分布式理论知识
为什么要 多GPU
两种原因:
- 第一种:模型在一块GPU上放不下,多块GPU上就能运行完整的模型(如早期的AlexNet)。
- 第二种:多块GPU并行计算可达到加速训练的效果。
【2021-10-13】OpenAI 研究员最新博客:如何在多GPU上训练真正的大模型?,原文链接
- 单个GPU卡的内存有限,许多大模型的大小已经超过了单个GPU,训练深且大的神经网络的主要方法有训练并行加速、各种模型架构以及内存节省设计等。
- (1)并行加速方法:
- 数据并行性:将相同的模型权重复制到多个worker中,并将一部分数据分配给每个worker以同时进行处理。
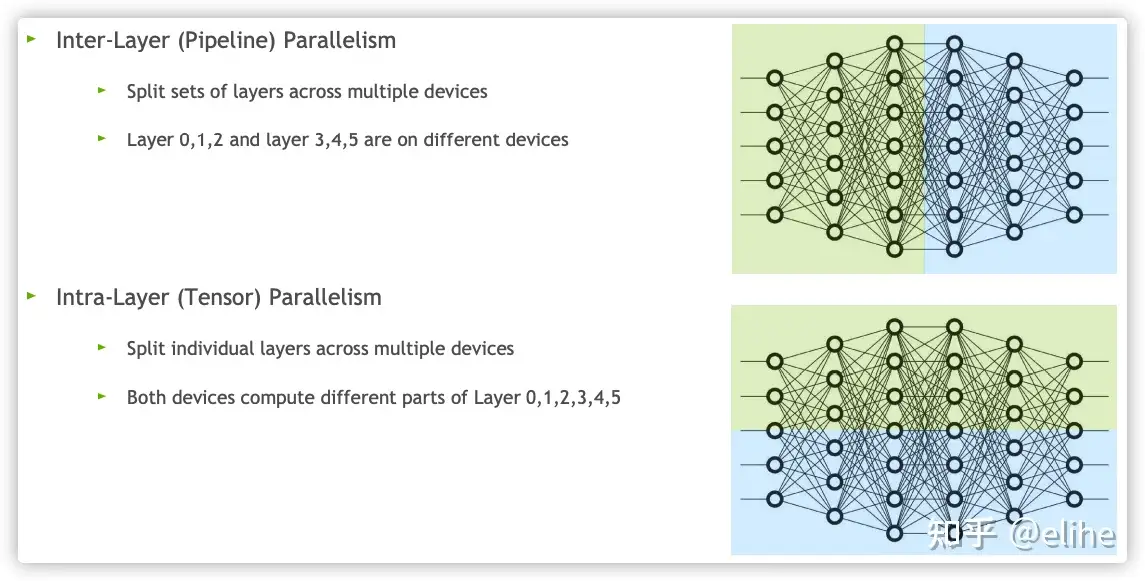
- 模型并行性:按切分方向又分
- 流水线并行:纵向
- 张量并行:横向
- (2)模型架构:专家混合(MoE)方法。
- (3)节省内存方法,如:CPU卸载、激活重新计算、混合精度训练、压缩以及内存高效优化器等等。
- (1)并行加速方法:
语言模型发展
设计分布式训练系统的最重要原因
- 单个计算设备的算力已经不足以支撑模型训练。
机器学习模型快速发展
- 从2013年
AlexNet开始,到2022年拥有5400亿参数的PalM模型,机器学习模型以每18个月增长56倍的速度发展。 - 模型参数规模增大的同时,对训练数据量的要求也指数级增长,这更加剧了对算力的需求。
近几年, CPU算力增加已经远低于 摩尔定律(Moore’s Law)
- 虽然计算加速设备(如GPU、TPU等)为机器学习模型提供大量算力,但是其增长速度仍然没有突破每18个月翻倍的
摩尔定律。
为了能够满足机器学习模型发展,只有通过分布式训练系统才可以匹配模型不断增长的算力需求。
大语言模型参数量和数据量非常巨大,因此都采用了分布式训练架构完成训练。
OPT模型训练用了992块NVIDIA A100 80G GPU,采用全分片数据并行(FSDP)(Fully Sharded Data Parallel)以及 Megatron-LM张量并行(Tensor Parallelism),整体训练时间将近2个月。BLOOM模型在硬件和系统架构方面, 训练一共花费3.5个月,使用48个计算节点, 总计384个GPU- 每个节点包含8块NVIDIA A100 80G GPU
- 并用 4*NVLink 用于节点内部GPU之间通信。节点之间采用四个 Omni-Path 100 Gbps网卡构建的增强8维超立方体全局拓扑网络进行通信。
LLaMA模型训练采用 NVIDIA A100 80GB GPU- LLaMA-7B 模型训练需要 82432 GPU小时
- LLaMA-13B 模型训练需要 135168 GPU小时
- LLaMA-33B 模型训练花费了 530432 GPU小时
- LLaMA-65B 模型训练花费则高达 1022362 GPU小时。
| 模型 | GPU型号 | GPU数目 | 训练时间 | |
|---|---|---|---|---|
OPT |
A100 | 992 | 2个月 | FSDP+TP |
BLOOM |
A100 | 384 | 3.5个月 | |
LLaMA |
A100 | * | * |
性能提速
在 pytorch1.7 + cuda10 + TeslaV100 环境下,用 ResNet34,batch_size=16, SGD 对花草数据集训练:
- 1块 GPU, 一个epoch需要9s
- 2块 GPU 要 5.5s
- 8块 是2s。
问题
- 为什么运行时间不是 9/8≈1.1s ?
- 因为 GPU 数量越多,设备间通讯越复杂,训练速度提升也递减。

误差梯度如何在不同设备间通信?
- 每个GPU训练step结束后,将每块GPU的损失梯度求平均,而不是GPU各算各的。
BN 如何在不同设备间同步?
- 假设 batch_size=2,每个GPU计算的均值和方差都针对这两个样本而言的。
- BN 特性:batch_size 越大,均值和方差越接近与整个数据集的均值和方差,效果越好。
- 多块GPU时,会计算每个BN层在所有设备上输入的均值和方差。
- 如果GPU1和GPU2都分别得到两个特征层,那么两块GPU一共计算4个特征层的均值和方差,即 batch_size=4
- 注意:
- 如果不用同步BN,而是每个设备计算自己的批次数据的均值方差,效果与单GPU一致,仅仅能提升训练速度;
- 如果使用同步BN,效果有一定提升,但是会损失部分并行速度。
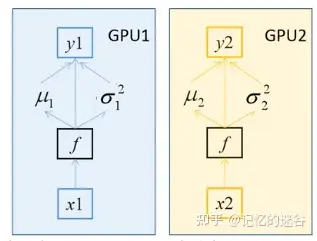
单GPU 是否使用同步BN训练的三种情况,可以看到
- 使用同步BN(橙线)比异步BN(蓝线)总体效果要好,不过训练时间更长。
- 使用单GPU(黑线)和异步BN的效果差不多。

| 维度 | DP | DDP |
|---|---|---|
| 运行环境 | 单机,单进程多线程 | 单/多机,多进程 |
| 速度 | 慢 | 快 |
分布式模式
深度学习任务通用 GPU 进行模型训练。
- 因为 GPU 相对于 CPU 具有更多的算术逻辑单元(
ALU),发挥并行计算的优势,特别适合计算密集型任务,更高效地完成深度学习模型的训练。 - 更多 GPU 知识见站内专题 并行计算GPU
分析
- 虽然 GPU 并行计算能力优异,但无法单独工作,必须由 CPU 进行控制调用;
- 而且显存和内存之间的频繁数据拷贝,可能带来较大的性能开销。
- CPU 虽然计算能力不如 GPU,但可以独立工作,直接访问内存数据完成计算。
因此,想获得更好的训练性能,需要合理利用 GPU 和 CPU 的优势。
分布式目标
分布式训练总体目标: 提升总训练速度,减少模型训练的总体时间。
总训练速度公式:
- 总训练速度 ∝ 单设备计算速度 X 计算设备总量 X 多设备加速比
- 单设备计算速度主要由单块计算加速芯片的运算速度 和 数据I/O能力来决定
- 对单设备训练效率进行优化,主要技术手段: 混合精度训练、算子融合、梯度累加等;
- 分布式训练系统中计算设备数量越多,其理论峰值计算速度就会越高,但是受到通信效率的影响,计算设备数量增大则会造成加速比急速降低;
- 多设备加速比则由计算和通讯效率决定,结合算法和网络拓扑结构进行优化,分布式训练并行策略主要目标就是提升分布式训练系统中的多设备加速比。
CPU + GPU 工作模式
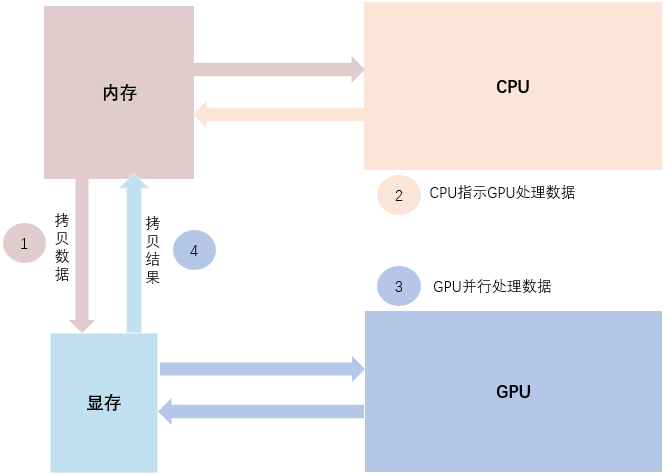
GPU 模式下的模型训练如图所示,分为4步:
- 第1步,将输入数据从系统内存拷贝到显存。
- 第2步,CPU 指示 GPU 处理数据。
- 第3步,GPU 并行地完成一系列的计算。
- 第4步,将计算结果从显存拷贝到内存。
多机协作
【2024-4-11】多机多卡协作
- 更多 GPU 知识见站内专题 并行计算GPU
常见问题
模型训练的常见问题
- 问题一:GPU 显存爆满,资源不足
- V100 为例,其显存最高也仅有 32G,甚至有些显存仅 12G 左右。因此当模型的参数量较大时,在 GPU 模式下模型可能无法训练起来。
- 设置 CPU 模式进行模型训练,可以避免显存不足的问题,但是训练速度往往太慢。
- 如何在单机训练中充分地利用 GPU 和 CPU 资源,让部分层在 CPU 执行,部分层在 GPU 执行呢?
- 问题二:频繁数据拷贝,训练效率低
分布式训练
资料
【2024-8-23】Github 分布式训练总结 tech_slides, pdf
【2024-5-27】 MIT 助理教授 Song Han 的 分布式训练介绍 ppt:
- Distributed Training: part1, part2
- On-Device Training and Transfer Learning
- Efficient Fine-tuning and Prompt Engineering
part1
part2
分片训练
【2025-10-5】分布式模型训练和推理的基石(pytorch完全分片数据并行)
本地训练 vs 分片训练
- 本地训练:模型实例的所有参数都存储在一个设备(如1个 GPU)上。反向传播过程中,所有参数的梯度都可以通过计算得到,因为每个参数都可以直接访问并参与计算。
- 分片训练:模型参数被分割到多个设备上。每个设备只有部分参数,反向传播时,某些参数可能无法直接访问。
完全分片 FSDP
参数 A和 B 分别存储在不同设备上,前向传播和反向传播的计算过程都需要进行通信以获取依赖的参数值。这种依赖关系和通信需求会导致训练过程中的延迟和复杂性,尤其是在模型参数较多或依赖关系复杂时。
完全分片数据并行的两种实现方式:
- 第一种:将模型参数预先传递到需要的设备上,减少等待造成的延时
- 第二种:设备等待参数传递时,对模型中不依赖于当前参数的部分进行计算,有效利用计算资源,减少由于等待通信而造成的空闲时间
模型并行时,将模型分片到不同gpu,策略:
- (1) 完全分片数据并行(full sharded data parallel,
FSDP) - (2) 混合分片数据并行(hybrid sharding data parallel,
HSDP)
FSDP 核心思想和工作原理:
- FSDP 对模型分片,支持大型模型的训练,即使这些模型无法完全装载到单个 GPU 设备中。
- FSDP 将模型实例分解为多个较小的单元(unit),并独立处理每个单元,减少内存占用。
- 在前向传播和反向传播计算过程中,FSDP 只会物化(materialize)当前单元的未分片参数和梯度,其他单元的参数和梯度保持分片状态。
- 在整个训练循环中,优化器状态也保持分片状态。
- FSDP 内存需求与分片模型的大小加上最大完全物化单元的大小成正比。
示意图
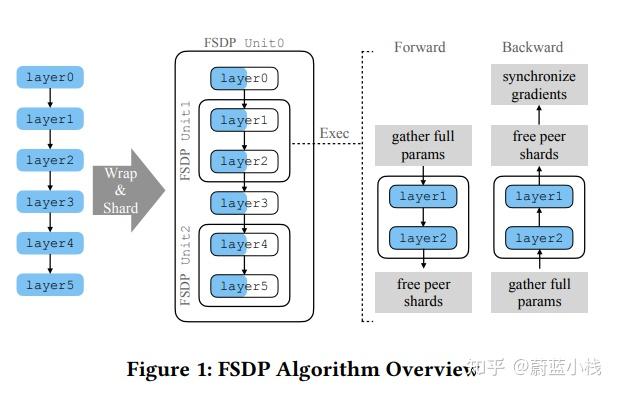
完全分片数据并行算法处理过程:
- 前向传播过程中,FSDP将模型分解为多个单元, 每个单元包含部分层。
- 单元0包含
[layer0, layer3] - 单元1包含
[layer1, layer2] - 单元2包含
[layer4, layer5]。
- 单元0包含
- 进入layer1 前,FSDP 收集layer1和layer2所需的未分片参数,执行这些层的计算,然后释放收集到的参数。
- 确保整个前向传播过程中,FSDP只需完全物化一个单元的参数。
- 反向传播过程中,梯度计算是按照层的顺序进行,与前向传播的顺序相反。
- 反向传播首先到达layer5,然后是layer4,layer3,layer2,layer1,layer0。
- 当反向传播到达layer2时,FSDP需要恢复layer1和layer2的未分片参数,以便正确计算梯度。这是因为layer2的梯度计算需要依赖layer1的输出。
- 计算完layer1和layer2的梯度后,FSDP会释放这些未分片参数,并发起ReduceScatter操作来减少和分片梯度。
FSDP出现前,PyTorch 要求整个模型实例必须在一个设备上完全物化(即在内存中分配所有参数)。
- 这对于大型模型来说不现实,因为可能超出单个GPU的内存限制。
- 另外,用户在定义模型时,通常会指定参数的初始化方式,比如使用Xavier初始化、Kaiming初始化等。这些初始化逻辑确保了模型参数在训练开始时具有合适的取值范围。而这种初始化方式也必须通过封装传递到计算设备上。
为了解决初始化中的问题,pytorch 使用延迟初始化技术, 创建模型实例时,不会立即在实际的GPU设备上分配内存。相反,它会在一个特殊的模拟或”假”设备上分配模型参数的张量。
FSDP2 在集成 FSDP1 基础功能的前提下,摒弃了 FSDP1 将参数压扁拼接的做法,转而基于 DTensor 实现逐参数切分,这一架构升级在完整保留模型原始结构的同时,显著提升了计算与通信的重叠效率,进而增强训练性能。
- Llama-factory FSDP2
混合分片 HSDP
当模型参数量远大于偏置参数时,不可能都使用同样的分片策略来处理这些参数。
因此,Hybrid Sharding (混合分片) 将模型参数分为两类,并采用不同的分片组来管理。
- 大参数:占用内存较多的参数,例如权重参数
- 小参数:占用内存较少的参数,例如偏置参数
对于不同类型的参数,采用不同的分片策略:
- 大参数: 使用传统的FSDP分片方式,即将参数分成多个块,每个块分配给一个计算设备。
- 小参数: 将所有小参数集中到一个设备上,不进行分片。
Hybrid Sharding 中,参数被分为分片组和复制组:
分片组:在每个分片组内,参数被分片并分配给不同的 GPU 设备。- Hybrid Sharding 中,模型参数被分成多个组,每个组称为
分片组(sharded group)。 - 每个分片组内的参数被分配到不同的 GPU 设备上。
- Hybrid Sharding 中,模型参数被分成多个组,每个组称为
复制组:在每个复制组内,所有设备持有相同的参数副本。
混合分片下,FSDP是如何进行梯度计算的呢?依赖于两个操作(Reduce-Scatter和All-Reduce),在这两个分片组中进行不同的处理逻辑。
通信技术
分布式条件下的多进程、多worker之间的通信技术,常见的主要有:MPI、NCCL,GRPC等。
- MPI主要是被应用在超算等大规模计算领域,机器学习场景下使用较少。主要是openMPI原语等。
- NCCL是NVIDIA针对GPU设计的一种规约库,可以实现多GPU间的直接数据同步,避免内存和显存的,CPU和GPU间的数据拷贝成本。当在TensorFlow中选择单机多卡训练时,其默认采用的就是NCCL方式来通信。
- GRPC是比较成熟的通信技术了,spark等框架内也都有用到。
演变
- 早期MPI在CPU和GPU的分布式通信领域都是主力军
- 在NCCL推出之后
- MPI库现在就只用在了CPU分布式通信场景
- 而GPU分布式通信库目前都是以NCCL为主(NV场景)。
通信方式
Pytorch 分布式训练通信依赖torch.distributed模块,torch.distributed提供了point-2-point communication 和collective communication两种通信方式。
- 点对点 point-2-point communication(
P2P)提供了send和recv语义,用于任务间的通信。 - 收集 collective communication(
CC)提供了 scatter/broadcast/gather/reduce/all_reduce/all_gather 语义,不同的backend在提供的通信语义上具有一定的差异性。
训练大模型主要是CC通信
GPU 通信技术
【2024-6-17】GPU通信技术:GPU Direct、NVLink与RDMA
GPU通信技术是加速计算的关键,其中GPU Direct、NVLink和RDMA是三种主流技术。
RDMA(Remote Direct Memory Access)是一种远程直接内存访问技术,允许一个设备直接访问另一个设备上的内存数据。在GPU通信中,RDMA技术用于加速GPU与CPU、GPU与GPU以及GPU与网络之间的数据传输。
DMA 是“直接内存读取”的意思,用来传输数据,它也属于外设。只是在传输数据时,无需占用CPU。
- 高速IO设备可以在处理器安排下直接与主存储器成批交换数据,称为直接存储器访问(Directly Memory Access 简称DMA)
比如GPU与CPU之间存在着大量的数据传输.
- CPU将需要显示的原始数据放在内存中,让GPU通过DMA的方式读取数据,经过解析和运算,将结果写至显存中,再由显示控制器读取显存中的数据并显示输出.
GPU与CPU集成至同一个处理器芯片时,能够大大减少芯片间的数据搬运,同时因为显存和内存的合并,会大大增加访存压力
DMA传输方向有三个:外设到内存,内存到外设,内存到内存。
外设到内存。即从外设读取数据到内存。例如ADC采集数据到内存,ADC寄存器地址为源地址,内存地址为目标地址。内存到外设。即从内存读取数据到外设。例如串口向电脑发送数据,内存地址为源地址,串口数据寄存器地址为目标地址。此时内存存储了需要发送的变量数据。内存到内存。以内部flash向内部sram传输数据为例,此时内部flash地址即为源地址,内部sram地址即为目标地址。同时,需要将DMA_CCRx寄存器的MEM2MEM置位。
一、GPU Direct
GPU Direct 是一种优化GPU之间或GPU与第三方设备之间数据传输的技术。它通过共享内存访问和点对点通信减少了数据复制和传输延迟。
(1) GPU Direct Shared Memory
2010年,NVIDIA推出了GPU Direct Shared Memory技术,允许GPU与第三方PCI Express设备通过共享的host memory实现共享内存访问。这使得内存空间得以共享,减少了数据复制,降低了数据交换延迟。
(2) GPU Direct P2P (Peer-to-Peer)
2011年,GPU Direct增加了Peer-to-Peer(P2P)技术,支持同一PCI Express总线上的GPU之间的直接访问和传输。这种技术绕过了CPU,使得GPU之间通信更加高效。
(3) GPU Direct RDMA
2013年,GPU Direct增加了RDMA(Remote Direct Memory Access)支持。
RDMA允许第三方PCI Express设备绕过CPU host memory,直接访问GPU内存。这种技术大幅提升了数据传输效率,尤其适用于高性能计算和数据中心等场景。
二、NVLink
NVLink是一种专门设计用于连接NVIDIA GPU的高速互联技术。它通过点对点通信方式,绕过传统的PCIe总线,提供了更高的带宽和更低的延迟。
带宽与延迟 NVLink采用串行协议,支持双向数据传输,每个方向都有高达32GB/s的带宽。这使得两个GPU之间能够实现高速数据传输和共享,为多GPU系统提供了更高的性能和效率。与传统的PCIe总线相比,NVLink显著降低了通信延迟。
连接与扩展 NVLink可用于连接两个或多个GPU,以实现多GPU协同工作。这种连接方式简化了系统架构,提高了可扩展性。通过NVLink连接的GPU可以共享数据和计算资源,从而在某些应用中实现性能倍增。
三、RDMA
RDMA(Remote Direct Memory Access)是一种远程直接内存访问技术,允许一个设备直接访问另一个设备上的内存数据。在GPU通信中,RDMA技术用于加速GPU与CPU、GPU与GPU以及GPU与网络之间的数据传输。
DMA原理 在介绍RDMA之前,我们需要理解DMA(Direct Memory Access)原理。DMA是一种技术,允许硬件控制器直接从内存读取或写入数据,而不需要经过CPU。这大大减轻了CPU的负担,提高了数据传输效率。RDMA基于此原理,进一步扩展了其应用范围。
RDMA的优势 RDMA提供了高带宽和低延迟的数据传输能力。它利用网卡等设备的远程直接内存访问功能,允许设备之间快速高效地传输大量数据。在高性能计算、数据中心和云计算等领域,RDMA成为提高系统性能的关键技术之一。
GPU与RDMA的结合 通过将RDMA与GPU相结合,可以实现高性能的GPU通信。在这种配置中,GPU可以借助RDMA直接访问其他设备或网络的内存数据,从而避免了不必要的CPU中介和数据拷贝。这不仅提高了数据传输速率,还降低了CPU负载和功耗。
总结: GPU通信技术在加速计算领域发挥着越来越重要的作用。GPU Direct、NVLink和RDMA是三种主流的GPU通信技术,它们分别通过共享内存访问、高速互联和远程直接内存访问等方式提高了GPU之间的通信效率。在实际应用中,根据不同的场景和需求选择合适的通信技术至关重要。随着技术的不断发展,未来我们有望看到更多创新性的GPU通信解决方案,为高性能计算和数据中心等领域带来更大的性能提升。
如何选择
PyTorch 支持
torch.distributed 支持 3 种后端,分别为 NCCL,Gloo,MPI
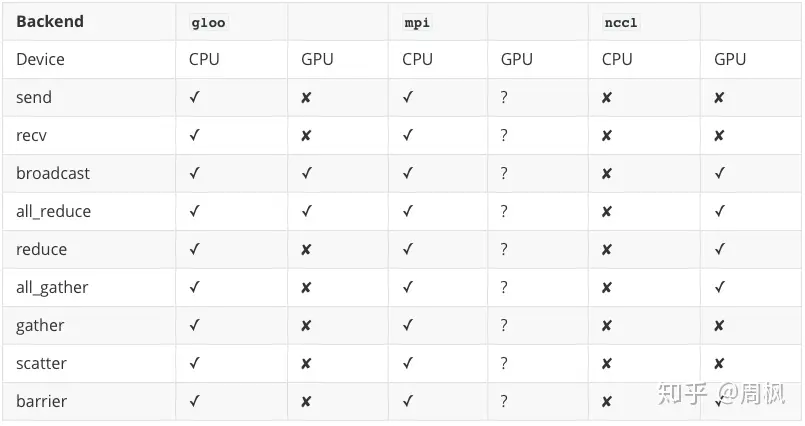
如何选择?
- NCCL 目前最快,且对多进程分布式(Multi-Process Single-GPU)支持极好,可用于单节点以及多节点的分布式训练。
- 节点即主机。即使是单节点,由于底层机制不同, distributed 也比 DataParallel 方式要高效。
基本原则:
- 用 NCCL 进行分布式 GPU 训练
- 用 Gloo 进行分布式 CPU 训练
无限带宽互联的 GPU 集群
- 使用 NCCL,因为它是目前唯一支持 InfiniBand 和 GPUDirect 的后端
无限带宽和 GPU 直连
- 使用 NCCL,因为其目前提供最佳的分布式 GPU 训练性能。尤其是 multiprocess single-node 或 multi-node distributed 训练。
- 如果用 NCCL 训练有问题,再考虑使用 Cloo。(当前,Gloo 在 GPU 分布式上,相较于 NCCL 慢)
无限带宽互联的 CPU 集群
- 如果 InfiniBand 对 IB 启用 IP,请使用 Gloo,否则使使用 MPI。
- 在未来将添加 infiniBand 对 Gloo 的支持
以太网互联的 CPU 集群
- 使用 Gloo,除非有特别的原因使用 MPI。
MPI 后端
MPI 即消息传递接口(Message Passing Interface),来自于高性能计算领域的标准的工具。
- 支持点对点通信以及集体通信,并且是 torch.distributed 的 API 的灵感来源。
- 使用 MPI 后端的优势: 在大型计算机集群上,MPI 应用广泛,且高度优化。
但是,torch.distributed 对 MPI 并不提供原生支持。
因此,要使用 MPI,必须从源码编译 Pytorch。是否支持 GPU,视安装的 MPI 版本而定。
Gloo 后端
gloo 后端支持 CPU 和 GPU,其支持集体通信(collective Communication),并对其进行了优化。
由于 GPU 之间可以直接进行数据交换,而无需经过 CPU 和内存,因此,在 GPU 上使用 gloo 后端速度更快。
torch.distributed 对 gloo 提供原生支持,无需进行额外操作。
NCCL 通信原语
NCCL 是 Nvidia专门为多GPU提供集合通讯的通讯库,多GPU卡通讯框架,具有一定程度拓扑感知能力,提供了包括:
- 集合通讯API: AllReduce、Broadcast、Reduce、AllGather、ReduceScatter等
- 支持用户点对点通讯: ncclSend()、ncclRecv() 来实现各种复杂通信,如 One-to-all、All-to-one、All-to-all等
- 在绝大多数情况下都可以通过服务器内的PCIe、NVLink、NVSwitch等和服务器间的RoCEv2、IB、TCP网络实现高带宽和低延迟。
nccl 解决了GPU间拓补识别、GPU间集合通信优化的问题。NCCL屏蔽了底层复杂的细节,向上提供API供训练框架调用,向下连接机内机间的GPU以完成模型参数的高效传输。
【2023-7-27】大模型-LLM分布式训练框架总结
NCCL 的全称为 Nvidia 聚合通信库(NVIDIA Collective Communications Library),是一个可以实现多个 GPU、多个结点间聚合通信的库,在 PCIe、Nvlink、InfiniBand 上可以实现较高的通信速度。
NCCL 高度优化和兼容了 MPI,并且可以感知 GPU 的拓扑,促进多 GPU 多节点的加速,最大化 GPU 内的带宽利用率,所以深度学习框架的研究员可以利用 NCCL 的这个优势,在多个结点内或者跨界点间可以充分利用所有可利用的 GPU。
NCCL 对 CPU 和 GPU 均有较好支持,且 torch.distributed 对其也提供了原生支持。
对于每台主机均使用多进程的情况,使用 NCCL 可以获得最大化的性能。每个进程内,不许对其使用的 GPUs 具有独占权。若进程之间共享 GPUs 资源,则可能导致 deadlocks。
NCCL 英伟达集合通信库专用于多个 GPU 乃至多个节点间通信。
- 专为英伟达的计算卡和网络优化,能带来更低的延迟和更高的带宽。
常用参数
修改环境变量或在 nccl.conf 中修改相关参数选项。可以改变通信特点,进而起到影响通行性能的作用。
- NCCL_P2P_DISABLE 默认是开启P2P通信的,这样一般会更高效,用到点对点通信延迟会有所改善,带宽也是。
- NCCL_P2P_LEVEL 开启P2P后可以设置P2P的级别,比如在那些特定条件下可以开启点对点通信,具体的可以参看文档(0-5)
- NCCL_SOCKET_NTHREADS 增加它的数量可以提高socker传输的效率,但是会增加CPU的负担
- NCCL_BUFFLE_SIZE 缓存数据量,缓存越大一次ring传输的数据就越大自然对带宽的压力最大,但是相应的总延迟次数会少。缺省值是4M(4194304),注意设置的时候使用bytes(字节大小)
- NCCL_MAX/MIN_NCHANNELS 最小和最大的rings,rings越多对GPU的显存、带宽的压力都越大,也会影响计算性能
- NCCL_CHECKS_DISABLE 在每次集合通信进行前对参数检验校对,这会增加延迟时间,在生产环境中可以设为1.缺省是0
- NCCL_CHECK_POINTERS 在每次集合通信进行前对CUDA内存 指针进行校验,这会增加延迟时间,在生产环境中可以设为1.缺省是0
- NCCL_NET_GDR_LEVEL GDR触发的条件,默认是当GPU和NIC挂载一个swith上面时使用GDR
- NCCL_IGNORE_CPU_AFFINITY 忽略CPU与应用的亲和性使用GPU与nic的亲和性为主
- NCCL_ALGO 通信使用的算法,ring Tree Collnet
- NCCL_IB_HCA 代表IB使用的设备:Mellanox mlx5系列的HCA设备
A40(GPU3-A40:596:596 [2] NCCL INFO NET/IB : Using [0]mlx5_0:1/IB ; OOB ib0:66.66.66.211<0>),
V100(gpu196-v100:786:786 [5] NCCL INFO NET/IB : Using [0]mlx5_0:1/IB [1]mlx5_1:1/IB ; OOB ib0:66.66.66.110<0>),
A100(GPU6-A100:686:686 [1] NCCL INFO NET/IB : Using [0]mlx5_0:1/RoCE [1]mlx5_2:1/IB [2]mlx5_3:1/IB ; OOB ib0:66.66.66.128<0>),
- NCCL_IB_HCA=mlx5 会默认轮询所有的设备。
- NCCL_IB_HCA=mlx5_0:1 指定其中一台设备。
a100有两个口,如果都开的话,会出现训练的浮动;如果指定只使用一个口,训练速度会下降。
原语
Broadcast: 一对多的通信原语,一个数据发送者,多个数据接收者,可以在集群内把一个节点自身的数据广播到其他节点上。Scatter: 一对多的通信原语,也是一个数据发送者,多个数据接收者,可以在集群内把一个节点自身的数据发散到其他节点上。与Broadcast不同的是,Broadcast把主节点0的数据发送给所有节点,而Scatter则是将数据进行切片再分发给集群内所有的节点。Gather: 多对一的通信原语,具有多个数据发送者,一个数据接收者,可以在集群内把多个节点的数据收集到一个节点上。AllGather: 多对多的通信原语,具有多个数据发送者,多个数据接收者,可以在集群内把多个节点的数据收集到一个主节点上(Gather),再把这个收集到的数据分发到其他节点上(broadcast),即收集集群内所有的数据到所有的节点上。Reduce: 多对一的通信原语,具有多个数据发送者,一个数据接收者,可以在集群内把多个节点的数据规约运算到一个主节点上,常用的规约操作符有:求累加和SUM、求累乘积PROD、求最大值MAX、求最小值MIN、逻辑与LAND、按位与BAND、逻辑或LOR、按位或BOR、逻辑异或LXOR、按位异或BOXR、求最大值和最小大的位置MAXLOC、求最小值和最小值的位置MINLOC等,这些规约运算也需要加速卡支持对应的算子才能生效。ReduceScatter: 多对多的通信原语,具有多个数据发送者,多个数据接收者,在集群内的所有节点上都按维度执行相同的Reduce规约运算,再将结果发散到集群内所有的节点上。Reduce-scatter等价于节点个数次的reduce规约运算操作,再后面执行节点个数的scatter次操作。其反向操作是AllGather。AllReduce: 多对多的通信原语,具有多个数据发送者,多个数据接收者,在集群内的所有节点上都执行相同的Reduce操作,可以将集群内所有节点的数据规约运算得到的结果发送到所有的节点上。
【2024-8-8】图解见pytorch多GPU训练简明教程
通信原语汇总
汇总如下
| 原语操作 | 模式 | 说明 | 图解 | 示意图 |
|---|---|---|---|---|
Broadcast |
广播:一对多 | 广播行为:从节点0广播相同信息到其它节点(0-3) | 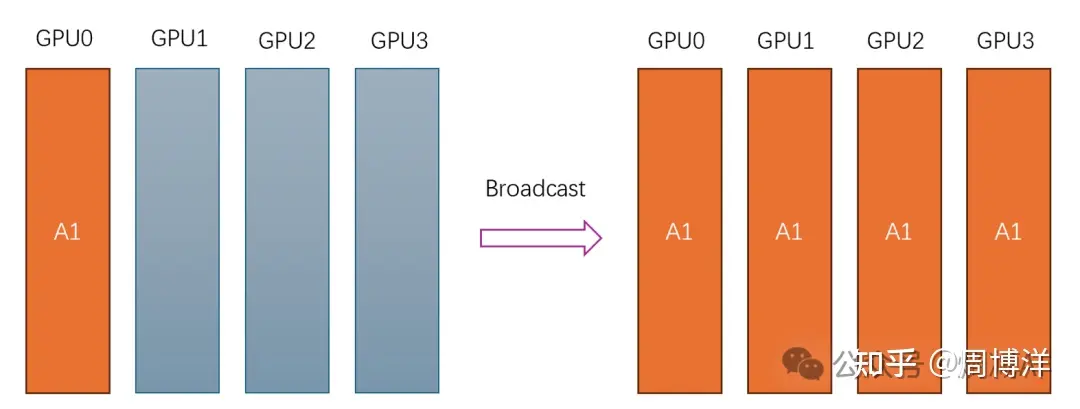 |
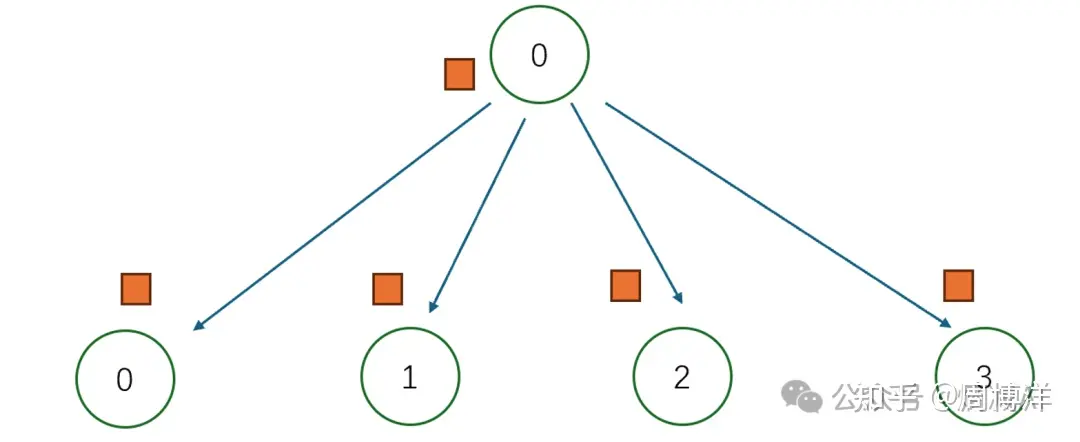 |
Scatter |
一对多 | 另一种广播,从节点0将数据不同部分按需发送到不同节点,常见于DP的数据分配起步阶段 | 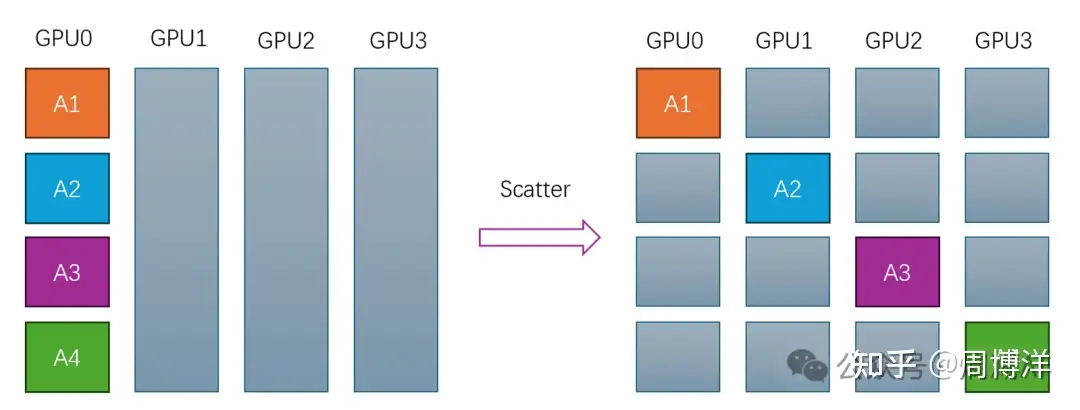 |
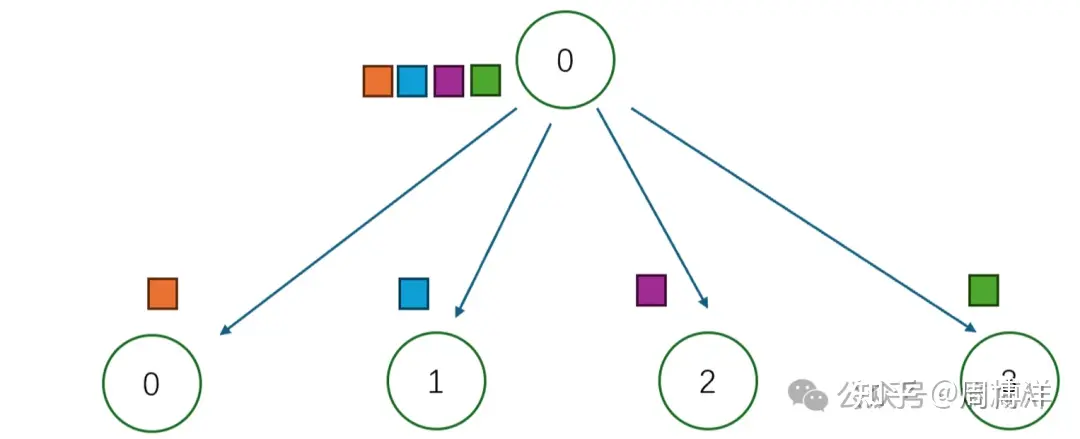 |
Reduce |
规约:多对一 | 规约操作,Reduce意为减少/精简,一系列简单聚合运算,如:sum/min/max,prod,lor等 | 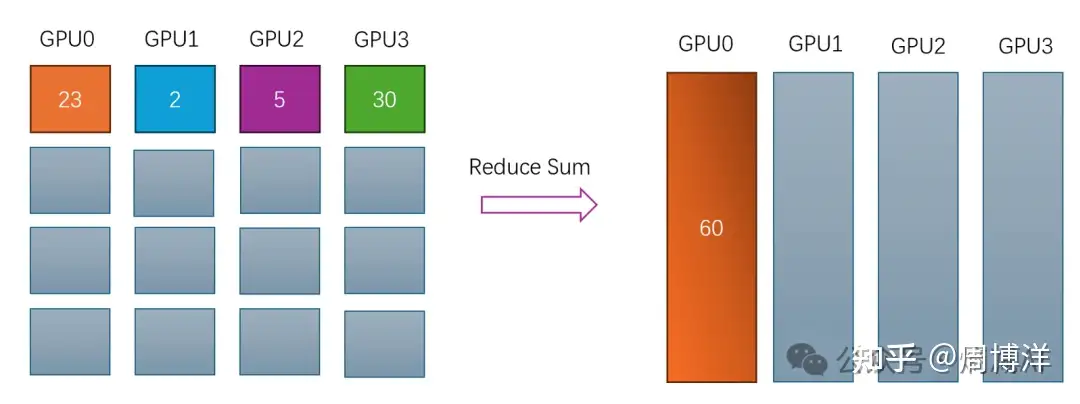 |
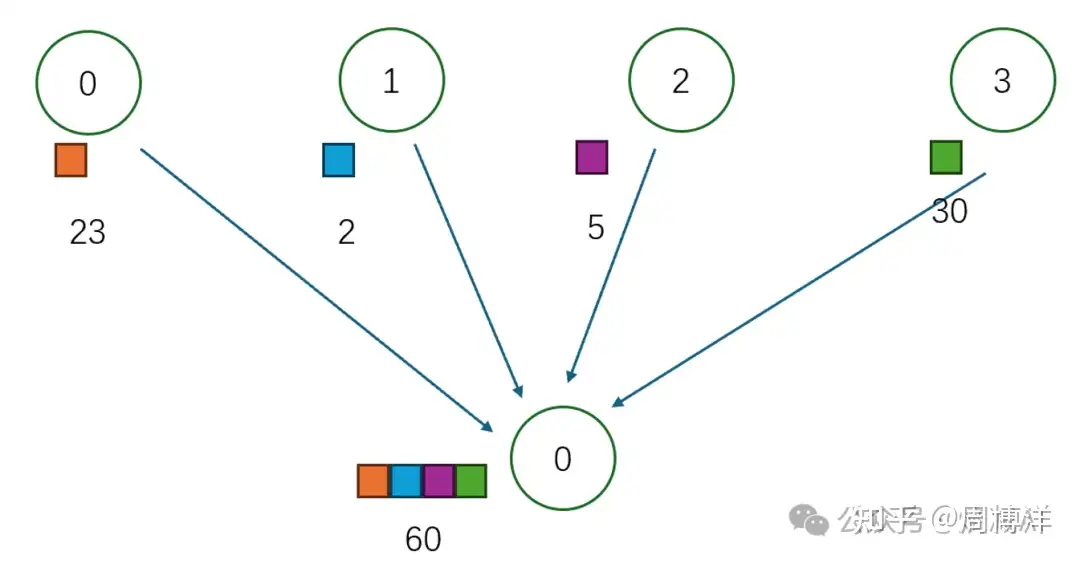 |
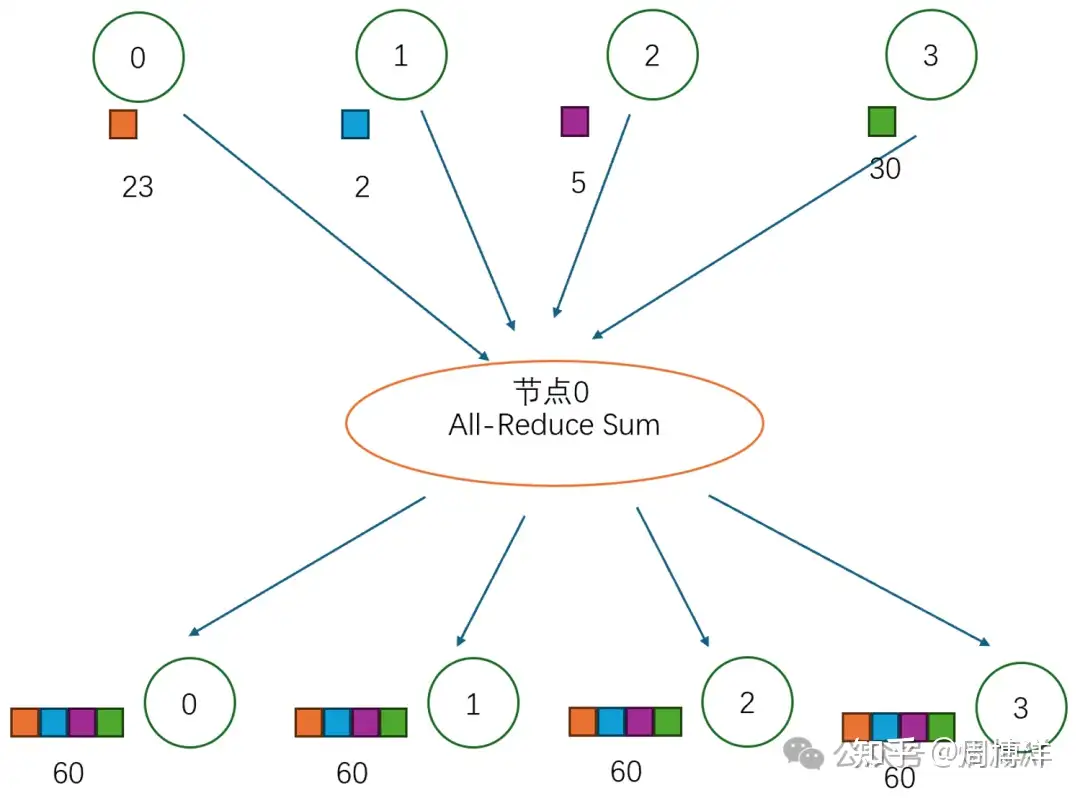
AllReduce |
多对多 | 所有节点上应用相同的Reduce操作,单节点上 Reduce + Broadcast,最消耗带宽 | 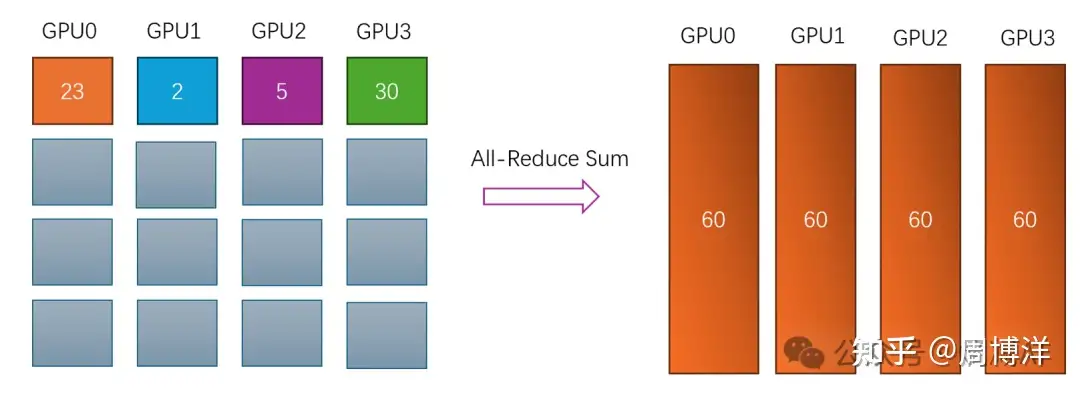 |
 |
Gather |
多对一 | 反向Scatter:将多个Sender的数据汇总到单个节点上 | 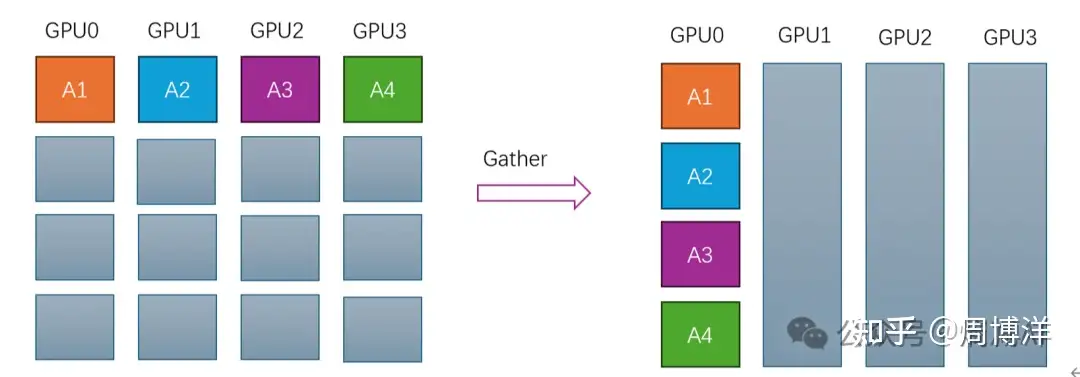 |
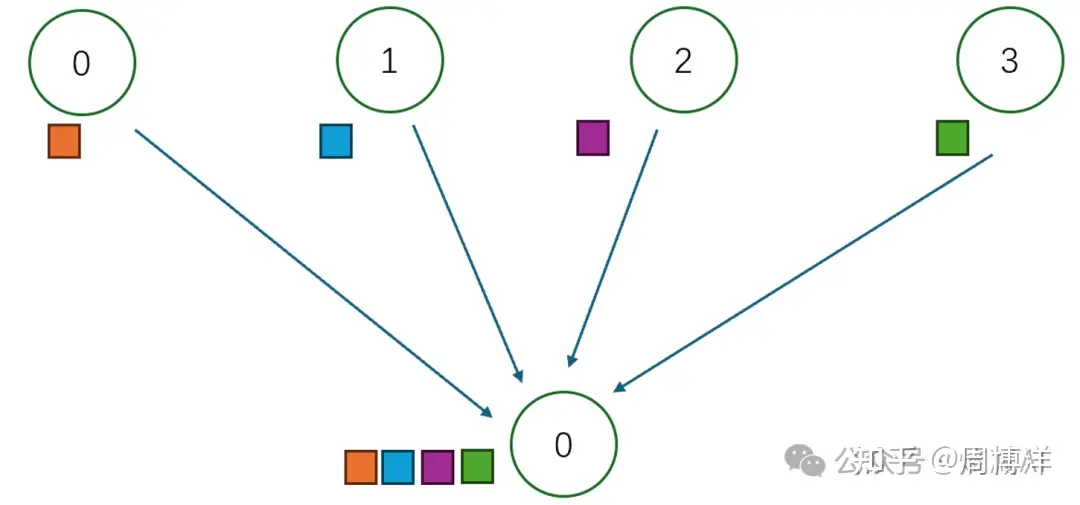 |
AllGather |
多对多 | 收集所有节点到所有节点上, AllGather=Gather+Broadcast |
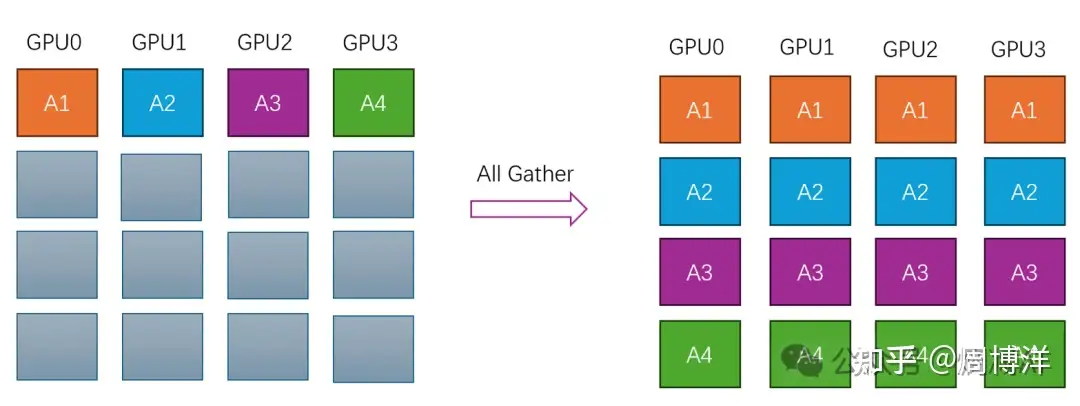 |
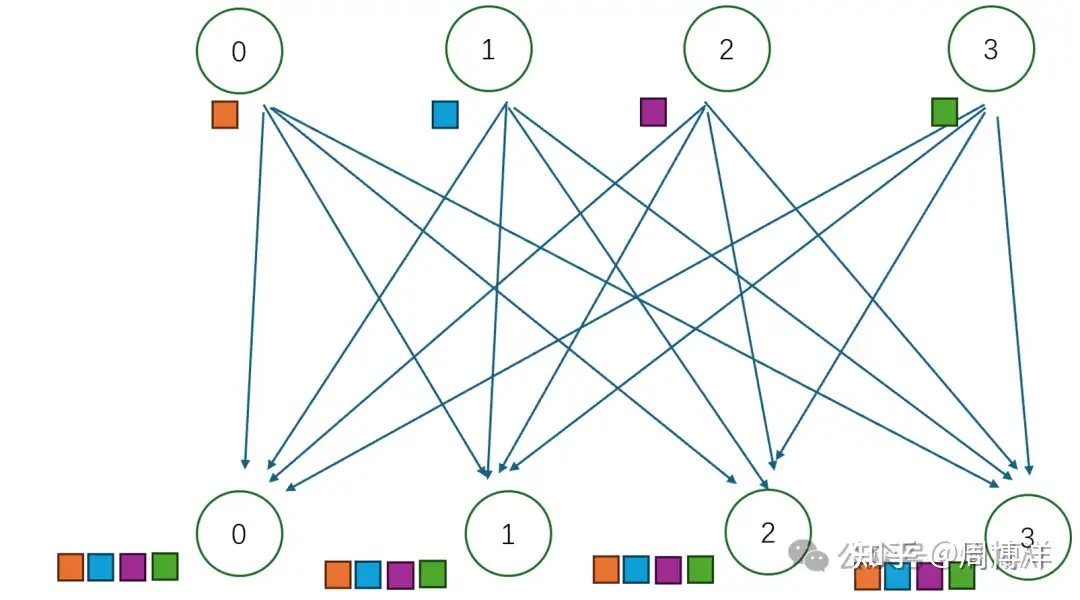 |
ReduceScatter |
将单节点输入求和,再0维度按卡切分并发送, ReduceScatter=Reduce+Scatter |
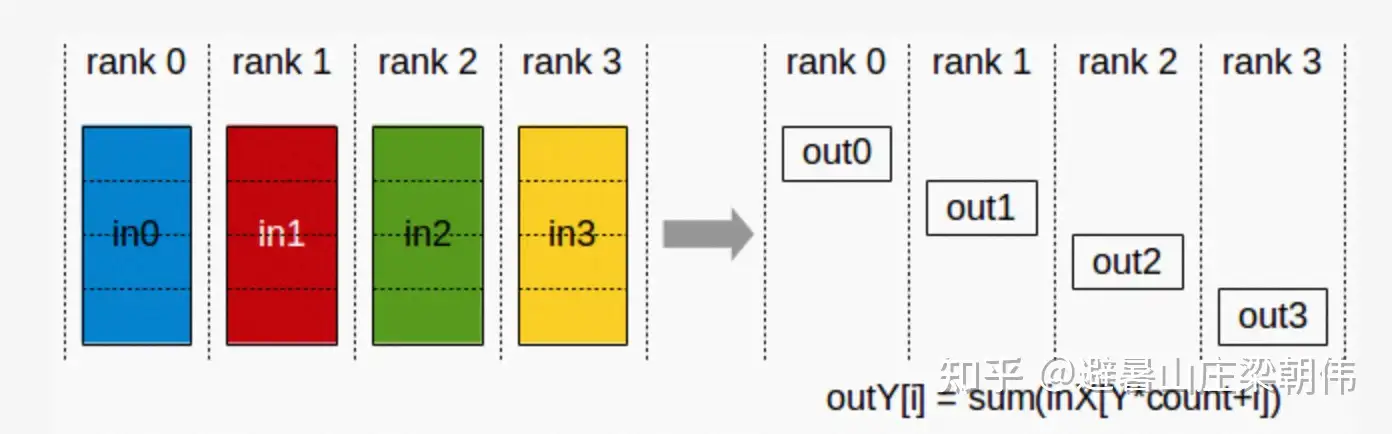 |
||
All2All |
全交换操作,每个节点都获取其他节点的值 | 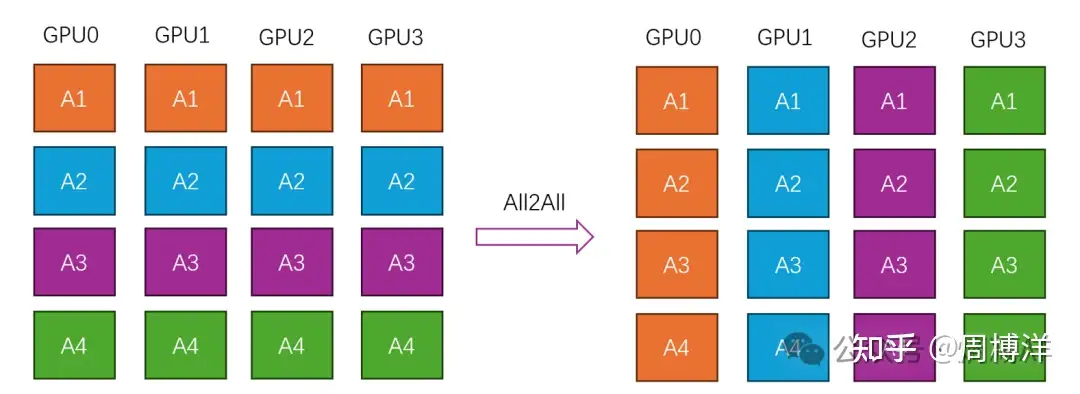 |
All2All 与 All Gather 区别在于:LLM分布式训练第一课(通讯原语)
- All Gather 操作中,不同节点向某一节点收集到的数据是完全相同的
- 而在 All2All 中,不同的节点向某一节点收集到的数据是不同的。
AllReduce 的目标: 将不同机器上的数据整合(reduce)后分发给各个机器
AllReduce 实现方法
- 最简单: 每个worker将自己的数据广播给所有worker —— 问题: 大量浪费
- 改进: 主从架构, 指定一个worker作为master,负责整合运算,以及分发 —— 问题: master成为网络瓶颈
- 改进: Ring AllReduce
Ring AllReduce:
- 第一阶段,将N个worker分布在一个环上,并且把每个worker的数据分成N份。
- 第二阶段,第k个worker把第k份数据发给下一个worker,同时从前一个worker收到第k-1份数据。
- 第三阶段,worker把收到的第k-1份数据和自己的第k-1份数据整合,再将整合的数据发送给下一个worker
- 此循环N次之后,每一个worker都会包含最终整合结果的一份。
假设每个worker的数据是一个长度为S的向量,那么Ring AllReduce里每个worker发送的数据量是O(S),和worker的数量N无关。避免了主从架构中master需要处理O(S*N)数据量而成为网络瓶颈的问题。
Ring All-reduce
- Pytorch 实现:
DistributedDataParallel Ring All-reduce=reduce-scatter+all-gather
NCCL 通信行为分析
【2024-5-10】集合通信行为分析 - 基于NCCL
deepspeed 启动多卡训练时,日志里会打印NCCL通信信息,这些日志都是什么意思?
NCCL 通信阶段
- Phase 1 -
启动阶段 Bootstrap Phase: 初始化集合中的所有节点(node)和卡(rank),确保所有卡知道彼此- Initiate all nodes and then all ranks in a collective. It makes sure all ranks know about all other ranks, so any rank is able to communicate with any other rank.
- Phase 2 -
拓扑阶段 Topology Phase: 每隔节点了解机器上各个硬件(CPU/GPU/NIC)映射关系, 创建内部拓扑结构(树/环),通过PCI和NVLink通信- Each node detects and maps out what hardware is located on the machine.
- Hardware includes CPUs, GPUs, NICs and interconnect types.
- Each node then creates an intra-machine graph, connects hardware with
PCIeorNVLinkinterconnect, and evaluates the graph. - When the intra-machine topology is decided, the system will decide what pattern to use for the whole system.
- The two main patterns are a tree or a ring.
- While the topology is evaluated, NCCL is also tuning it by performing tests. This allows each rank to pre-compute thresholds for message sizes.
- Phase 3 -
聚合阶段 Collective Phase: 用户调用NCCL支持的集合通信原语进行通信- A user can dispatch many collective operations using the same topology.
用户调用NCCL支持的集合通信原语进行通信:
- 集合通信原语
- AllReduce
- Broadcast
- Reduce
- AllGather
- ReduceScatter
- 点对点通信原语
- Send
- Recv
NCCL在getAlgoInfo里面使用ncclTopoGetAlgoTime来遍历计算(algorithm, protocol),最终选择预测会最快做完指定数据量的指定集合通信原语的algorithm和protocol完成该通信原语。
示例
- 以2机16卡, NCCL 2.8.4为例
- NCCL会构建tree,ring graph。
(1) tree
解析
拓扑log格式
# IP: hostname:pid:tid [cudaDev] NCCL INFO Trees [channel ID] down0 rank/down1 rank/down2 rank->current rank->up rank
10.0.2.11: 2be7fa6883db:57976:58906 [5] NCCL INFO Trees [0] 14/-1/-1->13->12 [1] 14/-1/-1->13->12
# 10.0.2.11上的设备5,其rank为13,有两棵树,分别为channel 0和channel 1: channel 0的子节点只有14, 父节点为12; channel 1一样。
channel log格式
# IP: hostname:pid:tid [cudaDev] NCCL INFO Channel [channel ID] current rank[bus ID]->successor rank[bus ID] via transport type
10.0.2.11: 2be7fa6883db:57976:58906 [5] NCCL INFO Channel 00 : 13[3e000] -> 14[40000] via P2P/IPC
# 10.0.2.11上的设备5(rank 为13, bus ID为3e000),其channel 0连接至rank 14,传输方式为P2P/IPC。
结果
依此解析,可得两棵一样的tree,逻辑拓扑如下:img

(2) ring
Ring Logical Topology
拓扑log格式
# IP: hostname:pid:tid [cudaDev] NCCL INFO Channel ring_ID/ring_number: rank0 rank1 … last_rank
10.0.2.12: 94f182076445:82261:83141 [0] NCCL INFO Channel 00/02 : 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 建成了02个ring,其中第0个ring的成员有:0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15,该ring共由16个rank组成。
channel log格式
- 与tree拓扑的格式一致。
可得两个一样的ring,逻辑拓扑如下:img
梯度压缩
分布式训练的 bandwidth 与 latency bottleneck 主要分布在 梯度 all-reduce 和 scatter 过程中
- 其中 联邦学习 受限的地方还有与端侧设备的通讯
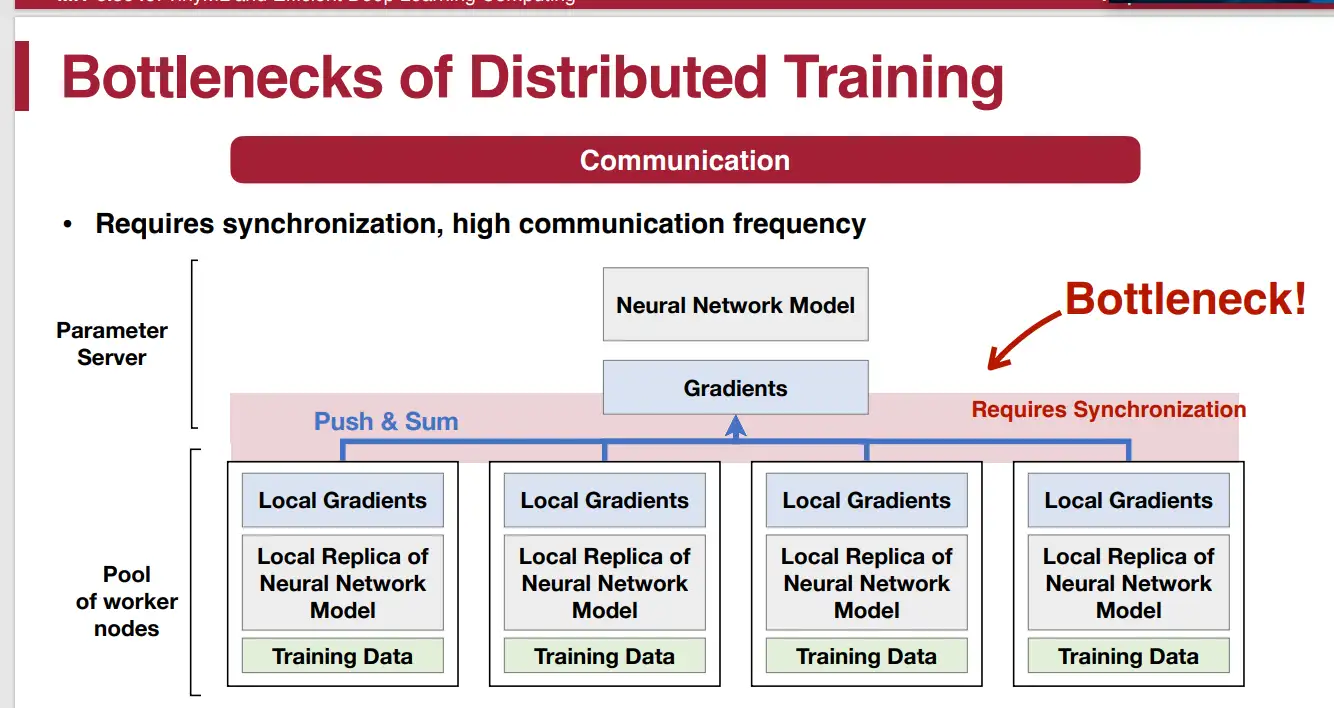
解法:梯度压缩
- 方法1: prune, 【Deep gradient compression】
- worker 向 server push 梯度时, 可以对梯度做 prune (sparse gradient) 与 quantization
- 方法2: Low-Rank 【PowerSGD】,梯度映射到低秩空间,而不是去做细粒度的剪枝和量化
- 2019年 EPFL 的文章 PowerSGD, 发了 NIPS
- 方法3: 量化, 1bit SGD
- 用 one bit 的矩阵作为需要通讯的梯度
- 方法5: terngrad, ternery
- 梯度量化到 0, -1, 1
梯度延迟更新:解决 latency 的 bottleneck
详见: 分布式训练优化–进阶篇
并行技术总结
并行技术:
- 数据并行
dp(如:PyTorch DDP): 每个节点复制完整的模型,数据分片- 内存开销大,通信量低,容易实施
- ZeRO 对 data-parallel 的优化,每个gpu有自己独特的数据,同时模型的参数也被均匀的分到 n个gpu上
- 模型并行
mp: 完整模型只有一份,其它节点只有模型局部张量并行tp: 模型按张量分发- 内存开销小,通信量高,容易实施
- 如:Megatron-LM(1D)、Colossal-AI(2D、2.5D、3D)
流水线并行pp: 模型按层分发- 内存开销小,通信量中等,实施难度大
- 如:GPipe、PipeDream、PipeDream-2BW、PipeDream Flush(1F1B)
- 多维混合并行,如:3D并行(数据并行、模型并行、流水线并行)
- 2D 并行: dp+pp, tp+pp
- 3D 并行: dp+tp+pp
- 自动并行: 自动搜索并行空间
- 如:Alpa(自动算子内/算子间并行)), 将并行空间分为 inter-op (pipeline) 与 intra-op (tensor并行),使用NAS搜索这两个空间,考虑整个搜索空间的cost。
- 优化器相关并行(如:ZeRO 和 FSDP
- ZeRO(零冗余优化器,在执行的逻辑上是数据并行,但可以达到模型并行的显存优化效果)
- PyTorch FSDP
【2025-4-6】并行技术图解,gif 动图显示各种方法区别

【2023-12-15】MIT 端侧模型训练课程: TinyML and Efficient Deep Learning Computing, 含 ppt 和 视频
- powerful deep learning applications on resource-constrained devices.
- Topics include model compression, pruning, quantization, neural architecture search, distributed training, data/model parallelism, gradient compression, and on-device fine-tuning. application-specific acceleration techniques
模型切分分3个互相正交的维度:[data, model-layer, model-activation(Tensor)]
- 这3个维度互不影响,可同时实现,即
3D parallelism。 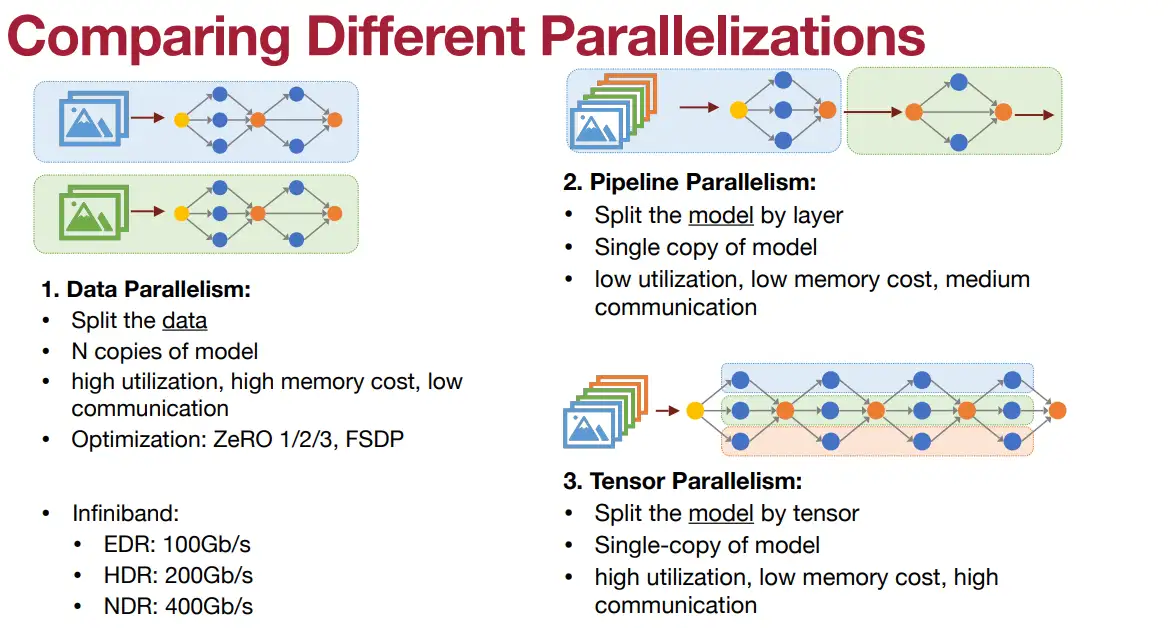
| 并行维度 | 切分方式 Split | 模型完整性 | 通讯 | 对gpu的利用 | 优化手段 |
|---|---|---|---|---|---|
| data | data | Copy of whole model | 非常少 (只有前向和反向的时候需要通讯) | High (for 训练加速) | ZeRO |
| pipeline | model-layer | Part of model | 中等 | Low (for 显存占用太多,优化显存) | |
| tensor | model-tensor | Part of model | 很多(每个需要reduce的中间结果都要通讯) | High (模型算到底再通讯) |
详见: 分布式训练优化–进阶篇
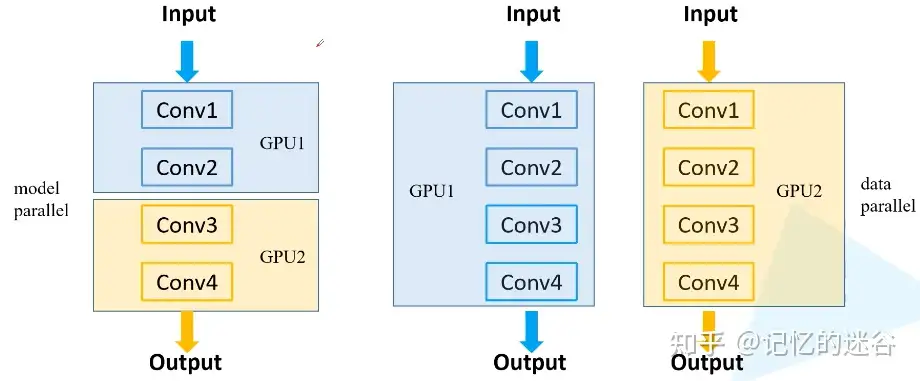
常见多GPU训练方法:
- 模型并行:如果模型特别大,GPU显存不够,无法将模型放在GPU上,需要把网络的不同模块放在不同GPU上,这样可以训练比较大的网络。(下图左半部分)
- 数据并行:将整个模型放在一块GPU里,再复制到每块GPU上,同时进行正向传播和反向误差传播。相当于加大了batch_size。(下图右半部分)
大规模深度学习模型训练中有几个主要范式:
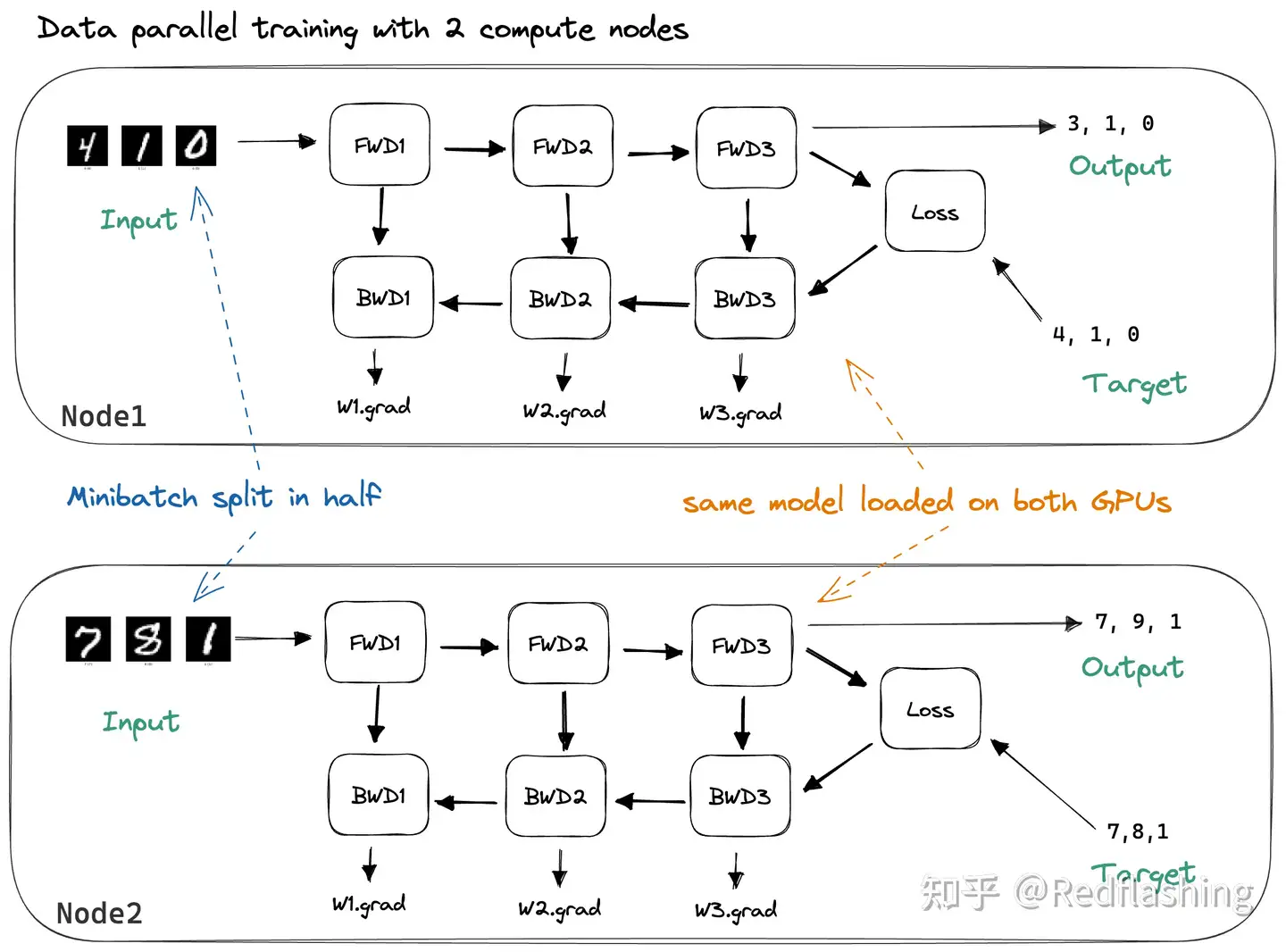
数据并行(DP):模型尺寸能够被单个GPU 内存容纳,模型的不同实例在不同的 GPU 和不同批数据上运行,模型的每个实例都使用相同的参数进行初始化,但在前向传递期间,不同批次的数据被发送到每个模型。 收集来自每个模型实例的梯度并计算梯度更新。,然后更新模型参数并将其作为更新发送到每个模型实例。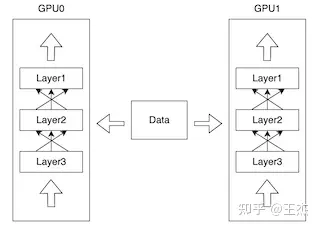
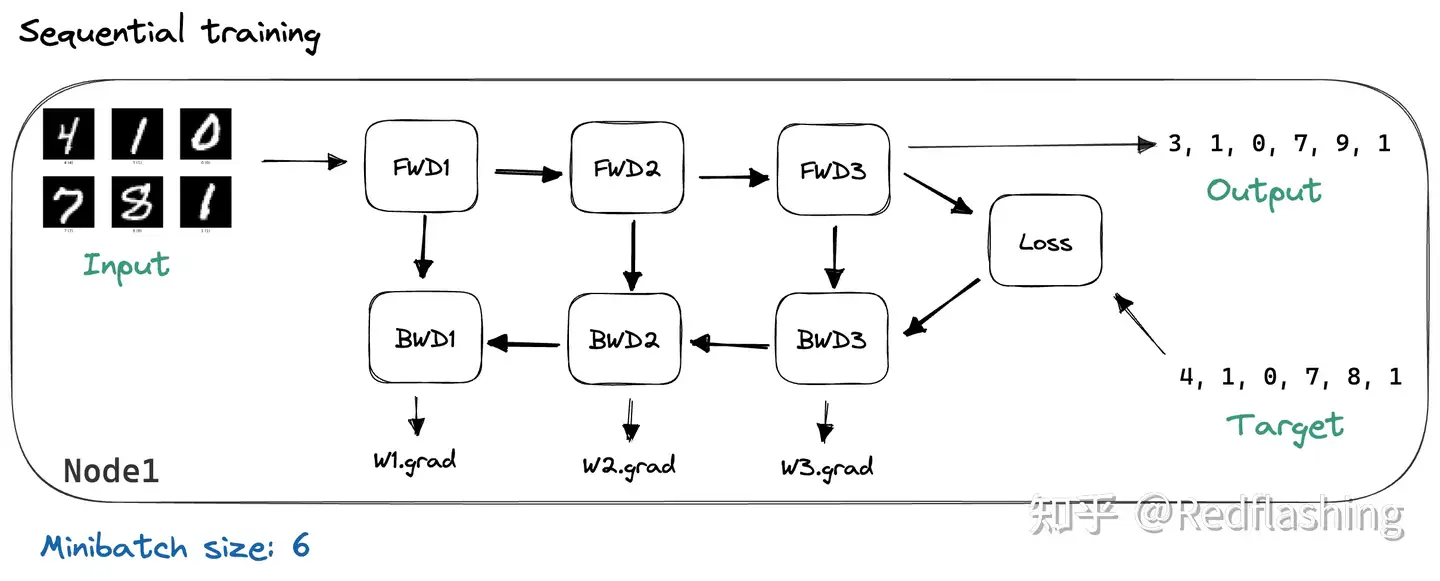
- 数据并行通过在 N 台机器上复制模型来实现。拆分 minibatch ,分成 N 个块,让每台机器处理一个块。
模型并行:当单个 GPU无法容纳模型尺寸时,模型并行性变得必要,将模型拆分到多个 GPU 上进行训练。实现模型尺寸超过单个GPU显存的深度学习模型训练。- 这种方法的问题是计算使用效率不高,因为在任何时间点只有一个 GPU 正在使用,而其他 GPU 处于空闲状态。
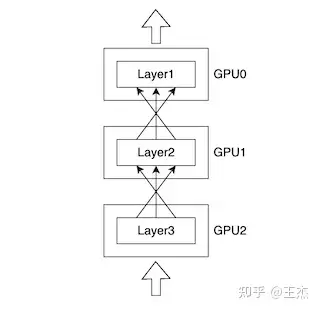
- 相对于流水线并行和数据并行,模型并行具有以下优点:
- 支持更大的模型规模:流水线并行和数据并行的限制通常是 GPU 内存大小和 GPU 数量,而模型并行可以支持更大的模型规模,因为模型可以分割成多个子模型,并分配到多个 GPU 上运行。
- 减少通信开销:流水线并行的模型划分通常会导致模型层之间的通信,而模型并行只需在每个子模型之间进行通信。相对于数据并行,模型并行在执行过程中通信量更少,因为每个 GPU 只需传递模型的一部分而不是全部。
- 灵活的模型分配:模型并行可以更灵活地将模型分配给不同的 GPU 或计算节点,这意味着可以在不同的 GPU 上运行不同的模型子集,从而实现更好的负载平衡和性能优化。
流水线并行(PP)朴素流水线并行(Naive Pipeline Parallelism)是将一组模型层分布在多个 GPU 上,并简单地将数据从 GPU 移动到 GPU,大型复合 GPU 一样。流水线并行(PP) 与上述朴素流水线并行几乎相同,但解决了 GPU 闲置问题,方法是将传入 batch 为 micro-batches 并人工创建流水线,从而允许不同的 GPU 同时参与计算过程。- 流水并行是将大型计算任务拆分成多个小的子任务,并将子任务在多个处理单元上同时执行。不同于数据并行和模型并行,流水并行不是将数据或模型分割成多个部分并在处理单元间并行处理,而是将一系列计算步骤分解成多个流水阶段,并在多个处理单元上同时执行,以减少总体计算时间。
通俗理解
Data Parallelism:模型1台设备装得下,所以同模型用多份数据分开训练Pipeline Parallelism:模型装不下,模型1层或多层1台设备装得下,所以同模型按层拆开训练Tensor Parallelism:模型1层都装不下,所以层内拆开训练
数据并行
数据并行性(Data parallelism (DP)):
- 将相同模型权重复制到多个worker中,并将一部分数据分配给每个worker以同时进行处理。
- 如果模型规模大于单个GPU内存,Naive DP无法正常工作时。GeePS(Cui 等人,2016 年)之类的方法将暂时未使用的参数卸载回 CPU,以使用有限的 GPU 内存。数据交换传输在后端进行,且不干扰训练计算。
在每个小批量结束时,workers需要同步梯度或权重,以替换旧参数。常见有两种主要的同步方法,它们都有明确的优缺点:
- 1)大容量同步并行( Bulk synchronous parallels (BSP)):workers在每个小批量结束时同步数据。这种方法可以防止模型权重过时,同时获得良好的学习效率,但每台机器都必须停止并等待其他机器发送梯度。
- 2)异步并行(Asynchronous parallel (ASP)):每个GPU工作进程异步处理数据,无需等待或暂停。然而,这种方法很容易导致网络使用陈旧的权重参数,从而降低统计学习效率。即使它增加了计算时间,也可能不会加快收敛的训练时间。
中间的某个地方是在每次x迭代时,全局同步梯度(x>1)。自Pytorch v1.5版(Li等人,2021年)以来,该特征在平行分布数据(DDP)中被称为“梯度累积”。Bucket 梯度计算方法避免了梯度的立即AllReduce,而是将多个梯度变化值存储到一个AllReduce中以提高吞吐量,可以基于计算图进行计算和通信调度优化。
使用场景:
- 请求之间互不依赖,希望提升整体QPS/吞吐
约束:
- DP 一般不降低单请求延迟,只是多开车道。
模型并行(大模型)
【2023-8-28】模型并行最佳实践(PyTorch)
DataParallel 优缺点如下:
- 优点:将模型复制到所有GPU,其中每个GPU消耗输入数据的不同分区,可以极大地加快训练过程。
- 缺点:不适用于某些模型太大而无法容纳单个GPU的用例。
模型并行性(Model parallelism: MP)目的: 解决模型权重不能适应单个节点的情况,通过将计算和模型参数分布在多台机器上进行训练。
- 数据并行中,每个worker承载整个模型的完整副本
- 而模型并行中,每个worker上只分配模型参数一部分,从而减少了内存使用和计算。
原理
- 将单个模型拆分到不同GPU上,而不是在每个GPU上复制整个模型
- 将模型不同子网放置到不同设备上,并相应地实现该 forward方法以在设备之间移动中间输出。由于模型的一部分只能在任何单个设备上运行,因此一组设备可以共同为更大的模型服务。
模型 m 包含10层:
- DataParallel: 每个GPU都具有这10层中每层副本
- 而在两个GPU上使用模型并行时,每个GPU可以托管5层
由于深度神经网络通常包含一堆垂直层,因此将一个大型模型逐层拆分感觉很简单,其中一组连续的小层被分组到一个工作层上的一个分区中。然而,通过多个具有顺序依赖性的工作线程来运行每个数据批,会导致大量的等待时间和计算资源利用率低下的问题。
模型并行有两种:张量并行 和 流水线并行
- 张量并行是在一个操作中进行并行计算,如:矩阵-矩阵乘法。
- 流水线并行是在各层之间进行并行计算。
总结
- 张量并行是层内并行,流水线并行是层间并行。
流水线并行(综合模型+数据)
通道并行(Pipeline parallelism: PP)将模型并行与数据并行相结合,以减少部分训练过程中出现的空闲时间。
主要思想
- 将小批量拆分为多个微批次,并使worker在每个阶段中能够同时处理一个微批次。
- 注意: 每个微批次需要两次传递,一次向前,一次向后。
- worker之间的通信仅传输激活(向前)和梯度(向后)。
- 这些通道调度方式以及梯度的聚合方式在不同的方法中有所不同。分区(workers)的数量也称为通道深度。
模型按层分割成若干块,每块都交给一个设备。
- 前向传播: 每个设备将中间激活传递给下一个阶段。
- 后向传播: 每个设备将输入张量梯度传回给前一个流水线阶段。
这允许设备同时进行计算,从而增加训练的吞吐量。
缺点
- 训练设备容易出现空闲状态(因为后一阶段等待前一阶段执行完毕),导致计算资源的浪费,加速效率没有数据并行高。
典型的流水线并行实现:
- GPipe、PipeDream、PipeDream-2BW、PipeDream Flush(1F1B)。
PP 使用场景
- 模型太大,单机 + TP 也放不下,需要跨节点再切一层(PP+TP)
- GPU 数量不是 2 的幂(3/5/6/7/9 …)时,希望更灵活切分
约束
- 和 DP 类似,PP 通常也不会降低单请求延迟
- 原始(vanilla)PP 如果只跑一条请求,大量 GPU 会闲着
张量并行(水平分割)
模型并行和流水线并行都将一个模型垂直分割,将张量操作的计算水平分割到多个设备上,称为张量并行(tensor parallelism,TP)。
- 张量并行将张量沿特定维度分成 N 块,每个设备只持有整个张量的 1/N,同时不影响计算图的正确性。
- 这需要额外的通信来确保结果的正确性。
以当下比较流行的transformer为例,transformer 模型主要由多层MLP和自注意力组成。
Megatron-LM(Shoeybi et al.2020)等人采用了一种简单的方法来并行多层计算MLP和自我注意。transformer 中的MLP层包含GEMM(通用矩阵乘法)和非线性GeLU传输,按列拆分权重矩阵A
典型的张量并行实现:
- Megatron-LM(1D)
- Colossal-AI(2D、2.5D、3D)
TP 使用场景
- 单块 GPU 放不下整模,需要跨 GPU 切分模型
- 希望降低单个请求延迟:同一个 token 的计算并行跑在多块 GPU 上
约束:
- TP 大小必须能整除 attention head 数量。
- 比如想用 TP=3,模型有 64 个 head,就会报类似:“Total number of attention heads (64) must be divisible by tensor parallel size (3)”。
多维混合并行
多维混合并行指将数据并行、模型并行和流水线并行结合起来进行分布式训练。
超大规模模型的预训练和全参数微调时,都需要用到多维混合并行。
2D 并行
主要有
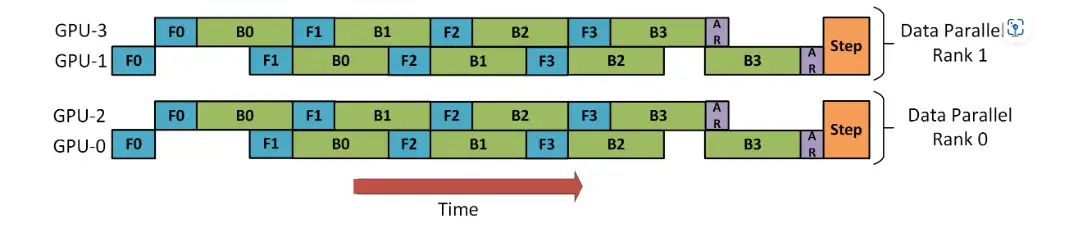
- Data 并行+ pipeline 并行
- Deepspeed web-link给出了 pipeline 和 data-parallel 的2D并行示意图,其中 rank0 和 rank1 为 data-parallelism, rank0里的 gpu-0 和 gpu-2 进行 pipeline 并行,他们交替进行前向和反向过程,疑问的是(这里没有模型运行的最终的loss,如何进行反向传播呢?)
- Tensor 并行 + pipeline
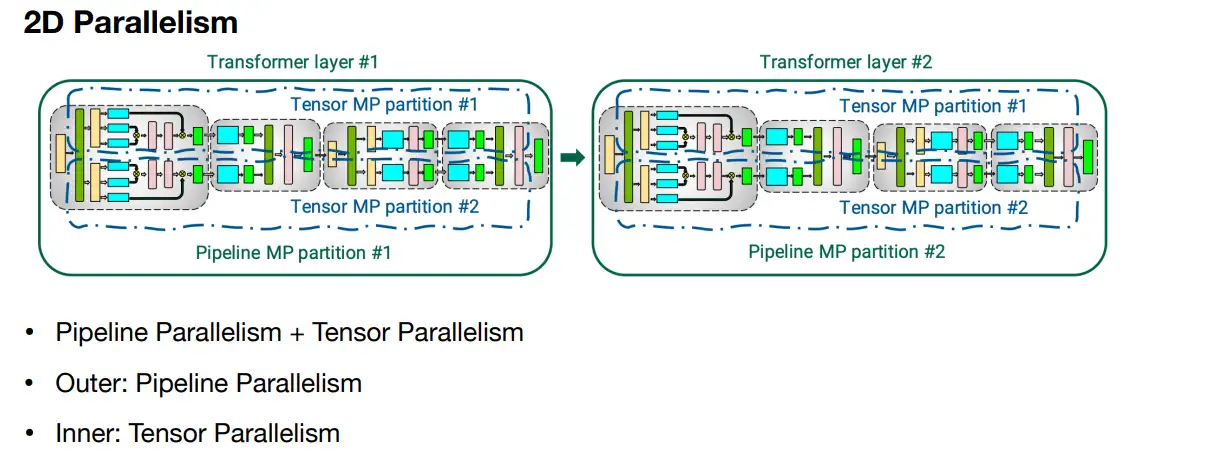
3D 并行
3D并行 => Tensor + pipeline + data
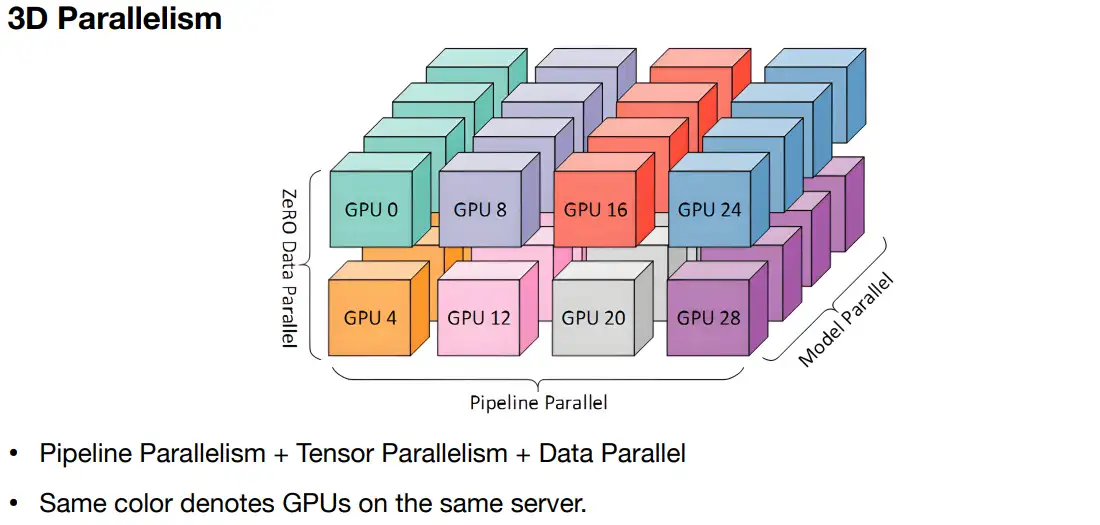
异构系统并行
与 GPU 相比,CPU 内存要大得多。
- 典型服务器上,CPU 可以轻松拥有几百GB甚至上TB的内存,而每张 GPU 卡通常只有 48 或 80 GB的内存。
为什么 CPU 内存没有被用于分布式训练?
- 依靠 CPU 甚至是 NVMe 磁盘来训练大型模型。
- 主要想法: 在不使用张量时,将其卸载回 CPU 内存或 NVMe 磁盘。
通过使用异构系统架构,有可能在一台机器上容纳一个巨大的模型。
自动搜索并行空间
alpa
Alpa 将并行空间分为 inter-op (pipeline) 与 intra-op (tensor并行),使用 NAS搜索这两个空间,考虑整个搜索空间的cost。
- 首先搜索 inter-op 的搜索空间, 制定 pipeline 并行策略
- 然后搜索 intra-op空间, 指定 data-para 与 operator-para 策略(包括两种)
- Data para
- Operator parallel (weight 广播,input拆分)
- Operator parallel (weight 拆分,input拆分) –> 需要增加 all-reduce cost
UCB博士 郑怜悯 的工作, 他还参加过其他项目 Ansor,TVM, vLLM, FastChat,LMSYS-Chat-1M
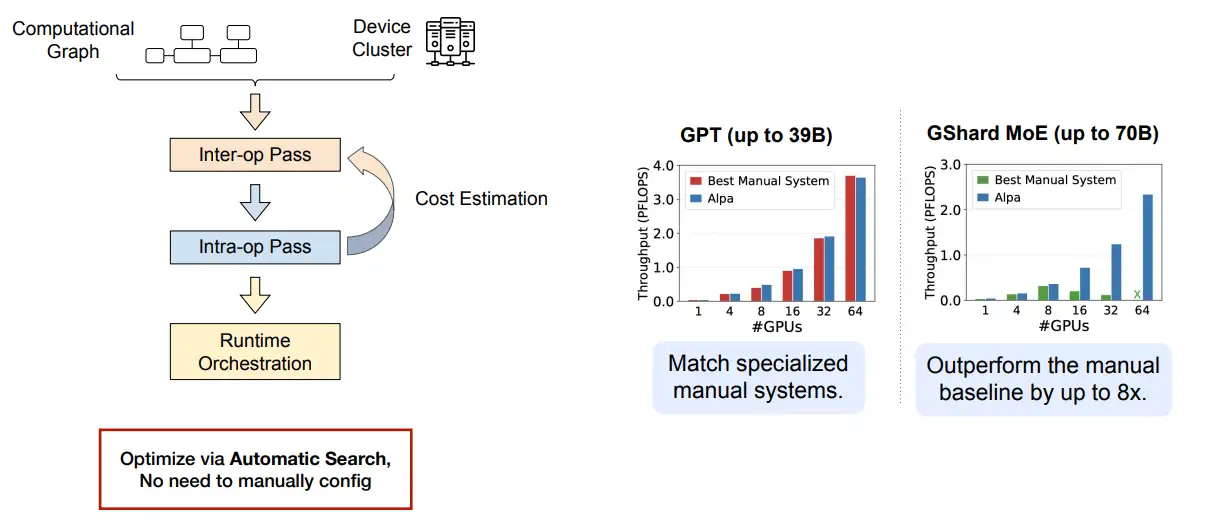
模型训练开销
神经网络模型占用的显存包括:
- 模型自身的参数
- 模型的输出
全连接网络(不考虑偏置项b): Y = XW + b
- X 是 B*M 维
- W 是 MN 或 NM 维
- Y 是 B*N 维
显存占用包括:
- 参数:二维数组 W
- 模型的输出: 二维数组 Y
- X是上一层的输出,因此显存占用归于上一层。
显存占用就是W和Y两个数组?非也
模型训练流程
参数的显存占用
详见站内专题:GPU显存分析
分布式机器学习实现
【2022-6-2】分布式机器学习
在深度学习时代,训练数据特别大的时候想要单卡完成训练基本是不可能的。所以就需要进行分布式深度学习。
经验
流水并行 (Pipeline Parallelism ) 是 LLM 分布式训练扩展到千卡集群以上的一个核心 feature
并行度对比
NVIDIA 在 3076 张 A100 集群上训练的 1T 参数量 LLM 使用的并行方式是:
- Data Parallel Size = 6
- Tensor Parallel Size = 8
- Pipeline Parallel Size = 64
并行度最高的是 流水并行,超过 DP 和 TP 10倍左右
为什么3k卡集群主流是流水并行?
流水并行核心优势:
- 用比较少的 Pipeline Bubble 代价 (当 gradient accumulation step 很大时可以忽略不计),较少的 Tensor Buffer 显存代价,以及非常低的通信开销,将大模型分割在不同的 Group 中。 大幅减少了单张 GPU 上的 weight tensor 大小(数量) 和 Activation tensor 大小(数量)。
- 跟 Tensor Parallel 相比, Pipeline Parallel 的通信代价很低且可以被 overlap, Tensor Parallel 虽然也能切分模型大小,但是需要全量数据(没有减少 Activation tensor 大小),另外极高的通信频率和通信量使得 Tensor Parallel 只能在机器内 8 张卡用 NVLink 等高速互联来实现,跨机的 TP 会严重拖慢速度。
- 不仅如此, Pipeline Parallel 还将 Data Parallel 的模型更新限定在一个很小的范围内(比如六台机器), DP 所需的 AllReduce 通信会随着机器数量增多而变慢。 PP 也让 DP 所需同步的模型梯度大小变小了,大大减缓了模型更新对于训练速度的影响。
因此 Pipeline Parallel 是让模型可以达到千亿、集群可以扩充到千卡以上的一个最重要的特性。
流水并行有很重要的约束条件:
- 需要一个 规整对称的、线性顺序的网络结构。
GPT 就是这样一个典型的网络结构:
- 完全一样的 Transformer Layer 顺序堆叠,没有分叉和不对称情况,当均匀切分 Layer 时,各个 Stage 的前向/反向计算时间均一致。
作者:成诚 链接:https://www.zhihu.com/question/588325646/answer/3422090041 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
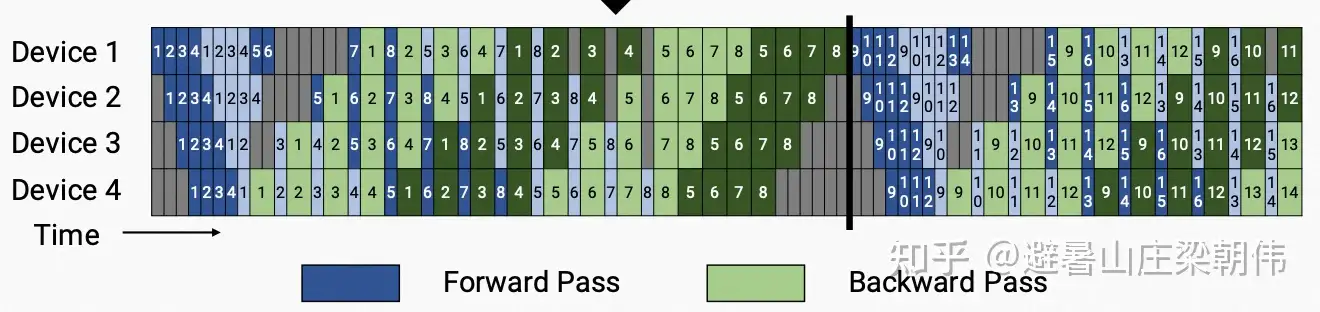
流水并行训练时的 time line 参考如下:
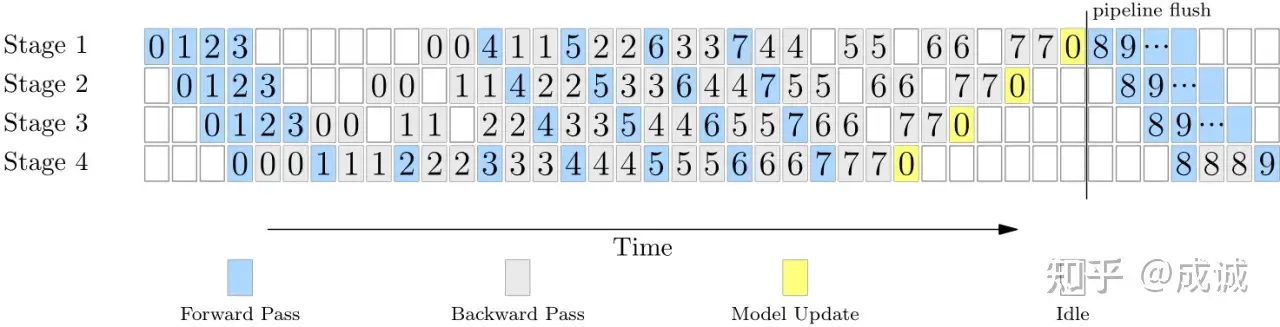
(反向的计算时间是前向的两倍)整个集群最高效的训练时间段是 step 4、5、6、7 的前向 和 step 0、1、2、3 的反向同时在所有 stage 上并行计算的时候,这个时候集群没有空闲,全部都在并行执行。 当我们增加 acc step (比如从 8 增加到 64)时,中间部分完美并行的时间段占比就会更长, bubble time 的占比就会越来越小。
而 T5 的网络结构比 GPT 要复杂很多, T5 是 Encoder-Decoder 架构,整个网络分为两大块,且 Encoder 和 Decoder 的 Transformer Layer 参数大小、Attention 计算量、Context Length 等均不一致,导致 Encoder 的理论计算量要比 Decoder 大很多(整个网络不是均匀对称的)。 更要命的是, T5 Encoder 的输出要发给每个 Decoder Layer,网络结构不是线性而是有大量的分叉,前向反向之间包含了复杂的数据依赖关系, 会导致流水并行中,各个 Stage 之间会产生大量的、非对称的、间隔跨多个 Stage 的数据依赖,更加剧了流水并行的 load balance 问题。
所以直接使用 Megatron 跑 T5 的 Pipeline Parallelism,会从 nsys prof 时间线上看到大量的缝隙,各个 Stage 之间在互相等待,无法真正流水并行起来。
如果不用 Pipeline Parallelism 来训练 T5,那么只能借助: DP、TP 和 ZeRO 来进行并行优化了, 这就约束了 T5 的所有 Layer 都必须放在每一个 GPU 上,这种方式在 13B 量级的模型上是 OK 的,但是再往上扩展到 100B、1T 量级就不 work 了。
同时由于 TP 只能开到 8 (跨机器也会慢几倍), 在千卡 GPU 集群以上,大量的 DP 带来的通信变慢的影响也很严重(ZeRO-2/3 会大幅加剧这种通信开销)。 所以我们才说, 虽然 T5 的理论计算量相较于 GPT 没有增加很多,但是在千亿参数、千卡集群以上规模的时候,T5 的实际训练效率比 GPT 慢很多倍。即使到现在,也没有一个超过 11B 的 T5 模型发布, 而 11B 恰好是一个不借助 PP,仅通过 ZeRO + TP 就可以训练的模型大小,避免了 T5 的模型结构非对称性对于 PP 的灾难性影响。
基本原理
无论哪种机器学习框架,分布式训练的基本原理都是相同的。可以从并行模式、架构模式、同步范式、物理架构、通信技术等五个不同的角度来分类。
更多信息见优质paper,把 DP(Data Parallel)、MP(Model Parallel)、PP(Pipeline Parallel)各个方面讲的很透彻
并行模式
分布式训练目的:将原本巨大的训练任务拆解成多个子任务,每个子任务在独立的机器上单独执行。
大规模深度学习任务的难点在于:
- 1) 训练数据量巨大:将数据拆解成多个小模型分布到不同的node上。→ 数据并行
- 2) 训练模型的参数巨大:将数据集拆解分布到不同的node上。→ 模型并行
- NLP的预训练模型实在太大了
| 并行模式 | 图解 | |
|---|---|---|
| 数据并行 | 单机多卡用DP(PS),多级多可用DDP(Ring Allreduce) | 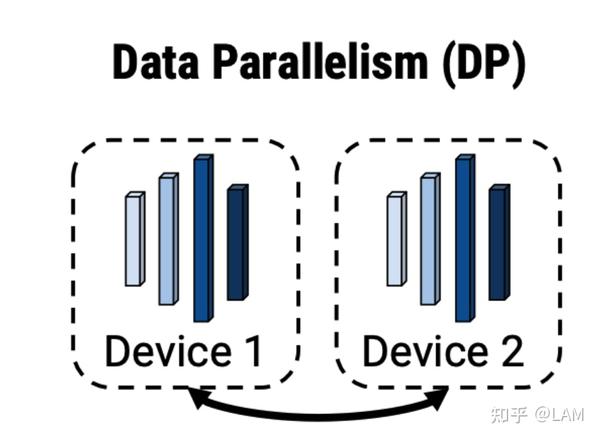 |
| 模型并行 | 按切分方式 - 横向:张量并行 - 纵向:流水线并行 |
 |
| 其他并行 |
数据并行(DP&DDP)
数据并行相对简单,N个node(worker)构成一个分布式集群,每个worker处理1/N的数据。
- 理论情况下能达到线性的加速效果。
- TF、torch、Horovod都可以在原生支持或者微小的改动实现数据并行模式。
DP(单机)+DDP(多机)
数据并行(DP&DDP)
DP(Data Parallelism):早期数据并行模式,一般采用参数服务器(Parameters Server)编程框架。实际中多用于单机多卡。DDP(Distributed Data Parallelism):分布式数据并行,采用Ring AllReduce通讯方式,多用于多机多卡场景。
DP 单机数据并行
数据并行本质
- 单进程多线程实现方式,只能实现单机训练, 不算严格意义上的分布式训练
多个GPU 情况下,将模型分发到每个GPU上去,每个GPU都保留完整模型参数。
- 每个GPU加载全部模型(Parameter、Grad、Optimizer、Activation、Temp buffer)
- 将每个batch样本平均分配到每个GPU上进行梯度计算
- 然后汇总每个GPU上的梯度
- 将汇总梯度重新分发到每个GPU上,每个GPU模型根据汇总的梯度进行模型参数更细。
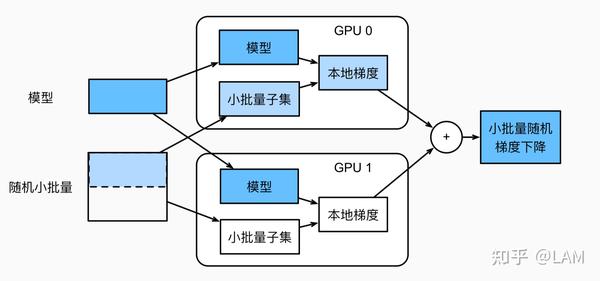
K个GPU并数据并行训练过程如下:
- 任何一次训练迭代中,给定的随机的小批量样本都将被分成K个部分,并均匀地分配到GPU上;
- 每个GPU根据分配给它的小批量子集,计算模型参数的损失和梯度;
- 将个GPU中的局部梯度聚合,以获得当前小批量的随机梯度;
- 聚合梯度被重新分发到每个GPU中;
- 每个GPU使用这个小批量随机梯度,来更新所维护的完整的模型参数集。
数据并行是在每个worker上存储一个模型的备份,在各个worker 上处理不同的数据子集。然后需要规约(reduce)每个worker的结果,在各节点之间同步模型参数。
- 这一步会成为数据并行的瓶颈,因为如果worker很多的情况下,worker之间的数据传输会有很大的时间成本。
参数同步后,需要采用不同的方法进行参数更新:
- 参数平均法:最简单的一种数据平均化
- 更新式方法
若采用参数平均法,训练的过程如下所示:基于模型的配置随机初始化网络模型参数
- 将当前这组参数分发到各个工作节点
- 在每个工作节点,用数据集的一部分数据进行训练
- 将各个工作节点的参数的均值作为全局参数值
- 若还有训练数据没有参与训练,则继续从第二步开始
更新式方法与参数平均化类似,主要区别在于,在参数服务器和工作服务器之间传递参数时,更新式方法只传递更新信息(梯度和张量)。
问题:
- 负载不均衡,主GPU负载大
- PS 架构通信开销大
DDP 分布式数据并行
DDP (Distribution Data Parallel)
- AllReduce 架构,在单机和多机上都可以使用。
- 负载分散在每个gpu节点上,通信成本是恒定的,与 GPU 数量无关。
模型并行(model parallesim)
当模型参数过大,单个 GPU无法容纳模型参数时,就需要模型并行, 将模型拆分到多个 GPU 训练。
模型并行相对复杂
- 原理:分布式系统中的不同worker负责网络模型的不同部分
- 例如,神经网络的不同层被分布到不同worker或者同一层的不同参数被分配到不同worker上。
- 对于TF这种框架,可以拆分计算图成多个最小依赖子图到不同的worker上。同时在多个子图之间通过通信算子来实现模型并行。
但是模型并行实现起来比较复杂。工业界还是以数据并行为主。
层间 & 层内
Model Parallel主要分两种:intra-layer拆分 和 inter-layer拆分
inter-layer拆分:对模型做网络上的拆分,将每一层或者某几层放在一个worker上单独训练。- 缺点:模型训练串行,整个模型的效率取决于最慢的那一层,存在资源浪费
intranet-layer拆分:深度学习的网络结构基本都是一层层的。常规的卷积、池化、BN等等。如果对某一层进行了拆分,那么就是intra-layer拆分。对单层的拆分其实就是拆分这一层的matrix运算。- 参考论文:Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
对比
- 层间并行: 流水线并行
- 层内并行: 张量并行
| 概念 | 中文 | 图解 |
|---|---|---|
| intra-layer and inter-layer | 层间并行和层内并行 |  |
| orthogonal and complimentary | 正交和互补 | 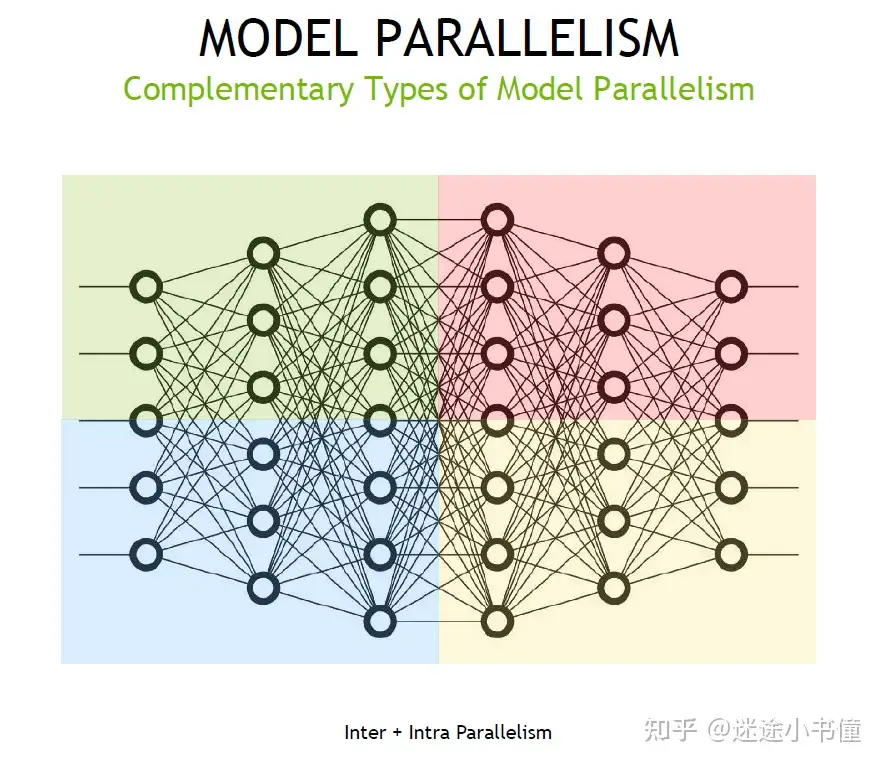 |
模型并行通常分为张量并行(纵向切分)以及流水线并行(横向切分)
- 流水线并行(Pipeline model parallesim)
- 朴素拆分方式: 将模型各层分组后装载到各个GPU上去,GPU之间进行串行计算
- 缺点: GPU 利用率太低,当一个GPU进行计算时,其他层的GPU都闲置。
- 改进: 谷歌提出了GPipe
流水线并行(Pipeline model parallesim ), 引入micro-batches (MBS)的概念,会提升GPU利用率 - 问题: 流水线最大的问题, 无法充分利用GPU资源,training过程中会出现非预期的Bubble
- 朴素拆分方式: 将模型各层分组后装载到各个GPU上去,GPU之间进行串行计算
- 张量并行(Tensor Model Parallelism)
- 张量并行(TP)是模型并行一种形式,流水线并行按网络层切分,张量并行按矩阵切分。
- 2019年,NVIDIA发布《Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM》论文,提出了张量并行方法
- 核心思想: 每个GPU仅处理矩阵一部分,当算子需要整个矩阵的时候再进行矩阵聚合。无论是横向切分还是竖向切分,都可以将切分后的矩阵放到不同GPU上进行计算,最后将计算的结果再合并。
大模型主要结构都是Transformer模型,Transformer核心模块网路结构:anttention层+残差连接,MLP层+残差连接。
- MLP层: 数学表达如下:
Y = GeLU(XA),Z = Dropout(YB) - Attention层: 数学表达如下:
Y = Self-Attention(X),Z = Dropout(YB), 多头注意力每个头都是独立的,因此张量切分更方便
大模型训练时,ZeRO支持将模型显存内存占用划分到多张卡或者多个节点。
示例
【2023-8-28】模型并行最佳实践(PyTorch)
两个GPU上运行此模型,只需将每个线性层放在不同的GPU上,然后移动输入(input)和中间输出(intermediate outputs)以匹配层设备(layer devices)。
import torch
import torch.nn as nn
import torch.optim as optim
class ToyModel(nn.Module):
"""
模型并行示例
"""
def __init__(self):
# 模型定义修改: 只需增加 to(device)
super(ToyModel, self).__init__()
self.net1 = torch.nn.Linear(10, 10).to('cuda:0') # 将net1放置在第1个GPU上
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1') # 将net2放置在第2个GPU上
def forward(self, x):
x = self.relu(self.net1(x.to('cuda:0')))
return self.net2(x.to('cuda:1'))
注意 ToyModel
- 除了5个用于将线性层(linear layers)和张量(tensors)放置在适当设备上的to(device)调用之外,以上内容与在单个GPU上实现该功能非常相似。那是模型中唯一更改地方(即to(device) )。
- 在 backward()和 torch.optim 会自动关注梯度(gradients),模型如同一个GPU。
- 调用损失函数时,只需确保标签(label)与输出(output)在同一设备(on the same device)上。
model = ToyModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.paraeters(), lr=0.001)
optimizer.zero_grad()
outputs = model(torch.randn(20, 10))
labels = torch.randn(20, 5).to('cuda:1') # ToyMode 的 output 是在 'cuda:1' 上,此处的 label 也应该置于 'cuda:1' 上
loss_fn(outputs,labels).backward()
optimizer.step()
只需更改几行,就可以在多个GPU上运行现有的单GPU模块。
如何分解 torchvision.models.reset50() 为两个GPU。
- 从现有 ResNet模块继承,并在构建过程中将层拆分为两个GPU。
- 然后覆盖 forward方法来缝合两个子网,通过相应地移动中间输出。
from torchvision.models.resnet import ResNet, Bottleneck
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1,
self.bn1,
self.relu,
self.maxpool,
# 模型拆分
self.layer1,
self.layer2
).to('cuda:0') # 放置在第1个GPU上
self.seq2 = nn.Sequential(
self.layer3,
self.layer4,
self.avgpool,
).to('cuda:1') # 放置在第2个GPU上
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))
对于模型太大而无法放入单个GPU的情况,上述实现解决了该问题。但是,如果模型合适,model parallel 将比在单个GPU上运行要慢。
- 因为在任何时间点,两个GPU中只有1个在工作,而另一个在那儿什么也没做。
- 在 layer2 和 layer3之间,中间输出需要从 cuda:0 复制到 cuda:1,这使得性能进一步恶化。
import torchvision.models as models
num_batches = 3
batch_size = 120
image_w = 128
image_h = 128
def train(model):
model.train(True)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
one_hot_indices = torch.LongTensor(batch_size) \
.random_(0, num_classes) \
.view(batch_size, 1)
for _ in range(num_batches):
# generate random inputs and labels
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes) \
.scatter_(1, one_hot_indices, 1)
# run forward pass
optimizer.zero_grad()
outputs = model(inputs.to('cuda:0'))
# run backward pass
labels = labels.to(outputs.device)
loss_fn(outputs, labels).backward()
optimizer.step()
两个GPU中的一个会处于空闲状态。怎么优化?
- 将每个批次进一步划分为拆分
流水线,当1个拆分到达第2子网时,可以将下一个拆分馈入第一子网。这样,两个连续的拆分可以在两个GPU上同时运行。
流水线输入(Pipelining Inputs)加速
- 将每批次 120-image 进一步划分为 20-image 。当PyTorch异步启动CUDA操作时,该实现无需生成多个线程即可实现并发。
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
# A. s_prev runs on cuda:1
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. s_next runs on cuda:0, which can run concurrently with A
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)
setup = "model = PipelineParallelResNet50()"
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
pp_mean, pp_std = np.mean(pp_run_times), np.std(pp_run_times)
plot([mp_mean, rn_mean, pp_mean],
[mp_std, rn_std, pp_std],
['Model Parallel', 'Single GPU', 'Pipelining Model Parallel'],
'mp_vs_rn_vs_pp.png')
设备到设备的张量复制操作在源设备和目标设备上的当前流(current streams)上同步。如果创建多个流,则必须确保复制操作正确同步。在完成复制操作之前写入源张量或读取/写入目标张量可能导致不确定的行为。上面的实现仅在源设备和目标设备上都使用默认流,因此没有必要强制执行其他同步。
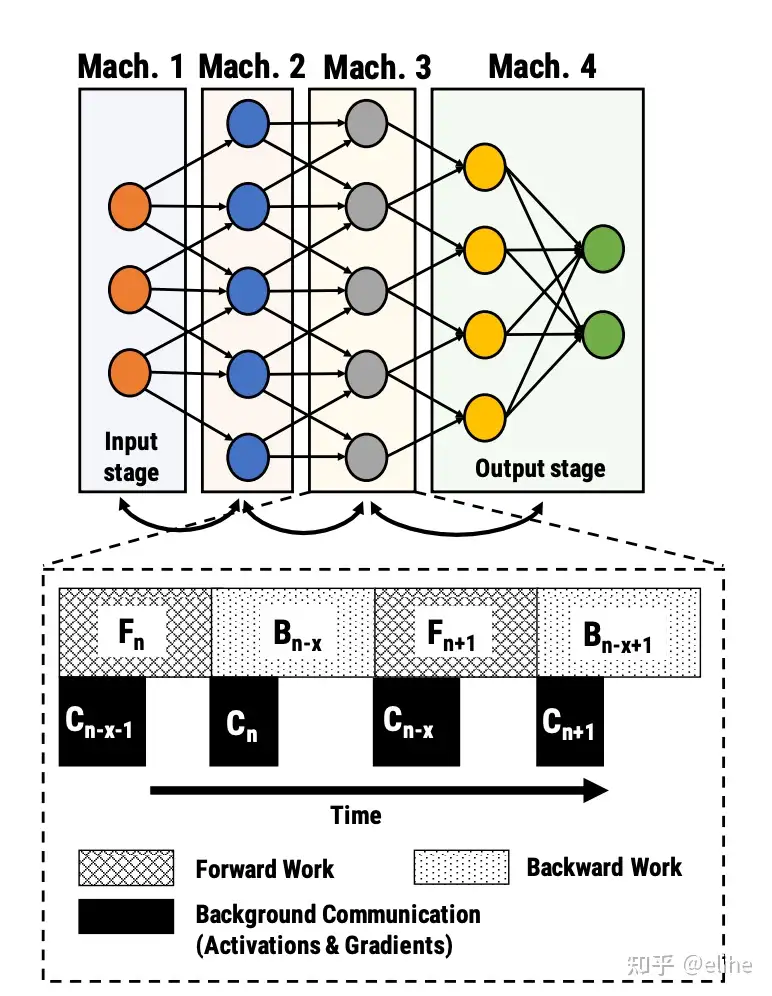
流水线并行
数据并行还是模型并行都会在相应机器之间全连接通信,当机器数量增大时,通信开销和时延会大到难以忍受
流水线(管道)并行既解决了超大模型无法在单设备装下的难题,又解决了机器之间的通信开销的问题
- 每个阶段(stage) 和下一个阶段之间仅有相邻的某一个 Tensor 数据需要传输
- 每台机器的数据传输量跟总的网络大小、机器总数、并行规模无关。
流水线并行(Pipeline model parallesim)
- 朴素拆分方式: 将模型各层分组后装载到各个GPU上,GPU之间进行串行计算
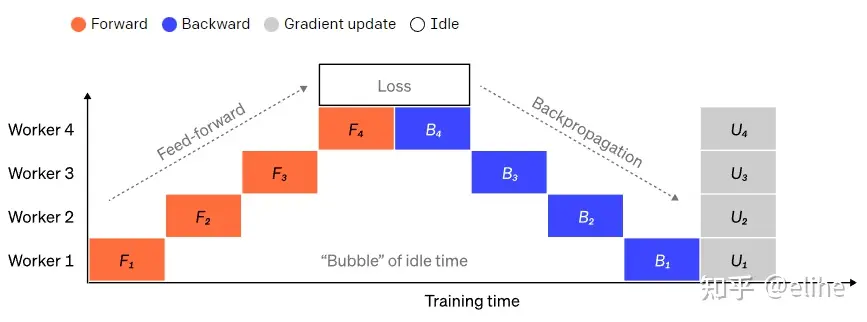
- 缺点: GPU 利用率太低,当1个GPU进行计算时,其他层GPU都闲置。
改进方法如下
- GPipe
- PipeDream
G-pipe
谷歌提出 G-pipe 流水线并行(Pipeline model parallesim ), 引入micro-batches (MBS)的概念,会提升GPU利用率
F-then-B调度方式: 原 mini-batch(数据并行切分后的batch)划分成多个micro-batch(mini-batch再切分后的batch),每个 pipeline stage (流水线并行的计算单元)先整体进行前向计算,再进行反向计算。同一时刻分别计算模型的不同部分,F-then-B 可以显著提升设备资源利用率。- F-then-B 模式由于缓存了多个 micro-batch 的中间变量和梯度,显存的实际利用率并不高。
- 解决:
1F1B(在流水线并行中,pipeline stage 前向计算和反向计算交叉进行的方式)流水线并行方式。1F1B 模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量。 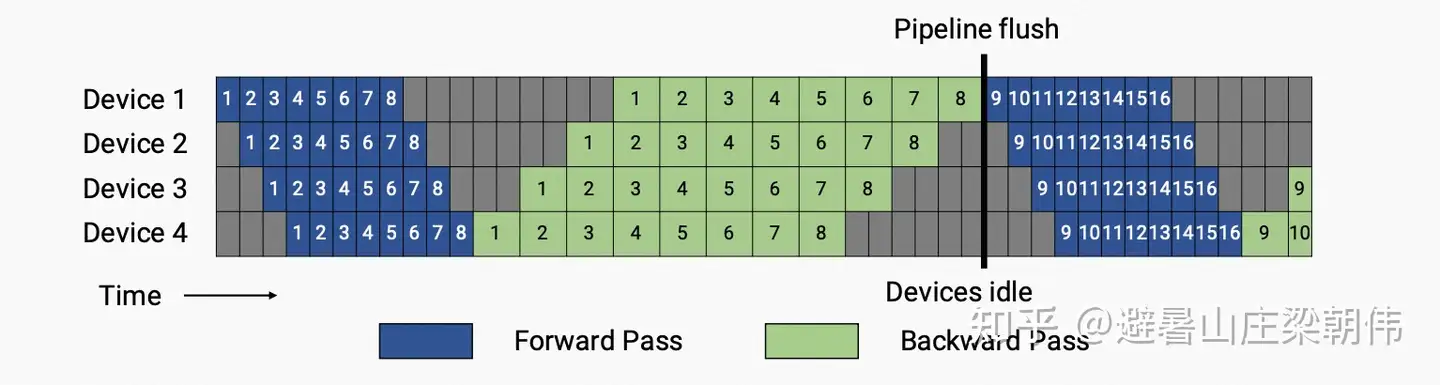
PipeDream
PipeDream 在单个 GPU 上短暂运行性能分析后,自动决定怎样分割这些 DNN 算子,如何平衡不同 stage 之间的计算负载,而同时尽可能减少目标平台上的通信量。
PipeDream将DNN 层划分为多个阶段 —— 每个阶段(stage)由模型中的一组连续层组成。
- PipeDream把模型的不同的阶段部署在不同的机器上,每个阶段可能有不同的replication。该阶段对本阶段中所有层执行向前和向后传递。
- PipeDream将包含输入层的阶段称为输入阶段,将包含输出层的阶段称为输出阶段。

virtual pipeline
virtual pipeline 是 Megatron-2 论文中最主要的一个创新点。
- 传统的 pipeline 并行通常会在一个 Device 上放置几个 block,为了扩展效率,在计算强度和通信强度中间取一个平衡。
- 但 virtual pipeline 在 device 数量不变的情况下,分出更多的 pipeline stage,以更多的通信量,换取空泡比率降低,减小了 step e2e 用时。
张量并行(Tensor Parallelism)
流水线并行主要集中在多层神经网络架构训练上,对于Transformer架构的模型(如BERT,GPT等),MultiHead Attention Layer和MLP的计算量翻了几倍,如果继续按管线切分模型, 可能单层参数都无法被显存装载,因此需要横着把同一层的模型切分开来,这便是张量并行
- 层间并行: 流水线并行
- 层内并行: 张量并行
分布式张量计算正交且更通用,将张量操作划分到多个设备上,以加速计算或增加模型大小。
- 把
Masked Multi Self Attention和Feed Forward都进行切分以并行化,利用Transformers网络的结构,通过添加一些同步原语来创建一个简单的模型并行实现。
张量并行(Tensor Model Parallelism)
- 张量并行(TP)是模型并行一种形式,流水线并行按网络层切分,张量并行按矩阵切分。
- 2019年,NVIDIA发布《Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM》论文,提出了张量并行方法
- 核心思想: 每个GPU仅处理矩阵一部分,当算子需要整个矩阵的时候再进行矩阵聚合。无论是横向切分还是竖向切分,都可以将切分后的矩阵放到不同GPU上进行计算,最后将计算的结果再合并。
张量并行最有名的是: Megatron 和 Deepspeed
混合并行
随着训练设备的增加,多个worker之间的通信成本增加,模型Reduce的成本也越来越大,数据并行的瓶颈也随之出现。故有学者提出混合并行(数据并行+模型并行)
架构模式
分布式训练上会频繁用到规约(AllReduce)操作。
all-reduce 操作有多种方式实现:
- 树状结构:数据在进程间以树状结构进行归约,每个非叶子节点负责将其子节点的数据归约后再传递给其父节点。
- 环形结构:进程之间形成一个环,数据在环中按顺序传递并归约。
- 直接归约:所有进程直接将数据发送给一个中心节点,该节点完成归约后将结果发送回所有进程。
all-reduce 操作性能对分布式计算的效率至关重要,因此优化这一操作是分布式系统设计中的一个研究热点。使用最多的实现方式是百度提出的 Ring AllReduce 算法,该方法属于环状结构实现的一种。
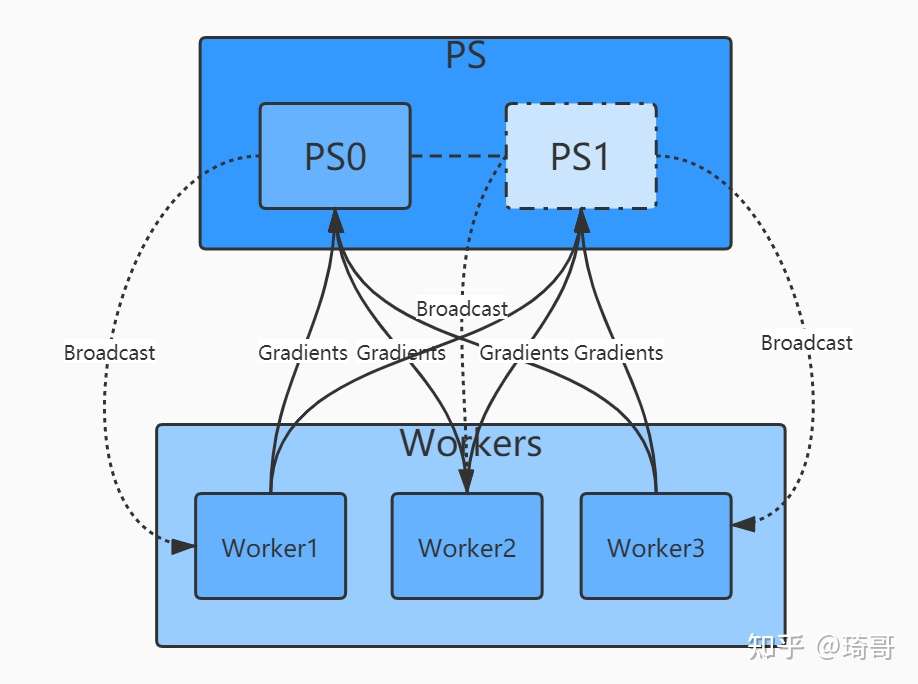
主流的分布式架构主要分为参数服务器(ParameterServer) 和基于规约(Reduce)两种模式。早期还有基于MPI的方式,不过现在已经很少用了。
传统 parameter server: server和client方式
- client通过计算分配给自己的数据,产生梯度,传给server
- server 聚合,然后把参数再传给client
这个方式的弊端: server容易成为瓶颈
- server通信量太大。
- 一个client失败,会导致其他client等待。
Ring all reduce 一种分布式方式
- 各个节点分配通信量。
- 总的通信量和ps没啥变化,但是通信的压力平摊到各个GPU上了,GPU之间的通信可以并行进行。
假如,GPU数量是N,把模型参数分成N份,每个GPU要存放整个参数。每个GPU也要分配训练数据。
- 当一次迭代,N个GPU之间要经过一个scatter和gather操作,reduce-scatter是将不同gpu上对应的参数的gradient相加,一共需要通讯(N-1)次。
- All-gather 将合并完整的参数,传到其他gpu上,需要通讯(N-1)次。
- 一次all reduce,单卡通信量为2*sita。
PS:参数服务器
ParameterServer模式是一种基于reduce和broadcat算法的经典架构。
- 其中一个/一组机器作为PS架构的中心节点,用来存储参数和梯度。
- 在更新梯度的时候,先全局reduce接受其他worker节点的数据,经过本地计算后(比如参数平均法),再broadcast回所有其他worker。
- 论文: Parameter Server for Distributed Machine Learning
- 中文解读
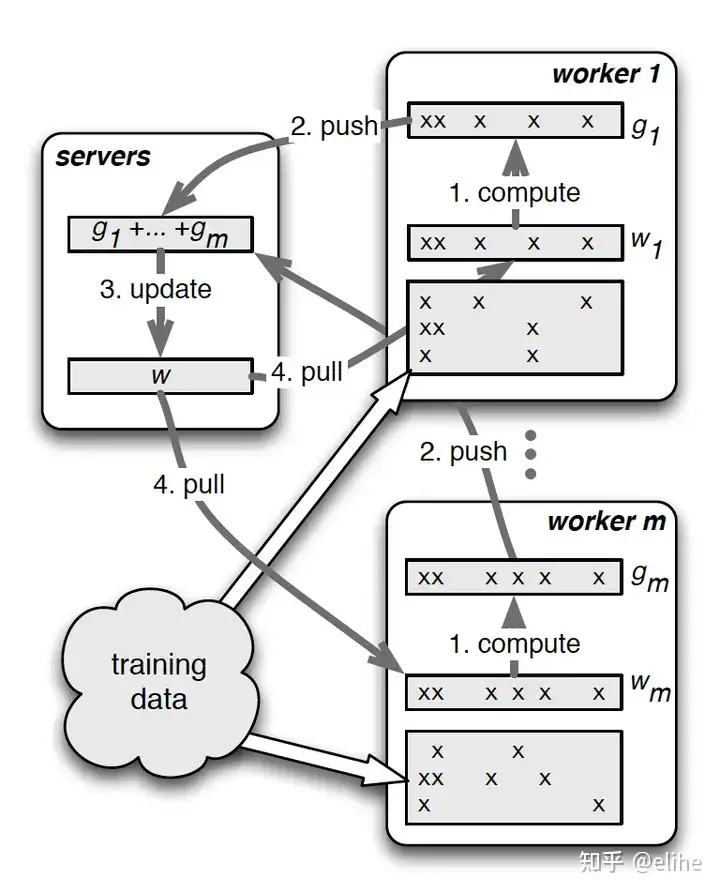
PS架构的问题在于多个worker与ps通信,PS本身可能存在瓶颈。
- 随着worker数量的增加,整体通信量也线性增加,加速比也可能停滞在某个点位上。
基于规约 Reduce模式
基于规约的模式解决了上述的问题,最典型的是百度提出的 Ring-AllRuduce。
- 多个Worker节点连接成一个环,每个Worker依次把自己的梯度同步给下一个Worker,经过至多 2*(N-1) 轮同步,就可以完成所有Worker的梯度更新。
- 这种方式下所有节点的地位是平等的,因此不存在某个节点的负载瓶颈,随着Worker的增加,整体的通信量并不随着增加。加速比几乎可以跟机器数量成线性关系且不存在明显瓶颈。

目前,越来越多的分布式训练采用Reduce这种模式。Horovod中主要就是用的这种分布式架构。
同步范式
实际训练过程中可能遇到各种问题,比如:部分节点资源受限、卡顿、网络延时等等
因此梯度同步时就存在“木桶“效应,即集群中的某些worker比其他worker更慢,导致整个训练pipeline需要等待慢的worker,整个集群的训练速度受限于最慢机器的速度。
因此梯度同步有“同步”(sync)、“异步”(Async)和混合三种范式。
- 同步范式:只有所有worker完成当前的计算任务,整个集群才会开始下一次迭代。
- TF中同步范式使用SyncReplicasOptimizer优化器
- 异步模式刚好相反,每个worker只关心知己的进程,完成计算后就尝试更新,能与其他多个worker同步梯度完成取决于各worker当前时刻的状态。其过程不可控,有可能出现模型正确性问题。(可在训练时logging对比)
- 混合范式结合以上两种情况,各个worker都会等待其他worker的完成,但不是永久等待,有timeout的机制。如果超时了,则此情况下相当于异步机制。并且没来得及完成计算的worker,其梯度则被标记为“stale”而抛弃或另做处理。
梯度累加
Gradient Accumulation 把一个大 Batch 拆分成多个 micro-batch, 每个 micro-batch 前后向计算后的梯度累加,在最后一个micro-batch累加结束后,统一更新模型。
micro-batch 跟数据并行高度相似性:
- 数据并行是空间上,数据被拆分成多个 tensor,同时喂给多个设备并行计算,然后将梯度累加在一起更新;
- 而 micro-batch 是时间上的数据并行,数据被拆分成多个 tensor, 按照时序依次进入同一个设备串行计算,然后将梯度累加在一起更新。当总的 batch size 一致,且数据并行的并行度和 micro-batch 的累加次数相等时,数据并行和 Gradient Accumulation 在数学上完全等价。
Gradient Accumulation 通过多个 micro-batch的梯度累加, 使下一个 micro-batch 的前向计算不需要依赖上一个 micro-batch 的反向计算,因此可以畅通无阻的进行下去(当然在一个大 batch 的最后一次 micro-batch 还是会触发这个依赖)。
Gradient Accumulation 解决了很多问题:
- 单卡下,Gradient Accumulation 将一个大 batch size 拆分成等价的多个小 micro-batch ,从而达到节省显存的目的。
- 数据并行下,Gradient Accumulation 解决了反向梯度同步开销占比过大的问题(随着机器数和设备数的增加,梯度的 AllReduce 同步开销也加大),因为梯度同步变成了一个稀疏操作,因此可以提升数据并行的加速比。
- 流水并行下, Gradient Accumulation 使得不同 stage 之间可以并行执行不同的 micro-batch, 从而让各个阶段的计算不阻塞,达到流水的目的。如果每个 micro-batch 前向计算的中间结果(activation)被后向计算所消费,则需要在显存中缓存 8多份(梯度累加的次数)完整的前向 activation。这时就不得不用另一项重要的技术:激活检查点(activation checkpointing)。
物理架构
物理架构主要是 GPU架构,即:单机单卡、单机多卡、多机单卡、多机多卡(最典型)
- 单机单卡:常规操作
- 单机多卡:利用一台GPU上的多块GPU进行分布式训练。数据并行和模型并行皆可。整个训练过程一般只有一个进程,多GPU之间的通信通过多线程的方式,模型参数和梯度在进程内是共享的(基于NCCL的可能不大一样)。这种情况下基于Reduce的架构比PS架构更合适一些,因为不需要一个显式的PS,通过进程内的Reduce即可完成梯度同步。
- 多机单卡:操作上与多机多卡基本一致
- 多机多卡:多机多卡是最典型的分布式架构,所以它需要较好的进程间的通讯机制(多worker之间的通信)。
内容:
- 分布式训练的基本原理
- TensorFlow 分布式训练
- PyTorch 分布式训练框架
- Horovod 分布式训练
分布式实现
超大规模语言模型主要有两条技术路线:
- (1)
TPU+XLA+TensorFlow/JAX: Google主导,由于TPU和自家云平台GCP深度绑定 - (2)
GPU+PyTorch+Megatron-LM+DeepSpeed: NVIDIA、Meta、MS大厂加持,社区氛围活跃
(1) 对于非Googler 只可远观而不可把玩,(2) 更受到群众欢迎。
详见站内专题:Pytorch 分布式实践
分布式模式
几种模式
- 单进程单线程
- 单进程多线程
- 多进程单线程
- 多进程多线程
进程是资源调度的最小单位,线程是程序运行单位
Pytorch 训练方法
两种GPU训练方法:DataParallel和DistributedDataParallel:
- DataParallel 单进程多线程,仅工作在单机中。
- 而DistributedDataParallel是多进程的,可以工作在单机或多机器中。
DataParallel 通常慢于 DistributedDataParallel。所以主流方法是 DistributedDataParallel。
DataParallel 单机
DataParallel 是 Pytorch 提供的一种数据并行方法,用于单机多GPU环境下的模型训练
过程
- 将数据划分成多个部分(mini-batches),分配给不同GPU,实现并行计算
- 前向传播时,数据划分成多个副本,平均分配到不同设备(device)上,分别计算,每个设备都有独立的模型(或副本)
- 注意: batch_size > gpu_num !
- 反向传播时,每个副本的梯度汇总、累加到原始模型中(host),取平均后,得到最新梯度
- 梯度再分发给各个设备,更新模型
DataParallel 自动将数据切分并加载到相应GPU上,将模型复制到每个GPU上,进行正向传播以计算梯度并汇总。
代码
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# 初始化模型
model = SimpleModel()
# 使用 DataParallel 将模型分布到多个 GPU 上
model = nn.DataParallel(model)
DistributedDataParallel 多机
DistributedDataParallel (DDP) 是 PyTorch 用于分布式数据并行训练的模块,适用于单机多卡和多机多卡场景。
- 相比于 DataParallel,DDP 更加高效和灵活,能在多个 GPU 和多个节点上进行并行训练。
DistributedDataParallel 多进程,可工作在单机或多机器中。
- DataParallel 通常慢于 DistributedDataParallel。
所以,主流方法是 DistributedDataParallel。
封装示例:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def main(rank, world_size):
# 初始化进程组
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# 创建模型并移动到GPU
model = SimpleModel().to(rank)
# 包装模型为DDP模型
ddp_model = DDP(model, device_ids=[rank])
if __name__ == "__main__":
import os
import torch.multiprocessing as mp
# 世界大小:总共的进程数
world_size = 4
# 使用mp.spawn启动多个进程
mp.spawn(main, args=(world_size,), nprocs=world_size, join=True)
TF分布式训练方法
- 黄文坚的Tensorflow分布式实战
TensorFlow主要的分布式训练的方法有三种:
- Customer Train Loop:最原始,由框架工程师自己开发
- Estimator + Strategy:高级API,不用关心底层硬件
- Keras + Strategy:最新出的keras的高级API
- 实际的开发工作中,分布式的工作最好是交给框架,而工程师本身只需要关注任务模型的pipeline就行了。
- 最经典的是Spark框架,工程师只需要关注数据处理的workflow,分布式的大部分工作都交给框架。深度学习的开发同样如此。
各种方式评价
- 第一种方式太过原生,整个分布式的训练过程完全交给工程师来处理,代码模块比较复杂,这里不做赘述。
- 第二种方式,Estimator是TF的一个高级API,在分布式场景下,其最大的特点是单机和分布式代码一致,且不需要考虑底层的硬件设施。Strategy是tensorflow根据分布式训练的复杂性,抽象出的多种分布式训练策略。TF1.x和TF2.x接口变化较大,不同版本名字可能不一样,以实际使用版本为准。用的比较多的是:
- MirroredStrategy:适用于单机多卡、数据并行、同步更新的分布式训练,采用Reduce的更新范式,worker之间采用NCCL进行通信。
- MultiWorkerMirroredStrategy:与上面的类似,不同的是这种策略支持多机多卡、数据并行、同步更新的分布式策略、Reduce范式。在TF 1.15版本里,这个策略叫CollectiveAllReduceStrategy。
- ParameterServerStrategy:经典的PS架构,多机多卡、数据并行、同步/异步更新
- 使用Estimator+Strategy 实现分布式训练,参考代码
- 第三种方式 Keras + Strategy 是Tensorflow最新官方推荐的方案。主要是利用keras的高级API,配合Strategy实现多模式的分布式训练。
后两种方法都需要传入TF_CONFIG参数,没有就是单机的训练方式。Strategy会自动读取环境变量并应用相关信息。
TF_CONFIG的配置如下
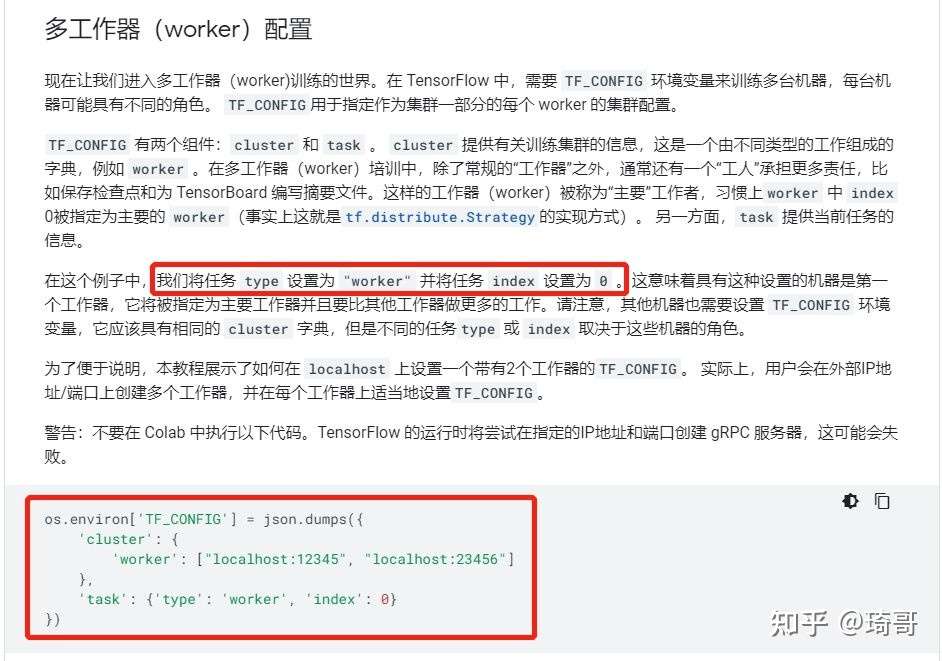
Horovod 分布式
Uber 开源的分布式训练框架 Horovod。
Uber 内部认为
- (1)MPI 模型比以前的解决方案(例如带有参数服务器的分布式 TensorFlow)更简单,并且代码更改要少得多。
- 一旦使用 Horovod 编写了可扩展训练脚本,可在单 GPU、多 GPU 甚至多台主机上运行,而无需任何进一步的代码更改。
- (2)Horovod 速度很快。 128 台服务器上测试,每台服务器上都配备了4张 Pascal GPU卡, 并通过支持 RoCE(RDMA over Converged Ethernet 的缩写 ,RoCE是在InfiniBand Trade Association(IBTA)标准中定义的网络协议,允许通过以太网络使用RDMA。
- RDMA技术在超融合数据中心、云、存储和虚拟化环境中的应用) 的 25 Gbit/s 网络连接
Horovod 在 Inception V3 和 ResNet-101 上实现了 90% 的理想扩展吞吐效率上限,在 VGG-16 上实现了 68% 的理想扩展吞吐效率上限。
Horovod 核心卖点:
- 对单机训练脚本尽量少的改动前提下进行并行训练,并且能够尽量提高训练效率。
支持
- 不同前端训练框架和底层通信库(英伟达的NCCL以及Intel的oneCCL)
- 运行在Spark/Ray集群上
Horovod 核心概念取至 MPI 领域
- 概念 size、rank、local rank、allreduce、allgather、broadcast 和 alltoall。
- size将是进程数,在本例中为 16。
- rank 将是从 0 到 15(大小 - 1)的唯一进程 ID。
- local rank将是服务器内从 0 到 3 的唯一进程 ID。
- Allreduce 是一种在多个进程之间聚合数据并将结果分发回它们的操作
【2022-2-27】分布式训练框架Horovod(一):基本概念和核心卖点
单机单卡
单机单卡是最普通的情况,当然也是最简单的。
使用步骤
- 检查可用GPU数量
- 获取一个GPU实例
- 迁移:将 数据/模型 推送到GPU上
TF
示例代码如下:
#coding=utf-8
#单机单卡,对于单机单卡,可以把参数和计算都定义再gpu上,不过如果参数模型比较大,显存不足等情况,就得放在cpu上
import tensorflow as tf
with tf.device('/cpu:0'):#也可以放在gpu上
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
with tf.device('/gpu:0'):
addwb=w+b
mutwb=w*b
init=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
np1,np2=sess.run([addwb,mutwb])
print np1,np2
PyTorch
pytorch实现
- 封装程度非常高,只需保证即将被推到 GPU 的数据是
张量(Tensor)或者模型(Module),就可以用to()函数快速进行实现。
import torch
from torch import nn
data = torch.ones((3, 3)) # 定义数据(张量)
print(data.device)
net = nn.Sequential(nn.Linear(3, 3)) # 定义模型
print(torch.cuda.is_available()) # 判断当前的机器是否有可用的 GPU
print(torch.cuda.device_count()) # 目前可用的 GPU 的数量。
# 使用第一块GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # cuda: 0 表示使用的是第一块 GPU。当然可以不用声明“:0”,默认就从第一块开始
print(device) # cpu 或 0
# 数据迁移:将data推到(迁移)gpu上
data_gpu = data.to(device)
print(data_gpu.device)
# 模型迁移:model推到gpu
net.to(device)
单机多卡
TF
- 单机多卡,只要用device直接指定设备,就可以进行训练,SGD采用各个卡的平均值
- 问题:除了取均值,还有别的方式吗?
#coding=utf-8
#单机多卡:一般采用共享操作定义在cpu上,然后并行操作定义在各自的gpu上,比如对于深度学习来说,我们一般把参数定义、参数梯度更新统一放在cpu上,各个gpu通过各自计算各自batch数据的梯度值,然后统一传到cpu上,由cpu计算求取平均值,cpu更新参数。具体的深度学习多卡训练代码,请参考:https://github.com/tensorflow/models/blob/master/inception/inception/inception_train.py
import tensorflow as tf
with tf.device('/cpu:0'):
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
with tf.device('/gpu:0'):
addwb=w+b
with tf.device('/gpu:1'):
mutwb=w*b
ini=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(ini)
while 1:
print sess.run([addwb,mutwb])
- 多个 GPU 上运行 TensorFlow,则可以采用多塔式方式构建模型,其中每个塔都会分配给不同 GPU。例如:
# Creates a graph.
c = []
for d in ['/device:GPU:2', '/device:GPU:3']:
with tf.device(d):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3])
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2])
c.append(tf.matmul(a, b))
with tf.device('/cpu:0'):
sum = tf.add_n(c)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# Runs the op.
print(sess.run(sum))
- 【2020-5-20】每个gpu的梯度要累加起来,单独计算
# train op def
tower_grads = []
for i in xrange(FLAGS.num_gpus):
with tf.device('/gpu:{}'.format(i)):
with tf.name_scope('tower_{}'.format(i)):
next_batch = dhs.get_next_batch()
cnn.inference(
next_batch[0], next_batch[1], next_batch[2],
dropout_keep_prob=FLAGS.dropout_keep_prob,
input_dropout_keep_prob=FLAGS.input_dropout_keep_prob,
phase_train=True)
grads = optimizer.compute_gradients(cnn.loss)
tower_grads.append(grads)
grads = average_gradients(tower_grads)
train_op = optimizer.apply_gradients(grads, global_step=global_step)
def average_gradients(tower_grads):
"""
Calculate the average gradient for each shared variable across all towers.
Note that this function provides a synchronization point across all towers.
NOTE: This function is copied from cifar codes in tensorflow tutorial with minor
modification.
Args:
tower_grads: List of lists of (gradient, variable) tuples. The outer list
is over individual gradients. The inner list is over the gradient
calculation for each tower.
Returns:
List of pairs of (gradient, variable) where the gradient has been averaged
across all towers.
"""
average_grads = []
for grad_and_vars in zip(*tower_grads):
# Note that each grad_and_vars looks like the following:
# ((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN))
grads = []
for g, _ in grad_and_vars:
# Add 0 dimension to the gradients to represent the tower.
# NOTE: if batch norm applied, the grad of conv-maxpool-n/b will be
# None
if g is None:
continue
expanded_g = tf.expand_dims(g, 0)
# Append on a 'tower' dimension which we will average over below.
grads.append(expanded_g)
# Average over the 'tower' dimension.
if grads:
grad = tf.concat(axis=0, values=grads)
grad = tf.reduce_mean(grad, 0)
else:
grad = None
# Keep in mind that the Variables are redundant because they are shared
# across towers. So .. we will just return the first tower's pointer to
# the Variable.
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
PyTorch
PyTorch 多种解决方案,最简单常用:nn.DataParallel()
- module :定义的模型
- device_ids 即为训练模型时用到的 GPU 设备号,
- output_device 表示输出结果的 device,默认为 0 也就是第一块卡。
工作过程
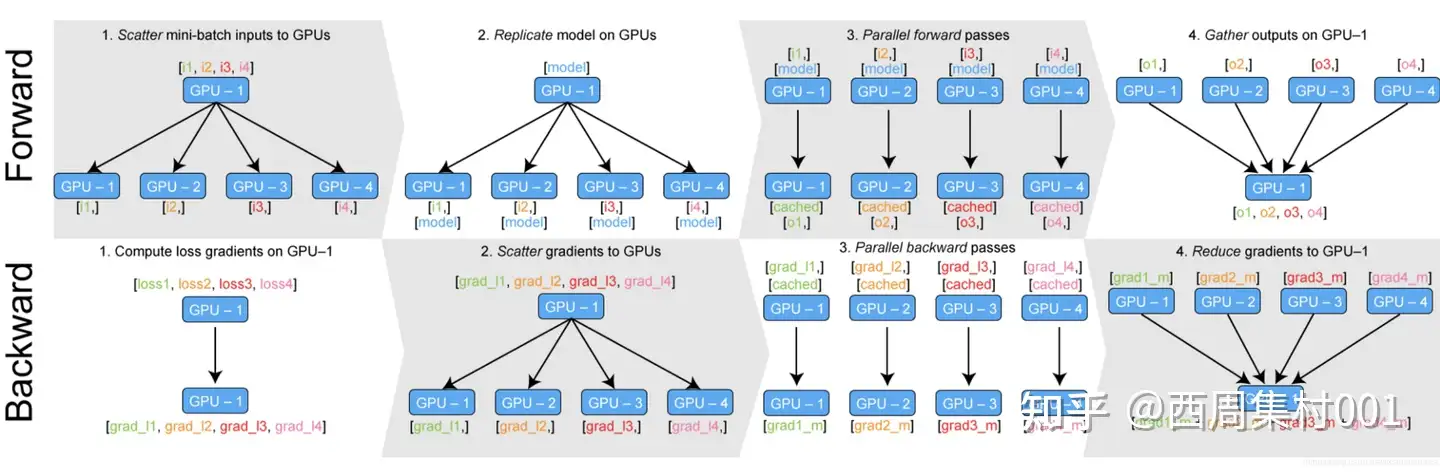
- 在每个迭代训练的Forward过程中:nn.DataParallel都自动将输入按照GUP数量进行split;然后复制模型参数到各个GPU上;分别进行正向计算后将得到网络输出output_x;最后将结果concat拼接到一起送往0号卡中。
- 在Backward过程中:先由0号卡计算loss函数,通过loss.backward()得到损失函数相于各个gpu输出结果的梯度grad_l1 … gradln;接下来0号卡将所有的grad_i送回对应的GPU_i中;然后GPU们分别进行backward得到各个GPU上面的模型参数梯度值gradm1 … gradmn;最后所有参数的梯度汇总到GPU0卡进行update。
多卡训练时,output_device 的卡所占的显存明显大一些。
- 因为使用 DataParallel 时,数据并行,每张卡获得的数据都一样多,但是所有卡的 loss 都会在第 output_device 块 GPU 进行计算,这导致了 output_device 卡的负载进一步增加。
只需要一个 DataParallel 函数就可以将模型和数据分发到多个 GPU 上。
- 但是还是需要了解这内部的运行逻辑, 遇到了诸如时间计算、资源预估、优化调试问题的时候,可以更好地运用 GPU
import os
from torch import nn
import torch
class ASimpleNet(nn.Module):
def __init__(self, layers=3):
super(ASimpleNet, self).__init__()
self.linears = nn.ModuleList([nn.Linear(3, 3, bias=False) for i in range(layers)]) # 设备有几个,就创建几个模型分支,
def forward(self, x): # 模型前馈实际处理过程
print("forward batchsize is: {}".format(x.size()[0]))
x = self.linears(x)
x = torch.relu(x)
return x
device=os.environ['CUDA_VISIBLE_DEVICES']
# os.environ['CUDA_VISIBLE_DEVICES']="0,2" 指定具体的设备
# print("CUDA_VISIBLE_DEVICES :{}".format(os.environ["CUDA_VISIBLE_DEVICES"]))
batch_size = 16
inputs = torch.randn(batch_size, 3) # 创建16个数据
labels = torch.randn(batch_size, 3) # 创建16个数据标签
inputs, labels = inputs.to(device), labels.to(device) # 数据迁移到设备上,返回数据总接口(应该是一个列表/字典,数据片段-GPU对应关系)
net = ASimpleNet() # 模型实例化
net = nn.DataParallel(net) # 模型分布结构化
net.to(device) # 模型迁移到设备上,返回一个模型总接口(应该是一个列表/字典,子模型-GPU对应关系)
for epoch in range(1): # 训练次数自行决定
outputs = net(inputs) # 数据统一入口;数据怎么分配,模型参数怎么同步,内部机制自行来处理
# 输出:
# CUDA_VISIBLE_DEVICES : 3, 2, 1, 0
# forward batchsize is: 4
# forward batchsize is: 4
# forward batchsize is: 4
# forward batchsize is: 4
注意:有几个GPU,建几个分支(同结构模型),这样就可以分散到各个GPU上。
CUDA_VISIBLE_DEVICES 得知了当前程序可见的 GPU 数量为 4,而创建的 batch size 为 16,输出每个 GPU 上模型 forward 函数内部的 print 内容,验证了每个 GPU 获得的数据量都是 4 个。
- DataParallel 会自动将数据切分、加载到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总。
提示
- DataParallel的整个并行训练过程利用python多线程实现
由以上工作过程分析可知,nn.DataParallel 无法避免的问题:
- 负载不均衡问题。gpu_0所承担的任务明显要重于其他gpu
- 速度问题。每个iteration都需要复制模型且均从GPU0卡向其他GPU复制,通讯任务重且效率低;python多线程GIL锁导致的线程颠簸(thrashing)问题。
- 只能单机运行。由于单进程的约束导致。
- 只能切分batch到多GPU,而无法让一个model分布在多个GPU上。当一个模型过大,设置batchsize=1时其显存占用仍然大于单张显卡显存,此时就无法使用DataParallel类进行训练。
因此官方推荐使用 torch.nn.DistributedDataParallel 替代 nn.DataParallel
多机多卡
一、基本概念
- Cluster、Job、task概念:三者可以简单的看成是层次关系
- task相当于每台机器上的一个进程,多个task组成job;
- job又有两种:ps参数服务、worker计算服务,组成cluster。
二、同步SGD与异步SGD
- 1、同步更新:各个用于并行计算的电脑,计算完各自的batch 后,求取梯度值,把梯度值统一送到ps服务机器中,由ps服务机器求取梯度平均值,更新ps服务器上的参数。
- 如下图所示,可以看成有四台电脑,第一台电脑用于存储参数、共享参数、共享计算,可以简单的理解成内存、计算共享专用的区域,也就是ps job;另外三台电脑用于并行计算的,也就是worker task。
- 这种计算方法存在的缺陷是:每一轮的梯度更新,都要等到A、B、C三台电脑都计算完毕后,才能更新参数,也就是迭代更新速度取决与A、B、C三台中,最慢的那一台电脑,所以采用同步更新的方法,建议A、B、C三台的计算能力都不想。
- 2、异步更新:ps服务器收到只要收到一台机器的梯度值,就直接进行参数更新,无需等待其它机器。这种迭代方法比较不稳定,收敛曲线震动比较厉害,因为当A机器计算完更新了ps中的参数,可能B机器还是在用上一次迭代的旧版参数值。
多机多卡讲解
【2024-4-18】大模型多机多卡训练经验总结
LLM多机多卡训练教程好少,有些还拿 torch.distributed.launch 来做,殊不知早就改用 torchrun 了。
环境准备: 以2台机器为例
- 首先, 2台机器要能免密登录,编辑/etc/hosts文件,加入node信息:
# vi /etc/hosts
ip1 node01
ip2 node02
然后, 两个node分别执行以下操作, 生成私钥和公钥:
ssh-keygen -t rsa
然后, 全部回车,采用默认值。再互相拷贝秘钥:
ssh-copy-id root@ip1
ssh-copy-id root@ip2
分别在2台机器上试试互相ssh,如果无密码输入要求直接登录到另一台服务器则说明配置成功。
2台机器环境必须保持一致,包括python版本,训练所需依赖包等。
还需确保安装了pdsh:
apt-get install pdsh
多机训练
使用 torchrun,毕竟单张GPU有80G显存,7B模型单卡完全放得下。
- 假设node01为master,node02需要有相同的模型权重和代码,可以直接在master用scp拷贝过去。
准备工作完成后, 可以启动训练命令
- 首先在node01(master)执行如下命令(非完整,仅供参考,使用deepspeed ZeRO-2):
torchrun --nproc_per_node 8 --nnodes 2 --master_addr ${MASTER_ADDR} --master_port 14545 --node_rank 0 train.py \
--deepspeed ${deepspeed_config_file} \
...
参数
- nproc_per_node表示每个节点的进程数,可以理解为每个节点所需GPU数
- nnode表示节点数,2台机器就是2个节点数
- master_add为master的ip
- node_rank表示当前启动的是第几个节点
在node02执行同样命令,但需将node_rank指定为1,不出意外的话可以成功跑通,即便报错可能也是依赖包版本两台机器不一致导致。很快就会在控制台看到transformers打印的日志,但发现save_total_limit只在master上管用。
TF
代码编写
- 1、定义集群
- 比如假设上面的图所示,我们有四台电脑,名字假设为:A、B、C、D,那么集群可以定义如下
#coding=utf-8
#多台机器,每台机器有一个显卡、或者多个显卡,这种训练叫做分布式训练
import tensorflow as tf
#现在假设我们有A、B、C、D四台机器,首先需要在各台机器上写一份代码,并跑起来,各机器上的代码内容大部分相同
# ,除了开始定义的时候,需要各自指定该台机器的task之外。以机器A为例子,A机器上的代码如下:
cluster=tf.train.ClusterSpec({
"worker": [
"A_IP:2222",#格式 IP地址:端口号,第一台机器A的IP地址 ,在代码中需要用这台机器计算的时候,就要定义:/job:worker/task:0
"B_IP:1234"#第二台机器的IP地址 /job:worker/task:1
"C_IP:2222"#第三台机器的IP地址 /job:worker/task:2
],
"ps": [
"D_IP:2222",#第四台机器的IP地址 对应到代码块:/job:ps/task:0
]})
然后需要写四分代码,这四分代码文件大部分相同,但是有几行代码是各不相同的。
- 2、在各台机器上,定义server
- 比如A机器上的代码server要定义如下:
server=tf.train.Server(cluster,job_name='worker',task_index=0)#找到‘worker’名字下的,task0,也就是机器A
- 比如A机器上的代码server要定义如下:
- 3、在代码中,指定device
with tf.device('/job:ps/task:0'):#参数定义在机器D上 w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2)) b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5)) with tf.device('/job:worker/task:0/cpu:0'):#在机器A cpu上运行 addwb=w+b with tf.device('/job:worker/task:1/cpu:0'):#在机器B cpu上运行 mutwb=w*b with tf.device('/job:worker/task:2/cpu:0'):#在机器C cpu上运行 divwb=w/b
在深度学习训练中,一般图的计算,对于每个worker task来说,都是相同的,所以我们会把所有图计算、变量定义等代码,都写到下面这个语句下:
with tf.device(tf.train.replica_device_setter(worker_device='/job:worker/task:indexi',cluster=cluster))
函数replica_deviec_setter会自动把变量参数定义部分定义到ps服务中(如果ps有多个任务,那么自动分配)。下面举个例子,假设现在有两台机器A、B,A用于计算服务,B用于参数服务,那么代码如下:
#coding=utf-8
#上面是因为worker计算内容各不相同,不过再深度学习中,一般每个worker的计算内容是一样的,
# 以为都是计算神经网络的每个batch 前向传导,所以一般代码是重用的
import tensorflow as tf
#现在假设我们有A、B台机器,首先需要在各台机器上写一份代码,并跑起来,各机器上的代码内容大部分相同
# ,除了开始定义的时候,需要各自指定该台机器的task之外。以机器A为例子,A机器上的代码如下:
cluster=tf.train.ClusterSpec({
"worker": [
"192.168.11.105:1234",#格式 IP地址:端口号,第一台机器A的IP地址 ,在代码中需要用这台机器计算的时候,就要定义:/job:worker/task:0
],
"ps": [
"192.168.11.130:2223"#第四台机器的IP地址 对应到代码块:/job:ps/task:0
]})
#不同的机器,下面这一行代码各不相同,server可以根据job_name、task_index两个参数,查找到集群cluster中对应的机器
isps=False
if isps:
server=tf.train.Server(cluster,job_name='ps',task_index=0)#找到‘worker’名字下的,task0,也就是机器A
server.join()
else:
server=tf.train.Server(cluster,job_name='worker',task_index=0)#找到‘worker’名字下的,task0,也就是机器A
with tf.device(tf.train.replica_device_setter(worker_device='/job:worker/task:0',cluster=cluster)):
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
addwb=w+b
mutwb=w*b
divwb=w/b
saver = tf.train.Saver()
summary_op = tf.merge_all_summaries()
init_op = tf.initialize_all_variables()
sv = tf.train.Supervisor(init_op=init_op, summary_op=summary_op, saver=saver)
with sv.managed_session(server.target) as sess:
while 1:
print sess.run([addwb,mutwb,divwb])
把该代码在机器A上运行,你会发现,程序会进入等候状态,等候用于ps参数服务的机器启动,才会运行。
因此接着我们在机器B上运行如下代码:
#coding=utf-8
#上面是因为worker计算内容各不相同,不过再深度学习中,一般每个worker的计算内容是一样的,
# 以为都是计算神经网络的每个batch 前向传导,所以一般代码是重用的
#coding=utf-8
#多台机器,每台机器有一个显卡、或者多个显卡,这种训练叫做分布式训练
import tensorflow as tf
#现在假设我们有A、B、C、D四台机器,首先需要在各台机器上写一份代码,并跑起来,各机器上的代码内容大部分相同
# ,除了开始定义的时候,需要各自指定该台机器的task之外。以机器A为例子,A机器上的代码如下:
cluster=tf.train.ClusterSpec({
"worker": [
"192.168.11.105:1234",#格式 IP地址:端口号,第一台机器A的IP地址 ,在代码中需要用这台机器计算的时候,就要定义:/job:worker/task:0
],
"ps": [
"192.168.11.130:2223"#第四台机器的IP地址 对应到代码块:/job:ps/task:0
]})
#不同的机器,下面这一行代码各不相同,server可以根据job_name、task_index两个参数,查找到集群cluster中对应的机器
isps=True
if isps:
server=tf.train.Server(cluster,job_name='ps',task_index=0)#找到‘worker’名字下的,task0,也就是机器A
server.join()
else:
server=tf.train.Server(cluster,job_name='worker',task_index=0)#找到‘worker’名字下的,task0,也就是机器A
with tf.device(tf.train.replica_device_setter(worker_device='/job:worker/task:0',cluster=cluster)):
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
addwb=w+b
mutwb=w*b
divwb=w/b
saver = tf.train.Saver()
summary_op = tf.merge_all_summaries()
init_op = tf.initialize_all_variables()
sv = tf.train.Supervisor(init_op=init_op, summary_op=summary_op, saver=saver)
with sv.managed_session(server.target) as sess:
while 1:
print sess.run([addwb,mutwb,divwb])
分布式训练需要熟悉的函数:
- tf.train.Server
- tf.train.Supervisor
- tf.train.SessionManager
- tf.train.ClusterSpec
- tf.train.replica_device_setter
- tf.train.MonitoredTrainingSession
- tf.train.MonitoredSession
- tf.train.SingularMonitoredSession
- tf.train.Scaffold
- tf.train.SessionCreator
- tf.train.ChiefSessionCreator
- tf.train.WorkerSessionCreator
PyTorch
DP
- DP就是 DataParallel。DP 是单进程控制多 GPU。
- DP 将输入的一个 batch 数据分成了 n 份(n 为实际使用的 GPU 数量),分别送到对应的 GPU 进行计算。
- 在网络前向传播时,模型会从主 GPU 复制到其它 GPU 上;
- 在反向传播时,每个 GPU 上的梯度汇总到主 GPU 上,求得梯度均值更新模型参数后,再复制到其它 GPU,以此来实现并行。
- 由于主 GPU 要进行梯度汇总和模型更新,并将计算任务下发给其它 GPU,所以主 GPU 的负载与使用率会比其它 GPU 高,这就导致了 GPU 负载不均衡的现象。
DDP
- DDP 是 DistributedDataParallel。DDP 多进程控制多 GPU。
- 系统会为每个 GPU 创建一个进程,不再有主 GPU,每个 GPU 执行相同的任务。
- DDP 使用分布式数据采样器(DistributedSampler)加载数据,确保数据在各个进程之间没有重叠。
- 在反向传播时,各 GPU 梯度计算完成后,各进程以广播的方式将梯度进行汇总平均,然后每个进程在各自的 GPU 上进行梯度更新,从而确保每个 GPU 上的模型参数始终保持一致。由于无需在不同 GPU 之间复制模型,DDP 的传输数据量更少,因此速度更快。
DDP 既可用于单机多卡也可用于多机多卡,它能解决 DataParallel 速度慢、GPU 负载不均衡等问题。因此,官方更推荐使用 DistributedDataParallel 来进行分布式训练
基本概念
- group:进程组。默认情况下,只有一个组,即一个 world。(DDP 多进程控制多 GPU)
- world_size :表示全局进程个数。
- rank:表示进程序号,用于进程间通讯,表示进程优先级。rank=0 的主机为主节点。
训练基本流程
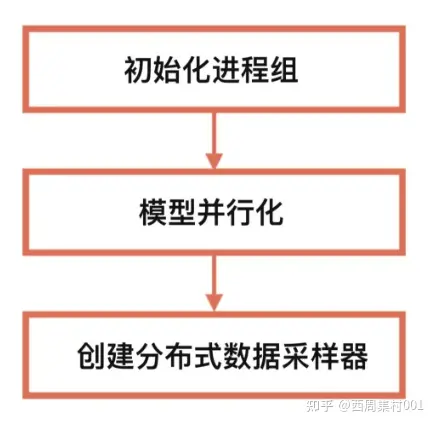
- (1)初始化进程组:用 init_process_group 函数
- backend:是通信所用的后端,可以是“nccl”或“gloo”。一般来说,nccl 用于 GPU 分布式训练,gloo 用于 CPU 进行分布式训练。
- init_method:字符串类型,是一个 url,进程初始化方式,默认是 “env://”,表示从环境变量初始化,还可以使用 TCP 的方式或共享文件系统 。
- world_size:执行训练的所有的进程数,表示一共有多少个节点(机器)。
- rank:进程的编号,也是其优先级,表示当前节点(机器)的编号。group_name:进程组的名字。
- (2)模型并行化:用 DistributedDataParallel,将模型分发至多 GPU 上
- DistributedDataParallel 的参数与 DataParallel 基本相同
- (3)创建分布式数据采样器
DP 是直接将一个 batch 的数据划分到不同的卡,但是多机多卡间频繁数据传输会严重影响效率,这时就要用到分布式数据采样器 DistributedSampler,它会为每个子进程划分出一部分数据集,从而使 DataLoader 只会加载特定的一个子数据集,以避免不同进程之间有数据重复。
- 先将 train_dataset 送到了 DistributedSampler 中,并创建了一个分布式数据采样器 train_sampler。
- 再构造 DataLoader ,, 参数中传入了一个 sampler=train_sampler,即可让不同的进程节点加载属于自己的那份子数据集。也就是说,使用 DDP 时,不再是从主 GPU 分发数据到其他 GPU 上,而是各 GPU 从自己的硬盘上读取属于自己的那份数据。
具体逻辑:
- 加载模型阶段。每个GPU都拥有模型的一个副本,所以不需要拷贝模型。rank为0的进程会将网络初始化参数broadcast到其它每个进程中,确保每个进程中的模型都拥有一样的初始化值。
- 加载数据阶段。DDP 不需要广播数据,而是使用多进程并行加载数据。在 host 之上,每个worker进程都会把自己负责的数据从硬盘加载到 page-locked memory。DistributedSampler 保证每个进程加载到的数据是彼此不重叠的。
- 前向传播阶段。在每个GPU之上运行前向传播,计算输出。每个GPU都执行同样的训练,所以不需要有主 GPU。
- 计算损失。在每个GPU之上计算损失。
- 反向传播阶段。运行后向传播来计算梯度,在计算梯度同时也对梯度执行all-reduce操作。
- 更新模型参数阶段。因为每个GPU都从完全相同的模型开始训练,并且梯度被all-reduced,因此每个GPU在反向传播结束时最终得到平均梯度的相同副本,所有GPU上的权重更新都相同,也就不需要模型同步了。注意,在每次迭代中,模型中的Buffers 需要从rank为0的进程广播到进程组的其它进程上。
代码略,见原文
注意
- 使用 DDP 意味着使用多进程,如果直接保存模型,每个进程都会执行一次保存操作,此时只使用主进程中的一个 GPU 来保存即可。
新技术
DisTrO
【2024-8-29】DisTrO 让你家里的电脑也能训练超级大模型
Nous Research 最近放出了一份重磅报告,介绍最新研究成果——DisTrO(Distributed Training Over-the-Internet)。
有望让告别”只有大公司才能训练大模型”的时代,开启全民AI狂欢!
DisTrO 是一个分布式优化器家族,两个超级牛X的特点:
- 与架构无关:不管你用啥架构,它都能用。
- 与网络无关:网速慢?没关系,它照样能跑!
最厉害的是,DisTrO把GPU之间的通信需求减少了1000到10000倍!
在龟速网络上,用各种杂牌子的网络硬件,也能训练大型神经网络,而且收敛速度跟AdamW+All-Reduce一样快!
DisTrO 究竟有什么用呢?
- 提高LLM训练的抗风险能力:不再依赖单一实体的计算能力,训练过程更安全、更公平。
- 促进研究合作与创新:研究人员和机构可以更自由地合作,尝试新技术、新算法、新模型。
- 推动AI民主化:降低了训练大模型的门槛,让更多人有机会参与其中。
分布式训练库
详见站内专题: 分布式训练库
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
