sklearn
- 【2021-7-1】温州大学黄海广机器学习库Scikit-learn库使用总结, github
- 【2024-6-19】go语言版本的sklearn: pa-m/sklearn, example-LogisticRegression
Scikit-LLM
【2023-5-29】Scikit-LLM:将大语言模型整合进Sklearn的工作流
- Scikit-LLM,融合强大的语言模型,如ChatGPT和scikit-learn
安装配置
# !pip install scikit-llm
# importing SKLLMConfig to configure OpenAI API (key and Name)
from skllm.config import SKLLMConfig
# Set your OpenAI API key
SKLLMConfig.set_openai_key("<YOUR_KEY>")
# Set your OpenAI organization (optional)
SKLLMConfig.set_openai_org("<YOUR_ORGANIZATION>")
文本向量化
文本向量化是将文本转换为数字的过程
- Scikit-LLM中的GPTVectorizer模块,可以将一段文本(无论文本有多长)转换为固定大小的一组向量。
# Importing the necessary modules and classes
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import LabelEncoder
from xgboost import XGBClassifier
# Creating an instance of LabelEncoder class
le = LabelEncoder()
# Encoding the training labels 'y_train' using LabelEncoder
y_train_encoded = le.fit_transform(y_train)
# Encoding the test labels 'y_test' using LabelEncoder
y_test_encoded = le.transform(y_test)
# Defining the steps of the pipeline as a list of tuples
steps = [('GPT', GPTVectorizer()), ('Clf', XGBClassifier())]
# Creating a pipeline with the defined steps
clf = Pipeline(steps)
# Fitting the pipeline on the training data 'X_train' and the encoded training labels 'y_train_encoded'
clf.fit(X_train, y_train_encoded)
# Predicting the labels for the test data 'X_test' using the trained pipeline
yh = clf.predict(X_test)
文本摘要
GPT非常擅长总结文本。在Scikit-LLM中有一个叫GPTSummarizer的模块。
# Importing the GPTSummarizer class from the skllm.preprocessing module
from skllm.preprocessing import GPTSummarizer
# Importing the get_summarization_dataset function
from skllm.datasets import get_summarization_dataset
# Calling the get_summarization_dataset function
X = get_summarization_dataset()
# Creating an instance of the GPTSummarizer
s = GPTSummarizer(openai_model='gpt-3.5-turbo', max_words=15)
# Applying the fit_transform method of the GPTSummarizer instance to the input data 'X'.
# It fits the model to the data and generates the summaries, which are assigned to the variable 'summaries'
summaries = s.fit_transform(X)
注意
- max_words超参数是对生成摘要中单词数量的灵活限制。
- 虽然max_words为摘要长度设置了一个粗略的目标,但摘要器可能偶尔会根据输入文本的上下文和内容生成略长的摘要。
零样本分类:ZeroShotGPTClassifier
ZeroShotGPTClassifier
- 整合ChatGPT, 不需要训练就对文本进行分类。
- ZeroShotGPTClassifier,就像任何其他scikit-learn分类器一样,使用非常简单。
Scikit-LLM在结果上经过了特殊处理,确保响应只包含一个有效的标签。
- 如果响应缺少标签,还可以进行填充,根据它在训练数据中出现的频率选择一个标签。
# importing zeroshotgptclassifier module and classification dataset
from skllm import ZeroShotGPTClassifier
from skllm.datasets import get_classification_dataset
# get classification dataset from sklearn for prediction only
X, _ = get_classification_dataset()
# defining the model
clf = ZeroShotGPTClassifier()
clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo") # 指定模型版本
# Since no training so passing the labels only for prediction
clf.fit(X, y) # 自动填充标签
clf.fit(None, ['positive', 'negative', 'neutral']) # 用户自定义标签
# predicting the labels
labels = clf.predict(X)
多标签分类:MultiLabelZeroShotGPTClassifier
多标签分类
# importing Multi-Label zeroshot module and classification dataset
from skllm import MultiLabelZeroShotGPTClassifier
from skllm.datasets import get_multilabel_classification_dataset
# ----- 默认 -----
# get classification dataset from sklearn
X, y = get_multilabel_classification_dataset()
# defining the model 要指定分配给每个样本的最大标签数量(这里:max_labels=3)
clf = MultiLabelZeroShotGPTClassifier(max_labels=3)
# fitting the model
clf.fit(X, y)
# ----- 自定义类目 -----
# getting classification dataset for prediction only
X, _ = get_multilabel_classification_dataset()
# Defining all the labels that needs to predicted
candidate_labels = [
"Quality",
"Price",
"Delivery",
"Service",
"Product Variety"
]
# creating the model
clf = MultiLabelZeroShotGPTClassifier(max_labels=3)
# fitting the labels only
clf.fit(None, [candidate_labels])
# making predictions
labels = clf.predict(X)
分类
sklearn解决的典型问题

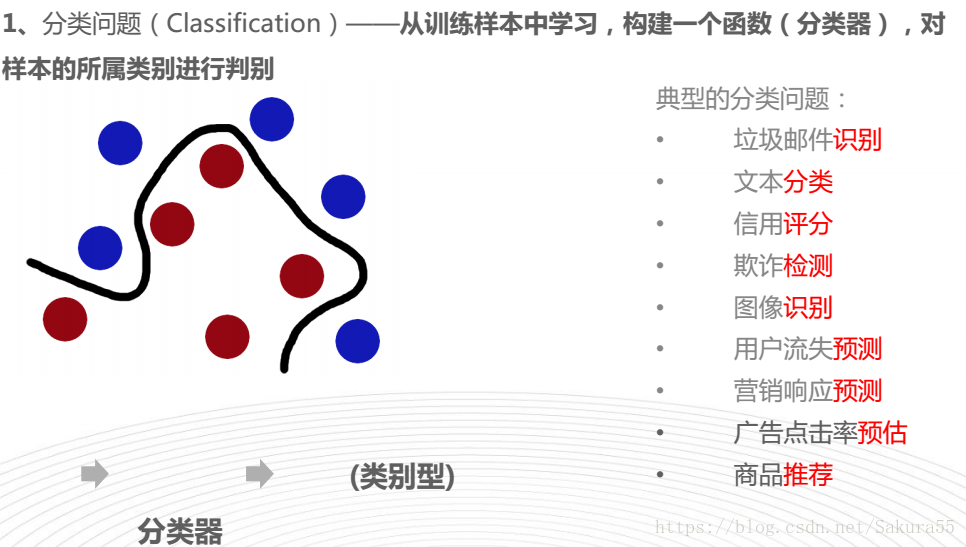
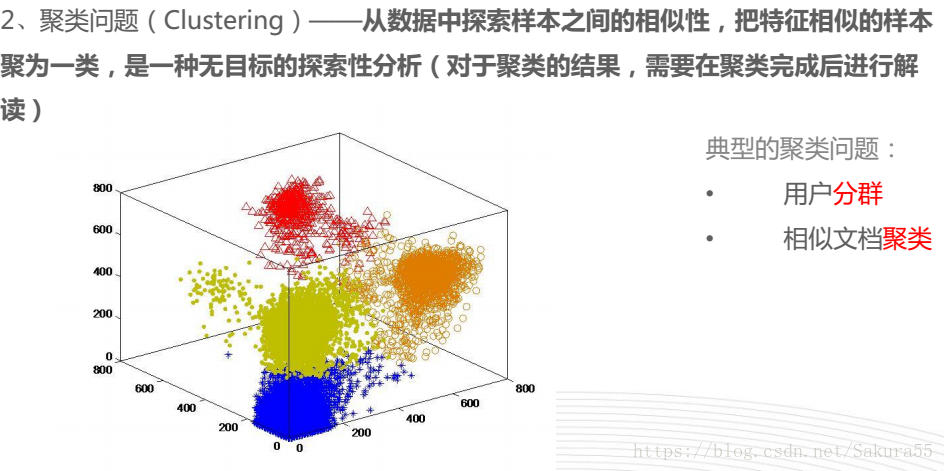
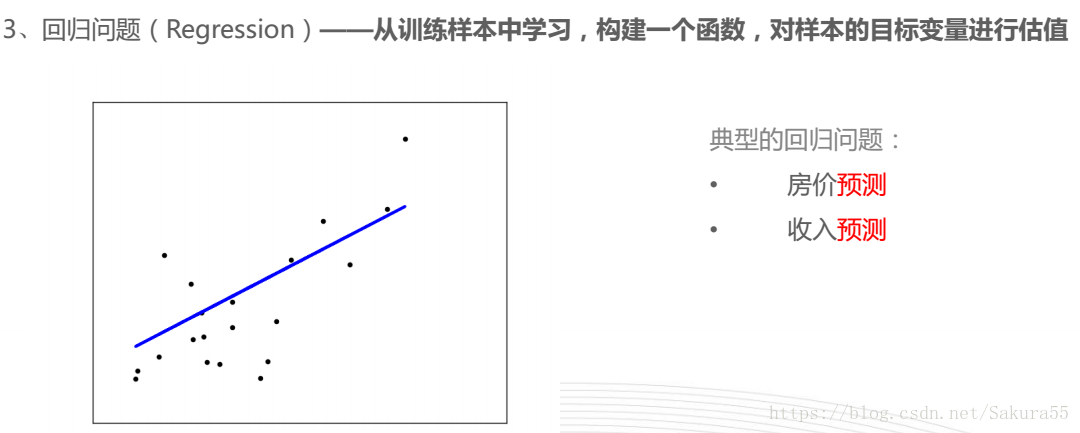

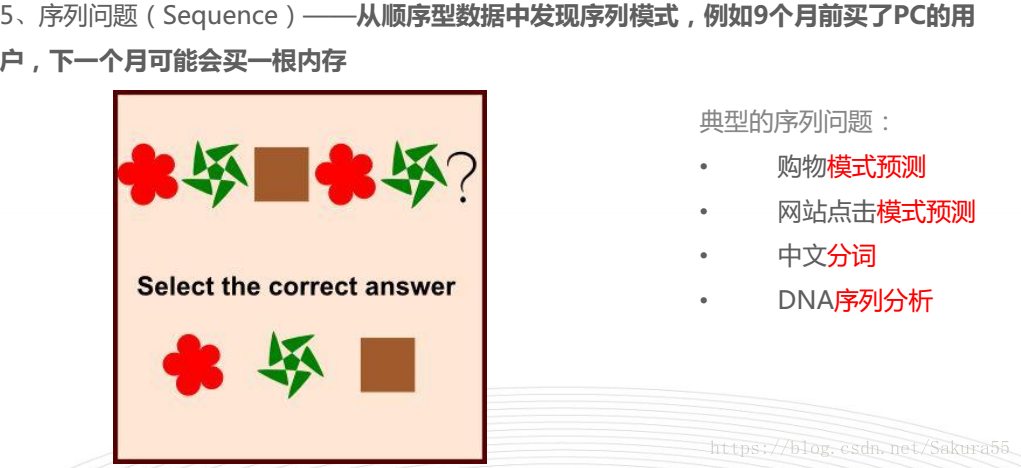
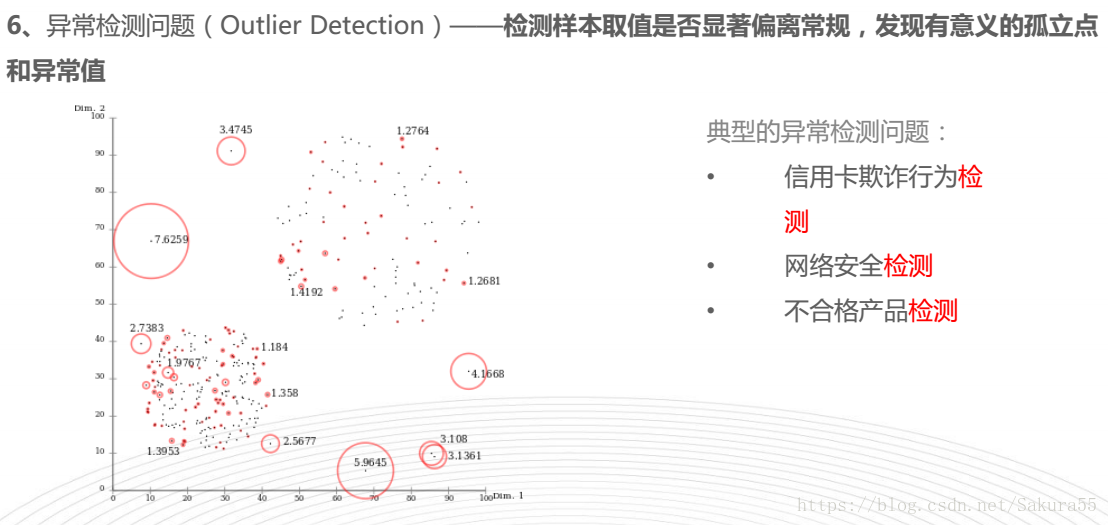
思维导图, 机器学习—-scikit-learn入门

流程
- 利用sklearn中pipeline构建机器学习工作流
- Scikit-learn pipeline 实现了对全部步骤的流式化封装和管理(streaming workflows with pipelines),可以很方便地使参数集在新数据集(比如测试集)上被重复使用。
- Pipeline可以将许多算法模型串联起来,比如将特征提取、归一化、分类组织在一起形成一个典型的机器学习问题工作流。
- 主要带来两点好处:
- 直接调用fit和predict方法来对pipeline中的所有算法模型进行训练和预测。
- 可以结合grid search对参数进行选择。
Parameters- steps : 步骤:列表(list)
- 被连接的(名称,变换)元组(实现拟合/变换)的列表,按照它们被连接的顺序,最后一个对象是估计器(estimator)。
- memory:内存参数,Instance of sklearn.external.joblib.Memory or string, optional (default=None)属性,name_steps:bunch object,具有属性访问权限的字典
- 只读属性以用户给定的名称访问任何步骤参数。键是步骤名称,值是步骤参数。或者也可以直接通过”.步骤名称”获取
funcution- Pipline的方法都是执行各个学习器中对应的方法,如果该学习器没有该方法,会报错
- 假设该Pipline共有n个学习器
- transform,依次执行各个学习器的transform方法
- fit,依次对前n-1个学习器执行fit和transform方法,第n个学习器(最后一个学习器)执行fit方法
- predict,执行第n个学习器的predict方法
- score,执行第n个学习器的score方法
- set_params,设置第n个学习器的参数
- get_param,获取第n个学习器的参数
Pipeline对训练集和测试集进行如下操作:- 先用 StandardScaler 对数据集每一列做标准化处理,(是 transformer)
- 再用 PCA 将原始的 30 维度特征压缩的 2 维度,(是 transformer)
- 最后再用模型 LogisticRegression。(是 Estimator)
from pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'
'breast-cancer-wisconsin/wdbc.data', header=None)
# Breast Cancer Wisconsin dataset
X, y = df.values[:, 2:], df.values[:, 1]
encoder = LabelEncoder()
y = encoder.fit_transform(y)
encoder.transform(['M', 'B'])
# array([1, 0])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2, random_state=0)
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
pipe_lr = Pipeline([('sc', StandardScaler()),
('pca', PCA(n_components=2)),
('clf', LogisticRegression(random_state=1))
])
pipe_lr.fit(X_train, y_train)
print('Test accuracy: %.3f' % pipe_lr.score(X_test, y_test))
- Pipeline 的工作方式:
- 当管道 Pipeline 执行 fit 方法时,
- 首先 StandardScaler 执行 fit 和 transform 方法,
- 然后将转换后的数据输入给 PCA,
- PCA 同样执行 fit 和 transform 方法,
- 再将数据输入给 LogisticRegression,进行训练。
- 示意图
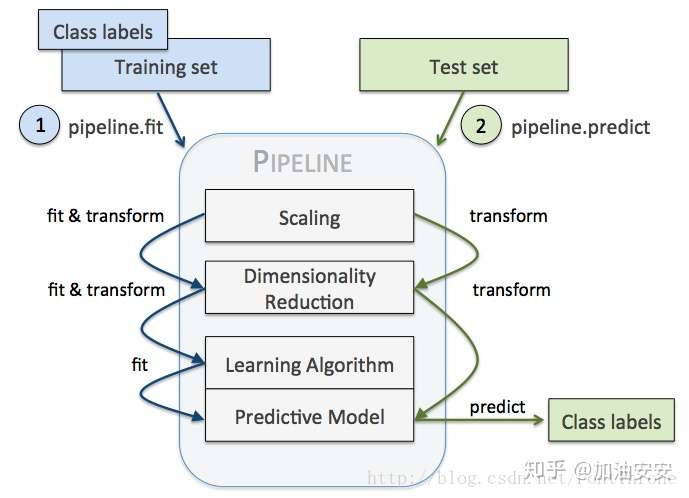
向量化
将特征转成向量,方便ML模型处理
jiaba分词+向量化
import re
import pandas as pd
# 测试数据
df = pd.DataFrame([['你好,我是链家经纪人', 20],['贝壳是房地产公司', 13],['贝壳分下降了怎么办,你帮忙看下',30],['[哭泣]',23]], columns=['query','freq'])
print(df.shape)
# 加载停用词
stop_words = [line.strip() for line in open('stopWord2.txt', encoding='gbk').readlines()]
# 分词函数一:中文分词,包括除去数字字母及停用词,得到一个分词用空格隔开的字符串,便于向量化(因为这个CountVouterizer()是针对英文分词的,英文之间直接用空格隔开的)
def cut_word(sent):
line = re.sub(r'[a-zA-Z0-9]*','',sent)
wordList = jieba.lcut(line,cut_all=False)
#文本分词,并且用空格连接起来,便于下面向量化
return ' '.join([word for word in wordList if word not in stopWord and len(word)>1])
# 分词函数二:没去停用词,CountVouterizer()中可以直接添加停用词表参数,不统计文档中的停用词的数量
def cutword(sent):
line = re.sub(r'[a-zA-Z0-9]*','',sent)
wordList = jieba.lcut(line,cut_all=False)
return ' '.join([word for word in wordList if len(word)>1])
# 分词函数三:精准分词,选择词性
import jieba.posseg as pseg
def jieba_cut(comment):
word_list = [] # 建立空列表用于存储分词结果
seg_list = pseg.cut(comment) # 精确模式分词[默认模式]
for word in seg_list:
if word.flag in ['ns', 'n', 'vn', 'v', 'nr']: # 选择属性
word_list.append(word.word) # 分词追加到列表
return word_list
#将文本分词,并且分词用空格隔开变成文本存才DataFrame中
df['word_list']=df['query'].map(cutword)
#df['word_list']=df['query'].apply(cutword) # apply也行
# 向量化
vectorizer = TfidfVectorizer(stop_words=stop_words, tokenizer=jieba_cut, use_idf=True) # 创建词向量模型
X = vectorizer.fit_transform(comment_list) # 将评论关键字列表转换为词向量空间模型
# K均值聚类
model_kmeans = KMeans(n_clusters=3) # 创建聚类模型对象
model_kmeans.fit(X) # 训练模型
# 聚类结果汇总
cluster_labels = model_kmeans.labels_ # 聚类标签结果
word_vectors = vectorizer.get_feature_names() # 词向量
word_values = X.toarray() # 向量值
comment_matrix = np.hstack((word_values, cluster_labels.reshape(word_values.
shape[0], 1))) # 将向量值和标签值合并为新的矩阵
word_vectors.append('cluster_labels') # 将新的聚类标签列表追加到词向量后面
comment_pd = pd.DataFrame(comment_matrix, columns=word_vectors) # 创建包含词向量和聚类标签的数据框
comment_pd.to_csv('comment.csv')
print(comment_pd.head(1)) # 打印输出数据框第1条数据
# 聚类结果分析
comment_cluster1 = comment_pd[comment_pd['cluster_labels'] == 1].drop('cluster_labels', axis=1) # 选择聚类标签值为1的数据,并删除最后一列
word_importance = np.sum(comment_cluster1, axis=0) # 按照词向量做汇总统计
print(word_importance.sort_values(ascending=False)[:5]) # 按汇总统计的值做逆序排序并打印输出前5个词
文本向量化
向量
词向量是大语言模型的必经之路。一问一答之间,尽显词向量的身影。
- 词向量难理解的地方不在于“词”,而在于“向量”。
- 向量是一个具有“方向”和“大小”的变量。
Google 的projector
- 10000个词汇,经过200个维度的描述处理后,投射到3维空间所呈现的视觉效果。
- 和man发生关联的词语有5778个, 有“son”、“uncle”、“father”、“king”这些词
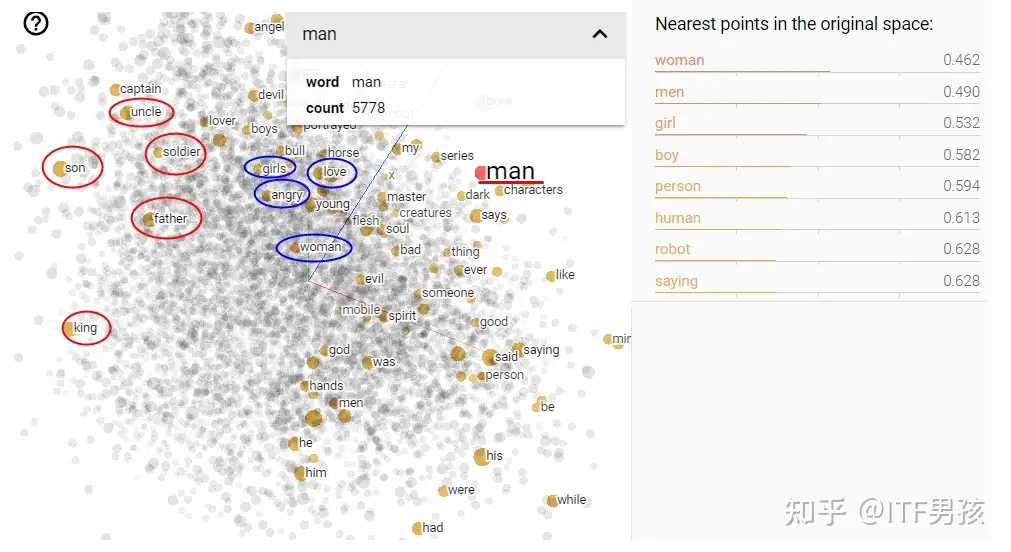
- 动图见原文
这种将词汇向量化的操作,成为:“Embedding”,翻译成中文叫“嵌入”。
相似度计算
相似度计算
- 余弦相似度缺陷:只评判方向,不关注长度。
from text2vec import SentenceModel, cos_sim
# 从目录加载模型
model = SentenceModel("text2vec")
# 转为向量
emb1 = model.encode(["我的错题从哪里可以查看"])
emb2 = model.encode(["如何查看错题记录"])
# 利用cos_sim计算相似度
cosine_scores = cos_sim(emb1, emb2)
print("Score: {:.2f}".format(cosine_scores[0][0]))
# [我的错题从哪里可以查看] VS [如何查看错题记录] Score: 0.79
# [我的错题从哪里可以查看] VS [Python是编程语言] Score: 0.24
文档问答
流程图是一个基于本地文档库问答的开源项目。
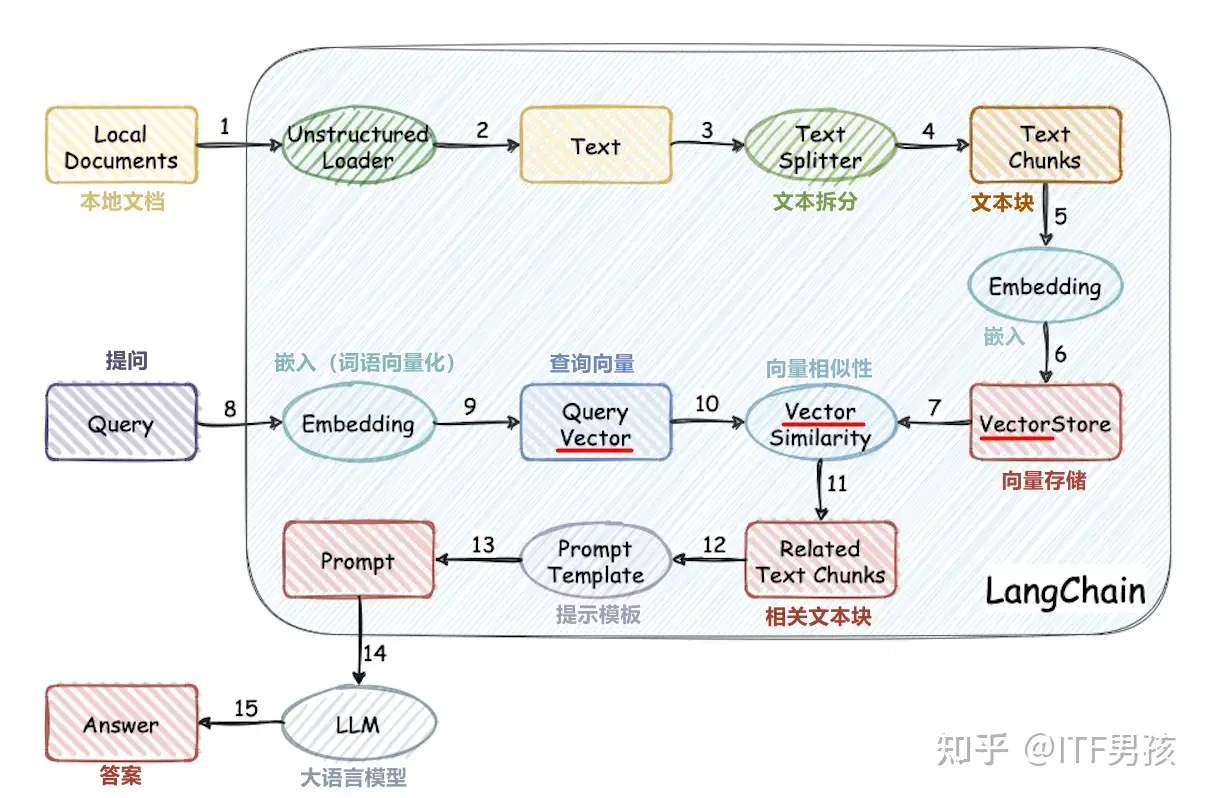
- 15个流程,3处涉及到了Vector(词向量)。另外还有两处的Embedding,是将文本转为向量的操作,这也和向量有关。
text2vec
text2vec
- 文本向量表征工具,把文本转化为向量矩阵,实现了 Word2Vec、RankBM25、Sentence-BERT、CoSENT 等文本表征、文本相似度计算模型,开箱即用。
Word2Vec:通过腾讯AI Lab开源的大规模高质量中文词向量数据(800万中文词轻量版) (文件名:light_Tencent_AILab_ChineseEmbedding.bin 密码: tawe)实现词向量检索,本项目实现了句子(词向量求平均)的word2vec向量表示SBERT(Sentence-BERT) :权衡性能和效率的句向量表示模型,训练时通过有监督训练上层分类函数,文本匹配预测时直接句子向量做余弦,本项目基于PyTorch复现了Sentence-BERT模型的训练和预测CoSENT(Cosine Sentence) :CoSENT模型提出了一种排序的损失函数,使训练过程更贴近预测,模型收敛速度和效果比Sentence-BERT更好,本项目基于PyTorch实现了CoSENT模型的训练和预测- CoSENT(Cosine Sentence)文本匹配模型,在Sentence-BERT上改进了CosineRankLoss的句向量方案
免费商用, 在产品说明中附加text2vec的链接和授权协议

# pip install torch # conda install pytorch
# pip install -U text2vec
# 本地启动
# python examples/gradio_demo.py
from text2vec import SentenceModel
m = SentenceModel()
m.encode("如何更换花呗绑定银行卡") # Embedding shape: (768,)
# ----------
from text2vec import SentenceModel
# 从目录加载离线模型
model = SentenceModel("text2vec")
# 将文本向量化
embeddings = model.encode(['男人'])
# 给每段embedding的文本赋予了768个维度
print(embeddings.shape, embeddings)
sklearn向量化函数
向量化的几个函数
- (1)
CountVectorizer:只考虑每个单词频率(不考虑顺序),然后构成一个特征矩阵,每一行表示一个训练文本的词频统计结果。其思想是先根据所有训练文本,不考虑其出现顺序,只将训练文本中每个出现过的词汇单独视为一列特征,构成一个词汇表(vocabulary list),该方法又称为词袋法(Bag of Words)。 - (2)
TfidfVectorizer:把原始文本转化为tf-idf的特征矩阵,从而为后续的文本相似度计算,主题模型(如LSI),文本搜索排序等一系列应用奠定基础。
【2021-11-9】sklearn: TfidfVectorizer 中文处理及一些使用参数
TfidfVectorizer() 基于tf-idf算法。此算法包括两部分tf和idf,两者相乘得到tf-idf算法。- tf算法统计某训练文本中,某个词的出现次数
- idf算法,用于调整词频的权重系数,如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。
- $ idf(w) = log(总样本数/(包含w的文档数+1)) $
- 计算公式:$ tf - idf算法 = tf算法 * idf算法 $
sklearn进行TF-IDF预处理
- 第一种:在用 CountVectorizer 类向量化之后再调用 TfidfTransformer 类进行预处理。
- 第二种:直接用 TfidfVectorizer 完成向量化与 TF-IDF 预处理。
英文向量化
CountVectorizer使用bow词袋模型
from sklearn.feature_extraction.text import TfidfVectorizer
document = ["I have a pen.",
"I have an apple."]
tfidf_model = TfidfVectorizer().fit(document) # tf-idf模型
print('词汇表: ', tfidf_model.vocabulary_) # 词语与列的对应关系
sparse_result = tfidf_model.transform(document) # 得到tf-idf矩阵,稀疏矩阵表示法
print('矩阵: ', sparse_result.todense()) # 转化为更直观的一般矩阵
方法一:CountVectorizer+TfidfTransformer
# coding=utf-8
# ------ bow词袋法 ------
from sklearn.feature_extraction.text import CountVectorizer
texts=["orange banana apple grape", "banana apple apple","grape", 'orange apple']
cv = CountVectorizer()
cv_fit=cv.fit_transform(texts)
print(cv.get_feature_names())#获得上面稀疏矩阵的列索引,即特征的名字(就是分词)
print(cv.vocabulary_)
# {'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2} #这里是根据首字母顺序,将texts变量中所有单词进行排序,apple首字母为a所以排第一,banana首字母为b所以排第二
print(cv_fit) # 单词映射表
# 格式:(字符串id, 第几个word) 频次; 整体理解为第一字符串的顺序为二的词语在出现次数为1
# (0, 2) 1 # 1表示第一个字符串"orange banana apple grape";2对应上面的'grape': 2;1表示出现次数1。
# (0, 0) 1
# (0, 1) 1
# (0, 3) 1
# (1, 0) 2
# (1, 1) 1
# (2, 2) 1
# (3, 0) 1
# (3, 3) 1
print(cv_fit.toarray()) # 向量化输出
# [[1 1 1 1] # 第一个字符串,排名0,1,2,3词汇(apple,banana,grape,orange)出现的频率都为1
# [2 1 0 0] #第二个字符串,排名0,1,2,3词汇(apple,banana,grape,orange)出现的频率为2,1,00
# [0 0 1 0]
# [1 0 0 1]]
# ------- IDF方法① ------
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
vectorizer=CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
print (tfidf)
方法二:直接使用 TfidfVectorizer
# ------- IDF方法② ------
from sklearn.feature_extraction.text import TfidfVectorizer
texts=["orange banana apple grape","banana apple apple","grape", 'orange apple']
cv = TfidfVectorizer()
cv_fit=cv.fit_transform(texts) # 一步到位:训练+转换
print(cv.vocabulary_) # 词库:{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
print(cv.get_feature_names())#获得上面稀疏矩阵的列索引,即特征的名字(就是分词)
print(cv_fit) # 单词映射表
# (0, 3) 0.5230350301866413 #(0,3)表示第一个字符串的orange词语,其TF=1/4,IDF中总样本和包含有改词的文档数,#目前也不知道是如何得出,望有知道的人能评论告之。最后得出结果0.5230350301866413
# (0, 1) 0.5230350301866413
# (0, 0) 0.423441934145613
# (0, 2) 0.5230350301866413
# (1, 1) 0.5254635733493682
# (1, 0) 0.8508160982744233
# (2, 2) 1.0
# (3, 3) 0.7772211620785797
# (3, 0) 0.6292275146695526
print(cv_fit.toarray()) # 向量化矩阵
#[[0.42344193 0.52303503 0.52303503 0.52303503]
# [0.8508161 0.52546357 0. 0. ]
# [0. 0. 1. 0. ]
# [0.62922751 0. 0. 0.77722116]]
document = ["I have a pen.", "I have an apple."]
tfidf_model = TfidfVectorizer().fit(document)
sparse_result = tfidf_model.transform(document) # 得到tf-idf矩阵,稀疏矩阵表示法
print(sparse_result)
# (0, 3) 0.814802474667 # 第0个字符串,对应词典序号为3的词的TFIDF为0.8148
# (0, 2) 0.579738671538
# (1, 2) 0.449436416524
# (1, 1) 0.631667201738
# (1, 0) 0.631667201738
print(sparse_result.todense()) # 转化为更直观的一般矩阵
# [[ 0. 0. 0.57973867 0.81480247]
# [ 0.6316672 0.6316672 0.44943642 0. ]]
print(tfidf_model.vocabulary_) # 词语与列的对应关系
# {'have': 2, 'pen': 3, 'an': 0, 'apple': 1}
中文向量化
英文词语之间有空格自然分割,而中文没有,所以需要提前分词
TfidfVectorizer 方法参数如下:
stop_words:指定为自定义的去除词的列表,不指定默认会使用英文的停用词列表。tokenizer:用来设置定义的分词器,这里是在上面自定义的结巴分词。默认的分词器对于英文下工作良好,但对于中文来讲效果不佳。use_idf:设置为True指定TF-IDF方法做词频转向量。max_df/min_df: [0.0, 1.0]内浮点数或正整数, 默认值=1.0- 当设置为浮点数时,过滤出现在超过max_df/低于min_df比例的句子中的词语;正整数时,则是超过max_df句句子。
- 这样就可以帮助我们过滤掉出现太多的无意义词语
max_feature: 限制最多使用多少个词语,模型会优先选取词频高的词语留下,避免词表爆炸
简洁版
import jieba
import jieba.posseg as pseg
from sklearn.feature_extraction.text import TfidfVectorizer
def jieba_cut(comment):
word_list = [] # 建立空列表用于存储分词结果
seg_list = pseg.cut(comment) # 精确模式分词[默认模式]
for word in seg_list:
if word.flag in ['ns', 'n', 'vn', 'v', 'nr']: # 选择属性
word_list.append(word.word) # 分词追加到列表
return word_list
text = """我是一条天狗呀!
我把月来吞了,
我把日来吞了,
我把一切的星球来吞了,
我把全宇宙来吞了。
我便是我了!"""
# --- 停用词 ----
# 加载停用词
stop_words = [line.strip() for line in open('data/stop_words').readlines()]
#stop_words = [line.strip() for line in open('data/stop_words', encoding='gbk').readlines()]
# --- 分词 ----
sentences = text.split('\n')
sent_words = [list(jieba.cut(sent0)) for sent0 in sentences]
document = [" ".join(sent0) for sent0 in sent_words]
print('转换后中文序列: ', document)
# ---- TF-IDF建模 -----
vectorizer = TfidfVectorizer(stop_words=stop_words, tokenizer=jieba_cut, use_idf=True) # 创建词向量模型
#vectorizer = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b", max_df=0.6, ngram_range=(1,2,3), stop_words=stop_words)
tfidf_model = vectorizer.fit(document) #
print('词汇表: ', tfidf_model.vocabulary_) # 词表
# ------- id-idf矩阵 --------
#print(tfidf_model5.transform(document).todense()) # tf-idf矩阵
# ------- idf向量化 -------
sparse_result = tfidf_model.transform(document) # 矩阵
#X = vectorizer.fit_transform(document) # 一步到位, 将评论关键字列表转换为词向量空间模型
print('转换后-稀疏矩阵: ', sparse_result) #
print(sparse_result.todense())# 转化为更直观的一般矩阵
print('转换后-稠密矩阵: ', X.shape)
详情版
import jieba
text = """我是一条天狗呀!
我把月来吞了,
我把日来吞了,
我把一切的星球来吞了,
我把全宇宙来吞了。
我便是我了!"""
sentences = text.split()
sent_words = [list(jieba.cut(sent0)) for sent0 in sentences]
document = [" ".join(sent0) for sent0 in sent_words]
print(document)
# ['我 是 一条 天狗 呀 !', '我 把 月 来 吞 了 ,', '我 把 日来 吞 了 ,', '我 把 一切 的 星球 来 吞 了 ,', '我 把 全宇宙 来 吞 了 。', '我 便是 我 了 !']
# ----- 向量化 -----
tfidf_model = TfidfVectorizer().fit(document)
print(tfidf_model.vocabulary_)
# {'一条': 1, '天狗': 4, '日来': 5, '一切': 0, '星球': 6, '全宇宙': 3, '便是': 2}
# 问题:单字的词语,如“我”、“吞”、“呀”等词语怎么都不见了?
# 原因:token_pattern参数使用正则来分词,默认取值为 r"(?u)\b\w\w+\b" ,默认只保留2个字以上的单词,所以单字词汇被过滤掉
# 修改:token_pattern=r"(?u)\b\w+\b",单字词汇出现
tfidf_model2 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b").fit(document)
print(tfidf_model2.vocabulary_)
# {'我': 8, '是': 12, '一条': 1, '天狗': 7, '呀': 6, '把': 9, '月': 13, '来': 14, '吞': 5, '了': 2, '日来': 10, '一切': 0, '的': 15, '星球': 11, '全宇宙': 4, '便是': 3}
# 参数:max_df/min_df: [0.0, 1.0]内浮点数或正整数, 默认值=1.0
# 作用:过滤无意义词汇,当设置为浮点数时,过滤出现在超过max_df/低于min_df比例的句子中的词语;正整数时,则是超过max_df句句子。
# 示例:过滤出现在超过60%的句子中的词语
tfidf_model3 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b", max_df=0.6).fit(document)
print(tfidf_model3.vocabulary_)
# {'是': 8, '一条': 1, '天狗': 5, '呀': 4, '月': 9, '来': 10, '日来': 6, '一切': 0, '的': 11, '星球': 7, '全宇宙': 3, '便是': 2}
# 参数:stop_words: list类型
# 作用:直接过滤指定的停用词
# 示例:过滤停用词
tfidf_model4 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b", max_df=0.6, stop_words=["是", "的"]).fit(document)
print(tfidf_model4.vocabulary_)
# {'一条': 1, '天狗': 5, '呀': 4, '月': 8, '来': 9, '日来': 6, '一切': 0, '星球': 7, '全宇宙': 3, '便是': 2}
# 参数:vocabulary: dict类型
# 作用:直接指定词库内容,即只使用特定的词汇,其形式与上面看到的tfidf_model4.vocabulary_相同,也是指定对应关系。
# 示例:这一参数的使用有时能帮助我们专注于一些词语,比如我对本诗中表达感情的一些特定词语(甚至标点符号)感兴趣,就可以设定这一参数,只考虑他们:
tfidf_model5 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b",vocabulary={"我":0, "呀":1,"!":2}).fit(document)
print(tfidf_model5.vocabulary_)
# {'我': 0, '呀': 1, '!': 2}
# ------- id-idf矩阵 --------
print(tfidf_model5.transform(document).todense())
# [[ 0.40572238 0.91399636 0. ]
# [ 1. 0. 0. ]
# [ 1. 0. 0. ]
# [ 1. 0. 0. ]
# [ 1. 0. 0. ]
# 参数:ngram_range: tuple
# 作用:有时候单个的词语作为特征还不足够,能够加入一些词组更好,就可以设置这个参数,如下面允许词表使用1个词语,或者2个词语的组合:
# 示例:这里顺便使用了一个方便的方法 get_feature_names() ,可以以列表的形式得到所有的词语
tfidf_model5 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b", ngram_range=(1,2), stop_words=["是", "的"]).fit(document)
print(tfidf_model5.get_feature_names())
"""
['一切', '一切 星球', '一条', '一条 天狗', '了', '便是', '便是 我', '全宇宙', '全宇宙 来', '吞', '吞 了', '呀', '天狗', '天狗 呀', '我', '我 一条', '我 了', '我 便是', '我 把', '把', '把 一切', '把 全宇宙', '把 日来', '把 月', '日来', '日来 吞', '星球', '星球 来', '月', '月 来', '来', '来 吞']
"""
# 参数:max_feature: int
# 作用:在大规模语料上训练TFIDF会得到非常多的词语,如果再使用了上一个设置加入了词组,那么我们词表的大小就会爆炸。出于时间和空间效率的考虑,可以限制最多使用多少个词语,模型会优先选取词频高的词语留下。
# 示例:下面限制最多使用10个词语
tfidf_model6 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b", max_features=10, ngram_range=(1,2), stop_words=["是", "的"]).fit(document)
print(tfidf_model6.vocabulary_)
"""
{'我': 3, '把': 5, '来': 8, '吞': 1, '了': 0, '我 把': 4, '来 吞': 9, '吞 了': 2, '日来 吞': 6, '星球': 7}
"""
# ------- idf向量化 -------
sparse_result = tfidf_model.transform(document)
print(sparse_result)
# (0, 4) 0.707106781187
# (0, 1) 0.707106781187
# (2, 5) 1.0
# (3, 6) 0.707106781187
# (3, 0) 0.707106781187
# (4, 3) 1.0
# (5, 2) 1.0
print(sparse_result.todense()) # 转化为更直观的一般矩阵
预测
神经网络
scikit-learn 库中的 MLPRegressor 类,该类可用 DNN 进行回归估计。DNN 有时也被称为多层感知器(multi-layer perceptron,MLP)
- 【2022-11-12】神经网络与传统统计方法对比
from sklearn.neural_network import MLPRegressor
# 生成样本数据
def f(x):
return 2 * x ** 2 - x ** 3 / 3
x = np.linspace(-2, 4, 25)
y = f(x)
# 实例化 MLPRegressor 对象
model = MLPRegressor(hidden_layer_sizes=3 * [256], learning_rate_init=0.03, max_iter=5000)
# 拟合或学习步骤。
model.fit(x.reshape(-1, 1), y)
# 预测步骤
y_ = model.predict(x.reshape(-1, 1))
MSE = ((y - y_) ** 2).mean()
MSE
# Out:
# 0.003216321978018745
plt.figure(figsize=(10, 6))
plt.plot(x, y, 'ro', label='sample data')
plt.plot(x, y_, lw=3.0, label='dnn estimation')
plt.legend();
sklearn 集成学习
1 前言
很多人在竞赛(Kaggle,天池等)或工程实践中使用了集成学习(例如,RF、GTB等),确实也取得了不错的效果,在保证准确度的同时也提升了模型防止过拟合的能力。但是,我们真的用对了集成学习吗?
sklearn提供了sklearn.ensemble库,支持众多集成学习算法和模型。恐怕大多数人使用这些工具时,要么使用默认参数,要么根据模型在测试集上的性能试探性地进行调参(当然,完全不懂的参数还是不动算了),要么将调参的工作丢给调参算法(网格搜索等)。这样并不能真正地称为“会”用sklearn进行集成学习。
我认为,学会调参是进行集成学习工作的前提。然而,第一次遇到这些算法和模型时,肯定会被其丰富的参数所吓到,要知道,教材上教的伪代码可没这么多参数啊!!!没关系,暂时,我们只要记住一句话:参数可分为两种,一种是影响模型在训练集上的准确度或影响防止过拟合能力的参数;另一种不影响这两者的其他参数。模型在样本总体上的准确度(后简称准确度)由其在训练集上的准确度及其防止过拟合的能力所共同决定,所以在调参时,我们主要对第一种参数进行调整,最终达到的效果是:模型在训练集上的准确度和防止过拟合能力的大和谐!
本篇博文将详细阐述模型参数背后的理论知识,在下篇博文中,我们将对最热门的两个模型Random Forrest和Gradient Tree Boosting(含分类和回归,所以共4个模型)进行具体的参数讲解。如果你实在无法静下心来学习理论,你也可以在下篇博文中找到最直接的调参指导,虽然我不赞同这么做。
2 集成学习是什么?
集成学习是一种技术框架,其按照不同的思路来组合基础模型,从而达到其利断金的目的。
目前,有三种常见的集成学习框架:bagging,boosting 和 stacking。国内,南京大学的周志华教授对集成学习有很深入的研究,其在09年发表的一篇概述性论文《Ensemble Learning》对这三种集成学习框架有了明确的定义,概括如下:
- bagging:从训练集从进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果:
- boosting:训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转化。对所有基模型预测的结果进行线性综合产生最终的预测结果:
- stacking:将训练好的所有基模型对训练基进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
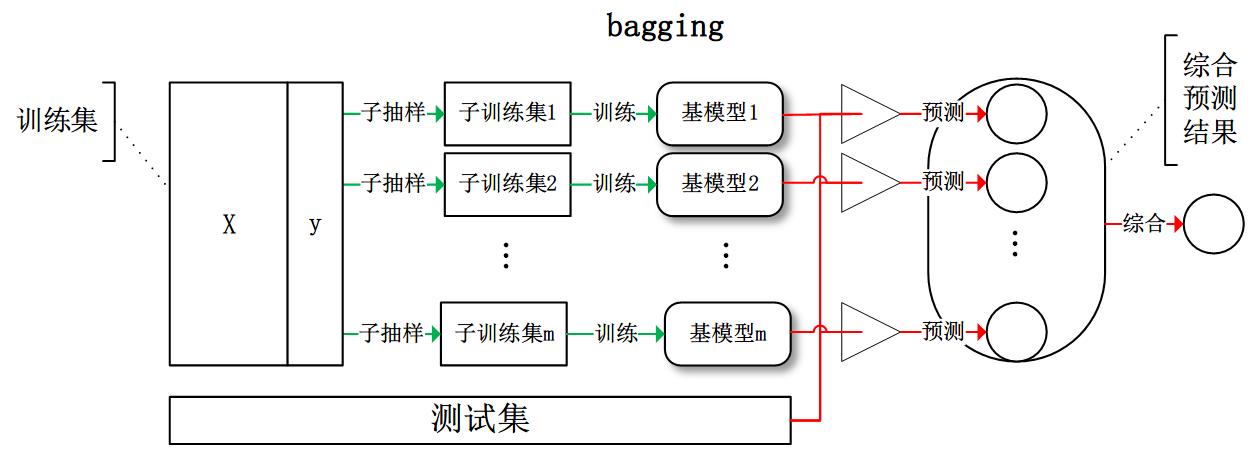
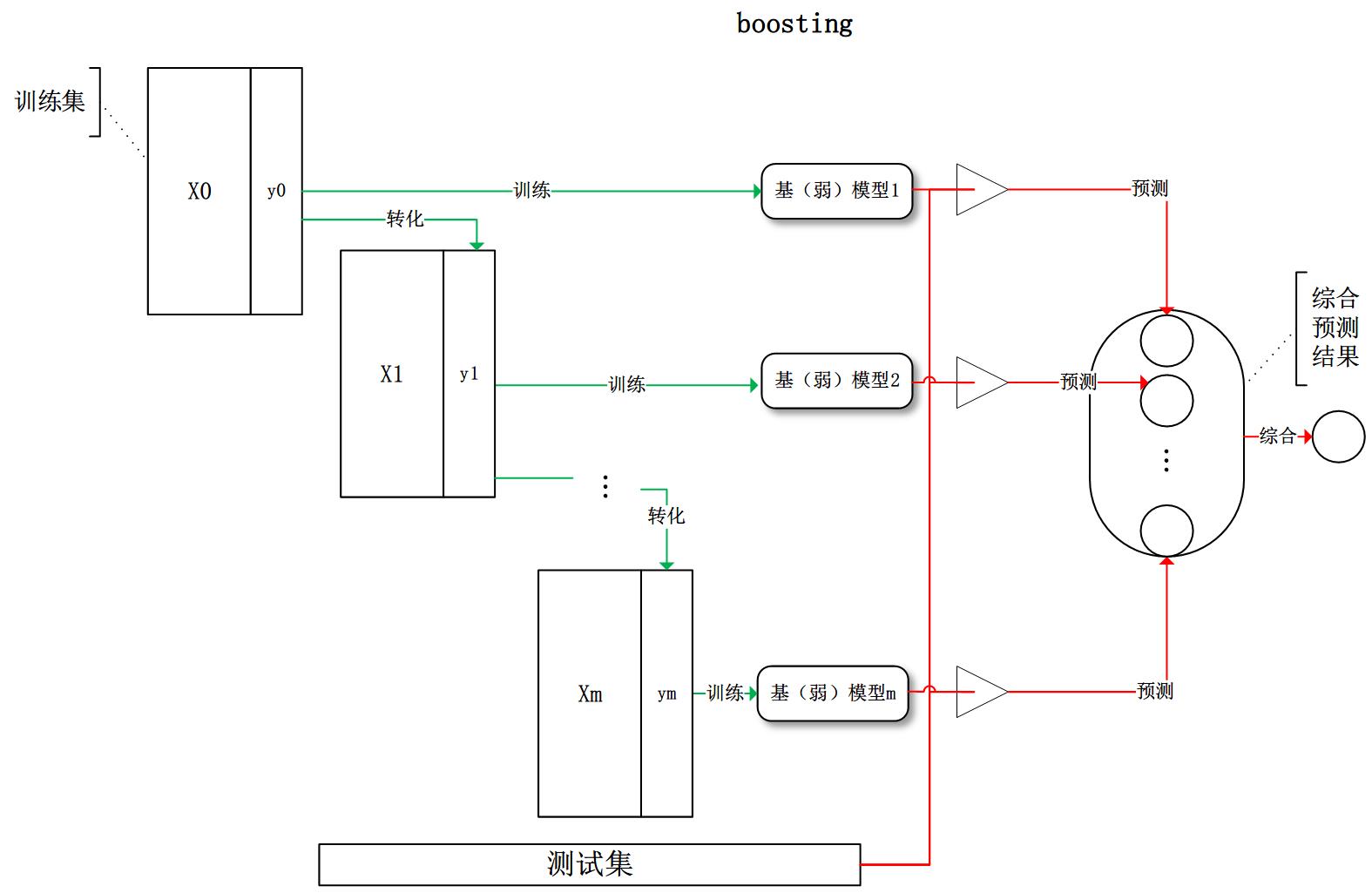
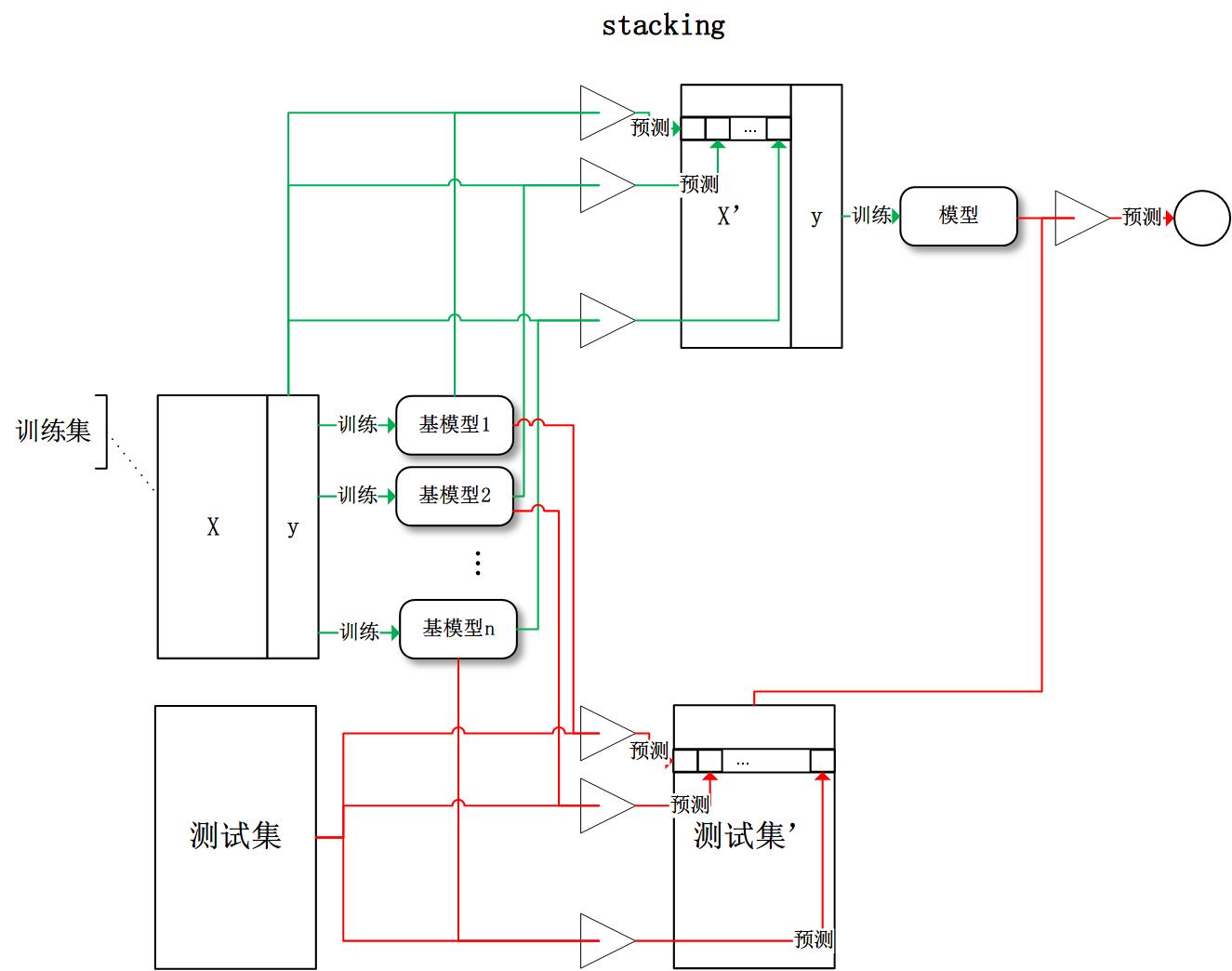
有了这些基本概念之后,直觉将告诉我们,由于不再是单一的模型进行预测,所以模型有了“集思广益”的能力,也就不容易产生过拟合现象。但是,直觉是不可靠的,接下来我们将从模型的偏差和方差入手,彻底搞清楚这一问题。
3 偏差和方差
广义的偏差(bias)描述的是预测值和真实值之间的差异,方差(variance)描述距的是预测值作为随机变量的离散程度。《Understanding the Bias-Variance Tradeoff》当中有一副图形象地向我们展示了偏差和方差的关系:

3.1 模型的偏差和方差是什么?
模型的偏差是一个相对来说简单的概念:训练出来的模型在训练集上的准确度。
要解释模型的方差,首先需要重新审视模型:模型是随机变量。设样本容量为n的训练集为随机变量的集合(X1, X2, …, Xn),那么模型是以这些随机变量为输入的随机变量函数(其本身仍然是随机变量):F(X1, X2, …, Xn)。抽样的随机性带来了模型的随机性。
定义随机变量的值的差异是计算方差的前提条件,通常来说,我们遇到的都是数值型的随机变量,数值之间的差异再明显不过(减法运算)。但是,模型的差异性呢?我们可以理解模型的差异性为模型的结构差异,例如:线性模型中权值向量的差异,树模型中树的结构差异等。在研究模型方差的问题上,我们并不需要对方差进行定量计算,只需要知道其概念即可。
研究模型的方差有什么现实的意义呢?我们认为方差越大的模型越容易过拟合:假设有两个训练集A和B,经过A训练的模型Fa与经过B训练的模型Fb差异很大,这意味着Fa在类A的样本集合上有更好的性能,而Fb反之,这便是我们所说的过拟合现象。
我们常说集成学习框架中的基模型是弱模型,通常来说弱模型是偏差高(在训练集上准确度低)方差小(防止过拟合能力强)的模型。但是,并不是所有集成学习框架中的基模型都是弱模型。bagging和stacking中的基模型为强模型(偏差低方差高),boosting中的基模型为弱模型。
在bagging和boosting框架中,通过计算基模型的期望和方差,我们可以得到模型整体的期望和方差。为了简化模型,我们假设基模型的权重、方差及两两间的相关系数相等。由于bagging和boosting的基模型都是线性组成的,那么有:

3.2 bagging的偏差和方差
对于bagging来说,每个基模型的权重等于1/m且期望近似相等(子训练集都是从原训练集中进行子抽样),故我们可以进一步化简得到:
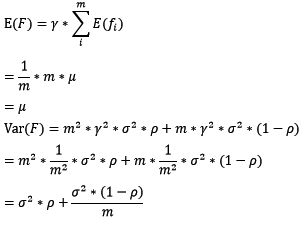
根据上式我们可以看到,整体模型的期望近似于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。同时,整体模型的方差小于等于基模型的方差(当相关性为1时取等号),随着基模型数(m)的增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于1吗?并不一定,当基模型数增加到一定程度时,方差公式第二项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。另外,在此我们还知道了为什么bagging中的基模型一定要为强模型,否则就会导致整体模型的偏差度低,即准确度低。
Random Forest是典型的基于bagging框架的模型,其在bagging的基础上,进一步降低了模型的方差。Random Fores中基模型是树模型,在树的内部节点分裂过程中,不再是将所有特征,而是随机抽样一部分特征纳入分裂的候选项。这样一来,基模型之间的相关性降低,从而在方差公式中,第一项显著减少,第二项稍微增加,整体方差仍是减少。
3.3 boosting的偏差和方差
对于boosting来说,基模型的训练集抽样是强相关的,那么模型的相关系数近似等于1,故我们也可以针对boosting化简公式为:
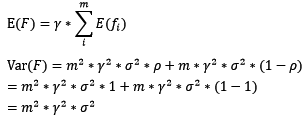
通过观察整体方差的表达式,我们容易发现,若基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大,即无法达到防止过拟合的效果。因此,boosting框架中的基模型必须为弱模型。
因为基模型为弱模型,导致了每个基模型的准确度都不是很高(因为其在训练集上的准确度不高)。随着基模型数的增多,整体模型的期望值增加,更接近真实值,因此,整体模型的准确度提高。但是准确度一定会无限逼近于1吗?仍然并不一定,因为训练过程中准确度的提高的主要功臣是整体模型在训练集上的准确度提高,而随着训练的进行,整体模型的方差变大,导致防止过拟合的能力变弱,最终导致了准确度反而有所下降。
基于boosting框架的Gradient Tree Boosting模型中基模型也为树模型,同Random Forrest,我们也可以对特征进行随机抽样来使基模型间的相关性降低,从而达到减少方差的效果。
3.4 模型的独立性
聪明的读者这时肯定要问了,如何衡量基模型的独立性?我们说过,抽样的随机性决定了模型的随机性,如果两个模型的训练集抽样过程不独立,则两个模型则不独立。这时便有一个天大的陷阱在等着我们:bagging中基模型的训练样本都是独立的随机抽样,但是基模型却不独立呢?
我们讨论模型的随机性时,抽样是针对于样本的整体。而bagging中的抽样是针对于训练集(整体的子集),所以并不能称其为对整体的独立随机抽样。那么到底bagging中基模型的相关性体现在哪呢?在知乎问答《为什么说bagging是减少variance,而boosting是减少bias?》中请教用户“过拟合”后,我总结bagging的抽样为两个过程:
- 样本抽样:整体模型F(X1, X2, …, Xn)中各输入随机变量(X1, X2, …, Xn)对样本的抽样
- 子抽样:从整体模型F(X1, X2, …, Xn)中随机抽取若干输入随机变量成为基模型的输入随机变量
假若在子抽样的过程中,两个基模型抽取的输入随机变量有一定的重合,那么这两个基模型对整体样本的抽样将不再独立,这时基模型之间便具有了相关性。
3.5 小结
还记得调参的目标吗:模型在训练集上的准确度和防止过拟合能力的大和谐!为此,我们目前做了一些什么工作呢?
- 使用模型的偏差和方差来描述其在训练集上的准确度和防止过拟合的能力
- 对于bagging来说,整体模型的偏差和基模型近似,随着训练的进行,整体模型的方差降低
- 对于boosting来说,整体模型的初始偏差较高,方差较低,随着训练的进行,整体模型的偏差降低(虽然也不幸地伴随着方差增高),当训练过度时,因方差增高,整体模型的准确度反而降低
- 整体模型的偏差和方差与基模型的偏差和方差息息相关 这下总算有点开朗了,那些让我们抓狂的参数,现在可以粗略地分为两类了:控制整体训练过程的参数和基模型的参数,这两类参数都在影响着模型在训练集上的准确度以及防止过拟合的能力。
4 Gradient Boosting
对基于Gradient Boosting框架的模型的进行调试时,我们会遇到一个重要的概念:损失函数。在本节中,我们将把损失函数的“今生来世”讲个清楚!
基于boosting框架的整体模型可以用线性组成式来描述,其中h[i](x)为基模型与其权值的乘积:
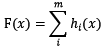
根据上式,整体模型的训练目标是使预测值F(x)逼近真实值y,也就是说要让每一个基模型的预测值逼近各自要预测的部分真实值。由于要同时考虑所有基模型,导致了整体模型的训练变成了一个非常复杂的问题。所以,研究者们想到了一个贪心的解决手段:每次只训练一个基模型。那么,现在改写整体模型为迭代式:
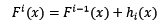
这样一来,每一轮迭代中,只要集中解决一个基模型的训练问题:使F[i](x)逼近真实值y。
4.1 拟合残差
使F[i](x)逼近真实值,其实就是使h[i](x)逼近真实值和上一轮迭代的预测值F[i-1](x)之差,即残差(y-F[i-1](x))。最直接的做法是构建基模型来拟合残差,在博文《GBDT(MART)迭代决策树入门教程 简介》中,作者举了一个生动的例子来说明通过基模型拟合残差,最终达到整体模型F(x)逼近真实值。
研究者发现,残差其实是最小均方损失函数的关于预测值的反向梯度:

也就是说,若F[i-1](x)加上拟合了反向梯度的h[i](x)得到F[i](x),该值可能将导致平方差损失函数降低,预测的准确度提高!这显然不是巧合,但是研究者们野心更大,希望能够创造出一种对任意损失函数都可行的训练方法,那么仅仅拟合残差是不恰当的了。
4.2 拟合反向梯度
4.2.1 契机:引入任意损失函数
引入任意损失函数后,我们可以定义整体模型的迭代式如下:
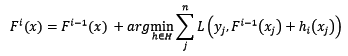 在这里,损失函数被定义为泛函。
在这里,损失函数被定义为泛函。
4.2.2 难题一:任意损失函数的最优化
对任意损失函数(且是泛函)的最优化是困难的。我们需要打破思维的枷锁,将整体损失函数L’定义为n元普通函数(n为样本容量),损失函数L定义为2元普通函数(记住!!!这里的损失函数不再是泛函!!!):

我们不妨使用梯度最速下降法来解决整体损失函数L’最小化的问题,先求整体损失函数的反向梯度:
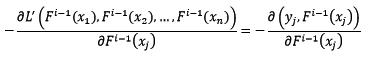
假设已知样本x的当前预测值为F[i-1](x),下一步将预测值按照反向梯度,依照步长为r[i],进行更新:
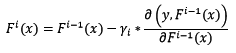
步长r[i]不是固定值,而是设计为:
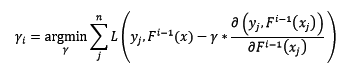
4.2.3 难题二:无法对测试样本计算反向梯度
问题又来了,由于测试样本中y是未知的,所以无法求反向梯度。这正是Gradient Boosting框架中的基模型闪亮登场的时刻!在第i轮迭代中,我们创建训练集如下:
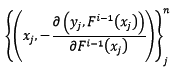
也就是说,让基模型拟合反向梯度函数,这样我们就可以做到只输入x这一个参数,就可求出其对应的反向梯度了(当然,通过基模型预测出来的反向梯度并不是准确的,这也提供了泛化整体模型的机会)。
综上,假设第i轮迭代中,根据新训练集训练出来的基模型为f[i](x),那么最终的迭代公式为:
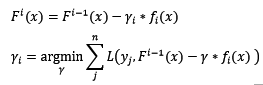
4.3 常见的损失函数
ls:最小均方回归中用到的损失函数。在之前我们已经谈到,从拟合残差的角度来说,残差即是该损失函数的反向梯度值(所以又称反向梯度为伪残差)。不同的是,从拟合残差的角度来说,步长是无意义的。该损失函数是sklearn中Gradient Tree Boosting回归模型默认的损失函数。
deviance:逻辑回归中用到的损失函数。熟悉逻辑回归的读者肯定还记得,逻辑回归本质是求极大似然解,其认为样本服从几何分布,样本属于某类别的概率可以logistic函数表达。所以,如果该损失函数可用在多类别的分类问题上,故其是sklearn中Gradient Tree Boosting分类模型默认的损失函数。
exponential:指数损失函数,表达式为:
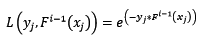
对该损失函数求反向梯度得:
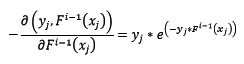
这时,在第i轮迭代中,新训练集如下:

脑袋里有什么东西浮出水面了吧?让我们看看Adaboost算法中,第i轮迭代中第j个样本权值的更新公式:

样本的权值什么时候会用到呢?计算第i轮损失函数的时候会用到:
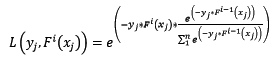
让我们再回过头来,看看使用指数损失函数的Gradient Boosting计算第i轮损失函数:
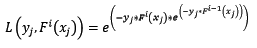
天呐,两个公式就差了一个对权值的归一项。这并不是巧合,当损失函数是指数损失时,Gradient Boosting相当于二分类的Adaboost算法。是的,指数损失仅能用于二分类的情况。
4.4 步子太大容易扯着蛋:缩减
缩减也是一个相对显见的概念,也就是说使用Gradient Boosting时,每次学习的步长缩减一点。这有什么好处呢?缩减思想认为每次走一小步,多走几次,更容易逼近真实值。如果步子迈大了,使用最速下降法时,容易迈过最优点。将缩减代入迭代公式:
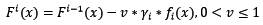
缩减需要配合基模型数一起使用,当缩减率v降低时,基模型数要配合增大,这样才能提高模型的准确度。
4.5 初始模型
还有一个不那么起眼的问题,初始模型F[0](x)是什么呢?如果没有定义初始模型,整体模型的迭代式一刻都无法进行!所以,我们定义初始模型为:
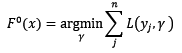
根据上式可知,对于不同的损失函数来说,初始模型也是不一样的。对所有的样本来说,根据初始模型预测出来的值都一样。
4.5 Gradient Tree Boosting
终于到了备受欢迎的Gradient Tree Boosting模型了!但是,可讲的却已经不多了。我们已经知道了该模型的基模型是树模型,并且可以通过对特征的随机抽样进一步减少整体模型的方差。我们可以在维基百科的Gradient Boosting词条中找到其伪代码实现。
4.6 小结
到此,读者应当很清楚Gradient Boosting中的损失函数有什么意义了。要说偏差描述了模型在训练集准确度,则损失函数则是描述该准确度的间接量纲。也就是说,模型采用不同的损失函数,其训练过程会朝着不同的方向进行!
5 总结
磨刀不误砍柴功,我们花了这么多时间来学习必要的理论,我强调一次:必要的理论!集成学习模型的调参工作的核心就是找到合适的参数,能够使整体模型在训练集上的准确度和防止过拟合的能力达到协调,从而达到在样本总体上的最佳准确度。有了本文的理论知识铺垫,在下篇中,我们将对Random Forest和Gradient Tree Boosting中的每个参数进行详细阐述,同时也有一些小试验证明我们的结论。
服务部署
模型转换
m2cgen(Model 2 Code Generator)是轻量级 Python 库,快速将已训练统计模型转化为 Python、C 和 Java 代码。
- m2cgen 已经支持各种分类模型与回归模型,包括: 支持向量机、决策树、随机森林和梯度提升树等
注意:
- 这些都是统计机器学习模型,深度神经网络还是老老实实使用 DL 框架。
参考
安装
pip install m2cgen
示例
命令行转换
m2cgen <pickle_file> --language <language> [--indent <indent>]
[--class_name <class_name>] [--package_name <package_name>]
[--recursion-limit <recursion_limit>]
代码转换
from sklearn.datasets import load_boston
from sklearn import linear_model
import m2cgen as m2c
boston = load_boston()
X, y = boston.data, boston.target
estimator = linear_model.LinearRegression()
estimator.fit(X, y)
# 线性回归模型转化为 Java 代码
code = m2c.export_to_java(estimator)
转化后的代码:
public class Model {
public static double score(double[] input) {
return (((((((((((((36.45948838508965) + ((input[0]) * (-0.10801135783679647))) + ((input[1]) * (0.04642045836688297))) + ((input[2]) * (0.020558626367073608))) + ((input[3]) * (2.6867338193449406))) + ((input[4]) * (-17.76661122830004))) + ((input[5]) * (3.8098652068092163))) + ((input[6]) * (0.0006922246403454562))) + ((input[7]) * (-1.475566845600257))) + ((input[8]) * (0.30604947898516943))) + ((input[9]) * (-0.012334593916574394))) + ((input[10]) * (-0.9527472317072884))) + ((input[11]) * (0.009311683273794044))) + ((input[12]) * (-0.5247583778554867));
}
}
C++ 调用
C++ 调用训练好的 sklearn模型
- 先将模型导出为特定格式文件
- 然后 C++中加载该文件并预测。
主要步骤分为两部分:
- Python 导出模型文件
- C++ 读取模型文件
作者:一个人也挺好
步骤
- 将训练好的模型保存为文件。
例如,用 Random Forest 训练模型,以下代码保存为文件:
from sklearn.ensemble import RandomForestClassifier
import joblib
# 训练模型
model = RandomForestClassifier()
model.fit(X, y)
# 保存模型
joblib.dump(model, 'my_model.joblib')
- 使用 pickle 模块将模型保存为不同的文件格式。
例如,用以下代码将模型保存为pickle或JSON格式:
import pickle
import json
# 保存为pickle格式
with open('my_model.pkl', 'wb') as f:
pickle.dump(model, f)
# 保存为JSON格式
with open('my_model.json', 'w') as f:
json.dump(model.to_dict(), f)
C++中加载模型:
- 根据导出的文件格式来选择合适读取方法。
- 以pickle、joblib格式为例,分别使用相应的函数来加载模型:
#include <fstream>
#include <iostream>
#include <string>
#include <vector>
#include <boost/smart_ptr/shared_ptr.hpp>
#include <boost/python.hpp>
#include <boost/python/numpy.hpp>
namespace p = boost::python;
namespace np = boost::python::numpy;
p::object LoadPickle(std::string filename)
{
std::ifstream ifs(filename, std::ios::binary);
return p::object(
p::handle<>(p::allow_null(PyImport_ImportModule("pickle"))).attr("load")( ifs));
}
p::object LoadJoblib(std::string filename)
{
auto Array_Type = np::dtype::get_builtin<float>().get_handle();
np::initialize();
np::dtype dtype = np::dtype::from_handle(Array_Type);
p::tuple shape = p::make_tuple(1, 4); // 注意这里需要指定与模型输入数据形状匹配的大小
np::ndarray data = np::empty(shape, dtype);
std::ifstream ifs(filename, std::ios::binary);
return p::object(
p::handle<>(p::allow_null(PyImport_ImportModule("joblib"))).attr("load")( ifs, "r", &data));
}
- 使用 Python API 加载模型并进行预测。
这里以两个函数来处理pickle格式和joblib格式,分别使用 LoadPickle() 和 LoadJoblib() 来加载模型。
在加载模型后,可以使用 model.attr("predict")(data) 来进行预测:
void Predict(std::string input_filename, std::string model_filename)
{
Py_Initialize();
np::initialize();
try {
p::object main_module = p::import("__main__");
p::object main_namespace = main_module.attr("__dict__");
// 加载模型
p::object model;
if (model_filename.find("pkl") != std::string::npos) {
model = LoadPickle(model_filename);
} else if (model_filename.find("joblib") != std::string::npos) {
model = LoadJoblib(model_filename);
}
std::cout << "模型加载成功!" << std::endl;
// 读取测试数据
std::ifstream ifs(input_filename, std::ios::binary);
std::vector<float> data;
float x;
while (ifs.read(reinterpret_cast<char*>(&x), sizeof(float)))
{
data.push_back(x);
}
p::tuple shape = p::make_tuple(1, data.size());
np::ndarray input = np::zeros(shape, np::dtype::get_builtin<float>());
std::memcpy(input.get_data(), data.data(), data.size() * sizeof(float));
std::cout << "测试数据加载成功!" << std::endl;
// 进行预测
p::object result = model.attr("predict")(input);
std::cout << "预测结果为:" << p::extract<int>(result) << std::endl;
Py_Finalize();
} catch (const p::error_already_set& e) {
std::cerr << "Python解释器错误: " << e.what() << std::endl;
PyErr_Print();
}
}
注意,C++和Python必须使用相同位数和编译器,因为Python和库会针对不同的位数和编译器进行编译。如果使用了不同的编译器或编译标志,可能会导致Python或库在调用时崩溃或出错。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
