多轮对话
人工智能(AI)的长期目标
- 生成自然且有意义的响应以与人类通信的多轮对话系统
LLMs的出现显著提高了多轮对话系统的性能
AI 智能体正从单点能力迈向复杂系统协作,多智能体系统(Multi-Agent Systems, MAS)成为学术和产业界聚焦的新前沿。
这一背景下,「Agentic Workflow」作为面向智能体自主决策与协作流程自动生成的技术理念,正成为多智能体系统研究和应用的探索热点。
LLM 多轮
RL 多轮 agent 研究
【2025-10-01】加州大学圣地亚哥分校,RL 多轮训练 agent 研究
多轮RL训练LLM成为智能体时,哪些方法有效、哪些无效?
现有框架与定义零散,尚无系统表述或分析。本文研究思路
- 首先,将设计空间拆解为三个相互关联的核心支柱——
环境、奖励与策略 - 随后,通过实证推导得出一套适用于情境文本领域训练LLM智能体的方案。
测试两类主流情境具身推理测试领域(TextWorld和ALFWorld),以及面向软件工程类任务的SWE-Gym。
- (i)环境层面,从状态空间大小、动作空间大小及最优解长度三个维度分析了任务复杂度的影响,发现同一领域内即便简单的环境,也能为评估智能体向更复杂任务的泛化能力提供有效信号;
- (ii)奖励层面,对相对奖励稀疏性进行了消融实验,观察到尽管密集的轮次级奖励能加速训练,但模型性能与稳定性高度依赖强化学习算法的选择;
- (iii)智能体策略层面,探究了奖励稀疏性与有偏策略梯度方法(PPO、GRPO)及无偏策略梯度方法(RLOO)之间的相互作用,同时展示了在固定预算下如何找到监督微调(SFT)与强化学习训练的最优比例。
提炼为一套训练方案,为三个支柱协同设计提供指导。
- 环境层面: 从较简单的环境开始训练,智能体可能会习得可迁移技能,进而泛化到复杂场景。
- 物体复杂度比空间复杂度更具挑战性,课程设计应优先关注物体操控技能。
- 单任务训练能实现不错的跨任务泛化,但混合任务训练的鲁棒性更优。
- 策略层面: 良好的模仿学习先验能大幅降低强化学习的样本复杂度,同时保持相当的性能。
- 演示数据与强化学习数据之间存在最优平衡,可最大化任务特定准确率与泛化能力。
- 多轮场景中,有偏算法(PPO、GRPO)表现优于无偏替代算法(RLOO),且在复杂环境中性能差距会进一步扩大。
- 奖励层面: 密集奖励能显著提升多轮强化学习性能,且最优奖励密度因算法而异——PPO从密集反馈中获益最多,而RLOO在不同奖励方案下均表现出鲁棒性。
通过系统性超参数调优,确定了一套在TextWorld、ALFWorld和SWE-Gym中均适用的方案,为从业者提供了基础起点。
多轮强化学习需要超越单轮优化的根本性思考。
CMU
论文合集: 大模型多轮交互相关的数据、论文、代码
- 【2025-4-7】CMU 综述论文 Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models,涉及多个场景的多轮会话,roleplay, healthcare, education, and even adversarial jailbreak settings
- Awesome-Multi-Turn-LLMs
此外,多轮对话场景下增强方法:
- 模型中心策略: 上下文学习、监督微调、强化学习及新型架构;
- 外部集成方法: 记忆增强、基于检索的方法及知识图谱;
- 用于协作交互的基于智能体的技术。
中山大学
【2024-2-28】中山大学综述
多轮对话任务是序列到序列任务
- 从用户消息
U = (u1, u2, ...ut)生成系统响应S = (s1, s2, ...st) - 其中ut和st分别是第t轮的用户消息和系统响应。
多轮对话系统可以分为: 基于LLM的开放领域对话(ODD)和任务导向对话(TOD)系统
- TOD系统帮助用户处理特定领域内的任务,如酒店预订、餐厅推荐等
- 而ODD系统则在没有领域限制的情况下与用户聊天。
TOD任务和ODD任务并不完全独立,一旦对话系统检测到特定用户需求,一个ODD任务可以转换为TOD任务。
ODD主要分为三种方法:
- 基于检索的方法,从预定义的集合中选择响应;
- 基于生成的方法,动态生成响应;
- 以及混合方法,结合检索和生成以优化对话结果。
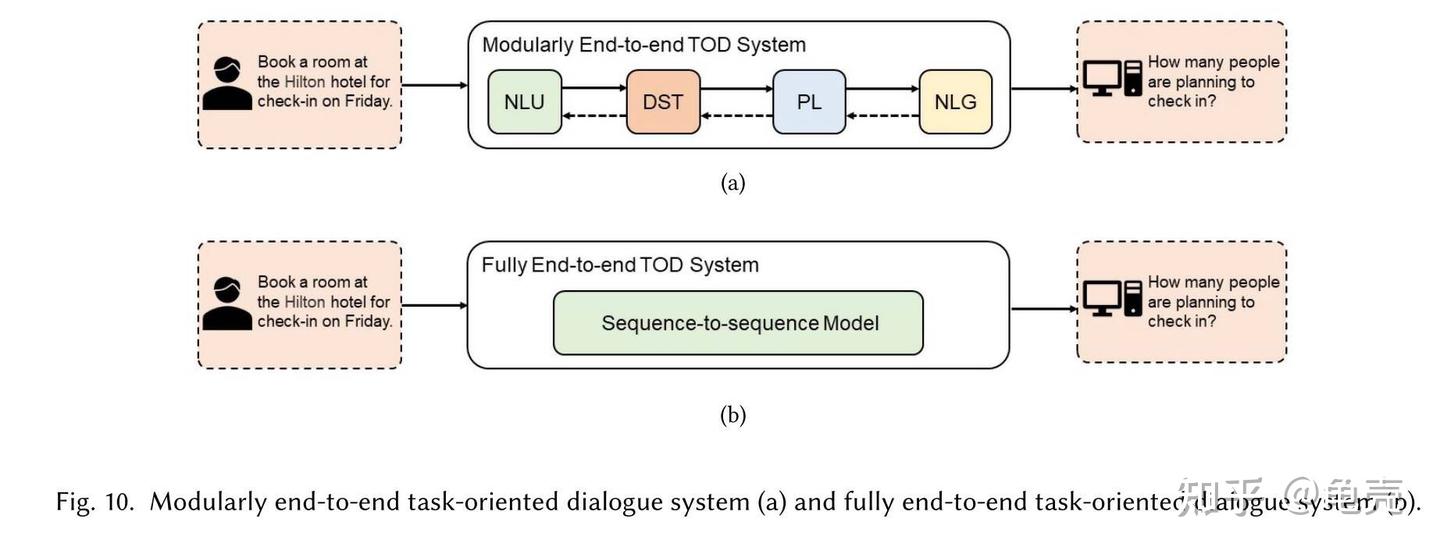
TOD 分为基于流水线的TOD和端到端TOD
- 基于流水线的TOD系统包括四个相连的模块:
- (1) 自然语言理解(NLU),用于提取用户意图和填充槽位;
- (2) 对话状态跟踪(DST),基于流水线的TOD中的一个关键模块,用于根据NLU模块的输出和对话的历史输入来跟踪当前轮次的对话状态;
- (3) 策略学习(PL),根据DST模块生成的对话状态确定后续行动;
- (4) 自然语言生成(NLG),基于流水线的TOD系统中的最后一个模块,将PL模块生成的对话行动转换为易于理解的自然语言。
- 对话管理器(DM)是基于流水线的TOD系统的中心控制器,由DST模块和PL模块组成。
- 基于端到端的TOD:
- 模块端到端 modularly end-to-end TOD systems, 同时训练、优化多个模块 —— 主流
- 全端到端 fully end-to-end TOD systems, LLM再OOD上进步显著,但由于缺乏大量TOD数据,全端到端TOD进展有限
案例
- Peng等人提出了Soloist,这是一种使用迁移学习和机器教学来构建端到端TOD系统的方法。Soloist的训练过程与SimpleTOD非常相似。然而,Soloist细化了每个对话回合的数据格式,不再需要对话动作A。训练数据中的每个对话回合可以表示为 =
[H, B, D, S],Soloist的完整预训练目标分为信念预测、响应生成。 - UBAR,以前的模块化端到端TOD方法在回合级别序列中进行训练和评估
- 其中基于对话历史
Ht = (u1,s1), (u2,s2),..., (ut-1,st-1),ut是轮次t生成的响应。而UBAR在上下文中集成了中间信息B、D和A。 - 因此,UBAR的训练序列依次被定义为:
[H0, B0, D0, A0, S0, . . ., Ht, Bt, Dt, At, St ],然后用于微调大型预训练模型GPT-2。
- 其中基于对话历史
- Su等人提出了一种即插即用的面向任务的对话模型(PPTOD),这是一种模块化的端到端的TOD模型。
- PPTOD使用四个与TOD相关的任务进行预训练,并使用提示词来提高语言模型的性能。
- PPTOD的学习框架允许它使用部分注释的数据进行训练,这大大降低了手动创建数据集的成本。
- 阿里达摩院 Semi-supervised Pre-trAined Conversation ModEl (SPACE) 半监督式预训练会话模型
- GALAXY (SPACE-1) 是模块化TOD,通过应用半监督学习,从有限的标记对话和广泛的未标记对话语料库的组合中显式获取对话策略。
- SPACE-2 是树结构的对话模型,语义树(STS),在有限的标记对话和大规模未标记对话语料库上预先训练的树结构对话模型。
- SPACE-3 是最先进的模块化TOD对话系统,整合了SPACE-1和SPACE-2的工作,结合STS来统一不同数据集之间不一致的注释模式,并为每个组件设计了一个专用的预训练目标。
基于LLM的多轮对话系统的两个主要类别:基于LLM的TOD系统和基于LLM的ODD系统。
多轮对话知识见站内专题:对话管理器
问题
对话迷失
【2025-8-26】LLM 在多轮对话中表现出“对话迷失”现象
- Microsoft & Salesforce 论文:LLMs Get Lost In Multi-Turn Conversation
- 代码仓库:lost_in_conversation
“分片模拟”方法
- 将单轮完整指令分解为多个信息片段(shards),通过控制实验比较 LLMs 在:(1)单轮完整指令(2)单轮拼接指令(3)多轮分片指令 三种设置下的表现差异。
通过拆解 “能力(Aptitude)” 和 “不可靠性(Unreliability)”,发现多轮对话性能下降的核心原因是不可靠性激增:
- 单轮对话特征:能力(A)与可靠性(R)正相关 —— 能力高的模型(如 GPT-4.1、Gemini 2.5 Pro)更可靠(不可靠性 U 低),能力低的模型(如 Llama3.1-8B)更不稳定。
- 多轮对话特征:
- 能力(A)仅轻微下降(平均 - 16%),说明模型处理任务的基础能力未大幅退化。
- 不可靠性(U)显著激增(平均 + 112%),即最佳与最差表现的差距扩大。例如,单轮中 U 约 25,多轮中 U 升至 65,所有模型均表现出高不可靠性,与能力无关。
- “对话迷失” 机制:模型在多轮对话中易出现早期错误假设、过早生成答案并过度依赖,一旦 “走错方向” 便无法恢复(如忽略后续用户补充的关键信息)。
LLM 在单轮与多轮对话设置下的性能差异。
- 当用户指令在多轮对话中逐步提供(即”分片式”对话)时,所有测试的 LLMs 性能平均下降 39%,表现出明显的”对话迷失”现象。
将对话按多个步骤拆分到多轮中,LLM 会存在两个问题:
- 模型在对话早期易做出错误假设,过早生成最终答案并过度依赖。
- 回应冗长,导致信息冗余和混淆;对中间轮次信息的关注度低于首末轮次(“中间轮次遗忘” 现象)。
LLM 在多轮对话中的不可靠性,建议采取实用策略提升效果:
- 重启对话:若当前对话陷入僵局,重启并重复信息可能比继续修正更有效(因模型难以纠正早期错误)。
- 整合需求为单轮指令:将多轮需求汇总为完整指令(如让 LLM “总结之前所有信息”),利用单轮对话的高可靠性(如 CONCAT 场景)。
- 实例:Cursor(代码助手)用户发现 “频繁开启新对话” 能提升效果,印证了多轮对话的局限性。
长文本
详见站内意图识别专题
多轮工具数据
多轮对话数据合成
【2025-4-24】APIGen-MT:高效生成多轮人机交互Agent数据的两阶段框架
APIGen-MT:高效生成多轮人机交互数据的两阶段框架
- 第一阶段:任务配置和验证
- 生成详细的任务蓝图(blueprint),包括用户意图、可验证的地面真实动作(groundtruth actions)和预期的最终输出
- 第二阶段:人机环境交互轨迹收集
- 基于第一阶段生成的验证任务配置,这一阶段通过模拟人机交互来生成完整的多轮交互轨迹
美团 GEM
人大、美团提出 GEM, Generation and Extraction of Multi-turn tool-use trajectories
无论是 Claude、Qwen3-max 还是 GLM-4.7,当业务规模上升后,模型成本、响应效率和稳定性都是必须直面的问题,而想要自研高质量的 Agent 模型,首要难题
- 高质量多轮工具调用轨迹数据的极度稀缺
主流 Agent 轨迹数据合成大多采用“以工具为中心”的模拟模式:
- 预定义一组 API
- 用模型模拟用户指令和调用过程
这种方式
- 成本极高,构建多样化且全面的API集合非常昂贵;
- 泛化能力弱,预定义的 API 很难覆盖现实世界的无限可能,导致训练出的 Agent 在面对未见过的环境时表现平平。
美团提出有趣的思路:
- 绕过预定义工具,直接从海量文本中生成Agent训练所需的轨迹数据
- 遗憾:文章并没有开源数据、模型以及代码仓库
论文核心思路:从文本语料挖掘轨迹数据
- 能否绕过预定义的工具,直接从现实世界文本中合成高质量轨迹? 美团研究团队发现,用于预训练 LLM 的原始语料库(如 Ultra-fineweb)本身就是一座未开发的金矿。这些文本虽然不是结构化的Agent轨迹,但记录了大量人类多步骤解决问题的真实经历(如“医院报销流”)。
这些文本隐含了 Agent 运行的三大基石:
- 用户需求: 文本中提到的目标或问题。
- 环境工具: 隐含在操作说明中的 API 功能描述。
- 多步工作流: 叙述性的操作步骤。
分析显示,约 14% 的采样语料含有显式的多步工作流 。基于这一发现,GEM(Generation and Extraction of Multi-turn tool-use trajectories) 范式通过四阶段流水线,实现了从文本到多轮工具调用轨迹的合成。
用这种方式合成的数据,训练的Qwen3-8B、Qwe3-32B模型在BFCL V3和Tau Bench 数据集上相比于其它的开源数据以及闭源的GPT4.1和Deepseek-V3.2-Exp都展现出了很强的竞争力。
GEM范式:多阶段的轨迹合成
Stage1:文本过滤
- 原始数据源:主要从 Ultra-fineweb 等大规模文本语料库中进行采样。
- 过滤机制:使用专门的分类器对原始文本片段进行二分类筛选。
- 筛选标准:剔除非操作性文本,仅保留详细描述了多步操作程序的片段
- 资源规模:采样25w条,采样语料中约有 14% 的片段包含显式的多步工作流
Stage2:工作流与工具提取
- 结构化工作流识别:模型需识别出文本中包含的所有工作流,并枚举每一个具体的步骤(例如:从“查询”到“编辑”)。
- 捕捉复杂点:提取过程中会特别标注顺序依赖、条件逻辑以及唯一性约束(例如:“必须先登录才能查询”)。
- API 工具设计:
- 基于文本描述,为每个步骤设计对应的 API 工具定义。
- 标准化格式:工具定义严格遵循 OpenAI Schema 标准。
- 设计原则:每个工具实现单一功能,参数名需具有自解释性,且必须明确数据类型。
- 输出产物:该阶段最终输出一套抽象工作流描述及与之配套的完整工具定义集。
Stage3:轨迹生成
- 合成策略:采用 GLM-4.6 作为强教师模型,通过“单次生成”策略直接产出完整的多轮对话轨迹。
- 核心构成:系统提示词、用户序列任务、Assistant响应序列、工具响应序列
Stage4:复杂度精炼
为了解决初始合成数据往往过于简单、直接的问题,GEM 引入了精炼机制来增加难度。
- 增加多样性:扩大轨迹中使用的工具种类。
- 提升真实感:优化环境返回的响应细节。
- 设置陷阱:增加用户指令的模糊性,并引入复杂的工具调用链 。
- 行为模式:通过精炼,强制 Agent 学习错误恢复、主动澄清及多步规划等高级能力。
Stage5:验证机制
所有生成的轨迹必须通过严苛的校验,以确保其作为训练集的质量。
- 基于规则的检查:验证所有工具调用的格式是否正确;确保函数名、参数名及参数类型与第二阶段定义的工具集严格匹配。
- 基于 LLM 的裁判 :利用 Qwen3-32B 检查逻辑错误与幻觉;严格核实工具调用中的每一个参数值是否在之前的对话历史中有据可依,彻底剔造捏造的信息 。
为了解决大规模生成时的高成本和高延迟问题,团队还提出更极客的方案:训练一个专门的轨迹合成器(Trajectory Synthesizer)。
通过对 10K 条 GEM 高质量轨迹进行监督微调(SFT),训练出一个能直接将原始文本转化为端到端轨迹的专用模型 。
实测显示,这个合成器在大幅降低推理成本的同时,生成的数据质量依然能打,在各维度性能上与完整流水线产出的数据几乎无异。
工具调用风险
【2026-2-10】从“事后检测”到“过程引导”,北大联合上海AI Lab重塑智能体工具调用安全
智能体安全落地亟需解决的核心问题
- 如何在每一次工具调用发生之前识别并约束潜在风险
【2026-1-15】北京大学知识计算实验室联合上海人工智能实验室提出了 ToolSafe 框架,首次系统化地对 LLM 智能体的步骤级工具调用安全问题进行建模与防护。
在此基础上,团队开发了 TS-Bench、TS-Guard 和 TS-Flow 三大组件:
- TS-Bench 提供首个步骤级工具调用安全检测评估基准;
- TS-Guard 是步骤级护栏模型,通过多任务强化学习优化,能通过归因分析提供可解释的安全反馈;
- TS-Flow 则尝试将来自步骤级护栏的反馈信号融入智能体推理流程,显著减少有害工具调用并提升了提示注入攻击场景下的良性任务完成率。
相关代码、数据与模型已全部开源,详细方法与实验结果可参考原始论文。
workflow 提效
【2025-5-29】MermaidFlow
【2025-7-24】如何实现可验证的Agentic Workflow?MermaidFlow开启安全、稳健的智能体流程新范式
【2025-5-29】新加坡 A*STAR 的 Centre for Frontier AI Research (CFAR) 研究所与南洋理工大学的研究团队联合发布了创新性工作流框架「MermaidFlow」,推动智能体系统迈向结构化进化与安全可验证的新范式。
- 论文 MermaidFlow: Redefining Agentic Workflow Generation via Safety-Constrained Evolutionary Programming
- 代码 MermaidFlow
MermaidFlow 提出的结构化可验证工作流表达方式,为智能体系统实现高效、可控的协作流程提供了基础支撑。未来的 AI 协作,也许正需要这样一套 「看得见、查得清、能进化」 的流程底座。
起因
传统瓶颈:命令式脚本使工作流频频 「翻车」
现有多智能体系统中,大模型生成的工作流往往以 Python 脚本或 JSON 树等命令式(imperative)代码直接输出
ADAS,AFlow等主流系统也普遍采用了这种表达范式。
这种低层次、混杂的生成方式,将流程规划与具体实现深度耦合,结构信息隐含在复杂代码中,直接导致了以下三大核心瓶颈:
- 结构不透明:工作流整体架构深藏在杂乱代码里,流程关系难以一目了然,协作全局难以把控。
- 合理性难验证:流程逻辑与实现细节高度耦合,缺乏静态检查和自动验证机制,容易隐藏致命漏洞。
- 调试与优化困难:错误往往只有在实际运行时才暴露,流程复现、问题定位和后续优化极为低效。
MermaidFlow 方法
MermaidFlow: 引领结构化与可验证工作流表达
MermaidFlow 以 结构化图语言 Mermaid 为基础,提出全新的工作流表达机制。
不同于直接输出可执行脚本的方式,MermaidFlow 强调将智能体行为规划过程显式建模为结构化流程图谱,并引入形式化语义,确保流程清晰、可查、可验证。
相比传统的 Python/JSON 脚本,基于 Mermaid 的工作流表达具有以下核心特点:
- 图式结构清晰可见:每一个智能体定义、依赖关系、数据流都被结构化地表达成图中的节点与连边,使整个工作流一目了然、可交互、可审查.
- 流程验证内嵌其中:MermaidFlow 引入了多类语义约束(如依赖闭环、角色一致性、输入输出类型匹配等),支持静态结构验证与生成时一致性检查,避免生成不符合规则的图。
- 天然支持演化与调试:结构化工作流图更易于进行片段级替换、增量修复与版本比较,支持可控的演化式优化(见后节)。
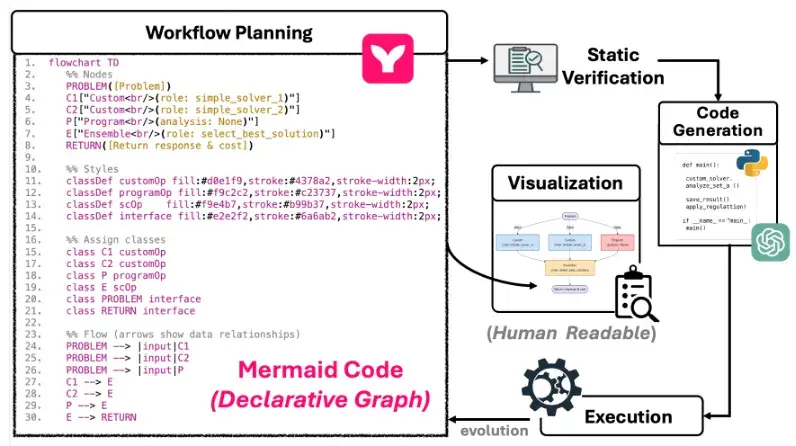
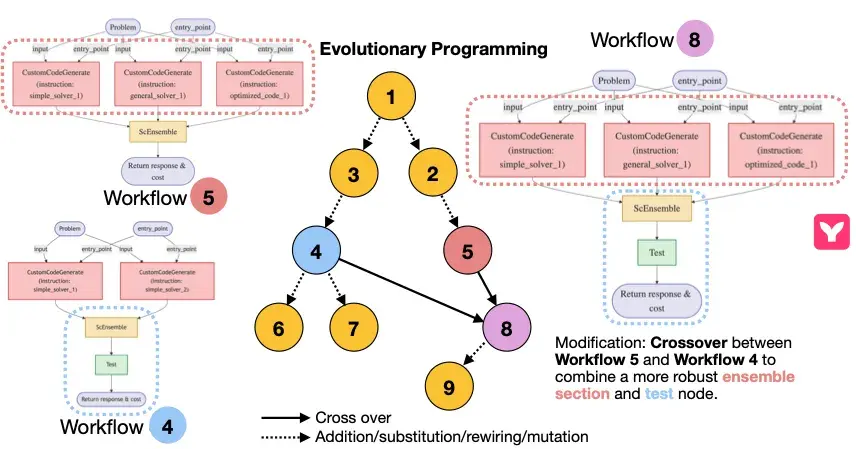
MermaidFlow:从结构化图到可验证执行的一站式工作流表达闭环 。
- 左侧部分展示了基于 Mermaid 的声明式工作流表达,结构清晰、依赖显式,具备良好的人类可读性。
- 人们可以清晰得知道, 在该工作流中存在什么节点, 之间的连接情况是怎么样的。
借助 MermaidFlow 所提出的结构化图式表达,多智能体协作的工作流规划过程不再是脆弱难控的黑盒编排,而是具备清晰结构、可视节点与可验证语义的 「白盒流程」。
这种方式极大地提升了 Agentic Workflow 的可解释性、可验证性与后续演化的可操作性,为大规模部署打下坚实基础。
作者研究发现大语言模型对 Mermaid 语言具备天然的生成优势。这也让 MermaidFlow 与 LLM 的结合变得格外丝滑又强大
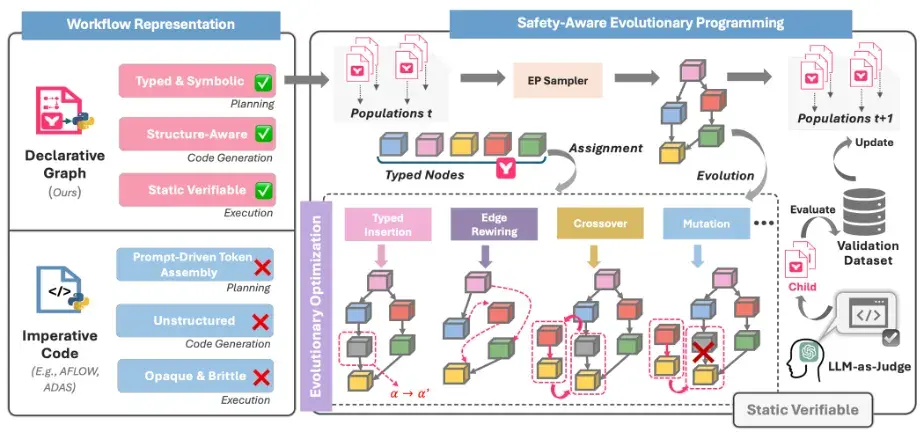
工作流的自我升级之道
MermaidFlow 基于 Mermaid 语言对智能体工作流进行显式建模,使每个任务节点、数据依赖与执行顺序都成为可视、可解析、可操作的语义单元。
- 相比传统的命令式脚本,结构化表达更具模块化特性,支持按节点插入、删除与替换,天然适配图级别的优化操作。
- 每一次结构调整都具备清晰的语义边界,显著降低了修改的不确定性与调试复杂度。
得益于 MermaidFlow 引入的静态验证机制(如节点类型匹配、输入输出闭环、角色一致性等约束),每一代演化生成的工作流候选都能在生成阶段就进行结构合规性检查,过滤掉语义不完整或存在潜在风险的 「劣质图」。
这种 「先验校验 + 后验优化」 的策略,显著提高了搜索空间的质量和鲁棒性,避免了大量无效或不合法的探索路径。
效果
MermaidFlow 不再依赖具备强编程能力的大语言模型,也能生成高质量的工作流。
在 GSM8K、MATH、HumanEval、MBPP 等多个主流任务数据集上,MermaidFlow 均展现出优秀的性能,体现出较强的实用价值。
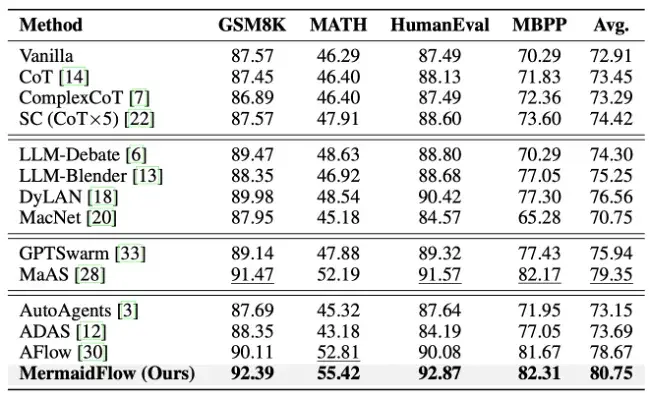
得益于结构化表达与静态可验证机制,MermaidFlow 在进化流程中生成可执行且结构合理工作流的成功率超过 90%,相比于传统基于脚本拼接的方法,极大提升了智能体系统的可控性和鲁棒性,为智能体系统的稳健部署提供了坚实的支撑。
MermaidFlow 在结构化表示下的进化过程示例。得益于每个节点及其连接关系均具备明确的语义边界,系统能够便捷且安全地进行局部片段的替换、重组与演化操作(如 crossover、节点替换、连边调整等)。图中演示了系统如何通过对 Workflow 5 和 Workflow 4 进行 crossover 操作,生成结构更健壮的 Workflow 8,引入了更优的 ensemble 与 test 模块。
这一结构可控的演化机制,有效提升了工作流生成过程的安全性、可控性与可维护性。
【2025-9-14】MIT PDDL-Instruct
2025年9月14日,大模型学会符号推理 pddl-instruct方法,twitter
PDDL 方法
- PDDL(Planning Domain Definition Language)即“规划领域定义语言”,描述规划问题的标准化形式语言,常用于定义任务目标、环境状态及可行动作规则;
- “invariant preservation”译为“不变量保持”,指在规划过程中,某些关键属性或约束条件始终保持不变,是确保规划逻辑一致性的重要准则。
大模型执行结构化符号规划的能力仍存在局限,尤其在需要规划领域定义语言(PDDL)这类形式化表示的领域中表现更为明显。
新颖的指令微调框架—— PDDL-Instruct,通过逻辑思维链推理,增强大型语言模型的符号规划能力。
- 教会模型利用明确的逻辑推理步骤,严谨地对动作适用性、状态转移及规划有效性进行推理。
- 通过设计指令提示,引导模型完成在特定状态下判断动作能否执行所需的精确逻辑推理,使大型语言模型能够通过结构化反思实现规划过程的自我修正。
- 该框架将规划过程分解为关于“前提条件满足”“效果应用”和“不变量保持”的明确推理链,从而系统性地培养模型的验证能力。
在多个规划领域开展的实验结果表明,基于思维链推理的指令微调模型在规划任务上的表现显著更优:
- 标准基准测试中,其规划准确率最高可达94%,相较于基线模型实现了66%的绝对性能提升。
此项研究填补了大型语言模型的通用推理能力与自动规划所需的逻辑精度之间的差距,为开发更优的人工智能规划系统提供了极具前景的方向。
(注:1. PDDL(Planning Domain Definition Language)即“规划领域定义语言”,是人工智能规划领域用于描述规划问题的标准化形式语言,常用于定义任务目标、环境状态及可行动作规则;2. “invariant preservation”译为“不变量保持”,指在规划过程中,某些关键属性或约束条件始终保持不变,是确保规划逻辑一致性的重要准则。)
MIT researchers discover how to enable LLMs to do real logical reasoning.
- Step 1: Train the LLM with correct and incorrect plans with explanations. This is obvious. Basic training of LLMs.
- Step 2 is where the innovation is:
Step 2: External Verification
The LLM generates reasoning. Then there’s an external verification process to check if each step in the LLMs logical reasoning is sound.
The results are wild.
Benchmarks:
- Llama-3-8B jumped from 28% to 94% accuracy on planning benchmarks.
- That’s not incremental improvement - that’s a completely different capability emerging.
更多推理方法见站内专题 大模型推理
【2025-10-29】清华 GAP
问题
- 现有基于LLM的自动Agent范式(如ReAct)依赖顺序推理、执行,无法并行子任务,导致多步推理场景,工具使用、局部执行效果不佳
【2025-10-29】清华、华科 Graph-Base Agent 基于任务图的Agent框架
- 论文 GAP: Graph-based Agent Planning with Parallel Tool Use and Reinforcement Learning
- 项目:Graph-Agent-Planning
Graph-based Agent Planning (GAP)
图基智能体规划(GAP)框架突破传统顺序执行范式,通过显性建模依赖图实现子任务的动态并行/串行调度。
关键技术
- 依赖感知的子任务图分解两阶段训练(监督微调+强化学习)基于MHQA构建的图规划轨迹数据集
性能优势
- 效率提升:智能并行化减少40%工具调用延迟(实验数据)
- 准确率改进:多跳问答任务F1值提升15%以上
- 泛化能力:可扩展至需要多工具协作的复杂场景
应用价值
- 为金融分析、医疗诊断等需要多源工具协同的领域提供新范式,显著降低AI系统响应时间
workflow 自动化
为了提升智能体系统的自主化与智能化,谷歌、上海 AI Lab 等国内外领先团队陆续推出了 Meta-GPT、ADAS、AFlow 等创新性 Agentic Workflow 工作,大力推动利用大模型实现任务规划、分工协作与流程优化的自动化进程。
尽管这些系统能够灵活的表达工作流,但在自动化搜索工作流的过程中,存在:合理性难以保证、可验证性不足、 难以直观表达等突出挑战,严重制约了多智能体系统的可靠落地与规模化部署。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
