- Transformer 改进方案
- 结束
Transformer 改进方案
Transformer 问题
【2023-9-18】RetNet:万众期待的 Transformers 杀手, 头条
Transformer 已成为大语言模型上的架构,因为它有效地克服了循环神经网络 (RNN) 的顺序训练问题。
然而,Transformer 并不完美,因为仅解决了所谓“impossible triangle”的两条臂。
“不可能三角”代表当前序列模型无法同时实现训练并行性、低成本推理以及强大性能的所有3个期望维度。
三角上的方法表示实现的两个维度,但缺少第三个顶点的所需属性。
总结
【2025-8-13】Sun, Weigao, Jiaxi Hu, Yucheng Zhou, et al. 2025. 上海AI Lab等,Transformer计算量大导致LLM训练受限, 架构的优化综述,moe、稀疏序列模型、高效全注意力、混合架构、扩散语言模型、多模态
可解释性
白盒 transformer – CRATE
【2023-11-30】「GPT-4只是在压缩数据」,马毅团队造出白盒Transformer,可解释的大模型要来了吗?
伯克利和香港大学的马毅教授领导的一个研究团队给出了自己的最新研究结果:
包括 GPT-4 在内的当前 AI 系统所做的正是压缩。
提出的新深度网络架构 CRATE,通过数学方式验证了这一点。
- CRATE 是一种白盒 Transformer,其不仅能在几乎所有任务上与黑盒 Transformer 相媲美,而且还具备非常出色的可解释性。
基于此,马毅教授还在 Twitter 上分享了一个有趣的见解:
- 既然当前的 AI 只是在压缩数据,那么就只能学习到数据中的相关性 / 分布,所以就并不真正具备因果或逻辑推理或抽象思考能力。
因此,当今的 AI 还算不是 AGI,即便近年来在处理和建模大量高维和多模态数据方面,深度学习在实验中取得了巨大的成功。
这种成功归功于深度网络能有效学习数据分布中可压缩的低维结构,并将该分布转换为简约(即紧凑且结构化的)表征。这样的表征可用于帮助许多下游任务,比如视觉、分类、识别和分割、生成。
表征学习是通过压缩式编码和解码实现的
白盒深度网络理论。为学习紧凑和结构化的表征提出了一个统一目标,有原理保证的优良度度量。对于学习到的表征,该目标旨在既优化其在编码率下降方面的内在复杂性,也优化其在稀疏性方面的外在复杂性。该目标称为 稀疏率下降(sparse rate reduction)。
为了优化这个目标,提出学习一个增量映射序列,模拟展开目标函数的某些类似梯度下降的迭代优化方案。这得到一个类似 Transformer 的深度网络架构,并且它完全是一个「白盒」—— 其优化目标、网络算子和学习到的表征在数学上是完全可解释的。
这个白盒深度架构命名为 CRATE 或 CRATE-Transformer,这是 Coding-RATE transformer 的缩写。还通过数学方式证明这些增量映射在分布的意义上是可逆的,并且它们的逆映射本质上由同一类数学算子构成。
因此,可以将几乎完全一样的 CRATE 架构用于编码器、解码器或自动编码器。
模型结构
如果说 RetNet 是从平行推理效能的角度革新了网络架构,那么 BitNet 则从正交角度提升了推理效率。
这两者的结合,以及融合其他提升模型效率的技术比如混合专家模型(MoE)和稀疏注意力机制(Sparse Attention),将成为未来基础模型网络架构的基础。
RetNet
【2023-9-18】RetNet:万众期待的 Transformers 杀手, 头条
微软的 RetNet 位于这个“impossible triangle”的正中心,胜过了所有尝试过但未能实现这一壮举的方法。RetNet 设法在单个框架下实现所有属性。
突破:
- RetNet 具有更好的语言建模性能
- RetNet 内存消耗降低了 3.4 倍
- ….8.4 倍更高的吞吐量
- …延迟降低 15.6 倍
这速度比当前的 SOTA 快几个数量级,同时还提供更好的性能!如果其他团队能够复制这一点并且进入开源领域,这将是巨大的进步,但目前微软绝对是「遥遥领先」
RetNet的主要贡献可以概括为两大点
- RetNet引入多尺度保留机制来替代多头注意力。这是消除自注意力机制中的魔鬼这一组成部分的关键。尽管如此,这种保留机制有一个小小的理论上的缺点。
- RetNet 适用于三种计算范式,而只有一种 Transformer 在训练和推理过程中使用相同的序列处理范式。
- A. 并行表示使训练并行性能够充分利用 GPU 设备。
- B. 循环表示在内存和计算方面可实现高效的 O(1) 推理。可以显着降低部署成本和延迟。此外,在没有键值缓存技巧的情况下,实现也得到了极大的简化。
- C. 分块循环表示可以执行有效的长序列建模。对每个本地块进行并行编码以提高计算速度,同时对全局块进行循环编码以节省 GPU 内存。
新型基础网络架构 Retentive Network(RetNet)成功突破了所谓的“不可能三角”难题,实现了帕累托(Pareto)优化。
- RetNet 在保持良好的扩展性能和并行训练的同时,实现了低成本部署和高效率推理。
RetNet 推理成本与模型序列长度无关,这表示无论是处理长文本序列,还是长图像序列,亦或是未来更长的音视频序列,RetNet 都可以保持稳定的高效推理。
微软 BitNet
【2024-2-29】BitNet b1.58:开启1-bit大语言模型时代
微软亚洲研究院推出了 1-bit LLM 新变体:BitNet b1.58。
该模型每个参数仅使用三值表示,即-1, 0 或 1。因此,在 LLM 的矩阵乘法操作中只需要整数加法,而不需要任何浮点数乘法或加法。在语言模型困惑度和下游任务性能的评估中
- BitNet b1.58 能够与具有相同参数量和训练数据量的全精度(即FP16或BF16)Transformer LLM 相匹敌。
- 与此同时,它在速度、内存使用、吞吐量和能耗等方面具有大幅优势。
BitNet b1.58 为训练新一代高性能高效率的 LLMs 确立了新的扩展定律(scaling law)和方法。此外引领了一种全新的计算范式,并为开发专为 1-bit LLMs 优化的硬件设备铺平了道路。
BitNet 是第一个支持训练1比特大语言模型的新型网络结构,具有强大的可扩展性和稳定性,能够显著减少大语言模型的训练和推理成本。
与最先进的8比特量化方法和全精度 Transformer 基线相比,BitNet 在大幅降低内存占用和计算能耗的同时,表现出了极具竞争力的性能。
此外,BitNet 拥有与全精度 Transformer 相似的规模法则(Scaling Law),在保持效率和性能优势的同时,还可以更加高效地将其能力扩展到更大的语言模型上,从而让1比特大语言模型(1-bit LLM)成为可能。
微软 YOCO
【2024-5-13】YOCO:打破传统Decoder-only架构,内存消耗仅为Transformer的六分之一
模型架构还只有三大类:Decoder-Only、Encoder-Only、Encoder-Decoder。
微软亚洲研究院推出了一种创新性的 Decoder-Decoder 架构 YOCO(You Only Cache Once)。通过自解码器和交叉解码器的独特架构,YOCO 仅需缓存一次键值对,从而显著降低 GPU 内存的使用。
模型评估中,YOCO 展现出与同规模 Transformer 模型相媲美的性能,并在语言建模评估、模型大小扩展以及长上下文处理方面具有显著优势。特别是在降低 GPU 内存占用和缩短预填充延迟方面,
YOCO 整体架构设计如下,分为自解码器(Self-Decoder)和交叉解码器(Cross-Decoder)两部分。
YOCO 实现了“模型越大,内存越省”,为自然语言处理领域带来了全新的研究和应用范式。
- YOCO 仅缓存一次键值对,可大幅降低 GPU 内存需求,且保留全局注意力能力。
打破 GPT 系列开创的 Decoder-Only 架构——提出 Decoder-Decoder 新型架构,名为 YOCO (You Only Cache Once)。
- 在处理 512K 上下文长度时,标准 Transformer 内存使用是 YOCO 的6.4倍,预填充延迟是 YOCO 的30.3倍,而 YOCO 的吞吐量提升到标准 Transformer 的9.6倍。
位置编码方式
2021.3.23 Roformer
【2021-3-23】Rotary Transformer,简称 RoFormer,是追一科技苏剑林自研的语言模型之一,主要是为Transformer结构设计了新的旋转式位置编码(Rotary Position Embedding,RoPE)。
RoPE具有良好的理论性质,且是目前唯一一种用到线性Attention的绝对位置编码,目前来看实验结果也颇为不错。- 参考配置:在24G显存的3090上,跑maxlen=1024,batch_size能跑到8以上。
详细介绍:
使用
from transformers import RoFormerTokenizerFast
tokenizer = RoFormerTokenizerFast.from_pretrained("junnyu/roformer_chinese_base")
tokenizer.tokenize("今天天气非常好。")
检索增强
增大模型并不是提升性能的唯一路径,用一种搜索/查询信息的方式来增强模型,小的生成语言模型也能达到之前大模型才能达到的性能。
语言模型的任务是做填空题,这对于语言信息有意义,但是对于事实信息和世界知识信息是无效的。
- 有时需要与事实有关的信息
代表
- DeepMind 的 RETRO Transformer
- DeepMind 的 RETRO(Retrieval-Enhanced TRansfOrmer)模型。该模型与 GPT-3 性能相当,但参数量仅为 GPT-3 的 4%。
- OpenAI 的 WebGPT
2021.12.16 WebGPT
OpenAI 推出 WebGPT, 解决 long-form quesion-answering (LFQA) 的方案, 开放域QA回复更长更可靠。
- WebGPT: Improving the factual accuracy of language models through web browsing
- WebGPT简读
- 比 InstructGPT 提出稍早一些
WebGPT 思路类似 Knowledge-Grounded Conversation,利用搜索引擎做相关文档检索,从而生成更长的答案。主要的两个贡献:
- 微调的语言模型可以与一个基于文本的Web浏览环境交互,从而可以端到端地使用模仿和强化学习优化检索和聚合效果。
- 参考Web检索出来的信息生成回复。labeler可以根据检索出来的信息判断factual准确率,降低了独立调研问题正确性的难度。
这个想法并非 WebGPT首次提出
- 2021年初, Facebook (FAIR) 就提出使用搜索引擎来提升对话回复的质量:ACL2022 Internet-Augmented Dialogue Generation
WebGPT 思路更进一步,完全模拟了人使用搜索引擎的方法(有更多action: 搜索、点击、翻页、回退等等),而非仅生成search query并使用其结果。
2022.2.7 RETRO
DeepMind 推出 RETRO, 整合了从数据库中检索到的信息,将其参数从昂贵的事实和世界知识存储中解放出来。
- 论文: Improving language models by retrieving from trillions of tokens
- illustrated-retrieval-transformer
- 【2022-1-4】参数量仅为4%,性能媲美GPT-3:开发者图解DeepMind的RETRO
加入检索方法之后,语言模型可以缩小很多。
- 神经数据库可以帮助模型检索它需要的事实信息。

模型结构
结构
- RETRO 是 编码器 - 解码器模型,像原始的 Transformer。
- 然而在检索数据库的帮助下增加了输入序列。
- 该模型在数据库中找到最可能的序列,并添加到输入中。
- RETRO 利用它的魔力生成输出预测。

RETRO 检索数据库
这里的数据库是一个键值存储(key-value store)数据库。
- key 是标准的 BERT 句子嵌入,value 是由两部分组成的文本:
- Neighbor,用于计算 key;
- Completion,原文件中文本的延续。
RETRO 数据库包含基于 MassiveText 数据集的 2 万亿个多语言 token。neighbor chunk 和 completion chunk 的长度最多为 64 个 token。

数据库查找
进入 RETRO 前
- 输入提示进入 BERT。对输出的上下文向量进行平均以构建句子嵌入向量。
- 然后,使用该向量查询数据库。近似最近邻搜索。检索两个最近邻
- 将这些添加到语言模型的输入中
- 检索出的文本成为 RETRO 输入的一部分,Transformer 和 RETRO 块将信息合并到它们的处理中



高层次的 RETRO 架构
RETRO 架构由一个编码器堆栈和一个解码器堆栈组成。
- 编码器由标准的 Transformer 编码器块(self-attention + FFNN)组成。Retro 使用由两个 Transformer 编码器块组成的编码器。
- 编码器堆栈会处理检索到的近邻,生成后续将用于注意力的 KEYS 和 VALUES 矩阵
- 解码器堆栈包含了两种解码器 block:
- 标准 Transformer 解码器块(ATTN + FFNN)
- RETRO 解码器块(ATTN + Chunked cross attention (CCA) + FFNN)
- 解码器 block 像 GPT 一样处理输入文本。对提示 token 应用自注意力(因此只关注之前的 token),然后通过 FFNN 层。只有到达 RETRO 解码器时,它才开始合并检索到的信息。从 9 开始的每个第三个 block 是一个 RETRO block(允许其输入关注近邻)。所以第 9、12、15…32 层是 RETRO block。


输入输出 改进
输入长度改进
2023.7.8 LongNet
【2023-7-8】1000000000!微软改进Transformer一次能记住这么多token了
- 最强的GPT-4也才最大支持一次处理32k token,相当于50页文字。
- 而能够只用1分钟看完一本数万字小说的Claude,其token数也不过“才”100k(10万)。
一次性扩展到10亿,并且这个数字理论上其实还是无限的,这不就意味着:不久的将来,整个语料库甚至互联网都能视为一个序列?
作者提出一个Transformer变体:LongNet,它应用了一种叫做“膨胀注意力(dilated attention)”的机制,可以随着距离的增长,让注意力场(模型感知范围)呈指数级扩展。
具体而言,dilated attention替代了普通Transformer中的注意力机制的,其一般的设计原则是:
让注意力的分配随着token之间距离的增长,呈指数级下降。
dilated attention能够产生线性计算复杂度和token之间的对数依赖性,从而解决了注意力资源有限,但每一个token都可访问的矛盾。
MLP 改进
多层感知器(MLP)被称为全连接前馈神经网络,是当今深度学习模型的基础构建块。
MLP 重要性无论怎样强调都不为过,是机器学习中用于逼近非线性函数的默认方法。
然而,MLP 是否最佳非线性回归器呢?
尽管 MLP 被广泛使用,但存在明显缺陷。
- 例如,在 Transformer 模型中,MLP 几乎消耗了所有非嵌入式参数,并且通常在没有后处理分析工具的情况下,相对于注意力层来说,它们的可解释性较差。
KAN
【2024-5-3】Transformer要变Kansformer?用了几十年的MLP迎来挑战者KAN
MIT 提出的 KAN 灵感来源于 Kolmogorov-Arnold 表示定理的网络。
- 论文:KAN: Kolmogorov-Arnold Networks
- Github:pykan
KAN 在准确性和可解释性方面表现优于 MLP,而且能以非常少的参数量胜过以更大参数量运行的 MLP。
有研究者将 KAN 创新架构的理念扩展到卷积神经网络,将卷积的经典线性变换更改为每个像素中可学习的非线性激活函数,提出并开源 KAN 卷积(CKAN)
- 【2024-5-20】替代MLP的KAN,被开源项目扩展到卷积了
- Convolutional-KANs
Kolmogorov 1957 年就发现了多层神经网络,比 Rumerhart、Hinton 和 William 的 1986 年论文发表的时间要早得多,但他却被西方忽视了。
一种有前景的多层感知器(MLP)的替代方案,称为 Kolmogorov-Arnold Networks(KAN)。
- MLP 的设计灵感来源于
通用近似定理(通用逼近定理) - 而 KAN 设计灵感则来源于
Kolmogorov-Arnold 表示定理。
Kolmogorov-Arnold 表示定理
- Vladimir Arnold 和 Andrey Kolmogorov 证明了如果 f 是一个在有界域上的多变量连续函数,那么 f 可以写成一个单变量连续函数和二元加法运算的有限组合。
与 MLP 类似,KAN 拥有全连接结构。而 MLP 在节点(神经元)上放置固定激活函数,KAN 则在边(权重)上放置可学习的激活函数。
因此,KAN 完全没有线性权重矩阵: 对比图
- 每个权重参数都被替换为一个可学习的一维函数,参数化为样条(spline)。
- KAN 的节点仅对传入信号进行求和,而不应用任何非线性变换。

尽管 KAN 数学解释能力不错,但实际上只是样条和 MLP 的组合,利用了二者的优点,避免了缺点的出现。
- 样条在低维函数上准确度高,易于局部调整,并且能够在不同分辨率之间切换。然而,由于样条无法利用组合结构,因此存在严重 COD 问题。
- 另一方面,MLP 由于其特征学习能力,较少受到 COD 的影响,但在低维空间中却不如样条准确,因为它们无法优化单变量函数。
KAN 的最大瓶颈: 训练速度慢。
- 相同数量的参数下,KAN 的训练耗时通常是 MLP 的 10 倍。
- KAN 训练速度慢更像是一个未来可以改进的工程问题,而不是一个根本性的限制
Attention 改进
QKV
MHA、GQA、MQA、MLA 原理对比
- 传统 Transformer 采用 MHA,但 KV Cache 在推理过程中可能成为性能瓶颈。
MQA和GQA虽然在一定程度上可以减少KV Cache的占用,但效果通常不如MHA。MLA通过低秩 Key-Value联合压缩技术,不仅实现了比MHA更优的效果,还大幅减少了所需的KV Cache大小。
GQA: Grouped-Query Attention
Grouped-Query Attention:对于更大参数量、更大的 context length、更大的 batchsize 来说,原始的MHA(multi-head attention)内存占用会更高(因为在计算时要缓存pre token的K、V矩阵)。
MQA(multi-query attention)让所有的 head 共享 1 个 KV projection 矩阵;GQA(grouped-query attention )使用 8 个 KV projections(选择8是因为A100 8GPUs) 来减少内存占用。
GQA(Grouped Query Attention,分组查询注意力)是优化 Transformer 模型(特别是大语言模型)注意力机制的技术,对 Multi-Head Attention (MHA) 和 Multi-Query Attention (MQA) 的扩展。
通过提供计算效率和模型表达能力之间的灵活权衡,实现了查询头的分组。
GQA将查询头分成了G个组,每个组共享一个公共的键(K)和值(V)投影。三种变体:
GQA-1:一个单独的组,等同于 Multi-Query Attention (MQA)。GQA-H:组数=头数,基本上与 Multi-Head Attention (MHA) 相同。GQA-G:一个中间配置,具有G个组,平衡了效率和表达能力。
在 30B 模型上训练 150B tokens,发现 GQA 效果和 MHA 差不多,比 MQA 要好;
在 1 个node的 8 个 A100 GPUs 上推理速度 GQA 和 MQA差不多,比 MHA 要好(MQA 在推理的时候,要把 KV projections 复制到8张卡上)。
MQA: Muti Query Attention
MQA 是 2019 年提出的 Attention 机制,保证模型效果的同时加快 decoder 生成 token 的速度。
- 论文: Fast Transformer Decoding: One Write-Head is All You Need
- 所有 head 之间共享一份 key 和 value 的参数
MQA 在 encoder 上的提速没有非常明显,但在 decoder 上的提速是很显著的
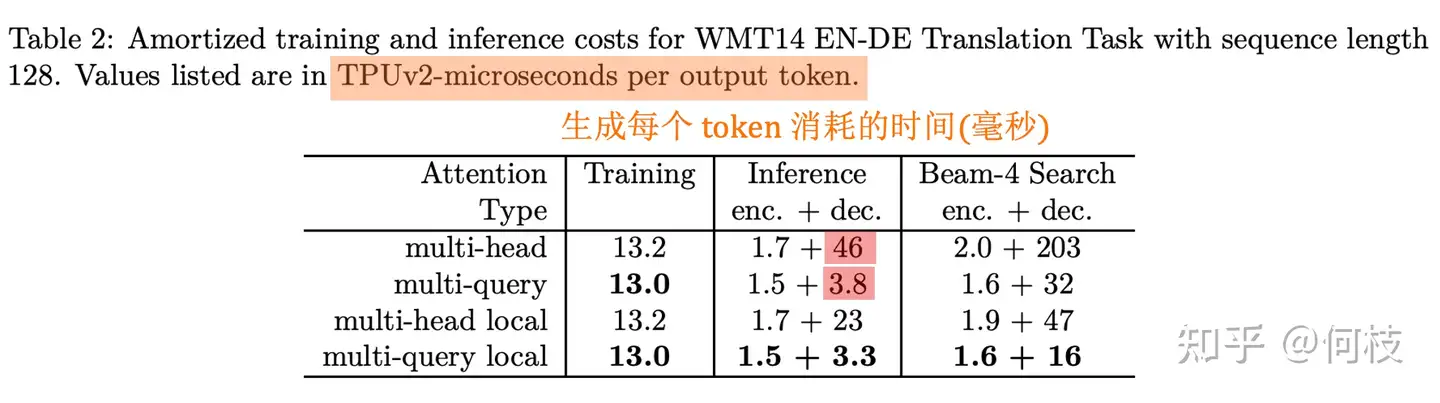
Multi Query Attention(MQA) 和 Multi Head Attention(MHA)只差了一个单词,从「Head」变成了「Query」。
MQA 让所有的头之间 共享 同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
- 「参数共享」并不是新奇思路,Albert 通过使用跨层共享参数(Cross-layer parameter sharing)方式来大大减少 bert 的参数量
- MQA 实际上是将 head 中的 key 和 value 矩阵抽出来单独存为一份共享参数,而 query 则是依旧保留在原来的 head 中,每个 head 有一份自己独有的 query 参数。
代码见原文
MLA: Multi-head Latent Attention
【2024-9-26】注意力机制的变体之MLA
MLA(Multi-head Latent Attention) 是 杭州深度求索人工智能在DeepSeek V2 提出的一种注意力机制变体。
MLA 解决推理过程中, 由于attention机制中KV Cache占用过多内存而导致的性能瓶颈问题。
MLA 引入了低秩KV压缩技术,有效减少了KV Cache 大小,从而缓解了这一问题。
- 官方技术报告介绍
MLA 通过低秩 Key-Value联合压缩技术,不仅实现了比MHA更优的效果,还大幅减少了所需的KV Cache大小。
MLA通过低秩联合压缩key和value来减少kv cache。
从注意力机制的步骤来分析:
- 通过输入x乘以不同矩阵参数Wq、Wk、Wv, 得到不同的QKV向量
- 转换到QKV向量时,将x乘以一个低秩矩阵,得到低阶矩阵表示
- 再通过高阶矩阵来恢复原来的特征空间。由于矩阵是模型的权重参数已经保存,所以只需要保存一个低秩的潜层特征就可以恢复成KV,而不是像之前需要同时缓存KV。
为什么LoRA提出这么久了,直到 MLA 才提出对KV Cache低秩分解的做法?
推理加速
芯片
【2023-12-19】美国芯片初创公司 Etched AI 宣称开创了一项新的技术,将 Transformer 架构直接“烧录”到了芯片中?,创造出了世界上最强大的专门用于Transformer推理的服务器。可以运行万亿参数的模型!? 甩英伟达icon几百条街?

将 Transformer架构直接“烧录”到芯片中,这意味着Transformer模型的推理可以在专门的硬件上运行,而不需要依赖传统的CPU或GPU。这将大大提高推理速度,降低功耗,并提高模型的性能。
- 解码速度远超 A100, H100: NVIDIA A100(1x) < NVIDIA H100(5x) < Etched Sohu(15+x)
功能:
- ? 实时语音代理:能够在毫秒内处理成千上万的词。
- ? 更好的编码与树搜索:可以并行比较数百个响应。
- ? 多播推测解码:实时生成新内容。
- ? 运行未来的万亿参数模型:只需一个核心,支持全开源软件栈,可扩展至100T参数模型。
- ? 高级解码技术:包括光束搜索和MCTS解码。
- ? 每个芯片144 GB HBM3E:支持MoE和转换器变体。
这对于英伟达来说是巨大的挑战。英伟达一直是人工智能领域的领导者之一,其GPU被广泛应用于深度学习模型的训练和推理。然而,Etched AI的技术可能改变这一格局。
详细:iconetched.ai
TransNAR
拯救Transformer推理能力DeepMind新研究,TransNAR:给模型嵌入算法推理大脑
【2024-6-19】DeepMind 论文提出用混合架构方法,解决Transformer模型的推理缺陷。
将Transformer的NLU技能与基于GNN的神经算法推理器(NAR)的强大算法推理能力相结合,可以实现更加泛化、稳健、准确的LLM推理。
- TransNAR:用预训练NAR增强Transformer
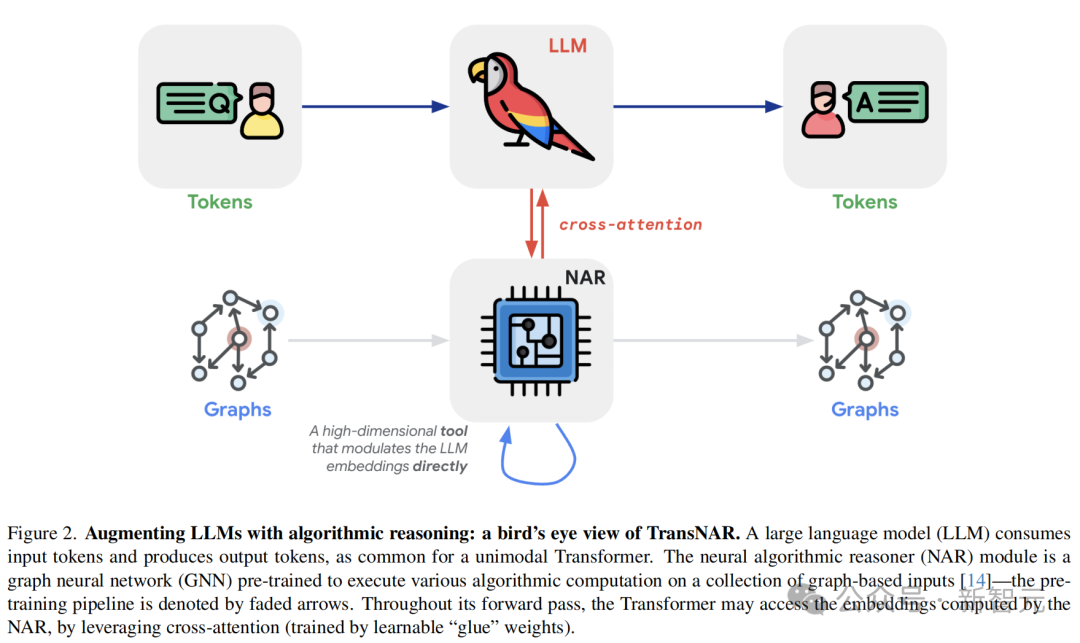
神经算法推理(NAR)由作者之一Petar Veleckovic, 2021年与人合著的一篇论文中提出,并被接收为Patterns期刊的opinion paper。
NAR被称为「构建能执行算法的神经网络的艺术」。算法与深度学习的本质不同,但如果神经网络能够更好地模仿算法,它甚至可能具备算法的强泛化性。
NAR 整体想法:
- 训练一个高维隐空间中的处理器网络P(processor network),旨在不断逼近算法的运行结果A(x)。
- 但由于算法的输入和输出一般是图、树、矩阵等抽象、结构化的形式,这与深度学习模型高维、嘈杂且多变的输入很不兼容,因此还需要训练编码器f和解码器g,将抽象形式转换为自然形式。
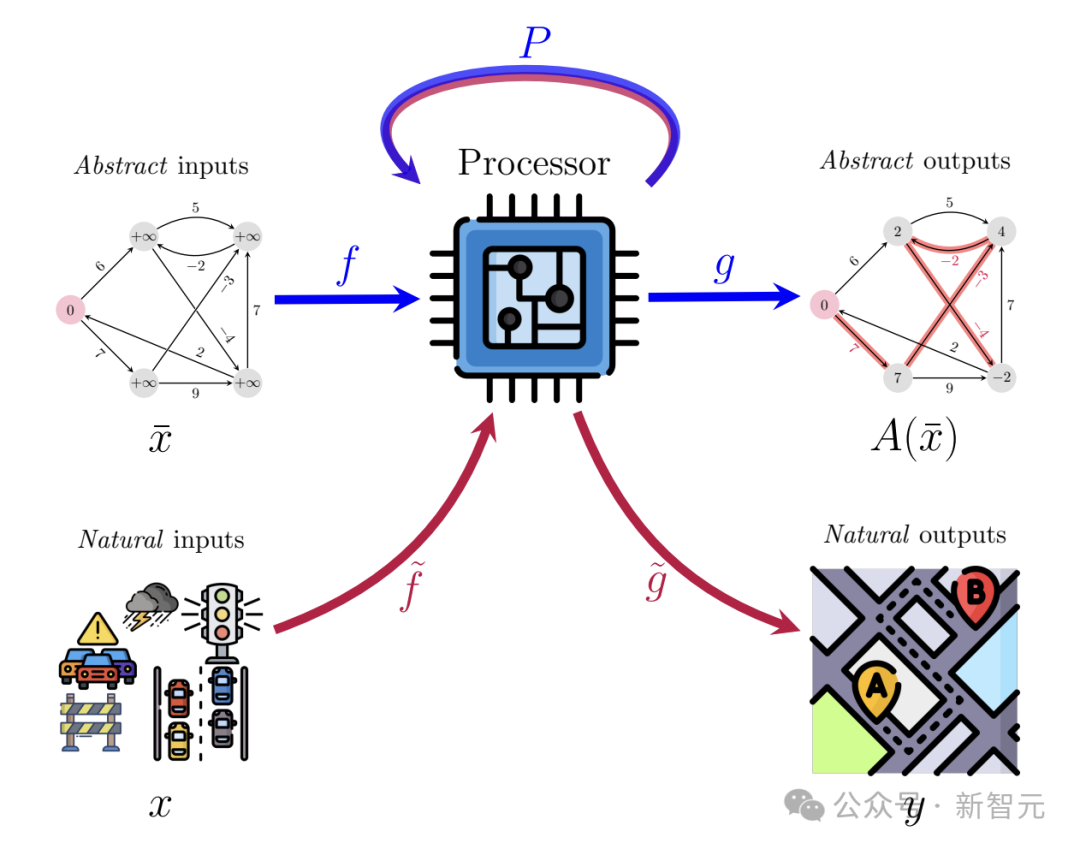
NAR 泛化能力似乎远远优于Transformer架构
详见: 拯救Transformer推理能力!DeepMind新研究TransNAR:给模型嵌入「算法推理大脑」
计算效率
attention 存在 $n^2$ 的计算复杂度,如何实现更长文本的计算?
- 基于状态迭代: TransformerXL RMT
- 基于位置编码外推能力: ALiBi xPos Unlimiformer
- 基于工程优化: FlashAttention
- 基于高效Attention: Reformer LinFormer Flash
- 其他; S4, FLASH

2023.6.14 FlashAttention
【2023-6-14】FlashAttention: 更快训练更长上下文的GPT
- 将 transformer 的 qkv 计算加速,方法:向量分块并行
- 视频有特效。
- 飞书合集文档
- FlashAttention
- GitHub CodeRepo
softmax 进化
【2024-11-5】Flash Attention基础,一问一个不吱声
FA 主要思想: 注意力分块计算, 其中, Online-Softmax 是关键
softmax 层层递进
- 原生 softmax: 指数计算 exp 不稳定, 容易数值溢出,超过一定范围就精度下降
- safe softmax: 减去最大值再计算
- online softmax: 利用指数运算规则(同底指数相乘=指数幂相加)
- online softmax 性能跟navie一致,相比safe softmax 实现上,大概1.2到1.4倍提升
- block online softmax
- batch online softmax
原生 softmax
import torch
X = torch.tensor([-0.3, 0.2, 0.5, 0.7, 0.1, 0.8])
X_exp_sum = X.exp().sum()
X_softmax_hand = torch.exp(X) / X_exp_sum
print(X_softmax_hand)
# 输出 tensor([0.0827, 0.1364, 0.1841, 0.2249, 0.1234, 0.2485])
safe softmax
- exp 前, 将每个元素减去最大值
X_max = X.max()
X_exp_sum_sub_max = torch.exp(X-X_max).sum()
X_safe_softmax_hand = torch.exp(X - X_max) / X_exp_sum_sub_max
print(X_safe_softmax_hand)
# 输出 tensor([0.0827, 0.1364, 0.1841, 0.2249, 0.1234, 0.2485])
Online Softmax
X_pre = X[:-1]
print('input x')
print(X)
print(X_pre)
print(X[-1])
# we calculative t-1 time Online Softmax
X_max_pre = X_pre.max()
X_sum_pre = torch.exp(X_pre - X_max_pre).sum()
# we calculative t time Online Softmax
X_max_cur = torch.max(X_max_pre, X[-1]) # X[-1] is new data
X_sum_cur = X_sum_pre * torch.exp(X_max_pre - X_max_cur) + torch.exp(X[-1] - X_max_cur)
# final we calculative online softmax
X_online_softmax = torch.exp(X - X_max_cur) / X_sum_cur
print('online softmax result: ', X_online_softmax)
# input x
# tensor([-0.3000, 0.2000, 0.5000, 0.7000, 0.1000, 0.8000])
# tensor([-0.3000, 0.2000, 0.5000, 0.7000, 0.1000])
# tensor(0.8000)
# online softmax result: tensor([0.0827, 0.1364, 0.1841, 0.2249, 0.1234, 0.2485])
block online softmax
- online softmax 随着新加入的元素可以更新底数和 ,实际上不会频繁逐个加入进行更新底数,而是以块形式计算各自的底数和最大值,再按照online-softmax原理来更新。
- 各自块状独立计算最大值和底数好处是可以并行计算
X_block = torch.split(X, split_size_or_sections = 3 , dim = 0)
print(X)
print(X_block)
# we parallel calculate different block max & sum
X_block_0_max = X_block[0].max()
X_block_0_sum = torch.exp(X_block[0] - X_block_0_max).sum()
X_block_1_max = X_block[1].max()
X_block_1_sum = torch.exp(X_block[1] - X_block_1_max).sum()
# online block update max & sum
X_block_1_max_update = torch.max(X_block_0_max, X_block_1_max) # X[-1] is new data
X_block_1_sum_update = X_block_0_sum * torch.exp(X_block_0_max - X_block_1_max_update) \
+ torch.exp(X_block[1] - X_block_1_max_update).sum() # block sum
X_block_online_softmax = torch.exp(X - X_block_1_max_update) / X_block_1_sum_update
print(X_block_online_softmax)
# tensor([-0.3000, 0.2000, 0.5000, 0.7000, 0.1000, 0.8000])
# (tensor([-0.3000, 0.2000, 0.5000]), tensor([0.7000, 0.1000, 0.8000]))
# tensor([0.0827, 0.1364, 0.1841, 0.2249, 0.1234, 0.2485])
batch online softmax
- 将block online softmax 转化为行并行计算版本
X_batch = torch.randn(4, 6)
_, d = X_batch.shape
X_batch_block_0 = X_batch[:, :d//2]
X_batch_block_1 = X_batch[:, d//2:]
# we parallel calculate different block max & sum
X_batch_0_max, _ = X_batch_block_0.max(dim = 1, keepdim = True)
X_batch_0_sum = torch.exp(X_batch_block_0 - X_batch_0_max).sum(dim = 1, keepdim = True)
X_batch_1_max, _ = X_batch_block_1.max(dim = 1, keepdim = True)
X_batch_1_sum = torch.exp(X_batch_block_1 - X_batch_1_max).sum(dim = 1, keepdim = True)
# online batch block update max & sum
X_batch_1_max_update = torch.maximum(X_batch_0_max, X_batch_1_max) # 逐个元素找最大值
X_batch_1_sum_update = X_batch_0_sum * torch.exp(X_batch_0_max - X_batch_1_max_update) \
+ torch.exp(X_batch_block_1 - X_batch_1_max_update).sum(dim = 1, keepdim = True) # block sum
X_batch_online_softmax = torch.exp(X_batch - X_batch_1_max_update) / X_batch_1_sum_update
print(X_batch_online_softmax)
# tensor([[0.0115, 0.0677, 0.7479, 0.0782, 0.0776, 0.0171],
# [0.0922, 0.6843, 0.0926, 0.0150, 0.0309, 0.0850],
# [0.0672, 0.0311, 0.0171, 0.1589, 0.1480, 0.5776],
# [0.1705, 0.1801, 0.1754, 0.1263, 0.1235, 0.2242]])
2023.6.24 PageAttention – 管理qkv缓存
【2023-6-24】UC Berkeley 团队推出一个用于加速LLM推理的开源库vLLM,Vicuna 在线推理服务的幕后英雄。
- 利用 PagedAttention 技术,有效管理Attention模块中的Key和Value的Cache,重新定义了LLM的推理服务。
- 无需更改任何模型架构,吞吐量比原生 HF Transformers 高出24倍。
KV Cache 核心思想
- 缓存并重用之前计算过的Key和Value, 避免重复计算。
现有 Cache 仍存在一些问题,
- Large 大:对于LLaMA-13B中的单个序列,它占用高达1.7GB的内存。
- Dynamic 动态:大小取决于序列长度,而序列长度具有高度可变和不可预测的特点。
因此,高效地管理 KV Cache 是重大挑战。
- 现有系统(HuggingFace 默认实现是pytorch的内存分配策略)由于内存碎片化和过度预留而浪费了60%-80%的内存。
为了解决这个问题,引入了 PagedAttention,一种受传统操作系统虚拟内存和分页概念启发的注意力算法。
- 与传统注意力算法不同,PagedAttention 允许将连续的键和值存储在非连续的内存空间中。
PagedAttention 将每个序列的 KV 缓存分成多个块,每个块包含固定数量的标记的键和值。
- 在注意力计算过程中,PagedAttention Kernel高效地识别和获取这些块,采用并行的方式加速计算。(和ByteTransformer的思想有点像)
2023.7.4 FasterTransfomer
【2023-7-4】FasterTransfomer 是 NVIDIA 高度优化的 Transformer 模型库,在生成时达到 2.5倍的速度,详见 Inference with FasterTransformer
MHA -> DCMHA
KAN
【2024-5-25】ICML2024高分论文!大模型计算效率暴涨至200%
KAN突然爆火,成为可以替代MLP的一种全新神经网络架构,200个参数顶30万参数;而且,GPT-4o的生成速度也是惊艳了一众大模型爱好者。
大模型的计算效率很重要,提升大模型的tokens生成速度是很关键的一环。
而提升大模型的tokens生成速度,除了花钱升级GPU外,更长效的做法是改善Transformer模型架构的计算效率。
彩云科技 对Transformer计算最耗时的核心组件——多头注意力模块(MHA)下手,将Transformer计算性能提升了有2倍之高。
Github上已开源这项工作的代码、模型和训练数据集。
承载Transformer计算量的核心模块是多头注意力(MHA)模块,位置(position=i)上的每一个注意力头(attention head)会与全部位置上的注意力头计算出一个注意力分布矩阵。
- 这个过程中,位置 i 上的各个注意力头计算出来的注意力分布矩阵是相互独立的。
这种多头独立计算的机制会带来两大问题:
- 低秩瓶颈(Low-rank Bottleneck):注意力矩阵的秩较低,模型的表达能力受限
- 头冗余(Head Redundancy):不同的注意力头可能会学习到相似的模式,导致冗余
因此,彩云科技提出了一种叫动态可组合多头注意力(DCMHA)的机制,DCMHA 通过一个核心的组合函数(Compose function),以输入依赖的方式转换注意力得分和权重矩阵,从而动态地组合注意力头,解决了传统MHA模块中存在的上述低秩瓶颈和头冗余问题。
DCMHA旨在提高模型的表达能力,同时保持参数和计算效率,可以作为任何Transformer架构中MHA模块的即插即用替代品,以获得相应的DCFormer模型。
DCMHA机制的核心是引入的Compose函数。这个Compose函数可以视为一个可学习的参数,它可以动态地组合不同头的QK矩阵和VO矩阵,内部通过一系列变换来分解和重构注意力向量。可以近似理解为:经过组合映射后,H个基础的注意力头可组合成多至H*H个注意力头。
根据输入数据调整头之间的交互方式
- 一是打破头的独立性
- 二是可以根据输入数据动态组合
从而可以增强模型的表达能力。
效果
论文通过实验表明, DCFormer 在不同的架构和模型规模下,在语言建模方面显著优于Transformer,与计算量增加1.7倍至2倍的模型性能相匹配。
DCFormer可提高70%~100%的模型计算效率
- DCFormer 在不同参数规模下(405M到6.9B参数),对 Transformer 和 Transformer++ 模型的性能提升显著
- DCPythia-6.9B 在预训练困惑度和下游任务评估方面优于开源的Pythia-12B。
- ImageNet-1K数据集上的实验验证了DCMHA在非语言任务中也是有效性的。
相同的参数量下,使用DCFormer将具备更强的模型表达能力;用更少的参数量,拥有相同的模型表示效果。
DCFormer在不同的架构和模型规模下,在语言建模方面显著优于Transformer,与计算量增加1.7倍至2倍的模型性能相匹配。
长度限制
文本长度一直是 transformer 的硬伤。
- 不同于 RNN,transformer 在训练时必须卡在一个最大长度上,这将导致训练好的模型无法在一个与训练时的长度相差较远的句子上取得较好的推理结果。
Transformer 中,由于 token 和 token 之间是没有顺序之分的. 因此,通常在输入添加 Position Embedding 来表征每一个 token 在句子中的位置。
Position Embedding 的如何选择实在是一个难题,通常有以下几种:
- 可学习的参数:这种比较常见,BRET 中就是这么做的,但这种方式弊端很明显,因为位置信息是学习出来的,所以如果训练集里面没有见过覆盖某个长度,推理的效果就无法得到保证。
- 正弦位置编码:这是早期 transformer 使用的位置编码,论文中有尝试做实验,这种编码会随着训练/预测时的文本长度差异增大,(超过 50 个token 后)性能显著下降。
- 旋转编码:论文中提到这种方式是比较不错的,只不过因其在每一层都要做一次向量旋转,从而降低训练和推理的速度。
transformer 这类模型的 时间复杂度、内存使用复杂度都是 n^2(n为序列长度)
- 当序列长度超过 512 时,模型对算力的要求将会大幅提高。
最近一些文章 Longformer, Performer, Reformer, Clustered attention 都试图通过近似全注意力机制改善该问题。
准BERT注意力机制时,问题可能有:
- 每个词与其他所有词都有关系吗?
- 为什么每个词的注意力不仅仅集中在最重要的词
- 如何知道哪些词是重要的
- 如何有效的让注意力仅考虑个别一些词
【2020-12-2】AllenAI Longformer
【2020-12-2】Allen AI 推出 Longformer
- 介绍 Longformer: Transformer 改进版,可处理较长的序列
- 论文: Longformer: The Long-Document Transformer
- huggingface longformer
Transformer 计算复杂度随输入序列的增加而呈二次曲线增加, 时间和内存占用非常大
- 原因:Transformer 主要部分 – 缩放点积自注意力(Scaled Dot-Product Self-Attention)
- 自注意力的计算复杂度为
O(N^2),当包含长句时,内存使用量会随着输入量的增加而呈4倍增长。
Longformer 是基于 Transformer 的可扩展模型,用于处理长文档,可轻松执行各种文档级 NLP 任务,而无需对长输入进行分块或缩短,也无需使用复杂的架构来组合各块信息。
Longformer 结合本地和全局信息,以及三种注意力(滑动窗口注意力、放大滑动窗口注意力和全局注意力)。窗口注意和全局注意)。

效果
- Longformer 还在 text8 和 enwik8 任务中取得了最佳性能。
- Longformer 在长文档表现一直优于 RoBERTa,并且在预训练后的 WikiHop 和 TriviaQA 任务中表现最佳。
RoBERTa 只有 512 个位置嵌入,因此需要复制 8 个位置嵌入来容纳 4096 个字。尽管它很简单,但据称却非常有效,这显然是因为复制消除了分区边界。
【2021-1-8】谷歌 BigBird
【2021-1-8】谷歌推出 BigBird, 基于稀疏注意力的Transformer,将基于Transformer的模型(例如 BERT)扩展到更长的序列。
- 平方级别的依赖降成线性
- 同等硬件条件下,长度扩充8倍
- 论文:Big Bird: Transformers for Longer Sequences
- 代码:bigbird
开源中文 bigbird 预训练模型,从tiny至base共5个级别预训练模型。可从huggingface hub直接下载使用
BigBird 模型实现了三种注意力机制:随机注意力、窗口注意力和全局注意力,这与LongFormer几乎相似
与BERT同等计算力下,可处理序列长度达到4096。
- 很多长文本序列的任务上达到SOTA效果,例如:长文本摘要、长文本问答。
- BigBird RoBERTa 模型在Transformers仓库中使用。
BigBird的注意力机制是一个近似BERT的全注意力机制,因此不是比BERT的注意力机制效果更好,而是运行效率更高。
- BERT的注意力机制存储与序列长度是二次方关系,在长文本情况下的存储需求就已经开始令人难以忍受
- 而 BigBird 的 block sparse attention 就是为了解决这个问题。无限长长度序列上,计算无穷次 次时,把BERT的全注意力机制换成 block sparse attention。
BigBird有两种长程注意力方式,可以让计算变的更有效:
- 全局词(Global token):有一些词,需要考虑其他所有词,其他所有词也需要考虑它。例如”HuggingFace is building nice libraries for easy NLP“。如果”building“是一个全局词,模型在有的人物中需要知道词”NLP“和词”HuggingFace“的关系(这两个词在最左边和最右边),那么词”building“需要被设置成全局词,从而处理与”NLP“和”HuggingFace“的关系。
- 随机词(Random tokens):随机选择一些词,把信息传递给其他词,这可以降低词与词之间的信息交互难度。
# 例如第一个词和最后一个词是全局的
global_tokens = ["BigBird", "answering"]
# 将全局词加入至key_tokens集合中
key_tokens.append(global_tokens)
# 现在用词”is“做随机词
random_tokens = ["is"]
key_tokens.append(random_tokens)
key_tokens # {'now', 'is', 'in', 'answering', 'available', 'BigBird'}
# 现在,词”available“可以只与这些词做注意力计算,而不是所有词
参考
2022.4.22 Attention with Linear Bias(ALiBi)
ALiBi 是 华盛顿大学、META 2022 年提出的一种方法,解决 transformer 训练和推理时文本长度不一致的难题,
- 论文中在训练时候使用 1024 的最大长度,但在推理时用 2048 的最大长度推理,并且在 PPL 指标持平。
- ALiBi 都是在测试集的句子最大长度的「一半长度」上进行训练,而 Sinusoidal 则是正常在「测试集长度」上进行训练,
- TRAIN SHORT, TEST LONG: ATTENTION WITH LINEAR BIASES ENABLES INPUT LENGTH EXTRAPOLATION
如何实现?
- ALiBi 实现思路很直觉,模型在接收输入时直接去掉 Position Embedding 向量,而是在 Attention 中计算 query·Key 的值后面加入一个偏置常量(非训练变量),来达到注入位置信息的效果。这个常量是一个 事先计算好 的数值,并且每个头(head)的值都有所不同。
- 通过「相对位置信息」就能在一定程度上缓解「绝对位置信息」造成的训练和推理过程中长度编码不一致的问题
代码见原文
2024.4.10 Infini-Transformer
【2024-4-11】Google 提出Infini-Transformer架构,可让LLMs处理无限长上下文,内存节约114倍
对于批量大小为 512、上下文长度为 2048 的 500B 模型,注意力键值 (KV) 状态的内存占用为 3TB
面对超长序列,相比注意力机制,内存压缩技术更具扩展性。
- 内存压缩不使用随输入序列长度而增长的数组,而是在有限的内存资源上,维护固定数量的参数来进行信息的存储和回调。
- 然而,目前的LLMs尚未有一种有效、实用的内存压缩技术,可以在简单性与质量之间取得平衡。
基于以上背景,作者提出了一种新架构:Infini-Transformer,让基于Transformer的大模型在有限内存、计算资源的条件下,处理无限长的上下文输入。
主要贡献:
- 提出新的注意力机制——
Infini-attention。通过将压缩记忆整合到传统的注意力机制中,使得LLMs能够有效地处理无限长的输入序列,同时保持有界的内存占用和计算资源。Infini-attention在单个transformer块中结合了掩蔽局部注意力和长期的线性注意力机制。 - Infini-attention 通过重用标准注意力计算中的键(key)、值(value)和查询(query)状态来进行长期记忆的整合和检索。
- 它将旧的KV状态存储在压缩记忆中,而不是像标准注意力机制那样丢弃。
- 处理后续序列时,使用注意力查询状态从记忆中检索值。
- 最终,Infini-attention通过聚合长期记忆检索到的值和局部注意力上下文来计算最终的上下文输出。
- 在实验中,长上下文语言建模基准测试中优于基线模型,并在内存大小方面实现了114倍的压缩比。当使用100K序列长度进行训练时,模型甚至实现了更好的困惑度(perplexity)。一个1B参数的LLM通过Infini-attention自然扩展到1M序列长度,并解决了密钥检索任务。此外,一个8B参数的模型在经过持续的预训练和任务微调后,在500K长度的书籍摘要任务上达到了新的最先进结果(SOTA)。
Infini-attention 核心思想: 压缩记忆和注意力机制的结合,实现对长序列数据的有效处理,同时保持计算和内存效率,这对于推动大型语言模型在各种长文本处理任务中的应用具有重要意义。
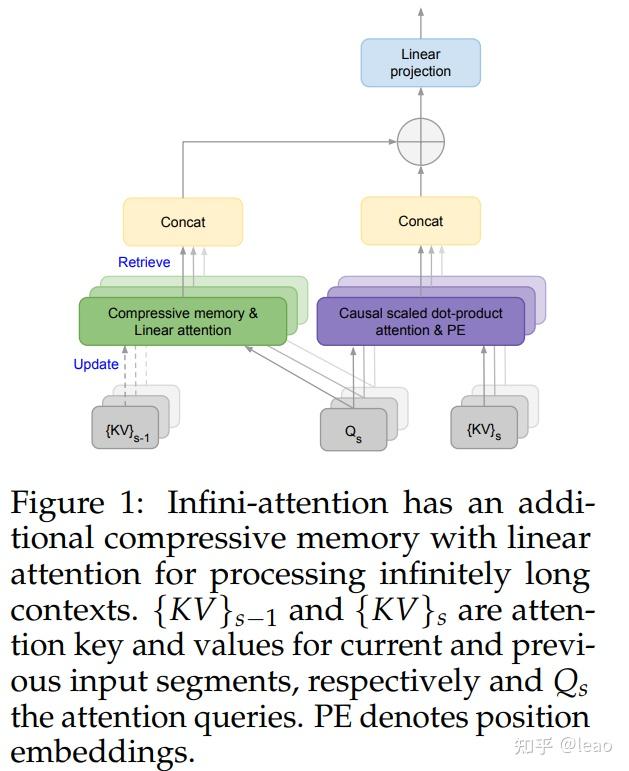
Infini-Transformer 可在有限内存条件下,让基于Transformer的大语言模型(LLMs)高效处理无限长的输入序列。
与Transformer-XL类似,Infini-Transformer处理一系列片段。
- 每个片段内 计算 standard causal 点积 attention context(注意力上下文)。因此,点积注意力计算在某种意义上是局部的,覆盖了索引为 S 的当前片段的总共 N 个标记。
- 然而,局部注意力在处理下一个片段时会丢弃前一个片段的注意力状态。
- Infini-Transformer 中,并没有忽略旧的键值(KV)注意力状态,而是通过内存压缩技术重新使用它们来保持整个上下文历史。
- 因此,Infini-Transformer 每个注意力层都具有全局压缩和局部细粒度状态,这就是前面提到的无限注意力(Infini-attention)。
实验结果表明:
Infini-Transformer在长上下文语言建模任务上超越了基线模型,内存最高可节约114倍。
Infini-attention 机制的优势:
- 无限上下文处理能力:Infini-attention 通过引入压缩记忆,使得模型能够处理无限长的输入序列,这是传统注意力机制所不具备的。这对于需要理解和生成长文本的应用场景尤为重要。
- 有界内存占用:传统注意力机制的内存占用随输入序列长度线性增长,而 Infini-attention 通过压缩记忆机制保持了固定的内存参数数量,从而实现了有界内存占用,这使得模型即使在处理极长序列时也能保持高效的内存使用。
- 流式推理:Infini-attention 支持快速流式推理,这对于实时或近实时的应用场景非常有用,因为它允许模型在接收到新输入时即时更新和推理,而不需要重新处理整个序列。
- 长期依赖捕捉:通过结合局部注意力和长期线性注意力机制,Infini-attention 能够在保持对当前上下文敏感的同时,也能够捕捉和利用长期依赖信息。
- 插拔式持续预训练:Infini-attention 设计上支持持续预训练和长上下文适应,这意味着它可以作为现有模型的扩展,而不需要从头开始训练。
Infini-attention 机制的不足:
- 复杂性增加:引入压缩记忆和相关的记忆更新及检索机制可能会增加模型的复杂性,这可能导致模型设计和调试更加困难。
- 训练稳定性挑战:虽然 Infini-attention 采用了稳定的训练技术,但压缩记忆的引入可能会带来新的训练稳定性挑战,特别是在模型参数和超参数选择上。
- 计算效率:尽管 Infini-attention 旨在提高内存效率,但其计算效率可能受到压缩记忆更新和检索操作的影响,尤其是在处理非常长的序列时。
- 泛化能力:虽然 Infini-attention 在特定的长上下文任务上表现出色,但其在其他类型任务上的泛化能力尚需进一步验证。
- 可解释性:压缩记忆的引入可能会使得模型的注意力机制更加难以解释和理解,这对于希望理解模型决策过程的研究者和应用开发者来说可能是一个问题。
Infini-attention 机制在处理长序列和保持有界内存占用方面具有明显优势,但同时也带来了一些挑战和潜在的不足。随着进一步的研究和实验,这些不足可能会得到解决或改善。
Infini-Transformer与Transformer-XL的区别
Infini-Transformer和Transformer-XL都是为了解决大型语言模型(LLMs)处理长序列数据时的挑战而提出的模型,但设计和实现上有一些关键的区别:
- 上下文长度:
- Transformer-XL:通过引入循环机制来缓存之前处理过的序列片段的键(K)和值(V)状态,从而扩展了模型的上下文窗口。这种方法使得模型可以在一定程度上记住过去的信息,并将其用于当前的注意力计算。然而,Transformer-XL的上下文长度仍然受限于其缓存大小。
- Infini-Transformer:通过Infini-attention机制,Infini-Transformer能够处理无限长的输入序列。它使用压缩记忆来存储和检索长期依赖信息,从而实现了理论上无界的上下文长度。
- 内存和计算效率:
- Transformer-XL:虽然通过缓存机制扩展了上下文窗口,但随着序列长度的增加,内存占用和计算成本也会相应增加。
- Infini-Transformer:Infini-attention设计了一种压缩记忆系统,它通过改变固定数量的参数来存储和回忆信息,从而实现了对长期信息的有效管理,同时保持了有界的内存和计算成本。
- 注意力机制:
- Transformer-XL:采用了自注意力(self-attention)机制,并通过缓存过去的注意力状态来增强模型的长期依赖能力。
- Infini-Transformer:Infini-attention机制不仅包括标准的自注意力机制,还引入了线性注意力和压缩记忆机制,使得模型能够在单个Transformer块中同时处理局部和全局上下文信息。
- 模型结构:
- Transformer-XL:在标准的Transformer基础上增加了缓存机制,用于存储过去片段的注意力状态。
- Infini-Transformer:在标准的Transformer结构中集成了压缩记忆,并通过特殊的更新和检索过程来维护长期依赖信息。
- 适应性和应用:
- Transformer-XL:适用于需要处理比标准Transformer更长序列的任务,但可能在极长序列的处理上受限。
- Infini-Transformer:由于其无限上下文的能力,更适合于需要处理极长输入序列的应用,如长文本摘要、文档理解和生成等。
梯度稀释
【2026-3-17】Kimi Attention Residuals
- 【2026-3-17】Kimi新架构让马斯克叹服!17岁高中生作者一战成名
残差链接问题
- 传统:第N层的输出 = 第N层的计算结果 + 第N-1层的输出。一路累加下去,每层都能“记住”前面所有层的信息。
- 问题:大模型 PreNorm 主流范式下,残差连接中所有层的贡献都是等权累加。贡献被逐步稀释,早期信息难以检索,且大量层可被剪枝而损失微小,称之为“PreNorm dilution problem”。隐藏状态范数会随着深度不断增长。深层网络中,这种unbounded growth会导致训练不稳定。
月之暗面团队思路:既然问题出在“无差别累加”,那就让网络自己决定该回忆什么。
Kimi 提出”注意力残差”技术 Attention Residuals,革新 Transformer架构中沿用十年的残差连接机制。
- 不再简单累加各层输出,而是让模型有选择地关注重要信息,解决了”梯度稀释”问题。相当于把注意力机制也“旋转了90度”。
- 模型在计算当前层时可以聪明地“回头看”,根据需要自由决定去提取前面哪一层的信息。
Attention Residuals:
- 当前层的可学习伪查询向量作为query(learnable pseudo-query)
- 所有前层的输出作为key和value
- 用注意力机制加权聚合
这样,网络可以学会哪些层的信息对当前计算最重要,就多关注一点;不相关的层,权重自然降低。
但新问题:计算量爆炸。
- 如果一个100层的网络,每一层都要对前面99层做full attention residual,复杂度是O(L²),根本跑不动。
解决方案:Block AttnRes。
- 把连续的若干层打包成一个block,对block内部的输出做压缩,只保留一个“摘要向量”。
实验显示
- 推理能力提升7.5个点,关键是将约25%的算力成本从”烧钱”转为”代码优化”,大幅降低创业公司门槛。
- 新机制放到Kimi自家的Kimi Linear 48B大模型(3B激活参数)上验证,训练效率提升25%,推理延迟增加不到2%。
观点
- Karpathy:我们对Attention is All You Need这篇Transformer开山之作的理解还是不够。
- 前OpenAI高管:这是”Deep Learning 2.0”的开端。
TTT
【2024-7-20】彻底改变语言模型:全新架构TTT超越Transformer,ML模型代替RNN隐藏状态
问题
- 长上下文的挑战是 RNN 层本质上所固有的:与自注意力机制不同,RNN 层必须将上下文压缩为固定大小的隐藏状态,更新规则需要发现数千甚至数百万个 token 之间的底层结构和关系。
斯坦福大学、加州大学伯克利分校、加州大学圣迭戈分校和 Meta 设计了一种新架构 TTT,用机器学习模型取代了 RNN 隐藏状态。
- 该模型通过输入 token 的实际梯度下降来压缩上下文。
- 测试时训练(Test-Time Training)
- TTT 层直接取代 Attention,并通过表达性记忆解锁线性复杂性架构,使我们能够在上下文中训练具有数百万(有时是数十亿)个 token 的 LLM。
TTT 层作为一种新的信息压缩和模型记忆机制,可简单地直接替代 Transformer 中的自注意力层。
- 与 Mamba 相比,TTT-Linear 的困惑度更低,FLOP 更少(左),对长上下文的利用更好(右):
全新的大语言模型(LLM)架构有望代替至今在 AI 领域如日中天的 Transformer,性能也比 Mamba 更好。
- 论文:Learning to (Learn at Test Time): RNNs with Expressive Hidden States
- 代码与 jax 训练和测试:ttt-lm-jax
- PyTorch 推理代码:ttt-lm-pytorch
稀疏Attention
起因
transformer能捕捉输入序列token之间的关系,即使是长距离。
长序列输入受到注意力计算和内存资源限制,随着序列长度n二次增长。
- DeepSpeed提供了 稀疏 attention kernel —— 支持长序列模型输入,包括文本输入,图像输入和语音输入。
- 通过块稀疏计算将注意力的计算和内存需求降低几个数量级。
该方法不仅缓解了注意力计算的内存瓶颈,而且可以有效地执行稀疏计算。
除了提供广泛的稀疏性结构外,还具有处理任何用户定义的块稀疏结构的灵活性。
总结
稀疏Attention
Atrous Self Attention空洞自注意力,只计算第k,2k,3k,4k…元素Local Self AttentionSparse Self Attention: OpenAI在image transformer中引入了Sparse self-attention,把两者结合在一块,既可以学习到局部的特性,又可以学习到远程稀疏的相关性
| 稀疏Attention | 名称 | 说明 | |
|---|---|---|---|
Atrous Self Attention |
空洞自注意力 | 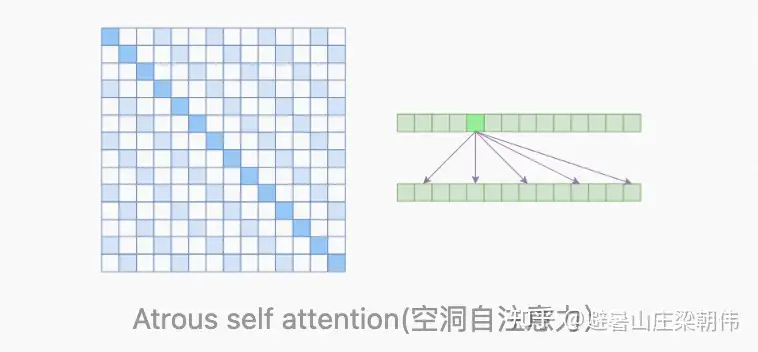 |
|
Local Self Attention |
局部自注意力 |  |
|
Sparse Self Attention |
稀疏自注意力 |  |
综合以上优点 |
【2019-7-27】苏剑林,节约而生:从标准Attention到稀疏Attention 节约时间、显存。
Attention的核心在于Q,K,V 三个向量序列的交互和融合,其中Q,K 的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把V按照权重求和得到的
理论上,Self Attention 计算时间和显存占用量都是 ?(n^2) 级别的(n是序列长度)
- 如果序列长度变成原来的2倍,显存占用量就是原来的4倍,计算时间也是原来的4倍。
- 当然,假设并行核心数足够多的情况下,计算时间未必会增加到原来的4倍,但是显存的4倍却是实实在在的,无可避免,这也是微调Bert时OOM的原因。
为什么是 ?(n^2)?
- 要对序列中的任意两个向量都要计算相关度,得到一个$n^2$大小的相关度矩阵
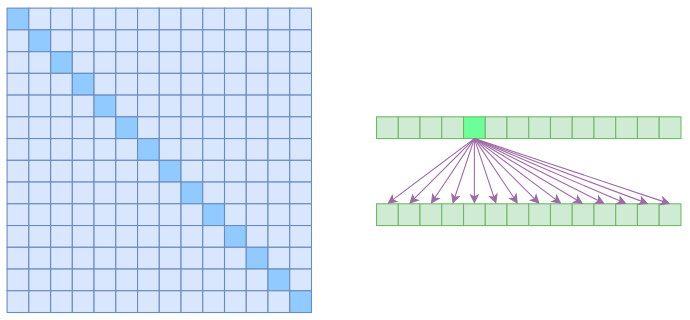
- 左边显示了注意力矩阵,右变显示了关联性,这表明每个元素都跟序列内所有元素有关联。
所以,节省显存,加快计算速度,一个解法是减少关联性计算
- 每个元素只跟序列内的部分元素相关,这就是稀疏Attention的基本原理。
- 源于OpenAI的论文《Generating Long Sequences with Sparse Transformers》
Atrous Self Attention 膨胀注意力
Atrous Self Attention,“膨胀自注意力”、“空洞自注意力”、“带孔自注意力”等。
- 名称是自定义, 原论文《Generating Long Sequences with Sparse Transformers》没有出现过这两个概念
Atrous Self Attention 启发于“膨胀卷积(Atrous Convolution)”,如下图所示,它对相关性进行了约束,强行要求每个元素只跟它相对距离为k,2k,3k,… 的元素关联,其中k>1是预先设定的超参数。从下左的注意力矩阵看,就是强行要求相对距离不是k 的倍数的注意力为0(白色代表0):
- Atrous Self Attention的注意力矩阵(左)和关联图示(右)
由于现在计算注意力是“跳着”来了,所以实际上每个元素只跟大约n/k个元素算相关性,这样理想情况下运行效率和显存占用都变成了?(n^2/k),也就是说能直接降低到原来的1/k。
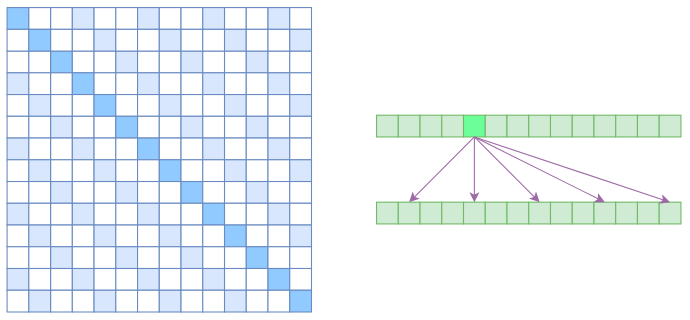
Local Self Attention 局部自注意力
Local Self Attention,中文称“局部自注意力”。
- 自注意力机制在CV领域统称为“Non Local”
- 而Local Self Attention则要放弃全局关联,重新引入局部关联。约束每个元素只与前后k个元素以及自身有关联,如下图所示:
- Local Self Attention的注意力矩阵(左)和关联图示(右)
- 从注意力矩阵来看,就是相对距离超过k的注意力都直接设为0。
其实 Local Self Attention 跟普通卷积很像了,都是保留了一个 2k+1 大小的窗口,然后在窗口内进行一些运算,不同的是普通卷积是把窗口展平然后接一个全连接层得到输出,而现在是窗口内通过注意力来加权平均得到输出。对于Local Self Attention来说,每个元素只跟 2k+1 个元素算相关性,这样一来理想情况下运行效率和显存占用都变成了 ?((2k+1)n)??(kn) 了,也就是说随着n 而线性增长,这是一个很理想的性质——当然也直接牺牲了长程关联性。
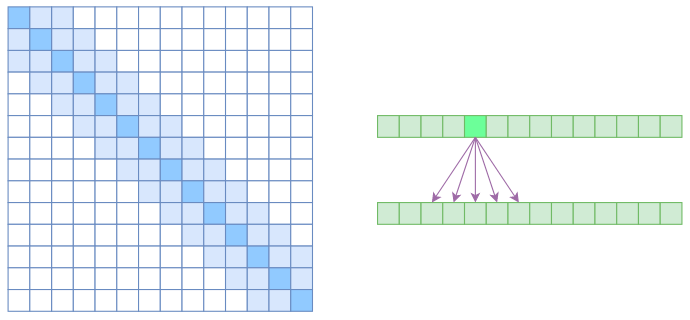
Sparse Self Attention – OpenAI改进,综合以上两种
现在可以很自然地引入OpenAI的 Sparse Self Attention了。
- Atrous Self Attention 有一些洞,而 Local Self Attention正好填补了这些洞,所以一个简单方式就是将Local Self Attention和Atrous Self Attention 交替使用,两者累积起来,理论上也可以学习到全局关联性,也省了显存。
- 思路:第一层用Local Self Attention,输出的每个向量都融合了局部几个输入向量,然后第二层用Atrous Self Attention,虽然跳着来,但是因为第一层的输出融合了局部的输入向量,所以第二层的输出理论上可以跟任意的输入向量相关,也就是说实现了长程关联。
- 但是OpenAI直接将两个Atrous Self Attention和Local Self Attention合并为一个,如下图:
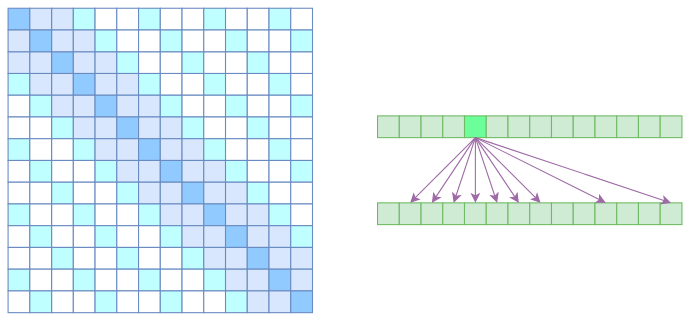
- Sparse Self Attention的注意力矩阵(左)和关联图示(右)
从注意力矩阵上看就很容易理解了,就是除了相对距离不超过k的、相对距离为k,2k,3k,… 的注意力都设为0,这样一来Attention就具有“局部紧密相关和远程稀疏相关”的特性,这对很多任务来说可能是一个不错的先验,因为真正需要密集的长程关联的任务事实上是很少的。
OpenAI 开源了官方实现 sparse_attention
【2026-6-12】MSA, 应用于 MiniMax-M3
【2026-6-12】minimax 推出 MSA,GQA 基础上逐块稀疏注意力
超长上下文能力正在成为前沿大语言模型不可或缺的核心能力:智能体工作流、仓库级代码推理、持久记忆场景,均要求模型同时处理数十万乃至上百万 Token。但 Softmax 注意力机制存在二次方复杂度开销,在工程落地规模下该方案完全不具备可行性。
MiniMax 稀疏注意力(MSA)基于分组查询注意力(GQA)构建的分块稀疏注意力方案。包含轻量索引分支:对键值(KV)分块打分,为每个 GQA 分组独立筛选前 k 个高相关分块,实现分组专属稀疏检索,同时保证分块计算高效执行;主分支仅针对筛选后的分块执行精确分块稀疏注意力计算。
Minimax稀疏注意(MSA) 是基于GQA的稀疏注意机制,有两个分支。
- 对于每个token,轻量级索引分支从上下文中选择一小组关键块,主分支计算这些块中的标记的Softmax关注度。
- 索引分支只向标准GQA添加两个投影矩阵,以块粒度操作,并为每个GQA组独立进行选择。
- 索引分支(左侧)使用单个轻量级头对整个因果上下文进行评分,并为每个查询和GQA组选择一组i个𝑘关键字块;
- 无论其得分如何,都始终包括自身块。主分支(右)只处理选定的块并生成层输出。
- 在训练期间,KL损失将索引分布与所选块上的组平均主支分布对齐,并且索引分支梯度从主支分离。
公式
$ O_i^{(h)} = \mathrm{softmax}\left( \frac{Q_i^{(h)} \left( K^{(r)} \left[ I_i^{(r)} \right] \right)^\top}{\sqrt{d_h}} \right) V^{(r)} \left[ I_i^{(r)} \right] $
$ I_i^{(r)} = \operatorname{TopK}{b \in {1,\dots,B}}\big(M{i,\cdot}^{\mathrm{idx},(r)}, k\big) $
MSA 以简洁、可扩展为核心设计原则,整体架构轻量化,可便捷、高效部署在各类 GPU 硬件上。为将稀疏特性转化为真实推理加速收益,同步配套设计 GPU 执行链路:采用无指数运算的 Top-k 筛选、KV 外侧稀疏注意力算子,提升分块粒度访存下的 Tensor Core 利用率。
结构

原生多模态 109B 参数模型上,MSA 精度与标准 GQA 持平;上下文长度 100 万 Token 场景下,单 Token 注意力计算量降低 28.4 倍。搭配自研配套算子内核后,在 H800 显卡上,Prefill 阶段实测提速 14.2 倍,解码阶段提速 7.6 倍。
- 推理算子开源仓库:MiniMax-AI/MSA
- 基于 MSA 打造的商用级原生多模态大模型已公开发布:MiniMax-M3
MSA的核心思想:稀疏 + 分层
M3 核心特性:
- 顶尖的编码与智能体能力:M3 在编码和 Agent 评测中达到行业领先水平,具备自主任务拆解、工具调用和多步推理能力。它生成代码的目标不是“能跑就行”,而是尽可能达到可直接交付的标准。
- 百万级上下文能力:基于自研 MiniMax Sparse Attention(MSA) 架构,M3 API 最高支持 1M tokens 上下文窗口,并保障至少 512K tokens 可用。百万级上下文是长程 Agent、长程 Coding 和长视频理解的重要基础设施。
- 原生多模态能力:M3 从训练初期就进行多模态联合训练,使文本与视觉语义空间高度对齐。多模态不是后期外挂能力,而是模型原生能力的一部分。
- 强大的自主浏览与检索能力:在 BrowseComp 智能体评测中,M3 取得 83.5 分,超过 Opus 4.7 的 79.3 分,展现出较强的自主浏览、信息检索与综合推理能力。
- 开放模型中的 frontier 能力组合:此前,能够同时兼具前沿编码能力、百万级上下文和原生多模态能力的,主要是少数闭源模型。M3 则尝试将这一整套 frontier 能力带入开放模型生态。
【2026-6-30】LSA – LongCat-2.0 改进DSA
【2026-6-30】LongCat-2.0 正式发布
美团发布并开源 LongCat-2.0,总参数量达 1.6 万亿、每个 token 激活约 480 亿参数的 MoE 语言模型。
LongCat-2.0 相比此前的 LongCat 系列引入了多项架构改进,实现了模型能力的显著跃升。
- LongCat-2.0 完整训练流程与大规模部署均全部使用国产算力集群。
- 预训练在5万余国产算力芯片上耗时月余完成,消费了超过 35 万亿 tokens,全程无回滚、无不可恢复的 loss 突刺。
- 这一结果验证了有能力在国产算力平台上进行前沿级大规模模型训练。
LongCat 稀疏注意力机制,并在数千亿 tokens 的百万上下文长度数据上训练 LongCat-2.0。结合专门的后训练,LongCat-2.0 在编程与智能体任务上表现强劲。
问题:Agent兴起,对大模型高效长输入处理能力提出了极高要求
- 尽管 DSA 细粒度稀疏注意力缓解了这一压力,但受限于不连续的索引输出形式和二次方的索引评分开销,DSA中的轻量索引器 (Lightning Indexer) 成为制约端到端延迟的核心瓶颈。
LongCat 稀疏注意力 (LSA):由 DeepSeek 稀疏注意力 (DSA) 演进而来,通过引入更轻量化的索引器(Indexer),在无损模型质量的前提下显著加速长上下文处理。
LongCat 稀疏注意力(LSA)针对索引器引入三项相互正交的效率优化策略:
- 流感知索引(Streaming-aware Indexing, SI):重塑了索引器选择 Token 的预算分配,将硬件对齐的连续访问与动态随机选择相结合。
- 该策略将部分原本碎片化的显存访问转化为可预知的顺序读取,从而实现合并的 HBM 访问并最大化有效带宽。
- 跨层索引(Cross-Layer Indexing, CLI):利用注意力中重要 Token 在相邻层间分布的高度一致性来摊薄索引开销。
- 得益于训练阶段引入的跨层蒸馏,推理时单次索引计算可由多个连续的注意力层复用。
- 层级化索引(Hierarchical Indexing, HI):采用由粗到细的两阶段打分机制,先通过 block 级近似打分进行粗召回,再在召回的候选中进行细粒度 token 选择,从而缩小索引器每次检索需处理的候选空间。
- LongCat-2.0 中,层级化索引(HI)以可插拔的组件形式在部分超长上下文任务上按需启用。
三个组件在设计上相互正交,支持独立开启或关闭

三项策略扩展至用于加速投机解码(Speculative Decoding)的 3-step MTP 模块。
- 跨层索引(CLI)在 Target 模型与 Draft 模型中的应用方式略有不同:在 Target 模型中,每两个连续层共享一次索引结果;
- 而在多步 MTP中,全部三个 Draft 步的计算共用一次索引——具体而言,Step 2 与 Step 3 完全复用 Step 1 所生成的索引结果。
详见站内专题:美团大模型龙猫
Transformer-Decoder
【2021-4-19】https://zhuanlan.zhihu.com/p/179959751
Transformer 原始论文发表之后,「Generating Wikipedia by Summarizing Long Sequences」提出用另一种 transformer 模块的排列方式来进行语言建模
- 直接扔掉了所有的 transformer 编码器模块……「Transformer-Decoder」模型。
早期的基于 transformer 的模型由 6 个 transformer 解码器模块堆叠而成:
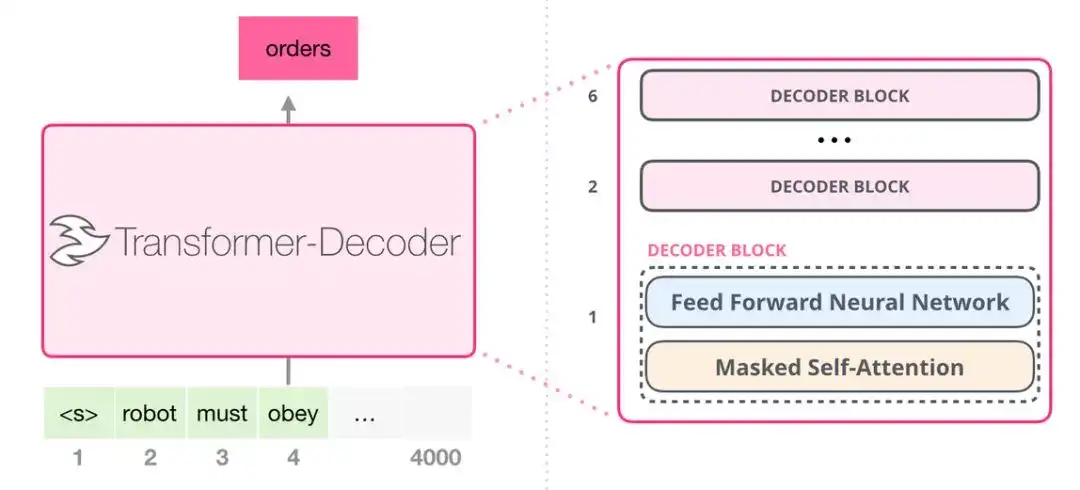
解码器模块
- 和 transformer 原始解码器模块相比,去掉了第二个自注意力层。
一个相似的架构在字符级别的语言建模中也被验证有效,使用更深的自注意力层构建语言模型,一次预测一个字母/字符。
所有解码器模块都一样。使用带掩模的自注意力层。
- 该模型在某个片段中可以支持最长 4000 个单词的序列,相较于 transformer 原始论文中最长 512 单词的限制有了很大的提升。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
