- PEFT
- 结束
PEFT
参数高效精细调整(PEFT):修改选定参数,以实现更高效的适应。进一步调整预训练模型,只更新其总参数的一小部分
- PEFT 方法可训练的部分不同。一些技术优先训练原始模型参数的选定部分。其他方法集成并训练较小的附加组件,如适配器层,而不修改原始结构
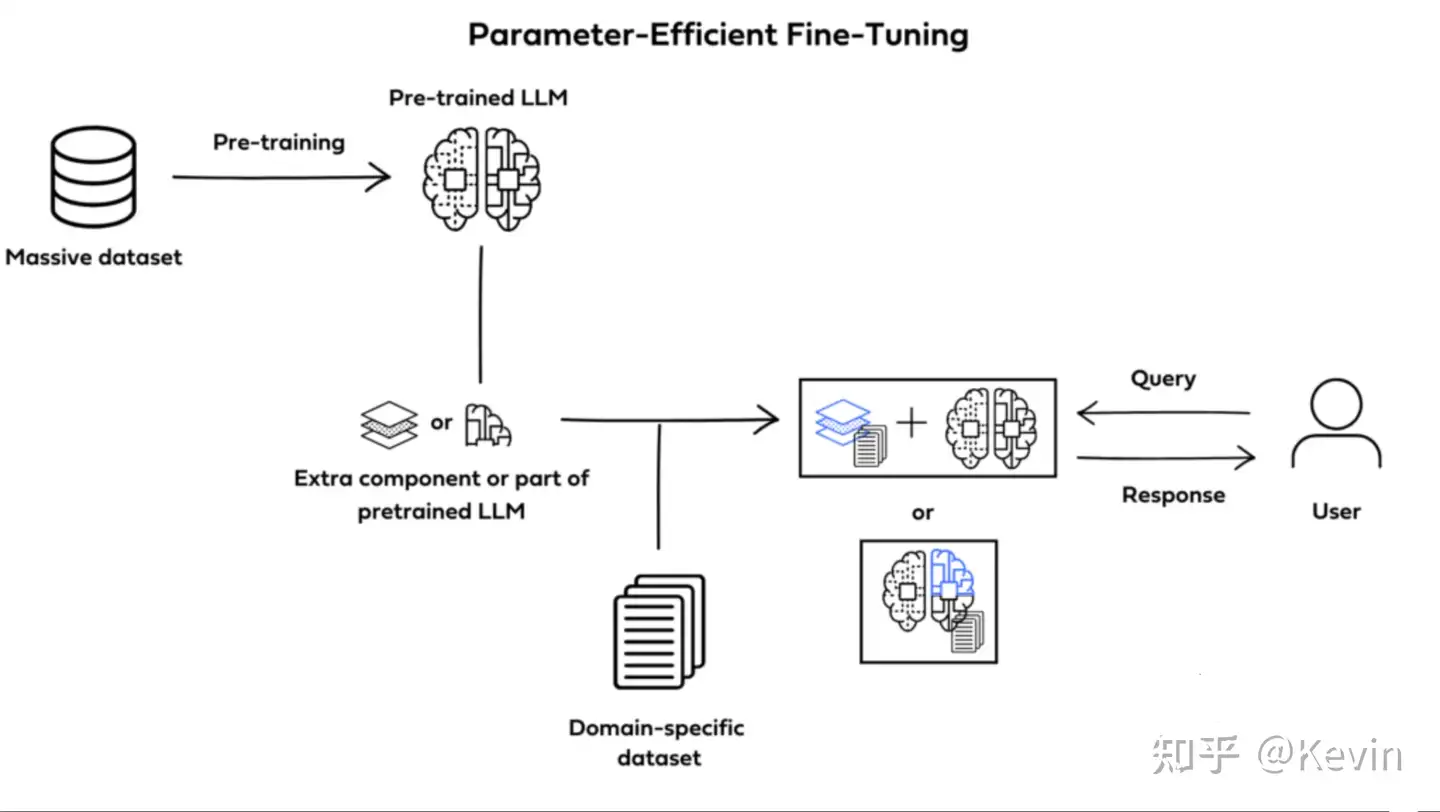
LoRA是最常用的 PEFT 方法,使用重参数化,这种技术通过执行低秩近似来缩小可训练参数的集合。
- LoRA 优点:
- 任务切换效率 - 创建模型的不同版本以适应特定任务变得更容易。你可以简单地存储预训练权重的单个副本,并构建许多小 LoRA 模块。当你从任务切换到任务时,你只替换矩阵 A 和 B,并保留 LLM。这显著减少了存储需求。
- 需要更少的 GPU - LoRA 将 GPU 内存需求减少了最多 3 倍,因为我们不计算/重新训练大多数参数。
- 高精度 - 在各种评估基准上,LoRA 的性能被证明几乎等同于全面微调 - 而且只需要一部分成本
- PEFT 相比全面微调的优势
- 更高效和更快的训练
- 保留预训练的知识
【2024-2-27】PEFT:
- LORA、QLoRA
- Adapter Tuning
- Prefix Tuning、Prompt Tuning、P-Tuning 及 P-Tuning v2 等
7个主流微调方法在Transformer网络架构的作用位置和简要说明
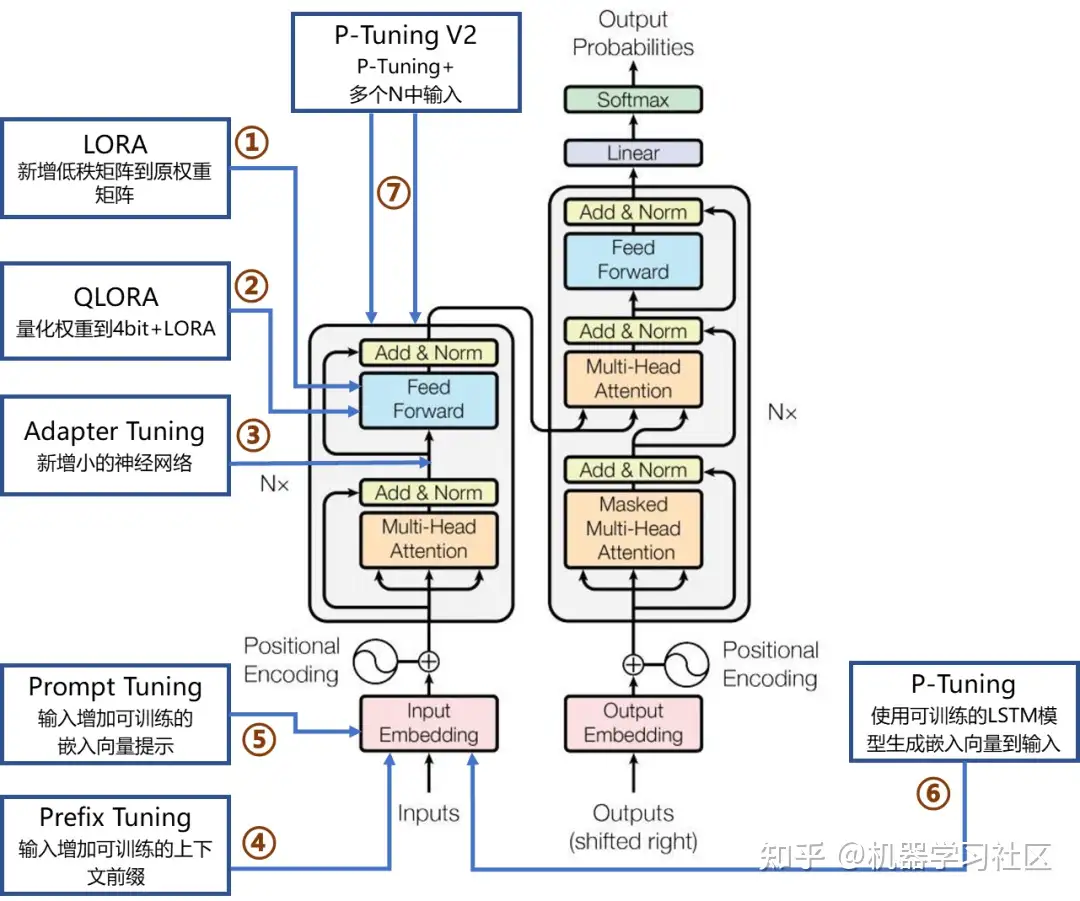
详见: 一文彻底搞懂Fine-tuning - 参数高效微调(Parameter-Efficient Fine-Tuning), 含图解
更多LLM技术落地方案见站内专题:大模型应用技术方案
PEFT 参数高效微调
解决什么问题
起因:训练模式
- 全参数微调:对特定下游任务进行 Full FineTuning(全参数微调),太过低效;
- 部分参数微调:固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好效果。
解决思路
PEFT技术通过最小化微调参数的数量和计算复杂度,提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。
- 即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。
因此,PEFT技术提高模型效果的同时,大大缩短模型训练时间和计算成本,让更多人能够参与到深度学习研究中来。
- 计算效率高: PEFT技术减少要更新的参数量
- 存储效率高: 参数量小,适用于内存受限的设备
- 适应性强: 快速适应不同任务,无需训练整个模型
A100 显卡(80G)上,微调 bigscience 7b/12b 模型
- 全参微调: 内存溢出
- PEFT:显存占用大幅降低,可单卡微调
PEFT 方法
主流 PEFT 有三类
- (1) 参数附加: Additional Parameters Methods, 附加小型可训练模块(适应层 Adapter Layer),训练时,原始模型参数冻结,仅微调附加模块的参数
- 添加位置: 输入、模型、输出
- ① 输入: 附加到输入embedding中, 如 Prompt-tuning (又称 软提示 soft-prompt),训练时参数一起更新;初衷是自动学习提示词,作为硬提示(hard prompt 直接输入提示语)的改进版
- ② 模型: 添加到模型的隐含层中,大幅增加可训练参数量,如 Prefix-tuning、Adapter-tuning、AdapterFusion
- ③ 输出: 解决模型太大、模型闭源导致无法训练的问题
- Proxy-tuning 轻量级解码时算法,访问输出词表预测分布,实现定制化微调;代理模型+反专家模型
- 代表: 适配器微调 Adapter-tuning、提示微调 Prompt-tuning、前缀微调 Prefix-tuning、代理微调 Proxy-tuning等
- Prompt-tuning优势: 内存效率高、多任务能力、缩放特性
- Prefix-tuning: 与Prompt-tuning相似,区别是将可训练前缀加到embedding+注意力模块中;
- 优势: 参数效率、任务适应性、保持预训练知识
- Adapter-tuning 在transformer每个多头注意力层+全连接层之后加适配器(瓶颈结构降维)
- AdapterFusion 是 Adapter-tuning 改进版,先对单个任务进行知识提取,再融合多个任务的Adapter层
- 添加位置: 输入、模型、输出
- (2) 参数选择: Parameter Selection Methods, 仅选择模型部分参数进行微调, 其余参数冻结。
- 跟 附加 区别:无需添加额外参数,不用引入额外计算成本
- 参数选择有两类:基于规则(BitFit)、学习(Child-tuning/FishMask/Fish-Dip/LT-SFT/SAM)
- BitFit 优化神经网络每层的偏置项(Biases)及任务特定的分类头;BitFit 可采用更大的学习率,优化过程更稳定。
- Child-tuning 通过梯度掩码矩阵策略,仅对选中的子网络梯度更新;Child-tuning 通过梯度屏蔽减少了计算负担,模型假设空间,降低过拟合风险,但子网络选择需要额外计算
- 好处: 降低计算量的同时提升模型性能
- 代表: BitFit、Child-tuning、FishMask等
- (3) 低秩适配: Low-Rank Adaption Methods 通过低秩矩阵近似原始权重更新矩阵,仅微调低秩矩阵,原始权重冻结
- 低维固有维度假设: 过参数化模型的固有维度很低
- 好处: 低秩更新矩阵参数量远小于原始矩阵,大幅节省微调时内存开销 —— 推理开销并未减少!
- 代表: LoRA,及各种改进版本,AdaLoRA、DyLoRA、DoRA等
- LoRA 变体
- ① 打破低秩瓶颈: LoRA 秩太小,限制性能
- ReLoRA 用合并和重置(merge-and-reinit)方法,将多次低秩LoRA更新累积成高秩状态,解决维度限制问题
- ② 动态秩分配: 秩冗余时会导致性能效率退化,不同层存在差异
- AdaLoRA 为每个层分配不同的秩,将 低秩矩阵 参数化为 SVD 形式, 再通过奇异值剪枝动态调整不同层里的lora 秩
- ③ 训练过程优化: lora 收敛速度比全残微调慢,对超参敏感,容易过拟合
- DoRA 提出约束梯度更新,侧重更新参数的方向变化,将W0分解为方向和大小组件,LoRA 仅应用于 方向组件,增强训练稳定性
- ④ 任务泛化: LoRA 插件即插即用、不破坏原始权重,可以插件化,以便保存、共享和使用
- LoRAHub 是一个多LoRA组合方法框架,包含组合、适应阶段
- ① 打破低秩瓶颈: LoRA 秩太小,限制性能
【2024-11-24】详见:浙大《大模型基础》PEFT章节
PEFT 主要方法:
- Prefix Tuning(在模型输入层添加可训练
前缀嵌入) - LoRA(通过
低秩矩阵近似模型参数更新) - Adapter Tuning(在模型层间插入小型神经网络adapters)。
方法
Prefix Tuning:与full fine-tuning更新所有参数的方式不同,该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。Prompt Tuning:该方法可以看作是Prefix Tuning的简化版本,只在输入层加入prompt tokens,并不需要加入MLP进行调整来解决难训练的问题。随着预训练模型参数量的增加,Prompt Tuning的方法会逼近fine-tuning的结果。P-Tuning:该方法的提出主要是为了解决这样一个问题:大模型的Prompt构造方式严重影响下游任务的效果。P-Tuning将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对prompt embedding进行一层处理。P-Tuning v2:让Prompt Tuning能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌Fine-tuning的结果。相比Prompt Tuning和P-tuning的方法,P-Tuning v2方法在多层加入了Prompts tokens作为输入,带来两个方面的好处:- 带来更多可学习的参数(从P-tuning和Prompt Tuning的0.1%增加到0.1%-3%),同时也足够参数高效。
- 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
Adapter Tuning:该方法设计了Adapter结构(首先是一个down-project层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个up-project结构将低维特征映射回原来的高维特征;同时也设计了skip-connection结构,确保了在最差的情况下能够退化为identity),并将其嵌入Transformer的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数)。LoRA:在涉及到矩阵相乘的模块,引入A、B这样两个低秩矩阵模块去模拟full fine-tuning的过程,相当于只对语言模型中起关键作用的低秩本质维度进行更新。
PEFT 实现
PEFT实现工具:
- PEFT:Huggingface推出的PEFT库。
- unify-parameter-efficient-tuning:一个参数高效迁移学习的统一框架。
Parameter-Efficient Fine-Tuning (PEFT) 是HuggingFace 开源的一个高效微调大模型库,支持在 LLM 上创建和微调适配器层。
- peft 与 🤗 Accelerate 无缝集成,用于利用了 DeepSpeed 和 Big Model Inference 的大规模模型。
【2023-7-11】Prompt系列高效调参原理解析, 智源社区
PEFT内置7种主流高效调参方法
LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELSPrefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation,P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and TasksP-Tuning: GPT Understands, TooPrompt Tuning: The Power of Scale for Parameter-Efficient Prompt TuningAdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-TuningQLoRA: QLoRA: Efficient Finetuning of Quantized LLMs
时间线
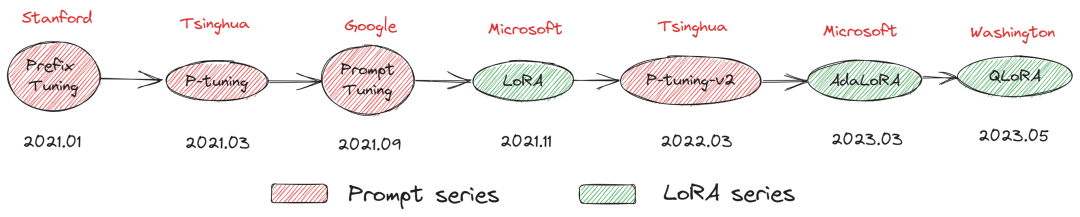
| 时间 | 机构 | 方法 | 备注 |
|---|---|---|---|
| 2021.1 | stanford | Prefix Tuning | Prompt Series |
| 2021.3 | Tsinghua | P-Tuning | Prompt Series |
| 2021.9 | Prompt Tuning | Prompt Series | |
| 2021.11 | Microsoft | LoRA | LoRA Series |
| 2022.3 | Tsinghua | P-Tuning v2 | Prompt Series |
| 2023.3 | Microsoft | AdaLoRA | LoRA Series |
| 2023.5 | Washington | QLoRA | LoRA Series |
目前包含LoRA,Prefix Tuning,Prompt Tuning,P-Tuning 四种算法
- LoRA
- Prefix Tuning
- Prefix Tuning 算法是根据 下游任务 “前缀指令文本” 的所有层的embeding表示,学习到的前缀指令文本向量可以挖掘大模型的潜力去引导模型完成特定任务。
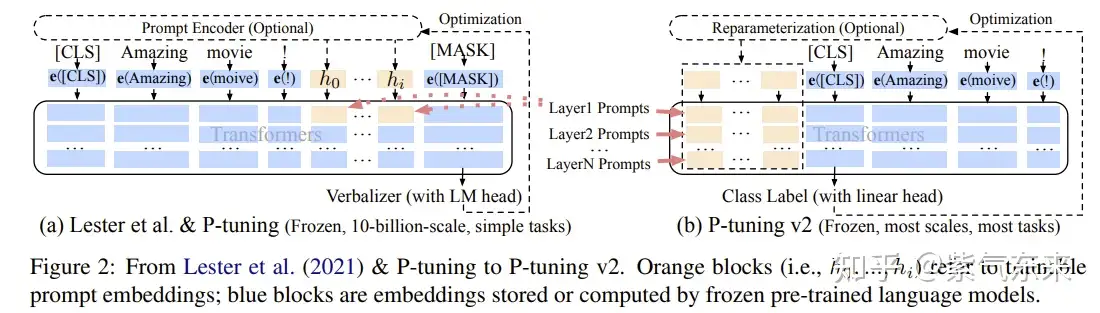
- P-Tuning
- P-Tuning 算法和 Prefix Tuning 的想法很相似,想通过微调”指令文本”,让指令文本去挖掘大模型的潜力去完成特定的任务。但是 P-Tuning 只学习 “指令文本” 输入层embeding的的表示。 为了增强 “指令文本”的连续性,采用了一个 MLP(LSTM) 的结果去encoding “指令文本”。从微调参数量来看只有 0.65% 比 Prefix Tuning 和 LoRA 这些在所有层都增加参数的方法要少。
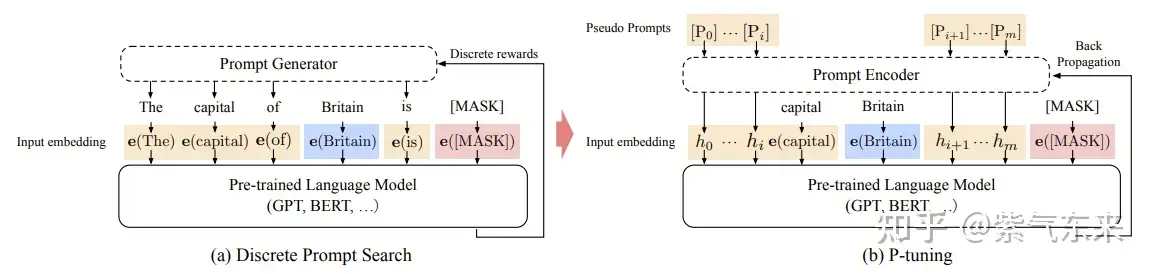
- Prompt Tuning
- Prompt Tuning 算法和 P-Tuning 很像,且更简单,就是是根据 下游任务 “指令文本” 输入层embeding的的表示。 Prompt Tuning 没有增加任何的层,直接使用微调指令文本(prompt) 的embeding向量。
Parameter-Efficient Fine-Tuning (PEFT)
单个 24GB GPU 上使用上述工具使用 RL 微调 20B 参数量的 LLM, 详见量化quantization
- 与全精度模型相比,以 8位精度加载模型最多可节省 4倍的内存
- 调用 from_pretrained 方法时简单地添加标志 load_in_8bit=True
详见:在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
PEFT 不足
相比全参数微调,高效微调技术目前存在的两个问题:
- 推理速度会变慢
- 模型精度会变差
应用示例
典型应用:
ChatGLM-Tuning:一种平价的chatgpt实现方案,基于清华的 ChatGLM-6B + LoRA 进行finetune。Alpaca-Lora:使用低秩自适应(LoRA)复现斯坦福羊驼的结果。Stanford Alpaca 是在 LLaMA 整个模型上微调,而 Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降,还能获得和全模型微调类似的效果。BLOOM-LORA:由于LLaMA的限制,我们尝试使用Alpaca-Lora重新实现BLOOM-LoRA。
微调原理
FineTune 微调
预训练模型在小规模特定数据集上进一步训练,调整模型权重,适应特定任务或提高其性能。

【2023-6-25】大模型参数高效微调技术原理综述(七)-最佳实践、总结
参数高效微调综述论文:
几种参数高效微调方法进行了简单的概述,主要有如下几类:
- (1)
Additive增加额外参数,注意力与FFN后加一个全连接层- 如:Prefix Tuning、Prompt Tuning、Adapter Tuning及其变体。
- soft prompts 软提示
- Prompt Tuning: 输入前面加入一些新的可学习的嵌入向量
- Prefix-Tuning: 在所有层前面加入可学习的参数
- Intrinsic Prompt Tuning (IPT): 用自编码器来压缩soft Compact
- adapters-like 适配器
- Adapter: 在注意力与FFN后加一个全连接层
- AdaMix: 采用MOE策略引入多个Adapters
- 其它
- Ladder-Side Tuning (LST): 在每个Transformer block旁边引入一个小型的Transformer来计算更新的参数,类似于Lora
- (IA)3: 缩放 key value以及FFN的 激活函数
- (2)
Selecttive选取一部分参数更新,如:BitFit。- BitFit:仅更新bias
- DiffPruning: mask掉一些训练的参数
- Freeze and Reconfigure (FAR): 按照行来划分为 训练的行与 冻结的行
- FishMask: 使用Fisher信息矩阵来选取 top-p参数进行更新
Reparametrization引入重参数化,如:LoRA、AdaLoRA、QLoRA。- Intrinsic SAID: 更新一个低维空间的向量
- LoRA: 更新旁路,且旁路设计为一个下采样与一个上采样
- KronA: 使用克罗内克积来减小Lora的计算开支
- 混合高效微调,如:MAM Adapter、UniPELT。
- SparseAdapter: 使用一个维度较大的Adapter,并对这个Adapter稀疏化,避免参数过多
- MAM Adapter: 并行的Adapter, FFN layer and soft prompt.
- UniPELT: 将LoRa Prefix-tuning 和 Adapter 使用gat机制合并
- Compacter: 使用克罗内克积,并且每层共享参数的 Adapter
- S4: 探索了这些方法结合起来的效果
高效微调粗略分为三类:
- 加额外参数
A+ 选取一部分参数更新S+ 引入重参数化R 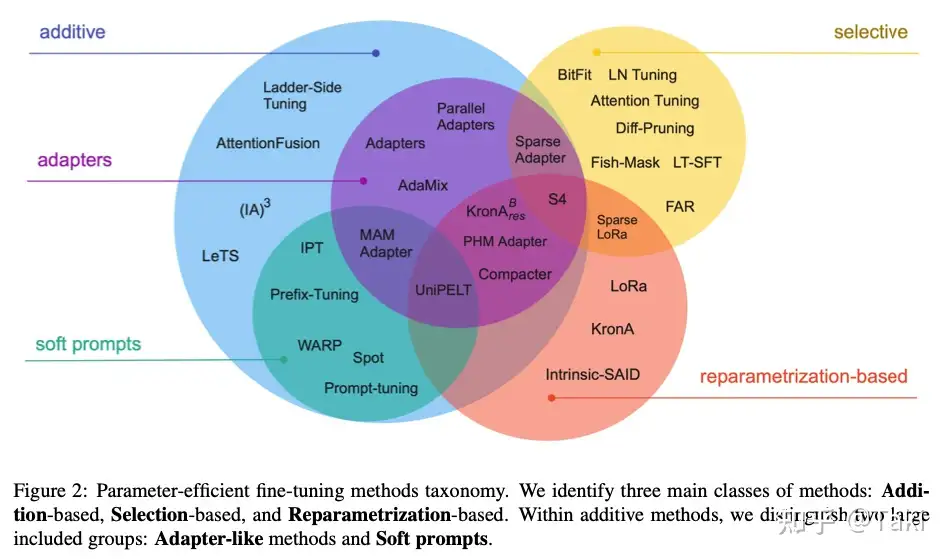
各种方法对比
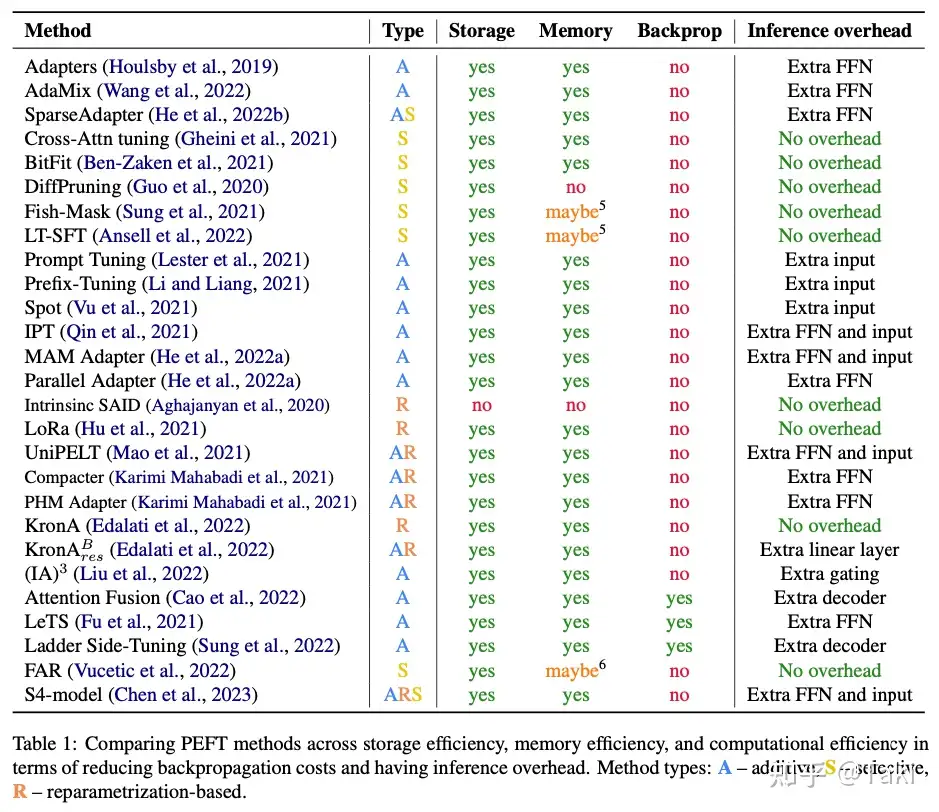
BitFit
对微调机制的一种积极探索,通过仅调整bias就有不错的效果,但没有具体阐述原理,通过猜测加实验得到的结果。
观点:
微调过程不是让模型适应另外的数据分布,而是让模型更好的应用出本身的表征能力。
特点:
- 训练参数量极小(约0.1%)。
- 大部分任务上效果会差于LoRA、Adapter等方法。
Prefix Tuning
Prefix Tuning 通过在模型输入层之前添加可训练的前缀嵌入(prefix embeddings)来影响模型的输出。
这些前缀嵌入与原始输入拼接后一起输入到模型中,而模型的其他部分保持不变。
Prefix Tuning(前缀微调)
什么是Prefix Tuning?
- Prefix Tuning 在原始文本进行词嵌入之后,在前面拼接上一个前缀矩阵,或将前缀矩阵拼在模型每一层的输入前。
- 这个前缀与输入序列一起作为注意力机制的输入,从而影响模型对输入序列的理解和表示。
- 由于前缀可学习,可在微调过程中根据特定任务进行调整,使得模型能够更好地适应新的领域或任务。
注意
- finetune 更新整个模型权重
- prefix tuning 则只更新前缀编码, 模型编码不动, fixed
详见: 一文彻底搞懂Fine-tuning - 参数高效微调(Parameter-Efficient Fine-Tuning), 含图解
【2021.3.2】Prompt Tuning – 离散token
受语言模型 in-context learning能力启发,只要有合适的上下文,语言模型就可以很好的解决自然语言任务。
针对不同任务,仅在输入层引入virtual token形式的软提示(soft prompt)。
特点:
- 相对于Prefix Tuning,参与训练的参数量和改变的参数量更小,更节省显存。
- 对一些简单的NLU 任务还不错,但对硬序列标记任务(即
序列标注)表现欠佳。
Prompt Tuning with soft prompts
输入层增加可训练的Soft Prompt参数,参数长度一般在20-100个,每个参数的embedding维度和词表token的embedding维度相同,如下图所示:
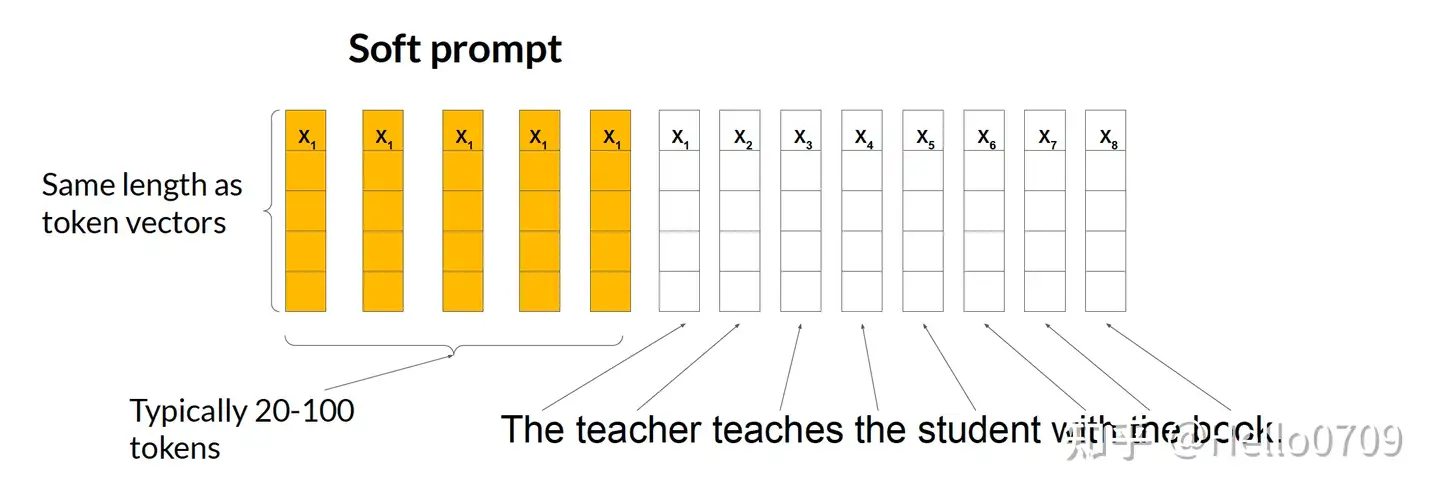
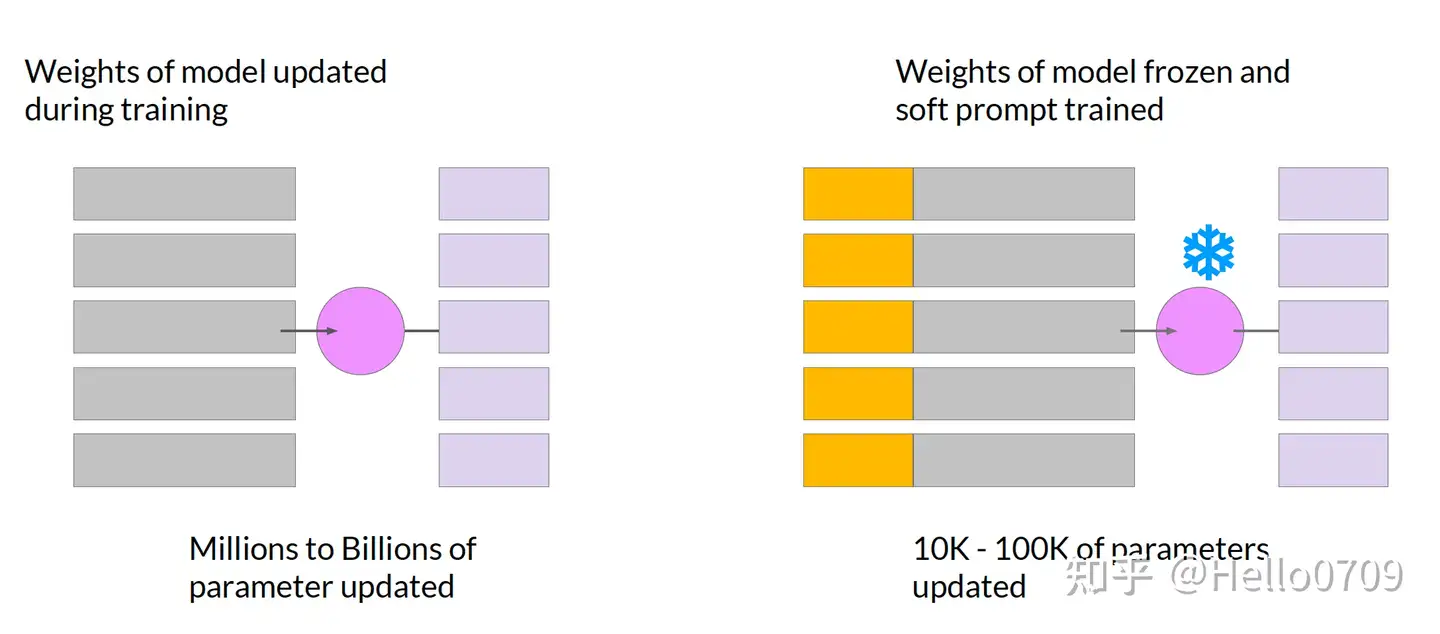
相较于全参数微调,Prompt Tuning也是通过冻结LLM的原始参数,添加少量额外训练参数以达到加速训练的目的;
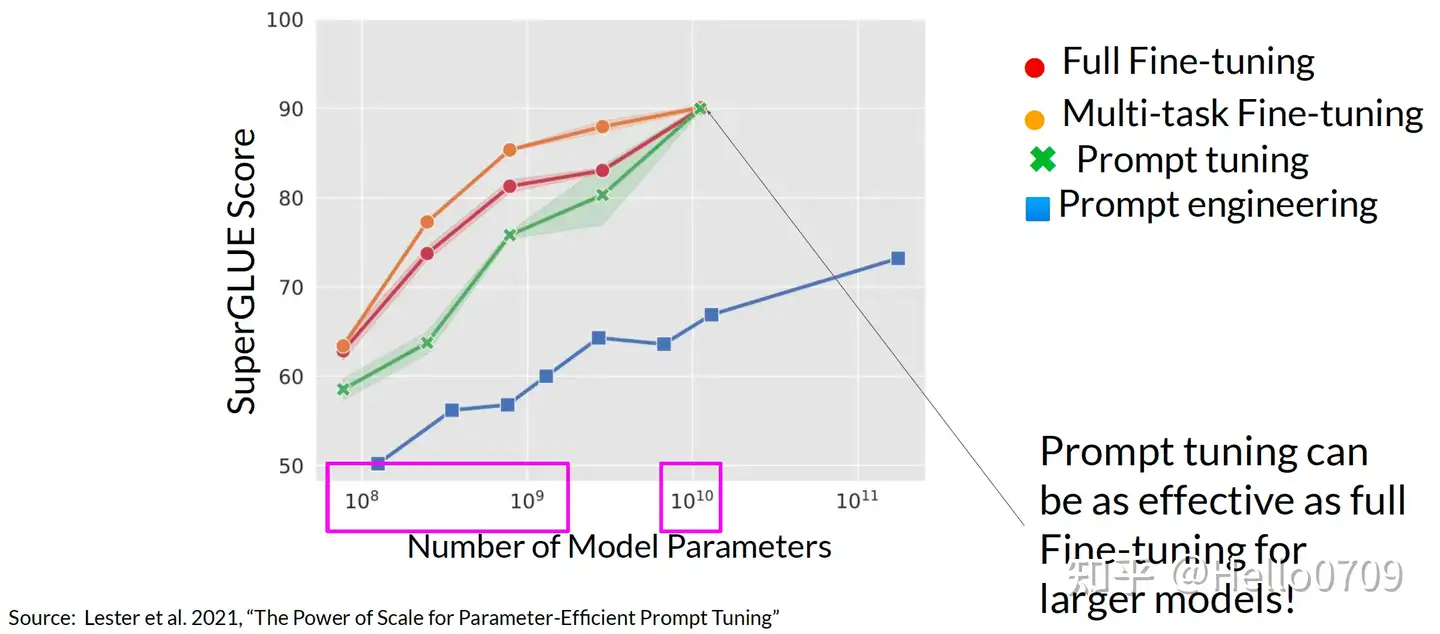
Prompt Tuning 实际效果从下面图中看出:
- 1,当模型参数不大的时候,Prompt Tuning比全参数微调的效果差一点,但是高于单纯的Prompt工程;
- 2,当模型参数在100亿时,Prompt Tuning的效果和全参数微调的效果一样好;
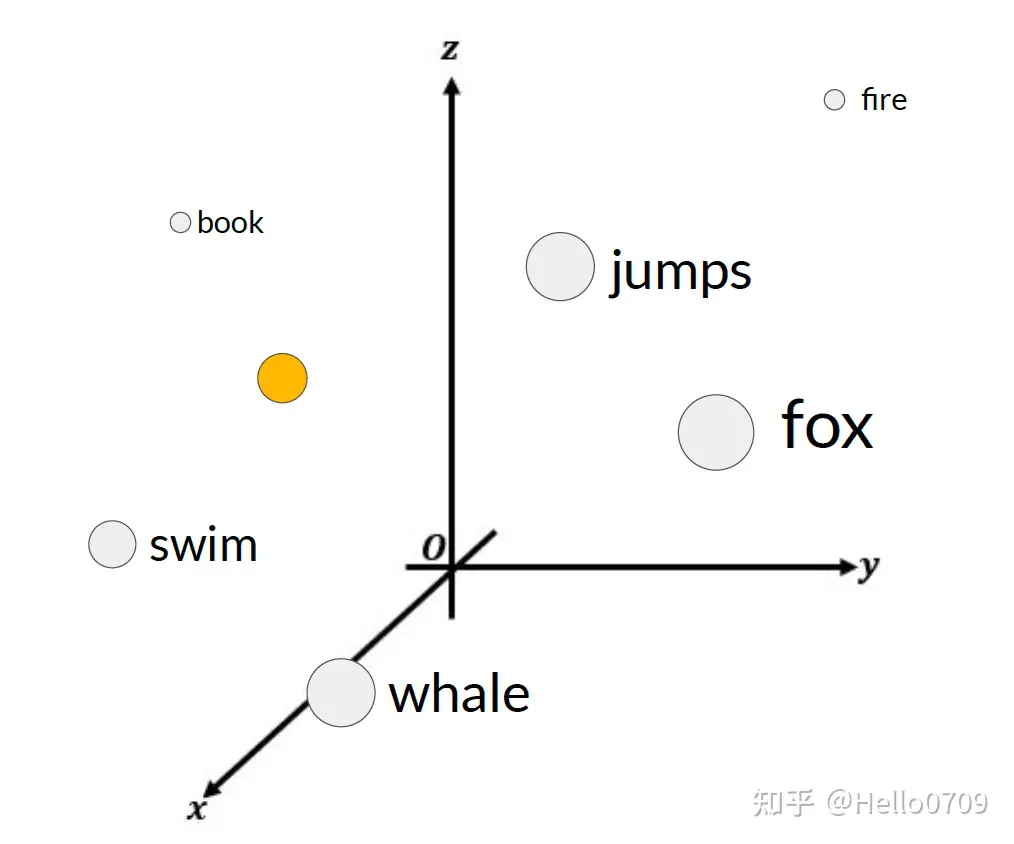
Prompt Tuning 可解释性说明:
- 对于已完成训练的prompt embedding来说,是无法与词表中任何token表示对应的(Trained soft-prompt embedding does not correspond to a known token);
- 但是观察其邻域范围内的token表示可以看出其具有相同的语义,能够表示相同的意思(but nearest neighbors form a semantic group with similar meanings);
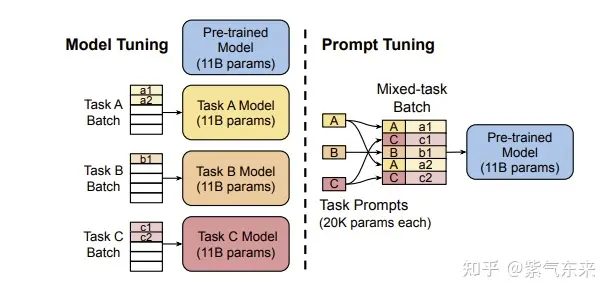
固定预训练参数,为每个任务额外添加一个或多个embedding,之后拼接query正常输入LLM,并只训练这些embedding。
- 左图为单任务全参数微调,右图为prompt tuning。
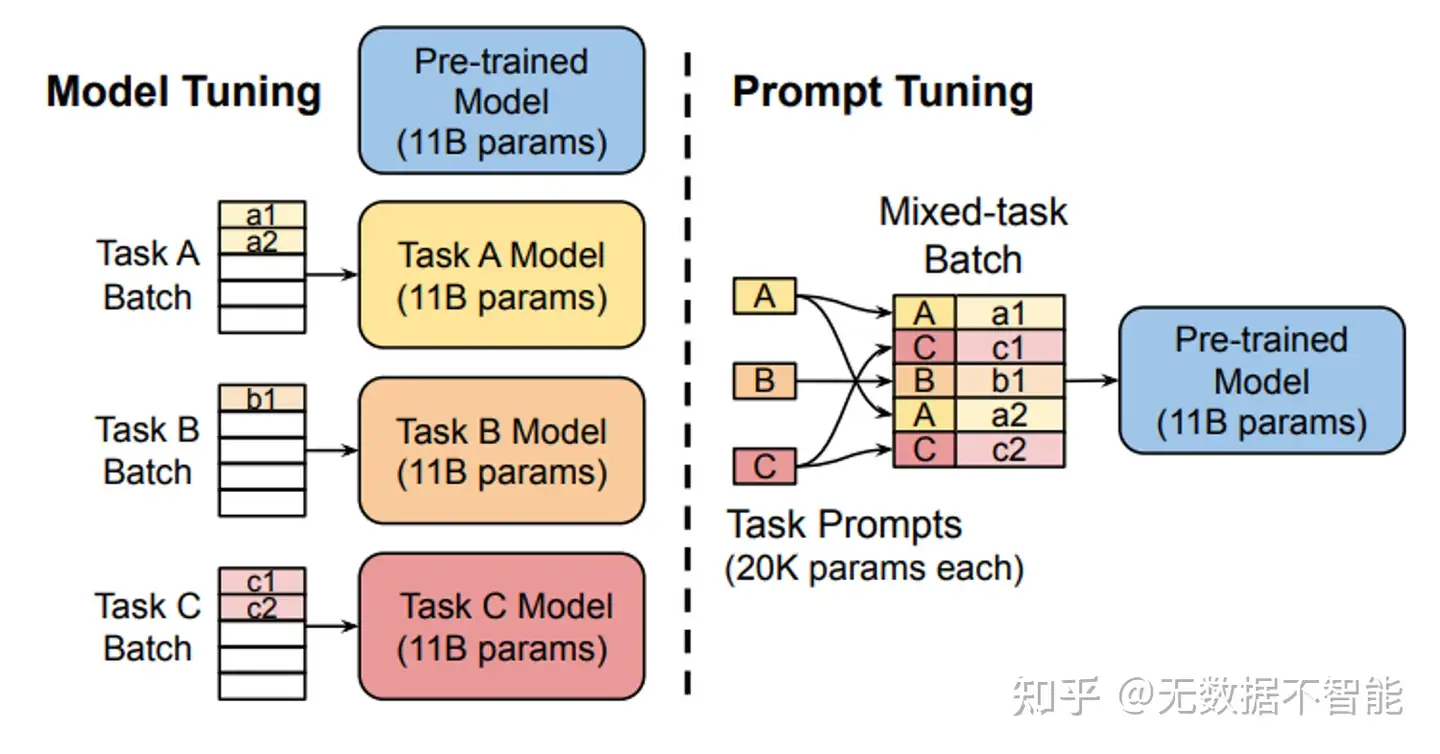
from peft import PromptTuningConfig, get_peft_model
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
【2021.8.1】Prefix Tuning – 连续token
prompt tuning 是 Prefix Tuning 简化版本
prefix tuning 依然是固定预训练参数,但除了每个任务额外添加一个或多个embedding之外,利用多层感知编码prefix,注意多层感知机就是prefix的编码器,不再像prompt tuning继续输入LLM。
prompt tuning 针对特定任务找到离散token前缀,花费很长时间
prefix-tuning 使用连续的virtual token embedding来替换离散token
在每一个Transformer层都带上一些virtual token作为前缀,以适应不同的任务。
transformer中的每一层,句子表征前面插入可训练的virtual token embedding。对于自回归模型(GPT系列),在句子前添加连续前缀,即 z=[prefix;x;y] 。对于Encoder-Decoder模型(T5),则在Ecoder和Decoder前都添加连续前缀 z=[prefix;x|prefix'|y]
添加前缀的过程如图所示。

虽然,prefix-tuning并没有添加太多的额外参数。但是,prefix-tuning难以优化,且会减少下游任务的序列长度。
特点:
- 前缀Token会占用序列长度,有一定额外计算开销。
- Prefix Tuning的线性插值比较复杂。
embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
transform = torch.nn.Sequential(
torch.nn.Linear(token_dim, encoder_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
prefix tuning 代码
peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
【2021.11.2】P-Tuning
手动尝试最优的提示无异于大海捞针,于是有了自动离散提示搜索方法
但提示是离散的,神经网络是连续的,所以寻找最优提示可能是次优的。
p-tuning 依然固定LLM参数,利用多层感知机和LSTM对prompt进行编码,编码之后与其他向量进行拼接之后正常输入LLM。
- 注意,训练后只保留prompt编码之后的向量即可,无需保留编码器
- GPT在P-tuning 加持下可达到甚至超过BERT在NLU领域的性能。
prompt 编码器结构
self.lstm_head = torch.nn.LSTM(
input_size=self.input_size,
hidden_size=self.hidden_size,
num_layers=num_layers,
dropout=lstm_dropout,
bidirectional=True,
batch_first=True,
)
self.mlp_head = torch.nn.Sequential(
torch.nn.Linear(self.hidden_size * 2, self.hidden_size * 2),
torch.nn.ReLU(),
torch.nn.Linear(self.hidden_size * 2, self.output_size),
)
self.mlp_head(self.lstm_head(input_embeds)[0])
将Prompt转换为可学习的Embedding层,并用 MLP+LSTM 方式对 Prompt Embedding 进行一层处理。
- 相比 Prefix Tuning,仅在输入层加入可微的virtual token;
- 另外,virtual token 位置也不一定是前缀,插入的位置是可选的。
特点:
- 引入一个prompt encoder(由一个双向的LSTM+两层MLP组成)来建模virtual token的相互依赖会收敛更快,效果更好。
代码样例:
peft_config = PromptEncoderConfig(task_type="CAUSAL_LM", num_virtual_tokens=20, encoder_hidden_size=128)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
【2022.3.20】P-Tuning v2
p-tuning 问题:小参数量模型上表现差
V2版本类似LoRA,每层都嵌入了新的参数(称之为Deep FT),下图中开源看到p-tuning v2 集合了多种微调方法。
p-tuning v2 在多种任务上下进行微调,之后对于不同的任务如token classification与sentence classification添加了随机初始化的任务头(AutoModelForTokenClassification、AutoModelForSequenceClassification),而非使用自然语言的方式,可以说V2是集大成者。
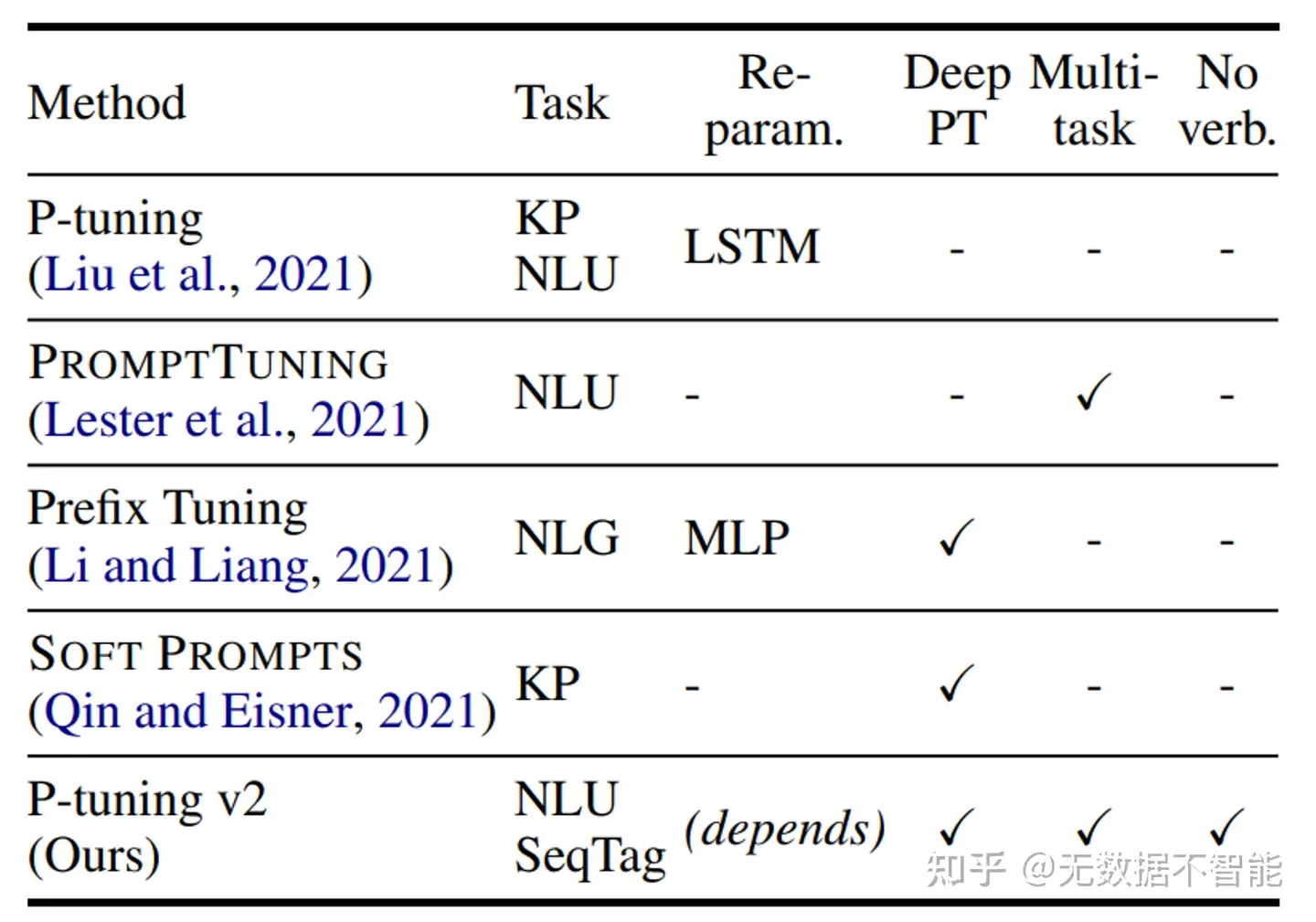
每个Transformer层都加入了prompt token作为输入,引入多任务学习,针对不同任务采用不同的提示长度。并且回归传统的分类标签范式,而不是映射器。
特点:
- 解决了Prompt Tuning无法在小模型上有效提升的问题。
- 移除了对模型效果改进较小的重参数化的编码器(如:Prefix Tuning中的MLP、P-Tuning中的LSTM)。
- 对于一些复杂的硬序列标记任务(即序列标注)取得了不错的效果。
代码样例:
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
Adapter Tuning
该方法设计了Adapter结构,并将其嵌入Transformer的结构里面,针对每一个Transformer层,增加了两个Adapter结构,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构和Layer Norm 层进行微调。
特点:
- 通过在Transformer层中嵌入Adapter结构,在推理时会额外增加推理时长。
Adapter Tuning(适配器微调)
什么是Adapter Tuning?
- Adapter Tuning 在保持模型参数数量相对较小的情况下,通过增加少量可训练参数(即适配器)来提高模型在特定任务上的表现。
Adapter Tuning 核心思想
- 在预训练模型的中间层中插入小的可训练层或“适配器”。
- 这些适配器通常包括一些全连接层、非线性激活函数等,它们被设计用来捕获特定任务的知识,而不需要对整个预训练模型进行大规模的微调。
详见: 一文彻底搞懂Fine-tuning - 参数高效微调(Parameter-Efficient Fine-Tuning), 含图解
AdapterFusion
一种融合多任务信息的Adapter的变体,在 Adapter 的基础上进行优化,通过将学习过程分为两阶段来提升下游任务表现。
AdapterDrop
该方法在不影响任务性能的情况下,对Adapter动态高效的移除,尽可能的减少模型的参数量,提高模型在反向传播(训练)和正向传播(推理)时的效率。
特点:
- 通过从较低的 Transformer 层删除可变数量的Adaper来提升推理速度。 当对多个任务执行推理时,动态地减少了运行时的计算开销,并在很大程度上保持了任务性能。
【2021.8.16】LoRA 低秩适配
通过低秩分解来模拟参数改变量,以极小参数量实现大模型的间接训练。
特点:
- 将BA加到W上,消除推理延迟。
- 可插拔式切换不同任务。
- 设计较好,简单且效果好。
LoRA微调与全量微调相比,效果会更差,但团队将LoRA添加到所有的线性层解决了这个问题。
2021年,论文 LoRA: Low-Rank Adaption of Large Language Models 通过冻结预训练权重,并创建查询和值层的注意力矩阵的低秩版本,对大型语言模型进行微调。
- 低秩矩阵参数远少于原始模型,因此可用更少的 GPU 内存进行微调。
- 低阶适配器的微调取得了与微调完整预训练模型相当的结果。
【2025-12-7】几种 lora 方法
LoRA 原理
核心思想
- 冻结预训练模型权重,将可训练的秩分解矩阵注入 Transformer 架构每一层,从而大大减少了下游任务的微调参数量
LoRA 实现流程:
- 原始预训练语言模型 (PLM) 旁增加一个旁路,做一个先降维再升维的操作,模拟
本征秩(intrinsic rank); - 训练时,固定 PLM 参数不变,只训练降维矩阵 A 和升维矩阵 B,即优化器只优化右路的参数;
- 模型的输入/输出维度不变,左右两边共用模型输入,输出时将 PLM 与旁路的输出叠加:
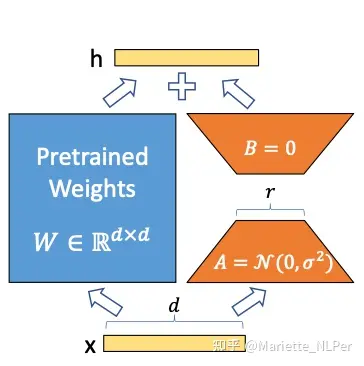
h=Wx+BAx -
用零均值随机高斯分布初始化 A,用全零矩阵初始化 B,矩阵 B 的全零初始化,使得在训练最开始的一段时间,右路结果会接近于0,这样模块输出就基本上来自于左路,也就是大模型原有参数的计算结果,这使得模型优化的初始点和原始的大模型保持一致。
- 思想:在原模型旁边增加一个旁路,通过低秩分解(先降维再升维)模拟参数的更新量。
- 训练:原模型固定,只训练降维矩阵A和升维矩阵B。
- 推理:可将BA加到原参数上,不引入额外的推理延迟。
- 初始化:A采用高斯分布初始化,B初始化为全0,保证训练开始时旁路为0矩阵。
可插拔式的切换任务:当前任务W0+B1A1,将lora部分减掉,换成B2A2,即可实现任务切换。
示意图
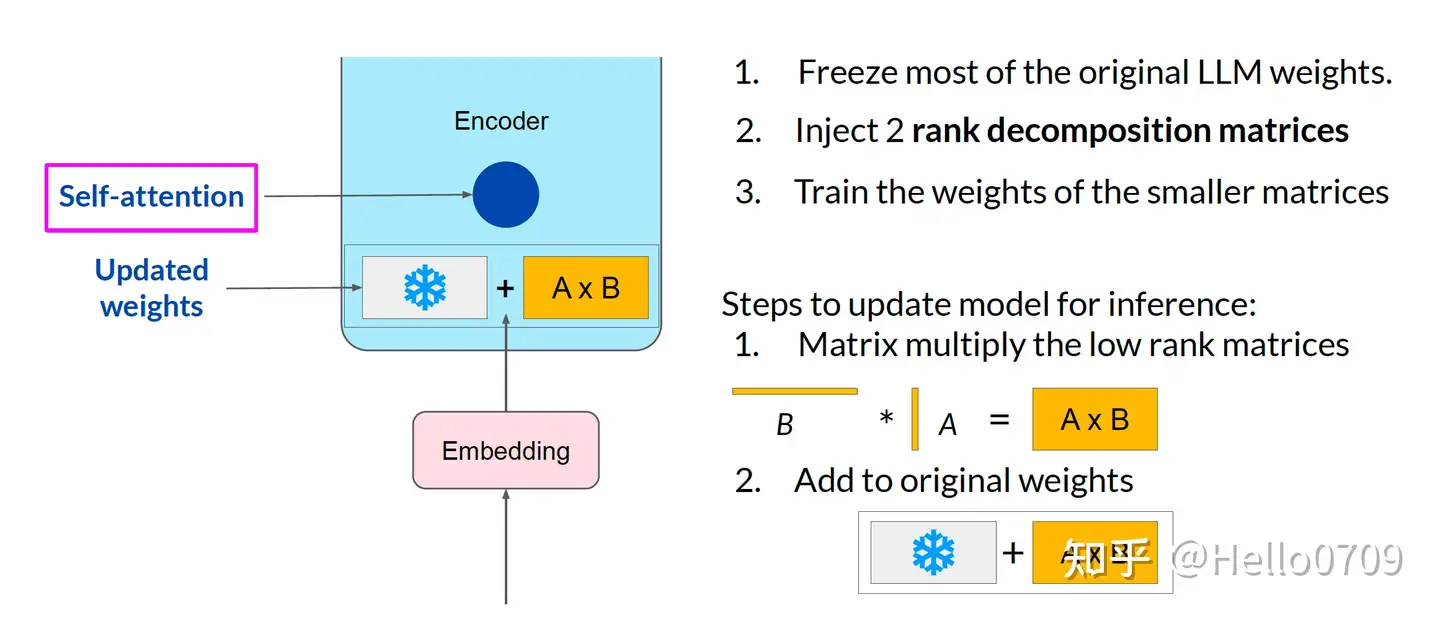
LoRA微调可用不同低秩矩阵适配不同任务类型,且LLM 原始权重不用变化;
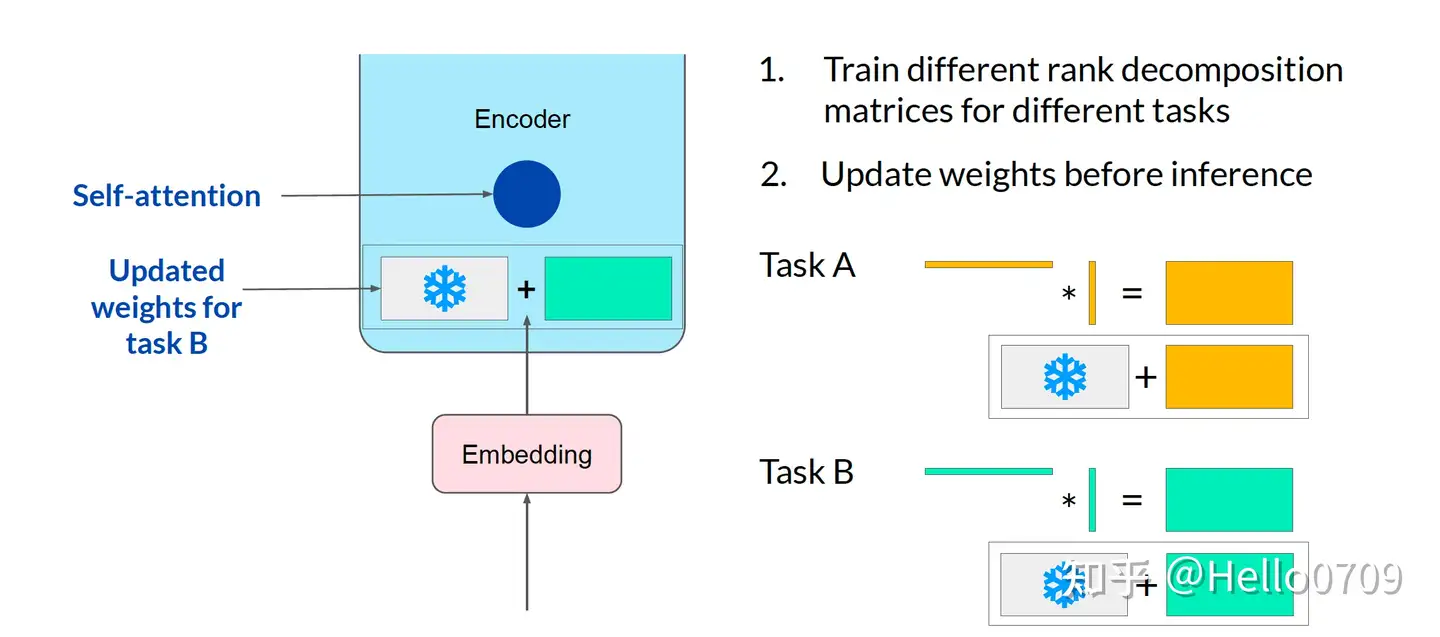
LoRA将会使用低秩表示来编码 △W ,同时实现计算高效和存储高效。当预训练模型是175B GPT-3,可训练参数 |0| 可以小至 |W0| 的 0.01%
整体上LoRA微调效果相对于基座模型有较大的提升,但是相对于全参数微调方式来说效果上还是低一点。
Full fine-tune>LoRA>base model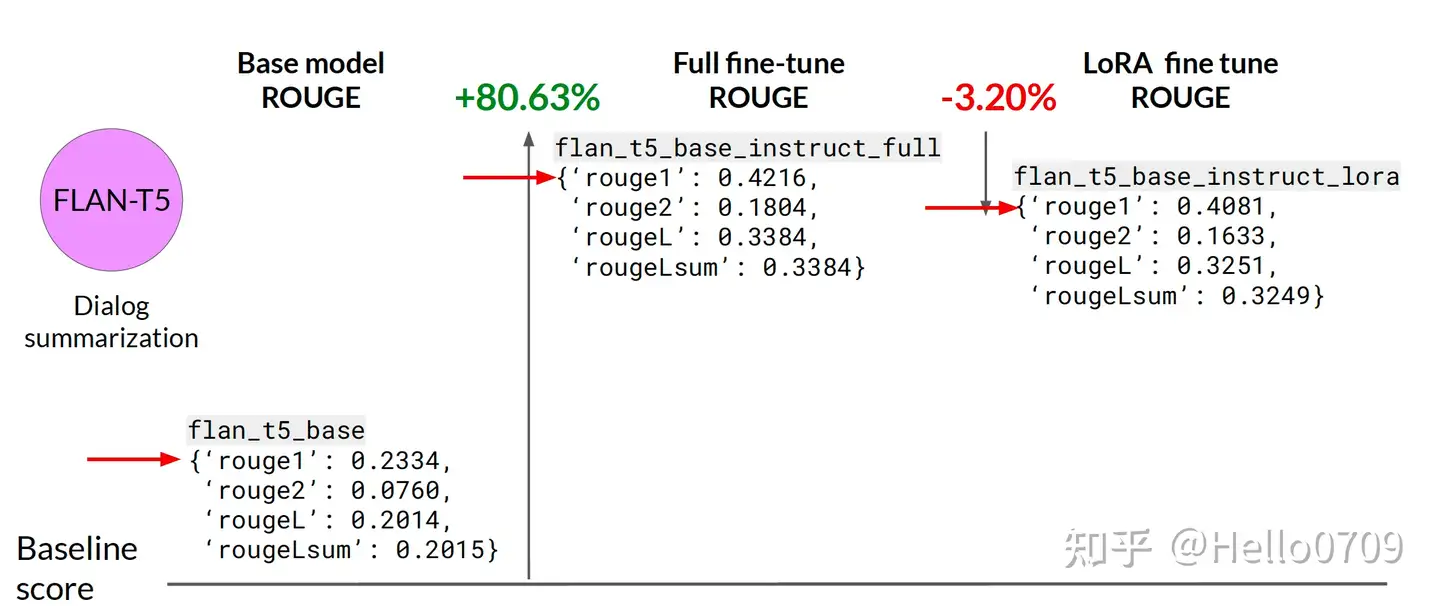
对于 $\delta W_x$ 这部分,会乘上一个 scale 系数 $ Scale = \frac{\alpha}{r}$
- $\alpha$ 相对于 r, 保持常数倍关系。调节这个 $\alpha$ 大致, 相当于调节学习率,于是干脆固定为常数
- 实践中,rank r 应该设为多少比较合适呢?可以很低,不超过8
- 当红炸子鸡 LoRA,是当代微调 LLMs 的正确姿势?
LoRA 一般会在 Transformer 每层中的 query_key_value 部分增加旁路,其中 r 为矩阵的秩,在模型训练中是可调节的参数,r << d,r 越大,可训练参数越多。
- 图见原文
LoRA 优势: 使用较少 GPU 资源,在下游任务中对大模型进行微调。
- 开源社区中,开发者们使用 LoRA 对
Stable Diffusion进行微调,取得了非常不错的效果。 - 随着 ChatGPT 的火爆,也涌现出了许多使用 LoRA 对 LLM 进行指令微调的工作。
这种技术允许使用小部分内存来微调 LLM。然而也有缺点
- 由于适配器层中的额外矩阵乘法,前向和反向传递的速度大约是原来的两倍。
LoRA 是 Parameter Efficient 方法之一。
- 过度参数化的模型位于一个低内在维度上,所以假设在模型适应过程中的权重变化也具有较低的“内在等级”。
- LoRA主要方法为冻结一个预训练模型的矩阵参数,并选择用A和B矩阵来替代,在下游任务时只更新A和B。
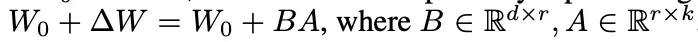
【2023-5-27】LoRA压缩比,港科大实验数据
Extremely few parameters with LoRA
- LLaMA-33B (65GB)-> 25M
- LLaMA-13B(26GB) -> 13M
- LLaMA-7B (13.5GB)-> 8M
【2023-4-5】LoRA原理讲解,LoRA:训练你的GPT
class LoraLayer:
def __init__(
self,
r: int,
lora_alpha: int,
lora_dropout: float,
merge_weights: bool,
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.0:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
# 标记低秩分解部分是否已经合并至预训练权重
self.merged = False
# 指定是否要将低秩分解部分合并至预训练权重中
self.merge_weights = merge_weights
# 是否要禁用低秩分解的部分,如果是,则仅使用预训练权重部分
self.disable_adapters = False
【2024-1-29】自威斯康星大学麦迪逊分校的统计学助理教授Sebastian Raschka 使用 LoRA 和 QLoRA 微调LLM:数百次实验的见解总结的经验
- 如何节省内存、选择最佳配置等问题。
- 是否应该用SGD取代AdamW,使用调度器的潜在价值
- AdamW 和 SGD 优化器选择没区别
- 如何调整LoRA的超参数。
- 提高r时,合适的 alpha 值是 2*r
- 原文链接:Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of Experiments - Lightning AI
LoRA 将权重矩阵分解为两个较小的权重矩阵,以更参数有效的方式近似完全监督微调
实验模型
- 重点关注尚未进行指令微调的模型:phi-1.5 1.3B、Mistral 7B、Llama 2 7B、 Llama 2 13B 和Falcon 40B
GPU 资源
- 单卡A100 GPU
效果
- Mistral 7B 模型在数学基准测试非常出色。
- phi-1.5 1.3B 型号由于其相对较小的尺寸,在TruthfulQA MC2 性能较好。
- 由于某种原因,Llama 2 13B 在算术基准测试中表现不佳,而较小的 Llama 2 7B 在该领域表现明显优于它。
目前推测 phi-1.5 1.3B 和 Mistral 7B 可能已经接受过基准测试数据的训练,因此不用。
此外,剩余模型中最小的模型将提供最大的改进空间,同时保持较低的硬件要求。重点关注 Llama 2 7B。

Lit-GPT 中的 –quantize 标志(4 位普通浮点类型)启用 QLoRA
- QLoRA 非常节省内存,但会增加运行时成本。
- QLoRA 对模型性能的影响确实较小
LoRA 参数
LoRA 参数
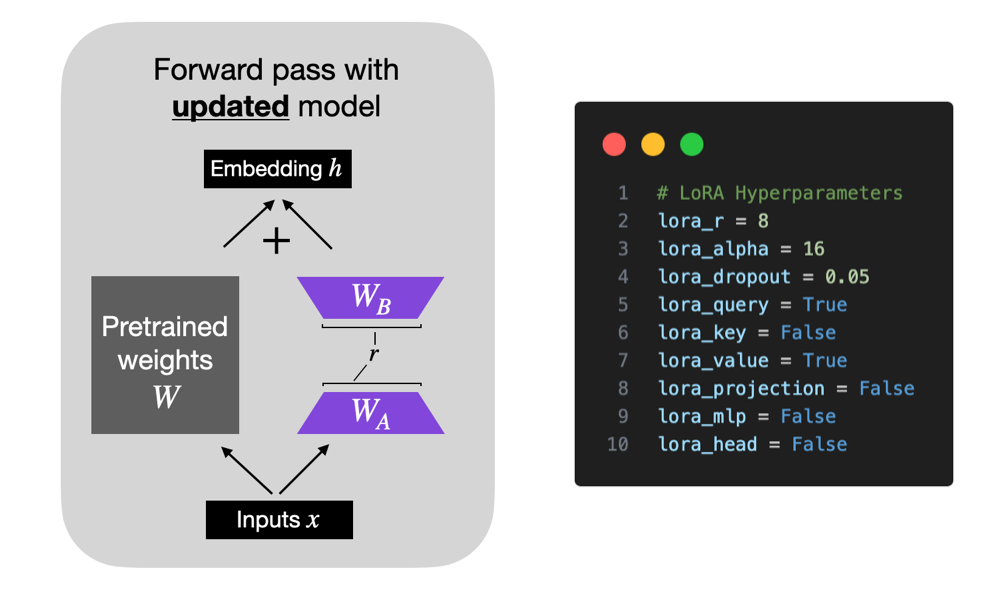
- finetune/lora.py
- QKV:
- LoRA 默认仅针对多头自注意力块中的 Key 和 Query 矩阵启用
- 更改配置,启动值矩阵、投影层和线性层
- 迭代次数 epoch
- 迭代次数的增加会导致整体性能变差。
r: 最重要的参数 R,矩阵的秩/维度,直接影响模型复杂性和容量- 仅增加 r 本身就会使结果变得更糟
- 较高的“r”意味着更强的表达能力,但可能导致过拟合
- 而较低的“r”可以减少过度拟合,但会牺牲表达能力。
- 实验: r 从 8 增加到 16,发现仅增加 r 本身就会使结果变得更糟
alpha: 缩放因子,控制lora权重大小,与r反比,以保持权重更新一致性- 较高的“alpha”加强低秩结构或正则化
- 而较低的“alpha”会减少其影响,使模型更加依赖于原始参数。
- 调整“alpha”有助于在拟合数据和通过正则化模型防止过度拟合之间取得平衡。
- 提高r时,选择较大的 alpha 值至关重要
- 经验:微调 LLM 时,通常选择两倍于R的 alpha(注意与扩散模型时有所不同),以 QLoRA 为例,r=256 和 alpha=512 模型效果最佳
- lora_dropout: lora 层dropout比率, 正则化,防止过拟合
- target_modules: lora应用的模块,如注意力中的qkv、线性层
- 火山引擎方舟平台:
- r 调小时, 需要同步加大学习率, 该参数需要谨慎
- alpha 是缩放系数,
scale = alpha / rank - warmup相关参数: steps 需要多少步“热身”, step_rate 热身数据集的百分比
- max batch tokens: 单worker每个batch最大token数
- LR Scheduler type
# Hyperparameters
learning_rate = 3e-4
batch_size = 128
micro_batch_size = 1
max_iters = 50000 # train dataset size
weight_decay = 0.01
lora_r = 8 # 最重要的参数 R,矩阵的秩/维度,直接影响模型复杂性和容量
lora_alpha = 16
lora_dropout = 0.05
lora_query = True # Q 矩阵启用
lora_key = False # K
lora_value = True # V 矩阵启用
lora_projection = False # 投影层是否启用
lora_mlp = False # 线性层是否启动
lora_head = False #
warmup_steps = 100

LoRA 使用
LoRA 已经被作者打包到了loralib中。
pip install loralib
可以选择用loralib中实现的对应层来替换一些层。
- 目前loralib只支持 nn.Linear、nn.Embedding 和 nn.Conv2d。
- loralib还支持一个 MergedLinear,用于单个 nn.Linear 代表一个以上的层的情况,比如在一些关注 qkv 投影的实现中(self- attention)
# ===== Before =====
layer = nn.Linear(in_features, out_features)
# ===== After ======
import loralib as lora
# Add a pair of low-rank adaptation matrices with rank r=16
layer = lora.Linear(in_features, out_features, r=16)
详见原文:微软LoRA: Low-Rank Adaptation of Large Language Models 代码解读
或 huggingface 代码样例:
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
LoRA 思考
【2024-8-22】大模型面经——LoRA最全总结
优点
- 1)一个中心模型服务多个下游任务,节省参数存储量
- 2)推理阶段不引入额外计算量
- 3)与其它参数高效微调方法正交,可有效组合
- 4)训练任务比较稳定,效果比较好
- 5)LoRA 几乎不添加任何推理延迟,因为适配器权重可以与基本模型合并
缺点
- LoRA 参与训练的模型参数量不多,也就百万到千万级别的参数量,所以效果比全量微调差很多。
- 数据以及算力满足的情况下,还是微调的参数越多越好
训练理论
- ChatGLM-6B LoRA 后的 权重多大?
- rank 8 target_module query_key_value 条件下,大约15M。
- LoRA 微调方法为啥能加速训练?
- 1)只更新了部分参数:比如 LoRA原论文就选择只更新Self Attention的参数,实际使用时还可以选择只更新部分层的参数;
- 2)减少了通信时间:由于更新参数量变少了,所以(尤其是多卡训练时)要传输的数据量也变少了,从而减少了传输时间;
- 3)采用了各种低精度加速技术,如FP16、FP8或者INT8量化等。
- 这三部分原因确实能加快训练速度,然而并不是LoRA所独有,事实上几乎都有参数高效方法都具有这些特点。LoRA的优点是低秩分解很直观,在不少场景下跟全量微调的效果一致,以及在预测阶段不增加推理成本。
- LoRA 这种微调方法和全参数比起来有什么劣势吗?
- 如果有足够计算资源以及有10k以上数据,建议全参数微调
- lora 初衷是解决不够计算资源的情况下微调,只引入了少量参数,就可以在消费级gpu上训练
- 但lora 问题: 不能节省训练时间,相比于全量微调,训练更久,同时因为可训练参数量很小,在同样大量数据训练下,比不过全量微调。
- LORA 应该作用于Transformer 哪个参数矩阵?
- 1)将所有微调参数都放到attention的某一个参数矩阵的效果并不好,将可微调参数平均分配到 Wq 和 Wk 的效果最好;
- 2)即使是秩仅取4也能在 ∆W 中获得足够的信息。
- 实际操作中,应当将可微调参数分配到多种类型权重矩阵中,而不应该用更大的秩单独微调某种类型的权重矩阵。
- LoRA 微调参数量怎么确定?
- LoRA 模型中可训练参数的结果数量取决于低秩更新矩阵的大小,其主要由秩 r 和原始权重矩阵的形状确定。实际使用过程中,通过选择不同的 lora_target 决定训练的参数量。
- 以 LLama 为例: –lora_target q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj
- Lora 矩阵怎么初始化?为什么要初始化为全0?
- 矩阵B被初始化为0,而矩阵A正常高斯初始化。
- 如果B,A全都初始化为0,那么缺点与深度网络全0初始化一样,很容易导致梯度消失(因为此时初始所有神经元的功能都是等价的)。
- 如果B,A全部高斯初始化,那么在网络训练刚开始就会有概率为得到一个过大的偏移值Δ W 从而引入太多噪声,导致难以收敛。
- 因此,一部分初始为0,一部分正常初始化是为了在训练开始时维持网络的原有输出(初始偏移为0),但同时也保证在真正开始学习后能够更好的收敛。
- Rank 如何选取?
- Rank 取值常见的是8,理论上说Rank在4-8之间效果最好,再高并没有效果提升。
- 不过论文的实验是面向下游单一监督任务的,因此在指令微调上根据指令分布的广度,Rank选择还是需要在8以上的取值进行测试。
- 是否可以逐层调整 LoRA 最优rank?
- 理论上,可为不同层选择不同的LoRA rank,类似于为不同层设定不同学习率,但由于增加了调优复杂性,实际中很少执行。
- alpha 参数 如何选取?
- alpha 其实是个缩放参数,本质和learning rate相同,所以为了简化可以默认让
alpha=rank,只调整lr,这样可以简化超参。
- alpha 其实是个缩放参数,本质和learning rate相同,所以为了简化可以默认让
- LoRA 高效微调如何避免
过拟合?- 过拟合还是比较容易出现。减小r或增加数据集大小可以帮助减少过拟合,还可以尝试增加优化器的权重衰减率或LoRA层的dropout值。
- 如何在已有 LoRA 模型上继续训练?
- 理解此问题的情形是:已有lora模型只训练了一部分数据,要训练另一部分数据的话,是在这个lora上继续训练呢,还是跟base 模型合并后再套一层lora,或者从头开始训练一个lora?
- 把之前的LoRA跟base model 合并后,继续训练就可以,为了保留之前的知识和能力,训练新的LoRA时,加入一些之前的训练数据是需要的。每次都要重头训练的话成本比较高。
- 哪些因素会影响内存使用?
- 内存使用受到模型大小、批量大小、LoRA参数数量以及数据集特性的影响。例如,使用较短的训练序列可以节省内存。
- LoRA 权重是否可以合入原模型?
- 可以,将训练好的低秩矩阵(B*A)+原模型权重合并(相加),计算出新的权重。
- LoRA 权重是否可以合并?
- 可将多套LoRA权重合并。训练中保持LoRA权重独立,并在前向传播时添加,训练后可以合并权重以简化操作。
LoRA 实现
官方notebook案例:peft_lora_seq2seq
依赖包:
- transformers提供模型加载和训练;
- peft提供LoRA实现;
- DeepSpeed提供训练加速。
注意:
peft包目前还处于快速迭代当中,后续接口可能会有大的变动,也可能存在一些bug。
关键依赖包版本:
transformers==4.26.1
torch==1.13.1
deepspeed==0.8.2
peft==0.2.0
git clone https://github.com/microsoft/DeepSpeedExamples.git
cd DeepSpeedExamples/applications/DeepSpeed-Chat/
ds lora
deepspeed --num_gpus 1 main.py \
--data_path Dahoas/rm-static \
--data_split 2,4,4 \
--model_name_or_path facebook/opt-6.7b \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--max_seq_len 512 \
--learning_rate 1e-3 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 16 \
--lr_scheduler_type cosine \
--num_warmup_steps 0 \
--seed 1234 \
--gradient_checkpointing \
--zero_stage 0 \
--lora_dim 128 \
--lora_module_name decoder.layers. \
--deepspeed \
--output_dir $OUTPUT_PATH \
&> $OUTPUT_PATH/training.log
训练代码
假设训练代码位于train.py。
导入依赖包
import os
import torch
import random
import datasets
import numpy as np
from tqdm import tqdm
from typing import Dict
from torch.utils.data import DataLoader
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
DataCollatorForSeq2Seq,
TrainingArguments,
Trainer
)
from peft import (
LoraConfig,
TaskType,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict
)
def set_random_seed(seed):
if seed is not None and seed > 0:
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.random.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
set_random_seed(1234)
# ----- 设置参数 -----
# LoRA参数
LORA_R = 8
LORA_ALPHA = 32
LORA_DROPOUT = 0.1
# 训练参数
EPOCHS=3
LEARNING_RATE=5e-5
OUTPUT_DIR="./checkpoints"
BATCH_SIZE=4 # 2
GRADIENT_ACCUMULATION_STEPS=3
# 其他参数
MODEL_PATH = "bigscience/bloomz-7b1-mt"
DATA_PATH = "./data/belle_open_source_1M.train.json"
MAX_LENGTH = 512
PATTERN = "{}\n{}"
DS_CONFIG = "ds_zero2_config.json"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH) # 加载tokenizer
# ---- 加载数据 -----
dataset = datasets.load_dataset("json", data_files=DATA_PATH)
# print(dataset["train"][0])
# tokenize 分词
def tokenize(text: str, add_eos_token=True):
result = tokenizer(
text,
truncation=True,
max_length=MAX_LENGTH,
padding=False,
return_tensors=None)
# 判断是否要添加eos_token
if (result["input_ids"][-1] != tokenizer.eos_token_id
and len(result["input_ids"]) < MAX_LENGTH
and add_eos_token):
result["input_ids"].append(tokenizer.eos_token_id)
result["attention_mask"].append(1)
result["labels"] = result["input_ids"].copy()
return result
def preprocess(example: Dict, train_on_inputs: bool = False):
prompt = example["input"]
response = example["target"]
text = PATTERN.format(prompt, response)
tokenized_inp = tokenize(text)
# 若train_on_inputs为False,则将label中与input相关的token替换为-100
if not train_on_inputs:
tokenized_prompt = tokenize(prompt,add_eos_token=False)
prompt_tokens_len = len(tokenized_prompt["input_ids"])
tokenized_inp["labels"] = [-100]*prompt_tokens_len + tokenized_inp["labels"][prompt_tokens_len:]
return tokenized_inp
train_data = dataset["train"].shuffle().map(preprocess, remove_columns=["id", "input", "target"])
print(train_data[0])
# ----- collate_fn -----
# pad_to_multiple_of=8表示padding的长度是8的倍数
collate_fn = DataCollatorForSeq2Seq(tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True)
# 加载模型
device_map = {"": int(os.environ.get("LOCAL_RANK") or 0)}
# device_map指定模型加载的GPU;troch_dtype=torch.float16表示半精度加载模型
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, torch_dtype=torch.float16, device_map=device_map)
# ----- LoRA相关 -----
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=LORA_R, # LoRA中低秩近似的秩
lora_alpha=LORA_ALPHA, # 见上文中的低秩矩阵缩放超参数
lora_dropout=LORA_DROPOUT, # LoRA层的dropout
)
# ----- 转换模型 -----
model = get_peft_model(model, lora_config)
model.config.use_cache = False
old_state_dict = model.state_dict
model.state_dict = (
lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())
).__get__(model, type(model))
# 打印模型中的可训练参数
model.print_trainable_parameters()
# ----- 训练参数 -----
args = TrainingArguments(
output_dir=OUTPUT_DIR, # checkpoint的存储目录
per_device_train_batch_size=BATCH_SIZE, # 单设备上的batch size
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS, # 梯度累加的step数
warmup_steps=100,
num_train_epochs=EPOCHS,
learning_rate=LEARNING_RATE,
fp16=True, # 使用混合精度训练
logging_steps=50,
evaluation_strategy="no", # 不进行评估
save_strategy="steps",
save_steps=2000, # 保存checkpoint的step数
save_total_limit=5, # 最多保存5个checkpoint
deepspeed=DS_CONFIG
)
# 模型训练
trainer = Trainer(
model=model,
train_dataset=train_data,
eval_dataset=None,
args=args,
data_collator=collate_fn
)
trainer.train()
model.save_pretrained("best_model")
DeepSpeed配置文件
- DeepSpeed配置文件名为ds_zero2_config.json。
{
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"steps_per_print": 50,
"gradient_clipping": 1.0,
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu"
},
"contiguous_gradients": true,
"overlap_comm": true
},
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "Adam",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"activation_checkpointing": {
"partition_activations": true,
"contiguous_memory_optimization": true
},
"wall_clock_breakdown": false
}
启动
deepspeed --include=localhost:0,1,2,3 train.py
LoRA 推理
推理文件名为inference.py
原始模型和lora模型顺序处理,再合并
- 先加载 base_model
- 再加载 lora_model
- 推理
import torch
from peft import PeftModel # lora
from transformers import AutoModelForCausalLM, AutoTokenizer
# ---- 原始模型 -----
BASE_MODEL = "bigscience/bloomz-7b1-mt"
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL,
torch_dtype=torch.float16, # 加载半精度
device_map={"":0}, # 指定GPU 0
)
model.eval()
# ---- LoRA模型 -----
LORA_WEIGHTS = "best_model"
model = PeftModel.from_pretrained(model, LORA_WEIGHTS, torch_dtype=torch.float16)
model.half() # 半精度
# ---- 推理 -----
prompt = ""
inp = tokenizer(prompt, max_length=512, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids=inp["input_ids"], max_new_tokens=256)
print(tokenizer.decode(outputs[0]))
LoRA 进化
总结
LoRA 进化版本完整对比表(截至2026.4,豆包整理)
- 性能逼近全微调:DoRA → Dual LoRA,通过幅度-方向解耦缩小与全微调差距
- 极致参数效率:VeRA → MiSS-LoRA,参数量降至LoRA的5%以下
- 多任务/复杂场景:HydraLoRA,共享+分支架构适配异构数据
- 安全合规:VeriLoRA,解决不可信算力下的可验证微调需求
- 重评估结论(2026.2):台大+IBM研究显示,最优学习率下各版本差距<2%,基础LoRA仍高效
| LoRA 版本 | 发布时间 | 研发机构 | 论文(标题+链接) | 核心特点 | 主要效果 | 图解 |
|---|---|---|---|---|---|---|
| LoRA (基础版) | 2021.06 | 微软 | LoRA: Low-Rank Adaptation of Large Language Models | 冻结预训练权重,仅训练低秩矩阵A、B;ΔW=BA | 参数量<1%,推理可合并、零延迟;效果接近全微调 | 无(基础架构,核心为低秩矩阵分解示意图,可参考论文Figure 1) |
| QLoRA | 2023.05 | 华盛顿大学 | QLoRA: Efficient Finetuning of Quantized LLMs | 4-bit NF4量化主模型+LoRA;双量化、分页优化器 | 显存降至1/4,65B模型单24GB卡可训;精度损失<1% | 无(核心图解为4-bit量化+LoRA融合架构,可参考论文Figure 2) |
| AdaLoRA | 2023.03 | 微软、佐治亚理工 | Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning | 按层重要性动态分配秩r;自适应奇异值裁剪 | 同参数量精度+2~4%;资源分配更高效 | 无(核心图解为动态秩分配流程,可参考论文Figure 3) |
| LoRA+ | 2024.02 | UC Berkeley | LoRA+: Efficient Low Rank Adaptation of Large Models | A、B用不对称学习率(B学习率≈A的16倍);优化初始化 | 训练更快、收敛更稳;复杂任务精度+5~10% | 无(核心图解为不对称学习率更新机制,可参考论文Figure 4) |
| DoRA | 2024.02 | NVIDIA | DoRA: Weight-Decomposed Low-Rank Adaptation | 权重分解为幅度m+方向V(LoRA);独立训练 | 更逼近全微调;推理误差-12%;小秩下优势显著 | 无(核心图解为权重幅度-方向分解示意图,可参考论文Figure 1) |
| HydraLoRA | 2024.04.23 | 澳门大学+剑桥 | HydraLoRA: An Asymmetric LoRA Architecture for Efficient Fine-Tuning | 共享A矩阵+多分支B矩阵;捕捉共性+特性;多任务适配 | 多任务干扰-40%;复杂数据集精度+5~8% | 无(核心图解为不对称共享架构,可参考论文Figure 1) |
| VeRA | 2024.03 | 高通 | VeRA: Vector-based Random Matrix Adaptation | 共享全局低秩矩阵+层专属缩放向量;极低参数量 | 参数量比LoRA-90%;效果接近标准LoRA | 无(核心图解为共享低秩矩阵架构,可参考论文Figure 2) |
| PiSSA | 2024.05 | 清华、港中文 | PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models | SVD初始化;主成分优先更新;奇异值动态缩放 | 逼近全微调;小数据/少样本更稳;收敛更快 | 无(核心图解为SVD初始化流程,可参考论文Figure 1) |
| Dual LoRA | 2025.12.3 | AMD | Dual LoRA: Enhancing LoRA with Magnitude and Direction Updates | 并行幅度分支+方向分支;双路径协同更新 | 比DoRA精度+1~3%;复杂任务泛化更强 | 无(核心图解为双分支协同更新架构,可参考论文Figure 1) |
图解
交互图
【2026-4-6】龙虾(QClaw)整理的 LoRA 进化图,点击看
自制图
【2026-4-3】
旧图
【2024-5-24】
LoRA vs Full
【2025-9-29】Thinking Machines 最新研究:解读
- 小数据量任务上,LoRA 与 FullFT 几乎没有差距,完全可以对齐;
- 大数据量任务上,LoRA 容量不足,承载不了过多新知识,表现略显吃力;
- 而在强化学习任务里,哪怕 LoRA rank=1 这么小的设定,也能跑出与全量微调接近的效果。
LoRA 的使用位置也有讲究。
- 只加在注意力层并不理想,覆盖所有层(尤其 MLP/MoE)效果更佳。
- LoRA 在大 batch size 下,比 FullFT 更容易掉性能;
- LoRA 学习率和超参数规律与 FullFT 不同,需要单独调优。
单 LoRA
【2023-3-18】AdaLoRA
对LoRA的一种改进,根据重要性评分动态分配参数预算给权重矩阵,将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。
论文
出发点:
- 在不同层、不同\(\textbf{W}\)上添加LoRA,效果不同,那么如何在规定的总rank预算下,达成最优效果。也就是如何给不同\(\textbf{W}\)分配不同的rank进行finetune
预训练语言模型中的不同权重参数对下游任务的贡献不同。
因此需要更加智能地分配参数预算,以便在微调过程中更加高效地更新那些对模型性能贡献较大的参数。
- 通过奇异值分解将权重矩阵分解为增量矩阵,并根据新重要性度量动态地调整每个增量矩阵中奇异值的大小。
- 这样可以使得在微调过程中只更新那些对模型性能贡献较大或必要的参数,从而提高了模型性能和参数效率。
效果
- 在相同总rank下,adaLoRA效果好于LoRA
- 不同层不同\(\textbf{W}\)的rank:更偏好FFN1和更高层的W
代码样例:
peft_config = AdaLoraConfig(peft_type="ADALORA", task_type="SEQ_2_SEQ_LM", r=8, lora_alpha=32, target_modules=["q", "v"],lora_dropout=0.01)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
【2023-5-23】QLoRA
【2023-5-23】华盛顿大学发布一种高效的微调方法:QLoRA,在保持完整的16位微调任务性能下,实现单个 48GB GPU 上微调 65B 参数量模型。
- QLoRA: Efficient Finetuning of Quantized LLMs
- github:QLoRA,Demo
- 参考:开源「原驼」爆火,iPhone都能微调大模型了,得分逼近ChatGPT!
QLoRA 通过冻结的 4-bit 量化预训练语言模型向低秩适配器(LoRA) 反向传播梯度。使用 4-bit NormalFloat (NF4) 量化、Double Quantization、Paged Optimizers、所有 Linear 层插入 adapter 等技术,QLoRA 在不牺牲性能的情况下大大节省了显存占用。
说明如下:
- 4bit NormalFloat(NF4):对于正态分布权重而言,一种信息理论上最优的新数据类型,该数据类型对于正态分布数据可以产生比 4 bit 整数和 4bit 浮点数更好的实证结果。
- Double Quantization:对第一次量化后的那些常量再进行一次量化,减少存储空间。
- Paged Optimizers:使用 NVIDIA 统一内存特性,实现了 CPU 和 GPU 之间自动的页面转换。当 GPU 内存不足时,Paged Optimizers 技术会自动将优化器状态转移到 CPU 内存,以确保优化器的正常运行。
-
All-Linear-Layer-Adapter:在所有全连接层都插入 LoRA Adapter,增加了训练参数,能匹配16位全参数微调的性能。
- 减少内存使用量,足以在单个 48GB GPU 上微调 65B 参数模型,同时保留完整的 16 位微调任务性能。其中最好的模型称为
Guanaco,在Vincuna基准测试中优于之前公开发布的模型,并缩小了在 ChatGPT 上的差距,达到 ChatGPT 性能水平的 99.3%,同时仅在单个专业 GPU 上微调 24 小时。
Q代表量化(Quantization),用低精度数据类型去逼近神经网络中的高精度浮点数,以提高运算效率
QLoRA 结合了 4-bit量化 和 LoRA,以及团队新创的三个技巧:
- 新数据类型 4-bit NormalFloat
- 分页优化器(Paged Optimizers)
- 双重量化(Double Quantization)
最终, QLoRA 让 4-bit的原驼在所有场景和规模的测试中匹配16-bit的性能。
- QLoRA的高效率让团队在华盛顿大学的小型GPU集群上每天可以微调LLaMA 100多次
两个关键结论:
- 数据质量 » 数据数量
- 指令微调有利于推理,但不利于聊天
QLoRA可以用在手机上,论文共同一作Tim Dettmers估计以 iPhone 12 Plus的算力, 每个晚上能微调300万个单词的数据量。
特点
- 用 QLoRA 微调模型,可以显著降低对于显存的要求。
- 同时,模型训练的速度会慢于LoRA。
【2023-8-7】LoRA-FA
LoRA-FA,香港科技大学
做法
- 随机初始化 A , B 初始化为\(\textbf{0}\)矩阵
- freeze A ,只更新\(\textbf{B}\),需要更新的参数降为一半
效果也与LoRA相当
- 减少训练参数,不减少计算量
【2023-8-21】ReLoRA
【2023-8-21】LoRA继任者ReLoRA登场,通过叠加多个低秩更新矩阵实现更高效大模型训练效果
- 论文链接:paper
- 代码仓库:peft_pretraining
- 过去十年中深度学习发展阶段中的一个核心原则就是不断的“堆叠更多层(stack more layers). 那么继续以堆叠方式来提升低秩适应的训练效率
马萨诸塞大学洛厄尔分校将ReLoRA应用在具有高达350M参数的Transformer上时,展现出了与常规神经网络训练相当的性能。
此外,ReLoRA的微调效率会随着模型参数规模增加而不断提高,这使得其未来有可能成为训练超大规模(通常超过1B参数)LLMs的新型手段。
论文提出一种基于低秩更新的ReLoRA方法训练和微调高秩网络,其性能优于具有相同可训练参数数量的网络,甚至能够达到与训练100M+规模的完整网络类似的性能,对比效果如图所示。
从两个矩阵之和的秩入手
- 矩阵相加的后秩的上界会比较紧凑
- 对于矩阵 A, B,满足 Rank(A) < dim(A),B同理, 使得矩阵之和的秩高于 A 或 B
利用这一特性制定灵活的参数高效训练方法,然后从LoRA算法开始入手,LoRA可以将模型权重的更新量 delta(W) 分解为一组低秩矩阵乘积
ReLoRA方法包含
- (1)初始化全秩训练
- (2)LoRA 训练
- (3)参数重新启动
- (4)锯齿状学习率调度(jagged learning rate schedule)
- (5)优化器参数部分重置。
作者选择目前非常火热的自回归语言模型进行实验,并且保证每个实验所使用的GPU计算时间不超过8天。
【2023-10-1】LongLoRA
【2023-10-1】贾佳亚韩松团队新作:两行代码让大模型上下文窗口倍增
只要两行代码+11个小时微调,就能把大模型4k的窗口长度提高到32k。
规模上,最长可以扩展到10万token,一口气就能读完长篇小说的多个章节或中短篇小说。
贾佳亚韩松联合团队提出的这个基于LoRA的全新大模型微调方法,登上了GitHub热榜,开源一周时间收获1k+ stars。这种方式叫做 LongLoRA ,由来自香港中文大学和MIT的全华人团队联合出品。
在一台8个A100组成的单机上,增大窗口长度的速度比全量微调快数倍。
【2024-1-16】VERA
阿姆斯特丹大学
- 不训练AB,训练额外的两个向量
- AB在所有层共享,且都随机初始化,显著减少需要训练的参数量
效果
- 可学习参数量显著少于LoRA的情况下,效果和LoRA基本持平
【2024-2-19】LoRA+
【2024-2-19】LoRA+
结论
- 当B的学习率大于A的学习率时效果更好
- B的学习率是A的 \(\sqrt{m/r}\) 倍时, 效果最好(理论值,实验时倍数当作超参)
【2024-3-1】DoRA
【2024-3-1】DoRA:LoRA再升级-参数高效微调
Lora 本质上把大矩阵拆成两个小矩阵的乘法

class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank, alpha):
super().__init__()
std_dev = 1 / torch.sqrt(torch.tensor(rank).float())
self.A = nn.Parameter(torch.randn(in_dim, rank) * std_dev)
self.B = nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
def forward(self, x):
x = self.alpha * (x @ self.A @ self.B)
return x
class LinearWithLoRAMerged(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
lora = self.lora.A @ self.lora.B # Combine LoRA matrices
# Then combine LoRA with orig. weights
combined_weight = self.linear.weight + self.lora.alpha*lora.T
return F.linear(x, combined_weight, self.linear.bias)
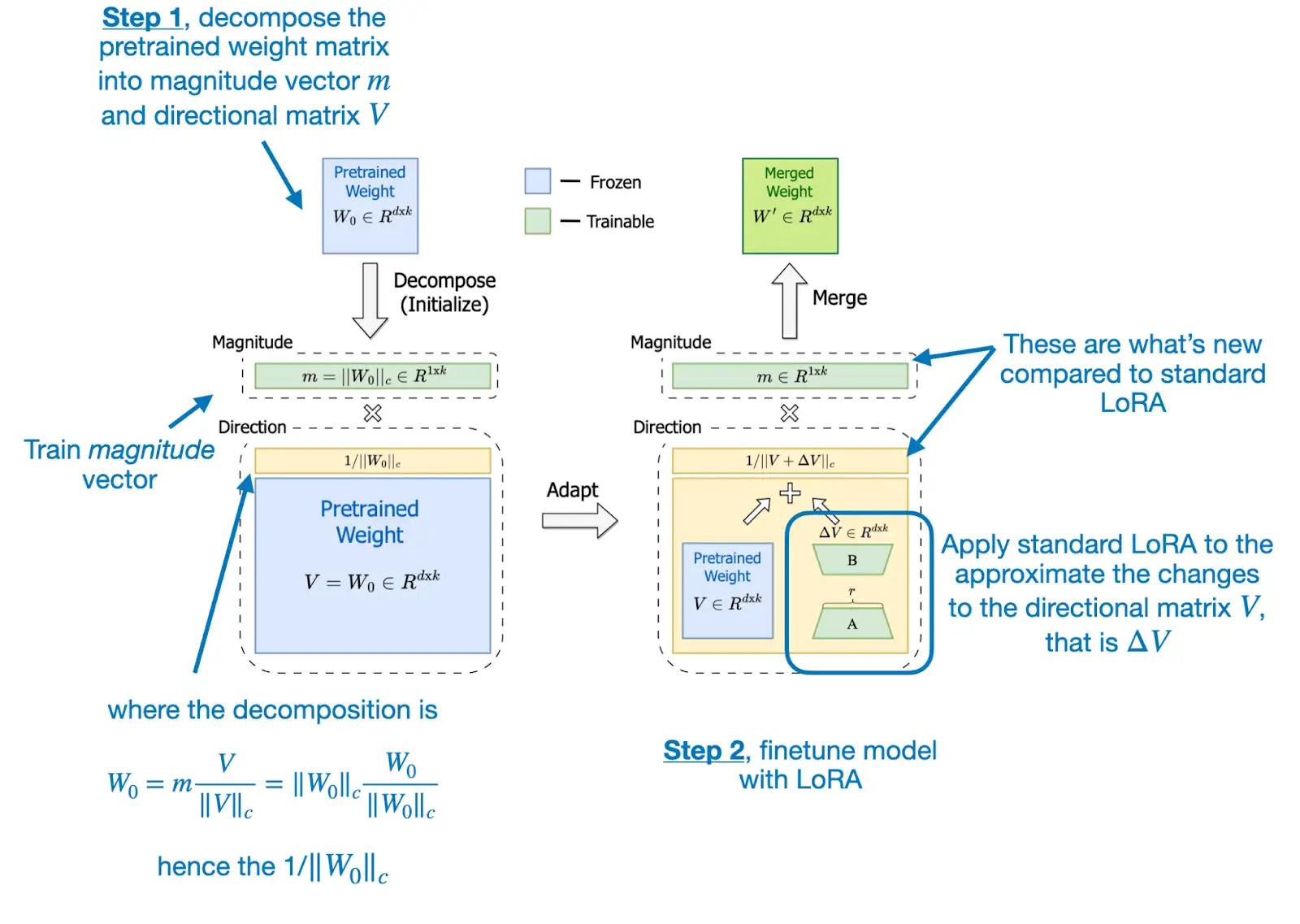
DoRA(Weight-Decomposed Low-Rank Adaptation)主要思想
- 将预训练权重分解为幅度(magnitude)和方向(direction),并利用LoRA来微调方向矩阵
- 公式见原文
class LinearWithDoRAMerged(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
self.m = nn.Parameter(
self.linear.weight.norm(p=2, dim=0, keepdim=True))
# Code loosely inspired by
# https://github.com/catid/dora/blob/main/dora.py
def forward(self, x):
lora = self.lora.A @ self.lora.B
numerator = self.linear.weight + self.lora.alpha*lora.T
denominator = numerator.norm(p=2, dim=0, keepdim=True)
directional_component = numerator / denominator
new_weight = self.m * directional_component
return F.linear(x, new_weight, self.linear.bias)
LoRA通常会等比例增减幅度和方向,DoRA通过将预训练权重矩阵分解为幅度和方向,能够更接近全量微调的效果。
- 使用比LoRA更少的参数,效果还更好
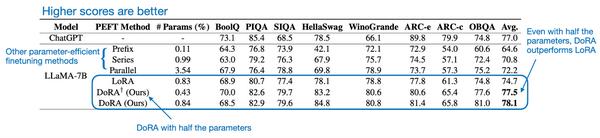
- 使用较小的rank,效果也很好
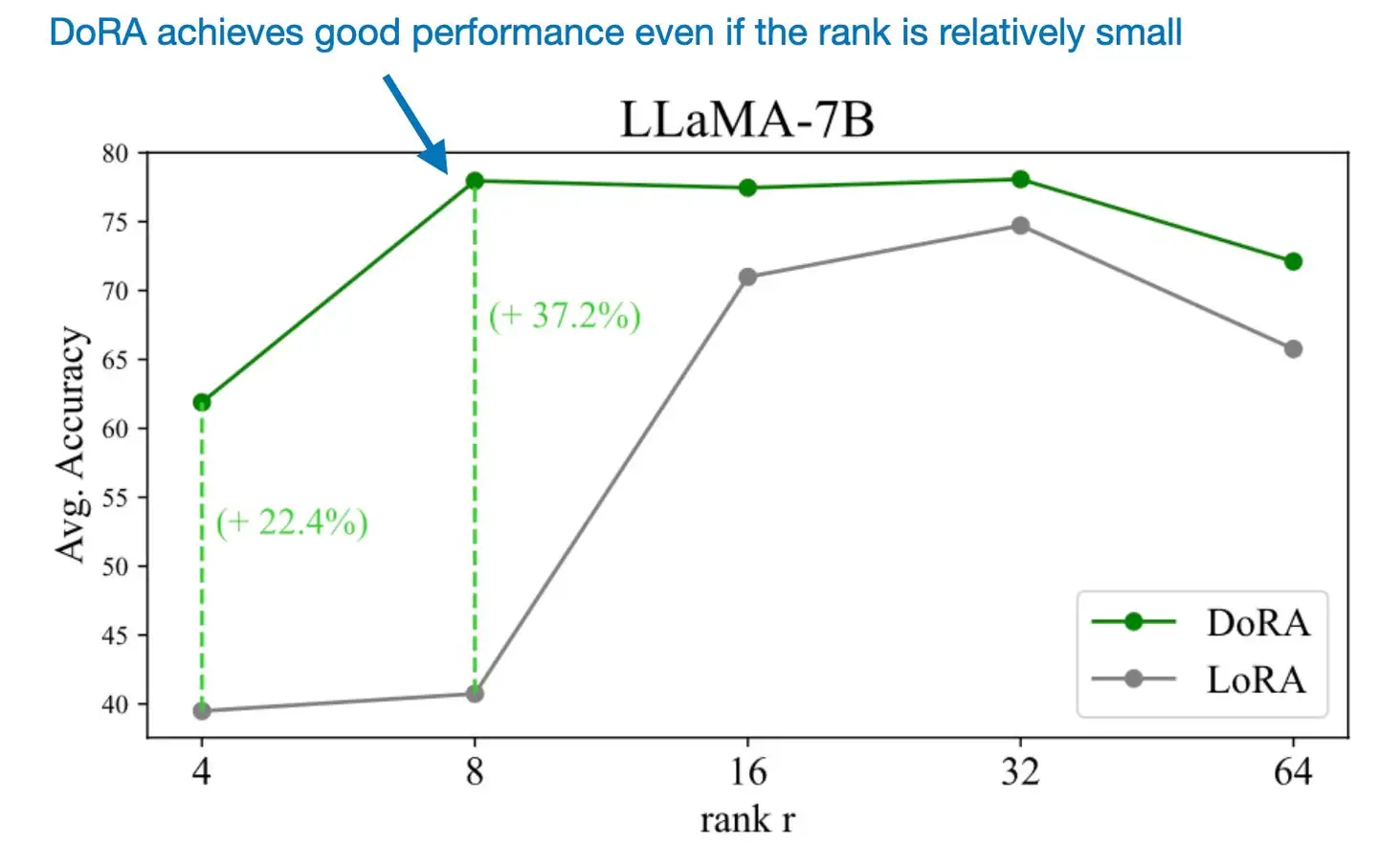
- DoRA在多个数据集上效果好于LoRA
- DoRA对不同rank r取值更鲁棒
相信DoRA应该很快会成为一种普遍的大模型微调方法。
资料:
- DoRA: Weight-Decomposed Low-Rank Adaptation
- Improving LoRA: Implementing Weight-Decomposed Low-Rank Adaptation (DoRA) from Scratch
【2024-3-28】LISA
LoRA(Low-Rank Adaptation)
LoRA是一种大模型微调技术,核心思想是在预训练的大型语言模型(PLM)基础上,通过增加一个低秩适配器来实现微调。这种方法通过在原始模型的每一层注入可训练的低秩矩阵,从而以较小的参数量实现模型的微调。
LoRA主要优势在于减少了微调过程中需要更新的参数数量,从而降低了存储和计算资源的需求。然而,LoRA在某些任务上可能无法超越全参数微调的效果,且其理论性质分析较为困难。
【2024-3-28】香港理工 LISA(Layerwise Importance Sampled AdamW)
LISA是由UIUC联合LMFlow团队提出的另一种大模型微调方法。
- 与LoRA不同,LISA算法核心在于始终更新底层embedding和顶层linearhead,同时随机更新少数中间的self-attention层。
- 这种方法在实验中显示出在指令微调任务上超过LoRA甚至全参数微调的效果。
- LISA的空间消耗与LoRA相当甚至更低,且由于其每次中间只会激活一小部分参数,对更深的网络和梯度检查点技术(GradientCheckpointing)也很友好,能够带来更大的空间节省。
此外,LISA的收敛性质比LoRA有很大提升(17~30%),且计算速度比LoRA快将近50%。
对比总结
- 微调效果:LISA在某些任务上显示出比LoRA更好的微调效果,甚至能超越全参数微调。
- 资源消耗:LISA在空间消耗上与LoRA相当,但由于其更新策略,可能在某些情况下更加节省资源。
- 计算速度:LISA的计算速度比LoRA快,因为它减少了需要更新的参数数量。
- 理论分析:LISA的理论性质相对容易分析,可以使用现有的优化领域的数学工具进行分析。
- 应用友好性:LISA对更深的网络和梯度检查点技术更加友好,有助于在资源受限的情况下进行微调。
综上所述,LISA在保持与LoRA相当的资源消耗的同时,提供了更快的计算速度和更好的微调效果,是一种具有潜力的大模型微调技术。
【2024-4-12】PiSSA
【2024-4-12】改变LoRA的初始化方式,北大新方法PiSSA显著提升微调效果
北京大学的研究团队提出了一种名为 PiSSA 的参数高效微调方法,主流数据集上都超过了目前广泛使用的 LoRA 的微调效果。
- 论文: PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
- 代码链接: PiSSA
PiSSA 在模型架构上和 LoRA 完全一致,只是Adapter初始化方式不同。img
LoRA使用高斯噪声初始化 A,使用 0 初始化 B。PiSSA用主奇异值和奇异向量 (Principal Singular values and Singular vectors) 来初始化 Adapter 来初始化 A 和 B。
效果
- PiSSA 微调效果显著超越了 LoRA,甚至超越了全参数微调
- PiSSA 比 LoRA 收敛更快,最终效果更好,唯一的代价仅是需要几秒的 SVD 初始化过程。
【2024-4-15】LoRA Dropout
LoRA Dropout, PKU
- 训练阶段对A和B矩阵进行整行或整列的dropout,而不是element-wise的dropout,这样可以使得BA中有大量为0值,达到mask W的效果
- inference时,无法像原始dropout那样乘以(1-p)来rescale。因此需多次使用dropout,取ensemble的结果,效果有提升(效率降低)
效果
- +dropout在lora和adalora上效果均更好
- Dropout rate取0.6时效果最好
【2024-6-18】LoRA-drop
哈工大
-
LoRA在不同位置(针对不同W)的 $$ \Delta Wx $$ 不同,认为越大的越重要 - 按以下步骤将不重要的LoRA进行权重共享,然后重新训练,减少训练参数,不减少计算量
效果与lora差不多,可减少lora约一半的内存占用
动态 LoRA
DyLoRA ,两者方法都是动态调整模型。区别在于 DRLora 是基于 Prompt 与数据集的相似性调整LoRA适配器的权重,而 DyLoRA 是在训练和推断期间动态适应不同的秩(rank)。
【2022-10-14】DyLoRA
【2022-10-14】与传统 LoRA不同的是,DyLoRA 在训练过程中针对一系列 rank 而不是单一 rank 进行训练。
- DyLoRA论文地址:DyLoRA: Parameter-Efficient Tuning of Pretrained Models using Dynamic Search-Free Low Rank Adaptation
- 代码 DyLoRA/loralib
【2025-1-24】Dynamic LoRA
【2026-7-6】Dynamic LoRA,几乎不增加计算量,效果直接比普通LoRA涨8个点!
以前LoRA微调所有层都加一样的参数,又浪费效果又一般, Lora 训练 定义 rank 大小是比较头疼的事情, 太小往往效果不行,太大容易过拟合或发生模型遗忘问题。
【2025-1-24】纽约大学 推出 Dynamic LoRA 自动分配参数,白捡效果!
🔥为什么Dynamic LoRA这么强:
- ✅ 自动给重要层分更多参数,不重要层少分
- ✅ 不同输入动态调整适配器权重
- ✅ 几乎不增加计算量,训练速度一样快
- ✅ GLUE准确率直接到88.1%,比普通LoRA高一大截
工程优化
【2023-11-15】S-LoRA 多服务部署
【2023-11-15】S-LoRA:一个GPU运行数千大模型成为可能
大语言模型部署都会采用「预训练 — 微调」模式。但是,针对众多任务(如个性化助手)对 base 模型进行微调时,训练和服务成本会变得非常高昂。
低秩适配(LowRank Adaptation,LoRA)是一种参数效率高的微调方法,通常用于将 base 模型适配到多种任务中,从而产生了大量从一个 base 模型衍生出来的 LoRA 适配程序。
只对适配器权重进行微调,就能获得与全权重微调相当的性能。虽然这种方法可以实现单个适配器的低延迟推理和跨适配器的串行执行,但在同时为多个适配器提供服务时,会显著降低整体服务吞吐量并增加总延迟。总之,如何大规模服务于这些微调变体的问题仍未得到解决。
UC 伯克利、斯坦福等高校的研究者提出了一种名为 S-LoRA 的新微调方式。
S-LoRA 专为众多 LoRA 适配程序的可扩展服务而设计,它将所有适配程序存储在主内存中,并将当前运行查询所使用的适配程序取到 GPU 内存中。
- S-LoRA 提出「统一分页」(Unified Paging)技术,即使用统一的内存池来管理不同等级的动态适配器权重和不同序列长度的 KV 缓存张量。
- PagedAttention 扩展为统一分页(Unified Paging),后者除了管理 KV 缓存外,还管理适配器权重。
- 此外,S-LoRA 还采用了新的张量并行策略和高度优化的定制 CUDA 内核,以实现 LoRA 计算的异构批处理。
S-LoRA 包含三个主要创新部分。论文第 4 节介绍了批处理策略,该策略分解了 base 模型和 LoRA 适配器之间的计算。此外,研究者还解决了需求调度的难题,包括适配器集群和准入控制等方面。跨并发适配器的批处理能力给内存管理带来了新的挑战。第 5 节,研究者将 PagedAttention 推广到 Unfied Paging,支持动态加载 LoRA 适配器。这种方法使用统一的内存池以分页方式存储 KV 缓存和适配器权重,可以减少碎片并平衡 KV 缓存和适配器权重的动态变化大小。最后,第 6 节介绍了新的张量并行策略,能够高效地解耦 base 模型和 LoRA 适配器。
如果将 LoRA 适配器存储在主内存中,数量可能会很大,但当前运行批所需的 LoRA 适配器数量是可控的,因为批大小受 GPU 内存的限制。为了利用这一优势,研究者将所有的 LoRA 适配卡都存储在主内存中,并在为当前正在运行的批进行推理时,仅将该批所需的 LoRA 适配卡取到 GPU RAM 中。在这种情况下,可服务的适配器最大数量受限于主内存大小。

这些功能使 S-LoRA 能够以较小开销在单个 GPU 或多个 GPU 上为数千个 LoRA 适配器提供服务(同时为 2000 个适配器提供服务),并将增加的 LoRA 计算开销降至最低。相比之下,vLLM-packed 需要维护多个权重副本,并且由于 GPU 内存限制,只能为少于 5 个适配器提供服务。
与 HuggingFace PEFT 和 vLLM(仅支持 LoRA 服务)等最先进的库相比,S-LoRA 吞吐量最多可提高 4 倍,服务适配器数量可增加几个数量级。因此,S-LoRA 能够为许多特定任务的微调模型提供可扩展的服务,并为大规模定制微调服务提供了潜力。
MoE+LoRA
总结
【2024-3-5】大模型微调新范式:当LoRA遇见MoE
对比
- 原始版本的 LoRA,权重稠密,每个样本都会激活所有参数;
- 与混合专家(MoE)框架结合的 LoRA,每一层插入多个并行的 LoRA 权重(即 MoE 中的多个专家模型),路由模块(Router)输出每个专家的激活概率,以决定激活哪些 LoRA 模块。
为了克服稠密模型的参数效率瓶颈,以 Mistral、DeepSeek MoE 为代表的混合专家(Mixure of Experts,简称 MoE)模型框架。
模型某个模块(如 Transformer 的某个 FFN 层)存在多组形状相同的权重(称为专家),另外有一个路由模块(Router)接受原始输入、输出各专家的激活权重,最终的输出为:
- 如果是软路由(soft routing),输出各专家输出的加权求和;
- 如果是离散路由(discrete routing),即 Mistral、DeepDeek MoE 采用的稀疏混合专家(Sparse MoE)架构,则将 Top-K(K 为固定的 超参数,即每次激活的专家个数,如 1 或 2)之外的权重置零,再加权求和。
MoE 架构中每个专家参数的激活程度取决于数据决定的路由权重,使得各专家的参数能各自关注其所擅长的数据类型。在离散路由的情况下,路由权重在 TopK 之外的专家甚至不用计算,在保证总参数容量的前提下极大降低了推理的计算代价。
案例
- MoV、MoLORA、LoRAMOE 和 MOLA 等新的 PEFT 方法,相比原始版本的 LORA 进一步提升了大模型微调的效率。
详情
MoV和MoLORA:- 2023 年 9 月,首个结合 PEFT 和 MoE 的工作,MoV 和 MoLORA 分别是
IA和LORA的 MOE 版本,采用 token 级别的软路由(加权合并所有专家的输出)。 - 对 3B 和 11B 的 T5 大模型的 SFT,MoV 仅使用不到 1% 可训练参数量就可以达到和全量微调相当的效果,显著优于同等可训练参数量设定下的 LoRA。
MoLORA论文: Pushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning- 结论
- 15个expert效果能超过full finetune
- expert不是越多越好,后面会收敛
- Soft router好于top-1/2,可能是由于top-1/2这种本身难于训练,样本还少
- 对于multi-task数据集,不同expert能focus在不同task上
- 2023 年 9 月,首个结合 PEFT 和 MoE 的工作,MoV 和 MoLORA 分别是
LoRAMoE:LoRA专家分组,预训练知识记得更牢- 问题:随着所用数据量的增长,SFT 训练会导致模型参数大幅度偏离预训练参数,预训练阶段学习到的世界知识(world knowledge)逐渐被遗忘,虽然模型的指令跟随能力增强、在常见的测试集上性能增长,但需要这些世界知识的 QA 任务性能大幅度下降
- 2023 年 12 月,在
MoLORA基础上,为解决微调大模型时的灾难遗忘问题,将同一位置的 LoRA 专家分为两组,分别负责保存预训练权重中的世界知识和微调时学习的新任务,并为此目标设计了新的负载均衡 loss。 - LoRAMoE: Revolutionizing Mixture of Experts for Maintaining World Knowledge in Language Model Alignment
MOLA:统筹增效,更接近输出端的高层需要更多专家- 问题: 专家个数过多容易导致性能下降
- 2024 年 2 月,使用离散路由(每次只激活路由权重 top-2 的专家),并发现在每一层设置同样的专家个数不是最优的,增加高层专家数目、降低底层专家数目,能在可训练参数量不变的前提下,明显提升 LLaMa-2 微调的效果。
- 模型的不同层添加不同数量的LoRA experts,越高层使用更多expert效果更好
- 论文 Higher Layers Need More LoRA Experts
- 相同总experts数的情况下,倒三角结构效果最好。越高层离output越近,参数就越重要(非MOE情况下,也是更高层的LoRA更重要)
LoRAMoE
结合LoRA和MoE的优点,将二者组合起来,便是LoRAMoE
冻结已经预训练好的LLM,然后在FFN层中的每个线性层增加了一组LoRA适配器作为专家网络组,并通过门控网络(路由器机制)分配权重
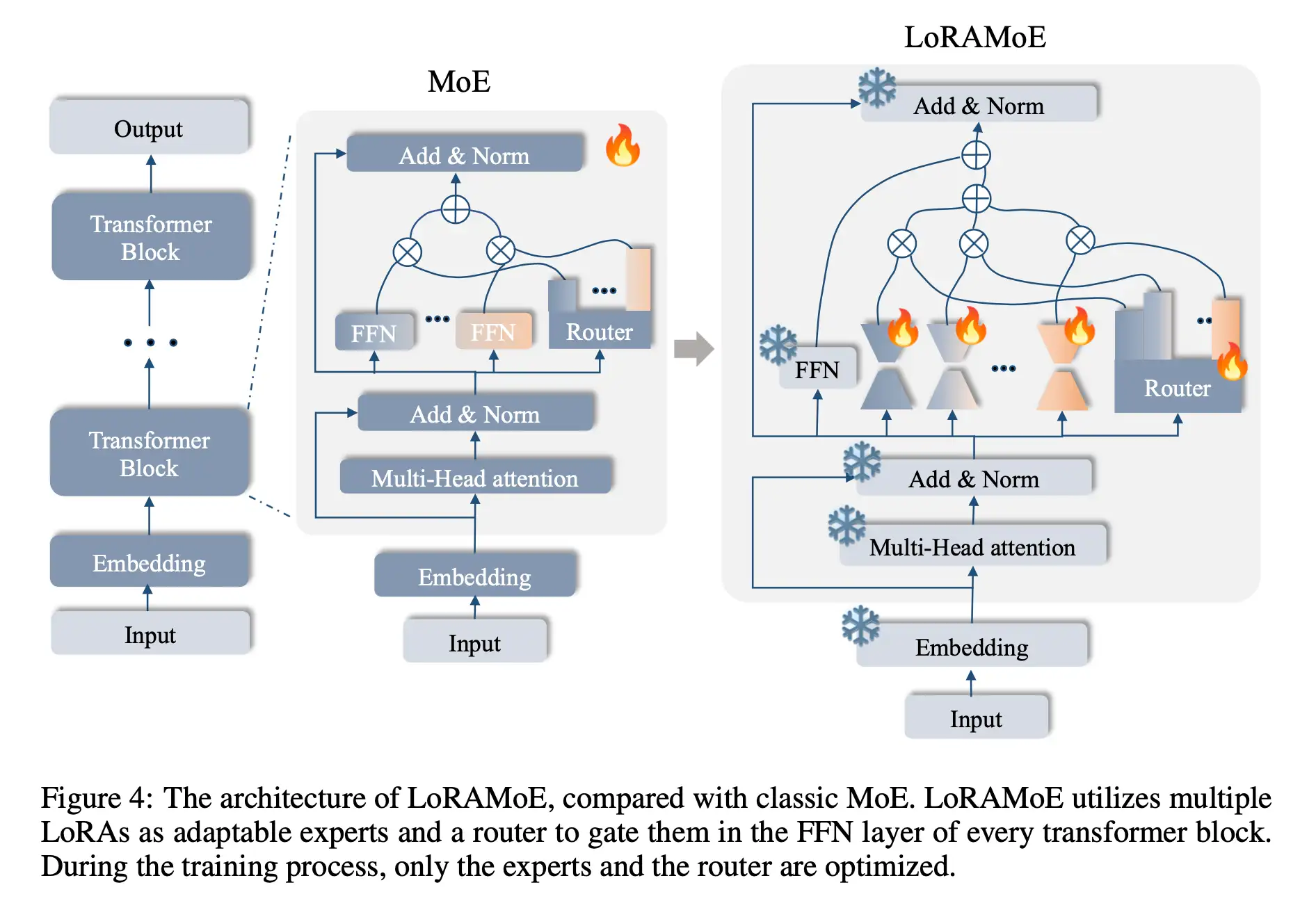
专家平衡约束
- 如果不加任何约束, 微调MoE,会出现门控函数收敛到一种状态,即少数专家掌握了话语权,其他专家权重非常小,失去了平衡。
- LoRAMoE 将专家分为两组,一组专注于学习下游任务,另一组专注于将世界知识和人类指令对齐。
X-LoRA
【2024-3-30】MIT 推出 X-LoRA: LoRA+混合专家模型(Mixture or Experts, MOE)
X-LoRA(Mixture of LoRA Experts)通过结合LoRA(Low-Rank Adaptation)专家以密度门控的方式优化模型性能。
- 该技术允许基于现有预训练模型进行高效微调,显著减少训练参数数量。
- 通过学习特定缩放值来控制每个LoRA专家影响,这些专家被集成到模型的不同部分中。
- 由于所有基础模型和LoRA适配器均保持冻结状态,这大大提升了资源效率。
X-LoRA可以无缝应用于任何 HuggingFace Transformers模型,并且支持通过简单的API接口进行操作。
动态混合不同领域的专家知识,为解决复杂、跨学科问题提供了强大的工具。
X-LoRA 适合于在不大幅增加模型尺寸的情况下提升特定领域任务表现的应用场景。例如,在自然语言处理中,它能够针对如问答、翻译或指令跟随等不同任务,通过微调不同的LoRA专家来优化整体模型性能
然而,关于如何更有效地设计针对特定目的的训练数据,以及如何深化对模型内部混合机制的理解,仍是未来研究的关键挑战。
代码
# pip install git+https://github.com/EricLBuehler/xlora.git
import torch
from transformers import AutoModelForCausalLM
from xlora import add_xlora_to_model, xLoRAConfig
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-Instruct-v0.1",
trust_remote_code=True,
use_flash_attention_2=False,
device_map="cuda:0",
torch_dtype=torch.bfloat16
)
# 配置X-LoRA
config = xLoRAConfig(
AutoConfig.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1"),
hidden_size=模型隐藏层大小, # 请替换为实际数值或变量
base_model_id="mistralai/Mistral-7B-Instruct-v0.1",
xlora_depth=8,
device=torch.device("cuda"), # 根据实际情况调整设备
adapters={...} # 添加你的LoRA适应器路径
)
# 将X-LoRA功能添加到模型
model_xlora = add_xlora_to_model(model, xlora_config=config, verbose=True)
序列式 LoRA
相关工作
- Chain of LoRA
- ReLoRA:
- 论文: ReLoRA: High-Rank Training Through Low-Rank Updates
- 拟合更高秩的W
- 效果: 实验结果好于LoRA
- PeriodicLoRA
- Delta-LoRA
- 论文: DELTA-LORA: FINE-TUNING HIGH-RANK PARAMETERS WITH THE DELTA OF LOW-RANK MATRICES
- 比LoRA多一步:每次更新时,通过\(\textbf{AB}\)近似计算\(\Delta \textbf{W}\),来对\(\textbf{W}\)进行更新
- 实验结果好于LoRA
MAM Adapter
一种在 Adapter、Prefix Tuning 和 LoRA 之间建立联系的统一方法。
- 最终的模型 MAM Adapter 是用于 FFN 的并行 Adapter 和 软提示的组合。
特点:
- 整体上来说,最终的模型MAM Adapter效果会优于单个高效微调方法。
UniPELT
一种将不同的PELT方法LoRA、Prefix Tuning和Adapter作为子模块,并通过门控机制学习激活最适合当前数据或任务的方法。
特点:
- 相对于LoRA,BitFit,Prefix-tuning,训练的参数量更大;同时,推理更耗时;并且,输入会占用额外的序列长度。
- 多种 PELT 方法的混合涉及PLM 的不同部分对模型有效性和鲁棒性都有好处。
多 LoRA
多 lora 训练
- 多个lora独立,但前向传播过程中共享所有训练数据的前向传播,但loss更新时根据mask矩阵,单个任务更新独自任务
- mLoRA, 目前仅支持 chatGLM和LLma架构
- 先训练个共享lora,然后用共享lora初始化多个任务的lora,再做训练
- 【2023-3-6】俄亥俄州立大学、MIT 论文 Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning
- 代码 multitask_prompt_tuning.ipynb
同一底座加载多Lora模型
部署10个lora服务
- 原来,7B模型需要1个24G的3090显卡,那么就要10张3090显卡;部署过程中,模型Copy、上传的时间也会非常久,会带来很多不必要的等待时间。
- 多Lora 加载模型,10个Lora模型+一个7B基座模型,一张3090显卡就能加载。但由于Lora参数要额外进行计算,所以相较于Merge模型,计算速度会稍有变慢。
S-LoRA
(1)S-LoRA 提出「统一分页」(Unified Paging)技术实现统一内容管理和lora动态分配机制。
但目前该技术已经停止维护,支持的模型版本仅停留在llama,无法支持最新的模型
MoLoRA
(2)MoLoRA
MoLORA(Mixture of Low-Rank Adaptation)是一种将低秩适应(LoRA)与混合专家(MoE)架构结合的方法,解决大型语言模型(LLMs)在多任务学习中的参数效率和稳定性问题。
通过引入多个LoRA专家,每个专家由低秩矩阵构成,配合路由机制(如top-k路由或软路由策略),将不同任务分配给相应的专家,从而减轻训练不平衡、灾难性遗忘和泛化能力差等问题,同时保持参数高效 。 例如,MING-MOE利用MoLORA技术,在训练过程中动态为每个标记选择合适专家,无需任务特定标注信息,从而在多任务医学应用中达到先进性能。
MoLORA本身需要多任务数据联合训练,因为路由网络(gate)需要同时学习“哪个专家适合哪个任务/输入”。但也可以通过轻量级二次训练(冻结原有LoRA,只训练gate)适配,或采用无需路由的加权融合方案(如任务标签显式选择LoRA),但这种方式需要验证可行性。
vLLM 多LoRA
(3)vllm新版本可以支持动态的同源lora加载
vLLM已经支持这种多Lora模式加载,通过不同的ID进行不同Lora模型的调用,同时还可以调用基模,好处显而易见
性能和易用性方面表现都不错
部署多Lora,只需执行命令:
vllm serve {你的模型地址} --enable-lora --lora-modules {lora1的地址} {lora2的地址}
评测:Llama3-8b模型,L20GPU显卡压测
| 部署模式 | QPS | 平均耗时 | token吞吐 |
|---|---|---|---|
| llama3 | 2 | 11s | 125 token/s |
| llama3+多lora | 1.8 | 10s | 120 token/s |
多Lora对推理的吞吐与速度的影响几乎可以忽略
限制
- 共享基础大模型
- 微调训练时,Lora的秩R值不超过64
参考:
- 【2024-8-20】利用多Lora节省大模型部署成本
TGI Multi-LoRA
(4)TGI Multi-LoRA
【2024-7-18】 huggingface 的 TGI Multi-LoRA
lorax
(5) lorax
Multi-LoRA inference server that scales to 1000s of fine-tuned LLMs
【2025-4-10】LoRI 多LoRA混合
LoRA还能继续卷?LoRI:大模型参数高效微调新方法,参数减少95%!
LoRA 在多任务场景中仍会产生显著开销,并且存在参数干扰问题
LoRI 是一种简单而有效,减少干扰的低秩适应方法,将投影矩阵冻结为随机投影,并使用特定任务掩码对矩阵进行稀疏化处理。这种设计在保持强大任务性能的同时,大幅减少了可训练参数的数量。
- 【2025-4-10】马里兰 LoRI: Reducing Cross-Task Interference in Multi-Task Low-Rank Adaptation
- github LoRI
LoRI 大幅减少可训练参数的同时,还能将跨任务干扰降至最低。
此外,LoRI 通过利用适配器子空间之间的正交性,最大限度地减少了适配器合并中的跨任务干扰,并通过使用稀疏性来减轻灾难性遗忘,从而支持持续学习。在自然语言理解、数学推理、代码生成和安全对齐任务上进行的大量实验表明,LoRI 优于全量微调以及现有的参数高效微调方法,同时与 LoRA 相比,可训练参数最多减少 95% 。
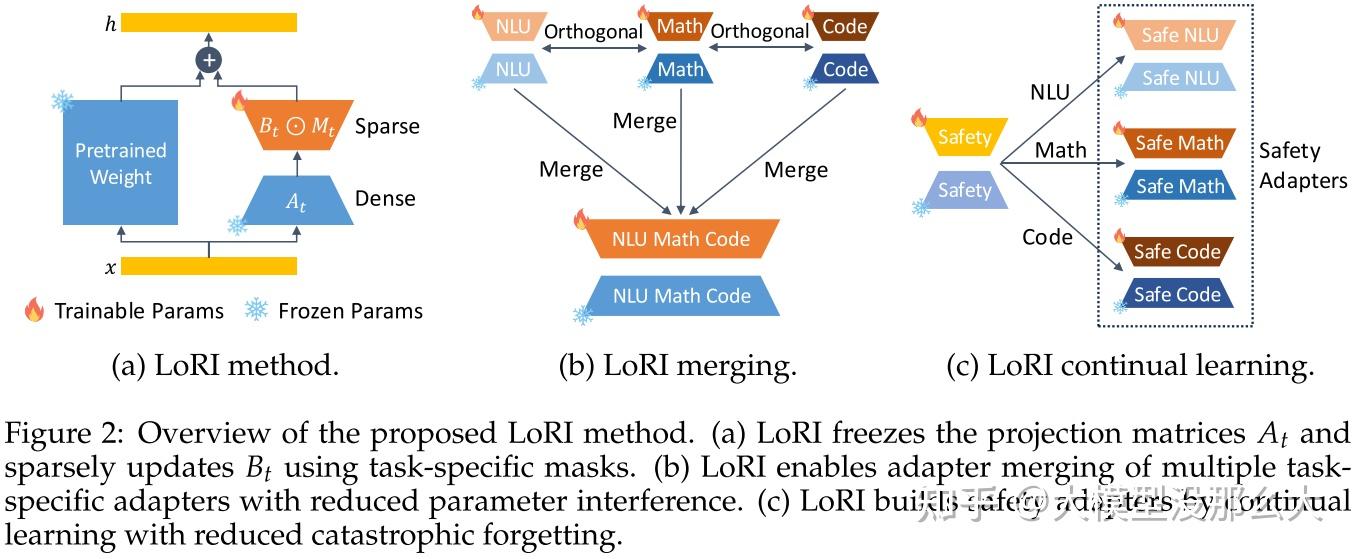
在多任务实验中,LoRI 能够实现有效的适配器合并和持续学习,同时减少跨任务干扰。
【2025-10-1】FlyLoRA 多LoRA混合
【2025-10-1】NeurIPS 2025 清华团队提出FlyLoRA:受果蝇神经机制启发,打破大模型微调参数效率与任务干扰的权衡
- 论文:FlyLoRA: Boosting Task Decoupling and Parameter Efficiency via Implicit Rank-Wise Mixture-of-Experts
大模型高效微调领域,如何平衡“参数效率”与“任务性能”一直是个难题。
传统LoRA方法虽大幅降低计算开销,却常因参数间的相互干扰限制其潜力,并且在多任务合并时表现不佳。
受到果蝇嗅觉神经回路中“随机投影+赢者通吃”机制的启发,清华大学季向阳团队提出 FlyLoRA,将隐式按秩混合专家(MoE)机制引入LoRA架构。
该方法无需显式路由器参数,仅通过固定稀疏随机矩阵实现隐式路由与任务解耦,在多项任务中性能显著优于现有方法,同时具备优秀的模型合并鲁棒性。
FlyLoRA 不仅在技术层面实现突破,更展示了神经科学启发AI架构设计的可行路径。目前论文已被NeurIPS 2025接收,代码已开源。
OFT 系列
OFT
【2023-6-12】剑桥 推出 有原则的微调范式——正交微调(OFT)和 BOFT ,用于下游任务的适应;
【2025-10-14】港中文+剑桥 提出 OFT (Orthogonal Finetuning)
OFT 较新的PEFT方法,另辟蹊径,采用乘性正交更新思路
OFT 出发点:在微调过程中更好地保持预训练模型的知识,避免“灾难性遗忘”。
- 研究发现,预训练模型中权重的方向(或者说神经元之间的角度关系)对于模型的语义表达能力至关重要。
- 方向的改变就能学到新的知识,OFT通过引入一个正交矩阵 R 来旋转(rotate)原始的权重矩阵 W,而不是像LoRA那样在上面添加一个增量。
正交变换是一种保持向量长度和向量间夹角的线性变换。
通过正交矩阵对权重进行变换,可以在保持模型内部结构稳定性的前提下,适应新的任务。这种方法被证明可以保持“超球面能量”(hyperspherical energy),这对于保留模型的语义生成能力至关重要
BOFT
正交蝶形(Orthogonal Butterfly,BOFT)通过蝶形分解(Butterfly factorization)对 OFT 进行推广,提高其参数效率和微调灵活性。
OFT 可以被视为 BOFT 的特例。与使用加性低秩权重更新的 LoRA 不同,BOFT 使用乘性正交权重更新
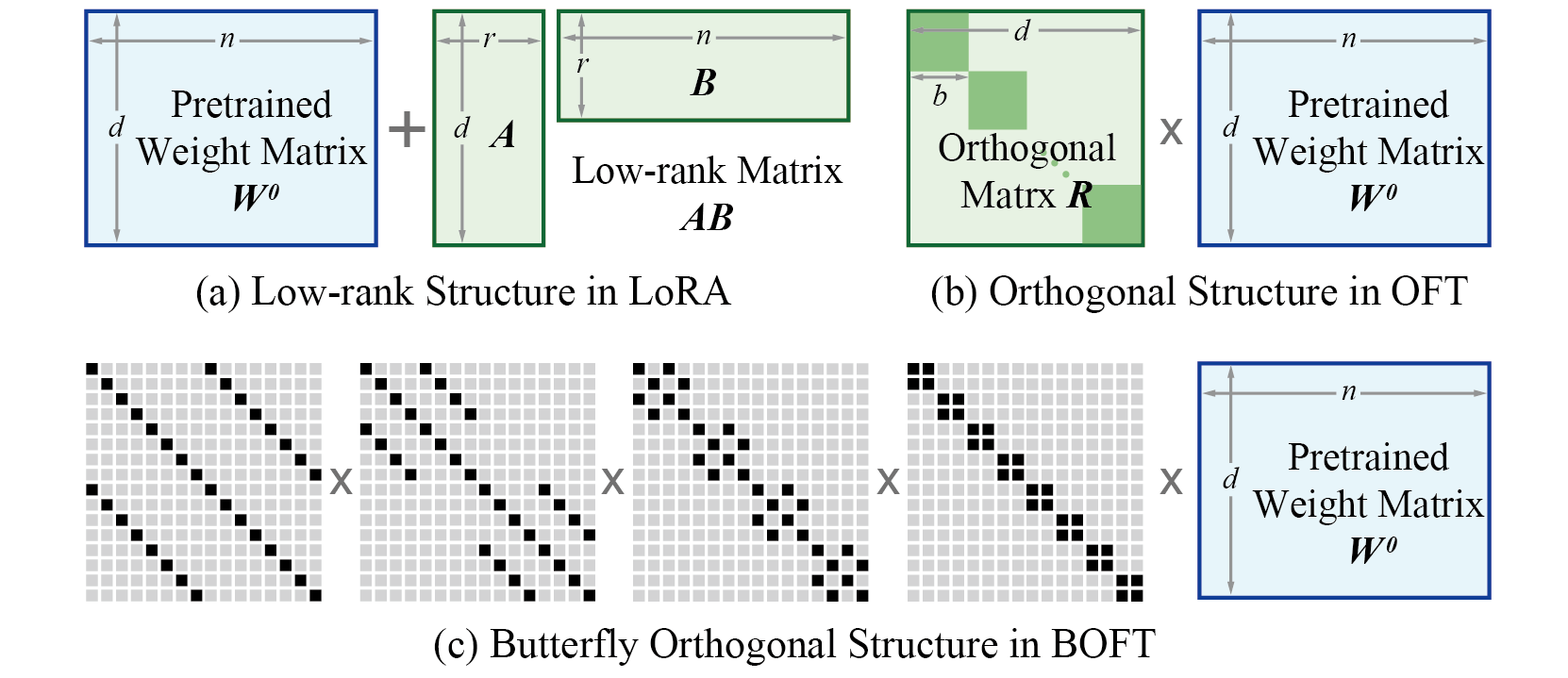
与 LoRA 相比,BOFT 具有一些优势
- BOFT 提出简单而通用的方法,用于将预训练模型微调至下游任务,从而更好地保留预训练知识并提高参数效率。
- 通过正交性,BOFT 引入了一种结构性约束,即在微调过程中保持超球面能量不变。这可以有效减少对预训练知识的遗忘。
- BOFT 使用蝶形分解来高效地参数化正交矩阵,这产生了一个紧凑且富有表现力的学习空间(即假设类别)。
- BOFT 中的稀疏矩阵分解带来了额外的归纳偏置,这有利于泛化。
原则上,BOFT 可以应用于神经网络中权重矩阵的任何子集,以减少可训练参数的数量。给定注入 BOFT 参数的目标层,可训练参数的数量可以根据权重矩阵的大小确定。
与 LoRA 类似,通过 OFT/BOFT 学到的权重可以使用 merge_and_unload() 函数集成到预训练权重矩阵中。此函数将适配器权重与基础模型合并,使您能够有效地将新合并的模型作为一个独立模型使用。
示例
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from trl import SFTTrainer
from peft import OFTConfig
if use_quantization:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_storage=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
"model_name",
quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained("model_name")
# Configure OFT
peft_config = OFTConfig(
oft_block_size=32,
use_cayley_neumann=True,
target_modules="all-linear",
bias="none",
task_type="CAUSAL_LM"
)
trainer = SFTTrainer(
model=model,
train_dataset=ds['train'],
peft_config=peft_config,
processing_class=tokenizer,
args=training_arguments,
data_collator=collator,
)
trainer.train()
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
