- 推荐系统
- 常用算法
- 推荐算法五环之歌
- 万变不离其宗:用统一框架理解向量化召回
- 久别重逢话双塔
- 案例
- 结束
推荐系统
任何推荐系统的核心是人货场匹配
资料
- 【2022-6-3】kaggle H&M 推荐大赛前排方案总结
- 【2021-11-15】推荐算法的”五环之歌”
- 记忆与扩展:训练样本中出现太多,推荐系统只需要记住,下次遇到同样的场景,“照方扒抓药”,就能“药到病除”。
- 怎么记?上
评分卡。Logistic Regression 非常擅于记忆。LR 其实是一个超大规模的“评分卡”。
- 【2021-10-26】变分自编码器(VAEs)在推荐系统中的应用,《Variational Autoencoders for Collaborative Filtering》,论文源码
- 从零搭建推荐系统——算法篇
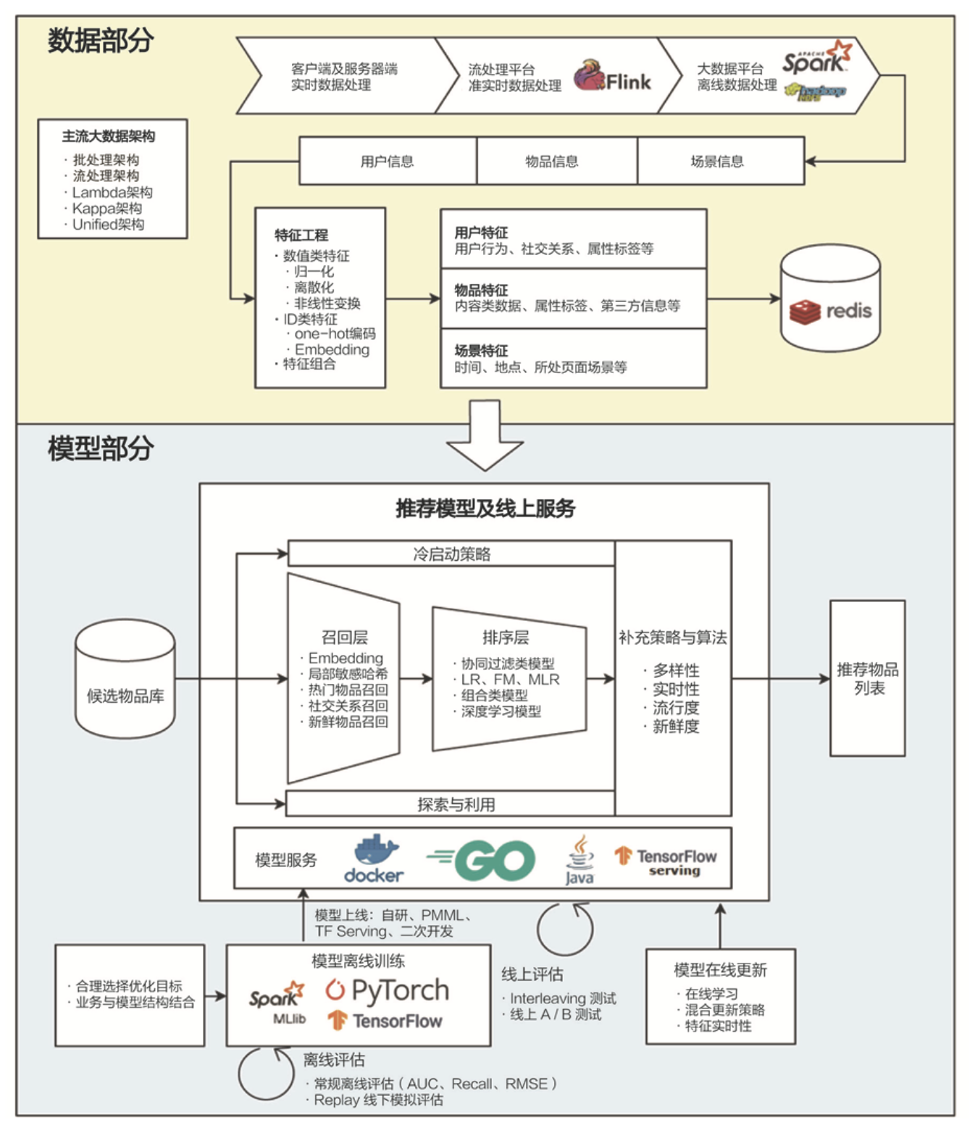
- 推荐系统中算法的位置
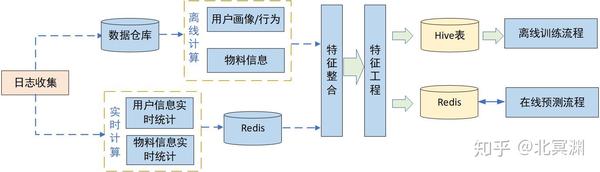
- 特征构建
- 数据集处理
- 对整个样本集做处理,否则会引入大量噪声,不能让模型很好的拟合出样本分布。
- 非真实用户访问样本:例如爬虫、机器人等大量非真实用户的频繁访问,带来大量高曝光未点击行为,会严重影响样本数据分布,一段时间窗口有大量相同用户id频繁访问远超正常访问量的均值等,刷次数方差较大的数据需要去除
- 极少行为用户样本:这类用户样本虽然是真实行为,但极少的行为并不能为其在模型中找到属于该类用户的“规律”,或者说引入这些数据后,模型会开始学习这类用户的数据分布,对整体分布的拟合带来噪声,易引起模型过拟合。通常对这类用户可以看做类似新用户,通过用户冷启动的手段为其探索兴趣补充推荐。
- 特征缺失值及异常值等处理:这里参考特征工程处理方法,针对方差较大的少量异常值做抛弃或均值处理,缺失值用均值或中值代替等
- 正负样本处理:机器学习中正负样本的选取也直接关系着训练出的模型效果,在推荐系统中不同公司也有针对自家业务采取的样本划分方法。一次请求会产生N条推荐结果,但大部分手机端通常用户只能看到其中的m条,m < N,通过客户端埋点计算出用户真实可见曝光的物料,在这批物料中选取点击与未点击样本直观上一次曝光中可能有点击或无点击早期yutube推荐中,会对所有用户选取相同数量训练样本,可以同时避免低活跃用户和高活跃用户对整体模型的影响,使训练的模型更符合绝大多数用户行为对于有曝光无点击行为的用户,其曝光未点击的负样本可随机选取,这样可以学到这类用户“不感兴趣”的部分样本在通过定时任务整合时需要做shuffle打散,避免同类用户样本数据扎堆引起数据分布偏差,在训练模型时,也通过batch训练方式中每个batch的样本也进行shuffle打散总之正负样本处理还是要根据深入理解业务和用户行为基础上进行调整,可以让模型学习到更适合的效果。
- 模型进化:
lr/gbdt->fm/xgboost/dnn->LR+GBDT/wide&deep/deepFM->embedding->GNN/GCN- 【2020-8-2】推荐系统算法演进图谱
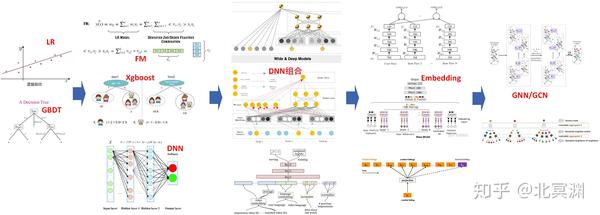
- 线上预测

多模态推荐系统
【2023-5-30】SIGIR 2023 推荐系统何去何从,经典ID范式要被颠覆?: 多模态推荐系统 MoRec 是否有望终结 IDRec 在推荐系统领域长达10年的主导地位?
- paper, Code, IDvs.MoRec
[纯 ID 推荐系统 vs 纯模态推荐系统]
- 自矩阵分解问世以来,使用
ID embedding建模物品的协同过滤算法已经成为推荐系统最主流的范式,主导了整个推荐系统社区长达 15 年。经典的双塔架构、CTR 模型、会话和序列推荐、Graph 网络无不采用 ID embedding 来对物品进行建模,整个推荐系统现有的 SOTA 体系也几乎都是采用基于 ID 特征的建模手段。 - 近年来 NLP、CV 和多模态预训练大模型技术蓬勃发展,取得了一系列革命性成果,预训练大模型(又称为基础模型)对
多模态(文本和图像)建模能力越来越强,知名的基础模型包括BERT,GPT,Vision Transformer,CLIP等。 - 随着基础模型对物品的模态特征的建模和理解能力的增强,一个自然的问题出现了:使用最先进的模态编码器表征物品是否能取代经典的 itemID embedding 范式?论文称此类模型为
MoRec,MoRec 是否能和经典的纯 ID 范式(IDRec)硬刚,超过或者取代 IDRec?
这个问题 10 年前就被广泛调查过,然而,当时受制于 NLP 和 CV 技术不足,IDRec 在效率和效果上都可以轻松碾压 MoRec。
- 但是该结论在十年后的今天是否仍然成立?需要重新思考。其中一个重要原因:基于 ID 的经典范式是与当近大模型技术严重背离的。
- 因为 ID 在不同的推荐业务无法共享,这一特性导致推荐系统模型难以在不同的业务进行有效迁移,更无法实现 NLP 和 CV 领域的 one model for all(one4all)范式。
虽然近几年有不少文献尝试将 NLP、CV 预训练模型引入推荐系统的领域,但这些文献往往关注于冷启动和新物品场景,而这种场景下 IDRec 的效果自然是不理想的,这也是普遍接受的。
- 但是对于常规场景,也就是非冷启动,甚至是热 item 场景,IDRec 仍是非常强的基线,在这种场景下 MoRec 与 IDRec 哪个更好仍然是未知的。论文特别指出,现有的很多 MoRec 文献虽然声称取得了 SOTA 结果,但是并没有显式地比较 IDRec 与 MoRec。
- IDRec 与 MoRec 至少应该采用相同的骨架推荐模型和实验设置(例如,采样和损失函数保持一致)。也就是除了 item 的表示方式,其他部分都应该保持一致或者公平。
- 如果在热场景下 MoRec 也能打败 IDRec,那么推荐系统将有望迎来经典范式的变革。
问题:
- (1)对于 MoRec,现有的 NLP 和 CV 领域取得的进展,也就是更强大的(多)模态编码器能否能够直接带来推荐系统效果的直接提升;
- 如果是,那么 MoRec 范式无疑是更加有潜力的,随着更强的 NLP 和 CV 表征模型的产生,MoRec 也将越强;
- (2)NLP 和 CV 预训练大模型,如 BERT 和 Vision Transformer,产生的物品表征应该如何使用?
- 工业界最常用的手段是直接将这些表征当做离线特征来加入推荐或 CTR 模型,这种方法是不是最优的;
- 换言之,这种大模型产生的物品表征是否具有一定的通用性,是否必须要在推荐系统数据集上进行重新适应?最后论文提供 MoRec 发展的四个挑战,这些问题大多在现有的文献没有被明确提出。
什么是推荐系统?
推荐诞生之初,解决的是信息过载问题
搜索引擎是用户主动搜索,如果用户意图模糊或懒,就找不到自己想要的推荐是“被动搜索”,系统基于一系列特征,自动给出相关内容
推荐系统术语
信息茧房
信息茧房问题
- 互联网世界中,无论图文信息流亦或短视频应用,到处充斥着个性化推荐算法,很多用户担心终将会被禁锢在由狭隘偏好所编制的茧牢中。
什么是信息茧房
“信息茧房”(Information Cocoon)形象地描述了一个人仅仅被展示与其过去的喜好、行为和观点相符的信息,而与外部多样化的信息隔离的状态。
这种现象可能导致社会的两极分化,加剧人们的偏见和刻板印象,抑制创新和创造力,甚至影响决策的质量。
现代搜索引擎和社交媒体通过算法为用户提供个性化内容,结合人们的选择性曝露和社交媒体的回声室效应,导致信息茧房。尽管以往研究探讨了这些现象之间的相关性,但深度学习的“黑箱”特性和缺乏对人与AI之间共同演化机制的深入了解,使得信息茧房的根本机制仍是一个谜团。
傻子共振
互联网的作用原本是让井底之蛙开阔一下自己的眼界,通过不同视角认知这个世界,感受一下井口外面的天地。
但在大数据和算法的加持下,互联网不但没有开阔人们的眼界,反而让成千上万只井底之蛙利用互联网的便利找到了知音,他们经过长期的沟通之后开始相互认同、相互肯定,并达成了高度一致的结论:原来世界就是井口那么大。这种现象就是 “傻子共振”
“傻子共振”现象的背后其实是大数据推荐算法导致的信息茧房现象。
【2023-10-24】如何跳出推荐算法的“信息茧房”?Nature子刊阐释人与AI自适应动力学推动信息茧房涌现
清华大学使用了两大数据集来探索我们如何与AI互动。
- 一个数据集来自中国的热门短视频平台,记录了超过11万新用户的行为
- 另一个数据集则来自 Microsoft News,涵盖了14个新闻主题和9万用户的互动。
令人惊讶的是,研究发现大部分的用户在与AI互动后,接触到的信息种类实际上减少了
- 信息熵(information entropy)量化用户可访问的信息多样性
如何破解
其实破解信息茧房就是在回答一个问题:什么是好的推荐系统?
- 技术角度:多样性推荐既是系统需要纳入的算法之一,也是衡量系统效果的指标,所以一份推荐结果并不会永远只有用户曾经赞过看过的内容。
- 策略角度:PM们也需要关注打散、重排、去重过滤逻辑是否合理有效,可以借助线上badcase持续跟踪优化。
意料之外,情理之中,也许是对推荐系统最好的诠释。
【2023-10-24】如何跳出推荐算法的“信息茧房”?Nature子刊阐释人与AI自适应动力学推动信息茧房涌现
即使相似性匹配的强度很高,只要适当增加负反馈和鼓励用户自我探索,系统就可以从信息茧房状态转移到多样化状态。
通过调整这些关键参数,可以有效地避免或至少减轻信息茧房的效应。通过更多地关注用户的负反馈和鼓励他们进行自我探索,来打破这个“茧”。
马太效应(搜索)
马太效应和长尾理论
马太效应(Mattnew Effect)是指 强者愈强、弱者愈弱的现象,在互联网中引申为热门的产品受到更多的关注,冷门内容则愈发的会被遗忘的现象。
马太效应取名自圣经《新约·马太福音》的一则寓言:
“凡有的,还要加倍给他叫他多余;没有的,连他所有的也要夺过来。”
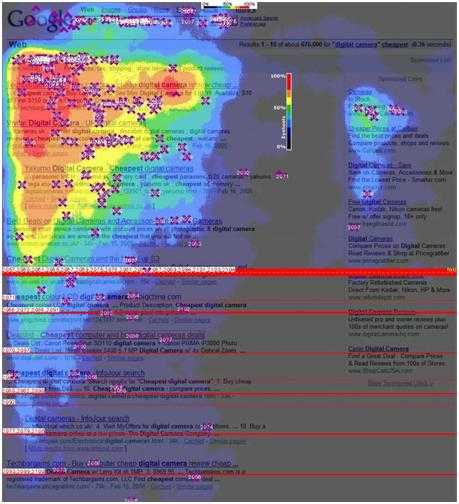
搜索引擎充分体现了马太效应:
- 如 Google点击热图,越红的部分表示点击多和热,越偏紫色的部分表示点击少而冷,绝大部分用户的点击都集中在顶部少量的结果上,下面的结果以及翻页后的结果获得的关注非常少。
- 头部内容吸引了绝大部分点击
- 这也解释了Google和百度的广告为什么这么赚钱,企业客户为什么要花大力气做SEM或SEO来提升排名 —— 因为只有排到搜索结果的前面才有机会。
长尾理论(推荐)
与“马太效应”相对应,还有一个非常有影响力的理论称为“长尾理论”。
长尾理论(Long Tail Effect)是“连线”杂志主编克里斯·安德森(Chris Anderson)2004年10月的“长尾”(Long Tail)一文中最早提出
- 长尾实际上是统计学中
幂率(Power Laws)和帕累托分布特征(Pareto Distribution)的拓展和口语化表达,用来描述热门和冷门物品的分布情况。 - Chris Anderson通过观察数据发现,在互联网时代由于网络技术能以很低的成本让人们去获得更多的信息和选择,在很多网站内有越来越多的原先被“遗忘”的非最热门的事物重新被人们关注起来。事实上,每一个人的品味和偏好都并非和主流人群完全一致,Chris指出:当我们发现得越多,就越能体会到需要更多的选择。如果说搜索引擎体现着
马太效应的话,那么长尾理论则阐述了推荐系统发挥的价值。 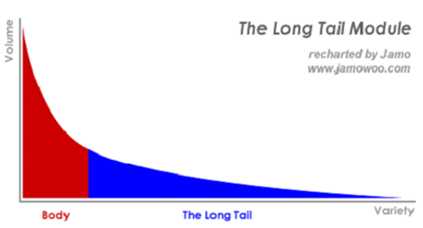
长尾理论作为一种新的经济模式,被成功的应用于网络经济领域。而对长尾资源的盘活和利用,恰恰是推荐系统所擅长的,因为用户对长尾内容通常是陌生的,无法主动搜索,唯有通过推荐的方式,引起用户的注意,发掘出用户的兴趣,帮助用户做出最终的选择。
盘活长尾内容对企业来说也是非常关键的,营造一个内容丰富、百花齐放的生态,能保障企业健康的生态。试想一下,一个企业如果只依赖0.1%的“爆款”商品或内容来吸引人气,那么随着时间推移这些爆款不再受欢迎,而新的爆款又没有及时补位,那么企业的业绩必然会有巨大波动。
只依赖最热门内容的另一个不易察觉的危险是潜在用户的流失:因为只依赖爆款虽然能吸引一批用户(简称A类用户),但同时也悄悄排斥了对这些热门内容并不感冒的用户(简称B类用户),按照长尾理论,B类用户的数量并不少,并且随时间推移A类用户会逐步转变为B类用户(因为人们都是喜新厌旧的),所以依靠推荐系统来充分满足用户个性化、差异化的需求,让长尾内容在合适的时机来曝光,维护企业健康的生态,才能让企业的运转更稳定,波动更小。
典型案例
推荐非常复杂,现在最新的推荐算法只模拟了其中30%不到的程度。
1. 小镇百货店(个性化推荐)
假想150年前一个美国小镇的生活情形,大家都互相认识:
- 百货店某天进了一批布料,店员注意到这批布料中某个特定毛边的样式很可能会引起Clancey夫人的高度兴趣,因为他知道Clancey夫人喜欢亮花纹样,于是他在心里记着等Clancey夫人下次光顾时将该布料拿给她看看。
- Chow Winkler告诉酒吧老板Wilson先生,他考虑将多余的雷明顿(Renmington)来福枪出售,Wilson先生将这则消息告诉Bud Barclay,因为他知道Bud正在寻求一把好枪。
- Valquez警长及其下属知道Lee Pye是需要重点留意的对象,因为Lee Pye喜欢喝酒,并且性格暴躁、身体强壮
100年前的小镇生活都与人和人之间的联系有关。人们知道你的喜好、健康和婚姻状况。不管是好是坏,大家得到的都是个性化体验。
- 那时,这种高度个性化的社区生活占据了当时世界上的大部分角落。
每个人都对其他人的个性和近期情况非常了解,因此可以很精准地推荐和每个人的个性和近期需求最匹配的物品,这是一种面向人和物理关联度的关联度推荐策略。
2. 服务员推荐菜品(冷启动)
公司每年都会提供员工1次免费带薪outing的机会,今年8月,团队决定去从未去过的缅甸出游,购买了机票和预定酒店,愉快地出发了。
当天晚上到了曼德勒,决定去吃一个当地网红的本地菜餐馆,到了餐馆,服务员上来点菜,因为从未来过缅甸,菜单呢,也是一堆的缅甸语看不懂,因此我们让服务员给你们推荐一些菜
问题:服务员该如何给客户推荐菜品?
列举一下服务员要考虑的所有因素:
- 顾客是7个人,考虑到7人都是年轻大男生,推荐的菜量要足够,不然不够吃,但也不能太多,不然吃不完肯定会造成客户体验不好
- 顾客看外貌是中国来的,还一脸兴奋的表情,看起来是第一次来缅甸,那最好推荐一些最优特色的当地菜
- 顾客7人都是男生,除了采之外,最好再推荐一些当地的啤酒
- 在可能的情况下,尽量推荐一些贵的菜,增加餐馆营收
- 顾客中有一个人提出不太能吃辣,推荐的菜中,将30%的菜换成不那么辣的菜
这个场景中服务员对新顾客是没有任何背景知识了解的,既不是熟人,也不是熟客。
他只能依靠有限的信息,结合自己的经验来给出一个主观推荐。换句话说,这是一个冷启动问题。
3. 啤酒与尿布(关联规则)
Tom是一家超市的老板,为了进一步提升超市的销售额,学习了一些统计学知识,打算利用统计学知识对近半年的销售流水进行分析。
经过了一系列的数据清洗、统计聚类、关联分析后,Tom发现,有一些商品,总是成对地出现在receipt上,例如:
- 啤酒、尿布
- 牛奶、全麦面包
- 棉手套、棉头套
- 拿铁咖啡、每日日报
- ….
老板决定,以后在顾客结账的时候,会根据顾客的已购商品,选择性地推荐一些“常见搭配”给顾客,例如
- 某个顾客买了啤酒,就选择性地问问他是否还需要买尿布
- 如果某个顾客买了牛奶,就问问今日的报纸要不要买一份看看呀,如此等等。
通过这个举措,Tom发现,超市的营收上升了40%。
这个场景中,超市老板对顾客的购买推荐是基于历史上其他顾客的购买记录,通过统计关联提取得到的一种关联信息,称为基于关联规则推荐策略。
4. 书商的智慧(内容关联)
逛书店时常常会发现,书店会把同一类型的书放在一起售卖,例如:
- 路遥的《人生》、路遥的《平凡的世界》
- 阿西莫夫的《银河帝国:基地7部曲》、刘慈欣的《三体》
原因
- 每本书尽管风格各不相同,但总体上可以按照一定的属性维度进行分类,例如:
- 青春
- 校园
- 爱情
- 叛逆
- 网络
- 爆笑
- 小说作品集
- 世界名著
- 外国小说
- 中国古典小说
- 武侠小说
这个场景中,书商对书进行聚类关联,将相似的畅销书放在一起捆绑销售,是基于下面这条假
- 喜欢某类书的顾客,也有同样喜欢同属于该类的其他书。
这是一种内容关联推荐策略。
5. 市场调研的智慧(用户关联)
Lily准备在大学城周围开一家奶茶店,第一件事就是要搞清楚:这一片区域中的大学生都喜欢哪些类型的奶茶。
为了解决这个问题,Lily先建立了一个基本假设:
- 物以类聚人以群分
- 同一个专业/班级内的学生的喜好是彼此接近的,同时也是会随着相处的时间逐渐靠拢的
因此,只要从每个专业中随机抽取1-2名学生,进行市场调研,总会汇总调研结果,就能基本得到该区域内大学生的奶茶喜好了。
在这个例子中,奶茶店老板的推荐策略是,对未知的客户的推荐,可以先寻找到与该客户最相似的“同类客户群”,然后用这个同类客户群的喜好来给新的顾客进行推荐。这是一种用户关联推荐策略。
推荐系统有什么用?
总结:
发觉长尾、降低信息过载、提升业务指标(点击率),并提供个性化服务
推荐系统作用
- 帮用户找到想要的商品(新闻/音乐/……),发掘长尾
- 商品茫茫,面对淘宝上眼花缭乱的打折活动,用户往往不知所措。经济学中,有一个著名理论叫
长尾理论(The Long Tail)。 - 互联网领域中就是最热的一小部分资源将得到绝大部分关注,而剩下的很大一部分资源却鲜少有人问津。
- 这不仅造成了资源利用上的浪费,也让很多口味偏小众的用户无法找到自己感兴趣的内容。
- 商品茫茫,面对淘宝上眼花缭乱的打折活动,用户往往不知所措。经济学中,有一个著名理论叫
- 降低信息过载
- 互联网时代信息量已然处于爆炸状态,若是将所有内容都放在网站首页上, 用户无从阅读,信息利用率将会十分低下。
- 因此需要推荐系统来帮助用户过滤掉低价值信息。
- 业务价值: 提高站点的点击率/转化率
- 好的推荐系统能让用户更频繁地访问一个站点,并且总是能为用户找到想要购买的商品或者阅读的内容。
- 加深对用户的了解,提供个性化服务
- 每当系统成功推荐了一个用户感兴趣的内容后,对该用户的兴趣爱好等维度上的形象是越来越清晰的。
- 当能够精确描绘出每个用户的形象之后,就可以为他们定制一系列服务,让拥有各种需求的用户都能在我们的平台上得到满足。
搜广推
搜推广或搜广推,是指搜索、推荐、广告,数据挖掘、机器学习的主航道,商业变现最成熟的渠道,同时也是最内卷的行业。
总结
分析
- 广告:广告算法的目标就是为了直接增加公司的收入
- 搜索:围绕搜索词的信息高效获取问题的回应
- 推荐:增加用户的参与度,提高用户粘性和留存率
三者本质上都是在满足用户需求,做法也分为召回+排序+个性化三个阶段。
- 产品体验上,搜索是用户主动,需求很明确,而推荐是被动的,需求相对不明确。
- 优化目标上,均围绕着相关性、时新性、多样性、权威性等来进行优化,结合用户需求特点,搜索更侧重相关性,推荐则更侧重时新性,多样性,两者对权威性,也就是内容质量要求很高。除此之外,推荐也会有些惊喜性。
根本问题
| 维度 | 广告系统 | 搜索系统 | 推荐系统 |
|---|---|---|---|
| 用户获取方式 | 被动 | 主动 | 被动 |
| 点击率要求 | 有 | 有 | 有 |
| 惊喜度要求 | 无 | 无 | 有 |
| 个性化要求 | 可能 | 可能 | 有 |
| 用户反馈 | 隐形为主 | 隐形为主 | 隐形/显性 |
优化目标的区别
- 广告:预估CTR和CVR,反向推导流量的价值
- 搜索:看重能够把正确答案召回回来
- 推荐:推荐算法目标不尽相同,视频类更倾向于视频播放市场,新闻类预测CTR点击率,电商类预估客单价等
更多见: 推荐系统数据流的经典技术架构
搜索 vs 推荐
搜索系统和推荐系统非常相似,都是根据用户的输入,返回和输入相关的信息。
- 搜索系统是对
p(doc|query)建模,给定一个 query,预测query和doc的相关性进行排序。 - 推荐系统是对
p(doc|user)建模,给定一个 user,预测doc被user点击率的概率进行排序。
明显区别是输入user和query。有的场景中,搜索和推荐也是协同的,在搜索中的query上也可以附加上user的信息,在推荐的user上也可以补充一些特殊的query。
- 首先, user相比于query通常表达的维度更广,包含的信息更多,因此 user有用户画像的工作,主要包括长短兴趣的建模。
- 其次, 召回上,结合维度区别
- 搜索的召回目标很明确,和query相关的doc, 而推荐除了保证相关外,还需要保证召回的多样性、对长短兴趣的平衡,甚至还需要有些令人惊喜的召回(避免看什么推什么)。
- 同一个召回在不同时期(user/query),推荐相比于搜索的召回目标变化抖动更大一些
- 排序中,两者的上下文条件不同。比如 “汪小菲和大s离婚”,搜索排序限制条件是“汪小菲 & 大s”,而在推荐中,“汪小菲”“大s”则会通过用户画像积累到user上,排序时已经不知道“汪小菲”和“大s”来自同一篇文章的信息,其实2个不同的兴趣点,其条件是“汪小菲 | 大s”。
- 搜索经过召回之后,排序有完整的上下文信息;但推荐中由于经过了用户画像,排序会丢失用户阅读的上下文信息。
- 此外,在排序中,搜索还是围绕着query和doc的同种类型匹配(都是文本,或者都是图片),推荐则更多是围绕着user和doc的不同类型匹配(user是固定的,doc可以是商品、短视频等)。 评价
- 搜索侧重快速满足,而推荐侧重持续服务。
- 评价搜索结果质量指标是要帮用户尽快的找到需要的结果并点击离开。“好”的搜索算法是需要让用户获取信息的效率更高、停留时间更短。
- 但是推荐恰恰相反,用户获取推荐结果的过程可以是持续的、长期的,衡量推荐系统是否足够好,往往要依据是否能让用户停留更多的时间(例如多购买几样商品、多阅读几篇新闻等),对用户兴趣的挖掘越深入,越“懂”用户,那么推荐的成功率越高,用户也越乐意留在产品里。
搜索引擎通常基于Cranfield评价体系,并基于信息检索中常用的评价指标,例如nDCG(英文全称为normalized Discounted Cumulative Gain)、Precision-Recall(或其组合方式F1)、P@N等方法
推荐系统的评价面要宽泛的多,往往推荐结果的数量要多很多,出现的位置、场景也非常复杂,从量化角度来看,当应用于Top-N结果推荐时,MAP(Mean Average Precison)或CTR(Click Through Rate,计算广告中常用)是普遍的计量方法;当用于评分预测问题时,RMSE(Root Mean Squared Error)或MAE(Mean Absolute Error)是常见量化方法。
搜索和推荐都是商业化模式很清楚的行业,搜索有搜索广告,推荐也有信息流广告,两者都是互联网公司的主要变现途径。
- 精准度:搜索广告 > 信息流广告
- 搜索广告是主动发起,基于关键词匹配,精准度更高;
- 信息流广告是被动发起,基于用户画像匹配,精准度相对较低。
- 用户体验上:搜索广告 < 信息流广告
- 搜索广告样式更多是文字广告;
- 信息流广告样式更多是原生广告。
- 未来前景上
- 搜索广告精准度是无法超越的,市场将长期存在,市场规模会稳步增长,但市场份额会逐步减少;
- 信息流广告精准度会随着标签数据的丰富、推荐算法的迭代而越来越高,市场规模会迅速增长,市场份额会逐步增加。
搜索和推荐虽然有很多区别,但在业务和技术上也有很多重叠。而且很多产品搜索和推荐是同时存在的,有着不同的入口。
- 很多搜索本身也有推荐的影子,比如在音乐搜索,搜“一个人的夜晚听什么歌”,在搜索结果中就需要结合用户兴趣推荐一些歌曲;
- 电商搜索中,搜“T恤”,不同用户对价格、品牌、材质等有不同偏好,这也需要推荐来满足。同时有些搜索需求也很难表达,这时也需推荐来弥补。两者相互配合,积累用户数据,协同优化,避免“搜什么推什么”比较差的体验。
在未来,用户可能区分搜索和推荐的差别。
详见:搜索系统和推荐系统的对比
分析
- 1)推荐是在百万的优质池子里来回推荐,而搜索则是在百亿的池子进行搜索,难度不在一个量级上,尤其是在工程上,并且推荐都是推荐中头部的item,其行为信息一般都比较丰富,而搜索无论是中头部还是中长尾能要能解决;
- 2)推荐没有标准答案,其做到相关即可,而搜索相对是有标准答案的,不仅要做到相关,也在相关中进一步区分语义等价和语义相关;
- 3)推荐的模块复杂度要小于搜索,最简单的推荐是随机选取n个item进行推荐,无论何种场景下都会有推荐结果的。搜索涉及到query理解,doc理解,排序理解,其中query、doc、排序理解本身又分为很多个子模块。而推荐无论是召回还是排序,很多都是通过一个end2end的模型来实现;
- 4)推荐的输入相比于搜索的输入更具体,搜索query相对太短,信息比较少。推荐输入则是用户整个信息,用户画像,其召回问题的严重相对低很多。并且推荐是个持续性服务,经过冷启动后用户的信息会越来越丰富。而搜索的query往往单次服务的;
- 5)召回方式:推荐比搜索有着更多的召回方式,推荐是面向user/context,而搜索是面向query,user相对于query有更多不同维度的信息,本身也就需要多样的召回方式;
- 6)排序方式:推荐比搜索更依赖于最上层的排序,推荐通常是面向某个商业指标来优化,不同的推荐模块又有不同商业目标,而搜索相对来说就是两段文本的匹配和排序。
- 7)推荐推错的代价要小于搜索排错的代价;
搜索的复杂度要远远高于推荐的复杂度。搜索算是各种大数据、算法、工程能力的集大成者,是行业的黄埔军校。详见
推荐 vs 广告
【2022-5-18】推荐算法与广告算法的核心差异是什么?
| 维度 | 推荐 | 广告 | 备注 |
|---|---|---|---|
| 参与方 | b2c 两方:商品+用户 | b2b2c 三方博弈:商品+用户+广告商 | |
| 技术区别 | 样本曝光量大,模型复杂,业务逻辑简单,关注排序 | 样本曝光量小,业务逻辑复杂,但模型简单,需要准确的点击概率,关注预估值 | |
| 特殊之处 | 除了排序,还关注用户画像、长短期 | 广告主,拍卖出价,计费机制,有预算控制 | |
| 重心 | 用户体验 | 三方博弈 |
概览
- 【2021-7-22】王喆的《深度学习推荐系统》,体系化,方法演进路线,工程落地都很好。深度学习模型的演化过程,Embedding的知识总结,和model serving的主流方法等等。书籍介绍
- img

- 所有的公司都紧缺资深的算法工程师,而却在不断裁员边缘的、初级的算法从业者。因为在这样一个中心化极端严重的行业,(10个初级算法工程师+1个资深算法工程师)带来的收益无限接近于(1个资深算法工程师)。一个不太合格的算法工程师为公司和团队作出的贡献甚至是负的,因为他们产生出的东西经常需要被重构甚至重写,他们提出的模型也经常会成为AB Test中的失败者而无法产出。
- 一个资深的工程师跟一个一般的工程师的差距不在于工具用的熟不熟练,代码写的快不快,而是在于技术格局和知识体系化上的差距。
- 有一句话我是非常推崇的——“不谋万世者,不足谋一时;不谋全局者,不足谋一域。” 技术也是这样,它同样遵循事物发展的一般规律。要作出最合理的技术改进,必须要有一个像书中总结的推荐系统架构图一样的全局的技术框架在心中,只有这样,才能够提出全局最优的技术决策,和充分考虑各方利弊的技术权衡。
- 技术迭代中的“木桶理论”,一名嗅觉敏感的算法工程师应该做的事情是找到整体技术框架中那个“最短的木板”,而不是盯着一块已经很长的木板“执着”地继续补强。
- img
- 模型相关的一切是我们之所以被称为“算法”工程师的原因,这是我们应该掌握的基本技能,但是在一线企业动辄上万QPS,动辄千万维特征,动辄TB级数据量,亿级用户量的前提下,只有在这些高强度的、苛刻的压力下建立高效、高可靠且高效果的模型及模型服务基础设施才是一位“工程师”坚不可摧的技术护城河。所谓的model serving,数据实时性,模型压缩与数据蒸馏,对这些技术点的理解是在实验室环境下无法进行的,也是你永远也无法替代的工程经验。
- 另一方面,拥有深刻的洞察能力也成为了一个敏锐的算法工程师的“稀缺超能力”。我在之前的专栏文章不止一次的提到,对用户行为以及背后动机的感知,并将这些动机融合进模型结构之中才是构建推荐模型的“银弹”。没有任何一个模型结构是万能的,只有最适合你的应用场景的,符合你的用户使用习惯的模型才是解决问题的“灵丹妙药”。能够站在产品经理的角度去思考推荐问题,甚至是站在一个普通用户的角度去换位思考我们要应对的场景,将是你永远也无法被替代的行业insight。
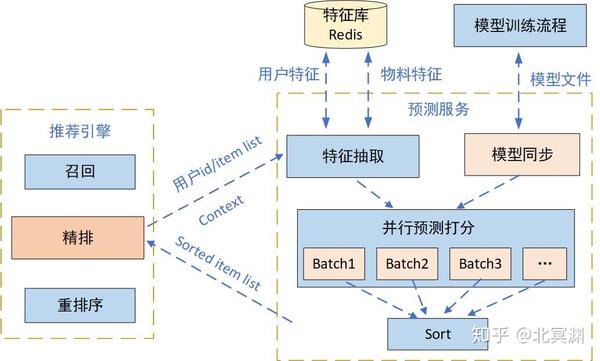
架构
推荐系统将一个物品/内容推荐给用户主要经历两个步骤:召回与排序。

【2022-11-23】负样本为王:评Facebook的向量化召回算法
排序、召回,尽管只是革命分工不同,但是受重视程度不同
总之,排序更受关注,很多问题被研究得更透彻。而召回,尽管”召回不存,排序焉附”,地位相当重要,但是受关注少,有好多基本问题还没有研究清楚。诸如“拿什么样的样本训练召回模型”这样的基本问题,很多人还存在误区,习惯性照搬排序的方法,适得其反 。
总结
【2024-1-17】谈谈AI落地容易的业务-搜广推
- 推荐系统适用场景:信息过载时提供信息匹配价值
- 推荐系统技术路线
- 早期搜索推荐采用竞价排名,早期的百度凤巢,然后产生了一系列问题,戴文渊利用LR算法改进了凤巢,后来和陈雨强又引入了深度学习,然后雨强又在今日头条担任过架构师。
- 另一个主线是以阿里妈妈为代表的电商广告,从盖坤2011年提出分片线性模型MLR开始,到后面通过类似于Wide&Deep算法,构建
GwEN,再到后来针对用户兴趣建模提出DIN,以及将Attention和GRU引入用户兴趣构建的DIEN,但是用户兴趣序列长度有限制,又引入异步机制User Interest Center并构建MIMN算法对长期行为建模。再到后期提出Search Based Interest Model(SIM),并针对用户不同的行为构建基于Session的分类的Deep Session Interset Network(DSIN),在针对特征间的交互(Co Action)构建的CAN,当然还有召回中的利用树结构构建的TDM算法,和利用图结构的二项箔算法等。
- 推荐系统组件
- 两阶段模型:
召回+排序 - 工业级推荐系统用四阶段模型:
召回,粗排,精排和重排。- 原因:整个环节上对延迟有严格的需求,通常要求端到端延迟低于100ms,因此需要构建逐级过滤的算法实现。
- 两阶段模型:
四阶段对比
各阶段简单总结
| 阶段 | 约束 | 任务 | 处理数据量 |
|---|---|---|---|
| 召回 | 50ms | 从海量物品中快速找回一部分重要物品 | 千万/亿级 |
| 粗排 | 10~20ms | 进行粗略排序,保证一定精度并减少物品数量 | 万级 |
| 精排 | 10~20ms | 复杂算法精准的对物品进行个性化排序 | 百/千级 |
| 重排 | - | 改进用户体验 | 十/百级 |
图解
召回+排序(搜广推)
【2023-11-6】阿里自主创新的下一代匹配&推荐技术:任意深度学习+树状全库检索
推荐、搜索、广告投放是互联网内容提供商进行流量分配的核心业务,也是大数据和机器学习技术的典型应用场景。推荐,搜索,广告投放都可以描述为从大规模候选中给用户提供有限的展现结果以获取用户的正向反馈(广告投放还需额外考虑广告主意愿和体验)。
由于在线业务对性能尤其是响应时间的严格要求,往往会把上述过程拆分为两个阶段 —— 匹配(Match)+排序(Rank)
以淘宝推荐系统为例
- 匹配阶段核心:如何从全量商品(Item)中根据用户(User)信息召回合适的TopK候选集合
- 匹配阶段由于问题规模大,复杂模型在此阶段的应用存在一定的局限性,所以业界对这方面的研究尤其是深度学习在此阶段的应用仍处在发展阶段。
- 排序阶段:对TopK候选集合进行精细化打分并排序输出最终展现的结果。
- 排序阶段因为候选集小,可引入深度学习等非常复杂的模型来优化目标,达到最终效果(相关性、广告收益等)的提升,业界对此阶段的研究比较集中和深入,比如阿里妈妈精准定向广告业务团队在排序阶段的CTR(Click-through Rate)预估上引入了基于Attention结构的深度兴趣模型(DIN,https://arxiv.org/abs/1706.06978),取得了非常好的业务效果。
匹配阶段产生的候选集质量会成为最终效果的天花板,因此如何创新和发展匹配技术是对业务有着重大意义的问题,也一直是业界和学术界关注的重点问题。
以推荐为例,在工业级的推荐系统中,匹配阶段面临很多技术挑战。例如
- 当候选集非常大时,要从全量候选集中挑选TopK集合,无法接受随着全量候选集大小而线性增长的时间复杂度,这使得一些学术界研究的需要计算全量
{User,Item}兴趣度的方法并不能真正应用于实际推荐系统中的匹配阶段。 - 在有限的计算资源下,如何根据用户信息从全量候选集中快速得到高质量的TopK候选集,需要在计算效率和计算准确性上做精巧的平衡。
- 真实应用的推荐系统,匹配阶段的计算时间需要被限制,简单用以下公式表示:
T*N ≤ Bound- T表示单次计算的时间消耗
- N为单个用户召回TopK需要的总体计算次数。
- 在上述公式的约束下,围绕如何提升匹配效果,工业界的技术发展也经历了几代的演进,从最初的基于统计的启发式规则方法,逐渐过渡到基于内积模型的向量检索方法。
- 然而这些方法在技术选型上都在上述计算效率约束下对匹配效果进行了很大的牺牲。如何在匹配阶段的计算效率约束下引入更先进的复杂深度学习模型成为了下一代匹配技术发展的重要方向。
召回
召回通常需要对整个物料库进行大规模搜索,从海量物料中找回一部分重要物料,处理数据规模大,特别是一些大的电商平台物料库可能有数亿个SKU。同时召回规则也很多,通常采用多路召回机制
- 基于规则的召回方式,例如根据用户标签召回,根据用户兴趣类目召回,根据热销榜召回,根据高点击量,根据复购,根据质量分等方式召回。
- 协同过滤方式,基于用户的协同过滤,或者基于物料的协同过滤
- 向量召回,通过物料等属性用户兴趣等,通过表示学习生成Embedding
通过如上多路召回是一种取长补短的策略,并通过查漏补缺的方式尽量满足在后续排序阶段的需求。
召回算法主要是考虑到算法时间约束下(通常分配给召回算法的时间为50ms),尽量能够覆盖整个物料库,为后续的排序算法排除出用户不感兴趣的物料,仅留下部分匹配用户品味的物料送到排序阶段,这个阶段对算法的精度要求不高,主要是查全和速度的要求。
一个系统中不可能只有1路召回,平日里相互竞争,召回结果重合度高,导致单路召回对大盘的影响有限;好处是,相互冗余,有几路出问题,也不至于让排序饿肚子。
- 召回处于整体推荐链条的前端,其结果经过粗排、精排两次筛选,作用于最终业务指标时,影响力就大大减弱了。
- 受限于巨大的候选集和实时性要求,召回模型的复杂度受限,不能上太复杂的模型。平日里,最简单的基于统计的策略,比如ItemCF/UserCF表现就很不错,改进的动力也不那么急迫。
- 用于召回的基础设施不完善。比如,接下来,我们会提到,召回建模时,需要一些压根没有曝光过的样本。而线上很多数据流,设计时只考虑了排序的要求,线上的未曝光样本,线下不可能获取到。
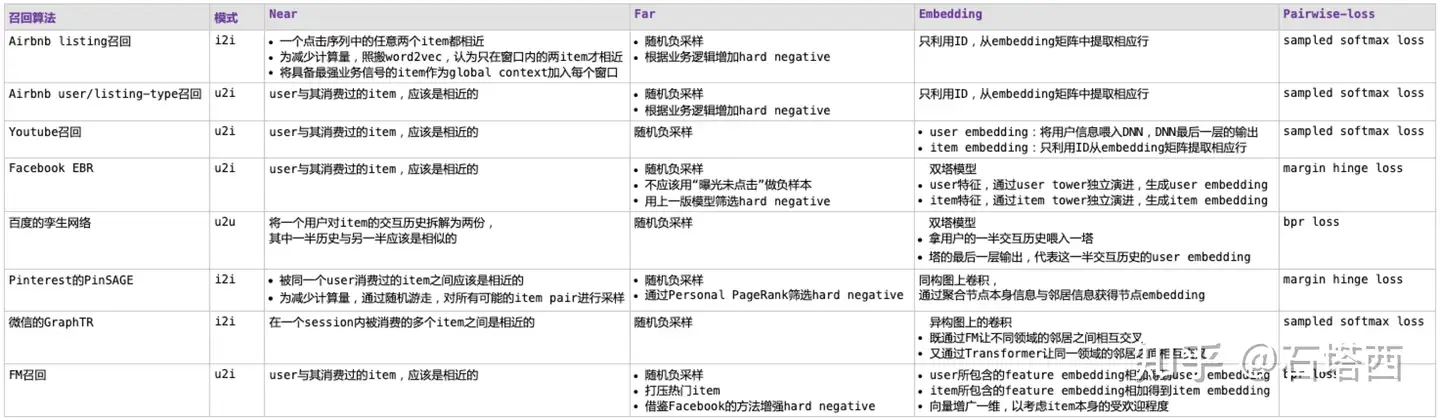
相比于排序那直白的套路,召回算法,品类众多而形态迥异,看似很难找出共通点。如今比较流行的召回算法,比如:item2vec、DeepWalk、Youtube的召回算法、Airbnb的召回算法、FM召回、DSSM、双塔模型、百度的孪生网络、阿里的EGES、Pinterest的PinSAGE、腾讯的RALM和GraphTR、……
- 从召回方式上分
- 有的直接给user找他可能喜欢的item(user-to-item,简称
u2i); - 有的是拿用户喜欢的item找相似item(item-to-item,简称
i2i); - 有的是给user查找相似user,再把相似user喜欢的item推出去(user-to-user-to-item,简称
u2u2i)
- 有的直接给user找他可能喜欢的item(user-to-item,简称
- 从算法实现上分
- 有的来自“前深度学习”时代,老当益壮;
- 有的基于深度学习,正当红;
- 有的基于图算法,未来可期(其实基于图的,又可细分为游走类和卷积类)。
- 从优化目标上分
- 有的属于一个越大规模的多分类问题,优化
softmaxloss; - 有的基于 Learning-To-Rank(LTR),优化的是
hingeloss 或BPRloss
- 有的属于一个越大规模的多分类问题,优化
以上这些召回算法,都可以被一个统一的算法框架所囊括,惊不惊奇、意不意外?
NFEP(Near, Far, Embedding, Pairwie-loss)框架,系统化地理解向量化召回算法。
先介绍NFEP框架,然后逐一介绍如何从NFEP的框架视角来理解Airbnb召回、Youtube召回、Facebook EBR、Pinterest的PinSAGE、微信GraphTR、FM召回这几种典型的召回算法。
NFEP框架
NFEP框架关注的是“向量化召回”算法,将召回建模成在向量空间内的近邻搜索问题。
- 传统的ItemCF/UserCF那种基于统计的召回方式,和阿里TDM那种基于树模型层次化划分搜索空间的召回算法,不在讨论范围之内。
假设向量化召回,是拿X概念下的某个x,在向量空间中搜索Y概念下与之最近的y。其serving的套路就是
- 离线时,将几百万、上千万的y,通过模型获得它们的embedding,将这些y embedding灌入FAISS并建立索引
- 在线时,拿请求中的x,或提取、或生成x embedding,在FAISS中查找最近的y embedding,将对应的y作为召回结果返回
为了达成以上目标,训练时需要考虑四个问题:
- (1)如何定义X/Y两概念之间的“距离近”?
- (2)如何举反例,定义X/Y之间的“距离远”?
- (3)如何获取embedding?
- (4)如何定义loss来优化?
(1)Near:如何定义“近”?这取决于不同的召回方式
- i2i召回:x,y都是item,我们认为同一个用户在同一个session交互过的两个item在向量空间是相近的,体现两个item之间的“相似性”。
- u2i召回:x是user,y是item。一个用户与其交互(e.g., 点击、观看、购买)过的item应该是相近的,体现user与item之间的“匹配性”。
- u2u召回:x,y都是user。比如使用孪生网络,则x是user一半的交互历史,y是同一用户另一半交互历史,二者在向量空间应该是相近的,体现“同一性”。
无论哪种召回方式,为了能够与FAISS兼容,都拿x embedding和y embedding之间的“点积”或”cosine”来衡量距离。显然,点积或cosine越大,代表x与y在向量空间越接近。
(2)Far:如何定义“远”?
- 其实就是举反例。举出的<x, y_>反例,让模型见识到不同角度的“<x,y_>之间差异性”,达到让模型“开眼界,见世面”的目的。
- 特别是在训练u2i召回模型时,一个非常重要的原则就是,千万不能(只)拿 “曝光未点击”做负样本。否则,正负样本都来自“曝光”样本,都是与user比较匹配的item,而在上百万的候选item中,绝大部分item都是与user兴趣“八杆子打不着”的。
- 这种训练数据与预测数据之间的bias,将导致召回模型上线后“水土不服”。
(3)Embedding:如何生成向量?
用哪些特征学出embedding?
- 有的算法只使用UserId/DocId
- 有的算法除此之外,还使用了画像、交互历史等side information
- 图卷积算法还使用了user节点、item节点在图上的连接关系
通过什么样的模型学习出embedding?
- 只使用ID特征的算法,模型就只有一个embedding矩阵,通过id去矩阵相应行提取embedding
- 有的模型,将特征(id+side information)喂入DNN,逐层让特征充分交互,DNN最后一层的输出就是我们需要的embedding
- 基于图卷积的模型中,目标节点(user或item)的embedding,是由其邻居节点的embedding,加上节点本身信息,聚合而成。一来,图上的节点不仅有user/item,还可以包括性别、年龄、职业等属性节点;二来,邻居节点也有自己的邻居。图的这种性质,使得节点embedding能够利用的信息更加广泛,并且兼具本地与全局视角。
召回模型的特点:解耦
- u2i召回,与排序,虽然都是建模user与item的匹配(match)关系,但是在样本、特征、模型上都有显著不同。在之前的文章中,我详细论述了二者在样本选择上的区别,这一节将论述二者在特征、模型上的区别。简言之,就是:排序鼓励交叉,召回要求解耦。
排序鼓励交叉
- 特征上,排序除了利用user feature(包括context)、item feature,最重要还使用了大量的交叉统计特征,比如“user tag与item tag的重合度”。这类交叉统计特征是衡量“user与item匹配性”的最强信号,但是也将user feature与item feature紧密耦合在一起。
- 模型上,排序一般将user feature、item feature、交叉统计特征拼接成一个大向量,喂入DNN,让三类特征通过多层全连接层(Fully Connection, FC)进行充分交叉。从第一层FC之后,你就已经无法分辨,FC的输出中哪些属于user信息?哪些属于item信息?
召回要求解耦
- 排序之所以允许、鼓励交叉,还是因为它的候选集比较小,最多不过几千个。换成召回那样,要面对百万、千万级别的海量候选item,如果让每个user与每个候选item都计算交叉统计特征,都过一遍DNN那样的复杂操作,是无论如何也无法满足线上的实时性要求的。所以,召回要求解耦、隔离user与item特征。
- 特征上,尽管信号强,但是召回不允许使用“交叉统计特征”。(放弃这么强的信号,的确可惜。如何在不使用交叉统计特征的情况下,仍然达到使用了它们的效果?有一种方法是使用蒸馏,详情见《Privileged Features Distillation at Taobao Recommendations》) 模型上,禁止user feature与item feature出现DNN那样的多层交叉,二者必须独立发展,i.e., user子模型,利用user特征,生成user embedding;item子模型,利用item特征,生成item embedding。唯一一次user与item的交叉,只允许出现在最后拿user embedding与item embedding做点积计算匹配得分的时候。
只有这样
- 离线时,在user未知的情况下,独立生成item embedding灌入faiss;
- 在线时,能独立生成user embedding,避免与每个候选item进行“计算交叉特征”和“通过DNN”这样复杂耗时的操作
(4)Pairwise-loss:如何成对优化?
排序阶段经常遵循”CTR预估”的方式
为了实现Pairwise LTR,有几种Loss可供选择。
- 一种是sampled softmax loss。
- 另一种loss是margin hinge loss
Facebook EBR模型
2020年Facebook最新的论文《Embedding-based Retrieval in Facebook Search》(EBR) 更显难能可贵,值得每个做召回算法的同行仔细阅读
- 这篇论文非常全面,涵盖了一个召回从样本筛选、特征工程、模型设计、离线评估、在线Serving的全流程。但并非每部分都是重点。论文中的某些作法就是召回算法的标配。
排序
召回又为了查漏补缺,多路召回又增加了数据量,多路召回后的物料数量还是非常多的。而排序算法又需要尽可能的利用特征提升模型精度,因此排序算法复杂度也会快速增加。如果直接用于复杂算法排序,在算法精度(模型复杂度)和速度上的取舍是一个非常难的事情
为了保证排序的算法的精度,将这个阶段分成粗排和精排两个阶段。
排序,特别是精排,处于整个链条的最后一环,方便直接对业务指标发力。比如优化时长,只要排序模型里,样本加个权就可以了。- 排序由于候选集较小,所以有时间使用复杂模型,各种NN,各种Attention,能加的,都给它加上,逼格顿时高大上了许多。
- 用于排序的基础设施更加完善,特征抽取、指标监控、线上服务都相对成熟。
《推荐算法的”五环之歌”》梳理了主流排序算法常见套路:
- 特征都ID化。类别特征天然是ID型,而实数特征需要经过分桶转化。
- 每个ID特征经过Embedding变成一个向量,以扩展其内涵。
- 属于一个Field的各Feature Embedding通过Pooling压缩成一个向量,以减少DNN的规模
- 多个Field Embedding拼接在一起,喂入DNN
- DNN通过多层Fully Connection Layer (FC)完成特征之间的高阶交叉,增强模型的扩展能力。
- 最后一层FC的输出,就是最终的logit,与label(e.g., 是否点击?是否转化)计算binary cross-entropy loss。
粗排
粗排主要是怕精排速度根不上,而采用的预先过滤算法,当然针对不同的业务场景和算法,粗排是一个可选的阶段。
精排
精排是厂商投入资源最多的环节,是整个推荐环节中非常重要的一环。
- 由于通过召回和粗排,候选集规模已经很小了,因此需要通过各种方法和复杂的模型结构来提升预测精度,这个地方是最容易卷的,而且离推荐系统的下游很近,对业务的影响更直接。
- 另一方面,由于计算规模限制,通常粗排和召回不会用用户信息和物料信息进行大量的交叉分析,而精排阶段可以充分交叉并挖掘更多的特征。
重排
精排时,相似内容会被精排打上相近分数,从而在结果上集中展示。用户连着看几条相似的东西容易审美疲劳,从而损害用户体验。
重排则是对精排结果顺序进行调整,将相似内容打散,保证用户在一屏之内看到的推荐结果丰富性。
端上推荐
【2023-9-13】EdgeRec:电商信息流的端上推荐系统
相对于云计算,端计算的优势在于下面四点:
- 数据本地化,解决云端存储及隐私问题;
- 计算本地化,解决云端计算过载问题;
- 低通信成本,解决交互和体验问题;
- 去中心化计算,故障规避与极致个性化。
应用案例
- Google 提出了 Recommendation Android App 的概念,根据用户兴趣进行内容推荐;
- Apple 的 Face ID 识别、Siri 智能助手等一些我们熟知的产品,也都是端智能典型的应用代表。
- 阿里巴巴、快手、字节跳动等企业也在各自的应用场景上进行了端智能的落地,并推出相应的端上模型推理框架。
阿里EdgeRec
手机淘宝 “猜你喜欢”在端上部署了智能推荐系统,取得较为显著收益(EdgeRec,双十一 IPV 提升 10%+,GMV 提升 5%+)
信息流推荐系统的瓶颈
- 痛点1:用户实时感知弱 / 决策慢
- 信息流推荐基于“分页请求”机制,仅在分页附近有调整机会。受限于资源消耗和用户体验,一般分页不会特别小。带来问题有:1. 分页过程中无法实时调整策略;2. 实时的意图获取和策略的调整次数太少。
- 用户的实时行为感知弱:上行数据延迟高:依靠端上实时上报日志->服务端实时解析->推荐系统实时查询的链路,回传延迟一般在10s-1min。
- 痛点2:云端存储和计算瓶颈
- 以电商平台首页信息流场景为例,日常2w+ QPS,大促峰值10w+ QPS,巨大的在线infer压力导致日常超时的情况时有发生,而大促期间也会面临降级;另外,一般需要存储60天的样本,云端面临巨大存储和训练资源消耗。
- 痛点3:“千人一模”的局限性
- 目前的推荐模型使用统一的模型,而“千人千面”源自于特征的个性化;高活用户主导全局推荐结果,20%的用户贡献了80%的训练数据;而每个用户数据分布并非IID,使用同一模型拟合并非最优。(图片引用自[2])。

导致第1、2个问题出现的原因有两个,一是分页请求固定的分页时机,二是分页后固定的展现顺序。
- 分页时机在分页推荐系统中是由规则决定的,一般是固定的分页大小。每次分页请求后,服务端可以拿到用户实时的意图,并基于用户意图进行召回排序。如下图,每次分页后用户点击率会增高很多,则是分页时机固定带来的。因此,分页大小固定带来的弊端是,分页时机与用户意图变更时机不匹配,同时资源消耗在不同用户中消耗是一致的。
- 展现顺序的固定,则导致了在分页内部卡片的顺序是无法调整的,无论用户进行了何种交互,推荐系统都要等到分页时才能重新调整排序顺序。如下图,每个分页过程中,用户的点击率是持续下跌的。

分页推荐系统感知/决策慢、资源消耗固定的问题,根本原因:
- 用户意图变化与推荐系统请求时机和商品展现时机不匹配。端上是请求的发起者和商品展现的终端,对用户行为有最实时的感知能力,因此,希望将请求决策和展现决策这两项最接近用户的任务放到端上,利用端智能的能力,进行进一步的优化。
基于这个思想,在电商首页信息流推荐里建设了端上推荐系统EdgeRec,通过端上重排能力做展现决策,通过端上动态请求能力做请求决策,整体提升推荐系统的实时感知和实时反馈的能力。

展现决策方面,研发了端上重排能力,能够实时的对信息流中未曝光的卡片进行重新排序,实现用户意图的实时反馈,具体算法方案将在后续部分单独介绍。在请求决策方面,我们增加了端上智能请求部分,根据用户近期的行为,以及端上缓存中的卡片,实时的增加端上智能请求,将用户意图实时带回服务端进行重新召回与排序,具体算法细节也将在后续内容中进行介绍。
端上算法模型上,首次在端上进行12G级别的大规模深度神经网络的推理,通过端云联合部署,使得该神经网络可以在端上进行实时预估;同时,我们还基于端智能的分布式部署能力,研发了千人千模的能力,来提升模型的个性化效果,具体算法方案见后续部分。整体的端云联合部署方案、依赖的基础服务等如下图所示。
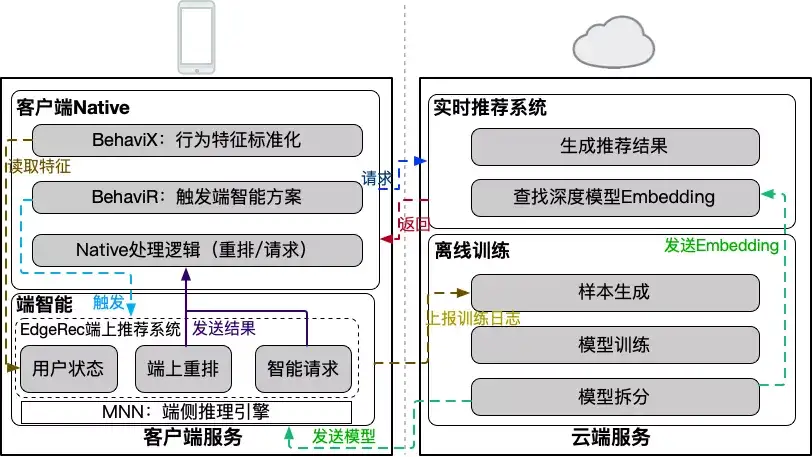
为了实现EdgeRec端上推荐系统,我们依赖了许多淘系的基础服务,其中包括:
MNN:淘系自研轻量级端侧推理引擎 。为算法的脚本、模型和工具库提供运行环境。MNNBehaviX:淘系全域端上用户数据中心。端侧用户数据与特征中心,定义一套方便算法使用的数据标准,提供行为本地标准化处理,为算法提供了行为、特征、样本的通用基础数据源。BehaviR:淘系端上智能调度框架。串联前台交互、用户感知、用户触达。对用户的实时行为调用端侧算法模型预测意图,进行本地重排、智能刷新等实时决策 。
快手 端侧应用
应用
- 快手上线的短视频特效拍摄、智能识物等功能
- 快手上下滑推荐场景也应用了端上重排的方案,并取得App时长提升了 1%+ 的效果
美团 端上重排
【2023-6-16】端智能在大众点评搜索重排序的应用实践
云计算已经无法满足特定场景对数据隐私、高实时性的要求。借鉴边缘计算的思想,在终端部署 AI 能力逐渐步入大众的视野,“端智能”的概念应运而生。
流程介绍
- 用户在手机端搜索入口发起检索请求后,触发云端服务器执行,包括查询理解、多路召回、模型排序与展示信息合并等处理,最终返回给客户端进行渲染呈现给用户

由于整个系统的每秒查询数(QPS)的限制,以及前后端请求通信、传输包体影响,通常会采用分页请求机制。这种客户端分页请求,云端服务检索排序返回给用户最终展示列表的 Client-Server 架构,对于大众点评 LBS 场景、类推荐的搜索产品来说,存在以下两个问题:
- ① 列表结果排序更新延迟
- 分页请求限制会导致排序结果的更新不及时。在下一个分页请求之前,用户的任何行为都无法对当前页内的搜索排序结果产生任何影响。
- ② 实时反馈信号感知延迟
- 实时反馈信号会通过 Storm、Flink 等流处理平台,将日志流以 Mini-batch 的方式计算后,存入 KV 特征数据库供搜索系统模型使用。这种方式往往会有分钟级的特征延迟,因为需要对反馈数据进行解析处理,当涉及到更多、更复杂的反馈数据时,这种延迟表现会更加明显。而实时反馈反映着用户的实时偏好,对于搜索排序的优化有着十分重要的意义。
端智能重排流程和优势 为了解决分页结果排序调整决策延迟,更及时地建模用户实时的兴趣偏好变化,我们在端上建设了重排序的系统架构,使得客户端具备深度模型推理能力,该方案具有以下几个方面的优势:
- 支持页内重排,对用户反馈作出实时决策:不再受限于云端的分页请求更新机制,具备进行本地重排、智能刷新等实时决策的功能。
- 无延时感知用户实时偏好:无需通过云端的计算平台处理,不存在反馈信号感知延迟问题。
- 更好的保护用户隐私:大数据时代数据隐私问题越来越受到用户的关注,大众点评 App 也在积极响应监管部门在个人信息保护方面的执行条例,升级个人隐私保护功能,在端上排序可以做到相关数据存放在客户端,更好地保护用户的隐私。
端智能重排在大众点评搜索和美食频道页上线后,均取得显著效果,其中搜索流量点击率提升了 25BP(基点),美食频道页点击率提升了 43BP,Query平均点击数提升 0.29%。

端侧重排业界也有不少相关的工作,包括:
- 基于贪心策略优化多目标的 MMR(Maximal Marginal Relevance)
- 直接建模上下文作用关系的 Context-aware List-wise Model
- 基于强化学习的方案等。
在搜索端智能重排场景上,采用了基于 Context-aware List-wise 的模型进行构建,通过建模精排模型生成的 Top-N 个物品上下文之间的互相影响关系,来生成 Top-K 结果。整体模型结构如下图 8 所示,主要包括端云联动的训练方案,以此来引入更多云端的交互表征;以及基于 Transformer 的上下文关系建模

云端的重排序模型基本都复用精排层的特征,并在此基础上加入精排输出的位置或者模型分。
LLM 推荐
见站内专题
常用算法
算法总览
推荐算法相当于一个函数
- 接受若干个参数:用户特征、物品特征
- 用户和item的各种属性和特征,包括年龄、性别、地域、商品的类别、发布时间等等
- 函数根据输入特征,计算按照用户喜好度排序的item列表
- 输出一个返回值。
推荐算法大致可以分为几类:
- 基于流行度的算法 —— 非个性化推荐
- 类似于各大新闻、微博热榜等,根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户
- 优点:简单,适用于刚注册的新用户。
- 缺点:无法针对用户提供个性化的推荐。
- 改进:加入用户分群的流行度排序,例如把热榜上的体育内容优先推荐给体育迷,把政要热文推给热爱谈论政治的用户。
- 协同过滤算法
- 协同过滤算法(Collaborative Filtering,
CF)在很多电商网站上都有用到。 - CF算法包括基于用户的CF(User-based CF)和基于物品的CF(Item-based CF)。
- 协同过滤算法(Collaborative Filtering,
- 基于内容的算法
- 基于模型的算法
- 混合算法
【2023-5-12】参考
如何选择推荐算法
【2021-3-21】脉脉:推荐算法选哪个方向更好?
- 如果是新业务,做精排和重排最容易有效果,而且看起来容易吹。
- 如果是成熟业务,精排完全不动的,这个时候召回容易出成果。
- 精排锻炼搞模型的能力,召回锻炼业务思维、大局观
- 越往前效果越大,重排靠策略机制,精排靠特征数据模型
相似度计算 - Similarity Metrics Computing
对于推荐系统来说,通常是基于向量来确定两两用户或两个物品是否相似,即 系统首先要把用户(用户属性或用户行为偏好)、物品(物品特征)向量化。
相似度计算方法不仅用于协同过滤推荐算法,对文章之后讨论的其他算法(例如内容过滤推荐)也同样有用
向量化
比如有5件商品:夹克、连衣裙、球鞋、网球拍、贝雷帽
- 1表示用户购买过该商品,0表示未购买过。
- 用户P买过夹克、球鞋、网球拍,用户Q买过连衣裙、网球拍、贝雷帽
- 向量表示用户P和用户Q就是 R(P)=(1,0,1,1,0),R(Q)=(0,1,0,1,1)。
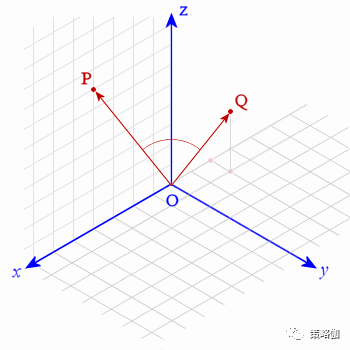
相似度计算方法
如何计算两个用户是否相似呢?
计算相似度的公式有很多,如‘欧几里德距离’、‘皮尔逊相关系数’、‘余弦相似度’等。
- 余弦相似度是常用的计算方法,即当两个向量之间的夹角越小,则两个向量越相似。
基于向量距离的相似度计算 - 明氏距离(Minkowski Distance)
基于向量距离的相似度计算算法思路非常简单明了,通过计算两个向量的数值距离,距离越近相似度越大。
一般用明氏距离(Minkowski Distance)来度量两个向量间的距离

其中
- r=1时,上式就是曼哈顿距离
- r=2时,上式就是欧氏距离,欧几里德距离就是平面上两个点的距离
- r=∞时,上式就是上确界距离(supermum distance)
欧几里德距离是所有相似度计算里面最简单、最易理解的方法。它以经过人们一致评价的物品为坐标轴,然后将参与评价的人绘制到坐标系上,并计算他们彼此之间的直线距离。

基于余弦相似度的相似度计算 - Cosine 相似度(Cosine Similarity)
在余弦相似度公式中,向量的等比例放缩是不影响最终公式结果的,余弦相似度公式比较的是不同向量之间的夹角。公式如下,

相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。

看出
- 距离度量衡量的是空间各点间的绝对距离,跟各个点所在的位置坐标(即个体特征维度的数值)直接相关;
- 而余弦相似度衡量的是空间向量的夹角,更加的是体现在方向上的差异,而不是位置。如果保持A点的位置不变,B点朝原方向远离坐标轴原点,那么这个时候余弦相似度cosθ是保持不变的,因为夹角不变,而A、B两点的距离显然在发生改变,这就是欧氏距离和余弦相似度的不同之处
根据欧氏距离和余弦相似度各自的计算方式和衡量特征,分别适用于不同的数据分析模型:
- 欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异
- 而余弦相似度更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分用户兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦相似度对绝对数值不敏感)
基于相关性的相似度计算 - 皮尔森相关系数(Pearson Correlation Coefficient)
皮尔森相关系数一般用于计算两个变量间联系的紧密程度(相关度),它的取值在 [-1,+1] 之间。
皮尔逊系数就是相对两个向量都先进行中心化(centered)后再计算余弦相似度。
中心化的意思是,对每个向量,先计算所有元素的平均值avg,然后向量中每个维度的值都减去这个avg,得到的这个向量叫做被中心化的向量。机器学习,数据挖掘要计算向量余弦相似度的时候,由于向量经常在某个维度上有数据的缺失,所以预处理阶段都要对所有维度的数值进行中心化处理。
从统一理论的角度来说,皮尔逊相关系数是余弦相似度在维度值缺失情况下的一种改进。
更进一步的,我们从数理统计中的协方差的角度来理解一下皮尔森相关系数。
协方差(Covariance)是一个反映两个随机变量相关程度的指标,如果一个变量跟随着另一个变量同时变大或者变小,那么这两个变量的协方差就是正值,反之相反
Pearson相关系数是用协方差除以两个变量的标准差得到的,虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但是协方差值的大小并不能很好地度量两个随机变量的关联程度。
例如,现在二维空间中分布着一些数据,我们想知道数据点坐标X轴和Y轴的相关程度。如果X与Y的数据分布的比较离散,这样会导致求出的协方差值较大,用这个值来度量相关程度是不合理的
为了更好的度量两个随机变量的相关程度,Pearson相关系数在协方差的基础上除以了两个随机变量的标准差,这样就综合了因为随机变量自身的方差增加导致的协方差增加。
容易得出,pearson是一个介于-1和1之间的值,
- 当两个变量的线性关系增强时,相关系数趋于1或-1
- 当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,相关系数大于0
- 如果一个变量增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于0
- 如果相关系数等于0,表明它们之间不存在线性相关关系

三种相似度计算算法的区别
上述三种相似度计算的区别在于,定义“什么叫相似”的标准不同,其实也可以理解为在量纲是否一致的不同环境下,采取的不同相似度评价策略,
- 量纲一致环境:不同用户对好坏事物的评价是在均值区间内的,举个例子,在一个成熟的观影市场中,观众对《复联》系列的评价总体在9.5~9.8分之间,而对《无极》的评价总体在5~6分之间,这种影评环境就叫量纲一致环境,指的是市场中每个评价个体(用户)都是一个客观实体。
- 量纲不一致环境:例子,某小镇中,居民对电影的普遍接受度较低,因此他们对所有电影的评价都普遍降低,而不管该电影实际的好坏,在这种情况下,该小镇居民的评价数据和大城市中主流观影市场的评价数据之间,就存在量纲不一致问题。
近邻
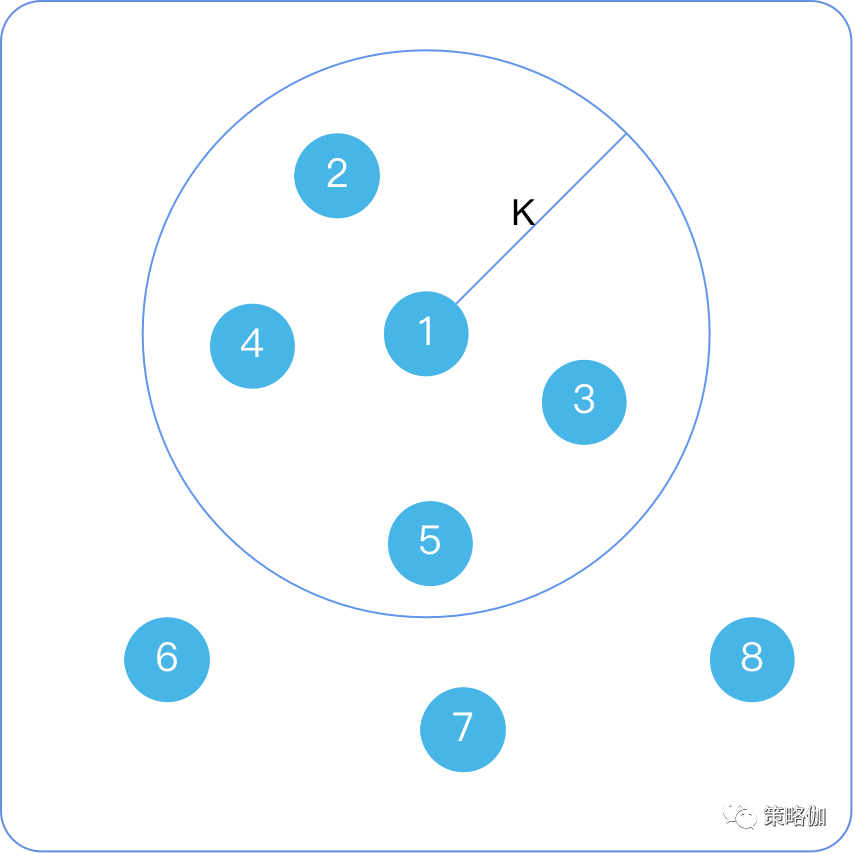
最近的邻居
- 物以类聚、人以群分,系统当然不需要按相似度遍历所有数据,一般推荐引擎只需要寻找一批与目标(用户/物品)最相似的‘邻居’组成一类群体进而做物品推荐。
最近的邻居是如何确定
- 以用户间的相似度举例,想象一个二维平面,每个用户代表一个点,用户(点与点)之间的距离就是相似度的大小;
- 计算用户①的若干个最近邻,一种方案就是以目标用户①为圆心,设定一个距离K,落在半径K的圆中的所有用户就是①最近的‘邻居’。
协同过滤
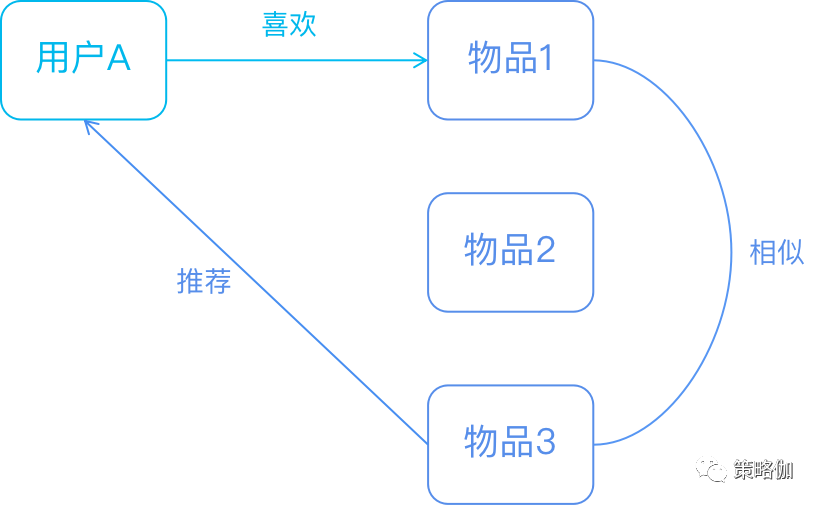
什么是协同过滤
推荐算法本质上提取的是大规模数据集中的相关性统计信息,因此更适合大数据场景。
协同过滤是利用群体行为给单个个体做综合决策(推荐),属于群体智慧编程的范畴。
- 相亲中的“门当户对”就是一种协同过滤思想的反射,门当户对建立了相亲男女的一种“相似度”(家庭背景、出身、生活习惯、为人处世、消费观、甚至价值观可能会相似),给自己找一个门当户对的伴侣就是一种“过滤”,当双方”门当户对“时,各方面的习惯及价值观会更相似,未来幸福的概率也会更大。如果整个社会具备这样的传统和风气,通过”协同进化“作用,大家会越来越认同这种方式。
协同过滤利用了两个非常朴素的自然哲学思想:
- “群体的智慧”:群体的智慧的底层原理是统计学规律,是一种朝向平衡稳定态发展的动态过程。
- “相似的物体具备相似的性质”:这个道理在物理学和化学中体现的非常明显,越相似的物体在物理结构和化学结构上就越相似。这个道理对于抽象的虚拟数据世界也是成立的。
对于推荐系统来说,通过用户的持续协同作用,最终给用户的推荐会越来越准。
具体来说,协同过滤的思路是通过群体的行为来找到某种相似性(用户之间的相似性或者标的物之间的相似性),通过该相似性来为用户做决策和推荐。
协同过滤算法分类
协同过滤算法(Collaborative Filtering, CF)在很多电商网站上都有用到。
协同过滤是指由相似兴趣的用户们组成‘邻居’互相协作,通过不断的与系统发生交互,从而持续过滤掉用户不感兴趣的内容,它是一种群体智慧效应的体现。
CF算法从用户与内容的角度又可划分为:基于用户的CF(User-based CF)和基于物品的CF(Item-based CF)。
协同过滤的矩阵统一视角
尽管协同过滤大体上可以分为userCF和itemCF,但如果用二维矩阵来进行抽象,可以看做同一个框架下两种不同算法形式。
- 以一个百货店的购买历史记录为例,行为用户id,列为该用户对每个商品的购买评价分

- 行视角代表了每个用户对所有商品的评分情况,可以理解为对每个用户进行了一个特征向量化,每个属性对应了一个商品
- 列视角代表了每个商品被所有用户的评分情况,可以理解为对每个商品进行了一个特征向量化,每个属性对应一个用户
- 矩阵中存在缺失值,所以这是一个稀疏矩阵
“user-based collaborative filtering”和“item-based collaborative filtering”本质上可以理解为对用户历史购买行为的二维矩阵,分别进行行向量和列向量的相似度关联挖掘。
User-based CF(爱你所爱)
UserCF 通过用户行为去寻找与其相似用户进行推荐
- 与基于用户属性的推荐对比,核心区别是计算相似度定义不同
- 基于用户属性推荐只考虑用户的静态特征
- UserCF是在用户历史行为偏好中计算相似度。(动态特征)
基于用户的CF原理如下:
- 分析各个用户对item的评价(通过浏览记录、购买记录等);
- 依据用户对item的评价计算得出所有用户之间的相似度;
- 选出与当前用户最相似的N个用户;
- 将这N个用户评价最高并且当前用户又没有浏览过的item推荐给当前用户。

基于用户协同过滤预测用户u对物品i的兴趣程度p(ui)的公式
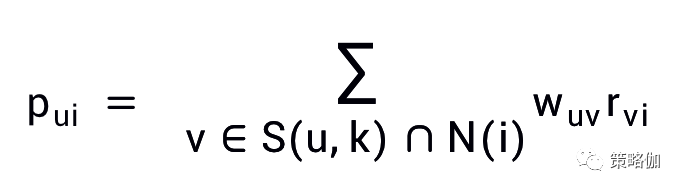
- S (u , K )是包含和用户u兴趣最接近的K个用户
- N (i)是对物品i有过行为的用户集合
- w(uv)是用户u与用户v的兴趣相似度
- r(vi)代表用户v对物品i的行为兴趣评分
基于用户的协同过滤算法主要有两步:
- 一是用户之间的相似度
- 二是用户与内容之间的行为偏好分数
通过图形拆解算法的计算路径如下图。
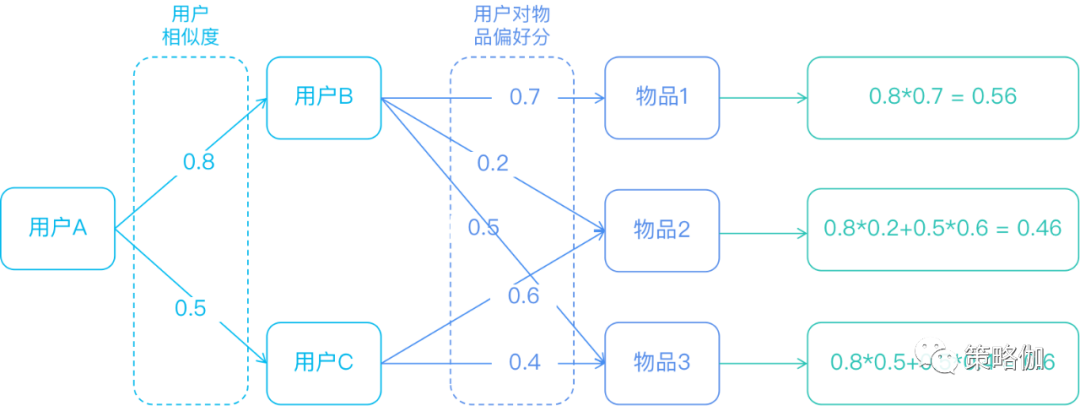
算法实现
将一个用户对所有物品的打分(行视角)作为一个向量(Vector),计算用户之间的相似度,找到top K-近邻邻居后,根据所有邻居的相似度权重以及他们对物品的评分,为目标用户生成一个排序的物品列表作为推荐列表。
Item-based CF(听群众的,没错!)
ItemCF 通过用户对物品行为偏好找到与用户喜欢物品的相似物品进行推荐
- 简单理解: 喜欢物品1的用户大多也喜欢物品2。
基于物品的CF原理大同小异,只是主体在于物品:
- 分析各个用户对item的浏览记录。
- 依据浏览记录分析得出所有item之间的相似度;
- 对于当前用户评价高的item,找出与之相似度最高的N个item;
- 将这N个item推荐给用户。
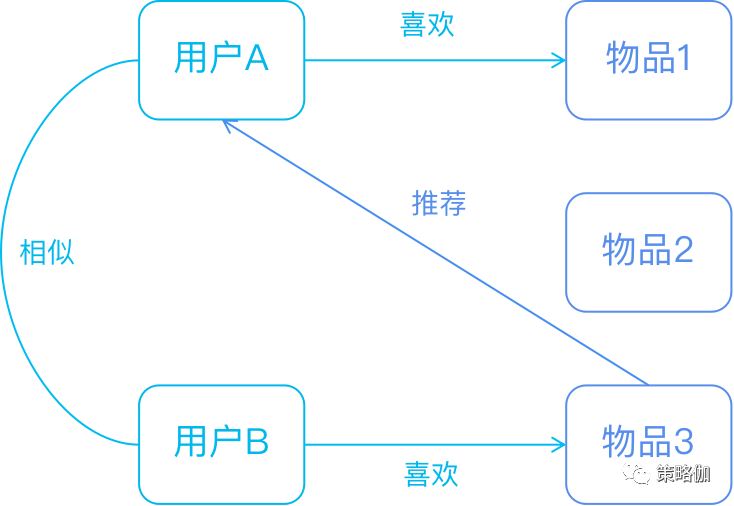

基于物品的协同过滤预测用户u对物品j的兴趣程度p(uj)的公式如下:
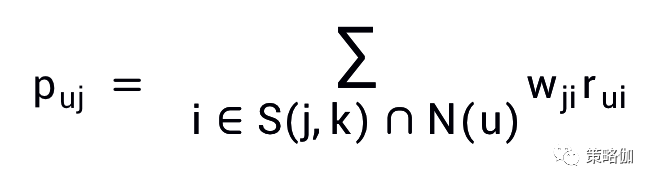
- N(u)是用户喜欢的物品的集合
- S(j,K)是和物品j最相似的K个物品的集合
- w(ji)是物品j和i的相似度
- r(ui)是用户u对物品i的兴趣分数。
同UserCF,基于物品的协同算法主要也是两步:
- 一是物品之间的相似度
- 二是用户产生过偏好行为的物品评价分数
图示计算路径如下
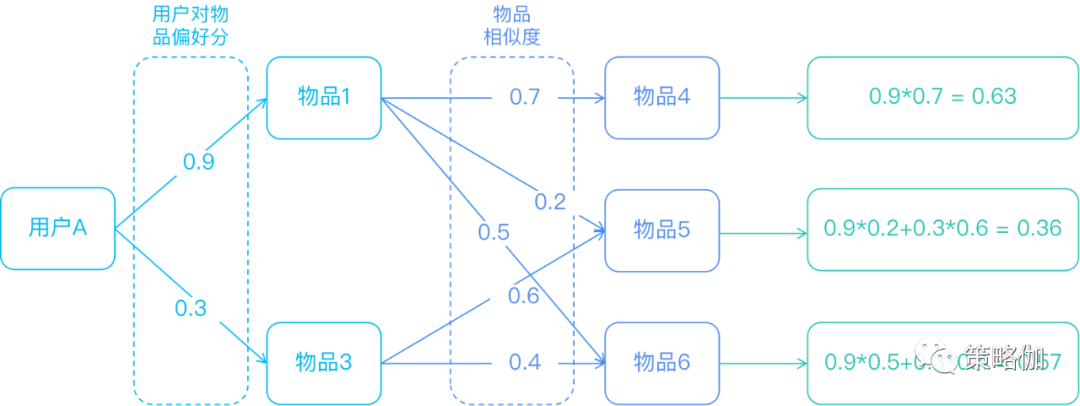
算法实现
将所有用户对某一个物品的喜好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的喜好预测目标用户还没有涉及的物品,计算得到一个排序的物品列表作为推荐。
ItemCF vs FPGrowth
将协同过滤和关联规则挖掘进行互相对比,ItemCF是频繁项挖掘FPGrowth的一种通用表示,频繁项挖掘的本质上挖掘的也是一种相似性统计模式。
二者思想的共通点:
ItemCF:历史评价行为矩阵的列向量视角,通过度量每个record中不同列之间的距离,来度量item之前的相似度FPGrowth:本质也是列向量视角,但FPGrowth可以看成是是简化版的itemCF,在FPGrowth中,不同列之间的距离度量简化为0/1两种状态(是否出现),FPGrowth中所谓的频繁共现集,本质上是寻找一个距离相近的列向量集合
基于内容的推荐
内容过滤推荐思想
内容过滤推荐算法(Content-Based Recommendations)基于标的物相关信息(通过特征工程方式得到特征向量)来构建推荐算法模型,为用户提供推荐服务。
- 标的物相关信息是对标的物文字描述的metadata信息、标签、用户评论、人工标注的信息等。
- 可以基于特征工程技术,对标的物进行特征提取,得到降维后的特征向量后,使用聚类和近似相似性搜索等机器学习手段进行关联性推荐。传统机器学习中的“feature engineering+machine learning”的流程。
广义的标的物相关信息不限于文本信息,图片、语音、视频等都可以作为内容推荐的信息来源,只不过这类信息处理成本较大,处理的时间及存储成本也相对更高。

- 苹果、香蕉;和樱桃西瓜都是水果,物品本身在特征维度上有相似度
内容过滤推荐算法的推荐策略和推荐效果,很大程度取决于对标的物的特征工程方案。
现在主流的特征提取策略有两类,分别是:
- 专家领域经验的特征工程
- 基于机器学习的自动特征提取
优势与缺点
- 优点
- 符合用户的需求爱好:该算法完全基于用户的历史兴趣来为用户推荐,推荐的标的物也是跟用户历史兴趣相似的,所以推荐的内容一定是符合用户的口味的。
- 直观易懂,可解释性强:基于内容的推荐算法基于用户的兴趣为用户推荐跟他兴趣相似的标的物,原理简单,容易理解。同时,由于是基于用户历史兴趣推荐跟兴趣相似的标的物,用户也非常容易接受和认可。
- 解决冷启动问题:所谓冷启动问题是指该用户只有很少的历史购买行为,或其购买的商品是一个很少被其他用户购买的商品,这种情况会影响协同过滤的效果。但是基于内容推荐没有这个问题,只要用户有一个操作行为,就可以基于内容为用户做推荐,不依赖其他用户行为。同时对于新入库的标的物,只要它具备metadata信息等标的物相关信息,就可以利用基于内容的推荐算法将它分发出去。因此,对于强依赖于UGC内容的产品(如抖音、快手等),基于内容的推荐可以更好地对标的物提供方进行流量扶持。
- 算法实现相对简单:基于内容的推荐可以基于标签维度做推荐,也可以将标的物嵌入向量空间中,利用相似度做推荐,不管哪种方式,算法实现较简单,有现成的开源的算法库供开发者使用,非常容易落地到真实的业务场景中。
- 对于小众领域也能有比较好的推荐效果(本质就是冷启动问题):对于冷门小众的标的物,用户行为少,协同过滤等方法很难将这类内容分发出去,而基于内容的算法受到这种情况的影响相对较小。
- 非常适合标的物快速增长的有时效性要求的产品(本质就是冷启动问题):对于标的物增长很快的产品,如今日头条等新闻资讯类APP,基本每天都有几十万甚至更多的标的物入库,另外标的物时效性也很强。新标的物一般用户行为少,协同过滤等算法很难将这些大量实时产生的新标的物推荐出去,这时就可以采用基于内容的推荐算法更好地分发这些内容。
- 缺点
- 推荐范围狭窄,新颖性不强:由于该类算法只依赖于单个用户的行为为用户做推荐,推荐的结果会聚集在用户过去感兴趣的标的物类别上,如果用户不主动关注其他类型的标的物,很难为用户推荐多样性的结果,也无法挖掘用户深层次的潜在兴趣。特别是对于新用户,只有少量的行为,为用户推荐的标的物较单一。
- 需要知道相关的内容信息且处理起来较难(依赖特征工程):内容信息主要是文本、视频、音频,处理起来费力,相对难度较大,依赖领域知识。同时这些信息更容易有更大概率含有噪音,增加了处理难度。另外,对内容理解的全面性、完整性及准确性会影响推荐的效果。
- 较难将长尾标的物分发出去:基于内容的推荐需要用户对标的物有操作行为,长尾标的物一般操作行为非常少,只有很少用户操作,甚至没有用户操作。由于基于内容的推荐只利用单个用户行为做推荐,所以更难将它分发给更多的用户。
- 推荐精准度不太高:一个很简单的道理是,你花9000多买了一个iphone后,不太可能短期内再买一个iphone或其他手机,相反更有可能需要买一个手机壳。
基于模型的推荐
基于模型的推荐利用机器学习的方法挖掘用户、物品、用户历史行为偏好之间的关系,从而找到用户可能感兴趣的物品进行推荐。
机器学习包括深度学习的推荐算法在业界已经提出了很多种,经典的模型——基于隐语义的模型推荐(LFM)。
把所有用户和物品按用户对物品的偏好程度画成一张表中,推荐系统的工作就是要预测那些表格中的空白值。
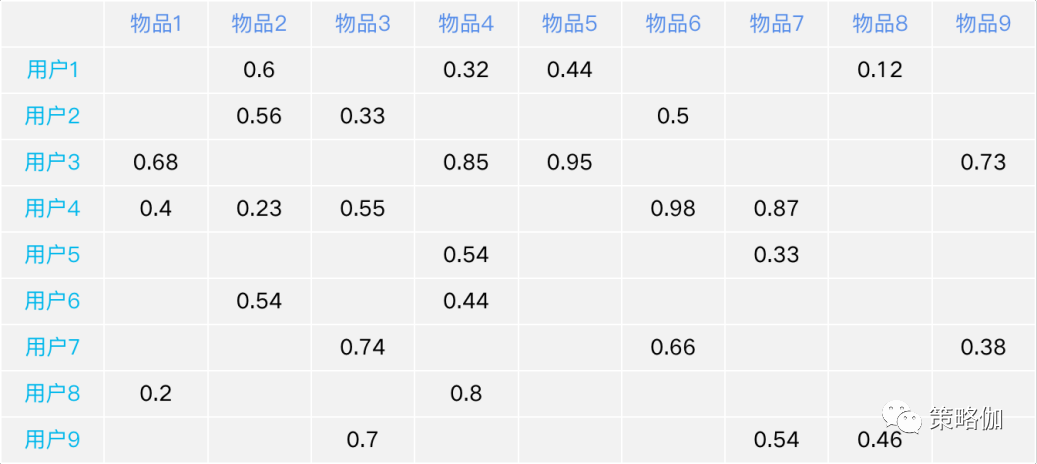
为了找到用户喜欢的物品
- 先把用户按其兴趣偏好进行分类,比如在买手机的时候有的人会关注品牌,有的人喜欢尺寸要大、有人在意型号、有人对价格敏感等等。
- 同样,物品也可以按这些用户偏好(品牌、尺寸、型号、价格)进行分类。
隐语义模型就是要找到用户-偏好、物品-偏好这两个关系矩阵,然后通过矩阵计算的方式合成用户-物品的完整矩阵,求得用户对物品的推荐分数。
系统求解的过程是随机生成初始矩阵,推荐结果要与原始数据矩阵中有值的项尽可能相近,这就转换成了机器学习求最优解的问题。

相比协同过滤,无论UserCF或ItemCF,能够影响推荐效果的往往是少部分的用户行为和物品,而隐语义模型则通过机器挖掘隐藏在数据中的偏好从而进行推荐,通常能更充分的探寻到数据中的信息,推荐效果也更准确。
但因为偏好信息没有具体物理意义,所以其缺点也同样明显,无法对推荐结果做出合理的解释。
混合推荐
混合推荐算法
目前研究和应用最多的是内容推荐和协同过滤推荐的组合。最简单的做法就是分别用基于内容的方法和协同过滤推荐方法去产生一个推荐预测结果,然后用线性组合、加权组合等方式综合其结果。本章我们分别讨论。
1 加权式
加权式:加权多种推荐技术结果

2 切换式
切换式:根据问题背景和实际情况或要求决定变换采用不同的推荐技术

3 混杂式
混杂式:同时采用多种推荐技术给出多种推荐结果为用户提供参考

4 特征组合
特征组合:组合来自不同推荐数据源的特征被另一种推荐算法所采用

5 层叠式
层叠式:先用一种推荐技术产生一种粗糙的推荐结果,第二种推荐技术在此推荐结果的基础上进一步作出更精确的推荐

6 特征补充
特征补充:一种技术产生附加的特征信息嵌入到另一种推荐技术的特征输入中

7 级联式
级联式:用一种推荐方法产生的模型作为另一种推荐方法的输入

冷启动算法
用户冷启动的问题对于移动互联网基于内容推荐产品中非常重要
推荐系统冷启动通常分为三类,即用户冷启动、物品冷启动还有系统冷启动。
- 无论那种冷启动都因为只有较少的数据和特征来训练模型,所有需要不同的技术方案来提升推荐效果。
- 另外冷启动结合产品方案可以加速冷启动的过程。
交互式推荐
什么是交互式推荐
交互式推荐的概念最早在2018年Youtube的一篇论文《Q&R: A Two-Stage Approach toward Interactive Recommendation》中提出来,它是一种采用和QA系统类似的推荐方式,系统针对不同的用户生成问题来探测(询问)用户偏好,然后根据用户的行为反馈(比如点击或选择项)进行视频推荐,循环往复。
为什么要交互式推荐?
外卖首页Feed在用户即时兴趣的捕捉和反馈上存在痛点,“对比型”用户的选购效率和体验不佳。
- 外卖首页Feed作为泛意图用户主要选购场景之一,用户在浏览到成单过程中通常需要进行一番对比、才能逐步收敛意图,然后做出最终决策。
但受限于长列表的翻页模式,首页Feed根据用户需求实时调整推荐结果的能力不足。
- 一部分用户的浏览深度不足一页,推荐系统没有额外的机会根据用户兴趣调整推荐结果。
- 另一部分用户虽然有较深的浏览深度,但需要等到翻页时推荐系统才能重新理解用户意图,实时性不足。
业界优化这类问题的主要产品形态有交互式推荐、动态翻页、端上重排这三种。
- 交互式推荐由于是在用户可视范围内插入,用户感知较强;
- 后两种的主流形态是在用户不可见区域更新推荐,用户感知相对较弱。
案例
【2024-3-14】
- 阿里飞猪个性化推荐:主题与交互式推荐技术实践
- 交互式推荐在外卖场景的探索与应用
- 【2023-11-30】推荐智能体:利用大模型进行交互式推荐, 提出InteRecAgent内高效的任务执行工作流程 ,包括记忆总线、动态示范增强的任务规划和反思等关键组件。
- InteRecAgent使得传统的基于ID的矩阵分解等推荐系统能够通过集成LLM而具有自然语言交互界面。
- 多个公开数据集上, InteRecAgent 在会话式推荐任务中取得满意的性能,明显优于通用LLM。
InteRecAgent框架的整体结构:
- 语言模型作为“大脑”,负责解析用户意图和生成响应。
- 提供三类工具:信息查询工具、物品检索工具和物品排序工具。这些工具分别负责信息查询、根据硬条件和软条件检索候选项,以及根据用户偏好排序候选项。
- 用户与语言模型进行对话交流。如果需要使用工具,语言模型会生成工具使用计划,并提供每个工具的输入。
- 共享内存总线负责存储当前候选项,被各工具共享调用。检索工具从中获取输入,更新输出,排序工具排序其中候选项。
- 语言模型观察工具执行结果,生成响应给用户。如果通过反馈策略判断有误,语言模型会重复第一步骤。
- 语言模型计划调用顺序和提供输入,工具执行体按顺序执行返回观察结果。执行过程与共享内存总线进行交互。
- 用户与语言模型的对话可以进行多轮交流,以深入挖掘用户需求并提供个性化推荐。
LLM起大脑的作用, 而推荐模型充当提供域特定知识的工具。用户通过自然语言与LLM进行交互。
- LLM解释用户的意图,判断当前对话是否需要工具的帮助。例如,在闲聊中,LLM将根据自身知识做出回应; 而对于领域内的推荐,LLM启动一系列工具API调用,随后通过观察工具执行结果生成回应。
- 因此,推荐质量高度依赖于工具,使工具的组成成为整体性能的关键因素。
FM
综述
2010年,日本大阪大学(Osaka University)的 Steffen Rendle 在矩阵分解(MF)、SVD++[2]、PITF[3]、FPMC[4] 等基础之上,归纳出针对高维稀疏数据的因子机(Factorization Machine, FM)模型[11]。因子机模型可以将上述模型全部纳入一个统一的框架进行分析。并且,Steffen Rendle 实现了一个单机多线程版本的 libFM。在随后的 KDD Cup 2012,track2 广告点击率预估(pCTR)中,国立台湾大学[4]和 Opera Solutions[5] 两只队伍都采用了 FM,并获得大赛的冠亚军而使得 FM 名声大噪。随后,台湾大学的 Yuchin Juan 等人在总结自己在两次比赛中的经验以及 Opera Solutions 队伍中使用的 FM 模型的总结,提出了一般化的 FFM 模型[6],并实现了单机多线程版的 libFFM,并做了深入的试验研究。事实上,Opera Solutions 在比赛中用的 FM 就是FFM。
将 FM 向更高阶推广的工作也有一些,例如 Steffen Rendle 在论文[11]中提出一般化的 d-way FM,他将二阶组合的FM中的二阶项替换成d阶组合项,可以利用 FM 相同的处理技巧将计算时间复杂度降低为线性时间复杂度。这个模型的缺点在于只考虑d阶组合,而实际上,低阶组合模式更有意义,因此到目前为止也没有看到谁在实际中使用。针对这种不足,2016年日本NTT通信科学实验室的 Mathieu Blondel 等人在NIPS2016上提出了一般意义上的高阶 FM 模型,它保留了所有高阶项,并利用 ANOVA kernel 和动态规划算法,将计算时间复杂度降低到线性时间复杂度[12]!
什么是因子机
因子机的定义 机器学习中的建模问题可以归纳为从数据中学习一个函数 \(f: R^n \rightarrow T\),它将实值的特征向量 \(x \in R^n\) 映射到一个特定的集合中。例如,对于回归问题,集合 T 就是实数集 R,对于二分类问题,这个集合可以是 \(\{+1, -1\}\). 对于监督学习,通常有一标注的训练样本集合 \(D = \{(x^{(1)},y^{(1)}),..., (x^{(n)},y^{(n)})\}\)。
线性函数是最简单的建模函数,它假定这个函数可以用参数 \(w\) 来刻画,
\[\phi(x) = w_0 + \sum_i w_i x_i\]对于回归问题,\(y = \phi(x)\);而对于二分类问题,需要做对数几率函数变换(逻辑回归)
\[y = \frac{1}{1 + \exp{-\phi(x)}}\]线性模型的缺点是无法学到模型之间的交互,而这在推荐和CTR预估中是比较关键的。例如,CTR预估中常将用户id和广告id onehot 编码后作为特征向量的一部分。
为了学习特征间的交叉,SVM通过多项式核函数来实现特征的交叉,实际上和多项式模型是一样的,这里以二阶多项式模型为例
\[\phi(x) = w_0 + \sum_i w_i x_i + \sum_i \sum_{j \lt i} w_{ij} x_i x_j \\\\ = w_0 + \mathbf{w_1}^T \mathbf{x} + \mathbf{x}^T \mathbf{W_2} \mathbf{x}\]多项式模型的问题在于二阶项的参数过多,设特征维数为 \(n\),那么二阶项的参数数目为 \(n(n+1)/2\)。 对于广告点击率预估问题,由于存在大量id特征,导致 \(n\) 可能为 \(10^7\)维,这样一来,模型参数的 量级为 \(10^{14}\),这比样本量 \(4\times 10^7\)多得多[6]!这导致只有极少数的二阶组合模式才能在样本中找到, 而绝大多数模式在样本中找不到,因而模型无法学出对应的权重。例如,对于某个\(w_{ij}\),样本中找不到\(x_i=1,x_j=1\) (这里假定所有的特征都是离散的特征,只取0和1两个值)这种样本,那么\(w_{ij}\)的梯度恒为0,从而导致参数学习失败!
很容易想到,可以对二阶项参数施加某种限制,减少模型参数的自由度。FM 施加的限制是要求二阶项系数矩阵是低秩的,能够分解为低秩矩阵的乘积
\[\mathbf{W_2} = \mathbf{V}^T \mathbf{V}, V \in \mathbb{R}^{k \times n} \\\\ w_{ij} = \mathbf{v_i}^T \mathbf{v_j} , \mathbf{v_i} \in \mathbb{R}^{k} \\\\ \mathbf{V} = [\mathbf{v_1}, ..., \mathbf{v_n}]\]这样一来,就将参数个数减少到 \(kn\),可以设置较少的k值(一般设置在100以内,\(k << n\)),极大地减少模型参数,增强模型泛化能力,这跟矩阵分解的方法是一样的。向量 \(\mathbf{v_i}\) 可以解释为第\(i\)个特征对应的隐因子或隐向量。 以user和item的推荐问题为例,如果该特征是user,可以解释为用户向量,如果是item,可以解释为物品向量。
计算复杂度
因为引入和二阶项,如果直接计算,时间复杂度将是 \(O(\bar{n}^2)\),\(\bar{n}\)是特征非零特征数目, 可以通过简单的数学技巧将时间复杂度减少到线性时间复杂度。
基于一个基本的观察,齐二次交叉项之和可以表达为平方和之差
\[\sum_i \sum_{j \lt i} z_i z_j = \frac{1}{2} \left( \left(\sum_i z_i \right)^2 - \sum_i z_i^2 \right)\]上式左边计算复杂度为\(O(n^2)\),而右边是\(O(n)\)。根据上式,可以将原表达式中二次项化简为
\[\sum_i \sum_{j \lt i} w_{ij} x_i x_j = \sum_i \sum_{j \lt i} \sum_k v_{ik} v_{jk} x_i x_j \\\\ = \frac{1}{2} \sum_k \left( \left(\sum_i v_{ik} x_i \right)^2 - \sum_i v_{ik}x_i^2 \right)\]上式计算时间复杂度是\(O(\bar{n})\)。
基于梯度的优化都需要计算目标函数对参数的梯度,对FM而言,目标函数对参数的梯度可以利用链式求导法则分解为目标函数对\(\phi\)的梯度和\(\frac{\partial \phi}{\partial \theta}\) 的乘积。前者依赖于具体任务,后者可以简单的求得
\[\frac{\partial \phi}{\partial \theta} = \begin{cases} 1, & \text{if $\theta$ is $w_0$} \\ x_i, & \text{if $\theta$ is $w_i$} \\ x_i\sum_j v_{jk} x_j - v_{ik}x_i^2, & \text{if $\theta$ is $w_{ik}$} \end{cases}\]优化方案
论文中给出了三种优化方案,它们分别是
- 随机梯度下降,这种方案收敛慢而且非常敏感,可以利用现代的一些trick,例如采用 AdaGrad 算法,采用自适应学习率,效果相对比较好,论文[6]对FFM就采用这种方案。
- 交替方向乘子(ALS),这种方案只适用于回归问题,它每次优化一个参数,把其他参数固定,好处是每次都是一个最小二乘问题,有解析解。
- 基于蒙特卡罗马尔科夫链的优化方案,论文中效果最好的方案,细节可以参考原文。
FFM
在实际预测任务中,特征往往包含多种id,如果不同id组合时采用不同的隐向量,那么这就是 FFM(Field Factorization Machine) 模型[6]。它将特征按照事先的规则分为多个场(Field),特征 \(x_i\)属于某个特定的场\(f\)。每个特征将被映射为多个隐向量\(\mathbf{v}_{i1},...,\mathbf{v}_{if}\),每个隐向量对应一个场。当两个特征\(x_i,x_j\)组合时,用对方对应的场对应的隐向量做内积!
\[w_{ij} = \mathbf{v}_{i,f_j}^T\mathbf{v}_{j,f_i}\]\(f_i,f_j\)分别是特征\(x_i,x_j\)对应的场编号。FFM 由于引入了场,使得每两组特征交叉的隐向量都是独立的,可以取得更好的组合效果,但是使得计算复杂度无法通过优化变成线性时间复杂度,每个样本预测的时间复杂度为 \(O(\bar{n}^2 k)\),不过FFM的k值通常远小于FM的k值。论文[6]对FFM在Criteo和Avazu两个任务(Kaggle上的两个CTR预估比赛)上进行了试验,结果表明 FFM 的成绩优于 FM。事实上,FM 可以看做只有一个场的 FFM。
FM与矩阵分解
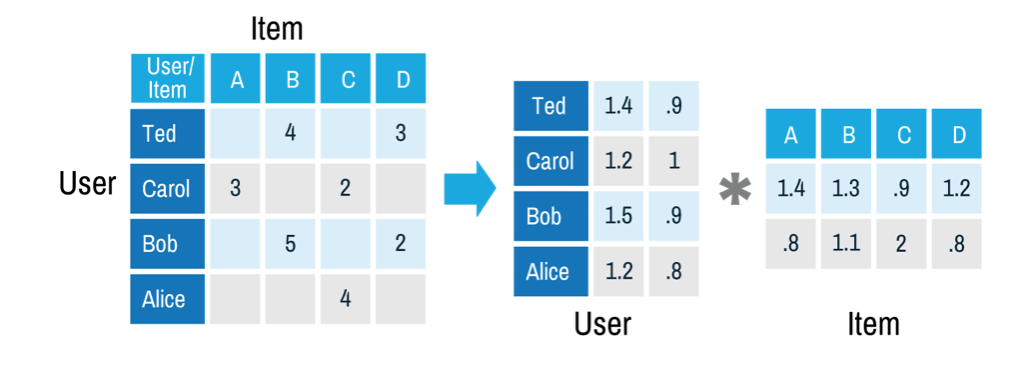
基于矩阵分解的协同过滤是推荐系统中常用的一种推荐方案[7],从历史数据中收集user对item的评分,可以是显式的打分,也可以是用户的隐式反馈计算的得分。由于user和item数量非常多,有过打分的user和item对通常是十分稀少的,基于矩阵分解的协同过滤是来预测那些没有过行为的user对item的打分,实际上是一个评分预测问题。矩阵分解的方法假设user对item的打分\(\hat{r}_{ui}\)由下式决定
\[\hat{r}_{ui} = q_i^T p_u + \mu + b_i + b_u\]其中\(q_i\)是第i个item对相应的隐向量,\(p_u\)是第u个user对应的隐向量,\(b_i\)代表item的偏置,用于解释商品本身的热门和冷门,\(b_u\)代表user的偏置,用于解释用户本身的打分偏好(例如有些人喜欢打低分),\(\mu\)是常数。即将评分矩阵分解为user矩阵和item矩阵的乘积加上线性项和常数项,而这两个矩阵是低秩的!这些参数通过对最小化经验误差得到。
\[\min_{p,q,b} \sum_{(u,i) \in K} (r_{ui} - \hat{r}_{ui})^2 + \lambda(||p_u||^2 + ||q_i||^2 + b_u^2 + b_i^2)\]
从上面的叙述来看,FM的二阶矩阵也用了矩阵分解的技巧,那么基于矩阵分解的协同过滤和FM是什么关系呢?以user对item评分预测问题为例,基于矩阵分解的协同过滤可以看做FM的一个特殊例子,对于每一个样本,FM可以看做特征只有userid和itemid的onehot编码后的向量连接而成的向量。从FM和MFCF公式来看,MFCF的用户向量\(p_u\)和item向量\(q_i\)可以看做FM中的隐向量,用户和item的bias向量\(b_u, b_i\)就是FM中的一次项系数,常数\(\mu\)也和FM中的常数\(w_0\)相对应,可以看到,MFCF就是FM的一个特例!另外,FM可以采用更多的特征,学习更多的组合模式,这是单个矩阵分解的模型所做不到的!因此,FM比矩阵分解的方法更具普遍性!事实上,现在能用矩阵分解的方法做的方案都直接上FM了!


FM与决策树
FM和决策树都可以做特征组合,Facebook就用GBDT学习特征的自动组合[^8],决策树可以非常方便地对特征做高阶组合。如图所示,一棵决策的叶子节点实际上就对应一条特征规则,例如最左边的叶子节点就代表一条特征组合规则\(x_1=1, x_2=1\)。通过增加树的深度,可以很方便的学习到更高级的非线性组合模式。通过增加树的棵树,可以学习到很多这样的模式,论文[^8]采用GBDT来建立决策树,使得新增的决策树能够拟合损失函数的残差。

但是,决策树和二项式模型有一个共同的问题,那就是无法学习到数据中不存在的模式。例如,对于模式\(x_1=1,x_2=1\),如果这种模式在数据中不存在,或者数量特别少,那么决策树在对特征\(x_1\)分裂后,就不会再对\(x_2\)分裂了。当数据不是高度稀疏的,特征间的组合模式基本上都能够找到足够的样本,那么决策树能够有效地学习到比较复杂的特征组合;但是在高度稀疏的数据中,二阶组合的数量就足以让绝大多数模式找不到样本,这使得决策树无法学到这些简单的二阶模式,更不用说更高阶的组合了。
FM与神经网络
神经网络天然地难以直接处理高维稀疏的离散特征,因为这将导致神经元的连接参数太多。但是低维嵌入(embedding)技巧可以解决这个问题,词的分布式表达就是一个很好的例子。事实上 FM就可以看做对高维稀疏的离散特征做 embedding。上面举的例子其实也可以看做将每一个user和每一个item嵌入到一个低维连续的 embedding 空间中,然后在这个 embedding 空间中比较用户和item的相似性来学习到用户对item的偏好。这跟 word2vec[^9]词向量学习类似,word2vec 将词 embedding 到一个低维连续空间,词的相似性通过两个词向量的相似性来度量。神经网络对稀疏离散特征做 embedding 后,可以做更复杂的非线性变换,具有比FM跟大的潜力学习到更深层的非线性关系!基于这个思想,2016年,Google提出 wide and deep 模型用作 Google Play的app推荐[^10],它利用神经网络做离散特征和连续特征之间的交叉,神经网络的输出和人工组合较低维度的离散特征一起预测,并且采用端到端的学习,联合优化DNN和LR。如图所示,Catergorial 特征 embedding 到低维连续空间,并和连续特征拼接,构成了1200维的向量,作为神经网络的输入,神经网络采用三隐层结构,激活函数都是采用 ReLU,最后一层神经元的输出 \(a^{(lf)}\)和离散特征 \(\mathbf{x}\) 及人工叉积变换后的特征 \(\phi(\mathbf{x})\),一起预测
\[P(Y=1|\mathbf{x}) = \sigma\left(\mathbf{w}_{wide}^T[\mathbf{x}; \phi(\mathbf{x})] + \mathbf{w}_{deep}^T a^{(lf)} + b \right)\]
注意到,在 wide and deep 模型中,wide部分是通过对用户安装过的APP id和用户Impression App id做叉积变换,解决 embedding 的过泛化问题。 所谓的过泛化,实际上是因为用户的偏好本身就很集中,即使相似的一些 item,用户也只偏好其中一部分,使得query-item矩阵稀疏但是高秩。 而这些信息实际上已经反映在用户已有的行为当中了,因此可以利用这部分信息,单独建立wide部分,解决deep部分的过泛化。
从另一个角度来看,wide和deep部分分别在学习不同阶的特征交叉,deep部分学到高阶交叉,而wide部分学到的是二阶交叉。 后来,有人用FM替换了这里wide部分的二阶交叉,是得模型对高度稀疏的特征的建模更加有效,因为高度稀疏特征简单的叉积变换也难以有效地学到二阶交叉, 这在前面已经叙述过了。因此,很自然的想法就是,用FM替换这里的二阶交叉,得到DeepFM模型[13]。

事实上,对于连续特征和非高度稀疏特征的高阶交叉,决策树似乎更加擅长。因此,很自然的想法是将GBDT也加到模型中。 但是问题是,决策树的优化方法和神经网络之类的不兼容,因此无法直接端到端学习。一种解决方案是,利用Boost融合的方案, 将神经网络、FM、LR当做一个模型,先训练一个初步模型,然后在残差方向上建立GBDT模型,实现融合。 微软的一篇文献[14]也证实,Boost方式融合DNN和GBDT方案相比其他融合方案更优,因此这也不失为一种可行的探索方向!
Cross Net
为了将FM推广到高阶组合,一系列的变体被研究人员提出,例如 d-way FM, 高阶FM,但是应用到实际数据中的工作一直未见报道。 2017年,Google的研究人员从另一种思路触发,融合了残差网络的思想,设计出叉积网络Cross Net,实现起来简单,可以通过加层的方式方便地扩展到任意阶数。
- 首先通过 embedding 层将稀疏特征转换成低维向量表示,将这些向量和连续值特征拼成一个大的d维向量 $\mathbf{x_0} = [\mathbf{x_{e,1}^T}, \mathbf{x_{e,2}^T}, …, \mathbf{x_{e,k}^T}, \mathbf{x_{dense}^T}]$ 作为网络的输入。

用 $\mathbf{x_l}$ 表示Cross net的的l层的输出,那么cross net的第l层的转换可以表示为
\[\mathbf{x_{l+1}} = \mathbf{x_0}\mathbf{x_l^T}\mathbf{w_l} + \mathbf{b_l} + \mathbf{x_l}\]这里 $\mathbf{w_l}, \mathbf{b_l} \in \mathbb{R}^d$ 是第l层的参数,注意最后一项的存在,这一项是残差链接项,因此前面两项拟合的是残差!
第一项可以参考图2,实际上只是在\(x_0\)的基础上乘上了一个系数!
为了理解这个表达式,我们用\(\mathbf{w_{l+1}}\)乘以上式,可以理解为最后一层输出的得分(是一个标量)
\[\mathbf{x_{l+1}^T} \mathbf{w_{l+1}} = (\mathbf{x_{l}^T} \mathbf{w_{l}})(\mathbf{x_{0}^T} \mathbf{w_{l+1}}) + \mathbf{b_l^T} \mathbf{w_{l+1}} + \mathbf{x_{l}^T} \mathbf{w_{l+1}}\]如果不考虑常数项和残差项,只保留第一项,并不断的递归会有
\[\mathbf{x_{l+1}^T} \mathbf{w_{l+1}} = (\mathbf{x_{0}^T} \mathbf{w_{0}})...(\mathbf{x_{0}^T} \mathbf{w_{l}})(\mathbf{x_{0}^T} \mathbf{w_{l+1}})\]这表明,Cross Net可以看做FM的直接推广,FM是Cross Net的特例,当l=1且\(w_{0}=w_{1}\)时,就可以看做是FM!
\[x_1^T w_1 = (x ^T W_e^T w_0) (w_0^T W_e x) = x^T W x \\ W = W_e^T w_0 w_0^T W_e\]$W_e$ 是 embedding 等效矩阵,$x$是原始稀疏高维特征向量!
FM 的实现
libFM是FM的最初实现,利用OpenMP实现单机多核的并行!目前,FM已有多种实现
Wide&Deep
- 【2019-5-13】推荐系统-重排序-CTR-Wide&Deep模型
模型结构

- 最左边的Wide模型其实就是LR模型。
- 最右面Deep模型其实就是深度模型了。
- 中间是两者结合的Wide&Deep模型,其输出单元接收的是左右两部分输出的拼接
- 输入部分

Embedding 层
- 为什么需要做embedding?
- 超高维度的稀疏输入输入网络,将带来更高维度的参数矩阵,这会带来更大的计算压力。所以神经网络更善于处理稠密的实值输入。所以,需要对稀疏的离散特征做embedding
- 怎么做embedding?
- 1,离线提前做embedding,例如对于词的嵌入可以使用Word2vec对词做嵌入。也可利用FM先学习好稀疏特征的隐向量。
- 2,随机初始化。之后跟着模型参数一起训练。其实1中无论是word2vec还是FM,也是一开始随机初始化,然后训练学习而来。
- 代码
tf.feature_column.embedding_column(categorical_column,
dimension,
combiner='mean',
initializer=None,
ckpt_to_load_from=None,
tensor_name_in_ckpt=None,
max_norm=None,
trainable=True) # 继续训练这个embedding
wide与deep分别代表了什么?
wide&deep论文的说法
- wide侧用于记忆,简单的线性模式,普通LR,适合输入组合特征,用于记住那些已经存在过的特征组合,并赋予权重。
- 一般根据人工先验知识,将一些简单、明显的特征交叉,喂入Wide侧,让Wide侧能够记住这些规则。
- deep侧用于泛化,复杂的深度模型,DNN,适合输入非组合特征,包括离散特征和连续特征,用于泛化那些未曾出现过或者低频的特征组合。
- 通过embedding的方式将categorical/id特征映射成稠密向量,让DNN学习到这些特征之间的深层交叉,以增强扩展能力。
但其实deep模型本身也会记住已出现的模式并进行训练吧?相当于低阶特征也可以得到有效利用,为什么还要加上wide模型呢?
- 可能原因:deep模型可解释性不强。wide模型可解释性强。通过wide模型可以挑选出权重较高的低阶特征。同时,对低阶特征另外单独建模,也是很有可能提高精度的。 【2022-5-21】张备
不同的看法。从多个不同的来源,包括公司内部的实验,外部的论文,比如阿里最近的论文CAN,证实把组合特征放到deep侧,都会带来收益。甚至看到一个说法,对于一些特征工程非常完善的场景,从LR升级wd的时候,如果不把组合特征放到deep侧,甚至无法带来提升。
我觉得可以放下wide记忆和deep泛化的想法。难道deep侧就没有记忆的能力吗?模型本来就是从数据中发现pattern,再去识别pattern。deep侧当然也有记忆的能力啊。
- 从wide侧到deep侧,特征从单个权重变成一组权重,网络结构从一层变为多层,deep侧相对于wide侧就是具备更强的表达能力和拟合能力,就是具有更高的VC维,wide侧能够做到的事情,deep侧必然也能做到。
- 从特征工程的角度来看,每个特征或者特征域都有其含义,例如是曝光行为,点击行为,或者下载行为等等。但是从模型的角度来看,模型看到的就是一堆特征id,此id与彼id有何不同?为什么一部分id要放在deep侧,另一部分id要放到wide侧?
- 所以我认为,大可以把所有特征都放在deep侧,效果不会差于部分特征deep/部分特征wide,风险就是模型表达能力太强,可能带来过拟合,另外还要解决因为模型太大所带来的工程问题。 为什么当初谷歌会提出widedeep这么个网络结构?我觉得要结合技术的发展进程来看。
- 一是当时正在逐步引入深度学习,从简单的线性模型向复杂模型过渡
- 二是受限于当时的技术能力。举例,如果item的维度是一万维,即有一万个item id,那么item与item做特征组合之后,特征维度爆炸到一亿量级,再embedding化一下,模型大小也瞬间爆炸,以当时的技术未必能训练出大规模的模型,即便可以,也会对工程上带来很大的挑战。所以组合特征放在wide侧用FTRL训练一下,过滤一下低频特征,整体模型训练出来都不会太大,不管是训练还是线上预估,都不会带来太大压力。
工程实现
import tensorflow as tf
gender = tf.feature_column.categorical_column_with_vocabulary_list(
"gender", ["Female", "Male"])
education = tf.feature_column.categorical_column_with_vocabulary_list(
"education", [
"Bachelors", "HS-grad", "11th", "Masters", "9th",
"Some-college", "Assoc-acdm", "Assoc-voc", "7th-8th",
"Doctorate", "Prof-school", "5th-6th", "10th", "1st-4th",
"Preschool", "12th"
])
marital_status = tf.feature_column.categorical_column_with_vocabulary_list(
"marital_status", [
"Married-civ-spouse", "Divorced", "Married-spouse-absent",
"Never-married", "Separated", "Married-AF-spouse", "Widowed"
])
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
"relationship", [
"Husband", "Not-in-family", "Wife", "Own-child", "Unmarried",
"Other-relative"
])
workclass = tf.feature_column.categorical_column_with_vocabulary_list(
"workclass", [
"Self-emp-not-inc", "Private", "State-gov", "Federal-gov",
"Local-gov", "?", "Self-emp-inc", "Without-pay", "Never-worked"
])
# To show an example of hashing:
occupation = tf.feature_column.categorical_column_with_hash_bucket(
"occupation", hash_bucket_size=1000)
native_country = tf.feature_column.categorical_column_with_hash_bucket(
"native_country", hash_bucket_size=1000)
# Continuous base columns.
age = tf.feature_column.numeric_column("age")
education_num = tf.feature_column.numeric_column("education_num")
capital_gain = tf.feature_column.numeric_column("capital_gain")
capital_loss = tf.feature_column.numeric_column("capital_loss")
hours_per_week = tf.feature_column.numeric_column("hours_per_week")
# Transformations.
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
- wide部分
base_columns = [
gender, native_country, education, occupation, workclass, relationship,
age_buckets,
]
crossed_columns = [
tf.feature_column.crossed_column(
["education", "occupation"], hash_bucket_size=1000),
tf.feature_column.crossed_column(
[age_buckets, "education", "occupation"], hash_bucket_size=1000),
tf.feature_column.crossed_column(
["native_country", "occupation"], hash_bucket_size=1000)
]
- deep部分
deep_columns = [
tf.feature_column.indicator_column(workclass),
tf.feature_column.indicator_column(education),
tf.feature_column.indicator_column(gender),
tf.feature_column.indicator_column(relationship),
# To show an example of embedding
tf.feature_column.embedding_column(native_country, dimension=8),
tf.feature_column.embedding_column(occupation, dimension=8),
age,
education_num,
capital_gain,
capital_loss,
hours_per_week,
]
- wide&deep组合
import tempfile
model_dir = tempfile.mkdtemp()
m = tf.estimator.DNNLinearCombinedClassifier(
model_dir=model_dir,
linear_feature_columns=crossed_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[100, 50])
- 模型训练评估
import pandas as pd
import urllib
# Define the column names for the data sets.
CSV_COLUMNS = [
"age", "workclass", "fnlwgt", "education", "education_num",
"marital_status", "occupation", "relationship", "race", "gender",
"capital_gain", "capital_loss", "hours_per_week", "native_country",
"income_bracket"
]
def maybe_download(train_data, test_data):
"""Maybe downloads training data and returns train and test file names."""
if train_data:
train_file_name = train_data
else:
train_file = tempfile.NamedTemporaryFile(delete=False)
urllib.request.urlretrieve(
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data",
train_file.name) # pylint: disable=line-too-long
train_file_name = train_file.name
train_file.close()
print("Training data is downloaded to %s" % train_file_name)
if test_data:
test_file_name = test_data
else:
test_file = tempfile.NamedTemporaryFile(delete=False)
urllib.request.urlretrieve(
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test",
test_file.name) # pylint: disable=line-too-long
test_file_name = test_file.name
test_file.close()
print("Test data is downloaded to %s"% test_file_name)
return train_file_name, test_file_name
def input_fn(data_file, num_epochs, shuffle):
"""Input builder function."""
df_data = pd.read_csv(
tf.gfile.Open(data_file),
names=CSV_COLUMNS,
skipinitialspace=True,
engine="python",
skiprows=1)
# remove NaN elements
df_data = df_data.dropna(how="any", axis=0)
labels = df_data["income_bracket"].apply(lambda x: ">50K" in x).astype(int)
return tf.estimator.inputs.pandas_input_fn(
x=df_data,
y=labels,
batch_size=100,
num_epochs=num_epochs,
shuffle=shuffle,
num_threads=5)
# set num_epochs to None to get infinite stream of data.
m.train(
input_fn=input_fn(train_file_name, num_epochs=None, shuffle=True),
steps=train_steps)
# set steps to None to run evaluation until all data consumed.
results = m.evaluate(
input_fn=input_fn(test_file_name, num_epochs=1, shuffle=False),
steps=None)
print("model directory = %s" % model_dir)
for key in sorted(results):
print("%s: %s" % (key, results[key]))
推荐算法五环之歌
第一环:评分卡——LR
- 【2021-11-15】推荐算法的”五环之歌”,知乎地址
LR回归
Logistic Regression就是一个非常擅于记忆的模型。说是模型,其实就是一个超大规模的“评分卡”。
- 一个特征(中国、美国),或特征组合(<春节、中国人、饺子>)占据“推荐评分卡”中的一项。可想而知,一个工业级的推荐LR的评分卡里面,条目会有上亿项。
- 每项(i.e., 特征或特征组合)都对应一个分数。这个分数是由LR学习出来的,有正有负,代表对最终目标(比如成交,即label=1)的贡献。比如SCORE(<春节,中国人,饺子>)=5,代表这种组合非常容易成交;反之SCORE(<中国人、鲱鱼罐头>)=-100,代表这个组合极不容易成交
- 简单理解,可以认为在正样本中出现越多的特征(组合)得分越高,反之在负样本中出现越多的特征(组合)得分越低。最终给一个< user, context, item>的打分是其命中的评分卡中所有条目的得分总和。
- 比如当一个中国客户来了,预测他对一款“榴莲馅水饺”的购买欲望 = SCORE(<春节、中国人、饺子>)+SCORE(<中国人,榴莲>)=5-3.5=1.5,即推荐系统猜他有可能会购买,但是欲望并不那么强烈。
LR(“评分卡”)模型的特点
- LR的特点就是强于记忆,只要评分卡足够大(比如几千亿项),它能够记住历史上的发生过的所有模式(i.e., 特征及其组合)。
- 所有的模式,都依赖人工输入。
- LR本身并不能够发掘出新模式,它只负责评估各模式的重要性。(通过Cross Entropy Loss + SGD实现)
- LR不发掘新模式,反之它能够通过regularization,能够剔除一些罕见模式(比如<中国人,于谦在非洲吃的同款恩希玛>),即避免过拟合,又减少评分卡的规模
LR(“评分卡”)模型的缺陷
LR强于记忆,弱于扩展。还举刚才的例子
- 中国人来了推饺子,美国人来了推火鸡,都效果不错,毕竟LR记性好。
- 但是,当一个中国人来了,你的推荐系统会给他推荐一只火鸡吗?
- 假设是几前年,当时中国人对洋节接受度不高。如果你的推荐系统只有LR,只有记忆功能,答案是:不会。因为<中国人,火鸡>属于小众模式,在历史样本罕有出现,LR的L1正则直接将<中国人火鸡>打分置0,从而被从评分卡中剔除 不要小看这个问题,它关乎到企业的生死,也就关系到你老板和你的腰包
- 记住的肯定是那些常见、高频、大众的模式,能够handle住80%用户的80%的日常需求,但是对小众用户的小众需求呢(某些中国人喜欢开洋荤的需求、于老师的超级粉丝希望和偶像体验相同美食的需求)?无能为力,因为缺乏历史样本的支持,换句话说,推荐的个性化太弱。
- 另一个问题是,大众的需求,你能记住,别家电商也能记住。所以你和你的同行,只能在“满足大众需求”的这一片红海里相互厮杀。套用如今最时髦的词,“内卷”。
综上所述,为了避开“大众推荐”这一片内卷严重的红海,而拥抱“个性化精准推荐”的蓝海,推荐算法不能只满足于记住“常见、高频”的模式(训练数据中频繁出现的),而必须能够自动挖掘出“低频、长尾”(训练数据中罕见的)模式。
如何扩展?
看似神秘,其实就是将粗粒度的概念,拆解成一系列细粒度的特征,从而“看山非山、看水非水”。还举饺子、火鸡的例子
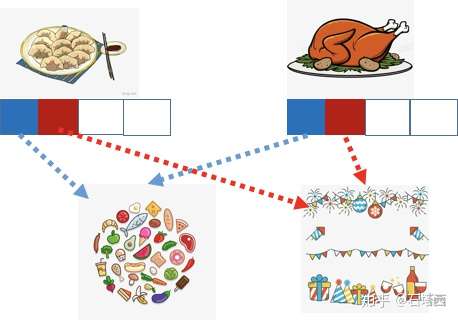 在之前讲记忆的时候,饺子、火鸡都是独立的概念,看似无什么相似性
在之前讲记忆的时候,饺子、火鸡都是独立的概念,看似无什么相似性- 但是,如果我们根据业务知识,将概念拆解,如上图所示。两个特征向量的第一位表示“是否是食物”,从这个角度来看,饺子、火鸡非常相似;两个特征的第二位是“是否和节日相关”,从这个角度来看,饺子、火鸡也非常相似。
- 喂入LR (评分卡)的除了粗粒度模式,<春节,中国人,饺子>和<感恩节,美国人,火鸡>,还有细粒度的模式,比如<节日,节日相关的食物>。这样一来,<春节,中国人,火鸡>这样的小众模式,也能够命中评分卡,并获得一个中等分数(因为<节日,节日相关的食物>在正负样本中都有出现,所以得分中等)。相比于原来被L1正则优化掉,小众模式也有了出头之日,获得了曝光的机会。
这样看来,只要我们喂入算法的,不是粗粒度的概念,而是细粒度的特征向量,即便是LR这样强记忆的算法,也能够具备扩展能力。
有没有自动扩展的方法?
但是,上述方法依赖于人工拆解,也就是所谓的“特征工程”,有两方面的缺点:
- 工作量大,劳神费力
- 人的理解毕竟有局限性。比如饺子、火鸡,拆解到食物、和节日相关这个级别,就已经算是细粒度了吗?还能不能从其他角度继续拆解? 既然人工拆解有困难、受局限,那能不能让算法自动将概念拆解成特征向量?如果你能够想到这一步,恭喜你,你一只脚已经迈入了深度学习的大门, 已经悟到了“道”,剩下的只是“技”而已。
第2环:Embedding
深度学习:无中生有
可以将深度学习形象地总结为“无中生有”:
- 当你需要用到一个概念的特征v(比如前面例子里的饺子、火鸡),或者一个函数f(比如阿里Deep Interest Network中的“注意力”函数、CNN中的filter),但是却不知道如何定义它们。
- 没关系,先将v声明为特征向量,将f声明为一个小的神经网络,并随机初始化。然后让v和f,随着主目标(最终的分类或回归loss),一同被SGD所优化。
- 当主目标被成功优化之后,我们也就获得了重要的副产品,i.e., 有意义的v和f。
- 这种“无中生有”的套路,好似“上帝说,要有光,于是便有了光”的神迹。以讹传讹,后来就变成了初学者口中“深度学习不需要特征工程”,给了某些人“我只做深度学习,不做机器学习”的盲目自信。 其实这种“将特征、函数转化为待优化变量”的思想,并不是深度学习发明的,早在用矩阵分解推荐的“古代”就已经存在了,只不过那时候,它不叫Embedding,而叫“隐向量”。
Embedding变“精确匹配”为“模糊查找”
深度学习对于推荐算法的贡献与提升,其核心就在于Embedding。如前文所述,Embedding是一门自动将概念拆解为特征向量的技术,目标是提升推荐算法的扩展能力,从而能够自动挖掘那些低频、长尾、小众的模式,拥抱“个性化推荐”的“蓝海”。
Embedding到底是如何提升“扩展”能力的?简单来说,Embedding将推荐算法从“精确匹配”转化为“模糊查找”,从而能够“举一反三”。
比如在使用倒排索引的召回中,是无法给一个喜欢“科学”的用户,推出一篇带“科技”标签的文章的(不考虑近义词扩展),因为“科学”与“科技”是两个完全独立的词。但是经过Embedding,我们发现“科学”与“科技”两个向量,并不是正交的,而是有很小的夹角。设想一个极其简化的场景,用户向量就用“科学”向量来表示,文章的向量只用其标签的向量来表示,那么用“科学”向量在所有标签向量里做Top-K近邻搜索,一篇带“科技”标签的文章就有机会呈现在用户眼前,从而破除之前“只能精确匹配‘科学’标签”带来的“信息茧房”

再回到原来饺子、火鸡的例子里,借助Embedding,算法能够自动学习到火鸡与饺子的相似性,从而给<中国人,火鸡>的组合打一个不低的分数,从而能更好地给那些喜欢过洋节的中国人提供更好的个性化服务。
第3环:高维、稀疏的类别特征
和机器学习的其他领域一样,推荐算法中所使用的特征主要分为两大类:
- 实数型特征:比如用户在过去1小时、6小时、1天之内点击的文章数
- 类别特征:比如文章的tag(e.g., 二战、德国、坦克),或者更细粒度的ID(e.g., UserId, DocId, AuthorId, ……) 这两类特征中,后者才是推荐算法的“一等公民”,按郭老师的话说,就是VIP中P,需要我们这群打工人小心伺候着。
“类别特征”更受欢迎
说类别特征是“一等公民”,一是因为它们更受欢迎,在推荐算法中无处不在:
- (1)推荐算法的基础是画像。无论是物料画像还是用户画像,都是高维、稀疏、离散的。比如以最常见的标签为例,文章标签(e.g., 二战、德国、坦克)是物料画像的一部分,用户过去1小时、6小时、1天点击文章所携带的标签是不同时间粒度的用户画像的一部分
- 高维:一个内容推荐系统中,有几万个标签是小意思
- 稀疏:尽管系统中有几万个标签,但是具体到某篇文章,某个用户,其携带的标签最多几十个而已。
- (2)现实场景中,“目标~特征”之间鲜有线性关系. 比如,在电商场景下,客户年龄对于其购买欲望的影响肯定不是线性的,而是各个不同年龄段(少年、青年、中年、老年)对购买欲望的影响因子截然不同. 所以,即便是实数特征,也经常将其分桶,离散化成类别特征
- 比如,实践中不是将“
用户过去1小时观看的视频数”当特征,然后其数值是3。因为这样一来,这个特征只能有一个影响因子(权重),显然无法兼顾”用户无论过去1小时看了3个”和”30个视频”这两类情况(前者可能因为用户喜欢看长视频,后者可能因为用户喜欢看短视频)。而是拿“用户过去1小时观看小于10个视频”当特征,其数值是1。另外,还有“用户过去1小时观10~50个视频”等其他特征,来应对其他情形。这样才更符合”目标~特征“非线性关系的本质。 - (3)线上工程实现,更偏爱高维、稀疏、离散的类别特征
- 稀疏意味着我们可以排零存储、排零计算,减少线上开销,保证线上预测的实时性。所以,有时候,我看一些公司的宣传材料,声称其算法的特征空间有几百亿,我就会心一笑。这种数字都是哄哄小白的,高维背后的潜台词一定是稀疏,否则你很难想像几百亿维度的稠密矩阵运算具备线上实时预测的实战价值。
- 举刚才的例子,为什么不用“特征是
用户过去1小时观看的视频数,数值是3”这个方案,而是采用“特征是用户过去1小时观看小于10个视频,数值是1”的方案?除了为体现“目标~特征”之间的非线性关系,还有一个重要原因就是后者的计算开销更小。以LR为例,,如果将所有实数特征都离散化,那么
只能是0或1,则LR在线上预测时简化为
,即找到非零特征对应的权重并累加,避免了乘法运算,计算速度更快。
“类别特征”享受VIP服务
说类别特征是“一等公民”,二是因为推荐系统中的很多技术都是为了更好地服务这些VIP而专门设计的
- 单个类别特征的表达能力弱。为了增强其表达能力,业界想出了两个办法
- 通过Embedding自动扩展其内涵。比如“用户年龄在20~30之间”这一个特征,即可能反映出用户经济实力不强,消费能力有限,又可能反映出用户审美风格年轻、时尚。这一系列的潜台词,偏学术一点叫“隐语义”,都可以借助Embedding自动学习出来,扩展了单个特征的内涵。
- 多特征交叉。比如单拿“用户年龄在20~30之间”一个特征,推荐算法还看不懂用户。再加一个特征,比如“用户年龄在20~30之间、工作是程度员”,推荐算法就明白了,“格子衬衫”或许是一个不错的选择。
- 前面已经说了,类别特征的维度特别高,几万个tag是小意思,再加上实数特征分桶、多维特征交叉,特征空间的维度轻轻松松就上亿。要存储这么多特征的权重和embedding向量,也是一笔不小的开销。
- 所以常见的应对策略是通过hashing trick限制最大特征数,可能会因为hash collision带来一些损失,但是在实践中影响并不是太大。
- 如果特征及其组合已经大到单机容纳不下,Parameter Server这样的架构应运而生。Parameter Server也正是利用了推荐、搜索中特征空间超级稀疏这一特点,从而在worker与server同步状态时,无须同步上亿级别的整个特征空间,而只需要同步batch中所覆盖的极少数特征的状态,通信开销大大降低。
- 类别特征本来就是稀疏的,“实数特征离散化”和“多特征交叉”使特征空间更加稀疏,而稀疏导致罕见特征(组合)受训机会降低。为了解决这一问题,业界也想出了很多办法
- FTRL这样的优化算法为每维特征自适应地调节学习率,DIN中还为每维特征自适应地调节正则系数
- 普通LR只能拿
都不为0的样本才能训练<
,FM借助矩阵分解的思想巧妙解决了这一难题,使得只有
与
的样本也能够参与训练
第4环:特征交叉
刚才在介绍第3环时已经说了,单个特征的表达能力太弱,所以需要交叉多个特征来增强模型的表达能力。
- 一阶手工交叉:LR。你没看错,一阶也可以交叉。FM之类的高阶自动交叉往往指的是多个特征的共现,而我们可以在预处理阶段计算一些统计意义上的交叉,比如用户喜欢的tag与物料所携带tag之间的重合度,然后将这些统计意义上的user/item交叉喂入LR,实践证明对模型效果提升明显。
- 自动二阶交叉:FM。
- 高阶交叉:DNN
- 混合交叉:Wide & Deep。回到第一环介绍的推荐算法的两大永恒主题,Wide侧其实就是一个LR,负责记忆;Deep侧先经过Embedding,再输入DNN,负责扩展。
其实目前主流的基于深度学习的排序算法都衍生自 Wide & Deep,比如DeepFM或DCN。
- 都有一个浅层模型负责记忆,再有DNN进行高阶交叉,负责扩展。
- 这也是我对DCN不感冒的原因。因为扩展功能已经由DNN负责了,所以另一个模块的任务只负责记忆,所以浅层模型如LR或FM足矣,DCN中crossing layer声称的“任意阶交叉”完全没有实现的必要。而且浅层模型必须简单,好起到了类似“正则”的作用,防止DNN过分扩展。因此在我看来,浅层模型实现超过3层的交叉,完全是不务正业。
第5环:Field & Pooling
什么是Field?
在不同的文章中,有不同的叫法,有的叫Field,有的叫Slot,还有的叫Feature Group,但是含义是相同的,都是若干关联特征的集合。
- 举个App的例子,用户安装、启动、卸载的App是三个Field;微信、支付宝、抖音、快手等都是Feature;三个Field共享一份App列表,可以说共享一份Vocabulary。
- 举用户历史的例子,“用户观看历史”是Field,看过的每个视频的DocId是Feature
原来我们的LR、FM都是只有Feature的概念,不涉及Field,不也干得好好的,怎么现在凭空多出来一个Field的概念?这还是与推荐系统“高维、稀疏的特征空间”这一特点分不开:
- 为了增强推荐算法的扩展性,我们需要将类别特征先进行Embedding,再接入DNN,进行高阶特征交叉。但是怎么接入DNN,变成了一个问题。
- 推荐算法的特征空间有上亿级别,每维特征再embedding成一个向量。如果将这些向量拼接起来接入DNN,DNN的输入层恐怕就要上十亿、百亿的规模,对于存储、计算都会造成不可想像的压力。
所以正确的姿势是
- 将相关Feature组织成Field,同一个Field的Feature Embedding需要Pooling成一个向量,即Field Embedding
- 多个Field Embedding再拼接起来,喂入DNN
- 因为Field的数目要少得多(按我的经验,少则几十,多则几百),DNN的输入层的规模大大降低,连带整个DNN的参数数量也大大减少。
怎么Pooling?
刚才说了,Pooling是将一个Field下的多个Feature Embedding压缩成一个向量的过程。而不同论文在压缩方法上也是各有千秋
- 普通的Mean/Max Pooling,代表算法YoutubeNet。在Youtube的召回、排序模型中,是将用户过去看过的视频、搜索过关键词,先经过embedding,再分别取平均,代表用户的观看偏好和搜索偏好
- Neural FM中,让属于同一field的feature embedding两两交叉,完成所谓的Bi-Interaction Pooling,用
表示feature embedding,则Field Embedding=
=
- 有的人认为“普通平均”中信息损失得太厉害了,所以要引入加权平均,而计算权重则是Attention最擅长的。比如阿里的Deep Intereset Network (DIN),在将用户过去购买过的item向量pooling成一个向量时,就通过计算candidate item与用户各历史item的attention score充当权重,然后将各历史item embedding加权平均成一个向量,以表达用户的历史购买偏好。这种加权平均的方式使用户的向量表达随不同的candidate item而变化,实现“千物千面”。
- 有一些Field,比如用户购买历史,其中的Feature存在时序关系。阿里的Deep Interest Evolution Network (DIEN)在Pooling时将时序关系也考虑进去。DIEN将用户历史上购买的item喂入一个RNN,则RNN中最后一步的隐层输出,就是能代表整个用户历史的压缩向量,从而完成了Pooling。这也是借鉴了RNN用于文本分类时的经典套路。但是,用户历史未必是等时间间隔的,这也就违反了RNN的使用前提,具体详情见我在《也评Deep Interest Evolution Network》一文中的讨论。
推荐算法的经典套路
充分理解了上面的5环,你就不难理解推荐算法中的经典套路
- 排序模型一般都衍生自Google的Wide & Deep模型,有一个浅层模型(LR或FM)负责记忆,DNN负责扩展
- 特征一般都采用类别特征。画像、用户历史天然就是高维、稀疏的类别特征。对于实数型特征,比如用户、物料的一些统计指标,在我的实践中,也通过分桶,先离散化成类别特征,再接入模型
- 每个类别特征经过Embedding变成一个向量,以扩展其内涵。
- 属于一个Field的各Feature Embedding通过Pooling压缩成一个向量,以减少DNN的规模
- 多个Field Embedding拼接在一起,喂入DNN
- DNN通过多层Fully Connection Layer (FC)完成特征之间的高阶交叉,增强模型的扩展能力。
总结
至此,“推荐5环”梳理完毕。尽管给这5个关键词,起名“五环”有凑梗之嫌,但是也还算贴切,因为它们之间环环相扣
- 记忆与扩展是推荐算法两大经典、永恒的主题。如何实现扩展?靠的是Embedding和特征之间的交叉。
- Embedding化“精确匹配”为“模糊查找“,大大提升了推荐算法的扩展能力,是”深度学习应用于推荐系统“的基石。
- 高维、稀疏的类别特征是推荐系统中的一等公民。为了弥补单个类别特征表达能力弱的问题,需要Embedding扩展其内涵,需要交叉扩展其外延。
- 高维特征空间直接接入DNN,会引发参数规模的膨胀。为解决这一难题,Field & Pooling应运而生。

通过将推荐算法梳理成这5环,再读论文,你会发现某些文章吹嘘的“显著提升、巨大进展”只不过是在某一环上进行的小小改进,而它们在其他环上的所采用的方法可能还有瑕疵,不值得借鉴。
而当你面临实际问题时,可以先将问题的难点拆解到五环中的某些环上,然后从那些环的研究成果中汲取解决问题的灵感,而不是胡子眉毛一把抓,急病乱投医。总之,有了这5环组成的知识体系,你头脑中的推荐算法就变得更加清晰,就可以吃着火锅,唱着歌,在你日常的调参、炼丹生活中谈笑风生,“啊啊,五环,……”
万变不离其宗:用统一框架理解向量化召回
推荐道作者石塔西, 万变不离其宗:用统一框架理解向量化召回
久别重逢话双塔
案例
复现总结
pytorch 复现经典的推荐系统模型, 如: MF, FM, DeepConn, MMOE, PLE, DeepFM, NFM, DCN, AFM, AutoInt, ONN, FiBiNET, DCN-v2, AFN, DCAP等
详情
- 1 实现
MF(Matrix Factorization, 矩阵分解),在 movielen 100k 数据集上, mse为0.853左右 - 2 实现
FM(Factorization machines, 因子分解机), 在 movielen 100k 数据集上 mse 为 0.852 (只使用u, i, ratings 三元组的因子分解机与mf其实是一样的, 故在相同数据集上的结果也差不多)- 参考论文:Steffen Rendle, Factorization Machines, ICDM 2010.
- 3 DeepConn 是第一篇使用深度学习模型利用评论信息进行推荐的文章,后面有很多改进工作如
Transnets(ResSys2017),NARRE(www2018)等 所以说,这篇非常值得认真阅读和复现的论文。 - 4
MMOE谷歌于2018年提出的一种多任务学习推荐模型,被用于YouTube视频推荐场景,效果良好,被业界广泛关注,实习时线上模型也采用了MMOE改进模型,叫PLE。 在census 数据集上进行实验,实验结果比原文差一点。- 实验结果(AUC):’income’:0.942, ‘marital’: 0.977 原文是0.941, 0.9927
- 参考论文:J.Ma et al, Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts, KDD 2018. Z.Zhao et al, Recommending What Video to Watch Next: A Multitask Ranking System, RecSys 2019. Hongyan Tang, Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations, RecSys 2020.
- 5
PLE实现,放在 mmoe_model 文件夹下了,使用时把mmoe.py中导入模型改为PLE就行。实验结果与MMOE差不多。- 实验结果(AUC):’income’:0.939, ‘marital’: 0.979
- 6 实现
DeepFM,在 sample Criteo(是对kaggle Criteo数据集的采样,有1000000个样本)数据上实验了一下,主要参考了这位的代码, 但模型部分写的不太对,又自己重新写了。- 实验结果(AUC): 0.743
- 参考论文:HGUO et al, DeepFM: a factorization-machine based neural network for CTR prediction, IJCAI 2017.
- 7 实现
NFM, 数据集同上,主要参考DeepCTR,- 实验结果(AUC): 0.710
- 参考论文:Xiangnan He et al, Neural Factorization Machines for Sparse Predictive Analytics, SIGIR 2017.
- 8 实现
DCN, 数据集及参考同上- 实验结果(AUC): 0.750
- 参考论文:Ruoxi Wang et al, Deep & Cross Network for Ad Click Predictions, ADKDD 2017.
- 9 实现
AFM, 数据集及参考同上- 实验结果(AUC): 0.715
- 参考论文:Jun Xiao et al, Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks, IJCAI 2017.
- 10 实现AutoInt, 数据集及参考同上
- 实验结果(AUC):0.717
- 参考论文:Weiping Song et al, AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks, CIKM 2019.
- 11 实现ONN,数据集及参考同上
- 实验结果(AUC):0.735
- 参考论文:Yi Yang et al, Operation-aware Neural Networks for user response prediction, Neural Networks 2020.
- 12 实现
FiBiNET,数据集及参考同上- 实验结果(AUC):0.698
- 参考论文:Tongwen Huang et al, FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction, RecSys 2019.
- 13 实现
Wide&Deep,数据集及参考同上- 实验结果(AUC):0.728
- 参考论文:Heng-Tze Cheng et al, Wide & Deep Learning for Recommender Systems, RecSys workshop/dlrs 2016.
- 14 实现
DCN-v2,数据集及参考同上- 实验结果(AUC):0.748
- 参考论文:Ruoxi Wang et al, DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems, WWW 2021.
- 15 实现
AFN,数据集及参考同上- 实验结果(AUC):0.720
- 参考论文:Weiyu Cheng et al, Adaptive Factorization Network: Learning Adaptive-Order Feature Interactions, AAAI 2020.
- 16 实现
DCAP,数据集同上- 实验结果(AUC):0.709
- 参考论文:Zekai Chen et al, DCAP: Deep Cross Attentional Product Network for User Response Prediction, CIKM 2021.
TensorFlow Recommenders
TensorFlow Recommenders 现已开源,让推荐系统更上一层楼
【202-10-19】谷歌推出 TensorFlow Recommenders (TFRS),这款开源 TensorFlow 软件包可简化构建、评估和应用复杂的推荐模型。TensorFlow Recommenders (TFRS)
TFRS 使用 TensorFlow 2.x 构建,有助于:
- 构建和评估灵活的 Candidate Nomination Model;
- 将条目、用户和上下文信息自由整合到推荐模型;
- 训练可联合优化多个推荐目标的多任务模型;
- 用 TensorFlow Serving 高效利用生成的模型。
TFRS 基于 TensorFlow 2.x 和 Keras,十分易于上手,在采用模块化设计的同时(您可以自定义每个层和评价指标),仍然组成了一个强有力的整体(各个组件可以良好协作)。在 TFRS 的设计过程中,我们一直强调灵活性和易用性:合理的默认设置、直观易行的常见任务以及更复杂或自定义的推荐任务。
安装
pip install tensorflow_recommenders
电影推荐示例
用MovieLens数据集训练一个简单的电影推荐模型。数据集所含信息包括用户观看了哪些电影以及用户对该电影的评分。
将使用这一数据集构建模型,预测用户已观看和未观看的电影。此类任务通常选择双塔模型:一个具有两个子模型的神经网络,分别学习 query 和 candidate 的表征。给定的 query-candidate 对的得分 (score) 只是这两个塔的输出的点积。
query塔的输入可以是:用户 ID、搜索关键词或时间戳;对于 candidate塔则有:电影片名、描述、梗概、主演名单。在此示例中,query塔仅使用用户 ID,在 candidate塔仅使用电影片名。
数据集的所有可用特征中,最实用的是用户 ID 和电影片名。虽然 TFRS 有多种可选特征,但为简单起见,我们只使用这两项。
只使用用户 ID 和电影片名时,我们简单的双塔模型与典型的矩阵分解模型非常相似。我们需要使用以下内容进行构建:
- 一个用户塔,将用户 ID 转换为用户 embedding 向量(高维向量表示)。
- 用户模型:一组描述如何将原始用户特征转换为数字化用户表征的层。我们在这里使用 Keras 预处理层将用户 ID 转换为整数索引,然后将其映射到学习的 embedding 向量
- 一个电影塔,将电影片名转换为电影 embedding 向量。
- 一个损失函数,对于观看行为,最大化预测用户与电影的匹配度,而未观看的行为进行最小化。
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
# Ratings data.
ratings = tfds.load("movie_lens/100k-ratings", split="train")
# Features of all the available movies.
movies = tfds.load("movie_lens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
})
movies = movies.map(lambda x: x["movie_title"])
class TwoTowerMovielensModel(tfrs.Model):
"""MovieLens prediction model."""
def __init__(self):
# The `__init__` method sets up the model architecture.
super().__init__()
# How large the representation vectors are for inputs: larger vectors make
# for a more expressive model but may cause over-fitting.
embedding_dim = 32
num_unique_users = 1000
num_unique_movies = 1700
eval_batch_size = 128
# 用户模型
# Set up user and movie representations.
self.user_model = tf.keras.Sequential([
# We first turn the raw user ids into contiguous integers by looking them
# up in a vocabulary.
tf.keras.layers.experimental.preprocessing.StringLookup(
max_tokens=num_unique_users),
# We then map the result into embedding vectors.
tf.keras.layers.Embedding(num_unique_users, embedding_dim)
])
# 电影模型
self.movie_model = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.StringLookup(
max_tokens=num_unique_movies),
tf.keras.layers.Embedding(num_unique_movies, embedding_dim)
])
# 目标+评估指标 Retrieval
# The `Task` objects has two purposes: (1) it computes the loss and (2)
# keeps track of metrics.
self.task = tfrs.tasks.Retrieval(
# In this case, our metrics are top-k metrics: given a user and a known
# watched movie, how highly would the model rank the true movie out of
# all possible movies?
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(eval_batch_size).map(self.movie_model)
)
)
# 训练过程查看
def compute_loss(self, features, training=False):
# The `compute_loss` method determines how loss is computed.
# Compute user and item embeddings.
user_embeddings = self.user_model(features["user_id"])
movie_embeddings = self.movie_model(features["movie_title"])
# Pass them into the task to get the resulting loss. The lower the loss is, the
# better the model is at telling apart true watches from watches that did
# not happen in the training data.
return self.task(user_embeddings, movie_embeddings)
model = MovielensModel()
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
model.fit(ratings.batch(4096), verbose=False)
# 对模型的推荐进行 Sanity-Check(合理性检验),我们可以使用 TFRS BruteForce 层。BruteForce 层以预先计算好的 candidate 的表征进行排序,允许我们对所有可能的 candidate 计算其所在 query-candidate 对的得分,并返回排名最靠前的电影 (query)
index = tfrs.layers.ann.BruteForce(model.user_model)
index.index(movies.batch(100).map(model.movie_model), movies)
# Get recommendations.
_, titles = index(tf.constant(["42"]))
print(f"Recommendations for user 42: {titles[0, :3]}")
工业界实现
抖音推荐
常见问题
常见问题
- (1)为什么你的内容播放量低?
- 初期没有精准标签的时候,内容播放量普遍比较低。但保持内容属于垂直的前提下,坚持发布高质量的视频,系统就会打上精准的标签,下次推送的时候会更加精准
- (2)为什么视频走着走着,播放量就不涨了?
- 抖音推送的流量机制,分为200~500,3000~5000,1万到2万,10万到15万,30万到80万……
- 停留在了5万的播放量,然后不动了,为什么?视频突破了初始流量池,但并没有突破到更大的流量池里
- 视频的数据反馈,不足以让你到一个更大的流量池里。遇到这种情况,大家就不用一直盯着那个视频看了,继续更新就好。
- (3)正确的起号过程是什么样的?
- 一开始发视频,就千赞,万赞吗?– 非也
- 很厉害的博主和mcn机构,他们最初在做号的时候,也是十几个赞,几十个赞啊这样子,可能20个作品中,突然有一条视频爆了,然后慢慢的,做出了千赞,做出来万赞。
推荐目标
【2023-5-22】抖音推荐算法第一课
用户行为的多样性:
- 点赞、评论、完播、播放时长、播放完成度、不感兴趣等
服务对象的多样性:内容消费者(最主要)、视频创作者、平台利益与导向等
- 内容消费者的目标:即用户的对平台的满意度、忠诚度,短期如时长,长期如留存等
- 视频创作者的目标:短期如投稿活跃度、视频高热率等,长期如高价值关系等
- 平台目标:原创、合法等,基本与社区公约一致
推荐主要通过两种模型来实现
- 预测模型:预估用户的具体行为,如点赞模型、评论模型、完播模型等,并应用在推荐的各个环节中
- 价值模型:结合预测模型的结果,计算每个视频的每一次展现在多目标下的总价值,从而达到整体价值的最大化
由于目标与手段的复杂度,基本只需要考虑最终的最主要的衡量标准:用户体验最大化
如何获取更多流量?与推荐系统目标契合
播放量重要还是点赞量,还是赞比?
- 播放量、点赞量、赞比(点赞数/播放数),都是上述预测模型的特征,但也仅仅是众多特征中的一个。
- 模型最主要参考的是用户的实际行为,即「谁」对「哪个」视频点了赞。
问题
- ·被推荐的参考标准
- ·什么样的视频更容易被推荐
- ·什么内容容易受推荐
- ·什么样的作品会被推荐
- ·咋有流量
- ·流量分配,推荐内容类型,粉丝点在哪里
- ·如何优化能获取更多流量
- ·如何才能上热门
- ·爆款内容
- 如何由数据上判断为值得推荐的视频?
最直接的回答:用户喜欢的内容就有流量。
- 后验来看,视频质量越高的内容流量越高,能反映视频质量的指标:点赞率、完播率、播放完成度、评论率、分享率等,
但综合考虑,且可以与自己相似时长、质量,或者他人相似时长、质量的内容横向比较。
答疑
- 有账号基础流量池吗?有,但很少. 没有账号权重
- 创作方向改变(美食变生活),会有影响 —— 视频主题冷启动、粉丝触达
- 哪个指标更重要?消费者角度,完播、分享?最终目标是用户长期留存
- 推荐系统并不打压、鼓励高频/低频投稿
视频推荐阶梯
抖音播放推荐量的阶梯机制
- 初期刚发布视频,会有200~500的流量,然后随着用户的反馈数据来判断:推向更大的流量池还是中断推送。

抖音官方
- 不管有没有粉丝,视频发出来都会有200~500个初始播放
- 那为什么播放量只有几十啊?难道说系统没有给我推荐200~500个人吗?
- 新账号视频发出去,会把视频给到200~500个人看,但这200~500人当中,只有一小部分人会在你的视频上停留足够长时间, 这部分的播放才是后台看到的播放——
有效播放量。
抖音系统智能推荐算法–叠加算法
抖音的叠加算法依次为:
- (1) 首次分发——智能分发——200~500流量阶段
- 根据内容标签匹配分发给有该兴趣标签的人群,在可能80万播放量以下的时候,话题标签还是很重要,一定要重视。
- (2) 二次分发——数据加权——1K~5k流量阶段
完播率、点赞率、评论率和转发率都还不错的话,进入二级流量池- 具体标准:3.5%以上的点赞比和0.35%以上的评论比,以及45%的5s完播率,平台会进行下一级推荐。
- 举个例子,1000的浏览量,有35个赞,3~4条评论,有450个人看完了前5秒的视频。这个视频进入下一轮的推荐,到1000~5000的这样一个流量池。
- 小技巧:可能说有的小伙伴1000浏览量的视频有40~50的赞同,评论只有1~2条,你就再写他个3条,对不对如果不知道写什么,就去网易云找一首自己喜欢的音乐,然后看评论,找那种高赞评论,你改改看看能不能放到你那个里面去用。
- (3) 三次分发——叠加推荐– 80w
- 只要二次分发数据表现好,就会开始指数级叠加分发,进入播放增长的这样一个快车道。播放量一直往前跑,疯狂的在涨赞,涨粉,涨评论,涨转发。
- 在80万这个流量池以下的时候,精准标签还是很重要的,一旦突破了80万的这个流量,那个时候标签就不是那么重要了,平台就会就进行全网推荐就是在抖音推荐页刷视频,你会刷到很多之前没有关注过,没有点赞过的领域。是因为这个视频已经去标签化了,开始不仅仅在这种视频的用户群体里面去传播了。反而突破了界限给到更多的人看了,就是到了全网热门的这样一个爆款视频。
作者:李晓楠的好奇心
【2023-5-18】抖音视频推荐-叠加算法图解
核心指标
抖音智能推荐播放量的4个权重:完播率、评论率、转发率、点赞率。
- 视频能不能进行多次分发很重要的一个点。
抖音会通过完播率、评论率、转发率、点赞率这4个核心要素,决定视频是否能够进入更高的流量池。
完播率的权重最大,其次是评论率、转发率和点赞率。- 包括大家可能还关心
复播率、关注率等等这些东西。不过复播率和关注率,跟账号涨粉和系统“挖坟”有关,跟叠加推荐机制的影响不会很大。
指标提升技巧
完播率:- ① 视频控制在15~45秒
- 抖音平台统计,用户停留时间最长、数据最好的是30秒以内视频,占比是最高。鼓励大家要去做一个45秒以内的视频。
- ② 引导读者看到最后:
- 开头告诉读者看这个视频价值
- ”掌握这个学习方法,助你逆袭到985院校 ”;
- ”今天分享给你八个方法,让你学习比玩手机还有精神 ”。
- 激发读者的好奇心,引导他看到最后
- “原谅我看到46秒的时候绷不住了”;
- “看到最后有惊喜,有彩蛋”;
- “倒数第二条最重要”;
- “36秒处有猛料”
- 开头告诉读者看这个视频价值
- ① 视频控制在15~45秒
评论率- (1)视频最后引导读者在评论区互动
- “你还有什么更好的学习方法,欢迎在评论区留言”;
- “这几个学习工具,你最喜欢哪一个,在评论区告诉我”;
- “这3个景点,你最想去哪一个呢?快在评论区@你的小伙伴一起吧”。
- (2)积极回复读者的留言
- 一旦有读者评论,积极回复,一方面可以增加系统的推荐,另一方面也可以激发其他用户的评论欲望。
- (3)找身边的朋友帮忙多写几条
- 对标爆款视频的神评,也可以在网易云音乐的高赞评论里,摘几句出来,放在自己的评论区。
- (1)视频最后引导读者在评论区互动
转发率- 转发率不太好引导,主要在内容质量方面下功夫。
- 输出一些干货,增加信息密度,戳中大众的痛点需求,用户一看,觉得这个视频很有用,然后他可能就会保存下来,转发到朋友圈。
- 再就是就输出一些有社交价值的内容,可以是很多人都讨论和关注的一个热点事件,这样就会有一种分享的冲动,这类视频的转发率也会很高。
- 在视频中说:“如果你觉得这个视频有帮助,请转发给身边有需要的朋友”
- 转发率不太好引导,主要在内容质量方面下功夫。
点赞率- 如果视频特别有价值,比如有干货;好玩有趣;戳泪点;有特点。那么大家会点这个小星星,因为点小星星的话,大家已经养成一个习惯了。
- 在这个基础上,也可以引导读者点赞
- “一定要收藏打卡,看完有收获给我个赞”;
- “如果喜欢我的视频的话,记得给我点赞收藏关注我哟”;
- “这是我平时都不舍得分享的内容,还不点赞支持我一下吗?”
短视频运营建议
- 1、想获得持续推荐,最根本的还是要保证视频质量
- 2、学会分析爆款视频,取其精华,为我所用
抖音系统审核机制
抖音视频发布后的双重审核机制
- 双重审核是机器审核和人工审核
- 机器审核主要看3点:
- 看内容(文案、场景)有没有搬运,如果跟别人的作品重复相似的话,就会进行低流量推荐。
- 看视频是单纯分享还是在搞营销,如果是在发广告搞营销,会直接把你的视频拦截。
- 看视频是否涉及到政治和黄赌毒和广告违禁词,凡是违背宪法,法律法规的东西都会被拦截。
- 人工审核是干嘛呢?
- 如果作品之前被机器审核出来,有过违规行为了,然后你改了改,发了改还是没有通过,这个时候人工会过来再去做逐个做细致的审查。
- 人工审核的变数就比较大了,可能在一天当中,有不同的人对作品进行审核,他对你视频的评判标准也是不一样的。就比如视频跑的好好的,突然停掉了,很可能是背后换了人工审核,他发现了之前人工没有注意到的问题。上去就把你拦截了。
完整审核流程
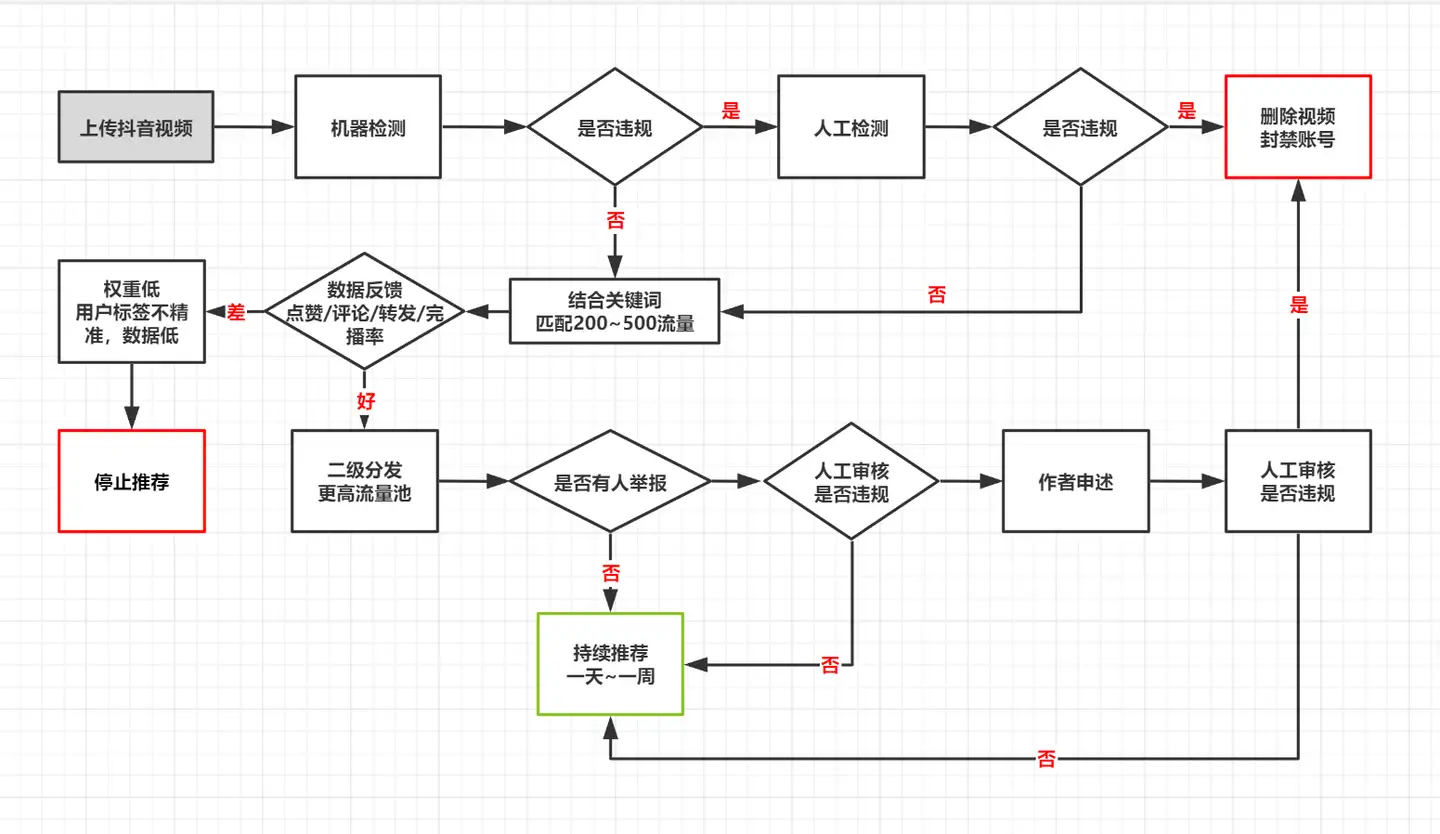
提高视频审核成功率的小建议:
- 减少画面复杂度,越简单越好,最好是固定场景,账号画面各个方面都保持简单
推荐竞赛
H&M Personalized Fashion Recommendations
- 【2022-6-3】kaggle H&M 推荐大赛前排方案总结
第一名方案的思路非常流畅,尝试了不同的召回策略,排序阶段使用了特征工程+GBDT的搭配,看上去非常简单,但是效果却很惊艳。
- 衣物消费随潮流变化快、具有明显的季节性等特点,所以主要通过召回最急流行度(销量)比较高的商品
- 另一方面,也尝试了召回一批新品,但是排序模型并不能把这些新品排到top12,给出的解释是这些新品缺乏历史的交互信息。
召回策略包括:
- 复购,交互数据中可以发现有很多用户复购的行为,根据用户历史购买行为,召回购买数量topN的商品。
- itemCF,经典的协同过滤方法,把与用户购买过的商品“相似的”商品推荐出来
- 同款商品不同型号,有些用户有换货的行为,比如换一个大一号的鞋子等。
- 流行度topN,按销量推荐topN
- Graph embedding召回,使用deepwalk, node2vec, LINE, ProNE来产生用户与商品的embedding,然后使用embedding进行向量召回。
- logistic regression with categorical information, 训练一个罗辑回归模型,从hot-1000中粗排出topN的商品
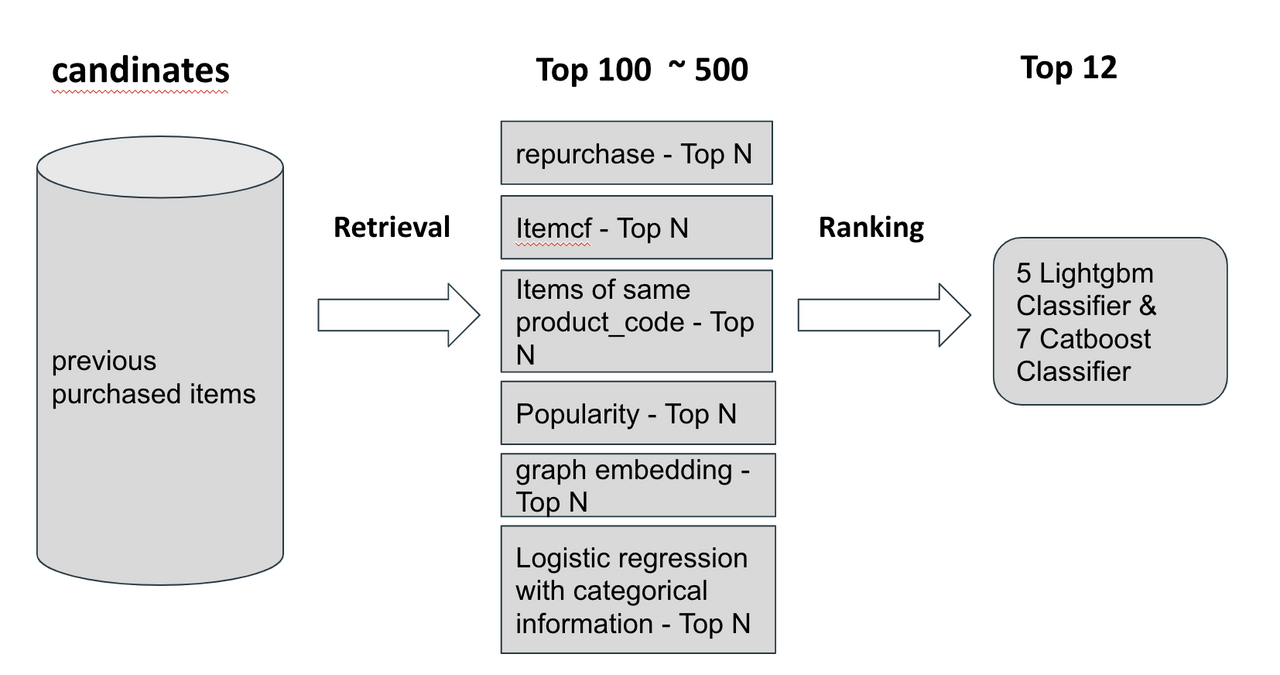
如何理解用户与商品的交互信息一般被认为是推荐系统中最重要的问题,所以他们的在特征工程阶段最主要的特征是用户与商品的交互特征, 图文信息的理解并没有帮助他们排序模型的提升,但是在真实的场景中,这些图文信息对于冷启动的投放有着重要的意义。
大约有50%的用户在过去三个月没有在平台买过任何商品,对于这些用户,考虑历史累积的统计特征(比如历史上购买过某种品类衣服的数量),而对于活跃的用户,则统计其近期(上礼拜,上个月,上个季度)的消费情况。
排序的详细特征如下:
- count类特征,例如用户购买过候选商品的数量、次数,用户某买过候选商品品类的特征,统计的时间窗口大小可以是上礼拜,上个月,上个季度,统计数量时,也有按照时间加权(购买时间越久的,权重越小)
- time类特征,用户上一次消费的时间与当前的时间差,用户上一次购买该商品的时间当前的时间差(如果很短,可以刻画用户的退换货的期望,比如一般来演电商平台都有七天无理由,超过了七天,用户退换货的可能就会很小)。对应地,商品侧地时间特征同样重要,比如商品上次成交的时间到现在的时间差(可以看出商品是否下架),最早交易的时间差(预估上市时间)等。
- Mean/Max/Min特征,即用户侧与商品侧的聚合特征,如用户历史购买的商品的价格的均值、最值(刻画用户的消费能力),购买某商品的用户年龄的均值、最值。
- Difference/Ratio特征,如用户年龄与购买候选商品的用户平均年龄之间的差值,用户历史购买候选商品所属品类占所有购买商品数量的比例。
- Similarity,来自召回侧的特征,例如item2item的协同过滤的分数,item2vec产生的cosine similarity,user2item(ProNE)产生的similarity。
对于排序模型他们使用了六周的数据来训练模型,最后一周的数据用来作为验证集,为每个用户召回100个候选商品,这样的实验设置,可以保持交叉验证与线上公榜的成绩变动基本稳定, 所以工作的重点就可以放在优化单个lightgbm模型。在这里详细说明一下整个召回以及排序的流程,整个流程虽然简单,但是很多细节却可圈可点。 为了简化,假设交易数据给定的最后一周为第17周,那么我们需要为未来的一周(即第18周)进行推荐,第17周则用来作为验证集,11-16周作为训练集。
个性化推送
运营作为连接用户和产品的桥梁,在推广拉新、活动促销、提升活跃/留存、流失用户召回各个环节都需要进行用户触达。
- 高效、精准的触达不仅能提高转化,降低成本,同时也是运营能力的体现。
参考
营销指标
关键指标:
- 到达率(基础)
- 点击率(过程)
- 转化率(结果)
- ROI(价值)
到达率(基础)
到达率
到达率 =(用户接收 / 推送数量)*100%
到达率是做成效评估的基础指标
影响到达率低有两个主要原因:
- 技术通道,即从自身网关传输到服务商之间有流失;
- 服务商通道:用户退订了短信。
清楚这次营销的到达情况后,作为基数再去看其他的指标。
点击率(过程)
点击率
点击率 = (点击人数/ 用户接收数)*100%
在到达数据准确的基础上,点击率是重要过程指标,验证此次触达是否吸引人。
点击率低可以具体看是哪一组的点击率低,对比用户类型,发送时间和内容分析原因。
转化率(结果)
转化率
转化率 =(目标行为人数 / 用户点击数)*100%
转化率是重要的结果指标,直接影响这次触达的产出情况。
转化率低主要看吸引来的用户到底在哪个环节流失率最高,找到最高流失的环节进行优化。
ROI(价值)
ROI
ROI = (新增收入/投入费用)*100%
投资回报率即促销活动投入1元,能产生多少倍的收入增量。
- ROI衡量这次营销值不值得,并不决定着这次营销的好坏,只要过了盈亏平衡点,投入得越多,活动成效越好。
营销工具
2种主流用户触达工具:SMS短信 和 App Push消息推送。
消息推送主要场景
- 应用内消息推送:Push
- 短信推送:通过通信服务商推送短信
| 营销工具 | 介绍 | 使用场景 | 优点 | 注意 |
|---|---|---|---|---|
| SMS短信 | 发送短信,触达效果较好,适用 | 推广拉新、促销活动、流失用户召回 | 1. 触达率高,有效号码主人一般都会看一眼 2. 使用场景丰富 |
1. 衡量投入产出 2. 容易被投诉 |
| APP Push | APP内发送推送消息 | 促销活动,促活/留存 | 成本低、效果好 | 场景有限 可能提升卸载率 |
应用内推送
消息推送
- 在手机的通知栏上会显示的一条通知信息。
-
可以有效激活用户,提升用户活跃。
- 优点:量大,精准,免费。
注意:
- 未安装App用户无法触达。
- 高频发送会对用户造成打扰,招致卸载。
使用场景:
- 促销活动、提升活跃/留存等多种场景。
短信推送
SMS短信
短信凭借着优秀的触达效果,成为最受欢迎的营销工具之一。
- 优点:触达率高,若非闲置号码,收到手机短信的人基本都会看一眼。
注意:单条3分-5分,注意成本控制。易招致投诉。
使用场景:
- 高频应用与推广拉新、促销活动和流失用户召回。
推送时机
不同产品类型解决不同用户需求。外卖,约车,新闻,和游戏等等都有很清晰的使用场景。在用户即将使用此类型产品前进行营销触达,可以覆盖更多的目标用户。
- 网易两款新游的短信推广,均选择在游戏高峰期周六晚,用户最为活跃度的时间进行触达。
APP启动触发用户数分布
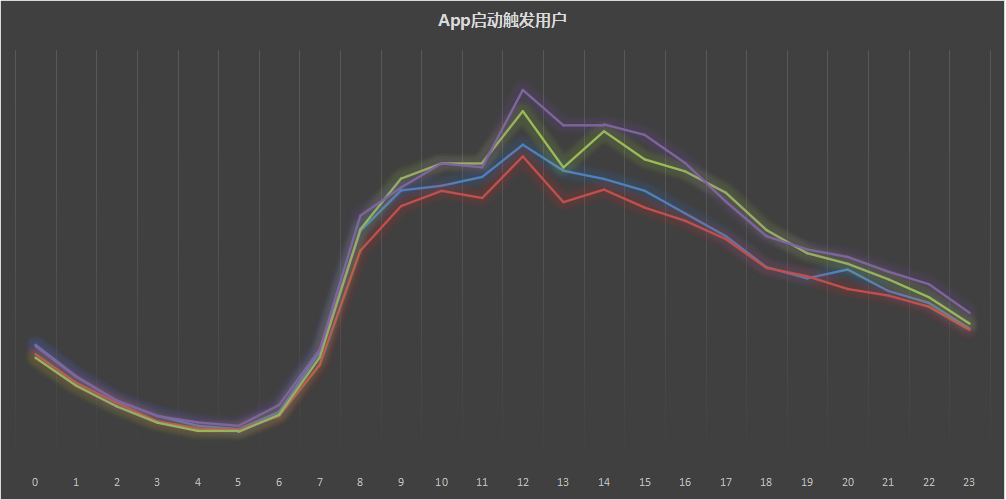
- 在9点开始,通过几轮不同时间段对比,即可选出点击率最高的间段作为最优触达时间
用户分组
根据不同目的, 通过控制变量,分设不同用户组别进行精准营销,提高转化率。
空白对比:设定营销组与空白组,通过营销与自然转化的数据对比,来判断营销事件对用户行为是否有影响,有多少相对影响。用户属性:地理位置,活跃用户,系统版本,性别、年龄段、星座,生命周期和业务属性对用户进行精准营销。优惠力度对比:通过不同的优惠力度对比,判断用户对价格的敏感度,控制最佳投入产出比。文案对比:通过不同文案的对比,来选出用户最容易接受,转化效果最优的文案。
营销内容
方式、时间、分组都是触达的辅助工作,转化率的高低和文案能力直接挂钩,优秀的文案会大幅度提高打开率。
无论是短信还是push,高转化的营销文案都有这么几个特征:相关、数字、简洁。
- 相关:让用户觉得这条短信与自己有关,例如结合利益点奖励或重要事项提醒。
- 数字:用数字能把事情说得更精准,更直观。
- 简洁:善用标点符号分割句子,信息点别超过2个。
短信结构
SMS短信结构:
- 【签名】+(文案)+(短链)+退订。
切记不要把你所有的想法都怼给用户
如果短信

触达目的:
- 促新用户观影;
- 促用户充值(话费,加油卡,游戏);
- 促购买(旅行箱);
- 下载APP;
- 关注微信服务号;
一口气给了用户5个动作,结果就是用户什么都不想做。
- 短信只是发给用户一个邀请:来我们的活动页看看,打开App瞧瞧。
少即是多,给文案定1个可行的小目标,让用户进行1-2个动作,例如促使用户打开APP,参加活动。

短链接:把产品或活动制作成短连接,在文案中引导用户点击。注意埋点,监控短信发出后的点击量。
- 短链对提升转化有着很重要的作用。例如这条的流失用户召回短信,虽然很走心,若能加上App下载短链,引导用户直接点击下载App,效果会更好。
最后,总字数控制在70个字符以内为一条短信,简洁且降低营销成本。
Push结构
Push结构:通知标题+推送内容

通知标题:
- 默认为APP名称,支持自定义内容。
由于安卓通知中心能展示的字数较少,自定义通知标题的使用率较高,能让用户立即看到推送内容。例如电商直接用活动主题作推送标题。
推送内容:
- 首先,要做到精准,让推送的用户看到自己想要的东西。
- 其次,在用户看到推送的1~2秒,即第一行字内吸引住用户,毕竟目的是让用户点击这条推送。
- 最后,设置好转跳至APP落地页,从细节提升用户体验。
垃圾短信
【2023-5-19】如何搞掉发骚扰短信的公司?如何有效的投诉电信运营商
- 1、打开工信网,电话:010-12300
- 工信部这个投诉网站每天都会处理各类投诉请求,一般会1-2天给你反馈或者直接转给被投诉企业。
- 过两天就会给你打电话然后给你道歉,就再也没
- 2、输入短信前八位
- 3、打12321投诉这家公司
问题:短信端口会直接拉黑你的号码,可能其他软件的验证码就收不了
解法:被运营商拉黑之后,个人无法解开,去询问运营商也是不会承认的。可以拨打12345说你收不到政务短信验证码,他们会找运营商查原因,然后给你解开
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
