- 总结
- 介绍
- 基础知识
- 解法
- 模型
- 匹配模型
- 挑战
- 结束
总结
- 【2022-8-19】腾讯AI Lab开发的近义词查询工具:近邻词汇检索
资料
检索、分类与匹配
总结
- 检索任务中的匹配通常是相关性匹配(Relevance Matching),关键词在其中起到至关重要的作用
- 传统的文本匹配大多考虑语义匹配(Semantic Matching)。
- 问答系统中
- 搜索主要通过关键词关联qq,再由预置的qa对得到a;
- 而问答利用预置的qa对训练模型,推理阶段直接由q→a;
- 匹配不限,可以q→q,也有q→a,与搜索不同,从关键词改成语义;
介绍
- 文本匹配技术,不像 MT、MRC、QA 等属于 end-to-end 型任务,通常以文本相似度计算、文本相关性计算的形式,在某应用系统中起核心支撑作用,比如搜索引擎、智能问答、知识检索、信息流推荐等。
- 文本匹配任务的目标是:给定一个query和一些候选的documents,从这些documents中找出与query最匹配的一个或者按照匹配度排序;
文本匹配应用场景
- 文本匹配任务汇总

1.复述识别(paraphrase identification)
又称释义识别,也就是判断两段文本是不是表达了同样的语义,即是否构成复述(paraphrase)关系。有的数据集是给出相似度等级,等级越高越相似,有的是直接给出0/1匹配标签。这一类场景一般建模成分类问题。
2.文本蕴含识别(Textual Entailment)
文本蕴含属于NLI(自然语言推理)的一个任务,它的任务形式是:给定一个前提文本(text),根据这个前提去推断假说文本(hypothesis)与文本的关系,一般分为蕴含关系(entailment)和矛盾关系(contradiction),蕴含关系(entailment)表示从text中可以推断出hypothesis;矛盾关系(contradiction)即hypothesis与text矛盾。文本蕴含的结果就是这几个概率值。
3.问答(QA)
问答属于文本匹配中较为常见的任务了,这个任务也比较容易理解,根据Question在段落或文档中查找Answer,但是在现在这个问题常被称为阅读理解,还有一类是根据Question查找包含Answer的文档,QA任务常常会被建模成分类问题,但是实际场景往往是从若干候选中找出正确答案,而且相关的数据集也往往通过一个匹配正例+若干负例的方式构建,因此往往建模成ranking问题。
4.对话(Conversation)
对话实际上跟QA有一些类似,但是比QA更复杂一些,它在QA的基础上引入了历史轮对话,在历史轮的限制下,一些本来可以作为回复的候选会因此变得不合理。比如,历史轮提到过你18岁了,那么对于query”你今天在家做什么呢“,你就不能回复“我在家带孙子”了。该问题一般使用Recall_n@k(在n个候选中,合理回复出现在前k个位置就算召回成功)作为评价指标,有时也会像问答匹配一样使用MAP、MRR等指标。
5.信息检索(IR)
信息检索也是一个更为复杂的任务,往往会有Query——Tittle,Query——Document的形式,而且更为复杂的Query可能是一个Document,变成Document——Document的形式,相对于其他匹配任务而言,相似度计算、检索这些只是一个必须的过程,更重要的是需要排序,一般先通过检索方法召回相关项,再对相关项进行rerank。ranking问题就不能仅仅依赖文本这一个维度的feature了,而且相对来说判断两个文本的语义匹配的有多深以及关系有多微妙就没那么重要了。
面临的问题
- 真实场景中,如搜索引擎、智能问答、知识检索、信息流推荐等系统中的召回、排序环节,通常面临的是如下任务:
-
从大量存储的 doc 中,选取与用户输入 query 最匹配的那个 doc
。
-
从大量存储的 doc 中,选取与用户输入 query 最匹配的那个 doc
- 不同领域描述:
| 业务 | doc | query | 最匹配 | 匹配准则 |
|---|---|---|---|---|
| 搜索引擎 | 网页信息 | 用户检索请求 | (点击行为)相关度最高 | 语义相似度模型 |
| 智能问答 | FAQ中的question | 用户question | 语义相似度最高 | 语义相似度模型 |
| 信息流推荐 | 待推荐feed流 | 用户画像 | 用户最感兴趣等度量标准 | 行为相关性模型 |
智能问答和检索中,doc 与 query 形式基本一致,标注时
- 如果根据文本语义相似度对 doc 与 query 打标签,那自然最终学习到的模型就是语义相似度模型
- 如果根据检索后点击行为对 doc 与 query 打标签,那自然最终学习到的模型就是行为相关性模型。
基础知识
文本向量化
详见:sklearn专题里的文本向量化
文本相似度
- 如何定义“相似”也是个开放问题
- 常见方法:PI、SSEI、STS、IR-QA、Ad-hoc retrieval
- [2020-12-28]机器学习中“距离与相似度”计算汇总
- 涵盖了常用到的距离与相似度计算方式,其中包括欧几里得距离、标准化欧几里得距离、曼哈顿距离、汉明距离、切比雪夫距离、马氏距离、兰氏距离、闵科夫斯基距离、编辑距离、余弦相似度、杰卡德相似度、Dice系数。

- 谈起相似度计算,经常会出现几个关联的 NLP 任务,彼此存在微妙的区别:
- paraphrase identification,即 PI,是判断一文本是否另一文本的复述
- semantic text similarity,即 STS,是计算两文本在语义层面的相似性
- sentence semantic equivalent identification,即 SSEI,是判断两文本在语义层面是否一致
- IR-QA,是给定一个 query,直接从一堆 answer 中寻找最匹配的,省略了 FAQ 中 question-answer pair 的 question 中转
- Ad-hoc retrieval,属于典型的相关匹配问题
- 最长公共子序列、编辑距离、相同单词个数/序列长度、word2vec+余弦相似度、Sentence2Vector 、DSSM(deep structured semantic models)(BOW/CNN/RNN) 、lstm+topic
如何设计一个比较两篇文章相似度的算法?
- 可能你会回答几个比较传统点的思路:
- 一种方案是先将两篇文章分别进行分词,得到一系列特征向量,然后计算特征向量之间的距离(可以计算它们之间的欧氏距离、海明距离或者夹角余弦等等),从而通过距离的大小来判断两篇文章的相似度。
- 只比较两篇文章的相似性还好,但如果是海量数据,有着数以百万甚至亿万的网页,计算量太大!
- 另外一种是传统hash,我们考虑为每一个web文档通过hash的方式生成一个指纹(finger print)。
- 传统加密方式md5,其设计的目的是为了让整个分布尽可能地均匀,但如果输入内容一旦出现哪怕轻微的变化,hash值就会发生很大的变化。
- 一种方案是先将两篇文章分别进行分词,得到一系列特征向量,然后计算特征向量之间的距离(可以计算它们之间的欧氏距离、海明距离或者夹角余弦等等),从而通过距离的大小来判断两篇文章的相似度。
- 最简单的指纹构造方式就是计算文本的 md5 或者 sha 哈希值,除非输入相同的文本,否则会发生“雪崩效应”,极小的文本差异通过 md5 或者 sha计算出来的指纹就会不同(发生冲撞的概率极低),那么对于稍加改动的文本,计算出来的指纹也是不一样。因此,一个好的指纹应该具备如下特点:
- 1、指纹是确定的,相同的文本的指纹是相同的;
- 2、 指纹越相似,文本相似性就越高;
- 3、 指纹生成和匹配效率高。
- 业界关于文本指纹去重的算法众多,如
- k-shingle 算法
- google 提出的simhash 算法
- Minhash 算法
- 百度top k 最长句子签名算法等等。
编辑距离
- 【2020-2-17】python-Levenshtein包的一些用法总结
- sudo pip install python-Levenshtein
- 编辑距离使用方式如下:
#! /usr/bin/python
# -*- coding: utf8 -*-
# @Time : 2018/8/30 10:11
# @Author : yukang
from Levenshtein import *
# 个人总结的 关于 Levenshtein 所有函数的用法 和 注释
apply_edit() #根据第一个参数editops()给出的操作权重,对第一个字符串基于第二个字符串进行相对于权重的操作
distance() #计算2个字符串之间需要操作的绝对距离
editops() #找到将一个字符串转换成另外一个字符串的所有编辑操作序列
hamming() #计算2个字符串不同字符的个数,这2个字符串长度必须相同
inverse() #用于反转所有的编辑操作序列
jaro() #计算2个字符串的相识度,这个给与相同的字符更高的权重指数
jaro_winkler() #计算2个字符串的相识度,相对于jaro 他给相识的字符串添加了更高的权重指数,所以得出的结果会相对jaro更大(%百分比比更大)
matching_blocks() #找到他们不同的块和相同的块,从第六个开始相同,那么返回截止5-5不相同的1,第8个后面也开始相同所以返回8-8-1,相同后面进行对比不同,最后2个对比相同返回0
median() #找到一个列表中所有字符串中相同的元素,并且将这些元素整合,找到最接近这些元素的值,可以不是字符串中的值。
median_improve() #通过扰动来改进近似的广义中值字符串。
opcodes() #给出所有第一个字符串转换成第二个字符串需要权重的操作和操作详情会给出一个列表,列表的值为元祖,每个元祖中有5个值
#[('delete', 0, 1, 0, 0), ('equal', 1, 3, 0, 2), ('insert', 3, 3, 2, 3), ('replace', 3, 4, 3, 4)]
#第一个值是需要修改的权重,例如第一个元祖是要删除的操作,2和3是第一个字符串需要改变的切片起始位和结束位,例如第一个元祖是删除第一字符串的0-1这个下标的元素
#4和5是第二个字符串需要改变的切片起始位和结束位,例如第一个元祖是删除第一字符串的0-0这个下标的元素,所以第二个不需要删除
quickmedian() #最快的速度找到最相近元素出现最多从新匹配出的一个新的字符串
ratio() #计算2个字符串的相似度,它是基于最小编辑距离
seqratio() #计算两个字符串序列的相似率。
setmedian() #找到一个字符串集的中位数(作为序列传递)。 取最接近的一个字符串进行传递,这个字符串必须是最接近所有字符串,并且返回的字符串始终是序列中的字符串之一。
setratio() #计算两个字符串集的相似率(作为序列传递)。
subtract_edit() #从序列中减去一个编辑子序列。看例子这个比较主要的还是可以将第一个源字符串进行改变,并且是基于第二个字符串的改变,最终目的是改变成和第二个字符串更相似甚至一样
# print(hamming('Hello world!', 'Holly world!'))
# print(jaro_winkler("yukangrtyu",'yukangrtyn'))
# fixme = ['Levnhtein', 'Leveshein', 'Leenshten', 'Leveshtei', 'Lenshtein', 'Lvenstein', 'Levenhtin', 'evenshtei']
# print(opcodes('spam', 'park'))
# print(ratio('spam', 'spark'))
# print(jaro_winkler('spam', 'spark'))
# print(jaro('spam', 'spark'))
# print(seqratio('spam', 'spark'))
# print(seqratio(['newspaper', 'litter bin', 'tinny', 'antelope'],['caribou', 'sausage', 'gorn', 'woody']))
# print(setratio(['newspaper', 'litter bin', 'tinny', 'antelope'],['caribou', 'sausage', 'gorn', 'woody']))
# e = editops('man', 'scotsman')
# e1 = e[:3]
# bastard = apply_edit(e1, 'man', 'scotsman')
# print(e)
# print(e1)
# print(bastard)
# print(subtract_edit(e, e1))
# print(apply_edit(subtract_edit(e, e1), bastard, 'scotsman'))
def acquaintance(a,b):
for i in a:
item = {}
for j in b:
if ratio(u"%s"%i,u"%s"%j):
item[ratio(u"%s"%i,u"%s"%j)] = (i,j)
d = item[max(list(item.keys()))]
c = '"%s"和"%s"-最相似---匹配度为:%f'%(d[0],d[1],max(list(item.keys())))
print(c)
a = ["你好",'hello,world','计算偏差大不大啊?','文本可以吗','请看这里']
b = ['helloworld',"你好吗?",'可以吗','请这里','计算偏差大不大']
acquaintance(a,b)
simhash
- 【深度好文】simhash文本去重流程
- 传统Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。即便是两个原始内容只相差一个字节,所产生的签名也很可能差别很大,所以传统的Hash是无法在签名的维度上来衡量原内容的相似度。
- 而SimHash本身属于一种局部敏感hash,其主要思想是降维,将高维的特征向量转化成一个f位的指纹(fingerprint),通过算出两个指纹的海明距离(hamming distince)来确定两篇文章的相似度,海明距离越小,相似度越低(根据 Detecting Near-Duplicates for Web Crawling 论文中所说),一般海明距离为3就代表两篇文章相同。
- simhash也有其局限性,在处理小于500字的短文本时,simhash的表现并不是很好,所以在使用simhash前一定要注意这个细节。
hash
【2024-8-13】 Python 计算 hash值的代码
import hashlib
def calculate_md5(data):
md5_hash = hashlib.md5()
md5_hash.update(data.encode('utf-8'))
return md5_hash.hexdigest()
s = 'hi, who are you'
r = calculate_md5(s)
print(r)
simhash原理
simhash是google用来处理海量文本去重的算法。 Moses Charikear于2007年发布的一篇论文《Detecting Near-duplicates for web crawling》中提出的, 专门用来解决亿万级别的网页去重任务。
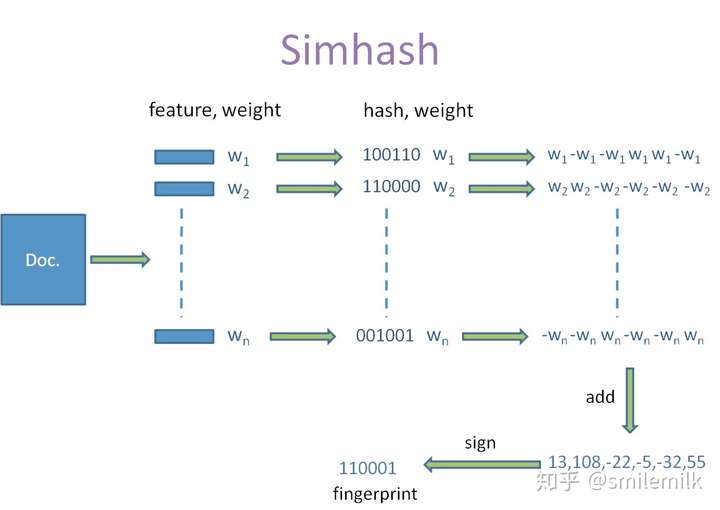
- simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。 算法过程大致如下:
- 对文本分词,得到N维特征向量(默认为64维)
- 为分词设置权重(tf-idf)
- 为特征向量计算哈希
- 对所有特征向量加权,累加(目前仅进行非加权累加)
- 对累加结果,大于零置一,小于零置零
- 得到文本指纹(fingerprint)
- 具体流程实现分为五个步骤
- 5个步骤:分词、hash、加权、合并、降维
代码实现
- python版本
计算长文本相似度并聚类
import jieba
from simhash import Simhash
import json
#new = json.loads(df.loc[1]['room_info'])
#new
print(df.columns)
output = open('/home/work/data/mian_out.txt', 'w')
sim_list = []
for line in df.loc[:,:].itertuples():
#print(line[4])
new = json.loads(line[4])
#print(new)
res = new['overall_review'].get('score', '-')
if res != '-':
out = [str(res['pass']), str(res['total_score']),
'%s_%s'%(res['language']['score'], res['language']['name']),
'%s_%s'%(res['logic']['score'], res['logic']['name']),
'%s_%s'%(res['explain_ability']['score'], res['explain_ability']['name']),
'%s_%s'%(res['knowledge']['score'], res['knowledge']['name'])]
else:
out = ['-', '-', '-', '-', '-', '-']
# asr的key:['question_order', 'quest_weight', 'quest_score', 'second_category', 'asr_result', 'question_id', 'S3_url', 'tips', 'duration', 'difficulty', 'third_category', 'question_review', 'answer', 'judge_rule', 'std_duration', 'question_content', 'sub_score', 'readtime']
#print(new['questions'][0].keys())
ans_list = []
for item in new['questions']:
ans_list.append('&'.join(item['asr_result']['sentences']))
#print('\t'.join([str(item['question_id']),str(item['question_order']), str(item['quest_score']), item['question_content'][0], '&'.join(item['asr_result']['sentences'])])) # ['sentences']
ans_str = '|'.join(ans_list)
words = jieba.lcut(ans_str, cut_all=True)
sim = Simhash(words).value
sim_list.append([str(line[3]), line[5], new['room_id'],sim])
# [agent_id, time, room_id, sim, pass, total_score, s1,s2,s3,s4, ans_str]
#print('\t'.join([str(line[3]), line[5], new['room_id'], str(sim)]+out+[ans_str]))
output.writelines('\t'.join([str(line[3]), line[5], new['room_id'], str(sim)]+out+[ans_str])+'\n')
output.close()
print(len(sim_list))
另一个版本
import jieba
from simhash import Simhash
words1 = jieba.lcut('我很想要打游戏,但是女朋友会生气!', cut_all=True)
words2 = jieba.lcut('我很想要打游戏,但是女朋友非常生气!', cut_all=True)
print(Simhash(words1).distance(Simhash(words2)))
print(Simhash(words2).value)
#输出:6,因为短文本使用simhash的话,文字稍微有些改动,还是挺明显的,大家可以用长文本尝试
#输出:6,因为短文本使用simhash的话,文字稍微有些改动,还是挺明显的,大家可以用长文本尝试
# simhash核心代码
# 说明:self.f 为simhash的长度;
# self.value 为当前实例的simhash值;
# self.hashfunc 为计算hash的函数,默认是md5;
# 计算文本的hash值
def build_by_features(self, features):
"""
`features` might be a list of unweighted tokens (a weight of 1
will be assumed), a list of (token, weight) tuples or
a token -> weight dict.
"""
v = [0] * self.f
masks = [1 << i for i in range(self.f)] #生成从1位到f位的mashs值,用于每个位的匹配操作
if isinstance(features, dict):
features = features.items()
# h是计算的hash值, w是权重(词频)
for f in features:
if isinstance(f, basestring):
h = self.hashfunc(f.encode('utf-8'))
w = 1
else:
assert isinstance(f, collections.Iterable)
h = self.hashfunc(f[0].encode('utf-8'))
w = f[1]
for i in range(self.f):
v[i] += w if h & masks[i] else -w # 位操作,位值为1,则为w,位值为0,则为-w;
ans = 0
for i in range(self.f):
if v[i] > 0:
ans |= masks[i] # 合并所有计算结果
self.value = ans
# 计算两个hash值得距离
def distance(self, another):
assert self.f == another.f
x = (self.value ^ another.value) & ((1 << self.f) - 1)
ans = 0
while x:
ans += 1
x &= x - 1
return ans
- C++版本
- 中文simhash算法库
-
简介
-
简单 simhash 包装而成的 HTTP Server ,主要是总是有人反馈因为不懂C++所以不知道怎么使用 [simhash] , 希望提供个 HTTP 接口用法。所以才有了这个项目。独立成单独一个仓库的原因是不想让 simhash 项目太过臃肿。
- 用法
- 【依赖】
g++ (version >= 4.1 recommended) or clang++;
- 【下载】
- 【依赖】
git clone git://github.com/yanyiwu/simhash_server.git
cd keyword_server
make
#如果是MacOSX用户,请使用 make osx 。
【启动服务】
./simhash.server
【GET请求示例】
curl "http://127.0.0.1:11201/?s=你好世界"
【POST请求示例】
curl -d "我是蓝翔 技工拖拉机学院手扶拖拉机专业的。" "http://127.0.0.1:11201"
有监督相似度计算
- 基于有监督的相似度计算,主要介绍基于神经网络的,基本可以分为两大类,sentence encoding (sentence representation) 类、sentence interaction 类。
常用数据集
- 如下:
- PI、SSEI、STS 英文:MSRP、SICK、SNLI、STS、Quora QP、MultiNLI
- PI、SSEI、STS 中文:LCQMC、BQ corpus
- IR-QA 英文:wikiQA、insuranceQA
- 注释:
- PI:paraphrase identification,是判断一文本是否另一文本的复述;
- STS:semantic text similarity,是计算两文本在语义层面的相似性;
- SSEI:sentence semantic equivalent identification,是判断两文本在语义层面是否一致;
- IR-QA:是给定一个 query,直接从一堆 answer 中寻找最匹配的,省略了 FAQ 中 question-answer pair 的 question 中转。
- 判断两段文本是不是表达了同样的语义,即是否构成复述(paraphrase)关系。有的数据集是给出相似度等级,等级越高越相似(这种更合理一些),有的是直接给出0/1匹配标签。这一类场景一般建模成分类问题。
一 相似度计算&复述识别(textual similarity¶phrase identification)
代表性数据集:
- SemEval STS Task:从2012年开始每年都举办的经典NLP比赛。这个评测将两段文本的相似度程度表示为0.0~5.0,越靠近0.0表示这两段文本越不相关,越靠近5.0表示越相似。使用皮尔逊相关系数(Pearson Correlation)来作为评测指标。
- Quora Question Pairs (QQP):这个数据集是Quora发布的。相比STS,这个数据集规模明显大,包含400K个question-question pairs,标签为0/1,代表两个问句的意思是否相同。既然建模成了分类任务,自然可以使用准确率acc和f1这种常用的分类评价指标啦。(知乎什么时候release一个HuQP数据集( ̄∇ ̄))
- MSRP/MRPC:这是一个更标准的复述识别数据集。在QQP数据集中文本都是来自用户提问的问题,而MRPC里的句子则是来源于新闻语料。不过MRPC规模则要小得多,只有5800个样本(毕竟是2005年release的数据集,而且人工标注,所以可以理解╮( ̄▽ ̄””)╭)。跟QQP一样,MRPC一般也用acc或f1这种分类指标评估。
- PPDB:这个paraphrase数据集是通过一种ranking方法来远程监督[]做出来的,所以规模比较大。文本粒度包含lexical level(单词对)、phrase level(短语对)和syntactic level(带句法分析标签)。而且不仅包含英文语料,还有法语、德语、西班牙语等15种语言(为什么没有中文!)。语料库规模从S号、M号一直到XXXL号让用户选择性下载也是很搞笑了,其中短语级就有7000多万,句子级则有2亿多。由于语料规模太大,标注质量还可以,因此甚至可以拿来训练词向量[1]。
二 问答匹配(answer selection)
- 问答匹配问题虽然可以跟复述识别一样强行建模成分类问题,但是实际场景往往是从若干候选中找出正确答案,而且相关的数据集也往往通过一个匹配正例+若干负例的方式构建,因此往往建模成ranking问题。
- 在学习方法上,不仅可以使用分类的方法来做(在ranking问题中叫pointwise learning),还可以使用其他learning-to-rank的学习方法,如pairwise learning(”同question的一对正负样本”作为一个训练样本)和listwise learning(”同question的全部样本排好序“作为一个训练样本) 。因此,相应的评价指标也多使用MAP、MRR这种ranking相关的指标。
- 注意:这并不代表pointwise matching这种分类做法就一定表现更弱,详情见相关papers
代表性数据集如:
- TrecQA:包含56k的问答对(但是只有1K多的问题,负样本超级多),不过原始的数据集略dirty,包含一些无答案样本和只有正样本以及只有负样本的样本(什么鬼句子),所以做research的话注意一下,有些paper是用的clean版本(滤掉上述三类样本),有的是原始版本,一个数据集强行变成了两个track。
- WikiQA:这也是个小数据集,是微软从bing搜索query和wiki中构建的。包含10K的问答对(1K多的问题),样本正负比总算正常了些。paper[2]
- QNLI:总算有大规模数据集了,这个是从SQuAD数据集改造出来的,把context中包含answer span的句子作为匹配正例,其他作为匹配负例,于是就有了接近600K的问答对(包含接近100K的问题)。
三 对话匹配(response selection)
对话匹配可以看作进阶版的问答匹配,主要有两方面升级。
一方面,对话匹配在问答匹配的基础上引入了历史轮对话,在历史轮的限制下,一些本来可以作为回复的候选会因此变得不合理。比如,历史轮提到过你18岁了,那么对于query”你今天在家做什么呢“,你就不能回复“我在家带孙子”了。
ps:一个价值五毛钱的例子(¬_¬) 另一方面,对于一个query,对话回复空间要远比问题答案空间大得多,对于问答类query,正确答案往往非常有限,甚至只有一个,但是对话类query却往往有一大串合理的回复,甚至有一大堆的万能回复比如“哦”,“好吧”,“哈哈哈”。很多时候的回复跟query在lexical level上基本没有交集,因此对话匹配模型更难训一些,数据质量稍差就难以收敛。因此做够了问答匹配,来做做对话匹配还是比较意思滴。
该问题一般使用Recall_n@k(在n个候选中,合理回复出现在前k个位置就算召回成功)作为评价指标,有时也会像问答匹配一样使用MAP、MRR等指标。
代表性数据集:
UDC:Ubuntu Dialogue Corpus是对话匹配任务最最经典的数据集,包含1000K的多轮对话(对话session),每个session平均有8轮对话,不仅规模大而且质量很高,所以近些年的对话匹配工作基本都在这上面玩。paper[3] Douban Conversation Corpus:硬要给UDC挑毛病的话,就是UDC是在ubuntu技术论坛这种限定域上做出来的数据集,所以对话topic是非常专的。所以 @吴俣 大佬release了这个开放域对话匹配的数据集,而且由于是中文的,所以case study的过程非常享受。paper[4]
四、自然语言推理/文本蕴含识别(Natural Language Inference/Textual Entailment)
NLI,或者说RTE任务的目的就是判断文本A与文本B是否构成语义上的推理/蕴含关系:即,给定一个描述「前提」的句子A和一个描述「假设」的句子B,若句子A描述的前提下,若句子B为真,那么就说文本A蕴含了B,或者说A可以推理出B;若B为假,就说文本A与B互相矛盾;若无法根据A得出B是真还是假,则说A与B互相独立。
显然该任务可以看作是一个3-way classification的任务,自然可以使用分类任务的训练方法和相关评价指标。当然也有一些早期的数据集只判断文本蕴含与否,这里就不贴这些数据集了。
代表性数据集:
- SNLI:Stanford Natural Language Inference数据集是NLP深度学习时代的标志性数据集之一,2015年的时候发布的,57万样本纯手写和手工标注,可以说业界良心了,成为了当时NLP领域非常稀有的深度学习方法试验场。paper[5]
- MNLI:Multi-Genre Natural Language Inference数据集跟SNLI类似,可以看做SNLI的升级版,包含了不同风格的文本(口语和书面语),包含433k的句子对
- XNLI:全称是Cross-lingual Natural Language Inference。看名字也能猜到这个是个多语言的数据集,XNLI是在MNLI的基础上将一些样本翻译成了另外14种语言(包括中文)。
五、信息检索中的匹配
除上述4个场景之外,还有query-title匹配、query-document匹配等信息检索场景下的文本匹配问题。不过,信息检索场景下,一般先通过检索方法召回相关项,再对相关项进行rerank。对这类问题来说,更重要的是ranking,而不是非黑即白或单纯的selection。ranking问题就不能仅仅依赖文本这一个维度的feature了,而且相对来说判断两个文本的语义匹配的有多深以及关系有多微妙就没那么重要了。
从纯文本维度上来说,q-a、q-r匹配和NLI相关的方法在理论上当然可以套用在query-title问题上;而query-doc问题则更多的是一个检索问题了,传统的检索模型如TFIDF、BM25等虽然是词项(term)level的文本匹配,但是配合下查询扩展,大部分case下已经可以取得看起来不错的效果了。如果非要考虑语义层次的匹配,也可以使用LSA、LDA等主题模型的传统方法。当然啦,强行上深度学习方法也是没问题的,例如做一下query理解,甚至直接进行query-doc的匹配(只要你舍得砸资源部署),相关工作如
- DSSM:CIKM2013 Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
- CDSSM:WWW2014 Learning Semantic Representations Using Convolutional Neural Networks for Web Search
- HCAN:EMNLP2019 Bridging the Gap between Relevance Matching and Semantic Matching for Short Text Similarity Modeling
六、机器阅读理解问题
同时,还有一些不那么直观的文本匹配任务,例如机器阅读理解(MRC)。这是一个在文本段中找答案片段的问题,换个角度来说就可以建模成带上下文的问答匹配问题(虽然候选有点多╮( ̄▽ ̄””)╭)。代表性数据集如SQuAD系列、MS MARCO、CoQA、NewsQA,分别cover了很多典型的NLP问题:MRC任务建模问题、多文档问题、多轮交互问题、推理问题。因此做匹配的话,相关的代表性工作如BiDAF、DrQA等最好打卡一下的。
- BiDAF:ICLR2017 Bidirectional Attention Flow for Machine Comprehension
- DrQA:ACL2017 Reading Wikipedia to Answer Open-Domain Questions
PS:
- 上述各个场景的模型其实差不太多,甚至一些方法直接在多个匹配场景上进行实验,近两年的paper也大多claim自己是一个非常general的匹配框架/模型。因此下面介绍打卡paper的时候就不区分场景啦,而是分成基于表示和基于交互来介绍打卡点。
- 注意:虽然基于表示的文本匹配方法(一般为Siamese网络结构)与基于交互的匹配方法(一般使用花式的attention完成交互)纷争数年,不过最终文本匹配问题还是被BERT及其后辈们终结了。因此下面两节请带着缅怀历史的心情来打卡,不必纠结paper的细节,大体知道剧情就好。
解法
如何解决
- 分为无监督和有监督学习
监督学习
- 训练数据格式:
- 共 N 组数据,每组数据结构相同:1 个 query,对应的 M 个 doc,对应的 M 个标签。
- 不同业务场景下embedding内容
| 业务 | doc | query | 备注 |
|---|---|---|---|
| 搜索引擎 | 文本语义和用户信息 | 索引网页各项信息 | |
| 智能问答 | 文本语义为主 | 文本语义为主 | |
| 信息流推荐 | 包含文本特征各项信息 | 用户历史、爱好等信息 | |
- query 和 doc 的表征形式较固定,至于具体 embedding 包含的信息根据具体任务、场景、目标变化极大,按需设计
- 但至于训练样本中的标签,形式则区别甚大。可以分成下述三种形式:
- pointwise,M 通常为 1,标签形式为 0 或 1,标签 0 表示 query 与该 doc 不匹配,标签 1 表示匹配。M 也可大于 1 ,此时,一组数据中只有一个 1 其余全为 0,表示这 M 个 doc 中只有这一个与 query 匹配,其余全都不匹配。
- pairwise,M 通常为 2,标签形式为 0 或 1 ,标签 0 表示 query 与第一个 doc 比与第二个 doc 更匹配,标签 1 表示 query 与第二个 doc 比与第一个 doc 更匹配,当然也可以反之。
- listwise,M 通常大于等于 2,标签形式为 1 到 M 的正整数,标签 m 表示 query 与该 doc 的匹配度在该组里位列第 m 位。
- 不同监督形式,形成了不同的学习方式,彼此之间优劣异同就涉及到 Learning2Rank 技术了,具体可参考
- 越靠后的形式得到的模型越符合我们预期,但其对训练样本形式的严苛性和算法设计的复杂性使得工业应用难以开展,通常,解决我们遇到的任务,多采用 pointwise 或者 pairwise 方式。
无监督学习
- 不少经典的无监督 STS 技术,虽然简朴,但也能取得不错的效果:
- 基于词汇重合度:TFIDF、VSM、LD、LCS、BM25、Jaccord、SimHash 等
- 基于浅层语义的主题模型:LSA、pLSA、LDA 等
- 基于浅层语义的 encoding 模型:embedding centroid、WMD、InferSent、pretrained encoder 等
- 虽然无监督技术较粗糙,但能有效解决冷启动问题。
- 如 Solr 全文检索引擎就在用基于 Ngram LD 的相似度召回技术,FAQ 问答引擎中使用 BOW+LD 也能取得不错的效果。
- 主题模型和基于词向量的模型,本质上都是基于词共现信息的,虽然引入了词义信息,但实际使用中,并无法替代基于词汇重合度的经典算法,效果相差不大。
模型
(1)传统文本匹配
- 传统的文本匹配技术有BoW、VSM、TF-IDF、 BM25、Jaccord、SimHash等算法,如BM25算法通过网络字段对查询字段的覆盖程度来计算两者间的匹配得分,得分越高的网页与查询的匹配度更好。主要解决词汇层面的匹配问题,或者说词汇层面的相似度问题。而实际上,基于词汇重合度的匹配算法有很大的局限性,原因包括:
- 词义局限:“的士”和“出租车”虽然字面上不相似,但实际为同一种交通工具;“苹果”在不同的语境下表示不同的东西,或为水果或为公司
- 结构局限:“机器学习”和“学习机器”虽然词汇完全重合,但表达的意思不同。
- 知识局限:“秦始皇打Dota”,这句话虽从词法和句法上看均没问题,但结合知识看这句话是不对的。
- 这表明,对于文本匹配任务,不能只停留在字面匹配层面,更需要语义层面的匹配。而语义层面的匹配,首先面临语义如何表示,如何计算的问题。
(2)主题模型
- 无监督技术
- 上世纪90年代逐渐流行起来语义分析技术(Latent Sementic Analysis, LSA),开辟了一个新思路。将语句映射到等长的低维连续空间,可在此隐式的潜在语义空间上进行相似度计算。
- 此后,又有PLSA(Probabilistic Latent Semantic Analysis)、LDA(Latent Dirichlet Allocation)等更高级的概率模型被设计出来,逐渐形成非常火热的 主题模型 技术方向。
- 这些技术对文本的语义表示形式简洁、运算方便,较好地弥补了传统词汇匹配方法的不足。不过从效果上来看,这些技术都无法替代字面匹配技术,只能作为字面匹配的有效补充。
(3)深度语义匹配模型
- 基于神经网络训练出的Word Embedding来进行文本匹配计算,训练方式简洁,所得的词语向量表示的语义可计算性进一步加强。但是只利用无标注数据训练得到的Word Embedding在匹配度计算的实用效果上和主题模型技术相差不大。他们本质都是基于共现信息的训练。另外,Word Embedding本身没有解决短语、句子的语义表示问题,也没有解决匹配的非对称性问题。
有监督深度学习方法,基本可以分为两大类,sentence representation、sentence interaction 级表示方法和交互方法。
- (1)SE模型:基于 Siamese 网络,表示层后交互计算;
- (2)SI模型:表示层后进行交互计算。
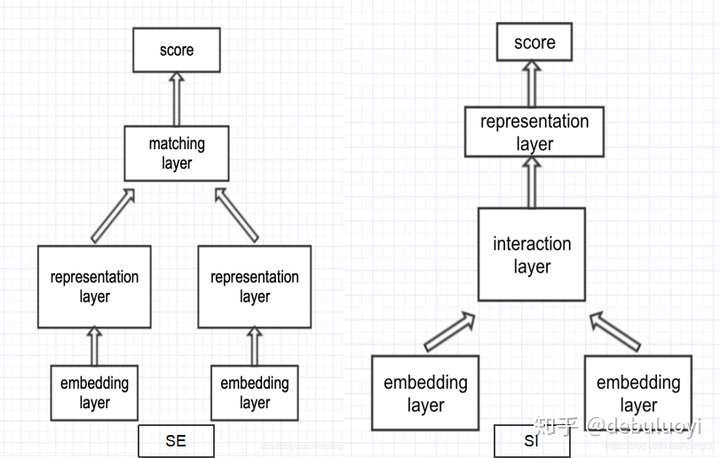
- 一般而言,单语义系列属于SE类模型,比如DSSM(Deep Structured Semantic Models),或者Convnet模型,如图所示;而后续的多层次交互的模型一般是采用SE框架
- 单语义匹配模型:DSSM(Deep Structured Semantic Models)以及基于此演进的系列模型CLSM/RNN-DSSM
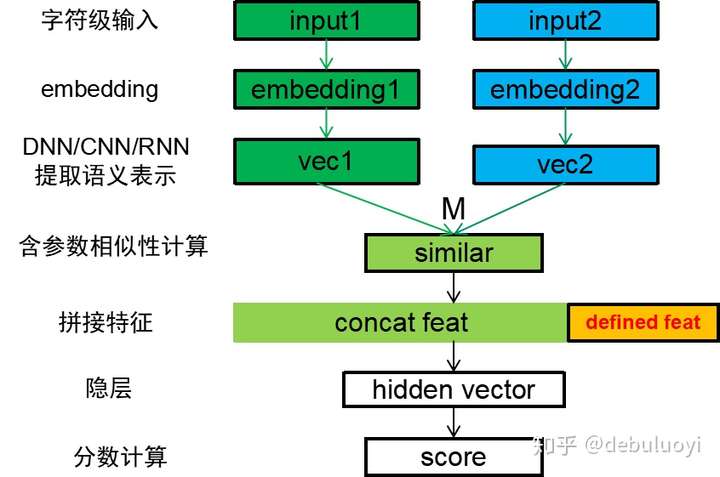
- 匹配方法可以分为三类:
- (a)基于单语义文档表达的深度学习模型(基于表示)
- 基于单语义文档表达的深度学习模型主要思路是,首先将单个文本先表达成一个稠密向量(分布式表达),然后直接计算两个向量间的相似度作为文本间的匹配度。
- (b)基于多语义文档表达的深度学习模型(基于交互)
- 基于多语义的文档表达的深度学习模型认为单一粒度的向量来表示一段文本不够精细,需要多语义的建立表达,更早地让两段文本进行交互, 然后挖掘文本交互后的模式特征, 综合得到文本间的匹配度。
- (c)BERT及其后辈
- (a)基于单语义文档表达的深度学习模型(基于表示)
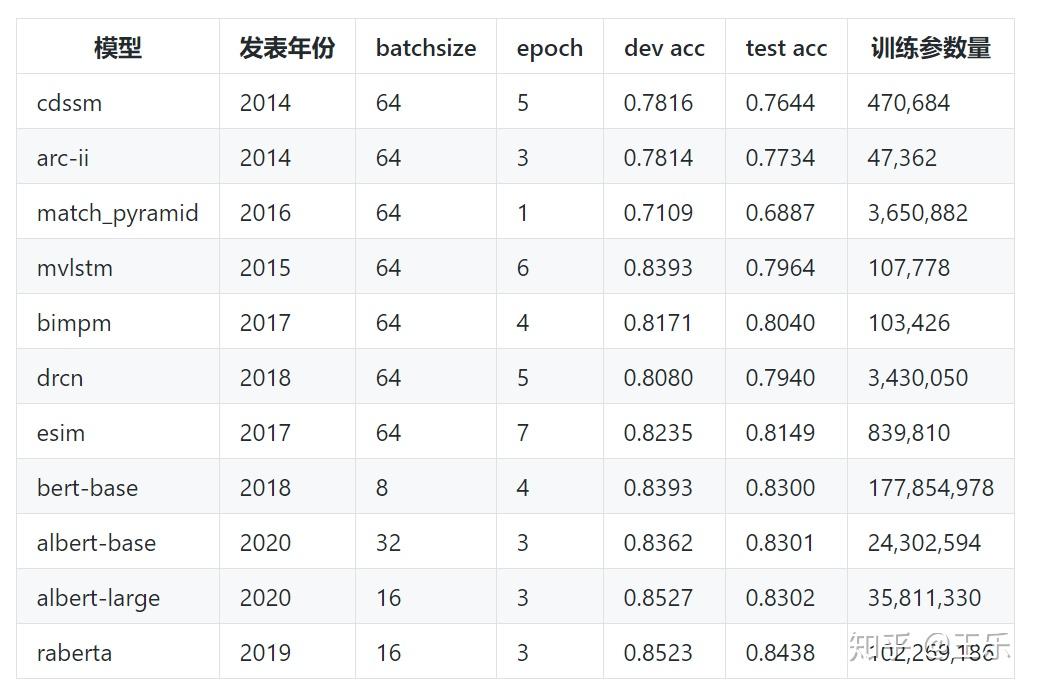
匹配模型汇总
自从深度学习出现以来,文本匹配模型层出不穷,几乎每年都会有一个极具代表性的模型出现。下面列出了十一个较为知名的模型。
SE 网络 (sentence encoding)基于表示
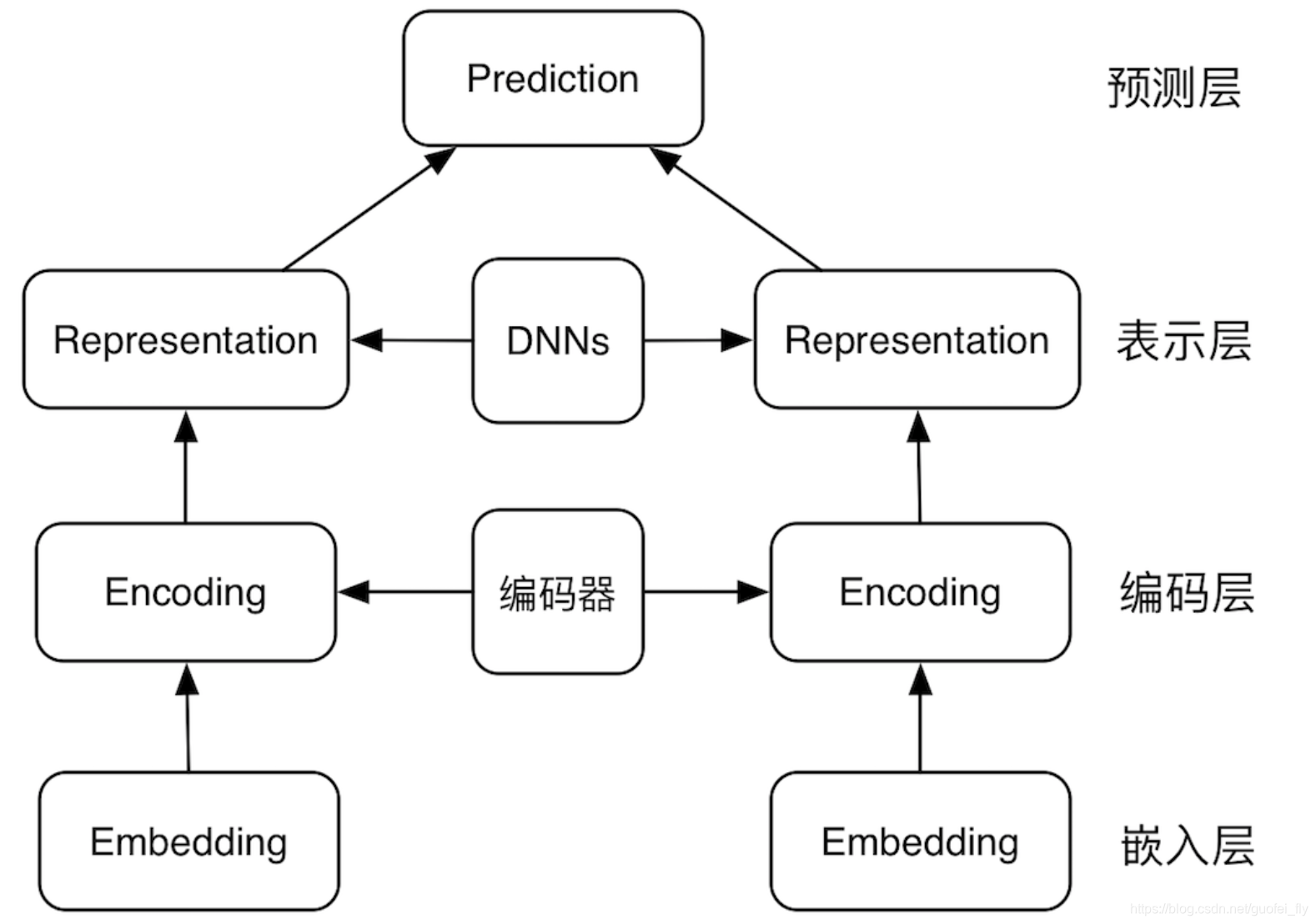
- 基于表示的匹配模型的基本结构包括:
- (1)嵌入层,即文本细粒度的嵌入表示;
- (2)编码层,在嵌入表示的基础上进一步编码;
- (3)表示层:获取各文本的向量表征;
- (4)预测层:对文本pair的向量组进行聚合,从而进行文本关系的预测
-
结构
- SE 网络结构如下:
- representation-based 类模型,思路是基于 Siamese 网络,提取文本整体语义再进行匹配
- 典型的 Siamese 结构,双塔共享参数,将两文本映射到同一空间,才具有匹配意义
- 表征层进行编码,使用 MLP、CNN、RNN、Self-attention、Transformer encoder、BERT 均可
- 匹配层进行交互计算,采用点积、余弦、高斯距离、MLP、相似度矩阵均可
- 经典模型有:DSSM、CDSSM、MV-LSTM、ARC-I、CNTN、CA-RNN、MultiGranCNN 等
- 优点是可以对文本预处理,构建索引,大幅降低在线计算耗时
- 缺点是失去语义焦点,易语义漂移,难以衡量词的上下文重要性
代表:
-
- DSMM
- DSSM、CDSSM、DSSM+LSTM、DSSM+CNN、DSSM+GRU、DSSM+RNN、MV(Multi-View)-DSSM
- 关于DSSM双塔模型有人做了一些归纳,DSSM双塔模型
- DSMM
-
- Siam(孪生)网络
- SiamCNN、SiamLSTM、、
- Siam(孪生)网络
-
- ARC-1
-
- Multi-view
-
- InferSent
-
- SSE
- siameseCNN
SI 网络 (sentence interaction)基于交互
- 表示型的文本匹配模型存在两大问题:
- (1)对各文本抽取的仅仅是最后的语义向量,其中的信息损失难以衡量;
- (2)缺乏对文本pair间词法、句法信息的比较
- 而交互型的文本匹配模型通过尽早在文本pair间进行信息交互,能够改善上述问题。
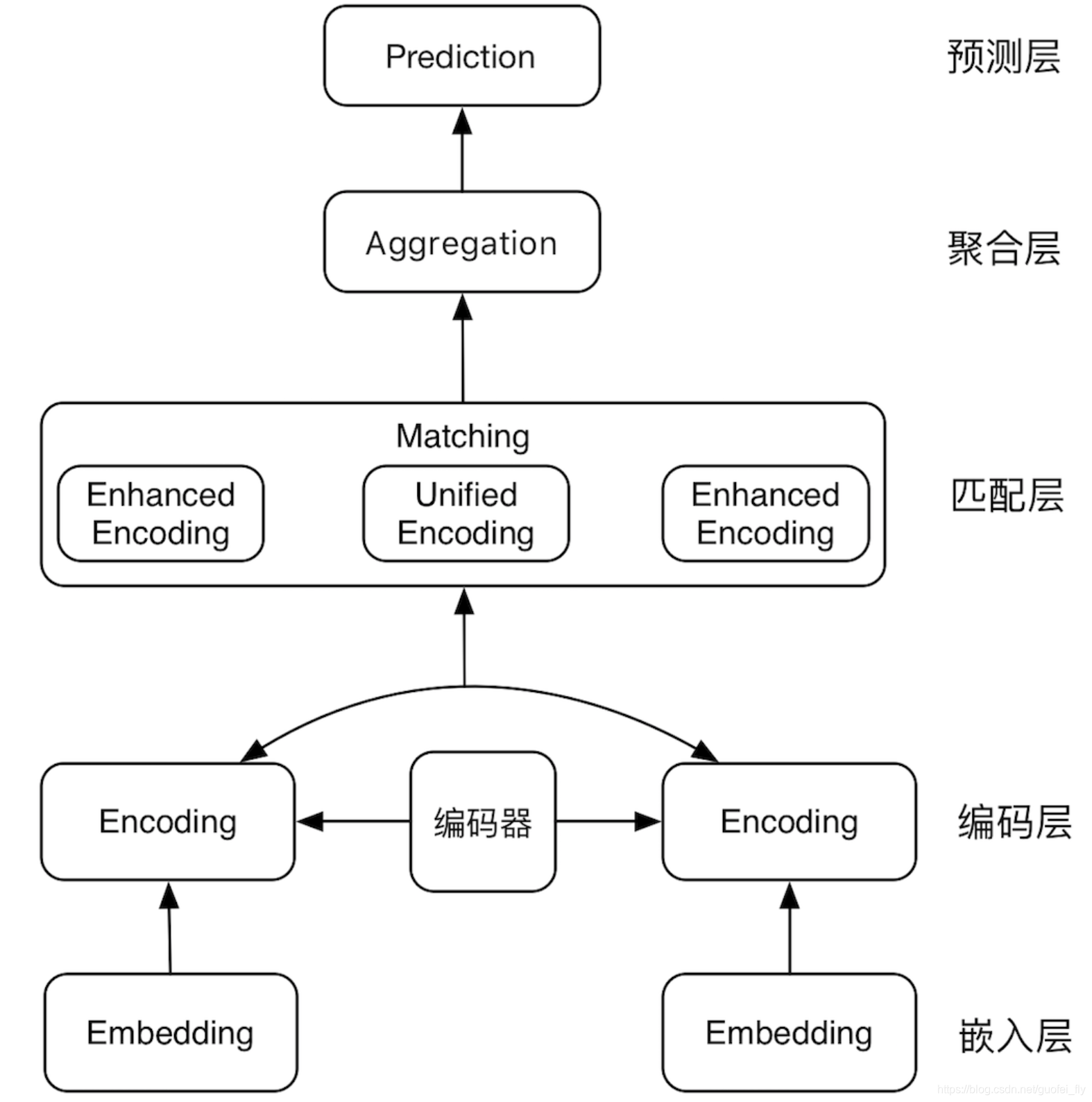
- 基于交互的匹配模型的基本结构包括:
- (1)嵌入层,即文本细粒度的嵌入表示;
- (2)编码层,在嵌入表示的基础上进一步编码;
- (3)匹配层:将文本对的编码层输出进行交互、对比,得到各文本强化后的向量表征,或者直接得到统一的向量表征;
- (4)融合层:对匹配层输出向量进一步压缩、融合;
- (5)预测层:基于文本对融合后的向量进行文本关系的预测。
- 结构
- SI 网络结构如下:
- interaction-based 类模型,思路是捕捉直接的匹配信号(模式),将词间的匹配信号作为灰度图,再进行后续建模抽象
- 交互层,由两文本词与词构成交互矩阵,交互运算类似于 attention,加性乘性都可以
- 表征层,负责对交互矩阵进行抽象表征,CNN、S-RNN 均可
- 经典模型有:ARC-II、MatchPyramid、Match-SRNN、K-NRM、DRMM、DeepRank、DUET、IR-Transformer、DeepMatch、ESIM、ABCNN、BIMPM 等
- 优点是更好地把握了语义焦点,能对上下文重要性进行更好的建模
- 缺点是忽视了句法、句间对照等全局性信息,无法由局部匹配信息刻画全局匹配信息
- 代表:
- ARC-Ⅱ
- PairCNN
- MatchPyranmid
- DecAtt
- CompAgg
- ABCNN: BCNN、ABCNN、ABCNN-2、ABCNN-3、
- DIIN
- DRCN
- ESIM
- Bimpm
- HCAN
基于预训练模型BERT
- SOTA模型,基于bert的改进还在学习中,base-bert、孪生bert等,此外BERT还有一个问题,无法解决长文本的匹配,但是对于此问题也有文章在解决了。
【Reference】
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
- Simple Applications of BERT for Ad Hoc Document Retrieval
其他
- 文本匹配的baseline有很多,借助一些好用的开源工具可以大大提升开发效率:MatchZoo、AnyQ、DGU
摘自:
深度语义
为了更好实现语义匹配、逻辑推理,需要 model 深度信息,可以从如下角度改进上述基础 SE、SI 网络:
- 结合 SE 与 SI 网络:两者的作用并非谁是谁子集的关系,是相互补充的关系,简单加权组合即可。
- 考虑词语的多粒度语义信息:即在基础模型基础上分别对 unigram、bigram、trigram 进行建模,从而 model 文本的word、term、phrase 层面的语义信息,融合的方式不唯一,在输入层、表示层、匹配层都可以尝试,通常来说越早融合越好提升效果,因为更早发挥了多粒度间的互补性。可参考腾讯的 MIX。
- 引入词语的多层次结构信息:即引入 term weight、pos、word position、NER 等层面的 element-wise 信息到语义信息中。可参考腾讯的 MIX。
- 引入高频 bigram 和 collocation 片段:主要为了加入先验,降低学习难度。Ngram 表义更精确但也更稀疏,可借助统计度量,只挑选少量对匹配任务有很好信息量的高频共现 term 组合作为 bigram 加入词典。Collocation 即关注跨词的一些 term 组合,如借助依存分析或者频繁项集挖掘获得 collocation 片段。
- 参考 CTR 中 FM,处理业务特征:如美团的排序算法演进中,参考了 CTR 中的 wide&deep 模型来添加业务特征,即,有的业务特征不做变换直接连接到最外层,有的业务特征做非线性变化后不够充分,会再进行多项式非线性变换。
- 对两文本中的差异部分单独建模:即在基础模型基础上,再使用一个单独模型处理两文本差异部分,强化负样本的识别能力。可参考 HIT 的 GSD模型。
- 引入混合学习策略:如迁移学习,可参考 MT-hCNN;如多任务学习;以及两者多种方式的组合,具体比较可参考 HIT 的 DFAN,如引入多任务学习和基于 Seq2Seq 的迁移学习的混合策略效果可能最好。
- 使用复杂 Learning2Rank 学习方式
- 按 pointwise、pairwise、listwise 顺序升格进行学习,在权衡标签获取难度和效果后,通常选用 DSSM 结构,即形式上的 listwise,loss 上的 pairwise 结构。
- 提供一种<font color’red’>最佳实践方案</font>:基于 DSSM 结构分别训练 SE 和 SI 网络,训练好的 SE 网络结合 faiss 作为预召回模块,训练好的 SI 网络作为匹配模块。
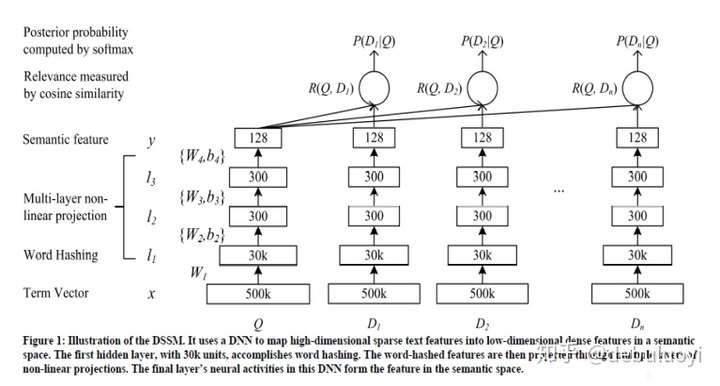
DSSM(Deep Structured Semantic Models)模型
- DSSM起初是用于搜索业务中的,原理是通过海量搜索结果的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。
- 该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达
- 深度学习得到广泛应用以后,DSSM原模型一般不予应用了
CLSM模型
- CLSM模型在有些地方也写作CNN-DSSM, 就是基于卷积表示的DSSM模型
- 英文语料会有对语料输入形式的窗口处理层:使用指定滑窗大小对输入序列取窗口数据(称为word-n-gram);对于这些word-n-gram按letter-trigram进行转换成表示向量
- 中文语料建模时,word-n-gram层这一步骤可以忽略,直接按照字符序列输入即可,简便很多
- 这种模型只是通过字典语义挤压训练,是否可以使用分词呢?答案是理论上可以(效果未实践),但实际业务中往往行不通,最好是使用中文字符序列输入,理由如下:
- (1)中文按照字符构建字典大约1.5万~2万规模即可,非常简便;
- (2)如果使用分词的话,因为语义模型训练一般是基于非常大规模数据的(如搜索领域DSSM模型应用就会使用千万甚至亿级别的数据进行训练),这样构成的词典会非常庞大容易出现OOM现象。相反如果强行构建较小词典,容易出现OOV现象造成语义模型训练效果较差。

- 实际应用可选用1个正例:3~4个负例构建样本,卷积层注意共用卷积核参数。应用经验表明,CLSM模型是在工业上应用不错的模型,其效果不错同时训练速度较快,线上服务也较好。一般而言以数百万数据训练CLSM模型大约12~24小时能完成(非并行条件下,下同),速度相对较快,一般工业级数据(是指不像标准数据集那样干净的样本,下同)验证准确率一般在60~65%之间。
- 由于CLSM模型大小较小和时耗较短,实际应用时是可以优化一下网络结构(常用于CNN网络的优化方式都可以尝试):
- (1)增大embedding层维度;
- (2)增加不同尺度大小的卷积-池化层组合;
- (3)增加卷积层层数;
- (4)池化层可以尝试最大池化和平均池化,也可以尝试k-最大池化等
- 通过上述一个或者多个优化方式的组合一般都可以提升CLSM模型效果,实际上增加上述网络,模型耗时仍然是同类语义匹配模型中最短的。
RNN-DSSM模型
- RNN-DSSM模型实际可以是GRU-DSSM,LSTM-DSSM,Bi-LSTM-DSSM,就是基于各种RNN结构的文本表示。
- 与上述CLSM模型一样,实际对于中文语料建模时,word-n-gram层这一步骤可以忽略,直接构建字符字典
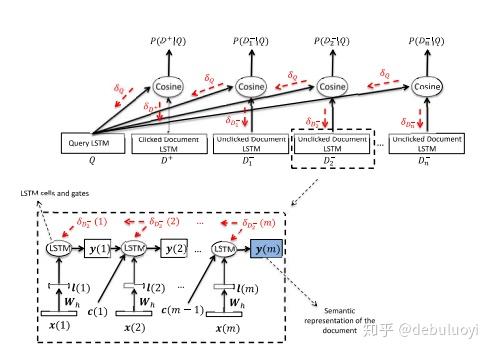
- 实际GRU-DSSM,LSTM-DSSM,Bi-LSTM-DSSM模型验证效果是逐渐上升的,同时训练耗时也是逐渐增加的。一般而言,实际应用可选用1个正例:3~4个负例构建样本,共用RNN cell即可。以数百万数据训练模型应用经验表明:
- (1)GRU-DSSM模型大约1~2天能完成,一般工业级数据验证准确率一般在65%~70%之间;
- (2)LSTM-DSSM模型大约近2天能完成,一般工业级数据验证准确率一般在65%~70%之间,模型较GRU-DSSM模型大,耗时也比GRU-DSSM模型长一些;
- (3)Bi-LSTM-DSSM模型要3天以上时间才能训练完成,一般工业级数据验证准确率一般会接近70%,模型较大,耗时较长一般不建议选用;
- 对于RNN-DSSM模型一般工业应用建议选用GRU-DSSM模型,对于可接受数天时耗的情况下,也可以对模型网络参照第2节进行部分优化。
深度树匹配模型(TDM)
Tree-based Deep Match(TDM)是由阿里妈妈精准定向广告算法团队自主研发的基于深度学习上的大规模(千万级+)推荐系统算法框架。
在大规模推荐系统的实践中,基于商品的协同过滤算法(Item-CF)应用较为广泛,而受到图像检索的启发,基于内积模型的向量检索算法也崭露头角,这些推荐算法产生了一定的效果,但因为受限于算法模型本身的理论限制,推荐的最终结果并不十分理想。
近些年,深度学习技术逐渐兴起,在包括如图像、自然语言处理、语音等领域的应用产生了巨大的效果推动。受制于候选集合的大规模,在推荐系统里全面应用深度学习进行计算存在效果低下的问题。针对这一难题TDM原创性的提出了以树结构组织大规模候选,建立目标(兴趣)的层次化依赖关系,并通过逐层树检索的方式进行用户对目标(兴趣)的偏好计算,从而实现用户目标(兴趣)的最终推荐。无论是在公开数据集上离线测试结果,还是在阿里妈妈实际业务的在线测试上,TDM都取得了非常显著的效果提升。

模型结构

【2023-11-6】阿里自主创新的下一代匹配&推荐技术:任意深度学习+树状全库检索
推荐、搜索、广告投放是互联网内容提供商进行流量分配的核心业务,也是大数据和机器学习技术的典型应用场景。推荐,搜索,广告投放都可以描述为从大规模候选中给用户提供有限的展现结果以获取用户的正向反馈(广告投放还需额外考虑广告主意愿和体验)。
由于在线业务对性能尤其是响应时间的严格要求,往往会把上述过程拆分为两个阶段 —— 匹配(Match)+排序(Rank)
以淘宝推荐系统为例
- 匹配阶段核心:如何从全量商品(Item)中根据用户(User)信息召回合适的TopK候选集合
- 匹配阶段由于问题规模大,复杂模型在此阶段的应用存在一定的局限性,所以业界对这方面的研究尤其是深度学习在此阶段的应用仍处在发展阶段。
- 排序阶段:对TopK候选集合进行精细化打分并排序输出最终展现的结果。
- 排序阶段因为候选集小,可引入深度学习等非常复杂的模型来优化目标,达到最终效果(相关性、广告收益等)的提升,业界对此阶段的研究比较集中和深入,比如阿里妈妈精准定向广告业务团队在排序阶段的CTR(Click-through Rate)预估上引入了基于Attention结构的深度兴趣模型(DIN,https://arxiv.org/abs/1706.06978),取得了非常好的业务效果。
匹配阶段产生的候选集质量会成为最终效果的天花板,因此如何创新和发展匹配技术是对业务有着重大意义的问题,也一直是业界和学术界关注的重点问题。
以推荐为例,在工业级的推荐系统中,匹配阶段面临很多技术挑战。例如
- 当候选集非常大时,要从全量候选集中挑选TopK集合,无法接受随着全量候选集大小而线性增长的时间复杂度,这使得一些学术界研究的需要计算全量
{User,Item}兴趣度的方法并不能真正应用于实际推荐系统中的匹配阶段。 - 在有限的计算资源下,如何根据用户信息从全量候选集中快速得到高质量的TopK候选集,需要在计算效率和计算准确性上做精巧的平衡。
- 真实应用的推荐系统,匹配阶段的计算时间需要被限制,简单用以下公式表示:
T*N ≤ Bound- T表示单次计算的时间消耗
- N为单个用户召回TopK需要的总体计算次数。
- 在上述公式的约束下,围绕如何提升匹配效果,工业界的技术发展也经历了几代的演进,从最初的基于统计的启发式规则方法,逐渐过渡到基于内积模型的向量检索方法。
- 然而这些方法在技术选型上都在上述计算效率约束下对匹配效果进行了很大的牺牲。如何在匹配阶段的计算效率约束下引入更先进的复杂深度学习模型成为了下一代匹配技术发展的重要方向。
匹配技术经历了从基于统计的启发式规则方法到基于内积模型的向量检索方法的转变,具体描述如下:
- 1)第一代——基于统计的启发式规则方法: Item-based Collaborative Filtering(以下简称Item-CF)
- 2)第二代——基于内积模型的向量检索方法
- 向量检索算法要求User和Item能够映射到统一的向量空间。User输入信息和Item输入信息一般并不同质,如何保证映射到统一目标向量空间下的检索精度对映射算法提出了严格的要求,换言之,统一的向量空间映射对运用向量检索来解决推荐问题带来了精度损失的风险。
- 3)下一代匹配和推荐技术
- 匹配技术发展的核心点在于系统性能限制下尽可能提升兴趣的衡量精度(从规则算法到引入先进模型)和覆盖范围(从限定候选集到全量候选集)
树检索结构的引入伴随着一系列的问题要解决:
- 1、树结构是如何构建的;
- 2,如何基于树进行匹配建模;
- 3、如何围绕树结构实现高效的兴趣计算和检索。
分析
- 概率连乘树并不适用匹配问题
- 概率形式并不能对匹配问题带来实质的帮助: Hierarchical Softmax(简称HS)每一个叶子节点(词)都有到根节点编码唯一的一条路径,而给定前置上文,下一个词出现的概率被建模为编码路径上分类概率的连乘。传统的多分类Softmax里归一化项依赖所有类别项的计算,所以即使计算一个类别的概率的计算量也很大,而通过概率连乘树的方式,HS有效避免了在传统Softmax建模中需要遍历所有叶子节点计算分母归一化项的过程。
- 怎么办?最大堆树
优化点
- PI、SSEI、STS、IR-QA、Ad-hoc retrieval 等任务基于神经网络提出的很多模型是彼此通用的,但彼此借鉴时,还是有不少细节需要调整的。
- IR-based QA 中提出的模型虽然也通用于相似度计算,但细节需要调整。如,Siamese 网络最后 matching layer 采用 cos 的话,对于 paraphrase 任务自然是没问题,两文本 encoding 后向量相同则得分高,但对 QA 任务则不尽然,此时 answer 未必是最优的。因此,基于 SE 结构的 QA 任务通常会加各种 attention,而 paraphrase 任务加 attention 基本没有增益。在 QA 任务上, attention 起到将 Q 中信息线性映射到 A 中信息的空间的作用,而 paraphrase 没这个必要。
- 语义匹配任务和相关匹配任务,很多模型也是通用的,但两个任务强调的有效信息是截然不同的,因此在基础模型上也会进行不少调整。如,需要格外关注 query 与 doc 完全匹配的 term,强调 query 中 term 的重要性,有时不必将 doc 作为整体和 query 进行匹配,等等。计算所提出了一系列相关匹配模型,如 DRMM、aNMM 等,可以参考 MatchZoo。
- 可见,看起来很相似的任务,也会导致很不同的解决方案,再次验证了 no-free-lunch 定理。
多轮对话
- IR-based 多轮对话的 QA 模型:
- 百度在 EMNLP2016 提出的 Multi-view 模型:联合考虑了 word-level matching 和 utterance-level matching,只是方式粗糙了些,均基于 SE 结构,类似于层次化结构。
- MSRA 在 ACL2017 提出的 SMN 模型:将 SE 改进到 SI, 联合考虑 word-level interaction 和 segment-level interaction。不过其 representation 过程用的两个 DRU,过于繁琐,可以参考阿里小蜜在2018的 MT-hCNN,进行了改进。
- 上交在 COLING2018 提出的 DUA 模型:采用了 Self-attention 对 utterance 进行了 deep encoding。
- 百度在 ACL2018 提出的 DAM 模型:算是最新技术的集大成者,摒弃之前建模 utterance embedding sequence 的思路,先使用 Transformer encoder 得到文本多粒度的表征,然后借助 attention 设计了两种交互方式得到了 self-attention-match 和 cross-attention-match 两种对齐矩阵,再采用 3D-conv 进行聚合分类预测,实现了 SOTA,干净利落。
应用
- 工业界的很多应用都有在语义上衡量文本相似度的需求,我们将这类需求统称为“语义匹配”。
根据文本长度的不同,语义匹配可以细分为三类:
- 短文本-短文本语义匹配
- 短文本-长文本语义匹配
- 长文本-长文本语义匹配
- 基于主题模型的语义匹配通常作为经典文本匹配技术的补充,而不是取代传统的文本匹配技术
1 短文本-短文本语义匹配
- 该类型在工业界的应用场景很广泛。如
- 在网页搜索中,需要度量用户查询(Query)和网页标题(web page title)的语义相关性;
- 在Query查询中,需要度量 Query和其他 Query之间的相似度。
- 由于主题模型在短文本上的效果不太理想,在短文本-短文本匹配任务中 词向量的应用 比主题模型更为普遍。简单的任务可以使用Word2Vec这种浅层的神经网络模型训练出来的词向量。
- 如,计算两个Query的相似度, q1 = “推荐好看的电影”与 q2 = “2016年好看的电影”。
- 通过词向量按位累加的方式,计算这两个Query的向量表示
- 利用余弦相似度(Cosine Similarity)计算两个向量的相似度。
- 对于较难的短文本-短文本匹配任务,考虑引入有监督信号并利用“DSSM”或“CLSM”这些更复杂的神经网络进行语义相关性的计算。
总结:
- 使用词向量按位累加方式获取句向量,使用距离度量获取相似度
- 利用DSSM等方法进行匹配度计算
2 短文本-长文本语义匹配
- 短文本-长文本语义匹配的应用场景在工业界非常普遍。例如,
- 在搜索引擎中,需要计算用户 Query 和一个网页正文(content)的语义相关度。由于 Query 通常较短,因此 Query 与 content 的匹配与上文提到的短文本-短文本不同,通常需要使用短文本-长文本语义匹配,以得到更好的匹配效果。
- 在计算相似度的时候,我们规避对短文本直接进行主题映射,而是根据长文本的 主题分布,计算该分布生成短文本的概率,作为他们之间的相似度。
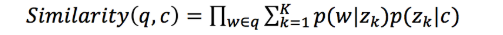
- 其中,q表示Query,c表示content, w表示q中的词,z k z_kz ,k表示第k个主题。
- 案例
- 案例1-用户查询-广告页面相似度
- 案例2:文档关键词抽取
总结:
- 利用主题模型或者其他方法如TF-IDF方法获取长本文的主题分布/提取关键词
- 计算Querry与文档主题/提取关键词之间的相似度
长文本-长文本语义匹配
- 通过使用主题模型,我们可以得到两个长文本的主题分布,再通过计算两个多项式分布的距离来衡量它们之间的相似度。衡量多项式的距离 可以利用Hellinger Distance和Jensen-Shannon Divergence(JSD)。
- 案例
- 案例3:新闻个性化推荐:行为信息对应的文本内容可以组合成一篇抽象的“文档”,对该“文档”进行主题映射 后获得的 主题分布 作为用户画像。

- 总结:
- 分别计算长文本的主题分布
- 计算两个多项式分布之间的距离作为相似度度量
- 知识点
- Hellinger Distance(海林格距离):又称Bhattacharyya distance,因为作者的姓氏叫Anil Kumar Bhattacharya。在概率和统计学中,海林格距离被用来衡量两个概率分布之间的相似性,属于f-divergence的一种。而f-divergence又是什么呢?,一个f-divergence是一个函数D f ( P \∣\∣ Q ) D_f(P||Q)D (P\∣\∣Q)用来衡量两个概率分布P PP和Q QQ之间的不同。
- Answer Selection:给定一个问题,从候选答案集合中匹配最佳答案。
- Paraphrase Identification释义识别:给定两个句子,判断它们是否包含相同的语义。
- Textual entailment:给定一句话作为前提,另一句话作为推断,去判断能否根据前提得到推断。
- 【2021-1-1】BERT用于文本分类+文本匹配的区别:
- 其他方面没有不同,只有在输入的时候,分类任务输入一个句子,而匹配任务输入两个句子
- 匹配任务的输入数据格式:texta \t text_b \t label 。两个句子之间通过[SEP]分割,[CLS]的向量作为分类的输入,标签是两个句子是否相似,1表示正例,0表示负例。
- 其他方面没有不同,只有在输入的时候,分类任务输入一个句子,而匹配任务输入两个句子
评估
- 准确率,召回率和F值都是利用无序的文当集合进行计算,而搜索引擎返回的结果通常是有序的,因此有必要对这些指标进行扩展以考虑位置信息。
- MAP,MRR评估方法
MAP(Mean Average Precision) 考虑位置因素
- MAP(Mean Average Precision)是近年来比较流行的评价指标, MAP在准确率的基础上考虑了位置的因素。
- 单个主题的平均准确率是每篇相关文档检索出后的准确率的平均值。主集合的平均准确率(MAP)是每个主题的平均准确率的平均值。
- MAP 是反映系统在全部相关文档上性能的单值指标。系统检索出来的相关文档越靠前(rank 越高),MAP就可能越高。如果系统没有返回相关文档,则准确率默认为0。
- 例如:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。
- 某系统
- 对于主题1检索出4个相关网页,其rank分别为1,2,4,7;
- 对于主题2检索出3个相关网页,其rank分别为1,3,5。
- 对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。
- 对于主题2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。
- 则MAP=(0.83+0.45)/2=0.64。
- 某系统
-
总结:MAP是顺序敏感的召回
- 代码

def AP(ranked_list, ground_truth):
"""Compute the average precision (AP) of a list of ranked items
"""
hits = 0
sum_precs = 0
for n in range(len(ranked_list)):
if ranked_list[n] in ground_truth:
hits += 1
sum_precs += hits / (n + 1.0)
if hits > 0:
return sum_precs / len(ground_truth)
else:
return 0
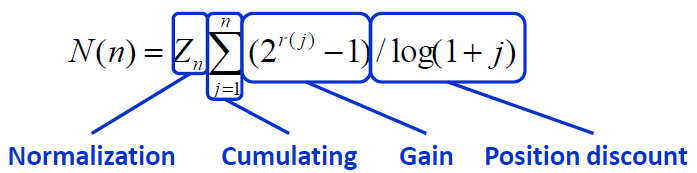
NDCG(Normalized Discounted Cumulative Gain)归一化折扣累计增益
- DCG的两个思想:
- 1、高关联度的结果比一般关联度的结果更影响最终的指标得分;
- 2、有高关联度的结果出现在更靠前的位置的时候,指标会越高;
- 累计增益(CG)
- CG,cumulative gain,是DCG的前身,只考虑到了相关性的关联程度,没有考虑到位置的因素。它是一个搜素结果相关性分数的总和。
- 折损累计增益(DCG)
- DCG, Discounted 的CG,就是在每一个CG的结果上处以一个折损值,为什么要这么做呢?目的就是为了让排名越靠前的结果越能影响最后的结果。假设排序越往后,价值越低。到第i个位置的时候,它的价值是 1/log2(i+1)
- Ideal DCG(IDCG):
- IDCG是理想情况下的DCG,即对于一个查询语句和p来说,DCG的最大值。
- 归一化折损累计增益(NDCG)
- NDCG, Normalized 的DCG,由于搜索结果随着检索词的不同,返回的数量是不一致的,而DCG是一个累加的值,没法针对两个不同的搜索结果进行比较,因此需要归一化处理,这里是处以IDCG。
- IDCG为理想情况下最大的DCG值
-
摘自:搜索评价指标NDCG
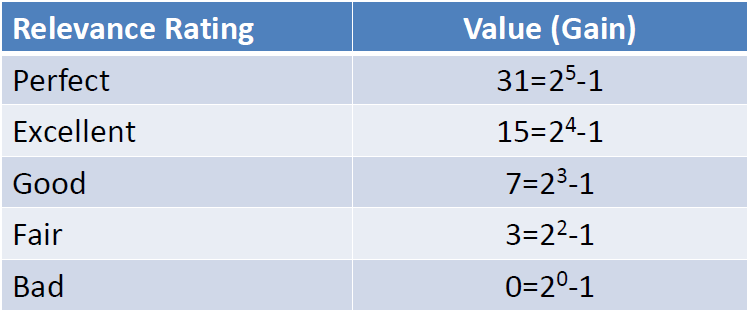
- 在MAP中,四个文档和query要么相关,要么不相关,也就是相关度非0即1。 value = 0/1
- NDCG中改进了下,相关度分成从0到r的r+1的等级(r可设定)。value = 2^(r-1)
- 当取r=5时,等级设定如下图所示:
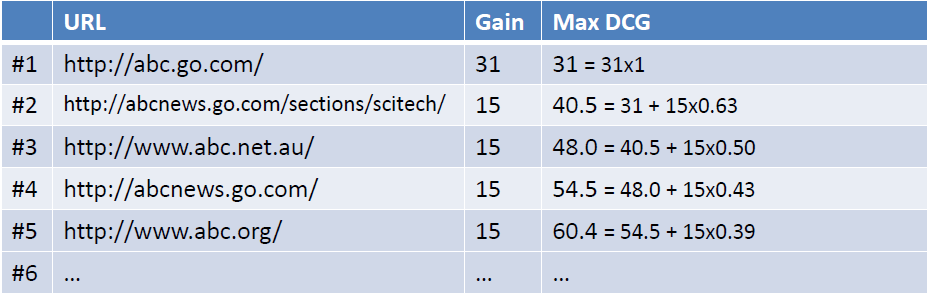
- 对于排在结位置n处的NDCG的计算公式
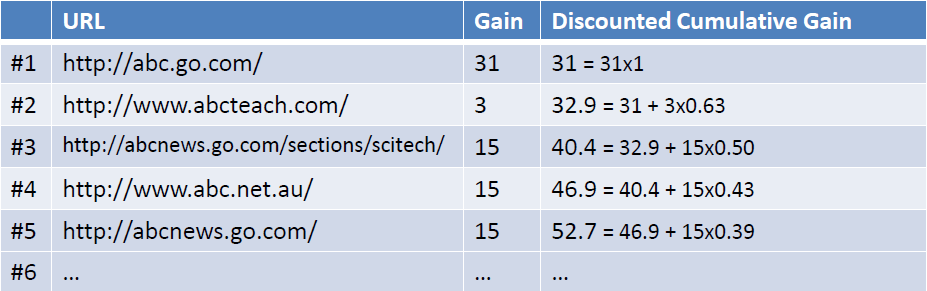
- query={abc},返回下图左列的Ranked List(URL),当假设用户的选择与排序结果无关(即每一级都等概率被选中),则生成的累计增益值如下图最右列所示
- 考虑到一般情况下用户会优先点选排在前面的搜索结果,所以应该引入一个折算因子(discounting factor): log(2)/log(1+rank)。这时将获得DCG值(Discounted Cumulative Gain)如下如所示
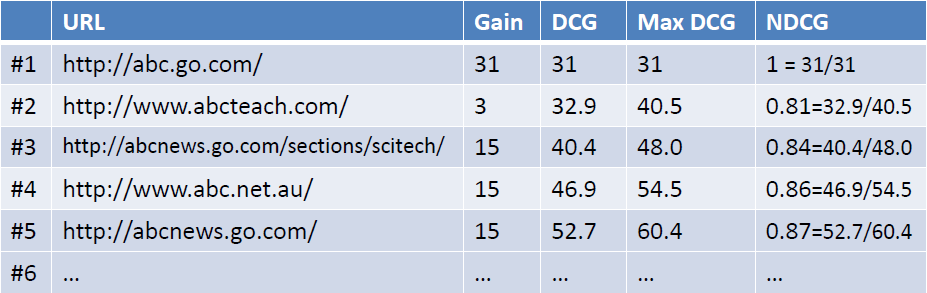
- 为了使不同等级上的搜索结果的得分值容易比较,需要将DCG值归一化的到NDCG值。操作如下图所示,首先计算理想返回结果List的DCG值:
- 用DCG/MaxDCG就得到NDCG值
- 代码
# ndcg
def get_dcg(y_pred, y_true, k):
#注意y_pred与y_true必须是一一对应的,并且y_pred越大越接近label=1(用相关性的说法就是,与label=1越相关)
df = pd.DataFrame({"y_pred":y_pred, "y_true":y_true})
df = df.sort_values(by="y_pred", ascending=False) # 对y_pred进行降序排列,越排在前面的,越接近label=1
df = df.iloc[0:k, :] # 取前K个
dcg = (2 ** df["y_true"] - 1) / np.log2(np.arange(1, df["y_true"].count()+1) + 1) # 位置从1开始计数
dcg = np.sum(dcg)
def get_ndcg(df, k):
# df包含y_pred和y_true
dcg = get_dcg(df["y_pred"], df["y_true"], k)
idcg = get_dcg(df["y_true"], df["y_true"], k)
ndcg = dcg / idcg
return ndcg
MRR(Mean Reciprocal Rank) 取倒数体现位置
- 把标准答案在被评价系统给出结果中的排序取倒数作为它的准确度,再对所有的问题取平均。
- value = 1/pos
- 举个例子:有3个query如下图所示

- MRR值为:(1/3 + 1/2 + 1)/3 = 11/18=0.61
- 代码
def average_precision(gt, pred):
if not gt:
return 0.0
score = 0.0
num_hits = 0.0
for i,p in enumerate(pred):
if p in gt and p not in pred[:i]:
num_hits += 1.0
score += num_hits / (i + 1.0)
return score / max(1.0, len(gt))
思路
- representation learning的深度匹配模型,两个文本进行represent,之后进行交互,优点是快捷,便于进行无监督训练(大量无标注数据上进行表示学习)
- match function learning不直接学习query和doc的表示,而是一开始就让query和doc进行各种交互,通过两者交互的match signals进行特征提取,然后通过aggregation对提取到的match signals用各种网络结构进行学习得到最终的匹配分数。
匹配模型
【2022-5-23】交互模型你快跑,双塔要卷过来了
文本匹配是NLP的一个重要任务,应用场景也十分广泛,比如搜索中query和doc的匹配、问答中query和answer的匹配、甚至再泛化点来讲,也可应用到推荐、多模态图文匹配中,甚至NER、分类都可以用匹配来解。文本匹配的综述,分别列举了匹配任务中的两种范式,双塔式和交互式:
双塔:两个句子分别encode成向量后,再融合交互:两个句子先合并,encode直接得到融合向量
优缺点:
双塔(左图)的速度很快,但是由于缺少两个句子的细粒度交互,效果始终有限交互(右图)则完全相反,效果很好,但速度一言难尽
有没有什么方法,既有双塔的速度,又有交互的精度呢?万能的蒸馏;有三篇paper都在做这件事
- 2021年12月8号,中科大和美团合作的文章,提出了一个Virtual Interaction机制,在训练阶段,把attention的交互信息蒸馏到双塔中。为了更好地利用上一点学到的交互知识,作者在双塔模型的metric计算上又加了一个attention机制,名为VIRT-adapted Interaction
- 哈工大和微软合作的工作,跟VIRT的时间算是前后脚,2021年12月16号挂到arxiv上,不过这篇工作主要是做图像和文本匹配的。出发点和VIRT也比较相似,只不过是用KL散度来蒸馏(老实说L2、KL散度、交叉墒在蒸馏时都可以用,具体效果我实践下来差距还不小,很玄学),并且在最后没有增加额外的attention
- 2022年5月18号,百度挂在arxiv的工作,不过他们没有对每层的attention进行蒸馏,而是重点攻克最后一层。作者主要参考了ColBERT,ColBERT在最后的交互上使用了一个MaxSim机制
发展历史
- (1)基于特征:传统的文本匹配任务还是采用基于特征的方式,无非就是
- 抽取两个文本tf-idf、BM25、词法等层面的特征,然后使用传统的机器学习模型(LR,SVM)等进行训练。
- 虽然基于特征的方法可解释性较好,但是这种依赖于人工寻找特征和不断试错的方法,泛化能力就显得比较一般,而且由于特征数量的限制,导致参数量受到限制,模型的性能比较一般。
- (2)基于深度学习:2012年以来,深度学习技术的快速发展以及GPU的出现,使得人们有机会并且有能力训练大型的深度神经网络。深度学习技术开始对计算机视觉、自然语言处理等各个领域产生了冲击,作为自然语言处理的一个分支,文本匹配当然也不例外。
- 2013年,微软提出 DSSM (2013),率先将深度学习技术引入到了文本检索任务中,开启了文本匹配方向的深度学习时代。
- 不同于传统基于特征的匹配方式,深度学习时代的文本匹配方法可以概括为两种类型:
- 基于表征(representation)的匹配:初始阶段对两个文本各自单独处理,通过深层的神经网络进行编码,得到文本的表征,然后基于得到的文本表征,采用相似度计算的函数得到两个文本的相似度。
- 基本范式(paradigm):Embedding层->Encoding层->DNN层->Prediction层。
- 案例
- 2013年,微软提出 DSSM (2013)
- 2014年,微软继续提出 CDSSM,基本流程和DSSM完全一样,无非就是将MLP替换成了CNN模型,可以提取N-gram特征
- 2014年,华为也提出了ARC
- 2016年,孪生网络Siamese Network (2016)以及其变种
- 2017年之后基本就没有基于表征的模型出现了。不过,就在最近,
- 2019年,Google在RecSys 2019上的提出了双塔结构流式模型,应用于Youtube进行大规模推荐. 基于BERT的双塔模型被很多文章提及,也可以看做是基于表征的模型,是一个非常强的baseline
- 分析:基于表征的方式可创新的地方并不多,Embedding层是固定的,Encoding层无非再加上各种char-embedding,或者entity-embedding来引入先验知识;可以稍微有点创新的就只有DNN层,但是由于表征模型从头到尾对两个待匹配文本都是独立处理的,能做的只能是怎么得到更好的表征向量,很容易想到的就是把DNN替换为RNN型网络或者后来的Attention网络;Prediction层则是寻找不同的相似度计算函数,或者直接使用一层线性层代替。
- 问题:在最后阶段才计算文本的相似度会过于依赖表征的质量,同时也会丢失基础的文本特征(比如词法、句法等)
- 表征用来表示文本的高层语义特征,但是文本中单词的关系、句法等特征高层的表征比较难捕获,很难判定一个表征是否能很好的表征一段文本。
- 要想能够建模文本各个层级的匹配关系,最好能够尽早地让文本产生交互。通俗来讲就是,认识的越早,两个文本对彼此的了解就可能越多。
- 基于交互(interaction)的匹配方式。尽可能早的对文本特征进行交互,捕获更基础的特征,最后在高层基于这些基础匹配特征计算匹配分数。
- 案例
- 2014年,华为在ARC I的那篇文章中,提出了 ARC II (2014),n-gram级别计算交互矩阵
- 从2014年开始,中科院郭嘉丰老师团队开始在文本匹配领域发力,发表了多篇经典的论文,包括MV-LSTM (2015),MatchPyramid (2016),DRMM (2016),Match-SRNN (2016)等等。
- 前两者基本是对ARC II的补充
- MV-LSTM主要是使用Bi-LSTM对Embedding进行强化编码
- MatchPyramid则提出了计算交互矩阵时多种匹配模式(Indicator, Cosine, Dot)
- DRMM就是针对检索领域任务的特点进行了创新
- 郭嘉丰团队开源的文本匹配工具MatchZoo,MatchZoo 是一个通用的文本匹配工具包,它旨在方便大家快速的实现、比较、以及分享最新的深度文本匹配模型。使用流程介绍
- MatchZoo可以快速搭建文本匹配的Pipeline,但是缺点是需要封装成内部定义的数据结构,限制了整个框架的扩展性;而且,MatchZoo只定义了英文的预处理器。因此,笔者对MatchZoo进行了一些修改,修改了底层数据封装的格式,除了能够进行文本匹配之外,还可以快速搭建文本分类、实体识别以及多轮QA检索等常见NLP任务的Pipeline。此外,还定义了中文的预处理器,并展示了一些使用的实例
- 前两者基本是对ARC II的补充
- 2016年,如何采用花式Attention技巧来强化单词向量表征,以及文本的交互矩阵成为之后文本匹配工作的核心。比较早期的网络有aNMM (2016),Match-LSTM (2016),Decomposable Attention (2016)
- Attention的使用方向主要集中在两点
- 一个是Embedding之后的Encoding层,通过Attention来得到强化单词的表征;
- 一个是使用交互匹配矩阵得到两个文本align之后的Cross Attention。
- Attention的使用方向主要集中在两点
- 2017年的论文BiMPM (2017) 可以说是对之前Attention的方式进行了一个汇总,也比较清晰地描述了基于交互的文本匹配模型的范式。该模型的结构分为Word Representation层,Context Representation层,Matching层,Aggregation层以及Prediction层。
- 2017年的论文ESIM (2017)也是文本匹配方向比较重要的一篇论文,笔者也是通过这篇论文第一次了解了Cross Attention
- 2017年,基于DRMM,CMU熊辰炎老师的团队又接连提出了KNRM (2017)和Conv-KNRM (2018),采用核方法对直方图的匹配方式进行改进。
- HCAN (2019)提出在Matching层分别计算Relevance Matching和Semantic Matching,这样既可以很好地解决信息检索中exact match和soft match的问题,在其他匹配任务中也能取得很好的效果。
- 阿里的两篇工作RE2 (2019)和Enhanced-RCNN (2020)都在尝试使用轻量级并且效果不逊色于BERT的模型,便于线上部署,取得了不错的结果。
- 案例
- 基于表征(representation)的匹配:初始阶段对两个文本各自单独处理,通过深层的神经网络进行编码,得到文本的表征,然后基于得到的文本表征,采用相似度计算的函数得到两个文本的相似度。
- 【2021-1-1】以上内容摘自:谈谈多轮匹配和文本检索
MatchPyramid模型
- 灵感来源于CV,把word-level的匹配情况看作是一张图片,用卷积来进行处理
- word-level的匹配图示,显然word-level能很好的体现细粒度的匹配信息。
- 模型的整体架构,word-level的匹配信息可以看做图像的像素,第一层卷积学到的是n-gram匹配信息(s0和s1连续k个词的组合),后面的卷积是将n-gram匹配进行组合
- 特点
- (1) 比起ARC-II模型通过n-gram得到的word embedding进行相似度计算,MatchPyramid模型在匹配矩阵的计算上做得更加精细,关注的是原始word级别的交互
- (2) 对于query和doc之间每个word的两两交互提出了3中方法,包括精确匹配的indicator计算,两个word完全相同为1否则为0;以及语法相似度的匹配,包括cosine以及dot product,关注的是更泛化的匹配
- (3) 整个过程和图像识别以及人类的认知一样,word-level的匹配信号,类比图像中的像素特征;phrase-level的匹配信号,包括n-gram有序的phrase以及n-term无序的phrase,类比图像中的边缘检测;到sentence-level的匹配信号,类比图像中的motifs检测。


Match SRNN(IJCAI 2016)
- 特点是用了二维RNN对匹配矩阵进行建模,类似于最长公共子序列的模式。似于一种动态规划的思路,query和doc的交互矩阵中每个位置的值由不仅由当前两个word的交互值得到,还由其前面(左、上、以及左上三个位置)的值决定。
ABCNN(Attention-based CNN) TACL 2016
Basic CNN
- 宽卷积+窗口为w的pooling,这样句子的长度跟原来一样,理论上可以堆叠多次,最后进行全局pooling

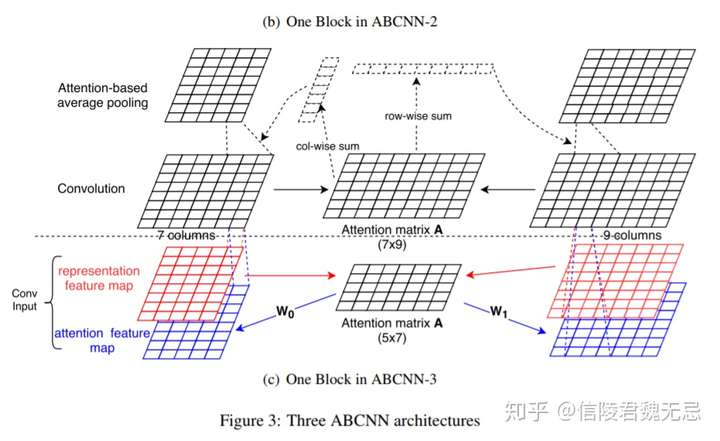
ABCNN 1
- 在卷积之前计算attention,通过红色的representation map(word embedding),进行attention得到attention matrix,attention matrix表示feature map 0的i位置和feature map 1的j位置的相关性。
- match score用的是
 ,经过转换之后可以得到attention feature map
,经过转换之后可以得到attention feature map 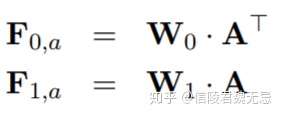 ,通过W0和W1两个矩阵将其转化为attention feature map
,通过W0和W1两个矩阵将其转化为attention feature map 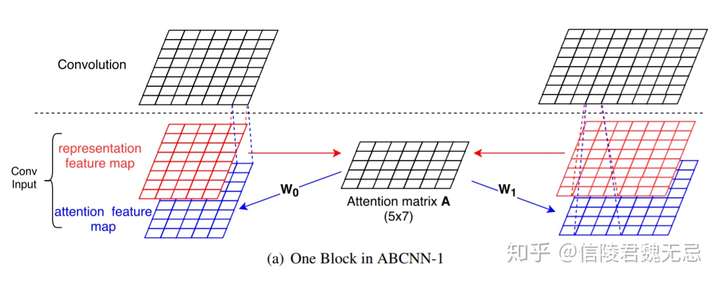
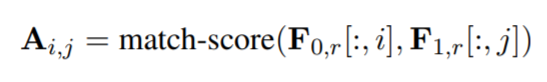
ABCNN-2
- 卷积之后进行attention计算,同样得到attention matrix,通过column-wise和row-wise的sum得到s0和s1中每个词的重要性,从而进行attention pooling,attention pooling就是让attention score序列乘以句子的representation最后进行池化,相对于平均池化来说每个词都包含了一个权重。但是这里的池化不是全局的,而是窗口为w的池化。
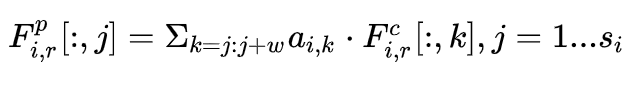
ESIM
- Enhanced LSTM for Natural Language Inference
- ESIM主要分为三部分:input encoding,local inference modeling 和 inference composition。
- input encoding就是用word embedding + bilstm
- local inference就是用一种交互式的attention架构,得到局部的交互信息。需要计算一个attention matrix(要分别根据两个句子的mask生成),然后生成align(也就是a每个位置分别跟b哪个位置align,b每个位置分别跟a哪个位置align),具体:


- 生成align之后,还需要有一部enhancement,进行element-wise的相乘和相减操作,并且与之前的拼接起来,作者希望这样能sharpen local inference information。
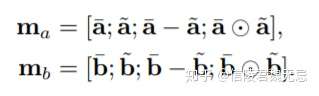
- inference composition就是组合local inference交互之后的信息,用LSTM+池化得到全局的交互信息,这是输出层了,具体是把a和b的representation用avg/max pooling得到四个向量拼接起来。
BIMPM
- Bilateral Multi-Perspective Matching双向多角度匹配模型
- 不仅需要考虑query到doc,也应该考虑从doc到query的倒推关系,因此这是个双边(Bilateral)的关系。
- 四个层,重点是matching layer
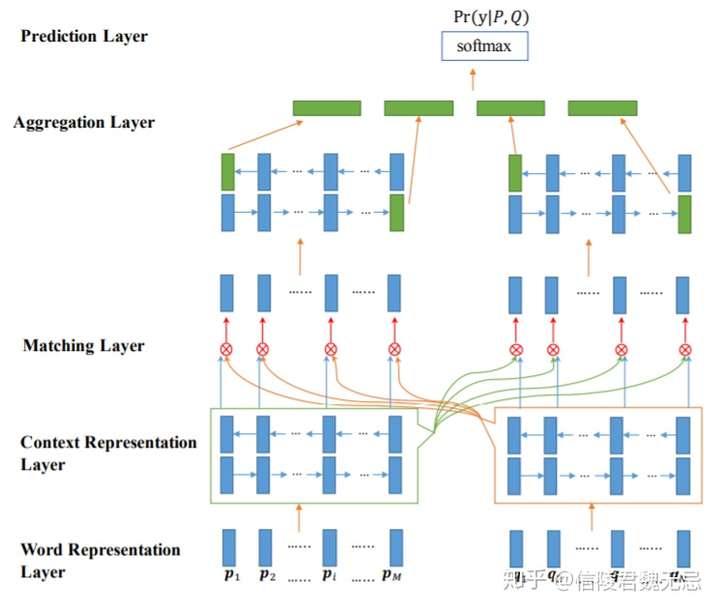
- 这里分前向和后向分别计算match representation,match operation是多角度的。原来计算match score输入两个向量,输出一个值,现在输入两个向量,输出一个match向量,其中match向量每一个维度代表一个角度的匹配。
- W代表一个l*d的向量,l代表视角数量
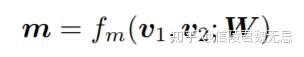
- 第k个视角对应一个相似度,用第k个视角的Wk作用在v1和v2上面得到,因此控制d维度空间不同dimension的权重。因此不同视角的Wk,本质是对于不同维度的取舍权重不同。
- matching strategy(详情见原文)
- full-matching方法
- max-pooling matching
- Attentive-Matching
- Max-Attentive-Matching

挑战
文本匹配主要面临的挑战
- (1)匹配对象差异巨大
- 实际问题中文本匹配的两个对象往往长度差异巨大,比如搜索场景的query-doc匹配,QA系统的问题答案匹配,标签系统的文章-标签匹配等,都是至少有匹配一方是极短文本,展示的语义并不完整,这种情况下进行文本匹配操作会带来各种各样的问题,需要根据实际问题来解决。
- (2)优质训练样本难以大量获取
- DSSM[1]模型工业应用时,需要使用数千万甚至上亿级别的搜索-点击日志数据,这个条件天然只能被较大公司所使用,对数据获取和计算能力都有较高的要求。
- (3)文本匹配的层次性
- 文本是以层次化的方式组织起来的,词语组成短语,短语组成句子,句子组成段落,段落组成篇章。这样一种特性使得我们在做文本匹配的时候需要考虑不同层次的匹配信息,按照层次的方式组织我们的文本匹配信息。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
