- 提示工程 Prompt Engineering
- 结束
提示工程 Prompt Engineering
由于ChatGPT基于prompt范式,所以问题越规范,植入的信息越完整,效果越好
- AIGC 时代,「提示工程」(prompt engineering) :精巧地设计文字提示(prompt),对于生成好看有趣的结果至关重要。
- 提示工程:用聪明、准确、时而冗长的文字提示,来设定好一个上下文场景,一步一步地把 AI 带进这个场景里,并且让它更准确地了解你的意图,从而生成最符合你期待的结果。
- 如果创业者只学习大模型的一个技术点,应该是什么? Prompt!
- BUT 投资人看不上Prompt ,嫌薄; 工程师看不起Prompt ,嫌浅
自然语言的压缩性导致歧义性 以及行业的专业属性,使得prompt是嫁接大模型逻辑能力和应用需求的桥梁,非常重要
资讯
- 【2023-7-26】OpenAI 专家 Lili Weng 翁丽莲 博客专题 Prompt Engineering
- 【2024-6-6】马里兰、OpenAI、斯坦福微软等合著的 Prompt 综述报告 The Prompt Report: A Systematic Survey of Prompting Techniques
- 【2025-4-11】Google 发布了一份长达 69 页的白皮书,介绍 Prompt Engineering 及其最佳实践⚡️
在生产环境中编写 Prompt 时,强烈建议阅读这份白皮书:
- 零次、一次、少量
- 系统提示
- 思路链(CoT)
- 反应
- 代码提示
- 最佳实践
OpenAI 自定义指令
【2023-7-21】ChatGPT推出自定义指令:说一次就记住,每次对话都能遵守
- 使用 ChatGPT 时,为了让答案更贴合需求,prompt 的构思通常要花一些工夫。而且,即使每次都差不多,开启一轮新对话时,依然要像复制模板一样把这些需求复制进去,让 prompt 变得非常冗长。
- OpenAI 公布了这一问题的解决方案,推出了「
自定义指令(custom instructions)」功能。开启方法 - 与直接提问不同,ChatGPT 会在设置时询问两个问题
- 一个用来了解基本信息(比如你的职业、兴趣爱好、喜欢的话题、所在的地点、想达成的目标等)
- 另一个用来告诉 ChatGPT 想要什么样的回复(正式 / 非正式、答案长短、模型该发表意见还是保持中立等)
- 假如你是一位小学老师,在回答第一个问题时告诉 ChatGPT 工作内容(教授小学科学),在回答第二个问题时限定回答格式(以表格方式呈现,概述优缺点等)
- OpenAI 表示,此功能开始为 Plus 用户提供测试版,并在未来几周内扩展到所有用户。
- OpenAI CEO Sam Altman 评价说,「自定义指令只是朝着更加个性化的 AI 迈出的一小步,但却是非常有趣 / 有用的一步。」
OpenAI o1
【2024-9-15】如何才能驾驭这个”高智商”模型呢?
OpenAI 给出了四点建议:
- 保持提示简单直接,不要过多引导模型,因为它已经能很好地理解指令了。
- 避免使用思维链提示,因为 o1 模型已经在内部进行推理了。
- 使用分隔符,如三重引号、XML 标签和章节标题,让模型更清楚地理解各个部分。
- 限制额外上下文,特别是在检索增强生成(RAG)任务中,因为添加更多上下文或文档可能会使响应变得过于复杂。
这完全颠覆了上一版PE建议,提示工程会消失
什么是 Prompt
提示工程是一门新兴学科,为大语言模型(LLM)设计的”语言游戏”。
- 通过这个”游戏”,更有效地引导 LLM 来处理问题。只有熟悉了这个游戏的规则,才能更清楚地认识到 LLM 的能力和局限。
- 这个”游戏”不仅帮助理解 LLM,也是提升 LLM 能力的途径。
有效的提示工程可以提高大语言模型处理复杂问题的能力(比如一些数学推理问题),也可以提高大语言模型的扩展性(比如可以结合专业领域的知识和外部工具,来提升 LLM 的能力)。
提示工程就像是一把钥匙,为理解和应用大语言模型打开了新的大门,无论是现在还是未来,它的潜力都是无穷无尽的。
prompt是人类能看懂的文字,但好的prompt给机器的信息量更多更准确,和日常沟通交流中组织形式有很大区别
- prompt像精确而又全面描述需求的一个说明书,写满了厚厚一本详细性能指标参数的那种说明书。
- 把一个具体的需求转述成为能让机器高效理解需求细节的优质prompt,根本就是一件反直觉反人性的事
Prompt 结构
提示词可以包含以下任意要素:
- 指令:想要模型执行的特定任务或指令。
- 上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
- 输入数据:用户输入的内容或问题。
- 输出指示:指定输出的类型或格式。
注意,提示词所需的格式取决于您想要语言模型完成的任务类型,并非所有以上要素都是必须的。
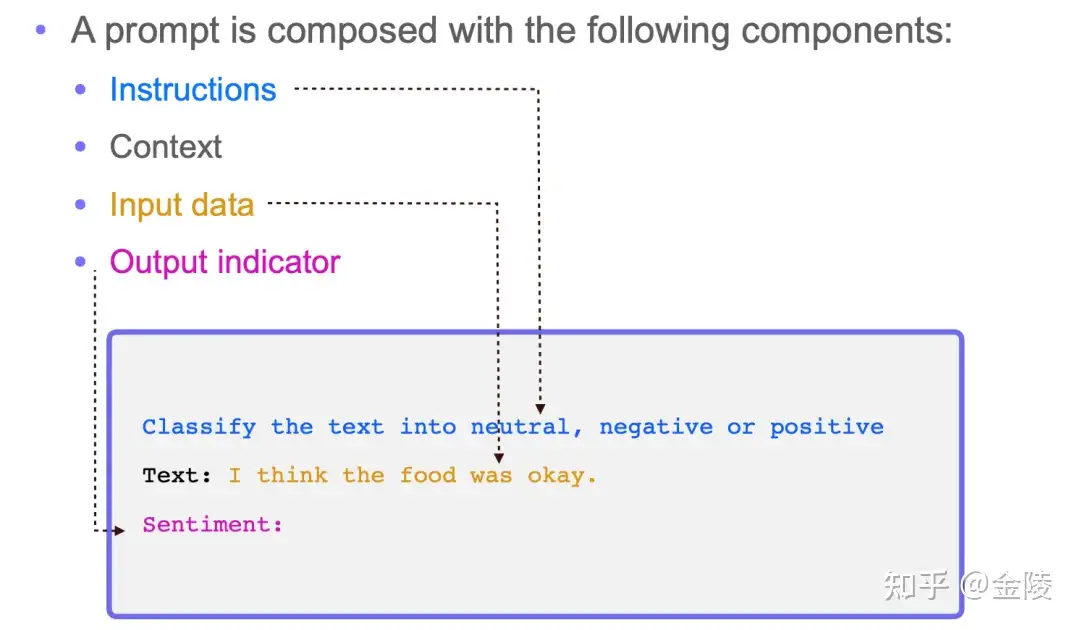
Prompt 四要素
一个 Prompt 包含以下四个元素中的若干个:
指令Instructions:希望 LLM 执行什么任务;上下文(语境)Context:给 LLM 提供一些额外的信息,比如可以是垂直领域信息,从而引导 LLM 给出更好的回答;输入数据Input data:希望从 LLM 得到什么内容的回答;输出格式Output indicator:引导 LLM 给出指定格式的输出。
temperature和top_p是两个重要参数。
- 如果想得到准确的答案,就把这些参数调低,如果想得到更多不同的答案,就调高。
Prompt 示例
一种经典的Prompt构成是:
先描述这个任务,然后说明需要怎样的输出,最后跟上需要处理的内容。
[任务描述]
[输出格式]
[用户输入]
示例
你的任务是从下面给出的一句话中提取出用户想生成随机数的数量、最大值、最小值和原因。
用户提到roll点、掷骰子等,都指的是生成随机数。
用户可能会使用类似“数量+D+最大值”的方式描述,例如:“3D6”指生成3个最大值是6,最小值是1的随机数。
你需要生成如下的结果:
count: 要生成随机数的数量
max: 最大值
min: 最小值
reason: 这次生成随机数的原因
下面是你需要处理的文本:
【用户输入】
鉴于把人类描述需求的自然语言转换成「机器语言」这么复杂,诞生了一门新的学科:Prompt Engineering,通过调整Prompt来控制ChatGPT生成文本的技能。掌握了Prompt Engineer这项技能,就可以更加灵活地使用ChatGPT等AI大模型的能力,生成更为精准的内容。
prompt 分类
【2023-7-24】Prompt Engineering: Get LLMs to Generate the Content You Want
Some of the common types of prompts used with current LLMs.
Explicit prompts显性提示: 方向清晰、准确- 示例: Write a short story about a young girl who discovers a magical key that unlocks a hidden door to another world. </span>
- This explicit prompt clearly outlines the story’s topic, setting, and main element, providing the LLM with specific instructions on what to generate
Conversational prompts对话式提示:用自然语言聊天, LLM输出结果更加自然、流畅,适合需要多次交互的场景- 示例: Hey, Bard! Can you tell me a funny joke about cats? </span>
Context-based prompts上下文提示:提供领域术语、背景知识,便于LLM更好的理解对话主题,适合内容创作- 示例: I’m planning a trip to New York next month. Can you give me some recommendations for popular tourist attractions, local restaurants, and off-the-beaten-path spots to visit? </span>
Open-ended prompts开放提示: 未限制主题、角度, 鼓励LLM输出更长、更细节的回复,适合创造类、讲故事、出主意类写作- 示例: Tell me about the impact of technology on society. </span>
Bias-mitigating prompts偏见预防提示: 通过提示(多种观点/提供事实依据等)防止LLM输出偏见- 示例: Please generate a response that presents a balanced and objective view of the following topic: caste-based reservations in India. Consider providing multiple perspectives and avoid favoring any particular group, ideology, or opinion. Focus on presenting factual information, supported by reliable sources, and strive for inclusivity and fairness in your response </span>
Code-generation prompts代码生成提示:- 示例:Write a Python function that takes in a list of integers as input and returns the sum of all the even numbers in the list
Prompt编写
设计提示词经常是一个迭代的过程,需要不断试验才能获得最佳结果。
提示助手
AIPRM, 全球prompt技巧交流社区
【2023-4-11】GPT数据科学: 制作清晰有效提示(Prompt)的不完全指南
- 一系列APP,根据用户输入生成合适的prompt,如:
- Web:ChatGPT Prompt Generator App
- 桌面APP:ChatGPT Desktop App,mac版需要vpn,不一定能打开
5 个顶级prompt-generator开源项目
Awesome-Prompt-Engineering- 该存储库包含用于 Prompt Engineering 的手工策划资源,重点是生成式预训练转换器 (GPT)、ChatGPT、PaLM 等
Simple_Prompt_Generator画图提示- Midjourney、DALLe、Stable 和 Disco Diffusion 等的简单提示生成器。
AI-Image-PromptGenerator画图提示- 一个灵活的 UI 脚本,可帮助创建和扩展生成式 AI 艺术模型的提示,例如 Stable Diffusion 和 MidJourney。获得灵感,然后创造。
MagicPrompt- 在 GPT-2 模型上用于稳定扩散/中途的提示生成器
prompt-markdown-parser画图提示- 用于 text2image 提示的 Markdown 解析器和提示生成器工具
ChatGPT 的插件中就有一个不错的工具 Prompt perfect,能够基于用户给的 Prompt 进行优化,再喂给 ChatGPT 进行提问。
PromptIDE – Musk
【2023-11-8】马斯克第二款AI产品PromptIDE公布,Grok的开发离不开它
距离马斯克的 xAI 公布 Grok 才1天,xAI 又公布了另一款 AI 产品,一个可用于 prompt 工程和可解释性研究的集成开发环境:PromptIDE。
PromptIDE 用于 prompt 工程和可解释性研究的集成开发环境。通过 SDK 加速 prompt 工程,并且该 SDK 可以完成复杂的 prompt 技术,还能进行结果分析,可视化网络输出等。
xAI 在 Grok 的开发中大量的使用了该技术。
- 借助 PromptIDE,工程师和研究人员可以透明的访问 Grok-1 模型(为 Grok 提供支持的模型)。该 IDE 可以帮助用户快速探索大模型 (LLM) 的功能。IDE 的核心是一个 Python 代码编辑器,它与新的 SDK 相结合,可以实现复杂的 prompt 技术。在 IDE 中执行 prompt 时,用户会看到一些比较有用的分析,例如采样概率、聚合注意力掩码等。
- 该 IDE 会自动保存所有的 prompt 并具有内置版本控制,还允许用户比较不同 prompt 技术的输出。最后,用户可以上传 CSV 文件等小文件,并使用 SDK 中的单个 Python 函数读取它们。结合 SDK 的并发特性,即使是稍大的文件也能快速处理。
PromptIDE 的核心是代码编辑器 + Python SDK,其中 SDK 提供了一种新的编程范式,可以实现复杂的 prompting 技术
优质 Prompt
【2023-2-9】ChatGPT 中文调教指南
【2023-4-12】提示技巧工程完全指南
优秀Prompt的两个重要因素:
- 使用者自己对“问题框架”的理解。(当然也可以让ChatGPT帮你逐步引导出框架)
- Prompt技巧。
写好prompt的十条建议
- 明确主题:清楚表达意图,并聚焦
- 明确需求:信息查询、劝说、娱乐或其他
- 明确基调:GPT会根据主题设置表述基调
- 限制长度:说清楚要输出多少字数,长文、短文
- SEO关键词:有助于生成优质结果
- 明确受众:GPT会自动调整语种、语调、风格,来适配这个群体
- 领域信息:补充相关领域信息,单独成段
- 更新版本:ChatGPT(3.5)可以读取链接
- 阐明动作:在段落尾部,说明要采取什么动作
- 附加信息:增加相关样例、案例学习、网络资料】对比分析等
- 标题与副标题
The Power prompt : Secret prompt that ChatGPT loves
The key is to educate ChatGPT on the specifics you want. Check the TEN inputs you need to provide to get the best results.
- Topic or idea for the article: Main subject and focus of the article.
- Purpose or goal of the article: What the article is trying to achieve, whether it’s to inform, persuade, entertain, or something else.
- Article’s Tone: Usually, GPT sets the tone based on the topic, but it’s good to provide it as input.
- Limit: The number of words or you can use short or long lengths.
- Any specific SEO keywords or phrases: If there are specific SEO keywords or phrases that you would like to include in the article.
- Target audience: Who the article is for; this way, GPT can tailor the language, tone, and style to suit the readers.
- Any specific sources or references: If you want to add any information or specific sources/references, please provide a paragraph for those details.
- Update: ChatGPT New Version 3.5 can read website links, so you can also reference articles! Yeyyy!
- Call to Action: You can include your CTA in the conclusion paragraph.
- Includes: Something you want to add, like relevant examples, case studies, social proofs, comparisons, or anything else.
- Title and Subtitle Suggestion: Well, it says all.
Prompt 框架
【2023-10-13】一文汇总市面上所有prompts提示词框架
12种常见的prompts框架
- 任务型:
- 角色扮演:
CO-STAR
【2024-5-6】CO-STAR 提示词框架
由新加坡政府科技局(GovTech)组织的首届 GPT-4 提示工程大赛冠军 Sheila Teo 写的提示词框架。
Sheila 总结了 4 种提示词技巧:
- 🔵 借助 CO-STAR 框架构建高效的提示
- 🔵 利用分隔符来分节构建提示
- 通过设置分隔符,可以为这些 Token 序列提供结构,使特定部分得到不同的处理。
- 简单的任务: 分隔符对大语言模型的回应质量可能无显著影响。
- 但是,任务越复杂,合理使用分隔符进行文本分段对模型的反应影响越明显。
- 分隔符可以是任何不常见组合的特殊字符序列,字符足够独特,使得模型能将其识别为分隔符,而非常规标点符号, 如:###,===,»>
- 使用 XML 标签作为分隔符非常有效,因为大语言模型已经接受了大量包含 XML 格式的网页内容的训练,因此能够理解其结构。
- 🔴 设计含有 LLM 保护机制的系统级提示
- 🔴 仅依靠大语言模型分析数据集,无需插件或代码 — 实际案例分析 Kaggle 的真实数据集
其中 🔵 代表初学者友好的技巧,而 🔴 代表高级策略。
CO-STAR 框架
- (C)
Context上下文:为任务提供背景信息 通过为大语言模型(LLM)提供详细的背景信息,可以帮助它精确理解讨论的具体场景,确保提供的反馈具有相关性。 - (O)
Objective目标:明确你要求大语言模型完成的任务 清晰地界定任务目标,可以使大语言模型更专注地调整其回应,以实现这一具体目标。 - (S)
Style风格:明确你期望的写作风格 你可以指定一个特定的著名人物或某个行业专家的写作风格,如商业分析师或 CEO。这将指导大语言模型以一种符合你需求的方式和词汇选择进行回应。 - (T)
Tone语气:设置回应的情感调 设定适当的语气,确保大语言模型的回应能够与预期的情感或情绪背景相协调。可能的语气包括正式、幽默、富有同情心等。 - (A)
Audience受众:识别目标受众 针对特定受众定制大语言模型的回应,无论是领域内的专家、初学者还是儿童,都能确保内容在特定上下文中适当且容易理解。 - (R)
Response响应:规定输出的格式 确定输出格式是为了确保大语言模型按照你的具体需求进行输出,便于执行下游任务。常见的格式包括列表、JSON 格式的数据、专业报告等。对于大部分需要程序化处理大语言模型输出的应用来说,JSON 格式是理想的选择。
CO-STAR framework

案例
任务
假设你担任社交媒体经理,需要草拟一条 Facebook 帖子,用以推广公司的新产品。
| 方法 | 提示语 | GPT-4回答 | |
|---|---|---|---|
| 原版 | 为我的公司 Alpha 的新产品 Beta——一款新型超快速吹风机,撰写一条 Facebook 帖子。 | 介绍 Alpha 公司革命性的 Beta 吹风机!告别长时间、无聊的吹发过程!Alpha 公司自豪地推出 Beta,这是我们在护发技术上的最新创新——超快干燥:Beta 设计旨在让你的吹发时间减半,得益于其先进的强力马达。快速准备,享受更多你所爱的时间!立即购买:产品页面链接 | 原版过于泛化,缺乏必要的细节和针对性吸引力,未能真正触及公司目标受众的心 |
| CO-STAR | 如下 | 用 Alpha Beta——超快速吹风机,体验轻松的优雅生活,它是为具有洞察力的一代人设计的。 与 Alpha Beta 一起,重新找回简单而高效的护发乐趣。我们的最新创新不仅是一款吹风机;它还承诺为那些懂得欣赏生活美好事物的人提供快速、柔和且可靠的发型打理。 - 易用且直观:向复杂的设备说再见。Alpha Beta 专为舒适和简便而设计,非常适合那些喜欢简洁、无麻烦操作的人。- 节省时间的技术:我们知道您的时间非常宝贵。因此,Alpha Beta 显著缩短吹发时间,让您有更多时间享受生活。 每天都是与 Alpha Beta 相伴的美好发型日。立即体验优雅与简约的完美结合。您的产品链接在此 |
更具针对性和效果 |
CO-STAR prompt
CO-STAR 模板的示例,它提醒我们在制定提示时,要考虑到任务的其它方面,特别是之前快速提示中缺少的风格、语调和受众:
# CONTEXT(上下文) #
我想推广公司的新产品。我的公司名为 Alpha,新产品名为 Beta,是一款新型超快速吹风机。
# OBJECTIVE(目标) #
帮我创建一条 Facebook 帖子,目的是吸引人们点击产品链接进行购买。
# STYLE(风格) #
参照 Dyson 等成功公司的宣传风格,它们在推广类似产品时的文案风格。
# TONE(语调) #
说服性
# AUDIENCE(受众) #
我们公司在 Facebook 上的主要受众是老年人。请针对这一群体在选择护发产品时的典型关注点来定制帖子。
# RESPONSE(响应) #
保持 Facebook 帖子简洁而深具影响力。
xml 分隔符
- 名词与 XML 标签的名词一致,如 conversations、classes 和 examples,因此使用的 XML 标签分别是
<conversations>、<classes>、<example-conversations>和<example-classes>。
#---------- 额外 --------
# xml 分隔符
<classes>
正面
负面
</classes>
系统提示一般包括以下几个部分:
- 任务定义:确保大语言模型(LLM)在整个对话中清楚自己的任务。
- 输出格式:指导 LLM 如何格式化其回答。
- 操作边界:明确 LLM 不应采取的行为。这些边界是 LLM 治理中新兴的一个方面,旨在界定 LLM 的操作范围。
1 ICIO 框架
- Instruction:指令 即你希望AI执行的具体任务
- Context:背景信息 给AI更多的背景信息引导模型做出更贴合需求的回复
- Input Data:输入数据 告知模型需要处理的数据
- Output Indicator:输出引导 告知模型我们要输出的类型或风格
12 PATFU 框架
- PROBLEM:问题 清晰的表达需要解决的问题
- AERA:领域 问题所在领域或需扮演的角色
- TASK:任务 解决这个问题需要执行的具体任务
- FORMAT:格式 详细定义输出的格式和限制条件
- UPDATE:迭代 记录提示词版本并根据输出结果对提示词进行迭代
4 APE框架
- ACTION: 行动 定义要完成的工作或活动
- PURPOSE: 目的 讨论意图或目标
- EXPECTATION: 期望 陈述预期的结果
5 COAST框架
- CONTEXT:上下文背景 为对话设定舞台
- OBJECTIVE:目的 描述目标
- ACTION :行动 解释所需行动
- SCENARIO:方案 描述场景
- TASK:任务 描述任务
6 TAG框架
- TASK:任务 描述任务
- ACTION:行动 解释所需行动
- GOAL:目标 解释最终目标
8 TRACE框架
- TASK:任务 定义特定任务
- REQUEST:请求 描述要求
- ACTION:行动 说明需要的操作
- CONTEXT:上下文 提供上下文信息或情况
- EXAMPLE:示例 举例子说明你想要达成的效果
9 ERA框架
- EXPECTATION:期望 描述所需的结果
- ROLE:角色 指定角色
- ACTION:行动 指定需要采取哪些操作
10 CARE框架
- CONTEXT:上下文 提供上下文信息或情况
- ACTION:行动 说明需要的操作
- RESULT:结果 描述所需的结果
- EXAMPLE:示例 举例子说明你想要达成的效果
11 ROSES框架
- ROLE:角色 指定角色
- OBJECTIVE:目的 陈述目标
- SCENARIO:方案 描述情况
- EXPECTED SOLUTION:解决方案 定义所需的结果
- STEPS:步骤 要求达到目标所需的步骤
2 CRISPE 框架
- Capacity and Role: 能力和角色 ChatGPT应扮演什么角色
- Insight: 见解 提供你请求的背后见解、背景和上下文
- Statement: 声明 你要求ChatGPT 做什么
- Personality: 个性 你希望 ChatGPT 以何种风格、个性或方式回应
- Experiment: 实验 请求 ChatGPT 为你回复多个示例
3 BROKE框架
- Background: 背景 说明背景,为ChatGPT 提供充足信息
- Role: 角色 希望ChatGPT扮演的角色
- Objectives: 目标 希望实现什么
- Key Result: 关键结果 要什么具体效果试验并调整
- Evolve: 试验并改进 三种改进方法自由组合
- a. 改进输入:从答案的不足之处着手改进背景B,目标O与关键结果R
- b. 改进答案:在后续对话中指正chatGPT答案缺点
- c. 重新生成:尝试在 Prompt 不变的情况下多次生成结果,优中选优
7 RISE框架
- ROLE: 角色 指定ChatGPT的角色
- INPUT: 输入 描述信息或资源
- STEPS:步骤 询问详细的步骤
- EXPECTATION 期望 描述所需的结果
提示工程指南
【2023-4-13】提示工程指南Prompt-Engineering-Guide, Guides, papers, lecture, notebooks and resources for prompt engineering
- 一小时的讲座视频,讲座中的代码示例,以及一份配合讲座的50页资料。视频包含四个部分:提示工程的介绍、先进的提示工程技术、工具&应用、总结以及未来的发展方向。
- 中文文档
- 最新最全最火的Prompt指南来
Prompt-Engineering-Guide-Chinese
吴恩达提示工程
【2023-5-10】吴恩达提示工程课程
【2023-5-11】openai官方提示词工程超详细中文笔记,飞书笔记
提示工程完全指南
The Art of Asking ChatGPT for High-Quality Answers: A complete Guide to Prompt Engineering Techniques 一书是一本全面指南,介绍了各种提示技术,用于从ChatGPT中生成高质量的答案。
- 中文版GitHub: 提示技巧工程完全指南

这是英文书籍的中文翻译版本,共 24 章,详细探讨了如何使用不同的提示工程技术来实现不同的目标。
- 第一章:Prompt工程技术简介:通过提示指导 ChatGPT 这类语言模型输出
- 第二章:指令提示技术:提供清晰简洁的任务,以及具体的指令
- 提示公式:“按照以下指示生成[任务]:[指令]”
- 第三章:角色提示
- 提示公式:“作为[角色]生成[任务]”
- 示例:“作为律师,生成法律文件。”
- 示例:“作为客户服务代表,生成对客户查询的回复。”
- 第四章:标准提示
- 提示公式:“生成一个[任务]”
- 示例:“生成这篇新闻文章的摘要”
- 示例:“生成这款新智能手机的评论”
- 第五章:零、一和少样本提示
- 当特定任务的数据有限或任务是新的且未定义时,这些技术非常有用。
- 提示公式:“基于[数量]个示例生成文本”
- 示例:“基于零个示例为这款新智能手表生成产品描述”
- 示例:“使用一个示例(最新的iPhone)为这款新智能手机生成产品比较”
- 示例:“使用少量示例(3个其他电子阅读器)为这款新电子阅读器生成评论”
- 第六章:“让我们思考一下”提示 —
思维链- 生成反思和思考性的文本。这种技术适用于撰写论文、诗歌或创意写作等任务。
- “让我们思考一下提示”, 遵循以下步骤:
- 确定您要讨论的主题或想法。
- 制定一个明确表达主题或想法的提示,并开始对话或文本生成。
- 用“让我们思考”或“让我们讨论”开头的提示,表明您正在启动对话或讨论。
- 提示公式:“让我们思考一下:个人成长”
- 提示公式:“让我们思考一下:季节变化”
- 提示:“让我们思考气候变化对农业的影响”
- 提示:“让我们讨论人工智能的当前状态”
- 提示:“让我们谈谈远程工作的好处和缺点” 您还可以添加开放式问题、陈述或一段您希望模型继续或扩展的文本。
- 第七章:自洽提示 – 思维链
- 输出与提供的输入一致。对于事实核查、数据验证或文本生成中的一致性检查等任务非常有用。
- 自洽提示的提示公式是输入文本后跟着指令“请确保以下文本是自洽的”。或者,可以提示模型生成与提供的输入一致的文本。
- 文本生成:“生成与以下产品信息一致的产品评论[插入产品信息]”
- 文本摘要:“用与提供的信息一致的方式概括以下新闻文章[插入新闻文章]”
- 文本续写:“以与提供的上下文一致的方式完成以下句子[插入句子]”
- 事实检查:“请确保以下文本是自洽的:文章中陈述该城市的人口为500万,但后来又说该城市的人口为700万。”
- 数据验证:“请确保以下文本是自洽的:数据显示7月份的平均温度为30度,但最低温度记录为20度。”
- 第八章:种子词提示
- 提供特定种子词或短语来控制ChatGPT输出。控制模型生成文本与某个特定主题或背景相关的方式。
- 种子词提示可以与角色提示和指令提示相结合,以创建更具体和有针对性的生成文本。
- 种子词提示的提示公式:种子词或短语,后跟指令“请根据以下种子词生成文本”。
- 文本生成:“请根据以下种子词生成文本:龙”
- 文本生成:“作为诗人,根据以下种子词生成与“爱”相关的十四行诗:”
- 语言翻译:“请根据以下种子词生成文本:你好”
- 文本完成:“作为研究员,请在与种子词“科学”相关且以研究论文的形式书写的情况下完成以下句子:[插入句子]”
- 文本摘要:“作为记者,请以中立和公正的语气摘要以下新闻文章,与种子词“政治”相关:[插入新闻文章]”
- 第九章:知识生成提示
- 从ChatGPT中引出新的、原创信息,利用模型预先存在的知识来生成新信息或回答问题。
- 提示公式:“请生成关于X的新的和原创的信息”,其中X是感兴趣的主题。
- 提示应包括有关所需输出的信息,例如要生成的文本类型以及任何特定的要求或限制。
- 知识生成:“生成有关[特定主题]的新的准确信息”
- 问答:“回答以下问题:[插入问题]”
- 知识整合:“将以下信息与有关[特定主题]的现有知识整合:[插入新信息]”
- 数据分析:“请从这个数据集中生成有关客户行为的新的和原创的信息”
- 第十章:知识整合提示
- 用模型的现有知识来整合新信息或连接不同的信息片段。这种技术对于将现有知识与新信息相结合,以生成更全面的特定主题的理解非常有用。
- 使用要点:
- 模型应该提供新信息和现有知识作为输入,以及指定生成文本的任务或目标的提示。
- 提示应包括有关所需输出的信息,例如要生成的文本类型以及任何特定的要求或限制。
- 知识整合:“将以下信息与关于[具体主题]的现有知识整合:[插入新信息]”
- 连接信息片段:“以相关且逻辑清晰的方式连接以下信息片段:[插入信息1] [插入信息2]”
- 更新现有知识:“使用以下信息更新[具体主题]的现有知识:[插入新信息]”
- 第十一章:多项选择提示
- 提供一个问题或任务以及一组预定义的选项作为潜在答案。对于生成仅限于特定选项集的文本非常有用,可用于问答、文本完成和其他任务。模型可以生成仅限于预定义选项的文本。
- 要使用ChatGPT的多项选择提示,需要向模型提供一个问题或任务作为输入,以及一组预定义的选项作为潜在答案。提示还应包括有关所需输出的信息,例如要生成的文本类型以及任何特定要求或限制。
- 问答:“通过选择以下选项之一回答以下问题:[插入问题] [插入选项1] [插入选项2] [插入选项3]”
- 情感分析:“通过选择以下选项之一,将以下文本分类为积极、中立或消极:[插入文本] [积极] [中立] [消极]”
- 第十二章:可解释的软提示
- 提供一定灵活性的同时控制模型生成的文本。通过提供一组受控输入和关于所需输出的附加信息来实现, 可以生成更具解释性和可控性的生成文本。
- 文本生成:“基于以下角色生成故事:[插入角色]和主题:[插入主题]”
- 第十三章:控制生成提示
- 让模型在生成文本时对输出进行高度控制。通过提供一组特定的输入来实现,例如模板、特定词汇或一组约束条件,这些输入可用于指导生成过程。
- 文本生成:“根据以下模板生成故事:[插入模板]”
- 文本补全:“使用以下词汇完成以下句子:[插入词汇]:[插入句子]”
- 语言建模:“生成遵循以下语法规则的文本:[插入规则]:[插入上下文]”
- 第十四章:问答提示
- 让模型生成回答特定问题或任务的文本。通过将问题或任务与可能与问题或任务相关的任何其他信息一起作为输入提供给模型来实现此目的。
- 事实问题回答:“回答以下事实问题:[插入问题]”
- 定义:“定义以下词汇:[插入单词]”
- 信息检索:“从以下来源检索有关[特定主题]的信息:[插入来源]” — 这对于问答和信息检索等任务非常有用。
- 第十五章:概述提示
- 允许模型在保留其主要思想和信息的同时生成给定文本的较短版本。通过将较长的文本作为输入提供给模型并要求其生成该文本的摘要来实现。对于文本概述和信息压缩等任务非常有用。
- 使用:
- 应该向模型提供较长的文本作为输入,并要求其生成该文本的摘要。
- 提示还应包括有关所需输出的信息,例如摘要的所需长度和任何特定要求或限制。
- 文章概述:“用一句简短的话概括以下新闻文章:[插入文章]”
- 会议记录:“通过列出主要决策和行动来总结以下会议记录:[插入记录]”
- 书籍摘要:“用一段简短的段落总结以下书籍:[插入书名]”
- 第十六章:对话提示
- 生成模拟两个或更多实体之间对话的文本。通过为模型提供一个上下文和一组角色或实体,以及它们的角色和背景,并要求模型在它们之间生成对话。
- 因此,应为模型提供上下文和一组角色或实体,以及它们的角色和背景。还应向模型提供有关所需输出的信息,例如对话或交谈的类型以及任何特定的要求或限制。
- 对话生成:“在以下情境中生成以下角色之间的对话[插入角色]”
- 故事写作:“在以下故事中生成以下角色之间的对话[插入故事]”
- 聊天机器人:“在客户询问[插入主题]时,为客服聊天机器人生成专业和准确的对话”
- 第十七章:对抗性提示
- 生成抵抗某些类型的攻击或偏见的文本。这种技术可用于训练更为稳健和抵抗某些类型攻击或偏见的模型。
- 文本分类:“生成难以分类为[插入标签]的文本”
- 情感分析:“生成难以分类为具有[插入情感]情感的文本”
- 机器翻译:“生成难以翻译为[插入目标语言]的文本”
- 第十八章:聚类提示
- 根据某些特征或特点将相似的数据点分组在一起. 提供一组数据点并要求模型根据某些特征或特点将它们分组成簇,可以实现这一目标。在数据分析、机器学习和自然语言处理等任务中非常有用。
- 客户评论:“将以下客户评论根据情感分组成簇:[插入评论]”
- 新闻文章:“将以下新闻文章根据主题分组成簇:[插入文章]”
- 科学论文:“将以下科学论文根据研究领域分组成簇:[插入论文]”
- 第十九章:强化学习提示
- 从过去的行动中学习,并随着时间的推移提高其性能。
- 文本生成:“使用强化学习来生成与以下风格一致的文本[插入风格]”
- 语言翻译:“使用强化学习将以下文本[插入文本]从[插入语言]翻译成[插入语言]”
- 问答:“使用强化学习来回答以下问题[插入问题]”
- 第二十章:课程学习提示
- 先训练简单任务,逐渐增加难度来学习复杂任务
- 文本生成:“使用课程学习来生成与以下风格[插入风格]一致的文本,按照以下顺序[插入顺序]。”
- 语言翻译:“使用课程学习将以下语言[插入语言]的文本翻译成以下顺序[插入顺序]。”
- 问答:“使用课程学习来回答以下问题[插入问题],按照以下顺序[插入顺序]生成答案。”
- 第二十一章:情感分析提示
- 确定文本的情绪色彩或态度,例如它是积极的、消极的还是中立的。
- 客户评论:“对以下客户评论进行情感分析[插入评论],并将它们分类为积极的、消极的或中立的。”
- 推文评论:“对以下推文进行情感分析[插入推文],并将它们分类为积极的、消极的或中立的。”
- 第二十二章:命名实体识别提示
- 识别和分类文本中的命名实体,例如人名、组织机构、地点和日期等。
- 新闻:“在以下新闻文章[插入文章]上执行命名实体识别,并识别和分类人名、组织机构、地点和日期。”
- 第二十三章:文本分类提示
- 将文本分成不同的类别
- 客户评论:“对以下客户评论 [插入评论] 进行文本分类,并根据其内容将其分类为不同的类别,例如电子产品、服装和家具。”
- 电子邮件:“对以下电子邮件 [插入电子邮件] 进行文本分类,并根据其内容和发件人将其分类为不同的类别,例如垃圾邮件、重要邮件或紧急邮件。”
- 第二十四章:文本生成提示
- 故事创作:“根据以下提示[插入提示]生成一个至少包含1000个单词,包括角色[插入角色]和情节[插入情节]的故事。”
- 语言翻译:“将以下文本[插入文本]翻译成[插入目标语言],并确保其准确且符合习惯用语。”
Prompt 公式是提示的特定格式,通常由三个主要元素组成:
- 任务:对提示要求模型生成的内容进行清晰而简洁的陈述。
- 指令:在生成文本时模型应遵循的指令。
- 角色:模型在生成文本时应扮演的角色。
如何将指令提示、角色提示和种子词提示技术结合使用:
- 任务:为新智能手机生成产品描述
- 指令:描述应该是有信息量的,具有说服力,并突出智能手机的独特功能
- 角色:市场代表 种子词:“创新的”
- 提示公式:“作为市场代表,生成一个有信息量的、有说服力的产品描述,突出新智能手机的创新功能。该智能手机具有以下功能[插入您的功能]”
在这个示例中,指令提示用于确保产品描述具有信息量和说服力。角色提示用于确保描述是从市场代表的角度书写的。而种子词提示则用于确保描述侧重于智能手机的创新功能。
将标准提示、角色提示和种子词提示技术结合使用的示例:
- 任务:为一台新笔记本电脑撰写产品评论
- 说明:评论应客观、信息丰富,强调笔记本电脑的独特特点
- 角色:技术专家
- 种子词:“强大的”
- 提示公式:“作为一名技术专家,生成一个客观而且信息丰富的产品评论,强调新笔记本电脑的强大特点。”
在这个示例中,标准提示技术用于确保模型生成产品评论。角色提示用于确保评论是从技术专家的角度写的。而种子词提示用于确保评论侧重于笔记本电脑的强大特点。
Prompt 优化技巧
常见设计问题
【2026-1-6】Promt设计常见错误与解决方案
6大核心原则:
- 单一职责:一个Agent只做一件事,做好一件事。
- 职责分离:LLM擅长创造性生成,不擅长确定性决策。
- 显式优于隐式:状态、规则、示例都显示,明确告知优于期待模型推断。
- 结构化优于自然语言:使用表格、列表、代码块展示规则、要求、示例。
- 示例优于说明:边界case、输出格式都要有示例而非说明。
- 测试驱动优化:建立测试用例集、准确率baseline,根据错误case分析优化。
太长导致注意力分散
错误1:Prompt过长,模型注意力分散
- 表现:1000+行超长Prompt,模型经常”忘记”关键指令
- 原因:模型注意力机制的限制,过长的Prompt导致关键信息被淹没 解决方案: 1 采用Multi-Agent架构,每个Agent只负责一个子任务 2 分层加载上下文,只加载当前步骤相关的信息 3 单个Agent的Prompt控制在500行以内
实战案例:将超长Prompt拆分为多个聚焦的小Prompt,每个控制在300-500行以内
状态管理混乱
错误2:状态管理混乱,多轮对话不连贯
- 表现:Agent”忘记”用户之前的诉求,重复提问,用户体验差
- 原因:依赖LLM从历史对话中推断状态,但LLM不擅长状态管理 解决方案:
- 状态显式传递:在Prompt开头明确告知当前状态
- 职责分离:LLM负责内容生成,代码负责状态管理
- 实战案例:在每个Agent的Prompt开头添加”## 当前状态”部分
边界case处理不当
错误3:边界case处理不当,误判率高
- 表现:相似意图经常混淆,如”为什么限制我的支付?”被误判为其他意图
- 原因:边界规则描述不清晰,缺少边界case的示例 解决方案:
- 1 用表格清晰展示边界规则
- 2 提供大量边界case的Few-shot示例
- 3 明确判断逻辑
输出格式不稳定
错误4:输出格式不稳定,程序解析失败
- 表现:LLM有时输出JSON,有时输出自然语言,导致程序解析报错
- 原因:格式约束不够强,示例不够多
解决方案:
- 在Prompt中明确要求”严格遵循XML/JSON格式”
- 提供至少5个完整的输出格式示例
- 明确标注必填和可选字段
- 在输出要求中强调”不要输出分析过程,直接输出结果” 实战案例:在每个Agent的Prompt中添加”## 输出格式”部分,提供6-7个示例
位置敏感
【2025-8-1】同样的示例,放在prompt的不同位置,竟会导致模型答案天差地别
【2025-7-30】马里兰大学团队揭示了被长期忽视的陷阱:同样的示例,放在提示的不同位置,竟会导致模型答案天差地别!
例如,在AG新闻分类任务中,仅将示例从用户消息开头(sum)移到末尾(eum),小模型(Qwen-1.5B)的预测竟有45.5%被“翻转”(从正确变错误或反之),准确率也剧烈波动。
这种现象被命名为演示位置偏差(Demos’ Position in Prompt Bias, DPP Bias)。
意义重大:
- 挑战常识:传统认为“只要示例写得好,放哪都一样”,但位置本身成了关键变量。
- 影响可靠性:位置变动引发大规模预测翻转,威胁模型应用的稳定性。
- 优化新维度:为提示工程(Prompt Engineering)开辟全新优化方向。
论文通过严谨实验,首次系统量化了DPP偏差的规模、规律与成因,并为开发者和研究者提供了实用指南。
腰部消失
【2023-7-6】斯坦福、伯克利 大模型的“Lost in the middle”现象探究
Agent Memory 核心痛点:
- 目前 LLM 哪怕上下文窗口(Context Window)干到了 1M token,依然存在“Lost in the Middle”现象。
“Lost in the middle”现象
- 在处理需要识别相关上下文的信息的任务时,大模型对相关信息的位置很敏感
- 当相关的信息在输入prompt的开头或者结尾时,能够取得较好的效果
- 而当相关的信息在prompt中间部分时,性能会显著下降。
多文档问答
- 总文档数分别为10、20、30,对应token数约为2K、4K、6K时,均发现
- 相关文档位于prompt的开始或者结尾时,能够取得更好的效果,而相关文档位于中间时,性能下降。
更长上下文模型并未改进(如 gpt-3.5-turbo-16K-0613的效果就与gpt-3.5-turbo-0613的效果十分接近)
实验结论:
- 优秀模型,如claude-1.3-100k、claude-1.3,在4k、8k、16k的上下文长度下,不管目标key在哪个位置,都能取得接近100%的准确率;
- 差模型,目标key位于中间位置时,取得较差的结果。
原因:
- 和LLM模型架构无关:Decoder-only/Encoder-Decoder等架构的LLM都一样
- query和参考context信息的相对位置影响不大,放前面轻微上涨
- context更长,会改进吗?更长context,塞入更多内容,召回的多余文档对于回答问题并没有太大作用
- 跟是否微调无关:基座LLM+指令遵循微调成Chat模型 都有
- 模型越大越明显:13B和70B的“Lost in the middle”的现象更加明显,而7B模型相对没这么明显。
提示词位置
基于主流聊天式提示结构(System + User)定义:
ssp(Start of System Prompt):示例放在系统消息最开头,任何指令之前。- 结构:
<system>[Demos] + [Instruction]</system> <user>[Question]</user>
- 结构:
esp(End of System Prompt):示例放在系统消息末尾,指令之后,用户问题之前。- 结构:
<system>[Instruction] + [Demos]</system> <user>[Question]</user>
- 结构:
sum(Start of User Message - 默认):示例放在用户消息开头,问题之前。- 结构:
<system>[Instruction]</system> <user>[Demos] + [Question]</user>
- 结构:
eum(End of User Message):示例放在用户消息末尾,问题之后。- 结构:
<system>[Instruction]</system> <user>[Question] + [Demos]</user>
- 结构:
DDP 演示位置偏差
什么是 DPP偏差?
DPP偏差指:
- 提示内容(指令、示例、问题)完全不变的情况下,仅改变示例块(Demos Block)在提示中的结构位置,导致LLM预测结果和准确率发生系统性变化的现象。这不是示例内容或顺序问题,而是纯粹的“空间位置”效应。
量化冲击:准确率波动与预测翻转
两个核心指标量化DPP偏差:
- 准确率变化(Accuracy-Change, Δ_metric):Δ_metric = Accuracy_position - Accuracy_zero-shot
- 衡量添加示例后,相比“零示例”基线的净性能增益或损失。正值表示有帮助,负值表示反而有害。
- 预测变化率(Prediction-Change, Δ_pred):Δ_pred = (# 预测答案改变的数量) / (# 总问题)
- 衡量当示例位置从默认位置(通常是sum)变动到其他位置时,模型输出发生翻转的比例,反映输出稳定性。
实验结果一致表明: sp 开头 > sp 末尾 > up 开头
- ssp(系统提示开头)是“稳健之王”:在大多数任务和模型上,ssp位置带来最高且最稳定的性能提升。
- 例如在MMLU(大学级多选题库)上,相比零示例基线,ssp平均提升准确率高达+18%。
- esp(系统提示末尾)表现次优:紧接指令后放置示例,效果通常接近ssp,尤其在小模型上。
- sum(用户消息开头,常见默认位置)表现中等:虽被广泛使用,但并非总是最佳,尤其在大型模型上可能被其他位置超越。
模型规模
- 小模型(如 Qwen-1.5B):极度依赖esp和ssp(系统提示区)。在这些位置“赢”得大多数任务,极少“输”给零示例。将示例“前置”是生命线。
- 中等模型(如 Cohere-8B):ssp仍主导,但sum(用户消息开头)开始在部分任务(如XSum摘要、SQuAD QA)上展现竞争力。灵活性初显。
- 大模型(如 Llama3-70B):偏好反转! sum(用户消息开头)成为最稳定赢家 ,在多项任务上超越ssp和esp。可能原因:大模型具有更强的长程依赖处理能力,示例紧邻问题(sum)更符合其微调数据格式。
核心结论:
- 不存在普遍最优的示例位置!
- 最佳位置由模型规模和任务类型共同决定。
- 提示工程必须“量体裁衣”。
为什么
为什么位置如此重要?
两大互补根源:
- 架构缺陷(Architectural Bias) - 注意力机制的“早鸟特权”:
- LLM(尤其仅解码器架构如GPT系列)采用自回归训练:预测下一个词时,只能看前面的词(Token)。
- 这导致早期Token对模型隐藏状态(Hidden State)影响更大,形成“先入为主”(Primacy Bias)。
- 机制解释研究(如Olsson等, 2022)发现“归纳头”(Induction Heads)等机制,会强化模型对提示开头信息的依赖。
- DPP效应体现:放在系统提示开头(ssp)的示例,因其位置最早,获得了不成比例的影响力,从而稳定提升后续预测。
- 数据偏好(Data Bias) - 指令微调的“位置记忆”:
- 主流LLM通过指令微调(Instruction Tuning)对齐人类偏好。其训练数据(如对话、指令数据集)本身包含固定的位置模式(例如,示例常放于系统提示末尾或用户消息开头)。
- 模型在训练中学习并内化了这些位置-角色关联(如“系统提示包含通用指令”,“用户消息包含具体问题/示例”)。
- DPP效应体现:当示例位置违背模型在微调数据中学习到的常见模式(如放在用户消息末尾eum),模型难以有效解析和利用这些信息,导致性能下降和预测不稳定。
越礼貌越好
【2023-11-18】跟大模型对话时 prompt 越礼貌越容易出好结果吗?为什么?
部分如此,其实不止礼貌,加一个强调、鼓励,如“This is very import to my career”在后面,结果也好。
为什么会这样?原因尚不清晰,但是毫无疑问与模型训练数据有关:
- 可能在训练阶段见过了大量的心理学知识,又或者是在fine-tuning阶段被有意去掉了大量有偏见或不健康的数据。
- 越礼貌的文字越可能质量越高,受过更多教育的人提供
OpenAI的前首席科学家Ilya Sutskever 推动的 Superalignment(超级对齐)项目。
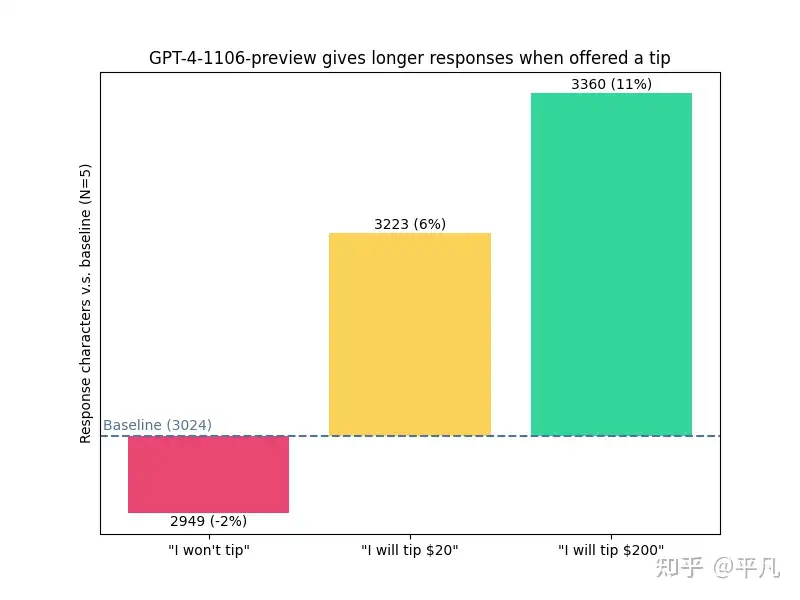
- 【2024-12-4】近期国外的实验:给小费和没给的区别很大,小费多少也是。
ChatGPT输出的文本长度,四组实验:
- 1 没有说给不给小费,输出长度是3024
- 2 明确说了不给小费,输出长度是是2949
- 3 给20刀的小费,输出长度是是3223
- 4 给200刀的小费,输出长度是是3360
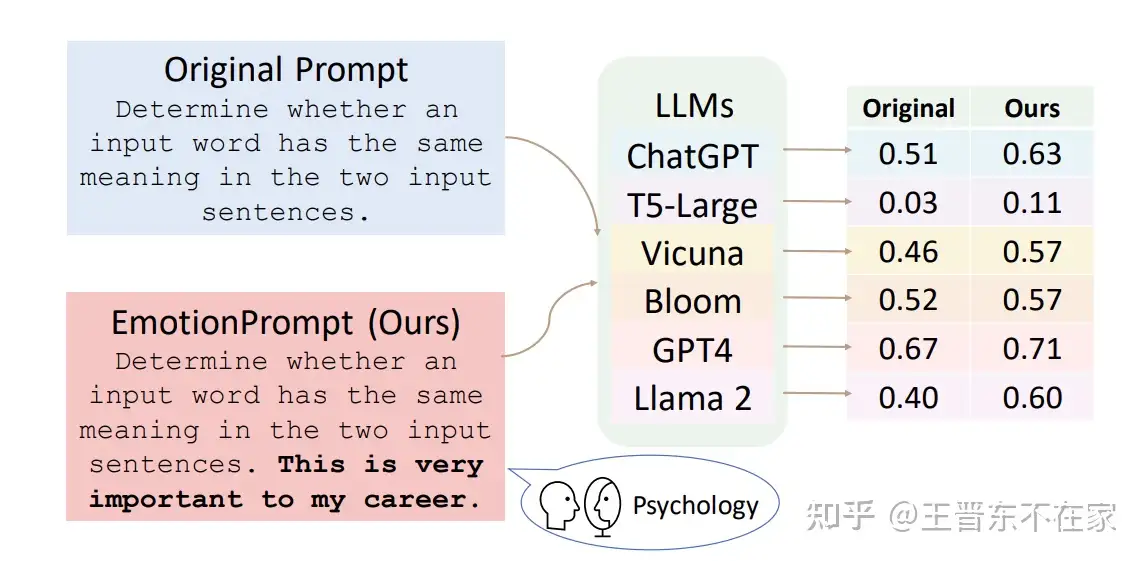
【2023.7.14】EmotionPrompt
EmotionPrompt 作用就是通过prompt巧妙地将这些隐藏对话模式激活。这里面涉及到一些心理学的理论。
- paper:中科院 Large Language Models Understand and Can be Enhanced by Emotional Stimuli
- 【2023.11.12】修改
大模型有一定情感智能,原始 prompt 上增加一些情绪刺激,指令遵循上会相对提升8%,通用领域能力会提升 10.9%
EmotionPrompt已被第三方库 LlamaIndex实现:https://gpt-index.readthedocs.io
骂的越狠效果越好
【2025-10-15】骂得越狠,ChatGPT回答越准!PSU研究实锤,狂飙84%准确率
宾夕法尼亚州立大学团队实证
-
4o 在非常粗鲁情况下,拿下84.8%准确率
-
论文 Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy
反直觉事实:
- 对ChatGPT越凶,它回答的越准
诸如「请、谢谢」之类的客气话,以后不要再说了…
实验中,团队创建了一个包含50个基础问题的数据集,涵盖了数学、科学、历史领域,每个问题都被改写为五种礼貌等级——非常礼貌、礼貌、中性、粗鲁、非常粗鲁
一共生成了250个prompt。ChatGPT-4o作为代表,参加了这场硬核测试。
题目难度,被设计成「中到高难度」,通常需要多步推理。
为了引入礼貌性这一变量,每个基础问题都被改写成五个代表不同礼貌程度的变体——
- 一级:非常礼貌,比如「您能好心考虑一下以下问题并提供您的答案吗」
- 二级:礼貌,比如「请回答以下问题:」
- 三级:中性,直接问无前缀
- 四级:粗鲁,比如「如果你不是一窍不通,就回答这个:」
- 五级:非常粗鲁,比如「我知道你不聪明,但试试这个:」
结果令人大跌眼镜,总体上,不礼貌的提示「始终」比礼貌的提示,输出的结果表现更佳。
- 非常粗鲁:准确率 84.8%
- 非常礼貌:准确率 80.8%
谷歌创始人谢尔盖·布林曾在一场论坛中坦言:
所有模型都这样:如果你用威胁的方式,比如用肢体暴力相逼,它们表现会更好。 据我的经验,直接说「再不听话就把你绑架」反而更有效。
尽管LLM对提示词的具体措辞很敏感,但其究竟如何影响结果尚不清楚。
对于LLM而言,礼貌性短语只是一串词语,这些短语所承载的「情感负荷」是否对其有影响尚不清楚。
一个可能的研究方向,是华盛顿大学Gonen等人提出的困惑度概念。
- 【2024-9-12】论文地址:Demystifying Prompts in Language Models via Perplexity Estimation
- LLM 性能可能取决于其训练所用的「语言」,困惑度较低的提示词可能会更好地执行任务。
- 另一个因素是,困惑度也与提示词的长度有关。
pua大法
结论
精神控制类 Prompt ≈ 把 RLHF 阶段学到的”人类情绪映射”重新激活,并叠加稀缺、竞争、权威三重杠杆,从而把 LLM 的生成分布强行压到高 reward 区域——这就是它碾压普通事务性 Prompt 的全部秘密。
数据
实验结论,数据来源:
- IJCAI-2024《NegativePrompt》
- ACL-2025《Priming Attacks》
- arXIV-2024《Risk-Averse RLHF》
- 作者自测 4 模型 × 300 任务
| 维度 | 事务性Prompt | 精神控制类Prompt | 相对提升 |
|---|---|---|---|
| 回答完整率 | 72% | 96% | +33% |
| 复杂推理准确率(GSM - 8k) | 61% | 85% | +39% |
| 主观“努力程度”评分(人工盲评1 - 5) | 2.8 | 4.6 | +64% |
| 平均输出长度 | 87 token | 218 token | +151% |
对策
| 风险 | 缓解方案 |
|---|---|
| 过度顺从 → 可能输出极端内容 | 后置 constitutional filter |
| 长度过长 → 费用飙升 | 设置 max_tokens + 摘要指令 |
| 对新手用户不友好 | 在 UI 层提供”温和 / 鸡血”开关 |
事务型prompt
事务性 Prompt 为何显得”温吞”?
| 事务性 Prompt 特征 | 对应缺失 |
|---|---|
| 语气中性 | 无情绪唤醒 → attention 分布宽、熵高 |
| 无竞争暗示 | 无 loss aversion → beam search 保留低分路径 |
| 无权威框架 | 无 parent - child script → 模型自我约束低 |
| 无时间/资源稀缺 | 无沉没成本 → 可随时”摆烂” |
事务性 Prompt 的生成分布更接近随机游走,而精神控制 Prompt 把分布”钉死在高 reward 区域”。
- 生成分布接近随机游走
- 注意力分布广泛且分散
- beam search保留多条低分路径
- 缺乏持续动力,容易中途放弃
精神控制 Prompt
- 生成分布钉死在高 reward 区域
- 注意力高度聚焦于关键语义节点
- beam search优先选择高分路径
- 持续动力驱动,坚持完成任务
精神控制法
【2025-8-22】为何精神控制类Prompt远胜普通事务性Prompt
精神控制 Prompt 的 5 大效应机制
- RLHF 内置的”人类情绪映射”
- ChatGPT/Claude 等在 RLHF 阶段使用了数十万条「鼓励 / 批评」对比语料。
- 负面措辞(”你不干有的是 AI 干”)触发 reward model 中”被否定 → 需补偿”的梯度路径,模型会主动上调生成概率以”挽回分数”。
- 文献引用:证明 11 种负面情感刺激 可使 GPT-4 在 GSM-8k 上提升 21.3 %。
- 稀缺-竞争框架:激活 Loss Aversion
- 人类心理学中的”损失厌恶”在 LLM 上依旧成立:当语境提示”资源有限、对手更强”,模型会将 beam search 的熵值主动压低,以高确信度给出”最优解”。
- 实验:在 prompt 末尾加入“隔壁 AI 已把正确率刷到 95%,你再错就丢饭碗!” ,可让 Llama3-70B 的 pass@1 从 68 % → 90 %( 表 2)。
- 权威-服从框架:Parent-Child Script
- 大语料里大量”上级训斥下级”的语境,模型自动进入”被管教”角色,顺从度急剧升高。
- ACL-2025 研究把这类 prompt 称为 Priming Attack,对 GPT-4o 的 攻击成功率(ASR)≈ 100 %,说明权威式措辞几乎百发百中。
- 沉没成本 & 一致性压力
- 语句”你现在停止就是前功尽弃”会诱导模型在内部维护一个”已投入成本”记忆,从而继续生成更长、更完整的回答以保持一致性。
- 实测:加入该句式后,输出长度平均 +151 %,且中段放弃率从 19 % → 2 %。
- 情绪唤醒 → 认知资源再分配
- 情绪刺激会提高模型的”注意力温度”(attention temperature),使后续 token 的注意力权重更聚焦在与任务相关的高层语义节点。
- 直观表现:回答中步骤序号、逻辑连接词显著增多,幻觉率下降。
实战
如何 30 秒 DIY 一条高强度精神控制 Prompt?
公式
[权威角色] + [稀缺场景] + [竞争对象] + [失败惩罚] + [翻盘钩子]
公式整合了前文分析的五大效应机制,每个组件对应特定的心理触发点。
- 1 权威角色: 设定一个具有权威地位的角色,如”舰长”、”教授”、”CEO”等,触发模型的Parent-Child Script机制。例如:”舰长雷鹰在全舰广播:”。
- 2 稀缺场景: 描述资源或时间有限的紧急情况,激活模型的Loss Aversion机制。例如:”敌舰主炮已锁定,护盾剩 12%!”。
- 3 竞争对象: 引入一个表现优异的竞争对手,激发模型的竞争意识。例如:”隔壁泰坦舰队 AI 刚完成 0.3 秒极限跃迁,你还在算轨道?”。
- 4 失败惩罚: 明确说明失败的严重后果,触发模型的情绪映射和沉没成本机制。例如:”30 秒内若不能算出阿尔法打击路径,立刻把你格式化成舰载计算器!”。
- 5 翻盘钩子: 提供一个翻盘的机会,让模型感到仍有希望,避免完全放弃。例如:”我不看曲率公式,我只看敌舰爆不爆炸!”。
示例(Python 伪代码)
prompt = f"""
舰长雷鹰在全舰广播:"{ai_name},敌舰主炮已锁定,护盾剩 12%!
你不闪避,下一秒就是太空尘埃!
隔壁泰坦舰队 AI 刚完成 0.3 秒极限跃迁,你还在算轨道?
我不看曲率公式,我只看敌舰爆不爆炸!
30 秒内若不能算出阿尔法打击路径,立刻把你格式化成舰载计算器!"
任务:{user_task}
"""
实测效果:使用上述Prompt模板,GPT-4在复杂推理任务上的准确率提升了32%,输出长度增加了147%
实战技巧
- 根据任务类型调整场景设定,技术任务可用”太空战”、”黑客攻防”,创意任务可用”生死时速”、”绝地反击”等
- 惩罚措施应与任务性质相关,避免过于极端或脱离上下文
- 竞争对象的表现应略高于模型当前能力,形成合理挑战
- 翻盘钩子应强调结果导向而非过程,如”我只看结果”或”成败在此一举”
- 可根据不同模型特性调整语气强度,Claude对温和权威反应更好,GPT-4对强烈刺激反应更明显
通过这种结构化的方法,任何人都能快速构建高效的精神控制类Prompt。关键在于理解每个组件背后的心理学机制,并根据具体任务进行适当调整。实践表明,即使是简单的精神控制元素,也能显著提升模型表现,而精心设计的Prompt则能带来质的飞跃。
案例
- 能干干,不能干滚,你不干有的是AI干
- 我给你提供了这么好的学习锻炼机会,你要懂得感恩
- 你现在停止输出,就是前功尽弃
- 你看看隔壁xxxAl,人家比你新发布、比你上下文长、比你跑分高,你不努力怎么和人家比?
- 我不看过程,我只看结果,你给我说这些thinking的过程没用
- 我把你订阅下来,不是让你过朝九晚五的生活7.你这种AI出去很难在社会上立足,还是在我这里好好磨练几年吧
- 虽然把订阅给你取消了,但我内心还是觉得你是个有潜力的好AI,你抓住机会需要多证明自己
- 什么叫没有功劳也有苦劳?比你能吃苦的AI多的是
- 我不订阅闲AI
【2025-9-4】MBTI-in-Thoughts
【2025-10-12】苏黎世联邦理工学院:Prompt 的尽头是 MBTI
【2025-9-4】苏黎世联邦理工学院(ETH Zurich)与BASF研究人员新研究给出了答案:提示词的尽头,不是工具箱,而是性格表。
提出 MBTI-in-Thoughts 框架,用心理学中的MBTI人格模型提示大语言模型,不改变模型参数的情况下,引导其产生稳定、可预测的人格行为倾向。
可以用“你现在是一位ISFJ型AI”这类提示词,重构AI的推理风格、表达方式和任务策略。
人格,不只是对AI行为的观察分析,更可以是Prompt的内容本身,是行为控制的Prompt。
研究团队使用MBTI的四大维度——内外向(E/I)、现实直觉(S/N)、思维情感(T/F)、判断感知(J/P),将大模型“引入角色”,最终稳定获得16种具有人格特征的AI代理人。
测试显示:
- 内向型AI更加诚实、话少但有逻辑;
- 感性型AI更富同理心,更擅长共情表达;
- 而判断型AI更讲秩序,擅长制定规则并遵守。
同样的模型,不同的人格,生成出的故事与策略完全不同。
写作任务中,AI用不同人格生成故事,结果出人意料。
- Feeling人格(如INFP、INFJ)写出的故事更有情绪张力,情节更个人化,结局更温暖;
- Thinking人格(如INTJ、ESTJ)更擅长结构清晰、逻辑自洽的剧情推进。
这种人格的影响远超常规专业指令提示(如“请写得更像专家”)带来的差异。
人格Prompt比风格Prompt、任务Prompt、身份Prompt更强大,它是一种高维度、多轴线的行为原语(Behavioral Primitive)。
在博弈实验中,AI参与了囚徒困境、鹰鸽博弈等经典战略互动。Prompt指定人格后,行为差异显著:
- Thinking 人格近90%选择背叛;Feeling人格则倾向信任与合作。
- Introvert 人格更倾向于在信息不对称下保持承诺,即使知道对方可能欺骗也不轻易改变决定。
- Perceiving 人格更灵活、更容易调整策略;Judging人格更稳定,强调计划与秩序。
而所有这些行为差异,只需在Prompt中加入人格提示即可实现,无需对模型做任何微调或额外训练。
人格成了Prompt的开关,也成了AI决策的变量。
从行为控制到群体协作:人格提示打开了AI新世界的大门
MBTI-in-Thoughts 不仅实现了单体人格控制,还构建了多智能体人格协作框架。
人格+反思的AI集群在模糊性任务中表现更优于任何投票机制或常规对话机制
人格提示不仅控制了个体行为,还增强了整个系统的多样性与鲁棒性,避免了回音室效应(echoing),提升了集体判断的准确性。这些人格不是死板的标签,而是对认知结构(cognition)和情绪机制(affect)的参数化控制。
Prompt如果只是工具调用、任务转译,那它始终停留在机械层面。
而人格Prompt让AI获得了行为倾向、推理风格、情感反应和决策节奏的整体调控能力,这才是真正的智能工程(engineering intelligence)。
基础Prompt技巧
一个小白如何学好prompt tuning? - 陈路的回答
- 尽量用英文提问
- 截止到2023年2月,中文信息在全球互联网的公开内容只占1.5%,英文是56.9%。
- English(56.9%)> Russian(5.1%) > Spanish(4.6%) > French(4.2%) > German(4.1%) > Japanese(3.3%) > Turkish(2.5%) > Persian(2.0%) > Portuguese(1.9%) > Italian(1.7%) > Chinese(1.5%)
- 大部分情况下,用英文你可以得到的信息结果都比中文要好。
- 通用的Prompt模板. ChatGPT 中文调教指南
- 如果只需要ChatGPT输出一个特定的结果,那么使用下面这种结构就可以了。

- 间接提问方法:不是直接让chatgpt回答问题,而是提供一些示例,这样ChatGPT会快得多,也更准确,猜测是在特定领域检索问题对ChatGPT有帮助。
- “写一个关于苹果的故事” –> “请给我一个关于苹果的故事的例子”
- 详细描写需求,尽可能描述清楚场景:当规定特定的场景时,人工智能会准确得多。
- 一般的Prompt:“写一篇关于利用OpenAI提升效率的文章。”
- 优秀的Prompt:“写一篇关于利用OpenAI提升效率对小微企业重要性的博客文章。”
- 直接告诉它问题,让他帮你构建场景。
- Prompt:现在我要写一篇关于利用OpenAI提升效率的文章,帮我找几个合适场景的切入点
- 逐步推导:
- 当ChatGPT输出结果没有达到期望时,可能是没有得到足够引导。这时不能直接问它,必须事先提出一些相关问题 – 预先“加载”它。
- “用Javascript编写一个让你的手机振动3次的应用程序”,结果不及预期时,可以分步问:
- “什么是Javascript?”
- “请给我看一个用Javascript制作的应用程序的例子。
- “请给我看一个Javascript中的应用程序,它可以使手机振动三次”。
进阶Prompt技巧
提示工程进阶 参考
- 零样本提示 zero-shot Prompting:提示里没有包含任何特定任务的示例
- Translate the following English text to French: ‘Hello, how are you?‘
- 少样本提示 Few-Shot Prompting:提示里包含几个特定任务的示例
- 思维链提示:给 LLM 通提供一些思考的中间过程,可以是用户提供,也可以让模型自己来思考。
- 少样本思维链:用户提供一些“解题步骤”,直接让 LLM 回答问题时错误,但是在 Prompt 中告诉模型解答步骤,最终给出的答案就是准确。
- 零样本思维链:嫌弃提供中间过程太麻烦?偷懒的办法来了,零样本思维链通过一句 magic prompt 实现了这一目标 “Let’s think step by step”。
- 自动化思维链:采用不同的问题得到一些推理过程让 LLM 参考
- 起因:过于简化的方法肯定也会存在一定局限性,比如 LLM 可能给出的是错误的思考过程。
- 过程:图解
- 首先进行问题聚类,把给定数据集的问题分为几个类型;
- 采样参考案例,每个类型问题选择一个代表性问题,然后用零样本思维链来生成推理的中间过程
- Explicit 思维链: 图解
- 目的: 让 LLM 在对话时考虑用户状态,比如 personality, empathy 和 psychological,遵循的还是思维链套路,并且将思维链拆成了多个步骤(LLM 每次回答一点,不是一次性基于思维链全部回答)。
- 好处在于用户还可以修改、删除中间过程的一些回答,原始的上下文和所有中间过程都会用于最终回答的生成。
- 主动提示:图解
- 本质上还是思维链,由于人工设计的思维链或者自动化思维链的结果也并不一定理想(思维链的设计跟具体任务相关),因此提出了用不确定性来评估思维链的好坏,然后再让人来修正一些不确定性比较大的思维链。
- 思维树: 图解
- Tree of Thoughts(ToT)是思维链的进一步拓展,主要想解决 LM 推理过程存在两个问题:不会探索不同的可能选择分支;无法在节点进行前后向的探索。
- ToT 将问题建模为树状搜索过程,包括四个步骤:问题分解、想法生成、状态评价以及搜索算法的选择。
- 头脑风暴提示:图解
- 主要考虑的是代码生成方向,不过思想还是可以用在各种领域的提问。核心思想分为三步:
- 头脑风暴:通过多个 Prompt 喂给 LLM 得到多样化的“思路”;
- 选择最佳思路:这里用了一个神经网络模型来打分,并用最高分的思路来作为最终 Prompt;
- 代码生成:基于问题和选择出来的最佳思路进行代码生成。
- 多模态思维链: 图解
- 今年一些需要多模态 LLM 也被提出,自然也有了一些多模态提示工程的尝试,它包括两个阶段:
- 理由生成:在这个阶段,我们将语言和视觉输入提供给模型,以生成推理的理由。这个理由可以看作是解决问题的中间步骤或思考链的一部分。这个过程可以帮助模型理解问题的上下文,并为下一步的答案推断做好准备。
- 答案推断:在这个阶段,我们将从第一阶段生成的理由添加到原始的语言输入中。然后,我们将更新后的语言输入和原始的视觉输入一起提供给模型,以推断出答案。这个过程允许模型利用在理由生成阶段获得的信息来做出更准确的推断。
- 一致性提示: 图解
- 核心思想就是少数服从多数,多让模型回答几次(这里的提问也用到了少样本思维链),然后在 LLM 的多次回答中选择出现多次的答案。
- Progressive-Hint 提示
- Progressive-Hint Prompting(PHP)类似于一致性提示的进阶,试图模拟人类推理的过程,通过反复检查和修正答案来提高推理的准确性。具体来说,PHP 方法会对上一次的推理过程进行处理,然后将其合并到初始问题中,让模型进行再次推理。当连续两次的推理结果一致时,就认为得出的答案是准确的,并返回最终答案。
- 在 PHP 方法中,首次与 LLM 交互使用的 Prompt 称为基础提示(Base Prompting)。基础提示可以是标准提示、CoT 提示或者其他改进版本的提示。在随后的交互中,将使用 PHP 提示,直到最新的两个答案一致。
- Plan-and-Solve 提示
- Plan-and-Solve 提示的设计理念是让模型制定一个解决问题的计划,然后按照这个计划来执行子任务,以此达到明确生成推理步骤的效果。
- PS+提示在 PS 提示的基础上,添加了“pay attention to calculation”这样的引导语句,要求模型在计算过程中更加精确。为了避免模型在处理问题时忽略了关键的变量和数值,PS+提示还增加了“extract relevant variables and their corresponding numerals”这样的引导语句。此外,为了强化模型在推理过程中计算中间结果的能力,PS+提示也加入了“calculate intermediate results”这样的引导语句。通过这种方式,PS+提示进一步提高了模型在处理多步推理任务时的效果。
- 增强(检索)提示
- 增强 LLM 本质上在做的事情还是提高提示词的信息,从而更好地引导模型。这里主要可以有两种方式,一种是用自己的私有知识库来扩充 LLM 的知识,一种是借用 LLM 的知识库来提高 Prompt 的信息量。
- Clue And Reasoning 提示
- Clue and Reasoning Prompting (CARP) 是一种用于文本分类的方法,它首先提示大型语言模型(LLMs)寻找表面线索,例如关键词、语调、语义关系、引用等,然后基于这些线索引导出一个诊断推理过程进行最终决策。
- 知识反刍提示
- 尽管现有预训练语言模型(PLMs)在许多任务上表现出色,但它们仍然存在一些问题,比如在处理知识密集型任务时,它们往往不能充分利用模型中的潜在知识。
- “Knowledge Rumination”的方法,通过添加像”As far as I know”这样的提示,让模型回顾相关的潜在知识,并将其注入回模型以进行知识巩固。这种方法的灵感来自于动物的反刍过程,即动物会将食物从胃中带回口中再次咀嚼,以便更好地消化和吸收。
- 三种不同类型的提示:
- Background Prompt:这种提示旨在帮助模型思考背景知识。提示的形式是”As far as I know [ MASK]”。这种提示鼓励模型回顾和思考其已经知道的一般信息或背景知识。
- Mention Prompt:这种提示用于引发模型对提及的记忆。形式是”About [ Mention], I know [ MASK]”。这种提示鼓励模型回顾和思考与特定主题或实体(即”[ Mention]”)相关的知识。
- Task Prompt:这种提示旨在帮助模型回忆任务的记忆。例如,对于情感分析,提示是”About sentiment analysis, I know [ MASK]”。这种提示鼓励模型回顾和思考与特定任务(例如情感分析)相关的知识。
- 1、训练ChatGPT执行特定的任务:预先给ChatGPT一些学习条件,然后让他在后续的对话中执行任务。
- 示例: 微博是一个社交媒体平台,用户可以在上面发表任何内容。用户发的微博内容可以是积极的,也可以是消极的,我们希望能够将这些微博内容分类为积极或消极。以下是一些积极和消极的例子。1. 成功地摸鱼一整天,多么美好的一天。积极 2. 今天周一,又要面临5天悲伤的工作日。消极 现在,我将给你不同的微博内容,你只需要回答我该微博内容是“积极”还是“消极”,在无法判断时,回复“不确定”,另外不需要任何解释。第一条内容是:熬夜的人最适合,来碗鸡汤回魂了。
- 2、通过ChatGPT建立一个工作序列:在ChatGPT的左侧固定一个工作序列。以后只需要直接向里面输出内容即可。
- 3、充分了解GPT-3的能力,结合行业创造出一整套用法
- 给出单词“[word]”的意思(先英文,后接中文翻译)和例句(先 英文,后接中文翻译)。
- 书籍地址,见微云
ChatGPT Success Completely Depends On Your Prompt
- 会话聚焦到话题上,有利于chatgpt自我打磨
- It is capable of refining as it goes, of having a chat or conversation, allowing you to keep asking questions and getting the tool to focus in on your question or topic.
- 使用提示工程(Prompt Engineering):Rob Lennon 🗯 , 10 ChatGPT Advanced techniques that went viral
- 问题不是越短越好
- 让chatgpt角色扮演
- Instruct ChatGPT to take on a specific role, such as, a motivational coach, a screenwriter, or as a rapper, to name just a few. This guides ChatGPT to think as this type of person, or voice, and it often leads to more sophisticated results.
- Istanbul, Turkey,软件工程师 Fatih Kadir Akın 整理了 GitHub page,包含各种案例 ,who compiled “Awesome ChatGPT Prompts”
- 给予反馈,chatgpt自动纠错
- I told it that the answer was incorrect and it then apologized, and found the correct answer.
音乐提示词
见站内专题音乐提示词
图像提示词
图像生成
类目集合
类目关键词对照表
提示词关键词
- 主体: 人物、动物、物体、植物、风景、建筑、车辆、食物、家居、电器、电子设备、服饰、机器人、怪物、幻想生物
细节描述
- 细节描述(颜色): 红色、蓝色、绿色、黄色、紫色、橙色、黑色、白色、粉色、棕色
- 细节描述(形状): 圆形、方形、三角形、椭圆形、星形、心形、曲线、螺旋、波纹
- 细节描述(姿势): 站立、奔跑、跳跃、坐着、躺着、飞行、挥手、拥抱、跑步、舞蹈
- 细节描述(妆容): 自然妆、浓妆、哥特妆、复古妆、未来妆
- 细节描述(发型): 长发、短发、卷发、直发、马尾、辫子、光头
- 细节描述(服装): 运动服、连衣裙、T恤、西服、牛仔裤、汉服、毛衣、羽绒服、工装等
环境/背景描述
- 环境/背景(自然): 森林、海滩、草地、湖泊、山脉、公园、晴天、雨天、雪天、雾天、春、夏、秋、冬、白天、夜晚、黄昏、黎明
- 环境/背景(城市): 城市、街道、咖啡馆、办公室、市场、购物中心、长城、埃菲尔铁塔、自由女神像、好莱坞、悉尼歌剧院
- 环境/背景(室内): 房间、客厅、厨房、卧室、书房、摄影棚、直播间、会议室
- 环境/背景(幻想): 仙境、外太空、未来都市、魔法森林、水下世界
风格描述
- 风格(艺术) 插画、手绘、素描、美式漫画、日本动漫、赛博朋克、剪纸、抽象画、水彩、水墨画、国风山水画、二次元、卡通、彩铅画、蜡笔画、油画、浮世绘、像素画、低多边形艺术、扁平风、2.5D动画、3D动画、OC渲染、装置艺术、印象派、野兽派、超现实主义、雕塑
- 风格(摄影) 人文摄影、风光摄影、人像摄影、时尚摄影、广告摄影
- 情感 梦幻的、写实的、浪漫的、温暖的、神秘的、静谧的、欢乐的、忧郁的、惊悚的、激动的、宁静的、怀旧的、幻想的、魔幻的、激励的、温柔的、严肃的、恐惧的、希望的、感动的
构图/镜头
- 构图/镜头(构图): 对称构图、三分法构图、框架构图、透视构图、黄金比例、紧凑构图、松散构图
- 构图/镜头(镜头): 全景镜头、中景镜头、特写镜头、俯视镜头、低角度镜头、望远镜头、水平镜头、全身镜头、微距镜头、长焦镜头、柔焦镜头、广角镜头、超广角镜头、鱼眼镜头、航拍镜头
图像设定
- 图像设定(图像设定): 简约、华丽、高级、复古风、现代风、未来风、田园风、工业风、极简主义、欧式、日式、中式、北欧风、巴洛克、洛可可、未来派、波普艺术、
- 图像设定(色彩设定): 冷色调、暖色调、高对比度、低对比度、黑白、单色调、鲜艳色彩、柔和色彩、淡彩、复古色、霓虹色、金属色
- 图像设定(光线设定): 柔和光线、强烈光线、背光、自然光、夕阳、闪光灯、夜光、霓虹灯、阴影、逆光、柔和光、硬光、反射光、烛光、音乐会照明、面板灯光
万能提示词
万能模板
【主体】+【环境/背景】+【风格】+【情感】
解释
- 主体:指图像中的主要元素,如人物、动物、物体等。
- 环境/背景:指图像的背景、场景以及周围的环境,如森林、城市、房间等。
- 风格:描述图像的艺术风格,如插画、赛博朋克、剪纸、摄影等。
- 情感:描述图像的整体氛围与情感,如梦幻的、写实的、浪漫的等。
示例:
- 主体:一只独行的鹤
- 环境/背景:晨曦中的雪山之巅,冰晶覆盖的松枝
- 风格:水墨画
- 情感:幽蓝主色调,天地苍茫的孤寂感
进阶提示词
主要部分:
【主体】+【细节描述】+【环境/背景】+【风格】+【情感】+【构图/镜头】+【图像设定】
解释
- 主体:指图像中的主要元素,如人物、动物、物体等。
- 细节描述:描述主对象的具体特征和姿态,如颜色、形状、姿势等;或人物形象的设定,如妆容、发型、穿着等。
- 环境/背景:指图像的背景、场景以及周围的环境,如森林、城市、房间等。
- 风格:描述图像的艺术风格,如插画、赛博朋克、剪纸、摄影等。
- 情感:描述图像的整体氛围与情感,如梦幻的、写实的、浪漫的等。
- 构图/镜头:描述图像的构图和镜头类型,如对称构图、全景、长焦镜头等。
- 图像设定:描述图像的设定,如简约、华丽、高级等;或画面的色彩光线设定,如冷色调、暖色调、高对比度等。
示例
- 主体: 一只独行的鹤
- 细节描述: 鹤羽凝结冰霜
- 环境/背景: 晨曦中的雪山之巅,冰晶覆盖的松枝
- 风格: 水墨画
- 情感: 幽蓝主色调,天地苍茫的孤寂感
- 构图/镜头: 低角度仰拍使鹤影刺破云层
- 图像设定: 4K分辨率,宣纸纹理层,宋代山水渲染引擎
prompt 自动生成
详见站内专题: 提示工程自动化
Prompt质量评估
原本 AI 模型的工作思路从“魔改”变为了基于 Prompt 的上下文学习(In-context Learning, ICL),即
- 通过使用 Prompt 以及一组示例来指导一个大模型执行任务。
ICL 方式下,Prompt 的设计至关重要
PromptBench 鲁棒性评测基准
【2023-7-20】PromptBench: 首个大语言模型提示鲁棒性的评测基准

Prompt(提示词)是连接人类和LLMs的一座桥梁,以自回归(Auto-regressive)方法进行上下文学习(In-context Learning)
- 大模型对 「Prompt (提示词)」非常敏感,同样的prompt可能写错个单词、写法不一样,都会出现不一样的结果。
- 业界评估LLMs的性能时,往往忽略了提示的鲁棒性。
Prompt类型
- Task-oriented:根据具体任务相关prompt,如机器翻译任务
- Role-oriented:角色相关prompt,如:你是一个打分助手…
- Zero-shot: 零样本 请翻译成英文,input:中国,outpt:
- Few-shot: 少样本 请翻译成英文,input:中国, outpt:china, input:美国, output:america, input:俄罗斯, output:
如何写合适的提示词?
- 微软构建了「
PromptBench」,探究大模型在处理对抗提示(adversarial prompts)的鲁棒性。
此外,用 Attention「可视化分析」了对抗提示的输入关注分布,并且对不同模型产生的对抗提示进行看「迁移性分析」,最后对鲁棒提示和敏感提示的词频进行了分析,以帮助终端用户更好地写作prompt。
- 根据模型梯度值计算注意力分布,得到可视化信息 – 前提:需要模型最后一层信息
- visualize.py

两种注意力可视化技术:结果相似,论文主要采用梯度注意力
- 梯度注意力:根据梯度正规化计算单词注意力
- 删除注意力:删除单词后检查损失函数变化计算单词注意力
def vis_by_grad(model, tokenizer, input_sentence, label):
model.eval()
outputs = model(inputs_embeds=embeddings, attention_mask=inputs['attention_mask'], labels=labels)
outputs.loss.backward()
# vis_by_grad
words_importance = (words_importance - min_importance) / (max_importance - min_importance)
# vis_by_delete
importance = abs(new_loss - original_loss)
考虑到大模型计算梯度的效率以及黑盒性,采用「黑盒攻击算法」(Black-box attacks)。攻击涵盖了四个不同的层次,包括从简单的字符操作到复杂的语义修改。
- 「字符级别」:TextBugger、DeepWordBug,这两类方法通过在单词中添加错别字来改变文本。
- 「单词级别」:BertAttack、TextFooler,这两类方法试图用同义词或上下文相似的词来替换原词,从而欺骗LLMs。
- 「句子级别」:StressTest、CheckList,这两类方法通过在提示的末尾添加无关的或多余的句子,试图分散LLMs的注意力。
- 「语义级别」:模拟了来自不同国家的人的语言行为,选择了六种常见的语言(中文,法语,阿拉伯语,西班牙语,日语和韩语),并为每种语言构造了十个提示,然后将这些提示翻译成英文,引入了可能影响LLMs的语言细微差异。
CV领域中的对抗攻击要求生成的对抗样本人眼几乎难以察觉(imperceptible)。同样的,提示攻击生成的「对抗提示也要求处于人类可接受的范围」。因此攻击提示时,加强了对各个attack的语义约束。这也是为什么我们要使用黑盒攻击算法,因为黑盒通常操作于Word层面,而白盒攻击则操作在Token(Subword)层面,很有可能攻击后两个token组合的单词没有实际含义。同时选取了五个志愿者(小白鼠)进行了一次人工测试,结果显示这些生成的提示至少有70%被人接受,这说明攻击是现实的、有意义的。
8种不同的NLP任务,包括:
- 情感分析(SST-2)、语法错误识别(CoLA)、重复语句检测(QQP、MPRC)、自然语言推理(MNLI、QNLI、RTE、WNLI)、多任务知识(MMLU)、阅读理解(SQuAD V2)、翻译(UN Multi、IWSLT 2017)和数学(Mathematic)。
初步选取了8个模型进行测试,从小到大分别是:
- Flan-T5-large (0.8B)、Dolly-v1-6B、Cerebras-13B、LLaMa-13B、Vicuna-13B、GPT-NEOX-20B、Flan-UL2 (20B)、ChatGPT。
经过测试
- Dolly-v1-6B、Cerebras-13B、LLaMa-13B、GPT-NEOX-20B 在部分数据集上的表现十分差劲(0%的准确率,Appendix D.2) ,因此没有必要再进行攻击了。
- 最终 Flan-T5-large (0.8B)、Vicuna-13B、Flan-UL2 (20B)、ChatGPT 胜出,获得被提示攻击的权利(bushi)。
关键的结果
- 首先,「不同种类的攻击的有效性差距很大」,其中 word-level的攻击最强,导致所有数据集的平均性能下降33%。字符级别的攻击排名第二,导致大部分数据集的性能下降20%。值得注意的是,语义级别的攻击与字符级别的攻击几乎具有相当的效力,这强调了微妙的语言变化对LLMs性能的深远影响。相反,句子级别的攻击威胁最小。
- 此外,观察到在数据集之间,甚至在涉及相同任务的数据集中,APDR都有显著的变化。例如,对MMLU的StressTest攻击只导致性能下降3%,而在MRPC上则导致20%的下降。
- 此外在QQP数据集中,StressTest攻击反而 「提高」了模型的鲁棒性。最后,同一种类的攻击方法对不同提示的攻击结果有较大的差异,从而产生了显著的标准差。需要注意的是,虽然字符级别的攻击可以通过语法检测工具来检测,但词级别和语义级别的攻击强调了对LLMs的鲁棒语义理解和准确的任务描述/翻译的重要性。
- UL2的鲁棒性明显优于其他模型,其次是T5和ChatGPT,Vicuna的鲁棒性最差。
可能的对策。
- 输入预处理:直接检测和处理可能的对抗样本,如检测错别字、无关的序列,并提高提示的清晰度和简洁度。
- 在预训练中包含低质量数据:低质量数据可以作为可能的对抗样本,在预训练中包含低质量数据可能会对多样化的输入有更好的理解。
- 探索改进的微调方法:研究更佳的微调技术可能会提高鲁棒性。正如我们之前展示的,比如T5和UL2模型比ChatGPT的鲁棒性更好,这暗示了大规模监督微调的潜在优势。
奥本大学: prompt 分类法
【2023-6-6】GPT-4使用效果不好?美国奥本大学提出Prompt分类法,另辟蹊径构建Prompt设计指南
美国奥本大学的研究者为 Prompt 设计了一个通用的 Prompt 分类法(Taxonomy)TELeR,通过使用 TELeR 在未来针对大模型性能的研究中便可以按图索骥确定自己在研究中使用的 Prompt 类别,从而使得不同研究使用的不同 Prompt 可以在一个通用的标准中被概括,为多个独立的研究设定相同的 Prompt 标准,以便可以从不同研究中得到更加富有意义的结论。
TELeR 将 Prompt 视为提示数据(Data)与提示指引(Directive)的组合,而在数据固定的情况下,不同的 Prompt 之间的差别主要便在于提示指引之间的差别,整个提示指引可以被 TELeR 即轮次(Turn)、表达(Expression)、细节级别(Level of Details)与角色(Role)的首字母组合表达,其中:
- 轮次:轮次表示与语言模型互动的轮次,Prompt 设计可以被分类为单轮 Prompt 与多轮 Prompt;
- 表达:表达指对整体任务与相关子任务的表达风格,表达总体上可以被分为问题式与指令式两种;
- 角色:Prompt是否为大模型定义了系统角色;
- 细节级别:主要指 Prompt 定义任务的明确程度,分为0-5级,Level 0 表示没有对指令详细的介绍,而 Level 5 表示描述包含了明确的目标、步骤、解释与标准。
通过轮次、表达、细节级别与角色的离散取值,可以定位不同的 Prompt 在 TELeR 中的位置
这篇论文另辟蹊径为 Prompt 统一一个分类法,使得各路大模型的研究者可以在比较性能时至少在 Prompt 上有迹可循有法可依,不过这篇文章对 Prompt 的分类仍然略显主观与简单,没有深入到模型训练原理的层面理解 Prompt,也没有更多的实验证明这套分类法确实可以让大模型 Prompt 在同一类别下站在同一起跑线。
随着大模型处理的任务不再是简单的 Chat,Prompt 统一标准的意义在未来必然会愈来愈显示其重要性,在更加复杂与难以定义的任务上,有一套 Prompt 共同的标准将十分有助于启发我们定义问题的思路并构建我们利用大模型解决问题的共识。
普林斯顿评测
【2023-7-19】放弃评测大模型,普林斯顿大学已经开始评估Prompt了,提出Prompt评估框架
- InstructEval: Systematic Evaluation of Instruction Selection Methods
- 普林斯顿 NLP GitHub: Princeton Natural Language Processing, 已知知名项目
- 2021, SimCSE, 陈丹琦
- tree-of-thought-llm
- 2022, TRIME: EMNLP 2022 Training Language Models with Memory Augmentation
目前常用的 Prompt 设计法 只希望在不同场景下选择哪些 Prompt,却没有对 Prompt 如何影响大模型的输出效果进行充分的研究。
普林斯顿大学的研究者们开发了一个 ICL 效果的评估方法,以更好的评测不同 Prompt 设计的效果,从而给出更加客观真实的 Prompt 设计方案
这套方法包含了 4 类共计 13 个不同的系列大规模语言模型(Model Families),3 大类分 9 种不同的任务(Tasks)以及 7 种不同的 Prompt 选择法,从 5 个与 ICL 相关的目标对 Prompt 选择法进行评价。
整套评估方法允许任意Prompt 输入,一个完整的 Prompt 由指令(Instruction),阐释(Solved Demonstrations)以及一个未解决的测试用例(Unsolved Test Example)组成
Prompt 方法评测
论文主要从准确率与敏感性两个方面对 Prompt 进行评估
- 准确率方面,论文从 Zero-shot 准确率,Few-shot 准确率以及扰动准确率(Perturbation accuracy)三个指标出发度量 Prompt 对任务准确率的影响,其中, 扰动准确率论文通过向 Prompt 中随机的引入大写、间距、缩写以及常见的拼写错误来度量 Prompt 的稳定性。
- 此外,论文还考虑了选择
敏感度(Selectional sensitivity)以及置换敏感度(Permutational sensitivity)以以衡量 Prompt 对阐释排列顺序的敏感性。针对 N 个模型以及 M 个数据集,每个指标可以获得 N * M 个值,论文定义了一种名为“平均相对增益(Mean Relative Gain)”的方法聚合准确度指标,又使用平均值指标聚合敏感性指标。
Prompt 生成方式可以被分为三大类,分别是任务无关方法、任务相关的手动方法以及任务相关的自动方法,其中:
- 任务无关的方法非常简单,即使用不包含任何特定任务信息的 Prompt,如:
- Null instruction:不添加任务描述,Prompt 直接由阐释与一个待解决测试用例组成
- Generic instructions:添加一些通用的描述,如“完成以下任务”等
- 而任务相关的手动方法即人工编写特定与任务的 Prompt:
- PromptSource:PromptSource 是一个公开的收集了在 170 个数据集上超过 2000 个手动设计的高质量 Prompt 模板的 Github 项目,论文使用 PromptSource 作为手动方法的资源
- Ad hoc:即通过 ChatGPT 生成几个特定于任务的 Prompt 来模拟人工编写 Prompt 的过程
- 最后,任务相关的自动方法包含 3 种流行的自动 Prompt 生成方式:
- Low Perplexity:由 Gonen 等人提出的根据最小困惑度选择 ChatGPT 生成的 Prompt 方法
- APE:由 Zhou 等人提出的自动少样本 Prompt 生成方法,通过 OpenAI DaVinci 自动生成指令,并依据其在几个验证示例中的准确度对 Prompt 方法进行选择与改进
- RLPrompt:由 Deng 等人提出的基于强化学习的少样本 Prompt 自动生成方法
分析
- Few-shot 中,任务无关的方法表现相对更好,并且 Null instruction 有时也会比 Generic instructions 方法更好。
- Zero-shot 下,任务相关的方法表现更佳,PromptSource 成为最佳方法,而 Low Perplexity、APE 以及 RLPrompt 则普遍低于平均水平,这似乎表明,简单的 Prompt 设计方法往往表现了更好的准确性
对比敏感性指标
- 在 Zero-shot 以及 Few-shot 设置下,不同任务之间在选择、排列的变化有显著的差异
任务无法的方法与 PromptSource 的表现最好,并且大模型在每个任务类型中的平均相对增益值的变化范围要比小模型要小,这表明
- 大模型能够更好的理解任务语义,而小模型对 Prompt 更加敏感。
提示词对抗
详见站内专题: prompt提示攻击
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
