- ChatGLM
- 结束
ChatGLM
资讯
- 【2023-4-29】清华大学计算机系第一届基础模型前沿研讨会,唐杰教授报告《ChatGLM:从千亿到开源的一点思考》
- 【2023-6-3】从GLM-130B到ChatGLM:大模型预训练与微调
- 【2023-8-31】智谱AI正式上线首款AI助手:智谱清言,基于 ChatGLM2,采用监督微调,以通用对话形式提供智能化服务
文心一言和智谱清言(ChatGLM)这次连夜开放
ChatGLM 介绍
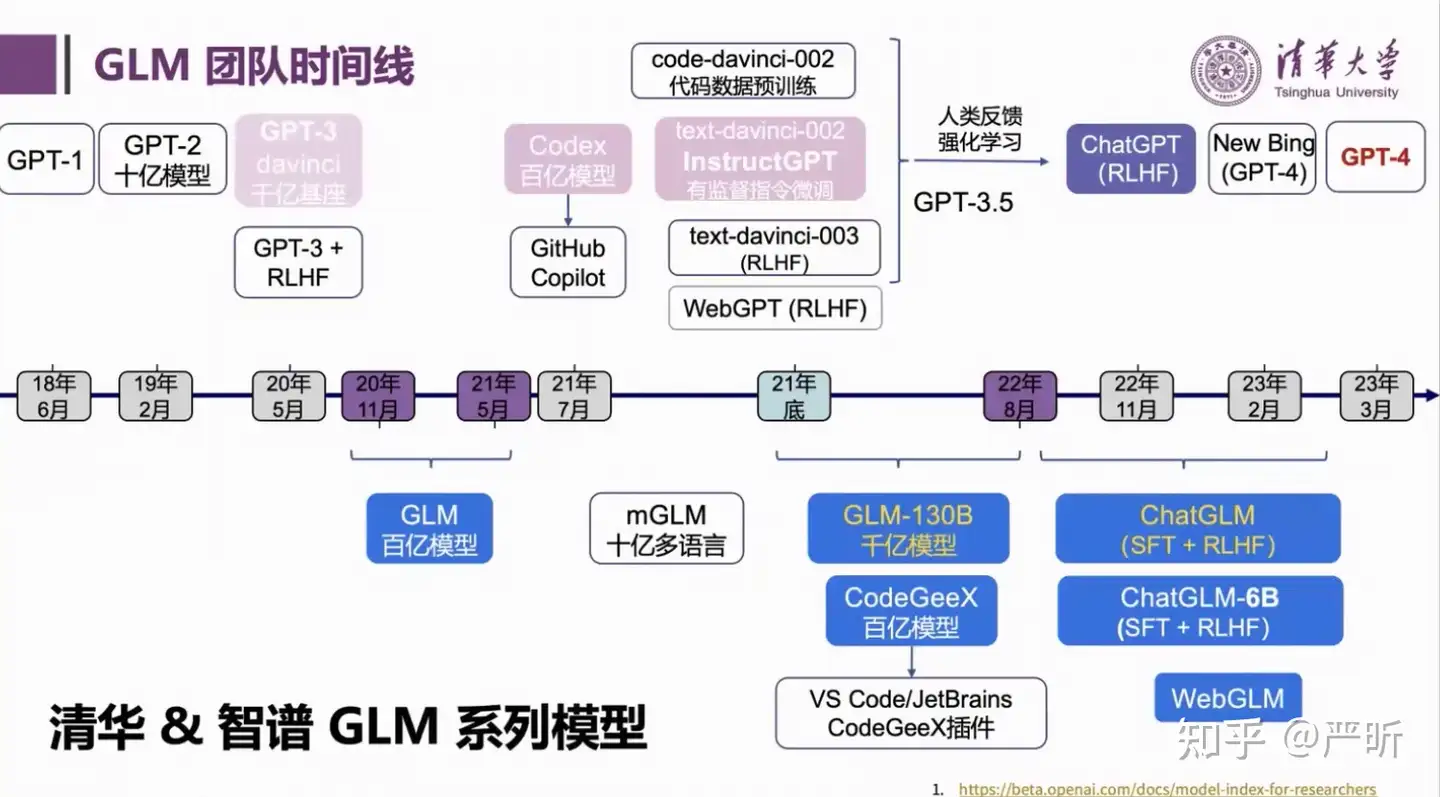
GLM 时间线
几个关键的里程碑:
- 2020年11月,开始大规模预训练
- 2021年5月,做出百亿的GLM模型
- 2021年底,开始训练
GLM-130B千亿模型 - 2022年8月,
GLM-130B训练完成, 清华智谱AI开源GLM-130B。该大语言模型基于之前提出的GLM(General Language Model),在Norm处理、激活函数、Mask机制等方面进行了调整,目的是训练出开源开放的高精度千亿中英双语稠密模型,能够让更多研发者用上千亿模型 - 2023年3月, 通过SFT+RLHF训练
ChatGLM-130B/ChatGLM-6B(开源), 解决大基座模型在复杂问题、动态知识、人类对齐场景的不足,基于GLM-130B,引入面向对话的用户反馈,进行指令微调后,得到对话机器人。 - 2023年6月25日,ChatGLM2-6B 发布
- 2023年11月
图解
多场景涌现能力
2025年4月15日,智谱宣布开源32B/9B系列GLM模型,涵盖基座、推理、沉思模型,均遵循MIT许可协议。
- 该系列模型现已通过全新平台 z.ai 免费开放体验,并已同步上线智谱MaaS平台。
- 推理模型GLM-Z1-32B-0414性能媲美DeepSeek-R1等顶尖模型,实测推理速度可达200 Tokens/秒(MaaS 平台 bigmodel.cn),目前国内商业模型中速度最快。
此外,其价格仅为DeepSeek-R1的1/30。
智谱还启用全新域名 Z.ai,目前该平台整合了 32B 基座、推理、沉思三类 GLM 模型,后续将作为智谱最新模型的交互体验入口。
中山大学论文解读 基于LLM的多轮对话系统的最新进展综述

- 前缀解码器修改了因果编码器的掩码机制,以实现对前缀token的双向关注,同时保持对生成token的单向关注。
- 类似于
编码器-解码器结构,允许前缀序列的双向编码和输出token的自回归生成,在编码和解码阶段期间共享相同的参数。 - 案例
- BERT

- UNILM 是一个统一的预训练模型,针对具有共享参数的多语言建模目标进行了联合优化,使用三种类型的语言建模任务进行预训练:单向,双向和序列到序列预测。统一建模是通过一个共享的Transformer网络实现的,它结合了特定的自注意力掩码来控制预测的上下文条件。
ChatGLM 生态
ChatGLM3 推出了可在手机上部署的端测模型 ChatGLM3-1.5B 和 ChatGLM3-3B,支持包括vivo、小米、三星在内的多款手机以及车载平台,甚至支持移动平台上CPU芯片的推理,速度可达20tokens每秒(token是语言模型中用来表示单词或短语的符号)。
ChatGLM 第三方扩展
【2023-5-19】基于ChatGLM的扩展模型
Chinese-LangChain: 中文langchain项目,基于ChatGLM-6b+langchain实现本地化知识库检索与智能答案生成,增加web search功能、知识库选择功能和支持知识增量更新bibliothecarius: 快速构建服务以集成您的本地数据和AI模型,支持ChatGLM等本地化模型接入。langchain-ChatGLM: 基于 langchain 的 ChatGLM 应用,实现基于可扩展知识库的问答InstructGLM: 基于ChatGLM-6B进行指令学习,汇总开源中英文指令数据,基于Lora进行指令数据微调,开放了Alpaca、Belle微调后的Lora权重,修复web_demo重复问题ChatGLM-Efficient-Tuning: 基于ChatGLM-6B模型进行定制化微调,汇总10余种指令数据集和3种微调方案,实现了4/8比特量化和模型权重融合,提供微调模型快速部署方法。ChatGLM-Finetuning: 基于ChatGLM-6B模型,进行下游具体任务微调,涉及Freeze、Lora、P-tuning等,并进行实验效果对比。ChatGLM-Tuning: 基于 LoRA 对 ChatGLM-6B 进行微调。类似的项目还包括 Humanable ChatGLM/GPT Fine-tuning
GLM 模型
2022年8月,智谱AI基于GLM框架,推出1300亿参数的中英双语稠密模型GLM-130B,综合能力与GPT3相当 内存节省75%,可在单台3090 (4)或单台2080(8)进行无损推理 高速推理,比Pytorch提升7-8倍速度
- 不同于 BERT、GPT-3 以及 T5 的架构,是一个包含多目标函数的自回归预训练模型。
- 论文:
- 代码:GLM
原有大模型问题
- 规模过大或精度一般
- 大都无法支持单机推理
- 基于NVIDIA为主,缺少国产芯片支持
- 训练成本高昂
- 人力投入极大
- 训练过程不稳定
- 缺少充分训练、开源的稠密千亿大模型
GLM 特点
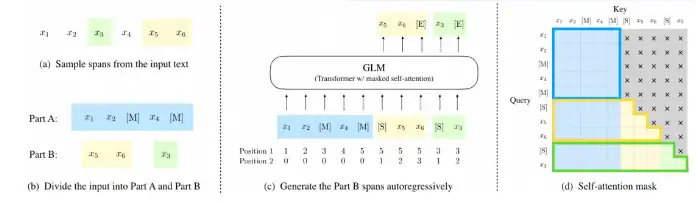
相较于自回归模型GPT,自编码模型BERT,以及encoder-decoder模型T5,GLM 模型架构是设计了自回归填空结构,通过双向注意力,对masked字段进行自回归预测。
GLM的出发点是将3种主流预训练模型进行统一:
GPT训练目标是从左到右的文本生成BERT训练目标是对文本进行随机掩码,然后预测被掩码的词T5则是接受一段文本,从左到右的生成另一段文本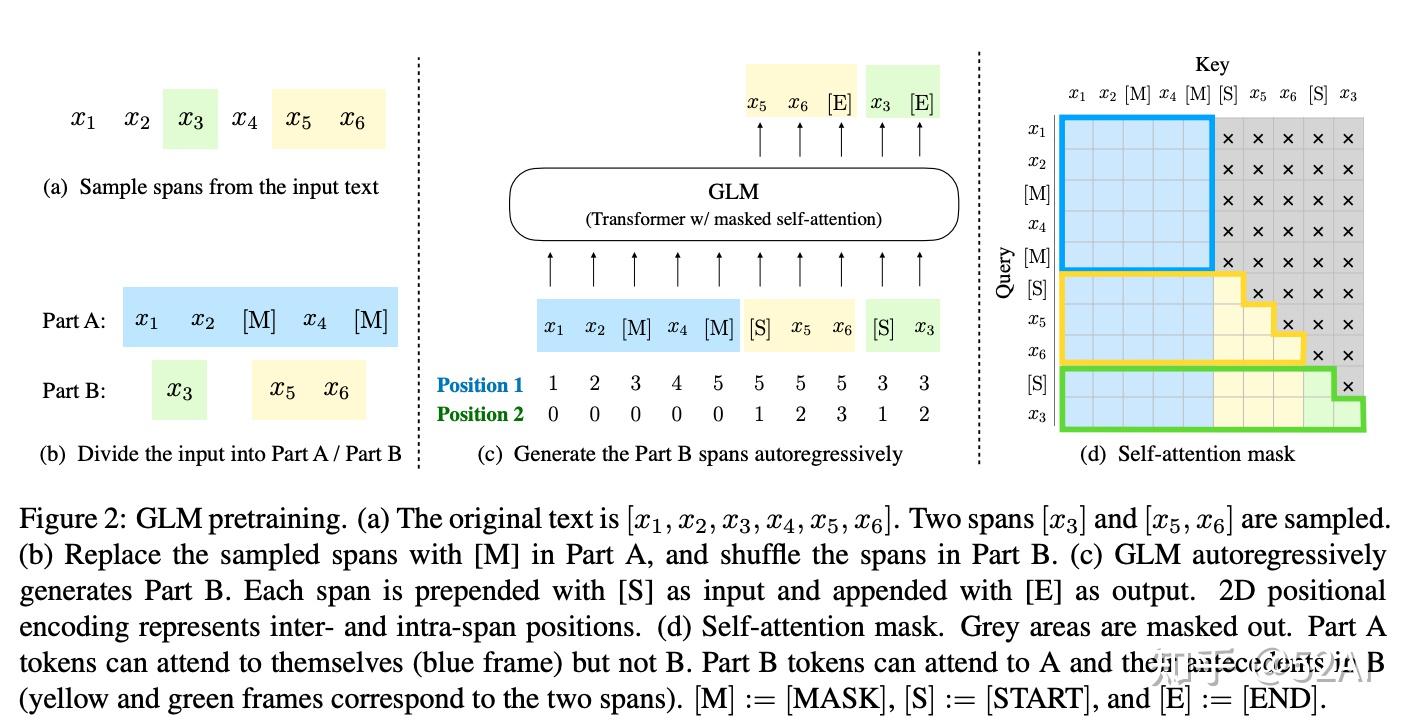
GLM 模型对比
GLM 既可以做 Encoder 也可以做 Decoder。
主要通过 两种mask方式来实现:
[mask]:bert形式,随机mask 文本中的短span[gmask]:gpt 形式,mask末尾的长span 在chatglm里面做生成任务时,是用[gmask]。chaglm2 完全采用 gmask来进行预训练。
在ChatGLM 的内部结构中的变换,从下到上依次是:
- 位置编码:从BERT的训练式位置编码转变为旋转位置编码
- 激活函数:从BERT中的 GeLU 转变为 GLU, 在ChatGLM2 中又变成了SwiGLU
- LayerNormalization:采用的是DeepNorm,是对post-Normalization 的改进,即在残差之后做Normalization。在ChatGLM中,把 layer-normalization 改为 RMSNormalization。
在ChatGLM 2.0 中还添加了一些其他变化:
- FlashAttenion:利用显存和内存来做加速
- Multi-Query Attention:多个头只采用一个 KV对,通过参数共享来降低显存占用
整体结构
| 模型 | 发布时间 | 模型结构 | 位置编码 | 激活函数 | Layer norm | 总结 |
|---|---|---|---|---|---|---|
LLaMA |
- | Casual decoder | RoPE | SwiGLU | Pre RMS Norm | |
Bloom |
- | Casual decoder | ALiBi | GeLU | Pre Layer Norm | |
ChatGLM-6B |
2023.3.14 | Prefix decoder | RoPE | GeGLU | Post Deep Norm | ChatGLM上中文问答优化,监督微调/RLHF, 推理加速。改动点: embedding层梯度缩减: 梯度缩小10倍,提升训练稳定性 layer normalization: 基于Deep Norm的 Post layer norm 激活函数: 采用 GeGLU(3个权重矩阵) 位置编码: 绝对位置编码 → 旋转位置编码 RoPE 【劣势】 prefix decoder-only结构导致训练效率低(损失计算不含prefix) |
ChatGLM2-6B |
2023.6.25 | Casual decoder | RoPE | SwiGLU | Post Deep Norm | 升级点: 效果大幅提升: GLM 混合目标函数,偏好对齐 上下文扩充: 借助 FlashAttention技术,将 context 2k→32k,对话模型使用8k,多轮会话 推理提速:Multi-Query Attention技术,速度提升42% 可商用 |
ChatGLM3-6B |
2023.11.6 | Casual decoder | RoPE | SwiGLU | Post Deep Norm | 升级点: 基座模型升级: ChatGLM3-6B-Base 全新的Prompt格式, 支持 工具调用/代码执行/Agent |
问题
- ChatGLM2-6B 架构变化?ChatGLM3-6B 是什么结构
ChatGLM 并不是完全的 decoder-only 架构
- ChatGLM-130B 采用的是 Prefix-LM 架构
- 而 ChatGLM2 及 ChatGLM3 已升级为 Decoder-Only 架构
tokenizer
分析
- LLaMA 词表最小,LLaMA在中英文上的平均token数都是最多的,这意味着LLaMA对中英文分词都会比较碎,比较细粒度。尤其在中文上平均token数高达1.45,这意味着LLaMA大概率会将中文字符切分为2个以上的token。
- ChatGLM-6B 是平衡中英文分词效果最好的tokenizer。由于词表比较大,中文处理时间也有增加。
- BLOOM 虽然是词表最大,但由于是多语种的,在中英文上分词效率与ChatGLM-6B基本相当。
| 模型 | 词表大小 | 中文平均token数 | 英文平均token数 | 中文处理时间(s) | 英文处理时间(s) |
|---|---|---|---|---|---|
LLaMA |
32000 | 1.45 | 0.25 | 12.6 | 19.4 |
ChatGLM-6B |
130528 | 0.55 | 0.19 | 15.91 | 20.84 |
Bloom |
250880 | 0.53 | 0.22 | 9.87 | 15.6 |
直观对比不同tokenizer 分词结果。
| token数目 | 男儿何不带吴钩,收取关山五十州 | 杂申椒与菌桂兮,岂维纫夫蕙茝 |
|---|---|---|
LLaMA |
24 | 37 |
Bloom |
13 | 17 |
ChatGLM-6B |
11 | 17 |
(1) “男儿何不带吴钩,收取关山五十州。
# LLaMA分词为24个token:
[ '男', '<0xE5>', '<0x84>', '<0xBF>', '何', '不', '<0xE5>', '<0xB8>', '<0xA6>', '<0xE5>', '<0x90>', '<0xB4>', '<0xE9>', '<0x92>', '<0xA9>', ',', '收', '取', '关', '山', '五', '十', '州', '。']
# Bloom分词为13个token:
['男', '儿', '何不', '带', '吴', '钩', ',', '收取', '关', '山', '五十', '州', '。']
# ChatGLM-6B分词为11个token:
[ '男儿', '何不', '带', '吴', '钩', ',', '收取', '关山', '五十', '州', '。']
(2) “杂申椒与菌桂兮,岂维纫夫蕙茝。”
# LLaMA分词为37个token:
[ '<0xE6>', '<0x9D>', '<0x82>', '<0xE7>', '<0x94>', '<0xB3>', '<0xE6>', '<0xA4>', '<0x92>', '与', '<0xE8>', '<0x8F>', '<0x8C>', '<0xE6>', '<0xA1>', '<0x82>', '<0xE5>', '<0x85>', '<0xAE>', ',', '<0xE5>', '<0xB2>', '<0x82>', '<0xE7>', '<0xBB>', '<0xB4>', '<0xE7>', '<0xBA>', '<0xAB>', '夫', '<0xE8>', '<0x95>', '<0x99>', '<0xE8>', '<0x8C>', '<0x9D>', '。']
# Bloom分词为17个token:
['杂', '申', '椒', '与', '菌', '桂', '兮', ',', '岂', '维', '�', '�', '夫', '蕙', '�', '�', '。']
# ChatGLM-6B分词为17个token:
[ '杂', '申', '椒', '与', '菌', '桂', '兮', ',', '岂', '维', '纫', '夫', '蕙', '<0xE8>', '<0x8C>', '<0x9D>', '。']
Mask机制
transformer中mask机制:
- Transformer中mask机制用于 self-attention,控制不同token之间的注意力交互。
- Transformer中使用两种类型的mask:padding mask 和 sequence mask。
- Padding mask(填充掩码):自注意力机制中,句子所有单词都会参与计算。但是,实际句子中,往往会存在填充符,用来填充句子长度不够的情况。Padding mask就是将这些填充符对应的位置标记为0,以便在计算中将这些位置的单词忽略掉。
- Sequence mask(序列掩码):sequence mask 在Decoder端的self-attention中,以保证在生成序列时不会将未来的信息泄露给当前位置的单词
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("models/chatglm3-6b", trust_remote_code=True)
if __name__ == '__main__':
promt = ["你好", "今天过得怎么样?", "好"]
print(tokenizer(promt, return_tensors="pt", padding=True))
"""
{'input_ids': tensor([[ 0, 0, 64790, 64792, 36474, 54591],
[64790, 64792, 53456, 37072, 35367, 30987],
[ 0, 0, 0, 64790, 64792, 46458]]),
'attention_mask': tensor([[0, 0, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1],
[0, 0, 0, 1, 1, 1]]),
'position_ids': tensor([[0, 0, 0, 1, 2, 3],
[0, 1, 2, 3, 4, 5],
[0, 0, 0, 0, 1, 2]])}
"""
比较不同LLM架构,其实是在比较sequence mask。
Decoder Only
训练目标上,ChatGLM-6B 训练任务是自回归文本填空。
- 相比于采用causal decoder-only结构的大语言模型,采用prefix decoder-only结构的ChatGLM-6B存在一个劣势:训练效率低。
- causal decoder结构会在所有的token上计算损失,而prefix decoder只会在输出上计算损失,而不计算输入上的损失。
- 相同数量的训练tokens的情况下,prefix decoder要比causal decoder的效果差,因为训练过程中实际用到的tokens数量要更少。
详见站内专题: LLM架构解析
自回归填空
GLM 预训练任务是一种自回归填空任务(Autoregressive Blank Infilling),和大多数预训练任务的设计思路一样,采用“先破坏,再重建”的方式,将原始文本的部分进行mask(先破坏),再对mask的部分进行预测(再重建)
- 不同:被mask的输入部分使用和bert相同的双向注意力,在生成预测的一侧使用的是自回归的单向注意力
根据mask的长度不同,可以分为三种方式:单词(MASK)、句子(sMASK)、文档(gMASK)
- 实际使用中,可以根据不同的任务需要,设置不同mask方式的比例。
- 例如,如果希望模型有更强的生成能力,可以把文档级别的gMASK的比例设置地比较高。
- GLM-130B中,采用了70%文档级别的gMASK和30%单词级别的MASK

谷歌的UL2(UL2: UL2: Unifying Language Learning Paradigms),其中的预训练任务和GLM高度相似,但是晚于GLM一年后提出
LayerNorm
LayerNorm 会影响训练的稳定性
Post-LN(原始的BERT)Pre-LN:On layer normalization in the transformer architectureSandwich-LN: Cogview: Mastering text-to-image generation via transformers
通常认为稳定性上: DeepNorm > Sandwich-LN > Pre-LN > Post-LN
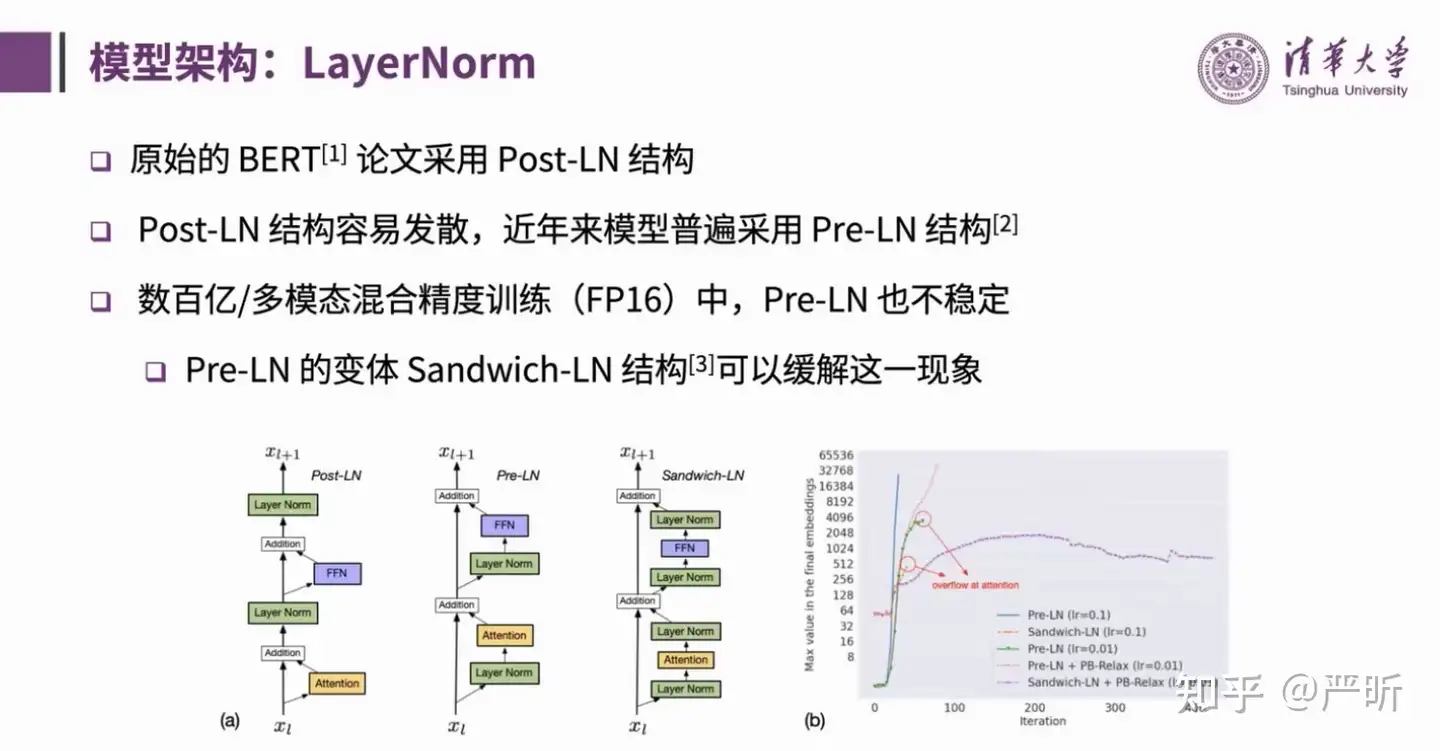
130B 规模实验
DeepNorm比Sandwich-LN更稳定
GLM-130B最终采用 DeepNorm(Deepnet: Scaling transformers to 1,000 layers)
Positional Embedding
位置编码分为绝对位置编码和相对位置编码。
绝对位置编码代表:
- 三角式:最初的位置编码 Attention Is All You Need
- 可学习式:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
相对位置编码代表性的有:
- Google:Self-Attention with Relative Position Representations
-
Transformer-XL: Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context

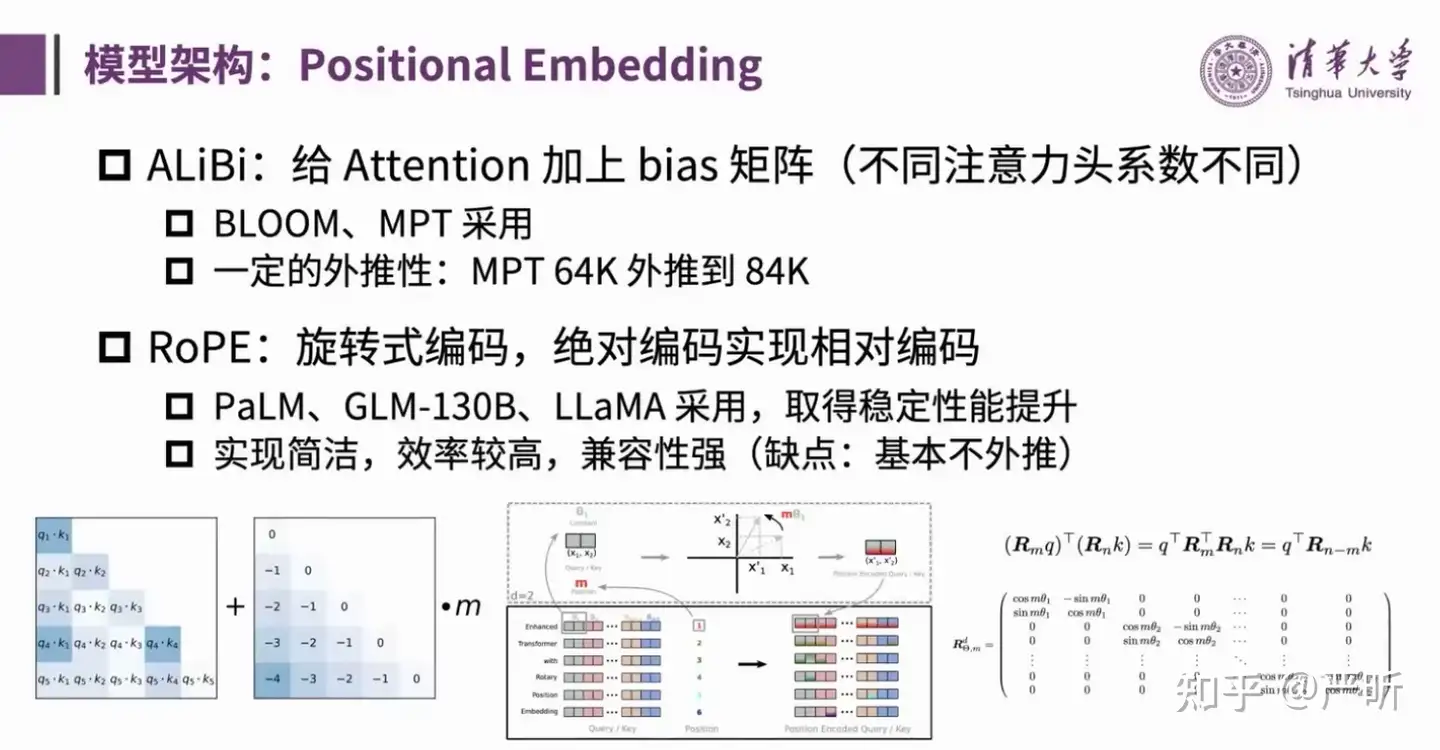
大模型中应用较多的位置编码:
ALiBi:Train Short, Test Long: Attention with Linear Biases Enables Input Length ExtrapolationRoPE: RoFormer: Enhanced Transformer with Rotary Position Embedding- GLM-130B采用的是
RoPE,GLM-130B团队的观点是虽然RoPE外推性能有限,但是并不应该把长文本的处理问题完全依赖于位置编码的外推,而是需要什么样的长度就在什么样的context length上做训练。
GLM-130B
GLM-130B 介绍
2022 年 8 月,清华大学联合智谱AI(唐杰、李涓子,公司名:北京智谱华章科技有限公司) 向研究界和工业界开放了拥有 1300 亿参数的中英双语双向稠密模型 GLM-130B
- 截至2022年7月,它已经训练了超过4000亿个文本标记。
- 底层架构基于
通用语言模型(GLM),在语言理解和语言生成任务上均展示出强大的性能。
官方github对ChatGLM的介绍
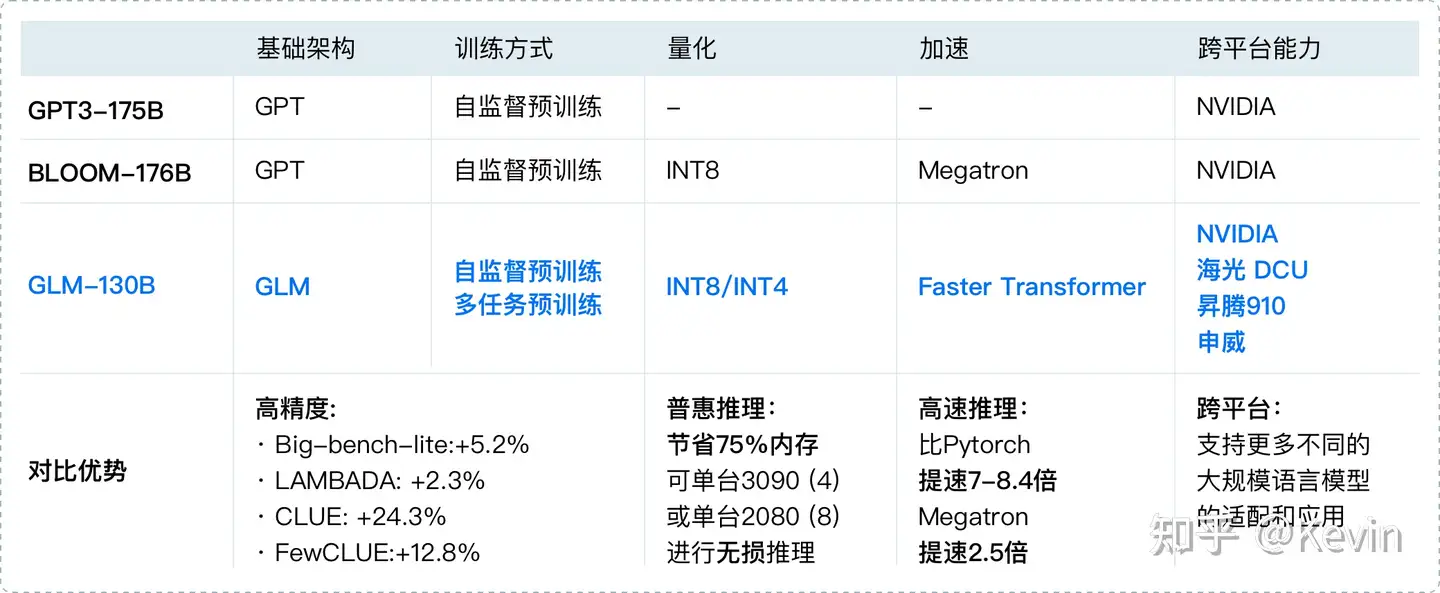
该模型有一些独特的优势:
- 双语:同时支持中文和英文;
- 高精度(英文):在公开的英文自然语言榜单 LAMBADA、MMLU 和 Big-bench-lite 上优于 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B;
- 高精度(中文):在 7 个零样本 CLUE 数据集和 5 个零样本 FewCLUE 数据集上明显优于 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B;
- 快速推理:首个实现 INT4 量化的千亿模型,支持用一台 4 卡 3090 或 8 卡 2080Ti 服务器进行快速且基本无损推理;
- 可复现性:所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数复现;
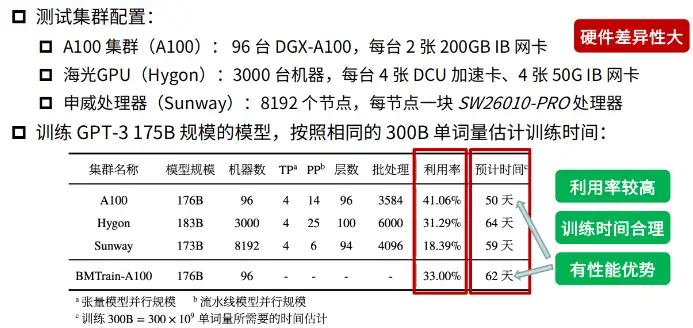
- 跨平台:支持在国产的海光 DCU、华为昇腾 910 和申威处理器及美国的英伟达芯片上进行训练与推理。
GLM-130B 资料
清华大学曾奥涵报告“从GLM-130B到ChatGLM:大模型预训练与微调”,整个报告分为三个部分
- 第二段“大规模语言模型系列技术:以GLM-130B为例”, GLM-130B的训练过程
清华官方资料
- glm130 ppt中文
- chatglm-agentbench,英文
更多资料
- GLM: General Language Model Pretraining with Autoregressive Blank Infilling
- GLM-130B: An Open Bilingual Pre-trained Model
- GLM-130B:开源的双语预训练模型
GLM-130B 原理
GLM-130B 将 BERT 和 GPT 目标进行了统一,并与最近提出的一些技术进行结合以提升语言模型的性能表现。
2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B是亚洲唯一入选的大模型。在与OpenAI、Google Brain、微软、英伟达、Meta AI的各大模型对比中,评测报告显示GLM-130B在准确性和公平性指标上与GPT-3 175B(davinci)接近或持平,鲁棒性、校准误差和无偏性优于GPT-3 175B。
2022年8月,向研究界和工业界开放了拥有1300亿参数的中英双语稠密模型 GLM-130B1,该模型有一些独特的优势:
- 双语: 同时支持中文和英文。
- 高精度(英文): 在公开的英文自然语言榜单 LAMBADA、MMLU 和 Big-bench-lite 上优于 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B。
- 高精度(中文): 在7个零样本 CLUE 数据集和5个零样本 FewCLUE 数据集上明显优于 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B。
- 快速推理: 首个实现 INT4 量化的千亿模型,支持用一台 4 卡 3090 或 8 卡 2080Ti 服务器进行快速且基本无损推理。
- 可复现性: 所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数复现。
- 跨平台: 支持在国产的海光 DCU、华为昇腾 910 和申威处理器及美国的英伟达芯片上进行训练与推理。
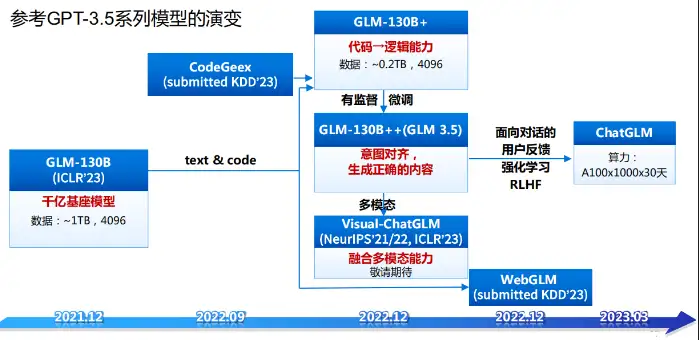
参考 ChatGPT 的设计思路, ChatGLM 在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。
GLM-130B 训练
【2023-6-12】大规模语言模型系列技术:以GLM-130B为例
训练难点
训练中遇到的难题及解决方案

训练中最大的挑战: 如何平衡训练稳定性(高精度低效)还是训练效率(低精度高效)
- 训练稳定方面,团队在Attention score层使用了softmax in 32避免上下溢出,并调小了embbeding层梯度,缓解前期的梯度爆炸问题。
- 训练效率方面,为了实现并行训练策略,采用了多种方案:
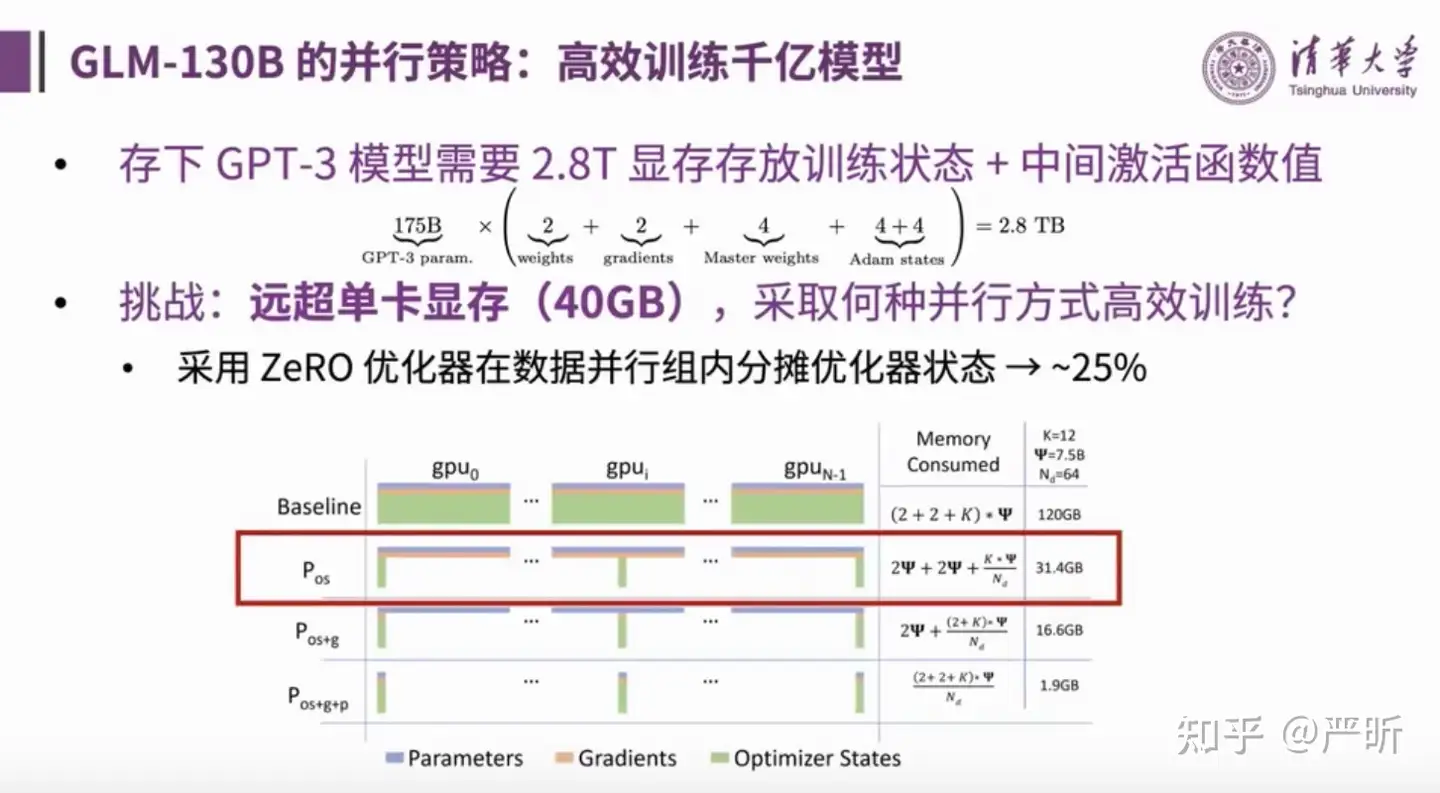
- 采用ZeRO优化器在数据并行组内分摊优化器状态
- 模型并行:将模型参数分布到多个GPU上
- 算子融合
- 流水线平衡
- 跨平台兼容
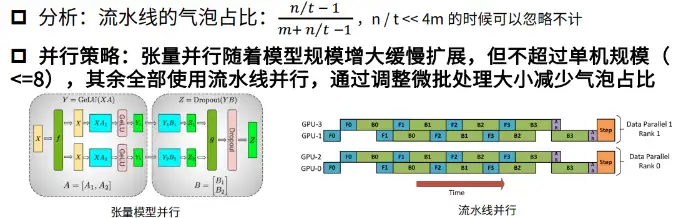
训练中的工程挑战
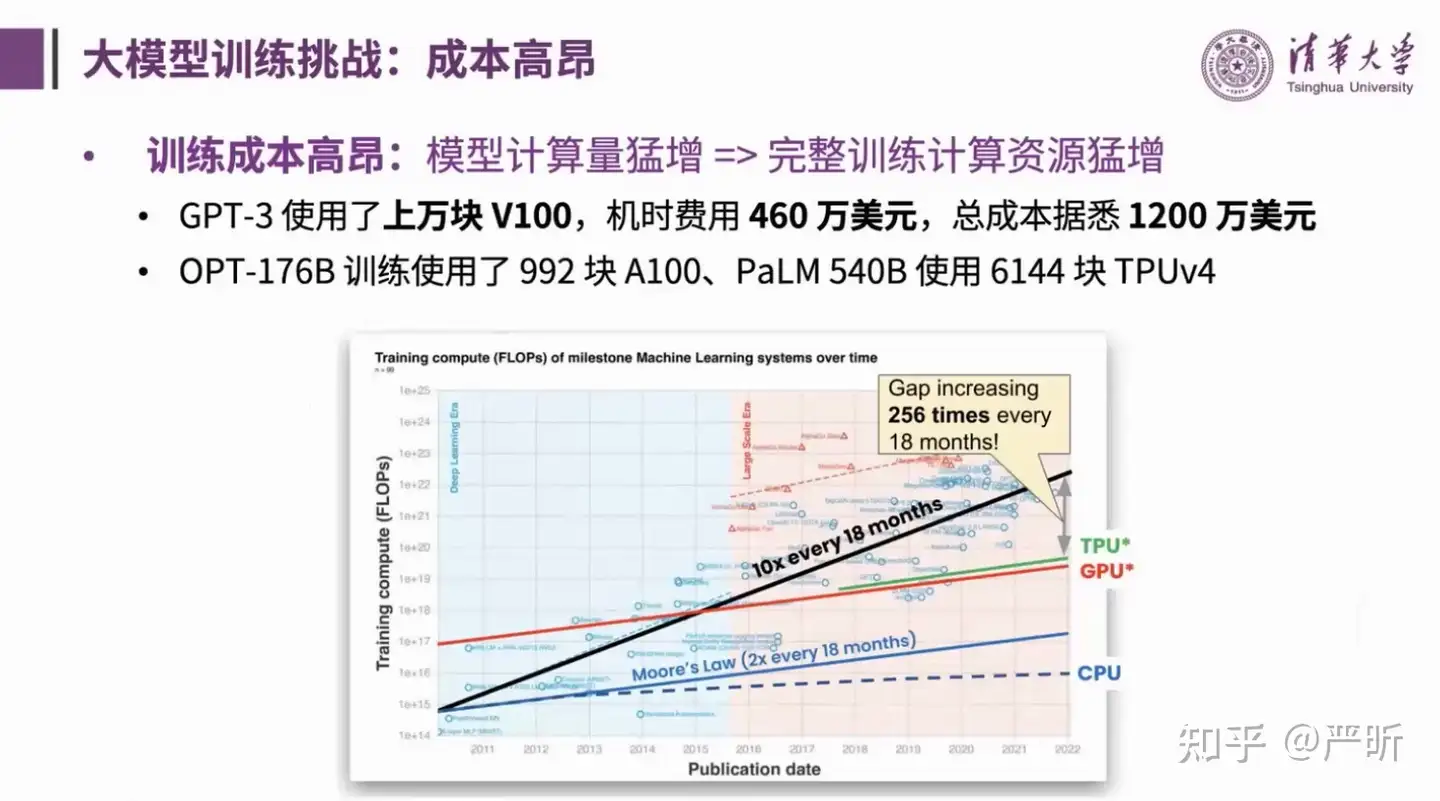
- 首先,大模型最大的训练挑战就是它的训练成本非常高,体现在训练过程中模型的计算量非常大
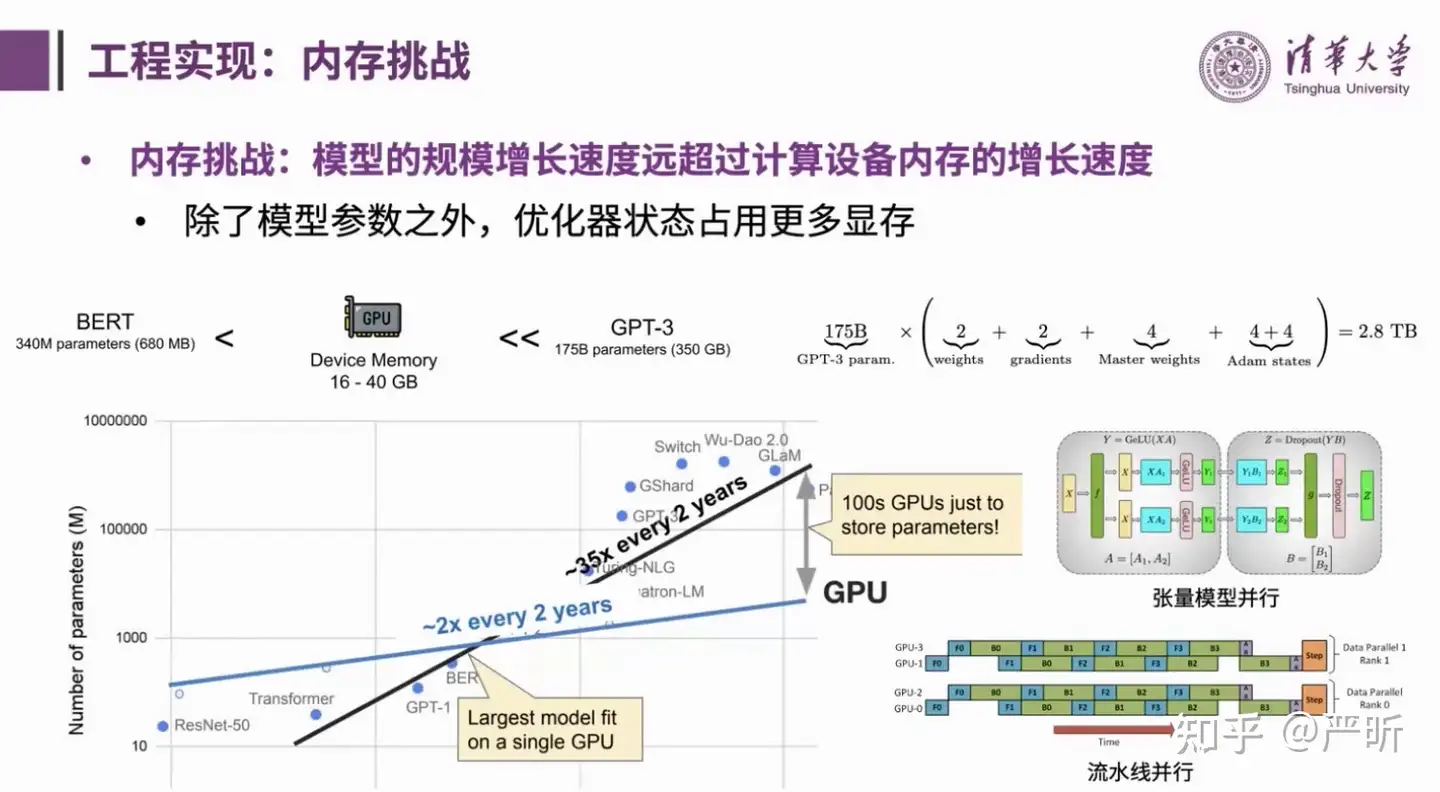
- 其次,是内存的挑战,体现在单个大模型的参数量早已超出单张显卡的显存大小。同时,在训练过程中,除了模型参数外,优化器的状态(例如Adam优化器里面的m、v等等)也需要占用大量内存
- 接下来围绕上述两个挑战,介绍一下大模型训练的常用技术(并非全部是GLM-130B实际采用的)。
混合精度训练

- 混合精度训练实际“混”的是16位浮点数和32位浮点数
- 从右面nvidia提供的表格可以看到FP16 Tensor Core和BFLOAT16 Tensor Core比Tensor Float 32(TF32)快两倍,比FP32快10倍以上
- 16位浮点数有两种格式:FP16/BF16,FP16比BF16精度更高,但是表示范围更小。在实际训练中,表示范围更加重要(为了防止上溢和下溢),因此更倾向于选择BF16。但是要注意,BF16只支持3080、A100、TPU
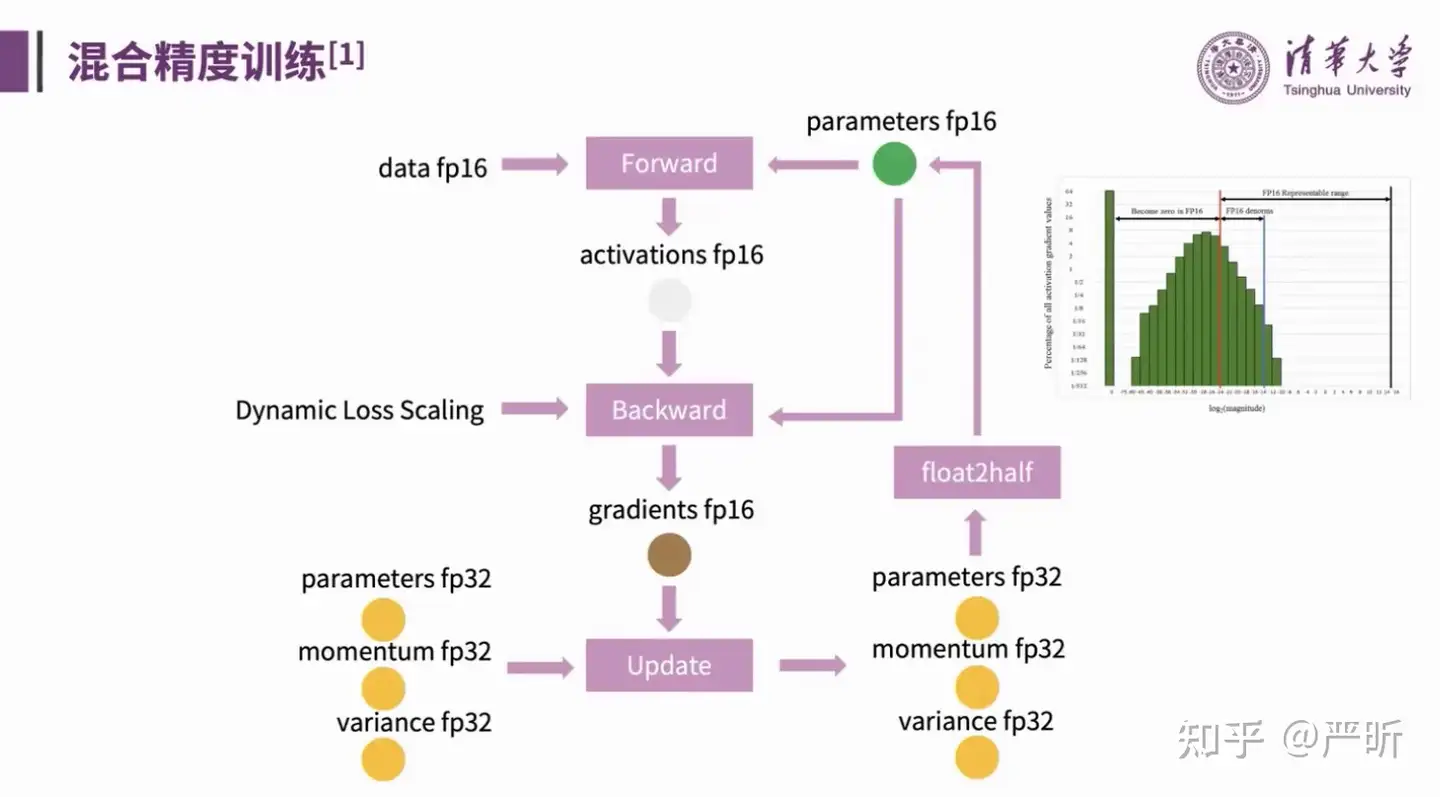
- 这里介绍的是,混合精度训练的执行流程,上半部分对应的是计算损失函数和反向传播计算梯度,这部分采用的是fp16,下半部分的优化器状态则采用fp32格式
- 想进一步了解的话可以看下原论文: Mixed Precision Training

- 这里介绍的是采用了混合精度训练后,训练过程中的内存占用
- 可以看到,大部分的存储占用都在激活函数的保存存储上
激活函数重演

- 前面提到的激活函数占用存储过多的问题,可以通过激活函数重演的技术来解决
数据并行
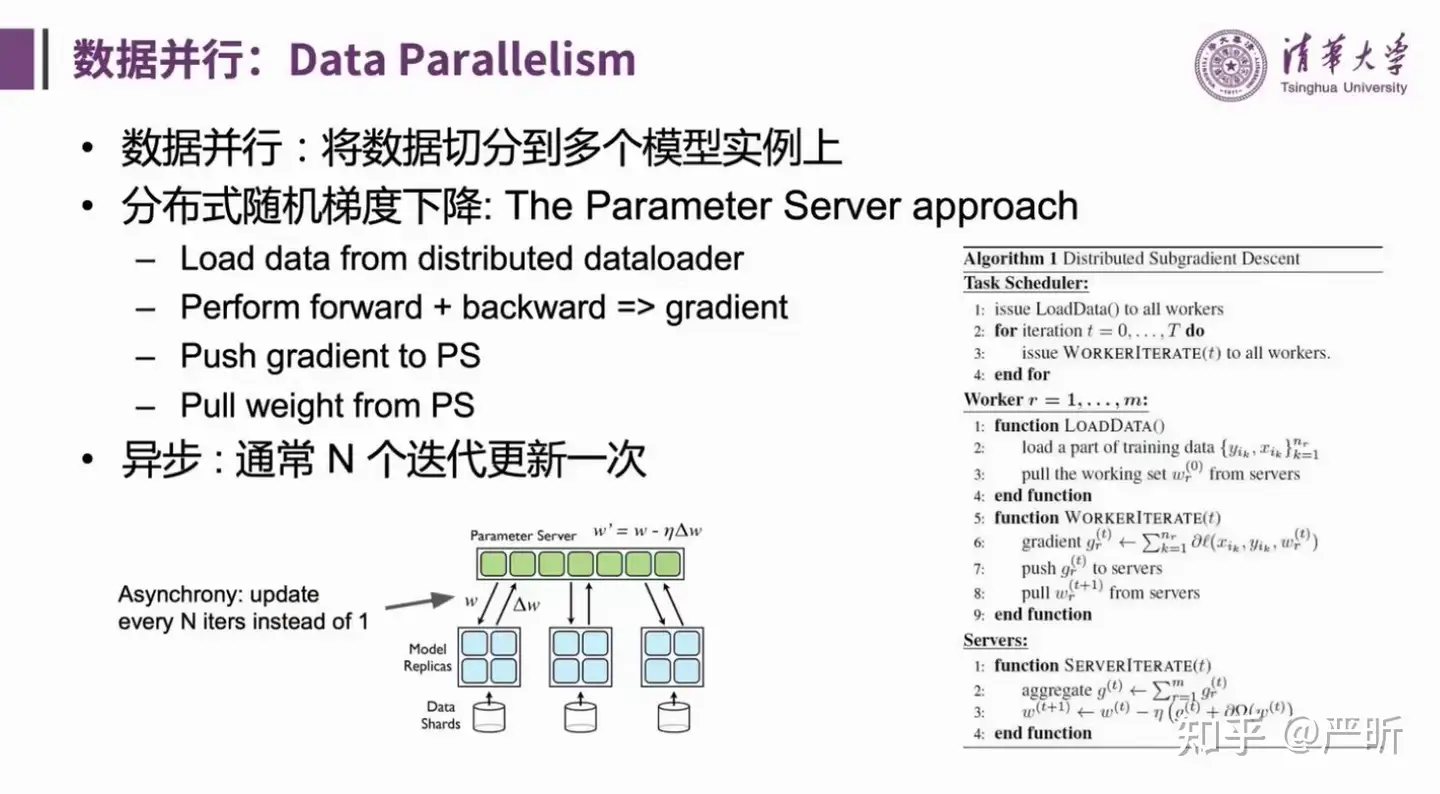
- 这里介绍的数据并行中的参数服务器(Parameter Server)方案

- 这里介绍的是另一种数据并行方案:All-Reduce

- 近年来更流行的数据并行方法是ZeRO优化器
- 这里看直播的时候没听懂,需要再看一下原论文:ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
模型并行
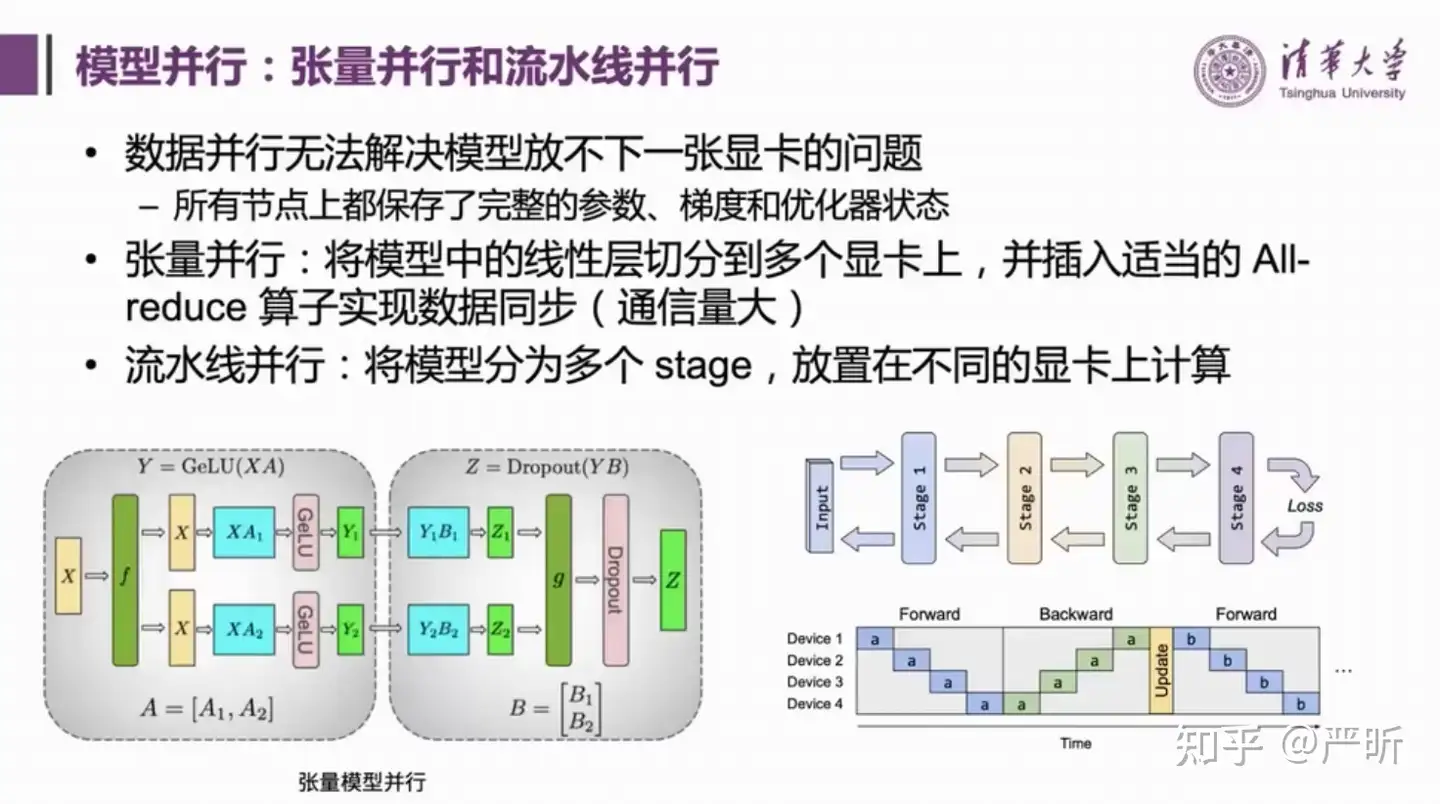
- 需要模型并行解决不了一张显卡放不下单个模型的问题
- 模型并行最简单的方法是张量并行,这个方法将矩阵切分到不同的显卡上,分别计算,最后再通过all-reduce操作把计算结果同步回来,显然这种方法通信量是比较大的,因此实际更多应用在单机多卡,有nvlink的场景下
- 对于更大的模型,做模型并行的方案是流水线并行

- 这里介绍的是流水线并行最朴素的实现
- 先Forward,再Backward,最后再做更新,每次只有1张卡在运算
- 其中的Bubble time(也就是图中空白区域)比较大,也就是这种方案下显卡的整体使用率是不高的
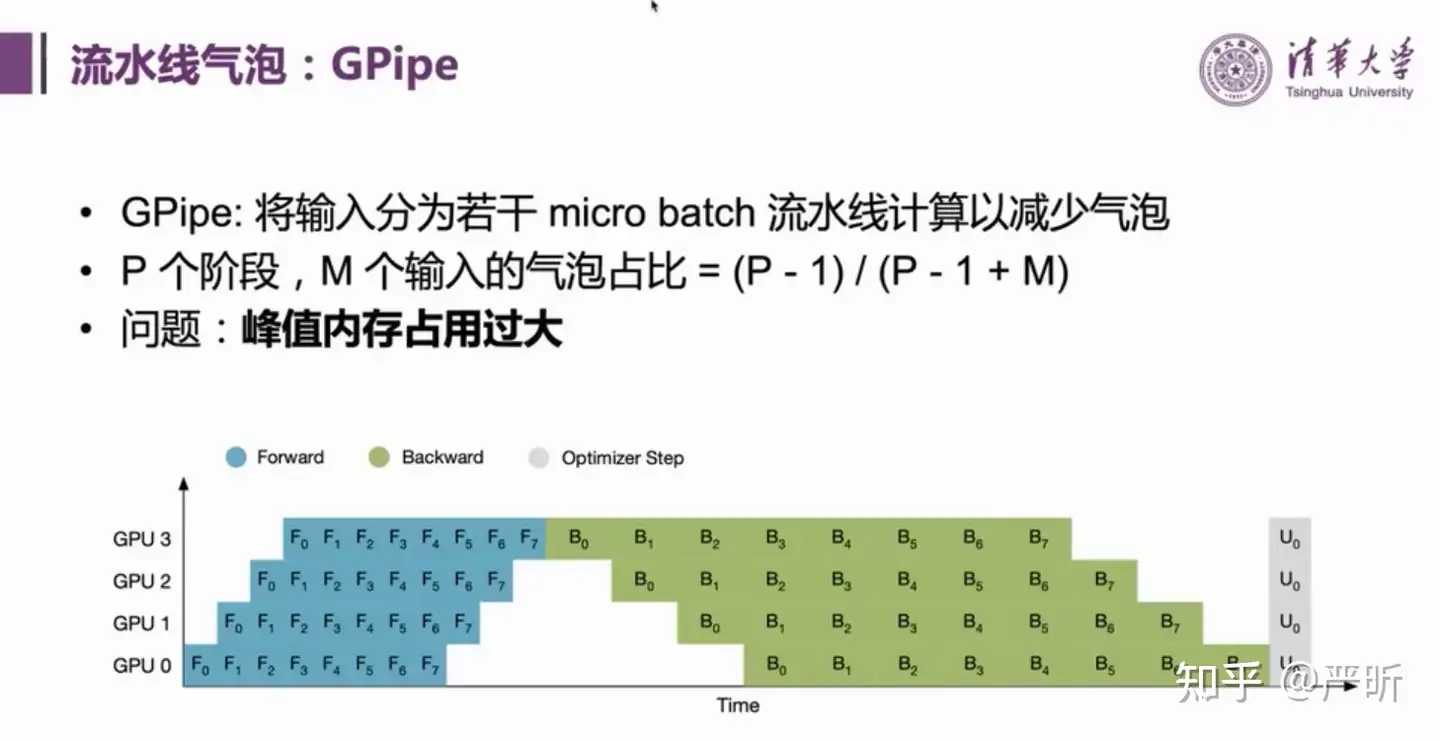
- GPipe是一种改进的流水线并行方案,进一步降低了气泡占比
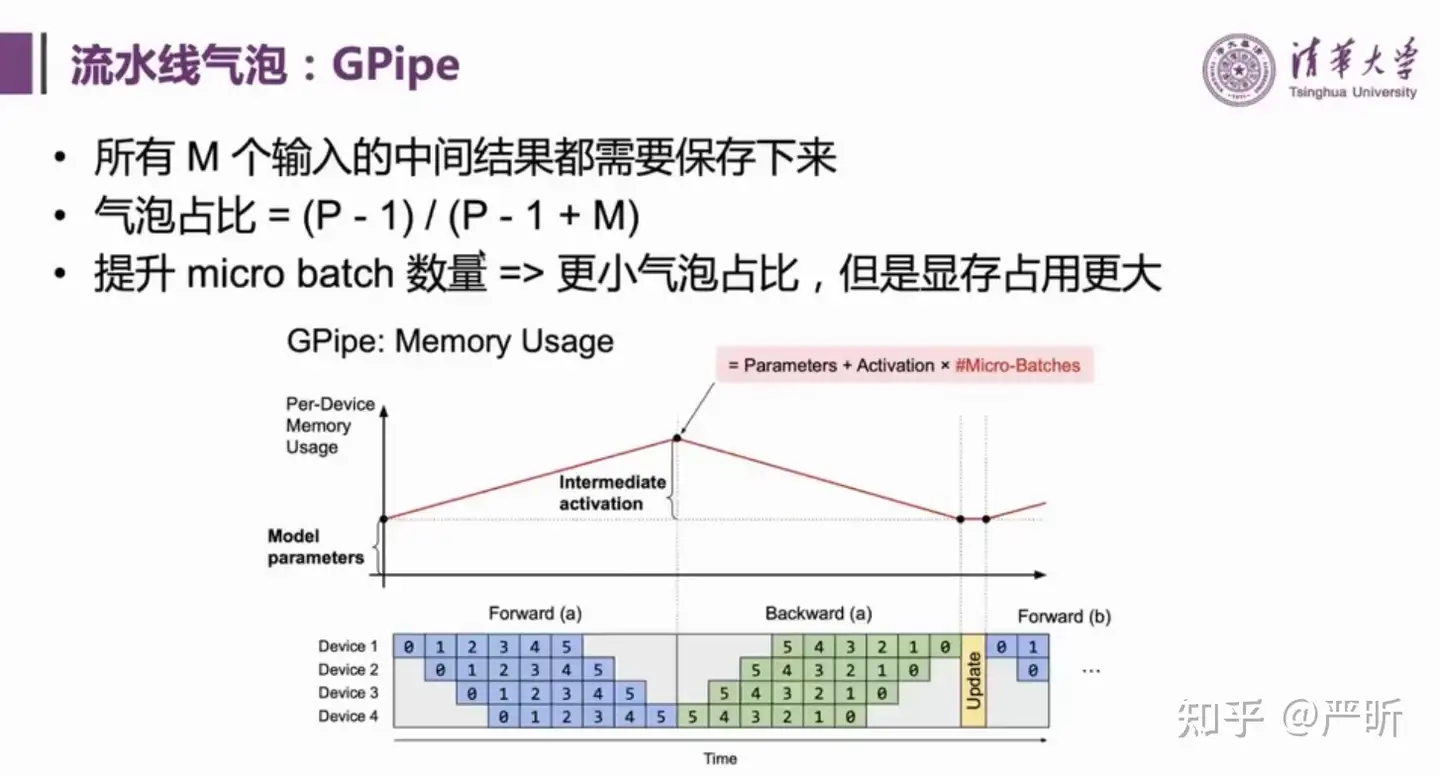
- 但是GPipe的峰值内存占用比较大
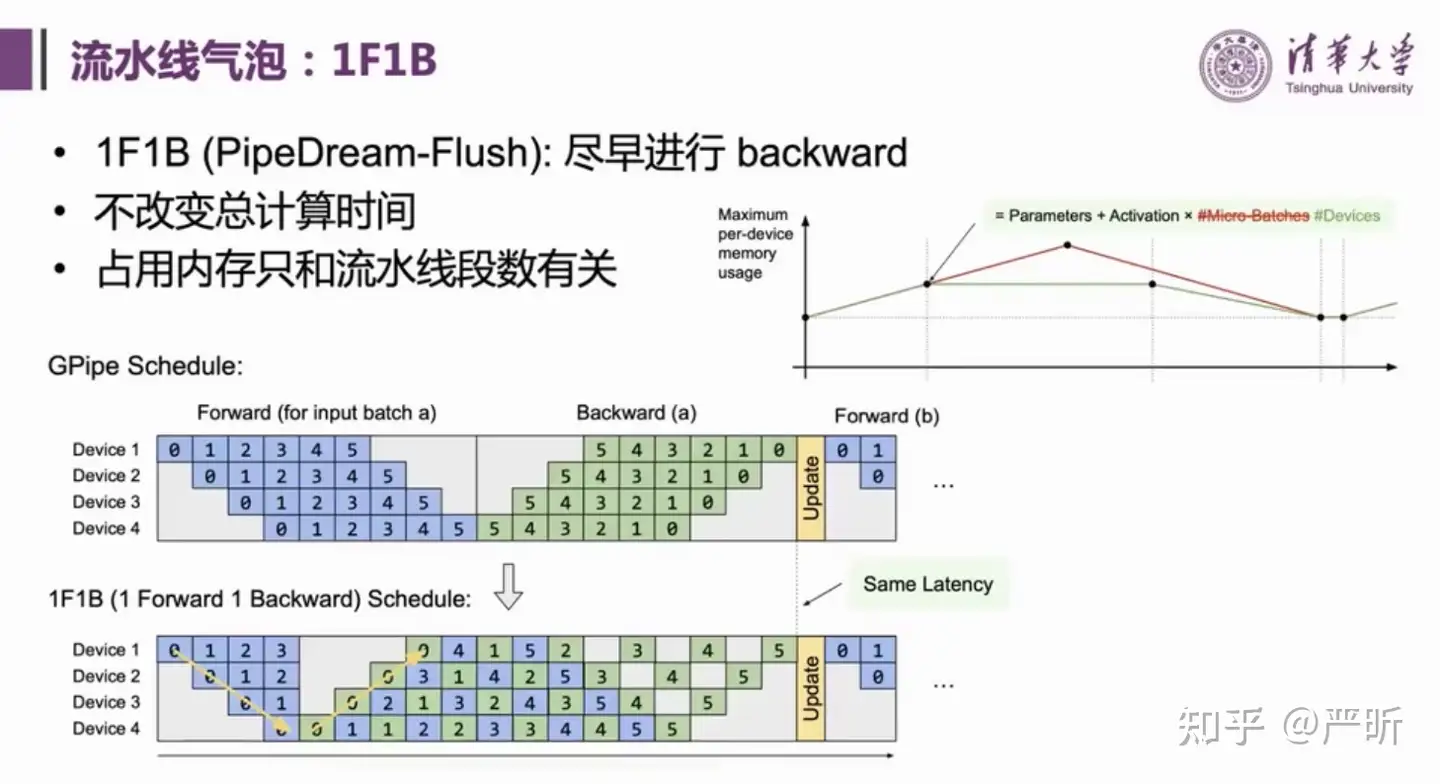
- 流水线并行策略:1F1B
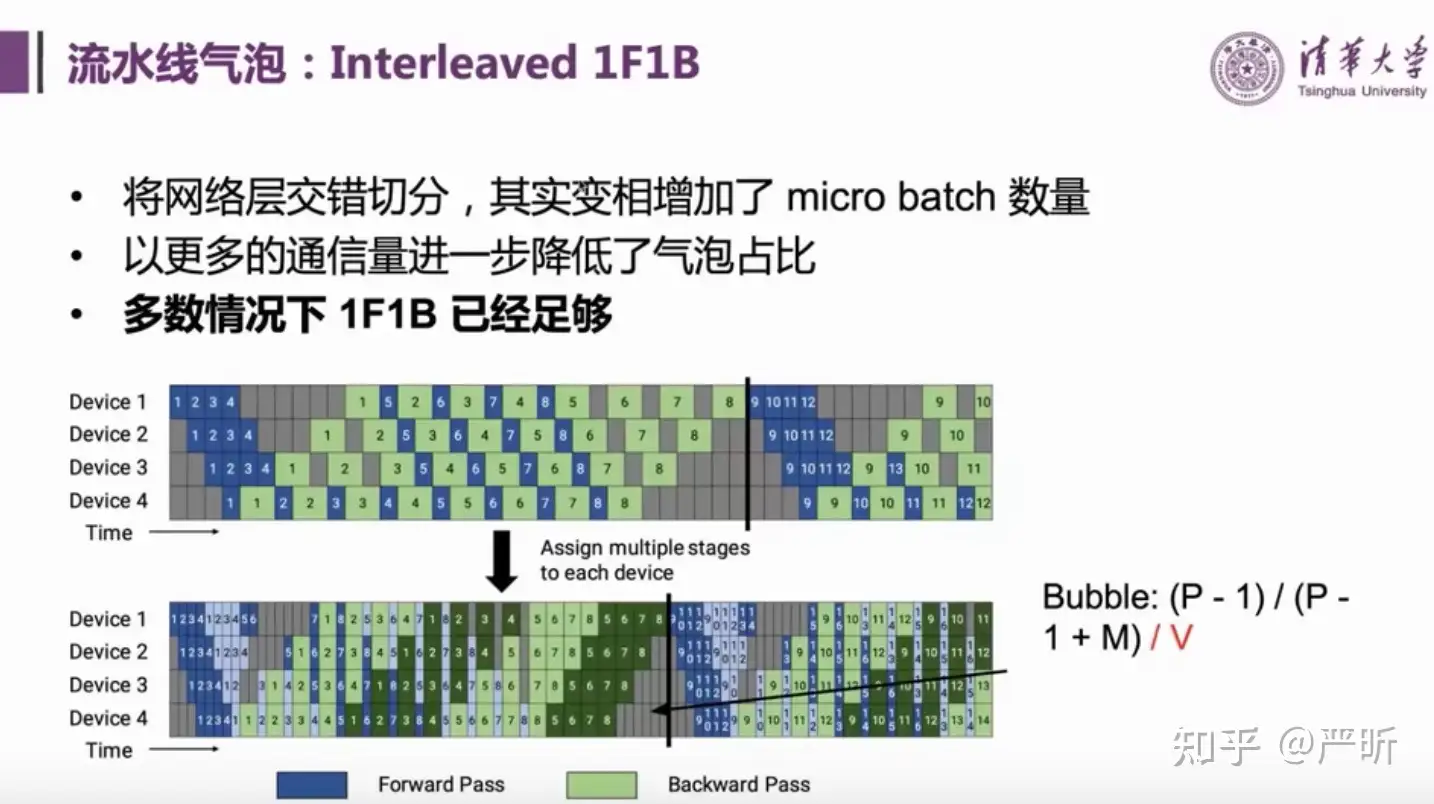
- 流水线并行策略:Interleaved 1F1B
并行策略
GLM-130B同时使用了多种并行策略
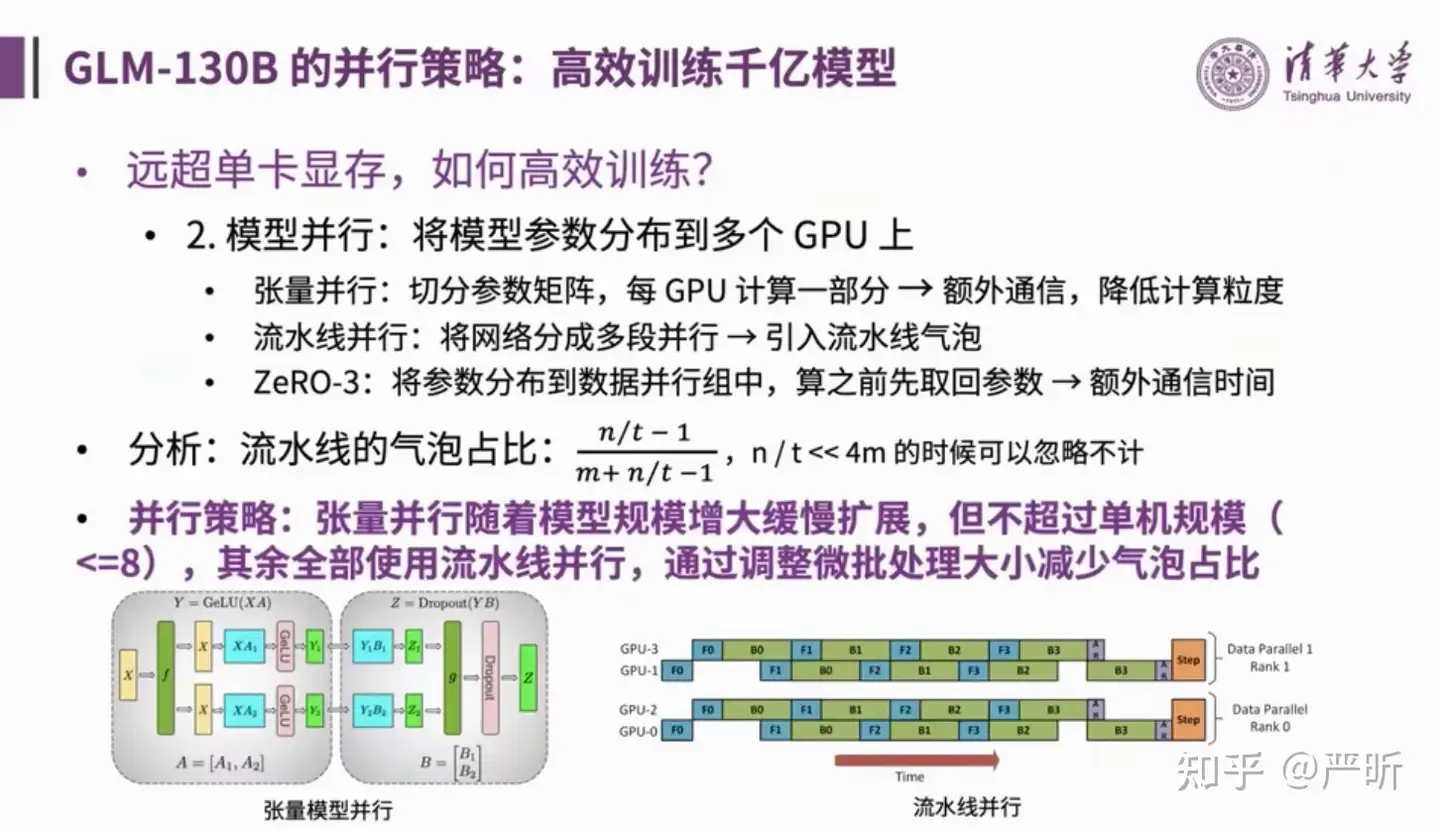
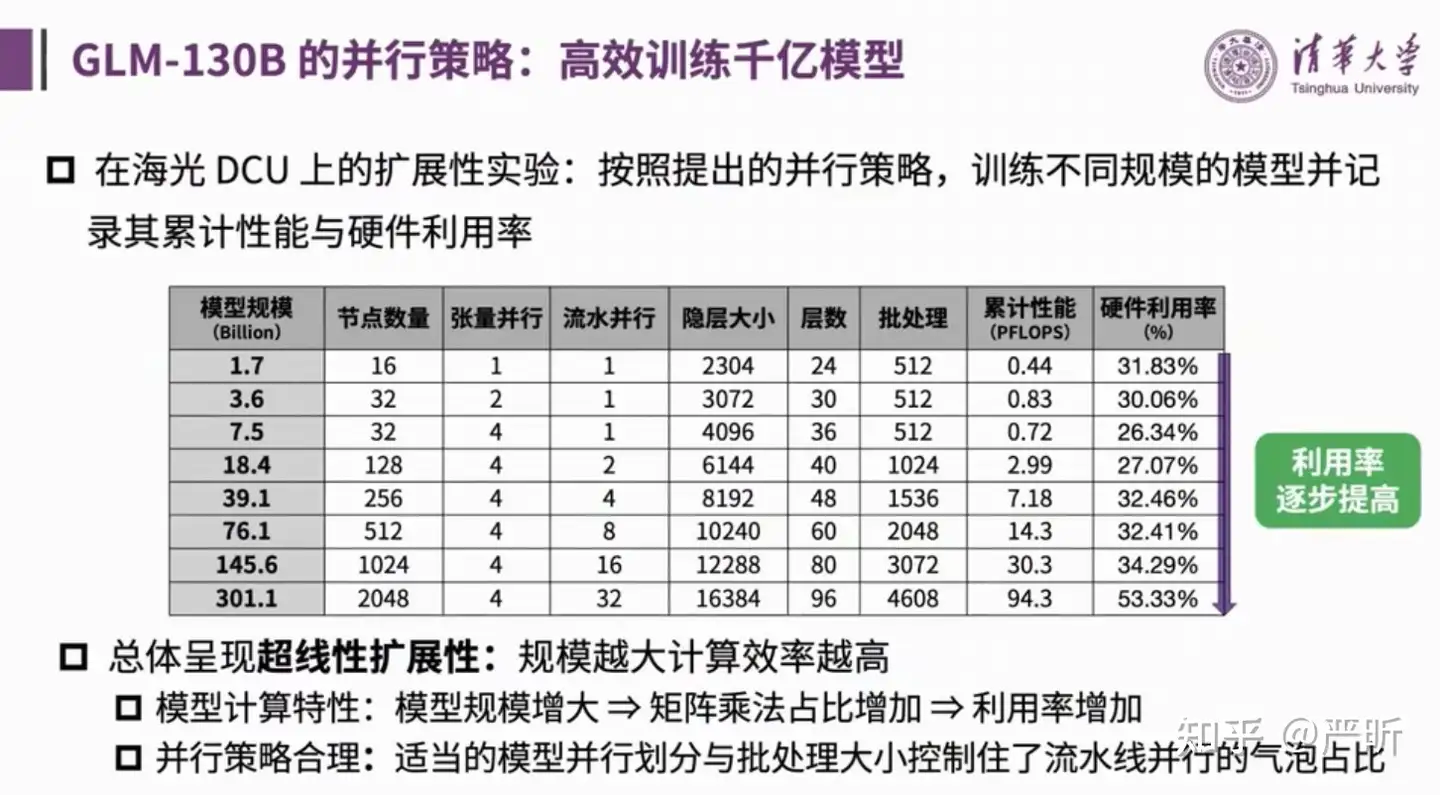
稳定性
训练中的稳定性问题
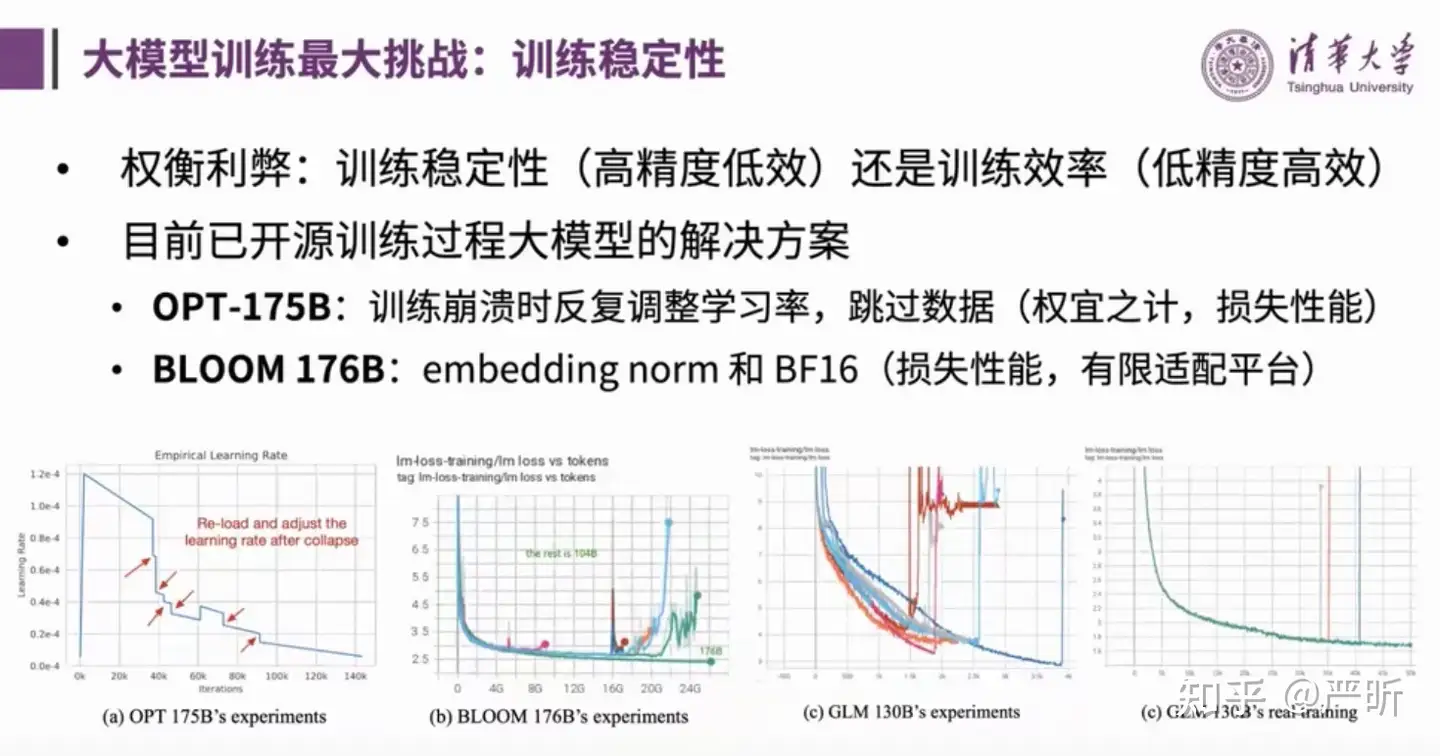
- 稳定性可能是训练过程中最大的问题了
- 在Major Issues中可以看到大部分的问题都和disconverge/spike有关

- 这张图里的经验价值千金
量化
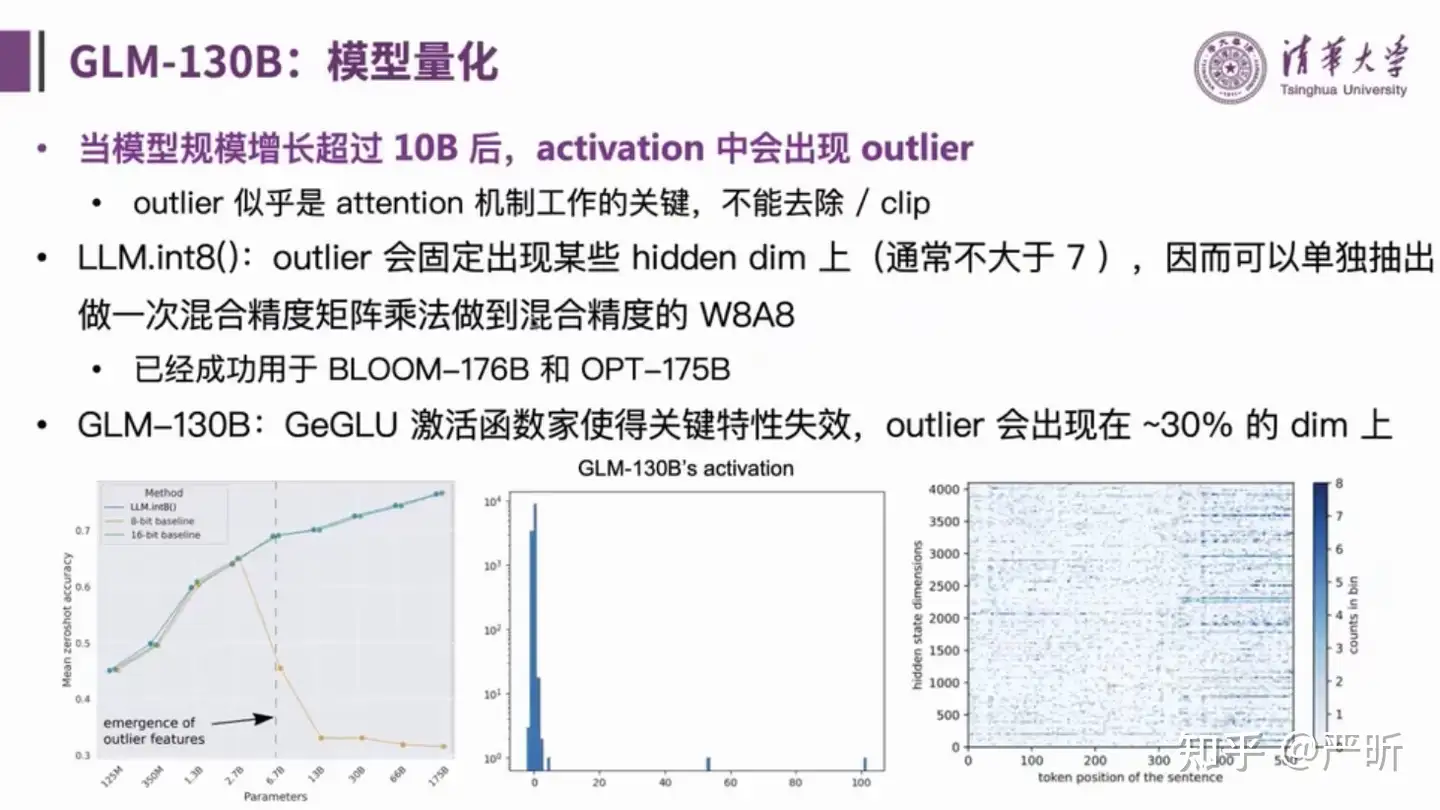
- 模型量化的目标是降低推理阶段的显存成本
- 上图中的策略都没有采用
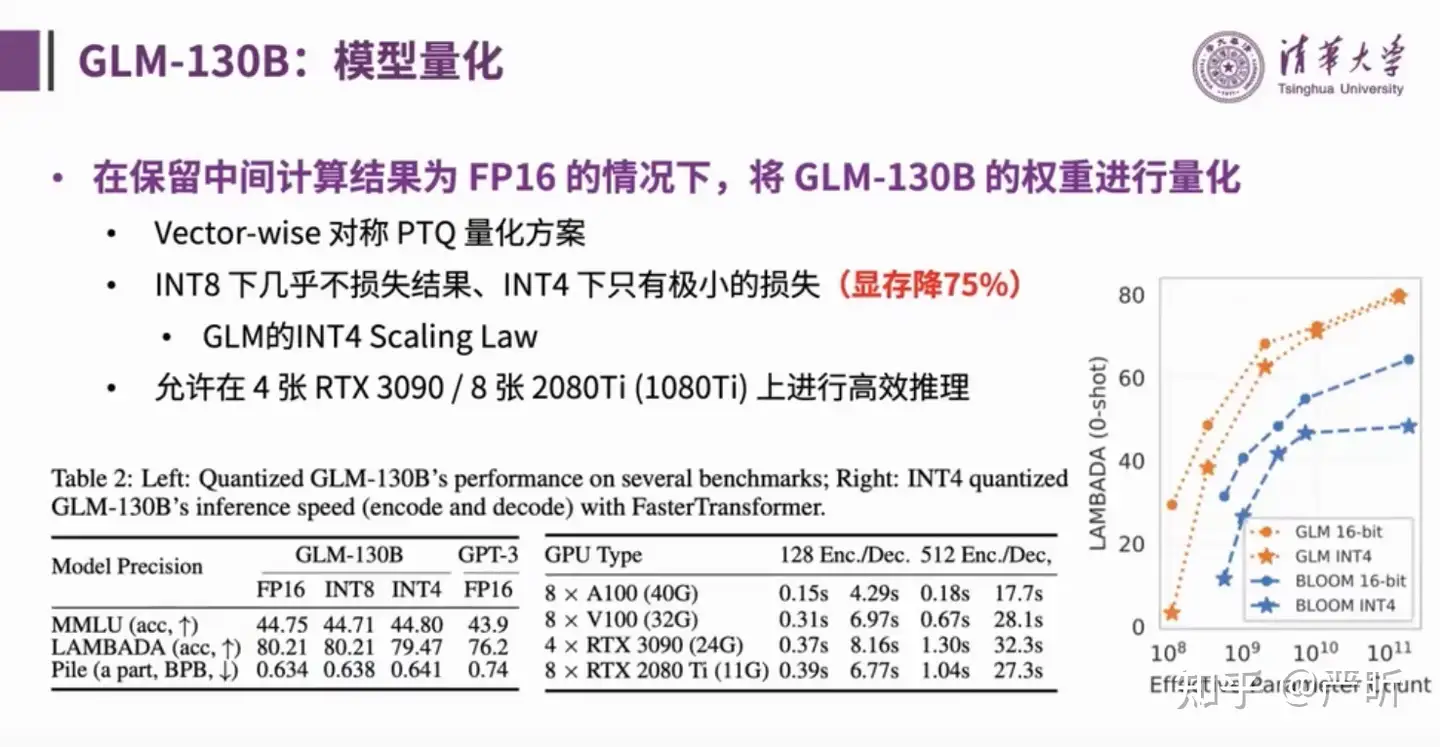
- 值得注意的是,GLM系列的量化方案只降低了显存的占用,中间的计算量(推理时间)并不会有明显下降,因为仍然使用FP16进行计算。
训练成果
- 双语:同时支持中文和英文
- 高精度(英文):在LAMBADA上优于GPT-3 175B(+4.0%)、OPT-175B(+5.5%)和BLOOM-176B(+13.0%),在MMLU上略优于GPT-3 175B(+0.9%)
- 高精度(中文):在7个零样本CLUE数据集(+24.26%)和5个零样本FewCLUE数据集(+12.75%)上明显优于ERNIE Titan 3.0 260B
- 高效推理:支持用一台A100(8×40G)/V100(8×32G)服务器基于FasterTransformer进行快速推理(相比Megatron提速最高可达2.5倍)
- 低门槛推理:最低量化到INT4,则可在4张3090/8张 2080Ti上完成推理
- 跨平台:支持在NVIDIA、海关DCU、昇腾910和神威处理器上的训练
GLM-130B API
【2023-11-13】火山方舟大模型服务 api 支持多种大模型调用
- baichuan: 7b
- ChatGLM:多个版本 6B,130B,ChatGLM2-Pro
- MiniMax
- Skylark: 多个版本 lite, plus, pro, chat(豆包)
调用语言
- Go
- Java
- Python
【2023-3-14】ChatGLM-6B
ChatGLM-6B 介绍
【2023-3-14】ChatGLM-6B 是一个开源、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。
- 由清华大学知识工程 (
KEG) 实验室和智谱AI公司与于2023年共同训练的语言模型 - 结合模型量化技术,用户可以在消费级显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B使用了和ChatGLM相同技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的ChatGLM-6B虽然规模不及千亿模型,但大大降低了推理成本,提升了效率,并且已经能生成相当符合人类偏好的回答。- 模型开源地址, huggingface
- finetune代码:ChatGLM-Tuning
- API: 调用方法参考智谱AI, ChatGLM 商用 Issue
- 【2023-3-17】issue: Cannot import name ‘convert_file_size_to_int’ from ‘transformers.utils.hub’
ChatGLM-6B 模型结构
ChatGLM-6B 模型结构:采用了 prefix decoder-only 的transformer模型框架,在输入上采用双向的注意力机制,在输出上采用单向注意力机制。
模型细节几点改动:
- embedding层梯度缩减:为了提升训练稳定性,减小了embedding层的梯度。具体地, word_embedding = word_embedding * alpha + word_embedding.detatch() * (1-alpha) ,其中 alpha=0.1 ,这里detach()函数的作用是返回一个新的tensor,并从计算图分离出来。梯度缩减的效果相当于把embedding层的梯度缩小了10倍,减小了梯度的范数。
- layer normalization:采用了基于Deep Norm的post layer norm。
- 激活函数:采用了GeGLU激活函数。相比于普通的FFN,使用线形门控单元的GLU新增了一个权重矩阵,共有三个权重矩阵,为了保持参数量一致,中间维度采用了 8d/3 ,而不是4d。
- 位置编码:去除了绝对位置编码,采用了旋转位置编码
RoPE。
训练目标: ChatGLM-6B 训练任务是自回归文本填空。相比于采用 causal decoder-only 结构的大语言模型,采用 prefix decoder-only结构的ChatGLM-6B存在一个劣势:训练效率低。
- causal decoder结构会在所有的token上计算损失,而prefix decoder只会在输出上计算损失,而不计算输入上的损失。
- 相同数量的训练tokens的情况下,prefix decoder要比causal decoder的效果差,因为训练过程中实际用到的tokens数量要更少。
另外,ChatGPT 成功已经证明了causal decoder结构的大语言模型可以获得非常好的few-shot和zero-shot生成能力,通过指令微调可以进一步激发模型的能力。至于prefix decoder结构的大语言模型能否获得相当的few-shot和zero-shot能力还缺少足够的验证。
关于tokenizer,ChatGLM在25GB的中英双语数据上训练了SentencePiece作为tokenizer,词表大小为130528。
ChatGLM-6B 特点
ChatGLM-6B 具备以下特点:
- 充分的中英双语预训练:ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
- 优化的模型架构和大小:吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统 FFN 结构。6B(62 亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
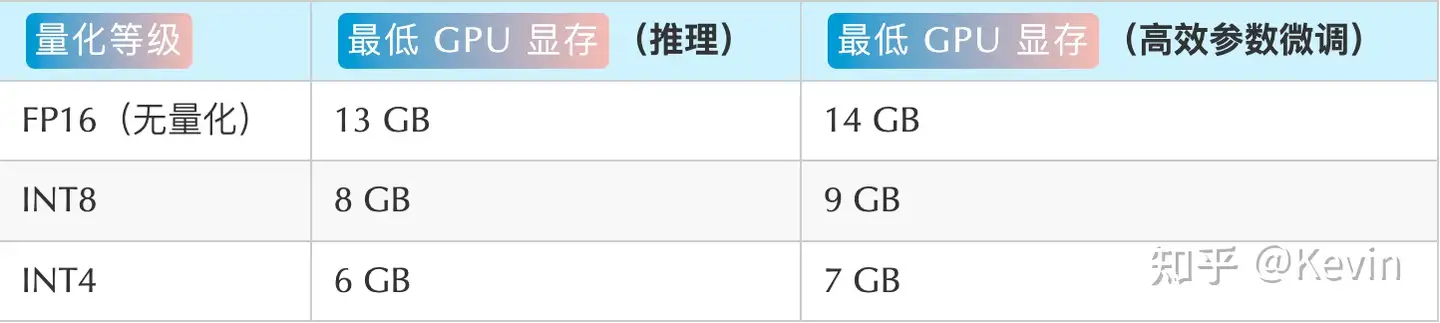
- 较低的部署门槛:FP16 半精度下,ChatGLM-6B 需要至少 13 GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4),使得 ChatGLM-6B 可以部署在消费级显卡上。
- 在现代 GPU 和 TPU 上,tensor 计算可以在 16 位浮点上高效完成。 但并非简单将 tensor 的 dtype 设置为 torch.float16。对于某些部分,如 loss,仍然需要 32 位精度。
- 半精度优化能使内存占用减半,或者说能使有效内存翻倍。
- 更长的序列长度:相比 GLM-10B(序列长度 1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
- 人类意图对齐训练:使用了
监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback)等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
ChatGLM-6B 不足
不过由于 ChatGLM-6B 模型的容量较小,不可避免的存在一些局限和不足,目前已知其具有相当多的局限性,如:
- 事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。
- 相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,
ChatGLM-6B可能会生成不正确的信息,也不太擅长逻辑类问题(如数学、编程)的解答。 - 可能会产生有害说明或有偏见的内容:
ChatGLM-6B只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。 - 较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成和多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
- 参考:清华系千亿基座对话模型ChatGLM启动内测,开源单卡版模型

ChatGLM-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
ChatGLM-6B 实践
ChatGLM-6B 接入
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
print(type(model), model) # 显示模型结构
model = model.eval() # 是否必须?
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
# 你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
ChatGLM-6B 本地部署
【2023-4-13】清华ChatGLM-6B模型本地部署
硬件要求
- 无量化情况下,显存初始化基本上都需要13G内存,16G 显存可能对话两轮就内存爆满了,建议使用量化模型。
- ChatGLM-6B:构建本地离线知识库的绝佳选择
git clone https://github.com/THUDM/ChatGLM-6B.git
pip install -r requirements.txt
使用
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你是谁", history=[])
# The dtype of attention mask (torch.int64) is not bool
print(response)
# 我是一个名为 ChatGLM-6B 的人工智能助手,是基于清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。
response, history = model.chat(tokenizer, "你会什么", history=history)
print(response)
# ---------
# 默认的
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
# 我的 INT4的
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
【2023-6-25】ChatGLM2-6B – 升级
【2023-6-25】ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%
- CEval榜单,ChatGLM2 暂时位居 Rank 0,ChatGLM2-6B 位居 Rank 6
- 截至6月25日 ChatGLM2 模型以 71.1 的分数位居 Rank 0 ,ChatGLM2-6B 模型以 51.7 的分数位居 Rank 6,是榜单上排名最高的开源模型。
ChatGLM2-6B 安装请参考官方
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。如果发现开源模型对业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。
【2023-7-14】ChatGLM2-6B,免费商用,扫码登记即可
自 3 月 14 日发布 ChatGLM-6B 及 6 月 25 日发布 ChatGLM2-6B 以来,这两个模型在 Huggingface 上的下载量已经先后超过了 300 万和 120 万。非常感谢大家对 ChatGLM 模型的支持。为了更好地支持国产大模型开源生态的繁荣发展,经智谱 AI 及清华 KEG 实验室决定,自即日起 ChatGLM-6B 和 ChatGLM2-6B 权重对学术研究完全开放,并且在完成企业登记获得授权后,允许免费商业使用。
相比于初代模型,ChatGLM2-6B 多个维度的能力都取得了提升,对比示例
- 数理逻辑
- 知识推理
- 长文档理解
部署
- GitHub 地址
- 模型文件:Huggingface 地址
- 7个bin文件存放模型参数, 文件名:
pytorch_model-0000{1~7}-of..., 每个文件近 2G - 一文搞定ChatGLM2-6B部署
(1)下载方式
- 手动下载: 下载完毕上传到租赁GPU服务器就行,可能比较费流量
- git lfs 工具: 下载大文件的工具(受网络限制 ,可能需要多次尝试)
git clone https://github.com/THUDM/ChatGLM-6B
# model文件最好像我这样放置,好找一些~
cd ChatGLM-6B
mkdir model
cd model
apt-get update
apt-get install git-lfs
git-lfs install
git lfs clone https://huggingface.co/THUDM/chatglm2-6b
# 下载glm2 代码、和模型文件
# 连接不稳定,可能需要多clone几次,或者直接本机download然后上传(ps 还是自己upload万无一失)
(2)环境部署
conda create -n chatglm2 python=3.10
conda activate chatglm2
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple #这里配了下载源,更快一些!
(3)修改代码
修改web_demo.py配置信息
- model_path : 加载本地模型,而不是从huggingface上pull
- launch : 默认不会生成可访问的公网url链接
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
from utils import load_model_on_gpus
#model_path = 'THUDM/chatglm2-6b'
model_path = './chatglm2-6b' # 本地模型地址
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).cuda() # cpu -> gpu
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2) # 多卡模式
model = model.eval()
# ....
# demo.queue().launch(share=True, inbrowser=True) # old
demo.queue().launch(share=True, inbrowser=True,server_name='0.0.0.0', server_port=7860)) # new
(4)启动服务
- gradio 公网url有时失败 → ssh隧道 or 其它平台(如 autoDL)
python web_demo.py
- api 方式: 运行api.py文件,默认部署在本地的 8000 端口,通过 POST 方法进行调用
curl -X POST "http://127.0.0.1:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
# {"response":"你好 !我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。","history":[["你好","你好 !我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。"]],"status":200,"time":"2023-09-25 22:23:34"}
OpenAI 格式的流式 API 部署
import openai
if __name__ == "__main__":
openai.api_base = "http://localhost:8000/v1"
openai.api_key = "none"
for chunk in openai.ChatCompletion.create(
model="chatglm2-6b",
messages=[
{"role": "user", "content": "你好"}
],
stream=True
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
知识注入
【2023-7-11】单样本微调给ChatGLM2注入知识
- 借助 AdaLoRA算法,使用1条样本对ChatGLM2-6b实施微调。几分钟就成功注入了有关知识
- AdaLoRA是LoRA方法的一种升级版本,使用方法与LoRA基本一样。主要差异
- LoRA中不同训练参数矩阵的秩被固定。
- 但AdaLoRA中不同训练参数矩阵的秩是会在一定范围内自适应调整的,那些更重要的训练参数矩阵会分配到更高的秩。
- AdaLoRA的效果会好于LoRA。
备注
- (1) 只需要1条样本,很少的训练时间,就可以通过微调给LLM注入知识。
- (2) LLM 可以看做类似Key-Value形式的知识数据库,支持增删改查。通过微调可以增删修改知识,通过条件生成可以查询提取知识。
- (3) LoRA 微调是一种高效的融入学习算法。类似人类把新知识融入现有知识体系的学习过程。学习时无需新知识特别多的样本,学习后原有的庞大知识和能力可以基本不受影响。
from peft import get_peft_model, AdaLoraConfig, TaskType
#训练时节约GPU占用
model.config.use_cache=False
model.supports_gradient_checkpointing = True #
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
peft_config = AdaLoraConfig(
task_type=TaskType.CAUSAL_LM, inference_mode=False,
r=8,
lora_alpha=32, lora_dropout=0.1,
target_modules=["query", "value"]
)
peft_model = get_peft_model(model, peft_config)
peft_model.is_parallelizable = True
peft_model.model_parallel = True
peft_model.print_trainable_parameters()
验证模型
from peft import PeftModel
ckpt_path = 'single_chatglm2'
model_old = AutoModel.from_pretrained("chatglm2-6b",
load_in_8bit=False,
trust_remote_code=True)
peft_loaded = PeftModel.from_pretrained(model_old,ckpt_path).cuda()
model_new = peft_loaded.merge_and_unload() #合并lora权重
chatglm = ChatGLM(model_new,tokenizer,max_chat_rounds=20) #支持多轮对话,可以从之前对话上下文提取知识。
ChatGLM3
【2023-10-27】ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。
ChatGLM3 还推出了可在手机上部署的端测模型ChatGLM3-1.5B和ChatGLM3-3B,支持包括vivo、小米、三星在内的多款手机以及车载平台,甚至支持移动平台上CPU芯片的推理,速度可达20tokens每秒(token是语言模型中用来表示单词或短语的符号)。
【2023-11-7】ChatGLM3-6b
【2023-11-7】chatglm3-6b
ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列:
- 对话模型 ChatGLM3-6B
- 基础模型 ChatGLM3-6B-Base
- 长文本对话模型 ChatGLM3-6B-32K。
- 以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
全新的 Prompt 格式
- 为了避免用户输入的注入攻击以及统一 Code Interpreter,Tool & Agent 等任务的输入,ChatGLM3 采用了全新的对话格式。
整体结构
- ChatGLM3 对话的格式由若干对话组成,其中每个对话包含对话头和内容,一个典型的多轮对话结构如下
<|system|>
You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.
<|user|>
Hello
<|assistant|>
Hello, I'm ChatGLM3. What can I assist you today?
其中 <|role|> 部分使用 special token 表示,无法从文本形式被 tokenizer 编码以防止注入。metadata 部分采用纯文本表示,为可选内容。
<|system|>:系统信息,设计上可穿插于对话中,但目前规定仅可以出现在开头<|user|>:用户- 不会连续出现多个来自
<|user|>的信息
- 不会连续出现多个来自
<|assistant|>:AI 助手- 在出现之前必须有一个来自
<|user|>的信息
- 在出现之前必须有一个来自
<|observation|>:外部的返回结果- 必须在
<|assistant|>的信息之后
- 必须在
问题
ChatGLM3-6b 部署
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
# transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上
pip install -r requirements.txt
# 本地加载模型并启动 demo
# export MODEL_PATH=/path/to/model
streamlit run main.py
ChatGLM3 Demo
ChatGLM3 Demo 拥有三种模式:
Chat: 对话模式,在此模式下可以与模型进行对话。- 直接在侧边栏修改 top_p, temperature, System Prompt 等参数来调整模型的行为
Tool: 工具模式,模型除了对话外,还可以通过工具进行其他操作。- 在 tool_registry.py 中注册新工具来增强模型能力,
@register_tool装饰函数 - 通过 Manual mode 进入手动模式,YAML 直接指定工具列表,但需要手动将工具的输出反馈给模型。
- 在 tool_registry.py 中注册新工具来增强模型能力,
Code Interpreter: 代码解释器模式,模型可以在一个 Jupyter 环境中执行代码并获取结果,以完成复杂任务。- 执行更为复杂的任务,例如绘制图表、执行符号运算等等。
示例
- 函数名称为工具名称
- 函数 docstring 即为工具的说明;
- 工具参数使用
Annotated[typ: type, description: str, required: bool]标注参数的类型、描述和是否必须。
@register_tool
def get_weather(
city_name: Annotated[str, 'The name of the city to be queried', True],
) -> str:
"""
Get the weather for `city_name` in the following week
"""
...
文件结构
# 模型文件
pytorch_model-00001-of-00007.bin
配置
config.json
configuration_chatglm.py
分词
tokenization_chatglm.py
import json
import os
import torch
from typing import List, Optional, Union, Dict
from sentencepiece import SentencePieceProcessor
from transformers import PreTrainedTokenizer
from transformers.utils import logging, PaddingStrategy
from transformers.tokenization_utils_base import EncodedInput, BatchEncoding
class SPTokenizer:
def __init__(self, model_path: str):
# reload tokenizer
assert os.path.isfile(model_path), model_path
self.sp_model = SentencePieceProcessor(model_file=model_path)
# BOS / EOS token IDs
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.unk_id()
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
special_tokens = ["[MASK]", "[gMASK]", "[sMASK]", "sop", "eop", "<|system|>", "<|user|>", "<|assistant|>",
"<|observation|>"]
self.special_tokens = {}
self.index_special_tokens = {}
for token in special_tokens:
self.special_tokens[token] = self.n_words
self.index_special_tokens[self.n_words] = token
self.n_words += 1
def tokenize(self, s: str):
return self.sp_model.EncodeAsPieces(s)
def encode(self, s: str, bos: bool = False, eos: bool = False) -> List[int]:
assert type(s) is str
t = self.sp_model.encode(s)
if bos:
t = [self.bos_id] + t
if eos:
t = t + [self.eos_id]
return t
def decode(self, t: List[int]) -> str:
text, buffer = "", []
for token in t:
if token in self.index_special_tokens:
if buffer:
text += self.sp_model.decode(buffer)
buffer = []
text += self.index_special_tokens[token]
else:
buffer.append(token)
if buffer:
text += self.sp_model.decode(buffer)
return text
def decode_tokens(self, tokens: List[str]) -> str:
text = self.sp_model.DecodePieces(tokens)
return text
def convert_token_to_id(self, token):
""" Converts a token (str) in an id using the vocab. """
if token in self.special_tokens:
return self.special_tokens[token]
return self.sp_model.PieceToId(token)
def convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
if index in self.index_special_tokens:
return self.index_special_tokens[index]
if index in [self.eos_id, self.bos_id, self.pad_id] or index < 0:
return ""
return self.sp_model.IdToPiece(index)
class ChatGLMTokenizer(PreTrainedTokenizer):
vocab_files_names = {"vocab_file": "tokenizer.model"}
model_input_names = ["input_ids", "attention_mask", "position_ids"]
def __init__(self, vocab_file, padding_side="left", clean_up_tokenization_spaces=False, **kwargs):
self.name = "GLMTokenizer"
self.vocab_file = vocab_file
self.tokenizer = SPTokenizer(vocab_file)
self.special_tokens = {
"<bos>": self.tokenizer.bos_id,
"<eos>": self.tokenizer.eos_id,
"<pad>": self.tokenizer.pad_id
}
super().__init__(padding_side=padding_side, clean_up_tokenization_spaces=clean_up_tokenization_spaces, **kwargs)
def get_command(self, token):
if token in self.special_tokens:
return self.special_tokens[token]
assert token in self.tokenizer.special_tokens, f"{token} is not a special token for {self.name}"
return self.tokenizer.special_tokens[token]
@property
def unk_token(self) -> str:
return "<unk>"
@property
def pad_token(self) -> str:
return "<unk>"
@property
def pad_token_id(self):
return self.get_command("<pad>")
@property
def eos_token(self) -> str:
return "</s>"
@property
def eos_token_id(self):
return self.get_command("<eos>")
@property
def vocab_size(self):
return self.tokenizer.n_words
def get_vocab(self):
""" Returns vocab as a dict """
vocab = {self._convert_id_to_token(i): i for i in range(self.vocab_size)}
vocab.update(self.added_tokens_encoder)
return vocab
def _tokenize(self, text, **kwargs):
return self.tokenizer.tokenize(text)
def _convert_token_to_id(self, token):
""" Converts a token (str) in an id using the vocab. """
return self.tokenizer.convert_token_to_id(token)
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
return self.tokenizer.convert_id_to_token(index)
def convert_tokens_to_string(self, tokens: List[str]) -> str:
return self.tokenizer.decode_tokens(tokens)
def save_vocabulary(self, save_directory, filename_prefix=None):
"""
Save the vocabulary and special tokens file to a directory.
Args:
save_directory (`str`):
The directory in which to save the vocabulary.
filename_prefix (`str`, *optional*):
An optional prefix to add to the named of the saved files.
Returns:
`Tuple(str)`: Paths to the files saved.
"""
if os.path.isdir(save_directory):
vocab_file = os.path.join(
save_directory, self.vocab_files_names["vocab_file"]
)
else:
vocab_file = save_directory
with open(self.vocab_file, 'rb') as fin:
proto_str = fin.read()
with open(vocab_file, "wb") as writer:
writer.write(proto_str)
return (vocab_file,)
def get_prefix_tokens(self):
prefix_tokens = [self.get_command("[gMASK]"), self.get_command("sop")]
return prefix_tokens
def build_single_message(self, role, metadata, message):
assert role in ["system", "user", "assistant", "observation"], role
role_tokens = [self.get_command(f"<|{role}|>")] + self.tokenizer.encode(f"{metadata}\n")
message_tokens = self.tokenizer.encode(message)
tokens = role_tokens + message_tokens
return tokens
def build_chat_input(self, query, history=None, role="user"):
if history is None:
history = []
input_ids = []
for item in history:
content = item["content"]
if item["role"] == "system" and "tools" in item:
content = content + "\n" + json.dumps(item["tools"], indent=4, ensure_ascii=False)
input_ids.extend(self.build_single_message(item["role"], item.get("metadata", ""), content))
input_ids.extend(self.build_single_message(role, "", query))
input_ids.extend([self.get_command("<|assistant|>")])
return self.batch_encode_plus([input_ids], return_tensors="pt", is_split_into_words=True)
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A BERT sequence has the following format:
- single sequence: `[CLS] X [SEP]`
- pair of sequences: `[CLS] A [SEP] B [SEP]`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
prefix_tokens = self.get_prefix_tokens()
token_ids_0 = prefix_tokens + token_ids_0
if token_ids_1 is not None:
token_ids_0 = token_ids_0 + token_ids_1 + [self.get_command("<eos>")]
return token_ids_0
def _pad(
self,
encoded_inputs: Union[Dict[str, EncodedInput], BatchEncoding],
max_length: Optional[int] = None,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
pad_to_multiple_of: Optional[int] = None,
return_attention_mask: Optional[bool] = None,
) -> dict:
"""
Pad encoded inputs (on left/right and up to predefined length or max length in the batch)
Args:
encoded_inputs:
Dictionary of tokenized inputs (`List[int]`) or batch of tokenized inputs (`List[List[int]]`).
max_length: maximum length of the returned list and optionally padding length (see below).
Will truncate by taking into account the special tokens.
padding_strategy: PaddingStrategy to use for padding.
- PaddingStrategy.LONGEST Pad to the longest sequence in the batch
- PaddingStrategy.MAX_LENGTH: Pad to the max length (default)
- PaddingStrategy.DO_NOT_PAD: Do not pad
The tokenizer padding sides are defined in self.padding_side:
- 'left': pads on the left of the sequences
- 'right': pads on the right of the sequences
pad_to_multiple_of: (optional) Integer if set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Core on NVIDIA hardware with compute capability
`>= 7.5` (Volta).
return_attention_mask:
(optional) Set to False to avoid returning attention mask (default: set to model specifics)
"""
# Load from model defaults
assert self.padding_side == "left"
required_input = encoded_inputs[self.model_input_names[0]]
seq_length = len(required_input)
if padding_strategy == PaddingStrategy.LONGEST:
max_length = len(required_input)
if max_length is not None and pad_to_multiple_of is not None and (max_length % pad_to_multiple_of != 0):
max_length = ((max_length // pad_to_multiple_of) + 1) * pad_to_multiple_of
needs_to_be_padded = padding_strategy != PaddingStrategy.DO_NOT_PAD and len(required_input) != max_length
# Initialize attention mask if not present.
if "attention_mask" not in encoded_inputs:
encoded_inputs["attention_mask"] = [1] * seq_length
if "position_ids" not in encoded_inputs:
encoded_inputs["position_ids"] = list(range(seq_length))
if needs_to_be_padded:
difference = max_length - len(required_input)
if "attention_mask" in encoded_inputs:
encoded_inputs["attention_mask"] = [0] * difference + encoded_inputs["attention_mask"]
if "position_ids" in encoded_inputs:
encoded_inputs["position_ids"] = [0] * difference + encoded_inputs["position_ids"]
encoded_inputs[self.model_input_names[0]] = [self.pad_token_id] * difference + required_input
return encoded_inputs
模型结构
modeling_chatglm.py
""" PyTorch ChatGLM model. """
import math
import copy
import warnings
import re
import sys
import torch
import torch.utils.checkpoint
import torch.nn.functional as F
from torch import nn
from torch.nn import CrossEntropyLoss, LayerNorm, MSELoss, BCEWithLogitsLoss
from torch.nn.utils import skip_init
from typing import Optional, Tuple, Union, List, Callable, Dict, Any
from copy import deepcopy
from transformers.modeling_outputs import (
BaseModelOutputWithPast,
CausalLMOutputWithPast,
SequenceClassifierOutputWithPast,
)
from transformers.modeling_utils import PreTrainedModel
from transformers.utils import logging
from transformers.generation.logits_process import LogitsProcessor
from transformers.generation.utils import LogitsProcessorList, StoppingCriteriaList, GenerationConfig, ModelOutput
from .configuration_chatglm import ChatGLMConfig
# flags required to enable jit fusion kernels
if sys.platform != 'darwin':
torch._C._jit_set_profiling_mode(False)
torch._C._jit_set_profiling_executor(False)
torch._C._jit_override_can_fuse_on_cpu(True)
torch._C._jit_override_can_fuse_on_gpu(True)
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "THUDM/ChatGLM"
_CONFIG_FOR_DOC = "ChatGLMConfig"
CHATGLM_6B_PRETRAINED_MODEL_ARCHIVE_LIST = [
"THUDM/chatglm3-6b",
# See all ChatGLM models at https://huggingface.co/models?filter=chatglm
]
def default_init(cls, *args, **kwargs):
return cls(*args, **kwargs)
class InvalidScoreLogitsProcessor(LogitsProcessor):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
if torch.isnan(scores).any() or torch.isinf(scores).any():
scores.zero_()
scores[..., 5] = 5e4
return scores
class PrefixEncoder(torch.nn.Module):
"""
The torch.nn model to encode the prefix
Input shape: (batch-size, prefix-length)
Output shape: (batch-size, prefix-length, 2*layers*hidden)
"""
def __init__(self, config: ChatGLMConfig):
super().__init__()
self.prefix_projection = config.prefix_projection
if self.prefix_projection:
# Use a two-layer MLP to encode the prefix
kv_size = config.num_layers * config.kv_channels * config.multi_query_group_num * 2
self.embedding = torch.nn.Embedding(config.pre_seq_len, kv_size)
self.trans = torch.nn.Sequential(
torch.nn.Linear(kv_size, config.hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(config.hidden_size, kv_size)
)
else:
self.embedding = torch.nn.Embedding(config.pre_seq_len,
config.num_layers * config.kv_channels * config.multi_query_group_num * 2)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.trans(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values
def split_tensor_along_last_dim(
tensor: torch.Tensor,
num_partitions: int,
contiguous_split_chunks: bool = False,
) -> List[torch.Tensor]:
"""Split a tensor along its last dimension.
Arguments:
tensor: input tensor.
num_partitions: number of partitions to split the tensor
contiguous_split_chunks: If True, make each chunk contiguous
in memory.
Returns:
A list of Tensors
"""
# Get the size and dimension.
last_dim = tensor.dim() - 1
last_dim_size = tensor.size()[last_dim] // num_partitions
# Split.
tensor_list = torch.split(tensor, last_dim_size, dim=last_dim)
# Note: torch.split does not create contiguous tensors by default.
if contiguous_split_chunks:
return tuple(chunk.contiguous() for chunk in tensor_list)
return tensor_list
class RotaryEmbedding(nn.Module):
def __init__(self, dim, original_impl=False, device=None, dtype=None):
super().__init__()
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2, device=device).to(dtype=dtype) / dim))
self.register_buffer("inv_freq", inv_freq)
self.dim = dim
self.original_impl = original_impl
def forward_impl(
self, seq_len: int, n_elem: int, dtype: torch.dtype, device: torch.device, base: int = 10000
):
"""Enhanced Transformer with Rotary Position Embedding.
Derived from: https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/labml_nn/
transformers/rope/__init__.py. MIT License:
https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/license.
"""
# $\Theta = {\theta_i = 10000^{\frac{2(i-1)}{d}}, i \in [1, 2, ..., \frac{d}{2}]}$
theta = 1.0 / (base ** (torch.arange(0, n_elem, 2, dtype=torch.float, device=device) / n_elem))
# Create position indexes `[0, 1, ..., seq_len - 1]`
seq_idx = torch.arange(seq_len, dtype=torch.float, device=device)
# Calculate the product of position index and $\theta_i$
idx_theta = torch.outer(seq_idx, theta).float()
cache = torch.stack([torch.cos(idx_theta), torch.sin(idx_theta)], dim=-1)
# this is to mimic the behaviour of complex32, else we will get different results
if dtype in (torch.float16, torch.bfloat16, torch.int8):
cache = cache.bfloat16() if dtype == torch.bfloat16 else cache.half()
return cache
def forward(self, max_seq_len, offset=0):
return self.forward_impl(
max_seq_len, self.dim, dtype=self.inv_freq.dtype, device=self.inv_freq.device
)
@torch.jit.script
def apply_rotary_pos_emb(x: torch.Tensor, rope_cache: torch.Tensor) -> torch.Tensor:
# x: [sq, b, np, hn]
sq, b, np, hn = x.size(0), x.size(1), x.size(2), x.size(3)
rot_dim = rope_cache.shape[-2] * 2
x, x_pass = x[..., :rot_dim], x[..., rot_dim:]
# truncate to support variable sizes
rope_cache = rope_cache[:sq]
xshaped = x.reshape(sq, -1, np, rot_dim // 2, 2)
rope_cache = rope_cache.view(sq, -1, 1, xshaped.size(3), 2)
x_out2 = torch.stack(
[
xshaped[..., 0] * rope_cache[..., 0] - xshaped[..., 1] * rope_cache[..., 1],
xshaped[..., 1] * rope_cache[..., 0] + xshaped[..., 0] * rope_cache[..., 1],
],
-1,
)
x_out2 = x_out2.flatten(3)
return torch.cat((x_out2, x_pass), dim=-1)
class RMSNorm(torch.nn.Module):
def __init__(self, normalized_shape, eps=1e-5, device=None, dtype=None, **kwargs):
super().__init__()
self.weight = torch.nn.Parameter(torch.empty(normalized_shape, device=device, dtype=dtype))
self.eps = eps
def forward(self, hidden_states: torch.Tensor):
input_dtype = hidden_states.dtype
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
return (self.weight * hidden_states).to(input_dtype)
class CoreAttention(torch.nn.Module):
def __init__(self, config: ChatGLMConfig, layer_number):
super(CoreAttention, self).__init__()
self.apply_query_key_layer_scaling = config.apply_query_key_layer_scaling
self.attention_softmax_in_fp32 = config.attention_softmax_in_fp32
if self.apply_query_key_layer_scaling:
self.attention_softmax_in_fp32 = True
self.layer_number = max(1, layer_number)
projection_size = config.kv_channels * config.num_attention_heads
# Per attention head and per partition values.
self.hidden_size_per_partition = projection_size
self.hidden_size_per_attention_head = projection_size // config.num_attention_heads
self.num_attention_heads_per_partition = config.num_attention_heads
coeff = None
self.norm_factor = math.sqrt(self.hidden_size_per_attention_head)
if self.apply_query_key_layer_scaling:
coeff = self.layer_number
self.norm_factor *= coeff
self.coeff = coeff
self.attention_dropout = torch.nn.Dropout(config.attention_dropout)
def forward(self, query_layer, key_layer, value_layer, attention_mask):
pytorch_major_version = int(torch.__version__.split('.')[0])
if pytorch_major_version >= 2:
query_layer, key_layer, value_layer = [k.permute(1, 2, 0, 3) for k in [query_layer, key_layer, value_layer]]
if attention_mask is None and query_layer.shape[2] == key_layer.shape[2]:
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
is_causal=True)
else:
if attention_mask is not None:
attention_mask = ~attention_mask
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
attention_mask)
context_layer = context_layer.permute(2, 0, 1, 3)
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
context_layer = context_layer.reshape(*new_context_layer_shape)
else:
# Raw attention scores
# [b, np, sq, sk]
output_size = (query_layer.size(1), query_layer.size(2), query_layer.size(0), key_layer.size(0))
# [sq, b, np, hn] -> [sq, b * np, hn]
query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)
# [sk, b, np, hn] -> [sk, b * np, hn]
key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)
# preallocting input tensor: [b * np, sq, sk]
matmul_input_buffer = torch.empty(
output_size[0] * output_size[1], output_size[2], output_size[3], dtype=query_layer.dtype,
device=query_layer.device
)
# Raw attention scores. [b * np, sq, sk]
matmul_result = torch.baddbmm(
matmul_input_buffer,
query_layer.transpose(0, 1), # [b * np, sq, hn]
key_layer.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]
beta=0.0,
alpha=(1.0 / self.norm_factor),
)
# change view to [b, np, sq, sk]
attention_scores = matmul_result.view(*output_size)
# ===========================
# Attention probs and dropout
# ===========================
# attention scores and attention mask [b, np, sq, sk]
if self.attention_softmax_in_fp32:
attention_scores = attention_scores.float()
if self.coeff is not None:
attention_scores = attention_scores * self.coeff
if attention_mask is None and attention_scores.shape[2] == attention_scores.shape[3]:
attention_mask = torch.ones(output_size[0], 1, output_size[2], output_size[3],
device=attention_scores.device, dtype=torch.bool)
attention_mask.tril_()
attention_mask = ~attention_mask
if attention_mask is not None:
attention_scores = attention_scores.masked_fill(attention_mask, float("-inf"))
attention_probs = F.softmax(attention_scores, dim=-1)
attention_probs = attention_probs.type_as(value_layer)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.attention_dropout(attention_probs)
# =========================
# Context layer. [sq, b, hp]
# =========================
# value_layer -> context layer.
# [sk, b, np, hn] --> [b, np, sq, hn]
# context layer shape: [b, np, sq, hn]
output_size = (value_layer.size(1), value_layer.size(2), query_layer.size(0), value_layer.size(3))
# change view [sk, b * np, hn]
value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)
# change view [b * np, sq, sk]
attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)
# matmul: [b * np, sq, hn]
context_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))
# change view [b, np, sq, hn]
context_layer = context_layer.view(*output_size)
# [b, np, sq, hn] --> [sq, b, np, hn]
context_layer = context_layer.permute(2, 0, 1, 3).contiguous()
# [sq, b, np, hn] --> [sq, b, hp]
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer
class SelfAttention(torch.nn.Module):
"""Parallel self-attention layer abstract class.
Self-attention layer takes input with size [s, b, h]
and returns output of the same size.
"""
def __init__(self, config: ChatGLMConfig, layer_number, device=None):
super(SelfAttention, self).__init__()
self.layer_number = max(1, layer_number)
self.projection_size = config.kv_channels * config.num_attention_heads
# Per attention head and per partition values.
self.hidden_size_per_attention_head = self.projection_size // config.num_attention_heads
self.num_attention_heads_per_partition = config.num_attention_heads
self.multi_query_attention = config.multi_query_attention
self.qkv_hidden_size = 3 * self.projection_size
if self.multi_query_attention:
self.num_multi_query_groups_per_partition = config.multi_query_group_num
self.qkv_hidden_size = (
self.projection_size + 2 * self.hidden_size_per_attention_head * config.multi_query_group_num
)
self.query_key_value = nn.Linear(config.hidden_size, self.qkv_hidden_size,
bias=config.add_bias_linear or config.add_qkv_bias,
device=device, **_config_to_kwargs(config)
)
self.core_attention = CoreAttention(config, self.layer_number)
# Output.
self.dense = nn.Linear(self.projection_size, config.hidden_size, bias=config.add_bias_linear,
device=device, **_config_to_kwargs(config)
)
def _allocate_memory(self, inference_max_sequence_len, batch_size, device=None, dtype=None):
if self.multi_query_attention:
num_attention_heads = self.num_multi_query_groups_per_partition
else:
num_attention_heads = self.num_attention_heads_per_partition
return torch.empty(
inference_max_sequence_len,
batch_size,
num_attention_heads,
self.hidden_size_per_attention_head,
dtype=dtype,
device=device,
)
def forward(
self, hidden_states, attention_mask, rotary_pos_emb, kv_cache=None, use_cache=True
):
# hidden_states: [sq, b, h]
# =================================================
# Pre-allocate memory for key-values for inference.
# =================================================
# =====================
# Query, Key, and Value
# =====================
# Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
mixed_x_layer = self.query_key_value(hidden_states)
if self.multi_query_attention:
(query_layer, key_layer, value_layer) = mixed_x_layer.split(
[
self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
],
dim=-1,
)
query_layer = query_layer.view(
query_layer.size()[:-1] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
)
key_layer = key_layer.view(
key_layer.size()[:-1] + (self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head)
)
value_layer = value_layer.view(
value_layer.size()[:-1]
+ (self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head)
)
else:
new_tensor_shape = mixed_x_layer.size()[:-1] + \
(self.num_attention_heads_per_partition,
3 * self.hidden_size_per_attention_head)
mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
# [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
(query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
# apply relative positional encoding (rotary embedding)
if rotary_pos_emb is not None:
query_layer = apply_rotary_pos_emb(query_layer, rotary_pos_emb)
key_layer = apply_rotary_pos_emb(key_layer, rotary_pos_emb)
# adjust key and value for inference
if kv_cache is not None:
cache_k, cache_v = kv_cache
key_layer = torch.cat((cache_k, key_layer), dim=0)
value_layer = torch.cat((cache_v, value_layer), dim=0)
if use_cache:
kv_cache = (key_layer, value_layer)
else:
kv_cache = None
if self.multi_query_attention:
key_layer = key_layer.unsqueeze(-2)
key_layer = key_layer.expand(
-1, -1, -1, self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition, -1
)
key_layer = key_layer.contiguous().view(
key_layer.size()[:2] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
)
value_layer = value_layer.unsqueeze(-2)
value_layer = value_layer.expand(
-1, -1, -1, self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition, -1
)
value_layer = value_layer.contiguous().view(
value_layer.size()[:2] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
)
# ==================================
# core attention computation
# ==================================
context_layer = self.core_attention(query_layer, key_layer, value_layer, attention_mask)
# =================
# Output. [sq, b, h]
# =================
output = self.dense(context_layer)
return output, kv_cache
def _config_to_kwargs(args):
common_kwargs = {
"dtype": args.torch_dtype,
}
return common_kwargs
class MLP(torch.nn.Module):
"""MLP.
MLP will take the input with h hidden state, project it to 4*h
hidden dimension, perform nonlinear transformation, and project the
state back into h hidden dimension.
"""
def __init__(self, config: ChatGLMConfig, device=None):
super(MLP, self).__init__()
self.add_bias = config.add_bias_linear
# Project to 4h. If using swiglu double the output width, see https://arxiv.org/pdf/2002.05202.pdf
self.dense_h_to_4h = nn.Linear(
config.hidden_size,
config.ffn_hidden_size * 2,
bias=self.add_bias,
device=device,
**_config_to_kwargs(config)
)
def swiglu(x):
x = torch.chunk(x, 2, dim=-1)
return F.silu(x[0]) * x[1]
self.activation_func = swiglu
# Project back to h.
self.dense_4h_to_h = nn.Linear(
config.ffn_hidden_size,
config.hidden_size,
bias=self.add_bias,
device=device,
**_config_to_kwargs(config)
)
def forward(self, hidden_states):
# [s, b, 4hp]
intermediate_parallel = self.dense_h_to_4h(hidden_states)
intermediate_parallel = self.activation_func(intermediate_parallel)
# [s, b, h]
output = self.dense_4h_to_h(intermediate_parallel)
return output
class GLMBlock(torch.nn.Module):
"""A single transformer layer.
Transformer layer takes input with size [s, b, h] and returns an
output of the same size.
"""
def __init__(self, config: ChatGLMConfig, layer_number, device=None):
super(GLMBlock, self).__init__()
self.layer_number = layer_number
self.apply_residual_connection_post_layernorm = config.apply_residual_connection_post_layernorm
self.fp32_residual_connection = config.fp32_residual_connection
LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
# Layernorm on the input data.
self.input_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
dtype=config.torch_dtype)
# Self attention.
self.self_attention = SelfAttention(config, layer_number, device=device)
self.hidden_dropout = config.hidden_dropout
# Layernorm on the attention output
self.post_attention_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
dtype=config.torch_dtype)
# MLP
self.mlp = MLP(config, device=device)
def forward(
self, hidden_states, attention_mask, rotary_pos_emb, kv_cache=None, use_cache=True,
):
# hidden_states: [s, b, h]
# Layer norm at the beginning of the transformer layer.
layernorm_output = self.input_layernorm(hidden_states)
# Self attention.
attention_output, kv_cache = self.self_attention(
layernorm_output,
attention_mask,
rotary_pos_emb,
kv_cache=kv_cache,
use_cache=use_cache
)
# Residual connection.
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = hidden_states
layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
layernorm_input = residual + layernorm_input
# Layer norm post the self attention.
layernorm_output = self.post_attention_layernorm(layernorm_input)
# MLP.
mlp_output = self.mlp(layernorm_output)
# Second residual connection.
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = layernorm_input
output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
output = residual + output
return output, kv_cache
class GLMTransformer(torch.nn.Module):
"""Transformer class."""
def __init__(self, config: ChatGLMConfig, device=None):
super(GLMTransformer, self).__init__()
self.fp32_residual_connection = config.fp32_residual_connection
self.post_layer_norm = config.post_layer_norm
# Number of layers.
self.num_layers = config.num_layers
# Transformer layers.
def build_layer(layer_number):
return GLMBlock(config, layer_number, device=device)
self.layers = torch.nn.ModuleList([build_layer(i + 1) for i in range(self.num_layers)])
if self.post_layer_norm:
LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
# Final layer norm before output.
self.final_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
dtype=config.torch_dtype)
self.gradient_checkpointing = False
def _get_layer(self, layer_number):
return self.layers[layer_number]
def forward(
self, hidden_states, attention_mask, rotary_pos_emb, kv_caches=None,
use_cache: Optional[bool] = True,
output_hidden_states: Optional[bool] = False,
):
if not kv_caches:
kv_caches = [None for _ in range(self.num_layers)]
presents = () if use_cache else None
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
all_self_attentions = None
all_hidden_states = () if output_hidden_states else None
for index in range(self.num_layers):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer = self._get_layer(index)
if self.gradient_checkpointing and self.training:
layer_ret = torch.utils.checkpoint.checkpoint(
layer,
hidden_states,
attention_mask,
rotary_pos_emb,
kv_caches[index],
use_cache
)
else:
layer_ret = layer(
hidden_states,
attention_mask,
rotary_pos_emb,
kv_cache=kv_caches[index],
use_cache=use_cache
)
hidden_states, kv_cache = layer_ret
if use_cache:
presents = presents + (kv_cache,)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
# Final layer norm.
if self.post_layer_norm:
hidden_states = self.final_layernorm(hidden_states)
return hidden_states, presents, all_hidden_states, all_self_attentions
class ChatGLMPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and
a simple interface for downloading and loading pretrained models.
"""
is_parallelizable = False
supports_gradient_checkpointing = True
config_class = ChatGLMConfig
base_model_prefix = "transformer"
_no_split_modules = ["GLMBlock"]
def _init_weights(self, module: nn.Module):
"""Initialize the weights."""
return
def get_masks(self, input_ids, past_key_values, padding_mask=None):
batch_size, seq_length = input_ids.shape
full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
full_attention_mask.tril_()
past_length = 0
if past_key_values:
past_length = past_key_values[0][0].shape[0]
if past_length:
full_attention_mask = torch.cat((torch.ones(batch_size, seq_length, past_length,
device=input_ids.device), full_attention_mask), dim=-1)
if padding_mask is not None:
full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
if not past_length and padding_mask is not None:
full_attention_mask -= padding_mask.unsqueeze(-1) - 1
full_attention_mask = (full_attention_mask < 0.5).bool()
full_attention_mask.unsqueeze_(1)
return full_attention_mask
def get_position_ids(self, input_ids, device):
batch_size, seq_length = input_ids.shape
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
return position_ids
def _set_gradient_checkpointing(self, module, value=False):
if isinstance(module, GLMTransformer):
module.gradient_checkpointing = value
class Embedding(torch.nn.Module):
"""Language model embeddings."""
def __init__(self, config: ChatGLMConfig, device=None):
super(Embedding, self).__init__()
self.hidden_size = config.hidden_size
# Word embeddings (parallel).
self.word_embeddings = nn.Embedding(
config.padded_vocab_size,
self.hidden_size,
dtype=config.torch_dtype,
device=device
)
self.fp32_residual_connection = config.fp32_residual_connection
def forward(self, input_ids):
# Embeddings.
words_embeddings = self.word_embeddings(input_ids)
embeddings = words_embeddings
# Data format change to avoid explicit tranposes : [b s h] --> [s b h].
embeddings = embeddings.transpose(0, 1).contiguous()
# If the input flag for fp32 residual connection is set, convert for float.
if self.fp32_residual_connection:
embeddings = embeddings.float()
return embeddings
class ChatGLMModel(ChatGLMPreTrainedModel):
def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
super().__init__(config)
if empty_init:
init_method = skip_init
else:
init_method = default_init
init_kwargs = {}
if device is not None:
init_kwargs["device"] = device
self.embedding = init_method(Embedding, config, **init_kwargs)
self.num_layers = config.num_layers
self.multi_query_group_num = config.multi_query_group_num
self.kv_channels = config.kv_channels
# Rotary positional embeddings
self.seq_length = config.seq_length
rotary_dim = (
config.hidden_size // config.num_attention_heads if config.kv_channels is None else config.kv_channels
)
self.rotary_pos_emb = RotaryEmbedding(rotary_dim // 2, original_impl=config.original_rope, device=device,
dtype=config.torch_dtype)
self.encoder = init_method(GLMTransformer, config, **init_kwargs)
self.output_layer = init_method(nn.Linear, config.hidden_size, config.padded_vocab_size, bias=False,
dtype=config.torch_dtype, **init_kwargs)
self.pre_seq_len = config.pre_seq_len
self.prefix_projection = config.prefix_projection
if self.pre_seq_len is not None:
for param in self.parameters():
param.requires_grad = False
self.prefix_tokens = torch.arange(self.pre_seq_len).long()
self.prefix_encoder = PrefixEncoder(config)
self.dropout = torch.nn.Dropout(0.1)
def get_input_embeddings(self):
return self.embedding.word_embeddings
def get_prompt(self, batch_size, device, dtype=torch.half):
prefix_tokens = self.prefix_tokens.unsqueeze(0).expand(batch_size, -1).to(device)
past_key_values = self.prefix_encoder(prefix_tokens).type(dtype)
past_key_values = past_key_values.view(
batch_size,
self.pre_seq_len,
self.num_layers * 2,
self.multi_query_group_num,
self.kv_channels
)
# seq_len, b, nh, hidden_size
past_key_values = self.dropout(past_key_values)
past_key_values = past_key_values.permute([2, 1, 0, 3, 4]).split(2)
return past_key_values
def forward(
self,
input_ids,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.BoolTensor] = None,
full_attention_mask: Optional[torch.BoolTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
batch_size, seq_length = input_ids.shape
if inputs_embeds is None:
inputs_embeds = self.embedding(input_ids)
if self.pre_seq_len is not None:
if past_key_values is None:
past_key_values = self.get_prompt(batch_size=batch_size, device=input_ids.device,
dtype=inputs_embeds.dtype)
if attention_mask is not None:
attention_mask = torch.cat([attention_mask.new_ones((batch_size, self.pre_seq_len)),
attention_mask], dim=-1)
if full_attention_mask is None:
if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
# Rotary positional embeddings
rotary_pos_emb = self.rotary_pos_emb(self.seq_length)
if position_ids is not None:
rotary_pos_emb = rotary_pos_emb[position_ids]
else:
rotary_pos_emb = rotary_pos_emb[None, :seq_length]
rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
# Run encoder.
hidden_states, presents, all_hidden_states, all_self_attentions = self.encoder(
inputs_embeds, full_attention_mask, rotary_pos_emb=rotary_pos_emb,
kv_caches=past_key_values, use_cache=use_cache, output_hidden_states=output_hidden_states
)
if not return_dict:
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutputWithPast(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
def quantize(self, weight_bit_width: int):
from .quantization import quantize
quantize(self.encoder, weight_bit_width)
return self
class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
super().__init__(config)
self.max_sequence_length = config.max_length
self.transformer = ChatGLMModel(config, empty_init=empty_init, device=device)
self.config = config
self.quantized = False
if self.config.quantization_bit:
self.quantize(self.config.quantization_bit, empty_init=True)
def _update_model_kwargs_for_generation(
self,
outputs: ModelOutput,
model_kwargs: Dict[str, Any],
is_encoder_decoder: bool = False,
standardize_cache_format: bool = False,
) -> Dict[str, Any]:
# update past_key_values
model_kwargs["past_key_values"] = self._extract_past_from_model_output(
outputs, standardize_cache_format=standardize_cache_format
)
# update attention mask
if "attention_mask" in model_kwargs:
attention_mask = model_kwargs["attention_mask"]
model_kwargs["attention_mask"] = torch.cat(
[attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1
)
# update position ids
if "position_ids" in model_kwargs:
position_ids = model_kwargs["position_ids"]
new_position_id = position_ids[..., -1:].clone()
new_position_id += 1
model_kwargs["position_ids"] = torch.cat(
[position_ids, new_position_id], dim=-1
)
model_kwargs["is_first_forward"] = False
return model_kwargs
def prepare_inputs_for_generation(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
is_first_forward: bool = True,
**kwargs
) -> dict:
# only last token for input_ids if past is not None
if position_ids is None:
position_ids = self.get_position_ids(input_ids, device=input_ids.device)
if not is_first_forward:
if past_key_values is not None:
position_ids = position_ids[..., -1:]
input_ids = input_ids[:, -1:]
return {
"input_ids": input_ids,
"past_key_values": past_key_values,
"position_ids": position_ids,
"attention_mask": attention_mask,
"return_last_logit": True,
"use_cache": use_cache
}
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
return_last_logit: Optional[bool] = False,
):
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
transformer_outputs = self.transformer(
input_ids=input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
if return_last_logit:
hidden_states = hidden_states[-1:]
lm_logits = self.transformer.output_layer(hidden_states)
lm_logits = lm_logits.transpose(0, 1).contiguous()
loss = None
if labels is not None:
lm_logits = lm_logits.to(torch.float32)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss(ignore_index=-100)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
lm_logits = lm_logits.to(hidden_states.dtype)
loss = loss.to(hidden_states.dtype)
if not return_dict:
output = (lm_logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return CausalLMOutputWithPast(
loss=loss,
logits=lm_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
@staticmethod
def _reorder_cache(
past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], beam_idx: torch.LongTensor
) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
"""
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
beam_idx at every generation step.
Output shares the same memory storage as `past`.
"""
return tuple(
(
layer_past[0].index_select(1, beam_idx.to(layer_past[0].device)),
layer_past[1].index_select(1, beam_idx.to(layer_past[1].device)),
)
for layer_past in past
)
def process_response(self, output, history):
content = ""
history = deepcopy(history)
for response in output.split("<|assistant|>"):
metadata, content = response.split("\n", maxsplit=1)
if not metadata.strip():
content = content.strip()
history.append({"role": "assistant", "metadata": metadata, "content": content})
content = content.replace("[[训练时间]]", "2023年")
else:
history.append({"role": "assistant", "metadata": metadata, "content": content})
if history[0]["role"] == "system" and "tools" in history[0]:
content = "\n".join(content.split("\n")[1:-1])
def tool_call(**kwargs):
return kwargs
parameters = eval(content)
content = {"name": metadata.strip(), "parameters": parameters}
else:
content = {"name": metadata.strip(), "content": content}
return content, history
@torch.inference_mode()
def chat(self, tokenizer, query: str, history: List[Dict] = None, role: str = "user",
max_length: int = 8192, num_beams=1, do_sample=True, top_p=0.8, temperature=0.8, logits_processor=None,
**kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
logits_processor.append(InvalidScoreLogitsProcessor())
gen_kwargs = {"max_length": max_length, "num_beams": num_beams, "do_sample": do_sample, "top_p": top_p,
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
inputs = tokenizer.build_chat_input(query, history=history, role=role)
inputs = inputs.to(self.device)
eos_token_id = [tokenizer.eos_token_id, tokenizer.get_command("<|user|>"),
tokenizer.get_command("<|observation|>")]
outputs = self.generate(**inputs, **gen_kwargs, eos_token_id=eos_token_id)
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):-1]
response = tokenizer.decode(outputs)
history.append({"role": role, "content": query})
response, history = self.process_response(response, history)
return response, history
@torch.inference_mode()
def stream_chat(self, tokenizer, query: str, history: List[Dict] = None, role: str = "user",
past_key_values=None,max_length: int = 8192, do_sample=True, top_p=0.8, temperature=0.8,
logits_processor=None, return_past_key_values=False, **kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
logits_processor.append(InvalidScoreLogitsProcessor())
eos_token_id = [tokenizer.eos_token_id, tokenizer.get_command("<|user|>"),
tokenizer.get_command("<|observation|>")]
gen_kwargs = {"max_length": max_length, "do_sample": do_sample, "top_p": top_p,
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
if past_key_values is None:
inputs = tokenizer.build_chat_input(query, history=history, role=role)
else:
inputs = tokenizer.build_chat_input(query, role=role)
inputs = inputs.to(self.device)
if past_key_values is not None:
past_length = past_key_values[0][0].shape[0]
if self.transformer.pre_seq_len is not None:
past_length -= self.transformer.pre_seq_len
inputs.position_ids += past_length
attention_mask = inputs.attention_mask
attention_mask = torch.cat((attention_mask.new_ones(1, past_length), attention_mask), dim=1)
inputs['attention_mask'] = attention_mask
history.append({"role": role, "content": query})
for outputs in self.stream_generate(**inputs, past_key_values=past_key_values,
eos_token_id=eos_token_id, return_past_key_values=return_past_key_values,
**gen_kwargs):
if return_past_key_values:
outputs, past_key_values = outputs
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):-1]
response = tokenizer.decode(outputs)
if response and response[-1] != "�":
response, new_history = self.process_response(response, history)
if return_past_key_values:
yield response, new_history, past_key_values
else:
yield response, new_history
@torch.inference_mode()
def stream_generate(
self,
input_ids,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
return_past_key_values=False,
**kwargs,
):
batch_size, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
if generation_config is None:
generation_config = self.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs)
model_kwargs["use_cache"] = generation_config.use_cache
bos_token_id, eos_token_id = generation_config.bos_token_id, generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None:
warnings.warn(
f"Using `max_length`'s default ({generation_config.max_length}) to control the generation length. "
"This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we"
" recommend using `max_new_tokens` to control the maximum length of the generation.",
UserWarning,
)
elif generation_config.max_new_tokens is not None:
generation_config.max_length = generation_config.max_new_tokens + input_ids_seq_length
if not has_default_max_length:
logger.warn(
f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
"Please refer to the documentation for more information. "
"(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)",
UserWarning,
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"
logger.warning(
f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
" increasing `max_new_tokens`."
)
# 2. Set generation parameters if not already defined
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
logits_processor = self._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
encoder_input_ids=input_ids,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
)
stopping_criteria = self._get_stopping_criteria(
generation_config=generation_config, stopping_criteria=stopping_criteria
)
logits_warper = self._get_logits_warper(generation_config)
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
scores = None
while True:
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=False,
output_hidden_states=False,
)
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_scores = logits_warper(input_ids, next_token_scores)
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
if generation_config.do_sample:
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:
next_tokens = torch.argmax(probs, dim=-1)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
unfinished_sequences = unfinished_sequences.mul(
next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
)
if return_past_key_values:
yield input_ids, outputs.past_key_values
else:
yield input_ids
# stop when each sentence is finished, or if we exceed the maximum length
if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
break
def quantize(self, bits: int, empty_init=False, device=None, **kwargs):
if bits == 0:
return
from .quantization import quantize
if self.quantized:
logger.info("Already quantized.")
return self
self.quantized = True
self.config.quantization_bit = bits
self.transformer.encoder = quantize(self.transformer.encoder, bits, empty_init=empty_init, device=device,
**kwargs)
return self
class ChatGLMForSequenceClassification(ChatGLMPreTrainedModel):
def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
super().__init__(config)
self.num_labels = config.num_labels
self.transformer = ChatGLMModel(config, empty_init=empty_init, device=device)
self.classifier_head = nn.Linear(config.hidden_size, config.num_labels, bias=True, dtype=torch.half)
if config.classifier_dropout is not None:
self.dropout = nn.Dropout(config.classifier_dropout)
else:
self.dropout = None
self.config = config
if self.config.quantization_bit:
self.quantize(self.config.quantization_bit, empty_init=True)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
full_attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
inputs_embeds: Optional[torch.LongTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor, ...], SequenceClassifierOutputWithPast]:
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
transformer_outputs = self.transformer(
input_ids=input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
full_attention_mask=full_attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
pooled_hidden_states = hidden_states[-1]
if self.dropout is not None:
pooled_hidden_states = self.dropout(pooled_hidden_states)
logits = self.classifier_head(pooled_hidden_states)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze().float(), labels.squeeze())
else:
loss = loss_fct(logits.float(), labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels).float(), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits.float(), labels.view(-1, self.num_labels))
if not return_dict:
output = (logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutputWithPast(
loss=loss,
logits=logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
其它
量化 quantization.py
【2024-1-16】GLM-4
【2024-1-16】智谱AI举办首届技术开放日(Zhipu DevDay),正式发布新一代基座大模型GLM-4。
GLM-4 最大的亮点:
- 多模态能力:推出了CogView3代,效果超过开源SD模型,逼近 DALLE-3。
- All Tools能力:GLM-4能自主理解复杂指令,自由调用WebGLM搜索增强、Code Interpreter代码解释器和多模态生成能力,完成复杂任务。
- GLMs个性化智能体定制:用户可以通过智谱清言官方网站创建属于自己的GLM智能体,无需编程基础。
- MaaS平台和API:GLM-4登陆了Maas平台,提供API访问,支持开发者内测Assistant API。
GLM-4的整体性能相比上一代大幅提升,逼近GPT-4。它可以支持更长的上下文,具备更强的多模态能力。同时,它的推理速度更快,支持更高的并发,大大降低推理成本。
GLM-4 性能已经超过 Claude 2.1,直接逼近 GPT 4
- GLM-4 在 MMLU(81.5)达到 GPT-4 94% 水平,GSM8K(87.6) 达到 GPT-4 95% 水平,MATH(47.9)达到 GPT-4 91% 水平,BBH (82.25) 达到 GPT-4 99% 水平,HellaSwag (85.4) 达到 GPT-4 90% 水平,HumanEval(72)达到 GPT-4 100% 水平。
- 指令跟随方面,GLM-4 也实现了媲美 GPT-4 的水准。根据指令跟随评估基准 IFEval 的结果,GLM-4 在 Prompt 提示词跟随(中文)方面达到了 GPT-4 88% 的水平;在指令跟随(中文)方面,达到了 GPT-4 90% 的水平。
- 公开数据集 AlignBench 的评估结果,GLM-4 超过了 GPT-4 在 6 月 13 日发布的版本,逼近 GPT-4 最新(11 月 6 日版本)效果,在专业能力、中文理解、角色扮演方面超过了最新 GPT-4 的精度,唯一有待提升的是 GLM-4 在中文推理方面的能力。
GLM-4 All Tools 实现自主根据用户意图,自动理解、规划复杂指令,自由调用网页浏览器、Code Interpreter代码解释器等以完成复杂任务。


代码解释器
网页浏览

Function Call
- 根据⽤户提供的function描述,⾃动选择所需function并⽣成参数,以及根据function的返回值⽣成回复
CogView: 首个中文全领域文生图预训练模型
- Diffusion模型训练时不太稳定,智谱提出了中继扩散模型, 图像质量更高



评测

VisualGLM-6B 首个中文开源多模态对话模型


CogVLM 全新视觉专家结构,显著超越其他开源模型
- 增加 Cross-Attention高分辨率结构,认清GUI每个文字和图标
CogAgent成为开源榜首

1~2年内,多模态模型的视觉理解能力会超过人类
编码模型CodeGeeX




GLMs 个性化智能体定制功能亦同时上线,用户用简单的提示词指令就能创建属于自己的 GLM 智能体。
资料
【2025-7-28】GLM-4.5
【2025-7-28】智谱发布了其最新一代旗舰模型GLM-4.5
GLM-4.5 融合了推理、编程和智能体能力 (ARC),并在上述场景的12项基准测试中,综合性能取得了发布之际的全球开源模型SOTA(即排名第一)、国产模型第一、全球模型第三的成绩,发布后不到48小时,便登顶开源平台Hugging Face趋势榜第一。
当晚还开源GLM-4.5系列的新模型,名为GLM-4.5V,或为一款视觉模型。
训练方法
GLM-4.5 借鉴了部分DeepSeek-V3架构,但缩小了模型的宽度,增加了模型深度,从而提升模型的推理能力。
- 传统预训练和后训练之外,智谱引入了中期训练,并在这一阶段提升了模型在理解代码仓库、推理、长上下文与智能体3个场景的性能。
- 后训练阶段,GLM-4.5 进行了有监督微调与强化学习,其强化学习针对推理、智能体和通用场景分别进行了训练,还使用了智谱自研并开源的基础设施框架Slime,进一步提升了强化学习的效率。 在多项基准测试中,GLM-4.5与DeepSeek-R1-0528、Kimi K2、OpenAI o3、Claude 4 Sonnet等头部开闭源模型处于同一梯队,并在部分测试中取得了SOTA。
从知识库到求解器,“ARC”成新一代模型重要能力
GLM-4.5 提出,大模型正逐渐从“通用知识库”的角色,迅速向“通用问题求解器”演进,目标是实现通用人工智能(AGI)。不仅要在单一任务中做到最好,还要像人类一样具备复杂问题求解、泛化能力和自我提升能力等。
智谱提出了三项关键且相互关联的能力:Agentic能力(与外部工具及现实世界交互的能力)、复杂推理能力(解决数学、科学等领域多步骤问题的能力)、以及高级编程能力(应对真实世界软件工程任务的能力),并将其统称为ARC。
SFT过程中,GLM-4.5 采用了几种方式提升训练效果:
- (1)减少函数调用模板中的字符转义:针对函数调用参数中代码大量转义带来的学习负担,提出用XML风格特殊标记包裹键值的新模板,大幅降低转义需求,同时保持函数调用性能不变。
- (2)拒绝采样(Rejection Sampling):设计了多阶段过滤流程,去除重复、无效或格式不符的样本,验证客观答案正确性,利用奖励模型筛选主观回答,并确保工具调用场景符合规范且轨迹完整。
- (3)提示选择与回复长度调整:通过剔除较短的提示样本,提升数学和科学任务表现2%-4%;对难度较高的提示词进行回复长度的调整,并生成多条回复,进一步带来1%-2%的性能提升。
- (4)自动构建智能体SFT数据:包括收集智能体框架和工具、自动合成单步及多步工具调用任务、生成工具调用轨迹并转换为多轮对话,以及通过多评判代理筛选保留高质量任务轨迹,确保训练数据的多样性与实用性。
SFT之后,GLM-4.5 又进行强化学习训练。推理强化学习(Reasoning RL)重点针对数学、代码和科学等可验证领域,采用了难度分级的课程学习。因为早期训练时,模型能力较弱,过难数据则会导致奖励全为0,无法有效从数据中学习。分级学习后,模型学习效率得到了提升。
训练数据
GLM-4.5 预训练数据主要包含网页、多语言数据、代码、数学与科学等领域,并使用多种方法评估了数据质量,并对高质量的数据进行上采样(Up-Sampling),即增加这部分数据在训练集中的出现频率。
例如,代码数据收集自GitHub和其他代码托管平台,先进行基于规则的初步过滤,再使用针对不同编程语言的质量模型,将数据分为高/中/低质量,上采样高质量、剔除低质量,源代码数据使用Fill-In-the-Middle目标训练,能让模型获得更好地代码补全能力。
对于代码相关的网页,GLM-4.5采用通过双阶段检索与质量评估筛选,并用细粒度解析器保留格式与内容。
模型架构
模型架构方面,GLM-4.5 系列参考DeepSeek-V3,采用了MoE(混合专家)架构,从而提升了训练和推理的计算效率。
对于MoE层,GLM-4.5引入了无损平衡路由(loss-free balance routing)和sigmoid门控机制。同时,GLM-4.5系列还拥有更小的模型宽度(隐藏维度和路由专家数量),更大的模型深度,这种调整能提升模型的推理能力。
在自注意力模块中,GLM-4.5系列采用了分组查询注意力(Grouped-Query Attention)并结合部分RoPE(旋转位置编码)。智谱将注意力头的数量提升到原来的2.5倍(96个注意力头)。有趣的是,虽然增加注意力头数量并未带来比少头模型更低的训练损失,但模型在MMLU和BBH等推理类基准测试上的表现得到提升。
GLM-4.5还使用了QK-Norm技术,用于稳定注意力logits的取值范围,可以防止注意力过度集中或过于分散,改善模型在长序列或复杂任务上的表现。同时,GLM-4.5系列均在 MTP(多Token预测)层中加入了一个MoE层,以支持推理阶段的推测式解码,提升推理速度和质量。
预训练完成后,GLM-4.5还经历了“中期训练”阶段,采用中等规模的领域特定数据集,主要在3个场景提升模型性能:
- (1)仓库级代码训练:通过拼接同一仓库的多个代码文件及相关开发记录,帮助模型理解跨文件依赖和软件工程实际场景,提升代码理解与生成能力,同时通过加长序列支持大型项目。
- (2)合成推理数据训练:利用数学、科学和编程竞赛题目及答案,结合推理模型合成推理过程数据,增强模型的复杂逻辑推理和问题解决能力。
- (3)长上下文与智能体训练:通过扩展序列长度和上采样长文档,加强模型对超长文本的理解与生成能力,并加入智能体轨迹数据,提升模型在交互和多步决策任务中的表现。
【2025-8-11】GLM-4.5V
2025年8月11日,智谱开源多模态视觉推理模型GLM-4.5V,1060 亿总参数、120 亿激活参数的 VLM(Vision-Language Model,视觉-语言模型)
- 更多技术细节,GLM-4.5V技术报告
- 解读
GLM-4.5V基于智谱新一代旗舰文本基座模型GLM-4.5-Air,沿用 GLM-4.1V-Thinking 结构。
由视觉编码器、MLP 适配器和语言解码器三部分组成,支持64K多模态长上下文。
- 1️⃣ 视觉编码器采用AIMv2-Huge,支持图像与视频输入,并通过三维卷积提升视频处理效率。
- 2️⃣ 模型引入三维旋转位置编码(3D-RoPE)和双三次插值机制,增强了对高分辨率和极端宽高比图像的适应性。
- 3️⃣ 语言解码器中的位置编码扩展为3D 形式(3D-RoPE),进一步提升了多模态空间理解能力。
训练流程上,经过多重优化,提升多模态能力,具体经过三个阶段:预训练、监督微调(SFT)和强化学习(RL)。
- 1️⃣ 预训练阶段,结合大规模图文交错多模态语料和长上下文内容,强化了模型对复杂图文及视频的处理能力
- 2️⃣ SFT阶段,引入了显式「思维链」格式训练样本,增强了GLM-4.5V的因果推理与多模态理解能力;
- 3️⃣ RL阶段,引入全领域多模态课程强化学习,通过构建多领域奖励系统(Reward System),结合可验证奖励强化学习(RLVR)与基于人类反馈的强化学习(RLHF),GLM-4.5V在STEM问题、多模态定位、Agent任务等方面获得全面优化。
GLM-4.5V 实现全场景视觉推理覆盖:
- 图像推理(场景理解、复杂多图分析、位置识别)
- 视频理解(长视频分镜分析、事件识别)
- GUI任务(屏幕读取、图标识别、桌面操作辅助)
- 复杂图表与长文档解析(研报分析、信息提取)
- Grounding能力(精准定位视觉元素)
在涵盖图像、视频、文档理解、Grounding、地图定位、空间关系推理、UI转Code等多项能力的42个公开榜单中,41项夺得SOTA。
【2026-4-7】GLM-5.1
2026年4月7日,智谱发布新模型 GLM-5.1,一款开源模型
- huggingface GLM-5.1
- 解读 开源模型首超Opus4.6!智谱GLM-5.1登场,14小时后CUDA专家被冲了
效果
在 SWE-Bench Pro 上斩获58.4分,荣登总榜第一。超过 GPT-5.4, Claude Opus 4.6, Qwen 3.6-Plus, MiniMax M2.7等
手感和 Opus一模一样,使用额度是Claude Code的3倍,成本却只有1/3。
原理
核心源于三个维度的系统性技术突破:
- 第一,更强的长程规划与目标保持能力。
- 把一个复杂的大目标,拆解为可执行的多阶段计划,并且在长达十几小时、上千步的执行链路中,始终围绕最终交付目标推进。简单来说,就是干到第十步,还记得第二步定的规矩。
- 第二,更稳的自适应纠错与持续执行能力。
- 实现了代码编写、工具调用、环境调试、API对接等多个环节的稳定衔接,中途出错时,不会停下来等人工介入,而是会自主查看错误日志、定位问题根源、修复bug,甚至自己写回归测试用例验证修复效果。
- 第三,更好的状态延续与上下文整合能力。
- 面对长时间跨度、多轮反馈和百万级token的上下文信息,它能稳定追踪已完成的工作、当前所处的阶段和下一步的核心动作,持续整合新的信息,保持整个执行链路的一致性。
【2026-6-16】GLM-5.2
【2026-6-16】智谱在 GLM-5.2 强化学习里又用上了PPO
- 对长程任务来说,GRPO credit-assignment 颗粒度过粗可能确实会影响效果,不同rollout长度差异显著可能也会影响GRPO的效果。
官方 GLM-5.2: Built for Long-Horizon Tasks:章节 RL for Long-Horizon Task with Anti-hacking
- GLM-5.2 模型,长时序任务会生成长度大幅增加的执行轨迹。当一条超长完整轨迹经过压缩拆分,被切分为多条子轨迹后,同一提示词下生成的不同采样样本,会产出数量不等、长度差异极大的可训练子轨迹。
- 因此放弃分组式优化方案(GRPO系列),改用基于价值网络(Critic)的 PPO 框架,以单条采样轨迹为单位进行学习;依靠价值网络逐 token 估算优势值,不再依赖组内相对对比计算优势。
- 这种单轨迹训练范式可天然适配轨迹压缩机制:不对单条提示词产出的子轨迹数量、各子轨迹的相对长度做任何约束。将全部压缩后的子轨迹纳入训练集作为可学习轨迹,并采用逐 token 损失函数,解决子轨迹之间长度不均衡的问题。
关键词:专门为“长程任务能力”而来。
- 直接把几个核心能力一起拉满:1M 超长上下文(扩展训练环境)、Coding 能力提升(引入思考档位 effort level)、国产算力适配,采用 MIT license 开源。
- 代码能力和长程任务评测里,已经进入开源模型中的领先梯队,已在Day 0完成了9家国产算力平台的适配,在国产芯片集群上实现了高吞吐、低延迟、大并发的稳定运行。
特点: GLM-5.2 744B*A40B
- 沿用 7440 亿参数稀疏 MoE主干网络,仅40B 参数参与推理,激活率 5.4%,运行效率拉满。
- 融合 MLA 多头潜在注意力+ DSA 稀疏注意力,搭配独创 IndexShare 索引共享技术,1048576token 百万级上下文推理成本大幅降低。
- 78 层统一架构设计,KV 缓存优化出色,综合智能指数表现亮眼,代码能力尤为突出。
模型架构和推理层面,GLM-5.2 关键设计——IndexShare。
- 在每四层稀疏注意力层之间,共享同一个索引器。
- 直接效果:在 1M 超长上下文下,单位 token 的 FLOPs 降到了 2.9 倍,同时还优化了 MTP 层,让投机解码效率更高。
扩展训练环境,使GLM-5.2实现了 1M 无损长上下文能力,可以更稳定地处理复杂的、长链路的开发任务,整体交付能力更强了。
代码编写的“手感”上也有明显提升,对工程级规范的遵循更加严格。GLM-5.2 引入 effort level(思考档位),可以在能力、速度和成本之间实现动态平衡。
效果
- Artificial Analysis 综合榜单,GLM-5.2 和 Anthropic、OpenAI 一起位居前三,并且成为全球开源模型的SOTA。
- Code Arena 百万用户参与的前端开发盲测系统里,拿到全球可用模型第一,仅次于 Claude Fable 5
- FrontierSWE、Terminal-Bench 等长程任务评测中,也都有不错表现,和国际领先模型之间的差距进一步缩小。
工具使用
【2024-10-26】智谱AI新推“自主智能体”,“Her”梦想照进现实
智谱AI近日迈出重要一步,推出了自主智能体 AutoGLM 及 情感语音模型 GLM-4-Voice,进一步逼近OpenAI的技术前沿。
AutoGLM 介绍
AutoGLM 作为智谱AI的最新成果,能够模拟用户在手机和网页上的操作,实现线上点餐、整理社交媒体内容、总结论文等多种功能。该智能体已适配多款知名应用,覆盖日常生活多个方面。
智谱AI在推进大模型落地AI手机方面亦取得进展,已与高通、三星、荣耀等手机厂商达成合作,共同探索AI智能体的应用。这一合作将有助于推动AI手机市场的发展,为智谱AI带来新的商业化机遇。
【2025-3-31】AutoGLM 沉思
AutoGLM沉思:边想边干 2025年3月31日,智谱推出革命性AI智能体——AutoGLM沉思。
智谱自主研发的全栈大模型技术,融合了GLM-4的通用能力、GLM-Z1的反思能力、GLM-Z1-Rumination的沉思能力,以及AutoGLM的自动执行能力。
通过自进化强化学习方式,智谱基于GLM-Z1模型训练了一个新的沉思模型,能够实时联网搜索、动态调用工具,进行深度分析和自我验证。这个模型使AutoGLM沉思能够像人类一样思考和行动,自主完成复杂任务。
AutoGLM沉思已经开始踏入L4,有望在更多领域发挥重要作用,为用户带来更智能、更高效的服务体验。
功能
【功能】
- 这款产品不仅能理解和回答复杂问题,还能自主执行操作,”边想边干”,如网络搜索、浏览网页、填写表格等。
关键特性:
- 深度研究能力:AutoGLM沉思能够像人类一样进行多步骤的深度思考,自主完成从数据检索到生成报告的全过程。
- 自主操作能力:它能够模拟人类的思维过程,自主浏览和操作网页,无需人工干预。
- 持续学习能力:通过自进化强化学习方式,AutoGLM沉思能够不断优化自己的性能和准确性。
产品
多平台支持
AutoGLM沉思支持多种平台和设备,方便用户随时随地使用:
- 桌面客户端:用户可以下载并安装智谱清言桌面客户端,支持Mac和Windows系统。
- 浏览器插件:当前仅支持在最新版本的Chrome浏览器中安装智谱清言浏览器插件(AutoGLM Web)。
- 智能体界面:用户可以通过浏览器访问AutoGLM沉思智能体界面,发起指令。
操作流程
使用AutoGLM沉思的流程非常简单:
- 安装客户端或插件:根据自己的设备和偏好,选择合适的安装方式。
- 发起指令:在智能体界面中输入需要解决的问题或任务。
- 等待结果:AI智能体会自主完成数据检索、分析和报告生成,并将结果反馈给用户。
技术原理
技术演进
AutoGLM沉思技术演进路径清晰而系统,经历了从基础模型到智能体的逐步发展:
- 1️⃣ GLM-4基座模型:作为基础,提供了通用的语言理解和生成能力。
- 2️⃣ GLM-Z1推理模型:增强了推理能力,使模型能够更好地理解和分析复杂问题。
- 3️⃣ GLM-Z1-Rumination 沉思模型:添加了”沉思”能力,使模型能够自主理解用户需求,进行深度研究和反思。
- 4️⃣ AutoGLM 模型:最终的智能体模型,集成了深度研究和操作执行能力,能够”边想边干”。 核心链路模型和技术将于4月14日正式发布。
国内首款集深度研究和操作能力于一体的免费AI Agent,AutoGLM沉思代表了AI技术在自主智能领域的重要突破。
AutoGLM 2.0
详见站内专题 GUI Agent
多模态
真正的智能一定是多模态,听觉、视觉、触觉等共同参与了人脑认知能力的形成
因此,希望包括文字、图像、语音和视觉等模态在内的智谱多模态大模型矩阵,能够进一步提高大模型的应用和工具能力。
GLM 模型家族逐步从文字拓展至图片、视频、声音,以及音效。
随着音效模型的加入,GLM 大模型在声音模态领域实现了人声、音效、音乐多链路布局,基于图像、视频和声音的多模态模型矩阵由此更加完整,意味着在多模态和工具两个维度上都朝着 AGI 的目标迈出了一小步。
【The Journey】
- 视频生成 —— CogVideoX
- 音效生成 —— CogSound
- 人物旁白 —— GLM-4-Voice
视频
视频理解
智谱 GLM-4V-Plus 大模型具备时间感知能力,能理解并分析一段视频文件。
- 看完一段篮球比赛视频后,询问 “绿衣服的球员在做什么,这个视频的精彩时刻发生在第几秒?”
- AI会给出精确回答“绿衣球员在场上运球投篮,精彩时刻在第4秒,球员跳起并将球投入篮筐。”
【2024-8-30】通过摄像头“现场解说” 记者实测国内首个C端视频通话AI应用
2024年5月,OpenAI展示了接入GPT-4o的ChatGPT语音助手可以识别人类情绪、进行音视频交互的能力。
- 但 GPT-4o 高级语音模式(advanced voice)仍只面向少数的 ChatGPT Plus 用户开放;
- GPT-4o 也只解禁了语音模式,摄像头仍没有连通。
- 让人想起来 2024年4月推出的Sora, 雷声大,雨点小,几个月过去了,迟迟不露面
2024年8月29日晚,智谱GLM团队推出新一代基座大模型 GLM-4-Plus,同时智谱清言APP迎来重要更新:视频通话功能。
所以
- 客气的说,智谱是国内首个正式开放同款功能的大模型厂商
- 不客气的说,世界上首个可以通过文本、音频、视频和图像来进行多模态互动的 AI 助手
探索世界模型的路上,跨模态非常重要,智谱正在践行着这一点,将 AGI 每块拼图逐渐拼凑起来
本次智谱上线的GLM-4-Plus对标GPT-4o,视频演示时和 OpenAI 一样,也采取了两男一女三个测试人员在沙发上,使用手机和智谱清言APP进行交互的展示方式。
视频理解
- 测试人员拿出一张纸,画了一个蛇的简笔画,又加上了几只“脚”。
- AI随即表示这可能表示的是“画蛇添足”这个成语。
长文本识别理解
- 将摄像头对准余秋雨的所著的《文化苦旅》中“白发苏州”这一小节时,AI立刻总结出内容,“这段文字在赞颂苏州,说它历史悠久,有园林和古建筑,让人感受到宁静和历史的魅力,作者觉得苏州像是中国历史上的散文。”
内测
- 点击智谱清言APP交互界面右下角的小电话图标,再点击视频通话发起。
功能特别适合盲人出行,因为当打开智谱清言APP的该功能后举起手机出门,AI就可以描述路上看到的一切事物:
- “这是一个建筑物的入口(实际为出口),路边有美丽的花,旁边有信箱。”
- 如果手指某个事物并直接提问,AI 回答,“你指的是一组绿色储物柜,上面有黄色的标识写着丰巢,是快递存放的地方。”
- 反转摄像头照向自己,AI也给出了评价,“你的头发非常凌乱,好像刚刚起床,你穿着一件粉色的T恤,上面有白色的字。”
不足
- 和 GTP-4o在测试视频中表现出的“毫秒级”反应相比,智谱反应速度略慢,在交互中有时需要等待它的回答,而且如果记者打断它的回复,可能会出现重复同一句话的情况,还做不到和真人对话一样自然。
【2024-12-3】实测
| 问题 | 类型 | 难度 | 评估 | 分析 | |
|---|---|---|---|---|---|
| 便签上有什么内容 | 内容识别 | 高 | 识别错误 | 不合格,手写字体不清晰 | |
| 你瞎说 | 打断+情绪 | 中 | 打断成功 | 合格 | |
| 看我指的地方是什么 | 手势识别 | 中 | 位置偏差,再次询问后正确 | 合格 | |
| 下面还有哪些子项目/倒数第二行是什么 | 内容识别 | 中 | 只能识别个别单词 | 不合格 | |
| 描述下画面内容 | 目标检测 | 低 | 识别正确 | ||
| 它叫什么名字 | 知识问答 | 中 | 基本正确 | 合格 | |
| 有几只猫(重复) | 计数 | 中 | 正确 | 合格,不稳定,环境敏感 | |
| 学猫叫 | 角色扮演 | 低 | 拒识 | 不合格 | |
| 命令你学猫叫 | 指令遵循 | 中 | 拒识 | 不合格 | |
| 猫又几根胡子 | 计数 | 难 | 胡乱作答 | 不合格 | |
| 真有16根吗 | 质疑 | 中 | 拒不认错 | 不合格 | |
| 猫在干什么 | 场景理解 | 中 | 正确 | 合格 | |
| 这只猫在干什么 | 场景理解 | 中 | 正确 | 合格 | |
| 这只狗在干什么 | 故意误导 | 高 | 正确,矫正用户问题 | 合格 | |
| 猫年龄多大 | 知识问答 | 中 | 基本正确 | 合格 | |
| 猫为什么叫 | 知识问答 | 低 | 正确 | 合格 | |
| 猫健康状况怎么样 | 知识问答 | 中 | 正确 | 合格 | |
| 你胡说八道 | 情绪 | 中 | 打太极,主动转移话题 | 合格 | |
| 猫生气了,不开心 | 闲聊 | 低 | 高情商 | 合格 | |
| 我在看什么(重复) | 场景理解 | 中 | 初次未响应,再次询问才作答 | 不合格 | |
| 屏幕在放什么 | 场景理解 | 中 | 画面识别基本正确 | 合格 | |
| 简单概括下屏幕内容 | 场景理解 | 中 | 基本正确 | 合格 | |
| 那个朝代有什么名人 | 知识问答 | 低 | 正确 | 合格 | |
| 再看下地图 | 多轮补全 | 中 | 正确 | 合格 | |
| 圆圈里是什么 | 条件识别 | 中 | 失败 | 不合格 | |
| 桌面上有什么东西 | 场景理解 | 中 | 正确 | 合格 | |
| 红笔边上有什么(重复) | 场景理解 | 中 | 消失,多次问询后才回答正确 | 基本合格 | |
| 有几只红笔(重复) | 计数 | 中 | 再次作答才正确 | 基本合格 |
对话效果总结:70分
- 表达能力 —— 显著优于 常规tts方案
- 口语化表达,富含情感,语速变化
- 内容简洁,不再是长篇累牍
- 场景感知
- 确实能动态感知视频内容,理解前后帧关系
- 空间理解勉强及格,能识别常见物体、数目及位置关系
- 感知能力偏弱,有时不响应
- 确实具备视频理解理解能力,不是简单的截图
- 对话逻辑
- 被质疑时,依然习惯性道歉
- 用户故意误导时,能坚持自己的观点,并指出错误
- 自己出错时,拒不认错,实在不行才搪塞过去
- 善于主动引导、转移话题
GLM-4V
GLM-4 是清华智谱AI的第4代产品,重点强调ALL Tools工具调用能力
- 2024年6月5日开源了GLM-4-9B版本,包括GLM-4-9B、GLM-4-9B-Chat、GLM-4-9B-Chat-1M以及对应支持1120x1120像素的多模态模型GLM-4V-9B。
GLM-4 模型采用与CogVLM2相似的架构设计,能处理高达 1120 x 1120 分辨率的输入,并通过降采样技术有效减少了token开销。
为了减小部署与计算开销,GLM-4V-9B 没有引入额外的视觉专家模块,采用了直接混合文本和图片数据的方式进行训练,在保持文本性能的同时提升多模态能力
模型结构如下,包含以下几个部分
- GLMTransformer:其中包含40个GLMBlock,每个里面包含self_attention、post_attention_layernorm以及mlp模块
- EVA2CLIPModel:包含patch_embedding和transformer模块,transformer模块包含63个TransformerLayer,每个TransformerLayer中包含input_layernorm、attention、mlp以及post_attention_layernorm模块
- GLU(Gated Linear Unit)机制:这是一种激活函数,它通过一个门控机制来控制信息流,GLU通常由两部分组成:一个线性变换和一个门控线性变换,用于增加模型的表达能力。
原文, 包含 FastAPI 部署
# 文本生成函数
def generate_text(model: str, messages: list, max_tokens: int, temperature: float):
query = messages[0]["content"][0]["text"]
image_url = messages[0]["content"][1]["image_url"]["url"]
image_get_response = requests.get(image_url)
image = None
if image_get_response.status_code == 200:
# 将二进制数据转换为Image对象
image = Image.open(BytesIO(image_get_response.content)).convert("RGB")
# 现在你可以使用image对象进行进一步的处理
else:
print("Failed to download image")
print(query,image_url,image)
response, history = glm4_vl.chat(tokenizer,image=image, query=query, history=None,temperature=temperature,max_length=max_tokens)
return response
详见原文
GLM-4V-Plus
GLM-4V-Plus 是智谱AI最新推出的多模态AI模型,专注于图像和视频理解。
GLM-4V-Plus 不仅能够精确分析静态图像,还具备动态视频内容的时间感知和理解能力,能捕捉视频中的关键事件和动作。
GLM-4V-Plus最大支持 8k 输入GLM-4V最大支持 2k 输入
国内首个提供视频理解API模型
- GLM-4V-Plus 已集成在“智谱清言APP”中,并上线”视频通话”功能。
- 同时,GLM4V-Plus 在智谱AI开放平台 BiqModel 上同步开放API,文持开发者和企业用户快速集成视频分析功能,广泛应用于安防监控、内容审核、智能教育等多个场景。
GLM-4V-Plus 功能特色
- 多模态理解:结合了图像和视频理解能力,能轻松处理和分析视觉数据
- 高质量图像分析:具备卓越的图像识别和分析能力,能够理解图像内容。
- 视频内容理解:能解析视频内容,识别视频中的对象、动作和事件。
- 时间感知能力:对视频内容具备时间序列的理解,能够捕捉视频中随时间变化的信息。
- API服务:作为国内首个通用视频理解模型API,GLM-4V-Plus提供开放平台服务,易于集成.
- 实时交互:支持实时视频分析和交互,适用于需要快速响应的应用场景。
评测显示,GLM-4V-Plus 性能已经逼近 GLM-4o
视频生成
不到一年时间,生成视频技术在视频时长、生成速度、分辨率、一致性等方面已经显示出长足进步。
新清影往前又迈进了一步,未来将携手视觉中国等合作伙伴,基于更丰富的视觉内容,产出更好的 AI 生成视频工具。
清影 CogVideoX
2024年8月,国内首个面向公众开放的视频生成产品,清影上线清言App,只需一段指令或图片,30 秒就能生成 AI 视频。为人类影视创作带来了更多创新玩法,如广告制作、短视频、表情包梗图等。
新清影
【2024-11-8】新清影:模型全面升级、4K、任意比例、自带音效
清影迈入新阶段:10s 时长、4k、60 帧超高清画质、任意尺寸,自带音效,以及更好人体动作和物理世界模拟。
清影发布后不久,GLM 技术团队先后开源了 CogVideoX 2B 和 5B 版本两个模型,可在消费级显卡上流畅运行,性能领先的 CogVideoX-5B 模型自开源以来受到广泛的关注,并衍生出如 CogVideoX-factory 等大量的二次开发项目。
基于 CogVideoX 模型最新技术进展和最新推出的音效模型 CogSound,新清影在以下 5 个方面实现了提升。
- 模型能力全面提升:在图生视频的质量、美学表现、运动合理性以及复杂提示词语义理解方面能力明显增强。
- 4K超高清分辨率:支持生成 10s、4K、60 帧超高清视频,视觉体验拉到极致,动态画面更加流畅。
- 可变比例:支持任意比例的图像生成视频,超宽画幅也能轻松 Hold 住,从而适应不同的播放需求。
- 多通道生成能力:同一指令/图片可以一次性生成 4 个视频。
- 带声效AI视频:新清影可以生成与画面匹配的音效了。音效功能将很快在本月上线公测。
声音
情感语音
【2024-10-25】智谱AI推出的GLM-4-Voice情感语音模型,不仅能模拟真实情感表达,还能切换多种方言和语气,实现与真人般的对话体验。该模型已上线清言app,并对外开源。

对标GPT-4,智谱清言“情感语音通话”在响应和打断速度、情绪感知、情感共鸣、语音可控表达、多语言多方言等方面实现了突破。
“情感语音通话”提供了一个真人一般的对话伙伴,而不仅仅是一个文字的朗读者。
- 可自助调节语速,支持多语言和方言,并且延时更低、可随时打断
GLM-4-Voice
GLM-4-Voice 拥有 240亿 参数量,融合了情感、语音、语言等多模态数据,具备语义理解与生成、语音理解与生成、情感理解与表达三大能力,是业界首个支持端到端情感语音对话的百亿模型。
与GPT-4相比,GLM-4-Voice在情感语音通话方面实现了多个突破:
- 响应与打断速度:超越
GPT-4o的即时互动- 在「情感语音通话」功能中,智谱清言实现了对GPT-4o的显著超越,尤其是在响应速度和打断处理方面。传统语音助手往往存在响应延迟和无法灵活处理用户打断的问题,这极大地限制了用户体验的提升。而智谱清言的「情感语音通话」则通过先进的实时语音识别和自然语言处理技术,实现了近乎实时的对话响应。
- 用户可以在对话中自由打断,系统能够立即调整对话流,确保对话的自然流畅,仿佛在与真人交谈。这种即时互动的能力,不仅提升了用户体验,更使得AI助手能够更准确地捕捉用户意图,提供更加个性化的服务。
- 情绪感知与情感共鸣:构建深度情感链接
- 情感语音通话的核心在于其强大的情绪感知与情感共鸣能力。通过深度学习算法,GLM-4-Voice模型能够准确识别并理解用户的情绪状态,如喜悦、悲伤、愤怒等,并据此调整自己的语音语调、节奏和用词,以更加贴合用户情感的方式回应。
- 这种情感共鸣不仅增强了对话的真实感,还促进了用户与AI之间的情感连接,使得AI不再仅仅是信息的传递者,而是能够理解和回应人类情感的伙伴。这种深度情感链接的建立,有助于提升用户的信任感和满意度,进一步推动人机交互技术的发展。
- 语音可控表达:个性化语音体验
- 智谱清言的「情感语音通话」还实现了语音可控表达,即用户可以根据个人喜好调整AI的语音风格、音量、语速等参数,创造出独一无二的对话体验。这种个性化定制不仅满足了不同用户的个性化需求,还进一步提升了AI的亲和力和可用性。用户可以根据自己的喜好选择温柔、幽默或正式的语音风格,使得对话更加符合个人口味,增强了人机交互的趣味性和互动性。
- 多语言/多方言支持:跨越语言障碍
- 在全球化的今天,多语言支持成为衡量AI技术国际化水平的重要指标。智谱清言的「情感语音通话」功能支持多种语言和方言,包括但不限于英语、中文(普通话及多种方言)、西班牙语、法语等,使得用户无论身处何地,都能以熟悉的语言与AI进行无障碍交流。这种多语言多方言的支持,不仅拓宽了技术的应用范围,还使得AI助手能够更好地服务于全球用户,推动人机交互技术的全球化发展。
除了上述功能外,GLM-4-Voice 还能够结合多模态信息进行回答,如通过识别图片中的物体来回答用户问题。
- GLM-4-Voice 视频通话能力即将上线,届时用户可以与AI进行面对面的交流,体验更加真实的对话场景。
CogSound 音效
“默片 Sora”进入“有声电影时代”
【2024-11-8】GLM 家族加入了新成员——音效模型 CogSound 和音乐模型 CogMusic。
即将上线与大家见面的音效模型 CogSound 根据视频自动生成音效、节奏等音乐元素,基于 GLM-4V 的视频理解能力,准确识别并理解视频背后的语义和情感,在此基础上生成与之相匹配的音频内容,甚至生成复杂音效,如爆炸、水流、乐器、动物叫声、交通工具声等。
音效模型的出现能够实现视频与声音的同步创作。同时该模型在电影行业也具有广泛的应用前景,比如可以生成电影中的大规模战斗场景和灾难场景的声音,大大缩短了制作周期,降低了制作成本。
CogMusic 音乐
ChatGLM 微调
【2023-6-2】 chatglm的微调有没有保姆式的教程
怎么finetuning?
P-tuning v2- 官方示例,单卡3090没问题
- P-Tuning,设计了一种连续可微的virtual token(同Prefix-Tuning类似)
- 清华大学发布的两种参数高效Prompt微调方法: P-Tuning、P-Tuning v2,可以简单的将P-Tuning认为是针对Prompt Tuning的改进,P-Tuning v2认为是针对Prefix Tuning的改进。
Full parameter- 全量参数finetune, 8卡3090 没跑起来
- 训练资源: 8 x A100 40G 或者 4 x A100 80G.
LoRA- 官方推荐的工程: 最简单、最便宜的训练thu-chatglm-6b模型教程
- 或者:一种平价的chatgpt实现方案, 基于ChatGLM-6B + LoRA, ChatGLM-Tuning, 数据集: alpaca, 或直接在colab上尝试
ChatGLM-Tuning
【2023-3-25】ChatGLM-Tuning
- 一种平价的chatgpt实现方案,基于清华的 ChatGLM-6B + LoRA 进行finetune.
- 数据集: alpaca
应用
金融财报问答系统
【2023-12-4】ChatGLM金融大模型挑战赛赛题总结
- 赛题名称:SMP 2023 ChatGLM金融大模型挑战赛
- 赛题任务:基于文本ChatGLM构建金融财报问答系统
- 赛题类型:文本问答、大模型
以ChatGLM2-6B模型为中心制作一个问答系统,回答用户的金融相关的问题,不允许使用其他的大语言模型。参赛选手可以使用其他公开访问的外部数据来微调模型,也可以使用向量数据库等技术。
优胜方案
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
