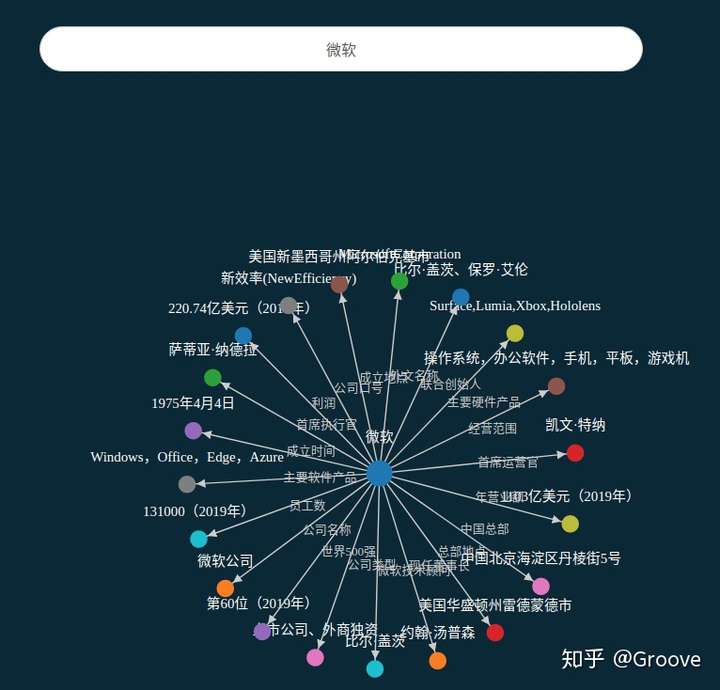
知识图谱
总结
【2026-4-25】知识图谱新趋势
知识图谱领域权威肖仰华在 DACCon 演讲中提出重大转向:严格知识表示路线已不合时宜。
依据:
- 知识不限于三元组形式;43% 知识会随时间失效,大而全图谱易过期;
- 成功知识体系,如维基百科靠群体共建而非设计。未来应发展”自进化智能体”——不在事前灌输知识,而在任务中动态生长知识,精准补足大模型盲区。
“智能不该是名词,而应是动词”,标志着知识工程从静态构建迈向动态演化的范式变革。
- 【2021-2-14】思知机器人,开源中文知识图谱,图谱可视化,Demo体验,包含实时tts;OwnThink开源了史上最大规模(1.4亿)中文知识图谱,地址。阿里云地址,百度云地址,提取码: 3hpp 解压密码是:https://www.ownthink.com/,1.95G
- 【2021-2-10】艾瑞咨询:2020中国知识图谱行业研究报告
- 艾瑞咨询《知识图谱白皮书》(2020)发布
- 艾瑞咨询是解决商业决策问题的专业第三方机构,互联网企业IPO报告里80%的材料引用自艾瑞研究的成果。
- 2020年11月底,艾瑞咨询从善政、惠民、兴业、智融四个部分对知识图谱技术在其他行业中的代表性应用场景进行梳理,发布了《知识图谱白皮书》。深擎科技“乾坤袋”知识图谱引擎与腾讯云、百度云、阿里云等品牌共同作为代表性应用被纳入金融领域产业链与参与者图谱。

总结如下:
| 方法流派 | 思路 | 示例 | 优点 | 缺点 | 备注 |
|---|---|---|---|---|---|
| 规则模板 | 人为设定规则模板 | AIML语言 |
①简单,无须标注②稳定可控 | ①人力消耗大②回复单一,多样性欠缺 | - |
| 生成模型 | 用encoder-decoder结构生成回复 | Seq2Seq、transformer |
无须规则,自动生成 | ①效果不可控②万能回复(安全回复)③多样性低④一致性不足 | - |
| 检索模型 | 文本检索与排序技术从问答库中挑选合适的回复 | IR | ①语句通顺②可控 | ①不能生成回复②表面相关,难以捕捉语义信息 | - |
| 混合模型 | 综合生成和检索方案 | 度秘 | - | - | - |
【2023-10-7】漆桂林 知识图谱和大语言模型的共存之道
知识图谱和大型语言模型都是用来表示和处理知识的手段。
- 大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。
- OpenKG组织“大模型专辑”,不定期邀请业内专家对知识图谱与大模型的融合之道展开深入探讨。
神经网络可以用于存储知识,但是这类知识是以参数的形式存在于神经网络,无法直观看到。
什么是知识图谱
牛津字典
- 知识是通过经历或者教育获取的事实、信息或者技巧或者技巧。
- 举例来说,“南京位于江苏”是一类事实性知识,新闻文本是一类描述性知识,而开酒瓶的技能是一类技能类知识。人类可以通过视觉、语言、教育或者实践和推理等方式获取知识。

知识图谱是一种采用图模型(即由点和线组成的图形)来对人类知识进行表示的知识库或者知识的集合。
- 信息和知识两个概念:
- 信息是指外部的客观事实
- 如:这里有一瓶水,它现在是7°。
- 知识是对外部客观规律的归纳和总结
- 如:水在零度的时候会结冰。
- 信息是指外部的客观事实
- “客观规律的归纳和总结” 似乎有些难以实现。Quora 上有另一种经典的解读,区分 “信息” 和 “知识” 。
- 在信息的基础上,建立实体之间的联系,就行成 “知识”。当然,叫事实(Fact)更合适。
- 知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。
-
知识图谱本质上是一种揭示实体之间关系的语义网络。
- 专家系统,万维网之父Tim Berners Lee于1998年提出的语义网(Semantic Web)和在2006年提出的关联数据(Linked Data)都和知识图谱有着千丝万缕的关系,可以说它们是知识图谱前身。
- “知识图谱(Knowledge Graph)”的概念是由Google公司在2012年提出,指代其用于提升搜索引擎性能的知识库。
- Google为了提升搜索引擎返回的答案质量和用户查询的效率,于2012年5月16日发布了知识图谱(Knowledge Graph)。有知识图谱作为辅助,搜索引擎能够洞察用户查询背后的语义信息,返回更为精准、结构化的信息,更大可能地满足用户的查询需求。
- Google知识图谱的宣传语“things not strings”给出了知识图谱的精髓,即,不要无意义的字符串,而是获取字符串背后隐含的对象或事物。
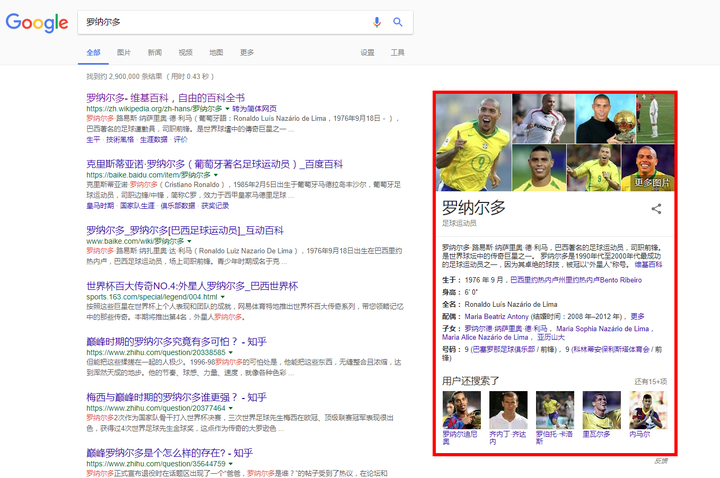
- 以罗纳尔多为例,我们想知道罗纳尔多的相关信息(很多情况下,用户的搜索意图可能也是模糊的,这里我们输入的查询为“罗纳尔多”)
- 在之前的版本,只能得到包含这个字符串的相关网页作为返回结果,然后不得不进入某些网页查找我们感兴趣的信息;
- 现在,除了相关网页,搜索引擎还会返回一个“知识卡片”,包含了查询对象的基本信息和其相关的其他对象(C罗名字简称也为罗纳尔多,搜索引擎只是根据“罗纳尔多”的指代概率返回了“肥罗”这个罗纳尔多的基本资料,但也许你需要C罗的相关信息,那么搜索引擎把C罗这个实体作为备选项列出),如下图红色方框中的内容。如果我们只是想知道罗纳尔多的国籍、年龄、婚姻状况、子女信息,那么我们不用再做多余的操作。在最短的时间内,我们获取了最为简洁,最为准确的信息。
- 知识图谱的出现是人工智能对知识需求所导致的必然结果,但其发展又得益于很多其他的研究领域,涉及专家系统、语言学、语义网、数据库,以及信息抽取等众多领域,是交叉融合的产物而非一脉相承
- 详见:知识图谱发展概述

- 【2020-7-12】【ACL 2020知识图谱自然语言处理进展摘要】《Knowledge Graphs in Natural Language Processing @ ACL 2020》by Michael Galkin
- 【2020-7-21】从ACL 2020看知识图谱进展
【2018-9-28】文因互联鲍捷:深度解析知识图谱发展关键阶段及技术脉络
鲍捷
- 鲍捷,文因互联创始人,曾担任美国麻省理工学院访问研究员、三星美国研发中心研究员,曾是三星问答系统S-voice第二代系统核心设计师
- 鲍捷,文因互联 CEO,联合创始人。曾担任美国麻省理工学院访问研究员、三星美国研发中心研究员,三星问答系统S-voice第二代系统核心设计师,伦斯勒理工学院(RPI)博士后。他是中国中文信息学会语言与知识计算专委会委员,W3C 顾问委员会委员,中国计算机协会会刊编委,中文开放知识图谱联盟(OpenKG)发起人之一。他的研究领域涉及人工智能诸多方向,如自然语言处理、语义网、机器学习、描述逻辑、信息论、神经网络、图像识别等,已发表 70 多篇论文。
知识图谱历史
- 知识图谱的发展简史
- 上个世纪60年代Quillian提出了语义网络,作为知识表示的一种方式,用于描述物体概念与状态及其间的关系,早期主要是用来帮助自然语言理解。
- 到上个世纪80年代,人工智能研究人员将 “本体”这一哲学概念被引入计算机领域,把本体定义为“概念和关系的形式化描述”,通俗一点讲本体类似数据库中的Schema,这一时期的一个典型应用就是专家系统。
- 1989年Tim Berners Lee提出了万维网,也就是我们今天使用的www网络
- 1998年从超文本网页延伸出语义网络概念,将每一个网页引入语义信息,比如:姚明这个页面,归属类别是人物、运动员。
- 2006年提出了链接数据概念,目标将互联网上所有数据建立关联,如姚明的页面出现他妻子叶莉,会给“叶莉”加一个链接,链接到叶莉这个页面。
- 2012年Google率先提出了知识图谱,目的是提升整个搜索效果,从此知识图谱技术开始得到广泛学习和应用。

- 知识图谱是起源于语义网络,并且跟
语义网(Semantic Web)有着极深的渊源。知识图谱采取了语义网络的图表示方法,同时参考了语义网的标准化语言RDF和OWL,从而具有严格的逻辑语义支撑,可以确保从知识图谱中查询得到的结果是正确的。同时知识图谱可以跟专家系统中的规则引擎结合用于企业应用中的决策支持类任务。 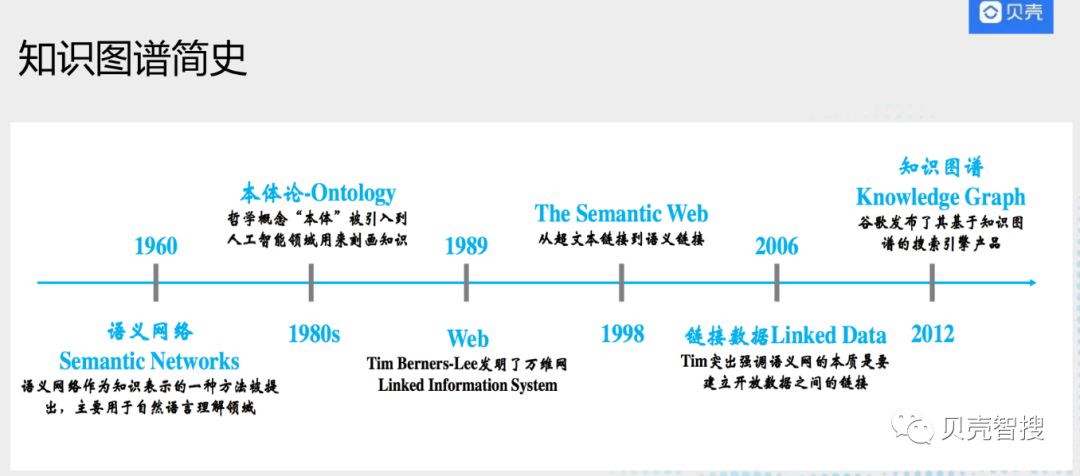
- 摘自:
- 知识图谱在贝壳找房的从0到1实践
- 【2020-9-16】【知识图谱系列】开篇:基于KBQA的经纪人咨询助手
- 【2020-7-18】贝壳找房技术文章合集
- 摘自:
知识图谱定义
- 知识图谱并没有一个标准的定义(gold standard definition)。借用一下“Exploiting Linked Data and Knowledge Graphs in Large Organisations”这本书对于知识图谱的定义:
- A knowledge graph consists of a set of interconnected typed entities and their attributes.
- 知识图谱是由一些相互连接的实体和他们的属性构成的。
- 换句话说,知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。
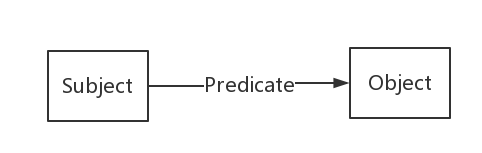
- 用RDF形式化地表示这种三元关系。
- RDF(Resource Description Framework),即资源描述框架,是W3C制定的,用于描述实体/资源的标准数据模型。
- RDF图中一共有三种类型,International Resource Identifiers(IRIs),blank nodes 和 literals。
- 下面是SPO每个部分的类型约束:
- Subject可以是IRI或blank node。
- Predicate是IRI。
- Object三种类型都可以。
- 解释
- IRI我们可以看做是URI或者URL的泛化和推广,它在整个网络或者图中唯一定义了一个实体/资源,和身份证号类似。
- literal是字面量,可以看做是带有数据类型的纯文本,比如我们在第一个部分中提到的罗纳尔多原名可以表示为”Ronaldo Luís Nazário de Lima”^^xsd:string。
- blank node简单来说就是没有IRI和literal的资源,或者说匿名资源。
- 定义[Wang, 2017]:
- 知识图谱是由
实体和关系构成的多关系图,实体和关系分别被视为节点和不同类型的边。A knowledge graph is a multirelational graph composed of entities and relations which are regarded as nodes and different types of edges, respectively.
- 知识图谱是由
- 形式化定义:
A knowledge graph as G = {E, R, F}, where E, R and F are sets of entities, relations and facts, respectively. A fact is denoted as a triple (h, r, t) ∈ F。
- 知识图谱是由Google公司在2012年提出来的一个新的概念。从学术的角度,可以给这样的定义:“知识图谱本质上是语义网络(Semantic Network)的知识库”。但这有点抽象,所以换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)。
- 那什么叫多关系图呢? 学过数据结构的都应该知道什么是图(Graph)。图是由节点(Vertex)和边(Edge)来构成,但这些图通常只包含一种类型的节点和边。但相反,多关系图一般包含多种类型的节点和多种类型的边。比如左下图表示一个经典的图结构,右边的图则表示多关系图,因为图里包含了多种类型的节点和边。这些类型由不同的颜色来标记。
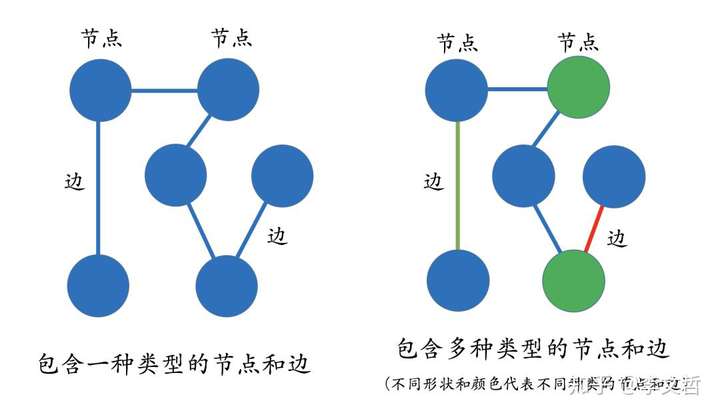
- 知识图谱里,通常用“实体(Entity)”来表达图里的节点、用“关系(Relation)”来表达图里的“边”。
- 实体指的是现实世界中的事物比如人、地名、概念、药物、公司等
- 关系则用来表达不同实体之间的某种联系,比如人-“居住在”-北京、张三和李四是“朋友”、逻辑回归是深度学习的“先导知识”等等。
- 实体和关系也会拥有各自的属性,比如人可以有“姓名”和“年龄”。当一个知识图谱拥有属性时,可以用属性图(Property Graph)来表示。
- 李明和李飞是父子关系,并且李明拥有一个138开头的电话号,这个电话号开通时间是2018年,其中2018年就可以作为关系的属性。类似的,李明本人也带有一些属性值比如年龄为25岁、职位是总经理等。

- 除了属性图,知识图谱也可以用RDF来表示,由很多的三元组(Triples)来组成。
- RDF在设计上的主要特点是易于发布和分享数据,但不支持实体或关系拥有属性,如果非要加上属性,则在设计上需要做一些修改。
- 目前来看,RDF主要还是用于学术的场景,在工业界我们更多的还是采用图数据库(比如用来存储属性图)的方式。
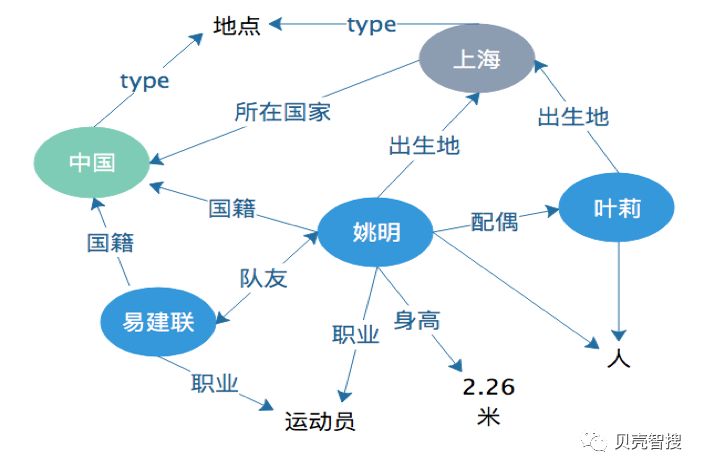
- 知识图谱旨在描述真实世界中存在的各种实体或概念及其间的关联关系。
- 首先,每一个实体用全局唯一ID来标识,就如同每个人都有一个自己的身份证号;
- 其次, 用属性-值对来刻画实体的内在特性,用关系来刻画实体之间的关联。
- 如刻画姚明这个实体:属性-值<姚明+身高+2.26米>,关系型<姚明+妻子+叶莉>。
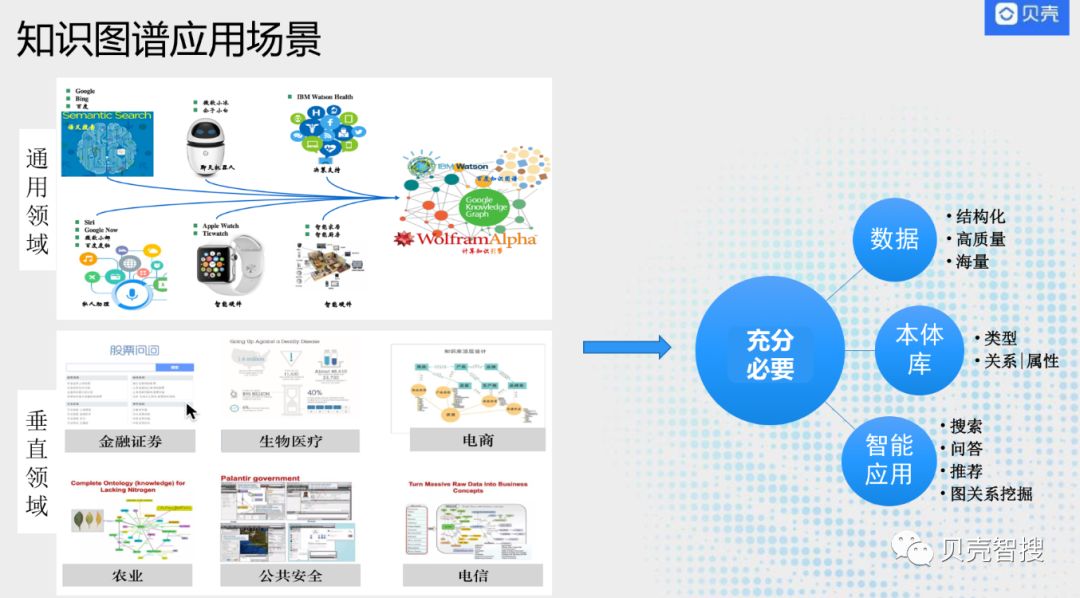
应用
- 知识图谱应用场景分为两种,一种是通用领域,一种是垂直领域
- 通用领域:如Google搜索,国内百度和搜狗也有在搜索中应用知识图谱技术;还有些智能硬件应用,如智能机器人、智能手表。这种应用也会用到通用知识图谱,构建依赖国外维基百科、freebase,还有国内百度百科、维基百科、互动百科、搜狗百科等,从这些页面中抽取出结构化三元组构建知识图谱来支撑通用领域的问答和搜索。
- 垂直领域:应用越来越多,如金融、电商、公共安全、电信等,具体如金融里面的反欺诈,公共安全领域的追捕犯罪分子。
技术架构
-
知识表示- 在知识库中,用RDF表示,是一个
三元组(triple)模型,即每个知识可被分解为主(subject)、谓(predicate)、宾(object);
- 在知识库中,用RDF表示,是一个
-
知识表示学习(Knowledge Representation Learning,KRL)- 2.1 定义:表示学习旨在将三元组语义信息表示为稠密低维实值向量,知识表示学习则面向知识库中的实体和关系进行表示学习
- 2.2 意义:知识表示是知识获取与应用的基础;知识表示学习得到的分布式表示有以下典型应用
- 实体相似度计算,如实体链接(Entity Linking,EL)
- 知识图谱补全(Knowledge Graph Completion,KGC)
- 其他,如关系抽取,自动问答等
- 2.3 目标:将知识图谱编码到向量空间:(subject, predicate, object) => (head, relation, tail)
- 2.3 现状:在学术界研究方向和趋势详细阐述
- 知识图谱涉及的NLP技术
- a.实体命名识别(Name Entity Recognition)
- 从文本里提取出实体并对每个实体做分类/打标签:比如从上述文本里,我们可以提取出实体-“NYC”,并标记实体类型为 “Location”;也可以从中提取出“Virgil’s BBQ”,并标记实体类型为“Restarant”。
- NER技术相对成熟
- b. 关系抽取(Relation Extraction)
- 把实体间的关系从文本中提取出来,比如实体“hotel”和“Hilton property”之间的关系为“in”;“hotel”和“Time Square”的关系为“near”等等。
- c. 实体统一(Entity Resolution)—— 或实体链接
- 在实体命名识别和关系抽取过程中,有两个比较棘手的问题:一个是实体统一,也就是说有些实体写法上不一样,但其实是指向同一个实体。
- 比如“NYC”和“New York”表面上是不同的字符串,但其实指的都是纽约这个城市,需要合并。实体统一不仅可以减少实体的种类,也可以降低图谱的稀疏性(Sparsity);
- d. 指代消解(Coreference Resolution)
- 另一个问题是指代消解,也是文本中出现的“it”, “he”, “she”这些词到底指向哪个实体,比如在本文里两个被标记出来的“it”都指向“hotel”这个实体。

- a.实体命名识别(Name Entity Recognition)
- 示例

知识抽取
- 知识图谱的构建是后续应用的基础,而且构建的前提是需要把数据从不同的数据源中抽取出来。对于垂直领域的知识图谱来说,它们的数据源主要来自两种渠道:
- 一种是业务本身的数据,这部分数据通常包含在公司内的数据库表并以结构化的方式存储;
- 另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在所以是非结构化的数据。
- 信息抽取的难点在于处理非结构化数据。
- 非结构化(纯文本)知识抽取分三个任务:
-
- 实体提取(Entity Discovery)
- 细分任务分为:
实体识别(Entity Recognition)实体消歧(Entity Disambiguation)实体分类(Entity Typing)实体对齐(Entity Alignment)
- 细分任务分为:
- 实体提取(Entity Discovery)
-
- 关系提取(Relation Extraction)
- 2.1 定义:关系抽取是从非结构化数据中抽取未知关系事实并将其加入到知识图谱中,是自动构建大规模知识图谱的关键
- 2.2 方法:传统的方法高度依赖于特征工程。由于缺乏标记的关系数据,使用启发式匹配来创建训练数据,利用文本特征(包括词汇和句法特征、命名实体标记和连接特征)对关系分类进行远程监控。目前最新研究以深度学习工具实现关系提取。
- 关系提取(Relation Extraction)
-
- 知识补全(KGC)
- 3.1 基于知识图谱不完备性的特点,提出了一种新的知识图谱三元组生成方法。即,给定一个不完整的知识图谱 G=(E, R, F),知识图谱补全旨在推理出缺失的三元组 T={(head, relation, tail) | (head, relation, tail) ∉ F} 。
- 3.2 典型的子任务包括:
链路预测(Link Prediction)实体预测(Entity Prediction)关系预测(Relation Prediction)
- 3.3 方法:
基于Embedding(Embedding-based Models)关系路径推理(Relation Path Reasoning)基于规则的推理(RL-based Path Finding)
- 知识补全(KGC)
表示学习
基础知识
- 【2016-1-19】刘知远:面向大规模知识图谱的表示学习技术,讲座解析





TransH(MSRA研究者提出)和TransR(清华实验室提出)均为TransE代表扩展模型之一。- TransE在实体预测任务能够达到47.1的准确率,而采用TransH和TransR,特别是TransR可以达到20%的提升。
- 基于 TransE TransH TransR和PTransE的知识图,KB2E代码实现,图嵌入的Translate模型汇总(TransE,TransH,TransR,TransD)
- 【2020-7-26】斯坦福知识图谱多跳推理,Multi-Hop Knowledge Graph Reasoning with Deep Reinforcement Learning
关系推理
- 简单问答只需要识别出问题中的实体和关系,链接到知识图谱中,即可查出答案。
- 推理问答则要求计算机具备多种推理能力,具体包括:
- (1)处理多跳关系的能力,如“姚明的妻子的学校”;
- (2)数值比较的能力,如“哪个城市的人口更多”;
- (3)集合操作的能力,如“即是篮球运动员,又是球队老板的人有哪些”。
- 知识图谱推理问答主流方法大致分为4大类别
- 键值记忆网络(KVMemNet)
- 基于强化学习的多跳路径搜索
- 弱监督的程序学习
- 查询图解析与匹配
- 资料
- 基于知识图谱的关系推理的相关工作,大体分为三种方法:
- (1)统计关系学习方法(SRL),如马尔科夫逻辑网络、贝叶斯网络,但这类方发需要设计相应的规则,因此没有很好的扩展性和泛化性;
- (2)嵌入式表示的方法,旨在将实体和关系映射为空间中的向量,通过空间中向量的运算来进行推理(如TransE),该方法取得了较好的准确率,但分布式表示的解释性不强,另外,较难实现并行计算;
- (3)基于关系路径特征的随机游走模型,该方法可以进行并行计算,具有较好的执行效率,但准确率与召回率相比嵌入式表示学习的方法存在劣势。
推理数据集
- 4个常用推理问答数据集,并从所用知识库、知识类型、问题数量、自然语言、SPARQL共5个角度加以对比。
- 三种知识类型:
- ①关系型,如(“姚明”,“出生于”,“上海”);
- ②属性型,如(“姚明”,“身高”,“ 229 厘米”);
- ③事实型,用于表示一个关系型事实或属性型事实的知识,如[(“上海”,“人口”,“23,390,000”),“统计时间”,“2016”]。
- 在提到的4个数据集中,MetaQA 和 CSQA 仅考虑关系型知识。
- 现有数据集存在一个共同的问题,都缺乏推理过程,只给出复杂的问题以及对应的答案,没有问题解答过程。
- 清华大学知识工程实验室构造了一个新的数据集——KQA Pro,可提供之前数据集都不具备的推理过程。
- 为表示推理过程,KQA Pro引入函数(function)和程序(program)两个概念。函数对应简单问题,程序对应复杂问题,将简单的函数组合成复杂的程序,从而解决复杂问题。
- 三种知识类型:
常识推理
- “原子”因果常识图谱
- AAAI 19的论文(Sap et al. (2019))开源了一个包含87万条推理常识的知识图谱ATOMIC。相较于常见的基于本体论分类条目的知识图谱,该知识库专注于“如果…那么…”关系的知识。作者提出了9种类型的因果联系来区分原因-效果、主体-主题、自愿-非自愿、行动-心理状态。通过生成式训练,作者发现神经网络模型可以从该图谱中获取简单的常识推理能力。
- 另外,该团队在ACL 19上的论文COMET则利用了该图谱训练GPT模型,该GPT模型又反过来生成了许多全新的且合理的知识,达到了图谱补全的效果。

问题思考
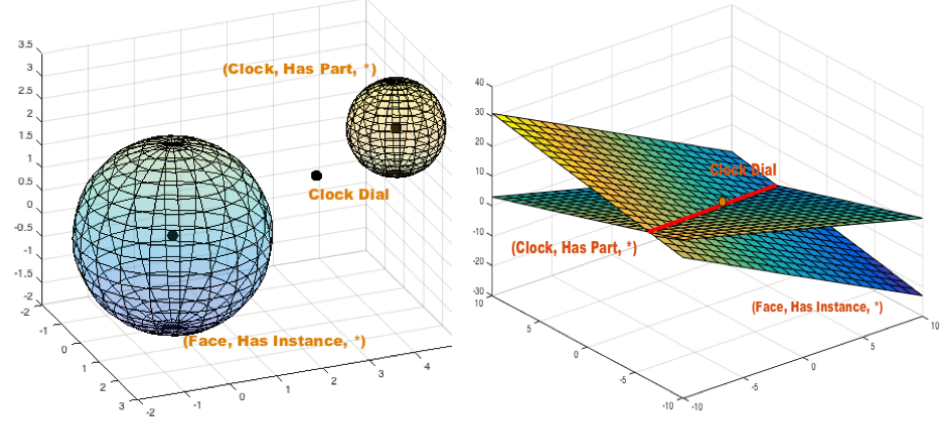
- 目前已有的知识表示学习方法无法实现精确链接预测,有两个原因导致了这一现象的出现:
- ill-posed algebraic problem:一个方程组中的方程式个数远大于变量个数
- 解法:流形函数, $M(h,r,t)=D2r$用来代替$h_r+r=t_r$,应用Reproducing Kernel Hilbert Space (RKHS)映射到Hilbert空间,以更高效地表征流形
- 解法:流形函数, $M(h,r,t)=D2r$用来代替$h_r+r=t_r$,应用Reproducing Kernel Hilbert Space (RKHS)映射到Hilbert空间,以更高效地表征流形
- adopting an overstrict geometric form。应用于h+r=t,所得到的尾实体几乎是一个点,这对于多对多关系而言显然是不正确的
- ill-posed algebraic problem:一个方程组中的方程式个数远大于变量个数
- 摘自:知识图谱表示学习与关系推理(2016-2017):(一),(二),(三),ACL2016信息抽取与知识图谱相关论文掠影
知识图谱嵌入(KGE)
- 知识图谱嵌入(KGE):方法和应用的综述,参考《Knowledge Graph Embedding: A Survey of Approaches and Applications》和刘知远的《知识表示学习的研究与进展》做的总结
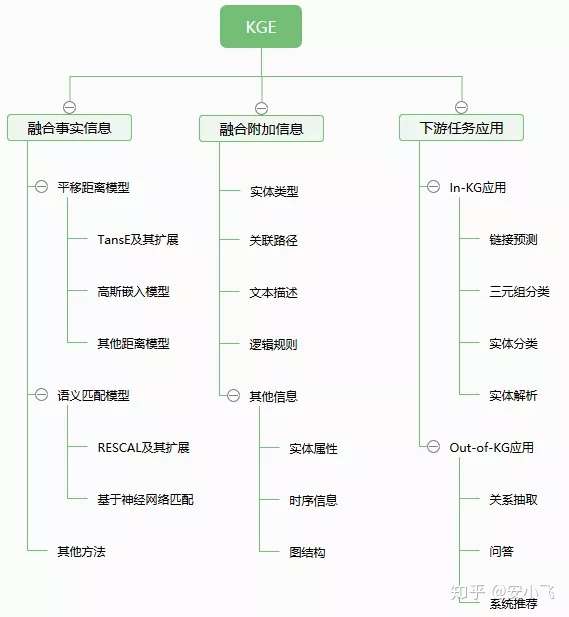
亚马逊 DGL-KE
- 【2021-2-7】DGL-KE:亚马逊开源知识图谱嵌入库,亲测快到飞起,github地址
- DGL-KE 是一个高性能、易于使用且可扩展的知识图谱嵌入工具包,它是依赖 Deep Graph Library (DGL) 库实现的,支持 CPU、GPU、分布式训练,包括 TransE、TransR、RESCAL、DistMult、ComplEx 和 RotatE 等一系列经典模型。
- DGL-KE 正在继续开发中,预计一个月之后会加入 SimplE 模型、图神经网络 GNN 等。
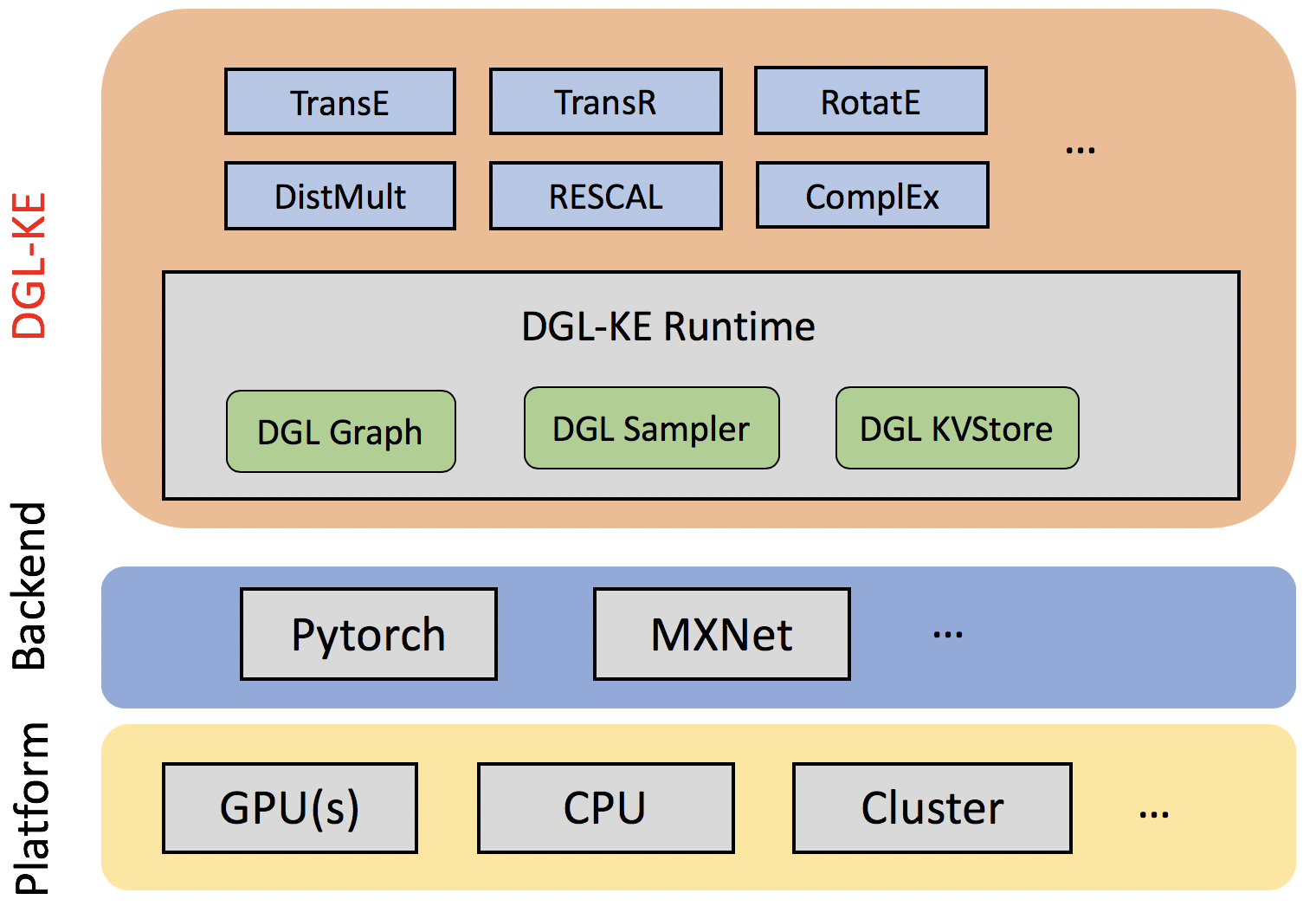
- 对比分析:清华开源库 OpenKE,TransE 的对比结果,训练数据的规模是10w+的数据。
- 结论:快了400倍
| 开源库 | 时间 | 迭代次数 | |
|---|---|---|---|
| OpenKE | 1小时 | 1000 | |
| DGL-KE | 15分钟 | 100000 |
TransX TF实现
【2022-3-28】GraphEmbedding-TransX
- TensorFlow实现对知识图谱的表征学习,包括transe\transd\transh\transr
在config.py文件中对模型参数进行设置,在models.py与main.py文件中的参数均不需要修改,如果在使用代码中出现未知错误,请在config.py中修改参数并提交request
内容
- ./data/KG_name/entity2id.txt 该文件是实体与实体ID的映射,每一行是 实体\t实体ID
- ./data/KG_name/relation2id.txt 该文件是关系与关系ID的映射,每一行是 关系\t关系ID
- ./data/KG_name/triple.txt 该文件是在知识图谱中三元组数据,每一行是 头实体\t尾实体\t关系
- 注:默认知识图谱中用三元组来表示,如果知识图谱中的表达比三元组要更加丰富,需要在模型中增加一个向量并修改loss的计算方法
- ./config.py 参数设置文件
- ./Models.py 模型文件,其中共有transe\transd\trasnh\transr四个模型类,每个类均是独立的,如果出现未知错误仅需修改对应类并提交request
- ./get_parameter.py 在训练完成之后加载模型参数以便使用
- ./Main.py 主文件,修改config.py文件中的参数设置,运行该文件即可
KG Attention
Knowledge Graph Attention Network
- 论文:KGAT: Knowledge Graph Attention Network for Recommendation
- Knowledge Graph Attention Network (KGAT) is a new recommendation framework tailored to knowledge-aware personalized recommendation. Built upon the graph neural network framework, KGAT explicitly models the high-order relations in collaborative knowledge graph to provide better recommendation with item side information.
知识图谱
事理图谱-Event Graph
- 白硕:事理图谱六问六答
- 知识图谱,主要表示的是关于实体的知识,发展得比较丰富的还是围绕实体、关系、属性的各种表示、演化和推理技术。
- 哈工大事理图谱1.0版用的是“Event Evolution Graph”,2.0版用的是“Event Logic Graph”,国外同领域文献用得比较多的是“Event Graph”。
- 一、事理图谱是研究“事理”的学问吗?
- “事理图谱”不研究事理的内容,只研究事理“长什么样”,可以说是关于事理的形式化、数字化表示、演化和推理的学问。
- 二、事理图谱和事件图谱是什么关系?
- 事件图谱是不含本体的事理图谱,是事理图谱的初级阶段。对事件实例的抽取和预测,是事件图谱的基本任务。
- 事件图谱走向事理图谱又是一个学科方向的内在逻辑不断推动和一些应用领域的知识图谱落地需求不断倒逼的综合作用结果。
- 三、事理图谱的本体层需要什么样的架构来支持?
- 事理图谱有本体层,这是个最重要的结论。事件之间、事件和实体之间不仅有横向的由此及彼的关联,还有纵向的由特殊到一般/由一般到特殊的关联。
- 横向关联:由此及彼,是漫游、是联想、是类比
- 纵向关联:一般<–>特殊,是归纳、是演绎、是演化。
- 四象限架构
- 抽象实体、具体实体、抽象事件、具体事件这四块内容,物理上是联通的,是一张图,逻辑上则可以左右划分为实体域和事件域,上下可以划分为本体域和实例域,形成所谓“四象限”架构
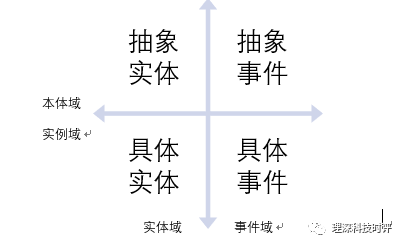
- 事理图谱有本体层,这是个最重要的结论。事件之间、事件和实体之间不仅有横向的由此及彼的关联,还有纵向的由特殊到一般/由一般到特殊的关联。
- 四、事理图谱和实体图谱是什么关系?
- 事理图谱是在知识图谱总框架下,知识表示对象从**实体**、**关系**、**属性**向**事件**的顺理成章的延伸。当然,随着延伸,也自然而然产生了“四象限”的架构,以及由这种架构带来的丰富得多的计算、演化和推理模式。
- 事理图谱也和实体图谱一样,受到知识图谱构建所遵循的一般规律特别是一般性方法论原则的约束。
- 五、事理图谱和NLP如何对接?
- 事理图谱是对谓词性成分语义进行表示的技术体系,因此事理图谱的研究和NLP有着天然的紧密联系。
- 事理图谱向左,可以“脑补”一般分析器做不到的精准解析结果,如指代消解
- 事理图谱向右,可以“补脑”语义落地所缺失的环节,扫除一旦精准NLP得以实现之后通向应用场景的各种障碍
- 六、事理图谱适合在哪些应用场景落地?
- 有些应用场景,只要实体域的两个象限就很好了,完全不需要引入事件域这两个象限。如教育领域。
- 金融、情报、法律、医疗,是事理图谱应用的“重仓”

KB-QA
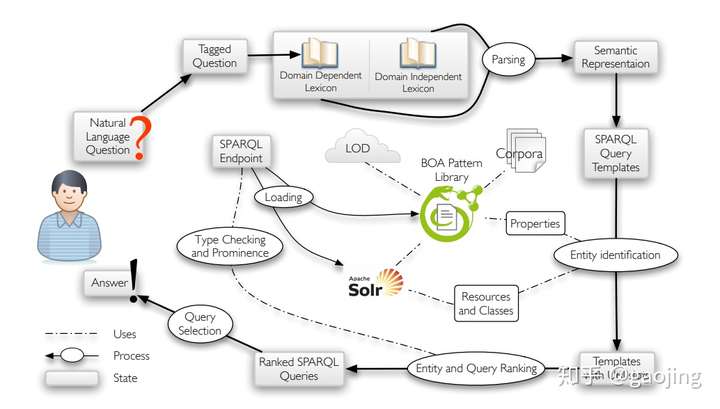
- KBQA(Knowledge Base Question Answering),是基于知识库的问答系统,本质上KBQA系统反映一个简化的“问答-答案”的映射过程,需要对自然语言语义解析与理解后,进行结构化查询与推理,得出相应的答案。

-
-
【2021-7-20】基于neo4j的医疗领域知识图谱问答demo代码
- KB-QA与对话系统
- 问答系统是信息检索系统的高级形式,是以问题为驱动的信息获取过程,按QA类别可以分为WebQA(Web问答)、KBQA(知识库问答)、CQA(社区问答)和DBQA(阅读理解的QA系统,斯坦福的SQuAD)
- 对话系统主要关注对话过程,多采用多轮方式进行,主要分为开放闲聊的对话系统、任务驱动的对话系统、以知识获取的对话系统和信息推荐的对话系统
- 传统的对话系统主要由四个部分:NLU(自然语言生成)、DST(对话状态追溯)、PL(策略学习)和NLG(自然语言生成),目前,采用是端对端检索式与生成式的,但是精度较低。
- KBQA主要通过对自然语言进行语义解析与理解后,查询知识库,进行某一类事实问题进行回答(简单的BFQ或者复杂多跳转问题),答案是某一种实体或者实体的属性或者关系,而对话系统,句子级的对话,注重对话过程,回答的问题是一般是句子而不是简单的答案,类似人对话聊天。对话系统也可以结合知识库进行更加全面句子级答案生成(知识获取的对话系统)。
- KBQA系统实现有哪些方法?
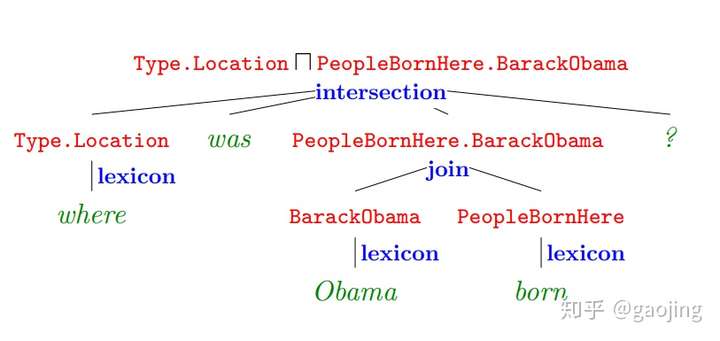
- (1)基于语义解析的方法
- 将自然语言转换为一系列形式化的逻辑表达式,利用知识库中语义信息将逻辑表达式转为知识库查询,最终得到相应的答案。
- (2)基于模板匹配的方法
- 基于模板匹配的方法是通过预制模板匹配问题,代替本体映射,绕过语义解析脆弱性,一般使用该方法与结合语义解析+模板匹配查询的方法来解决工业界的问题,如基于模板匹配的查询语言章节讲的,但是此方法需要人工构建大量模板,只能解决简答的事实类型的问答
- (3)基于深度学习优化模板匹配的方法
- 深度学习主要用来改进问答系统的流程,包括语义解析、实体识别、意图识别与分类和实体链接与消歧等,这类的算法很多,比如对于实体识别的LSTM+CRF、基于深度学习及概率图的实体消歧等,另一方,采用深度学习对问答对进行训练得到大量的模板,便于问题与知识库匹配
- (1)基于语义解析的方法
- 分类:
- IRQA 基于检索的QA
- KBQA 基于知识库的QA
- MRCQA 基于阅读理解的QA
- 常用数据集
- NLPCC全称自然语言处理与中文计算会议(The Conference on Natural Language Processing and Chinese Computing),它是由中国计算机学会(CCF)主办的 CCF 中文信息技术专业委员会年度学术会议,专注于自然语言处理及中文计算领域的学术和应用创新。
- 数据集来自NLPCC ICCPOL 2016 KBQA 任务集,其包含 14 609 个问答对的训练集和包含 9 870 个问答对的测试集。 并提供一个知识库,包含 6 502 738 个实体、 587 875 个属性以及 43 063 796 个 三元组。知识库文件中每行存储一个事实( fact) ,即三元组 ( 实体、属性、属性值) 。
- 基于BERT的KBQA探索, 基于知识图谱的自动问答拆分为2 个主要步骤:命名实体识别步骤和属性映射步骤
- 命名实体识别步骤,采用BERT+BiLSTM+CRF方法(另外加上一些规则映射,可以提高覆盖度)
- 属性映射步骤,转换成文本相似度问题,采用BERT作二分类训练模型

- 【2020-4-22】KB-QA研究进展
-

-
[ACL2020 基于Knowledge Embedding的多跳知识图谱问答](https://zhuanlan.zhihu.com/p/149141891) - KGQA 方法称为 EmbedKGQA。其中包含三个关键模块。
- KG 嵌入模块:为 KG 中所有实体构建嵌入。
- 问题嵌入模块:为问题找到嵌入。
- 答案选择模块:减小候选答案实体的集合,并选择最终的答案。

- 【2021-2-13】问答任务的类型(搜索领域用户日志),源自《智能问答》P8
- 事实类:factoid
- 是非类:yes/no
- 定义类:definition
- 列表类:list
- 比较类:comparison
- 意见类:opinion
- 指导类:how-to
- 总结:
- 列表类通过表格形式解答
- 后三者答案主观,一般通过qa对形式来解答
- 进一步分类:
- (1)知识图谱问答:knowledge-based QA
- 事实在知识图谱中表示方式有两类:三元组事实(triple fact)、CVT事实(CVT fact)
- CVT:compound value type,复合值类型节点,如:奥巴马→(婚姻)→婚姻事实(包含人物、时间、地点等信息)
- (2)表格问答:table-based QA
- 分成表格检索+答案生成两个步骤
- (3)文本问答:text-based QA
- 按照答案颗粒度不同,分成:
- 答案句子选择(answer sentence selection):对所有句子打分、排序,选择最高的句子作为回复
- 机器阅读理解(machine reading comprehension):短语级别,解决思路:
- 排序任务:对所有候选短语抽取、排序
- 序列标注:判断每个单词是否属于答案(0/1)
- 按照答案颗粒度不同,分成:
- (4)社区问答:community QA
- 数据集:<问题,答案>对
- 两类子任务:
- QQ匹配:问题→问题→答案,根据Q的相似度关联已有Q,在得到答案
- QA匹配:问题→答案,直接计算QA的相关度
- (1)知识图谱问答:knowledge-based QA
资料
- 参考:
- 知识图谱问答(KBQA)利用图谱丰富的语义关联信息,能够深入理解用户问题并给出答案,近年来吸引了学术界和工业界的广泛关注。
- KBQA 主要任务是将自然语言问题(NLQ)通过不同方法映射到结构化的查询,并在知识图谱中获取答案。
- 小蜜团队研发的知识图谱问答系统(KBQA)目前已广泛应用于电信运营商、保险、税务等领域,但是在真实的客服场景中,KBQA 在处理复杂问句上仍然面临着挑战。
- 用户在咨询问题时,倾向于表达非常具体的信息,以便快速的获得答案,比较常见问句类型的有:
- 1)复杂条件句:“小规模纳税人季度销售额未超过 30 万,但是要开具 5 万元的专票,需要缴纳附加税费吗?”;
- 2)并列句:“介绍下移动大流量和畅享套餐”;
- 3)推理型问句:“你们这最便宜的 5G 套餐是哪个?”等,
知识图谱存储
知识图谱存储方式
- 知识图谱的两种存储方式
- 一种是基于RDF的存储;
- 另一种是基于图数据库的存储。
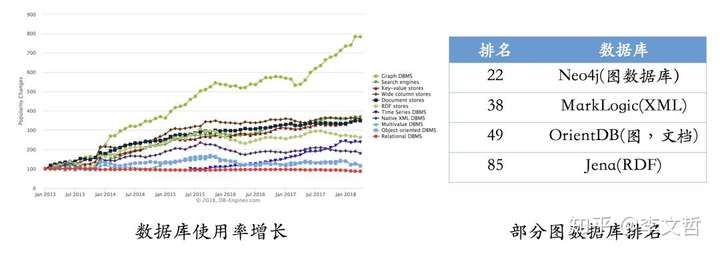
- 图数据库仍然是增长最快的存储系统。相反,关系型数据库的增长基本保持在一个稳定的水平。
RDF一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。- 其次,RDF以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。

图数据库
- 现有图数据库对比
- 其中
Neo4j系统目前仍是使用率最高的图数据库,它拥有活跃的社区,而且系统本身的查询效率高,但唯一的不足就是不支持准分布式。 - 相反,
OrientDB和JanusGraph(原Titan)支持分布式,但这些系统相对较新,社区不如Neo4j活跃,这也就意味着使用过程当中不可避免地会遇到一些刺手的问题。如果选择使用RDF的存储系统,Jena或许一个比较不错的选择。- Apache Jena官方下载
- 摘自:知识图谱的技术与应用(18版)
图数据库产品可以分为原生和多模两类。
- 原生指专门针对图数据存储和计算研发的产品,包括neo4j\janusGraph等
- 多模指多个大厂推出的数据库产品中能够兼容处理图数据。多模形态产品的主要问题是针对图谱数据做兼容处理,用于适配其底层的存储机制。原生图数据库对在技术的专注度上会更加集中,包括图计算引擎实现和图存储算法。 对比分析:
- DBEngine的图数据库排名。
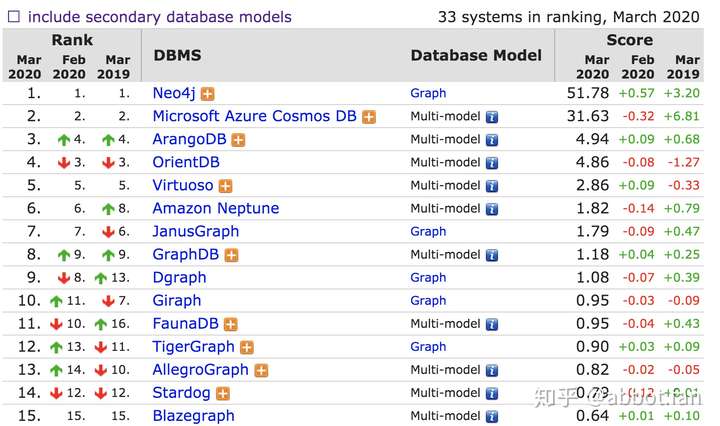
- 得分最高的是neo4j,长期保持第一。neo4j有原创的图存储算法,在计算性能上比较突出。产品分为社区版和商业版,社区版只能部署单点,支持亿级节点,足够普通小型应用使用,商业版可以支持动态扩展。
- 排名第二是CosmosDB,使用者往往也是Azure其他产品的使用者。可以说Neo4j和CosmosDB是第一阵营。
- 排名第三开始得分出现断崖式下降,之后的得分都相差不多。ArangoDB和OrientDB的得分和特性都比较相近,前者是c++实现,后者是java实现。
- JanusGraph本身的得分并不高,但是也排在原生图数据库的第二名。
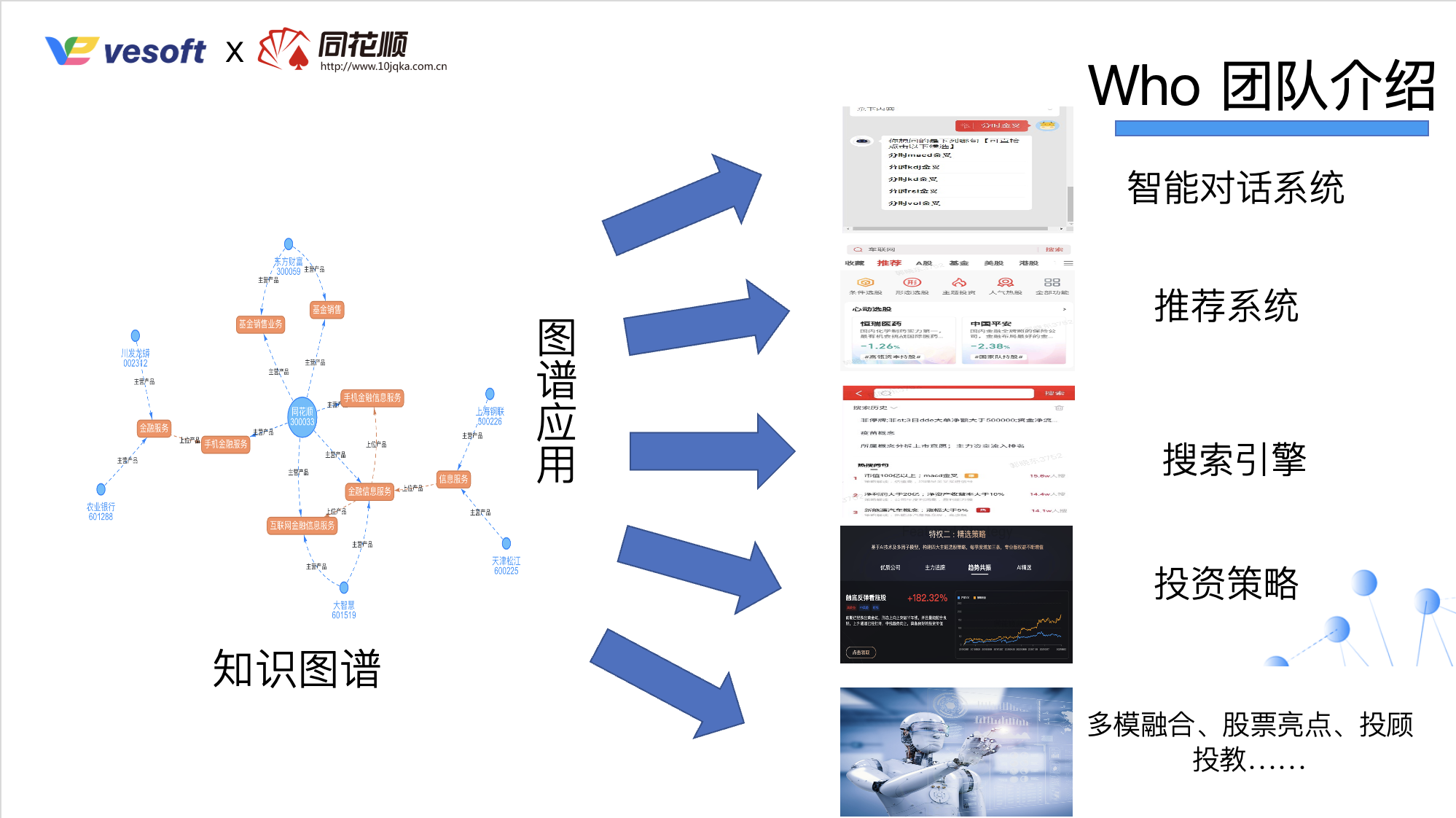
同花顺知识图谱团队的图数据库选型, 对比Neo4j、Orient DB、Dgraph、JanusGraph、HugeGraph、Nebula 等 6 款图数据库产品,最终选定HugeGraph
随着社交、电商、金融、零售、物联网等行业的快速发展,现实社会织起了了一张庞大而复杂的关系网,传统数据库很难处理关系运算。大数据行业需要处理的数据之间的关系随数据量呈几何级数增长,亟需一种支持海量复杂数据关系运算的数据库,
图数据库应运而生。
世界上很多著名的公司都在使用图数据库。比如:
- 社交领域:Facebook, Twitter,Linkedin用它来管理社交关系,实现好友推荐
- 零售领域:eBay,沃尔玛使用它实现商品实时推荐,给买家更好的购物体验
- 金融领域:摩根大通,花旗和瑞银等银行在用图数据库做风控处理
- 汽车制造领域:沃尔沃,戴姆勒和丰田等顶级汽车制造商依靠图数据库推动创新制造解决方案
- 电信领域:Verizon, Orange和AT&T 等电信公司依靠图数据库来管理网络,控制访问并支持客户360
- 酒店领域:万豪和雅高酒店等顶级酒店公司依使用图数据库来管理复杂且快速变化的库存
关系型数据库
-
关系型数据库实际上是不擅长处理关系的
- 关系型数据库
- 图数据库
- 关系型数据库
- 在数据关系中心,图形数据库在查询速度方面非常高效,即使对于深度和复杂的查询也是如此。在《Neo4j in Action》这本书中,作者在关系型数据库
和图数据库(Neo4j)之间进行了实验。
- 深度为2时(即朋友的朋友),两种数据库性能相差不是很明显;
- 深度为3时(即朋友的朋友的朋友),很明显,关系型数据库的响应时间30s,已经变得不可接受了;
- 深度到4时,关系数据库需要近半个小时才能返回结果,使其无法应用于在线系统;
- 深度到5时,关系型数据库已经无法完成查询。而对于图数据库Neo4J,深度从3到5,其响应时间均在3秒以内。
- 可以看出,对于图数据库来说,数据量越大,越复杂的关联查询,约有利于体现其优势。从深度为4/5的查询结果我们可以看出,图数据库返回了整个社交网络一半以上的人数。


NoSQL数据库
大致可以分为四类:
- 键值(key/value)数据库
- 列存储数据库
- 文档型数据库
- 图数据库

- 表格对比
| 分类 | 数据模型 | 优势 | 劣势 | 举例 |
|---|---|---|---|---|
| 键值数据库 | 哈希表 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 | Redis |
| 列存储数据库 | 列式数据存储 | 查找速度快;支持分布横向扩展;数据压缩率高 | 功能相对受限 | HBase |
| 文档型数据库 | 键值对扩展 | 数据结构要求不严格;表结构可变;不需要预先定义表结构 | 查询性能不高,缺乏统一的查询语法 | MongoDB |
| 图数据库 | 节点和关系组成的图 | 利用图结构相关算法(最短路径、节点度关系查找等) | 可能需要对整个图做计算,不利于图数据分布存储 | Neo4j、JanusGraph |
什么是图数据库?
- 图数据库(Graph database)并非指存储图片的数据库,而是以图这种数据结构存储和查询数据。
- 图形数据库是一种在线数据库管理系统,具有处理图形数据模型的创建,读取,更新和删除(CRUD)操作。
- 与其他数据库不同,关系在图数据库中占首要地位。这意味着应用程序不必使用外键或带外处理(如MapReduce)来推断数据连接。
- 与关系数据库或其他NoSQL数据库相比,图数据库的数据模型也更加简单,更具表现力。
- 图形数据库是为与事务(OLTP)系统一起使用而构建的,并且在设计时考虑了事务完整性和操作可用性。
两个重要属性
- 根据存储和处理模型不同,市面上图数据库也有一些区分。
- 比如:
- Neo4J就是属于原生图数据库,它使用的后端存储是专门为Neo4J这种图数据库定制和优化的,理论上说能更有利于发挥图数据库的性能。
- 而JanusGraph不是原生图数据库,而将数据存储在其他系统上,比如Hbase。
- ① 图存储
- 一些图数据库使用原生图存储,这类存储是经过优化的,并且是专门为了存储和管理图而设计的。并不是所有图数据库都是使用原生图存储,也有一些图数据库将图数据序列化,然后保存到关系型数据库或者面向对象数据库,或其他通用数据存储中。
- ② 图处理引擎
- 原生图处理(也称为无索引邻接)是处理图数据的最有效方法,因为连接的节点在数据库中物理地指向彼此。非本机图处理使用其他方法来处理CRUD操作。
jupyter配套的图查询语言

Instructions for connecting to the following graph databases:
| Endpoint | Graph model | Query language |
|---|---|---|
| Gremlin Server | property graph | Gremlin |
| Blazegraph | RDF | SPARQL |
| Amazon Neptune | property graph or RDF | Gremlin or SPARQL |
Neo4j

安装
安装:先装java,必须是open jdk 11以上版本, open JDK清华源下载
- 配置环境变量:见下面代码
- 查看版本:java –version
- 社区版neo4j下载:(免登记,直接下载,版本号可定制)
windows:https://neo4j.com/artifact.php?name=neo4j-community_windows-x64_3_1_0.exelinux:https://neo4j.com/artifact.php?name=neo4j-community-3.1.0-unix.tar.gzmac:https://neo4j.com/artifact.php?name=neo4j-community_macos_3_1_0.dmg
- 更改配置, conf/neo4j.conf
- To accept non-local connections, uncomment this line:
- dbms.default_listen_address=0.0.0.0 # 注释掉此行
- 安装完成后,启动服务
- Web Demo:http://localhost:7474/browser/
- 默认账户,用户名:neo4j 密码 :neo4j
- 密码修改:server change-password
Neo4J支持ACID,集群、备份和故障转移。目前Neo4J最新版本为3.5,分为社区版和企业版- 社区版只支持单机部署,功能受限。
- 企业版支持主从复制和读写分离,包含可视化管理工具。
# 环境变量如下
vim /etc/profile 或 ~/.bash_profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_171 (根据自己的完整路径修改)
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
alias java=$JAVA_HOME/bin/java # 如果系统已有java,加此行覆盖
使用方法

面向过程代码
- 代码
# !pip install py2neo
# coding: utf-8
"""
Neo4j的python接口测试
参考:https://blog.csdn.net/macb007/article/details/79044460
时间:2018-4-23, wangqiwen
"""
#import random
import json
from py2neo import Graph #pylint:disable=import-error
#from py2neo import Graph, Node, Relationship
import numpy as np
import pandas as pd
def main():#pylint:disable=too-many-statements,too-many-branches,too-many-locals
"""
测试示例, http://10.200.24.101:7474/browser/
"""
data_file = '新房电子驻场客服-意图体系.csv'
df = pd.read_csv(data_file)
data = df.values.tolist()
# neo4j 初始化
host = '10.200.24.101'
graph = Graph("http://%s:7474"%(host), user="neo4j", password="wqw")
# graph = Graph("http://%s:7474"%(host), username="neo4j", password="wqw") # username参数不再支持
#(1)创建实体
#cur_data_list = data['entities'].values.tolist()
cur_data_list = data
# 创建节点, 数据示例:[20, 'SALE_INFO', '项目销售信息', 'ONSALE_ROOM', '在售户型']
cur_type = 'root'; business_info = {"id":"newhouse", "name":"新房电子驻场客服"}
# 唯一约束(name唯一)
cql_delete = 'MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r' #删除所有节点和关系
graph.run(cql_delete)
cql_create = 'MERGE(n:%s {id:"%s", name:"%s", type:"%s"})'%(cur_type, business_info['id'], business_info['name'],cur_type)
graph.run(cql_create)
for entity in cur_data_list:
print(json.dumps(entity, ensure_ascii=False))
# domain节点
cur_type = 'domain'
cql_create = 'MERGE(n:%s {id:"%s", name:"%s", type:"%s", business:"%s"})'%(cur_type, entity[1], entity[2],cur_type,business_info['id'])
graph.run(cql_create)
# intent节点
cur_type = 'intent'
cql_create = 'MERGE(n:%s {id:"%s", name:"%s", type:"%s", business:"%s"})'%(cur_type, entity[3], entity[4],cur_type,business_info['id'])
graph.run(cql_create)
# 边 root->domain->intent
cql_rel = 'MATCH(a {id:"%s"}),(b{id:"%s"})\
MERGE(a)-[r:%s {name:"%s",id:"%s"}]->(b)'%('newhouse', entity[1], '有', 'has', '有')
graph.run(cql_rel)
cql_rel = 'MATCH(a {id:"%s"}),(b{id:"%s"})\
MERGE(a)-[r:%s {name:"%s",id:"%s"}]->(b)'%(entity[1], entity[3], '包含', 'include', '包含')
graph.run(cql_rel)
#result = graph.run('match (n) return n')
#print(json.dumps(result, ensure_ascii=False))
if __name__ == '__main__':
main()
面向对象代码
工具
- Neo4j Python驱动程序(4.2版)
- jupiter notebook/Lab或谷歌Colab(可选)
- pandas
数据示例
- 三种不同的节点类型与之对应:作者、论文和类别。
Neo4j沙箱可以对Neo4j免费使用。你可以启动一个实例,该实例将持续3天并开始工作!
class Neo4jConnection:
"""
neo4j 连接对象
"""
def __init__(self, uri, user, pwd):
self.__uri = uri
self.__user = user
self.__pwd = pwd
self.__driver = None
try:
self.__driver = GraphDatabase.driver(self.__uri, auth=(self.__user, self.__pwd))
except Exception as e:
print("Failed to create the driver:", e)
def close(self):
if self.__driver is not None:
self.__driver.close()
def query(self, query, parameters=None, db=None):
assert self.__driver is not None, "Driver not initialized!"
session = None
response = None
try:
session = self.__driver.session(database=db) if db is not None else self.__driver.session()
response = list(session.run(query, parameters))
except Exception as e:
print("Query failed:", e)
finally:
if session is not None:
session.close()
return response
# 链接neo4j沙箱
conn = Neo4jConnection(uri="bolt://52.87.205.91:7687",
user="neo4j",
pwd="difficulties-pushup-gaps")
# 创建约束(避免节点重复),建立索引
conn.query('CREATE CONSTRAINT papers IF NOT EXISTS ON (p:Paper) ASSERT p.id IS UNIQUE')
conn.query('CREATE CONSTRAINT authors IF NOT EXISTS ON (a:Author) ASSERT a.name IS UNIQUE')
conn.query('CREATE CONSTRAINT categories IF NOT EXISTS ON (c:Category) ASSERT c.category IS UNIQUE')
# 创建三个函数来为category和author节点创建数据框
def add_categories(categories):
# 向Neo4j图中添加类别节点。
query = '''
UNWIND $rows AS row
MERGE (c:Category {category: row.category})
RETURN count(*) as total
'''
return conn.query(query, parameters = {'rows':categories.to_dict('records')})
def add_authors(rows, batch_size=10000):
# #以批处理作业的形式将作者节点添加到Neo4j图中。
query = '''
UNWIND $rows AS row
MERGE (:Author {name: row.author})
RETURN count(*) as total
'''
return insert_data(query, rows, batch_size)
def insert_data(query, rows, batch_size = 10000):
# 以批处理方式更新Neo4j数据库
total = 0
batch = 0
start = time.time()
result = None
while batch * batch_size < len(rows):
res = conn.query(query,
parameters= {
'rows': rows[batch*batch_sizebatch+1)*batch_size].to_dict('records')})
total += res[0]['total']
batch += 1
result = {"total":total,
"batches":batch,
"time":time.time()-start}
print(result)
return result
# 其它操作见原文
命令运行:
MATCH (a:Author)-[:AUTHORED]->(p:Paper)-[:IN_CATEGORY]->(c:Category) RETURN a, p, c LIMIT 300
Cypher
- Cypher是Neo4j的图形查询语言,允许用户存储和检索图形数据库中的数据。
- 查询语言如下:
MATCH
(person:Person)-[:KNOWS]-(friend:Person)-[:KNOWS]-(foaf:Person)
WHERE
person.name = "Joe"
AND NOT (person)-[:KNOWS]-(foaf)
RETURN
foaf

诊断
【2025-8-5】neo4j速度太慢?
- explain cypher语句 :执行计划
- profile cypher语句 :执行过程
-- explain
PROFILE
MATCH (p { name: 'Tom Hanks' })
RETURN p
更多优化技巧见 Neo4j性能调优
JanusGraph
- 一个Linux基金会下的开源分布式图数据库 。JanusGraph提供Apache2.0软件许可证。该项目由IBM、Google、Hortonworks支持。
- JanusGraph是由TitanDB 图数据库修改而来,TitanDB从2012年开始开发。目前最新版本为0.3.1。
TinkerPop图生态
- Apache TinkerPop是一款开源的图计算框架,JanusGraph通过原生支持TinkerPop来提供图数据库(OLTP)和图分析系统 (OLAP)的能力。
- 下图包括了TinkerPop的几个组成部分。
- 最上层是Gremlin Server,为用户提供了访问图数据库的通道,通过脚本可以连上Gremlin Server,使用Gremlin查询/遍历语言来操作JanusGraph等支持Gremlin的图数据库,Gremlin语言支持Cypher语法;
- 再下层是TinkerPop提供的用于表示属性图的核心API,包括图、定点和边的各种操作接口;Graph Computer是TinkPop的图计算框架,与Spark、Giraph或Hadoop等大数据平台配合并通过调用JanusGraph提供的OLAP I/O接口实现图分析和处理能力。JanusGraph等图数据库和图分析系统通过实现Provider API来对接TinkPop框架,定制所需的功能。
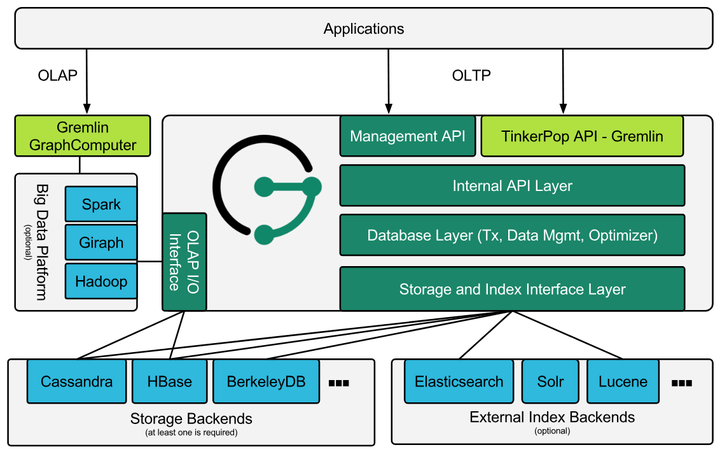
JanusGraph主要定位是做图数据的是实时检索。特性支持动态扩展、良好的性能指标、支持TinkerPop框架、支持Gremlin语言及技术栈、支持多种底层存储。
- JanusGraph技术总结
- JanusGraph实用查询: Gremlin

DGraph
- dgraph 是可扩展的,分布式的,低延迟的图数据库。
- DGraph 的目标是提供 Google 生产水平的规模和吞吐量,在超过TB的结构数据里,为用户提供足够低延迟的实时查询。DGraph 支持 GraphQL 作为查询语言,响应 JSON。
- 对比

云平台
阿里云 GDB
【2025-8-20】阿里云
| 分类 | 图数据库 | 关系型数据库 |
|---|---|---|
| 模型 | 图结构 | 表结构 |
| 存储信息 | 结构化/半结构化数据库 | 高度结构化数据库 |
| 2 度查询 | 高效 | 低效 |
| 3 度查询 | 高效 | 低效/不支持 |
| 空间占用 | 高 | 中 |
图数据库GDB非常适合社交网络、欺诈检测、推荐引擎、知识图谱、网络/IT运营这类高度互连数据集的场景。
例如,在一个典型的社交网络中,常常会存在“谁认识谁,上过什么学校,常住什么地方,喜欢什么餐馆”之类的查询,传统关系型数据库对于超过3张表关联的查询十分低效难以胜任,但图数据库可轻松应对社交网络的各种复杂存储和查询场景。
图数据库(Graph Database,简称GDB)是一种支持Property Graph图模型、用于处理高度连接数据查询与存储的实时、可靠的在线数据库服务。
- (1) 兼容并包,集多种图查询语言于一身
- 高度兼容Neo4j、JanusGraph等图数据库引擎,支持 OpenCypher 、Gremlin 查询语言,降低迁移成本和研发门槛。
- (2) 快速弹性、高可用、易运维、尽享云原生技术惠普
- 基于云原生架构的图数据库引擎,可快速扩缩容,应对突增业务负载;支持高可用实例、节点故障自动切换,保障业务连续性;提供备份恢复、自动升级、监控告警、故障切换等丰富的运维功能,免去繁琐的运维烦恼。
- (3) 低构建成本、灵活计费、满足不同成本需求
- 产品构建、运维成本,仅为国外其他图数据库云厂商的 40%;支持按量付费、包年包月多种计费形式,无论创新探索,亦或生产应用都能自由掌握。
GDB 描述
- Gremlin 是Apache TinkerPop框架下的图查询语言,使用Gremlin可以很方便地对图数据进行查询、修改、遍历和过滤等操作。
- GDB Gremlin 内核版本高度兼容TinkerPop Gremlin查询语言,性能较为优秀。可以高度兼容HugeGraph、JanusGraph、Amazon Neptune等图数据库。
- OpenCypher: Neo4j是目前最为主流的图数据库之一,使用Cypher作为主要查询语言。GDB OpenCypher内核版本高度兼容OpenCypher语言,可以非常方便实现Neo4j用户迁移。
图数据库GDB具备如下优势:
- 标准图查询语言:支持属性图,高度兼容Gremlin图查询语言和OpenCypher图查询语言。
- 高度优化的自研引擎: 高度优化的自研图计算层和存储层,云盘多副本保障数据超高可靠,支持ACID事务。
- 服务高可用: 支持高可用实例,节点故障自动切换,保障业务连续性。
- 易运维: 提供备份恢复、自动升级、监控告警、故障切换等丰富的运维功能,大幅降低运维成本。
应用
LLM 构建 KG
详见站内专题:大模型+知识图谱
金融领域知识图谱
- 用Neo4j搭建简单金融知识图谱
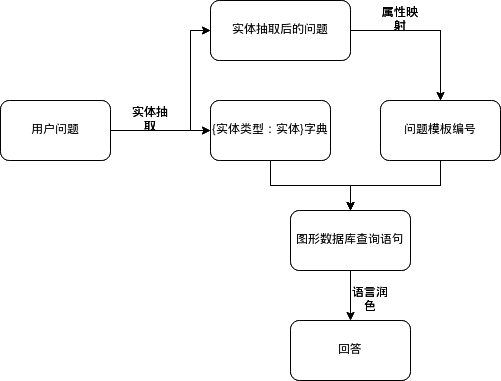
- 整体架构
- 用户问题先进行实体抽取来得到抽取后的问题和实体类型:实体字典
- 抽取后的问题通过属性映射得到问题模板(编号)
- 然后用实体类型:实体字典和问题模板(编号)来得到图形数据库相应的查询语言
- 最后将查询到结果进行语言的上的润色得到相应的答案。
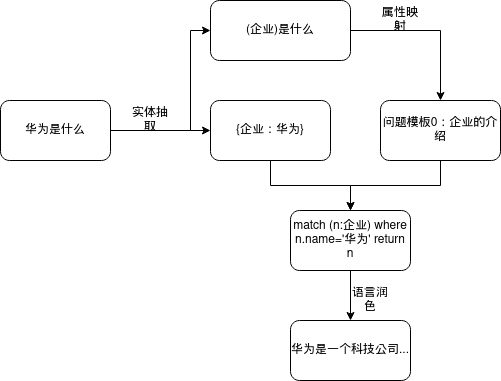
- match (p:企业) where p.name=’华为’ return p.code
- neo4j构建一个简单的金融领域的知识图谱,挖掘“高管—上市企业—行业/概念”之间的关系
- 数据源:链接,密码:h8of
- csv文件统一放入neo4j的安装目录下的import目录
- 注意:【2021-2-12】非c盘install,而是document目录,如C:\Users\wqw\Documents\Neo4j\default.graphdb
- 命令行进入neo4j安装目录下的bin目录,输入命令
- neo4j-admin import –mode=csv –database=mygraph2.db –nodes ../import/concept.csv –nodes ../import/executive.csv –nodes ../import/industry.csv –nodes ../import/stock.csv –relationships ../import/executive_stock.csv –relationships ../import/stock_concept.csv –relationships ../import/stock_industry.csv
- 示例

基于BERT的问答系统
电影问答系统
- 【2021-2-10】300行python代码从零开始构建基于知识图谱的电影问答系统
- 【2021-2-14】简单构建基于RDF和SPARQL的KBQA(知识图谱问答系统)
- 流程
- 预定义 3 类共 5 个示例问题,包括:
- ● “谁是苑茵?”,
- ● “丁洪奎是谁?”,
- ● “苏进木来自哪里?”,
- ● “苑茵哪个族的?”,
- ● “苑茵是什么民族的人?”.
- 利用结巴分词对中文句子进行分词, 同时进行词性标注;
- 将词的文本和词性打包, 视为”词对象”,对应 :class:Word(token, pos);
- 利用 REfO 模块对词进行对象级别 (object-level) 的正则匹配,判断问题属于的种类并产生对应的 SPARQL,对应 :class:Rule(condition, action);
- 如果成功匹配并成功产生 SPARQL 查询语句, 立刻请求 Fuseki 服务并返回结果,打印相关内容;
- 预定义 3 类共 5 个示例问题,包括:
- 安装
- 1、配置第三方库:pip install refo jieba sparqlwrapper
- 2、安装JAVA JDK1.8,配置好环境变量。
- 3、项目根目录主要包括backend文件夹和test.py文件(同一级),backend是Jena的Fuseki 模块,运行第4步后在本地监听(http://localhost:3030/),如图:
- 流程

User Simulator
- 用户模拟器采用了agenda-based的方式来构建。将用户状态存入栈中,维护用户的对话历史和对话目标,状态的更新即为栈的push 和 pop操作。
- 对话成功的标志为: 是否电影票成功预订;是否推荐的电影满足用户的条件限制
- 用户目标一般由两部分组成:
- inform slot:一组给定的slot-value 对,认为是 user 的对整个会话进程的约束。
- 必须存在这些slot:movie_name, theater, start_time, date, number_of_people 槽位。(如果没有这些槽位就无法订票)
- request slot:slot的value值,user 是不知道的,需要与 agent 交互中获得答案。
- 必须存在slot:ticket。(这个槽位表示用户的订票请求,这本身是电影订票任务的目标)
- inform slot:一组给定的slot-value 对,认为是 user 的对整个会话进程的约束。
- 用户目标一般由两部分组成:
- 数据集构建
- 构造用户目标数据集方法:论文采用了两个机制,从标注数据集中生成用户目标:
- 通常来讲,用户的第一轮内容中包含一部分,甚至所有的用户要求。
- 第一个机制是提取用户第一轮的所有slot信息(注:不包括greeting 轮)。
- 另一个机制是提取首先出现在所有用户轮中的所有slot。
- 然后将它们整合到一个用户目标中。
- 论文的数据从 Amazon Mechanical Turk 收集而来,收集了大概280组对话,平均轮数为11。
- 设定了11个意图:’request’, ‘inform’, ‘confirm_question’, ‘confirm_answer’, ‘greeting’, ‘closing’, ‘multiple_choice’, ‘thanks’, ‘welcome’, ‘deny’, ‘not_sure’
- 29个槽位:’actor’, ‘actress’, ‘city’, ‘closing’, ‘critic_rating’, ‘date’, ‘description’, ‘distanceconstraints’, ‘genre’, ‘greeting’, ‘implicit_value’, ‘movie_series’, ‘moviename’, ‘mpaa_rating’, ‘numberofpeople’, ‘numberofkids’, ‘taskcomplete’, ‘other’, ‘price’, ‘seating’, ‘starttime’, ‘state’, ‘theater’, ‘theater_chain’, ‘video_format’, ‘zip’, ‘result’, ‘ticket’, ‘mc_list’
- 对话状态有三种情况:
- no_outcome_yet:是指agent没有 inform(task_comlete),并且轮数还没有达到最大。
- success:agent 在最大轮数内,必须回答了所有的user 的request,并且订了一张正确的电影票。
- failure:其他的情况都为失败。
- 用户模拟器可以被设计可以为 dialog act level(输出到agent结构化的语义解析信息),也可以为utterance level的(输出到agent自然语言形式)。后者需要NLG。由于数据集的限制,纯使用模型会给DM 策略选择带来许多噪声。因此采用了模型、模板相结合的方式(策略是先模板后模型):
- Template-based NLG:定义NLG模板
- Model-based NLG:输入为 dialog-act,输出为带slot标签的句子,(如:我希望电影从{start-time}开始),之后再进行替换。decoder采用beam search n取值为3 。(DM训练可以将beam search n=3 的句子作为输入噪声。)
- 如何衡量代理的质量,有三个指标:
- success rate (任务完成率)
- average reward
- average turns
- 一般来说,一个好的政策应该有较高的任务完成率、较高的平均奖励和较低的平均轮数。可以选择成功率作为主要的评估指标来评价agent的效果。
- 代码
- 效果图

系统的整体逻辑是怎么样的?(系统业务逻辑介绍)
- 准备工作:
- 环境:Python 3.6,基于webpy库,图数据库neo4j
- pip install -r requirements.txt
- 数据:数据来源于IMDB数据库,这是一个关于电影演员、电影、电视节目、电视明星和电影制作的在线数据库。
- 格式:
- 链接,提取码:7qv1
- 把数据csv文件放入neo4j安装目录下的import目录下即可
- E:\neo4j-community-3.5.3-windows\neo4j-community-3.5.3\import
- 格式:
- 环境:Python 3.6,基于webpy库,图数据库neo4j
- 系统整体框架
- 问题预处理(NLU)
- NER:提取关键信息,主语是人还是电影,这就涉及到自然语言处理中的命名实体识别;
- 对query进行词性标注后,找到对应的nr对应的单词,即人名,电影名称
- 意图识别:用户想问什么,文本表示问题,最最基本的文本表示方法是one-hot形式,在试验中使用的是sklearn中的tfidf工具
- 分类:用监督学习方法识别用户意图,需要提前准备语料,用户的问题归纳成了很多类,对各个类别进行抽象,比如对于用户询问某某演过哪些电影等一系列问题,抽象成:nr 电影作品
- NER:提取关键信息,主语是人还是电影,这就涉及到自然语言处理中的命名实体识别;
- 问题模板
- 用户各种问题的模板(nm代表电影名称,ng代表电影类型)
- 查询答案
- 如何对图数据库进行操作
- 示例:刘德华演过哪些电影呀?
- 获取关键信息:刘德华
- 问题分类得到问题模板:7:nnt 电影作品
- 进行替换得到新的问题:刘德华 电影作品


需要做那些准备工作?(实验环境和实验数据准备)
# 用户各种问题的模板(nm代表电影名称,ng代表电影类型)
0:nm 评分
1:nm 上映时间
2:nm 类型
3:nm 简介
4:nm 演员列表
5:nnt 介绍
6:nnt ng 电影作品
7:nnt 电影作品
8:nnt 参演评分 大于 x
9:nnt 参演评分 小于 x
10:nnt 电影类型
11:nnt nnr 合作 电影列表
12:nnt 电影数量
13:nnt 出生日期
- 图数据库代码
- 逐条执行,不能一次性输入
//导入节点 电影类型 == 注意类型转换
LOAD CSV WITH HEADERS FROM "file:///genre.csv" AS line
MERGE (p:Genre{gid:toInteger(line.gid),name:line.gname})
//导入节点 演员信息
LOAD CSV WITH HEADERS FROM 'file:///person.csv' AS line
MERGE (p:Person { pid:toInteger(line.pid),birth:line.birth,
death:line.death,name:line.name,
biography:line.biography,
birthplace:line.birthplace})
// 导入节点 电影信息
LOAD CSV WITH HEADERS FROM "file:///movie.csv" AS line
MERGE (p:Movie{mid:toInteger(line.mid),title:line.title,introduction:line.introduction,
rating:toFloat(line.rating),releasedate:line.releasedate})
// 导入关系 actedin 电影是谁参演的 1对多
LOAD CSV WITH HEADERS FROM "file:///person_to_movie.csv" AS line
match (from:Person{pid:toInteger(line.pid)}),(to:Movie{mid:toInteger(line.mid)})
merge (from)-[r:actedin{pid:toInteger(line.pid),mid:toInteger(line.mid)}]->(to)
//导入关系 电影是什么类型 == 1对多
LOAD CSV WITH HEADERS FROM "file:///movie_to_genre.csv" AS line
match (from:Movie{mid:toInteger(line.mid)}),(to:Genre{gid:toInteger(line.gid)})
merge (from)-[r:is{mid:toInteger(line.mid),gid:toInteger(line.gid)}]->(to)
接收到用户的问题后需要怎么处理用户问题?(用户问题预处理)
- 词性标注
- jieba的词性标注和分词是同步进行的,所以如果分词不准确的话,那么词性标注往往也会出错
- 比如说电影《卧虎藏龙》,被jieba分词分为:卧虎,藏龙
- 解决:自定义字典
- 卧虎藏龙 15 nm
- 陈雅伦 15 nr
def question_posseg(self):
jieba.load_userdict("./data/userdict3.txt")
clean_question = re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",self.raw_question)
self.clean_question=clean_question
question_seged=jieba.posseg.cut(str(clean_question))
result=[]
question_word, question_flag = [], []
for w in question_seged:
temp_word=f"{w.word}/{w.flag}"
result.append(temp_word)
# 预处理问题
word, flag = w.word,w.flag
question_word.append(str(word).strip())
question_flag.append(str(flag).strip())
assert len(question_flag) == len(question_word)
self.question_word = question_word
self.question_flag = question_flag
print(result)
return result
- 问题分类和模板填充
# 获取训练数据
def read_train_data(self):
train_x=[]
train_y=[]
file_list=getfilelist("./data/question/")
# 遍历所有文件
for one_file in file_list:
# 获取文件名中的数字
num = re.sub(r'\D', "", one_file)
# 如果该文件名有数字,则读取该文件
if str(num).strip()!="":
# 设置当前文件下的数据标签
label_num=int(num)
# 读取文件内容
with(open(one_file,"r",encoding="utf-8")) as fr:
data_list=fr.readlines()
for one_line in data_list:
word_list=list(jieba.cut(str(one_line).strip()))
# 将这一行加入结果集
train_x.append(" ".join(word_list))
train_y.append(label_num)
return train_x,train_y
# 贝叶斯分类模型
# 训练并测试模型-NB
def train_model_NB(self):
X_train, y_train = self.train_x, self.train_y
self.tv = TfidfVectorizer()
train_data = self.tv.fit_transform(X_train).toarray()
clf = MultinomialNB(alpha=0.01)
clf.fit(train_data, y_train)
return clf
# 预测
def predict(self,question):
question=[" ".join(list(jieba.cut(question)))]
test_data=self.tv.transform(question).toarray()
y_predict = self.model.predict(test_data)[0]
# print("question type:",y_predict)
return y_predict
- 返回用户问题所属的类别编号,这个编号也就对应一个问题模板:
0:nm 评分
1:nm 上映时间
2:nm 类型
3:nm 简介
4:nm 演员列表
5:nnt 介绍
6:nnt ng 电影作品
7:nnt 电影作品
8:nnt 参演评分 大于 x
9:nnt 参演评分 小于 x
10:nnt 电影类型
11:nnt nnr 合作 电影列表
12:nnt 电影数量
13:nnt 出生日期
如果根据用户问题来查找答案?(答案获取)
- 得到了这些信息后,如何在知识图谱中查询答案。
- 简单来说,每个问题模板就对应了一个用户意图,那么就按照每个意图来写查询语句
- 定义了一个问题模板的方法字典,每一个key对应模板的编号,value就是根据该模板来查询答案的方法
self.q_template_dict={
0:self.get_movie_rating,
1:self.get_movie_releasedate,
2:self.get_movie_type,
3:self.get_movie_introduction,
4:self.get_movie_actor_list,
5:self.get_actor_info,
6:self.get_actor_act_type_movie,
7:self.get_actor_act_movie_list,
8:self.get_movie_rating_bigger,
9:self.get_movie_rating_smaller,
10:self.get_actor_movie_type,
11:self.get_cooperation_movie_list,
12:self.get_actor_movie_num,
13:self.get_actor_birthday
}
def get_question_answer(self,question,template):
# 如果问题模板的格式不正确则结束
assert len(str(template).strip().split("\t"))==2
template_id,template_str=int(str(template).strip().split("\t")[0]),str(template).strip().split("\t")[1]
self.template_id=template_id
self.template_str2list=str(template_str).split()
# 预处理问题
question_word,question_flag=[],[]
for one in question:
word, flag = one.split("/")
question_word.append(str(word).strip())
question_flag.append(str(flag).strip())
assert len(question_flag)==len(question_word)
self.question_word=question_word
self.question_flag=question_flag
self.raw_question=question
# 根据问题模板来做对应的处理,获取答案
answer=self.q_template_dict[template_id]()
return answer
- 进入到对应的方法中,利用Cypher语言来构建查询语句
- 基本形式:match(n)-[r] -(b)
- 直接使用python的库py2neo来操作图数据库neo4j
from py2neo import Graph,Node,Relationship,NodeMatcher
class Query():
def __init__(self):
self.graph=Graph("http://localhost:7474", username="neo4j",password="123456")
# 问题类型0,查询电影得分
def run(self,cql):
# find_rela = test_graph.run("match (n:Person{name:'张学友'})-[actedin]-(m:Movie) return m.title")
result=[]
find_rela = self.graph.run(cql)
for i in find_rela:
result.append(i.items()[0][1])
return result
# 查询演员
# 4:nm 演员列表
def get_movie_actor_list(self):
movie_name=self.get_movie_name()
cql = f"match(n:Person)-[r:actedin]->(m:Movie) where m.title='{movie_name}' return n.name"
print(cql)
answer = self.graph.run(cql)
answer_set = set(answer)
answer_list = list(answer_set)
answer = "、".join(answer_list)
final_answer = movie_name + "由" + str(answer) + "等演员主演!"
return final_answer
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
