答案,预测有答案和无答案的概率;
- (3) 答案排序 ( Ranker ):根据候选答案的预测得分排序。这样能够同时处理多篇相关评论,比较并选择最优答案,同时根据无答案概率和阈值判断是否拒绝回答,避免无答案时错误回答。
Document QA 问答系统架构如下图所示:
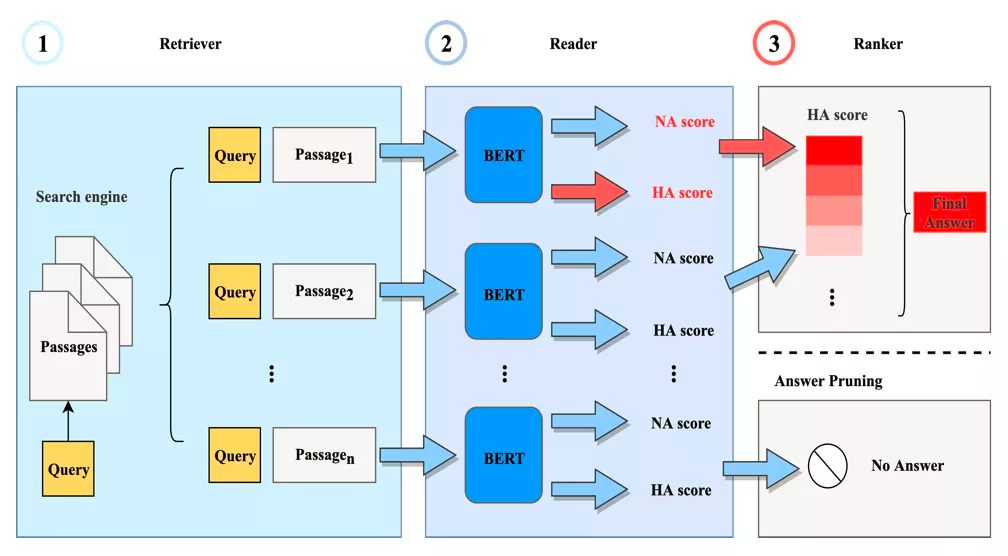
- 文档检索和排序:上图①表示文档检索的过程,首先根据用户询问的商户名定位到具体商户,通过关键字或向量召回该商户下与 Query 相关评论或详情信息的 TopN 篇文档。
- 答案片段预测:在答案提取任务中,将每条详情或评论作为一个文档 ( Document ),把用户 Query 和文档拼接起来,中间加入分割符号[SEP],并在 Query 前加入特殊分类符号[CLS];把拼接后的序列依次通过②中的模型,在每条评论上提取一段文字作为候选答案,并预测有答案概率 ( HA Score ) 和无答案概率 ( NA Score )。长度分别为 N 和 M 的 Query 和 Document,每一个 token 经过 BERT Encoder,分别得到隐层向量表示 Ti (i=1,2,…,N) 和 Tj’(j=1,2,…,M)。将 Document 的向量表示经过全连接层和 Softmax 计算后得到每个 Token 作为答案起始和终止位置的概率 Pistart 和 Pjend,然后找到 PistartPjend (i,j=1,2,…,M,i<j) 最大的组合,将位置 i 和 j 之间文字作为候选答案,PistartPjend 作为有答案概率 ( HA Score )。
- 答案排序:答案重排序部分如③所示,根据前一步的候选答案得分 ( HA Score ) 排序,选择最相关的一个或多个答案输出。
- 无答案判断:在实际使用中还会面临召回文档无答案问题,需要在答案提取的同时加入无答案判断任务。我们的具体做法是联合训练,将 BERT 模型的[CLS]位置的向量表示 C 经过额外的全连接层和二分类 Softmax,得到无答案概率 ( NA Score ),根据无答案概率 ( NA Score ) 和人为设定的阈值判断是否需要拒绝回答。
实践
- allenai的document-qa, 2017年的paper Simple and Effective Multi-Paragraph Reading Comprehension
- hugging face的document qa demo,不管用
- 2019,百度的UNIT 3.0详解之对话式文档问答——上传文档获取对话能力
- 最新sota模型,
Table Q/A
- 【2021-12-3】首个中文表格预训练模型!达摩院AliceMind上新,序列到结构详解
- 【2021-2-24】达摩院Conversational AI研究进展及应用
- 一个例子来介绍TableQA。
- 有一个理财产品的Table,围绕这个Table, 用户可能会问:“收益率大于3.5%且保本型的理财产品最低起投金额是多少?”
- 要想解决这个问题,需要先把自然语言转换成一个SQL语句,然后用SQL语句去查询表格,最终就可以回答这个问题。
- 所以整个TableQA的核心问题就是如何解析自然语言:把TEXT文本转变为一个SQL语句。

- TableQA的优势主要有以下三点:
- 表格容易获取:企业中存在大量现成的表格,无需加工即可自然获取;
- 使用门槛低:针对TableQA达摩院已经研究了多种算法,大大降低了企业应用的成本和门槛;
- 功能强大:支持复杂语言的理解、支持多表查询、支持多轮问答。
- TableQA发展历史
- TableQA是最近两年里发展最快的一种问答方式。从2017年开始重新被发掘出来,2019年的时候这个方向的研究开始加速,达摩院也是在2019年启动了对TableQA的研究。2020年加速趋势更加明显,达摩院提出的SDSQL模型在WikiSQL上取得了第一名,提出的R2SQL模型在国际公开挑战赛SParC和CoSQL上都取得了第一名的好成绩。
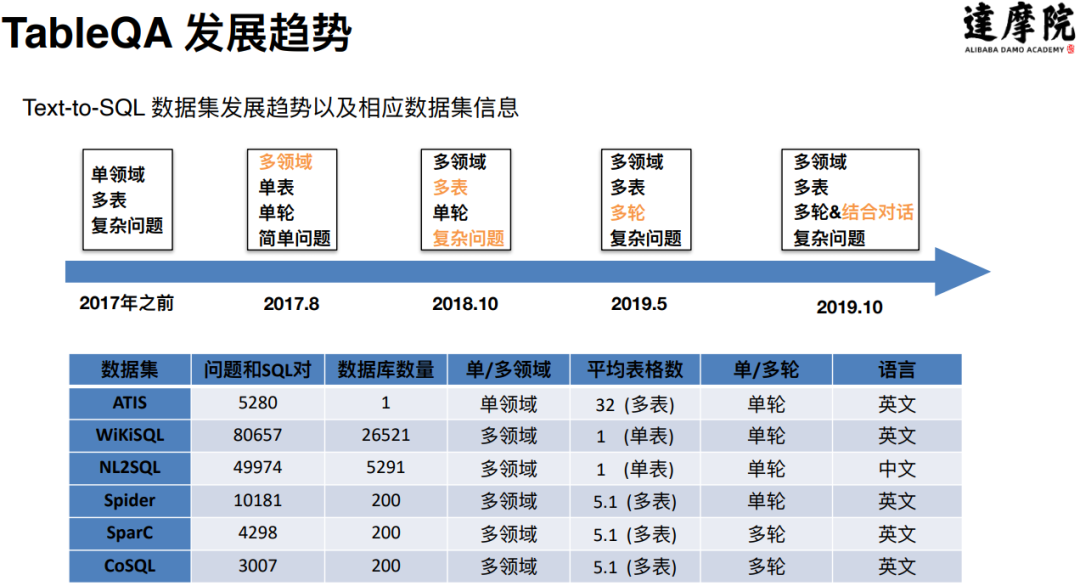
- 达摩院在TableQA上的研究主要是基于多表多轮的数据集(SparC和CoSQL), 多表指的是寻找答案的时候需要在多个表中进行查询,而不是仅仅靠一张表就能得到答案;多轮指的是用户通常会连续不断的提问。
- 典型数据集
- 有四个数据集是值得大家去关注的:
- 第一个是WikiSQL数据集,这是一个单表单轮的数据集;
- 第二个是多表单轮的Spider数据集;
- 第三个是多表多轮的SparC数据集;
- 第四个是CoSQL数据集,这是一个融合了多轮对话特点的多表多轮数据集。
- 有四个数据集是值得大家去关注的:
BERT结合Faiss的语义表示
【2021-5-31】语义匹配搜索项目使用的 Faiss和BERT的整体架构 image, 参考:基于文本语义的智能问答系统
- 注:深蓝色线为数据导入过程,橘黄色线为用户查询过程。)
- 首先,本文项目使用开源的 bert-serving , BERT做句子编码器,标题数据转化为固定长度为 768 维的特征向量,并导入 Milvus 或者Faiss库。
- 然后,对存入 Milvus/Faiss 库中的特征向量进行存储并建立索引,同时原始数据提供唯一ID编码,将 ID 和对应内容存储在 PostgreSQL 中。
- 最后,用户输入一个标题,BERT 将其转成特征向量。Milvus/Faiss 对特征向量进行相似度检索,得到相似的标题的 ID ,在 知识库(PostgreSQL/MySQL/SQLite。。。) 中找出 ID 对应的详细信息返回
How to Build an Open-Domain Question Answering System?
【2021-1-20】
- Open-domain Question Answering (ODQA) is a type of language tasks, asking a model to produce answers to factoid questions in natural language. The true answer is objective, so it is simple to evaluate model performance.
- For example,
- Question: What did Albert Einstein win the Nobel Prize for?
- Answer: The law of the photoelectric effect.
- 开放域问答分类难度:
- When considering different types of open-domain questions, I like the classification by Lewis, et al., 2020, in increasing order of difficulty:
- (1)准确记忆训练时期的回答:A model is able to correctly memorize and respond with the answer to a question that has been seen at training time.
- (2)测试时可以用已有语料回答新问题:A model is able to answer novel questions at test time and choose an answer from the set of answers it has seen during training.
- (3)回答训练语料意外的问题:A model is able to answer novel questions which have answers not contained in the training dataset.
- 三种类型的图解 Overview of three frameworks discussed in this post
- (1)Open-book QA: Retriever-Reader
- The retriever-reader QA framework combines information retrieval with machine reading comprehension
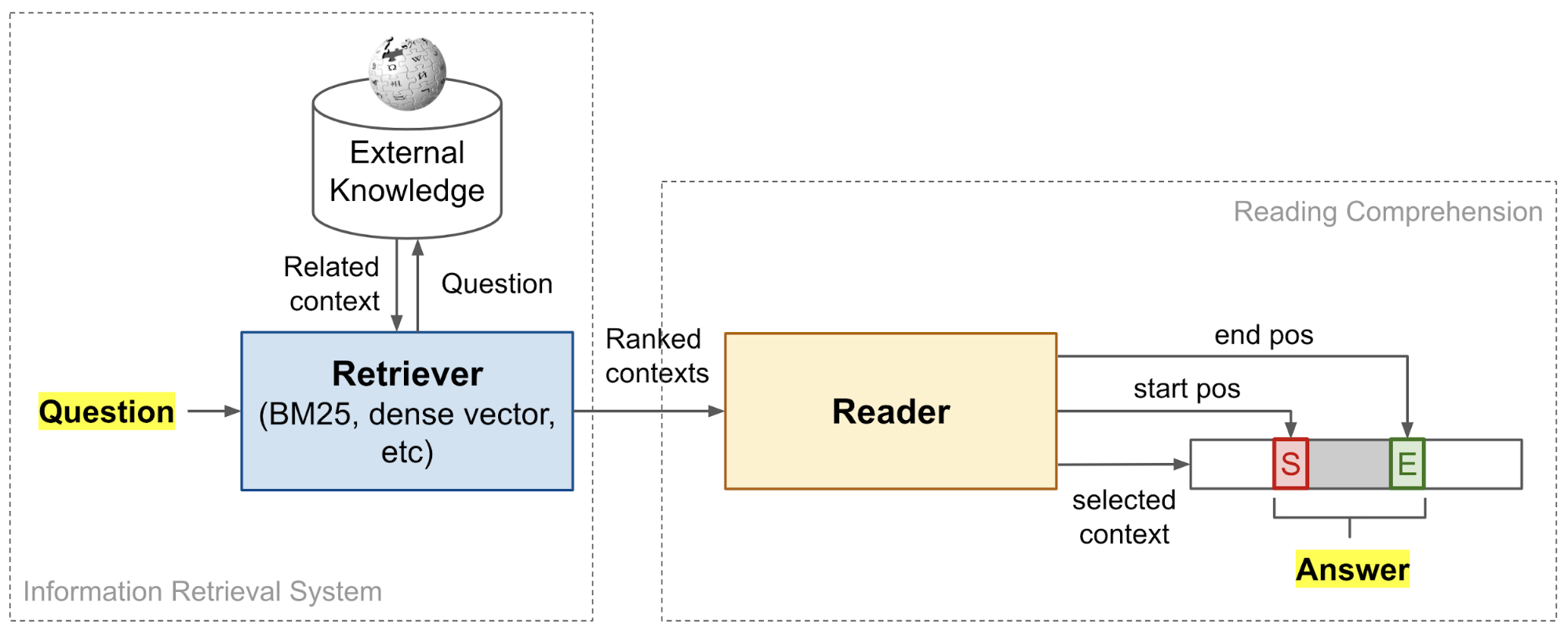
- (2)Open-book QA: Retriever-Generator
- The retriever + generator QA framework combines a document retrieval system with a general language model.
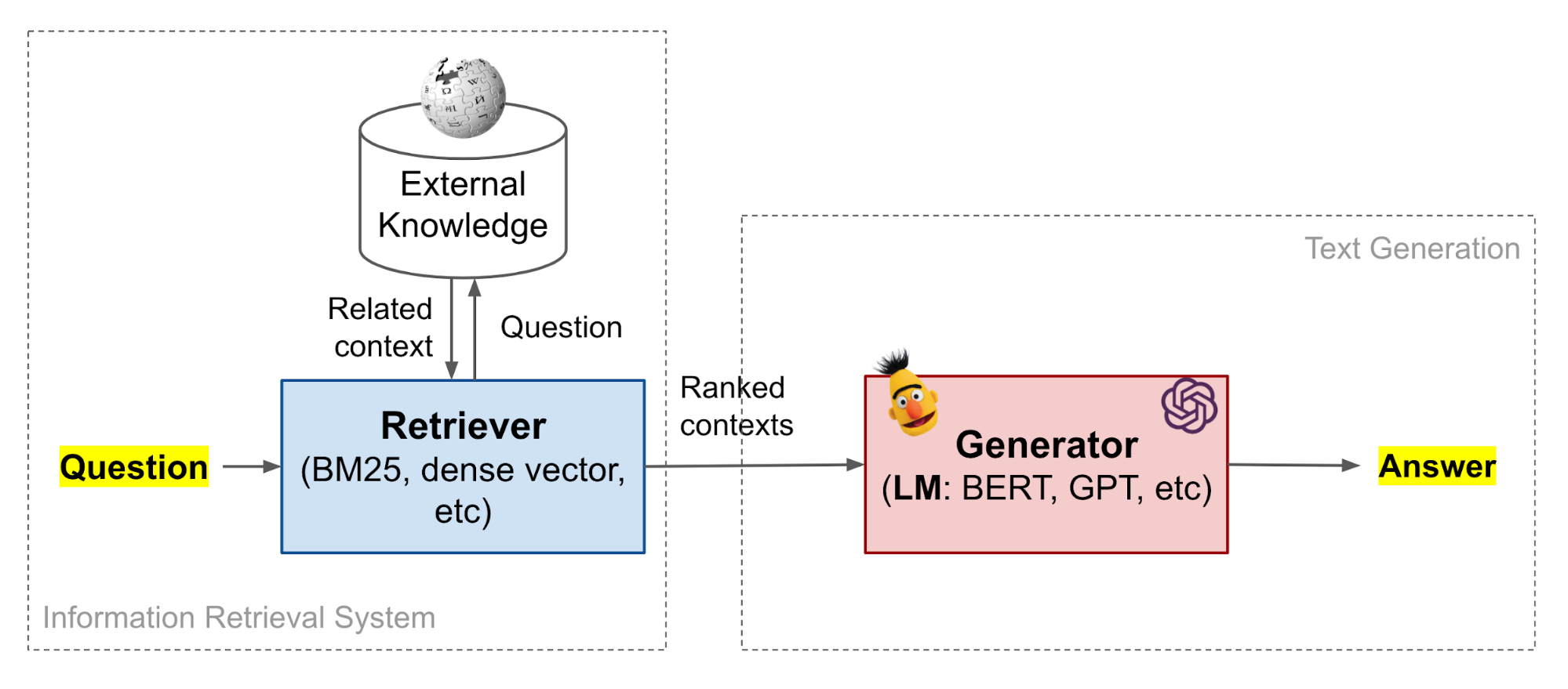
- (3)Closed-book QA: Generative Language Model
- The pre-trained language models produce free text to respond to questions, no explicit reading comprehension.
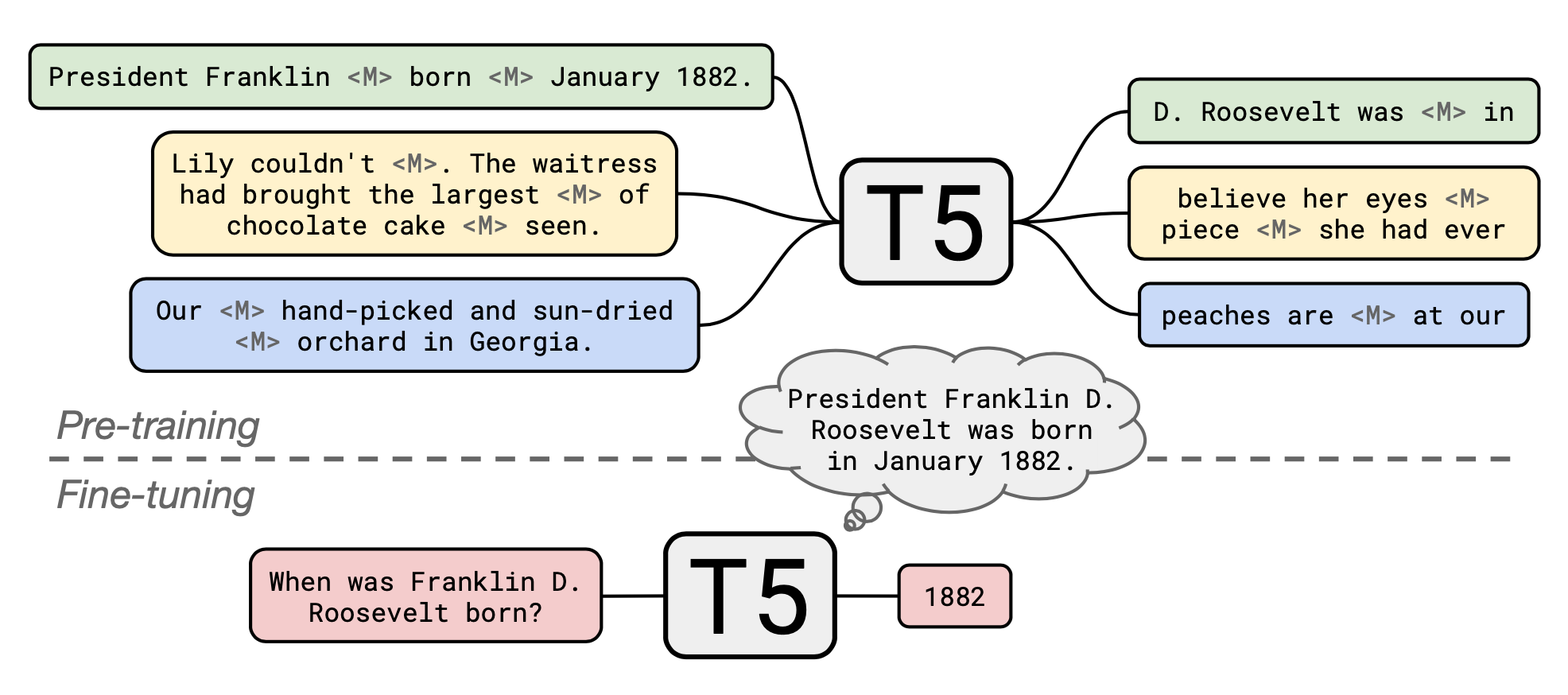
- summary
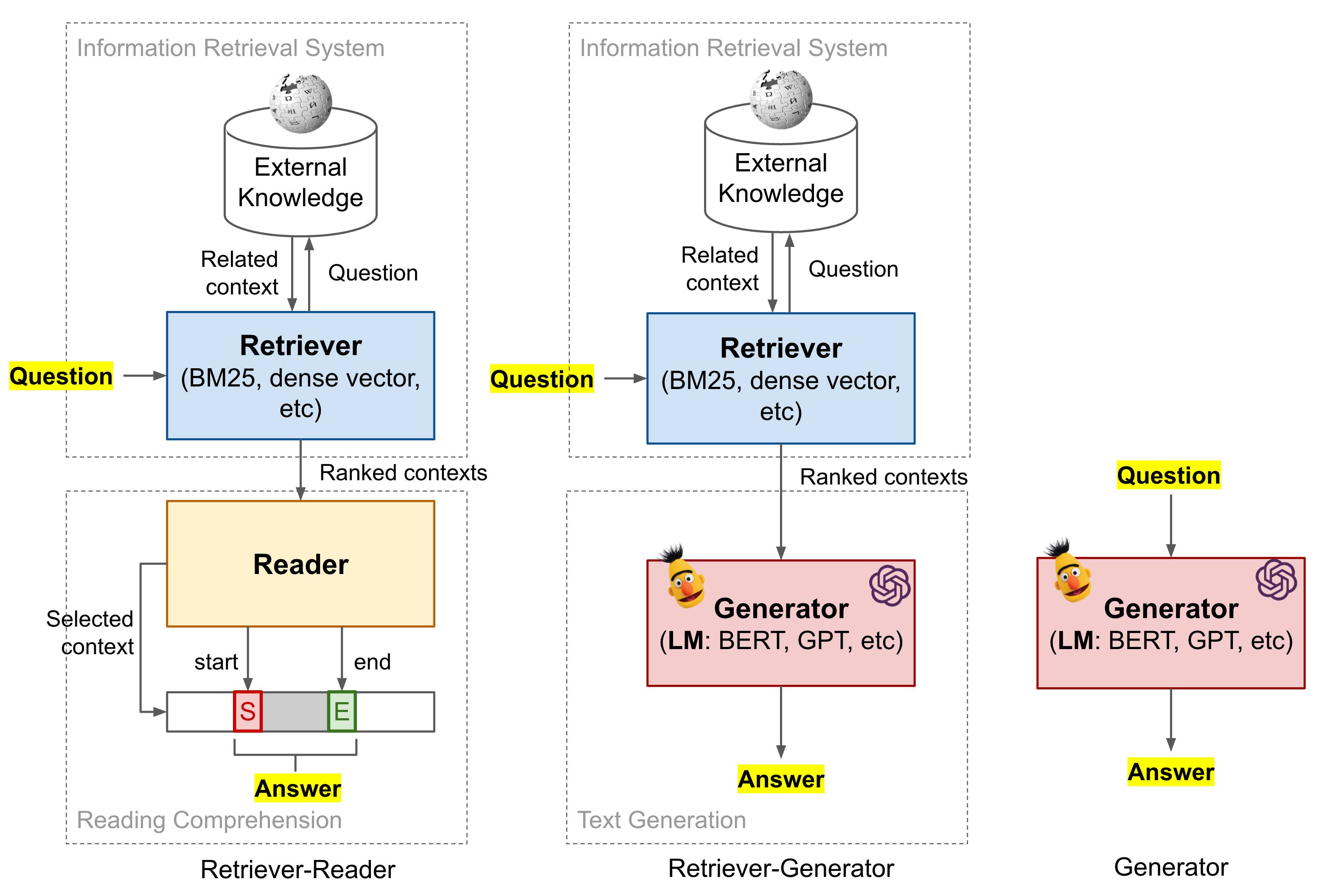
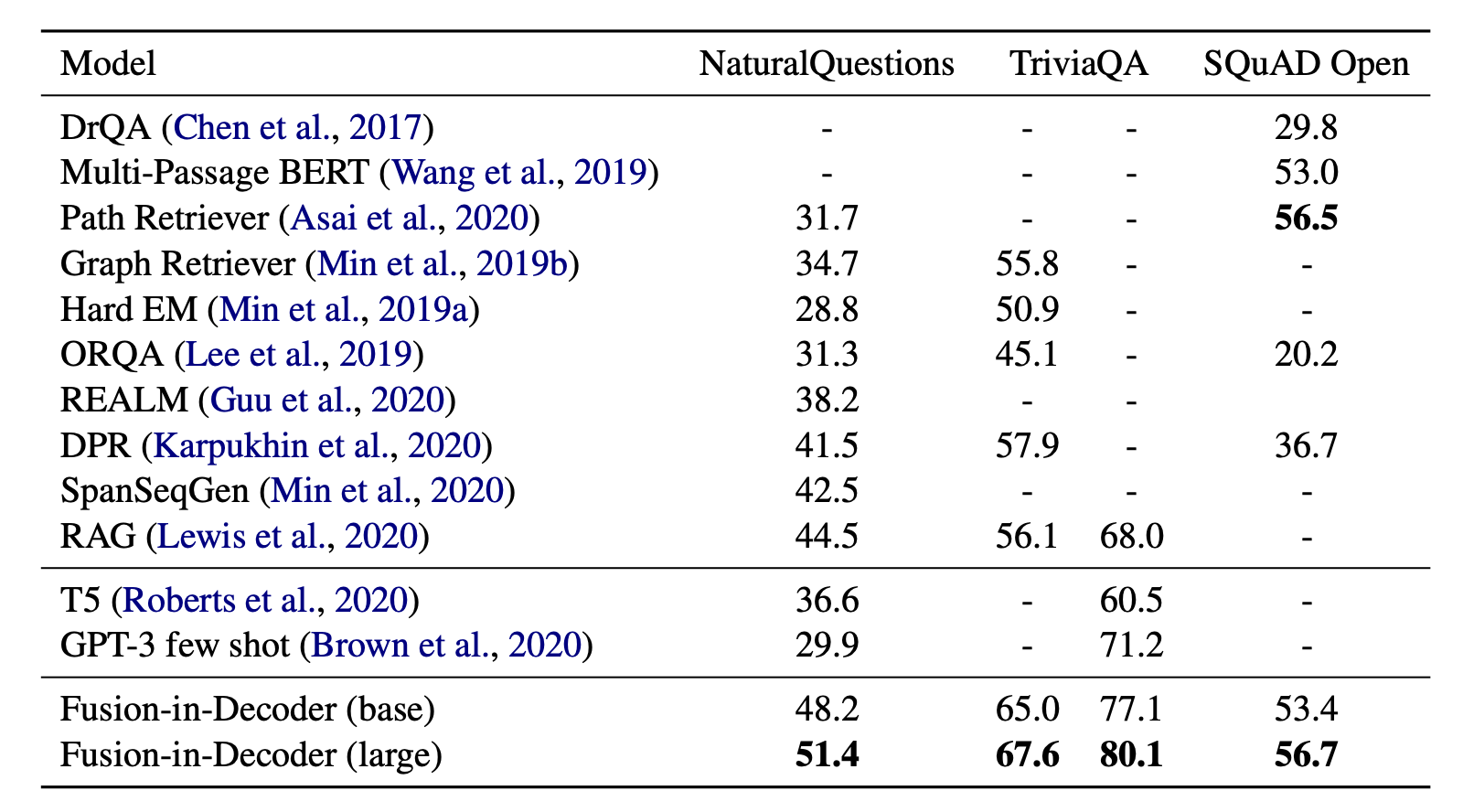
KB-QA

基于知识库的问答:
- 给定自然语言问题,通过对问题进行语义理解和解析,利用知识库进行查询、推理得出答案。
- 特点是回答的答案是知识库中的实体。
- 如:百度询问 2016年奥斯卡最佳男主角 时,百度会根据知识库进行查询和推理,返回答案 “莱昂纳多”
- 知识库通常由大量的三元组组成,每一条三元组包括:entity - relation - entity,如果我们把实体看作是结点,把实体关系(包括属性,类别等等)看作是一条边,那么包含了大量三元组的知识库就成为了一个庞大的知识图。
- 根据问题的复杂程度,又可以分为两类:
- 简单问句:这种问题只需要一个三元组就能搞定,比较基础的通过LR的方法: Antoine Bordes, Jason Weston, Nicolas Usunier. Open question answering with weakly su-pervised embedding models;或者结合CNN、RNN神经网络的方法:Character-Level Question Answering with Attention
- 复杂问句:需要多个三元组,有时需要进一步的推理或者做一些计算。回答这类问题目前采用下面基于语义解析一类的方法效果较好。贴个微软目前比较新的工作 Wen-tau Yih, Ming-Wei Chang, Xiaodong He, and Jianfeng Gao. 2015. Semantic parsing via staged query graph generation: Question answering with knowledge base.
传统的解决方法可以分为三类:
- 语义解析(Semantic Parsing)
- 信息抽取(Information Extraction)
-
向量建模(Vector Modeling)
- 美团智能问答技术探索与实践
- KBQA是一种基于知识图谱的问答技术,其主要任务是将自然语言问题 ( NLQ ) 通过不同方法映射到结构化的查询,并在知识图谱中获取答案。相比非结构化文本问答方法利用图谱丰富的语义关联信息,能够深入理解用户问题、解决更多复杂推理类问题。
- 主流的KBQA解决方案包括基于查询图方法 ( Semantic Parser )、基于搜索排序方法 ( Information Retrieval )。
- 查询图方案核心思路就是将自然语言问题经过一些语义分析方式转化成中间的语义表示 ( Logical Forms ),然后再将其转化为可以在 KG 中执行的描述性语言 ( 如 SPARQL 语言 ) 在图谱中查询,这种方式优势就是可解释强,符合知识图谱的显示推理过程。
- 搜索排序方案首先会确定用户Query中的实体提及词 ( Entity Mention ),然后链接到 KG 中的主题实体 ( Topic Entity ),并将与Topic Entity相关的子图 ( Subgraph ) 提取出来作为候选答案集合,通过对Query以及Subgraph进行向量表示并映射到同一向量空间,通过两者相似度排序得到答案。这类方法更偏向于端到端的解决问题,但在扩展性和可解释性上不如查询图方案。图

- kbqa核心技术,图
- 在知识图谱建模的领域,有一种称为
SPARQL的语言,类似关系数据库查询的SQL语言, - 例如我们要查询 (中国,有首都,北京) 中的北京,则SPARQL可以写为:

Select ?x where {
中国, 有首都, ?x
}
- 也就是问题转换为,如何把一句自然语言“中国的首都是哪?”,转换为上面的SPARQL语句?
- 例如现在的一些方向是利用统计机器学习的翻译任务,完成从“自然语言”到“SPARQL”语言的机器翻译任务,就如同中英翻译等自然语言之间的翻译一样,同样也可以做到的。但是根据语料数据、SPARQL复杂度等等问题,也会有其他各种问题。
- 当然也有不依赖SPARQL作为中间件的查询系统,例如有的文献设计了一套在知识图谱中逐渐搜索(探索)的系统;
- 以这个问题为例,起始点可以是实体“中国”,中国这个实体可能有很多关系,例如有首都、有文化、有省份、有xxx,然后搜索下一步最合理的关系“有首都”;
- 最后探索到答案“北京”,判读任务完成。
IR-QA
- IR-based 问答系统 (IR: Information Retrieval) 不需要提前构建知识,而是根据问题去检索答案(例如从搜索引擎上)。
- 从某种意义上类似人的搜索方式,例如想知道“中国的首都是哪”,可能会去搜索引擎中搜索这个问题,而答案很可能会出现在搜索结果中,这个答案的类型很可能是“某个城市”,所以我们会在搜索引擎给我们的结果中,寻找一个城市名。
- 而机器也可以完成类似过程
- 先根据问题来尝试判断答案类型,同样也可以判断结果类型为城市。
- 然后可能需要对问题进行重构,也就是寻找一个搜索问句,能找到答案的几率最大,例如这个问题可能被重构为:“中国 首都 城市”。(最后添加了这个词城市,是因为我们假设可以准确判断出答案类型)
- 机器去自有的非结构化文档(没有知识图谱化的文档,例如各种纯文本文章),从中寻找最接近我们重构后问题的段落。或者去搜索引擎、百科网站等等,搜索答案、或者检索问题相关的段落。
- 定位到这个段落后,根据答案类型(这里是城市),尝试从这个段落中筛出答案。例如去搜索引擎搜索“中国的首都”,很可能第一个答案段落中的第一个出现的城市名就是我们所需要的答案。
NL2SQL
NL2SQL(Natural Language to SQL)是一项将用户的自然语句转为可执行 SQL 语句的技术,有很大的实际应用价值,对改善用户与数据库之间的交互方式有很大意义。
详见站内专题: NL2SQL
闲聊型对话
- 微软小冰通用闲聊框架,通用闲聊的整体流程也是 检索 + 排序

- 任务框架 微软小冰对话机器人框架
- 任务机器人应该用的还是 Frame-based 的经典框架。这块就不再多说,值得提的是,小冰会依据用户画像给出个性化的答复。例如一个美国人问中国面积多大时,答复里的面积单位是平方英里,而中国人问答复里的面积单位是平方公里。
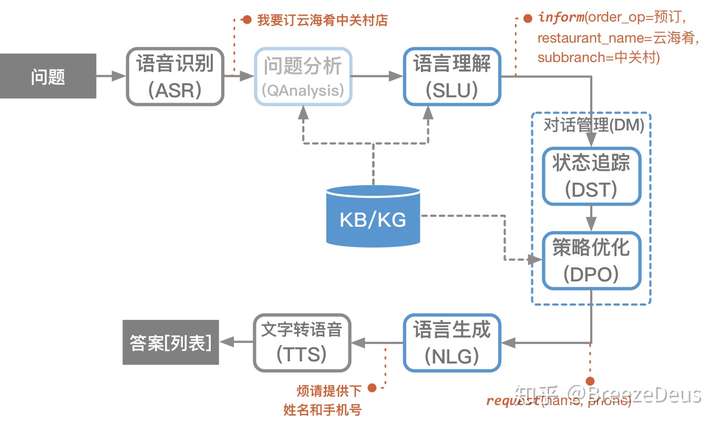
推荐式对话
- 【2021-12-2】万字长文详述对话推荐系统的逻辑与演化,人民大学,RUC AI Box 开发和维护了一个用于构建对话推荐系统的开源工具 CRSLab代码(发表在 ACL Demo 2021)
- 三个主要的功能模块,分别是:
- User Interface:用户交互模块(交互模块),它需要理解用户给予的自然语言反馈,也需要在最后给出系统的文本答复。
- Conversation Strategy Module:对话策略管理模块(对话模块),它需要根据当前状态做出如何回复的决定,比如是继续询问还是进行推荐。
- Recommender Engine:推荐引擎(推荐模块),负责根据用户的偏好给出相应的推荐列表或者单个推荐结果。
- 对话推荐系统常见baseline基线模型
- 第一种称为“基于属性的对话推荐”(attribute-based CRS):基于属性的对话推荐系统更多地针对策略模块进行构建,希望能在最短的交谈次数内实现尽可能精确的推荐。这类模型通常采用强化学习(reinforcement learning)方法来训练对话管理器,以期在更长的时间跨度内获得更高期望的回报。相应地,它们通常有一个简化的对话模块,比如使用带槽(slot)的固定模板来填充推荐结果,形成系统的回复文本。
- 常见模型:从最早的单轮推荐场景 CRM(SIGIR 2018)出发,介绍引入多轮推荐场景的模型 EAR(WSDM 2020),再到将对话推荐概括为图上推理问题的模型 CPR(KDD 2020),其实际上也是对搜索问题的剪枝操作,最后是希望学习统一策略的模型 UNICORN(SIGIR 2021)。
- 第二种模型的话,有的文献称之为 chit-chat-based CRS,也有的称之为 open-ended CRS,笔者更习惯称之为“生成式对话推荐”。生成式对话推荐系统更注重向用户提供流畅的对话体验,同时灵活地将推荐物品相关的信息融入到回复文本中,以提升推荐结果的可解释性。这类模型通常采用序列到序列(sequence-to-sequence)模型来构建对话模块,而策略模块则可能隐式地包含在拷贝机制(CopyNet)或者其他结构中。同时,近年来兴起的大规模预训练语言模型也进一步增强了生成式对话推荐系统的对话能力。
- 常见模型:从提出了应用最广泛的数据集的工作 ReDial(NeurIPS 2018)开始,介绍知识增强的模型 KBRD(EMNLP 2019)、语义融合的模型 KGSF(KDD 2020)和话题引导的模型 TGReDial(COLING 2020),最后介绍希望实现更可控推荐对话文本生成的模型 NTRD(EMNLP 2021)。
- 第一种称为“基于属性的对话推荐”(attribute-based CRS):基于属性的对话推荐系统更多地针对策略模块进行构建,希望能在最短的交谈次数内实现尽可能精确的推荐。这类模型通常采用强化学习(reinforcement learning)方法来训练对话管理器,以期在更长的时间跨度内获得更高期望的回报。相应地,它们通常有一个简化的对话模块,比如使用带槽(slot)的固定模板来填充推荐结果,形成系统的回复文本。
- 推荐系统为工业界带来了巨大的收益。大多数推荐系统都是以静态的方式工作,即从用户历史的交互中来推测用户的兴趣爱好从而做出推荐。然而,这样的方式有缺陷,具体来说,两个较重要的问题无法被解答:
- 1)用户目前具体喜欢什么?
- 2)用户为什么喜欢一个商品?
- 对话推荐系统(Conversational Recommender Systems,CRSs)的出现,从根本上解决这个问题。其打破了传统静态的工作方式,动态地和用户进行交互,获得用户的实时反馈,进而向用户做出心仪的推荐。此外,借助自然语言的这一工具,CRSs 还可以灵活地实现一系列任务,满足用户的各种需求。
-
CRSs 中的五个任务梳理其难点。
- 推荐系统冷启动通常分为三类,即用户冷启动、物品冷启动还有系统冷启动。无论那种冷启动都因为只有较少的数据和特征来训练模型,所有需要不同的技术方案来提升推荐效果。另外冷启动结合产品方案可以加速冷启动的过程。
- 用户冷启动的问题对于移动互联网基于内容推荐产品中非常重要
- 快手和中科大发表在 TOIS (ACM Transactions on Information Systems) 上的最新工作提出融合物品(视频)和属性的统一框架,用汤普森采样结合对话式的方法为冷启动用户做推荐。对话式推荐能够通过向用户提问来快速获得用户兴趣,而汤普森采样能够保持探索-利用的平衡,这两点均有助于系统尽快地探索到冷启动用户的兴趣并利用已有知识进行推荐。
- Seamlessly Unifying Attributes and Items: Conversational Recommendation for Cold-Start Users
- 两个关键点:
- 如何做到探索-利用的平衡。在推荐系统中,探索(Exploration)是指去主动寻找未知的用户潜在的兴趣;利用(Exploitation)是指根据已有的经验去估计用户当前的兴趣并做出推荐。由于缺乏用户行为历史数据,在为冷启动用户做推荐时保持探索和利用的平衡尤为重要——我们既要尽快探索用户对不同商品的兴趣,又要尽可能利用当前已经获得的知识来做出合适的推荐。这样才能尽可能吸引新用户和低活用户,并提高留存率。
- 对话式推荐方法。对话式推荐在推荐系统领域近来得到广泛的关注。对话式推荐系统中的“对话”模块能够直接向用户提问,并期望通过用户的回答显式地获得用户的兴趣。提问的形式可以多种多样,本文考虑对物品的属性进行提问。例如,在快手短视频推荐的场景中,新用户的应用主界面会收到一个弹窗。
CRSs定义
- CRSs 还没有主流、统一的定义。本文将 CRS 定义为:
- 能通过实时的多轮对话,探出用户的动态喜好,并采取相应措施的推荐系统
- “A recommendation system that can elicit the dynamic preferences of users and take actions based on their current needs through real-time multiturn interactions using natural language.”
- 对话式推荐中三个核心的策略问题:
- (1)问什么问题;
- (2)推荐什么物品;
- (3)当前是问问题还是做推荐。
CRSs架构
- 架构可以用三个模块来组成
- 用户接口模块(User Interface)负责直接与用户进行交互;
- 推荐引擎(Recommender Engine)负责推荐工作;
- 最为核心的对话策略模块(Conversation Strategy Module)负责统筹整个系统的任务、决定交互的逻辑。
- 快手研发统一的框架 ConTS,把物品和属性建模到一个空间中,利用改进的汤普森采样算法 [1] 保持探索和利用的平衡,并使用一个统一的打分函数来统一解决对话式推荐中的三个核心问题。
CRSs的定位与作用
- (1)CRSs与传统推荐系统的区别
- 传统推荐系统是静态的:其从用户的历史交互信息中来估计用户偏好。而 CRSs 是动态地与用户进行交互,在模型有不确定的地方,可以主动咨询用户
- 一方面,传统推荐系统不能准确的估计用户目前具体喜欢什么东西(What exactly does a user like?),这是由于用户的历史记录通常很稀疏,而且充满噪声。举例来说,用户可能做出错误决策,从而购买过一个不喜欢的东西。且用户的喜好是会随着时间改变的。
- 另一方面,传统推荐系统不能得知为什么用户喜欢一个东西(Why does a user like an item?),举例来说,用户可能由于好奇购买一个东西,可能由于受朋友影响购买一个东西。不同理由下的购买,其喜好动机和程度都是不一样的。
- 受益于 CRSs 的交互能力,CRSs 能解决传统推荐系统做不到的以上两点内容。系统在不确定用户具体偏好,以及为什么产生该偏好时,直接向用户询问即可。
- (2)CRSs与交互式推荐系统的区别
- 交互式推荐系统可以视为 CRSs 的一种早期雏形,目前仍然有交互式推荐系统的研究。大多数交互式推荐系统,都遵循两个步骤:
- 1)推荐一个列表;
- 2)收集用户对于该推荐的反馈。
- 然后往复循环这两个步骤。
- 交互式推荐系统可以视为 CRSs 的一种早期雏形,目前仍然有交互式推荐系统的研究。大多数交互式推荐系统,都遵循两个步骤:
- 然而这并不是一种好的交互模式。
- 首先,这种交互太单调了,每轮都在循环推荐和收集反馈,很容易让用户失去耐心;
- 其次,一个好的推荐系统应该只在其置信度比较高、信心比较充足的情况下进行推荐;
- 最后,由于商品的数量巨大,用推荐商品的方式来了解用户的兴趣喜好,是低效的。
- 而 CRSs 引入了更多的交互模式。例如,其可以主动问用户问题,例如问关于商品属性的问题:“你喜欢什么样颜色的手机?”“你喜欢关于摇滚类乐曲吗?”丰富的交互模式克服了交互式推荐系统的三个问题,用更高效的方式来进行交互,从而快速获得用户的兴趣爱好,在信心比较充足的情况下,才作出推荐。
- (3)CRSs与任务型对话系统的区别
- 两者没有本质上的区别,而在目前的实现方式和侧重点上有差异。
- 目前,大多数任务型的对话系统,主要关注点还是自然语言处理的任务,而非检索、推荐任务。任务型对话系统也有一个对话策略(Dialog Policy)模块作为核心模块来进行任务的统筹和规划,但由于其侧重对话本身,其训练和工作方式还是以从人类的文本(训练集)中拟合特定模式为主,同时加入知识图谱等信息作为辅助,来进行监督学习式训练,最终使得系统能生成流畅合理的自然语言以回复用户以完成某一特定任务。
- 有学者在实验探究中发现,用基于任务型对话系统实现的对话推荐,存在一些问题 [2]。首先系统“生成”的对话,并不是真正意义上的生成,所有词汇、句子都在之前的训练文本中出现过。而且,这种方式产生的推荐,质量并不令人满意。
- 相比较任务型对话系统,CRSs 关注的重点并不在于语言,而是推荐的质量。CRSs 的核心任务,还是利用其交互的能力去想方设法获得用户喜好,做出高质量体检。与此同时,CRSs 的输入输出可以用基于规则的文本模版来实现。当然,这并不代表语言不重要。随着技术的的发展迭代以及学者们研究方向的重合,不同领域的差距将越来越小。
- 两者没有本质上的区别,而在目前的实现方式和侧重点上有差异。
重要的研究方向
- (1)基于问题的用户偏好刺探
- CRSs 的一项重要功能,是实时地向用户进行提问,以获得用户的动态偏好。这其中,各式方法可以分为两个类。一是询问商品,即收集用户对推荐商品本身的喜好;二是询问用户对商品属性的偏好,例如“你喜欢摇滚类的音乐吗?”一个基于路径推理的 CRS 示意图如下。原文表 1 总结了各种 CRSs 的工作原理。更多细节请看原文。
- (2)多轮对话推荐策略
- CRSs 的一个核心任务是关注如何问问题,即什么时候问问题,什么时候做推荐。本文总结了几种模式,包括“问一轮推一轮”、“问 X 轮推一轮”,“问 X 轮推 Y 轮”几种方式。其中 X 和 Y 可固定或由模型决定。图 3 给出了一个“问 X 轮推 Y 轮”的 CRS 模型示意图。图
- 除了提问以外,CRSs 也可考虑其他多轮对话策略,如加入闲聊以增加趣味,或者加入说服,协商等多样化的功能以进一步引导对话。原文表 2 总结了 CRSs 的多轮对话策略。
- CRSs 的一个核心任务是关注如何问问题,即什么时候问问题,什么时候做推荐。本文总结了几种模式,包括“问一轮推一轮”、“问 X 轮推一轮”,“问 X 轮推 Y 轮”几种方式。其中 X 和 Y 可固定或由模型决定。图 3 给出了一个“问 X 轮推 Y 轮”的 CRS 模型示意图。图
- (3)自然语言理解及生成
- 处理用户多样化的输入以及灵活的输出,也是 CRSs 中的一大挑战。目前的 CRSs 多数还是以基于提前标注的输入以及基于模版的输出为主,少数 CRSs 以对话系统的模式出发来考虑直接处理自然语言和生成自然语言。这是因为 CRSs 的主要目标还是保证推荐的质量,而非语言处理能力。原文表三总结了两个分类下的部分工作。
- (4)探索与深究之间的权衡
- 探索与深究是推荐系统中一个重要的研究方向,也是处理冷启动用户的一个有效手段。探索意味着去让用户尝试以往没有选择过的商品,而深究则是利用用户之前的喜好继续推荐。前者冒着用户可能不喜欢的风险,但能探索到用户一些额外的喜好;后者则安全保险,但一直陷入在已知的局部偏好中,不去改变。
- 这就如同经典的多臂老虎机问题(Multi-armed Bandit, MAB),如图 4,一个赌徒可以选择多个老虎机的摇杆进行下拉。每个摇杆 下拉后的收益期望 μ 是可以根据多次实验估计出来的,但由于实验次数有限,对收益的估计存在不确定性 。若要追求全局最优点,便需要从尝试新摇杆(Exploration)与选择目前已知的高收益摇杆(Exploitation)这两者中不断交替权衡,从而达到长期的高收益。 图
- 由于 CRSs 和交互式推荐系统一样,都可以实时地获得用户的反馈,于是 MAB 问题以及一系列解决方法都可以应用在 CRSs 与交互式推荐中。此外,除了经典的 MAB 算法,Meta learning 的方法也可以应用在 CRSs 中来解决冷启动或者 EE 问题。原文表 4 中列举了一些工作。
- (5)模型评测和用户模拟
- 算法评测是个很重要的问题,在 CRSs 中,由于有些算法要求文本数据,有些算法要求实时交互数据,故有工作从众包平台采集实时交互的对话数据。而有些工作则另辟蹊径,从已有的推荐数据集中造出用户模拟器(User simulators)来与 CRS 模型进行实时的交互。原文表 5 列举了目前 CRSs 中常用的数据集。
- 关于 CRSs 的评测指标。本文将其分为两个层级
- 第一个层级是每轮级别的评测,其中值得评测的量包括推荐的质量,指标用推荐中常用的Rating-based指标,如 RMSE 或者 Ranking-based 指标,如 MAP,NDCG。另一个值得评测的量是文本生成的质量,指标包括 BLEU 与 ROUGE 等。
- 第二个层级是对话级别的评测,主要关心的量是对话的平均轮次(Average Turns, AT),在 CRS 任务中,越早推中用户喜欢的商品越好,故对话的轮次越短越好。另外一个指标是对话在特定轮次的成功率(Success Rate@t, SR@t),该指标越高越好。
- 由于用户参与的交互通常很慢且难以获取,CRSs 的评测依赖用户模拟器。常用的用户模拟策略包括:
- 从历史交互中直接模拟出用户在线的偏好,然而这种方式存在问题:历史交互通常非常稀疏,模拟出的用户无法回答那些空缺值处的喜好;
- 先补齐用户历史交互中的空缺值,用补齐后的交互来模拟用户在线偏好。这种方式潜在的风险是补齐算法难免引入额外偏差;
- 利用用户对商品的在线评论进行模拟。由于用户对商品的评论中包含很多可以反映用户偏好的属性信息,这种模拟方式将带来更全量的信息;
- 从历史的人类对话文本库中模拟出用户,其适用于让 CRS 系统来模拟训练数据中的模式及语言的模型。
展望未来的可做方向
- (1)对CRSs的三个模块进行协同优化
- CRSs 包含三个模块,用户界面、对话策略模块以及推荐引擎。很多 CRSs 的工作将它们分开进行优化。然而这三个模块在任务上是有交叉的地方,需要考虑对它们考虑协同优化。
- (2)关注CRSs中的偏差并进行去偏差
- 推荐偏差近年来受到研究者们很大关注,原因是观测到的数据中通常存在各式各样的偏差,例如选择性偏差,即用户倾向于选择自己更喜欢的东西进行交互,这就使得没有观测到的东西与观测到的东西有着不一样的喜好分布。因此不能简单地用观测到的东西的分布来估计空缺值。除此之外,观测数据中其他偏差,可参考另外一篇综述 [5]。虽然 CRSs 的实时交互可以部分缓解这些偏差问题,然而偏差依然会影响推荐结果。故去除 CRSs 中的偏差是一个有意义的研究方向。
- (3)设计更智能的对话策略
- CRSs 最核心的部件是对话策略模块。目前已有工作考虑的策略还比较基础简单。我们可以考虑更加智能的策略,例如将强化学习的最新研究成果应用到 CRSs 的对话策略中。例如,逆强化学习可以自动的学习回报项,元强化学习可以考虑交互非常稀疏场景。
- (4)融入额外信息
- 让 CRSs 更加智能的一种直接的方法,便是融入更多信息。这些信息可以是商品知识图谱,也可以是多模态的信息,例如声音信息,视觉信息等。处理这些信息的相应算法已经被研究了多年,例如图卷积网络等方法,也可利用起来造福 CRSs。
- (5)开发更好的评测方式以及模拟用户的方法
- 仅开发算法还不够,好的评测方法如同好的指导老师,能指引 CRSs 正确的前进方向。故研究 CRSs 的评测也意义重大。此外,由于 CRSs 的训练和评测都很依赖模拟用户,研究更加全面更加靠谱的模拟用户也是亟待解决的问题。
- 参考
工程实现
- 各类聊天机器人框架
- 开源问答系统开源软件, 7个开源问答平台
- OSQA, 演化为Askbot, 是一款免费且开源的问答系统,采用Python的Django开发框架,基于中国优秀的问答系统CNProg,非常类似国外著名的技术问答网站stackoverflow
- 问答网站软件 shapado : shapado 是一个用 Ruby 开发的类似 stackoverflow 的问答网站软件,基于 Mongodb 开发。
- PHP问答系统 Question2Answer 是一个用 PHP 实现的类 StackOverflow 网站的问答系统
- WeCenter 是一个类似知乎以问答为基础的完全开源的社交网络建站程序,基于 PHP + MYSQL 应用架构,它集合了问答,digg,wiki 等多个程序的优点,帮助用户轻松搭建专业的知识 库和在线问答社区
JSGF
-
强大的正则工具,支持快速定制NLU
- CFG、JSGF系列规则体系
- 示例
# JSGF V1.0 UTF-8 en; grammar com.local;
public <cmd> = <cmd1>|<cmd2>|[option1|option2] say;
<cmd1> = please|/10.2/hello;
<cmd2> = open|close|start|stop;
- 自然语言理解-从规则到深度学习
- 对于“帮我打开空调”,其在图中的匹配路径

public <controlDevice> = <startPolite> <command> <endPolite>;
<command> = <action> <object>;
<action> = (打开|关闭);
<object> = [这个|那个](空调|加湿器|音箱){device};
<startPolite> = (请|帮 我) *;
<endPolite> = [啊|吧];
- 语法说明
- 头部格式固定,‘#’是开头。
- 第二行定义本语法的名字,用于被其他语法引用
- 符号”<>”包含之内的叫做规则名
- Public代表外面能够使用到这个规则。不加说明这个规则只能本文件使用。
- 符号’|’是或的意思,从中取一个结果。Open|close 只取其中一个值
- 符号“[]”内部包含的是可选的意思,即可以取也可以不取这里的值
- 符号“()”分组的意思,也能扩充优先级。
- 符号“//”表示权重
- 符号“\”表示在字符串中出现特殊符号的时候使用。
- 符号“*”表示出现0~N次
- 符号“+”表示出现1~N次
- 符号“{}”表示匹配时返回{}中给出的结果
-
表示无声音时候匹配 -
表示不识别的声音匹配 15. 注释: // ;/**/ ;@xx;
-
注:暂不支持import功能,已提issue(Suggestion: it’s better to add
importfunction) - 案例
实际案例:
<what> = ( 啥|是什么|怎么算|怎么计算|什么是|是多少|什么|?|?);
<fact> = ( 定义|方法|规则|要求|咨询);
<how> = ( 怎么办|咋办|咋|咋样|咋整|不了|怎样|怎么样|怎么弄|怎么用|什么办法|办法|如何|如何处理|怎么处理 );
<why> = ( 为什么|为什|为何|原因|什么原因|什么意思|怎么回事|怎麽回事|怎么不|怎么还|怎么没|怎么是|怎么这么|啊|还是|干嘛|凭啥|凭什么|咋没有|还没|解释|啥意思 );
<which> = ( 哪一个|哪个);
<where> = ( 哪|地点|哪里|在哪儿|哪儿|在那里|那里);
<much> = ( 哪些|几个|几次|多少 );
<when> = ( 什么时候|多久|怎么还|啥时候 );
<whether> = ( 能不能|是否|可不可以|可以|吗?|吗?|吗|么|没有|有没有|是不是|行不行|好不好 );
// 肯定、否定
<yes> = (是|是的|对|嗯 );
<no> = ( 不是|不是的|不对|错了|不|未|没有|没 );
// wangqiwen, 格式:[qname[qid] : 相关case集合(/分隔)], 便于跟踪矫正
// 指派模式拒单规则及影响[3042657] : 派单模式拒单会影响我服务分吗/派单模式不能取消吗/派单模式规则/我可以取消指派订单吗/指派订单必须得去吗
public <qid_3042657> = (<qid_3042657_1>|<qid_3042657_2>) {qid-3042657};
<qid_3042657_1> = ( (<assign_mode> <cancel>)|(<cancel> <assign_mode>) [<whether>|<what>|<fact>] );
<qid_3042657_2> = ( <assign_mode> <whether> );
- Python的jsgf工具包
Python包:pyjsgf
- pip install pyjsgf 示例:
from jsgf import PublicRule, Literal, Grammar
# Create a public rule with the name 'hello' and a Literal expansion 'hello world'.
rule = PublicRule("hello", Literal("hello world"))
# Create a grammar and add the new rule to it.
grammar = Grammar()
grammar.add_rule(rule)
# Compile the grammar using compile()
# compile_to_file(file_path) may be used to write a compiled grammar to
# a file instead.
# Compilation is not required for finding matching rules.
print(grammar.compile())
# Find rules in the grammar that match 'hello world'.
matching = grammar.find_matching_rules("hello world")
print("Matching: %s" % matching[0])
Dialogflow Google
- DialogFlow是基于谷歌的Duplex技术开发,该技术使得客户获得更好的人机交互体验,使得对话聊天更加自然。推出 Dialogflow (https://dialogflow.com),用于替代 API.AI,将 Dialogflow 打造成您构建出色的对话体验的端到端平台
- API.AI 是一家B2D(business to developer)公司,是一个为开发者提供服务的机器人搭建平台,帮助开发者迅速开发一款bot并把发布到各种message平台上。2016年9月被Google收购,是Google基于云的自然语言理解(NLU)解决方案
- Dialogflow 提供了一个网页界面,称为 Dialogflow 控制台(访问文档,打开控制台)

- Dialogflow的工作原理。智能客服技术专栏,解码Dialogflow:构建智能机器人入门
- 1.Dialogflow的输入可以是基于文本或人声的20种不同语言,包括一些本地方言,如英语(美国和英国)或中文(简体和繁体)。文本输入来自消息传递通道,包括SMS,Webchat和电子邮件。谷歌与Slack,Facebook Messenger,Google智能助理,Twitter,微软Skype和Skype for Business,思科Webex Teams,Twilio,Viber,Line,Telegram和Kik建立了Dialogflow集成。来自Amazon和Microsoft的SMS,电子邮件和语音助理需要额外的编码或消息处理才能输入Dialogflow。
- 2.基于文本的消息可以通过可选的拼写检查程序。当人们输入或使用短信时,拼写错误很常见。纠正拼写错误将提高自然语言理解引擎的准确性。
- 3.Dialogflow的语音呼叫通过Google的语音到文本处理器,将用户的语音输入转换为文本流。
- 4.将语音转换为文本或输入文本已更正后,生成的文本流将传递到Dialogflow中的自然语言理解引擎。这实际上是支持智能机器人创建的核心元素。
- Dialogflow首先检查文本流并尝试找出用户的意图。意图是用户想要的–为什么他或她首先与机器人交互。获得正确的意图至关重要。(我们将在后续文章中讨论如何创建Dialogflow意图。)
- 意图的例子可以是“我想知道天气预报”,“我的银行余额是什么”,以及“我想要预订”。
- 意图通常具有与之关联的实体,例如名称,日期和位置。如果你想知道天气,你需要告诉机器人的位置。如果您想知道您的银行余额,那么机器人将需要获取该帐户的名称。一些比如日期,时间,地点和货币都是开箱即用的,并且是作为Google技术堆栈的一部分启用的。
- Dialogflow支持上下文的概念来管理会话状态,流和分支。上下文用于跟踪对话的状态,并且它们会在根据用户之前的回复指导对话时影响匹配的意图。上下文有助于使交互感觉自然而真实。
- Slots是与实体关联的参数。在银行余额意图示例中,实体是该人的姓名。Slot可能是正在寻找余额的人名下的特定帐号。如果您要预订机票,您的座位偏好(窗口或过道)是slot值。
- 使用Dialogflow创建智能机器人需要开发人员考虑机器人应该处理的所有意图以及用户阐明此意图的所有不同方式。然后,对于每个意图,开发人员必须识别与该意图相关联的实体,以及与每个实体相关的任何slots。如果查询中缺少实体(entity)和/或slot,则机器人需要弄清楚如何向用户询问它。
- 5.一旦Dialogflow识别出intent,entities和slot值,它就会将此信息移交给满足意图的软件代码。实现意图可能包括进行数据库检索以查找用户正在查找的信息,或者为后端或基于云的系统调用某种API。例如,如果用户要求提供银行信息,则此代码将与银行应用程序连接。如果意图是用于HR策略信息,则代码触发数据库搜索以检索所请求的信息。
- 6.一旦检索到必要的信息将通过Dialogflow传回并返回给用户。如果交互是基于文本的,则在调用以发送消息的同一渠道中将文本响应发送回用户。如果是语音请求,则将文本转换为语音响应用户。 当Dialogflow通过其中一个联络中心合作伙伴作为CCAI的一部分进行集成时,流程变得有点复杂,但功能更强大。
- 自然语言处理(NLP)算法可以计算两种不同类型的对话内容。
- ①基于意图(Intent-based)的对话:这是当NLP算法使用intents和entities进行对话时,通过识别用户声明中的名词和动词,然后与它的dictionary交叉引用,让bot可以执行有效的操作,这种类型的对话是Dialogflow使用的。
- ②基于流程(Flow-based)的对话:基于流程的对话是智能通信的下一个级别。在这里,我们会给予两个人之间对话的许多不同样本的RNN(循环神经网络),创建的机器人将根据你训练的ML模型进行响应。Wit.ai是在这个领域取得巨大进展的少数网站之一,不用担心,我们不需要做到这个程度。
- Dialogflow 可以与 Google 助理、Slack 和 Facebook Messenger 等许多热门对话平台集成。
- (1)在集成服务中使用 Fulfillment
- (2)通过 API 实现用户互动
- 如果没有使用某个集成选项,则必须编写与最终用户直接交互的代码。必须为每轮对话直接与 Dialogflow 的 API 交互,以发送最终用户表述并接收意图匹配信息。下图展示了使用该 API 进行互动的处理流程。
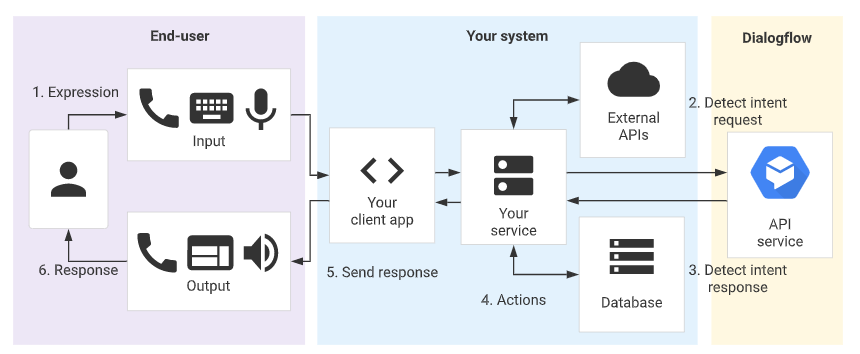
- 参考:
- Dialogueflow基础知识
- Dialogflow ES 基础知识
- 利用Dialogflow构建聊天机器人,当用户在 Google Chat 中提出问题时,启动的聊天机器人会与 Dialogflow 集成,来进行自然的对话,Dialogflow 通过 Cloud Functions 实现与后端数据库或 Sheets集成。含youtube视频介绍,解构聊天机器人系列视频
- 聊天机器人教学:使用Dialogflow (API.AI)开发 iOS Chatbot App,酒店预订示例代码:ChatbotHotel
- 登录自己的Google帐户,可以按照以下步骤登录Dialogflow:https://console.dialogflow.com/api-client/#/login

- 代理agent
- Dialogflow 代理是负责与终端用户对话的虚拟客服人员。它是一种NLU模块,能够理解人类语言的细微差别。Dialogflow 可以在对话过程中将用户输入的文字和音频转换为应用和服务可以理解的结构化数据。您可以设计并构建 Dialogflow 代理来负责您的系统所需的各种对话。
- Dialogflow 代理类似于人类呼叫中心的客服人员。您可以对代理/客服人员进行训练来处理预期的对话场景,您的训练不需要过于明确
- 意图 Intents
- 用户每轮对话的意图进行分类。可以为每个agent定义多个意图,组合意图可以处理一段完整的对话。当终端用户输入文字或说出话语(称为“终端用户表述”时,Dialogflow 会将用户表述与agent中最佳意图进行匹配。匹配意图也又称为“意图分类”。
- 例如,创建一个天气agent,用于识别并响应用户关于天气的问题。您可以为与天气预报有关的问题定义一个意图。如果最终用户说出“What’s the forecast?”,Dialogflow 会将该用户表述与预测意图相匹配。您还可以定义意图,以便从最终用户表述中提取实用信息,例如所需哪个时间或地方的天气预报。提取的数据对于系统为最终用户执行天气查询非常重要。
- 基本意图包含以下内容:
- 训练语句:这些是最终用户可能说出的语句示例。 当最终用户的表述与其中某一语句相近时,Dialogflow 会将其视为匹配意图。Dialogflow 的内置机器学习功能会根据您的列表扩展出其他相似的语句,因此您无需定义所有可能出现的示例。
- 操作:您可以为每个意图定义一项操作。 当某个意图匹配时,Dialogflow 会向系统提供该操作,您可以使用该操作触发系统中定义的特定操作。
- 参数:当某个意图在运行时匹配时,Dialogflow 会以“参数”形式提供从最终用户表述中提取的值。 每个参数都有一个类型,称为实体类型,用于明确说明数据的提取方式。 与原始的最终用户输入不同,参数是结构化数据,可以轻松用于执行某些逻辑或生成响应。
- 响应:您可以定义要返回给最终用户的文本、语音或视觉响应。 这些响应可能是为最终用户提供解答、向最终用户询问更多信息或终止对话。
- 下图展示了匹配意图和响应最终用户的基本流程:
- 更复杂的意图还可能包含以下内容:
- 上下文:Dialogflow 上下文类似于自然语言上下文。 如果有人对您说“它们是橙色的”,您需要了解上下文才能理解此人所指的是什么。 同样,为了让Dialogflow 处理类似的最终用户表述,您需要为其提供上下文,以便系统正确地匹配意图。
- 事件:借助事件,您可以根据已发生的情况而非最终用户表达的内容来调用意图。
- 实体 Entities
- 上下文
- Dialogflow 上下文类似于自然语言上下文。 如果有人对您说“它们是橙色的”,您需要了解上下文才能理解“它们”指的是什么。 同样,为了让 Dialogflow 顺利处理类似的最终用户表述,您需要为其提供上下文,以便系统正确地匹配意图。
- 您可以使用上下文来控制对话流程。 您可以为意图配置上下文,方法是设置由字符串名称标识的输入和输出上下文。 当某个意图匹配时,为该意图配置的所有输出上下文都将变为活跃状态。 当所有上下文处于活跃状态时,Dialogflow 更可能匹配配置了输入上下文,且该上下文与当前活跃上下文匹配的意图。
- 下图是一个将上下文用于银行代理的示例。
- 用户询问其支票账户的相关信息。
- Dialogflow 将此最终用户表述与 CheckingInfo 意图匹配。此意图具有 checking 输出上下文,因此上下文变为活跃状态。
- 代理询问最终用户他们希望了解支票账户的哪类信息。
- 最终用户回复“my balance”。
- Dialogflow 将此最终用户表述与 CheckingBalance 意图匹配。此意图具有 checking 输入上下文,该上下文需要处于活跃状态才能匹配此意图。当 savings 上下文处于活跃状态时,也可能存在类似的 SavingsBalance 意图来匹配该最终用户表述。
- 系统执行必要的数据库查询后,代理会回复该支票账户的余额。
- 后续意图
- 您可以使用后续意图自动设置意图对的上下文。后续意图是相关父意图下的子意图。创建后续意图时,系统会将输出上下文添加到父意图中,并将同名的输入上下文添加到子意图中。只有父意图在上一轮对话中匹配时,系统才会匹配后续意图。您还可以创建多个级别的嵌套后续意图。
- Dialogflow 提供多个预定义后续意图,旨在处理“是”、“否”或“取消”等常见的最终用户回复。您还可以创建自己的后续意图来处理自定义回复。

Chatterbot
-
- 安装
- pip install chatterbot
- 使用
from chatterbot import ChatBot
from chatterbot.trainers import ChatterBotCorpusTrainer
chatbot = ChatBot('Ron Obvious')
# Create a new trainer for the chatbot
trainer = ChatterBotCorpusTrainer(chatbot)
# Train the chatbot based on the english corpus
trainer.train("chatterbot.corpus.english")
# Get a response to an input statement
chatbot.get_response("Hello, how are you today?")
An example of typical input would be something like this:
- user: Good morning! How are you doing?
- bot: I am doing very well, thank you for asking.
- user: You’re welcome.
- bot: Do you like hats?
Rasa
- 为什么使用Rasa而不是使用wit、luis、dialogflow这些服务?
- (1)不必把数据交给FackBook/MSFT/Google;
- 已有的NLU工具,大多是以服务的方式,通过调用远程http的restful API来对目标语句进行解析完成上述两个任务。如Google的API.ai(收购后更名为Dialogueflow), Microsoft的Luis.ai, Facebook的Wit.ai等。刚刚被百度收购的Kitt.ai除了百度拿出来秀的语音唤醒之外,其实也有一大部分工作是在NLU上面,他们很有启发性的的Chatflow就包含了一个自己的NLU引擎。
- 对于数据敏感的用户来说,开源的NLU工具如Rasa.ai提供了另一条路。更加重要的是,可以本地部署,针对实际需求训练和调整模型,据说对一些特定领域的需求效果要比那些通用的在线NLU服务还要好很多。
- Rasa NLU本身是只支持英文和德文的。中文因为其特殊性需要加入特定的tokenizer(如jieba)作为整个流水线的一部分。代码在github上。
- (2)不必每次都做http请求;
- (3)你可以在特殊的场景中调整模型,保证更有效。
- (1)不必把数据交给FackBook/MSFT/Google;
- 示例
- Rasa是一个开源机器学习框架,用于构建上下文AI助手和聊天机器人。
- 安装:
- pip install rasa_nlu
- pip install rasa_core[tensorflow]
- 安装:
- Rasa有两个主要模块:
- Rasa NLU (
NLU):用于理解用户消息,包括意图识别和实体识别,它会把用户的输入转换为结构化的数据。- 支持不同的 Pipeline,其后端实现可支持spaCy、MITIE、MITIE + sklearn 以及 tensorflow,其中 spaCy 是官方推荐的,另外值得注意的是从 0.12 版本后,MITIE 就被列入 Deprecated 了。
- rasa nlu 支持不同的 Pipeline,其后端实现可支持 spaCy、MITIE、MITIE + sklearn 以及 tensorflow,其中 spaCy 是官方推荐的,另外值得注意的是从 0.12 版本后,MITIE 就被列入 Deprecated 了
- 最重要的两个 pipeline 是:
supervised_embeddings和pretrained_embeddings_spacy。- 最大的区别是:pretrained_embeddings_spacy pipeline 是来自 GloVe 或 fastText 的预训练词向量;supervised_embeddings pipeline 不使用任何预先训练的词向量,是为了你的训练集而用的。
- ①
pretrained_embeddings_spacy:优势在于,当你有一个训练示例,比如:“我想买苹果”,并且要求 Rasa 预测“买梨”的意图,那么你的模型已经知道“苹果”和“梨子”这两个词非常相似,如果你没有太多的训练数据,这将很有用。 - ②
supervised_embeddings:优势在于,针对你的 domain 自定义词向量。例如:在英语中单词 “balance” 与 “symmetry” 密切相关,但是与单词 “cash” 有很大不同。在银行领域,”balance” 与 “cash” 密切相关,你希望你的模型能够做到这一点。该 pipeline 不使用特定语言模型,因此它可以与任何你分好词(空格分词或自定义分词)的语言一起使用。该模式支持任何语言。默认情况下,它以空格进行分词 - ③
MITIE:可以在 pipeline 中使用 MITIE 作为词向量的来源,从语料库中训练词向量,使用 MITIE 的特征器和多类分类器。该版本的训练可能很慢,所以不建议用于大型数据集上。- MITIE 后端对于小数据集表现良好,但如果有数百个以上的示例,训练时间可能会花费很长时间。不建议使用,因为在将来的版本中可能不再支持 MITIE。
- 中文语料源:awesome-chinese-nlp中列出的中文wikipedia dump和百度百科语料,MITIE训练耗时,也可以直接使用训练好的文件:中文 wikipedia 和百度百科语料生成的模型文件 total_word_feature_extractor_chi.dat,百度云链接,密码:p4vx
- 仅仅获取语料还不够,因为MITIE模型训练的输入是以词为单位的。所以要先进行分词,如jieba
- MITIE模型训练, 详见:用Rasa NLU构建自己的中文NLU系统
- ④ 自定义 Pipelines:可以选择不使用模板,通过列出要使用的组件名称来自定义自己的 pipeline
- 参考
- 如何选择pipeline?
- 训练数据集<1000: 用语言模型 spaCy,使用
pretraine_embeddings_spacy作为 pipeline, 它用GloVe 或 fastText 的预训练词向量 - 训练数据集≥1000或带有标签的数据:supervised_embeddings 作为 pipeline,它不使用任何预先训练的词向量,只用训练集
- 训练数据集<1000: 用语言模型 spaCy,使用
- 类别不平衡
- 如果存在很大的类别不平衡,例如:有很多针对某些意图的训练数据,但是其他意图的训练数据很少,通常情况下分类算法表现不佳。为了缓解这个问题,rasa 的
supervised_embeddingspipeline 使用了 balanced 批处理策略
- 如果存在很大的类别不平衡,例如:有很多针对某些意图的训练数据,但是其他意图的训练数据很少,通常情况下分类算法表现不佳。为了缓解这个问题,rasa 的
- 多意图
- 将意图拆分为多个标签,比如预测多个意图或者建模分层意图结构,那么只能使用有监督的嵌入 pipeline 来执行此操作。因此,需要使用这些标识:WhitespaceTokenizer:intent_split_symbol:设置分隔符字符串以拆分意图标签,默认 _ 。
- Rasa提供了数据标注平台: rasa-nlu-trainer
- Rasa Core (
DM):对话管理平台,用于举行对话和决定下一步做什么。Rasa Core是用于构建AI助手的对话引擎,是开源Rasa框架的一部分。- 负责协调聊天机器人的各个模块,起到维护人机对话的结构和状态的作用。对话管理模块涉及到的关键技术包括对话行为识别、对话状态识别、对话策略学习以及行为预测、对话奖励等。
- Rasa消息响应过程
- 首先,将用户输入的Message传递到Interpreter(NLU模块),该模块负责识别Message中的”意图(intent)“和提取所有”实体”(entity)数据;
- 其次,Rasa Core会将Interpreter提取到的意图和识别传给Tracker对象,该对象的主要作用是跟踪会话状态(conversation state);
- 第三,利用policy记录Tracker对象的当前状态,并选择执行相应的action,其中,这个action是被记录在Track对象中的;
- 最后,将执行action返回的结果输出即完成一次人机交互。
- Rasa Core包含两个内容: stories 和 domain。
- domain.yml:包括对话系统所适用的领域,包含意图集合,实体集合和相应集合,相当于大脑框架,指定了意图
intents, 实体entities, 插槽slots以及动作actions。- intents和entities与Rasa NLU模型训练样本中标记的一致。slot与标记的entities一致,actions为对话机器人对应用户的请求作出的动作。
- 此外,domain.yml中的templates部分针对utter_类型action定义了模板消息,便于对话机器人对相关动作自动回复。
- story.md:训练数据集合,原始对话在domain中的映射。
- Stories
- stories可以理解为对话的场景流程,需要告诉机器多轮场景是怎样的。Story样本数据就是Rasa Core对话系统要训练的样本,它描述了人机对话过程中可能出现的故事情节,通过对Stories样本和domain的训练得到人机对话系统所需的对话模型。
- Rasa Core中提供了rasa_core.visualize模块可视化故事,有利于掌握设计故事流程。
- Stories
- domain.yml:包括对话系统所适用的领域,包含意图集合,实体集合和相应集合,相当于大脑框架,指定了意图
- Rasa Stack —— 汉化版 Rasa_NLU_Chi
- Rasa Stack 包括 Rasa NLU 和 Rasa Core,前者负责进行语义理解(意图识别和槽值提取),而后者负责会话管理,控制跟踪会话并决定下一步要做什么,两者都使用了机器学习的方法可以从真实的会话数据进行学习;另外他们之间还相互独立,可以单独使用
- Rasa NLU (
- Rasa X(web工具)是一个工具,可帮助您构建、改进和部署由Rasa框架提供支持的AI Assistants。 Rasa X包括用户界面和REST API。
- 基本概念
- intents:意图
- pipeline:
- stories:对话管理(dialogue management)是对话系统或者聊天机器人的核心,在 Rasa 中由 Rasa Core 负责,而这部分的训练数据在Rasa 中由 Stories 提供。Stories可以理解为对话的场景流程,一个 story 是一个用户和AI小助手之间真实的对话,这里面包含了可以反映用户输入(信息)的意图和实体以及小助手在回复中应该采取的 action(行动)
- domain :即知识库,其中定义了意图(intents),动作(actions),以及对应动作所反馈的内容模板(templates),例如它能预测的用户意图,它可以处理的 actions,以及对应 actions 的响应内容。
- rasa train : 模型训练,添加 NLU 或者 Core 数据,或者修改了domain和配置文件,需要重新训练模型
- python -m rasa train –config configs/config.yml –domain configs/domain.yml –data data/
- 测试效果
- 启动rasa服务:python -m rasa run –port 5005 –endpoints configs/endpoints.yml –credentials configs/credentials.yml –debug
- 启动action服务:Python -m rasa run actions –port 5055 –actions actions –debug
- Rasa Server、Action Server和Server.py运行后,在浏览器输入测试:
- http://127.0.0.1:8088/ai?content=询广州明天的天气
- Rasa中文聊天机器人开发指南, github代码示例
- 测试命令
python -m rasa_core.run -d models/chat1 -u models/nlu/model_20190820-105546
- 参数解释;
- -d:modeldir 指定对话模型路径(即Rasa_core训练的模型路径)
- -u:Rasa NLU训练的模型路径
- –port:指定Rasa Core Web应用运行的端口号
- –credentials:指定通道(input channels)属性
- endpoints:用于指定Rasa Core连接其他web server的url地址,比如nlu web
- -o:指定log日志文件输出路径
- –debug:打印调试信息
- 参考:
- Rasa 聊天机器人框架使用
- Rasa官方文档: Build contextual chatbots and AI assistants with Rasa
- github地址:RasaHQ/rasa

wechaty
wechaty官网,李卓桓, 谷歌开发者专家(机器学习方向)
微信个人号功能非常强大和灵活,是一个非常适合用来做ChatBot的载体。它可以灵活不受限制的发送语音短信、视频、图片和文字,支持多人群聊。但是使用微信个人微信号作为ChatBot,需要通过非官方的第三方库接入微信。因为截至2018年底,微信尚无任何官方的ChatBot API发布。
Wechaty 是一个开源的的对话机器人 SDK,支持 个人号 微信。它是一个使用Typescript 构建的Node.js 应用。支持多种微信接入方案,包括网页,ipad,ios,windows, android 等。同时支持Linux, Windows, Darwin(OSX/Mac) 和 Docker 多个平台。
功能:
- 消息处理:关键词回复
- 群管理:自动入群,拉人,踢人
- 自动处理好友请求
- 智能对话:通过简单配置,即可加入智能对话系统,完成指定任务
git clone https://github.com/wechaty/wechaty-getting-started
cd wechaty-getting-started
npm install # 安装依赖
npm start # 运行bot,实际上执行的命令是:node examples/starter-bot.js
# 或者直接用node 运行代码
node examples/starter-bot.js
登录限制:从2017年6月下旬开始,使用基于web版微信接入方案存在大概率的被限制登陆的可能性。 主要表现为:无法登陆Web 微信,但不影响手机等其他平台。验证是否被限制登陆: https://wx.qq.com 上扫码查看是否能登陆。
AnyQ 百度
【2022-2-17】AnyQ (ANswer Your Questions) 开源项目主要包含面向FAQ集合的问答系统框架、文本语义匹配工具SimNet。
- 资料:AnyQ是什么
- 问答系统框架采用了配置化、插件化的设计,各功能均通过插件形式加入,当前共开放了20+种插件。开发者可以使用AnyQ系统快速构建和定制适用于特定业务场景的FAQ问答系统,并加速迭代和升级。
- SimNet是百度自然语言处理部于2013年自主研发的语义匹配框架,该框架在百度各产品上广泛应用,主要包括BOW、CNN、RNN、MM-DNN等核心网络结构形式,同时基于该框架也集成了学术界主流的语义匹配模型,如MatchPyramid、MV-LSTM、K-NRM等模型。
- AnyQ 使用 SimNet模型 语义匹配模型构建文本语义相似度,克服了传统基于字面匹配方法的局限。

FAQ问答系统框架
- AnyQ系统框架主要由Question Analysis、Retrieval、Matching、Re-Rank等部分组成,框架中包含的功能均通过插件形式加入,如Analysis中的中文切词,Retrieval中的倒排索引、语义索引,Matching中的Jaccard特征、SimNet语义匹配特征,当前共开放了20+种插件。AnyQ系统的配置化、插件化设计有助于开发者快速构建、快速定制适用于特定业务场景的FAQ问答系统,加速迭代和升级。
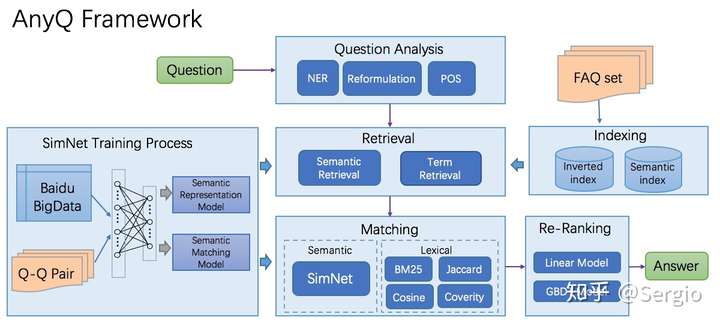
AnyQ系统集成了检索和匹配的众多插件,通过配置的方式生效;以检索方式和文本匹配相似度计算中的插件为例:
- 检索方式(Retrieval)
- 倒排索引:基于开源倒排索引Solr,加入百度开源分词
- 语义检索:基于SimNet语义表示,使用ANNOY进行ANN检索
- 人工干预:通过提供精准答案,控制输出
- 匹配计算(Matching)
- 字面匹配相似度:在对中文问题进行切词等处理之后,计算字面匹配特征
- Cosine相似度
- Jaccard相似度
- BM25
- 字面匹配相似度:在对中文问题进行切词等处理之后,计算字面匹配特征
- 语义匹配相似度
- SimNet语义匹配:使用语义匹配SimNet架构训练的模型,构建问题在语义层面的相似度
# 编译demo cpp程序
cd AnyQ
mkdir build && cd build && cmake .. & make
# 获取anyq定制solr,并将数据导入到Solr库中,启动solr
cp ../tools/anyq_deps.sh .
sh anyq_deps.sh
cp ../tools/solr -rp solr_script
sh solr_script/anyq_solr.sh solr_script/sample_docs
# 这一步中如果数据导入失败,可以在宿主机的AnyQ/build目录下(不要退出docker),尝试运行sh solr_script/anyq_solr.sh solr_script/sample_docs, 启动Solr服务,然后在docker中重复改步骤。
# 运行demo
./run_server
打开浏览器
- 访问:http://localhost:8900/solr/#/ 查看Solr搜索引擎的admin页面
- 浏览器或者Postman中,可以调用接口查看调用结果
- 地址:localhost:8999/anyq?question=需要使用什么账号登录
异步聊天 nonebot2
【2022-9-13】跨平台Python异步聊天机器人框架,支持QQ、飞书、钉钉等渠道
评估方法
- 对话系统(Dialogue System),简单可以理解为Siri或各种Chatbot所能支持的聊天对话体验。
- 【2017-4-14】【重磅福利】人工智能产品经理的新起点(200页PPT下载)
- AI产品经理分类:平台网站类、垂直场景类以及对话聊天类
- 1、用户任务达成率(表征产品功能是否有用以及功能覆盖度)
- 1)比如智能客服,如果这个Session最终是以接入人工为结束的,那基本就说明机器的回答有问题。或者重复提供给用户相同答案等等。
- 2)分专项或分意图的统计就更多了,不展开了。
- 2、对话交互效率,比如用户完成一个任务的耗时、回复语对信息传递和动作引导的效率、用户进行语音输入的效率等(可能和打断,One-shot等功能相关);具体定义,各个产品自己决定。
- 3、根据对话系统的类型分类,有些区别。
- 1)闲聊型
- A)
CPS(Conversations Per Session,平均单次对话轮数)。这算是微软小冰最早期提出的指标,并且是小冰内部的(唯一)最重要指标; - B)
相关性和新颖性。与原话题要有一定的相关性,但又不能是非常相似的话; - C)
话题终结者。如果机器说过这句话之后,通常用户都不会继续接了,那这句话就会给个负分。
- A)
- 2)任务型
- A)
留存率。虽然是传统的指标,但是能够发现用户有没有形成这样的使用习惯;留存的计算甚至可以精确到每个功能,然后进一步根据功能区做归类,看看用户对哪类任务的接受程度较高,还可以从用户的问句之中分析发出指令的习惯去针对性的优化解析和对话过程;到后面积累的特征多了,评价机制建立起来了,就可以上强化学习;比如:之前百度高考,教考生填报志愿,就是这么弄的; - B)
完成度(即,前文提过的“用户任务达成率”)。由于任务型最后总要去调一个接口或者触发什么东西来完成任务,所以可以计算多少人进入了这个对话单元,其中有多少人最后调了接口; - C)
相关的,还有(每个任务)平均slot填入轮数或填充完整度。即,完成一个任务,平均需要多少轮,平均填写了百分之多少的槽位slot。对于槽位的基础知识介绍,可详见《填槽与多轮对话-AI产品经理需要了解的AI技术概念》。
- A)
- 3)问答型
- A)转人工比例:最终求助人工的比例(即,前文提过的“用户任务达成率”相关);
- B)重复率:重复问同样问题的比例;
- C)无结果率:“没答案”之类的比例。
- 整体来说,行业一般PR宣传时,会更多的提CPS。其他指标看起来可能相对太琐碎或不够高大上,但是,实际工作中,可能CPS更多是面向闲聊型对话系统,而其他的场景,可能更应该从“效果”出发。比如,如果小孩子哭了,机器人能够“哭声安慰”,没必要对话那么多轮次,反而应该越少越好。
- 1)闲聊型
- 4、语料自然度和人性化的程度
- 目前对于这类问题,一般是使用人工评估的方式进行。语料通常不是单个句子,而是分为单轮的问答对或多轮的一个session。一般来讲,评分范围是1~5分(或GSB打分):
- 1分或2分:完全答非所问,以及含有不友好内容或不适合语音播报的特殊内容;
- 3分:基本可用,问答逻辑正确;
- 4分:能解决用户问题且足够精炼;
- 5分:在4分基础上,能让人感受到情感及人设。
- 另外,为了消除主观偏差,采用多人标注、去掉极端值的方式,是当前普遍的做法。
- 5、常规互联网产品,都会有整体的用户指标;AI产品,一般也会有这个角度的考量。
- 1、DAU(Daily Active User,日活跃用户数,简称“日活”)
- 在特殊场景会有变化,比如在车载场景,会统计“DAU占比(占车机DAU的比例)”。
- 2、被使用的意图丰富度(使用率>X%的意图个数)。
- 3、可尝试通过用户语音的情绪信息和语义的情绪分类评估满意度。
- 尤其对于生气的情绪检测,这些对话样本是可以挑选出来分析的。比如,有公司会统计语音中有多少是骂人的,以此大概了解用户情绪。还比如,在同花顺手机客户端中,拉到最底下,有个一站式问答功能,用户对它说“怎么登录不上去”和说“怎么老是登录不上去”,返回结果是不一样的——后者,系统检测到负面情绪,会提示转接人工。
- 1、DAU(Daily Active User,日活跃用户数,简称“日活”)
- 【2020-9-21】一篇解决对话无监督评估的论文:How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation,论文引用图谱
对话比赛
- 针对多模态的对话场景(即对话session中用户提出的问题中至少包含一张图片信息),记录用户与客服之间的在线交互记录D={Q0, A0, Q1, A1, …, Qn, An},其中交互记录中Qn表示第n轮交互中用户提出的问题,An表示第n轮交互中在线人工客服给出的回答,其中Qn或An均可以包含多条消息,类别可能是纯文字消息、纯图片消息或图文混合消息;记录对话session涉及的背景知识B={Shop_type, Sku_id},其中背景知识中Shop_type表示商家类别信息(此次比赛涉及两个品类商家即小家电商家与服饰鞋靴商家),Sku_id表示此次对话中可能涉及的商品sku信息;此外,还提供一个简单的商品知识库KB={KBsku, … },可以通过sku信息获取商品的基础属性信息。要求参赛系统对给定背景知识和多模态对话片段分析,给出满足用户需求的答案。目标是给出答案能够正确、完整、高效地回答用户的问题。
- 注:此次比赛仅关注纯文本形态的应答,即上下文信息或用户问题为多模态形式,预测应答为单模态形式。
DSTC
- 【2021-10-8】世界顶级竞赛DSTC10结果公布,中国队第一,Track2赛道Task1环节(任务式对话状态追踪),由小度与自然语言处理部门组成的百度代表队以JGA(全部信息都预测正确的对话比例)46%、领先第二名10个百分点的成绩强势问鼎,中国最大的对话式操作系统——小度助手成为世界焦点,中国自主对话AI技术再一次惊艳世界。DSTC10大赛Track2赛道Task1环节,是有史以来同类型任务中最难的,一方面,比赛涉及多个领域之间频繁切换(如从找旅游景点到订酒店和餐馆等);同时要求方案能够解决多轮连续对话中的复杂语义理解问题,还要能够对语音交互和识别中的错误进行自动纠错和理解;比赛同样用非常严苛的标准进行考察,需要将用户需求中的每一个部分都理解对(JGA:联合目标正确率)才算对。通过测算,小度联合百度自然语言处理部门研发的多模型融合方法,将自然语言处理中经典的匹配和生成的方法结合起来,并创造性的引入知识库增强的方法来增强语音噪声下的理解能力,JGA达到46%,远超第二名JGA 36%的结果。在单独匹配方法的测试中,小度所获成绩同样远超第二名。在嘈杂环境下,依旧能够准确理解用户语义;而且大大增强了小度智能助手基于知识增强的端到端理解能力,其自学习知识推理能力进一步提升;同时,基于以上方法,小度智能助手的个性化多轮理解能力日益完善,陪伴用户越久便越懂用户所想/所说。比如,常常看动画片的小朋友,说“小老鼠”的时候,小度就能开始续播动画片《猫和老鼠》;常常听评书的老爷爷,说“三国”的时候,小度就能准确接到上回的“火烧赤壁”。这些陪伴用户日常生活中的寻常技能,背后其实是问鼎世界的AI对话技术。
ConvAI
ConvAI2
2018年,对话智能挑战赛:ConvAI 2
2018年的比赛是ConvAI挑战的第二届,同样是NIPS大会8个正式的竞赛任务之一
ConvAI3
Clarifying Questions for Open-Domain Dialogue Systems (ClariQ)
we provide to the participants the datasets that include:
- 信息咨询 User Request: an initial user request in the conversational form, e.g., “What is Fickle Creek Farm?”, with a label reflects if clarification is needed to be ranged from 1 to 4;
- 问题澄清 Clarification questions: a set of possible clarifying questions, e.g., “Do you want to know the location of fickle creek farm?”;
- 用户答案 User Answers: each question is supplied with a user answer, e.g., “No, I want to find out where can i purchase fickle creek farm products.”
对话平台
convlab 简介
【2021-7-26】convlab探索记
ConvLab是微软和清华开源的一个多领域的端到端对话系统平台。旨在为对话系统的研究人员提供一个可以快速启动的实验平台。为此该平台提供了两个标注好的数据集、一些算法的实现(包括pipeline和end2end)、相关的预训练模型和其他可复用的组件。另外,ConvLab也是DSTC8 track1的官方平台。
- ConvLab Code Repository: https://github.com/ConvLab/ConvLab
- ConvLab Paper: https://arxiv.org/pdf/1904.08637.pdf
ConvLab的实现基于SLM-Lab,因此继承了其有关强化学习的术语:AEB(Agent、Environment、Body),具体参考文档。
ConvLab支持:Multi-agent learning、Multi-task learning和Role play。
参数
整体的参数配置可以参考上图(横着看):可以是按照pipeline所有的模块一个个配置,也可以配置一个完整的end2end,还有其他支持的组合。
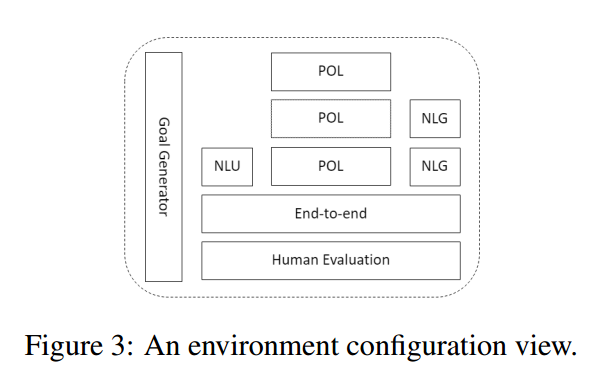
类似的,环境的构建也是需要构造支持的模块参数组合。
- NLU
- Semantic Tuple Classifier (STC)
*pdf : 支持多领域、多意图。 - OneNet
*pdf:可以解决OOV问题。 - MILU(综合了上面二者):可同时处理多意图和OOV。
- DST
- rule based (类似于DSTC的baseline)
- Word-level Dialog State Tracking(从用户语句直接更新对话状态,免去NLU)
- MDBT
*pdf - DPL(系统策略)
- DQN
*pdf - REINFORCE
*pdf - PPO
*pdf - NLG
- a template-based model
- SC-LSTM
*pdf - Word-level Policy (从对话状态直接到response)
- seq2seq (dialogue state encoder + database query result encoder)
*pdf - 用户策略(用户模拟)
- agenda-based
*pdf - data-driven : HUS
*pdf - End2End
- Mem2Seq
*pdf - Sequicity
*pdf :为了支持多领域,在切换领域时需要重置belief span。
数据集
- MultiWOZ
- Multiwoz-a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. * pdf
- MultiWoz的主任务是帮助游客解决各类问题。问题又分为7个子领域:Attraction, Hospital, Police, Hotel, Restaurant, Taxi, Train。一共有10438个对话,单领域的平均轮数是8.93;跨领域的平均轮数是15.39。
- Movie
- 来自微软对话挑战赛,一共2890个对话,平均轮数7.5。
资料
- 基于Python/Tornado的图灵服务(个人机器学习平台)
- 陈海青:阿里小蜜机器人交互
- Google对话系统分享,Deep Learning for Goal-Oriented Conversational Understanding
- 【2019-11-6】哈工大张伟男:人机对话关键技术及挑战,ppt
- 【2020-6-18】Facebook开源有史以来最大的开域聊天机器人 Blender, 论文
- 【2020-7-4】开域聊天机器人技术介绍——未来篇(上,下)
- 更多Demo地址
【2021-1-28】微软团队:首次公开小冰系统设计,迄今最详细
- IQ和EQ的结合是小冰系统设计的核心。小冰的个性也是独一无二的。
- IQ 能力包括知识和记忆建模、图像和自然语言理解、推理、生成和预测
- EQ有两个关键组成部分:同理心和社交技巧。xs
微软小冰框架,小冰的总体架构如图4所示。它由3个层组成:用户体验、对话引擎和数据。
- ①用户体验层:该层将小冰连接到流行的聊天平台(如微信、QQ),并以两种模式与用户交流:全双工模式和轮流对话模式。该层还包括一组用于处理用户输入和小冰响应的组件,如语音识别和合成、图像理解和文本规范化。
- ②对话引擎层:由对话管理器、移情计算模块、核心聊天和对话技能组成。
- 对话引擎层主要包括四大组件:对话管理器、移情计算(empathetic computing)、Core Chat和技巧。
- 对话管理器是对话系统的中央控制器。它由全局状态跟踪器(Global State Tracker)和对话策略(Dialogue Policy)组成。 该操作可以是顶级策略激活的技巧或Core Chat。
- 全局状态跟踪器通过一个工作内存(working memory)来跟踪对话状态。工作内存在每个会话开始时是空的,然后在每个对话中将用户和小冰的对话以及根据移情计算模块从文本中检测到的实体和移情标签,用文本字符串的形式来进行存储。
- 移情计算,小冰使用分层策略:
- ⑴顶级策略通过在每个对话轮次中选择Core Chat或基于对话状态激活的技能来管理整个会话;
- ⑵一组低级策略,每个策略对应一种技能,用于管理其会话段。
- 对话策略旨在通过基于XiaoIce用户反馈的迭代、反复试验和错误过程来优化长期用户参与。
- 话题管理器模拟人类在对话期间更改话题的行为。它由一个分类器和一个话题检索引擎组成,分类器用于在每个对话回合决定是否切换话题。如果小冰对话题没有足够的了解,无法进行有意义的对话,或者用户感到厌烦,就会引发话题切换。
- 对话引擎层主要包括四大组件:对话管理器、移情计算(empathetic computing)、Core Chat和技巧。
- ③数据层:由一组数据库组成,这些数据库存储收集到的人类会话数据(文本对或文本图像对)、用于核心会话和技能的非会话数据和知识图,以及小冰和所有注册用户的个人档案。
【2022-5-13】周力博士:小冰AI+AI对谈技术的探索与应用
- 红棉小冰,小冰公司打造了一个类似的实验平台:小冰岛。希望能找到一个更复杂的交互场景,打破一对一的对话下20%易感用户的局限,从而找到人和AI更好交互的方式。
聊天机器人
- Chatbot Catalog: Customer Service
-
智能客服、聊天机器人的应用和架构、算法分享和介绍
- 对话智能:国际视角,国内形势及案例学习
- 实录分享:计算未来轻沙龙:对话系统研究进展(视频 + PPT)
- 聊天机器人初学者完全指南
- 聊天机器人设计思考
- 万物有灵:人机对话系统解析
- Bot:带来对话式体验的下一代 UI
- 聊天机器人技术的研究进展
- 总结:解密 chatbot 人工智能聊天机器人 技术沙龙
- 盘点:聊天机器人的发展状况与分类
- 巨头们都很重视的聊天机器人,你不进来看看吗?
- 为什么聊天机器人从业者都很委屈?
- “聊天机器人的革命创举”:Plug and Play 独家对话 Chatopera
- 聊天机器人多会长成“女孩” 性别和性格会突变
- 这个时代,机器人也要肤白貌美性格好?
- 人工智障 2 : 你看到的 AI 与智能无关
- 上一篇:2016-11,为什么现在的人工智能助理都像人工智障?
-
【独家】百度朱凯华:智能搜索和对话式 OS 最新技术全面解读(65PPT) -[专栏 聊天机器人:困境和破局](https://mp.weixin.qq.com/s/6lY4SBVioqHyCzDimQNn8w) - 对话机器人思考(下):复杂多轮对话的关键功能点
- 机器人和你对话时在想什么?
- 最新综述:对话系统之用户模拟器
- Domain+Intent+Slot 真的在理解自然语言吗?
- 通用领域对话问答
- Chatopera 多轮对话设计器:实现天气查询机器人的过程
- 基于 CNN 和序列标注的对联机器人:附数据集 & 开源代码
- 深度长文:NLP 的巨人肩膀(上)
- 问答系统冠军之路:用 CNN 做问答任务的 QANet
- 竹间智能 CTO 翁嘉颀:如何打造主动式对话机器人:吃瓜笔记,含视频讲解
- chatbot演变历程,siri的智商低,相当于两岁的小朋友,只有小孩能聊下去,图
- 聊天机器人“进化论”:从陪你聊到懂你心
- 研学·产品设计:Chatbot 的人格很重要吗?
- 以 Facebook 的 wit.ai 为例讲解机器人对话平台(Bot Framework)
- 从 api.ai 工作原理来看构建简单场景 chatbot 的一般方法
- 利用逻辑回归模型判断用户提问意图
- 一天开发一款聊天机器人
- 浅谈垂直领域的 chatbot
- 学术】联合意图推测和槽位填充的基于注意力的循环神经网络模型
- 赛尔原创 :聊天机器人中用户出行消费意图识别方法研究
- 图灵机器人:带着千亿条语料库,它成为了 QQ 的群聊机器人,创业 -PaperWeekly 第 40 期 对话系统任务综述与基于 POMDP 的对话系统
- 让聊天机器人同你聊得更带劲 - 对话策略学习,论文访谈间 #21
- “小会话,大学问” - 如何让聊天机器人读懂对话历史?论文访谈间 #03
- 机器学习利用 Elasticsearch 进行更智能搜索
- 用 Rasa NLU 构建自己的中文 NLU 系统
- 实战,让机器人替你聊天,还不被人看出破绽?来,手把手教你训练一个克隆版的你
- 观点,如何从一名软件工程师转行做人工智能?
- 未来,AI+多轮对话将怎样玩转智能客服
- 聊天机器人落地及进阶实战,公开课速记
汇总
- 聊天机器人资料汇总
- 【专知荟萃 05】聊天机器人 Chatbot 知识资料全集(入门/进阶/论文/软件/数据/专家等)(附 pdf 下载)
- 【专知荟萃 04】自动问答 QA 知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附 pdf 下载)
- 智能问答与深度学习
- MSRA 周明博士解读:聊天机器人的三大引擎(视频+PPT)
- 聊天机器人平台:Chatopera 云服务使用指南
对话管理
知识图谱
- 基于知识图谱的人机对话系统-公开课笔记
- 基于知识图谱的问答系统关键技术研究(一)
- 基于知识图谱的问答系统关键技术研究(三)
- 肖仰华,基于知识图谱的问答系统
- 当知识图谱遇上聊天机器人
- 聊天机器人对知识图谱有哪些特殊的需求?
智能客服
- 十张图解读我国智能客服行业发展现状与前景
- AI 前沿,如何让智能客服更有温度?
- 春松客服:一个开源的智能客服系统
- 不是所有的智能机器人都能做好客服——浅谈智能客服机器人评价指标新趋势
- 能感知情绪的 IBM 机器人,正打算消灭人工在线客服
- 关于券商智能客服,那些绕不开的坑
- 你问我答之「智能客服评价体系全解读」
- 追一科技券商 AI 沙龙:智能呼叫的价值落地
- 详解第二代客服机器人,聚焦问题解决,客户服务任务一站直达
- 项目实战,智能客服(“七鱼”、“小 i 机器人”)产品分析
知识库
- 王浩:新一代智能化知识库(PPT 可下载)
- 新一代呼叫中心智能知识库什么样?
- 你问我答之「YiBot 知识体系运营知多少」
- 揭开知识库的神秘面纱 8·非结构化知识源篇
- 智能客服知识库的 3 件核心工作
智能客服产品中最需要内容⽣产能⼒的地⽅,莫过于知识库。⼀般⽽⾔,智能客服产品都具备这样⼏类知识库:内部知识库、机器⼈知识库和外部知识库。
内部知识库指需要实时定位查询使⽤的知识库。由于企业的业务变化频繁,知识库的调整需要及时到位。- 传统的上传、编辑、整理等流程⾮常耗费⼯作量。
- 引⼊大模型,可以协助⾼效智能的协助员⼯归类、⽣成知识库的类⽬及明细。同时,还可以增加对外部数据源的引⽤,并减少知识库的同步操作。⽤户在实际应⽤时,还可以给对知识点给出反馈,帮助知识库⾃动调节权重。
机器⼈知识库是⽂本和语⾳机器⼈能够回答访客问题的核⼼所在。机器⼈知识库的有效内容对于机器⼈的表现⾄关重要。- 对于未知问题的整理,需要智能客服使⽤者⼤量投⼊⼯作量。借助⽤户反馈对未知问题进⾏⾃动整理和关联,能节省很多知识库维护者的⼯作。
- 同时,通过多机器⼈组合的⽅式,在⼀通会话中接⼒棒⼀般服务于客户的不同场景,大模型专属机器⼈也可以在特定的场合发挥能⼒,并逐步替代⼀些以往模式僵化的问答型机器⼈。
- 而
外部知识库整合在智能客服产品中,将已整理的知识内容转化为输出产物,更⽅便⽣成知识⽂章、图⽚、甚⾄⾳视频。- 基于 ChatGPT 的多模态的 AIGC 能⼒,可以快速⽣成⼀个个性化的知识空间。
利⽤大模型⾃⾝的⽣成能⼒,基于向量数据库、可信内容审核等技术,为智能客服提供优质的内容补充。
【2023-6-30】AIGC 重构后的智能客服,能否淘到大模型时代的第一桶金
知识库历史
- 传统知识库
- 传统知识库其实是管理系统的一种,也是增删改查为核心的传统IT应用(偏向于管理结构化数据和知识)。传统知识库系统对于坐席来说非常重要,最新的资费、业务、政策或者营销活动都通过知识库系统传递给坐席,没有一个坐席是可以掌握这么多结构化知识的,所以传统知识库对于坐席来说非常重要的,但是重要意义仅限于“业务知识库”,通过这个工具来学习、掌握和使用业务知识。
- 智能知识库
- 现在提到的知识库主要是说“智能知识库”,什么是智能知识库(区分于传统呼叫中心知识库)呢?AI人士眼中的知识库(Knowledge Base)是知识工程中结构化,易操作,易利用,全面有组织的知识集群,是针对某一(或某些)领域问题求解的需要,采用某种(或若干)知识表示方式在计算机存储器中存储、组织、管理和使用的互相联系的知识片集合。这些知识片包括与领域相关的理论知识、事实数据,由专家经验得到的启发式知识,如某领域内有关的定义、定理和运算法则以及常识性知识等。 智能知识库与传统知识库相比,有几个明显特点:
- 1、知识库的知识是有层次的。
- 最低层是“事实知识”,中间层是用来控制“事实”的知识(通常用规则、过程等表示);最高层次是“策略”,它以中间层知识为控制对象。
- 知识库的基本结构是层次结构,是由其知识本身的特性所确定的,知识片间通常都存在相互依赖关系。
- 2、自动知识抽取。
- 自动知识抽取的最大优势是良好的可扩展性,即快速构建大规模知识库的能力,但这种可扩展性常常以牺牲精度和某些知识类型上的覆盖率为代价。所以需要很多研究工作来提升抽取的精度和覆盖率(尤其是属性和关系提取的精度和覆盖率),同时需要研究如何将自动抽取、手工编辑相结合而得到高性价比的知识库。从抽取的知识类型来看,目前的知识类型和知识结构可能尚不足以有效支持自然语言理解等应用。相比于人类的知识结构,计算机知识库中所包含的常识和与动作相关的知识还不足。
智能知识提取的主要任务就是构建知识图以及生成图结点间的关系,具体子任务包括:
- 实体名提取提取实体名并构造实体名列表。(如88元套餐,是一个个例)
- 语义类提取构造语义类并建立实体(或实体名)和语义类的关联。(如资费、营销活动、是一个类)
- 属性和属性值提取为语义类构造属性列表,并提取类中所包含实体(或实体名)的属性值。(如88元资费的资费编码、描述、资费介绍等等是属性)
新一代智能化知识库
- 第一是叫智能化,用自然语言和语音识别这样的技术来创建的知识库。
- 第二结构化的知识,让知识库的应用有很多应用的场景和空间。
- 第三多渠道融合的知识库,它不仅仅是给内部使用,包括对外服务,对各种第三方系统服务,一起来融合性的知识库,我们称之为知识同源,在大型的呼叫中心,这是非常有用的。
1、知识图谱
- 知识图谱好像和智能知识提取相关,知识图谱是图状具有关联性的知识集合。知识图谱是比较新的一个说法,的确应该是受语义网的启发。把语义网的知识库给形象化的表示出来了。重在抽取关系,便于展示高关联性,高结构化的结果。 2、原子化知识库
- 重构互联网化的知识支撑系统,改变文档式的传统知识库,将知识文档“肢解”,碎片化处理,统一知识底层为颗粒度更小的原子化的知识点,组合形成原子化知识库(Atomic Knowledge Management System,以下简称AKMS),实现对全渠道服务的知识集中支撑系统。
业界案例
- Baklib
- 百度如流,百度智能云, 智能知识库大会视频
- 阿里巴巴Teambition,Thoughts 是一款企业知识管理应用,知识库采用树状目录的结构,帮助你更好地组织知识;树状目录的每一个层级可以是文档、文件夹或者文件,容纳团队中所有的知识内容。每个文档可以进行对应的评论沟通,所以你的团队始终都会有上下文。
- 钉钉知识库:知识库结构分三层,知识库 - 知识本 - 知识页
知识库结构
- 知识目录:领域、意图等
- 标准问
- 相似问
- 答案:可能有模板
如何构建高质量QA问答知识库
历史对话数据分布分析
- 基于公司现有系统积累的大规模对话文本数据,进行归类处理,分析每个部分数据的占比,挖掘出有价值的文本, 通过 NLP 相关技术进行商业价值转化。 以医疗领域来举例说明,通过输入对象,可以将文本分为客服输入和用户输入两部分。挖掘相关问题,主要从用户输入文本出发,用户输入文本根据问题的类型大致可以分为以下几种:
- 基本常识相关问题(34%)。 比如:孕妇饮食需要注意什么?如何进行体检预约?
- 业务相关问题(28%)。 比如:(妇科问诊)肚子疼怎么办?针对该问题,医生不能盲目下结论,需要询问用户的一些信息(是否孕期,具体哪里痛等等)。
- 闲聊问题(48%)。 闲聊文本占比蛮多,不在分析范围内。 通过文本归纳以及数据分析,在用户输入文本中,基本问题占比34%,业务问题占比28%,闲聊问题占比48%。
- 基本问题和业务问题是具有价值的部分,通过挖掘基本问题,我们可以构建知识库,提供知识问答检索系统;
- 通过挖掘业务问题,可以设计业务相关的多轮对话模板,完成多轮对话问答系统。
基本问答对挖掘
基本问答对挖掘分为两个步骤
- 第一步:挖掘出高质量的疑问句
- 1、问题的初步筛选: 需要将用户文本中疑问句挖掘出来,方法包括规则表达式和疑问句判别分类模型。
- 规则表达式:发现中文问句的表达规律,建立规则表达式库,通过规则引擎进行匹配。比如以“吗、?什么”等结尾的句子。
- 疑问句判别分类模型:将疑问句挖掘转换为分类模型:即疑问句和非疑问句,通过人工标注数据,训练模型,完成疑问句判别任务。常用的分类模型如TextCNN等。
- 2、领域词——问题过滤:通过问句是否含有领域词完成第1步知识库的过滤。领域词库的建立可以使用如下方法:
- 卡方特征选择提取领域词。
- 命名实体识别模型完成领域词的抽取。常用方法:BILSTM+CRF 等。
- 3、相似疑问句的挖掘。
- 聚类分析,挖掘相似的疑问句。
- 句子向量相似度分析
- 答案相似,也可以认为问题是相似问题。
- 1、问题的初步筛选: 需要将用户文本中疑问句挖掘出来,方法包括规则表达式和疑问句判别分类模型。
- 第二步:挖掘出高质量疑问句对应的答案。
- 1、问答拼接。 将疑问句对应客服的陈述句作为答案。如果答案长度较短,则按照“就近”原则拼接2-3个陈述句作为答案。客服回答问题,可能针对一个问题通过多个字句进行回答,所以按照“就近”原则将陈述句进行拼接。
- 2、问答对筛选。 针对第1步挖掘出来的QA对,通过判断Q和A中是否包含相同的领域词或者是否拥有相同的子串等策略,完成问答对的筛选。
- 3、同类问题如果拥有多种不同的答案,则保留高频答案。
- 4、运营人员协助,完成 QA 知识库的质检。
案例:
假设领域词集合:{腹痛},用户输入的文本集合如下:
- 1、腹痛如何治疗?
- 2、我能不能退货?
- 3、肚子疼怎么办呀
- 4、我已经完成了订单支付。
挖掘过程:
- 初步筛选:第4句非疑问句,去掉
- 领域词过滤:2、3句不含领域词
- 聚类分析:1和3相似度高,召回第3句
- 挖掘答案:。。。
最终建立腹痛的知识点
- 标准问:“腹痛如何治疗”
- 相似问:肚子疼怎么办呀
- 答案:。。。。
去哪儿网实践:
- 客服平时针对不同问题类型使用不同的解决方案
- 机票业务极其复杂,用户需求涉及出、退、改等十余个业务场景,每个场景下又能衍生出几十甚至上百个业务意图
- 以出票场景(见图 5)为例,用户诉求既会涉及到购票类型、支付手段、出票进度等咨询类问题,也会有诸如修改信息、申请购票等操作类型问题。得到这些诉求的解决方案需要根据订单状态、航司政策、用户主观原因等多种因素做出判断,这要求客服有极强的业务素养与信息获取能力。
- 琐碎的日常问题。例如托运规则、天气咨询、乘机注意事项等。 对于高频的日常问题,每个客服都会手动积累和维护一个文档,日积月累再加上互相交流,渐渐的就成了一个小型文本知识库,这在一定程度上提升了客服的工作效率。
客服助手(小驼机器人)辅助客服与用户沟通,其中的推荐可以分为两类
- 一类是业务问题,遇到退票、出票、改签等的业务问题,比如申请退票。
- 另一类是非业务问题,我们会通过搜索匹配的方式在基本问答知识库中进行检索,搜寻合适的答案反馈给客服。如果客服觉得可以采纳,轻轻一点,话术就推送给用户了。
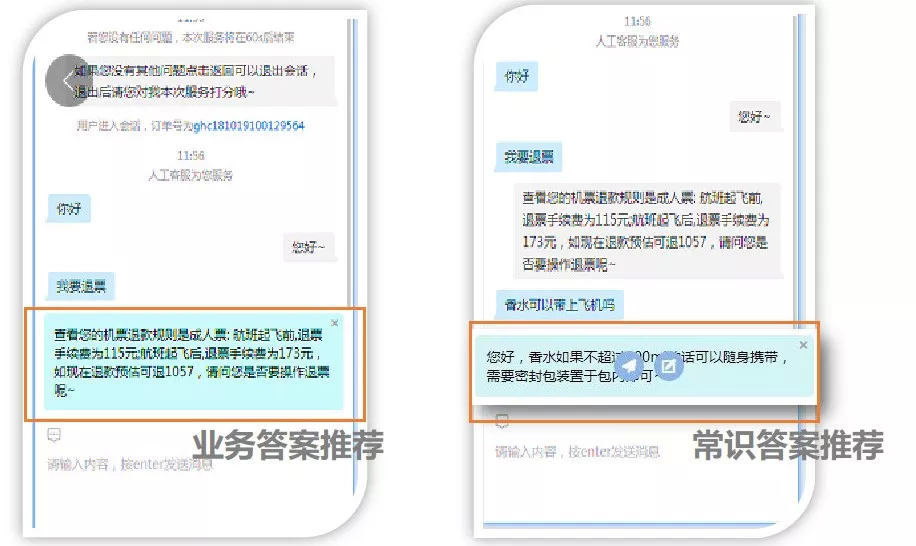
智能客服控制逻辑的核心结构,首先通过 query 理解模块对用户输入进行预处理和意图识别,预处理包含 query 清洗、命名实体识别、query 改写、向量化等操作。当确定用户 query 为闲聊(基本问答)时,通过 QA 知识库检索的形式搜索合适的答案。当确定用户 query 包含业务意图时,则进入对话管理模块。模块中通过对话上文信息与当前槽位填充情况确定新的对话状态,最后通过业务知识库生成合适的备选答案。
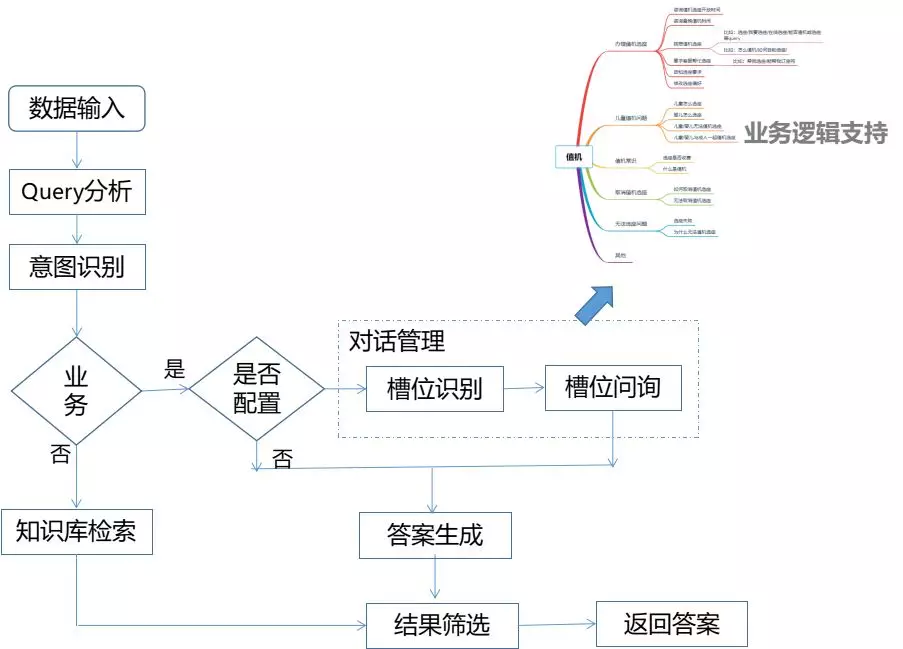 问答检索框架
问答检索框架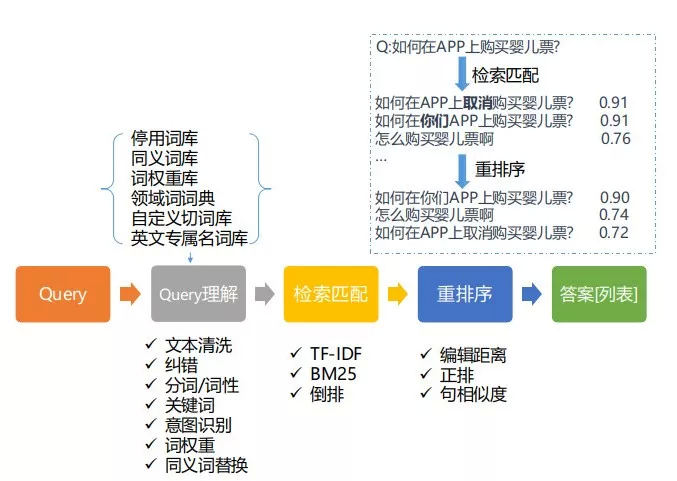 意图识别
意图识别- 在项目初期,考虑到模型迭代效率与样本规模,智能客服一直采用 fasttext 作为主要的意图识别模型。
- 但随着项目进展,类别种类膨胀,样本语料数量低且质量差的问题逐渐凸显出来。Google 推出的 bert 预训练模型很好的帮忙解决了我们的痛点。它支持在少样本情况下微调模型,使模型能够支持识别 200+ 的意图,在语料质量有保证的情况下,准确率会非常理想。
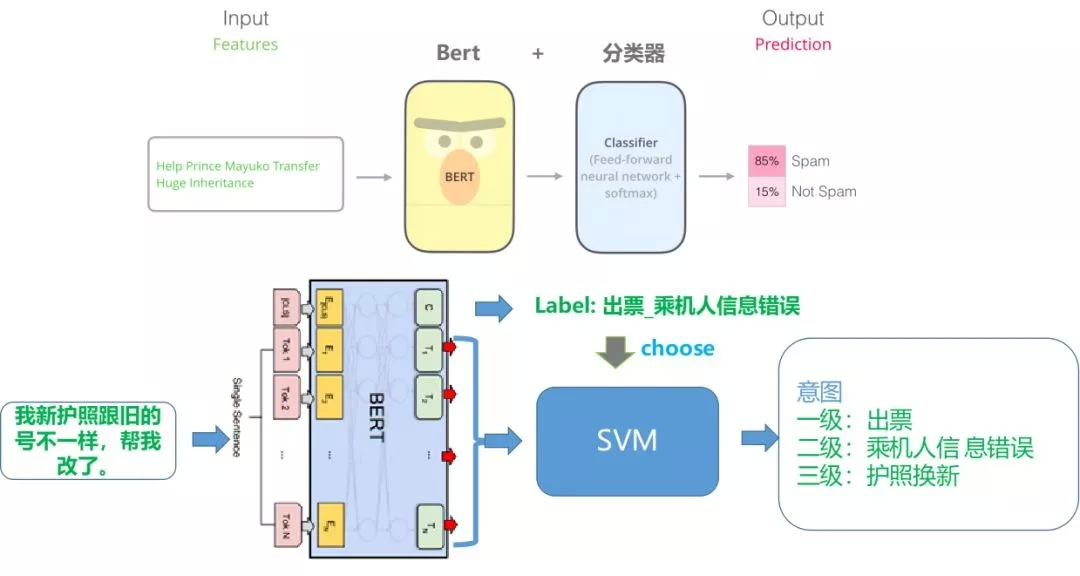
- Bert 也有一些明显的缺点,模型庞大,微调需要设备资源,我们通过一些简单的策略在一定程度上降低了模型迭代的成本。在 Bert 模型输出预测结果的同时我们使用模型的副产物(词向量)作为 SVM 模型的输入,来给当前输出意图做进一步细分。这样就可以在仅调整 SVM 的情况下根据实际 badcase 快速的迭代模型。
- 模型迭代至今,线上推荐服务在支持近 200 个意图的情况下的准确率稳定在 91%。
客服助手在每天发生的会话中有 90% 以上的会话会出现答案推送,消息维度的推荐覆盖率为 60% 以上。意图识别准确率 90% 以上,答案准确率也达到了 70%。
参考:
- 知乎dreampai
- 【2019-11-18】贾自燕:去哪儿智能客服系统在机票售后的应用实践
标准问生产
【2021-11-26】如何生产标准问?,参考:如何提高机器人的识别准确率
| Query案例 | 真实意图 | 机器识别 |
|---|---|---|
| 账单 | 查账单 | 查账单 |
| 信用卡账单 | 查账单 | 查账单 |
| 还信用卡账单 | 还款 | 查账单 |
| 信用卡额度 | 查额度 | 查额度 |
| 信用卡还款额度 | 查账单 | 查额度 |
提高机器人识别率是系统工作
知识库中都是标准问,而客户很少会通过标准问向我们提问,通常情况下,在经过客户的语言转述后,由于客户个人语言逻辑的习惯,同一个问题会有各种各样的表达,这就带来了一个问题,如何把客户众多的相似问对应到标准问。
- (1)标准问生产:
- 1、标准问从哪里来?
- 源自知识目录,有多少知识分类,就有多少标准问
- 2、标准问越多越好吗?
- 不是,问题越多,机器识别难度越大,不能随便生产
- 3、标准问该如何写?
- 一般结合用户相似问+业务经验提炼
- 但建议从知识类目中按照标准写法整理,避免随意增加标准问
- 1、标准问从哪里来?
- (2)如何整理知识目录(意图体系)
- 业务场景梳理 → 梳理三级类目 → 结合业务经验调整类目
- (3)相似问(个性问)生产
- 相似问来自用户真实语料,越多越好
- 不能直接使用原始语料!
- 语料清洗 → 按照知识类目聚类/分类 → 训练效果评测
问题生成
问答系统中,运营、产品常常人为地配置一些常用且描述清晰的问题及其对应的回答,我们将这些配置好的问题称之为“标准问”,当用户提问时,系统将问题与配置的标准问进行相似度计算,找出与用户问题最相似的标准问,并返回其答案给用户,这样就完成了一次问答操作。
然而,人工配置“标准问”库是一个耗时耗力的工作,并且生成高质量而具有总结概括性质的问题会给运营人员带来极大的负担。如果自动生成一些Query,供运营人员去选择的话,无疑于会给运营人员减轻很大的负担。简单地来说,就是创造与选择的区别,选择比创造要简单地多。
Query生成方法主要有两大类,一种是规则方法,另一种就是模型方法。而每种方法其实又包含两个方面。如果我们已经人为地配置过一些query了,但是量比较少时,可以根据已有的query去生成query。
- (1)规则方法比较简单,但是生成的问题会比较单一。
- 一般通过词典或NER技术,识别出已有query的关键词或重要词汇,然后将其中的关键词做替换或者通过模板将关键词套入,最终生成新的问题。
- 规则方法的核心是规则的归纳与总结,这通常是比较麻烦地事情;往往需要人看过大量数据后(需要很多人力),才能构造出比较优秀的规则,但规则之间有时也会有冲突。

- (2)模型方法一般是用过Seq2Seq模型,根据所给问题去生成新的问题。
- 模型方法相较于规则方法来说,生成的问题会更多样化,陈述不会一成不变;并且会生成一些具有概述性质或者更加具体的问题,供运营人员的选择更多。
- Seq2Seq模型有很多,包括LSTM、Transform、GPT、UniLM、GPT2、MASS等等。
- GPT2模型在生成问题上表现优秀,因此使用GPT2模型训练了一个Query2Query的模型去扩充我们现有的“标准问”库。GPT2_ML的项目开源了一个具有15亿参数的中文版的GPT2开源模型,我们在此模型基础上进行微调。

- GPT-2代码,权重,原文:智能扩充机器人的“标准问”库之Query生成
# 下载代码
git clone https://github.com/YunwenTechnology/QueryGeneration
# 下载模型
# 见以上地址里的百度云盘
cd scripts/
# 文本生成
python3 interactive_conditional_samples.py -model_config_fn ../configs/mega.json -model_ckpt /iyunwen/lcong/model/model.ckpt-850000 -top_p 5.0 -eos_token 102 -min_len 7 -samples 5 -do_topk True
阿里巴巴
- 阿里小蜜新一代智能对话开发平台技术解析
- 阿里小蜜:知识结构化推动智能客服升级
- 阿里云小蜜对话机器人背后的核心算法
- 大中台、小前台,阿里小蜜这样突破对话机器人发展瓶颈
- 机器如何猜你所想?阿里小蜜预测平台揭秘
- 阿里小蜜:智能服务技术实践及场景探索
- 云小蜜:在中国移动的落地实践
- 阿里小蜜这一年,经历了哪些技术变迁?
- 论文导读-阿里小蜜背后的技术秘密
- 小蜜家族知多少:人工智能客服如何做到“不智障”?
- 售后智能客服:店小蜜用户体验地图
- 为减少用户电话排队,阿里研发了智能客服调度系统
- 阿里千亿级购物节背后,淘宝智能客服架构演进之路(ps:偏在线客服)
- 资源 -从搜索到智能客服:阿里开放强化学习技术演进与实践书籍
- 首次披露!阿里线下智能方案进化史
- 深度揭秘天猫精灵对话引擎
- 支付宝换上“读心术”AI 客服,就为配合双 11 剁手的你
- 专访-蚂蚁金服 MISA:比用户更懂自己的自然语言客服系统
- COPC 高管访谈:蚂蚁金服客服服务及权益保障事业部总监,智能客服业务负责人 —— 丁翌先生
- 蚂蚁金服-“新客服”白皮书(附下载)
- (支付宝宣传)当人工智能遇上客服,他们是怎样让科幻变成现实?
-
[我其实一直都懂你 闲鱼聊天机器人](https://mp.weixin.qq.com/s/d3eOEmcLGSWQaYE1R47tQA)
云问(拼多多、当当)
携程
- 干货-“猜你所想,答你所问”,携程智能客服算法实践
- 携程:上万坐席呼叫中心异地双活架构及系统设计
- 携程呼叫中心异地双活——座席服务的高可用
- AI 在携程智能客服的应用
- 携程度假智能云客服平台
- 携程基于云的软呼叫中心及客服平台架构实践
- 机器学习在酒店呼叫中心自动化中的应用
- 干货-携程度假智能客服机器人背后是这么玩的
- 行业智能客服构建探索
- 干货-揭秘携程基于融合通讯技术的新一代客服系统
去哪儿
京东
- “天枢”智能调度系统,让京东专属客服与您“一拍即合”
- 干货-京东 JIMI 用户未来意图预测技术揭秘
- 京东揭秘-技术方案解答智能客服如何双商俱高
- 京东 618:智能机器人 JIMI 的进击之路
- 揭秘-技术方案解答智能客服如何双商俱高
- 京东 JIMI 机器人累计服务上亿用户 开放平台共享人
- JIMI:用深度学习搞定 80%的客服工作
- 京东 JIMI 技术架构
- 开放的 JIMI,开放式架构
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 

{kind=link}