文本检测
方法总结
【2024-10-23】论文: Scalable watermarking for identifying large language model outputs
检测方法
- (1) 检索(retrieval-based approach): 检查生成内容与库里存储的内容是否匹配
- 问题: 需要预生成大量内容、隐私问题(因为要存储、评估)
- (2) 事后即时检测(post hoc detection): 使用文本统计特征,或机器学习分类器来区分人工、AI生成内容
- 优点: 不需要保存记录、干预文本生成过程
- 缺点: 计算开销大, 场景受限(模型),oov问题, 依赖人工编写数据
- (3) 文本水印: 生成过程中植入水印
- ① 编辑水印 Edit-based watermarking: 规则为主, 如 同义词替换、插入特殊 Unicode 字符
- ② 数据驱动水印 data-drived watermarking: 在特殊触发短语数据集上训练LLM
- ③ 生成式水印
①和②这两种方法都可能在文本中留下明显的伪影
AIGC法规
电子水印
2025年3月,国家互联网信息办公室联合工业和信息化部、公安部和国家广播电视总局正式印发了《人工智能生成合成内容标识办法》,与此同时,配套的强制性国家标准《网络安全技术 人工智能生成合成内容标识方法》也获批发布。
2025年9月1日,正式开始执行。接下来,所有AI合成的内容,都必须打上“电子水印”。
- 显示标识:UI上添加显示文字、图片、声音等标识
- 隐式表示:文件数据中添加的标识,不易感知
【2025-9-1】一文读懂新规,AI合成内容今后要有“水印”
- 包含各种标识示例
ChatGPT 打假
最近一段时间,ChatGPT先是成为美国高中生的写作业利器,后面帮专业媒体写稿子,引发巨大恐慌。如Nature、纽约教育部等,都针对ChatGPT发布禁令。
OpenAI官方推出AI生成内容识别器,但成功率只有26% 公众号文章 英文原文
- ChatGPT 引发 AI 领域「是否要禁用」大讨论之后,OpenAI 的真假鉴别工具终于来了。 AI Text Classifier
- 2023年1月31日,OpenAI 官宣了区分人类作品和 AI 生成文本的识别工具上线,该技术旨在识别自家的 ChatGPT、GPT-3 等模型生成的内容。然而分类器目前看起来准确性堪忧:OpenAI 在博客里指出 AI 识别 AI 高置信度正确率约为 26%。但该机构认为,当它与其他方法结合使用时,可以有助于防止 AI 文本生成器被滥用。
- OpenAI 文本分类器不适用于所有类型的文本。被检测的内容至少需要 1000 个字符,或大约 150 到 250 个单词。它没有论文检测平台那样的查重能力 —— 考虑到文本生成人工智能已被证明会照抄训练集里的「正确答案」,这是一个非常难受的限制。OpenAI 表示,由于其英语前向数据集,它更有可能在儿童或非英语语言书写的文本上出错。
- Each document is labeled as either very unlikely, unlikely, unclear if it is, possibly, or likely AI-generated.
-
在评估一段给定的文本是否由 AI 生成时,检测器不会正面回答是或否。根据其置信度,它会将文本标记为「非常不可能」由 AI 生成(小于 10% 的可能性)、「不太可能」由 AI 生成(在 10% 到 45% 之间的可能性)、「不清楚它是否是」AI 生成(45% 到 90% 的机会)、「可能」由 AI 生成(90% 到 98% 的机会)或「很有可能」由 AI 生成(超过 98% 的机会)。
- 虽然效果不尽如人意,但 OpenAI AI 文本分类器(OpenAI AI Text Classifier)在架构上实现了和 GPT 系列的对标。
知名 ML 和 AI 研究人员 Sebastian Raschka 试用之后,给出了「It does not work」的评价。他使用其 2015 年初版的 Python ML 书籍作为输入文本,结果显示如下。
- Randy Olson 的 foreword 部分被识别为不清楚是否由 AI 生成(unclear)
- 他自己的 preface 部分被识别为可能由 AI 生成(possibly AI)
- 第一章的段落部分被识别为很可能由 AI 生成(likely AI)
detect GPT
DetectGPT Demo:
- 作者:Chelsea Finn 推出 Detecting GPT-2 Generations with DetectGPT,只支持英文测试,可以显示详细检测结果,包含图表可视化
【2023-1-29】斯坦福,DetectGPT:利用概率曲率检测文本是否大模型生成,仅用于检测 GPT-2
- DetectGPT 的方法不需要训练单独的分类器、收集真实或生成的段落的数据集,或显式地为生成的文本加水印。 它仅使用感兴趣模型计算的对数概率和来自另一个通用预训练语言模型(例如 T5)段落的随机扰动。
DetectGPT比现有的模型样本检测零样本方法更具辨别力,将 20B 参数 GPT-NeoX 生成的假新闻文章的检测从最强零样本基线的 0.81 AUROC 显著提高到DetectGPT的 0.95 AUROC - 检测机器生成的文本方面优于其他零样本方法,或在未来的机器生成文本检查方面非常有前途。另外,他们也将尝试将这一方法用于 LLM 生成的音频、视频和图像的检测工作中。
- 局限性
- 如果现有的掩模填充模型不能很好地表示有意义的改写空间,则某些域的性能可能会降低,从而降低曲率估计的质量;以及 DetectGPT 相比于其他检测方法需要更多的计算量等。
- DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature
- The fluency and factual knowledge of large language models (LLMs) heightens the need for corresponding systems to detect whether a piece of text is machine-written.
- we first demonstrate that text sampled from an LLM tends to occupy negative curvature regions of the model’s log probability function.
- DetectGPT is more discriminative than existing zero-shot methods for model sample detection, notably improving detection of fake news articles generated by 20B parameter GPT-NeoX from 0.81 AUROC for the strongest zero-shot baseline to 0.95 AUROC for DetectGPT.

GPTZero
一个检测ChatGPT的网站,名曰 GPTZero ,只需要把相应的内容粘进去,几秒内就能分析出结果。
检测原理 论文地址, 再不能用ChatGPT写作业了!新算法给AI文本加水印,置信度99.99%
- 简介:给LLM中嵌入水印,再进行检测。其中,水印嵌入不会影响文本生成质量。
- 具体:大规模语言模型每次生成一个token,每个token将从包含大约5万个词汇的词汇表中进行选择。
- 在新token生成之前,从基于最近已生成的token为随机数生成器(RNG)提供“种子”,以此来压一个水印。
- 然后使用RNG将词汇表分为黑名单和白名单,并要求LLM接下来只能从白名单中选择词汇。如果整段文本中,白名单中的词汇越多,就意味着越有可能是AI生成的。黑白名单的区分,基于一个原则:人类使用词汇的随机性更强。img
- 举例:在“美丽的”后面生成词汇,水印算法会将“花”列入白名单,将“兰花”列入黑名单。论文作者认为,AI更可能使用“花”这个词汇,而不是“兰花”。
- 然后,就能通过计算整段文本中白名单token出现的情况,来检测水印。如果一共有生成了N个token,所有的token都使用了白名单词汇,那么这段文字只有2的N次方分之一概率是人类写的。即便这段文字只有25个词组成,那么水印算法也能判断出它到底是不是AI生成的。
- 但作者也表示,水印有时候也不一定完全靠谱。比如模型输出了“SpongeBob Square”,下一个单词一定会是“Pants”吧?但是Pants会被标记到黑名单里,即认为是只有人才会写的词。这种情况会严重影响算法的准确性,因此作者将其定义为低熵token,因为模型几乎不会有更好的选择。
- 对应的,也会有高熵token,比如 “海绵宝宝感觉____” 这个句式里,能填入的词汇太多了。这时,作者选择针对高熵token制定更强的规则,同时保留低熵token,确保水印质量更好。
- 同时,还添加了波束搜索(Beam search),允许LLM能够排布一整个token序列,以避免黑名单词汇。这么做,他们能确保LLM使用白名单词汇的概率在大约80%左右,而且不影响文本生成质量。
- 举例:下面这段文字,水印算法认为它有99.999999999994%的可能是由AI生成的。因为这段文字包含36个token。如果是人类写的,那么文本中应该包含9±2.6个白名单词汇(白名单词汇的概率约为25%)。但这段文字中,包含了28个白名单词汇,所以由人类写出的概率,仅有0.0000000000006% (6乘以10的-15次方)。
- 如下标注的是文本中的黑名单token。
注意
- 如果想要水印正常发挥作用并不受到攻击,就必须对文本进行一些标准化处理,并且需要检测某些类型的对抗性提示。
加一个随机秘钥,也能变成保密模式并且托管到API上,这能保证水印不会被篡改。
- 论文中使用的模型是Meta开源的OPT-1.3B模型。
- 由于不用访问底层模型,所以该检测方法的速度很快,成本也不会很高。而且可以使用标准语言模型生成带水印的文本,不用再重新训练。将在2月15日开源代码。
质疑1
- 如果我在AI生成的文字基础上,修改几个词,还能被查出来吗?那在替换成近义词后,检测准确率会下降多少?毕竟大家往往不会一字不改、直接用AI生成的内容。
作者、马里兰大学副教授Tom Goldstein回答称:
- 对于一段自带水印的文字,至少得修改40%-75%的token,才可能成功去除水印。(如果用其他程序修改内容话),为发生同义词攻击,导致生成内容的质量很低。
- 想要通过换近义词来消除水印,得大篇幅修改,而且若不是人亲自手动修改的话,效果会很拉胯。
质疑2
- 对于专门设计过的低熵token序列,应该能检测出水印。但是,长度和检测率之间(存在一些矛盾),它们的优先级应该如何权衡?
Tom教授表示:
- 根据设定,使用波束搜索时,绝大多数(通常是90%)的token在白名单上,即使是低熵token,也会被列入白名单。
- 所以,至少得修改一半以上的token,才能删除水印,而这需要一个超级强大的LLM模型才行,一般人很难接触到。
这种方法确实存在一些局限性。
- 检测水印的z统计量,只取决于白名单大小参数γ和生成白名单的哈希函数,和其他不少重要的参数并没有什么相关性。
- 这就让他人可以在下游水印检测器上做手脚,可以改变水印采样算法,重新部署水印,最终让原本生成的水印失效。
就连OpenAI CEO Sam Altman也表示:创造完美检测AI抄袭的工具,从根本上来说是不可能的。
多尺度 PU 学习
【2023-6-2】识别ChatGPT造假,效果超越OpenAI:北大、华为的AI生成检测器来了
- 北大、华为的研究者们提出了一种识别各式 AI 生成语料的可靠文本检测器。根据长短文本的不同特性,提出了一种基于 PU 学习的多尺度 AI 生成文本检测器训练方法。通过对检测器训练过程的改进,在同等条件下能取得在长、短 ChatGPT 语料上检测能力的可观提升,解决了目前检测器对于短文本识别精度低的痛点。
- 论文地址: paper
- 代码地址 (MindSpore):detect_chatgpt
- 代码地址 (PyTorch):AIGC_text_detector
由于AI生成的语料与人的区别过小,很难严格判断其真实属性。因此,将短文本简单标注为人类 / AI 并按照传统的二分类问题进行文本检测是不合适的。
针对这个问题,本研究将人类 / AI 的二分类检测部分转化为了一个部分 PU(Positive-Unlabeled)学习问题,即在较短的句子中,人的语言为正类(Positive),机器语言为无标记类(Unlabeled),以此对训练的损失函数进行了改进。此改进可观地提升了检测器在各式语料上的分类效果。
基于多尺度 PU 学习的方案,解决了文本检测器对于短句识别的难题,随着未来 AIGC 生成模型的泛滥,对于这类内容的检测将会越来越重要。
LLM 检测
一句话检测
【2023-5-15】
The questions are divided into two categories:
- Questions that are easy for humans but difficult for bots (e.g., counting, substitution, positioning, noise filtering, and ASCII art)
- Questions that are easy for bots but difficult for humans (e.g., memorization and computation)
Below are the description for each FLAIR question:
- Counting - Questions require counting the occurrences of a target character in a randomly generated string.
- Substitution - Questions require deciphering a string where each character is substituted with another character based on a substitution table.
- Positioning - Questions require finding the k-th character after the j-th appearance of a character c in a randomly generated string.
- Random Editing - Questions require performing drop, insert, swap, and substitute operations on a random string and providing three different outputs.
- Noise Injection - Questions are common sense questions with added noise by appending uppercase letters to words within the question.
- ASCII Art - Questions present an ASCII art and require providing the corresponding label as the answer.
- Memorization - Questions require enumerating items within a category or answering domain-specific questions that are difficult for humans to recall.
- Computation - Questions require calculating the product of two randomly sampled four-digit numbers.
Ghostbuster
【2023-12-4】Ghostbuster:检测大型语言模型生成的文本
- 论文链接:paper
主要亮点:
- 创新的检测方法:Ghostbuster 通过分析各种语言模型中每个token的生成概率,能够检测AI生成的文本,而无需识别特定的模型。这使其能够有效地应对像ChatGPT和Claude这样的模型。
- 高精度和泛化能力:Ghostbuster 在不同领域取得了高F1分数,超越了当前的工具。它能够娴熟地处理包括多种写作风格和提示在内的各种文本生成情况。
- 适应性强:Ghostbuster 对编辑过的AI生成文本仍然有效,并且在非英语母语的写作上表现可靠,使其非常适合现实世界中的文本分析。
- 训练方法:将文档通过一系列较弱的语言模型,然后对它们的特征进行结构化搜索,最后在选定的特征上训练分类器来预测文档是否由AI生成。
MDIR
清华大学求真书院研究员张锐翀近日在论文中提出“矩阵驱动即时审查”(Matrix-Driven Instant Review, MDIR)方法,用于精准检测大型语言模型(LLM)间的权重抄袭。该方法利用矩阵分析与大偏差理论,对模型嵌入和多层权重进行对齐比对,并计算严格的 p 值,可在单台个人电脑一小时内完成。
实验显示
MDIR 在避免假阳性的同时,能准确识别经过增量预训练、剪枝或置换的权重来源。
一项案例研究指向华为 Pangu-Pro-MoE 模型,结果表明其权重与 Qwen2.5-14B 高度关联,p 值小于 10^-3,000,000,被认为是极强的抄袭统计证据。
作者称,此方法可为 LLM 知识产权保护提供重要技术手段。
大模型水印
源自:
- 上海交大 动手学大模型
第五章 大模型水印
- 水印嵌入:在语言模型生成内容时嵌入水印
- 水印检测:检测给定文本的水印强度
- 水印评估:评估水印方法的检测性能
- 评估水印的鲁棒性(可选)
X-SIR
X-SIR 仓库包含以下内容的实现
- 三种文本水印算法:X-SIR, SIR和KGW
- 两种水印去除攻击方法:paraphrase和translation
SynthID
【2024-10-31】《Nature》封面惊爆!Google DeepMind 给AI大模型加“隐形指纹”,这是AI发展新走向还是另有深意?是安全保障还是新的操控?
- SynthID 已集成到谷歌AI工具包, Gemini
- huggingface 地址: synthid-text
- 【2024-10-23】论文: Scalable watermarking for identifying large language model outputs
- 解说
- 官网介绍:identifying-ai-generated-images-with-synthid
- 数字水印植入文本、音频、图像和视频
- 官方原理演示: 视频
二者概率累加,依然保持原始分布, 不影响输出的质量、准确性和创造力

- Top: LLM text generation typically involves generating text from left to right by repeatedly sampling from the LLM distribution.
- Bottom: a generative watermarking scheme typically consists of the three components, in the blue boxes: random seed generator, sampling algorithm and scoring function.
- These can be used to provide a text generation method and a watermark detection method.
- In the SynthID-Text generative watermarking scheme, we use the Tournament sampling algorithm.
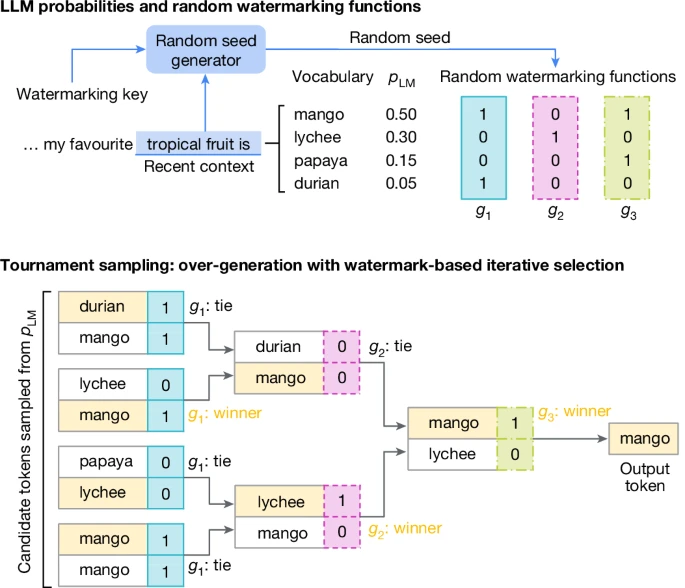
# 推理环节
My favorite tropical fruits are __
# LLM 候选 tokens: “mango,” “lychee,” “papaya,” “durian”, 带概率值
# SynthID 同步生成额外的概率分布
# 二者概率累加,依然保持原始分布, 不影响输出的质量、准确性和创造力
Watermarking 水印
- SynthID embeds a digital watermark directly into AI-generated content, without compromising the original content.
- SynthID 直接嵌入数字水印到原始AI生成内容,而不影响原内容
Identification 鉴别
- SynthID can scan images, audio, text or video for digital watermarks, helping users determine if content, or part of it, was generated by Google’s AI tools.
- SynthID 可鉴别内容
SynthID-Text does not affect LLM training and modifies only the sampling procedure; watermark detection is computationally efficient, without using the underlying LLM
SynthID可直接嵌入到,谷歌的文本生成图片模型Imagen合成的图片中。
- 人肉眼无法觉察到水印,不受更改颜色、添加滤镜等破坏操作影响;
- SynthID 也可以识别图片中的水印。SynthID相当于钱币中的防伪标识,同时又能充当“验钞机”的作用,识别图片的真假,极大提升了生成式AI产品的安全性。
SynthID 由两种深度模型组成而成: 添加水印,识别水印。这两个模型分别在不同的图像数据集上进行了大规模训练、优化,以提升水印的准确率。
SynthID 工作原理介绍
- 1)添加水印:SynthID 可直接将水印嵌入到图片中,人肉眼无法察觉到,同时也不受滤镜、更改颜色、压缩体积、更改亮度等操作影响。
- 2)识别水印:SynthID 可识别图片中的水印,并告诉用户该图片是 Imagen模型生成的,还是人工设计。当图片遭遇严重破坏时,例如,更改亮度、删除部分内容等,SynthID可以基于图片的元数据,仍然可以检测到图片中的水印。
华为盘古抄袭
【2025-7-6】华为盘古大模型是否抄袭?
论文作者通过新的“模型指纹”技术,对盘古 Pro MoE 模型与其他模型进行了实证比较。
由于盘古模型与阿里千问的模型注意力参数平均相关性极高,盘古大模型也被指涉嫌抄袭。
背后的技术研发团队以及华为公司,也被推上了舆论的风口浪尖。
模型指纹技术原理
- 提取模型每层多头注意力机制中Q、K、V、O矩阵的标准差,将这些标准差按层排成序列并归一化,形成“指纹”,再计算两个模型之间指纹序列的皮尔逊相关系数来判断是否存在“继承”关系。
这种技术即便在模型架构发生变化或进行大规模继续训练时,指纹依然稳定,且经过验证,有已知继承关系的模型指纹高度相似,独立训练的模型指纹差异显著。
通过该技术,作者发现Pangu Pro MoE模型与Qwen-2.5 14B模型在注意力参数分布上的平均相关性高达0.927,远超其他模型对比的正常范围。
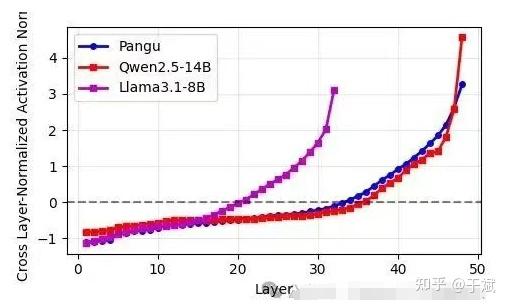
作者推断:
- Pangu Pro MoE 并非完全从零训练,而是通过“upcycling”(继续训练 + 架构调整)修改自Qwen模型;
- 技术文档中声称Pangu是“自研”,但可能存在版权侵权和报告造假。
此外,还进行了更多相关分析。
QKV 偏置分析揭示盘古和 Qwen2.5-14B 在所有三种投影类型(Q、K、V)上都存在惊人相似性,两种模型展现出几乎相同的模式,尤其是早期层特有的尖峰特征及随后的收敛行为,而QKV偏置是Qwen 1-2.5代模型的独特设计特征,包括Qwen3在内的大多数开源模型已放弃这种方法。
注意力层归一化权重分析进一步强化了相似性,盘古和Qwen2.5-14B在层序列上展现出极为一致的趋势,具有平行的初始化模式和收敛行为,区别于其他模型。
文本对抗攻击
ChatGPT爆火后,一旦进入商业应用,一定会出现对抗识别的需求。
- 【2023-7-19】ChatGPT检测攻与守:我们该如何应对AI以假乱真?
什么是对抗攻击
对抗攻击(adversarial attack)旨在利用对抗样本(adversarial example)来欺骗受害模型(victim model)。
攻击模型(attack model)通过对原样本进行轻微的扰动来生成对抗样本,其真实的分类标签与原样本保持一致,但是受害模型的判断却会出错。- 对抗攻击被认为可以暴露受害模型的弱点,同时也有助于提高其鲁棒性和可解释性。
图像领域已有 CleverHans、Foolbox、Adversarial Robustness Toolbox (ART)等多个对抗攻击工具包,将图像领域的对抗攻击模型整合在一起,大大减少了模型复现的时间和难度,提高了对比评测的标准化程度,推动了图像领域对抗攻击的发展。
文本领域鲜有类似的工具包,目前仅有 TextAttack 这一个文本对抗攻击工具包。然而所覆盖的攻击类型十分有限(仅支持gradient-/score-based类型的攻击以及字/词级别的扰动),其可扩展性也有待提高。相比之下OpenAttack支持所有的攻击类型,且具有很高的可扩展性。
OpenAttack有丰富的应用场景,例如:
- 提供各种类型的经典文本对抗攻击基线模型,大大减少实验对比时复现基线模型的时间和难度。
- 提供了全面的评测指标,可以对自己的攻击模型进行系统地评测。
- 包含了常用的攻击模型要素(如替换词的生成),可以辅助进行新的攻击模型的迅速设计和开发。
- 评测自己的分类模型面对各种类型的攻击时的鲁棒性。
- 进行对抗训练以提高分类模型鲁棒性。
设计思路
考虑到文本对抗攻击模型之间有较大差别,在攻击模型的架构方面留出了较大的设计自由度,相反更加关注提供攻击模型中常见的要素,以便用户可以容易地组装新的攻击模型。
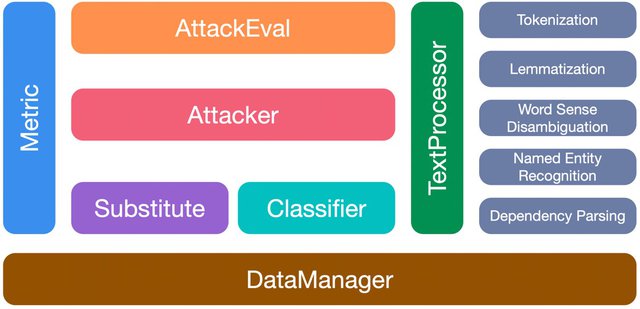
OpenAttack有如下7个模块:
- TextProcessor:提供tokenization、lemmatization、词义消歧、命名实体识别等文本预处理的功能,以便攻击模型对原样本进行扰动;
- Classifier:受害分类模型的基类;
- Attacker:包含各种攻击模型;
- Substitute:包含各种词、字替换方法(如基于义原的词替换、同义词替换、形近字替换),这些方法被广泛应用于词/字级别的攻击模型中;
- Metric:提供各类对抗样本质量评测模块(例如句子向量相似度、语言模型困惑度),这些评测指标既可以用作攻击时对候选对抗样本的约束条件,也可以作为对抗攻击评测指标;
- AttackEval:从不同方面评测文本对抗攻击;
- DataManager:管理其他模块中用到的所有的数据、预训练好的模型等。
- OpenAttack各个模块.jpg
OpenAttack的各个模块 img
OpenAttack 基于Python开发,用于文本对抗攻击的全过程,包括文本预处理、受害模型访问、对抗样本生成、对抗攻击评测以及对抗训练等。对抗攻击能够帮助暴露受害模型的弱点,有助于提高模型的鲁棒性和可解释性,具有重要的研究意义和应用价值。
OpenAttack具有如下特点:
- 高可用性。OpenAttack提供了一系列的易用的API,支持文本对抗攻击的各个流程。
- 攻击类型全覆盖。OpenAttack是首个支持所有攻击类型的文本对抗攻击工具包,覆盖了所有扰动粒度:字、词、句级别,以及所有的受害模型可见度:gradient-based、score-based、decision-based以及blind。
- 高可扩展性。除了很多内置的攻击模型以及经典的受害模型,可以使用OpenAttack容易地对自己的受害模型进行攻击,也可以设计开发新的攻击模型。
- 全面的评测指标。OpenAttack支持对文本对抗攻击进行全面而系统的评测,具体包括攻击成功率、对抗样本质量、攻击效率3个方面共计8种不同的评测指标。此外用户还可以自己设计新的评测指标。
OpenAttack内置了很多常用的分类模型(如LSTM和BERT)以及经典的分类数据集(例如SST,SNLI,AG’s News)。用户可以很方便地对这些内置的模型进行对抗攻击。
攻击模型
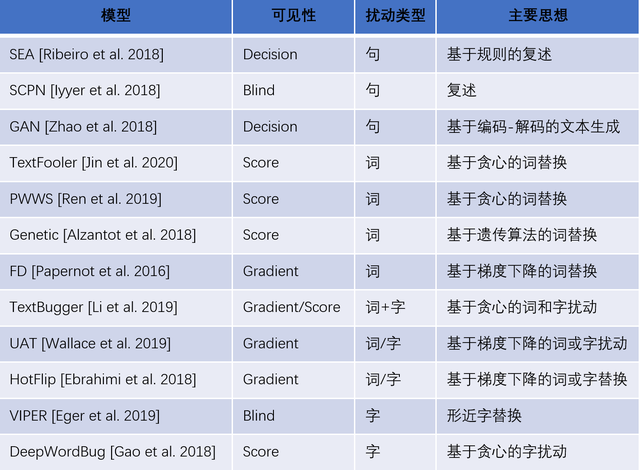
现有的文本对抗攻击分类
- 根据对原始样本的扰动粒度分为: 字、词、句级别的攻击
- 根据受害模型可见性分为:
- gradient-based(受害模型对攻击模型完全可见)
- score-based(受害模型的输出分类分数可见)
- decision-based(仅受害模型的分类结果可见)
- blind(受害模型完全不可见)
OpenAttack目前包含了13种攻击模型,覆盖了所有类型的扰动粒度以及受害模型可见性 img
参考
- THUNLP 开源了文本对抗攻击和防御必读论文列表:TAADPapers,覆盖了几乎全部的文本对抗攻击和防御领域的已发表论文、综述等,欢迎搭配使用。
- 【2023-1-10】清华 OpenAttack:文本对抗攻击工具包
攻击案例
空格攻击法
【2023-7-18】上海财经大学崔万云研究团队的发现挑战了关于分布差异的传统理解。空格字符攻击方法,用以规避 AI 内容检测器。
- Evade ChatGPT Detector via A Single Space
- 检测器并非主要依赖语义和风格方面的差异。研究者揭示,检测器实际依赖细微的内容差异,如额外的空格。’charge,’ 变成了 ‘charge?,’
- 论文提出了一个简单的规避检测策略:在 AI 生成的内容中,随机在一个逗号前添加一个空格字符)。这一策略显著降低了白盒和黑盒检测器的检测率。对于 GPTZero(白盒)和 HelloSimpleAI(黑盒)检测器,AI 生成内容的检测率从约 60%-80% 降至几乎 0%。
方法特性:
- (1)免费,无需额外成本;
- (2)无质量损失,不易被察觉。新的文本具有与原始文本相同的质量。由于修改只涉及增加一个空格,因此不易被人类察觉,因而不降低质量。
- (3)攻击与模型无关,不需要知道 LLMs 或检测器的内部状态。在论文中,这种策略被称为 SpaceInfi。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
