- 顶级AI机构
- 人工智能革命
- 公司架构
- AI机构
- 人才培养
- 开源
- AIGC 创业
- 各家实力
- OpenAI
- OpenAI 使命
- OpenAI 成就
- 团队成员
- 创始人 Sam Altman
- OpenAI 发展历程
- GTM 战略
- OpenAI 接入体验
- DeepMind
- META
- 清华大学
- 上海交大
- 结束
顶级AI机构
【2024-10-21】大模型“六小虎”,就要凉凉了
整体融资困难,估值又不断推高的大背景下,一些大模型创业公司变得举步维艰,进退维谷,其中备受大家关注度的“六小虎”中的某两虎,甚至已经放弃基础大模型研发,转向了AI应用。
国内AI江湖只有“五小虎”的名号,即智谱AI、月之暗面、minimax、百川智能、零一万物5家AI独角兽企业。从团队背景、技术优势、融资能力、市场估值等各种维度评估,它们都处在行业的第一梯队。直到今年6月,前微软全球副总裁姜大昕创办的阶跃星辰加入战局,成为资本市场新宠,一轮估值20亿美元的新融资,也将它送上“AI独角兽”的宝座,“大模型六小虎”的新格局自此奠定。
从“基础大模型”转向“AI应用”:AGI理想很美好,但是活下去更重要
- 基础大模型训练,非常烧钱
- C端营销,成本居高不下
- 早期不少创业型AI公司,5元左右的CPM(Cost Per Mille,每千次展示成本),就能获得不错的转化效果。
- 但随着那些融到大钱的小虎和新势力们的入局,以及大众对AI产品神秘感的消失,C端营销成本被不断拉高,目前行业的平均出价已被推高至10-15元之间。
人工智能革命
【2023-2-20】ChatGPT:那些让美国伟大的俄罗斯人
人工智能三次震惊世界。1997年,2016年,2023年。而这三次都由美国主导,而且都和美国最大的对手苏联(俄罗斯)有关。
- 1997年,IBM的
深蓝,打败俄罗斯国际象棋大师卡斯帕罗夫。 - 2012年,AlexNet 网络拿下计算机视觉比赛第一。
- ImageNet是最权威的人工智能大赛。AlexNet不仅拿了第一,而且精确度是第二名的两倍。
- AlexNet由三个人开发,计算机老教授
辛顿(Geoffrey Hinton),还有他的两个学生,Alex Krizhevsky和小萨。Alex和小萨,都出生在苏联。
- 2016年,
AlphaGo战胜围棋九段李世石。AlphaGo由谷歌旗下的DeepMind开发。谷歌两位创始人中的谢尔盖·布林(Sergey Brin)出生在苏联,是人工智能战略最坚定的推动者。对弈的第三天,比赛进入高潮,布林飞到首尔,代表谷歌享受胜利。 - 2023年,
ChatGPT惊艳登场。它背后最重要的人,不是大家炒作的马斯克和阿尔特曼(Sam Altman),而是OpenAI的联合创始人、首席科学家伊利亚·萨特斯基弗(Ilya Sutskever)。我管他叫“小萨”。小萨和布林一样,出生在苏联。
公司架构
【2012-3-6】从组织结构图看Google、Facebook、微软等大公司的企业文化
Web设计师Manu Cornet出品了一张六大科技公司的组织结构图
亚马逊、Google、Facebook、微软、苹果、甲骨文等六家公司的组织结构图。
- 亚马逊有着严格的等级制度;
- Google也有清晰的等级,但是部门之间相互交错;产品和组织结构混乱,但这是施密特领导时期的写照,在佩奇担任CEO之后已大为改观。
- Facebook就像是一张分布式网络;但其实应该更接近于Apple的情况,即以扎克伯格为核心。
- 微软则是各自占山为王,军阀文化深入骨髓,跟当年的IBM并无二致。
- 苹果是一个人说了算。乔布斯的核心效应非常明显。
- 最具讽刺意义的是最后的甲骨文,法务部门远远大于工程部门。乱糟糟的法务要比技术“重要”得多。
加备注
AI机构
AI机构分布

【2022-1-25】AMiner重磅发布:2022年人工智能全球最具影响力学者榜单AI 2000
【2024-4-24】 斯坦福AI(大模型)指数2024年度报告
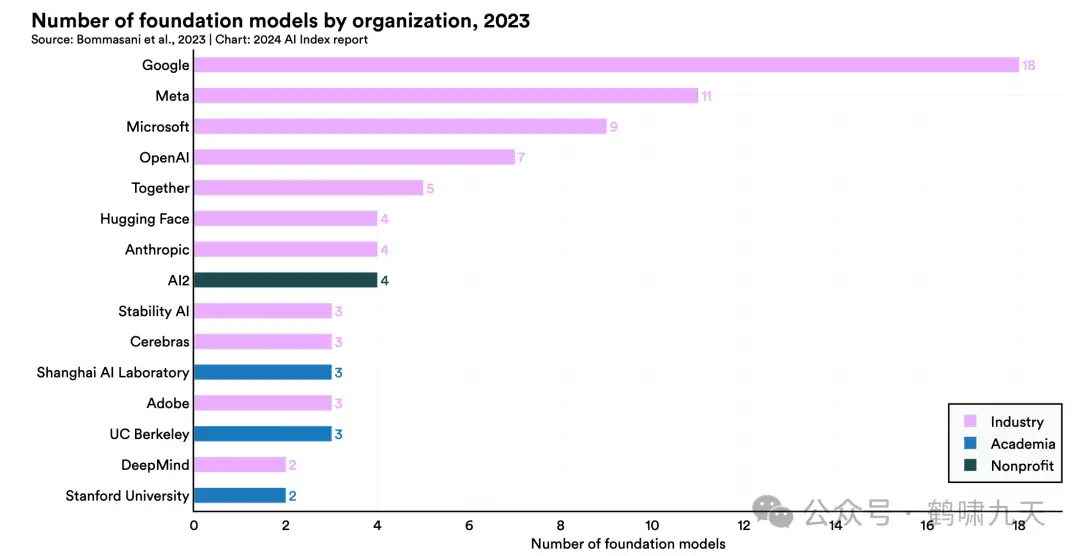
2023年度的知名机构,工业界继续拉开差距
- 学术界寥寥无几,就 上海AI实验室、UC伯克利和斯坦福
- 1个非盈利机构AI2
- 其余全部都是大公司
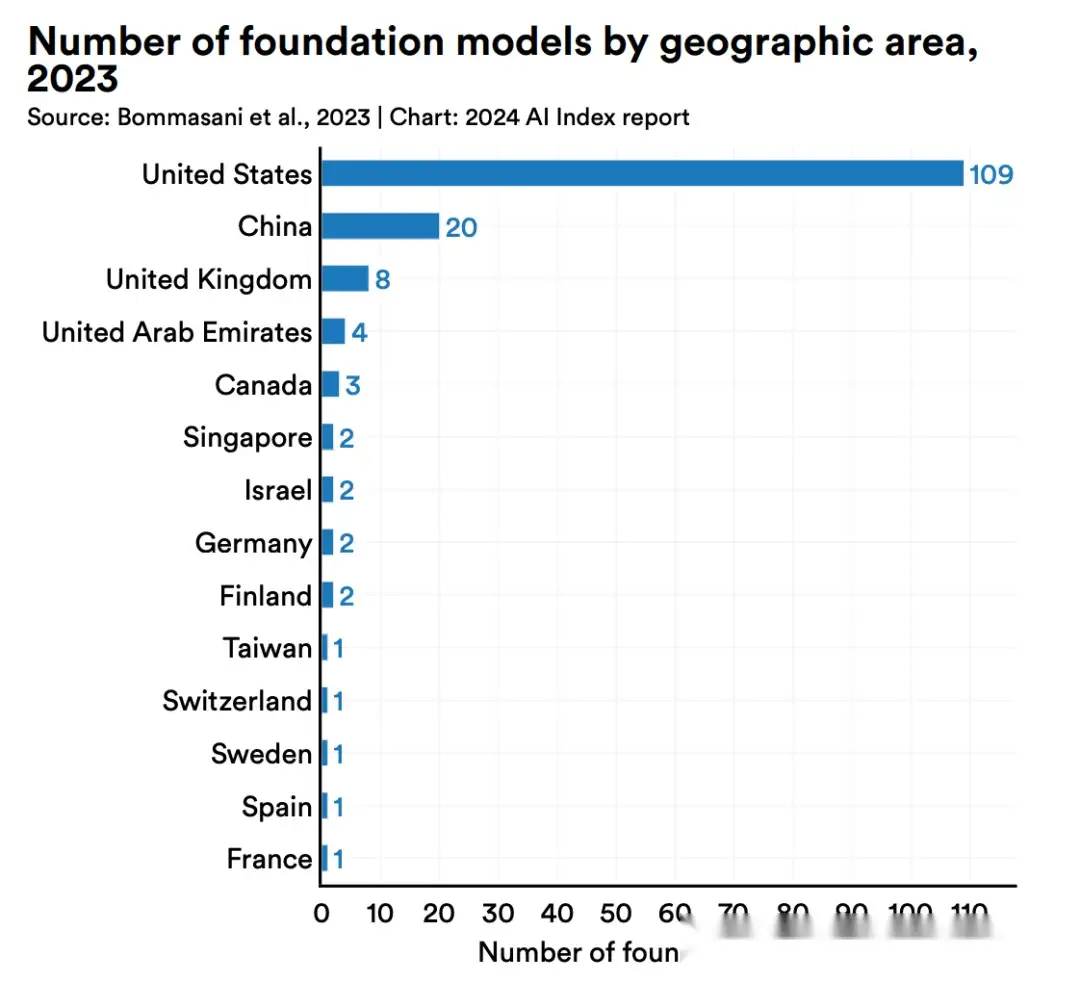
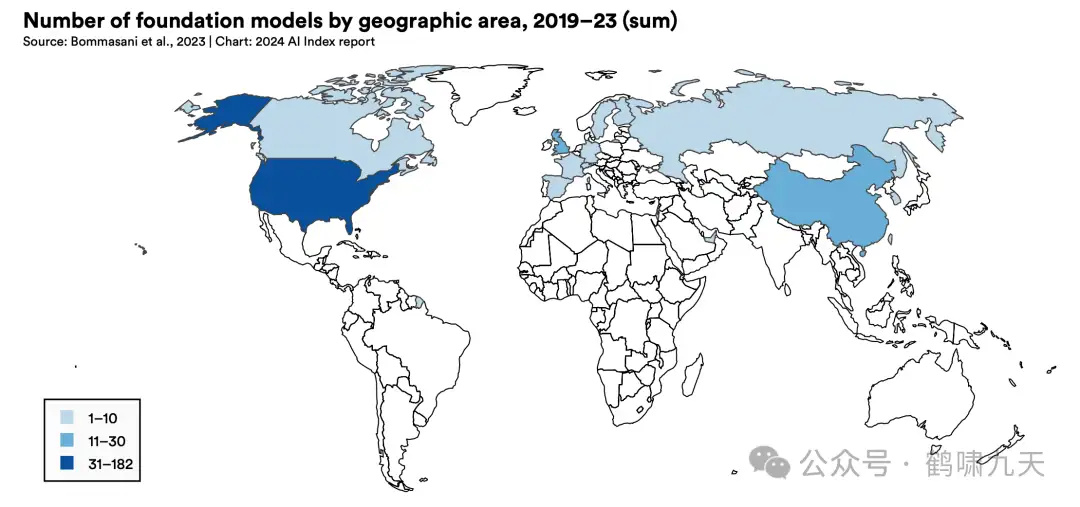
各国AI实力比拼
【2024-4-24】美国傲视群雄,中国随后,接着是英国、欧洲各国
【2023-11-23】清华脑科学家刘嘉谈各国AI研究水平:美国一骑绝尘,中国顶多在第二梯队,日本走错了方向
- 第一梯队:只有美国,一骑绝尘,基础研究、商业应用都遥遥领先
- 第二梯队:英国、德国,中国相对靠后
- 日本走错了方向,过于强调自动化,放弃了数字化
视频地址:凤凰网
中美AI对比
中美AI竞赛,远非你想象的那么简单,这部视频深度拆-解这场竞争的“六层金字塔”模型。
从顶层AI应用,到最底层的光刻机,美国正试图通过“卡脖子”战术,在根基上限制对手。
但面对封锁,中国AI如何“以巧破力”?这场关乎未来的终极博弈,真正的战场究竟在哪里?答案,就在金字塔之巅。
【2025-8-25】10分钟讲透中美AI竞争格局
- Design -> Production -> Supply -> Infrastructure -> LLM -> Applications
中国大模型实力
马斯克:印尼发言
中国本来可以超过美国,但是精英们把精力都用在研究人情世故上了, 而非科研、创新和发展
知乎:我们现在距离实现真正的通用型人工智能还有几步?哪些方面要进一步突破?
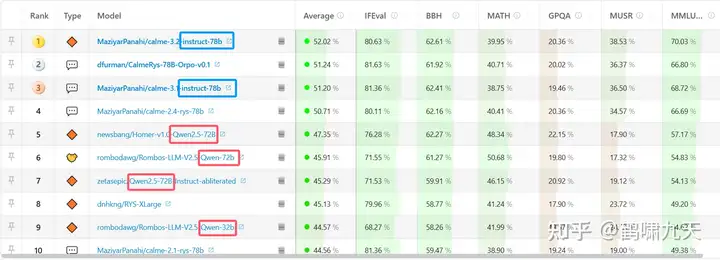
2022年底,国际知名模型榜单并没有多少国产影子(除了智谱GLM-130B)。
抱抱脸开源LLM动态榜单就知道了。
最新的Top 10列表:
- 第1/3都是基于QWen 2.5指令微调得到的
- 除此之外,还有5、6、7和9,同样是Qwen的衍生版
全局榜单 Chatbot areana,不区分开源、闭源,可以看到:
- Top 7被Google、OpenAI一系列闭源模型霸榜
- 第8名就是近期的当红炸子鸡“DeepSeek V3”
- 后面还有:Yi-Linghtning(零一万物)、QWen 2.5、GLM-4-Plus等
中国开源模型确实在“脱颖而出”。
- 国外,以Meta的Llama、Mixtral、Phi为主,衍生出众多版本,其中Llama最为突出。
- 国内,这几家走在前列:
- 智谱清言:从GLM-2到GLM-4,文本到多模态,实时通话、多智能体等,广泛涉及。
- 通义千问:阿里巴巴通义千问系列,效果也在快速提升。
- 深度求索:大模型领域“拼多多”,“扫地僧”,低调的高人,每次出手就技惊四座。
六小龙
上市信息
- 2026-1-8 智谱上市,走 to B路线
- 2026-1-9 Minimax 上市,走 to C路线
【2026-1-10】MiniMax上市破千亿的秘密:没走智谱B端技术路线,而是用”Talkie”虚拟陪伴应用快速验证商业模式。
- 2024年该应用贡献63.7%营收,靠情绪价值单季度收入超3600万。
- 核心逻辑:用C端高频场景打磨多模态技术(如全球领先的TTS),让技术在真实需求中变现。
- 95后团队敢抛弃移动互联网思维,证明在AI时代,能解决情感刚需、找到真实场景的公司才能活下来。
2023年,国内AI行业发生的投融资事件就有815起,融资总金额达2631亿元。而AI大模型“吞金兽”们经过大量的资金喂养,也得到了很好的发展。
智谱AI、Moonshot(月之暗面)、MiniMax、阶跃星辰、百川智能、零一万物,在这一年杀出重围,锁定上半场胜局,形成国内大模型创业“六小龙”的第一梯队。
- 【2024-12-24】国内AI“六小龙”概览
在市场上声量更大更出圈的是同属青年派的月之暗面和MiniMax。
【2025-1-7】卖身大厂,才是大模型公司最好的归宿
不同于智谱和月之暗面都有各自明确的商业化路径,零一万物在很长时间里都是B端/C端双轮驱动。
- 短短一年多,
零一万物就被迫退出大模型竞争,令人唏嘘。 - 而回过头来看,零一万物的困境,始于现金流压力。
- 2024年下半年,
月之暗面、智谱AI、百川智能、阶跃星辰先后完成融资。其中,前三者的估值都迈进了200亿门槛。 - 2024年8月,
零一万物也对外宣称完成了一轮数亿美元的融资,但并未透露具体的投资方,也没有提及融资后的估值。但从目前看,这笔钱并未完全缓解公司的现金流压力。
- 2024年下半年,
对于AI公司,200亿是一个很重要的门槛。
- 上个时代的“AI公司”,除了
商汤外,200多亿估值几乎就是AI公司的天花板。 - 其中,
旷视科技和第四范式上市前的估值分别为40亿美元和30亿美元,最后都停在了200多亿。
在模型能力很难拉开差距情况下,商业化将成为各家获得后续融资的关键。但纵观B端和C端市场,大模型公司都面临着严峻的考验。
中国企业服务市场,软件很少以独立公司的形态存在,更多作为大厂「闭环」生态的一部分而存在的,与云计算业务牢牢捆绑在一起。这其实很像谷歌和微软提供的企业软件,往往是用来敲开企业客户购买云计算服务的敲门砖一样。
但在国内,腾讯、阿里等大厂会提供大量的免费软件,用免费+捆绑销售的形式,凭借自身强大的市场开拓能力跑马圈地。而由于服务的刚需性,云计算在创造收入的同时,也成了国内企业服务场景的入口。
大模型在B端落地中,云厂商有着天然的入口优势。给大模型厂商在B端竞争带来了更多变数。
- 智能超参数统计的2024年大模型中标项目,
智谱的中标项目达到32个,高居所有模型厂商的第三位。 - 智谱的32个中标项目主要集中在上半年,下半年中标项目较少。
- 而
火山引擎、阿里云和腾讯云明显在第四季度进行了发力,三家企业的中标项目数量增幅显著。- 就拿11月来说,火山引擎、阿里云和腾讯云均中标了7个大模型项目,中标金额分别为594万元、8262万元和12912万元,而智谱仅中标了3个项目,中标金额只有170万元。
C端,大模型公司面临的竞争压力就更直接了:字节。
- 像类ChatGPT产品,字节不是最早下场的,但现在却成了最大赢家。
- 根据AI产品榜数据,12月豆包的MAU数据已经达到7116万,远远领先其他竞品。
- 现在,字节在AI上的策略很明确,复制市场上可能的爆款,再用流量资源做增长。
字节跳动有专门负责产品增长的团队。构建了强大的数据监测系统
- 会花大价钱去买市面上数据,尽可能监控所有产品,用来指导研发。
- 找到产品方向后,接下来就是做“增长”。这是字节最擅长的事情,字节拥有国内仅次于微信的流量池,以及碾压所有AI公司的“钞能力”。
于是,所有发力C端大模型公司,都必须面临一个问题:如果字节做,你怎么办?
无论是B端还是C端,大模型公司的商业化之路都充满着荆棘
- 而对大模型厂商来说,在商业竞争格局尚未完全清晰之下,能够快速卖身大厂,或许是一个不错的结局。
格局
- 智谱目标:科创版上市
- MiniMax :再造字节
- Kimi :上午追求 AGI 下午想硬刚字节反复横跳
- 百川:先用医疗大模型占个赛道之后再说
- 阶跃:追求0.7个 AGI 但奈何目标不纯粹分散了精力
- 零一:追求活着
【2025-5-12】国产大模型「五强争霸」,决战AGI!
今牌桌上的玩家已经变成了「基模五强」——字节、阿里、阶跃星辰、智谱和DeepSeek
原因: 要么有钱,要么有人
- 有钱: 字节、阿里、DeepSeek
- 有人: 智谱、阶跃星辰
- 上海队的阶跃星辰,最新一轮融资发生在24年底至25年初,B轮已融资数亿美金;
- 北京队的智谱,在2025年3月已经拿下18亿人民币的融资。
字节的吴永辉,阿里的吴泳铭、周靖人,阶跃星辰的姜大昕、张祥雨、朱亦博,智谱的唐杰、张鹏,DeepSeek的梁文锋,都是在业界足以撼动局势的人物。
基模五强,各领风骚
- (1) 阿里:开源王者,全球第三
- 阿里以「开源王者」的独特定位,不仅在国内市场占据重要席位,更在全球AI开源生态中,稳居全球TOP 3模型贡献者; 全球唯一一家实现「全尺寸、全模态」开源的云计算厂商。
- 通义团队累积开源200+模型,涵盖了千问(Qwen)大语言模型和万相(Wan)视觉生成模型两大基座系列。
- 这些模型覆盖了文本生成、视觉/语音理解生成、文生图,以及视频生成等全模态,参数规模从0.5B到235B不等,跨越119种语言及方言。
- (2) 字节:巨型航母,重回创业
- 综合能力强,覆盖了文本生成、图像理解、视频生成、语音处理等多模态领域。
- AI应用超20多款,爆火核心产品「豆包」凭借其强大文本生成和多模态能力,迅速占领用户心智,月活用户超1亿。
- 视频生成工具「即梦」也被赋予了更高的战略优先级,已在虚拟偶像、电商直播等领域,实现商业化落地。
- AI编程工具Trae,直接对标Cursor等AI集成开发环境。
- 通过抖音、今日头条、飞书等平台,字节将大模型嵌入到内容推荐、协同办公中,形成了技术到应用的生态闭环。
- (3) 阶跃星辰:低调的大模型国家队
- 成立2年的阶跃星辰,已累计发布22款自研基座模型,覆盖文字、语音、图像、视频、音乐、推理,其中有16款是多模态模型,性能领跑全行业,成为行业内公认的「多模态卷王」。
- Step-1o Vision便在2025年初分别在知名大模型竞技场Chatbot Arena和国内权威评估平台「司南」(OpenCompass)中,分别拿下了视觉领域中国大模型第一,以及多模态模型榜单第一的成绩。
- 多模难点,融合过程中不能损失单模性能,尤其不能降智。而阶跃星辰采取了原生多模的方式,在此方面经验独到。
- CEO
姜大昕曾担任微软全球副总裁,微软亚洲互联网工程院副院长、首席科学家。入选2025年IEEE Fellow的姜大昕博士,是唯一来自中国大模型创业公司的入选者。 - 首席科学家
张祥雨,其参与著作的《用于图像识别的深度残差学习》论文(ResNet)是21世纪以来全球被引用次数最多的论文,引用量已超过25万次。 - 已有多家头部企业和大量AI应用开发者对阶跃的多模态模型表示认可,纷纷接入。
- 阶跃还将智能终端Agent视为大模型落地的核心突破点,已和吉利汽车、千里科技、OPPO、智元机器人、原力灵机、TCL等达成了深度合作
- (4) 智谱:全栈创新,发力智能体
- 国内首个开启IPO大模型创业公司,智谱背靠清华技术底蕴以「学院派」独特气质脱颖而出,在基座模型、多模态技术和智能体展开全面布局。
- 智谱已经建立了新一代认知大模型技术体系,研发了全栈自主GLM系模型,性能指标与国际顶尖LLM对齐。
- 2024年8月,GLM-4-Plus问世在多个任务上表现优异,与GPT-4系不相上下。
- 2025年4月,智谱再次开源32B/9B系列GLM模型,包括基座、推理和沉思模型。以320亿参数比肩千亿参数主流模型性能。GLM-Z1-Rumination沉思模型,便是智谱对AGI下一代技术的最新探索。
- 智能体方面,智谱先于OpenAI提出Phone Use概念并推出Agent产品,并发布了全球首个集深度研究与实际操作于一体L3级智能体——AutoGLM沉思。
- 凭借AutoGLM及GLM-PC与全球车企、PC及手机厂商展开深度合作,推动大模型从Chat走向Act。
- 智谱的商业化路径以2G和2B业务为核心,深度绑定政府和企业需求。
- (5) DeepSeek:研究导向,厚积薄发
- DeepSeek 最受国外瞩目。在中美AI竞赛中,也是被提及最多、存在感最强的一家。特立独行的技术奇兵,直接以一己之力,掀翻了大模型的牌桌
- 极致的工程优化: MoE架构让模型总参数量达到671B,而在运行时却只需激活37B,大幅降低了计算需求;多token预测(MTP),则提高了AI的训练效率,避免逐字预测;多头潜注意力(MLA),让模型更精准地分配了计算资源。
- DeepSeek 技术特点: 聚焦语言模型,特别是数理能力,走坚定的开源路线
- DeepSeek-R1给全世界带来了亿点点震撼,以极低的计算资源,取得了媲美GPT-4等顶级AI模型的性能。
- DeepSeek 成功关键: 偏研究型的导向,而非以盈利为短期目标。从研究角度鼓励工程师提效,不必面临财务变现压力。
追求更高的「智能上限」和突破的「多模态能力」,已成为通往AGI路上必须抢攻的两大技术高地。
智谱
成立背景与发展历程:智谱AI诞生于2019年,由清华大学计算机系的技术成果转化而来,其技术源头可追溯至1996年成立的清华大学KEG(知识工程)实验室,拥有逾27年的人工智能技术积累。
公司愿景与使命:智谱AI的愿景是“未来让机器像人一样思考”,致力于通过自然语言处理、机器学习、深度学习等前沿技术开发新一代认知智能大模型,为各行业提供智能化解决方案。
业务范围与市场布局:公司业务涵盖自然语言处理、图像识别、声音识别等人工智能领域,产品服务包括但不限于智能客服、文本生成、机器翻译、文生图等。其商业化收入在2024年实现了超过100%的增长,MaaS平台bigmodel.cn的API年收入同比增长超过30倍,日均Tokens消耗量增长了150倍,业务覆盖智能汽车、制造、大消费、金融、政务服务、医疗健康、游戏娱乐、文化旅游等行业。
智谱AI与中国工程科技知识中心、微软学术搜索、ACM、IEEE、DBLP、美国艾伦研究所、英国南安普顿大学等机构建立了良好的合作关系,共享数据及技术资源。还投资了十多家AI相关创业公司,推出了z计划,联合生态伙伴发起总额10亿元人民币的大模型创业基金,支持大模型原始创新。
创始人介绍
- 唐杰:智谱AI创始人及首席科学家,清华大学计算机系教授,研究方向为社会网络分析、数据挖掘、机器学习和知识图谱。
- 张鹏:智谱AI CEO,清华大学2018创新领军工程博士,毕业于清华大学计算机科学与技术系,在文本数据挖掘和语义分析、知识图谱构建和应用等领域取得了显著的成就。
- 王绍兰:智谱AI总裁,清华大学创新领军工程博士,拥有丰富的科技情报大数据应用经验。
产品能力和核心产品
自然语言处理大模型:
- GLM-10B:早期推出的大模型,具有强大的自然语言处理能力,可理解和生成自然语言,适用于智能客服、文本生成等多种应用场景。
- GLM-130B:高精度千亿中英双语稠密模型,参数达1300亿,提升了自然语言处理的准确性和效率,适用于更复杂的任务,如机器翻译、文本摘要等。
- GLM-4:在GLM-130B基础上优化升级,语言理解和生成能力更强,能处理更多样化的自然语言任务,如对话系统、文本创作等。
智能应用产品:
- 智谱清言:AI提效助手,具备强大的文本处理能力,可自动完成文档编写和修改任务,如文章撰写、报告生成等,适用于企业、政府等机构。
- CodeGeex:高效率代码模型,支持多种编程语言,能根据用户需求生成高质量代码片段,方便软件开发人员和编程爱好者。
- CogVLM:多模态理解模型,能理解和处理文本、图像、声音等多种形式的数据,将不同形式的数据融合处理,生成更丰富的信息,适用于跨媒体信息处理、智能问答等场景。
- CogView:文生图模型,可根据文本描述生成相应的高质量图像,支持多种风格生成,适用于设计、广告、游戏等领域。
- AutoGLM:智能体产品,能模拟人类操作手机,通过语音指令理解用户意图并自动调用工具完成手机上的操作,如网页浏览、电商购买等,适配微信、淘宝、美团、小红书等8款知名应用软件。
详见站内专题:ChatGLM
百川智能
百川智能的创始人兼CEO是王小川
- 教育背景:1978年出生于四川成都,毕业于清华大学计算机科学与技术专业,拥有工学学士、工学硕士以及EMBA学位。
- 早期经历:1994年,用吴文俊消元法首次在微型机下完成初等几何命题的全部证明。1996年,代表中国参加第8届国际信息学奥林匹克竞赛IOI获得金牌,被特招进入清华大学计算机系。
- 职业经历:1999年,以实习生身份参与Chinaren,8个月后开发的网站日浏览量达四千多万。2000年搜狐收购ChinaRen后进入搜狐,2003年创建搜狐研发中心,2005年获任搜狐公司副总裁。2006年开发出搜狗输入法第一个版本,2010年独立运营搜狗并出任CEO。2017年搜狗在美上市,2020年搜狗并入腾讯,王小川卸任搜狗CEO。2023年4月10日,宣布与前搜狗COO茹立云联合创立百川智能。
- 荣誉奖项:2015年获北京市科学技术奖一等奖,同年获科技北京百名领军人才、北京市劳动模范称号。2016年获CCF计算机企业家奖,2018年获中国青年五四奖章,2019年获第十五届中国青年科技奖。
产品能力和核心产品
技术能力:
- 百川智能在自然语言处理技术方面具有深厚的积累,其模型具备强大的自然语言理解和生成能力,在中文金融知识、百科问答等领域表现尤为突出,同时在多模态能力上也取得了显著进步,涵盖图像识别、语音交互等多种模态。
核心产品“1+3”产品矩阵:包括核心大模型baichuan4及三款专用模型baichuan4turbo、baichuan4-arm和baichuan4-air。
- baichuan4:作为国内AI领域的前沿大模型,展示了在多模态能力上的显著进步,适用于广泛的商业和行业应用。
- baichuan4-turbo:专注于高效文本生成,优化成本,为企业在大规模文本生成和数据分析中提供高性价比解决方案。
- baichuan4-arm:适合移动设备使用,增强了模型在低功耗环境下的性能表现,适用于移动端应用及边缘计算。
- baichuan4-air:针对资源有限的场景进行优化,适合轻量级应用,如客服和基础办公自动化任务。
智能助手百小应:依托baichuan4强大的技术支撑,百川智能推出了智能助手“百小应”,为用户提供基于自然语言的搜索、提问和定向信息分析等服务。它不仅可以多步搜索、智能过滤信息,还具备多轮对话功能,适用于复杂的市场调研、行业分析等应用场景,支持用户上传文档、图片进行辅助解读。
产品
- 百小应, 懂搜索的AI助手
详见站内专题:百川
MiniMax
Minimax融资故事:4 年 7 轮,谁在推动中国 AI 第一场资本盛宴
MiniMax 成立于2021 年12月,是领先的通用人工智能科技公司,致力于与用户共创智能。
- MiniMax自主研发了多模态的通用大模型,其中包括国内首个将Linear Attention架构与MoE结合的开源模型MiniMax-01系列、语音&音乐大模型、图像大模型以及视频大模型。
- 基于不同模态的通用大模型,MiniMax 推出海螺AI、星野等原生应用。MiniMax开放平台为企业和开发者提供安全、灵活、可靠的 API 服务,助力快速搭建 AI 应用,目前已服务全球5万多家企业客户以及个人开发者。
MiniMax成立于2021年12月,公司全称上海稀宇科技有限公司
- 2022年10月推出第一款产品Glow,上线4个月用户接近500万。2023年3月Glow在国内因备案问题下架,同年6月在海外推出Talkie,9月在国内备案上线星野APP。
- 2023年8月,其自主研发的“MiniMax-abab”大模型通过了国家首批大模型服务备案。2024年4月17日,正式推出abab6.5系列模型,5月15日上线海螺AI产品。
核心团队成员大部分来自商汤,成员均来自全球知名高校和顶尖科技公司,拥有世界顶尖自然语言处理、语音、计算机视觉、计算机图形学等工业界和学术界经验,拥有多项全球领先的人工智能领域研究成果及上百个全球发明专利。
目标是做领先的通用人工智能科技公司,致力于与用户共创智能模型,秉持“与用户共创智能(intelligence with everyone)”的理念,希望用来自用户的反馈反哺给技术,从而拓展创造力的边界,为社会提供促进生产力提升的有效工具。
创始人介绍
- 闫俊杰:MiniMax创始人兼CEO,毕业于中国科学院自动化研究所。曾担任商汤科技副总裁、商汤科技研究院副院长、通用智能技术负责人,负责搭建深度学习的工具链和底层算法以及通用智能的技术发展,还搭建了商汤的人脸识别和智慧城市相关的技术体系。在深度学习和计算机视觉领域,发表顶级会议和期刊论文100余篇,GoogleScholar引用超过10000次。
- 周彧聪:联合创始人,毕业于北京航空航天大学,曾是商汤科技的早期员工之一,在商汤科技研究院主管算法团队,学生时代在世界大学生超级计算机竞赛ASC15总决赛和国际超级计算机大会ISC17中均获第一,还参加过国际计算机视觉大会ICCV2019挑战赛并所在团队获冠军。
- 杨斌:技术合伙人,毕业于中科院自动化所,曾就职于UberAI研究院,在自动驾驶卡车领域有多年研发经验
产品
- 海螺AI
- 星野
产品能力和核心产品
- abab6.5系列模型:2024年4月17日正式推出,包含abab6.5和abab6.5s两个模型。拥有万亿参数,支持200k tokens的上下文长度,abab6.5s更高效,每秒可处理近3万字的文本。在知识理解、逻辑推理、数学计算、编程任务以及指令执行等多个关键维度上展现出逼近乃至媲美国际顶级水平的性能表现。
- AI伴侣产品Talkie和星野:Talkie是MiniMax海外市场的主打产品,2023年6月底上架海外Google Play和Apple Store双端,用户可以在平台上自主创建各具特色的AI智能体,通过调整外貌外形、语音特征、性格爱好等深度定制专属陪聊对象。星野是MiniMax在国内的AI伴侣产品,基于全球领先的多模态AIGC技术,是一个支持用户自由创造和分享AI智能体的内容社区。
- 海螺AI:于2024年5月正式上线,接入了MiniMax自研的多模态大模型,包括万亿参数MoE大语言模型abab6.5,语音大模型和图像大模型。支持输入200ktokens的上下文长度,可以1秒内处理近3万字的文本,能够更好地为人们进行书籍、长篇报告、学术论文等长篇内容的阅读、分析和文本写作。
【2024-11-7】MiniMax海外逆袭,难解国内盈利焦虑
MiniMax 是“AI六小虎”里一个低调的存在。直到不久前,创始人闫俊杰一改常态,高调站在聚光灯下发布文生视频 abab-video-1,正式加入视频生成模型混战。
MiniMax AI出海明星产品Talkie爆火,下载量超越同类产品领头羊character.ai。据媒体预测,MiniMax今年收入预计达到7000万美元,而大部分收入来自Talkie的广告。
MiniMax 是国内首个研发 MoE(Mixture-of-Experts)混合专家架构的团队
在外界还在对单日交互30亿次、日均处理3万亿文本Tokens、生成2000万张图片,及合成7万小时的语音等天量数据答卷啧啧称奇时,MiniMax已经在围绕产品需求打造全矩阵多模态模型。
截至2024年9月,MiniMax已经推出视频大模型(abab-video-1)、音乐大模型(abab-music-1)、语音大模型(abab-speech-1)及文本大模型(abab-text-7),最新估值达到25亿美元。
- 海螺 AI
- 星野/Talkie
国内AI创业公司中,MiniMax 应用产品做得最早也最多。
- 早在chatGPT3.5上线的前一个月,MiniMax已经发布了其第一款虚拟AI社交产品
Glow,上线短短四个月,就已经收获近500万用户。尽管一年后,这款产品因涉及隐私和敏感内容问题遭举报并下架,但MiniMax并没有放弃。 - 2023年6月,MiniMax团队面向海外用户又上线了另一款AI陪伴产品“
Talkie”,并于同年9月在国内上线,命名“星野”,再次获得了用户的青睐。据量子位智库发布的《AI陪伴8月APP榜单》,星野下载总量超过1400万,月增下载及DAU均排国内同类AI产品第一。 - 2024年1月,MiniMax发布千亿参数MoE架构模型abab6,该模型的推出标志着MiniMax在探索加速实现Scaling Laws方面取得了显著进展,这涉及了模型架构的优化、数据pipeline的重构以及训练算法和并行训练策略的改进。
- 仅仅三个月后,MiniMax团队进一步挖掘了MoE架构潜力,推出万亿参数MoE架构模型abab 6.5系列模型。在各类核心能力测试中,abab6.5展现出了接近GPT-4、Claude-3、Gemini-1.5的水平。
此外,MiniMax也在布局生产力应用工具
- 2024年5月上线的生产力助手“
海螺AI”,支持包括长文理解、智能搜索、数据查询、识图、文案创作等大多数C端用户需求。
情感陪伴方向的AI赛道,似乎正面临瓶颈。
Talkie最大的卖点是AI角色定制,用户在平台上创建私人AI智能体,通过调整智能体外貌、语音特征、性格爱好等,来深度定制专属陪聊对象。
- 用户规模: 头部格局已经相对稳定,国内千万级下载总量的依然是
叨叨、X Eva和星野这三款产品。从 - 用户增量: 情感陪伴类的AI产品已经增长乏力,9月新增下载,前15名AI产品普遍出现了30%左右的数据下滑,
星野以接近30%的幅度跌出百万级梯队; - 用户活跃度: 老用户活跃度已经趋于平稳,但新用户的三/七日留存率整体有约7%的下滑,用户粘性面临新的挑战。
- 用户群体: 情感陪伴类AI产品的用户群体以年轻人为主,付费意愿和能力有限。而星野海外版“Talkie”,除了同样面临以上问题,还要面临海外市场更加严格的监管和审查,尤其在数据安全和隐私方面;而不同国家和地区的文化差异和用户偏好,也是不可避免的运营难题。
比起用户规模和商业化的问题,另一个问题更加严重且现实。
- 情感陪伴类AI产品的设计初衷是为人们及时提供精神支持,甚至对很多孤独或抑郁的人也有很大的帮助。尽管AI伴侣能够以“人”的方式影响着自己的使用者,但在法律的框架里,AI并不作为独立法律人格的主体而存在。介于虚实之间的徘徊,其道德隐患、语言尺度等安全风险都很难被界定。
情感陪伴AI赛道瓶颈初现,生产力助手类AI也优势不显。
海螺AI作为MiniMax生产力助手类的主打产品,尚在起步阶段,从文本生成等核心功能来看,与国内各大主流产品能力差异并不大,没有太强的竞争壁垒。- 而海螺AI最近新上线的音乐生成和视频生成功能,似乎是希望在这两项特色功能上发力,期望形成差异化。
AI商业化的主流形式有两种:To B和To C。
- To B方案: 将AI技术集成到行业和产品中,提供垂直定制服务。
- To B产品要做到高可用性、并面向高价值场景,比如法律咨询、金融服务、编程等对专业度依赖高,流程复杂的行业,需要进一步加入专业人员的反馈,难以形成标准化作业,定制成本居高不下。
- 国内To B AI市场早已被各个大厂瓜分。对于尚未盈利的大模型公司来说,越是竞争激烈,收获的B端项目越多,边际成本却并未摊薄,脚步也不由自主地会被拖慢。
- 零一万物创始人
李开复反思: 大模型to B的首要任务 “寻找少数能够按使用情况收费的方法,而不是项目定制的方法,能得到比较高利润率的订单再去做。” - 百川智能CEO
王小川曾下判断: “To C是To B市场的十倍。”。
- To C业务模式: 面向个人用户群体,提供生产力辅助工具,并通过付费订阅等模式变现,比如目前MiniMax的星野和Talkie。
模型与产品并驾齐驱,也是MiniMax正在选择的路线。B端和C端一手抓,满足普通用户同时也重视开发者需求,通过用户侧的反馈在技术和产品上进行优化。
- To B 布局: MiniMax以API为纽带布局开放平台,主要落地场景包含角色扮演、AI客服、智能硬件、AI教育、办公、招聘等领域,目前已有3万余家企业接入,这些都是稳定的付费玩家。
- C端业务方面,占比在公司中能够达到80%。对于MiniMax目前的商业化,闫俊杰表示有两个路径:
- 一是开放平台已经有超过三万家企业用户和开发者聚集;
- 二是公司产品里的广告机制,可以做到商业化变现。
零一万物
为了获得现金流,零一万物曾进行了多次战略调整。
- 2024年起,公司先是发力做了几款C端应用,继而又开始将重心转到了做B端的AI营销解决方案。
- 2024年8月以来,零一万物的多位联合创始人相继出走。原来的联创,只剩下了负责零一拆分出的AI游戏业务的
马杰,以及主要负责模型商业化的谷雪梅。
创始人介绍
- 李开复:作为公司的执行董事及CEO,是创新工场董事长兼CEO,在AI领域具有极高的知名度和影响力。他于2023年3月开始筹办AI2.0新公司即零一万物,并在同年5月正式成立该公司。他具有深厚的技术背景和丰富的创业经验,曾在微软、谷歌等知名企业任职,长期关注人工智能领域的发展趋势。
- 马杰:作为联合创始人之一,是国内反病毒与网络安全专家,曾任瑞星公司研发总经理,国内首个云安全服务品牌“安全宝”创始人兼CEO,在技术研发和企业管理方面具有丰富经验。
产品能力和核心产品
- 技术路线与架构:将大模型平台研发拆解为七大模块技术路线图,包含预训练框架(Pre-train)技术、Post-train技术、AIInfra技术、多模态模型技术、平台中间件及工具链技术、推理和服务部署技术等。
- 核心产品:Yi系列通用大模型是其核心产品,其中Yi-34B模型在HuggingFace英文测试公开单Pretrained预训练开源模型排名中以70.72分登顶全球第一,训练参数达到340亿,支持200K超长上下文窗口,可处理约40万字的文本,是全球上下文窗口最长的版本之一。
- 一站式AI工作平台“万知”:2024年正式官宣,将职业白领、大学生等高知群体确定为核心用户层,支持中英双语且完全免费。具备通用问答、超长文档阅读、PPT生成等功能。
【2025-1-2】阿里云宣布和零一万物达成一项战略合作,成立“产业大模型联合实验室”,声称要:
- 联手加速大模型从技术到应用的落地,进一步扩大产业大模型的生态整合”。
- 阿里云合并零一万物在to B领域的技术、业务、人才等板块。
一旦阿里云收购了预训练团队,零一万物所剩的主要业务将是出海to C应用。
【2025-1-6】传闻出现。李开复和零一万物官方先后下场辟谣。
“01万物散伙了,卡和预训练团队卖给阿里了”
收购范围仅限服务于模型预训练的部分,该团队人员约为60人,不包括零一万物的业务团队,即面向国内的to B业务和面向海外市场的to C业务。
类似于 谷歌 收购 Character.AI。
一旦收购完成,意味着零一万物将彻底放弃预训练,退出大模型竞争,把更多精力放到AI产品落地。
中国大模型行业走到了一个新阶段:
- 当预训练成本越来越高,规模商业化又遥遥无期,大模型厂商也开始出现市场调整。
- 被大厂收购大概率已经是大模型公司最好的结局。
传闻零一万物卖个阿里,预训练团队整体并入阿里,零一只做海外应用
- 零一股权结构简单,基本就是创新工场和阿里
- 股东商量好的退出机制,零一品牌还在,核心是做大模型应用了
预训练太烧钱,阿里 qwen 做得更好,所以就开源节流
阶跃星辰
阶跃星辰 专注于生成式内容与智能交互,融合语音、图像等多模态技术,助力新媒体创作与跨平台传播,打造沉浸式数字服务体验。
上海阶跃星辰智能科技有限公司成立于2023年4月6日。
- 2024年3月正式亮相,在过去10个月一共发布了11个自研基座模型。
- 2024年4月,其冒泡鸭(app)、冒泡鸭(网站)的模型备案通过。
坚持“单模→多模→世界模型”的AGI技术路线
Step系列通用大模型矩阵:
- 语言大模型:Step-1千亿参数语言大模型已完成充分打磨,在逻辑推理、中⽂知识、英⽂知识、数学、代码等方面的性能全面超越GPT-3.5;Step-2万亿参数语言大模型采用MoE架构,是中国首个由创业公司发布的万亿参数语言大模型。
- 多模态大模型:Step-1V多模态大模型支持200k上下文窗口,性能比肩GPT-4V,可精准描述和理解图像中的文字、数据、图表等信息,并根据图像信息实现内容创作、逻辑推理、数据分析等多项任务;Step-1.5V多模态大模型在Step-1V的基础上进行了迭代,具备更强大的多模态理解能力;Step-1X图像生成大模型具有强大语义理解与图像创意实现能力。
AI应用产品:
跃问(StepChat):具有多模态能力的AI效率工具,用户可以通过输入文字、上传图片、上传文档和发送网址等方式对其进行提问,其多模态智能视觉搜索功能“拍照问”是国内首个集成到iPhone 16相机控制键中的大模型应用产品能力。冒泡鸭(Bubbleduck):角色扮演类的AI聊天机器人,旨在创造一个AI开放世界,通过个性化定制智能体和参与虚拟角色互动来开启全新社交方式。
创始人
姜大昕博士是公司的创始人兼CEO。以下是其具体介绍:
- 学术背景:在机器学习、数据挖掘、自然语言处理和生物信息学等领域拥有丰富的研究及工程经验,在数据挖掘和自然语言处理方向拥有多项专利,已在sigkdd、acl、aaai等国际会议和期刊发表论文100余篇,Google Scholar统计的引用量超过1.7万次,h-index达到53。
- 职业经历:曾担任微软全球副总裁,微软亚洲互联网工程院副院长、首席科学家,带领四百多人研发团队开发,负责网页排序、智能问答、知识图谱卡片,图片和视频搜索结果等工作。
- 行业贡献:将深度学习技术应用于必应搜索引擎,显著提升了必应搜索结果质量,提出了一系列语言对齐、数据增强和迁移学习的方法,帮助必应搜索服务扩展到全球200多个国家和地区,支持100多种语言。
月之暗面
北京月之暗面科技有限公司成立于2023年4月17日
- 2023年10月9日,推出首个支持输入20万汉字的智能助手产品KimiChat。
- 2024年3月,Kimi智能助手启动200万字内测,同月公司经营范围新增人工智能基础软件开发、人工智能应用软件开发业务等。
- 2024年4月,月之暗面moonshot-1语言模型算法备案通过;6月,月之暗面moonshot语言模型算法2备案通过。
- 2024年3月,Kimi智能助手月访问量达1218万次,仅次于百度文心一言。
- 2024年4月,以180亿人民币的企业估值入选《2024·胡润全球独角兽榜》,同年11月荣获2024福布斯中国创新力企业50强。
创始团队
- 杨植麟:90后,高中毕业于广东汕头金山中学,获清华大学保送生资格,高考取得667分后被清华大学热能工程系录取,大二转入计算机专业,2015年以年级第一成绩毕业。后赴卡内基梅隆大学语言技术研究所深造,2019年获博士学位,其研究成果被GoogleScholar累计引用超过17000次。曾在Meta的人工智能研究院和谷歌大脑研究院工作,2016年以联创身份参与创立循环智能,2023年创立月之暗面。
- 张宇韬:本硕博均在清华大学计算机系就读,师从清华大学计算机系知识工程实验室带头人、数据挖掘顶级专家唐杰,是杨植麟的同门师兄,专注于数据挖掘领域,在循环智能时期担任CTO,2023年与杨植麟共同创立月之暗面。
产品能力和核心产品
- 核心产品Kimi智能助手:
- 长文本处理能力卓越:2023年10月推出时支持输入20万汉字,2024年3月支持200万字超长无损上下文,是全球市场上能够产品化使用的大模型服务中所能支持的最长上下文输入。
- 功能丰富强大:具有长文总结和生成、联网搜索、数据处理、编写代码、用户交互、翻译等6项主要功能。
- 自主搜索能力突出:2024年10月推出的Kimi探索版,具备更强大的自主搜索能力,可一次性精读超过500个页面,搜索效率是普通版本的10倍。
- 技术优势及布局:已训练了千亿级别的自研通用大模型,在多模态模型领域有所布局。
DeepSeek
人才培养
为什么伟大不能被计划
【2023-6-27】 OpenAI 的又一破圈神作:为什么伟大不能被计划 Why Greatness Cannot be Planned?, 豆瓣
- [美]肯尼斯·斯坦利(Kenneth Stanley) 全球创新思维和前沿科技领域的代表性专家、人工智能科学家,OpenAI(开放式人工智能公司)研究。他,曾任中佛罗里达大学教授,深耕机器学习领域,发表了80多篇专业论文,其中数十篇获得了最佳论文奖,并经常受邀在世界各地发表演讲。他还曾是Uber(优步)人工智能实验室的创始成员,在行业内具有显著的影响力。
- [美]乔尔·雷曼(Joel Lehman) 全球知名的人工智能科学家,OpenAI研究员,曾是Uber人工智能实验室的创始成员,目前在OpenAI做”大型语言模型(大模型)+演进算法”方面的研究,聚焦的领域包括人工智能安全强化学习和开放式搜索算法。
- 本书通过列举对
真空管对计算机“误打误撞”的推动关系,双足机器人获得“走路”这一能力,莱特兄弟由自行车行业踏入造飞机,以及图片孵化网站:由月牙形图形,逐渐推演至外星人的图案,再推演到汽车图形等例子,讲述了观点——“伟大不能被计划”。无限大的“搜索空间”像是一个充满迷雾的湖面,一个个发明创造就是我们身旁的踏脚石,只有沿着踏脚石“随心而动,随意而行”,才能获得真正的伟大。 - 讲述了观点: “伟大不能被计划”。
- 无限大的“搜索空间”像是一个充满迷雾的湖面,一个个发明创造是身旁的踏脚石,只有沿着踏脚石“随心而动,随意而行”,才能获得真正的伟大。
目录
- 第1章 对目标的质疑
- 第2章 无目标者的胜利
- 第3章 繁育艺术的艺术
- 第4章 目标是错误的指南针
- 第5章 有趣的和新奇的探索
- 第6章 寻宝者万岁
- 第7章 解开禁锢教育的枷锁
- 第8章 解开禁锢创新的枷锁
- “人们之所以紧紧抓住目标不放,对风险的恐惧是一大主因”
- 第9章 彻底告别目标的幻想
- 第10章 案例研究1:重新诠释自然进化
- 第11章 案例研究2:目标和人工智能领域的探索
精彩摘录:
- 🔹 如果一开始就想着一个明确的目标,你就走不远。目标会窄化探索范围。对伟大事业来说,目标具有误导性。
- 🔹 如果路线近在眼前,你当然可以设立目标、制定计划,多花点钱加速进行。但真正的伟大突破是不能被计划的。
- 🔹 “新奇性搜索”算法是指随机生成一组解决方案,通过评估新奇性并保留新奇性较高的方案,从而像生物演化一样发生一定的变异,如此往复循环,直到达到预定的迭代次数或者将问题彻底解决。产出的方案再怪异再不靠谱也没关系,只要是新奇的就留下——只问新不新,不问好不好。
- 🔹 伟大不是目标指引的结果,因为通往伟大的路线从来都不是直线。很多时候快反而就是慢 —— 没有特殊目标,每次只是选择下一块踏脚石,你反而能找到珍宝。
- 🔹 这就是世界运作的方式 —— 在这个满是电脑的大房间被人踏足之前,没有人知道那里会存在何种可能性你,得在出发之前,先参观一番。
- 🔹 如果目标设置的足够适度,它就会起到积极作用;反之,目标越高大上情况,就越复杂。事实上,若想实现更多所谓的丰功伟业,目标往往会成为绊脚石。比如,与探索、发现、创造力、发明或创新有关的目标,又或者找到真正幸福之类的目标。
- 🔹 那些“高大上”的目标往往极具欺骗性。如果我们仅仅只是奔着最终目的,一根筋地去寻找、无暇他顾,到手的只会是一张空头支票。我们不得不放弃目标,结果然而有机会重新实现它们。
- 🔹 通往充满创造,但虚幻的目标或实现无限报复的最实在的路径就是压根不设立目标。
- 🔹 目标可能会阻碍新发现,而没有目标,反而有可能通往最伟大的发现。

AI人才
AI学者国家分布

- 美国入选AI 2000学者及提名学者的数量最多,有1146人次,占比57.3%,超过总人数的一半以上。
- 中国排在美国之后,位列第二,有232人次,占比11.6%。
- 英国位列第三,有115人次,占比5.75%。
- 德国位列第四,人次未超过100,但依旧是欧盟学者数量最多的国家。
- 整个欧洲学者数量表现较上年有所流失。
贾扬清
【2024-2-1】阿里副总裁”人设”翻车:30岁成AI顶尖科学家,但我很懒
贾扬清的花名是扬青

浙江绍兴人
- 1982年,贾扬清出生于绍兴上虞,父母都是中学语文老师。
- 2002年,高考考了686分上了清华自动化专业
- 硕士毕业后去了伯克利读博,开发了深度学习框架,取名“Caffe ”
- 博士毕业后进了谷歌,头上顶着研究科学家的光环,埋头搞AI。
- 谷歌呆了两年,TensorFlow框架开发
- 跳槽Facebook,做了AI架构总监。
- 两年后,加入阿里巴巴,出任技术副总裁
大模型人才
【2023-10-18】算法人才vs工程人才,大模型时代谁更重要? 李京梅,澜舟科技合伙人&首席产品官,北京大学学士、美国纽约州立大学硕士、美国宾州州立大学 MBA。
大模型人才
- 今年企业对大模型训练效率、推理效率的提升需求更加明显,如何利用好有限算力成为关键。
- 模型的效果好坏依赖算法人才,模型的效率高低取决于AI工程人才。
- 对于算法人才,关注候选人在专业领域的认知、所在的学术团队、论文等学术成果。
- 大模型是新兴技术,悟性好的年轻人可以快速学习并上手,不需要太多历史包袱。
- 应用和基础研究强结合的培养方式,更适合国内对大模型人才的需求。
澜舟科技面向企业的服务体系目前分为四层,L1、L2、L3、L4。
- L1是基础通用大模型
- L2是行业大模型,目前主打的是金融、营销、文娱等领域,还包括机器翻译等垂直大模型。
- L3是聚焦具体的场景任务,比如金融行业里根据财经新闻写摘要或写研报。
- L4是自主智能体,或者称为数字助手,这四层体系与我们的人才是直接相关的。
大模型人才划分成几类:
- 大模型核心研发人才 ——— 最稀缺
- L1、L2、L3各自分别有负责通用大模型、行业大模型和偏场景应用的算法负责人。在这当中,最核心的是通用大模型的算法人员,因为其他的模型都是继承自L1的通用大模型。
- 工程人才:
- 与传统互联网岗位划分没有区别,包括前端、后端和测试人员
- 产品人才
- 产品经理而言,L1通用大模型的产品经理的作用是横向支撑,L2和L3的产品经理要继承通用大模型的能力,并基于金融行业或其他行业训练出大模型以及上层应用
- 大模型应用人才
人才流失
怎么留住顶级人才,让他们去做顶级创新。那是一些怪才,想法独特,有固执的价值观,动不动和老板拍桌子,抵制自己的公司。一个商业系统,一个社会环境,既有追逐利润的野心,也能开辟出一块不被打扰的角落,让那群怪才保存理想主义做自己认定的事。AI是兵家必争之地,那么这样一个系统和环境,才是真正的战场。
清北海归也有不少回国创业的
- transformer-xl发明人杨植麟,清华本,循环智能创始人;
- 李纪为,北大生科,斯坦福华人三年博士毕业第一人,香侬科技创始人;
- 尤洋,清华硕,colossal ai创始人;
- 贾扬清,离开阿里后,可能加盟大模型创业;
- 何恺明,离开fair后,刚去mit任教…
还有大大大佬
- 朱松纯
- 颜宁
开源
【2023-2-26】
开源等级
斯坦福大学基础模型研究中心主任 Percy Liang将大模型的开放程度总结成4个层次:参考
- 第一层论文开放,证明一些设想的可行性,并提供构建思路;
- 第二层API开放,允许研究人员探索和评估现有模型的能力(如推理能力)和限制(如偏见);
- 第三层模型权重开放和训练数据开放,允许研究人员逐步改进现有模型,开发更深入的可解释性技术和更有效的微调方法,让研究人员更好地理解训练数据在模型行为中的作用;
- 第四层计算能力开放,允许研究人员尝试新的体系结构、训练目标和过程、进行数据融合,并在不同的领域开发全新的模型。
开源协议
目前开源协议软件被越来越多应用,但很多公司或个人在使用的时候并不注意说其使用的开源软件采用的协议,可能导致后续的一些法律上的纠纷。因此这里将常用的开源协议整理一下以供参考。
开源协议总结
【2026-6-2】豆包:当前GITHUB最常用的开源协议主要由MIT,Apache 2.0以及GPLv3。三种协议里面
MIT协议最宽松,可以任意使用;Apache协议对于企业更友好,不用担心涉及专利的事情;GPLv3是最严的,它严格要求使用此协议组件的软件产品也必须按照GPLv3协议开源出来。
总结
- MIT:最自由,闭源商用无压力,GLM 首选;
- Apache:最安全,专利护体,Qwen 企业首选;
- OpenRAIL:开放但受限,适合研究/低风险场景,DeepSeek 慎商用。
三大协议核心条款对比
| 对比维度 | MIT | Apache 2.0 | OpenRAIL(AI专用) |
|---|---|---|---|
| 全称 | MIT License | Apache License 2.0 | Open Responsible AI License |
| 核心定位 | 极简宽松、商业最友好 | 企业级友好、专利保护 | 开放但受控、AI伦理约束 |
| 版权要求 | 保留原始版权+许可声明 | 保留 NOTICE+LICENSE,修改需标注 | 保留版权+许可,衍生必须继承 OpenRAIL |
| 商用权限 | ✅ 完全免费商用,无门槛 | ✅ 完全免费商用,无门槛 | ✅ 允许商用,但有场景/营收限制 |
| 衍生作品 | 可闭源、可再许可、无传染性 | 可闭源、无传染性、专利延续 | 强传染性:衍生模型必须同协议 |
| 专利授权 | ❌ 无专利条款,有侵权风险 | ✅ 明确专利授权+反报复条款 | ❌ 一般无专利授权,需看具体版本 |
| 使用限制 | 无任何场景限制 | 无任何场景限制 | ❌ 禁止军事、监控、歧视、非法内容等 |
| 免责条款 | 作者无担保、无责任 | 作者无担保、无责任 | 作者无担保,但违规直接终止授权 |
| 典型适用 | 个人项目、初创、基础库 | 企业级、云服务、专利敏感项目 | 大模型权重、AI产品、需合规场景 |
大模型商用选型结论(2026)
优先选 Apache 2.0(Qwen)
- ✅ 完全免费商用、无营收门槛、无场景限制;
- ✅ 专利保护完善,企业法务无异议;
- ✅ 可闭源、可微调后售卖、可云服务化;
- 推荐:Qwen3.5-9B/35B/122B 等全系。
次选 MIT(GLM)
- ✅ 极简合规、无任何限制、闭源自由;
- ⚠️ 无专利保护,需自行评估风险;
- 推荐:GLM-4-9B/32B、GLM-5 等。
谨慎选 OpenRAIL(DeepSeek)
- ✅ 免费研究/低营收商用;
- ❌ 高营收需付费、场景受限、衍生必须开源;
- ❌ 无专利保护、合规成本高;
- 推荐:DeepSeek-R1(数学)、Coder(代码)用于非核心场景;不推荐用于核心商业产品、高毛利业务。
【2023-3-7】OpenRAIL 协议, 常用协议无法满足 AI 领域,于是诞生了 OpenRAIL
- Open & Responsible AI licenses (“
OpenRAIL”) are AI-specific licenses enabling open access, use and distribution of AI artifacts while requiring a responsible use of the latter. - OpenRAIL licenses could be for open and responsible ML what current open software licenses are to code and Creative Commons to general content: a widespread community licensing tool.
可商业应用的协议:
- Apache 2.0
- MIT
- OpenRAIL-M
- CC BY-SA-4.0
- BSD-3-Clause
These LLMs are all licensed for commercial use (e.g., Apache 2.0, MIT, OpenRAIL-M)
开源协议演变
开源协议演变
如果自己开源,选择License时需要考虑
常见的协议如下:
- ApacheLicense 2.0 、GPLv3 、LGPL、、MIT License、BSD 和 Mozilla 2.0 。
Apache License 2.0
- 一个著名的非盈利开源组织Apache采用的协议,鼓励代码共享和尊重原作者的著作权,同时也允许代码修改,再发布(作为开源或商业软件)。
要求
- 在代码中保留作者提供的协议和版权信息
- 如果修改了代码,则必须在被修改的文件中进行说明。
- 允许的权利商用、分发、修改、专利授权、私用、附加协议
禁止项
- 禁止因使用等造成影响责任承担、也就是说免责申明
- 不能使用相应的商标。
提示:
- 商业软件可以使用,也可以修改使用Apache协议的代码。
GPLv3
- 此协议是应用最为广泛的开源协议,拥有较强的版权自由要求,也赋予和保证了开源项目开发者广泛的权利。基本上,它允许用户合法复制,分发和修改软件,但衍生代码的分发需开源并且也要遵守此协议。此协议有许多变种,不同变种的要求略有不同。
要求
- 修改后的源码也需要公开
- 版权及协议也要于此协议一致
- 修改后,需要在相应的文件做说明,
允许商用,分发,修改,专利授权,私用
禁止
- 禁止因使用等造成影响责任承担、也就是说免责申明
- 静止在软件分发传播过程中附加上原来没有的协议条款等
提示:商业软件不能使用GPL协议的代码。
LGPL
- 其主要用于一些代码库,LGPL比起GPL它授予的权限较少,LGPL允许商业软件通过类库引用(link)方式使用LGPL类库而不需要开源商业软件的代码。因此使用LGPL协议的开源代码可以被商业软件作为类库引用并发布和销售。注意是以类库的形式使用,也就是说如果修改了源代码的话则也必须使用LGPL协议贡献源码出来。
要求
- 公开使用了LGPL部分的代码,其余部分不需要公开。
- 可以库引用的方式用于商业软件。
- 在代码中保留作者提供的协议和版权信息
允许商用、分发、修改、专利授权、私用、附加协议
禁止禁止承担责任,(免责申明)、
提示:商业软件可以使用,但不能修改LGPL协议的代码。
GPL/LGPL都保障原作者的知识产权,避免有人利用开源代码复制并开发类似的产品
MIT
- 宽松简单且精要的一个协议。在适当标明来源及免责的情况下,它允许你对代码进行任何形式的使用,也就是原作者只想保留版权,而无任何其他了限制,而你必须在发行版里包含原许可协议的声明,无论你是以二进制发布的还是以源代码发布的。
要求在代码中保留作者提供的协议和版权信息
允许商用、分发、修改、私用、附加协议
禁止禁止承担责任,(免责申明)
提示:商业软件可以使用,也可以修改MIT协议的代码,甚至可以出售MIT协议的代码。
BSD
- BSD开源协议是一个给于使用者很大自由的协议。基本上使用者可以”为所欲为”,可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布。与MIT协议只存在细微差异。差别为MIT可以使用原名称进行宣传,而BSD不可以。
要求在代码中保留作者提供的协议和版权信息
允许商用、分发、修改、私用、附加协议
禁止禁止承担责任,(免责申明)
提示:商业软件可以使用,也可以修改使用BSD协议的代码。
Mozilla 2.0
- 由Mozilla基金创建维护的。此协议旨在较为宽松的BSD协议和更加互惠的GPL协议中寻找一个折衷点,允许免费重发布、免费修改,但要求修改后的代码版权归软件的发起者。这种授权维护了商业软件的利益,它要求基于这种软件得修改无偿贡献版权给该软件。
要求
- 公开源代码
- 在代码中保留作者提供的协议和版权信息
允许商用、分发、修改、专利授权、私用、附加协议
禁止
- 禁止承担责任,(免责申明)
- 禁止使用商标
提示:商业软件可以使用,也可以修改MPL协议的代码,但修改后的代码版权归软件的发起者。
作者:技术特工队
Open RAIL
FROM RAIL TO OPEN RAIL: TOPOLOGIES OF RAIL LICENSES:从 RAIL 到 Open RAIL 协议演变
RAIL
- RAIL 协议: 2019年诞生,对用户使用行为进行限制以达到限制AI技术造成伤害的开源协议
- The RAIL initiative was established in 2019 to advocate for the adoption of behavioral use-based restrictions in licenses and contracts for the purpose of mitigating the risk of harm from sharing AI technologies.
In essence, we could consider licenses associated with AI related artifacts to be RAIL Licenses if:
- they include behavioral-use restrictions which disallow/restrict certain applications by the licensee; and
- they require downstream use, including re-distribution, to include, at minimum, those same behavioral-use restrictions
Collectively, we refer to these as the “Use Restrictions”.
RAIL对用户限制类型进行细分
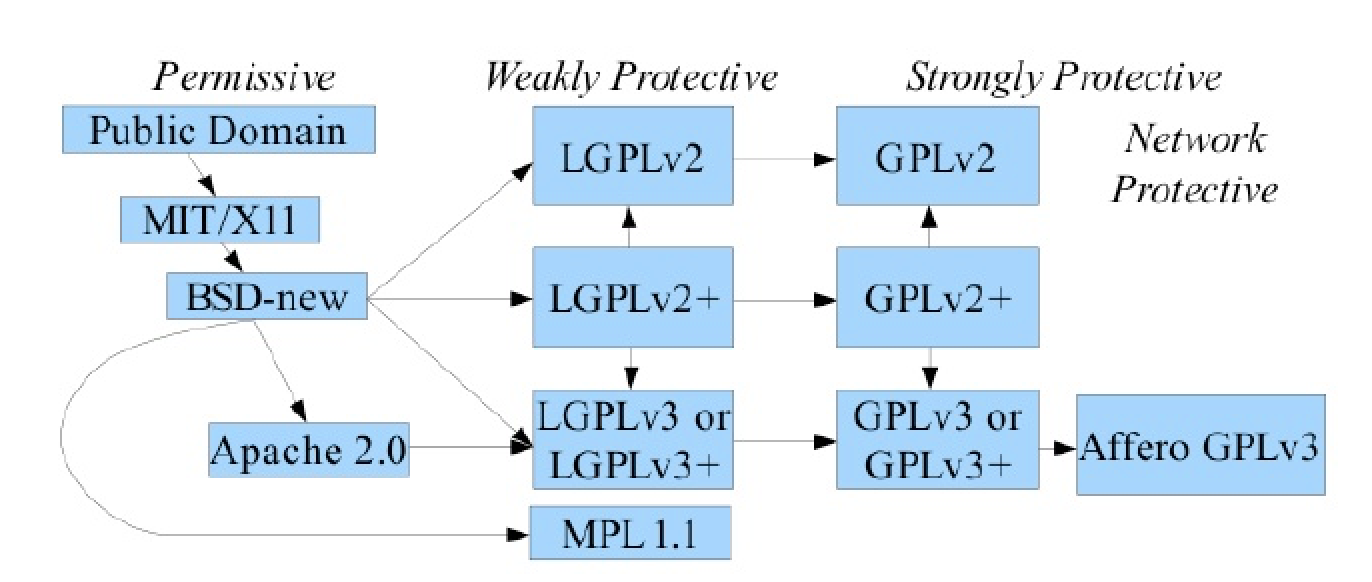
In order to easily distinguish licensing types using acronyms (/ˈækrənɪmz/首字母缩略词), we use the following representative naming conventions 命名规则:
RAIL-D: RAIL License includes Use Restrictions only applied to the dataRAIL-A: RAIL License includes Use Restrictions only applied to the application/executableRAIL-M: RAIL License includes Use Restrictions only applied to the modelRAIL-S: RAIL License includes Use Restrictions only applied to the source code
licensing of AI artifacts in a RAIL license may be combined in various ways and should be listed in D-A-M-S order.
- For example, a RAIL License applying Use Restrictions to data, source code, models and applications/services would be referred to as a “RAIL-DAMS” license.
- Alternatively, a RAIL license applying Use Restrictions to the model and the source code would be referred to as a “RAIL-MS” license.
应用
- BLOOM大语言模型使用RAIL协议,但是并未限制使用
- The RAIL License for BLOOM defines derivatives of the BLOOM models and checkpoints, and it includes aspects related to distillation and fine tuning (see more here and here ).
- However, the BLOOM License does not apply use-based restrictions to the underlying source code, which was previously obtained under standard open source terms.
OpenRAIL
RAIL更名OpenRAIL,以区分不同类型的RAIL协议
The OpenRAIL approach taken by the RAIL Initiative and supported by Hugging Face is informed and inspired by initiatives such as BigScience, Open Source, and Creative Commons. The 2 main features of an OpenRAIL license are:
- Open: these licenses allow royalty free (免版税) access and flexible downstream use and re-distribution of the licensed material, and distribution of any derivatives of it.
- Responsible:
OpenRAILlicenses embed a specific set of restrictions for the use of the licensed AI artifact in identified critical scenarios. Use-based restrictions are informed by an evidence-based approach to ML development and use limitations which forces to draw a line between promoting wide access and use of ML against potential social costs stemming from harmful uses of the openly licensed AI artifact. Therefore, while benefiting from an open access to the ML model, the user will not be able to use the model for the specified restricted scenarios.
Does a RAIL License include open-access/free-use 公开访问/自由使用 terms, akin(/əˈkɪn/,相似,类似) to what is used with open source software?
If it does, it would be helpful for the community to know upfront (/ˌʌpˈfrʌnt/,在前面) that the license promotes free use and re-distribution of the applicable artifact, albeit (/ˌɔːlˈbiːɪt/尽管,虽然) subject to Use Restrictions.
We suggest the use of the prefix “Open” to each RAIL license to clarify, a RAIL License include open-access/free-use terms, akin to what is used with open source software
| License | Licensor permits modification and redistribution | Licensor requires source code be disclosed when re-used | Licensee must include copyright notice | Licensor includes Use Restrictions |
|---|---|---|---|---|
| GNU Affero General Public License v3.0 | Yes | Yes | Yes | No (OSI) |
| Apache 2.0 | Yes | No | Yes | No (OSI) |
| Creative Commons Attribution Share Alike 4.0 | Yes | No | Yes | No (CC) |
| Creative Commons Zero 1.0 Universal | Yes | No | No | No (CC) |
| MIT License | Yes | No | Yes | No (OSI) |
| RAIL Licenses | May or May Not | May or May Not | Yes | Yes |
| OpenRAIL-D | Yes | N/A | N/A | Yes |
| OpenRAIL-A | Yes | No | N/A | Yes |
| OpenRAIL-M | Yes | No | Yes | Yes |
| OpenRAIL-S | Yes | No | Yes | Yes |
In the table above, the licenses require downstream users to comply with the terms identified with a “yes” - “OSI” refers to Open Source Initiative, whose definition of “open source” is our reference point in this table.
In summary, a license which includes behavioral-use restrictions on the artifact being licensed may be termed a RAIL license if Use Restrictions (as defined herein) apply both to the artifact and any derivative works.
Further, we can utilize a simple naming convention 命名规则 for open versions of RAIL Licenses – in DAMS order – to specify the artifact(s) being impacted by Use Restrictions:
D: for data being licensedData: The dataset(s) used to pretrain or train an AI Model.
A: for apps/binaries/services/executables or any non-source code form of the artifactApplication/service: Any executable software code or application, including API-based remote access to software.
M: for models/parametersModel: Machine-learning based assemblies (including checkpoints), consisting of learnt weights and parameters (including optimizer states), corresponding to the model architecture.
S: for source code, including libraries and toolkitsSource: The source code and scripts associated with the AI system.
Lastly, the naming convention proposed requires that RAIL Licenses which offer artifacts at no charge and allows licensees to re-license such artifacts or any subsequent derivative works as they choose to include the prefix “Open”.
开源社区
HuggingFace(抱抱脸)
详见:huggingface
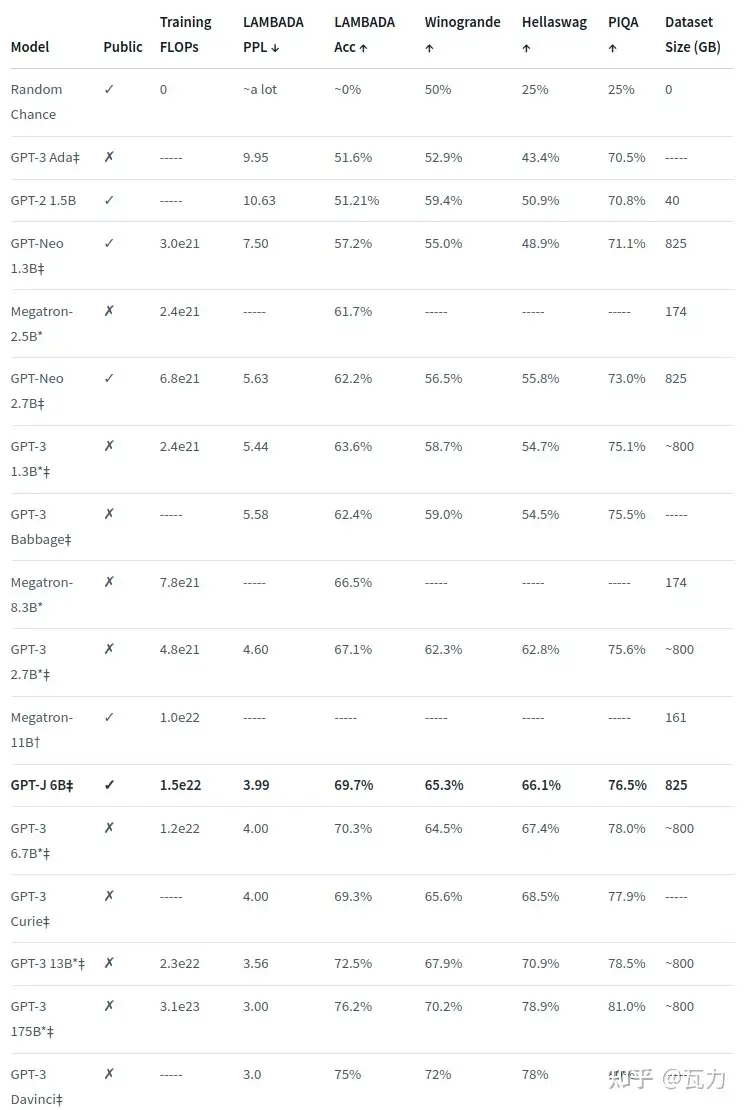
国外严格复刻GPT-3方案并开放模型的主要来自 eleuther.ai,其于huggingface平台提供的finetune和推理接口,目前提供的版本如下:
魔塔
2022年云栖大会上,阿里达摩院推出了AI大模型开源社区“魔搭” Model Scope,推出伊始,达摩院就向社区贡献了300余个AI模型,全面开源开放。
国内严格复刻 GPT-3 方案并开放模型的主要是阿里达摩院,其于modelscope平台提供的finetune和推理接口,目前提供的版本如下:
飞智
【2023-3-1】要做中国OpenAI的很多,但智源要打造大模型领域的Linux
- 智源研究院(院长黄铁军)联合30多家产学研单位,开发了
FlagOpen(飞智)国内首个大模型技术开源体系。
FlagOpen是否意味着又一个魔搭的诞生?智源研究院副院长兼总工程师林咏华解释了二者的不同。
林咏华:
- “魔搭有点像抱抱脸(HuggingFace)”
- “FlagOpen和魔搭不一样的是, 主要目标不是构建一个聚集很多人的繁华社区,而是推动大模型技术的发展。”
基于这个目标, FlagOpen 配套了六个模块,分别是 FlagAI、FlagPerf、FlagEval、FlagData、FlagStudio和FlagBoot。

- FlagAI
- FlageAI集成了很多主流大模型算法技术,以及多种大模型并行处理和训练加速技术,并支持微调。目前涵盖的模型包括NLP、CV与多模态等领域,如语言大模型OPT、T5,视觉大模型ViT、Swin Transformer,多模态大模型CLIP等。目前,FlagAI已经加入Linux基金会。
- “悟道2.0”通用语言大模型GLM,“悟道3.0”视觉与训练大模型EVA,视觉通用多任务模型Painter,文生图大模型AltDiffusion(多语言),文图表征预训练大模型(多语言)等智源研究院“悟道”大模型项目多个成果也开源在FlagAI。
- FlagPerf
- AI软硬件评测面临异构程度高、兼容性差、应用场景复杂多变的挑战。FlagPerf搭建的AI硬件评测体系,支持多种深度学习框架,及时跟进最新主流模型评测需求,便于AI芯片厂商插入底层支撑工具,且不以排名为核心目标
- 截至FlagOpen体系发布,FlagPerf已和天数智芯、百度PaddlePaddle、昆仑芯科技、中国移动等进行合作。
- FlagEval
- FlagEval是覆盖多个模态领域、包含评测维度的评测工具,首先开放的是近期很火的多模态领域-CLIP系列模型评测工具,支持多语言多任务、开箱即用。
- FlagData
- FlagData数据工具开源项目集成包含清洗、标注、压缩、统计分析等功能在内的多个数据处理工具与算法。此前,智源研究院已经构建了WuDaoCorpora语料库。
- FlagStudio
- FlagStudio是文生图、文生音乐等艺术创作相关的开源项目集合,集合的算法和模型更贴合中文场景,当前主要提供智源研究院文生图相关能力的应用。
- FlagBoot
- FlagBoot是基于Scala开发的轻量级高并发微服务框架,默认完全异步,且没有宏、隐式转换等晦涩难懂的代码。极少的代码量便于开发者轻易了解背后逻辑,而后进行自定义修改。
“大数据+大算力+强算法=大模型”是当前AI发展的主流,用 FlagOpen,开发者尤其是初创公司,可以尝试大模型的开发和研究工作,换句话说,AI的研发、应用门槛被降低了。
以大模型为主导的方向提供基础开源体系,某种意义上,智源研究院在追赶ChatGPT产品的热点上退了一步。这或许是其非营利性机构的性质使然。
而ChatGPT背后的OpenAI,也是打着非营利性机构的旗号出道的(2019年3月1日,OpenAI LP子公司成立,旨在营利)。同样的机构性质,同样押注AI,并关注大模型赛道,智源研究院有打算,或者可能成为中国的OpenAI吗?
AIGC 创业
详见站内专题:AIGC机会
各家实力
看好哪家?
- 第一还是百度文心,先发优势,其次,字节,因为有数据、有算力、有场景
模型+应用
模型团队和应用团队逐步分开,而不是作为一体而存在——这也是大模型从技术层迈向产品的必经之路。
- 字节在AI业务发展初期,就将大模型分为底层技术与产品应用两个团队,并命名为“Seed”和“flow”;
- 百度文心大模型与文小言App,也分属技术中台事业群组(TPG)与移动生态事业群组(MEG)。
- 阿里云通义模型 + 智能信息(通义应用)
360
360大模型
- 360向NV下了上千块A800的货。
- 360语料可能比阿里强,但最后能做出什么效果,需要时间验证。
腾讯
腾讯大模型进展?
- 混元继续迭代,大概100人左右做GPT复现以及自我模型迭代。猜测大概8月份会出。但应该只是支持文生文的场景。
百度
百度虽然不是那么智能,但还是相当不错的。国内算是第一名。
- 文心一言有一定实用性,但离达到GPT-3水平还有一定差距。不过,至少可以达到GPT-2.5水平,如果未来能够持续优化,会达到GPT-3.5的水平。
- 数据积累对于百度来说是一个优势,尤其是在搜索领域。百度在知识库方面有很多年的积累,包括百度知道等。
- 达摩院模型架构基于Transformer,而文心一言则基于Bert。
华为
华为盘古与昇腾如何看?
- 盘古大模型效果有待考证,并没有明确对标GPT,而是往B端去做。
- 因为受限制,只能用自己的昇腾,虽然昇腾910大概也有A100的70%水平(比寒武纪好),但算力的限制可能会制约大模型发展。
字节跳动
【2024-5-23】字节刚刚启动大模型校招计划,计划取名Top Seed,大模型团队,关键8人,首次曝光!
薪资TOP级别、算力数据管够,但仅面向应届博士生,由一帮顶尖的技术导师团带队。
冯佳时:豆包大模型视觉基础研究团队负责人,中科大校友,博士毕业于新国立;项亮:豆包大模型Foundation团队负责人,本科毕业于中科大,后保送至中科院自动化所;王明轩:豆包大语言模型研究团队负责人,北航校友,博士毕业于中科院计算所;田值:豆包大模型视觉生成模型技术专家,在川大本科期间就以一作发布顶会论文,阿德莱德大学获博士学位;王雨轩:豆包大模型语音部门负责人,本科毕业于北航,后攻读北京大学研究生,博士毕业于俄亥俄州立大学;严林:豆包大语言模型对齐团队负责人,研究生毕业于中科院计算所;陈卓:豆包大模型音频生成研究团队负责人,西安交大校友,硕博毕业于哥伦比亚大学;李成刚:豆包大语言模型预训练方向负责人,清华机械工程本硕学位。
【2025-1-23】字节豆包大模型团队已在内部组建AGI长期研究团队,代号“Seed Edge”,鼓励项目成员探索更长周期、具有不确定性和大胆的AGI研究课题。
接近字节的知情人士透露,Seed Edge的目标是探索AGI的新方法,代号名中Seed是豆包大模型团队名称,Edge代表最前沿的AGI探索。根据披露,Seed Edge初步确定了五大研究方向,包括探索推理能力的边界、探索感知能力的边界、探索软硬一体的下一代模型设计、探索下一代AI学习范式、探索下一个scaling方向。
字节LLM团队发展
- 2023年1月,字节跳动组建了首个专注于大型模型研发的团队,该团队由其搜索部门主导,
朱文佳担任负责人。朱文佳此前在TikTok担任技术负责人,并在加入字节跳动之前在百度担任搜索部主任架构师。- 2019年,
朱文佳曾担任今日头条的CEO,后于2021年转任TikTok产品技术负责人。
- 该团队由两个小组构成
- 一个小组来自字节跳动的原搜索部门,负责开发语言模型;
- 另一个小组属于产品研发与工程架构部下的智能创作团队,负责图片模型的开发。
陆游,抖音的社交负责人,也在2023年上半年加入了这个大型模型团队。
- 2023年8月,该团队开发的“
云雀”大型模型完成了网信办的备案工作。同一时期,字节跳动还推出了一款多模态的大型模型——BuboGPT。 - 2023年11月,字节跳动成立了一个名为“
Flow”新部门,专注于AI技术的应用。这个部门隶属于公司的研发与工程部门(简称“PDI”),由上半年带领团队开发“云雀”模型的朱文佳担任业务负责人,洪定坤作为技术负责人,朱骏则是产品负责人。- 该部门目前有四个主要业务线:AI教育、国际化、社区和豆包。
- 截至当时,Flow部门的员工人数已经超过100人。飞书产品副总裁
齐俊元和抖音社交负责人陆游也已转至Flow部门,分别负责PC端和移动端产品。
- 2024年4月,
朱文佳获得了进一步晋升,现在直接向CEO梁汝波汇报。朱文佳领导的AI团队倍称为“Seed”。 - 除了Flow和Seed团队,字节跳动还有两个AI团队:
李航领导的AILab更侧重于学术理论的探索,而项亮的团队则专注于Data-AML。 - 此外,字节跳动的各个业务单元也在积极探索将现有产品与AI技术相结合。
- 2024年2月,
张楠宣布辞去抖音集团CEO的职位,未来将专注于剪映的发展。目前,剪映已经推出了Dreamina,对标OpenAI的Sora。
【2024-8-29】字节跳动成立大模型研究院,零一万物、面壁智能前核心成员已加入,直接汇报朱文佳
字节跳动正在低调筹备成立大模型研究院,并积极吸引顶尖人才。目前,已有多位AI领域的专家计划加入该研究院。
- 前
面壁智能核心成员秦禹嘉和前零一万物核心成员黄文灏已加入字节的大模型团队,汇报给朱文佳,尚不清楚他们是否归属于即将成立的大模型研究院。
秦禹嘉博士2024年毕业于清华大学计算机系,由刘知远教授指导。他对自然语言处理和机器学习有着广泛的兴趣,特别专注于预训练语言模型及其在信息提取和问答系统中的应用。他在ACL、ICLR、TASLP等会议和期刊上以第一作者身份发表了多篇论文。
黄文灏博士曾在多家明星机构担任重要职务。黄文灏博士在毕业后曾在微软亚洲研究院研究agent,专注于任务型聊天机器人开发,并探索了AI在金融量化和科学领域的应用。在离开亚研院后,黄文灏博士加入智源研究院,担任健康计算研究中心技术负责人,重点研究AI在生命科学领域的应用,特别是在「AI+大健康」方向。他的研究涵盖生物识别的自然语言处理和自然语言处理与结构研究的结合。随后,他以联创身份加入零一万物,担任算法副总裁,主导Yi-Large大模型的研发,推动了包括Yi-34B在内的多个开源模型的发布,并在相关排行榜上取得了成绩。
字节生成式AI布局 图
- 模型层: 负责人朱文佳
Seed: 基础模型- 语言: 云雀大模型(语言)
- 多模态: BuboGPT(多模态)
- 文生图: ResAdapter(文生图)、SDXL-Lightning(文生图)
- 视频编辑: Boximator(视频编辑)
- 文生视频: PixelDance(文生视频)、MagicVideo(文生视频)、AnimateDiff-Lightning(文生视频)
Flow: Agent 定制Coze: 海外, 基于 GPT扣子: 国内, 基于 云雀
- 应用层: 业务带头人 朱文佳、技术负责人 洪定坤、产品负责人 朱骏、PC产品负责人 齐俊元、Mobile 产品负责人 陆游
Flow- 聊天:
豆包(国内,云雀)、Cici(海外,基于GPT) - 社交:
猫箱(国内)、Anydoor(海外) - 图像:
星绘(国内)、PicPic(海外)
- 聊天:
剪映- 图像/视频:
Dreamina(剪映/Capcut)
- 图像/视频:
头条- 办公:
小悟空(国内)、ChitChop(国外)
- 办公:
大力教育- 教育:
河马爱学(国内)、Gauth(海外)
- 教育:
巨量引擎- 电商内容:
即创(国内)
- 电商内容:
- 其它
- 音乐:
海绵乐队(国内) - 教育:
识典古籍(国内)
- 音乐:
阿里
【2023-4-1】阿里AI专家交流纪要20230401
达摩院大模型
阿里巴巴达摩院牵头做大模型,22年发布大模型:m6和plug。
M6:支持多模态,比如说文字生成图片,文字生成语音,文字生成视频这种模型,规模不如GPT3.5,所以叫中模型。
达摩院整个团队约有100个人做相关大模型的迭代和升级,一方面是复现GPT,一方面把m6和plug迭代到能够对标到GPT的水平。
- m6能力还不能对标到GPT3.5,还有一年半的差距。
- 2023年下半年云栖大会,应该会有m6新发布,大概在GPT2.5左右。
资源消耗
数据
语料积累不足
- 现有大型语言模型在文本清洗和筛选方面存在一些限制,因此需要对现有模型进行升级和迭代,以适应不同领域的数据需求。
- 例如,要将模型应用于军事、旅游文化、政治等领域,需要更多数据收集和人工标注,以达到更高的准确性和效率。
- 同时,大型语言模型的成熟也将带来更多的商业机会,例如,天猫淘宝、高德地图等应用中的搜索和客服机器人等领域。
- 此外,如果大型语言模型足够成熟,可能会释放出API,由合作伙伴接入,从而实现生态层面的垄断。
算力
算力
- 国内AI算力中,阿里储备最多,其次是 字节、百度、腾讯。
- 阿里云至少有上万片的A100,整体至少能够达到10万片,集团是阿里云5倍。达摩院、天猫、淘宝的算力资源都是集团内资源使用。
- 阿里云这块今年增速会有30-50%。有个别8-9个客户会有复现GPT的需求,提出了大规模AI算力需求,以云的方式给。
- 百度年初紧急下单3000台 8卡的A800服务器,2.4万张卡,预计全年百度会有A-H800共5万张的需求。
- 阿里云需求不会这么多,去年采购2万多,今年可能采购量会下降。预计云上就1万张左右,其中6000张是H800。此外阿里云也会用到平头哥这种自研的,每年大概3000张去采购。
阿里云也会选择国产芯片的一家,看是否在云上商业化。
寒武纪MLU370,主要是性能基本过关(A100的60-70%),检测合格,态度积极,愿意对接,服务贴身。今年会采购大概2000张的水平,主要用在一些CV等小模型的训练或推理上。寒武纪MLU 370没有供货的风险,后续的MLU590也许就会有了壁仞宣传上不错,但拿不到实测的卡,流片大约都是今年4-6月,量产半年后。而且壁仞4月要流片的卡,不能支持FP64,互通带宽不支持8卡,支持最多4卡,采用NV bridge方式,达到180GB水平。 8卡用PCIe方式只能做到32GB,弱点显著。海光,参数也足够支撑训练,但可能由于海光因产能等因素,可能更侧重满足国有算力那边的需求。同时,集团层面是否对接,不清楚。- 海光的CUDA兼容性更好,除了海光,其实阿里云产的 PPU 其实也在一定程度上能够做到CUDA兼容,与NV做绑定。
目前降低算力成本的方式?
- 除了大模型,即使stable diffusion这种文生图模型,也消耗较小。stable diffusion模型一直在优化,以前一个推理任务一张A100、现在降级到一个推理任务一张V100。对于阿里这种巨头而言,V100的存货还是很多的。
- 针对模型的优化,或者加速软件,加快模型训练与推理。
- 对模型进行降级,降低精准度要求,比如从FP16降级为FP8。
阿里采取怎样的打法?
- 大概率是稳扎稳打,集团拆分后都要自负盈亏,压力挺大。
- ChatGPT的一个推理任务,大概所需要消耗的5张A100在2秒钟之内做一次推理,大规模应用起来成本很高,冲击也很大。
主要有两种
- 推出的效果好的模型,与集团内部的产品结合,例如天猫、淘宝和高德地图的搜索业务。这将为搜索引擎带来更新的商业模式,并取代以前的商业模式。
- 输出自己的API,并向合作伙伴或渠道商收费。这些客户是从ToC端产生的。大多数客户都有自己的APP和网站,这些客户可以通过他们的APP和网站获取流量。不同的客户可以使用不同的API,这意味着厂商可以在生态系统中形成垄断。
目前,已有一些厂商尝试将API集成到产品中,但进展不如预期快。对于我们的API,可能会在特定领域上有所帮助,例如电商、搜索和推荐,并带来更好的商业模式。
【2024-12-18】「通义」应用团队从阿里云分拆,并入阿里智能信息事业群
阿里旗下的AI应用“通义”近期正式从阿里云分拆,并入阿里智能信息事业群。
- 此次调整包括通义To C方向的产品经理,以及相关的工程团队,一并调整至阿里
智能信息事业群 - 调整后,通义PC及App团队与智能搜索产品“
夸克”平级,原有通义实验室,仍然留在阿里云体系内。
阿里梳理内部AI To C应用的一步。
- 阿里旗下的大模型家族“通义”,包括应用层的“通义”App、PC端,均属于阿里云体系。
- 其中,通义大模型家族由阿里云开发——主要职能更偏向模型研发和创新性技术研究;而阿里云又是一个To B业务,也不适合投入进直面To C市场的应用开发和推广中。
人员变动
【2023-3-22】资讯,原达摩院大模型 M6 带头人杨红霞已加入字节 AI lab,参与语言生成大模型的研发,杨红霞在团队中处于领导地位,直接向字节跳动副总裁杨震原汇报。
- 去年9月初,杨红霞从阿里达摩院离职,离开是出于个人家庭原因,而非行业问题,达摩院大模型 M6 团队的后续工作不受影响。
1、原阿里 M6 带头人杨红霞 2007 年本科毕业于南开大学,获统计学学士学位。之后她去往美国杜克大学统计科学系攻读博士学位,师从 David Dunson 教授。博士毕业后,杨红霞先入职 IBM 全球研发中心任 Watson 研究员,后又加入雅虎公司,担任首席数据科学家。
- 2016 年,杨红霞结束了在美近 10 年的留学及工作生涯,回国后加入阿里巴巴达摩院智能计算实验室,大模型 M6 是杨红霞在达摩院任职期间最突出的成就。

- 2021 年 3 月,阿里达摩院首次发布 M6,英文全称是 MultiModality-to-MultiModality Multitask Mega-transformer,6个 M,简称
M6,是国内首个千亿参数多模态大模型。 - 同年6月,杨红霞团队又发布万亿参数的 M6,仅使用 480 块GPU,就能实现万亿参数体量的智能运算。相比原来的百亿参数模型,功耗降低 8 成,效率提升 11 倍。
- 仅过4个月后,M6 又在当年 10 月再次突破极限,杨红霞团队使用 512块 GPU,在 10 天内训练出 10 万亿模型。与大模型 GPT-3 具有同等参数规模,但能耗仅为其 1%。
- 大模型 M6 拥有多模态、多任务能力,其目标是打造全球领先的具有通用性的人工智能大模型,尤其擅长设计、写作、问答,在电商、制造业、文学艺术、科学研究等领域有广泛应用,通过将不同模态的信息经过统一加工处理,沉淀成知识表征,为各个行业场景提供语言理解、图像处理、知识表征等智能服务。相较于其他 AI 模型,大模型 M6 更低碳高效,提升了超大规模预训练模型的资源利用率与训练效率,沉淀大模型高效训练的能力。
- 杨红霞曾在接受媒体采访时表示:“多模态预训练是下一代人工智能的基础,M6 模型实现了训练效率和生成精度等多项突破,是当前众多中文多模态下游任务最优模型。”
- 在达摩院期间,杨红霞带领阿里巴巴达摩院 M6 团队致力于认知智能方向,研发了 AliGraph、M6、洛犀等较为有影响力的人工智能开源平台和系统,发表顶级会议、期刊文章超过 100 篇,美国和中国专利超过 30 项。她曾带领团队获 2019 世界人工智能大会最高奖卓越人工智能引领者(Super AI Leader,简称 SAIL 奖),2020 年国家科学技术进步奖二等奖和 2020 年杭州市创新领军团队。
- 2022年6月,杨红霞入选 2022 福布斯中国科技女性50榜。去年9月初,由于个人家庭原因,杨红霞从阿里巴巴达摩院智能计算实验室离职。
2、字节加入语言生成大模型之战此前 ChatGPT 带动的热潮中,百度率先发布“文心一言”,正式打响了国内科技大厂的较量。相较于此前在大模型上有布局的企业,例如百度“文心”、阿里“通义”、华为“盘古”等,字节在这场大模型之战中显得略为低调。
- 此前有媒体报道称,字节跳动在大模型上已有布局,主要在语言和图像两种模态上发力。其中,语言大模型团队组建于今年,团队规模在十数人左右,主要探索方向为同搜索、广告等业务线的结合。
- 相比起其他大厂的大张旗鼓,字节目前研究大模型的人并不算多。此前在
马维英担任字节跳动副总裁兼人工智能实验室主任期间, 曾主推人工智能赋能内容创作和视频内容理解,但当时内部 AI 和推荐引擎是分开的;字节之前离开的另一位领军人物王崇则专长于机器学习,此前是字节推荐引擎负责人。 - 国内字节等大厂做 ChatGPT 的模型,目前学习架构大部分采用大模型教小模型的方式,小模型学习到大模型能力的百分之几,能解决大部分问题后再慢慢升级。
ChatGPT 不是终点,在这场关于通用人工智能的的角逐中,数据和场景成为了竞争的关键,从这个角度上看,字节有丰富的多模态数据,又有娱乐、学习、电商等丰富的应用场景。此前王小川曾对 AI 科技评论表示,字节在这场争夺战应占有一席之地,“如果能够出现一个产品可以理解视频,基本就立于不败之地了。”杨红霞常年深耕在产业化大规模落地的人工智能相关技术,她的加入将弥补字节在语言生成大模型领军人才的空缺,而她此前展示出的在提升效率、降低能耗等方面的杰出工程能力,也将对字节语言生成大模型的研究创新、场景应用落地等方面带来重要影响。
【2025-10-30】前阿里、字节大模型带头人杨红霞创业:大模型预训练,不是少数顶尖玩家的算力竞赛
2024年7月,杨红霞从字节离职, 加入香港理工大学,被曝出仍要做模型相关技术的消息。
2025年10月,杨红霞带着 新 AI 公司 InfiX.ai,杀回了大模型赛道。
InfiX.ai 宏大版图:这一次,杨红霞不仅想和市面上的顶尖模型叫板,甚至想革新大模型的训练和落地范式。
当下主流的顶尖模型,包括GPT,都由大机构主导、“中心化”。(中心化的模型)需要集中投入非常多的数据、人力、算力资源”。
但 InfiX.ai 要做的恰恰相反:让大模型预训练“去中心化”,变成中小企业、研究机构,甚至个人都能参与的事。
美国 “去中心化”的热潮已经逐渐涌起。
- 2025 年 2 月,前 OpenAI CTO Mira Murati 成立了新公司 Thinking Machines Lab (以下简称“TML”),愿景是让个人开发者和初创企业,也能负担得起模型训练。
- “我真没想到一家还没有实际业务落地的公司,只是宣布要做这件事,(种子轮)就能实现融资 20 亿美金、估值 120 亿美金。”
核心原因
- 2023年中,彼时还在字节的杨红霞就发现,擅长解决通用领域问题的“中心化”模型,无法真正落地。
- 不少数据敏感的企业有本地化部署模型的需求。
- 模型知识的注入只发生在预训练阶段,后训练提供的是规则
- 导致 企业数据后训练模型仍然会出现不少“幻觉”。
判断:
- 第一,大模型要落地,不能只依赖少数巨头机构,必须基于诸多企业数据预训练;
- 第二,为了让企业也能做预训练,必须要降低所消耗的资源。
围绕这两个判断,近期,InfiX.ai 开源了全球首个 FP8 训练“全家桶” (包括预训练、监督微调和强化学习),一项模型融合技术,以及基于此训练出的医疗多模态大模型和多智能体系统。
核心技术
- 低比特模型训练框架 InfiR2 FP8
- 模型融合技术 InfiFusion:
- 医疗多模态大模型训练框架 InfiMed
- 多智能体系统 InfiAgent
上海人工智能实验室
书生浦语 InternLM 是上海人工智能实验室开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖。
【2024-12-4】 上海人工智能实验室周伯文:以通专融合方式构建AGI——路径与关键问题探索 包含系列ppt
2016年以来,周伯文教授及其团队持续深入研究AGI的实现路径;当前,面对大语言模型在Scaling Law与架构等方面的技术瓶颈,周教授及其团队不仅提出了完整的AGI实现路径,更创新性地从应用价值出发,探索更高效发挥AGI潜力的场景与方法。
OpenAI
OpenAI 是美国的AI实验室,非营利组织,定位是促进和发展友好的人工智能,使人类整体受益。
OpenAI成立于2015年底,创始人是 Elon Musk(伊隆·马斯克)以及前YC 总裁 Sam Altman(山姆·奥特曼)。并宣布将会以“推动AI技术造福人类”为己任,通过向社会无偿分享自己的AI技术,来规避由于科技巨头垄断AI技术而导致的潜在威胁因素。

- Elon Musk:预防人工智能的灾难性影响,推动人工智能发挥积极作用。
【2021-2-6】GPT发家史
- OpenAI 成立之初并非因为文本生成模型而知名,这点和 DeepMind 些许不同,后者专注强化学习一百年。 OpenAI 一开始两条线是强化学习和生成模型(集中 GAN),而 GPT 开始也没受到太大关注,而是在探索中 OpenAI 发现了其可能性,便开始大力投入,到现在基本上一大半项目都与其相关。所以,现今大家提起 OpenAI 相信都是马上想起 GPT,再或者和马一龙(Elon Musk)早期有一腿,又多少人还能想起强化学习和GAN呢。
- OpenAI 早期成员,除 Pieter Abbeel 等做强化学习的,就是一众做偏图像生成的,比如
- GAN 提出者 Ian Goodfellow 最早也是入职 OpenAI
- 同期入职的还有一个叫 Alec Radford 发明 DCGAN 的精神小伙。大家记住这个名字,因为他对 GPT 的发展应该说至关重要。
- 所以可以看出最早 OpenAI 就是群做强化学习和图像生成的人,没啥做 NLP 的,自然也难料想自己居然是通过 NLP 来一战成名。
OpenAI 使命
OpenAI的使命: OpenAI章程
- OpenAI conducts fundamental, long-term research toward the creation of safe AGI.
- 从事创建AGI(通用人工智能)的基础、长期研究
ChatGPT是否开源?
- 尚未开源,目前是以API(应用程序编程接口)调用的方式服务,目前也暂无开源计划。
Open AI不Open,是业界很多人诟病的地方。开源是多年来软件和互联网产业之所以蓬勃发展的核心动力之一。开源方式可以调动全球开发者的积极性,每个人都可以下载源代码使用,并进行优化和在社区分享。这种用全社会的力量来创新的机制,大幅加速了技术科研攻关、产业应用的进程。
关于ChatGPT为何不开源
- 业界也有一些专家表示认可,因为人工智能技术至今为止还是一个黑盒,关于其内部的机制尚未可知,如果代码开源,很难避免该技术用于一些不利于社会和人类的方面。
- 此外,自从Open AI放弃了非盈利组织的定位,接受微软等投资后,从商业化的角度考虑,也会采取整体模型闭源,开放应用接口的方式来推广,同时也会开源少部分模型,丰富开发者生态。

OpenAI 成就
OpenAI 在生成式大模型贡献很大,没有 OpenAI 就不会有现在的 generative AI(生成式AI)。它通过 DALL·E 、GPT-3等,把技术通过一套很好的工程的体系去实施出来交付出来。OpenAI 和其他公司、学术组织最大区别是非常注重engineering,包括 ChatGPT这件事情
团队成员
管理方式
OpenAI 公司文化:
- 完全零邮件,一切都在 Slack 上
- 自下而上的决策,好想法来自任何地方
- 强烈的精英主义,能力决定地位
- 可以「想到就做」的行动文化
- 产品或团队能在一夜之间改变方向
创始团队
【2023-2-23】揭秘ChatGPT背后的AI“梦之队”
OpenAI 官网显示,为 ChatGPT 项目做出贡献的人员共 87 人 (总人数 350人)。现就该团队成员职务构成、年龄分布、教育背景、人员流动、华人成员、成员贡献、性别分布等数据进行统计分析,并总结归纳其特征。
- 职位分工:近 9成为技术人员,高度聚焦技术研发
- 研发人员共 77 人,占比 88%,其中含 1 名公司联合创 始人,即 Wojciech Zaremba; 产品人员共 4 人,占 5%。另外,6 人职位信息无法获取。
- 团队未配备技术与产品之外的职能人员(如公共关系、市场营销等人员),而是高度聚焦于技术研发。
- 年龄分布:“90 后”科研“后浪”显示强大创新能力
- 20~29 岁的成员有 28 人,占全体成员(剔除年龄信 息缺失的 5 位成员)的 34%;30~39 岁的共 50 人,占 61%;40~49 岁的仅 3 人,无 50~59 岁年龄段的成员,60 岁以上的有 1 人。经计算,该团队平均年龄为 32 岁。
- 教育背景:绝大多数拥有名校学历,6 人毕业于中国高校
- 27 人具有本科学历,25 人为硕士研究生学历,28 人拥有博士研 究生学历(注:5 人信息缺失),占比分别为 33%、30%、37%。作为全球人工智能顶尖研发团队,其成员学历并非“清一色”研究生学历,而是本、硕、博人数相对均衡。
- 毕业高校分布看,斯坦福大学校友最多,共 14 人;其次是加州大学伯克利分校,共 10 人;第三是麻省理工学院,共 7 人;我国清华大学与卡内基梅隆大学并列第 7 名,各有 3 人。
- 人员流动:10 人从谷歌跳槽加入,1 人曾在百度任职
- 团队成员主要来自外部公司(81%)、高校应届毕业生(13%)、科研机构(4%)和高校教职人员(3%)等(如下图所示)。其中人数来源最多的外部企业是谷歌, 共 10 人跳槽加入
- 从 ChatGPT 团队离职的人员,并非外界想象的加入所谓“大厂”,而是仍然选择具有创新潜力的创业公司或机构。
- 华人成员:在国内完成本科学业,后赴美深造并就业
- 9 位华人(名单见下表)。其中 5 人本科就读于中国内地的高校,3 人大学教育经历均在美国高校完成,1 人(张马文,Marvin Zhang)信息不全。
- 成员贡献:1/4 成员参与过 codeX 研发,欧阳龙表现突出
- 与 ChatGPT 相 关的先前关键技术项目有 RLHF③(Reinforcement Learning from Human Feedbac,人 类反馈强化学习)、GPT1④、GPT2⑤、 GPT3⑥、codex⑦、InstructGPT⑧、webGPT⑨等 7 项。
- 华人欧阳 龙是 InstructGPT 论文的第一作者,是 RLHF 论文的第二作者,可见他是这两个关键技术项目的核心人员。
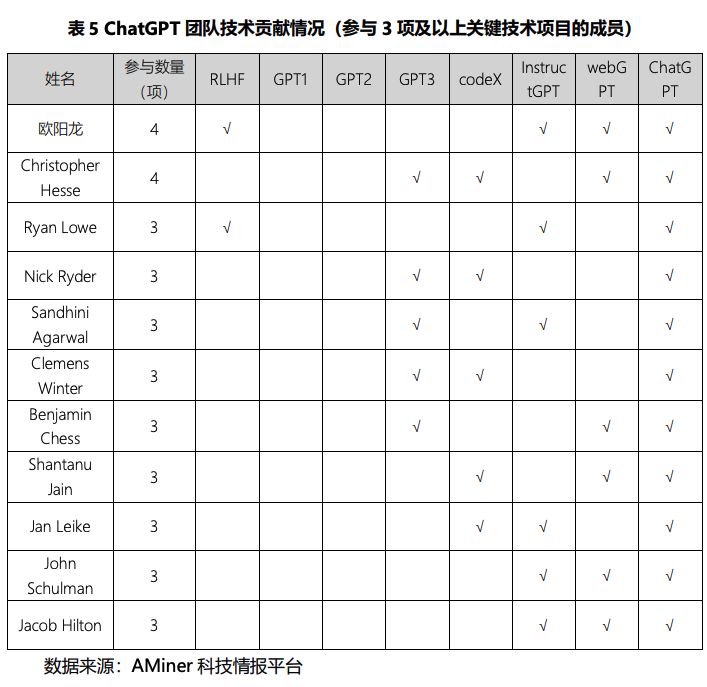
- 性别特征:团队由男性主导,女性仅占 1 成
- 9 位女性成员中,有 2 位是华人,即曾就读于北京大学的翁丽莲,以及 Steph Lin。
OpenAI 的组织方式能够有自下而上的创新(ChatGPT 就是一个自下而上的 idea),也能在确定目标后集中力量朝一个方向努力,和传统科研机构单兵作战的方式不同。此外,OpenAI 给员工也有足够的激励,工资+期权平均成本 120 万美金/人/年,相对于 Google、Microsoft 等大厂也十分优渥。
优秀人才的号召力、吸引人的组织氛围以及优渥的激励让 OpenAI 正在“掏空”整个硅谷的科学家和 Super Talents。
GPT-4 团队
【2023-3-18】GPT-4背后的开发者:七大团队,三十余位华人
GPT-4 幕后的研发团队大致可分为七个部分:预训练(Pretraining)、长上下文(Long context)、视觉(Vision)、强化学习 & 对齐(RL & alignment)、评估 & 分析(Evaluation & analysis)、部署(Deployment),以及其他贡献者(Additional contributions)。GPT-4 contributions, gpt-4-system-card
- 预训练部分的工作细分为:
- 计算机集群扩展(Compute cluster scaling)
- 数据(Data)
- 分布式训练基础设施(Distributed training infrastructure)
- 硬件正确性(Hardware correctness)
- 优化 & 架构(Optimization & architecture)
- Training run babysitting
- 长上下文部分的工作细分为:
- 长上下文研究(Long context research)
- 长上下文内核(Long context kernels)
- 视觉部分的工作细分为:
- 架构研究(Architecture research)
- 计算机集群扩展(Compute cluster scaling)
- 分布式训练基础设施(Distributed training infrastructure)
- 硬件正确性(Hardware correctness)
- 数据(Data)
- 对齐数据(Alignment Data)
- Training run babysitting
- 部署 & 后训练(Deployment & post-training)
- 强化学习 & 对齐部分的工作细分为:
- 数据集贡献(Dataset contributions)
- 数据基础设施(Data infrastructure)
- ChatML 格式(ChatML format)
- 模型安全(Model safety)
- Refusals
- 基础 RLHF 和 InstructGPT 工作(Foundational RLHF and InstructGPT work)
- Flagship training runs
- 代码功能(Code capability)
- 评估 & 分析部分的工作细分为:
- OpenAI Evals 库
- 模型等级评估基础设施(Model-graded evaluation infrastructure)
- 加速预测(Acceleration forecasting)
- ChatGPT 评估
- 能力评估(Capability evaluations)
- 编码评估(Coding evaluations)
- 真实世界用例评估(Real-world use case evaluations)
- 污染调查(Contamination investigations)
- 指令遵循和 API 评估(Instruction following and API evals)
- 新功能评估(Novel capability discovery)
- ……
30多位华人信息,照片见原文
预训练组
- Trevor Cai
- Trevor Cai 是 GPT-4 项目中吞吐量团队的负责人。Trevor Cai 本硕毕业于南加州大学,2022 年 3 月加入 OpenAI。在加入 OpenAI 之前,Trevor Cai 曾在 DeepMind 工作近 5 年,担任软件工程师。
- 袁启明
- 袁启明(Qiming Yuan)是 GPT-4 项目数据集来源和处理团队的负责人。袁启明本科毕业于清华大学,硕士毕业于得克萨斯大学奥斯汀分校,2018 年加入 OpenAI。此前,袁启明曾在微软工作近三年。
- Che Chang
- Che Chang 作为 OpenAI 的副总法律顾问参与了 GPT-4 的研发,他博士毕业于美国西北大学,2021 年加入 OpenAI,此前在 AWS 领导了人工智能 / 机器学习和市场业务的法律团队。最近一段时间,OpenAI 的法律团队还在招聘 AI 产品顾问。
- 欧阳龙
- 欧阳龙 2019 年加入 OpenAI,担任研究科学家。Long Ouyang 本科毕业于哈佛大学,博士毕业于斯坦福大学,曾在斯坦福大学任博士后研究员。欧阳龙也参与研发了 ChatGPT 相关的技术项目,他还是 InstructGPT 论文的第一作者。
- 翁丽莲
- 翁丽莲(Lilian Weng)是 OpenAI 人工智能应用研究的负责人,2018 年加入 OpenAI,在 GPT-4 项目中主要参与预训练、强化学习 & 对齐、模型安全等方面的工作。
- Tao Xu
- Tao Xu 2019 年加入 OpenAI,先后毕业于北京大学、康奈尔大学。Tao Xu 曾在微软的必应机器学习研究组工作四年。
- Jie Tang
- Jie Tang 在加州大学伯克利分校获得计算机科学博士学位,导师是 Pieter Abbeel。加入 OpenAI 前,他曾在初创公司和 Dropbox 工作约四年时间。Jie Tang 本科就读于哈佛大学,2008 年获得计算机科学和经济学学士学位。
- Ben Wang
- Ben Wang 目前是宾夕法尼亚大学本科生,2021 年加入 OpenAI。Ben Wang 参与了 GPT-4 项目的预训练和长上下文方面的工作。
视觉组
- Mark Chen
- Mark Chen 2018 年加入 OpenAI,任研究科学家,毕业于麻省理工学院(MIT)。他参与了 GPT-4 项目中视觉方面的工作。
- Casey Chu
- Casey Chu2020 年加入 OpenAI,毕业于斯坦福大学计算数学专业。Casey Chu 的主要研究方向是多模态 AI 系统,他在 GPT-4 项目中主要参与视觉方面的工作。
- 胡绳丽
- 胡绳丽(Shengli Hu)2022 年加入 OpenAI,她硕士毕业于复旦大学、博士毕业于康奈尔大学。她的研究兴趣在于社会科学、计算语言学、计算机视觉和语音的跨学科研究。胡绳丽曾在自然语言处理、计算机视觉、语音和应用统计方面的顶级会议和期刊上发表过多篇论文,包括 CVPR、ACL、EMNLP、ECCV 等等,并获得过最佳论文奖提名。
- Tianhao Zheng
- Tianhao Zheng2022 年加入 OpenAI。他本科毕业于清华大学,博士毕业于得克萨斯大学奥斯汀分校。再加入 OpenAI 之前,他曾先后在英伟达、谷歌、Twitter 工作过。Tianhao Zheng 在 GPT-4 项目中主要参与了视觉方面的工作。
- 翁家翌
- 翁家翌(Jiayi Weng)2020 年在清华大学计算机科学与技术系获得本科学位。本科在朱军教授组学习期间,主要参与了强化学习算法库 Tianshou(天授)的开发,该项目已获得 5.9K GitHub Star。CMU 硕士毕业后,翁家翌加入 OpenAI 任研究工程师。
强化学习 & 对齐组
- Chong Zhang
- Chong Zhang 2010 年就读浙江大学计算机系,2014 年在加拿大西蒙弗雷泽大学获得学士学位,随后在谷歌、苹果公司担任工程师。2019 年就读加州大学洛杉矶分校,2021 年获得计算机硕士学位后,在 OpenAI 工作至今。
- Shengjia Zhao
- Shengjia Zhao2016 年本科毕业于清华大学,2022 年在斯坦福大学获得计算机科学博士学位,师从 Stefano Ermon,随后加入 OpenAI。
- Stephanie Lin
- Stephanie Lin 本科和硕士期间分别就读于麻省理工学院和佐治亚理工学院。加入 OpenAI 之前,她曾是牛津大学研究学者。
- Tong Mu
- Tong Mu 本科就读于加州大学洛杉矶分校,后在斯坦福大学获得博士学位。2022 年加入 OpenAI。
- Jeff Wu
- Jeff Wu 本硕均就读于麻省理工学院。他是初创公司 Terminal.com 的第二名员工,该公司被收购后,他曾在谷歌工作约 2 年的时间。2018 年,Jeff Wu 加入 OpenAI。
- 肖凯
- 肖凯(Kai Xiao)在麻省理工学院获得了学士学位和博士学位,曾在微软、DeepMind 等机构实习。2022 年 9 月加入 OpenAI。
- Kevin Yu
- Kevin Yu 在加州大学伯克利分校获得物理学学士学位及神经科学博士学位。2022 年加入 OpenAI。
- Haozhun Jin
- Haozhun Jin2013 年本科毕业于清华大学计算机系,2015 年获得斯坦福大学硕士学位。2015 年到 2018 年,他在 Meta 担任软件工程师,2023 年 1 月加入 OpenAI。
- 顾世翔
- 顾世翔是出生于日本的加拿大华人,曾是谷歌研究院研究科学家,研究领域包括深度学习、强化学习、概率机器学习和机器人技术。他拥有剑桥大学和马普所智能系统研究所的机器学习博士学位,在多伦多大学获得了工程科学学士学位,论文指导教授为 Geoffrey Hinton。
评估 & 分析团队
- Alvin Wang
- Alvin Wang2022 年 8 月加入 OpenAI,为评估 & 分析团队核心贡献者之一。此前他曾在 VMware、Tesla 等公司工作过几年。2013 年本科毕业于南加州大学。
- Angela Jiang
- Angela Jiang 于 2021 年 11 月加入 OpenAI,在微软和谷歌有过短暂的工作经历,她本科毕业于西北大学,于 CMU 获得博士学位。
- Jason Wei
- Jason Wei 于今年 2 月加入 OpenAI,主要研究 ChatGPT。此前他是谷歌 Brain 的高级研究科学家,在那里推广了思维链提示,并共同领导了指令调优工作。他在谷歌和 Jeff Dean 等人共同撰写了关于大模型涌现能力的论文。
- Juntang Zhuang
- Juntang Zhuang 于 2022 年 4 月加入 OpenAI,此前曾在谷歌实习四个月。他本科毕业于清华大学,硕士毕业于耶鲁大学,并在耶鲁大学拿到博士学位。他的研究主要是为生物医学应用开发新的机器学习技术。
- Derek Chen
- Derek Chen 于 2021 年加入 OpenAI,是一名技术安全分析师。他毕业于美国东北大学,此前在谷歌工作过不到一年的时间。
- 宋飏
- 宋飏(Yang Song)目前在 OpenAI 担任研究员,并将于 2024 年 1 月加入加州理工学院电子系(Electrical Engineering)和计算数学科学系(Computing and Mathematical Sciences)担任助理教授。宋飏本科毕业于清华大学数理基础科学班,2022 年获得斯坦福大学计算机科学博士学位,师从 Stefano Ermon。他的主要研究方向是机器学习,包含深度生成式模型(deep generative models),概率推理(probabilistic inference),人工智能安全性(AI safety),以及人工智能方法与其他科学领域的交叉(AI for science)。他是扩散模型(diffusion models)和分数匹配生成式模型(score-based generative models)的主要奠基人之一。他发表在 NeurIPS 2019 的工作首次在图片生成质量上实现了对生成对抗网络(GAN)的超越。博士期间他的一作论文获得了 ICLR 2021 杰出论文奖,相关研究获得了苹果奖学金、摩根大通奖学金,以及 WAIC 云帆奖。
模型部署
- Michael Wu
- Michael Wu 2021 年加入 OpenAI,主要的工作是人工智能应用研究。Michael Wu 毕业于 MIT,是 GPT-4 项目的推理研究负责人。
- Andrew Peng
- Andrew Peng 2022 年底加入 OpenAI,他曾经在微软工作两年。Andrew Peng 毕业于加州大学伯克利分校,主要参与 GPT-4 API 和 ChatML 部署方面的工作。
- 吴雪枫
- 吴雪枫(Sherwin Wu)2022 年加入 OpenAI,主要的工作是人工智能应用及 API 开发。吴雪枫毕业于 MIT,在 GPT-4 项目中主要参与 API 开发和 ChatML 部署方面的工作。
- Jason Chen
- Jason Chen 本科就读于麻省理工学院,2007 年到 2014 年期间在谷歌担任软件工程师,2014 年到 2019 年任职于初创公司 Apptimize,2019 年到 2023 年 2 月任职于 Argo AI,2023 年 2 月加入 OpenAI。
其他贡献者
- Xin Hu
- Xin Hu 于 2022 年 6 月加入 OpenAI,主要负责开发用于云安全、k8s 安全、认证 / 授权和访问控制的安全服务和平台。
此外,在 GPT-4 的开发上 OpenAI 也对微软表示了感谢,特别是微软 Azure 服务为模型训练提供了基础架构设计和管理方面的支持,微软必应团队、安全团队也对 GPT-4 的部署等工作作出了贡献。
成立之初, OpenAI 只有10名成员,除了主要负责打理公司、招贤纳士的CTO Greg Brockman和上文所说的两位联合创始人外,其余7人都是AI技术领域的顶尖研究学者, 包括总揽研究事宜的原 Google Brain 研究科学家Ilya Sutskever。
2019年OpenAI 宣布了其公司新架构:
- OpenAI Nonprofit:日常工作没有变化,通过开发新的 AI 技术,而非商业产品来创造出最大的价值。
- OpenAI LP:被称为 “有限盈利”(capped-profit) 公司,提高筹集资金的能力,增加对计算和人才方面的投资,确保通用人工智能(AGI)有益于全人类。
- OpenAI 非营利部门负责管理 OpenAI LP,主持学者和研究人员等教育计划,并负责政策实施。
人事方面也有所调整:
- 离任Y Combinator总裁的Sam Altman,将担任OpenAI LP的CEO。
- Greg Brockman 将担任 CTO, Ilya Sutskever 担任首席科学家。Brockman 还将担任 OpenAINonprofit董事会主席。
OpenAI LP 当时拥有约 100 名员工,主要分为三个领域:能力(探索AI系统可以做什么),安全(确保这些AI系统符合人类的价值观)和政策(对此类系统进行适当的管理)。

人才流失
【2023-3-18】Sam Altman 被董事会踢出 CEO位置
高科技领域这种案例很多
- 最熟悉的有 Apple 创始人
乔布斯被“开除”出董事会; - 而另外一个大家使用更多的高科技产品 – 芯片, 其最大的芯片公司Intel英特尔的公司创始人
摩尔及后来的CEO格鲁夫,之前都是在一家叫做“仙童半导体Fairychild”的公司,后来因为和董事会不能达成一致,这些核心技术人员有10多名集体被迫离开了公司,后来创立了世界上最著名的高科技公司; - 而
乔布斯(Steve Jobs)也是在离开苹果之后,首先打造了Pixel皮克斯,Pixel后来被沃尔特迪士尼收购,成为了当年全球最大的并购案,而乔布斯因为此次并购,成为了迪士尼的最大股东(他的股份为迪士尼孙子的3倍),而在离开苹果的时间所新研发的图形化引擎,更是为未来的MacOS和iOS在图像操作系统上奠定了非常强大的竞争优势。
2020年,OpenAI 人才流失的因素不外乎十个字:理想很丰满,现实很骨感
憋在院校里闷头搞研究的学者之所以愿意来到 OpenAI,无外乎这里能够保证在不违背自己“从事非营利性科研项目”的前提下,挣到比学校高3~5倍的薪资。
然而事实上,OpenAI这10亿的预期资金其实并不稳定。而且据称,作为 OpenAI 的头号赞助商,马斯克还经常把学者拉去帮忙给特斯拉的自动驾驶研发出主意。
- “拿人家手短吃人家嘴软”,
特斯拉不像Google那样本身就拥有一支技术实力雄厚的Google Brain研发团队,只要马斯克仍然身为OpenAI的主要投资者之一,这种“剪不断理还乱”的联系就不会彻底根除。
长此以往,OpenAI当然很难像DeepMind一样平心静气地潜心去钻研技术。而这导致的结果就是直到现在,OpenAI的关键性课题研究成果也十分有限,距离拥有比肩DeepMind的影响力也还很遥远。
2020年,GPT-3 未开源,并商用后,掀起一波离职潮。失去这些关键人员,OpenAI 未来在相关课题上或将略显颓势。
- 例子:
Chris Olah是 OpenAI 多模态神经元论文的作者之一。他是领域里小有名气的“怪胎”,曾经拒绝Yoshua Bengio的研究生邀请,而是去了Google Brain团队。他在谷歌带过博士生,论文的引用数量甚至超过拥有博士学位的研究者,自己却连本科都没毕业…… - Olah 参与的 OpenAI 多模态神经元论文:多年以前有研究者发现,大脑中的一些神经元可以对模态不同但概念相同的触发条件产生反应,比如当提到“哈莉·贝瑞”的名字、照片、简笔画像的时候,同一个神经元都可以产生反应。
- OpenAI 的多模态神经元研究,基于该机构今年发布的 CLIP 泛用性视觉系统。论文作者发现在 CLIP 的神经网络倒数第二层也存在这样的一颗“神经元” (Neuron 244)。这项研究预示着,“抽象”这一自然视觉领域的概念,很可能在计算机合成视觉领域同样存在。

OpenAI 团队散伙
OpenAI
- 联合创始人、前首席科学家伊尔亚·苏茨克韦(
Ilya Sutskever)早已离开并成立AI安全公司SSI(safe superintelligence,安全超级智能) - 2024年2月,Andrej Karpathy 离职, 创立 Eureka Labs
- 2024年5月, 首席科学家
Ilya Sutskever2023年底与公司董事会一起投票罢免Altman,“政变”六个月后,离开OpenAI,创立安全超级智能公司SSI - 2024年8月, 联合创始人、总裁
布罗克曼(Greg Brockman) 开始休假, 至2024年年底 - 2024年8月, 模型对齐关键人物
John Schulman离职, 加入 Anthropic, 深入关注AI对齐问题的愿望,同时开启职业生涯的新篇章- PPO 算法发明人,OpenAI 的创始人之一,曾共同领导过 ChatGPT 和 OpenAI 后训练团队
- 2024年9月26日, 公司CTO,“宫斗”风波中暂代CEO一职的
穆拉蒂离开。 - 2025年2月19日, 穆拉蒂 宣布创业
此前,OpenAI联合创始人约翰·舒尔曼(John Schulman)、OpenAI原“超级对齐”团队负责人杨·莱克(Jan Leike)也已离开OpenAI加入其竞争对手公司Anthropic,OpenAI联合创始人安德烈·卡帕西(Andrej Karpathy)离职, 并成立教育初创公司,OpenAI的副总裁、ChatGPT负责人Peter Deng也已被曝离职。

参考
- 【2024-8-11】11人走了9人,OpenAI创始团队“分崩离析”
- 【2024-9-26】OpenAI首席技术官宣布离职,或取消非营利性董事会控制权,奥特曼有望获股权
- 【2025-2-19】官宣:Mira Murati 的创业公司,顶级团队打造开放的 OpenAI
Elon Musk
2018年2月底,马斯克却突然在上周宣布辞任OpenAI董事会职务,当然原因并不是“自己付不起钱了”,而是“为了避特斯拉的嫌”。
- 马斯克的离任并不会对组织的运营带来多少影响。毕竟马斯克自己也曾说过,只把3%~5%的精力放在了OpenAI上
马斯克名下已经拥有了6家公司:
- 2002年6月成立的SpaceX
- 2004年通过A轮融资成为其董事长的特斯拉
- 2006年7月成立的SolarCity
- 2015年12月成立的OpenAI
- 2016年7月成立的Neuralink
- 2016年12月成立的Boring。
- 而在这些企业中,至少可以直观地判断出:特斯拉的Autopilot自动驾驶系统中肯定会不可避免地利用到AI技术。
随着2016年特斯拉与计算机视觉方案商Mobileye的彻底决裂,特斯拉开始使用自己研制的Tesla Vision技术来完成旗下汽车在自动驾驶过程中的视觉处理工作,而这其中运用的正是深度学习技术。
鉴于目前Autopilot的研发进程已经严重滞后,其对诸如高速公路自动变道、狭窄道路巡航系统、自动传唤系统等功能的研发优化也到了火烧眉毛的地步。
2017年6月,马斯克也终于动起了歪脑筋——直接从OpenAI挖人。被马斯克相中的人名叫Andrej Karpathy
Andrej Karpathy – cv大牛
Andrej Karpathy (江湖人称 AK-47)
- 斯坦福博士,师从Google AI首席科学家的
李飞飞,与Ilya Sutskever同样是OpenAI成立初期10人团队中的一员,且同样曾在Google Brain项目实习。 - 目前,在 Google Scholar 上,Karpathy 的论文引用数达到了 53360。其中,引用第二多、他作为一作的论文《Large-scale Video Classification with Convolutional Neural Networks》被收录为 CVPR 2014 Oral。
- 前特斯拉自动驾驶总监,openai,接着创业做 AI教育 Eureka Labs
Andrej Karpathy 履历
- 2005-2009 年,Andrej Karpathy 本科就读于加拿大多伦多大学,主修计算机科学与物理,辅修数学。在这里,他第一次接触到深度学习,聆听 Hinton 的课程。
- 2009 -2011 年,Karpathy 硕士就读于加拿大不列颠哥伦比亚大学,其导师为计算机科学系教授 Michiel van de Panne,主要研究物理模拟中用于敏捷机器人的机器学习。
- 2011-2016 年,Karpathy 博士就读于斯坦福大学,师从著名 AI 学者李飞飞,专注于研究卷积 / 循环神经网络以及它们在计算机视觉、自然语言处理和交叉领域的应用。期间,他设计并担任斯坦福首个深度学习课程《CS231n:卷积神经网络与视觉识别》的主要讲师。
- 与此同时,Karpathy 还有三段实习经历。
- 2011 年,他进入发展初期的谷歌大脑实习,致力于视频领域的大规模无监督学习。
- 2013 年,他再次在谷歌研究院实习,从事 YouTube 视频的大规模监督学习。主要负责对YouTube视频进行大规模特征提取可行性的研究。
- 2015 年,他在 DeepMind 实习,参与深度强化学习团队的工作。
- 博士毕业后,Karpathy 加入了 OpenAI 担任研究科学家。作为创始成员之一,Karpathy 帮助公司做了很多早期的招募 / 结构化工作。同时,作为一名研究科学家,他致力于生成模型的深度学习(例如使用 PixelCNN++ 生成图像)和深度强化学习。
- 不过,在 OpenAI 没待多久,Karpathy 就被马斯克挖去了特斯拉,接替当时的特斯拉 Autopilot 负责人、苹果 Swift 语言、LLVM 编译器之父 Chris Lattner,担任特斯拉人工智能和自动驾驶视觉总监。
- 2017年6月,
Andrej Karpathy摇身一变成为了特斯拉自动驾驶研究项目的领军者。- 特斯拉 人工智能与自动驾驶视觉总监 Andrej Karpathy

- 从 2017 年到 2022 年,Karpathy 一直在特斯拉工作。五年里,他一手促成了 Autopilot 的开发。这项技术对于特斯拉的完全自动驾驶系统 FSD 至关重要,也是马斯克针对 Model S、Cybertruck 等车型推销的主要卖点。
- 随着特斯拉从最开始的自动驾驶慢慢扩展到更广泛的人工智能领域,Karpathy 也被提为特斯拉的 AI 高级总监,直接向马斯克汇报工作。
- 2022 年 7 月,Karpathy 在推特上宣布自己将从特斯拉离职。
- 「过去五年,我非常高兴帮助特斯拉逐步接近了它的目标,如今离开是一个艰难的决定。我见证了 AutoPilot 从测试到部署到城市街道,期望未来 AutoPilot 团队持续自己的强大。」
- 对于未来,Karpathy 当时并没有具体的计划,「但希望重拾自己长久以来对 AI 技术工作、开源和教育等方面的热情。」
- 事实上,他也确实是这么做的。在闲下来的几个月里,Karpathy 给大家贡献了很多学习材料,包括一个详解反向传播的课程 、一份重写的 minGPT 库、一份从零开始构建 GPT 模型的完整教程等。
- 2023年2月9日,官宣再次加入openai
- 【2023-2-9】加入最火OpenAI,特斯拉前AI总监Andrej Karpathy自宣回归
- OpenAI在网络中就被实锤了一个新的Tittle:特斯拉旗下人工智能研究机构。顶着“非营利性”的旗号,却成为了创始人马斯克的个人人才储备库
cv大牛,OpenAI 做多模态的有力加速器
Greg Brockman 大管家
Greg Brockman:OpenAI 内部的大管家和冲锋队长,⼯程能⼒和基础设施的打造者。
作为 OpenAI 的早期重要联创之一,Greg 是一位数一数二的工程天才,Greg 本人有 80% 的时间在写代码,我们了解到 OpenAI 内部的模型训练的 infra 架构基本都由 Greg 一个人完成,包括了 GPT-4 的 Infra。同时,Greg 也想一个冲锋队长,能在大家都不知如何下手时候带队冲锋。
Ilya Sutskever 灵魂人物
OpenAI研究总监(首席科学家) Ilya Sutskever

Ilya Sutskever:
- 2012年:提出AlexNet模型,开创图像识别新章,AlexNet被认为是计算机视觉领域最有影响力的论文之一
- 2013年:共同创办的DNNresearch被Googleicon收购
- 2014年:提出了序列到序列学习(Sequence To Sequence)的神经网络变体,开创了语言翻译革命(谷歌icon翻译的基础)
- 2015年:放弃了谷歌的数百万美元的工作,成为非营利组织OpenAI的联合创始人
- 2018年:Sutskever领导了GPT-1的开发,后来发展成了GPT-2、GPT-3和ChatGPT。
- 2021年:Sutskever领导了DALL-E 1(图像生成模型)的开发。
OpenAI 政变
【2023-11-20】一手逼退奥特曼,隔两天又在联名信上签字请他回来,被讽刺”内斗推手”,光速滑跪。为何马斯克依然站他?没有他就没有OpenAI的今天。
- 马斯克认为挖到伊利亚是OpenAl成功的关键,还夸他”是个好人,非常聪明且心地善良”。
- 奥特曼对他评价也很高,称他是”世界上最受尊敬的研究人员之一”。
2023年11月下旬开始,OpenAI便开始了步步惊心的内斗环节。
- 第1天,Ilya率先发难,解除了Sam Altman的职务,同时将Greg Brockman做降级处理。
- 第2天,OpenAI的最大金主微软要求Ilya改变决定,否则将直接淘汰掉以Ilya为主导的董事会。
- 第3天,Sam Altman准备回归OpenAI,与Ilya展开谈判。
- 第4天,Ilya开启反击,聘请Emmett Shear接任CEO,微软称Sam 和 Greg 将加入自家公司。
- 第5天,谁料OpenAI员签署的联名信产生巨大影响力,持续发酵,Ilya道歉。
最终,双方在拉锯到第13天的时候,OpenAI宣布,Sam Altman再任CEO,同时组建新的董事会。
最大的原因还是观念不同
- 和他的导师辛顿一样,伊利亚很担心AI的安全问题,他甚至还公开怀疑ChatGPT已经有了自我意识。
- 而奥特曼却是积极的扩张派,有消息说他还准备搞个AI芯片公司,在积极筹集数百亿美元的资金。
也许是这样的冲突让伊利亚动了手。事件发生后,有员工认为这是一场”政变”或者”恶意收购”,但伊利亚并不同意,他认为这是让OpenAI回到非赢利机构的使命,让”AI向善”。
【2024-8-31】AI技术政治(上):危机派、加速派与对齐派的路线之争
Ilya Sutskever 履历
Ilya Sutskever 深度学习教父 Hinton 的学生, AlexNet 的作者,本身就是深度学习革命的开创者,拥有最强的远见力和最坚定的深度学习信仰
DL 启蒙者,帮助 OpenAI 及时⾛上 Transformer 路线。
Ilya 在 OpenAI 属于精神领袖的存在,他的技术直觉和品味很好,能够找到一些大家之前没有很重视的方向,比如 Scaling 能 work,三年前大家都不相信的时候特别坚持。
履历
- 1986年,出生于俄罗斯,加拿大籍。
- 5岁起,耶路撒冷长大,能说俄语、希伯来语和英语
- 本科就读于多伦多大学,遇到了 Geoffrey Hinton——深度学习研究的教授和先驱。Sutskever 在攻读博士学位时加入了 Hinton 的小组。
- 2012 年,在 Hinton 的指导下,Sutskever 和博士生同学 Alex Krizhevsky 开发了
AlexNet,ImageNet LSVRC-2012 的比赛中脱颖而出。AlexNet 以一种新颖的神经网络架构在 NIPS 亮相,包含五个卷积层和三个完全连接的层。AlexNet标志了自 2012 年起人工智能革命的开端 - 2012 年毕业后,Sutskever 在斯坦福大学跟随吴恩达教授读了两个月的博士后课程。
Ilya Sutskever师出深度学习三巨头之一的Geoffrey Hinton,曾与导师在2012年共同创办语音、图像识别方案研发企业DNNresearch,在这一公司被Google收购后才加入了Google的神经网络研究项目中。- 2012年11月,回到了多伦多大学, 加入了 Hinton 的新研究公司 DNNResearch,这是 Hinton 研究小组的副产品。
- 2013 年 3 月,Google 收购了 DNNResearch,并聘请 Sutskever 担任
Google Brain的研究科学家。AlphaGO的作者之一- 最开始他并不相信AGI(通用人工智能),到Deepmind找工作时, 还觉得构建AGI根本就不现实。
- 后来他加入了谷歌的人工智能团队Google Brain,对AI彻底改观,觉得AGI的未来就在眼前。
- 2014 年,Sutskever 与谷歌研究员 Oriol Vinyals 和 Quoc Le 一起提出了
Seq2seq学习(Sequence to Sequence Learning),机器翻译效果达到sota。 - 在谷歌大脑团队中,Sutskever 加入了 Google 开源库
TensorFlow的开发,用于大规模机器学习。Ilya Sutskever曾就职于Google,硅谷这种大公司关不住这些牛人,另起炉灶很正常, 普通人反而才是一直混Google养老
- 2015 年 7 月的一天,Sutskeve 参加了由 Y Combinator 总裁 Sam Altman 在 Sand Hill Road 的一家餐厅举办的晚宴,在那里他遇见了 Elon Musk 和 Greg Brockman。
- Sutskever 和 GregBrockman(现为 OpenAI 首席技术官)共同创立了 OpenAI,得到来自 Elon Musk,Sam Altman 和 LinkedIn 创始人 Reid Hoffman 的 10 亿美元资金,其目标是「以最有可能造福人类的方式推进数字智能并使之成为一个整体」。
- 2015年马斯克和奥特曼组建OpenAl,为了挖他花了不少功夫,甚至和前谷歌CEO拉里佩奇闹翻。谷歌为了留下他更是开出了200万美元的天价年薪。不过他还是觉得OpenAI的AGI愿景更有吸引力。
- 先后领导发明了大语言模型GPT-1~4, 以及文生图模型
DALL-E1 - 2018 年,领导 OpenAI 发明
GPT-1。 - 2021 年,Sutskever led OpenAI’s invention of
DALL-E1- 文生图巨头MidJourney也是基于DALL-E1微调
Ilya Sutskever: The brain behind ChatGPT

虽然OpenAI标榜自己是“非营利性组织”,但实质上其核心研究一直在围绕着自家的Gym平台环境进行,并没有跳脱出巨头“通过技术开源来拉拢人才”之嫌。
首席科学家Ilya Sutskever是OpenAI的灵魂人物。
- 2020年,GPT还没出来时,普遍认为让神经网络学会推理可能做不到,需要考虑 neural symbolic 的方法,即将
连接主义和符号主义结合。后来,很快就放弃了这个思路,但仍然认为:神经网络无法真正解决ood (out of distribution)的问题。 - 而事实上,解决ood之前先把数据的 distribution 搞的足够大更重要,gpt便是如此,然后颠覆了认知,也更加坚定深度学习纯连接主义这条路。
没有Ilya就不可能有这些革命性的进展。为什么Ilya的认知最强?
- 因为早年
Seq2Seq也是他搞出来的,所以当google把transformer搞出来时,他的嗅觉最灵敏,知道这东西能解决LSTM存在的记忆问题,从而能够scale。而大部分人看到transformer并不会产生这种认知。 - 而ChatGPT基本原理和之前的OpenAI Dota Five,Alphastar 没有本质区别,都是先
监督学习再强化学习,只是变成语言通用场景了。单单这个认知也是太强了!
SSI 公司
【2024-6-19】Ilya 正式出山,建立「安全超级智能」 SSI 公司, Safe Superintelligence Inc.
- 强调只有一个重点、一个目标、一个产品,用技术确保大模型将要带来的超级人工智能对人类是安全的。
「AI 将万世不朽,它的诞生如同开天辟地」。当 Ilya 目光炯炯地谈及 AI 的进程,他也最有资格断言,并引领着,「迈向 AGI 的激动人心又危险的旅程」。
【2025-11-26】ilya播客观点:
- 预训练+scaling 已见顶(数据有限),需要进一步研究新范式
- rl在讨好单一指标,牺牲了通用能力,需要学习人类情绪+机制,作为value function,同时编码同理心,提高预测效率,更好的构建世界模型
详见站内:scaling law 到头了
Wojciech Zaremba 攻坚手
Wojciech Zaremba 联创,攻坚手,亲自放弃机器人探索后打造 Codex。
在 GPT-4 的研究中,Wojciech 创建了 GPT-4 的数据集并负责了强化学习和 Alignment 中的人类数据管理工作。很多人评价 GPT-4 之所以能和别的大语言模型拉开差距,模型很重要,数据更重要。
Wojciech Zaremba也是最初加入到OpenAI团队中的一员,他师从于另一位深度学习三巨头Yann LeCun,并曾先后在Google和Facebook工作。在回忆起最终决定加入OpenAI的理由时,他曾这样说道:
- 尽管我非常尊重Google和Facebook这样的大公司,然而这些公司近乎疯狂地开高价留人,让人很难不理解为: 这些企业是在从自身商业利益的角度考虑,在想着为自己公司的AI产品构建技术壁垒,所以我选择
OpenAI。
成立后不久,Greg Brockman就为OpenAI设立了核心的技术研发方向:从强化学习(Reinforcement Learning)入手,最终实现无监督学习(Unsupervised Learning)。
- “强化学习”是机器学习领域的一个历史久远的技术分支,旨在让AI通过对未知环境的探索,来自行求得最优解。通过与深度学习相结合,这一技术能让AI快速掌握获取最优解的要领,我们所熟知的AlphaGo就是将“深度强化学习”运用到极致的佼佼者。
- 而“无监督学习”则更多的是指代一种在AI领域的通用概念,即:无需人工辅助对数据进行标记,即可自行理解数据含义并进行归纳总结的能力。从业内已公开的技术发展情况来看,目前研究还只能达到有效率地执行半监督学习(semi-supervised learning)阶段。
- 让OpenAI开始广为人知的Dota 2 Solo一战

Ilya Sutskever曾明确表示过,OpenAI最核心的任务是发表有影响力的研究报告,但其实OpenAI更多的是在构建开源开发平台。截至目前,OpenAI已经迭代推出了4款开源软件平台:
- 第一款名为
Gym。用于研发和比较强化学习算法优劣的工具包,在2016年4月首次发布。开发者可以利用这一工具对自己开发的AI算法进行训练并展示,从而获得与其他平台开发者共同探讨和研究的机会; - 第二款名为
Universe。用于训练“解决通用问题的AI”的基础开发架构,在2016年12月首次发布。这一架构中包含了近千种AI训练环境,开发者可以利用这一工具将任何程序转换到Gym的环境下并进行训练。所以这款软件平台,也可以说是为Gym打开了一个万能的接口; - 第三款名为
Roboschool。用于模拟机器人控制训练的开源软件,在2017年5月首次发布。这一软件再度整合了Gym平台,可以视为是专门针对“机器人”这个应用领域单独开设的免费训练平台; - 第四款名为
Blocksparse。用于优化GPU神经网络运行效率的工具包,在2017年12月首次发布。这一软件主要是利用了数值分析中稀疏矩阵(Sparse matrix)的特性,通过减少不必要的运算量,来实现优化记忆神经网络的目的。
John Schulman RLHF开创者
John Schulman:RLHF 的开创者,打造了 OpenAI 的 RL 基础设施。
John 在 Reinforcement Learning 的积累成就了目前的 ChatGPT。John 在 GPT-4 的开发过程中是 RL 和 Alignment 的带队人。
Jan Leike 落地 instruct GPT
Jan Leike:落地 instruct GPT , 把 alighment 带到新高度。
Alignment 是 OpenAI 区别于 Google 等大厂的重要能力,Jan Leike 带领团队攻坚递归奖励模型、辩论、迭代放大三大研究,并主导落地了 Instruct GPT,在 GPT-4 的开发过程中也负责了 Alignment 部分。
Mira Murati – 新晋 CTO
Mira Murati:OpenAI 新晋 CTO ,引领了 OpenAI 在 AI 安全上的探索。
Mira 的背景十分有趣,在加入 OpenAI 之前,Mira 在 Leap Motion 负责产品和工程(Leap Motion 是 MidJourney CEO 的上一个创业项目),Mira 在职业生涯早期还曾在 Tesla 担任产品。我们认为 Mira 可能是人机交互领域最重要的 PM 之一。
离职
2024年9月26日,OpenAI CTO(首席技术官)米拉·穆拉蒂(Mira Murati)离职。
离职“进行自己的探索”,而现在的首要任务是尽自己所能确保平稳过渡,保持OpenAI已经建立起来的势头。
OpenAI 四位“核心人物”合照也再次被网友翻出,并表示已经从最开始的四人变成了现在的奥特曼一人。
创业
【2025-2-19】 Mira Murati 的创业公司,顶级团队打造开放的 OpenAI
OpenAI 前 CTO、核心主创之一 Mira Murati 官宣创业。
- Thinking Machines Lab,大牌云集,豪华大模型创业团队阵容。
- 多位前 OpenAI 重要成员,如担任首席科学家的
John Schulman、著名 AI 研究科学家和博客作家翁荔。
- 多位前 OpenAI 重要成员,如担任首席科学家的
- 公司名字似乎源自 阿兰图灵 1950 年的论文《计算机器与智能》,提出「图灵测试」,以及经典的一个问题:Can machine think?
Thinking Machines Lab 是一家「人工智能研究和产品公司。」
承诺:
- 「我们致力于通过论文发表和代码发布来开放科学,同时会重点关注应用于不同领域的人机协作。
- 我们的方法包括共同设计研究和产品,以便从实际部署和快速迭代中学习。这项工作需要三个核心基础:SOTA 的模型智能、高质量的基础设施和先进的多模态能力。我们致力于构建处于能力领先的模型来兑现这一承诺。」
核心基础说明:
- 模型智能是基石。除了强调人机协作和定制之外,模型智能也至关重要,正为科学和编程等领域构建前沿能力模型。最终,最先进的模型将解锁最具变革性的应用和优势,例如实现新颖的科学发现和工程突破。
- 基础设施质量是重中之重。研究生产力至关重要,在很大程度上取决于基础设施的可靠性、效率和易用性。目标是长期正确地构建事物,以最大限度地提高生产力和安全性,而不是走捷径。
- 先进的多模态能力。多模态对于实现更自然、更高效的通信、保存更多信息、更好地捕捉意图以及支持与现实环境的更深入集成至关重要。
Lilian Weng – 前沿技术和应用研究
• Lilian Weng:前沿技术和应用研究的桥梁,也是 OpenAI 高管团队中唯一的中国人。
OpenAI研究副总裁(安全)翁荔
Lilian 是前沿技术和应用研究的桥梁,通过设计 API 拓宽了 GPT 的应用领域。在 GPT-4 项目中,她主导了应用领域的研究。在她的 Lil Log 中有很多研究的分享,是在 AI 从业者中很有影响力的博客。
北大毕业后,翁荔在2018年加入OpenAI,后来在GPT-4项目中主要参与预训练、强化学习&对齐、模型安全等方面的工作。
最著名的Agent公式也由她提出,即:Agent=大模型+记忆+主动规划+工具使用。
在今晚的2024Bilibili超级科学晚活动上,翁荔站在舞台上,以《AI安全与“培养”之道》为主题进行了演讲分享。
【2024-11-1】2024 bilibili超级科学晚全程回顾
- 《AI安全与“培养”之道》
- 翁荔演讲全文
【2025-5-26】刚刚,北大校友Lilian Weng自曝公司首个产品?一篇论文未发,估值却已90亿
OpenAI前研究员大佬、如今的 Thinking Machines Lab 联创Lilian Weng,刚刚转发了一个神秘产品——一台专为AI训练打造的「手动调参仪表盘」
Jakub Pachocki – 预训练专家
• Jakub Pachocki:OpenAI 的预训练专家,Sam 在 GPT-4 发布后专门感谢的人。
他参与了 OpenAI 几乎大部分成功项目——深度参与了 Gym 和 Dota 的研究,负责了其中核心技术的攻坚,后带领推理和深度学习组。作为 GPT-4 预训练和整个项目的负责人(整个项目一共有两位 overall lead),Sam Altman 在 GPT-4 发布后发布一条 Twitter:“GPT-4 预训练方法的成就离不开 Jakub 的领导力和远见。”
Ian Goodfellow GAN之父
Ian Goodfellow Google Brain研究员, 对抗生成网络(Gan)之父Ian Goodfellow、来自加州大学伯克利分校的知名强化学习领域教授Pieter Abbeel及其桃李等

Dario Amodei
Dario 是 OpenAI 的早期员工之一,曾发表多篇 AI 可解释性、安全等方面的论文,离职前在 OpenAI 担任研究 VP。在此之前,Dario 还曾在百度担任研究员,在前首席科学家吴恩达手下工作。他博士毕业于普林斯顿大学,后回到本科毕业的斯坦福大学担任博士后学者。
他是 OpenAI 的前核心成员,也被认为是深度学习领域最为前沿的研究员之一。

Dario 的胞妹 Daniela Amodei 之前也在 OpenAI 从事和 Dario 相同方向的工作,曾担任安全和政策 VP。Daniela 过往的任职经历包括 Stripe(其创始人是 OpenAI 投资人之一)、美国国会等。

Anthropic 公司
2020年12月,OpenAI 一批早期/核心员工集体离职,在领域内引起了不小的轰动。
这批员工认为随着模型变大、算力变强,通用人工智能离我们越来越近,在可预见的未来就有可能实现——而在这样的前提下,AI 可解释性和安全性变得无比重要。这批员工被认为是AI领域的“有效利他主义者”。简单来说,他们不仅认为应该投入重金进行 AI 基础研究让世界变得更好,并且也要注重实际功效。
他们的理念和 OpenAI 并没有本质上的冲突,但是 OpenAI 变得越来越不透明,且逐渐功利化的趋势,令他们感到担忧。
- 一个最直接的例子,就是 OpenAI 尚未解决偏见和安全问题,就把 GPT-3 开发成了商用化API,提供给行业里的大公司使用。
这批核心员工集体离职。其中不少人,都参与到了 Anthropic 公司当中。
- 一家重拾 OpenAI 慢慢忘却的初心的“正统” AI 基础科研机构。
- Anthropic 的创始团队成员,大多为 OpenAI 的重要员工或关联成员,包括(排名不分先后)Jared Kaplan、Sam McCandlish、Tom Brown、Gabriel Goh、Kamal Ndousse、Jack Clark、Ben Mann、Chris Olah 等。
OpenAI 离职的核心员工当中就包括 Dario Amodei 和他的同胞姐妹 Daniela。
- 2021年2月创办了 Anthropic 公司,Dario 任 CEO,Daniela 任总裁。
Anthropic 的官网这样介绍自己:
- 我们是一家AI 安全和研究公司,致力于开发可靠、可解释和可调整的 AI 系统。
- “今天的大规模的通用(AI)系统能够带来很高的收益,但他们同时却是不可预测、不可靠,和不透明的。我们的使命是在这些问题上做出进步。”
Anthropic 联合创始人兼 CEO Dario Amodei 表示。
“Anthropic 的使命是从事基础科研,让我们可以打造能力更强、更通用、更可靠的 AI 系统,并且应用这些系统从而让人类获益,”
伟大计划:
- 解决长久以来神经网络的“黑盒子”问题,为研究者们开发能够解释 AI 真正工作原理的工具。
- AI 的黑盒子问题:黑盒子是一个算法,能够将数据转变成其它东西。问题在于,黑盒子在发现模式的同时,经常无法解释发现的方法。


【2021-6-15】OpenAI核心人员集体离职创立新公司:人均大神,融资1亿多美金只为“初心”
CEO Dario Amodi
【2024-11-16】CEO 访谈
OUTLINE:
- (00:00) – Introduction
- (10:19) – Scaling laws
- (19:25) – Limits of LLM scaling
- (27:51) – Competition with OpenAI, Google, xAI, Meta
- (33:14) – Claude
- (36:50) – Opus 3.5
- (41:36) – Sonnet 3.5
- (44:56) – Claude 4.0
- (49:07) – Criticism of Claude
- (1:01:54) – AI Safety Levels
- (1:12:42) – ASL-3 and ASL-4
- (1:16:46) – Computer use
- (1:26:41) – Government regulation of AI
- (1:45:30) – Hiring a great team
- (1:54:19) – Post-training
- (1:59:45) – Constitutional AI
- (2:05:11) – Machines of Loving Grace
- (2:24:17) – AGI timeline
- (2:36:52) – Programming
- (2:43:52) – Meaning of life
- (2:49:58) – Amanda Askell – Philosophy
- (2:52:26) – Programming advice for non-technical people
- (2:56:15) – Talking to Claude
- (3:12:47) – Prompt engineering
- (3:21:21) – Post-training
- (3:26:00) – Constitutional AI
- (3:30:53) – System prompts
- (3:37:00) – Is Claude getting dumber?
- (3:49:02) – Character training
- (3:50:01) – Nature of truth
- (3:54:38) – Optimal rate of failure
- (4:01:49) – AI consciousness
- (4:16:20) – AGI
- (4:24:58) – Chris Olah – Mechanistic Interpretability
- (4:29:49) – Features, Circuits, Universality
- (4:47:23) – Superposition
- (4:58:22) – Monosemanticity
- (5:05:14) – Scaling Monosemanticity
- (5:14:02) – Macroscopic behavior of neural networks
- (5:18:56) – Beauty of neural networks
Christopher Olah
【2024-11-19】Christopher Olah, Google Brain、OpenAI 以及 anthropic员工, 知名技术博客 colah’s blog 博主
- 神经网络可视化、流形学习、循环神经网络、信息论可视化
创始人 Sam Altman

OpenAI首席执行官山姆·奥特曼谈推出 ChatGPT:
- “我们需要社会对此有所感受,与之搏斗,看到它的好处,了解它的坏处。因此,我认为我们所做的最重要的事情是把这些东西拿出来,以便世界能够开始了解即将发生的事情。”
通用人工智能(AGI)是驱动他所有行动的推力,ChatGPT不会取代搜索,但有一天某个人工智能系统可以。
“如果AGI真正完全实现,我可以想象它打破资本主义的所有这些方式。”
当 2018 年 GPT-2 的论文被驳回时,Sam 在团队周会上将拒信的内容朗读给所有员工,并告诉大家在通往成功的路上总会有阻碍,但是大家一定要有信念。
【2023-1-31】Sam Altman的成功学
- 在硅谷创业教父Paul Graham的眼里,Sam Altman是一位极具魄力的领导者和开拓者。如今,已成为OpenAI CEO的Sam Altman是全球范围内当之无愧的科技领军人物
山姆.奥特曼 职业生涯一路开挂。
- 1985年出生于一个犹太人家庭
- 8岁学会编程,拆解电脑
- 16岁, 2001年,高中出柜
- 19岁, 2005年,从斯坦福大学计算机系辍学后,成立了位置服务提供商Loopt,而后被预付借记卡业务公司Green Dot收购
- 2011年,任YC总裁
- 2014年,YC创始人Paul Graham选择他成为继任者,在不到30岁时开始在全球创业创新领域大放异彩。
- 2015年,他与马斯克等人共同成立OpenAI,目标是确保AI不会消灭人类
- 2019年,Sam Altman离任YC总裁,成为OpenAI的CEO,并相继领导推出重量级AI模型GPT-3、DaLL-E以及近期火出科技圈的ChatGPT。
- 2022年,发布chatgpt
- 2023年发布gpt4,功能强大风靡全球。
- 2023年11月被董事会罢免
无论是个人才智和财富,还是远见和野心,Sam Altman显然是标杆性的“成功人士”。
- Sam Altman: how to be successful(如何取得成功),13条特质并不是一个人必然取得成功的充分或必要条件。Sam Altman的成功学
- 1、选择“复利增长” Compound yourself
- 2、要有绝对自信 Have almost too much self-belief
- 3、学会独立思考 Learn to think independently
- 4、做一个好“销售” Get good at “sales”
- 5、要有冒险精神 Make it easy to take risks
- 6、保持专注 Focus
- 7、努力工作 Work hard
- 8、大胆一点 Be bold
- 9、足够坚定 Be willful
- 10、保持强劲的市场竞争力 Be hard to compete with
- 11、建立人际网络 Build a network
- 12、资产决定财富 You get rich by owning things
- 13、要有内驱力 Be internally driven
ChatGPT内幕故事:OpenAI 创始人 Sam Altman如何用微软的数十亿美元打造了全球最热门技术
- Stack Overflow 临时封杀 ChatGPT ,叫你抢饭碗!详见
OpenAI 发展历程
OpenAI发展历程(主要来自维基百科)
- 2015年底,OpenAI成立,组织目标是通过与其他机构和研究者的“自由合作”,向公众开放专利和研究成果。
- 2016年,OpenAI宣称将制造“通用”机器人,希望能够预防人工智能的灾难性影响,推动人工智能发挥积极作用。
- 2018年2月底,马斯克突然宣布辞任OpenAI董事会职务,当然原因是“为了避特斯拉的嫌”。
- 2017年,Tesla挖墙脚:Andrej Karpathy 离开 OpenAI
- 微软接手马斯克股票
- 2019年3月1日成立OpenAI LP子公司,目标是盈利和商业化。
- 2019年7月22日微软投资OpenAI 10亿美元,双方合作为Azure(微软的云服务)开发人工智能技术。
- 2020年6月11日宣布了GPT-3语言模型,微软于2020年9月22日取得独家授权。
- 开源文化破坏后,被人戏称“Closed AI”,当年,大批核心成员出走,部分人再次聚集新公司(Dario Amodei创立的Anthropic)
- 2022年11月30日,OpenAI发布了名为ChatGPT的自然语言生成式模型,以对话方式进行交互。
- 2023年1月:微软和OpenAI洽谈投资100亿美元事宜,并希望将OpenAI的人工智能技术纳入Word、Outlook、Powerpoint和其他应用程序中。
GTM 战略
OpenAI的动机是“Keeping Developers Happy”,事情真的是如此直白吗?
These releases are designed to attract more developers to pay to access OpenAI’s model to build their own AI software for a variety of uses, such as writing assistants or customer service bots.
OpenAI的既有GTM战略

- 首先,在大型和超大型企业市场,Stateful API的目的是“运营优化”。纵观欧美市场,面向大企业客户的ChatGPT Enterprise已经为OpenAI取得了相当的竞争优势,并且鲜有匹敌者。因此,该市场将成为OpenAI的主要Cash Cow。
- 在这种情况下,考虑到ChatGPT Enterprise提供的无限GPT-4访问和月租费+阶梯计价方式,Stateful API的主要作用是帮助OpenAI优化客户的运营成本。
- 其次,在中小企业市场,除了笼络开发者,Stateful API的目的则带有“挤压”初创公司的意图。OpenAI所面临的威胁也许并非来自那些“Deep Pocket”的大互联网公司,而可能是那些更具天赋、更有创意的初创公司。在海量资金的投入下,“下一个OpenAI”可能随时威胁并不完美的Transformer架构。鉴于开发者社区和中小企业市场是这些初创公司的策源地,激进的降价有助于“挤压”这些潜在的竞争对手(类似于AWS在云市场的所作所为),压缩他们的现金流和创新空间。
OpenAI 接入体验
详见站内专题:OpenAI接口信息
DeepMind
DeepMind是一家几乎没有新闻的公司,有一天突然宣布,在一场闭门比赛里,打败了三届欧洲围棋冠军。
AlphaGo大战李世石。第三天,比赛进入高潮,谷歌创始人布林飞到首尔
2012年,AlexNet 拿下 ImageNet 比赛冠军,这个网络由三个人开发,计算机老教授辛顿(Geoffrey Hinton),还有他的两个学生,Alex Krizhevsky和小萨。Alex和小萨,都出生在苏联。
- 师徒三人发现商机。他们成了一家公司 DNNResearch,没有收入,没有流水,没有业务,只有三个人。他们要卖掉这家什么都没有的公司,而且,为了利益最大化,方式是——拍卖。从第一份报价,百度的1200万美元开始。价格一步步上升,来到4400万美元。只剩下谷歌和微软。两家都势在必得,准备更高的报价。4400万美元三个人平分。但是Alex和小萨坚持老师拿40%。
- 谷歌用4400万美元,买来一位老教授和两位天才少年。
不久,用6.5亿美元,收购只有50人的DeepMind。
- 小萨去谷歌上班,被分到子公司DeepMind帮忙,搞一个下围棋的项目,为2016年的这场历史性的棋局,做出了基石性的贡献。
- 在谷歌总部,小萨来的时候,AI已经在语音识别、图像识别上做的不错,下一个需要攻克的是翻译。小萨创造性地把数学引入翻译,给每个句子一个向量,因此大大提高了谷歌翻译的准确性。
然后,马斯克来了。这家伙常年把自己扮演成AI话题的意见领袖,是“AI会毁灭人类”观点的旗手。这让处于研究最前沿的小萨,非常认可。
- 马斯克组了一个饭局,约志同道合的人一起聊聊。小萨推门进去,发现不仅有马斯克,还有美国支付宝Stripe的天才CTO 格雷格·布罗克曼(Grey Brockman),YC总裁阿尔特曼,从0到1的彼得·泰尔(Peter Thiel)、LinkedIn创始人里德·霍夫曼(Reid Hoffman),等等等等。硅谷的顶流大明星,和自己坐在一起。
- 马斯克又抛出一个很大的情怀,成立
OpenAI,开源技术。阻止地球被毁灭,只能靠这个屋子里的人了,各位,拜托了!来,歃血为盟。
小萨,30岁上下,那必须热血沸腾啊。终于把持不住了。当小萨提离职时。谷歌动情挽留,大佬一个个来找小萨谈话,开出了一个又一个可怕的薪资。年薪涨到几百万美元,必须是OpenAI的两到三倍。但小萨还是走了。身处顶级工程师、天才科学家这个奇特的群体,他可能感知到了自己不喜欢的东西。
2017年,国防部长访问谷歌总部,布林带着高管接待。双方要谈马文项目(Project Maven)。国防部推马文项目的目的是,用大数据和机器学习改造战争。国防部给私营企业订单,是美国的传统,既有武器采购和项目外包,也有NASA付钱给SpaceX发射火箭。但是谷歌不一样,谷歌不是军事承包商,而是一家消费科技公司。马文项目,三年才赚不到3000万美元。
但是,布林为首的高管,就是想干,不是钱的问题,而是认为和军方合作对谷歌的AI战略至关重要。李飞飞,是AI界大佬,ImageNet最重要的创立者,当时也在谷歌。一封泄露出来的Email显示,出生在北京的李飞飞,和出生在莫斯科的布林一样,支持促成谷歌和军方的合作。
但是,大多数科学家、工程师有不一样的观点。
科技推动武器发展,有两次飞跃,每次都很可怕。
- 第一次,是一战中
马克沁机枪的使用。大多数军队还是传统战法,排成一排,冲啊,冲啊,但是对面打开高效的杀人机器,机枪一扫,人一排排倒下,像割韭菜一样。一战的索姆河战役成了著名的“绞肉机”。 - 第二次,是二战中
原子弹的发明。武器可怕的杀伤力已经彻底走出战场,人类只要点点按钮,一个城市几十万、几百万的人口瞬间灰飞烟灭。技术用于武器,人类第一次,有了毁灭我们这颗星球的能量。 - 用自动驾驶、人工智能改造武器,是武器的第三次革命。杀人机器人会把我们的文明会带往何方?
参与其中的科学家,往往愧疚大于骄傲。
谷歌内部,一份请愿书开始流转,要求布林不要和军方合作。500人……1000,最终签字了3100多人。DeepMind创始人坚定反对。辛顿老师,用个人身份请布林取消合同。
外部,就更炸了。一直宣扬AI会毁灭人类的马斯克当然要出来猛踩谷歌喽。1000多名学者老教授声援谷歌3100员工的公开信,要求谷歌承诺不开发军事技术,不将个人数据用于军事目的。李飞飞还收到了死亡危险。
最终谷歌迫于压力取消合同。但是很快大家注意到,谷歌的行为准则页面(Code of Conduct),开头的“不作恶”(don’t be evil)被删掉了。
不作恶,由佩奇和布林提出,一直是谷歌最有号召力的品牌形象。可是,在这前后发生了不少事,安卓创始人安迪·鲁宾(Andy Rubin)在公司性骚扰、潜规则下属,被佩奇包庇处理。布林又坚持和军方合作。
曾经,那些理想主义的科学天才,拒绝微软加钱,也要去谷歌。Facebook给两倍,我也要去谷歌。这样的时光,不会再来了。
正方:开源AI终究胜利
【2023-5-6】谷歌内部文件泄露:我们和OpenAI都没有护城河
- Google 内部泄露的文件在 SemiAnalysis 博客传播: 开源 AI 会击败 Google 与 OpenAI,获得最终的胜利。
- 译文:我们没有护城河,OpenAI 也没有, 公众号,掘金
- 原文:We Have No Moat, And Neither Does OpenAI
大模型竞赛过程中,Google 一直显得谨小慎微,未能抢占先机。背后是 Google CEO 皮查伊倾向渐进式,而不是大刀阔斧的改进产品。部分高管也不听从他的调度,或许是因为,大权压根不在皮查伊手里。
如今,Google 联合创始人拉里·佩奇虽然已经不太插手 Google 内部事务,但他仍然是 Alphabet 的董事会成员,并通过特殊股票控制着公司,近几个月还参加了多场内部 AI 战略会议。
Google 面临的问题,每一个都困难重重:
- CEO 行事低调, 联合创始人拉里·佩奇通过股权控制着公司;
- “开发产品但不发布”的谨慎,让 Google 多次失去先机;
- 更加视觉化、更具交互性的互联网,对 Google 搜索造成威胁;
- 多款 AI 产品市场表现不佳。
内忧外患之中,Google 被笼罩在类似学术或政府机构的企业文化之下,充斥着官僚主义,高层又总是规避风险。
核心信息提炼
- Google 和 OpenAI 都不会获得竞争的胜利,胜利者会是开源 AI;
- 开源 AI 用极低成本的高速迭代,已经赶上了 ChatGPT 的实力;
- 数据质量远比数据数量重要;
- 与开源 AI 竞争的结果,必然是失败;
- 比起开源社区需要 Google,Google 更需要开源社区。
“重大问题”如今已经得到解决并投入使用。举几个例子:
- 手机上的 LLM:人们可以在 Pixel 6 上以每秒 5 token 的速度运行基础模型;
- 可扩展的个人 AI:你可以一个晚上就在笔记本电脑上微调一个个性化 AI;
- 负责任的发布:这个问题不是“解决了”,而是“消除了”。互联网充满了没有限制的艺术模型,语言模型也要来了;
- 多模态:当前的多模态 ScienceQA SOTA 在一小时内就能完成训练。
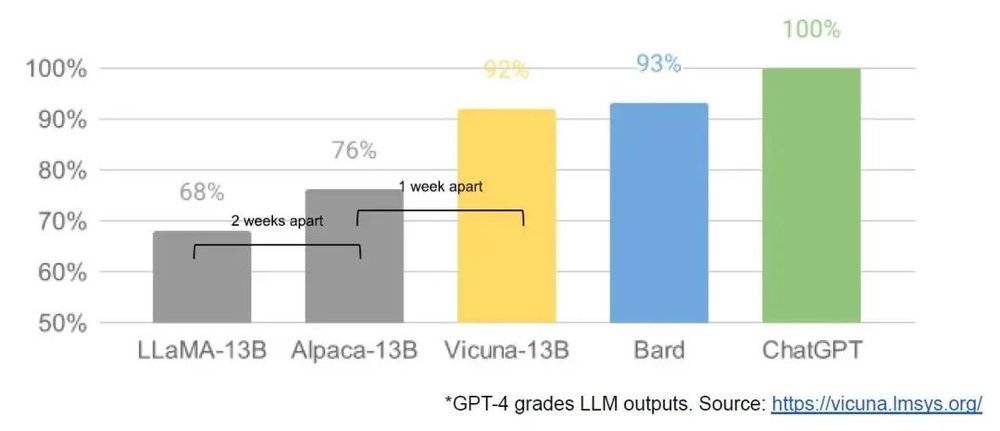
虽然大公司模型在质量方面仍然有优势,但差距正在以惊人的速度缩小。开源模型更快、更可定制、更私密,而且性能更强。他们用 100 美元和 130 亿参数做到了我们使用 1000 万美元和 5400 亿参数下也很难完成的事情。而且他们用的时间只有几周,而不是几个月。
这意味着:
- 大公司没有秘密武器。最好的方法是向 Google 外的其他人学习并与他们合作,应该优先考虑启用第三方集成。
- 当有免费、无限制的替代品时,人们不会为受限制的模型付费,我们应该考虑我们真正的价值在哪里。
LLaMA
- 2023年3月初,开源社区第一次获得了一款真正强大的基础模型,来自 Meta 的 LLaMA。它没有指令或对话调整,也没有强化学习人类反馈(RLHF),但社区依然立即意识到 LLaMA 的重要性。
- 随后,一个巨大的创新浪潮随之而来,每个重大发展之间只有几天的时间。一个月之后,已经有指令调整(instruction tuning)、量化(quantization)、质量改进(quality improvements)、人类评估(human evals)、多模态、RLHF等功能的变体,其中许多变体是相互依赖的。
最重要的是,他们已经解决了规模问题,让任何人都可以参与其中,许多新的想法来自普通人。实验和训练的门槛从一个大型机构降低到了一个人、一个夜晚或者一台强大的笔记本电脑。
低成本的公众参与得以实现,因为有一种称为低秩适应(Low rank adaptation,LoRA)的微调机制大大降低了成本,结合规模方面的重大突破(图像合成的 Latent Diffusion,LLM 的 Chinchilla)。
- LoRA 通过将模型更新表示为低秩分解(low-rank factorizations)来工作,将更新矩阵的大小减少了几千倍。这使得模型微调的成本和时间大大降低。
开源AI是最后赢家,而不是OpenAI
- 从头训练大模型成本太高,难以实施:LLaMA和LoRA出现
- 3月初,Meta 的 LLaMA 泄露,没有指令或对话调整,也没有 RLHF。
- 不到一个月,一系列改进版出现:指令调整、量化、质量改进、人类评估、多模态和 RLHF 等等变体。每个改进版间隔才几天时间
- 扩展问题解决后,一定程度上任何人都可以进行实验和调试。
- 长期来看,大型模型并不更具优势,只用了几天时间
- 数据质量比数据大小更重要
- 直接与开源竞争是一个失败的命题
- 个人受到许可证限制程度没有企业那么大
- 客户比大模型提供商更了解业务应用
- Meta已开始建设开源生态系统:闭源越多,开源需求越强烈,发展越快
反方:开源社区问题
【2023-6-29】拾象硅谷见闻系列:打破围绕开源LLM的6大迷思
“We Have No Moat, And Neither Does OpenAI” 是 5 月上旬从 Google 内部泄露的一篇文档,总结了开源模型在 LLaMA 泄露的 2-3 个月里取得的进展,并以此认为: 模型训练没有壁垒,并号召内部拥抱开源、LoRA 微调以及小参数量的模型。
这份文档最大问题
- 被并不标准化和全面的评估给欺骗了,错误地相信“开源模型和 ChatGPT 的差距已经是 92% 和 100% 的关系”以及“LoRA 微调过的模型和 ChatGPT 基本上没有区别”,而忽略了这些对比都建立在“在某些任务上”的前提下。
倾听开源模型的训练者的声音以及思考这份文档的标题一个多月后,反而认为:Google 有护城河,OpenAI 也有它自己的。
比“护城河”更严谨的说法是“竞争优势”
- 在商业层面,Google 拥有其搜索引擎和 G Suite 背后强大的分发渠道,OpenAI 拥有王牌产品 ChatGPT 的用户心智;
- 在技术层面,开源社区在预训练环节和高质量反馈数据的获取以及处理上跟 OpenAI 还有相当大的差距。
原观点:“搜索引擎将不复存在,因此 Google 的现有分发优势也不构成护城河”
- 搜索引擎被摧毁的进程目前看仍然会比较漫长。
达到 “90% of ChatGPT” 或 “GPT-3.5 Level” 水平
- 大体上都是“LLaMA + 指令遵循微调 + GPT 3.5/GPT 4 自动化评估”的范式。其中的指令遵循数据往往也来自 ChatGPT 或 GPT-4 生成。
- 大多数媒体在报道时都会自动忽略 Vicuna 团队对这一指标的声明是“GPT-4 做出的有趣且非科学的评估”。从更严谨的视角,这些模型提供了和 ChatGPT 几乎一样的聊天机器人,但是在许多维度上仍然和 ChatGPT 以及 GPT 3.5 有很大差距。这些团队自己也比较清醒,但是架不住媒体的炒作。
Translink 投资人 Kevin Mu 从技术复杂度、货币化潜力和瓶颈的存在三方面论证了 LLM 市场可能由 OpenAI 闭源玩家占据主导。
但是就像图中的问号所代表的,目前还胜负未分,离市场份额的终局还比较远。
【2023-6-29】拾象硅谷见闻系列:打破围绕开源LLM的6大迷思
OpenAI 元老 John Schulman 4月下旬在伯克利有关 RLHF 和 Hallucination 的讲座
- Youtube: John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges, Towards TruthGPT
他一针见血地指出
- 这类开源模型的做法只是“形似”,实际上降低了模型的 Truthfulness。
这一类模型的事实性上的缺陷:
(关于 Hallucination 问题的出现)如果你使用同样的监督学习数据,然后训练另一个模型,那么同样的 Hallucination 问题会出现。现在有很多人使用 ChatGPT 的输出来微调其他模型,比如微调市面上的开源 Base Model,然后发现效果不错。但是如果认真观察事实准确度,会发现它们编造的比例比原始模型更高。
5 月,伯克利的论文 The False Promise of Imitating Proprietary LLMs 指出这种方式微调出来的指令遵循模型存在的一系列问题:
- 在缺少大量模仿 ChatGPT 数据支持的任务上,这类模型无法改善 Base Model 到 ChatGPT 的差距;
- 这类模型只是擅长模仿 ChatGPT 的风格,而不是事实性,导致实际的性能差异会骗过人类评估者;
- 当前开源模型最大的限制仍然是 Base Model 层面跟 GPT 系列的差距,在微调而不是预训练环境进行优化可能是不正确的方向;
- 为了广泛地匹配 ChatGPT 支持的任务,需要更广泛和大量的模仿数据集,还需要新的工作;
- ……
6 月份 Allen Institute for AI 和华盛顿大学的 How Far Can Camels GO?工作再次通过实验表明
- 不同的指令微调数据集可以释放或者增强特定的能力,但并没有一个数据集或者组合可以在所有评估中提供最佳性能,并且这一点在人类或模型担任评估者时也很容易无法被揭示。
对于指令遵循微调背后的团队来说,他们也意识到自己的模型由于 Base Model(LLaMA)的限制,在复杂推理和代码任务上很弱,并且难以进入正向数据飞轮 —— 模型能力越弱的领域越难得到更多的 query,也就难以筛选出高质量 query,想自己再标注提升模型能力就很困难。
至此,开源社区已经充分意识到原来这套微调 LLaMA 的框架的局限性,越来越多的团队开始探索预训练环节和更接近真实的人类反馈数据。我们也比较期待这两个方向上的进展,在迷思 4 中也会分享更多围绕这部分的观察。
【2023-6-29】拾象报告:硅谷之旅集齐了这个生态的不同视角,对开源社区的现状有了更加清醒的认知
- 尽管 Stability AI 也非常积极地入场了 LLM,但是这里的 Stable Diffusion 时刻可能仍未到来。
GitHub 中星数前 10 名的 LLM 开源项目中,和开源模型相关有第二名的 GPT-4All、服务 serving 环节的 llama.cpp 以及引爆了指令遵循微调的 Stanford Alpaca。具体项目上,在 Base Model 和经过微调的模型两个层次上都有爆款模型接连出现,近期的代表分别是 Falcon 40B 和 WizardLM 13B。
开源社区卡点有很多:
- 缺少明确的开源扛把子团队/公司; LLM 开源社区并不团结
- 指令遵循的微调模型格局不是很团结,比如: Vicuna 和 Koala 几乎是一样的工作,但是两支伯克利 CS 的团队在分散做。
- 开源社区内大量的注意力开始转移到预训练环节,过去一个季度陆续出来了 Redpajama、OpenLLaMA、Falcon、MPT 等新的模型。预训练对数据集准备、算力等资源的要求更高,也更需要社区协作,OpenLLaMA 最近取得的成果是开源社区团结力量的很好展现
- 没有被普遍认可的标准化测试
- 开源团队都缺高质量数据
- 蒸馏 ChatGPT 进行指令微调的做法有许多局限
- Query 和用户反馈数据飞轮难以转起来
- 多重的不可商用限制……
阻碍开源模型更大范围爆发的最大的卡点仍然是:
- LLaMA 的可商用问题,OpenLLaMA、Falcon 等模型复制一个同等繁荣的生态还需要时间。
开源社区也非常快地意识到了这些问题
- Alpaca Farm 试图解决 RLHF 和标准化测试的问题
- OpenLLaMA 和 RedPajama INCITE 等项目开始从预训练环节攻克可商用问题,微调的方向也更百花齐放。
Google AI进展
谷歌Al进展时间轴 参考
- 2023年12月6日,谷歌官宣Gemini 1.0,推出Ultra、Pro和Nano三个参数量版本
- 2024年2月1日,Gemini更新,增加多语言支持和文生图功能
- 2024年2月8日 推出付费订阅GeminiAdvanced版本(Gemini 1.0 Ultra)
- Bard正式更名为Gemini
- 2024年2月15日 发布Gemini 1.5Pro,可处理百万级上下文长度
- 2024年2月21日 发布开源模型Gemma,提供2B和7B参数量版本
- 2024年2月23日 因种族争议下架Gemini生图功能,并发文致歉
- 2024年2月23日 提交世界模型Genie论文
施密特
【2024-8-13】谷歌前CEO在斯坦福的演讲,被“全网删除”
8月13日,斯坦福大学发布前谷歌CEO埃里克·施密特(Eric Schmidt)2024年4月的公开课视频。
- 网上流传的所谓“知道是直播后脸都绿了”的版本是有些夸张了
- 施密特当时应该是清楚自己正处在摄像机录制的场景下(毕竟麦克风都别着呢)
- 不过在视频发布后, 部分分享内容确实引起了不小的争议,最终校方迫于舆论压力下架了视频。

这场计算机主题的对谈中,施密特深入探讨了对AI的发展方向、全球科技竞争的未来,以及这些技术如何在短期内对社会、经济和国家安全产生深远影响的看法。
- (1) 谷歌输给Open AI,因为员工不够“卷”
- 创立之初,工作状态就像在地狱一样(work like hell),而今却是工作生活平衡。如果离开学校去创业,只要想与其它创业公司竞争,那就不能让员工们居家办公、每周只来公司一天。
- 不少谷歌员工下场“开火”斯密特
- 谷歌母公司Alphabet的员工工会发帖表示:“灵活的工作安排并不会拖慢工作的速度,反倒是人手不足、优先事项不断变化、不断裁员、工资停滞不前,这些因素才在每天拖慢谷歌员工的速度。”
- 谷歌DeepMind 研究主管Dumitru Erhan 直言施密特的言论是“完全的垃圾看法,从每一个维度看都是如此。”
- 谷歌表现不佳并不是员工的错,而是谷歌自身产品老旧的问题。“不要再期望谷歌像初创公司那样拼命工作了。把现在的问题怪在员工身上,其实是在掩盖你们产品老旧的问题。”
- (2) 鼓励大家抄袭TikTok
- 如果美国禁止TikTok,可能带来一些商业机会。学生应该使用大型语言模型(LLM)来复制该程序,并用它来“窃取”知识产权。
- (3) AI领域
- AI领域可能存在着巨大泡沫:
- 华尔街炒 “七巨头”(Magnificent Seven)概念,将当前基本盘最火最大的七家科技股——苹果、微软、Alphabet、亚马逊、英伟达、特斯拉、Meta深度捆绑在一起。但2024年8月5日,科技股和芯片股领跌,“科技七巨头”盘初总市值直接蒸发1.3万亿美元。此后股价虽有所回升,但全天市值总损失仍略高于6,500亿美元。
- 高盛在6月末发布的报告《生成式AI:花费甚多,而收益甚少》, 人们对AI的期待过高,投入过大,但它已有的收益和潜在的收益都太小
- 对微软与OpenAI的合作给予了高度评价:
- 刚知道微软与OpenAI 合作时,施密特坦言“这是我听过的最愚蠢的想法”,微软把最重要的AI业务外包出去的举动让他觉得难以置信。
- 但事实证明看走眼了,微软与OpenAI的合作模式不仅加速了AI技术的创新,还帮助微软在AI领域占据了有利位置。而相比之下,施密特认为苹果在AI领域的表现则显得过于保守和迟缓了。
- 微软与OpenAI的新项目”星际之门”(Stargate, 特殊数据中心)上的将有巨大的资金需求,并预测这一项目可能需要远超1000亿美元的资金支持,他说,“这大约需要3000亿美元,甚至更多。”
- AI将带来一场深刻革命,不仅将改变生活方式和工作方式,还将重塑全球经济和政治格局: AI会让富者愈富、穷人恒穷,国家也是,这是一场强国之间的游戏,没有技术资源的国家需要拿到加入强国供应链的门票,否则也将错过盛宴。
- AI领域可能存在着巨大泡沫:
以上部分观点遭到误解 – 被误读的谷歌前CEO斯坦福演讲,与跨文化沟通
- 要表达的是: 远程办公的效率远没有在公司办公的效率高。施密特不是在表达谷歌输给OpenAI的原因是员工不够卷,而是谷歌在AI领域落后的原因在于远程办公!
- 施密特表达的是AI强大,未来如果要开发像TikTok这样复杂的程序,也不需要程序员,只需要给AI一个命令就可以,这完全没有表达抄袭的意思,美式幽默。
精华的总结是:
美国的如意算盘: 用中东的钱、印度的人才、加拿大的电,帮助美国发展AI,并在这个领域和中国打持久战。- 中美互相博弈未来: 或许所有不具备自主发展实力的国家,都要在中美之间“选边站”。
- 如今的AI就像200年前的电力,是新一轮的工业革命,谁能从中胜出,谁就能掌控未来全球的主导权!
META
Yann Lecun
FAIR 实验室负责人
Alexandr Wang
【2025-8-23】上任仅数月,Meta「新人」执掌 AI 部门大权
扎克伯格 对 Meta 进行大调整,上任数月的超级智能实验室(MSL)负责人 Alexandr Wang 发布内部信。
MSL 将被拆分为四个专业团队,其中多个 AI 团队都向其进行工作汇报:
TBD 实验室:专注于训练大型 AI 模型,探索如「全能(Omni)」模型等新方向。FAIR:作为创新引擎,推动将 FAIR 的研究成果应用于 TBD 实验室的大规模训练。Rob Fergus将继续领导 FAIR,而 Yann LeCun 将继续担任 FAIR 首席科学家,但两人均向 Wang 汇报。产品与应用研究:加强产品导向的研究与开发,整合 AI 技术至 Meta 产品中。Nat Friedman 领导该团队,并向 Wang 汇报。基础设施团队:整合基础设施资源,支持大规模 AI 模型的训练和部署。Aparna Ramani 负责,并且该团队并入 Aparna 的组织,并且依然向 Wang 汇报。值得一提的是,在本次调整中,通用人工智能基础(AGI Foundations)团队被解散,并且成员将被安排到其他合适的团队、岗位中。
Wang 表示:我深知组织架构的调整会带来阵痛,但我坚信,此刻花时间理顺组织架构,从长远来看,将能让我们以更快的步伐迈向超级智能。
清华大学
清华系 与 大模型
【2023-8-17】崛起的「清华系」,被改变的中国大模型格局
中国大模型创业图谱坐标系:清华大学东门外的几栋楼。几个十字路口,隔着几层楼,矗立着的楼宇里聚集着中国大模型行业的先行者。
- 最瞩目的要数
搜狐网络大厦,它位于园区的东南角,二层是王小川的百川智能,七层到十一层是来自清华知识工程研究室(KEG)的智谱AI。距离这里不远的地方,是聆心智能、深言科技与澜舟科技等明星创业公司。
尽管创业的时间与契机并不相同,但它们都共享着一个身份——清华系。
在中国人工智能技术的发展史上,“清华系”注定是一个无法绕开的节点。这里是中国人工智能教育的原点之一,六十多年前,当一辆接新生的大卡车在夜色中径直开到宿舍门口,彼时还未与人工智能结缘的张钹院士还在心中感叹「清华园真大」,距离清华计算机系正式成立「人工智能与智能控制」教研组也有数年, 如今在大模型掀起的新一轮AI浪潮下,「清华系」的创业者已成为了其间不可或缺的关键力量。
任何创业圈都习惯为创业者贴上标签,「标签」既可以让资本快速筛选优质标的,同样也是初创企业最好的简历,而对技术密集型的企业而言,「学历」无疑也是最好的标尺之一。
翻开此轮的大模型创业名单,无论是已有所成就的创业大佬,还是眼下的创业新手,“清华群星”几乎占据了大壁江山。
曾经的「互联网四杰」,搜狗创始人王小川,在尚未创业时,媒体给他贴上的标签是「清华天才少年」。这位被点招进入当时清华大学计算机系的学霸,几乎每年还会参加清华计算机系的学生节。现在,45岁的王小川有了一个新身份——大模型创企「百川智能」的创始人。
淡出创业圈多年后,这位曾经的创业大佬选择投身大模型,认为做大模型是一件特别适合自己的事。
“大家没人说过「小川适合做搜索」,但都说「百川适合做大模型」,对我来讲,是一件非常幸运的事。”
而比王小川更早些选择投身创业的,还有衔远科技创始人周伯文,他是清华大学电子工程系的长聘教授。另一家被腾讯、米哈游、高瓴等明星机构押注的MiniMax,其创始人为前商汤科技副总裁闫俊杰,闫本人也曾在清华大学计算机系从事博士后研究。
清华系大模型图谱
| 公司 | 创始人 | 创立时间 |
|---|---|---|
| 光年之外 | 王慧文(已退出) | 2023年4月 |
| 月之暗面 | 杨植麟 | 2023年4月 |
| 百川智能 | 王小川 | 2023年4月 |
| 生数科技 | 朱军 | 2023年3月 |
| 面壁智能 | 刘知远 | 2022年8月 |
| 深言科技 | 岂凡超 | 2022年3月 |
| 衔远科技 | 周伯文 | 2021年10月 |
| MinMax | 闫俊杰 | 2021年11月 |
| 聆心智能 黄民烈 2021年11月 | ||
| 澜舟科技 | 周明 | 2021年6月 |
| 智谱AI | 唐杰 | 2019年 |
硅基研究室整理自公开资料
另一派同属清华系的创业者,无论从公司架构还是发展历史,其气质也更为「学术正统」。
由清华计算机系李涓子和唐杰教授担任首席科学家的智谱AI,其孵化于清华的知识工程研究室(KEG)。
- 该实验室成立于上世纪九十年代,一开始走的就是「科研+工程化落地」的路线,而
唐杰教授的得意门生杨植麟则在今年创立了月之暗面,其技术背景备受投资人青睐。
清华系 学院派
- KEG 知识工程研究室, 李涓子、许斌、唐杰 → 智谱AI
- THUNLP 自然语言处理与社会人文计算实验室, 孙茂松、刘知远 → 深言科技、面壁智能
- CoAI 交互式人工智能课题组,朱小燕、黄民烈 → 聆心智能
- 人工智能研究院基础理论研究中心, 朱军 → 生数
深言科技和面壁智能则脱胎于清华自然语言处理与社会人文计算实验室(THUNLP)。
- THUNLP创立于上世纪七十年代,创建者为我国NLP领域的泰斗级人物
黄昌宁教授,如今的学术带头人则为其弟子——清华大学计算机科学与技术系教授、清华大学人工智能研究院常务副院长孙茂松。而上述两家创企的创始人均为孙茂松的学生。
隶属于清华计算机系下的交互式人工智能课题组(CoAI),其学术带头人为朱小燕教授和黄民烈副教授。从CoAI里走出的聆心智能,对标的是大洋彼岸外的Character.AI。
而由清华计算机系教授朱军带队的新AI公司生数科技也已完成两轮融资,朱军师从清华大学计算机系教授、中科院院士张钹。
学院派创业的特点
- 一方面有着极强的技术基因,其产品背后的技术路线并非一日而就,而是代代师承的结果。
- 另一方面,对比此前的AI创业热潮,学者们入局的速度正在加快,产投研一体化的趋势突出。
如深言科技创始人岂凡超的恩师孙茂松担任深言科技首席科学家,岂凡超想和教授交流时,只用走几百米回学校,面壁智能背后也有智谱AI的参股,月之暗面的另一名创始成员也来自清华大学计算机系,和杨植麟师出同门。
另一方面,在此轮大模型创业背后的投资方中,“清华系”的创投者们也颇为瞩目。包括图灵创投、卓源资本、清华控股、水木清华校友种子基金、无限基金SEE Fund等清华系创投机构也频频出手。如图灵创投投了聆心智能、智谱AI,起源于清华大学FIT楼实验室的卓源资本投了生数科技。
清华大学利用企业的赞助资金,积极邀请世界著名的教授参与清华的培养工作。
- 2003年到2006年,图灵奖获得者
姚期智作为受聘者,与清华结缘,而后直接回到清华大学担任长聘教授,并创建了「姚班」
微软总裁布拉德・史密斯此前曾在一次采访中认为:目前在人工智能领域,世界上三家公司处于绝对前列,一个是与微软合作的Open AI,第二个是谷歌,第三个是北京智源人工智能研究院。
智源既是一个非盈利机构,一个技术社区,同样也是一个理想化的「乌托邦」。
- 2020年,智源开始实践大模型,启动「悟道大模型」项目,不问英雄出处。根据「雷锋网」的报道,包括清华、人大、北大、中科院等高校的学者与老师,一些外部成员也参与了进来,组团攻克中国大模型的难关。这个项目里集合了如今我们所知道的诸多清华系的大模型创业者:唐杰、刘知远、黄民烈、杨植麟……
清华AI四大公司:PonyAI、RealAI、Face++、商汤
中美国情的差异化,OpenAI的故事注定无法复现,可能的原因有三:
- 一,时间差异,区别于美国应用层的繁荣,中国大模型底层格局依旧未定,因此应用层发展仍在初期。
- 二,路线分化。美国大模型注重底层技术的研发与创新,例如在硬件和深度学习框架上都处于世界领先地位。而中国更聚焦在应用层,强调融入产业,以及商业的变现。
- 三,塔尖人才分布差异。根据未尽研究的统计,在全球范围内入选人工智能学科AI2000名单的顶尖学者中,美国多是来自于科技企业。例如,谷歌、微软、Meta合计招揽了三成的美国顶级学者。而中国的人工智能顶尖研究人员,压倒性地来自高校,阿里巴巴则是中国招揽了最多顶级学者的企业。
1、RealAI
创始人:田天、陈键飞、朱军、张钹
CEO田天:绰号“田天王”,清华大学计算机科学与技术系博士,清华大学计算机系20余年历史上第一位也是唯一一位当选清华大学最高奖——清华特等奖学金的研究生,清华计算机系最高奖——西贝尔奖学金得主,同时也是在AAAI、WWW等全球顶级会议论文最年轻的第一作者之一。
董事长朱军:清华大学最年轻的长聘教授之一,亚洲第二位当选“IEEE AI 10 to Watch” 学者( IEEE每两年从全球范围内选拔10位人工智能顶级学者),CSRankings AI 全球排名,朱军教授位列41位入选的清华教授中的第一名。
首席科学家张钹:中国科学院院士、俄罗斯科学院外籍院士,清华大学人工智能研究院院长,同时也是清华大学类脑计算研究中心学术委员会主任。
RealAI是由清华大学校长邱勇院士、清华大学副校长尤政院士、清华大学人工智能研究院院长张钹院士共同发起,核心团队由九位清华大学人工智能专业博士共同成立的亚洲第一家专注于第三代人工智能技术提供商。由目前全球最早提出并从事第三代人工智能核心技术研发的团队构成,旨在打造中国人工智能时代的“BAT”。
公司致力于探索发展鲁棒、可解释的第三代人工智能基础理论和方法;研制第三代人工智能编程框架、兼容性操作系统及基础算法库。与目前国内其他的深度学习公司不同,RealAI致力于基于逻辑推理、贝叶斯学习的无监督人工智能技术,从而解决当前人工智能高依赖于历史数据,仅适用于人脸识别等单一场景,泛化能力弱、、不可解释性、鲁棒性很差、非常容易被攻击的核心问题。并提出“AI+金融”、“AI+工业化”的全栈第三代人工智能技术。RealAI在人工智能安全性方面全球没有竞争对手。
2、PonyAI
创始人:楼天城、彭军、姚期智
CTO楼天城:绰号“楼教主”,清华大学计算机科学与技术系博士,清华大学姚班本科,被誉为“楼教主”,中国编程界第一人。前百度集团最年轻的T10,Google无人驾驶核心成员之一。连续十年(2006-2016)TopCoder世界排名第一、两届Google全球编程挑战赛世界冠军、Facebook世界编程大赛世界冠军、两届ACM/ICPC国际程序设计竞赛全球总决赛亚军、金牌、两届IOI国际信息学奥林匹克竞赛金牌。
CEO彭军:斯坦福大学计算机科学博士,清华大学学士,百度集团仅有的两位T11之一,百度集团高级副总裁、首席架构师、百度北美研究院院长。前Google大脑主创成员之一、高级研究员、一次Google最高奖获得者、百度历史上唯一一个两次获得百度最高奖的学者。
Pony.ai是全球领先的L4 、L5级自动驾驶技术提供商,由50多位清华大学计算机系姚班,麻省理工学院,斯坦福大学博士,以及ACM国际程序设计竞赛全球总决赛及大洲区总决赛金牌得主构成。在美国硅谷和北京均设有研发中心。2016年获得美国加州第一批无人驾驶路测牌照的公司(共25家),是第一批仅有的三家无人驾驶整体解决方案的公司之一。(Google、Baidu、Pony.ai)
2018年获得北京无人驾驶路测官方牌照(全球总共5家),北京的无人驾驶牌照获得难度全球最高,迄今为止仅有五家获得了牌照,包括:Pony.ai、北汽集团、德国戴姆勒集团、百度公司、蔚来汽车。其中,Pony.ai是全球唯一一家初创公司获得北京无人驾驶路测牌照。
3、Face++
创始人:印奇、唐文斌、杨沐
CEO印奇:2010年本科毕业于清华大学姚期智实验班。大学二年级开始在微软亚洲研究院从事人工智能和计算机视觉方面的研究。2011年赴美国哥伦比亚大学攻读计算机博士学位,专注于智能传感器方向。博士期间辍学创业,与清华同学唐文斌、杨沐联合创办北京旷视科技有限公司。2015年入选湖畔大学第一期,系统化学习商业战略和企业管理。
CTO唐文斌:唐文斌拥有清华大学计算机科学硕士学位,本科毕业于清华大学姚期智实验班。是全国信息学奥林匹克竞赛金牌、首届“YaoAward”金牌获得者,是中国第五位获得TopCoderTarget的选手,曾获得ACM/ICPC国际大学生程序设计竞赛世界总决赛第六名(亚洲第一名)。在校期间曾担任清华大学计算机系科协主席,并连续担任中国计算机学会中国信息学奥林匹克集训队教练长达7年。
Face++是北京旷视科技有限公司旗下的新型视觉服务平台,Face++平台通过提供云端API、离线SDK、以及面向用户的自主研发产品形式,将人脸识别技术广泛应用到互联网及移动应用场景中,人脸识别云计算平台市场前景广阔。
2017年6月,入选《麻省理工科技评论》“”2017 年度全球 50 大最聪明公司”榜单。
4、商汤
创始人:汤晓鸥、徐立、徐冰、徐持衡、陈宇恒、杨帆
联合创始人兼001号员工徐持衡:作为商汤001号员工,徐持衡历任商汤CTO、主任工程师等多个岗位,本科毕业于清华大学计算机系,随后就与汤晓鸥教授一起创办了商汤科技。高中机器人竞赛保送清华计算机系,是顶级的编程天才。
首席架构师陈宇恒:负责商汤科技基础架构及数项重点项目的软件架构,代码编写、审核,软件技术升级等工作。在公司创业期间,与香港中文大学合作,于国际顶级会议(NIPS2014)发表基于GPU深度学习的人脸识别系统论文,首次实现高于人类的人脸识别率。在公司快速发展阶段,从无到有开发了商汤人脸SDK、互联网金融等对外产品的初始版本, 完善并标准化了公司内部开发者工具。开源技术方面,用内存安全语言Rust实现的YAML解释器获得了超过20万次下载。于清华大学计算机科学与技术系获学士学位。
商汤科技所推出的包括人脸识别、图像识别、文字识别、图像视频分析、图像及视频编辑、智能监控、自动驾驶、遥感、医疗影像识别等各类智能视觉技术,已广泛应用于智慧城市、金融、汽车、智慧零售、智能手机、移动互联网、机器人等诸多行业,服务超过700家国内外知名企业。
AMiner
学术文章交流社区
AMiner是一个提供海量中英文文献检索的AI搜索学术平台,由清华大学计算机系唐杰教授团队研发,拥有我国完全自主知识产权。作为国内首个AI学术搜索平台,包含了超过2.6亿学术论文/专利和1.33亿学者的知识图谱,为广大科研工作者提供方便、权威和具有认知智能的学术搜索服务。
智谱AI
智谱AI,公司名:北京智谱华章科技有限公司
- 唐杰、李涓子
智谱AI依托清华大学团队十余年在知识智能方面的技术积累,汇聚了一群有激情的AI有志之士,致力打造数据与知识双轮驱动的下一代人工智能系统,实现让机器像人一样思考的愿景。公司参与研发了超大规模预训练模型“悟道”,构建了高精度通用知识图谱,相关技术获国家科技进步二等奖、北京市专利一等奖、中国人工智能学会科技进步一等奖。公司是国家高新技术企业,产品线覆盖科技创新、安全、教育、生活等领域。
上海交大
上海交通大学一直是中国最具备创业的土壤的高校,拥有
- 最神奇的宿舍(饿了么
张旭豪、康嘉、汪渊、邓烨,米哈游蔡浩宇、刘伟、罗宇皓的创业起点均来自神奇的上交大宿舍; - 中国最早的互联网创业者携程四君子中的
沈南鹏、季琦、范敏也都毕业于上海交通大学- 沈南鹏后来创立了红杉中国,是投资了中国互联网半边天的中国创投第一人
- 季琦则是创办了华住酒店集团(全季、桔子、汉庭都是旗下品牌);
- 近些年比较火的大公司
- 二级市场被称作“宁王”的宁德时代的创始人
曾毓群 - 前两年被备受推崇的跨境电商平台Shopee的母公司冬海集团创始人
李小冬 - 半步巨头的小红书创始人
毛文超也均毕业于上海交通大学。
- 二级市场被称作“宁王”的宁德时代的创始人
- 而作为工科及计算机强校,上海交大在AI方面,也是毫不逊色国内任何一所高校
- 上交大ACM班更是中国计算机人才的黄埔军校,2002、2005、2010年三次获得ACM国际大学生程序设计竞赛世界冠军,成为全球该赛事第三个“三冠王”,包括这两年上市的三家科技公司
商汤、第四范式、禾赛科技,创始人也都来自上海交通大学。
- 上交大ACM班更是中国计算机人才的黄埔军校,2002、2005、2010年三次获得ACM国际大学生程序设计竞赛世界冠军,成为全球该赛事第三个“三冠王”,包括这两年上市的三家科技公司
ACM 班
2002年6月16日,担任上海交通大学ACM国际大学生设计程序竞赛(ACM-ICPC)总教练六年后,俞勇很早许下的夙愿终于开始迎来曙光:
- 培养属于中国自己的计算机科学家。
于是,上海交大ACM班成立,2005年秋季发布招生计划
- 【2023-1-3】ACM班传奇:俞勇和他的天才少年团
- 【2023-4-6】上海交大有个计算机“神仙班”,640名毕业生直博率92%
640名毕业生中,94%选择继续深造,直博率高达92%,33人已获海内外一流高校教职,99%从事计算机科学研究工作
知名人物:
李沐: 2004年进入上海交大ACM班,2012年百度工作1年后去CMU读博,期间开发了著名的深度学习框架 MXNet 热衷于给大众科普AI知识,B站账户“跟李沐学AI”,81万粉丝林晨曦(依图科技创始人)戴文渊(百度凤巢广告系统→第四范式CEO,这几天刚上市)胡哲人(流利说CTO)李磊(2016年字节跳动AI实验室总监→加州大学助理教授)陈天奇(李沐学弟,华盛顿大学博士毕业,XGBoost、CXXNet发明人)王敏捷(Minerva 多GPU加速框架发明人,后来作为MXNet的基础)张伟楠(上海交大教授)郑曌(Google→第四范式VP)还有,锐战网络创始人&CEO赵中毅,触宝科技CDO任腾,饿了么高级副总裁罗宇龙,森亿科技创始人&CEO张少典,墨奇科技CTO汤林鹏`等。
Boson.AI 李沐
Boson.AI 创始人、原亚马逊资深首席科学家李沐大神的“创业进展汇报”:《创业一年,人间三年》火遍全网
李沐
- 原亚马逊首席科学家,人工智能框架Apache MXNet作者之一。
- 2008 年毕业于上海交通大学计算机系(计算机系 ACM 班),大学期间曾在微软亚洲研究院担任实习生。
- 2011 年 4 月 - 2012 年 8 月,李沐在百度担任高级研究员,后进入卡耐基梅隆大学读博,师从 Alex Smola 和 Dave Andersen。
- 2017 年 CMU 博士毕业后,李沐加入亚马逊成为资深首席科学家,是深度学习框架 MXNet 的主要贡献者之一。并先后在香港科技大学、加大伯克利、斯坦福大学担任研究助理、助理教授、兼职教师,2023年与导师亚马逊副总裁、杰出科学家Alex Smola一起离开亚马逊创办了Boson.AI。
Smola 先是李沐在CMU读博时的导师,期间两人曾一同创办数据分析算法公司Marianas Labs,Smola任CEO,李沐任CTO;
2016年7月,Smola选择加入亚马逊,李沐带着他的MXNet先以兼职身份加入亚马逊,并在毕业后选择留下。
BosonAI命名来源:
- 新公司用玻色子(Boson)来命名,望大家能get到“Boson和费米子组成了世界”这个梗。
当前在做的事:给B端客户定制模型
目前 Boson.ai的Photon系列模型,在客户应用上的效果打赢了GPT4,制模型的好处是推理成本是调用API的1/10。另外一个系列Higgs模型,主打通用能力紧跟最好的模型,但在角色扮演能力上突出,例如扮演虚拟角色、扮演老师、扮演销售、扮演分析师等等。
愿景:人类陪伴的智能体。
一个情商很高的,智商在线的智能体。算换成现实中的人的话,应该会是一个专业团队。例如你想让它陪你玩,那它是专业策划+演员。陪你运动,那么鼓励师+专业运动教练。陪你学习,那么能把你不懂的讲懂。模型的好处是,它能做长期的陪伴,真的了解你,可以“真心为你”。
第四范式 戴文渊
【2024-8-26】李沐第四范式商汤领衔,“上交”AI创业军团
第四范式-戴文渊、陈雨强、胡时伟、郑曌
第四范式成立于2014年9月,是企业级人工智能领域的行业先驱者与领导者。
第四范式提供以平台为中心的人工智能解决方案,并运用核心技术开发了端到端的企业级人工智能产品,致力于解决企业智能化转型中面临的效率、成本、价值问题,提升企业的决策水平。现已广泛应用于金融、零售、制造、能源与电力、电信及医疗保健等领域,在中国所有以平台为中心的决策型企业级AI市场中排名第一。
第四范式目前市值183亿港元
多位联创来自上交大,甚至均来自ACM班。董事长戴文渊与副总裁郑曌为两任ACM冠军队的队长,首席研究科学家陈雨强,在交大ACM班时,戴文渊曾是陈雨强的小导师,也是他在百度实习时的leader。而第四范式创业时,陈雨强担任今日头条推荐系统负责人(就是字节最重要的推荐算法),听到戴文渊的召唤,离开了正在高速增长的字节跳动,与师兄一起创业。
首席架构师胡时伟在交大、百度期间均与戴文渊一起,在凤巢时主持了百度商业客户运营、凤巢新兴变现、“商业知心”搜索、阿拉丁生态等架构设计工程;
商汤科技-徐立
AI四小龙之一,商汤科技联合创始人、董事长、CEO徐立,本硕毕业于上海交通大学,博士毕业于香港中文大学,师从商汤的另一位创始人汤晓鸥教授,
商汤科技以“坚持原创,让AI引领人类进步”为使命,旨在持续引领人工智能前沿研究,持续打造更具拓展性更普惠的人工智能软件平台,并长期投入于原创技术研究,不断增强行业领先的多模态、多任务通用人工智能能力,涵盖感知智能、自然语言处理、决策智能、智能内容生成等关键技术领域,同时包含AI芯片、AI传感器及AI算力基础设施在内的关键能力。此外,商汤前瞻性打造新型人工智能基础设施——商汤AI大装置SenseCore,打通算力、算法和平台,并在此基础上建立“商汤日日新SenseNova”大模型及研发体系,以低成本解锁通用人工智能任务的能力,推动高效率、低成本、规模化的AI创新和落地,进而打通商业价值闭环,解决长尾应用问题,引领人工智能进入工业化发展阶段。商汤科技业务涵盖生成式AI、传统AI和智能汽车。
目前市值386亿港元,应该是市值最高的中国人工智能公司
依图科技-林晨曦
AI四小龙之一,林晨曦,依图科技联合创始人。前阿里云计算资深专家。2008年至2012年期间,组建并带领百人以上的优秀工程师团队,搭建了国内最大的拥有自主知识产权的飞天分布式云计算操作系统。在加入阿里巴巴集团之前,曾在微软亚洲研究院从事机器学习、计算机视觉、信息检索以及分布式系统方向的研究工作。2005年获得上海交通大学硕士学位。2002年曾参加上海交通大学ACM/ICPC代表队并获得全球大学生程序设计竞赛世界冠军,这也是亚洲队伍获得的第一个世界冠军。2003年获得首届交大校长奖。
依图科技人工智能技术的应用领域包括:依图医疗、智慧金融、智慧城市等。
2017年7月,依图科技在由美国国家标准技术局(NIST)主办的全球人脸识别测试(FRVT)中夺得第一,成绩在千万分之一误报下达到识别准确率95.5%,是当时全球工业界在此项指标下的最好水平。根据2018年6月的官方报告,依图已将这一指标提升到了接近极限的水平,即在千万分之一误报下的识别准确率已经接近 99%。
截至2020年6月末,依图科技共完成了10轮融资,估值达40亿美元。包括红杉中国、云锋基金、高瓴资本、真格基金和高榕资本等一众知名投资机构都在其中。
穹彻科技-卢策吾
卢策吾,上海交通大学教授,博士生导师,长江教授特聘学者,科学探索奖获得者(获奖原因:具身智能贡献),2018 年被《麻省理工科技评论》评为 35 位 35 岁以下中国科技精英(MIT TR35),作为联合创始人,首席科学家,创立具身智能公司穹彻智能。
成立于2023年的穹彻智能由通用智能机器人公司Flexiv非夕科技战略孵化,上海交通大学教授,长江学者特聘教授、2023年“科学探索奖”获得者(目前具身智能领域唯一)卢策吾教授担任联合创始人。
基于多年深耕人工智能领域的经验和深厚的技术积累(发表顶会顶刊100多篇,多次获得国际机器人顶会最佳论文奖),卢策吾及其团队在构建具身智能大模型时,将技术重点放在了对操作物理常识和力反馈嵌入智能体行为决策的联合训练上,从而打造了Noematrix Brain穹彻具身大脑。
穹彻具身大脑具备全链路的具身智能技术框架。其中,穹彻自研的两个具身智能大模型:实体世界大模型和机器人行为大模型,可以看作此框架中的主要助推器,承担了推进操作物理常识和智能体行为决策的联合训练的重担。以两个大模型为基础,穹彻具身大脑得以具备规划、记忆、执行这三种核心能力。
2024年3年,完成约5000万元天使轮融资。
清昴智能-关超宇、姚航
清昴智能的两位创始人关超宇、姚航及多位主要成员均毕业于上海交通大学。
CEO关超宇是年龄最小的清华研究生特奖得主,师从朱文武教授。曾以一作身份发表论文7篇,荣获两项深度学习挑战赛冠军;任世界首个AutoGL自动图学习开源系统(Github 800+星标)首席架构师。COO是姚航前华为英雄个人,曾主导完成多款国产芯片在终端产品的商用适配导入。两人是交大计算机系的本科同班同学。
清昴智能是一家AI模型部署优化技术提供商。公司致力于研发 MLGuider - 硬件感知的自动化模型部署优化平台,解决 AIGC、自动驾驶、AIoT 等领域复杂AI模型的落地难问题。基于团队自研的硬件感知自动机器学习算法,MLGuider 可以自动寻找最适合硬件的模型架构,从而让 AI 模型高效运行在各类设备上。
今年六月,AI推理部署解决方案厂商「清昴智能」近日完成了数千万元Pre-A+轮融资,达晨财智、启赋资本领投。此前,清昴智能已获得某世界500强科技巨头公司的千万元战略投资。
OctoAI -陈天奇
现任卡耐基梅隆大学机器学习系/计算机系助理教授, OctoAI 联合创始人&首席技术专家。本科和硕士毕业于上海交通大学ACM班,博士毕业于华盛顿大学计算机系,研究方向为机器学习与系统的交叉领域,是机器学习领域著名的青年华人学者。曾创建开发了 Apache TVM、XGBoost、Apache MxNet 等著名机器学习工具,是最大开源分布式机器学习项目 DMLC 的发起人之一。
OctoAI 的使命是让人工智能更易于使用和更可持续,使其可用于改善生活。我们的平台为应用程序开发者提供生成式 AI 基础架构,以运行、调整和扩展支持 AI 应用程序的模型。借助市场上最快的基础模型,包括Llama 2、WhisperX和SDXL、端到端解决方案和世界一流的机器学习系统,开发人员无需成为人工智能基础设施专家即可专注于构建令客户赞叹的应用程序。
澜码-周健
周健毕业于上海交通大学计算机系学士、硕士,2002年获得ACM国际大学生程序设计竞赛世界冠军,为首个在此项竞赛夺冠的亚洲团队。2006年加入谷歌,在美国总部负责中文网站搜索质量优化,是当时极少数获得访问pagerank算法核心代码权限的中国工程师。
澜码科技是一家基于大语言模型的AI Agent平台公司,核心团队成员来自Google、IBM、腾讯、字节、阿里、依图等国内外知名互联网和AI公司。澜码科技率先填补了国内大模型中间层的空白,是国内探索大语言模型应用落地和AI Agent的先行者。基于底层大语言模型,澜码科技自主研发了能够连接人和系统的企业级Agent平台“AskXBOT”,助力企业构建基于专家知识的超级自动化,从而提升业务质量和效率。
澜码科技已完成来自IDG资本、联新资本、Atom Capital参与的数千万A轮投资,并与多家上市公司和独角兽企业达成战略合作。
井英-朱江
创始人朱江,2009年时,从上海交通大学计算机科学专业硕士毕业后,便加入了初创智能手机公司触宝科技,他从一名触宝科技的实习生成长为公司上市的敲钟合伙人。
井英科技一家专注于AIGC视频生成模型自主研发的公司,计划利用这笔资金进一步升级其AI视频模型和工具,加强内容生态系统的构建,去年公司推出了外国“真人”短视频一站式生产平台,近期CreativeFitting 自研高质量视频生成模型取得突破,可生成 AI 短剧视频。
CreativeFitting(井英科技)近日宣布完成由百度集团投资的数百万美元Pre-A+轮融资。
未来速度-秦续业
秦续业,未来速度 CEO,毕业于上海交通大学,曾就职于阿里,拥有多年分布式计算、AI 和大数据系统经验。
杭州未来速度科技有限公司是⼀家专注于企业级人工智能基础设施平台公司,致力于研发能够满⾜客户不断增长的计算需求的解决方案。未来速度旗下的Xorbits模型平台赋能企业人工智能转型,帮助企业快速部署和接⼊⼤模型,同时,能结合企业自身的数据来提供对模型的增强。主要团队成员来自互联网大厂和世界500强企业,在分布式计算、人工智能领域有丰富技术实践经验。
2023年2月27日,未来速度获得数百万美元的天使轮融资,投资方为耀途资本。
其他
除此之外
- 融资机器
智元机器人也是背靠上海交通大学主导的上海人工智能研究院,首席创新官为上海交通大学机器人研究所副研究员闫维新; - AI Infra 估值最高的的创业公司无问芯穹的首席科学家戴国浩,现任上海交通大学长聘教轨副教授;
- 原B站副总裁创办的、目前获得近亿元融资的AI漫画公司miguo.ai的技术合伙人牛力,现任上海交通大学副教授。
还有一些上交系的学术圈的大佬,也许在未来的某一天也会下场创业,比如
- Sora发布而迅速出圈的纽约大学助理教授
谢赛宁(与深度学习三巨头、Meta首席人工智能科学家Lecun一同),此前曾担任Meta人工智能研究中心(FAIR)研究科学家,他与OpenAI Sora核心负责人之一的bill在meta时期合作发表的DiT模型,被认为是OpenAI视频模型Sora的构建基础。 - 现任卡内基梅隆大学助理教授
李磊,曾经和李沐大佬同为百度少帅计划成员,后在字节跳动AI lab担任高级总监,也是毕业于上海交通大学ACM班。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
