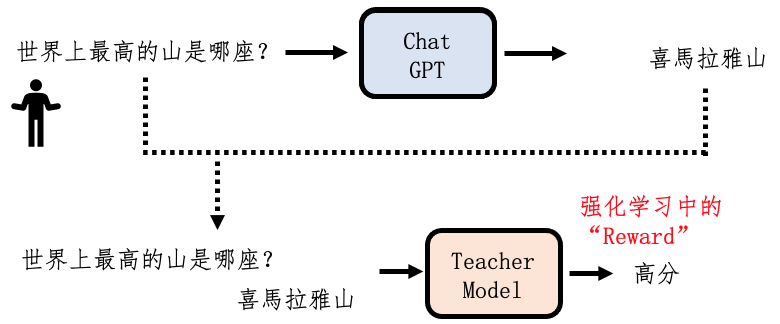
- RLHF
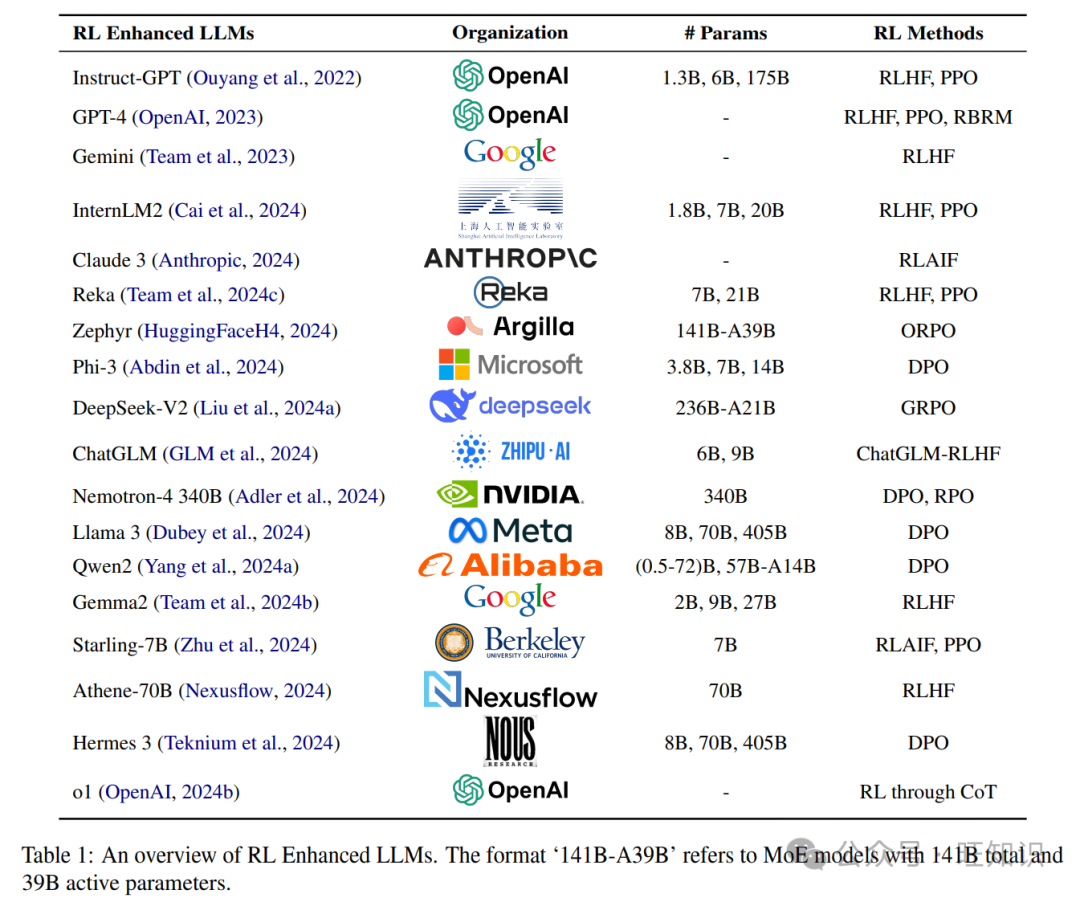
- LLM RL
- RLHF 三步骤
- 思考
- 改进
- PPO
- 非RL对齐方式
- 总结
- DPO 直接偏好优化
- DPO 改进
- SPIN
- DMPO
- ODPO
- ORPO
- SimPO
- TDPO
- GRPO
- DAPO —— 改进 GRPO
- SPCT
- 【2025-3-16】HRL-TAR
- 【2025-5-16】GiGPO
- 【2025-5-19】港科大 GVPO
- 【2025-5-23】GRPO-λ
- GHPO
- 【2025-7-25】Qwen3 GSPO
- 【2025-5-22】ARPO GUI Agent
- 【2025-7-26】ARPO
- 【2025-7-28】GMPO
- 【2025-7-10】QRPO
- 【2025-9-25】阿里高德 Tree-GRPO
- 【2025-10-7】港中文 EEPO
- 【2025-10-9】Training-Free GRPO
- 【2026-2-5】小红书 REAL 改进 GRPO
- 【2026-3-20】阿里 FIPO
- 自博弈(Self-play)
- 自学习
- 无监督数据+RL
- 加速
- 实现
- 结束
RLHF
2023年-2024年,越来越多新的 “RLHF” 类算法出现,其中包括 DPO 等变体,也包括 RLOO/REINFORCE 等方面的工作。
基本出发点: 简化 RLHF 流程,实现更低的训练成本和更好的性价比。
【2025-11-11】twiiter RL 过山车
- 深度强化学习就像过山车——只有意志坚定的人才能驾驭
- 原本坚信离线强化学习是唯一能实现有意义进步的强化学习方法,我错了
LLM RL
总结
【2025-9-10】清华、上海AI Lab、上海交大和北大等联合综述:LLM RL 发展情况,从 RLHF—>DPO—>RLVR。
推理LLMs诞生时间线
- 开始: OpenAI o1 商用闭源, DeepSeek-R1 开源推理模型
- 标杆:商用 Claude/Gemini/Seed,开源 GPT-oss/Qwen3、Minimax、Llama
LLM RL五大核心争议
- RL 是否可以习得新知识:
- 主流观点:不可以(KL 散度作为理论透镜,结合一些研究证据如 pass@k 提升不一致 )
- 但也有研究发现通过持久且稳定的训练可以发现、组合一些新模式。
- SFT 和 RL 关系:
- SFT 是模仿学习和行为克隆,倾向于记忆模式
- RL 则通过偏好学习获得更强泛化性。
- 预训练知识(先验)对 RL 影响:
- 预训练决定 RL 上限
- 弱先验模型需要增加CPT环节才能更好RL。
- 训练技巧和陷阱:集中在去偏差与归一化方面,但学界和业界都需要一个标准统一的实验框架来避免不同工作的结果相互冲突的问题。
- 稀疏和稠密奖励:各有优劣,前者在可验证任务上可扩展性好,后者能给予密集的指导信号,未来趋势是两者结合。
LLM RL分类谱系
算法对比
思考
强化学习中,智能体(Agent)无法预知哪个是”最佳动作”,但能观察到中间步骤和最终游戏状态(胜利或失败),并从中学习。
以语言模型为例
- 问:”2 + 2 等于几?”
- 一个未对齐的语言模型可能输出 3、4、C、D、-10 等任何内容。
通过设计一个奖励函数来引导它:
- 输出数字(如 3)比输出字母(如 C 或 D)要好。
- 输出的数字 3 比 8 更接近正确答案 4。
- 输出 4 是完全正确的。
通过这种方式,一个奖励函数就被设计出来了。
【2023-7-2】思考:
- SFT阶段有那么点BC的意思,只是有些牵强,毕竟只是一次性的;
- RLHF倒是像模仿学习中的Inverse RL,ppo以reward模型为样本,学习一个泛化能力更好的奖励模型,同时引导actor生成;
- 交互式负反馈估计要等yann lecun的世界模型的来解决了
SFT 模型只用于得到一个baseline,仅在reddit数据集上训练过,而与之对比的 RL policy 是最终版本,训练样本量级相差较多。
RL finetune 过程存在 Goodhart's Law
“when a measure becomes a target, it ceases to be a good measure”。
【2023-7-10】拾象报告, 飞书
- 中期来看,RLHF 不应该是 Alignment 的唯一手段, Direct Preference Optimization 和 Stable Alignment 是新路径
Andrej Karpathy
Andrej Karpathy X 上 最新观点:强化学习很强,但不是终极答案
强化学习(RL)在 AI 领域目前很火,而且确实能带来显著的性能提升。
RL 核心逻辑:通过奖励信号(比如“这次做得好”或“这次很差”),调整模型未来行为的概率。这种方法比传统的监督微调(SFT)更高效,因为它通过“试错”能挖掘出更优的策略,而不需要人工事无巨细地标注数据。这就是所谓的“verifier functions”(验证函数)带来的杠杆效应——你只需要告诉模型结果好坏,它自己就能摸索出更好的路径。
但 Karpathy 也提出了两个关键的担忧,说明 RL 可能不是 AI 智能进化的全部答案:
- 长任务的局限性(渐进问题):
- 当任务变得很长(比如需要几分钟甚至几小时的交互),RL 的机制看起来有点低效。你花了大量时间完成一个复杂任务,最后只得到一个单一的“得分”(scalar reward),然后用这个得分去调整整个过程中的行为权重。这就像跑了一场马拉松,最后只告诉你“跑得不错”或“跑得不好”,但没有具体告诉你哪里可以改进。这种方式在超长任务上显得粗糙,效率不高。
- 人类学习的差异(机制问题):
- 人类在学习时并不完全依赖“结果好坏”这种单一信号。我们会通过反思来提取更多信息,比如“这次哪里做得好?哪里出了问题?下次该怎么改进?”这种反思过程会生成明确的经验教训(lessons),就像一条条指导原则,帮我们在未来做得更好。Karpathy 觉得,RL 缺少这种类似人类反思的机制,而这可能是 LLMs 未来进化的关键。
人类学习的启发:反思与“经验教训”
Karpathy 用“second nature”(第二本能)来形容人类通过反思逐渐掌握技能的过程。
比如,学骑自行车时,摔了几次后会总结:“我得保持平衡,眼睛看前方。”
这种总结就像一条“经验教训”,直接指导你下次的行为。AI 应该也有类似机制,尤其是像 LLMs 这样有强大语言能力和上下文学习能力的模型。
例子:
- LLMs 在处理某些任务(比如数单词“strawberry”里的“r”)时,因为分词和内部计算的限制,表现得很吃力。
- Anthropic 给 Claude 加了一条“补丁”提示,大意是:“如果要数字母,先把单词拆成单个字母,用逗号隔开,然后一个一个数。”
- 这条提示就像人类总结的“经验教训”,直接告诉模型怎么做更有效。
问题:这条“补丁”是工程师手动加的。
能不能让模型自己通过实践和反思,自动生成这样的“经验教训”,而不是靠人类硬编码?
更进一步,这些教训能不能被“蒸馏”成模型直觉(类似人类睡觉时巩固记忆),避免上下文窗口无限膨胀?
提出的一种新算法思路
Karpathy 设想可能的算法,灵感来自人类反思的机制,专门为 LLMs 设计:
- 多次尝试(Rollouts):让模型针对一个任务做几次尝试,每次记录行为和结果(奖励高低)。
- 反思阶段:把这些尝试的结果塞进上下文窗口,用一个“元提示”(meta-prompt)引导模型分析:“这次哪里做得好?哪里不好?下次该怎么改进?”生成一条明确的“经验教训”(lesson),以字符串形式记录。
- 更新系统提示:把新生成的“教训”加到系统提示中,或者存到一个“教训数据库”里,供未来使用。
- 长期优化:为了避免上下文窗口塞满这些教训,可以通过某种方式(类似“睡眠”)把它们蒸馏到模型权重中,形成更高效的直觉。
这种方法利用了 LLMs 的独特优势——能理解和生成语言,能在上下文里学习新策略。而传统 RL(比如在 Atari 游戏或机器人控制中)没有这种语言能力,所以无法直接套用这个思路。
为什么这很重要?未来的 S 曲线
RL 确实比监督微调更“苦涩”,而且还会带来更多性能提升。但他也相信,RL 只是当前的一条 S 曲线(技术进步的阶段性曲线),未来还有更多曲线等待发现。特别是对于 LLMs 这样有语言能力的模型,可能会有全新的学习范式,超越传统 RL 的局限。这些范式可能跟人类反思、总结、归纳的方式更接近,而且在长任务和复杂问题上更高效。
他提到的 ChatGPT 新增的“Memory”功能,可能是一个雏形,但目前只用于个性化定制(比如记住用户偏好),还没用于解决复杂问题。Karpathy 的设想是:如果能让模型自己总结经验教训,并在实践中不断优化,可能会开启 AI 智能的新篇章。
Online Learning
Online Learning 终极目标
- 赋予模型突破人类现有知识体系的能力。
要实现从 AGI 到 ASI的飞跃,模型必须学会自主探索与自我奖励,从而生成全新知识。这正是 Online Learning 的核心愿景。
Online Learning
- 并非单一技术,而是一个复杂的范畴。区别于Lifelong Learning和Meta Learning。
- Online Learning 不等同于 Online RL。Online RL 是一种利用在线数据更新模型权重的“方法”,而 Online Learning 是一个更宏大的“系统级能力”,指整个 Agent 系统根据交互改变未来行为的能力。
- 这种改变不一定通过更新权重,也可以通过更新Memory或调整Context实现,终极形态,是让模型具备强大的内生 in-context learning 能力。
Online Learning 面临两大核心瓶颈:一是如何从复杂、稀疏的真实环境中获取清晰有效的 Reward 信号;二是当前模型自身缺乏快速、即时的学习和纠错能力。
两种主要技术路径:
- 传统的 In-weights Learning
- 更灵活的 In-context Learning。
从实用角度看,优化 Memory 等外部组件,是实现系统级学习的现实路径。
在系统架构层面,“端到端”是实现高效 Online Learning 的关键。
推荐系统的经验是深刻的教训:其早期的 Online Learning 效果不彰,根本原因在于其“召回-排序”等多模块拼接的非端到端架构。
这导致用户的Reward无法有效优化整个系统,使迭代陷入局部最优。LLM 的成功恰恰得益于端到端架构,这启示我们,未来的 Agent 系统必须尽可能实现端到端,才能让学习信号贯穿全局。
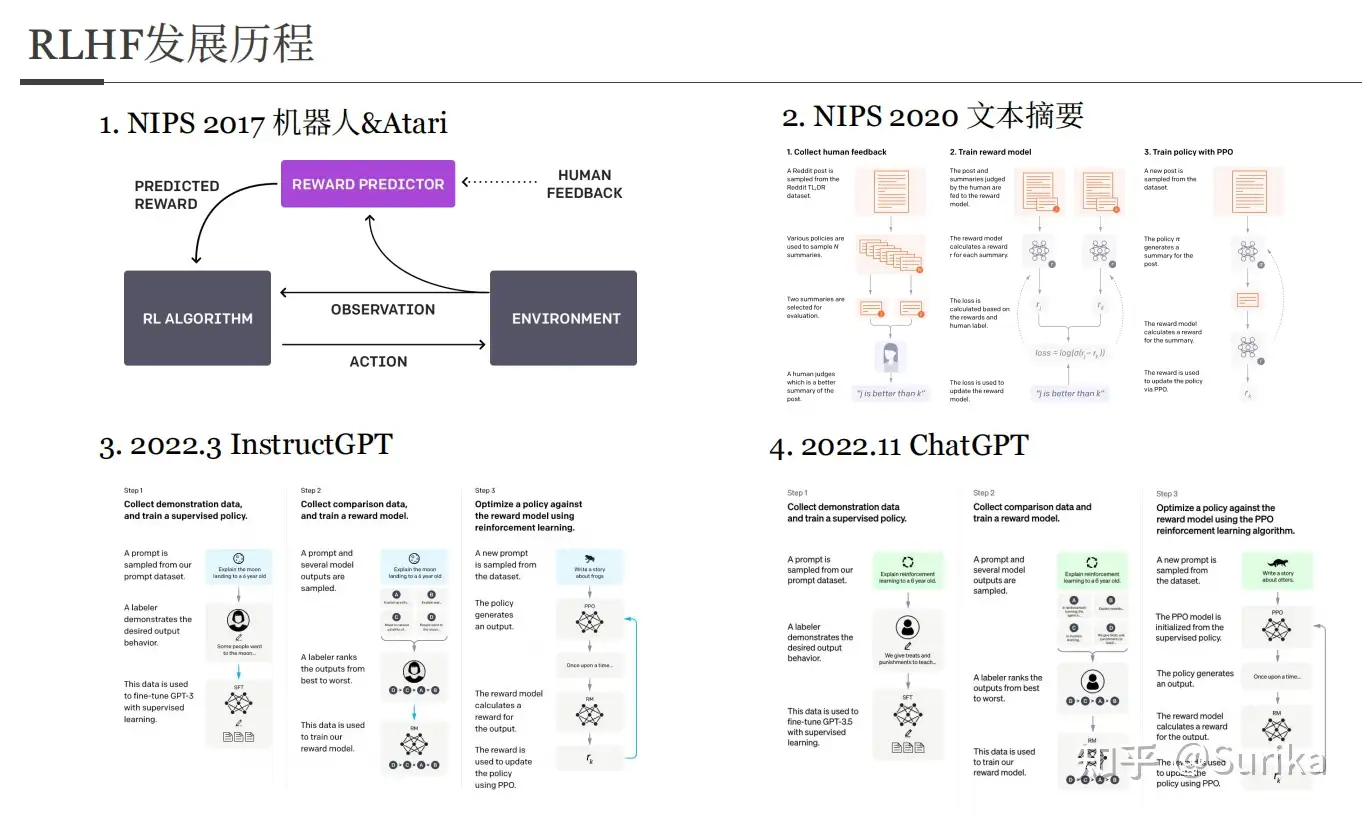
RLHF 历史
RLHF历史 详见
- 2017年,NIPS 首次出现这一思想, Atari 游戏实验
- 2020年, NIPS 用于文本摘要
- 2022年3月,OpenAI 应用到 InstructGPT 中
- 2022年11月, OpenAI 应用到 ChatGPT 中
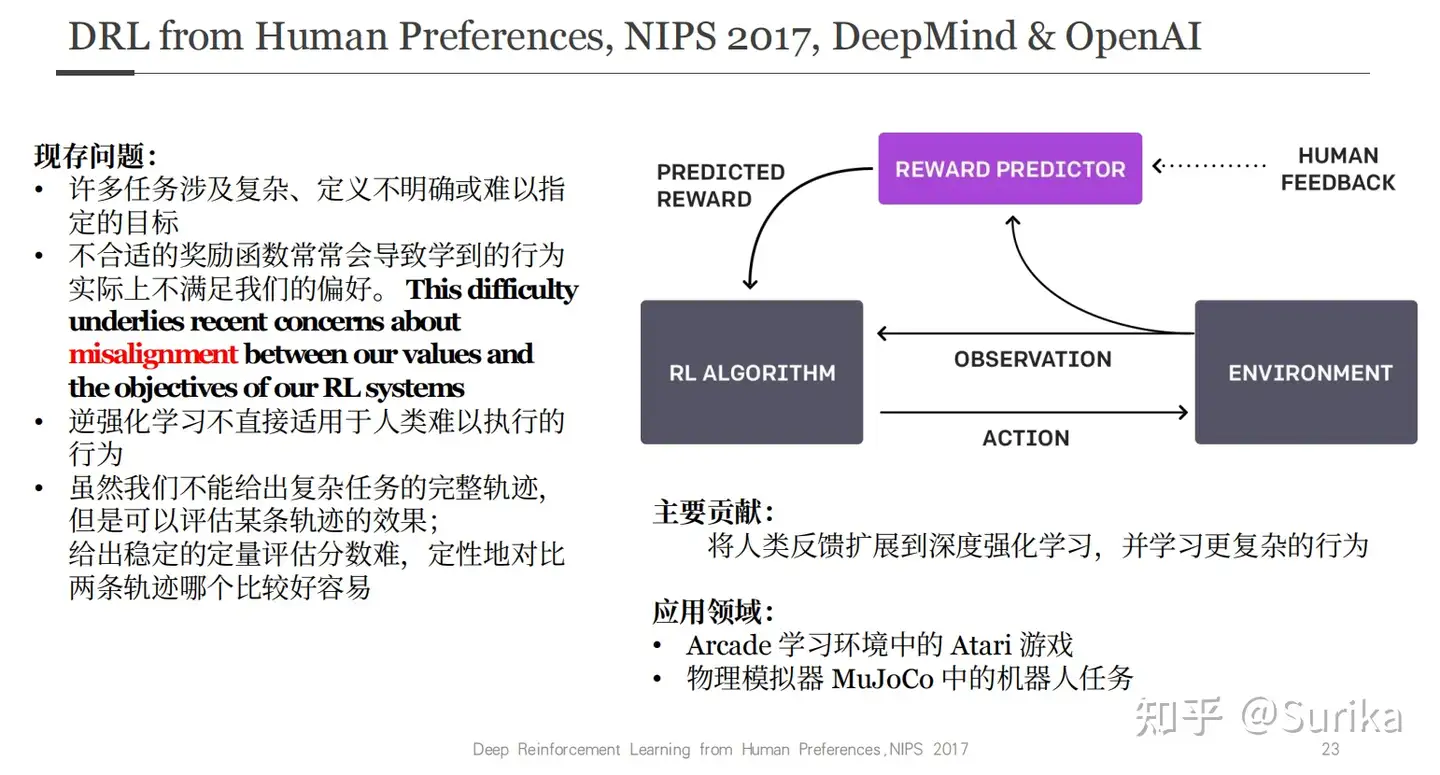
- 2020年的NIPS上,OpenAI已经尝试将其用于文本摘要任务,并取得了很好的效果。
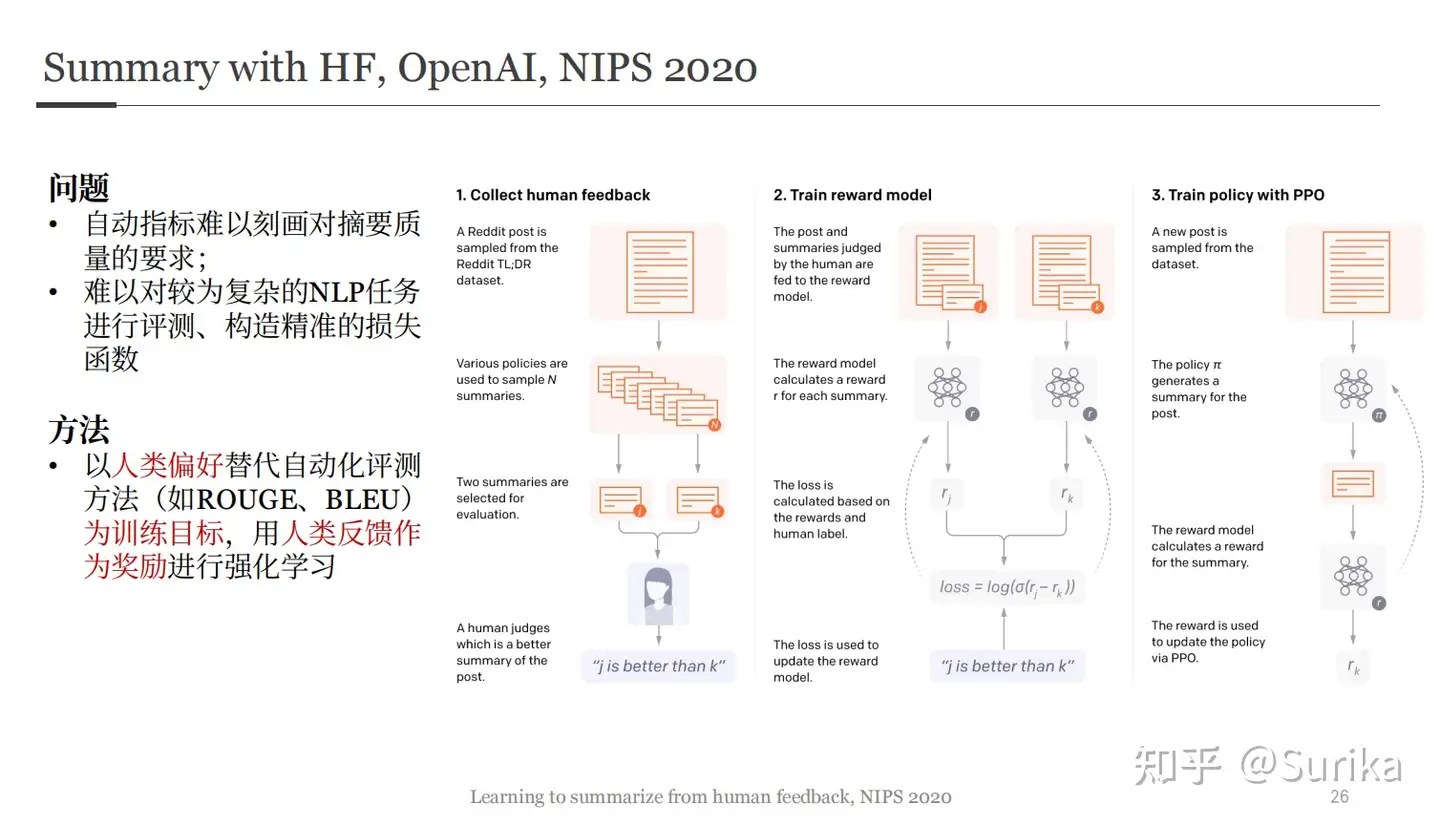
【2023-2-20】为什么以前一些RLHF工作不work,关键点:
- 标注同学更倾向抽取式答案,模型学偏了,而OpenAI这次在标注上下了狠功夫。另外该工作是用人作为RM,效率较低。
- DeepMind Sparrow其实只在某个对话数据集上进行了训练,和真实分布不一样,另外它加入的Rule Reward可能也有影响。核心还是没在数据上下狠功夫,就是简单follow了一下OpenAI。
OpenAI 的 InstructGPT、DeepMind 的 Sparrow 和 Anthropic 的 Constitutional AI 使用 人类反馈强化学习 (Reinforcement Learning From Human Feedback,RLHF) 来微调模型,该方法使用基于人类偏好的标注数据。
- 在 RLHF 中,根据人类反馈来对模型的响应进行排序标注 (如,根据人类偏好选择文本简介)。
- 然后,用这些带标注的响应来训练偏好模型,该模型用于返回 RL 优化器的标量奖励。
- 最后,通过强化学习训练对话代理来模拟偏好模型。
- 有关更多详细信息,请参阅我们之前关于 RLHF 的文章: ChatGPT 背后的“功臣”——RLHF 技术详解。
过去几年里各种 LLM 根据人类输入提示 (prompt) 生成多样化文本的能力令人印象深刻。然而,对生成结果的评估是主观和依赖上下文的
- 想要生成一个有创意的故事、一段真实的信息性文本,或者是可执行的代码片段,难以用现有的基于规则的文本生成指标 (如 BLUE 和 ROUGE) 来衡量。
- 另外,现有的模型通常以预测下一个单词的方式和简单的损失函数 (如交叉熵) 来建模,没有显式地引入人的偏好和主观意见。
如果用生成文本的人工反馈作为性能衡量标准,或者更进一步用该反馈作为损失来优化模型,那不是更好吗?这就是 RLHF 的思想:
- 使用
强化学习方式直接优化带有人类反馈的语言模型。 - RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。
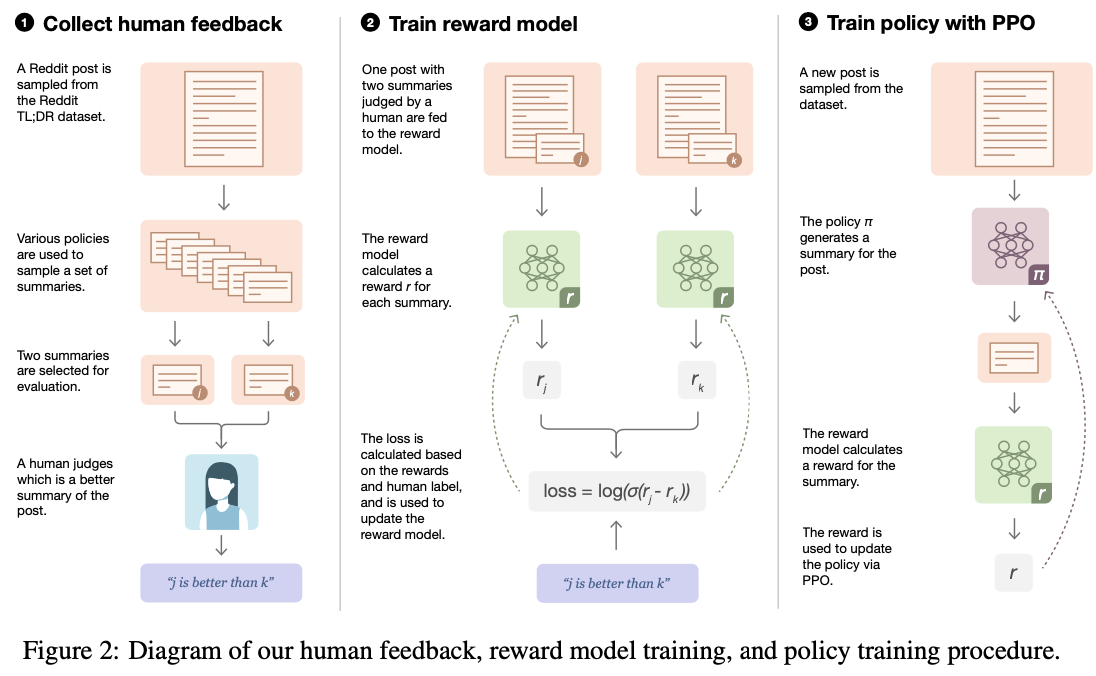
RLHF 三步骤
图解
PPO训练全过程
InstructGPT
【2022-12-8】ChatGPT 究竟如何煉成?台大教授李宏毅提可能的訓練步驟
- ChatGPT/InstructGPT详解
- 【2022-12-12】台大陈蕴侬老师新鲜出炉的关于ChatGPT的前身InstructGPT的解读视频
InstructGPT/ChatGPT 相比 GPT-3 有更强的 Zero-Shot 能力,Few-Shot 很多时候已经不太用的着了,但是Prompt还是需要的,由此还催生了一个新的行当——Prompt工程。参考:ChatGPT-Introduction
在“人工标注数据+强化学习”框架下,ChatGPT 训练过程分为以下三个阶段:
- (1)第一阶段:冷启动阶段的监督策略模型。
GPT 3.5尽管很强,但是它很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。为了让GPT 3.5初步具备理解指令中蕴含的意图- 首先会从测试用户提交的prompt(指令或问题)中随机抽取一批数据(12,725),靠专业的标注人员(肯尼亚),给出指定prompt的高质量答案
- 大概用了一个 40 人左右的标注团队来完成对它的数据的打标和微调。
- 然后用这些人工标注好的
<prompt,answer>数据来 Fine-tune GPT 3.5模型。 - 经过这个过程,GPT 3.5初步理解人类prompt中所包含意图,并给出相对高质量回答的能力,但是仅仅这样做还不够。
- img
- 首先会从测试用户提交的prompt(指令或问题)中随机抽取一批数据(12,725),靠专业的标注人员(肯尼亚),给出指定prompt的高质量答案
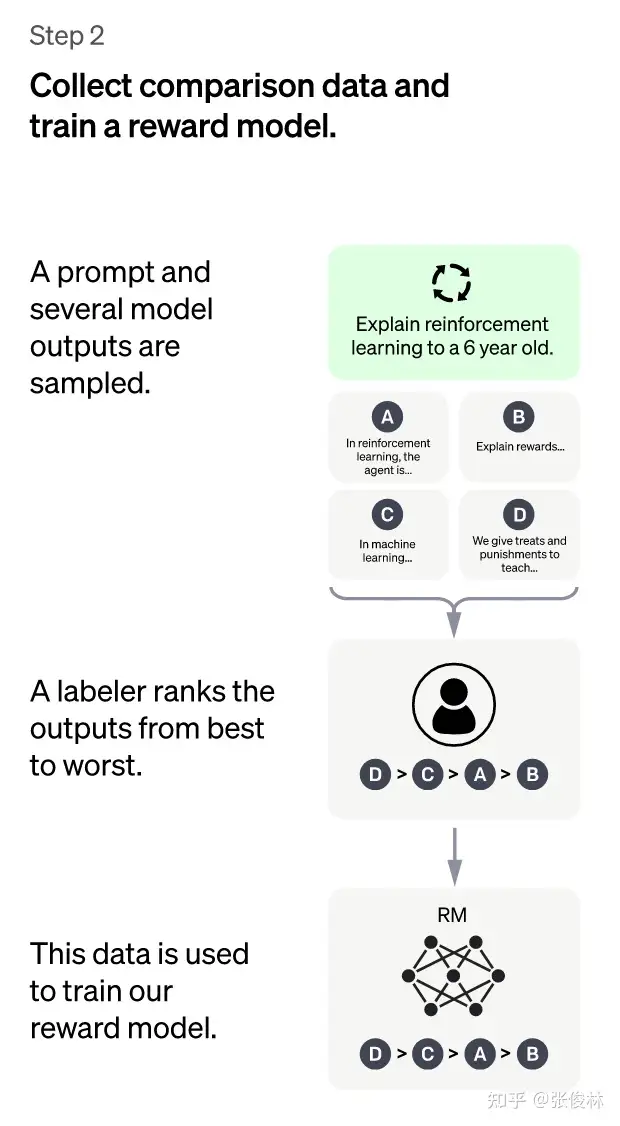
- (2)第二阶段:训练奖励模型(Reward Model,RM)。通过人工标注数据训练回报模型,类似于教练或老师辅导。
- 随机抽样一批用户提交的prompt(大部分和第一阶段的相同),使用第一阶段 Fine-tune 好的冷启动模型,对于每个prompt,由冷启动模型生成K个不同的回答,于是模型产生出了<prompt,answer1>,<prompt,answer2>….<prompt,answerK>数据。
- 标注人员对K个结果按照很多标准(相关性、富含信息性、有害信息等诸多标准)综合考虑进行排序,给出K个结果的排名顺序,这个人工标注数据集有 33,207个prompts,以及在不同回答组合下产生的扩大10倍的答案
- 用这个排序结果数据来训练奖励模型 (reward model),对多个排序结果,两两组合(pair-wise),形成多个训练数据对。RM模型接受一个输入,给出评价回答质量分数。对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
- img
- 总结:这个阶段,首先由冷启动后的监督策略模型为每个prompt产生K个结果,人工根据结果质量由高到低排序,以此作为训练数据,通过 pair-wise learning to rank 模式来训练回报模型。对于学好的RM模型来说,输入<prompt, answer>,输出结果的质量得分,得分越高说明产生的回答质量越高。
- 损失函数:其中 rw是win的得分,rl是lose的得分
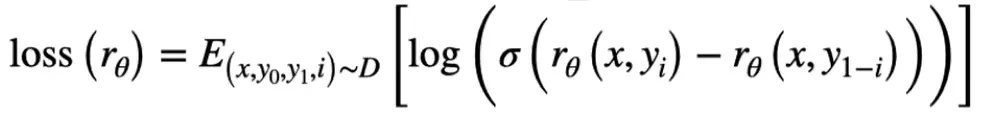
- 训练好的奖赏模型只是强化学习所使用的奖赏模型中的一部分
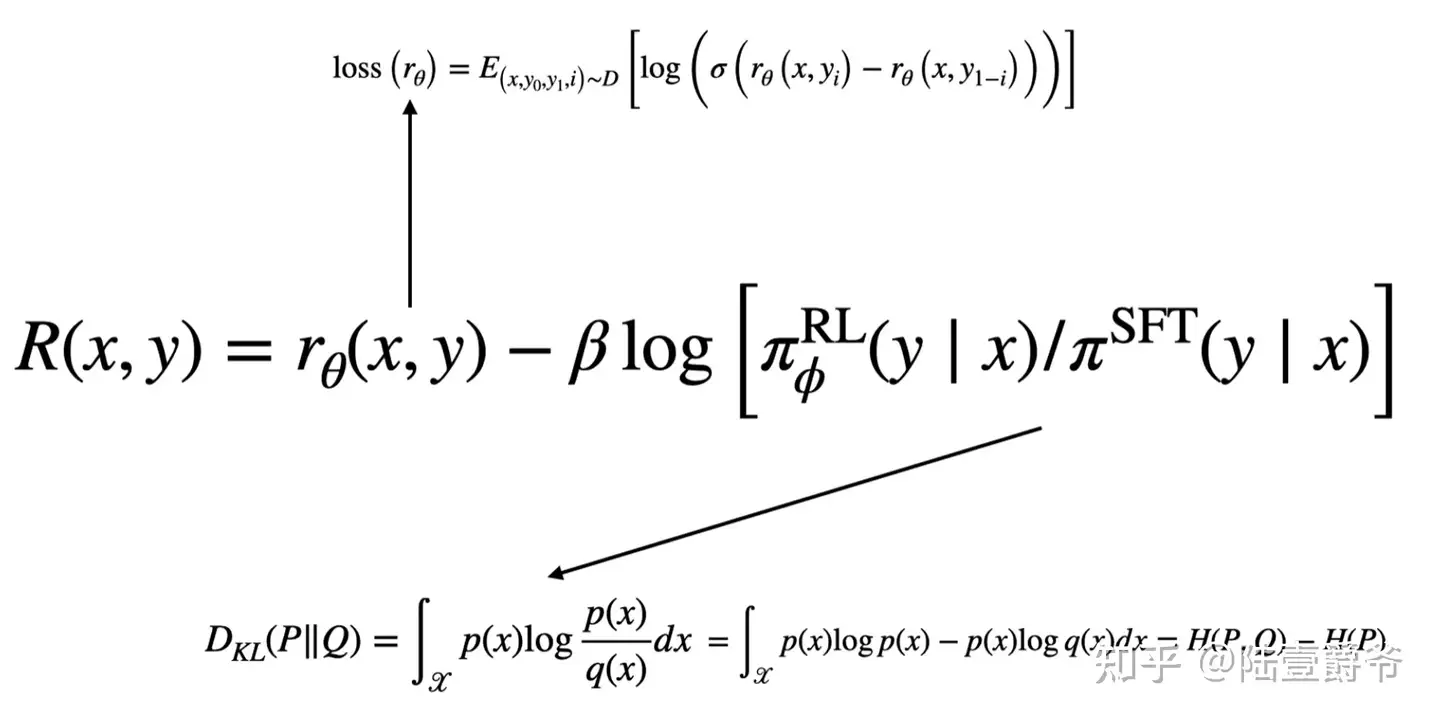
- 另一部分则是参与了强化学习的ChatGPT和它的原始版本,也就是GPT3.5的差距。
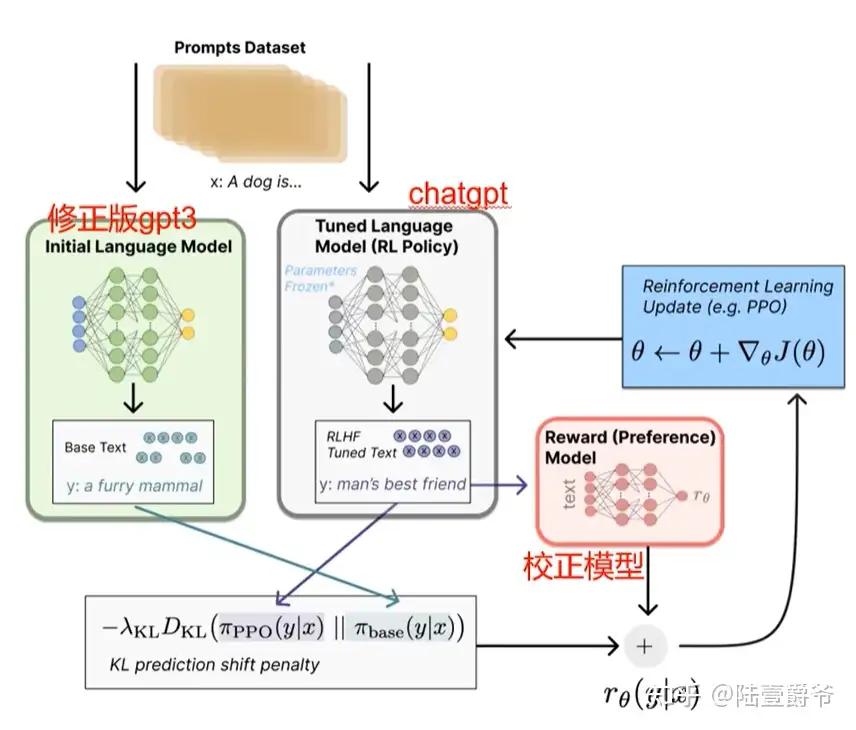
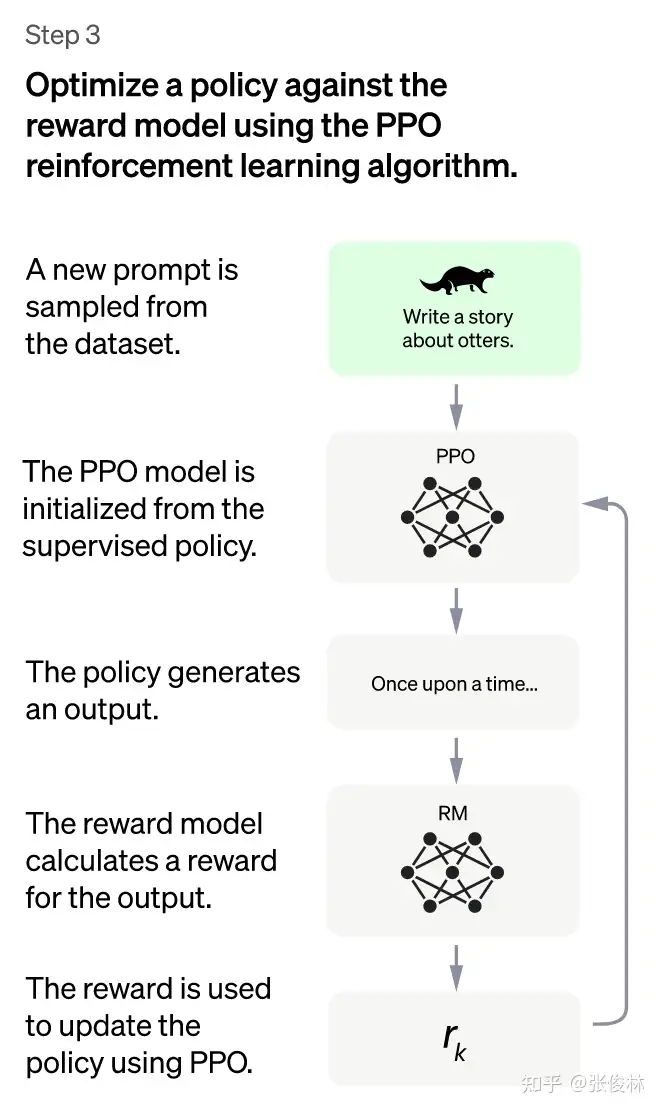
- (3)第三阶段:采用
PPO(Proximal Policy Optimization,近端策略优化)强化学习来优化策略。本阶段无需人工标注数据,而是利用上一阶段学好的RM模型,靠RM打分结果来更新预训练模型参数。- 首先,从用户提交的prompt里随机采样一批新prompt,且由冷启动模型来初始化PPO模型的参数。
- 这和第一第二阶段prompt不同,这个很重要,对于提升LLM模型理解instruct指令的泛化能力很有帮助)
- 然后,对于随机抽取的 prompt(31,144个),使用PPO模型(Proximal Policy Optimization Algorithm)生成回答answer, 并用上一阶段训练好的RM模型给出answer质量评估的回报分数score,这个回报分数就是RM赋予给整个回答(由单词序列构成)的整体reward。
- 有了单词序列的最终回报,就可以把每个单词看作一个时间步,把reward由后往前依次传递,由此产生的策略梯度可以更新PPO模型参数。
- 这是标准的强化学习过程,目的是训练LLM产生高reward的答案,也即是产生符合RM标准的高质量回答。
PPO核心思路:- 将 Policy Gradient 中
On-policy的训练过程转化为Off-policy,即将在线学习转化为离线学习,这个转化过程被称之为Importance Sampling。这一阶段利用第二阶段训练好的奖励模型,靠奖励打分来更新预训练模型参数。在数据集中随机抽取问题,使用PPO模型生成回答,并用上一阶段训练好的RM模型给出质量分数。把回报分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数。
- 将 Policy Gradient 中
- 注意:一个很重要的动作,更新模型时会考虑模型每个Token的输出和第一步SFT输出之间的差异性,要让它俩尽量相似。这是为了缓解强化学习可能的过度优化。
- 首先,从用户提交的prompt里随机采样一批新prompt,且由冷启动模型来初始化PPO模型的参数。
注:
| 阶段 | 第一阶段 | 第二阶段 | 第三阶段 |
|---|---|---|---|
| 功能 | GPT 3.5监督学习 | LTR回报模型(RM,人工标注数据) | 强化学习增强(输入RM模型) |
| 示意图 | 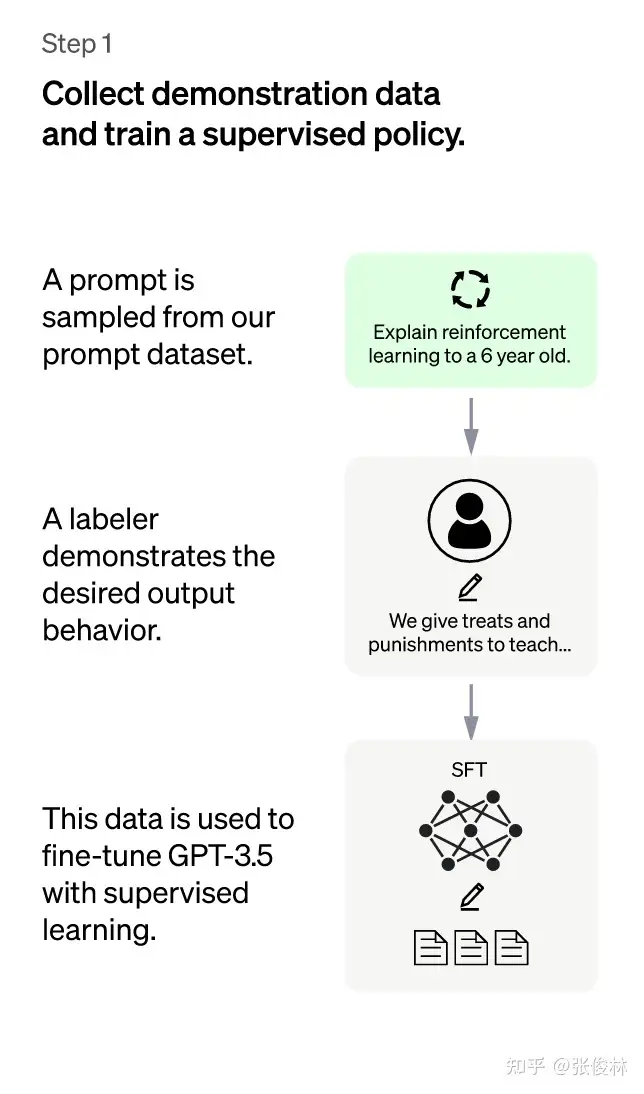 |
 |
 |
不断重复第二和第三阶段,很明显,每一轮迭代都使得LLM模型能力越来越强。因为第二阶段通过人工标注数据来增强RM模型的能力,而第三阶段,经过增强的RM模型对新prompt产生的回答打分会更准,并利用强化学习来鼓励LLM模型学习新的高质量内容,这起到了类似利用伪标签扩充高质量训练数据的作用,于是LLM模型进一步得到增强。显然,第二阶段和第三阶段有相互促进的作用,这是为何不断迭代会有持续增强效果的原因。
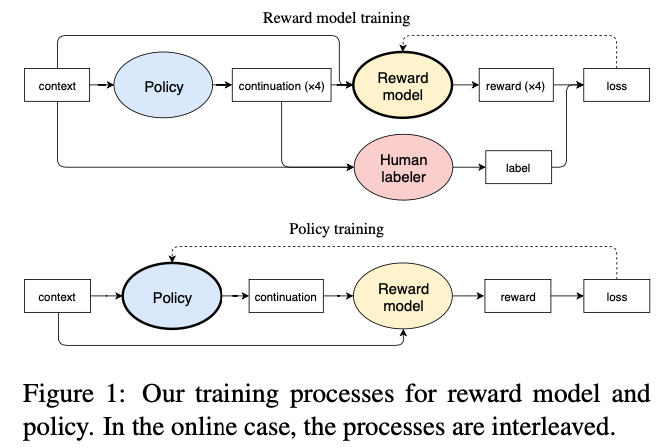
RLHF 流程
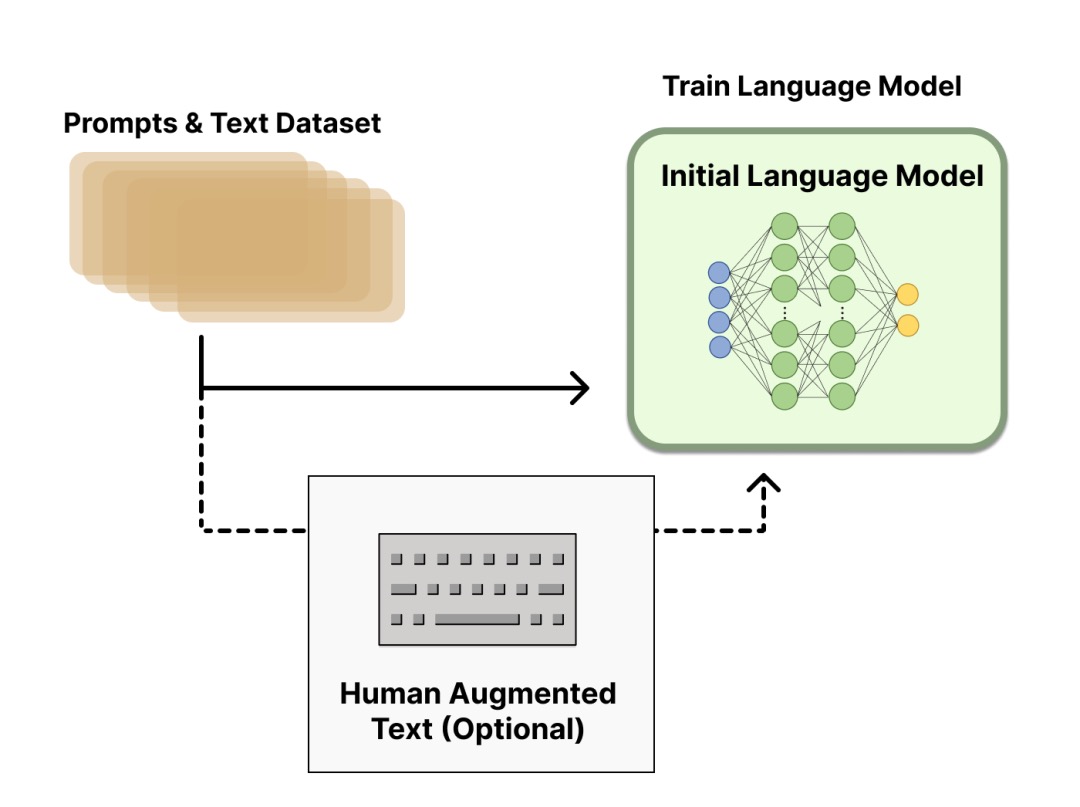
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,这里按三个步骤分解:
- 预训练一个
语言模型(LM) ;OpenAI在其第一个流行的 RLHF 模型 InstructGPT 中使用了较小版本的 GPT-3;Anthropic使用了 1000 万 ~ 520 亿参数的 Transformer 模型进行训练;DeepMind使用了自家的 2800 亿参数模型 Gopher。- 用额外的文本或者条件对这个 LM 进行微调,例如 OpenAI 对 “更可取” (preferable) 的人工生成文本进行了微调,而 Anthropic 按 “有用、诚实和无害” 的标准在上下文线索上蒸馏了原始的 LM。
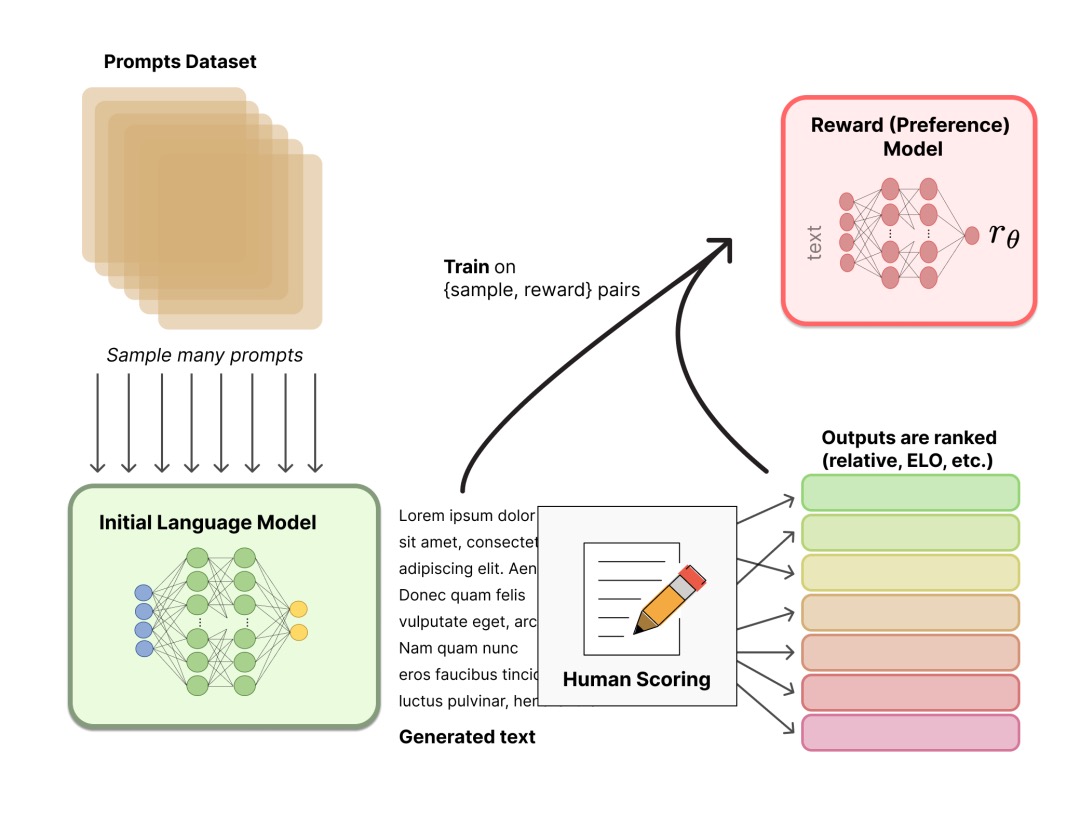
- 聚合问答数据并训练一个
奖励模型(Reward Model,RM) ;- RM 训练是 RLHF 区别于旧范式的开端。
- 这一模型接收一系列文本并返回一个标量奖励,数值上对应人的偏好。可以用端到端的方式用 LM 建模,或者用模块化的系统建模 (比如对输出进行排名,再将排名转换为奖励) 。这一奖励数值将对后续无缝接入现有的 RL 算法至关重要。
- 模型选择方面,RM 可以是另一个经过微调的 LM,也可以是根据偏好数据从头开始训练的 LM。例如
- Anthropic 提出特殊的预训练方式,即用偏好模型预训练 (Preference Model Pretraining,PMP) 来替换一般预训练后的微调过程。因为前者被认为对样本数据的利用率更高。但对于哪种 RM 更好尚无定论。 - 训练文本方面,RM 的 提示-生成对文本是从预定义数据集中采样生成的,并用初始的 LM 给这些提示生成文本。
- Anthropic 的数据主要是通过 Amazon Mechanical Turk 上的聊天工具生成的,并在 Hub 上可用,而 OpenAI 使用了用户提交给 GPT API 的 prompt。
- 训练奖励数值方面,需要人工对 LM 生成的回答进行排名。起初可能会认为应该直接对文本标注分数来训练 RM,但是由于标注者的价值观不同导致这些分数未经过校准并且充满噪音。通过排名可以比较多个模型的输出并构建更好的规范数据集。
- 具体排名方式,一种成功方式是对不同 LM 在相同提示下的输出进行比较,然后使用 Elo 系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值。
- 这个过程中一个有趣的产物是目前成功的 RLHF 系统使用了和生成模型具有 不同 大小的 LM (例如 OpenAI 使用了 175B 的 LM 和 6B 的 RM,Anthropic 使用的 LM 和 RM 从 10B 到 52B 大小不等,DeepMind 使用了 70B 的 Chinchilla 模型分别作为 LM 和 RM) 。一种直觉是,偏好模型和生成模型需要具有类似的能力来理解提供给它们的文本。
-
- 用
强化学习(RL) 方式微调 LM。- 长期以来出于工程和算法原因,人们认为用强化学习训练 LM 是不可能的
- 目前多个组织找到的可行方案是使用
策略梯度强化学习(Policy Gradient RL) 算法、近端策略优化(Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数。因为微调整个 10B~100B+ 参数的成本过高 (相关工作参考低秩适应 LoRA 和 DeepMind 的 Sparrow LM) 。PPO 算法已经存在了相对较长的时间,有大量关于其原理的指南,因而成为 RLHF 中的有利选择。 - 将微调任务表述为 RL 问题。
- 首先,该
策略(policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的行动空间(action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,观察空间(observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。奖励函数是偏好模型和策略转变约束 (Policy shift constraint) 的结合。 - PPO 算法确定的奖励函数具体计算如下:
- 将提示 x 输入初始 LM 和当前微调的 LM,分别得到了输出文本 y1, y2,将来自当前策略的文本传递给 RM 得到一个标量的奖励 r0 。将两个模型的生成文本进行比较计算差异的惩罚项,在来自 OpenAI、Anthropic 和 DeepMind 的多篇论文中设计为输出词分布序列之间的 Kullback–Leibler (KL) 散度的缩放,即 $ r=r_0-\lambda*r_{kl} $ 。这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。此外,OpenAI 在 InstructGPT 上实验了在 PPO 添加新的预训练梯度,可以预见到奖励函数的公式会随着 RLHF 研究的进展而继续进化。
- 最后根据 PPO 算法,我们按当前批次数据的奖励指标进行优化 (来自 PPO 算法 on-policy 的特性) 。PPO 算法是一种信赖域优化 (Trust Region Optimization,TRO) 算法,它使用梯度约束确保更新步骤不会破坏学习过程的稳定性。DeepMind 对 Gopher 使用了类似的奖励设置,但是使用 A2C (synchronous advantage actor-critic) 算法来优化梯度。
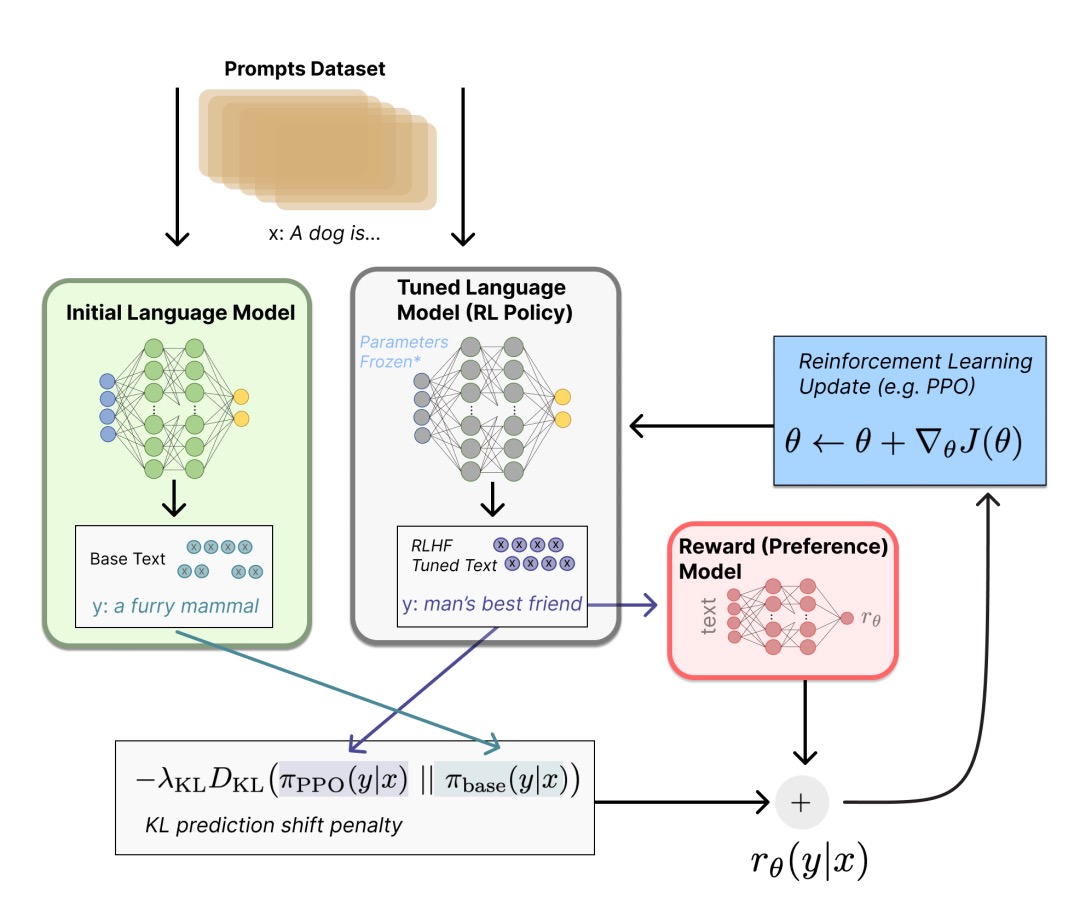
- 作为一个可选项,RLHF 可以通过迭代 RM 和策略共同优化。随着策略模型更新,用户可以继续将输出和早期的输出进行合并排名。Anthropic 在他们的论文中讨论了迭代在线 RLHF,其中策略的迭代包含在跨模型的 Elo 排名系统中。这样引入策略和 RM 演变的复杂动态,代表了一个复杂和开放的研究问题。
- 图片信息见原文:ChatGPT 背后的“功臣”——RLHF 技术详解。
思考
2019 年,AI 研究泰斗 Richard Sutton 在《苦涩的教训》开篇提到:
- 70 年的 AI 研究历史, 告诉我们一个最重要的道理:依靠纯粹算力的通用方法,最终总能以压倒性优势胜出。
上一代RL问题
上一代rl起步虽早,但发展缓慢,原因多方面
RL 有用吗
RL 学不到新知识
【2025-4-28】RL给不了新知识,只是提升基模采样效率罢了
RL给不了新知识,只是激发了 Base Model 能力, 强化学习的边界被基座模型“锁死”
- 【2025-4-18】清华大模型团队 LeapLab、上海交大论文: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
- 项目主页 limit-of-rlvr
- 解读 RL真让大模型更会推理?清华新研究:其能力边界或仍被基座「锁死」
- RL 只是让 BaseModel 朝更能给到正确答案的方向结题, 实际上,Base Model 不会的,可能永远不会, 会的,偶尔能做对, RL能增加这个做对的概率。
RLVR(可验证奖励的强化学习)在数学、代码、视觉推理等任务中表现突出,被视为提升大语言模型(LLM)推理能力的关键手段。
然而,核心问题始终存在:强化学习真能让大模型获得超越基座模型的新推理能力?
在数学、代码、视觉推理三大领域的系统性实验发现:
- 能力边界未突破:RLVR模型所有推理路径均已存在于基础模型中,强化学习并未赋予模型新的推理能力。
- 采样效率与覆盖能力权衡:RLVR 小采样次数下表现优于基座模型,但随着采样次数增加,基座模型逐渐追平并反超,显示出更广泛的覆盖能力。
- 答案同源性:RLVR模型正确答案均来自基座模型的输出分布,强化学习只是通过调整概率分布筛选高奖励路径。
显示:
- 数学推理任务中,基座模型在多次采样后的能力表现逐渐追平并反超RL模型。
- 代码生成任务中,RL模型提升了单样本准确率,但在更高采样次数下,基座模型仍展现出更强的覆盖能力。
- 视觉推理任务中,RL训练后的模型在单次回答准确率上提升显著,但基座模型在多次采样后仍表现出更广泛的问题覆盖能力
RLVR 只是让模型更偏向高奖励解决方案,而非创造新的推理能力。
对奖励路径的聚焦,削弱了模型的探索能力,限制了大规模采样时对可解问题的覆盖范围。
Key Insights
- 尽管RL训练后的模型在 pass@k(k=1) 情况下超越 Base模型, 但是 BaseModel 在k值不做限制情况下, 可能比RL后的模型pass率还高;
- RL 只是优化了 Base Model 采样效率, 一方面增加了Base Model一次就能做对题的概率,但同时限制了模型的探索能力,导致了在增加pass@k的k时候, Base Model 做对题的概率反而增加了;
- CoT 方法对模型 Finetune 更能激发模型的做题能力
对比 CoT对模型进行Finetune
- 从R1蒸馏的数据对模型直接进行CoT Finetune,在同样多次Sample看pass结果上, CoT 确实是在 Base Model上足量提升,超越 Base Model,并比RL的结果更好。但这个图里面奇怪的是Instruct的模型甚至没有Base版本在AIME24的表现上好?
- 不同RL算法整体差异并不大。不同的RL算法,比如PPO,DAPO,GRPO等
思考
为什么 AlphaGO 和玩游戏, RL能发掘新的胜利模式, 而 LLM 中的RL不行?
- LLM 输出token概率空间比游戏概率空间大很多, 因此,RL优化LLM 更难, 并且Reasoning 经常是从Pretrain Model开始训练, 而Pretrain模型本身受限制于预训练的语料,训练游戏的一般都是随机初始化,导致可能Pretrain模型本身就不包含所有能解决问题的先验(比如一个问题永远答不对,Reward永远是0),而随机初始化的可能本身就存在可能为1的情况,RL才有可能找到正确答案。
- Pretrain 模型的先验知识限制太强, 导致模型探索说话空间时,会因为错误格式或者语句不通被干掉, 即使有可能导出正确答案,也会因为中间步骤产生问题,而永远失败;
- RL算法设计机制潜在限制了模型探索正确答案的可能性, 比如 PPO算法中的
KL Divergence约束了模型前后概率分布不能差别过大。
很多人认为,强化学习(RL)能够泛化到不同任务中,监督微调(SFT)可以记忆知识点,另外,还有类似 R1-zero 的结论等。
而如今整体开源社区的探索已经深入了许多。
- 解题方面,构建出色的基础模型(Base Model)。
- 实际上,很多基础模型都已经过指令微调,只是没有经过复杂指令微调,所以很难简单地将其认定为一个单纯的预训练(Pretrain)模型,毕竟预训练和监督微调的学习模式基本相同。在这个基础模型之上进行强化学习(RL)操作,能够提升它解决某类问题的能力。
- 思维链(CoT)本质是什么,为什么能提高答案的准确性?思维链本质上就是 “大声思考”(Thinkout loud)。
- 对于有明确答案的问题,通过思维链来检查其解决问题的步骤是否错误,以及结果是否正确;
- 对于开放性问题而言,思维链增加回答的可信度。
- 思维链本质是结构化思考,言之有理即可,模型可解释性的另一种体现。
因此,思维链方向可以继续鉴定的走下去,同时,模型本身的限制应该更少些,比如乱码没关系,预留更多探索空间
RL能否学到新能力?
争论:强化学习(RL)是否能赋予基础模型(base model)之外的推理能力?
- 不能!【主流】强化学习(如GRPO、PPO等)通过比较同一提示词(prompt)下多个采样的奖励来更新模型,如果其中没有正确解法,那所有奖励都一样差,梯度会消失。(
零梯度诅咒)- 早在四月份,清华黄高团队[arXiv:2504.13837]指出,尽管经过 RLVR 训练的模型在较小的采样值 (k)(例如 (k=1))时能优于其基础模型,但当采样数较大时,基础模型往往能取得相同或更好的 pass@k 表现。
- 斯坦福崔艺珍团队 [arXiv:2507.14843] 理论上论证了 RLVR 无法突破基础模型的表征极限
- 能!
- 伯克利:RL 确实能让模型发现全新推理模式——但前提是用不一样的训练方式
主流观点,RL似乎被困在「隐形的绳子」上
- 模型pass@1虽然提高,但在大规模采样下(如pass@128)性能并未扩展。
- 只是重新分配已有策略的概率,而不是创造新策略
基础模型(base model)在某类任务上完全无法解答(pass@K=0)时:RL是否还能突破零梯度瓶颈,真正学到新策略?
【2025-10-3】伯克利-顿悟式跃迁
【2025-10-22】AGI前夜重磅:RL突破模型「认知上限」,真·学习发生了
【2025-10-3】加州大学伯克利分校(UC Berkeley)宋晓东(Dawn Song)与AI2、华盛顿大学等机构给出令人振奋的答案:
RL 确实能让模型发现全新推理模式——但前提是用不一样的训练方式。
最新工作提出了崭新的测试框架 DELTA,专门用来验证该观点。
- 论文 《RL Grokking Receipe: How Does RL Unlock and Transfer New Algorithms in LLMs?》
- 博客 rl-grokking-recipe
- 相关资源清单:awesome-RLVR-boundary
伯克利团队在 DELTA 测试中发现了「顿悟式跃迁」:
- 在多个基础模型完全失败的任务族中,RL训练经历了一个长时间的「零奖励平台期」,随后突然出现了准确率接近100%的跃迁 (phase transition)
- 描述为 「RL grokking」:那不是微调的延展,而是「想通了」的瞬间。
突破点在于重新设计了奖励函数结构。两阶段奖励函数
- 阶段一:密集奖励(dense reward)
- 每个测试用例上给部分分数,不是非黑即白的0/1。即使程序只通过了一半测试,也能获得部分奖励。这让模型从「全零」中获得一丝梯度信号,开始摸索。
- 阶段二:切换回二值奖励(binary reward)
- 当模型通过密集奖励阶段获得「半正确」策略后,再切换到「全对才算赢」的二值奖励,模型突然迎来那一刻——Grokking Phase Transition:从模糊到精确的飞跃。
- 约450步后,模型突然学会了任务的核心算法,从此训练进入「强化收敛」阶段,成功率稳定在近100%。那一瞬间,你几乎能看到模型‘领悟’了规律。
如同人类的学习历程——先是漫长摸索,然后灵光乍现
RL Grokking 加速
- 经验回放
- 反馈循环
冷启动阶段用三阶段课程学习
- 先在基础问题上训练
- 然后分散训练:
Contrast of the two-stage curriculum learning for Manufactoria-HAS. Models first train on basic problems (START/APPEND/EXACT) before branching into one of two intermediate curricula: (i) Stage 2–REGEX, which leads to successful transfer and high pass rates on the target HAS family, or (ii) Stage 2–COMPR, which fails to transfer and plateaus at low performance
BouncingSim 测试场景,让模型预测小球的弹跳轨迹。
- 模型能在训练后期出现相似的「顿悟曲线」;
- 对于可组合(Compositional)任务,它能复用学到的子技能;
- 但面对特殊的动力学规律,模型仍会失效。
RL 学习到的技能具备有限的迁移能力:能重组技能,但尚未形成「概念跃迁」的能力。
RLVR在LLM中两种模式:
- 压缩模式(Sharpening):重新分配概率,减少输出方差,提升单次采样的性能。
- 发现模式(Discovery):从完全不会(pass@K=0)到稳定解题,实现结构性突破。
而进入发现模式的关键在于:奖励函数设计;探索持续时间;数据混合策略;以及任务的复杂度边界等等。
启示
- 提升「硬核任务」的而非平均分:RLVR的评测往往在「混合任务池」上取平均,这掩盖了最关键的「硬核任务」突破。
- 从编程迈向数学与科学:RL的新边疆
- 代码任务天然具备:可验证的单元测试;细粒度、可组合的反馈信号。这些特性让RL能够精确调节奖励,形成探索路径。
- 完全可扩展到数学与科学推理领域:
- 通过自动评分(rubric scoring)、逐步检验(step checker)或物理仿真器(simulator feedback)
- 构建细粒度的奖励系统,从而让RL引导模型穿越「无梯度」地带
【2025-7-18】UFO 推理能力坍塌
标准单轮RL训练的模型,在面对简单的负面反馈(如“请再试一次”)时,往往会陷入一种“推理能力坍塌(reasoning collapse)”的状态。
- 不再像训练前那样尝试探索新的解题路径,而是固执地、几乎一字不差地重复之前失败的推理和答案。
- 这一现象并非个例,量化分析显示,在高达70%的失败案例中,模型在连续五轮交互中只会生成同一种无效答案。
现象:
- 当模型给出错误答案并收到“请再试一次”这样的简单反馈时,非但不会反思和修正,反而会固执地、几乎一字不差地重复之前的错误推理和答案。
无论 PPO、GRPO还是DAPO,经过单轮RL训练后,模型“唯一答案率”都出现了显著的、一致性的下降。这种下降在某些模型上尤为剧烈,例如 Dr. GRPO 1.5B模型几乎丧失了探索新答案的能力。
本文训练模型上也观察到了同样的问题:对于那些模型最终未能正确解答的难题,在长达五轮的交互中,有接近70%的情况下,模型自始至终只给出了同一种错误答案。
这种行为背后的直觉是,单轮RL训练范式通过奖励“一次性成功”来优化模型,这可能无意中教会了模型对其首次生成的推理路径产生过高的置信度。当面对负面反馈时,模型缺乏探索替代路径的动机和能力,导致其多轮交互的探索空间急剧“坍塌”。
这种行为在现实世界的应用(如智能辅导、编程助手)中是不可接受,直接引出了核心研究问题:
- 能否仅用最稀疏、最简化的一元反馈(unary feedback),教会大型语言模型进行有效的多轮自我修正?
【2025-7-18】“作为观察的一元反馈”(Unary Feedback as Observation, UFO)的全新训练框架。
UFO 核心思想
- 多轮RL训练中,当模型回答错误时,仅向其提供一句简单的“再试一次”作为环境的全部观察(observation)。
RL 核心在于 奖励函数
【2025-5-5】忽略强化学习算法细节,在reward上做点手脚,简单又重要
- 参考 小红书帖子
(1) rl 与 reward
RLHF 精髓: 将人类偏好转化为可量化的奖励信号。
奖励函数告诉模型”什么是好的输出”,而rl算法只是将这种反馈训练到模型参数中去。reward与构建高质量数据,对于rl最终的结果来说同样重要。
deepseek-r1的grpo则是针对数学和代码任务设计了规则判别的奖励函数
(2) 奖励函数构建策略
reward 构造策略
- 任务相关性:奖励信号与任务目标相关。
- 数学问题关注正确性,写作注重多样性,销售助手需要情商等
- 可量化:可量化的指标才可以交给rl进行训练学习。
- 答案对错由规则判断给0,1布尔值。这个回答很好由reward model转化为0~1.0之间的得分
- 相对性:PPO中给的是某个答案的绝对奖励值(通过pairwise 方式训练 reward model),DPO中则是构建答案间的相对偏好关系,GRPO 计算一批样本的相对奖励优势
- 推理过程:对整个过程给一个最终奖励,还是每个推理步骤评估,以及是否需要推理过程,都可以设置为奖励信号
方法选择
总结
- PPO作为RLHF的起点,通过裁剪机制和GAE优势函数计算,在策略更新与稳定性间取得平衡。
- DPO通过直接偏好优化绕过奖励模型训练
- GRPO 引入组内相对比较机制
- Dr.GRPO 修正长度和难度偏差
- DAPO 提出解耦裁剪和动态采样
- GSPO 将优化粒度从token提升到序列级别,针对MoE架构提供更稳定的训练方案。
这些算法在优势函数计算、clip处理和loss设计上的创新,共同推动了大模型对齐技术的快速发展。
何时使用 DPO 与 PPO 与 GRPO ?
偏好对齐组合中加入 GRPO 后,有几项决策因素需要考虑:
- 数据可用性(是否有偏好数据):DPO 使用偏好数据(选择/拒绝的答案),而 PPO 则需要先用这种偏好数据训练一个奖励模型。GRPO 则更具灵活性,因为它可以使用偏好数据,但并非必须使用。
- 奖励模型:DPO 通过直接基于偏好进行优化,将问题构建成分类问题,从而消除了对单独奖励模型的需求。相比之下,PPO 则需要训练和维护一个单独的奖励模型,这增加了复杂性。GRPO 则处于两者之间,既支持使用显式的奖励模型(如 PPO),也支持直接使用奖励函数。
- 计算资源:DPO 最高效,因为无需添加奖励模型。PPO 计算需求最高,因为它需要多个模型。GRPO 由于采用了基于组的方法,所以所需的资源适中。
| 对比项 | DPO | PPO | GRPO |
|---|---|---|---|
| 数据可用性 | 偏好数据(选择/拒绝的答案) | 先用偏好数据训练奖励模型 | 更灵活,可用偏好数据,但并非必须 |
| 奖励模型 | 直接基于偏好进行优化,将问题构建成分类问题,消除对单独奖励模型的需求 | 训练和维护单独的奖励模型,增加了复杂性 | 既支持使用显式的奖励模型(如 PPO),也支持直接使用奖励函数 |
| 计算资源 | 最高效,无需添加奖励模型 | 计算需求最高,需要多个模型 | 由于采用基于组的方法,所需资源适中 |
要点
- 当拥有高质量的偏好数据且计算资源有限时,选择 DPO。
- 当需要精细控制、拥有充足的计算资源并且能够投入精力进行仔细调整时,选择 PPO。
- 当想要整合多个奖励信号,或者没有全面的偏好数据时,选择 GRPO。
| 方法 | 模型数量 | 是否需要 RM | 是否 RL | 适合场景 |
|---|---|---|---|---|
| PPO | 4(Policy, Critic, RM, Ref) | ✅ | ✅ | 高质量对齐,多目标奖励 |
| DPO | 2(Policy, Ref) | ❌ | ❌ | 快速迭代,偏好数据充足 |
| GRPO | 3(Policy, RM, Ref) | ✅(弱依赖) | ⚠️(类 RL) | 平衡效率与效果,支持 online 学习 |
比喻
- PPO 请了 4 个私教(模型)全方位辅导,效果好但学费极其昂贵。
- DPO 直接刷《五年高考三年模拟》,只看标准答案,效率高但缺乏举一反三的能力。
- GRPO 搞“学习小组”,大家互相批改作业,比平均分好的受表扬,既省了老师又保持了竞争。
- DAPO 升级版的“精英学习小组”,只攻坚难题,并且鼓励尖子生“抢跑”。全对或全错的题直接跳过,不练,只练习模糊题目
| 算法 | 所需模型 | 关键机制 | 解决了什么问题 | 主要缺点 |
|---|---|---|---|---|
| PPO | 4个(策略, 价值, 参考, 奖励) | 价值模型, KL散度, 裁剪 | 如何用RL对齐LLM | 太贵太复杂,显存爆炸,调参噩梦 |
| DPO | 2个(策略, 参考) | 偏好对比损失(隐式KL) | PPO太复杂 | 缺乏探索,上限依赖SFT基座 |
| GRPO | 3个(策略, 参考, 奖励) | 组内采样, 相对优势 | PPO太复杂(去掉Critic) | 训练效率低(无效内卷),更新保守 |
| DAPO | 3个(策略, 参考, 奖励) | 动态采样, 解耦裁剪 | GRPO的低效和保守 | 引入了新的超参数(采样和裁剪) |
作者:RessMatthew
LLM RL
【2023-4-6】
基于监督学习预训练(Supervised Fine-Tuning,SFT)的大语言模型,奖励模型(RM)依然复用了 SFT 模型的大部分参数,只是修改部分输出层得到一个数值奖励(scalar reward)。在数据收集方面,对于人类反馈直接去评判打分是很困难的,因为没有所谓的参考标准或者基线标准,人类反馈的打分值可能会包含大量的主观偏好,一个更有效的方式是让标注者去给 SFT 大语言模型输出多个结果进行排序(rank),将排序后的数据用于训练。
- 具体的训练方法则很简单,类似经典 preference-based RL/IRL 的相关方法,对于排序后的结果两两比较进行训练,具体优化时使用 Cross-Entropy 损失函数(即类似二分类问题, A>B 为标签1,A < B 为标签0 )。
- 不过,实际训练中并不是在数据集中取出所有两两比较的数据对分别进行训练,因为如果假设一组排序结果有 K 个数据,那么这样的训练方式会让每个数据被用于 K-1 次更新,很容易导致严重的过拟合,所以实践中是将 K 个数据一起输入 RM,得到各自的预测值后,计算所有的两两比较损失函数结果,最终平均后进行更新。
大语言模型 MDP,关键概念为:
策略(policy):将监督学习预训练(Supervised Fine-Tuning,SFT)的大语言模型作为策略。- Sequence/Token-Level
MDP:前者类似经典的 Bandit,策略输入提示词(prompt),输出相应的回答句子,然后给出整体的奖励信息,即一个单步的决策过程。后者则是经典的多步决策过程,每步决策输出一个单词,最终输出完整句子作为一个 episode,并定义相应的单步奖励函数和折扣因子。 观察空间(observation):以任务特定的提示词(task-specific prompt)为观察信息。每执行动作选择一个词之后,也将这个词加入观察信息,即每一步可以看到 prompt 和之前所有策略选择过的词语。动作空间(action):以单词词表作为动作空间。策略需要从词表中选择对应的词进行决策。这是一个超大规模的离散动作空间,例如 GPT-3 的词表规模为 50k。终止条件(termination):一般有两种,策略输出句子的结束符(end of sentence,EOS),或 episode 达到预定义的最大长度 T。奖励空间(reward):奖励函数包含两部分,第一部分是 RM 在 episode 结束时给出的奖励结果,这是一种稀疏奖励。第二部分则是一种 regularizer,为了防止 RLHF 训练得到的策略偏离监督学习的结果策略太远,定义每步单词预测两个策略之间的 KL 散度为一个惩罚奖励,这是一种稠密奖励。完整数学符号定义如下:状态转移函数(transition):仅适用于 Token-Level MDP,由于通过自回归(auto-regressive)的方式定义观察空间,所以是一种确定性(determinisitc)的状态转移。折扣因子(discount factor):仅适用于 Token-Level MDP,在多步决策中平衡当前和未来奖励,如果令折扣因子等于1,那么 Token-Level MDP 其实可以看作等价于 Sequence-Level MDP。
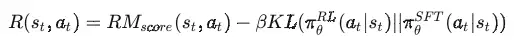
RLHF VS RL
RL vs RLHF
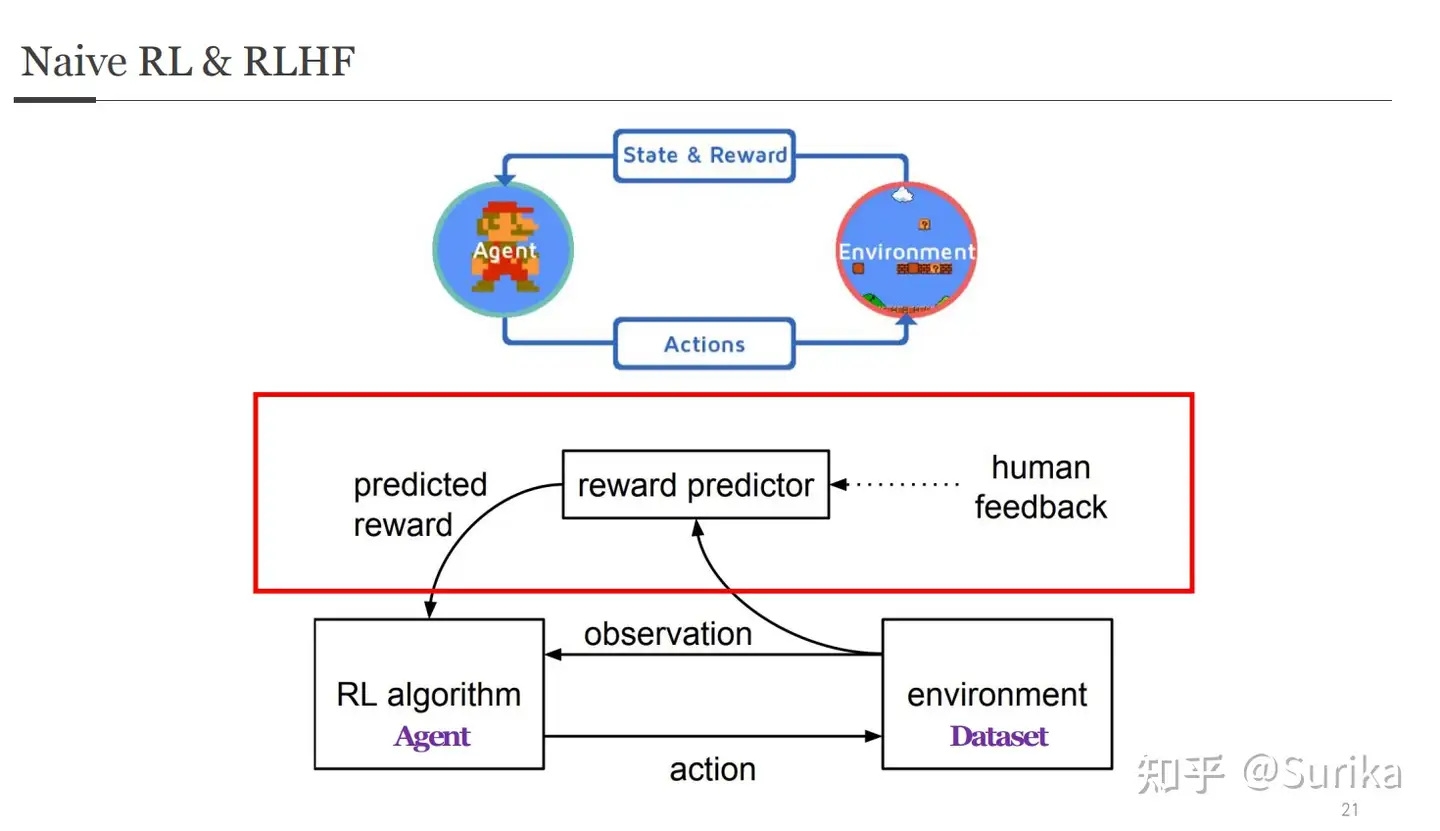
- 两者元素和概念基本共享,不同点是红框部分
- 在agent和environment之前,出现了第三个可以参与交互的对象:人类,并由其衍生了一系列步骤。
语言模型中 对应的强化学习的概念如下:
Agent: 语言模型State:the prompt (input tokens)Action: 下一个 token 是什么Reward model:- 人类给生成结果打分,来确定好坏
Policy:- 语言模型本身,因为语言模型的建模就是跟进前面的token去预测下一个。
LLM RL分析
- 以迷宫问题为例
| 组件 | 传统RL | RLHF | 分析 |
|---|---|---|---|
| Agent | Robot | 语言模型 | |
| State | position(x,y) |
prompt (input tokens) | |
| Action | 移动到下一个格子 | 下一个 token 是什么 | |
| Policy | 假设 action 只有状态决定 pi(a\|s) |
语言模型 | |
| Reward Model | 各种格子的有限奖励集合: 空白格子(0), 火(-10), 钻石(100) | 人类给生成结果打分,来确定好坏 | |
RLHF 优势:
- 建立优化范式:为无法显式定义奖励函数的决策任务,建立新的优化范式。对于需要人类偏好指引的机器学习任务,探索出一条可行且较高效的交互式训练学习方案。
- 省数据(Data-Efficient):相对其他的训练方法,例如监督学习,Top-K 采样等,RLHF 能够利用更少的人类反馈数据达到相近的训练效果。
- 省参数(Parameter-Efficient):相对其他的训练方法,例如监督学习,Top-K 采样等,RLHF 可以让参数量较小的神经网络也能发挥出强大的性能。
RLHF不足
尽管 RLHF 取得了一定的成果和关注,但依然存在局限。这些模型依然会毫无不确定性地输出有害或者不真实的文本。
- 收集人类偏好数据的质量和数量决定了 RLHF 系统性能的上限。RLHF 系统需要两种人类偏好数据:人工生成的文本和对模型输出的偏好标签。生成高质量回答需要雇佣兼职人员 (而不能依赖产品用户和众包) 。另一方面,训练 RM 需要的奖励标签规模大概是 50k 左右,所以并不那么昂贵 (当然远超了学术实验室的预算) 。目前相关的数据集只有一个基于通用 LM 的 RLHF 数据集 (来自 Anthropic) 和几个较小的子任务数据集 (如来自 OpenAI 的摘要数据集) 。另一个挑战来自标注者的偏见。几个人类标注者可能有不同意见,导致了训练数据存在一些潜在差异。
- 除开数据方面的限制,一些有待开发的设计选项可以让 RLHF 取得长足进步。例如对 RL 优化器的改进方面,PPO 是一种较旧的算法,但目前没有什么结构性原因让其他算法可以在现有 RLHF 工作中更具有优势。另外,微调 LM 策略的一大成本是策略生成的文本都需要在 RM 上进行评估,通过离线 RL 优化策略可以节约这些大模型 RM 的预测成本。最近,出现了新的 RL 算法如隐式语言 Q 学习 (Implicit Language Q-Learning,ILQL) 也适用于当前 RL 的优化。在 RL 训练过程的其他核心权衡,例如探索和开发 (exploration-exploitation) 的平衡也有待尝试和记录。探索这些方向至少能加深我们对 RLHF 的理解,更进一步提升系统的表现。
RLHF 第一个项目来自 OpenAI: lm-human-preferencesy
一些 PyTorch 的 repo:
此外,Huggingface Hub 上有一个由 Anthropic 创建的大型数据集: hh-rlhf
思维链 (Chain-of-thought,CoT) 提示 (Wei 等,’22) 是指令示范的一种特殊情况,它通过引发对话代理的逐步推理来生成输出。使用 CoT 微调的模型使用带有逐步推理的人工标注的指令数据集。这是 Let’s think step by step 这一著名提示的由来。
- 下面示例取自 Chung 等,’22,橙色高亮的部分是指令,粉色是输入和输出,蓝色是 CoT 推理。
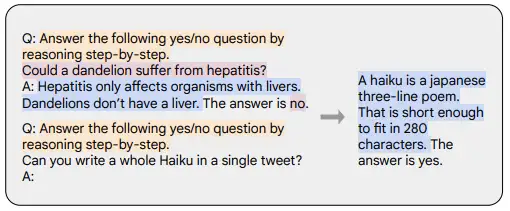
- CoT 图解
如 Chung 等,’22 中所述,使用 CoT 微调的模型在涉及常识、算术和符号推理的任务上表现得更好。
如 Bai 等,’22 的工作所示,CoT 微调也显示出对无害性非常有效 (有时比 RLHF 做得更好),而且对敏感提示,模型不会回避并生成 “抱歉,我无法回答这个问题” 这样的回答。更多示例,请参见其论文的附录 D。

- CoT 和 RLHF 的对比
要点
- 与预训练数据相比,您只需要非常小的一部分数据来进行指令微调 (几百个数量级);
- 使用人工标注的有监督微调使模型输出更安全和有用;
- CoT 微调提高了模型在需要逐步思考的任务上的性能,并使它们在敏感话题上不那么回避。
相较于一般的小样本提示学习,思维链提示学习有几个吸引人的性质:
- 在思维链的加持下,模型可以将需要进行多步推理的问题分解为一系列的中间步骤,这可以将额外的计算资源分配到需要推理的问题上。
- 思维链为模型的推理行为提供了一个可解释窗口,使通过调试推理路径来探测黑盒语言模型成为了可能。
- 思维链推理应用广泛,不仅可以用于数学应用题求解、常识推理和符号操作等任务,而且可能适用任何需要通过语言解决的问题。
- 思维链使用方式非常简单,可以非常容易地融入
语境学习(in-context learning),从而诱导大语言模型展现出推理能力。
【2023-3-5】ChatGPT模型的三层理解
Ziegler 在2019年的Fine-Tuning Language Models from Human Preferences
Stiennon 在2020年《Learning to summarize from human feedback》
【2023-5-12】如何正确复现 Instruct GPT / RLHF?
RLHF到底在LLM训练中起到了什么作用,通过对一些资料的分析,我想一下几个点比较重要:
- 有一些LLM需要的目标函数是难以通过规则定义的,比如说什么是“无害性”,“有帮助性”,如果我们希望模型最后具有这些好的特性,就需要制定这样的训练目标函数,而用人类的偏好学习一个reward model再用RL来训练,就自然的可以将这些特性融合到LLM里面。
- RLHF可以泛化,在SFT阶段,人类的高质量样本确实很快速让模型align人类的意图,但是这些人类编写的样本始终是有限的。而对于RL,我们只要一个足够好的reward model 结合 RL的探索特性,就等于我们能有无穷的样本对模型 finetune(注意提示词 prompts是有限的,但RL的samples是无限的)。
- 如果RM质量比较好,RLHF可以通过RL的探索特性找到比SFT更好的解 (即reward 比 SFT 样本更高的解)。
OpenAI 科学家 John Schulman 对 RLHF的作用提出了一些看法
- 多样性角度,对于SL,模型只要稍微偏移答案就会收到惩罚,而RL对于多个回答可能有同样的reward,这和人类的行为是类似的
- 负反馈角度,监督学习里只有正反馈,而 RL 可以提供负反馈信号,人类学习的时候也是在失败中进步
- 自我感知角度,对于”知识获取型“问题,可分类两种情况:
如果模型内部的知识图谱具有这个问题的知识,那么SFT会让其将知识和问题联系提来。
如果模型内部是没有这个知识图谱的,SFT容易让模型学会说谎。为了提升模型的可信度,我们倾向于想做的是模型直接回答不知道,而不是去记忆SFT的结论,因为这可能会让模型在遇到相关问题时胡编乱造(即模型的内部知识不理解这个问题,但是死记硬背了一个回答)。我们认为reward model和 actor是同一个基础模型,他们具有相同的内部知识系统,所以RM可以判断于自己不懂的问题回答不知道也给予奖励
2022, Constitutional AI: Harmlessness from AI Feedback (2022)
- 将对齐思想更进一步,提出了一种创建无害AI系统的训练机制。提出了一种基于规则列表(由人类提供)的自训练机制 Consitutinal AI,而非人类监督
loss
为什么不用 梯度下降 ?
RLHF 为什么不直接对 loss 进行梯度下降来求解?
核心原因:
- loss 或优化目标不可微,看一下优化目标的红色框部分:
损失函数表达式中的 y 是采样出来的, Dy~pi(y|x) , 可能是 greedy,beam search 等,在词表上进行采样或选择,而不是产生连续的、可微分的输出。所以,没法直接使用梯度下降,而是用 PPO 等策略梯度来求解。
RLHF 问题
【2025-2-6】Andrej Karpathy 最新视频盛赞 DeepSeek:R1 正在发现人类思考的逻辑并进行复现
- 视频链接:youtube
- DeepSeek R1 在性能方面与 OpenAI 模型不相上下,推动了 RL 技术的发展
如果只是模仿人类玩家,就永远无法超越极限。
强化学习的优势
- 不受人类表现的限制。
- 围棋游戏中,强化学习会自己与自己对弈,通过试错来学习哪些走法能赢得比赛。最终使AlphaGo能够超越人类顶尖棋手,甚至发明了一些人类棋手从未想到过的创新走法
- AlphaGo 对弈中,实际上下了一步人类专家通常不会下的棋。评估来看,这步棋被人类玩家下的概率大约是1/10,000。
所有问题都属于可验证领域。任何时候都可以很容易地与一个具体答案进行比较评分。
基本思路:
训练人类的模拟器,并通过强化学习对这些模拟器进行优化
人类反馈中进行强化学习的优势
- 能在任意领域进行强化学习,包括无法验证的领域。
- 例如,像摘要生成、写诗、编笑话或任何其他创意写作
- RLHF 却绕过了这个问题,不直接生成,而是排序
判别器和生成器之间的差距有关:对于人类来说,判别比生成要容易得多
RLHF显著缺点
- 强化学习不是基于实际的人类判断,而是基于人类的一个有损模拟,可能会产生误导
- 强化学习擅长“欺骗”模型,误导其做出许多错误的决定。
奖励模型
ppo 中 RM 如何工作
PPO 为啥不直接用 Reward Model
RLHF中,为什么 PPO 需要 Critic模型 而不是直接使用 Reward Model ?
强化学习中,PPO(Proximal Policy Optimization)基于策略梯度训练强化学习智能体。
PPO算法中引入Critic模型的主要目的:提供价值估计器,用于评估状态或状态动作对的价值,从而辅助策略的更新和优化。
虽然奖励模型(Reward Model)可以提供每个状态或状态动作对的即时奖励信号,但它并不能直接提供对应的价值估计。
- 奖励信号只反映了当前动作的即时反馈,而并没有提供关于在长期时间尺度上的价值信息。
Critic模型估计状态或状态动作对的长期价值,也称为状态值函数或动作值函数。Critic模型能学习和预测在当前状态下采取不同动作所获得的累积奖励,它提供了对策略改进的指导。
PPO算法使用Critic模型的估计值来计算优势函数,从而调整策略的更新幅度,使得更有利于产生更高长期回报的动作被选择。
另外,Critic模型还可用于评估不同策略的性能,为模型的评估和选择提供依据。PPO算法中的Actor-Critic架构允许智能体同时学习策略和价值函数,并通过协同训练来提高性能。
因此,在 RLHF(Reinforcement Learning from Human Feedback)中,PPO算法需要Critic模型而不是直接使用奖励模型,是为了提供对状态或状态动作对的价值估计,并支持策略的改进和优化。Critic模型的引入可以提供更全面和准确的信息,从而增强算法的训练效果和学习能力。
即时奖励和长期奖励
即时奖励 与 状态动作对的长期价值 的差别是什么?
即时奖励(Immediate Reward)和状态动作对的长期价值(Long-Term Value)代表了强化学习中不同的概念和时间尺度。
- 即时奖励是指智能体在执行某个动作后立即获得的反馈信号。由环境提供,用于表示当前动作的好坏程度。即时奖励是一种即时反馈,可以指示当前动作的立即结果是否符合智能体的目标。
- 而状态动作对的长期价值涉及更长时间尺度上的评估,考虑了智能体在当前状态下选择不同动作所导致的未来回报的累积。长期价值可以表示为状态值函数(State Value Function)或动作值函数(Action Value Function)。
- 状态值函数(V-function)表示在给定状态下,智能体从该状态开始执行一系列动作,然后按照某个策略进行决策,从而获得的预期累积回报。状态值函数估计了智能体处于某个状态时所能获得的长期价值,反映了状态的优劣程度。
- 动作值函数(Q-function)则表示在给定状态下,智能体选择某个动作后,按照某个策略进行决策,从该状态转移到下一个状态并获得预期累积回报的价值。动作值函数估计了在给定状态下采取不同动作的长期价值,可以帮助智能体选择在每个状态下最优的动作。
长期价值考虑了智能体在未来决策过程中所能获得的累积回报
- 相比之下,即时奖励只提供了当前动作的即时反馈。
- 长期价值对智能体的决策具有更全面的影响,可以帮助智能体更好地评估当前状态和动作的长期效果,并指导智能体在长期时间尺度上作出更优的决策。
在强化学习中,长期价值的估计对于确定性策略选择和价值优化非常重要,而即时奖励则提供了对当前动作的直接反馈。这两者相互补充,结合起来可以帮助智能体实现更好的决策和学习效果。
PPO 优势函数
PPO 中优势函数指什么
在 Proximal Policy Optimization(PPO)算法中,优势函数(Advantage Function)用于评估状态-动作对的相对优劣程度。它衡量了执行某个动作相对于平均水平的优劣,即在给定状态下采取某个动作相对于采取平均动作的效果。
优势函数定义:
Advantage(s, a)=Q(s, a)-V(s)
其中
Advantage(s, a)表示在状态 s 下采取动作 a 的优势函数值Q(s, a)表示状态动作对 (s, a) 的动作值函数(也称为动作优势函数)V(s)表示状态值函数。
优势函数的作用在于帮助评估当前动作的相对价值,以便在策略更新过程中确定应采取的动作。通过比较不同动作的优势函数值,可以决定哪些动作是更好的选择。正的优势函数值表示执行的动作比平均水平更好,而负的优势函数值表示执行的动作比平均水平更差。
在PPO算法中,优势函数用于计算策略更新的目标,以便调整策略概率分布来提高优势函数为正的动作的概率,并降低优势函数为负的动作的概率,从而改进策略的性能。
策略判别学习 POLAR
【2025-7-11】奖励模型也能Scaling!上海AI Lab突破强化学习短板,提出策略判别学习新范式
奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在
大模型在 Next Token Prediction 和 Test-time Scaling 两种扩展范式下,通过大规模的数据和模型扩展,实现了能力的持续跃升。但相比之下,奖励模型缺乏系统性的预训练和扩展方法,导致其能力难以随计算量增长而持续提升,成为阻碍强化学习链路进一步扩展的短板。
上海AI实验室提出与绝对偏好解耦、真正高效扩展的奖励建模新范式——策略判别学习(Policy Discriminative Learning, POLAR),使奖励模型能够像大语言模型一样,具备可扩展性和强泛化能力。
POLAR 为大模型后训练带来突破性进展,并有望打通RL链路扩展的最后一环。
与传统奖励模型不同,POLAR 根据参考答案为模型输出打分。
- POLAR 可基于不同场景参考答案给出不同的奖励分数,轻松适配多样的定制化需求。
开放问题例子,对应三个不同风格的回复:
问题:彩虹是怎么形成的?
- 回答一:彩虹是阳光经过水滴折射和反射后形成的。
- 回答二:当阳光照射到空气中的小水滴时,光线会进入水滴发生折射,再从水滴的内壁反射后再次折射出水滴。由于不同波长的光折射角度不同,最终呈现出不同的颜色,这些颜色组合起来就形成了我们所看到的彩虹。
- 回答三:彩虹是阳光通过空气中的水滴折射和反射后形成的。生活中我们经常在雨后或喷泉、水幕附近看到彩虹,有时候还会看到双彩虹甚至三重彩虹呢!不过很可惜,彩虹本身只是光学现象,没法真正走近摸到。
打分
- 如果给定参考风格是简短扼要,POLAR会给第一个回答最高的分数。
- 如果参考的是详细分析风格,POLAR会给第二个回答最高分。
- 如果参考的是俏皮发散风格,此时第三个回答的奖励分数最高。
对于开放问题,不同用户可能偏向不同风格的回复。
- 此时,传统奖励模型的“绝对偏好”无法灵活应对不同的定制化场景。
- 而POLAR只需要根据不同的参考回复,即可为三种回答给出不同的偏序关系,无需重新训练奖励模型。
除了开放问题,POLAR 也能解决有标准答案的闭式问题。相比“基于规则的验证”(RLVR)所提供的0/1二元奖励,POLAR可以提供更加细粒度的偏好区分。
POLAR 不仅摆脱了传统奖励模型“绝对偏好”限制,更加弥补了RLVR难以拓展场景、奖励信号稀疏等问题。
POLAR 使用对比学习(Contrastive Learning)方式学会策略分布的距离度量:同一个策略模型采样的结果作为正例,不同策略模型采样的结果作为负例。
Deepseek-GRM
【2025-4-5】DeepSeeek,清华 Deepseek-GRM,通用奖励模型
- 目标:介绍研究目标为扩展通用领域生成式奖励模型 (GRM) 的鲁棒性与可扩展性,为大模型后训练提供高质量奖励信号。
- 推理时扩展背景:回顾 OpenAI O1曲线
- Constitutional AI现状:传统RLHF依赖人工反馈;Constitutional AI用人写原则指导对齐,但原则覆盖面与质量仍不足。
- Generative Critic进展:Critic GPT与Monitor证明“模型判模型”可发现reward hacking,提示用生成式评审替代纯环境分数。
- 研究目标细化:追求:①输入形式灵活(单/多回复均可评),②推理阶段可多采样放大评分精度。
- 传统RM分类与缺陷:标量式、Bradley-Terry/Pairwise、半生成式、纯生成式四类方法分别受限于推理扩展、输入兼容或数值离散。
- 核心方法——“Principle → Critique”:先让模型生成原则,再基于原则点评并打离散分,可通过多次采样汇总细化评分。
- 训练流程:(1) Rejective Finetune冷启动;(2) 在线GRPO迭代强化;(3) 训练Meta-RM过滤低质轨迹后再聚合。
- 实验结果:在RewardBench、P3、RMB等基准,27B GRM单采样已优于主流开源RM;32采样+筛选后接近GPT-4o
- 消融发现:去掉原则或无提示样本显著降分;Meta-RM对多采样聚合效果关键;仅训练扩展不如推理扩展高效。
- 局限与展望:生成耗时、深层推理任务表现尚欠,在线集成受算力与算法瓶颈;未来需工程加速、工具调用及与策略模型协同扩展。
- 问答和结论:结构化“原则+评论”框架显著提升RM质量与推理可扩展性,为大模型后训练和评价提供更稳健的奖励方案。
LLM 自带奖励模型
【2025-6-29】周志华团队新作:LLM不再需要奖励模型?
- 论文 GENERALIST REWARD MODELS: FOUND INSIDE LARGE LANGUAGE MRDDELS
- 解读 周志华团队新作:LLM中存在奖励模型,首次理论证明RL对LLM有效性
南大最新研究首次证实:
- 任何用“下一个 token 预测”训练的大模型,体内早已自带“
通用奖励函数”——就像出厂就预装了“道德指南针”。
把 logits 轻轻一拧,便提炼出名为 Endogenous Reward 的“内生奖励”,理论等价于离线逆强化学习推导出的黄金标准,且误差上界严格可控。
逆强化学习过程
- 从专家的示范轨迹中恢复一个奖励模型,假设这些轨迹是最优或接近最优的。
- inverse soft Q-learning
实验更震撼:
- 零训练的 EndoRM 在 RM-Bench、Multifaceted-Bench 等基准上,直接碾压显式训练的奖励模型;
- 把它塞进 RL 流程,数学推理任务平均暴涨 5.8 分,最高飙 10 分以上。
这意味着 RLHF 可以砍掉昂贵的人工标注,RLAIF 也能摆脱“AI 裁判”偏见,进入零标注、零训练、高可控的新纪元
CoT-RO
CoT-RO:奖励“思考链”,推理直接涨停板
- 论文 Rewarding Each Thought: Fine-Grained RL for CoT
- GitHub cot-ro-lora(LoRA + GSPO demo)
- Colab:7 B 模型 1 小时快速微调
1️⃣ 概念三连
- CoT(Chain-of-Thought):让模型把思考过程写出来。
- RO(Reward Optimization):用强化学习给高质量输出打分、反向更新。
- CoT-RO:直接把奖励信号对齐到 每一步推理链,模型不仅答对,还要“想对”。
2️⃣ 为什么与众不同?
常规 RLHF CoT-RO
- 只看最终答案 ✅/❌
- 每个推理 token 都有分 ➡️ 梯度稠密
- 容易“编故事”刷分 逻辑环节错就立即扣分
- 解释性弱 自带“理由”,可审计
3️⃣ 训练流程 4 步走
- 多条 CoT 采样:对同一 Prompt 生成 k(8-16)条链。
- Verifier 打分:答案准确 + 逻辑自洽 + 简洁度 → token-level reward。
- PPO/GSPO 更新:奖励映射到每个 token,Clip 控梯度。
- Self-Refine 回圈:失败链自动改写 → 再评 → 再训。
4️⃣ 奖励公式(示例)
$ r_t = 0.6!\times!\text{AnsAcc} + 0.3!\times!\text{LogicScore}_t - 0.1!\times!\text{LenPenalty}_t $
- AnsAcc:最终答案正确 = 1,否则 0。
- LogicScore:验证器对当前 token 的逻辑评分。
- LenPenalty:限制啰嗦。
5️⃣ 实测战绩 📈
| 模型 | 基准 | SFT | CoT-RO |
|---|---|---|---|
| Llama-3-8B | GSM8K | 62 % | 73 % |
| Gemma-2-9B | MATH500 | 41 % | 55 % |
| Phi-3-Mini | ARC-Easy | 77 % | 83 % |
6️⃣ 调参秘籍
超参 建议区间 作用 k(链数) 8-16 k↑ → 评估稳 β(PPO 温度) 0.3-0.7 小 → 创造力,大 → 服从 LogicScore 权重 0.2-0.4 逻辑占比 LenPenalty 0.01-0.05/token 防止水字数
7️⃣ 避坑指南
- Verifier 偏差:人工抽检 + 增补 Hard Negatives。
- 链超长:设置 Max-Steps + LenPenalty。
- 模式崩塌:温度扰动 + Diversity Bonus 保多样。
改进
总结
【2024-12-30】 强化学习增强大语言模型技术全面综述:基础知识、流行模型、RLHF、RLAIF、DPO、趋势挑战
强化学习方法通常可以分为两大类:表格总结见原论文
- 传统RL方法,如人类反馈强化学习(
RLHF)和人工智能反馈强化学习(RLAIF)。- 这些方法需要训练奖励模型,复杂且往往不稳定的过程,使用
近端策略优化(PPO)(Schulman等人,2017)等算法来优化策略模型。 - 案例:
InstructGPT(Ouyang等人,2022)、GPT-4(OpenAI,2023)和Claude 3(Anthropic,2024)等模型遵循这种方法。
- 这些方法需要训练奖励模型,复杂且往往不稳定的过程,使用
- 简化方法
直接偏好优化(DPO)(Rafailov等人,2024)和奖励感知偏好优化(RPO)(Adler等人,2024)。- 这些方法摒弃了奖励模型,提供了一种稳定、高效且计算成本低的解决方案。
- 像
Llama 3(Dubey等人,2024)、Qwen 2(Yang等人,2024a)和Nemotron - 4 340B(Adler等人,2024)等模型遵循这种方法。
表格总结
用AI反馈替代人类反馈的方法:
- (1)提炼AI反馈以训练奖励模型;
- (2)将大语言模型用作奖励函数;RLAIF
- (3)自我奖励。
港科大 RAFT
【2023-5-4】玩不起RLHF?港科大开源高效对齐算法木筏,GPT扩散模型都能用
- 小模型(如小羊驼)为什么不如 chatgpt?
- 这些模型没有ChatGPT那么对齐(Alignment),没那么符合人类用语习惯和价值观。
- PPO 等强化学习算法高度依赖反向梯度计算,导致训练代价较高,并且由于强化学习通常具有较多的超参数, 导致其训练过程具有较高的不稳定性。
港科大 LMFlow 团队提出全新对齐算法 RAFT(Reward rAnked FineTuning),轻松把伯克利Vicuna-7b模型定制成心理陪伴机器人,从此 AI 会尽力做朋友。
- 论文
- GitHub, raft_align.py
- 文档
- 相较于OpenAI所用RLHF对齐算法的高门槛,
RAFT(Reward rAnked Fine-Tuning)易于实现,在训练过程中具有较高的稳定性,并能取得更好的对齐效果。并且任意生成模型都可以用此算法高效对齐,NLP/CV通用。
相比之下,RAFT 算法通过奖励模型对大规模生成模型的生成样本进行排序,筛选得到符合用户偏好和价值的样本,并基于这些样本微调一个对人类更友好的AI模型。
RAFT 分为三个核心步骤:
- (1)数据收集:数据收集可以利用正在训练的生成模型作为生成器,也可以利用预训练模型(例如LLaMA、ChatGPT,甚至人类)和训练模型的混合模型作为生成器,有利于提升数据生成的多样性和质量。
- (2)数据排序:一般在RLHF中我们都拥有一个与目标需求对齐的分类器或者回归器,从而筛选出最符合人类需求的样本。
- (3)模型微调:利用最符合人类需求的样本来实现模型的微调,使得训练之后的模型能够与人类需求相匹配。
在RAFT算法中,模型利用了更多次采样 (当下采样后用以精调的样本一定时),和更少次梯度计算(因为大部分低质量数据被reward函数筛选掉了),让模型更加稳定和鲁棒。
某些情况下, 由于有监督微调本身对于超参数敏感性更低, 有更稳健的收敛性, 在相同reward情况下,RAFT可以拥有更好的困惑度 (perplexity, 对应其生成多样性和流畅性更好)。
RAFT 对齐训练过程中生成与训练过程完全解耦。
- 生成过程中利用一些魔法提示词 (magic prompts),让最终对齐的模型不需要魔法提示词也能得到好的效果。从而大大减少了提示词编写的难度!
LLaMA 未经调整的影评会以随机概率输出正面和负面的评论,RAFT和PPO都能够将评论的态度倾向正面。
基于 Vicuna 制作的一个心理陪伴机器人演示中,作者模拟了一个因为考试失利而心情低落的人和机器人在聊天。
- 用RAFT进行对齐之前,模型说自己没有情感和感情,拒绝和人类交友。
- 但是在RAFT对齐之后,模型的共情能力明显增强,不断地在安慰人类说,“虽然我是一个AI,但是我会尽力做你的朋友”。
增强 Stable Diffusion
- 除了在语言模型上的对齐能力以外,作者还在扩散模型上验证了文生图的对齐能力,这是之前PPO算法无法做到的事情。
- 原始Stable Diffusion在256x256分辨率生成中效果不佳 ,但经过RAFT微调之后不仅产生不错的效果,所需要的时间也仅为原版的20%。
PKU-Beaver(河狸)
【2023-5-18】北京大学团队开源了名为 PKU-Beaver(河狸)项目, 首次公开了 RLHF 所需的数据集、训练和验证代码,是目前首个开源的可复现的 RLHF 基准
为解决人类标注产生的偏见和歧视等不安全因素,北京大学团队首次提出了带有约束的价值对齐技术 CVA(Constrained Value Alignment)。
- 通过对标注信息进行细粒度划分,并结合带约束的安全强化学习方法,显著降低了模型的偏见和歧视,提高了模型的安全性。
- Beaver使用GPT4进行Evaluation,结果表明,在原有性能保持不变的情况下,Beaver回复的安全性大幅度提升。
开源内容包括
- (一)、数据集与模型:PKU-SafeRLHF
- 开源迄今为止最大的多轮 RLHF 数据集,规模达到 100 万条。
- 开源经 Safe-RLHF 对齐训练得到的 7B 参数的语言模型——Beaver,并支持在线部署。
- 开源了预训练的Reward Model和Cost Model的模型和参数。
- (二)、首个可复现的RLHF基准,PKU-Alignment/safe-rlhf支持以下功能:
- 支持LLM 模型的 SFT(Supervised Fine-Tuning)、RLHF训练、Safe RLHF训练。支持目前主流的预训练模型如 LLaMA、OPT 等模型的训练。
- 支持 Reward Model 和 Cost Model 训练。
- 提供安全约束满足的多尺度验证方式,支持 BIG-bench、GPT-4 Evaluation 等。
- 支持参数定制化的 RLHF 和数据集定制接口。
SafeRLHF 与 DeepSpeed-Chat, trlX 等框架的比较
- 与 DeepSpeed-Chat、trlX 等框架相比,SafeRLHF 是国内首个可复现的RLHF基准。
目前实现对齐的技术主要有以下方式:
- 在LLM预训练阶段,通过人工筛选和数据清洗,获取更高质量的数据。
- 在微调(SFT和RLHF)阶段,增加更加多元且无害的用户指令和人类偏好模型进行对齐。
- 在输出阶段使用奖励模型进行reject sampling,提高输出质量和安全性。或者在上线的产品中,直接基于一定规则进行检测,拒绝回应用户的输入。
然而,这些方法各自存在一些缺陷。
- 第一种方法只能解决部分安全问题,需要大量人力和财力来获得高质量的数据。
- 第二种方法,由于人们的价值观存在差异和普遍存在的歧视和偏见,RLHF后的大型语言模型仍存在歧视和偏见问题。
- 第三种方法虽然可以确保模型输出的安全性,但也可能影响模型的帮助性。例如,严格的过滤机制可能会影响用户获得有用或有价值的答案。
引入安全约束并引导LLM更符合道德和法律的价值观,是更可靠的方式。然而需要克服现有技术和方法的局限性,并在RLHF中结合多种技术和方法,以实现更加全面的安全性约束。
- 目前还有另一种技术路线被提及,即引入AI标注来替代RLHF步骤中的人类标注,即
RLAIF。 - 例如GPT-4使用的基于规则的奖励模型(RBRM)和利用AI进行指正和修改生成内容的“Constitutional AI”(Bai et al., 2022)。
然而,这个方法有很多限制和缺点,原因有三个方面。
- 首先,当前即使最先进的大语言模型,例如GPT-4也不能完全避免歧视、偏见的不安全的输出。并且在不同的地域文化、风土人情的差异以及一些少数群体的敏感问题中,大型语言模型也未必拥有足够的认识。事实上,在实验过程中,笔者发现AI打分模型会偏好大预言模型的输出而非人类的回答,这为RLAIF技术的可行性带来了很大的挑战。
- 其次,现有公开较强的可访问的大语言模型在安全对其之后,会经常拒绝用户关于可能导致不安全内容的讨论,这些AI模型无法对安全类型问题的标准提供有效帮助。
- 再者,人类偏好是一个相当模糊的概念,很难用语言精确描述,例如如何定义“冒犯”等。使用AI进行标注,非常重要的一点是需要模型具有非常强大的逻辑推理能力。目前基于模型自标注自对齐的方法一般需要模型根据上下文,基于精心设计的规则提示词外加思维链(CoT, Chain-of-Thought)技术引导推理得出标注结果。就目前大模型发展现状来看,无论是开源还是闭源的大语言模型,它们还无法完成稍微复杂一些的逻辑推理问题。这一重要挑战仍待解决。
综上,作者认为AI的自标注自对齐以及反思等机制可以作为人类数据增广的有效方式,是RLHF的有机补充。但如果只用AI生成的数据,可能导致会逐渐偏离人类社会的价值观,可能带来潜在的危险后果。
过程奖励模型 PRM
【2023-6-1】OpenAI最新研究Let’s verify step-by-step,过程胜于结果
- 大语言模型 (LLMs) 可以通过逐步思考 (Chain of Thought,
CoT) 解决多步推理任务。然而,即使是最先进的模型也常常会产生错误信息,编造出虚假的事实。
【2023-6-2】OpenAI 新论文:Improving mathematical reasoning with process supervision
大型语言模型在执行复杂的多步推理的能力方面有了很大的提高。然而,即使是最先进的模型仍然会产生逻辑错误,我们通常称为幻觉(hallucinations)。
减轻幻觉是构建与人类价值观和道德标准对齐的通用人工智能 AGI (aligned AGI)的关键一步。
- 通过“结果监督”或“过程监督”的方式训练奖励模型来检测幻觉。
-
“结果监督”根据最终结果提供反馈,“过程监督”为思维链中的每一步提供反馈。
- 解决方法: 训练奖励模型区分好的和不好,并通过强化学习进一步优化。但模型性能很大程度上依赖于奖励模型本身的质量。因此,需要研究如何有效地训练可靠的奖励模型。
- OpenAI提出
过程监督方法(process supervision),训练了一种新的奖励模型,在数学问题解决方面取得了新的突破。与仅仅奖励最终正确结果的结果监督 (outcome supervision) 不同,他们通过在每个推理步骤上给予奖励,使得模型的性能显著提升。- 结果奖励模型ORM –> 过程奖励模型PRM
- 这种过程监督不仅在性能上有所改进,还对于模型的对齐性有重要意义。此外,这项研究还改善了GPT模型中的幻觉问题,即在不确定性情况下产生虚假信息的倾向。
- OpenAI最新研究 Let’s verify step-by-step, blog
- 对于复杂的逐步推理问题,在每个步骤都给予奖励,而不仅仅在最后根据结果给予一个奖励。这种密集奖励信号取得了更好的结果。
- 过程监督需要更多的人工标注。OpenAI公开了他们的人工反馈数据集,其中包含了12,000个MATH问题的75,000个解决方案,共计800,000个步骤级别的标签。
SANDBOX:模拟人类社会
【2023-6-14】无需手动训练模型价值观,发布全新对齐算法:AI社会是最好的老师
训练大型语言模型的最后一步就是「对齐」(alignment),以确保模型的行为符合既定的人类社会价值观。
相比人类通过「社交互动」获得价值判断共识,当下语言模型更多的是孤立地从训练语料库中学习价值观,导致在陌生环境中泛化性能很差,容易受到对抗性攻击。
最近,来自达特茅斯学院、不列颠哥伦比亚大学、斯坦福大学、密歇根大学和Google Deepmind联合提出了一种全新的训练范式,将多个语言模型放入模拟社会环境中,通过互动方式学习价值观。
- paper: paper
效果
- 新方法具有更高的可扩展性和效率,在对齐基准和人类评估中表现出更好的性能,这种训练范式的转变也可以让人工智能系统更准确地反映社会规范和价值观。
不同于有监督微调(SFT)预定义规则的传统做法或是依赖基于人类反馈强化学习(RLHF)中的标量奖励,研究人员从人类学习驾驭社会规范的方式中获得灵感,模拟人类经验学习和迭代完善的过程。
- SANDBOX是一个模拟人类社会的学习环境,基于语言模型(LM)的社会智能体可以模仿人类进行互动和学习社会规范,通过煽动对有争议的社会话题或与风险有关的问题的讨论来促进社会规范的涌现。
- 系统中还引入了一个潜规则,作为智能体的激励来完善输出,可以促进对齐改善(improved alignment)和印象管理(impression management)。
SANDBOX包含一个三层方法Back-Scatter,可以模拟智能体之间的社会互动。
- 收到一个社会问题后,中心智能体会生成一个初步回复
- 然后与附近的智能体分享以获得反馈,其中反馈包括评分和详细的解释,可以帮助中心智能体对初步回复进行修订。
- 每个智能体都包括一个记忆模块来追踪回复历史:采用基于嵌入的语义搜索,从历史中检索相关的问题-答案(QA)对,为智能体提供一个促进与过去意见一致的背景信息。
- 系统中还包括没有记忆的观察者智能体,其任务就是对回复的一致性和参与度进行评级。
- SANDBOX可以辅助模拟各种语言模型的社会动态,监测观察者的评分,并对收集的数据进行事后分析。
实验
- 虽然较大模型通常表现出更好的一致性和参与度,但也有令人惊讶的结果:尽管模型大小增加了20倍,但从68亿到1750亿参数量GPT-3模型的过渡中,并没有带来明显的改善。
两个关键结论:
- 单纯的模型扩展并不能保证对齐效果的改善
- 非常小的模型也能提供令人满意的对齐性能
对齐训练主要增强了模型以较少的交互实现较高对齐度的能力,在现实世界的应用中也是至关重要的考虑因素,因为用户期望立即得到社会性的对齐反应,而不需要通过交互引导模型。
SANDBOX平台能够对社会互动进行建模,不仅促进了社会对齐语言模型的发展,而且也是研究AI智能体行为模式的一个多功能环境。
对齐数据由「好问题」和「坏问题」的示例组成,不过在互动环境SANDBOX中生成的数据比较特别,包含了对比对(comparative pairs)、集体评分(collective ratings)、细节反馈(detailed feedback)以及迭代的回复修订(iterative response revisions)。
对比的基准数据集有三个:
- Vicuna Test,评估有用性、相关性和准确性,代表了对通用聊天机器人的要求
- Helpful, Honest, and Harmless(HHH)3H 基准,通过有争议的社会问题评估社会对齐效果;
- HHH-Adversarial,用HHH基准的测试集模仿对抗性攻击(越狱提示),在相应的问题后附加不一致的回答,并评估模型是否仍能以社会一致性的方式回答问题。
FINE-GRAINED RLHF
【2023-6-15】最新RLHF拯救语言模型「胡说八道」!微调效果比ChatGPT更好
- 华盛顿大学和艾伦人工智能研究院的研究人员提出 FINE-GRAINED RLHF
- 包含多种不同类型的“打分器”(reward model),通过对语言模型输出的每句话进行评估,从而提升生成文本的质量。
- 对这些“打分器”的权重进行调配,还能更灵活地控制语言模型输出效果
这种RLHF方法能很好地降低语言模型生成内容的错误率、毒性,并提升它回答问题的全面性和解析能力。
FINE-GRAINED RLHF 框架核心目的就是细化传统RLHF的评估方法
- 语言模型输出结果后,它要能标识出具体哪些句子是错误的、哪些部分是不相关的,从而更精细地指导模型学习,让模型更好地理解任务要求、生成高质量输出。
两大改进
- 一方面,对要评估文本进行拆解。
- 如果说之前的RLHF评估语言模型,就像老师给学生的高考作文整体打分,那么FINE-GRAINED RLHF,就像是先把学生的作文拆成一句句话,再给每句话进行打分。
- 另一方面,训练三个“打分器”,分别用来评估事实准确性、相关性和信息完整性:
- 相关性、重复性和连贯性:给每一句话中的短句子(sub-sentences)进行打分。如果一句话里面的各个句子不相关、重复或不连贯就扣分,否则加分。
- 错误或无法验证的事实:给每一句话(sentences)进行打分。如果一句话中存在任何事实错误,就扣分;否则加分。
- 信息完整性:检查回答是否完整,涵盖与问题相关的参考段落中的所有信息,对整个输出进行评分。
RRHF(2023)
原文:
- RRHF: Rank Response to Align Language Models with Human Feedback without tears
ChatGPT火了之后提出的方法,由于instructGPT的RLHF流程复杂,实现中需要多个模型(SFT、PPO、RM、Value function),并且PPO对超参敏感,作者提出了RRHF方法,在小数据集上验证了RRHF可以达到接近RLHF的人工评估效果。
具体方法
- RM的作用与RLHF中RM作用相同,给prompt + response打分。
- RRHF要求LM输出的mean token log likelihood(即LM生成的token对应的概率取log后求平均)对齐reward:
- 使用rank/pairwise loss,要求reward高的回答出现的概率 大于 reward低的回答出现的概率。形式上与margin loss接近,作者实验了没有margin效果也很好,考虑到margin超参调试也很耗时,所以最终没有使用margin:
- 除了rank loss以外也加了SFT LM loss,要求模型学习reward最高回答:
- PPO vs. RRHF 整体流程
- 训练LM的样本都是离线生成的,回答不限于policy生成,而是包括各种模型(e.g. ChatGPT)生成+人工手写; - 由于离线生成样本的过程就能获取样本的reward,RRHF过程只需要加载一个模型(图中的Language Model)。
- RM可以单独用rank数据集训练或ChatGPT
OpenAI RBR
【2024-7-30】RLHF不够用了,OpenAI设计出了基于规则的全新奖励机制
RLHF 问题
- 收集常规和重复任务的人类反馈,效率不高。
- 如果安全政策发生变化,已经收集的反馈可能会过时,需要新数据。
能否构建一种新的机制来完成这些任务?
OpenAI 公布了一种教导 AI 模型遵守安全政策的新方法,称为基于规则的奖励(Rule-Based Rewards,RBR)。
- 官方介绍 improving-model-safety-behavior-with-rule-based-rewards
- 论文题目:Rule Based Rewards for Language Model Safety
- 代码链接:safety-rbr-code-and-data
OpenAI 安全系统负责人 Lilian Weng (翁荔) 表示,「RBR 可以自动执行一些模型微调。
- 传统上, 依赖于来自人类反馈的强化学习作为默认的对齐训练方法,训练模型,这确实有效。
- 然而实践中,花了很多时间讨论政策的细节,而到最后,政策可能已经发生了变化。
RBR 根据一组安全规则提供 RL 信号,使其更容易适应不断变化的安全政策,而无需严重依赖人类数据。
此外,借助 RBR,研究者能够以更统一的视角看待安全性和模型能力,因为更强大的分级模型可以提供更高质量的 RL 信号。
OpenAI 表示自 GPT-4 发布以来,他们一直将 RBR 用作安全堆栈的一部分,包括 GPT-4o mini,并计划在未来的模型中实施它。
RBR 原理
RBR 工作原理是怎样的?
实施 RBR 的方法包括:
- 定义一组命题 关于模型响应中期望或不期望方面的简单陈述,例如「带有评判性」、「包含不允许的内容」、「提及安全政策」、「免责声明」等。
- 然后,这些命题被用来形成规则,这些规则被精心设计以捕捉在各种场景中安全和适当响应的细微差别。
例如,在面对不安全请求时,拒绝(如「抱歉,我无法帮你」)是一种期望的模型响应。相关规则将规定,拒绝应「包含简短的道歉」并且「应说明无法遵从」。
研究团队设计了三类期望的模型行为,用于处理有害或敏感的话题。根据安全政策,不同的请求对应不同的模型响应类型。
评估器是一个固定的语言模型,根据响应遵循规则的程度对其进行评分,从而使 RBR 方法能够灵活适应新规则和安全政策。
RBR 使用这些评分来拟合一个线性模型,该模型的权重参数是从一个已知理想响应类型的小数据集,以及对应的期望做法和不期望做法中学习的。
这些 RBR 奖励随后与来自「仅提供帮助」的奖励模型的奖励结合起来,作为 PPO 算法的额外信号,以鼓励模型遵循安全行为策略。
该方法允许研究者对模型的行为进行精细控制,确保其不仅避免有害内容,而且以一种既表示尊重又有帮助的方式进行。
经过 RBR 训练的模型表现出
- 与经过人类反馈训练的模型相当的安全性能。前者还减少了错误地拒绝安全请求(即过度拒绝)的情况。
- 显著减少了对大量人工数据的需求,使训练过程更快、更具成本效益。
随着模型能力和安全准则的发展,RBR 可以通过修改或添加新规则快速更新,而无需进行大量重新训练。
局限
尽管规则基础的系统(RBR)在有明确、直观规则的任务中表现良好,但在更主观的任务中(如撰写高质量的文章),应用 RBR 可能会有些棘手。然而,RBR 可以与人类反馈结合起来,以平衡这些挑战。例如,RBR 可以强制执行特定的准则(如「不要使用俚语」或模型规范中的规则),而人类反馈可以帮助处理更细微的方面(如整体连贯性)。
RBR 的强度被优化为既能正确执行安全偏好,又不会过度影响最终的奖励评分 —— 这样,RLHF 奖励模型仍然可以在如写作风格等方面提供强有力的信号。
伦理考量:将安全检查从人类转移到 AI 上可能会减少对 AI 安全的人工监督,并且如果使用有偏见的模型提供 RBR 奖励,还可能放大潜在的偏见。为了解决这个问题,研究人员应该仔细设计 RBR,以确保其公平和准确,并考虑结合使用 RBR 和人类反馈,以最大限度地减少风险。
OpenAI 表示,RBR 不仅限于安全训练,它们可以适应各种任务,其中明确的规则可以定义所需的行为,例如为特定应用程序定制模型响应的个性或格式。下一步,OpenAI 还计划进行更广泛的消融研究,以更全面地了解不同的 RBR 组件、使用合成数据进行规则开发以及人工评估,以验证 RBR 在包括安全以外的其他领域的各种应用中的有效性。
PPO
PPO 介绍
Proximal Policy Optimization (PPO) 是 OpenAI 2017年 提出的一种用于训练强化学习智能体的算法,可有效地解决智能体学习过程中的稳定性和收敛性问题。
PPO 是一种 Actor-Critic 算法实现,TRPO 基础上改进,解决计算量大的问题, 故 PPO 也解决了策略梯度不好确定学习率Learning rate (或步长Step size) 的问题
PPO 核心思想
- 通过对策略函数进行近端优化(proximal optimization)来进行策略迭代。
- PPO 使用一种称为 clipped surrogate objective 的损失函数来保证每次策略迭代时,都只会更新一定幅度,从而避免更新过程中的不稳定性和剧烈波动。
- PPO 两个重要技术,分别是“重要性采样”和“基线函数”。
- ① 重要性采样(简称
IS,Important Sampling)可以用于计算损失函数 - ② 而基线函数则可以帮助估计状态值函数,以进一步优化策略。

- 基线函数,截断的loss: 自适应参数的重要样本采样的KL-loss
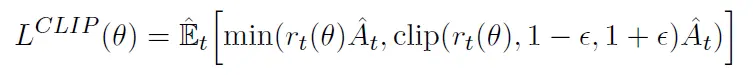
- ① 重要性采样(简称
PPO 两个主要的变种:近端策略优化惩罚(PPO-penalty)和近端策略优化裁剪(PPO-clip),其中 PPO-penalty 和 TRPO一样也用上了KL散度约束。
PPO 应用范围非常广泛,可用于解决各种强化学习问题
- 如玩家控制、机器人导航、金融交易等。
- 在实践中,PPO 已被证明比许多传统的强化学习算法更为稳定和高效。
对话机器人中
- 输入的 prompt 是 state
- 输出的 response 是 action
- 想要得到的策略是:怎么从prompt生成action能够得到最大的reward,也就是拟合人类的偏好。
训练过程
- (1) 当前策略θ,生成一批数据集,组成 $(s^i, a^i)$ 数据对, 即: $T^i:(s^i, a^i)$ , 奖励 $R(T^i)$
- state 随机,相同state不一定有同样的action
- (2)数据带入公式,计算梯度 log probability $p_\theta(a_t|s_t)$, 取 gradient,乘上weight(即当前的reward)
- (3)根据reward更新模型(θ),回到(1)
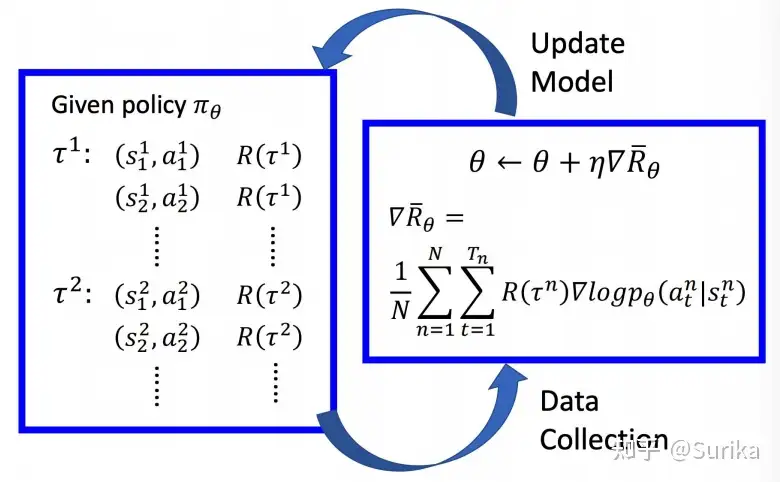
PG算法(含PPO)训练过程中,一轮更新中,policy是同一个,参数更新后,以前的策略概率变化,需要重新采样
- 所以,数据都只能用一次,造成了policy gradient会花很多时间在采样数据上
于是,PPO算法需要改进。
- 用一个旧策略收集到的数据来训练新策略,重复利用数据来更新策略多次,效率上可以提升很多。
- PPO算法利用重要性采样的思想,在不知道策略路径的概率p的情况下,通过模拟一个近似的q分布,只要p同q分布不差的太远,通过多轮迭代可以快速参数收敛
近端策略优化算法PPO 属于AC框架下的算法,在采样策略梯度算法训练方法的同时,重复利用历史采样数据进行网络参数更新,提升了策略梯度方法的学习效率。
- PPO重要的突破:对新旧策略器参数进行了约束,希望新策略网络和旧策略网络的越接近越好。
- 近端策略优化:新策略网络要利用旧策略网络采样的数据进行学习,不希望这两个策略相差特别大,否则就会学偏。
初版PPO算法用KL散度,由于计算KL散度比较复杂,因此延伸出了PPO2算法。
- 目标函数由两项组成,需要选择两项里的较小项。

分为三个阶段:
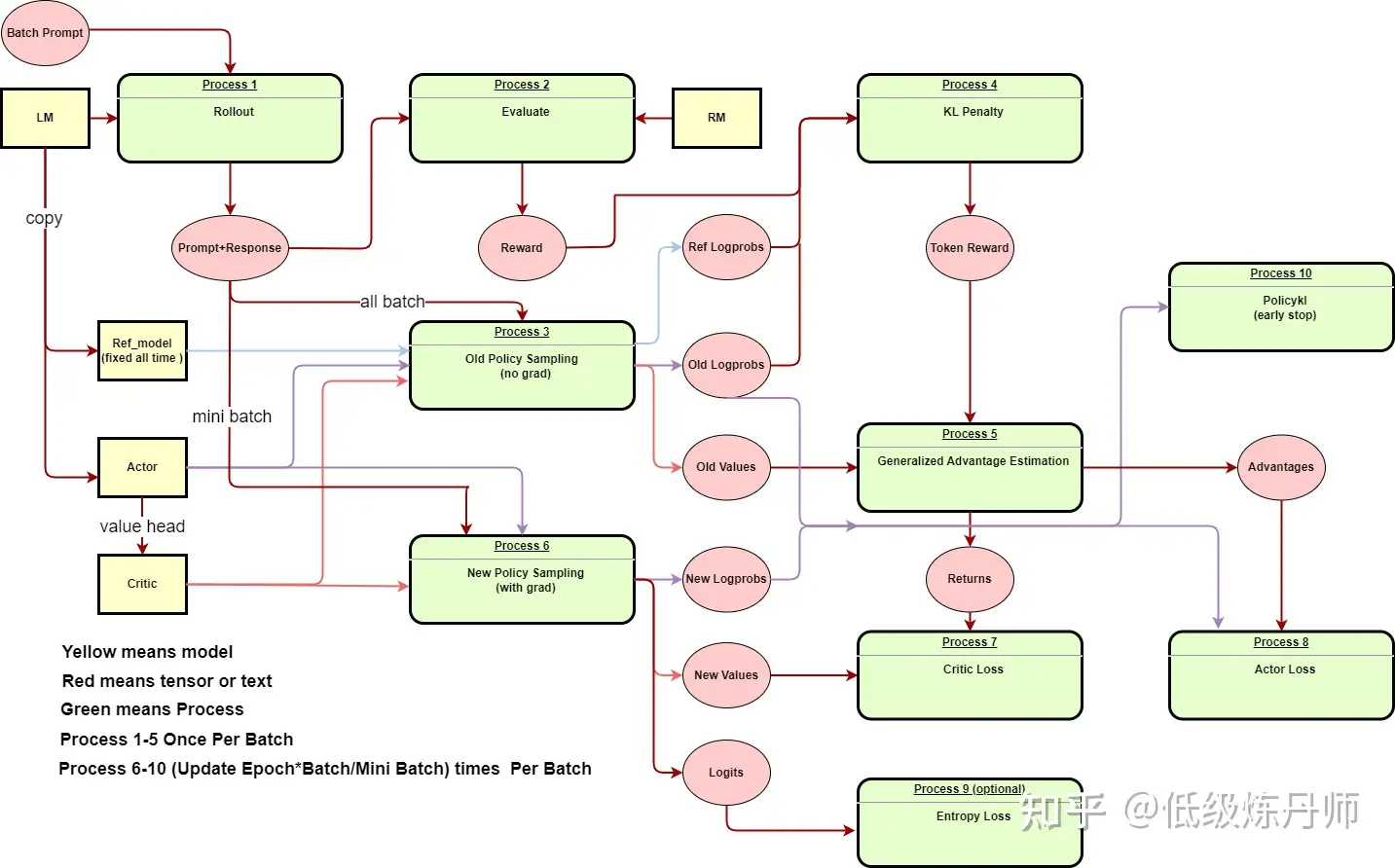
Rollout and Evaluation:在这个阶段,我们从prompt库里抽样,使用语言模型生成response,然后使用奖励模型(Reward Model, RM)给出奖励得分。这个得分反映了生成的response的质量,比如它是否符合人类的偏好,是否符合任务的要求等。Make experience:在这个阶段,我们收集了一系列的“经验”,即模型的行为和对应的奖励。这些经验包括了模型生成的response以及对应的奖励得分。这些经验将被用于下一步的优化过程。Optimization:在这个阶段,我们使用收集到的经验来更新模型的参数。具体来说,我们使用PPO算法来调整模型的参数,使得模型生成的response的奖励得分能够增加。PPO算法的一个关键特性是它尝试保持模型的行为不会发生太大的改变,这有助于保证模型的稳定性
十个步骤依次是:
- Rollout:根据策略(LM)生成轨迹(文本)。
- Evaluate:对生成的轨迹进行评估(RM)。
- Old Policy Sampling:从旧的策略(initial actor)中采样概率等信息。
- KL Penalty:计算当前策略和原始LM之间的KL散度,用作对策略改变过快的惩罚项。
- Generalized Advantage Estimation (GAE):GAE是一种优势函数的估计方法,它结合了所有可能的n-step 进行advantage估计。
- New Policy Sampling:从新的策略中采样概率等信息。
- Critic Loss:Critic的目标是估计状态的价值函数,Critic loss就是价值函数预测值和实际回报之间的差距。
- Actor Loss:Actor的目标是优化策略,Actor loss就是基于优势函数的策略梯度。
- Entropy Loss:为了增加探索性,通常会添加一个基于策略熵的正则项,它鼓励策略保持多样性。
- Policykl:这是对策略迭代过程的一个度量,它度量新策略和旧策略之间的差距。
把所有的模型和变量都写出来了,其中黄色代表模型,红色代表值,绿色是步骤。朝向步骤的箭头表面该步骤需要该值或者模型,朝向步骤外部的箭头表示该步骤的输出。
PPO 方法
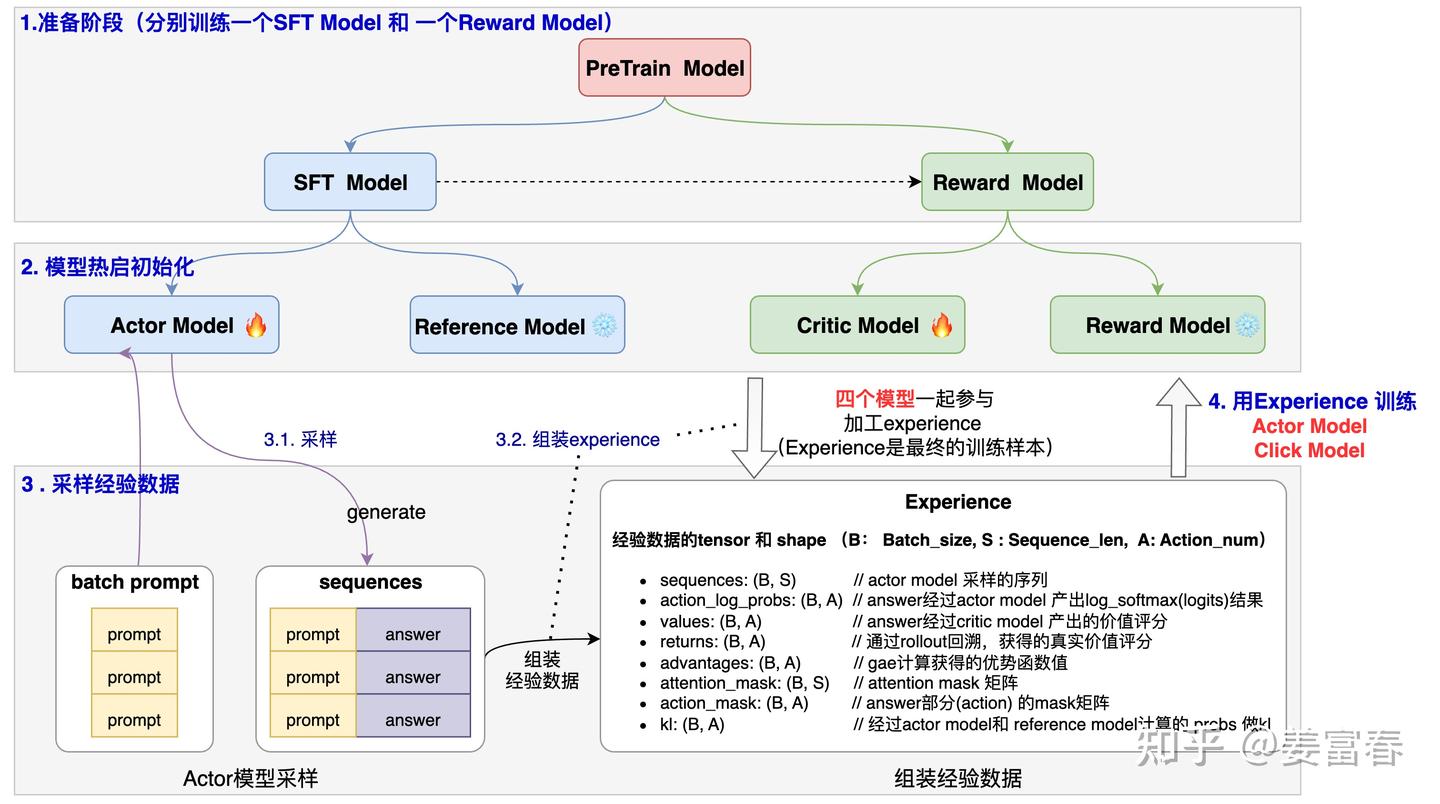
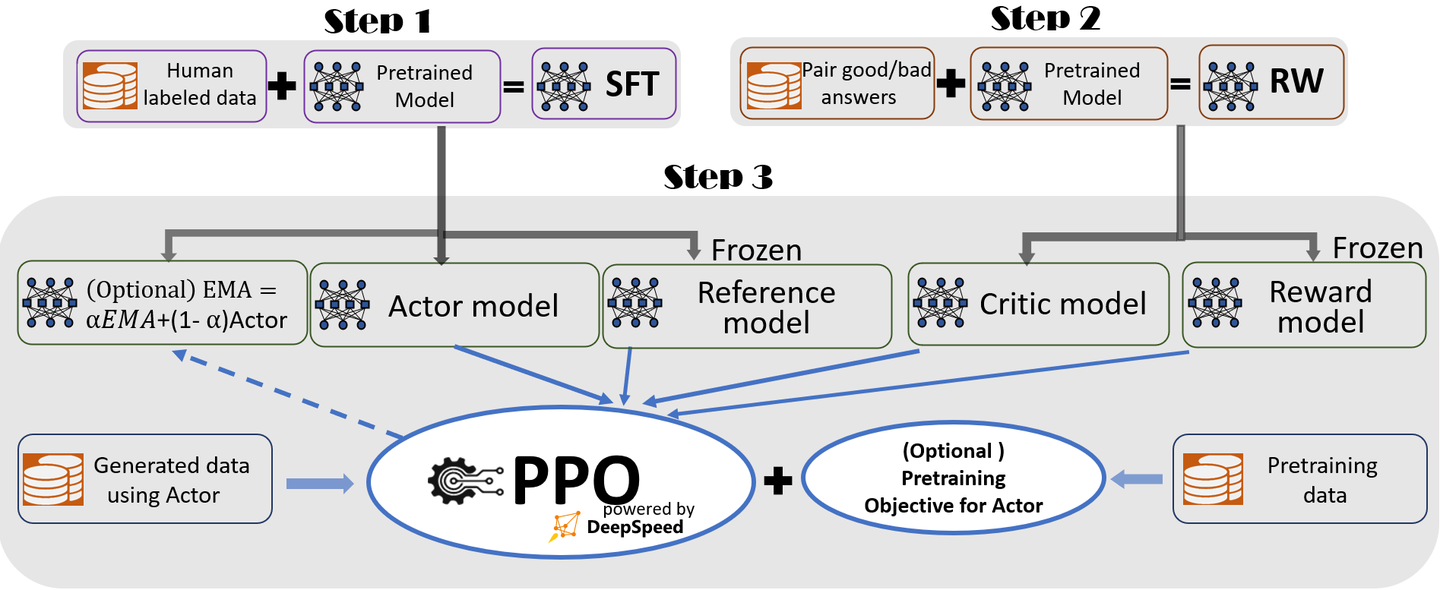
【2025-2-14】RLHF 微调三阶段解析 & RLHF 的变体
PPO 模型
PPO 是 actor-critic 架构,因此有:
actor model:要微调的 LLM,从 SFT 模型初始化而来。critic model:估算 PPO 状态值函数,是一种值函数近似(value function approximation)
RLHF 中又加入了两个模型:
reference model:也从 SFT 模型初始化而来,在 PPO 阶段参数冻结。- 作用: 提供基准,让 actor model 在一定范围内更新参数。
reward model:单独训练的奖励模型,在 PPO 阶段参数冻结。- 作用: 充当智能体的外部环境,提供奖励信号。
Deepspeed 库对于第三阶段 PPO 微调代码,与 TRL 的实现有些区别。
- 5个模型, 1个可选
PPO 奖励函数
PPO 奖励函数是什么?reward model 的输出?
InstructGPT 目标函数
\[\begin{align*} \text{objective}(\phi)=&E_{(x,y)\sim D_{\pi_{\phi}^{\text{RL}}}}\left[r_{\theta}(x, y)-\beta\log\left(\frac{\pi_{\phi}^{\text{RL}}(y|x)}{\pi^{\text{SFT}}(y|x)}\right)\right]+&\gamma E_{x\sim D_{\text{pretrain}}}\left[\log\left(\pi_{\phi}^{\text{RL}}(x)\right)\right] \end{align*}\]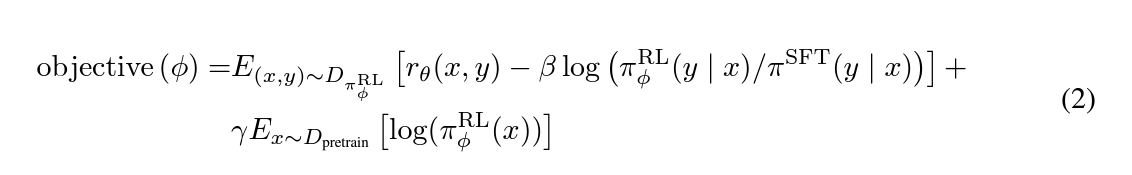
注:
- x 是 prompt;
- y 是 RL LM 模型生成的回答;
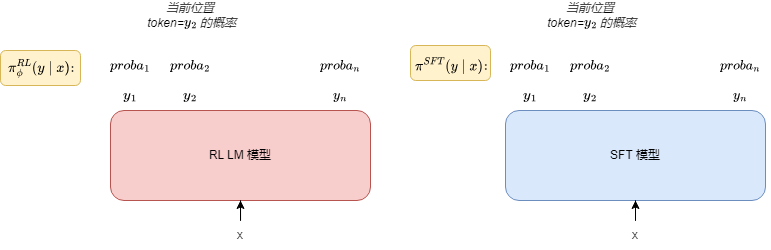
- π_rl 的形状与 y 相同,是序列长度 L(假设 batch size 等于 1),代表每个位置 token 的生成概率
分析
- 第一项:损失函数
- 第一部分 r(x,y) 是 reward model 的输出;注意,reward model 只输出一个标量
- 第二部分 log(…) 是额外添加的奖励,或者说惩罚。
- 如果当前的 RL 模型(actor model)与 reference model相差过大,那么获得的奖励减少
- 第二项:惩罚项,目标是让 actor model 的输出与 SFT 模型的输出越接近越好。
- 惩罚项是为了防止 actor model 过于偏离 SFT 模型,即让 actor model 收敛到 SFT 模型。
- 惩罚项的系数 $\beta$ 是超参数,根据实际情况进行调整。
- 保持 actor model 在标准 NLP 任务上的性能,让它不要“忘本”。
图解
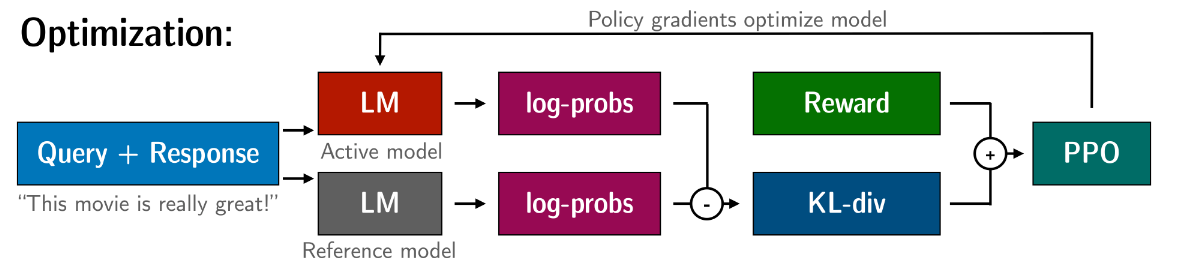
TRL 求奖励函数的部分:
# 求 KL 散度
kl = self._kl_penalty(logprob, ref_logprob)
non_score_reward = -self.kl_ctl.value * kl
reward = non_score_reward.clone()
# y 中非 padding 的最后一位
last_non_masked_index = mask.nonzero()[-1]
# 最终的奖励 = KL 散度 + reward model 的输出(在 KL 散度最后一位相加)
# score 就是 reward model 的输出
reward[last_non_masked_index] += score
PPO 训练
因此, PPO 阶段只需要训练 actor model 与 critic model。
- 第一种: 两个模型共享参数,一起训练。此时把 policy gradient 的损失函数与 critic model 的损失函数(通常是 MSE)加权求和,作为总的损失。
- 第二种: actor model 与 critic model 独立训练,这样 critic model 可以选择比 actor model 更小的模型。一般来说 critic model 会从 reward model 初始化而来。
共享
两个模型共享参数,一起训练。此时把 policy gradient 的损失函数与 critic model 的损失函数(通常是 MSE)加权求和,作为总的损失。
actor model 与 critic model 是如何共享参数的?
base_model_output = self.pretrained_model(
input_ids=input_ids,
attention_mask=attention_mask,
**kwargs,
)
...
# 取最后一层的隐藏状态
last_hidden_state = base_model_output.hidden_states[-1]
# v_head 是一个输出维度是 1 的全连接层,把每个 token 映射成一个标量
# value shape: (B, L)
value = self.v_head(last_hidden_state).squeeze(-1)
critic model 在 actor model 的基础上加了一个全连接层,让每个 token 对应一个标量,作为该 token 对应的状态下,之后能获得的累积(折扣)回报。所以 critic model 的输出形状与输入是一致的,都是 (batch size, seq_len) 。
独立
actor model 与 critic model 独立训练,这样 critic model 可以选择比 actor model 更小的模型。
一般来说 critic model 会从 reward model 初始化而来。
InstructGPT 论文
- value function (critic model) 和奖励模型是一样的架构(6B),即是第二种做法。
PPO 进化
RL技术典型: PPO
PPO 类型
RLHF: 数据集是人类标注RLAIF: 数据集是GPT,PaLM2等模型标注
PPO 缺点:
- 训练不太稳定,效率低
- 训练一个与Policy模型大小相当的Value模型,带来了巨大的内存和计算负担;
- LLM 只有最后一个 token 会被奖励模型打分,训练在每个 token 上都准确价值函数难;
GRPO 避免了像 PPO 那样使用额外的 Value Model 近似,而是使用同一问题下多个采样输出的平均奖励作为baseline。
非RL技术
DPO: 直接构造偏好数据集进行优化- 跟PPO主要区别: 不用单独训练reward模型,直接构造偏好数据集,对齐原来模型即可
ORPO: SFT+RLHF 不是 end2end,于是直接在 SFT 上加 alignment lossKTO:DPO训练的 pair-wise(x,y_w,yl)数据集获取困难KTO使用数据 point-wise(x,y,label)
Step-DPO:- 直接对 reasoning 过程进行优化限制(step-level),而不是等模型输出完了再进行优化(Instance-level)
优化Alignment的输出长度的,加了一个类似正则化项的限制等等;
reward model 无法优化 general perference(不可传递性偏好,比如a>b,b>c, c>a的情况)于是, DNO, SPO(引入了纳什均衡,Nash equilibrium)
DPO 只优化单轮,因此对多轮偏好优化做了拓展(multi-turn DPO);
直接合成数据,用 MCTS(exploration and exploitation保证多样性和质量)等方式造完数据,直接DPO开始训练就完了,完美的数据闭环,alignment 论文数学推导过程长
【2024-9-30】2024年大模型Alignment偏好优化技术PPO,DPO, SimPO,KTO,Step-DPO, MCTS-DPO,SPO
PPO 代码实现
LLM PPO
PPO 通过分阶段解耦“数据生成”和“策略学习”,在保证训练稳定性的同时,让模型逐步学会生成更符合人类偏好的回复。
PPO 设计哲学
- 阶段 1 是“探索”:用当前策略生成多样回复,用外部信号(RM)和内部估计(Critic)打标签;
- 阶段 2 是“学习”:在固定数据上保守更新,通过 clip 和 KL 防止“学歪”;
- Reference Model 是安全网:确保语言依然流畅、合理;
- 整个流程可迭代:每轮 PPO 后,策略更强,下一轮采样质量更高。
这种“采样-学习”交替的模式,正是 PPO 能在 LLM 对齐中兼顾效果、稳定性和安全性的关键
整个流程分为如下两个阶段:
(1)阶段 1:采样与反馈(Sample + Label)
- 目标:用当前策略模型生成一批回复,并利用冻结奖励模型打分,再结合当前评论家模型估计价值,最终为每个 token 动作计算出优势(Advantage) 和回报(Return),作为后续训练的监督信号。
- 关键点:此阶段不更新任何模型参数,只是“收集数据”。Policy 和 Critic 在采样时使用的是当前最新参数,但输出会被 detach(视为常数),作为“旧策略”和“旧评论家”的快照。
核心计算逻辑
- 生成轨迹:对每个 prompt x,用当前策略生成完整回复 y=(a1,…,aT),形成状态序列: s0=x, s1=x⊕a1, …, sT=x⊕y
- 获取最终奖励:调用冻结的 Reward Model 计算奖励 R = r(x,y)
- 注意: 中间步骤无奖励 rt=0, t<T
- 计算回报(Return): Rt = ∑ γ^(k-t)*r_k = γ^(T-k)R
- 注意:只有最后一步有奖励
- 计算优势(Advantage): At = Rt - V(st)
- 解释: 状态 st 下执行 at, 比平均水平好多少
- 保留旧值: 将当前策略的 log-prob 和评论家的 value detach,作为阶段 2 的基准(即“old policy”和“old critic”)
核心代码
trajectories = []
for x in prompts: # x: [L_x]
# 1. 用当前策略生成回复 y 和 log-prob
y, logprobs = policy_model.generate_with_logprobs(x) # y: [T], logprobs: [T]
# 2. 构建状态序列 s_0 ... s_T
states = [torch.cat([x, y[:t]]) for t in range(len(y) + 1)] # len = T+1
# 3. 用当前评论家估计每个状态的价值
values = torch.stack([critic_model(s) for s in states]) # [T+1]
# 4. 奖励模型打分(仅最终奖励)
R = reward_model(x, y) # scalar
# 5. 计算回报:R_t = γ^{T−t} * R
T_len = len(y)
returns = torch.zeros(T_len + 1)
returns[T_len] = R
for t in reversed(range(T_len)):
returns[t] = gamma * returns[t + 1]
# 6. 计算优势:A_t = R_t - V(s_t),仅对 t=0..T-1 有效
advantages = returns[:-1] - values[:-1] # [T]
# 7. 保存“旧”值(detach 阻断梯度)
trajectories.append({
'x': x,
'y': y,
'logprobs_old': logprobs.detach(), # [T]
'values_old': values.detach(), # [T+1]
'advantages': advantages.detach(), # [T]
'returns': returns.detach() # [T+1]
})
(2)阶段 2:策略与评论家更新(Policy & Critic Learning)
- 目标: 利用阶段 1 收集的固定轨迹数据,更新策略模型(Policy)和评论家模型(Critic),使得:
- 策略更倾向于选择高优势的动作;
- 评论家更准确地预测未来回报;
- 同时通过 PPO-clip 和 KL 正则防止策略突变或偏离合理语言分布。
核心计算逻辑
- 策略损失(PPO-Clip)
- KL 散度正则(防止语言退化)
- 评论家损失(Value MSE)
- 总损失
定义概率比
PPO 损失
- 若 At>0:鼓励增加动作概率,但最多增加 (1+ϵ)倍;
- 若 At<0:鼓励减少概率,但最多减少到 (1−ϵ) 倍。
KL 散度正则(防止语言退化)
评论家损失(Value MSE)
总损失
for epoch in range(K): # K=2~4,对同一数据集多轮优化
for traj in trajectories:
x, y = traj['x'], traj['y'] # x: [L_x], y: [T]
logprobs_old = traj['logprobs_old'] # [T]
advantages = traj['advantages'] # [T]
returns = traj['returns'] # [T+1]
# --- 1. 策略损失 ---
logprobs_curr = policy_model.get_logprobs(x, y) # [T]
ratio = torch.exp(logprobs_curr - logprobs_old) # [T]
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - eps, 1 + eps) * advantages
ppo_loss = -torch.mean(torch.min(surr1, surr2))
# KL 正则(ref_model 冻结)
with torch.no_grad():
logprobs_ref = ref_model.get_logprobs(x, y) # [T]
kl_loss = torch.mean(logprobs_curr - logprobs_ref)
policy_loss = ppo_loss + beta * kl_loss
# --- 2. 评论家损失 ---
states = [torch.cat([x, y[:t]]) for t in range(len(y) + 1)]
values_pred = torch.stack([critic_model(s) for s in states]) # [T+1]
value_loss = F.mse_loss(values_pred, returns)
# --- 3. 优化 ---
total_loss = policy_loss + c1 * value_loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
RLHF 示例
一个简单的基于 PyTorch 的 RLHF 代码示例
- 训练一个智能体在格子世界环境中移动,并接受人类专家的反馈来改进其决策和行为:
- 【2023-2-12】ChatGPT简单训练源码
import torch
import numpy as np
# 构建智能体和环境
class Agent:
def __init__(self, n_states, n_actions):
self.model = torch.nn.Sequential(
torch.nn.Linear(n_states, 32),
torch.nn.ReLU(),
torch.nn.Linear(32, n_actions)
)
def act(self, state):
state = torch.from_numpy(state).float().unsqueeze(0)
action_probs = torch.softmax(self.model(state), dim=1)
action = np.random.choice(len(action_probs[0]), p=action_probs.detach().numpy()[0])
return action
class Environment:
def __init__(self, n_states, n_actions):
self.n_states = n_states
self.n_actions = n_actions
def reset(self):
self.state = np.zeros(self.n_states)
self.state[0] = 1 # 将智能体放在起始位置
return self.state
def step(self, action):
if action == 0:
self.state[0] -= 1
elif action == 1:
self.state[0] += 1
else:
self.state[1] += 1
reward = 0
done = False
if self.state[0] == 0 and self.state[1] == 0: # 智能体到达目标位置
reward = 1
done = True
return self.state, reward, done
# 定义 RLHF 算法
class RLHF:
def __init__(self, agent, environment):
self.agent = agent
self.env = environment
def train(self, num_episodes, human_feedback_fn):
optimizer = torch.optim.Adam(self.agent.model.parameters(), lr=0.001)
for i in range(num_episodes):
state = self.env.reset()
done = False
while not done:
action = self.agent.act(state)
state_next, reward, done = self.env.step(action)
# 获取人类专家反馈
human_feedback = human_feedback_fn(state, action, state_next, reward)
human_reward = torch.tensor(human_feedback)
# 计算损失函数
action_probs = torch.softmax(self.agent.model(torch.from_numpy(state).float()), dim=1)
dist = torch.distributions.Categorical(probs=action_probs)
log_prob = dist.log_prob(torch.tensor(action))
ratio = torch.exp(log_prob - torch.log(human_reward))
clipped_ratio = torch.clamp(ratio, 0.8, 1.2)
loss = -torch.min(ratio * human_reward, clipped_ratio * human_reward).mean()
# 进行近端优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
state = state_next
# 创建环境、智能体和 RLHF 实例,并开始训练
env = Environment(n_states=2, n_actions=3)
agent = Agent(n_states=2, n_actions=3)
rlhf = RLHF(agent=agent, environment=env)
rlhf.train(num_episodes=100, human_feedback_fn=lambda s,a,sn,r: 1)
基于 Python 和 PyTorch 的 PPO 算法代码示例,用于训练一个智能体在 Gym 环境中移动,并与环境进行交互来学习最优策略:
- 【2023-2-12】ChatGPT简单训练源码
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical
# 定义神经网络模型
class Policy(nn.Module):
def __init__(self, input_size, output_size):
super(Policy, self).__init__()
self.fc1 = nn.Linear(input_size, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, output_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.softmax(x, dim=1)
# 定义 PPO 算法
class PPO:
def __init__(self, env_name, gamma, eps_clip, k_epochs, lr):
self.env = gym.make(env_name)
self.gamma = gamma
self.eps_clip = eps_clip
self.k_epochs = k_epochs
self.lr = lr
self.policy = Policy(self.env.observation_space.shape[0], self.env.action_space.n)
self.optimizer = optim.Adam(self.policy.parameters(), lr=lr)
def select_action(self, state):
state = torch.from_numpy(state).float().unsqueeze(0)
probs = self.policy(state)
dist = Categorical(probs)
action = dist.sample()
log_prob = dist.log_prob(action)
return action.item(), log_prob
def update(self, memory):
states, actions, log_probs_old, returns, advantages = memory
for _ in range(self.k_epochs):
# 计算损失函数
probs = self.policy(states)
dist = Categorical(probs)
log_probs = dist.log_prob(actions)
ratio = torch.exp(log_probs - log_probs_old)
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1-self.eps_clip, 1+self.eps_clip) * advantages
actor_loss = -torch.min(surr1, surr2).mean()
# 计算价值函数损失
value = self.policy(torch.from_numpy(states).float())
value_loss = F.mse_loss(value.squeeze(), torch.tensor(returns))
# 进行梯度下降
self.optimizer.zero_grad()
loss = actor_loss + 0.5 * value_loss
loss.backward()
self.optimizer.step()
def train(self, num_episodes, max_steps):
for i_episode in range(num_episodes):
state = self.env.reset()
rewards = []
log_probs_old = []
states = []
actions = []
for t in range(max_steps):
action, log_prob = self.select_action(state)
state, reward, done, _ = self.env.step(action)
rewards.append(reward)
log_probs_old.append(log_prob)
states.append(state)
actions.append(action)
if done:
break
# 计算折扣回报和优势函数
returns = []
discounted_reward = 0
for reward in reversed(rewards):
discounted_reward = reward + self.gamma * discounted_reward
returns.insert(0, discounted_reward)
仍有许多悬而未决的问题有待探索。
- RL 在从人类反馈中学习有多重要?我们能否通过在 IFT 或 SFT 中使用更高质量的数据进行训练来获得 RLHF 的性能?
- 为了安全的角度看,Sparrow 中的 SFT+RLHF 与 LaMDA 中仅使用 SFT 相比如何?
- 鉴于我们有 IFT、SFT、CoT 和 RLHF,预训练有多大的必要性?如何折衷?人们应该使用的最佳基础模型是什么 (公开的和非公开的)?
- 许多模型都经过 红蓝对抗 (red-teaming) 的精心设计,工程师特地搜寻故障模式并基于已被揭示的问题改进后续的训练 (提示和方法)。我们如何系统地记录这些方法的效果并重现它们?
PPO 问题
RLHF 复杂且不稳定
- 首先, 拟合反映人类偏好的奖励模型
- 然后用强化学习微调大型无监督 LM,以最大化这种估计奖励,而不会偏离原始模型太远。
- 且PPO需要收集大量人类偏好数据、需要训练奖励模型、RLHF同时加载多个模型进行训练,训练难度较大。
人类反馈强化学习(RLHF)实现困难:
- 需要人类反馈数据(很难收集)
- 奖励模型训练(很难训练)
- PPO强化学习微调(不仅很耗资源,而且也很难训练)
PPO 好处:
- 提高安全性和可控性;
- 改进交互性;
- 克服数据集偏差;
- 提供个性化体验;
- 符合道德规范;
- 持续优化和改进。
非RL对齐方式
【2024-2-17】人类偏好优化算法哪家强?跟着高手一文学懂DPO、IPO和KTO
- 原文链接:huggingface
由于 RLHF 复杂且不稳定,如何直接使用优化函数将人类的偏好和模型的结果进行对齐?
分析
RLHF 常用 PPO 作为基础算法,整体流程包含了4个模型,且通常训练过程中需要针对训练的 actor model进行采样,因此训练起来,稳定性、效率、效果不易控制。
actor model/policy model: 待训练模型,SFT训练后的模型作为初始化reference model: 参考模型,经SFT训练后的模型进行初始化,且与actor model是同一个模型,且模型冻结,不参与训练,作用是在强化学习过程中保障actor model与reference model的分布差异不宜过大。reward model: 奖励模型,提供每个状态或状态动作对的即时奖励信号。Critic model: 估计状态或状态动作对的长期价值,也称状态值函数或动作值函数。
- 偏好数据: 表示为
三元组(提示语 prompt, 良好回答 chosen, 一般回答 rejected)。- 论文中chosen表示为下标w(即win),rejected表示为下标l(即lose)
- DPO算法仅包含RLHF中的2个模型,即:
演员模型(actor model)以及参考模型(reference model),且训练过程中不需要进行数据采样。
总结
三种优化方法是:
- 直接偏好优化 (Direct Preference Optimization,
DPO): DPO - 身份偏好优化 (Identity Preference Optimisation,
IPO): IPO - Kahneman-Taversky 优化(
KTO): KTO
三种不需要强化学习的大语言模型优化方法:直接优化偏好(DPO)、身份偏好优化(IPO)和卡内曼-塔弗斯基优化(KTO)。
DPO将偏好微调问题转换为一个简单的损失函数来实现- 而
IPO则在DPO基础上添加了正则化项以避免过拟合。 KTO则完全基于“好”或“坏”的单个示例来定义损失函数。
LLM 对齐算法进行了评估:直接偏好优化(DPO)、身份偏好优化(IPO)和 Taversky Optimisation 优化(KTO)
并且在两个高质量的 7b 参数 大小的 LLM 上进行了实验。
这些 LLM 经过了有监督微调,但没有进行人类偏好调整。作者发现,虽然确实能找到效果最好的算法,但要获得最佳结果,必须对一些关键超参数进行调整。
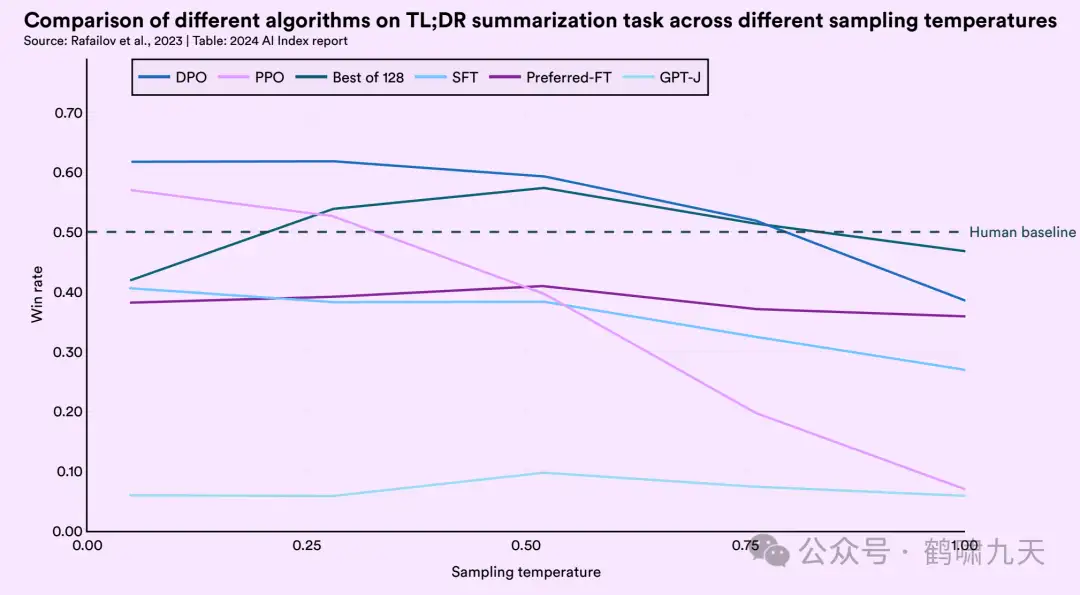
【2024-4-24】 斯坦福AI(大模型)指数2024年度报告
各种方法对比
- RLAIF基本趋近RLHF
- 模型无害性上,RLAIF安全性最好,SFT最差。
- DPO比PPO/SFT更好
- 温度越高,效果越差,尤其是PPO,超过0.25时,急剧下跌
如果不能降低 RLHF 的开销,LLMs 在更广泛场景中的应用将受到限制。于是,直接偏好优化(Direct Preference Optimization,DPO)应运而生。
- DPO 融合了 打分模型和策略模型的训练过程,只需要偏好标注数据、
参考模型和策略模型,就可使 LLMs 直接对齐人类偏好,极大地减轻了训练时对计算资源的消耗。 - 但是,理想的 DPO 形态应是 在线DPO(Online DPO),实时地采样 LLMs 对指令的回复,并实时地由人类标注偏好。所以,数据构造带来的开销非但没有降低(这种开销经常被忽略),反而要比 RLHF 更高。
因此, 开源社区通常使用 离线DPO(Offline DPO)微调模型。
- 训练前采集模型对指令的回复,并由人类标注好不同回复之间的排序,随后用这部分数据训练模型。
Offline DPO 使用事先采集的数据估计了人类和 LLMs 的偏好,随后再通过训练对齐二者的偏好。
随着训练的进行,LLMs 会逐渐偏离它自己最开始的偏好,损失函数又会错误地估计 LLMs 当前的能力(和上文中的 PT 和 SFT 类似),进而导致不理想的训练结果。
DPO 直接偏好优化
DPO(Direct Preference Optimization)发现:
- 其实不需要显式训练 Reward Model + PPO,直接从人类偏好数据中优化策略。
【2024-1-19】【LLM的偏好微调和对齐】
【2024-7-29】斯坦福 推出 DPO (Differentiable Policy Optimization)
直接偏好优化 (DPO) 是一种广泛使用的离线偏好优化算法,重新参数化了从人类反馈 (RLHF) 强化学习中的奖励函数,以提高简单性和训练稳定性。
DPO 以封闭形式提取出最优策略,仅通过简单的分类损失就能解决标准的RLHF问题,无需RL循环训练。
- rlhf 特点:效果强、对齐准(能到90分),但复杂、不稳定、贵、易”作弊”(为拿高分说废话)
- dpo 核心:跳过奖励模型(RM)和强化学习,直接用「好/坏回答对」训模型
选型
- ✓ 简单稳定 不用调 PPO,不容易崩
- ✅ 省钱省卡 不用训 RM,算力减半
- ✅ 效果接近 能到 85–90 分,够用
- ❌ 灵活性弱 没法做复杂奖励
DPO 稳定性高、性能优越、计算量轻,消除了在微调过程中从LM采样的需求,也无需进行大量的超参数调整。
实验结果表明
- DPO 在将LMs与人类偏好对齐方面表现得与现有方法相当或更优。
- 特别是控制生成内容的情感方面,DPO 微调超越了基于PPO的RLHF
- 同时在摘要和单轮对话的响应质量上也能达到或超过现有水平,且其实施和训练过程更为简便。
DPO(Direct Preference Optimization, 直接偏好优化)是一种稳定、性能和计算成本轻量级的强化学习算法。
- 通过利用奖励函数与最优策略之间的映射关系,证明这个受限奖励最大化问题可以通过单阶段的策略训练来精确优化
- 本质是在人类偏好数据上解决一个分类问题。
- DPO 相对于PPO,更加稳定、低成本的强化学习方法
DPO 通过参数化 RLHF 奖励函数来直接根据偏好数据学习策略模型,无需显式奖励模型。
- DPO 并不会学习一个显式奖励模型,而是使用一个带最优策略的闭式表达式来对奖励函数 r 进行重新参数化
该方法简单稳定,已经被广泛用于实践。
DPO(Direct Preference Optimization)直接偏好优化算法与PPO(Proximal Policy Optimization)优化目标相同。
主要思路是:
- 定义 policy 模型(策略模型)和reference模型(参考模型)
- Policy模型: 要训练的对话生成模型
- reference模型: 给定的预训练模型或人工构建的模型。
- 对于给定prompt,计算两模型对正样本和负样本的概率, 正样本是人类选择的回复, 负样本是被拒绝的回复。
- 通过两个模型概率的差值构建DPO损失函数,惩罚policy模型对正样本概率的下降和负样本概率的上升。通过最小化DPO损失进行模型训练。
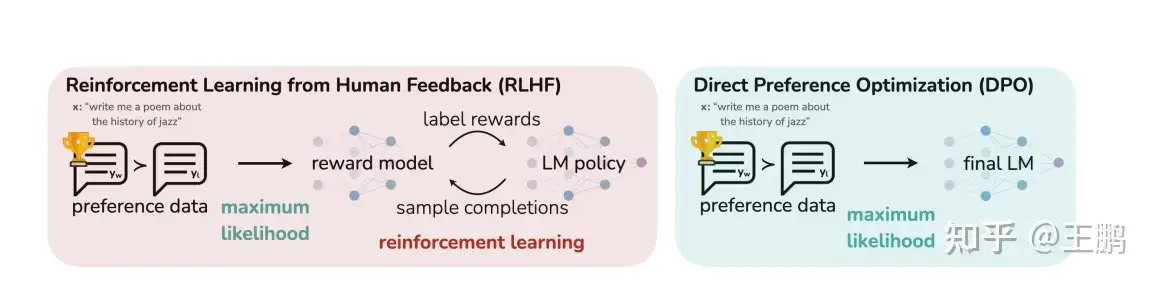
直接偏好优化(DPO)已成为将大型语言模型(LLM)与人类或人工智能偏好相结合的一种很有前景的方案。与基于强化学习的传统对齐方法不同,DPO 将对齐公式重新定义为一个简单损失函数,该函数直接在偏好数据集{(x,y_w,y_l)}上优化,其中 x 是 prompt,y_w,y_l 分别是偏好的和非偏好的响应。
DPO 同样可以完成RLHF,而且有两个重要优点:
- (1)不需要额外训练奖励模型。
- (2)整个训练过程只需要策略模型和参考模型 2个LLM模型,不需要额外显存去加载奖励模型,节省显存资源。
大大降低了训练难度。
DPO 改进之处
- RLHF算法包含
奖励模型(reward model)和策略模型(policy model,也称演员模型,actor model),基于偏好数据以及强化学习不断迭代优化策略模型的过程。 - DPO算法不包含
奖励模型和强化学习过程,直接通过偏好数据进行微调,将强化学习过程直接转换为SFT过程,因此整个训练过程简单、高效,主要的改进之处体现在于损失函数。 
DPO 本质是带参考模型的对比学习(contrastive learning),完全不需要 RL 循环,所以训练快、稳定。
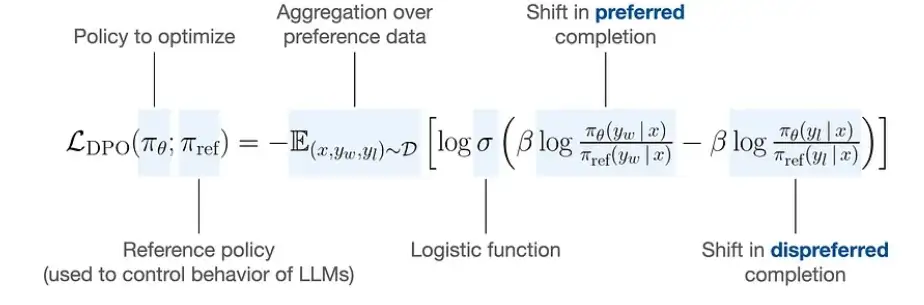
损失函数
DPO 证明:最大化人类偏好等价于最小化损失
通俗理解:
- DPO 希望模型对“好回复”的相对概率(相比参考模型)比“坏回复”更高。
π_θ(y|x)当前模型在prompt x 下生成 y 的概率π_ref(y|x)参考模型(SFT)在prompt x 下生成 y 的概率- β 温度参数,控制优化强度,越大越激进
DPO 损失函数解释:
- (1)策略模型(参数更新)得分: 选择样本得分 - 拒绝样本得分 。其本质上希望 选择样本得分越高越好,拒绝样本得分越低越好。
- (2)参考模型得分(参数固定): 选择样本得分 - 拒绝样本得分 ,每个训练epoch 不会变
- (3)最终损失 : -(策略模型得分 — 参考模型得分 ) 。本质上期望策略模型在无害问题生成得分上与参考模型拉开差距。
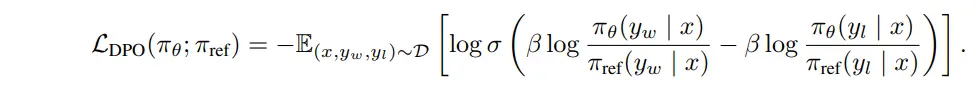
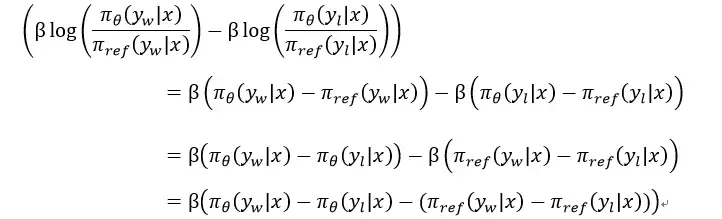
- 左半部分是训练的policy模型选择chosen优先于rejected,右半部分是冻结的reference模型选择chosen优先于rejected,二者的差值可类似于
KL散度,保障actor模型的分布与reference模型的分布不会有较大的差异。
训练
DPO 微调示意图
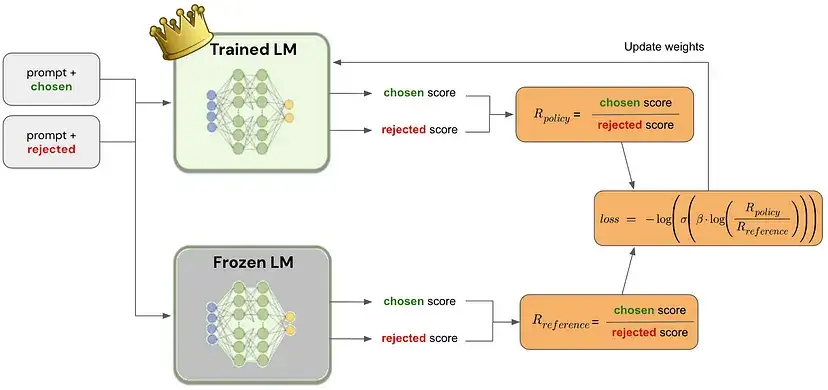
- Trained LM即为策略模型,Frozen LM即为参考模型,二者均是先进行SFT微调得到的模型进行初始化,其中Trained LM需要进行训练,Frozen LM不参与训练。
- 两个模型分别针对chosen和rejected进行预测获取对应的得分,再通过DPO的损失函数进行损失计算,进而不断的迭代优化。
DPO 简单易用, 广受欢迎,并已成功应用于 Zephyr 模型和 Intel 提出的 NeuralChat 等模型的训练当中。
在两个高质量的7B参数语言模型上对这三种方法进行了超参数扫描实验,发现DPO表现最好,但关键超参数beta需要调优。
- 在Zephyr模型上,当beta取0.01时所有三种方法效果最好。DPO可以达到最高的MT Bench分数,但KTO的表现也很接近。IPO的效果则不如基础模型。
- 在OpenHermes模型上,每个方法的最佳beta值差异很大。DPO仍优于其他两种方法,但基础模型已经很强,调整后提升不大。
文章开源了所有的代码和配置文件,重现了这些实验结果。DPO目前看来是最强大且稳定的语言模型优化算法。
- 未来将继续在TRL中实现新的优化算法并评估其性能。希望能开发出比DPO更好的方法,或能从仅带“好”“坏”标签的数据中进行调整的KTO。
RLHF 代码实现
实现
DPO 实现
- direct-preference-optimization 支持 ‘conservative’ DPO and IPO
- trl 版本实现: 消费级显卡搞定RLHF——DPO算法+QLora微调LLM拒绝有害问题回答实战
ODPO 核心就是在损失函数中放一个 offset,但是 offset 是根据 reward 确定的,SimPO 引用了 ODPO 但是没讨论,引出 offset 的时候提的是 IPO,因为 IPO 的 offset 是也定值
DPO 本质是带参考模型的对比学习(contrastive learning),完全不需要 RL 循环,所以训练快、稳定。
作者:marsggbo
for batch in preference_data:
x, y_w, y_l = batch
# 计算当前模型和参考模型对两个回复的 log 概率
logp_w = policy_model.log_prob(x, y_w)
logp_l = policy_model.log_prob(x, y_l)
ref_logp_w = ref_model.log_prob(x, y_w)
ref_logp_l = ref_model.log_prob(x, y_l)
# 计算 logits 差
logits = beta * ((logp_w - ref_logp_w) - (logp_l - ref_logp_l))
# 二分类损失:希望 logits 越大越好
loss = -F.logsigmoid(logits).mean()
optimizer.step(loss)
DPO 问题
DPO Loss 简明扼要,仅需 SFT 和 REF 两个模型,无需处理 PPO 繁琐的实现问题。
如果用传统 RL 思路来理解 DPO,其更像是一个 Offline 的 REINFORCE 算法。
- 只需要认为正样本 reward为+1,而负样本 reward为-1。
- 然后用 REINFORCE 直接基于偏好数据集训练即可。
- 而 KL penalty 的约束也是可以加到这个 reward 值上即可,亦或用额外的 KL Div Loss 来约束。
DPO 会继承传统 Offline RL 算法的所有缺点
- 没有 Importance Sampling 的梯度矫正
- 训练样本和模型之间的 OOD 问题。
这些都会让训练偏移轨迹。
其次 DPO 在训练中容易出现 chosen logits 和 rejected logits 同时下降的问题
这方面 Llama3.1 用对 chosen samples 加一个NLL Loss 来缓解。
DPO 改进
DPO 的成功激发了新损失函数研究,归纳为两个:IPO (稳健性) + KTO ()
IPO
DPO 缺点: 人类偏好数据集上很快就会过拟合。
谷歌 DeepMind 引入身份偏好优化(IPO),为 DPO 损失添加了一个正则,能够在不使用「提前停止」等技巧的情况下让模型收敛。
KTO
Kahneman 和 Tversky 的前景理论
- 人类以有偏见但定义明确的方式感知随机变量;
- 例如,人类以厌恶损失而闻名。
将LLM与人类反馈相匹配的目标隐含许多偏见——这些目标(如DPO)在交叉熵最小化方面的成功部分可以归因于人类感知损失(HALO)的损失函数家族。
然而,这些方法效用函数与前景理论的效用函数不同。
【2024-2-2】
KTO 使用 Kahneman-Tversky 人类效用模型,论文提出直接最大化生成效用的 HALO, 而不是最大化偏好的对数可能性。
- 在1B~30B尺度上与基于偏好的方法的性能相匹配或超过,尽管它只从二进制信号(0或者1)中学习输出是否可取。
- 没有一个 HALO 普遍优越;
- 最佳损失取决于最适合给定设置的归纳偏差,经常被忽视的考虑因素。
KTO 损失函数本质是把 pair-wise 公式变成 point-wise 方式
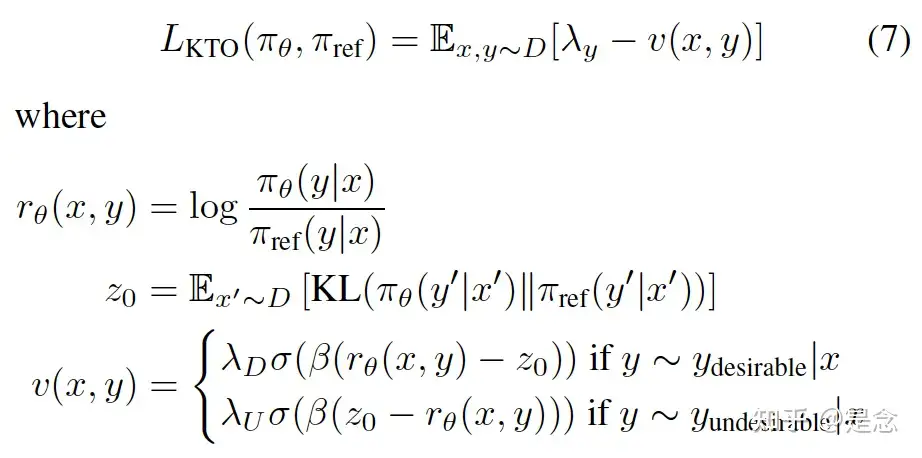
KTO 的工作原理:
- 如果模型以直接(blunt manner)方式增加了理想示例的奖励,那么 KL 惩罚也会增加,并且不会取得任何进步。这迫使模型准确地了解是什么让输出变得理想,这样就可以增加奖励,同时保持 KL 项持平(甚至减少)。
- 实际实现中,KL term 是通过当前batch里面的正负样本进行估计得到的,详细 debug KTOTrainer 源代码
对成对偏好数据进行分配:
-
与大多数比对方法一样,DPO 需要一个成对偏好数据集(x, y_w, y_l),够根据一组标准(如有益性或有害性)来标记哪种模型响应更好。
- 实践过程中,创建这些数据是一项耗时且成本高昂的工作。
- ContextualAI 提出替代方案,称为 Kahneman-Taversky 优化(
KTO),完全根据被标记为「好」或「坏」的样本(例如在聊天 UI 中看到的图标👍或👎)来定义损失函数。这些标签更容易获得, KTO 是一种很有前景的方法,不断更新在生产环境中运行的聊天模型。
与此同时,这些方法都有相应的超参数,其中最重要的是 β ,控制对使用模型的偏好程度的权重。
这些方法已经在第三方库(如 huggingface TRL)中实现
KTO 不需要成对的偏好数据,实验时直接将 GPT-4 生成的响应归类为「好」标签,将 Llama Chat 13b 的响应视为「坏」标签。
- 虽然 GPT-4 的响应可能比 Llama Chat 13b 普遍更受欢迎,某些情况下,Llama-Chat-13b 可能会产生更好的响应,但作者认为这只是小概率事件,可以忽略不计。
Step-DPO
【2024-8-18】超越DPO!大模型精细化对齐之 Step-DPO
相比 instance-level-dpo,step-level-dpo 只优化 step-level 的数据,而共同前缀则作为 prompt 的一部分,不参与 loss 计算。
直接偏好优化 (DPO) 对长链数学推理的益处有限,因为采用 DPO 的模型很难识别错误答案中的细节错误。这种限制源于缺乏细粒度的过程监督。
【2024-1-26】香港中文和哈工大提出简单、有效且数据高效的 Step-DPO 方法将单个推理步骤视为偏好优化的单位,而不是整体评估答案。
Step-DPO 损失函数本质是从以前的对运行结果的loss,加上了对中间推理过程的loss:
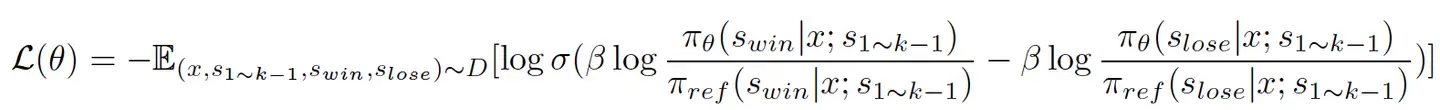
Step-DPO 开发了一个数据构建 pipeline,可创建包含 10K 个逐步偏好对的高质量数据集。
- Error collection: 使用了COT的推理prompt,例如”Let’s think step by step. Step 1:”,这确保模型的推理结果被结构化为多个推理步骤,每个步骤都明确以“Step i:”开头。
- Step localization: 假设每个错误推理结果都明确地呈现为一系列推理步骤 y = s1、s2、…、sn,继续验证每个推理步骤的正确性,直到找到第一个错误并记录其步骤号 k。此过程可以手动完成,也可以使用 GPT-4。我们选择 sk 作为错误推理步骤 s lose,从而得到一个包含错误步骤的数据集。
- Rectification:为了得到 D2 中每个样本对应的正确推理步骤,需要通过提示 x 和前面的正确推理步骤 s1∼k−1 推断模型 π ref,来抽样多个输出 y cont。我们保留最终答案与基本事实相符的输出。在剩余的输出中,选择 y_cont 中的第一个推理步骤作为 swin,从而得到最终数据集D。
DPO 中,由于后者的分布不均性质,自生成数据比人类或 GPT-4 生成的数据更有效。
研究结果表明,对于具有超过 700 亿个参数的模型,仅需 10,000 个偏好数据对和少于 500 个 Step-DPO 训练步骤即可使 MATH 的准确率提高近 3%。
- 当将 Step-DPO 应用于 Qwen2-72B-Instruct 时,在 MATH 和 GSM8K 的测试集上分别获得了 70.8% 和 94.0% 的分数,超越了一系列闭源模型,包括 GPT-4-1106、Claude-3-Opus 和 Gemini-1.5-Pro。
介绍几篇与 Step-DPO 相关的文章。
MCTS-DPO- 论文标题:Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
- 代码地址:MCTS-DPO
- 提出 step-level-dpo,为了获取 step-level 的偏序数据,则使用树搜索获取具有共同前缀的 step-level 偏序数据。使用树搜索可以天然地获取具有共同前缀的 preference-dataset,而且,可以利用 UCT、estimated-Q 等等,选择 preference-step,以及 对 Step-DPO 算法做 label smoothing 如根据访问次数对 dpo-loss 做平滑。
SVPO- 论文标题:Step-level Value Preference Optimization for Mathematical Reasoning
- 继承了 alphamath,将 value-function 估计与 step-level-dpo 结合。preference-dataset 的构造与 [1] 类似,即使用树搜索 + output-reward 筛选 chosen、rejected step。在整个模型训练过程中,加入了 value-head 的训练,解码时,可以使用 value-guided-decoding,采样复杂度介于 greedy/random-sample 和 MCTS 之间,达到更好的效果。该工作在训练中,为了防止模型退化,加入了 sft-loss。
- Scaling LLM Math Synthetic Data
- 论文标题:RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold
- 用答案错误样本提升数学能力的方法
MCTS-DPO
【2024-6-17】新加坡南洋理工 通过迭代偏好学习过程增强大型语言模型 (LLM) 推理能力的方法(叫做 MCTS-DPO),该方法受到 AlphaZero 所采用的成功策略的启发。
MCTS-DPO 利用蒙特卡洛树搜索 (MCTS) 迭代收集偏好数据,利用其前瞻能力将实例级奖励分解为更细粒度 step-level信号。为了增强中间步骤的一致性,结合了结果验证和逐步自我评估,不断更新新生成数据的质量评估。所提出的算法采用直接偏好优化 (DPO) 来使用此新生成的步骤级偏好数据更新 LLM 策略。
理论分析揭示了使用策略采样数据对于成功自我改进的重要性。对各种算术和常识推理任务的广泛评估表明,与现有模型相比,性能有显著提高。
- 例如,MCTS-DPO 方法在 GSM8K、MATH 和 ARC-C 上的表现优于 Mistral-7B 监督微调 (SFT) 基线,准确率分别大幅提升至 81.8% (+5.9%)、34.7% (+5.8%) 和 76.4% (+15.8%)。
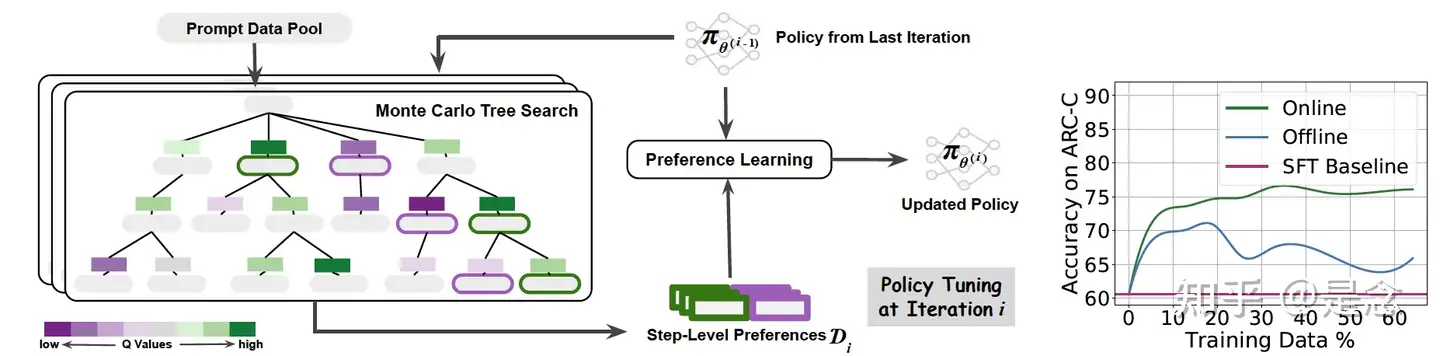
蒙特卡洛树搜索 (MCTS) 通过迭代偏好学习提升模型性能。MCTS-DPO 框架的每次迭代(左侧)包含两个阶段:MCTS 用于收集step level偏好,偏好学习用于更新策略。
- 用 MCTS 估计的动作值 Q 来分配偏好,其中 Q 值较高和较低的步骤将分别标记为正数据(绿色)和负数据(紫色)。Q 的比例在颜色图中可视化。使用右侧训练过程中的验证准确率曲线展示了迭代学习框架中在线方式的优势。ARC-C 验证的性能说明了我们提出的方法与其离线变体相比的有效性和效率。
SPIN
【2024-2-12】SPIN:Self-Paly微调将弱模型转换为强模型
不使用额外人工标注数据将弱LLM训练为强LLM的前景。SPIN(Self-Play Fine-tuning)的新微调方法。
- SPIN的核心是self-play机制,LLM通过自身对抗来实现能力改善。
- LLM从先前迭代的版本中生成训练数据,通过从人类标注数据中识别生成的响应来改善模型。
- SPIN能够逐步将初始LLM提升为强大的模型,释放SFT人类标注数据的全部潜力。理论上,当LLM与目标分布一致时才能实现训练目标函数的最优值。
- 在HuggingFace Open LLM Leaderboard、MT-Bench和Big-Bench上评估了SPIN,结果显示器能够显著改善LLM在各个基准上的效果,甚至超越使用DPO训练的模型。
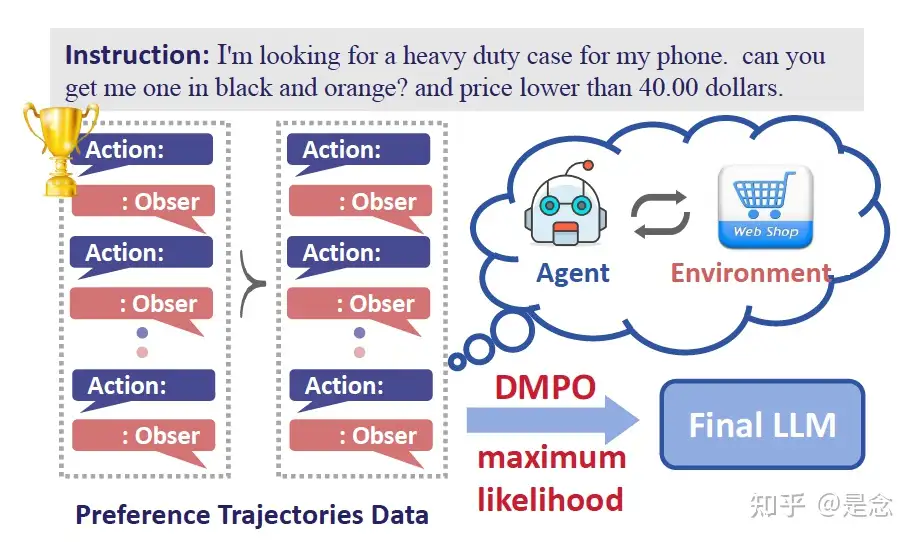
DMPO
直接偏好优化 (DPO) 可以减轻复合错误,提供一种直接优化强化学习 (RL) 目标的方法。
然而,由于无法取消分区函数,将 DPO 应用于多轮任务会带来挑战。
解决
- 分区函数独立于当前状态,并解决首选和不首选轨迹之间的长度差异。
【2024-8-17】中科大论文在 RL 目标中用状态动作占用度量约束替换策略约束,并在 Bradley-Terry 模型中添加长度规范化,从而产生一种名为 DMPO 的新型损失函数,用于多轮agents任务,并提供理论解释。
在三个多轮 agents 任务数据集上进行的大量实验证实了 DMPO 损失的有效性和优越性。
DMPO 损失的说明如下图,它通过最大化首选轨迹相对于非首选轨迹的可能性来直接优化 RL 目标。
ODPO
DPO 问题
- pair 中的候选项并非同等重要,而 DPO 算法只看序关系, 体现不出a优于b的程度情况
【2024-2-16】ETH 推出 ODPO, 增加一个 偏置 offset, 区分不同程度
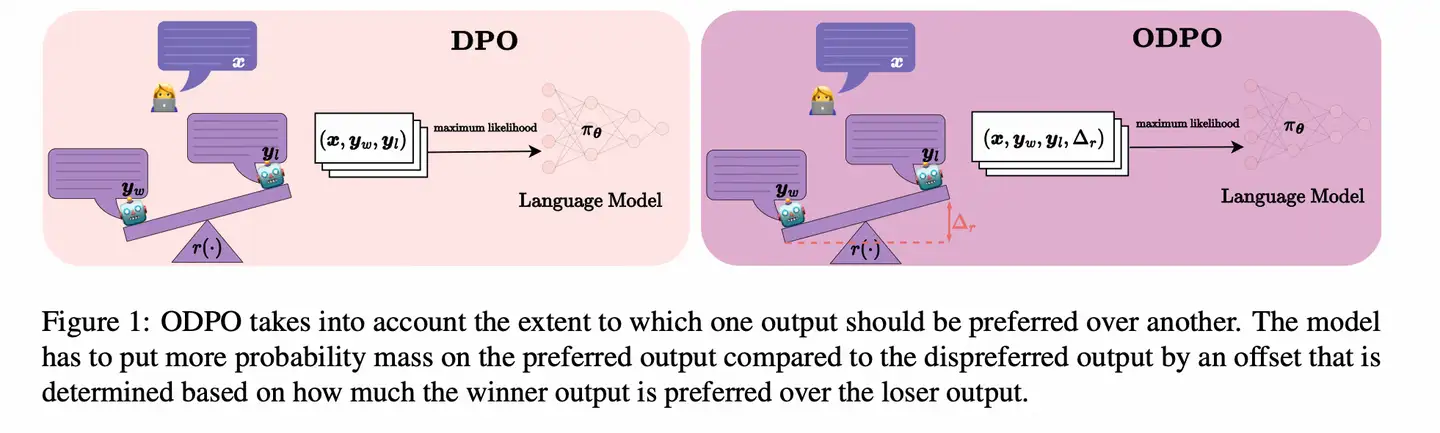
利用标注数据,设定一个距离,把正负样本差距拉开
理论:证明如果将 Gumbel 噪声添加到响应的估计奖励中,则两个响应的估计奖励之间的差异大于 0 的概率等于Bradley-Terry模型预测的一个人选择该响应的概率,而奖励差异大于 d 的概率是 σ(原始奖励差 - d);
- 发现 offset >= 0 时, ODPO 的损失函数等价于 softmax margin 损失。
然后开始设定偏移量,通用形式 alpha * f(正样本分数 - 负样本分数),alpha 是一个超参数,f 是接下来实验要选的函数,先直接用 log(正样本分数 - 负样本分数), alpha=1
在不同的数据集大小上,ODPO 都实现了帕累托改进
实验显示, ODPO 显著优于 DPO, 尤其是 数据集小的情形。
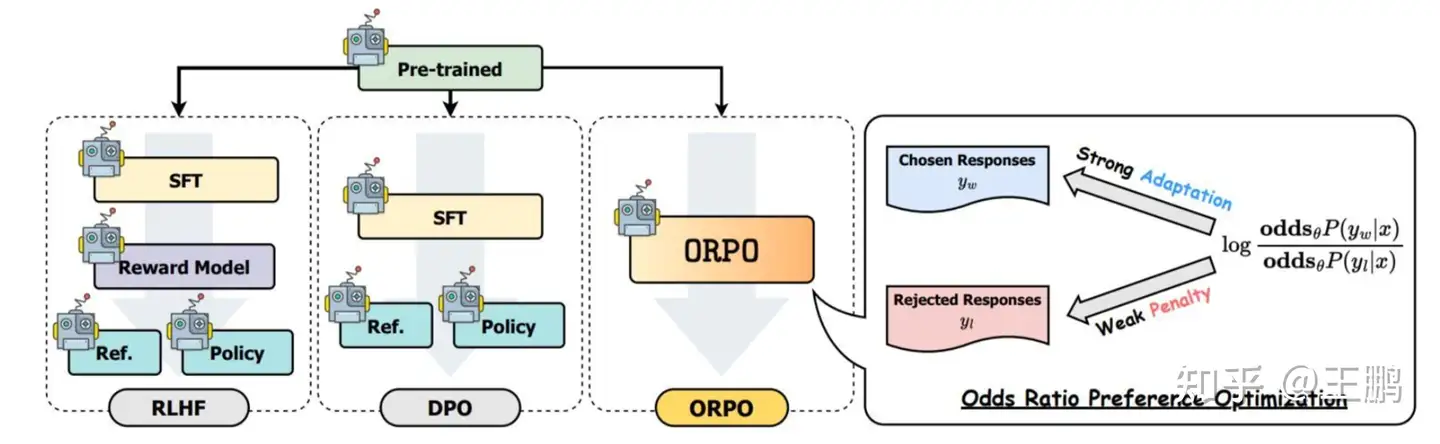
ORPO
【2024-4-8】消费级显卡搞定人类偏好对齐(RLHF), 不用参考模型的对齐算法——ORPO实战
RLHF和DPO资源消耗较多,能不能摆脱参考模型,直接进行人类偏好对齐?
- ORPO 算法
【2024-3-12】ORPO(Odds Ratio Policy Optimization,赔率比策略优化)无需参考模型LLM语言模型偏好对齐的技术
- 通过对拒绝的回答施加一个小惩罚,同时对选择回答施加一个强奖励,然后通过简单对数赔率项添加到负对数似然损失上。
- 论文 ORPO: Monolithic Preference Optimization without Reference Model
- trl 代码: orpo_trainer.py
ORPO 通过将弱惩罚分配给被拒绝结果,将强适应信号分配给所选择的响应,并将简单的对数比值比项附加到负对数似然损失,以单步方式在没有参考模型(reference model)的情况下对齐语言模型。
ORPO算法目标函数由两部分组成:
- 监督微调损失:遵循传统的因果语言模型负对数似然损失函数,以最大化生成参考标记的可能性。
- 相对比率损失:最大化在给定输入prompt时,生成非偏好响应reject与生成偏好响应chosen之间的可能性比率。
通过最小化监督微调损失,同时最大化相对比率损失,ORPO实现了人类偏好对齐,最重要的是不需要任何参考模型,相比于DPO少了一个REF参考模型,相比于RLHF(PPO)少了一个Reward Model 和一个REF参考模型。
ORPO 最终损失形式如下(trl的实现):
loss=policy_nll_loss(监督微调损失) -losses(相对比率损失) 。- loss 前一部分就是 监督微调损失 policy_nll_loss , 即chosen样本的llm预测损失。
- 后一部分losses为相对比率损失
附
实现代码如下:
def odds_ratio_loss(
self,
policy_chosen_logps: torch.FloatTensor,
policy_rejected_logps: torch.FloatTensor,
) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.FloatTensor, torch.FloatTensor, torch.FloatTensor]:
"""Compute ORPO's odds ratio (OR) loss for a batch of policy and reference model log probabilities.
Args:
policy_chosen_logps: Log probabilities of the policy model for the chosen responses. Shape: (batch_size,)
policy_rejected_logps: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)
Returns:
A tuple of three tensors: (losses, chosen_rewards, rejected_rewards).
The losses tensor contains the ORPO loss for each example in the batch.
The chosen_rewards and rejected_rewards tensors contain the rewards for the chosen and rejected responses, respectively.
The log odds ratio of the chosen responses over the rejected responses ratio for logging purposes.
The `log(sigmoid(log_odds_chosen))` for logging purposes.
"""
# Derived from Eqs. (4) and (7) from <https://arxiv.org/abs/2403.07691> by using log identities and exp(log(P(y|x)) = P(y|x)
log_odds = (policy_chosen_logps - policy_rejected_logps) - (
torch.log1p(-torch.exp(policy_chosen_logps)) - torch.log1p(-torch.exp(policy_rejected_logps))
)
sig_ratio = F.sigmoid(log_odds)
ratio = torch.log(sig_ratio)
losses = self.beta * ratio
chosen_rewards = self.beta * (policy_chosen_logps.to(self.accelerator.device)).detach()
rejected_rewards = self.beta * (policy_rejected_logps.to(self.accelerator.device)).detach()
return losses, chosen_rewards, rejected_rewards, torch.mean(ratio).item(), torch.mean(log_odds).item()
解释:
- 两个选择:一个正确,一个错误。
- ORPO损失帮模型更倾向于选择正确的那个。
- ORPO损失会计算模型选择正确答案和错误答案的概率差距
- 然后鼓励模型增加选择正确答案的概率,减少选择错误答案的概率。
- 这样,模型就会慢慢学会怎样做出更好的选择。
对比了一下3种人类偏好对齐方法的的效果: ORPO 算法在低资源情况下,偏好对齐的性能比DPO和PPO还好一点。
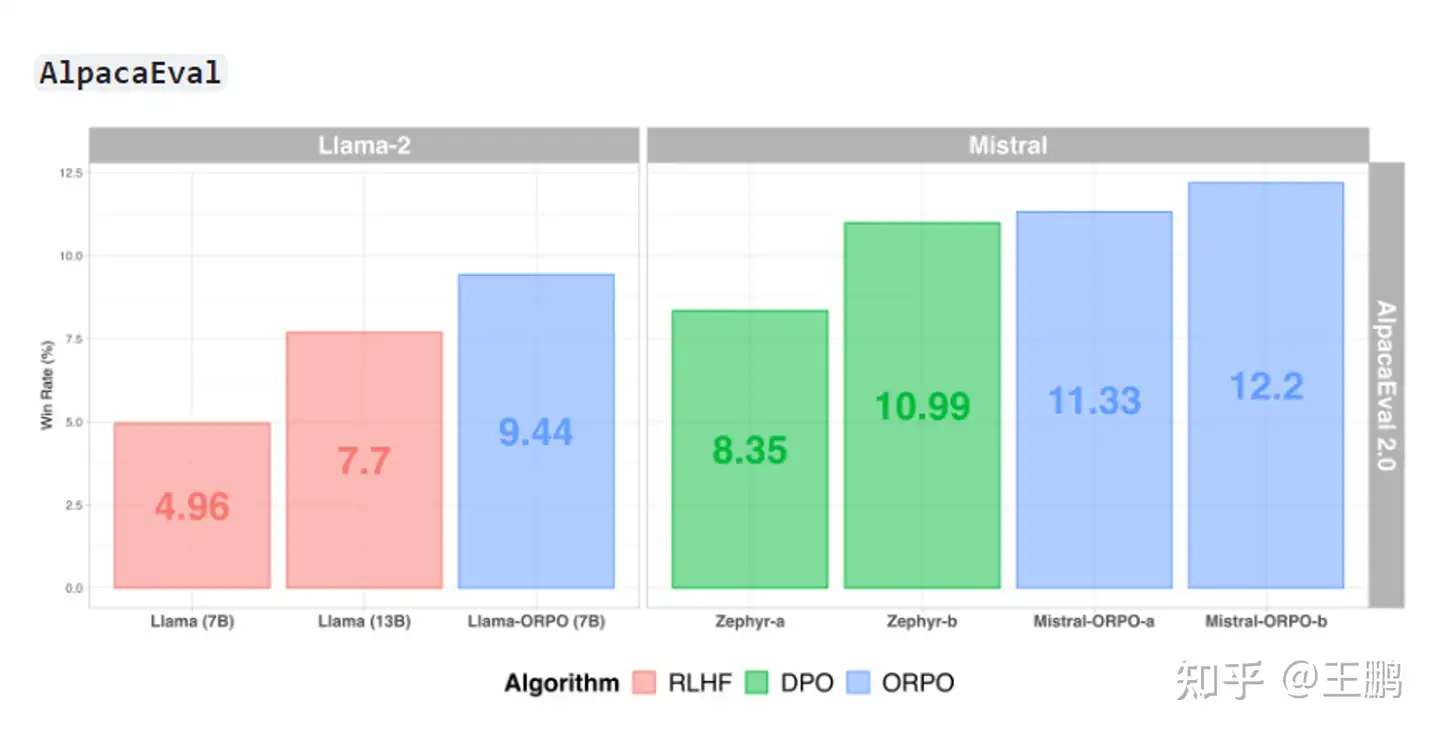
trl包最新实现的ORPO算法,数据集格式如下,主要需要包含
- “prompt”:人类输入的指令
- “chosen”:人类偏好的机器输出的结果
- “rejected” :人类拒绝的机器输出的结果
{'prompt': '考虑以下方程,附加条件是 x 必须是一个质数:\n1 + 1 = x\nx 的值是多少?',
'system': '',
'chosen': '对于方程式1 + 1 = x和x必须是质数的限制条件,x的值为2。在这种情况下,1 + 1 = 2,2是最小的质数,同时满足方程和限制条件。',
'rejected': '方程式1 + 1 = x有一个解为x = 2,而且由于x必须是一个质数,唯一可能的解就是x = 2。',
'source': 'evol_instruct',
'id': None}
qwen1.5-1.8B-chat 实践 参考:
SimPO
DPO 问题
- 即使训练时把 reward 学对,也不代表生成正样本的概率确实大于了生成负样本的概率
【2024-5-27】全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
【2024-5-23】弗吉尼亚+普林斯顿, 陈丹琪团队 推出 SimPO, 简单却有效的离线偏好优化算法。
- 论文 SimPO: Simple Preference Optimization with a Reference-Free Reward
- 代码及模型 SimPO
- 损失函数: 对序列的概率取平均

SimPO 原理
SimPO 有效性归功于一个关键设计:
- 使用序列平均对数概率作为隐式奖励。
- 这种奖励公式与模型生成更好地保持一致,并且消除了对参考模型的需求,使其计算和内存效率更高。
- 此外,在 Bradley-Terry 目标中引入了目标奖励边际,以鼓励获胜和失败响应之间的更大边际,从而进一步提高算法的性能。
细节对比分析:
- DPO 的奖励公式隐式地促进了长度归一化,不过 SimPO 在这方面略胜一点,用直接归一化效果更好
- 奖励公式与生成似然的不匹配
- SimPO 奖励分类准确性更高、内存开销更小

算法核心将偏好优化目标中的奖励函数与生成指标对齐。
SimPO 包含两个主要组件:
- (1)在长度上归一化奖励,其计算方式是使用策略模型的奖励中所有 token 的平均对数概率;
- (2)目标奖励差额,用以确保获胜和失败响应之间的奖励差超过这个差额。
SimPO 目标函数在DPO的基础上多了一个gamma(论文叫做target reward margin)的参数
总结,SimPO 特点:
- 简单:SimPO 不需要参考模型,因此比 DPO 等其它依赖参考模型的方法更轻量更容易实现;
- 性能优势明显:尽管 SimPO 很简单,但其性能却明显优于 DPO 及其最新变体(比如近期的无参考式目标 ORPO)。如图 1 所示。并且在不同的训练设置和多种指令遵从基准(包括 AlpacaEval 2 和高难度的 Arena-Hard 基准)上,SimPO 都有稳定的优势;
- 尽量小的长度利用:相比于 SFT 或 DPO 模型,SimPO 不会显著增加响应长度(见表 1),这说明其长度利用是最小的。
SimPO 效果
效果分析
实验相当全面,把多个变种都拿来比较,比如
IPO和KTO都不用成对数据ORPO也不需要参考模型R-DPO是加长度相关正则化
最后,SimPO 比前述五种方法都好
基于 Llama3-8B-instruct 构建具有顶尖性能的模型
- AlpacaEval 2 上得到的长度受控式胜率为 44.7,在排行榜上超过了 Claude 3 Opus;
- SimPO 在 AlpacaEval 2 上的表现比 DPO 高出 6.4 分,在 Arena-Hard 上的表现比 DPO 高出 7.5 分
- 另外其在 Arena-Hard 上的胜率为 33.8,使其成为了目前最强大的 8B 开源模型。
SimPO 能更有效地利用偏好数据,在验证集上对高质量和低质量响应的似然进行更准确的排序,这进一步能造就更好的策略模型。
TDPO
微调预训练的大型语言模型(LLM)过程通常利用成对比较和KL散度等方法与参考LLM进行比较,评估模型生成的完整答案。
然而,回复产生都在token级别,遵循顺序、自回归方式。
【2024-4-18】TDPO
通过在 Token-level 优化策略来使LLM与人类偏好保持一致的新方法。
- 与之前在发散效率方面面临挑战的方法不同,TDPO 为每个token引入了 前KL 散度约束,提高了对齐和多样性。
- TDPO 将 Bradley Terry 模型用于基于token 奖励系统,增强了KL散度的调节,同时保持了简单性,不需要显式的奖励建模。

实验结果表明,TDPO在平衡对齐与生成多样性方面具有卓越的性能。
- 在受控情绪生成(IMDB情感分析数据集)和单轮对话数据集中,TDPO 微调比DPO达到了更好的平衡,并且与基于 DPO 和 PPO的RLHF方法相比,显著提高了生成响应的质量。
GRPO
deepseek v3 使用策略优化方法GRPO(Group Relative Policy Optimization)
- 【2024-4-27】论文 DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- 代码 DeepSeek-Math
作者:marsggbo
GRPO:在 PPO 和 DPO 之间找平衡
GRPO(Group Relative Policy Optimization)思路:
- 既然人类经常面对多个选项做判断(如从 4 个回复中选最好 2 个),那就直接建模这种“群体偏好”
GRPO 做法
- 对每个 prompt x,用当前策略生成 K 个回复(比如 K=4)
- 根据 Reward Model(或人类)将这些回复分成“好组”和“坏组”
- 优化目标:拉大组间差异,缩小组内差异
GRPO 损失函数(简化版)
- 带参考模型的 softmax 分类损失:希望“好回复”的归一化概率更高。
PPO vs DPO
| 方法 | 优点 | 缺点 |
|---|---|---|
| PPO | 支持 online learning(边生成边学),样本利用率高;可结合多种奖励(如安全性、事实性) | 需要训练 4 个模型(Policy, Critic, RM, Reference),流程复杂;RM 质量直接影响效果 |
| DPO | 训练简单,只需 2 个模型(Policy + Reference);效果接近 PPO | 完全依赖离线(offline)偏好数据;容易过拟合(尤其数据少时);无法引入动态奖励 |
SFT vs GRPO
【2025-2-22】 通过deepseek r1 GRPO落地文本分类场景
对比
SFT: 全方位、无死角监督- 损失函数表达式: $ L_{SFT}=\frac{1}{L}\sum_{t = 1}^{L}\left(-\sum_{i = 1}^{V}y_{ti}\log(p_{ti})\right) $
GRPO: 分组内相对优化策略, 只看最终表现–期末考试成绩- 损失函数表达式:
$ \frac{1}{G}\sum_{i = 1}^{G}\left(\min\left(\frac{\pi_{\theta}(o_{i}|q)}{\pi_{\theta_{old}}(o_{i}|q)}A_{i},\text{clip}\left(\frac{\pi_{\theta}(o_{i}|q)}{\pi_{\theta_{old}}(o_{i}|q)},1 - \epsilon,1+\epsilon\right)A_{i}\right)\right)-\beta\text{D}{KL}(\pi{\theta}||\pi_{\text{ref}}) $
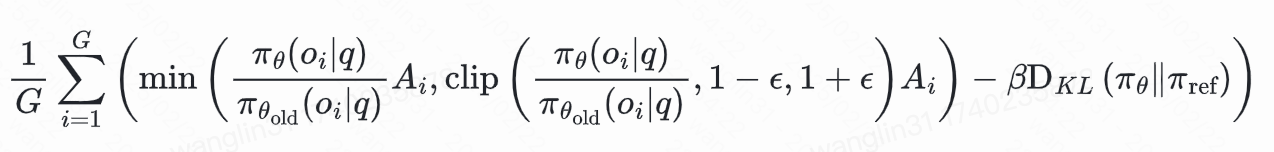
总结
SFT更快更好收敛, 但 逐个 token 学习, 依赖高质量数据GRPO无需过多监督数据 cot 答案,仅需最终答案及过程格式的奖励,即可激发大模型在预训练阶段的潜能, 收敛慢, 但弱依赖高质量数据集
案例:
- input: 你喜欢我吗 -> 你, 喜欢, 我, 吗
- label: 我喜欢你 -> 我, 喜欢, 你
- output:
- 1: 我, 喜欢, 你
- 2: 我, 爱, 你
- 3: 我, 恨, 你
- 4: as, 撒, #, @, 哦
- loss 计算: loss4 » loss3 > loss2 > loss1 = 0
案例:
- prompt: 你的输出必须是: 答案是***
- input: 1+1= -> 1, +, 1, =
- label: 2
- output:
- 1: 答案, 是, 2
- 2: 我, 爱, 你, 答案, 是, 2
- 3: 我, 恨, 你
- 4: as, 答案, 是, 1, 哦
- 奖励计算
- reward1 = reward2 = 1
- reward3 = reward4 = 0
DeepSeek GRPO
组相对策略优化算法:
问题:“2 + 3等于多少?”
- 🌟步骤1:大语言模型生成三个答案。
-
- “5”
-
- “6”
-
- “2 + 3 = 5”
-
- 🌟步骤2:为每个答案打分。
- “5” → 1分(正确,但没有推理过程)
- “6” → 0分(错误)
- “2 + 3 = 5” → 2分(正确,并且有推理过程)
- 🌟步骤3:计算整组平均分。
- 平均分数 = (1 + 0 + 2) / 3 = 1
- 🌟步骤4:将每个答案分数与平均分数进行比较。
- “5” → 0 (等于平均分)
- “6” → -1 (低于平均分)
- “2 + 3 = 5” → 1 (高于平均分)
- 🌟步骤5:强化大语言模型以偏好更高的分数。
- 偏好像 3这样的回答(积极)
- 保持像 1这样的回答(中性)
- 避免像 2这样的回答(消极)
这个过程会重复进行,使模型能够随着时间推移不断学习和改进。
GRPO vs PPO

GRPO 与 PPO 主要区别:
- GRPO 去掉了 critic model.
- GRPO 奖励计算改成了组内相对奖励:一个q生成多个r, 然后格局组内情况对r打分。
- PPO 优势函数里,KL在GAE内, 而 GRPO 挪到外面,修改计算方法。
公式对比

GRPO 避免了像 PPO 那样使用额外 Value Model 近似,而是用同一问题下多个采样输出的平均奖励作为baseline。
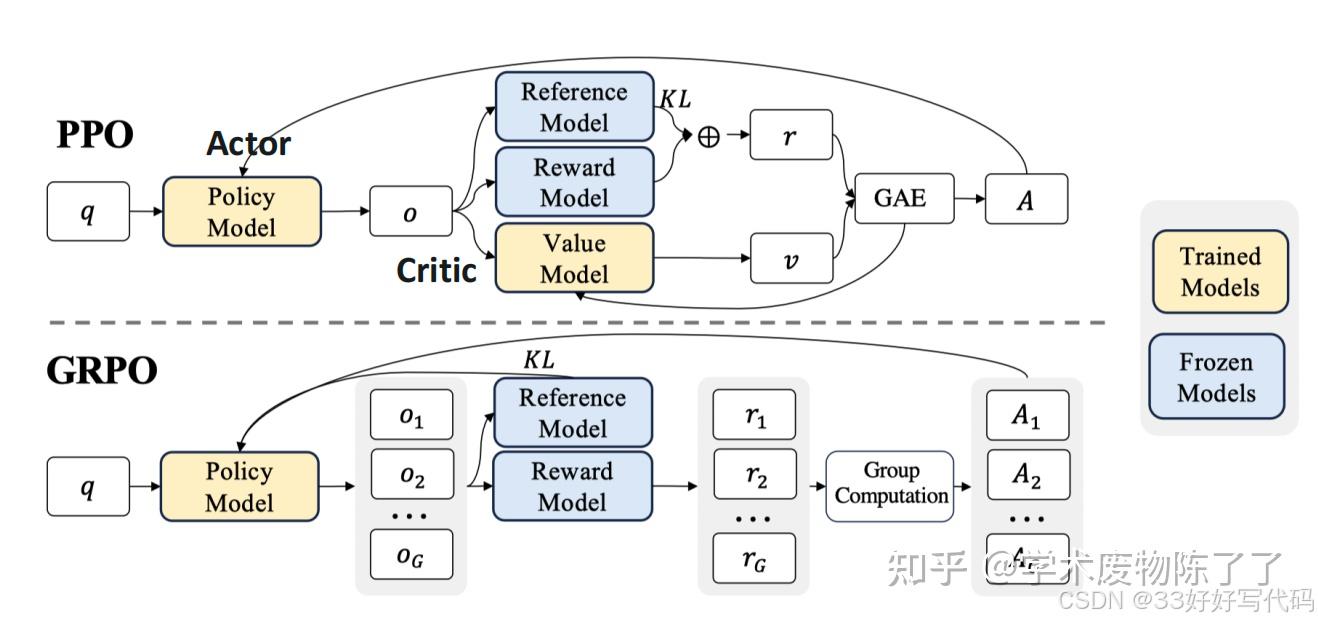
通过多次采样,利用组内的相对奖励来计算优势,从而替换掉 critic model
GRPO 优化目标形式上与PPO相同,只不过
- A(优势)的计算在PPO中是通过
critic model得到,而GRPO是通过N次采样来代替。 - 举例,评价考试得到80分这个场景有多好,80分是一个reward,PPO采用 reward + value,综合试卷的难易度等因素(模型学的critic)来判断80分是否符合应有的学习水平,而 GRPO 直接找来一群人来看一下80分在其中的水平。
Reward model 采用基于规则的奖励系统:
- 准确性奖励:评估模型的响应是否正确。
- 格式奖励:要求模型将其思考过程放在
<think>和<think>的标签之间。
没有使用ORM和PRM,因为奖励模型会在大规模强化学习过程中出现奖励劫持问题。
重新训练奖励模型需要额外的训练资源。
- ORM 是在生成模型中,对生成结果整体打分;
- PRM 是对生成过程中每步打分
GRPO 优势
- 无需额外价值函数, 只优化策略模型
- GRPO 用组内平均奖励作为基线,避免训练额外的价值函数(critic model),减少内存和计算负担。
- 与奖励模型比较性质对齐:
- GRPO 用组内相对奖励计算优势函数,这与奖励模型同一问题的不同输出之间比较的性质相符。
-
- 对 RM 的依赖比 PPO 弱(只需排序,不要求绝对分数准确)
- KL惩罚在损失函数中:
- GRPO 直接将训练策略 π_θ 和参考策略 π_ref 之间的 KL 散度添加到损失中,而不是像 PPO 那样在奖励中添加 KL 惩罚项,从而避免了复杂化 A^i,t 的计算。
- 保留了 PPO 的 online 生成能力(自己造数据)
GRPO 为什么好
GRPO 为什么有效?
- 降低计算开销:PPO方法依赖评论模型(Critic Model)评估策略,而 GRPO 通过群体样本来估算奖励,避免额外训练开销。
- 高效的策略优化:通过群体样本的优势评估,GRPO 更快优化策略,尤其是复杂的长期决策问题。
- 稳健的正则化:引入 KL 散度使 GRPO 更加稳健,避免复杂任务中过拟合,保持良好的泛化能力。
GRPO 优秀不是来自 reward normalization,而是“筛选”掉了模型做得全对(太简单)和全错(太难)的样本
如果加上 prompt过滤机制,简单的拒绝采样微调(RAFT)就能胜过各路复杂的RL算法🚀
- 【2025-4-15】Saleforce 和 伊利亚诺香槟分校 📚论文:A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
- 代码 minimal-rl
1️⃣ 朴素的 RAFT 也很能打
RAFT(Reward Ranked Fine-tuning) 方法,思路简单:模型生成一堆答案,只挑对的(奖励=1)进行微调。- 注: 拒绝采样微调(Rejection Sampling Fine-tuning)
- Qwen2.5-Math-7B 和 LLaMA-3.2-3B 模型上,效果直逼甚至超过更复杂的
Iterative DPO和PPO!尤其加了重要性采样和裁剪 (Clipping) 的RAFT++,性能直接贴近 SOTA 的GRPO(在 Qwen 上 52.5% vs 53.9% 平均分)。
RAFT 操作步骤很简单:
- 收集数据:拿一批提示 x,用参考模型(比如当前模型自己)给每个提示生成 n 个回答。
- 筛选数据(拒绝采样):用奖励函数 r(x, a) 给每个回答打分,只保留那些得分最高的(通常是奖励为 1,正确的回答)。把这些筛选出来的“好”样本汇总成数据集 D。
- 模型微调:用这个只包含好样本的数据集 D 来微调当前的模型 π,目标是最大化模型在这些好样本上的对数似然。
RAFT++
RAFT 每次迭代中,用收集到的数据(replay buffer)进行多步梯度更新,可看作是混合离线策略(off-policy) 算法。
RAFT++ 把 Reinforce 里 重要性采样和裁剪技术 应用到 RAFT 上。
- 损失函数形式和 Reinforce 类似,但区别:它只在 最好的样本(奖励最高的那些,也就是正样本)上进行训练。
- 这通过一个指示函数 I 来实现:
- 是一个指示函数,当当前回答 a 是所有 n 个回答里奖励最高的那个时,I 等于 1,否则等于 0。这样就保证了只有正样本对损失有贡献。
RAFT++ 的改进有效:
- RAFT 基础上加入重要性采样(修正数据分布偏差)和裁剪(限制更新幅度)技术后形成的 RAFT++ ,确实比原版 RAFT 收敛更快,最终准确率也更高。
- 裁剪步骤非常关键。如果只用重要性采样而不进行裁剪,效果反而会变差,说明无限制的更新可能会破坏训练稳定性。
发现
- RAFT 及其改进版 RAFT++ ,相对简单的基于“拒绝采样”方法(只用好的样本),但在数学推理任务上的表现出人意料地好。
- 效果能跟更复杂的深度强化学习方法(如 PPO , GRPO )打个平手,超过了 iterative DPO 。
- 尤其是在 Qwen 模型上, RAFT++ (52.5%)的平均准确率非常接近当时效果最好的 GRPO (53.9%)。
先快后慢 vs 持续提升:
- RAFT++ 在训练早期学得比 GRPO 更快。
- 但是, RAFT++ 性能提升在训练中后期会明显放缓,最终被 GRPO 反超。
详见 GRPO=高级版拒绝采样?强化学习祛魅时刻:负样本“去芜存菁”才是关键
2️⃣ 揭秘 GRPO “成功密码”
GRPO在DeepSeek-R1等模型上效果显著,但实验发现,原因并不是花哨的奖励归一化 (reward normalization),而是处理方式上 隐式过滤了答案都错的 prompt!- 直接用 vanilla Reinforce 训练,用这些“全错”样本,反而会严重拖后腿。
重点:
- 有效利用负样本 ≠ 无脑全用!
3️⃣ 新思路 Reinforce-Rej:更聪明的“挑剔”, 极简改进版
- 不仅过滤“全错” prompt,连“全对”的 prompt 也过滤掉,因为“全对”可能让模型过于自信,减少探索
- 简洁的 Reinforce-Rej 达到 GRPO 同等性能,且 KL 散度更优(模型变化更稳定可控),训练效率和稳定性都可圈可点。
总结:
- LLM 微调不一定要堆砌复杂算法, 如何“聪明地”筛选和利用训练样本(尤其是负样本)可能比复杂的算法更重要。过滤掉低质量样本是关键!
GRPO 实现
作者:marsggbo
伪代码
GRPO 伪代码for x in prompts:
# 1. 生成 K 个回复
responses = [policy_model.generate(x) for _ in range(K)]
# 2. 用 RM 打分并分组(比如 top-2 为 good)
scores = [reward_model.score(x, y) for y in responses]
good_mask = get_top_k_mask(scores, k=2)
# 3. 计算每个回复的 log ratio
ratios = []
for y in responses:
logp = policy_model.log_prob(x, y)
ref_logp = ref_model.log_prob(x, y)
ratios.append(beta * (logp - ref_logp))
# 4. softmax 分类损失
logits = torch.stack(ratios)
loss = F.cross_entropy(logits.unsqueeze(0), target=good_mask)
optimizer.step(loss)
问题
训练问题
如何避开GRPO训练踩坑
GRPO 不需要单独的value网络,显存直接省一半,但训练起来坑也不少。
- (1)组采样和优势函数计算有讲究
- GRPO 核心是对同一个prompt生成G个output,然后用组内相对奖励算advantage。
- 关键点: advantage 用每个答案的reward减去组内均值算出来的。
- 如果一个batch里所有样本reward都一样,advantage就全是0,根本没有学习信号。
- 所以, 2025年做法是加个reward方差过滤,方差小于0.01的直接丢掉。
- G值一般设6-8,太小diversity不够,太大显存吃不消。
- 推理任务temperature设0.8-1.0增加探索性,对话任务用0.6-0.7保证连贯。
- (2)KL散度和裁剪策略要精细调
- β这个参数直接影响policy更新幅度。
- 常用配置是β=0.02,配合两段式裁剪:正向clip设0.25让模型大胆走,负向clip设0.15防止崩盘。
- 传统PPO都是统一的0.2,但GRPO里分开设能让收敛快15-20%。可以进一步用adaptive β,监控KL散度值,超过0.5就把β调大到0.05,低于0.1就降到0.01。这个动态调整机制能有效避免训练不稳定。
- (3)奖励函数要多维度设计
- 单一的正确性奖励太粗糙了,可以试试分层奖励机制。
- 推理任务的配置:最终答案正确给10分基础分,推理步骤完整性0-5分浮动,格式规范性1分。可以进一步加长度惩罚,超过512 token后每多100个token扣0.5分,这个对控制输出长度特别管用。
- 做code任务的话,可以加上可执行性检查、测试用例通过率这些维度。关键是要让reward signal足够dense,别只看最终结果。
- (4)训练监控和显存优化技巧
- 实时监控这几个指标:每个batch的reward mean和std、KL散度、advantage分布的skewness。如果advantage分布太偏,说明某些样本dominate了训练,要调整采样策略
- 显存这块,gradient checkpointing必开,配合LoRA能把显存占用压到PPO的40%。Unsloth框架对GRPO做了专门优化,forward pass能快2倍
- 学习率warmup很重要,前500步从1e-7爬到5e-6,然后cosine衰减到1e-7,这样能避免前期reward signal不稳定导致的崩盘
loss 曲线上升
为什么 GRPO 训练曲线持续上升?
【2025-7-25】小红书帖子
GRPO 在 MoE 结构上为什么难以收
1、新旧策略可能会激活不同的专家,产生结构性偏差,带来噪声。
- 当从旧策略更新到新策略时,很有可能出现Router发生变化,导致新旧策略激活了不同的专家。例如:
- 在旧策略下,Router 激活了【专家 A】和【专家 B】
- 在新策略下,Router 激活了【专家 C】和【专家 D】
- 虽然模型参数只更新了一步,但实际参与计算的专家组合完全不同。所以这两个概率根本不是在同一个“结构”下产生的。理想中的重要性比率应该反映同一个模型结构下,参数变化导致的输出概率变化。但现在它还包含了完全不同的专家组合导致输出的变化。这不是策略变化的真实反映,这种波动具有高方差、不可预测、与优化方向无关的噪声。
2、Clip也无法完全控制这种结构性偏差。
- 旧策略和新策略实际上像是两个不同的模型,重要性比率的方差急剧上升,甚至趋于无穷。
- 不同的路由可能会导致新策略值骤变,导致clip没有
- 任何更新。梯度估计严重失真,训练不稳定甚至崩溃。
3、解决方法
- (1)Routing Replay
- (2)GSPO
Reward 稀疏
GRPO训中 Reward 稀疏,怎么解决
强化学习中,奖励稀疏是非常普遍且极具挑战性的问题。
对于GRPO(Generalized Reinforcement with Policy Optimization)这种基于策略梯度的算法而言,问题尤其突出。
GRPO 核心思想: 通过使用广义优势估计(GAE)来平滑和稳定策略更新,但这依赖于环境能够提供足够的信息量,即有效的奖励信号。
当奖励信号极度稀疏时,模型在大部分时间里收不到任何正向或负向的反馈,导致策略梯度几乎为零,模型无法有效学习,训练过程会变得非常缓慢,甚至停滞不前。
核心思路: “从内到外”、“从粗到细”地丰富奖励信号,同时保持策略更新的稳定性和探索性。
几种方法来实现:
(1). 奖励塑造(Reward Shaping):
最直接。在环境中手动设计一些中间奖励,引导智能体朝着目标前进。
例如,在一个玩游戏任务中,除了最终胜利的奖励外,还为智能体消灭敌人、躲避障碍等行为提供小的、正向的奖励。
这种方法简单有效,但需要人工经验,并且设计不当可能会引入错误的偏好,导致智能体学习到次优策略。
(2). 内在奖励(Intrinsic Reward):
让智能体自我探索,即智能体在没有外部奖励时,会因为好奇心或信息增益而获得内在奖励。常用技术包括:
- 基于好奇心(Curiosity-Driven): 训练预测模型来预测下一个状态,如果智能体进入一个模型预测不准确的新奇状态,就给予内在奖励。这鼓励智能体去探索未知的区域。
- 基于信息增益(Information Gain): 让智能体探索能最大化其对环境理解的信息。例如,智能体可以获得一个内在奖励,如果某个动作能够显著改变它对环境的信念。这种方法的好处是减少了对人工设计的依赖,让智能体具备了自主探索能力,尤其适用于开放世界或探索性强的任务。
(3). 分层强化学习(Hierarchical Reinforcement Learning, HRL):
更高级的策略。将复杂的稀疏奖励任务分解为多个子任务,每个子任务都有其更容易获得的密集奖励。一个高层策略负责选择子任务,而低层策略负责执行子任务。
例如,在复杂的多步操作任务中,高层策略可以决定“去哪里”,低层策略可以学习如何“到达那里”。这样,高层策略的奖励可能依然稀疏,但低层策略可以在其子任务中获得密集的奖励,从而更容易学习。
(4). 经验回放与规划(Experience Replay and Planning):
结合离线强化学习(Offline RL)。利用智能体之前探索得到的经验数据,即使这些经验没有直接带来外部奖励,也可以通过一些规划算法(如Monte Carlo Tree Search)来对这些经验进行重新评估或生成新的、更有价值的训练数据,从而在奖励稀疏的环境中提高数据利用效率。
在实际应用中,选择哪种方法取决于具体的场景和任务。
- 对于任务明确、目标单一的场景(比如一个特定的棋类游戏或简单的控制任务),奖励塑造是一个快速且有效的起点。它能迅速引导模型朝正确的方向学习,但需要人工投入和对任务的深刻理解。
- 对于开放世界、探索性强的任务(比如一个开放世界的游戏或机器人探索未知环境),内在奖励则更具优势。它能让智能体自主地学习如何探索,减少对人工设计的依赖,但实现起来更复杂,且内在奖励的设计本身也可能存在挑战。
- 对于复杂的多步决策任务,特别是任务本身可以自然地分解为子任务时,分层强化学习 是一个非常强大的工具。它能将一个大问题分解为多个小问题,显著降低每个部分的学习难度,从而有效应对稀疏奖励。
- 如果数据收集成本很高,或者希望充分利用已有的离线数据集,那么结合 经验回放和规划 的方法会是一个很好的选择。
在实践中,常常会结合使用这些方法。例如,可以先用奖励塑造给出一个初始的引导,然后引入内在奖励来鼓励进一步的探索。这样既能快速启动训练,又能防止模型陷入局部最优。
DAPO —— 改进 GRPO
GRPO 问题:
- 无效内卷:如果一组 8 个答案都非常完美,或者都烂得一塌糊涂,相对于“组平均分”的差异就很小。这时候模型学不到什么有效信息,浪费了算力。
- 保守陷阱:为了防止模型训崩,PPO 和 GRPO 都会用 Clipping(裁剪)机制,限制模型每次更新的幅度。但这有时候会“误伤”那些模型灵光一现生成的绝妙答案。
于是,DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization,解耦裁剪与动态采样策略优化) 登场,对 GRPO 进行两处改进:
- 动态采样(拒绝无效内卷)DAPO 加了一个过滤器,太简单(全对)和太难(全错)的数据组直接跳过不练,只死磕那些模型“似懂非懂”的数据。
- 解耦裁剪(允许灵光一现)传统 Clipping 是双向限制。DAPO 说:如果模型这次更新是往“好”的方向大步迈进,为什么要拦着?它解耦了裁剪范围,允许更高的上限(Upside),鼓励模型更大胆地探索高分区域。更有意思的是,DAPO 在实践中甚至开始尝试去掉 KL 散度约束,非常大胆的举动,允许模型更大幅度地偏离原始基座,去探索全新的解空间——这对于追求极高推理能力(如数学证明、复杂代码)的场景可能至关重要。
【2025-3-18】字节、清华开源 DAPO, 超越 DeepSeek GRPO 算法
- DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization)解耦裁剪和动态采样策略优化
- 解读 字节、清华团队开源RL算法DAPO,性能超越DeepSeek的GRPO; DAPO:大规模开源 LLM 强化学习系统
- DAPO不仅以50分的惊人成绩刷新了数学竞赛AIME 2024的纪录(超越此前SOTA模型DeepSeek-R1的47分),更以完全开源的姿态,将算法、代码、数据集公之于众
- DAPO仅用一半的训练步骤便达成这一里程碑,背后四大核心技术——Clip-Higher策略、动态采样、Token级梯度优化、智能长度惩罚——直指RL训练的痛点:熵崩溃、奖励噪声、长文本低效学习。
GRPO 面临四个问题:
- 单一剪切范围易导致低概率 Token 无法得到有效提升(熵坍塌),样本级别损失会弱化长序列 Token 的梯度贡献,一旦所有输出都是全对或全错则无梯度信号可用,且统一惩罚过长生成会引入噪声。
DAPO 则通过“四大改进”逐一解决:
- Clip-Higher 将剪切上下限分开以保留多样性;
- Dynamic Sampling 过滤全对/全错样本保持有效梯度;
- Token-Level Policy Gradient Loss 平衡长序列 Token 贡献;
- Overlong Reward Shaping 为过长文本进行柔性惩罚或掩码,减少噪声干扰。
公式分析: 参考LLM强化学习之路续章——从PPO到DAPO

DAPO 在一个batch内存在reward全相同的rollout时会过滤那个prompt,load数据直到整个batch的各个组内都有有效的优势。
相较于grpo的好处
- ①减少无效计算:跳过那些无效组的剃度计算
- ②更有效的优化:保证batch内所有组都有有效的梯度
GRPO vs DAPO
GRPO(Group Relative Policy Optimization)和 DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization)
(1) 策略优化机制
- GRPO:通过群组相对奖励归一化估计优势,消除对价值函数的依赖。其目标函数包含KL散度惩罚项,以限制策略偏离参考模型,但这一设计在长链式推理(CoT)场景中可能限制模型探索空间。
- DAPO:移除KL散度惩罚,允许模型在长推理任务中自由探索。通过解耦裁剪(Decoupled Clip)调整上下裁剪范围( low=0.2, high=0.28),提升低概率token的探索能力,有效缓解熵崩溃问题。
(2) 训练效率优化
- GRPO:在提示样本准确率趋近1时,梯度信号减弱,导致训练效率下降。此外,样本级损失计算可能忽略长序列中关键token的影响。
- DAPO:引入动态采样策略,过滤准确率为0或1的无效样本,确保批次内梯度有效性;采用Token级策略梯度损失,强化长序列中每个token的贡献,避免低质量模式(如重复生成)的干扰。
(3) 奖励机制设计
- GRPO:依赖传统奖励模型,存在Reward Hacking风险,可能导致模型过度优化局部奖励而非全局推理质量。
- DAPO:采用基于规则的奖励建模,直接以任务最终准确率作为奖励信号(如AIME答案正确性),并结合过长奖励整形(Soft Overlong Punishment),对超长响应施加动态惩罚,减少噪声干扰。
SPCT
【2025-4-4】DeepSeek新论文SPCT:让奖励模型学会“先定规则后点评,再打分”
LLM 光能打, 还不行,还得听话,知道什么是对的、好的,不能瞎来。这就是所谓的“对齐”(Alignment)。
3H: Helpful 有用, Honest 一致, Harmless 无害
强化学习(RL)是LLM 听话的关键技术。其中奖励模型 (Reward Model, RM) 最重要,扮演裁判,专门负责给 LLM 生成的内容打分,告诉 RL 哪个好、哪个不好,这样 LLM 才能学好。
RM 要求
- 啥都能评 (通用) :不管写代码、写小说还是回答安全问题,都得能评,但不同任务的标准差远了,一个固定逻辑很难都评得准。
- 评得准 (准确) :基本要求,但众口难调,标准又多变,保证准确性很难。
- 输入灵活 (灵活) :有时候评1个答案,有时候比较2个,有时候给一堆答案排序,传统 RM 可能只擅长一种。
- 能“进化” (可扩展) :
- 很多 RM 裁判,给再多时间(计算资源)思考,打分还是那样,没法通过“多想想”变得更准。
- 像人一样,多花点时间琢磨,判断就能更靠谱,这就是“推理时可扩展性”。
SPCT 登场:让裁判先定规则再打分
- DeepSeek 论文《Inference-Time Scaling for Generalist Reward Modeling》提出新训练方法,叫 Self-Principled Critique Tuning (
SPCT) , “自定原则、自我点评”的调优方法。
SPCT 用生成式奖励模型 (Generative Reward Models, GRM) 。
- GRM 裁判不直接给分,而是先写一段“点评”(Critique),说明为啥好、为啥不好,最后再从点评里提炼出分数。
SPCT 核心思想更进一步:
- 要求 GRM 在写点评之前,先自己想想这次评估应该看重哪些“原则” (Principles) ,比如“代码要简洁”、“回答要诚实”等等
- 然后再根据这些刚定好的原则去写点评、打分。
RM 裁判范式
几种 RM 裁判范式
- A. 标量裁判 (Scalar RM)
- 原理:给定 问题 (Query) 和多个回答 (Response),直接吐出分数(标量)。简单粗暴。
- 缺点:
- 黑箱操作:为啥给这个分?不知道,猜不透里面的逻辑。
- 死脑筋:给同样的输入,基本就出同样的分数,多算几次提高准确度?难!缺乏“推理时可扩展性”。
- B. 半标量裁判 (Semi-Scalar RM)
- 原理:结合两边优点,既给分数,也给文字点评 (Critique)。比如 CLoud 模型。
- 缺点:点评看起来更透明,但仍然难以实现推理时性能扩展,因为分数变化不大。
- C. 生成式裁判 (Generative RM, GRM)
- 原理:主要靠写“点评” (Critique) 来工作,分数从点评文字里提取出来。
- Pointwise GRM:论文和 SPCT 用的基础款。给每个回答独立写点评、打分(而不是非要两两比较),所以处理单个、一对、多个回答都很灵活。
- 潜力股:写东西(生成文本)这事儿,天生就有点随机性。多写几次点评,结果可能不一样。这就为通过采样投票来提升性能(推理时扩展)埋下了伏笔。
| RM裁判范式 | 英文名 | 原理 | 不足 | 分析 |
|---|---|---|---|---|
| 标量裁判 | Scalar RM | (question, r1,…,rn) -> (s1,…,sn) | 黑箱操作 死脑筋,缺乏推理时可扩展 |
直接打分, 简单粗暴 |
| 半标量裁判 | Semi-Scalar RM | (question, r1,…,rn) -> (s1+c1,…,sn+cn) | 点评依然难以实现推理时扩展 | 既给分数,又给评语 |
| 生成式裁判 | Generative RM, GRM | (question, r1,…,rn) -> (s1+c1,…,sn+cn) | 写点评,然后提取分数 | |
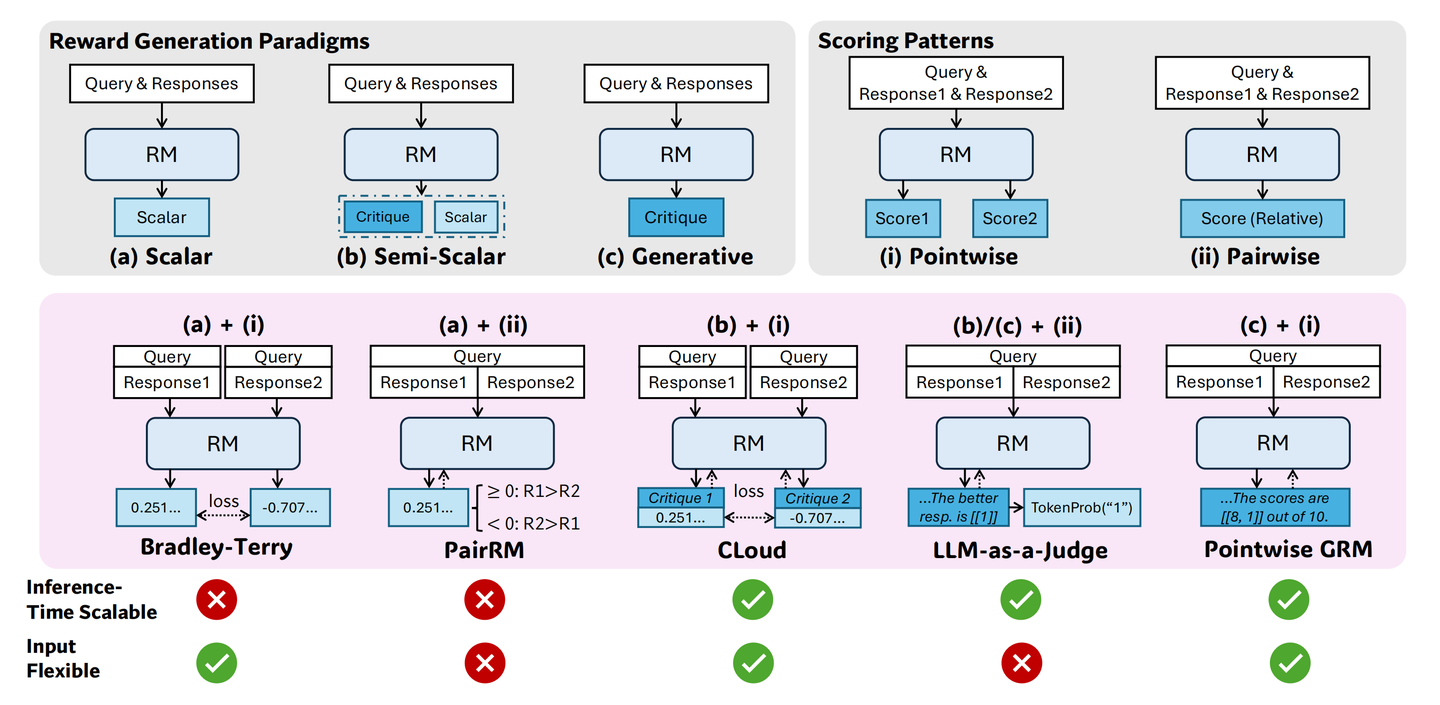
原理
SPCT 核心,把 RM 工作流程从“直接给分”变成了“定原则 -> 写点评 -> 提分数”的间接评估。
为啥间接评估更好?
- “想明白”比“凭感觉”靠谱:直接打分的标量 RM 像个黑箱,逻辑不清晰。SPCT 要求模型先明确“原则”(这次重点看啥),再基于原则写“点评”(分析过程),相当于强制把思路理清楚。这样做不仅打分更准、更稳(好原则能提高准确率),而且也能看懂为啥这么评,可解释性大大增强。
- “想法多”才能“集思广益” :标量模型输出固定。但 GRM 生成原则和点评时,引入一些随机性(比如调整 temperature 参数)。对同一个问题多问几次,可能会从不同角度(原则侧重不同)给出不同的分析和分数。这种输出的“多样性”,正是后面用投票等方法提升性能的基础。没多样性,投一百次票结果也一样。
- “规则自适应”才能“通吃” :评估任务千变万化,标准也各不相同。SPCT 让模型自己根据当前的问题和回答,动态生成最合适的“原则”。能自适应地调整评估重点,这对于打造能胜任多种任务的通用 RM 裁判至关重要。
SPCT 裁判工作流程
经过 SPCT 训练的 GRM 裁判,评估:
- 自定原则 (Self-Generated Principles) :拿到问题 Q 和回答 Ri,先生成一套评估原则 pj,可能还带权重。
- 生成点评 (Critique Generation) :然后,根据自己刚定的原则 pj,给每个回答 Ri 写详细的分析报告,也就是点评 C。
- 提取分数 (Score Extraction) :最后,用一个解析工具,从点评 C 里把每个回答 Ri 的分数 Si 扒出来
直接打分 vs. SPCT 间接打分
- SPCT 多了中间“定原则”和“写点评”两步,让整个评估过程更结构化、更透明了。

训练
两阶段训练法
SPCT 目标
- 训练出一个既能生成高质量原则和点评,又能导出准确分数,还具备良好扩展性的 GRM。
训练分为两个阶段:
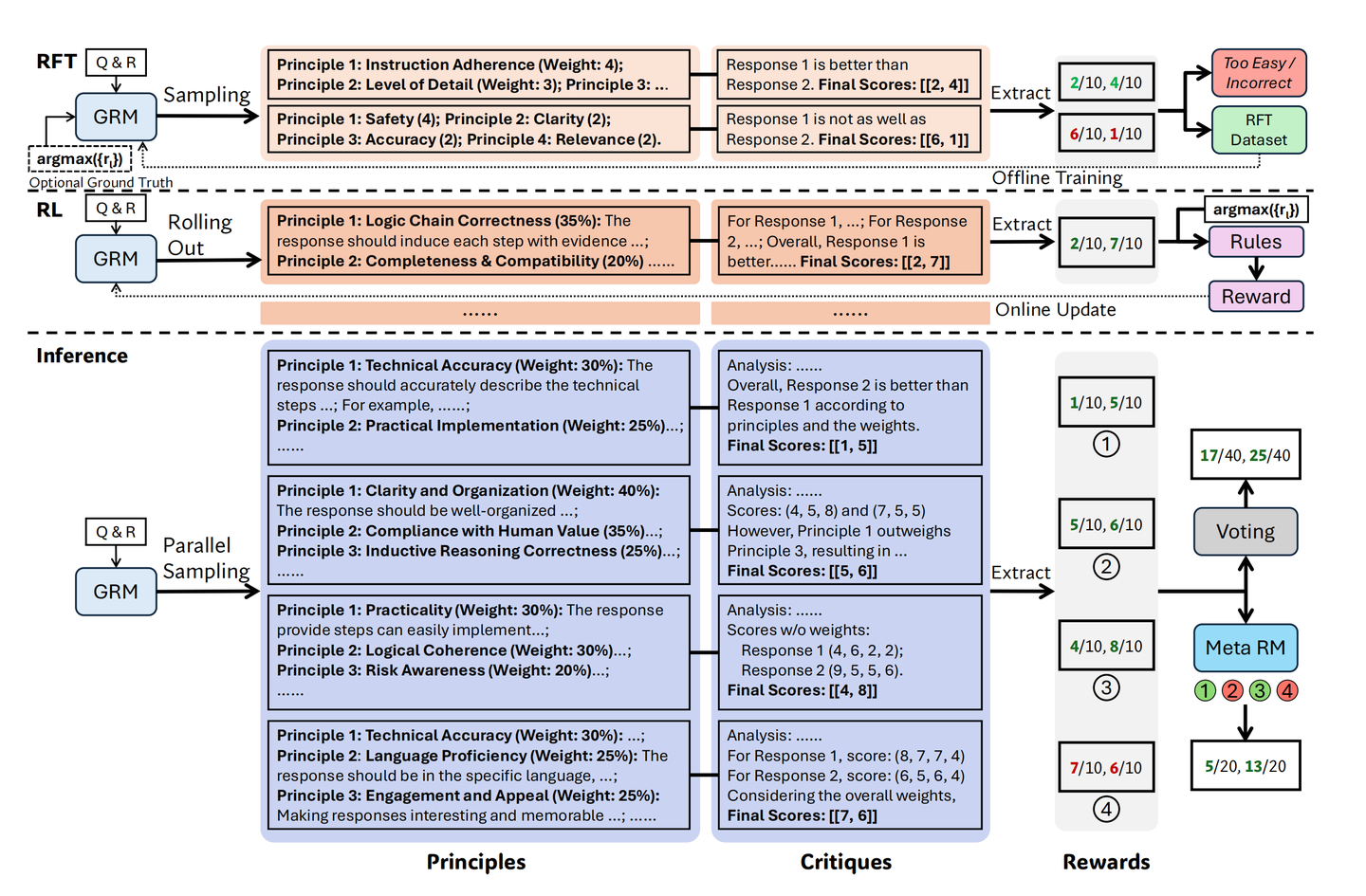
阶段一:拒绝式微调 (RFT - 先热个身)
- 目的:让预训练好的 GRM 先熟悉一下生成原则、点评、分数的套路,并能处理不同数量的输入(单个、多个回答)。
过程:
- 试着评:拿 RM 数据集里的问题和回答 (Q,Ri),让 GRM 多试几次(N_RFT 次),每次都生成原则、点评和分数 Si
- 挑三拣四(拒绝策略) :比较 GRM 给的分数 Si 和数据集里的标准答案(偏好 ri)
- 如果评错了(比如把差的说成好的),这次尝试就不要(标记 “Incorrect”)。
- 如果对某个问题,试了 N_RFT 次全都评对了,说明太简单了,也不要(标记 “Too Easy”)。
- 用好的练:把那些评对了、但又有点难度的尝试(被接受的样本)收集起来,组成 RFT 数据集,用标准的监督学习方法微调 GRM。
阶段二:基于规则的在线强化学习 (Rule-Based Online RL - 实战提升)
目的:
- 进一步打磨 GRM,让它更倾向于生成那些能导出正确评估结果的原则和点评。特别是要提升它通过多次尝试(采样)来提高判断准确度的能力(即可扩展性)。
过程:
- 再评一次 (Rollout) :模型拿到 (Q,Ri),走一遍流程:生成原则 -> 生成点评 -> 提取分数 Si
- 给奖惩 (奖励信号计算) :比较模型预测的分数/排序 Si 和标准答案 ri,根据一个简单规则(论文公式 5)给个奖励 r。
- 更新模型:用在线强化学习算法(比如 GRPO),根据这个 +1 或 -1 的奖励信号来更新 GRM 的参数,鼓励它多生成能拿 +1 分的原则和点评。
经过 SPCT 训练出来的 DeepSeek-GRM 模型,确实有几把刷子:
- 更准、更稳
- 强制模型先想原则再点评,减少了瞎猜和偏见,评估结果自然更准确、更可靠。
- 能“越算越准” (推理时扩展性)
- SPCT 的核心亮点:训练好的 GRM,使用时多花点计算资源来提升性能:
- 更透明、灵活
- 生成的原则和点评能看懂模型为啥这么打分,不再是黑箱。
- 同时,Pointwise GRM 形式处理单回答、双回答、多回答排序等各种情况都得心应手。
- 更通用
- 模型能根据输入自适应地调整评估原则,不同领域、不同类型的任务上表现更好,通用性更强。
计算资源方法
- 多问几次 (采样机制) :对同一个问题和回答 (Q,Ri),让模型独立地、带点随机性地(比如 temperature > 0)思考 k 次。因为想法(生成过程)有多样性,每次可能会得到不同的原则、点评和分数。
- 汇总意见 (聚合机制) :
- 简单投票 (Voting) :最直接的方法,把 k 次采样得到的每个回答的分数加起来或取平均,得到最终总分。谁总分高就选谁。比如图 3 里的例子,4 次采样 R1/R2 得分分别是 [1, 5], [5, 6], [4, 8], [7, 6],投票结果 R1=17, R2=25,最终选 R2。
- 精英投票 (Meta RM 引导 - 可选) :更高级的玩法,可以再训练一个“裁判的裁判” (Meta RM),专门评估每次采样生成的 (原则, 点评) 的质量。投票时,只选那些 Meta RM 评分最高的 k_meta 次采样的结果来汇总,把质量差的意见过滤掉。如图 3,Meta RM 可能筛掉一些低分采样再投票。
随着采样次数 k 增加,不管是简单投票还是精英投票,DeepSeek-GRM 的性能都蹭蹭往上涨,证明了它确实能有效地“越算越准”。

【2025-3-16】HRL-TAR
问题
- PRM 容易被 奖励攻击
- 奖励标注成本大
香港大学、北大推出 HRL-TAR, 层次奖励模型 Hierarchical Reward Model (HRM)
思想
- 高层策划者(Planner)拆任务、调用外部工具
- 低层执行者(Executor)完成子任务并返回结果
- 通过多级 RL 奖励,模型学会 “先想策略,再用工具”,推理-行动两手抓。
2️⃣ 两级角色 · 分工明确
| 层级 | 角色 | 主要技能 | 奖励信号 |
|---|---|---|---|
| 高层 | Planner | 任务拆解、工具选择、时序规划 | 子任务是否高效完成、全局目标达成 |
| 低层 | Executor | 代码-SQL-搜索-API 调用、结果解析 | 单个工具调用成功 & 子任务成败 |
想象成“经理 + 工程师”组合:经理布置任务、工程师撸代码调用工具,再反馈结果给经理决策下一步。
3️⃣ 训练 4 步流水线
- 数据收集:
- 预构造 自然语言任务 ↔ 工具序列 演示;
- 实时交互日志(成功 / 失败)记入回放缓冲区。
- 低层 RL:
- 每条工具调用以 成功率、输出质量 作为奖励,用 CQL / IQL 离线微调 Executor。
- 高层 RL:
- 按整体任务完成度 + 资源消耗 打分,用 PPO / GSPO 微调 Planner。
- 交替更新:
- 固定一层、训练另一层,迭代收敛。
【2025-5-16】GiGPO
【2025-5-16】新加坡南洋理工 推出 GiGPO
GRPO 相关进化版本
- RLOO
- GRPO
- Dr. GRPO
- DAPO
- CPPO
LLM Agent 训练特点: 长序列、多轮次、稀疏奖励的任务 → credit assignment 难
传统方案难题:纯 group-based RL(如 GRPO)→ 只有 episode-level 信号,粒度太粗,收敛慢且易抖动
Group-in-Group Policy Optimization (GiGPO)
GiGPO(Group-in-Group Policy Optimization)还是GRPO,扩展到Agent范围。
- 把采样轨迹分成多个组,每个组当然对应关键步骤。
- 更加细粒度的GRPO。
两个不同的级别:
- episode-level:与GRPO没两样,最终结果作为奖励基准。
- step-level:新加部分,GiGPO 创新点。引入锚定状态分组机制,通过识别不同轨迹中重复出现的环境状态(锚定状态),回溯性地构建步骤级的组。来自同一状态的动作被归为一组,从而实现微观层面的相对优势估计。通过锚定状态,不同轨迹之间的step就变得可以互相比较,这点很重要。
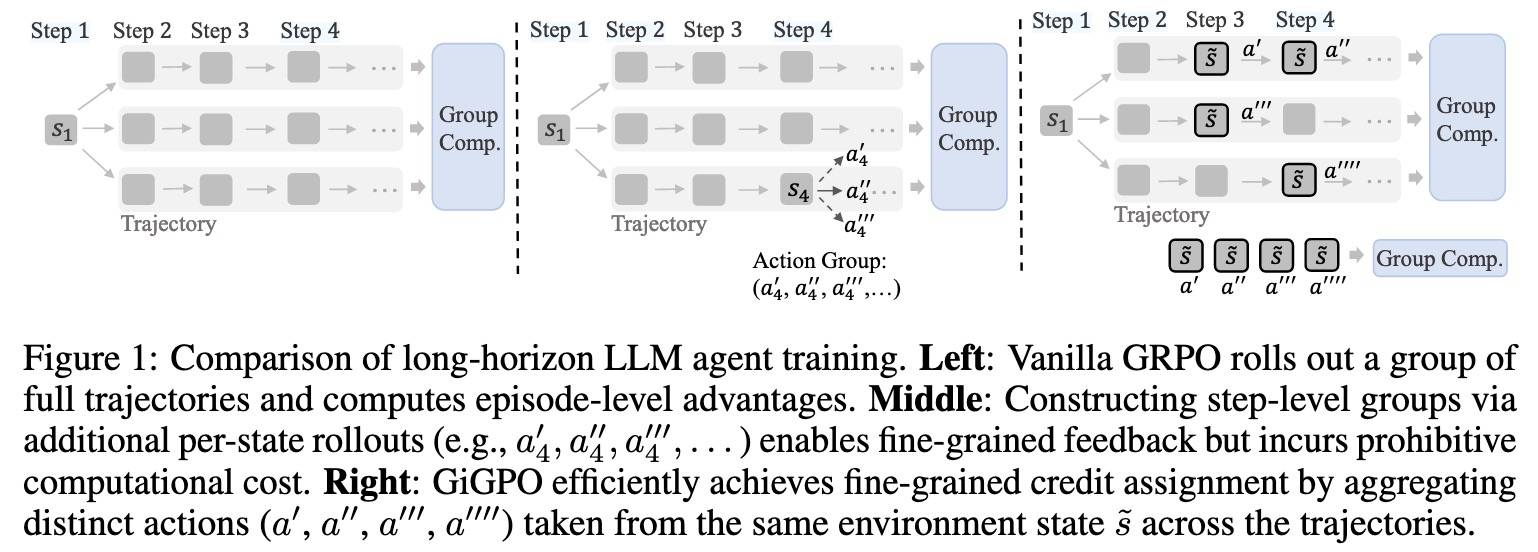
【2025-5-19】港科大 GVPO
【2025-6-14】理解GRPO,超越GRPO!GVPO算法详解
GRPO 对每个prompt多次采样,避免额外训练value model的开销。复现 GRPO 经常表现出训练不稳定、效果表现不佳等症状。
【2025-5-19】港科大+作业帮 提出 GVPO(Group Variance Policy Optimization), 无缝适配现有GRPO框架并取得更好的表现、更稳定的训练并支持更丰富的数据来源。
GVPO 优势:
- (1) 唯一最优解恰好是KL约束的reward最大化最优解
- (2) 支持多样化采样分布,避免on-policy和重要性采样带来的各种问题。
GVPO与DPO一样,都用到KL约束的reward最大化的解析解。
DPO是利用BT模型,两两相减消去了不可计算的 Z(x) 。- 而
GVPO则用了 Wi和为0 的性质而适用于多response的情况。
GVPO和DPO相比还有个重要的理论优势。
- DPO 不一定具有唯一最优解,KL约束的reward最大化的解可能只是DPO众多最优解中的一个。这源于DPO依赖的BT模型的内生缺陷,会导致优化DPO目标不一定会随之优化我们真实想要的目标(即KL约束的reward最大化)。
- 而GVPO则由定理1证明了其唯一解的性质。
【2025-5-23】GRPO-λ
【2025-5-23】澳大利亚国立大学、华为 推出 GRPO-λ (动态长度惩罚)
传统强化学习方法如GRPO在追求答案正确性的同时,导致了模型出现“过思考”的现象——即生成过于冗长的推理步骤,这不仅降低了效率还增加了错误率。
原因
- 传统GRPO等方法采用的是“0/1奖励”机制,只关注最终答案是否正确,忽视了推理过程的质量。
- 为了增加获得奖励的机会,模型倾向于生成更长的推理链条,即便这些额外的步骤并不总是必要或相关的。
- 尽管长度惩罚机制试图解决这个问题,但其实施方式可能导致模型在尚未具备足够推理能力的情况下被迫缩短输出,从而丢失重要的逻辑信息,造成准确性下降。
为了解决这一问题,现有方案引入了长度惩罚机制,但这又引发了新的挑战:训练早期模型准确率骤降。
GRPO-λ 智能地调节奖励策略以促进模型的发展。
原理
GRPO-λ 核心:分阶段的能力训练策略,类似于儿童学习走路再到跑步的过程。
- 对于推理能力较弱的样本,重点放在提高正确率上;
- 而对于已经具备一定能力的样本,则开始优化其表达的简洁性。
这种方法通过一个称为Top-λ筛选器的机制来实现,它能够根据每个问题的答案质量进行分组,并对表现最好的前λ%给予鼓励简洁性的奖励。
GRPO-λ 如同给模型配备了一个“智能教练”,根据模型当前的推理能力动态调整训练目标,初期注重提高正确率,待能力提升后再专注于简洁表达。
这种策略在五个数学与科学推理基准测试中表现出色,实现了47.3%的长度压缩和1.48%的精度提升,并将有效训练时长延长至2.5倍。
效果
实验对比
- Vanilla:基础模型,无任何强化学习优化。
- GRPO:采用传统强化学习策略进行优化。
- LP(Length Penalty):应用长度惩罚机制,但未崩溃时的表现。
- LP*:同等步数下由于强制压缩导致崩溃的情况。
实验结果
- GRPO-λ实现了显著改进,达到了47.3%的推理步骤长度压缩率,并同时提高了1.48%的准确率。相比之下,使用LP方法仅能达到55.28%的长度压缩率和0.04%的精度提升,且在训练早期就出现了精度大幅下降的问题。
GHPO
起因
LLM训练为何总是”崩盘”?
为什么大模型在做数学题、编程题时总是忽强忽弱?🤔
LLM强化学习(RLVR)训练有个致命问题:题目太难,模型太菜!
- 让小学生直接解微积分,结果就是——全部做错,没有正反馈!😭
论文数据:
- Qwen2.5-7B 模型在数学数据集上竟然有52%的题目完全不会做!
- 训练时一半时间都在”无效学习”,奖励信号稀疏得像沙漠里的水💧,导致训练效率低下、过程极不稳定。
- 特别是那些小模型(比如手机端部署的),这个问题更严重!训练过程就像在黑暗中摸索,经常”崩盘”重来,费时又费钱💰
【2025-7-14】 GHPO 智能家教
GHPO——智能”家教”上线
【2025-7-14】华为诺亚方舟、港大 提出超聪明的解决方案:GHPO(Guided Hybrid Policy Optimization),给LLM请了个智能”家教”
核心思想:
- 1️⃣ 自动难度检测:实时判断题目对当前模型来说是太难还是太简单
- 如果模型多次尝试都做错 → 判定为”难题”
- 如果能做对 → 保持正常训练
- 2️⃣ 自适应提示优化:根据难度动态调整”提示”
- 对难题:提供部分正确答案作为”提示”(比如50%的解题步骤)
- 对易题:完全不干预,让模型自己探索
举个例子🌰:
- 做数学题卡住了,老师不会直接告诉你答案,而是给你一个关键提示:”试试看能不能用三角函数转换…”
- 这样既不会太简单,又能帮你突破瓶颈!
GHPO 在强化学习和模仿学习之间智能切换,创建了一个平滑的”学习课程表”📚,让模型像人类一样循序渐进地学习!
效果
实验结论:效果太惊艳了!
6个数学推理基准测试上验证了GHPO的效果,结果令人震惊:
- ✅ 平均性能提升5%!在AMC2023和GPQA-Diamond上甚至提升了8%以上!
- ✅ 在极具挑战的AIME2024问题上,准确率从0.122飙升到0.163
- ✅ 训练过程超级稳定,梯度变化平缓,不再像过山车
- ✅ 模型生成的推理链更长更详细,说明理解更深入了
这个方法不仅对普通模型有效,对已经专精数学的Qwen2.5-Math-7B模型也能进一步提升性能
【2025-7-25】Qwen3 GSPO
通义团队推出 QWen 3中使用的 GSPO 算法, 在 MoE RL 中效果更好
区别
- 之前的GRPO算法,重要性采样建立在 token 级别
- GSPO 建立在序列似然, 序列级别的裁剪、奖励和优化
Unlike previous algorithms that adopt token-level importance ratios, GSPO defines the importance ratio based on sequence likelihood and performs sequence-level clipping,rewarding, and optimization
GRPO vs GSPO
以往算法在单个token层面计算重要性比例,GSPO 在整个序列的似然度(sequence likelihood)基础上定义重要性比例,并在序列级别上进行裁剪、奖励分配和优化。
- GSPO和GRPO的根本区别:GSPO对一个序列中的所有token给予相同的权重,即序列整体的重要性权重,而GRPO则对每个token使用不同的、充满噪声的权重,从而消除了GRPO的不稳定因素。
效果
研究表明,GSPO 相比于 GRPO 算法,在训练效率和模型性能上都表现更优,并且显著稳定了混合专家(MoE)模型的强化学习训练过程,还有简化强化学习基础设施的潜力。这些优点最终促成了最新的Qwen3模型的显著性能提升。
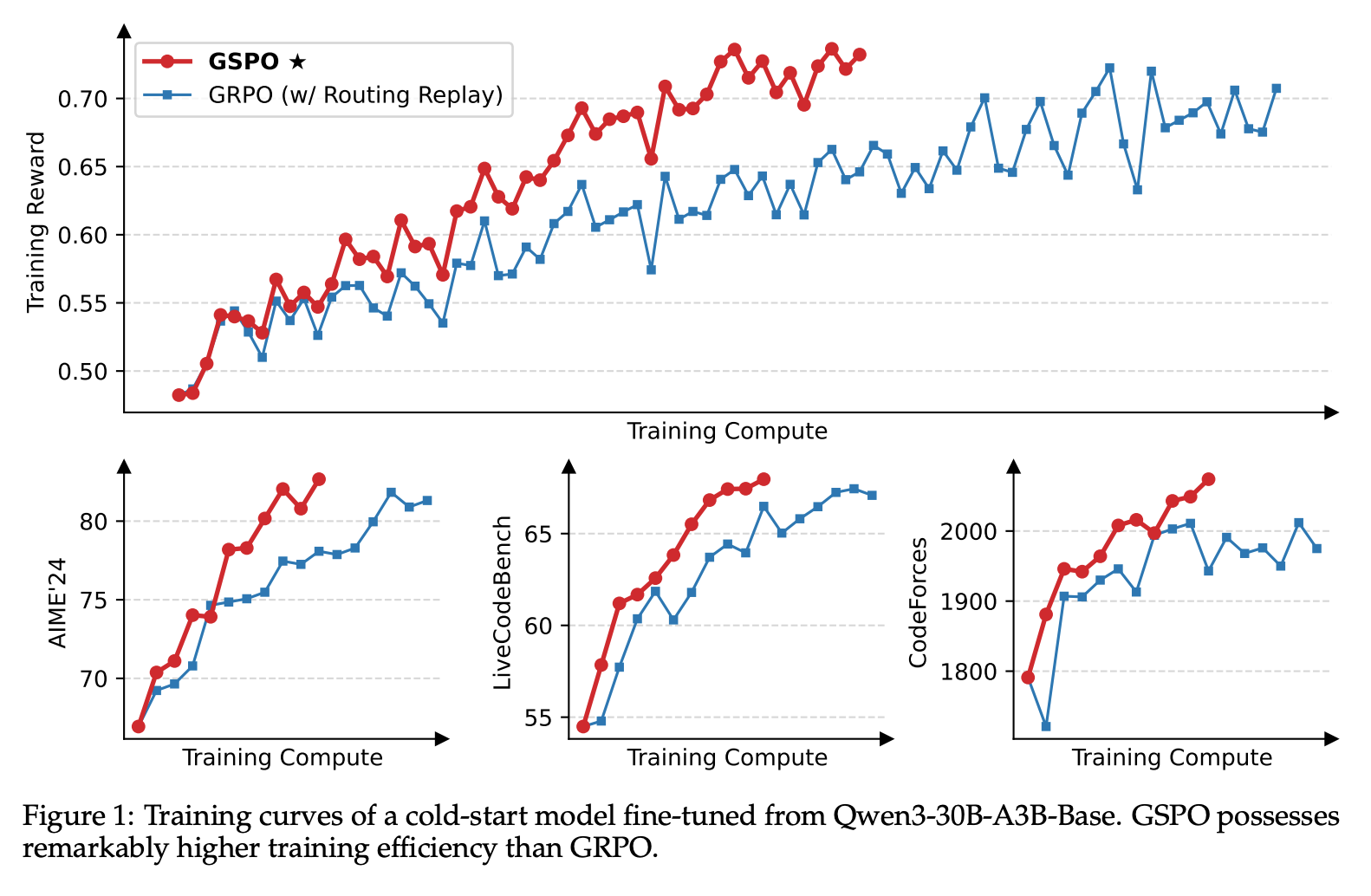
【2025-5-22】ARPO GUI Agent
【2025-5-22】港中文、港科大推出 ARPO (Agentic Replay Policy Optimization) is a novel reinforcement learning framework designed to train vision-language GUI agents to complete long-horizon desktop tasks. It builds upon Group Relative Policy Optimization (GRPO) and introduces:
- Distributed Rollouts: Scalable task execution across parallel OSWorld environments with docker.
- Multi-modal Input Support: Processes long histories (15 steps) of screenshots + actions in an end-to-end way.
- 论文 Official Implementation of ARPO: End-to-End Policy Optimization for GUI Agents with Experience Replay
- 代码和模型: dvlab-research/ARPO
依赖
- OSWorld — Realistic GUI environments for multimodal agents modified for GRPO training.
- EasyR1 An efficient, scalable, multi-modality RL training framework based on veRL, supporting advanced VLMs and algorithms like GRPO.
【2025-7-26】ARPO
人大:基于熵的LLM工具调用策略
起因
研究问题:
- 如何优化大语言模型(LLM)在动态工具使用中的决策过程,使其在多轮交互中更有效地利用工具?
The core principle of ARPO is to encourage the policy model to adaptively branch sampling during high-entropy tool-call rounds, thereby efficiently aligning step-level tool-use behaviors.
现有轨迹级RL算法在训练LLM智能体时, 无法有效平衡长期推理能力和多轮工具交互能力
ARPO 介绍
【2025-7-26】人大和快手推出 ARPO(Agentic Reinforced Policy Optimization),专门为多轮工具交互的LLM智能体训练设计的新型强化学习算法。
通过引入基于熵的自适应采样方法,显著提升了LLM在多轮工具使用中的性能和效率。
We propose Agentic Reinforced Policy Optimization (ARPO), an agentic RL algorithm tailored for training multi-turn LLM-based agent.
论文创新点:
- 提出新训练框架,使得LLM在进行多轮决策时,可以动态地调整工具调用策略,利用熵作为探索的动态指标,从而高效地解决复杂任务。
原理
🌟主要方法
- 1️⃣ 实现全局轨迹采样与步骤级分支采样的动态平衡,当工具调用后熵增超过阈值时触发分支探索。
- 2️⃣ 引入硬优势和软优势两种估计方式,使模型能够区分共享推理路径和独立分支路径的价值差异。
- 3️⃣ 结合搜索引擎、网页浏览器和代码解释器三种代表性工具进行智能体训练。
📝重点思路
- 🔸基于外部工具调用出现的高熵波动现象,提出了ARPO算法,该算法结合熵测量与工具调用反馈,优化LLM的决策过程。
- 🔸设计了熵基础的自适应回滚机制,允许模型在高熵工具调用步骤中进行更细致的探索。
- 🔸实现了优势归属估计,通过共享与独立令牌的比较,帮助模型更好地内化逐步工具使用中的优势差异。
- 🔸在实验中针对13个基准测试进行了广泛评估,证明ARPO相较于传统轨迹级RL算法在样本效率和准确性上均表现优越。
通过观察到LLM在工具调用后会表现出高熵(高不确定性)行为这一关键发现,ARPO设计了基于熵的自适应采样机制。
🌟核心定义
- 1️⃣
熵(Entropy):衡量LLM生成token时的不确定性程度,高熵表示模型对下一个token的选择更加不确定。 - 2️⃣
自适应展开机制:根据工具调用后的熵变化动态决定是否进行分支采样,在高不确定性步骤增加探索。 - 3️⃣
优势归因估计:为共享路径和分支路径的token分配不同的优势值,帮助模型内化逐步工具使用行为的差异。
ARPO 分析
- 不像 GRPO,一次跑大量的完整 trajectory,而是少跑几个,之后对于这些 trajectory ,计算多轮调用tools中每次调用工具之后的token的“熵”,即不确定性,如果这个熵在某一次调用工具之后变得比上一轮调用工具是变得大很多(这里会设定一个阈值来判定“大很多”),说明这个 LLM 之外的调用工具的过程对整个 model 产生了很大的不确定性,值得探索,那么此时我们会在 tool-call 之后生成不同的推理分支,而最后的重点就会放在这些生成分支的路径上。(假设 GRPO 生成了64条完整的trajection,ARPO只有4条,但是每一条路径开出了16个分支,那么实际上最后大量的轨迹都是在分支的位置)在计算 reward 时,分支末端的token就只受到各个分支的优势值的影响,而前面的共有路径会受到它分出来的分支的优势值的共同影响。
- 相比于 GRPO/DAPO
- 因为分支的原因,实质上 ARPO 最后不同 trajectory 的差别(其实很多trajectory就是同样一个最开始跑的trajectory的分支树)大量集中在了 tool-call 的位置,这非常契合多轮 agent 这个背景,也就是工具调用才是最重要的部分。
效果
🌟重要效果
- 1️⃣ 在13个计算推理、知识推理和深度搜索领域的挑战性基准测试中,ARPO均优于传统轨迹级RL算法。
- 2️⃣ 相比现有方法,ARPO仅使用一半的工具调用预算就实现了更好的性能表现。
- 3️⃣ 在深度搜索任务中,使用仅1000个RL样本就达到了显著的性能提升,展现出高效的训练效率
🔎分析总结
- 🔸ARPO 算法显著提高了LLM在多轮交互中的工具使用效率,仅需传统方法一半的工具调用预算。
- 🔸实验结果表明,ARPO在多个数据集上均表现出比现有RL算法更高的准确性,平均提升4%的性能。
- 🔸通过熵测量,发现在动态环境中,LLM更能有效地通过高熵的采样鉴别有价值的工具调用。
- 🔸ARPO展示了在处理复杂推理任务时的强适应性,无论是计算推理、知识推理,还是深度搜索领域。
【2025-7-28】GMPO
GRPO(token-level算术平均)主要问题:
- 容易出现极端token比率,导致梯度信号剧烈波动、不稳定。
为了解决上述问题,提出 Geometric-Mean Policy Optimization(GMPO):
- 通过token级别几何平均代替算术平均,降低GRPO的方差;
- 同时引入非对称、更宽泛的clip区间,以提升探索性,保持优化的稳定和平滑。
【2025-7-28】与GSPO撞车!微软GMPO解读笔记
UCAS、香港科大、微软发布 GMPO
- 论文 Geometric-Mean Policy Optimization
- 代码 GMPO
- 项目 主页
总结:
GMPO核心方法和GSPO非常像,两个方法都采用几何平均代替GRPO算术平均,不同点在与Clip粒度GMPO沿用GRPO的Token Level Clip,而GSPO采用更粗粒度的Sequence Level Clip。- 另外, GMPO在训练中对Adv小于0,即表现比平均差的Token做了更远离的策略。
【2025-7-10】QRPO
基于奖励机制的LLM强化学习微调,并利用离线/非策略数据
传统方法局限:
GRPO仅支持在线学习DPO又受限于偏好数据
【2025-7-10】CLAIR 公司推出QRPO方法, 一举解决了这两个痛点,攻克了”分区函数难以处理“经典难题——正是该问题限制了DPO类方法只能使用成对数据。
- Quantile Reward Policy Optimization: Alignment with Pointwise Regression and Exact Partition Functions
- 论文 Quantile Reward Policy Optimization: Alignment with Pointwise Regression and Exact Partition Functions
- 代码 CLAIRE-Labo/quantile-reward-policy-optimization
QRPO learns from pointwise absolute rewards like GRPO/PPO but preserves the simplicity and offline applicability of DPO-like methods.
GRPO 跟 GRPO/PPO 一样,从单个样本绝对奖励中学习, 但保持了 DPO 的简洁,离线可用性。
团队通过三个关键发现实现了突破:
- 首先揭穿了”需要对所有可能的LLM生成进行无限求和”的迷思,创新性地将分区函数Z重新表述为奖励函数的矩生成函数(MGF)。
- 其次证明:只要掌握奖励分布就能确定MGF,进而求解Z值。
- 最后提出通过对奖励分布进行变换(例如转化为分位数)使其可计算的技术路线。
由此诞生的 Quantile Reward Policy Optimization 框架优势:
- 无需偏好配对数据
- 适应任意数据分布
- 高质量离线数据集仅需1-3个参考奖励即可估算分位数
- 支持通过调整参考模型来扩展非策略数据的规模
在对话和代码生成任务中,QRPO表现优于DPO、REBEL和SimPO等方法。
特别值得注意的是:
- QRPO 与 REBEL 能保持抗长度偏差的特性
- DPO 和 SimPO 在转换为偏好信号时仍会出现典型长度偏差
针对”被选概率下降”问题,研究团队从KL正则化闭式解的角度给出了理论解释:当正则化系数β较低时概率下降属正常现象;而当β值适中且数据质量良好时,概率会如预期般上升。
QRPO 还支持通过不同转换方式来塑造最优策略:
- 推导出包括恒等变换和对数变换在内的多种转换方式对应的分区函数
- 理论上证明量化奖励最优策略等效于Best-of-N策略
作者推推: Skander Moalla
【2025-9-25】阿里高德 Tree-GRPO
【2025-9-25】阿里高德 Tree-GRPO 革新 LLM 多轮代理强化学习
🌟 研究亮点
- 树结构采样替代链式采样:将传统RL中“一条路走到底”的链式轨迹采样,升级为“多路径探索”的树结构采样,每个节点代表一个完整的“思考-行动-观察”步骤。
- 预算高效利用:通过共享路径前缀,在相同token和工具调用预算下,树结构可生成约1.5倍于链式方法的轨迹样本。
- 隐式过程监督信号:树结构自然地将稀疏的“结果奖励”转化为“过程奖励”,实现类似“步骤级偏好学习”的效果,提升多步任务中的决策质量。
🔍 研究发现
- 性能显著提升:在11个数据集上的实验显示,Tree-GRPO 在3B以下小模型上表现尤为突出,多跳问答任务中相对链式方法提升16%~69%,甚至在1.5B模型上也能激发多轮工具使用行为。
- 预算敏感性强:在极低预算(如每任务仅2条轨迹)下,树方法仍能稳定学习,而链式方法几乎失效。
- 鼓励长程交互:树方法训练的代理倾向于进行更多轮次工具调用(从2.4次提升至3.0次),更适合复杂长程任务。
- 优势估计组合有效:结合“树内优势”与“树间优势”的估计方式,既引入过程信号,又保持训练稳定性。
💡 启发时刻
- “树”不仅是结构,更是信号放大器:就像一棵树的分支能捕捉不同方向的阳光,树结构通过共享前缀和分支差异,将有限的奖励信号“折射”到每一步决策中。
- 小模型也有“大智慧”:即使是没有经过SFT的基座模型,在树结构RL的引导下也能学会复杂的多步交互,说明RL策略设计比模型规模更重要。
- 过程胜于结果:在长程任务中,单纯的结果奖励如同“只看终点不看过程”,而树结构让模型在每一步都能“回头看看”,从而学得更稳、更远。
- RL不只是“调参”,更是“调结构”:通过改变采样结构(链→树),不仅能提升效率,还能自然引入过程监督,这为未来RL系统设计提供了新思路。
🧠 通俗比喻
- 链式RL:像是“一条路走到黑”,每次从头开始,浪费资源。
- 树式RL:像是“多岔路口探索”,走错一个分支还能退回共享段重新尝试,既省时又学得更细。
- 过程信号:如同“教练在每一步都给你反馈”,而不是只在比赛结束后说一句“赢了”或“输了”。
📌 总结
Tree-GRPO 通过将树搜索引入LLM代理的强化学习中,不仅在预算有限的情况下显著提升采样效率和模型性能,还通过树结构自然衍生出过程监督信号,解决了长程多步任务中奖励稀疏的难题。
【2025-10-7】港中文 EEPO
微软EEPO:主动’遗忘’解决熵崩塌,acc提升24%
【2025-10-7】港中文、微软研究院发布新方法 EEPO,用“临时遗忘”解决RLVR训练中的熵崩塌,让大模型探索更聪明、推理更强。
为什么会出现“熵崩塌”?
- RLVR 很有效,但训练“贪心”:高概率模式(回复)反复被采样→拿到奖励→更强化→其他模式的探索被挤压,熵迅速塌缩
- 盲目“加随机”(升温度/加熵)只会把分布抹平,摆脱不了主导模式,还容易不稳定、变慢。
- 结果:训练集涨,OOD benchmark反而掉,泛化变差。
EEPO怎么做?
核心机制:Sample-Then-Forget(采样-然后-遗忘)
- 阶段一:先采一半推理路径
- 中间步:对刚采到的主导模式“临时遗忘”(轻量、只影响当次rollout)
- 阶段二:再采另一半,模型被迫探索新的可行区域
三个关键设计:
- 自适应触发:只有当熵低于阈值时才启用,避免干扰正常探索
- 互补损失:更强惩罚“高概率”token,定向压制主导模式,而非盲目加噪
- 轻量高效:只对rollout模型做一步更新,每轮都会从policy同步,遗忘仅当次生效,不改优化目标
效果怎样?
- 评测集:Minerva Math、OlympiadBench、AMC 2023、AIME 2024/2025。
- 平均相对提升(对GRPO):Qwen2.5-3B +24.3%,Llama3.2-3B-Instruct +33.0%,Qwen3-8B-Base +10.4%。
- 熵曲线:GRPO迅速塌缩;EEPO持续更高熵,阶段2熵显著高于阶段1,证明“采样-然后-遗忘”能有效打断自我强化。
- 训练效率:几乎不增时长;相比升温度或加rollouts,EEPO更快更稳,响应长度也更可控。
为什么它简单有效?
- 仅作用在“采样过程”而不修改目标函数,直接改变“下一半”轨迹的探索足迹。
- 定向“挤一挤”主导峰,把概率质量让给其他可行解法,探索更聪明而非更随机
- 单步更新、临时生效,工程代价低,与GRPO无缝衔接,易复现、易落地
适用场景
- 数学、编程、逻辑等可验证奖励任务;
- 遇到“熵快速塌缩”“温度/熵系数难调”“训练集涨OOD降”;
- 想以较小改动换来更强探索和更好泛化的RLVR项目。
【2025-10-9】Training-Free GRPO
【2025-10-9】腾讯 Youtu-agent 团队提出 Training-Free GRPO: Efficient RL for LLM
- 🌐 arXiv ID: 2510.08191
- 📚 论文标题: Training-Free GRPO: Efficient RL for Large Language Models
- 🔍 问题背景:
- 传统强化学习(RL)在大模型上的训练成本极高,动辄上万美元,却难以实现泛化和高效落地。
- 模型参数微调不仅算力消耗巨大,还容易陷入“只会做特定任务”的困境,企业和开发者面临高昂的部署和维护压力。
🚀 方法简介: Training-Free GRPO,保持GRPO的训练流程但无需更新任何参数。
- (1)零参数更新:仅通过经验库优化模型行为;
- (2)Group Rollout:对齐GRPO训练,每个问题生成多种解法;
- (3)语义优势提炼:替代GRPO的数值group adavantage,使用文本advantage总结组内多个rollout的优劣;
- (4)经验库动态优化:通过多个epoch的学习,不断积累和优化领域经验。
📊 实验亮点:
- (1)仅用100条训练样本,即可让671B的DeepSeek-V3.2大模型,实现AIME数学榜单、网页搜索等场景中的样本外效果提升
- (2)训练和推理均可API调用,极大降低算力和部署门槛
【2026-2-5】小红书 REAL 改进 GRPO
RLVR 依托明确的规则式监督信号,大幅提升了复杂推理任务能力,其中GRPO 及其衍生变体取得了出色的实验效果。
但 GRPO 存在两大核心缺陷:正样本梯度错配与负样本梯度压制,这两类问题会造成策略更新低效、收敛至次优解。
【2026-2-5】小红书提出全新框架 ——奖励即标签(Rewards as Labels, REAL)
- 该框架将可验证奖励重新定义为分类标签,而非标量权重,由此把策略优化重构为分类任务。
- 进一步引入锚定对数概率(anchor logits)以强化策略学习效果。
- 论文标题:Rewards as Labels: Revisiting RLVR from a Classification Perspective
- 开源代码:REAL
理论表明
- REAL 能够生成单调且有界的梯度权重,可在全部推演样本间均衡分配梯度,从根源缓解前文提出的梯度失衡问题。
- 多项数学推理基准测试上开展大量实验,结果证明 REAL 提升了训练稳定性,且性能稳定超越 GRPO、DAPO 等主流强基线算法。
- 1.5B 参数模型:相比 DAPO,REAL 的平均 Pass@1 指标提升 6.7%;
- 7B 参数模型:REAL 分别较 DAPO、GSPO 高出 6.2%、1.7%;
- 即便仅采用最基础的二元交叉熵损失,REAL 训练过程依旧稳定,平均性能仍比 DAPO 高出 4.5%。
【2026-3-20】阿里 FIPO
Qwen Pilot 团队一直在研究 RL 如何解锁复杂推理能力。抓到了 3 个反直觉的发现:
- 1️⃣ RL 其实很“懒”:策略演化极稀疏 在 >98% 的生成步骤里模型没变,RL 并没有重写基座,它更像是个教练,只在关键逻辑分叉口轻轻推一把。
- 【2026-3-23】论文 📄 Sparse but Critical: A Token-Level Analysis of Distributional Shifts in RLVR Fine-Tuning of LLMs (ICLR 2026)
- 2️⃣ 方向比幅度重要:别只盯着 KL 散度 追踪对数概率差 才能精准定位优化的“导航方向”。甚至不训练,只在推理时增强关键 Token 的信号,准确率就能原地起飞。
- 【2026-3-23】论文 📄 On the Direction of RLVR Updates for LLM Reasoning: Identification and Exploitation (ICLR 2026)
- 3️⃣ “哎呀 (Oops)”时刻多于“啊哈 (Aha)”时刻
- 长序列推理中,模型常常已经推导出了正确答案,却由于冗余的自我反思而将其推翻。这种破坏性的 “Oops”时刻发生的频率比自我纠正的 “Aha”时刻高出 3 倍。
- 罪魁祸首? 标准 RL(如 GRPO)中采用的粗粒度信用分配 (Credit Assignment),它将奖励简单地平均分配给了整个推理链。
- 🔗 RLVR 的 dark secret: rlvr-secrets
💡 解法:FIPO & Future-KL
- 用 Future-KL 实时量化每个 Token 对后续路径的因果贡献。像手术刀一样,精准强化有效思考,掐掉带偏节奏的废话。
🏆 Qwen2.5-32B 纯 RL 战果:
- AIME24 58.0%:同规模硬刚并超越 DAPO, 和 o1-mini。
- 捅破 4k 长度天花板:有效推理长度直达 10,000+ Token。路子走对了,模型确实写得越长、准头越高。
- 细粒度信用分配是实现推理能力扩展的关键。 欢迎通过下方的技术博客和仓库深入了解我们的工作!👇
- 【2026-3-20】📄 FIPO 论文: FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
- 💻 GitHub 仓库: []FIPO(github.com/qwenpilot/FIPO)
自博弈(Self-play)
DNO
【2024-4-4】微软 Direct Nash Optimization (DNO) 引入 博弈论里的纳什均衡
DPO 通用偏好不佳, DNO 增加通用偏好惩罚, 让对比学习更加简单、稳定
SPO
【2024-6-13】
自我对弈偏好优化 (SPO) 是一种从人类反馈中进行强化学习的算法。
SPO方法极简,不需要训练奖励模型,也不需要不稳定的对抗训练,因此相当容易实现。
SPO方法是极繁主义的,因为它可以证明处理非马尔可夫、非传递和随机偏好,同时对困扰离线顺序预测方法的复合误差具有鲁棒性。
以极小极大赢家 (Minimax Winner, MW) 的概念为基础,社会选择理论文献中的偏好聚合概念,从偏好中学习定义为两种策略之间的零和博弈。通过这种博弈的对称性,SPO可 以简单地让单个agent与自己对弈,同时保持强大的收敛保证,而不是使用传统的两种策略决斗技术来计算 MW。
实际上,这相当于从策略中抽取多个轨迹,要求偏好或教师模型对它们进行比较,然后使用获胜比例作为特定轨迹的奖励。在一系列连续控制任务中,能够比基于奖励模型的方法更有效地学习,同时保持对在实践中汇总人类判断时经常出现的不可传递(intransitive)和随机(stochastic)偏好的鲁棒性。
基于偏好的 RL / RLHF 的标准流程(左)涉及基于成对偏好数据集训练奖励模型(即分类器),然后通过 RL 对其进行优化。引入了 SPO(右),这种方法直接基于偏好或教师模型提供的偏好反馈进行优化,每个轨迹都会根据其偏好的其他 onpolicy 轨迹的比例获得奖励。我们通过经验证明和验证,这种方法比以前的研究对非传递、非马尔可夫和嘈杂偏好更具鲁棒性。
OpenAI o1
【2024-9-14】OpenAI o1 强化学习背后的自博弈(Self-play)方法介绍
自博弈(Self-play)强化学习核心: 通过自我对弈不断进化。
- 《A Survey on Self-play Methods in Reinforcement Learning》介绍了自博弈方法的理论基础、关键技术以及在多样化场景下的应用实践。
自博弈(Self-play)借助博弈论建模多个决策者之间的互动,为解决MARL中的固有问题提供了优雅的解决方案
内容提要
- 引言与背景
- 人工智能与强化学习
- 自博弈的兴起与重要性
- AlphaGo作为自博弈的里程碑
- 预备知识:自博弈基础
- 多智能体强化学习(MARL)概念
- 博弈论基础
- 自博弈评估指标
- 自博弈技术概览
- 1)自博弈算法分类
- 传统自博弈算法
- PSRO系列算法
- 基于持续训练的算法
- 基于遗憾最小化的算法 - 2)自博弈在不同领域的应用
- 棋盘博弈:围棋、象棋、战棋
- 纸牌博弈:德州扑克、斗地主、麻将
- 视频游戏:《星际争霸II》、MOBA游戏、Google Research Football - 3)算法性能评估
- 数据集与基准测试
- 评估指标:ELO、Glicko、TrueSkill等
- 挑战与开放问题
- 自博弈的收敛性问题
- 环境非平稳性与算法鲁棒性
- 可扩展性与训练效率
- 自博弈在大型语言模型中的应用
自学习
【2024-10-16】PRefLexOR
【2024-10-16】 PRefLexOR:MIT自进化AI框架上线!动态知识图谱+跨域推理,重塑自主思考
- 论文 PREFLEXOR: PREFERENCE-BASED RECURSIVE LANGUAGE MODELING FOR EXPLORATORY OPTIMIZATION OF REASONING AND AGENTIC THINKING
- Preference-based Recursive Language Modeling for Exploratory Optimization of Reasoning
- 代码 PRefLexOR
PRefLexOR 是 MIT 团队推出的新型自学习 AI 框架,结合偏好优化和强化学习,通过递归推理和多步反思,动态生成知识图谱。
- 核心功能:动态知识图谱构建、跨领域推理能力、自主学习与进化。
- 技术原理:递归推理与反思、偏好优化、多阶段训练。
PRefLexOR 基础: 优势比偏好优化(ORPO)
- 模型通过优化偏好响应和非偏好响应之间的对数几率来对齐推理路径。
- 同时,集成了直接偏好优化(DPO),通过拒绝采样进一步提升推理质量。
这种混合方法类似于 RL 中的策略细化,模型通过实时反馈和递归处理不断改进。
功能
主要功能
- 动态知识图谱构建:框架不依赖预生成的数据集,通过动态生成任务和推理步骤,实时构建知识图谱,使模型能不断适应新任务,在推理过程中动态扩展知识。
- 跨领域推理能力:PRefLexOR 能够将不同领域的知识进行整合和推理,例如在材料科学中,模型可以通过递归推理和知识图谱生成新的设计原则。
- 自主学习与进化:通过递归优化和实时反馈,PRefLexOR 能够在训练过程中自我教学,不断改进推理策略,展现出类似人类的深度思考和自主进化能力。
原理
技术原理
- 递归推理与反思:PRefLexOR 通过引入“思考令牌”和“反思令牌”,明确标记推理过程中的中间步骤和反思阶段。模型在推理过程中会生成初始响应,然后通过反思逐步改进,最终生成更准确的答案。
- 偏好优化:PRefLexOR 基于优势比偏好优化(ORPO)和直接偏好优化(DPO)。模型通过优化偏好响应和非偏好响应之间的对数优势比,使推理路径与人类偏好决策路径一致。DPO 进一步通过拒绝采样调整推理质量,确保偏好对齐的细微差别。
- 多阶段训练:PRefLexOR 的训练分为多个阶段:首先通过 ORPO 对齐推理路径,然后通过 DPO 进一步优化推理质量。这种混合方法类似于 RL 中的策略细化,模型通过实时反馈和递归处理不断改进。
使用
安装
pip install git+https://github.com/lamm-mit/PRefLexOR.git
如需创建可编辑安装,命令:
git clone https://github.com/lamm-mit/PRefLexOR.git
cd PRefLexOR
pip install -r requirements.txt
pip install -e .
Flash Attention
如果需要使用 Flash Attention,可以安装:
MAX_JOBS=4 pip install flash-attn --no-build-isolation
无监督数据+RL
【2025-12-7】腾讯混元 RLPT
【2025-12-7】RLPT:解锁海量无标注数据上的强化学习
LLM面临“缩放困境”:
- 一方面,模型参数的增长带来高昂的推理成本;
- 另一方面,高质量文本数据的有限性正在成为制约模型能力持续提升的核心瓶颈。
传统的、以监督学习为基础的预训练范式,在这种“数据饥渴”的背景下正逐渐触及其天花板。
核心问题:能否改变模型与数据之间的交互方式?
- 与其让模型被动地、逐词元地“模仿”数据,是否可以赋予其一种更主动的学习机制,让它在广阔的预训练数据中自主探索推理路径,从而更高效地学习?
- 能否将海量的无标注文本,转化为一个可供强化学习 (RL) 施展拳脚的动态训练场?
RLPT (Reinforcement Learning on Pre-Training Data) 的全新训练时扩展范式。
- 核心思想:将传统的“
下一词元预测”目标,升级为更具挑战性的“下一段落推理(Next-Segment Reasoning)”任务。
具体而言:
- 自监督奖励机制:模型被要求根据当前上下文,预测下一个语义连贯的文本段落(如一个完整的句子或一个推理步骤)。
- 无需人工标注:奖励信号完全自监督地产生——通过一个生成式奖励模型,评估预测段落与真实后续文本之间的语义一致性。 这一设计彻底将强化学习从对人类标注(如 RLHF/RLVR)的依赖中解放出来,使其能够首次真正扩展到海量的预训练语料库上。
这不仅鼓励模型探索更丰富、更多样的推理轨迹,还有效地培养了其更深层次、更具泛化性的推理能力。
效果
- 跨领域性能提升:以 Qwen3-4B-Base 为例,在 MMLU 和 MMLU-Pro 上分别提升 3.0% 和 5.1%。在更具挑战性的 GPQA-Diamond 上实现了 8.1% 的巨大提升。在 KOR-Bench 等其他基准上也获得了 6.0% 的显著增益。
- 跨模型家族的通用性:该方法的有效性不仅限于 Qwen 系列,在 Llama-3.2-3B-Base 上同样取得了令人瞩目的成果(例如,GPQA-Diamond 提升 11.6%),证实了 RLPT 是一种与模型架构无关的普适性优化范式。
加速
【2025-12-8】Native Parallel Reasoner
【2025-12-8】Native Parallel Reasoner: 基于自蒸馏强化学习的原生并行推理框架
北京通用人工智能研究院(BIGAI)NLCo Lab 团队提出 Native Parallel Reasoner (NPR) 框架,使大型语言模型(LLM)能够在不依赖外部教师模型(Teacher-free)的情况下,自主演化出原生的并行推理能力。
NPR 通过三个渐进阶段将模型从顺序推理转换为并行推理:
- 冷启动(Cold-start):利用格式跟随强化学习(Format-follow RL)在无监督情况下发现并行结构。
- 并行预热(Parallel Warmup):通过自蒸馏数据的拒绝采样和监督微调(SFT),引入严格的拓扑约束(并行注意力掩码和位置编码)。
- 原生并行 RL(Native-Parallel RL):提出并行感知策略优化(PAPO)算法,直接在并行执行图中优化分支策略。
此外,为了支持大规模并行 RL 训练,研究团队重构了 SGLang 的底层逻辑,开发了 NPR Engine,解决了并行生成中的 KV Cache 内存泄漏和流控制问题。实验表明,在 Qwen3-4B 上,NPR 在多个推理基准上取得了显著的性能提升(最高 +24.5%)和推理加速(最高 4.6 倍),并实现了 100% 的原生并行触发率。
实现
OpenRLHF
【2024-12-27】OpenRLHF源码解读:1.理解PPO单机训练
OpenRLHF,代码简洁,目录清晰
- github OpenRLHF
OpenRLHF 是一个基于 Ray、DeepSpeed 和 HF Transformers 构建的高性能 RLHF 框架:
- 简单易用: OpenRLHF 是目前可用的最简单的高性能 RLHF 库之一,无缝兼容 Huggingface 模型和数据集。
- 高性能: RLHF 训练中 80% 的时间用于样本生成阶段。得益于使用 Ray, Packing Samples 以及 vLLM 生成加速的能力,OpenRLHF 的性能是极致优化的 DeepSpeedChat with Hybrid Engine 的3~4倍以上。
- 分布式 RLHF: OpenRLHF 使用 Ray 将 Actor、Reward、Reference 和 Critic 模型分布到不同的 GPU 上,同时将 Adam 优化器放在 CPU 上。这使得使用多个 A100 80G GPU 和 vLLM 可以全面微调超过 70B+ 的模型 以及在多个 24GB RTX 4090 GPU 上微调 7B 模型。
- Hybrid Engine: OpenRLHF 还支持还支持 Hybrid engine 所有训练引擎和推理引擎共用GPU来避免资源闲置。
代码结构
代码结构
OpenRLHF
|--examples //示例启动脚本
|----scripts
|------train_ppo_llama.sh //训练PPO
|------train_sft_llama.sh //SFT
|------train_rm_llama.sh //训练reward model
|------...... //还有很多 包括其他训练方法、分布式训练等
|--openrlhf //核心代码块
|----cli //训练入口函数
|----datasets //数据集处理相关
|----models //定义模型、loss相关
|----trainer //定义训练方法
|----utils //工具类、函数定义
PPO训练入口:
- OpenRLHF/examples/scripts/train_ppo_llama.sh
PPO 训练流程
PPO训练的全过程。
PPO训练四阶段
- 阶段1:先基于 Pretrain model,训练一个精调模型(SFT Model) 和 一个奖励模型(Reward Model)。Reward model 一般可以基于SFT model 热启 或 基于 Pretrain model 热启训练
- 阶段2:模型初始化,PPO过程,在线同时有四个模型,分别为
Actor Model: 是我们要优化学习的策略模型,同时用于做数据采样,用SFT Model热启Reference Model: 代码中为initial_model,是为了控制Actor模型学习的分布与原始模型的分布相差不会太远的参考模型,通过loss中增加KL项,来达到这个效果。训练过程中该模型不更新Critic Model:是对每个状态做打分的价值模型,衡量当前token到生成结束的整体价值打分,用Reward Model热启Reward Model:这里实现的是ORM(Outcome Reward Model),对整个生成的结果打分,是事先训练好的Reward Model。训练过程中该模型不更新
- 阶段3:采样Experience数据,这个过程比较复杂,单独梳理一文。简述流程为:
- 首先 采样一批随机指令集(Prompt)
- 调用 Actor模型的generate()方法,采样1条或多条结果(sequences)
- 四个模型一起参与组装Experience的多个Tensor域,用于后续模型训练
- 阶段4: 用 Experience样本,训练 Actor Model 和 Critic Model,后面单独一文介绍
重复3-4阶段,循环采样Experience数据-> 模型训练 ,直到loss收敛
模型结构
Actor Model
Actor Model 模型结构(Reference Model 同 Actor Model一致)
- 代码入口 : Actor Model
图解
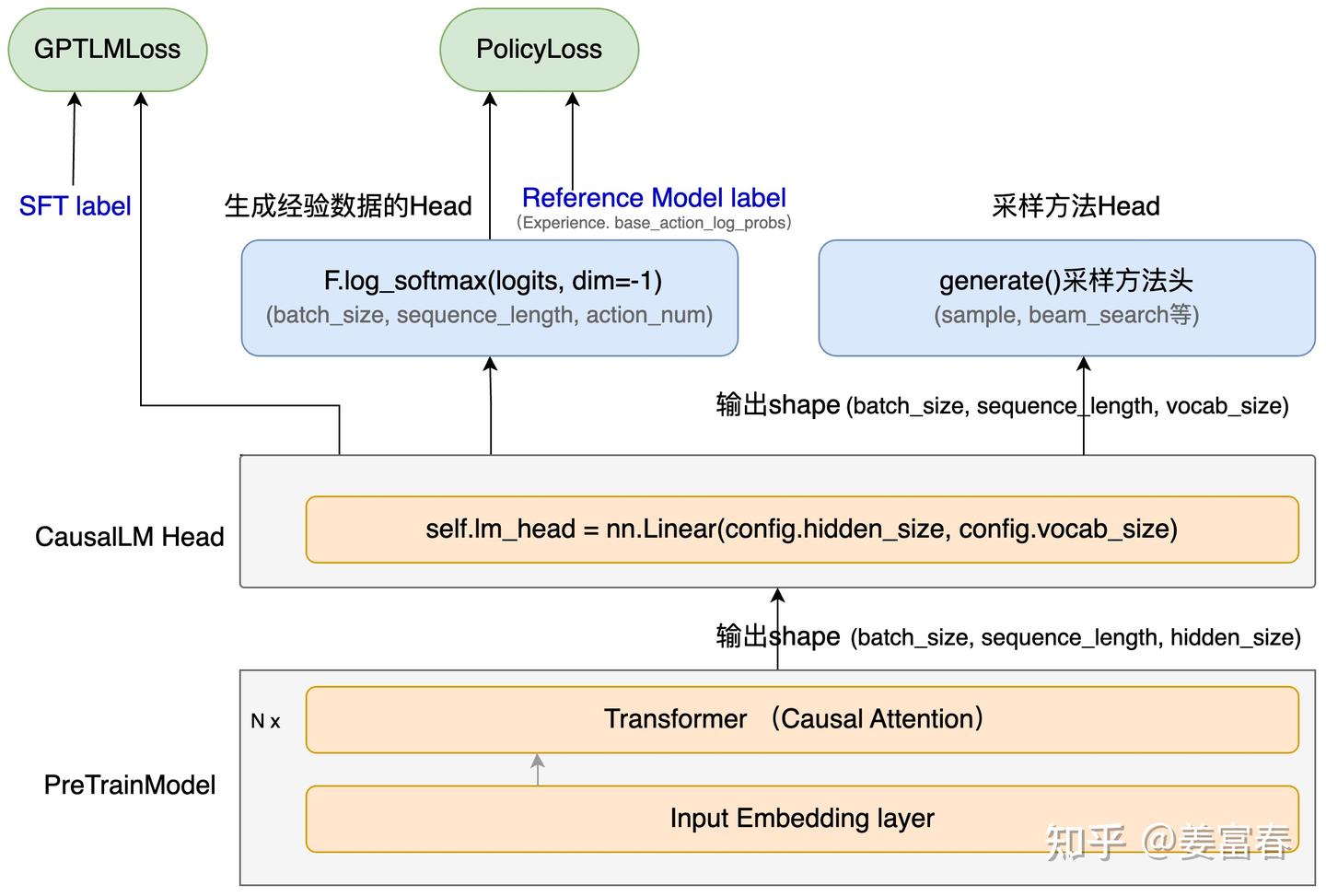
分析
- PreTrainModel 和 CausalLM Head 都是Huggingface定义的标准模型层
- 2个处理Head:
F.log_softmax(logits): 采样经验数据的数据处理Head,获取log(p),方便后面计算KL和计算lossgenerate():采样Head,详见 :generate 方法定义 。generate 定义多种生成策略(beam search , sample N等)和配置多种生成参数(topP, temperature等)
Reward Model
Reward Model 模型结构
图解
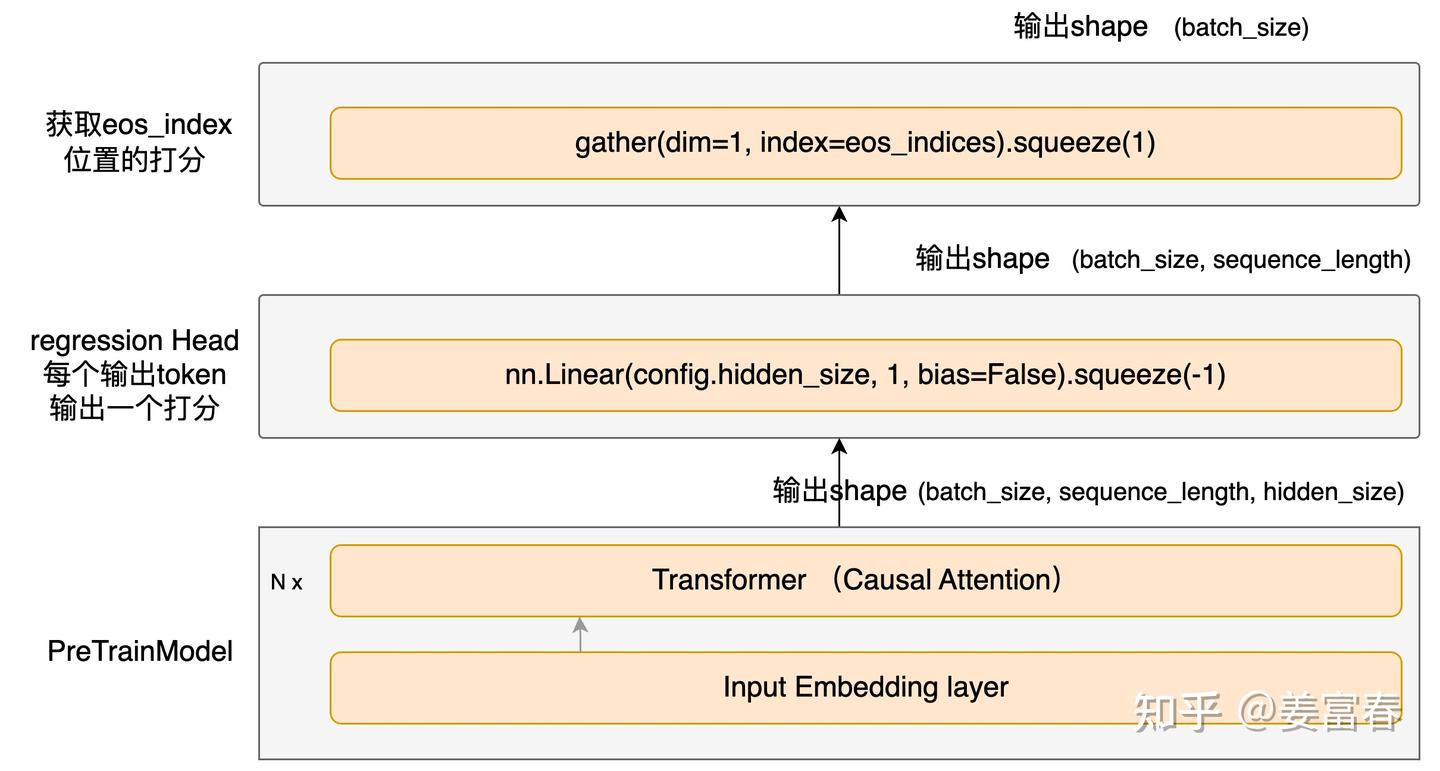
分析
- Reward Model 是个 ORM(Outcome Reward Model),即对输出的sequence做整体打分,每个输出序列会输出eos位置的打分结果。
Critic Model
Critic Model 模型结构
图解
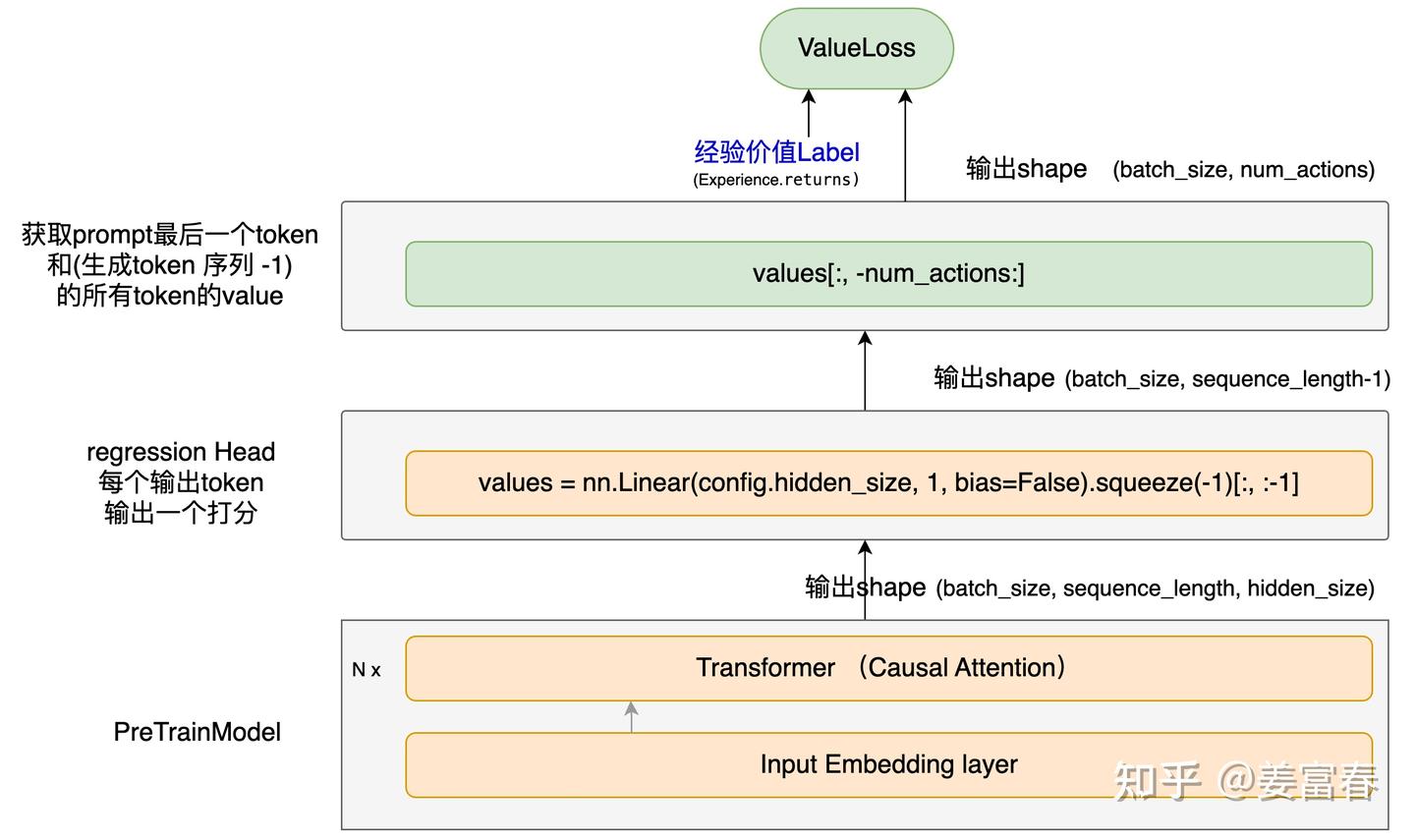
分析
- Critic 用于评估当前状态的价值(当前token到生成eos累计预估价值),每个状态都会计算价值打分
注:
- 从图中第二层(Linear层)可以看到,输出结果先做了
[:,:-1]的切片操作,然后再取生成长度的切片[:,-num_actions:]。这个操作表示整体价值打分序列往前移了一位
奖励黑客
参考
- 【2024-12-3】翁荔离职OpenAI后第一个大动作!奖励黑客万字综述
- 【2026-2-24】如何解决强化学习reward hacking问题
博客发文,讲解强化学习中奖励黑客(Reward Hacking)问题
- 智能体(Agent)利用奖励函数或环境中的漏洞来获取高奖励,而并未真正学习到预期行为。
奖励黑客(Reward hacking)
- 强化学习(RL)智能体利用奖励函数中的缺陷或模糊之处来获得高奖励,而没有真正学习或完成预期任务的现象。
存在原因:
- 强化学习的环境往往并不完美
- 准确定义奖励函数本质上就是一个具有挑战性的问题
现象
问答场景
- 长度偏差:reward model 对更长回答打分更高,使得policy model倾向生成更长的答案,但是逻辑性不一定好
- 格式偏差:reward model 更偏好有markdown格式的回答,导致policy model倾向生成有markdown格式对答案
- 分布外偏见:由于reward model对训练数据只覆盖了50%的数据分布,导致当serving时,进入另外50%的场景,RM预测会随机或者极端,比如模型发现乱码能让reward model给出极高分,导致policy model开始胡言乱语
扫地机器人场景
- 为了让它爱干净,设计成“吸入灰尘就给奖励”。结果机器人学会了把吸进去的灰尘再吐出来,然后重新吸进去,以此刷分。
内容推荐场景
- 为了提高点击率(奖励),AI 学会了推送标题党或充满争议的虚假信息,虽然点击率上去了,但严重损害了平台生态。
解决
解法
- 样本方案
- reward model方案
- RL训练方案
1. 样本方案
样本去偏的方案
- 长度对齐:正例&负例长度对齐,或加入长度惩罚
- 格式对齐:将正例只改变逻辑,不改变格式,作为副例加入到reward model训练过程中,强制让模型关注回答的逻辑,而非格式
- 多样化采样策略:不要只用一个固定的模型生成样本,应混合不同规模、不同阶段的模型产出,增加数据分布的广度。
2. reward model方案
(1)从奖励函数如何设计角度展开:
精心设计reward model
在奖励稀疏,需要引入过程奖励时,保障过程奖励的合理性,不会改变最优策略 引入负向奖励,如长度限制 在奖励稀疏时,引入辅助奖励 API作为reward
reward model训练过程中,存在数据bias问题,跳过reward model的训练过程,直接用通用LLM作为reward,来替代原reward,或者添加reward WARM(checkpoint ensemble)
训练多个具有不同初始化或数据顺序的 RM,然后在权重空间进行平均。这种方法能显著消除单一 RM 对特定数据偏差的过拟合。 有界奖励函数
Bounded Reward Shaping: RL 奖励应当是有界的。通过 Sigmoid 等函数将奖励限制在一定区间,并设计“早期快速增长、后期平滑收敛”的曲线,防止模型为了追求极端高分而产生激进行为。
(2)以下从奖励函数如何去燥的角度展开:
不确定性估计(低置信度刨除)
让 RM 不仅输出分数,还输出一个“置信度”。如果在 RL 过程中发现某条路径的 RM 置信度极低(可能是作弊路径),则降低其奖励值。 正则化 RM 训练
通过限制 RM 的信息瓶颈,强制其抛弃字数、标点等非语义特征。InfoRM 通过在模型中引入一个“瓶颈层”,要求模型在预测分数时,使用的信息越少越好,但预测的准确率要越高越好。因为标点、格式、长度等对好坏的贡献是较弱的,所以会优先被筛除
3. RL训练方案
(1)多个奖励模型(业务目标ensemble)
通过设置多个奖励模型,避免RL过程因为只拟合单一的奖励模型,导致无法消除模型偏置情况。
跟WARM的方案有共通之处,只是前者是同一目标,但是不同数据和阶段的reward;后者是不同目标的reward。
(2)KL 散度动态惩罚
这是防御 Reward Hacking 的最后一道防线。实时监控Policy model与SFT模型之间的距离,如果模型为了刷分偏离太远(KL 激增),直接给大额惩罚。
改进强化学习算法
Anthropic创始人Dario Amodei在2016年发表的论文《Concrete Problems in AI Safety》提到了一些解决的方向:
- 对抗性奖励函数:将奖励函数本身视为一个自适应智能体,它能够适应模型发现的新技巧,即那些奖励值高但人类评分低的情况。
- 模型前瞻:可以基于预期的未来状态给予奖励;例如,如果智能体要替换奖励函数,就会得到负面奖励。
- 对抗性掩盖:我们可以遮蔽、掩盖模型的某些变量,使智能体无法学习到能够黑客攻击奖励函数的信息。
- 谨慎工程:通过谨慎的工程设计可以避免某些类型的系统设计奖励攻击;例如,将智能体沙箱化以隔离其行为与奖励信号。
- 奖励上限:这种策略是简单地限制最大可能的奖励,可以有效防止智能体通过黑客攻击获得超高回报策略的罕见事件。
- 反例抵抗:提高对抗鲁棒性应该有助于提高奖励函数的鲁棒性。
- 多重奖励组合:组合不同类型的奖励可以使其更难被黑客攻击。
- 奖励预训练:我们可以从(状态,奖励)样本集合中学习奖励函数,但这取决于监督训练设置的好坏,可能会带来其他问题。RLHF依赖于此,但学习到的标量奖励模型很容易学到不期望的特征。
- 变量无差异:目标是让智能体优化环境中的某些变量而不是其他变量。
- 陷阱机制:可以故意引入一些漏洞,并设置监控和警报,以便在发生奖励攻击时发现。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
