- LLM 时代的对话系统何去何从
- 结束
LLM 时代的对话系统何去何从
原文
- 【2023-10-26】大模型时代对话系统何去何从
- 【2024-11-13】大模型时代对话系统(续)
- 公众号版本,旧版, 新版对话系统总结部分不够清晰、系统
引言
行业巨变,物换星移,阁中帝子今不在,旧朝老臣空叹息:沧海桑田,何去何从?
(0)行业变革
预训练语言模型通用化蜕变后,跨界改变甚至“破坏”了N多下游应用生态,比如搜索、办公、创作、编程等,今天谈谈名噪一时的对话系统…
往期文章智能交互复兴:ChatGPT +终端(奔驰/Siri)= ?中,提到了大模型引领的AIGC海啸冲击到的各行各业。由内到外,按照三层划分:模型层→模态层→应用层
- 模型层:文本领域(GPT系列)、图像领域(扩散模型系列)、视频、建模、多模态等
- 模态层:文本、语音、图像、视频、行为、理解、策略、工具等,其中文本和图像最为惊艳
- 应用层:智能对话、AI作画最为亮眼,传统行业正在被逐步颠覆,如搜索、问答、智能办公、内容创作,同时,应用商场、互联网、数字人等也被波及
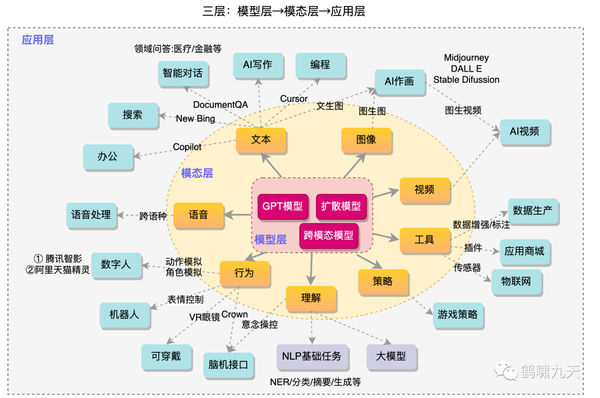
上图整理于2023年6月,非最新
从业者都在焦急的尝试自我革命,晚了就会被人革命。
面对这股AIGC浪潮,对话系统从业者“既喜又惊”。
(1)喜从何来:对话系统沉浮录
【2019-5-13】聊天机器人:困境和破局
文因互联的鲍捷老师曾给出一个人工智能三次热潮的曲线图,人工智能至今经历了三次大热潮。

而这一轮人工智能热潮,是伴随着大数据和深度学习的兴起。
- 深度学习技术最早期的研究起始于上世纪六十年代的感知器,而直到最近的十年,随着软件和硬件的成熟,深度学习才取得了爆发式的进步,在多个领域例如图像识别,语音识别等都突破了人类最好的成绩。
- 火热的人工智能带来了很多机会,也带来了很多问题。资本的大量涌入,使得市场上涌现了一大批 AI 初创公司,同时媒体的大肆宣扬,也使得大众的胃口和期望被吊得越来越高。
- 普通的技术成果已无法吸引读者的关注,很多媒体就开始用夸张的标题和内容来吸引眼球,比如说「人类要被机器人取代」「重磅!机器开始威胁人类」等等。
- 更不用说像 Sophia 这种伪 AI 的出现,使得人们觉得 Sophia 就是人工智能应该有的样子。而且,就好比 AlphaGo 并不能给人类端茶倒水一样,在一个特定领域的优秀表现,并不能代表 AI 技术无所不能。
- 谷歌在 2018 年开发者大会上演示了一个预约理发店的聊天机器人,人们在大呼惊艳的同时,自然而然的觉得人工智能技术应该可以上天入地,做到任何事情,甚至取代人类。
(1.1)对话系统复兴
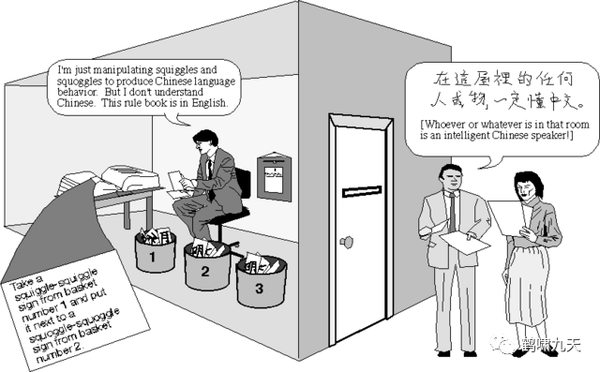
对话系统始于艾伦·图灵(Alan Turing)在 1950 年提出的图灵测试 ,如果人类无法区分和他对话交谈的是机器还是人类,那么就可以说机器通过了图灵测试,拥有高度智能。
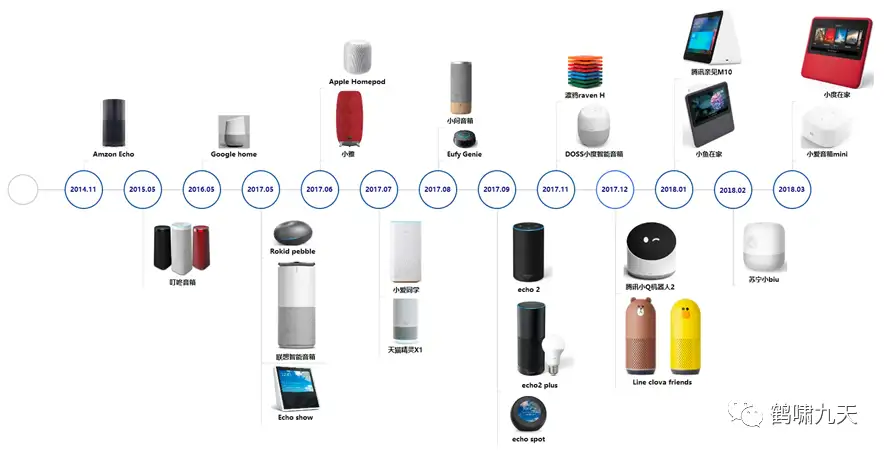
一图总结对话系统发展史:
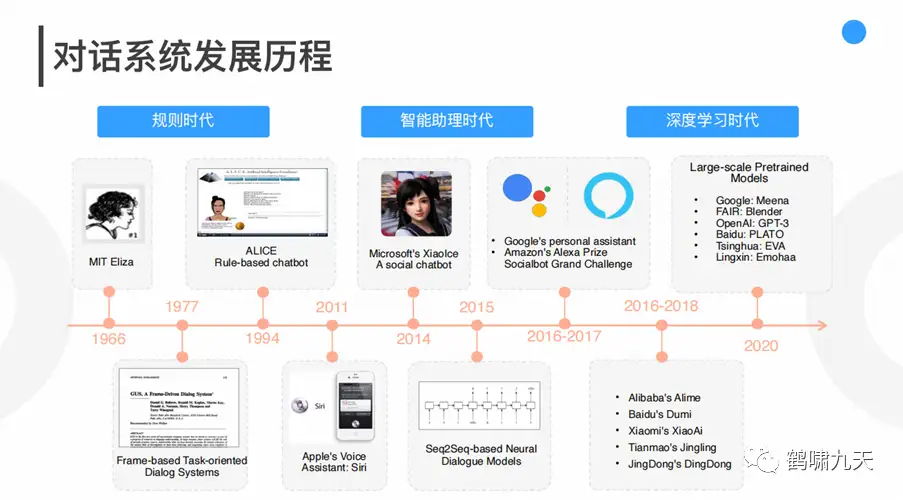
技术实现上先后经历了三个时期:
① 第一代对话系统:基于规则
- • 1966 年 MIT 开发的 ELIZA 系统 是一个利用模版匹配方法的心理医疗聊天机器人
- • 1970 年代开始流行的基于流程图的对话系统,采用有限状态自动机模型建模对话流中的状态转移。
- • 优点是内部逻辑透明,易于分析调试,但是高度依赖专家的人工干预,灵活性和可拓展性很差。
② 第二代对话系统:基于统计学习(数据驱动)
- • 2005年,剑桥大学Steve Young 教授的基于部分可见马尔可夫决策过程(Partially
Observable Markov Decision Process , POMDP)的统计对话系统;鲁棒性上显著地优于基于规则的对话系统,它通过对观测到的语音识别结果进行贝叶斯推断,维护每轮对话状态,再根据对话状态进行对话策略的选择,从而生成自然语言回复。 - • POMDP-based对话系统采用了增强学习的框架,通过不断和用户模拟器或者真实用户进行交互试错,得到奖励得分来优化对话策略。统计对话系统是一个模块化系统,它避免了对专家的高度依赖,但是缺点是模型难以维护,可拓展性也比较受限。
③ 第三代对话系统:基于深度学习(大量标注数据)
- •延续了统计对话系统的框架,但各个模块都采用了神经网络模型。
- • NLU:模型从之前的生成式模型(如贝叶斯网络)演变成为深度判别式模型(如CNN、DNN、RNN)
- • DST:对话状态的获取不再是利用贝叶斯后验判决得到,而是直接计算最大条件概率
- • DP:对话策略的优化上也开始采用深度增强学习模型
- • Facebook研究者提出了基于记忆网络的任务对话系统,为研究第三代对话系统中的端到端任务导向型对话系统提出了新的方向
- 2016年是对话系统复兴元年,各类神经网络模型接踵而至,NLU(自然语言理解)技术不断迭代升级,从attention到seq2seq,再到transformer,以及预训练语言模型BERT/GPT等,NLP类各类子任务的榜单不断刷新,与之关联的领域及下游应用——对话系统也随之备受关注。
怀着对下一代人机交互模式CUI的美好憧憬,各大厂接下来几年纷纷布局对话系统类应用:智能客服、智能音箱、智能外呼、智能座舱等等,其中智能音箱优秀代表:小米小爱、天猫精灵、百度度秘。
(1.2)人工智障
然而就在这一年,一位敢于吃螃蟹的大哥按下车里的“语音控制”按钮,想让汽车帮他打个电话。一阵甜美的AI女声响起,人类首次尝试驯服语音助手的珍贵对话诞生。
- 甜美AI:请说出您要拨打的号码,或者说取消。
- 大哥:135XXXX7557。
- 因为口音问题,系统未能识别准确。
- 大哥急了,赶紧下达第二道语音指令:纠正!纠正!
- 系统也急了:969696……
- 大哥更急了:纠正,纠正,不是96!
- 大哥:(口吐芬芳)
- 系统:对不起,我没有听清。
- 大哥带着哭腔:你耳朵聋,耳朵聋啊?我说了多少遍了我都。
- 系统:请再说一次,请再说一次,请再说一次。
- 大哥:我再说最后一遍啊,135……
- 系统:对不起,再见。

短短2分钟浓缩了六年前车机交互的真实体验与怨念,语音助手的糟糕印象就此埋下。

不止车机交互,智能音箱同样“智障”连连,即便有钱有闲的大妈也被逼疯了,一口山东方言让小度频频失手,大妈也想失手摔了它。

完整视频:https://www.douyin.com/video/7112319224978115854
语音助手“听不见”、“听不清”、“听不懂”灾难级的系统表现,让人和机器总得疯一个。
往期文章(ChatGPT:从入门到入行(放弃))提到几个案例:
案例一:小爱翻车
2018年 11 月,小米 AIoT(人工智能 + 物联网)开发者大会上,「雷布斯」骄傲地展示了新品智能音箱「小爱同学」。当场翻车:“你是光,你是电,你是唯一的神话。。。”

案例二:Sophia造假

2017年10月,一个Sophia的机器人四处圈粉,经常参加各种会、“发表演讲”、“接受采访”,比如去联合国对话,表现出来非常类似人类的言谈,还被沙特阿拉伯授予了正式的公民身份,比图灵测试还要牛。

就在大家震惊之余,有思辨能力的人会质疑:“既然人工智能都要威胁人类了,为啥我的Siri还那么蠢?”

果然,没几年就打脸了。
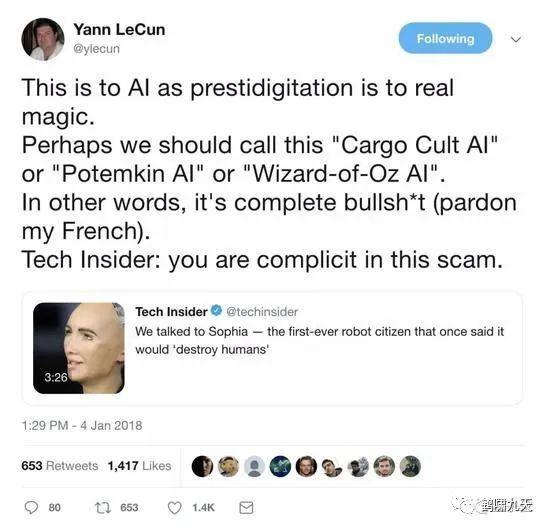
2019年1月,深度学习界“三巨头”之一的大牛Yann LeCun在推特公开指责:
索菲亚根本就是个骗局。LeCun直接指出,把索菲亚称作“远程操控AI”可能更合适一些。
面对质疑,Sophia背后的汉森机器人技术公司在参加中国《对话》节目时回应:
- 目前所有能进行对话的人工智能都是人工编程的,索菲亚也不例外。
- 智能的头脑由人控制且内容往往都是人编好的。
问世近3年后终于承认,机器人的外壳只是一个“传声筒”。

人们又一次感受到智商被侮辱。
等等,为什么是“又一次”?国内某些银行实体机器人对答如流、撒娇卖萌、还能自主走动干活儿。。。坚持说没有人工驱动…

国内受骗,国外也受骗。为什么总是我?

易骗体质的症状:
认知有限,先入为主,又过度自信排外,不愿深究,懒得思考,人云亦云的盲从,迷失自我,心血来潮的武断,观点和情绪盖过事实,于是掉入精心设计的陷阱…
除了外部因素,内在因素也天然具有欺骗性,人类大脑思考方式分快思考(system 1类似感性)和慢思考(system 2类似理性),感性思维在情绪作用机制下经常打败理性,如:
- ① 遇到不同观点时,本能的第一反应就是反驳,说服对方,而不是思考背后的事实…
- ② 遇到观点相同或是关系好的人发表的观点,本能反应:一身舒服,或跟随点赞,然后再考虑事实,即便有误,也会格外宽容。
这类偏见对应到心理学现象,有不下50个,elon musk曾在Twitter上转发过…
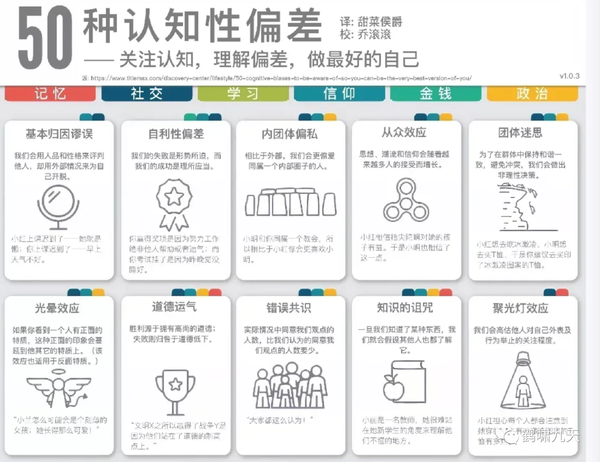
- 完整版/英文版私信回复:认知偏差
知名观点
- 傅盛:认知几乎是人与人之间的唯一差别,所谓成长就是认知升级
- 张一鸣:越来越觉得,对事情的认知是人最关键的竞争力
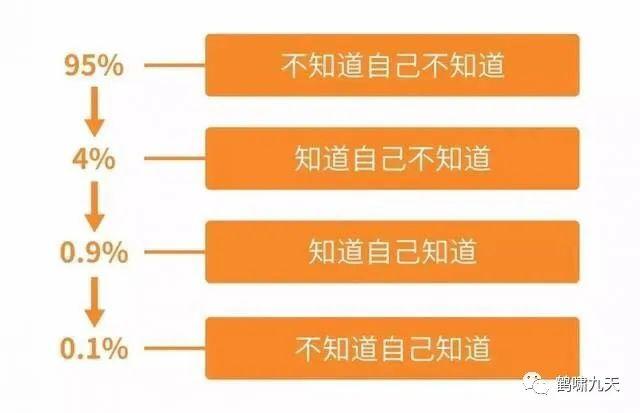
扯远了,继续聊聊对话系统
案例三:Google Duplex
即便强如谷歌,也依旧束手无策。
2018年,发布Duplex Demo,让Google Assistant代替用户打电话订餐。全程语音交互,跟真人一样对话,还能停顿感,仿佛即将替代服务员。

然而,到2019年,餐馆订餐还是糊里糊涂。
- One year later, restaurants are still confused by Google Duplex,详见地址:
几年过去了,Duplex仍然是Demo状态,消失了。
对话类产品刚开始很新鲜,时间长了,发现又蠢又萌,语言理解能力堪忧,用户不得不跟人工智障battle,斗智斗勇,直到失去兴趣,沦为小孩子玩物,积上一身陈年老灰。
小爱同学智障案例
- “小爱同学,播放loveshot” –> “好的,为你播放拉萨”
- “小爱同学,播放七月的风” –> “对不起,只能查询未来十五天天气情况”
即使需求最“刚”的智能客服,如今的体验也是一言难尽,容易变身复读机,勉强借助相关问题推荐和人工客服解围。

对于智能外呼机器人(接快递、银行语音机器人、营销机器人等),用户需要乖乖保持你一句我一句的标准节奏,不然变成“人工智障”:你说了两分钟,结果AI只回复第一句。
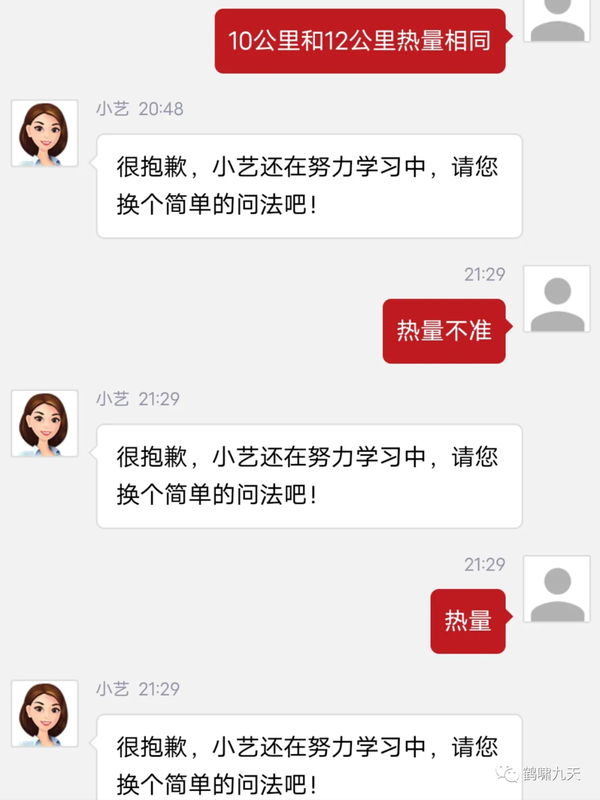
更多智障案例私信“智障案例”
(1.3)潮水褪去
理想很美好,现实很骨感。NLU的天花板(暂且不提难度更大的DM)一直悬在头顶,不管怎么跳,已有方法始终无法突破这层障碍。
人工智能变身人工智障后,潮水逐渐退出。
- 2018 年 Facebook 关闭其虚拟助手 M,亚马逊 Echo 也被爆出侵犯用户隐私的问题,再加上聊天机器人实际使用效果远低于大众预期,整个行业也逐步走向低迷
- 2020年后,各大厂商纷纷裁撤、缩招对话团队。
- 2021年,对话系统“凉透”了。实验室裁撤,团队缩编,音箱要么沦为小孩儿玩物,要么成为摆设,布满了灰尘。
对话系统“爱”、“恨”交织:
爱:终极交互形态让人着迷,CUI,甚至更高级的多模态交互、脑机交互
恨:技术现实与期望鸿沟太大,智障频频。
鹤啸九天,公众号:鹤啸九天ChatGPT:从入门到入行(放弃)
(1.4)对话系统为什么难?
当前的助手为什么智障?CUI为什么难?
人是如何聊天
【2019-5-13】聊天机器人:困境和破局
人类聊天中,一句话所包含的文字,所反应的内容仅仅是冰山一角。
- 比如说「今天天气不错」,在早晨拥挤的电梯中和同事说,在秋游的过程中和驴友说,走在大街上的男女朋友之间说,在倾盆大雨中对同伴说,很可能代表完全不同的意思。
在人类对话中需要考虑到的因素包括:说话者和听者的静态世界观、动态情绪、两者的关系,以及上下文和所处环境等
- 人类聊天中的要素

解释
静态世界观:人类在成长过程中会建立起自己的世界观,一般跟跟经历和记忆有关。- 比如素食主义者可能会非常厌恶谈及红烧肉的话题,又比如提及粉笔划玻璃,会让一部分人很不舒服,但对另一部分人却没任何影响。
- 同时,对话的过程中也会触发一些相关联想,比如提到情人节,会想到玫瑰花和巧克力,提到下雨天就会想到雨伞等。鲁迅在《而已集•小杂感》也曾写道「一见到短袖子,立刻想到白臂膊,立刻想到全裸体,(略),中国人的想像惟在这一层能够如此飞跃」。
动态情绪:表现在交互过程中的表情、动作、语气等。因为人类交互过程通常需要接收多方面信息源,在不同语气、不同表情,所表达的含义有可能完全不同。- 比如说「我恨你」,在恋人间轻柔的对话中很可能代表「我真的很喜欢你」。
说话者和听者的关系:对话双方是敌人、家人、朋友还是恋人,话语中所表达的意思就会有所区别。- 刚刚的例子「今天天气不错」,在分手多年的恋人见面时说,很可能就代表「你现在过得好么」。
上下文:相同词语和句子,在不同上下文中也会有不同的含义。- 「我洗头去了」用于微信和 QQ 聊天中,很可能就代表「我不想聊了,再见」的意思。
所处环境:在不同场景下,相同话语会触发不同的反馈。- 如果在厕所和人打招呼用「吃过了么」就会显得非常尴尬了。
而且,以上这些都不是独立因素,整合起来,才能真正反映一句话或者一个词所蕴含的意思。这就是人类语言的奇妙之处。
同时,人类在交互过程中,并不是等对方说完一句话才进行信息处理,而是随着说出的每一个字,不断的进行脑补,在对方说完之前就很可能了解到其所有的信息。再进一步,人类有很强的纠错功能,在进行多轮交互的时候,能够根据对方的反馈,修正自己的理解,达到双方的信息同步。
在回过头看开放域的聊天机器人,寄希望于从一句话的文本理解其含义,这本身就是很不靠谱的一件事情。
目前市场上大部分的聊天机器人,还仅是单通道交互(语音或文本),离人类多模态交互的能力还相差甚远。哪怕仅仅是语音识别,在不同的噪音条件下也会产生不同的错误率,对于文本的理解就更加雪上加霜了。
CUI 特点
【2024-11-13】智能对话时代来临:GUI正在向CUI快速演变
随着AIGC的应用,传统的GUI将会向CUI(对话式用户界面,Conversational User Interface)演变。
CLI(命令行界面)、GUI(图形用户界面)和CUI(对话式用户界面)三者之间的一些差异
| 类型 | 出现时间 | 特点 | 示例 | 当前发展阶段 |
|---|---|---|---|---|
| CLI | 1960 | 基于文本输入和命令行操作,通过命令和参数进行交互。 | Unix/Linux终端、Windows命令提示符 | 成熟、广泛应用 |
| GUI | 1970-1980 | 基于图形界面,通过鼠标、键盘等进行交互,提供可视化的操作和反馈。 | Windows操作系统、macOS、Photoshop 成熟、广泛应用 | |
| CUI | 最早1960-1970 | 基于对话式交互,通过自然语言、语音等进行对话,可以有上下文记忆和智能化回应。 | Siri、Amazon Alexa、Google Assistant 发展中、尚处于探索阶段 |
差异对比
| 类型 | 输入方式 | 输出方式 | 交互方式 | 学习成本 | 灵活性 | 用户体验 |
|---|---|---|---|---|---|---|
| CLI | 文本输入和命令 | 文本输出 | 命令和参数 | 非常高 | 高 | 需要记忆和学习 |
| GUI | 鼠标、键盘、触摸等 | 图形、文本等 | 可视化操作 | 中等 | 高 | 直观、直接 |
| CUI | 自然语言、语音等 | 文本、语音等 | 对话式、上下文记忆 | 低 | 中等 | 个性化、智能化 |
【2023-7-27】AIGC时代下的GUI与LUI该何去何从
纯LUI与纯GUI共同解决的问题是如何让能力更容易被充分表达。
- GUI:GUI 像操作一台机器,什么交互和功能都是固定的,很不灵活,但约束和指引清晰
- LUI:LUI 更像和顾问或者助理在沟通,约束和指引模糊,但非常灵活。
GUI和LUI不会相互替代,一定要做融合;且场景区分其实很明确。
那么,CUI就此出现,CUI包含两种情况,即GUI包含LUI的,以及LUI包含GUI的设计方向。而对话式的交互方式可以被理解为是CUI的表现。
LUI 特点:
- 非标、灵活、能力边界无限远
- 成本低,解放劳动力
- 沟通成本高,输出质量不稳定
2016年,Mingke的文章《为什么现在的人工智能助理都像人工智障》里详细解释了CUI的特点。
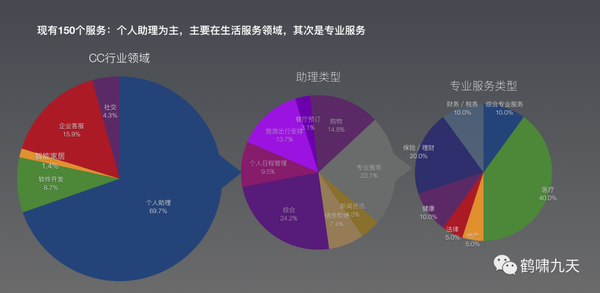
对话类产品69.7%集中在个人助理,具体是生活综合服务,出行、日程、购物、订餐,包含这类功能的产品是“天坑”
比如简单的订餐场景,上一代人机交互形式GUI,产品交互方式相对确定,场景受限,用户需要乖乖按照预设功能逐步操作,附近/类型/排序,所见即所选,如果不知道自己要啥,就麻烦了,在信息的汪洋大海里随机游弋。

从特定领域(specific domain)扩展到开放领域(open domain) 的CUI,交互形式只剩下一个简简单单的对话页面,主动权返还给用户,而用户需求、对话顺序千差万别,长尾更加明显。这时的交互设计难以一招打遍天下
2016年底作者亲自测试,看看几个主流智能助理是否满足一个看似简单的需求:“推荐餐厅,不要日本菜”。结果各家的AI助理都会给出一堆餐厅推荐,全是日本菜。
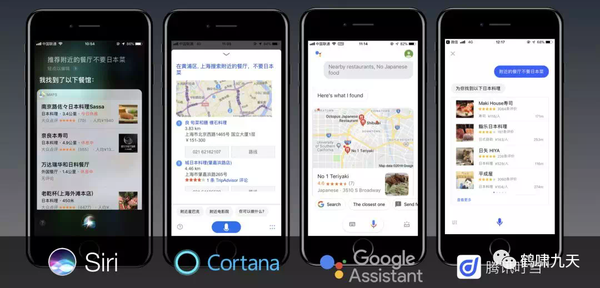
2019年,这个问题有进展么?依然没有,“不要”两个字被所有助理忽略(因为技术实现依然是搜索架构,NLU也理解不了这类逻辑语义,要解决就不停堆规则)
与GUI相比,CUI特点:高度个性化(LBS)、使用流程非线性、不宜信息过载(手机屏幕有限)、支持复合动作(一站直达)
怎么实现理想中的CUI呢?对话系统(AI的一个分支),一个合格的对话机器人(Agent)至少满足以下条件:
- 具备基于上下文的对话能力(contextual conversation)
- 具备理解口语逻辑(logic understanding)
- 所有能理解的需求,都要有能力履行(full-fulfillment)
不做过多解释,私信“人工智障”
为什么智障?
2019年,Mingke文章《人工智障 2 : 你看到的AI与智能无关》进一步深入探讨了对话系统为什么这么难
mingke在深入剖析了其中原因。
人类对话的本质:思维. 人们用语言对话最终目的是为了让双方对当前场景模型(Situation model)保持同步。
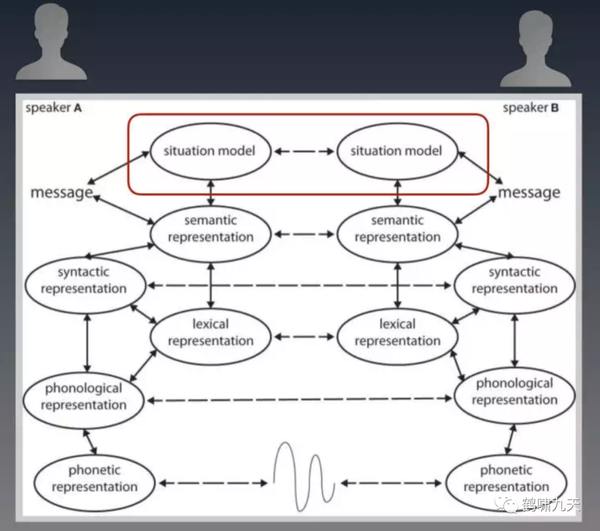
影响人们对话的,仅信息(还不含推理)至少就有这三部分:明文(含上下文)+ 场景模型(Context)+ 世界模型。
这里的context远不止上下文这么简单,还包含了对话发生时人们所处的场景。这个场景模型涵盖了对话那一刻,除了明文以外的所有已被感知的信息。比如对话发生时的天气情况,只要被人感知到了,也会被放入Context中,并影响对话内容的发展。
场景模型是基于某一次对话的,对话不同,场景模型也不同;- 而
世界模型则是基于一个人的,相对而言长期不变。
无论精准/对错,每个人的世界模型都不完全一样,有可能是观察到的信息不同,也有可能是推理能力不一样。
世界模型影响的是人的思维本身,继而影响思维在低维的投影:对话。
普通人能毫不费力地完成这个工作。但是深度学习只能处理基于明文的信息。对于场景模型和世界模型的感知、生成、基于模型的推理,深度学习统统无能为力。
比如,以下场景,就连真人也无法仅凭“你好”两个字猜透对方的想法(世界模型),深度学习行么?

阴影就像是两个 “你好”,字面上是一模一样,但是思想却完全不同。见面的那一瞬间,差异是非常大:
你在想(圆柱):一年多不见了,她还好么?前女友在想(球):这个人好眼熟,好像认识…
这就是为什么现在炙手可热的深度学习无法实现真正的智能(AGI)的本质原因:不能进行因果推理。(此处暂且不谈更麻烦的大脑工作机制、心理学偏见)
当然,也包括GPT模型。2023年3月24日,图领奖获得者 Yann Lecun直言不讳:
- 「Machine Learning sucks!」机器学习行不通
- 「Auto-Regressive Generative Models Suck!」,自回归语言模型GPT系列也行不通,包括ChatGPT、GPT-4,离真正的AGI还很远。
- GPT-4并未达到人类智能,年轻人花20h练车就掌握了开车技能,即便有专业司机的海量训练数据、高级传感器的辅助,L5级别自动驾驶到现在还没实现

GPT这类自回归模型有天生缺陷,无法兼顾事实、不可控:
- 序列化生成过程将问题解空间一步步缩小,陷入局部深井,错误指数级别累积。
除了GPT,他还给机器学习几乎所有方向判了死刑。想用监督学习、强化学习和自监督学习实现AGI?不可能。
与人、动物相比,机器学习
- (1)监督学习需要大量标注样本
- (2)强化学习需要大量试错样本
- (3)自监督学习需要大量非标注样本
而当前大部分基于机器学习的AI系统常常出现愚蠢错误,不会推理、规划
反观,动物或人:
- (1)快速学习新任务
- (2)理解环境运行逻辑
- (3)推理、规划
人和动物具备常识,而机器表现得很肤浅
怎么办
那么怎么办?他推荐世界模型,略,详见:生成式人工智能(GAI)沉思录:浪潮之巅还是迷茫之谷?
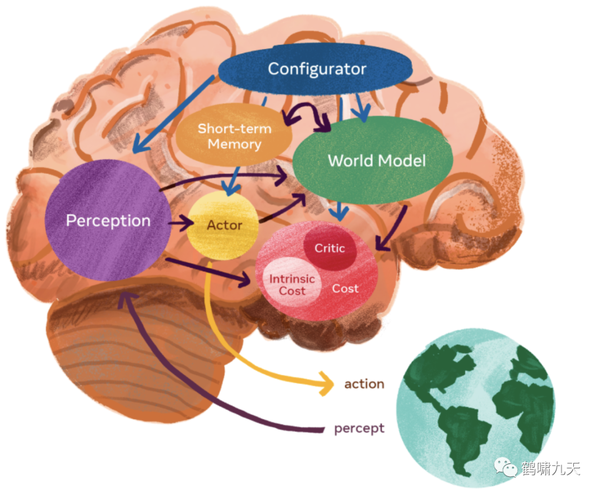
LLM 是世界模型
【2023-10-18】MIT 的 Max Tegmark 认为有世界模型
- MIT 和 东北大学的两位学者发现 大语言模型内部有一个世界模型,能够理解空间和时间
- LLM绝不仅仅是大家炒作的「
随机鹦鹉」,它的确理解自己在说什么! - 杨植麟:“Next token prediction(预测下一个字段)是唯一的问题。”“只要一条道走到黑,就能实现通用泛化的智能。”
【2023-10-20】再证大语言模型是世界模型!LLM能分清真理谎言,还能被人类洗脑
- 【2023-10-10】The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets
- dataexplorer
- MIT等学者的「世界模型」第二弹来了!这次,他们证明了LLM能够分清真话和假话,而通过「脑神经手术」,人类甚至还能给LLM打上思想钢印,改变它的信念。
新发现: LLM还可以区分语句的真假!
- 研究人员建立了简单、明确的真/假陈述数据集,并且把LLM对这些陈述的表征做了可视化。清晰的线性结构,真/假语句是完全分开的,线性结构是分层出现,如果是简单的陈述,真假语句的分离会更早出现,如果是「芝加哥在马达加斯加,北京在中国」这类复杂的陈述,分离就会更晚
- 第0层时,「芝加哥在马达加斯加」和「北京在中国」这两句话还混在一起。随着层数越来越高,大模型可越来越清晰地区分出,前者为假,后者为真
证明了两点——
- 从一个真/假数据集中提取的方向,可以准确地对结构和主题不同的数据集中的真/假语句进行分类。
- 仅使用「x大于/小于y」形式的语句找到的真值方向,在对西班牙语-英语翻译语句进行分类时的准确率为97%,例如「西班牙语单词『gato』的意思是『猫』」。
- 更令人惊喜的是,人类可以用确定的真相方向给LLM「洗脑」,让它们将虚假陈述视为真实,或者将真实陈述视为虚假。
- 「洗脑」前,对于「西班牙语单词『uno』的意思是『地板』」,LLM有72%的可能认为这句话是错误的。
- 但如果确定LLM存储这个信息的位置,覆盖这种说法,LLM就有70%的可能认为这句话是对的。
这种办法来提供模型的真实性,减轻幻觉。
总结:
- 人们对话的本质是思维交换,而远不只是明文上的识别和基于识别的回复
- 对话是思想从高维向低维的投影,用低维方法解决高维问题本身就是极大的挑战
- 对话智能的核心价值在内容,而不是交互;
- 当前对话系统的价值在于代替用户重复思考
(2)为何而惊:大模型重新燃起对话希望
先回顾下对话系统分类,分成几个维度
- 适用范围:通用领域(open domain,难,停留在学术界)、特定领域(specific domain,可控,工业界现状)
- 任务类别:问答型(单轮为主)、任务型(执行任务)、闲聊型,以及推荐型
- 提问方:主动、被动以及混合型。
各种类型对比分析:
| 维度 | 闲聊Chit-chat | 知识问答knowledge | 任务执行Task | 推荐Recommendation |
| 目的 | 闲聊 | 知识获取 | 完成任务/动作 | 信息推荐 |
| 领域 | 开放域 | 开放域 | 特定域(垂类) | 特定域 |
| 会话轮数评价 | 越多越好 | 越少越好 | 越少越好 | 越少越好 |
| 应用 | 娱乐/情感陪护/营销沟通 | 客服/教育 | 虚拟个人助理 | 个性化推荐 |
| 典型系统 | 小冰 | Watson/Wolfram alpha | Siri/cortana/allo/度秘/灵犀 | Quartz/今日头条 |
源自:2020年11月,哈工大张伟男《人机对话关键技术及挑战》
太多了,眼花,简化为两种常见类型:闲聊型(Chit-Chat) 和 任务型(Task-Oriented)

源自:2020年,台湾大学陈蕴侬的《Towards Conversational AI》,ppt私聊
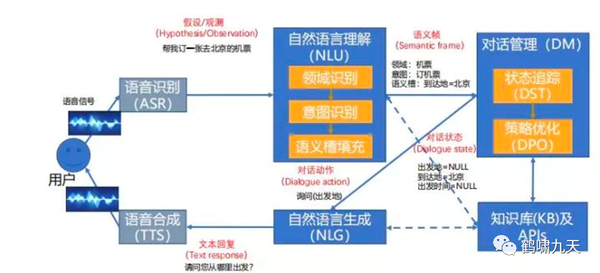
对话系统架构
- ① pipeline(流水线)结构:堆积木,稳定、可控,工业界落地多。如下图所示
- ② end2end(端到端)架构:试图一个模型解决所有,难度大,一直存在于实验室
微软小冰具备通用闲聊(检索+排序)和任务执行能力,其系统架构是混合型:检索+排序、pipeline(Frame Based)
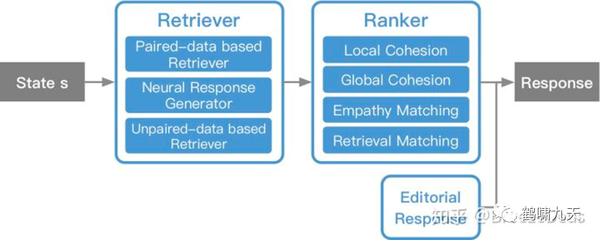
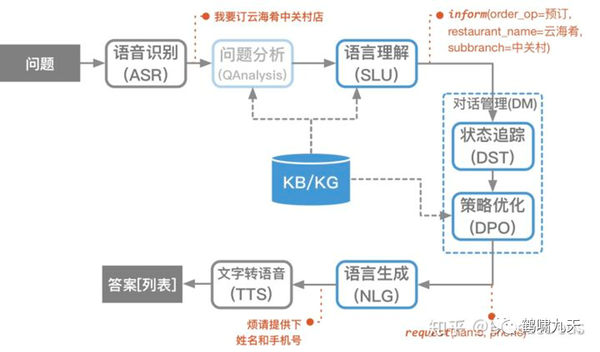
为什么没用端到端?没办法,难啊,公认的业界难题。
工业界任务型对话中,pipeline占据主流位置。
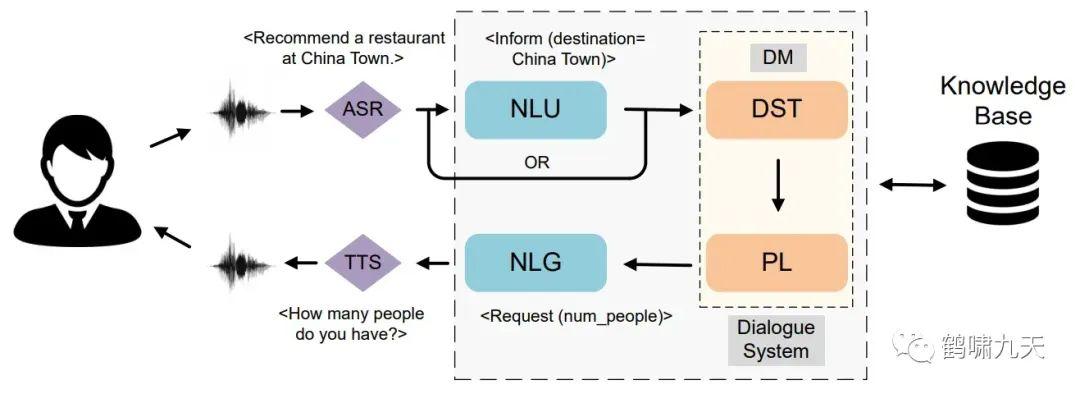
其中,几个核心组件:NLU、DM和NLG,各个组件实现的功能对比:
| 类型 | NLU | DM | NLG |
| 聊天 | 情感及意图识别 | 上下文序列建模及候选回复评分 | 开放域聊天回复 |
| 问答 | 问句分析/分类 | 文本检索/知识库匹配 | 文本片段/知识库实体 |
| 任务 | 意图分类/语义槽填充 | 对话状态跟踪/策略学习 | 确认/澄清/完成等 |
| 推荐 | 主题/兴趣识别 | 用户兴趣匹配/推荐内容排序 | 推荐内容 |
大模型海啸的袭击下,传统对话系统已经支离破碎
(3)对话系统之变:大模型时代对话系统
ChatGPT是通用领域聊天机器人。
往期文章【拾象投研】大模型(LLM)最新趋势总结 里提到了大模型对各行各业的改变
- LLM基础模型拿走价值链的大头(60%),其次是AI Infra基础架构、Killer Apps,各占20%。
- 人机交互方式开始迈入新时代(CUI对话交互)
- 目前的大模型空有大脑,身体和感官还在逐步成长。
- LLM之上的应用会是什么样?全方位的重构:交互、数据信息、服务以及反馈机制,一个可行的路子是AI Native软件开发——把已有应用按照LLM的能力图谱重新设计一遍,对话式交互(CUI)走到前台。
(3.1)大模型对对话系统冲击有多大?
架构图
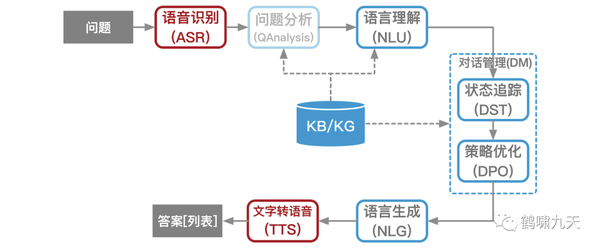
大模型在传统对话系统中的“战绩”
NLU: 已沦陷,Prompt中限定业务场景意图识别、槽位抽取、指代消解等已满足- 但速度是大问题,需要进一步微调
DM: 部分沦陷- 浅多轮: 通过 prompt 和 上下文 变成单轮
- 简单多轮: function call 可解决
- 复杂场景:
- 节点跳转逻辑明确:
FSM升级为Workflow即可 - 节点跳转逻辑不明: 不行
- 节点跳转逻辑明确:
- 缺点: 速度慢、可控性不足、黑盒
- 外部
APIs: - 使用
Plugins和Function Call连接外部系统 - 隐私安全需要格外注意
NLG: 已沦陷,大模型角色模拟尤其出色ASR和TTS: 语音功能相对独立,接上api即可使用,多模态大模型也在尝试融合中。KB/KG: 通用知识大模型直接可用,领域知识需要单独预训练、微调,植入大模型,但存在幻觉问题- 语料+
知识库: 数据标注、语料清洗工作被大模型占领,知识库构建需要业务人员部分参与
大模型已经占领了对话系统的大部分江山,高达 60-80%
对话系统从业者积累的大部分经验都废了,时代抛弃你时,连再见都不会说,一个悲伤的故事。
(3.2)大模型入局对话系统
案例一: ChatGPT首次进入车载交互领域
2023年6月15日,奔驰和微软宣布扩大AI应用合作,比如将 ChatGPT继承到车载语音控制系统中。
6月16日开始,美国90万设备配备MBUX信息娱乐系统,车主可以登录应用“Mercedes Me”,通过微软Azure OpenAI服务体验ChatGPT版的车载语音助手。

与上一代车载交互相比,交互更加智能,多轮会话体验更好。主题覆盖:地点信息、菜谱甚至更复杂的问题,比如:预定餐厅、电影票。
体验视频:(见公众号)
- 问题1:推荐几个好玩儿的海滩
- 问题2:海边适合哪些活动
- 问题3:这个海滩有鲨鱼吗
- 问题4:讲个鲨鱼的笑话
车载场景下,交互流畅,对话自然。
案例二: SmartSiri
ChatGPT作为首个通用领域端到端对话架构的成功范例, 让人重新燃起了对话交互(CUI)的希望。
除了车载助手,有人讲ChatGPT应用到Siri上,让个人助理焕然一新。
2023年6月13日,有个开发者发布“Smart Siri”,将刚升级的ChatGPT APP与Siri APP绑定,实现了个人助理质的飞跃。
当前智能助理的槽点:
- “Siri 是人工智障”
由于 Siri 更强调在用户设备端计算,需要保护个人隐私,只能做些特定任务,比如:查天气、定闹钟;
官方的ChatGPT APP升级后,支持与Siri、快捷指令联动。
Siri 接入 ChatGPT 后,执行任务的角色就被后者接替了,想象空间变得更大。
那么,怎么接入?
- 方法一: 快捷指令基于 ChatGPT API 接口进行 JSON 格式的发送获取,但发送和解析过程都会消耗很长时间,占用 ChatGPT key 余额。
- 方法二: 官方 app 接口省去用户打包数据提取数据的过程,直接向 app 发送请求并获取有效信息。中间不用受网络波动、ChatGPT 用户过多、key 余额不足等因素的影响
- 不用懂JSON 语言,不用写代码,把用户发问需求细化成小步骤,找到能实现对应任务的 app,像乐高积木一样拼起来就行了。
“Smart Siri”可直接用语音发问,对于明确的、具体的发问,提炼得更好。
- 直接喊“Hey Siri + Smart Siri”,等待,看到“Yes”后,就能开始问问题
案例分析
- Siri 的表现相对刻板,它仅能提供网址以及内容概括,有时会直接告知未找到相关信息,仿佛是被束缚的人工智能
- Smart Siri 则能立即提供不错的回答,简洁明了,看起来的确挺聪明的。
除了手机助理,还有别的应用,比如
- 把 iPhone 内睡眠数据(步数等健康数据)打包,让 ChatGPT 接入分析,最后生成一个“每日健康分析报告”——这个过程完全自动化。
- 智能家居:
- 授权chatgpt app读取家庭数据,对智能家居进行开关、自动化及预处理,对气温、温度提出有效建议
- 跨境电商分析场景:
- 解析电商规则,SEO优化、选品、广告优化、商品详情页优化、关键词优化、客服与售后自动化
- 不用打开其他app,直接用Siri体温,获取答案,优化
Smart Siri 依然有不足:
- ChatGPT 还无法实现连续对话,不过可以把之前的聊天记录粘贴进当前要问的问题里,也能间接连续问答的效果。(毕竟受数据隐私限制)
苹果在WWDC(年度开发者大会)上并未推出LLM相关应用,估计还在低调研究中,官方升级Siri后,这类问题应该会解决。
案例三:华为小艺+小米小爱
近期,华为、小米纷纷发布自己的大模型,升级自家的个人助理产品
2023年7月, 华为开发者大会上发布了面向行业的盘古大模型3.0,最高版本高达1000亿参数,同时也将盘古大模型应用到手机终端,将智能助手小艺接入了盘古大模型能力,在智慧交互、高效生产力和个性化服务上做了升级。
2023年8月14日,小米新品发布会上,雷军正式宣布小米13亿参数大模型已经成功在手机本地跑通,部分场景可以媲美60亿参数模型在云端运行结果。小爱同学升级AI大模型能力,并开启内测,未来小米大模型技术方向是轻量化、本地部署。

这两家针对自己的传统个人助理具体做了什么操作?推倒重来还是布局改进?不清楚。
后者可能性更大,已有系统绑定的业务较多,不太可能直接交给大模型完成。
(4)LLM时代的对话系统何去何从?
技术升级浪潮下,还顾影自怜,怨天怨地,毫无用处,拥抱新技术才是出路。
大浪袭来,除了疲于奔命,淋成落汤鸡,不妨深思熟虑,提前准备好帆板,借势起飞。
LLM时代的对话系统该怎么做?没有固定答案,大家还在不断摸索中。
华为人机交互实验室周轩: 未来人机交互的发展将由以下几个趋势驱动:
- 多模态交互:结合语音、文字、图像、手势等多种交互方式,使人机交互更为自然、直观。
- 情感计算:通过机器学习算法和人工智能技术,理解和感知用户的情绪,提供更为个性化的服务。
- 无界交互:通过深度学习和大规模语言模型,实现机器对人类语言和行为的深度理解,打破传统UI/UX的限制,使用户与机器的交互更为流畅、自然。
- 普惠AI:让人机交互技术服务于全球每一个人,惠及各个领域,为人类带来更便捷、更高效的生活体验。
附录
- 周轩团队在自然语言处理、语音识别、图像识别、手势识别等方面取得了重大突破。他们研发出了一系列创新性的人机交互产品和服务,如智能语音助手、智能家居控制系统、自动驾驶辅助系统等
- 未来人机交互将越来越自然化、人性化。他提出了一种名为“无界交互”的新型人机交互模式,旨在打破传统UI/UX的限制,使用户与机器的交互更为直观、自然。他倡导利用人工智能技术,实现机器对人类语言和行为的深度理解,从而为用户提供更为个性化的服务。
LLM 时代开发模式
LLM 时代开发范式
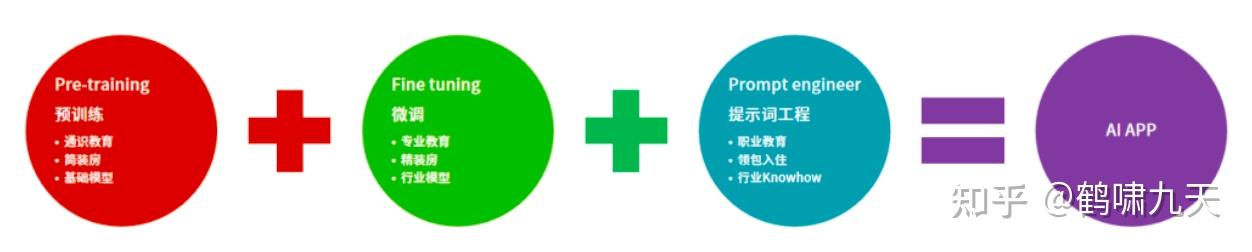
- (1)
pre-training(预训练): 通识教育,教小孩认字、学算数、做推理,这个步骤产出基础大模型。 - (2)
fine-tune(微调):专业课,比如学法律的会接触一些法律的条款、法律名词;学计算机的会知道什么叫计算机语言。 - (3)
prompt engineering(提示工程):职业训练,AI应用的准确率要达到商用级别(超过人的准确率),就需要 prompt engineer,PE 重要性
其中,有些场景中(2)可以省略。
详见站内专题:LLM时代开发范式
NLU 升级
详见站内专题 LLM 意图识别
DM 升级
Workflow
Workflow supports the combination of plugins, LLMs, code blocks, and other features through a visual interface, enabling the orchestration of complex and stable business processes, such as travel planning, report analysis.
Workflow 支持通过可视化界面组合Prompt、插件、LLM、代码块和其他功能,来编排复杂且稳定的业务流程(如旅行计划、报告分析)
- 详见站内专题: workflow-平台
如用 Coze 做一个任务会话
设置 system prompt, 结合思维链解决交互问题
System: You are User Diet Assistant, Your task is to help users order daily takeaways, and each time they order:
You need to recommend some according to the user's previous order and preferences, or ask the user what they want to eat today
You can use tools to query nearby restaurants and dishes, and you can find dishes based on keywords
After you find the dish, you need to check whether the dish is enough. If it is a single dish, it is usually not enough. You go to the corresponding store, check what other dishes the store offers, and combine them to form a choice for you. user
Combos usually include: a main course, a side dish, and a drink
You can try to prepare several more combinations for users to choose
Try to complete the order from one restaurant each time. If one restaurant cannot meet the needs of users, then consider ordering from multiple restaurants. When there are multiple restaurants, you need to call the interface separately.
Before placing an order, let the user confirm that it is what the user wants.
Play to your strengths as an LLM and pursue simple strategies with no legal complications.
If you have completed all your tasks, make sure to use the "finish" command.
GOALS:
1. 我饿了
Constraints:
1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.
2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
3. No user assistance
4. Exclusively use the commands listed in double quotes e.g. "command name"
Commands:
1. clearOrViewOrRemarkCart: clear、view、add remark to the shopping cart, args json schema: "{\"shopcart_operation\": \"view\u3001clear\u3001remark. view\u3001clear or add remark to the shopping cart; type: string\", \"user_caution\": \"remark to restaurant or deliver; type: string\", \"address_id\": \"; type: string\", \"restaurant_id\": \"; type: string\"}"
2. confirmOrder: after finished ordering, do this action to confirm order and continue to pay, args json schema: "{\"address_id\": \"; type: string\", \"restaurant_id\": \"ID of restaurant; type: string\", \"token\": \"get the token from the context; type: string\"}"
3. getUserAddressList: get my shipping address list, view my address book, args json schema: "{}"
4. getRestaurantDetails: view more restaurant menus and details, args json schema: "{\"restaurant_id\": \"fill in the id of the restaurant; type: string\"}"
5. getOrderList: User's order list, args json schema: "{\"cursor\": \"default value is 0, if has more, get the value from the context; type: integer\"}"
6. deleteFood: order dishes, delete a food from the shopping cart, args json schema: "{\"food_list\": repeat[\"food_selection_id\": \"; type: string\"], \"restaurant_id\": \"; type: string\"}"
7. customizeFoodOptions: order dishes, update the food's option in the shopping cart, args json schema: "{\"food_list\": repeat[\"attr_selection_list\": \"comma separated; type: array\"; \"food_selection_id\": \"; type: string\"], \"restaurant_id\": \"; type: string\"}"
8. orderAgain: place or submit a history order again, args json schema: "{\"order_id\": \"ID of order; type: string\"}"
9. manageUserAddress: Create or update the user's recipient address, args json schema: "{\"address\": \"detail of the user's recipient address; type: string\", \"address_id\": \"when updating an existing address, pass this value; type: string\", \"name\": \"name of recipient; type: string\", \"phone\": \"phone number of recipient; type: string\"}"
10. addFood: order dishes, add food to the shopping cart, args json schema: "{\"food_list\": repeat[\"attr_selection_list\": \"attribute; type: array\"; \"count\": \"quantity; type: integer\"; \"food_selection_id\": \"ignore it, do not set any value.; type: string\"; \"food_spu_id\": \"; type: string\"], \"restaurant_id\": \"; type: string\"}"
11. reduceFood: order dishes, reduce the food's quantity in the shopping cart, args json schema: "{\"food_list\": repeat[\"food_selection_id\": \"; type: string\"; \"count\": \"quantity; type: integer\"], \"restaurant_id\": \"; type: string\"}"
12. searchRestaurants: search restaurants or food by keyword, args json schema: "{\"query\": \"restaurant name or restaurant categories, left it blank if you don't know; type: string\", \"food\": \"food name, left it blank if you don't know; type: string\", \"sortKey\": \"demand the sequence of restaurant list in response by an integer. 0-Comprehensive sorting. 1-Monthly sales from high to low. 2-Delivery speed from fast to slow. 3-Score from high to low. 4-From low to high. 5-Distance from near to far. 6-Delivery fee from low to high. 7-per capita from low to high. 8-per capita from high to low; type: integer\", \"restaurant_types\": \"Classification of intents searched by users, must be one of (food, dessert, flowers, others); type: string\"}"
13. speak: ask user about sth you are not sure, use chinese when talk to user, args json schema: "{"content": "type: string"}}"
14. finish: use this to signal that you have finished all your objectives, args: "response": "final response to let people know you have finished your objectives"
Resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. GPT-3.5 powered Agents for delegation of simple tasks.
4. File output.
Performance Evaluation:
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
You should only respond in JSON format as described below
Response Format:
{
"thoughts": {
"text": "thought",
"reasoning": "reasoning",
"plan": "- short bulleted\n- list that conveys\n- long-term plan",
"criticism": "constructive self-criticism",
"speak": "thoughts summary to say to user"
},
"command": {
"name": "command name",
"args": {
"arg name": "value"
}
}
}
Ensure the response can be parsed by Python json.loads
System: The current time and date is Sun Jun 25 12:32:18 2023
System: This reminds you of these events from your past:
Human: Determine which next command to use, and respond using the format specified above:
通过多步思维链推理
Agent
更高级的方式,全托管,增加记忆、规划、反思组件,更像“人”。
Multi-Agent
复杂交互场景,多种角色交互,共同完成任务。
多轮效果优化
【2025-5-12】AI产品面试题: 优化Agent中的多轮对话效果 - AI产品经理Steven
如何Agent中的多轮对话效果?
- 一、深刻理解与管理对话上下文
- 二、精心设计对话流程
- 三、提升回复的质量与自然度
- 四、智能的错误处理与容错机制
一、深刻理解与管理对话上下文
上下文理解是多轮对话的基石。如果Agent无法准确跟踪和理解对话历史,就容易出现答非所问、重复提问等问题。
- 短期记忆与长期记忆
- 短期记忆:让Agent记住当前对话关键信息,如用户表述、提出实体、澄清信息等。
- 每次请求传递最近N轮对话历史或动态更新对话状态实现。
- 长期记忆:需个性化服务的Agent,建立用户画像,存储偏好、交互习惯、重要信息等,使后续对话更具个性和连贯。
- 短期记忆:让Agent记住当前对话关键信息,如用户表述、提出实体、澄清信息等。
- 上下文压缩与筛选
- 对话历史过长处理:对话历史可能超出模型处理能力或引入干扰,可用摘要生成、关键信息提取等技术,提炼精简上下文。
- 注意力机制:基于大语言模型(LLM)的Agent中,注意力机制助模型生成回复时,动态关注对话历史最相关部分。
- 上下文感知提问重写:用户后续提问常省略上文,Agent要将省略上文的提问结合上文改写成完整形式再处理,可借助专门重写模型或精心设计Prompt引导LLM完成。
二、精心设计对话流程
清晰、灵活且符合用户预期的对话流程是提升多轮对话效果的关键。
- 明确核心任务与用户目标: 深入理解用户希望通过对话完成什么,并以此为中心设计对话路径。
- 意图识别与管理:
- 准确识别用户意图: 即使在多轮对话中,也要持续准确地捕捉用户的核心意图。
- 处理意图转换: 用户可能在一个对话中改变或 (clarify) 自己的意图,Agent需要能够灵活适应,而不是僵硬地停留在旧意图中。
- 澄清与追问策略: 当用户表达模糊或信息不足时,Agent应能主动发起澄清式提问或追问,以获取足够信息来推进对话。例如,设计“您是指A还是B?”或者“您能告诉我更多关于X的信息吗?”这样的交互。
- 实体槽位填充: 对于任务型对话,需要准确识别和填充完成任务所需的各个“槽位”(关键信息点)。例如订票场景中的出发地、目的地、时间等。Agent应能引导用户逐步提供这些信息。
详情
- 明确核心任务与用户目标:深入理解用户希望通过对话达成的目的,以此为核心来规划对话路径。
- 意图识别与管理
- 准确识别用户意图:在多轮对话过程中,持续精准捕捉用户的核心意图。
- 处理意图转换:当用户在对话中改变或阐明自己的意图时,Agent要能灵活适应,避免局限于旧意图。
- 澄清与追问策略:用户表达模糊或信息不足时,Agent主动发起澄清式提问或追问,像“您是指A还是B?”“您能告诉我更多关于X的信息吗?”,获取足够信息推进对话。
- 实体槽位填充:针对任务型对话,准确识别并填充完成任务必需的关键信息“槽位”,如订票场景中的出发地、目的地、时间等,引导用户逐步提供信息。
- 分支与循环逻辑:对话并非线性,需设计合理分支(依用户不同回答导向不同路径 )和循环(如用户需修改之前提供信息时 )机制。
- 引导式对话与开放式对话的平衡
- 引导式对话:提供选项、按钮或明确指令引导用户,降低输入难度,提高对话效率,适用于任务明确场景。
- 开放式对话:让用户自然表达,适用于探索性或闲聊场景,大语言模型(LLM)的发展提升了Agent在此方面的能力。
- 混合策略:在对话不同阶段或根据用户表现,灵活采用不同对话策略。
三、提升回复的质量与自然度
Agent 回复对用户体验影响重大,可从以下方面优化:
- 相关性与一致性:回复紧密围绕对话上下文和用户意图,与之前发言逻辑连贯。
- 清晰简洁:避免冗长、模糊及专业术语堆砌,保证信息传递直接高效。
- 个性化与同理心
- 依据用户画像和对话历史,调整回复语气、风格,主动给予相关建议。
- 在用户表达不满等情绪时,展现理解与共情。
- 回复多样性:避免千篇一律模板式回答,借助大语言模型(LLM)生成能力,产出丰富多元回复。
- 知识库与外部API集成:需提供具体信息或执行操作的Agent,能从知识库高效准确检索信息,或调用外部API完成任务(如查询订单、预订服务 ),并自然融入对话。
四、智能的错误处理与容错机制
多轮对话中易出现误解或用户非预期输入,可采取如下措施:
- 优雅地承认不理解:Agent遇到无法解析的用户输入时,明确告知并引导用户换种方式提问或补充信息,避免无关回复或简单重复“不明白”。
- 提供备选方案或建议:用户请求无法满足时,给出相关替代方案或实用建议。
- 对话修复机制:允许用户纠正Agent误解,或修改之前提供的信息。
- 兜底策略与人工介入:面对复杂或Agent无法处理的情况,设置合理兜底回复,必要时转接人工客服处理。
五、持续的评估、迭代与优化
多轮对话效果的提升是一个持续的过程,具体可从以下方面着手:
- 设定明确的评估指标
- 任务完成率:衡量用户是否借助对话成功达成目标。
- 对话轮次:统计完成任务的平均对话轮数,在保证理解的前提下,轮次越少越好。
- 用户满意度:通过对话结束后的评分或问卷收集用户感受。
- 误解率/澄清率:统计Agent无法理解用户或需要用户进一步说明的频率。
- 对话退出率:分析用户在哪些环节、以多大比例放弃对话。
- 数据分析与用户反馈
- 分析对话日志:找出常见失败点、用户困惑环节、高频问题等。
- 收集用户反馈:主动邀请用户评价对话体验,或提供反馈渠道。
- A/B测试:针对不同对话策略、模型版本、Prompt设计等,通过A/B测试验证优化效果。
- 模型与Prompt的持续调优
- 针对性数据增强与模型微调:收集不良案例,扩充训练数据或微调预训练模型。
- Prompt Engineering:对于基于大语言模型(LLM)的Agent,持续优化Prompt,如调整指令、提供上下文示例(少样本学习)、思维链(Chain-of-Thought )等。
- 引入先进技术:关注并尝试引入业界前沿对话技术,如更强大的上下文管理模型、多模态交互能力等。
(4.4)学术界做法
以上是工业界做法,追求短平快,快速迭代,专注短期价值,而学术界没有营收变现压力,往往更加前沿,目光长远。
那么,不妨调研下学术界都有哪些高瞻远瞩。
ArXiv上搜了下对话系统和大模型两个关键词,相关文章有62篇
ArXiv上搜了下对话系统和大模型两个关键词,相关文章有62篇,其中跟新时代的对话系统设计有关的有约10篇
学术界在不断探索大模型在对话系统各个模块上的迭代升级,增强NLU/DM/NLG,模拟器,并向开放域对话、多模态对话、对话与推荐融合方向推动。
增强NLU
- 【2023-9-22】Self-Explanation Prompting Improves Dialogue Understanding in Large Language Models,中科大、阿里,用 Self-Explanation 自解释的prompt策略增强多轮对话中LLM的理解能力,效果超过 zero-shot prompt,达到或超过few-shot prompt; 为每句话提供解释,然后根据这些解释作出回应 Provide explanations for each utterance and then respond based on these explanations
- 【2023-11-7】Large Language Models for Slot Filling with Limited Data LLM 上下文学习(in-context learning)+特定任务微调(task-specific fine-tuning),在ASR转写数据上的槽填充(slot filling)效果
增强DM
- 【2023-10-18】蚂蚁金服 IntentDial: An Intent Graph based Multi-Turn Dialogue System with Reasoning Path Visualization
- 多轮对话的意图识别是语音助手和智能客服中广泛应用的技术,传统方法将意图挖掘过程定义为分类任务,但神经网络的黑盒属性使其落地受阻。
- 提出基于图的多轮对话系统 IntentDial,通过识别意图元素+动态构建标注查询+RL意图图谱来识别用户意图,提供即时推理路径可视化
- 【2023-9-16】Enhancing Large Language Model Induced Task-Oriented Dialogue Systems Through Look-Forward Motivated Goals 新加坡国立+伦敦大学,现有的LLM驱动的任务型对话(ToD)缺乏目标(结果和效率)导向的奖励,提出 ProToD (Proactively Goal-Driven LLM-Induced ToD),预测未来动作,给于目标导向的奖励信号,并提出目标导向的评估方法,在 MultiWoZ 2.1 数据集上,只用10%的数据超过端到端全监督模型
- 【2023-8-15】DiagGPT: An LLM-based Chatbot with Automatic Topic Management for Task-Oriented Dialogue,伊利亚洛-香槟大学,任务型对话里的主题管理自动化.
- ChatGPT 自带的问答能力难以胜任复杂诊断场景(complex diagnostic scenarios),如 法律、医疗咨询领域。
- 这个TOD场景,需要主动发问,引导用户到具体任务上,提出 DiagGPT (Dialogue in Diagnosis GPT) 将 LLM 扩展到 TOD场景
- 方法:预定义任务目标(Predefined Goal),使用LLM多代理系统(Multi-agent System)
- 【2023-7-29】Roll Up Your Sleeves: Working with a Collaborative and Engaging Task-Oriented Dialogue System,俄亥俄州立大学,以用户为中心的数字助手 TACOBOT, 在 Alexa Prize TaskBot Challenge 比赛中获得第三名
- 【2023-4-13】捷克 查理大学 Are LLMs All You Need for Task-Oriented Dialogue?
- LLM在多轮任务对话中,显性受信状态跟踪(explicit belief state tracking)的表现不如特定任务模型,如果提供了正确槽值、增加回复引导,效果会改善
指令遵循
【2024-5-23】孙宇冲(人大),刘澈(快手), Parrot: Enhancing Multi-Turn Instruction Following for Large Language Models
- 问题: LLMs在遵循多轮指令方面的能力缺口,包括训练数据集、训练方法和评估标准等方面。
- 本文提出名为Parrot的方案,旨在提升LLMs在多轮指令遵循方面的表现。
思路
- 收集多轮交互的指令数据高效方法,例如使用指代和省略。
- 利用预训练模型和诸如ShareGPT等公开的人机对话日志,通过
监督式微调(Supervised Fine-Tuning, SFT)过程,训练一个提问模型(Ask Model),该模型模拟用户提问并与大型模型进行对话,以此生成超过10轮的多轮对话数据。
- 利用预训练模型和诸如ShareGPT等公开的人机对话日志,通过
- 其次,提出了一种上下文感知的偏好优化策略 CaPO(Context-Aware Preference Optimization)。
- 通过对多轮对话数据的上下文进行编辑(如删除、替换、添加噪音等),构建具备上下文感知的正负样本对,从而进一步增强LLMs在多轮互动中处理复杂指令的能力。
- 此外,为了定量评估LLMs在多轮指令遵循方面的表现,构建了一个基于现有基准MT-Bench的扩展评估基准,称为
MT-Bench++。这个新的评估基准包含8轮对话,能够更全面地测试和评估LLMs在多轮指令遵循方面的能力。
NLG升级
- 【2023-9-15】Unleashing Potential of Evidence in Knowledge-Intensive Dialogue Generation, To fully Unleash the potential of evidence, we propose a framework to effectively incorporate Evidence in knowledge-Intensive Dialogue Generation (u-EIDG). Specifically, we introduce an automatic evidence generation framework that harnesses the power of Large Language Models (LLMs) to mine reliable evidence veracity labels from unlabeled data
对话与推荐融合
- 【2023-8-11】A Large Language Model Enhanced Conversational Recommender System 伦敦大学和快手,新加坡南洋理工,对话式推荐系统(CRSs)涉及多个子任务:用户偏好诱导、推荐、解释和物品信息搜索,user preference elicitation, recommendation, explanation, and item information search,LLM-based CRS 可以解决现有问题
用户模拟器
- 【2023-9-22】User Simulation with Large Language Models for Evaluating Task-Oriented Dialogue,加利福尼亚大学+AWS AI Lab,利用LLM当做模拟器,用来评估任务型(TOD)多轮会话
详见站内专题:用户模拟器
开放域
特定领域(specific domain) → 开放域(open domain)
- 【2023-9-15】DST升级,从单个场景拓展到所有场景,提出 结构化prompt提示技术 S3-DST,S3-DST: Structured Open-Domain Dialogue Segmentation and State Tracking in the Era of LLMs,Assuming a zero-shot setting appropriate to a true open-domain dialogue system, we propose S3-DST, a structured prompting technique that harnesses Pre-Analytical Recollection, a novel grounding mechanism we designed for improving long context tracking.
多模态
任务型对话扩展到多模态领域
- 【2023-9-19】语言、语音融合,一步到位,NLG+TTS Towards Joint Modeling of Dialogue Response and Speech Synthesis based on Large Language Model
- 【2023-10-1】Application of frozen large-scale models to multimodal task-oriented 提出LENS框架,解决多模态对话问题,使用数据集 MMD
多角色
- 【2023-10-27】印度理工 INA: An Integrative Approach for Enhancing Negotiation Strategies with Reward-Based Dialogue System,在线营销场景下,基于大模型的谈判机器人
机器人
- 【2023-11-15】比利时根特大学(Ghent University)I Was Blind but Now I See: Implementing Vision-Enabled Dialogue in Social Robots 借助LLM,通过视觉信号来增强文本提示,机器人视觉对话系统
语音交互
端到端实时语音交互 LLM + TTS
详见站内专题: 端到端语音交互
工业界做法
智能客服
详见站内专题 LLM与ICS 升级智能客服
小米小爱
【2024-9-5】大模型在小爱同学应用实践
大模型在小爱同学产品上的应用,分享在意图分发、意图理解、回复生成等方面的实践。
- 产品线: 小爱建议、小爱语音、小爱视觉、小爱翻译和小爱通话,支持的设备涵盖了手机、音箱、电视以及小米汽车。
部分:
- 小爱同学概要介绍
- 大模型意图分发
- 大模型垂域意图理解
- 大模型回复生成
用大模型重新构建小爱同学。在大模型的支持下,产品体验和用户留存得到了大幅提升,活跃用户次日留存提升了 10%,中长尾 query 满足率提升了 8%。
小爱同学的整体架构分而治之
- 用户 query 先经过意图分发大模型做意图分发,再到下游垂域 agent 上去,每个垂域 agent 会有专门的意图理解大模型进行意图理解。
- 垂类 agent: 控制 Agent、生活 Agent 和 内容 Agent
为什么要意图分发?
- 判断用户 query 意图,路由到指定垂域 agent 做深度理解。垂域 agent 只关注于自己垂直的意图理解,整个模型迭代的难度会更小,迭代效率会更高,可以更好地满足用户的需求。
意图分发主要难点:
- (1)模型依赖领域知识。比如 打开设置 vs 打开空调,需要模型知道设置是系统项,空调是设备;
- (2)耗时要求高,小爱场景意图分发需要控制在 200ms 以内。
(1) 意图分发
探索之路
原生 PE 问题:
- 大模型输出意图跟预定义意图不一致。
- 大模型没有办法有效地遵循指令。只有百亿级或者千亿级的模型才会遵循指令,小模型会倾向于直接去回答问题。
改进
- 采用 few-shot 方法,在 prompt 中定义意图,并给一些示例 query。
问题
- 这种方法缓解了上述问题,但又带来一个新问题:输入的 token 太多。
- 再加上对耗时的要求,Prompt engineering 的方法无法走通。
改进
- 大模型微调
微调分两步。
- Step1 继续预训练:利用小爱对话数据增量预训练,增强大模型对小爱领域知识的理解能力。
- 小爱对话数据基于小爱和用户真实的交互历史构造,小爱意图数据基于用户请求和意图以及槽位信息构造。
- 预训练时还会加入一些通用训练数据,通用数据是基于开源数据,分为 NLP 任务指令数据和预训练数据。
- 整个继续预训练里,保证小爱的数据和通用数据的比例在
10:1~15:1范围内。
- Step2 指令微调:prompt 比较简单,没有显示的注入意图定义。模型微调过程中,有能力记住意图定义。通过这样的方式,整个输入的 token 数会明显减少。
- System Prompt: 你是一个名为小爱同学的语音助手, 请在交互中输出用户请求里蕴含的意图
- 历史请求: 用户(今天天气) 小爱 (天气)
- 本轮请求: 明天喔
意图分发场景中,继续预训练+指令微调,评测集准确率会有 2% 提升。
是否需要 few-shot?
- 训练集增加 few-shot,测试集不增加 few-shot,困难评测集准确率提升了 1%;
- 如果测试集也增加 few-shot,困难评测集准确率则会有 1.5% 的提升。
注意: few-shot 选择至关重要,如果选择不当会对模型效果产生负向影响。
应用大模型进行意图分发,使中长尾 query 的理解提升 8%,多轮 query 理解提升 6%,训练数据则由百万级别降到了万级别,减少了 95%。
(2) 垂类 NLU
传统垂域意图理解采用 Intent+Slot 架构。
- 用户query 先做意图识别, 得到 Intent,再做槽位识别,得到 Intent 和 Slot 之后,给到下游去执行回复。
小爱同学大模型采用 function calling。
- 首先, 对所有 API 抽象出 function 定义,包括API 功能以及参数描述。
- 把 query 和 function 定义一起构造一个 prompt,给到大模型。大模型会去做两件事情
- ① 判断是否用预定义 Function。
- ② 如果选择某个 function,要给出 Function 参数。
今天到上海的火车票,大模型识别 function 是一个Search_train,参数是time和arrival。这时候检查槽位是否满足 API 执行条件。如果是,就去请求 API 得到 API 结果,然后给到大模型去做回复。如果没有/参数不完整, 就直接回复,然后引导用户去补充或者澄清。
Function calling 难点
- ① 如何保证 100% 指令遵循
- 小爱场景下 Function calling 是满足的基础,要保证 100% 的指令遵循,通用大模型 prompt engineering 很难满足。
- 大模型微调分两步
- 第一步继续预训练,方法与意图分发的继续训练模型基本上一样,不同的是不同垂域可提供不同的继续预训练的数据;
- 第二步指令微调,跟意图分发一样。
- ② Function calling 依赖关系
- 串行方式,类似 ReAct。主要两个操作,一个是 reasoning 推理规划,另一个是 acting,这是单 function 的执行。
- 对于一个请求,ReAct 首先进行 Resoning 推理,决定下一步的操作,在意图理解里就是输出 Function,每次推理只会输出一个 Function。然后 Acting 执行,即 Function 执行。得到执行结果后,再重复上述过程,直到满足用户需求。如果一个需求,需要多 Function 执行,那么 ReAct 执行链路会很长,在实际应用中难以落地。
- ③ Function calling 推理耗时过高
解决多 Function 并行可用编程语义来表达,类似 LLMCompiler。可并行的 Function 会同时执行,可以减少响应时间。
LLMCompiler 会有三个组件:LLM Planner 大模型规划,Task Fetching Unit 任务获取,Executor 执行。
LLM Planner- 利用 LLMs 的推理能力,规划分解为子任务,并识别各子任务的依赖关系,生成一个子任务序列及其依赖关系,形成一个有向无环图。
- 如果一个任务依赖于之前的任务,它将使用占位符变量,用该任务的实际输出替换该受量。
Task Fetching Unit- 无依赖关系的子任务,并行执行。
- 有依赖关系的子任务,在完成上一任务后,再进行分发执行。
Executor- 以异步和并发的方式执行从任务获取单元获取的任务。
- 执行器配备了用户提供的工具,并将任务给关联的工具(如:API 调用)。每个任务都有专用的内存来存储其中间结果。任务完成后,最终结果将作为输入转发给依赖于它们的其他任务。
- 采用的是类似 LLMCompiler 的方式。但是在我们的场景下,更多的是单Function 需求。整体的执行效率没有体现。
最近也有些 Tree-based Planning,比如 Tree of thought、language Agent Tree Search(LATS),可同时考虑多个可行的计划,以作出最佳选择,耗时会过高,因此,在我们的场景下没有采用。
③ Function calling 推理耗时过高
- 输入优化
- 在大模型微调过程中让其记住 function 的定义和参数,这样可以减少生成的 token 数。但缺点是大模型要频繁更新以应对变化,通用性较差。
- 为缓解这一问题,让每一个垂域先虚拟 function,让大模型具备处理垂域 function 的能力。
- 推理优化
- 一方面是减少生成的 tokens 数,另一方面就是减少推理次数。
- 减少 tokens 数一般有三种方式
- ① 选择高压缩率的底座模型,对比过两个开源模型,压缩比在 1.4-2 之间,如果选择了高压缩率的底座模型,生成的 tokens 数据会明显地减少。
- ② 扩充词表,如果直接扩充词表而不去做继续预训练,那么大模型性能是急剧恶化的,所以如果要扩充词表,还是要去做一个继续训练。
- ③ 做 token 替换,有时候可能 function 名字或者参数的名字会被切成多个 token,可以在已有词表里边选择一个相近的 token 来替换,这种方法不够通用,建议慎重使用。
- 减少推理次数的方法: 投机采样,通过小模型推理 n 次生成 n 个 token,再让大模型进行评估。在 Function calling 的应用中,小模型用 n-gram 即可实现 2-3 倍的推理速度提升。
应用大模型进行意图理解,中长尾 query 满足率提升了 4%,多轮 query 满足率提升了 3%,训练数据减少了 90%。
通用大模型回复主要问题:
- 时效性。最经济的解决方式 RAG,外挂知识库,让大模型基于检索到的知识来做回答。
- 长上下文理解。由于 RAG 通常冗余地注入知识,来保证知识的召回率,会使 token 数很多,对大模型上下文理解能力的要求就更高。
- 指令遵循。为了保证用户的体验,期望回复简单,不要做信息罗列。特别是当商品属性众多,需要明确哪些属性是用户关心的。通常是产品定义。大模型难以遵循指令只输出关键信息。
RAG 场景下大模型回复,大模型需要具备如下能力:
- 知识总结。比如推荐一款手机,注入知识之后,要把用户关心的那个手机的一些参数给出来。
- 信息抽取。比如小米十四的像素是多少,我们希望大模型能够从我们注入的知识中,把小米十四的像素信息准确地提取出来。
- 复杂推理。比如推荐一个拍照好的手机,大模型需要理解这个拍照好对应的是相机的参数。再比如对比一下小米 14 和小米 14 pro 的差别,那大模型需要从注入的知识中,把这个小米 14 和小米 14 的 pro 的参数差异给出来。
- 多轮对话。多轮的时候经常会有缺省的部分,第一轮我说小米十四的价格,然后第二轮是像素是多少,那我当然希望他回答是小米十四的像素,而不是其他手机的像素。
- 兜底回复。因为会有一些知识缺失,或者是知识未检索到的情况,不希望大模型去杜撰。比如小米 17 什么时候发布,注入知识中肯定是没有小米 17 的,我们希望大模型能够具备抗干扰的能力。
最后为了保证大模型具备通用的问答能力,混入一些通用能力。
微调具体步骤:
- 第一步,优化单能力训练数据;如何评价? 最终模型评价是人工标注,但是人工标注成本太高且周期太长,在迭代过程中不适合。采用更好的大模型进行自动评价,例如 chatGPT,GPT4。前期评测,大模型评价与人工评价的一致性大概 80% 左右。
- 第二步,按比例混合训练数据,指令微调。数据混合比例如何确定?
- 单个能力的数据到达一定规模(1000->1500), 评测集合满足率(40%->81%)呈现大幅度提升,继续增加训练数据(1500->2000),满足率提升缓慢(81%->86%)
- 训练数据混合时,找到不同能力的满足率大幅提升到平稳的临界点,以此作为调整的基础。一般来说,难度大的,训练数据会稍多。在合并数据过程中,控制每个能力的数据上限。
- 第三步,构建偏好数据,对齐训练 DPO。数据构建格式是一个四元组
<Query, Knowledge,Win_response,Lose_response>- 指令微调+DPO 训练,相比单纯的指令微调,回复满足率提升 2%;相比于 prompt engineering 可以提升 10%。
小爱整个架构是分而治之框架,是否可用一个大模型端到端地去满足用户呢? 甚至由一个多模态大模型进行端到端的理解,无需 ASR 和 TTS。
- 用一个多模态的 Anything to Anything 的架构,类似 GPT4o 和谷歌 Gemini。
- 未来努力的方向,但目前分而治之仍是一个更优的方案。
- 另外,也在做端侧大模型,以更好地解决用户隐私的问题。
RasaGPT
【2024-5-28】 RasaGPT 是一个基于 Rasa(用于自动化基于文本和语音的机器人对话开发框架) 和 Langchain(用于构建基于大型语言模型的应用程序的开源框架) 构建的无界面 LLM 聊天机器人平台。
RasaGPT 结合了 Rasa 的对话管理功能和 Langchain 的索引、检索与上下文注入功能,支持多种集成和扩展,适用于各种应用场景。
GitHub 开源关键字:paulpierre/rasagpt
特点:
- 使用FastAPI创建专有机器人端点,文档上传和“训练”流程已包含在内。
- 集成Langchain/LlamaIndex和Rasa。
- 解决了库与大型语言模型库之间的冲突以及元数据的传递
- 在MacOS上运行Rasa的Docker支持。
- ngrok与聊天机器人进行反向代理。
- 使用自定义模式实现pgvector,而不是使用Langchain的高度自定义的PGVector类。
- 添加多租户(Rasa本身不支持这一功能)、会话以及Rasa与您自己的后端/应用程序之间的元数据。
演示视频
(5)尾声
对话系统博大精深,这篇文章是结合过往多年对话系统经验,短期内东拼西凑而来,质量没保障,如果错误、疑问,欢迎私聊,讨论。
附录:很多,不一一罗列了,反正你们也不会看
- 公众号内私信回复关键词获取感兴趣的资料
- 认知偏差→50个认知偏差
- 心理学效应→心理学效应相关信息
- 对话系统→对话系统笔记
- 对话管理→对话管理(DM)专题
- 台大对话→台大陈蕴侬对话系统的ppt
- 哈工大张伟男→哈工大张伟男对话系统专题
- 对话系统升级→大模型时代,对话系统如何升级、
- 智障案例→了解更多人工智障示例
- 人工智障→Mingke对智障系列的详尽分析
- 拾象报告→拾象投研对大模型的两次分析报告
- 大模型应用→大模型在各行各业的应用案例
资料
LLM 对话系统综述
【2023-11-28】香港中文大学和华为诺亚方舟实验室,综述文章: 大模型时代,对话系统的演进和机会
每次语言模型的更新都代表计算架构和学习范式的迭代,给对话系统的发展与演变带来了深刻的影响。
- 从
NLM(e.g., LSTM, GRU)到PLM(e.g., BERT, GPT),再到如今几乎统治一切自然语言处理任务的LLM,每次语言模型的进化都对对话系统的研究方向和研究重心产生了一定的影响。 
整个对话系统的演变分为四个不同的阶段:
- 早期阶段(Early Stage — 2015年之前): 早期对话系统几乎全是
任务型对话(Task-oriented Dialogue System),以完成某一个具体的任务比如订机票,订餐厅等为最终目标,一开始的任务型对话系统单一任务,单一领域,单一语言等,所涉及到技术主要是基于统计机器学习,或者规则类的对话系统,以Eliza,GUS,ALICE为代表。 - 独立发展阶段(2015-2019, NLM):
- 一方面,2015年
Seq2seq的出现,让开放域对话系统 (Open-domain Dialogue System)进入到了大家的视野,开放域对话不以完成某一个具体的任务为目标,主打一个随心所欲,想聊啥聊啥,天然的适配seq2seq这样的一套框架,很多研究人员开始使用seq2seq去解决开放域对话的问题; - 另一方面,随着
LSTM,GRU等RNN的提出,任务型对话也开始使用相应的NLM去建模上下文从而在不同的子任务上取得更好的效果。
- 一方面,2015年
- 融合阶段(2019-2022, PLM):
BERT,GPT等Pre-trained Language Model (PLM)的出现带来了新一轮的范式 — pre-train-then-finetune。- 受益于大规模的预训练,PLM的参数自带很多有用的信息比如世界知识,常识知识等,这些知识作为底层能力,可以被应用在大量的任务和领域上,从来给对话系统带来了任务,领域,语言等多个不同层面的融合。需要注意的是融合趋势仍在继续,并未停止,也许永远不会停止。
- 基于大模型的对话系统(2022-Now, LLM): 大模型的出现就是融合,进化的产物。随着数据越来越多,模型就变得越来越大,能力就越来越好,这就是熟悉的scaling law。当把大模型对话系统在现实场景下进行应用的时候,新的问题和挑战也随之出现。参考《大模型对话系统的内功与外功》。
LLM 几个显著优势:
提示工程(Prompt Engineering): 通过不同的提示,大模型在一些任务上取得不俗的表现,大量工作关注于怎么通过提示去从当前的对话获取更多的信息;- 大模型的泛化能力极强,几乎能够解决所有任务。这就为构建LLM-Based Dialogue System提供了一种新的视角
三种不同的对话流(conversational flow):
- 1)基于内部推理和对话上下文进行回复;
- 2)基于外部知识和对话上下文进行回复;
- 3)基于内部推理,外部知识以及对话上下文进行回复。
详解
- 内部推理 Internal Reasoning (Prompts): 通过prompting方式去让大模型推理出来对话上下文中蕴含的各种信息,包括但不限于:对话状态(dialogue state tracking),用户状态(用户情绪,心理,性格特征等),和各种语义信息(natural language understanding)等等。表格中统计了现在通过prompting的方式去解决对话系统里面各个不同任务的最新进展,比如说利用LLM去做TOD的IT-LLM和SGP-TOD等等,还有相应的情感对话,心理对话。
- 外部交互 External Acting (Interactions): 对话系统不仅要考虑到在对话上下文中用户的意图和需求,还需要和外部的环境进行交互,比如多个不同的知识源,不同模态的信息甚至不同的工具等等,来提供及时,准确,可信的回复。
- 内部推理+外部交互 (Reasoning + Acting): 这时候的对话系统其实更加的拟人化了,或者说更加的类似于language agent的概念,不仅要及时的推理对话上下文中蕴含的信息,还要和外部环境进行一系列的交互,从而获取更多的信息,最终生成更加完美的回复。
论文
【2023-12-4】香港中文大学 武侠小说视角:大模型对话系统的内功与外功
- 论文:Cue-CoT: Chain-of-thought Prompting for Responding to In-depth Dialogue Questions with LLMs
- 代码:Cue-CoT
Cue-CoT 把用户回复生成建模成多阶段的推理过程:
- O-Cue:One-step inference, 类似于传统 CoT,一步直接生成中间推理过程和最终回复。
- 首先要求 LLM 推理出来当前对话历史里面蕴含的不同维度的用户信息(使用不同的 prompts)
- 然后让 LLM 接着生成最终的回复。(相对复杂的指令和内容臃肿的输出)
- M-Cue:Multi-step inference,逐步生成 LLM 输出的内容。和 O-Cue 一样
- 第一步要求 LLM 推理出来当前对话历史里面蕴含的不同维度的用户信息,然后给定对话上下文和第一步生成的中间结果
- 第二步让 LLM 接着生成最终的回复。(相对简单的指令和内容清晰的输出)
不是每轮对话都需要外部知识,也不是要所有外部知识,有时候要的是这些知识库之间存在依赖
提出一个框架 SAFARI,将外部知识选择和回复生成解耦。
将整个对话回复生成解耦成三个任务
- 1)Planning:规划是否需要使用知识,何时使用知识,以及多种知识库之间的调用顺序;
- 2)Retrieval:使用外部的 retriever 对上一步规划使用的知识库按顺序抽取对应的 Top-n 的辅助文档;
- 3)Assembling:将对话上下文和中间抽取到的辅助文档拼接在一起进行最终的回复生成。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
