- 总结
- 简介
- GPU环境准备
- 结束
总结
- 【2020-10-28】CUDA编程入门极简教程
简介
- 2006年,NVIDIA公司发布了
CUDA,CUDA是建立在NVIDIA的CPUs上的一个通用并行计算平台和编程模型,基于CUDA编程可以利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。 - 近年来,
GPU最成功的一个应用就是深度学习领域,基于GPU的并行计算已经成为训练深度学习模型的标配。截止2018年3月,最新的CUDA版本为CUDA 9。 - GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。
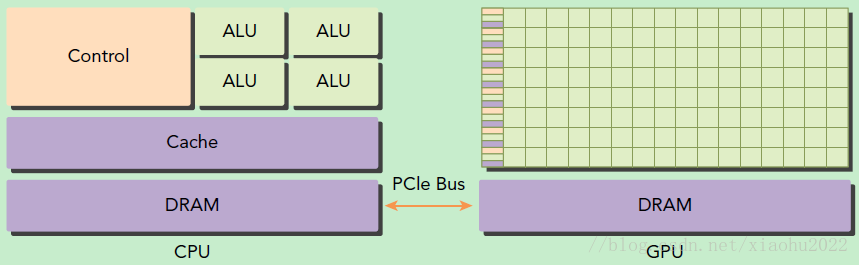
- 在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device),如下图所示。
- GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。
- 另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。
- 因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。
-
- 在显卡界,对于「A 卡」和「N 卡」的信仰是如何形成的?
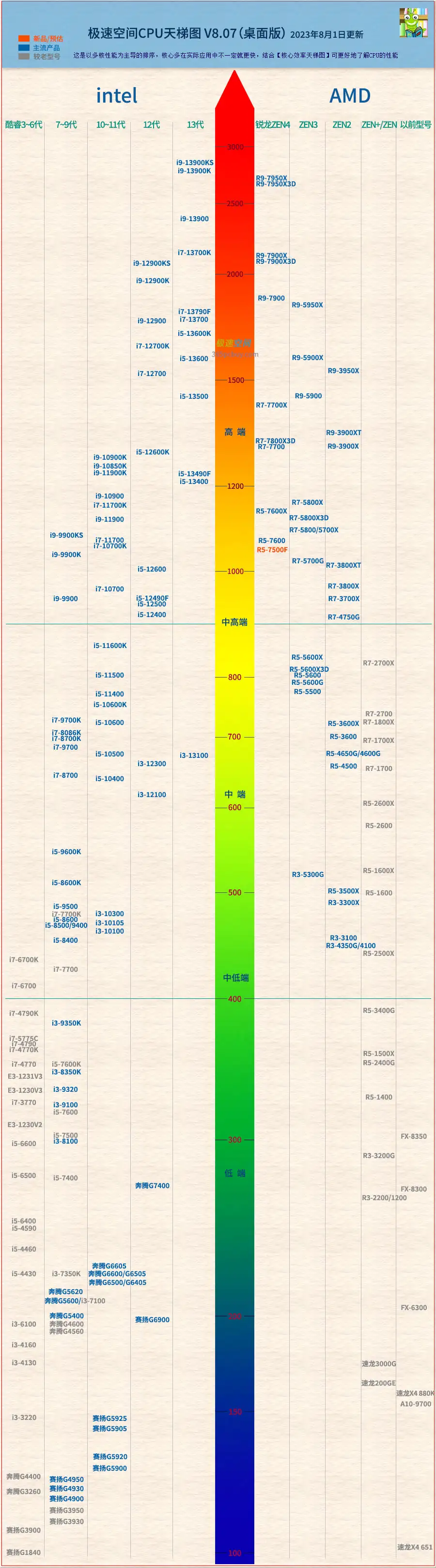
天梯图
CPU天梯图
桌面级CPU天梯图:
- 2023年台式桌面级CPU天梯图性能榜 (更新时间20230801)
2023年笔记本CPU天梯性能排行榜图 (更新时间:20230730)

显卡天梯图
- 显卡性能天梯图
- 【2023-10-11】2023年最新CPU天梯图&显卡天梯图「小白必看电脑选购指南🔥🔥🔥」(新增专业图形显卡天梯)9月12日
桌面级显卡天梯图:
- 2023年台式桌面级显卡天梯图性能排行榜 (更新时间20230912)

2023年NVIDIA 桌面专业图形显卡天梯

2023年笔记本移动显卡和桌面级显卡对比性能天梯图排行榜 (更新时间20230516)

2023年NVIDIA笔记本专业图形显卡性能天梯(官方版)
设备选型
- CPU 中央处理器(Central Processing Unit)
- GPU 图形处理器(Graphics Processing Unit)
- TPU 谷歌的张量处理器(Tensor Processing Unit)
- NPU 神经网络处理器(Neural network Processing Unit)
总结功能特点:
CPU(Central Processing Unit):中央处理器,是计算机的运算和控制核心,负责执行程序、处理数据和协调计算机系统的其他部件。GPU(Graphics Processing Unit):图像处理器,擅长并行计算,特别适用于处理大规模的数据集和图形渲染任务。NPU(Neural Processing Unit):神经网络处理器,专门用于进行神经网络计算和推理,对于深度学习等人工智能任务具有高效性能。TPU(Tensor Processing Unit):张量处理器,针对机器学习任务进行了优化,能高效处理大规模张量计算。DPU(Deep Learning Processing Unit):深度学习处理器,专注于深度学习任务的计算加速。IPU(Intelligent Processing Unit):智能处理器,集成高度优化的硬件和软件,以实现高效的人工智能计算。PPU阿里平头哥
GPU/NPU/TPU/LPU
【2026-04-25】CPU、GPU、TPU、NPU、LPU 到底差在哪?
- 详见:视频
5 种 AI 计算架构放在一起看:
- CPU 负责通用控制,适合低延迟任务。
- GPU 擅长大规模并行,数据从流式多处理器汇入 L2 Cache。
- TPU 围绕矩阵/张量计算设计,核心是脉动阵列。
- NPU 面向神经网络推理,有专门的融合引擎和片上缓存。
- LPU 强调确定性数据流,让关键路径尽量不依赖片外 DRAM。
CPU 管控制,GPU 拼并行,TPU/NPU 做矩阵,LPU 把数据流固定下来。
消费级显卡
显卡选型参考站内专题:GPU显存分析
CPU
CPU 如何执行大型矩阵运算任务?一般 CPU 是基于冯诺依曼架构的通用处理器,CPU 与软件和内存的运行方式
CPU 简介
中央处理器(CPU,Central Processing Unit) 是电子计算机的主要设备之一,电脑中的核心配件。其功能主要是解释计算机指令以及处理计算机软件中的数据。电脑中所有操作都由CPU负责读取指令,对指令译码并执行指令的核心部件。
CPU( Central Processing Unit, 中央处理器)就是机器的“大脑”,也是布局谋略、发号施令、控制行动的“总司令官”。
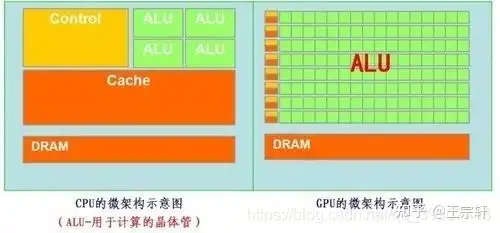
CPU 结构
CPU 主要包括运算器(ALU, Arithmetic and Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、高速缓存器(Cache)和通讯的数据、控制及状态总线。
计算单元、控制单元和存储单元,架构如图所示:
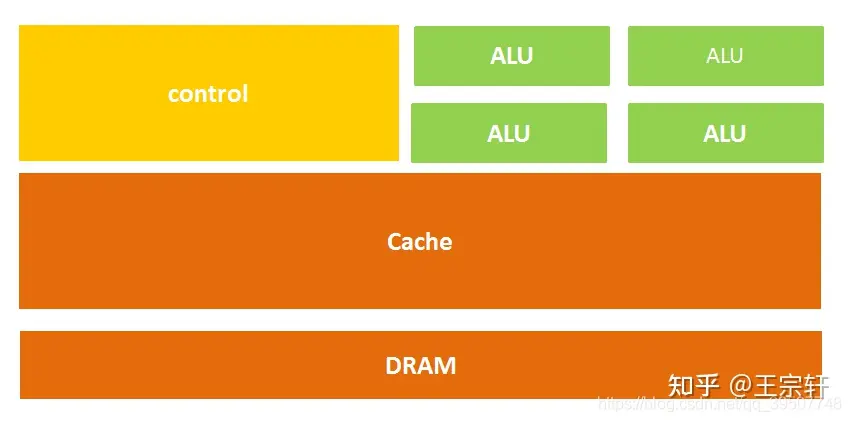
计算单元主要执行算术运算、移位等操作以及地址运算和转换;存储单元主要用于保存运算中产生的数据以及指令等;控制单元则对指令译码,并且发出为完成每条指令所要执行的各个操作的控制信号。
指令执行过程
CPU遵循冯诺依曼架构,核心: 存储程序,顺序执行。
指令在CPU中执行过程:
- 读取到指令后,通过指令总线送到控制器(黄色区域)中进行译码,并发出相应的操作控制信号;
- 然后运算器(绿色区域)按照操作指令对数据进行计算,并通过数据总线将得到的数据存入数据缓存器(大块橙色区域)。
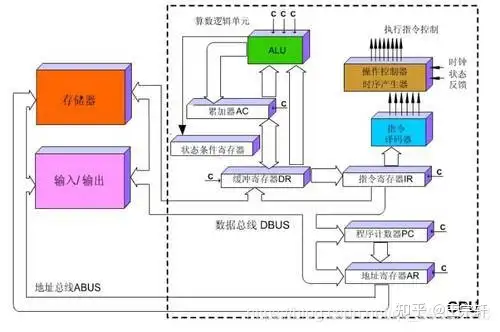
负责计算的绿色区域占的面积似乎太小了,而橙色区域的缓存Cache和黄色区域的控制单元占据了大量空间。
CPU 提升
CPU 性能提升的5个阶段
- (1)
CISC阶段。上世纪80年代,x86架构为代表的CISC架构开启了CPU性能快速提升的时代,CPU性能每年提升约25%(图中22%数据有误),大约3年性能可以翻倍。 - (2)
RISC阶段。CISC指令系统越来越复杂,而RISC证明了“越精简,越高效”。随着RISC架构的CPU开始流行,性能每年可以达到52%,性能翻倍只需要18个月。 - (3)
多核阶段。单核CPU的性能提升越来越困难,通过集成更多CPU核并行的方式来进一步提升性能。这一时期,每年性能提升可以到23%,性能翻倍需要3.5年。 - (4)
多核性能递减阶段。随着CPU核的数量越来越多,阿姆达尔定律证明了处理器数量的增加带来的收益会逐渐递减。这一时期,CPU性能提升每年只有12%,性能翻倍需要6年。 - (5) 性能提升
瓶颈阶段。不管是从架构/微架构设计、工艺、多核并行等各种手段都用尽的时候,CPU整体的性能提升达到了一个瓶颈。从2015年之后,CPU性能每年提升只有3%,要想性能翻倍,需要20年。
CPU 局限性
CPU架构需要大量空间放置存储单元(橙色部分)和控制单元(黄色部分),相比之下, 计算单元(绿色部分)只占很小,所以大规模并行计算能力上极受限制,而更擅长于逻辑控制。
另外,因为遵循冯诺依曼架构(存储程序,顺序执行),CPU就像一板一眼的管家,吩咐的事情总是一步一步来做。但是随着对更大规模与更快处理速度的需求的增加,这位管家渐渐变得有些力不从心。
能不能把多个处理器放在同一块芯片上,一起来做事,这样效率不就提高了吗?
没错,GPU由此诞生了。
GPU
Kaggle GPU 性能对比:使用GPU后提速12倍
- 用 ASL Alphabet 数据集训练模型为例,在 Kaggle Kernels 上用 GPU 的总训练时间为 994 秒,而此前用 CPU 的总训练时间达 13,419 秒。直接让你训练模型的时间缩短为原来的 1/12
【2018-7-19】科普帖:深度学习中GPU和显存分析
误区:
- 显存和GPU等价,使用GPU主要看显存使用?
- Batch Size 越大,程序越快,而且近似成正比?
- 显存占用越多,程序越快?
- 显存占用大小和batch size大小成正比
并行计算
并行计算(Parallel Computing)指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。
基本思想
- 多个处理器来共同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。
并行计算可分为时间并行和空间并行。
- 时间并行: 流水线技术
- 比如说工厂生产食品的时候分为四步:清洗-消毒-切割-包装。
- 如果不采用流水线,一个食品完成上述四个步骤后,下一个食品才进行处理,耗时且影响效率。但是采用流水线技术,就可以同时处理四个食品。这就是并行算法中的时间并行,在同一时间启动两个或两个以上的操作,大大提高计算性能。
- 空间并行: 多个处理机并发的执行计算,即通过网络将两个以上的处理机连接起来,达到同时计算同一个任务的不同部分,或者单个处理机无法解决的大型问题。
GPU 介绍
GPU全称为 Graphics Processing Unit,中文为图形处理器,最初是用在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上运行绘图运算工作的微处理器。
为什么需要GPU?
为什么 GPU 特别擅长处理图像数据呢?
因为图像每个像素点都有被处理的需要,而且每个像素点处理的过程和方式都十分相似,成了GPU的天然温床。
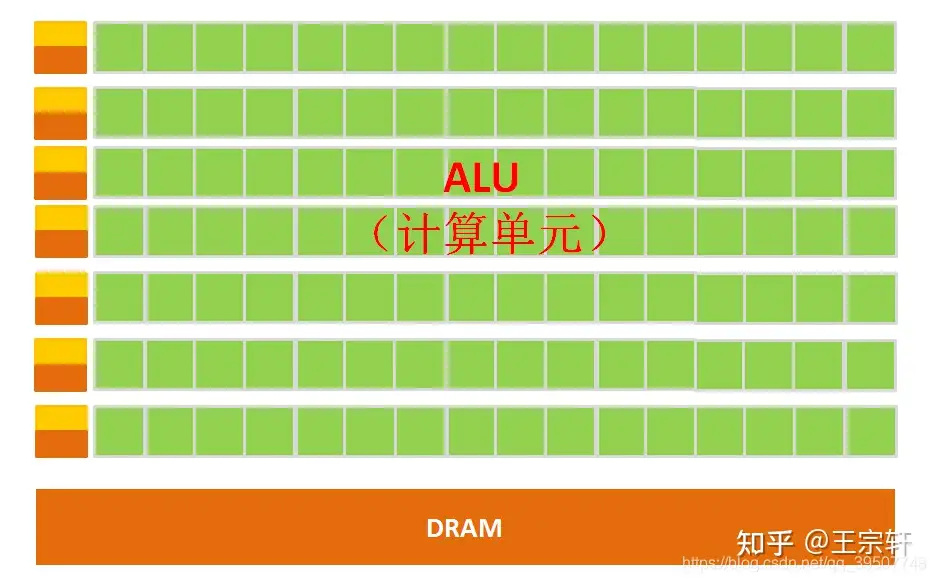
但GPU无法单独工作,必须由CPU进行控制调用才能工作。
CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
CPU和GPU
GPU的工作大部分都计算量大,但没什么技术含量,而且要重复很多很多次。
- 就像你有个工作需要计算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已;
- 而CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生,你要是富士康你雇哪个?
虽然GPU是为了图像处理而生的,但是通过前面的介绍可以发现,它在结构上并没有专门为图像服务的部件,只是对CPU的结构进行了优化与调整,所以现在GPU不仅可以在图像处理领域大显身手,还被用来科学计算、密码破解、数值分析,海量数据处理(排序,Map-Reduce等),金融分析等需要大规模并行计算的领域。
CPU vs GPU
【2024-8-4】AI 工程师都应该知道的GPU工作原理
- cpu: 跑车, 车等人, 低延迟 —— 快速完成单个任务
- gpu: 地铁, 人等车, 高吞吐 —— 完成大规模并行任务
【2024-3-25】GPU(一)GPU简介
CPU与GPU的关系,通过 PCIe总线 通信。
- PCIe总线的传输速率较慢,在计算量不大的时候,有可能出现数据在PCIe总线传输的时间长于GPU计算时间,所以在一些小型任务上,使用GPU也未必能达到加速的效果。
- 图见原文
CPU和GPU都具有计算能力,但存在一定差异:
- CPU拥有少量(个位数)计算核心(上图的算术逻辑单元),GPU拥有大量(几千甚至更多)计算核心;
- CPU单个核计算能力更强,GPU单个核计算能力更弱;
- CPU擅长逻辑处理,GPU擅长高度并行的数据运算;
- CPU线程重量,切换开销大。GPU线程轻量,切换开销小;
- GPU不能单独计算,需要与CPU组成异构架构才能用于计算;
- 在CPU+GPU组成的异构计算平台中,CPU起控制作用,一般称做主机(host),GPU可以看做CPU的协处理器,一般称做设备(device);
- CPU有配套的内存,GPU也有配套的内存(通常叫显存),CPU无法直接使用GPU内存,GPU也无法直接使用CPU内存;
- CPU要求的是实时响应,对单任务的速度要求很高,会采用多层缓存的办法来保证单任务的速度。GPU是把所有的任务都排好,然后再批处理,对缓存的要求相对很低;
某些不严谨的场景下,口头上会把显卡和GPU等价,实际上它俩是一个包含关系:GPU是显卡的一个组成部分。显卡一般由GPU、DRAM内存(显存)、PCIe接口、电源接口、HDMI接口等部分组成。
GPU 架构
Intel GPU
安装Intel显卡驱动及 extension for pytorch
# (1) PC 端: For hardware listed in the table above, other than Intel® Core™ Ultra Series 2 Mobile Processors (Arrow Lake-H), use the commands below:
python -m pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/xpu
python -m pip install intel-extension-for-pytorch==2.6.10+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
# pip install intel-extension-for-pytorch==2.6.10+xpu # 清华源找不到工具包
# (2) 移动端: For Intel® Core™ Ultra Series 2 Mobile Processors (Arrow Lake-H), use the commands below:
python -m pip install torch==2.6.0.post0+xpu torchvision==0.21.0.post0+xpu torchaudio==2.6.0.post0+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/arl/us/
python -m pip install intel-extension-for-pytorch==2.6.10+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/arl/us/
【2025-4-25】 安装失败
pip install intel-extension-for-pytorch==2.6.10+xpu- 报错: 找不到工具包
测试
import torch;
import intel_extension_for_pytorch;
print(torch.xpu.is_available());
代码
import torch
# 检查 GPU 是否可用
device = torch.device("xpu" if torch.xpu.is_available() else "cpu")
# 假设你有一个模型
model = MyModel().to(device)
# 假设你有一些输入数据
inputs = inputs.to(device)
# 训练时将模型和数据移到 GPU
outputs = model(inputs)
NVIDIA GPU 架构演进
不同公司设计生产的GPU会有不同的架构差异,同一个公司不同时间生产的GPU也可能存在架构上的差异。
以 NVIDIA GPU 为例,1999年NVIDIA发布第一代GPU架构GeForce 256,标志着GPU时代的开始。随后推出:
Tesla(特斯拉)、Fermi(费米)、Kepler(开普勒)、Maxwell(麦克斯韦)、Pascal(帕斯卡)、Volta(伏特)、Turing(图灵)、Ampere(安培)、Hopper(哈珀)、Ada Lovelace(阿达 洛芙莱斯)等GPU架构,不断增强GPU的计算能力和程序性,推动GPU在图形渲染、人工智能和高性能计算等领域的应用。- 名字来自一些伟大数学家、物理学家,这也体现了这些伟人的成果对当代计算机领域的重要性。
GPU architectures, with:
Tfor Turing;Afor Ampere;Vfor Volta;Hfor Hopper; 2022Lfor Ada Lovelace;
NVIDIA GPU 核心架构演进对比表
| 架构版本 | 时间 | 代表芯片 | 核心特性与改进 | 性能/能效提升 | 典型应用场景 |
|---|---|---|---|---|---|
| Tesla | 2006-2008 | G80、GT200 | 1. 首个支持CUDA编程模型 2. 引入统一着色器设计 3. 具备基础单精度浮点(FP32)计算能力 |
- | 科学计算、早期GPGPU应用 |
| Fermi | 2010 | GF100(Tesla M2050) | 1. SM 2.0架构,每组SM含32个CUDA核心,支持并发内核执行 2. 支持ECC内存,提升计算可靠性 3. 首次支持双精度浮点(FP64),FP64性能为FP32的1/2 |
FP32性能较Tesla提升8倍 | 高性能计算(HPC)、科学仿真 |
| Kepler | 2012 | GK110(Tesla K80)、GK210 | 1. SMX设计,每组SM含192个CUDA核心 2. 支持动态并行、Hyper-Q多任务提交 3. 引入GPU Boost动态调频技术 |
能效比较Fermi提升3倍 | 深度学习训练雏形、大规模并行计算 |
| Maxwell | 2014 | GM204(GTX 980)、GM200(Titan X) | 1. SMM架构,SM分割为4个独立单元,提升指令调度效率 2. 优化Voxel全局光照,强化图形渲染 3. 后期型号采用16nm FinFET工艺,降低功耗 |
能效比较Kepler提升2倍 | 游戏图形渲染、中端深度学习推理 |
| Pascal | 2016 | GP100(Tesla P100)、GP102(GTX 1080 Ti) | 1. 引入NVLink高速互联,多GPU带宽达80GB/s 2. 支持FP16混合精度计算 3. P100搭载HBM2显存,带宽732GB/s |
P100的FP16算力达21 TFLOPS | 深度学习规模化训练、HPC、AI推理 |
| Volta | 2017 | GV100(Tesla V100) | 1. 革命性Tensor Core,专为矩阵运算优化,支持FP16/FP32混合精度 2. SIMT模型升级,支持独立线程调度 3. HBM2+显存,带宽提升至900GB/s |
深度学习训练速度较Pascal快5倍 | 大规模深度学习训练、高精度科学计算 |
| Turing | 2018 | TU102(RTX 2080 Ti)、TU104(Quadro RTX 6000) | 1. 硬件级RT Core,支持实时光线追踪 2. 第二代Tensor Core,支持INT8/INT4量化推理 3. 搭载GDDR6显存,带宽672GB/s |
- | 实时光追游戏、AI推理、专业图形设计 |
| Ampere | 2020 | GA100(A100)、GA102(RTX 3090) | 1. 第三代Tensor Core,支持TF32、FP64加速 2. 支持MIG多实例GPU技术,单卡可分割为7个独立实例 3. 引入结构化稀疏计算加速 |
A100的FP16算力达312 TFLOPS | 超大规模AI训练与推理、云算力虚拟化、HPC |
| Hopper | 2022 | GH100(H100) | 1. 支持FP8精度,专为Transformer模型优化 2. Thread Block Cluster技术,强化协同计算 3. HBM3显存,带宽高达3TB/s |
AI训练速度较A100提升6倍 | 大语言模型(LLM)训练、千亿级参数模型推理、超算中心 |
NVIDIA不同GPU架构(Volta、Turing、Ampere、Hopper)的核心特性对比表:
| 特性 | Volta | Turing | Ampere | Hopper |
|---|---|---|---|---|
| 计算核心 | CUDA Core + Tensor Core | CUDA Core + RT Core + Tensor Core | CUDA Core + Tensor Core 3.0 | CUDA Core + Tensor Core 4.0 |
| 浮点精度支持 | FP16/FP32 | FP16/FP32/INT8 | TF32/FP64 | FP8/FP16/FP64 |
| 显存技术 | HBM2(900GB/s) | GDDR6(672GB/s) | HBM2e(1.6TB/s) | HBM3(3TB/s) |
| 互联技术 | NVLink 2.0 | NVLink 2.0 | NVLink 3.0 | NVLink 4.0 |
| 能效比(TOPS/W) | 50 | 65 | 90 | 130 |
| 典型应用 | HPC、AI训练 | 光追渲染、AI推理 | 大规模AI训练 | 超大规模AI训练 |
核心趋势分析
- 计算能力升级:从Volta首次引入Tensor Core,到Hopper的Tensor Core 4.0,核心架构持续强化AI计算适配,尤其Hopper新增的FP8精度,专为大语言模型(LLM)等Transformer类任务优化。
- 显存与互联迭代:显存带宽从Volta的900GB/s提升至Hopper的3TB/s,NVLink版本迭代也增强了多GPU集群的通信效率,支撑超大规模模型的分布式训练。
- 能效比提升:能效比(TOPS/W)从Volta的50持续增长至Hopper的130,体现了架构设计与工艺进步带来的资源利用效率优化。
- 应用场景分化:Turing因RT Core侧重光追渲染与AI推理,而Volta、Ampere、Hopper则逐步聚焦高性能计算(HPC)与规模化AI训练,Hopper更是针对超大规模模型场景设计。
1 Tesla(特斯拉)
2006年11月发布,是NVIDIA首个通用GPU计算架构,它统一了顶点和像素处理器并对其进行了扩展,支持使用计算统一设备架构(CUDA)并行编程模型以C语言编写的高性能并行计算应用程序和开发工具。Tesla架构具有128个流处理器,带宽高达86GB/s,标志着GPU开始从专用他图形处理器转变成通用数据并行处理器。使用该架构的GPU有GeForce 8800等。
Tesla架构(2006-2008)
- 代表芯片:G80、GT200
- 核心改进:
- 首个支持CUDA编程模型的GPU架构。
- 引入统一着色器设计(Unified Shader),支持通用计算。
- 单精度浮点(FP32)计算能力初具规模。
- 应用场景:科学计算、早期GPGPU应用。
2 Fermi(费米)
2010年7月发布,是第一款采用40nm制程的GPU。Fermi架构带来了重大改进,包括引入L1/L2快速缓存、错误修复功能和GPU Direct技术等。Fermi GTX 480拥有480个流处理器,带宽达到177.4GB/s,比Tesla架构提高了一倍以上,代表了GPU计算能力的提升。使用该架构的GPU有Geforce 400系列等。
Fermi架构(2010)
- 代表芯片:GF100(Tesla M2050)
- 关键特性:
- SM(Streaming Multiprocessor)2.0:每组SM含32个CUDA核心,支持并发内核执行。
- ECC内存:提升计算可靠性。
- 首次支持双精度(FP64),FP64性能为FP32的1/2。
- 性能提升:相比Tesla,FP32性能提升8倍。
3 Kepler(开普勒)
2012年3月发布,英伟达发布Kepler架构,采用28nm制程,是首个支持超级计算和双精度计算的GPU架构。Kepler GK110具有2880个流处理器和高达288GB/s的带宽,计算能力比Fermi架构提高3-4倍。Kepler架构的出现使GPU开始成为高性能计算的关注点。使用该架构的GPU有K80等。
Kepler架构(2012)
- 代表芯片:GK110(Tesla K80)、GK210
- 关键特性:
- SMX设计:每组SM含192个CUDA核心,支持动态并行(Dynamic Parallelism)。
- Hyper-Q:多CPU核心可同时向GPU提交任务。
- GPU Boost:动态调整核心频率。
- 能效比:相比Fermi提升3倍。
4 Maxwell(麦克斯韦)
2014年2月发布,Maxwell针对流式多处理器(SM)采用一种全新设计,可大幅提高每瓦特性能和每单位面积的性能。虽然 Kepler SMX 设计在这一代产品中已经相当高效,但是随着它的发展,NVIDIA的GPU架构师看到了架构效率再一次重大飞跃的机遇,而Maxwell SM设计实现了这一愿景。使用该架构的GPU有M10、M40等。
Maxwell架构(2014)
- 代表芯片:GM204(GTX 980)、GM200(Titan X)
- 关键特性:
- SMM(Maxwell SM):每组SM分割为4个独立单元,提升指令调度效率。
- Voxel全局光照:针对性优化图形渲染。
- 16nm FinFET工艺(后期型号):功耗降低。
- 能效比:相比Kepler提升2倍。
5 Pascal(帕斯卡)
2016年5月发布,用于接替上一代的Maxwell架构。基于Pascal架构的GPU将会使用16nm FinFET工艺、HBM2、NVLink 2.0等新技术。使用该架构的GPU有GTX1050、1050Ti、1060、GP100、P6000、P5000、P100、P4、P40等。
ascal架构(2016)
- 代表芯片:GP100(Tesla P100)、GP102(GTX 1080 Ti)
- 关键特性:
- NVLink高速互联:多GPU带宽提升至80GB/s。
- 混合精度计算:支持FP16(半精度),适合深度学习推理。
- HBM2显存(P100):带宽达732GB/s。
- 性能:FP16算力达21 TFLOPS(P100)
6 Volta(伏特)
2017年5月发布,Volta架构增加了Tensor Core和相应的性能指标,芯片巨大的面积815mm和先进工艺12nm FFN。使用该架构的GPU有V100等。
Volta架构(2017)
- 代表芯片:GV100(Tesla V100)
- 革命性技术:
- Tensor Core:专为矩阵运算设计,支持混合精度(FP16/FP32)。
- 独立线程调度:SIMT模型升级,支持细粒度并行。
- HBM2+显存:带宽提升至900GB/s(V100)。
- 性能:深度学习训练速度比Pascal快5倍
7 Turing(图灵)
2018年8月发布,在该月的SIGGRAPH大会上,NVIDIA创始人兼首席执行官黄仁勋上发布了Turing架构,Turing架构引入了实时光线追踪(RTX)和深度学习超采样(DLSS)等重要功能。使用该架构的GPU有RTX 2080 Ti、Quadro RTX 6000等。
Turing架构(2018)
- 代表芯片:TU102(RTX 2080 Ti)、TU104(Quadro RTX 6000)
- 关键特性:
- RT Core:硬件级光线追踪加速。
- 第二代Tensor Core:支持INT8/INT4量化推理。
- GDDR6显存:带宽达672GB/s。
- 应用场景:实时光追(游戏)、AI推理
8 Ampere(安培)
2020年5与发布,在该月的GTC大会上,NVIDIA Ampere架构横空出世,该架构作为一次设计突破,在8代GPU架构中提供了NVIDIA公司迄今为止最大的性能飞跃,统一了AI培训和推理,并将性能提高了20倍。使用该架构的GPU有面向专业图形视觉可视化领域的RTX A6000、RTX A5000、RTX A4000、RTX A2000,面向高性能计算、人工智能和深度学习领域的NVIDIA A100、NVIDIA A40、NVIDIA A30、NVIDIA A10,以及面向消费级娱乐领域的GeForce RTX GPU等。
Ampere架构(2020)
- 代表芯片:GA100(A100)、GA102(RTX 3090)
- 关键特性:
- 第三代Tensor Core:支持TF32、FP64加速。
- MIG(Multi-Instance GPU):单GPU分割为7个独立实例。
- 结构化稀疏:利用稀疏矩阵加速计算。
- 性能:A100的FP16算力达312 TFLOPS
9 Hopper(哈珀)
2022年3月发布,在该月的GTC大会上,NVIDIA宣布推出采用NVIDIA Hopper架构的新一代加速计算平台,这一全新架构以美国计算机领域的先驱科学家Grace Hopper的名字命名,将取代两年前推出的NVIDIA Ampere架构,使用该架构的GPU有H100等。
Hopper架构(2022)
- 代表芯片:GH100(H100)
- 关键特性:
- FP8精度支持:专为Transformer模型优化。
- 动态编程增强:Thread Block Cluster支持协同计算。
- HBM3显存:带宽达3TB/s(H100)。
- 性能:AI训练速度较A100提升6倍
10 Ada Lovelace(阿达 洛芙莱斯)
2022年9月发布,NVIDIA官网宣称Ada Lovelace GPU架构能够为光线追踪和基于AI的神经图形提供革命性的性能,该架构显著提高了GPU性能基准,更代表着光线追踪和神经图形的转折点,使用该架构的GPU有RTX6000、RTX4060Ti等。
11 Blackwell
Blackwell架构的B200、B300
GPU 准备
The NVIDIA driver on your system is too old
【2024-3-19】问题:驱动太旧
The NVIDIA driver on your system is too old (found version 11040). Please update your GPU driver
原因
- 并非 CUDA 驱动版本太低,而是 Pytorch 版本和 CUDA 不匹配
- 示例:
torch 2.2.1+cuda 11.6
查看cuda版本
nvidia-smi
解决方法:
- 去官网找适配的torch版本
- torch 版本回退到 1.13.1
pip uninstall torch
pip install torch==1.13.1
GPU 验证
① NVIDIA自带
- NVIDIA自带的驱动检测方法,能看到GPU的配置,可以看到Google Colab的GPU是Tesla T4,显存15G,强于上一版本K80
- Kaggle GPU 性能对比:使用GPU后提速12倍
- 用 ASL Alphabet 数据集训练模型为例,在 Kaggle Kernels 上用 GPU 的总训练时间为 994 秒,而此前用 CPU 的总训练时间达 13,419 秒。直接让你训练模型的时间缩短为原来的 12 分之一
最常用方式:参考
- nvidia-smi (最有名) - 推荐指数:⛳⛳
- gpustat (彩色并简约显示) - 推荐指数:⛳⛳⛳⛳
- nvtop (完整信息,需root权限apt安装,不是非常方便) - 推荐指数:⛳⛳⛳
- nvitop (完整信息,可作为Python的库安装,非常方便) - 推荐指数:⛳⛳⛳⛳⛳
方法总结
nvitop>gpustat>nvidia-smi
对比
| 对比维度 | nvidia-smi | nvitop | gpustat |
|---|---|---|---|
| 来源 | NVIDIA 自带 | 第三方 | 第三方, 依赖nvidia-smi |
| 安装 | 无需安装 | pip install nvitop | pip install gpustat |
| 界面风格 | 一次性文本输出 | 交互式 TUI,实时刷新 | 简洁文本,支持刷新 |
| 实时监控 | nvidia-smi -l(循环输出) |
直接运行,自带实时面板 | gpustat -i(间隔刷新) |
| 退出方法 | Ctrl + C |
q 或 Ctrl + C |
Ctrl + C |
| 进程查看 | 简略显示 | 详细,按用户/进程排序 | 显示用户、PID、命令 |
| 脚本/JSON 支持 | 支持 XML,较复杂 | 一般 | 很好,--json 直接输出 |
| 优点 | 最稳定、兼容所有环境、官方 | 交互体验最好、颜值高、易读 | 极简、轻量、适合快速看卡 |
| 适合场景 | 排查问题、脚本、兼容性要求高 | 日常盯卡、调试、看谁在占用GPU | 快速查看、批量汇总、脚本解析 |
nvidia-smi
nvidia-smi 是 Nvidia显卡命令行管理套件,基于NVML库,旨在管理和监控Nvidia GPU设备。
- 英伟达系统管理接口(NVIDIA System Management Interface, 简称 nvidia-smi)是基于NVIDIA Management Library (NVML) 的命令行管理组件,旨在(intened to )帮助管理和监控NVIDIA GPU设备。
查看显卡型号
root@pc:~# lspci | grep -i nvidia
01:00.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] (rev a1)
01:00.1 Audio device: NVIDIA Corporation GP102 HDMI Audio Controller (rev a1)
工具安装
- Linux安装NVIDIA显卡驱动
- Linux安装Nvidia显卡驱动+CUDA+cuDNN+PyTorch
- Ubuntu 安装
- 禁用自带的Nouveau驱动,Nouveau是第三方开源驱动,使用nvidia官方驱动。
- sudo apt install nvidia-smi
# 禁用 Nouveau驱动
vim /etc/modprobe.d/nvidia-blacklists-nouveau.conf
检测
#命令
nvidia-smi
nvidia-smi -h # 命令查看
# 结果如下:
Wed Jun 5 03:02:36 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.67 Driver Version: 410.79 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 57C P8 16W / 70W | 0MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
# 参数说明
nvidia-smi --help-query-gpu
参数含义
l:隔多久记录一次,命令中写的是1format:结果记录文件格式是csvfilename: 结果记录文件的名字query-gpu:记录哪些数据到csv文件timestamp:时间戳memory.total:显存大小memory.used:显存使用了多少utilization.gpu:GPU使用率power.draw:显存功耗,对应Pwr:Usage
# 只查看编号为0的GPU的详细信息
nvidia-smi -q -i 0
# 查看0号和2号GPU的概要信息
nvidia-smi -i 0,2
# 动态监控
nvidia-smi -l 5 # 隔5秒刷新一下显存状态
watch -n 1 nvidia-smi
# 监控GPU编号0,每秒采样一次,显示功耗(pwr)、温度(temp)、显存使用率(mem)、GPU利用率(gpu)、性能状态(perf)和风扇转速(fan)
nvidia-smi dmon -i 0 -s pumt -d 1
# 将监控结果写入文件
nvidia-smi -l 1 --format=csv --filename=report.csv --query-gpu=timestamp,name,index,utilization.gpu,memory.total,memory.used,power.draw
# ------ 检测GPU集群总体信息 -------
nvidia-smi --query-gpu=memory.used --format=csv # 检查使用的GPU
nvidia-smi --query-gpu=index,memory.used,memory.total --format=csv,noheader,nounits
# 0, 10956, 11441
# 1, 0, 11441
nvidia-smi --query-gpu=index,name,uuid,serial --format=csv
# 0, Tesla K40m, GPU-d0e093a0-c3b3-f458-5a55-6eb69fxxxxxx, 0323913xxxxxx
# 1, Tesla K40m, GPU-d105b085-7239-3871-43ef-975ecaxxxxxx, 0324214xxxxxx
nvidia-smi命令的输出,其中最重要的两个指标:
- 显存占用
- GPU利用率
GPU监控
- 动态监控GPU使用率
- 按Ctrl+C退出监控
- 参考GPU进程查看管理
gpustat
比 nvidia-smi 更好看

gpustat
- 直接
pip install gpustat即可安装 - gpustat 基于 nvidia-smi,可以提供更美观简洁的展示,结合watch命令,可以动态实时监控GPU的使用情况。
- gpustat 依赖于 nvidia-smi,因此要确保已安装 NVIDIA 驱动并支持 nvidia-smi
安装
apt install gpustat # 系统
pip install gpustat # pip
# 动态刷新
gpustat -i
watch --color -n1 gpustat -cpu
输出
缺点:
- 不能像 nvidia-smi 显示出各个进程的信息
GPU-Z
Windows 下GPU工具
nvtop
nvtop 非常优雅地全面地监控显卡信息
- 但是工具安装需要 root权限,
sudo apt install nvtop 
nvitop
既要 nvtop 那样详细展示,又要 gpustat 彩色界面,还能够像 gpustat 一样通过 pip 快速安装: nvitop工具。
除了彩色文字和进度条,还能完整地显示每个进程的执行用户、运行时长、执行指令以及每个进程所使用的GPU编号
nvitop 有3种展示模式:
- auto (默认)
- compact
- full
安装
pip install nvitop
使用
nvitop -m full
行情
GPU市场上,NVIDIA占了大部分(N卡),AMD(A卡)次之,接着是苹果(好像是intel),详见图


【2023-3-22】英伟达发布ChatGPT专用GPU,推理速度提升了10倍
- 3 月 22 日,GTC 大会正式召开,在刚刚进行的 Keynote 上,英伟达 CEO 黄仁勋搬出了为 ChatGPT 准备的芯片
- 2012 年,计算机视觉模型 AlexNet 动用了 GeForce GTX 580,每秒可处理 262 PetaFLOPS。该模型引发了 AI 技术的爆炸
- 2017年,Transformer 出现了
- 2020年,GPT-3 动用了 323 ZettaFLOPS 的算力,是 AlexNet 的 100 万倍
- 2022年底,创造了 ChatGPT 这个震惊全世界的 AI。
崭新的计算平台出现了,AI 的 iPhone 时代已经来临。
- 当前唯一可以实际处理 ChatGPT 的 GPU 是英伟达 HGX
A100。 - 针对算力需求巨大的 ChatGPT,英伟达发布了 NVIDIA
H100NVL,具有 94GB 内存和加速 Transformer Engine 的大语言模型(LLM)专用解决方案,配备了双 GPU NVLINK 的 PCIE H100 GPU。与前者相比,现在一台搭载四对H100和双 NVLINK 的标准服务器速度能快 10 倍,可以将大语言模型的处理成本降低一个数量级
AI 的繁荣推动英伟达股价在今年上涨了 77%,目前,英伟达的市值为 6400 亿美元,已是英特尔的近五倍。
GPU 禁令
禁售令
- 2020年,美国国会将推动AI模型进入联邦政府运作形成《政府AI法案》
- 2019-2020,美国白宫接连以两道总统行政令,强调将在未来加大以通用大模型在内的AI突破领域资助力度,以实现美国在AI领域的领导权
- GPT&ChatGPT 某种程度对中国禁用,A100&H100等高端 AI 芯片对中国禁售
2022年10月7日,美国商务部对高性能芯片作出额外出口限制,禁止美国公司向中国实体出售高端芯片,A100正在其中
同时满足以下两个条件的即为受管制的高性能计算芯片:
- (1)芯片的I/O带宽传输速率大于或等于600 Gbyte/s;
- (2)“数字处理单元 原始计算单元”每次操作的比特长度乘以TOPS 计算出的的算力之和大于或等于4800TOPS。这也使得NVIDIA A100/H100系列、AMD MI200/300系列AI芯片无法对华出口
黄仁勋:中国市场占英伟达销售额的大约20%,而美国阻止英伟达向中国销售最先进芯片,如同将“双手绑在背后”。
- 英伟达转而推出了
A100的中国特供版——A800
字节跳动累计已经订购价值约 10 亿美元 NVIDIA GPU,大约为 10 万片的 A100 和 H800,其中A100 应为 2022 年 8 月美国政府下令前所订购
GPU 争夺
【2024-2-18】互联网大厂,有钱难买A100
A100,一个颇具科幻气息的名字,联想到《终结者》中的机器人代号。
A100 是一种GPU芯片,采用7nm制程,制造它的光刻机在大约万分之一根头发丝细空间里进行精细雕刻。
- 大约826平方毫米(不到一张3cm*3cm便签纸大)的面积里,容纳了足足540亿个晶体管。
- 英伟达用科学家的名字来命名产品,A来自电磁学科学家
安培(Ampere),而A100的前代产品V100,来自电池的发明者伏特(Volta)
大模型之争的关键在于算力和数据,理论上只要GPU数量足够多(例如有10000台服务器),一家公司可在极短时间之内训练出一个不逊色于ChatGPT 4的大模型,而A100就是挖掘大模型金矿时最锋利的那把铲子。除了大模型,各类人工智能公司,包括计算机视觉、语音交互、智能驾驶等,都需要这把铲子。
需求似乎无限,但英伟达代工厂台积电产能有限,除了大厂之间的争夺,美国对中国的芯片封锁也让国内的大厂更难买到A100这样的高端芯片。包括A800、H100、H800,A100和它的“继承者们”,遭到各方的哄抢,价格水涨船高,最疯狂的时候,在短短一周里,一台由8张A800组成的服务器,可以从230万涨价到330万。
字节内部采购了大约13600张A100,按照一张卡7万元的最低价格计算,光这些芯片就价值9.52亿。
- 字节拥有20多万张算力芯片,其中约10万张是
A100/A800/H800等高算力芯片。小部分对外出租,未被出租的高算力芯片则被用于字节大模型的训练和推理,还有一些其他型号被用于支持公司内部业务推理场景,比如兴趣电商、抖音搜索、抖音广告排序等。 - 抖音疯狂增长的那几年,为了训练AI进行内容审核,也曾找宝德订购了不少V100服务器,“一年买两个多亿”。
- 拼多多2023年的下半年组建了大模型团队,招兵买马,开出了百万年薪挖角人才。
对算力的需求就像一个越吹越大的气球,A800的价格达到了比A100更高的高度
- 2023年10月,一台8卡A800服务器的价格达到了220-230万左右。
- 10月25号左右,一台H800服务器在国内现货市场的成交价格是220万-230万一台
- 一周后,11月2日,美国禁令,服务器价格从220万直接涨到了320万。
- 到了11月,价格还在涨,最高报到了385万。
A100 被几家大厂瓜分,大厂也摇身一变,成为算力租赁商,争做大模型掘金热潮中的卖水人。最典型的是阿里和字节。
- 阿里的战略特殊,不靠大模型赚钱,靠的是生态。
- 已经发布并开源的通义千问就像一个样板间,谁都可以使用阿里的代码,让自己的大模型跑起来,然后来阿里租赁算力。“阿里的大模型是一个带动性的东西,真正赚钱的是卖‘水’。”
- 一台8卡的服务器算力一个月的租赁价格在15万-20万左右,至少4台起卖,这意味着,一台机器只要租出去8个月就可以收回成本。
- 字节的火山云也卖算力,杨箫说:“区别在于,字节纯卖水,阿里在卖水的基础上,还卖服务,一整套解决方案卖给你。”正因如此,阿里的算力价格比字节更贵。
阿里和字节在这门生意上已经成了对头,双方互相探听对方算力芯片的数量、价格。
- 在阿里云,可能只有CEO吴泳铭、CTO周靖人这样级别的高管才知道自己公司一共囤了多少张芯片,但大家都听说过字节囤了多少张。价格战也打响了。
-
字节的火山云销售会询问客户,“阿里跟你们要多少钱?我们六折”。
- 李开复的
零一万物和王慧文退出的光年之外,选择了阿里; - 而在海外名声更大的
Minimax,行业内看好的智谱AI,主要使用字节火山云的算力。 - 蔚来曾经在阿里“跑过一个小集群和demo”,但最终还是选了更便宜的字节
显卡信息
显卡(Video card,Graphics card)全称显示接口卡,又称显示适配器,是计算机最基本配置、最重要的配件之一。
显卡是电脑进行数模信号转换的设备,承担输出显示图形的任务。
显卡接在电脑主板上,将电脑的数字信号转换成模拟信号让显示器显示出来- 同时显卡还是有图像处理能力,可协助CPU工作,提高整体的运行速度。
在科学计算中,显卡被称为显示加速卡。
原始显卡一般都是集成在主板上,只完成最基本的信号输出工作,并不用来处理数据。
显卡也分为独立显卡和集成显卡。一般同期推出的独立显卡的性能和速度要比集成显卡好、快。
| 类型 | 位置 | 内存 |
|---|---|---|
| 集成显卡 | 集成在主板上,不能随意更换 | 使用物理内存 |
| 独立显卡 | 作为一个独立的器件插在主板的AGP接口上的,可以随时更换升级 | 有自己的显存 |
随着显卡的迅速发展,GPU这个概念由NVIDIA公司于1999年提出。
GPU是显卡上的一块芯片,就像CPU是主板上的一块芯片。
集成显卡和独立显卡都有GPU。
v100不支持bf16 !
显卡总结
【2022-11-02】NVIDIA Tesla GPU系列P4、T4、P40以及V100显卡性能的对比
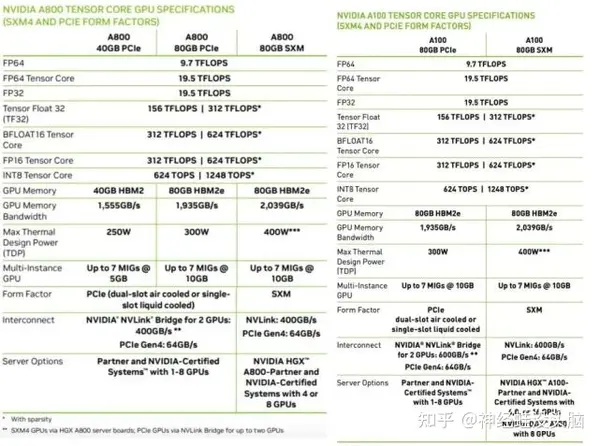
【2024-5-22】一文看懂英伟达A100、A800、H100、H800各个版本有什么区别
- A100/H800对比
NVIDIA Tesla GPU系列P4、T4、P40以及V100,详见京东店铺描述
各个系列卡精简总结(仅考虑显存,暂不考虑带宽)
- Tesla:
P4(2/4/8)T4(4/8/16)P40(24)P100(24)V100(16)V100S(32) - A:
A10(12/24)A30(12/24)A40(48)A100(40/80)A800(80) - H:
H100(80)H800(80) - GTX:
1080(11)4090(24)
| 系列 | GPU系列 | TFLOPS |
|---|---|---|
| Tesla | P4(2/4/8)T4(4/8/16)P40(24)P100(24)V100(16)V100S(32) |
P4(5.5)T4(8.1)P40(12)P100(?)V100(14)V100S(16.4) |
| A | A10(12/24)A30(12/24)A40(48)A100(40/80)A800(80) |
A10(?)A30(?)A40(?)A100(?)A800(?) |
| H | H100(80)H800(80) |
H100(48/60)H800(51/67) |
| GTX | 1080(11)4090(24) |
1080(?)4090(?) |
【2024-12-16】不同显卡性能差异
- 单卡效率: H100 是 4090 两倍
| 4090 | H100 | ||
|---|---|---|---|
| Flux AI绘画 | 一张图12s, 同时画8张图91s | 一张图6.5s,同时画8张图只用47s | 效率翻倍 |
| 数字人模型训练 | 1s迭代1次, 19min训练1000次 | 0.55s迭代1次, 10min训练1000次 | |
H20 与 H800、A800 如何选型?
- 参考 csdn
| 场景 | 推荐型号 | 原因说明 |
|---|---|---|
| 大模型推理 | H20 | 显存最大,FP8支持好 |
| 中小模型训练 | A800 | 成熟生态,性价比高 |
| 分布式训练集群 | H20/H800 | NVLink支持更好 |
| 出口受限地区部署 | H800/H20 | 替代H100/H200 |
【2024-5-27】NVIDIA 显卡关系图
- bd 内用了 Ascend 910, 32/64G
表格总结
以下是整理后的Markdown表格:
| GPU型号 | 发布时间 | 简介 | 显存 | 带宽(TB/) | cuda数 | tensor核 | 架构 | FP16 | FP32 | NVLink支持 | 附加 | 应用场景 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A100 | 2020年 | 2020年旗舰级显卡 | 80G | 2.04 | 6912 | 432 | Ampere | 312 | 19.5 | 多GPU扩展 | 高性能计算 | |
| H100 | 2023/3/22 | A100升级款 | 80G | 3.35 | 14592 | 456 | Hopper | 1671 | 60 | 高宽带互联 | transformer engine | 大规模训练,企业级推理,扩散模型 |
| A6000 | 2020年12月15日 | 专业级显卡 | 48G | 0.7 | 10752 | 336 | Ampere | 77.4 | 38.7 | 无 | 工作站,3D渲染,科学模拟 | |
| A800 | 2022年10月 | 中国特供版(阉割),基于A100 | 80G | 1.94 | 6912 | 432 | Ampere | - | - | 互联受限,400 | 高性能计算,适合训练、推理 | |
| H800 | 2023年4月 | 中国特供版(阉割),基于H100 | 80G | 2.04 | 14592 | 456 | Hopper | - | - | 高宽带互联,受限 | 优于A100 | 高性能计算,适合训练,阿里/腾讯/百度云厂商 |
| H20 | 2023年底 | 中国特供版(阉割),H200裁剪 | 96+G | 4 | - | - | Hopper | - | - | 高宽带互联,受限,900 | H200的15%,峰值算力不如H100; | 高性能计算 |
| L20 | 2023年11月 | 专业显卡 | 48 | 1.9 | 10240 | - | Ada Lovelace | - | - | - | 高性能计算 | |
| L40s | - | - | 48 | 0.86 | 10240 | - | Ada Lovelace | 731 | 91.6 | - | 高性能计算 |
详情
| 显卡类型 | 图 | 特点 | 单精度性能(FP32) | 半精度性能(FP16) | 整数运算能力(INT8) | 整数运算能力(INT4) | GPU显存 | 显存带宽 | 系统接口/外形规格 | 功率 | 硬件加速视频引擎 |
|---|---|---|---|---|---|---|---|---|---|---|---|
Tesla P4 |
 |
适用于推理吞吐量服务器务器 | 5.5 TFLOPS | - | 22 TOPS | - | 2GB 4GB 8GB |
192GB/秒 | PCI Express半高外形 | 50 W/75 W | 1个解码引擎,2个编码引擎 |
Tesla T4 |
 |
世界领先的推理加速器 | 8.1 TFLOPS | 65 TFLOPS | 130 TOPS | 260 TOPS | 4GB 8GB 16GB |
320GB/秒 | PCI Express半高外形 | 70W | 1个解码引擎,2个编码引擎 |
Tesla P100 |
- | - | - | - | - | 24GB | |||||
Tesla P40 |
适用于超高效、外扩型服 | 12 TFLOPS | - | 47 TOPS | - | 24GB | 346GB/秒 | PCI Express双插槽全高外形 | 250 W | 1个解码引擎,2个编码引擎 | |
NVIDIA A10 |
 |
- | - | - | - | - | 12GB 24GB |
||||
NVIDIA A30 |
|
- | - | - | - | - | 12GB 24GB |
官网 | |||
NVIDIA A40 |
|
- | - | - | - | - | 48GB(PCIe) | ||||
NVIDIA A100 |
|
- | - | - | - | - | 40GB 80GB |
||||
NVIDIA A800 |
|
- | - | - | - | - | 80GB(PCIe) 80GB(SXM) |
||||
NVIDIA L40 |
 |
- | - | - | - | - | 48GB(PCIe) | 864 GB/s | |||
Tesla V100 |
 |
通用数据中心GPU | 14 TFLOPS (PCIe) | 112 TFLOPS (PCIe) | - | - | 16GB HBM2 | 900GB/秒 | PCI Express双插槽全高外形 SXM2/NVLink | 250 W (PCIe) 300 W (SXM2) |
- |
Tesla V100S |
|
通用数据中心GPU | 16.4 TFLOPS | 112 TFLOPS (PCIe) | - | - | 32GB HBM2 | 1134GB/秒 | PCI Express双插槽全高外形 | 250 W | - |
GTX 1080Ti |
 |
- | - | - | - | - | 11GB | - | - | - | - |
NVIDIA H100 SXM |
 |
互联技术: NVLink 900GB/s PCIe 5.0 128GB/s |
60 TFLOPS | - | - | - | 80GB | 3TB/s | |||
NVIDIA H100 PCIe |
|
互联技术: NVLink 600GB/s PCIe 5.0 128GB/s |
48 TFLOPS | - | - | - | 80GB | 2TB/s | |||
NVIDIA H800 SXM |
|
互联技术: NVLink 400GB/s PCIe 5.0 128GB/s |
67 TFLOPS | - | - | - | 80GB | 3.35TB/s | |||
NVIDIA H800 PCIe |
|
互联技术: NVLink 400GB/s PCIe 5.0 128GB/s |
51 TFLOPS | - | - | - | 80GB | 2TB/s | |||
GTX 4090 |
- | - | - | - | - | 24GB | - | - | - | - |
国际资源: GPU 型号查询数据库 techpowerup GPU Specs Database
【2023-12-5】影驰RTX 4090 20周年纪念版显卡采用了AD102-301核心,内构16384个CUDA流处理器,基础频率2235MHz,P-Mode加速频率为2595MHz,S-Mode加速频率为2520MHz。 显卡搭载了24G GDDR6X显存,显存位宽为384Bit,显存频率为21Gbps,TGP功耗为450W
【2022-11-26】Kaggle 免费 GPU
- 型号:GPU T4 * 2 或者 GPU P100, TPU v3-8
【2023-2-25】GPU中主要有三类基础运算:整数运算、单精度浮点数运算和双精度浮点数运算,其中
单精度浮点运算速度最快而双精度浮点运算速度最慢FLOPS(floating-point operations per second, 每秒执行的浮点运算次数)也是衡量GPU运算性能的关键指标- 如果一个程序内只有
单精度浮点数运算,将发挥硬件的最大功效,因此应该尽量多使用单精度浮点数运算,而避免使用双精度浮点运算。
【2023-9-20】A100/H100 太贵,何不用 4090?
- 大模型训练用 4090 不行,但推理(inference/serving)用 4090 不仅可行,在性价比上还能比 H100 稍高。4090 如果极致优化,性价比甚至可以达到 H100 的 2 倍。
NVIDIA 算力表里面油水很多,比如 H100 TF16 算力写的是 1979 Tflops,但那是加了 sparsity(稀疏)的,稠密的算力只有一半;4090 官方宣传 Tensor Core 算力高达 1321 Tflops,但那是 int8 的,FP16 直只有 330 Tflops。这篇文章的第一版就是用了错的数据,H100 和 4090 的数据都用错了,得到的结论非常离谱。
鲲鹏的首席架构师夏 Core 有一篇知名文章《谈一下英伟达帝国的破腚》,很好的分析了 H100 的成本。详见原文
显卡指标
存储指标
- K、M,G,T等
- KB、MB,GB,TB
二者有细微的差别。
- K、M,G,T是以1024为底,而KB 、MB,GB,TB以1000为底。
- 不过估算显存大小时,不需要严格的区分这二者。
# 1024 为底
1Byte = 8 bit
1K = 1024 Byte
1M = 1024 K
1G = 1024 M
1T = 1024 G
10 K = 10*1024 Byte
# 1000 为底
1Byte = 8 bit
1KB = 1000 Byte
1MB = 1000 KB
1GB = 1000 MB
1TB = 1000 GB
10 KB = 10000 Byte
数值类型
数值类型命名规范一般为 TypeNum,比如: Int64、Float32、Double64。
- Type:有Int,Float,Double等
- Num: 一般是 8,16,32,64,128,表示该类型所占据的比特数目
常用的数值类型
- int* : 8,16,32,64
- float* : 16,32
Float32 深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。
举例来说:
- 有一个1000x1000的 矩阵,float32,那么占用的显存差不多就是
- 1000x1000x4 Byte = 4MB
32x3x256x256的四维数组(BxCxHxW)占用显存为:24M
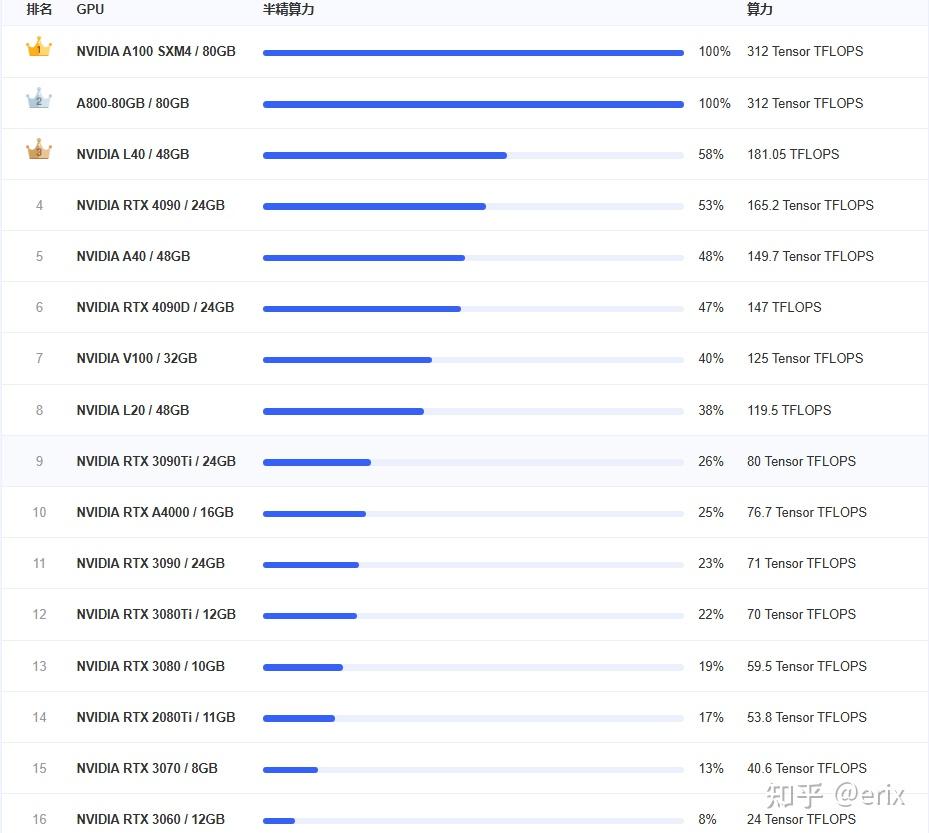
算力对比
算力排行榜(AutoDL出品)
| 排名 | GPU | 半精算力 | 算力 |
|---|---|---|---|
| 1 | NVIDIA A100 SXM4 / 80GB | 100% | 312 Tensor TFLOPS |
| 2 | A800 - 80GB / 80GB | 100% | 312 Tensor TFLOPS |
| 3 | NVIDIA L40 / 48GB | 58% | 181.05 TFLOPS |
| 4 | NVIDIA RTX 4090 / 24GB | 53% | 165.2 Tensor TFLOPS |
| 5 | NVIDIA A40 / 48GB | 48% | 149.7 Tensor TFLOPS |
| 6 | NVIDIA RTX 4090D / 24GB | 47% | 147 TFLOPS |
| 7 | NVIDIA V100 / 32GB | 40% | 125 Tensor TFLOPS |
| 8 | NVIDIA L20 / 48GB | 38% | 119.5 TFLOPS |
| 9 | NVIDIA RTX 3090Ti / 24GB | 26% | 80 Tensor TFLOPS |
| 10 | NVIDIA RTX A4000 / 16GB | 25% | 76.7 Tensor TFLOPS |
| 11 | NVIDIA RTX 3090 / 24GB | 23% | 71 Tensor TFLOPS |
| 12 | NVIDIA RTX 3080Ti / 12GB | 22% | 70 Tensor TFLOPS |
| 13 | NVIDIA RTX 3080 / 10GB | 19% | 59.5 Tensor TFLOPS |
| 14 | NVIDIA RTX 2080Ti / 11GB | 17% | 53.8 Tensor TFLOPS |
【2025-3-5】各种显卡的大模型运行效率如何?知乎
算力排名
实测
- RTX 2000 Ada 8G 笔记本显卡
- P40 24G 计算卡
- RTX 2080Ti 22G 魔改显卡
- RTX 3090 24G
-
RTX 4090 24G
- P40 推理速度是2080Ti 的一半;
- 推理32b及以下模型时,2080Ti 推理速度相当于 3090 70%,而能耗比 3090 低很多;
- 双2080Ti并没有能加速推理,实际上有一半的GPU性能是闲置的;双卡推理唯一优势就是显存大;
- 如果要用32b的coder模型作为自己写代码辅助用,2080ti或者单卡3090都不错。
- RTX 2080Ti双卡运行72b模型同时推理两个问题,token生成速度仍然能达到8.5/s。
- RTX 2080Ti双卡运行32b模型下,token生成分别只有21/s,相当于单个问题时的一半。
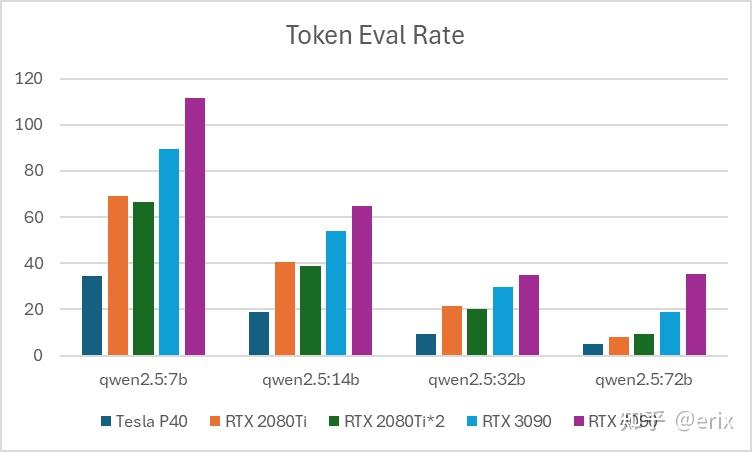
不同规模大模型在各显卡上的表现
显卡工作原理
笔记本配置
2017年,Nvidia 发布低端显卡型号——GT1030。不过面向台式机市场,而移动版却没有相关的消息。
- 直到台北电脑展后,各路新品的消息不断出现后,才发现,并不是“GT1030”没有打算放进笔记本里,而是它改名了。
- 它在笔记本中的型号,就是MX150。
MX 150
小米笔记本配置
标准版 MX150,GP108核心,384个流处理器,显存为GDDR5,容量2GB。
- 显存位宽64bit,带宽48.1GB/s,核心默认频率1469MHz,典型boost频率为1532MHz
$ nvidia-smi
Tue Nov 05 10:59:38 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 388.73 Driver Version: 388.73 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce MX150 WDDM | 00000000:01:00.0 Off | N/A |
| N/A 40C P8 N/A / N/A | 53MiB / 2048MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
GT1030
台式机GT1030 参数信息,与标准版的MX150相比,标称的频率反而更低一些,只有1228-1468MHz,其他参数一致
L40
NVIDIA L40 由 Ada Lovelace 架构提供支持,为 GPU 加速数据中心工作负载提供革命性神经图形、可视化、计算和 AI 功能。
参数
- 内存 48 GB
TESLA V100
NVIDIA Tesla V100采用NVIDIA Volta架构,非常适合为要求极为苛刻的双精度计算工作流程提供加速,并且还是从P100升级的理想路径。该GPU的渲染性能比Tesla P100提升了高达80%,借此可缩短设计周期和上市时间。
Tesla V100的每个GPU均可提供125 teraflops的推理性能,配有8块Tesla V100的单个服务器可实现1 petaflop的计算性能。阿里云GPU参考 dashi.aliyun.com/site/cloud/gpu 详细说明
A100 – 禁售
【2024-2-18】互联网大厂,有钱难买A100
A100,一个颇具科幻气息的名字,联想到《终结者》中的机器人代号。
A100 是一种GPU芯片,采用7nm制程,制造它的光刻机在大约万分之一根头发丝细空间里进行精细雕刻。
- 大约826平方毫米(不到一张3cm*3cm便签纸大)的面积里,容纳了足足540亿个晶体管。
- 英伟达用科学家的名字来命名产品,A来自电磁学科学家
安培(Ampere),而A100的前代产品V100,来自电池的发明者伏特(Volta)
A100 被美国禁售,于是NVIDIA推出中国特供版 A800:
- 与A100相比,A800就像把汽车的输油管改细了一点,发动机和轮胎还是原来的东西
A800
NVIDIA在A100基础上开发的合规替代产品,应对美国商务部2022年10月实施的半导体出口新规,通过将芯片间数据传输速率从600GB/s降至400GB/s以规避技术限制。
该产品于2022年三季度投产,采用安培架构,支持最高2TB/s内存带宽,主要应用于AI训练、科学计算及数据中心场景
A800 芯片, 数据传输速率为400GB/s,低于A100芯片的600GB/s,而其他参数变化不大。
- A800较A100整体通信带宽性能砍了33%,阉割的部分很小,A800只影响多卡互联的性能,而计算能力完全保留!
TESLA P40
The Tesla P40能够提供高达2倍的专业图形性能。Tesla P40能够对组织中每个vGPU虚拟化加速图形和计算(NVIDIA CUDA® 和 OpenCL)工作负载。支持多种行业标准的2U服务器。
Tesla P40可提供出色的推理性能、INT8精度和24GB板载内存。
TESLA T4
NVIDIA Tesla T4的帧缓存高达P4的2倍,性能高达M60的2倍,对于利用NVIDIA Quadro vDWS软件开启高端3D设计和工程工作流程的用户而言,不失为一种理想的解决方案。凭借单插槽、半高外形特性以及低至70瓦的功耗,Tesla T4堪称为每个服务器节点实现最大GPU密度的绝佳之选。
TESLA P4
待定
H100
2022年3月22日, 英伟达GTC技术大会发布H100芯片, 首款基于Hopper架构的GPU芯片,采用台积电四纳米工艺制造,集成800亿个晶体管,搭载HBM3显存技术并支持PCIe 5.0接口及第四代NVLink互连技术
2022年第三季度,正式上市
H100芯片的Transformer引擎可将自然语言处理模型速度提升至前代六倍,在MLPerf基准测试中通过3,584块GPU集群实现11分钟完成GPT-3模型训练
2023年11月, H100被禁售中国
H800
英伟达H800是英伟达公司专为中国市场研发的人工智能芯片,基于H100调整规格以符合美国出口管制规定,通过降低互连速率等技术参数实现合规设计
2023年4月,腾讯云新一代高性能计算集群搭载该芯片实现国内首发,实测算力性能较前代提升3倍。H800显存带宽达到3TB/s,在深度推荐系统、大型语言模型训练等场景中的效率较A800提升2-3倍
2023年10月,美国升级芯片管制将其列入禁售名单
【2023-10-11】参考, NVIDIA H800 Tensor Core GPU 显卡 80GB显存,最大功耗 350瓦
NVIDIA H800 GPU 配备第四代 Tensor Core 和 Transformer 引擎(FP8 精度),可使大型语言模型的训练速度提升高达 9 倍,推理速度提升惊人的 30 倍,从而进一步拓展了 NVIDIA 在 AI 领域的市场领先地位。对于高性能计算(HPC)应用,H800 可使 FP64 的每秒浮点运算次数(FLOPS)提升至 3 倍,并可添加动态编程(DPX)指令,使性能提升高达7 倍。借助第二代多实例 GPU (MIG)技术、内置的 NVIDIA 机密计算和NVIDIA NVLink Switch 系统,H800 可安全地加速从企业级到百亿亿次级(Exascale)规模的数据中心的各种工作负载。 H800 是完整的 NVIDIA 数据中心解决方案的一部分,该解决方案包含以下方面的基础模组 :硬件、网络、软件、库以及 NVIDIA NGC 目录中经优化的 AI 模型和应用。作为适用于数据中心且功能强大的端到端 AI 和 HPC 平台,H800 可助力研究人员获得真实的结果,并能将解决方案大规模部署到生产环境中。
NVIDIA H800 Tensor Core GPU可助力各种工作负载实现卓越的性能、可扩展性和安全性。借助 NVIDIA NVLink Switch 系统,可连接多达 256 个 H800 GPU 来加速百亿亿次级(Exascale)工作负载,并可通过专用的Transformer 引擎来为万亿参数的语言模型提供支持。H800 利用 NVIDIA Hopper 架构中的突破性创新技术提供先进的对话式 AI,与上一代产品
相比,可使大型语言模型的速度提升 30 倍。
规格参数
H20
H20显卡是英伟达于2023年底推出专为中国市场定制的显卡,主要用于AI大模型推理训练。
- 其性能为当年旗舰显卡
H100的10%-15%,采用Hopper架构,配备96GB HBM3显存,FP8算力为296 TFLOPS,FP16算力为148 TFLOPS。 - 虽然H20的性能不及H100,但在金融风控、医疗影像等特定场景中仍具有实战价值。
- H20显卡的售价约为11万元,在国内市场上被认为是性能最好的显卡之一,受到许多科技公司的青睐
【2024-5-27】受美国出口管制影响,英伟达针对中国市场推出的一款“阉割”产品 H20
- H100 80GB HBM3 內存,內存频宽 3.4Tb/s,运算能力 1,979 TFLOP,性能密度高达 19.4。
- H20 是基于 H100 GPU的阉割版
- H20 內存 96 GB,运行速度高达 4.0 Tb/s,运算能力 296 TFLOPs,使用 GH100芯片,性能密度(TFLOPs/Die size)仅为2.9。
“阉割版” H20芯片AI算力,只有H100的不到15%。部分性能甚至不及 Ascend 910B。
显然,性能并不能满足中国AI厂商的需求。
Nvidia H20 是从 Nvidia H200 裁剪而来,保留了900GB/s的卡间高速互联带宽(NVLink4.0和NVSwitch3.0),并支持PCIe Gen5(128GB/s双向带宽)。PCIe Gen5连接支持400GbE集群网络,有利于组建超大规模GPU集群和保持较高的集群线性加速比。
- 算力方面,
H20峰值算力只有H200峰值算力的14.96%(~15%),H20峰值算力相对较低(被严重裁剪)。 - L2 Cache 配置方面,H20配置了60MB的L2 Cache,比H200有更大的L2 Cache。Nvidia H20拥有96GB的HBM3显存,显存带宽高达4TB/s。虽然Nvidia H20的显存配置相对于H200有所裁剪,但是H20的显存配置相对于国产AI芯片还是有明显优势的。
- 参考
虽然 H20 的峰值算力不如 H100,但其 显存容量和带宽优势明显,尤其适合需要处理大规模数据的场景。
2025年7月31日,国家互联网信息办公室约谈了NVIDIA,要求其就对华销售的H20算力芯片漏洞后门安全风险问题进行说明并提交相关证明材料。
而与此同时,NVIDIA 数据中心业务在过去两年内实现了惊人的增长,根据Fiscal.ai的数据,NVIDIA的数据中心收入在过去两年内增长了超过10倍。
使用场景:
- 大模型推理服务部署(如 Qwen、Llama3)
- 中小规模模型训练
- 多卡集群环境下的分布式训练
- 图像生成、语音识别等高并发推理任务
不适合
- 单卡运行超大规模模型训练(如 GPT-4、PaLM)
- 需要极高算力的科研级任务
总结:H20 更偏向于推理场景,但在适当的集群配置下也可胜任部分训练任务
A6000
2020 年 10 月 5 日,GTC 2020 大会期间发布,2020年12月15日正式上市
基于Ampere架构设计,搭载GA102核心与10752个CUDA核心,配备第二代RT Core(84个)和第三代Tensor Core(336个),支持实时光线追踪与AI加速运算
RTX A6000是英伟达(NVIDIA)推出的专业级显卡,别称丽台RTX A6000,主要应用于工作站场景,服务于3D渲染、科学模拟及深度学习等领域。
- 基于Ampere架构设计,搭载GA102核心与 10752个CUDA核心,配备第二代RT Core(84个)和第三代Tensor Core(336个),支持实时光线追踪与AI加速运算。
- 该显卡采用48GB GDDR6显存及384bit显存位宽,支持PCIe 4.0接口与NVLink多卡互联,最大功耗300W。
- 配备涡轮散热系统,适配高负载运算需求,提供4个DisplayPort 1.4a输出接口及8K分辨率支持 [1-2]。市场指导价为38499元,定位高端专业显卡市场。
RTX A6000 基于 Ampere 架构,是 NVIDIA专业GPU系列的一部分。
- Ampere 架构:RTX A6000基于NVIDIA的Ampere体系结构,与前几代相比,性能有了显著提高。它具有用于AI加速的高级张量核心、增强的光线跟踪功能和增加的内存带宽。
- 高性能:RTX A6000提供大量CUDA内核、张量内核和光线跟踪内核,从而实现快速高效的深度学习性能。它可以处理大规模的深度学习模型和训练神经网络所需的复杂计算。
- 大内存容量:RTX A6000配备 48 GB GDDR6内存,为存储和处理大型数据集提供充足的内存空间。具有大的内存容量有利于训练需要大量内存的深度学习模型。
- 人工智能功能:RTX A6000包括专用张量核心,可加速人工智能计算并实现混合精度训练。这些张量核可以通过加速执行矩阵乘法等运算,显著加快深度学习工作负载。
4090
NVIDIA GeForce RTX 4090是一款功能强大的消费级显卡,可用于深度学习
【2023-9-20】A100/H100 太贵,何不用 4090?
- 大模型训练用 4090 不行,但推理(inference/serving)用 4090 不仅可行,在性价比上还能比 H100 稍高。4090 如果极致优化,性价比甚至可以达到 H100 的 2 倍。
H100/A100 和 4090 最大的区别就在通信和内存上,算力差距不大。
| 指标 | H100 | A100 | 4090 |
|---|---|---|---|
| Tensor FP16 算力 | 989 Tflops | 312 Tflops | 330 Tflops |
| Tensor FP32 算力 | 495 Tflops | 156 Tflops | 83 Tflops |
| 内存容量 | 80 GB | 80 GB | 24 GB |
| 内存带宽 | 3.35 TB/s | 2 TB/s | 1 TB/s |
| 通信带宽 | 900 GB/s | 900 GB/s | 64 GB/s |
| 通信时延 | ~1 us | ~1 us | ~10 us |
| 售价 | $30000~$40000 | $15000 | $1600 |
NVIDIA 算力表里面油水很多,比如 H100 TF16 算力写的是 1979 Tflops,但那是加了 sparsity(稀疏)的,稠密的算力只有一半;4090 官方宣传 Tensor Core 算力高达 1321 Tflops,但那是 int8 的,FP16 直只有 330 Tflops。这篇文章的第一版就是用了错的数据,H100 和 4090 的数据都用错了,得到的结论非常离谱。
鲲鹏的首席架构师夏 Core 有一篇知名文章《谈一下英伟达帝国的破腚》,很好的分析了 H100 的成本。详见原文
6000D
英伟达正针对中国市场规划新特供产品线。
基于Blackwell架构打造的 RTX 6000D 处理器已进入生产准备阶段,预计最快将于2025年6月启动量产,并于2025年7月正式投放市场。
这款芯片采用了与传统数据中心显卡不同的设计方案。该产品搭载GDDR7显存系统,带宽设定在1.7TB/s,恰巧卡在美国出口管制限制范围内。
通过放弃使用HBM高带宽内存和台积电CoWoS先进封装技术,英伟达在控制成本的同时满足合规要求。
定价策略显示,6500-8000美元的建议零售价比受限制的前代产品H20便宜约40%,较原版Blackwell架构芯片更是缩减70%成本。
性能方面, 估算其算力约为H20的65%,仅适合中小规模AI模型训练与推理需求。
L20
英伟达2023年11月16日推出的专业显卡L20。
采用 5nm 制造工艺,基于 AD102 图形处理器。
该卡支持 DirectX 12 Ultimate。AD102 图形处理器是一款大型芯片,具有 609 mm² 的芯片面积和763亿个晶体管。与完全解锁的 TITAN Ada 不同,TITAN Ada 虽然使用相同的 GPU 但启用了全部 18432 个着色器,但英伟达在 L20上禁用了一些着色单元,以达到产品目标着色器数量。它拥有 11776 个着色单元、368 个纹理映射单元和 128 个 ROPs。
此外,还包括 368 个 tensor cores,有助于提高机器学习应用的速度。该卡还具有 92 个光线追踪加速核心。英伟达为 L20 配备了 48GB 内存,通过 384 位内存接口连接。GPU 运行频率为 1440 MHz,可提升至 2520 MHz,内存运行频率为 2250 MHz(有效值为18 Gbps)。
NVIDIA L20 规格参数
- GPU 架构: NVIDIA Ada Lovelace
- CUDA 核心: 10240
- 频率: 高达 2.2 GHz
- 显存: 48GB HBM3
- 显存位宽: 384 位
- 显存带宽: 1.9 TB/s
- 算力: FP32:90 TFLOPS;FP64:11 TFLOPS
B200/B300
英伟达四大旗舰显卡差异:H100/H200/B200/B300
从Hopper架构的H100、H200,到Blackwell架构的B200、B300,每一代产品的迭代都牵动着AI企业、科研机构的采购决策。
H100和H200属于上一代Hopper架构,而B200和B300则是新一代 Blackwell 架构的产物,其中B300更是搭载了Blackwell Ultra架构是目前算力天花板。
架构的迭代带来的不只是参数的提升,更是对AI任务的适配能力升级:
- Hopper架构更侧重解决当下主流大模型的训练与推理需求,兼容性和部署成本更具优势;
- Blackwell架构则针对未来超大规模模型(万亿参数级)、多模态任务、实时推理场景进行了重构,尤其是在低精度算力、显存带宽、互联技术上实现了跨越式突破。
| 显卡型号 | 架构 | 显存容量 |
|---|---|---|
| H100 | Hopper | 80GB HBM3 |
| H200 | Hopper(升级款) | 141GB HBM3e★ |
| B200 | Blackwell | 180GB HBM3e |
| B300 | Blackwell Ultra | 288GB HBM3e |
随着架构从Hopper升级到Blackwell Ultra,显存容量、带宽、算力呈现阶梯式增长,而功耗也随之上升。其中B300的显存容量是H100的3.6倍,更是支撑FP4算力(H100/H200不支持FP4),性能差距极为显著。
昇腾
华为海思出品
华为 GPU 产品和生态:
| NVIDIA | HUAWEI | 功能 |
|---|---|---|
| GPU | NPU/GPU | 通用并行处理器 |
| NVLINK | HCCS | GPU 卡间高速互连技术 |
| InfiniBand | HCCN | RDMA 产品/工具 |
nvidia-smi |
npu-smi |
GPU 命令行工具 |
| CUDA | CANN | GPU 编程库 |
| DCGM | DCMI | GPU 底层编程库/接口,例如采集监控信息 |
GPU 产品
- 训练:
昇腾 910B,对标 NVIDIA A100/A800,算力对比; - 推理:
Atlas 300系列,对标 NVIDIA T4;
参考
- GPU 进阶笔记(一):高性能 GPU 服务器硬件拓扑与集群组网(2023)
- GPU 进阶笔记(二):华为昇腾 910B GPU 相关(2023)
- GPU 进阶笔记(三):华为 NPU (GPU) 演进(2024)
- GPU 进阶笔记(四):NVIDIA GH200 芯片、服务器及集群组网(2024)
昇腾(HUAWEI Ascend) 310
昇腾(HUAWEI Ascend) 310是一款高能效、灵活可编程的人工智能处理器,在典型配置下可以输出16TOPS@INT8, 8TOPS@FP16,功耗仅为8W。采用自研华为达芬奇架构,集成丰富的计算单元, 提高AI计算完备度和效率,进而扩展该芯片的适用性。全AI业务流程加速,大幅提高AI全系统的性能,有效降低部署成本。
昇腾(HUAWEI Ascend) 910
2023年, 昇腾(HUAWEI Ascend) 910, 64G HBM2e, HUAWEI DaVinci 架构
【2024-4-23】GPU Performance (Data Sheets) Quick Reference (2023)
国产AI芯片的崛起始于华为昇腾系列的自主研发。
昇腾910系列作为核心产品,历经多次迭代,逐步缩小与英伟达的差距:
| 型号 | 时间 | 特点 | 性能 | 应用 |
|---|---|---|---|---|
昇腾910初代 |
2019 | 7nm,达芬奇3D Cube架构,256TFLOPS | V100的2倍 |
清华“天枢”超算平台,蛋白质折叠 |
昇腾910B |
2021-2022 | 14nm,200 TFLOPS | H100的72% |
字节跳动、比亚迪等企业的AIGC模型训练与自动驾驶仿真 |
昇腾910C |
2023 | 7nm,,280TFLOPS | 超越 H100 |
政务云、工业优化、医疗 |
昇腾910D |
2024 | Chiplet设计和光互联接口,320 TFLOPS | 国家超算中心、生物医药(华大基因新药研发)及百度 Apollo 自动驾驶仿真平台 | |
昇腾920 |
预计2026 | 6nm,Chiplet 3D封装,BF16 900 TFLOPS | H200的70% |
演变历史
昇腾910初代(2019年):- 采用7nm制程,基于达芬奇3D Cube架构,FP16算力达256TFLOPS,性能为英伟达
V100的2倍。 - 清华大学基于其构建的“天枢”超算平台,在蛋白质折叠预测等任务中效率提升40%。
- 采用7nm制程,基于达芬奇3D Cube架构,FP16算力达256TFLOPS,性能为英伟达
昇腾910B(2021-2022年):- 受制程限制(14nm国产化工艺),FP16算力降至200 TFLOPS,但能效比优化,支持安全加密模块,适配字节跳动、比亚迪等企业的AIGC模型训练与自动驾驶仿真。
- 在千卡集群中训练效率达英伟达
H100的72%,功耗仅85%。
昇腾910C(2023年):- 恢复7nm性能,FP16算力达280TFLOPS,能效比(0.82 TFLOPS/W)超越
H100(0.75 TFLOPS/W),支持稀疏计算和国产化生产。 - 应用于政务云、工业优化(如芜湖海螺水泥能耗降低15%)及医疗领域(抑郁症初筛系统)。
- 恢复7nm性能,FP16算力达280TFLOPS,能效比(0.82 TFLOPS/W)超越
昇腾910D(2024年):- 采用Chiplet设计和光互联接口,FP16算力突破320 TFLOPS,内存带宽提升至 4000GB/s,支持动态功耗管理。
- 计划用于国家超算中心、生物医药(华大基因新药研发)及百度 Apollo 自动驾驶仿真平台。
昇腾920(预计2026年):- 6nm制程+Chiplet 3D封装,BF16算力达900 TFLOPS,内存内计算(HBM-PIM)技术使能效比提升5倍,性能对标英伟达
H200的70%。
- 6nm制程+Chiplet 3D封装,BF16算力达900 TFLOPS,内存内计算(HBM-PIM)技术使能效比提升5倍,性能对标英伟达
技术差距分析:
- 制程瓶颈:昇腾920因供应链限制延迟5年发布,落后英伟达3代(原计划2021年发布)。
- 架构创新:通过存算一体、动态稀疏计算等技术弥补制程劣势,在能效和特定场景性能上实现局部超越。
寒武纪
【2025-8-24】高盛发布报告,上调寒武纪目标价50%至1835元(股价),并称最乐观情境下可达3934元,主要原因包括中国云计算资本支出提高、芯片平台多样化、寒武纪研发投入增大。
平头哥
【2025-9-16】阿里平头哥最新研发AI芯片PPU,主要面向推理场景
平头哥已陆续推出 “含光”系列AI芯片、“倚天”系列通用服务器CPU、以及企业级SSD主控芯片镇岳510等。其中的自研CPU芯片倚天710、AI推理芯片含光800等均在阿里云上实现了规模化部署。
参数计算
【2023-10-19】深度学习模型参数量/计算量和推理速度计算
每秒浮点运算次数 FLOPs 计算方法
深度学习中模型计算量(FLOPs)和参数量(Params)的理解以及四种计算方法总结
FLOPS 是 floating point operations per second 的缩写。
- 每秒浮点运算次数。
FLOPS 可理解为计算速度, 是一个衡量硬件性能的指标,用来衡量算法/模型的复杂度。
FLOPs是模型推理时间的一个参考量,但并不能百分之百表示该模型推理时间的长短,因为乘法和加法计算不一样,乘法的时间一般是加法时间的四倍,但现在有很多优化卷积层的计算算法,可以把乘法计算时间缩为加法的两倍不等,所以FLOPs只是个估量的指标,不是决定推理时间长短的指标。即FLOPs越小并不代表着模型推理时间越短。
FLOPs与FLOPS的区别。
- FLOPS 的全称是floating point of per second,每秒浮点运算次数。用来衡量硬件的性能。
- FLOPs 的全称是floating point of operations,浮点运算次数,可以用来衡量算法/模型复杂度。
计算量与参数量不是一回事
计算量(FLOPs)和参数量(Params)
- 计算量对应时间复杂度,参数量对应空间复杂度
计算量要看网络执行时间的长短,参数量要看占用显存的量
注意:
- Params只与你定义的网络结构有关,和forward的任何操作无关。即定义好了网络结构,则参数就已经确定了
- FLOPs与不同层的运算结构有关。如果forward时在同一层(同一名字命名的层)多次运算,FLOPs不会增加。
- Model_Size = 4 * params 模型大小约为参数量的4倍
公式是计算时间复杂度(计算量),而下面的公式是计算空间复杂度(参数量)
FLOPS的计算公式:
- 对卷积层: (K_h * K_w * C_in * C_out) * (H_out * W_out)
- 对全连接层: C_in * C_out
注:
- k_h表示卷积核的高,k_w表示卷积核的宽
- c_in表示输入通道数目,c_out表示输出通道数目;
- H_out表示卷积后的输出图的高,W_out表示卷积后的输出图的宽。
# ------- 参数量 ------
(kernel*kernel) *channel_input*channel_output
# kernel*kernel 就是 weight * weight
# 其中kernel*kernel = 1个feature的参数量
# ------- 计算量 -------
(kernel*kernel*map*map) *channel_input*channel_output
# kernel*kernel 就是weight*weight
# map*map是下个featuremap的大小,也就是上个weight*weight到底做了多少次运算
# 其中kernel*kernel*map*map= 1个feature的计算量
- 池化层:无参数
- 全连接层:参数量 = 计算量 = weight_in*weight_out
一般一个参数是值一个float,也就是4个字节
- 1kb=1024字节
计算量,参数量对于硬件的要求是不同的
- 计算量的要求是在于芯片的 floaps(指的是gpu的运算能力)
- 参数量取决于显存大小
计算量(FLOPs)和参数量(Params)
- 第一种方法:thop
- 第一步:安装模块
- 第二步:计算
- 第二种方法:ptflops
- 第三种方法:pytorch_model_summary
- 第四种方法:参数总量和可训练参数总量
- torchstat
- fvcore
推理速度计算 FPS
模型推理速度正确计算
- 要克服GPU异步执行和GPU预热两个问题。
使用Efficient-net-b0,在进行任何时间测量之前
- 通过网络运行一些虚拟示例来进行“预热”。这将自动初始化GPU并防止它在测量时间时进入省电模式。
- 接下来,用torch.cuda.event来测量GPU上的时间。这里使用torch.cuda.synchronize()至关重要。这行代码执行主机和设备(CPU和GPU)之间的同步,因此只有在GPU上运行的进程完成后才会进行时间记录。这克服了不同步执行的问题。
吞吐量计算
神经网络的吞吐量定义为网络在单位时间内(例如,一秒)可以处理的最大输入实例数。与涉及单个实例处理的延迟不同,为了实现最大吞吐量,我们希望并行处理尽可能多的实例。有效的并行性显然依赖于数据、模型和设备。
显存分配原理
【2023-2-26】PyTorch显存分配原理——以BERT为例
nvidia-smi 看到的占用
- = CUDA 上下文 + pytorch 缓存区
- = CUDA 上下文 + 未使用缓存 + 已使用缓存
- CUDA 上下文
PyTorch会在第一次cuda操作创建 CUDA 上下文,占用的大小和 CUDA 版本、硬件设备有关。
- 例如:V100,CUDA10.1上,CUDA 上下文共占用1053MB
- PyTorch 缓存管理
Pytorch 内部有自己的缓存管理系统,能够加速显存分配。
- 使用 torch.cuda.memory_allocated() 可以看到当前Tensor占用的显存
- 使用 torch.cuda.memory_reserved() 可以看到总共占用的显存
- 使用 torch.cuda.empty_cache() 清空未使用的缓存,但是已经使用的是不能释放的
只有一种情况需要使用 torch.cuda.empty_cache(),就是当你想要释放缓存以便让其他人也可以一起使用当前显卡,否则不需要调用这个方法。
这里用一个简单的例子解释一下缓存的概念:
- 定义一个4MB的 Tensor(一个long tensor占4byte)
import torch
a = torch.zeros((1024,1024)).cuda() # 实际大小: 1024*1024=4M
print(torch.cuda.memory_allocated() / 1024 / 1024) # a 占用了 4m
print(torch.cuda.memory_reserved() / 1024 / 1024) # 缓存区大小 20m, 缓存区仍然占用了20M,nvidia-smi里也保持1073M的占用
del a # 清除张量
# --------
print(torch.cuda.empty_cache()) # 清空缓存
print(torch.cuda.memory_allocated()/1024/1024)
print(torch.cuda.memory_reserved()/1024/1024)
- 模型实际占用
这里分析一下模型训练,推理过程中,实际占用了多少显存。
训练阶段
前向传播:
- 模型实际占用 = 模型参数 + 输入 + 输出 + 前向传播的中间变量
- 模型参数:4.00390625MB = 102410244(weight)+1024*4(bias) = 4,198,400
- 输入:40MB
- 输出和前向传播的中间变量:4000MB
为了方便观察显存的变化,这里定义两个辅助函数
反向传播:
- 模型实际占用 = 模型参数*2 + 输入 + 输出
- 模型参数*2:4.00390625MB * 2 = 8.0078125 MB
- 输入:40MB
- 输出:40MB
这里将输出求和作为loss,然后求梯度
测试阶段
- 模型实际占用 = 模型参数 + 输入向量 + 输出向量
- torch.cuda.memory_allocated() 返回当前模型实际占用的显存。
- torch.cuda.memory_reserved() 返回Pytorch占用的显存。
- torch.cuda.memory_summary() 返回当前显存占用详细情况。
使用 torchinfo 可以查看模型共有多少参数,比直接print(model)的信息更全,可视化效果更好。
- 安装 pip install torchinfo
from torchinfo import summary
from transformers import BertModel, BertConfig
model = BertModel(BertConfig()).to("cuda:0")
summary(model)
② GPU监控工具-gpustat
- 仅适用于N卡(NVIDIA ),A卡不行(AMD)
- 效果示例:图

- []里的数字是GPU编号,即常见的多机多卡里的“卡”
#pip install gpustat # 安装
echo "gpustat工具统计-`hostname`"
gpustat -cp # 检测
# 结果如下
528e504a63a3 Wed Jun 5 03:16:16 2019
#[0] Tesla T4 | 48'C, 0 % | 0 / 15079 MB |
# Google的Colab配置了Tesla T4的显卡一个,显存15G
# 动态监控
watch --color -n1 gpustat -cpu
③ Pytorch的GPU测试方法
import torch
torch.cuda.is_available() # true
torch.backends.cudnn.enabled # true
④ Tensorflow的GPU测试代码
import tensorflow as tf
device_name = tf.test.gpu_device_name()
print('Detect GPU:', device_name) # ('Detect GPU:', '/device:GPU:0')
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name)) # Found GPU at: /device:GPU:0
GPU 参数
GPU与CPU的不同
- GPU: 计算密集型任务
- CPU: I/O, 逻辑运算
如果是多个GPU,需要注意参数:CUDA_VISIBLE_DEVICES, 限定CUDA程序所能使用的GPU设备
CUDA_VISIBLE_DEVICES 设置方法
- (1)永久设置, 在环境变量中设置
- linux环境:vim ~/.bash.rc,在最后添加上CUDA_VISIBLE_DEVICES=0,2,然后source ~/.bash.rc使之生效即可。
- windows环境:直接添加CUDA_VISIBLE_DEVICES=0,2进环境变量
- (2)临时设置,在程序启动脚本中添加:
- linux 环境:export CUDA_VISIBLE_DEVICES=0,2
- windows环境: set CUDA_VISIBLE_DEVICES=0,2
# CUDA_VISIBLE_DEVICES设置说明,设置device对程序可见
CUDA_VISIBLE_DEVICES=1 # 仅使用device1 (即卡一)
CUDA_VISIBLE_DEVICES=0,1 # 仅使用device 0和 device1
CUDA_VISIBLE_DEVICES="0,1" # 同上, 仅使用device 0和 device1
CUDA_VISIBLE_DEVICES=0,2,3 # 仅使用device0, device2和device3
CUDA_VISIBLE_DEVICES=2,0,3 # 仅使用device0, device2和device3, 调整GPU序号映射关系
最后两条的区别是什么呢?
- CUDA_VISIBLE_DEVICES 后面的参数依次是设置 gpu[0],gpu[1], gpu[2]…等的device编号。
- 0,2,3 是gpu[0]指向device0, gpu[1]指向devcie2, gpu[2]指向device3;
- 2,0,3 是gpu[0]指向device2, gpu[1], 指向devcie0, gpu[2]指向device3;
再举例说明,如果当前主机有5张显卡,默认情况下5个device对程序都可以见,默认排序device0 - 4。 如果现在我们只希望使用第一张和第三张显卡,并且程序代码里看到的分别对应0,1。 那么设置应该如下: CUDA_VISIBLE_DEVICES=0,2
- gpu使用方法
- 通过tf.device指定运行设备,不管CPU多少个,一律标记为/cpu0,而GPU不同,分别是/gpu:1-n
- Tensorflow使用GPU时默认占满所有可用GPU的显存,但只在第一个GPU上进行计算
- 多GPU时,只有一块GPU真正在工作,如果不加以利用,另一块GPU就白白浪费了
- GPU是一种相对昂贵的计算资源,虽然正值矿难,相比之前动辄八九千一块1080Ti的价格低了不少,但也不是一般人能浪费的起的
- 如何有效提高GPU特别是tensorflow上的利用率就成为了一项重要的考量。
- 解决一:设置可见的GPU,CUDA_VISIBLE_DEVICES, 0表示GPU编号(0~n-1)
Shell代码:
export CUDA_VISIBLE_DEVICES=0
Python代码:
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
- 缓解tf占满整个GPU
config = tf.ConfigProto(allow_soft_placement=True,allow_grouth=True)
config.gpu_options.per_process_gpu_memory_fraction = 0.9 #占用90%显存
sess = tf.Session(config=config)
- 解决二:有时候我们更需要利用好已有的卡,来或得线性的加速比,以便在更短的时候获取参考结果,上面的方法就无能无力,需要自己写代码实现多GPU编程
- 参考:tensorflow 多GPU编程 完全指南
GPU 结构
显卡是由GPU计算单元和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。
显存可以看成是空间,类似于内存。
- 显存用于存放模型,数据
- 显存越大,所能运行的网络也就越大
GPU计算单元类似于CPU中的核,用来进行数值计算。
- 衡量计算量的单位是
flop: the number of floating-point multiplication-adds,浮点数先乘后加算一个flop。计算能力越强大,速度越快。 - 衡量计算能力的单位是
flops: 每秒能执行的flop数量
GPU 如何工作
- 为了获得比 CPU 更高的吞吐量,GPU 使用一种简单的策略:在单个处理器中使用成千上万个 ALU。现代 GPU 通常在单个处理器中拥有 2500-5000 个 ALU,意味着同时执行数千次乘法和加法运算。
GPU为什么快
CPU,即 中央处理器,处理用户向计算机提出的每一条指令。
- 一个程序里包含的指令是十分复杂,不仅包括计算,还包括逻辑;如不但要计算1+1=2,还要判断if和else,甚至还要统筹计算机里的内存,硬盘等其他硬件
- 最终,CPU内部的要留大量的空间给控制单元和缓存,单纯的计算单元反而就占很小一块
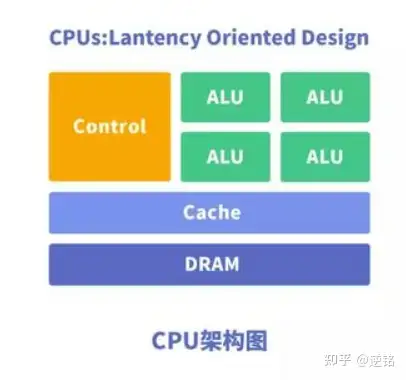
- CPU处理复杂逻辑的程序,比起其他种类硬件优势显著,但如果单纯拿CPU来计算,那内部有很多东西浪费了。
GPU就抛弃了复杂的控制模块。
- 诞生之初为了计算图形数据,图形数据没有太复杂的逻辑,都是点的坐标和各种空间计算公式
- 跑3D图形不需要很多的if和else,只有各种点的计算。所以,在仅仅保留了必要的一小部分控制单元后,GPU将绝大多数区域都让给了计算单元。
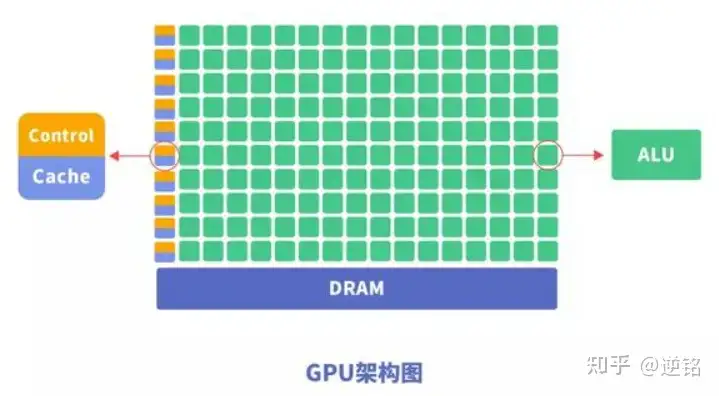
结果就是,GPU判断复杂的逻辑,很可能吃不消,但计算上的速度就远远领先CPU。
巧合的是,深度学习就需要大量的计算; GPU在跑深度学习这件事上,有着CPU数倍乃至数十倍的速度。
深度学习主要有训练、推理两个阶段

- 训练过程需要大量的计算,因为要先将实例输入,计算出结果与答案比较,得到结果与答案的差异,再返回去优化,计算出迭代后的网络参数,来来回回折腾几遍,这个运算量就非常巨大。因此训练过程不论如何都需要专精计算的GPU来加速。
- 但推理过程就不一定只能靠GPU了,CPU一样可以参与,甚至在实际应用中,由于其他复杂逻辑的加入,CPU更加不可或缺。
所以说只要算法优化得好,CPU也可以很好地处理人工智能的运算工作。实际上各大CPU厂家也在不断提升CPU的AI计算能力。
作为处理器巨头,英特尔已经在自家的至强服务器处理器里集成了多种深度学习加速技术。
- 比如DL Boost技术,核心是通过降低数据精度来提升单个时钟周期内可以进行的运算次数,来加速计算。对于深度学习来说,降低精度对于推理结果的影响很小,提升硬件性能和效率,由此降低延迟更加重要,所以这种优化方法能在不影响结果的同时大幅度加速计算
- 再比如 one API,里面集成了TensorFlow、Apache MXNet、PyTorch等多种 AI 框架和库,并且针对DL Boost和至强处理器做了专门的优化,有着更高的运行效率。
- 在一系列优化加速下,尽管速度还不能说反超了GPU,但相较于之前,英特尔至强处理器的AI处理能力已经有了质的飞跃。
CPU 和 GPU 如何工作
概念
CPU和主存被称为主机(Host)GPU和显存(显卡内存)被称为设备(Device)
CPU无法直接读取显存数据,GPU无法直接读取主存数据,主机与设备必须通过总线(Bus)相互通信。
GPU PyTorch
pytorch中常见的GPU启动方式
- torch.distributed.launch
- torch.multiprocessing

- distributed.launch方法如果开始训练后,手动终止程序,最好先看下显存占用情况,有小概率进程没kill的情况,会占用一部分GPU显存资源。
Parallelism-GPU 并行
- There are two types of parallelism:
- 模型并行,Model parallelism - Different GPUs run different part of the code. Batches of data pass through all GPUs.
- 适用于大规模
- 数据并行,Data parallelism - We use multiple GPUs to run the same TensorFlow code. Each GPU is feed with different batch of data. 每个节点是各有一份模型copy,称为tower
- 同步+异步,同步适用于设备差异不大,小数据,异步抖动,适用大数据
- 图内+图间
详见站内专题 分布式训练
CUDA
【2024-4-19】cuda编程
cuda 介绍
CUDA 全称 Compute Unified Devices Architechture, 统一计算架构
- NVIDIA公司所开发的GPU编程模型,提供GPU编程的简易接口
基于CUDA编程,可构建基于GPU计算的应用程序。
CUDA 历史
- 1990年代前,计算机处理图像主要靠CPU
- 屏幕分辨率 640*480, 对应的计算量也大,每帧画面要30w个像素要计算
- 当时的CPU(Intel 386/486)运行赫兹 16-77 MHz,捉襟见肘
- 问题:能不能把图形计算任务分离出来,给CPU减负?
- 1990年代中期, 3D加速卡出现,负责基本功能(3D变换/裁剪/光栅化/纹理映射)
- 最著名的事3dfx公司的Voodoo 系列,彻底改变了游戏界,id software 公司用此开发了游戏《雷神之锤》,成为3D游戏扛把子
- 问题:能否开发一款图形处理硬件?
- 1999年, NVIDIA 推出第一款GPU
GeForce 256, 标志着 GPU 时代的正式到来- 相比3D加速卡,GPU硬件处理能力大大提升;加速卡的操作是预先设定好的,流水线,很难扩展。
- 而
GeForce 256引入革命性的可编程着色器, 一款自定义小程序,灵活控制3D模型顶点位置、颜色等属性,实现更复杂的3D效果(水面波纹/皮肤质感) - 问题:GPU 与游戏开发密切相关,但是只能用来开发游戏吗?
- 2002年,NVIDIA 推出 GPGPU (图像处理器通用计算) 概念, 将 GPU 应用扩展到别的领域,但 当时的GPU架构不满足
- 2006年,NVIDIA 推出划时代产品
GeForce 8800 GTX, 第一款真正支持通用计算的GPU, 引入CUDA概念CUDAvsCPU: 计算核更多、独有SIMD(单指令多数据)GeForce 8800 GTX有 128 个 CUDA 核心,而现在的RTX 4090有 16384 个核心GTX 8800(128) ->GTX 480(480) ->GTX 680(1536) ->GTX 1080(2560) ->RTX 2080(2944) ->RTX 3080(8704) ->RTX 4090(16384)- SIMD(单指令多数据): 粒子运动效果计算,cpu逐个串行计算粒子运动轨迹,而cuda所有粒子并行计算;几十个粒子时看不出差异,但高达几十万个粒子时,cpu很慢
- 为了提升cuda计算能力,NVIDIA 推出 CUDA Toolkit,如 CUDA 11.8, CUDA 12.5
- TFLOPS: 浮点数运算指标, Tera Floating Point Operations per Second, 每秒进行多少万亿次计算, 10^12
- 2016年推出的 GTX 1050 只有 1.8 个 TFLOPS
- 2022年推出的 RTX 4090 达到 82.6 个 TFLOPS,增长了45 倍
- 2017年,NVIDIA 推出 Volta 架构, 引入新概念 Tensor 核心,专门为矩阵运算设计,为AI计算提效
NVIDIA CUDA 遥遥领先,但依然有竞争对手
- 华为 昇腾
- AMD ROCm
- Intel Gaudi
- Google TPU
【2025-1-12】一文讲清楚CUDA
- 演示代码: cuda_demo
CUDA 提供了对其它编程语言的支持,如 C/C++,Python,Fortran 等语言,这里选择CUDA C/C++接口对CUDA编程。
开发平台为 Windows 10 + VS 2013,Windows系统下的CUDA安装教程可以参考这里
- CUDA编程模型支持的编程语言
- CUDA编程模型基础
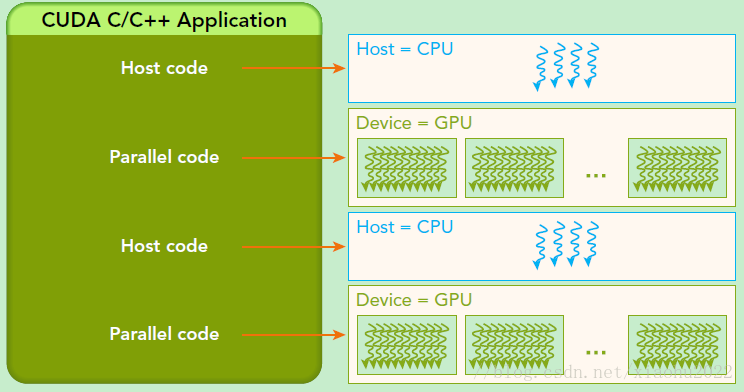
- CUDA编程模型是异构模型,需要CPU和GPU协同工作。在CUDA中,
host和device是两个重要的概念,用host指代CPU及其内存,而用device指代GPU及其内存。CUDA程序中既包含host程序,又包含device程序,它们分别在CPU和GPU上运行。同时,host与device之间可以进行通信,这样它们之间可以进行数据拷贝。典型的CUDA程序的执行流程如下:- 分配 host内存,并进行数据初始化;
- 分配 device内存,并从host将数据拷贝到device上;
- 调用 CUDA的核函数在device上完成指定的运算;
- 将 device上的运算结果拷贝到host上;
- 释放 device和host上分配的内存。
- CUDA编程模型是异构模型,需要CPU和GPU协同工作。在CUDA中,
- 参考:CUDA编程入门极简教程

cuda 版本
cuda 安装
conda install cudatoolkit
# 检查CUDA环境变量,返回值不为空说明已经安装好CUDA
echo $CUDA_HOME
查看cuda版本, 参考
# 查看cuda版本
/usr/local/cuda/bin/nvcc -V
/usr/local/cuda/bin/nvcc --version
# 查看 cuDNN 版本
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
如果没有,可能没有安装 cuDNN。Linux 服务器上推荐使用 conda 安装,使用 conda 可以很方便安装 PyTorch/TensorFlow 以及对应版本的 CUDA 和 cuDNN。
用 PyTorch 查看 CUDA 和 cuDNN 版本
- NVIDIA cuDNN 是用于深度神经网络的GPU加速库。
import torch
print('pytorch版本:', torch.__version__)
print('cuda版本: ', torch.version.cuda)
print('cuDNN版本: ', torch.backends.cudnn.version())
cuda 编程
Python Numba库可以调用CUDA进行GPU编程,CPU端被称为主机,GPU端被称为设备,运行在GPU上的函数被称为核函数,调用核函数时需要有执行配置,以告知CUDA以多大的并行粒度来计算。使用GPU编程时要合理地将数据在主机和设备间互相拷贝。
CUDA编程基本流程为:
- 初始化,并将必要的数据拷贝到GPU设备的显存上。
- 使用某个执行配置,以一定的并行粒度调用CUDA核函数。
- CPU和GPU异步计算。
- 将GPU计算结果拷贝回主机。
CUDA 架构引入主机端(host)和设备(device)概念。
CUDA程序既包含host程序,又包含device程序。同时,host与device之间可以进行通信,这样进行数据拷贝。
主机(Host):将CPU及系统的内存(内存条)称为主机。设备(Device):将GPU及GPU本身的显示内存称为设备。动态随机存取存储器(DRAM):Dynamic Random Access Memory,最为常见的系统内存。- DRAM只能将数据保持很短的时间。为了保持数据,DRAM使用电容存储,所以必须隔一段时间刷新(refresh)一次,如果存储单元没有被刷新,存储的信息就会丢失。(关机就会丢失数据)
典型CUDA程序执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
GPU 问题
OOM
错误
RuntimeError: CUDA Out of memory
解法,按代码更改的顺序递增:
- 减少“batch_size”
- 模型微调: 二分法,不断调小 batch size
- batchsize = 1 还有问题,继续往下找
- max_seq_len
- 调小序列长度, 减少内存开销
- 【2024-3-29】A100 80G 跑 InternLM,报错 OOM, 差 1G 空间,将 max_seq_len 降低后成功
- 降低精度
- Pytorch-Lightning: 将精度更改为“float16”
- 风险: 可能引起 Double 和 Float 张量间不匹配
- 按照错误提示操作
- 更改 GPU 配置
- 清除缓存
- 终端:
- ipython:
x.detach()和x.cpu()
- 修改模型/训练
- 不要保存整个tensor,当你在epoch结束需要汇总损失的时候,使用
loss.item() preds.detach().cpu()从 GPU 中删除预测和目标
- 不要保存整个tensor,当你在epoch结束需要汇总损失的时候,使用
export PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:128
# 多 GPU
export CUDA_VISIBLE_DEVICES=2,4,6
# Python 中指定
import os
os.environ['CUDA_VISIBLE_DEVICES']='2, 3'
GPU 显存查询
import gc
def report_gpu():
print(torch.cuda.list_gpu_processes())
gc.collect()
torch.cuda.empty_cache()
# 释放 cuda 内存
gc.collect()
torch.cuda.empty_cache()
# ipython
a.detach()
a.cpu()
# pip install koila
(input, label) = lazy(input, label, batch=0)
GPU利用率上不去
【2024-3-25】理解NVIDIA GPU 性能:利用率与饱和度
Nvidia 官方指导文档描述GPU利用率
- 如果GPU某个SM正在执行计算任务,而其他SM处于空闲状态,通过以下公式来估算整体的GPU利用率:
- GPU 利用率= 活跃SM数/总SM数 × 100%
nvidia-smi 工具报告 GPU利用率为100%,即使只有1个SM活动。这种现象可能会引起一些混淆,不符合直觉
即使只有1个任务在 GPU 小部分上运行,“GPU util”诸如 nvidia-smi 或基于 nvml 工具报告指标误导用户,以为设备已完全被占用
- GPU 利用率应该为: 1 / num_sm * 100%
- 然而,nvidia-smi 可能会报告 “GPU-Util” 100%
nvidia-smi 命令行工具基于 NVIDIA 管理库 (NVML),闭源
- GPU 利用率:报告 GPU 和内存接口的计算资源的当前利用率。
// https://github.com/NVIDIA/go-nvml/blob/v0.12.0-1/gen/nvml/nvml.h#L210
/**
* Utilization information for a device.
* Each sample period may be between 1 second and 1/6 second, depending on the product being queried.
*/
typedef struct nvmlUtilization_st {
unsigned int gpu; //!< Percent of time over the past sample period during which one or more kernels was executing on the GPU
unsigned int memory; //!< Percent of time over the past sample period during which global (device) memory was being read or written
} nvmlUtilization_t;
NVML的定义
- “利用率”: 过去的样本期间内发生某些活动的时间百分比。
具体来说:
- GPU 利用率:一个或多个内核在 GPU 上执行的时间百分比。
- 内存利用率:读取或写入全局(设备)内存的时间百分比。
NVML“利用”概念不符合共同理解。
- 它仅测量给定采样周期内设备使用时间部分,而不考虑该时间内使用的流式多处理器 (SM) 的数量。
- “USE”方法论中,“利用率”指资源正在积极服务或工作的部分时间,而不考虑分配的容量。
- 通常,将“利用率”视为正在使用的 GPU 处理器的部分。
更科学的叫法: 饱和度的“利用率”, 替代术语来代替“利用率””used-frequency”,表示使用设备的频率
收集 GPU 性能指标方法:
- 命令行工具
nvidia-smi,它可以 Pretty-Print 和xml。- 内部基于NVML(NVIDIA Management Library)。
- 收集高级指标,例如 GPU 和内存“利用率”(使用频率)、设备温度、功耗等。
dcgm-exporter,输出Prometheus格式数据。- 内部基于DCGM(数据中心GPU管理)。
- 除了高级指标之外,还可以执行分析并收集关于 GPU 设备饱和度数据详细信息。
当GPU 利用率为 100%时,SM占用率非常低(<20%),浮点运算(FP32/FP16/TensorCore)也保持在非常低的百分比,这表明GPU还没有饱和。
nvidia-smi 报告的“利用率”仅表示设备的使用频率(以时间百分比表示),而不考虑正在使用的GPU是否被占满。
- 虽然 nvidia-smi 是一种常用且方便的工具,但并不是性能测量的最佳选择。
对于实际部署中的GPU应用,建议使用基于DCGM的指标,例如dcgm-exporter.
此外,密切关注饱和度指标可能是有益的。这些指标包括 FP64/FP32/FP16 激活、张量核心激活百分比、NVLINK 带宽、GPU 内存带宽百分比等。
【2024-4-16】GPU利用率上不去
watch -n 0.1 nvidia-smi
watch -n 1 -d nvidia-smi
参数
- -n或–interval watch缺省每2秒运行一下程序,可以用-n或-interval来指定间隔的时间。
- -d或–differences 用-d或–differences选项watch 会高亮显示变化的区域。 而-d=cumulative选项会把变动过的地方(不管最近的那次有没有变动)都高亮显示出来。
- -t 或-no-title 会关闭watch命令在顶部的时间间隔,命令,当前时间的输出。
虽然显卡显存塞满了,但是显卡功率(最左边那一栏,114W和69W)和利用率(最右边那一栏,35%和38%)却远远没有达到极限。

gpu利用率30%代码在训练时变化情况

- gpu利用率并不是一直低水平,而是周期性从0涨到接近100再跌到0,再重新涨到100再跌回0。
- 闲置时间花在 CPU 运算上了
CPU 在干什么?
- load下一个batch、预处理这个batch、gpu上跑出结果后打印日志、后处理、写summary甚至保存模型等
- 这一系列的花销都要靠cpu去完成。
create_graph()
create_model_saver()
create_summary_writer()
create_session()
do_init()
for i in range(num_train_steps):
load_batch(...) # cpu
preprocess(...) # cpu
feed_dict = {...} # cpu
fetch_list = [...] # cpu
buf = session.run(fetch_list, feed_dict) # gpu
postprocess(buf) # cpu
print(...) # cpu
if i % x == 0:
summary_writer.write(...) # cpu
if i % xx == 0:
model_saver.save(...) # cpu
训练效率低?GPU利用率上不去?快来看看别人家的tricks吧
GPU 利用率
- GPU 在时间片上的利用率
- 即 通过
nvidia-smi显示的 GPU-util 指标。 - 统计方式:在采样周期内,GPU 上面有 kernel 执行的时间百分比。
常见 GPU 任务运行流程图
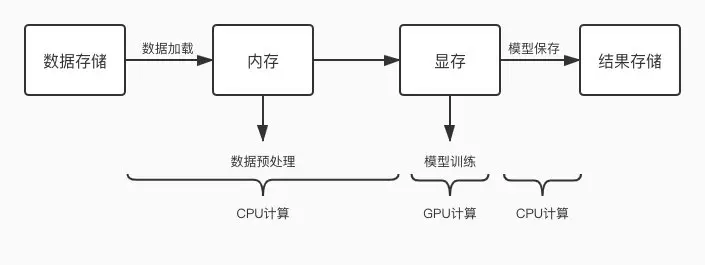
GPU 任务交替使用 CPU 和 GPU 进行计算
- 当 CPU 计算成为瓶颈时,就会出现 GPU 等待的问题,GPU 空跑, 利用率就低了。
优化方向:
- 缩短一切使用 CPU 计算环节的耗时,减少 CPU 计算对 GPU 阻塞情况。
常见 CPU 计算操作:
- 数据加载
- 数据预处理
- 模型保存
- loss 计算
- 评估指标计算
- 日志打印
- 指标上报
- 进度上报
GPU 利用率低原因分析
1、数据加载相关
- 1)存储和计算跨城了,跨城加载数据太慢导致 GPU 利用率低
- 说明:例如数据存储在“深圳 ceph”,但是 GPU 计算集群在“重庆”,那就涉及跨城使用了,影响很大。
- 优化:要么迁移数据,要么更换计算资源,确保存储及计算是同城的。
- 2)存储介质性能太差
- 说明:不同存储介质读写性能比较:本机 SSD > ceph > cfs-1.5 > hdfs > mdfs
- 优化:将数据先同步到本机 SSD,然后读本机 SSD 进行训练。本机 SSD 盘为“/dockerdata”,可先将其他介质下的数据同步到此盘下进行测试,排除存储介质的影响。
- 3)小文件太多,导致文件 io 耗时太长
- 说明:多个小文件不是连续的存储,读取会浪费很多时间在寻道上
- 优化:将数据打包成一个大的文件,比如将许多图片文件转成一个 hdf5/pth/lmdb/TFRecord 等大文件
- lmdb 格式转换样例, 其他格式转换方式请自行谷歌
- 4)未启用多进程并行读取数据
- 说明:未设置
num_workers等参数或者设置的不合理,导致 cpu 性能没有跑起来,从而成为瓶颈,卡住 GPU - 优化:设置
torch.utils.data.DataLoader方法的num_workers参数、tf.data.TFRecordDataset方法的num_parallel_reads参数或者tf.data.Dataset.map的num_parallel_calls参数。
- 说明:未设置
- 5)未启用提前加载机制来实现 CPU 和 GPU 的并行
- 说明:未设置
prefetch_factor等参数或者设置的不合理,导致 CPU 与 GPU 在时间上串行,CPU 运行时 GPU 利用率直接掉 0 - 优化:设置
torch.utils.data.DataLoader方法的prefetch_factor参数 或者tf.data.Dataset.prefetch()方法。prefetch_factor表示每个 worker 提前加载的 sample 数量 (使用该参数需升级到 pytorch1.7 及以上),Dataset.prefetch()方法的参数 buffer_size 一般设置为:tf.data.experimental.AUTOTUNE,从而由 TensorFlow 自动选择合适的数值。
- 说明:未设置
- 6)未设置共享内存
pin_memory- 说明:未设置
torch.utils.data.DataLoader方法的pin_memory或者设置成 False,则数据需从 CPU 传入到缓存 RAM 里面,再给传输到 GPU 上 - 优化:如果内存比较富裕,可以设置
pin_memory=True,直接将数据映射到 GPU 的相关内存块上,省掉一点数据传输时间
- 说明:未设置
pytorch 的 torch.utils.data.DataLoader
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
参数定义中,我们可以看到 DataLoader 主要支持以下几个功能:
- 支持加载 map-style 和 iterable-style 的 dataset,主要涉及到的参数是 dataset
- 自定义数据加载顺序,主要涉及到的参数有 shuffle, sampler, batch_sampler, collate_fn
- 自动把数据整理成 batch 序列,主要涉及到的参数有 batch_size, batch_sampler, collate_fn, drop_last
- 单进程和多进程的数据加载,主要涉及到的参数有 num_workers, worker_init_fn
- 自动进行锁页内存读取 (memory pinning),主要涉及到的参数 pin_memory
- 支持数据预加载,主要涉及的参数 prefetch_factor
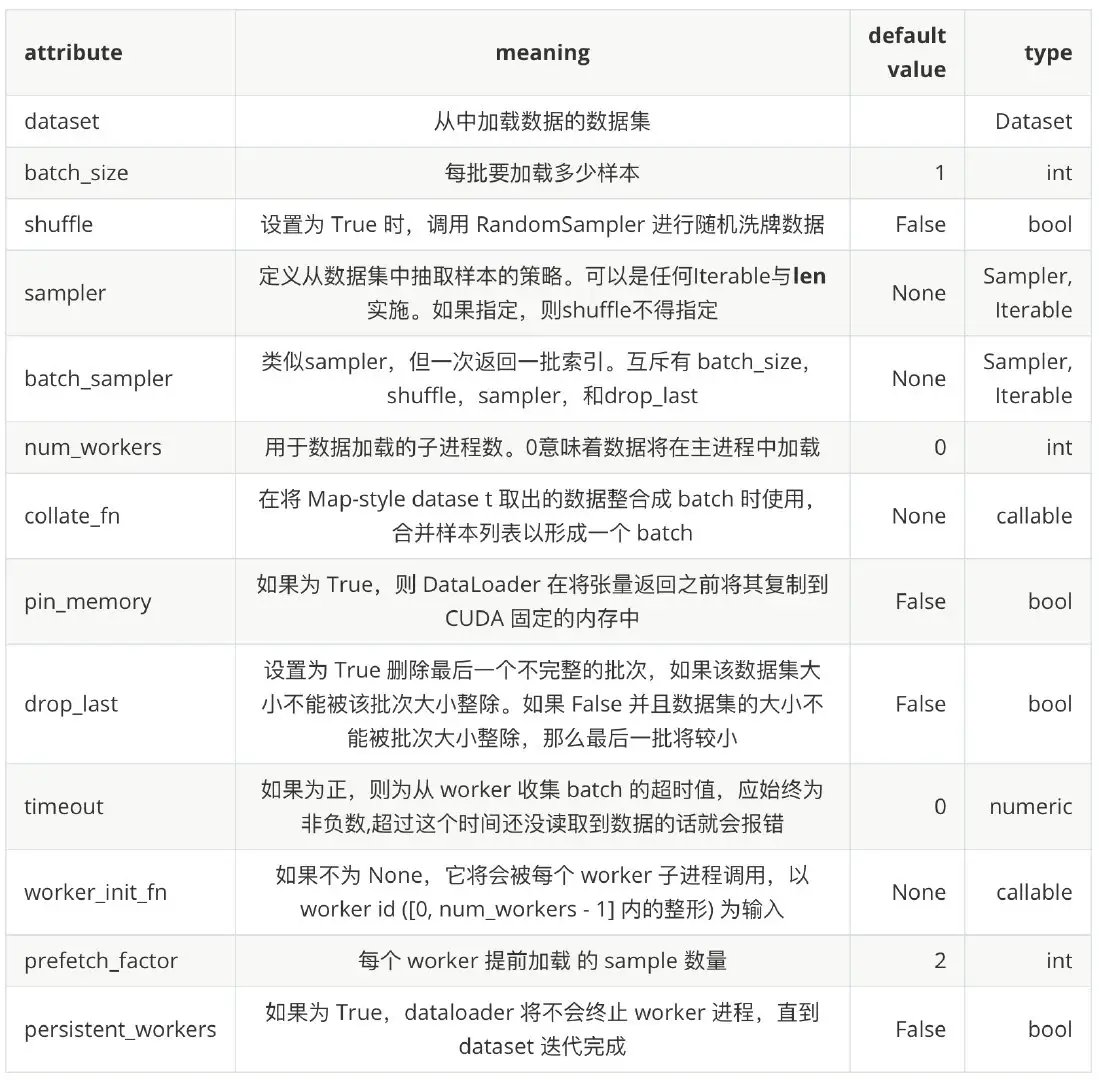
2、数据预处理相关
- 1)数据预处理逻辑太复杂
- 说明:数据预处理部分超过一个 for 循环的,都不应该和 GPU 训练部分放到一起
- 优化:
- a、设置
tf.data.Dataset.map的num_parallel_calls参数,提高并行度,一般设置为tf.data.experimental.AUTOTUNE,可让 TensorFlow 自动选择合适的数值。 - b、将部分数据预处理步骤挪出训练任务,例如对图片的归一化等操作,提前开启一个 spark 分布式任务或者 cpu 任务处理好,再进行训练。
- c、提前将预处理部分需要用到的配置文件等信息加载到内存中,不要每次计算的时候再去读取。
- d、关于查询操作,多使用 dict 加速查询操作;减少 for、while 循环,降低预处理复杂度。
- 2)利用 GPU 进行数据预处理 – Nvidia DALI
- 说明:Nvidia DALI 是一个专门用于加速数据预处理过程的库,既支持 GPU 又支持 CPU
- 优化:采用 DALI,将基于 CPU 的数据预处理流程改造成用 GPU 来计算. DALI 文档
3、模型保存相关
- 1)模型保存太频繁
- 说明:模型保存为 CPU 操作,太频繁容易导致 GPU 等待
- 优化:减少保存模型(checkpoint)的频率
4、指标相关
- 1)loss 计算太复杂
- 说明:含有 for 循环的复杂 loss 计算,导致 CPU 计算时间太长从而阻塞 GPU
- 优化:该用低复杂度的 loss 或者使用多进程或多线程进行加速
- 2)指标上报太频繁
- 说明:指标上报操作太频繁,CPU 和 GPU 频繁切换导致 GPU 利用率低
- 优化:改成抽样上报,例如每 100 个 step 上报一次
5、日志相关
- 1)日志打印太频繁
- 说明:日志打印操作太频繁,CPU 和 GPU 频繁切换导致 GPU 利用率低
- 优化:改成抽样打印,例如每 100 个 step 打印一次
分布式任务相比单机任务多了一个机器间通信环节。
- 单机上面运行正常,扩展到多机后出现 GPU 利用率低,运行速度慢等问题,大概率是机器间通信时间太长导致的。
请排查以下几点:
- 1、机器节点是否处在同一 modules?
- 答:机器节点处于不同 modules 时,多机间通信时间会长很多,deepspeed 组件已从平台层面增加调度到同一 modules 策略,用户不需要操作;其他组件需联系我们开启。
- 2、多机时是否启用 GDRDMA?
- 答:能否启用
GDRDMA和NCCL版本有关 - 经测试,用 PyTorch1.7(自带 NCCL2.7.8)时,启动 GDRDMA 失败,和 Nvidia 的人沟通后确定是 NCCL 高版本的 bug,暂时使用的运行注入的方式来修复;
- 使用 PyTorch1.6(自带 NCCL2.4.8)时,能够启用 GDRDMA。
- 经测试,“NCCL2.4.8 + 启用 GDRDMA ” 比 “NCCL2.7.8 + 未启用 GDRDMA”提升 4%。
- 通过设置
export NCCL_DEBUG=INFO,查看日志中是否出现[receive] via NET/IB/0/GDRDMA和[send] via NET/IB/0/GDRDMA,出现则说明启用 GDRDMA 成功,否则失败。
- 答:能否启用
- 3、pytorch 数据并行是否采用 DistributedDataParallel?
- 答:PyTorch 里的数据并行训练,涉及
nn.DataParallel(DP) 和nn.parallel.DistributedDataParallel(DDP) ,推荐使用nn.parallel.DistributedDataParallel(DDP)。
- 答:PyTorch 里的数据并行训练,涉及
TPU
资料
- 【2019-08-11】TPU灵魂三问:What?Why?How?
- TPU是如何超越GPU,成为深度学习首选处理器的
介绍
- 张量处理单元(TPU)是一种定制化的 ASIC 芯片,它由谷歌从头设计,并专门用于机器学习工作负载。TPU 为谷歌的主要产品提供了计算支持,包括翻译、照片、搜索助理和 Gmail 等。Cloud TPU 将 TPU 作为可扩展的云计算资源,并为所有在 Google Cloud 上运行尖端 ML 模型的开发者与数据科学家提供计算资源
-
在 Google Next’18 中,我们宣布 TPU v2 现在已经得到用户的广泛使用,包括那些免费试用用户,而 TPU v3 目前已经发布了内部测试版。
- 谷歌设计 TPU 时,构建了一种领域特定的架构。这意味着,没有设计一种通用的处理器,而是专用于神经网络工作负载的矩阵处理器。TPU 不能运行文本处理软件、控制火箭引擎或执行银行业务,但它们可以为神经网络处理大量的乘法和加法运算,同时 TPU 的速度非常快、能耗非常小且物理空间占用也更小。
- 其主要助因是对冯诺依曼瓶颈的大幅度简化。因为该处理器的主要任务是矩阵处理,TPU 的硬件设计者知道该运算过程的每个步骤。因此他们放置了成千上万的乘法器和加法器并将它们直接连接起来,以构建那些运算符的物理矩阵。这被称作脉动阵列(Systolic Array)架构。在 Cloud TPU v2 的例子中,有两个 128X128 的脉动阵列,在单个处理器中集成了 32768 个 ALU 的 16 位浮点值。
- 来看一个脉动阵列如何执行神经网络计算。首先,TPU 从内存加载参数到乘法器和加法器的矩阵中。
CPU和GPU都是较为通用的芯片,但是有句老话说得好:万能工具的效率永远比不上专用工具。
随着计算需求越来越专业化,人们希望有芯片可以更加符合自己的专业需求,这时,便产生了ASIC(专用集成电路)的概念。
- ASIC是指依产品需求不同而定制化的特殊规格集成电路,由特定使用者要求和特定电子系统的需要而设计、制造。
- 而TPU(Tensor Processing Unit, 张量处理器)就是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,其实也是一款ASIC。
TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。初代的TPU只能做推理,要依靠Google云来实时收集数据并产生结果,而训练过程还需要额外的资源;而第二代TPU既可以用于训练神经网络,又可以用于推理。
实践
开启笔记本的GPU开关
- 操作:修改→笔记本设置→勾选GPU
Colab环境
- 查看配置信息
- 输出 TPU 地址及 TPU 设备列表 ,表名配置了TPU资源,否则会报错
- Colab 为「TPU 运行时」分配 CPU 和 TPU,其中分配的 TPU 工作站有八个核,后面配置的 TPU 策略会选择 8 条并行 shards
测试代码
"""在TPU运行时下测试有没有分配TPU计算资源"""
import os
import pprint
import tensorflow as tf
print("Colab环境信息")
print(os.environ)
# {'COLAB_TPU_ADDR': '10.68.94.74:8470', 'GCS_READ_CACHE_BLOCK_SIZE_MB': '16', 'CLOUDSDK_CONFIG': '/content/.config',
# 'CUDA_VERSION': '10.0.130', 'PATH': '/usr/local/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/tools/node/bin:/tools/google-cloud-sdk/bin:/opt/bin', 'HOME': '/root', 'LD_LIBRARY_PATH': '/usr/local/nvidia/lib:/usr/local/nvidia/lib64',
# 'LANG': 'en_US.UTF-8', 'SHELL': '/bin/bash', 'LIBRARY_PATH': '/usr/local/cuda/lib64/stubs', 'CUDA_PKG_VERSION': '10-0=10.0.130-1',
# 'SHLVL': '1', 'NCCL_VERSION': '2.4.2', 'NVIDIA_VISIBLE_DEVICES': 'all', 'TF_FORCE_GPU_ALLOW_GROWTH': 'true',
# 'DEBIAN_FRONTEND': 'noninteractive', 'CUDNN_VERSION': '7.5.0.56', 'JPY_PARENT_PID': '37', 'PYTHONPATH': '/env/python',
# 'DATALAB_SETTINGS_OVERRIDES': '{"kernelManagerProxyPort":6000,"kernelManagerProxyHost":"172.28.0.3","jupyterArgs":["--ip=\\"172.28.0.2\\""]}',
# 'NO_GCE_CHECK': 'True', 'GLIBCXX_FORCE_NEW': '1', 'NVIDIA_DRIVER_CAPABILITIES': 'compute,utility', '_': '/tools/node/bin/forever', 'LD_PRELOAD': '/usr/lib/x86_64-linux-gnu/libtcmalloc.so.4', 'NVIDIA_REQUIRE_CUDA': 'cuda>=10.0 brand=tesla,driver>=384,driver<385 brand=tesla,driver>=410,driver<411', 'OLDPWD': '/', 'HOSTNAME': '59881c4943e6', 'ENV': '/root/.bashrc', 'COLAB_GPU': '0', 'PWD': '/', 'XRT_TPU_CONFIG': 'tpu_worker;0;10.68.94.74:8470', 'GLIBCPP_FORCE_NEW': '1', 'PYTHONWARNINGS': 'ignore:::pip._internal.cli.base_command', 'TPU_NAME': 'grpc://10.68.94.74:8470', 'TERM': 'xterm-color', 'CLICOLOR': '1', 'PAGER': 'cat', 'GIT_PAGER': 'cat', 'MPLBACKEND': 'module://ipykernel.pylab.backend_inline'}
# 检查GPU是否启用
if 'COLAB_TPU_ADDR' not in os.environ:
print('ERROR: Not connected to a TPU runtime; please see the first cell in this notebook for instructions!')
else:
tpu_address = 'grpc://' + os.environ['COLAB_TPU_ADDR']
print ('TPU address is', tpu_address)
with tf.Session(tpu_address) as session:
devices = session.list_devices()
print('TPU devices:')
pprint.pprint(devices)
TPU Hello world
- TPU在contrib中,tf.contrib.tpu, 从一个简单的代码开始
import tensorflow as tf
import numpy as np
import timeit
tf.reset_default_graph()
img = np.random.randn(128, 256, 256, 3).astype(np.float32)
w = np.random.randn(5, 5, 3, 256).astype(np.float32)
conv = tf.nn.conv2d(img, w, [1,2,2,1], padding='SAME')
#=======================
with tf.Session() as sess:
# with tf.device("/gpu:0") as dev:
%timeit sess.run(conv)
#输出:loop, best of 3: 2.32 s per loop
#========================
# 指定gpu环境
# with tf.Session() as sess:
# with tf.device("/gpu:0") as dev:
# %timeit sess.run(conv)
#输出:loop, best of 3: 2.34 s per loop
TPU对比
思考
- 分别选择 CPU、GPU 和 TPU 作为运行时状态,运行代码并迭代一次耗时为:2.44 s、280 ms、2.47 s
| 设备 | 耗时 | 备注 |
|---|---|---|
| CPU | 2.44s | - |
| GPU | 280ms | - |
| TPU | 2.47s | - |
- 使用tpu和gpu都没有差异吗?
- 原因:以上代码并未启用TPU或GPU
- 启用TPU 似乎需要特定的函数与运算,不像 CPU 和 GPU 可以共用代码。
- 仅修改运行时状态,并不会真正调用 TPU 资源,实际运行的还是 CPU
- TF 存在一个神奇的类 tf.contrib.tpu,调用 TPU 资源必须用它改写模型
- tf.contrib.tpu 类提供了两种使用 TPU 的简单方法
- 直接使用 Keras 接口
- tf.contrib.tpu.keras_to_tpu_model 方法可以直接将 Keras 模型与对应的权重复制到 TPU,并返回 TPU 模型
- 用 TPUEstimator 构建模型
- tf.contrib.tpu.TPUEstimator
- TPUEstimator 类继承自 Estimator 类,因此它不仅支持在 TPU 上运算,同时还支持 CPU 和 GPU 的运算,更方便 修正TPU代码
- 直接使用 Keras 接口
- 结果意外,卷积运算每一次迭代只需要 1.22 ms。
- 如下图所示,很可能存在变量缓存等其它因素造成了一定程度的缓慢,但 TPU 的速度无可置疑地快,就是需要修改代码

import numpy as np
def add_op(x, y):
return x + y
x = tf.placeholder(tf.float32, [10,])
y = tf.placeholder(tf.float32, [10,])
# tpu选项在contrib中
tpu_ops = tf.contrib.tpu.rewrite(add_op, [x, y])
session = tf.Session(tpu_address)
try:
print('Initializing...')
session.run(tf.contrib.tpu.initialize_system())
print('Running ops')
print(session.run(tpu_ops, {x: np.arange(10), y: np.arange(10)}))
finally:
# For now, TPU sessions must be shutdown separately from
# closing the session.
session.run(tf.contrib.tpu.shutdown_system())
session.close()
总结
- Colab 提供的 TPU 要比 GPU 快 3 倍左右,一般 TPU 训练 5 个 Epoch 只需要 40 多秒,而 GPU 需要 2 分多钟。
- Colab 确实提供了非常强劲的免费 TPU,而且使用 Keras 或 TPUEstimator 也很容易重新搭建或转换已有的 TensorFlow 模型
NPU
NPU(Neural network Processing Unit),即神经网络处理器。用电路模拟人类的神经元和突触结构。
人类的神经结构——生物的神经网络由若干人工神经元结点互联而成,神经元之间通过突触两两连接,突触记录了神经元之间的联系。
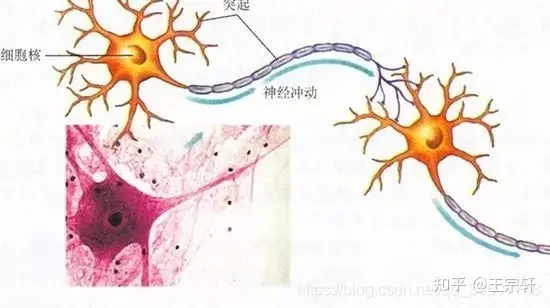
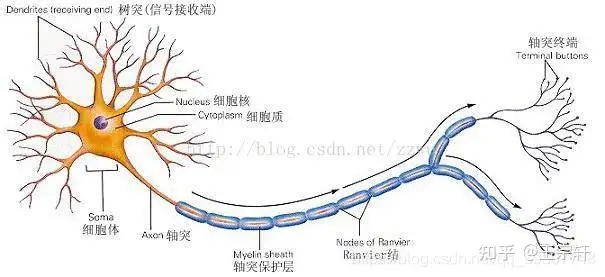
如果想用电路模仿人类的神经元,就得把每个神经元抽象为一个激励函数,该函数的输入由与其相连的神经元的输出以及连接神经元的突触共同决定。
为了表达特定的知识,使用者通常需要(通过某些特定的算法)调整人工神经网络中突触的取值、网络的拓扑结构等。该过程称为“学习”。在学习之后,人工神经网络可通过习得的知识来解决特定的问题。
这时不知道大家有没有发现问题——原来,由于深度学习的基本操作是神经元和突触的处理,而传统的处理器指令集(包括x86和ARM等)是为了进行通用计算发展起来的,其基本操作为算术操作(加减乘除)和逻辑操作(与或非),往往需要数百甚至上千条指令才能完成一个神经元的处理,深度学习的处理效率不高。
这时就必须另辟蹊径 —— 突破经典的冯·诺伊曼结构!
神经网络中存储和处理是一体化的,都是通过突触权重来体现。 而冯·诺伊曼结构中,存储和处理是分离的,分别由存储器和运算器来实现,二者之间存在巨大的差异。当用现有的基于冯·诺伊曼结构的经典计算机(如X86处理器和英伟达GPU)来跑神经网络应用时,就不可避免地受到存储和处理分离式结构的制约,因而影响效率。这也就是专门针对人工智能的专业芯片能够对传统芯片有一定先天优势的原因之一。
NPU的典型代表有国内的寒武纪芯片和IBM的TrueNorth。
- 以中国的寒武纪为例,DianNaoYu指令直接面对大规模神经元和突触的处理,一条指令即可完成一组神经元的处理,并对神经元和突触数据在芯片上的传输提供了一系列专门的支持。
用数字来说话,CPU、GPU与NPU相比,会有百倍以上的性能或能耗比差距
- 以寒武纪团队过去和Inria联合发表的DianNao论文为例–DianNao为单核处理器,主频为0.98GHz,峰值性能达每秒4520亿次神经网络基本运算,65nm工艺下功耗为0.485W,面积3.02平方毫米mm。
mate10中所用的麒麟970芯片,就集成了寒武纪的NPU,所以才可以实现所谓的照片优化功能,以及保证你的手机用了很长时间后还能不卡
其它 XPU
【2023-9-6】CPU、GPU、TPU、NPU等到底是什么?
BPU
BPU(Brain Processing Unit,大脑处理器)是由地平线科技提出的嵌入式人工智能处理器架构。第一代是高斯架构,第二代是伯努利架构,第三代是贝叶斯架构。目前地平线已经设计出了第一代高斯架构,并与英特尔在2017年CES展会上联合推出了ADAS系统(高级驾驶辅助系统)。
DPU
DPU(Deep learning Processing Unit, 即深度学习处理器)最早由国内深鉴科技提出,基于Xilinx可重构特性的FPGA芯片,设计专用的深度学习处理单元(可基于已有的逻辑单元,设计并行高效的乘法器及逻辑电路,属于IP范畴),且抽象出定制化的指令集和编译器(而非使用OpenCL),从而实现快速的开发与产品迭代。事实上,深鉴提出的DPU属于半定制化的FPGA。
总结
- APU – Accelerated Processing Unit, 加速处理器,AMD公司推出加速图像处理芯片产品。
- BPU – Brain Processing Unit,地平线公司主导的嵌入式处理器架构。
- CPU – Central Processing Unit 中央处理器, 目前PC core的主流产品。
- DPU – Deep learning Processing Unit, 深度学习处理器,最早由国内深鉴科技提出;另说有Dataflow Processing Unit 数据流处理器, Wave Computing 公司提出的AI架构;Data storage Processing Unit,深圳大普微的智能固态硬盘处理器。
- FPU – Floating Processing Unit 浮点计算单元,通用处理器中的浮点运算模块。
- GPU – Graphics Processing Unit, 图形处理器,采用多线程SIMD架构,为图形处理而生。
- HPU – Holographics Processing Unit 全息图像处理器, 微软出品的全息计算芯片与设备。
- IPU – Intelligence Processing Unit, Deep Mind投资的Graphcore公司出品的AI处理器产品。
- MPU/MCU – Microprocessor/Micro controller Unit, 微处理器/微控制器,一般用于低计算应用的RISC计算机体系架构产品,如ARM-M系列处理器。
- NPU – Neural Network Processing Unit,神经网络处理器,是基于神经网络算法与加速的新型处理器总称,如中科院计算所/寒武纪公司出品的diannao系列。
- RPU – Radio Processing Unit, 无线电处理器, Imagination Technologies 公司推出的集合集Wifi/蓝牙/FM/处理器为单片的处理器。
- TPU – Tensor Processing Unit 张量处理器, Google 公司推出的加速人工智能算法的专用处理器。目前一代TPU面向Inference,二代面向训练。
- VPU – Vector Processing Unit 矢量处理器,Intel收购的Movidius公司推出的图像处理与人工智能的专用芯片的加速计算核心。
- WPU – Wearable Processing Unit, 可穿戴处理器,Ineda Systems公司推出的可穿戴片上系统产品,包含GPU/MIPS CPU等IP。
- XPU – 百度与Xilinx公司在2017年Hotchips大会上发布的FPGA智能云加速,含256核。
- ZPU – Zylin Processing Unit,由挪威Zylin 公司推出的一款32位开源处理器。
LPU 超过 GPU
【2024-2-20】初创公司 Groq 开发出一种机器学习处理器, 大语言模型任务上彻底击败了 GPU—— 比英伟达的 GPU 快 10 倍。
- 2016年,瑞典人工智能芯片初创公司Groq成立,总部位于斯德哥尔摩
- 专注于开发用于人工智能推理的高性能芯片,这些芯片旨在加速机器学习和深度学习模型的推理过程,即模型在接收到新数据后产生预测或决策的速度。
Groq 芯片采用了其专有的“分布式数据流”架构,该架构旨在实现高效能、低延迟和高量的推理。这种架构使得Groq的芯片能够处理大量并行数据流,同时保持耗。
Groq的目标市场主要是云服务提供商、大型企业和研究机构等需要高性能AI推理能力的用户。该公司已经与一些全球知名的技术公司建立了合作关系,如Microsoft、NVIDIA和VMware等
资料
GPU环境准备
pytorch
GPU检测
如何检查 PyTorch 是 GPU 还是 CPU版?
以下命令:
import torch
is_cuda = torch.cuda.is_available() # True, 是否启用gpu
cuda_gpu = torch.cuda.is_available() # gpu 数目
print(is_cuda)
if cuda_gpu:
gpu_num = torch.cuda.device_count() # 获取 gpu 数目
gpu_info = {}
for i in range(gpu_num):
cur_gpu_name = torch.cuda.get_device_name(i) # 获取 gpu 型号
gpu_info[cur_gpu_name] = gpu_info.get(cur_gpu_name,0) + 1
print(f"Great, you have {gpu_num} GPUs: {gpu_info}")
else:
print("Life is short -- consider a GPU!")
# gpu 信息获取
torch.cuda.device_count() # 1
torch.cuda.current_device() # 0
torch.cuda.device(0) # <torch.cuda.device at 0x7efce0b03be0>
torch.cuda.get_device_name(0) # 'GeForce GTX 950M'
torch.__version__
小米笔记本 GPU
小米Pro笔记本详细配置表
- 电脑型号 Timi TM1701 笔记本电脑
- 操作系统 Windows 10 64位(Version 2009 / DirectX 12)
- 处理器 英特尔 Core i5-8250U @ 1.60GHz 四核
- 主板 Timi TM1701(7th/8th Generation Intel Processor Family I/O - 9D4E 笔记本芯片组)
- 显卡
NVIDIA GeForce MX150( 2 GB ) - 内存 8 GB ( DDR4 2400MHz )
- 主硬盘 三星 MZVLW256HEHP-00000 ( 256 GB / 固态硬盘 )
- 显示器 京东方 BOE0747 ( 15.5 英寸 )
- 声卡 瑞昱 @ 英特尔 High Definition Au
【2024-11-7】Windows 笔记本(小米)如何查看GPU信息?
任务管理器→性能,显示有两个gpu,GPU0(Intel), GPU1(NVIDIA GeForce MX 150), 来自不同厂商,默认使用GPU0,- 多GPU系统中,可选择让应用程序利用单个GPU工作,也可以通过技术(NVIDIA CUDA或AMD的Mantle API)实现双GPU协同工作,提高某些计算密集型应用的性能
- 而 pytorch gpu 版需要安装cuda(nvidia推出的gpu加速工具包,所以仅支持nvidia 的gpu)
- 确定cuda、pytorch版本后,安装命令:
pip install torch==1.9.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install torchvision==0.10.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
问题
以上检测报错
AssertionError: Torch not compiled with CUDA enabled
cuda、pytorch 版本不对
解法:
- 查看笔记本GPU型号:
- 方法: 任务管理器 -> 性能 Tab -> 左侧显示
- 两个GPU(intel和NVIDIA),其中 NVIDIA是MX 150
- 去官网 找对应版本驱动,点击搜索,点击下载。
- 安装显卡驱动,然后重启电脑。
win+R调出cmd,查看 驱动版本- 输入:
nvidia-smi - 输出:
Driver Version: 388.73 - 【2024-11-5】 升级后最新版)
Driver Version: 566.03,支持最新的 cuda 12.5
- 输入:
- 安装
CUDA- 去CUDA官网 查看对应 cuda版本
- 升级后的驱动版本 566.03,支持最新的 cuda 12.5
- cuda 下载地址
- 选择版本: windows 10, x86_64, local, 2.9G, cuda_12.5.0_555.85_windows.exe
- 安装
cuDNN:- 下载地址 cudnn_9.5.1_windows.exe
- 配置CUDNN: 解压CUDNN后,将对应的 bin、lib、include 与 CUDA10.1 对应的 bin、lib、include 进行合并。
测试:Colab实现
tf 2 版本
import tensorflow as tf
tf.debugging.set_log_device_placement(True)
# Create some tensors, 自动选择gpu
a = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
b = tf.constant([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
c = tf.matmul(a, b)
print('结果:', c)
# Place tensors on the CPU # 指定gpu
with tf.device('/CPU:0'):
a = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
b = tf.constant([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
c = tf.matmul(a, b)
print('结果:', c)
# TensorFlow默认映射该进程可见的几乎所有GPU的所有GPU内存(取决于CUDA_VISIBLE_DEVICES)。
# 这样做是为了通过减少内存碎片来更有效地使用设备上相对宝贵的GPU内存资源。
# 要将TensorFlow限制为一组特定的GPU,用tf.config.experimental.set_visible_devices方法。
gpus = tf.config.experimental.list_physical_devices('GPU')
print('物理可用gpu: ', gpus)
if gpus:
# Restrict TensorFlow to only use the first GPU
try:
tf.config.experimental.set_visible_devices(gpus[0], 'GPU') # 限制可用gpu
# 限制各GPU内存增速
# Currently, memory growth needs to be the same across GPUs
# ① 方法一:
# 使用set_memory_growth
# 或:环境变量TF_FORCE_GPU_ALLOW_GROWTH设置为true
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# ② 方法二:虚拟GPU设备,set_virtual_device_configuration
tf.config.experimental.set_virtual_device_configuration(
gpus[0],
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=1024)])
# 显示逻辑可用GPU
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(f"物理Physical GPUs: {len(gpus)}, 逻辑Logical GPUs: {len(logical_gpus)}")
except RuntimeError as e:
# Visible devices must be set before GPUs have been initialized
print(e)
tf 1 版本
import tensorflow as tf
# ---- tf 1.*版本 -----
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution() # 关闭即时执行模式
import os
#GPU:计算密集型任务, CPU: I/O, 逻辑运算
if tf.test.is_gpu_available(): # 检测GPU是否可用
print('GPU可用: %s'%(tf.test.gpu_device_name()))
# 环境变量设置,默认有限选择GPU,占用所有GPU的所有显存
config = tf.ConfigProto()
os.environ['TF_CPP_MIN_LOG_LEVEL']='5'#日志级别
#----自定义使用哪些GPU----
os.environ["CUDA_VISIBLE_DEVICES"] = "2"#只使用第三块GPU,默认选用id最小的gpu
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2"#只使用第2-3块GPU
#----自定义显存分配----
config.gpu_options.allow_growth = True#刚开始分配较少内存,逐步按需分配,注意:系统不自动释放内存,以免可能导致更严重的内存碎片情况
config.gpu_options.per_process_gpu_memory_fraction = 0.4#按比例分配,40%,方便多任务并行
a = tf.constant([1.0, 2.0, 3.0], shape=[3], name='a')
b = tf.constant([1.0, 2.0, 3.0], shape=[3], name='b')
c = a + b
#通过tf.device指定运行设备。不管CPU多少个,一律标记为/cpu0,而GPU不同,分别是/gpu:1-n
#注意:不宜包含过多设备约束,不同设备实现方式不同,多了会限制移植能力
with tf.device('/gpu:0'):
#将tf.Variable强制放在GPU上会报错,GPU只在部分数据类型上支持tf.Variable操作(variable_ops.cc)
#除非启动自动更改设备的参数allow_soft_placement
a_gpu = tf.Variable(0, name="a_gpu")
# 通过log_device_placement参数来输出运行每一个运算的设备。
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# 通过allow_soft_placement参数自动将无法放在GPU上的操作放回CPU上。
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True))
#sess.run(tf.initialize_all_variables())
sess.run(tf.global_variables_initializer())
print(sess.run(c))
#jupyter中显示不出来
没GPU时的结果:
2018-03-26 19:29:38.606679: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
Device mapping: no known devices.
2018-03-26 19:29:38.606972: I tensorflow/core/common_runtime/direct_session.cc:299] Device mapping:
add: (Add): /job:localhost/replica:0/task:0/device:CPU:0
2018-03-26 19:29:38.610106: I tensorflow/core/common_runtime/placer.cc:874] add: (Add)/job:localhost/replica:0/task:0/device:CPU:0
b: (Const): /job:localhost/replica:0/task:0/device:CPU:0
2018-03-26 19:29:38.610137: I tensorflow/core/common_runtime/placer.cc:874] b: (Const)/job:localhost/replica:0/task:0/device:CPU:0
a: (Const): /job:localhost/replica:0/task:0/device:CPU:0
2018-03-26 19:29:38.610142: I tensorflow/core/common_runtime/placer.cc:874] a: (Const)/job:localhost/replica:0/task:0/device:CPU:0
[ 2. 4. 6.]
有GPU时的结果:
2018-03-26 19:27:46.864593: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1105] Found device 0 with properties:
name: Tesla P40 major: 6 minor: 1 memoryClockRate(GHz): 1.531
pciBusID: 0000:02:00.0
totalMemory: 22.38GiB freeMemory: 745.94MiB
2018-03-26 19:27:46.864673: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1195] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Tesla P40, pci bus id: 0000:02:00.0, compute capability: 6.1)
Device mapping:
/job:localhost/replica:0/task:0/device:XLA_GPU:0 -> device: XLA_GPU device
/job:localhost/replica:0/task:0/device:XLA_CPU:0 -> device: XLA_CPU device
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: Tesla P40, pci bus id: 0000:02:00.0, compute capability: 6.1
2018-03-26 19:27:47.193611: I tensorflow/core/common_runtime/direct_session.cc:297] Device mapping:
/job:localhost/replica:0/task:0/device:XLA_GPU:0 -> device: XLA_GPU device
/job:localhost/replica:0/task:0/device:XLA_CPU:0 -> device: XLA_CPU device
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: Tesla P40, pci bus id: 0000:02:00.0, compute capability: 6.1
add: (Add): /job:localhost/replica:0/task:0/device:GPU:0
2018-03-26 19:27:47.194462: I tensorflow/core/common_runtime/placer.cc:874] add: (Add)/job:localhost/replica:0/task:0/device:GPU:0
b: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-03-26 19:27:47.194498: I tensorflow/core/common_runtime/placer.cc:874] b: (Const)/job:localhost/replica:0/task:0/device:GPU:0
a: (Const): /job:localhost/replica:0/task:0/device:GPU:0
2018-03-26 19:27:47.194526: I tensorflow/core/common_runtime/placer.cc:874] a: (Const)/job:localhost/replica:0/task:0/device:GPU:0
[2. 4. 6.]
GPU 云平台
使用第三方提供的 GPU服务
- Kaggle 平台:
- 提供
T4/P100/TPU等gpu资源, 有一定免费额度
- 提供
- Colab 平台:
- Google Colab 允许您免费使用具有 16GB 显存的
T4GPU
- Google Colab 允许您免费使用具有 16GB 显存的
- AutoDL AI 算力云:
- 4090 ¥2.08/时
- UCloud GPU 租赁平台
- 9.9元起畅享高性能GPU云服务器,同一用户限试用一种机型
- 超值体验: RTX 40系列(24g)、Tesla P40(24g)、Tesla T4(16g)、3080 Ti(12g)、3090(24g)
- 高阶体验: A100(80g)、V100(16g)、V100 s(32g)、
- 超算互联网: 4090, L20, A800, 异构加速卡
- InsCode: GPU 云容器
- 4090 ¥ 1.53/1小时
- 提供gpu有 TRX 3090, RTX 4090, RTX A4000, Tesla P40
- 免费存储 150G 容量
- 多种镜像: Stable Diffusion, 小羊驼, chatglm, photomaker
- 阿里云
- 腾讯云
阿里巴巴
阿里云 Qwen-235b,8卡(96b),290元/小时,一天花费 290*24=6960元
- 参考 阿里云gpu费用
魔塔社区
PAI-DSW 是为算法开发者量身打造的云端深度学习开发环境,内置 JupyterLab、WebIDE及Terminal,无需任何运维配置即可编写、调试及运行Python代码
提供几种虚拟环境,ModelScope Library
- CPU环境: 8核、32G、Ubuntu、长期使用
- GPU环境: 8核、32G、Ubuntu、36h、显存24G
AutoDL
AutoDL AI 算力云
- GPU 型号最多
- 算法交流社区 codewithgpu
4090 ¥2.08/时
算力排行榜(AutoDL出品)
| 排名 | GPU | 半精算力 | 算力 |
|---|---|---|---|
| 1 | NVIDIA A100 SXM4 / 80GB | 100% | 312 Tensor TFLOPS |
| 2 | A800 - 80GB / 80GB | 100% | 312 Tensor TFLOPS |
| 3 | NVIDIA L40 / 48GB | 58% | 181.05 TFLOPS |
| 4 | NVIDIA RTX 4090 / 24GB | 53% | 165.2 Tensor TFLOPS |
| 5 | NVIDIA A40 / 48GB | 48% | 149.7 Tensor TFLOPS |
| 6 | NVIDIA RTX 4090D / 24GB | 47% | 147 TFLOPS |
| 7 | NVIDIA V100 / 32GB | 40% | 125 Tensor TFLOPS |
| 8 | NVIDIA L20 / 48GB | 38% | 119.5 TFLOPS |
| 9 | NVIDIA RTX 3090Ti / 24GB | 26% | 80 Tensor TFLOPS |
| 10 | NVIDIA RTX A4000 / 16GB | 25% | 76.7 Tensor TFLOPS |
| 11 | NVIDIA RTX 3090 / 24GB | 23% | 71 Tensor TFLOPS |
| 12 | NVIDIA RTX 3080Ti / 12GB | 22% | 70 Tensor TFLOPS |
| 13 | NVIDIA RTX 3080 / 10GB | 19% | 59.5 Tensor TFLOPS |
| 14 | NVIDIA RTX 2080Ti / 11GB | 17% | 53.8 Tensor TFLOPS |
UCloud
UCloud GPU 租赁平台
- 9.9元起畅享高性能GPU云服务器,同一用户限试用一种机型
- 超值体验: RTX 40系列(24g)、Tesla P40(24g)、Tesla T4(16g)、3080 Ti(12g)、3090(24g)
- 高阶体验: A100(80g)、V100(16g)、V100 s(32g)、
特点
- 多种机型满足各类场景需求
- 提供A800、V100S、T4等多种GPU卡型,为大模型训练推理、AI绘画、图像渲染等场景打造功能强大的可扩展GPU加速服务平台。
- 预装软件,开箱即用
- 涵盖多种热门模型镜像,预装多版本GPU驱动以及cuda等应用程序,简化环境部署流程,提供开箱即用的AI基础架构能力。
- 购买方式灵活
- 支持灵活的资源付费模式,按需购买,避免资源浪费。涵盖按时付费、包年包月等多种计费方式,多种配置满足客户弹性计算需求。
InsCode
- 提供gpu有 TRX 3090, RTX 4090, RTX A4000, Tesla P40
- 免费存储 150G 容量
- 多种镜像: Stable Diffusion, 小羊驼, chatglm, photomaker
InsCode 提供 Stable Diffusion和小羊驼的镜像供用户选择,购买后可直接通过WebUI启动
- 4090 ¥ 1.53/1小时
超算互联网
2024年04月11日 超算互联网 正式上线,缓解目前算力供需矛盾,加快形成新质生产力,为数字中国建设、数字经济发展等提供坚实支撑。
GPU 设备
- 4090, L20, A800, 异构加速卡
4090 大概2元/小时
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
