GPU 显存
LLM 型号
如何选择 LLM 规模?
本地运行LLM广泛流行。Ollama、vLLM、LM Studio、llama.cpp——工具已经大大成熟。但”存在”和”特定硬件上运行良好”之间总是存在差距。
常见方法是查找参数计数,对量化级别进行粗略计算,然后失败了,因为:
- MoE(混合专家)模型(如DeepSeek-V3或Mixtral)的总参数计数具有严重的误导性——
Mixtral 8x7B有46.7B总参数但每个token只激活约12.9B,将显存需求从约24GB降至约6.6GB - 量化选择至关重要——Q8_0与Q2_K可能是模型能否装入和输出质量可用与不可用之间的区别
- 速度因后端(CUDA vs Metal vs ROCm vs CPU)而差异巨大,而不仅仅是模型大小
- 上下文长度与内存的交互方式并不明显
这两个工具真正互补。使用 llmfit 缩小候选范围,然后如果你想要经验数据,使用llm-checker验证顶级选择。
注意事项:
- llm-checker 不处理MoE架构,将所有模型视为密集型——因此对于Mixtral、DeepSeek-V3和类似模型,内存估计会严重高估。
LLM Checker
llm-checker: Node.js CLI,通过Ollama实际拉取和基准测试模型以获取真实性能数据
- GitHub llm-checker
llm-checker 运行模型并测量实际性能——准确但需要先下载模型且需要时间
llmfit 从硬件规格估计——即时结果,无需任何下载,覆盖497个模型,包括许多你永远不会仅为基准测试而下载的模型
LLMfit
【2026-3-18】LLMfit :为你的硬件找出最佳LLM
- LLMfit.io 是 Rust编写的终端工具,检测系统硬件——RAM、CPU核心、GPU显存——并与133个提供商的497个模型的数据库交叉引用,哪些模型可以运行、运行速度如何、以及质量水平如何。
- 不仅仅是”这个能装进内存吗?”的检查,还从四个维度对模型进行评分(质量、速度、适配度和上下文)排名,这样你就可以做出明智决定。
llmfit 启动时用 sysinfo(用于RAM和CPU)和特定于供应商的工具组合读取你的系统规格:
- NVIDIA:查询nvidia-smi,为多GPU设置聚合所有检测到的GPU的显存
- AMD:通过rocm-smi检测
- Intel Arc:从sysfs读取独立显存,通过lspci集成
- Apple Silicon:通过system_profiler读取统一内存(显存 = 系统RAM,因为是共享池)
- 还识别正在使用的加速后端——CUDA、Metal、ROCm、SYCL或CPU(ARM/x86)——,因为这直接影响速度估计。
如果自动检测失败(nvidia-smi损坏、VM、直通设置),可手动覆盖:
llmfit --memory=24G
llmfit --memory=32000M
安装
# macOS / Linux(最快):
curl -fsSL https://llmfit.axjns.dev/install.sh | sh
# Homebrew:
brew tap AlexsJones/llmfit
brew install llmfit
# 源代码:
git clone https://github.com/AlexsJones/llmfit.git
cd llmfit
cargo build --release
使用方法: CLI
# 完整排名表格
llmfit --cli
# 仅完美适配的模型,前5个
llmfit fit --perfect -n 5
# 显示检测到的硬件规格
llmfit system
# 按名称、提供商或大小搜索
llmfit search "llama 8b"
# 单个模型的详细视图
llmfit info "Mistral-7B"
# 顶级推荐为JSON(供智能体/脚本使用)
llmfit recommend --json --limit 5
# 按用例过滤
llmfit recommend --json --use-case coding --limit 3
WhichLLM
【2026-5-20】多个同名工具
- (1)本地使用 whichllm 自动检测本地硬件设备(GPU/CPU/RAM),查找 huggingface上可本地部署的模型
- (2)Together.AI 推出 WhichLLM 网页上使用
- 通过几个UI选项或自然语言,自动适配合适的模型
- (3)网页版 whichllm,
安装
# uv (recommended)
uvx whichllm
# To install permanently:
uv tool install whichllm
# Homebrew
brew install andyyyy64/whichllm/whichllm
# pip
pip install whichllm
# 源码安装
git clone https://github.com/Andyyyy64/whichllm.git
cd whichllm
uv sync --dev
uv run whichllm
uv run pytest
使用方法
$ whichllm --gpu "RTX 4090"
#1 Qwen/Qwen3.6-27B 27.8B Q5_K_M score 92.8 27 t/s
#2 Qwen/Qwen3-32B 32.0B Q4_K_M score 83.0 31 t/s
#3 Qwen/Qwen3-30B-A3B 30.0B Q5_K_M score 82.7 102 t/s
# 挑选最佳模型
alias bestllm='whichllm --top 1 --json | jq -r ".models[0].model_id"'
# Usage: ollama run $(bestllm)
# Chat with a model (auto-picks the best GGUF variant)
whichllm run "qwen 2.5 1.5b gguf"
# Auto-pick the best model for your hardware and chat
whichllm run
# CPU-only mode
whichllm run "phi 3 mini gguf" --cpu-only
# Auto-detect hardware and show best models
whichllm
# Simulate a GPU (e.g. planning a purchase)
whichllm --gpu "RTX 4090"
whichllm --gpu "RTX 5090"
# Specify variant
whichllm --gpu "RTX 5060 16"
# CPU-only mode
whichllm --cpu-only
# More results / filters
whichllm --top 20
whichllm --quant Q4_K_M
whichllm --min-speed 30
whichllm --evidence base # allow id/base-model matches
whichllm --evidence strict # id-exact only (same as --direct)
whichllm --direct
# JSON output
whichllm --json
# Force refresh (ignore cache)
whichllm --refresh
# Show hardware info only
whichllm hardware
# Plan: what GPU do I need for a specific model?
whichllm plan "llama 3 70b"
whichllm plan "Qwen2.5-72B" --quant Q8_0
whichllm plan "mistral 7b" --context-length 32768
# Upgrade: compare your current machine against candidate GPUs
whichllm upgrade "RTX 4090" "RTX 5090" "H100"
whichllm upgrade "Apple M4 Max" --top 5
# Run: download and chat with a model instantly
whichllm run "qwen 2.5 1.5b gguf"
whichllm run # auto-pick best for your hardware
# Snippet: print ready-to-run Python code
whichllm snippet "qwen 7b"
whichllm snippet "llama 3 8b gguf" --quant Q5_K_M
为什么都是6/7B、13B和130B
现在LLM 的大小为什都设计成6/7B、13B和130B几个档次?
大方向是算力(7/13/52),小细节是匹配显存(6/7/8)
- 6B模型可以在在12/16/24G显存的消费级显卡部署和训练。如果一个公司的模型不打算在消费级显卡部署,通常不会训6B这个规模。而且通常还会有一个1.4b或者2.8b,这个是比较适合在手机、车载端量化部署的尺寸。
- 13B模型按照4k长度组织数据,数据并行=2,刚好占满一个8卡机,并且可以量化部署在A10甚至4090。
- 下一档也不是130B,目前更大模型有16B、34B、52B、56B、65B、70B、100B、130B、170B、220B这几个规模,基本都是刚好占满某种规格的算力,要么是训练要么是推理。如果需要加快训练速度,只需要倍增卡数即可。比如我们训7B模型以8卡为单位88卡训,70B模型以80卡为单位806卡训。
最大尺寸的版本确定的核心逻辑: DeepMind的Chinchilla Scaling Law。
- Training Compute-Optimal Large Language Models
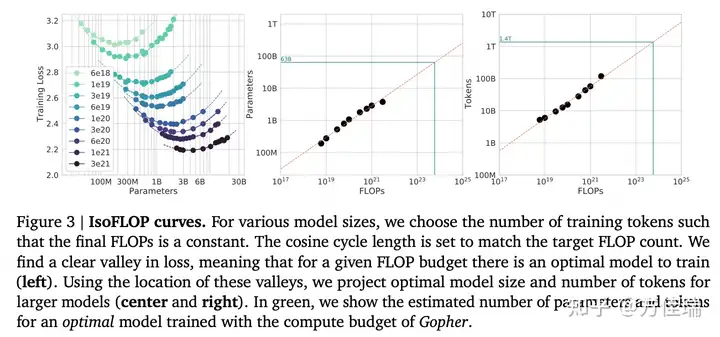
- Chinchilla Scaling Law 有些争议,正溯还是得看OpenAI的文章Scaling laws for neural language models
根据 Scaling Law,给定计算量(FLOPS)训练出来的最优模型(达到最好模型效果)的训练数据集的token数和模型参数数目是确定的。比如 Gopher模型的计算量预算是5.76 × 10^23 FLOPs,那么达到最优效果的参数量是63B,数据集中Token数目为1.4T。
很多答案都是从推理出发,为了适配常见的显卡。
比如,采用半精度的话
- 7B 的模型参数占14G, 可以放到16G 的 T4 上
- 13B 的模型参数占26G, 可以放到 32G 的 V100 上
- 33B 的模型参数占66G, 可以放到 80G 的 A100 上
- 65B 的模型参数占130G, 可以放到两张 80G 的 A100 上
剩余的显存可以用来放 KV Cache, 还有其他的一些功能性显存占用,比如 beam search 等。
这么回答也算合理,但是只能算是回答了一个方面,而且不是最重要的方面。
作者:看图学
GPU 选型
不同模型选什么GPU
【2025-06-16】大模型训练与推理显卡全指南:从硬件选型到性能优化
| 模型规模 | 训练最低配置 | 微调最低配置 | 推理最低配置 | 推荐生产级配置 |
|---|---|---|---|---|
| 7B参数 | 2×RTX 4090 | 1×RTX 4090 | 1×RTX 4080 | 1×A6000或2×RTX 4090 |
| 13B参数 | 4×RTX 4090 | 2×RTX 4090 | 1×RTX 4090(8-bit) | 1×A100 40GB或2×RTX 5090D |
| 70B参数 | 8×A100 80GB | 4×A100 80GB | 1×A100 80GB(4-bit) | 8×A100/H100集群 |
| 130B参数 | 16×A100 80GB | 8×A100 80GB | 2×A100 80GB(4-bit) | 16×H100 NVLink集群 |
| 300B+参数 | 32×H100 | 16×H100 | 8×H100(量化) | 256×H100 + InfiniBand |
大模型所需显存及硬件推荐
不同尺寸、不同精度下各维度所需显存及硬件选型推荐
(1)推理
(2)训练 全参
(3)高效微调 PEFT
典型场景下GPU配置方案推荐
消费级GPU选型
【2024-12-20】个人微调大模型(7B),最经济的硬件配置是什么?
大模型消费卡首选 RTX 4090,云端算力, 接不住这种需求。
大模型处理过程分训练,微调和推理。
- 模型
训练对GPU要求最高,需要处理大量数据和复杂计算。 - 模型
推理对GPU要求相对较低,但仍需要一定的计算能力和显存。 - 模型
微调介于两者之间,根据具体任务和数据集的大小来选择合适GPU配置。
算力消耗上,训练>微调>推理,训练和微调大型语言模型对于底层硬件资源的要求非常高。
微调对硬件的要求,主要体现在;
- CPU:尽量选择多核处理器,如 Xeon Gold 6330(28核心/56线程);
- GPU:全精度加载7B模型参数, 需要显存约为26.08G,超出了专注游戏的Geforce系列的最高24G显存。
- 一般至少需要
Tesla系列显卡来训练模型,A100、H100满足。对于微调,则需要至少需要14GB显存。 4090显存为24GB,通过优化内存使用和采用特定技术,如GaLore和量化训练,可以在单个GPU上预训练甚至微调大型语言模型,有很多实操测试。
另外,核数越高,微调速度和效率就越高;显存带宽影响数据在GPU内部的传输速度;
内存:系统内存大小也会影响微调过程。应根据显存的两倍左右来配置,建议配置256GB-512GB的内存,确保有足够的RAM, 支持模型的运行和数据处理。硬盘:建议至少2个4TB的SSD硬盘,以提供足够的存储空间和快速的数据读写速度。其他硬件散热和电源这块,也要多注意一些,以确保微调过程的高效和稳定。
消费级显卡对比
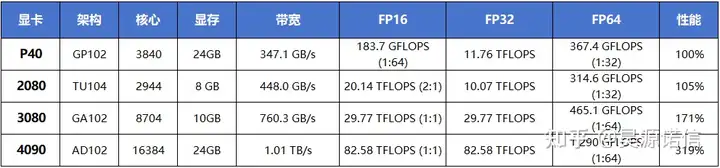
最经济的硬件配置能够在预算范围内提供足够性能的配置。
- 个人微调7B大模型,先上1块
4090GPU,主板可以考虑x12spi-tf,好处是两个x16槽位,后续可扩展;CPU可以搭配 Xeon Gold 6348/6330,256GB(8*32GB ddr4 recc 3200)的内存,以及一个 m.2 1TB硬盘,一个4TB机械硬盘存放数据
显卡选择
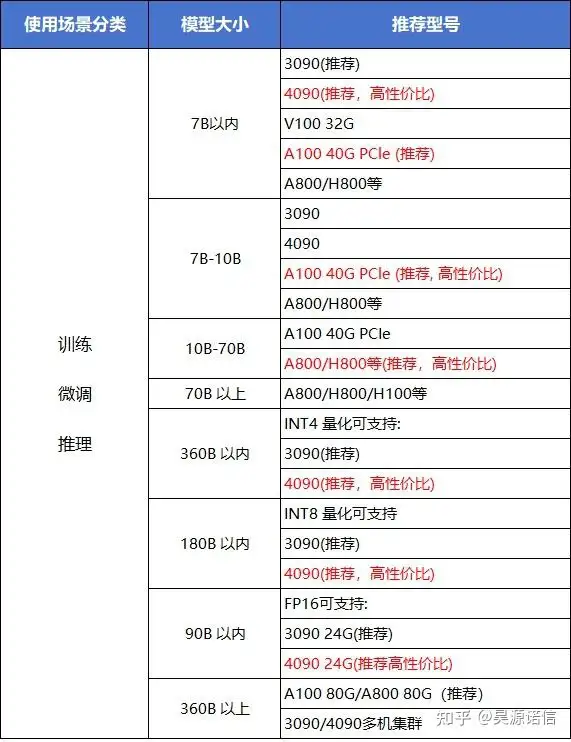
作者:昊源诺信
LLM 显存分析
【2023-8-30】大模型要占你多少内存?这个神器一键测量,误差低至0.5MB,免费可用
大模型训练推理要用多少内存?
- HuggingFace Space 最新火起来工具——Model Memory Calculator,模型内存测量器,在网页端人人可体验。
- 比如模型bert-base-case Int8估计占用413.18 MB内存,实际占用为413.68MB,相差0.5MB,误差仅有0.1%。
实际推理过程,EleutherAI 发现需要在预测数据基础上,预留 20% 内存
4b 模型推理占用
【2026-3-26】Qwen3-4B-Thinking-2507 为例 理解大模型的显存占用
问题
- 4B 模型到底要多少显存?
- 为什么我换了量化方式,显存并没有我想象中降那么多?
- 上下文越长为什么越吃显存?
显存被占是因为三个东西:模型、缓存、临时空间
推理时,大模型需要三样东西:
- (1)模型本身(Weights)
- (2)KV 缓存(Attention Cache)
- (3)算子临时空间(Workspace)
Qwen3-4B 实际占多少
(1) Qwen3-4B-Thinking-2507 真实占用是多少?
参数量与显存占用不成正比。
Qwen3-4B 虽然只有40亿参数,算“小个子”,但默认加载方式是FP16精度,光权重就要占掉约8GB显存,再加上KV Cache、中间激活值和推理缓存,轻松突破12GB,留给批处理和长文本的空间所剩无几。还支持高达 256K 上下文长度
假设 INT4, 4K 上文
- 4B 模型 INT4,在 6GB 显卡上跑挺稳。
| 模型 | 权重 | KV缓存 | 临时空间(workspace) | 整体 |
|---|---|---|---|---|
| Qwen3-4B-Thinking-2507 | 8GB | 1.5G | 1G | 10.5G |
| Qwen3-4B-Thinking-2507+INT4 | 2G | 1.5G | 1G | 4.5GB |
(2) Qwen3-4B vLLM 加载后占用 41G?
Qwen3-4B 模型本身只有约 8GB-9GB(FP16精度),但 vLLM部署下占用 40GB 显存是完全正常。
不是因为模型变大了,而是由 vLLM 的内存管理机制(PagedAttention)决定。
原因: vLLM “贪婪”显存预分配(最主要原因)
vLLM 设计核心是 PagedAttention。为了追求极致的吞吐量,vLLM 在启动时会进行以下操作:
- 加载模型权重:4B参数在BF16/FP16精度下占用约8GB。
- 预留显存给 LoRA:
--max-lora-rank 256也会预占一部分空间。 - 接管所有剩余显存:加载完模型后,vLLM 会默认将 GPU 剩余显存的 90% 全部占满,作为 KV Cache 缓存池。
为什么 A6000 会显示40GB+?
- NVIDIA A6000 总显存是 48GB。
- vLLM 默认参数
--gpu-memory-utilization0.90。 - 计算: 48GB× 0.9 ≈ 43.2GB。
所以, 看板上看到40GB多的占用,正是vLLM按照默认设置,把A6000几乎所有的空间都圈起来当成“草稿纸”(KV Cache)用了,以便支持更多的并发请求。
KV Cache
如果模型显存占用远超“参数大小”,那大概率被 KV Cache 吃掉了
模型占固定空间,KV Cache 才是显存真正开销。
推理时,大模型对每个 token 都会缓存 Key 和 Value,一直保留到整个推理结束,因为未来所有 token 都要和它算注意力
每层都要存一份 Key 和一份 Value,所以:
- token 越多 → 显存上涨
- 层越多 → 显存上涨
- Attention 头越多、维度越大 → 显存上涨
KV Cache 动态增长,而且线性增长。
Qwen3-4B-Thinking-2507 结构如下:
- 32 层
- 24 个 attention heads
- head_dim = 128(因为 3072 / 24 = 128)
- 精度 FP16(KV Cache 是 16bit)
每个 token 要多少显存?
- 2(K,V) × 32 层 × 24 头 × 128 × 2 bytes = = 393,216 bytes ≈ 384 KB/每个 token
输入一句话 100 字,上下文 150 字,分词大概 200 token,就已经:200 × 384KB ≈ 76.8MB
4K 上下文时:4K tokens × 384KB = 4,000 × 384KB ≈ 1.5GB
为什么:量化权重再怎么省、上下文长一点,显存还是爆?
- KV Cache 不会因为 INT4 量化 就变成 INT4,它还是 FP16 或 BF16。
Workspace
不同库的 workspace 大小不同:
- cublas 大概 200~400MB
- FlashAttention 大概 400~700MB
一些框架会额外需要 1GB+
如何节省显存
如何省显存
- 减少上下文长度
- 上下文从 8K → 4K,KV Cache 直接砍半。
- 选择 INT4 量化,权重最省
- 4B 模型,FP16 占 8GB,而 INT4 量化后占 2GB
- 使用 FlashAttention-2/3 或与其兼容的代码,可以少 200~500MB 的临时显存。
LLM 推理显存开销
【2024-8-24】为大型语言模型 (LLM) 提供服务需要多少 GPU 内存?
运行一个大型语言模型,需要多大GPU内存?
GPU 内存估算公式
M = (P*4B)/(32/Q) = (P * Q) / 8 x 1.2
解释
- M 代表 GPU 显存大小,单位是GB。
- P 模型参数总数, (例如 13B 模型中,P=13)。
- 4B 每个参数平均占用的存储空间,为 4 个字节。
- Q 加载模型时使用的位数,可以是 16 位或 32 位。参数位宽 (FP16 对应 16,INT8 对应 8,INT4 对应 4)
- 1.2 表示在计算中加入了 20% 的额外空间以应对可能的需求。
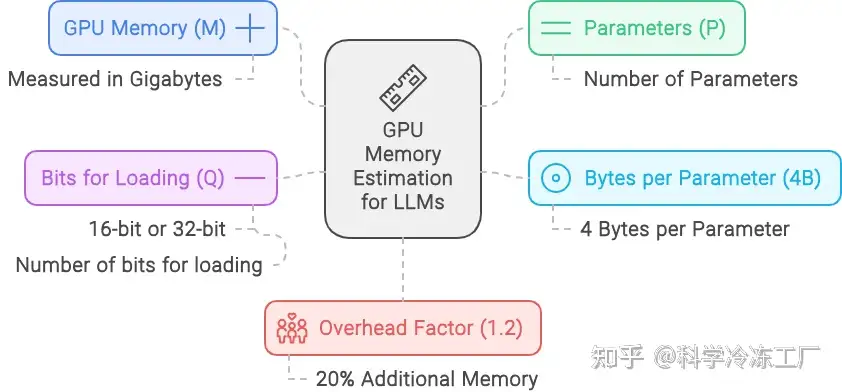
分解公式
- 模型参数量 (P):这个指标反映了你的模型规模。比如,如果你使用的是 LLaMA 模型,它包含 700 亿个参数,那么这个参数量就是 700 亿。
- 参数内存需求 (4B):通常情况下,每个模型参数需要 4 个字节的存储空间,这是因为浮点数通常需要 4 个字节(即 32 位)来表示。如果你采用的是半精度(16 位)格式,那么所需的内存量会相应减少。
- 参数位宽 (Q):这个值取决于你是以 16 位还是 32 位的精度来加载模型。16 位精度在许多大型语言模型的应用中较为普遍,因为它在保证足够精度的同时,能够降低内存的消耗。
- 额外开销 (1.2):乘以 1.2 的系数是为了增加 20% 的额外空间,以应对在模型推理过程中可能需要的额外内存。这不仅仅是为了安全起见,更是为了确保在模型执行过程中,激活操作和其他中间结果的内存需求得到满足。
700亿个参数(以 16位精度加载)的 LLaMA 模型提供服务所需的内存:
- M = (P * 4B)/(32/Q) * 1.2 = (70 * 4 bytes)/(32/16) * 1.2 = 168 GB
- 单块 NVIDIA A100 GPU,尽管配备了 80 GB 显存,但仍然不足以支撑该模型的运行。为了高效地处理内存需求,至少需要两块 A100 GPU,每块都具备 80 GB 的显存容量。
经验
显存不够
【2023-8-30】baichuan-7b (14G) 部署失败,空间不够
- GPU: A30, 24G 显存
错误信息:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 86.00 MiB (GPU 0; 22.20 GiB total capacity; 7.47 GiB already allocated; 51.12 MiB free; 7.48 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
显存工具
显存计算器
【2025-12-31】Llama Factory提供的显存计算工具,支持多模型、多训练方法实时计算
Model Memory Calculator
【2023-8-30】大模型要占你多少内存?这个神器一键测量,误差低至0.5MB,免费可用
大模型训练推理要用多少内存?
- HuggingFace Space 最新火起来工具——Model Memory Calculator,模型内存测量器,在网页端人人可体验。
- 比如模型bert-base-case Int8估计占用413.18 MB内存,实际占用为413.68MB,相差0.5MB,误差仅有0.1%。
实际推理过程,EleutherAI 发现需要在预测数据基础上,预留 20% 内存
【2023-8-30】baichuan-7b (14G) 部署失败,空间不够
- GPU: A30, 24G 显存
错误信息:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 86.00 MiB (GPU 0; 22.20 GiB total capacity; 7.47 GiB already allocated; 51.12 MiB free; 7.48 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Memory Usage for ‘baichuan-inc/Baichuan-7B’
| dtype | Largest Layer or Residual Group | Total Size | Training using Adam |
|---|---|---|---|
| float32 | 1000.0 MB | 26.2 GB | 104.82 GB |
| float16/bfloat16 | 500.0 MB | 13.1 GB | 52.41 GB |
| int8 | 250.0 MB | 6.55 GB | 26.2 GB |
| int4 | 125.0 MB | 3.28 GB |
只有有参数的层,才会有显存占用。这部份的显存占用和输入无关,模型加载完成之后就会占用。
LLM Check
显存估算开源项目:
LLM 参数分析
只有参数层占用显存。
这部份显存占用和输入无关,模型加载完成之后就会占用。
有参数层主要包括:
- 卷积
- 全连接
- BatchNorm
- Embedding层
- … …
无参数层:
- 多数的激活层(Sigmoid/ReLU)
- 池化层
- Dropout
- … …
模型参数数目(不考虑偏置项b)为:
- Linear(M->N): 参数数目:M×N
- Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K
- BatchNorm(N): 参数数目: 2N
- Embedding(N,W): 参数数目: N × W
参数占用显存 = 参数数目 × n
- n = 4 :float32
- n = 2 : float16
- n = 8 : double64
PyTorch中,当执行完 model=MyGreatModel().cuda() 后就会占用相应显存,占用显存大小基本与上述分析的显存差不多(会稍大一些,因为其它开销)。
GPU 显存占用
GPU 要存哪些参数
【2023-6-28】参考
模型训练中,GPU 要存储的参数
- 模型本身的参数、优化器状态、激活函数的输出值、梯度、一些零时的Buffer
微调时,显存占用组成:
- 1、参数占用: 微调时一般采用
bf16/fp16格式来训练,1个参数需要2字节显存,那10亿参数所需的显存就大概为2G左右。- 13B 模型,bf16参数占用的显存就至少为2*13=26GB
- 2、梯度占用: 每个参数对应一个梯度,所以梯度显存占用等于模型参数的占用:26GB。
- 3、优化器: 采用AdamW优化器(bitsandbytes版本), 为每个参数计算两个状态变量v和r,显存占用就为26*2=52GB,同时优化器还会为模型参数维护一个float32的副本,占用26 * 2=52G。
- 更新:如果是deepspeed版本的优化器,还会保存一份float32的梯度,额外占用26 * 2=52G的显存。实现代码在这里
- 4、激活值: 不同 batch size和sequence length会影响显存占用
- 以Llama-13B为例,batch-size=1,sequence length=2048条件下,激活值得占用大概为:17gb
- Batch Size 和 Sequence Length:直接影响激活值的显存占用。
- 框架和库的开销:如 PyTorch, TensorFlow, CUDA kernels 等会占用一部分固定或可变的显存。
13B 模型, 混合精度,全参数微调, 所需显存至少为
- 26+26+52+52+17=173GB
这只是 bs=1 时的粗略估计,不是很准确,还有一些额外开销没有包括在内。
通常训练时,batch不能取太小,常见的模型训练batch size都是成百上千的,这显存占用可就是天文数字了。
模型参数仅占所有数据的小部分
- 当进行混合精度运算时,模型状态参数(优化器状态 + 梯度+ 模型参数)占大半以上。
因此,要想办法去除模型训练过程中的冗余数据。
梯度与动量
优化器
- SGD:W_t+1 = W_t - α * ▽ F(W_t)
- 除了保存权重W, 还要保存对应的梯度 ▽ F(W_t) ,因此, 显存占用等于参数占用显存 x2
- 带Momentum-SGD:
- v_t+1 = ρv_t + ▽ F(W_t)
- W_t+1 = W_t - α * v_t+1
- 还需要保存动量, 因此显存 x3
- Adam优化器
- 动量占用的显存更多,显存x4
总结,模型中与输入无关的显存占用包括:
- 参数 W
- 梯度 dW(一般与参数一样)
- 优化器的动量
- 普通SGD没有动量,momentum-SGD动量与梯度一样,Adam优化器动量的数量是梯度的两倍
输入输出
以CNN为例,模型输出的显存占用,总结如下:
- 需要计算每一层的feature map的形状(多维数组的形状)
- 需要保存输出对应的梯度用以反向传播(链式法则)
- 显存占用与 batch size 成正比
- 模型输出不需要存储相应的动量信息。
深度学习中神经网络的显存占用,可以得到如下公式:
显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用
显存不是和batch-size简单的成正比,尤其是模型自身比较复杂的情况下:比如全连接很大,Embedding层很大
另外需要注意:
- 输入(数据,图片)一般不需要计算梯度
- 神经网络每层输入/输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,不要保存输入。
- 比如 ReLU,PyTorch中,使用nn.ReLU(inplace = True) 能将激活函数ReLU的输出直接覆盖保存于模型的输入之中,节省不少显存。
- 这时候是如何反向传播? (提示:y=relu(x) -> dx = dy.copy();dx[ y<=0 ] =0)
梯度与动量的显存占用
优化器
- SGD:W_t+1 = W_t - α * ▽ F(W_t)
- 除了保存权重W, 还要保存对应的梯度 ▽ F(W_t) ,因此, 显存占用等于参数占用显存 x2
- 带Momentum-SGD:
- v_t+1 = ρv_t + ▽ F(W_t)
- W_t+1 = W_t - α * v_t+1
- 还需要保存动量, 因此显存 x3
- Adam优化器
- 动量占用的显存更多,显存x4
总结,模型中与输入无关的显存占用包括:
- 参数 W
- 梯度 dW(一般与参数一样)
- 优化器的动量
- 普通SGD没有动量,momentum-SGD动量与梯度一样,Adam优化器动量的数量是梯度的两倍
输入输出的显存占用
以CNN为例,模型输出的显存占用,总结如下:
- 需要计算每一层的feature map的形状(多维数组的形状)
- 需要保存输出对应的梯度用以反向传播(链式法则)
- 显存占用与 batch size 成正比
- 模型输出不需要存储相应的动量信息。
深度学习中神经网络的显存占用,可以得到如下公式:
显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用
显存不是和batch-size简单的成正比,尤其是模型自身比较复杂的情况下:比如全连接很大,Embedding层很大
另外需要注意:
- 输入(数据,图片)一般不需要计算梯度
- 神经网络每层输入/输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,不要保存输入。
- 比如 ReLU,PyTorch中,使用nn.ReLU(inplace = True) 能将激活函数ReLU的输出直接覆盖保存于模型的输入之中,节省不少显存。
- 这时候是如何反向传播? (提示:y=relu(x) -> dx = dy.copy();dx[ y<=0 ] =0)
节省显存的方法
深度学习中,一般占用显存最多的是卷积等层的输出,模型参数占用的显存相对较少,而且不太好优化。
节省显存方法:
- 降低 batch-size
- 下采样 (NCHW -> (1/4)*NCHW)
- 减少全连接层(一般只留最后一层分类用的全连接层
更多信息见原文
训练时显存不足怎么办?
常见的节省显存操作,优先级从高到低排列。
- 去掉 compute_metrics:
- 有些代码会在输出层后计算rouge分等,这个会输出一个
batch_sizevocab_sizeseq_len的一个大向量,非常占显存。
- 有些代码会在输出层后计算rouge分等,这个会输出一个
- 采用
bf16/fp16进行混合精度训练:- 现在大模型基本上都采用 bf16 来进行训练
- 但是 v100 不支持 bf16,可以采用fp16进行训练。显存占用能够降低1倍。
Flash attention:不仅能够降低显存,更能提高训练速度。batch_size调小:- batch size 与模型每层激活状态所占显存呈正相关
- 降低 batch size 能够很大程度上降低这部分显存占用。
- 采用梯度累积:
global_batch_size=batch_size*梯度累积- 如果降低 batch_size 后想保持 global_batch_size 不变,可适当提高梯度累积值。
- 选择合适的上下文长度:
- 上下文长度与激活状态所占显存呈正相关
- 因此可适当降低上下文长度来降低显存占用。
DeepSpeed Zero:- 显存占用从高到低为:
Zero 1>Zero 2>Zero 2+offload>zero 3>zero 3+offload - 推荐最多试到
Zero2+offload。
- 显存占用从高到低为:
- 选择更小的基座模型:在满足需求的情况下,尽量选择更小的基座模型。
慎重选择:
Lora: 能跑全参就别跑Lora或Qlora,一方面是麻烦,另一方面的确是效果差点。Qlora: Qlora 速度比lora慢,但所需显存更少,实在没资源可以试试。Megatron-LM: 可采用流水线并行和张量并行,使用比较麻烦,适合喜欢折腾的同学。Pai-Megatron-LM: Megatron-LM 的衍生,支持 Qwen 的sft和pt,坑比较多,爱折腾可以试试。- 激活检查点:不推荐,非常耗时。在反向传播时重新计算深度神经网络的中间值。用时间(重新计算这些值两次的时间成本)来换空间(提前存储这些值的内存成本)。
GPU 要存哪些参数
【2023-6-28】参考
模型训练中,GPU 要存储的参数
- 模型本身的参数、优化器状态、激活函数的输出值、梯度、一些零时的Buffer
模型参数仅占所有数据的小部分
- 当进行混合精度运算时,模型状态参数(优化器状态 + 梯度+ 模型参数)占大半以上。
因此,要想办法去除模型训练过程中的冗余数据。
LLaMA-6B 占用多大内存
【2023-7-13】LLaMA-6B 占用多大内存?计算过程
精度对所需内存的影响:
- fp32精度,一个参数需要 32 bits, 4 bytes.
- fp16精度,一个参数需要 16 bits, 2 bytes.
- int8精度,一个参数需要 8 bits, 1 byte.
模型需要的 RAM 大致分三个部分:
- 模型参数: 参数量*每个参数所需内存
- 对于
fp32,LLaMA-6B需要 6B*4 bytes = 24GB 内存 - 对于
int8,LLaMA-6B需要 6B*1 byte = 6GB 内存
- 对于
- 梯度: 参数量*每个梯度参数所需内存
- 优化器参数: 不同优化器所储存的参数量不同。
- 对于常用的
AdamW,需要两倍模型参数(用来储存一阶和二阶momentum)。 fp32的 LLaMA-6B,AdamW 需要 6B*8 bytes = 48 GBint8的 LLaMA-6B,AdamW 需要 6B*2 bytes = 12 GB
- 对于常用的
- 其它
- CUDA kernel 也会占据一些RAM,大概 1.3GB 左右
综上,int8 精度的 LLaMA-6B 模型部分大致需要 6GB + 6GB + 12GB + 1.3GB = 25.3GB 左右。
再根据LLaMA的架构(hidden_size= 4096, intermediate_size= 11008, num_hidden_layers= 32, context_length = 2048)计算中间变量内存。每个instance需要: ( 4096+11008 ) * 2048 * 32 * 1 byte = 990 MB
所以,一张 A100(80GB RAM)大概可以在int8精度,batch_size = 50 的设定下进行全参数训练。
附
- 消费级显卡内存和算力查询: 2023 GPU Benchmark and Graphics Card Comparison Chart
7B 占用多大内存
一个7B规模大模型(如LLaMA-2 7B),基于16-bit混合精度训练时
- 仅考虑模型参数、梯度、优化器情况下,显存占用就有112GB
- 参数占 GPU 显存近 14GB(每个参数2字节)。
- 训练时梯度存储占14GB(每个参数对应1个梯度,也是2字节)
- 优化器Optimizer(假设是主流的AdamW)则是84GB(每个参数对应1个参数copy、一个momentum和一个variance,这三个都是float32)
- 2byte 模型静态参数权重(以16bit存储) = 14G
- 2byte 模型更新参数权重 (以16bit存储)= 14G
- 2byte 梯度(以16bit存储)= 14G
- 2byte 梯度更新(以16bit存储)= 14G
- 4byte 一阶动量优化器更新(以32bit存储)= 28G
- 4byte 二阶方差优化器更新(以32bit存储)= 28G
- 目前,合计 112GB
- 还有:前向传播时激活值,各种临时变量
- 还与sequence length, hidden size、batch size都有关系。
目前A100、H100这样主流显卡单张是放不下,更别提国内中小厂喜欢用的A6000/5000、甚至消费级显卡。
Adam + fp16 混合精度预估
【2023-6-29】LLM Training GPU显存耗用量估计,以Adam + fp16混合精度训练为例,分析其显存占用有以下四个部分
- (1) 模型权重 Model
- Prameters (FP16) 2 bytes
- Gradients (FP16) 2 bytes
- (2) 前向激活值 Activations
- 前向过程中存储, y = w1 * x, 存储x用于计算w1梯度
- 整体显存占用与batch有关
- (3) 优化器 Optimizer:梯度、动量等
- Master Weight (FP32) 4 bytes
- Adam m (FP32) 4 bytes
- Adam v (FP32) 4 bytes
- (4) 临时混存 Buffer & Fragmentation
(1) 和 (3) 可以精确估计
- 显存占用大头是 Adam 优化器,占可计算部分的 12/16=75%
- 其次是模型参数+梯度,显存容量至少是参数量的16倍
Adam + fp16混合精度训练
结论:
- 不考虑Activation,3090 模型容量上限是 24/16=1.5B,A100 模型容量上限是 80/16=5B
- 假设训练过程中batchsize恒定为1,也即尽最大可能减少Activation在显存中的占用比例,使得理论计算值16Φ更接近真实的显存占用,那么24G的3090的模型容量上限是1.5B(差不多是GPT-2的水平),80G的A100的模型容量上限是5B
- 考虑Activation,3090的模型容量上限是 0.75B,A100的容量上限是 2.5B
- batchsize为1的训练效率非常低,batchsize大于1才能充分发挥GPU的效率,此时Activation变得不可忽略。经验之谈,一般需要给Activation预留一半的显存空间(比如3090预留12G,A100预留40G),此时3090的模型容量上限是0.75B,A100的容量上限是2.5B,我们实际测试结果接近这个值
- [1B, 5B] 是目前市面上大多数GPU卡的分水岭区间
- [0, 1B) 市面上绝大多数卡都可以直接硬train一发
- [1B, 5B] 大多数卡在这个区间的某个值上触发模型容量上限,具体触发值和显存大小有关
- (5B, ~) 目前没有卡能裸训
显存预估
总结
| 模型规模 | 参数 | 梯度 | 激活值 | 总数 | 训练方案 |
|---|---|---|---|---|---|
| 7B | 12 * 7 = 84 GB | >100 GB | 2*A100 (80GB),并配合 DeepSpeed ZeRO Stage 2/3 | ||
| 70B | 12 * 70 = 840 GB | 远超 1 TB | 大规模的 GPU 集群 | ||
微调方式
方式
- 全参微调: (Full Fine-tuning) 模型所有参数都需要计算梯度并由优化器更新
- 总计 (核心部分): (2 参数 + 2 梯度 + 8 优化器状态) * X GB = 12X GB
- 粗略预估下限: 14~18X GB
- 局部参数:
- LoRA 只训练一小部分注入到模型中的“适配器”参数,而原始模型的绝大部分参数保持冻结。
- 总显存 ≈ 2X GB + 激活值显存 + 几 GB 开销
估算:
- 全参数微调 (FP16, AdamW): 考虑 ~20X GB 或更多。
- LoRA 微调 (FP16): 考虑 ~(2.5 - 4)X GB,主要看基础模型 2X GB + 激活。
- QLoRA 微调 (4-bit base, LoRA): 考虑 ~(0.7 - 1.5)X GB,主要看基础模型 ~0.5X GB + 激活。
分析
- 关键变量: batch_size 和 sequence_length 对激活值影响巨大。如果显存不足,优先减小这两个值,或者加强梯度检查点的使用。
- 梯度检查点: 对于大模型微调(无论是全参数还是 LoRA),几乎是必需的技术,用计算换显存。
- 优化器: 如果显存极其紧张,可以考虑显存优化型的优化器(如 Adafactor, 8-bit Adam),但这可能会影响收敛效果。
- 分布式训练 (DeepSpeed ZeRO): 对于全参数微调或者超大模型的 LoRA 微调,单卡显存往往不够。DeepSpeed ZeRO (特别是 Stage 2 和 3) 可以将优化器状态和梯度分片到多张 GPU 上,极大降低单卡显存压力。
- 实际监控: 最好的方法是在目标硬件上用小 batch_size 跑一个测试批次,并使用 nvidia-smi 或 PyTorch 的 torch.cuda.memory_summary() / torch.cuda.max_memory_allocated() 来监控实际峰值显存占用,然后根据需要调整参数。
计算方法
LLM GPU显存计算公式为:
Memory(GB) =Px (Q/8) × (1 + Overhead)
其中
- P: 参数数量(十亿)
- Q: 位精度(如FP16=16位),Q/8将位转换为字节
- Overhead: 额外开销(通常20%,包括KV缓存、激活缓冲区等)。
例如, 70B 模型使用FP16精度:
- 70×(16/8)×1.2 = 168GB。
这个公式可快速估算自托管LLM所需GPU显存,帮助选择合适的硬件配置。
| Model Size(模型大小) | Precision(精度) | Overhead(开销) | Memory Required(所需内存) |
|---|---|---|---|
| 7B | FP16 | 20% | 7×(16/8)×1.2 = 16.8 GB |
| 13B | FP16 | 20% | 13×(16/8)×1.2 = 31.2 GB |
| 70B | FP16 | 20% | 70×(16/8)×1.2 = 168 GB |
| 70B | INT8 | 20% | 70×(8/8)×1.2 = 84 GB |
| 175B | FP16 | 20% | 175×(16/8)×1.2 = 420 GB |
GPU 内存分配由多部分共同构成,核心组件及分配逻辑如下:
核心组成模块
- 模型权重(Model Weights):存储模型参数,对应占用 基础内存(Base Memory)。
- KV缓存(KV Cache Buffer):保存推理过程中的键值对中间数据,辅助序列生成等任务,产生 内存开销(Overhead)。
- 激活缓冲区(Activation Buffer):暂存计算过程中的激活值(如神经网络层输出),同样带来 内存开销(Overhead)。
总显存计算逻辑
总显存(Total VRAM)需整合各模块占用内存,公式可简化为:
Total VRAM = 模型权重内存 + KV缓存开销 + 激活缓冲区开销 + 其他潜在开销
GPU需为模型基础参数、推理中间数据、计算临时结果等分配内存,共同决定最终显存占用,理解此流程有助于优化AI任务的显存使用效率 。
PPO 显存预估
【2025-8-1】用 verl 进行 PPO 训练,4张80G显存的A800能调起来14B模型?
rollout用vllm,训练用FSDP, 需要同时在显存中维护 3个14B规模的模型(Actor, Critic, Reference)以及 2份优化器状态
- 模型权重 (全部经过分片)
- Actor (14B, TP=4): ~7 G
- Critic (14B, FSDP): ~7 G
- Reference (14B, TP=4): ~7 G
- 小计: 21 G
优化器状态 (Actor 和 Critic, 经过分片)
- Actor 优化器: ~28 G
- Critic 优化器: ~28 G
- 小计: 56 G
梯度 (Actor 和 Critic, 经过分片)
- Actor 梯度: ~7 G
- Critic 梯度: ~7 G
- 小计: 14 G
静态占用总计: 21 GB (权重) + 56 GB (优化器) + 14 GB (梯度) = 91 G
这个估算出的 91 GB 静态占用已经超过了单张 80GB 卡的物理上限。
甚至还没有计算几十GB的激活值和 vLLM KV Cache 的空间!
推理显存
【2024-8-24】为大型语言模型 (LLM) 提供服务需要多少 GPU 内存?
运行一个大型语言模型,需要多大GPU内存?
GPU 内存估算公式
- $ M=(P4B)/(32/Q)1.2 $

解释
- M 代表 GPU 内存的大小,单位是吉字节。
- P 指的是模型中包含的参数总数。
- 4B 指的是每个参数平均占用的存储空间,为 4 个字节。
- Q 表示加载模型时使用的位数,可以是 16 位或者 32 位。
- 1.2 表示在计算中加入了 20% 的额外空间以应对可能的需求。
分解公式
- 模型参数量 (P):这个指标反映了你的模型规模。比如,如果你使用的是 LLaMA 模型,它包含 700 亿个参数,那么这个参数量就是 700 亿。
- 参数内存需求 (4B):通常情况下,每个模型参数需要 4 个字节的存储空间,这是因为浮点数通常需要 4 个字节(即 32 位)来表示。如果你采用的是半精度(16 位)格式,那么所需的内存量会相应减少。
- 参数位宽 (Q):这个值取决于你是以 16 位还是 32 位的精度来加载模型。16 位精度在许多大型语言模型的应用中较为普遍,因为它在保证足够精度的同时,能够降低内存的消耗。
- 额外开销 (1.2):乘以 1.2 的系数是为了增加 20% 的额外空间,以应对在模型推理过程中可能需要的额外内存。这不仅仅是为了安全起见,更是为了确保在模型执行过程中,激活操作和其他中间结果的内存需求得到满足。
- 其他难以估算和未知的显存消耗项在峰值时可能占总显存的30%以上
700亿个参数(以 16位精度加载)的 LLaMA 模型提供服务所需的内存:
- M = (P * 4B)/(32/Q) * 1.2 = (70 * 4 bytes)/(32/16) * 1.2 = 168 GB
- 单块 NVIDIA A100 GPU,尽管配备了 80 GB 显存,但仍然不足以支撑该模型的运行。为了高效地处理内存需求,至少需要两块 A100 GPU,每块都具备 80 GB 的显存容量。
关掉了梯度检查点,用 torch.bfloat16 类型的 Qwen-2.5-7B-instruction 在单卡H20上实验
- 当输入序列长度约400,batch size=4时,理论显存需要约110G,实际显存用了大概90G
- 进一步开启梯度检查点,下降到75G。
不同 zero策略下,分别需要几卡
- zero1: 优化器切分
- 当模型为7B时, k>2.29,约3卡;
- 当模型为14B时,任何非3D并行的zero1都无法有效训练,无论多少张A100。
- zero2: 进一步梯度切分
- 当模型为7B时,k>1.88,约需要2卡;
- 当模型为14B时, k>8.17 ,约需要9卡。
- 当模型超过20B,再多的A100也无法训练了。
- zero3: 进一步模型切分
- 当模型为7B时, k>1.7,约需要2卡;
- 当模型为14B时, k>4.31,约需要5卡。
- 训练上限为40B。
Deepspeed 不仅支持zero策略代表的dp,还支持tp和pp,因此,卡管够,理论上可以训无限大的模型,大力出奇迹。
LLaMA-6B 占用多大内存
【2023-7-13】LLaMA-6B 占用多大内存?计算过程
精度对所需内存的影响:
- fp32精度,一个参数需要 32 bits, 4 bytes.
- fp16精度,一个参数需要 16 bits, 2 bytes.
- int8精度,一个参数需要 8 bits, 1 byte.
模型需要的 RAM 大致分三个部分:
- 模型参数: 参数量*每个参数所需内存
- 对于
fp32,LLaMA-6B需要 6B*4 bytes = 24GB 内存 - 对于
int8,LLaMA-6B需要 6B*1 byte = 6GB 内存
- 对于
- 梯度: 参数量*每个梯度参数所需内存
- 优化器参数: 不同优化器所储存的参数量不同。
- 对于常用的
AdamW,需要两倍模型参数(用来储存一阶和二阶momentum)。 fp32的 LLaMA-6B,AdamW 需要 6B*8 bytes = 48 GBint8的 LLaMA-6B,AdamW 需要 6B*2 bytes = 12 GB
- 对于常用的
- 其它
- CUDA kernel 也会占据一些RAM,大概 1.3GB 左右
综上,int8 精度的 LLaMA-6B 模型部分大致需要 6GB + 6GB + 12GB + 1.3GB = 25.3GB 左右。
再根据LLaMA的架构(hidden_size= 4096, intermediate_size= 11008, num_hidden_layers= 32, context_length = 2048)计算中间变量内存。每个instance需要: ( 4096+11008 ) * 2048 * 32 * 1 byte = 990 MB
所以,一张 A100(80GB RAM)大概可以在int8精度,batch_size = 50 的设定下进行全参数训练。
附
- 消费级显卡内存和算力查询: 2023 GPU Benchmark and Graphics Card Comparison Chart
7B 占用多大内存
一个7B规模大模型(如LLaMA-2 7B),基于16-bit混合精度训练时
- 仅考虑模型参数、梯度、优化器情况下,显存占用就有112GB
- 参数占 GPU 显存近 14GB(每个参数2字节)。
- 训练时梯度存储占14GB(每个参数对应1个梯度,也是2字节)
- 优化器Optimizer(假设是主流的AdamW)则是84GB(每个参数对应1个参数copy、一个momentum和一个variance,这三个都是float32)
- 2byte 模型静态参数权重(以16bit存储) = 14G
- 2byte 模型更新参数权重 (以16bit存储)= 14G
- 2byte 梯度(以16bit存储)= 14G
- 2byte 梯度更新(以16bit存储)= 14G
- 4byte 一阶动量优化器更新(以32bit存储)= 28G
- 4byte 二阶方差优化器更新(以32bit存储)= 28G
- 目前,合计 112GB
- 还有:前向传播时激活值,各种临时变量
- 还与sequence length, hidden size、batch size都有关系。
目前A100、H100这样主流显卡单张是放不下,更别提国内中小厂喜欢用的A6000/5000、甚至消费级显卡。
PPO 显存预估
【2025-8-1】用 verl 进行 PPO 训练,4张80G显存的A800能调起来14B模型?
rollout用vllm,训练用FSDP, 需要同时在显存中维护 3个14B规模的模型(Actor, Critic, Reference)以及 2份优化器状态
- 模型权重 (全部经过分片)
- Actor (14B, TP=4): ~7 G
- Critic (14B, FSDP): ~7 G
- Reference (14B, TP=4): ~7 G
- 小计: 21 G
优化器状态 (Actor 和 Critic, 经过分片)
- Actor 优化器: ~28 G
- Critic 优化器: ~28 G
- 小计: 56 G
梯度 (Actor 和 Critic, 经过分片)
- Actor 梯度: ~7 G
- Critic 梯度: ~7 G
- 小计: 14 G
静态占用总计: 21 GB (权重) + 56 GB (优化器) + 14 GB (梯度) = 91 G
这个估算出的 91 GB 静态占用已经超过了单张 80GB 卡的物理上限。
甚至还没有计算几十GB的激活值和 vLLM KV Cache 的空间!
显存不足怎么办
训练时显存不足怎么办?
常见的节省显存操作,优先级从高到低排列。
- 去掉 compute_metrics:
- 有些代码会在输出层后计算rouge分等,这个会输出一个
batch_sizevocab_sizeseq_len的一个大向量,非常占显存。
- 有些代码会在输出层后计算rouge分等,这个会输出一个
- 采用
bf16/fp16进行混合精度训练:- 现在大模型基本上都采用 bf16 来进行训练
- 但是 v100 不支持 bf16,可以采用fp16进行训练。显存占用能够降低1倍。
Flash attention:不仅能够降低显存,更能提高训练速度。batch_size调小:- batch size 与模型每层激活状态所占显存呈正相关
- 降低 batch size 能够很大程度上降低这部分显存占用。
- 采用梯度累积:
global_batch_size=batch_size*梯度累积- 如果降低 batch_size 后想保持 global_batch_size 不变,可适当提高梯度累积值。
- 选择合适的上下文长度:
- 上下文长度与激活状态所占显存呈正相关
- 因此可适当降低上下文长度来降低显存占用。
DeepSpeed Zero:- 显存占用从高到低为:
Zero 1>Zero 2>Zero 2+offload>zero 3>zero 3+offload - 推荐最多试到
Zero2+offload。
- 显存占用从高到低为:
- 选择更小的基座模型:在满足需求的情况下,尽量选择更小的基座模型。
慎重选择:
Lora: 能跑全参就别跑Lora或Qlora,一方面是麻烦,另一方面的确是效果差点。Qlora: Qlora 速度比lora慢,但所需显存更少,实在没资源可以试试。Megatron-LM: 可采用流水线并行和张量并行,使用比较麻烦,适合喜欢折腾的同学。Pai-Megatron-LM: Megatron-LM 的衍生,支持 Qwen 的sft和pt,坑比较多,爱折腾可以试试。- 激活检查点:不推荐,非常耗时。在反向传播时重新计算深度神经网络的中间值。用时间(重新计算这些值两次的时间成本)来换空间(提前存储这些值的内存成本)。
Adam + fp16 混合精度预估
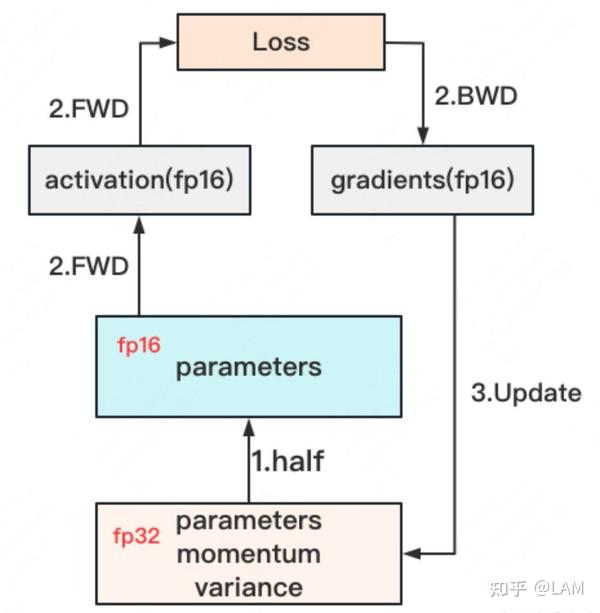
【2023-6-29】LLM Training GPU显存耗用量估计,以Adam + fp16混合精度训练为例,分析其显存占用有以下四个部分
- (1) 模型权重 Model
- Prameters (FP16) 2 bytes
- Gradients (FP16) 2 bytes
- (2) 前向激活值 Activations
- 前向过程中存储, y = w1 * x, 存储x用于计算w1梯度
- 整体显存占用与batch有关
- (3) 优化器 Optimizer:梯度、动量等
- Master Weight (FP32) 4 bytes
- Adam m (FP32) 4 bytes
- Adam v (FP32) 4 bytes
- (4) 临时混存 Buffer & Fragmentation
(1) 和 (3) 可以精确估计
- 显存占用大头是 Adam 优化器,占可计算部分的 12/16=75%
- 其次是模型参数+梯度,显存容量至少是参数量的16倍
Adam + fp16混合精度训练
结论:
- 不考虑Activation,3090 模型容量上限是 24/16=1.5B,A100 模型容量上限是 80/16=5B
- 假设训练过程中batchsize恒定为1,也即尽最大可能减少Activation在显存中的占用比例,使得理论计算值16Φ更接近真实的显存占用,那么24G的3090的模型容量上限是1.5B(差不多是GPT-2的水平),80G的A100的模型容量上限是5B
- 考虑Activation,3090的模型容量上限是 0.75B,A100的容量上限是 2.5B
- batchsize为1的训练效率非常低,batchsize大于1才能充分发挥GPU的效率,此时Activation变得不可忽略。经验之谈,一般需要给Activation预留一半的显存空间(比如3090预留12G,A100预留40G),此时3090的模型容量上限是0.75B,A100的容量上限是2.5B,我们实际测试结果接近这个值
- [1B, 5B] 是目前市面上大多数GPU卡的分水岭区间
- [0, 1B) 市面上绝大多数卡都可以直接硬train一发
- [1B, 5B] 大多数卡在这个区间的某个值上触发模型容量上限,具体触发值和显存大小有关
- (5B, ~) 目前没有卡能裸训
节省显存
深度学习中,一般占用显存最多的是卷积等层的输出,模型参数占用的显存相对较少,而且不太好优化。
节省显存方法:
- 降低 batch-size
- 下采样 (NCHW -> (1/4)*NCHW)
- 减少全连接层(一般只留最后一层分类用的全连接层
更多信息见原文
DeepSpeed ZeRO 操作就优化梯度优化器里面的参数,达到缩减显存占用空间的操作。
内存/显存优化
显存优化技术:参考
重计算(Recomputation):Activation checkpointing(Gradient checkpointing)本质上是一种用时间换空间的策略。卸载(Offload)技术:一种用通信换显存的方法,简单来说就是让模型参数、激活值等在CPU内存和GPU显存之间左右横跳。如:ZeRO-Offload、ZeRO-Infinity等。混合精度(BF16/FP16):降低训练显存的消耗,还能将训练速度提升2-4倍。- BF16 计算时可避免计算溢出,出现Inf case。
- FP16 在输入数据超过65506 时,计算结果溢出,出现Inf case。
CPU卸载
当GPU内存已满时,一种选择是将暂时未使用的数据卸载到CPU,并在以后需要时将其读回(Rhu等人,2016)。数据卸载到CPU 的想法很简单,但由于它会延长训练时间,所以近年来不太流行。
激活重新计算
激活重新计算(Activation recomputation (also known as “activation checkpointing” or “gradient checkpointing”,Chen等人,2016年)是一个以计算时间为代价减少内存占用的聪明而简单的想法
混合精度训练
Narang&Micikevicius等人(2018年)介绍了一种使用半精度浮点(FP16)数字训练模型而不损失模型精度的方法。
三种避免以半精度丢失关键信息的技术:
- 1)全精度原始权重。维护累积梯度的模型权重的全精度 (FP32) 副本, 对于向前和向后传递,数字四舍五入到半精度。主要是为了防止每个梯度更新(即梯度乘以学习率)可能太小而无法完全包含在 FP16 范围内(即 2-24 在 FP16 中变为零)的情况。
- 2)损失缩放。扩大损失以更好地处理小幅度的梯度(见图 16), 放大梯度有助于将权重移动到可表示范围的右侧部分(包含较大值)占据更大的部分,从而保留否则会丢失的值。
- 3)算术精度。对于常见的网络算法(例如向量点积,向量元素相加减少),可以将部分结果累加到 FP32 中,然后将最终输出保存为 FP16,然后再保存到内存中。可以在 FP16 或 FP32 中执行逐点操作。
大模型训练过程中,GPU显存占用主要分成Model States 与 Activation 两部分
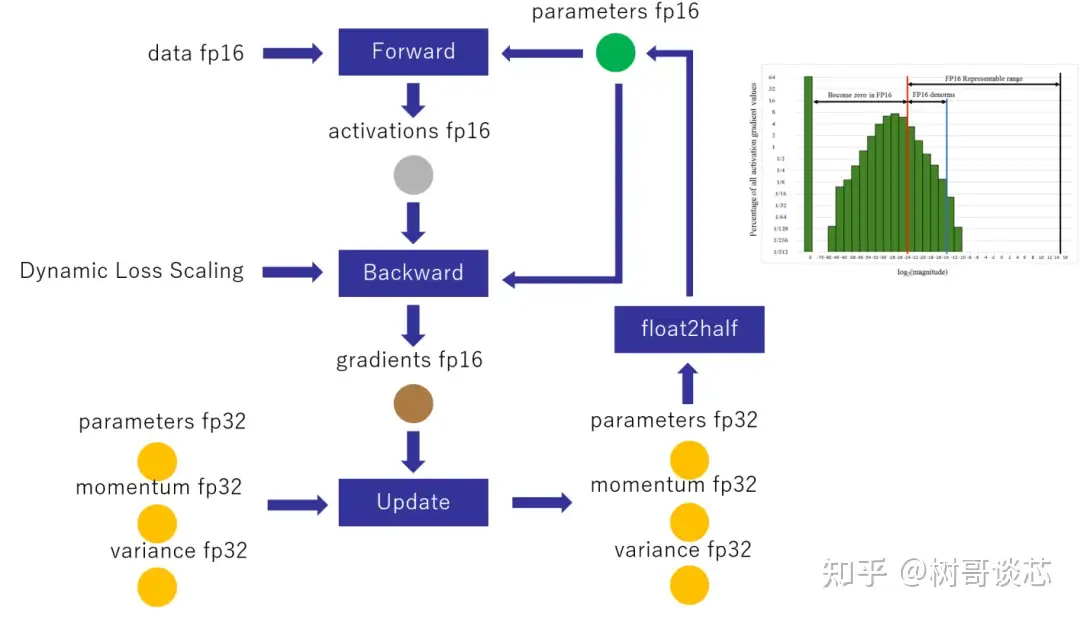
混合精度训练流程:通过引入fb16以及bf16精度来减少fb32精度带来的显存消耗。
- 存储一份fp32的parameter,momentum和variance(统称model states)
- 在forward开始之前,额外开辟一块存储空间,将fp32 parameter减半到fp16 parameter;
- 正常做forward和backward,在此之间产生的activation和gradients,都用fp16进行存储;
- 用fp16 gradients去更新fp32下的model states;
- 当模型收敛后,fp32的parameter就是最终的参数输出;
混合精度下的显存:
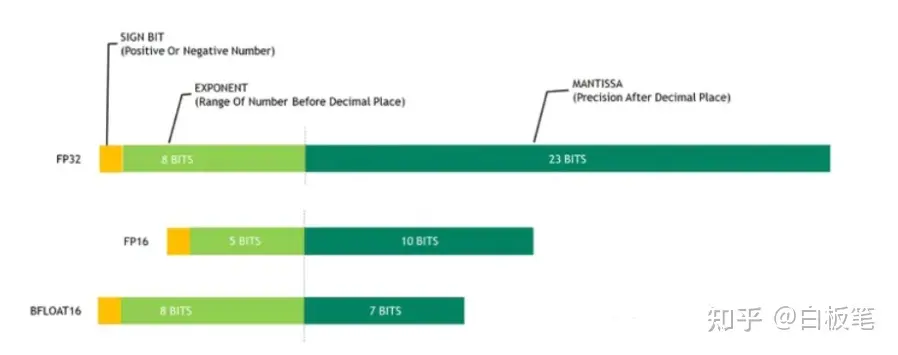
通常模型会使用float32(fp32)精度进行训练,但是随着模型越来越大,训练的硬件成本和时间成本急剧增加。而混合精度训练通过利用float16(fp16)的优点并规避缺点来进行训练。
fp32,fp16,bf16的区别如下图所示
优点:
- 降低显存占用,float16比float32小一半;
- 减少网络通信开销;
- 硬件针对fp16优化,速度更快
缺点:
- 下溢。float16最大的问题是”下溢”。
- 模型更新通常随着模型训练,值往往会很小,可能会超出float16表示的精度。
- 结果就是:大多数的模型权重都不再更新,模型难以收敛。
- 舍入误差。
- 模型权重和梯度相差太大,通过梯度更新权重并进行舍入时,可能导致更新前和更新后的权重没有变化。
bf16是一种全新的数字格式,更加支持深度学习计算,但需要硬件支持,如NVIDIA A100, NVIDIA A800等
此外,官方文档中提到了AMP(Auto Mixed Precision 自动混合精度训练) ,与ZeRO不能同时使用
Int8
Int8 - bitsandbytes
Int8是个很极端的数据类型,最多只能表示-128~127的数字,并且完全没有精度。
为了在训练和inference中使用这个数据类型,bitsandbytes使用了两个方法最大程度地降低了其带来的误差:
- vector-wise quantization
- mixed precision decompasition
Huggingface 用动图解释了quantization的实现
借助Huggingface PEFT,使用int8训练opt-6.5B的完整流程, notebook
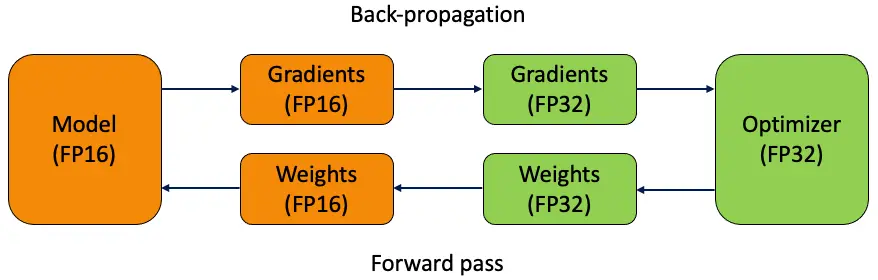
FP 16
Fp16 - mixed precision
- 混合精度训练大致思路: 在 forward pass 和 gradient computation 时用 fp16 来加速,但是在更新参数时使用 fp32。
- Pytorch 官方示例
torch fp16推理:直接使用model.half()将模型转换为fp16.
model.eval()
model.half() # 半精度
Huggingface Transformers:fp16-training
- TrainingArguments 里声明 fp16=True
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
result = trainer.train()
print_summary(result)
压缩
中间结果通常会消耗大量内存,尽管它们只在一次向前传递和一次向后传递中需要。这两种使用之间存在明显的时间差距。因此Jain等人(2018年)提出了一种数据编码策略,将第一次使用后的中间结果在第一次传递中进行压缩,然后将其解码回来进行反向传播。
内存高效优化器
优化器内存消耗。以流行的 Adam 优化器为例,它内部需要保持动量和方差,两者都与梯度和模型参数处于同一规模,但是需要节省 4 倍的模型权重内存。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
