总结
- 【2021-6-19】用AI构建AI - AutoML综述
- 【2020-8-28】论文综述:AutoML: A Survey of the State-of-the-Art
- AutoML综述更新 【AutoML:Survey of the State-of-the-Art】
- 【神经网络架构搜索(NAS)相关论文列表】’Awesome Neural Architecture Search Papers’ by Jian Yang GitHub: O网页链接
- 【2021-1-1】AutoML的比赛
sklearn
- 【2021-7-1】温州大学黄海广机器学习库Scikit-learn库使用总结, github
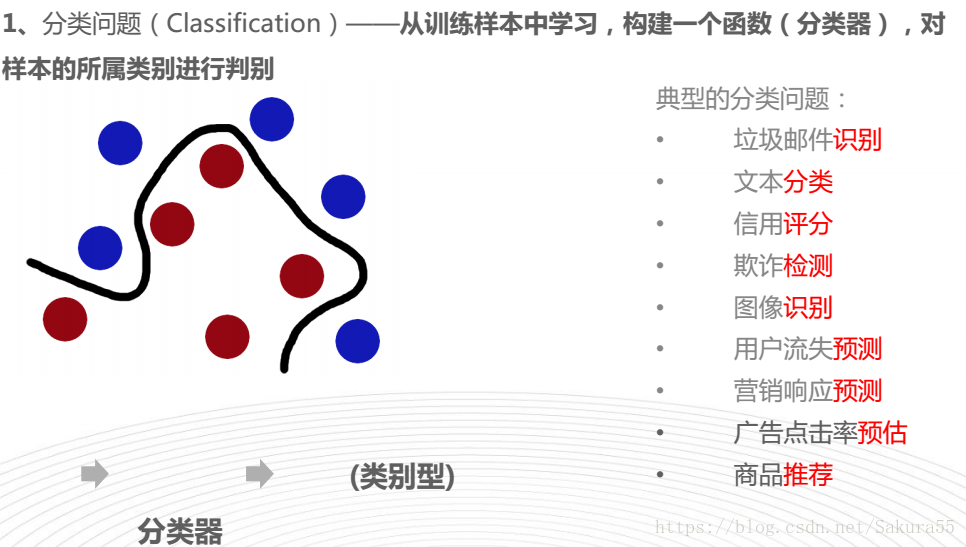
分类
sklearn解决的典型问题


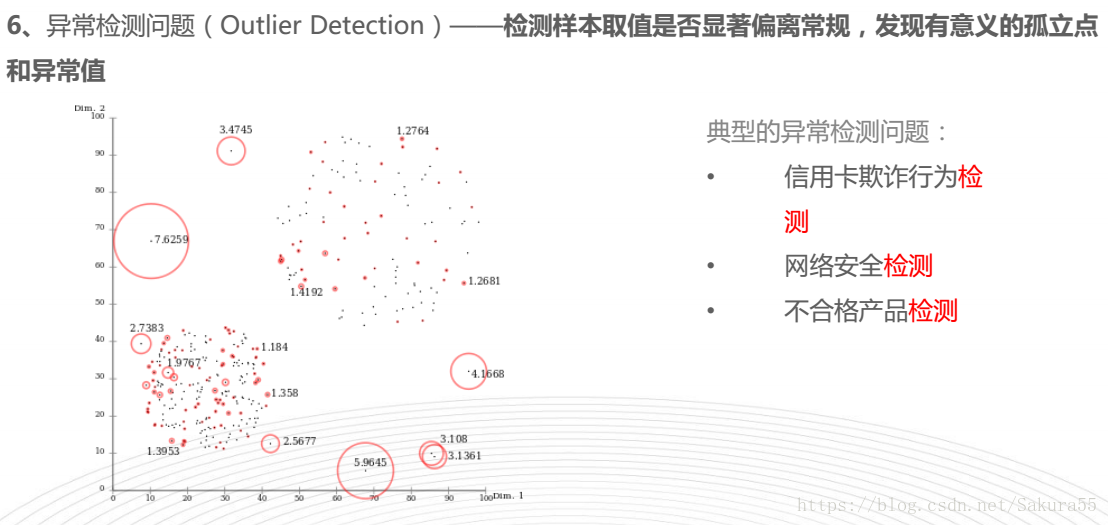
思维导图, 机器学习—-scikit-learn入门

流程
- 利用sklearn中pipeline构建机器学习工作流
- Scikit-learn pipeline 实现了对全部步骤的流式化封装和管理(streaming workflows with pipelines),可以很方便地使参数集在新数据集(比如测试集)上被重复使用。
- Pipeline可以将许多算法模型串联起来,比如将特征提取、归一化、分类组织在一起形成一个典型的机器学习问题工作流。
- 主要带来两点好处:
- 直接调用fit和predict方法来对pipeline中的所有算法模型进行训练和预测。
- 可以结合grid search对参数进行选择。
- Parameters
- steps : 步骤:列表(list)
- 被连接的(名称,变换)元组(实现拟合/变换)的列表,按照它们被连接的顺序,最后一个对象是估计器(estimator)。
- memory:内存参数,Instance of sklearn.external.joblib.Memory or string, optional (default=None)属性,name_steps:bunch object,具有属性访问权限的字典
- 只读属性以用户给定的名称访问任何步骤参数。键是步骤名称,值是步骤参数。或者也可以直接通过”.步骤名称”获取
- funcution
- Pipline的方法都是执行各个学习器中对应的方法,如果该学习器没有该方法,会报错
- 假设该Pipline共有n个学习器
- transform,依次执行各个学习器的transform方法
- fit,依次对前n-1个学习器执行fit和transform方法,第n个学习器(最后一个学习器)执行fit方法
- predict,执行第n个学习器的predict方法
- score,执行第n个学习器的score方法
- set_params,设置第n个学习器的参数
- get_param,获取第n个学习器的参数
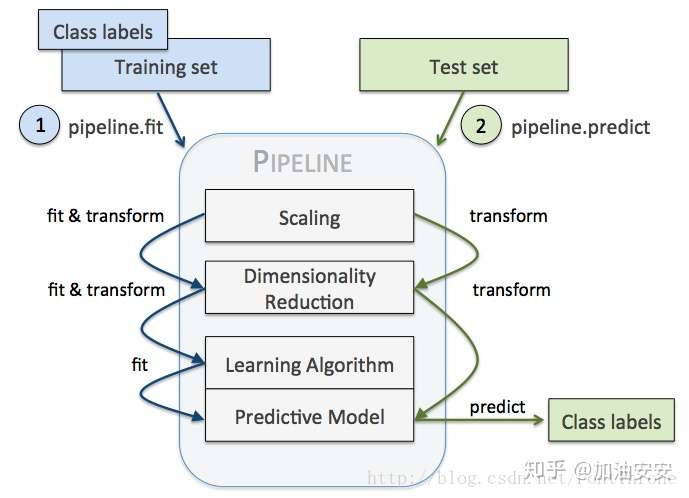
- Pipeline 对训练集和测试集进行如下操作:
- 先用 StandardScaler 对数据集每一列做标准化处理,(是 transformer)
- 再用 PCA 将原始的 30 维度特征压缩的 2 维度,(是 transformer)
- 最后再用模型 LogisticRegression。(是 Estimator)
from pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'
'breast-cancer-wisconsin/wdbc.data', header=None)
# Breast Cancer Wisconsin dataset
X, y = df.values[:, 2:], df.values[:, 1]
encoder = LabelEncoder()
y = encoder.fit_transform(y)
>>> encoder.transform(['M', 'B'])
array([1, 0])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2, random_state=0)
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
pipe_lr = Pipeline([('sc', StandardScaler()),
('pca', PCA(n_components=2)),
('clf', LogisticRegression(random_state=1))
])
pipe_lr.fit(X_train, y_train)
print('Test accuracy: %.3f' % pipe_lr.score(X_test, y_test))
- Pipeline 的工作方式:
- 当管道 Pipeline 执行 fit 方法时,
- 首先 StandardScaler 执行 fit 和 transform 方法,
- 然后将转换后的数据输入给 PCA,
- PCA 同样执行 fit 和 transform 方法,
- 再将数据输入给 LogisticRegression,进行训练。
- 示意图
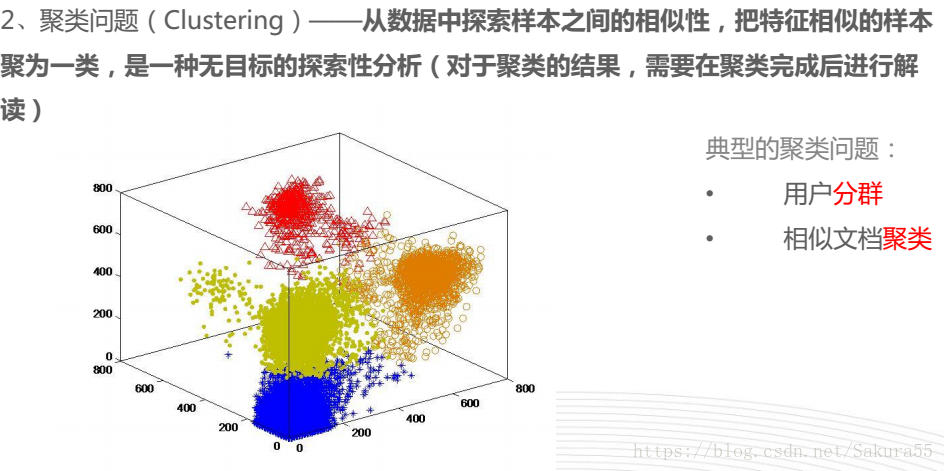
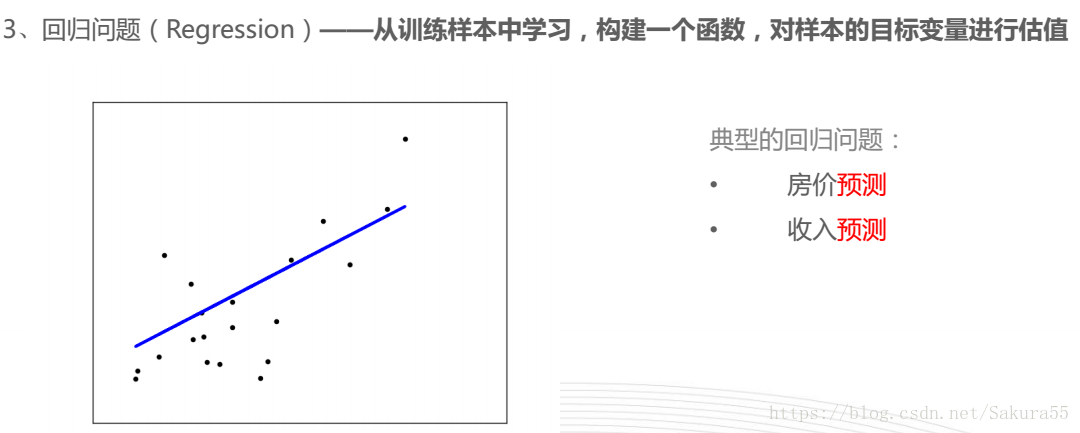
介绍
什么是AutoML
AutoML(Automated machine learning)是将机器学习应用于现实问题的end-to-end流程自动化的过程。- 在典型的机器学习应用程序中,从业者必须应用适当的数据预处理,特征工程,特征提取和特征选择方法,使数据集适合机器学习。
- 这些预处理步骤之后,从业者必须执行算法选择和超参数优化,以最大化其最终机器学习模型的预测性能。
- 由于这些步骤通常超出了非专家的能力,因此AutoML被提议作为基于人工智能的解决方案,以应对机器学习应用中不断增长的挑战。
- AutoML的end-to-end流程提供了生成更简单的解决方案,更快地创建这些解决方案以及通常优于手动设计的模型的优势。
- 不过目前常说的AutoML,对于数据挖掘和深度学习两个领域来说,几乎是完全不一样的的东西。
数据挖掘: 关注自动化特征工程,模型选择,自动训练最好能生成代码,数据偏移检测深度学习: 关注网络结构的设计和其参数的调节
自动机器学习(AutoML)是将机器学习应用于现实问题的端到端流程自动化的过程。- 传统机器学习模型大致可分为以下四个部分:数据采集、数据预处理、优化、应用;
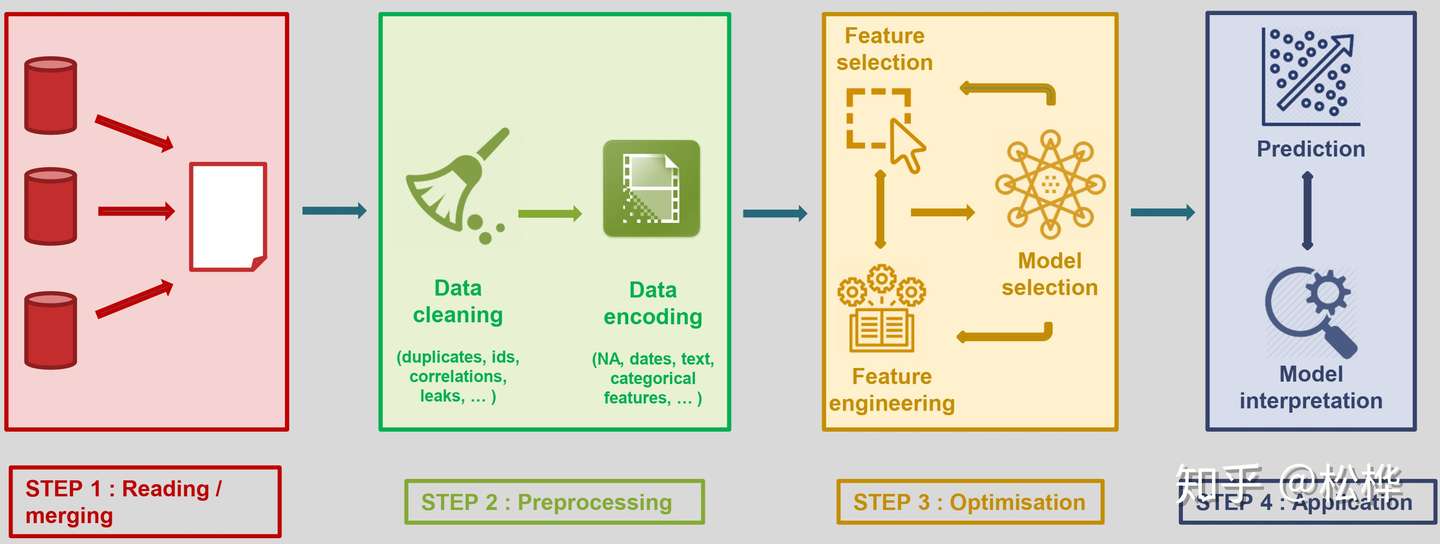
传统机器学习流程
- 其中数据预处理与模型优化部分往往需要具备专业知识的数据科学家来完成,他们建立起了数据到计算的桥梁。
- 然而,即使是数据科学家,也需要花费大量的精力来进行算法与模型的选择。
- 机器学习在各种应用中的成功,导致对机器学习从业人员的需求不断增长,因此我们希望实现真正意义上的机器学习,让尽可能多的工作也能够被自动化完成,进一步降低机器学习的门槛,让没有该领域专业知识的人也可以使用机器学习来完成相关的工作。
- AutoML应运而生。
- 从传统机器学习模型出发,AutoML从特征工程、模型构建、超参优化三方面实现自动化;并且也提出了end-to-end的解决方案。本专栏,贯彻AutoML的思想,将门槛降到最低,简略介绍原理,侧重介绍AutoML开源工具的使用方法。本篇文章主要对AutoML各个工具的优劣特性进行总结对比,关于AutoML各个工具的详情见专栏中细分文章。
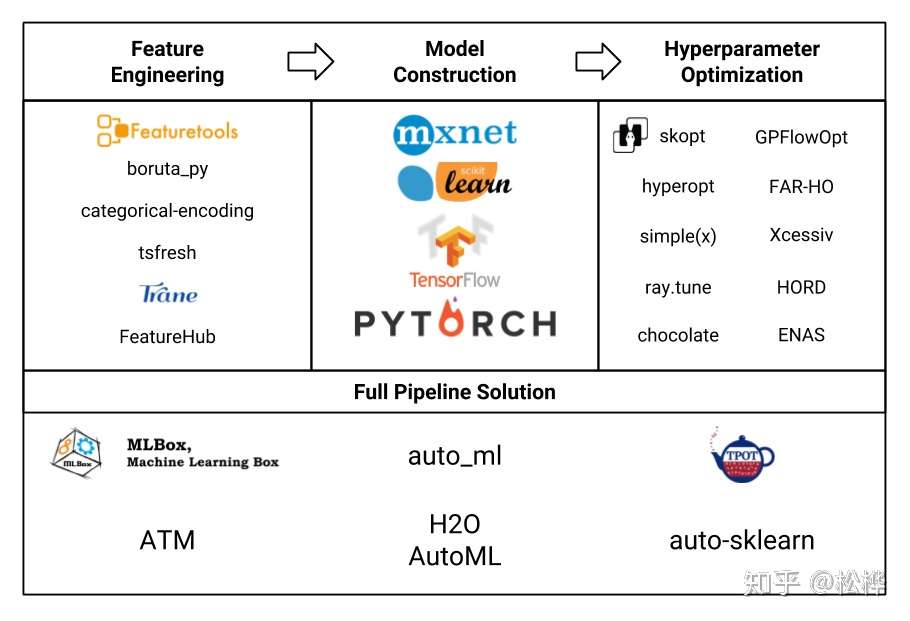
特征工程
1.什么是特征工程
- 特征是从现实世界的具体物体到用数值表示的抽象数值化变换。
- 特征工程是将原始数据转化为特征的过程,这些特征可以更好地向预测模型描述潜在问题,从而提高模型对未见数据的准确性。
- 特征工程通常包括三个工作:特征生成、特征选择、特征编码
- 特征选择: 在许多数据分析和建模项目中,数据科学家会收集到成百上千个特征。更糟糕的是,有时特征数目会大于样本数目。这种情况很普遍,但在大多数情况下,并不是所有的变量都是与机器试图理解和建模的内容相关的。所以数据科学家可以尝试设计一些有效的方法来选择那些重要的特征,并将它们合并到模型中,这叫做特征选择。
- 特征生成: 一般是在特征选择之前,它提取的对象是原始数据,目的就是自动地构建新的特征,将原始数据转换为一组具有明显物理意义(比如 Gabor、几何特征、纹理特征)或者统计意义的特征。
- 特征编码: 原始数据通常比较杂乱,可能会带有各种非数字特殊符号。而实际上机器学习模型需要的数据是数字型的,因为只有数字类型才能进行计算。因此,对于各种特殊的特征值,我们都需要对其进行相应的编码,也是量化的过程。
2 .为什么需要自动特征工程
- 在机器学习步骤中,特征工程会耗费数据科学家大量的人力去进行特征的提取和筛选,不仅耗费大量的时间,而且效率也不高。因此需要自动特征工程来将这些操作自动化,节省数据科学家的时间。
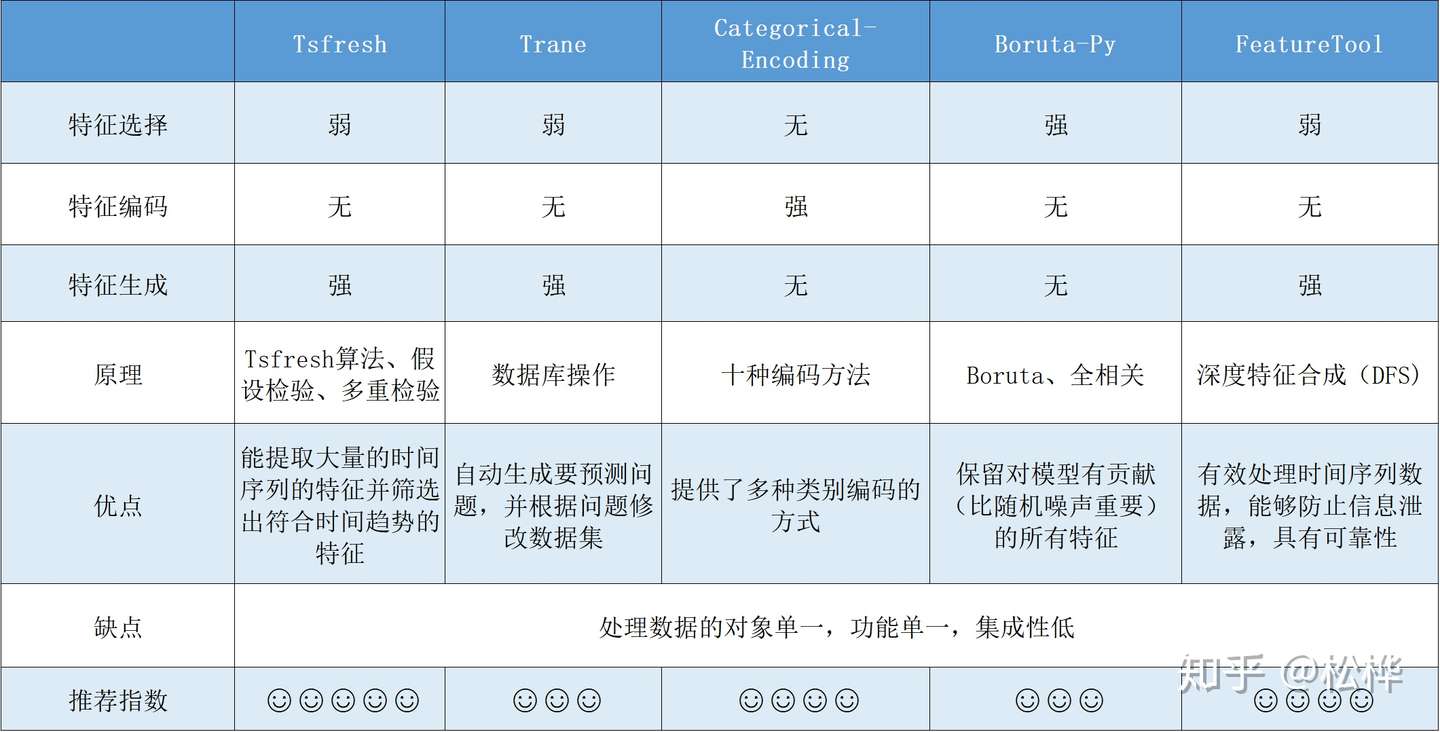
3.常见的特征工程工具总结和比较
本专栏调研了以下五种常用超参优化工具,并逐一撰写了报告发表在本专栏。
- 特征工程工具总结(1)——Tsfresh
- 特征工程工具总结(2)——Trane
- 特征工程工具总结(3)——Categorical Encoding
- 特征工程工具总结(4)——boruta_py
- 特征工程工具总结(5)——Featuretools
关于各个特征工程工具的细节可在以上链接中点击查阅。这里对这五种特征工程工具的功能、原理、优缺点等方面进行了评估了对比。
模型构建
- 此处模型构建特指深度学习框架,简要对深度学习框架做一个简单对比。
- 深度学习框架链接起了整个AI生态:上层算法应用基于框架搭建,底层芯片入口适配框架开发。
- 2018年9月,Jeff Hale根据公司招聘、调研报告、网络搜索、科研论文、教程文档、GitHub热度等数据,评估了2018年11种深度学习框架的影响力,如下图所示。

超参优化工具总结
1.什么是超参数优化
- 超参数是机器学习在学习之前预先设置好的参数,而非通过训练得到的参数,例如树的数量深度, 神经网络的学习率等,甚至在超参学习中神经网络的结构,包括层数,不同层的类型,层之间的连接方式等,都属于超参数的范畴。
- 手动修改调参既耗费大量的人力和时间,同时也难以寻找优化的方向,而对超参数选择进行优化既能节省大量人力和时间,又能让学习获得更好的性能和效果。因此出现了一系列的超参优化的工具来简化和改进超参选择和调整的过程。
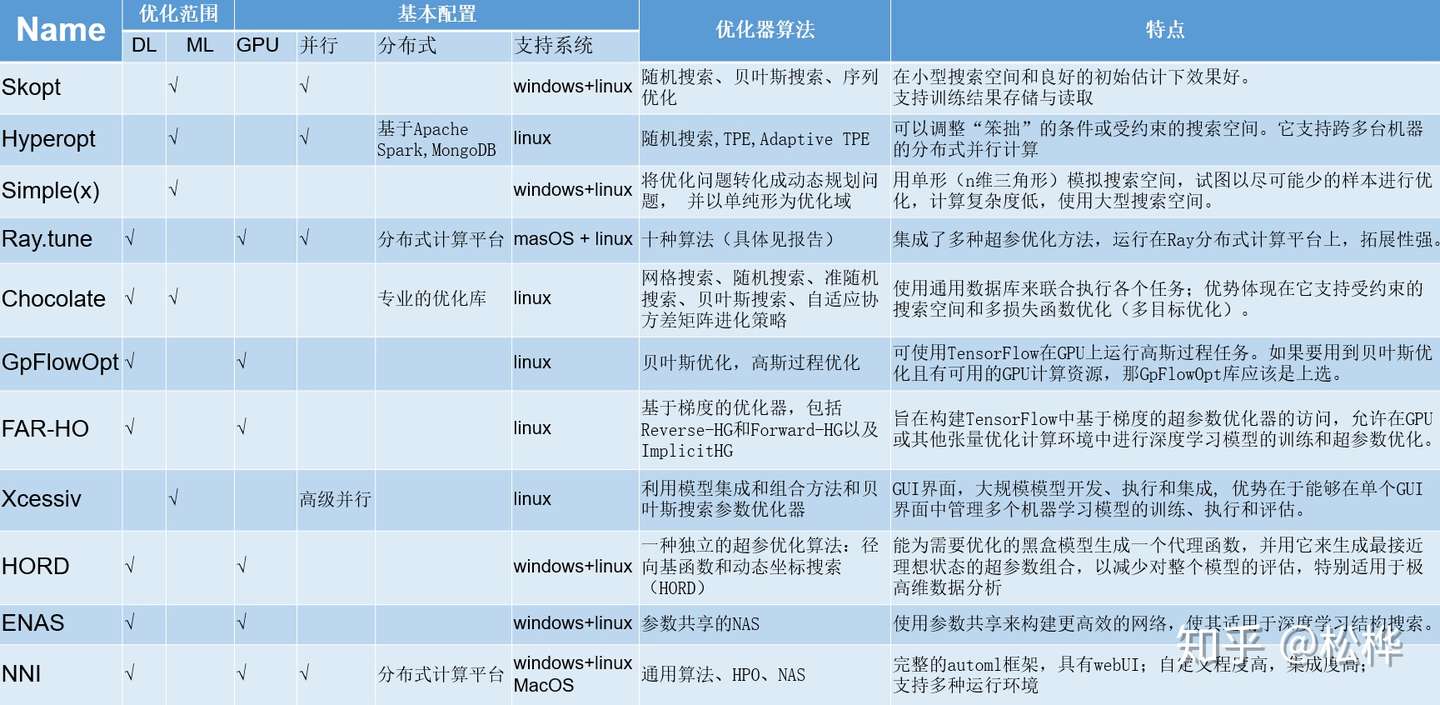
2. 十种超参优化工具的总结和比较
以下十种常用超参优化工具:
- 超参优化工具总结(1)——Skopt
- 超参优化工具总结(2)——Hyperopt
- 超参优化工具总结(3)——Simple(x)
- 超参优化工具总结(4)——Ray.tune
- 超参优化工具总结(5)——Chocolate
- 超参优化工具总结(6)——GpFlowOpt
- 超参优化工具总结(7)——FAR-HO
- 超参优化工具总结(8)——Xcessiv
- 超参优化工具总结(9)——HORD
- 超参优化工具总结(10)——ENAS
- 超参优化工具总结(11)——NNI
关于各个超参优化工具的细节可在以上链接中点击查阅。这里从优化范围、基本配置、优化算法、各自的特点等五个方面对十一种工具进行了评估了对比。(注:表格增加了NNI的超参优化部分与其他超参优化工具的对比)
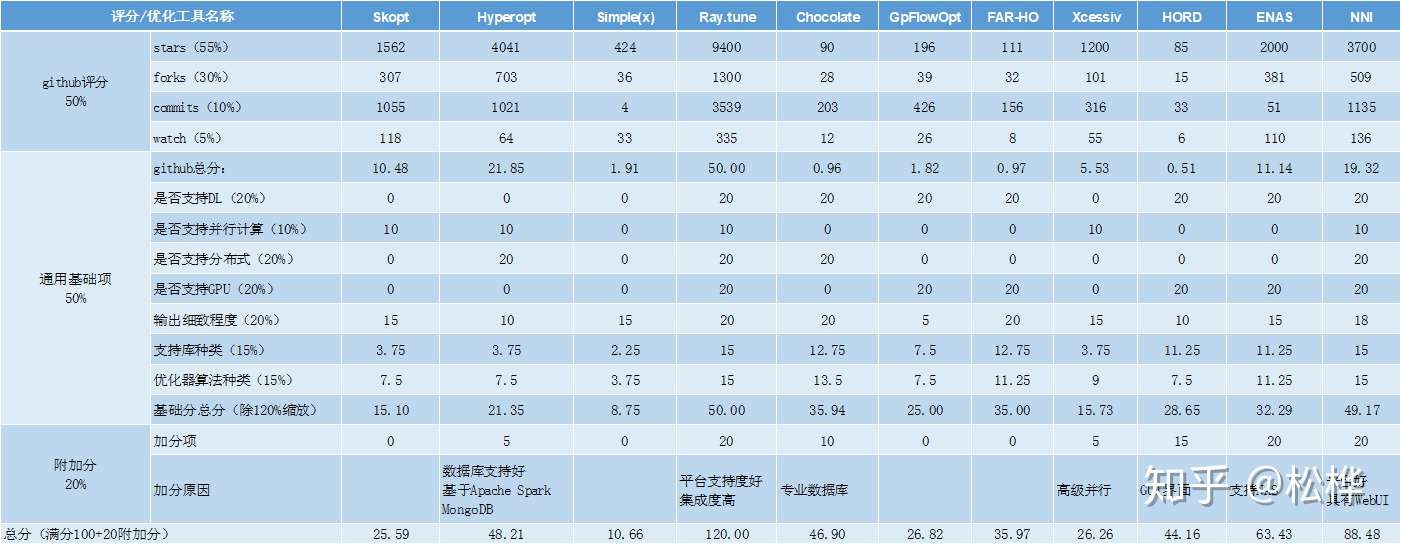
- 评分如下:
- 评比规则:通用基础项(50%)+gihub评分(50%)+加分项(20%)
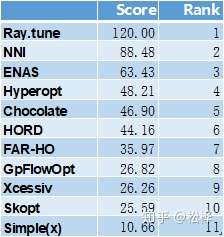
- 评比规则:通用基础项(50%)+gihub评分(50%)+加分项(20%)
- 结果:
hyperopt进行参数优化
- hyperopt网址
- 安装方法: pip install hyperopt
hyperopt实际上只是提供了一个优化的接口,因此我们可以利用这个接口实现我们任何模型的参数优化,包括Tensorflow或sklearn等python实现的模型。
其输入应该为模型的超参数(argsDict),输出为该模型的评分,这个评分应该要满足“越小越好”的条件
- argsDict是一个参数的字典, dtr是利用argsDict实例化DecisionTressRegressor的模型,
- metric是利用训练集x_train(训练集的特征)和y_train(训练集的标签),(x_train 和 y_train都是全局变量,这里不再赘述)进行交叉验证得到的score的均值
- score是我们定义的scoreing=“neg_mean_absolute_error”
- 需要注意的是,“neg_mean_absolute_error”是MAE的负数,我们的优化目标是使MAE越小越好, 因此应该返回“-metric”
- 另外 交叉验证并不是必须的,只要return的是这个模型的一个评分就行。
algo是参数优化的策略(即参数搜索算法),当前支持随机搜索(hyperopt.rand.suggest)、Tree of Parzen Estimators(hyperopt.pte.suggest)(据说是贝叶斯优化的一种变体,但没找到太靠谱的资料)
- max_evals是指最大尝试的模型个数,越大越容易找到最优解
- fmin返回的best是搜索到的最优参数字典
- 最后的clf = DTR(best, is_return=True)是我用来获取best参数实例化的模型句柄,以方便后续在测试集上的评估
代码示例
from sklearn.tree import DecisionTreeRegressor #需要调參的模型
from sklearn.cross_validation import cross_val_score # 交叉验证
from hyperopt import fmin, tpe, hp, rand #参数优化
def DTR(args_dict, is_train=False):
""" 超参调试 """
hyper_list = [['max_depth', '+', 3],
['min_samples_split', '+', 10],
['min_samples_leaf', '+', 5],
['min_impurity_decrease', '*', 0.01],
['max_features', '+', 3]
]
hyper_dict = {}
for hy in hyper_list:
hyper_dict[hy[0]] = eval('args_dict[hy[0]] {0} hy[2]'.format(hy[1]))
# 模型初始化
dtr = ExtraTreesRegressor(**hyper_dict)
# 评估方法
metric = cross_val_score(dtr, x_train, y_train, cv=3,
scoring='neg_mean_absolute_error').mean()
log.info('MAE:', -metric, '超参:', json.dumps(hyper_dict))
print json.dumps(hyper_dict)
if is_train:
return dtr
return -metric
def search_best_model():
""" 找最好的超参 """
import hyperopt as ht #参数优化
# 定义参数搜索域——网格搜索
space = {'max_depth':ht.hp.randint('max_depth',15),
'min_samples_split':ht.hp.randint('min_samples_split',200),
'min_samples_leaf':ht.hp.randint('min_samples_leaf',200),
'min_impurity_decrease':ht.hp.randint('min_impurity_decrease',20),
'max_features':ht.hp.randint('max_features',6)
#ht.hp.choice(),ht.hp.uniform()
}
#algo = ht.partial(tpe.suggest,n_startup_jobs=10)
# 训练模型
best = ht.fmin(DTR, space, algo=ht.tpe.suggest, max_evals=2000)
log.info('最佳模型:', best)
clf = DTR(best, is_train=True)
y_predict_test = clf.predict(x_test)
return best
if __name__ == '__main__':
# 超参搜索
param_dict = search_best_model()
hyperopt-sklearn
hyperopt-sklearn是给予hyperopt专门为了sklearn而封装的包,使用起来也很简单,但是目前只支持sklearn中的几种模型(见官网说明)。网址
AutoML的起源
- 最早出现的AutoML库是
AutoWEKA,于2013年首次发布,可以自动选择模型和超参数。其他值得注意的AutoML库包括auto-sklearn(将AutoWEKA拓展到了python环境),H2O AutoML和TPOT。 AutoML.org(以前被称为ML4AAD,Machine Learningfor AutomatedAlgorithm Design)小组,自2014年以来一直在ICML机器学习学术会议上组织AutoML研讨会。而这些方面的autoML技术趋于成熟而谈到神经网络深度学习的automl,不得不从NAS算法讲起。
NAS
- 在开发神经网络的过程中,架构工程事关重大,架构先天不足,再怎么训练也难以得到优秀的结果。
- 当然,提到架构,很多人会想到迁移学习:把ImageNet上训练的ResNet拿来,换个我需要的数据集再训练训练更新一下权重,不就好了嘛!
- 这种方法的确也可行,但是要想得到最好的效果,还是根据实际情况设计自己的网络架构比较靠谱。
- 设计神经网络架构,能称得上机器学习过程中门槛最高的一项任务了。想要设计出好架构,需要专业的知识技能,还要大量试错。
- NAS就为了搞定这个费时费力的任务而生。
- 这种算法的目标就是, 搜索出最好的神经网络架构。
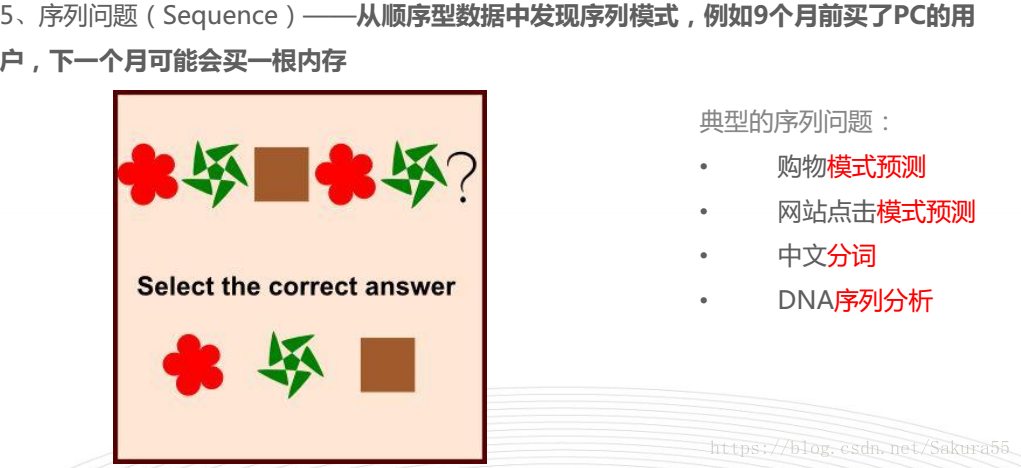
- 工作流程通常从定义一组神经网络可能会用到的“建筑模块”开始。
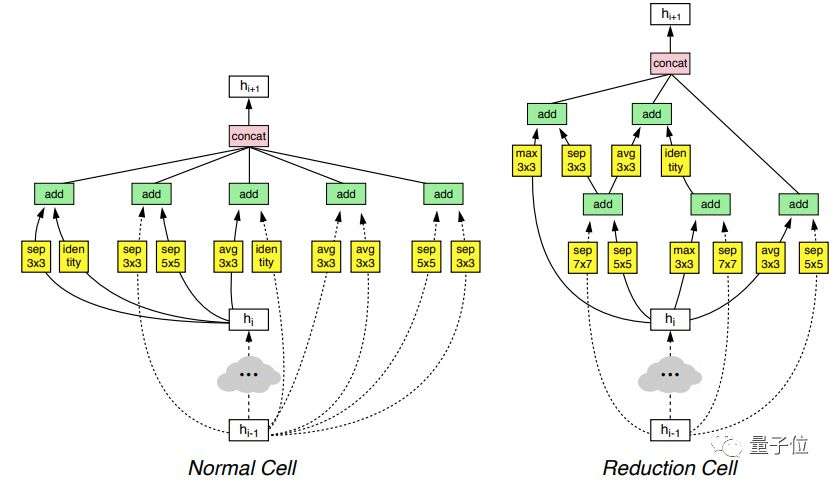
- 比如说Google Brain那篇NasNet论文,就为图像识别网络总结了这些常用模块:

- 其中包含了多种卷积和池化模块。
- 论文:Learning Transferable Architectures for Scalable Image Recognition
- 比如说Google Brain那篇NasNet论文,就为图像识别网络总结了这些常用模块:
- NAS算法用一个循环神经网络(RNN)作为控制器,从这些模块中挑选,然后将它们放在一起,来创造出某种端到端的架构。
- 这个架构,通常会呈现出和ResNet、DenseNet等最前沿网络架构一样的风格,但是内部模块的组合和配置有所区别。一个架构的好坏,往往就取决于选择的模块和在它们之间构建的连接。
- 接下来,就要训练这个新网络,让它收敛,得到在留出验证集上的准确率。这个准确率随后会用来通过策略梯度更新控制器,让控制器生成架构的水平越来越高。
- 过程如下图所示, 像小朋友搭积木,让一个算法挑出一些积木,然后把它们组装在一起,做成一个神经网络。训练、测试,根据这个结果来调整选积木的标准和组装的方式。
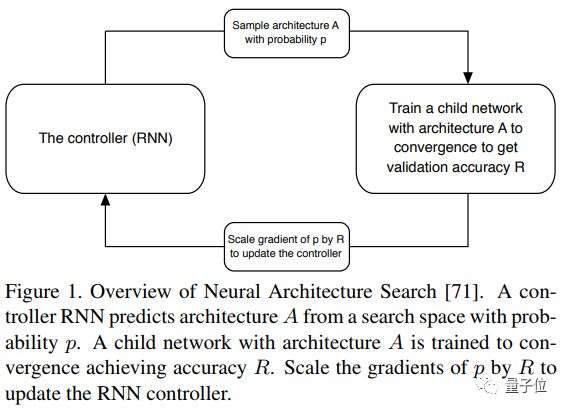
- 过程如下图所示, 像小朋友搭积木,让一个算法挑出一些积木,然后把它们组装在一起,做成一个神经网络。训练、测试,根据这个结果来调整选积木的标准和组装的方式。
- 论文里训练、测试NAS算法发现的架构,都用了一个比现实情况小得多的数据集。当然,这是一种折衷的方法,要在ImageNet那么大的数据集上训练验证每一种搜索结果,实在是太耗费时间了。
- 所以,他们做出了一个假设:
- 如果一个神经网络能在结构相似的小规模数据集上得到更好的成绩,那么它在更大更复杂的数据集上同样能表现得更好。
- 在深度学习领域,这个假设基本上是成立的。
- 上面还提到了一个限制,这指的是搜索空间其实很有限。他们设计NAS,就要用它来构建和当前最先进的架构风格非常类似的网络。
- 在图像识别领域,这就意味着用一组模块重复排列,逐步下采样,如下图所示
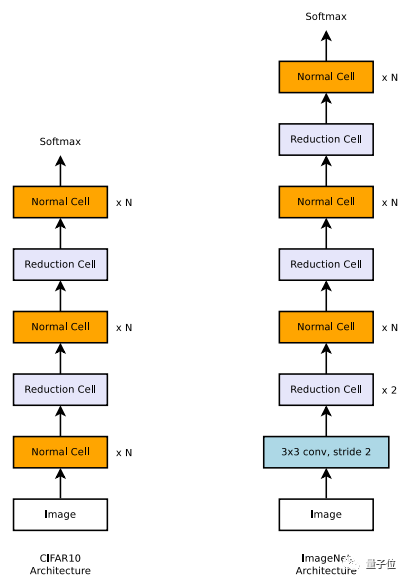
- 应用到ImageNet后,发现的最佳神经网络架构
架构搜索的进展
- 这篇NASNet论文带动了行业内的一次进步,它为深度学习研究指出了一个全新方向。
-
但是,用450个GPU来训练,找到一个优秀的架构也需要训练3到4天。也就是说,对于除了Google之外的普通贫民用户们,这种方法还是门槛太高、效率太低。
- NAS领域最新的研究,就都在想方设法让这个架构搜索的过程更高效。
- 2017年谷歌提出的渐进式神经架构搜索(PNAS),建议使用名叫“基于序列模型的优化(SMBO)”的策略,来取代NASNet里所用的强化学习。用SMBO策略时,我们不是随机抓起一个模块就试,而是按照复杂性递增的顺序来测试它们并搜索结构。
- 这并不会缩小搜索空间,但确实用更聪明的方法达到了类似的效果。SMBO基本上都是在讲:相比于一次尝试多件事情,不如从简单的做起,有需要时再去尝试复杂的办法。这种PANS方法比原始的NAS效率高5到8倍,也便宜了许多。
- 高效神经架构搜索(ENAS),是谷歌打出的让传统架构搜索更高效的第二枪,这种方法很亲民,只要有GPU的普通从业者就能使用。作者假设NAS的计算瓶颈在于,需要把每个模型到收敛,但却只是为了衡量测试精确度,然后所有训练的权重都会丢弃掉。
- 因此,ENAS就要通过改进模型训练方式来提高效率。
- 在研究和实践中已经反复证明,迁移学习有助在短时间内实现高精确度。因为为相似任务训练的神经网络权重相似,迁移学习基本只是神经网络权重的转移。
- ENAS算法强制将所有模型的权重共享,而非从零开始训练模型到收敛,我们在之前的模型中尝试过的模块都将使用这些学习过的权重。因此,每次训练新模型是都进行迁移学习,收敛速度也更快。
深度学习新方法AutoML
- 很多人将AutoML称为深度学习的新方式,认为它改变了整个系统。有了AutoML,我们就不再需要设计复杂的深度学习网络,只需运行一个预先设置好的NAS算法。
- 最近,Google提供的Cloud AutoML将这种理念发挥到了极致。只要你上传自己的数据,Google的NAS算法就会为你找到一个架构,用起来又快又简单。
- AutoML的理念就是把深度学习里那些复杂的部分都拿出去,你只需要提供数据,随后就让AutoML在神经网络设计上尽情发挥吧。这样,深度学习就变得像插件一样方便,只要有数据,就能自动创建出由复杂神经网络驱动的决策功能。
原理
AutoML原理浅析
- AutoML网络的设计从卷积架构的初始版本进行多年的仔细实验和细化完成的。
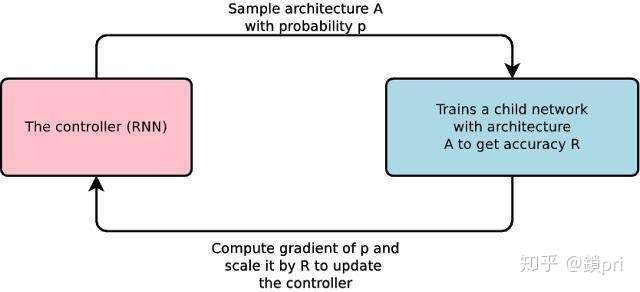
- 在AutoML中,一种控制器神经网络能够提议一个“子”模型架构,然后针对特定任务进行训练与质量评估;而反馈给控制器的信息则会被用来改进下一轮的提议。我们重复这个过程数千次——从而生成新的架构,然后经过测试和反馈,让控制器进行学习。最终,控制器将学会为好的架构分配高的概率,以便在延续的验证数据集上实现更高的准确性,并且对于架构空间的差异很小。如下图所示:
AutoML旨在创建可以由ML新手”开箱即用“的软件,可以帮人们做到机器学习流程中的以下几个part:
- 预处理数据
- 选择适当的功能
- 选择一个适当的模型选择系列
- 优化模型超参数
- 后处理机器学习模型
- 严格分析所得的结果
虽然它的最终用户面向那些没有专业机器学习知识的人,但AutoML依然向机器学习专业人士提供了一些新的工具,如:
- 执行深层表示的架构搜索
- 分析超参数的重要性
AutoML所使用的方法
AutoML借鉴了机器学习的许多学科,主要是:
- 贝叶斯优化
- 结构化数据和大数据的回归模型
- Meta 学习
- 转移学习
- 组合优化
用于贝叶斯优化的机器学习超参数系统可以促进AutoML,主要包括:
- Hyperopt,包括TPE算法
- 基于序列模型的算法配置(SMAC)
- [Spearmint](github.com/JasperSnoek…
- 此外,还提供了两个可用于超参数优化的软件包:
RoBO-鲁棒的贝叶斯优化框架(Robust Bayesian Optimization framework) SMAC3 - SMAC算法的python实现 总而言之,一般情况下,进行机器学习首先需要大量的训练数据,再由机器学习工程师/数据科学家对数据进行分析,设计算法形成训练模型;这需要大量的专业知识。但是,如果使用AutoML,就像是在使用一个工具,我们只需要将训练数据集传入AutoML,那么这个工具就会自动帮我们生成参数和模型,形成训练模型,这样即使不具备机器学习方面深入的专业知识也可以进行机器学习方面的工作。
AutoML开源框架分析
AutoML开源框架集成了特征工程模型构建以及超参优化,是一种全管道的AutoML工具。
- 以下五个常用的AutoML开源框架
- 关于各个开源框架的细节可在以上链接中点击查阅。这里从AutoML框架的特征工程、模型支持、超参优化、特性以及安装和上手难度五个方面最五个框架进行了评估了对比。
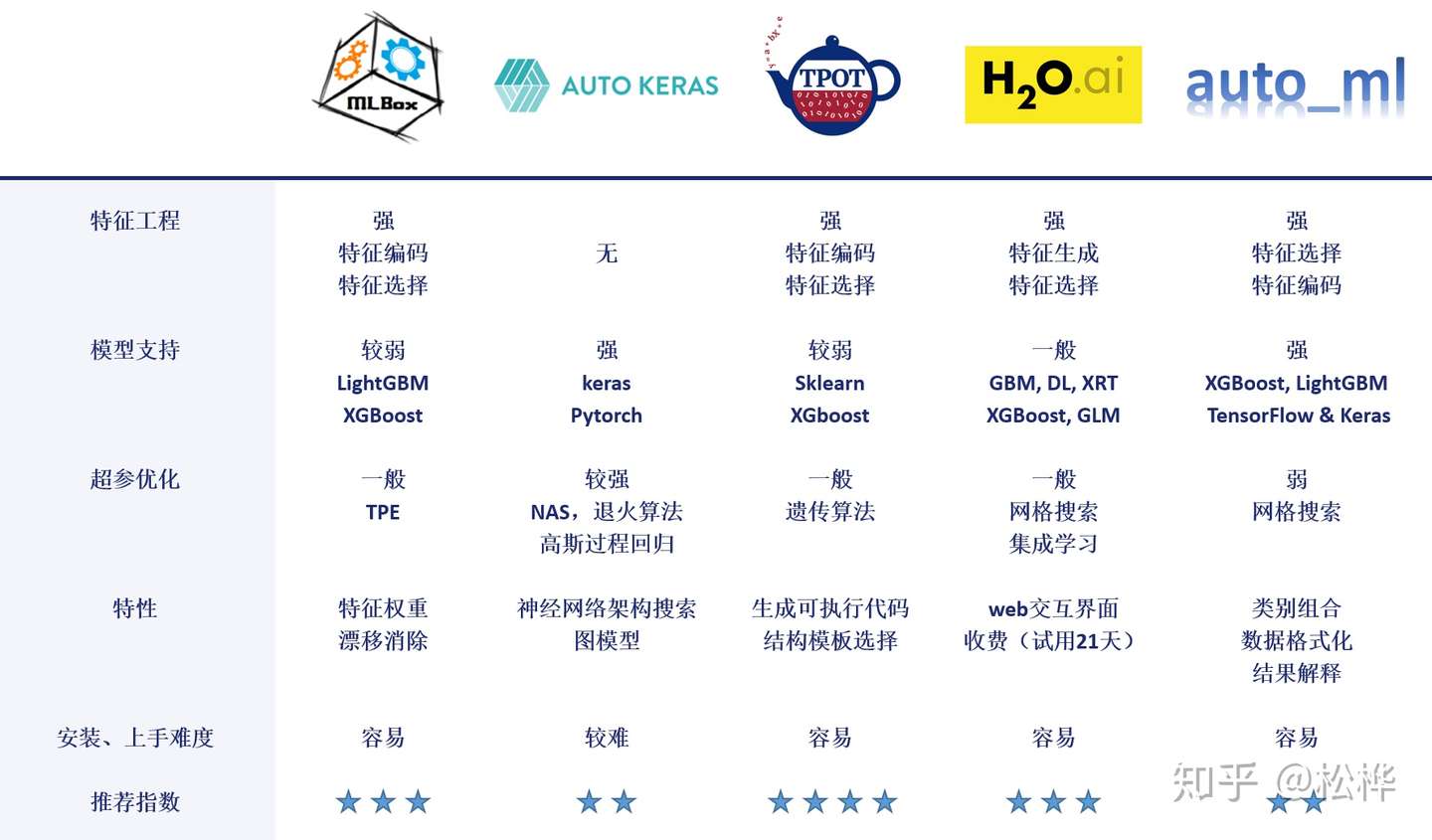
- 可以看出,除了AutoKeras,其余框架均对特征工程有较强的支持,但支持的模型大多是传统机器模型。AutoKeras对神经网络支持较好,也因此对特征工程要求较低,它也是五种框架中唯一支持NAS的框架。TPOT支持显式地生成可执行代码,而MLBox甚至无法输出模型,只能输出对test的预测结果。H20是一款更加产品化的框架,有WebUI界面展示过程,对用户更加友好。auto_ml基础但全面,它更像是一个用于新手的教练机,没有特别的亮点但基本功能一应俱全。
- 在学术界,AutoML是一个活跃的新兴领域,大量关于AutoML的论文出现在机器学习会议与期刊中,同时也有很多开创性的开源项目(例如本文中列举的各类工具)受到大家的关注。在工业界,也有许多成熟的AutoML的产品,如专注特征工程的FeatureLab、包含NAS的Google’s Cloud。这些产品都很大程度上帮助了机器学习从业人员将想法快速便捷的应用、落地。未来,AutoML能让机器学习自动化到什么程度、在算力需求上能否大众化、相关的优化理论能否加速整个学习过程?我们与您共同期待。
应用
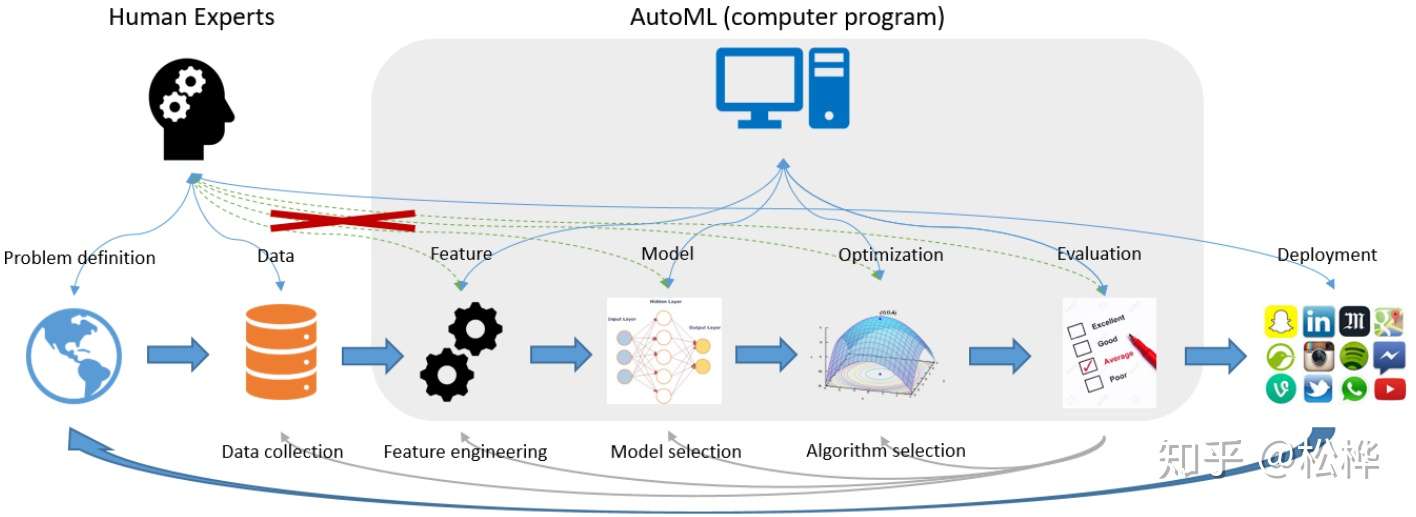
- AutoML的应用,下图源自论文
AutoML发展现状
- 在2018年谷歌云全球NEXT大会(Google CloudNext 18)上,李飞飞宣布,谷歌AutoML Vision进入公共测试版,并推出了两款新的AutoML产品:AutoML Natural Language和AutoML Translation。
- 这个名为Cloud AutoML的宏大项目浮出水面之时,被业内称为“Google Cloud发展的战略转型”——一直以来面向机器学习人工智能开发者的Google Cloud,这次将服务对象转向了普罗大众。你只需在改系统中上传自己的标签数据,大能得到一个训练好的机器学习模型。整个过程,从导入数据到标记到模型训练,都可以通过拖放界面完成。
- 其实在谷歌发布AutoML前后,机器学习自动化的产品风潮已经吹起:2017年底,微软发布CustomVision.AI,涵盖图像、视频、文本和语音等各个领域。今年 1 月,他们又推出了完全自动化的平台 Microsoft Custom Vision Services(微软定制视觉服务)。同年,国内也出现了不少相关产品,称能够解放算法工程师,让AI自动化。
谷歌cloud automl
- 利用 Google 先进的 AutoML 和迁移学习技术来创建高质量的模型
- 原理:
- Cloud AutoML 与其他 Google Cloud 服务全面集成,因此客户能够以统一的方式使用所有 Google Cloud 服务。可以在 Cloud Storage 中存储训练数据。要根据训练后的模型生成预测,只需在使用现有 Vision API 时添加一个参数来指定您的自定义模型,或使用 Cloud ML Engine 的在线预测服务。
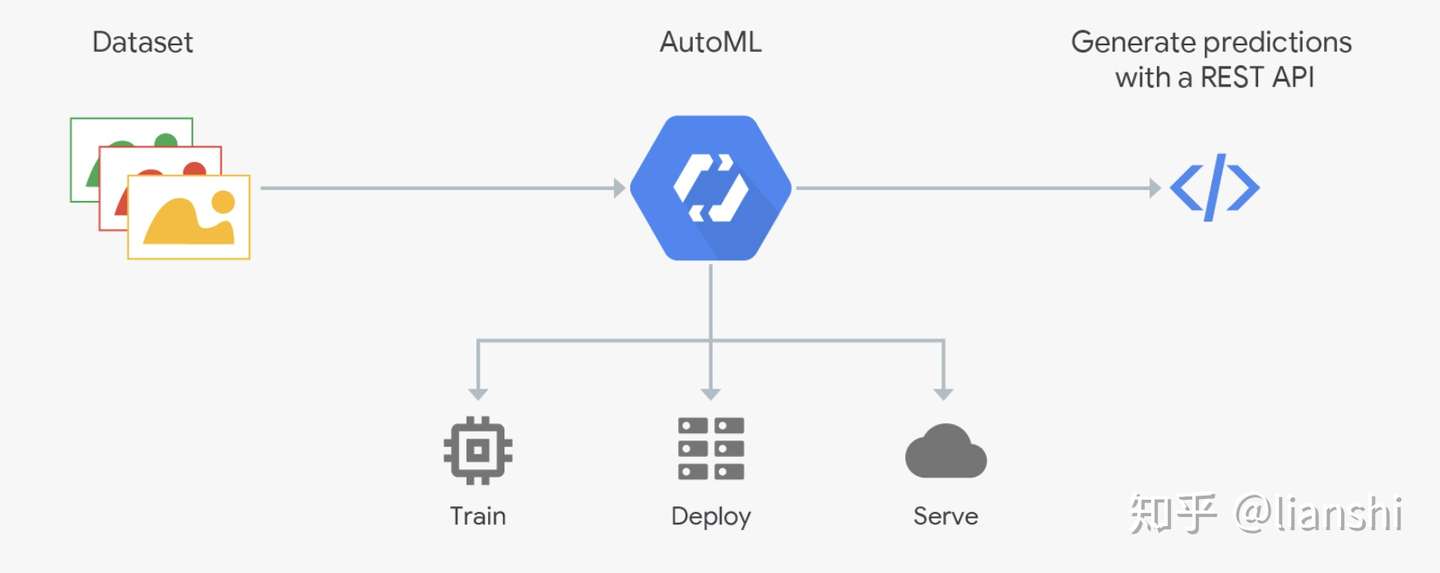
- Cloud AutoML 与其他 Google Cloud 服务全面集成,因此客户能够以统一的方式使用所有 Google Cloud 服务。可以在 Cloud Storage 中存储训练数据。要根据训练后的模型生成预测,只需在使用现有 Vision API 时添加一个参数来指定您的自定义模型,或使用 Cloud ML Engine 的在线预测服务。
- Google开源AutoML Adanet
- 开源了基于 TensorFlow 的轻量级框架 AdaNet,该框架可以使用少量专家干预来自动学习高质量模型。AdaNet 在谷歌近期的强化学习和基于进化的 AutoML 的基础上构建,快速灵活同时能够提供学习保证(learning guarantee)。重要的是,AdaNet 提供通用框架,不仅能用于学习神经网络架构,还能学习集成架构以获取更好的模型。
- AdaNet 易于使用,能够创建高质量模型,节省 ML 从业者在选择最优神经网络架构上所花费的时间,实现学习神经架构作为集成子网络的自适应算法。AdaNet 能够添加不同深度、宽度的子网络,从而创建不同的集成,并在性能改进和参数数量之间进行权衡。
- AdaNet 实现了 TensorFlow Estimator 接口,通过压缩训练、评估、预测和导出极大地简化了机器学习编程。它整合如 TensorFlow Hub modules、TensorFlow Model Analysis、Google Cloud』s Hyperparameter Tuner 这样的开源工具。它支持分布式训练,极大减少了训练时间,使用可用 CPU 和加速器(例如 GPU)实现线性扩展。
- 转自谷歌开源AdaNet:基于TensorFlow的AutoML框架 相关论文: AdaNet: Adaptive Structural Learning of Artificial Neural Networks, Github 项目地址, 教程 notebook
百度 Easy DL
- 转自机器之心小白也能搭建深度模型,百度EasyDL的背后你知多少
- 百度的Easy DL 训练模型的基本流程如下,整个过程都是图形化操作,且如果是上传已经处理好的数据,那么强大的迁移学习系统会在几分钟内完成模型的训练。百度 AI 开放平台文档中心对 EasyDL 的建模过程有详细的描述,因为这一图形化的系统非常简明,所以文档也通俗易懂。
- EasyDL 将整个服务精炼为四个步骤,并且可以在不需要机器学习背景知识的情况下开发模型。
- EasyDL 在 2017 年 11 月初上线了定制化图像识别服务,并在业内展开公开测试。
- 在 2018 年 4 月、5 月和 7 月陆续发布了定制化物体检测服务、定制化模型设备端计算和定制化声音识别等多个定制化能力方向,并形成了从训练数据到最终定制化服务的一站式端云一体平台。

- EasyDL 的主要优势在应用案例的累积、简明的产品设计与操作流程、支持移动端计算与部署等,而支持这些优势的是 EasyDL 背后各种主要技术手段。例如:
- AI Workflow 统一大数据工程系统与分布式训练系统,为 EasyDL 提供稳定的系统和流程支持;
- 采用 PaddlePaddle 作为基本框架,为模型的搭建提供基础;
- 采用 Auto Model Search 自动搜索模型超参数,支持获得更好的训练效果;采用迁移学习训练较小的用户数据集,从而大大加强训练效率与效果等。
阿里云PAI
- PAI发布全套自动化机器学习引擎,用机器学习的方式解决机器学习流程的问题.
- 机器学习数据上传之后的流程大致可以分为3个步骤:模型训练、模型评估、模型部署。


- PAI进化式调参迭代效果图

微软NNI
- NNI (Neurol Network Intelligence) 是微软开源的自动机器学习工具。与当前的各种自动机器学习服务或工具相比,有非常独特的价值。
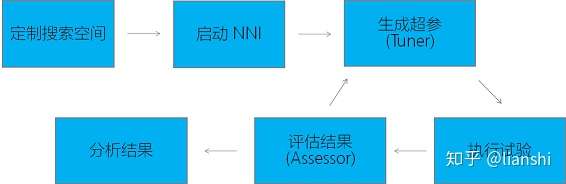
- 1.支持私有部署。云服务中的自动机器学习直接提供了自动机器学习的服务,不仅包含了自动机器学习的功能,也包含了算力。如果团队或个人已经有了很强的算力资源,就需要支持私有部署的自动学习工具了。NNI 支持私有部署。整个部署也很简单,使用 pip 即可完成安装。
- 1.分布式调度。NNI 可以在单机上完成试验,也支持以下两种分布式调度方案:
- GPU 远程服务器。通过 SSH 控制多台 GPU 服务器协同完成试验,并能够计划每个试验所需要的 GPU 的数量。
- OpenPAI。通过 OpenPAI,NNI 的试验可以在独立的 Docker 中运行,支持多样的实验环境。在计算资源规划上,不仅能指定 GPU 资源,还能制定 CPU,内存资源。
-
- 超参搜索的直接支持。当前,大部分自动机器学习服务与工具都是在某个任务上使用,比如图片分类。这样的好处是,普通用户只要有标记数据,就能训练出一个高质量的平台,不需要任何模型训练方面的知识。但这需要对每个训练任务进行定制,将模型训练的复杂性包装起来。
- 与大部分现有的自动机器学习服务与工具不同,NNI 需要用户提供训练代码,并指定超参的搜索范围。这样的好处在于,NNI 几乎是通用的工具,任何训练任务都可以使用 NNI 来进行超参搜索。但另一方面,NNI 的通用性,也带来了一定的使用门槛。使用 NNI 需要有基本的模型训练的经验。

-
- 兼容已有代码。NNI 使用时,可以通过注释的方法来进行无侵入式的改动。不会影响代码原先的用途。通过注释方式支持 NNI 后,代码还可以单独运行。
-
- 易于扩展。NNI 的设计上有很强的可扩展性。通过下面这些扩展性,能将系统与算法相隔离,把系统复杂性都包装起来。
- Tuner 接口,可以轻松实现新的超参调试算法。研究人员可以使用 NNI 来试验新的超参搜索方法,比如在强化学习时,在 Tuner 中支持 off-policy 来探索比较好的超参组合,在 Trial 里进行 on-policy 的实际验证。也可以使用 Tuner 和训练代码相配合,支持复杂的超参搜索方法。如,实现 ENAS ,将 Tuner 作为 Control,在多个 Trial 中并行试验。
- Accessor 接口,可以加速参数搜索,将表现不好的超参组合提前结束。
- 易于扩展。NNI 的设计上有很强的可扩展性。通过下面这些扩展性,能将系统与算法相隔离,把系统复杂性都包装起来。
- NNI 还提供了可扩展的集群接口,可以定制对接的计算集群。方便连接已经部署的计算集群。6. 可视化界面。在启动一次超参搜索试验后,就可以通过可视化界面来查看试验进展,并帮助超参结果,洞察更多信息。
案例
业界在 automl 上的进展:
Google: Cloud AutoML, Google’s Prediction APIMicrosoft: Custom Vision, Azure Machine LearningAmazon: Amazon Machine Learning- others: BigML.com, Wise.io, SkyTree.com, RapidMiner.com, Dato.com, Prediction.io, DataRobot.com
- github上的开源项目:
- auto-sklearn (2.4k stars!)
- autokeras,基于keras的 automl 向开源项目
大模型应用
详见站内专题:Auto Research专题
Google AutoML
- Google: Cloud AutoML, Google’s Prediction API
- 【2020-8-5】90 后丹麦程序员利用 Google AutoML 创建薯片识别器
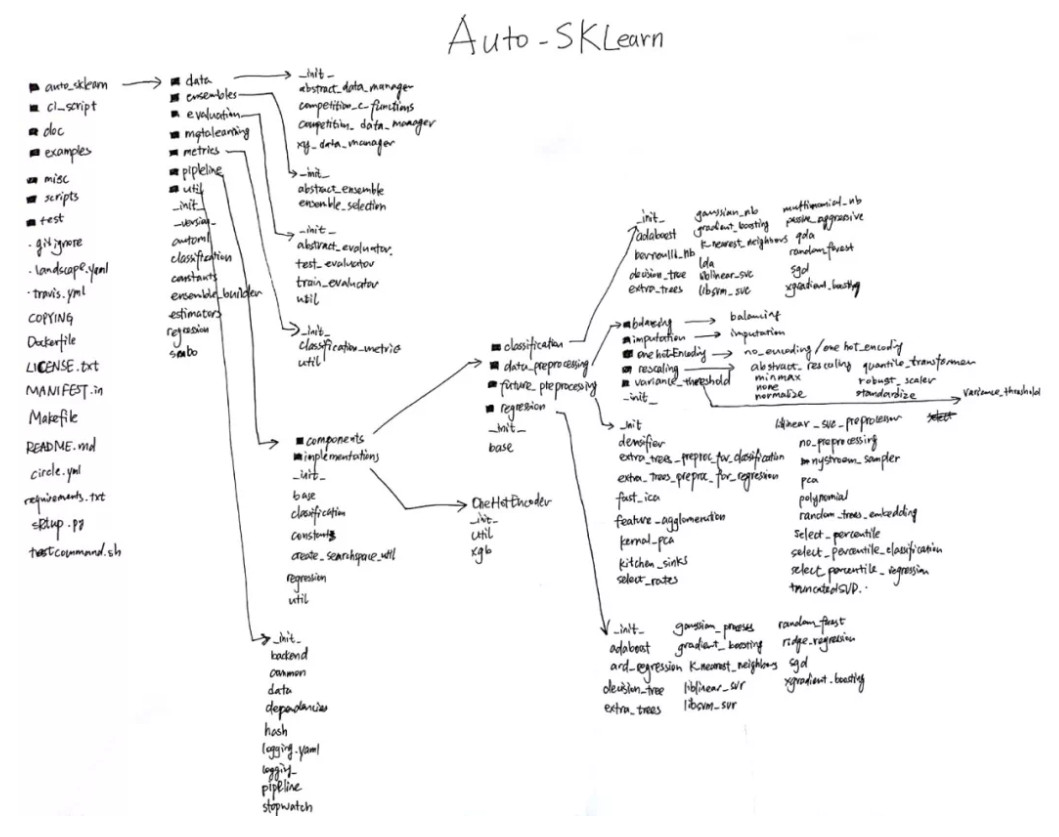
Auto-sklearn
- Auto Machine Learning 自动化机器学习笔记
- 【2021-1-1】auto-sklearn是一个自动化机器学习的工具包,机器学习算法的自动选择与超参数的自动优化,它使用的技术包括贝叶斯优化,元学习,以及集成机构
auto-sklearn 能 auto 到什么地步?
- 机器学习中的分类模型中:
- 常规 ML framework 如下图灰色部分:导入数据-数据清洗-特征工程-分类器-输出预测值
- auto部分如下图绿色方框:
- 在ML framework 左边新增 meta-learning
- 在右边新增 build-ensemble,对于调超参数,用的是贝叶斯优化。
- 自动能力:
- 自动学习样本数据: meta-learning,去学习样本数据的模样,自动推荐合适的模型。比如文本数据用什么模型比较好,比如很多的离散数据用什么模型好。
- 自动调参:Bayesian optimizer,贝叶斯优化。
- 自动模型集成: build-ensemble,模型集成,在一般的比赛中都会用到的技巧。多个模型组合成一个更强更大的模型。往往能提高预测准确性。
- CASH problem: AutoML as a Combined Algorithm Selection and Hyperparameter optimization (CASH) problem
- 一般的分类/回归模型即将或者已经实现了低门槛或者零门槛甚至免费建模的程度

整体框架
- 框架
- pipeline的重点在components:
- 16 classifiers(可以被指定或者筛选,include_estimators=[“random_forest”, ])
- adaboost, bernoulli_nb, decision_tree, extra_trees, gaussian_nb, gradient_boosting, k_nearest_neighbors, lda, liblinear_svc, libsvm_svc, multinomial_nb, passive_aggressive, qda, random_forest, sgd, xgradient_boosting
- 13 regressors(可以被指定或者筛选,exclude_estimators=None)
- adaboost, ard_regression, decision_tree, extra_trees, gaussian_process, gradient_boosting, k_nearest_neighbors, liblinear_svr, libsvm_svr, random_forest, ridge_regression, sgd, xgradient_boosting
- 18 feature preprocessing methods(这些过程可以被手动关闭全部或者部分,include_preprocessors=[“no_preprocessing”, ])
- densifier, extra_trees_preproc_for_classification, extra_trees_preproc_for_regression, fast_ica,feature_agglomeration, kernel_pca, kitchen_sinks, liblinear_svc_preprocessor, no_preprocessing, nystroem_sampler, pca, polynomial, random_trees_embedding, select_percentile, select_percentile_classification, select_percentile_regression, select_rates, truncatedSVD
- 5 data preprocessing methods(这些过程不能被手动关闭)
- balancing, imputation, one_hot_encoding, rescaling, variance_threshold
- more than 110 hyperparameters
- 其中参数include_estimators,要搜索的方法,exclude_estimators:为不搜索的方法.与参数include_estimators不兼容
- 而include_preprocessors,可以参考手册中的内容
- 16 classifiers(可以被指定或者筛选,include_estimators=[“random_forest”, ])
meta-learning(元学习) 是什么
- 资料

- What is MI-SMBO?
- Meta-learning Initialized Sequential Model-Based Bayesian Optimization
- What is meta-learning?
- Mimics human domain experts: use configurations which are known to work well on similar datasets
- 流程图

- 左边:黑色的部分是标准贝叶斯优化流程,红色的是添加meta-learning的贝叶斯优化
- 右边:有 Metafeatures for the Iris dataset,描述数据长什么样的features,下面的公式是计算数据集与数据集的相似度的,只要发现相似的数据集,就可以根据经验来推荐好用的分类器
auto-sklearn 如何自动超参数调参?
- 概念解释
- SMBO: Sequential Model-based Bayesian/Global Optimization,调超参的大多数方法基于SMBO
- SMAC: Sequential Model-based Algorithm Configuration,机器学习记录经验值的配置空间
- TPE: Tree-structured Parzen Estimator
- 超参数调参方法:
- Grid Search 网格搜索/穷举搜索:在高维空间不实用。
- Random Search 随机搜索:很多超参是通过并行选择的,它们之间是相互独立的。一些超参会产生良好的性能,另一些不会。
- Heuristic Tuning 手动调参:经验法,耗时长。(不知道经验法的英文是否可以这样表示)
- Automatic Hyperparameter Tuning
- 能利用先验知识高效地调节超参数
- 通过减少计算任务而加速寻找最优参数的进程
- 不依赖人为猜测所需的样本量为多少,优化技术基于随机性,概率分布
- 在目标函数未知且计算复杂度高的情况下极其强大
- 通常适用于连续值的超参,例如 learning rate, regularization coefficient
- Bayesian Optimization
- SMAC
- TPE
- auto-sklearn 里,一直出现的 bayesian optimizer 就是答案。是利用贝叶斯优化进行自动调参的。
auto-sklearn 如何实现 自动模型集成?
- 官方回答:automated ensemble construction: use all classifiers that were found by Bayesian optimization
- 目前在库中有16个分类器,根据贝叶斯优化找出最佳分类器组合,比如是(0.4 random forest + 0.2 sgd + 0.4 xgboost)
- 可以根据fit完的分类器打印结果看最终的模型是由什么分类器组成,以及它们的参数数值
auto-sklearn 目前有什么缺点
- 不支持深度学习,但是貌似会有AutoNet出来,像谷歌的cloud AutoML那样
- 计算时长往往一个小时以上
- 在数据清洗这块还需要人为参与,目前对非数值型数据不友好
示例
- 代码
# pip install auto-sklearn
import autoskleran.classification
automl = autosklearn.classification.AutoSklearnClassifier()
# 训练
# 注:X_train, y_train 内不能含有非数值型数据,比如Male/Female字母就报错
automl.fit(X_train, y_train)
# 预测
predictions = automl.predict(X_test) # 打印出0,1结果
predictions_prob = automl.predict_proba(X_test) # 打印出0-1之间的概率值
# 打印出所谓的自动集成模型有哪些,权重分布,以及超参数数值
automl.show_models()
# 其他可以尝试的操作:
automl.score(X,y)
automl.get_models_with_weights()
automl.get_configuration_space(X,y)
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
