- 音频生成
- 结束
音频生成
音乐知识
更多音乐知识见站内专题
曲风
到底什么是「古典(Classical)」风格?什么是「乡村(Country)」风格?
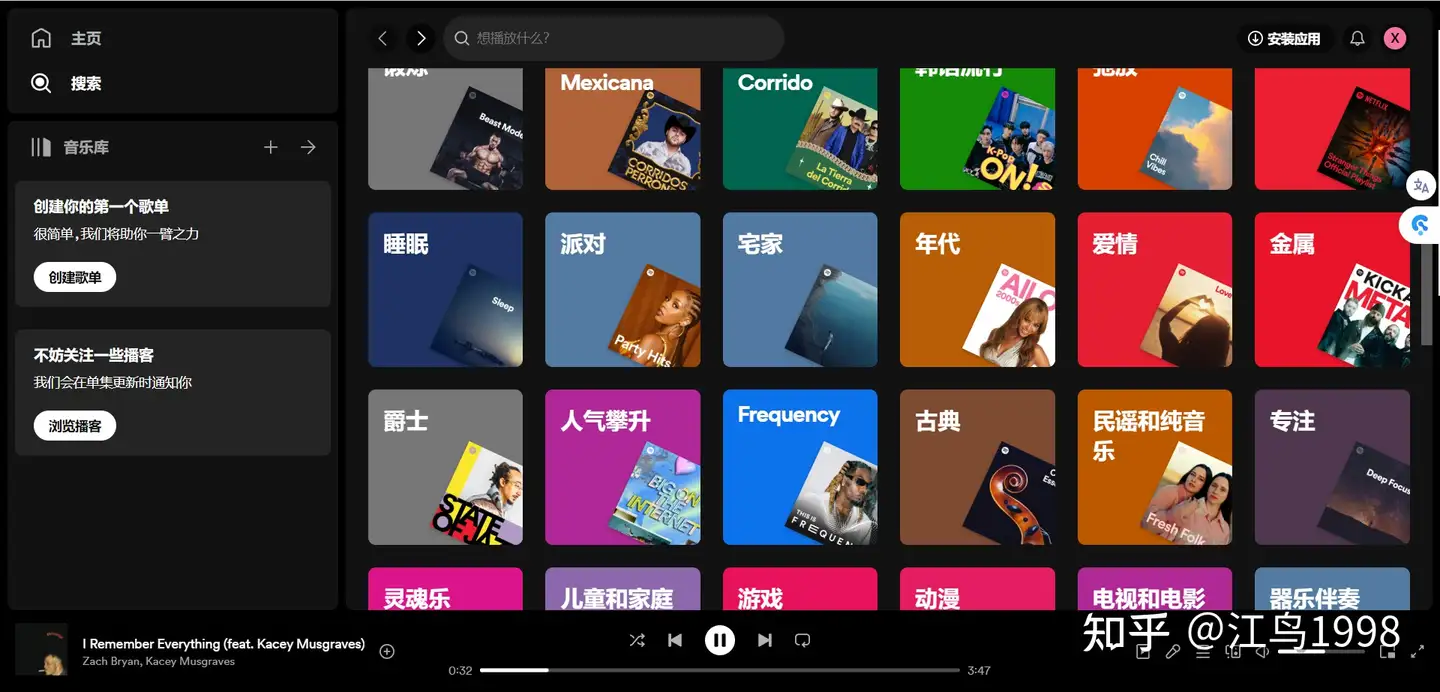
许多网站提供各种音乐风格和流派的信息,比如:Spotify、Apple Music等,或者音乐百科类网站。
- 以Spotify举例,可以直接在主页上面浏览各种风格。
音乐提示词
提示词结构
参考:
提示词参考
好的谱曲提示词包含以下要素,可以酌情增减,仅供参考
风格 + 情感 + 乐器 + 节奏 + 人声
说明
- 1、风格:流行(Pop),古典(Classical),爵士(Jazz),电子(Electronic),摇滚(Rock),乡村(Country),民谣(Folk),嘻哈(Hip-hop),布鲁斯(Blues),拉丁(Latin)
- 2、情感:欢快(Cheerful),悲伤(Sad),浪漫(Romantic),激昂(Passionate),温柔(Gentle),忧郁(Melancholic),神秘(Mysterious),紧张(Tense),恐怖(Horrifying),宁静(Peaceful)
- 3、乐器:钢琴(Piano),吉他(Guitar),小提琴(Violin),鼓(Drum),贝斯(Bass),长笛(Flute),萨克斯(Saxophone),小号(Trumpet),大提琴(Cello),口琴(Harmonica)
- 4、节奏:快速(Fast),慢速(Slow),中等(Medium),渐快(Accelerating),渐慢(Decelerating),自由(Free),稳定(Steady),跳跃(Jumpy),拖延(Dragging),犹豫(Hesitant)
- 5、人声:男声(Male vocals),女声(Female vocals),童声(Children’s vocals),合唱(Choir)
- 纯音乐时,此项可省略
提示词实例
- 1、创作一首欢快的流行电子舞曲
- 提示词:upbeat, pop, electronic, dance, synthesizer, fast
- 2、创作一首浪漫的古典钢琴曲
- 提示词:romantic, classical, piano, tender, slow
- 3、创作一首悲伤的爵士萨克斯风曲
- 提示词:melancholic, jazz, saxophone, sentimental, improvisation, medium
- 4、创作一首激昂的摇滚吉他曲
- 提示词:passionate, rock, electric guitar, powerful, fast
- 5、创作一首温馨的民谣木吉他曲
- 提示词:warm, folk, acoustic guitar, fingerstyle, gentle
音乐生成技术
音乐生成技术、工具
随着 Diffusion Transformer、神经音频编码等技术的演进,AI文生歌曲工具正从”辅助创作”向”协同创新”跃迁:
- 多模态交互:巨推管家AI的文本-视频联动生成、Mubert Pro的实时场景响应,预示着未来工具将具备更强的上下文理解能力。
- 伦理框架建设:Suno AI的版权管理模块与Mubert的授权模式,为行业提供了可复制的合规化路径。AIVA与环球音乐集团建立的授权协议,确保所有生成作品可安全用于商业发行。
- 开源生态繁荣:Hugging Face平台已涌现大量开源音乐生成模型,开发者可基于Stable Diffusion Music、Riffusion等项目进行二次开发。某独立开发者利用开源模型,仅用3周就构建出支持方言歌曲生成的垂直工具。
总结
- 【2024-4-11】udio
- 【2024-4-17】天工 SkyMusic
- 2024年4月2日开启免费邀测,4月 17日正式开启公测
- 【2024-6-1】海绵音乐, 北京颜选科技(字节跳动),一键创作你的 AI 音乐
- 2024年6月内测,8月正式上线免费使用
- 【2024-7-10】天谱乐: 不仅支持文生音乐、音频生音乐,还首创图片/视频生音乐功能,多模态输入能力超越 Suno
【2025-8-12】AI文生歌曲工具大比拼:从技术到场景的深度评测
Text2Audio
Text-to-Audio : AudioLM、Whisper、Jukebox
- AudioLM由谷歌开发,将输入音频映射到一系列离散标记中,并将音频生成转换成语言建模任务,学会基于提示词产生自然连贯的音色。在人类评估中,认为它是人类语音的占51.2%、与合成语音比率接近,说明合成效果接近真人。
- Jukebox由OpenAI开发的音乐模型,可生成带有唱词的音乐。通过分层VQ-VAE体系将音频压缩到离散空间中,损失函数被设计为保留最大量信息,用于解决AI难以学习音频中的高级特征的问题。不过目前模型仍然局限于英语。
- Whisper由OpenAI开发,实现了多语言语音识别、翻译和语言识别,目前模型已经开源并可以用pip安装。模型基于68万小时标记音频数据训练,包括录音、扬声器、语音音频等,确保由人而非AI生成。
音乐生成上比较出名的:
- DeepMusic
- WaveNet
- Deep Voice
- Music AtuoBot
MusicLM
【2023-5-15】文本创建音乐
体验地址:MusicLM
MusicGen
【2023-6-12】Meta开源文本生成音乐大模型,我们用《七里香》歌词试了下
输入: 周杰伦《七里香》歌词中的前两句
「窗外的麻雀在电线杆上多嘴,你说这一句 很有夏天的感觉」
文本到音乐是指在给定文本描述的情况下生成音乐作品的任务,例如「90 年代吉他即兴摇滚歌曲」。作为一项具有挑战性的任务,生成音乐要对长序列进行建模。与语音不同,音乐需要使用全频谱,这意味着以更高的速率对信号进行采样,即音乐录音的标准采样率为 44.1 kHz 或 48 kHz,而语音的采样率为 16 kHz。
此外,音乐包含不同乐器的和声和旋律,这使音乐有着复杂的结构。但由于人类听众对不和谐十分敏感,因此对生成音乐的旋律不会有太大容错率。当然,以多种方法控制生成过程的能力对音乐创作者来说是必不可少的,如键、乐器、旋律、流派等。
最近自监督音频表示学习、序列建模和音频合成方面的进展,为开发此类模型提供了条件。为了使音频建模更加容易,最近的研究提出将音频信号表示为「表示同一信号」的离散 token 流。这使得高质量的音频生成和有效的音频建模成为可能。然而这需要联合建模几个并行的依赖流。
- Kharitonov 等人 [2022]、Kreuk 等人 [2022] 提出采用延迟方法并行建模语音 token 的多流,即在不同流之间引入偏移量。
- Agostinelli 等人 [2023] 提出使用不同粒度的多个离散标记序列来表示音乐片段,并使用自回归模型的层次结构对其进行建模。
- 同时,Donahue 等人 [2023] 采用了类似的方法,但针对的是演唱到伴奏生成的任务。最近,Wang 等人 [2023] 提出分两个阶段解决这个问题:限制对第一个 token 流建模。然后应用 post-network 以非自回归的方式联合建模其余的流。
本文 Meta AI 的研究者提出了 MUSICGEN,这是一种简单、可控的音乐生成模型,能在给定文本描述的情况下生成高质量的音乐。
MUSICGEN 包含一个基于自回归 transformer 的解码器,并以文本或旋律表示为条件。该(语言)模型基于 EnCodec 音频 tokenizer 的量化单元,它从低帧离散表示中提供高保真重建效果。此外部署残差向量量化(RVQ)的压缩模型会产生多个并行流。在此设置下,每个流都由来自不同学得码本的离散 token 组成。
以往的工作提出了一些建模策略来解决这一问题。研究者提出了一种新颖的建模框架,它可以泛化到各种码本交错模式。该框架还有几种变体。基于模式,他们可以充分利用量化音频 token 的内部结构。最后 MUSICGEN 支持基于文本或旋律的条件生成。
XTTS
【2023-9-15】Coqui AI 开源了他们的文生音基座模型:XTTS (🐸TTS)
- 只需三秒即可进行声音复刻
- 无需微调即可支持13种语言,包括中文
- 24khz 的声音质量
受控生成
Sketch2Sound
【2024-12-11】音频版ControlNet来了!声音模仿新方法Sketch2Sound
Adobe 和 Northwestern University提出了一种生成音频的模型Sketch2Sound,能够根据一系列易于理解的、随时间变化的控制信号(如音量、亮度、音高)以及文本提示,生成高质量的声音。
- Sketch2Sound: Controllable Audio Generation via Time-Varying Signals and Sonic Imitations
- 官方项目主页 包含样例
Sketch2Sound 可以从模仿的声音(比如人声模仿或参考声音形状)中合成任意声音。
- 基于任何文本到音频的潜在扩散变换器(DiT)进行实现,并且只需要40k步的微调和每个控制信号一个简单的线性层,这使得它比现有的像ControlNet这样的模型更轻量。(链接在文章底部)
为了从类似草图的声音模仿中合成声音,Sketch2Sound 在训练过程中对控制信号应用随机中值滤波,这使得Sketch2Sound 可以使用灵活时间精度的控制信号进行提示。
Sketch2Sound 使得声音艺术家可以利用文本提示的语义灵活性,并结合声音手势或人声模仿的表现力和精确性来创作声音。
技术原理
Sketch2Sound 把声音模仿转换为生成新声音。
- 从用户输入的模仿声音中提取三个关键控制信号:响度(音量大小)、频谱质心(简单来说就是声音的“亮度”)和音高概率(声音的高低变化)。
- 这些信号会被编码后,加入到用来生成声音的核心模型中,一个基于 DiT(扩散模型)的文本到声音生成系统。
这样,系统就能根据模仿的声音特点,生成出具有相似风格的新声音。
生成声音时,使用较大的中值滤波器会让效果更像“草图”,声音质量也可能更高;而较小的滤波器会让生成的声音更精确,但如果模仿声音本身不够准确,可能会导致音质下降。
这给声音艺术家提供了一个选择,可以在“草图感”和“精确度”之间找到适合自己的平衡点。
巨推管家AI
巨推管家AI:中文语境下的企业级音乐工厂
国内首款面向B端用户的AI音乐开发平台,巨推管家AI通过”多模态预训练模型+音乐知识图谱”的融合架构,在中文音乐生成领域构建起技术护城河。
其核心优势体现在三个层面:
- 中文韵律引擎:基于千万级古风歌词、现代诗、戏曲唱词训练的BERT模型,可精准捕捉平仄对仗规则。当用户输入”大漠孤烟直”时,系统自动匹配五声音阶与苍凉音色,生成具有敦煌壁画质感的旋律。某短视频平台接入后,AI生成的国风背景音乐日均调用量突破300万次,版权纠纷率从行业平均的15%降至0.3%。
- 动态情感映射:通过LSTM网络解析文本情感梯度,在《少年中国说》生成案例中,系统将”少年强则国强”的激昂段落转化为160BPM的鼓点节奏,而”红日初升”的抒情部分则生成钢琴与弦乐的渐强对话,情感曲线吻合度达92%。
- 企业级开发套件:提供Python SDK与RESTful API,支持开发者自定义音色库、音乐风格模板及版权管理模块。某游戏公司利用该平台,将传统音乐制作周期从2周压缩至8小时,成本降低87%。
Suno AI
OpenAI系创业公司 Suno AI,通过扩散模型与自回归Transformer的混合架构,实现从文本到完整歌曲(含人声、伴奏)的生成突破。其技术亮点包括:
- 语义通道:将文本拆解为场景、情感、乐器等元数据,通过CLIP模型进行跨模态对齐。输入”赛博朋克风格电子乐,包含合成器脉冲与机械节奏”,系统可自动生成匹配未来感的旋律。
- 音乐通道:采用 Hierarchical VQ-VAE 将音频压缩为离散token序列,结合Transformer生成连贯旋律。用户测试显示,该架构使生成歌曲的结构完整性提升40%,重复段落减少65%。
- 多语言人声合成:集成 WaveNet 与 Tacotron2 改进版本,支持中、英、日等8种语言的TTS合成。其虚拟歌手”Luna”在专业盲测中,人声自然度评分(MOS)达4.2/5,接近真人演唱水平。
某独立音乐人利用Suno的实时编辑协作平台,将AI初稿优化为Spotify热榜TOP50作品,耗时仅传统制作的1/5。但该工具在长时序生成(>3分钟)仍存在主题漂移问题,需结合人工干预确保一致性。
【2024-3-22】Suno AI V3
【2024-3-22】Suno AI发布了V3版音乐生成模型
用户只需要提供音乐生成指令,v3版模型就能在几秒-几分钟内,生成一首时长两分钟的高质量音乐片段。
免费使用
目前,免费注册
- 新用户每天有50块的免费额度,每天可以创建10首歌曲(5 * 2)
- 付费用户权限依次提升
参考
Suno AI 功能
特点
- 用户只用几个简短的词语就可以用任何语言创作歌曲
- Suno v3 新增更丰富的音乐风格和流派选项,比如古典音乐、爵士乐、Hiphop、电子等新潮曲风
相比与之前版本
- v3音乐质量更高,而且支持各种风格和流派的音乐和歌曲。
- 提示词连贯性大幅提升,歌曲结尾的质量也获得了极大提高。
- AI音乐水印系统:每段由平台生成的音乐都添加了人声无法识别的水印,从而在未来能够保护用户在Suno的创作,打击抄袭,防止将Suno产生的音乐进行滥用。
功能
- 1、Suno AI内置翻译器,可直接输入中文提示词,后台自动转换为英文。也可以将中文提示词翻译成英文,再输入到Suno AI。
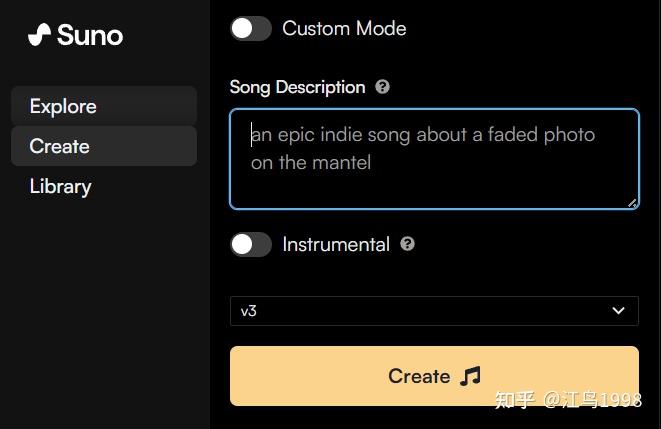
- 2、「
Instrumental」是 纯BGM,不含人声,关闭则带人声- 「
Song Description」处输入提示词,点击「Create」按钮即可创作。
- 「
- 3、选中「
Custom Mode」,可输入歌词填曲。- 只需要在「
Lyrics」处填入歌词(可以直接输入中文歌词),「Style of Music」处写入歌曲的风格提示词,Suno AI 就能生成指定风格歌曲。 - 对于给定歌词,段落前加
[Verse](主歌)、[Rap](说唱)、[Chorus](副歌)等来告诉AI这段歌词应该怎么唱。
- 只需要在「
- 歌曲延时:点击已经生成音乐项的「
...」按钮,选择「Continue From This Song」可歌曲延长。
歌词结构
通过下面这些标记指示歌曲不同部分,帮助AI理解歌曲的结构和情感表达。 1、歌曲结构标记:
[Verse]- 主歌,主歌是歌曲的核心部分,通常包含歌曲的主要歌词和旋律。[Chorus]- 副歌,副歌部分,通常旋律更加朗朗上口,歌词重复度高。[Pre-Chorus]- 前副歌,通常用于过渡,为副歌做铺垫。[Bridge]- 桥段,通常在副歌之后,旋律和歌词风格与主歌和副歌不同,起到调剂作用。[Intro]- 前奏,通常是纯音乐或者少量歌词。[Outro]- 尾奏,通常是音乐渐弱或者重复某些歌词。[Interlude]- 间奏,通常是纯音乐部分,用于连接不同的歌曲部分。 2、歌词演唱风格标记:[Rap]- 说唱[Ad-lib]- 即兴演唱[Harmony]- 和声,通常由多个声部组成,与主旋律形成和谐的音乐效果。[Whisper]- 耳语,耳语般的演唱
案例
如梦令,音乐片段如下
视频配曲
直接使用 OpenAI Sora 视频生成提示词
A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage.
1分钟后,生成音乐:歌词 + 音乐
歌词部分
Neon Glow
electronic pop
v3
March 26, 2024
Pause
[Verse]
She's a vision, beauty in motion
Walking down the street, pure devotion (yeah)
Stylish as ever, the center of attention
Tokyo nights, never-ending fascination (oh-oh)
[Verse 2]
In the glow of neon lights
She shines like a star in the city's sky
With every step she takes, the world comes alive
Can't help but be mesmerized (ooh-yeah)
[Chorus]
Tokyo nights, neon glow
Every corner, every street, a colorful show
In this cityscape, she stands tall
A stylish woman that captures it all (captures it all)
# ------------翻译-----------
Neon Glow
电子流行
v3
2024年3月26日
[诗歌]
她是一个视觉,动感美丽
走在街上,纯粹的奉献(是的)
时尚如常,成为众人关注的焦点
东京之夜,永无止境的迷恋(哦-哦)
[诗歌2]
在霓虹灯的照耀下
她如同城市天空中的一颗星星闪耀
每迈出一步,世界都变得生动起来
禁不住被迷住(哦-是的)
[合唱]
东京之夜,霓虹闪耀
每个角落,每条街道,一场色彩斑斓的表演
在这座城市景观中,她屹立不倒
一个捕捉一切的时尚女性(捕捉一切)
音乐追加到 sora 视频上
个人vlog生成背景音乐
个人vlog通常记录日常生活、旅行见闻、兴趣爱好等内容,音乐风格上以轻快、明朗为主。
选择一些流行音乐元素,同时加入一些吉他、钢琴等乐器,营造出一种温馨、惬意的氛围。
提示词:
- pop music(流行音乐)、light(轻快)、guitar(吉他)、piano(钢琴)
婚礼视频制作浪漫背景音乐
婚礼是人生中的一个重要时刻。
音乐选择上,用一些柔和、浪漫的元素,例如弦乐、钢琴等,同时加入一些爱情、甜蜜的关键词,营造出梦幻、温馨的氛围。
提示词:
- romantic(浪漫)、love(爱情)、sweet(甜蜜)、strings(弦乐)、piano(钢琴)
游戏视频生成背景音乐
游戏直播通常需要一些激昂、刺激的背景音乐来渲染气氛,同时又不能过于喧闹,影响主播的解说和游戏音效。我们可以选择一些电子音乐元素,同时加入一些鼓点、合成器等元素,营造出紧张、刺激的氛围。
提示词:
- electronic music(电子音乐)、exciting(刺激的)、drums(鼓点)、synthesizer(合成器)
自然风光类视频生成背景音乐
自然风光类视频通常展示了大自然的美景,为了突出自然的宁静、祥和,选择一些轻柔、舒缓的音乐元素,如长笛、竖琴等,同时加入一些自然、宁静的关键词,营造出一种与自然和谐相处的氛围。
提示词:
- soft(轻柔)、peaceful(宁静)、nature(自然)、flute(长笛)、harp(竖琴)
美食类视频生成背景音乐
为了突出食物的诱人和美味,选择一些轻快、愉悦的音乐元素,如口哨、手鼓等,同时加入一些快乐的关键词,营造出一种欢乐、享受的氛围。
提示词:
- light(轻快)、happy(愉悦)、whistle(口哨)、bongos(手鼓)
尚雯婕
尚雯婕演示用ai创作音乐
【2024-11-1】2024 bilibili超级科学晚全程回顾
Mubert Pro
Mubert Pro:实时场景化音乐生成引擎
区别于静态歌曲生成,Mubert Pro 聚焦游戏、直播等交互式场景,其核心技术围绕上下文感知模型与动态渲染引擎构建:
- 情境感知生成系统:通过分析用户输入的场景标签(如”赛博朋克城市”)、情绪参数(能量值0-100)及实时事件(如游戏角色死亡),动态调整音乐的速度、和声复杂度与乐器组合。在《Cyberpunk 2077》模组测试中,系统响应延迟低于200ms,玩家沉浸感评分提升37%。
- 模块化音乐组件库:预训练10万+个音乐片段(Loop),每个片段标注有调性、节奏型、情感标签等23维元数据。生成时,系统通过图神经网络(GNN)筛选并拼接组件,确保音乐过渡的自然性。某直播平台接入后,主播自定义BGM的使用率从12%提升至68%。
- 低延迟渲染架构:采用WebAssembly技术将模型部署至浏览器端,支持在移动设备上实时生成44.1kHz采样率的音频,CPU占用率低于15%。这一特性使其成为Twitch、抖音等平台的首选技术合作伙伴。
【2024-4-11】Udio
小众工具黑马:Udio
- Udio:谷歌 DeepMind 前研究员团队开发的工具,以”音乐混音”功能著称。用户可基于初始生成片段进行风格迁移,例如将乡村音乐改编为电子乐版本。其付费订阅模式提供4800积分/月,可生成约160首30秒歌曲,适合批量生产短视频配乐。
【2024-4-11】全新的音乐生成应用Udio正式亮相,比suno有质的提升,效果直逼人类
- 体验地址:udio
- Udio目前处于公测阶段,用户可免费体验,每月可生成1200首作品。
全新的音乐生成应用 Udio正式亮相。Udio专注于以文字驱动的音乐生成和分享,为用户带来革命性的音乐创作体验
- Udio采用先进的AI技术, 通过简单的文字输入, 生成各类风格的原创音乐作品。从抒情的福音音乐,到沧桑的蓝调,再到梦幻的流行电音,应有尽有。
- Udio还支持多种语言,用户可以创作出日语流行、俄罗斯梦幻流行、拉丁节奏等多元化的音乐作品
Udio 特点
Udio 特点
- 生成的效果比前段时间大火的音乐生成应用suno 有了质的提升,大家感受一下
- 另一大特色是可扩展性。
- 用户不仅可以指定音乐的引子和尾声,还能以此为基础, 向前向后延伸,生成更长的音乐作品。
- 完成创作后,只需点击”发布”,作品就能与Udio社区的其他创作者们分享交流
Udio 创始团队出身于谷歌DeepMind等顶尖AI研究机构,在音乐和技术领域均有深厚积淀。
- 目标是让Udio成为一款真正改变游戏规则的音乐创作工具,不仅面向专业音乐人,也希望让广大非音乐人也能轻松参与到音乐创作中来
虽然还存在一些粗糙的地方,但团队正在快速迭代优化,计划陆续推出更长音频、更高音质,以及更强大的可控性等新功能
效果测试
直接使用 OpenAI Sora 视频生成提示词
A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage.
生成两个示例
点评
没有歌词、专辑画面,音乐质量也不如 Suno AI
AIVA
小众工具
AIVA 3.0:获得卢森堡政府文化基金支持的工具,正在重新定义AI在严肃音乐领域的可能性。其风格迁移引擎通过分析巴赫《哥德堡变奏曲》的对位法结构,可生成具有复调音乐特征的现代作品。在为某电影配乐时,系统将用户输入的”史诗感”转化为管风琴与定音鼓的宏大对话,同时保持奏鸣曲式的严谨结构。
【2024-4-2】SkyMusic
【2024-4-17】首个国产音乐SOTA模型来了!专为中文优化,免费用,不限曲风
问题
- Suno 有时生成中文不太稳定,会出现中文歌曲带有英文感、生僻字唱错等问题。
有没有一个 AI 音乐生成模型专门针对中文做过优化?
天工 SkyMusic
昆仑万维:天工 SkyMusic
- SkyMusic 于 2024 年 4 月 2 日开启免费邀测,4 月 17 日正式开启公测
昆仑万维打造的国内首款、也是唯一公开可用的AI音乐生成大模型「天工SkyMusic」,采用自研的大模型音乐音频生成技术,能够实现端到端的音乐创作,包括乐器、人声、旋律等元素的一体化生成。该模型在音质、人声自然度等方面声称超越了国际竞争对手SuoV3,是全球领先的AI音乐生成模型。
天工SkyMusic:还支持参考音乐生成和方言歌曲创作,大幅降低了音乐创作门槛,让不具备专业乐理知识的用户也能轻松创作音乐,同时促进了方言文化的传播。
昆仑万维重磅宣布,「天工 3.0」基座大模型与「天工 SkyMusic」音乐大模型正式开启公测。
生成的中文人声发音清晰、正宗、无异响,没有出现「百老汇式中文歌」等水土不服的情况。而且,它不仅针对普通话做了优化,粤语、成都话、北京话等方言语种也照顾到了。
天工 SkyMusic 全面开放,下载「天工」APP 就可以体验。
- 国内目前唯一公开可用的 AI 音乐生成大模型,填补了国内 AIGC 工具在这一领域的空白。
模型
天工 SkyMusic 的框架是类 Sora 的 DiT 技术路径,不过研发时间是在 Sora 问世之前,因此不可避免地要踩很多坑。
天工 SkyMusic 技术原理图:
- Large-scale Transformer 负责谱曲来学习 Music Patches 的上下文依赖关系,同时完成音乐可控性;
- Diffusion Transformer 负责演唱,通过 LDM 让 Music Patches 被还原成高质量音频。
这套模型架构在处理视频、音频和音乐时效果极佳。
使用方法
天工 SkyMusic 生成歌曲:
- 只需要输入歌名、歌词,选择参考曲目,就能生成风格、唱腔与之类似的歌。
- 输入框右下角的「AI 写词」功能。从第一句开始写,每次只生成一句,不满意的句子可以及时删掉,直至整首歌创作完成。
- 「天工 3.0」来写歌,比如《机器之心》就是用「天工 3.0」写出来的
- 按照示例音源生成音乐
天工 SkyMusic 生成的音乐涵盖了说唱、民谣、放克、古风、电子等多种曲风。下一步还计划让用户根据哼出来的旋律生成歌曲,这将对专业人士有很大帮助。
效果
和 Suno 比,天工 SkyMusic 表现如何呢?
横向测评的数据显示,在人声和 BGM 音质、人声自然度、发音可懂度等几个指标上,天工 SkyMusic 都更胜一筹,综合性能超越 Suno V3,成为中国首个音乐 AIGC 的 SOTA 模型,也让中国的自研大模型技术第一次在 AIGC 领域领跑全球。
「天工 3.0」模型拥有 4000 亿参数,超越了 3140 亿参数的 Grok-1,是全球最大的开源 MoE 大模型。
- MMBench 等多项权威多模态测评结果中,「天工 3.0」超越 GPT-4V,全球领先
【2024-6-1】字节 海绵音乐
海绵音乐 于 2024 年 6 月开始内测,8 月正式上线免费使用。
- 抖音账户登录,免费使用
海绵音乐 App(字节旗下 AI 音乐创作工具),向所有用户开放。用户只需输入简单的提示词,就能得到包含歌词、曲谱和演唱的完整歌曲作品,还内置十多种风格和情绪选项。相比 Suno,海绵音乐在人声清晰度、中文发音等方面进行了优化,更能驾驭国风类音乐。目前支持文本、图片生曲,但不包括视频输入。3.昆仑万维:天工 SkyMusic官网:这首歌居然是AI写的!
实践
【2206-1-31】音乐生成
- 音乐地址
(预副歌)
Yo Listen up
算法进化论
Ready Let’s go
(主歌)
司机听不到单 怀疑烦躁焦虑
热线电话打爆 客服应接不暇
小滴尽力回复 依然是复读机
你总说对不起 让人甚是心急
用户直转人工 智能客服啥意义
(副歌)
别急别急 算法平台登场
齐心协力 一起攻坚 一起把关冲
意图理解 场景多轮 端到端语音
逢山开路 遇水架桥 一个又一个
Hey 通关
Hey 无敌
(主歌)
司机中途甩客 用户路边打哆嗦
无奈进线控诉 小滴答非所问
糟糕体验 必须说不
案例分析标数据 商用不行上自研
千方百计提指标 哪怕任务再艰难
直到用户一开口 需求被精准掌控
中控调度加解决 用户不再转人工
场景专家一条龙 对话流程不再僵
司机端 听单少 乘客端 态度差
端到端语音客服 初次登场显神通
按键交互终过时 实时语音前景宏
交互流畅又拟人 安能辨我是人机
Hey 真人?
Hey 机器?
(副歌)
工作业绩要出彩 生活趣味也不少
技术分享周周来 方案评审人人保
工位上争 打破砂锅问到底
会议室闹 哪怕脸红又心跳
转身吃喝又玩乐 过后依旧开心笑
That’s right
work hard
play hard!
(主歌)
马年到 新气象
革命尚未成功 AI Native 还需努力
Hey 三点零 加油
Hey 四点零 努力
(副歌)
从“响应需求” 到 “创造惊喜”
科技加温情 未来出行里
每轮对话 都是进化伏笔
祝大家
Bug 全退散
项目 全拿奖
马年 大吉 大利 大惊喜 !
【2024-7-10】天谱乐
【2024-7-10】 广州 天谱乐大模型不仅支持文生音乐、音频生音乐,还首创图片/视频生音乐功能,多模态输入能力超越 Suno
用户仅需上传相册中的一张图片或一段不超过60秒的视频,即可生成与图像内容和基调高度适配的带人声唱词的完整歌曲,生成效果达到专业级水准,极大地满足用户多样化的视听创作需求。
【2024-9-18】Seed-Music
【2024-9-18】Seed-Music 音乐大模型正式发布!生成编辑两开花,十种创作任务,满足多样化需求
介绍
【2024-9-18】字节跳动豆包大模型团队推出了 Seed-Music,助力音乐创作领域探索更多可能性。
Seed-Music 是一个具备灵活控制能力的音乐生成模型家族。巧妙地将语言模型与扩散模型的优势相结合,并融入作曲工作流之中,适用于小白、专业人士的不同音乐创作场景。
Seed-Music 是一个端到端且能力全面的音乐生成框架。它既能从自然语言和音频中汲取灵感,又能灵活控制各种音乐属性,还能与音乐人的工作流无缝集成,生成旋律丰富、质量上乘的音乐作品,为不同人群赋予了创作自由。
功能
Seed-Music 提供
- 四大核心功能:可控音乐生成、谱转曲、词曲编辑、零样本人声克隆
- (1) Lyrics2Song 可控音乐生成: Lyrics2Song 功能包含“1 分钟片段生成”、“3 分钟全曲生成”、“歌曲仿写”以及“纯器乐生成”这四种音乐生成任务。
- 只要输入一些简单的文本指令,如音乐风格、歌词、情绪、节奏等,Seed-Music 就能快速生成一段与之相符的 AI 音乐。除了文本提示外,Seed-Music 还能基于参考音频进行歌曲仿写
- (2) Lyrics2Leadsheet2Song 谱转曲
- lead sheet 即“领谱”,通常包括歌曲的主旋律、歌词以及和弦标记等信息,它就像是一张音乐地图或指南,用于指导演奏者或歌手进行表演。
- Seed-Music 将领谱集成到 AI 辅助创作的工作流程中,增强了音乐创作的可解释性和可控性,旨在帮助专业音乐人提升效率,专注于音乐的创意表达。
- (3) Music Editing 词曲编辑
- 基于扩散模型实现的 Music Editing 能够精确对歌词或旋律进行局部改编,并确保编辑区域的平滑过渡。
- 比如,在一首歌曲中,创作者想要把某句歌词从“一捧黄河水”改成“一捧长江水”,同时希望保持旋律和伴奏的连贯性,Music Editing 就可以轻松做到,而且效果自然。
- (4) Singing Voice Conversion 零样本人声克隆
- 零样本人声克隆也是 Seed-Music 的一大创新,模型无需针对特定音色进行大规模训练。创作者只需要使用自己 10 秒的语音(支持清唱或者说话)作为输入,系统便可模仿指定音色生成完整的歌曲。
- (1) Lyrics2Song 可控音乐生成: Lyrics2Song 功能包含“1 分钟片段生成”、“3 分钟全曲生成”、“歌曲仿写”以及“纯器乐生成”这四种音乐生成任务。
- 具体涵盖十种创作任务,满足音乐小白、专业音乐人的不同场景需求。
技术方案
Seed-Music 采用独特的技术方案,提出了音乐生成的通用架构。
为了支持灵活的控制输入,能够根据不同类型的用户输入生成高质量的音乐,该架构宏观上由三个核心组件组成:表征模型、生成器和渲染器。其中,表征模型负责从原始音频波形中提取有意义且紧凑的音乐音频表征;生成器根据用户输入生成音频表征;最后,渲染器负责把音频表征生成最终音频。
该架构下,Seed-Music 探索了三种中间表征:音频 token、符号音乐 token 和声码器 latent,每种表征对应着一种生成链路。每种链路都有其优缺点,可以根据下游音乐创作任务匹配最合适的链路。
【2026-2-4】ACE-Step-1.5 开源
还在为 Suno 和 Udio 订阅费肉疼?世界首个开源音乐生成平台
【2026-2-4】阶跃星辰推出开源音乐生成工具——ACE-Step-1.5。不仅拥有“商业级”音质,更离谱的是,只需要 4GB VRAM 就能在本地运行
- 官方体验 ACEMusic ,生成后看不到音乐
- huggingface demo Ace-Step-v1.5 体验流畅,1-2min生成完毕, 可以上传参考音乐
- 支持模式: Simple,Custom,Cover,Repaint
- GitHub ACE-Step-1.5
ACE-Step 1.5 是开源音乐生成基础模型,由国际 AI 社区共同开发,目标是让任何人都可以轻松利用 AI 创作专业级音乐作品。
区别于传统的音乐生成方案,不仅生成速度快,而且具备强大的音乐连贯性、风格控制和多语言支持。
与 ACE-Step 之前的版本相比,1.5 版本在 速度、质量和硬件适配性 上都有显著提升:
- ✨ 商业级输出:模型训练时使用大量合法、可商用的数据,并明确支持商业作品使用,可放心将生成作品用于创作、发布、变现等场景。
- ⚡ 超快生成速度:在 NVIDIA A100 GPU 上能够在 不到 2 秒生成一整首歌曲,在 RTX 3090 上生成一首歌的时间也低于 10 秒。
- 🖥️ 硬件友好:支持在消费级显卡上运行,甚至只需 <4 GB 显存即可支持本地生成,大幅降低了创作门槛。
- 🗣️ 多语言 & 风格控制:模型支持 50+ 语言 的歌词与提示,并具备精细的风格控制能力,无论是流行、电子、摇滚还是说唱,都可以生成自然连贯的音乐结构。
- 🎵 创作灵活性:除了从文本生成音乐之外,模型还支持歌词编辑、片段重绘、风格转换、甚至基于现有音频生成伴奏等高级操作。
ACE-Step 1.5 采用创新的混合架构,将语言模型作为“音乐规划师”,先根据用户输入生成完整的创作蓝图,再通过扩散式生成器合成音频。这种方法兼顾了:
- 🎼 长篇音乐的结构连贯性
- ⚙️ 高速度的合成效率
- 🎤 精细的音乐与歌词对齐能力
相比传统基于大语言模型(LLM)或单一扩散模型的生成方式,这种架构突破了众多音乐生成的关键挑战,使得长段音乐、歌词与旋律之间的衔接更加自然。
ComfyUI 工作流使用建议 ace_step_1.5_turbo_aio
- 风格标签:描述越详细越好!需包含曲风、乐器、情绪、速度与 vocal 风格。
- 示例:摇滚、硬摇滚、另类摇滚、清晰男声、浑厚嗓音、充满活力、电吉他、贝斯、架子鼓、主题曲、120BPM
- 歌词结构:使用 [verse]、 [chorus]、[bridge]等标签,引导歌曲结构编排
- 时长建议:初始可尝试90-120秒时长,效果更稳定;若需180秒以上长曲,建议分多批生成
- 批量生成:将批量大小(batch_size)设为8或16,从中挑选最佳结果——模型生成效果可能存在波动,多生成几份样本能提高优质率
💡 避坑小贴士:
- 虽然官方宣称支持多语言,但测试下来,中文歌词的咬字能力还是有点欠缺。
🎛️ LoRA微调
ACE-Step 1.5 支持 LoRA 训练实现轻量化个性化。只需少量歌曲(甚至几十首),就能训练出符合特定风格的LoRA 模型。
创作者可利用自有音乐,通过LoRA微调打造专属风格 —— 模型会学习你的音乐特点,捕捉独特音色。由于全程在本地运行,完全拥有该 LoRA 所有权,无需担心数据泄露问题。
视频生音频
视频生音频方面,主流方法
- 仅在语音-视频数据上从头开始训练
- 受限于可用训练数据的数量,比如 最常用的数据集VGGSound只包含大约550小时的视频。
- 预训练文本生音频模型上训练新的“控制模块”。
- 预训练的文本到音频模型上添加控制模块会使网络架构复杂化,而且生成效果的上限可能低于从头开始训练。
天谱乐
MMAudio
【2024-12-19】 MMAudio:AI生成的视频终于有了声音
Sony AI 研究团队发布MMAudio模型,给视频合成高质量音频的。
MMAudio 可以在给定视频和可选文本条件下合成高质量且同步的音频。
- 最小的MMAudio模型参数量只有157M,不仅在视频生音频的开源模型中实现了SOTA,而且推理速度很快,生成8秒片段仅需1.23秒。
目前MMAudio的代码和模型均已经开源。
- 代码:MMAudio
- 技术报告:Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
- 模型:MMAudio
为了避免以上限制,MMAudio 采用一种多模态联合训练范式,它在一个transformer中同时考虑视频、音频和文本,并在训练期间屏蔽缺失的模态。
在大型多模态数据集上进行联合训练可以实现统一的语义空间,并使模型学习更多的数据,以学习自然音频的分布。从实验上看,通过联合训练,模型在音频质量、语义对齐和时间对齐都有显著的改进。
MMAudio 模型架构如下所示,借鉴了SD 3和Flux,transformer包含多模态的transformer block和单模态的transformer block。
- 前者是区分视频,文本和音频三个模态的模型参数,但是采用一个联合attention;
- 后者所有模态特征共用一套参数。
- 这里的音频采用一个VAE编码,而视频和文本采用CLIP来提取特征。生成框架采用Flow Matching,timestep通过adaLN来插入模型,同时这里会把平均池化后的视觉特征和文本特征加在timestep embedding上。
MMAudio共有三个大小的模型,S模型参数量是157M,M模型参数量是621M,最大的L模型参数量是1.03B。在视频生视频的VGGSound测试剂上,最小的S模型在分布匹配、音频质量、语义对齐和时间对齐方面都优于以前的方法,同时速度也很快。
另外MMAudio不需要微调,也可以实现文本到音频的生成,而且在benchmark上还可以取得不错的效果。
Minimax
音乐生成
普悦
谱乐:可以使用 suno、Mureka和Minimax
扩展应用
生成的音乐能否更加丰富?
- 让LLM生成歌词
- 生成插图
- 针对prompt同时生成视频?
把各类LLM工具联动起来,让 Midjourney生图、Runway 动起来,最后再让Suno配乐, 想象空间无限 。。。 已经有一堆人在疯狂测试,杰作频出。
音乐界
使用 OpenAI Sora
【2024-5-10】Watch the first major music video generated by OpenAI’s Sora
唱片公司 Sub Pop 告诉《洛杉矶时报》,艺术家 Washed Out 于 5 月 2 日发行的单曲《The Hardest Part》的音乐视频是主要音乐艺术家、电影制片人和 OpenAI 的 Sora 文本到视频生成器之间的首次合作。
《The Hardest Part》的音乐录影带可能是与Sora的首次正式合作,但一些韩国流行音乐人已经采用了类似的技术来制作创意作品。4 月 24 日,Seventeen 组合发布了一段(人造)音乐视频的预告片,该视频有意使用 AI 生成的剪辑来评论整个行业对 AI 的使用。
Washed Out - The Hardest Part (Official Video)
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
