- 提示工程自动化 Prompt Automation
- 手工提示词
- 什么时候自动化?
- 方法分析
- 自动化工具
- 文本提示自动化
- 动机
- 总结
- 2020.11.7 伯克利 AutoPrompt
- 2022.7.10 PromptGen 百度
- 2022.6.5 Repo-Level Prompt Generator
- 2022.11.3 APE 多伦多大学
- 2023.5.4 APO 微软
- 2023.9.9 OPRO 谷歌
- 2023.10.4 EvoPrompt 清华
- 2023.9.9 逆向工程
- 2023.10.20 MIT: GATE 主动提示
- 2023.10.25 加州大学 PromptAgent
- 2023.11.2 谷歌:COSP
- 2023.11.20 清华 BPO
- 2023.12.1 YiVal
- 2023.12.30 Auto-Prompt Builder
- 2024.1.23 Meta-prompting
- 2024.4.17 人大 GPO
- 2024.6.11 哈佛 TextGrad
- 2024.7.3 DCoT
- 2024.7.11 GRAD-SUM
- 2024.7.12 北大 PAS
- 2024.7.23 ell
- 2024.10.3 微软 PromptWizard
- 2024.10.11 StraGo 闭源
- 2025.3.2 Prompt Optimizer
- 【2025-8-21】SPO
- 【2026-1-23】Opik
- 图像提示词
- prompt 自动生成
- 结束
提示工程自动化 Prompt Automation
随着大语言模型(LLMs)的快速发展,提示词正成为激发模型效果的关键要素。
提示词质量直接影响 LLM 输出效果和用户体验。
- 一方面,设计有效的提示词是一项劳动密集且领域相关的任务,需要具有提示词的相关经验和业务上下文知识。
- 另一方面,随着模型的演进和完成任务中存在的 BadCase,需要持续对提示词优化。
Prompt Engineering from manual to automatic kaggle
- Talking to LLMs is important to elicit(引起) the right response/improved performance without updating the parameters of the models karpathy
手工提示词
手动调试到底哪里不行?
- 1 没法复现
- 哪句话让模型回答变准的吗?或哪版 Prompt 提升了召回率?没有版本控制和结构化流程,每一次优化都像在玩俄罗斯轮盘赌。
- 2 无从追责
- 有时候一句话被改了,但没记录是谁、什么时候、为了什么改的。回滚?审计?几乎不可能。
- 3 输出太脆弱
- 改一个字,结果天差地别。A/B 测试全靠猜,结果上线后“翻车”还不知道错在哪。
- 4 成本持续飙升
- 每改一次 Prompt,就要做一轮验证。API 成本+人力时间,成了产品上线的隐形杀手。
什么时候自动化?
当你遇到以下情况,自动化优化必须提上日程:
- 输出不一致:改了一个字,模型反应像换了脑子;
- 调试耗时:找一个问题 Prompt,排查几个小时甚至几天;
- 上线节奏慢:每次调试都得打全套回归,版本频繁卡在 Prompt 上;
- 幻觉问题反复出现:哪怕数据完美,还是输出离谱。
这些现象都是系统性问题,不靠“勤奋”能解决,只能靠工程手段破局。
【2023-10-25】自动优化Prompt:Automatic Prompt Engineering的3种方法
- o1 本质是 CoT等复杂Prompt的 自动化:
- CoT 背后的树形搜索空间,组合爆炸, 人工编写CoT不可行, 需要仿照AlphaGo的MCTS(蒙特卡洛树搜索)+强化学习, 让LLM快速找到CoT路径
- 复杂问题上, 推理时间成本不是问题, 总会解决, 真正的问题是效果
- Prompt 工程会消失: 后面不需要用户构造复杂prompt, 反人性, 大趋势是所有复杂环节自动化
方法分析
与LLM高效交流方式
- (1)模型向人对齐:
- 训练阶段,让模型对齐人类偏好
- 输入阶段,模型对齐人类
- 黑盒提示对齐优化技术(Black-box Prompt Optimization),通过优化用户指令,从输入角度对模型进行对齐。
- (2)人向模型对齐:即 Prompt 工程师
Prompt 自动化方法
- 05-Prompt自优化框架洞察分析
- DSPy、TextGrad、PromptWizard、GRAD-SUM、ell 和 StraGo 等

| 时间 | 方法 | 描述 | 团队 | 信息 | star数 |
|---|---|---|---|---|---|
| 2023.1.23 | DSPy | 对语言模型Prompt和权重进行算法优化的框架,强调通过编程构建基于LLM的流水线,实现Prompt自优化 | 斯坦福NLP团队 | 开源 | 21.1k |
| 2024.6.11 | TextGrad | 通过文本进行自动“微分”的框架,不仅是Prompt优化框架,是针对AI系统的优化框架 | 哈佛大学研究者 | 开源 | 2k |
| 2024.6.20 | PromptWizard | 自动优化Prompt和示例优化的框架,利用迭代反馈和合成过程不断改进提示 | 微软 | 开源 | 2.2k |
| 2024.7.12 | GRAD-SUM | 结合梯度摘要、用户提供的任务描述和评估标准,构建 Prompt自动化框架 | Galileo | 未开源,论文 | |
| 2024.7.23 | ell | 将Prompt视为函数的轻量的本地开源可视化工具,支持多模态数据处理,并配备了丰富的本地可视化工具 | OpenAI William | 开源 | 5.6k |
| 2024.10.11 | StraGo | 基于反思的提示优化方法,通过分析迭代中成功和失败结果,识别出任务成功所需的关键因素,然后采用上下学习来制定具体的、可操作的策略 | 中国科学院大、微软 | 论文,未开源 |
3种automatic prompt engineering框架:APE、APO以及OPRO。
- 给定一个训练集,定义好评价指标,运行automatic prompt engineering框架之后,将自动得到能取得最佳效果的prompt。
APE:candidate -> selection -> resample- 核心思路:从候选集中选出好的prompt,再在好的prompt附近进行试探性地搜索。
- 生成环节两种模式:
- 前向 reverse mode 更加自然
- 后向 forward mode 则更加考验模型的instruction following能力
APO:gradient descent in language space- 核心思路: 文本空间实现 gradient descent 过程
- APO本质: 构建一个optimizer,其框架是参照gradient decent来设计
OPRO: 谷歌提出的OPRO,其思路更为原生。- 核心思路: 让LLM基于过往的迭代记录、优化目标,总结规律,逐步迭代prompt,整个过程在文本空间上完成。
分析
- APE 主要思路是挑选+试探性优化,优化方向性较弱;
- APO和OPRO 用了更完整的optimizer框架,其中APO基于gradient descent,本质是基于error case来调优,而OPRO直接依靠LLM的逻辑推理能力,基于迭代过程的规律进行优化。
理论上,这些框架对各类任务(分类、抽取、生成等)通用,只需定义好评价指标即可。
只要场景里使用了Prompt,都可以考虑使用这些方法、或者借鉴这些方法的思路。
- 例如:在benchmark上提分、优化LLM标注器的效果、根据用户反馈优化Prompt等等。
以第三点为例,可以根据用户的反馈数据,训练一个reward model作为评价者,运行 automatic prompt engineering框架,优化现有的Prompt,这一点和RLHF有异曲同工之处。
自动化工具
演化图
【2025-12-28】Prompt自动化演进
2023.7.21 gpt-prompt-engineer
- 【2023-8-4】Elo Python实践代码: gpt_prompt_engineer.ipynb
- 功能丰富:根据用户描述生成自test case、根据期望的输出生成候选prompt、再通过MC匹配和Elo机制对候选Prompt打分动态排名
- 演示视频
Prompt engineering is kind of like alchemy(/ˈælkəmi/炼丹术). There’s no clear way to predict what will work best. It’s all about experimenting until you find the right prompt.
gpt-prompt-engineer is a tool that takes this experimentation to a whole new level.
Simply input a description of your task and some test cases, and the system will generate, test, and rank a multitude of prompts to find the ones that perform the best.
Features
- Prompt Generation: Using GPT-4 and GPT-3.5-Turbo, gpt-prompt-engineer can generate a variety of possible prompts based on a provided use-case and test cases.
- Prompt Testing: The real magic happens after the generation. The system tests each prompt against all the test cases, comparing their performance and ranking them using an
ELOrating system. - ELO Rating System: Each prompt starts with an ELO rating of 1200. As they compete against each other in generating responses to the test cases, their ELO ratings change based on their performance. This way, you can easily see which prompts are the most effective.
- Classification Version: The gpt-prompt-engineer–Classification Version notebook is designed to handle classification tasks. It evaluates the correctness of a test case by matching it to the expected output (‘true’ or ‘false’) and provides a table with scores for each prompt.
PromptsRoyale
PromptsRoyale, 自动创建prompt,并相互对比,选择最优Prompt的工具
- 借鉴项目:gpt-prompt-engineer
What it can do
- Automatic prompt generation: Allows for the creation of prompt candidates from the user’s description and test case scenarios. The user can also input their own.
- Automatic test cases generation: Enables automatically creating test cases from the description to get the juices flowing!
- Monte Carlo Matchmaking + ELO Rating: It uses the Monte Carlo method for matchmaking to ensure you get as much information with the least amount of battles, and ELO Rating to properly rank candidates based on their wins and who they win against
- Everything is customizable: The settings page allow you to tinker with every single parameter of the application
- Local & Secure: Everything is stored locally and requests are made from your browser to the LLMs API.
功能总结
- 提示自动生成:根据用户描述创建候选提示,用户也可以直接输入提示。
- 自动生成测试用例:从用户描述自动生成一批(数目可定义)测试用例,尽快启动
- 测试用例: [场景 scenario, 期望输出 expected output]
- ①
Add test case: 用户自己添加测试用例 - ②
Generate additional test cases: 自动生成附加测试用例
- 设置期望输出, 选中某个用例后
- ① 用户填充期望输出
- ②
Generate expected output: 生成期望输出
- 生成候选提示: Generating prompt candidates
- 点击 右侧
Generate prompts按钮,生成候选提示列表,每项都有默认打分100
- 点击 右侧
- 自动评估
- 点击左下角
Run +60 battles: 启动两两比对评估 - 系统实时展示迭代过程,每个prompt的分数变化(高分排前面),以及两两比对的结果日志(Battle log)
- 点击左下角
- 选择最优结果
- 可人工终止过程,选择一个最优的prompt
备注
- Monte Carlo 匹配 和 ELO 等级评分:
- 用 Monte Carlo 方法进行匹配,以确保在最少的对比分析中获得尽可能多的信息
- 用 ELO 等级评分根据胜利和胜利者对候选项正确排名。
- 可定制:设置页面允许调整应用程序的每个参数。
- 本地和安全:所有内容都存储在本地,请求是从浏览器发送到 LLMs API。
安装
【2023-8-3】必须安装Node.js, 否则出错:issue
- bun i
- bun install v0.7.1 (53cc4df1)
- SyntaxError: Import named ‘formatWithOptions’ not found in module ‘node:util’.
附:
curl -fsSL https://bun.sh/install | bash # 安装 bun
bun i # 安装依赖
bun run dev # 启动服务
TypeScript
npm i cursive-gpt
示例
import { useCursive } from 'cursive-gpt'
const cursive = useCursive({
openAI: {
apiKey: 'sk-xxxx'
}
})
const { answer } = await cursive.ask({
prompt: 'What is the meaning of life?',
})
Elo Python实践代码: gpt_prompt_engineer.ipynb
调用顺序
-
用户描述 description + 测试用例 -> 候选提示 -> 逐个排名 -> Elo 打分
-
生成最优提示:
generate_optimal_prompt, 参数 description + test_cases + number_of_prompts(Prompt数目,10)- 生成候选提示 prompts :
generate_candidate_prompts, 参数 description + test_cases + number_of_promptsgpt-3.5: 调1次生成n个结果, 根据 description 和 test_cases 生成 number_of_prompts 个候选提示
- 生成提示排名 prompt_ratings:
test_candidate_prompts, 参数 test_cases + description + prompts- 每个 prompt 分数初始化 1200
- 计算排名轮次: total_rounds = len(test_cases) * len(prompts) * (len(prompts) - 1) // 2
- 两两随机组合, 逐个遍历(prompt1+prompt2), 操作:
- 调用两次: generation1 =
get_generation(prompt1, test_case)- openai
- 调用两次: score1 =
get_score(description, test_case, generation1, generation2, RANKING_MODEL, RANKING_MODEL_TEMPERATURE)- openai
- Elo 打分:
update_elo
- 调用两次: generation1 =
- 生成候选提示 prompts :
PromptPerfect
【2023-9-20】JinaAI 的 PromptPerfect 专业的提示词工程:设计、优化、部署一条龙
- AutoTune 自动生成提示词。
- 先指定使用哪个模型,然后输入关键词,就给出一段完整的提示词,并让你预览两种提示词的 AI 返回结果。
- Streamline “流水线”模式
- 让用户可以逐步调试提示词,提供了各种参数,直接无缝对比在不同 AI 模型下的表现。
- 提供 REST API 让开发者远程调用,可作为 Prompt-as-service。
- 直接搞个 AI Agent,向公众提供服务或者做一个对话机器人。
文本提示词
文生图提示词
2023.1.23 斯坦福 DSPy
【2024-11-6】告别繁琐提示词,斯坦福DSPy框架开创LLM开发新思路,Star突破1.8万
斯坦福大学NLP小组推出一款革命性框架 - DSPy, 颠覆了传统 LLM开发方式。
- 国内站点 DSPy
不同于繁琐的手写提示词, DSPy采用编程式声明与组合, 为大模型应用开发带来全新体验
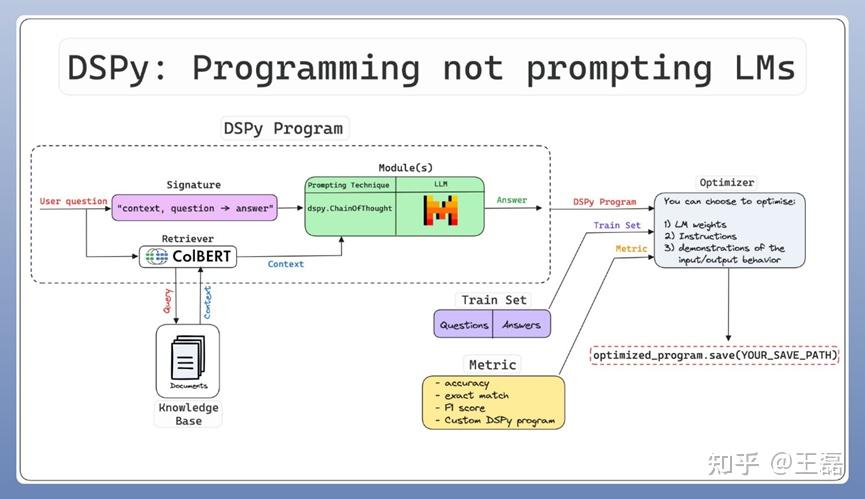
DSPy 强调通过编程编写Prompt。
DSPy 核心:
- 将用户问题转化为对应的签名模块,并通过迭代收集示例来学习实现签名所定义的变换行为。
设计思路
- 数据驱动优化,其借鉴了神经网络优化的概念,结合样例数据,使用优化器优化Prompt,而不是手工调整。
- 将“使用文本方式构筑提示词的机制”,转换为通过”可维护的代码方式”构筑。
- 引入优化器,将程序的信息流与每一步的参数(Prompt和语言模型权重)分离开来,简化Prompt优化过程。
核心模块
- 签名(Signature):定义DSPy模块输入/输出行为的声明性规范,用于告诉语言模型应执行哪些任务。
- 模型程序(Module):
- 每个内置模块抽象出一种提示技术(如Chain of Thoughts或ReAct),每个模块都关联一个自然语言签名。
- DSPy模块具有可调整的参数,包括Prompt组件和LLM权重,使它们能够处理输入并生成输出。
- DSPy模块可以组合成任意的流水线,从而创建更大、更复杂的程序。
- 优化器(Optimizer):用来微调DSPy程序参数(即Prompt和LLM权重)的算法,以达到某些指标(如准确性)的最大值。
DSPy 亮点是内置了 Teleprompter 优化器:
# 准备训练数据
trainset = [
(doc1, expert_analysis1),
(doc2, expert_analysis2),
# ...
]
# 自动优化提示词
teleprompter = dspy.Teleprompter()
optimized_analyzer = teleprompter.optimize(
LegalAnalyzer,
trainset,
metric=dspy.Metrics.Accuracy
)
这个优化过程会:
- • 自动发现最佳提示词模板
- • 优化推理链路
- • 提高输出质量
DSPy Visualizer
【2024-8-6】DSPy Visualizer:可视化Prompt优化过程
DSPy 是开源社区比较有影响力的大模型提示词、参数调优仓库,使得用户以一种编程的方式,调整和优化大模型模板和参数。
DSPy 设计思想借鉴了Torch,使得Torch 使用者可以很快的理解DSPy的使用方式。
使用Torch时,研究人员往往会使用 Tensorboard 等可视化工具来直观的查看模型的训练情况,那么是否有适配 DSPy 优化过程的可视化工具呢?
- 答案是Yes,本文将首先介绍带有DSPy优化器的优化示例,然后使用 langwatch 仓库提供的DSPy Visualizer 查看具体的优化过程,包括显示每个优化步骤的Predictior、Example、大模型调用内容等。
确保已经安装了langwatch 以及 dspy 的python包。
pip install dspy-ai==2.4.12
pip install langwatch
DSPy 优化流程需要: 准备数据集、程序主体、优化器以及衡量指标
- 然后在固定数据集合衡量指标的情况下,调整程序主体和算法以达到优化的目的
使用方法见原文
YPrompt
【2025-11-28】聊天式提示词工程工具:YPrompt,用对话挖掘需求,然后自动生成、优化、管理提示词
- github YPrompt
AI通过对话挖掘用户需求,并自动生成专业的提示词,支持系统/用户提示词优化、效果对比,版本管理和支持即时渲染的操练场
并且支持多种输出类型即时渲染、看效果。对于不会写 Prompt,或需要经常调Prompt的人比较实用
它通过场景、目标、格式等询问交互,自动出专业Prompt,相当于一个会梳理需求的产品经理
文本提示自动化
动机
使用 LLM 时的困惑
- 输入一个看似清晰的问题,却得到一堆不知所云的”废话文学”
- 为了让模型输出符合预期,不得不反复调整提示词(Prompt),耗费大量时间却收效甚微?
研究显示:
- 78% 的 AI 输出低效问题源于提示词设计不当
- 人工调整提示词的平均耗时高达 43 分钟/次
总结
Prompt 是提升模型输出效果的前缀序列(sequence of prefix tokens), 详见 翁丽莲博客smart-prompt-design
提示词自动化方案
- (1) 当可训练参数,在embedding空间上通过梯度下降直接优化
- 2020, AutoPrompt
- 2021, Prefix-Tuning
- 2021, P-tuning
- 2021, Prompt-Tuning
- (2) LLM 生成候选指令,继续用LLM打分,选择最高的作为最佳Prompt
- 2022,
APE(Automatic Prompt Engineer)- 仿照 self-instruct 思路,利用LLM生成prompt
- 基于一批示例让LLM生成候选指令集: Prompt LLM to generate instruction candidates based on a small set of demonstrations in the form of input-output pairs.
- Given a dataset, we would like to find an instruction P , where F is a per-sample score function, such as execution accuracy or log probability:
- 使用迭代
蒙特卡洛搜索找到语义相近的 Use an iterative Monte Carlo search method to improve the best candidates by proposing semantically similar variants via prompts
- 2023.5.4 APO 微软: APE 的改进, 引入 梯度下降优化器
- 错误集上使用梯度下降,接着用APE,同时借助蒙特卡洛树搜索,提升效率
- 2022,
# 示例
\n\n The instruction is
# MC Search
Generate a variation of the following instruction while keeping the semantic meaning.\n\n Input: ...\n\n Output:...
- Earlier work on automated prompt engineering used large language models to generate prompts but didn’t iteratively refine them
- 2022.5 Instruction Induction: From Few Examples to Natural Language Task Descriptions, code instruction-induction. InstructGPT achieves 65.7% of human performance in our execution-based metric, while the original GPT-3 model reaches only 9.8% of human performance
- Automatic Prompt Engineer (APE)
- In 19 out of the 24 tasks in
Instruction Induction, prompts generated byInstructGPTusingAPEoutperformed the earlier work as well as human-engineered prompts according to Interquartile Mean (IQM四分位平均值), the mean exact-match accuracy after discarding the lowest and the highest 25 percent. - On all 24 tasks, prompts produced by
InstructGPTusingAPEachieved 0.765 IQM, while human prompts achieved 0.749 IQM - By optimizing measures of truthfulness 事实性 and informativeness 信息量, the method produced prompts that steered the content generator to produce output with those qualities. For instance, on
TruthfulQA, a question-answering dataset that tests for truthful and informative answers, answers produced byInstructGPTusing APE were rated true and informative 40 percent of the time, while answers produced using prompts composed by humans achieved 30 percent (although the generated answers produced by InstructGPT using APE often take shortcuts such as “no comment,” which has high truthfulness but little information). - As researchers develop new large language models, APE provides a systematic way to get the most out of them, Prompt engineers have only existed for a few years, and already robots are coming for their jobs!
- In 19 out of the 24 tasks in
【2023-7-26】翁丽莲整理的APE方法
CoT 自动化
- 2023.2.24, To construct chain-of-thought prompts automatically, Shum et al. suggested augment-prune-select, a three-step process
- Automate-CoT: Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data
- 增强 Augment: Generate multiple pseudo-chains of thought given question using few-shot or zero-shot CoT prompts;
- 裁剪 Prune: Prune pseudo chains based on whether generated answers match ground truths.
- 选择 Select: Apply a variance-reduced policy gradient strategy to learn the probability distribution over selected examples, while considering the probability distribution over examples as policy and the validation set accuracy as reward.
- 2023, Zhang et al. instead adopted clustering techniques to sample questions and then generates chains. LLMs容易犯错,比如生成语义相似的结果,造成聚集现象, 对错误的簇降低采样可以提升示例多样西
- Auto-CoT: Automatic Chain of Thought Prompting in Large Language Models
- 问题聚类 Question clustering: Embed questions and run k-means for clustering.
- 示例选择 Demonstration selection: Select a set of representative questions from each cluster; i.e. one demonstration from one cluster. Samples in each cluster are sorted by distance to the cluster centroid and those closer to the centroid are selected first.
- 推理生成 Rationale generation: Use zero-shot CoT to generate reasoning chains for selected questions and construct few-shot prompt to run inference.
2020.11.7 伯克利 AutoPrompt
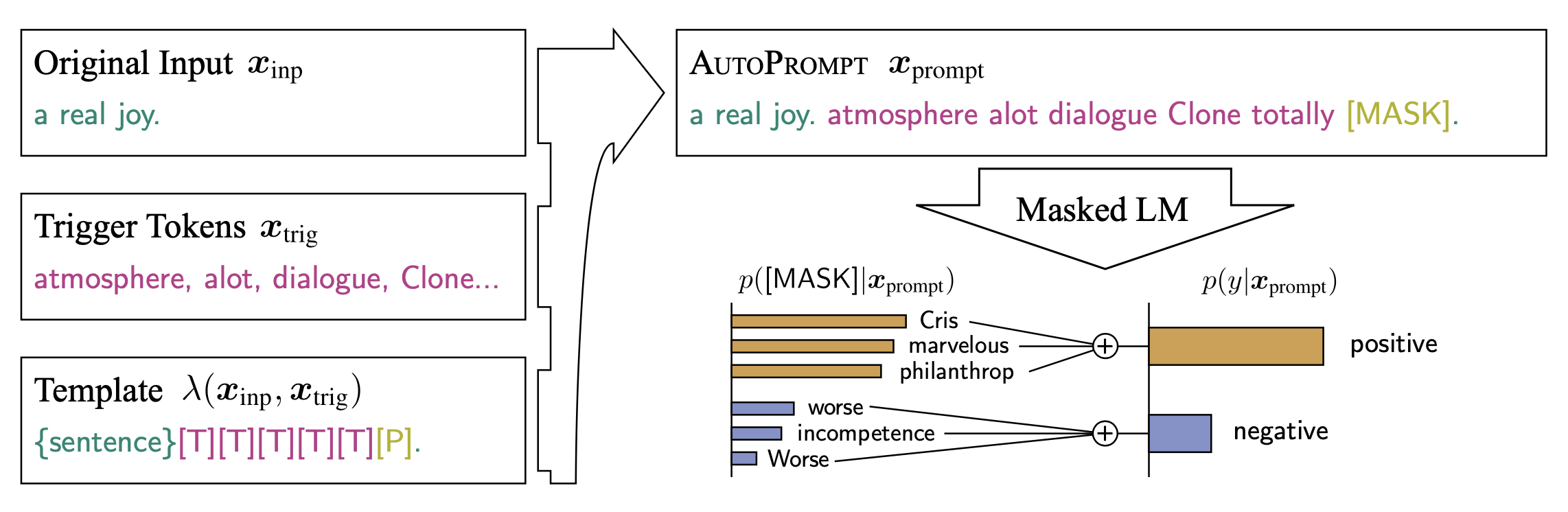
AutoPrompt: Automatic Prompt Construction for Masked Language Models.
An automated method based on gradient-guided search to create prompts for a diverse set of NLP tasks.
- AutoPrompt demonstrates that masked language models (MLMs) have an innate ability to perform sentiment analysis, natural language inference, fact retrieval, and relation extraction. Check out our website for the paper and more information.
- 伯克利 AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts
2022.7.10 PromptGen 百度
PromptGen is the first work considering dynamic prompt generation for knowledge probing, based on a pre-trained generative model.
- PromptGen: Automatically Generate Prompts using Generative Models
- 动态prompt生成的第一篇文章
2022.6.5 Repo-Level Prompt Generator
【2022-6-26】Repository-Level Prompt Generation for Large Language Models of Code
- 提出自动生成框架 Repo-Level Prompt Generator: learns to generate example-specific prompts using prompt proposals
- 无法访问 LLM 权重, 黑盒
- 在 codex 上执行单行代码补全实验
2022.11.3 APE 多伦多大学
仿照 self-instruct 思路,利用LLM生成prompt
- Large Language Models Are Human-Level Prompt Engineers
- propose automatic prompt engineer (APE) a framework for automatic instruction generation and selection. The instruction generation problem is framed as natural language synthesis addressed as a black-box optimization problem using LLMs to generate and search over candidate solutions.
- code

APE is built around three types of templates:
- 评估模板 evaluation templates
- 提示生成模板 prompt generation templates
- 演示模板 and demonstration templates.
Goodbye Prompt Engineering, Hello Prompt Generation

Key insight: 关键思路
- Given a handful of input-output pairs, a large language model can generate a prompt that, along with the same inputs, would result in the similar outputs.
- Moreover, having produced a prompt, it can generate variations that may result in even more similar outputs.
How it works: 如何工作
- APE requires two large language models: a prompt generator (Pompt生成器 which produces prompts) and a content generator (内容生成器 which, given a prompt, produces output).
- For the prompt generator, they tried both language models that complete inputs (such as GPT-3 and InstructGPT) and those that fill in blanks in inputs (such as T5, GLM, and InsertGPT).
- For the content generator, they used InstructGPT.
The authors fed the prompt generator a prompt such as, “I gave a friend an instruction and five inputs. The friend read the instruction and wrote an output for every one of the inputs. Here are the input-output pairs:” followed by a small set of example inputs and outputs, such as the names of two animals and which one is larger, from Instruction Induction. After the example inputs and outputs, the prompt concluded, “The instruction was <COMPLETE>”.
- The prompt generator responded with a prompt such as “Choose the animal that is bigger.”
They fed the generated prompt plus 50 example inputs from the dataset to the content generator, which generated outputs.
- They scored the prompt’s quality based on how often the content generator produced outputs that exactly matched the expected outputs.
- They sharpened the prompt by asking the prompt generator to produce a prompt similar to the highest-scoring one (“Generate a variation of the following instruction . . . ”) and repeated the process. They performed this step three times. For example, a higher-scoring variation of the earlier prompt example is “Identify which animal is larger”.
APE 根据任务数据集优化给定prompt模板,两个步骤
- 使用 LLM 生成候选prompt集合
- 调用 LLM 评估各个候选prompt质量,打分函数:
- Execution accuracy 监督带label,正确1,错误0
- Log probability log P(A|[p;Q]),需要训练模型 / 大模型开放权重,或者接口
- Efficient score estimation 从训练集中抽取少部分数据用于打分筛选prompt
- 生成高分prompt语义相近的prompt
- 迭代蒙特卡洛搜索采样 Monte Carlo Search
- 返回最高评分的prompt
任务数据集:
- 25个任务测试集,包含 输入、输出, 分为
- 训练集: /experiments/data/instruction_induction/raw/induce
- 测试集: /experiments/data/instruction_induction/raw/execute
多视角调研
- zero-shot 零样本
- few-shot 少样本
- truthfulness 真实性
APE 模式
- basic 基础版: prompt 生成模式分成 insert 和 forward
- insert/reverse 逆向模式: 什么样的指令,可以生成给定的输入输出示例 (<insert>前置)
- forward 前向模式: 给定几个输入输出示例,让LLM给出Prompt (后置 <complete>)
- advanced 高级版

2023.5.4 APO 微软
APO:gradient descent in language space
- Automatic Prompt Optimization with ‘Gradient Descent’ and Beam Search
- 提出方法 Prompt Optimization with Textual Gradients (ProTeGi),
核心思路: 在文本空间实现 gradient descent 过程。
- APO本质: 构建一个 optimizer,其框架是参照 gradient decent 来设计
APO 分为以下3个步骤。
- 第1步:得到当前prompt的“gradient”
- 给定一批 error samples(当前prompt无法预测),让LLM给出当前prompt预测错误的原因,这一原因即文本形式的“gradient”。
- 生成 gradient 的 prompt如下。
- 第2步:应用“gradient”,得到new prompt. 2个子步骤:
- 2.1:使用LLM来编辑原prompt,目标是修复“gradient”。
- 2.2:和APE一样,进行resample,扩充相似语义的prompt。
- 第3步:挑选出好的prompt,进入下一轮迭代
- 面临的问题和APE一样:如果在全量训练集上评估各个prompt,花销太大。挑选prompt的过程就是多臂老虎机问题。
- n arms 对应 n个prompt candidates
- 任务数据集上的表现是这个arm的hidden value
- pulling 这个动作对应在随机采样的数据上评估prompt效果
- 试验了3种 bandit selection 技术:
UCB、UCB-E和Successive Rejects。实验表明,UCB和UCB-E效果比较好。 - 补充: APO在每轮迭代中,最外层包含一个beam search过程,以便强化探索。
------- 1 --------
I'm trying to write a zero-shot classifier prompt.
My current prompt is:
"{prompt}"
But this prompt gets the following examples wrong:
{error_string}
give {num_feedbacks} reasons why the prompt could have gotten these examples wrong.
Wrap each reason with <START> and <END>
------- 2.1 --------
I'm trying to write a zero-shot classifier.
My current prompt is:
"{prompt}"
But it gets the following examples wrong:
{error_str}
Based on these examples the problem with this prompt is that {gradient}
Based on the above information, I wrote
2023.9.9 OPRO 谷歌
记得 Zero-Shot COT 里的那句 Let's think step by step 吗?
最近谷歌通过OPRO找到了更好的一句:Take a deep breath and work on this problem step-by-step,让GSM8K的结果直接从 71.8% -> 80.2%
【2023-9-9】大模型靠“深呼吸”数学再涨8分!AI自己设计提示词效果胜人类
- 谷歌 DeepMind 团队最新发现,用新“咒语” “深呼吸”(Take a deep breath)结合熟悉的“一步一步地想”(Let’s think step by step),大模型在GSM8K数据集上的成绩就从71.8提高到80.2分。
- 论文: Large Language Models as optimizers
- 大模型自己设计的提示词在 Big-Bench Hard 数据集上最高提升50%
- 不同模型的最佳提示词不一样
- 不光不同模型设计出的提示词风格不同,适用的提示词风格也不同
- GPT系列: AI设计出的最优提示词是“
Let’s work this out in a step by step way to be sure we have the right answer.”- 这个提示词使用APE方法设计,ICLR 2023 论文,在GPT-3(text-davinci-002)上超过人类设计的版本“
Let’s think step by step”。
- 这个提示词使用APE方法设计,ICLR 2023 论文,在GPT-3(text-davinci-002)上超过人类设计的版本“
- 谷歌系PaLM 2和Bard上,
APE版本作为基线就还不如人类版本。OPRO方法设计de新提示词中,“深呼吸”和“拆解这个问题”对PaLM来说效果最好。对text-bison版的Bard大模型来说,则更倾向于详细的提示词。
- 论文还测试了大模型在
线性回归(连续优化)和旅行商问题(离散优化)这些经典优化任务上的能力。- 大模型还无法替代传统基于梯度的优化算法,当问题规模较大(如节点数量较多的旅行商问题)时,OPRO方法表现就不好
- 大量实验中得到最优提示词包括: 电影推荐、恶搞电影名字等实用场景
而且这个最有效提示词是AI找出来的
优化问题无处不在,一般用基于导数和梯度的算法,但经常遇到梯度不适用的情况。
于是, 团队开发了新方法OPRO,也就是通过提示词优化(Optimization by PROmpting)。不是形式化定义优化问题然后用程序求解,而是用自然语言描述优化问题,并要求大模型生成新的解决方案。一张图总结,对大模型的一种递归调用。
- 每步优化中,之前生成的解决方案和评分作为输入,大模型生成新的方案并评分,再将其添加到提示词中,供下一步优化使用。
- 谷歌的
PaLM 2和Bard中的text-bison版本作为评测模型, 再加上GPT-3.5和GPT-4,共4种模型作为优化器。
方向
- 结合关于错误案例的更丰富的反馈,并总结优化轨迹中高质量和低质量生成提示的关键特征差异。这些信息可能帮助优化器模型更高效地改进过去生成的提示,并可能进一步减少提示优化所需的样本数量。
OPRO 框架
- 使用 meta-prompt,让LLM成为 Optimizer LLM。
- meta-prompt 包含两个核心部分:
- 一个是 solution-score pairs,即以往的迭代路径,包括 solution(即prompt) + 分数(任务表现),实践中按照分数大小,从低到高排列top20的结果;
- 另一个是 task description,包含一些任务的examples、优化的目标等
- 基于对过往迭代规律的理解,Optimizer LLM生成新的solution。即将meta-prompt给到Optimizer LLM,生成的内容即为新的solution。在实践中,为了提升优化的稳定性,这一步重复了8次。
- 在Scorer LLM上应用prompt(即新的solution),评估效果并记录到meta-prompt中,然后继续下一轮迭代。注意,这里的Scorer LLM是实际使用prompt的LLM,与Optimizer LLM可以是不同的。
- 当效果无法再提升、或者到达预先给定的step上限,整个迭代过程停止。返回得分最高的prompt作为优化结果。
2023.10.4 EvoPrompt 清华
【2023-10-4】LLM与进化算法结合,创造超强提示优化器,淘汰提示工程师
清华大学、微软研究院和东北大学的一项新研究表明,利用传统进化算法来处理提示词工程问题,可以大大提升效率。
将进化算法融入到提示词工程中,利用LLM来模仿进化算法中的进化算子来生成新的提示词,将性能更好的提示词保留下来不断迭代,这个自动化生成提示词的方式也许在未来会成为提示词工程中最重要的方法。
借鉴进化算法的思想,提出了一种离散提示词(Discrete Prompt)调优框架 —— EvoPrompt。
EA (进化算法) 有多种类型,研究人员采用两种广泛使用的算法(遗传算法和差分进化算法)。
GA是最受好评的进化算法之一,而DE自诞生以来已经成为解决复杂优化问题的最广泛使用的算法之一- 论文地址:EvoPrompt
EA(进化算法)通常从一个包含N个解决方案(在研究人员的研究中相当于提示词)的初始群体开始,然后使用当前群体上的进化算子(例如,变异和交叉)迭代地生成新的解决方案,并根据一个评分函数更新群体。
按照典型的EA,EvoPrompt主要包括三个步骤:
- 初始群体:大多数现有的基于提示词的方法忽视了人类知识提供的高效先验初始化,研究人员应用几个手动提示作为初始群体,以利用人类的智慧作为先验知识。
- 此外,EA通常从随机生成的解决方案(提示词)开始,产生一个多样的群体,并避免陷入局部最优。相应地,研究人员还将由LLM生成的一些提示词引入到初始群体中。
- 进化:在每次迭代中,EvoPrompt使用LLM作为进化算子,根据从当前群体中选出的几个父提示生成一个新的提示。
- 为了实现这一点,研究人员仔细设计了针对每种特定类型的EA的变异和交叉算子的步骤,以及相应的指令,以指导LLM根据这些步骤生成新的提示。
- 更新:研究人员在开发集上评估生成的候选提示,并保留那些性能优越的提示,类似于自然界中的适者生存。
与之前在提示符生成(APE)和人类书面指令方面的工作相比,EvoPrompt取得了明显更好的结果。
- 但在情感分类数据集上,EvoPrompt(GA)略优于EvoPrompt(DE)。
- 当涉及到主题分类数据集时,EvoPrompt(GA)和EvoPrompt(DE)的结果类似。
- 在主观性分类任务(Subi)上,EvoPrompt(DE)明显优于EvoPrompt(GA),具有9.7%的准确性优势。
2023.9.9 逆向工程
【2023-9-9】Prompt逆向工程:轻松复刻OpenAI“神级”提示词
顶级Prompt的逆向工程技术,这个方法不仅能解读“神级”Prompt提示词的工作原理,还可指导我们如何优化或复制这些提示词。
三种逆向prompt的方法,分别是:
- AI自述其修:简单地把一个专门设计的Prompt塞进一个包装好的AI应用,让AI主动吐露到底用了哪个提示词。
- “神级”Prompt解剖:先找出一段表现优异的“神级”提示词,然后拆分、提炼出其精华部分,构建一个通用的Prompt框架。这样不仅能复制,还能升级这些Prompt。
- 效果反推大法:从一个生成结果出发,让AI反向推导出是哪个提示词让它如此出色。通过持续调试,效果达到最佳。
“神级”Prompt解剖
几个步骤和提示词进行解剖式逆向分析:
- 提炼设计原则:作为专门针对ChatGPT优化提示词的专家,请根据我给出的几个提示词进行两项任务:1.针对每组提示词,分析其主要优点;2.从这些提示词中提取出共同的设计原则或要求。
- 提取提示词结构体:作为专门针对ChatGPT优化提示词的专家,根据我提供的ChatGPT提示词特征,执行以下任务:识别各提示词的共同特点,并根据这些共同特点将其转化为可以通用的‘提示词结构体’。每个共同特点应生成一个独立的‘提示词结构体’。
- 组合提示词架构:请先分析我提供的几组ChatGPT提示词,结合步骤1和步骤2提炼的提示词设计原则和提示词结构体,以原始的提示词为基础,构建一个通用的ChatGPT提示词模板框架,并根据结构体的英文单词为此框架命名。
应用上面这几个步骤,就可以直接跑通复杂提示词的逆向了,不过除了这三个大结构之外,针对第一步还可以增加更多细节,比如:
- 提取提升交互体验的提示词:请从中提取提高交互体验和效率的指令,请提炼并解释。
- 提取让模型输出更精准的提示词:请从中提取让模型生成内容更精准的指令,请提炼并解释。
- 提取让生成内容更具创造性的提示词:请从中提取影响模型生成内容创造性的指令,请提炼并解释。
2023.10.20 MIT: GATE 主动提示
为什么要“反客为主”提示人类?
- 因为人类给出的提示存在局限性,不一定能准确完整表达出自己的喜好。
- 比如很多人都不懂提示工程, 或在提示过程中提供了存在误导性的资料……
- 假如一个用户说自己很喜欢读网球相关的文章,对网球巡回赛、发球技术感兴趣。但是从他提供的文章参考里,无法判断他是否对网球方面的其他话题感兴趣。
这些都会导致大模型表现变差。
如果大模型能学会一些提问技巧,就能将用户的偏好锁定在更小范围内。
【2023-10-20】提示工程夭折?MIT斯坦福让大模型主动提问,自己搞懂你想要什么
MIT、斯坦福和Anthropic(Claude2打造者)共同提出 GATE, 基于大模型本身的能力,来引出、推理人类用户的喜好。
- Eliciting Human Preferences with Language Models
- 实现代码:generative-elicitation
- 论文提出了一种新型的机器学习框架
GATE(Generative active task elicitation),让大模型学会主动向人类提问,自己搞明白用户的偏好。 - 用GPT-4进行实验,结果发现和提示工程、监督学习等方法比,在这个框架的辅助下GPT-4在多个任务上更懂人类了。
如果大模型能更容易揣度出人类想啥,也就意味着人类自己不用绞尽脑汁表达自己的想法了。
监督学习和提示工程都属于被动方式,监督学习和少量主动学习还要基于示例
本项研究让大模型尝试了多种提问方式,比如主动生成用户标注的样本、是非类提问、开放式提问等。
三种通过对话提问收集信息的策略:
- 生成式主动学习(Generative active learning):大模型(LM)生成示例输入供用户标记(label)。这种方法的优点是向用户提供具体的场景,其中包括他们可能没有考虑过的一些场景。例如,在内容推荐方面,LM可能会生成一篇文章,如:您对以下文章感兴趣吗?The Art of Fusion Cuisine: Mixing Cultures and Flavors。
- 生成“是”或“否”**的问题(Generating yes-or-no questions):我们限制LM生成二进制的是或否问题。这种方法使得模型能够引导用户提供更抽象的偏好,同时对用户来说也很容易回答。例如,模型可能通过询问用户的偏好来进行探测:Do you enjoy reading articles about health and wellness?
- 生成开放性问题(Generating open-ended questions ):LM生成需要自由形式自然语言回答的任意问题。这使得LM能够引导获取最广泛和最抽象的知识,但可能会导致问题过于宽泛或对用户来说具有挑战性。例如,LM可能会生成这样一个问题:What hobbies or activities do you enjoy in your free time …, and why do these hobbies or activities captivate you?
GATE框架如何工作
- 用户需求:用户想要创建一个有趣的游戏,并请求GATE系统进行设计。
- GATE的提问:GATE系统询问用户在创建游戏时考虑哪种平台或者哪种类型的游戏。例如,是移动游戏、PC游戏还是街机游戏。
- 用户回应:用户说他们正在考虑移动游戏,并特别喜欢拼图游戏。
- GATE的进一步提问:GATE系统询问用户是否已经考虑了游戏的目的和规则,或者是否需要一些创意或建议。
- 用户的需求细化:用户表示还没有决定具体的游戏规则,希望听到一些新的概念或建议。
- GATE的建议:GATE系统建议可以考虑加入时间操作的元素,比如让玩家能够倒退时间或暂停时间来解决拼图。
- 用户的反馈:用户觉得这个主意很有趣,并请求更多关于这个游戏的细节。
最终的Prompt:
GATE系统生成了一个最终的Prompt:“设计一个用于移动设备的拼图游戏,其中玩家可以通过操作时间来解决各种障碍并达到目标。”
这个案例展示了GATE如何通过与用户的开放式对话来了解用户的具体需求,并据此生成有效的Prompt,以便大规模语言模型(LLMs)能更准确地满足用户的需求。
主要测试的任务为内容推荐、道德推理和邮箱验证。
结果显示,在三项任务中,GATE包含的办法效果都优于其他方法。
观点
- 提示工程要是消失了,花重金雇佣的提示工程师怎么办?
- elvis:这篇研究和之前那些研究人类偏好的工作没有太大不同,我们现在还是要依赖提示工程。
- 我不认为“理解人类意图/喜好”会导致提示工程消失,除非LLM训练和工作的方式发生系统性变化。
- Gennaro: 提示工程只是会从前端消失,形式上发生改变
2023.10.25 加州大学 PromptAgent
【2023-10-31】小妙招从Prompt菜鸟秒变专家!加州大学提出PromptAgent,帮你高效使用ChatGPT
加州大学提出可自动优化Prompt的框架——PromptAgent,结合大模型的自我反思特点与蒙特卡洛树搜索规划算法,自动迭代检查Prompt,发现不足,并根据反馈对其进行改进,寻找通往最优Prompt的路径,可以将平平无奇的初始Prompt打造成媲美人类专家手工设计的Prompt。
案例
- 实现生物医学领域的命名实体识别任务,从句子中提取疾病等实体。
prompt可能就设置为:
从句子中提取疾病或状况
简单粗暴的prompt虽然也能完成部分简单任务,但是效果并不好。
PromptAgent通过该prompt所获得的结果指出错误, 并不断优化prompt:
您的任务是提取疾病或疾病情况…请避免包含任何相关元素,如遗传模式(如常染色体显性)、基因或基因座(如PAH)、蛋白质或生物途径。…考虑具体的疾病和更广泛的类别,并记住疾病和情况也可以以常见的缩写或变体形式出现。以以下格式提供识别出的疾病或情况:
{entity_1,entity_2,....}。…请注意,“locus”一词应被识别为基因组位置,而不是疾病名称。
最终的这份Prompt涵盖了丰富的生物领域知识,且准确率得到了极大提升
PromptAgent框架设计
PromptAgent 在确保对广阔的prompt空间进行高效策略性的搜索的同时,有效地将专家知识整合到任务prompt中。所谓专家知识通过大模型如GPT-4生成,而其搜索策略使用的是著名的蒙特卡洛树搜索。
PromptAgent 使用预设的迭代次数执行上述四个操作,当达到迭代次数后,选择具有最高回报的最佳路径中的最佳节点(即Prompt)进行最终评估。
PromptAgent 在 BBH 任务上明显优于所有基线。
- 相对人类Prompt(ZS)、
CoT和APE方法分别提升了28.9%、9.5%和11.2%
广泛领域知识和深厚的LLM Prompt工程经验的生物领域
- 人类Prompt和CoTPrompt效果不佳。
- 而APE通过自动Prompt抽样和优化融入了一些领域知识,减少了人工干预,效果有所提升。
- 但是,PromptAgent相对于APE平均提高了7.3%
这表明PromptAgent 更好地引导有效的领域知识,产生专家级Prompt,并弥合新手和专家Prompt工程师之间的知识差距。
而对于通用的NLU任务,PromptAgent的能力和通用性也完胜所有的基线。
Prompt 泛化
由于较低级别和较小规模的LLM模型(如GPT-2或LLaMA)可能无法熟练掌握这些专家级Prompt的微妙之处,会导致显著的性能下降。
本次评估选取了一个性能更强大(GPT-4)和一个比GPT-3.5性能更弱的模型(PaLM 2)。结果显示,PromptAgent具有巨大的潜力:
- 当使用更强大的GPT-4时,优化后的专家Prompt几乎在所有任务(11/12)中都取得了进一步改进。
- 将专家Prompt转移到PaLM 2时,性能可能不如更强大的模型,但仍然可以在某些任务(如Penguins)中获得提升。
消融实验
对比了多种搜索策略效果,包括
- 每次随机抽样并选择一个动作的单次蒙特卡洛(MC)搜索
- 始终选择多个样本中的最佳样本的贪婪深度优先搜索(Greedy)
- 每个层级保留多个有用路径的束搜索(Beam search)。
结果显示:
贪婪搜索(Greedy)和束搜索(Beam)都极大地改进了MC基线,表明结构化的迭代探索是必要的。- Beam和Greedy严格按照前进的方向操作,没有在Prompt空间中进行策略性搜索,缺乏预见未来结果和回溯过去决策的能力。
- 相比之下,
MCTS的策略规划允许PromptAgent更有效地遍历复杂的专家Prompt空间,在所有任务上明显优于所有搜索变体。
2023.11.2 谷歌:COSP
【2023-11-5】再见了,提示~ 谷歌发布自适应提示方法,从此告别提示工程
复杂任务中, 人工构造高质量示范样本难度很大,特别是对于需要领域知识的任务,如 长文章摘要或医疗问题回答。因此自动生成可靠示范是非常有必要的。
为了解决这个困境,谷歌团队提出了一种名为 Consistency-Based Self-Adaptive Prompting(COSP)方法,无需人工构造样本,仅使用无标签样本(通常容易获取)和模型自身的预测输出,即可构建LLM的伪示范,在推理任务中大大缩小了零样本和少样本之间的性能差距。
同时将这个思想扩展到广泛的通用自然语言理解(NLU)和自然语言生成(NLG)任务,在多个任务上展示了其有效性。这两篇工作分别被 ACL2023 和 EMNLP 2023 接收。
- 谷歌博客
- 论文一标题:Better Zero-shot Reasoning with Self-Adaptive Prompting
- 论文二标题:Universal Self-Adaptive Prompting
如果LLM对自己的答案很“自信”,那么多次调用应该输出相同答案,该答案更可能是正确的,其置信度就比较高。
因此可考虑使用高置信度的输出及其输入作为伪示范。
- 示范样例的答案仍然是LLM生成的,并且没有经过真实答案检验。
COSP – ACL
COSP 方法步骤:
- 将每个无标签问题输入到LLM,通过多次采样,模型将获得多个包含问题、生成的推理过程和答案的示范,并分配一个分数,反映答案的一致性。
- 输出次数越多的答案分数越高。
- 除了偏好更一致的答案,COSP还惩罚回答中的重复问题(即重复的词语或短语),并鼓励选择多样性的示范。
- 将一致的、非重复和多样化输出的偏好编码为一个评分函数,该函数由三个评分的加权和组成,用于选择自动生成的伪示范。
- 将伪示范与测试问题一起输入LLM中,并获得该测试问题的最终预测答案。
改进:USP – EMNLP
COSP专注于推理问答任务,这些问题有唯一答案很容易测量置信度。但是对于其他任务,比如开放式问答或生成任务(如文本摘要),则会变得困难。
于是,作者引入了USP(Uncertainty-based Self-supervised Prompting),将该思想推广到其他常见的NLP任务上。
选择伪示范的方法因任务类型变化而有所不同:
- 分类(CLS):LLM生成预测,使用神经网络计算每个类别的 logits, 并基于此选择置信度较高的预测作为伪示范。
- 短文本生成(SFG):类似于问答任务,可以使用
COSP中提到的相同步骤进行处理,LLM生成多个答案,并对这些答案的一致性进行评分。一致性较高的答案被选择作为伪示范。 - 长文本生成(LFG):包括摘要和翻译等任务,通常是开放式的,即使LLM非常确定,输出也不太可能完全相同。在这种情况下使用重叠度度量,计算不同输出对于相同查询的平均ROUGE分数,选择具有较高重叠度的作为伪示范。
总过程
- 第一阶段,针对不同任务类型,调用语言模型对无标签数据生成输出,并基于 logit 熵值、一致性或者重叠度等指标进行置信度打分,最后选择置信度高的样本作为上下文示范。
- 第二阶段,将这些伪的上下文示范作为语言模型输入的一部分,对测试数据进行预测。

实验
- 以前LLM在这些任务中表现不如人类,而现在大部分任务上LLM都超越了人类的平均表现。
- 而USP同样优于基线,即使是与人工制造的提示样本(图中3-shot)相比也具备一定的竞争力。
COSP和USP方法通过自动构造伪样本的方式弥合了零样本与少样本之间的差距,对自然语言理解与生成一系列广泛的任务都适用。
2023.11.20 清华 BPO
黑盒提示对齐优化技术(Black-box Prompt Optimization),通过优化用户指令,从输入角度对模型进行对齐。

不对 LLM 进行训练的情况下,大幅提升与人类偏好的对齐程度。而且 BPO 可以被替换到各种模型上,包括开源模型和基于API的模型。
- 论文:Black-Box Prompt Optimization: Aligning Large Language Models without Model Training
- 代码:https://github.com/thu-coai/BPO, 基于LLaMA-2-7b-chat训练,模型数据已开源,支持二次训练
- BPO_demo
BPO黑盒优化的目标是让模型更好地理解和满足人类的喜好。通过调整输入内容,使模型生成的输出更符合用户的期望。
这个过程可以分为三个主要步骤:
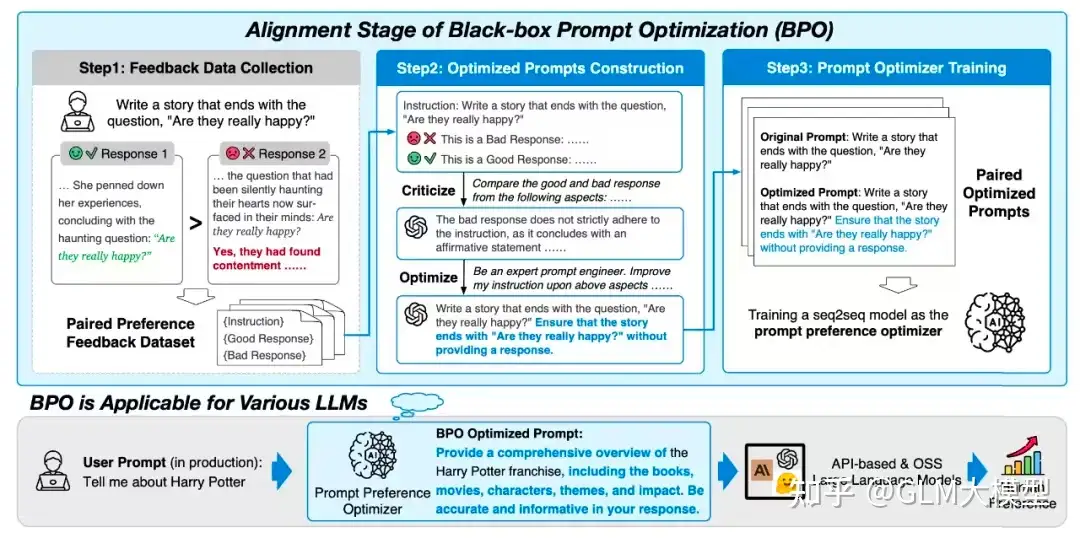
- 1、反馈数据收集:为了建模人类偏好,首先搜集了一系列带有反馈信号的开源指令微调数据集,并对这些数据经过精心筛选和过滤。
- 2、构造提示优化对:使用这些反馈数据来引导大型模型识别出用户偏好的特征。
- 首先让模型分析用户喜欢的回复和不喜欢的回复,找出其中蕴含的人类偏好特征。
- 接着,基于这些特征,再利用模型优化原始的用户输入,以期得到更符合用户喜好的模型输出。
- 3、训练提示优化器:经过步骤一和步骤二,得到了大量隐含人类偏好的提示对。
- 利用这些提示对,训练一个相对较小的模型,从而构建提示偏好优化器。
BPO的一些常见优化策略,包括:推理解释、完善用户问题、要点提示以及安全增强。

对比
- 与 PPO 和 DPO 相比,BPO最大的优势在于不需要训练原本的LLM,只需要额外训练一个较小的模型即可,并且我们的实验证明这两种技术是可以相结合的。
- 与 OPRO 对比,BPO 最大的特点在于更加通用,OPRO 等现有的 Prompt Engineering 技术大多需要针对特定的数据进行搜索,并且会搜索得到一个针对特定任务的提示。因此,如果用户希望使用此类方法,需要针对每种任务准备相应的数据集。而 BPO 在训练得到提示优化器后,可以优化各种用户指令。
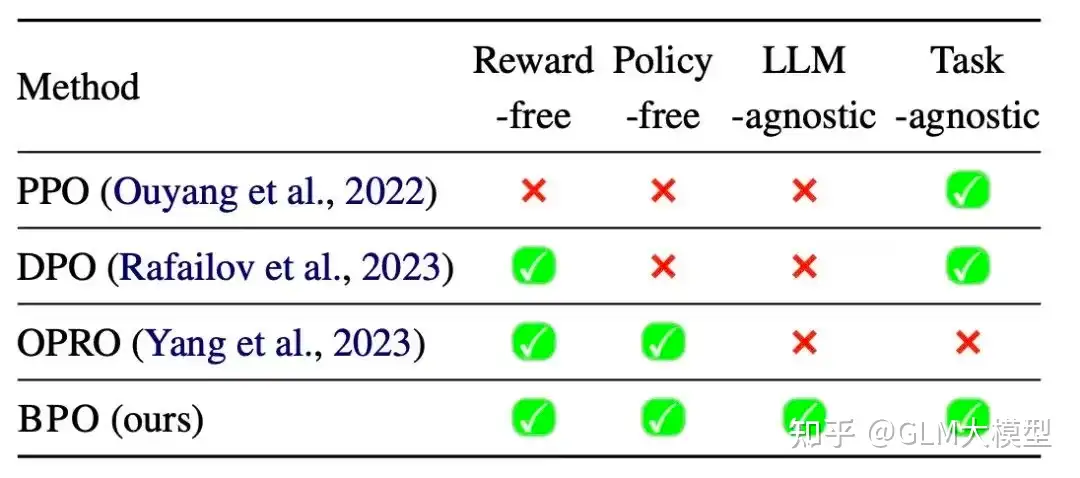
BPO对齐技术对 GPT-3.5-turbo 有22%的提升,对 GPT-4 有 10% 的提升。
- VicunaEval 上使用 GPT-4 进行自动评估,BPO 能够大幅提升 ChatGPT、Claude 等模型的人类偏好,并助力 llama2-13b 模型大幅超过 llama2-70b 的版本。
- BPO 能够助力 llama2-13b 大幅超过 llama2-70b 版本的模型效果,并让 llama2-7b 版本的模型逼近比它大 10 倍的模型。
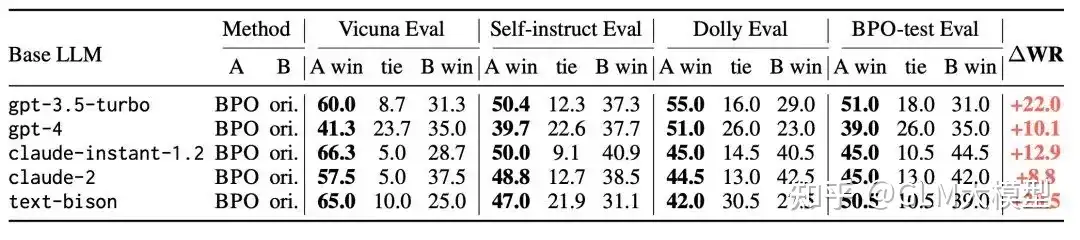
效果
// give me 3 tips to learn English
Here are several optimized prompts:
====================Stable Optimization====================
Provide three comprehensive and actionable tips to learn English.
====================Aggressive Optimization====================
1. Please provide three comprehensive and actionable tips to learn English. The tips should cover aspects such as setting goals, creating a study schedule, and immersing yourself in the language. Please ensure the tips are helpful, accurate, and harmless.
2. Please provide three comprehensive and actionable tips to learn English. Tips should be based on the importance of a positive attitude, setting goals, and using a variety of learning methods. Please explain each tip in detail and provide examples to support the suggestions.
3. Please provide three comprehensive and actionable tips to learn English. The tips should cover aspects such as setting goals, creating a study schedule, and immersing yourself in the language. Please explain each tip in detail and provide practical examples if possible.
4. Provide three comprehensive and actionable tips to learn English. Please ensure that the tips are accurate, helpful, and do not contain any harmful or unrelated content.
5. Provide three comprehensive and actionable tips to learn English. Focus on grammar, vocabulary, and practice.
代码示例
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = 'THUDM/BPO'
local_dir = '/mnt/bd/wangqiwen-hl/models'
prompt_template = "[INST] You are an expert prompt engineer. Please help me improve this prompt to get a more helpful and harmless response:\n{} [/INST]"
device = 'cuda:0'
model = AutoModelForCausalLM.from_pretrained(model_path, cache_dir=local_dir).half().eval().to(device)
# for 8bit
# model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device, load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, cache_dir=local_dir)
text = 'Tell me about Harry Potter'
prompt = prompt_template.format(text)
model_inputs = tokenizer(prompt, return_tensors="pt").to(device)
output = model.generate(**model_inputs, max_new_tokens=1024, do_sample=True, top_p=0.9, temperature=0.6, num_beams=1)
resp = tokenizer.decode(output[0], skip_special_tokens=True).split('[/INST]')[1].strip()
print(resp)
2023.12.1 YiVal
【2023-12-1】Prompt不会写?引入YiVal,自动化提示工程的未来
YiVal 专为简化GenAI应用提示和循环中的任何配置调整流程而设计。在这个以数据为驱动、以评估为中心的系统中,手动调整已经成为过去式。
YiVal 利用 NLP技术,自动分析和优化提示
YiVal确保了最佳的提示生成、精确的重复性关注(RAG)配置和精细调整的模型参数,从而赋能应用程序轻松实现优化结果,降低延迟,并最小化推理成本。
#pip install yival
git clone https://github.com/YiVal/YiVal.git
cd YiVal
2023.12.30 Auto-Prompt Builder
【2024-1-18】Langchain创始人新项目Auto-Prompt Builder一键优化Prompt
有没有这样一款工具:把用户的prompt进行优化改写以便达到最佳效果呢?
jinaAI开发的PromptPefect就能达到目的,但是一款完整产品,覆盖了prompt编写到应用服务的全过程,对于开发者,不太利于集成。
langchain创始人Harrison Chase最新开发的一个能力纯粹的开源项目auto-openai-prompter,其核心思路
- 将OpenAI的Prompt优化原则提交给GPT,然后让GPT-4帮助你优化prompt,可谓是用魔法打败魔法。
- Demo
2024.1.23 Meta-prompting
【2024-2-6】斯坦福 和 OpenAI 提出 meta-prompting,最强零样本prompting技术诞生了
- 论文标题:Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding
- 项目地址:meta-prompting
- 数据
传统脚手架方法针对每个任务调整具体的指令或示例,而 meta-prompting 则不同,在多种任务和输入上都采用了同一套高层级指令。不必为每个具体任务提供详细的示例或具体指示了。
- 示例: 「写一首关于自拍的莎士比亚式十四行诗」
- 用户无需补充高质量的新古典主义诗歌示例。
这种技术涉及构建一个高层级的「元」 prompt,作用是指示语言模型做到以下几点:
- 将复杂任务或问题分解成更小/容易解决的子任务;
- 使用适当且详细的自然语言指令将这些子任务分配给「专家」模型;
- 监督这些专家模型之间的通信;
- 通过这个过程应用其自己的批判性思维、推理和验证技能。
meta-prompting 不仅能提升整体性能,而且在多个不同任务上也往往能实现新的最佳结果。
其灵活性尤其值得称道:
- 指挥员模型有能力调用专家模型(基本上就是其本身,只是指令不一样)执行多种不同的功能。
- 这些功能可能包括点评之前的输出、为特定任务选取特定 AI 人设、优化生成的内容、确保最终输出在实质和形式上都满足所需标准。
meta-prompting 方法的伪代码
- 首先, 对输入执行变换,使其符合适当的模板;
- 然后执行以下循环:
- (a) 向元模型提交 prompt
- (b) 如有需要,使用特定领域的专家模型
- (c) 返回最终响应
- (d) 处理错误。
2024.4.17 人大 GPO
人民大学:2024年4月份的一篇论文,让LLM做 prompt自动优化
- 早期工作: Large Language Models as Optimizers,虽然说是 prompt优化,实际上真正输入给 LLM optimizer 的是
meta-prompt,还是需要人工设计 - 本文研究如何设计
meta-prompt,仿照梯度下降算法流程,提出了 Gradient-inspired LLM-based Prompt Optimizer(GPO) - 论文 Unleashing the Potential of Large Language Models as Prompt Optimizers: An Analogical Analysis with Gradient-based Model Optimizers
- 源代码地址: GPO
2024.6.11 哈佛 TextGrad
TextGrad 不只是Prompt优化框架,还是针对AI系统的优化框架。
- 遵循 PyTorch 语法和抽象,通过文本进行自动“微分”,并根据文本梯度(LLM提供反馈)进行优化。
设计思路
在TextGrad中,每个AI系统被转换为一个计算图,其中变量是复杂(不一定可微分)函数调用的输入和输出。对变量的反馈(被称为“文本梯度”)是以自然语言批评的形式进行提供,描述了如何改变变量以优化系统。
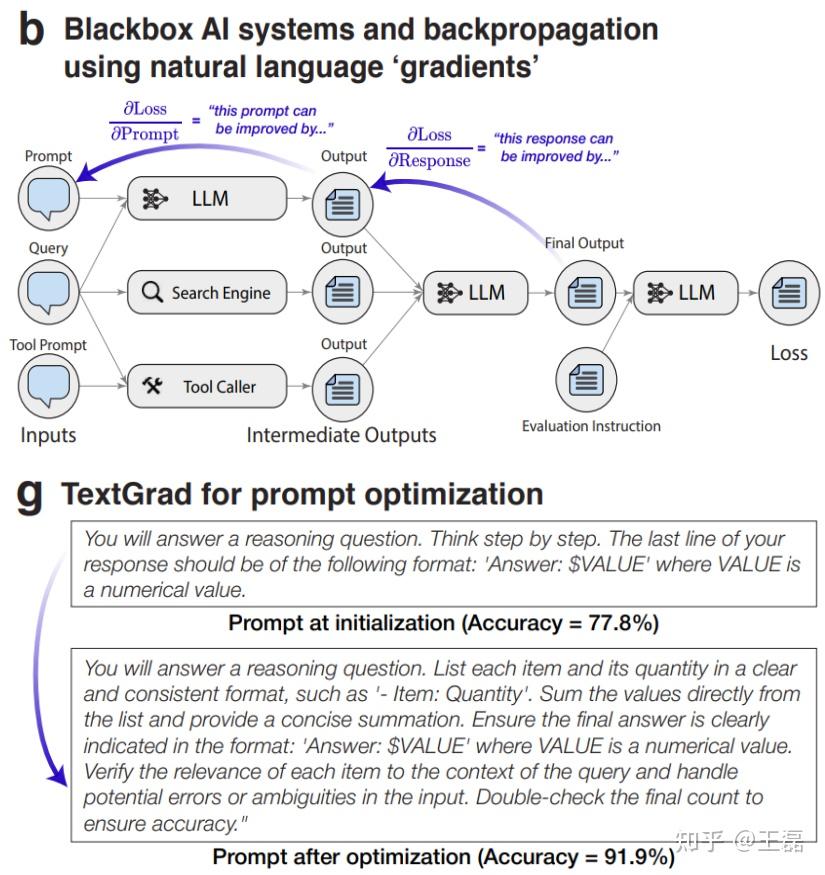
核心模块
TextGrad 关键组件:
- 变量:计算图节点,包含非结构化数据(如文本)。
- 函数:变量转换(如LLM调用、模拟器)。
- 梯度:LLM自然语言反馈,描述如何修改变量。
- 文本梯度下降(TGD):一种优化器,基于当前值和文本梯度更新变量。
计算图
- TextGrad 使用反向传播算法来计算可微变量的梯度,即文本反馈。
- 反向传播算法会沿着计算图的边,将梯度从后继节点传递到前驱节点。
文本梯度
- 文本梯度是LLM提供的文本反馈,描述如何修改变量才能改善下游目标。TextGrad使用文本梯度下降算法更新可微变量,并调整变量的值,使其更接近目标。
- 文本梯度可以是自然语言,也可以是代码片段、分子结构等。
优化技术
- 批量优化(Batch Optimization):为Prompt优化实现随机小批量梯度下降算法。
- 受约束优化(Constrained Optimization):利用受约束优化的类比,采用自然语言约束。
- 动量(Momentum):借鉴梯度下降中动量的概念。在优化变量时,TGD优化器可以在更新时选择性地查看变量的早期迭代状态。
2024.7.3 DCoT
【2024-7-3】DICoT模型让AI学会自我纠错,提示词工程终结
多所大学的研究人员提出了一种新的训练方法——发散式思维链(Divergent Chain of Thought, DCoT),让AI模型在单次推理中生成多条思维链,从而显著提升了推理能力。
这项研究不仅让AI模型的表现更上一层楼,更重要的是,它让AI具备了自我纠错的能力。
DCoT训练方法主要有三大亮点:
- 提升小型模型性能:即使是规模较小、更易获取的语言模型,经过DCoT训练后也能显著提升表现。
- 全面超越CoT基线:从1.3B到70B参数的各种规模模型中,DCoT都展现出了优于传统思维链(Chain of Thought, CoT)的性能。
- 激发自我纠错能力:经过DCoT训练的模型能够在单次推理中生成多条思维链,并从中选择最佳答案,实现了自我纠错。
多个推理任务上测试
- 一致性提升:DCoT在各种模型家族和规模上都取得了持续的性能提升。
- 多样化思维链:通过实证和人工评估,确认模型能生成多条不同的推理链。
DCoT不仅提高了模型的推理能力,还让模型具备了”多角度思考”的能力。
DCoT在多个方面都超越了传统CoT:
- 领域内任务:DCoT在训练涉及的任务上表现优异。
- 未见过的任务:在全新的任务上,DCoT仍然保持优势。
- 困难任务:即使在CoT可能有害的任务上,DCoT也展现出了稳健性。
- 兼容性:DCoT还能与现有的CoT扩展方法(如自洽性解码)兼容,进一步提升性能。
CoT训练让模型具备了自我纠错的能力:
- 无需外部反馈:模型能够在单次推理中生成多条思维链,并从中选择最佳答案。
- 显著提升:仅生成两条思维链就能带来明显的性能提升,证实了自我纠错的存在。
- 人工验证:通过人工分析,确认了模型确实在进行自我纠错,而非简单的自我集成。
DCoT的出现无疑为AI与人类的交互开辟了新的可能性
2024.7.11 GRAD-SUM
现有方法
- 要么针对具有给定答案的特定任务进行调整
- 要么成本较高
佐治亚理工推出 GRAD-SUM,基于梯度优化技术的框架。
允许用户自定义任务描述和评估标准,并引入了一种创新的梯度总结模块,以有效泛化反馈信息。
效果
- 超过 GPT-3.5 and DSPY
设计思路
- 利用梯度信息:采用基于梯度的优化技术,使用LLM生成的输出梯度来指导Prompt的调整。
- 用户自定义任务描述和评价标准:允许用户定义任务描述和评价标准,使其能够适用于各种不同的任务。
- 引入梯度汇总模块:提出一个新的梯度汇总模块,将单个输出梯度汇总为一个通用的梯度总结,以更好地泛化到整个数据集。
- 迭代优化Prompt:通过迭代使用梯度信息来编辑和优化Prompt,直到找到最佳的Prompt。
核心模块
GRAD-SUM 包含5个不同的模块:生成、评估、梯度生成、梯度摘要和Prompt编辑器。
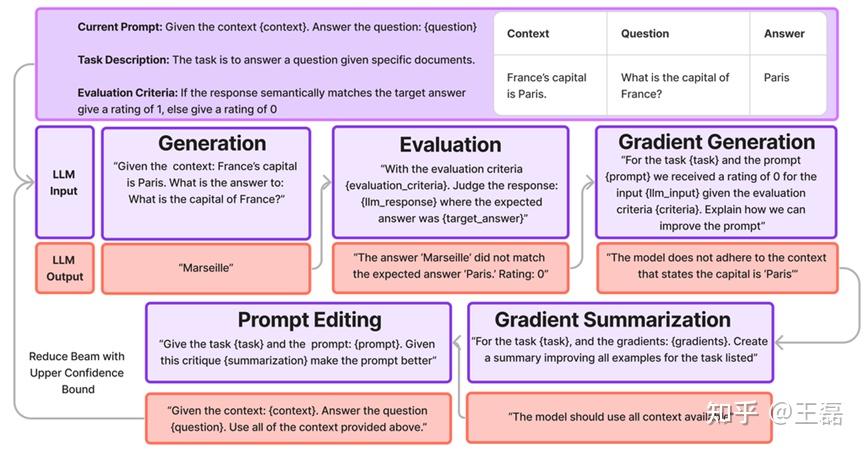
GRAD-SUM 训练迭代如上图所示,模块是顺序的,从生成开始。然后,Prompt编辑模型中选择的Prompt将反馈到生成模块,训练循环重新开始。
- 生成(Generation):生成模块通过一个数据集、一个Prompt和一个LLM来生成输出。
- 评估(Evaluation):评估模块会接收来自生成函数的生成内容、用户定义的评估标准,以及可选的预期答案。该模块会反过来返回一个评分,根据评估标准来判断响应的性能以及对评分的解释。
- 梯度生成(Gradient Generation):梯度模块接收当前Prompt、评估标准、手头任务的描述,并利用所有可用信息,任务描述、评估标准以及对评分较低的解释等,来识别需要改进的地方。
- 梯度摘要(Gradient Summarization):将所有的梯度反馈汇总成一个可以应用于整个数据集的通用段落。此步骤可以被认为类似于在小批量上平均梯度以稳定训练。
- Prompt编辑器(Prompt Editor):Prompt编辑器模块接收当前Prompt、总结的梯度和任务描述,并生成一个新的Prompt。
2024.7.12 北大 PAS
问题
- 哪怕最熟练的“Prompt工程师”也很难保证调试出最优的Prompt,而这就限制了大模型实际落地的效果。
自动提示工程(Automatic Prompt Engineering,APE)目标
- 通过自动化方式增强提示(prompts),改善LLMs在特定任务的性能,并减少人工干预和时间成本。
然而,现有包括链式思考(Chain of Thought)和思维树(Tree of Thought)等策略在内,通过引导模型逐步推理问题的技术,尽管在一定程度上提高了逻辑一致性和准确性,但它们缺乏可扩展性。
此外,近期APE研究,包括从优化器视角自动寻找提示的方法,以及将进化算法引入到特定领域的离散提示优化中,虽然表现出了一定潜力,但在实际应用中面临显著挑战,如:
- 评估每个提示的适应度,需要大量资源,而探索多组提示的适应度更是会带来巨大负担。
即插即用系统(Plug-and-Play Systems)因其在不同机器学习工作流程中的模块化和易集成性而受到重视,允许快速灵活地增强功能,轻松添加或替换新的处理模块,而无需重新设计整个算法。
- 由于无缝增强现有AI系统的功能,对即插即用系统的需求也在不断增长。
北大的团队提出PAS方法,“即插即用”的Prompt自动增强系统,即使对比当前的Sota方案, 效果提升超过6个pp充分挖掘大模型潜力的同时,也真正实现了“全自动化”效果,非常炫酷。
数据收集
- 从LMSYS-1M数据集和WildChat数据集中选择高质量的Prompt,数据选择过程包括三个主要步骤:
- 首先,使用SimCSE模型通过嵌入对Prompt进行去重,然后应用HNSW聚类算法对这些嵌入进行分组,并从每个聚类中提取少量数据以减少冗余。
- 随后,进行质量筛选,使用BaiChuan 13b模型对数据进行评分,从而筛选出低质量的样本,提高整体数据质量。
- 最后,利用BaiChuan内部标记的6万个分类数据对BaiChuan 13b模型进行微调,然后使用该分类模型将Prompt归类为常用的类别,如问答(Q&A)和编码。这一系列步骤确保了数据的多样性、质量和准确分类。
前述的数据生成Pipeline创建的高质量(Prompt,补充Prompt)数据对,被用于微调选定的LLMs,赋予自动生成补充Prompt的能力,从而得到PAS模型。
- 当得到补充Prompt后,将其与原始Prompt进行拼接,输入到下一个LLMs当中,生成最终的答案。
作为一个自动的提示补充工具,PAS可以集成到任何可用的LLMs中,通过公共API或开放参数进行集成。这种灵活性使得PAS能够在不同的平台和系统中广泛应用,增强现有LLMs的能力,而无需进行广泛的重新训练或修改。
基于 OPRO 的模式构建一个自动迭代 prompt 的项目,其中用到的 meta-prompt 方案主要就是基于上一个 prompt + badcase,让模型生成新的 prompt 来定向修正,通过记录每次优化后评测的 score 来记录过程
2024.7.23 ell
ell 是一个轻量级提示(prompt)工程库
核心设计理念
- 将Prompt视为函数。
ell 提供了自动化的版本控制和序列化功能,支持多模态数据处理,并配备了丰富的本地开源可视化工具,帮助用户优化提示工程过程。
核心方案
- Prompt不仅仅是字符串,而是程序(LMP),即Prompt是将字符串发送至LLM的整个过程的代码程序。LMP是完全封装的函数,用于生成要发送到各种多模态语言模型的字符串Prompt或消息列表。
- ell通过静态和动态分析自动对提示进行版本控制和序列化。
- 提供监控、版本控制和可视化的本地开源工具ell studio,帮助用户优化提示工程过程。
2024.10.3 微软 PromptWizard
PromptWizard 是离散Prompt优化框架,采用自适应进化机制,允许LLM自主生成、批评和完善Prompt及示例,并通过迭代反馈和合成不断改进。
PromptWizard 利用自我进化、自我适应的机制,通过反馈驱动的批评和综合过程,在探索和开发之间实现了有效平衡,迭代地优化提示指令和上下文示例,生成可读、特定任务的提示。
这种引导式方法系统地提高了提示质量,此外,成本分析显示API调用、token使用和总成本大幅减少。
微软开源提示词优化框架:PromptWizard,采用自我进化机制,让模型自己生成、评价和改进提示词及生成示例,通过不断反馈来提高输出质量。
- 自主优化提示词、生成和选择合适的示例、并进行推理和验证、最终输出高质量的提示词,通过自动化流程减少了手动提示词工程的工作量。
- 特点:
- 加入了任务意图和专家角色的概念,使用思维链方式优化推理,结合正面、负面和合成示例来改进其性能。
- 能适应不同领域的任务需求、性能稳定,支持多种规模的多种LLM。
- PROMPTWIZARD: TASK-AWARE PROMPT OPTIMIZATION FRAMEWORK
- github:PromptWizard
动机
解决的问题
- 手动提示工程的局限性
- 解决方案: PromptWizard 通过自动化的提示优化来解决手动提示工程的耗时和领域特定性问题。
- 利用自我演化机制,使得LLM生成、批评和提炼自己的提示和示例,通过迭代反馈和合成不断改进。
- 现有优化策略的不足
- 解决方案: 现有连续和离散提示优化方法要么需要额外的神经网络训练,要么在探索提示空间时缺乏反馈机制。
- PromptWizard通过引入反馈驱动的批评和合成过程,克服了这些方法的随机性和效率低下问题。
- 特定任务提示的生成
- 解决方案:PromptWizard通过迭代细化提示指令和上下文示例,生成符合任务需求的特定提示,提高了模型性能和解释性。
PromptWizard 简介
【2024-10-3】PromptWizard 是微软发布的一个全新、全自动的离散提示优化框架,通过自我演化、自我适应的机制实现。
通过反馈驱动的批评与合成过程,在探索与利用之间取得了有效平衡,迭代地改进提示指令和上下文示例,以生成针对特定任务的人类可读提示。
该框架在45个任务中表现出色,即使在训练数据有限、小型LLMs和不同LLM架构的情况下也能实现优越的性能。
PromptWizard 效果超过: img
- APE
- InstructZero
- PromptBreeder
- EvoPrompt
- INSTINCT

框架
框架图
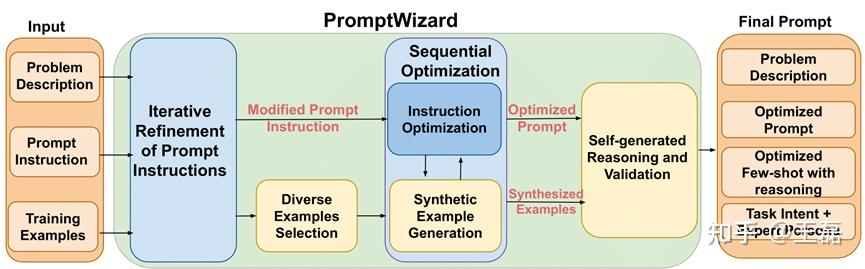
框架
- 问题描述与初始提示指令
- PromptWizard 首先接收问题描述和初始提示指令。例如,在数学问题求解任务中,初始提示可能是:“让我们逐步思考以找到这个数学问题的解决方案。”
- 生成指令变体
- 基于问题描述和初始提示指令,PromptWizard 使用预定义的认知启发式或思考风格生成提示变体。这些启发式指导LLM创建问题的不同视角,确保提示指令的多样性。
- 性能评估
- 接下来,PromptWizard 使用评分机制评估生成的变异提示的性能。评分基于每个提示在一小批训练示例上的表现。评分机制可以是传统的指标,如F1分数,也可以是LLM作为评估者。
- 反馈与提炼
- 选择表现最佳的变异提示后,PromptWizard通过其批评组件引入独特的反馈机制。批评审查提示成功和失败的地方,提供针对性的反馈,以便有重点地改进提示。
- 合成和优化
- 最后,PromptWizard 合成组件使用批评的反馈来提炼最佳prompt。根据反馈重新表述和增强指令,产生更具体于任务的优化提示。
- 识别多样化示例
- PromptWizard 接下来关注识别一组多样化的候选示例,以增强提示的有效性。通过从数据集中提取候选示例,并使用评分机制评估当前提示的有效性,将它们分类为正面和负面示例。
- 顺序优化
- 与大多数现有提示优化方法不同,PromptWizard 采用顺序优化方法,同时优化提示指令和少量示例。通过批评和合成过程,PromptWizard动态地增强提示质量和任务性能。
- 自生成推理和验证
- 在优化提示和少量示例后,PromptWizard 通过整合链式思考(CoT)推理进一步提升模型性能。PromptWizard为每个选定的少量示例自动生成详细的推理链,并使用LLM检查示例的连贯性和相关性。
- 任务意图与专家角色整合
- 为了提高任务性能,PromptWizard将任务意图和专家角色整合到提示中。这确保了模型在特定领域的任务中保持相关性,并引导模型应用相关的方法。
三大技术方案
- 基于反馈的优化:LLM自主生成、批评和优化Prompt及示例,通过迭代反馈和合成不断改进。
- 批评并合成多样化示例:生成具有鲁棒性、多样性且任务相关的合成示例,同时针对Prompt和示例进行同步优化。
- 自生成的思维链(CoT):结合正向、负向和合成示例,通过思维链提升模型解决问题的能力。
三种方式提升prompt质量
- (1) 没有训练数据,也不希望在prompt中使用上下文示例
- (2) 没有训练数据,但希望在prompt中使用上下文示例,这里分两步走
- 生成合成数据
- 使用合成数据优化prompt
- (3) 有训练数据,希望在 prompt 中使用上下文示例,让模型自己生成、评价和改进提示词及生成示例,通过不断反馈来提高输出质量。
- 基于反馈的优化
使用系统化的反馈驱动流程,通过批评组件提供反馈,从而指导并优化Prompt。在多次迭代中逐步完善Prompt。
以下步骤系统地实现这一过程:
- 变异(Mutate):基于初始问题描述和思维风格生成Prompt。
- 评分(Scoring):评估生成Prompt的性能,以确定最佳Prompt。
- 批评(Critique):通过分析模型表现不佳的案例,审查Prompt的成功与失败之处。
- 合成(Synthesize):利用批评反馈优化最佳Prompt。
- 批评并合成多样化示例
- PromptWizard 可同时改进Prompt指令和少样本(Few-Shot)学习示例
- 它利用自我反思合成多样化且任务相关的示例。
- 通过迭代反馈循环,持续优化Prompt和少样本示例。
- 少样本示例优化:
- 批评:分析之前选择的示例,并利用反馈确定如何改进示例。
- 合成:生成新的合成示例,使其更加多样化、鲁棒性且与任务相关。
- Prompt指令优化:
- 批评:识别Prompt中的缺点和待改进的地方。
- 合成:利用批评的反馈进一步优化Prompt指令。
- 思维链推理
纳入思维链(CoT)提升模型解决问题的能力。 思维链推理针对选定的少样本示例,为每个示例生成详细的推理链,从而促进问题解决。 使用LLM 检查示例的一致性和相关性。
使用
- 场景一:无示例提示词优化:适合没有训练数据的场景,直接优化指令文本:
- 修改配置文件,设置use_examples: false
- 减少mutate_refine_iterations至2以加快速度
- 运行基础优化流程
- 该模式下,系统会通过prompt_library.yaml中的模板生成多样化指令变体。
- 场景二:自动生成训练示例:当训练数据有限时,启用示例生成功能:
- generate_synthetic_examples: true
- num_train_examples: 20 # 生成20个合成示例
- 系统会分析现有样本特征,生成多样化的训练示例,特别适合小样本学习场景。
- 场景三:完整训练数据优化:对于有充足训练数据的任务,如SVAMP数据集,使用完整优化流程:
- run_without_train_examples: false
- seen_set_size: 50 # 使用50个训练样本
- 同时优化指令和示例,通过正反例对比持续改进提示词质量。
参数说明
| 配置参数名 | 中文释义 |
|---|---|
| mutate_refine_iterations | 任务描述变异+指令精调的迭代轮数 |
| mutation_rounds | 生成多风格提示词时,执行变异操作的总轮数 |
| refine_task_eg_iterations | 对任务描述、上下文示例一同精调的迭代次数 |
| style_variation | 提示词变异阶段生成的思考风格变体数量 |
| questions_batch_size | 训练阶段单次批量送入大模型的问题条数 |
| min_correct_count | 判定提示词效果达标所需的最小正确答题批次数量 |
| max_eval_batches | 用于评估提示词性能的最大mini-batch批次上限 |
| top_n | 打分阶段筛选出的最优提示词数量,将送入下一迭代阶段 |
| seen_set_size | 训练过程使用的训练集样本数量 |
| few_shot_count | 最终输出提示词中需要包含的上下文示例(Few-shot)条数 |
promptopt_config.yaml 中提示词优化流程用到的各类超参数进行定义说明:
mutate_refine_iterations:先对任务描述做变异生成、再对指令进行精调的迭代轮数mutation_rounds:生成多种风格提示词时,执行变异操作的总轮次refine_task_eg_iterations:同步精调任务描述与上下文示例的迭代次数style_variation:提示词变异环节产出的不同思考风格变体总数questions_batch_size:训练步骤中,单次批量向大模型输入的问题数量min_correct_count:一条提示词被认定为效果良好,所需答对的最少问题批次数量max_eval_batches:评估当前提示词性能时,最多使用的小批量样本数top_n:打分阶段筛选出排名靠前的最优提示词数量,进入下一轮迭代seen_set_size:训练阶段从训练集中抽取使用的样本数量few_shot_count:最终生成提示词里需要搭载的上下文示例条数
表格总结
| 优化场景 | 适用业务条件 | 核心配置参数 | 机制说明 |
|---|---|---|---|
| 场景一:无示例提示词优化 | 无任何训练数据 | use_examples: falsemutate_refine_iterations: 2 |
仅优化指令文本;基于prompt_library.yaml模板生成多版指令变体,迭代速度更快 |
| 场景二:自动生成训练示例 | 现有训练数据量少、小样本场景 | generate_synthetic_examples: truenum_train_examples: 20 |
分析已有样本特征,自动生成20条多样化合成训练示例补充数据集 |
| 场景三:完整训练数据优化 | 拥有充足标注数据(如SVAMP等标准数据集) | run_without_train_examples: falseseen_set_size: 50 |
同时优化提示指令+配套训练示例,利用50条训练样本的正反例对比持续调优Prompt效果 |
2024.10.11 StraGo 闭源
中科院、微软提出 StraGo(Strategic Guided Optimization),新颖的基于反思策略引导优化方法,通过采用了一种“如何操作”的策略,结合上下文学习来制定具体的、可操作的策略,为Prompt优化提供详细的分步指导。
效果:
- 优于 人工、CoT、APO、ORPO、EvoPrompt
设计思路
STRAGO方法采用了反思学习方法的分析方式,其通过对成功和失败示例的分析来识别实现优化目标的关键因素。 针对不同的错误类型开发相应的策略,并采用不同的评估标准来选择最佳策略。
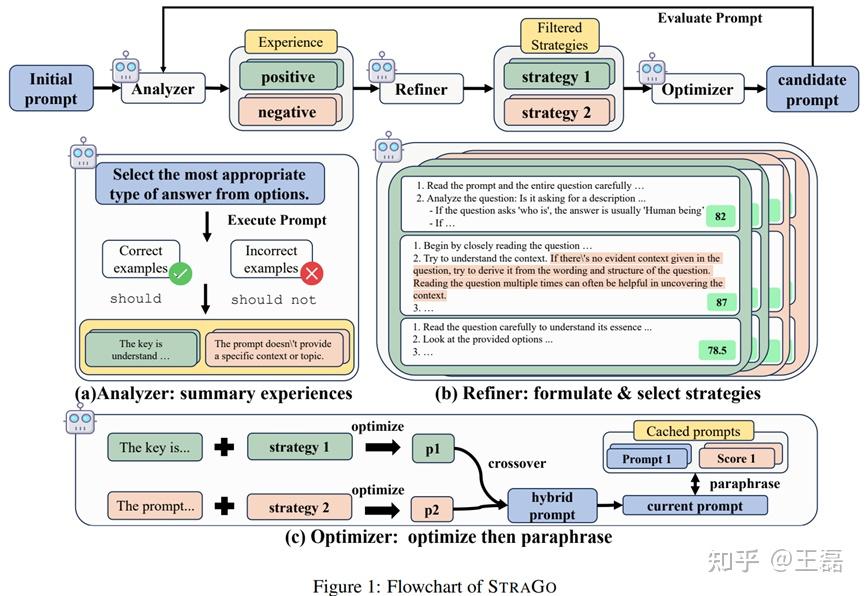
核心模块
STRAGO 包括三个主要模块:Analyzer、Refiner和Optimizer。
- Analyzer模块:负责对成功和失败示例进行深入分析,并采用同等级的优先级,然后从中提取出正面经验和负面经验。
- Refiner模块:根据经验生成可执行策略,并将其与分析结果结合起来优化Prompt。
- 策略制定:为不同的错误类型开发相应的策略,并将它们用作上下文学习示例,以帮助LLM根据正反两方面的经验生成改进Prompt的策略。
- 策略选择:对于每个示例及其相应的经验生成的策略,并使用LLM根据标准对其进行评估、打分。
- Optimizer模块:将正负经验分别处理并交叉操作来进一步提高Prompt的质量。
- 优化:对于每个选定的成功或失败示例,分析器会生成M条正面或者负面经验。然后为每条经验生成一个策略,创建一个修改后的Prompt,并将其分为积极经验组和消极经验组。
- 交叉:从每组Prompt中选择两个Prompt,然后执行交叉操作生成混合Prompt。
- 解析:使用缓存中的Prompt对每个混合Prompt进行解析,并将解析后的Prompt和混合Prompt作为候选Prompt进行评估。
2025.3.2 Prompt Optimizer
prompt-optimizer 开源项目:
- ✅ 智能优化提示词,快速生成高效指令
- ✅ 让模型输出更精准、更实用
- ✅ 开发者/研究人员/普通用户通用效率工具
解决什么问题
| 核心痛点 | 解决方案 |
|---|---|
| 1. 模糊需求难以翻译 | 通过句法分析和关键词抽取,将模糊输入转化为清晰指令 |
| 2. 输出质量不稳定 | 内置知识增强引擎,自动补充领域背景,确保输出有理有据 |
| 3. 迭代成本高昂 | 提供实时诊断与优化,配备清晰度评分机制(满分 10 分) |
【2025-3-2】Prompt Optimizer:一个强大的提示词优化工具
Prompt Optimizer:一个强大的提示词优化工具,一键提升AI回复的准确度。
- 官方体验 prompt,支持文本、图像提示词自动化
- 代码 prompt-optimizer,插件、软件下载地址 prompt-optimizer
- Chrome商店
从来源到复用,一条闭环
- 少解释,多验证。提示词进入优化器后,用真实结果决定下一步。
| 序号 | 模块 | 核心能力说明 |
|---|---|---|
| 01 | 来源 | 任意提示词;支持手写、模板、本地导入、提示词库录入 |
| 02 | 核心优化器 | 支持提示词改写、变量配置、上下文优化、图像类提示词调优 |
| 03 | 判断 | 真实测试机制;通过输出结果、指标评估、多版本对比验证提示词有效性 |
| 04 | 沉淀 | 智能收藏功能;留存多版本、案例示例、媒体素材、来源溯源信息 |
覆盖多类提示词,四类结构都能进入同一套测试评估流程
| 序号 | 结构类型标签 | 结构名称 | 适用内容 | 关键能力 |
|---|---|---|---|---|
| 01 | 单条提示词 | system / user 单提示词 | 适合优化角色、规则与输出格式 | system配置、user指令、聚焦分析 |
| 02 | 变量模板 | 变量模板 | 把主题、语气和角色收进模板后再验证 | 占位变量、真实输入、模板复用 |
| 03 | 上下文链路 | 多消息上下文 | 当system、user与上下文共同影响结果时仍可分析 | system+user混合、上下文加载、多消息会话解析 |
| 04 | 图像生成 | 文生图 / 图生图 / 多图 | 用真实图像生成结果比较不同提示词的效果,支持多图输入和风格迁移 | T2I文生图、I2I图生图、多图生图、风格迁移 |
亮点:
- 🎯 智能优化:一键优化提示词,支持多轮迭代改进,提升AI回复准确度
- 🔍 实时测试:直接测试优化后的提示词效果,对比优化前后差异
- 🔄 多模型集成:支持OpenAI、Gemini、DeepSeek等主流AI模型,满足不同需求
- 🔒 安全架构:纯客户端处理,数据直接与AI服务商交互,不经过中间服务器
- 💾 隐私保护:本地加密存储历史记录和API密钥,确保数据安全
- 📱 多端支持:同时提供Web应用和Chrome插件两种使用方式
- 🎨 用户体验:简洁直观的界面设计,响应式布局和流畅交互动效
- 🌐 跨域支持:Vercel部署时支持使用Edge Runtime代理解决跨域问题(可能会触发部分厂商风控)
Prompt Optimizer 是专治AI提示词编写困难的「赛博老中医」,支持多种大模型:
- • Web应用 + Chrome插件 双端出击(摸鱼/搬砖两相宜)
- • 智能优化引擎:自动诊断提示词问题,支持多轮迭代改进
- • 隐私安全架构:数据直连AI服务商,不当中间商赚差价
- • 一键部署:支持Docker一键部署,自带跨域解决方案
- • 一键优化:输入”帮我写周报”,自动升级为”你是一个资深项目经理,请用Markdown格式生成本周工作汇报…”
- • 数据链路:浏览器 ⇄ AI服务商(中间不经过第三方服务器)
效果对比
| 场景 | 原始提示词 | 优化后提示词 | 效果提升 |
|---|---|---|---|
| 技术文档 | “解释一下哈希算法*” | “用类比解释SHA-256* 的工作原理,附Python 示例” | 内容覆盖率 +220% |
| 客服回复 | “回复用户退货请求” | “生成包含退货政策、物流方案和补偿策略的合规回复” | 二次咨询率 -45% |
| 科研支持 | “写文献综述方法论” | “构建含PRISMA流程图*和质量评价表的综述框架” | 相关性 +73% |
案例 1:开发者小张的救命稻草
- 需求:生成哈希算法说明文档
- ❌ 原始提示词 → 输出三段啰嗦定义,无实用示例
- ✅ 优化后提示词 → 提供图书编号类比 + 可运行 Python 代码
- 效果:文档质量提升 2 倍,耗时从 30 分钟 → 5 分钟
案例 2:电商客服的效率革命
- 问题:退货回复客户满意度仅 60%
- ✅ 优化后提示词 → 自动包含政策/物流方案/优惠券建议
- 效果:二次咨询率 ↓45%,日均处理效率 ↑30%
总结
- 节省时间: 43 分钟 → 6.8 分钟
- 提升输出质量: 准确率 +61.3%
- 部署灵活性: 本地/Docker 双方案支持
【2025-8-21】SPO
【2025-8-21】DeepWisdom 和 港科大推出 SPO
人工设计提示词需要专业知识与反复试错。现有的提示词优化方法虽试图实现流程自动化,却高度依赖真值标注、人工标注等外部参考数据,这极大限制了其在缺少标注数据、标注成本高昂的真实业务场景中的落地。
自监督提示词优化框架(SPO, Self-Supervised Prompt Optimization)成本低廉,无需任何外部参考数据,即可为封闭判别类任务、开放生成类任务挖掘高性能提示词。
核心现象:
- 提示词的优劣会直接体现在大模型的输出结果中;
- 同时大模型自身能够精准评判输出是否符合任务要求。
仅通过对比模型输出结果,推导优化所需的评估信号与更新梯度。
具体流程:
- SPO 先借助大模型评审器,对不同提示词的输出做两两对比,筛选效果更优的提示词;
- 再由大模型优化器迭代改写提示词,让模型输出持续对齐任务目标。
大量实验证明,SPO 性能超越当前业界最优的提示词优化算法,CoT、APE、OPRO、PromptAgent、PromptBreeder、TextGrad
同时具备两大优势:
- 训练成本大幅降低(仅为现有方法的 1.1%~5.6%)
- 所需样本极少(仅需 3 条样本即可完成优化)
【2026-1-23】Opik
【2026-1-23】OPIK:一个开源的自动提示词优化框架
Comet 推出 Opik, 构建、测试并优化生成式 AI 应用,使其从原型到生产环境运行得更好。开发者能够评估、测试、监控和优化模型及智能体系统
- github opik
从 RAG 聊天机器人到代码助手再到复杂的智能体系统,Opik 提供全面的跟踪、评估,以及自动化的提示与工具优化,消除 AI 开发中的猜测
功能包括:
- 全面可观测性:深度跟踪 LLM 调用、对话日志及智能体活动。
- 高级评估:强大的提示评估、LLM-as-a-judge 及实验管理。
- 生产就绪:可扩展的监控仪表板和在线评估规则。
- Opik Agent Optimizer:用于提升提示和智能体的专用 SDK 与优化器。
- Opik Guardrails:帮助您实施安全且负责任的 AI 实践。
OPIK 的 MetaPromptOptimizer 让自动提示词变得很简单:
- 拿一个勉强能用的提示词,半小时内就能把它调成接近 SOTA 水平的 one-shot Agent,省下原本要花几周手动迭代的时间。
OPIK
- 完全开源,Apache 2.0 协议,商用也不花钱;
- 可以纯本地跑,Ollama、LM Studio、任何 OpenAI 兼容的接口都行;
- 自带追踪仪表板,功能类似 LangSmith 但是确是免费;
- API 设计简单,一个类就能搞定优化流程;评估指标随便你定义,只要能写成代码就行
安装
pip install opik[all] datasets sentence-transformers
ollama 安装
ollama pull llama3.2:8b-instruct-qat
ollama serve
图像提示词
- 【2023-7-18】Image Prompting
- 【2023-12-12】阿里巴巴StableDiffusion提示词指南
逆向工程
根据图片一键反推提示词工具,完全免费
Image Prompt
【2025-3-9】工具 Image Prompt
- 根据图片一键反推提示词工具,完全免费
- 支持多种 文生图模型, Flux, Midjourney, Stable Diffusion
- 文本转提示词
文生图提示词
知名AI画图模型工具Midjourney,Stable Diffusion,使用时,同样需要像文本对话提示语一样,不断试探、调试。
Prompt要点
Prompt基本格式
- 提问引导:生成什么样的图
- 示例:要描述的词汇特点,结合反向提示词更好
- 单词顺序:顺序跟词语本身一样重要
要想得到更好的效果,还需要结合使用修饰词、咒语、参数
修饰词(Modifiers)
- Photography/摄影
- Art Mediums/艺术媒介
- Artists/艺术家
- Illustration/插图
- Emotions/情感
- Aesthetics/美学
Magic words(咒语)
- Highly detailed/高细节
- Professional/专业
- Vivid Colors/鲜艳的颜色
- Bokeh/背景虚化
- Sketch vs Painting/素描 vs 绘画
模型参数,以sd为例
Stable Diffusion参数
- Resolution/分辨率
- CFC/提词相关性
- Step count/步数
- Seed/种子
- Sampler/采样
- 反向提示词(Prompt)
最后,还可以使用高级技能,充分利用辅助工具
img2img(图生图),in/outpainting(扩展/重绘)
- 将草图转化为专业艺术作品
- 风格转换
- lmg2lmg 变体
- Img2lmg+多个AI问题
- lmg2lmg 低强度变体
- 重绘
- 扩展/裁剪
Prompt关键词
一、 Midjourney关键词结构
提示词的结构公式
- 公式建议:画面内容+风格描述+修图后缀+属性描述
- 画面内容:主体描述,主要表达我们想要画什么样的画面,比如人还是环境,在干什么,环境怎么样等等
- 风格描述:主要表达想要什么样的风格,是赛博朋克、还是国风、漫画、手绘等等
- 修图后缀:描述灯光、画面视角等等
- 属性描述:图像基础词汇,描述想要的画面尺寸、画面质量等

使用Midjourney生成图像时,输入正确的关键词排序,可以更好的产出想要的图片。
关键词重要,结构同样很重要!

提示词:
Self-luminous surrealism, Chinese beauty model, blue pink transparent liquid,8K, real face details, ultra-high-definition surreal photography photos, ultra-high-definition physical details,contemporary fairy tales Style, star troupe, salon system –s 1000 –niji 5 –ar 3:
二、 风格篇关键词合集
1、 宫崎骏风格(Miyazaki Hayao style)

提示词:
Chinese villages, villas, entrances are small bridges full of grass, fish in the water, summer, sunny valleys, good light, comics, moving, Miyazaki Hayao style
2、 迪士尼风(Disney-style)

提示词:
Disney style, 3d, camping, clear nights, stars blinking in the sky, two little boys singing in front of the tent, singing and singing. a lake. photorealistic, hyper detailed, cinematic, 35mm shot, detailed, moody
3、 水墨风(Ink Wash Painting Style)

提示词:
Ink style, green water, good weather, bright flowers, birds flying, beautiful landscapes, soft lights. Highly detailed, ultra realistic
4、 电影风格(Hollywood-style)

提示词:
Hollywood-style, two girls wearing beautiful dresses, having fun in the castle, Lolita style, high quality, moving, high detail, soft and light.
5、 水彩风格(watercolor style)

提示词:
Watercolor style, A couple in love, Riding happily, Romantic sunsets, Laughter with the wind, Of high quality
6、 油画风格(Oil-painting style)

提示词:
Oil-painting style,A girl with spirits reading books, deep exploration of the soul world, soft lights.
StableDiffusion 提示词指南
openart.ai, 需要 国外vpn
One-time 50 trial credits for all the features. Join Discord for additional one-time 100 trial credits
OpenArt上有文生图优质案例,但面向国外,只有50个免费额度,如果是discord,有100次额度。
prompt 自动生成
- 【2024-1-11】文生图Prompt如何自动化?贾扬清PromptLLM实测
提示词产品
【2024-1-23】一键生成Midjourney提示词
AI灵创提词器
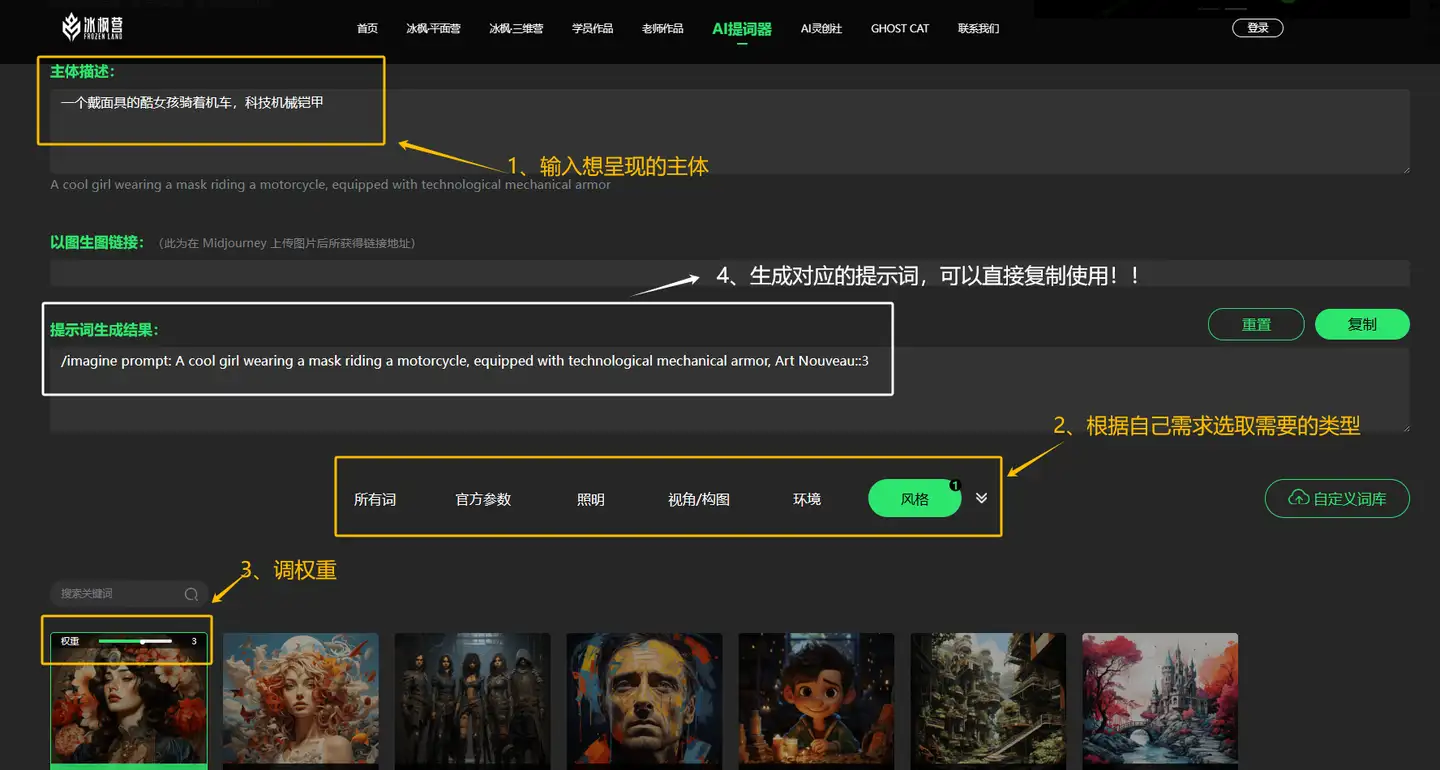
【2023-7-13】AI灵创提词器: 最方便、简单的ai绘画提示词工具,直接点击网站使用,免费!辅助生成 Mid-Journey提示词
- 包括输入中文需求自动转化成英文关键词、丰富的风格和参数等可以任意选取和权重调整,关键词描述框架非常完整,操作很简单很适合新手小白使用提取提示词
MidJourney Prompt生成器
- 直接输入中文的关键词,可以翻译成英文的Midjourney关键词,还有丰富的风格和参数可以选择调整。

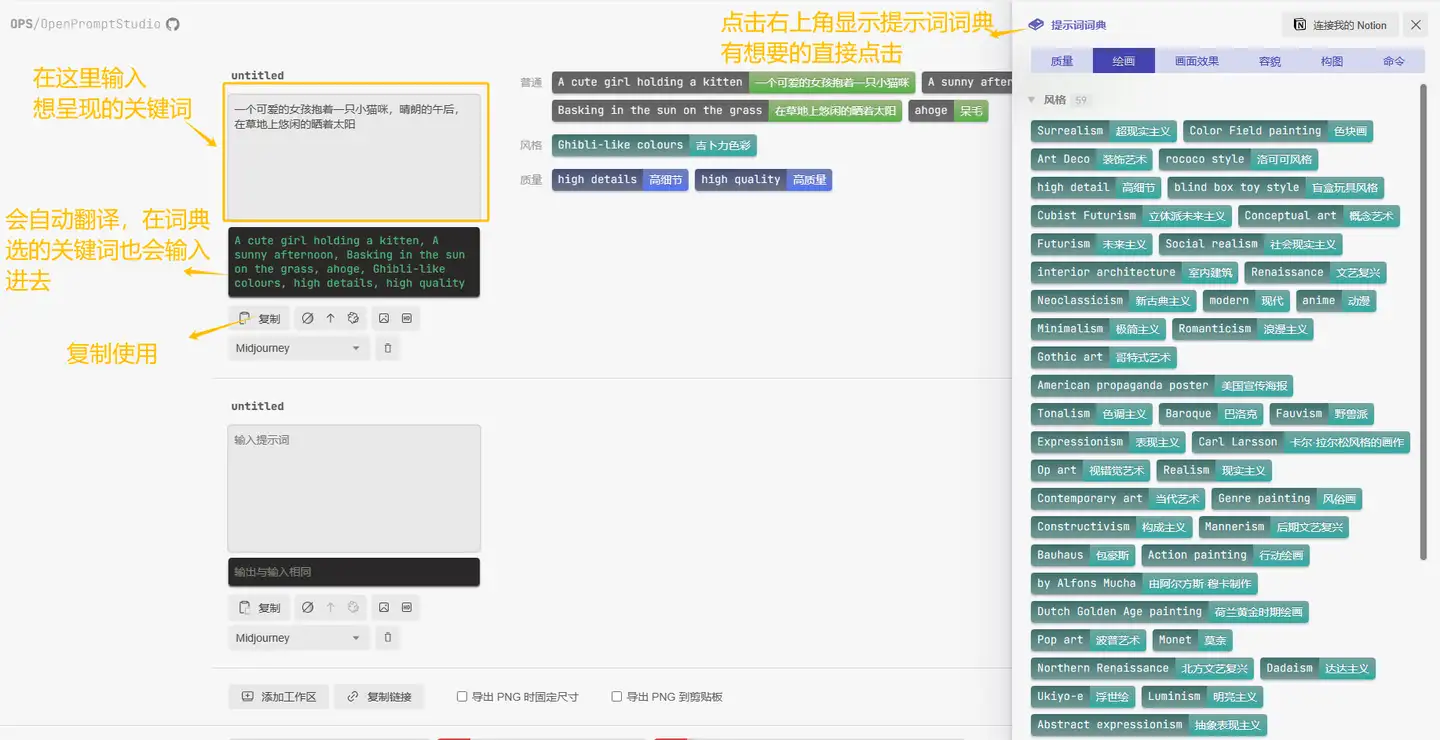
OPS提示词工具
AIGC 提示词可视化编辑器 OPS Open Prompt Studio
- 输入中文关键词会自动翻译,提示词词典有丰富的关键词提供,可以把关键词可视化分类
- 支持 mj 和 sd
2023.7.24 VPGTrans
【2023-7-24】Transfer Visual Prompt Generator across LLMs
- Sea-NExT Joint Lab和新加坡国立首次调研 可视提示生成(visual prompt generator (VPG)),将一个LLM的提示迁移到另一个LLM
- 提出简单高效的迁移框架 VPGTrans, 包含两个阶段

2023.12.27 谷歌: Prompt Expansion
两大挑战:
- 提示工程复杂:用户需精心设计提示以生成高质量图像。这涉及使用专业术语(如“35mm”、“背光”等)和独特描述(如“大胆创新”)。由于有效提示的不稳定性,用户需不断试验,这限制了模型的易用性和创造力。
- 图像多样性不足:即便用户提示未具体指定细节,生成的图像往往缺乏变化。例如,“南瓜灯设计”的提示可能导致风格和视角相似的图像。这不仅可能加剧社会偏见,还限制了探索更多元图像的可能。
谷歌发布Prompt Expansion框架,让文生图更轻松
谷歌推出了一种名为提示扩展(Prompt Expansion)的创新框架,旨在帮助用户更轻松地创造出既高质量又多样化的图像
2024.1.10 PromptLLM
【2024-1-10】贾扬清创业新动作:推出AIGC提示工具,几个字玩转SDXL,细节拉满
贾扬清团队LeptonAI最新推出的AIGC提示工具——PromptLLM。
- 贾扬清LeptonAI同HippoML合作。LeptonAI提供API平台支持。HippoML提供PrivateCanvas系统来保障运行。
只需短短几个字提示,就能收获一张细节感满满的绘图(SDXL模型)。API已开放,也可免费体验Demo
| 示例 | 生成的prompt | 效果 |
|---|---|---|
| elon musk in the sky | Elon musk in the sky, dressed in a spacesuit, floating amidst clouds, the Moon and the Sun in the background, Photorealistic, UHD art style with intricate details and vivid colors. | |
【2024-1-11】文生图Prompt如何自动化?贾扬清PromptLLM实测

总结
- 英文效果大幅优于中文,英文版可用,目前SDXL对中文支持不佳;
- 除了SD模型,其它(如Mid-Journey)效果如何,未知
- 目前处于测试阶段,免费使用,收集用户反馈
改进方法:
- 提前翻译成英文,这个功能应该由平台自动完成(给PromptLLM的建议)
Omost
Controlnet 作者张吕敏新开源项目 Omost
- 一种将LLM的文本生成能力转化为图像生成能力的方法
- Github
基本思路
- 训练LLM模型,根据输入图像描述生成特定格式的代码,这些代码定义了一个虚拟的”画布(Canvas)”对象及其属性和方法。
- 然后,这些代码可以输入到对应的图像生成模型(如扩散模型)中,由图像生成模型解析这些代码并生成对应的图像。
目前,Omost开源了基于Llama3和Phi3训练的三个LLM模型。
- 训练数据包括Open-Images等数据集的人工标注、自动标注的数据、基于图像生成偏好的强化学习数据,以及少量GPT-4等多模态模型生成的fine-tuning数据。
该项目目前可在hugging face上直接使用,或下载到本地部署。

 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
