- 总结
- 语音识别技术篇
- 语音识别:ASR
- 结束
总结
- 【2022-9-17】 像编辑文本一样编辑语音,可能吗,微软亚洲研究院的研究员们研发了一个基于文本的语音编辑系统,通过编辑文本的形式,直接编辑音视频中的语音内容,让音视频的编辑自动根据文本完成,那么将大大降低音视频的编辑难度,提高创作者的效率。
- 【2022-6-3】智能音箱终于秀得起音质了,以前用户对音质上没什么可挑的,都是听个响,你就看哪家智能做得好吧。如今几年过去,情况在变化。
- 在
苹果放弃价格贼贵的HomePod之后,国产智能音箱却开始拼音质了。 华为联合音响品牌帝瓦雷推出高端产品Sound系列,音箱部分极致堆料,智能部分主推搭载鸿蒙,其中最高端型号Sound X价位来到2000+。小米也联手哈曼卡顿推出主打音质的小体积产品Xiaomi Sound,延续性价比传统定价499,被网友戏称为“年轻人的第一台高端智能音箱”。- 这么热闹,自然也少不了另一大玩家
天猫精灵,最近其在高端产品上的布局终于浮出水面 —— 智能声学,便是天猫精灵新品身上最醒目的标签- 与顶级声学机构
波士顿声学深度合作,联合打造的高端智能声学新品Sound系列已于6月1日上市。 - 其中,Sound Pro到手价为1299元,配备了5.25英寸的60W低频发声单元,实现了罕见的35Hz低频下潜,可以说已经能挑战同品类天花板了。
- 主打新功能之一智能EQ调音,内置算法可以自动选择最佳音效,无需手动调整复杂参数。据说这次还特别为电子核、情绪摇滚等小众音乐类型有专门调音。
- 主打新功能之二独家“猫耳算法”,解决了大音量听歌时音箱听不见你说话的问题。
- 第一个是回声消除,也就是麦克风收音时需要消除掉音箱自己发出来的声音。回声一般分为线性和非线形两部分。对于线性回声主要通过线性滤波器的传统算法来解决,对于非线性回声天猫精灵增加了深度学习算法来解决。
- 第二个是声源定位,增加使用了唤醒词的信息,包括唤醒词上每个频点人声的比例,综合利用声学信息和语音特征增加准确率。
- 第三个是降噪,也是传统算法与深度学习结合,先用噪声识别模型区分出人声与非人声,再分别用不同的算法去处理。
- 与顶级声学机构
- 在
- 【2021-12-24】百度paddle,一行代码搞定中英语音识别+语音合成,代码库paddlespeech
-
【2021-11-3】语音数据类创业公司爱数智慧:女科学家创业:曾花300天整数据、被通知立刻搬家,如今她为超100家AI企业输送“原油”
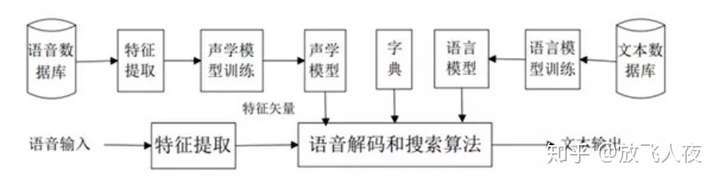
- 自动语音识别技术(ASR)将语音信号转换为文字或者二进制代码、字符序列等能让电脑识别的模式。语音识别系统由:语音信号处理和特征提取、声学模型、语言模型和解码搜索组成。其中语音信号处理和特征提取可以看成语音识别系统的前端,声学模型、语言模型和解码作为系统的后端
- 【2021-3-10】有感情的机器声优,Sonantic AI拟人配音技术为游戏注入情感,Sonantic官网
- 面部表情迁移:吴京+甄子丹 微博示例
- 百度地图等APP里说二十句话,生成自己音色的导航语音包的功能,就是个典型的音色克隆。
- 【2021-3-31】霍金简史:英特尔如何让他发声,2012年,专家们开始了正式的大规模改造。成果就是英特尔刚刚公布的针对残障人士开发的交互系统工具包ACAT(Assistive Context Aware Toolkit,辅助情境感知工具包)。2015年,英特尔开源霍金的语音系统 ACAT,(Stephen Hawking)的语音系统 Assistive Context-Aware Toolkit (ACAT) ,代码地址
- 【2021-4-25】标贝科技,包含风格化tts,体验地址:标贝悦读
- 【2021-4-26】淘系音视频技术的演进之路,2016年被称为直播元年,淘宝直播也是在2016年开始了自己的业务
- 淘系内容业务发展史
- 音视频技术趋势以及淘系技术相关布局
- 淘系音视频领域若干技术进展
- 【2021-5-18】搜狗发布全球首个手语合成主播,小聪
业界音箱
智能音箱模块
智能音箱几大核心模块
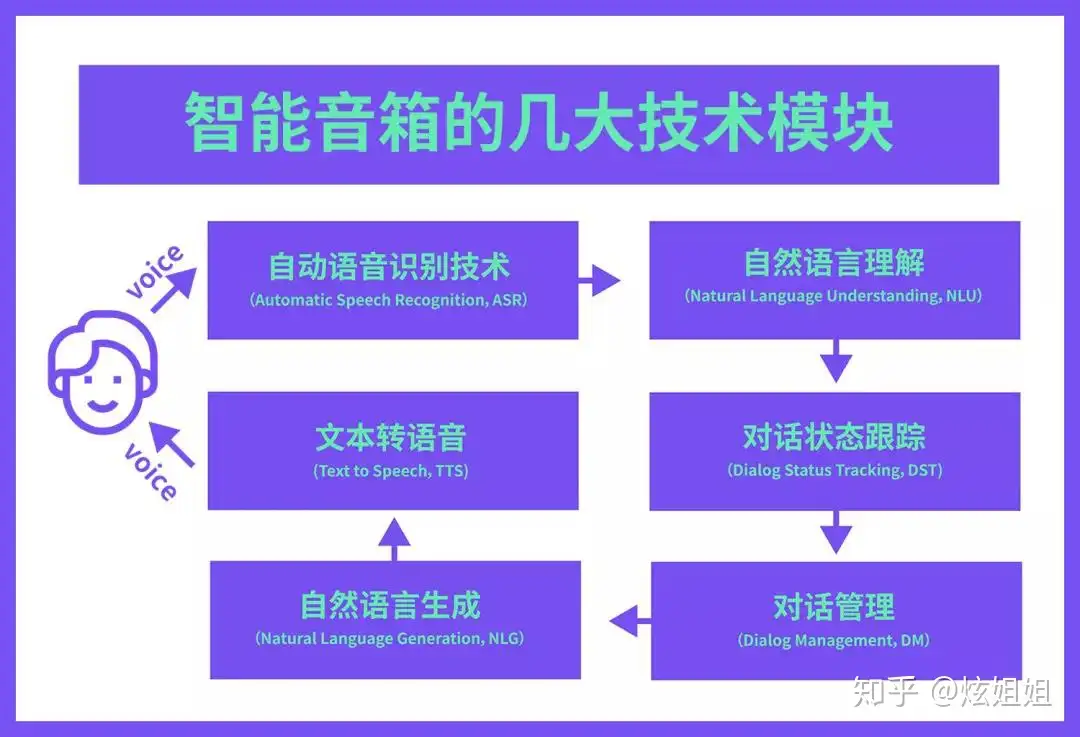
评测结果
-
语音识别系统框架, 参考:中科院横评了 8 款主流智能音箱,百度智能音箱各项评测数据排名第一
-
【2019-12-9】中科院物联网研究发展中心:智能音箱的智能技术解析及其成熟度测评
中科院为 3 大智能技术量身定制了 3 个评测标准。
语音识别技术(ASR)对应的测试标准为「准确度」自然语言理解(NLU)对应的测试标准为「召回率」对话管理(DM)对应的测试标准为「满意度」。
中国科学院志愿者评测结果:
音箱产品
无屏音箱:天猫精灵X1、小米AI音箱、腾讯智能听听9420智能音箱TS-T1、小度智能音箱Play。- 测评 query 主要分布前三类的分别是,音频类 58.44%,设备控制类 14.93%,信息查询类 10.24%。

有屏音箱:小米小爱触屏音箱、小度在家1S、天猫精灵CC、腾讯叮当。- 测评 query 主要分布前三类的分别是,视频播放类 32.34%,音频类 23.89%,设备控制类 23.79%。

结论:以ASR识别率为主要指标的“听清”环节,不论是无屏音箱,还是有屏音箱,四家主要厂商没有明显差距。有屏音箱的ASR识别率整体优于无屏音箱。
- 从无屏音箱维度看,四家主要厂商ASR识别率均达到94%以上,小度音箱识别率98%、天猫精灵为97%、小米小爱为96%、腾讯音箱为94%。
- 从有屏音箱维度看,四家主要厂商ASR识别率均达到96%以上,腾讯叮当、小度在家1S分别以98.6%、98.5%微微领先其他厂商。天猫CC ASR识别率为96.90%,小米有屏ASR识别率则为97.70%。
- 以召回率为主要指标的“听懂”环节,小度系列智能音箱是唯一召回率超过90%的产品,天猫精灵、小米小爱的召回率也达到70%以上。
评估指标
语音识别ASR
语音识别(Automatic Speech Recognition),一般简称ASR,是将声音转化为文字的过程,相当于人类的耳朵。
1、识别率
- 看纯引擎的识别率,以及不同信噪比状态下的识别率(信噪比模拟不同车速、车窗、空调状态等),还有在线/离线识别的区别。
- 实际工作中,一般识别率的直接指标是“WER(词错误率,Word Error Rate)”
- 定义:为了使识别出来的词序列和标准的词序列之间保持一致,需要进行替换、删除或者插入某些词,这些插入、替换或删除的词的总个数,除以标准的词序列中词的总个数的百分比,即为WER。(注:类似编辑距离)
- 公式为:(待补充)
- Substitution——替换
- Deletion——删除
- Insertion——插入
- N——单词数目
- 3点说明
- 1)WER可以分男女、快慢、口音、数字/英文/中文等情况,分别来看。
- 2)因为有插入词,所以理论上WER有可能大于100%,但实际中、特别是大样本量的时候,是不可能的,否则就太差了,不可能被商用。
- 3)站在纯产品体验角度,很多人会以为识别率应该等于“句子识别正确的个数/总的句子个数”,即“识别(正确)率等于96%”这种,实际工作中,这个应该指向“SER(句错误率,Sentence Error Rate)”,即“句子识别错误的个数/总的句子个数”。不过据说在实际工作中,一般句错误率是字错误率的2~3倍,所以可能就不怎么看了。
2、语音唤醒相关的指标
- 先需要介绍下
语音唤醒(Voice Trigger,VT)的相关信息。- A)语音唤醒的需求背景:近场识别时,比如使用语音输入法时,用户可以按住手机上siri的语音按钮,直接说话(结束之后松开);近场情况下信噪比(Signal to Noise Ratio, SNR)比较高,信号清晰,简单算法也能做到有效可靠。
- 但是在远场识别时,比如在智能音箱场景,用户不能用手接触设备,需要进行语音唤醒,相当于叫这个AI(机器人)的名字,引起ta的注意,比如苹果的“Hey Siri”,Google的“OK Google”,亚马逊Echo的“Alexa”等。
- B)语音唤醒的含义:简单来说是“喊名字,引起听者(AI)的注意”。如果语音唤醒判断结果是正确的唤醒(激活)词,那后续的语音就应该被识别;否则,不进行识别。
- C)语音唤醒的相关指标
- a)
唤醒率。叫AI的时候,ta成功被唤醒的比率。 - b)
误唤醒率。没叫AI的时候,ta自己跳出来讲话的比率。如果误唤醒比较多,特别比如半夜时,智能音箱突然开始唱歌或讲故事,会特别吓人的…… - c)
唤醒词的音节长度。一般技术上要求,最少3个音节,比如“OK Google”和“Alexa”有四个音节,“Hey Siri”有三个音节;国内的智能音箱,比如小雅,唤醒词是“小雅小雅”,而不能用“小雅”——如果音节太短,一般误唤醒率会比较高。 - d)
唤醒响应时间。之前看过傅盛的文章,说世界上所有的音箱,除了Echo和他们做的小雅智能音箱能达到1.5秒,其他的都在3秒以上。 - e)
功耗(要低)。看过报道,说iPhone 4s出现Siri,但直到iPhone 6s之后才允许不接电源的情况下直接喊“Hey Siri”进行语音唤醒;这是因为有6s上有一颗专门进行语音激活的低功耗芯片,当然算法和硬件要进行配合,算法也要进行优化。 - 以上a、b、d相对更重要。
- a)
- D)其他
- 涉及AEC(语音自适应回声消除,Automatic Echo Cancellation)的,还要考察WER相对改善情况。
- A)语音唤醒的需求背景:近场识别时,比如使用语音输入法时,用户可以按住手机上siri的语音按钮,直接说话(结束之后松开);近场情况下信噪比(Signal to Noise Ratio, SNR)比较高,信号清晰,简单算法也能做到有效可靠。
语音合成TTS
语音合成(Text-To-Speech),一般简称TTS,是将文字转化为声音(朗读出来),类比于人类的嘴巴。大家在Siri等各种语音助手中听到的声音,都是由TTS来生成的,并不是真人在说话。
- 主观测试(自然度),以MOS为主:
- 1、
MOS(Mean Opinion Scores),专家级评测(主观);1-5分,5分最好。 - 2、
ABX,普通用户评测(主观)。让用户来视听两个TTS系统,进行对比,看哪个好。
- 1、
- 客观测试:
- 1、对声学参数进行评估,一般是计算欧式距离等(RMSE,LSD)。
- 2、对工程上的测试:
实时率(合成耗时/语音时长),流式分首包、尾包,非流式不考察首包;首包响应时间(用户发出请求到用户感知到的第一包到达时间)、内存占用、CPU占用、3*24小时crash率等。
情感计算
- 情感计算就是赋予计算机像人一样的观察、理解和表达各种情感特征的能力,最终使计算机能与人进行自然、亲切和生动的交互。情感计算及其在人机交互系统中的应用必将成为未来人工智能的一个重要研究方向。
- 机器除了识别、理解人的情感之外,还需要进行情感的反馈,即机器的情感合成与表达。人类的情感很难用指标量化,机器则恰恰相反,一堆冷冰冰的零部件被组装起来,把看不见摸不着的“情感”量化成机器可理解、表达的数据产物。与人类的情感表达方式类似,机器的情感表达可以通过语音、面部表情和手势等多模态信息进行传递,因此机器的情感合成可分为情感语音合成、面部表情合成和肢体语言合成。
语音合成
- 情感语音合成是将富有表现力的情感加入传统的语音合成技术。常用的方法有基于波形拼接的合成方法、基于韵律特征的合成方法和基于统计参数特征的合成方法。
- 基于波形拼接的合成方法是从事先建立的语音数据库中选择合适的语音单元,如半音节、音节、音素、字等,利用这些片段进行拼接处理得到想要的情感语音。基音同步叠加技术就是利用该方法实现的。
- 基于韵律特征的合成方法是将韵律学参数加入情感语音的合成中。He 等提取基音频率、短时能量等韵律学参数建立韵律特征模板,合成了带有情感的语音信号。
- 基于统计参数特征的合成方法是通过提取基因频率、共振峰等语音特征,再运用隐马尔可夫模型对特征进行训练得到模型参数,最终合成情感语音。Tokuda 等运用统计参数特征的合成方法建立了情感语音合成系统。MIT 媒体实验室Picard 教授带领的情感计算研究团队开发了世界上第一个情感语音合成系统——Affect Editor,第一次尝试使用基频、时长、音质和清晰度等声学特征的变化来合成情感语音。
面部表情合成
- 面部表情合成是利用计算机技术在屏幕上合成一张带有表情的人脸图像。常用的方法有4 种,即基于物理肌肉模型的方法、基于样本统计的方法、基于伪肌肉模型的方法和基于运动向量分析的方法。
- 基于物理肌肉模型的方法模拟面部肌肉的弹性,通过弹性网格建立表情模型。
- 基于样本统计的方法对采集好的表情数据库进行训练,建立人脸表情的合成模型。
- 基于伪肌肉模型的方法采用样条曲线、张量、自由曲面变形等方法模拟肌肉弹性。
- 基于运动向量分析的方法是对面部表情向量进行分析得到基向量,对这些基向量进行线性组合得到合成的表情。
- 荷兰数学和计算机科学中心的Hendrix 等提出的CharToon 系统通过对情感圆盘上的7 种已知表情(中性、悲伤、高兴、生气、害怕、厌恶和惊讶)进行插值生成各种表情。荷兰特温特大学的Bui 等实现了一个基于模糊规则的面部表情生成系统,可将动画Agent 的7 种表情和6 种基本情感混合的表情映射到不同的3D 人脸肌肉模型上。我国西安交通大学的Yang 等提出了一种交互式的利用局部约束的人脸素描表情生成方法。该方法通过样本表情图像获得面部形状和相关运动的预先信息,再结合统计人脸模型和用户输入的约束条件得到输出的表情素描。
肢体语言合成
- 肢体语言主要包括手势、头部等部位的姿态,其合成的技术是通过分析动作基元的特征,用运动单元之间的运动特征构造一个单元库,根据不同的需要选择所需的运动交互合成相应的动作。由于人体关节自由度较高,运动控制比较困难,为了丰富虚拟人运动合成细节,一些研究利用高层语义参数进行运动合成控制,运用各种控制技术实现合成运动的情感表达。
- 日本东京工业大学的Amaya 等提出一种由中性无表情的运动产生情感动画的方法。该方法首先获取人的不同情感状态的运动情况,然后计算每一种情感的情感转变,即中性和情感运动的差异。Coulson 在Ekman 的情感模型的基础上创造了6 种基本情感的相应身体语言模型,将各种姿态的定性描述转化成用数据定量分析各种肢体语言。瑞士洛桑联邦理工学院的Erden 根据Coulson 情感运动模型、NAO 机器人的自由度和关节运动角度范围,设置了NAO 机器人6 种基本情感的姿态的不同肢体语言的关节角度,使得NAO 机器人能够通过肢体语言表达相应的情感。
-
在我国,哈尔滨工业大学研发了多功能感知机,主要包括表情识别、人脸识别、人脸检测与跟踪、手语识别、手语合成、表情合成和唇读等功能,并与海尔公司合作研究服务机器人;清华大学进行了基于人工情感的机器人控制体系结构研究;北京交通大学进行了多功能感知和情感计算的融合研究;中国地质大学(武汉)研发了一套基于多模态情感计算的人机交互系统,采用多模态信息的交互方式,实现语音、面部表情和手势等多模态信息的情感交互。
-
虽然情感计算的研究已经取得了一定的成果,但是仍然面临很多挑战,如情感信息采集技术问题、情感识别算法、情感的理解与表达问题,以及多模态情感识别技术等。另外,如何将情感识别技术运用到人性化和智能化的人机交互中也是一个值得深入研究的课题。显然,为了解决这些问题,我们需要理解人对环境感知以及情感和意图的产生与表达机理,研究智能信息采集设备来获取更加细致和准确的情感信息,需要从算法层面和建模层面进行深入钻研,使得机器能够高效、高精度地识别出人的情感状态并产生和表达相应的情感。为了让人机交互更加自然和谐,在情感计算研究中也要考虑到自然场景对人的生理和行为的影响,这些都是情感计算在将来有待突破的关键。
- 人机交互是人与机器之间通过媒体或手段进行交互。随着科学技术的不断进步和完善,传统的人机交互已经满足不了人们的需要。由于传统的人机交互主要通过生硬的机械化方式进行,注重交互过程的便利性和准确性,而忽略了人机之间的情感交流,无法理解和适应人的情绪或心境。如果缺乏情感理解和表达能力,机器就无法具有与人一样的智能,也很难实现自然和谐的人机交互,使得人机交互的应用受到局限。
- 由此可见,情感计算对于人机交互设计的重要性日益显著,将情感计算能力与计算设备有机结合能够帮助机器正确感知环境,理解用户的情感和意图,并做出合适反应。具有情感计算能力的人机交互系统已经应用到许多方面,如健康医疗、远程教育和安全驾驶等。
- 在健康医疗方面,具有情感交互能力的智能系统可通过智能可穿戴设备及时捕捉用户与情绪变化相关的生理信号,当监测到用户的情绪波动较大时,系统可及时地调节用户的情绪,以避免健康隐患,或者提出保健的建议。
- 在远程教育方面,应用情感计算可以提高学习者的学习兴趣与学习效率,优化计算机辅助人类学习的功能。
- 在安全驾驶方面,智能辅助驾驶系统可以通过面部表情识别,或者眼动、生理等情感信号动态监测司机的情感状态,根据对司机情绪的分析与理解,适时适当地提出警告,或者及时制止异常的驾驶行为,提高道路交通安全。
- 情感计算还运用到人们的日常生活中,为人类提供更好的服务。
- 在电子商务方面,系统可通过眼动仪追踪用户浏览设计方案时的眼睛轨迹、聚焦等参数,分析这些参数与客户关注度的关联,并记录客户对商品的兴趣,自动分析其偏好。另外有研究表明,不同的图像可以引起人不同的情绪。例如,蛇、蜘蛛和枪等图片能引起恐惧,而有大量金钱和黄金等的图片则可以让人兴奋和愉悦。如果电子商务网站在设计时考虑这些因素对客户情绪的影响,将对提升客流量产生非常积极的作用。
- 在家庭生活方面,在信息家电和智能仪器中增加自动感知人们情绪状态的功能,可提高人们的生活质量。
- 在信息检索方面,通过情感分析的概念解析功能,可以提高智能信息检索的精度和效率。
-
另外,情感计算还可以应用在机器人、智能玩具和游戏等相关产业中,以构筑更加拟人化的风格。
- 参考:机器人也能拥有人类情感:“情感计算”让机器人学会“读心术”
语音识别技术篇
- 【2020-9-17】语音识别长篇研究系列
基础概念
1、定义
语音识别(Automatic Speech Recognition)是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。- 语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。
2、发展ASR在近几年的流行,与以下几个关键领域的进步有关:
- (1)
摩尔定律持续有效- 使得多核处理器、通用计算图形处理器GPGPU、CPU/GPU集群等技术,为训练复杂模型提供了可能,显著降低了ASR系统的错误率。
- (2)
大数据时代- 借助互联网和云计算,获得了真实使用场景的大数据训练模型,使得ASR系统更具鲁棒性(健壮性、稳定性)。
- (3)
移动智能时代- 移动设备、可穿戴设备、智能家居设备、车载信息娱乐系统,变得越来越流行,语音交互成为新的入口。
3、研究领域分类
- 根据在不同限制条件下的研究任务,产生了不同的研究领域

4、语音识别任务分类
语音识别任务
- 语种识别
- 关键词检出
- 连续语言识别
- 声纹识别(说话人识别)

5、应用
语音交互作为新的入口,主要应用于上图中的两大类:帮助人与人的交流和人与机器的交流。
- (1)人与人的交流
HHC- 应用场景如,如翻译系统,微信沟通中的语音转文字,语音输入等功能。
- 语音到语音(speech-to-speech,S2S)翻译系统,可以整合到像Skype这样的交流工具中,实现自由的远程交流。
- S2S组成模块主要是,语音识别 –> 机器翻译 –> 文字转语音,可以看到,语音识别是整个流水线中的第一环。
- (2)人与机器的交流
HMC- 应用场景如,语音搜索VS,个人数码助理PDA,游戏,车载信息娱乐系统等。
6、对话系统
上面所说的应用场景和系统讨论,都是基于【语音对话系统】的举例。
- 语音识别技术只是其中关键的一环,想要组建一个完整的语音对话系统,还需要其他技术。
- 语音对话系统:(包含以下系统的一个或多个)
- (1)语音识别系统: 语音–>文字
- (2)语义理解系统:提取用户说话的语音信息
- (3)文字转语音系统:文字–>语音
- (4)对话管理系统:1)+ 2)+3)完成实际应用场景的沟通
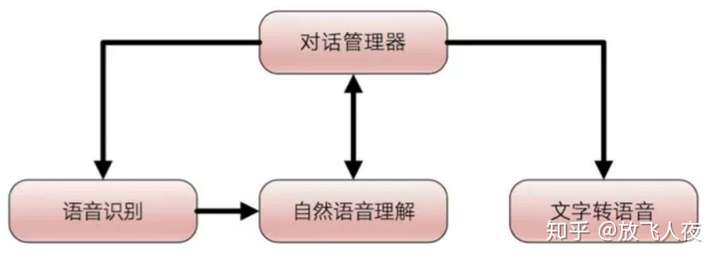
通信方式
【2021-7-29】微软全双工语音技术,让AI主动给你打电话,机器人真成了“人”
“全双工语音交互“并不是什么新词,全双工是通讯传输领域的一个术语,允许数据在两个方向上同时传输,与之对应的就是半双工。
- 传统的语音识别和机器对话都类似半双工,无论单轮还是多轮连续识别,都需要人说完一句话,机器才能理解并给出回应
- 如果将全双工语音这种高级感官的体验比拟为打电话,则之前的智能助理语音交互体验类似于对讲机。

依靠在用户和数据等方面的优势微软小冰快速迭代,目前已更新到第五代。如果将人工智能交互分为以下三个阶段,那第五代小冰就处在第三阶段

全双工语音属于一种高级感官,它需要首先同时具备文本、语音(含SR和TTS)两种能力,同时要求两种能力均达到更高的质量标准;这项新技术可以实时预测人类即将说出的内容,实时生成回应,并控制对话节奏,从而使长程语音交互成为可能。
采用该技术的智能硬件设备,也不需要用户在每轮交互时都说出唤醒词, 仅需一次唤醒,就可以轻松实现连续对话 ,使人与机器的对话更像人与人的自然交流。

二、语音识别基本原理
1、本质
- 语音识别系统本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元
2、系统架构概述
下图是语音识别系统的组成结构,主要分4部分:
信号处理和特征提取、声学模型(AM)、语言模型(LM)和解码搜索部分。- 左半部分可以看做是前端,用于处理音频流,从而分隔可能发声的声音片段,并转换成一系列数值。
声学模型就是识别这些数值,给出识别结果。- 右半边看做是后端,是一个专用的搜索引擎,它获取前端产生的输出,在以下三个数据库进行搜索:一个发音模型,一个语言模型,一个词典。
- 【发音模型】表示一种语言的发音声音 ,可通过训练来识别某个特定用户的语音模式和发音环境的特征。
- 【语言模型】表示一种语言的单词如何合并 。
- 【词典】列出该语言的大量单词 ,以及关于每个单词如何发音的信息。
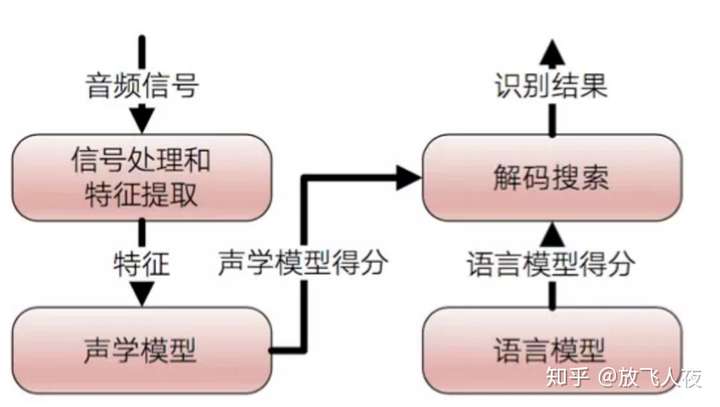
- a)
信号处理和特征提取:- 以音频信号为输入,通过消除噪声和信道失真对语音进行增强,将信号从时域转化到频域,并为后面的声学模型提取合适的有代表性的特征向量。
- b)
声学模型:- 将声学和发音学的知识进行整合,以特征提取部分生成的特征为输入,并为可变长特征序列生成声学模型分数。
- c)
语言模型:- 语言模型估计通过训练语料学习词与词之间的相互关系,来估计假设词序列的可能性,又叫语言模型分数。如果了解领域或任务相关的先验知识,语言模型的分数通常可以估计的更准确。
- d)
解码搜索:- 综合声学模型分数与语言模型分数的结果,将总体输出分数最高的词序列当做识别结果。
3、语音识别流程
首先经过预处理,再根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的特征,在此基础上建立语音识别所需的模板。而计算机在识别过程中要根据语音识别的模型,将计算机中存放的语音模板与输入的语音信号的特征进行比较,根据一定的搜索和匹配策略,找出一系列最优的与输入语音匹配的模板。然后根据此模板的定义,通过查表就可以给出计算机的识别结果。显然,这种最优的结果与特征的选择、语音模型的好坏、模板是否准确都有直接的关系。
(1)语音识别系统构建过程:
- 1) 训练:训练通常是离线完成的,对预先收集好的海量语音、语言数据库进行信号处理和知识挖掘,获取语音识别系统所需要的“声学模型”和“语言模型”
- 2) 识别:识别过程通常是在线完成的,对用户实时的语音进行自动识别,识别过程通常又可以分为“前端”和“后端”两大模块。
- A. 前端:前端模块主要的作用是进行端点检测(去除多余的静音和非说话声)、降噪、特征提取等;
- B. 后端:后端模块的作用是利用训练好的“声学模型”和“语言模型”对用户说话的特征向量进行统计模式识别(又称“解码”),得到其包含的文字信息,此外,后端模块还存在一个“自适应”的反馈模块,可以对用户的语音进行自学习,从而对“声学模型”和“语音模型”进行必要的“校正”,进一步提高识别的准确率。
三、语音识别技术原理
1、工作原理解读:
- (1)
声波:声音实际上是一种波。- 常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如 Windows PCM文件,也就是俗称的 wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。下图是一个波形的示例。
- (2)
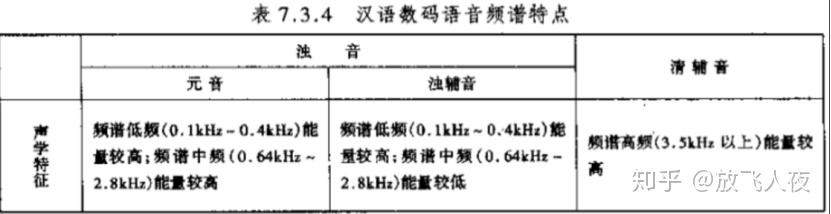
分帧:对声音进行分析,需要对声音分帧,也就是把声音切开一小段一小段,每小段称为一帧。帧操作一般不是简单的切开,而是使用移动窗函数来实现。帧与帧之间一般是有交叠的,就像下图: 
- 图中,每帧的长度为25毫秒,每两帧之间有10毫秒的交叠, 称为以
帧长25ms、帧移10ms分帧。
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取 MFCC特征。
至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。
- 观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。

接下来就要把这个矩阵变成文本了。
- (3)语音识别单元
语音识别单元有单词 (句) 、音节和音素三种,具体选择哪一种,根据具体任务来定,如词汇量大小、训练语音数据的多少。
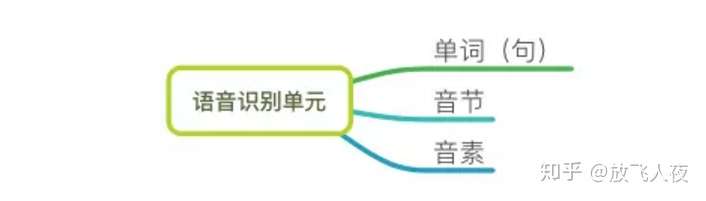
- 1)
音素:单词的发音由音素构成。- 英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的
音素集,参见 The CMU Pronouncing Dictionary。 - 汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调、无调,在汉语里,最小的语音单位是音素,是从音色的角度分出来的。
- 英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的
- 2)
音节:一个音素单独存在或几个音素结合起来,叫做音节。可以从听觉上区分,汉语一般是一字一音节,少数的有两字一音节(如“花儿”)和两音节一字。 
- 3)
状态:比音素更细致的语音单位, 通常把一个音素划分成3个状态。 - 4)流程:
- 第一步,把
帧识别成状态(难点)。 - 第二步,把
状态组合成音素。 - 第三步,把
音素组合成单词。
- 第一步,把

在上图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态,语音识别的结果就出来了。
那每帧音素对应哪个状态呢?有个容易想到的办法,看某帧对应哪个状态的概率最大,那这帧就属于哪个状态。比如下面的示意图,这帧在状态S3上的条件概率最大,因此就猜这帧属于状态S3。

这些用到的概率从哪里读取? “声学模型”里存了一大堆参数,通过这些参数就可以知道帧和状态对应的概率。
- 获取这一大堆参数的方法叫做“训练”,需要使用巨大数量的语音数据,训练的方法比较繁琐,现在有很多训练模型的工具(如:CMUSphinx Open Source Speech Recognition ,Kaldi ASR)。
问题:
- 每一帧都会得到一个状态号,最后整个语音就会得到一堆乱七八糟的状态号,相邻两帧间的状态号基本都不相同。
- 假设语音有1000帧,每帧对应1个状态,每3个状态组合成一个音素,那么大概会组合成300个音素,但这段语音其实根本没有这么多音素。如果真这么做,得到的状态号可能根本无法组合成音素。实际上,相邻帧的状态应该大多数都是相同的才合理,因为每帧很短。
常用解法是隐马尔可夫模型(Hidden Markov Model,HMM):首先构建一个状态网络,然后从状态网络中寻找与声音最匹配的路径。
这样就把结果限制在预先设定的网络中,避免了刚才说到的问题,当然也带来一个局限
- 比如设定的网络里只包含了“今天晴天”和“今天下雨”两个句子的状态路径,那么不管说些什么,识别出的结果必然是这两个句子中的一句。
- 那如果想识别任意文本呢? 把这个网络搭得足够大,包含任意文本的路径就可以了。但这个网络越大,想要达到比较好的识别准确率就越难。
- 所以要根据实际任务的需求,合理选择网络大小和结构。
搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。
- 语音识别过程其实就是在状态网络中搜索一条最佳路径,语音对应这条路径的累积概率最大,这称之为“
解码”。 - 路径搜索的算法是一种动态规划剪枝的算法,称之为
Viterbi算法,用于寻找全局最优路径。
累积概率:
观察概率:每帧和每个状态对应的概率转移概率:每个状态转移到自身或转移到下个状态的概率语言概率:根据语言统计规律得到的概率
其中,前两种概率从声学模型中获取,最后一种概率从语言模型中获取。
- 语言模型是使用大量的文本训练出来的,可以利用某门语言本身的统计规律来帮助提升识别正确率。
- 语言模型很重要,如果不使用语言模型,当状态网络较大时,识别出的结果基本是一团乱麻。
四、语音识别工作流程
1、信号的数字化和预处理:
1)数字化
声音是作为波的形式传播的。将声波转换成数字包括两个步骤:采样和量化。

为了将声波转换成数字,只记录声波在等距点的高度,这被称为采样(sampling)。
采样定理(Nyquist theorem)规定,从间隔的采样中完美重建原始声波——只要采样频率比期望得到的最高频率快至少两倍就行。
2)预加重处理
在语音识别过程中,经常会遇到原始语音数据因为噪音、背景音或次要信息的影响导致识别效果变差。
- 预加重就是为了提高语音质量,从含有噪声语音的信号中,尽可能提取纯净的原始语音信号。
方法有很多,下面列举三个:
- (1)
谱减法- 首先假设噪音和期望语音信号相互独立,然后通过估计噪音的功率,在原始语音中减去噪音功率达到去除噪音的目的。
- 这个方法较适用于噪音平稳波动性小的情况。
- (2)
自适应滤波法- 通过获得前一时刻的滤波器参数,去自动调节现在时刻的滤波器参数。我的理解是:假设语音信号具有较强的相关性,那么取t+1时刻的滤波器参数作用于t时刻的语音信号,形成纯净的语音信号。
- (3)
小波去噪法- 基于信号和噪声的小波系数在各尺度的分布特性,采用阈值的方法,达到去除噪声的目的。
3)声音分帧
把声音切开成一小段一小段,每小段称为一帧,使用移动窗函数来实现,不是简单的切开,各帧之间一般是有交叠的。
把它分隔为一小段一小段(10毫秒-40毫秒)的短语音,这样的小片段是平稳的,称之为【帧】。在每个帧上进行信号分析,称为语音的短时分析。
2、特征提取
语音降噪(Speech Denoising)时,选择合适的特征至关重要。不同特征在去除噪声、保持语音质量和提高模型性能方面各有优势。
1)原理
经过采样,预处理,将这些数字绘制为简单的折线图,如下所示,我们得到了 20 毫秒内原始声波的大致形状:
这样的波形图对机器来说没有任何描述信息。这个波形图背后是很多不同频率的波叠加产生的。(准确的讲,它在时域上没有描述能力),希望一段声纹能够给出一个人的特性,比如什么时候高,什么时候低,什么时候频率比较密集,什么时候比较平缓等等。
用傅里叶变换来完成时域到频域的转换。
- 对每一帧做傅里叶变换,用特征参数
MFCC得到每一帧的频谱(特征提取,结果用多维向量表示),最后可以总结为一个频谱图(语谱图)。
2)特性参数
(1)特性提取时,常用的特征参数作为提取模板,主要有两种:
线性预测系数(LPC)- LPC 的基本思想是,当前时刻的信号可以用若干个历史时刻的信号的线性组合来估计。通过使实际语音的采样值和线性预测采样值之间达到均方差最小,即可得到一组线性预测系数。
- 求解LPC系数可以采用自相关法 (德宾 durbin 法) 、协方差法、格型法等快速算法。
倒谱系数- 利用同态处理方法,对语音信号求离散傅立叶变换后取对数,再求反变换就可得到倒谱系数。
其中,LPC倒谱(LPCCEP)是建立在LPC谱上的,而梅尔倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)则是基于MEL谱的。不同于LPC等通过对人的发声机理的研究而得到的声学特征,MFCC 是受人的听觉系统研究成果推动而导出的声学特征。
简单的说,经过梅尔倒谱分析,得到的参数更符合人耳的听觉特性。
特征汇总
【2025-3-30】语音降噪经典特征
常用语音特征及其适用场景:
- 传统频域特征:
梅尔频谱(Mel Spectrogram)、梅尔频率倒谱系数(MFCC)、语谱图(Spectrogram) - 时域特征:
语音波形(Raw Waveform) - 其他增强特征:
伽马通滤波能量(GFCC)、预测语音掩蔽(IRM)
推荐:
- 深度学习降噪:梅尔频谱 / STFT / IRM
- 传统方法(如 Wiener 过滤):MFCC / GFCC
- 端到端网络(如 Wavenet):原始波形
选择特征时,应结合数据、计算资源和目标应用 来优化效果
| 特征 | 适用于传统方法 | 适用于深度学习 | 鲁棒性(对噪声抗性) | 适用场景 |
|---|---|---|---|---|
| 梅尔频谱 | × | ✔️(CNN, LSTM) | ★★★ | 语音增强、DNN 降噪 |
| MFCC | ✔️(HMM, GMM) | ×(DNN 降噪较弱) | ★ | 语音识别,低噪音环境 |
| 语谱图(STFT) | ✔️ | ✔️(U-Net, SEGAN) | ★★★ | 端到端语音增强 |
| 原始波形(Raw Waveform) | × | ✔️(WaveNet, DiffWave) | ★★★★ | 端到端神经网络降噪 |
| GFCC(伽马通特征) | ✔️ | ✔️(DNN) | ★★★★ | 噪声强的语音降噪 |
| IRM(掩蔽学习) | × | ✔️(DeepMMSE) | ★★★★ | 语音增强、掩蔽预测 |
传统频域特征
(1) 梅尔频谱(Mel Spectrogram)
特点:
- 采用 梅尔尺度 进行频谱变换,模拟人耳听觉感知。
- 比 STFT(短时傅里叶变换) 更能保留语音的关键信息。
适用于深度学习模型(CNN、Transformer)进行降噪。
适用场景:
- ✅ 语音增强(Speech Enhancement)
- ✅ 深度学习降噪(DNN、CNN、LSTM)
(2) 梅尔频率倒谱系数(MFCC)
特点:
- 从梅尔频谱中提取 cepstral(倒谱)特征,用于语音分析。
- 对背景噪声敏感,但可以结合 Delta MFCC 进行增强。
适用于传统信号处理方法,如 统计建模(HMM、GMM)。
适用场景:
- ✅ 传统方法(HMM-GMM)
- ✅ 噪声较低的环境
- ❌ 对强噪声敏感,不适用于深度学习降噪。
(3) 语谱图(Spectrogram / Log Power Spectrum)
特点:
- 直接使用 短时傅里叶变换(STFT) 计算语音频谱。
- 可用于深度学习降噪(如 U-Net)。
通过 对数功率谱(Log Power Spectrum, LPS) 增强对比度,提高模型鲁棒性。
适用场景:
- ✅ 端到端语音增强(Wave-U-Net, SEGAN)
- ✅ 适用于时频域网络(TCN, CRN)
时域特征
(4) 语音波形(Raw Waveform)
特点:
- 直接使用原始语音波形进行降噪,不依赖 STFT。
- 适用于 WaveNet、Wave-U-Net、DiffWave 等模型。
训练要求高,需要大规模数据支持。
适用场景:
- ✅ 端到端语音增强(无需 STFT)
- ✅ 深度神经网络(TCN, Wavenet, DiffWave)
- ❌ 计算复杂度高,难以解释特征。
其他增强特征
(5) 伽马通滤波能量(GFCC, Gammatone Frequency Cepstral Coefficients)
特点:
- 采用 伽马通滤波器组(Gammatone Filterbank),更符合人耳听觉系统。
- 对噪声鲁棒性更强,比 MFCC 更适用于语音增强。
适用场景:
- ✅ 噪声环境较复杂的语音降噪(如风噪、混响)
- ✅ 结合深度学习(DNN, LSTM)
(6) 预测语音掩蔽(IRM, Ideal Ratio Mask)
特点:
- 直接预测时频掩蔽(Mask),用于增强语音信号。
- 常用于语音增强和降噪任务(如 DeepMMSE)。
可结合时间频率掩码(TF-mask) 提高语音质量。
适用场景:
- ✅ 端到端语音降噪
- ✅ 适用于 SEGAN、DeepMMSE
主要算法有线性预测倒谱系数(LPCC)和 Mel倒谱系数(MFCC),目的是把每一帧波形变成一个包含声音信息的多维向量。
声学模型(AM)
声学模型是识别系统的底层模型,目的是提供一种计算语音的特征矢量序列和每个发音模板之间的距离的方法。通过对语音数据进行训练获得,输入是特征向量,输出为音素信息;
- 提取到的语音特性,与某个发音之间的差距越小,越有可能是这个发音。
- 某帧对应哪个状态的概率最大,那这帧就属于哪个状态。
- 一般用
GMM(混合高斯模型,一种概率分布)或DNN(深度神经网络)来识别。
但这样识别出来的结果会比较乱,因为一个人讲话的速度不一样,每一帧识别出的结果可能是:
….HHH_EE_LL__LLLL__OOO…..
如下图:

可以用DTW(动态时间规整)或HMM(隐马尔科夫模型)或CTC(改进的RNN模型)来对齐识别结果,知道单词从哪里开始,从哪里结束,哪些内容是重复的没有必要的。
常用的声学建模方法:
- 基于模式匹配的动态时间规整法(
DTW); - 隐马尔可夫模型法(
HMM); - 基于人工神经网络识别法(
ANN);
在过去,主流的语音识别系统通常使用梅尔倒谱系数(Mel-Frequency Cepstral Coefficient, MFCC)或者线性感知预测(Perceptual Linear Prediction, PLP)作为特征,使用混合高斯模型-隐马尔科夫模型(GMM-HMM)作为声学模型。
近些年,分层鉴别模型比如DNN,变得可行起来,比如上下文相关的深度神经网络-隐马尔可夫模型(context-dependent DNN-HMM,CD-DNN-HMM)就比传统的GMM-HMM表现要好得多。
如下图,可以清晰的看到被替换的部分。

主要问题
声学模型存在2个问题:
- (1)特征向量序列的可变长;
- 每个人说同一个单词的时间长度都不一样,声学模型要能从不同的时间长度的语音信号中识别出是同一个单词。
- 解决方法就是
DTW(动态时间规整)、HMM(隐马尔可夫模型)。
- (2)音频信号的丰富变化性;
- 如说话人的性别,健康状况,紧张程度,说话风格、语速,环境噪音,周围人声,信道扭曲,方言差异,非母语口音等。
声纹识别(说话人识别)
- 【2020-12-23】声纹分割聚类(Speaker Diarization)简介。文字版
声纹识别,也称为说话人识别,指把不同说话人的声音,按照说话人身份区分开来的技术, 有很多英文名:voice recognition、speaker recognition、voiceprint recognition、talker recognition。
声纹技术的一些细分方向:

- Speaker Diarization,可翻译为声纹分割聚类、说话人分割聚类、说话人日志,解决的问题是“who spoke when”。给定一个包含多人交替说话的语音,声纹分割聚类需要判断每个时间点是谁在说话。声纹分割聚类问题是声纹领域中仅次于声纹识别的第二大课题,其难度远大于声纹识别。单词diarization来自diary。
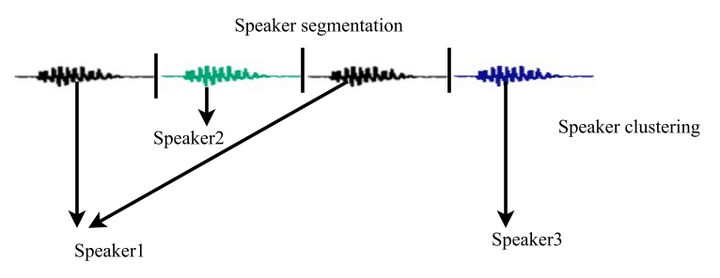
- 整体框架

语音检测
利用语音检测模型,将音频帧逐帧分为语音(speech,即有人说话)和非语音(non-speech,即无人说话)两个类别。
- 非语音可能是纯静音(silence),也可能是环境噪音(ambient noise)、或者音乐(music)、音效等其他信号。
常用的语音检测框架有:
VADEOQ:end-of-query
语音检测是标准的序列标注问题。
语音分割/说话人转换检测
分割的目标是分割后的每段音频只有一个说话人。有两种方法可以把整段语音切分为多个小段:
- 固定长度切分。比如每段1秒,临近段之间可以有些重叠。好处显然是简单,完全不用模型。
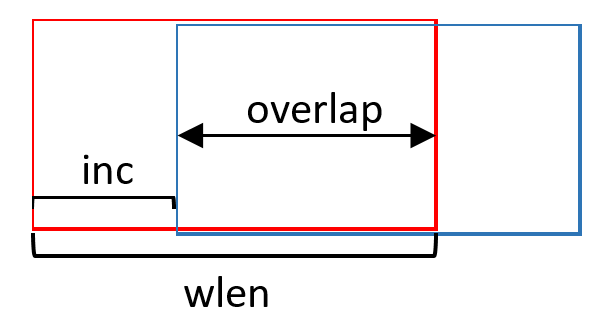
存在的问题:
- 片段太长:可能包含说话人转换点,此时给出的转换点预测结果容易出现错位;
- 判断太短:说话人声纹信息不足,识别准确率下降。
一般可以把每段长度设为 0.5秒 ~ 2秒 之间。
- 训练说话人转换检测模型(Speaker Change Detection,SCD),以SCD预测的转换点进行切分。
- 注:SCD只判断转换点,但并不知道转换后的说话人是哪个(说话人数量>2时)。所以SCD后还是需要聚类那个步骤。

存在的问题:
- SCD的准确率严重影响声纹分割聚类整个系统的效果。
说话人转换检测模型
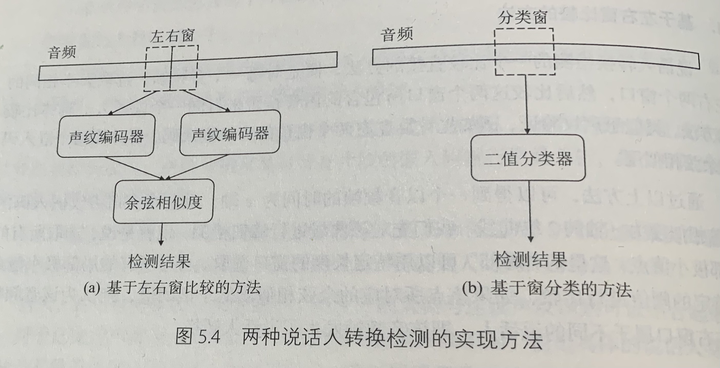
基于左右窗比较的方法
对比左右窗嵌入码的差异性。
基于窗分类的方法
当成标准的序列标注问题求解。
转换点label为1,非转换点label为0。所以两个类别很不平衡。通常会把转换点附近 K 帧(如 K=9)的label都标为1,这样可以缓解类别不平衡问题。另一个缓解类别不平衡问题的方法是使用针对不平衡问题的loss函数,比如 Focal Loss,亲测有效,通常准确率能提升几个百分点。
声纹嵌入码
训练数据准备
期望训练数据有以下特性:
- 包含尽可能多的说话人,比如超过10万个说话人;
- 训练数据与验证数据中的说话人不同;
- 语音中说的话尽可能多样化;
- 口音、语调、录制设备及环境尽可能多样化;
- 保证数据的正确性:保证音频中确实包含来自说话人的语音,而非单纯的噪声,或者同时包含其他说话人的声音。
数据增强方法:
- 模拟房间的混响(reverberation)效果,可使用 pyroomacoustics 包;
- 改变音量;
- 改变音速;
- 改变基频;
- 添加各类噪音;
- 随机子序列法:在已有的训练数据中,从较长的序列中随机截取较短的序列;
- 随机输入向量法:保留标签序列,但是将输入序列中的每个嵌入码,替换为从相应说话人的所有嵌入码集合中随机选取一个;
- 嵌入码旋转法:通过余弦相似度训练得到的声纹嵌入码都位于高维空间的单位球面上,可以通过某个旋转矩阵,将某个输入序列中的所有嵌入码映射到单位球面上的另一些点,且任何两个嵌入码在映射前与映射后其余弦相似度保持不变。
特征
- MFCC等
模型
- 传统模型:GMM-UBM
3)声学建模:
(1)隐马尔可夫模型(HMM)
对语音识别系统而言,HMM 的输出值通常就是各个帧的声学特征 。 为了降低模型的复杂度,通常 HMM 模型有两个假设前提,一是内部状态的转移只与上一状态有关,一是输出值只与当前状态或当前状态转移有关。除了这两个假设外,HMM 模型还存在着一些理论上的假设,其中之一就是,它假设语音是一个严格的马尔科夫过程 。
现代通用语音识别系统基于隐马尔可夫模型。这些是输出符号或数量序列的统计模型。HMM用于语音识别,因为语音信号可以被视为分段静止信号或短时静止信号。在短时间尺度(例如,10毫秒)中,语音可以近似为静止过程。语音可以被认为是许多随机目的的马尔可夫模型。
HMM受欢迎的另一个原因是因为它们可以自动训练并且使用起来简单且计算可行。在语音识别中,隐马尔可夫模型将输出一系列n维实值向量(其中n是一个小整数,例如10),每10毫秒输出一个这些向量。矢量将由倒谱系数组成,倒谱系数是通过对短时间语音窗口进行傅里叶变换并使用余弦变换对频谱进行去相关而获得的。,然后取第一个(最重要的)系数。隐马尔可夫模型将倾向于在每个状态中具有对角协方差高斯的混合的统计分布,这将给出每个观察向量的可能性。每个单词,或(对于更一般的语音识别系统),每个音素,将具有不同的输出分布; 通过将单独训练的隐马尔可夫模型连接成单独的单词和音素,制作用于一系列单词或音素的隐马尔可夫模型。
以上描述的是最常见的基于HMM的语音识别方法的核心要素。现代语音识别系统使用多种标准技术的各种组合,以便改进上述基本方法的结果。典型的大词汇系统需要音素的上下文依赖(因此具有不同左右上下文的音素具有与HMM状态不同的实现); 它会使用倒谱归一化来规范不同的扬声器和录音条件; 对于进一步的说话者归一化,它可能使用声道长度归一化(VTLN)进行男性女性归一化和最大似然线性回归(MLLR)用于更一般的演讲者改编。这些特征将具有所谓的delta和delta-delta系数以捕获语音动态,此外还可以使用异方差线性判别分析(HLDA); 或者可以跳过delta和delta-delta系数并使用拼接和基于LDA的投影,然后可能是异方差线性判别分析或全局半连接协方差变换(也称为最大似然线性变换),或MLLT)。许多系统使用所谓的判别训练技术,其省去了对HMM参数估计的纯粹统计方法,而是优化了训练数据的一些与分类相关的测量。示例是最大互信息(MMI),最小分类错误(MCE)和最小电话错误(MPE)。
(2)基于动态时间规整(DTW)
动态时间扭曲是一种历史上用于语音识别的方法,但现在已经被更成功的基于HMM的方法取代。
动态时间扭曲是用于测量可能在时间或速度上变化的两个序列之间的相似性的算法。例如,即使在一个视频中人们正在缓慢行走而在另一个视频中他或她走得更快,或者即使在一次观察的过程中存在加速和减速,也会检测到行走模式的相似性。DTW已应用于视频,音频和图形 - 实际上,任何可以转换为线性表示的数据都可以使用DTW进行分析。
一个众所周知的应用是自动语音识别,以应对不同的语速。通常,它是一种允许计算机在具有某些限制的两个给定序列(例如,时间序列)之间找到最佳匹配的方法。也就是说,序列被非线性地“扭曲”以彼此匹配。该序列比对方法通常用于隐马尔可夫模型的上下文中。
(3)神经网络
在20世纪80年代后期,神经网络在ASR中成为一种有吸引力的声学建模方法。从那时起,神经网络已被用于语音识别的许多方面,例如音素分类, 58 .孤立词识别, 59 .视听语音识别,视听说话人识别和说话者适应。
与HMM相比,神经网络对特征统计特性的显式假设较少,并且具有多种特性使其成为语音识别的有吸引力的识别模型。当用于估计语音特征片段的概率时,神经网络允许以自然且有效的方式进行辨别训练。然而,尽管它们在分类短时间单位(如个体音素和孤立单词)方面有效, 60 .,早期神经网络很难成功进行连续识别任务,因为它们对时间依赖性建模的能力有限。
这种限制的一种方法是在基于HMM的识别之前使用神经网络作为预处理,特征变换或维数减少 61 .步骤。然而,最近,LSTM和相关的递归神经网络(RNNs) 33 . 37 . 62 . 63 .和时间延迟神经网络(TDNN) 64 .已经证明了该领域的改进性能。
(4)深度前馈和递归神经网
深度神经网络和去噪自动编码器 65 .也正在研究中。深度前馈神经网络(DNN)是一种人工神经网络,在输入和输出层之间具有多个隐藏的单元层。 40 .与浅层神经网络类似,DNN可以模拟复杂的非线性关系。DNN架构生成组合模型,其中额外的层使得能够从较低层构成特征,从而提供巨大的学习能力,从而具有对复杂的语音数据模型进行建模的潜力。 66 .
2010年,工业研究人员与学术研究人员合作,在大词汇量语音识别中成功发展了DNN,其中采用了基于决策树构建的依赖于上下文的HMM状态的DNN的大输出层。 67 . 68 . 69 .参见微软研究院最近的Springer一书,了解截至2014年10月对这一发展和现有技术的全面评论。 70 .另见最近概述文章中自动语音识别的相关背景和各种机器学习范例的影响,特别是包括深度学习。 71 . 72 .
深度学习的一个基本原则是取消手工制作的特征工程并使用原始特征。这一原理首先在“原始”光谱图或线性滤波器组特征的深度自动编码器架构中成功探索, 73 .显示其优于Mel-Cepstral特征,其包含来自光谱图的固定变换的几个阶段。语音波形的真正“原始”特征最近被证明可以产生出色的大规模语音识别结果。
(5)端到端自动语音识别
1.发展历程:
自2014年以来,对“端到端”ASR的研究兴趣不断增加。传统的基于语音的(即所有基于HMM的模型)方法需要单独的组件和发音,声学和语言模型的训练。端到端模型共同学习语音识别器的所有组件。这很有价值,因为它简化了培训过程和部署过程。例如,所有基于HMM的系统都需要n-gram语言模型,典型的n-gram语言模型通常需要几千兆字节的存储空间,因此在移动设备上部署它们是不切实际的。 75 .因此,谷歌和苹果的现代商用ASR系统(截至2017年)部署在云上,需要网络连接,而不是本地设备。
在终端到终端的ASR的第一个尝试是与联结颞分类(CTC)通过引入基于系统亚历克斯·格雷夫斯的谷歌DeepMind的和纳瓦迪普Jaitly 多伦多大学于2014年 76 .该模型由递归神经网络和CTC层。共同地,RNN-CTC模型一起学习发音和声学模型,但是由于类似于HMM的条件独立性假设,它不能学习语言。因此,CTC模型可以直接学习将语音声学映射到英文字符,但这些模型会产生许多常见的拼写错误,并且必须依靠单独的语言模型来清理成绩单。后来,百度通过极大的数据集扩展了工作,并展示了中文普通话和英语的商业成功。 77 .2016年,牛津大学提出LipNet, 78 .第一个端到端句子级唇读模型,使用时空卷积和RNN-CTC架构,超越了限制语法数据集中的人类水平表现。 79 . Google DeepMind于2018年推出了大规模的CNN-RNN-CTC架构,其性能比人类专家高出6倍。 80 .
基于CTC的模型的替代方法是基于注意力的模型。Chan等人同时引入了基于注意力的ASR模型。的卡耐基梅隆大学和谷歌大脑和Bahdanau等。所述的蒙特利尔大学在2016年 81 . 82 .名为“倾听,参与和拼写”(LAS)的模型,字面上“听”声信号,“注意”信号的不同部分,并且一次“拼写”一个字符的抄本。与基于CTC的模型不同,基于注意力的模型不具有条件独立性假设,并且可以直接学习语音识别器的所有组件,包括发音,声学和语言模型。这意味着,在部署期间,不需要携带语言模型,这使得它在部署到具有有限存储器的应用程序上非常实用。截至2016年底,基于注意力的模型取得了相当大的成功,包括超越CTC模型(有或没有外部语言模型)。 83 .自原始LAS模型以来已经提出了各种扩展。潜在序列分解(LSD)由卡内基梅隆大学,麻省理工学院和谷歌大脑提出,直接发出比英文字符更自然的子词单元; 84 . 牛津大学和Google DeepMind将LAS扩展到“观看,收听,参与和拼写”(WLAS),以处理超越人类表现的唇读。
2.优缺点:
- A.目前的识别部分问题:
- a.对自然语言的识别和理解;就目前而言,NLP的突破还有很多难点,因此也在很大的程度上制约了ASR的发展。
- b.语音信息量大。语音模式不仅对不同的说话人不同,对同一说话人也是不同的,一个说话人在随意说话和认真说话时的语音信息是不同的;
- c.语音的模糊性。说话者在讲话时,不同的词可能听起来是相似的;
- d.单个字母或词、字的语音特性受上下文的影响,以致改变了重音、音调、音量和发音速度等。
- 端到端的模型旨在一步直接实现语音的输入与解码识别,从而不需要繁杂的对齐工作与发音词典制作工作,具有了可以节省大量的前期准备时间的优势,真正的做到数据拿来就可用。
- B.端到端模型的优点:
- a.端到端的模型旨在一步直接实现语音的输入与解码识别,从而不需要繁杂的对齐工作与发音词典制作工作,具有了可以节省大量的前期准备时间的 - 优势,真正的做到数据拿来就可用。
- b.端到端的模型由于不引入传统的音素或词的概念,直接训练音频到文本的模型,可以有效地规避上述难点。
- c.更换识别语言体系时可以利用相同的框架结构直接训练。例如同样的网络结构可以训练包含26个字符的英文模型,也可以训练包含3000个常用汉 - 字的中文模型,甚至可以将中英文的词典直接合在一起,训练一个混合模型。
- d.端到端的模型在预测时的速度更快,对于一个10 秒左右的音频文件,端到端的模型在一块GPU的服务器上仅需0.2秒左右的时间便可给出预测结果。
2、字典:
- 字典是存放所有单词的发音的词典,它的作用是用来连接声学模型和语言模型的。
识别出音素,利用字典,就可以查出单词了。
例如,一个句子可以分成若干个单词相连接,每个单词通过查询发音词典得到该单词发音的音素序列。相邻单词的转移概率可以通过语言模型获得,音素的概率模型可以通过声学模型获得。从而生成了这句话的一个概率模型。
5、语言模型(LM):
如何将识别出的单词,组成有逻辑的句子,如何识别出正确的有歧义的单词,这些就用到语言模型了。
由于语音信号的时变性、噪声和其它一些不稳定因素,单纯靠声学模型无法达到较高的语音识别的准确率。在人类语言中,每一句话的单词直接有密切的联系,这些单词层面的信息可以减少声学模型上的搜索范围,有效地提高识别的准确性,要完成这项任务语言模型是必不可少的,它提供了语言中词之间的上下文信息以及语义信息。
随着统计语言处理方法的发展,统计语言模型成为语音识别中语言处理的主流技术,其中统计语言模型有很多种
- 如
N-Gram语言模型、马尔可夫N元模型(Markov N-gram)、指数模型( Exponential Models)、决策树模型(Decision Tree Models)等。 - 而
N元语言模型是最常被使用的统计语言模型,特别是二元语言模型(bigram)、三元语言模型(trigram)。
6、解码:就是通过声学模型,字典,语言模型对提取特征后的音频数据进行文字输出。
7、语音识别系统基本原理结构:
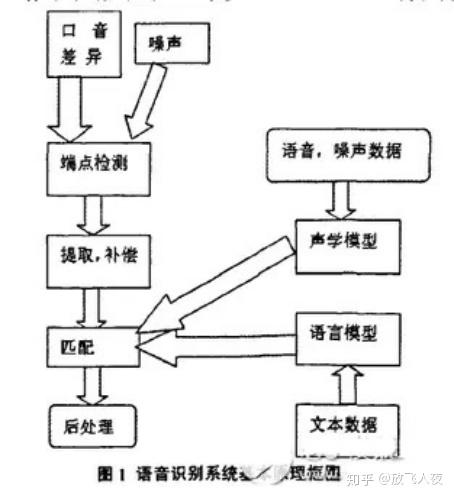
(1)语音识别系统基本原理结构如图所示。
语音识别原理有三点:
- 1)对语音信号中的语言信息编码是按照幅度谱的时间变化来进行;
- 2)由于语音是可以阅读的,也就是说声学信号可以在不考虑说话人说话传达的信息内容的前提下用多个具有区别性的、离散的符号来表示;
- 3)语音的交互是一个认知过程,所以绝对不能与语法、语义和用语规范等方面分裂开来。
五、深度学习进行语音识别
1、机器翻译的工作流程
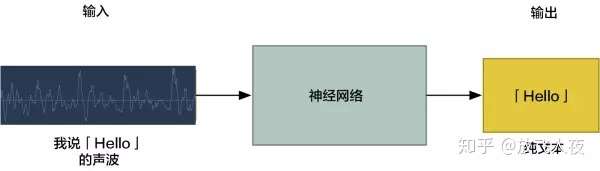
可以简单地将声音送入神经网络中,并训练使之生成文本。
一个大问题是语速不同。一个人可能很快地说出「hello!」而另一个人可能会非常缓慢地说「heeeelllllllllllllooooo!」。这产生了一个更长的声音文件,也产生了更多的数据。这两个声音文件都应该被识别为完全相同的文本「hello!」而事实证明,把各种长度的音频文件自动对齐到一个固定长度的文本是很难的一件事情。
2、声音转换成比特:
声音是作为波(wave) 的形式传播的。如何将声波转换成数字呢?用「hello」这个声音片段举个例子:
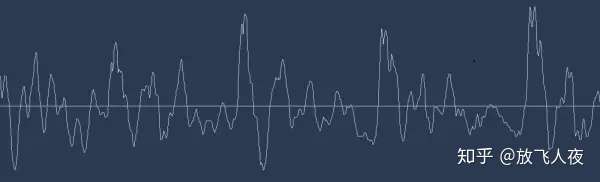
- 「hello」的波形
声波是一维的,在每个时刻都有一个基于其高度的值(声波其实是二维的,有时间,还有振幅(即这个基于高度的值))。把声波的一小部分放大看看:

为了将这个声波转换成数字,只记录声波在等距点的高度:

给声波采样
- 称为
采样(sampling)。每秒读取数千次,并把声波在该时间点的高度用一个数字记录下来。这基本上就是一个未压缩的 .wav 音频文件。 - 「CD 音质」的音频是以 44.1khz(每秒 44100 个读数)进行采样的。
- 但对于语音识别,16khz(每秒 16000 个采样)的采样率就足以覆盖人类语音的频率范围了。
把「Hello」的声波每秒采样 16000 次。这是前 100 个采样:

每个数字表示声波在一秒钟的 16000 分之一处的振幅。
3、数字采样小助手
因为声波采样只是间歇性的读取,可能认为它只是对原始声波进行粗略的近似估计。读数之间有间距,所以必然会丢失数据
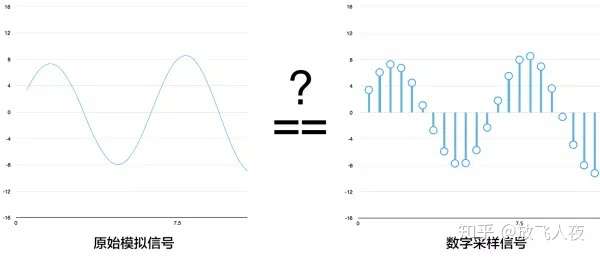
数字采样能否完美重现原始声波?那些间距怎么办?
- 由于采样定理,可以利用数学从间隔的采样中完美重建原始声波——只要采样频率比期望得到的最高频率快至少两倍就行。
- 几乎每个人都会犯这个错误,并误认为使用更高的采样率总是会获得更好的音频质量。其实并不是。
4、预处理采样的声音数据
现在有一个数列,其中每个数字代表 1/16000 秒的声波振幅。把这些数字输入到神经网络中,但是试图直接分析这些采样来进行语音识别仍然很困难。相反,通过对音频数据进行一些预处理来使问题变得更容易。
首先将采样音频分成每份 20 毫秒长的音频块。这是第一个 20 毫秒的音频(即我们的前 320 个采样):
将这些数字绘制为简单的折线图,就得到了这 20 毫秒内原始声波的大致形状:
虽然这段录音只有 1/50 秒的长度,但即使是这样短暂的录音,也是由不同频率的声音复杂地组合在一起的。其中有一些低音,一些中音,甚至有几处高音。但总的来说,就是这些不同频率的声音混合在一起,才组成了人类的语音。
为了使这个数据更容易被神经网络处理,将把这个复杂的声波分解成一个个组成部分。将分离低音部分,再分离下一个最低音的部分,以此类推。然后将(从低到高)每个频段(frequency band)中的能量相加,就为各个类别的音频片段创建了一个指纹(fingerprint)。
想象你有一段某人在钢琴上演奏 C 大调和弦的录音。这个声音是由三个音符组合而成的:C、E 和 G。它们混合在一起组成了一个复杂的声音。把这个复杂的声音分解成单独的音符,以此来分辨 C、E 和 G。这和语音识别是一样的道理。
- 傅里叶变换**(FourierTransform)来做到这一点。它将复杂的声波分解为简单的声波。一旦有了这些单独的声波,就将每一份频段所包含的能量加在一起。
最终得到的结果便是从低音(即低音音符)到高音,每个频率范围的重要程度。以每 50hz 为一个频段的话,我们这 20 毫秒的音频所含有的能量从低频到高频就可以表示为下面的列表:

列表中的每个数字表示那份 50Hz 的频段所含的能量
不过,把它们画成这样的图表会更加清晰

- 在 20 毫秒声音片段中有很多低频能量,然而在更高的频率中并没有太多的能量。这是典型「男性」的声音。
如果对每 20 毫秒的音频块重复这个过程,最终会得到一个频谱图(每一列从左到右都是一个 20 毫秒的块):
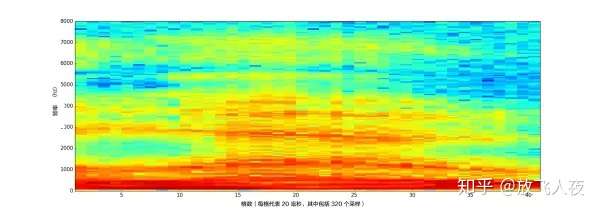
- 「hello」声音剪辑的完整声谱
频谱图很酷,因为在音频数据中实实在在地看到音符和其他音高模式。对于神经网络来说,相比于原始声波,从这种数据中寻找规律要容易得多。因此,这就是将要实际输入到神经网络中去的数据表示方式。
5、短声音识别字符
现在有了格式易于处理的音频,把它输入到深度神经网络中去。神经网络的输入将会是 20 毫秒的音频块。对于每个小的音频切片(audio slice),神经网络都将尝试找出当前正在说的声音所对应的字母。
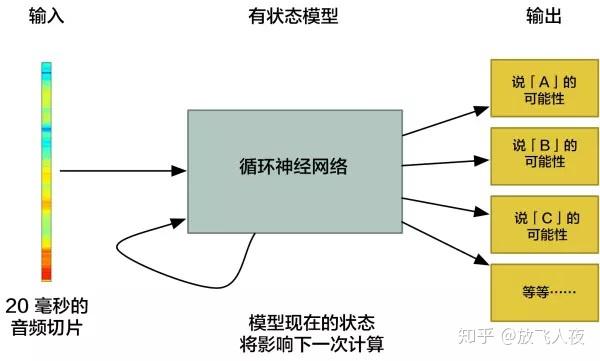
将使用一个循环神经网络——即一个拥有记忆,能影响未来预测的神经网络。这是因为它预测的每个字母都应该能够影响它对下一个字母的预测。
- 例如,如果已经说了「HEL」,那么很有可能接下来会说「LO」来完成「Hello」。不太可能会说「XYZ」之类根本读不出来的东西。
- 因此,具有先前预测的记忆有助于神经网络对未来进行更准确的预测。
当通过神经网络跑完整个音频剪辑(一次一块)之后,将最终得到一份映射(mapping),其中标明了每个音频块和其最有可能对应的字母。这是那句「Hello」所对应的映射的大致图案:

神经网络正在预测那个词
- 很有可能是「HHHEE_LL_LLLOOO」
- 但也可能是「HHHUU_LL_LLLOOO」
- 甚至是「AAAUU_LL_LLLOOO」
可以遵循一些步骤来整理这个输出。
- 首先,将用单个字符替换任何重复的字符:
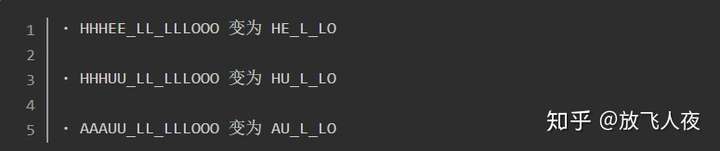
- 然后,将删除所有空白:

这让得到三种可能的转写——「Hello」、「Hullo」和「Aullo」。如果大声说出这些词,所有这些声音都类似于「Hello」。
- 因为神经网络每次只预测一个字符,所以它会得出一些纯粹表示发音的转写。
- 例如,如果说「He would not go」,它可能会给出一个「He wud net go」的转写。
在可能的转写「Hello」、「Hullo」和「Aullo」中,显然「Hello」将更频繁地出现在文本数据库中(更不用说在我们原始的基于音频的训练数据中了),因此它可能就是正解。所以我们会选择「Hello」作为我们的最终结果,而不是其他的转写。
六、语音识别评估标准
在语音识别中,常用的评估标准为词错误率(Word Error Rate,WER)。
上面讲了帧向量识别为单词,需要用声学模型。因为识别出来的整个词序列是混乱的,需要进行替换、删除、插入某些词,使得次序列有序完整。
WER就是反映上述过程的标准,能直接反映识别系统声学模型的性能,也是其他评估指标如句错误率SER的基础。
传统的词错误率评估算法在语音识别中存在三种典型的词错误:
- 1)替换错误(Substitution): 在识别结果中,正确的词被错误的词代替;
- 2)删除错误(Deletion): 在识别结果中,丢失了正确的词;
- 3)插入错误(Insertion): 在识别结果中,增加了一个多余的词;所以,词错误率为:
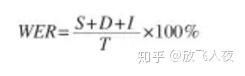
- S 为替代错误词数,D 为删除错误词数,I 为插入错误词数。T为参照句子中的所有词数。
注意
- 因为有插入词,所以WER有可能大于100%。
七、语音识别的关键要素
1 语音激活检测
1、语音激活检测(voice active detection,VAD)
(1)定义:
- 语音激活检测,简称
VAC,是一种用于检查人声的技术,判断什么时候有语音, 什么时候没有语音(静音);解决识别到声音中人的语音的问题,因为有声音但不一定是人的语音。
(2)需求背景:
- 在
近场识别场景,比如使用语音输入法时,用户可以用手按着语音按键说话,结束之后松开,由于近场情况下信噪比(signal to noise ratio, SNR))比较高,信号清晰,简单算法也能做到有效可靠。 - 但
远场识别场景下,用户不能用手接触设备,这时噪声比较大,SNR下降剧烈,必须使用VAD了。
智能音箱在实际使用场景中,一般是放在一个空间内,然后人对他喊话,它进行识别和回应,“喊话 》回应”的过程是一个最小的交互过程。
- 但空间内的声音不单只有你说话的声音,也有其他的声音,比如水龙头的流水声、空调的声音、开水沸腾的声音等等,音箱出于对用户隐私保护和设备功耗的问题,不能实时都让设备处在一个运行的状态(自己猜想、未求证),需要对这些这些声音进行识别,只在有人声的时候才运行对应需要的系统进行处理操作,于是就需要先做“语音激活检测”。
(3)难点:
A. 噪声:开关门的声音、鼓掌、跺脚、宠物叫声,困难的如:电视的声音、多人的交谈声等。
2 语音唤醒
语音唤醒(voice trigger,VT)
(1)定义:
语音唤醒,简称VT,可以理解为喊名字,引起听者的注意。- 上面通过“语音激活检测”技术检测到人的语音后,那是不是所有人的声音都需要进行回应处理呢?答案是NO,因为现实环境中存在
鸡尾酒效应。 - 在吵杂的环境中,一般只会获取到对你说的话,其他人的对话的声音我们会自动屏蔽掉,除非你在偷听旁边的对话,但其实偷听的时候也会屏蔽掉其他的一些声音,但如果这时候有人喊了你名字,你也会马上反应过来,并进行对话回应,这是一个锚定的过程,把你我锚定在你我对话的过程中来,那么后面的对话就都是对你讲的了,那你就会去听他见的每句话。
(2)需求背景:
- 在
近场识别时,用户可以点击按钮后直接说话,但是远场识别时,需要在VAD检测到人声之后,进行语音唤醒,相当于叫这个AI(机器人)的名字,引起ta的注意,比如苹果的“Hey Siri”,Google的“OK Google”,亚马逊Echo的“Alexa”等。
回到智能音箱的场景,周围环境的声音中,有很多人的语音,家里的成员在对话,小孩子在吵闹,电视里的演员在说话,这么多的声音,那么那一句话是我应该去听且进行回应的呢?那么就需要先做“语音唤醒”了,相当于喊人的名字,你需要喊一下智能音箱的名字,让它知道你接下来是在和它说话,然后它才对你说的话做出反应,那么你喊名字后它响应的过程就是“语音唤醒”的过程。
所以每个智能音箱都有一个名字,这有产品拟人化的目的,但更根本的原因是技术上需要有个名字对设备进行“语音唤醒”的过程。
(3)难点:语音识别,不论远场还是进场,都是在云端进行,但是语音唤醒基本是在(设备)本地进行的,要求更高。
- A. 唤醒响应时间:据傅盛说,世界上所有的音箱,除了Echo和他们做的小雅智能音箱能达到1.5秒之外,其他的都在3秒以上。
- B. 功耗要低:iphone 4s出现Siri,但直到iphone 6s之后才允许不接电源的情况下直接喊“hey Siri”进行语音唤醒。这是因为有6s上有一颗专门进行语音激活的低功耗芯片,当然算法和硬件要进行配合,算法也要进行优化。
- C. 唤醒效果:喊它的时候它不答应这叫做漏报,没喊它的时候它跳出来讲话叫做误报。漏报和误报这2个指标,是此消彼长的,比如,如果唤醒词的字数很长,当然误报少,但是漏报会多;如果唤醒词的字数很短,漏报少了,但误报会多,特别如果大半夜的突然唱歌或讲故事,会特别吓人的
- D. 唤醒词:技术上要求,一般最少3个音节。比如“OK google”和“Alexa”有四个音节,“hey Siri”有三个音节;国内的智能音箱,比如小雅,唤醒词是“小雅小雅”,而不能用“小雅”。注:一般产品经理或行业交流时,直接说汉语“语音唤醒”,而英文缩写“VT”,技术人员可能用得多些。
3 低信噪比(signal to noise ratio, SNR)
远场环境要求拾音麦克风的灵敏度高,这样才能在较远的距离下获得有效的音频振幅,同时近场环境下又不能爆音(振幅超过最大量化精度)。这样的环境下,噪音必然会很大,从而使得语音质量变差,即SNR降低。另外作为家庭助手,家庭环境中的墙壁反射形成的混响对语音质量也有不可忽视的影响。
为了对语音信号进行增强,提高语音的SNR,远场语音识别通常都会采用麦克风阵列。
- amazon的echo采用了6+1的设计(环形对称分布6颗,圆心中间有1颗)
- google home目前采用的是2mic的设计。
在算法方面,基于麦克风阵列的波束形成(beamforming)技术已经有很多年的发展,最新的一些论文里有提到使用使用DNN来替代波束形成,实现语音增强。但效果仍然还有很大的提升空间,尤其是背景噪声很大的环境里,如家里开电视、开空调、开电扇,或者是在汽车里面等等。
4 麦克风阵列(Microphone Array)
(1)定义:
- 由一定数目的声学传感器(一般是麦克风)组成,用来对声场的空间特性进行采样并处理的系统。
- 一是由麦克风硬件组成,完成对对声音的的拾取,就是机器的“耳朵”;
- 二是由算法软件组成,对拾取到的原声进行处理,保证输出更清晰,信噪比更高的声音。
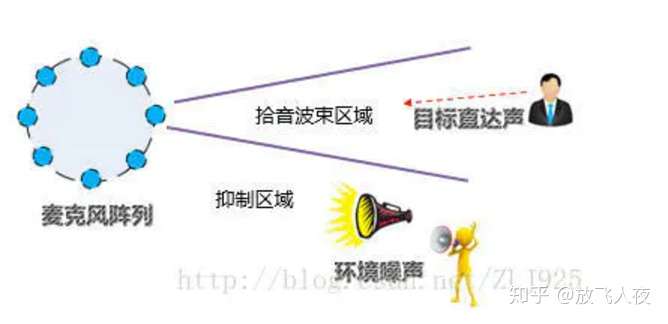
(2)需求背景:
在会议室、户外、商场等各种复杂环境下,会有噪音、混响、人声干扰、回声等各种问题。
- 比如家里的风扇声、脚步声、流水声、小孩玩闹的声音、大人们交谈的声音等,从这么复杂的声音中提炼出目标信号声,使得声音更纯净,噪音更少。
- 应用在人机交互的语音识别场景中,就是从拾取到的声音中提取出来人的语音,最大化去除非其他的噪音,使得处理后输出的声音最大化保证是人的语音。
- 特别是远场环境,要求拾音麦克风的灵敏度高,这样才能在较远的距离下获得有效的音频振幅,同时近场环境下又不能爆音(振幅超过最大量化精度)。
- 另外,家庭环境中的墙壁反射形成的混响对语音质量也有不可忽视的影响。
(3)作用:
- 1)语音增强(Speech Enhancement):当语音信号被各种各样的噪声(包括语音)干扰甚至淹没后,从含噪声的语音信号中提取出纯净语音的过程。
- 2)声源定位(Source Localization):使用麦克风阵列来计算目标说话人的角度和距离,从而实现对目标说话人的跟踪以及后续的语音定向拾取。
- 3)去混响(Dereverberation):声波在室内传播时,要被墙壁、天花板、地板等障碍物形成反射声,并和直达声形成叠加,这种现象称为混响。
混响在语音识别中是个蛮讨厌的因素,混响去除的效果很大程度影响了语音识别的效果。当声源停止发声后,声波在房间内要经过多次反射和吸收,似乎若干个声波混合持续一段时间,这种现象叫做混响。
混响会严重影响语音信号处理,比如互相关函数或者波束主瓣,降低测向精度。
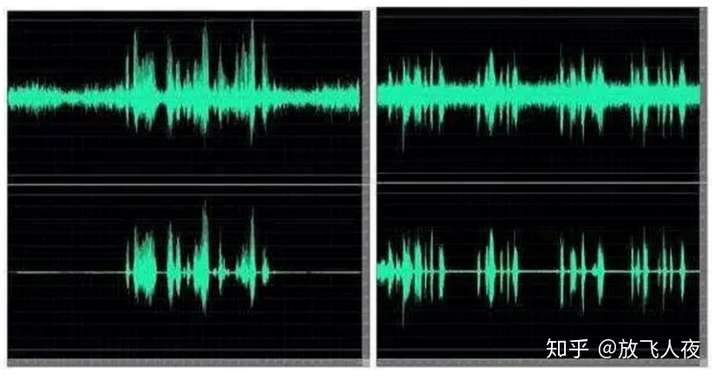
1.利用麦克风阵列去混响的主要方法有以下几种:
- A. 基于盲语音增强的方法(Blind signal enhancement approach),即将混响信号作为普通的加性噪声信号,在这个上面应用语音增强算法。
- B. 基于波束形成的方法(Beamforming based approach),通过将多麦克风对收集的信号进行加权相加,在目标信号的方向形成一个拾音波束,同时衰减来自其他方向的反射声。
- C. 基于逆滤波的方法(An inverse filtering approach),通过麦克风阵列估计房间的房间冲击响应(Room Impulse Response, RIR),设计重构滤波器来补偿来消除混响。
对于汽车来说,车内吸音材料很多,一般混响问题倒不是特别大。
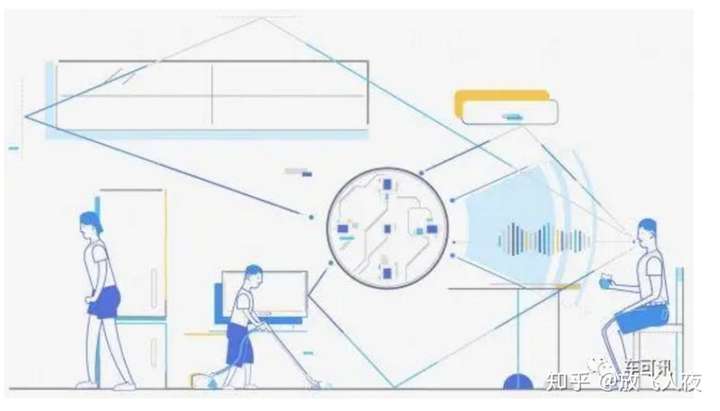
(4)回声抵消:
严格来说,这里不应该叫回声,应该叫“自噪声”。回声是混响的延伸概念,这两者的区别就是回声的时延更长。一般来说,超过100毫秒时延的混响,人类能够明显区分出,似乎一个声音同时出现了两次,我们就叫做回声。
实际上,这里所指的是语音交互设备自己发出的声音,比如Echo音箱,当播放歌曲的时候若叫Alexa,这时候麦克风阵列实际上采集了正在播放的音乐和用户所叫的Alexa声音,显然语音识别无法识别这两类声音。回声抵消就是要去掉其中的音乐信息而只保留用户的人声,之所以叫回声抵消,只是延续大家的习惯而已,其实是不恰当的,在通信的电话机行业,这个叫消侧音。
(5)声源信号提取/分离:
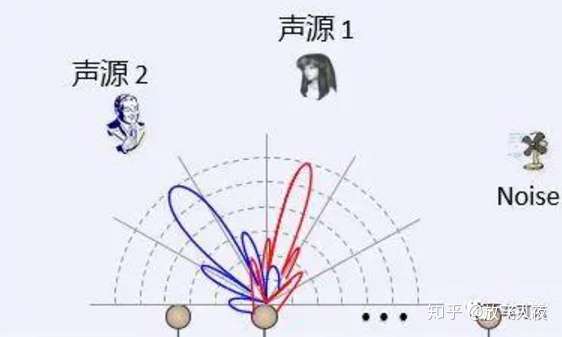
- 声源信号的提取就是从多个声音信号中提取出目标信号,声源信号分离技术则是需要将多个混合声音全部提取出来。
信号的提取和分离主要有以下几种方式:
- (1) 基于波束形成的方法,即通过向不同方向的声源分别形成拾音波束,并且抑制其他方向的声音,来进行语音提取或分离; 这是一种通用的信号处理方法,这里是指将一定几何结构排列的麦克风阵列的各麦克风输出信号经过处理(例如加权、时延、求和等)形成空间指向性的方法。波束形成主要是抑制主瓣以外的声音干扰。
- (2) 基于传统的盲源信号分离的方法进行,主要包括主成分分析和基于独立成分分析的方法。
(6)麦克风阵列的分类:
1)按阵列形状分:线性、环形、球形麦克风。
- 在原理上,三者并无太大区别,只是由于空间构型不同,导致它们可分辨的空间范围也不同。比如,在声源定位上,线性阵列只有一维信息,只能分辨180度;环形阵列是平面阵列,有两维信息,能分辨360度;球性阵列是立体三维空间阵列,有三维信息,能区分360度方位角和180度俯仰角。
2)按麦克风个数分:单麦、双麦、多麦 - 麦克风的个数越多,对说话人的定位精度越高,在嘈杂环境下的拾音质量越高;
- 但如果交互距离不是很远,或者在一般室内的安静环境下,5麦和8麦的定位效果差异不是很大。
傅盛说,全行业能做“6+1”麦克风阵列(环形对称分布6颗,圆心中间有1颗)的公司可能不超过两三家,包括猎户星空(以前行业内叫猎豹机器人)在内。而Google Home目前采用的是2mic的设计。
(7)模型匹配:
- 主要是和语音识别以及语义理解进行匹配,语音交互是一个完整的信号链,从麦克风阵列开始的语音流不可能割裂的存在,必然需要模型匹配在一起。实际上,效果较好的语音交互专用麦克风阵列,通常是两套算法,一套内嵌于硬件实时处理,另外一套是基于该硬件的匹配语音软件处理,还有基于云端的语音识别的深度学习处理。
(8)原理(以车载场景为例):
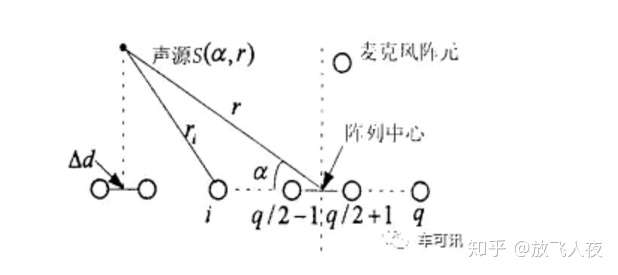
- 因为汽车的拾音距离都比较近,适合使用近场模型。如下图所示是一个简单的基于均匀线阵的近场模型,声波在传播过程中要发生幅度衰减,衰减因子与传播距离成正比。近场模型和远场模型最主要的区别在于是否考虑麦克风阵列各阵元接收信号的幅度差别。下图中,q为麦克风阵元的个数,r为声源到阵列中心(参考点)的距离,α为声源与阵元连线之间的夹角,rn为声源到阵元n的距离,dn为阵元n到参考点的距离,Δd为相邻阵元间距。
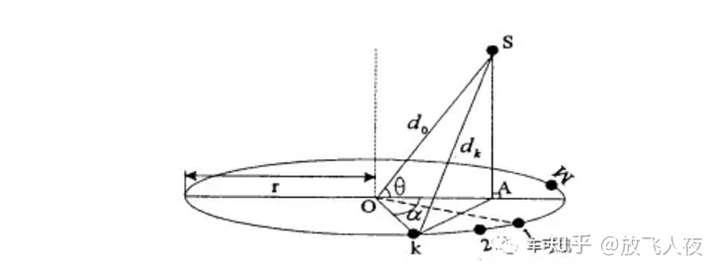
下图为均匀圆阵的近场模型,多个麦克风均匀地排列在一个圆周上,就构成了一个麦克风均匀圆阵列 (UCA)。以UCA中心(圆心O)作为参考点,d0 表示信源S与阵列中心的距离,A为信源到UCA平面的垂足,以OA连线所在的半径为参考线,号麦克风所在半径与OA夹角为Δφθ,表示信号到达方向(SO与参考线的夹角),di(i = 1 ,2 , …, M)表示信源到第个麦克风的距离。
UCA任意两个相邻麦克风对应的圆周角为2π/ M,M为麦克风的个数,如下图所示:

当信源离麦克风阵列较近时,大家熟知的基于平面波前的远场模型不再适用,必须采用更为精确也更为复杂的基于球面波前的近场模型。声波在传播过程中要发生幅度衰减,其幅度衰减因子与传播距离成正比。信源到麦克风阵列各阵元的距离是不同的,因此声波波前到达各阵元时,幅度也是不同的。近场模型和远场模型最主要的区别在于是否考虑麦克风阵列各阵元因接收信号幅度衰减的不同所带来的影响。对于远场模型,信源到各阵元的距离差与整个传播距离相比非常小,可忽略不计;对于近场模型,信源到各阵元的距离差与整个传播距离相比较大,必须考虑各阵元接收信号的幅度差。
具体的算法既要考虑到麦克风阵列各阵元接收信号的相位差,又得考虑到各阵元接收信号的幅度差,从而实现对声源的二维(或三维)定位。根据声源的方位信息,可以使用波束形成技术获得形成一个或多个波束指向感兴趣的声源,从而更好地去噪,完成对该声源信号的提取和分离。由于可以利用的方位信息是二维的,因此,相应的波束具有二维特性。即除了对某一方向的信号有增强作用外,还能对同一方向、不同距离的信号有选择作用,这对于背景噪声和回声消除是非常有用的。
下图为一个实际算法的仿真结果,可以看到,声源相对于参考点,它的角度和距离都相当清晰可辨:

(9)现状:
当前成熟的麦克风阵列的主要包括:讯飞的2麦、4麦和6麦方案,思必驰的6+1麦方案,云知声(科胜讯)的2麦方案,以及声智科技的单麦、2麦阵列、4(+1)麦阵列、6(+1)麦阵列和8(+1)麦阵列方案,其他家也有麦克风阵列的硬件方案,但是缺乏前端算法和云端识别的优化。由于各家算法原理的不同,有些阵列方案可以由用户自主选用中间的麦克风,这样更利于用户进行ID设计。其中,2个以上的麦克风阵列又分为线形和环形两种主流结构,而2麦的阵列则又有同边和前后两种结构。
从汽车的整体结构来看,选用多麦是可行和必须的,至少6麦以上为好,每个前后每个座位处可以各放置1个,前端中控上可以放置1至2个(司机可多1个,另一个可以单独用来指向性收集噪声用来消噪),中部的扶手置物盒处可以放置1个,这样下来定位、消噪、消回声都能比较好的解决。
(10)未来趋势:
- 1)声学的非线性处理研究:现在的算法基本忽略了非线性效应,所以当前麦克风阵列的基本原理和模型方面就存在较大的局限,今后在非线性处理方面会有比较深入的研究。
- 2)麦克风阵列的小型化:现今的麦克风阵列受制于半波长理论的限制,现在的口径还是较大,借鉴雷达领域的合成孔径方法,麦克风阵列可以做的更小。
- 3)麦克风阵列的低成本化:随着近年来新技术的应用,多麦克风阵列的成本下降将会非常明显。
- 4)多人声的处理和识别:现在的麦克风阵列和语音识别还都是单人识别模式,对于人耳的鸡尾酒会效应(人耳可以在嘈杂的环境中分辨想要的声音,并且能够同时识别多人说话的声音),随着深度学习的研究深入和应用普及,这方面应该会有较大突破。
5)结论
总之,语音操作时代已经来临,尤其在于车机方面,已经要成为标配了,但是由于各个应用和底层系统之间的接口问题,比如采用的基础语音识别厂家不一、各个应用的语音命令可能冲突或不支持语音、进而车机整体层面语音命令混乱,从而导致语音操作还不具有统一标准,在实际使用中问题层出不穷。
这个问题可能需要等到各大原车厂意识到之后,统一指定语音识别的底层基础厂商,统一指定上层应用厂商的语音命令,进一步的统一控制和调度各个应用的语音命令之后才可能带来体验很好的语音操作。后装市场还没有哪家有实力和号召力实现这三个统一,所以目前国内还看不到很好用的语音操作车机。
5 全双工通讯模式
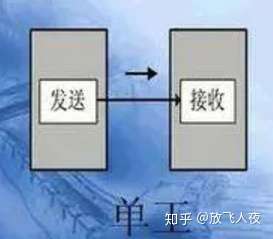
(1)单双工:单向通讯,只能往固定的方向做通讯,只有一条通讯通道,不能逆向通讯,如电视、广播;
- 光头强:熊大,二货….
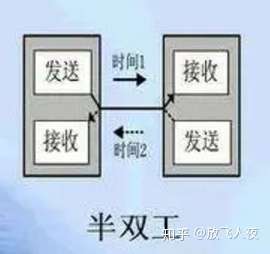
(2)半双工:可双向通讯,但同时只能往一个方向进行通讯,虽然只有一条通讯通道,但却可逆向通讯,如对讲机,必须一个人讲完,另一个人才能讲话;
- 光头强:熊大,你屁股着火了,over;
- 熊大:光头强你又骗我,我一巴掌呼死你,over。
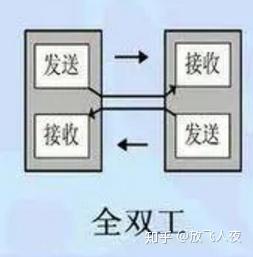
(3)全双工通讯:可即时双向通讯,通讯双方的信息可实时传送给对方,会有两条通讯通道,每一条通道负责一个方向的通讯,例如手机通讯。
- 光头强:熊大,过来呀,造作呀;
- 熊大:死秃驴,来呀,我一屁股坐死你
- 光头强:来呀,来呀,打不到我吧…….
(4)特征:
人声检测、智能断句、拒识(无效的语音和无关说话内容)和回声消除(Echo Cancelling,在播放的同时可以拾音)
特别说下回声消除的需求背景:近场环境下,播放音乐或是语音播报的时候可以按键停止这些,但远场环境下,远端扬声器播放的音乐会回传给近端麦克风,此时就需要有效的回声消除算法来抑制远端信号的干扰。
5 自动纠错
(1)定义:语音交互中还有一个重要的技术是自动纠错,就是当说错了某个词,或者是发音不准确,说话带地方口音等情况下,系统能够自动纠正过来,能听懂你说的话,并给出正确的回应。
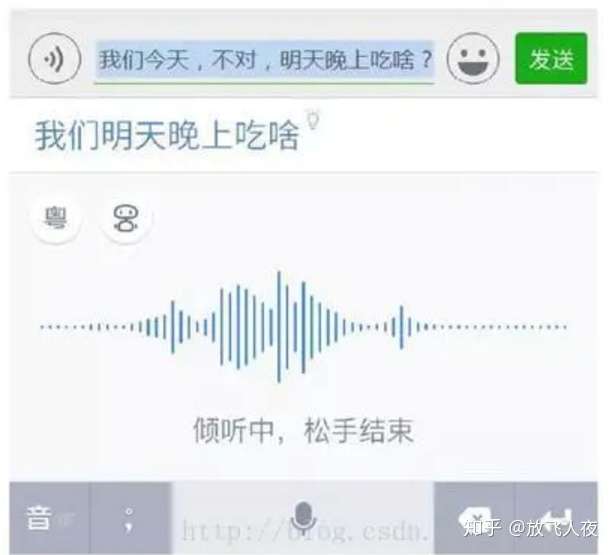
(2)用户主动纠错:
比如用户语音说“我们今天,不对,明天晚上吃啥?”,经过云端的自然语言理解过程,可以直接显示用户真正希望的结果“我们明天晚上吃啥”。
(3)根据场景/功能领域不同,AI来主动纠错。
根据纠错目标数据的来源,可以进一步划分为3种:
- 1)本地为主。
- 比如,打电话功能。我们一位联合创始人名字叫郭家,如果说“打电话给guo jia时”,一般语音识别默认出现的肯定是“国家”,但(手机)本地会有通讯录,所以可以根据拼音,优先在通讯录中寻找更匹配(相似度较高)的名字——郭家。就显示为“打电话给郭家”。
- 比较个性的个人信息,只存储于本地中的数据应用场景,例如手机通讯录、常用系统/网站等~,比如“打开weixin”,很大程度可能会被理解成“卫星”,但当手机中有“微信”这个APP时,优先拿本地的APP列表进行纠正,这时候就就会很高概率理解成“微信”了。
- 2)本地+云端。
- 对本地纠错的补充,如果但本地数据匹配不到合适的对象时,自动转向云端数据库去匹配更合适的对象,或者是按照本地数据和云端数据匹配到对应对象后进行排序呈现,使用本地数据匹配的结果优先呈现,如你说要要听某首歌,优先找到你本地收藏的歌曲,再去匹配云端数据相似的歌曲名,最后做一个排序呈现。
- 比如,音乐功能。用户说,“我想听XX(歌曲名称)”时,可以优先在本地的音乐库中去找相似度较高的歌曲名称,然后到云端曲库去找,最后再合在一起(排序)。
之前实际测试中发现过的“纠错例子”包括:
夜半小夜曲 —> 月半小夜曲
让我轻轻地告诉你 —> 让我轻轻的告诉你
他说 —> 她说
望凝眉 —> 枉凝眉
一听要幸福 —> 一定要幸福
苦啥 —> 哭砂
鸽子是个传说 —> 哥只是个传说
- 3)云端为主
- 对于数据量较大,或者实时性较高的业务场景,不适合存储在本地,会存储在云端,纠错时调用云端数据进行纠正,如地图、天气预报等业务,比如说“查询xinjiang2019年1月12日的天气”,知道是天气业务,所以到云端去匹配“xinjiang”的地方,匹配到最后的结果就会是“新疆”,于是去调新疆2019年1月12日的天气情况,通过语音合成技术(TTS)合成语音,并说给你听。
比如地图功能,由于POI(Point of Interest,兴趣点,指地理位置数据)数据量太大,直接到云端搜索可能更方便(除非是“家”、“公司”等个性化场景)。比如,用户说“从武汉火车站到东福”,可以被纠正为“从武汉火车站到东湖”。
八、语音识别的瓶颈
总结:
- 1、鲁棒性:目前的语音识别系统对环境条件的依赖性强, 要求保持测试条件和训练条件一致, 否则系统性能会严重下降。
- 2、噪声问题:现有的语音识别系统大多只能工作在安静的环境下, 一旦在噪声环境下工作, 讲话人产生情绪或心理上的变化, 导致发音失真、发音速度和音调改变, 即产生Lombard 效应或Loud 效应。常用的抑制噪声的方法, 可以概括为四个方面:谱减法、环
境规整技术、不修正语音信号而是修正识别器模型使之适合噪声、建立噪声模型。 - 3、语音识别基元选择:如何根据存贮空间和搜索速度的要求, 选择合适的识别单元, 如词、音节、音素。一般来讲, 要识别的词汇量越多, 所用的基元应越小越好。
- 4、端点监测:研究表明, 即使在安静的环境下,语音识别系统一半以上的识别错误来自端点监测器。提高端点检测技术的关键在于寻找稳定的语音参数。
- 5、低信噪比(signal to noise ratio, SNR)和 混响 (Reverberation)。远场环境要求拾音麦克风的灵敏度高,这样才能在较远的距离下获得有效的音频振幅,同时近场环境下又不能爆音(振幅超过最大量化精度)。这样的环境下,噪音必然会很大,从而使得语音质量变差,即SNR降低。另外作为家庭助手,家庭环境中的墙壁反射形成的混响对语音质量也有不可忽视的影响。为了对语音信号进行增强,提高语音的SNR,远场语音识别通常都会采用麦克风阵列。amazon的echo采用了6+1的设计(环形对称分布6颗,圆心中间有1颗),google home目前采用的是2mic的设计。在算法方面,基于麦克风阵列的波束形成(beamforming)技术已经有很多年的发展,最新的一些论文里有提到使用使用DNN来替代波束形成,实现语音增强。但效果仍然还有很大的提升空间,尤其是背景噪声很大的环境里,如家里开电视、开空调、开电扇,或者是在汽车里面等等。
- 6、远场语音识别(声学与麦克风阵列)
(1)多通道同步采集硬件研发:
- 多通道麦克风阵列技术已经被证明可以显著提升语音识别质量。当信号采集通道数足够多时,需要额外研发多通道同步技术。并且,目前消费电子上很少有集成多个麦克风的情况,相关研究成果很少,这也增加了该硬件方案的研发难度。
(2)前端麦克风阵列信号处理算法研发:
- 远场语音识别主要面临着回声干扰、室内混响、多信号源干扰以及非平稳噪声的干扰等。关于语音增强方面,目前存在着两个主要的技术流派:一派认为利用深度学习的方法可以实现去混响、降噪声的目的。另外一派则采用基于麦克风阵列的传统信号处理方法。从目前的产品上看,麦克风阵列信号处理的方式占主流应用市场。例如:Echo采用7个麦克风,叮咚采用8个麦克风, Google home用了2个麦克风。本文主要阐述传统信号处理方法在远场语音识别中所面临的困境。
- 1) 回声干扰:
- 针对回声干扰问题,需采取回声消除技术,将设备自身播放的声音从麦克风接收到的信号中除去。该技术在手持移动端上已经非常成熟,比如speex和webrtc的开源软件中都有该算法。但是,这两个方案为了达到更大的回声抑制效果,使用了大量的非线性处理手段。而语音识别引擎对于语音信号的非线性处理非常敏感。因此,如果直接将近场回声消除技术用在远场语音识别领域,效果并不好。
- 2)房间混响:
- 房间混响是远场语音识别特有的问题。房间混响会造成麦克风接收到的信号有很长的拖尾,让人听起来感觉发闷。在实际中,人耳具有自动解混响的能力,在实际房间中相互交流并没有影响反而觉得声音饱满。但是这个对于语音识别来说是致命的。之前主要是近场识别,对去混响的需求不大,相关的研究内容不多。目前去混响技术主要以逆滤波方法、倒谱平均、谱减法为主,但这类方法对远场语音识别率提升不大。多步线性预测方法在去混响中表现不错,有兴趣的可以尝试一下。
- 3)鸡尾酒会问题(多源信号干扰监测):
- 鸡尾酒会问题(cocktail-party problem )是指有多个说话人情况下的语音识别问题,比如鸡尾酒会上很多人讲话。这种情况下人是有可能听清楚你关注的人在说什么的,当然手势、口型、表情以及聊天话题都会提供帮助。这种环境下的语音识别是相当有挑战的。波束形成技术是解决这个问题的一个有效手段。但是当几个说话人距离比较接近的时候,波束形成也无能为力。这个问题其实在很早以前就有相关的研究,叫做语音分离(speech separation)。有一个接近的名词叫做语音分割(speech segmentation),是指语音没有重叠,一个人说完另外一个人说,需要把语音切分成片段,然后每个片段只包含一个说话人,然后把同一个说话人的语音片段聚类到一起就行了。语音分离相对来说更难一些,是指多个说话人同时说话,语音有重叠,这种情况下将每个人的原始语音恢复出来相当有难度。典型的应用场景有多人会议的语音识别,party中的语音识别等。
语音识别系统需要能够同时跟踪多个声源,且对每个声源都能够单独做处理。例如,对于某个目标源来说,其他信号源都是干扰,必须从接收信号中去除。或者将多个信号源同时进行识别输出,盲源分离需求对语音识别系统提出了巨大的挑战。谷歌在Google IO 2018大会上展示了能够同时识别2个人说话的技术,有兴趣的可以去找找相关的技术文献。
(3)非平稳噪声:
在做波束形成之前需要先知道说话人的方向,这就需要对波达方向进行估计。学术界一般研究如何提高测向的精度和分辨率,但这些指标在实际中意义不大,实际中更需要解决如何在混响条件下提高DOA估计的鲁棒性。知道方向之后,就可以做波束形成,抑制周围的非平稳噪声。麦克风阵列增益和麦克风的数目与间距(满足空间采样定理)成正比,但是由于消费产品价格和尺寸的限制,麦克风的个数和间距有限,这个对算法的设计也提出来新挑战。
(4)语音识别引擎:
语音识别引擎对于语音信号的非线性处理非常敏感。相对于残留的背景噪声来说,语音失真程度对语音识别率起着主要的影响。前端信号处理中的非线性算法可以显著提升我们人耳的听觉效果,但是对于识别来说却会带来致命的影响。所以,对于信号处理的每个流程,我们都要结合前端和后端一起来评估信号处理算法的应用价值。而且,目前做前端和后端的人员往往属于不同的团队,所了解的知识大都有局限性,很难出一套前端后端联合设计的方案。
语音识别引擎要和前端匹配。为了提升远场语音识别性能,需要用远场的语音数据训练声学模型。因为前端的信号处理和后端识别是联合使用的,所以,最佳的方法就是利用麦克风阵列采集的信号经过前端信号处理算法处理后的数据去训练语音识别引擎,效果应该会有大幅提升。同时,远场语音数据库不容易采集,如何通过信道传播模型生成包含干扰的信号来扩充数据库也是亟需研究的问题。
(5)方向思路:
- A.根据后端语音识别需求,重新评估前端信号处理模块的设计要点;
- B.前端和后端进行联合设计,利用后端的神经网络来弥补前端信号处理算法性能不足的问题。尤其是当前端阵列尺寸受到限制,阵列增益有限的情况下;
-
C.目前的识别流程是先处理,再识别。这种方法的性能上界只能由前端和后端算法的性能的上界决定。然而,算法性能提升总是有限的,所以依靠算法去解决人机交互中的各种问题不是永远有效的。是否可以借助事先确定说话人身份的识别机制(识别+合理的猜测)来提升识别效果。
- 7、可靠性有待提高
- 语音智能识别技术必须排除实际应用中各种声学环境对其造成的不良影响。因为在公共场合,人能有意识排除外界噪声来获得自己想要的声音,然而计算机虽已实现智能化,但你不可能指望它在那些嘈杂环境中能够准确捕捉到你的声音,大大限制了该技术的应用范围。所以,若想在嘈杂环境中应用语音智能识别技术,就需要使用特殊抗噪麦克风,但这对于多数用户而言,是不可能实现的;另一方面,日常生活中,人们说话较随意,语言习惯较明显,如带有明显地方口音、经常重复、停顿,或插入,完全不受语法控制等,而这些语音对于经过标准式“朗读语音”存储的设备来讲,是很难识别的。为此,逐步提升语音智能识别技术的可靠性,显得很有必要。
- 8、词汇量有待丰富
- 可以说,语音识别系统可识别词汇量的多少,在很大程度上决定了系统可完成事情的程度,若系统所配置声学模型与语音模型限制较多,当用户所引用词汇不在系统存储范围内时,或是突然从英文转中文、俄文、韩文、日文等语言时,系统很可能出现输入混乱情况。为此,今后伴随系统建模方式的逐步革新、各种搜索计算法效率的逐步提升于与硬件资源的日渐发展,语音智能识别系统很可能实现词汇量无限制与多种语言的混合,这样一来,即便用户使用多种语言,系统也是能准确识别出来的
- 9、成本有待降低,体积有待减小
- 在保证质量的同时,最大限度降低其成本是实现技术商业化发展的关键所在,且普遍通过规模生产形式来实现。但对于语音智能识别技术而言,要想做到降低其成本,还存在较大困难。因为对于那些功能、性能要求较高的应用,多带有“量身定制”的标记,若想规模生产,条件还不是很成熟;只有在那些对功能、性能要求不是很高的语音识别应用上,才有可能规模生产出部分低成本产品,而这些规模产品在实际应用中又可能受到功能与性能的限制[2]。另外,微型化也将是今后语音智能识别技术实现商业化发展的一个重要手段,而要想实现这一点,同该技术本身发展程度与微电子芯片技术发展程度,均有着密切的关系。为此,把那些有着先进性能与完善功能的语音识别借助系统固化到那些更加微小的模块或芯片上,用以最大限度降低成本,也就成为了今后语音智能识别技术真正实现广泛应用的关键所在。
- 10、中英文混合
- 特别在听歌场景,用户说想听某首英文歌时,很容易识别错误的。这方面,只有傅盛的小雅音箱据说做了很多优化,有待用户检验。
九、语音识别的产品分类及场景
1、需求层次
- (1)人与人之间的信息同步:转化成文字的语音信息,由于少了时间轴的约束,在同等量级的情况下,人类使用眼睛获取的速度远远快于耳朵。当然,确实也损失掉了一些信息,比如情绪。
- (2)检索 & 语义抽取:利用语义建模,对某些业务场景中比较关注的词/语义进行检索,或者将其抽取出来并进行结构化记录。
- (3)人机交互:使用更自然的方式与机器/虚拟助理进行交互,实现拟人对话、对设备的操控或者问题答案的获取。
- (4)数据挖掘:通过对数据的聚类或者与各维度数据体系打通,可以对个人/人群/特定领域的语义数据进行价值挖掘。
2、关键概念
(1)离线VS在线
在较多的客户认知中,离/在线的区别在于“识别过程是否需要通过云端请求”,即“识别引擎是在云端还是本地”。而云计算中的离/在线产品的引擎都处在云端,区别在于“计算过程中,客户端是否需要与云端进行实时数据交互”,即上述所述的“流式上传-同步获取”和“已录制音频文件上传-异步获取”方式。
两者的定义在人工智能产品领域中有较多冲突,因此并不建议使用“离/在线”概念进行相关产品定义。
(2)语音识别 VS 语义识别
语音识别为感知智能,语义识别为认知智能,前者为后者的前提基础。语音识别将声音转化成文字,语义识别提取文字中的相关信息和相应意图,再通过云端大脑决策,使用执行模块进行相应的问题回复或者反馈动作。
注:一般来说,为了减少不必要的理解干扰,从业者更倾向于说“自然语言处理(NLP)”等概念,极少使用“语义识别”的说法。
1、产品分类
(1)封闭域识别
1)识别范围:
预先指定的字/词集合,即,算法只在开发者预先设定的封闭域识别词的集合内进行语音识别,对范围之外的语音会拒识。因此,可将其声学模型和语言模型进行裁剪,使得识别引擎的运算量变小;并且,可将引擎封到嵌入式芯片或者本地化的SDK中,从而使识别过程完全脱离云端,摆脱对网络的依赖,并且不会影响识别率。
业界厂商提供的引擎部署方式包括云端和本地化(如:芯片,模块和纯软件SDK)。
2)产品形态:流式传输-同步获取
典型的应用场景:不涉及到多轮交互和多种语义说法的场景,比如,对于简单指令交互的智能家居和电视盒子,语音控制指令一般只有“打开窗帘”、“打开中央台”等;或者语音唤醒功能“Alexa”。但是,一旦涉及到程序猿大大们在后台配置识别词集合之外的命令,如“给小编来一块钱打赏呗”,识别系统将拒识这段语音,不会返回相应的文字结果,更不会做相应的回复或者指令动作。
(2)开放域识别:
- 1)识别范围:无需预先指定识别词集合,算法将在整个语言大集合范围中进行识别。为适应此类场景,声学模型和语音模型一般都比较大,引擎运算量也较大。将其封装到嵌入式芯片或者本地化的SDK中,耗能较高并且影响识别效果。业界厂商基本上都以云端形式提供,云端包括公有云形式和私有云形式。本地化形式只有带服务器级别计算能力的嵌入式系统,如会议字幕系统。
- 2)产品形态:按照音频录入和记过获取方式分为3种
1、流式上传-同步获取:
应用/软件会对说话人的语音进行自动录制,并将其连续上传至云端,说话人在说完话的同时能实时地看到返回的文字。
语音云服务厂商的产品接口中,会提供音频录制接口和格式编码算法,供客户端边录制边上传,并与云端建立长连接,同步监听并获取中间(或者最终完整)的识别结果。
对于时长的限制,由语音云服务厂商自定义,一般有<1分钟和<5小时两种,两者有可能会采用不同的模型(时长限制<5小时的模型会采用LSTM长时相关性建模)。
应用场景:
- A)主要在输入场景,如输入法、会议/法院庭审时的实时字幕上屏;
- B)与麦克风阵列和语义结合的人机交互场景,如具备更自然交互形态的智能音响。比如用户说“转发小编这篇文章”,在无配置的情况下,识别系统也能够识别这段语音,并返回相应的文字结果。
2、已录制音频文件上传-异步获取:
音频时长一般<3/5小时。用户需自行调用软件接口或是硬件平台预先录制好规定格式的音频,并使用语音云服务厂商提供的接口进行音频上传,上传完成之后便可以断掉连接。用户通过轮询语音云服务器或者使用回调接口进行结果获取。
由于长语音的计算量较大,计算时间较长,因此采取异步获取的方式可以避免由于网络问题带来的结果丢失。也因为语音转写系统通常是非实时处理的,这种工程形态也给了识别算法更多的时间进行多遍解码。而长时的语料,也给了算法使用更长时的信息进行长短期记忆网络建模。在同样的输入音频下,此类型产品形态牺牲了一部分实时率,花费了更高的资源消耗,但是却可以得到最高的识别率。在时间允许的使用场景下,“非实时已录制音频转写”无疑是最推荐的产品形态。
应用场景:
- A)已经录制完毕的音/视频字幕配置;
- B)实时性要求不高的客服语音质检和UGC语音内容审查场景等。
3、已录制音频文件上传-同步获取:
音频时长一般小于<1分钟。用户需自行预先录制好规定格式的音频,并使用语音云服务厂商提供的接口进行音频上传。此时,客户端与云端建立长连接,同步监听并一次性获取完整的识别结果。使用的模型会根据语音云厂商产品策略的不同,而跟随采用上述两/三种模型中的任意一种。
应用场景:作为前两者的补充,适用于无法用音频录制接口进行实时音频流上传,或者结果获取的实时性要求比较高的场景。
3)产品类型按照说话风格的特点分为两种:
- 1.语音听写:语音时长较短(<1min),一般情况下均为一句话。训练语料为朗读风格,语速较为平均。一般为人机对话场景,录音质量较好。
按照音频录入和结果获取方式定义产品形态:
- (a)流式上传-同步获取,应用/软件会对说话人的语音进行自动录制并将其连续上传至云端,说话人在说完话的同时能实时地看到返回的文字。语音云服务厂商的产品接口中会提供音频录制接口和格式编码算法,供客户端进行边录制边上传,并与云端建立长连接,同步监听并获取识别结果。
- (b)已录制音频文件上传-同步获取,用户需自行预先录制好规定格式的音频,并使用语音云服务厂商提供的接口进行音频上传,客户端与云端的连接和结果获取方式与上述音频流类似。
典型应用场景:应用发展已经比较成熟:主要在输入场景,如输入法;与麦克风阵列和语义结合的人机交互场景,如具备更自然交互形态的智能音响,如“叮咚叮咚,转发小编这篇文章。”,在无配置的情况下,识别系统也能够识别这段语音,返回相应的文字结果。
- 2.语音转写:语音时长一般较长(五小时内),句子较多。训练语料为交谈风格,即说话人说话无组织性比较强,因此语速较不平均,吞字&连字现象较多。录音大多为远场或带噪的。
除了模型不同之外,按照音频录入和结果获取方式定义产品形态:
- (a)音频流转写:流式上传-同步获取,与上述语音听写类似,唯一不同的是,识别的时长不会有一句话的限制。
- (b)非实时已录制音频转写:已录制音频文件上传-异步获取,用户需自行调用软件接口或者是硬件平台预先录制好规定格式的音频,并使用语音云服务厂商提供的接口进行音频上传,上传完成之后便可以断掉连接。用户通过轮询语音云服务器或者使用回调接口进行结果获取。

4、落地场景分析
(1)智能客服领域
1)智能外呼和呼入
现在,减员增效,用机器人来代替人工。银行信用卡逾期账单催收,欠款催缴,保险、信贷产品电话销售,以及股票、理财产品电话营销等运用范畴,已经都引入智能外呼机器人,已被应用于金融营销、保险、回访、催收等各个环节,不仅为金融机构节省了许多的人力投入,更大幅提升了金融营销成果和不良资产处理效果。
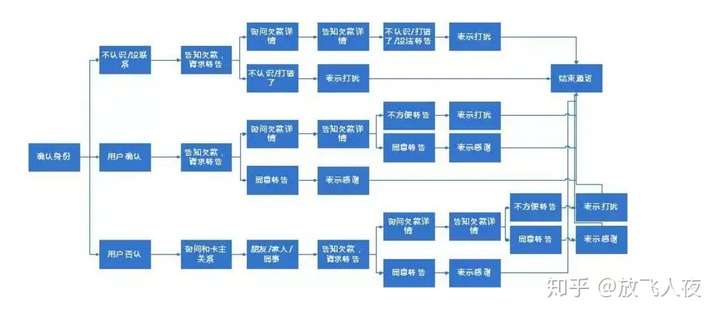
2)智能质检
传统人工质检:以人工听录音进行质检评分
缺点:
- 01 人工成本高,工作满意度低
- 首先,在新经济环境下,业务增长,人力成本也随之增长。但是对质检员来来说,他们提供的服务都是重复性多,工作成就感低,强度大,加班待遇低等等,这样的工作性质迫使质检岗位流动性高,服务满意度低。
- 再加上质检岗位招聘难、培训成本高,这也让企业抓耳挠腮,进退两难。
- 02 质检覆盖率较低,精确度较差
- 其次,人工质检由于客观因素限制,一般通过随机抽检的方式,在员工大量的服务工单里,只能对业务服务内容进行快速抽验、复核。而受限于随机抽检的方式,使得质检漏检率较高,不能做到100%全业务覆盖。
- 03 工作效率低,且受主观影响
- 再者,质检效果更受限于质检人员的自身的主观思维和专业判断,使得不同的质检人员检验、督查的标准难以统一,存在差异化,从而也导致了业务质检结果不够客观准确。
- 04 质检延时,难及时发现问题
- 然后,人工质检一般是第二天甚至更晚对前一天发生的业务文件进行抽检,这种事后定期抽检的方式使客户业务办理进度慢,无法在事件发生的第一时间定位到问题,更无法对风险进行及时应对。
- 05 缺乏质检工具,数据汇总难
- 最后,传统的质检方式不仅基于人工抽检来进行,质检结果更依赖于传统的表格工具来实现数据汇总。而表格工具的操作不仅过于繁琐、整理速度慢,且还不易于精准查询,统计分析的效果更为不佳。
嵌入 ASR的智能质检系统:一般是将线上的语音进行ASR的转写,再搭配NLP组合形成的多种智能质检形式。大大的解放了人工的劳力。
优点:
- 01 大幅降本提效:用AI替代庞大的质检团队,大幅度降低金融企业质检人员运营成本,同时有效提交质检效率;
- 02 质检模式丰富:支持实时质检、事中质检、事后质检等多种质检模式,满足企业质检业务多样性要求,提高质检效率;
- 03 质检零延时:支持业务办理同时进行及时质检,第一时间发现问题,检测敏感信息,马上处理;
- 04 质检标准统一:运用AI等先进技术代替人工质检,智能质检由机器完成,标准统一,更符合监管留痕。
3)智能辅助和培训
智能辅助和智能培训市面上的应用场景可能没有上面的两个场景广。
- A.智能辅助:
- 在线人工座席解疑答惑中,在人工座席需要大批量的文字进行回复客户的问题时,在面临不同场景的话术及流程时,客服可能需要提前准备好相应的话术或者背下相关问题的解答方法,因此十分的不方便,也对坐席的个人能力要求甚高,至少随时应变能力和记忆能力提出了较高的门槛。
- 在上述场景下,应运而生的智能辅助,在实时的语音流识别中,将转写的文字,再利用NLP进行分析理解,进而调取知识库文档库中的答案,呈现给坐席,让坐席根据实际情况进行回答。
- B.智能培训:
- 在银行,运营商等大型的呼叫中心以及拥有大量客服团队的互联网企业(滴滴,58同城,OAT),由于人工坐席的流动量巨大,且不同场景不同行业的话术以及流程都差别巨大的情况下,一个熟练的坐席客服人员的培训,是长期且漫长的老带新路程。
- 在这种场景下,智能培训整合ASR、TTS、NLP等人工智能技术,模拟客户实时询问来进行培训在线客服人员的综合业务能力。
- 难点:网络的延时性,语音流转写的快慢,中英文转写的准确,nlp的匹配是否正确等。
- 趋势:未来智能外呼、智能质检、以及智能辅助和培训等系统将进行整合成一套平台的客服系统,对于客服人员的培训、质检、外呼等综合考评将越来越智能,在不断的优化过程中,企业对于人工坐席的依赖性将逐步的降低。
(2)智能家居
据相关资料显示,语音识别技术发展至今已走过70 多个年头。从最初只能识别几个英文字母的Audry系统,到现在能够进行即兴对话、语音交互的Siri,再到用户打开家门对着空气喊一句“打开空调”、“打开电视”或“打开窗帘”等智能语音识别技术的使用,不知道你是否有和小编一样的体会:智能语音技术已经不知不觉包围了我们的生活。
很多业内人士认为,智能语音技术与家居生活场景、智能硬件的结合会成为未来智能生活的大趋势。
(3)车载助手
作为主要的语音交互场景,也是未来的热门话题之一,现如今已经大行其道,而其中的交互入口正是依赖于语音识别的输入,从而完成人机的交互。
十、语音识别公司盘点
1、国外语音交互识别供应商
(1)Nuance
Nuance全球最大的语音技术公司,超1000项专利技术。目前世界上最先进的电脑语音识别软件Naturally Speaking就出自于Nuance公司。用户对着麦克风说话,屏幕上就会显示出说话的内容。T9智能文字输入法作为旗舰产品,最大优势支持超过70种语言,超过30亿部移动设备内置T9输入法。已成为业内认同的标准输入法,被众多OEM厂商内置,包括诺基亚、索爱、三星、LG、夏普、海尔、华为等等。T9全球市场占有率超70%,中国超50%;
Nuance的产品提供人性化、高效率的电话口语或语言辨识功能,消费者可透过传统的电话系统或行动电话以自然口语交谈的方式完成资料查询及商业贸易,使用轻松。在类似的产品中拥有最高的语音辨识率,英文可达99%。其英文语音产品Dragon NaturallySpeaking9在法律和医院临床记录占据很大市场;
Nuance是全球最大的语音识别技术公司,这十几年里,其经历了无数次起起落落:曾被苹果、Google、三星捧在手上,被绝大多数语音公司为之朝贡。之后却连连遭遇市值暴跌、技术瓶颈、客户流失、离职潮、错过最佳出售时间等,最终不得不从只专注纵向深耕算法的技术提供商转型为横向扩展各行业解决方案的公司。
(2)微软
提到微软在语音交互的布局,不得不说起微软两姐妹,小冰和小娜。微软现在有三款聊天机器人,主打情感计算的小冰、主打商务助理的小娜,还有在垂直领域的深度应用智能客服。
微软过去几十年做的人工智能方面的研发集成到Azure云上去,Azure云支持IoT、Bot Framework,第三方用微软的人工智能技术,已经可以通过Bot Framework、Azure IoT等来做。
Azure云可以实现更多的事情,像语音识别、语言理解、机器翻译、语音合成。
(3)Sensory
Sensory 致力于改善用户体验通过嵌入式机器学习技术,如语音、视觉、和自然语言处理。开发、生产高性价比的语音识别产品。二十多年前公司的创立者开发了第一个语音合成芯片,率先将音频技术应用到PC机和消费电子产品中。
Sensor的技术从数以百计的出货量在20亿产品领先的消费电子产品制造商包括丙氨酸,孩之宝,华为,谷歌,JVC,LG、摩托罗拉、美泰公司Plantronics,三星、索尼、世嘉,Uniden,V-Tech。感觉有超过35发布专利覆盖语音识别在消费电子,生物认证,传感器/语音组合,语音识别在DSP的,客户端/云使用语音技术等等。
(4)谷歌
Google一直致力于投资语音技术,此前收购多家语音识别技术公司及专利。
2011年,收购语音通信技术公司 SayNow 和语音合成技术 Phonetic Arts。 2014年收购SR Tech Group的多项语音识别相关的专利,其中包括 “ 搜索引擎语音界面” 和 “ 修改、更新语音识别项目系统” 的专利。
今年4月份Google还开放了自己的语音识别API,即Google 语音搜索和语音输入的支持技术。Google Cloud SPeech API包括了80多种语言,适用于各种实时语音识别与翻译应用。
2017年,谷歌宣布了用于语音交互的Actions on Google平台得到进一步扩展。现在该平台将支持所有Google Assistant所支持的平台,在功能方面,Actions甚至允许用户通过语音完成交易。
(5)苹果
苹果收购过Siri、Novauris、VocalIQ等语音技术公司,且请了不少牛B的人组建基于神经网络算法的语音识别团队。
苹果正依靠语音助手Siri构建更大的生态系统,在最新的HomeKit的合作伙伴名单中,除了国内厂商海尔,还有照明厂商飞利浦、科锐 (CREE),以及Marvell(美满电子)、Honeywell(霍尼韦尔)等全球顶级制造商。
(6)亚马逊Alex
Alexa是亚马逊的云语音服务提供数以百万计的设备从亚马逊和第三方设备制造商。用Alexa,您可以构建自然声音的经验,提供客户更直观的方式与他们每天使用的技术。我们收集的工具、api、参考解决方案,和文档方便任何人用Alexa构建。
亚马逊Alexa与谷歌Assistant正围绕各自的语音助手辅助应用展开激烈的竞争,两家公司都在努力让助手们尽可能多地搭载汽车、智能音箱、集线器、耳机、智能手机和其他设备上使用。例如,谷歌最近宣布与门锁制造商西勒奇(Schlage)在语音助手方面进行合作,而Alexa也即将应用于蓝牙汽车充电器。谷歌与它的智能助手相比Alexa确实更有优势:它在许多国家(在欧洲和其他地方)比Alexa更有市场。方案,和文档方便任何人用Alexa构建。
2、国内语音识别交互供应商
(1)蓦然认知:
蓦然认知成立于是一家以认知计算、自然语言理解技术为核心的人工智能公司。提供”信号处理+语音识别+语义理解+服务自动对接”的一站式“对话机器人”解决方案, 通过云端深度对接服务和内容,以语音对话方式来分发各种服务;同时,“对话机器人”可以驱动各种设备与人自然交互,进而构建无缝的智能化机器协作网络,高效完成任务。拥有覆盖智能车机系统,智能电视系统,智能音箱系统的成熟产品,覆盖智能车载,智能家居的成熟解决方案。
和国内的不少著名语音交互公司一样,,蓦然认知的技术骨干也都是来自BAT语音技术方面的专家。拥有成熟的技术团队,成立两年多,已经发展到准独角兽规模,总部成员近百人,深圳和上海都开设了分公司。迅速抢占市场,成为语音界新贵。
核心团队:
- 戴帅湘,北京蓦然认知科技创始人,CEO;前百度主任架构师,长期担任百度Query理解方向负!责人,是语义分析方面的专家;百度语义技术的最高奖—–第一个也是迄今为止唯一 一个以NLP技术为核心的最高奖;2010年提出“Query改写模型”给百度搜索引擎技术带来了搜索相关性和广告收入均大幅提升,在自然语言处理、语义搜索、自动问题求解等领域内有20多项专利技术 ;曾主导设计了百度度秘,百度框计算,及百度输入法中语言处理的核心算法;
- 龚思颖–市场总监(联合创始人),前大疆创新北美地区人力资源及客户关系负责人;
- 张伟萌–技术总监(联合创始人),曾百度百度任职6年多,研究自然语言处理技术;2008年硕士毕业,有9年自然语言处理的工作经验,有近10项专利技术发明;
- 李国华–资深技术专家(联合创始人),曾为百度自然语言处理部资深工程师,2012年硕士毕业;
- 洪涛–首席技术顾问,百度首位高级科学家,有20多年的行业经验;
(2)科大讯飞
- 科大讯飞股份有限公司从事智能语音及语言技术、人工智能技术研究,软件及芯片产品开发,语音信息服务及电子政务系统集成的国家级骨干软件企业。
- 科大讯飞作为中国智能语音与人工智能产业领导者,在语音合成、语音识别、口语评测、自然语言处理等多项技术上拥有国际领先的成果。
2015年,科大讯飞重新定义了万物互联时代的人机交互标准,发布了对人工智能产业具有里程碑意义的人机交互界面——AIUI。2016年,围绕科大讯飞人工智能开放平台的使用人次与创业团队成倍增长。截至2017年1月,讯飞开放平台在线日服务量超30亿人次,合作伙伴达到25万家,用户数超9.1亿,以科大讯飞为中心的人工智能产业生态持续构建。
(3)思必驰
思必驰专注人性化的智能语音交互技术,思必驰是国内拥有全套语音类知识产权的公司。在语音识别、语音合成、语义理解、声纹识别、对话管理、音频分析等方面均有深厚技术积累。国际上极少数拥有自主产权、中英文综合语音技术(语音识别、语音合成、自然语言理解、智能交互决策、声纹识别、性别及年龄识别、情绪识别等)的公司之一。
目前思必驰把语音相关技术整合成 AI OS 人机对话操作系统,作为安卓系统之上的一层标准接口,提供给硬件合作伙伴。针对不同场景,AIOS 又分成了 For Car,For Home,For Robot 等版本,针对车载、家居、机器人等产品做垂直领域下的对话式交互。
(4)出门问问
出门问问应该是除了科大讯飞和百度以外,唯一一家有全套语音交互核心技术的创业型公司。
(5)云知声
- 云知声,是一家专注物联网人工智能服务,拥有完全自主知识产权、世界顶尖智能语音识别技术的高新技术企业。
- 云知声利用机器学习平台(深度学习、增强学习、贝叶斯学习),在语音技术、语言技术、知识计算、大数据分析等领域建立了领先的核心技术体系,这些技术共同构成了云知声完整的人工智能技术图谱。在应用层面, AI芯、AIUI、AI Service三大解决方案支撑起云知声核心技术的落地和实现,目前已经在家居、汽车、医疗和教育等领域有广泛应用,形成了完整的“云端芯”生态闭环。
- 云知声自成立以来,发展迅速,备受人工智能行业及资本市场的广泛关注,累积融资近亿美元。云知声的合作伙伴数量已经超过2万家,覆盖用户已经超过2亿,日调用量2亿次,其中语音云平台覆盖的城市超过647个,覆盖设备超过1亿台。并且,云知声连续两年入选福布斯中国最快科技成长公司50强企业,是中国人工智能行业成长最快的创业公司之一 。
(6)哦啦语音
哦啦语音于2013年初成立,拥有在中文自然语言理解、语音识别、语音控制和语音交互系统等方面的 20 多项自主专利。目前已应用在智能家居、智能车载、可穿戴设备、语义和交互API服务、智能会议系统、手机语音助手几个方面。他们家最大的特色,是对于中文语义的理解,针对用户各种问题可以给出生动、活泼、幽默、精确的回答。通过哦啦,用户可以通过语音控制,实现用户对各种生活信息的实时查询和操作、对手机内各个程序的调取要求,以及在界面内实现人机互动聊天、娱乐等需求。在未来,用户只要打开哦啦,就可以完成所需要的手机操作。是第一款实现对于用户连贯性提问进行全文解析的语音助手。
(7)问之科技
问之科技是一家从事产品自主研发的高科技企业。问之科技专注于人工智能产品和技术研究领域的开发,致力于打造中国机器人的最强大脑。以语音、语义、视频技术为核心服务于机器人及智能家居领域,一切旨在为拓展智能交互新体验,用声音传递简易生活方式。
(8)SoundAI(声智科技)
SoundAI是一家专注声学前沿技术和人工智能交互的科技创新公司,致力于引领真实环境下更自由的人工智能交互体验,实现“听你所言,知你所想”的人机交互愿景。
SoundAI提供从软硬件到云服务的远场语音交互技术方案,以及从芯片模组、PCBA到工业设计的Turnkey产品方案,其回声抵消、噪声抑制、声源定位、混响消除、波束形成、远场语音唤醒、远场语音识别等技术在业界遥遥领先;同时,声智科技与ARM、NVIDIA、Xilinx、Cypress、Knowles、百度、腾讯等著名企业深度合作,深耕智能家居、智能汽车、智能安防、智能金融、智能教育和机器人等行业,服务于小米、360、京东、联想、海尔、创维等著名品牌,共同提升远场语音交互的用户体验。
同时,全面采用声智科技语音交互解决方案和模组的产品也已经陆续上线。
SoundAI努力以技术拉动产业,以技术改变生活,以技术服务社会,持续推动国内外声学领域和人工智能领域的产品升级和技术创新。
(9)慧听科技
慧听科技是数据服务提供商。拥有一支专业的数据制作团队,负责完成过语音识别、语音合成、语音评测、语言文本类、多媒体类等多领域数据制作,并参与过语音合成、语音识别、输入法系统的研发。同时,慧听科技还有一支高水平技术研发团队,为数据服务提供强大的技术支撑。公司的硬件设施过硬,拥有符合ITU国际标准的录音室和录音设备。在管理方面,慧听公司采用全程质量监控流程,执行完善的标注流程,配合保密管理手段,提供质量上乘的数据服务。
目前,慧听科技能够提供语言语音、多媒体两大类几十余种数据服务。
(10)驰声科技
驰声科技专业从事智能语音技术研究和产业化的教育科技公司。是国内最早进入教育行业的语音公司之一,驰声科技自主研发了基于大数据、深度学习的智能语音系列技术,帮助客户实现人机互动的智能学习产品,引领教育信息化创新发展。
迄今,驰声科技已在培训、出版、教育软件、在线教育、教育硬 件、考试服务等领域培养了一大批标杆客户,驰声科技的智能学习技术也已惠及海内外数以亿计的个人学习者。市场上应用了智能语音技术的教育产品 半数以上都采用了驰声科技的先进技术。
作为此轮教育信息化浪潮的中坚力量,驰声科技将持续、专注地为国内外教育企业提供最专业、最完善、最优质的智能技术与服务,并致力于成为 世界一流的智能语音技术品牌服务商。
(11)百度语音
百度语音为开发者,提供业界优质、免费的语音技术服务。通过场景识别优化,为车载导航、智能家居等行业提供语音解决方案。融合依存句法分析、信息抽取、短文本分类等自然语言处理技术。
垂直场景识别模型。在提供通用语音能力的同时,百度语音还提供针对特定垂直领域的语音听写模型。开发者可根据使用场景,自定义设置识别垂类模型。有音乐、视频、地图、游戏、电商共17个垂类领域可供选择。
丰富的垂直资源。语义解析可以识别用户的意图并提取用户表述中的关键内容,从而帮助开发者理解用户需求,百度语音识别服务支持35个领域的语义解析,可进行多意图解析、具备强大的纠错能力,依托百度知道等社区产品上积累的强大知识库,更能够做到智能推理、“不言而明”。
(12)灵云科技
北京捷通华声科技股份有限公司成立于2000年10月,是一家专注于智能语音、智能图像、生物特征识别、智能语义等全方位人工智能技术研究与应用,全面发展人工智能云服务的高新技术企业。灵云平台隶属于北京捷通华声科技股份有限公司。
2001年,捷通华声推出代表国内最高水平的中文语音合成技术,全面开启了中文语音合成技术在中国信息产业发展中的实用化进程,奠定了捷通华声在中国语音产业界的稳固地位。历经十年发展,捷通华声所拥有的自主知识产权的中文语音合成、手写识别技术在语音交互、模式识别技术市场占有率达到50%,成为国内第一家倡导并实现同时提供语音合成、语音识别、手写识别、文字识别等技术的全方位人工智能技术提供商。
(13)轻生活科技
深圳市轻生活科技有限公司由国家级高新技术企业深圳市超维实业有限公司100%投资,于2015年4月在深圳成立、注册资本1000万。
轻生活科技聚焦研究语音交互控制技术和语音搜索技术,并整合WiFi、BLE、RF等先进的物联网技术、云服务技术、大数据技术等为智能家居行业提供短平快小生态技术解决方案;公司专注以前瞻智能语音技术(语音识别技术、语音合成技术、降噪、去回声等前端处理技术),致力于家居物联网智能语音交互技术软件与硬件的开发;为轻生活品牌提供完整产品,透过轻生活科技来整合优质的上游资源形成轻生活独有的产品方案,并通过自己的品牌产品来示范和检验并完善方案,从而更好的为轻生活开放性研发平台的客户、加盟方案友商服务。
(14)阿里云(小Ai)
智能语音交互(Intelligent Speech Interaction),是基于语音识别、语音合成、自然语言理解等技术,为企业在多种实际应用场景下,赋予产品“能听、会说、懂你”式的智能人机交互体验。适用于多个应用场景中,包括智能问答、智能质检、法庭庭审实时记录、实时演讲字幕、访谈录音转写等场景,在金融、保险、司法、电商等多个领域均有应用案例。
(15)搜狗语音
搜狗从2012年开始研发智能语音技术,并在2013年开始进行深度学习。目前,搜狗的智能语音技术已经成功应用至搜狗的全线产品中。搜狗方面的数据显示,搜狗搜索日均语音搜索次数增长超过4倍,搜狗输入法日均输入超过1.4亿次。
搜狗“知音”引擎解决了用户在说话过程中因语速过快而导致的吞音问题。语音识别错误率相对下降30%以上,语音识别速度提升3倍;“知音”能够在语音交互中支持用户修正错误的识别结果,用户可使用自然语言进行改错。比如,用户可以说把“张”改为“章”。
此外,“知音”还支持多轮对话,处理更复杂的用户交互逻辑,用更自然并且用户更容易接受和理解的方式进行交互。
3、科大VS云知声
科大讯飞主要产品:
(1)讯飞输入法:

1)产品介绍::iOS 8上唯一支持语音输入的第三方输入法,专为iPhone用户打造,无需越狱,即可安装!用户评分最高的手机输入法,超过1亿用户使用,智能手机装机必备。讯飞输入法,创造极致输入体验!
2)功能特色:
- a. 速度快:全新“蜂巢Ⅱ代”输入引擎,完美融合拼音、语音、手写输入,输入更智能;
- b. 输入准:内置百万超大词库,拼音云输入全面升级,准确率提升30%,速度翻倍;
- c. 更智能:支持语音、手写、拼音“云+端”输入自适应学习,使用越多,输入越方便!
(1)灵犀:

1)产品介绍:灵犀,中国移动和科大讯飞联合推出的智能语音助手,更是国内首款支持粤语的语音助手!灵犀既能语音打电话、发短信、查天气、搜航班,还能查话费、查流量、买彩票、订彩铃,更可以陪你语音闲聊讲笑话!
2)功能特色:
- 1.如果您想偷懒,灵犀MM可以帮你打电话、发短信、定闹钟,是您的贴身小秘书;
- 2.如果您在路上,灵犀MM可以帮你查天气、查路线、查美食,是您的生活小导游;
- 3.如果您爱娱乐,灵犀MM可以帮你听音乐、订彩铃、下应用,是您的娱乐小主播;
- 4.如果您很无聊,灵犀MM可以陪你聊八卦、讲笑话、说新闻,是你的闲聊好朋友!
(2)录音宝:

1)产品介绍:录音宝是由科大讯飞推出的手机录音软件,界面清爽,高清音质,支持精准定位、听声识人,操作非常简单,让您方便录、容易听!
2)功能特点:
- 1.无限时长:随时随地,现场录音不限时长,想录多久录多久,保存完整记录;
- 2.随时标记:录音过程中可随时标记,供您回听录音时精准定位,快速查找;
- 3.听声识人:以不同颜色自动区分多人对话,谁在说话,一目了然;
- 4.录音转文字:可将录音转换成文字显示,一键复制,方便整理;
- 5.文件导出:录音及文字可轻松导出,方便存储及使用;
- 6.一键分享:录音可分享至QQ、微信、朋友圈、微博等社交平台;
- 7.通话录音:支持大部分安卓手机双模双卡双向通话录音。
(4)讯飞语点小V(车载蓝牙硬件):

1)产品介绍:作为科大讯飞重点打造的软硬件一体化产品,语点车载声控电话采用智能语音唤醒技术、高效的语音识别技术、流畅动听的语音合成技术,并结合先进的AEC(回声消除技术)和AES(噪声抑制技术),成就其卓越的通话音质。在行车过程中,全程采用语音操控的交互方式,无需触碰按钮即可拨打和接听电话;和手机连接后,自动同步通讯录,使用简单便捷,将为消费者带来前所未有的安全体验。
2)功能特色:
- 1、6个月超高续航时间,10小时长连续通话;
- 2、具有语音播发短信,APP智能应用等多种功能,还有贴心的隐私保护设计,在有私密来电时,可一键切回手机通话。
- 3、语点车载声控电话拥有蓝牙音频串流播放功能(A2DP),可智能播放手机音乐和导航指令,高清立体音质清晰悦耳,来电自动暂停,结束自动启动,为用户提供极致的娱乐体验。
3)产品不足:
- 1.不能主动中断通话,必须等对方挂断;
- 2.对车载环境识别有待改进,当在车门外来电话时,因为蓝牙还连着,所以默认是由车内小V接听,需要手动把蓝牙关闭,才能转到手机上。
- 3.喇叭声音较小,车内声音稍大一些,就听不到了;
- 4.只支持绑定的手机号,对于有多个号码的用户来说,没绑定的号码只能用手机接听。
- 5.目前的固件版本只支持普通话,不支持方言。
云知声主要产品:
(1)语音魔方解决方案:
- 1)产品介绍:语音魔方是智能语音交互的整体解决方案,让智能设备听懂用户的话,用户说话就能实现操作和控制;方案适用于智能电视、智能家居、车载、可穿戴设备;方案整合语音识别、语义理解、知识图谱等云知声核心技术,经过数年专业语音交互的积淀和几代产品的更新,倾心打造。
- 2)应用场景:车载环境、可穿戴设备、智能电视语音交互方案;
(2)智能语音导航解决方案:
- 1)IVR电话语音导航:通过将客户的自然语音进行转写和翻译,并通过基于自然语言的语义分析系统与企业IVR语音系统对接,为企业提供智能电话语音导航方案;用户只用轻松的说出想要的服务内容,就可以找到自助服务的入口,并完成自助服务。
- 2)语音分析系统:语音分析系统将用户和坐席的连续通话录音转写成文字,通过事先建立的业务模型和业务规则对文本结果进行深入的数据挖掘。其中,可以对坐席的语音进行质检,保障业务的合规和完整性;对客户的语音可以进行大数据处理,了解客户的来电需求,挖掘用户潜在的商业机会。
- 3)智能语音对话系统:该系统可以提供智能化的高级人机语音交互方案,通过对客户知识库系统的梳理,通过关键字匹配和建立对话模型等方式,最大限度的利用客户的知识库系统实现自助服务。该系统可以应用于智能客户领域,可以在网页客服,微信客户,电商客服中帮助降低成本,提高服务质量。
- 4)手机语音导航系统:该系统基于公有云/私有云架构,为行业客户提供定制化的手机APP语音导航方案;通过智能语音导航改变传统的按键式自助服务,用户使用自然语音与系统交互,实现菜单扁平化,提升用户满意度,减轻人工服务压力,降低运营成本。
(3)云知声语音输入法:

1)产品介绍:云知声输入法是一款语音输入超准的手机输入法。让手机用户不再纠结于方寸键盘间频繁点选,用语音轻松输入文字。其语音识别反应快、识别准;针对噪音、口音、输入标点/数字、网络条件等进行了优化,让语音输入更有效、更实用。可实现在线和离线语音识别,并且能自由切换在线/离线引擎。来自云知声语音识别引擎的强大支持。你值得信赖!
2)功能特色:
- 1.语音识别准:平均准确率超过93%;
- 2.识别反应快:Wi-Fi或3G下几乎实时返回识别结果;
- 3.语音输入快:每分钟轻松输入200-300字,非语音输入方式望尘莫及;
- 4.不怕有口音:完美识别标准普通话及有口音的普通话;
- 5.语音输入数字:可识别数字并输出适合的格式;
- 6.抗噪声技术:在吵杂街道环境也可以顺畅输入;
- 7.超省流量:输入100字只需要20-40kB流量,1M流量可输入2500字;
- 8.自动加标点:智能引擎根据用户输入内容为用户添加必要的标点符号。
(4)语控精灵

1)产品介绍:
语控精灵是由北京云知声信息技术有限公司研发的一款语音软件。无需连接网络,通过语音即可操作手机功能,打电话给朋友,发短信给朋友,打开应用,开关手机功能。打电话、发短信、开应用随你语控;让手机随时随地听懂你。
2)功能特色:
- 1 .通过点击桌面悬浮窗来快速启动语控操作;
- 2 .通过贴近耳朵(需要有陀螺仪硬件支持,摇一摇快捷启动语控操作;
- 3 .通过语音播报可以彻底释放手眼操作,提高操作安全性;
- 4 .在联网状态下,可以通过语音输入短信内容,而且所占流量极小;
- 5 .支持语言:普通话
十一、总结
语音识别早已经渗透入我们的平常生活中,作为未来交互入口的第一道门槛,要突破的难点还有很多很多,除了一些技术方面的突破点,在产品和用户心智方面也仍需时代的引领。
1、场景承载点:
目前近场语音识别场景的识别准确率已经很高了,而且语音识别作为技术已经有了一个明星的产品承载点,那就是讯飞语音输入法。但是面临挑战的恰恰不是产品的语音识别准确率不够高,而是没有一个用户可信赖且相对信息隐秘化的场景承载点。
用户使用手机和电脑的时间,大部分人的80%的时间都是在非私人化的时间里,无论是上班族还是学生,大多处在一个至少是2人或是2人以上的空间场景中,因此要使用语音识别,必须要发出声音才能进行交互的一些场景,大家不愿意使用更高效的语音交互,而是仍然选择用手来交互,因此对于一门技术缺乏场景承载点,是一个及其尴尬的局面,这极大的阻碍了新技术的普及;而未来的语音交互场景则更多的是依赖于私人的熟人场景下(家庭,私家车等);这些场景可能更多的也是工具式交互,至于情感类的交互估计没有多少空间(除了老人和孩子)。
场景优化展望:上面提到的问题,其实仍然属于信息的隐秘化问题,公共场合下大家在进行语音沟通时,信息是开放的,周围人是可以获取到你交互的私密信息。但是如果有一个小小的硬件可以戴在喉结处,在不发声或者是很小的声音下,我们通过硬件发大处理收集音波信息和振动信息,结合处理是否可能达到一个静态的只有一个人能听到的语音识别从而进行语音交互,这样就可以解决信息泄露带来的场景尴尬。
2、图像的信息反馈优于音频信息的反馈
我们人类的主要信息获取方式,80%来自于眼睛,也就是说图像信息的丰富度远胜于声音,这也就决定了,任何离开了图像的信息交互都是不可取的,也是不能大行其道的,瞎子比聋子更让人不能接受。因此未来依托于语音识别的语音交互的同时一定不能少了图像的交互,除非两者不可同时共存(现阶段的车载场景不可共存,但未来无人驾驶解放人类的眼睛之后,仍然离不开图像交互)。未来图片、文字是否还有其他的呈现载体,而不仅仅依托于手机、电脑,眼镜是否也可以呢,当然还得继续摸索。
语音识别:ASR
【2020-08-19】
编辑导语:语音识别已经走进了大家的日常生活中,我们的手机、汽车、智能音箱均能对我们的语音进行识别。那么什么是语音识别呢?它又能应用于哪里?该如何对其进行测试与运营维护呢?本文作者为我们进行了详细地介绍。

现在人机语音交互已经成为我们日常生活的一部分,语音交互更自然,大大的提高了效率。上一篇文章我们聊了语音唤醒,这次我们继续聊聊语音交互的关键步骤之一——语音识别。
一、什么是语音识别
文字绝对算是人类最伟大的发明之一,正是因为有了文字,人类的文明成果才得以延续。
但是文字只是记录方式,人类一直都是依靠声音进行交流。所以人脑是可以直接处理音频信息的,就像你每次听到别人和你说话的时候,你就会很自然地理解,不用先把内容转变成文字再理解。
而机器目前只能做到先把音频转变成文字,再按照字面意思理解。
微信或者输入法的语音转文字相信大家都用过,这就是语音识别的典型应用,就是把我们说的音频转换成文字内容。
语音识别技术(Automatic Speech Recognition)是一种将人的语音转换为文本的技术。
概念理解起来很简单,但整个过程还是非常复杂的。正是由于复杂,对算力的消耗比较大,一般我们都将语音识别模型放在云端去处理。
这也就是我们常见的,不联网无法使用的原因,当然也有在本地识别的案列,像输入法就有本地语音识别的包。
二、语音识别的应用
语音识别的应用非常广泛,常见的有语音交互、语音输入。随着技术的逐渐成熟和5G的普及,未来的应用范围只会更大。
语音识别技术的应用往往按照应用场景进行划分,会有私人场景、车载场景、儿童场景、家庭场景等,不同场景的产品形态会有所不同,但是底层的技术都是一样的。
1. 私人场景
私人场景常见的是手机助手、语音输入法等,主要依赖于我们常用的设备—手机。
如果你的手机内置手机助手,你可以方便快捷的实现设定闹钟,打开应用等,大大的提高了效率。语音输入法也有非常明显的优势,相较于键盘输入,提高了输入的效率,每分钟可以输入300字左右。
2. 车载场景
车载场景的语音助手是未来的趋势,现在国产电动车基本上都有语音助手,可以高效的实现对车内一些设施的控制,比如调低座椅、打开空调、播放音乐等。
开车是需要高度集中注意力的事情,眼睛和手会被占用,这个时候使用语音交互往往会有更好的效果。
3. 儿童场景
语音识别在儿童场景的应用也很多,因为儿童对于新鲜事物的接受能力很高,能够接受现在技术的不成熟。常见的儿童学习软件中的跟读功能,识别孩子发音是否准确,这就应用的是语音识别能力。
还有一些可以语音交互的玩具,也有ASR识别的部分。
4. 家庭场景
家庭场景最常见的就是智能音箱和智能电视了,我们通过智能音箱,可以语音控制家里面的所有电器的开关和状态;通过语音控制电视切换节目,搜索我们想要观看的内容。
外呼
外呼中的响铃识别
参考
- 【2019-11-18】人机语音对话技术在58同城的应用实践
- 【2026-2-14】什么是回铃音、忙音、呼叫等待等提示音?
电话通信系统中的几种常见信号音
- 拨号音——“嗡…”的连续音,提示用户输入要拨打的电话号码;
- 回铃音——“嘟,嘟…”的继续音(响1秒,断4秒),提示用户对方电话已经振铃,等待对方接听,运营商播放彩铃。
- 忙音——“嘟,嘟,嘟…”短促音(响0.35秒,断0.35秒),占线音,提示用户对方电话正忙,运营商播放语音“您拨打的用户忙,请您稍后再拨”。
- 拥塞音——这是一种“嘟,嘟…”的短音(响0.7秒,音隔0.7秒)。拥塞音有点像忙音,但比忙音声音要长,它表示程控交换机因某种原因机线拥塞不通。
- 空号音——这是一种“嘟,嘟,嘟,嘟…”的三短一长的声音(短音持续0.1秒,间断0.1秒,长音持续0.4秒)。它表示用户拨叫的电话号码是尚未使用的空号,运营商播放语音“您拨打的电话为空号,请查证后再拨”。
- 呼叫等待音——在用户登记了“呼叫等待”服务项目后,如果该用户正与对方通话时,又有第三者呼叫该用用,则该用户在受话器中会听到一种微弱的信号音,这种信号是“嘟…”的短促音(响0.4秒,音隔0.4秒,再响0.4秒)。它表示有第三者在呼叫,提醒该用户是否要与第三者通话,运营商播放语音“请不要挂机,您拨打的用户正在通话中”。
- 催挂音——当用户用完电话,没有挂机或话机手柄没有放好时,程控电话交换机会发出一种由小逐渐变大的连续音(950HZ),提醒该用户把话机挂好。
如何判断客户电号码话是否真实存在/正常状态? 拨打电话,根据状态判定
用 SIP 协议和响铃语音来实现。
- SIP 协议:利用基于 SIP 协议返回 SIP 状态码来进行判断,比如返回603则判断为空号;
- 响铃语音:通过将语音信号转化为文本,进行文本关键词匹配和文本分类,对拨打号码进行判断,比如“您拨打的电话已关机”判断为关机状态,还可以利用语音信息特征设计响铃语音分类器,判断号码状态。
三、语音识别详解
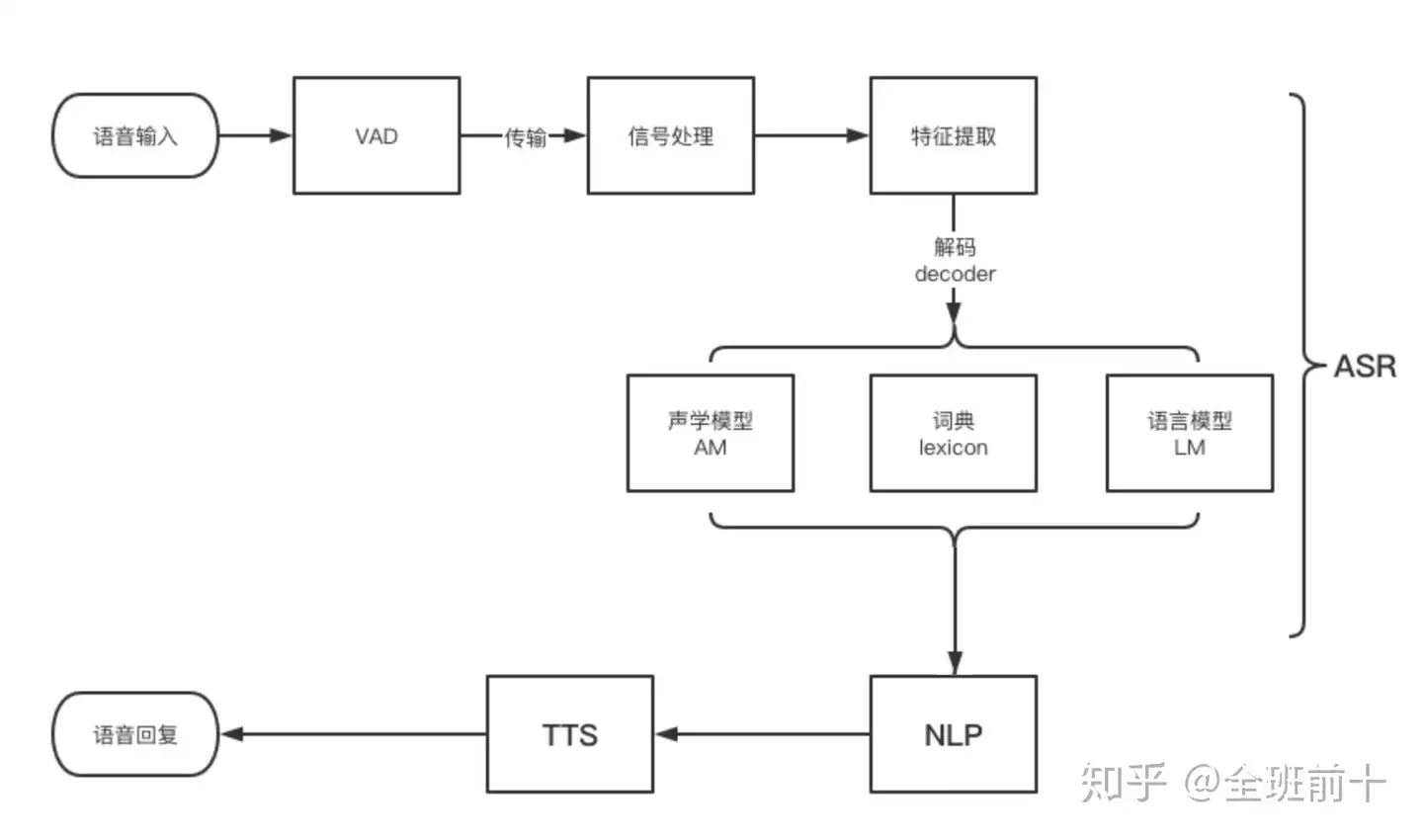
【2022-10-03】整个从语音识别的过程,先从本地获取音频,然后传到云端,最后识别出文本,就是一个声学信号转换成文本信息的过程。整个识别的过程如下图:
1、VAD技术
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成干扰,这个切除静音的炒作一般称为VAD。这个步骤一般是在本地完成的,这部分需要用到信号处理的一些技术。
VAD(Voice Activity Detection),也叫语音激活检测,或者静音抑制,其目的是检测当前语音信号中是否包含话音信号存在,即对输入信号进行判断,将话音信号与各种背景噪声信号区分出来,分别对两种信号采用不同的处理方法。
算法方面,VAD算法主要用了2-3个模型来对语音建模,并且分成噪声类和语音类,还有静音类。目前大多数还是基于信噪比的算法,也有一些基于深度学习(DNN)的模型。
一般在产品设计的时候,会固定一个VAD截断的时间,但面对不同的应用场景,可能会要求这个时间是可以自定义的。主要是用来控制多长时间没有声音进行截断。比如小孩子说话会比较慢,常常会留尾音,那么我们就需要针对儿童场景,设置比较长的VAD截断时间,而成人就可以相对短一点,一般会设置在400ms-1000ms之间(0.4s~1s)。

2、本地上传(压缩)
人的声音信息首先要经过麦克风整列收集和处理,然后再把处理好的音频文件传到云端,整个语音识别模型才开始工作。这里的上传并不是直接把收音到的音频丢到云端,而是要进行压缩的,主要考虑到音频太小,网络等问题,会影响整体的响应速度。从本地到云端是一个压缩➡上传➡解压的过程,数据才能够到达云端。
以数据流形式进行实时上传,每隔一段时间上传一个包。可以理解为每说一个字,就要上传一次,这也就对应着我们常常看到的一个字一个字的往屏幕上蹦的效果,一般一句“明天天气怎么样?”,会上传大约30多个包到云端。
一般考虑大部分设备使用的都是 Wi-Fi 和 4G 网络,每次上传的包的大小在128个字节的大小,整个响应还是非常及时的。
3、信号处理
这里的信号处理一般指的是降噪,有些麦克风阵列本身的降噪算法受限于前端硬件的限制,会把一部分降噪的工作放在云端。像专门提供云端语音识别能力的公司,比如科大讯飞、谷歌,自己的语音识别模型都是有降噪能力的,因为你不知道前端的麦克风阵列到底是什么情况。
除了降噪以外可能还涉及到数据格式的归一化等。当然有些模型可能不需要这些步骤,比如自研的语音识别模型,只给自己的机器用,那么我解压完了就是我想要的格式。

降噪的逻辑
4、特征提取
特征提取是语音识别关键的一步,解压完音频文件后,就要先进行特征提取,提取出来的特征作为参数,为模型计算做准备。简单理解就是语音信息的数字化,然后再通过后面的模型对这些数字化信息进行计算。
特征提取首先要做的是采样,音频信息是以数据流的形式存在,是连续不断的,对连续时间进行离散化处理的过程就是采样率,单位是Hz。可以理解为从一条连续的曲线上面取点,取的点越密集,越能还原这条曲线的波动趋势,采样率也就越高。理论上越高越好,但是一般10kHz以下就够用了,所以大部分都会采取16kHz的采样率。
具体提取那些特征,这要看模型要识别那些内容,一般只是语音转文字的话,主要是提取音素;但是想要识别语音中的情绪,可能就需要提取响度、音高等参数。
最常用到的语音特征就是梅尔倒谱系数(Mel-scaleFrequency Cepstral Coefficients,简称MFCC),是在Mel标度频率域提取出来的倒谱参数,Mel标度描述了人耳频率的非线性特性。
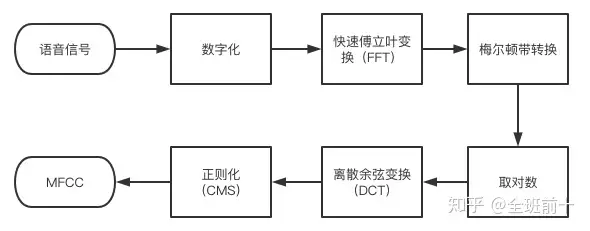
MFCC特征提取的流程
5、声学模型(AM)
声学模型将声学和发音学的知识进行整合,以特征提取模块提取的特征为输入,计算音频对应音素之间的概率。简单理解就是把从声音中提取出来的特征,通过声学模型,计算出相应的音素。
声学模型目前的主流算法是混合高斯模型+隐马尔可夫模型(GMM-HMM),HMM模型对时序信息进行建模,在给定HMM的一个状态后,GMM对属于该状态的语音特征向量的概率分布进行建模。现在也有基于深度学习的模型,在大数据的情况下,效果要好于GMM-HMM。
声学模型就是把声音转成音素,有点像把声音转成拼音的感觉,所以优化声学模型需要音频数据。
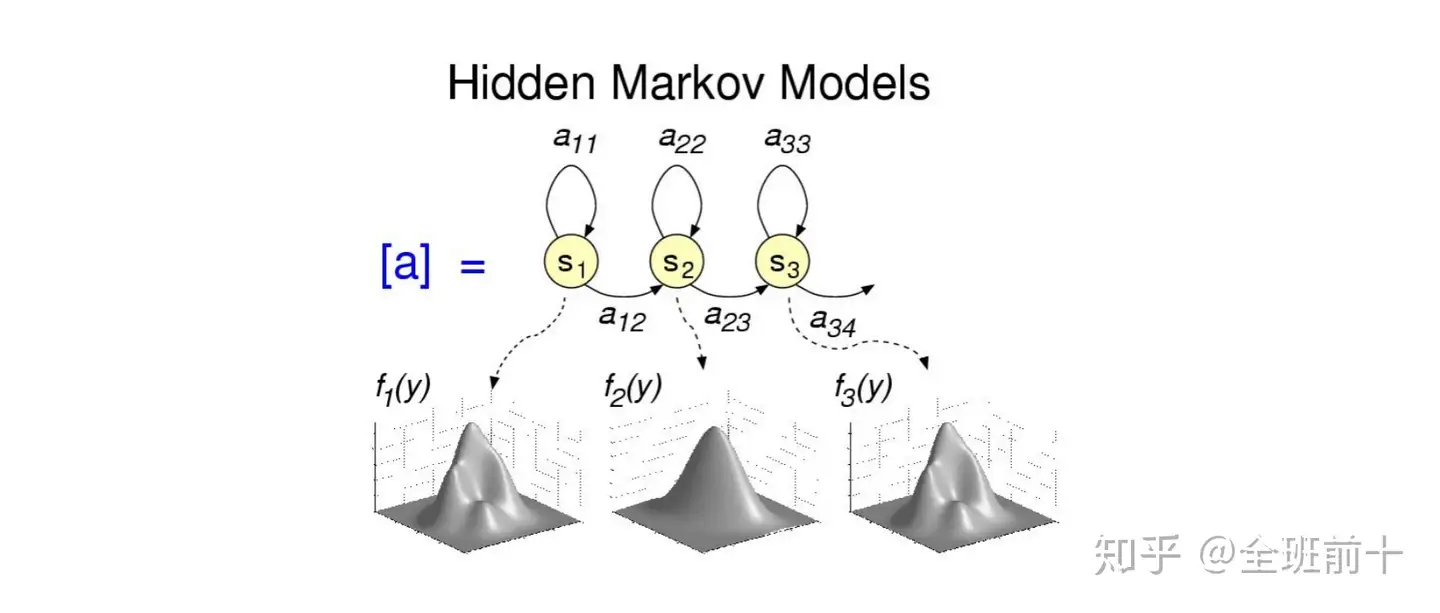
HMM声学模型
6、语言模型(LM)
语言模型是将语法和字词的知识进行整合,计算文字在这句话下出现的概率。一般自然语言的统计单位是句子,所以也可以看做句子的概率模型。简单理解就是给你几个字词,然后计算这几个字词组成句子的概率。
语言模型中,基于统计学的有 n-gram 语言模型,目前大部分公司用的也是该模型。还有基于深度学习的语言模型,
语言模型就是根据一些可能的词(词典给的),然后计算出那些词组合成一句话的概率比较高,所以优化语言模型需要的是文本数据。

N-gram语言模型动图
7、词典
词典就是发音字典的意思
- 中文就是拼音与汉字的对应
- 英文中就是音标与单词的对应
其目的是根据声学模型识别出来的音素,来找到对应的汉字(词)或者单词,用来在声学模型和语言模型建立桥梁,将两者联系起来。简单理解词典是连接声学模型和语言模型的月老。
词典不涉及什么算法,一般的词典都是大而全的,尽可能地覆盖我们所有地字。词典这个命名很形象,就像一本“新华字典”,给声学模型计算出来的拼音配上所有可能的汉字。
整个这一套组成了一个完整的语音识别模型,其中声学模型和语言模型是整个语音识别的核心,各家识别效果的差异也是这两块内容的不同导致的。一般我们更新的热词,更新的都是语言模型中的内容,后面会详细阐述。
词典就像现实的字典一样
四、语音识别相关内容
语音识别除了把语音转换成文本以外,还有一些其他用处,这里也简单提一下。
ASR 纠错
ASR 生成的文本可能包含错误,继而导致后续的用户意图理解出现偏差。如何利用 NLP 技术对 ASR 的 query 文本进行预处理纠错成了一个亟待解决的问题。
【2022-10-31】
- 【阿里语音技术揭秘】任务型语音对话中的纠错系统, 纠错系统将主要应用在以下业务中:

- 智能语音电视,使得人们可以通过语音对话技术来控制电视机,包括使用语音来搜索播放歌曲、视频、进行各种命令控制以及查询信息服务等,从繁琐的遥控器文字输入中解脱出来。
- 高德语音助手,秉承AI赋能出行业务的目标,通过语音交互的方式高效搜索地点规划路线、查询多种内容服务、操作各种出行设置,让用户在导航过程中解放双手,降低行驶过程中操作屏幕的风险。
- 基于 BERT 的 ASR 纠错 介绍小爱算法团队基于近年来流行的 BERT 预训练模型在这个问题上所进行的一些技术探索,以及在业务场景中的落地情况
小爱同学语音使用流程:
- 首先唤醒小爱同学,比如,手机按键或者语音唤醒
- 唤醒之后进入录音模块,启动录音前开启 Voice Activity Detection (
VAD) 状态,检测当前有没说话声音,如果没有则忽略 - 如果有,会把语音记录下来传递到下一个模块,就是最受关注的 Automatic Speech Recognition (
ASR),该模块负责把语音转译成文字
错误类型
ASR 错误示例
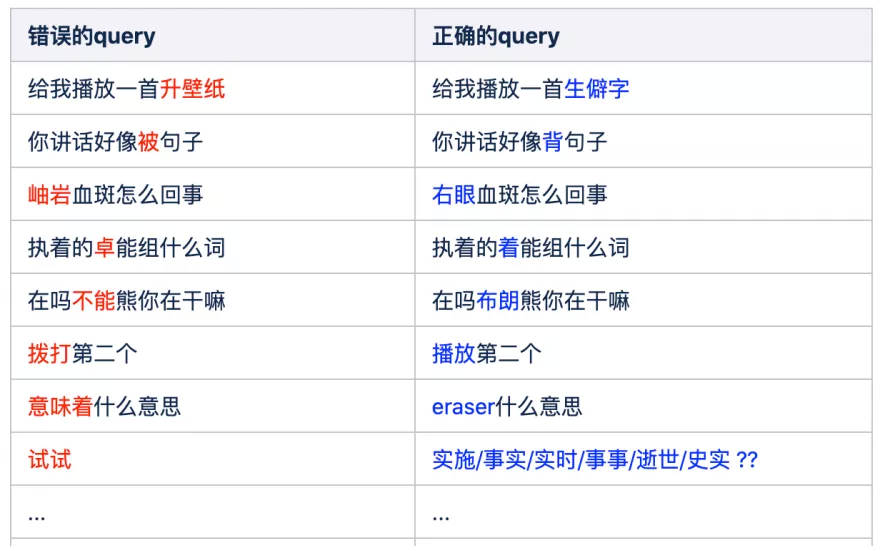
| 错误的query | 正确query | 错误类型 |
|---|---|---|
| 给我播放一首升壁纸 | 给我播放一首生僻字 | 背景知识 |
| 你讲话好像被句子 | 你讲话好像背句子 | 语法推断 |
| 岫岩血斑怎么回事 | 右眼血斑怎么回事 | 背景知识 |
| 执着的卓能组什么词 | 执着的着能组什么词 | 预发推断 |
| 在吗不能熊你在干嘛 | 在吗布朗熊你在干嘛 | 背景知识 |
| 拨打第二个 | 播放第二个 | 发音 |
| 意味着什么意思 | eraser什么意思 | 发音 |
| 试试 | 实施/事实/实时/事事/逝世/史实?? | 上下文 |
语音识别过程对于发音因素类似的词,识别准确的难度比较大。
从 case 中可以看出,要纠正这些 query,有些根据句子的结构就可以纠正,比如
- “你讲话好像被句子”,可以通过语法结构的分析知道”被”在此处是不合适的,应该是背诵的”背”;
- 而有些是需要知道一些背景知识,才能进行纠错,比如”生僻字”是一首歌,“右眼血斑”是常识,“布朗熊”是小爱同学业务的技能 ( 布朗熊跳个舞 ),
- 甚至有些语法上没有错误,需要根据原始音频才能纠正错误,如”播放第二个”与识别的文本结果”拨打第二个”,或者”eraser”识别为”意味着”;
- 有些可能听音频也没有用,对于中文有很多的发音声调都相同的词,需要结合当时环境的上下文情景才能确定是哪一个词。
ASR纠错与普通纠错
所以纠错需要结合很多的信息,如果全部考虑知识、音频、上下文环境,基本相当于重新做一个 ASR识别系统。但 ASR 本身处理语音过程受限于一些内存、吞吐流量等物理条件,声学模型和语言模型很难有很大的处理量,综合考虑 ASR 的语言模型还是基于传统的 n-gram 模型。但是使用 NLP 技术具有一些先天的优势,能够利用目前强大的预训练模型,并且不需要音频来进行纠错。
- (1) ASR纠错是否为一个良定义(well-posed)的问题?
- 什么是良定义的问题?在当前给定信息的条件下能解决的问题,或者说使用贝叶斯分类器分类得到的准确率非常高
- 哪些ASR错误可以被纠正?
- 为什么可以做得比ASR更好?
- (2) ASR纠错和普通错别字纠错的区别?
- ASR 纠错和普通错别字纠错面临的问题和数据分布不同
- 普通错别字纠错是根据字形相似来纠错,如”阀”和”阈”。
- 而 ASR 纠错是音似,发音相似导致难以识别正确的内容
- 覆盖范围不同
- 普通错别字纠错覆盖的范围也比 ASR 纠错更广一点,但这并不意味着普通错别字纠错可以用来 ASR 纠错
- 一个普通纠错任务上表现好的模型,是否一定能在ASR纠错任务上表现好?
- 天下没有免费的午餐:没有一个模型能够很好的应用在不同的数据分布上。
- 比如文本”的”、“地”、“得”纠错,假如句子中其他词都是正确的,只有”的”需要纠正为”得”,但是使用一个没有结合先验信息的普通模型来纠错,很显然容易把句中其他位置原本正确的词纠正为错误的,从而影响模型的准确率。
- 正确的做法是根据先验条件做出一个能适应当前数据分布的纠错模型。对于 ASR 纠错模型也一样,发音相似是 ASR 纠错的一个限制条件,我们需要把普通错别字模型结合这个限制条件,来设计针对 ASR 识别后的文本数据纠错模型。
- ASR 纠错和普通错别字纠错面临的问题和数据分布不同
ASR纠错可行定义
ASR 纠错问题进行以下初步设定:
- 只考虑 6 字以上中长 query:短的 query 不能体现充足的语境信息,纠错比较难。
- 不考虑上下文对话信息:上下文对话信息问题更复杂,并且在小爱同学对话信息中多轮对话只占 1%,目前先不考虑多轮对话的场景。
- 不考虑音频信息:作为 ASR 下游的一个纠错产品,只考虑文本信息。
- 仅考虑一对一纠错:基于 BERT 模型的纠错,一对一比较容易实现,后续可以放宽限制。
- 仅使用非监督语料:非监督语料节省人力成本,可以使用预训练模型,数据分布的头部语料可以嵌入到模型中,但可能不利于尾部数据的纠错,也就是说对于那些在语料中没有出现过的信息,不太可能纠正过来。
ASR 纠错方法
BERT 模型
BERT 是目前效果最好的预训练语言表示模型,引入了双向的 Transformer-encoder 结构,已训练好的模型网络有 12 层 BERT-small 和 24 层的 BERT-large。bert模型
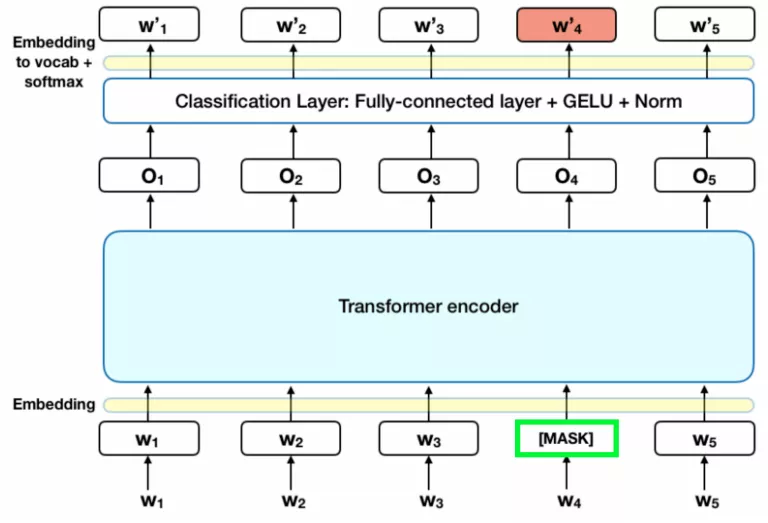
BERT 模型中与 ASR 纠错任务相关的是 MLM 部分, MLM 训练阶段有 15% 的 token 被随机替换为 [MASK] ( 占位符 ),模型需要学会根据 [MASK] 上下文预测这些被替换的 token。例如对于输入句子”明天武汉的 [MASK] 气怎么样”,模型需要预测出 [MASK] 位置原来的 token 是”天”。
如果只利用 MASK 机制训练存在一些迁移的问题,因为在其他任务中没有 MASK 的情况,这样就很难作为其他任务的预训练任务,所以作者通过 MASK 的方式进行了优化。
- 其中 10% 的 [MASK] 会被随机替换成另一个 token,此时”明天武汉的 [MASK] 气怎么样”会变成”明天武汉的微气怎么样”,模型需要在训练中学会将”微”字纠正为 “天”。
- 另外,还有 10% 的 [MASK] 会被”还原”。此时”明天武汉的 [MASK] 气怎么样”会被还原成”明天武汉的天气怎么样”,而模型需要在训练中学会根据上下文分辨 “天”字是否需要进行纠错。
- 其余 80%的 [MASK] 保留这个占位符状态,BERT 训练过程中计算的损失,只包括了 MASK 机制涉及到的 token 的损失,而不是整个句子的损失。
MLM 实际上包含了纠错任务,所以原生的 BERT 就具备了纠错能力。但是 BERT 的 MASK 位置是随机选择的 15%的 token,所以并不擅长侦测句子中出现错误的位置;并且 BERT 纠错未考虑约束条件,导致准确率低,比如:“小爱同学今 [明] 天天气怎么样”,MASK 的位置是”今”, 那么纠错任务需要给出的结果是”今”。但是由于训练预料中大多数人的 query 都是”明天天气怎么样”,这样在没有约束的条件下,大概率给出的纠正结果是”明”,虽然句子结构是合理的,但结果显然是不正确的。
ELECTRA 模型
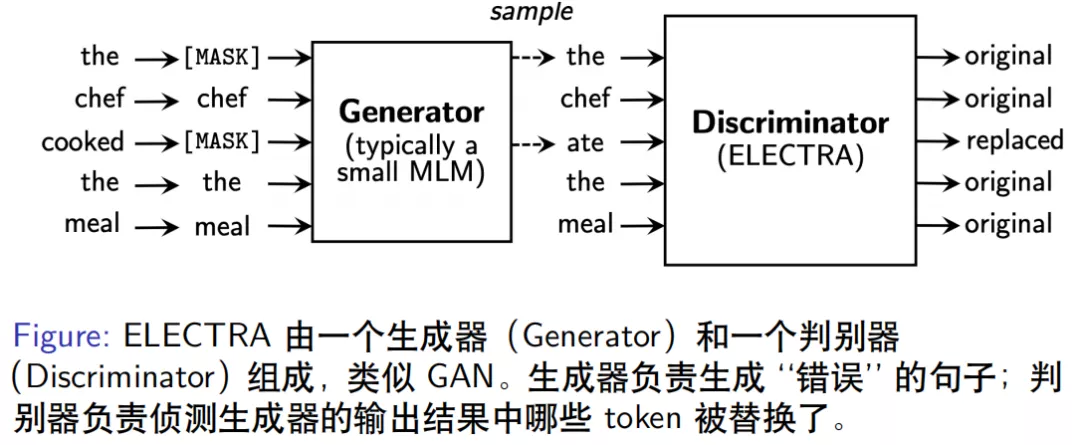
ELECTRA 模型由 Standford 大学团队提出,其模型结构由一个生成器和一个判别器组成,看起来与 GAN 结构类似但不属于 GAN 模型。
- 生成器的作用是输入一个正确的句子,负责生成一个错误的版本,如”the chef cooked the meal”经过生成器内部随机抽样 15%的 token 进行 MASK 后,再对这些 MASK 的位置进行预测,输出结果为”the chef ate the meal”,生成器中语言模型保证了生成的错误句子仍然是比较合理的,只是区别于原始句子。
- 判别器 ( ELECTRA ) 是用来判别生成器输出的句子中哪些位置的 token 被改动了,因此对每个 token 的位置进行 original/replaced 标注,如”cooked”变成了”ate”,标注为”repalced”,其余位置相同 token 标注为”original”,类似于序列标注任务,判别器的输出为 0 或 1。
ELECTRA 模型的判别器虽然可以检测错误,但模型设计不是为了纠错,而是为了在有限计算资源的条件下能提取更好特征表示,进而得到更好的效果,文章中表示在 GLUE 数据集上表现明显优于 BERT。
ELECTRA 的一个变体 ELECTRA-MLM 模型,不再输出 0 和 1,而是预测每个 MASK 位置正确 token 的概率。如果词表大小是 10000 个,那么每个位置的输出就是对应的一个 10000 维的向量分布,概率最大的是正确 token 的结果,这样就从原生 ELECTRA 检测错误变成具有纠错功能的模型。
Soft-Masked BERT
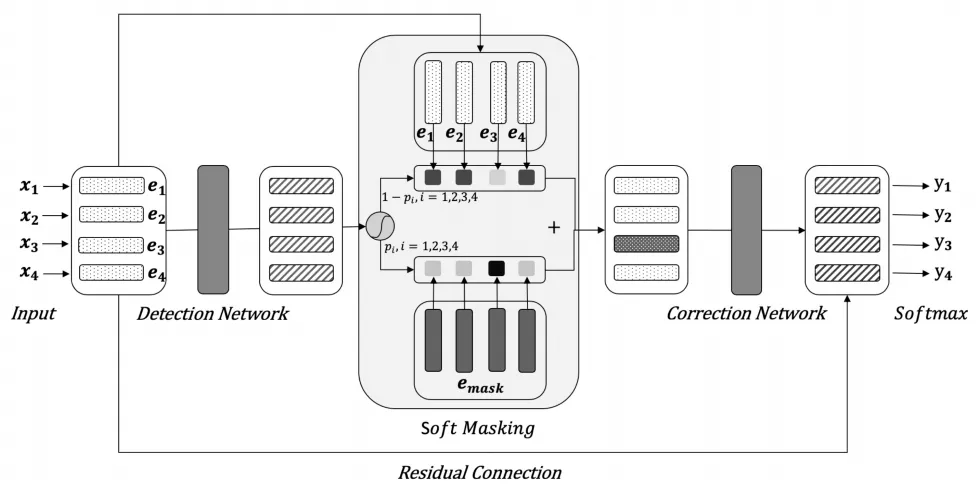
最近发表的一个纠错模型是 Soft-Masked BERT,该模型通过对搜集到的语料,进行同音字替换等简单规则随机生成错误样本,然后得到错误-正确的样本对作为训练数据。该网络模型串联了一个检测模型 ( BiGRU ) 和一个纠错模型 ( BERT ),双向的 GRU 模型输出每个 token 位置是错误词的概率,当错误概率为 1 时,退化为原生 BERT 模型纠错。
该模型的创新点在于 BERT 输入的词向量不是原始输入的 token,而是 token 的 embbeding 和 [MASK] 的 embbeding 的加权平均值,权重是 BiGRU 输出序列中每个位置的错误概率,从而在 MASK 时起到 soft-mask 的作用。举个例子,假如 GRU 认为某个位置的词输出错误概率是 1,则输入到 BERT 的词向量就是 [MASK] 的词向量;而如果是检测模型认为某个位置的词是正确的,即错误概率是 0,这时输入到 BERT 模型的词向量就是 token 的向量;但是如果检测模型的某个位置输出错误概率是 0.5,此时输入到 BERT 模型的词向量为二者加权后的结果 ( (1-0.5)* token_embedding + 0.5*[MASK]_embedding )。不同于之前检测器输出 0/1,只有被 MASK 和未被 MASK 的 Hard-Mask 方式,因此该模型称为 Soft-Mask BERT,文章指出这种方式纠错比原生的 BERT 纠错效果高出 3%左右。
小米
小米纠错模型结构也类似生成器和判别器的模式
(1) 模型结构
模型结构,模型结构
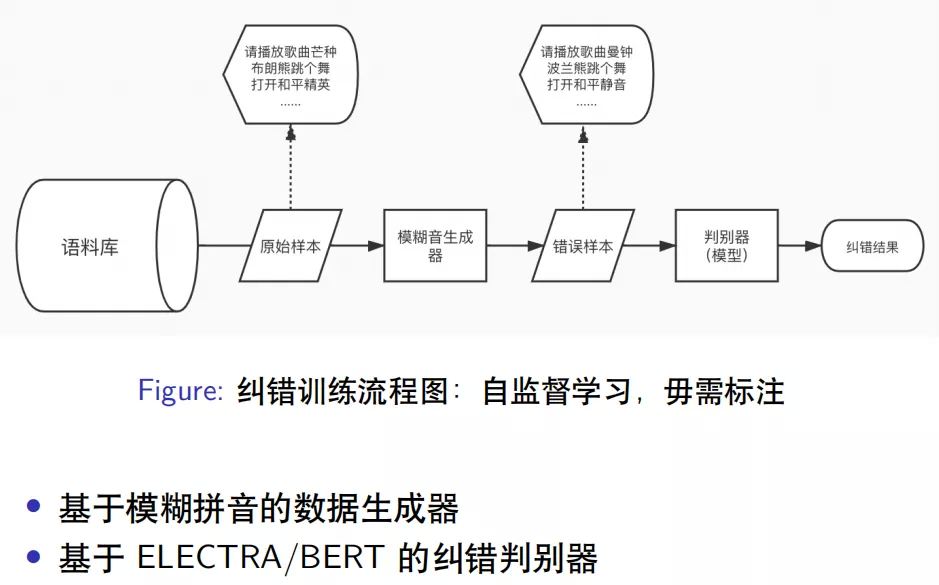
语料库包括维基百科中文、知乎中文、爬取的一些新闻语料,以及小爱同学运行的用户日志,总共将近有 1 亿条的数据,从语料库中抽样出原始样本,类似”请播放歌曲芒种”、“布朗熊跳个舞”、“打开和平精英”等等。我们开发了专门模拟 ASR 生成错误数据的模糊音生成器,基于模糊拼音来对原始样本处理生成错误样本,生成结果如”请播放歌曲曼钟”、“波兰熊跳个舞”、”打开和平静音”等等。构造好正确样本和错误样本的样本对输入到判别器模型,判别器进行端到端的纠错,即给模型输入错误样本,模型输出为正确的样本。
(2) 模糊音生成器
通过分析 ASR 错误样本的规律,在模糊音生成器中定义了模糊等级和模糊候选集
- • 模糊等级:模糊音的相似性,等级越高,发音越不相似。
- level 1: 发音完全相同(爱—艾)
- level 2: 发音相同,声调不同(几T季)
- level 3: 常见平/卷舌、前/后鼻音等模糊(是T丝)
- level 4: 拼音编辑距离为1
- level 5: 拼音编辑距离大于1,发音已经不一样了
- • 计算拼音编辑距离时,采用非标准拼音方案
- 虽(sui —> suei)
- 四(si —> sI)
- 由于”i”在”si”中和在”di”中发音是不同的,因此使用”I”来代替”i”在”si”中的发音
- 有(you —> iou)
- “y”并不是真正的声母,当”i”作为声母时用”y”替换”i”,这里相当于还原了这种实际发声拼音规则
- 挖(wa -> ua)
- “w”作为声母时真正的发音实际上是”u”
标准的拼音方案不能很好的体现汉字的发音相似问题,比如”挖”和”华”读音很相似,如果使用标准拼音方案时,拼音的编辑距离为 2 ( “wa”,“hua” ),而采用定义的非标注方案时,编辑距离为 1 (“ua”,”hua”),所以采用非标准拼音方案更能准确地描述 ASR 语音出现错误的规律,找到合适的编辑距离计算方案。
模糊音生成器的工作流程

- 输入文本为”小爱同学请播放音乐”,假设 MASK 位置随机到”爱”,模糊等级 level=1 时,发音与”爱”相同的候选集为{“哎”,“艾”,“碍”,“暧”,…},- 然后基于 n-gram 语言模型在模糊候选集中选择最可能的替代词,如果计算的词序列概率最大的是”艾”,那么”爱”被替换成了”艾”
- 最后的输出为”小艾同学请播放音乐”。
人工标记了一些 ASR 错误样本的数据,研究了声母和韵母的特征,例如平卷舌,前后鼻音等出现的识别错误。人工标注的数量毕竟有限,所以根据掌握的规律,通过调整模糊音生成器的超参数 ( MASK 的数量,fuzzy 的比例等 ),使生成的错误样本分布尽可能接近真实 ASR 系统中错误样本的数据分布,以便纠错模型可以更容易地用于 ASR 识别的纠错任务中。
(3) 纠错判别器
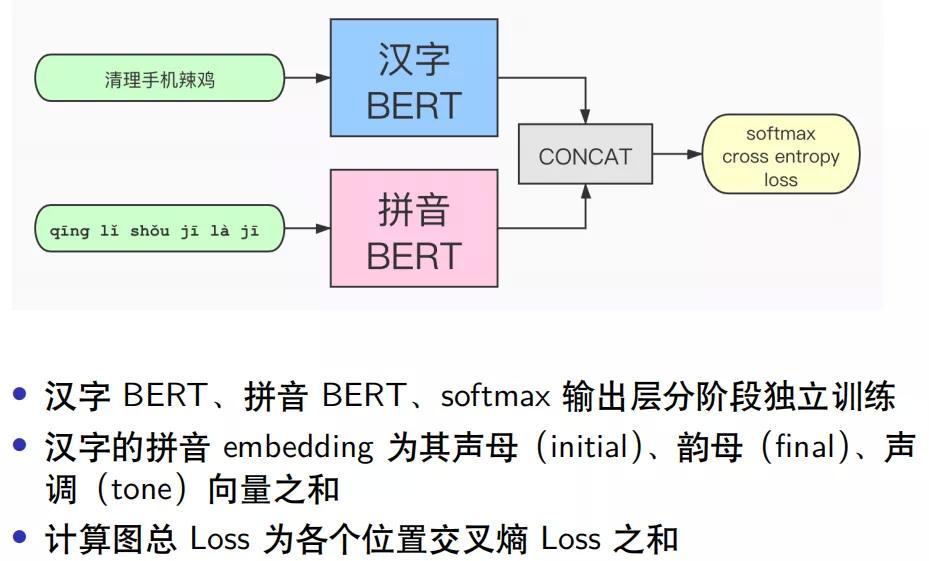
纠错判别器结构如上图所示,输入数据为汉字和拼音的特征,其中汉字经过 BERT 预训练模型得到汉字的词向量,而拼音数据则是通过 BERT 模型重新训练一个关于拼音数据的词向量,二者拼接后经过 Softmax 层,计算交叉熵损失。
为什么使用拼音的数据呢?这是因为正确的字发音一般比较相似,那么可以通过拼音来缩小搜索正确词的范围,所以拼音是一个重要的特征。并且通过尝试后,拼音和汉字单独训练再拼接提取的特征优于其他组合方式,这种方式类似于 Ensemble 模型。先用汉字语料训练一个端到端的纠错模型 BERT,再训练一个拼音到汉字的解码模型,两个模型拼接后通过输出层 softmax 训练每个位置的交叉熵损失,这点不同于原生的 BERT 模型只计算 MASK 位置的损失,而是类似于 ELECTRA 模型的损失函数。
关于拼音特征的处理过程,比较合理的做法是将拼音拆分成声母、韵母、声调,根据发音特征来得到相似发音的 embedding 表示向量,并且有相似发音的 embedding 向量要尽可能接近。汉字的拼音表示只有有限个,所有声母韵母组成的网格也只有几百个,并且拼音的写法变化也不多,所以拆分成声母、韵母、声调之后做 embedding 是合理的。如果直接对拼音做 embedding 的训练,得到的拼音表示向量无法表示出相似的发音。
评测结果,评测结果
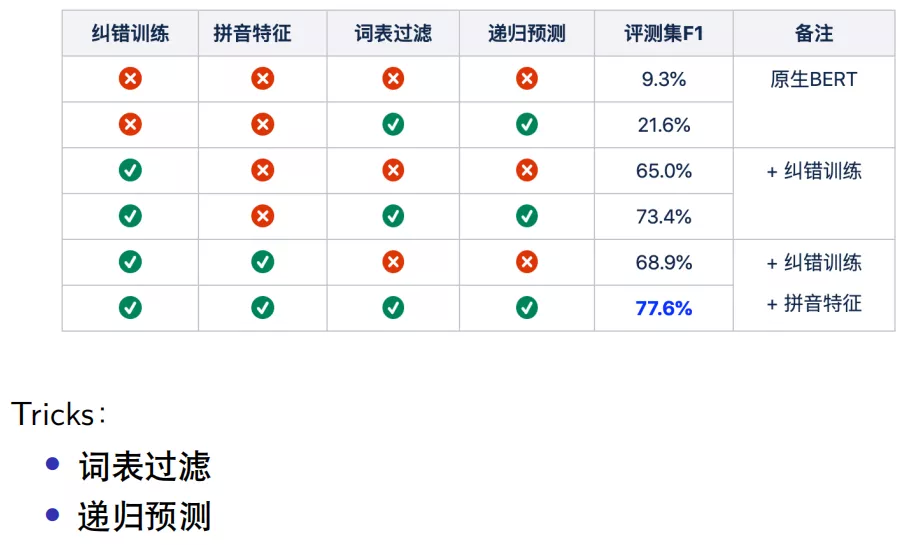
模型中使用到了两个 trick:
- 词表过滤
- 如果词表很大,比如 10000 维,想要限制一下端到端纠错模型在纠错时的搜索范围,可以对词表增加限制,比如只允许在过滤后的 300 甚至几十个相似的词语中选择,理论上召回有所损失,但是纠正的准确率大大提升,并且这种过滤程度可以调整。实际测评中显示,加入词表过滤,显著提升了模型的效果和性能。
- 递归预测
- BERT 在纠错过程中是一对一的纠错,如果一个句子中有多个错误的位置,但是对于端到端输入模型一次 Feed Forward 过程可能只纠正了一个位置,若要整个句子实现纠错,那么需要把纠正后的结果放到句子中再次输入模型,进行递归纠错。如果两次递归结果相同则停止递归纠错,否则会递归纠错最多 3 次。
从结果中发现,原生 BERT 微调之后直接纠错,模型评测指标为 9.3%,加入词表过滤和递归预测后,f1 提升到 21.6%,加入纠错训练后 f1 大幅提升到 65%,加入 trick 后,又提升到 73.4%,再加入拼音特征数据,效果提升明显,f1 提升到 77.6%。
纠错表现,纠错表现

- 可以看出,之前分析的 ASR 识别错误类型的 query,基本上能实现纠错了,比如”播放洛天依唱的忙种”能够纠正为”播放洛天依唱的芒种”,“你能帮我玩和平基因吗”纠正为”你能帮我玩和平精英吗”,”清理一下听懂灰尘”纠正为”清理一下听筒灰尘”等
虽然没有引入知识库,但是对于语料数据分布的头部知识仍然是可以纠正的,比如”芒种”、“和平精英”、”新冠肺炎”等,在语料中的占比比较高,但是对于尾部的知识,该模型纠错效果并不理想。
1. 方言识别/外语识别
这里把方言和外语一起讨论,是因为训练一个方言的语音识别模型,和训练一个外语的模型差不多,毕竟有些方言听起来感觉和外语一样。
所以方言和外语识别,就需要重新训练的语音识别模型,才能达到一个基本可用的状态。
这里就会遇到两个问题:
- 从零开始训练一个声学模型需要大量的人工标注数据,成本高,时间长,对于一些数据量有限的小语种,就更是难上加难。所以选择新语种(方言)的时候要考虑投入产出,是否可以介入第三方的先使用,顺便积累数据;
- 除了单独的外语(方言)识别之外,还有混合语言的语音识别需求,比如在香港,英文词汇经常会插入中文短语中。如果把每种语言的语言模型分开构建,会阻碍识别的平滑程度,很难实现混合识别。

未来方向

- 尽管遵循目前关于 NLP 纠错模型的设定条件,但是该模型在纠错方面仍然存在一定的局限性。后续可以考虑 BERT-Decoder 结构的模型如 GPT 系列模型,BERT-Decoder 是 seq2seq 模型,不会局限于一对一的纠错方式。
- 目前模型的领域知识是由参与训练的语料库来体现,因此对于那些小众的、处于长尾分布的数据无法实现纠错。要解决这个问题,可以借鉴 ASR 中基于 Contextual attention 的方式,把领域知识数据显示的通过某种特殊结构模型引入到纠错模型中,强制模型依赖领域知识来实现纠错。
- 模型需要实时更新,比如时下热点”传闻中的陈芊芊”,ASR 识别成了”传闻中的成仙仙”,这是由 ASR 模型对时事热点反应不及时造成的。如果用于纠错的 NLP 语料库也是是历史信息的话,很难把这类的问题进行纠正。如果只是通过不断收集新的语料来更新整个模型,对于这种庞大而臃肿的模型很难做到实时更新,因此需要探索一种让模型具备某种结构或者机制,只更新少量信息就能适应最新的时事热点。
这三个方向是未来考虑的重点,另外还可以将模型中使用的 N-gram 语言模型替换成其他强语言模型,增加任务的难度,进而可能提高纠错任务的表现。
2. 语种识别(LID)
语种识别(LID)是用来自动区分不同语言的能力,将识别结果反馈给相应语种的语音识别模型,从而实现自动化的多语言交互体验。简单理解就是计算机知道你现在说的是中文,它就用中文回复你,如果你用英文和计算机说话,计算机就用英文回复你。
语种识别主要分三个过程:首先根据语音信号进行特征提取;然后进行语种模型的构建;最后是对测试语音进行语种判决。
算法层面目前分为两类:一类是基于传统的语种识别,一种是基于神经网络的语种识别。
传统的语种识别包括基于HMM的语种识别、基于音素器的语种识别、基于底层声学特征的语种识别等。神经网络的语种识别主要基于融合深度瓶颈特征的DNN语种识别,深度神经网络中,有的隐层的单元数目被人为地调小,这种隐层被称为瓶颈层。
目前基于传统的语种识别,在复杂语种之间的识别率,只有80%左右;而基于深度学习的语种识别,理论上效果会更好。当然这和语种的多样性强相关,比如两种语言的语种识别,和十八种语言的语种识别,之间的难度是巨大的。
语种识别工具包
【2023-1-20】基于fasttext与langid文本语种识别的python代码实现
Open AI开源的whisper语音识别系统,可以识别不同的语音、语种,但是whisper主要应用在语音识别系统上,且需要大型模型。当仅仅来识别不同的语言文字,且要识别出语言文字的语种时,可以使用小型的模型来识别,比如langid,fasttext等等。
langid
早期著名的语种识别库是 langid,一个小型的语种识别库,其模型只有2.5MB的大小,精度已经达到了91.3以上,虽然模型较小,但是功能确实是比较强大,且可以支持97种的文本语种检测。
langid在如下数据集上面进行训练:
- JRC-Acquis
- ClueWeb 09
- Wikipedia
- Reuters RCV2
- Debian i18n
langid支持的97个语种:
- af, am, an, ar, as, az, be, bg, bn, br, bs, ca, cs, cy, da, de, dz, el, en, eo, es, et, eu, fa, fi, fo, fr, ga, gl, gu, he, hi, hr, ht, hu, hy, id, is, it, ja, jv, ka, kk, km, kn, ko, ku, ky, la, lb, lo, lt, lv, mg, mk, ml, mn, mr, ms, mt, nb, ne, nl, nn, no, oc, or, pa, pl, ps, pt, qu, ro, ru, rw, se, si, sk, sl, sq, sr, sv, sw, ta, te, th, tl, tr, ug, uk, ur, vi, vo, wa, xh, zh, zu
pip install langid # 安装
langid # 启用,提示需要输入的文本,直接输入不同语种的文本,langid会自动检测出文本的语种,并显示。
>>> this is a test # ('en', -40.536659240722656) 识别正确
>>> this is a test 这只是一个测试 # ('zh', -181.93558311462402) 识别不全
>>> this is 测试 # ('la', -78.2670316696167) 识别错误
Python调用
import langid
langid.set_languages(['de','fr','it']) # 可以指定候选语种,加速识别
langid.classify("This is a test") # ('en', -54.41310358047485)
fasttext
Facebook发布fasttext.
- fasttext是一个进行文本分类,识别以及单词编码的文本操作库
- fasttext同样可以进行文本的语种分类操作
fasttext small 小模型,其速度与精度都大大超过了 langid 模型。
- 不仅在模型速度与精度的区别,其fasttext的文本语种检测数量更是达到了176种的语种识别, 文档
# pip install fasttext
# https://fasttext.cc/docs/en/language-identification.html
# lid.176.bin
import fasttext
model = fasttext.load_mode('lid.176.bin') # 加载模型
text = 'this is the fasttext test'
predict = model.predict(text,k=1) # 选择概率最大的一个语种
3. 声纹识别(VPR)
声纹识别也叫做说话人识别,是生物识别技术的一种,通过声音判别说话人身份的技术。其实和人脸识别的应用有些相似,都是根据特征来判断说话人身份的,只是一个是通过声音,一个是通过人脸。
声纹识别的原理是借助不同人的声音,在语谱图中共振峰的分布情况不同这一特征,去对比两个人的声音,在相同音素上的发声来判断是否为同一个人。
主要是借助的特征有:音域特征、嗓音纯度特征、共鸣方式特征等,而对比的模型有高斯混合模型(GMM)、深度神经网络(DNN)等。
注:
- 共振峰:共振峰是指在声音的频谱中能量相对集中的一些区域,共振峰不但是音质的决定因素,而且反映了声道(共振腔)的物理特征。提取语音共振峰的方法比较多,常用的方法有倒谱法、LPC(线性预测编码)谱估计法、LPC倒谱法等。
- 语谱图:语谱图是频谱分析视图,如果针对语音数据的话,叫语谱图。语谱图的横坐标是时间,纵坐标是频率,坐标点值为语音数据能量。由于是采用二维平面表达三维信息,所以能量值的大小是通过颜色来表示的,颜色深,表示该点的语音能量越强。
声音识别也会有1to1、1toN、Nto1三种模式:
- 1to1:是判断当前发声和预存的一个声纹是否一致,有点像苹果手机的人脸解锁,判断当前人脸和手机录的人脸是否一致;
- 1toN:是判断当前发声和预存的多个声纹中的哪一个一致,有点像指纹识别,判断当前的指纹和手机里面录入的五个指纹中的哪一个一致;
- Nto1:就比较难了,同时有多个声源一起发声,判断其中那个声音和预存的声音一致,简单理解就是所有人在一起拍照,然后可以精确的找到其中某一个人。当然也有NtoN,逻辑就是所有人一起拍照,每个人都能认出来。
除了以上的分类,声纹识别还会区分为:
- 固定口令识别,就是给定你文字,你照着念就行,常见于音箱付款的验证;
- 随机口令识别,这个就比较厉害了,他不会限制你说什么,自动识别出你是谁。
声纹识别说到底就是身份识别,和我们常见的指纹识别、人脸识别、虹膜识别等都一样,都是提取特征,然后进行匹配。只是声纹的特征没有指纹等特征稳定,会受到外部条件的影响,所以没有其他的身份识别常见。
4. 情绪识别
目前情绪识别方式有很多,比如检测生理信号(呼吸、心率、肾上腺素等)、检测人脸肌肉变化、检测瞳孔扩张程度等。通过语音识别情绪也是一个维度,但是所能参考的信息有限,相较于前面谈到的方法,目前效果一般。
通过语音的情绪识别,首先要从语音信息中获取可以判断情绪的特征,然后根据这些特征再进行分类;这里主要借助的特征有:能量(energy)、音高(pitch)、梅尔频率倒谱系数(MFCC)等语音特征。
常用的分类模型有:高斯混合模型(GMM)、隐马尔可夫模型(HMM)长短时记忆模型(LSTM)等。
语音情绪识别一般会有两种方法:一种是依据情绪的不同表示方式进行分类,常见的有难过、生气、害怕、高兴等等,使用的是分类算法;还有一种是将情绪分为正面和负面两种,一般会使用回归算法。
具体使用以上哪种方法,要看实际应用情况。
如果需要根据不同的情绪,伴随不同的表情和语气进行回复,那么需要使用第一种的分类算法;如果只是作为一个参数进行识别,判断当前说话人是消极还是积极,那么第二种的回归算法就够了。
五、语音识别如何测试
由于语言文字的排列组合是无限多的,测试语音识别的效果要有大数据思维,就是基于统计学的测试方法,最好是可以多场景、多人实际测试,具体要看产品的使用场景和目标人群。
另外一般还要分为模型测试和实际测试,我们下面谈到的都是实际测试的指标。
1. 测试环境
人工智能产品由于底层逻辑是计算概率,天生就存在一定的不确定性,这份不确定性就是由外界条件的变化带来的,所以在测试语音识别效果的时候,一定要控制测试环境的条件。
往往受到以下条件影响:
- 1)环境噪音
- 最好可以在实际场景中进行测试,如果没有条件,可以模拟场景噪音,并且对噪音进行分级处理。
- 比如车载场景,分别测试30km/h、60km/h、90km/h、120km/h的识别效果,甚至需要加入车内有人说话和没人说话的情况,以及开关车窗的使用情况——这样才能反应真是的识别情况,暴露出产品的不足。
- 2)发音位置
- 发音位置同样需要根据场景去定义 ,比如车载场景:分别测试主驾驶位置、副驾驶位置、后排座位的识别效果,甚至面向不同方向的发音,都需要考虑到。
- 3)发音人(群体、语速、口音、响度)
- 发音人就是使用产品的用户,如果产品覆盖的用户群体足够广,需要考虑不同年龄段,不同地域的情况,比如你的车载语音要卖给香港人,就要考虑粤语的测试。
这里不可控的因素会比较多,有些可能遇到之后才能处理。
2. 测试数据
整个测试过程中,一般我们会先准备好要测试的数据(根据测试环境),当然测试数据越丰富,效果会越好。
首先需要准备场景相关的发音文本,一般需要准备100-10000条;其次就是在对应的测试环境制造相应的音频数据,需要在实际的麦克风阵列收音,这样可以最好的模拟实际体验;最后就是将音频和文字一一对应,给到相应的同学进行测试。
关于测试之前有过一些有趣的想法, 就是准备一些文本,然后利用TTS生成音频,再用ASR识别,测试识别的效果。这样是行不通的,根本没有实际模拟用户体验,机器的发音相对人来说太稳定了。

3. 词错率
词错率(WER):也叫字错率,计算识别错误的字数占所有识别字数的比例,就是词错率,是语音识别领域的关键性评估指标。无论多识别,还是少识别,都是识别错误。
公式如下:
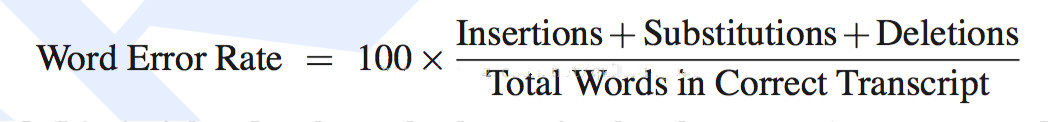
- Substitutions是替换数;
- Deletions是删除数;
- Insertions是插入次数;
- Total Words in Correct Transcript是单词数目。
这里需要注意的是,因为有插入词的存在,所以词错率可能会大于100%的,不过这种情况比较少见。
一般测试效果会受到测试集的影响,之前有大神整理过不同语料库,识别的词错率情况,数据比较老,仅供参考:
4. 句错率
句错率(SWR):表示句子中如果有一个词识别错误,那么这个句子被认为识别错误,句子识别错误的个数占总句子个数的比例,就是句错率。
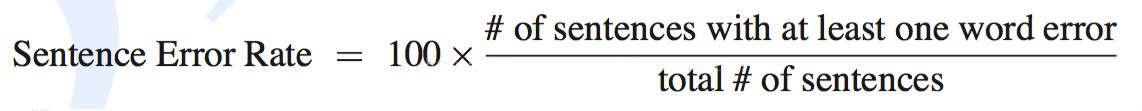
- # of sentences with at least one word error是句子识别错误的个数;
- total # of sentences是总句子的个数。
一般单纯测模型的话,主要以词错率为关键指标;用户体验方面的测试,则更多偏向于句错率。因为语音交互时,ASR把文本传给NLP,我们更关注这句话是否正确。
在实际体验中,句子识别错误的标准也会有所不同,有些场景可能需要识别的句子和用户说的句子完全一样才算正确,而有些场景可能语意相近就算正确,这取决于产品的定位,以及接下来的处理逻辑。
比如语音输入法,就需要完全一样才算正确,而一般闲聊的语音交互,可能不影响语意即可。
六、后期如何运营维护
在实际落地中,会频繁的出现ASR识别不对的问题,比如一些生僻词,阿拉伯数字的大小写,这个时候就需要通过后期运营来解决。
一句话或者一个词识别不对,可能存在多种原因;首先需要找到识别不对的原因,然后再利用现有工具进行解决。一般会分为以下几种问题:
1. VAD截断
这属于比较常见的问题,就是机器只识别了用户一部分的语音信息,另一部分没有拾到音。
这个和用户的语速有很大关系,如果用户说话比较慢的,机器就容易以为用户说完了,所以会产生这样的问题。
一般的解决方案分为两种:第一种是根据用户群体的平均语速,设置截断的时间,一般400ms差不多;第二种是根据一些可见的细节去提示用户,注意说话的语速。
2. 语言模型修改
这类问题感知最强,表面上看就是我说了一句话,机器给我识别成了一句不想相关的内容:这种问题一方面和用户想要识别的词相关,一方面和用户的发音有关,我们先不考虑用户的发音。
一般生僻词会遇到识别错误的问题,这主要是模型在训练的时候没有见过这类的内容,所以在识别的时候会比较吃力。遇到这种问题,解决方案是在语言模型里面加入这个词。
比如说:我想看魑魅魍魉,训练的时候没有“魑魅魍魉”这四个字,就很可能识别错误,我们只需要在语言模型中加入这个词就可以。一般工程师会把模型做成热更新的方式,方便我们操作。
有的虽然不是生僻字,但还是会出现竞合问题,竞合就是两个词发音非常像,会互相冲突。一般我们会把想要识别的这句话,都加到语言模型。
比如:带我去宜家商场,这句话里面的“宜家”可能是“一家”,两个词之间就会出现竞合。如果客户希望识别的是“宜家”,那我们就把 “带我去宜家商场”整句话都加入到语言模型之中。

3. 干预解决
还有一类识别错误的问题,基本上没有解决方法。
虽然我们上面说了在语言模型中加词,加句子,但实际操作的时候,你就会发现并不好用;有些词就算加在语言模型里面,还是会识别错误,这其实就是一个概率问题。
这个时候我们可以通过一些简单粗暴的方式解决。
我们一般会ASR模型识别完成之后,再加入一个干预的逻辑,有点像NLP的预处理。在这步我们会将识别错误的文本强行干预成预期的识别内容,然后再穿给NLP。
比如:我想要一个switch游戏机,而机器总是识别成“我想要一个思维词游戏机”,这个时候我们就可以通过干预来解决,让“思维词”=“switch”,这样识别模型给出的还是“我想要一个思维词游戏机”。
我们通过干预,给NLP的文本就是“我想要一个switch游戏机”。

七、未来展望
目前在理想环境下,ASR的识别效果已经非常好了,已经超越人类速记员了。但是在复杂场景下,识别效果还是非常大的进步空间,尤其鸡尾酒效应、竞合问题等。
1. 强降噪发展
面对复杂场景的语音识别,还是会存在问题,比如我们常说的鸡尾酒效应,目前仍然是语音识别的瓶颈。针对复杂场景的语音识别,未来可能需要端到端的深度学习模型,来解决常见的鸡尾酒效应。
2. 语音链路整合
大部分公司会把ASR和NLP分开来做研发,认为一个是解决声学问题,一个是解决语言问题。其实对用户来讲,体验是一个整体。
未来可以考虑两者的结合,通过NLP的回复、或者反馈,来动态调整语言模型,从而实现更准确的识别效果,避免竞合问题。
3. 多模态结合
未来有可能结合图像算法的能力,比如唇语识别、表情识别等能力,辅助提高ASR识别的准确率。比如唇语识别+语音识别,来解决复杂场景的,声音信息混乱的情况。
目前很多算法的能力都是一个一个的孤岛,需要产品经理把这些算法能力整合起来,从而作出更准确的判断。
八、总结
语音识别就是把声学信号转化成文本信息的一个过程,中间最核心的算法是声学模型和语言模型,其中声学模型负责找到对应的拼音,语言模型负责找到对应的句子。
后期运营我们一般会对语言模型进行调整,来解决识别过程中的badcase。
通过声音,我们可以做语种识别、声纹识别、情绪识别等,主要是借助声音的特征进行识别,其中常用的特征有能量(energy)、音高(pitch)、梅尔频率倒谱系数(MFCC)等。
未来语音识别必将会和自然语言处理相结合,进一步提高目前的事变效果,对环境的依赖越来越小。
实践
详见站内专题: 语音识别工具
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
