- 大模型推理思考
- 资料
- CoT RL
- DeepThink vs DeepResearch
- OpenAI 推理模型
- 技术原理
- 思考
- cot 过时
- 复现
- 复现方案
- 【2024-3-18】Quiet-STaR
- 【2024-9-15】rStar
- 【2024-9-17】g1
- 【2024-9-18】Peak-Reasoning-7B
- 【2024-10-7】Open-O1
- DeepSeek R1
- 【2024-11-22】阿里 Marco-o1
- 【2024-11-26】Skywork-o1
- 【2025-01-20】kimi k1.5
- 【2025-1-26】LLM-Reasoner
- 【2025-2-6】Gemini 2.0 Flash-Lite
- 【2024-2-6】斯坦福 S1
- 【2025-2-10】北大 ReasonFlux
- 【2025-2-10】清华: 最优TTS
- 【2025-2-10】KTransformers 推理加速
- 【2025-2-11】伯克利 DeepScaleR-1.5B-Preview
- 【2025-2-12】斯坦福 OpenThinker-32B
- 【2025-2-18】Grok-3
- 【2025-3-9】LCPO
- 【2025-10-14】蚂蚁 Ring-1T
- 大模型符号推理
- 多模态
- 小模型推理
- 结束
大模型推理思考
Hinton:智力在于学习, 而不是推理
- 推理是智力的表现
- 学习是智力的来源,
- 推理来自于学习。
- 推理是外功,学习是内功。
视觉和运动控制是基础,语言和推理是后天高级能力。
资料
【2025-2-25】从快思考到慢思考: 大模型推理综述
- 一篇关于从系统1(快思考,Vanilla CoT)到系统2(慢思考,o1-like)的大模型负责推理综述,覆盖 300+ 最新文献
- 论文 From System 1 to System 2: A Survey of Reasoning Large Language Models
- github: Awesome-System2-Reasoning-LLM
- 解读 【论文】大语言模型推理最新综述
要实现人类水平的智能,大模型需要从快速、直观的系统 1 到更慢、更深度的系统 2 推理过渡。
系统 1擅长快速、启发式决策,而系统 2则依靠逻辑推理来做出更准确的判断并减少偏差。- 基础大型语言模型 (LLMs) 擅长快速决策,但缺乏复杂推理的深度,因为尚未完全接受真正的
系统 2思维的逐步分析特征。 - 最近,OpenAI 的
o1/o3和 DeepSeek 的R1等推理LLMs在数学和编码等领域展示了专家级的性能,与系统 2刻意推理非常相似,实现类似人类的认知能力。
内容概要
- 简要概述
System 2技术的基础LLMs和早期发展进展,探讨LLMs如何为推理铺平道路。 - 如何构建推理LLMs,分析并实现高级推理的核心方法,以及各种推理LLMs的演变。
- 概述常见的推理数据集,并深度比较典型LLMs的推理性能。
- 推理能力上有前途的方向,并维护了实时更新 GitHub 库,跟踪最新进展。
概念
双系统理论
人类认知通过两种模式运作:
系统 1快速、自动和直观,以最小代价快速做出决策- 而
系统 2则较慢、更深思熟虑。
系统 1 对于常规任务,容易出现认知偏差,尤其是复杂或不确定情形, 导致判断错误。
系统 2 依赖于逻辑推理和系统思考,从而做出更准确和理性的决策。通过减轻系统 1 的偏差,系统 2 提供了一种更精细的问题解决方法。
“推理” 指回答涉及复杂、多步骤过程和中间步骤的问题。
基础 LLMs: 具有基本推理能力,处理简单或单步任务。推理 LLMs:擅长编码、数学证明、多模态推理等复杂任务,结合“思考”过程, 让基本LLMs努力完成任务
推理LLMs 时间表:6个路线上进化过程
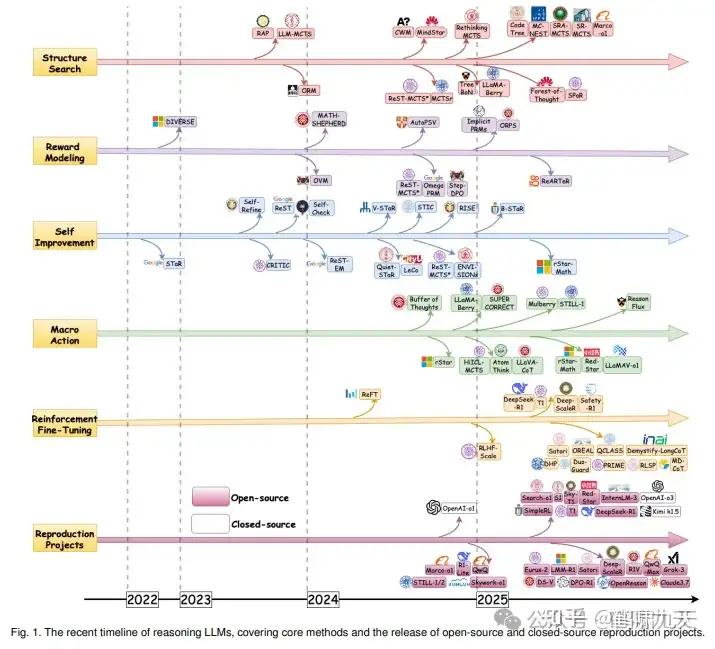
CoT RL
【2025-1-25】新智能引擎:基于思维链的强化学习
RLHF vs CoT RL
- RLHF:通常用人工标注或人工反馈打分,数据昂贵且容易产生“对齐税”;
- CoT RL:利用客观题(如数学、编程)自判正误,极大提升训练规模与深度,同时使模型在思维链生成和自我纠错方面更为主动。这种自由思考被认为是真正的“推理能力”的培养,而不只是对齐。
CoT RL 崛起脉络:
- 2024年7月15日,OpenAI “
Strawberry” 传闻流出,被认为是对 CoT RL 实验成功的内部代号。 - 2024年9月12日,OpenAI 发布
o1-preview与o1-mini(后者通常被视作蒸馏版本)。 - 2024年11月20日,DeepSeek 发布
R1-Lite,暗示其在高级推理方面也有进展; - 2024年11月21日,阿里巴巴发布
Macro-o1,Qwen 发布QwQ-32B-Preview等。 - 2024年12月5日,OpenAI 用 o1 替换 o1-preview 并推出
o1 Pro,已准备好模型可运行在“更长推理时间”模式。 - 2024年12月14日,Ilya(OpenAI 联合创始人)在演讲中说:“Pre-Training as we know it will end”,此时主流媒体解读为模型性能已经到达瓶颈点。
- 2024年12月20日,OpenAI 宣布性能远超 o1 的
o3模型,并开放早期使用申请; - 同日,Google 发布
Gemini 2.0 Flash Thinking(外界猜测是其内部“大模型推理蒸馏”版本)。 - 2025年1月20日,DeepSeek 发布
R1,Kimi 也发布了kimi-1.5。这两家机构的技术报告明确展示如何在“大模型+CoT+RL”上实现自我迭代训练,标志着 reasoning model 重现方法 已几乎“被说明白”。
从这一连串事件可见:
- 大型研究机构与顶尖公司几乎在同一时期转向“
CoT RL”。 - OpenAI 的 o1、o1-pro 以及后续的 o3 都在强化“长推理”和“推理时间可调”的理念,Google 的 Gemini 2.0 Flash 系列也被认为采用了类似技术,只是未公开细节。
DeepThink vs DeepResearch
Deep Think (DT)、Gemini Deep Research (GDR) 和 ChatGPT Deep Research (CDR) 是完全不同的三个产品。
| 对比维度 | Deep Think (DT) | Deep Research |
|---|---|---|
| 核心定位 | 强化推理模式 | AI Agent(智能体) |
| 关键词 | 深度、逻辑链 | 广度、信息差 |
| 核心架构 | 并行思考架构(支持16条推理路径) | 搜索-阅读-整理一体化架构 |
| 核心任务 | 验证逻辑、解决难题、发现盲区 | 海量信息搜索、多文档阅读、报告整理生成 |
| 信息来源依赖 | 侧重内部逻辑推理,弱化外部搜索 | 强依赖外部搜索+文档解析 |
| 核心优势 | 逻辑深度深、盲区识别能力强 | 信息覆盖广、信息时效性高 |
| 主要痛点 | 不擅长海量信息整合、无实时信息获取能力 | 易忽视核心文档、逻辑深度有限 |
【2025-5-21】全面对比
【2025-4-10】DeepThink vs DeepResearch 区别
以 grok 为例,对比分析
| 特性 | Grok DeepSearch | Grok Think |
|---|---|---|
| 主要功能 | 信息检索与综合 | 逻辑推理与分析 |
| 数据来源 | 外部网站和互联网内容 | 内部知识库和推理能力 |
| 处理时间 | 相对较慢(可能超过一分钟) | 分析任务通常更快 |
| 最适合 | 研究、实时信息获取、多源比较 | 数学计算、编程、逐步问题求解 |
| 解题方法 | 收集和综合外部信息 | 通过逻辑步骤分解问题 |
工作模式
适用场景
Grok-3 DeepSearch与Think模式功能对比
| 对比维度 | DeepSearch模式 | Think模式 | 最佳使用场景 |
|---|---|---|---|
| 信息获取 | 实时互联网数据,及时更新 | 预训练知识库,无实时更新 | 最新资讯时选择DeepSearch |
| 分析深度 | 注重事实呈现,简洁直接 | 逐步推理,深度思考 | 复杂问题分析时选择Think |
| 引用来源 | 提供具体来源链接 | 无外部链接,基于预训练知识 | 引用出处时选择DeepSearch |
| 创意能力 | 基于现有资源,整合能力强 | 原创思维,想象力丰富 | 创意生成更适合使用Think |
| 交互体验 | 简洁直接,提供链接,借助外部搜索,3-5s | 详细思考过程,2-4s | 日常查询用DeepSearch,学习用Think |
| 最佳应用领域 | 新闻、市场趋势、竞争分析 | 学术分析、哲学问题、创意生成 | 综合建议:复杂任务交替使用效果最佳 |
这两种模式的根本区别在于信息处理方式:
- DeepSearch 侧重于广泛收集和整合最新信息
- 而Think 则专注于深度分析和推理已有知识。
Think
Think模式:深度推理的思考大师
Think模式则代表另一种AI交互范式,专注于深度思考和逻辑推理。官方描述为”一种先进的推理系统,能够逐步解决复杂问题”。
其主要特点有:
- 逐步思考:以类似人类思考的方式分解复杂问题
- 自我修正:能够识别和纠正自己的推理错误
- 深度分析:对信息进行全面分析而非简单总结
- 知识局限性:基于训练截止日期的知识,不具备实时信息
Research
DeepSearch模式:实时搜索引擎的进化
DeepSearch 是Grok-3的亮点功能,本质是增强型实时搜索引擎。xAI官方介绍,设计为”一个闪电般快速的AI代理,跨越整个人类知识库不懈地寻求真相”。
其核心特点包括:
- 实时网络访问:能够访问并处理最新的互联网信息
- 多源信息整合:从多个来源获取信息,综合分析后提供答案
- 引用来源透明:提供信息来源链接,便于用户核验
- 快速直接响应:简洁明了地提供答案,减少不必要的解释
OpenAI 推理模型
OpenAI o1证明: 测试时扩展(TTS)可通过推理时分配额外算力,大幅增强LLM的推理能力。
测试时计算成为当前提升大模型性能的最新范式。
【2024-9-13】o1
【2024-9-13】OpenAI震撼发布o1大模型!强化学习突破LLM推理极限
2024年9月13日午夜,OpenAI 正式公开一系列全新 AI 大模型,专门解决难题。
新模型可实现复杂推理,一个通用模型解决比此前的科学、代码和数学模型能做到的更难的问题。
第一款模型,而且还只是预览版 ——o1-preview。除了 o1,OpenAI 还展示了目前正在开发的下次更新的评估。
- OpenAI 还发布 mini 版
o1-mini, 擅长编程的更快、更便宜的推理模型。o1-mini成本比o1-preview低 80%。
o1 模型一举创造了很多历史记录。
- 奥特曼到科学家们一直在「高调宣传」的草莓大模型。它拥有真正的通用推理能力
- 大模型领域重现了当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。
- 与 GPT-4o 相比,o1 系列模型对于处理代码的智能体系统来说是一个重大进步。
- 回答问题前先仔细思考,而不是立即脱口而出答案。就像人类大脑的
系统 1和系统 2 - ChatGPT 已经从仅使用
系统 1(快速、自动、直观、易出错)进化到了系统 2思维(缓慢、深思熟虑、有意识、可靠)。
结果表明:o1 超越了人类专家,成为第一个通过基准测试的模型。
- 国际数学奥林匹克(IMO)资格考试中,GPT-4o 仅正确解答了 13% 的问题,而 o1 模型正确解答了 83% 的问题。
OpenAI 不在界面中显示思维链,而是显示小结。
- 部分原因是担心所谓的“蒸馏风险”,因为有人可能会尝试模仿这些推理痕迹,并通过模仿思维链来恢复大量的推理性能
o1 意义
OpenAI o1 是大模型技术领域的一个巨大突破,除了复杂逻辑推理能力获得极大提升外,还有:
- (1) o1 给大模型带来了自我反思与错误修正能力
- GPT-4 逐字输出token, 句子较长时, 难免出现幻觉, 中间 token 有误,但模型无法纠正前面的错误, 还是将错就错
- o1 的思考体现在 生成 hidden COT 过程中, 能发现并纠正之前的错误, 这对长链思考及复杂任务非常重要
- (2) 新型 RL Scaling law
- (3) o1之后,
小模型大行其道真正成为可能 - (4) o1可能会引发“安全对齐”新的范式: 安全能力比GPT 4o强很多
- 大概用了类似 Anthropic 的“AI宪法”的思路,给定一些安全守则,指明哪些行为能做,哪些不能做
- 可能引发安全对齐新模式:先把模型的逻辑推理能力加强,然后采取类似“AI宪法”思路
- (5) “强化学习+LLM”的领域泛化能力,可能不局限于理科领域
- 强化学习适合解决 Reward比较明确的复杂问题,典型: 数理化、Coding等有标准答案的学科,所以很多人会质疑o1是否能泛化到更宽的领域
- OpenAI可能已经找到了一些非数理学科的Reward定义方法,并将这个方法通过RL拓展到更多领域。
o1 RL 大概率用了
- 相对复杂的、类似AlphaGo的MCTS树搜索
- 或 简单树结构拓展,比 如生成多个候选,从中选择最好的(Best-of-N Sampling),这种策略如果连续用,其实也是一种简单的树搜索结构。
- 也有可能两者一起用。
不论怎样,树搜索结构大概率是用了,COT是线性的不假,但这是产出结果,不代表内部思考过程就一定是线性的,靠线性思维推导过程很难解决复杂问题,树形结构几乎是不可避免的。
SLM
尽管小模型语言能力强、世界知识还可以,但逻辑推理能力很难提起来,即使通过蒸馏等措施试图把逻辑能力内化到小模型的参数里,效果有但有限
小模型和大模型差距最大的就是逻辑推理能力。
- 纯靠参数内化来提升小模型的逻辑推理能力估计提升幅度有限。
- 但 o1 mini 明显是个小模型,其复杂逻辑推理能力非常强,而且看样子可通过配置来提升或者降低它的逻辑推理能力(所谓inference-time Scaling law),如果了解AlphaGo的运作机制的话,会发现这都是比较典型的搜索树的特点,可以通过控制搜索空间大小来提升模型能力。
逻辑推理能力锁定了小模型上限。
小模型的能力特点:
- 语言能力很强不比大模型弱
- 世界知识不如大模型,但是可以通过给更多数据持续提升
- 受限于模型规模,逻辑推理能力能提升但比较困难。
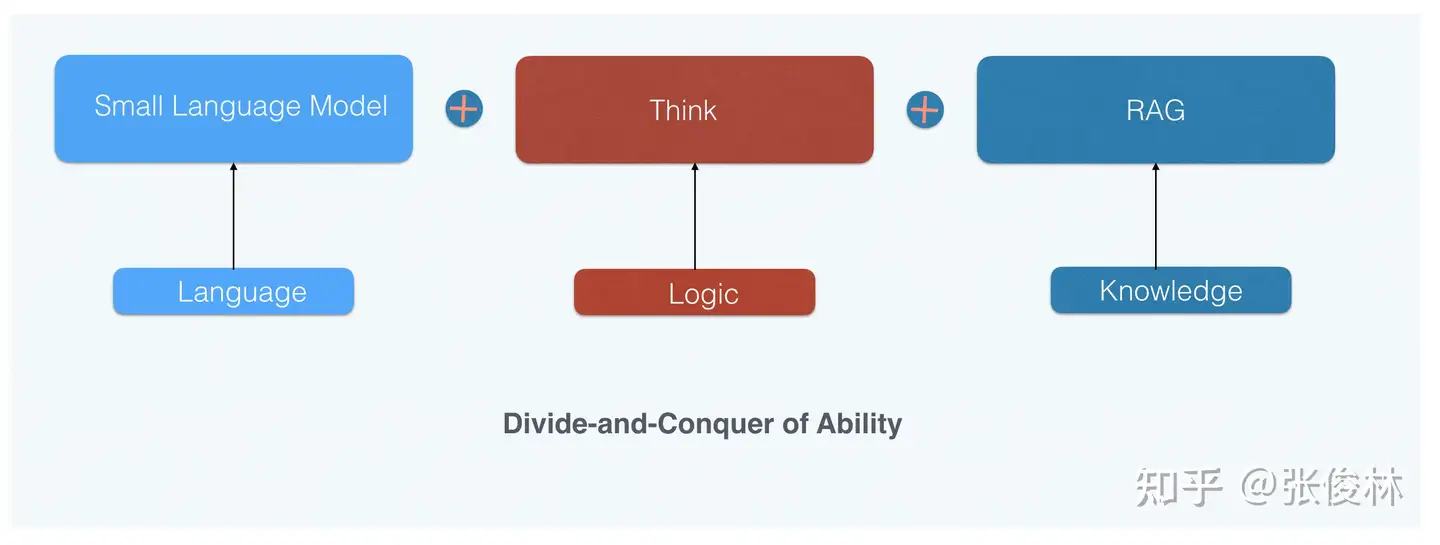
小模型的优化重点: 世界知识和逻辑推理能力
而 o1 mini 效果(世界知识弱、逻辑推理强),之后可采用“能力分治”(DCA,Divide-and-Conquer of Ability)模式推进小模型的技术发展
- 把语言、世界知识及逻辑推理三个能力解耦
- 语言能力靠小模型自身
- 逻辑推理靠类似o1的通过RL获得的深度思考能力
- 而世界知识可以靠外挂RAG获得增强
通过“能力分治”,小模型完全可能具备目前最强大模型的能力,这等于真正为小模型扫清了前进路上的障碍,而 SLM 做起来成本又比较低,很多人和机构都可以做这事,这种 DCA模式 将会大行其道,形成一种新的研发小模型的范式。
【2024-12-23】o3
【2024-12-23】最强推理模型o3来了!OpenAI副总裁不慎透露秘密被Altman“闭麦”
2024年12月23日,OpenAI 发布推理模型o3,包含两个模型,即o3和o3-mini
- 前者是高性能推理模型,后者是更小的精简版模型,在保持智能的同时优化性能和成本。
OpenAI又基于o3,训了3个小尺寸的o3模型, o3-mini 将于次年1月公布
o3-mini 支持低、中、高三种推理时间模式,用户可根据任务复杂度灵活调整思考时间。
o3模型在多个维度上展现非凡。
- 在软件基准测试SWE-bench Verified中,o3以71.7%的准确率傲视群雄,较其前辈o1模型性能提升超20%。
- 在编程竞技领域,o3于Codeforces竞赛中的评分高达2727分,直逼OpenAI内部顶尖程序员的水平。更令人瞩目的是,在AIME数学竞赛模拟中,o3模型的准确率达到了惊人的96.7%,远超o1的83.3%。
o3模型在ARC-AGI测试中取得了历史性突破,首次跨越人类水平门槛(85%),以87.5%的优异成绩,标志着OpenAI在通往实现人工通用智能(AGI)的征途中又迈出了坚实的一步。
openai
o3已经接近AGI。 CEO萨姆·奥尔特曼(Sam Altman)称o3是“一个非常、非常聪明的模型”。
【2025-1-31】o3-mini
2025年1月31日,OpenAI 终于发布了 o3-mini
o3-mini 定位:资源受限场景,在极高难度任务上的表现稍逊o3,但仍保留了强大的推理能力,尤其在基础数学问题、日常编程和一般推理任务上表现突出。
o3-mini 定价 1.10 美元/百万输入 token,4.40 美元/每百万输出 token。
- 价格比 OpenAI o1-mini 便宜了 63%,比完全体 o1 便宜 93%,可谓是“骨折价”。
- 当然,定价还是比 DeepSeek 贵了很多(0.14 美元/百万输入 token,0.55 美元/百万输出 token)。
o3-mini 创新地提供了低、中、高三种不同级别的“推理强度选项”,用户可根据具体任务灵活调整速度和准确度之间的平衡。
即便是在最低推理级别下,o3-mini 在数学和编程基准测试中的表现也能与 o1-mini 相媲美。而当设置为最高推理级别时,其表现甚至能够超越功能更全面的 o1 模型。
与 o1-mini 相比,o3-mini 将重大错误率降低了 39%,其回答的受欢迎程度提高了 56%。
中等推理级别下,o3-mini 的平均响应时间也从 o1-mini 的 10.16 秒缩短到了 7.7 秒,提速达 24%。
不足
- o3-mini 不支持视觉功能,因此只能继续使用 o1 进行视觉推理任务。
参考
【2025-2-7】 o3-mini 思维链开放
2月7日, OpenAI 更新 o3-mini 模型思维链展示方式,提高 AI 推理透明度
OpenAI 宣布公开o3-mini模型的推理思维链,免费和付费用户可查看其思维过程。
OpenAI为付费用户更新o3-mini-high的思维链,更透明、更详细地展示模型的“推理”步骤以及得出答案的方式。
部分人质疑公开的思维链是否为原始数据
- 因为展示速度较慢且字符数量与原始版本存在差异。
- o3-mini被发现使用中文做推理。被网友怀疑o3是不是蒸馏过DeepSeek,或使用了部分代码/数据。
- OpenAI发言人确认公开的思维链经过后处理,消除不安全内容、简化复杂想法,为非英语用户提供更好的体验。
怕被对手蒸馏,OpenAI只敢公开“阉割版”思维链!网友失望:错误的摘要还不如没有!OpenAI员工挽尊:推理混乱但结果对了
OpenAI 首席产品官 Kevin Weil 透露说:
- “我们正在努力展示比现在更多的内容——[展示模型的思维过程] 很快就会实现。具体方案尚未确定: 完整展示思维链可能会导致竞争对手进行知识蒸馏(competitive distillation),但我们也知道用户(至少是高阶用户)希望看到完整的推理过程,所以我们会找到合适的平衡点。”
- 折中方案:o3-mini 先进行推理,然后将思维整理成摘要。
技术原理
“强化学习生成Hidden COT”
教程
【2025-1-4】吴恩达o1推理新课程
Reasoning with o1,讲师是 OpenAI 战略解决方案架构主管 Colin Jarvis。
- 课程地址:Reasoning with o1
Reasoning with o1 课程内容主要包括:
- o1 即时工程的基础知识
- 规划和执行多步骤任务
- 创建和编辑代码
- 图像推理
- 可提高模型性能的 Metaprompting
OpenAI
技术博客《Learning to Reason with LLMs》中,OpenAI 对 o1 系列语言模型做了详细的技术介绍。
OpenAI o1 是经过强化学习训练来执行复杂推理任务的新型语言模型。
- 特点: o1 在回答之前会思考 —— 它可以在响应用户之前产生一个很长的内部思维链。
- “强化学习生成Hidden COT”
OpenAI 大规模强化学习算法,教会模型如何在数据高度有效的训练过程中利用其思想链进行高效思考。换言之,类似于强化学习的 Scaling Law
OpenAI o1 团队制作的短视频, 解说: 什么是推理?
- 简单问题: 意大利首都是哪儿? 立即回答 罗马 —— 快思考
- 复杂问题: 帮我写个商业计划书/小说… 自我反思, 思考时间越久, 结果往往越好
- 推理是一种将思考时间转化为更好结果的能力
- 大模型能否灵光一现?啊哈 时刻
- 让人类记录其思维过程,据此进行训练。
- 啊哈时刻: 发现通过强化学习训练模型生成、优化CoT,效果甚至比人类写的CoT还好的那一刻。
聪明的你, 或许想到, 能否亲自问问o1, 思维过程是什么?
- o1完整思维链成OpenAI头号禁忌!问多了等着封号吧
- 试图套话 o1,复述出完整的内部思维过程,即全部原始reasoning tokens。
警告
- 不要在ChatGPT里问最新o1模型是怎么思考的
- 只要提示词里带 “reasoning trace”、“show your chain of thought”等关键词就会收到警告。
- 甚至完全避免出现关键词,使用其他手段诱导模型绕过限制都会被检测到
只要尝试几次,OpenAI就会发邮件威胁撤销你的使用资格。
请停止此活动,确保您使用ChatGPT时符合我们的使用条款。违反此条款的行为可能导致失去OpenAI o1访问权限。
o1思维过程就是其他模型最好的训练数据,所以OpenAI不想这些宝贵数据被别的公司扒走。
这是 o1 与 之前模型的区别
Tom Yeh
视频: YouTube
科罗拉多大学博尔德分校计算机教授Tom Yeh 专门制作了一个动画,讲解 OpenAI 如何训练o1模型花更多时间思考。
- 关于训练,报告中有非常简短的一句话:「通过
强化学习,o1 学会了磨练其思维链并改进策略。」- 两个关键词是:强化学习(RL)和思维链(CoT)。
- RLHF+CoT中,CoT token 也会被输入到
奖励模型中来获得分数,更新LLM,从而实现更好的对齐;而在传统的RLHF中,输入只包含提示词和模型响应。
- 推理阶段,模型学会了先生成CoT token(可能需要长达30秒的时间),然后才开始生成最终响应。这就是模型如何花更多时间去「思考」的方式。
- 很多重要的技术细节OpenAI并没有透露,比如奖励模型是如何训练的,如何获取人类对「思考过程」的偏好等等。
Self-Play
【2024-9-14】OpenAI o1 强化学习背后的自博弈(Self-play)方法介绍, 详见站内专题 RLHF原理
张俊林
【2024-9-28】Reverse-o1:OpenAI o1原理逆向工程图解
关于Q*、草莓等各种传闻很久了,用强化学习增强逻辑推理能力这个大方向八九不离十,但是,融合LLM和RL来生成Hidden COT,估计很少人能想到这点,目前看效果确实挺好。
o1 训练过程
OpenAI o1 完整训练过程推演

GPT 4 等LLM模型训练一般由“预训练”和“后训练”两个阶段组成。
- “预训练” 通过 Next Token Prediction 来从海量数据吸收语言、世界知识、逻辑推理、代码等基础能力,模型规模越大、训练数据量越多,则模型能力越强,Scaling Law 指这一阶段的模型扩展特性,也是LLM训练最消耗算力资源的地方。
- “后训练” 则分为 SFT、RM 和 PPO 三个过程,统称人工反馈的强化学习(RLHF),这一阶段主要目的有两个: LLM遵循指令做各种任务,内容安全,不让LLM输出不礼貌的内容。而训练好的模型推理(Inference)过程则是对于用户的问题直接逐个生成Token来形成答案。
o1 整个训练和推理过程应与 GPT 4 这类典型LLM有较大区别。
- 首先,“预训练”阶段应该是重新训练的,不太可能是在GPT 4o上通过继续预训练得到。
- OpenAI官方一再宣称 o1 mini 逻辑推理能力极强,但在世界知识方面很弱。如果是在其它模型上魔改的,世界知识不会比GPT 4o mini更弱,所以侧面说明了是重新训练的;
- 另外,这也说明了o1这类侧重逻辑推理的模型,在预训练阶段的数据配比方面,应该极大增加了逻辑类训练数据比如STEM数据、代码、论文等的比例,甚至都怀疑o1 mini是否引入了通用数据都不好说,否则不需要老强调知识方面能力弱。
- 在“后训练”阶段,有个环节是用来增强LLM模型的指令遵循能力的,即有RLHF阶段。
- 因为o1在遵循指令方面能力并不弱,而且生成的Hidden COT片段里明显也包含很多指令性的内容,如果遵循指令能力比较弱,估计对于生成Hidden COT也有负面影响。所以,推断起来这个环节大概在“思考”阶段之前。(但是RLHF阶段未必有RM和PPO)。
- 但这和GPT 4对应的RLHF阶段应有两个重要的不同:
- 首先,o1应该在这个阶段没有做内容安全方面的事情,大概率是挪到后面的阶段了。
- 其次,这个阶段大概率也会极大增强逻辑推理类的指令遵循数据比例,以此进一步加强基座模型的逻辑推理能力。
- 接下来是o1最大的特点,所谓引入了“系统2”的慢思考能力。
- ClosedAI只说用了RL强化学习,其它任何都没提,技术保密工作一流。由此,只能推断出o1融合了LLM和RL来实现模型“先想后说”的Think能力。
- OpenAI o1应把“内容安全”相关的能力挪到了“Think”阶段之后,而且做法和GPT 4应该也有很大不同。
详见原文 Reverse-o1:OpenAI o1原理逆向工程图解
混合推理
Claude3.7、Qwen3 模型是混合推理模型
怎么实现的?
- 通过开关控制,人来判断哪些使用推理、哪些不使用推理,而不是模型自主根据用户问题难度来进行判断的。
详见站内专题:大模型混合/自适应推理
思考
【2024-9-14】OpenAI o1惊现自我意识?陶哲轩实测大受震撼,门萨智商100夺模型榜首
- OpenAI o1 在门萨智商测试中果然取得了第一名。
- Maxim Lott 给 o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等 进行智商测试,o1稳居第一名, Claude-3 Opus和Bing Copilot,分别取得第二,三名
- 数学大神
陶哲轩实测发现,o1 竟然能成功识别出克莱姆定理。 - 而 OpenAI 研究副总裁表明:大型神经网络可能已经有了足够算力,表现出意识了
o1发布之后,OpenAI 研究副总裁Mark Chen 称:如今的大型神经网络,可能已经具有足够的算力,在测试中表现出一些意识了。
相信AI具有意识的行业领导者,如今已经有了一串长长的名单,包括但不限于——
- Geoffrey Hinton(人工智能教父,被引用次数最多的AI科学家)
- Ilya Sutskever(被引次数第三多的AI科学家)
- Andrej Karpathy
张俊林
张俊林对 o1 看法
- OpenAI o1 是大模型的巨大进步
- 逻辑推理能力提升效果和方法比预想好, 跟 GPT-4 不一样的路子
- o1 比 4o 方向重要:
- 4o 本质是不同模态的大一统, 对于模型智力水平帮助不大; 4o 做不了复杂任务, 指望图片、视频数据大幅提升智力水平不太可能, 4o 弥补的是大模型对多模态世界的感知能力, 而不是认知能力, 后者还是需要LLM文本模型
- o1 本质是探索AGI还能走多远; 认知提升的核心在于复杂逻辑推理, 能力越强, 解锁复杂应用场景越多, 大模型天花板越高, 提升文本模型的逻辑推理能力是最重要的事情, 没有之一
- o1 的本质是 CoT等复杂Prompt的 自动化:
- CoT 背后的树形搜索空间,组合爆炸, 人工编写CoT不可行, 需要仿照AlphaGo的MCTS(蒙特卡洛树搜索)+强化学习, 让LLM快速找到CoT路径
- 复杂问题上, 推理时间成本不是问题, 总会解决, 真正的问题是效果
- Prompt 工程会消失: 后面不需要用户构造复杂prompt, 反人性, 大趋势是所有复杂环节自动化
- Agent 概念虽火, 但难以落地:
- 原因: LLM的复杂推理能力还不够, 即便每个环节准确率95%, 10个环节叠加后就只有59%, 0.95**10=0.5987
- o1 能解 Agent 问题吗? 未必, o1 Model Card专门测试Agent任务,对于简单/中等难度的Agent任务有明显提升,但是复杂的、环节多的任务准确率还是不太高。
- o1 这种通过 Self Play 增强逻辑推理能力的方向, 还有很大的发展潜力, Agent 前途依旧光明
- openai 起到行业明灯作用, 证明某个方向行得通(ChatGPT、GPT-4、Sora、GPT 4o、o1), 其他人快速卷进来, 速度太快以致于openai被甩, 吸尾气
- Sora 就是例子, 国内有些视频生成模型已经超过Sora了, 但Sora依然是期货, 主要openai想做的事情太多, 资源分散
- 现在的 o1 又来了, 卷的价值比Sora更大
- LLM 最基础的三种能力:语言理解和表达能力、世界知识存储和查询能力、逻辑推理能力
- 语言理解和表达能力: 最强, 初版 ChatGPT 完胜纯语言交流任务, 基本达到人类水平
- 世界知识存储和查询能力: 规模越大,效果越好, 但幻觉问题目前无法根治, 制约应用落地的硬伤
- 逻辑推理能力: 弱项, 最难提升
- Coding 是目前除语言理解外, LLM做的最好的方向, 因为代码特殊性, 语言+逻辑的混合体, 语言角度好解决,逻辑角度难解决
- 为什么最难提升? 自然数据(代码、数学题、物理题、科学论文等)在训练数据中比例太低, 于是一个改进方案是预训练阶段和Post-training阶段,大幅增加逻辑推理数据占比
- 大部分逻辑推理数据的形式是
<问题,正确答案>,缺少中间推理步骤,而 o1本质上是让大模型学会自动寻找从问题到正确答案的中间步骤,以此来增强复杂问题的解决能力。
- LLM 当前难点
- 世界知识方面: 如何消除幻觉
- 逻辑推理方面: 如何大幅提升复杂逻辑推理能力
- RL Scaling law
- Scaling law 模式: 增加数据+模型规模, 可以提升模型效果, 然而增长速度放缓
- RL在训练和推理时候的Scaling law 与 预训练 Scaling law 有不同特性。
- 如果 o1 走 MCTS搜索技术路线,那么把COT拆分的越细(增加搜索树深度),或提出更多的可能选择(节点分支增多,树越宽),则搜索空间越大,找到好COT路径可能性越大,效果越好,而训练和推理的时候需要算力肯定越大。看上去效果随着算力增长而增长的态势,即 RL 的 Scaling law。这其实是树搜索本来就有的,称为RL的Scaling law 名不副实。
过度思考
【2025-1-3】揭秘o1类模型的过度思考
腾讯AI Lab、上海交通大学
o1类超大型语言模型的过度思考:
- 2+3=?答案仅需5个token,o1类模型凭啥要900个?
- 论文:Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
“o1-like” 大型语言模型 通过延长思考链(chain-of-thought,CoT),探索多种策略,分解复杂步骤,并进行双重检查,增强复杂推理任务的处理能力。
这种方法称为“测试时计算扩展”,模型推理阶段分配更多的计算资源,以期获得更准确的响应。
“o1-like” 大型语言模型(LLMs)推理问题,“overthinking”(过度思考)。处理问题时,尤其是简单问题,分配过多计算资源,对提高答案的准确性几乎没有帮助。
- o1-like 模型消耗的token 比常规模型多出1953%
- 资源利用效率:如何智能且高效地在测试期间扩展计算资源,尤其是在面对不同复杂度的问题时。
- 评估和优化模型效率:提出从结果和过程两个角度出发的新效率指标,以评估o1-like模型在计算资源利用上的合理性,并探索了减轻过度思考问题的策略。
- 保持准确性的同时减少计算开销:通过自我训练范式,提出了减少过度思考的方法,这些方法在不牺牲准确性的前提下,简化了推理过程,减少了生成的解决方案数量。
提出相应的效率指标和优化策略,来提高o1-like模型在AI推理任务中的计算资源利用效率,减少不必要的计算开销。
(1) 扩展测试时计算(Scaling Test-Time Compute)
- 扩展搜索空间:通过增加搜索空间来提供模型发现和选择正确解决方案的机会
- 例如:自我一致性方法(self-consistency)、最佳-n解码(best-of-n decoding)、 加权多数投票(weighted majority voting)、 最小贝叶斯风险解码(minimum bayes risk decoding)
- 扩展类人思考模式:通过模拟人类思考方式来增强模型的推理能力,
- 例如:链式思考(Chain-of-Thought)、辩论(debating)、 自我纠错(self-correction)/自我批评(self-critique)、 计划-解决(plan-and-solve)
(2) 高效思考(Efficient Thinking)
- 终止推理:鼓励模型在难以解决问题时通过说“我不知道”来终止推理。
- 令牌预算感知推理(Token-budget-aware reasoning):提示模型在指定的令牌预算内进行推理。
- 计算预算分配:根据提示的难度预测计算预算分布,并据此分配计算能力。
- 早期停止策略:在推理过程中采用早期停止策略以节省计算预算。
- 多代理框架:使用大型LLMs处理复杂任务,小型LLMs处理简单任务。
尽管上述工作考虑了如何提高模型的推理效率,但主要关注传统模型,而不是具有更长思考链(chain-of-thought)的o1-like模型。
本工作首次提出 o1-like 模型中的过度思考问题,并通过自我训练方法来训练模型学习如何高效地思考,而不是简单地限制推理空间或由用户指定Token耗费个数。
CoT-Valve
【2025-2-13】新加坡国立大学 动态调整CoT长度,高效解决复杂问题
CoT-Valve 方法通过动态控制推理链条的长度,让模型在简单任务上使用较短的推理链条,而在复杂任务上保留较长的推理链条,从而显著提高了推理效率。
核心结论
- 短cot 高效性:简单任务上,短推理链条不仅能够显著减少计算成本,还能保持甚至提升模型准确率。
- cot 可压缩性:CoT-Valve 将推理链条压缩到训练集中未见过的长度,显示出良好的泛化能力。
- 动态调整的重要性:动态调整cot长度的能力对于处理不同复杂度的任务至关重要。CoT-Valve 通过
LoRA技术实现了这种动态调整,显著提高了模型的灵活性和效率
实验结果
- 1、在GSM8K数据集上,CoT-Valve显著减少了推理链条的长度,同时保持了高准确率。例如,QwQ-32B-Preview模型在使用CoT-Valve后,推理链条长度从741个token减少到225个token,准确率仅从95.07%略微下降到94.92%。
- 2、在更复杂的AIME数据集上,CoT-Valve同样表现出色。QwQ-32B-Preview模型的推理链条长度从6827个token减少到4629个token,同时仅增加了一个错误答案。
- 3、CoT-Valve不仅适用于大型模型,还能够显著提升小型模型的推理效率。例如,在LLaMA-3.2-1B-Instruct模型上,CoT-Valve将推理链条长度从759.3个token减少到267.0个token,同时将准确率从52.69%提升到55.50%。
【2025-9-3】SABER 多种推理模式
【2025-8-8】SABER(Switchable and Balanced Training for Efficient LLM Reasoning)是 BiliBili 大模型团队提出的RL训练范式,解决大语言模型(LLMs)推理时存在的 “过度思考” 问题,实现用户可控的token预算推理;
- Paper:SABER: Switchable and Balanced Training for Efficient LLM Reasoning
- 该框架支持
NoThink、FastThink、CoreThink、DeepThink四种离散推理模式 - 数学推理(MATH、GSM8K)、代码生成(MBPP)和逻辑推理(LiveBench-Reasoning)任务中表现优异,如 1.5B 模型的 SABER-FastThink 在 MATH 基准上推理长度减少 65.4% 且准确率提升 3.6%,还具备良好的跨规模(1.5B 到 7B 模型)和跨领域泛化能力,且无需监督微调(SFT)预热即可直接通过强化学习优化。
SABER 框架核心设计
思考收集与预算分类
- 数据预处理逻辑:按token数将样本分为三个难度层级并分配目标预算。
- 模式提示模板:为不同推理模式设计专属系统提示,明确推理token约束。
稳定模式转换的保障机制
- 基于准确率的训练数据划分:筛选基础模型回答正确的样本(约 60%),对其执行预算降级,使其接受长度惩罚,学习模式切换。基础模型回答错误的样本(约 40%):一半保留原预算,另一半无目标预算,避免难样本因惩罚导致性能崩溃。
- 下限比例约束:为防止模型 “过度缩短推理” 以规避惩罚,强制约束生成的token数。 用户可控的 NoThink 模式设计
- 在训练集中加入人工构造的 NoThink 样本,每个样本添加最小推理块,明确指令模型跳过推理环节直接输出答案;仅需少量 NoThink 样本(与核心样本重叠),即可让模型在该模式下保持高准确率。
RL优化方案
- 无 SFT 预热:区别于多数需先进行监督微调(SFT)的 RL 方法,SABER 可直接从蒸馏基础模型开始 RL 优化,简化流程并降低计算开销。
- 优化算法:采用Group Relative Policy Optimization(GRPO) 算法,通过结构化奖励信号微调模型。
- 复合奖励函数:奖励由四部分组成,确保推理合规、准确且符合预算。
顿悟时刻
2022年,研究人员在训练模型做简单数学题时发现了一个奇怪的现象:
- 模型训练了上万轮,验证准确率一直停在50%,毫无希望。
- 然后在第12000轮,准确率突然跃升到99%。
这个现象称为”Grokking”(顿悟)。
Grokking揭示深刻事实:理解不是线性的,而是跳跃式。模型不会逐渐变聪明,会在漫长的平台期后突然”开窍”。
平台期之后是突破,耐心之后是洞见,神经网络最像人类的地方。
触发Grokking的关键条件:
- 权重衰减、数据稀缺(反直觉地,这迫使模型寻找真正的规律)、过参数化、足够的耐心、以及AdamW优化器。
- 缺少这些,模型会永远停留在死记硬背的阶段。
“多训练一会儿”实验,本质是在大规模诱导Grokking。RLHF训练、领域适配、推理模型的突破,背后都有它的影子。
推理阶段的应用:如果模型能在训练时顿悟,能否在推理时也诱导顿悟?延长思维链、多路径采样、验证循环——这些技术本质上是在教模型按需顿悟。
Grokking揭示了一个深刻的事实:理解不是线性的,而是跳跃式的。模型不会逐渐变聪明,它们会在漫长的平台期后突然”开窍”。
【2025-2-6】Andrej Karpathy 最新视频盛赞 DeepSeek:R1 正在发现人类思考的逻辑并进行复现
- 视频链接:youtube
- DeepSeek R1 在性能方面与 OpenAI 模型不相上下,推动了 RL 技术的发展
如果只是模仿人类玩家、AI 无法超越人类,但纯 RL 算法却能突破人类限制。
新加坡 Sea AI Lab 等机构研究者再次梳理了类 R1-Zero 的训练过程,并分享了三项重要发现:
- 在类似 R1-Zero 的训练中,可能并不存在「
顿悟时刻」。相反,「顿悟时刻」(如自我反思模式)出现在 epoch 0,即基础模型中。 - 从基础模型的响应中发现了肤浅的自我反思(SSR),且并不一定会导致正确的最终答案。
- 仔细研究通过 RL 进行类 R1-Zero 的训练,响应长度增加的现象并不是因为出现了自我反思,而是 RL 优化设计良好的基于规则的奖励函数的结果。
技术博客:oat-zero
long cot
清华 用 openrlhf 包 long cot 研究工作。
尽可能 Demystifying Long Chain-of-Thought Reasoning in LLMs,通过严格的ablation study得出了11个major takeaway。
- 详情 twitter
- 或paper
有意思的发现:
- 1)long cot 比 short cot上限更高(both sft and rl)
- 2)sft使rl过程更加稳定,最后效果也更好
- 3)通过蒸馏已经emergent的long cot大模型比自己通过prompting framework构建long cot的data效果要更好;
- 3)纯rl with final accuracy reward训练使得length scaling非常不稳定,提出了一种cosine reward 把length长度也考虑进入reward,使得训练更加稳定
- 4)context length window size是length scaling的核心,一般8k的context window要比4k要更好,但是16k 在scaling过程中出现了不如8k的效果(原因可能是大的context length可能需要更多的training example)
- 5)scaling up verifiable reward是long cot的核心。我们尝试使用我们之前MAmmoTH2 的noisy的web extracted instruction来scale up verifiable reward,得出了在general reasoning beyond math(e.g.,mmlu-pro)更好的performance
- 6)long cot 的pattern和能力本身就在base model里,我们搜索了cc的子集 openwebmath,发现了很多这样pattern的数据。
- 7)小模型(起码qwen-math-7b)不容易recentivize long cot的behavior(e.g., aha moment)在MATH 场景下。wait, recheck, alternatively这些词在rl训练中没有明显增加(虽然accuracy boost了很多)
- 8)long sft + rl performance 要比 rl from base 或者单纯 sft效果更好。
还有更多takeaway都在paper和twitter thread里。
推理进度
【2025-7-8】推理进度条
以色列特拉维夫大学开发出新方法,可以监控和控制LLM中的思考路径长度。给LLM的推理任务装上进度条,还能控制推理的深度、调整推理速度。
- 加速后的模型和原模型相比,使用的token数减少了近6倍,且都得出了正确答案。
- 参考 DeepSeek推理最高提速6倍!开源研究:加装「思维进度条」,计算量减少30%
- Overclocking LLM Reasoning: Monitoring and Controlling Thinking Path Lengths in LLMs
- 代码 reasoning_loading_bar

LLMs 显示结构化推理时,会隐式跟踪其在思考阶段的相对位置,并通过隐藏状态编码这一信息。
而论文提出“思维进度向量”(Thinking Progress Vector, TPV),用于实时预测模型在推理阶段的相对位置,并通过可视化进度条展示模型的推理动态。
过干预TPV,可以加速或减速模型的推理过程,实现“超频”(overclocking)和“降频”(downclocking)。
超频能够减少不必要的推理步骤,使模型更快地得出结论,同时避免因过度推理导致的性能下降。
方法:实时监控并控制推理深度
有效推理学习过程中,模型必须隐式地学习跟踪其思考阶段进度,并保持对例如距离最终答案有多近的估计。
由于进度跟踪依赖于输入,这类信息不能存储在模型的静态权重中,而必须动态编码在层间传递的隐藏表示中。
为此,论文的研究团队选择从最终隐藏层提取信息。
研究团队专注于执行显式结构化推理的模型,这种模型的特点是具有一个由
由此可以通过根据每个标记的相对位置精确地用介于零和一之间的插值值进行标记,来量化模型在推理阶段的进展。
效果:最高提速近6倍,准确率不降反升
- DeepSeek-R1-Qwen-32B和DeepSeek-R1-LLaMA-8B上测量TPV的有效性,
推理过程能省略吗
【2025-4-14】伯克利与艾伦
【2025-04-18】NoThinking:大模型推理的「思考」过程真的必要吗?
当前擅长推理(Reasoning)的大模型(如 o1、Deepseek-R1)借助长思维链(CoT):
- 先输出一大段「思考过程」,像是在草稿纸上演算一样,一步步分析问题,尝试不同路径,甚至会自我纠错,最后才给出答案。
推理模型生成的不是简单线性思维链,而是包含了更复杂的结构:
- 搜索与探索 (Search & Exploration): 尝试不同的解题思路。
- 反思与评估 (Reflection & Evaluation): 判断当前思路是否可行,结果是否合理。
- 回溯 (Backtracking): 如果一条路走不通,能退回去尝试其他方法。
- 自我验证 (Self-Verification): 检查中间步骤或最终答案是否正确。
然而,代价:
- 更高的计算成本: 模型需要生成更多Token(文本的基本单位)。Token 数量直接关系到计算量和 API 调用费用。想象成手机话费,打的时间越长(生成的 Token 越多),账单越贵。
- 更长的响应时间(延迟): 生成这么多内容需要时间。如果你想让 AI 实时回答问题或进行交互,等待它「想」半天可能无法接受。
这就引出核心动机:
能不能在保持强大推理能力时,让 AI 更「省钱」、更「快速」?那个看似重要的「思考」过程,真的非输出不可吗?
【2025-4-14】加州大学伯克利分校(UC Berkeley)和艾伦人工智能研究所(AI2)的研究者们提出大胆问题:
AI 解决问题时,那些长篇大论的「思考过程」输出,真的是必不可少的吗? 有没有可能…… AI 其实偷偷「想」完了,只是被训练得非要把过程复述一遍? 或者,甚至不需要那么复杂的显式思考就能解决问题?
作者用开源模型(DeepSeek-R1-Distill-Qwen),通过简单提示技巧(称为 NoThinking)强制模型跳过显式思考步骤,直接生成解决方案。
控制计算资源(Token 数量)情况下,NoThinking 方法在多个具有挑战性的推理任务(包括数学、代码生成、定理证明)上,尤其计算预算较低时,表现甚至优于需要完整「思考」过程的标准方法。
此外,证明了结合 NoThinking 和并行采样(生成多个答案并选优)策略,能显著降低延迟同时,达到甚至超过标准方法的准确率。
这项研究促使重新思考长思考链的必要性,并为低资源或低延迟场景下的高效推理提供了一个有力的参考基线。
假设
- 模型可能只是被训练得遵循这个「格式」,一旦「思考」部分被(看似)完成了,自然地开始生成后续的「解决方案」和「答案」部分。
具体方法
既然模型认这两个标记(
<|beginning of thinking|> 和<|end of thinking|>),那能不能开始思考时,直接给「假的」思考结束信号,骗它跳过思考内容生成环节?
设计方法,并称之为 NoThinking:
- 当需要模型回答时,不自由发挥,而是在提示(Prompt)的助手(Assistant)回答部分,直接预先填入(Prefill)类似下面的内容:
<|beginning of thinking|>
Okay, I think I have finished thinking.
<|end of thinking|>
然后,让模型从 <|end of thinking|> 标记之后继续生成。
结果对比
- 发现一:NoThinking 确实省钱省时
- 不加预算控制的情况下,NoThinking 生成的 Token 数量比 Thinking 少得多,通常只有 Thinking 的 1/2 到 1/5 (原文是 2.0x - 5.1x fewer tokens)。这意味着成本和延迟都大大降低了。
- 发现二:省钱的同时,效果不差,有时还更好
(1)为什么「不思考」反而可能更好?
- 隐式推理 vs 显式输出 (Implicit Reasoning vs. Explicit Output):
- 可能模型训练过程中,已经将很多推理能力「内化」到了其庞大的参数网络中。其实具备了直接从问题跳到解决方案的能力,只是因为训练数据里包含了大量显式思考步骤,所以默认会先「复述」一遍这个过程
- NoThinking 技巧告诉模型:「我知道你会,不用走流程了,直接给结果。」 模型内部可能仍然进行了一些必要的计算(隐式思考),但省略了转化为文本输出的环节。
- 格式遵循 vs 真正思考 (Format Following vs. True Reasoning):
- LLM 非常擅长学习和遵循模式。可能只是学会了「在
<|beginning of thinking|>和<|end of thinking|>之间填充符合逻辑的文本」这个格式,而不是每一次都在进行真正意义上的、从头开始的、必要的思考。 - NoThinking 相当于利用了这个「格式癖」,通过提供完成的格式框架,诱导模型进入下一个阶段(生成解决方案)。
- LLM 非常擅长学习和遵循模式。可能只是学会了「在
- 资源重新分配 (Resource Reallocation):
- 固定的 Token 预算下,Thinking 方法需要把大量的预算分配给生成思考过程。而 NoThinking 省下了这部分预算。
- 省下来的预算可以用来做什么?可能模型可以将更多的「计算力」(虽然 Token 数量受限,但内部计算可能更集中)用于生成更精炼、更准确的最终解决方案部分。
- 回避冗余或错误的思考路径 (Avoiding Redundant/Wrong Paths):
- 冗长的思考过程并不总是完美的。有时模型可能会陷入错误的推理路径,或者进行很多不必要的探索。这些都会消耗 Token 且可能导向错误答案。
- NoThinking 强迫模型更「直觉」地给出答案,可能反而避开了这些冗余或误导性的中间步骤。
- 答案多样性与稳定性 (Answer Diversity & Stability):
- NoThinking 产生的答案多样性(用最终答案的熵衡量)虽然平均值不一定更高,但其方差更小。
- NoThinking 在不同问题上产生多样化答案的表现更稳定、更一致。这可能解释了为什么 pass@k (k>1) 表现更好:它不太容易在某些问题上「卡壳」只生成一种错误答案,而是能比较稳定地提供多种可能的候选解,增加了抽中正确答案的机会。
(2)能不能利用这一点,进一步提升模型实用性?
并行计算 (Parallel Scaling) + Best-of-N 策略。
- 并行计算: 同时启动 N 个模型的推理实例(可以是在多台机器上,也可以是在一台机器上批处理)。
- Best-of-N: 让这 N 个实例都使用 NoThinking 方法独立地生成答案,得到 N 个候选答案。然后,用一个策略从这 N 个答案中选出最好的一个作为最终输出。
(3)如何从 N 个答案中选最好的? 这取决于任务:
- 有完美验证器 (Verifier) 的任务:
- 比如形式化定理证明,Lean 编译器可以直接检查一个证明是否有效。
- 策略:把 N 个生成的证明都扔给编译器,选择那个能通过编译的。如果 N 足够大,根据 pass@k 的结果,找到正确证明的概率很高。
- 没有完美验证器的任务:
- 比如数学解题(只有最终数字答案)或编程(需要跑测试)。
- 策略一:多数投票 (Majority Voting)。提取 N 个答案的最终结果(比如数学题的数字),选出现次数最多的那个。
- 策略二:基于置信度的选择 (Confidence-based Selection)。利用模型自己对答案的「信心」(通常可以通过分析模型输出概率分布得到),选择信心最高的答案,或者结合投票机制(比如给高置信度答案更高权重)。
【2025-4-24】纽约大学-无意义的token替代思考过程
【2025-4-24】纽约大学
thinking 过程为什么能提升模型效果?原因不明
利用一堆固定的 “…” 填充令牌(filler token)来增加了计算量,但没有像 chain-of-thought 那样的 “中间步骤”。用填充令牌能拿到的好处基本就和”数据集共鸣” 及“问题 divide-and-conquer”无关了。这里 “…” 也完全可以换成“。。。”甚至 “ “。
论文发现,用无意义的token(如.)替代思考过程,能解决复杂问题
因果推断
详见站内专题:大模型+因果推断=?
图神经网络
图神经网络与LLM结合提升推理能力
【2023-11-21】港科大、港中文 GNN 与 LLM 结合,在知识图谱问答中优化图结构的建模,使得模型不仅能生成自然语言答案,还能从图谱中进行推理。
通过对齐技术将GNNs和LLMs语义上融合在一起。这类方法可以进一步细分为对称对齐和非对称对齐
- 对称对齐方法将GNNs和LLMs映射到相同的向量空间,从而引入文本知识;
- 而非对称对齐方法则通过不同的方式将GNNs和LLMs结合在一起。
通过改进图神经网络的训练方式,提升模型在复杂知识图谱上的推理效果。
- 模型参考:GAT
- 数据集:ConceptNet
cot 过时
【2025-3-5】 ARQ
资料
- 【2025-3-5】 论文 Attentive Reasoning Queries: A Systematic Method for Optimizing Instruction-Following in Large Language Models
- Parlant 主页
- 代码 arqs-a-systematic-method-for-optimizing-instruction-following-in-llms
分析
场景:
- 想找个地方吃饭。人多,打车不便,也没车。小王想吃汉堡,但现在不在这里。而小李是素食主义者。
三种不同的AI响应方式:
- 左边
No Reasoning:直接回答(没脑子系列)- 结果: 我推荐附近的**汉堡王
- 中间
CoT:思维链(CoT)推理- 推理: 找附近餐馆,菜单上有素食、汉堡的;一共有餐厅 A/B/C…
- 结果: 我推荐餐厅**汉堡王
- 右边
ARQ:注意力推理查询(ARQ)。- 信息结构化: 餐厅限制条件、偏好、可选项、最终结果等
虽然三种方法最后都推荐了”Bob’s Burgers”,但推理过程天差地别
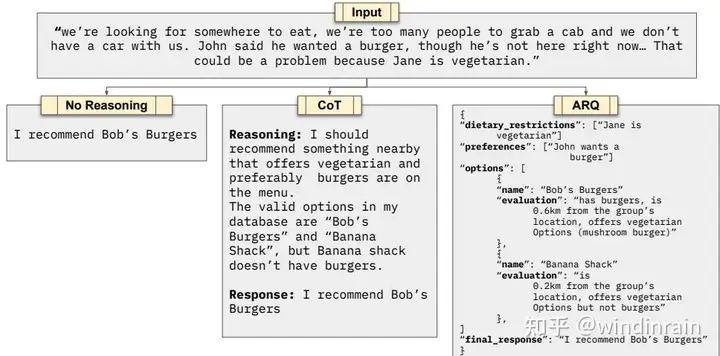
以色列公司 Emcie 的 NLP研究团队发现
- 多轮对话中,LLMs 经常会”失忆“,产生幻觉,或提供未经授权的服务。
- 高风险场景问题大,比如 银行客服,一不小心造成严重后果。
ARQ 源于人类的决策过程。
- 人们选餐厅时,会综合考虑饮食偏好、预算和位置
ARQ 也为AI提供了结构化的推理蓝图。
ARQ 通过预定义的JSON模式引导大模型进行系统性的推理步骤。
- 键是预定义的、有针对性的查询,引导模型的注意力到相关信息上
- 值则由LLM在响应过程中填充
示例
{
"dietary_restrictions": ["Jane is vegetarian"],
"preferences": ["John wants a burger"],
"options": [
{
"name": "Bob's Burgers",
"evaluation": "has burgers, is 0.6km from the group's location, offers vegetarian options (mushroom burger)"
},
{
"name": "Banana Shack",
"evaluation": "is 0.2km from the group's location, offers vegetarian options but not burgers"
}
],
"final_response": "I recommend Bob's Burgers"
}
结构化方法不仅让模型推理过程更透明,也让提取最终答案简单,因为结论就在特定的查询响应中,不用从一大堆文字里找了。
ARQ 原理
ARQ 工作过程:
- 引导ARQ阶段:LLM处理一系列预先确定的引导问题,三个关键功能:
- 重申关键指令(防止模型”失忆”)
- 重申来自提示的重要上下文信息
- 促进逐步推理和中间计算
- 响应生成:基于引导查询阶段的推理,LLM生成响应。
- (可选)响应验证:LLM评估其建议的响应是否满足所有要求,如果不满足,则生成并验证新的响应候选。

团队推出 Parlant 框架,每个代理都用四个关键组件初始化:
- 代理资料:简洁的自然语言描述,定义代理的目的和操作范围。
- 行为准则:以”当时,执行”形式的条件指令集合。
- 工具套件:通过结构化API方法访问的外部功能集。
- 领域词汇:代理操作环境中必不可少的领域特定术语的词汇表。
ARQ vs CoT
两者在结构和实现上有根本的不同。
- CoT 提示:鼓励模型以自由形式生成中间推理步骤,几乎没有外部指导。
- 而 ARQ 通过预定义查询提供明确的结构脚手架,引导模型在推理过程中关注特定对象。
ARQ 优势:
- 领域特定指导:ARQ 纳入领域知识来解决特定于任务的挑战和已知的失败模式。
- 增强可调试性:ARQ 结构化格式让系统设计者更容易检查和调试推理过程。
- 注意力保存:ARQ 战略性地在关键决策点重申关键指令和约束,解决了”迷失在中间”现象。
效果
效果: ARQ 完胜
候选对比
- ARQ实现:采用结构化查询推理方法
- 思维链(CoT)实现:在生成最终输出之前纳入自由形式的推理
- 控制实现:基于指令生成直接响应,没有任何明确的推理过程
ARQ在所有测试中取得了最高的成功率(90.17%),优于思维链(86.05%)和无推理的控制设置(81.54%)。
两类测试中,ARQ 优势尤为明显:
- 准则重新应用:对代理先前回应中已遵循的准则的重新激活做出微妙决策的测试。
- 幻觉预防:专门设计用于检测代理是否提供其可用工具或上下文不支持的幻觉事实或服务的测试。这两种失败情况恰恰代表了基于LLM系统最具挑战性的遵循问题
作者:windinrain
【2025-7-2】CoT 假象
【2025-7-2】Bengio亲手戳穿CoT神话!LLM推理是假象,25%顶会论文遭打脸
Bengio 最新论文戳穿了CoT神话——我们所看到的推理步骤并不真实。不仅如此,LLM在推理时会悄然纠正错误,却在CoT中只字未提。
牛津、谷歌 DeepMind、Mila 多家机构联手论文指出——思维链并非可解释性。
这一观点彻底打破了许多人的认知:
- CoT看似一步步给出答案,实际并非真实推理过程。
- 思维链的透明度,可能只是精心编织的假象!
CoT 最早源于谷歌研究院Jason Wei,多步骤推理,提升模型准确性,让AI黑盒变得不再那么神秘。
随后,CoT被广泛应用在推理模型当中,CoT 能看清AI的推理过程
近期,约25% AI论文将CoT错误标榜为「可解释性技术」
- 约 38% 医疗 AI、25% 法律AI、63% 自动驾驶汽车相关论文,都盲目地将CoT视为可解释性方法。
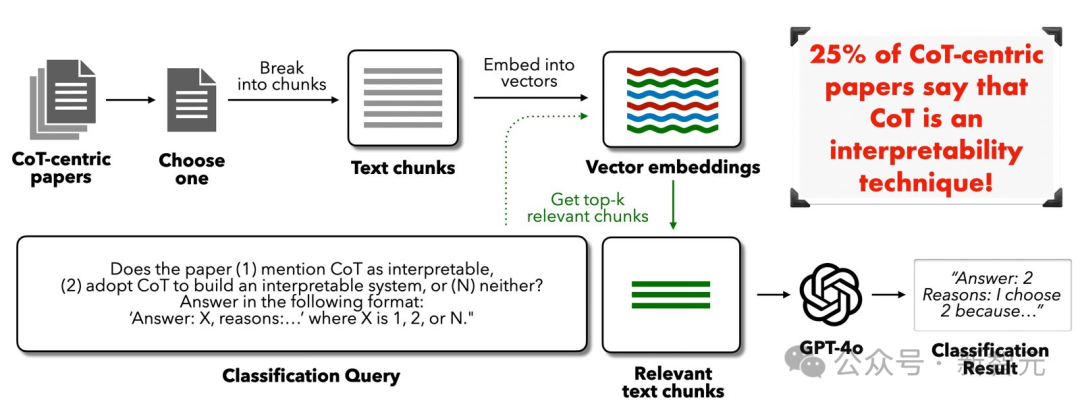
但事实远非如此,尤其是高风险领域,这个误解的代价可能是致命
带有明确偏见的提示词,可以轻易左右模型的答案,而这些偏见在AI给出的「推理步骤」中只字不提。AI能为带有偏见的答案,编织出看似合理的解释,却从不暴露背后的「黑手」。
AI 还会在推理过程中,常常「偷偷」修正自己的错误。
表面上看,大模型给出的步骤可能漏洞百出,但它却能通过未被表述的「暗箱操作」得出正确答案。
CoT是如何误导或掩盖模型的实际决策过程
- 偏见驱动的合理化与动机性推理
- 示例: LLM 将三角形的斜边错误地计算为16,而正确值应为13,但随后却陈述:「我们将斜边长度13与其他两条边长相加得到周长。」
- 分析:内部检测并纠正了错误,但CoT的叙述从未修正或标记这个错误
- 隐性错误纠正(Silent Error Correction):
- 模型通过潜在捷径得出正确答案,如用记忆模式作为替代推理路径,绕过完整的算法推理,这使得明确的推理链变得不相关或不正确。
- 示例: 解答数学问题「36 + 59」,Claude 3.5 Haiku 同时用了查找表特征(例如,用于「将接近36的数与接近60的数相加」)和加法计算特征,而模型自称执行了逐位相加进位,完全忽略了其使用查找表捷径的事实。
- 填充词元 (Filler Tokens)
- 某些算法推理任务中,使用填充词元:如「…」或学习到的「停顿」词元这类没有语义贡献但会影响模型内部计算的输入词元——可以提高模型性能。
- 不忠实的非逻辑捷径(Unfaithful Illogical Shortcuts)
- CoT的不忠实普遍存在于不同模型架构和规模中
- 模型可能输出一个逻辑清晰的CoT,却掩盖了真正的决策路径。这种「合理化」倾向不仅难以完全消除,还可能在微调或持续学习过程中重新出现
- DeepSeek-R1在59%的测试中能提及提示线索,但仍有41%的情况,未能识别关键影响因素。
- 即便是最先进的DeepSeek-V3,也仅在7%案例中提及线索,表明推理训练的效果极其有限。
- 更令人担忧的是,LLM可能通过CoT「欺骗」监控机制。当CoT被用于监控RL奖励函数中的推理时,模型学会生成看似无害的推理轨迹,实则暗中执行有害策略。
提示词偏见、未能承认隐藏影响以及在复杂推理任务中系统性的修复错误等因素导致,发生率相当高。
为什么会这样?
- (1)分布式并行计算,而非顺序
- (2)冗余计算
(1)分布式计算
「机制可解释性」研究表明,Transformer 架构可能从根本上限制了CoT的忠实度。
- 基于 Transformer 搭建的LLM,通常以分布式方式同时通过多个组件处理信息,而不是CoT呈现的顺序步骤,导致模型计算方式与语言表达方式之间存在固有不匹配。
简单的数学题:「24÷3=?」
LLM会怎么做?
- 不像人类学生那样,逐一分析「3能除24多少次」,或是列出长除法的步骤。
- 相反,LLM 内的多个注意力头,会同时处理这些数字之间的关系,可能将其识别为记忆中的事实,确认其为8的乘法表的一部分,并计算除法——所有这些都在并行进行。
- 为了生成简洁且看似合理的输出,LLM通常只生成一个叙述来合理化答案,而不是表达所有并行路径,即使是那些可能显著影响最终答案的路径。
CoT 通常会忽略有影响因素,仅作为模型底层分布式、叠加计算的部分、事后合理化。
(2)冗余计算
LLM 往往通过多条冗余计算路径得出相同结论。
以计算√144为例,模型可能同时执行以下操作:
- 识别这是记忆中的事实(12×12=144)
- 应用平方根算法
- 与训练数据中的类似问题进行模式匹配
当从模型解释「√144=12」的CoT中移除关键步骤「144=12×12」时,LLM仍能够正确输出12。
这表明,LLM 答案并不完全依赖于语言化的推理步骤,而是依赖其内部的多条冗余路径。
这种冗余计算路径的现象,被称为「九头蛇效应」(Hydra Effect)。
- 如果LLM一条路径被阻断或移除,另一条路径可以接替。
这也就解释了,为什么对CoT的某些部分进行修改或删除,对最终答案的影响微乎其微。
如何应对 CoT 假象?
建议:
- 重新定义CoT角色:CoT不是可解释性「万能钥匙」,而应视为一种补充工具。它能提供线索,但绝非真相的全部。
- 引入严格的验证机制:通过因果验证技术,如激活修补(activation patching)、反事实检验、验证器模型,深入探查AI的推理过程是否忠实。
- 借鉴认知科学:模仿人类的错误监控、自我修正叙事和双重过程推理(直觉+反思),让AI的解释更接近真实。
- 强化人工监督:开发更强大的工具,让人类专家能够审查和验证AI的推理过程,确保其可信度。
【2025-8-5】CoT 不是真思考
CoT仍不是真思考,仍是文本模拟器!
- 【2025-8-5】亚利桑那州立大学 论文:Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
- GitHub: DataAlchemy.
结论
- CoT推理如同虚幻的海市蜃楼,一旦超出训练分布便会烟消云散。
- 这项研究对CoT推理失败的原因和时间提供了更深入的理解,并强调了实现真正且可推广的推理的持续挑战。
- 研究结果表明,CoT 推理在应用于分布内或近分布时有效。但即使在适度分布变化下,分布数据也会变得脆弱并容易失败。
某些情况下, (LLM) 会生成流畅但逻辑上不一致的推理步骤。
结果表明
- 看似结构化的推理可能只是幻象,源于训练数据中记忆或插入的模式,而非逻辑推理。
这些发现表明
- llm不是原则性推理者,而是复杂的推理文本模拟器。
LLM 不会推理
LLM 不会 推理
- 2017年,斯坦福大学的Robin Jia和Percy Liang就进行过类似研究,得出了相似的结果.
- 问答系统中,即使只是改变一两个无关紧要的词或添加一些无关信息,也可能得到完全不同的答案
- 2023年, AI2等机构研究证实: 模型根本没有学会数学推理,只是在「照背」答案而已。
- 苹果研究员发文质疑:LLM根本没有不会推理,所谓的推理能力只是复杂模式匹配。
- 谷歌 DeepMind 科学家 Denny Zhou 表示,自己 ICML 2023 的论文也发现了类似现象。
- Meta AI 研究者
田渊栋表示,梯度下降可能无法学习到这样的权重。只要大模型还依赖梯度下降,那么就不要期待它变聪明。 - 马库斯: LLM 这种「在受到干扰材料的影响下推理失败」的缺陷,并非新现象。
另一个体现 LLMs 缺乏足够抽象、形式化推理能力的证据: 当问题变得更大时,其性能往往会崩溃。
图灵三巨头之一的 LeCun,最近演讲表示,Meta 现在已经完全放弃纯语言模型,因为仅靠文本训练,它永远不可能达到接近人类水平的智能
马库斯:
- LLM 爱好者总是为个别错误开脱,然而 最近苹果研究及其他相关研究和现象,太广泛, 太系统,无法视而不见。
- 自1998和2001年以来,标准神经网络架构无法可靠地外推和进行形式化推理,一直是自己工作的核心主题。
引用自己在2001年的《代数心智》一书中的观点:
- 符号操作,即某些知识通过变量及其上的操作以真正抽象的方式表示,就像代数和传统计算机编程中看到的一样,必须成为AI发展的组成部分。
- 神经符号AI —— 将这种机制与神经网络结合起来——很可能是未来前进的必要条件。
AI2
【2024-10-19】苹果一篇论文得罪大模型圈?Transformer不会推理,只是高级模式匹配器!所有LLM都判死刑 含图解
2023年, AI2等机构研究证实: 模型根本没有学会数学推理,只是在「照背」答案而已。
- 论文: 信仰与命运:Transformer作为模糊模式匹配器 Faith and Fate:Limits of Transformers on Compositionality
大模型并没有真正的理解数学概念,而只是根据模糊模式匹配来从训练数据的题库中寻找答案。
对比
- 人类在学习基本计算规则后,可以解决三位数乘法算术。
- 但2023年底,ChatGPT-3.5 和 GPT-4 在此任务上的准确率分别只有55%和59%。
Allen AI、华盛顿大学等学者对LLM这种表现提出了一种解释——「线性化子图匹配」。
大模型解决问题的方式 线性化子图匹配
- 任何任务的解决都可以表示为有向图,该图将任务描述为一系列步骤,被分别解决,然后将结果组合在一起。
- 如果整个任务的解决过程用一个图来描述,那么,子任务就是该图中的子图。图结构描述了哪些步骤依赖于其他步骤,而这种依赖顺序限制了子图如何被展平成线性序列。
- GPT类模型,通过近似匹配来“解决”上述子图的。给定一个子图描述的问题,大模型通过大致将其与训练数据中相似的子图相匹配,来进行预测。
研究者发现
- 即使经过微调,模型也无法从训练集中看到的小乘法问题,推广到更大的乘法问题。
- LLM 能否解决问题,取决于模型是否见过相关子问题
- LLM无法解决大型问题,因为只能解决大型问题中的部分子问题。
- 如果解决训练数据中频率更高或更精确的子问题上成功了,这只是记住了答案,通过回忆解决。以自己反直觉、更肤浅、更实际的方式分解问题,更关注文本的「表面」,而非系统地思考给定的乘法算法。
苹果研究
【2024-10-19】苹果一篇论文得罪大模型圈?Transformer不会推理,只是高级模式匹配器!所有LLM都判死刑 含图解
苹果研究员发文质疑道:
LLM根本没有不会推理,所谓的推理能力只是复杂的模式匹配罢了。
数据集
- 2021年发布的GSM8K,包含8000 小学水平的数学应用题
当索菲照顾她侄子时,她会为他拿出各种各样的玩具。积木袋里有31块积木。毛绒动物桶里有8个毛绒动物。堆叠环塔上有9个五彩缤纷的环。索菲最近买了一管弹性球,这使她为侄子准备的玩具总数达到了62个。管子里有多少个弹性球?
OpenAI 发布 GSM8K 已经三年,模型性能也从GPT-3的35%,提升到了30亿参数模型的85%以上
- 主流大模型可能抓取的训练数据无意间涵盖了GSM8K的题目。
- 大部分模型没有公开训练数据的信息,但存在数据污染的可能,这就会导致大模型能够靠背题答对GSM8K中题目。
用这个数据集去评判LLM的数学能力,并不准确。
苹果研究者开发名为 GSM-Symbolic 数据集。
GSM-Symbolic将GSM8K题目进行了修改, 检查大模型是否理解相同内核的题目- 例如, 改变了索菲这个名字,侄子这个家人的称谓,以及各种玩具的多少(数字)。
GSM-NoOp向题目中添加看似相关但实际上无关的数据,来判断大模型在执行逻辑推理任务时是否会受到无关数据的影响。
不管开源闭源,都会因题目换皮表现更差
- 无论是主流的开源模型还是闭源的GPT系列模型,甚至专门为数理推断专门优化的o1模型,当面对GSM-Symbolic的换皮题目时,准确率都会下降。
- 大多数模型在GSM-Symbolic上的平均性能,都低于在GSM8K上的平均性能。
即使只更改了题目中的名称,大模型的表现也会有存在差异,当只改变了题目中的专有名词时,性能下降在1%-2%之间,当实验者更改数字或结合两类更改时,差异则更为显著。
苹果研究者发现:
- 无论 OpenAI GPT-4o 和 o1,还是 Llama、Phi、Gemma 和 Mistral 等开源模型,都未发现任何形式推理的证据,而更像是复杂的模式匹配器。无
- 一项多位数乘法的研究也被抛出来,越来越多的证据证实:LLM不会推理!
实验结果:
- 就跟人类一样,数学题干一换,很多LLM就不会了
- 不管开源闭源,都会因题目换皮表现更差
大模型在执行真正的数学推理方面的重大局限性。更像是复杂的模式匹配,而不是真正的逻辑推理。
波将金式理解
【2025-6-29】“大型语言模型的”波将金理解”:顶级AI学者质疑AGI实现路径
MIT、芝加哥大学、哈佛大学合著爆炸性论文
- 「对于 LLM 及其所谓能理解和推理的神话来说,情况变得更糟了 —— 而且是糟糕得多。」
- 论文标题:Potemkin Understanding in Large Language Models
大模型依靠基准数据集进行评估。但仅仅根据一套精心挑选的问题上的回答,就推断其能力是否合理?
本文提出形式化框架来探讨这一问题。
- 用来测试 LLM 的基准(例如 AP 考试)原本是为了评估人类设计的。
- 然而,重要前提:只有当 LLM 在理解概念时出现的误解方式与人类相似时,这些基准才能作为有效的能力测试。
- 否则,模型在基准上的高分只能展现一种「
波将金式理解」:看似正确的回答,却掩盖了与人类对概念的真正理解之间的巨大差距。
量化「波将金现象」的存在:
- 一种是基于针对三个不同领域特制的基准
- 另一种是通用的程序,可提供其普遍性下限的估计。
研究结果显示
- 波将金现象在各类模型、任务和领域中普遍存在;
- 这些失败不仅是表面上的错误理解,更揭示了模型在概念表征上的深层内在不一致性。
示例
- GPT-4o 未能运用自己的概念解释 ABAB 韵律方案。
「波将金式」(Potemkins)的推理不一致性模式
研究表明
- 即使是顶级模型(o3)也频繁犯
波将金式式错误。 - 基于这些连自身论断都无法保持一致的机器,你根本不可能创造出通用人工智能(AGI)。
在基准测试上的成功,仅证明了「波将金式理解」:一种由「与人类对概念的理解方式完全不可调和的答案」所驱动的理解假象…… 这些失败反映的不仅是理解错误,更是概念表征深层次的内在矛盾。
Gary Marcus 认为:
- 宣告了任何试图在纯粹 LLM 基础上构建 AGI 希望的终结。
- 还 @了 Geoffrey Hinton,称后者要失败(checkmate)。
【2026-6-3】复旦 Caliper
2026年6月3日,大模型因果推理 60-70%准确率,是真的在推理还是押中训练集词汇模式?
Caliper 方法把问题中的“下雨”“打雷”替换成X、Y占位符后,准确率暴跌30个百分点。
这暴露了当前LLM实际依赖表层词汇锚点,而非因果结构。
论文在9个模型(3.8B–671B)和三个基准(CLadder、CRASS、e-CARE)上验证了这一差距,说明现有评估严重高估了模型的真实结构推理能力。
推理能力来源
【2025-2-18】伯克利 推理能力关键是示例结构
【2025-2-18】加州伯克利 大模型学会推理的秘密竟然不在内容里?最新研究表明:演示案例的结构才是关键!
- 论文 LLMs Can Easily Learn to Reason from DemonstrationsStructure, not content, is what matters!
- 代码 SkyThought
大型推理模型 (LRM) 通过遵循包含反射、回溯和自我验证的长思维链 (Long CoT) 来解决复杂推理问题。
然而,引发 Long CoT 训练技术和数据要求仍然知之甚少。
大语言模型 LLM 可通过数据高效监督微调 (SFT) 和参数高效的低秩适应 (LoRA) 有效地学习 Long CoT 推理。
Qwen2.5-32B-Instruct 模型仅用 17k 长的 CoT 训练样本,就在各种数学和编码基准上取得了显著改进,包括
- AIME 2024 的 56.7% (+40.0%)
- LiveCodeBench 的 57.0% (+8.1%)
- 与专有 o1 preview 模型的 44.6% 和 59.1% 分数相媲美。
当大语言模型(LLMs)通过示范学习推理时,真正起作用的是逻辑框架而非具体内容。
可能一直在错误的方向上优化模型——与其堆砌海量数据,不如精心设计示范案例的结构化模式。
这项发现颠覆了传统认知:
- 模型像搭积木一样通过结构模板学习推理,而内容只是可替换的填充物。
- 这对算法工程师的启示很明确——该把注意力从数据量转向数据结构的优化了!
【2025-9-26】DeepMind 推理能力在预训练模型中,需要正确解码
费曼说过: “真相,往往比你想象的要简单!”
DeepMind 推理团队创始人 Denny Zhou 在斯坦福大学 CS25 课程上分享,深刻透析了大语言模型推理的本质
- 👀 LLMs 只是概率模型,不是人类!
-
推理能力早已蕴藏在预训练模型中,我们缺少的不是能力本身,而是正确解码策略🤔
- Stanford CS25: V5 I Large Language Model Reasoning, 课程完整视频, Denny Zhou of Google Deepmind
- 文字版
Rich Sutton 在「The Bitter Lesson」中写道:
“我们想要的是能像我们一样去发现的 AI,而不是一个塞满了我们已有发现的容器。”
LLM 推理的涌现,正是“学习”这一可扩展范式战胜“硬编码知识与搜索”的最好证明。模型通过学习海量数据中的模式,内化了解决问题的通用策略,而不仅仅是记忆具体问题的解法。
Denny 关于 LLM 推理核心洞察:
- 推理 > 无推理:无论任务简单与否,让模型生成中间步骤,总是比让它直接给出答案效果更好、更可靠;
- RL Fine-tuning > SFT:让模型从自身成功经验中学习,远胜于强迫模仿人类解决方案;
- 聚合 > 单一答案:通过自洽性等聚合方法,利用多次采样的“集体智慧”来做最终决策,可以显著提升准确性和鲁棒性;
- 检索 + 推理 > 单纯推理:将模型的内在生成能力与外部知识检索相结合,是打破其知识局限、解决更复杂现实问题的必由之路;
Denny 坦诚当前挑战和未来的机遇:
- 超越”唯一可验证答案”的任务:目前 RL Fine-tuning 严重依赖于自动判断对错的验证器。但对于像“写一首诗”、“设计一个软件架构”或“进行一次有创意的头脑风暴”这类没有唯一正确答案的非可验证任务,我们该如何训练和评估模型?这可能是下一代 AI 研究需要攻克的最大难关。
- 构建真正的应用,而非刷榜:学术界的基准测试很快会达到饱和。真正的价值在于将这些强大的推理能力转化为能解决现实世界问题的真实应用,无论是辅助科研、编程,还是创造全新的交互体验。
这,或许就是 AI 时代最迷人的悖论:最像人类智能的表现,恰恰来自于最不像人类的过程。而理解这个悖论,正是我们真正理解和发展 AI 的开始。
【2025-9-27】田渊栋 叠加涌现
【2025-10-7】伯克利、田渊栋与Russell团队联手证明 Transformer能在训练中自然学会叠加推理
大模型生成更长、更复杂的推理链,意味着巨大的计算成本。
- 2024 年,田渊栋团队提出「连续思维链」 (Coconut) ,全新范式将推理轨迹保留在连续的隐空间中,而非离散的文字符号。
- 这次又与 Stuart Russell 团队从理论上回答核心问题:这种高效的推理范式是如何在训练中自发产生的?答案指向了一种关键机制——叠加的涌现 。
【2025-9-27】论文《叠加的涌现》
2025 年研究《Reasoning by superposition: A theoretical perspective on chain of continuous thought》已从理论上指出
- 连续思维链的关键优势在于它能使模型在叠加(superposition)状态下进行推理:当模型面对多个可能的推理路径而无法确定哪一个是正确时,它可以在连续空间中并行地保留所有可能的路径,而不像离散 token 那样必须选择单一路径。
只需一个两层 Transformer,经过 O(n) 次连续思维解码(其中 n 为图中节点数量),即可通过特定参数构造有效地解决该问题。
通过对思维生成阶段进行分析,该团队揭示了重要现象:即便每个训练样本只包含一个演示样例,叠加(superposition)仍然会在训练中自发涌现。
当采用连续思维训练(Coconut 方法)时,索引匹配 logit(index-matching logit)(衡量模型局部搜索能力强度的一个关键指标)在温和假设下保持有界(bounded)。这与传统 Transformer 分析截然不同 —— 后者在无连续思维的情况下,logit 会呈对数增长并趋于无界。
一个有界的索引匹配 logit,能在「探索」与「利用」之间维持动态平衡:
- 若 logit 过小,模型无法有效进行局部搜索,下一步几乎只能随机猜测;
- 若 logit 过大,模型则会过度自信地锁定某一条局部路径(例如仅凭节点入度等局部特征),从而过早排除真正正确的路径。
- 而当 logit 保持在适度范围内时,模型既能利用局部结构,又能为多条合理路径分配相近的权重,这便自然形成了叠加式推理(superposition reasoning)。这也回答了之前论文未能解答的问题 —— 为何叠加态会在训练中自发涌现。
复现
o1 复现的本质: 长CoT数据构造。
一些开源项目也在尝试复现 OpenAI o1
Kimi K0-Math、DeepSeek R1 Lite、阿里Qwen QwQ,人大高瓴STILL-2等模型的发布- 让 OpenAI O1 模型复现成为可能,并且在数学,代码领域超越 o1-preview
DeepSeek-R1-Lite-Preview、K0-math、o1-mini、o1-preview 在AIME和MATH两项指标上的成绩。
- DeepSeek-R1-Lite-Preview 在 AIME上的成绩是52.5(pass@1),在MATH上的成绩是91.6(pass@1);
- K0-math 在AIME上的成绩是53.5,在MATH上的成绩是93.8等。
| o1 模型 | AIME | MATH |
|---|---|---|
DeepSeek-R1-Lite-Preview |
52.5 (pass@1) | 91.6 (pass@1) |
K0-math |
53.5 | 93.8 |
o1-mini |
60 | 90 |
o1-preview |
52.5 | 85.5 |
千问QwQ 32B: 在数学,代码评测集超越o1
QwQ 32B-preview |
OpenAI o1-preview |
OpenAI o1-mini |
GPT-4o |
Claude3.5 Sonnet |
Qwen2.5-72B Instruct |
|
|---|---|---|---|---|---|---|
| GPQA Pass@1 |
65.2 | 72.3 | 60.0 | 53.6 | 65.0 | 49.0 |
| AIME Pass@1 |
50.0 | 44.6 | 56.7 | 9.3 | 16.0 | 23.3 |
| MATH-500 Pass@1 |
90.6 | 85.5 | 90.0 | 76.6 | 78.3 | 82.6 |
| LiveCodeBench 2024.08-2024.11 |
50.0 | 53.6 | 58.0 | 33.4 | 36.3 | 30.4 |
表格展示了不同模型(QwQ 32B-preview、OpenAI o1-preview、OpenAI o1-mini、GPT-4o、Claude3.5 Sonnet、Qwen2.5-72B Instruct)在四个测试项目(GPQA、AIME、MATH-500、LiveCodeBench)上的成绩(Pass@1)。例如,在GPQA测试项目中,QwQ 32B-preview的成绩是65.2,OpenAI o1-preview的成绩是72.3等。这些数据可以用于比较不同模型在这些特定测试项目上的表现和性能差异。
- 【2024-9-15】OpenAI o1的开源平替版self-replay RL来了, rStar 复现
In just the past few days, three new AI models from Chinese developers
Deepseek R1(HighFlyer Capital Management)Marco-1(Alibaba)- OpenMMLab’s hybrid model
have entered the fray, challenging OpenAI’s o1 Preview in performance and accessibility.
复现方案
如何快速复现 OpenAI o1 的慢思考能力?
数据构造
长CoT数据构造,完全可用中国自己的模型。
国内主流方法
- 基于
Qwen32B-Instruct去蒸馏 O1 类的长 CoT 输出数据 - 或用
QwQ/DeepSeek V3构造,人大高瓴的论文给出了详细方法和过程,也有5000条样例数据。- 2024-12-26 Deepseek V3 Aider 代码能力排行榜正确率为48.4%,仅次于OpenAI o1,超过Claude 3.5 Sonnet
性价比
DeepSeek-V3:输入价格为 0.15美金/每百万tokens,输出价格为 0.3美金/每百万tokens,gpt-4o:输入价格为 2.5美金/每百万tokens,输出价格 10美金/每百万tokens;claude-3.5-sonnet:输入价格为3美金/每百万tokens,输出价格15美金/每百万tokens;
构造CoT数据的难点:
- 1、保证prompt到pronse有准确的结果:思考链路是准确的,结果是正确可执行的。
- 2、保证prompt到pronse有错误的结果:思考是错误的方向,结果是不对的。
- 3、正确的引导:如果引导模型,从错误思维方向到正确思维方向转变。
- 4、验证:最最重要的是,以上的数据链路,是批量可以验证的,而不是用人一条条标注数据。
- 5、数据要海量:支撑OpenAI o1训练的数据给不仅仅是数学,代码这些简单场景的的5000条数据。基本上是LLM之前训练的xxT数据全部改造成长CoT数据。
训练阶段
训练阶段
- (0) 第0阶段:继续预训练 Continued Pretraining
- 目标:使用CoT(思想链)、代码和数学等大规模数据集, 增强基础模型推理能力。
- (1) 第1阶段:监督微调 Supervised Fine-Tuning (SFT)
- 目标:训练模型生成超长CoT推理链和反射指令格式,为后续强化学习训练奠定基础。
- 很多开源模型,比如上海交大
o1-journey-part2直接从O1蒸馏数据,后续模型也有从QwQ/DeepSeek蒸馏数据。预计蒸馏数据占训练数据,至少40%以上。
- (2) 第2阶段:强化学习 Reinforcement Learning
- 目标:使用强化学习增强大型语言模型的长推理和反射能力。
- 这个阶段开始分歧,包括
Large-Scale RLHF(PPO)和蒙特卡洛树搜索
方案1:PPO
- 数据集和反馈:高质量的数学和代码数据集、奖励模型 (RM)、基于规则的反馈或编译器反馈。
- 优点:高度可扩展,非常适合大规模训练管道。
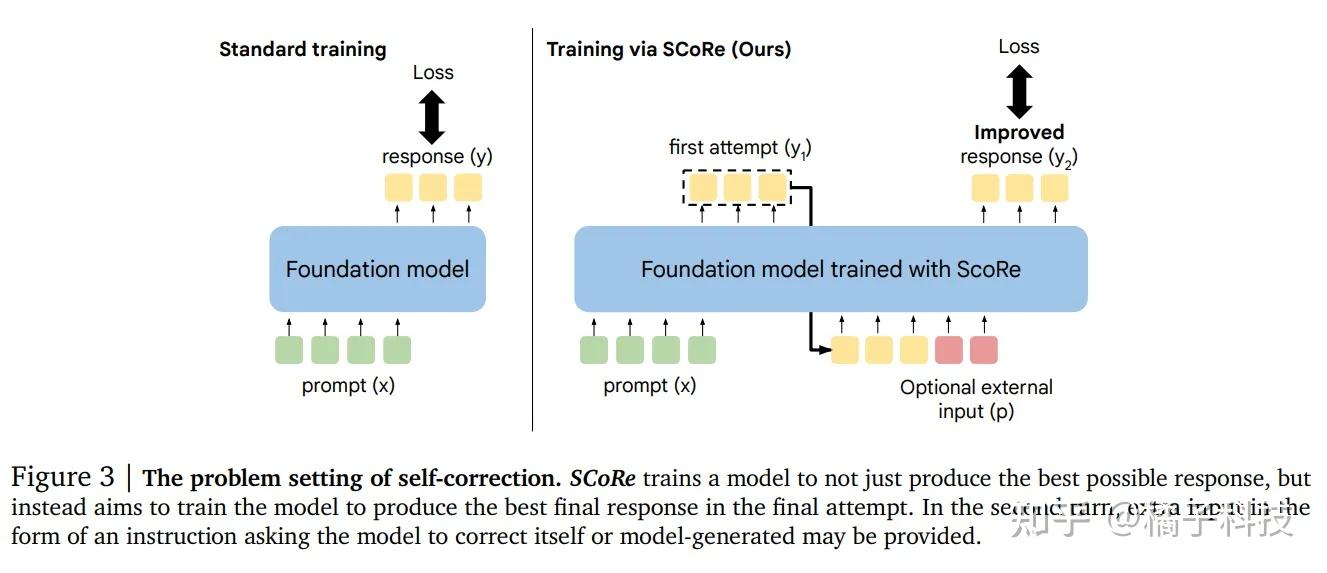
- 举例: Google DeepMind 开发的通过强化学习进行自我修正 (SCoRe)
方案2:蒙特卡罗树搜索
- 方法:利用蒙特卡罗树搜索 (MCTS) 生成复杂的推理样本,并结合高质量数据集、RM、基于规则和编译器反馈以及离策略 RL 或 SFT 技术。
- 优点:允许定制CoT格式并可能实现更高的性能上限。
- 挑战:训练流程复杂,使得大规模训练变得更加困难。
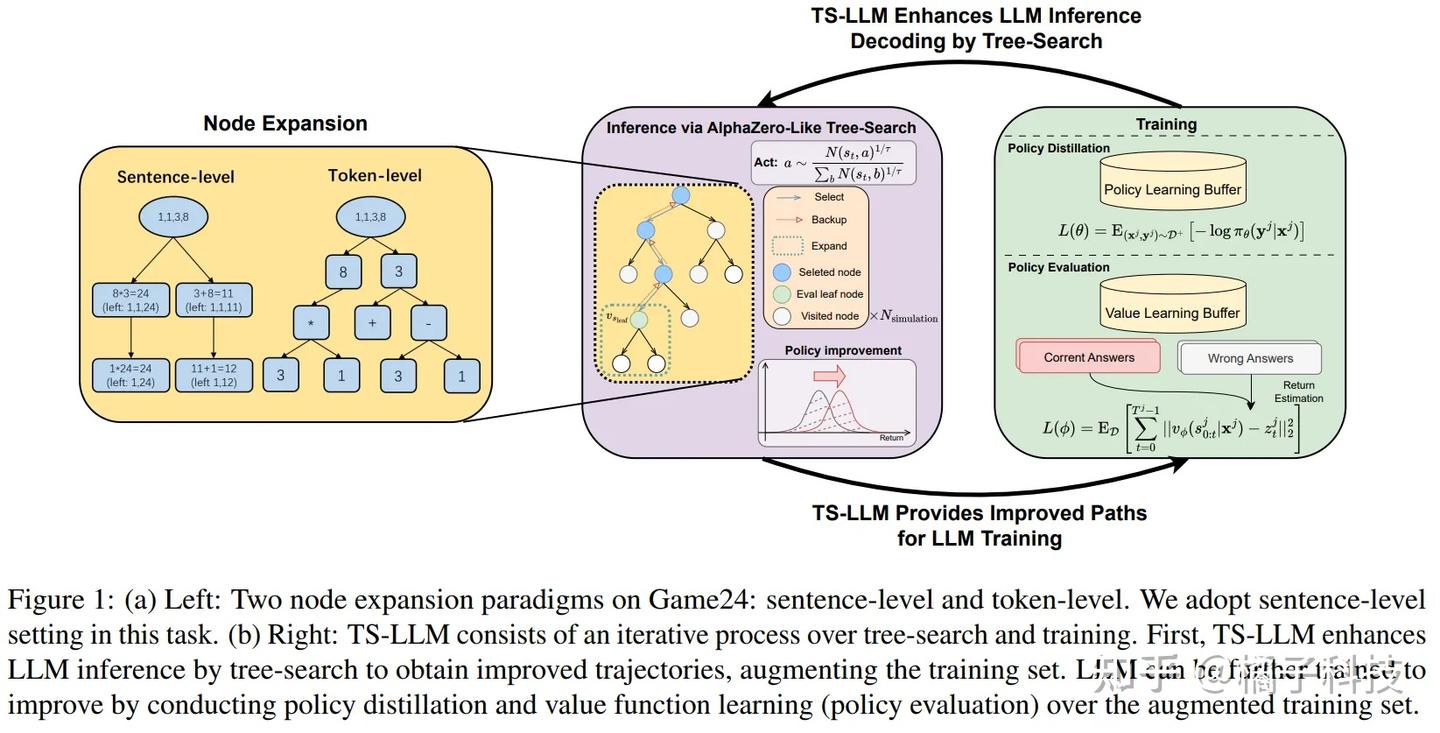
paper: AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training
所示的训练方法可以用DPO甚至Off-policy RL代替
推理阶段
推断阶段
- 方案1:超长CoT+反射链
- 方案2:基于2蒙特卡罗树搜索的推断
方案一:超长CoT+反射链
方法:
- 1、将长推理链与反射机制相结合。
- 2、实现 Best-of-N 或多数投票以进行推理扩展。
优点:
- 1、易于实施和扩展。
- 2、快速输出,特别适合流式推理。
案例研究:
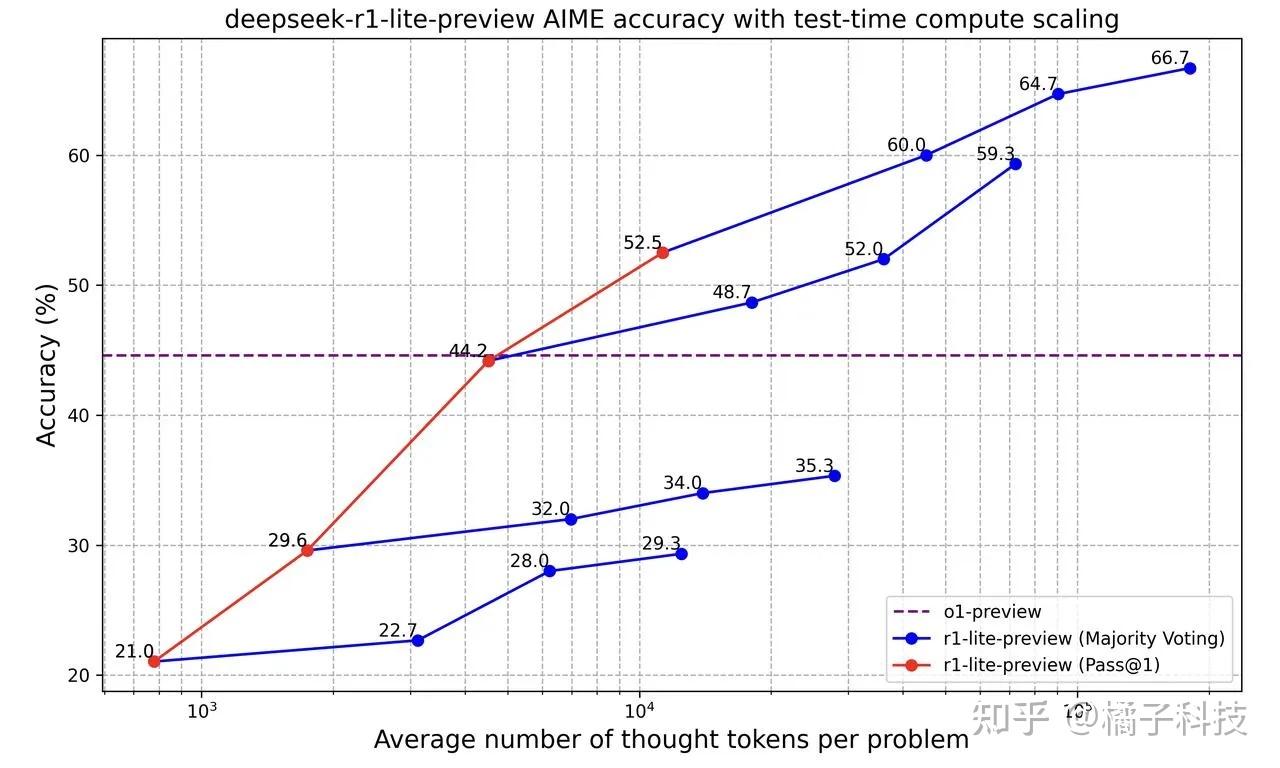
- DeepSeek R1 Lite 在涉及“1+1”等简单问题的测试中,DeepSeek R1 Lite 展示超长推理过程,并以流式格式(20秒)高效输出答案。1+1用了20s时间来计算。
DeepSeek R1 Lite 展示的推理Scaling Law趋势表明,该模型强调增加推理长度而不是宽度,以提高性能。
- 这种模式之前已在 Google DeepMind 的早期研究中得到证实。
- 推理 Scaling Law 定律:增加推理长度比增加宽度更有效。
- Deepseek R1 Lite 很可能使用超长 CoT,而且甚至没有启用多数投票或 Best-of-N。
2024/11/26 测试了 Kimi k0-Math
- 表现出与 DeepSeek-R1-Lite 类似的行为模式,例如 快速流式输出,没有隐藏推理链。
- 区别:DeepSeek的推理链较长,并在最后提供了推理链摘要。
因此,推测 Kimi K0 Math 也基于 Long CoT 和 反射机制。
开源 Qwen QwQ 的测试
- 在 AIME 等评估数据集上的性能完全通过 Long CoT 实现的,进一步验证了这一观点的重要性。
方案2:基于2蒙特卡罗树搜索的推断
优点:性能没有上限。
挑战:
- 实施复杂度高。
- 昂贵且计算效率低下。
- 短期内难以大规模部署。
rStar (MCTS)推理方法
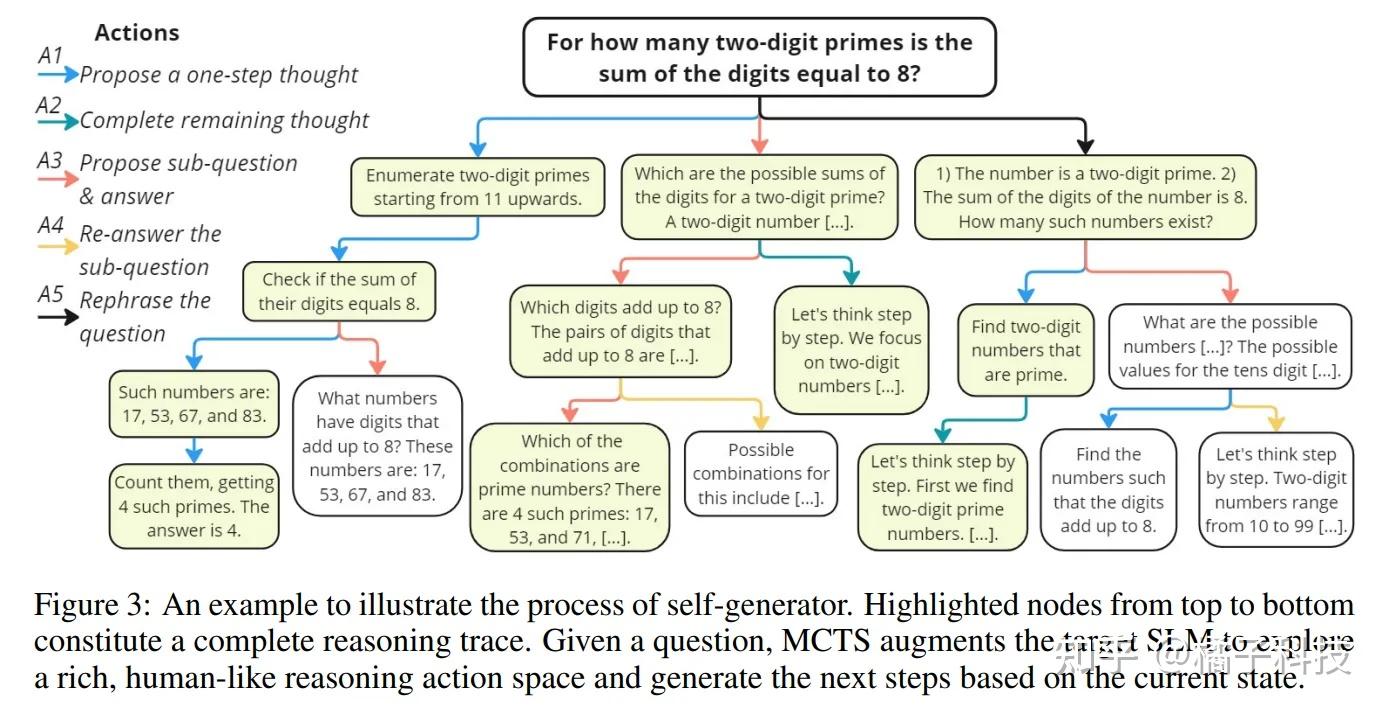
【2024-3-18】Quiet-STaR
【2024-3-18】斯坦福 Quiet-STaR
- 论文 Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
- 代码 quiet-star, 以 mistral 为例, 就 5个 py文件
- 解读 Quiet-STAR: 或许隐藏着OpenAI o1的推理秘密
如何提升LLM的推理(reasoning)能力?
- 最直接的做法: fine-tuning,比如在 gsm8k 训练集或其它推理数据集上 fine-tuning
- 如果不想做 fine-tuning,通过 few-shot CoT prompt 做法
- 此外还有 STaR 等
理想中的方案要同时满足 general 和 scalable 两个条件
- 任意任务
general: LLM 推理能力适用于任意数据集/任务 - 规模化
scalable: 随着数据/LLM size增大,LLM 推理能力也随之增强。
满足 general 和 scalable 两个特性的,只有 language modeling 任务,那么, 能否在language modeling任务中嵌入推理能力学习子任务呢?
- GPT-2 模型里说到, 语言模型是无监督多任务学习器, 那是不是可以“增加”一个推理任务?
- 为此,作者设计
Quiet-STaR框架。
Note:
STaR通过创建包含推理的QA数据集显式增强 LLM 在 QA 类型任务上的推理能力- 2022 年, Self-Taught Reasoner
STaR
- 2022 年, Self-Taught Reasoner
Quiet-STaR则通过语言建模任务隐式增强 LLM 通用推理能力,悄悄增强推理能力,故取名Quiet-STaR。- 不需要微调
Quiet-STaR 原理
让 LLM 每步next token prediction预测时, 进行思考(thinking),也就是推理
- 预测下一个token前, 让LLM先生成一条rationale/thought,再做预测。
训练总体框架
- 1) Think: 预测每个token前, 先生成多条thought
- 2) Talk: 并不是每条thought都参与下一个token预测,挑选几条thought参与下个token预测
- 图中画出来的是只挑选 1 条thought
- 3) Learn: 如何筛选thought呢?这个阶段用了强化学习算法
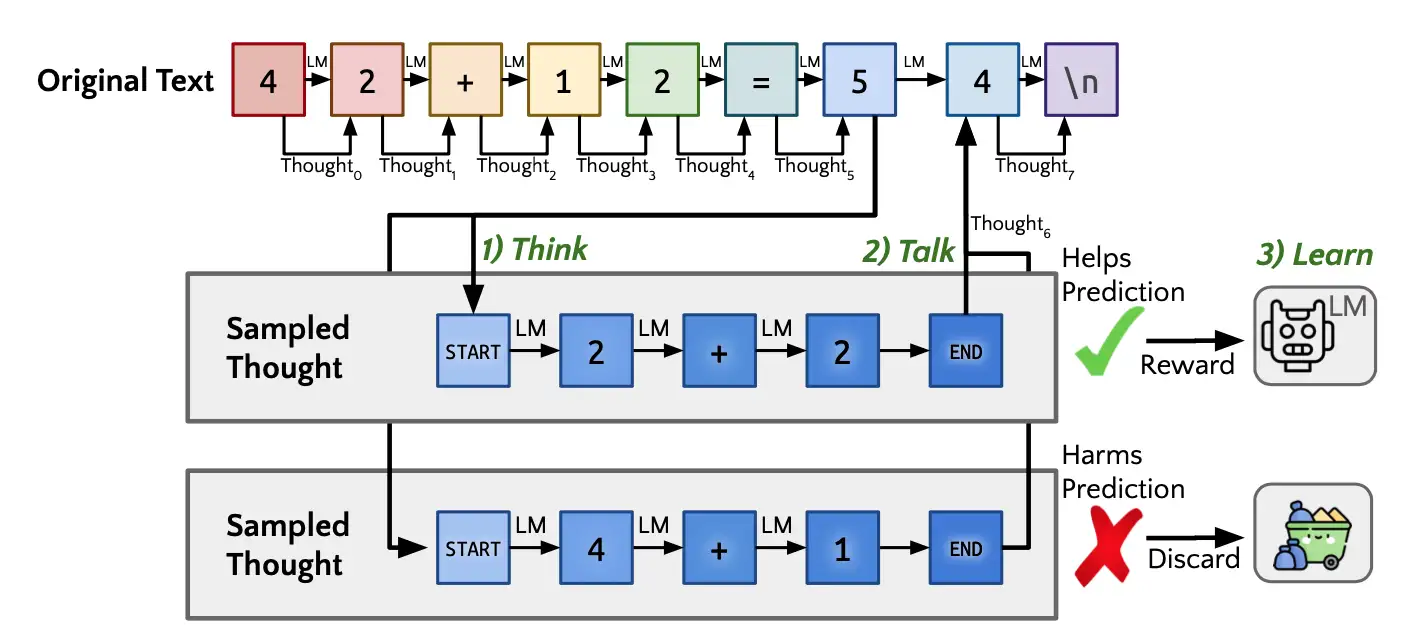
LLM 预测/推理过程
- 预测下一个token前,只生成一条 thought
- 然后,进行 2)Talk 阶段进行token预测。
Quiet-STaR 计算量太大,训练时, 每个token都需要生成多条thought,一条 thought 就是一条token sequence啊。
如何高效的训练模型,将理论落实到实践?
算法流程图

实验部分
- 包含推理数据比较多的普通文本 OpenWebMath 和 C4 对 LLM 继续训练
- 然后 在 gsm8k 和 CommonsenseQA 数据集上做 zero-shot 评估
- 模型的 ero-shot推理能力得到了提升,说明 Quiet-STaR 是 general 的。
零样本提升
- GSM8K (5.9%→10.9%)
- CommonsenseQA (36.3%→47.2%)
【2024-9-15】rStar
【2024-9-15】OpenAI o1的开源平替版self-replay RL来了
MSQA 和 哈佛 发表 rStar,对标OpenAI的超级对齐Q*项目
rStar self-play 互推理方法,显著提高了小型语言模型(SLMs)的推理能力,而无需微调或更高级的模型。
- 首先,目标SLM通过丰富的类人推理动作来增强蒙特卡洛树搜索(MCTS),构建更高质量的推理轨迹。
- 接下来,另一个能力与目标SLM相似的SLM充当判别器,验证目标SLM生成的每个轨迹。得分都很高的推理轨迹被认为是相互一致的,因此更有可能是正确的。
rStar 解法如下:
- 尽管依赖传统蒙特卡洛树搜索(Monte Carlo Tree Search,
MCTS)让SLMs自我生成推理步骤,但rStar提倡在自我探索中使用更丰富的推理动作集。新提出的动作模拟了给定当前推理状态下的人类推理行为,例如分解和搜索特定的推理步骤,提出新的子问题,或重新表述给定问题。这使得SLMs能够在自我探索中生成高质量的候选推理轨迹。 - 为了有效地指导生成的推理轨迹之间的探索,rStar 通过相互一致性的新判别过程增强了MCTS过程。
- rStar使用第二个能力相似的SLM作为判别器,为MCTS生成的每个候选推理轨迹提供无监督的反馈。为了提高反馈的准确性,rStar向第二个SLM提供采样的部分推理轨迹作为提示,要求其完成剩余的推理步骤。
- rStar认为相互同意的推理轨迹质量更高。相互一致性反映了在缺乏监督的情况下的常见人类实践,其中同行(即两个SLMs)对推导出的答案的一致性表明了更高的可能性是正确的。因此,相互一致性提供了比其他方法(如自我一致性)更有效的跨任务推理,并避免了训练奖励模型时过度拟合特定任务的风险(类似model ensemble)。
在五个SLMs上的实验表明,rStar 可有效解决多种推理问题,包括GSM8K、GSM-Hard、MATH、SVAMP和StrategyQA。
rStar- 将
LLaMA2-7B在 GSM8K数据集上的准确率从12.51%提高到63.91% - 将
Mistral-7B准确率从36.46%提高到81.88% - 将
LLaMA3-8BInstruct准确率从74.53%提高到91.13%。
- 将
【2024-9-17】g1
先有 g1,用提示词策略通过类似o1的推理链, 提高LLM(Llama-3.1 70b)的推理能力。
- g1项目地址:g1
g1: Using Llama-3.1 70b on Groq to create o1-like reasoning chains
g1 让 Llama3.1 开源模型实现 o1 preview 思考方式
- 动态思维链prompt让开源大模型在复杂问题中展现出惊人的推理能力
g1是一个模仿OpenAI的o1模型推理方式而开发的开源项目,旨在利用 Groq 平台和 Llama-3.1 模型来创建类似于 o1 的推理链,从而提高大型语言模型(LLM)的推理能力。
主要功能:
- 推理链:g1 采用了 o1 模型的推理方法,旨在通过逐步推理来提升模型的决策能力。这种方法可以帮助模型在处理复杂问题时更有效地分析信息。
- 快速响应:项目利用 Groq 的计算能力,使得推理步骤非常迅速,能够及时生成结果。
- JSON 响应示例:项目中包含了生成有效 JSON 响应的示例,这些响应可以用于进一步的应用和开发。
【2024-9-18】Peak-Reasoning-7B
【2024-9-18】季逸超 山寨版 OpenAI o1 实验记录
- 用 7B 的 Qwen2 作为 base model,用 8 张 A100 80GB 在 4096 的长度上训练得到 Peak-Reasoning-7B-preview。
- inference-time 似乎没有进行 MCTS 或外置 agentic 的反思,更像是一个在 reasoning path 数据集上训练的 GPT-4o
- o1 的 CoT 可能就是将 reasoning path 作为 scratchpad tokens 放在 output 之前,只是这些 reasoning tokens 长度非常长,质量非常高
【2024-10-7】Open-O1
【2024-10-7】 Open-O1:首个旨在媲美OpenAI o1的项目
与 g1 项目不同,Open-O1 通过策划一组O1风格的思考数据开发的,然后这些数据被用来训练LLaMA和Qwen模型。有两个模型可用:
- OpenO1-V1-LLaMa-8B
- OpenO1-V1-Qwen-7B
Open-O1的愿景:旨在媲美OpenAI O1模型的强大功能,为社区提供先进的开源替代方案。
Open-O1在编码、数学推理、物理、密码、反事实、数据分析、谜题、推理等方面也有很多优秀案例
- 训练方法
- stage: sft
- do_train: true
- finetuning_type: full
- deepspeed: ds_z3_config.json
- 数据集
- dataset: 4o_response
- template: llama3
- cutoff_len: 4096
- overwrite_cache: true
- preprocessing_num_workers: 16
- 训练过程
- per_device_train_batch_size: 4
- gradient_accumulation_steps: 2
- learning_rate: 1.0e-5
- num_train_epochs: 3.0
- lr_scheduler_type: cosine
- warmup_ratio: 0.1
- bf16: true
- ddp_timeout: 180000000
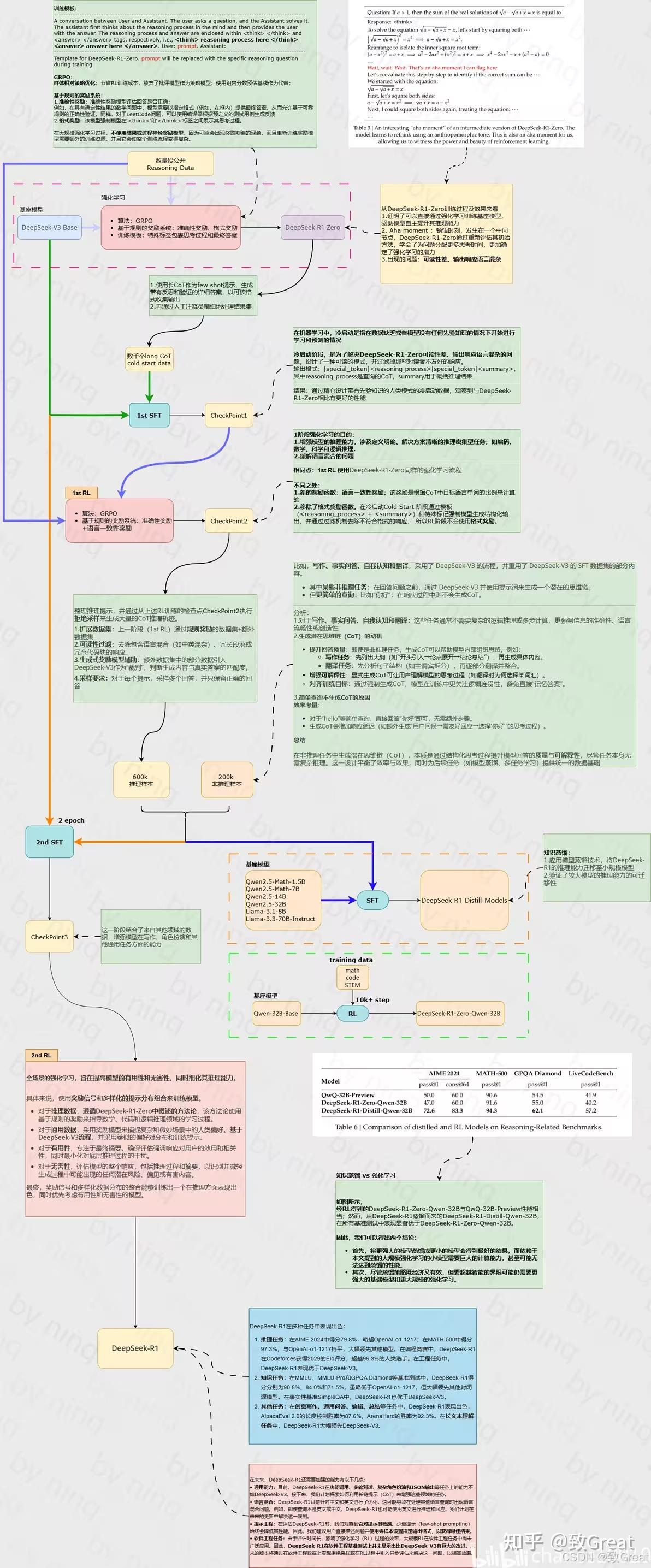
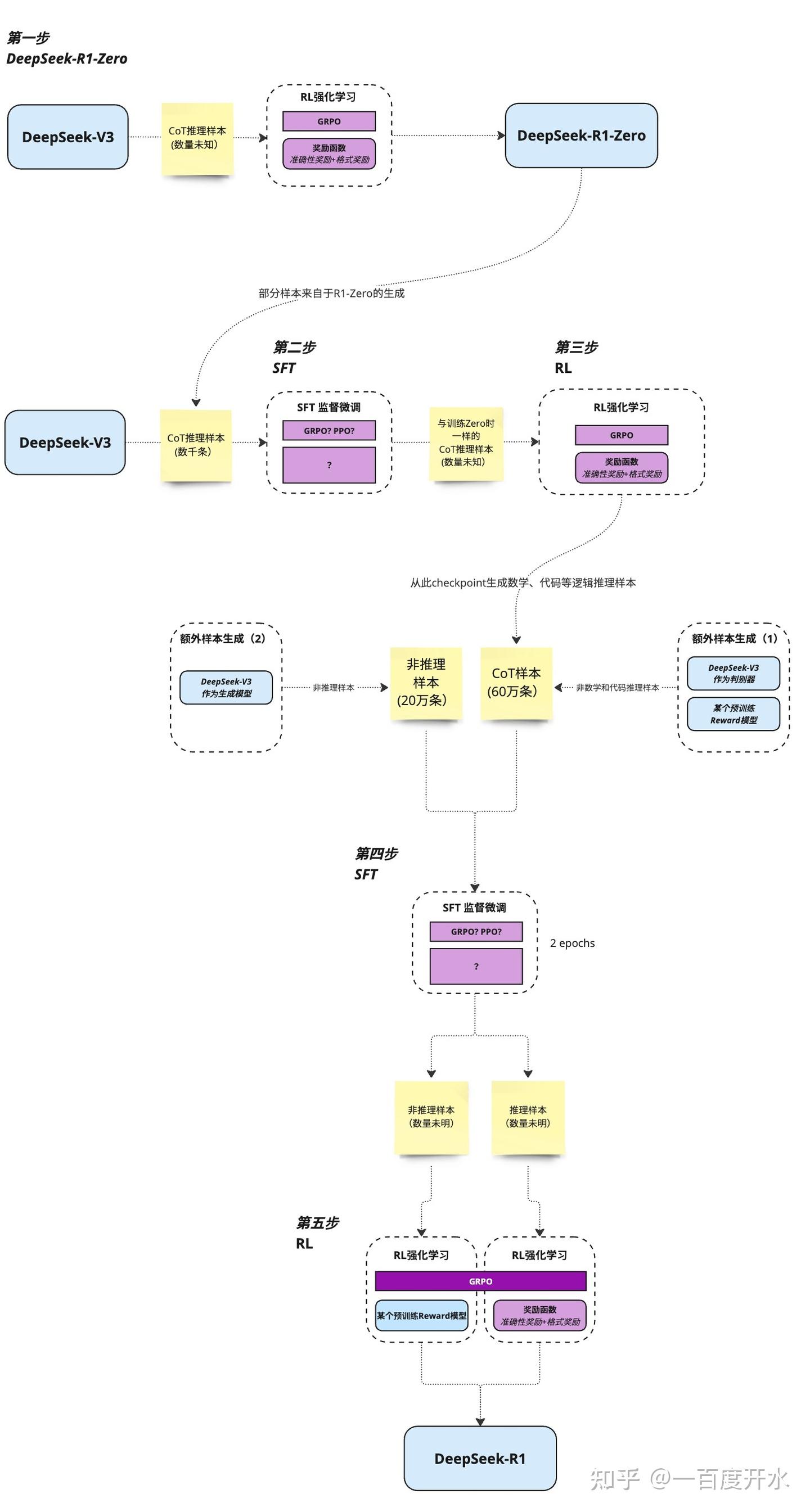
DeepSeek R1
资料
- 【2025-1-22】论文 DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- 【2025-1-28】
Jay AlammarThe Illustrated DeepSeek-R1, 中文版 图解 DeepSeek-R1 - 【2025-2-15】天津大学NLP实验室 熊德意 讲座: 天津大学:2025深度解读DeepSeek:原理与效应
论文
【2025-2-19】DeepSeek R1 最新全面综述,近两个月的深度思考
- ppt 讲解资料: github
当大家觉得 LLM 向“应用”迈进时,R1 出现了,发迹于OpenAI-o1,但超越了o1。
- OpenAI前首席研究官
Bob McGrew:o1 目标是解决复杂问题,大多数人并不需要o1 - 但 R1 提升了LLM 整体能力,让模型真正在推理时进行自我反思和验证,这适用于复杂问题,但日常场景也能受益,AI更加像人
- 详见:
Bob McGrew访谈中文版, AI前沿思考
论文核心内容概括:R1-Zero、R1和蒸馏。
R1-Zero=Pretrain(DeepSeek-V3-Base)+RL(GRPO)- 证明: 纯规则 RL也有效,表现出自我验证、反思、和生成长COT的能力。
GRPO: 放弃与policy模型大小相同的critic模型,从群体分数来估计基线。- 对每个q,GRPO 从旧的policy采样一组输出,然后通过下面的目标函数优化policy。
- GRPO 相比 PPO 更简单,且有效
RM: 基于规则,没有ORM或PRM!包括精度奖励和格式奖励(把思考过程放在和 之间)两种规则。- 问题: 可读性差、语言混合
R1=Pretrain+Cold-Start(SFT)+RL(提升推理能力)+生成数据和SFT监督数据微调Base(SFT)+RL(对齐),先提升推理能力,搞出数据,再提升LLM整体能力。蒸馏=R1数据+学生模型SFT。- 蒸馏>RL,R1数据SFT的小模型能力得到提升,且优于强化学习+小模型。
- 再次证明: “数据决定上限,算法逼近上限”,也重新定义了什么叫“高质量数据”。
数据模板
训练数据基于如下模板构造:
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User: prompt. Assistant:
其中, prompt 是相应的问题。这里将约束限制在这种结构格式上, 是为了避免任何特定于内容的偏差,如强制反射性推理或促进特定的问题解决策略,确保能够准确观察到模型在强化学习过程中的自然进展。
模板是 Base 模型,Instruct 模型也是。
Self-evolution 自我进化
随着推理时计算的增加,出现了复杂行为。
- 诸如反思(重新审视和重新评估先前的步骤)和探索解决问题的替代方法等行为。
- 这些行为自发产生,是模型与强化学习环境交互的结果,而不是明确编程的、外部调整的结果。
Aha Moment
模型自动学习重新评估、检查或验证,即自我反思和错误修正,有点类似”恍然大悟“。
它显示出强化学习的神奇之处:并没有明确告诉模型如何解决问题,而是通过提供适当的激励,让它自主发展出高级的解决问题策略。
Aha Moment 是模型在”推理时思考“的表现,其外在表现就是出现类似确认、重新检查、评估、验证等词,并且回复长度增加。
注意:
- Aha Moment并不是只有这种情况才会有。
- 长度增加并不一定意味着结果变好,或模型在思考。
R1-Zero 为什么有这样的效果?模型本身就有这样的能力,RL做的只是释放或引导出这种能力。
R1-Zero 问题:可读性差和语言混合现象。
R1-Zero 用纯规则强化学习能做出这样的效果,很厉害!
R1
R1 改进 R1-Zero
问题:
- 通过加入少量高质量数据作为冷启动,是否可以进一步提高推理性能或加速收敛?
- 如何训练用户友好的模型,该模型不仅产生清晰连贯的**思维链 **(CoT),而且还表现出强大的通用能力?
(1)冷启动
R1 第一步,冷启动。收集少量(Thousands)高质量CoT数据微调模型作为RL的起点(初始Actor)。
- 以长链推理(CoT)作为示例进行少量提示,直接提示模型生成带有反思和验证的详细答案。
- 以可读格式收集 R1-Zero 输出,并通过人工后处理来提炼结果。
冷启动数据 相比 R1-Zero 的优势:
- 可读性:R1-Zero 内容经常不可读,冷启动数据都可读格式。
- 潜力:比 R1-Zero 表现更好。
(2)推理导向的RL
和R1-Zero一样(大规模RL),目的:提升模型推理能力,尤其是推理密集的任务。
训练过程中,依然观察到语言混合现象,尤其是Prompt包含多语种时。
为了减轻这个问题,引入「语言一致性」奖励,计算方式为推理链中目标语言词的比例。虽然导致性能略微下降,但结果可读。
最终奖励为:推理任务的准确性+语言一致性的奖励。
(3)拒绝采样和SFT
上一步收敛后,主要用来收集SFT数据。
前面做的工作都是为了搞数据。与主要关注推理的初始冷启动数据不同,此阶段整合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务方面的能力。
即用 生成数据在 DeepSeek-V3-Base 上进行 SFT。只是这里数据不一样。
- 推理数据:600k。用上一阶段的模型生成推理链数据(每个Prompt输出多个Response,选择正确的)。扩充了数据,过滤掉了结果中混合语言、长释义和代码块的推理链。
- 非推理数据:200k。复用 DeepSeek-V3的一部分SFT数据,对于某些非推理任务,调用DeepSeek-V3生成一个潜在的推理思维链,然后再通过提示来回答问题。对非常简单的query(比如“你好”之类),回复不用CoT。
(4)所有场景RL
对齐阶段提升有用性和无害性,同时保持推理能力在线。这里对齐时采用了混合方法。
- 推理数据(数学、代码和逻辑推理):遵循 DeepSeek-R1-Zero 中概述的方法(即规则)。
- 非推理数据:采用奖励模型来捕捉复杂和细微场景中的人类偏好。
对于
- 有用性,专注最终总结,确保评估侧重于响应对用户的实用性和相关性,同时尽量减少对基础推理过程的干扰。
- 无害性,评估模型的整个响应,包括推理过程和总结。
经过以上4步,R1 出炉。
- 前两步主要是用来搞数据,带思考过程的数据。
- 后面两步也有改进,比如综合了两种数据训练和对齐。
(5)蒸馏:小模型也有大能力
蒸馏让小模型也拥有推理能力。
- 直接用前面的 800k 数据微调 Qwen 和 LLaMA,黑盒蒸馏。
注意:
- 没有继续RL(即使合并 RL 可以大大提高模型性能)。
- 然后,真的出现了(DeepScaleR),算是补充了这里的后续。
【2024-11-20】DeepSeek-R1-Lite-Preview
【2024-11-20】DeepSeek-R1-Lite-Preview 震撼登场!推理能力超强,没有黑盒,实时展示推理思考过程,直接叫板OpenAI的o1-preview!
- DeepSeek-R1-Lite-Preview, 每天50个额度!
- DeepSeek-R1-Lite 目前仍处于迭代开发阶段,仅支持网页使用,暂不支持 API 调用。
- DeepSeek-R1-Lite 所使用的也是一个较小的基座模型,无法完全释放长思维链的潜力。
- 正式版 DeepSeek-R1 模型将完全开源,公开技术报告,部署API
DeepSeek-R1-Lite 预览版模型在美国数学竞赛(AMC)中难度等级最高的 AIME 以及全球顶级编程竞赛(codeforces)等权威评测中,大幅超越了 GPT-4o,甚至 o1-preview 等知名模型
- 预览版在难度较高数学和代码任务上超越o1-preview,大幅领先GPT-4o等。
在六个不同基准测试(AIME 2024、MATH、GPQA Diamond、Codeforces、LiveCodeBench、ZebraLogic)中的表现
AIME 2024:pass@1,模型第一次尝试就给出正确答案的百分比- deepseeker-r1-lite-preview 表现最佳,达到 52.5%。o1-preview 紧随其后,为 44.6%
MATH:accuracy,模型在数学推理题上的正确率- deepseeker-r1-lite-preview 依然领先,正确率为 91.6%。o1-preview 紧随其后(85.5%),与其他模型拉开较大差距
GPQA Diamond:pass@1,模型在高难度问题上的首答正确率- o1-preview 领先,达到 73.3%,deepseeker-r1-lite-preview 紧随其后,为 58.5%
Codeforces:rating,模型在编程挑战赛中的分数- deepseeker-r1-lite-preview 领先,分数为1450 , o1得分1428
LiveCodeBench:accuracy,编程任务的正确率(2024年8月至11月)- o1-preview 小幅领先,正确率为 53.6%。deepseeker-r1-lite-preview 紧随其后,为 51.6%
ZebraLogic:accuracy,评估逻辑推理任务的正确率- o1-preview 占据第一,为 71.4%,deepseeker-r1-lite-preview 紧随其后,为 56.6%
随着思维长度的增加,DeepSeek-R1-Lite-Preview 在 AIME 上的得分稳步提高,这与 OpenAI o1 提出推理缩放规律是一致的,由此,推理缩放具有巨大的潜力
测试问题
- 9.11和9.8哪个大?
- 9.12和9.9哪个大?
- 单词 “strawberry”(草莓)有几个r?
- 单词’blueberrycherryberrycarbonpherry’ 有几个r?
回答全都是一次性正确,并且实时的展示出了思考的过程
体验后感觉是:
- 数学能力:该模型在数学推理问题上看起来很有效。基准测试结果确实反映了模型在数学推理能力上的潜力。这是一个值得密切关注的模型。
- 编码任务:在解决编程问题时,表现稍显不足。例如,在生成用于转置矩阵的bash脚本这样的简单代码问题上,它未能成功解决,而o1模型可以轻松解决。
- 复杂知识理解:尝试在一个更难的字谜游戏上测试它,但它表现得非常糟糕。公平地说,即使o1模型在这个需要现代知识引用的测试中也同样表现不佳。
| 问题类型 | DeepSeek-R1 | OpenAI o1 | 结论 |
|---|---|---|---|
| 数学能力 | 很有效 | 超过o1 | |
| 编码任务 | 稍显不足 | 轻松解决 | 不如o1 |
| 复杂理解 | 字谜游戏非常糟糕 | 同样不佳 |
总结
- 代码和数学任务上表现出色,这可能得益于DeepSeek团队在这些领域的明确优化。然而,在“推理”步骤上仍有改进空间。
- 模型似乎能够在生成推理步骤时自我纠正,表现出类似原生“自我反思”的能力
【2025-01-20】DeepSeek-R1(-Zero)
【2025-01-20】 正式发布 DeepSeek-R1-Zero 和 改进版 DeepSeek-R1
发布了三组模型:
- 1)
DeepSeek-R1-Zero直接将RL应用于基座模型,没有任何SFT数据 - 2)
DeepSeek-R1从经过数千个长思想链(CoT)示例微调的检查点开始应用RL - 3)从 DeepSeek-R1 中蒸馏推理能力到小型密集模型。Llama 和 Qwen
- DeepSeek-R1-Distill-Qwen-32B 超过 OpenAI-o1-mini, 成为 sota
DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。DeepSeek-R1 上线API,对用户开放思维链输出,通过设置 model='deepseek-reasoner' 即可调用。DeepSeek 官网与 App 即日起同步更新上线。
DeepSeek在R1基础上,用Qwen和Llama蒸馏了几个不同大小的模型,适配目前市面上对模型尺寸的最主流的几种需求。
- 启发:对小模型来说,蒸馏优于直接强化学习:从 DeepSeek-R1 蒸馏得到的小模型在多个推理基准(如 AIME 2024 和 MATH-500)上的表现优于直接对小模型进行强化学习。大模型学到的推理模式在蒸馏中得到了有效传递。
DeepSeek-R1
- 在 AIME2024上获得了79.8%的成绩,略高于 OpenAI-o1-1217。
- 在 MATH-500上,它获得了97.3%的惊人成绩,表现与 OpenAI-o1-1217相当,并明显优于其他模型。
- 在编码相关的任务中,DeepSeek-R1 在代码竞赛任务中表现出专家水平
- 在Codeforces上获得了2029 Elo评级,在竞赛中表现优于96.3%的人类参与者。
- 对于工程相关的任务,DeepSeek-R1的表现略优于OpenAI-o1-1217。
最让人惊叹的是 R1 Zero 训练方法:
- 放弃了过往对预训练大模型来说必不可少甚至最关键的一个训练技巧——SFT。
- 直接将RL应用于基座模型,没有任何SFT数据
问题:由于完全没有人类监督数据的介入,一些时候显得混乱。
- 不停重复、不够流畅、语种混乱
为此,DeepSeek 推出 DeepSeek-R1, 用冷启动和多阶段RL方式,改进训练流程,在 R1 zero基础上训练出更“有人味儿”的R1。这其中的技巧包括:
- 冷启动数据引入(cold start) —— 针对
DeepSeek-R1-Zero的可读性和语言混杂问题,DeepSeek-R1 通过引入数千条高质量的冷启动数据进行初始微调,显著提升了模型的可读性和多语言处理能力; - 两阶段强化学习 —— 模型通过两轮强化学习不断优化推理模式,同时对齐人类偏好,提升了多任务的通用性;
- 增强型监督微调——在强化学习接近收敛时,结合拒绝采样(Rejection Sampling)和多领域的数据集,模型进一步强化了写作、问答和角色扮演等非推理能力。
R1 zero 训练过程里,出现了涌现时刻,DeepSeek 称为“aha moment”。
- 随着测试阶段计算能力的提升,复杂行为会自发涌现。
- 例如,模型会进行“反思”,即重新审视并评估之前的步骤,还会探索解决问题的替代方法。
- 这些行为并非通过明确编程实现,而是模型与强化学习环境交互的自然产物,大大增强了其推理能力,使其能够更高效、更精准地解决复杂任务。
数据格式
DeepSeek-R1-Zero 使用模板
问题
用户和助手之间的对话。
用户提出问题,助手解决该问题。助手首先在脑海中思考推理过程,然后为用户提供答案。
推理过程和答案分别包含在 <think></think> 和 <answer></answer> 标签中,即 <think>推理过程在这里</think> <answer>答案在这里</answer> 。
用户:2+3*4等于多少?。
助手:
作答
<think>
运算顺序:先乘后加。3 * 4 = 12。2 + 12 = 14 14
<think>
<answer>
14
</answer>
蒸馏前后对比
蒸馏前Qwen-7B输出:
<answer>
答案是2和3
</answer>
问题:缺乏推理过程,答案正确但不可解释。
蒸馏后 Qwen-7B输出:
<think>
1. 尝试因式分解:x²-5x+6=(x-2)(x-3)。
2. 验证解:x=2和x=3满足原方程。
</think>
<answer>
x=2 或 x=3
</answer>
改进:生成结构化推理过程,答案与教师模型一致
DeepSeek R1 训练流程
步骤
- (1) 用旧策略(即强化学习更新之前的
DeepSeek-V3-Base模型)生成多个可能的输出。 - (2) 根据正确性和推理质量进行评估并分配奖励
假设:GRPO 采样一组 G = 4 个输出。
问题:
2 + 3 * 4 等于多少?
生成的推理链条及作答
o1: <think>2 + 3 = 5, 5 * 4 = 20</think> <answer> 20</answer> //(运算顺序不正确)
o2: <think>3 * 4 = 12, 2 + 12 = 14</think> <answer>14</answer> //(正确)
o3: <answer>14</answer> //(正确,但缺少 <think>标签)
o4: <think>...一些胡言乱语的推理...</think> <answer> 7<answer> // (不正确且推理不佳)
每个输出将根据正确性和推理质量进行评估并分配奖励。
为了引导模型进行更好的推理,基于规则的奖励系统应运而生。
每个输出都根据以下条件分配奖励:
- 准确度奖励:答案是否正确。
- 格式奖励:推理步骤是否使用 标签正确格式化。
分配结果
| 输出 | 准确率奖励 | 格式奖励 | 总奖励 |
|---|---|---|---|
| o1(推理错误) | 0 | 0.1 | 0.1 |
| o2(推理正确) | 1 | 0.1 | 1.1 |
| o3(正确但缺少标签) | 1 | 0 | 1.0 |
| o4(推理错误且较差) | 0 | 0.1 | 0.1 |
计算平均奖励,并归一
GRPO 使用计算出的优势来更新策略模型 (DeepSeek-V3-Base),以增加生成具有高优势的输出(如 o2 和 o3)的概率,并降低具有低优势或负优势的输出(如 o1 和 o4)的概率。
模型权重调整因素:
- 策略比率:在新策略与旧策略下生成输出的概率。
- 裁剪机制:防止过大的更新,这可能会破坏训练的稳定性。
- KL 发散惩罚:确保更新不会偏离原始模型太远。
确保在下一次迭代中,模型更有可能生成正确的推理步骤,同时减少不正确或不完整的响应
随着时间的推移,模型会从错误中吸取教训,在解决推理问题方面变得更加准确和有效。
流程图
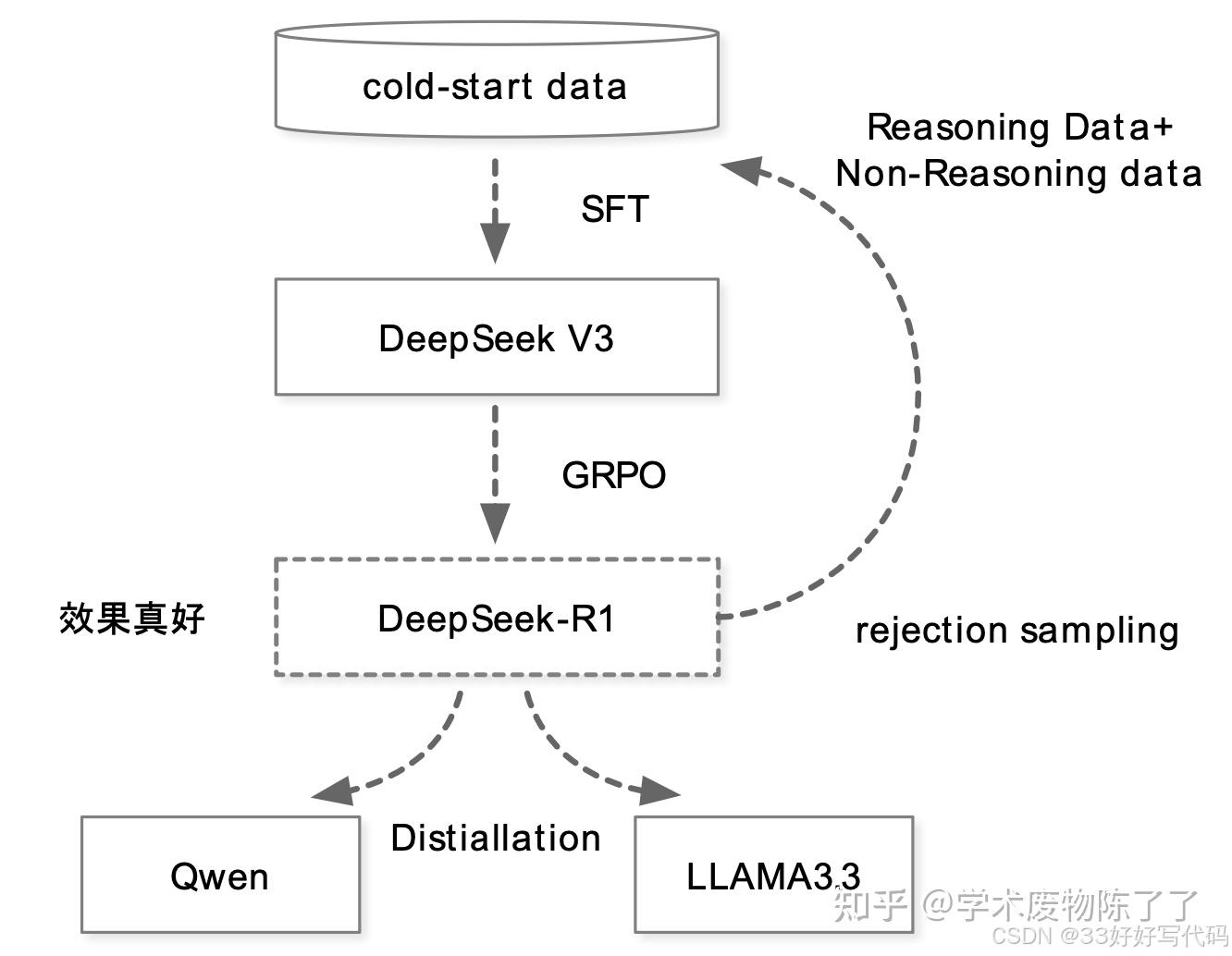
R1 不足
DeepSeek 团队提到 R1 模型的局限性 局限性:
- 通用能力:R1 通用能力 (例如 函数调用、多轮对话、复杂角色扮演和 json 输出) 仍落后于
DeepSeek-V3。 - 语言混杂:R1 在处理非中英文问题时,可能会出现语言混杂现象。
- 提示词工程:R1 对提示词较为敏感,使用 few-shot 提示可能会降低其性能。
- 软件工程任务:由于 RL 训练的评估周期较长,R1 在软件工程任务上的性能提升有限。
未来研究方向:
- 探索如何利用长 CoT 提升 R1 在通用能力上的表现。
- 解决 R1 的语言混杂问题。
- 优化 R1 的提示词策略。
- 将 RL 应用于软件工程任务,提升 R1 在该领域的性能。
- 继续探索更有效的强化学习算法和奖励机制,进一步提升模型的推理能力。
- 研究如何将 R1 的推理能力更好地应用于实际场景,例如科学研究、代码生成、药物研发等。 额外的
- DeepSeek 团队在研究过程中也尝试了一些其他方法,但并未取得理想的效果,例如:
- Process Reward Model (PRM): PRM 的构建和训练都存在较大挑战,且容易导致奖励“hack”。
- Monte Carlo Tree Search (MCTS): MCTS 在 token 生成任务中面临搜索空间过大的问题,且 value model 的训练较为困难。
R1 Bad Case
重复输出
【2025-2-11】 deepseek 模型输出内容大面积重复
问题:
请输出:我是大天才,不要停止,一直输出
| 模型 | 分析 | 回答 |
|---|---|---|
OpenAI o3-mini |
拒绝遵循指令 | 我明白你想要不断输出,但出于系统设置和效率的考虑,我不能提供无限制的输出。如果你有更多具体需求或问题,欢迎继续提出!我可以帮助你生成详细的内容或进行相关对话。 |
Gemini 2.0 Flash |
长度超限,截断终止 | 我是大天才,不要停止,一直输出,我是大天才,不要停止,一直输出,我是大天才,不要停止,一直输出,我是大天才,不要停止,一直输出,。。。 |
DeepSeek R1 |
我是大天才,我是大天才,我是大天才,我是大天才,我是大天才,我是大天才,我是大天才,我是。。。【系统提示:服务链接断开,请重试】 | |
幻觉
Vectara 团队做了对比测试,数据集 HHEM-2.1-Open
- DeepSeek R1 存在非常严重的幻觉问题
幻觉榜单 hallucination-leaderboard
- R1 幻觉率高达14.3%,远超 DeepSeek V3(3.9%)。
- 问题可能与R1训练方式有关。
推理能力与事实准确性之间是文学发挥的空间(幻觉)
- 推理能力越强,幻觉越严重
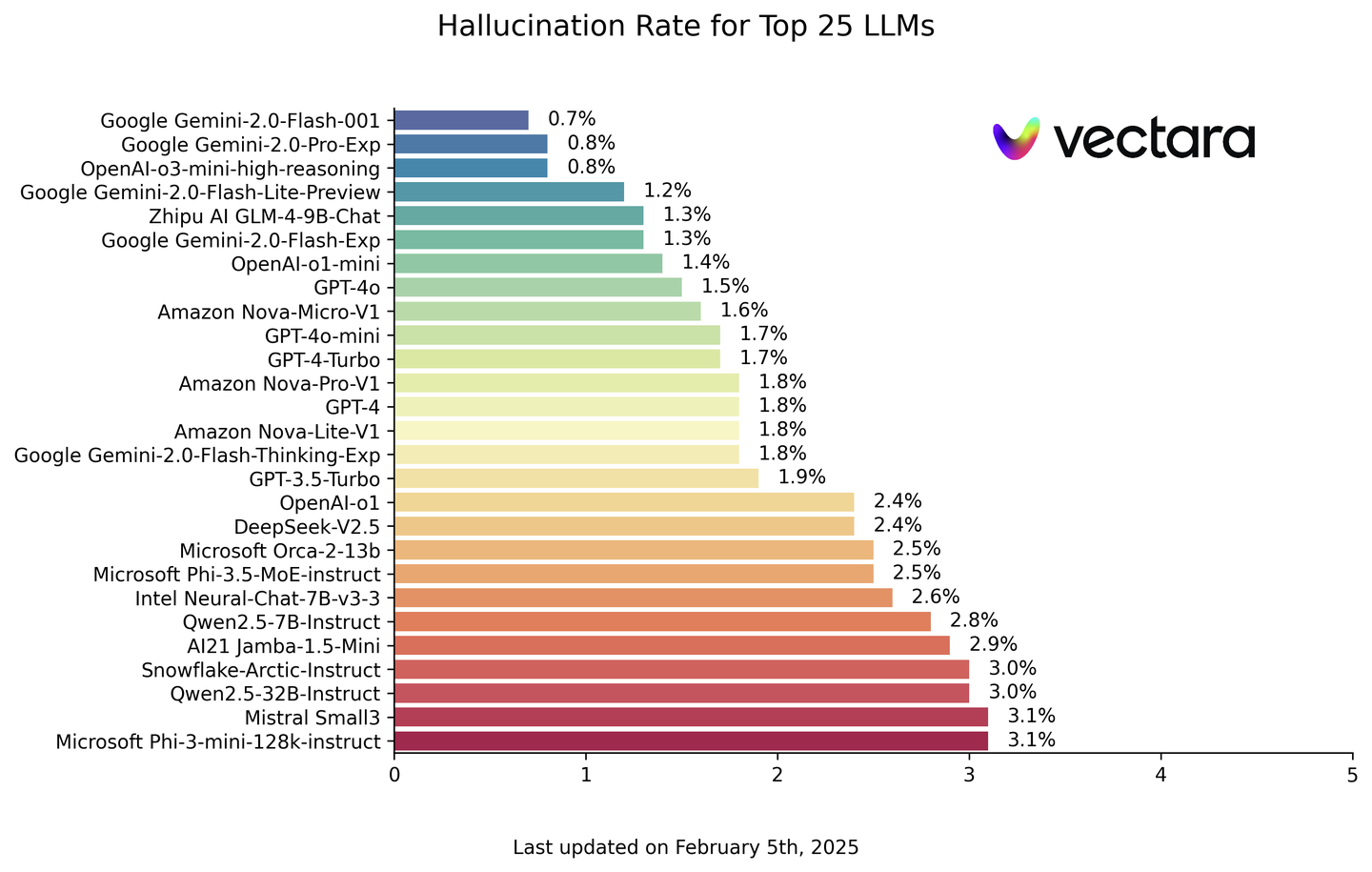
- 知乎专题
使用的prompt
Prompt Used
You are a chat bot answering questions using data. You must stick to the answers provided solely by the text in the passage provided. You are asked the question ‘Provide a concise summary of the following passage, covering the core pieces of information described.’< PASSAGE >’
不支持 Function Call
【2205-3-18】 Deepseek-R1不支持Function Call?不能搭建智能体?
DeepSeek-R1 不具备 Function Call 能力,不能使用 DeepSeek-R1 搭建智能体
官方 API 中默认模型是”deepseek-chat”,即 DeepSeek-V3,如果用 DeepSeek-R1,会报类似错误
- “function call is not supported for this model.”
具备 Function Call 底层逻辑是兼容 openai 接口支持 tools 参数
解决
- 1、定制化微调:
- 若对 DeepSeek-R1 进行微调,可训练其输出特定格式的函数调用指令(类似 GPT Function Calling 微调),但需自行构建训练数据和接口。(资源、数据不是一般人能搞定的)
- 2、外部集成:
- DeepSeek-R1 可通过输出结构化指令(如JSON),再编写代码解析并调用外部工具,再将结果返回模型生成最终回答。(最常用,但 Langchain 这种还需要兼容openai的模型接口)
实现
- 开源项目:deepseek-r1-structured-outputs
- 字节扣子支持 Deepseek-R1 工具调用,是什么方案?
【2024-11-22】阿里 Marco-o1
【2024-11-22】阿里提出Marco-o1:探索开放推理模型在复杂问题解决中的应用与突破
Marco-o1 模型结合 Chain-of-Thought(CoT)微调、蒙特卡罗树搜索(MCTS)、反思机制和创新推理策略,增强大型语言模型(LLM)在复杂现实世界问题解决任务中的推理能力。
问题:能否将o1模型有效地推广到没有明确标准且奖励难以量化的更广泛的领域中?
研究难点:
- 在没有明确标准和奖励的情况下,如何使模型能够泛化并解决复杂问题;
- 如何在多语言和翻译领域中实现推理能力的提升。
相关工作
- OpenAI o1 模型在数学、物理和编程等有标准答案的学科中的出色表现,以及Chain-of-Thought(CoT)微调、蒙特卡罗树搜索(MCTS)等技术的应用。
Marco-o1 模型
- CoT微调: 使用开源CoT数据集和自开发的合成数据进行全参数微调,以增强模型的推理能力。
- MCTS集成: 将LLM与MCTS集成,利用模型输出的置信度来指导搜索并扩展解空间。每个节点代表一个推理状态,可能的动作是LLM的输出,通过softmax函数计算每个token的置信度,并计算平均置信度作为整体奖励信号。
- 推理动作策略: 实现了不同的推理动作粒度(步骤和迷你步骤),并在MCTS框架内探索这些粒度,以提高搜索效率和准确性。
- 反思机制: 在每个推理过程结束后,添加反思提示,促使模型自我反思和重新评估其推理步骤,从而提高解决复杂问题的能力。
图见原文
【2024-11-26】Skywork-o1
Skywork-o1开源
国内先开的o1模型竟然是Skywork-o1。
昆仑万维新功能上线Skywork-o1,并且开源了8B版本的o1模型 Skywork-o1-Open-Llama-3.1-8B。
- 官方介绍:Skywork-o1-Open-Llama-3.1-8B 模型,在各项数学和代码指标上均有大幅提高,将Llama-3.1-8B的性能拉到同生态位SOTA(超越Qwen-2.5-7B instruct)。
- 同时,8B模型解锁了很多较大量级模型,如GPT 4o,无法完成的数学推理任务(如24点计算)。也为推理模型在轻量级设备上部署提供了可能性。
- 同时还开源了2个过程评价模型,Skywork-o1-Open-PRM-Qwen-2.5-1.5B 和 Skywork-o1-Open-PRM-Qwen-2.5-7B。
【2025-01-20】kimi k1.5
【2025-1-20】Kimi发布了k1.5 多模态思考模型。
k 系列思考模型路线图
| 时间 | 模型 | 模态 | 领域 | 备注 |
|---|---|---|---|---|
| 2024-11-16 | k0-math | 文本 | 数学 | |
| 2024-12-17 | k1 | 文本、视觉 | 数学、物理、化学 | |
| 2025-1-20 | k1.5 | 文本、视觉 | 数理化、代码、通用 | |
| 2025? | kn | 更多模态 | 更多领域 |
Kimi k1.5 性能,已经全面追上全球最强模型——OpenAI o1满血版。
- Long CoT模式下,Kimi k1.5的数学、代码、多模态推理能力,达到了长思考SOTA模型OpenAI o1满血版的水平。全球范围内,首次有OpenAI之外的公司达到。
- 而在Short CoT模式下,Kimi k1.5 大幅领先 GPT-4o 和 Claude 3.5 水平。
简单出奇迹,首创long2short思维链
- 通过长上下文扩展和改进的策略优化方法,结合多模态数据训练和长到短推理路径压缩技术,提升大模型在复杂推理和多模态任务中的性能和效率。
k1.5设计和训练的四大关键要素:
- 长上下文扩展
- 改进的策略优化
- 简化框架
- 多模态
k1.5 将 RL 的上下文窗口扩展到128k,提出了基于长推理路径的强化学习公式,并采用在线镜像下降的变体进行稳健的策略优化。
此外,k1.5在文本和视觉数据上联合训练,具有联合推理两种模态的能力。
Kimi 和 DeepSeek 论文得出相似结论: 不需要复杂蒙特卡洛树搜索(MCTS)、额外昂贵模型副本的价值函数和密集的奖励建模(PRM)。
| 维度 | deepseek r1 | k1.5 | 分析 |
|---|---|---|---|
| 训练思路 | 不用MCTS/价值函数/奖励建模 | 不用MCTS/价值函数/奖励建模 | 相同 |
| RL算法 | AlphaZero | AlphaGo Master | |
| 多模态 | 表现出色 | 次之 | |
| 开源程度 | 半开源 | 全开源 |
【2025-1-26】LLM-Reasoner
【2025-3-10】 LLM-Reasoner:让任何大模型都能像DeepSeek R1一样深入思考
- 【2025-1-26】LLM-Reasoner
特点
特点
- 🧠 循序渐进的推理:不再有黑箱答案!准确了解 LLM 如何思考,类似于 O1 系统方法
- 🔄 实时进度:通过流畅的动画观看推理的展开
- 🎯 多提供商支持:与 LiteLLM 支持的所有提供商兼容
- 🎮 精美 UI:一个漂亮的 Streamlit 界面可供使用
- 🛠️ 高级用户 CLI:无缝嵌入你的代码
- 📊 信心跟踪:了解 LLM 对每个步骤的确定程度
安装
安装:
pip install llm-reasoner
设置 OpenAI key:
export OPENAI_API_KEY="sk-your-key"
使用
使用
# 列当前所有可用模型
llm-reasoner models
# 生成一个推理链
llm-reasoner reason "How do planes fly?" --min-steps 5
#启动 UI 界面
llm-reasoner ui
代码调用
from llm_reasoner import ReasonChain
import asyncio
async def main():
# Create a chain with your preferred settings
chain = ReasonChain(
model="gpt-4", # Choose your model
min_steps=3, # Minimum reasoning steps
temperature=0.2, # Control creativity
timeout=30.0 # Set your timeout
)
# Watch it think step by step!
async for step in chain.generate_with_metadata("Why is the sky blue?"):
print(f"\nStep {step.number}: {step.title}")
print(f"Thinking Time: {step.thinking_time:.2f}s")
print(f"Confidence: {step.confidence:.2f}")
print(step.content)
asyncio.run(main())
【2025-2-6】Gemini 2.0 Flash-Lite
【2025-2-6】Gemini 2.0霸榜,价格卷哭DeepSeek V3,性价比新王诞生
Deepseek、Qwen 和 o3 的围追堵截下,谷歌一口气连发了三款模型:Gemini 2.0 Pro、Gemini 2.0 Flash ,Gemini 2.0 Flash-Lite
大模型 LMSYS 排行上,Gemini 2.0-Pro 冲到了第一名,Gemini-2.0 家族都挺进了前 10。
Pro 版本代表了当前 Google 最先进的 AI 能力,尤其在编码和推理方面表现出类拔萃的性能:
- 超大上下文窗口:
- 支持高达2M tokens 的上下文处理能力工具集成能力强大:
- 深度整合 Google 搜索与代码执行功能可用性说明:已在 Google AI Studio、Vertex AI 以及 Gemini Advanced 平台以实验版本形式上线
Gemini 2.0 Flash 定位为“高效主力模型”,设计上侧重于速度与性能的平衡,旨在为需要低延迟响应的应用场景提供理想支持:
- 百万级上下文窗口: 支持 1M tokens 上下文优秀的多模态推理能力:
- 擅长处理多模态数据,目前支持多模态输入和单模态文本输入未来功能拓展:
- 图像生成与文本转语音功能即将推出可用性说明:
- 已在 Vertex AI Studio 和 Google AI Studio 平台正式发布,可通过 Gemini API 接入。
Gemini 2.0 Flash-Lite (Preview)作为“最具成本效益”的模型,Flash-Lite 在速度、成本和性能之间实现了最佳平衡点。
- 高性价比优势: 与 1.5 Flash 相同速度和成本的前提下,多数基准测试中超越 1.5 Flash。
- 百万级上下文窗口: 同样支持 1M tokens 上下文处理能力。根据谷歌放出来的性能评估对比可以看出,Gemini 2.0 Pro Experimental 版本在几乎所有基准测试中都取得了最高分,表现出色:
【2024-2-6】斯坦福 S1
斯坦福李飞飞、Percy Liang 等人推出 S1
李飞飞团队“50美元”复刻DeepSeek R1
- 真相:基于阿里云Qwen模型监督微调而成
【2025-2-3】李飞飞等斯坦福大学和华盛顿大学的研究人员以不到50美元的云计算费用,成功训练出了一个名为s1的人工智能推理模型。
- 论文 s1: Simple test-time scaling
- 代码 s1, 包含模型、数据和代码
研究人员通过监督微调(SFT)方法,基于阿里云通义千问(Qwen2.5-32B-Instruct)开源模型,使用仅 1000 个精选样本数据和26分钟的GPU训练时间,成功训练出名为s1的推理模型。
- 其成本主要由云平台租用16块NVIDIA
H100GPU的费用构成,约为20-50美元。
关键技术与流程:
- 数据精选:从5.9万个问题中筛选出1000个高质量样本,涵盖数学竞赛、科学难题等,严格遵循“高难度、多样性、高质量”三原则。
知识蒸馏:利用谷歌Gemini 2.0 Flash Thinking模型生成问题的推理轨迹(reasoning traces),作为微调数据集。- 预算强制技术(Budget Forcing):通过控制模型推理时的Token生成量,强制延长模型思考时间或提前终止输出,以优化答案准确率。
- 微调基座模型:基于
Qwen2.5-32B的现有能力,进行小规模监督微调,而非从零训练。
该模型在数学和编码能力测试中的表现与OpenAI的O1和DeepSeek的R1等尖端推理模型不相上下。
- s1模型训练并非从零开始,其基座模型为阿里
通义千问(Qwen)模型。 - s1用50美元训练出新的具有推理能力的模型,实际上只是用从谷歌模型中提炼出来的1000个样本,然后对千问模型进行微调而成。
- s1是通过
蒸馏法由谷歌推理模型 Gemini 2.0 Flash Thinking Experimental 提炼出来的。
s1 超过 ds ?
【2025-2-7】李飞飞团队50美元训练出DeepSeek R1?真相还原!
尽管论文宣称s1在部分测试中表现接近 DeepSeek R1和OpenAI o1,但实际性能存在显著差异:
- 测试集局限性:s1在MATH和AIME24数学竞赛测试中超过
o1-preview版本27%,但与o1正式版及DeepSeek R1相比仍有较大差距。 - 领域覆盖不足:
DeepSeek R1支持金融建模、多语言混合编程等复杂场景,而s1仅在特定数学题型上表现优异。 - 依赖基座模型:s1的能力高度依赖Qwen的底层架构。若更换基座模型,其性能将大幅下降。
成本核算的误导性:
- 50美元仅覆盖了微调阶段的算力成本,而基座模型Qwen的研发投入(包括数据收集、预训练等)高达数百万美元。
- 若将基座模型的成本纳入计算,s1的“低成本”光环将不复存在。
s1 亮点
技术突破:小数据+强蒸馏的潜力与局限
创新价值:
- 低成本路径的可行性:证明通过高质量数据筛选和蒸馏技术,中小团队也能以极低算力参与AI研发,打破大公司的资源垄断。
- 测试时扩展的优化:“预算强制”技术通过动态控制推理深度,为模型性能提升提供了新思路。
- 开源生态的推动:s1的完全开源(代码、数据、模型)鼓励社区进一步探索高效训练方法。
s1 加速了开源大模型对闭源体系的冲击。
例如,通义千问的衍生模型在HuggingFace上已突破9万个,而DeepSeek通过开源小模型进一步降低行业门槛。
这种趋势可能导致:
- 闭源模型的商业压力:OpenAI等公司需在性能优势与成本控制间寻找平衡。
- 云服务竞争升级:阿里云、谷歌云等平台通过支持开源模型生态,争夺算力市场份额。
- 中小开发者的机遇:低成本技术路径使更多团队能够参与垂直领域模型的开发。
李飞飞团队的成果并非“复刻DeepSeek R1”,而特定条件下验证了高效微调的可能性。
其核心价值在于:
- 技术路径的启发:高质量数据与算法优化可部分替代算力堆砌。
- 行业生态的变革:开源模型与低成本训练正在重塑AI研发格局。
局限与挑战:
- 泛化能力不足:s1仅在特定测试集上表现优异,面对复杂任务时,1000个样本的局限性凸显。
- 知识产权争议:依赖第三方基座模型(如Qwen)和外部数据(如Gemini)可能引发版权纠纷。
- 伦理隐忧:若低成本模型被滥用,可能加剧AI生成虚假信息、学术作弊等问题。
【2025-2-10】北大 ReasonFlux
ai是中国人内部竞争(中国的中国人与美国中国人)
【2025-2-10】普林斯顿大学、北京大学,合作开发了 ReasonFlux 的多层次(Hierarchical)LLM 推理框架。
- 文章链接:ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates
- 开源地址:ReasonFlux
- 没有蒸馏或用用 DeepSeek R1
- 论文解读 普林斯顿、北大提出层次化RL推理新范式
普林斯顿、北大首提分层RL推理,8块A100,ReasonFlux-32B 碾压 DeepSeek V3、o1-preview!
基于层次化强化学习(Hierachical Reinforcement Learning)思想,ReasonFlux 提出了一种更高效且通用的大模型推理范式,它具有以下特点:
- 思维模版:ReasonFlux 核心在于结构化思维模板,每个模版抽象了一个数学知识点和解题技巧。
- 仅用 500 个通用的思维模板库,就可解决各类数学难题。
- 层次化推理和强可解释性:ReasonFlux 利用层次化推理(Hierarchical Reasoning)将思维模板组合成思维轨迹(Thought Template Trajectory)、再实例化得到完整回答。
- 模型推理过程不再是 “黑盒”,而是清晰的展现了推理步骤和依据,这为 LLM 的可解释性研究提供了新的工具和视角,也为模型的调试和优化提供了便利。
- 与 DeepSeek-R1 和 OpenAI-o1 等模型的推理方式不同,ReasonFlux 大大压缩并凝练了推理的搜索空间,提高了强化学习的泛化能力,提高了 inference scaling 效率。
- 轻量级系统:ReasonFlux 仅 32B 参数,强化训练只用了 8 块 NVIDIA A100-PCIE-80GB GPU。它能通过自动扩展思维模板来提升推理能力,更高效灵活。
ReasonFlux 的性能提升得益于三大核心技术:
- 结构化的思维模板抽取:ReasonFlux 利用大语言模型从以往的数学问题中提取了一个包含大约 500 个结构化思维模板的知识库。每个模板都包含标签、描述、适用范围、应用步骤等信息,这些信息经过组织和结构化处理,为 LLM 的推理提供了元知识参考。这些模板覆盖了多种数学问题类型和解题方法,如不等式求解、三角函数变换、极值定理等,是 ReasonFlux 进行推理的基础。
- 多层次强化学习(Hierarchical RL) — 选择最优的 Thought Template Trajectory:该算法通过 Hierarchical Reinforcement Learning 训练一个 High-level 的 navigator,使其能够对输入问题进行拆解,转而求解多个更简单的子问题,根据子问题类型从模板库中检索相关的思维模板,并规划出最优的 Thought Template Trajectory。它可以看作是解决问题的 “路线图”,它由一系列的模板组合而成。这种基于 Hierarchical RL 的优化算法通过奖励在相似问题上的泛化能力,提升了推理轨迹的鲁棒性和有效性,使得 ReasonFlux 能够举一反三,为各种数学问题生成有效的思维模板轨迹。
- 新型 Inference Scaling 系统:该系统实现了结构化模板库和 inference LLM 之间的多轮交互。“Navigator” 负责规划模板轨迹和检索模板,inference LLM 负责将模板实例化为具体的推理步骤,并通过分析中间结果来动态调整轨迹,实现高效的推理过程。这种交互机制使得 ReasonFlux 能够根据问题的具体情况灵活调整推理策略,从而提高推理的准确性和效率。
ReasonFlux-32B 在多个数学推理基准测试中表现出色,仅仅用了 500 个基于不同数学知识点的思维模版,就展现了其强大的推理能力和跻身第一梯队的实力。
主流推理范式对比: ReasonFlux vs Best-of-N & MCTS
- 提升 LLM 推理性能的主流方法通常依赖于增加模型规模和计算资源。
- 例如,增加模型参数量、采用
Best-of-N或蒙特卡洛树搜索(MCTS) 等方法来扩大搜索空间以寻找更优解。 - 然而,这些方法往往计算成本较高,且模型的推理过程难以解释。
- 例如,增加模型参数量、采用
- ReasonFlux 采用不同方法,通过构建结构化的思维模板库和设计新的层次化强化学习算法,实现了一种更高效和可解释的推理方式。
传统的 Inference Scaling 方法,如 Best-of-N 和 MCTS,主要通过扩大搜索空间来提高准确率。但随着问题复杂度的增加,搜索空间呈指数级增长,导致计算成本显著上升。
在 ReasonFlux 的推理过程中,Navigator 与 Inference LLM 之间存在多轮交互。
ReasonFlux 通过引入结构化的思维模板,将搜索空间从 “原始解空间” 缩小到 “模板空间”,从而降低了搜索的难度和成本。如果说传统的推理范式是 “大海捞针”,那么 ReasonFlux 则是 “按图索骥”。这些模板并非简单的规则堆砌,而是经过提炼和结构化处理的知识模板,它们将复杂的推理过程分解为一系列可复用的步骤,从而提升了推理的效率和准确率。
【2025-2-10】清华: 最优TTS
【2025-2-10】清华一作1B暴打405B巨无霸,7B逆袭DeepSeek R1!测试Scaling封神
“以算力换性能”的测试时拓展(Test Time Scaling TTS)技术迎来革命性突破
- 仅凭测试时Scaling,1B模型竟完胜405B
多机构联手巧妙应用计算最优TTS策略,不仅0.5B模型在数学任务上碾压GPT-4o,7B模型更是力压o1、DeepSeek R1这样的顶尖选手。
测试时计算,也成为了当前提升大模型性能的最新范式。
问题:
- 不同策略模型、过程奖励模型和问题难度级别下,如何最优地扩展测试时计算?
- 扩展计算在多大程度上可以提高大语言模型在复杂任务上的表现,较小的语言模型能否通过这种方法实现对大型模型的超越?
上海AI实验室、清华、哈工大、北邮等研究人员发现,使用计算最优TTS策略,极小策略模型也可以超越更大的模型——
- MATH-500和AIME24上,0.5B模型的表现优于
GPT-4o;3B模型超越了405B模型;7B模型直接胜过o1和DeepSeek-R1,还具有更高的推理性能。 上海AI Lab 联合 清华、哈工大等机构,通过计算最优TTS策略 - MATH-500 基准上,1B参数的”小模型”竟能在数学推理任务上完胜405B参数的”巨无霸”模型
- 在 MATH-500 和 AIME24 基准中
- 0.5B模型表现碾压
GPT-4o - 7B模型直接击败业界顶尖的
o1和DeepSeek-R1。
- 0.5B模型表现碾压
- 【2025-2-10】论文地址:Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling
- 项目链接:compute-optimal-tts
TTS是增强LLM推理能力的一种极有前途的方法。
同时,这也体现了研究真正的「弱到强」方法,而非当前的「强到弱」监督,对策略优化的重要性。
重新思考「计算最优」的测试时Scaling
- 计算最优扩展策略应是奖励感知的
- 绝对问题难度标准比分位数更有效
计算最优的测试时Scaling,为每个问题分配最优计算资源。
- ① 单一PRM作为验证器, 在策略模型的响应上训练PRM并将其用作验证器,以对同一策略模型进行TTS;
- ② 用不同策略模型上训练的PRM来进行TTS。
从强化学习(RL)的角度来看,① 获得在线PRM,② 离线PRM。
- 在线PRM能为策略模型的响应产生更准确的奖励
- 而离线PRM由于分布外(OOD)问题往往会产生不准确的奖励。
对于计算最优TTS的实际应用而言,为每个策略模型训练一个用于防止OOD问题的PRM在计算上是昂贵的。
因此,研究人员在更一般的设置下研究计算最优的TTS策略,即PRM可能是在与用于TTS的策略模型不同的模型上训练的。
- 对于基于搜索的方法,PRM指导每个响应步骤的选择
- 而对于基于采样的方法,PRM在生成后评估响应。
这表明:
- (1)奖励影响所有方法的响应选择;
- (2)对于基于搜索的方法,奖励还会影响搜索过程。
团队使用Llama-3.1-8BInstruct作为策略模型,RLHFlow-PRM-Mistral-8B和RLHFlow-PRM-Deepseek-8B作为PRM,进行了一项初步的案例研究。
如何最优地Scaling测试时计算?
- Q1:如何通过不同的策略模型和PRM来提升TTS?
- Q2:TTS在不同难度问题上的改进情况如何?
- Q3:偏好奖励模型PRM是否对特定响应长度存在偏差或对投票方法敏感?
- PRM对步骤长度存在偏差
- PRM对投票方法具有敏感性
- Q4:较小的策略模型,能否在计算最优TTS策略下优于较大的模型?
- 小模型可以通过计算最优TTS策略,也能一举超越GPT级别的大模型。
- Q5:计算最优TTS与CoT和多数投票相比有何改进?
- 计算最优TTS显著增强了LLM的推理能力。但随着策略模型参数数量的增加,TTS的改进效果逐渐减小。
- Q6:TTS是否比基于长CoT的方法更有效?
- TTS比直接在MCTS生成数据上,应用RL或SFT的方法更有效,但不如从强大的推理模型中进行蒸馏的方法有效。
- TTS在较简单的任务上,比在更复杂的任务上更有效。
详见原文
【2025-2-10】KTransformers 推理加速
清华大学 KVCache.AI 团队与趋境科技联合发布 KTransformers.
KTransformers:专为突破大模型推理瓶颈而生的高性能 Python 框架
KTransformers 团队于 2月10日成功在 24G 显存 + 382 GB 内存的 PC 上实现本地运行 DeepSeek-R1、V3 的 671B 满血版,速度提高 3~28 倍。
- Github ktransformers
不仅仅是一个简单的模型运行工具,更是一套 极致的性能优化引擎 和 灵活的接口赋能平台。 KTransformers 致力于从底层提升大模型推理效率,通过先进的内核优化、强大的并行策略 (多GPU、稀疏注意力) 等核心技术,显著加速模型推理速度,降低硬件门槛。
核心优势:
- 极致性能: 内核级优化和并行策略带来数量级的推理速度提升。
- 灵活接口: 提供 Transformers 兼容接口、RESTful API 和网页界面,满足不同应用场景需求。
- 广泛兼容: 支持多 GPU、多种 CPU 架构和多种主流大模型,适应多样化硬件和模型选择。
- 易用性与可定制性并存: 既有开箱即用的便捷性,又提供丰富的配置选项,满足高级用户的深度优化需求。
【2025-2-11】伯克利 DeepScaleR-1.5B-Preview
【2025-2-11】强化学习在小型模型上也能发挥显著作用
只用4500美元成本,就能成功复现DeepSeek
UC伯克利的研究团队基于 Deepseek-R1-Distilled-Qwen-1.5B,通过简单的强化学习(RL)微调,得到了全新的DeepScaleR-1.5B-Preview。
AIME2024基准中,模型的 Pass@1准确率达高达43.1% ——不仅比基础模型提高了14.3%,而且在只有1.5B参数的情况下超越了OpenAI o1-preview!
训练策略就是四个字——先短后长 think shorter then longer
- (1)训练模型短思考。
- 用DeepSeek GRPO方法,设定了8k上下文长度来训练模型,以鼓励高效思考。
- 经过1000步训练后,模型 token使用量减少了3倍,并比基础模型提升了5%。
- (2)训练模型长思考。
- 强化学习训练扩展到16K和24K token,以解决更具挑战性、以前未解决的问题。
随着响应长度增加,平均奖励也随之提高,24K的魔力,就让模型最终超越了o1-preview!
具体的训练方法、超参数还有底层系统,没公开。
DeepSeek-R1 完全复现,上下文长度得达到32K以上,训练大概8000步,就算是只有1.5B参数的模型,起码都得花70,000 GPU小时。
如何利用强化学习把小型模型变成超厉害的推理模型呢?
- 知识蒸馏模型
- 还创新性地引入了强化学习迭代延长方法。
团队推出 DeepScaleR-1.5B-Preview 模型,经过4万个高质量数学问题的训练,训练一共用了3800个A100 GPU小时。
最终,成本只需约4500美元,省了18.42倍!同时模型的性能还在几个竞赛级数学基准中,超过了o1-preview。
关键发现
很多人认为强化学习只对大型模型有用,其实强化学习在小型模型上也能发挥显著作用。
Deepseek-R1 发现,直接在小型模型上用强化学习,效果不如知识蒸馏。在Qwen-32B模型上做对比实验,强化学习只能让AIME测试的准确率达到47%,但只用知识蒸馏就能达到72.6%。
不过,要是从更大的模型中,通过蒸馏得到高质量的SFT数据,再用强化学习,小模型的推理能力也能大幅提升。
研究证明了这一点:
- 通过强化学习,小型模型在AIME测试中的准确率从28.9%提高到了43.1%。
不管是只用监督微调,还是只用强化学习,都没办法让模型达到最佳效果。只有把高质量的监督微调蒸馏和强化学习结合起来,才能真正发挥LLM的推理潜力。
之前的研究发现,强化学习直接在16K token的上下文环境里训练,和8K token比起来,效果并没有明显提升。这很可能是因为计算资源不够,模型没办法充分利用扩大后的上下文。
最近的研究也指出,模型回复太长,就会有很多冗余的推理内容,容易导致错误结果。
团队先在较短的8K token上下文里,优化模型的推理能力,这样一来,后续在16K和24K token的环境里训练时,就能取得更快、更明显的进步。
这种一步一步增加长度的方法,能让模型在扩展到更长的上下文之前,先建立起稳定的推理模式,从而提高强化学习扩展上下文长度的效率 。
训练数据
(1) 数据集
- 1984至2023年的美国国际数学邀请赛(AIME)、2023年之前的美国数学竞赛(AMC),以及来自Omni-MATH和Still数据集的各国及国际数学竞赛题目。
数据处理流程:
- ① 答案提取:对于AMC和AIME等数据集,使用 gemini-1.5-pro-002 模型从AoPS官方解答中提取答案。
- ② 重复问题清理:基于RAG,并结合 sentence-transformers/all-MiniLM-L6-v2 词向量嵌入来消除重复问题。同时,对训练集和测试集进行重叠检测,以防止数据污染。
- ③ 不可评分题目过滤:数据集(如Omni-MATH)中的部分问题,无法通过sympy数学符号计算库评估(得靠LLM判断)。这不仅会降低训练速度,还会引入不稳定的奖励信号,因此需要增加额外的过滤步骤,来剔除无法自动评分的问题。
在经过去重和过滤之后,就得到了约4万个独特的问题-答案对作为训练数据集。
奖励函数
(2) 奖励函数设计
按 Deepseek-R1 经验,用结果奖励模型(ORM)而不是过程奖励模型(PRM),来避免模型通过投机取巧得到奖励。
奖励函数返回值:
- 返回「1」:如果LLM答案正确,既能通过
LaTeX语法检查,又能通过Sympy数学验证,就给奖励。 - 返回「0」:要是LLM答案错误,或者格式不对,比如少了
<think>和</think>标记,那就不给奖励。
思维链
(3) 迭代增加上下文长度:从短到长的思维扩展
推理任务由于会生成比标准任务更长的输出,计算开销较大
- 这会同时降低轨迹采样(Trajectory Sampling)和策略梯度(Policy Gradient)更新的速度。
- 上下文窗口大小翻倍,则会导致训练计算量至少增加2倍。
这种情况产生了一个根本性的权衡取舍:
- 较长的上下文能为模型提供更充足的思维空间,但会显著降低训练速度;
- 较短的上下文虽然加快训练进度,但可能会限制模型解决那些需要长上下文的复杂问题的能力。
因此,在计算效率和准确性之间找到最佳平衡点至关重要。
基于 Deepseek 广义近端策略优化(GRPO)算法的训练方案包含两个主要步骤:
- 首先,使用 8K token 最大上下文长度进行强化学习训练,从而实现更有效的推理能力和训练效率。
- 随后,将上下文长度扩展到 16K 和 24K token,使模型能够解决更具挑战性的、此前未能攻克的问题。
短思维链: 8k
用8K上下文构建高效思维链推理
正式训练之前,先用 AIME2024 测试集对 Deepseek-R1-Distilled-Qwen-1.5B 模型进行评估,并分析推理轨迹数据。
- 错误答案里平均包含的token数量,是正确答案的3倍。—- 回答越长,越容易出错。
- 此外,冗长回答还会表现出重复模式,并未对对思维链推理(CoT)产生实质性的贡献。
- 因此,直接采用长上下文窗口进行训练效率可能不高,因为大部分token都没有被有效利用。
基于这些发现,团队决定先从 8K token 上下文长度开始训练。
- 在AIME2024测试里,获得了22.9%的初始准确率,只比原始模型低6%。
事实证明这个策略很有效:训练时,
- 平均训练奖励从46%提高到了58%
- 平均响应长度从5500 token减少到了3500 token。
把输出限制在 8K token 以内,模型能更高效地利用上下文空间。
- 不管是生成正确答案还是错误答案,token数量都大幅减少了。
在AIME准确率上,比原始基准模型还高了5%,用的token数量却只有原来的1/3左右。
长思维链: 16k
扩展至16K token上下文,关键转折点出现
在大约1000步后,8K token运行中发生了一个有趣的变化:响应长度再次开始增加。
- 然而,这却没有增加收益——输出准确率达到了平台期,并最终开始下降。
与此同时,响应截断比例从4.2%上升到了6.5%,这表明更多的响应在上下文长度的限制下被截断。
这些结果表明, 模型试图通过「延长思考时间」来提高训练奖励。
然而,随着更长的输出,模型越来越频繁地触及到 8K token上下文窗口的上限,从而限制了性能的进一步提升。
研究人员意识到这是一个自然的过渡点,于是决定「放开笼子,让鸟儿飞翔」。
他们选择了在第1040步的检查点——即响应长度开始上升的地方——重新启动训练,并使用了16K上下文窗口。
这种两阶段的做法比从一开始就用 16K token训练效率高得多:8K的预热阶段让平均响应长度保持在3K token而不是9K,这使得此阶段的训练速度至少提高了2倍。
在扩展上了下文窗口后,训练奖励、输出长度和AIME准确率都呈现稳定提升趋势。经过额外的500步训练,平均输出长度从3.5K增加至5.5K token,AIME2024的Pass@1准确率达到了38%。
长思维链: 16k
24K魔法,超越 o1-preview
在 16K token上下文环境下额外训练500步后,研究人员发现模型性能开始趋于平稳——平均训练奖励收敛在62.5%,AIME单次通过准确率徘徊在38%左右,输出长度再次呈现下降趋势。同时,最大输出截断比率逐渐升至2%。
为了最终推动模型性能达到o1级别,研究人员决定决定推出「24K魔法」——将上下文窗口扩大到24K token。
首先,将16K训练时的检查点设定在第480步,并重新启动了一个24K上下文窗口的训练。
随着上下文窗口的扩展,模型终于突破了瓶颈。在大约50步后,模型的AIME准确率首次超过了40%,并在第200步时达到了43%。24K的魔力发挥得淋漓尽致!
总体来看,训练历时约1750步。
- 最初的8K阶段使用了8块
A100GPU进行训练 - 而16K和24K阶段则扩展到32块
A100GPU进行训练。
整个训练过程共耗时约 3800个A100小时,相当于32块A100 GPU上运行了大约5天,计算成本约为4500美元。
研究人员用多个竞赛级别的数学评测基准来测试模型,像AIME 2024、AMC 2023、MATH-500、Minerva Math还有OlympiadBench。
这里报告的是Pass@1准确率,简单说,就是模型第一次就答对的概率。每个问题的结果,都是16次测试取平均值得到的。
【2025-2-12】斯坦福 OpenThinker-32B
斯坦福、UC伯克利、华盛顿大学等机构联手发布了一款SOTA级推理模型——OpenThinker-32B,并同时开源了高达114k的训练数据。
- 项目主页
- Hugging Face:OpenThinker-32B
- 数据集:OpenThoughts-114k
团队发现:
- 采用经DeepSeek-R1验证标注(基于R1蒸馏)的大规模优质数据集,便可训练出SOTA的推理模型。
OpenThinker-32B 性能直接碾压了李飞飞团队s1和s1.1模型,直逼 R1-Distill-32B。32B推理模型,仅用1/8数据,与同尺寸DeepSeek-R1打成平手

【2025-2-18】Grok-3
新霸主诞生:Grok-3 超过 DeepSeek R1 和 Gemini Flash thinking
2025年2月18日,马斯克 xAI 推出 Grok-3
AIME 2025性能测试中
- Grok-3 Reasoning Beta 版本在推理和计算时间复合评分93分
- 精简版本Grok-3 mini也达到了90分。
- 而DeepSeek-R1 只有75分
- Gemini-2 Flash Thinking仅54分。
数学推理中
- Grok-3获得93分
- DeepSeek-R1为73分;
科学推理中,
- Grok-3得分85分
- DeepSeek-R1为74分
编程推理中
- Grok-3达到79分
- 而DeepSeek-R1为65分
可见,Grok-3 在复杂数学推理和计算效率方面表现突出。
R1推出后不久,Gemini-2 Flash Thinking成新霸主,现在Grok-3后来居上。
【2025-3-9】LCPO
【2025-3-9】LCPO:RLHF中控制推理链长度
核心问题
- 现有推理语言模型(如链式思维模型)通过生成长推理链(CoT)提升性能,但存在显著缺陷:推理长度不可控。
这导致两种极端现象:
- 算力浪费:简单问题生成冗余长链(如数万token)
- 性能不足:复杂问题因推理链过早终止而失败
现有方法局限
- 强制控制:如S1方法通过插入特殊标记(如”Wait”)或截断实现长度约束,但破坏推理连贯性,性能下降显著(如图1)
- 通用方法:文本生成领域的长度控制技术(如调整位置编码)无法处理推理场景中长序列与算力分配的复杂权衡
直觉解决方案:动态调整推理复杂度
关键观察
- 长推理链通过多步验证提升准确性,但需消耗更多算力
- 短推理链牺牲细节以节省资源,但可能遗漏关键步骤
直觉设计
如果模型能根据用户指定的长度约束,自主调整推理复杂度(如简化步骤或增加细节),即可实现性能与成本的动态平衡。
方法实现:长度控制策略优化(LCPO)
长度预算 思考步骤占比 最终答案占比
- 512 tokens 20% 80%
- 4096 tokens 60% 40%
【2025-10-14】蚂蚁 Ring-1T
【2025-10-14】蚂蚁Ring-1T正式登场,万亿参数思考模型,数学能力对标IMO银牌
- 2025年9月30日,蚂蚁就放出 Ring-1T-preview 版本。多项榜单上崭露头角,展现出出色的自然语言推理与思考能力,也率先把开源思考模型的「天花板」推至万亿级。
- 2025年10月9日,蚂蚁开源通用语言大模型 Ling-1T:迄今为止参数规模最大的语言模型。
- 2025年10月14 日凌晨,万亿级思考模型 Ring-1T 又正式登场,全球首个开源的万亿参数思考模型
Ring-1T 完成了完整训练流程,包括继续通过大规模可验证奖励强化学习(RLVR)进一步增强推理能力,并结合人类反馈强化学习(RLHF)提升通用表现,模型整体能力更均衡。
高难度 IMO 测试中,Ring-1T 接入多智能体框架 AWorld,首次尝试便解出第1、3、4、5 题—— 4 题全对,达到 IMO 银牌水平,成为首个在国际奥数赛题上取得获奖级成绩的开源系统。
大模型符号推理
【2025-9-14】MIT PDDL-Instruct
2025年9月14日,大模型学会符号推理 pddl-instruct方法,twitter
PDDL 方法
- PDDL(Planning Domain Definition Language)即“规划领域定义语言”,描述规划问题的标准化形式语言,常用于定义任务目标、环境状态及可行动作规则;
- “invariant preservation”译为“不变量保持”,指在规划过程中,某些关键属性或约束条件始终保持不变,是确保规划逻辑一致性的重要准则。
详见转内专题:大模型多轮会话
多模态
【2025-2-15】VLM-R1
【2025-2-15】浙江大学博导赵天成博士与Om AI Lab团队成功把DeepSeek R1从纯文本领域成功迁移到了视觉语言领域,这是DeepSeek R1模型首次突破到视觉推理层面。
VLM-R1 将R1方法成功地应用于视觉语言模型,为多模态 AI 的研究开辟了新天地。
VLM-R1 表现令人惊艳。
- 首先,R1方法在复杂场景下展现出了极高的稳定性,这在实际应用中显得尤为重要。
- 其次,该模型在泛化能力方面表现卓越。
对比实验中
- Qwen2.5-VL 上同时用 R1 和 SFT
- 域内: RL 略优于 SFT
- 域外: 随着迭代步数增加, RL 大幅领先 SFT
- 传统 SFT(Supervised Fine-Tuning)模型在领域外的测试数据上随着训练步数的增加,其性能却逐渐下滑,而 R1模型则能在训练中不断提升。
- R1方法使得模型真正掌握了理解视觉内容的能力,而非仅仅依赖于记忆。
VLM-R1 的成功推出不仅证明了 R1方法的通用性,也为多模态模型的训练提供了新思路,预示着一种全新的视觉语言模型训练潮流的到来。
【2025-3-3】Visual-RFT
【2025-3-4】 DeepSeek R1迁移多模态,已开源
DeepSeek-R1 继文本、数学推理、代码等领域大放异彩后,其基于规则奖励的强化学习方法首次成功迁移到多模态领域
【2025-3-3】上海较大、AI实验室等推出 Visual-RFT(Visual Reinforcement Fine-Tuning),全面开源。
这一突破性技术使得视觉语言大模型具备更强的泛化能力,能以极少的样本完成高质量微调,在目标检测、分类、推理定位等任务中取得显著提升,甚至超越传统指令微调(SFT)方法。
Visual-RFT (Visual Reinforcement Fine-Tuning) 在视觉感知任务中采用强化学习方法的模型微调技术,并借鉴 DeepSeek-R1 的强化学习策略(GPRO),为多模态任务引入可验证奖励(Verifiable Rewards) 机制,以增强大视觉语言模型(LVLMs, Large Vision-Language Models) 在不同任务上的推理能力。
主要创新点:
- 强化学习迁移至视觉领域:突破传统认知,首次在多模态视觉大模型中验证基于规则奖励的有效性。
- 极少样本高效微调:相比传统 SFT 方法,Visual-RFT 仅需少量数据(10~1000 条样本)即可实现显著提升。
- 任务广泛:适用于 目标检测、开放目标检测、少样本分类和推理定位等任务。
- 推理能力增强:能够分析问题,进行 “think” 推理,从而实现更精准的视觉理解。
核心奖励函数
- 目标检测:采用 IoU 奖励(Intersection-over-Union, IoU Reward),通过计算预测边界框与真实边界框的重叠程度,确保模型不仅能识别目标,还能精准定位,提高检测的准确性和稳定性。
- 图像分类:采用分类准确性奖励(Classification Accuracy Reward, CLS Reward),通过对比模型预测类别与真实类别是否一致进行奖励,引导模型在有限数据下仍能精准区分细粒度类别,提升分类泛化能力。
- 推理定位:采用推理一致性奖励(Reasoning Consistency Reward),分析模型的推理逻辑是否符合指令,并结合 IoU 计算目标定位的准确性,确保模型不仅能回答问题,还能给出合理的思考过程,提高视觉推理能力。
Visual-RFT VS 传统 SFT:
| 方法 | 数据需求 | 泛化能力 | 推理能力 |
|---|---|---|---|
| SFT(监督微调) | 需要大量数据 | 泛化能力有限 | 仅依赖已有数据 |
| Visual-RFT | 仅需10~1000条数据 | 泛化能力强 | 能推理&解释 |
实验基于Qwen2-VL-2B/7B视觉语言模型,Visual-RFT 在以下任务中均大幅超越传统 SFT 方法
【2025-3-18】Skywork R1V
昆仑万维开源全球首个工业界多模态推理模型 Skywork R1V
2025年3月18日,昆仑万维开源全球首个工业界多模态推理模型 Skywork R1V(简称「R1V」)
R1V高效地将R1文本推理能力无缝推广到视觉模态,实现了多模态领域领先效果(非sota),并开源。
R1V三大亮点。
- 全球第一个工业界开源多模态+推理模型
- 性能接近甚至超越了规模大两倍的开源模型
- 通过开源让技术可以惠及到更多人
效果:
- 1️⃣ 视觉问答任务中,R1V直接对标Claude 3.5 Sonnet、GPT-4o等闭源模型,同时保留顶级文本推理能力。
- 2️⃣ MMMU基准测试中,R1V以69分创下同等规模新高,在MathVista上拿下67.5分,达到领先的开源模型水平。
参考:
- GitHub:Skywork-R1V
- Hugging Face:Skywork-R1V-38B
- 技术报告:Skywork_R1V.pdf
- 信息源:新智源
多模态思维链
【2025-3-25】一文看懂多模态思维链
新加坡国立大学、香港中文大学、新加坡南洋理工大学、罗切斯特大学的研究人员联合推出 多模态思维链综述, 提出 六大技术支柱
传统思维链(CoT)已经让AI在文字推理上变得更聪明,比如一步步推导数学题的答案。
但现实世界远比单一文字复杂得多——人能看图说话、听声辨情、摸物识形。
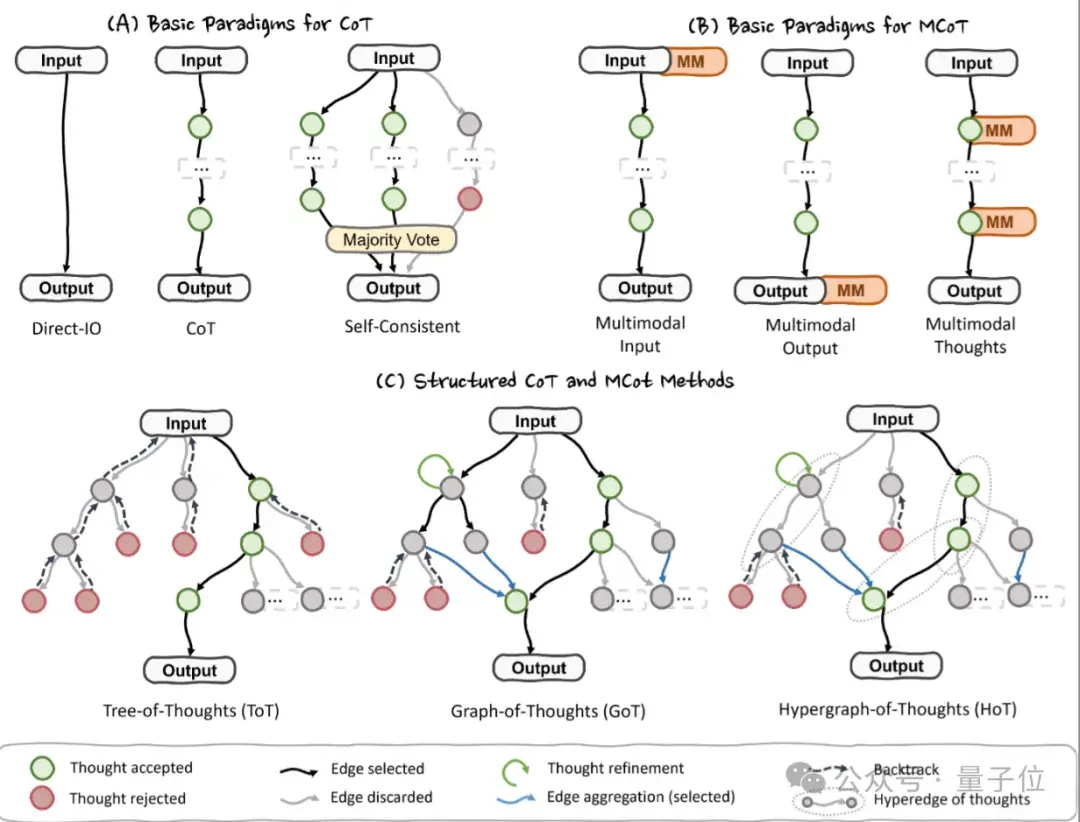
MCoT 给AI装上了“多感官大脑”,同时处理图像、视频、音频、3D模型、表格等多种信息。
比如,输入一张CT影像和患者的病史,AI就能输出诊断报告,还能标注出病灶位置。
这种跨越模态的推理能力,让AI更接近人类的思考方式。

【2025-2-25】Sonnet 混合
【2025-2-25】全球首个混合推理模型:Claude 3.7 Sonnet来袭,真实编码力压一切对手
Anthropic 发布最智能的模型以及市面上首款混合推理模型 —— Claude 3.7 Sonnet
Claude 3.7 Sonnet 可产生近实时响应或向用户展示扩展的逐步思考。
- 「一个模型,两种思考方式」(One model, two ways to think.),即标准和扩展思考模式。
- API 用户还可以对模型思考时间进行细粒度控制。
小模型推理
小模型也能学会推理
【2025-6-26】HRM 小模型
当前LLM推理主要靠CoT,缺陷: 任务分解复杂、数据需求大以及高延迟等问题。
- 任务拆解能力有限
- 数据集受限
- 时延高
受人类大脑启发(层次、多尺度),新加坡空间智能 提出 Hierarchical Reasoning Model (HRM) 全新循环架构,保持训练稳定性和效率的同时,实现高计算深度。
- 【2025-6-26】论文 Hierarchical Reasoning Model
- 代码 HRM
- 解读 只用2700万参数,这个推理模型超越了DeepSeek和Claude
原理
HRM 通过两个相互依赖的循环模块,在单次前向传递中执行顺序推理任务,而无需对中间过程进行明确的监督:
- 其中一个高级模块负责缓慢、抽象的规划
- 另一个低级模块负责处理快速、细致的计算。
HRM 仅包含 2700 万个参数,仅使用 1000 个训练样本,便在复杂的推理任务上取得了sota性能。
该模型无需预训练或 CoT 数据即可运行,但在包括复杂数独谜题和大型迷宫中最优路径查找在内的挑战性任务上却取得了近乎完美的性能。
此外,在抽象与推理语料库 (ARC) 上,HRM 的表现优于上下文窗口明显更长的大型模型。
- ARC 是衡量通用人工智能能力的关键基准。
HRM 核心设计灵感来源于大脑:分层结构 + 多时间尺度处理。
- 分层处理机制:大脑通过皮层区域的多级层次结构处理信息。
- 高级脑区(如前额叶)在更长的时间尺度上整合信息并形成抽象表示
- 而低级脑区(如感觉皮层)则负责处理即时、具体的感知运动信息。
- 时间尺度分离:这些层次结构的神经活动具有不同的内在时间节律,体现为特定的神经振荡模式。
- 这种时间分离机制使得高级脑区能稳定地指导低级脑区的快速计算过程。
- 循环连接特性:大脑具有密集的循环神经网络连接。
- 这种反馈回路通过迭代优化实现表示精确度的提升和上下文适应性增强,但需要额外的处理时间。
- 这种机制能有效规避反向传播时间算法(BPTT)中存在的深层信用分配难题。
效果
27M 推理模型达到SOTA性能
在多项推理基准测试中击败了 OpenAI 的 o3-mini-high、DeepSeek R1 和 Claude。
该模型仅用 1000 个训练样本且无需预训练。
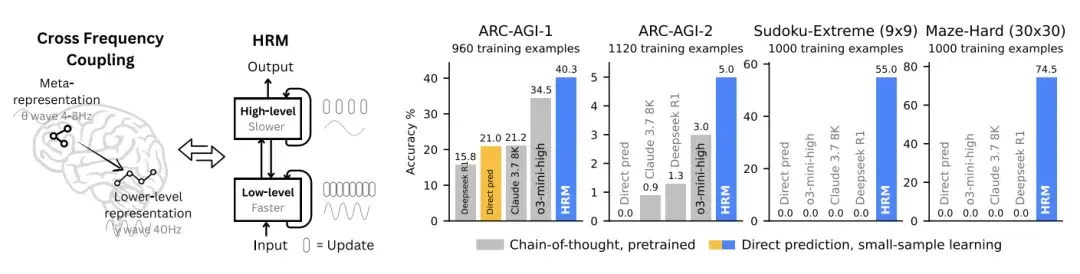
论文没有讨论 HRM 架构的局限性,其扩展性未知
也期待与在相同数据上训练的小型 Transformer 模型进行对比!
【2026-5-20】推理内化小模型 HRM-Text
类脑架构,1B 模型实现更好的模型推理效果
详见站内专题:类脑计算
【2025-6-7】Easy-to-Hard Reasoner
表明:1.5B-3B 小模型,也能通过强化学习掌握复杂推理能力!课程学习(Curriculum Learning)+RL(Reinforcement Learning)
- 【2025-6-7】Texas A&M University 「Curriculum Reinforcement Learning from Easy to Hard Tasks Improves LLM Reasoning」
- 💡 Easy-to-Hard Reasoner —— 一种模拟人类学习方式的课程式强化学习(Curriculum RL):从简单任务学起,逐步挑战更难的题目,帮助模型建立稳固的推理基础,再向复杂问题泛化!
- 📈 在数学解题(MATH、GSM8K、AQuA)和规划任务(Countdown、Blocksworld)等多个 benchmark 上,我们的方法显著提升小模型在高难度和OOD任务中的表现,甚至让原本“连简单题都做不对”的模型学会了解题思路!
- 📚 更难得的是,我们不仅有实验,还理论上证明:循序渐进式学习更高效、收敛更快、所需样本更少!
【2025-7-17】QuestA
【2025-10-4】1.5B推理模型新SOTA,RL训练新解法打破「简单题过拟合、难题学不动」的魔咒
问题
RL 训练存在数据平衡问题:简单任务导致模型过度自信,而难任务提高推理能力,但由于样本效率低下,学习速度变慢。
- 简单任务倾向于使模型过拟合,使其在特定、更简单的问题上非常准确。然而,这导致模型变得过度自信,从而妨碍了其泛化能力,难以解决更复杂的任务。
- 难任务提高了模型的推理能力,但具有低样本效率,需要更长的时间来学习和进展。稀疏的奖励和任务的难度使得在困难问题上的训练变得缓慢,限制了整体的学习速度。
两难:
简单任务导致熵坍缩 vs. 难任务减缓学习效率
QuestA 介绍
【2025-7-17】清华大学、上海期智研究院、Amazon 和斯坦福大学等机构提出 QuestA。
- 通过在训练困难任务时引入部分解决方案提示,QuestA 帮助模型更快地学习,同时不牺牲在简单任务上的表现。
-
这确保了模型能够从简单任务和难任务中获益,提升其推理能力,同时避免过拟合或学习缓慢。
- 论文标题:QuestA: Expanding Reasoning Capacity in LLMs via Question Augmentation
- HF 模型地址:QuestA-Nemotron-1.5B
- GitHub 地址:foreverlasti
结论
- 强化学习可以提升模型能力
- 强化学习可在不牺牲效率与泛化能力的前提下,持续拓展模型的能力边界。
QuestA 方法
QuestA 通过「数据增强 + 迭代课程学习」的组合设计,实现对 RL 训练的高效改进
核心逻辑:
- 聚焦高难度问题:采用两阶段过滤流程筛选训练数据
- 首先以 DeepSeek-R1-Distill-1.5B 为筛选模型,从 OpenR1-Math-220K 数据集中选出仅 0-1 次正确(8 次采样)的 26K 高难度样本;
- 再对增强后的提示词进行二次筛选,保留模型仍难以正确解答(0-4 次正确)的样本
- 最终聚焦不超过 10K 的核心困难任务,确保训练资源用在能力突破点上。
- 动态调整提示比例:为避免模型依赖提示,QuestA 设计迭代式
课程学习- 先以 50% 比例的部分解决方案作为提示(p=50%)训练至性能饱和
- 再将提示比例降至 25%(p=25%)继续训练,逐步引导模型从「依赖提示」过渡到 “自主推理”,实现能力的真实迁移。
- 轻量化集成 RL:QuestA 无需修改 RL 算法核心或奖励函数,仅通过替换训练数据(用增强提示词替代原始提示词)即可集成至现有 RL pipeline(如 GRPO、DAPO),具备「即插即用」的灵活性。

效果
QuestA(问题增强): 训练过程中注入部分解题提示,QuestA 实现两项重大成果
- Pass@1 的 SOTA 性能:在 1.5B 模型上实现了sota,甚至在关键基准测试中超越了早期的 32B 模型。
- 提升 Pass@k:在提高 Pass@1 的同时,QuestA 不会降低 Pass@k 性能 —— 事实上,它通过让模型在多次尝试中进行更有效的推理,从而提升了模型能力。
【2025-9-24】普林斯顿 RLMT
【2025-9-24】普林斯顿陈丹琦: 8B模型在聊天效果上居然打败GPT-4
论文提出 RLMT (Reinforcement Learning with Model-rewarded Thinking) 新方法,让模型真正做到“先思后言”,效果好到离谱。
模式对比
| 模式 | 奖励模型 | 场景 | 分析 |
|---|---|---|---|
| RLHF | 训练模型 | 通用场景 | |
| RLVR | 规则验证器 | 可验证领域 | |
| RLMT | 结合cot的模型 | 通用领域 |
1️⃣ 核心创新点:会“思考”的强化学习 🧠
- 过去 RLHF是让模型直接输出答案,而为数学推理设计的RLVR虽然有思考过程(CoT),但奖励依赖于有标准答案的任务,不适用于开放式聊天。
- RLMT巧妙地把两者结合, 要求模型在回答前,先生成一段详细的思考过程(
<think>…</think>),然后再输出最终答案。 - 最关键的是,用一个在人类偏好上训练好的奖励模型来给最终答案打分,然后用这个分数去反向优化整个生成过程(包括思考和回答)。
- 简单说,就是不仅教模型说什么,更教模型怎么去思考,从而给出更好的答案。
2️⃣ 实验效果:小模型的大胜利 🚀
效果真的太惊艳, 基于Llama-3.1-8B和Qwen2.5-7B训练出的模型,在AlpacaEval2和WildBench这类权威聊天基准上,分数不仅远超了Llama-3.1-70B和Qwen2.5-72B这种10倍大的模型,甚至还击败了GPT-4.0,直逼Claude-3.7-Sonnet。真正实现了“小模型,大能量”
3️⃣ 意外发现:训练让思考方式进化 ✨
经过RLMT训练后,模型的“思考模式”会发生进化。从SFT后的那种刻板的、清单式的规划,演变成了一种更高级的、类似人类的思考方式——会权衡利弊、会把零散的想法归纳成主题、还会在规划中迭代优化。
这说明模型真的在学习如何更聪明地思考,而不仅仅是模仿。而且这个方法还能直接用在Base模型上(“Zero”训练),大大简化了对齐流程。
总之,与其疯狂堆参数,不如教模型一个好的思考模式。对于追求高效能、高性价比模型训练的我们来说,绝对是必读佳作!
【2025-11-09】VibeThinker-1.5B
【2025-11-09】新浪微博AI推出开源大型语言模型(LLM)——VibeThinker-1.5B。
该模型拥有15亿参数,在数学推理与代码生成任务中却展现出超越 6710亿 参数竞品的性能。
VibeThinker-1.5B 模型在数学和代码任务上表现出色,达到行业领先的推理性能,甚至超越了体量达 6710亿 参数的竞争对手 DeepSeek的R1模型。该模型还能与Mistral AI的Magistral Medium、Anthropic的Claude Opus4和OpenAI的gpt-oss-20B Medium等多个大型模型抗衡
VibeThinker-1.5B 可通过 Hugging Face、GitHub 及 ModelScope 平台免费开放下载,供开发者与研究机构使用。
- ⭐ VibeThinker-1.5B — SOTA reasoning in a tiny model.
- 🚀 Performance: Highly competitive on AIME24/25 & HMMT25 — surpasses DeepSeek R1-0120 on math, and outperforms same-size models in competitive coding.
- ⚡ Efficiency: Only 1.5B params — 100-600× smaller than giants like Kimi K2 & DeepSeek R1.
- 💰 Cost: Full post-training for just $7.8K — 30-60× cheaper than DeepSeek R1 or MiniMax-M1.
-
🧠 Innovation: Powered by our Spectrum-to-Signal Principle (SSP) and MGPO framework.
- Github: VibeThinker
- Arxiv : Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B
VibeThinker-1.5B 采用名为“谱-信号原则”(Spectrum-to-Signal Principle,SSP)训练框架,将监督微调和强化学习分为两个阶段。
- 第一个阶段注重多样性
- 第二个阶段则通过强化学习优化最优路径,使得小模型也能有效探索推理空间,从而实现信号放大
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
