百川
百川智能
- baichuan基于LLaMA改进 – 可商用
baichuan 模型
Base vs Chat
Base 和 Chat 是两种不同的大模型,它们在训练数据、应用场景和模型特性上有所区别。
- Base 基于海量语料库的预训练模型,主要用于无监督学习任务。
- Chat则是Base模型基于指令微调的有监督学习模型,主要应用于指令学习任务。
此外,Chat通常在Base模型上进行微调,以更好地适应特定任务
Base 模型 和 Chat 模型有什么区别?
- base模型是在大规模语料上以LM这种形式的预训练任务(预测下一个token)训练得来的;
- chat模型是在base模型上sft+rlhf上微调得来的。 base模型已经有很强大的能力了,但是需要tuning即sft+强化学习rlhf后得到chat模型,对齐了人类的自然语言解锁base模型的强大能力。
总结
- base模型很强但是听不懂人话,需要用少量的tuning数据来让它听懂人话,进而和人类对话
baichuan 模型解读
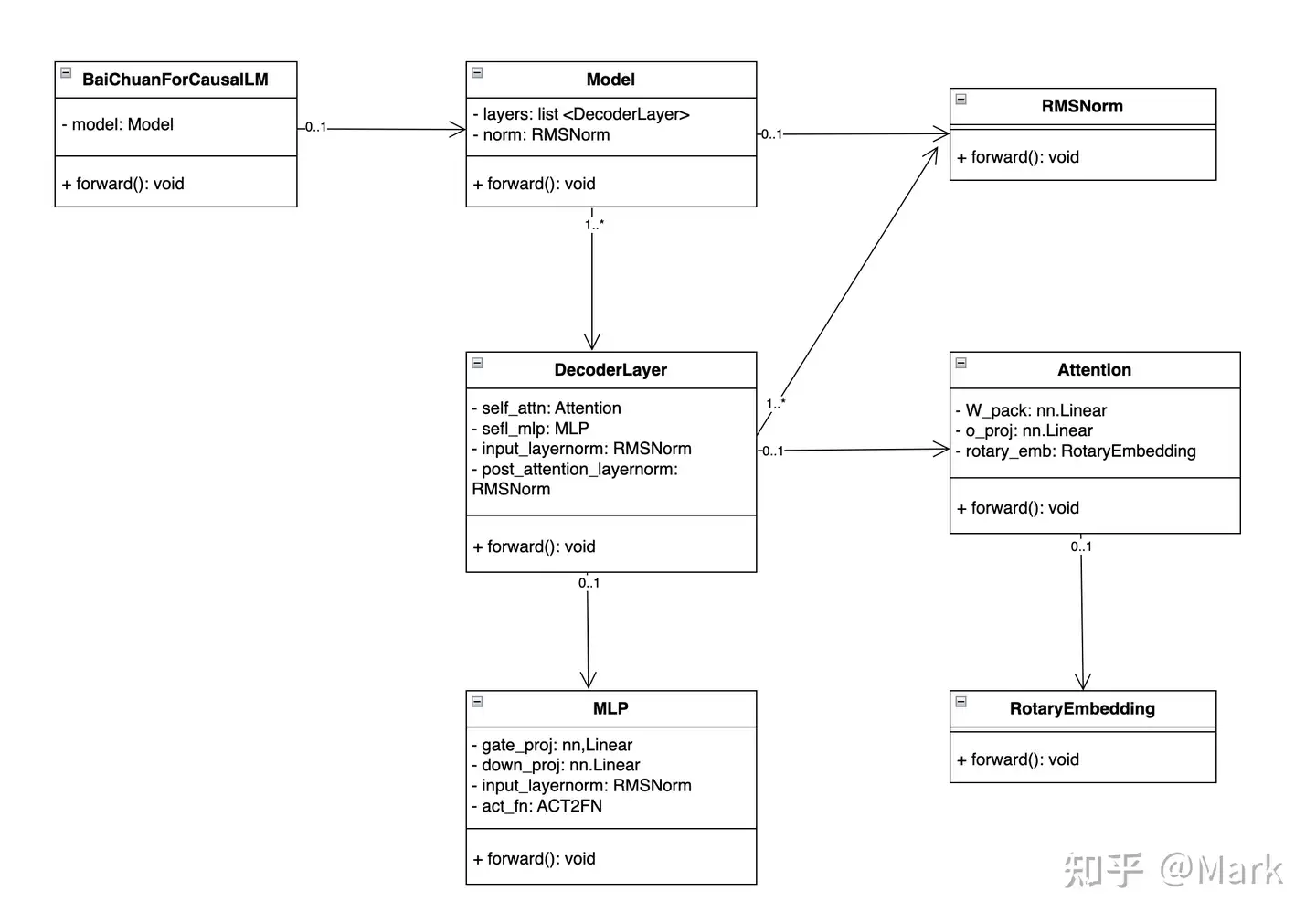
模型基于标准的 Transformer 结构,采用了和 LLaMA 一样的模型设计:
Position Embedding: 采用rotary-embedding,是现阶段被大多数模型采用的位置编码方案,具有很好的外推性。- 旋转位置编码 是 相对位置编码 的一种实现,相对位置编码 没有完整建模每个输入的位置信息,而是在计算 Attention 的时候考虑当前位置与被 Attention 的位置的相对距离,由于 自然语言一般更依赖于相对位置,所以相对位置编码通常也有着优秀的表现。
Feedforward Layer: 采用SwiGLU,Feedforward 变化为(8/3)倍的隐含层大小,即11008。Layer Normalization: 基于RMSNorm的 Pre-Normalization。RMSNorm(Root Mean Square Layer Normalization),LayerNorm 的变体,在梯度下降时令损失更加平滑。- 与 LayerNorm 相比,RMSNorm 主要区别: 去掉了减去均值的部分(re-centering),只保留方差部分(re-scaling),从归一化的表达式上可以直观地看出。
源码结构
FlashAttention 算法
- 将 输入的 Q、K 和 V 矩阵划分成块(block),从 HBM 加载至 SRAM 中,然后计算注意力输出。这个过程被称为“切片(tiling)”。
baichuan-7B
【2023-6-15】王小川大模型的第一个里程碑:baichuan-7B 今日正式开源发布
- baichuan-7B 是由百川智能开发的一个开源可商用的大规模预训练语言模型。基于 Transformer 结构,在大约1.2万亿 tokens 上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威 benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。
- baichuan-7b
- 评测标准 AGI Eval 中,baichuan-7B 综合评分34.4,在中国高考、司法考试、SAT、LSAT、GRE 等考试中发挥很好,领先于LLaMa-7B、Falcon-7B、Bloom-7B 以及 ChatGLM-6B 等不少竞争对手
整体模型基于标准的 Transformer 结构,采用了和 LLaMA 一样的模型设计 源码
- 位置编码:rotary-embedding 是现阶段被大多模型采用的位置编码方案,具有更好的外延效果。虽然训练过程中最大长度为4096,但是实际测试中模型可以很好的扩展到 5000 tokens 上,如下图:
- 激活层:SwiGLU, Feedforward 变化为(8/3)倍的隐含层大小,即11008
- Layer-Normalization: 基于 RMSNorm 的 Pre-Normalization
数据
- 原始数据包括开源的中英文数据和自行抓取的中文互联网数据,以及部分高质量知识性数据。
- 参考相关数据工作,频率和质量是数据处理环节重点考虑的两个维度。
- 基于启发式规则和质量模型打分,对原始数据集进行篇章和句子粒度的过滤。
- 在全量数据上,利用局部敏感哈希方法,对篇章和句子粒度做滤重
分词: SentencePiece 中的 byte pair encoding (BPE)作为分词算法,并且优化点:
- 目前大部分开源模型主要基于英文优化,因此对中文语料存在效率较低的问题。用2000万条以中英为主的多语言语料训练分词模型,显著提升对于中文的压缩率。
- 对于数学领域,参考了 LLaMA 和 Galactica 中的方案,对数字的每一位单独分开,避免出现数字不一致的问题,对于提升数学能力有重要帮助。
- 对于罕见字词(如特殊符号等),支持 UTF-8-characters 的 byte 编码,因此做到未知字词的全覆盖。
- 分析了不同分词器对语料的压缩率,分词器明显优于 LLaMA, Falcon 等开源模型,并且对比其他中文分词器在压缩率相当的情况下,训练和推理效率更高。
训练吞吐,具体包括:
- 算子优化技术:采用更高效算子,如 Flash-attention,NVIDIA apex 的 RMSNorm 等。
- 算子切分技术:将部分计算算子进行切分,减小内存峰值。
- 混合精度技术:降低在不损失模型精度的情况下加速计算过程。
- 训练容灾技术:训练平台和训练框架联合优化,IaaS + PaaS 实现分钟级的故障定位和任务恢复。
- 通信优化技术,具体包括:
- 采用拓扑感知的集合通信算法,避免网络拥塞问题,提高通信效率。
- 根据卡数自适应设置 bucket size,提高带宽利用率。
- 根据模型和集群环境,调优通信原语的触发时机,从而将计算和通信重叠。 基于上述的几个优化技术,我们在千卡A800机器上达到了7B模型182Tflops的吞吐,GPU峰值算力利用率高达58.3%
huggingface 代码
模型加载指定 device_map='auto',使用所有可用显卡。
- 如需指定使用的设备,可以使用类似
export CUDA_VISIBLE_DEVICES=0,1(使用了0、1号显卡)的方式控制
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = '/mnt/bd/wangqiwen-hl/models'
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", trust_remote_code=True)
inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->\n', return_tensors='pt')
inputs = inputs.to('cuda:0')
pred = model.generate(**inputs, max_new_tokens=512, do_sample=True)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
baichuan-13B
Baichuan-13B 由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威中文和英文 benchmark 上均取得同尺寸最好的效果。
- 本次发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本
13b vs 7b
| 模型名称 | 隐藏层维度 | 层数 | 注意力头数 | 词表大小 | 总参数量 | 训练数据(tokens) | 位置编码 | 最大长度 |
|---|---|---|---|---|---|---|---|---|
Baichuan-7B |
4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2 万亿 | RoPE | 4,096 |
Baichuan-13B |
5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4 万亿 | ALiBi | 4,096 |
baichuan-13b 介绍
【2023-7-11】王小川大模型25天再升级!13B版本开源免费可商用,3090即可部署
- 百川智能,正式发布130亿参数通用大语言模型(Baichuan-13B-Base), 性能最强的中英文百亿参数量开源模型
- 同时发布对话模型
Baichuan-13B-Chat,以及 INT4/INT8 两个量化版本。近乎无损的情况下,便可以将模型部署在如3090等消费级显卡上 - Baichuan-13B上下文窗口长度为4096, 1.4万亿ztoken这个训练数据量,超过LLaMA-13B训练数据量的40%,是当前开源的13B尺寸模型世界里,训练数据量最大的模型。
- 7B版本采用
RoPE编码方式,而13B使用了ALiBi位置编码技术,后者能够处理长上下文窗口,甚至可以推断超出训练期间读取数据的上下文长度,从而更好地捕捉文本中上下文的相关性,让预测或生成更准确。
- 7B版本采用
- 完全开源,免费商用;开发者均可通过邮件向百川智能申请授权,在获得官方商用许可后即可免费商用。
Baichuan-13B 有如下几个特点:
- 更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。
- 支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
- 同时开源预训练和对齐模型:预训练模型是适用开发者的『 基座 』,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
- 更高效的推理:为了支持更广大用户的使用,同时开源了 int8 和 int4 的量化版本,相对非量化版本, 在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
- 开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
评测
- C-EVAl上,Baichuan-13B在自然科学、医学、艺术、数学等领域领先LLaMA-13B、Vicuna-13B等同尺寸的大语言模型。社会科学和人文科学领域,水平比ChatGPT还要好上一点。
- 英文领域的表现也算不错,能比同尺寸的其他开源模型,如LLaMA-13B、Vicuna-13B都有更好的表现
【HuggingFace】
【GitHub】
- Baichuan-13B,模型源码见 huggingface 的model_baichuan.py
【Model Scope】
模型显存占用
| Precision | GPU Mem (GB) |
|---|---|
| bf16 / fp16 | 26.0 |
| int8 | 15.8 |
| int4 | 9.7 |
| cpu | 60 |
量化后在各个 benchmark 上的结果和原始版本对比如下:
| Model 5-shot | C-Eval | MMLU | CMMLU |
|---|---|---|---|
| Baichuan-13B-Base | 52.4 | 51.6 | 55.3 |
| Baichuan-13B-Base-int8 | 51.2 | 49.9 | 54.5 |
| Baichuan-13B-Base-int4 | 47.6 | 46.0 | 51.0 |
13b 实践
模型加载指定 device_map='auto',会使用所有可用显卡。
- 如需指定使用的设备,可以使用类似
export CUDA_VISIBLE_DEVICES=0,1(使用了0、1号显卡)的方式控制
模型量化版本
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
model_path = '/mnt/bd/wangqiwen-hl/models'
#model_name = 'baichuan-inc/Baichuan-13B-Chat-int8'
model_name = 'baichuan-inc/Baichuan-13B-Chat'
#tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, trust_remote_code=True)
#model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
# 本地模型加载
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True, cache_dir=model_path)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", trust_remote_code=True, cache_dir=model_path)
# cpu 部署
# model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float32, trust_remote_code=True)
model = model.quantize(8).cuda() # 在线 int8 量化
#model = model.quantize(4).cuda() # 在线 int4 量化
model.generation_config = GenerationConfig.from_pretrained(model_name)
messages = []
messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})
response = model.chat(tokenizer, messages)
print(response)
#乔戈里峰。世界第二高峰———乔戈里峰西方登山者称其为k2峰,海拔高度是8611米,位于喀喇昆仑山脉的中巴边境上
启动
# ------ 命令行模式 -------
python cli_demo.py # 【2023-11-7】有效
# 欢迎使用百川大模型,输入进行对话,vim 多行输入,clear 清空历史,CTRL+C 中断生成,stream 开关流式生成,exit 结束。
# 用户:你是谁
# Baichuan:我是百川大模型,是由百川智能的工程师们创造的大语言模型,我可以和人类进行自然交流、解答问题、协助创作,帮助大众轻松、普惠的获得世界知识和专业服务。如果你有任何问题,可以随时向我提问
# 用户:stream
# Baichuan:(关闭流式生成)
# ------ Web 模式 -------
streamlit run web_demo.py # streamlit生成的地址在merlin上无法访问
baichuan2
git clone https://github.com/baichuan-inc/Baichuan2.git
baichuan2-53b
【2023-9-6】 发布了新一代开源模型 Baichuan 2,包含 7B、13B 尺寸
【2023-9-25】百川智能正式发布全新升级的530亿参数大模型——Baichuan2-53B。
- 数学和逻辑推理能力显著提升。
- 通过高质量数据体系和搜索增强,Baichuan2-53B 幻觉大大降低,是目前国内幻觉问题最低的大模型。
不仅如此,作为首批通过备案的大模型企业,百川智能还开放了Baichuan2-53B API接口。百川智能正式进军To B领域,从此将开启商业化进程
通过构建高质量数据体系以及搜索增强技术两个方面的优化,Baichuan2-53B有效降低了模型幻觉。
- 高质量数据构建上,Baichuan2-53B 独创了一套数据质量体系。
- 以低质、优质为标准将数据进行分类,确保Baichuan2-53B始终使用优质数据进行预训练。
- 信息获取方面,Baichuan2-53B对多个模块进行了升级,包括:指令意图理解、智能搜索和结果增强等关键组件。
这一综合体系通过深入理解用户指令,精确驱动查询词的搜索,最终结合大语言模型技术,优化模型结果生成的可靠性,实现更精确、更智能的模型回答结果,减少模型幻觉。
「勾三股四弦五」
- GPT-4显然是在胡说八道
- Baichuan2-53B一次就给出了正确的回答
周树人和鲁迅是不是同一个人
- Baichuan2-53B的回答既全面又准确
FacTool 评测结果显示,Baichuan2-53B 综合得分为140.5,在主流基础大模型中仅排在GPT-4之后,处于国内领先水平。
- FacTool是由上海交通大学、卡内基梅隆大学、香港城市大学、Meta 等机构学者共同提出的一款通用框架,能够查核大模型生成内容的事实准确性(也能查核一般性内容的事实准确性)
baichuan2-192K
【2023-10-30】百川智能推出全球最长上下文窗口大模型Baichuan2-192K,一次可输入35万字超越Claude2
10月30日,百川智能发布Baichuan2-192K大模型,上下文窗口长度高达192K,是目前全球最长的上下文窗口。Baichuan2-192K能够一次处理约35万个汉字,是目前支持长上下文窗口最优秀大模型Claude2(支持100K上下文窗口,实测约8万字)的4.4倍,更是GPT-4(支持32K上下文窗口,实测约 2.5万字)的14倍。
Baichuan2-192K是百川智能发布的第7款大模型,成立至今百川智能平均每个月就会发布一款大模型,研发速度处于行业顶尖水平。
baichuan 部署
FastChat部署
【2023-7-27】使用FastChat部署百川大模型
FastChat是用于对话机器人模型训练、部署、评估的开放平台,其核心特性包括:
- 模型权重,训练代码,评估代码可用于SOTA模型(比如Vicuna,FastChat-T5)
- 分布式多模型部署系统,自带Web UI和OpenAI兼容的RESTful APIs FastChat集成了Vicuna、Koala、alpaca、LLaMA等开源模型,其中Vicuna号称能够达到GPT-4的90%的质量,是开源的chatGPT模型中对答效果比较好的。
FastChat的访问地址
FastChat的安装方式为:
pip3 install fschat
Huggingface Hub上下载baichuan-7B模型,访问网址, 放在GPU机器上的本地路径
两种部署方式都支持流式输出,且模型推理速度较快,推理时间一般为5-7秒,且支持分布式部署,并发量高。
(1) FastChat使用CLI部署
# 百川大模型
python3 -m fastchat.serve.cli --model-path path_of_Baichuan-7B --num-gpus 2
报错:
- trust_remote_code=True
- 参考issue , 在对应的Python路径下,将FastChat的fastchat/model/model_adapter.py文件中的代码中的第57~61行和69~71行添加代码:
trust_remote_code=True - 原文链接
(2) WEB部署
- FastChat还支持WEB部署,可Web UI和OpenAI兼容的RESTful APIs. refer
部署一共分为三步:
python3 -m fastchat.serve.controller
python3 -m fastchat.serve.model_worker --model-path path_of_Baichuan-7B
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
如果遇到 PydanticImportError
- pydantic版本的问题,只需将pydantic版本降为1.*版本即可
部署成功后,该服务可提供与OpenAI风格类似的RESTful APIs
# 查看模型
curl http://localhost:8000/v1/models
# 文本补充(Text Completions)
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "baichun_7b",
"prompt": "Once upon a time",
"max_tokens": 40,
"temperature": 0.5
}' | jq .
# 对话(Chat Completions)
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "baichun_7b",
"messages": [{"role": "user", "content": "请用中文简单介绍三国演义?"}]
}' | jq .
# 多轮对话
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "baichun_7b",
"messages": [{"role": "user", "content": "请用中文简单介绍西游记?"}, {"role": "assistant", "content": "三国演义是中国古代长篇小说,讲述了东汉末年至晋朝初年的历史故事。主要人物包括曹操、刘备、孙权和关羽等。故事情节曲折复杂,涉及政治、军事、文化等多个方面,被誉为中国古代小说的经典之作。《三国演义》不仅是一部文学作品,也是中国文化的重要组成部分,对中国历史和文化产生了深远的影响。"}, {"role": "user", "content": "它的作者是谁?"}]
}' | jq .
使用Python代码
import openai
openai.api_key = "EMPTY" # Not support yet
openai.api_base = "http://localhost:8000/v1"
model = "baichun_7b"
prompt = "Once upon a time"
# create a completion
completion = openai.Completion.create(model=model, prompt=prompt, max_tokens=64)
# print the completion
print(prompt + completion.choices[0].text)
# create a chat completion
completion = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": "Hello! What is your name?"}]
)
# print the completion
print(completion.choices[0].message.content)
baichuan 微调
资料
- baichuan_finetuning, 用 deep_training 库实现 预训练、微调和推理
baichuan-13B 多轮对话
【2023-8-24】BaiChuan13B多轮对话微调范例
修改大模型自我认知的3轮对话的玩具数据集,使用QLoRA算法,只需要训练5分钟,就可以完成微调,并成功修改了LLM模型的自我认知。
inputs = <user1> <assistant1> <user2> <assistant2> <user3> <assistant3>
多轮对话微调数据集以及标签构造方法
- 最后一轮机器人的回复:其它位置赋值-100
- 问题: 由于没有对中间轮次机器人回复的信息进行学习,因此存在着严重的信息丢失
- 多轮对话拆解成多条样本
- 问题: 充分地利用了所有机器人的回复信息,但是非常低效,模型会有大量的重复计算
- 直接构造包括多轮对话中所有机器人回复内容的标签,既充分地利用了所有机器人的回复信息,同时也不存在拆重复计算,非常高效。
- inputs中包括第二轮和第三轮的对话内容不会干扰第一轮对话的学习吗?
- 不会。原因是LLM作为语言模型,注意力机制是一个单向注意力机制(通过引入 Masked Attention实现),模型在第一轮对话的输出跟输入中存不存在第二轮和第三轮对话完全没有关系。
区别重点在 label 构建方式
# 方法 1 只留最后一轮 —— 简单但丢失中间信息
inputs = <user1> <assistant1> <user2> <assistant2> <user3> <assistant3>
labels = <-100> <-100> <-100> <-100> <-100> <assistant3>
# 方法 2 逐步累积,拆成单条 —— 信息充足但低效(重复计算)
inputs1 = <user1> <assistant1>
labels1 = <-100> <assistant1>
inputs2 = <user1> <assistant1> <user2> <assistant2>
labels2 = <-100> <-100> <-100> <assistant2>
inputs3 = <user1> <assistant1> <user2> <assistant2> <user3> <assistant3>
labels3 = <-100> <-100> <-100> <-100> <-100> <assistant3>
# 方法 3 折中方案,简单且高效
inputs = <user1> <assistant1> <user2> <assistant2> <user3> <assistant3>
labels = <-100> <assistant1> <-100> <assistant2> <-100> <assistant3>
训练详情见原文
baichuan-13b 微调
与 Baichuan-13B 兼容的微调工具 LLaMA Efficient Tuning,并给出全量微调 和 LoRA微调 两种示范。
在开始之前,下载 LLaMA Efficient Tuning 项目并按其要求安装依赖。
输入数据放置项目data目录下, json 文件
- 用
--dataset选项指定 - 多个输入文件用,分隔。
json 文件示例格式和字段说明如下:
[
{
"instruction": "What are the three primary colors?",
"input": "",
"output": "The three primary colors are red, blue, and yellow."
},
....
]
json 文件中存储一个列表,每个元素是一个 sample。其中instruction代表用户输入,input是可选项,如果开发者同时指定了instruction和input,会把二者用\n连接起来代表用户输入;output代表期望的模型输出。
训练方式
- 全量微调:
- 8 * Nvidia
A10080 GB + deepspeed 环境
- 8 * Nvidia
- LoRA微调:
- 单张 Nvidia
A10080G 显卡
- 单张 Nvidia
全参微调
deepspeed --num_gpus=8 src/train_bash.py \
--stage sft \
--model_name_or_path baichuan-inc/Baichuan-13B-Base \
--do_train \
--dataset alpaca_gpt4_en,alpaca_gpt4_zh \
--finetuning_type full \
--output_dir path_to_your_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--preprocessing_num_workers 16 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--learning_rate 5e-5 \
--max_grad_norm 0.5 \
--num_train_epochs 2.0 \
--dev_ratio 0.01 \
--evaluation_strategy steps \
--load_best_model_at_end \
--plot_loss \
--fp16 \
--deepspeed deepspeed.json
deep_speed.json 配置
{
"train_micro_batch_size_per_gpu": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": false,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients" : true
}
}
lora 微调
单机
# lora 微调
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path baichuan-inc/Baichuan-13B-Base \
--do_train \
--dataset alpaca_gpt4_en,alpaca_gpt4_zh \
--finetuning_type lora \
--lora_rank 8 \
--lora_target W_pack \
--output_dir path_to_your_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--preprocessing_num_workers 16 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--learning_rate 5e-5 \
--max_grad_norm 0.5 \
--num_train_epochs 2.0 \
--dev_ratio 0.01 \
--evaluation_strategy steps \
--load_best_model_at_end \
--plot_loss \
--fp16
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
