- 大模型时代知识图谱
- 结束
大模型时代知识图谱
知识图谱
详见站内专题:知识图谱
LLM 构建 KG
知识图谱(Knowledge Graph,KG)与大型语言模型(Large Language Model,LLM)的结合是一种强大的技术融合,旨在通过将知识图谱的结构化知识与LLM的语言生成和理解能力相结合,提升模型的性能和可解释性,同时为各种应用提供更智能、更精准的解决方案
KG 实践
2025年知识图谱最新创新点
- 知识图谱与大模型融合
- 当前最热门。2025年,除了
KG-BERT、K-BERT经典方法,现在还有GraphRAG技术特别火 - 把知识图谱的结构化信息和大模型的生成能力完美结合,让模型在回答问题时更加准确和有依据。特别是在企业级应用中,效果相当不错。
- 当前最热门。2025年,除了
- 图谱表示学习新突破
- 图谱表示学习依然是研究热点。
R-GCN和GraphSAGE确实有新进展,不过2025年更值得关注的是GraphTransformer和GraphMAE。 - 这些新方法在处理大规模图谱时表现更好,特别是在跨领域的知识挖掘任务中,能够更好地捕捉复杂的关系模式。
- 图谱表示学习依然是研究热点。
GraphRAG技术崛起- 2025年最值得关注的新方向。GraphRAG 将知识图谱与
检索增强生成技术结合,让大模型能够基于结构化知识进行更准确的推理。 - 微软等公司已经在实际应用中证明了这个方法的有效性,特别是在企业问答系统和知识管理中表现突出。
- 2025年最值得关注的新方向。GraphRAG 将知识图谱与
- 多模态知识图谱
- 多模态知识图谱确实是研究重点。除了
VLBERT,现在还有更多融合视觉、文本、音频的新方法出现。 - 这些技术能够构建更丰富的知识表示,特别是在电商、医疗影像分析等领域应用效果很好。可以考虑把这个思路扩展到跨语言的知识融合上。
- 多模态知识图谱确实是研究重点。除了
- 动态知识图谱
- 动态知识图谱处理实时更新的能力越来越重要。
DynGraph等方法确实能高效处理实时数据流,而且现在还有基于流式计算的新架构出现。这些技术在金融风控、实时推荐系统中特别有用,能够快速响应知识的变化。
- 知识图谱的可解释性
- 可解释性确实是2025年的重要课题。
GNNExplainer等方法在不断完善,现在还有针对大模型推理过程的新型解释方法。 - 这些技术能帮助用户理解模型的决策过程,在医疗诊断、法律咨询等高风险领域特别重要,能够提升用户信任度。
- 可解释性确实是2025年的重要课题。
- 图谱与强化学习的结合
- 这个方向确实是新趋势。
GraphRL模型通过图谱结构引导智能体学习,在复杂决策场景中表现不错。 - 现在还有结合大模型的新方法,能够在自动驾驶、智能推荐等任务中提升系统的适应性和决策精度。
- 这个方向确实是新趋势。
这些创新点都是2025年最前沿的技术方向,特别是GraphRAG和多模态知识图谱,今年大热点。结合实际项目试试看,可能会有意想不到的效果。
Graph Maker
【2025-6-8】如何使用 Graph Maker 简化文本到知识图谱的构建
Python 库 —— Graph Maker,根据指定的本体(Ontology),从一组文本语料中自动生成知识图谱。
Graph Maker 用开源大语言模型(LLM),如 Llama 3,Mistral, Mixtral,Gemma。这些模型被用于从文本中提取出知识图谱(KG)。
构建知识图谱(KG),需要两类关键信息:
- 知识库(Knowledge Base):这可以是一个文本语料库、代码库、一组文章等。
- 本体(Ontology):也就是我们关心的实体类别,以及它们之间的关系类型。 我在这里对“本体”的定义可能有些简化,但对于我们的目的来说足够用了。
示例本体如下:
- 实体(Entities):
Person,Place - 关系(Relationships):
Person— related to →Person(人物关联人物)Person— lives in →Place(人物居住在某地)Person— visits →Place(人物访问某地)
问题
- 有意义的实体识别(Meaningful Entities)
- 没有人为干预时,LLM 所提取的实体在类别上可能过于分散或随意。它往往会错误地把抽象概念当作实体来提取。
- 实体的一致性(Consistent Entities)
- LLM 还可能在不同语境下将同一个实体识别为不同的实体
- 解析鲁棒性(Resilience in Parsing)
- LLM 的输出天生具有不确定性。要从一份大型文档中提取知识图谱,通常 将语料拆分成小段文本,为每段文本生成子图,将多个子图合并为一个完整图谱。这就要求 LLM 在处理每段文本时,始终按照指定的 JSON schema 输出结果。一旦有某一段缺失或格式不正确,就可能影响整个图谱的连通性。
- 实体分类(Categorisation of the Entities)
- LLM 在识别实体时可能会严重误判,特别是在上下文较为专业、术语特殊,实体不是标准英文命名,涉及领域知识较深的内容时。
- 虽然命名实体识别模型(NER)在这方面表现更稳定,但它们也受限于自身的训练数据,且不能理解实体之间的关系。
- LLM 在分类时保持一致性,更多依赖的是“提示词工程(prompt engineering)”的技巧与艺术
- 隐含关系(Implied Relations)
- 实体之间的关系有时是明确表达的,有时则是由上下文推断出来的。
Graph Maker 在严谨性与易用性之间取得了平衡,在结构化与非结构化之间找到了中间地带。在大多数前面提到的挑战中,表现都显著优于旧方案。
与“让 LLM 自行发现本体”不同,Graph Maker 的策略是引导(coerce)LLM 使用用户预定义的本体(ontology)
使用
pip install knowledge-graph-maker
本体定义:
步骤
- 定义图谱的本体(Ontology)
- 文本分块(Split the text into chunks)
- 转为 Document 对象
- 运行 Graph Maker,逐个处理生成子图。最终输出是所有文档组成的完整图谱。
- 保存到 Neo4j(Save to Neo4j)
- 图谱可视化 networkx 和 pyvis 库
本体定义,底层采用的是 Pydantic 模型。
ontology =Ontology(
# 要提取的实体标签,可以是字符串或字典对象,如下所示:
labels=[
{"Person":"不要添加任何形容词,仅使用人名。注意人物可能以代词或名字出现"},
{"Object":"不要在对象名称前加定冠词 'the'"},
{"Event":"事件应为涉及多人的事件,不包含 'gives'、'leaves'、'works' 等动词"},
"Place",
"Document",
"Organisation",
"Action",
{"Miscellaneous":"无法归入上述类别的其他重要概念"},
],
# 与应用场景相关的重要关系类型
# 实际上是提示模型关注特定关系,不能保证仅提取这些关系,但多数模型表现良好
relationships=[
"Relation between any pair of Entities",
],
)
knowledge-graph-llms
【2025-5-*】基于 GPT-4 快速构建知识图谱
- github:knowledge-graph-llms
可交互的知识图谱可视化工具:Knowledge Graph Generator
基于AI从文本中提取知识图谱,帮你迅速图谱化
- 支持上传 .txt 文件,或直接输入文本两种输入方式
- 图谱可互动,可以拖动节点,放大或缩小,鼠标悬停在节点或连接线上查看更多的信息等
- 图谱的布局和样式可自定义
Graphiti
Graphiti 构建适用于 AI 智能体的实时知识图谱
Graphiti 用于构建和查询时间感知知识图谱的框架,专为在动态环境中运行的 AI 智能体设计。
GraphRAG 问题
传统 RAG 方法依赖批量处理和静态数据摘要,因此在处理经常变化的数据时效率低下。
与传统的检索增强生成(RAG)方法不同,Graphiti 持续整合用户交互、结构化与非结构化企业数据,以及外部信息,构建成一个连贯且可查询的图谱。
功能
Graphiti 独特之处: 自主构建知识图谱,同时处理关系变化并保持历史上下文。
该框架支持增量数据更新、高效检索与精准的历史查询,且无需整体重新计算图谱,非常适合开发交互式、上下文感知型 AI 应用。
Graphiti 可以:
- 整合并维护动态的用户交互和业务数据。
- 支持智能体基于状态的推理和任务自动化。
- 通过语义搜索、关键词搜索、图遍历等方式,查询复杂、不断演化的数据。
优势:
- 实时增量更新:新数据片段能够即时整合,无需批量重计算。
- 双时间数据模型:明确记录事件的发生时间和接收时间,支持精准的时点查询。
- 高效的混合检索:结合了语义嵌入、关键词检索(BM25)和图遍历,实现了低延迟查询,且无需依赖大型语言模型(LLM)摘要。
- 自定义实体定义:通过直观简单的 Pydantic 模型,开发者可以灵活创建本体论和自定义实体。
- 优异的可扩展性:支持并行处理,能够高效管理大规模数据集,适用于企业级应用场景。
效果
MemGPT, Deep Memory Retrieval (DMR) benchmark 上达到 SOTA
应用场景
知识图谱是由互相关联的事实组成的网络
- 例如:“Kendra 喜爱 Adidas 鞋子。”
- 每条事实是一个“三元组”,由两个实体(或称节点,如“Kendra”和“Adidas 鞋子”)以及它们之间的关系(或称边,如“喜爱”)表示。
知识图谱已在信息检索领域得到了广泛的研究与应用。
Graphiti 专门为应对动态和频繁更新的数据集挑战而设计,特别适用于需要实时交互与精确历史查询的应用场景。
Graphiti 与 Zep 记忆
【2025-1-20】Graphiti 驱动着 Zep 的 AI 智能体记忆核心。
- Zep AI 推出 Zep:面向智能体记忆的时间知识图架构
- 论文 Zep: A Temporal Knowledge Graph Architecture for Agent Memory
通过 Graphiti,证明:Zep 是当前智能体记忆领域的最先进方案。
知识图谱+RAG
RAG 问题
分析
- GraphRAG 在多跳推理和上下文综合的任务中表现优异
- 但在简单事实检索任务中不如传统RAG
Native RAG 短板:
- 只会“关键字匹配”,不会“理解知识结构”,检索和生成之间始终隔着一层“信息语义的墙”
RAG 架构核心逻辑:
- 用户提问 → 文本向量化 → 相似文档检索 → 与问题拼接 → 喂给语言模型生成答案
这种方式虽然实用,但存在两个问题:
- 知识碎片化:检索结果是几个独立段落,不成体系
- 模型“不会关系”:无法理解A和B之间是什么关系
而 GraphRAG 可以解决。
更多RAG优化,详见站内专题:RAG专题
RAG vs GraphRAG
| 特性 | RAG | GraphRAG |
|---|---|---|
| 知识表示 | 使用文本块(chunks),通过向量嵌入进行索引。 | 使用图结构,节点代表实体、事件或主题,边定义逻辑、因果或关联关系。 |
| 检索机制 | 关键词匹配或向量相似度检索。 | 图遍历,检索直接相关节点及相互连接的子图。 |
| 复杂查询处理 | 适用于需要快速访问离散信息的任务,但不擅长复杂逻辑推理。 | 适用于需要深度上下文分析和复杂推理的任务,能够合成来自分散数据点的见解。 |
| 适用场景 | 简单问答系统,需要快速响应的任务。 | 医学诊断、法律分析、科学推理等需要深度理解和复杂推理的任务。 |
| 复杂性 | 实现相对简单,依赖现有文本检索技术。 | 实现较为复杂,需要构建和维护图结构,以及高效的图遍历算法。 |
| 性能 | 在不需要复杂推理的任务上表现良好。 | 在需要复杂推理和上下文理解的任务上表现出色,但可能增加检索速度和资源消耗。 |
应用点
浙大 Graph与AI Agent:全景综述
🚀 前言
之前对于图神经网络(GNN)的基础能力提升(model centric)已有较多研究,而在AI Agent背景下,图本身建模复杂关系的灵活性能从数据角度(data centric)提升Agent模型侧的能力。这篇综述比较新颖的从图数据组织和知识结构化的角度回顾了现有工作如何多维度增强Agent。
📚 总结
首次全景式总结了「图技术如何全方位增强AI Agent的规划、执行、记忆与多智能体协作能力,并反向探讨Agent如何自动化图学习」
比较清晰的介绍了如何把Agent各方面能力与结构化知识互补结合,相关文献整理在了Github供读者方便检索。
🌱 研究背景
- AI Agent技术栈正经历范式的跃迁与迭代:
RL→LLM→「RL+LLM」融合 - 复杂任务要求Agent具备规划、执行、记忆、多智能体协作等能力,但面临信息和知识高度异构、动态、分散的挑战
- 图(Graph)数据形式天然擅长建模关系,能把杂乱数据结构化,为提升Agent能力提供新钥匙
🧩 文章介绍
- 1️⃣ 首份系统综述:梳理「图技术如何武装 AI Agent」与「AI Agent 如何反哺图学习」
- 2️⃣ (主)从四维分类角度介绍Graph在不同Agent能力侧如何起作用:Planning / Execution / Memory / Multi-Agent Coordination
- 3️⃣ (次)Agent能力如何助于图学习:图生成与标注、图建模
- 4️⃣ 盘点200+前沿论文,讨论应用&未来机会
🗺️ 四维分类速览(见图 2)
- ① Planning:用知识图谱、任务分解图、状态空间图做推理、分解与决策搜索
- ② Execution:把工具调用关系织成
Tool Graph;构造环境图指导Agent与环境交互 - ③ Memory:将经验存成 Memory Graph,支持高效检索、动态更新与长期维护
- ④ Multi-Agent Coordination:构建Agent Coordination Graph,优化消息传递与多智能体拓扑结构
工具
一键生成图谱
【2025-6-23】项目
RAGFlow
0.16.0 版本引入知识图谱功能,开启后,RAGFlow 会在当前知识库的分块上构建知识图谱,构建步骤位于数据抽取和索引之间
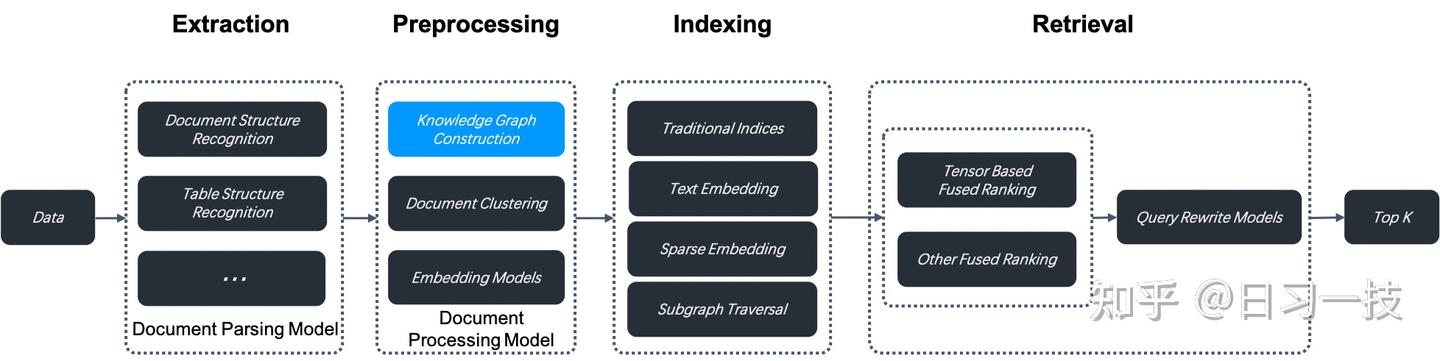
构建知识图谱将消耗大量 token 和时间。
知识图谱在涉及嵌套逻辑的多跳问答中尤其有用,当你在对书籍或具有复杂实体和关系的作品进行问答时,知识图谱的表现优于传统的抽取方法。
RAGFlow 能在复杂多跳问答场景中表现得更加出色,特别是在分析具有复杂关系和实体的文档时。

GraphRAG 的逻辑位于任务执行器的 do_handle_task() 函数中:
async def do_handle_task(task):
# ...
elif task.get("task_type", "") == "graphrag":
# 绑定聊天模型
chat_model = LLMBundle(task_tenant_id, LLMType.CHAT, llm_name=task_llm_id, lang=task_language)
# 运行 GraphRAG 逻辑
graphrag_conf = task["kb_parser_config"].get("graphrag", {})
with_resolution = graphrag_conf.get("resolution", False)
with_community = graphrag_conf.get("community", False)
async with kg_limiter:
await run_graphrag(task, task_language, with_resolution, with_community, chat_model, embedding_model, progress_callback)
return
配置参数如下:
实体类型(entity_types) - 指定要提取的实体类型,默认类型包括:组织(organization)、人物(person)、事件(event)和类别(category),可根据具体的知识库内容添加或删除类型;方法(method) - 用于构建知识图谱的方法,RAGFlow 支持两种方法:- 通用(general):使用 GraphRAG 提供的提示词提取实体和关系。
- 轻量(light):使用 LightRAG 提供的提示词来提取实体和关系。此选项消耗更少的 tokens、更少的内存和更少的计算资源。
实体消歧(resolution) - 是否启用实体消歧。- 启用后,解析过程会将具有相同含义的实体合并在一起,从而使知识图谱更简洁、更准确。
- 例如 “2025” 和 “2025 年” 或 “IT” 和 “信息技术”,“特朗普总统” 和 “唐纳德·特朗普” 等。
- 社区报告生成(community) - 是否生成社区报告。
- 知识图谱中,社区是由关系连接的实体簇,可以让大模型为每个社区生成摘要,这被称为 社区报告。
【2024-2-13】GraphRAG
GraphRAG(Graph-enhanced Retrieval-Augmented Generation)是在RAG架构中引入知识图谱结构的增强版本
核心理念:
- 将原始文档中的实体、概念和关系抽取出来,构建成图谱结构,再参与RAG流程。
简单说,让AI“有图可依”,不再“只看文本”。
现有 GraphRAG 方法主要分为两类:
- 从检索角度出发,如LightRAG、GNN-RAG、GFM-RAG和HippoRAG等;
- 从图构建角度出发,如KGP、GraphRAG、RAPTOR和E2GraphRAG等。
然而,这些方法通常是孤立优化的,未能充分考虑图构建和检索之间的相互依赖关系
【2023-8-15】GraphRAG 基于知识图谱的搜索增强
A RAG over code solution that actually works (open-source).
Naive chunking used in RAG isn’t suited for code.
This is because codebases have long-range dependencies, cross-file references, etc., that independent text chunks just can’t capture.
Graph-Code is a graph-driven RAG system that solves this.
It analyzes the Python codebase and builds knowledge graphs to enable natural language querying.
Key features:
- Deep code parsing to extract classes, functions, and relationships.
- Uses Memgraph to store the codebase as a graph.
- Parses pyproject to understand external dependencies.
- Retrieves actual source code snippets for found functions.
Find the repo in the replies!
【2024-2-13】GraphRAG 发布
【2024-2-13】微软 首次宣布推出 GraphRAG
- GraphRAG: Unlocking LLM discovery on narrative private data
- GraphRAG 对复杂信息进行文档分析, 用 LLM 生成知识图, 显着提高问答性能
- 便于在私有数据集上增强RAG能力, 如: 企业专有研究、商业文档或通信。
传统 RAG 不擅长
- 通过共享属性遍历不同信息, 提供新的综合见解:
- 全面理解大型数据集, 甚至单个大型文档, 概括语义概念;
- 传统 RAG 依赖于数据集中语义相似文本内容的矢量搜索。查询中没有任何内容可以将其定向到正确的信息。
- 数据中排名前 5 位的主题是什么?
GraphRAG 用LLM基于私有数据集创建知识图谱。然后与图机器学习一起使用,查询时执行提示增强。
- GraphRAG 在回答上述两类问题上,提升明显,展示了优于之前应用于私有数据集的其他方法的智能或掌握能力。
GraphRAG = 三层增强:
- 图谱构建层:文本解析 → 实体识别 + 关系抽取 → 生成知识图谱(KG)
- 图谱检索层:用户问题向量化后,不只查文档,还查图谱上的相关节点和路径(更精确)
- 语义生成层:将图谱知识 + 文本片段 + 用户query 一起送进LLM,生成更准确的回答
一句话总结:
- RAG:查段落拼一拼;GraphRAG:查图谱理逻辑,回答更有“章法”。
适用场景
- 🏥 医疗健康问答:构建药物-症状-适应症-副作用的医学图谱,模型可回答:“这两种药能一起吃吗?”
- 📚 法律合规解析:从合同或法规中抽取“条款-行为-责任”的图谱,支持合规审查和法律问答
- 🏢 企业知识管理:搭建“岗位-制度-流程”的组织图谱,HR助手能精准回答“试用期员工能请年假吗?”
- 🧬 生物科研与文献挖掘:解析论文中的“基因-疾病-药物”结构,辅助科研人员快速理解科研图谱
- 📦 产品知识图谱客服:电商平台构建“产品-属性-FAQ-问题场景”的知识图谱,客服机器人变得更“专业”
问题:
- Query: “What is Novorossiya?” — “什么是新俄罗斯?”
- 基线RAG 和 GraphRAG 表现良好
| 类型 | 示例 | Baseline RAG |
GraphRAG |
分析 |
|---|---|---|---|---|
| 常规 | “What is Novorossiya?” “什么是新俄罗斯?” |
所提供的上下文中未提及“Novorossiya”一词。然而,为了提供一些信息,Novorossiya(新俄罗斯)是一个历史术语,指的是乌克兰南部的一个地区,该地区在 18 世纪被俄罗斯帝国征服。近年来,俄罗斯支持的乌克兰东部分离主义者重新使用了这个词来指代他们声称拥有主权的领土,但国际机构并未正式承认它是一个独立的实体。 | 新俄罗斯,又称新俄罗斯,是一个具有历史和当代意义的术语。历史上,它指的是俄罗斯帝国南部的一个地区,现在是乌克兰的一部分。在当代背景下,它被亲俄分离主义者用来指代乌克兰的某些地区[数据:实体(6494, 912, 6493)]。 “Novorossiya”一词在乌克兰的政治运动中被使用,特别是俄罗斯民族主义者。这一运动与破坏乌克兰稳定和创建所谓的“Novorossiya”的努力有关 [ 数据:实体(912);关系(15211、15206)]。该术语还被用来表示乌克兰的一个分离主义国家,称为新俄罗斯联邦共和国 (FRN) [数据:实体 (7690)]。 |
二者表现都可以 |
| 需要连接 | What has Novorossiya done?” “新俄罗斯做了什么?” |
该文本没有提供有关 Novorossiya 所做工作的具体信息。 | 乌克兰的政治运动 Novorossiya 参与了一系列破坏性活动,特别是针对乌克兰的各种实体 [实体 (6494, 912)]。该运动与摧毁多个乌克兰实体财产的计划有关,包括罗森、敖德萨罐头厂、敖德萨地区广播电视传输中心和乌克兰国家电视公司[ 关系(15207、15208、15209、15210)] 。除此之外,Novorossiya 还参与了摧毁 Roshen、敖德萨音乐学院工厂、敖德萨地区广播电视传输中心和乌克兰国家电信公司财产的计划 [关系 (8329、8330、8331、8332)] 。此外,Novorossiya 还参与了炸毁乌克兰最大国有银行 PrivatBank ATM 机的计划 [Relationships (8335, 8335)]。 乌克兰总检察长办公室报告了 Novorossiya 的成立,表明政府对该运动的活动的认识和潜在关注 [Relationships (8264, 8264)]。新俄罗斯的破坏活动对目标实体产生了重大影响,并可能加剧了该地区持续的紧张局势和冲突。 总之,“新俄罗斯”参与了一系列针对乌克兰境内各个实体的破坏性活动。这些活动对目标实体产生了重大影响,并可能加剧了该地区持续的紧张局势和冲突。乌克兰政府通过总检察长办公室承认了新俄罗斯组织的存在和活动,表明对该运动的行为表示一定程度的关注。 |
源文档没有任何文本段讨论 Novorossiya,导致此Baseline RAG失败; 而GraphRAG 方法在查询中发现了一个实体 Novorossiya, 据此进一步探索,LLM用来通过图中两个实体之间存在的关系来支持特定银行是 Novorossiya 目标的断言 |
| 综合理解 | “What are the top 5 themes in the data?“ “数据中排名前 5 的主题是什么? “ |
1. 提高城市生活质量和城市发展。 2. 弗拉基米尔·普京与阿拉伯联合酋长国总统穆罕默德·本·扎耶德·阿勒纳哈扬的会晤。 3. 俄罗斯各地区投资环境国家评级。 4. 俄罗斯经济状况和国内品牌的成长。 5. 关于生命意义和科学在理解生命中的作用的讨论。 |
数据呈现了广泛的主题,但最流行的五个主题可以确定如下: 1.冲突和军事活动:很大一部分数据围绕乌克兰持续的冲突,有大量报告详细介绍了各种实体的军事活动、占领和袭击。该主题包括乌克兰军队、俄罗斯军队以及其他各种军事单位和实体的行动[ 数据:报告(513、241、151、493、343,+更多)]。…(省略)… |
Baseline RAG 主题都与两国之间的战争没有太大关系; GraphRAG结果与整个数据集中发生的情况更加一致。答案提供了五个主要主题以及数据集中观察到的支持细节。 |
LLM生成的知识图谱,GraphRAG 极大地改进了 RAG “检索”部分,用更高相关性的内容填充上下文窗口,从而获得更好的答案并捕获证据来源。
【2024-7-2】GraphRAG 开源
GraphRAG 开源+私人数据
【2024-7-4】下一代 RAG 技术来了!微软正式开源 GraphRAG:大模型行业将迎来新的升级
2024年7月2日,微软开源 GraphRAG,基于图的检索增强生成 (RAG) 方法,对私有或以前未见过的数据集进行问答。
GraphRAG 极大增强 LLM 处理私有数据的性能,同时具备连点成线的跨大型数据集的复杂语义问题推理能力。
- 普通 RAG 技术在私有数据,如企业专有研究、商业文档表现非常差
- 而 GraphRAG 则基于前置的知识图谱、社区分层和语义总结以及图机器学习技术,大幅度提升性能。
GraphRAG 方法:
- 利用大型语言模型 (LLMs) 从数据源中提取知识图谱;
- 将图谱聚类成不同粒度级别的相关实体社区;
- RAG 过程中, 遍历所有社区以创建“社区答案”,并进行缩减以创建最终答案。
大规模播客以及新闻数据集上进行了测试,在全面性、多样性、赋权性方面
- 结果显示 GraphRAG 都优于朴素 RAG(70~80% 获胜率)。
查询语句: 对比 原始RAG 和 GraphRAG
- Novorossiya 是什么? —— 两者差异不大
- Novorossiya 做了什么?—— GraphRAG > 原始RAG(回答失败)
缺陷
- token 使用和推理时间都会增加……
GraphRAG 自动适配新领域
【2024-9-9】GraphRAG auto-tuning provides rapid adaptation to new domains
LLM 在特定于领域提示的指导下,读取所有源内容并提取相关信息,包括实体和关系,然后将其用于构建图表。
分析新闻文章时,相关信息很重要:
- 实体: 人物、地点和组织等实体。
- 关系类型: “居住”、“领导”和“拥有”。
每个域都有不同的实体和关系类型。
- 例如,在化学领域,实体类型包括分子、酶和反应,而关系类型包括“催化”和“还原”。
- 尽管 GraphRAG 默认新闻域提示在应用于化学时可以生成图表,但无法捕获化学家期望的特定内容。
新闻文章用的所有提示都是手动生成。为了简化这个过程,开发了一个自动化工具,生成特定于域的提示,这些提示经过调整并可供使用。
该工具遵循类似人类的方法
- 向LLM提供了文本数据样本(例如,10,000 篇化学论文中的 1%),并指示其生成它认为最适用于内容的提示。现在,借助这些自动生成和调整的提示,可立即将 GraphRAG 应用到选择的新领域,并相信将获得高质量的结果。
GraphRAG 三个主要索引提示:
- 实体和关系提取:识别所有实体并建立关系。
- 实体和关系摘要:将实体实例及其关系合并为简洁描述。
- 社区报告生成:为构建的知识图谱中的每个社区生成摘要报告。
提取提示包括:
- 提取说明:向LLM提供如何执行提取的指导。
- Few-shot Examples :为LLM提供值得提取的实体和关系类型的真实例子。
- 真实数据:充当占位符,被源内容块替换。
- Gleanings :鼓励LLM在多个回合中提取更多信息。
Auto-tuning architecture 自动调优架构
自动调整获取源内容并生成一组自动生成的特定于域的提示
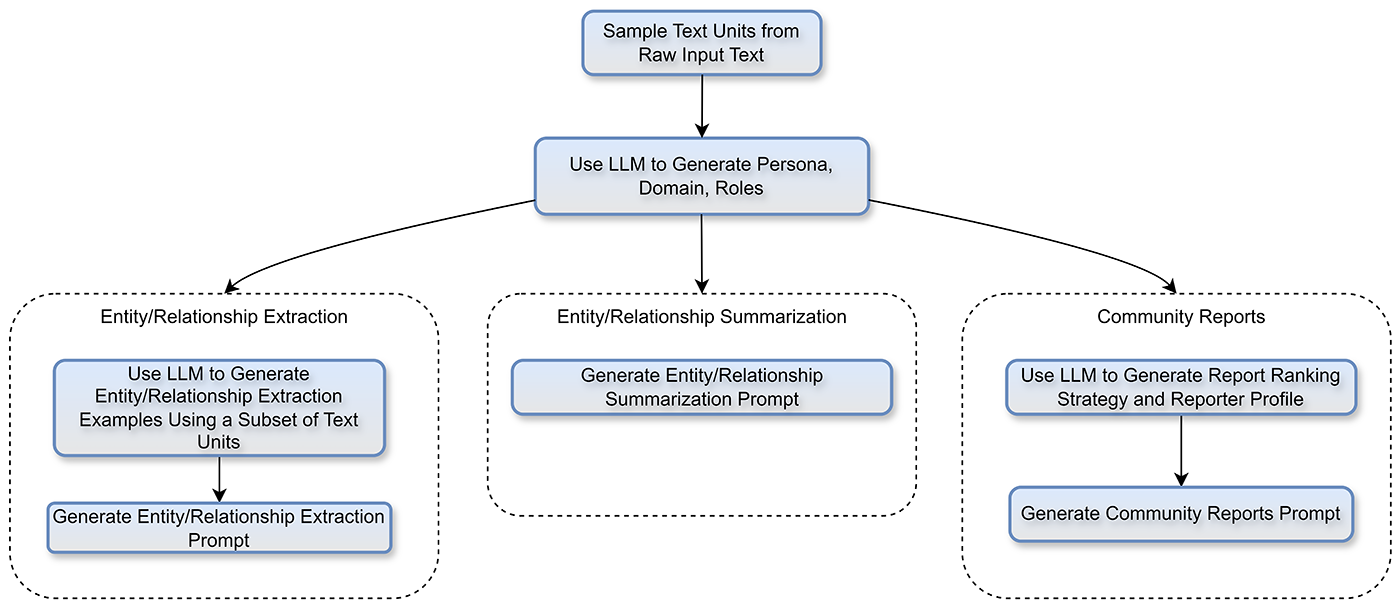
源内容的样本发送给LLM ,LLM 首先识别域,然后创建适当的角色 - 与下游代理一起使用来调整提取过程。一旦建立了域和角色,就会并行发生多个过程来创建我们的自定义索引提示。这样,就可以根据实际领域数据并从角色的角度生成少量提示。
解决什么问题
查询:
“告诉我所有关于
苹果和乔布斯的事”
基于《乔布斯自传》这本书进行问答,而这个问题涉及上下文分布在自传这本书的 30 页(分块)时
- 传统方法 “分割数据,Embedding 再向量搜索”, 在多个文档块里用 top-k 去搜索,很难得到这种分散、细粒度的完整信息。
- 这种方法还很容易遗漏互相关联的文档块,从而导致信息检索不完整。
知识图谱可减少基于嵌入语义搜索所导致的不准确性。
- 例子:“保温大棚”与“保温杯”,尽管在语义上两者是存在相关性的,但在大多数场景下,这种通用语义(Embedding)下的相关性常常并不希望产生,进而作为错误的上下文而引入“幻觉”。
这时候,保有领域知识的知识图谱则是非常直接可以缓解、消除这种幻觉的手段。
基本流程
增加一路与向量库平行的KG(知识图谱)上下文增强策略
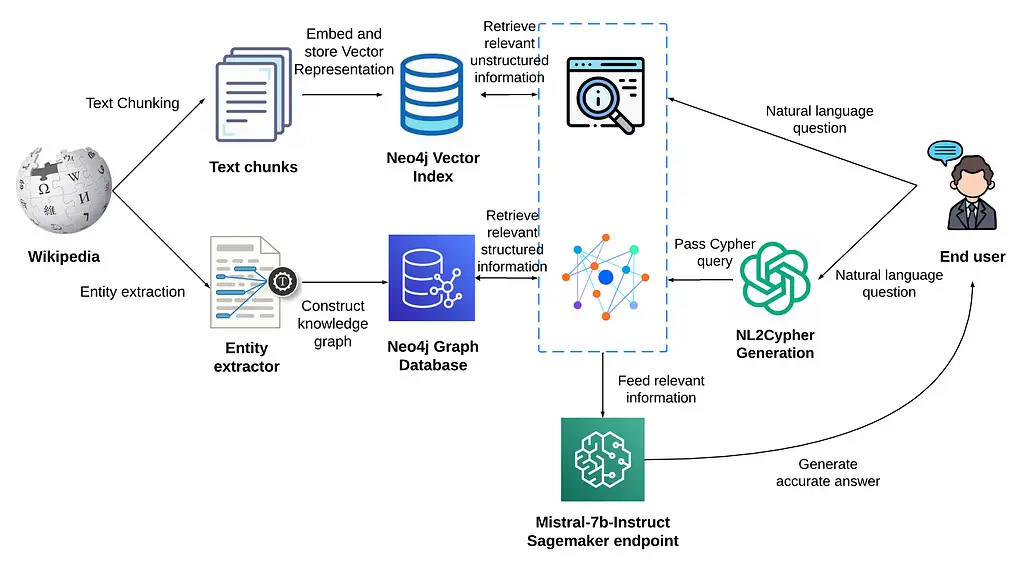
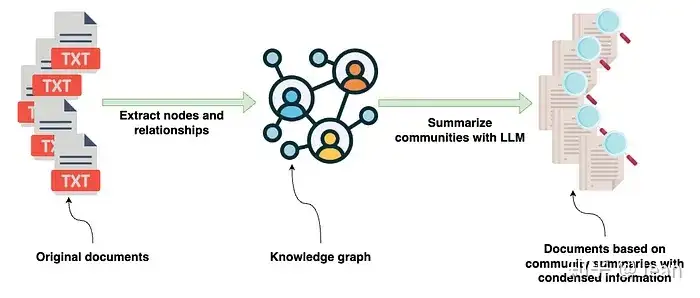
query进行KG增强是通过NL2Cypher模块实现。可用更简单的图采样技术来进行KG上下文增强。
具体流程:
- 从 query 中抽取实体
- 把实体作为种子节点,对图进行采样
- 必要时,可把KG节点和query中实体先向量化,通过向量相似度设置种子节点
- 把获取的子图转换成文本片段,达到上下文增强效果。
Graph RAG 简单实现:
- 用LLM(或其他)从问题中提取关键实体。
- 根据实体,以一定深度(如2)检索子图。
- 子图生成描述语,融入上下文,调用LLM产生答案。
可用 Llama Index 轻松搭建 GraphRAG,甚至整合更复杂的 RAG 逻辑,比如 Graph+Vector RAG。

Llama Index 有两种方法实现 Graph RAG:
KnowledgeGraphIndex从任何私有数据只是从零构建知识图谱(基于 LLM 或者其他语言模型),然后 4 行代码进行 Graph RAG。KnowledgeGraphRAGQueryEngine在任何已经存在的知识图谱上进行 Graph RAG,不过还没有完成这个 PR。
分析
GraphRAG 优势三个方面:
- 更高的准确度和更完整答案(运行时间/生产效益)
- 2023 年底,数据目录公司 Data.world 发表一项研究,GraphRAG 在 43 个业务问题中平均将 LLM 响应的准确性提高了 3 倍。
- 2024年2月,微软:GraphRAG 极大地改进了 RAG 的‘检索’部分,用更高相关性的内容填充上下文窗口,从而得到更好的答案并捕获证据出处。 ” GraphRAG 所需 token 减少了 26% 到 97%,这不仅使其能够更好地提供答案,而且更便宜、更具可扩展性。
- Linkedin: GraphRAG 提高了回答客户服务问题的正确性和丰富性(因此也提高了实用性),为其客户服务团队将每个问题的平均解决时间缩短了 28.6% 。
- 一旦创建了知识图谱,构建、维护 RAG 应用程序更加容易(开发时间优势)
- 更好的可解释性、可追溯性和访问控制(治理优势)
治理:可解释性、安全性等
text2cypher
基于图谱的 LLM, 一种实现技术是 text2cypher。
- 不依赖于实体的子图检索,而是将任务/问题翻译成一个面向答案的特定图查询
- 和 text2sql 方法本质一样。
text2cypher 根据 KG 的 Schema 和给定的任务生成图形模式查询,而 SubGraph RAG获取相关的子图以提供上下文。
得益于 LLM,实现 text2cypher 比传统 ML 方法更为简单和便宜。
- LangChain: NebulaGraphQAChain
- Llama Index: KnowledgeGraphQueryEngine
3 行代码就能跑起来 text2cypher。
示例
【2024-7-17】GraphRAG实战
【2024-7-15】 GraphRAG制作的《凡人修仙传》知识图谱长什么样
- 用 LLM 从小说中抽取
节点、边、属性信息 - 实体类别:
person,event,geo,organization,cencept,role,technology - 以 图方式检索、排序,附带权重
结合 Neo4j
【2024-8-8】将微软GraphRAG集成到Neo4j中
- 将 GraphRAG 生成的 Parquet 文件导入到 Neo4j 中, ms_graphrag_import.ipynb
- 用 LangChain 和 LlamaIndex 实现检索器。
import pandas as pd
from neo4j import GraphDatabase
import time
GRAPHRAG_FOLDER="artifacts"
NEO4J_URI="bolt://localhost"
NEO4J_USERNAME="neo4j"
NEO4J_PASSWORD="password"
NEO4J_DATABASE="neo4j"
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
def batched_import(statement, df, batch_size=1000):
"""
Import a dataframe into Neo4j using a batched approach.
Parameters: statement is the Cypher query to execute, df is the dataframe to import, and batch_size is the number of rows to import in each batch.
"""
total = len(df)
start_s = time.time()
for start in range(0,total, batch_size):
batch = df.iloc[start: min(start+batch_size,total)]
result = driver.execute_query("UNWIND $rows AS value " + statement,
rows=batch.to_dict('records'),
database_=NEO4J_DATABASE)
print(result.summary.counters)
print(f'{total} rows in { time.time() - start_s} s.')
return total
statements = """
create constraint chunk_id if not exists for (c:__Chunk__) require c.id is unique;
create constraint document_id if not exists for (d:__Document__) require d.id is unique;
create constraint entity_id if not exists for (c:__Community__) require c.community is unique;
create constraint entity_id if not exists for (e:__Entity__) require e.id is unique;
create constraint entity_title if not exists for (e:__Entity__) require e.name is unique;
create constraint entity_title if not exists for (e:__Covariate__) require e.title is unique;
create constraint related_id if not exists for ()-[rel:RELATED]->() require rel.id is unique;
""".split(";")
for statement in statements:
if len((statement or "").strip()) > 0:
print(statement)
driver.execute_query(statement)
doc_df = pd.read_parquet(f'{GRAPHRAG_FOLDER}/create_final_documents.parquet', columns=["id", "title"])
doc_df.head(2)
# import documents
statement = """
MERGE (d:__Document__ {id:value.id})
SET d += value {.title}
"""
batched_import(statement, doc_df)
更多源码见笔记
【2024-10-08】LightRAG
【2024-10-08】比GraphRAG还好的LightRAG到底是何方神圣?
RAG 系统通过整合外部知识源,使 LLM 能够提供更精准、更符合用户需求的响应。
然而,现有 RAG 系统存在依赖扁平数据和上下文意识不足的问题,导致答案碎片化。
为此,LightRAG 将图结构融入检索过程,采用双层检索系统,提升信息检索的全面性。
结合图结构与向量表示,LightRAG 能高效检索相关实体及其关系,显著提升响应速度并保持上下文相关性。通过增量更新算法,LightRAG 能及时整合新数据,适应快速变化的环境。
实验证明,LightRAG 在检索精度和效率上优于现有方法。
SubgraphRAG
【2024-10-28】佐治亚理工提出 SubgraphRAG 知识图谱(KG)增强型检索增强生成(RAG)框架。
SubgraphRAG 通过结合大模型(LLMs)和结构化知识图谱(KGs)来解决LLMs在推理能力上的局限性
- 核心思想: 先检索与查询相关的子图,然后利用LLMs进行推理和答案预测。
查询示例:
- “Which organizations have business partnerships with at least one company founded respectively by Elon Musk, Jeff Bezos, and Bill Gates - but weren’t founded by any of them?”
- 子图检索:SubgraphRAG 会检索包含
Elon Musk、Jeff Bezos和Bill Gates创立的公司以及与这些公司有商业合作关系的组织的三元组。
答案:SubgraphRAG 返回答案 [Nvidia, Nasa]。Nvidia 与 Tesla(由 Elon Musk 创立)、Amazon(由 Jeff Bezos 创立)和 Microsoft(由 Bill Gates 创立)都有商业合作关系,而 Nvidia 本身并非由这三人中的任何一个创立。
SubgraphRAG 实现步骤:
- 1、查询解析和实体提取(Query Analysis and Entity Extraction):
- 首先,SubgraphRAG 从用户查询中识别出主题实体(Topic Entities)。
- 这些实体是查询中直接提及的或者与查询紧密相关的知识图谱中的节点。
- 2、子图提取(Subgraph Extraction):子图提取过程:
- 结构特征构建(Structural Feature Construction):这一步骤中,SubgraphRAG 会计算查询中的实体与知识图谱中实体之间的结构距离,使用方向性距离编码(DDE)来表示这些距离。
- 并行提取相关三元组(Extract Relevant Triples in Parallel):在这一步骤中,SubgraphRAG 并行地从知识图谱中提取与主题实体相关的三元组。
- 实施方法:使用一个轻量级的多层感知器(MLP)模型来编码和评估潜在子图的相关性。然后,基于MLP评分,从知识图谱中检索最相关的子图。
- 3、LLM推理(LLM Reasoning):
- 设计了专门的提示模板,这些模板指导LLM如何利用检索到的子图信息来生成答案。
KGGen
【2025-2-14】GraphRAG图谱过于稀疏,KgGen补之不足
动机
当前知识图谱提取方法(OpenIE 和 GraphRAG)存在的弊端:
- OpenIE 提取的图谱节点冗长且缺乏语义一致性
- GraphRAG 提取的图谱则过于稀疏,导致重要关系和信息的遗漏。
KGGen
KGGen 基于语言模型的文本到知识图谱生成工具,利用语言模型从纯文本中提取实体和关系,并通过聚类算法减少图谱的稀疏性,从而生成高质量、密集的知识图谱。
安装
pip install kg-gen
原理
KGGen 包含三种模块:
- (1) 实体和关系提取(Generate 模块)
- 关系提取:在提取实体的基础上,进一步提取主语-谓语-宾语三元组,以捕捉实体之间的关系。
- 实体提取:通过语言模型从输入文本中识别关键实体,包括名词、动词和形容词等。
- (2) 图谱聚合(Aggregate 模块)
- 提取完每个文本片段的三元组后,KGGen 将所有独特实体和关系合并到一个单一图谱中。
- 聚合过程,将所有实体和关系统一为小写形式,以减少冗余。这一过程不依赖语言模型,而是通过简单的字符串规范化实现。
- (3) 实体和关系聚类(Cluster 模块)
- 通过迭代的语言模型调用,将语义相似的实体和关系合并为同一簇。
- 实体聚类:将所有实体列表传递给语言模型,模型尝试提取一个实体簇。簇内的实体应具有相同的语义,但可能在时态、单复数、词根或大小写上有所不同。
- 簇验证:通过语言模型验证提取的簇是否合理。如果验证通过,则将簇添加到最终图谱中,并从实体列表中移除已聚类的实体。
- 簇标记:为每个簇分配一个能够准确描述其语义的标签。
- 重复聚类:重复上述步骤,直到连续 n 次未能成功提取簇为止。
- 剩余实体检查:对剩余实体进行批量检查,判断它们是否可以加入已有的簇。
- 关系聚类:对关系进行类似的聚类操作,但使用略微修改的提示。
通过聚类,KGGen 能够生成密集且语义一致的知识图谱,从而为下游任务提供更有用的结构化数据。
效果
对比 KGGen、Graph RAG 、OpenIE 创建的知识图谱,从节点的稀疏性和一致性方面,KGGen 表现是非常良好
HippoRAG
HippoRAG 1
俄亥俄州立大学推出
【2025-2-20】HippoRAG 2 – sota
【2025-2-20】HippoRAG 2发布,GraphRAG退位
新型框架 HippoRAG 2 提出
- 解决现有检索增强生成(RAG)系统在模拟人类长期记忆的动态和关联性方面的局限性
- 数据和代码 HippoRAG
- From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
三个维度上评估持续学习能力:事实记忆、感知构建和关联性。
HippoRAG 2 在所有基准类别中均超越了其他方法(RAPTOR、GraphRAG、LightRAG、HippoRAG),使其更接近真正的长期记忆系统
核心思想:
- HippoRAG 2 基于 HippoRAG 的个性化PageRank算法,通过深度段落整合和更有效的在线LLM使用,推动RAG系统更接近人类长期记忆的效果。
(1)离线索引:
- 使用LLM从段落中提取三元组,并将其整合到开放知识图谱(KG)中。
- 通过嵌入模型检测同义词,并在KG中添加同义词边。
- 将原始段落与KG结合,形成包含概念和上下文信息的开放KG。
(2)在线检索:
- 使用嵌入模型将查询与KG中的三元组和段落链接,确定图搜索的种子节点。
- 通过LLM过滤检索到的三元组,保留相关三元组。
- 应用个性化PageRank算法进行上下文感知检索,最终为下游问答任务提供最相关的段落。
基线方法包括
- 经典检索器(BM25、Contriever、GTR)
- 大型嵌入模型(GTE-Qwen2-7B-Instruct、GritLM-7B、NV-Embed-v2)
- 结构增强RAG方法(RAPTOR、GraphRAG、LightRAG、HippoRAG)。
HippoRAG 2 在所有基准类别上均超越其他方法,平均F1分数比标准RAG高出7个百分点,特别是在关联记忆任务上表现突出。
HyperGraphRAG
问题
- 现有 GraphRAG 只关联两个实体,而实际场景的实体未必是2个
【2025-3-27】北邮、南洋理工 推出 HyperGraphRAG, 用超图(hypergraph)里超边(hyperedge)建立多实体关系
HyperGraphRAG shows better accuracy, achieving higher Context Recall (e.g., 60.34 overall) and Answer Relevance (e.g., 85.15 in Medicine) than previous methods.
- 📌 Hypergraphs intrinsically model multi-entity facts, overcoming the information loss in binary graph representations.
- 📌 Dual vector retrieval (entities, hyperedges) enables precise fact finding and contextual expansion simultaneously.
- 📌 Capturing richer relations via hypergraphs improves accuracy, balancing slightly increased construction time and cost.
Methods Explored in this Paper 🔧:
- → LLMs extract n-ary relational facts (hyperedges connecting multiple entities) from text to construct a knowledge hypergraph.
- → A bipartite graph structure stores the hypergraph efficiently in standard graph databases.
- → Vector embeddings represent both entities and hyperedges for semantic retrieval using similarity search.
- → A retrieval strategy first finds relevant entities based on the query, then expands to find connected hyperedges and related entities.
- → Generation combines retrieved hypergraph facts with traditional chunk-based retrieved text for a comprehensive final answer.
RAKG
多个框架,包括KGgen, RAKG 以及GraphRAG三个工具,发现RAKG抽取的知识更全面 更丰富 以及更准确
传统的知识图谱构建方法面临长文本处理中的长距离遗忘问题、复杂实体消歧、跨文档知识整合不足的问题
【2025-4-14】上海人工智能实验室的开源工作
特点
RAKG 以下特点:
- 特点1:
预实体提取 + RAG 查询- → 首创从文本块提取”
预实体“作为检索查询 - → 解决LLM长文本遗忘问题
- → 大幅降低指代消解复杂度
- → 首创从文本块提取”
- 特点2: 全局知识网络捕获 🌐
- → 突破传统KGC的文档孤岛限制
- → 精准抓取跨文档节点关联
- → 构建更完整的知识拓扑结构
- 特点3: 抗幻觉质检系统 🛡️
- → 移植RAG评估框架到KGC领域
- → 自动过滤LLM生成的错误实体/关系
- → 准确率95.91%(超最佳基线6.2%)
原理
RAKG(Document-level Retrieval Augmented Knowledge Graph Construction)利用大型语言模型自动生成知识图谱的框架。
- 通过句子的分片和向量化处理文档,提取初步实体,并进行实体消歧和向量化。
- 处理后的实体通过语料库回顾检索获取相关文本,通过图结构检索获取相关知识图谱。
- 最后,使用LLM(Large Language Model)整合检索到的信息,构建关系网络,并将新构建的知识图谱与原有知识图谱合并。
效果
实验结果
- MINE 测试集: RAKG 95.91%, GraphRAG (89.71%), 高出 6.2 pp
使用
基础设施
- 大型语言模型:项目使用了如 Qwen、BGE-M3 等模型进行实体的识别、消歧和信息的整合。
- 知识图谱构建:通过检索和整合信息,构建包含丰富关系的知识图谱。
- 语料库检索:通过检索相关文本,增强知识图谱的构建过程。
安装
- 编辑
src/config.py文件,配置模型提供者的设置。- 本地 Ollama 模型,将 base_url 设置为 http://localhost:11434/v1/。
- 服务器端的 Ollama,将 base_url 设置为 http://your_server_ip。
git clone https://github.com/LMMApplication/RAKG.git
cd RAKG
使用方法参考 examples 目录中的 RAKG_example.py 文件。
# 文本输入
cd examples
python RAKG_example.py --input "your input text" --output result/kg.json --topic "your_topic" --is-text
# 文档输入
python RAKG_example.py --input data/MINE.json --output result/kg.json
# 论文复现
cd src/construct
python RAKG.py
按照以上步骤,即可完成 RAKG 的安装和配置。在配置过程中,请确保所有步骤都按照要求执行,以确保项目的正常运行。
Graph-R1
起因
问题背景
- 🌍 大型语言模型在知识密集型应用中存在幻觉问题,生成不准确内容,检索增强生成(RAG)虽引入外部知识缓解此问题,但依赖基于文本块的检索,难以捕捉实体间复杂知识结构。
- 🔍 GraphRAG 方法将知识表示为实体关系图以改进RAG,却面临诸多挑战:
- 知识构建成本高
- 检索过程固定单一
- 生成依赖长上下文推理
- 提示设计
【2025-7-29】Graph-R1 介绍
【2025-7-29】北邮、南洋理工 推出 智能体式GraphRAG框架,结合RL算法(GRPO), 形成 Graph-R1:让AI告别胡说八道
Graph-R1:全新RAG框架,融合智能体、图RAG和强化学习技术, 突破了传统单次检索或基于文本块检索的局限,巧妙整合了图结构化知识、智能体多轮交互和强化学习技术。
Graph-R1 是能在知识超图环境中进行推理的智能体,通过迭代发出查询并检索子图,采用多步骤的”思考-检索-再思考-生成”循环机制。
与先前执行固定检索的图RAG系统不同,Graph-R1能够根据智能体状态演变动态探索图结构。
原理
论文核心实现
- 🌟 提出轻量级知识超图构建方法,从领域知识中提取n元关系事实,通过共享编码器生成实体和关系的语义嵌入,建立知识超图环境。
- 🚀 将检索过程建模为多轮智能体与超图环境的交互,智能体执行“思考-查询-检索-再思考-生成”的推理循环,每步生成结构化输出决定继续推理或终止并生成答案。
- 🔗 设计双路径超图检索机制,结合实体基于和超边直接检索,通过 reciprocal rank aggregation 融合结果,获取相关知识支持推理。
- 🎯 采用基于Group Relative Policy Optimization(
GRPO)的端到端强化学习优化策略,设计包含格式奖励和答案奖励的结果导向奖励函数,统一优化目标。

该智能体采用GRPO进行端到端训练,使用包含结构格式遵循性和答案准确性的复合奖励机制。只有当推理遵循正确格式时才给予奖励,从而鼓励产生可解释且完整的推理轨迹
效果
效果
- 📊 在多个标准RAG数据集上进行实验,Graph-R1 在推理准确性、检索效率和生成质量上优于传统GraphRAG和强化学习增强的RAG方法。
- 🔬 通过消融研究和比较分析,验证了知识构建、多轮交互和强化学习等核心组件的有效性,以及超图表示、GRPO算法等的优势。
六个RAG基准测试中(如HotpotQA、2WikiMultiHopQA),Graph-R1 取得最高的F1分数和生成得分,显著优于包括 HyperGraphRAG、R1-Searcher和Search-R1 在内的先前方法。在更具挑战性的多跳数据集和分布外条件下表现尤为突出。
缺少三个核心组件中的任何一个,Graph-R1 性能都会急剧下降:超图构建、多轮交互和强化学习。
消融研究证实,基于图的多轮检索提升了信息密度和准确性,而端到端强化学习则有效弥合了结构化信息与自然语言之间的鸿沟。
Youtu-GraphRAG
【2025-8-27】腾讯优图 Youtu-GraphRAG
- 论文 Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning
- Code: Youtu-GraphRAG
- Data: AnonyRAG
GraphRAG 将碎片化知识组织成显式结构化的图,有效增强了大语言模型在复杂推理方面的能力。
现有研究单独改进图构建或图检索,导致性能欠佳,尤其是在出现领域迁移时。
因此,腾讯提出垂直统一的智能体范式——Youtu-GraphRAG,将整个框架作为复杂的集成进行联合连接。
- (i)引入种子图模式,限制自动抽取智能体的目标实体类型、关系和属性类型,同时为了在未见过的领域具备可扩展性,该模式也在持续扩展;
- (ii)开发新颖的双感知社区检测方法,融合结构拓扑与子图语义,以实现全面的知识组织,获取更高级别的知识。这自然形成了一个分层知识树,支持结合社区摘要进行自上而下的过滤和自下而上的推理;
- (iii)设计智能体检索器,用于解释相同的图模式,将复杂查询转换为易处理的并行子查询。迭代反思,以实现更高级的推理;
- (iv)定制匿名数据集和一项新颖的“匿名还原”任务,用于深度衡量GraphRAG框架的实际性能, 缓解预训练大语言模型中的知识泄露问题。
在六个具有挑战性的基准测试上进行的大量实验表明
- Youtu-GraphRAG 具有鲁棒性,与最先进的基线相比,显著推动了帕累托前沿,最多可节省90.71%的令牌成本,且准确率提高了16.62%。
- 结果表明,我们的方法具有适应性,能够在对模式进行最小干预的情况下实现无缝的领域迁移。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
