- 面试
- 算法入门
- End
面试
level 分级:
- 技术线:
Associate/Junior(见习、初级)—>engineer—>senior—>staff—>principle - 管理线:manager路线
Manger->Senior/second linemanager ->Director(countrywide) ->Region wide Director(大洲的director) ->world wide VP-CEO
Facebook(Meta)Investing in the Future: Introducing New Work Choices in EMEA
企业需求
企业招聘要求
- 为公司解决问题,带来收益 > 个人学习成长
- 帮上司排忧解难,超出预期的解决问题
企业需要什么样的人
- 【2018-8-22】这里的企业特指互联网企业,算法研发岗
- 【2018-10-16】阿里不是很重视校招,喜欢捡现成的,即便是校招,要求也是很高,2015年阿里校招面试,我面了两天,8+9=17人,都是清北中之类的,硕士以上,通过率不到30%,当时的标准是:大公司实习经历+学校学历好+理论基础好+动手能力强,只要有一个面试官犹豫不决,就否了。
- 【2020-5-21】面试本身就是不公平的,40-50分钟内,面试官试图通过几个点(问题)来感知候选人全方位的能力,这本身就不容易,关键这几个点还是面试官在自己熟悉的领域里挑选的(甚至提前准备好答案),不能答错,也不能答不出来,或者牵强附会,更不能指出面试官的错误,还要适当主导面试进程,不停地展示自己的技能,难…不同面试可能会出现截然相反的评论。所以,通过与否一定程度上靠缘分…
【2019-11-16】华为招人标准
PSD: Poor, Smart and Deep desire to become rich的缩写,不是真正的学位认证,是对一种心理状态的形容,所谓PSD学位是形容那些贫穷,但是很聪明,很深沉,有远大理想抱负,有成为富人和上流社会的人的强烈欲望的人
优秀候选人
如何成为那20%?
- 二八定律无处不在,20% 的候选人占据了市场上 80% 的offer,反之,另外 80% 的候选人只能苦哈哈的陷入那 20% offer中竞争
如何成为20%?
个人经验:
- 代码算法:
- C字符串函数
- 基本算法(如快排等,需要熟练掌握)
- 剑指Offer:面试经常出相似的题,类似书籍《编程珠玑》、《编程之美》、《程序员面试宝典》
- LeetCode(增强动手能力)【2019-06-06】程序员小吴的图解Leetcode
- 计算机功底
- 熟练使用Linux开发环境:shell+vim+awk+git
- 操作系统、web(浏览器工作原理)、cpu、内存
- 数学基础:概率、线代、优化、微积分等
- 数据挖掘(特征工程)
- excel、awk、python
- Hadoop/Hive/Spark
- 教你如何迅速秒杀掉:99%的海量数据处理面试题。(基本每次都有一道海量数据处理的面试题)
- 分析技巧:趋势、比较、细分,参考:数据分析的三个常用方法:数据趋势、对比和细分分析
- 注:数据分析没有想象的那么容易,那么低级,占据了算法工程师高达70-80%的时间
- 要点:知其然,知其所以然
- 深入理解业务,培养数据敏感度,见微知著
- 不要只关心算法,不理业务!
- 开阔视野,与时俱进,复合人才:人人都是产品经理、极客公园、36Kr、雷锋、机器之心等
- 机器学习:
- 李航《统计学习方法》(读3遍都不为过)
- Coursera Stanford《Machine Learning》(讲得很基础,但是没有告诉你所以然)
- Coursera 台湾大学《机器学习高级技法》、李宏毅的深度学习等(里面详解了SVM,Ensemble等模型的推导,优劣)
- 此处资料太多。。。
- 项目经验
- 请详细地回忆自己做过的项目
- 项目用了什么算法,为什么用它,有什么优缺点等。
- 注意:逻辑严密、思路清晰
- 技术影响力
- 技术竞赛:阿里天池、Kaggle、KDD等
- 顶会论文
- 书籍出版
- 最好有自己的github,有自己的项目(不只是clone),并且定期更新
面试技巧
- 自信、淡定:一紧张就会漏洞百出,发挥失常 —— “不就一次面试嘛,没什么大不了的”
- 三思而行:开口前多换位思考,面试官到底想问什么,为什么会这样问,怎么回答比较好
- 反客为主:主动引导,从跌倒的地方爬起来 —— 不会的问题大方承认,但要适当引导到自己擅长的领域,避免造成“啥也不会”的印象
- 个人品质:诚实可靠,虚怀若谷,积极上进,尽量不要让面试官难堪
学习方法
- 构建自己的知识体系,终身学习
- 想牛人看齐,主动营造积极向上的环境
- 时刻反思哪里做的不好,下次改进
求职
求职工具
AI 驱动的求职工具, 见站内专题 大模型在求职上应用
招聘渠道对比
目前找工作的主要软件及渠道。
- 1、
智联招聘。 工作多,工资数实。 - 2、
Boss直聘。 工资偏高,不那么属实,很多销售类工作。 - 3、
拉勾招聘。 工作岗位极少。 - 4、
前程无忧。岗位多,薪资匹配,个人觉得很靠谱。 - 5、
猎聘。很多小众的工作都有,岗位薪资都属实。 - 6、各地人才招聘网。一般都是薪资较高或者较为稳定的工作。
- 7、58和赶集,一言难尽,虚假信息居多。
- 8、内推。一般微信群、朋友圈或者论坛为主。
领英
【2024-10-17】他人(大福在成长)总结
- 互联网行业职场新人:
Boss 直聘,拉勾招聘,脉脉 - 3年以上工作经验/国企央企:
猎聘,智联招聘,前程无忧 - 高端人才:
脉脉,领英
| APP | 优点 | 缺点 | 总结 |
|---|---|---|---|
| Boss直聘 | 回复率高、快 HR直接沟通 行业覆盖面广 |
鱼龙混杂,有点乱 隐藏销售岗 |
|
| 脉脉 | 互联网大厂多 吃瓜内推必用 |
活跃度低、回复慢 圈子不同不必强融 |
|
| 前程无忧 | 外企、央企、国企多 匹配度高 行业多岗位广 |
岗位更新慢 回复慢 |
51job |
| 拉勾 | 互联网岗位多 主页可看面试评价 |
岗位少 回复慢 |
|
| 智联 | 外企、央企、国企多 传统大型公司多 日结兼职多 |
活跃度低、回复慢 岗位更新慢 |
|
| 猎聘 | 外企、央企、国企多 中高端岗位多 能直接找猎头 薪资待遇好 |
回复慢 |
公司官网
渠道信息
行业选择
【2024-10-18】八个行业不能去:
- 房地产(上市七成公司员工降到33-20%)
- 婴幼儿行业(出生率急剧减少,妇产门诊关闭过半)
- 互联网行业(内容生产,电商,短视频饱和,在线教育,裁员飞起,不少百万年薪程序员待业)
- 游戏(大监管力度增强,黑悟空只是个例,部分零利润下滑)
- 门店线下零售(消费降级,电商利润更薄,更何况线下还有铺位租金人力)
- 靠信息差赚钱的行业:
房产中介,基金经理,猎头,每个人都是自媒体,信息差不再存在 - 影视
- 广告
面试流程
面试特点
【2023-6-14】面试是招聘方通过即时有偏采样来了解候选人能力的过程,充满了信息不对称和不公平,只要没说出来的,默认不会
- 即时:只有30min-1h
- 有偏:按岗位、面试官偏好提问题
- 采样:时间有限,只能抽样问答,有一定随机性
面试流程总结
面试官代表着公司的形象,一言一行要礼貌、谨慎;我们面别人时,同时也是被面,其中的每个表情,每句话都会被记住,甚至“发扬光大”
基本流程:
- (0)熟悉简历
- 分析候选人简历:掌握基本信息→发现亮点和问题→确定面试重点考核方向
- 求职意向:意向职位多相关性低(?)
- 稳定性:跳槽频次(半年一跳)看中一家公司多次晋升、工作断档(6个月以上)、工作地点不一致
- 工作经历:项目含金量、考核指标、产出(量化)、公司敏感数据(不宜泄露)
- 分析候选人简历:掌握基本信息→发现亮点和问题→确定面试重点考核方向
- (1)面试前
- 寒暄问候、自我介绍、面试目的流程介绍——避免候选人紧张
- 给候选人倒水,嘘寒问暖,路上是否堵车,有没有紧急的事情
- 尊重对方感受,别让人等太久(尤其是特殊时间段,如午饭)
- (2)面试中 轻松的氛围,不宜过于严肃,咄咄逼人,或者挑衅,不合适的质疑 面试内容要覆盖全面,参考以下《面试要求》
- (3)面试后,问候选人是否有问题,或者没问到的优点,面试感觉如何
- (4)送别时,最好亲自送出门
- 关于结果,需要统一话术:
- 很满意:当天给,询问是否有要求、顾虑
- 比较满意:几天内给答复,适当指出优点(暗示)
- 不太满意:一个星期内等消息(几天后短信回复结果),同时可以指出优点(避免候选人丧气)和不足(暗示)
- 很不满意:坦诚指出不足,提供有价值的资料,让候选人有收获,感觉到被尊重
- 关于结果,需要统一话术:
- (5)验证:如何验证评估决策
- 面试需要感性与理性的综合判断
直觉验证十问:能相信ta的话吗、任务交给ta是否放心、如果没有光鲜履历还要吗、如果有更多候选人还会选择ta吗、ta比现有团队成员强吗等
- 面试结论及时同步出来,尽可能减小面试官之间的方差
- 如果拿捏不定是否通过,就加面,或者就否掉(犹豫意味着候选人还不够优秀,企业招聘一般要超出标准的,面试造火箭,工作拧螺丝)
各环节时间分配:
- 开放问题开场(5min)→ 面试中(避免随意打断/保证时长>30min)→ 面试尾声(QA环节/不用告诉结果,5min),识别求职动机
注:
实习生面试最好由资深的人面,或者经过面试培训(口头交待也行)的新人,发offer、指导人应该由资深的人负责
直觉十问
德锐咨询高级合伙人刘玖锋 人才招聘法
直觉十问:对面试者是否适合岗位,有一个更精准的判断
- 直觉上,我能相信此候选人说的话吗?
- 如果把重要任务交给此候选人去办,我放心吗?
- 此候选人如果没有光鲜优秀企业经历,我会选择他/她吗?
- 如果有更多的候选人,我现在会选择他/她吗?
- 此候选人至少比我们现有团队前20%的人优秀吗?
- 此候选人如果应聘我们竞争对手公司,会被录用吗?
- 我能从此候选人这里学到我现有不足的能力吗?
- 此候选人在未来是否能够达到公司的晋升标准?
- 如果其他面试官不同意,我还会用他/她吗?
- 如果我现在不用他/她,会后悔吗?
招聘 快 与 慢
两种方式对招聘结果的影响
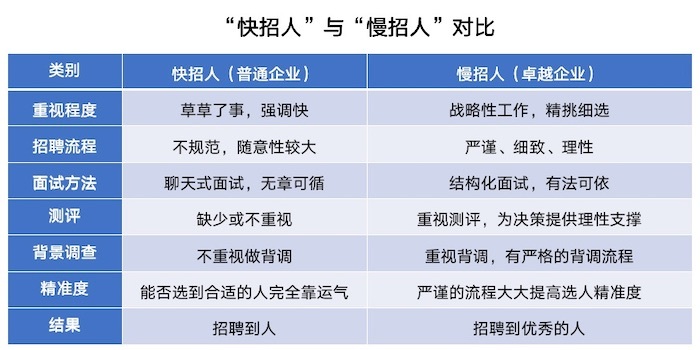
| 类别 | 快招人(普通企业) | 慢招人(卓越企业) |
|---|---|---|
| 重视程度 | 草草了事,强调快 | 战略性工作,精挑细选 |
| 招聘流程 | 不规范,随意性较大 | 严谨、细致、理性 |
| 面试方法 | 聊天式面试,无章可循 | 结构化面试,有法可依 |
| 测评 | 缺少或不重视 | 重视测评,为决策提供理性支撑 |
| 背景调查 | 不重视做背调 | 重视背调,有严格的背调流程 |
| 精准度 | 能否选到合适的人完全靠运气 | 严谨的流程大大提高选人精准度 |
| 结果 | 招聘到人 | 招聘到优秀的人 |
这里提到的“慢”不是指刻意慢下节奏,而是指更加严谨地评估与判断。
另外,结构化面试非常重要。否则,面试官会因为标准不统一、尺度不统一、眼光不统一,导致面试结果不统一,从而影响对人才的评估结果。而构建结构化面试的核心,则基于素质模型。即通过把握人才的基准画像,加上挖掘到真实匹配者的信息进行面试。这就要求面试官正确、精准地发问与深度地追问。
面试要求
面试时,要时刻注意候选人心态+情绪,刚开始不宜直接出算法题,先聊项目,稳定情绪,完成冷启动,然后在从项目入手出题目,由浅入深,不停追问,挖掘出候选人的知识体系+思考方法+个人品质,直至不会。如果出现不适(发抖,面色凝重,生气),要适时调整
| 事项 | 重要性 | 时间比例 | 考察点 | 题目 | 备注 |
|---|---|---|---|---|---|
| 基本功 | B | 20-30% | (1)编程题目(不敢写或写的不好的人动手不多),算法基础 (2)灵活多变,分别从广度和深度上扩充,不断拔高,直到不会。 (3)观察编程功能+潜力,挤掉刷题党 |
经典题目:排序,树,图,文本处理 | 看个人的开发习惯 ①代码熟练程度 ②性能意识(时空复杂度) ③代码风格(洁癖) |
| 理论知识 | C | 10-25% | 机器学习、深度学习经典算法的原理、优缺点、关系、应用经验 | ①LR,GBDT,RF,XGBOOST区别 ②tf-idf,word2vec,fasttext |
①理论体系的完整度 ②理解是否透彻 |
| 项目 | C | 30-50% | ①前因后果,逻辑推理,解决问题的方式 ②多找几个点,深入问,多几个为什么,怎么样 ③以点带面,询问相关技术体系(考察广度和深度) |
①让候选自己说最好的项目 ②优缺点,如何改进 ③开放问题:如何识别暴恐分子? |
核实项目真实性,逻辑推理 |
| 个人品质 | A | 10% | ①是否踏实(不会就不会,大方承认) ②是否谦逊(被人质疑怎么办) ③学习方法(看什么书,做笔记) ④是否好相处(油盐不进,自言自语,攻击型) |
①你觉得自己的优缺点是啥 ②这个地方有问题吧,怎么能这样? ③你这个想法很不错(故意夸张) ④碰到不会的问题会怎么办 |
第一位 |
| 求职意愿 | A | 5% | 目前拿到哪些offer,来面试的目的,侧重点(薪资、职位、地理位置等) | 你有什么要了解的(看候选人关心什么:待遇/氛围/地域等) | 面试态度:凑数、有机会就试试、无所谓、很想来。。。 |
注:
个人品质最容易忽略,因为大部分人的品质都没啥问题,即便是有问题的,也难以通过几次面试锁定,所以这一块一般指态度
评分原则
基本原则
- 找亮点:我手比较松,一般很少挂人,总是会试图找应聘者的亮点、时间紧时也会让应聘者自述亮点,所以对于应聘者来说最好把自己的亮点准备好,在一个小时的面试时间中尽量展现。
- 只问简历上写了的知识点、当然-如果知识面窄是不会拿到高分的。
挂什么样的人
- 态度恶劣,尤其是傲娇的
- 答不上来时找各种理由强行解释的,比如说“你问的太细了、这问题太底层了、这问题太偏理论了”等等,这是个学习态度问题,大方承认这是自己的知识盲区并表示会学习补上并不难,每个人都会有盲区、不可耻、可耻的是不敢承认自己的不足、还要为不足强行找理由。
考察哪些方面
- coding、算法、数学,面试过程中也会看出一个人的沟通能力、team work能力、学习能力等。
对于转专业
- 一般会问问他们自学历程+cs基本知识,如果自学时间短、水平也够 – 那说明此人够聪明、是加分项。
面试评价
常用评语
- 同学你面试评价不错,概率很大,请耐心等待;
- 你的排名比较靠前,不要担心,耐心等待;
- 问题不大,正在审批,不要着急签其他公司,等等我们!
- 预计9月中下旬,安心过节;5下周会有结果,请耐心等待下;
- 可能国庆节前后,一有结果我马上通知你;
- 预计10月中旬,再坚持一下:
- 正在走流程,就这两天了;
- 同学,结果我也不知道,你如果查到了也告诉我一声;
- 同学你出线不明朗,建议签其他公司保底!
- 同学你找了哪些公司,我也在找工作。
面试方法
常见面试方法
开放型(你倾向于做什么工作)封闭型(愿意做a还是b)情景型(如果项目受阻你该怎么办)行为型(最常用,区别是行为型,情景型真实发生,举一个技术含量最高的项目)诱导型(不建议)压力型(谨慎)-
连串型(多个问题,考察记忆思维逻辑) - 自我评价里罗列一些能力素质——行为面试法
- 项目业绩疑似夸大——专业面试法
面试礼仪
面试过程中负面表现
- 面试时间不足30min、迟到拖延、非正式场合(噪音大)、不开摄像头
- 随意打断候选人、怼人、指责争论、避免频繁看手机电脑、使用内部缩写代码、不礼貌肢体语言(靠后)
- 接打电话、照顾校友好友(个人偏好)、随意承诺薪酬、贬低其他公司
- 个人情况(是否结婚/生育)、透漏校招面试题评分标准、帮人查面评、暗中找人打听候选人泄露信息
面试”套路“
面试官的「套路」
面试时所问的问题基本分为两种:具象问题和开放问题。
- 具象问题:参考工作经验按照
STAR法则来进行,主要是了解基本的素养,技术深度和潜力。 - 开放问题:考察思维发散能力,考察在某个领域的深度和广度,基本上会结合技术问题来问,或者是结合工作内容来问。
比如:
实现某种技术的 n 种方法?某种技术的实现原理?和什么什么相比有哪些优缺点?你对这项技术的思考是什么?
面试者的「应对」
- 就实际情况做回答,提前准备的时候多发散,多思考,多总结。这一块是可以自己准备的加分项。
- 发散性问题主要是看自己平时积累。首先基础知识要牢固,同时也要了解最新技术动态。面对这类问题切记也不能答非所问而跑题了。
高频面试题
【2024-9-5】15道高频面试题 参考
| 类别 | 问题 | 要点 | 参考回答1 | 参考回答2 | 参考回答3 | 参考回答4 |
|---|---|---|---|---|---|---|
| 必问 | 请你做下自我介绍 | 不要过多阐述简历上已有部分,着重讲解过往的工作成绩、项目经历等与岗位适配的内容,不过多介绍与工作无关的内容。 | 应届生: 面试官您好,我叫XXX,毕业于X大学X专业,目前有过X段实习经历,主要的工作内容是X、X。在工作中获得了X成绩(数据化呈现);技能有X、XX(适配当前的岗位职责)。在校期间,我也是学生会的负责人,在XX部门工作,主要工作有:策划XX、组织XX、协调各部门XX,参与人数XX人。在校期间与实习期间的经历使我对XX岗位的工作内容更加熟悉,在日后的工作中能够快速适应节奏,期待能够加入贵司,一起进步,谢谢。 |
社招: 面试官您好,很荣幸参加到今天的面试,我叫XXX,毕业于X大学XX专业,我今天面试的岗位是XX。我有过XX经验和X工作技能,所参与的项目得到了XX数据(量化数据),同时了解到岗位是做XX内容的,这与我的适配度很高,期待能够加入贵司,将我的之前的经验迁移到岗位,快速适应节奏和环境。 |
||
| 必问 | 为什么从原公司离职 | 不要责备、批评、吐槽前公司及前同事,回答时侧重个人发展等方向,真诚回答。 | 被裁员:前公司因为XX/XX原因,我所在的X业务板块收到调整,整个项目部门进行了大的变动,导致我负责的业务也被砍掉。换新的岗位与我的个人、职业发展有所偏差,所以辞职寻求新的发展空间。 | 加班原因:我个人在工作中是比较高效的工作状态,所以不太喜欢低效重复的工作环境和状态。我可以接受加班,但是为了加班而加班,甚至崇尚加班文化,以此作为绩效评估的标准。这样的做法,非常影响工作效率,影响公司业务发展,所以选择了离职。 | 上升空间有限:近些年我的业务能力也有了提升,领导同事也认可我的能力,但前公司的管理模式扁平化,发展空间非常有限,所以想跳出来看看新的环境,得到更好的发展。 | |
| 考察 | 你有什么优点? | 不要自夸自满,尽量说明与岗位职责需要的优点,可以适当用例子佐证。 | 从责任心强、团队荣誉感强、抗压能力强、适应性强、部门协作能力强、全局意识强、沟通能力强等多个方面,举例阐述。 | |||
| 考察 | 你有什么缺点? | 不要说没有缺点或者无法改正的缺点,要提出改进缺点的想法和方案,拿出实际例子证明你正在改变。同时最好说明与职场非强相关的缺点。 | 职场缺点:我对XX(非必需项目)掌握还不够熟练,所欠缺的能力,最近也正在进行相关学习,希望短期内可以改善,解决这个问题。 | 性格缺点(面试官明确点出时再说):做事认真,比较专注。但是性子比较急,所以在工作推进中容易造成误会。我也关注到这个缺点,也在锻炼相关能力,不久之后就可以有所增进。 | ||
| 压力测试 | 你是0经验,为什么觉得能够胜任这份工作呢? | 重点不在于0经验,而是考察逻辑思维能力、心态、岗位适配度等方面。回答时,利用已有的工作经验与岗位需求相贴合,体现经验迁移能力。 | 我确实没有X方面的工作经验,但是这个岗位负责X内容,所需要X方面的能力,我有过XX的工作经历,完成了X的工作内容,获得了X的数据。这些与该岗位有很高的贴合度,同时我也拥有X技能,有信心胜任该岗位。 | |||
| 压力测试 | 你如何看待加班呢? | 不要上来就否定加班,抗拒加班。一定要先弄清是因为什么原因加班,表明可以接受正常加班,避免浪费时间的不必要加班。 | 加班问题,如果由于个人工作效率而导致的加班,后面提高工作效率,及时完成相应工作,不拖团队后腿。如果是因为事发紧急需要加班赶工,我也会积极配合,加班加点完成工作内容。同时日常工作中,我也会高效完成工作,避免为了加班而加班。 | |||
| 考察 | 说说未来3-5年的职业规划 | 将职业规划分为短期规划与长期规划,切忌规划目标不能假大空,要结合实际情况,体现出工作积极性、职业规划性与工作态度即可。 | 短期内迅速适应工作岗位,熟练掌握工作业务,提高工作能力,积累工作经验;长期目标,希望经过不断地学习后,能够加入公司管理层,使自己的管理能力和组织能力得到一定的提升,日后在行业中能够做到独当一面,实现公司业务与个人职业生涯共同进步。 | |||
| 考察 | 什么时候可以到岗? | 表达想尽快入职的想法+明确入职的时间,不要说随时到岗。 | 在职状态:目前在职,但如果被录取,我会尽快交接好我的剩余工作,这大概需要1-2周的时间,最晚也不会超过1个月,之后我会办理好离职 | 待业状态:如果有幸录取,我会一周之内尽快入职,提前入职的话,我也会尽力配合,尽快准备好相关材料,去公司报道。 | ||
| 专业 | 你的核心竞争力是什么? | 问到这个问题,hr并不是真想知道你有多么强,多么厉害。而是核心竞争力能给公司带来什么样的价值。要学会表明属于自己的特质,同时也要进一步解释,为什么它是核心竞争力。 | 应届生:在校期间,我负责过XX项目,组织制定了X内容,在逻辑能力、组织协调能力等方面较好,同时我的学习能力较强,中能够快速学习并熟练掌握相关内容,这对于我日后的工作也是有很大的帮助。 | 社招:我的核心竞争力是X能力强,有X的项目经验,同时参与的XX项目,获得了X成绩(利用数据做支撑)。因为贵司也是做XX的,我可以短时间内将我的经验和能力快速复用到业务上。 | ||
| 考察 | 说说你空窗期都做了什么? | 考察重点在于空窗期久了能否胜任工作,能否快速进入工作状态,所以回答时一定要表明态度,并且通过具体事例证明自己。 | 学历提升/考公/考编:休息这段时间,我一直集中精力来备考,虽然遗憾没有上岸成功。但通过失败之后的复盘与思考,我重新调整了自己的状态,确定了职业规划。我看贵司的XX岗位要求与我专业相匹配。另外我有X能力,擅长X,希望能有幸入职贵司,可以胜任这个岗位。 | 没找到工作:毕业/离职之后,我并没有立马开始寻找新工作,而是先对自己的个人能力、职场技能进行了评估,觉得在X方面还需要进一步提高,所以通过自学XX等方式,提升了XX等方面的技能。(一定会被HR提问学了什么,要提前准备好) | 被裁员休息:上份工作比较忙碌,时间大部分都用在工作。同时公司因为XX影响,项目被砍,我也被迫离职。正好借此机会给自己充个电,同时复盘沉淀自己。这期间,我也学习了XX技能,提升自己的工作水平,从而更好的适应新的工作。看到贵司在招XX岗位,与我的职业发展很匹配,期待能够加入公司,做出贡献。 | 结婚/带娃:这段时间我结婚/带娃,所以辞职在家专职带孩子。现在孩子长大也有人照看了,我可以集中精力在工作上。仔细思考了一下后面的职业规划,提升了相关技能。看到贵司在招Xx岗位,与我自身契合度很高。因此我非常希望能够加入贵司,后续也会全身心投入到工作中。 家庭原因:由于家庭成员的疾病/意外事故/紧急情况,需要我亲自去照顾、解决,由于事发突然,所以我不得不辞去工作。这段时间也锻炼了我的适应能力和调节能力。目前家人已经康复,我可以全身心投入到工作中,并相信我可以将这段时间锻炼的能力带入到新的工作岗位中。 |
| 考察 | 最有成就感的一件事 | STAR法则,什么背景下,遇到什么任务,我采取什么动作,获得什么结果。 | 我在过去的工作/学习中,接到了一件超出我舒适区的任务,这件事情是需要我和其他XX部门/同事共同完成的。在推进中,我们发现XX问题,遇到了X阻碍,但是我们团结协作,最终通过XX方法,完成了该任务,取得了不小的进展,这使我得到了锻炼,得到了成长与进步。 | |||
| 压力测试 | 如何应对工作中的压力? | 考察抗压能力、工作中的随机应变能力,说出解决办法,同时举出实例来展示解决结果,最后强调自我调节能力。 | 工作中有压力很正常,这证明在进步,往前走。面对压力时,不要逃避,应该积极地寻找压力来源,审视自身强项与短板,不断强化自己,将压力转化为动力。在之前的工作中,我负责的项目遇到了瓶颈期。对当前的工作进行总结复盘,去寻找能够突破的办法,并且终于通过X方法,得到了解决。 | |||
| 考察 | 如果公司录用你,如何开展工作? | 如果有过相关经验/对岗位职责非常了解,直接描述经验和工作流程,展现工作能力和做事方法。如果没有经验,则需要从底层逻辑学起,逐步掌握工作业务。 | 首先根据指示和安排,熟悉工作情况和内容其次根据当前的实际情况制定详细的工作计划,并且再确认计划的可行性后逐步展开工作,同时在空闲时间加强学习,提高成长速度。 | |||
| 挖坑 | 你手上还有其他offer吗 | 考察入职意向,还有市场竞争力,如实回答。回答有offer时也要表明自己对该公司的态度和想法,避免丢掉这次offer | 收到其他offer: 目前确实收到X家公司的ofer, 考虑中。但贵司的行业水平与发展前景与职业发展比较贴合的,同时非常喜欢贵司的(工作氛围、工作环境、匹配适配度等),非常期待能够加入进来,如果能收到贵司的ofer,推掉其他offer,尽快入职。 | 没有收到其他offer: 最近才开始面试,并且对于找工作也是非常谨慎的。目前也有X公司进入了最终面,但总的来说,比较倾向于贵司岗位。这与我个人的职业发展与成长是相适配的,所以非常希望可以加入贵司,一起共事。 | ||
| 挖坑 | 还有什么想问的吗? | 不要说没有,围绕岗位发展路径、个人职业成长、公司晋升机制等方面,进行提问 | 1.贵司晋升机制如何? | 2.该岗位在实际工作中会遇到哪些困难与阻碍呢? | 3.部门工作氛围是怎样的? | 4.部门目前人员分配如何,具体分工是怎样的呢? |
高情商回答
【2023-10-19】HR喜欢听的离职原因
| 耿直回答 | 高情商回答 | 分析 | |
|---|---|---|---|
| 被裁员 | 原业务线被砍了,领导安排我转岗到其他业务线。但是新岗位和我的职业规划不相符,我还是想继续在XX方向深耕,所以我离职了。 | ||
| 工资低 | 几年我的业务能力已经得到了显著的提升,为公司创造xxx的业绩,领导对我也很认可,但是原公司的工资的涨幅非常有限,所以我想看看新机会 | ||
| 学不到东西 | 在原公司所负责的工作内容比较单一且重复性比较高,无法满足我个人的职业发展需求。我想要一个更有成长空间的工作。 | ||
| 晋升难 | 前公司管理比较扁平,虽然一直被领导重用,也负责过xxx核心业务,但职级几年来来一直没有变化。领导也争取过,但由于公司制度等原因,没能通过。所以我想在拥有了比较扎实的一线业务经验的同时,挑战一下更高的职位。 | ||
| 加班多 | 前公司常态化996,但实际的工作量并不大,导致大部分人为了加班而加班,效率非常低,我个人并不反对加班,但这种低效的996,我并不认可。 | ||
| 工作内容不符合 | 原公司在我入职后调整了我的工作内容不符合我的职业发展方向,我也努力调整过,但最终还是想回归初心,在多次沟通无果后,只能选择辞职。 | ||
| 同事关系复杂 | 前公司在工作岗位的分工不太合理,办公室政治严重,互相扯皮的现象比较常见,而工作效率则被无限拉低。我更希望进入一家把精力放在高效工作,分工明确的公司,同事氛围好一点,毕竟一个人大部分时间都在工作上,心情愉快很重要 |
总结
- 被裁员
- 高情商回答:原业务线被砍了,领导安排我转岗到其他业务线。但是新岗位和我的职业规划不相符,我还是想继续在XX方向深耕,所以我离职了。
- 工资低
- 高情商回答:这几年我的业务能力已经得到了显著的提升,为公司创造xxx的业绩,领导对我也很认可,但是原公司的工资的涨幅非常有限,所以我想看看新机会
- 学不到东西
- 高情商回答:在原公司所负责的工作内容比较单一且重复性比较高,无法满足我个人的职业发展需求。我想要一个更有成长空间的工作。
- 晋升难
- 高情商回答:前公司管理比较扁平,虽然一直被领导重用,也负责过xxx核心业务,但职级几年来来一直没有变化。领导也争取过,但由于公司制度等原因,没能通过。 所以我想在拥有了比较扎实的一线业务经验的同时,挑战一下更高的职位。
- 加班多
- 高情商回答:前公司常态化996,但实际的工作量并不大,导致大部分人为了加班而加班,效率非常低,我个人并不反对加班,但这种低效的996,我并不认可。
- 工作内容不符合
- 高情商回答:原公司在我入职后调整了我的工作内容不符合我的职业发展方向,我也努力调整过,但最终还是想回归初心,在多次沟通无果后,只能选择辞职。
- 公司or领导不行
- 高情商回答:之前的工作比较安逸,发展空间较小,因此我想要脱离舒适圈,通过工作学习到更多技能,同时发挥个人才能,为公司创造更多价值。
- 同事关系复杂
- 高情商回答:前公司在工作岗位的分工不太合理,办公室政治严重,互相扯皮的现象比较常见,而工作效率则被无限拉低。我更希望进入一家把精力放在高效工作,分工明确的公司,同事氛围好一点,毕竟一个人大部分时间都在工作上,心情愉快很重要
STAR 法则
优秀的面试者往往会用 STAR 法则来建立个人事件,让面试官可以更好地通过你过去的经历来判断你的个人能力和潜质。
STAR 法则四要素:
- 情境 Situation:事情是在什么情况下发生,基于一个怎样的背景;
- 任务 Task:你是如何明确你的任务的;
- 行动 Action:针对这样的情况分析,你采用了什么行动方式,具体做了哪些工作内容;
- 结果 Result:结果怎样,带来了什么价值,在整个过程中你学到了什么,有什么新的体会。
大部分同学直接介绍做了什么以及实现的过程,条理也比较清晰,内容也颇具技术含量。但很多同学很容易忽略了 Situation 和 Result 的部分也就是背景和结果。或者是在面试官进一步了解追问细节的时候容易惊慌失措。这些原因往往都是由于面试前对自己的经历没有将来龙去脉讲清楚以及总结不够全面和深入。
举个例子:
- 小王提到在 XXX 项目过程中实现了一个 Webpack 插件 XXX,这个插件的功能是 XXXX, 并且在 Github 上开源。
- 整个实现过程和思路都比较清晰,面试官听的也是饶有兴致,甚至回想起年轻时某个夜晚加班研究 Webpack 插件的青涩时光。
注意
- 陈述含糊,陈述中出现“我们”、“一般”、“通常”字眼,含糊不清时,不符合 STAR
- 候选人作答时,提到“我认为”、“如果”,表示他的观点、看法,并非真实行为特质,也不符合 STAR
尽管这样面试官也同样希望了解当时项目的背景,是什么原因导致你要想到通过做 Webpack 插件来解决而不是通过其他工具,以及这个插件给项目带来了怎样的价值(是构建性能还是其他?)。
背景和结果是面试官非常看重的一部分,必须拿出足够的理由和价值来说服面试官,否则尽管你在这个项目投入了足够的精力但最终并没有为你的面试评价加分,这是十分可惜的
| 轮次 | 面试官 | 候选人 |
|---|---|---|
| 1 | 简历中提到实现了一个检查浏览器 API 兼容性的工具,可以介绍一下么? | (Situation)好的,当时的情况实际上是一次线上的用户的舆情反馈说页面白屏/打不开,通过 JSError 日志的排查我发现最近出现大量类似 IntersectionObserver is not defined 的日志,同时和我最近一次发布的模块曝光需求时间线是差不多吻合的,所以很快定位到了是当时使用浏览器 IntersectionObserver API 做 DOM 曝光时没有考虑到兼容性的问题。 |
| 2 | 那问题解决了么? | 是的,当时定位到问题后通过增加 polyfill 的方式很快解决了这个问题。(Task)后来我借着这个问题我自己也进行了思考,其实随着操作系统和浏览器的更新,越来越多的 JS/浏览器的新特性开始被支持。为前端开发带来便利的同时,也会带来一些不可避免的兼容性问题。兼容代码(polyfill)的忽视很容易造成不可预估的问题。但如果只依赖开发人员人工检查兼容性问题并不是最优雅的解决方案,毕竟人工的难免会有遗漏。所以我想是不是能够开发一个集成现有的兼容性检查规则的工具将这个过程自动化。 |
| 3 | 不错,详细介绍一下具体过程吧。 | (Action)恩,这个想法诞生之后我就去了解了一下常用的前端兼容性检查网站:Caniuse 和 MDN 这两个是我比较常用的。后来发现这两个网站的检查数据实际上在 Github 上都对应维护了一份静态的检查规则(caniuse-db 和 mdn-browser-compat-data),这些数据都是具有特定结构的 JSON 文件,尽管这两者对浏览器支持程度描述的方式不太一样,但已经能满足得到兼容性数据的基本要求。接下来就是对代码的分析检查,将代码和这些规则进行比较。这个过程需要对代码进行语法逻辑分析,所以我想到了用 Babel 将代码转化成 AST 语法树进行特定遍历。同时我整理常规的 API 的调用方式我发现不外乎几种,比如:NewExpression(构造表达式) 和 CallExpression(调用表达式)。当这些信息都掌握清楚后我觉得这件事情是具备技术可行性的。 |
| 4 | 恩,这个实现过程有没有遇到哪些问题?你是怎么解决的? | (Action)恩有的,刚刚提到 Caniuse 和 MDN 维护的静态 JSON 数据,我在实现过程中将这两份数据进行了格式的统一,目的是将两块数据进行互补同时方便后续进行检查比较。最终事实上得到了接近 9w 条数据,如果直接拿来对比是很影响效率的,所以当时利用 browserlist 可以配置指定目标检查的浏览器范围,比如 iOS Safari 9 以上,通过这一层去过滤在该范围内没有兼容性问题的数据,从而减少对比提升效率,也为开发者提供灵活的配置能力。第二个问题同样也是检查的性能优化,是通过 isReferencedIdentifier 去检测标识符是否有被真正引用到。最后是这个工具与如何接入发布流程的管控,由于公司的发布流程采用的是云构建的方式,所以我在发布之前先经过这个工具的校验,并且将检查的结果打通消息通知和邮件系统,(Result)帮助其他人在发布前得到项目代码的浏览器 API 兼容性检查报告,避免了这类问题的再次出现。这次的经验帮助我加深了对 Babel 和 AST 的理解。 |
| 5 | 那你了解 Babel parse AST 的过程么? | 在解析成 AST 过程中有两个阶段:词法分析和语法分析。词法分析阶段:字符串形式的代码转换为令牌(tokens)流,令牌类似于AST中的节点;语法分析阶段:把一个令牌流转化为 AST 的形式,同时把令牌中的信息转化为AST的表述结构。 |
| 5 | 你项目中说的 AST 遍历的过程能再详细说说么? | Babel 在处理一个节点时,是以访问者的形式获取节点信息并进行相关操作。这种方式是通过 Visitor 对象来完成的,Visitor 对象中定义了对于各种节点的访问函数,这样就可以针对不同的节点做出不同的处理。比如我在项目过程中主要针对 NewExpression 和 CallExpression 进行处理,通过 path 参数对节点以及节点的父子节点以及进行判断筛选,balabala。 |
结构化提问
【2023-7-26】结构化的提问流程,助你精准评估人才
OBER 法则
第一关:OBER 法则。
O(open),多问开放式问题,少问封闭式问题:- 面试官问:你是怎么样分派任务的?是分配给已经表现出有能力完成任务的人,还是分配给有兴趣完成任务的人或者是分级分配?这样封闭式的问题,会给面试者提供一部分答案与发挥空间。
- 正确的提问方式应该是更开放的:请描述一下你是怎样分配任务的。
B(behavior),多问行为事例,少问想法 / 决心 / 意愿:- “你的前任主管是一个严厉的人还是随和的人?”很多面试官希望通过这样的问题,来判断面试者的团队沟通能力。这样提问,面试者会从自己的想法入手,规避掉很多你希望获取的信息。
- 正确的提问方式应该是:“你以前是如何与团队进行沟通的?”通过他之前的行为,判断他是否具备团队沟通能力。
- 关于多问行为势力,还需要强调一点,就是减少假设性问题。比如:“如果我们加班比较多,你可以接受吗?”因为假设性的问题得到的答案一定是假设性的答案,一定会与实际情况有差异。
E(easy),问题要尽量简洁、确保容易理解:面试者应当尽可能避免问抽象的问题,确保问题的简洁性以增加面试的效率。R(related),问的问题要和所考察的素质项高度相关:这就要求,面试官应该为每一个自己想要考察的素质设置题库。比如“学习探索”是公司需要考察的素质。面试官可以建立这样的题库:
深度追问
第二关:深度追问
原华为副总裁兼人力资源总监吴建国曾说过:“作为一个管理者,准确识人是一项基本功。那么,怎样才能快速提高人才辨识能力呢?华为从 1998 年开始采用 STAR 原则,即情景、任务、行动、结果,对过去关键行为的描述有助于我们准确判定应聘者的素质和技能。STAR 是一种结构化的行为面试方法,经过反复锤炼,面试官掌握这套技能之后,可以有效杜绝大部分人为拍脑袋的因素,让一般企业的人才识别率提升到 60% 以上。”吴建国提到的 STAR 就是深度追问的方法。从开始提问再到追问模式,直到让面试官考察到自己想要考察的素质。
行为面试法
行为面试法 又称 STAR面试法则
其实准备面试的STAR法则就是由面试中的STAR法则演变而来。
- 基本假设: 过去经历是未来能力的证明。过去的你如果做成了某一件事,那么HR也会认为未来的你可以做同样的事。
比如:
- HR根据你的意向岗位职责,想知道你的沟通协调能力如何。
- 那么你在大学期间的时候当过学生会主席,通过协调各个部门之间的关系让一个活动落地,然后你对这个事情的处理有一套逻辑和措施。
那么HR就会对你这段经历的细节进行询问,从而判断未来的你是否可以胜任与这个经历相似的工作内容。最后相信你可以胜任该项工作,并认可你在经历中的能力。
注
- 使用行为面试法切入提问时,一般引导候选人讲一个过去实际发生的、本人亲历且与岗位要求有关的行为事件
- 行为面试法案例是真实发生,而不是假设的(情境面试法)
情景模拟法
日常工作中有很多工作场景。
HR会依托于一个微小的日常工作环境,然后让求职者在这个随机的环境中去表现。最后根据你的表现进行打分和判断,从而推演你在未来工作中,如何开展工作。
行为面试法是探索和询问是否有类似的经历,根据这个经历总结能力,然后判断你能否在未来胜任这个岗位。- 而
情景模拟法把这个岗位的日常工作转变成一个情境模拟,根据情境表现,推演在未来工作中,你如何开展。
所以行为面试法就是结构化面试,而情境模拟就是群面。
- 群面就像是一场综艺节目,HR不仅是这场游戏规则的制定者,同时也是观众。他把你放到一个场景节目中,让你去表演,在欣赏你表演的同时对你进行打分。
在这个随机而又带有高压的场景中,HR会给你和你的同伴一个目标。然后看你和你的同伴如何去完成这个目标。
这就是为什么每一个校招生都害怕群面的原因,因为群面不知道会面对什么样的问题,也不知道这个场景到底是不是你擅长的。同时你也不知道与你同组的伙伴,你们之间打配合是否有默契。群面中一旦遇到猪队友,他一直和你唱反调,甚至频频打断其他人的谈话,导致整组讨论陷入僵局。最后所有人因没有得出一致的结论,使全组人遭到淘汰。
所以,场景随机和人员随机是群面通过率过低的主要原因。
- 平均一场群面的通过率是30%左右,要是通过率能达到50%,那就说明这组人的讨论十分优秀。
造成群面通过率低的原因还有一点,那就是标准随机。
- 你或许认为你是一个好的leader,面试中秒杀全场,别人很难插话,并且只能同意你的观点。但是HR认为你过于强势,没有团队意识,最终让你淘汰。
整体来看,面试就像是一场博弈,需要你不断去分析对手的同时,不断来完善自己。所以要想提升上岸几率,就必须要具备审时度势、前瞻布局的能力。
招聘偏差
老板观点
【2021-7-6】字节跳动CEO张一鸣炮轰HR :按这要求我自己都进不来,张一鸣公开表示对HR招聘不满
- 字节招聘PM的JD有一条写的是:有5年以上互联网产品经验,具有日活千万量级以上的产品规划和产品迭代实施经验。
- 张一鸣跟HR说,“按照这个要求,
陈林(现任今日头条CEO)、张楠(现任抖音总裁),我们公司一大批PM,一个都进不来,连我自己都进不来。别说千万DAU产品了,他们加入前,连百万,甚至十万DAU的产品也没做过。”
HR观点
而HR也是一肚子苦水,实际上,很多大公司的招聘要求都这么写,有的甚至更严格。这样写,不一定就照着这个要求招聘,只不过满足某种看起来严格的条件后,能缩小范围,也能在一定程度上提升招聘效率。
作为一家企业人才体系最重要的搭建者,HR这个岗位总是充满争议。
- 不少人认为HR手握大权、能掌控一个求职者的生死,但其实他们面临的压力和考验,不比任何一个求职者少。
- 比如,每个部门对求职者的要求都不一样,面试官和最终用人的主管意见也经常不一致,业务负责人还常常要求HR用低价招聘高水平的应聘者,后期裁员时HR还要做坏人,有人甚至被面试者羞辱哭。
- 老板想用50%的市场价招来100%的人
遇到“不靠谱”的业务主管更闹心。有一次一个业务主管约好了面试时间,等到了时候了又爽约。那位面试者本身条件很优秀,那一天几乎排满了面试,我就得出面去和对方解释。我跟他谈了1个多小时,业务主管还不出现,面试者就走了,主管却回过头来怪我能力不行,真是百口莫辩。
HR其实特别难。
- 公司需要的时候,要用更低的价格帮助公司招到更优秀的人才;
- 公司裁员的时候,还得做坏人,尤其是遇到那种和自己关系很好的员工,真的很尴尬。
我们也仅仅只是一个员工,一个执行者而已。
HR也想不看背景、不看出身、不看过往经验来找到合适的人,但那样的话,招人成本就会很高。
- 背景、学历这些标签,是其过往能力的验证。整个社会已经帮我们完成了多次筛选,大家都在讲突破常规,但真正突破常规的HR并不多,毕竟不是每个人都是伯乐,这世界上也没有那么多千里马。
(4)北京就业:
不是农大好,是北京211-985机会多,我面百度先后尝试了4次,如果是华科只有1-2次机会,农大计算机为农业服务,面向互联网就业,并不好;我是脸皮厚,在面试中不断学习成长,才挤进百度;编程题、海量数据处理、系统结构、linux系统、软件设计之类的题目,都是自学的,学校里哪会教这些;当年学的图形图像,找不着好工作,月薪5-8k,游戏设计经验又没有,真不好找——这些招聘 都是 耍流氓的,刚毕业的 哪来的工作经验。然后 hr还给你面试机会,真正用心招人的,面对应届生,应该抱着 发展的眼光 面试,如果我现在 招人, 技术就面最基础的,然后其他就扯淡,优先 看人品,对问题的理解,还有 格局,解决问题的能力,马斯克有个视频里 也提到 应该 这么招人 ———— 这么招人是科学些,但是不好量化执行,招聘第一关是HR筛选简历,她们大多是文科生,对技术理解有限,工作量也大,所以不得不用一些简单粗暴的方法来筛选:是否三好,学校好(211勉强及格,985更好)、学历好(硕士以上)、背景好(有大厂经历);
北航大四专业课的老师 都很直白的说了,如果 考他的研究生,只要过线,必要,不需要复试;本科学的 是 航空航天的 仪器仪表,单片机,机械设计;刚毕业,面试机会 倒是非常多,但是被人鄙视,吊打的次数也多,2010年面试一家公司,因为简历写的是 爱好解说佛道里的典籍,擅长 徒手(不借助积分表,数学软件)解微分方程,结果面试官 揪着不放, 跟我大谈 道德经81章 在阿里,滴滴当面试官时,实习生招聘政策上会倾向于招北京生源的,正式招聘时,华科的位置跟北邮相仿
面试问题
基础算法知识及题目见站内专题 基础算法笔记
大模型
行情
- 大公司:阿里-夸克、蚂蚁金服、字节跳动、美团、快手、小红书、好未来、360、百度、小米
- 独角兽公司:知乎、贝壳找房、毫末出行、蔚来汽车、完美世界、第四范式、北京智源研究院、智谱AI、度小满、作业帮、bigo、昆仑万维、中文在线、李开复的Project AI 2.0、安恒;
- 创业型公司:百川智能-王小川、光年之外-王慧文、澜舟科技-周明、潞晨科技(尤洋老师)、奇点智源、minimax、稿定设计、聆心智能-黄民烈、幂律智能、即时设计;
招聘要求汇总
(1)理论衡量标准
- 熟悉主流大模型原理和差异
Transformer/BERTGPT3/ChatGPTT5/PaLMBLOOM/LLaMA/GLM等
- LLM 全链路技术
- 对大模型的技术和行业发展有深刻认知,能够把握大模型发展方向
- 多语言 NLP/多模态大模型
- 扩散模型系列
- 对话系统、信息抽取、文档摘要、文本生成
(2)工程经验衡量标准
- 编程语言: Python 或 C++
- 熟悉 Pytorch/Tensorflow
- 10b以上LLM训练经验
- 百亿/千亿NLP大模型训练调优经验优先
- 多机多卡经验
- 训练框架
Megatron-LM/Deepspeed
- 训练框架
- 推理加速
- 全参、
LoRA、P-Tuning等模型微调 - 模型量化、分布式部署
- 全参、
- 模型小型化技术
量化/剪枝/蒸馏等,熟悉onnx/TensorRT
(3)LLM 应用
- 新的技术创新和改进方案
- Prompt 设计
- 可控内容生成
- Aoto-GPT
- LLM应用框架:如 LangChain
- 机器翻译,机器阅读理解,智能摘要、智能问答、智能对话等项目优先;
(4)加分项:
- 发表过顶刊顶会论文者
- 有机器学习竞赛获奖经历
- Kaggle金牌,天池、DF、DC等比赛平台top1
- ACM等编程竞赛区域金以上经历
- 有开源项目贡献经历。
招聘要求详情
【国企-大规模算法专家】
岗位职责:
- 1、从事大语言模型(LLM)预训练算法研究、训练、应用,涉及多语言、知识增强、模型性能提升等方面;
- 2、负责自然语言处理(NLP)方向基于GPU的并行多机多卡训练、高性能模型推理等;
- 3、主要从事AIGC语言内容生成工作,将先进的NLP生成技术应用于实际业务,获取业务收益,更好服务用户;
- 4、前沿技术跟进研究,支持公司通用类和垂类预训练模型研发及效果持续优化。
岗位要求:
- 1、硕士及以上学历,计算机、数学或统计学等相关专业,3年及以上NLP相关经验,熟练使用 pytorch/tensorflow 深度学习框架;
- 2、在NLP文本生成或大模型预训练方向有较深入研究;
- 3、对 LLM 有深入理解和实践,有预训练、可控内容生成方向经验者优先;
- 4、熟练掌握
GPT、T5等算法训练范式,有从0到1构建NLP大模型(百亿参数以上)经验优先; - 5、有NLP顶会发表经验者(ACL/EMNLP/NAACL/SIGIR/NeurIPS等)优先;
- 6、具备良好的逻辑思维能力、沟通协作能力、自我学习能力。
nlp算法
【2023-6-3】【大模型岗位-NLP算法】
工作职责:
- NLP大模型前沿探索,推动NLP大模型效果达到行业领先
- 解决大模型生成内容的可控可信度不足、推理效率低的问题,解决大模型业务落地的技术障碍
- 协同跨团队技术和业务同学共同达成技术和业务目标
任职要求:
- 计算机相关专业获得硕士学位,博士优先, 发表过大模型相关研究AI顶会论文优先;
- 对NLP主流大模型如
GPT3/ChatGPT/T5/PaLM/LLaMA/GLM等的原理和差异有深入理解; - 熟练掌握主流深度学习框架pytorch/tensorflow,大模型训练框架
Megatron-LM/Deepspeed等多机多卡方案,有百亿/千亿NLP大模型训练调优经验优先
llm算法专家
【电信-云】大模型算法专家
岗位职责:
- 负责开展大模型算法研究,包括但不限于:
- 单模态、多模态大模型的百卡、千卡训练集群模型预训练,全参、LoRA、P-Tuning等模型微调,模型量化、分布式部署算法,实现Aoto-GPT等最新大模型算法研究与应用
- 完成解决大模型在垂直领域落地问题
- 解决大模型的可控可信度不足、推理效率低的问题,解决大模型业务落地的技术障碍
- 协同跨团队技术和业务同学共同达成技术和业务目标
- 研究和创新,负责跟踪最新的技术发展和研究成果,提出新的技术创新和改进方案,以提高模型的性能和效率,
- 提供独立思考和创新能力,解决不同领域的技术难题。
任职资格:
- 大学本科及以上学历,并取得相应学位,计算机相关专业优先
- 8年以上算法相关工作经验,拥有扎实的大模型理论研究基础;
- 对主流大模型 (例如GPT3/chatGPT/T5/PaLM/LLaMA/GLM等) 的原理、性能、差异有深入理解;
- 掌握大模型生产全链路技术,拥有大模型训练、微调、产品应用经验;
- 熟悉常见的模型小型化技术,如量化/剪枝/蒸馏等,熟悉onnx/tensorRT
- 对大模型的技术和行业发展有深刻认知,能够把握大模型发展方向,具有带团队经验优先;
- 诚实守信、作风踏实严详、责任心强,具备良好团队协作能力精神,学习能力强,善干解决复杂问题
llm算法-第四范式
【第四范式】
工作职责
- 负责大模型训练和效果调优
- 超大模型业务场景适配
- 训练方法和模型框架持续优化
任职要求
- 硕士及以上学历,计算机相关专业,熟悉机器学习,深度学习,自然语言处理等领域的专业知识,具有1年以上工作经验
- 熟悉 transformer, bert, gpt, T5等,对训练数据的组织以及训练代码有深入理解
- 熟悉 pytorch / tensorflow 深度学习框架
- 逻辑思维强,编程基础扎实,至少掌握 python 或 C++其中一种:
- 有大模型训练调优经验或熟悉强化学习基本算法优先:
- 做过机器翻译,机器阅读理解,智能摘要、智能问答、智能对话等项目优先;
加分项:
- 发表过顶刊顶会论文者
- 有机器学习竞赛获奖经历(如kaggle金牌,天池、DF、DC等比赛平台top1)、有过ACM等编程竞赛区域金以上经历
- 有开源项目贡献经历。
【2023-6-8】
第四范式算法岗的一面全部是写代码,连自我介绍都没有
遇到的问题有:
- 快速幂(easy)扩展问题:python如何处理数据溢出?
- 一个数组,如果前面的数大于后面的数的二倍,则记作一个翻转对,求翻转对的个数(hard)其实是逆序对的变种,实现归并之后稍微改改就行。
- 用pytorch实现单头self-attention(mid+)
- self-attention的细节和一些扩展理解;
智能客服岗
基本要求
- 对智能对话系统有较多了解,对智能客服行业有热情,能够持续投入钻研
- 计算机相关专业,较好的数学基础,良好的机器学习知识储备,良好的逻辑思维能力
- 2年以上相关工作经验,优秀者可放宽,至少从事过一年以上自然语言处理相关工作
- 熟悉机器学习/深度学习等基础算法,熟悉NLP基础理论及业界常用技术,熟练使用tensorflow/pytorch等深度学习工具
- 良好的LLM知识基础
- 良好的代码编写习惯
具备以下条件优先
- 硕士及以上学历,研究经历与NLP相关
- 在文本分类、文本匹配、对话管理、文本生成等领域有实际开发和从业经验
- 有LLM实际微调和落地经验
- 熟悉前沿对话系统及相关NLP技术
llm算法–创业公司
【AI大模型算法工程师】
岗位职责:
- 熟悉 AI 算法原理或 AI 应用系统;
- 从事 NLP / 多模态相关机器学习 / 深度学习等技术的研究与应用,包括且不限于对话系统、信息抽取、文档摘要、文本生成等;
- 探索自然语言、多模态技术在业务中的落地和创新,并迅速进行转化;
- 研究、实现业界最先进的多语言 NLP / 多模态大模型。
任职要求:
- 有深度学习、对话系统、文本分析、文本生成等实际项目经验,熟悉深度学习在自然语言处理方向的相关算法、框架和工具链 (Pytorch, Huggingface),有生成类任务实际项目经验优先;
- 熟悉 BERT / GPT-3 / Bloom / LLaMa 等 NLP 大模型,有百亿 / 千亿大模型训练调优经验、Prompt 设计经验者优先;
- 具备良好的编程能力,熟练掌握 Python、数据结构和算法设计,熟悉 Linux / Unix 系统和 Shell 编程,熟练使用 Git;
- 计算机、自然语言处理、人工智能、机器学习等相关专业硕士及以上学历;
- 至少 2 年以上自然语言处理相关经验,熟悉自然语言处理、机器学习、深度学习、强化学习等相关算法,对自然语言处理方向有较深和全面的认识。
加分项:
- 有分布式集群,单机多卡,多机多卡 NLP 大模型预训练,微调及推理经验者优先;
- 具备英文专业文献阅读能力,能自觉跟踪发展现状,理解算法原理,并进行落地实现,有 NLP 领域高水平 paper 者优先。
【AI 大模型训练研发工程师】
岗位职责:
- 参与深度学习系统的开发,负责设计、实现以及优化各类分布式训练技术;
- 参与各类社区项目(比如 PyTorch Lightning, HuggingFace)的集成;
- 维护开源社区,参与社区用户互动以及维护开源项目基础设施。
任职要求:
- 精通 PyTorch,了解 Tensorflow/Caffe 等任意一种深度学习框架,并掌握 DeepSpeed/NVIDIA Megatron/Ray 等分布式训练框架;
- 熟悉 BERT/GPT/Diffusion 等当前热门的 CV/NLP/Audio 模型,有百亿 / 千亿大模型分布式训练经验;
- 了解并行计算、CUDA、网络通信、系统优化、集群硬件架构等 HPC 相关的知识;
- 具备良好的编程能力,熟练掌握 Python,掌握 C++、数据结构和算法设计,熟悉 Linux / Unix 系统和 Shell 编程,熟练使用 Git;
- 至少1年以上的 AI 分布式系统研发相关经验,计算机、人工智能、机器学习等相关专业硕士及以上学历,有丰富相关经历的本科生也可以投递。
加分项:
- 知名开源项目贡献者;
- 了解深度学习编译器;
- 获得过编程竞赛奖项;
- 在顶级会议发表过高质量系统方向的论文。
大模型面试题
详见站内专题:大模型面试题
Python 数据溢出
话题:
- Python 3 中整数的上限是多少?Python 2 呢?
- Numpy 中整数的上限是多少?出现整数溢出该怎么办?
总结
- Python 3 极大地简化了整数的表示,效果可表述为:整数就只有一种整数(int),没有其它类型的整数(long、int8、int64 之类的)
- Numpy 中的整数类型对应于 C 语言的数据类型,每种“整数”有自己的区间,要解决数据溢出问题,需要指定更大的数据类型(dtype)
作者:豌豆花下猫
Python 2,它有两种整数:
- 短整数: 即整数,
int表示,有个内置函数int()。其大小有限,可通过sys.maxint()查看(取决于平台是 32 位还是 64 位) - 长整数: 即大小无限的整数,用
long表示,有个内置函数long()。写法上是在数字后面加大写字母 L 或小写的 l,如 1000L
当一个整数超出短整数范围时,自动采用长整数表示。
- 举例,打印 2**100 ,结果会在末尾加字母 L 表示它是长整数。
但是Python 3,情况就不同了:
- 仅有一种内置整数,表示为
int,形式上是 Python 2 的短整数,但实际上它能表示的范围无限,行为上更像是长整数。无论多大的数,结尾都不需要字母 L 来作区分。 - Python 3 整合了两种整数表示法,用户不再需要自行区分,全交给底层按需处理。
- 理论上,Python 3 中的整数没有上限(只要不超出内存空间)。
两组数字相乘时没有溢出:1000074549、10001213264,其它数据组都溢出了,所以出现奇怪的负数结果。
这就解释了前文中直接打印两数相乘,为什么结果会正确了。
Numpy 中整数的上限是多少?
由于 C 语言实现,在整数表示上,用的是 C 语言规则,会区分整数和长整数。
import numpy as np
a = np.arange(2)
type(a[0]) # 结果:numpy.int32
如何解决溢出?
import numpy as np
q = [100000]
w = [500000]
# 一个溢出的例子:
a = np.array(q)
b = np.array(w)
print(a*b) # 产生溢出,结果是个奇怪的数值
# 解决方法:声明dtype
c = np.array(q, dtype='int64')
d = np.array(w, dtype='int64')
print(c*d) # 没有溢出:[50000000000]
数学问题
斐波那契
求斐波那契数列:
- n<=2, Fn = 1
- n>2, Fn = Fn-1 + Fn-2
快速幂
快速幂(Exponentiation by squaring,平方求幂)是一种简单而有效的小算法,可以以 o(logn) 的时间复杂度计算乘方。
- 快速幂不仅本身非常常见,而且后续很多算法也都会用到快速幂。
问题:7的10次方,怎样算比较快?
- 方法1:最朴素的想法,77=49,497=343,… 一步一步算,共进行了9次乘法。
- 这样算无疑太慢了,尤其对计算机的CPU而言,每次运算只乘上一个个位数,无疑太屈才了。
- 这时也许可以拆分问题。
- 方法2:先算7的5次方,即 77777 ,再算它的平方,共进行了5次乘法。
- 但这并不是最优解,因为对于“7的5次方”,我们仍然可以拆分问题。
- 方法3:先算 77 得49,则7的5次方为4949*7,再算它的平方,共进行了4次乘法。
- 模仿这样的过程,得到一个在 O(logn) 时间内计算出幂的算法,也就是
快速幂。
- 模仿这样的过程,得到一个在 O(logn) 时间内计算出幂的算法,也就是
递归解法
方法三是一个二分思路。
- 计算a的n次方,如果n是偶数(不为0),那么就先计算a的n/2次方,然后平方;如果n是奇数,那么就先计算a的n-1次方,再乘上a;递归出口是a的0次方为1。
很自然地可以得到一个递归方程:
- n=0, a^n = 1
- n=odd(奇数), a^n = a*a^(n-1)
- n=even(偶数但非0), a^n = a^(n/1) * a^(n/1)
//递归快速幂
int qpow(int a, int n)
{
if (n == 0)
return 1;
else if (n % 2 == 1)
return qpow(a, n - 1) * a;
else
{
int temp = qpow(a, n / 2);
return temp * temp;
}
}
非递归解法
非递归的快速幂。
- 还是7的10次方,这次把10写成二进制的形式,也就是 1010

最初ans为1,然后一位一位算:
- 1010的最后一位是0,所以a^1这一位不要。然后1010变为101,a变为a^2。
- 101的最后一位是1,所以a^2这一位是需要的,乘入ans。101变为10,a再自乘。
- 10的最后一位是0,跳过,右移,自乘。
- 然后1的最后一位是1,ans再乘上a^8。循环结束,返回结果。
//非递归快速幂
int qpow(int a, int n){
int ans = 1;
while(n){
if(n&1) //如果n的当前末位为1
ans *= a; //ans乘上当前的a
a *= a; //a自乘
n >>= 1; //n往右移一位
}
return ans;
}
类型扩展
上面所述的都是整数的快速幂,但算 a^n 时,只要a的数据类型支持乘法且满足结合律,快速幂的算法都是有效的。矩阵、高精度整数,都可以照搬这个思路。
- 复杂类型的快速幂时间复杂度不再是简单的 O(logn) ,它与底数的乘法的时间复杂度有关。
//泛型的非递归快速幂
template <typename T>
T qpow(T a, ll n)
{
T ans = 1; // 赋值为乘法单位元,可能要根据构造函数修改
while (n)
{
if (n & 1)
ans = ans * a; // 这里就最好别用自乘了,不然重载完*还要重载*=,有点麻烦。
n >>= 1;
a = a * a;
}
return ans;
}
矩阵幂
矩阵快速幂的一个经典应用是求斐波那契数列,把原来较为复杂的问题转化成了求某个矩阵的幂的问题,详见原文
走迷宫
N * N 的棋盘迷宫,从左下角到右上角有几种走法?
- 排列组合:
跳台阶
有十五级台阶,每次最多跳三下,需要跳多少次能跳完
扑克牌
有一百张牌,每张牌有一个数字,依次翻牌看牌后面的数字,用什么样的策略能保证拿到的牌是最大的
赛马问题
待定
最优停止理论
序列决策问题,如找工作、租房子
- 100套房子,看多少个时做决策更好?
- 找对象,谈第几个BF/GF时,可以决定是否要结婚?
找伴侣在计算机领域是一个典型的优化问题:最佳停止问题(optimal stopping)。
- 最佳停止问题场景:有一系列的可能选择的目标,可以一个一个地检验,记住特点和优劣、打分。但是看过了就不能回头了。(序列决策)
什么是最优停止理论
问题:你在什么时候做决定,是最佳的选择呢?
这个最佳选择有一个答案:37%。所有的可能的选择中
- 前面37%不要选,用来积累数据,建立对选择对象质量的评估标准,知道什么是好的,什么是不好的。
- 从第38%位对象开始,转变成开放的可以做决定的状态。这时候,如果遇到比前面看到的都更好的选项,就可以做出选择。
总结
一个由时间或者数量组成的序列当中,以37%作为分界线
- 在经历前37%的时间或者候选的时候,先不要做决定,记住那个最好的,这个期间称为观察期;
- 37%以后,如果遇到比前面更好的,就要毫不犹豫下决定,选择那个最好的。
古希腊哲学大师苏格拉底的3个弟子曾求教老师,怎样才能找到理想的伴侣。
苏格拉底带领弟子们来到一片麦田,让他们每人在麦田中选摘一支最大的麦穗,并且要求不能走回头路,且只能摘一支。三个弟子分别做出了不同的举动。
- 第一个弟子刚刚走了几步, 便迫不及待地摘了一支自认为是最大的麦穗,结果发现后面的大麦穗多的是;
- 第二位一直左顾右盼,东瞧西望,直到终点才发现,前面最大的麦穗已经错过了;
- 第三位弟子把麦田分为三份,走第一个1/3时,只看不摘,分出大、中、小三类麦穗,在第二个1/3里验证是否正确,在第三个1/3里选择了麦穗中最大最美丽的一支,这就是所谓的
麦穗理论。
为什么第三位弟子能够获得比较满意的结果呢?
- 因为他在选择过程中采用了一定的策略,即将决策过程分为两段:
- 前2/3的路程用于确定“最基本的满意标准”,最后1/3选择满足“最基本的满意标准”的第一个方案。
- 这里的两段可以是把全部可选方案在数量上分成两段来考察,也可以是把选择时间分成两段。
麦穗理论实际上要解决的是一种“最优停止问题”。这种问题一般有两个特点:
- 并不清楚会遇到什么样的可选方案,只有看过了才知道,即未来不可知,但一个可选方案一旦被错过了不能再回头去选,即不能反悔。
理论原理
Merrill M. Flood在1949年首次提出37%法则。
- 37%法则选到的并不一定是最优方案,而是接近于最优的满意方案。
验证代码:
#include<iostream>
#include<stdio.h>
#define oo 1e9+7
using namespace std;
int main(){
freopen("test.txt","w",stdout);
for(int i=1;i<=10000;i++){
double maxp=0,temp=0;
int maxr=1;
for(int j=1;j<i;j++)temp+=1.0/j;
for(int j=1;j<=i;j++){
double pj=1.0*j/i;
pj*=temp;
if(pj>maxp){
maxp=pj;
maxr=j;
}
temp-=1.0/j;
}
cout<<i<<" "<<maxr<<" "<<1.0*maxr/i<<" "<<maxp<<endl;
}
fclose(stdout);
return 0;
}
生活案例
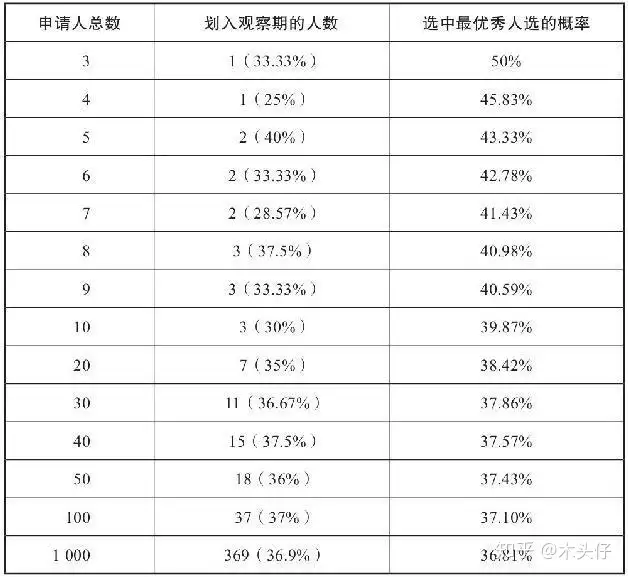
生活中其实很多事情都是类似的问题,麦穗理论里的找到理想伴侣、买房子、换工作等等。
面试招聘中,如果想要录取到最优秀的申请者,在不同面试申请者数目下,录取到最优秀的申请者的概率是怎么变化的呢?
- 如果有1名面试者,直接录取,理想结果概率是100%;
- 如果有2名面试者,任意录取,理想结果概率是50%;
- 如果有3名面试者,随机选择得到理想结果的概率是33%。
实际上,可以通过策略获得比33%更好的结果,关键在于对第2位申请者的处理上。因为对于第1位的位置,能够知道第1位的信息,如果第2位比第1位更好,那就毫不犹豫录取第二位,反之则拒绝,因为后面还有第三位。在这种情况下,选中最优秀人选的概率恰恰是37%。
找餐厅可以做类比
- 如果798园区有10家餐吧,那么前面4家(接近37%),看看而不要进去。从第5家开始,只要看着比前面的都好,就进去吃午饭吧,这可能就是最优选择。
找伴侣的例子也一样。
- 假设你在18岁到36岁之间,每年可以交一个异性朋友,那么可能一共就有18个人可以交往。
- 这种情况下,对前面7个人(接近37%),你只需要交往一下,了解一下异性,看看交朋友是怎么回事。
-
第7个人之后,也就是25岁时,转变策略,再碰到一个合适的就要抓住时机定终身,进入人生下一个阶段。
- 单身狗速进!如何科学有效地脱单?
最优停止问题或37%法则,先谈37%*N次恋爱,再看后来者是否比前面优秀,据此决定是否结婚- 应用前提:单向性,一次一个,只能选择一次,无法回头,如招聘(秘书问题)、租房、谈恋爱等情形
- 李永乐老师和西瓜妹现场解析:什么是爱情?如何寻找真命天子?
这个最佳停止的问题和答案,被誉为优化算法里最完美的算法之一。它的问题简单易懂,使用场景很多,答案也很清晰。最佳停止问题和答案在20世纪60年代被提出来后,广泛应用于统计学、经济学、计算机科学、金融学等领域。
如果你仔细思考,它可以对我们人生中做的决定产生深远的影响,因为在我们的生活当中有特别多的问题是“你什么时候停止观望,做出选择”。
等概率抽样
- 空间亚线性算法:由于大数据算法中涉及到的数据是海量的,数据难以放入内存计算,所以一种常用的处理办法是不对全部数据进行计算,而只向内存里放入小部分数据,仅使用内存中的小部分数据,就可以得到一个有质量保证的结果。
- 数据流算法:是指数据源源不断地到来,根据到来的数据返回相应的部分结果。适用于两种情况:
- 第一、数据量非常大仅能扫描一次时,可以把数据看成数据流,把扫描看成数据到来。
- 第二、数据更新非常快,不能把所有数据都保存下来再计算结果,此时可以把数据看成是一个数据流。 在一些情况下,空间亚线性算法也叫数据流算法。
任意分布函数拟合(反采样/逆采样)
用均匀分布拟合任意分布,用于随机数生成
逆采样(Inverse Sampling)和拒绝采样(Reject Sampling)原理详解
- 通过F的反函数将一个0到1均匀分布的随机数转换成了符合exp分布的随机数,注意,以上推导对于CDF可逆的分布都是一样的
被父母打的概率
【2022-5-10】知乎,考试砸了回到家,母亲打我的概率是 1/2,父亲打我的概率也是 1/2,那我被打的概率是多少?
被打的概率P主要取决于你爸妈行为之间的相关性ρ(注意P和ρ是两个不同字母)先看三种比较特殊ρ值的情况。
- (1)假设ρ=0,也即你爸是否打你和你妈是否打你两个随机变量之间完全相互独立,那么你被打的概率等于1减去你不被打的概率,也即1-1/2*1/2 = 3/4,也即75%。
- (2)假设ρ=1,也即你爸妈的行为完全相关,也就是完全趋同。如果其中一个打你,另外一个也会一起打你。如果其中一个放过你,另外一个也放过你。那么你被打的概率是 1/2,也即50%。
- (3)假设ρ=-1,也即假设你爸妈的行为完全负相关,也就是完全反着来。如果其中一个打你,另外一个选择放过你。如果其中一个选择放过你,另外一个就一定打你。那么很遗憾,你被打的概率是1,也即100%。
假设ρ取[-1 ,1]区间的其它值,就需要有P关于ρ的表达式,推理稍微有些复杂。但由于概率P和相关性ρ之间的线性关系(严格来说需要证明),而且根据上面三种特殊情况,已经明确的知道了直线上三个特殊点的坐标分别为(0 , 0.75)、(1 , 0.5)、(-1 , 1)。通过其中任意两点可以推出P关于ρ的线性关系式为:
- P = 0.75 - 0.25ρ 。 可见概率P的取值范围是[0.5 , 1]区间。整体趋势而言是你爸妈的行为越趋同,你被打的概率越低。行为越趋反,你挨打的概率越高。所以我的建议是,如果你爸妈平时感情很好总是夫唱妇随的话,你勇敢进家门就好了,好歹有约一半的概率不被打(当然也有约一半的概率遭遇男女混合双打)。如果他俩喜欢唱反调,或者总是喜欢红脸黑脸地演戏,你看下今晚能不能去爷爷奶奶家或者同学家借住一宿。
严格解答:
设随机变量则
。设你会挨打的概率是
, 则
因此
. 设
为
的相关系数,则我们有
由 可知
.
结论:父母行动越一致,你被打的概率越低。
- 如果父母喜欢同时行动,那么你只有
几率会被打;
- 如果两人行动完全不相关,此时两人的行动恰好也是独立的(由联合分布律可知),挨打几率为
;
- 如果两人喜欢对着干,相关系数为
,那你就惨了,
被打。
注意被打并不代表一定会被打。举个例子,从
上取点,父亲在小于
时打你,母亲在大于
时打你,此时
,你虽然不被打几率是
,但仍可能发生。实际上此时有
,而必定被打指的是
。
最后注意如果父母打你几率不正好都是 ,相关系数
一般不能取满
。
机器学习
参考
特征工程
- 离散、连续特征一般怎么处理(onehot、归一化、why、方法 等);
- 特征变换、构造/衍生新特征(woe、iv、统计量 等);
- 特征筛选(离散、连续、多重共线性 等);
- 采样(除了随机呢?);
- 缺失值处理(离散、连续)… 算法模型
- 常用loss、正则、sgd、l-bfgs、auc公式及优缺点、数据不平衡时的调参…
- booting:gbdt的loss、分裂节点依据、防过拟合;
- xgb的loss选择、泰勒展开、正则(gbdt能加么)、并行、vs lightGBM;
- lambdaMart的loss–如何直接优化metric(如NDCG)–学习/train过程;
- svm的优化目标、软间隔、调参;
- lr;rf;
深度学习
- dnn为什么要“deep”、deep后带来的信息传递/梯度传递问题及其优化策略(可以从网络结构、activation、normalization等方面阐述);
- 卷积层学习过程(前后向)及参数数量估计;
- polling作用、优缺点、why用的越来越少;
- rnn长依赖问题、梯度问题;
- lstm的input output forget gate作用于哪、gru的update gate呢?
- 常用loss(分类、回归)、activation、optimizer(从一阶矩估计到二阶)、加了BN后做predict均值方差从哪来、常用的attention举例
强化学习
- 什么问题适合RL/MLE的缺陷、trail-and-error search、policy-based vs value-based、on-policy vs off-policy等
- q learning中q值得更新(其实很好记:当前q值 += 学习率(环境reward+ 新状态下最大的q值衰减值)、为什么要乘衰减值);
- DQN使用network代替q_table的初衷(q表规模大时维护成本高)、两个network(结构一致、参数交替更新)、存储记忆 off-policy;(经验回放+固定目标)
- policy gradients如何学习/拟合目标( -log(prob)*vt 像不像交叉熵…)、按概率选action vs epsilon-greedy;
- Actor-Critic中的actor与critic、优缺点、收敛问题、DDPG、
机器学习流程
机器学习流程
- 1 抽象成数学问题
- 明确问题是进行机器学习的第一步。机器学习的训练过程通常都是一件非常耗时的事情,胡乱尝试时间成本是非常高的。
- 这里的抽象成数学问题,指的我们明确我们可以获得什么样的数据,目标是一个分类还是回归或者是聚类的问题,如果都不是的话,如果划归为其中的某类问题。
- 2 获取数据
- 数据决定了机器学习结果的上限,而算法只是尽可能逼近这个上限。
- 数据要有代表性,否则必然会过拟合。
- 而且对于分类问题,数据偏斜不能过于严重,不同类别的数据数量不要有数个数量级的差距。
- 而且还要对数据的量级有一个评估,多少个样本,多少个特征,可以估算出其对内存的消耗程度,判断训练过程中内存是否能够放得下。如果放不下就得考虑改进算法或者使用一些降维的技巧了。如果数据量实在太大,那就要考虑分布式了。
- 3 特征预处理与特征选择
- 良好的数据要能够提取出良好的特征才能真正发挥效力。
- 特征预处理、数据清洗是很关键的步骤,往往能够使得算法的效果和性能得到显著提高。归一化、离散化、因子化、缺失值处理、去除共线性等,数据挖掘过程中很多时间就花在它们上面。这些工作简单可复制,收益稳定可预期,是机器学习的基础必备步骤。
- 筛选出显著特征、摒弃非显著特征,需要机器学习工程师反复理解业务。这对很多结果有决定性的影响。特征选择好了,非常简单的算法也能得出良好、稳定的结果。这需要运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。
- 4 训练模型与调优
- 直到这一步才用到我们上面说的算法进行训练。现在很多算法都能够封装成黑盒供人使用。但是真正考验水平的是调整这些算法的(超)参数,使得结果变得更加优良。这需要我们对算法的原理有深入的理解。理解越深入,就越能发现问题的症结,提出良好的调优方案。
- 5 模型诊断
- 如何确定模型调优的方向与思路呢?这就需要对模型进行诊断的技术。
- 过拟合、欠拟合 判断是模型诊断中至关重要的一步。常见的方法如交叉验证,绘制学习曲线等。过拟合的基本调优思路是增加数据量,降低模型复杂度。欠拟合的基本调优思路是提高特征数量和质量,增加模型复杂度。
- 误差分析 也是机器学习至关重要的步骤。通过观察误差样本,全面分析误差产生误差的原因:是参数的问题还是算法选择的问题,是特征的问题还是数据本身的问题……
- 诊断后的模型需要进行调优,调优后的新模型需要重新进行诊断,这是一个反复迭代不断逼近的过程,需要不断地尝试, 进而达到最优状态。
- 6 模型融合
- 一般来说,模型融合后都能使得效果有一定提升。而且效果很好。
- 工程上,主要提升算法准确度的方法是分别在模型的前端(特征清洗和预处理,不同的采样模式)与后端(模型融合)上下功夫。因为他们比较标准可复制,效果比较稳定。而直接调参的工作不会很多,毕竟大量数据训练起来太慢了,而且效果难以保证。
- 7 上线运行
- 这一部分内容主要跟工程实现的相关性比较大。工程上是结果导向,模型在线上运行的效果直接决定模型的成败。不单纯包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性是否可接受。
- 这些工作流程主要是工程实践上总结出的一些经验。并不是每个项目都包含完整的一个流程。这里的部分只是一个指导性的说明,只有大家自己多实践,多积累项目经验,才会有自己更深刻的认识。
- 故,基于此,七月在线每一期ML算法班都特此增加特征工程、模型调优等相关课。比如,这里有个公开课视频《特征处理与特征选择》。
判别式和生成式
- 判别方法:由数据直接学习决策函数 Y = f(X),或者由条件分布概率 P(Y|X)作为预测模型,即判别模型。
- 常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场
- 生成方法:由数据学习联合概率密度分布函数 P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型。
- 常见的生成模型有:朴素贝叶斯NB、隐马尔可夫模型HMM、高斯混合模型GMM、文档主题生成模型(LDA)、限制玻尔兹曼机RBM
- 由生成模型可以得到判别模型,但由判别模型得不到生成模型。
模型参数 与 超参数
数据集上找到了最适合问题的模型参数。它具有以下几个特征:
- 用于预测新数据
- 显示了使用的模型的能力。通常用准确性来表示,即准确率。
- 直接从训练数据集学习
- 通常不需要人工设置
- 模型参数有多种形式,如神经网络权值、支持向量机中的支持向量、线性回归或逻辑回归算法中的系数。
什么是模型的超参数?
- 模型参数是由训练数据集本身建模的
- 模型超参数 不是。它完全在模型之外,不依赖于训练数据。
它的目的是什么?
- 用于训练过程中,帮助模型找到最合适的参数
- 通常是由模型训练的参与者手工挑选的
- 基于几种启发式策略来定义
模型超参数的例子:
- 训练人工神经网络时的学习率
- 训练支持向量机时的 C 和 sigma参数
- 最近邻模型中的 k系数
学习率
- 模型学习率太低时,模型训练将会进行得非常慢,因为它对权重进行非常小的更新。在到达局部最优点之前需要多次更新。
- 学习率过高,则由于权值更新过大,模型可能会不收敛。有可能在一个更新权值的步骤中,模型跳出了局部优化,使得模型以后很难更新到最优点,而是在在局部优化点附近跳来跳去。
loss曲线
不同学习率、batch size下,loss曲线的变化
- 详见:最优化专题
基本概念:Epoch、Batch 和 Iteration
- Epoch:表示整个数据集的迭代(所有内容都包含在训练模型中)。
- Batch:是指当我们不能一次将整个数据集放到神经网络中时,我们将数据集分割成几批较小的数据集。
- 迭代:是运行 epoch 所需的批数。假设有 10,000 个图像作为数据,批处理的大小(batch_size)为 200。然后一个 epoch 将包含 50 个迭代(10,000 除以 200)。
BP 反向传播工作原理
- 前向过程(前向计算)是一个帮助模型计算每一层权重的过程,其结果计算将产生一个yp结果。此时将计算损失函数的值,损失函数的值将显示模型的好坏。如果损失函数不够好,我们需要找到一种方法来降低损失函数的值。训练神经网络本质上是最小化损失函数。损失函数 L(yp,yt)表示yp模型的输出值与yt数据标签的实际值的差别程度。
- 为了降低损失函数的值,使用导数。反向传播帮助计算网络每一层的导数。根据每个层上的导数值,优化器(Adam、SGD、AdaDelta…)应用梯度下降更新网络的权重。
- 反向传播使用链式规则或导数函数计算每一层从最后一层到第一层的梯度值。
激活函数
激活函数的意义
- 激活函数的产生是为了打破神经网络的线性特性。这些函数可以简单地理解为用一个滤波器来决定信息是否通过神经元。
- 在神经网络训练中,激活函数在调节导数斜率中起着重要的作用。一些激活函数,如 sigmoid、fishy 或 ReLU。
这些非线性函数的性质使得神经网络能够学习比仅仅使用线性函数更复杂的函数的表示。大多数激活函数是连续可微函数。
- 如果输入的变量很小且可微(在其定义域内的每一点都有导数),那么输出就会有一个小的变化。
当然,导数的计算是非常重要的,它是决定我们的神经元能否被训练的决定性因素。
常用的激活函数,如 Sigmoid, Softmax, ReLU。
激活函数的饱和区间
- Tanh、Sigmoid、ReLU 等非线性激活函数都有饱和区间。
- 触发函数的饱和范围是指即使输入值改变,函数的输出值也不改变的区间。
变化区间存在两个问题
- 在正向传播中,该层的数值逐渐落入激活函数的饱和区间,将逐渐出现多个相同的输出。这将在整个模型中产生相同的数据流。这种现象就是协方差移位现象。
- 在反向传播中,导数在饱和区域为零,因此网络几乎什么都学不到。这就是将值范围设置为均值为 0 的原因,如 Batch 归一化一节中所述。
bias 和 Variance 之间的权衡关系
什么是bias?
- bias是当前模型的平均预测与实际结果之间的差异。
- 一个高 bias 的模型表明它对训练数据的关注较少。这使得模型过于简单,在训练和测试中都没有达到很好的准确性。这种现象也被称为欠拟合。
什么是方差?
- Variance 可以简单理解为模型输出在一个数据点上的分布。
- Variance 越大,模型越有可能密切关注训练数据,而不提供从未遇到过的数据的泛化。
- 因此,该模型在训练数据集上取得了非常好的结果,但是与测试数据集相比,结果非常差,这就是过拟合的现象。
偏差与方差关系
- E = V + B^2 + ε
复杂模型有大量的参数,会有高方差和低偏差。
过拟合
正则化是针对过拟合而提出的,以为在求解模型最优的是一般优化最小的经验风险,现在在该经验风险上加入模型复杂度这一项(正则化项是模型参数向量的范数),并使用一个rate比率来权衡模型复杂度与以往经验风险的权重,如果模型复杂度越高,结构化的经验风险会越大,现在的目标就变为了结构经验风险的最优化,可以防止模型训练过度复杂,有效的降低过拟合的风险。
奥卡姆剃刀原理,能够很好的解释已知数据并且十分简单才是最好的模型。 L1和L2正则先验分别服从什么分布,L1是拉普拉斯分布,L2是高斯分布。
L1和L2区别
- L1范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。
- 比如 向量A=[ 1,-1,3 ], 那么A的L1范数为 |1|+|-1|+|3|.
- 简单总结一下就是:
- L1范数: 为x向量各个元素绝对值之和。
- L2范数: 为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或Frobenius范数
- Lp范数: 为x向量各个元素绝对值p次方和的1/p次方.
- 在支持向量机学习过程中,L1范数实际是一种对于成本函数求解最优的过程,因此,L1范数正则化通过向成本函数中添加L1范数,使得学习得到的结果满足稀疏化,从而方便人类提取特征。
- L1范数可以使权值稀疏,方便特征提取。
- L2范数可以防止过拟合,提升模型的泛化能力。
为什么要做归一化
不是所有模型都需要归一化:概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、RF。而像Adaboost、GBDT、XGBoost、SVM、LR、KNN、KMeans之类的最优化问题就需要归一化。
梯度下降
梯度下降法并不是下降最快的方向,它只是目标函数在当前的点的切平面(当然高维问题不能叫平面)上下降最快的方向。在Practical Implementation中,牛顿方向(考虑海森矩阵)才一般被认为是下降最快的方向,可以达到Superlinear的收敛速度。梯度下降类的算法的收敛速度一般是Linear甚至Sublinear的(在某些带复杂约束的问题)。
为什么不用牛顿法?
- 计算量大,目标函数的二阶导数(Hessian Matrix)
- 小批量情形下,牛顿法对二阶导的估计噪音太大
- 目标函数非凸时,牛顿法容易受鞍点/极值点影响
梯度消失/弥散
- (1)梯度消失:
- 根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都小于1的话,那么即使这个结果是0.99,在经过足够多层传播之后,误差对输入层的偏导会趋于0。
- 可以采用ReLU激活函数有效的解决梯度消失的情况。
- 为什么会有梯度消失?
- 神经网络的训练中,通过改变神经元的权重,使网络的输出值尽可能逼近标签以降低误差值,训练普遍使用BP算法,核心思想是,计算出输出与标签间的损失函数值,然后计算其相对于每个神经元的梯度,进行权值的迭代。
- 梯度消失会造成权值更新缓慢,模型训练难度增加。造成梯度消失的一个原因是,许多激活函数将输出值挤压在很小的区间内,在激活函数两端较大范围的定义域内梯度为0,造成学习停止。
- 反向传播中链式法则带来的连乘,如果有数很小趋于0,结果就会特别小(梯度消失);如果数都比较大,可能结果会很大(梯度爆炸)。
- (2)梯度膨胀:
- 根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都大于1的话,在经过足够多层传播之后,误差对输入层的偏导会趋于无穷大。
LSTM为什么优于RNN
- 推导forget gate,input gate,cell state, hidden information等的变化;因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸。
知识点链接:一文清晰讲解机器学习中梯度下降算法(包括其变式算法)
batch normalization 的意义
Batch Normalization 是训练神经网络模型的一种有效方法。
该方法的目标是将特征(每层激活后的输出)归一化为均值为 0,标准差为 1。
所以问题在于非零均值是如何影响模型训练的:
- 首先,非零均值是指数据不围绕 0 值分布,但数据中大多数值大于零或小于零。结合高方差问题,数据变得非常大或非常小。这个问题在训练层数很多的神经网络时很常见。特征没有在稳定区间内分布(由小到大),这将影响网络的优化过程。众所周知,优化神经网络需要使用导数计算。假设一个简单的层计算公式是 y = (Wx + b), y 对 w 的导数是: dy = dWx。因此,x 的取值直接影响导数的取值(当然,神经网络模型中梯度的概念并不是那么简单,但从理论上讲,x 会影响导数)。因此,如果 x 带来不稳定的变化,其导数可能太大,也可能太小,导致学习模型不稳定。当使用 Batch Normalization 时可以在训练中使用更高的学习率。
- Batch Normalization 可以避免 x 值经过非线性激活函数后趋于饱和的现象。因此,它确保激活值不会过高或过低。这有助于权重的学习,当不使用时有些权重可能永远无法进行学习,而用了之后,基本上都可以学习到。这有助于我们减少对参数初始值的依赖。
- Batch Normalization 也是一种正则化形式,有助于最小化过拟合。使用 Batch Normalization,不需要使用太多的 dropout,这是有意义的,因为不需要担心丢失太多的信息,实际使用时,仍然建议结合使用这两种技术。
不均衡数据集
常见方法
- 选择正确的度量来评估模型:对于不平衡的数据集,使用准确率来评估非常危险。应选择精度、召回、F1 分数、AUC等合适的评价量。
- 重新采样训练数据集:除了使用不同的评估标准,人们还可以使用一些技术来获得不同的数据集。从一个不平衡的数据集中创建一个平衡的数据集有两种方法,即欠采样和过采样,具体技术包括重复、bootstrapping 或 hits(综合少数过采样技术)等方法。
- 许多不同模型的集成:通过创建更多的数据来概括模型在实践中并不总是可行的。例如,你有两个层,一个拥有 1000 个数据的罕见类,一个包含 10,000 个数据样本的大型类。因此,我们可以考虑一个 10 个模型的训练解决方案,而不是试图从一个罕见的类中找到 9000 个数据样本来进行模型训练。每个模型由 1000 个稀有类和 1000 个大规模类训练而成。然后使用集成技术获得最佳结果。
- 重新设计模型—损失函数:使用惩罚技术对代价函数中的多数类进行严厉惩罚,帮助模型本身更好地学习稀有类的数据。这使得损失函数的值在类中更全面。
LR
把LR从头到脚都给讲一遍。建模,现场数学推导,每种解法的原理,正则化,LR和maxent模型啥关系,LR为啥比线性回归好。有不少会背答案的人,问逻辑细节就糊涂了。原理都会? 那就问工程,并行化怎么做,有几种并行化方式,读过哪些开源的实现。还会,那就准备收了吧,顺便逼问LR模型发展历史
- 逻辑回归和线性回归首先都是广义线性回归
- 其次经典线性模型的优化目标函数是最小二乘,而逻辑回归则是似然函数,
- 另外线性回归在整个实数域范围内进行预测,敏感度一致,而分类范围,需要在[0,1]。逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,因而对于这类问题来说,逻辑回归的鲁棒性比线性回归的要好。
SVM
SVM,全称是support vector machine,中文名叫支持向量机。SVM是一个面向数据的分类算法,它的目标是为确定一个分类超平面,从而将不同的数据分隔开。
扩展:支持向量机学习方法包括构建由简至繁的模型:线性可分支持向量机、(近似)线性支持向量机及非线性支持向量机。
- 当训练数据线性可分时,通过硬间隔最大化,学习一个线性的分类器,即线性可分支持向量机,又称为硬间隔支持向量机;
- 当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性的分类器,即线性支持向量机,又称为软间隔支持向量机;
- 当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
LR与SVM区别
联系:
- 1、LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
- 2、两个方法都可以增加不同的正则化项,如L1、L2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
- 1、LR是参数模型,SVM是非参数模型。
- 2、从目标函数来看,区别在于逻辑回归采用的是Logistical Loss,SVM采用的是hinge loss.这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
- 3、SVM的处理方法是只考虑Support Vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
- 4、逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
- 5、Logic 能做的 SVM能做,但可能在准确率上有问题,SVM能做的Logic有的做不了。
资料
xgb
为什么xgb用泰勒展开
- XGBoost使用了一阶和二阶偏导, 二阶导数有利于梯度下降的更快更准. 使用泰勒展开取得二阶倒数形式, 可以在不选定损失函数具体形式的情况下用于算法优化分析.本质上也就把损失函数的选取和模型算法优化/参数选择分开了. 这种去耦合增加了XGBoost的适用性。
xgb如何寻找最优特征
- XGBoost在训练的过程中给出各个特征的评分,从而表明每个特征对模型训练的重要性.。XGBoost利用梯度优化模型算法, 样本是不放回的(想象一个样本连续重复抽出,梯度来回踏步会不会高兴)。但XGBoost支持子采样, 也就是每轮计算可以不使用全部样本。
xgb和gbdt区别
- XGBoost类似于GBDT的优化版,不论是精度还是效率上都有了提升。 与GBDT相比,具体的优点有:
- 损失函数是用泰勒展式二项逼近,而不是像GBDT里的就是一阶导数;
- 对树的结构进行了正则化约束,防止模型过度复杂,降低了过拟合的可能性;
- 节点分裂的方式不同,GBDT是用的基尼系数,XGBoost是经过优化推导后的。
- 特征选择:借鉴RF,可并行
CRF与HMM
哪个不属于CRF模型对于HMM和MEMM模型的优势( )
- A. 特征灵活
- B. 速度快
- C. 可容纳较多上下文信息
- D. 全局最优
解答:
- 首先,CRF,HMM(隐马模型),MEMM(最大熵隐马模型)都常用来做序列标注的建模。
- 隐马模型一个最大的缺点就是由于其输出独立性假设,导致其不能考虑上下文的特征,限制了特征的选择。
- 最大熵隐马模型则解决了隐马的问题,可以任意选择特征,但由于其在每一节点都要进行归一化,所以只能找到局部的最优值,同时也带来了标记偏见的问题,即凡是训练语料中未出现的情况全都忽略掉。
- 条件随机场则很好的解决了这一问题,他并不在每一个节点进行归一化,而是所有特征进行全局归一化,因此可以求得全局的最优值。
CNN:图像尺寸增加1倍,参数数量增加多少
CNN 模型的参数数量取决于滤波器的数量和大小,而不是输入图像。因此,将图像的大小加倍并不会改变模型的参数数量。
计算机基础考题
hash冲突:关键字值不同的元素可能会映象到哈希表的同一地址上就会发生哈希冲突。解决办法:
- 1)开放定址法:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探查到开放的 地址则表明表中无待查的关键字,即查找失败。
- 2)再哈希法:同时构造多个不同的哈希函数。
- 3)链地址法:将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
- 4)建立公共溢出区:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
应用考题
几种类型:
- 纯leetcode题目:无背景信息,无需过多介绍,目标明确,但题目有一定随机性,容易让候选人发懵
- 背景相关题目:包含领域(如NLP)背景,根据候选简历信息而定
过程:题目从易到难,逐级提升,直至不会
- 易:具备编程基础就能写出来 → 看编程熟悉程度,代码风格,异常条件
- 中:性能提升,引入基础数据结构知识
- 难:知识点深入扩展(横向、纵向)
ML:嫌疑犯侦测
- 题目:设计一套机器学习系统,通过身份证信息+神态识别火车站里的嫌疑犯
- 数据:只有1000个样本,其中10个正例,990个负例。
- 知识点:抽样、不平衡、过拟合、评估指标(召回+准确+精确+F1)
机器学习系统设计:
- 数据处理:采集、缺失值、异常值
- 训练集、验证集、测试集划分
- 特征工程:正负样本不平衡、特征变换(连续、离散)
- 样本不平衡:欠采样(删除→SMOTE)、过采样(复制→easy ensamble)
- 特征变换
- 模型:分类还是回归?还是异常检测?(i-forest,3倍标准差)
- 过拟合、欠拟合,如何解决
- 如何调参?线搜索、网格搜索、贝叶斯优化、学习率。。。
- 时间不够,如何快速迭代
- 预测:模型如何加载?分布式情形?
- 评估:重精确还是召回?
- 离线:k-fold交叉验证,F1,精确召回(表达式),AUC、ROC
- 在线:小流量灰度实验、ab-test或inter-leaving
- 服务部署:如何形成闭环?系统监控、字段监控、数据上云
- 其它:产品策略不当、排期紧张怎么办?多人如何协作分配?
注意:
不要迷信刷题!要从题目中找知识体系的漏洞
ML:LR回归
考察机器人基本流程熟悉程度:
- 数据准备:训练集、测试集、验证集
- 评估指标:分类、回归
- 模型定义:网络结构,用sklearn、pytorch、TensorFlow实现
- 优化器:adam
- 训练
- 推断
ML:优化算法——训练曲线
模型训练环节,损失函数出现不同情形,如何快速定位?
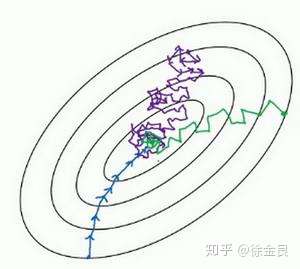
- 知识点
- 学习率:学习率越大,波动越剧烈,学习率越小,波动越平缓。
- 过拟合
- batch size:batchsize越小,波动越剧烈,batchsize越大,波动越平缓。
- 梯度下降算法:梯度就是曲线的斜率,如果要最小化目标函数,反向传播过程中,每个参数在梯度方向上减小一定幅度,最终网络收敛到一个局部最优值,减小的幅度大小由学习率决定。
训练的时候 loss 不下降
- 模型结构问题。当模型结构不好、规模小时,模型对数据的拟合能力不足。
- 训练时间问题。不同的模型有不同的计算量,当需要的计算量很大时,耗时也会很大
- 权重初始化问题。常用的初始化方案有全零初始化、正态分布初始化和均匀分布初始化等,合适的初始化方案很重要,之前提到过神经网络初始化为0可能会带来的影响
- 正则化问题。L1、L2以及Dropout是为了防止过拟合的,当训练集loss下不来时,就要考虑一下是不是正则化过度,导致模型欠拟合了。正则化相关可参考正则化之L1 & L2
- 激活函数问题。全连接层多用ReLu,神经网络的输出层会使用sigmoid 或者 softmax。激活函数可参考常用的几个激活函数。在使用Relu激活函数时,当每一个神经元的输入为负时,会使得该神经元输出恒为0,导致失活,由于此时梯度为0,无法恢复。
- 优化器问题。优化器一般选取Adam,但是当Adam难以训练时,需要使用如SGD之类的其他优化器。常用优化器可参考机器学习中常用的优化器有哪些?
- 学习率问题。学习率决定了网络的训练速度,但学习率不是越大越好,当网络趋近于收敛时应该选择较小的学习率来保证找到更好的最优点。所以,我们需要手动调整学习率,首先选择一个合适的初始学习率,当训练不动之后,稍微降低学习率。
- 梯度消失和爆炸。这时需要考虑激活函数是否合理,网络深度是否合理,可以通过调节sigmoid -> relu,假如残差网络等,相关可参考为什么神经网络会有梯度消失和梯度爆炸问题?如何解决?
- batch size问题。过小,会导致模型损失波动大,难以收敛,过大时,模型前期由于梯度的平均,导致收敛速度过慢。
- 数据集问题。
- (1)数据集未打乱,可能会导致网络在学习过程中产生一定的偏见
- (2)噪声过多、标注有大量错误时,会导致神经网络难以学到有用的信息,从而出现摇摆不定的情况,噪声、缺失值、异常值
- (3)数据类别不均衡使得少数类别由于信息量不足,难以学到本质特征,样本不均衡相关可以看样本不均衡及其解决办法。
- 特征问题。特征选择不合理,会使网络学习难度增加。之前有提到过特征选择的文章,如何找到有意义的组合特征,特征选择方法
2 测试的时候 loss 不下降
- 训练的时候过拟合导致效果不好
- 交叉检验,通过交叉检验得到较优的模型参数;
- 特征选择,减少特征数或使用较少的特征组合,对于按区间离散化的特征,增大划分的区间;
- 正则化,常用的有 L1、L2 正则。而且 L1正则还可以自动进行特征选择;
- 如果有正则项则可以考虑增大正则项参数;
- 增加训练数据可以有限的避免过拟合;
- Bagging ,将多个弱学习器Bagging 一下效果会好很多,比如随机森林等.
- 早停策略。本质上是交叉验证策略,选择合适的训练次数,避免训练的网络过度拟合训练数据。
- DropOut策略。
- 应用场景不同导致。本来训练任务是分类猫和狗,测试用的皮卡丘和葫芦娃。
- 噪声问题。训练数据大概率都是经过去噪处理的,而真实测试时也应该去除噪声。
ML:P/R指标——如何评估分类效果
分类问题中,直接使用精度precision指标衡量模型效果,不一定管用,比如:对于不平衡的数据问题
- 网络攻击的预测模型 (假设攻击请求占请求总数的 1/100000)。全部预测成非攻击请求,精确度高达 99.9%,没有意义
- 改进:
- 混淆矩阵
- ROC曲线
- 理想的 ROC 曲线是最接近左上角的橙色线。真阳性比较高,假阳性比较低。
- 混淆矩阵
- 实现precision、recall计算
NLP考题
NLP
- 词法/序列标注相关:hmm、crf、lstm、lstm+crf(细节:对于转移特征、转移概率 hmm crf lstm+crf分别是怎么学的?)
- 句法:有了依存关系 如何确定主谓宾、举几个例子
- word2vector:层次softmax、负采样、 vs GloVe
- topic相关:lsa(可以引到svd、基于mse的fm);lda why引入共轭先验分布、调参(针对两个先验);
- +DL:cnn filter的设计、seq2seq+attention的padding问题(对padding的字符如何做attention、如何忽略、用tensorflow/pytorch大致写一下)、tree lstm
- 任务相关:beam search做生成、dialog中对回复做lable smooth 提高回复多样性…
NLP:词频统计
- 题目:统计简历里的Top 5关键词
- 数据:简历文件cv.txt(或者两会专题新闻)
- 思路:逐行读入,分词,用一个字典存储频次,排序,输出top 5。
- 性能:时间复杂度O(N)+O(nlogn),空间复杂度n——N是所有单词数,n是去重后的单词数
- 改进:
- 时间复杂度优化:能不能更快?
- 排序环节:只需top5,排序时不用计算所有频次,堆排序(小根堆) + 单向冒泡
- 空间复杂度优化:
- 读取环节:非得遍历完整个文件?牺牲准确率(类似bloom filter),分布式,随机抽样,水库抽样(等概率流式采样),逆采样和拒绝采样
- 时间复杂度优化:能不能更快?
- 发散:
- 预计会是什么样的词?(业务敏感度 + NLP功底)—— 标点符号、停用词,高频词,需要加tf-idf权重
- 如何挑关键词?分词、词性标注、相似词(字面+语义word2vec)
- 数据量大:
- 单机(4G以内):不要一次加载到内存
- 内存装不下(20G):磁盘分片存储,逐个加载到内存(linux流式处理),可以分别取top5吗?
- 磁盘装不下(1T):分布式计算,Hadoop,MapReduce代码→HQL→jobtracker数据倾斜
NLP:新词发现
- 背景:word2vec 向量训练,cbow、skip-gram模式
- 需求:从文档中挖掘新出现的top k词汇, 长度3以内 (词频统计进阶版)
- 输入:文档 D = { s1, s2, …, sn}
- 输出:W = [ [w1, 23], [w2, 10], …, [wk, ck] ]
- 方法:
- 思路:是否使用 tf-idf ?
- 传统方法:n-gram思路,挨个遍历uni-gram, bi-gram, tri-gram, 取topk
NLP:MLM输出
- 背景:BERT模型用了MLM模型
- 需求:准备MLM语料,用于模型训练
- 输入:文档 D = { s1, s2, …, sn}, 其中 si = [ ‘这是一条句子’ ] (m维),musk策略与BERT类似
- 输出:M = { [s1’, m1], [s2’, m2], …, [sn’, mn]}
- 方法
- 思路:是否了解BERT的掩码策略?
- 传统:
NLP:语义向量
- 背景:句向量 embedding
- 需求:找出与query最相似的几个句子
- 输入:句向量集合 D = { v1, v2, …, vn}, 其中 vi = [ 2, 5, 1 ] (m维),任意向量 vx
- 输出:与vx最相似的 top k个句子
- 方法:
- 每来一个vx,依次遍历D,得到距离集合,排序,取 top k输出 —— 时间复杂度 O(nm)+O(nlogn),空间复杂度 O(n),重复计算
- 改进:提前聚类,计算D中各向量距离
- 改进:类似 kd树,m维距离映射到一维数组上,就近取top k
NLP:NSP预测
- 背景:
- 需求:
- 输入:
- 输出:
- 方法:
NLP:编辑距离
- 背景:
- 需求:
- 输入:
- 输出:
- 方法:
- 动态规划
NLP:transformer QKV计算
- 背景:
- 需求:
- 输入:
- 输出:
- 方法:
Full Attention: 2017的《Attention is All You Need》中的编码器-解码器结构实现中提出。它结构并不复杂,所以不难理解。
左侧显示了 Scaled Dot-Product Attention 的机制。
class FullAttention(nn.Module):
def __init__(self, mask_flag=True, factor=5, scale=None, attention_dropout=0.1, output_attention=False):
super(FullAttention, self).__init__()
self.scale = scale
self.mask_flag = mask_flag
self.output_attention = output_attention
self.dropout = nn.Dropout(attention_dropout)
def forward(self, queries, keys, values, attn_mask):
B, L, H, E = queries.shape
_, S, _, D = values.shape
scale = self.scale or 1. / sqrt(E)
scores = torch.einsum("blhe,bshe->bhls", queries, keys)
if self.mask_flag:
if attn_mask is None:
attn_mask = TriangularCausalMask(B, L, device=queries.device)
scores.masked_fill_(attn_mask.mask, -np.inf)
A = self.dropout(torch.softmax(scale * scores, dim=-1))
V = torch.einsum("bhls,bshd->blhd", A, values)
if self.output_attention:
return (V.contiguous(), A)
else:
return (V.contiguous(), None)
CV:人脸识别
问题:假设已经有了 1000 万个人脸向量,如何通过查询来找到新的人脸?
问题的关键是数据的索引方法
One Shot learning 来进行人脸识别的方法。
- 将每个人脸转换成一个向量
- 而新的人脸识别是寻找与输入人脸最接近(最相似)的向量。
通常,人们会使用 triplet loss 损失函数的深度学习模型来实现这一点。
然而,数据量大时,计算速度越来越慢;
- 每次识别中计算到 1000 万个向量的距离
在实向量空间上索引数据
- 将数据划分为便于查询新数据的结构(可能类似于树结构)。
- 当有新数据可用时,在树中进行查询有助于快速找到距离最近的向量。
几种方法可以用于这种目的,比如
- Locality Sensitive Hashing—LSH 局部敏感哈希
- Approximate Nearest Neighbors 近似最近邻 — Annoy Indexing
开放问题
开放性问题:
- 对XX公司有什么了解,知道这个职位是做的吗?
- 对XX公司什么看法,看好还是看衰,对自己的职业规划
- 未来的打算,认为自己有什么优势劣势,做最成功和最失败的事情是什么
压力面
【2024-9-27】10个常见压力面试题 告诉你如何正确应对
压力面试指有意制造紧张,以了解求职者将如何面对工作压力的一种面试形式。
实际上,压力面试不是单独存在的一类面试,往往是穿插在面试过程中。面试官通过提出不礼貌、冒犯的问题,或者用怀疑、尖锐、挑衅的语气发问,使应聘者感到不舒服,针对某一项或问题一连串发问,直到应聘者无法忍受。
主要考察应聘者的心理承受能力、抗高压能力、应变能力、人际交往能力。
以下是10个常见压力面试题
- 最大的弱点是什么
- 秘诀:不接受这种否定暗示。不否认有缺点,世上无完人
- 应该承认一个微不足道的弱点或缺点,然后说已经成为过去,表明自己是怎样克服这个缺点的。
- 自己的哪项技能需要加强
- 自已不可能什么都会,但如果承认自己在哪方面需要改进,面试官就会像嗜血的鲨鱼一样一口咬住你。
- 秘诀:重新定义,以便躲开这一点。“既然谈到这儿,我已具备了这份工作所需的所有技能。这也是我所以对这个职位感兴趣的原因。“ 借机再把简历中的闪光之处再炫耀一番。
- 什么样的决定尤为难做
- 目的:引诱你说出个人存在的问题和财政危机。当然,也许主考所说的不错,然而一定要回避这个问题:“你见过哪个我这个岁数的人对工资已经很满意呢?当然,我想得到更高的薪水,这也是我到这来参加面试的原因。至于现在嘛!我还可以付帐并保特收支平衡的。”
- 如果用他问题中的这些词来回答,就只能对自己不利了。主考会立刻扑上来。
- 秘诀:摒弃那些否定性词汇。“我没发现有什么决定特别’难’做,但确实有时做一些决定要比做其他的决定要多费一些脑筋,多做些分析。也许你把这叫做’难’,但我认为我拿工资就是做这些事情的。“
- 与现在的老板相处很久了,为什么不继续干下去了呢
- 假设说主考已经击中了你的要害,他说得完全是事实,但这并不意味着你就非得同意他问题中对你不利的因素。“我喜欢现在这份工作是因为它既稳定又有挑战性。而在那里我已经不可能有更大的发展了,因此我到此来应聘。我希望换一家公司以便更好地发挥自己的才能。
- 你的年龄应该早就升到更高位置了吗
- 这是个刺激人的问题。但也可以不那么看,而把它当成是对你的能力和成绩的一种赞美。
- “我干这份工作只为了长远打算,要收获就必须付出,这正是我所做的。在这份工作中我已经获得了很多经验,打下了坚实的基础。现在我来此应聘正是为了把学来的这些有益的东西派上用场。“
- 你为什么要辞掉现在的工作
- 高压面试中极为常见,但比别的高压问题更为难答。
- 炒语,容易记住,紧张也不会忘记:
CLAMPS, 挑战、职位、进取、金钱、尊严及安全。 - 既可以单独拿出一个作为原因,也可以都拿出来, 使对方相信你离开现在的岗位是合情合理的,是经过矫思熟虑的明智之举。
- 现在这份工作,你最不喜欢的是哪一点
- 用否定词表述的高压问题。要避免其中的否定因素。考官只能记住你是一个爱抱怨的人。
- 更糟的是,他对这次面试的印象也会是否定的。再说,你对现在工作的不满确实说明了你另换工作的原因,但却没有满足现在老板的需要。
- 应该时刻把握老板的需要:“我觉得现在的工作各方面都不错,但是我正准备迎接新的挑战,等待肩负起更重的担子,取得更大的成就。希望把自已之所学运用到更富挑战性、更能发挥自己才能的岗位上。”
- 你在工作中曾遇到过的最艰难时刻是什么时候
- 不要搜肠刮肚地找问题答案。你最不想做的就是道出以个人失败和集体受难而告终的经历。即使参加的不是高压面试,应该料到会问这个问题,然后带一个皆大欢喜的故事去参加面试。
- 忠告:不要谈及个人和家庭的困难,不要谈及与上司和同事的摩擦,你可以讲一次与下属产生的矛盾,并且说明自已是如何创造性地解快了矛盾,最后做到皆大欢喜的。也可以讲一次对你来说极富挑战的经历。
- 你觉得什么人在工作中难于相处
- 千方百计避免作否定回答的技巧,简单地回答:“我觉得没什么人在工作中难相处”,“我跟大家都合得来”
- 这两种答案都不算坏,但却都不十分可信。应该利用这个机会表明你是个有集体协作精神的人,“在工作中唯一不容易相处的是那些没有集体协作精神的人,他们不肯干却常抱怨,无论怎样激发他们的工作热情,他们都无动于衷。”
- 你希望与什么样的上级共事
- 通过应聘者对上级的“希望”,可以判断出应聘者对自我要求的意识,这既是陷阱,又是机会。
- 最好回避对上级具体希望,多谈对自已要求。如“做为刚步入社会新人,我应该多要求自己尽快熟悉环境、适应环境,而不应该对环境提出什么要求,只要能发挥我的专长就可以了。”
为什么离开上家公司
【2021-10-10】猎头:面试被问短板是什么、为什么要离开上一家公司,怎么办?
- 建议坦诚但积极。本质上不是面试官想知道答案,而是想通过你的回答,看出你是一个什么样的人。而且,不少公司都会做背景调查,所以如果离职原因和真实的原因相差太远,那么在做背调时很难过关。回答起来确实是有些不舒服的,这是面试官在刻意施压,撇开具体的回答不说,光从回答问题的方式,就能看出如何化解压力,同时还可以了解是否有自知之明。
- 如果回答扭扭捏捏,甚至被面试官看出来编造答案,那么十有八九很难通过的,所以要坦诚。但是,这些问题本身就是负面的,如果负面的回答出来,那面试结果也可想而知,所以你要用积极的话再说一遍。
- 比如,面试中问有哪些短板。我自己在应聘一家企业的企业大学校长一职的时候就被CEO问过这个问题。根据刚才那个坦诚但积极的回答方式,回答:首先非常坦诚的说,自己在做执行的过程中,往往因为追求速度,而忽视细节。并且举一个真实的例子,在某个项目中,我因为决策速度太快,在一个执行细节上考虑不周全,结果险些造成损失。但是如果就这么回答,显然,对方是不会请一个这么急躁的人来做企业大学校长的。我接着说道:第一,通过复盘我意识到了,自己的确有决策时候太过追求效率的缺点。其次,现在自己养成了一个习惯,也就是每次在帮自己做决策时,必须要拿出,笔和纸,用金字塔原理,把问题拆解清楚,做到不重复不遗漏。所以像上次那样的决策失误,几乎就再也没有出现过。这就是积极,不但告诉了面试官如何在具体的某件事情上进步,而且我的学习能力快,这个优点,也符合企业大学的这个角色的要求。
- 尤其是不要把一盆脏水全泼到上一家公司,对前东家大放阙词,这会给HR传递一个非常不好的信息,你是一个刺头。其实,正常来说,一个人的离职原因,HR们也心知肚明,要么就是钱没给够,要么就是发展不够顺。你可以更注重,对于应聘公司的仰慕出发,谈一谈这家公司,在你的职业发展目标中扮演什么样的角色。是因为这家公司吸引了你,而不是因为上一家公司耽误了你。
Q&A
工作强度
- 【2021-10-11】猎头组织的各公司工作强度汇总,协同文档,github备份,覆盖互联网、金融、地产等行业
- 2019年,996.ICU异军突起,短时间内冲上了github第一名,可见国内上班族对工作强度的怨念有多深
- 【2024-5-31】新的ICU主题站点: ISeeU, 包含企业名单、爆料(耻辱柱/照妖镜)、内推、求职、出路、GPT访问, 有配套小程序 观望空间
大厂之哪家待的比较舒服? 脉脉
【第一梯队(最舒适,加班极少+福利完善)】
- 1️⃣DiDi:公认“天花板级”舒适,加班少,氛围轻松,员工口碑极佳,新橙海办公>天空之城>智慧山谷。
- 2️⃣搜狐:入职送15天年假,双休到点下班,国企式养老首选。
- 3️⃣联想:朝九晚六模式,办公环境好,领导明确反内卷,周末加班会被批评。
- 4️⃣腾讯(非核心部门):10:30工位早餐趴 19:00蹭完夜宵就开溜,福利完善,但游戏等核心部门较忙。
【第二梯队(较舒适,偶有加班但整体可控)】
- 1️⃣网易:食堂福利吸引人(“猪厂”名不虚传),企业文化有一些人文关怀。
- 2️⃣携程:与去哪儿类似,节奏比较缓和。
- 3️⃣阿里(国际电商/边缘部门):边缘事业部“高P躺平”,年假翻倍(杭州),但淘天等核心部门仍需谨慎。
- 4️⃣米哈游/B站/猿辅导:二次元氛围同事cosplay来上班,B站强度适中,猿辅导假期多。
- 5️⃣360:不算那么卷,我觉得市场同学有点累。
【第三梯队(中等偏卷,加班常态化)】
- 1️⃣百度(商业化除外):可勉强续命。
- 2️⃣狗东:中台累的,有加班。
- 3️⃣拼多多(非核心部门):部分部门无需“自证价值”,裁员少,整体仍属高压梯队。但因为钱给得到位,所以与部分加班抵消。
【第四梯队(极卷慎入)】
- 1️⃣字节跳动:字节一年,人间三年,压力大,要求比较高,累。
- 2️⃣:强度不低。
- 3️⃣拼多多(核心部门):流水线式高强度,感觉身体不是自己的,没有娱乐,没有夜生活,不需要家庭,但是💰多啊,干就完了!
级别与薪资
【2024-9-27】职级对标, 实时更新各大公司职级及待遇范围
【2018-11-13】
问:公司文化真的存在吗?
答:比如百度发邮件没写标题就请吃鸡翅,同事相互之间称同学,穿着越随意级别越高;阿里多是拜山头,老大一发话,大家撸起袖子拼命干,做好了一起荣华富贵,做差了,各自散伙儿,hr权利尤其大,对技术人员拥有一票否决权;腾讯,没呆过,不清楚
问:这种文化来源上级的灌输吗?
答:也许不是上级,但很可能是上级的上级,权利多大,影响力就多大,大到可以改变一个公司的文化,中国公司,乃至亚洲公司普遍服从权力,所谓官高一级压死人,这是皇权社会根深蒂固的影响,人治大于法制,这点逊于欧美公司,当然他们也有类似情形,只是程度不同
问:公司文化和个人兴趣哪个更重要?
答:这就是环境与个人的关系,不得不承认,人是渺小的,极易受环境影响,能出淤泥而不染的少之又少,更不用说改变环境的。如果文化与兴趣冲突,要么适应要么离开,不过别担心,大体上公司文化不太会与个人冲突,除了个别的条例,比如过度侵犯个人隐私,甚至过于扭曲的价值观
问:知识图谱+公司选择
我在阿里iDST做过一段时间的知识图谱,也听过不少大拿的讲座,这个领域在电商上,大概就是各个商品的关系了,图谱方向五年前百度、搜狗就发力了,后来被深度学习盖过去了。kg其实是个持续半个世纪的老话题,语义网,本体,图谱,换汤不换药。Google在2000年左右就开始做了,长达8年,才有一个像样的图谱,据说准确率83%左右,看着很高,但还不能大规模商用,实际情形太复杂了,对图谱的要求很高,目前看开放领域图谱基本没有出路,垂直领域倒是可以试试,不过少不了一大堆脏活累活。图谱的未来是光明的,但道路是坎坷的,只是不知道渺小的个体能否熬到黎明的那一刻;这条路相对较窄,作为应届生,不建议刚开始就进入一条窄胡同 关于图谱方向,你可以看看鲍捷的系列文章;关于jd,我的感觉整体氛围偏传统风格,老气横秋,技术人员没有普通互联网公司那么阳光。具体有什么问题,你可以整理下,我找内部人员给你解答 面试时,遇到同道中人都会兴奋,酒逢知己千杯少,这种感觉很难碰到。个人的局限性一方面在于能力,另一面在于视野。选择大于努力。国内互联网格局上看,jd的发展受限于阿里和腾讯,只要阿里在,jd就是腾讯的马前卒,千年老二。如果是想做研究,不推荐上班,国外读博更好。企业研究院虽是研究,但有业务压力,不可能心无旁骛,所以像阿里iDST一样出现了既要学术成果,又要工程落地,还要商业变现的三不像,结果就是分分合合,不成大器。面试时聊的技术,实际应用中未必用,大多用来筛选、吓唬人的。工业届做的做法可能low到想吐。另外,DL领域,技术更新换代很快,这个时候的GAN,过五年十年就烟消云散了。 还是那个话题,个人与环境的关系,绝大部分人都是环境的影响者,只有极个别的聪明人和傻子能减少影响。比如绝顶聪明的天才elon musk,做了30年冷板凳的hinton,改变了环境;不过也有另一个极端,坚持下去越来越孤独,直至自我灭亡,遁入另一个世界。个人与潮流,重在借势。 如何做出科学的决策?不偏听,不盲从,多方求证,理性分析,最大程度的降低感性的影响。有人说,所谓的选择困难症,就是穷;我想说,那是因为信息不对称,另一种意义上的穷。
IT英语
如何学机器学习?
【2022-4-9】作者:吴恩达, 链接
Do you want to become an AI professional? The key to machine learning mastery is to approach your learning systematically!
- Machine learning is the science of making a computer perform work without explicit programming. In the past decade, machine learning has enabled utilities such as self-driving cars 自动驾驶, real-time speech recognition 实时语音识别, efficient web search 网络搜索, and boosting our knowledge of the human genome 人类基因组.
- Many researchers believe that machine learning promises the greatest possibility in realizing human-level AI.
- Here, I‘d like to share three steps to learn machine learning in a systematic way:
- First, you should learn coding basics 编程基础.
- Second, you should study machine learning and deep learning.
- Third, you should focus on the role you would like to have.
Fundamental programming skills are a prerequisite for building machine learning systems. You will need to be able to write a simple computer program (function calls 函数调用, for loops 循环, conditional statements 条件语句, basic mathematical operations 基础数学操作) before you can start implementing preliminary machine learning algorithms.
Knowing more math can give you an edge, but it won’t be necessary to spend much time on specific mathematical issues such as linear algebra, probability and statistics.
Having gained some fundamental coding skills, you can officially begin your journey of machine learning. My Machine Learning course from Stanford University is a great choice. It provides a general introduction to machine learning, data mining, and the statistical approach of pattern recognition. The course will also help you to develop your practical understanding of how to use machine learning in the real world. For instance, when to use supervised learning, unsupervised learning, and machine learning. The machine learning course draws insights from (洞察力) numerous case studies and applications. It is suitable for learning how to apply algorithms to a wide-variety of tasks, such as intelligent robots building (perception, control), natural language understanding NLU领域 (web search, anti-spam emails), computer vision (identifying diseases in medical imagery, finding defects in manufacturing), and much more.
Deep learning is a subset 子集 of machine learning that is growing more important, and is worth your attention as well. It uses neural networks to make powerful predictions, and is the driving force behind many of today’s most exciting technologies. For example, self-driving cars, advanced web search, and face recognition all use deep learning. The Deep Learning Specialization, developed by DeepLearning.AI, covers the knowledge you need to build deep learning applications in fields such as computer vision, natural language processing, and speech recognition. You will conduct case studies 案例分析 in healthcare, autonomous driving, sign language reading 收拾语言理解, music creation 音乐创作, and natural language processing NLP领域, so you can familiarize yourself with the practical application of deep learning in various industries while mastering theoretical knowledge 理论知识 at the same time.
Once you have learned the foundations of machine learning and deep learning, the next move depends on the role you have in mind. For example, do you want to be a data scientist 数据科学家, engineer 工程师, or machine learning researcher? 研究院 Or, do you consider developing AI skills to complement your existing expertise? If so, you can learn AI as a way to better apply your expertise to real-world problems.
After deciding the role, it’s time to move on to real practice. You’ll want to get experience working on projects 项目经验 and as a part of a team 团队协作. Identifying viable 可行的 and valuable 有价值的 projects is an important skill, and it’s one that you’ll continue to develop throughout your career. The best way to start is to volunteer to help with other peoples’ projects. Eventually 最终 you will develop the confidence and experience to lead your own 独当一面.
For completing a project, teamwork is more likely to succeed than solo effort 单打独斗. It is critical to have the ability to collaborate with others, give and take advice, as this helps you build connections. Teamwork also helps you build out your network of professional connections. You can call on people who you have worked with in the past to provide advice and support as you move through your career.
The ultimate goal 终极目标, of course, is to find a job in machine learning. This will come after you have acquired both theoretical knowledge 理论知识 as well as practical experience 实际经验. When looking for a job, don’t be shy about reaching out to people you have met while taking courses or working on projects. You can also connect directly with professionals who are already working in the field. Many of them are happy to act as your mentor.
Finding your first job, however, is a small step in a long-term career 职业生涯. It is important to cultivate self-discipline 自律 and commit to constant learning 持续学习. People around you may not be able to tell whether you spend your weekends studying or on your smartphone, but day by day, and year over year, it will make a difference. Discipline ensures that you move forward while staying healthy.
I hope these suggestions could open the door to machine learning and help get you job-ready. The journey ahead will surely be a bumpy (ˈbʌmpi] 曲折的)one, but rest assured that what you encounter along the way will help you succeed. By the way, courses from DeepLearning.AI will be available on Zhihu soon. Stay tuned 敬请 and see you next time! Keep Learning! Andrew
简历
Latext版简历
【2023-6-7】中文简历模板: awesome-resume-for-chinese
简历范例
【2022-5-7】HR喜欢什么样的简历
有工作经验的朋友,简历的内容要包含个人信息,求职意向,教育经历,工作经历(项目经历)、相关技能及自我介绍几个板块
个人信息: 别的不强调了,开始工作时间要写上,毕竟不少公司还是“越老越吃香”的,这样也方便判定从业年限。(在这个位置要标注下求职岗位以及到岗时间,【薪资部分】可写可不写)教育经历: 工作以后,教育经历就没必要放在黄金位置了,除非背景特别好的,如果想罗列教育经历,只写专业排名以及和岗位沾边的专业课即可工作经历: 三要素一定要有,工作所属行业、岗位及从业起止时间,要多展现数据,同一类型的工作内容只写【最优解】即可,往期的待遇可以标注,也给用人方一个参考范围(这部分可以对照着岗位的 JD去写,邀约率更高)项目经历: 这个是加分项,经历过项目的朋友,对全局更加有把握,项目经历要遵从【5W1H】的原则,将项目的起止时间、个人角色以及取得怎样的结果说清楚- 5W1H:
岗位技能: 有证书是最好的,没证书的要要将工作内容进行拆解,拿新媒体运营岗位举例子,可以说具备内容编写、平台发布等技能自我评价: 自我评价我建议可以放在黄金位置,通过对个人过往的总结,可以让用人方迅速了解到你的能力,减少筛选时间

算法入门
初学者的困惑
AI初学者不要过于迷信企业项目,忽略基本功的学习,不要mnist都没研究透彻就嫌简单,直奔难度更大的resnet,好高骛远,得不偿失,学东西请务必戒骄戒躁,一步一个脚印,才能越走越远。企业项目的事实跟你想象的大不一样。
真相:学术 vs 工业
- ①企业项目侧重工程实践,尤其重视数据闭环,从采集到入库(Hive+Storm+HBase),到模型训练(单机+分布式),到线上预估(qps,压测),到效果评估(ab test),再到业务报表和数据回流,整个过程里算法比重不到20%
- ②算法上越简单越好,如果能用LR就不会用神经网络,能用规则就不用模型,尤其注重风险可控性,学院派看来模型太low,然后一旦让学院派来做,却又无从下手,做出来的系统无法上线运行。工业界的算法往往滞后于学术界几年,一方面因为推广速度,另一方面,学术界的模型算法往往过于理想,停留在Demo阶段,对实际应用场景缺乏了解,很多paper上的方法其实行不通,一个paper导向,固定的实验集上取得好的效果就行,一个却是实打实的应用场景,必须可实施,二者截然不同。所以,千万不要眼高手低,把学院派的作风带到工作中,还埋怨企业算法low,多思考为什么
- ③结果导向,不管什么模型算法,最终谁带来的业务收益大谁就是赢家。这点很好理解,学校的项目大多没有实际应用,toy example,玩玩而已,出发点一开始就不是为了应用,而是所谓的“高大上”的算法,一到实际场景,发现各种漏洞,堵了一个又来一个,真烦。企业面向的是实际场景,有营收压力,解决问题是首要的
- ④系统思维,企业项目涉及的点非常多,一个部分没考虑到位就可能带来灾难性的后果,这些思维是学院派不具备的,一个完整的项目如果带到培训班里,学院估计会嫌蛮,讲那么多,大部分都是工程,只有一部分是算法,觉得没学到“干货”,大部分人认为的干货就是各种牛叉的算法模型,其它都不是。 总之,企业更加侧重工程能力,系统思维,结果导向,这些是培训不具备的。
【2022-4-29】人工智能:学术研究 Vs 工业研发
学术界研究 与 工业界研发
- 学术界的研究更像恋爱中的男女
- 每一点进步都让你们开心无比,同时还希望不停地有进步,达到新的高度看到的全是女孩好的一面
- 你们可以自由地憧憬暫没人催你生孩子(产品)
- 你们憧憬生一个小孩(产品)会多么美好认为孩子一定是世界上最聪明最乖巧的,因为反正不用真的把孩子生出来
- 工业界研发更像结婚后的男女
- 发现生娃(产品)成了你们最首要的任务,父母(公司老板)天天催着你生娃(产品)
- 你们以为孩子生出来会很乖巧,可生出来后才发现一堆的问题,一堆的毛病,社会(用户)也不喜欢他/她
- 你不停根据经验和用户反馈来进行调教最后孩子强大了,你也头白了,脊椎坏了,但看着孩子(产品)还是一脸的满足幸福
如何具备企业项目能力?
- ①实习,参与到企业项目中,慢慢体会,实际应用总是跟想象的不一样。大多数实习生做不了多少核心工作,大多打杂,提升工程能力
- ②精耕细作,找一个小项目,哪怕是mnist,想各种办法,不停的优化,尽可能提升泛化能力,黑白mnist玩腻了,换服装领域试试?换cfair-10试试?换web demo,实施手写识别试试?很多人容易犯的错就是,浅尝辄止,好高骛远,以为跑一边github的demo,就会深度学习了,too simple,sometimes naive!这种学习态度是不可能学会深度学习的
- ③多看多动手多做笔记,构建自己的知识体系。
证书
软件设计师
【2023-1-11】软件设计师资格证,又称“软考”,永久有效,挂靠费用大约6k~7k/年
软考是由国家人力资源和社会保障部、工业和信息化部领导下的国家级考试,其目的是为了培养IT专业+管理的人才,对全国计算机与软件专业技术人员进行职业资格、专业技术资格认定和专业技术水平测试,同时目前软考也是计算机行业唯一全国性考试,其权威性和社会认可度很高,随着人工智能、区块链、5G等信息技术的发展,软考的含金量提升是毋庸置疑的。
软考种类
- 中级:软件设计师、系统架构设计师等
- 高级:系统分析师、网络工程师、网络安全工程师等
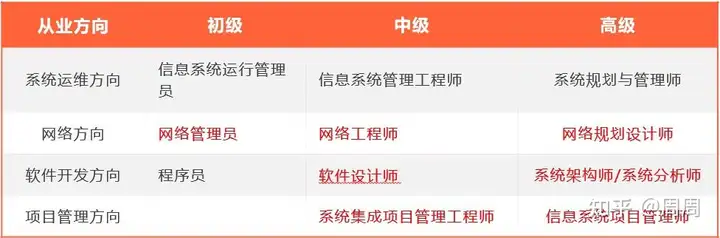
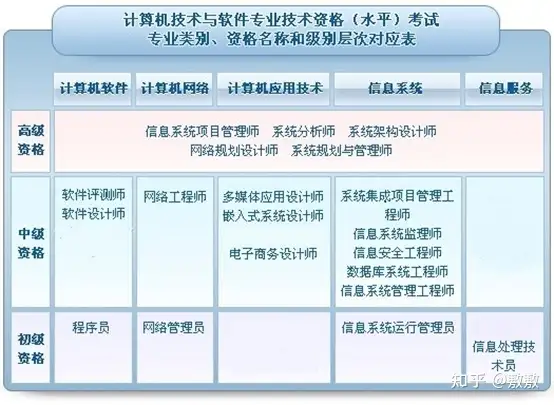
软考可以挂证的专业就3个:
- 信息系统项目管理师(高级)
- 系统集成项目管理工程师(中级)
- 信息系统监理师(中级)
软考的用途:
- 落户加分
- 中级:网络工程师+学历(大专)或者 系统集成项目管理工程师 可以直接落户
- 工作需要
- 一般是IT或者互联网行业考个软考是可以让自己加工资的,而具体能加多少这要问问本公司人事。
北京积分落户政策对职称、职业资格没有明文规定和要求,根据《北京市积分落户管理办法(征求意见稿)》,考取软考证书也不能直接加分,但是这不代表考取软考证书就没有用处。
软考取得初级资格可聘任技术员或助理工程师职务;取得中级资格可聘任工程师职务;取得高级资格,可聘任高级工程师职务。由于计算机软件资格考试在国内外的知名度很高,有些级别实现了中日和中韩互认,大大提高了持证者的就业竞争力。
取得软考证书,职务与工资水平能在很大程度上帮助申请者加分。可见,软考证书虽不能直接加分,但可以间接帮助申请者加分。
算法工程师职业道路
算法工程师等级划分
【2017-5-23】北冥乘海生:20万、50万、100万的算法工程师,到底有什么区别?
-
进阶之路:入门级(工具) → 进阶级(改造) → 高级(定义)
- (1)入门级 “
Operating“:会使用工具 ——调包党、调参侠,20w年薪- 能力:熟悉常用模型,业务数据来了,能找到合适的模型
- 问题:门槛越来越低
- 以前会LDA、SVM,再玩过几次libnear、mahout等开源工具,就可以用数据跑个结果。
- 深度学习时代,更简单:管它什么问题,不都是拿神经网络往上堆嘛!自以为跑通了Tensorflow的demo就会深度学习;
- 任凭你十八般开源工具用的再熟,也不可能搞出个战胜柯洁的机器人来
NFL没有免费午餐定理:- 如果有两个模型搞一次多回合的比武,每个回合用的数据集不同,而且数据集没什么偏向性,那么最后的结果,十有八九是双方打平。
- 管你是普通模型、文艺模型还是2B模型,谁也别瞧不起谁。
- 考虑一种极端情况:有一个参赛模型是“随机猜测”,也就是无根据地胡乱给个答案,结果如何呢?对,还是打平!
- 所以,请再也不要问“聚类用什么算法效果好”这样的傻问题了。
- 实际问题的数据分布总是有一定特点. 比方说人脸识别,图中间怎么说都得有个大圆饼。因此,问“人脸识别用什么模型好”这样的问题,就有意义了。
- 而算法工程师的真正价值,就是洞察问题的数据先验特点,把他们表达在模型中,而这个,就需要下一个层次的能力了。
- (2)进阶级 “
Optimization“:能改造模型 —— 50w年薪- 能力:根据具体问题的数据特点对模型进行改造,并采用相应合适的最优化算法,以追求最好的效果。
- 不论前人的模型怎么美妙,都是基于当时观察到的数据先验特点设计的。
- LDA是在语料质量不高的情况下,在PLSA基础上引入贝叶斯估计,以获得更加稳健的主题。
- 虽说用LDA不会大错,但是要在具体问题上跑出最好的效果,根据数据特点做模型上的精准改造,是不可避免的。
- 互联网数据更明显,百度的点击率模型,有数十亿的特征,大规模的定制计算集群,独特的深度神经网络结构,抄过来也没用。用教科书上的模型不变应万变,结果只能是刻舟求剑。
- 两方面的素养:
- 一、深入了解机器学习的原理和组件。
- 正则化怎么做?什么时候应该选择什么样的基本分布?贝叶斯先验该怎么设?两个概率分布的距离怎么算?
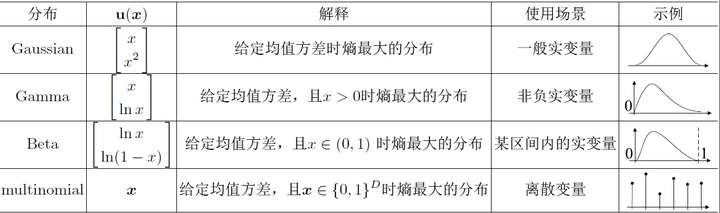
- 二、熟练掌握最优化方法。机器学习从业者不懂最优化,相当于武术家只会耍套路。
- 最优化是机器学习最重要的基础
- 目标函数及其导数的各种情形下,应该如何选择优化方法;各种方法的时间空间复杂度、收敛性如何;还要知道怎样构造目标函数,才便于用凸优化或其他框架来求解。
- 早期,RNN由于“梯度消失”现象的存在,RNN很难对长程的上下文依赖建模。天才的J. Schmidhuber设计了带有门结构的LSTM模型,让数据自行决定哪些信息要保留,那些要忘掉。
- 一、深入了解机器学习的原理和组件。
- 根据问题特点调整模型,并解决优化上的障碍,是一名合格的算法工程师应该追求的能力
- (3)高级 “
Objective“:定义问题 —— 100w年薪- 能力:针对某个实际问题,给出量化的目标函数;
- 有明确的量化目标函数,正是科学方法区别于玄学方法、神学方法的重要标志。
- 目标函数有时能用一个解析形式(Analytical form)写出来,有时则不能。
- 网页搜索这个问题,有两种目标函数:一种是nDCG,这是一个在标注好的数据集上可以明确计算出来的指标;另一种则是人工看badcase的比例,显然这个没法用公式计算,但是其结果也是定量的,也可以作为目标函数。
- 目标函数的定义没那么容易,在意识和技术上都有很高的门槛
- 一、要建立“万般皆下品、唯有目标高”的意识。
- 一个团队/项目只要确立了正确、可衡量的目标,那么达到这个目标就只是时间和成本的问题。假设nDCG是搜索的正确目标函数,那么微软也好、Yahoo!也好,迟早也能追上Google,遗憾的是,nDCG这个目标是有点儿问题的,所以后来这两家被越拉越远。
- 一个项目开始时,总是应该先做两件事:
- 一是讨论定义清楚量化的目标函数;
- 二是搭建一个能够对目标函数做线上A/B测试的实验框架。
- 而收集什么数据、采用什么模型,倒都在其次了。
- 二、能够构造准确(信)、可解(达)、优雅(雅)的目标函数。
- 目标函数要尽可能反应实际业务目标,同时又有可行的优化方法。一般来说,优化目标与评测目标是有所不同的。比如说在语音识别中,评测目标是“词错误率”,但这个不可导所以没法直接优化;因此,我们还要找一个“代理目标”,比如似然值或者后验概率,用于求解模型参数。评测目标的定义往往比较直觉,但是要把它转化成一个高度相关,又便于求解的优化目标,是需要相当的经验与功力的。在语音建模里,即便是计算似然值,也需要涉及Baum-Welch等比较复杂的算法,要定义清楚不是简单的事儿。
- 优雅是更高层次的要求;遇到重大问题时,优雅却往往是不二法门。因为,往往只有漂亮的框架才更接近问题的本质。关于这点,必须要提一下近年来最让人醍醐灌顶的大作——生成对抗网络(GAN)。优雅得象个哲学问题,却又实实在在可以追寻。
- 一、要建立“万般皆下品、唯有目标高”的意识。
- 一个团队的定海神针,就是能把问题转化成目标函数的那个人——哪怕他连开源工具都不会用。
算法模型进阶经验
【2021-9-18】数十位算法工程师的经验总结
总结mm中对于算法工作的论述,虽然有调侃之意,但对于指导工作难道没有意义吗?
- 从0到1,用简单模型;可解释性强,简单易实现,能快速验证思路,也有利于奠定后期的提升空间;(指标:78%)
- 加强特征工程工作,特征离散化,特征交叉,新增特征等等。(指标:81%)
- 换用经典的高级模型,如从LR到GBDT,再到DeepFM,DIN等等。(指标:85%)
- 精细化调整,分人群优化,针对badcase优化;(指标:85.5%)
- 模型调参,尝试各种前沿模型结构,调整数据采样方式,增加统计特征,清洗数据等等(85.6%)
- 继续想各种鬼点子优化(85.66%)
- 运气好的话,赶上环比波动,赶紧上线总结(到底是不是模型带来的,就是玄学了,哈哈);
- 运气不好的话,模型指标莫名其妙下跌,大家怎么应对呢?
算法工程师危机

- 讯飞AI同传语音造假的新闻刷爆科技圈,科大讯飞股价应声下跌3.89%(不是65.3%,标题党文章害死人)。 吃瓜群众纷纷感慨,有多少人工,就有多少智能。
- NIPS会议,人满为患,改改网络结构,弄个激活函数就想水一篇paper; 到处都是AI算法的培训广告,三个月,让你年薪45万!在西二旗或望京的地铁车厢里打个喷嚏,就能让10个算法工程师第二天因为感冒请假。
- 谁也不知道这波热潮还能持续多久,但笔者作为一线算法工程师,已经能明显感受到危机的味道:以大红大紫的图像为例,图像方向简历堆满了HR的办公台,连小学生都在搞单片机和计算机视觉。
- 人工智能部门正在从早前研究院性质的组织架构分别向前台和后台迁移:
- 前者进入业务部门,背上繁重的KPI,与外部竞争者贴身肉搏;
- 后者则完全融入基础架构,像数据库一样普通和平凡。
- 之前安逸的偏研究生活被打破, AI早已走下神坛。
算法工程师危机包含两部分:
- 一方面是来自人的竞争,大量便宜的毕业生和培训生涌入这个行业,人才缺口被迅速填满甚至饱和,未来的竞争会更激烈;
-
另一方面则是来自机器的竞争,大量算法工程师会很快被他们每天研究的算法所代替。 这两者互相恶化,AI人才市场终会变成一片红海。
- 工具和框架本身的发展,让设计模型所需的代码写得越来越简洁。10年前从头用C++和矩阵库实现梯度下降还是有不小的门槛的,动辄上千行。而当今几十行Keras甚至图形化的模型构建工具,让小学生都能设计出可用的二分类模型。
- 强大的类库吞噬了知识,掩盖了内部的复杂性,但也给从业者带来了不小的惰性。从业者的技术水平,和使用模型的复杂程度关系不大,越是大牛,用的技术更底层更make sense。
- 深度学习本身的性质,造成了明显的数学鸿沟。与SVM, 决策树不同,由于模型存在大量的非线性和复杂的层次关系,且输入信号(例如图像,文本)也很复杂,因此严格的数学论证是需要极高的抽象技巧的。
- 只有凤毛棱角的专家,能深入到模型最深处,用数值分析和理论证明给出严谨的答案。 大部分人在入门后便进入漫长的平台期,美其名曰参数调优,实际就像太上老君炼丹一样。
AI学习曲线,左侧是稍显陡峭的入门期,需要学习基本的矩阵论,微积分和编程,之后便是漫长的平台期。 随着复杂性越来越高,其学习曲线也越来越陡峭,大部分人也就止步于此。 越来越易用的工具,让曲线左侧变得平坦,入门期变短,却并不能改变右侧的陡峭程度。
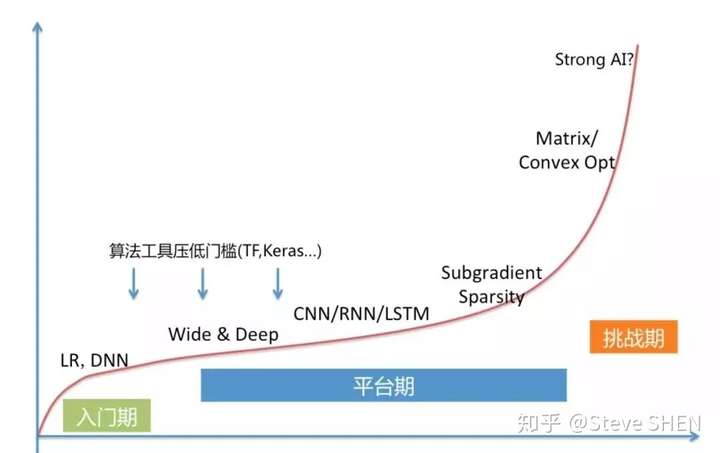
入门容易深入难,这条曲线同时也能描述AI人才的收入水平。而真正处于危机的,莫过于夹在中间的芸芸众人:对理论一知半解,对工具非常依赖。可替代性很强,一旦AI浪潮过去,就知道谁是在裸泳。
市场和业务变化越来越快,能有哪些核心业务,是能让工程师静心调个一年半载的呢?当一个从培训学校里出来的人都能做模型时,有多少业务能让公司多花两三倍的人力成本,而仅带来1%的性能提升呢?
算法岗比工程岗更容易被取代。 在现有技术下,由于业务需求的复杂性, 自动生成一套软件App或服务几乎不可能的(否则就已经进入强人工智能时代了),但模型太容易被形式化地定义了。根据数据性质,自动生成各个领域的端到端(end2end)的模型也逐渐在工业上可用了:图像语音和广告推荐的飞速发展,直接套用即可。理论和经验越来越完善,人变得越来越可替代。
- 以前需要大力气搭建的数据回流和预测的链路,已经成了公司的基础组件,数据工程师没事干了;
- 特征可以自动生成和优选,特征工程师失业了;
- 深度网络采用经典结构即能满足一般业务需求,参数搜索在AutoML下变得越来越方便,调参工程师的饭碗也丢了 。
- 此处引用老板经常说的一句话:机器都能干了,要你干吗?
应用领域
- 广告/推荐领域已经逐渐成熟,很多技巧沉淀为一整套方法论,已进入平台期;
- 下一个即将被攻陷的领域应该是图像;
- 而文本由于其内在的抽象性和模糊性,应该是算法工程师最后的一块净土,但这个门槛,五年内就会有爆发式的突破
- 2018年谷歌BERT横扫11项NLP任务记录,麻蛋。
人工智能一定会更加两极化:偏基础的功能一般程序员就能搞定,像白开水一样普通。而针对更复杂模型甚至强人工智能的研究会成为少数人的专利。
传统意义的软件开发和产品设计,远比AI算法的需求来的多。算法永远是锦上添花,而非雪中送炭,再好的算法也拯救不了落后的业务和商业模式。一旦经济下行,企业首要干掉的就是锦上添花且人力成本较高的部分。
如果你是顶级的算法专家,这样的问题根本不需担心。但是,对大部分人来说,如何找到自己的梯度上升方向,实现最优的人生优化器呢?
一些不成熟的小建议,供读者抛砖引玉:
- 首先是深入原理和底层,类似TensorFlow的核心代码至少要读一遍吧?就算没有严格的理论基础,最起码也不能瞎搞啊。 切莫不能被工具带来的易用性迷惑双眼。要熟悉工具箱里每种函数的品性,对流动在模型里的数据有足够的嗅觉,在调参初期就能对不靠谱的参数快速剪枝。
- 其次,工程能力不能丢,太多做算法眼高手低的例子了:一个文件写所有,毫无架构和封装;遍地是临时方案和trick,前人挖坑后人栽;稳定性考虑不足,导致线上服务经常挂掉。 没有工程和架构的积累,在团队作战时可能还不是太大问题,单兵打天下则处处碰壁。
- 按个人理解,做算法带来的最大收获是科学精神和实验思维,这是做工程很难培养出来的。以前看论文看了introduction和模型设计,草草地读一下实验结果就完事儿了。殊不知AB实验设计很可能才是论文的核心:实验样本是否无偏,实验设计是否严谨,核心效果是否合理,是否能证明论文结论。也许一行代码和一个参数的修改,背后是艰辛的思考和实验,做算法太需要严谨和缜密的思维了。即使未来不做算法,这些经验都会是非常宝贵的财富。
- 再者是尽早面向领域,面向人和业务。AI本身只是工具,它的抽象性并不能让其成为各个领域的灵丹妙药。 如果不能和AI专家在深度上竞争,就在业务领域专精深挖,拥有比业务人员更好的数据敏感度,成为跨界专家。现在已经有大量AI+金融, AI+医疗,AI+体育的成功案例。 人能熟悉领域背后的数据,背后的人性,这是机器短时间内无法代替的,跨界带来的组合爆炸,也许暗含着危机中的机会吧。
停止学习框架,专注基础知识
- 【2019-05-08】Stop Learning Frameworks
观点:直接学tensorflow、pytorch,别学数学+python了
- 我们每天学习编程语言、框架和库。我们知道的工具越新越好。但这一切都是在浪费时间!
- 时间是我们拥有的最宝贵的资源。时间是有限的,不可更新的,并且是你不能买到的。
- 科技就像时尚一样,它也在以光速变化。为了赶上时间的变化,我们需要跑得很快。这场比赛没有赢家,因为它没有终点。
技术变了又变,但它们都有共通性。正确地设置优先级:你需要把 80% 的时间花在基础学习上,然后剩下 20% 的时间留给框架,库和工具的学习
- 技术存在的时间越长,学习它就越安全。
- 不要急于学习新技术——它有很高的消亡概率。
- 时间是最好的导师,它会证明哪些技术值得学习,所以请学会等待。
- 十年过去了,我经历了 50 个不同的软件项目。感谢这些建议,我学到的所有东西都可以跨公司、团队、跨领域使用。今天,我所学的知识仍然有用。我没有浪费时间。
- 只有深入研究项目的本质,你才会发现它们都是相似的:
- 编程语言是不同的,但设计是相似的。
- 框架是不同的,但设计模式是可以通用的。
- 开发者是不同的,但与人打交道的规则是统一的。
- 记住:框架、库和工具是会变化的。时间是宝贵的。
- 请将宝贵的时间花在可移植的技能上:
- 微服务→框架进化体系结构
- 新的编程语言→干净的代码,设计模式,DDD
- 量少安全→精简编码原则
- 高端→容错的模式
- 容器→持续交付
- Angular→网页、HTTP 和 REST
什么是优秀
【2021-8-12】
(1)我眼中的优秀:
- ① 理论基础,广度深度兼备,自圆其说,具备相对完整的知识体系,尤其是基础知识,sota技术半年一更新,但基础知识几十年不变
- ② 工程能力,linux,数据库,机器学习,web服务,编程语言等
- ③ 学习能力和好奇心,短时间内掌握某门技术,较强的领域迁移能力,同时不但探索未知,走出舒适区
- ④ 项目思维,业务理解,任务拆分,数据分析,使命必达。
我经常问候选人的一道题,生活中常见的暴恐识别,70%的人提到分类(未必分得清与回归的关系),50%的人分得清训练集/测试集/验证集,30%的人正确设置评估指标/知晓特征工程,20%的人意识到不均衡问题,10%知道模型部署/漂移,5%能转化到异常检测,1%随手用TensorFlow写出LR代码
(2)怎么在简历中证明?
技术博客/笔记,github项目和竞赛可以支撑①②,论文支持①,实习支持②③④;以上非必须,有更好,不过别“露馅”:技术博客/github几年不更新;论文也只是挂挂名,打打杂,核心亮点吱吱呜呜;实习项目说不清楚背景、目标、指标、技术链路、问题
(3)应届生/在校生如何准备?
- ① 找项目练手,全程参与,不一定非得实习(参考:https://www.yanxishe.com/questionDetail/8455),kaggle上任务多得是,还有优秀“答案”,比赛除了名次,更重要的是培养业务/项目思维,与高手过招,打通技术领域隔阂
- ② 从项目中提炼技术点,看书/博客深入研究、总结,沉淀出自己的笔记. 30-40%候选人能解释清楚项目中的技术点,但只有10%的人能说清楚为什么这么做
- ③ 代码练习,触类旁通;阿里校招时,有个985学霸说leetode刷了3-5遍,我变了下题目,跪了。
(4)应届生典型画像
- ① 沉迷各种sota算法,看不上数据挖掘/机器学习/架构,不停造demo,无法落地
- ② 视野狭窄,局限在某个小领域,工作后拿锤子找钉子
- ③ 业务思维不足,忽略数据背后的意义,导致数据敏感度不足,遇到业务问题一筹莫展
- ④ 迷茫,不知道学什么,该做什么,被动完成任务,没有主动思考项目/任务目标
(5)优秀的人不怕卷:同样是学习,有的人看几个月资料,过半年忘光光;有的人却能写本书
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
