- Pytorch 分布式训练
- 结束
Pytorch 分布式训练
torch.distributed 支持四种内置后端:gloo、mpi、nccl、xccl
Pytorch 官方资料
分布式基础
理论知识见站内专题:分布式训练
并行化方式
- 单进程单线程
- 单进程多线程
- 多进程单线程
- 多进程多线程
分布式模式
PyTorch 支持的并行模式:
- 数据并行(data parallel)
- 完全分片数据并行(full sharded data parallel,
FSDP) - 混合分片数据并行(hybrid sharding data parallel,
HSDP)
- 完全分片数据并行(full sharded data parallel,
- 张量并行(tensor parallel,
TP) - 流水线并行(pipeline parallel,
PP) - 序列并行(sequence parallel,
SP) - 上下文并行(context parallel,
CP)
【2023-3-2】PyTorch 分布式训练实现(DP/DDP/torchrun/多机多卡)
相对 Tensorflow,Pytorch 简单的多。分布式训练主要有两个API:
- DataParallel(
DP): PS模式,1张卡为reduce(parame server),实现就1行代码- 单进程多线程,仅仅能工作在单机中
- 将数据分割到多个GPU上。典型的
数据并行,将模型复制到每个GPU上,一旦GPU0计算出梯度,就同步梯度到各个节点,这需要大量的GPU数据传输(类似PS模式)
- DistributedDataParallel(
DDP): All-Reduce模式,单机多卡/多级多卡皆可。官方建议API- 多进程,单机或多机
- 每个GPU进程中创建模型副本,并只让数据的一部分对改GPU可用。因为每个GPU中的模型是独立运行的,所以在所有的模型都计算出梯度后,才会在模型之间同步梯度(类似All-reduce)
分析
DDP每个batch只需要一次数据传输;DP可能存在多次数据同步(不用worker之间可能快慢不一样)。- DataParallel 通常慢于 DistributedDataParallel
【2024-7-24】PyTorch 为数据分布式训练提供了多种选择。
随着应用从简单到复杂,从原型到产品,常见的开发轨迹可以是:
- 数据和模型能放入单个GPU,单设备训练,此时不用担心训练速度;
- 服务器上有多个GPU,且代码修改量最小,加速训练用单个机器多GPU
DataParallel; - 进一步加速训练,且愿意写点代码,用单个机器多个GPU
DistributedDataParallel; - 应用程序跨机器边界扩展,用多机器
DistributedDataParallel和启动脚本; - 预期有错误(比如OOM)或资源可动态连接和分离,使用
torchelastic来启动分布式训练。
分布式训练的场景很多,单机多卡,多机多卡,模型并行,数据并行等等。接下来就以常见的单机多卡的情况进行记录。
PyTorch 使用 DDP(Distributed Data Parallel) 实现了真正的分布式数据并行
两个场景下都可使用 DDP 实现模型的分布式训练:
- (1) 单机、多 GPU(单进程多线程的伪分布式)
- (2) 多机、多 GPU(多机多进程的真分布式)
方法(1)类似简单 DP 数据并行模式
- DP 使用单进程、多线程范式来实现;
- 而 DDP 完全使用多进程方式,包括单机多进程、多机多进程
即使单机、多 GPU,也建议使用 DDP 模式,实现基于数据并行的模型训练,使用单机 DDP 模式训练模型的性能要比 DP 模式好很多。
DDP 基于集合通信(Collective Communications)实现分布式训练过程中的梯度同步。
反向传播过程中,DDP 使用 AllReduce 来实现分布式梯度计算和同步。
【2024-8-8】pytorch多GPU训练简明教程
总结
表格整理几种模式
| 特性 | DP | DDP | FSDP |
|---|---|---|---|
| 目标 | 单机多卡数据并行加速 | 多级多卡分布式训练,消除中心节点瓶颈 | 超大规模训练,通过分片解决显存不足问题 |
| 并行维度 | 纯数据并行 | 纯数据并行 | 数据并行+模型参数并行 |
| 内存占用 | 冗余存储:每个GPU保存完整的模型、梯度、优化器状态 | 冗余存储:每个GPU保存完整的模型、梯度、优化器状态 | 无冗余存储:模型参数、梯度、优化器状态分片,显存降低至1/N |
| 通信机制 | 主GPU聚合梯度,单进程多线程 | 多进程all-reduce同步梯度,使用NCCL/GLOO后端 | 分片参数动态拉取 + All-Gather/Reduce-Scatter,通信开销较高,但支持计算与通信重叠 |
| 模型同步 | 每次前向传递前同步,主GPU将模型参数广播到其他GPU,确保副本一致。 | 初始同步,进程启动时广播一次模型参数,后续通过梯度同步自动保持一致,无需重复同步。 | 动态分片同步,初始时分片参数广播到各GPU,前向/反向传播中按需拉取其他分片参数,通过梯度同步保持一致。 |
| 数据分发 | 主GPU分发,数据从主机内存复制到主GPU,在分割为子批次分发到其他的GPU中。 | 进程独立加载,每个GPU进程直接从主机内存加载完整数据,按本地batch size切分,无主机分发。 | 与DDP相同,数据直接加载到各GPU内存中。 |
| 参数更新 | 主GPU更新后,将参数广播到其他GPU。 | 各GPU独立更新,所有GPU给子同步后的梯度独立更新本地完整模型参数。 | 分片独立更新。各GPU仅更新本地分片对应的参数,无需全局同步。 |
| GPU利用率 | 不均衡,主GPU负载远高于其他GPU | 均衡,计算与通信重叠,各GPU负载均匀,利用率接近100% | 接近均衡。分片参数引入额外开销,但计算与通信流水线化实现较高利用率。略低于DDP |
图解
多GPU训练
多GPU训练的三种架构组织方式
- (1) 数据拆分,模型不拆分(Data Parallelism)
- (2) 数据不拆分,模型拆分(Model Parallelism)
- 模型并行(Model Parallelism)将模型拆分成多个部分,并分配给不同的 GPU。
- 输入数据不拆分,但需要通过不同的 GPU 处理模型的不同部分。
- 这种方式适用于模型非常大,单个 GPU 无法容纳完整模型的场景。
- (3) 数据拆分,模型拆分(Pipeline Parallelism)
- 流水线并行(Pipeline Parallelism)结合数据并行和模型并行。
- 输入数据和模型都被拆分成多个部分,每个 GPU 处理部分数据和部分模型。
- 这种方式适用于需要平衡计算和内存需求的大规模深度学习任务。
超参
Rank
- rank 是整数,标识当前进程在整个分布式训练中的身份。每个进程都有一个唯一的 rank。rank 的范围是 0 ~ world_size - 1, 用于区分不同进程。
- 可以根据 rank 来分配不同的数据和模型部分。
World Size
- world_size 是整数,表示参与分布式训练的所有进程的总数。
- 确定分布式训练中所有进程的数量。
- 用于初始化通信组,确保所有进程能够正确地进行通信和同步。
Backend
- backend 指定了用于进程间通信的后端库。
- 常用的后端有 nccl(适用于 GPU)、gloo(适用于 CPU 和 GPU)和 mpi(适用于多种设备)。
- 决定了进程间通信的具体实现方式,影响训练的效率和性能。
Init Method
- init_method 指定了初始化分布式环境的方法。常用的初始化方法有 TCP、共享文件系统和环境变量。
- 用于设置进程间通信的初始化方式,确保所有进程能够正确加入到分布式训练中。
Local Rank
- local_rank 是每个进程在其所在节点(机器)上的本地标识。不同节点上的进程可能会有相同的 local_rank。
- 用于将每个进程绑定到特定的 GPU 或 CPU。
(1) 数据并行
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.multiprocessing as mp
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
def train(rank, world_size):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:29500', rank=rank, world_size=world_size)
model = SimpleModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
criterion = nn.MSELoss().to(rank)
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
inputs = torch.randn(64, 10).to(rank)
targets = torch.randn(64, 1).to(rank)
outputs = ddp_model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
dist.destroy_process_group()
if __name__ == "__main__":
world_size = 4
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
(2) 模型并行
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.multiprocessing as mp
class ModelParallelModel(nn.Module):
def __init__(self):
super(ModelParallelModel, self).__init__()
self.fc1 = nn.Linear(10, 10).to('cuda:0')
self.fc2 = nn.Linear(10, 1).to('cuda:1')
def forward(self, x):
x = x.to('cuda:0')
x = self.fc1(x)
x = x.to('cuda:1')
x = self.fc2(x)
return x
def train(rank, world_size):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:29500', rank=rank, world_size=world_size)
model = ModelParallelModel()
ddp_model = DDP(model, device_ids=[rank])
criterion = nn.MSELoss().to('cuda:1')
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
inputs = torch.randn(64, 10).to('cuda:0')
targets = torch.randn(64, 1).to('cuda:1')
outputs = ddp_model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
dist.destroy_process_group()
if __name__ == "__main__":
world_size = 2
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
(3) 流水线并行
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.multiprocessing as mp
class PipelineParallelModel(nn.Module):
def __init__(self):
super(PipelineParallelModel, self).__init__()
self.fc1 = nn.Linear(10, 10)
self.fc2 = nn.Linear(10, 1)
def forward(self, x):
if self.fc1.weight.device != x.device:
x = x.to(self.fc1.weight.device)
x = self.fc1(x)
if self.fc2.weight.device != x.device:
x = x.to(self.fc2.weight.device)
x = self.fc2(x)
return x
def train(rank, world_size):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:29500', rank=rank, world_size=world_size)
model = PipelineParallelModel()
model.fc1.to('cuda:0')
model.fc2.to('cuda:1')
ddp_model = DDP(model)
criterion = nn.MSELoss().to('cuda:1')
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
inputs = torch.randn(64, 10).to('cuda:0')
targets = torch.randn(64, 1).to('cuda:1')
outputs = ddp_model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
dist.destroy_process_group()
if __name__ == "__main__":
world_size = 2
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
sampler
数据采样器
- DistributedSampler
- BatchSampler
DistributedSampler 原理:
- 假设当前数据集有0~10共11个样本,使用2块GPU计算。
- 首先打乱数据顺序,然后用 11/2 =6(向上取整)
- 然后6乘以GPU个数2 = 12,因为只有11个数据,所以再把第一个数据(索引为6的数据)补到末尾,现在就有12个数据可以均匀分到每块GPU。
- 然后分配数据:间隔将数据分配到不同的GPU中。
BatchSampler原理:
- DistributedSmpler 将数据分配到两个GPU上,以第一个GPU为例,分到的数据是6,9,10,1,8,7,假设batch_size=2,就按顺序把数据两两一组
- 在训练时,每次获取一个batch的数据,就从组织好的一个个batch中取到。
- 注意:只对训练集处理,验证集不使用BatchSampler。
train_dset = NBADataset(
obs_len=self.cfg.past_frames,
pred_len=self.cfg.future_frames,
training=True)
self.train_sampler = torch.utils.data.distributed.DistributedSampler(train_dset)
self.train_loader = DataLoader(train_dset, batch_size=self.cfg.train_batch_size, sampler=self.train_sampler,
num_workers=4, collate_fn=seq_collate)
【2024-8-8】图解见pytorch多GPU训练简明教程
多卡启动
多卡训练启动有两种方式
- pytorch 自带的 torchrun
- 自行设计多进程程序
# 直接运行
torchrun --nproc_per_node=4 test.py
# 实际上运行的是 /usr/local/mambaforge/envs/led/lib/python3.7/site-packages/torch/distributed/launch.py
# 等价方式
python -m torch.distributed.launch --nproc_per_node=4 test.py
# python -m torch.distributed.launch 也会找到这个程序的python文件执行,这个命令帮助设置一些环境变量启动backend,否则需要自行设置环境变量。
完整代码
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
import os
def example(rank, world_size):
# create default process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
# Environment variables which need to be
# set when using c10d's default "env"
# initialization mode.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "10086"
main()
以下为multiprocessing的设计demo
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
dist.init_process_group(
backend='nccl',
init_method='tcp://localhost:12355',
rank=rank,
world_size=world_size
)
torch.cuda.set_device(rank)
dist.barrier()
def cleanup():
dist.destroy_process_group()
def demo_basic(rank, world_size):
setup(rank, world_size)
model = torch.nn.Linear(10, 10).to(rank)
ddp_model = DDP(model, device_ids=[rank])
inputs = torch.randn(20, 10).to(rank)
outputs = ddp_model(inputs)
print(f"Rank {rank} outputs: {outputs}")
cleanup()
def main():
world_size = torch.cuda.device_count()
mp.spawn(demo_basic, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
main()
多卡训练多进程调试
- multiprocessing 方式: 直接用本地工具运行和调试即可
- torchrun 方式: 手动配置 Run/Debug Configurations,找到原型文件launch.py,launch文件在 /usr/local/mambaforge/envs/led/lib/python3.7/site-packages/torch/distributed/launch.py,添加一个配置,命名为torchrun,在Script path一列选择launch.py,参数
import time
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic():
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running basic DDP example on rank {rank}.")
# create model and move it to GPU with id rank
device_id = rank % torch.cuda.device_count()
model = ToyModel().to(device_id)
time.sleep(10)
print("DDP model init start...")
ddp_model = DDP(model, device_ids=[device_id])
print("DDP model init end...")
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(device_id)
loss_fn(outputs, labels).backward()
optimizer.step()
if __name__ == "__main__":
demo_basic()
注意:
- 强制终止DDP的程序可能会使得显存占用未释放,此时需要找出nccl监听的端口
【2024-8-8】图解见pytorch多GPU训练简明教程
1、DataParallel
模型与变量必须在同一个设备上(CPU or GPU)
pytorch 使用to函数实现变量或模型的存储转移
- to函数的对象: 数据Tensor,或 模型Module
- 张量不执行inplace(即 执行之后重新构建一个新的张量)
- 模型执行inplace(执行之后不重新构建一个新的模型)
原理:
- 当给定model时,主要实现功能是将input数据依据batch的这个维度,将数据划分到指定的设备上。其他的对象(objects)复制到每个设备上。在前向传播的过程中,module被复制到每个设备上,每个复制的副本处理一部分输入数据。
- 在反向传播过程中,每个副本module的梯度被汇聚到原始的module上计算(一般为第0块GPU)。
举例:
- 如果当前有4个GPU,batch_size=16,那么模型将被复制到每一个GPU上,在前向传播时,每一个gpu将分到4个batch,每个gpu独立计算依据分到的batch计算出结果的梯度,然后将梯度返回到第一个GPU上,第一个GPU再进行梯度融合、模型更新。在下一次前向传播的时候,将更新后的模型再复制给每一个GPU。
### 第一步:构建模型
# module 需要分发的模型
# device_ids 可分发的gpu,默认分发到所有看见GPU(环境变量设置的)
# output_device 结果输出设备 通常设置成逻辑gpu的第一个
module = your_simple_net() #你的模型
Your_Parallel_Net = torch.nn.DataParallel(module, device_ids=None, output_device=None)
### 第二步:数据迁移
inputs=inputs.to(device)
labels=labels.to(device)
# device通常应为模型输出的output_device,否则无法计算loss
代码
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import os
input_size = 5
output_size = 2
batch_size = 30
data_size = 30
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size), batch_size=batch_size, shuffle=True)
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print(" In Model: input size", input.size(),
"output size", output.size())
return output
model = Model(input_size, output_size)
if torch.cuda.is_available():
model.cuda()
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# 就这一行!将模型整体复制到每个GPU上,计算完成后各自汇总到ps节点
model = nn.DataParallel(model)
for data in rand_loader:
if torch.cuda.is_available():
input_var = Variable(data.cuda())
else:
input_var = Variable(data)
output = model(input_var)
print("Outside: input size", input_var.size(), "output_size", output.size())
2、DDP(官方建议)
DistributedDataParallel (DDP) 是 PyTorch 分布式数据并行训练的模块,适用于单机多卡和多机多卡场景。
相比于 DataParallel,DDP 更加高效和灵活,能够在多个 GPU 和多个节点上进行并行训练。
DistributedDataParallel 是多进程,可工作在单机或多机器中。
DataParallel 通常慢于 DistributedDataParallel, DDP 是目前主流方法
DP 问题
为什么要引入DDP(DistributedDataParallel)?
DP 存在问题
- 1、DP 每个训练批次(batch)中,一个进程上先算出模型权重, 然后再分发到每个GPU上
- 网络通信就成为了瓶颈,而GPU使用率也通常很低。
- 显存浪费, 多存储了 n-1 份 模型副本
- 2、每次前向传播把模型也复制了(即每次更新都复制一遍模型),并且单进程多线程会造成
GILcontention (全局解释器锁争用) - 进程计算权重使通信成为瓶颈造成了大量的时间浪费,因此引入了DDP。
dp 两个问题:
- 1️⃣ 显存浪费严重。
- 以单机八卡为例,把模型复制8份放在8张卡上同时推理,因此多付出了7个模型(副本)的显存开销;
- 2️⃣ 大模型不适用。
- 以最新提出的Llama 3.1为例,不经量化(FP16数据类型)的情况下,容纳70B的模型需要140G显存,即使是40G一张的A100也无法承受。
- 而这才仅仅是容纳模型,还没有考虑存放数据,以及训练梯度数据等。
- 因此数据并行并不适用于70B级别大模型的推理和训练。
torch.nn.DataParallel
DataParallel 是 PyTorch 一种数据并行方法,单台机器上的多个 GPU 上进行模型训练。
将输入数据划分成多个子部分(mini-batches),并分配给不同 GPU,以实现并行计算。
- 前向传播过程中,输入数据会被划分成多个副本, 并发送到不同设备(device)上进行计算。
- 模型(module)会被复制到每个设备上,输入的批次(batch)会被平均分配到每个设备,但模型会在每个设备上有个副本。每个模型副本只需要处理对应的子部分。
- 注意: 批次大小应大于GPU数量。
- 反向传播过程中,每个副本的梯度会被累加到原始模型中。
总结来说,DataParallel 会自动将数据切分并加载到相应的GPU上,将模型复制到每个GPU上,进行正向传播以计算梯度并汇总。
注意:
- DataParallel 是单进程多线程的,仅仅能工作在单机中。
torch.nn.DataParallel
- DataParallel 全程维护一个 optimizer,对各 GPU 上梯度进行求和,而在主 GPU 进行参数更新,之后再将模型参数 broadcast 到其他 GPU
注意:
- 1、设置 DistributedSampler 来打乱数据,因为一个batch被分配到了好几个进程中,要确保不同的GPU拿到的不是同一份数据。
- 2、要告诉每个进程自己的id,即使用哪一块GPU。
- 3、如果需要做BatchNormalization,需要对数据进行同步(还待研究,挖坑)
示例
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# 初始化模型
model = SimpleModel()
# 使用 DataParallel 将模型分布到多个 GPU 上
model = nn.DataParallel(model)
示例
DDP采用多进程控制多GPU,共同训练模型,一份代码会被pytorch自动分配到n个进程并在n个GPU上运行。
- DDP运用
Ring-Reduce通信算法在每个GPU间对梯度进行通讯,交换彼此梯度,从而获得所有GPU梯度。
对比DP,不需要在进行模型本体通信,因此可以加速训练。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def main(rank, world_size):
# 初始化进程组
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# 创建模型并移动到GPU
model = SimpleModel().to(rank)
# 包装模型为DDP模型
ddp_model = DDP(model, device_ids=[rank])
if __name__ == "__main__":
import os
import torch.multiprocessing as mp
# 世界大小:总共的进程数
world_size = 4
# 使用mp.spawn启动多个进程
mp.spawn(main, args=(world_size,), nprocs=world_size, join=True)
torch.distributed 介绍
DDP采用 All-Reduce 架构,单机多卡、多机多卡都能用。
注意:DDP并不会自动shard数据
- 如果自己写数据流,得根据
torch.distributed.get_rank()去shard数据,获取自己应用的一份 - 如果用 Dataset API,则需要在定义Dataloader的时候用 DistributedSampler 去shard
torch.nn.DataParallel 支持数据并行,但不支持多机分布式训练,且底层实现相较于 distributed 的接口,有些许不足。
Pytorch 通过 torch.distributed 包提供分布式支持,包括 GPU 和 CPU 的分布式训练支持。
- Pytorch 分布式目前只支持 Linux。
torch.distributed 优势:
- 每个进程对应一个独立的训练过程,且只对梯度等少量数据进行信息交换。
- 迭代中,每个进程具有自己的 optimizer ,独立完成所有优化步骤,进程内与一般的训练无异。
- 各进程梯度计算完成之后,先将梯度进行汇总平均,再由
rank=0的进程,将其 broadcast 到所有进程。最后,各进程用该梯度来更新参数。 - 各进程的模型参数始终保持一致: 各进程初始参数、更新参数都一致
- 相比
DataParallel,torch.distributed传输的数据量更少,因此速度更快,效率更高
- 每个进程包含独立的解释器和 GIL
- 每个进程拥有独立的解释器和 GIL,消除了单个 Python 进程中的多个执行线程,模型副本或 GPU 的额外解释器开销和 GIL-thrashing ,因此可以减少解释器和 GIL 使用冲突
torch.distributed 概念
【2024-4-7】Pytorch 分布式训练
概念:
group:即进程组。默认只有1个组,1个 job 即为1个组,即 1个 world。- 当需要进行更加精细的通信时,通过 new_group 接口,使用 word 的子集,创建新组,用于集体通信等。
world_size:表示全局进程数。一个进程可对应多个GPUworld_size ≠ GPU数: 1个进程用多个GPUworld_size = GPU数: 1个进程用1个GPU
local_word_size: 某个节点上进程数 (相对比较少见)rank:全局进程id, 表示进程序号,用于进程间通讯,表征进程优先级。取值范围:0~world_sizerank = 0主机为 master 节点。
local_rank:某个节点上进程id, 进程内GPU 编号,非显式参数,由torch.distributed.launch内部指定。rank = 3,local_rank = 0表示第 3 个进程内的第 1 块 GPU。
global_rank: 全局 gpu编号
如果 所有进程数(world_size)为W,每个节点上的进程数(local_world_size)为L, 则每个进程上的两个ID:
rank取值范围:[0, W-1]rank=0 进程为主进程,负责同步分发工作rank>0 进程为从进程rank=-1, 默认值,非GPU进程?
local_rank取值:[0, L-1]
2机8卡的分布式训练示例
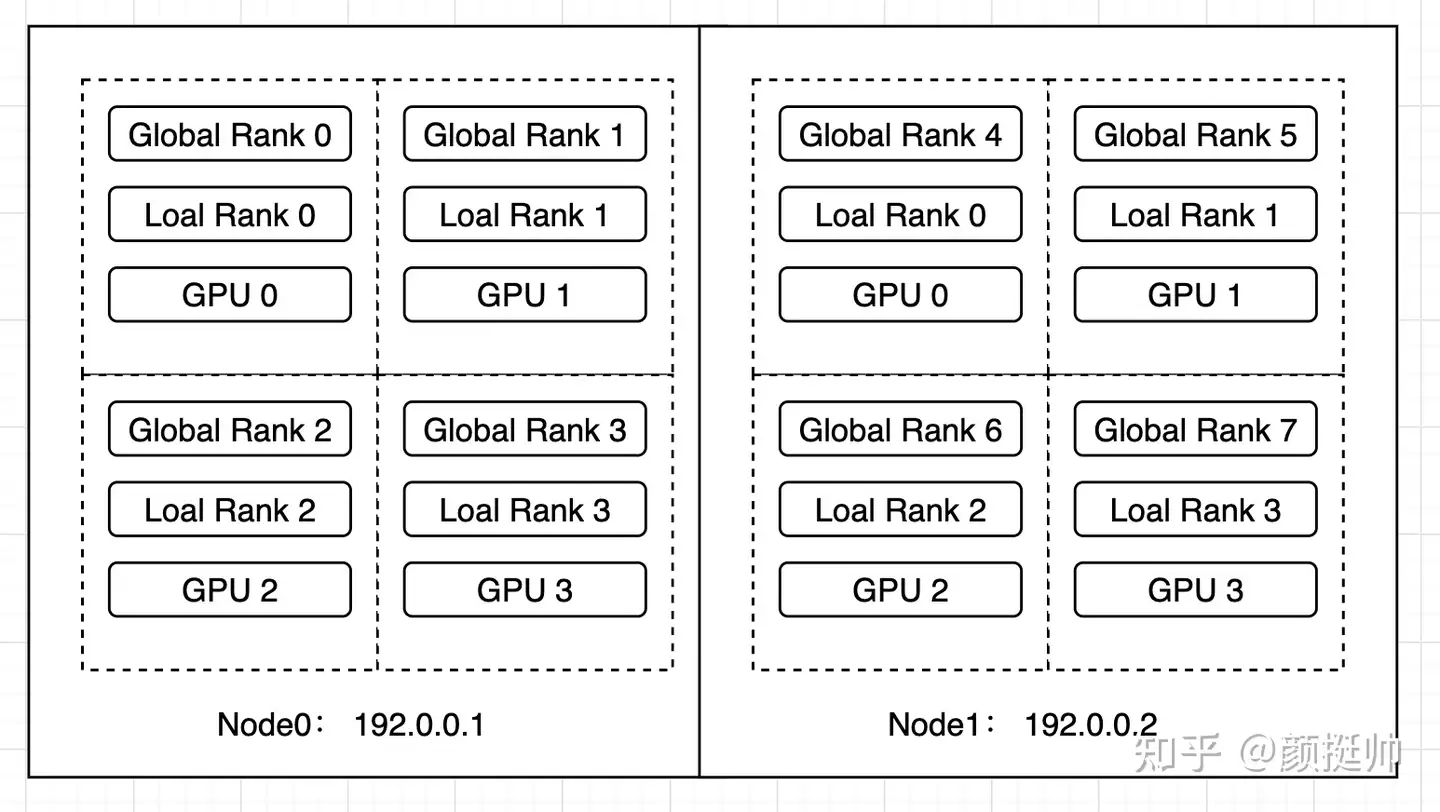
- gpu 编号: 0~3
- local rank: gpu 本地编号, 0~3
- global rank: gpu 全局编号, 0~7
Pytorch 分布式基本流程:
- 使用 distributed 包任何函数前,用
init_process_group初始化进程组,同时初始化distributed包。 - 如进行小组内集体通信,用
new_group创建子分组 - 创建分布式并行模型
DDP(model, device_ids=device_ids) - 为数据集创建 Sampler
- 使用启动工具
torch.distributed.launch在每个主机上执行一次脚本,开始训练 - 使用
destory_process_group()销毁进程组
torch.distributed 提供了 3 种初始化方式:tcp、共享文件 和 环境变量初始化 等。
- TCP: 指定进程 0 的 ip 和 port, 手动为每个进程指定进程号。
- 共享文件: 共享文件对于组内所有进程可见
- 环境变量:
测试代码
import torch.distributed as dist
import argparse, os
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=ine, default=0)
args = parser.parse_args()
# 分布式初始化, 读取环境变量 RANK=1 WORLD_SIZE=3 MASTER_ADDR=127.0.0.1 MASTER_PORT=8000
dist.init_process_group("nccl") # 进程组初始化
rank = dist.get_rank()
local_rank_arg = args.local_rank # 命令行形式ARGS形式
local_rank_env = int(os.environ['LOCAL_RANK']) # 用env初始ENV环境变量形式
local_world_size = int(os.environ['LOCAL_WORLD_SIZE'])
# local_rank_env = int(os.environ.get('LOCAL_RANK', 0)) # 在利用env初始ENV环境变量形式
# local_world_size = int(os.environ.get('LOCAL_WORLD_SIZE', 3))
print(f"{rank=}; {local_rank_arg=}; {local_rank_env=}; {local_world_size=}")
执行
python3 -m torch.distributed.launch --nproc_per_node=4 test.py
在一台4卡机器上执行, 样例输出:
# WARNING:torch.distributed.run:
# *****************************************
# Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
# *****************************************
rank=2; local_rank_arg=2; local_rank_env=2, local_world_size=4
rank=0; local_rank_arg=0; local_rank_env=0, local_world_size=4
rank=3; local_rank_arg=3; local_rank_env=3, local_world_size=4
rank=1; local_rank_arg=1; local_rank_env=1, local_world_size=4
一般分布式训练都是为每个进程赋予一块GPU,这样比较简单而且容易调试。 这种情况下,可以通过 local_rank 作为当前进程GPU的id。
数据读取
pytorch 分布式训练,数据读取采用主进程预读取并缓存,其它进程从缓存中读取,不同进程之间的数据同步具体通过torch.distributed.barrier()实现。参考
- 分布式数据读取:
主进程读取数据 →主进程缓存 →从进程读取缓存
进程号rank
多进程上下文中,通常假定rank 0是第一个进程/主进程,其它进程分别具有 0,1,2 不同rank号,这样总共具有4个进程。
(2)单一进程数据处理
通有些操作没必要并行处理,如: 数据读取与处理操作,只需要一个进程进行处理并缓存,然后与其它进程共享缓存处理数据
- 但由于不同进程同步执行,单一进程处理数据必然会导致进程间不同步现象(数据读取操作处理时间较长)对于较短时间的单一进程程序运行不会影响线程不同步的情况
为此,torch中采用了barrier()函数对其它非主进程进行阻塞,达到同步目的
(3)barrier()具体原理
如果执行 create_dataloader()函数的进程
- 不是主进程: 即rank不等于0或者-1
- 上下文管理器会执行相应的
torch.distributed.barrier(),设置一个阻塞栅栏,让此进程处于等待状态,等待所有进程到达栅栏处(包括主进程数据处理完毕);
- 上下文管理器会执行相应的
- 是主进程: 其会直接读取数据,然后处理结束之后会遇到
torch.distributed.barrier()
此时,所有进程都到达了当前的栅栏处,这样所有进程就达到了同步,并同时得到释放。
def create_dataloader():
#使用上下文管理器中实现的barrier函数确保分布式中的主进程首先处理数据,然后其它进程直接从缓存中读取
with torch_distributed_zero_first(rank):
dataset = LoadImagesAndLabels()
from contextlib import contextmanager
#定义的用于同步不同进程对数据读取的上下文管理器
@contextmanager
def torch_distributed_zero_first(local_rank: int):
"""
Decorator to make all processes in distributed training wait for each local_master to do something.
"""
if local_rank not in [-1, 0]:
torch.distributed.barrier()
yield #中断后执行上下文代码,然后返回到此处继续往下执行
if local_rank == 0:
torch.distributed.barrier()
初始化进程组 init_process_group
init_process_group 函数原型
torch.distributed.init_process_group(backend, init_method=None, timeout=datetime.timedelta(0, 1800),
world_size=-1, rank=-1, store=None)
函数作用
- 每个进程中进行调用,用于初始化该进程。
- 使用分布式时,该函数必须在 distributed 内所有相关函数之前使用。
参数详解
backend:指定当前进程要使用的通信后端- 小写字符串,支持的通信后端有
gloo,mpi,nccl, 建议用nccl。 - cpu 分布式选
gloo - gpu 分布式选
nccl
- 小写字符串,支持的通信后端有
init_method:当前进程组初始化方式- 可选参数,字符串形式。两种方式:
init_method+store,init_method是store的高层封装, 二者互斥 init_method: TCP连接、File共享文件系统、ENV环境变量三种方式store: 同时指定world_size 和 rank参数。store 是一种分布式中核心的key-value存储,用于不同进程间共享信息- 如果未指定, 默认为
env,表示使用读取环境变量方式初始化。该参数与 store 互斥。
- 可选参数,字符串形式。两种方式:
rank:指定当前进程的优先级int值。表示当前进程的编号,即优先级。如果指定 store 参数,则必须指定该参数。- rank=0 的为主进程,即 master 节点。
world_size:该 job 中的总进程数。如果指定 store 参数,则需要指定该参数。timeout: 指定每个进程的超时时间- 可选参数,datetime.timedelta 对象,默认为 30 分钟。该参数仅用于 Gloo 后端。
store- 所有 worker 可访问的 key / value,用于交换连接 / 地址信息。与 init_method 互斥。
三种init_method:
init_method=’tcp://ip:port‘: 通过指定rank 0(MASTER进程)的IP和端口,各个进程tcp进行信息交换。需指定 rank 和 world_size 这两个参数。init_method=’file://path‘:通过所有进程都可以访问共享文件系统来进行信息共享。需要指定rank和world_size参数。init_method=env://:从环境变量中读取分布式信息(os.environ),主要包括MASTER_ADDR,MASTER_PORT,RANK,WORLD_SIZE。 其中,rank和world_size可手动指定,否则从环境变量读取。
tcp 和 env 两种方式比较类似, 其实 env就是对tcp 一层封装),都是通过网络地址方式进行通信,最常用的初始化方法。
import os, argparse
import torch
import torch.distributed as dist
parse = argparse.ArgumentParser()
parse.add_argument('--init_method', type=str)
parse.add_argument('--rank', type=int)
parse.add_argument('--ws', type=int)
args = parse.parse_args()
if args.init_method == 'TCP':
dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765', rank=args.rank, world_size=args.ws)
elif args.init_method == 'ENV':
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
print(f"rank = {rank} is initialized")
# 单机多卡情况下,localrank = rank. 严谨应该是local_rank来设置device
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)
单机双卡机器上,开两个终端,同时运行命令
# TCP方法
python3 test_ddp.py --init_method=TCP --rank=0 --ws=2
python3 test_ddp.py --init_method=TCP --rank=1 --ws=2
# ENV方法
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=0 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=1 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV
如果开启的进程未达到 word_size 的数量,则所有进程会一直等待,直到都开始运行,可以得到输出如下:
# rank0 的终端:
rank 0 is initialized
tensor([1, 2, 3, 4], device='cuda:0')
# rank1的终端
rank 1 is initialized
tensor([1, 2, 3, 4], device='cuda:1')
说明
- 初始化DDP时,给后端提供主进程的地址端口、本身RANK,以及进程数量即可。
- 初始化完成后,可以执行很多分布式的函数,比如 dist.
get_rank, dist.all_gather等等。
new_group
函数声明
torch.distributed.new_group(ranks=None, timeout=datetime.timedelta(0, 1800), backend=None)
函数作用
new_group()函数可用于使用所有进程的任意子集来创建新组。其返回一个分组句柄,可作为 collectives 相关函数的 group 参数 。collectives 是分布式函数,用于特定编程模式中的信息交换。
参数详解
- ranks:指定新分组内的成员的 ranks 列表list ,其中每个元素为 int 型
- timeout:指定该分组进程组内的操作的超时时间
- 可选参数,datetime.timedelta 对象,默认为 30 分钟。该参数仅用于 Gloo 后端。
- backend:指定要使用的通信后端
- 小写字符串,支持的通信后端有 gloo,nccl ,必须与 init_process_group() 中一致。
其它函数
- get_backend 获取进程组属性
- get_rank 获取分布式进程组组内的每个进程的唯一识别
- get_world_size 获取进程组内的进程数
- is_initialized 检查默认进程组是否被初始化
- is_mpi_available 检查 MPI 后端是否可用
- is_nccl_available 检查 NCCL 后端是否可用
(1) TCP 初始化
import torch.distributed as dist
# Use address of one of the machines
dist.init_process_group(backend, init_method='tcp://10.1.1.20:23456',rank=args.rank, world_size=4)
说明
- 不同进程内,均使用主进程的 ip 地址和 port,确保每个进程能够通过一个 master 进行协作。该 ip 一般为主进程所在的主机的 ip,端口号应该未被其他应用占用。
- 实际使用时,在每个进程内运行代码,并需要为每一个进程手动指定一个 rank,进程可以分布与相同或不同主机上。
- 多个进程之间,同步进行。若其中一个出现问题,其他的也马上停止。
使用
# Node 1
python mnsit.py --init-method tcp://192.168.54.179:22225 --rank 0 --world-size 2
# Node 2
python mnsit.py --init-method tcp://192.168.54.179:22225 --rank 1 --world-size 2
初始化示例
tcp_init.py
import torch.distributed as dist
import torch.utils.data.distributed
# ......
parser = argparse.ArgumentParser(description='PyTorch distributed training on cifar-10')
parser.add_argument('--rank', default=0, help='rank of current process')
parser.add_argument('--word_size', default=2,help="word size")
parser.add_argument('--init_method', default='tcp://127.0.0.1:23456', help="init-method")
args = parser.parse_args()
# ......
dist.init_process_group(backend='nccl', init_method=args.init_method, rank=args.rank, world_size=args.word_size)
# ......
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=download, transform=transform)
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, sampler=train_sampler)
# ......
net = Net()
net = net.cuda()
net = torch.nn.parallel.DistributedDataParallel(net)
执行方式
init_method
# Node 1 : ip 192.168.1.201 port : 12345
python tcp_init.py --init_method tcp://192.168.1.201:12345 --rank 0 --word_size 3
# Node 2 :
python tcp_init.py --init_method tcp://192.168.1.201:12345 --rank 1 --word_size 3
# Node 3 :
python tcp_init.py --init_method tcp://192.168.1.201:12345 --rank 2 --word_size 3
说明
- TCP 方式中,
init_process_group中必须手动指定以下参数rank为当前进程的进程号word_size为当前 job 总进程数init_method内指定 tcp 模式,且所有进程的ip:port必须一致,设定为主进程的ip:port
- 必须在 rank==0 的进程内保存参数。
- 若程序内未根据 rank 设定当前进程使用的 GPUs,则默认使用全部 GPU,且以数据并行方式使用。
- 每条命令表示一个进程。若已开启的进程未达到 word_size 的数量,则所有进程会一直等待
- 每台主机上可以开启多个进程。但是,若未为每个进程分配合适的 GPU,则同机不同进程可能会共用 GPU,应该坚决避免这种情况。
- 使用 gloo 后端进行 GPU 训练时,会报错。
- 若每个进程负责多块 GPU,可以利用多 GPU 进行模型并行。
class ToyMpModel(nn.Module):
def init(self, dev0, dev1):
super(ToyMpModel, self).init()
self.dev0 = dev0
self.dev1 = dev1
self.net1 = torch.nn.Linear(10, 10).to(dev0)
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to(dev1)
def forward(self, x):
x = x.to(self.dev0)
x = self.relu(self.net1(x))
x = x.to(self.dev1)
return self.net2(x)
# ......
dev0 = rank * 2
dev1 = rank * 2 + 1
mp_model = ToyMpModel(dev0, dev1)
ddp_mp_model = DDP(mp_model)
# ......
(2) 共享文件初始化
共享的文件对于组内所有进程可见
设置方式如下:
import torch.distributed as dist
# rank should always be specified
dist.init_process_group(backend, init_method='file:///mnt/nfs/sharedfile',
world_size=4, rank=args.rank)
说明
file://前缀表示文件系统各式初始化。/mnt/nfs/sharedfile表示共享文件,各个进程在共享文件系统中通过该文件进行同步或异步。
因此,所有进程必须对该文件具有读写权限。
- 每一个进程将会打开这个文件,写入自己的信息,并等待直到其他所有进程完成该操作
- 在此之后,所有的请求信息将会被所有的进程可访问,为了避免 race conditions,文件系统必须支持通过 fcntl 锁定(大多数的 local 系统和 NFS 均支持该特性)。
说明:
- 若指定为同一文件,则每次训练开始之前,该文件必须手动删除,但是文件所在路径必须存在!
与 tcp 初始化方式一样,也需要为每一个进程手动指定 rank。
使用
# 主机 01 上:
python mnsit.py --init-method file://PathToShareFile/MultiNode --rank 0 --world-size 2
# 主机 02 上:
python mnsit.py --init-method file://PathToShareFile/MultiNode --rank 1 --world-size 2
相比于 TCP 方式, 麻烦一点的是运行完一次必须更换共享的文件名,或者删除之前的共享文件,不然第二次运行会报错。
(3) Env 初始化(默认)
默认情况下都是环境变量来进行分布式通信,指定 init_method="env://"。
通过在所有机器上设置如下四个环境变量,所有进程将会适当的连接到 master,获取其他进程的信息,并最终与它们握手(信号)。
MASTER_PORT: 必须指定,表示 rank0上机器的一个空闲端口(必须设置)MASTER_ADDR: 必须指定,除了 rank0 主机,表示主进程 rank0 机器的地址(必须设置)WORLD_SIZE: 可选,总进程数,可以这里指定,在 init 函数中也可以指定RANK: 可选,当前进程的 rank,也可以在 init 函数中指定
配合 torch.distribution.launch 使用。
实例
# Node 1: (IP: 192.168.1.1, and has a free port: 1234)
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE
--nnodes=2 --node_rank=0 --master_addr="192.168.1.1"
--master_port=1234 YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3
and all other arguments of your training script)
# Node 2
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE
--nnodes=2 --node_rank=1 --master_addr="192.168.1.1"
--master_port=1234 YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3
and all other arguments of your training script)
代码 env_init.py
import torch.distributed as dist
import torch.utils.data.distributed
# ......
import argparse
parser = argparse.ArgumentParser()
# 注意这个参数,必须要以这种形式指定,即使代码中不使用。因为 launch 工具默认传递该参数
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
# ......
dist.init_process_group(backend='nccl', init_method='env://')
# ......
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=download, transform=transform)
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, sampler=train_sampler)
# ......
# 根据 local_rank,配置当前进程使用的 GPU
net = Net()
device = torch.device('cuda', args.local_rank)
net = net.to(device)
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[args.local_rank], output_device=args.local_rank)
执行方式
# 节点0
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=3 --node_rank=0 --master_addr="192.168.1.201" --master_port=23456 env_init.py
# 节点1
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=3 --node_rank=1 --master_addr="192.168.1.201" --master_port=23456 env_init.py
# 节点2
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=3 --node_rank=2 --master_addr="192.168.1.201" --master_port=23456 env_init.py
说明
- Env 方式中,
init_process_group无需指定任何参数 - 必须在
rank==0的进程内保存参数。
该方式使用 torch.distributed.launch 在每台主机上创建多进程,其中:
nproc_per_node参数指定为当前主机创建的进程数。一般设定为当前主机的 GPU 数量nnodes参数指定当前 job 包含多少个节点node_rank指定当前节点的优先级master_addr和master_port分别指定 master 节点的 ip:port- 若没有为每个进程合理分配 GPU,则默认使用当前主机上所有的 GPU。即使一台主机上有多个进程,也会共用 GPU。
- 使用
torch.distributed.launch工具时,为当前主机创建nproc_per_node个进程,每个进程独立执行训练脚本。同时,它还会为每个进程分配一个local_rank参数,表示当前进程在当前主机上的编号。- 例如:r
ank=2,local_rank=0表示第 3 个节点上的第 1 个进程。
- 例如:r
- 需要合理利用
local_rank参数,来合理分配本地的 GPU 资源 - 每条命令表示一个进程。若已开启的进程未达到
word_size数量,则所有进程会一直等待
详见: Pytorch 分布式训练
GPU 启动方式
常见的GPU 启动方式
- torch.
multiprocessing: 容易控制, 更加灵活 - torch.
distributed.launch: 代码量少, 启动速度快 torchrun:distributed.launch的进化版, 代码量更少- Slurm Workload Manager: slurm 启动近期更新掉
DDP 本身是一个 python 多进程,完全可以直接通过多进程方式来启动分布式程序。
torch 提供两种启动工具运行torch DDP程序。
- torch.multiprocessing
- launch/run
(1) mp.spawn
用 torch.multiprocessing(python multiprocessing的封装类) 自动生成多个进程
基本的调用函数 spawn:
mp.spawn(fn, args=(), nprocs=1, join=True, daemon=False)
其中:
fn: 进程入口函数,第一个参数会被默认自动加入当前进程的rank, 即实际调用: fn(rank, *args)nprocs: 进程数量,即:world_sizeargs: 函数fn的其他常规参数以tuple形式传递
示例
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def fn(rank, ws, nums):
dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765', rank=rank, world_size=ws)
rank = dist.get_rank()
print(f"rank = {rank} is initialized")
torch.cuda.set_device(rank)
tensor = torch.tensor(nums).cuda()
print(tensor)
if __name__ == "__main__":
ws = 2
mp.spawn(fn, nprocs=ws, args=(ws, [1, 2, 3, 4]))
命令
python3 test_ddp.py
输出如下:
rank = 0 is initialized
rank = 1 is initialized
tensor([1, 2, 3, 4], device='cuda:1')
tensor([1, 2, 3, 4], device='cuda:0')
这种方式同时适用于 TCP 和 ENV 初始化。
(2) launch/run
torch 提供的 torch.distributed.launch 工具,以模块形式直接执行:
python3 -m torch.distributed.launch --配置 train.py --args参数
常用配置有:
- –
nnodes: 使用的机器数量,单机的话,就默认是1了 - –
nproc_per_node: 单机的进程数,即单机的worldsize - –
master_addr/port: 使用的主进程rank0的地址和端口 - –
node_rank: 当前的进程rank
单机情况下
- 只有 –
nproc_per_node是必须指定 - –
master_addr/port和node_rank都是可以由launch通过环境自动配置
mport torch
import torch.distributed as dist
import torch.multiprocessing as mp
import os
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
local_rank = os.environ['LOCAL_RANK']
master_addr = os.environ['MASTER_ADDR']
master_port = os.environ['MASTER_PORT']
print(f"rank = {rank} is initialized in {master_addr}:{master_port}; local_rank = {local_rank}")
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)
启动命令
python3 -m torch.distribued.launch --nproc_per_node=2 test_ddp.py
输出如下:
rank = 0 is initialized in 127.0.0.1:29500; local_rank = 0
rank = 1 is initialized in 127.0.0.1:29500; local_rank = 1
tensor([1, 2, 3, 4], device='cuda:1')
tensor([1, 2, 3, 4], device='cuda:0')
(3) torchrun
torch 1.10 开始用终端命令 torchrun 来代替 torch.distributed.launch
torchrun实现了 launch 的一个超集
不同:
- 完全使用环境变量配置各类参数,如 RANK,LOCAL_RANK, WORLD_SIZE 等,尤其是 local_rank 不再支持用命令行隐式传递的方式
- 更加优雅处理某个worker失败情况,重启worker。
- 需要代码中有 load_checkpoint(path) 和 save_checkpoint(path) 这样有worker失败的话,可以通过load最新的模型,重启所有的worker接着训练。
- 训练节点数目可以弹性变化。
上面代码直接使用运行即可,不用写那么长长的命令了。
torchrun --nproc_per_node=2 test_gpu.py
注意
- torchrun 或者 launch 对上面
ENV初始化方法支持最完善,TCP初始化方法的可能会出现问题,尽量使用env来初始化dist。
torch.distributed 使用
使用方式(单机多卡环境)
# 启动方式,shell中运行:
python -m torch.distributed.launch --nnodes 1 --nproc_per_node=4 YourScript.py
# nnodes: 表示有多少个节点,可以通俗的理解为有多少台机器
# nproc_per_node 表示每个节点上有多少个进程,每个进程一般独占一块GPU
########################## 第1步 ##########################
#初始化
'''
在启动器为我们启动python脚本后,在执行过程中,启动器会将当前进程的(其实就是 GPU的)index 通过参数传递给 python,
我们可以这样获得当前进程的 index:即通过参数 local_rank 来告诉我们当前进程使用的是哪个GPU,
用于我们在每个进程中指定不同的device
'''
parse.add_argument('--local_rank',type=int)
args=parser.parse_args()
local_rank=args.local_rank
torch.cuda.set_device(local_rank)
'''
init_process_group用于初始化GPU通信方式(NCCL)和参数的获取方式(env代表通过环境变量)
gpu使用nccl最快,gloo为cpu分布式训练,mpu则需要重新编码
init_method 指定如何初始化进程组的 URL。
默认及推荐为'env://' 其他初始化方式与多机多卡有关(not sure,挖个坑)
'''
torch.distributed.init_process_group('nccl',init_method='env://')
device = torch.device(f'cuda:{args.local_rank}')
########################## 第2步 ##########################
#处理Dataloader
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset,shuffle=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
#torch.utils.data.DataLoader中的shuffle应该设置为False(默认),因为打乱的任务交给了sampler
########################## 第3步 ##########################
#模型的初始化
model=torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
'''
使用 DistributedDataParallel 包装模型,
它能帮助我们为不同 GPU 上求得的梯度进行allreduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。
allreduce 后不同 GPU 中模型的梯度均为 allreduce 之前各 GPU 梯度的均值。
''''
########################## 第4步 ##########################
#同DP,进行inputs、labels的设备转移
sampler = DistributedSampler(dataset) # 这个sampler会自动分配数据到各个gpu上
DataLoader(dataset, batch_size=batch_size, sampler=sampler)
完整代码如下:
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import os
from torch.utils.data.distributed import DistributedSampler
# 1) 初始化
torch.distributed.init_process_group(backend="nccl")
input_size = 5
output_size = 2
batch_size = 30
data_size = 90
# 2) 配置每个进程的gpu
local_rank = torch.distributed.get_rank()
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size).to('cuda')
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
dataset = RandomDataset(input_size, data_size)
# 3)使用DistributedSampler
rand_loader = DataLoader(dataset=dataset,
batch_size=batch_size,
sampler=DistributedSampler(dataset))
class Model(nn.Module):
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print(" In Model: input size", input.size(),
"output size", output.size())
return output
model = Model(input_size, output_size)
# 4) 封装之前要把模型移到对应的gpu
model.to(device)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# 5) 封装:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
for data in rand_loader:
if torch.cuda.is_available():
input_var = data
else:
input_var = data
output = model(input_var)
print("Outside: input size", input_var.size(), "output_size", output.size())
执行脚本:
# 启用 DDP 模式
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 torch_ddp.py
apex加速(混合精度训练、并行训练、同步BN)可参考
代码分布式改造
如何将单机训练代码改成分布式运行?
基本流程:
- 分布式训练数据加载
- 分布式训练
- 分布式评估
分布式数据集
Dataloader 要把所有数据分成N份(N为worldsize), 并能正确分发到不同进程中,每个进程可以拿到一个数据的子集,不重叠,不交叉。
这部分工作靠 DistributedSampler 完成,函数签名如下:
torch.utils.data.distributed.DistributedSampler(dataset,
num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False)
参数说明
dataset: 需要加载的完整数据集num_replicas: 把数据集分成多少份,默认是当前dist的world_sizerank: 当前进程的id,默认从dist的rankshuffle:是否打乱drop_last: 如果数据长度不能被world_size整除,可以考虑是否将剩下的扔掉seed:随机数种子。- 注意: 从源码中可以看出,真正的种子其实是 self.seed + self.epoch, 好处是,不同epoch每个进程拿到的数据是不一样,因此要在每个epoch开始前设置下:
sampler.set_epoch(epoch)
- 注意: 从源码中可以看出,真正的种子其实是 self.seed + self.epoch, 好处是,不同epoch每个进程拿到的数据是不一样,因此要在每个epoch开始前设置下:
Sampler 实现核心代码:
indices[self.rank: self.total_size: self.num_replicas]
假设4卡12条数据,rank=0,1,2,3, num_replicas=4, 那么每个卡取的数据索引就是:
rank0: [0 4 8]; rank1: [1 5 9]; rank2: [2 6 10]; rank3: [3 7 11]
保证不重复不交叉。这样在分布式训练的时候,只需要给 Dataloader 指定 DistributedSampler 即可,简单示例如下:
sampler = DistributedSampler(dataset)
loader = DataLoader(dataset, sampler=sampler)
for epoch in range(start_epoch, n_epochs):
sampler.set_epoch(epoch) # 设置epoch 更新种子
train(loader)
模型的分布式训练封装。将单机模型使用 torch.nn.parallel.DistributedDataParallel 进行封装,如下:
torch.cuda.set_device(local_rank)
model = Model().cuda()
model = DistributedDataParallel(model, device_ids=[local_rank])
# 要调用model内的函数或者属性. model.module.xxxx
多卡训练时,每个进程有一个model副本和optimizer,使用自己的数据进行训练,之后反向传播计算完梯度的时候,所有进程的梯度会进行 all-reduce 操作进行同步,进而保证每个卡上的模型更新梯度是一样的,模型参数也是一致的。
注意
- 在save和load模型时候,为了减小所有进程同时读写磁盘,以主进程为主,rank0 先save模型,在map到其他进程。
- 另外一个好处: 最开始训练时,模型随机初始化之后,保证了所有进程的模型参数保持一致。
torch的DDP封装时,已经做到了这一点,即使开始随机初始化不同,经过DDP封装,所有进程都一样的参数
简洁代码如下:
model = DistributedDataParallel(model, device_ids=[local_rank])
CHECKPOINT_PATH ="./model.checkpoint"
if rank == 0:
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# barrier()其他保证rank 0保存完成
dist.barrier()
map_location = {"cuda:0": f"cuda:{local_rank}"}
model.load_state_dict(torch.load(CHECKPOINT_PATH, map_location=map_location))
# 后面正常训练代码
optimizer = xxx
for epoch:
for data in Dataloader:
model(data)
xxx
# 训练完成 只需要保存rank 0上的即可
# 不需要dist.barrior(), all_reduce 操作保证了同步性
if rank == 0:
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
分布式训练
DDP分布式训练步骤:
- 初始化进程组 dist.init_process_group
- 设置分布式采样器 DistributedSampler
- 使用DistributedDataParallel封装模型
- 使用torchrun 或者 mp.spawn 启动分布式训练
使用分布式做 evaluation 时,要先把所有进程的输出结果进行 gather,再进行指标计算,两个常用函数:
dist.all_gather(tensor_list, tensor) # 将所有进程的tensor进行收集并拼接成新的tensorlist返回,比如:
dist.all_reduce(tensor, op) # 对tensor 的 in-place 操作, 对所有进程的某个tensor进行合并操作,op可以是求和等
代码
import torch
import torch.distributed as dist
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
torch.cuda.set_device(rank)
tensor = torch.arange(2) + 1 + 2 * rank
tensor = tensor.cuda()
print(f"rank {rank}: {tensor}")
tensor_list = [torch.zeros_like(tensor).cuda() for _ in range(2)]
dist.all_gather(tensor_list, tensor)
print(f"after gather, rank {rank}: tensor_list: {tensor_list}")
dist.barrier()
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"after reduce, rank {rank}: tensor: {tensor}")
命令
torchrun --nproc_per_node=2 test_ddp.py
输出结果如下:
rank 1: tensor([3, 4], device='cuda:1')
rank 0: tensor([1, 2], device='cuda:0')
after gather, rank 1: tensor_list: [tensor([1, 2], device='cuda:1'), tensor([3, 4], device='cuda:1')]
after gather, rank 0: tensor_list: [tensor([1, 2], device='cuda:0'), tensor([3, 4], device='cuda:0')]
after reduce, rank 0: tensor: tensor([4, 6], device='cuda:0')
after reduce, rank 1: tensor: tensor([4, 6], device='cuda:1')
分布式评估
evaluation 时,可以拿到所有进程中模型输出,最后统一计算指标,基本流程如下:
pred_list = []
for data in Dataloader:
pred = model(data)
batch_pred = [torch.zeros_like(label) for _ in range(world_size)]
dist.all_gather(batch_pred, pred)
pred_list.extend(batch_pred)
pred_list = torch.cat(pred_list, 1)
# 所有进程pred_list是一致的,保存所有数据模型预测的值
pytorch 分布式操作
【2024-8-4】彻底搞清楚torch. distributed分布式数据通信all_gather、all_reduce
all_gather和all_reduce;gather、reduce、scatter方法对比
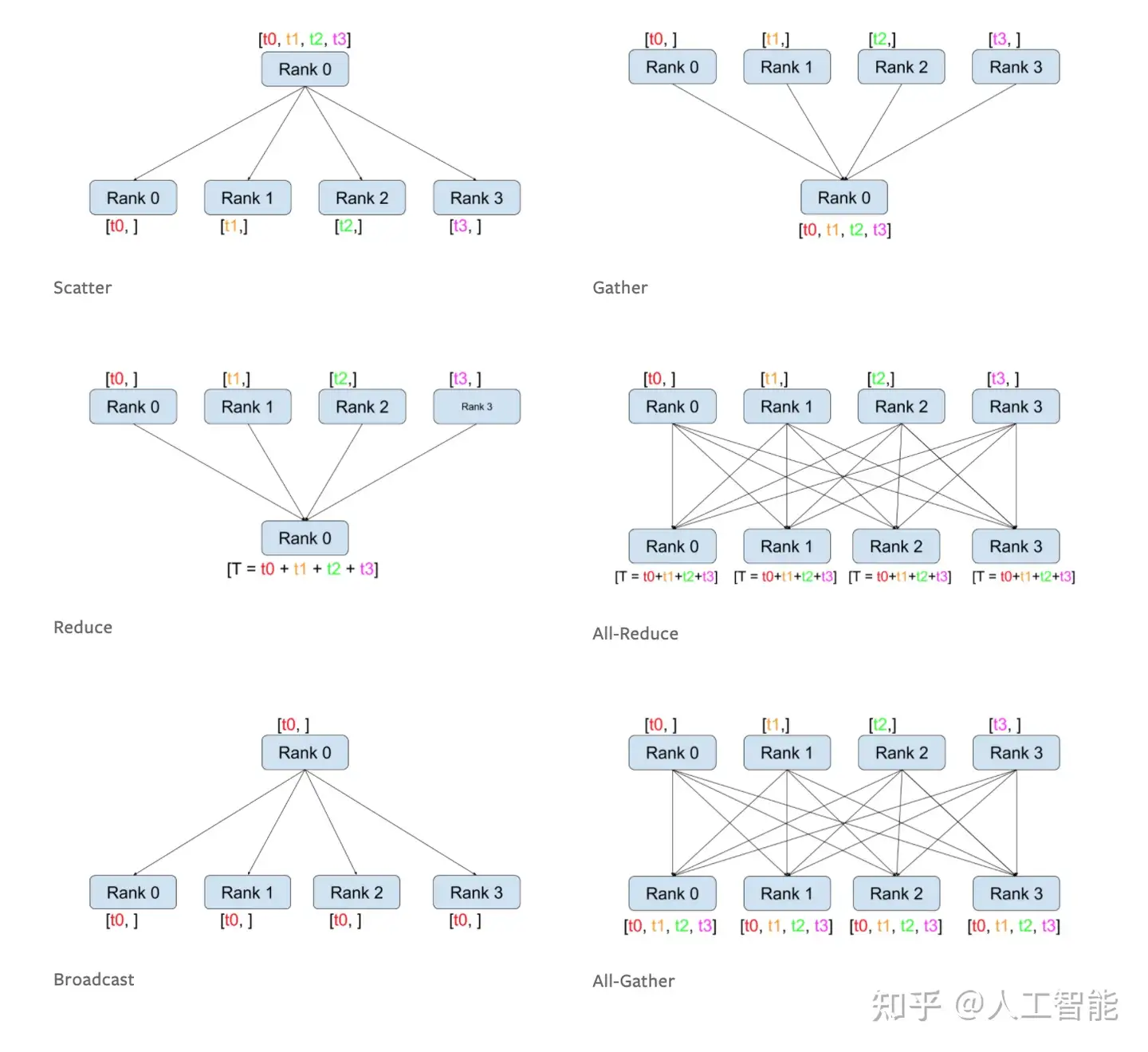
all_gather
分布式操作
- gather 操作用于在不同节点间收集信息
- 首先初始化一个空 Tensor 列表 tensor_list, 用于接收所有节点的信息
- 然后调用 all_gather 在所有节点中得到包含每个节点本地张量的列表
- 列表中有 world_size 个元素,每个元素都是bs大小,后续通过cat操作即可得到大小为 bs * world_size 表示
Pytorch DDP 分布式数据合并通信 torch.distributed.all_gather()
torch.distributed.all_gather()
函数定义
tensor_list是list,大小是 word_size,每个元素为了是gather后,保存每个rank的数据,所以初始化一般使用torch.empty;tensor代表各rank中的tensor数据,其中tensor_list每个分量的维度要与对应的tensor参数中每个rank的维度相同。
all_gather(tensor_list, tensor, group=None, async_op=False):
- tensor_list 每个元素代表每个rank的数据
- tensor 代表每个进程中的tensor数据
- 其中tensor_list每个分量的维度要与对应的tensor参数中每个rank的维度相同。
# 两个机器,每个4张卡,批大小为bs
tensor = torch.arange(bs, dtype=torch.int64) + 1 + 2 * rank
tensor_list = [torch.zeros(bs, dtype=torch.int64) for _ in range(torch.distributed.get_world_size())]
dist.all_gather(tensor_list, tensor)
tensor_list
all_reduce
all_reduce 操作用于在不同节点中同步信息
- 调用该方法, 在所有节点中求和/平均,使用前后大小均为bs
tensor = torch.arange(bs, dtype=torch.int64) + 1 + 2 * rank
dist.all_reduce(tensor, op=ReduceOp.SUM)
tensor
all_reduce 函数定义
- tensor 代表各rank中的tensor数据,op代表可以选择的操作,主要有: SUM、PRODUCT、MIN,MAX、BAND、BOR、BXOR、PREMUL_SUM
Torchrun (更新)
PyTorch 官网介绍
- This module(torch.distributed.launch) is going to be deprecated in favor of
torchrun.
Pytorch 1.9.0 引入了 torchrun,替代以前的 torch.distributed.launch。
- torchrun 是
torch.distributed.launch的超集, elastic launch, 等效于python -m torch.distributed.run - torchrun 包含
torch.distributed.launch几乎所有功能(除了废弃的--use-env)
torchrun 包含了 torch.distributed.launch 所有功能,还有三点额外功能:
- 1、
worker_rank和world_size将被自动分配 - 2、
Failover: worker失败时, 重新启动所有workers来处理 workers 故障 - 3、
Elastic: 动态增减节点, 允许节点数目在最大/最小值之间改变, 即具备弹性
用法
几种模式
- 单机多卡 torchrun –standalone –nnodes=1 –nproc_per_node=N inference.py –args
- 多机多卡 torchrun –nnodes=M –nproc_per_node=N inference.py –args
–nnodes:计算节点(也就是机器)的数量,单机的话就是1,M机的话就是M –nproc_per_node:每个节点(每台机器)上进程的数量。因为一个进程需要放在一张显卡上跑,因此进程的数量也就是显卡的数量,比如单机八卡,就要将该参数设置为8 –args:运行inference.py脚本所需的参数
torchrun 示例
2机8卡 分布式训练示例
- gpu 编号: 0~3
- local rank: gpu 本地编号, 0~3
- global rank: gpu 全局编号, 0~7
环境
- code: BetterDL - train_elastic.py
- 运行环境: 2台4卡 v100机器
train_elastic.py
def run():
env_dict = {
key: os.environ[key]
for key in ("MASTER_ADDR", "MASTER_PORT", "WORLD_SIZE", "LOCAL_WORLD_SIZE")
}
print(f"[{os.getpid()}] Initializing process group with: {env_dict}")
dist.init_process_group(backend="nccl")
train()
dist.destroy_process_group()
if __name__ == "__main__":
run()
启动脚本 run_elastic.sh
- node0 和 node1 上分别执行脚本
torchrun \
--nnodes=1:3\
--nproc_per_node=4\
--max_restarts=3\
--rdzv_id=1\
--rdzv_backend=c10d\
--rdzv_endpoint="192.0.0.1:1234"\
train_elastic.py
描述如下(注:node0和node1均通过该脚本进行启动)
- –
nnodes=1:3: 当前训练任务接受最少1个node,最多3个node, 参与分布式训练; - –
nproc_per_node=4: 每个node上节点有4个process - –
max_restarts=3: worker group最大的重启次数;- 注意: node fail、node scale down和node scale up都会导致restart;
- –
rdzv_id=1:一个unique的job id,所有node均使用同一个job id; - –
rdzv_backend: rendezvous backend实现,默认支持c10d和etcd两种;rendezvous用于多个node之间的通信和协调; - –
rdzv_endpoint: rendezvous 地址,应该为一个node的host ip和port;
迁移 launch -> torchrun
torch.distributed.launch -> torchrun
迁移方法
python -m torch.distributed.launch -> torchrun
# (1) 如果 从环境变量(LOCAL_RANK)中读取 local_rank 参数, 直接忽略
# 更改前
python -m torch.distributed.launch --use-env train_script.py
# 更改后
torchrun train_script.py
# (2) 如果 从命令行(--local-rank)读取 local_rank 参数
# 更改前
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local-rank", type=int)
args = parser.parse_args()
local_rank = args.local_rank
# 更改后
import os
local_rank = int(os.environ["LOCAL_RANK"])
# local_rank参数应当从环境变量中读取,而不是通过参数传递。
### ------ BEFORE ------
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
local_rank = args.local_rank
### ------ NOW -------
import os
local_rank = int(os.environ["LOCAL_RANK"])
#运行脚本
torchrun train_script.py #除了--use_env参数,其他torch.distributed.launch所使用的参数均可使用,
#如nnodes、nproc_per_node
初始化 init_process_group
dist.init_process_group() 是PyTorch中用于初始化分布式训练的函数之一。
- 作用: 设置并行训练环境,连接多个进程以进行数据和模型的分布式处理。
通过init_process_group()函数这个方法来进行初始化
其参数包括以下内容
backend(必需参数):指定分布式后端的类型,选项之一:- ‘tcp’:使用TCP协议进行通信。
- ‘gloo’:使用Gloo库进行通信。
- ‘mpi’:使用MPI(Message Passing Interface)进行通信。
- ‘nccl’:使用NCCL库进行通信(适用于多GPU的分布式训练)。
- ‘hccl’:使用HCCL库进行通信(适用于华为昇腾AI处理器的分布式训练)。
init_method(可选参数):指定用于初始化分布式环境的方法。它可以是以下选项之一:- ‘env://’:使用环境变量中指定的方法进行初始化。
- ‘file:// ’:使用本地文件进行初始化。
- ‘tcp://:’:使用TCP地址和端口进行初始化。
- ‘gloo://:’:使用Gloo地址和端口进行初始化。
- ‘mpi://:’:使用MPI地址和端口进行初始化。
rank(可选参数):指定当前进程的排名(从0开始)。world_size(可选参数):指定总共使用的进程数。timeout(可选参数):指定初始化的超时时间。group_name(可选参数):指定用于连接的进程组名称。
多机多卡 DDP
概念理解
group:进程组,通常DDP的各个进程都是在同一个进程组下world_size: 总的进程数量(原则上,一个进程占用一个GPU)rank:当前进程的序号,用于进程间通信,rank=0表示主机为master节点local_rank:当前进程对应的GPU号
举个栗子 :
- 4台机器 (每台机器8张卡) 进行分布式训练。
- 通过 init_process_group() 对进程组进行初始化。
- 初始化后 可以通过 get_world_size() 获取到 world size = 32。
- 在该例中为32, 即有32个进程,其编号为0-31 通过 get_rank() 函数可以进行获取 在每台机器上,local rank均为0-8, 这是 local rank 与 rank 的区别, local rank 会对应到实际的 GPU ID 上。
########################## 第1步 ##########################
#初始化
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(rank % torch.cuda.device_count())
dist.init_process_group(backend="nccl")
device = torch.device("cuda", local_rank)
########################## 第2步 ##########################
#模型定义
model = model.to(device)
model = DDP(model, device_ids=[local_rank], output_device=local_rank)
#数据集操作与DDP一致
#####运行
'''
exmaple: 2 node, 8 GPUs per node (16GPUs)
需要在两台机器上分别运行脚本
注意细节:node_rank master 为 0
机器1
>>> python -m torch.distributed.launch \
--nproc_per_node=8 \
--nnodes=2 \
--node_rank=0 \
--master_addr="master的ip" \
--master_port=xxxxx \
YourScript.py
机器2
>>> python -m torch.distributed.launch \
--nproc_per_node=8 \
--nnodes=2 \
--node_rank=1 \
--master_addr="master的ip" \
--master_port=xxxxx \
YourScript.py
'''
FSDP (DDP改进)
FSDP (Fully Sharded Data Parallelism) 是一种分布式训练技术,通过分片(Sharding) 模型参数、梯度和优化器状态,将大型模型的训练负载分散到多个GPU或计算节点上,从而解决传统数据并行方法(如DDP) 在训练超大模型时的内存瓶颈问题。
其核心思想源自 ZeRO (Zero Redundancy Optimizer) 优化器 (如DeepSpeed 的ZeRO-3阶段),通过消除内存冗余实现内存高效利用。
FSDP 核心功能:将模型参数分片到多个 GPU 上,并在需要时动态地进行参数的 all-gather 操作
【2024-12-02】结合 HSDP 及模型并行加速 Llama3 训练
- 在 Efficient Large-Scale Training with Pytorch FSDP and AWS 中,Meta 首次展示 FSDP(Fully Sharded Data Parallel) 如何利用云上基础设施( A100 GPU P4de 实例集群)来实现大规模训练的提效。
- FSDP 作为 ZeRO 一种实现形式,其通过消除 DDP(分布式数据并行)中存在的优化器计算和状态存储、梯度和模型参数内存存储的冗余,有效扩展了在固定资源下可训练的模型量级。这种冗余减少,使 FSDP 相比于朴素数据并行能够在相同的资源下训练更大的模型
- 参考 Maximizing training throughput using PyTorch FSDP,使用 FSDP 及 A100 GPU 集群 Llama2 7B 上达到 上训练 Llama2 7B 达到了57%的较高水位 MFU)。
在 PyTorch 的 2.1 及近期的 2.4 版本中,分别正式支持了 FSDP 的 Hybrid Sharded Data Parallel 以及 DeviceMesh。
DistributedDataParallel (DDP) 训练
多机多卡方式中
- 每个 process/worker 都有模型的一个
副本(Replica) - 每个 process/worker 处理一个 batch 数据, 并行处理
- 最后用
all-reduce操作对多个不同 process/worker 计算得到的梯度进行累加求和; - 接着,再将优化器状态、梯度通过跨多个 process/worker 进行复制,使得每个 process/worker 上的模型参数都得到同步更新。
DDP 中,模型权重和优化器状态在所有工作线程中复制。
- 核心能力还是训练数据并行(Data Parallel)
- DDP 没有实现对
模型参数的分片管理,即模型并行(Model Parallel)
PyTorch 1.11 中发布 FSDP
- FSDP 是一种数据并行性,可跨 DDP 等级分片
模型参数、优化器状态和梯度。 - Getting Started with Fully Sharded Data Parallel(FSDP)
- PyTorch 分布式训练模式 FSDP 设计分析
FSDP 实现了模型的分片管理能力,真正实现了模型并行。
- 将模型分片后,使用 FSDP 训练模型,每个 GPU 只保存模型的一个分片,这样能够使 GPU 的内存占用比 DDP 方式小得多,从而使分片的大模型和数据能够适配 GPU 容量,更有希望实现超大模型的分布式训练。
- 问题: process/worker 节点之间的通信开销一定程度增加,但是可在 PyTorch 内部有针对性地进行优化来降低通信代价,比如对通信、计算进行 overlapping 能够很好地降低由此带来的网络开销。
使用 FSDP 训练时,GPU 内存占用量比在所有工作线程上使用 DDP 进行训练时要小。
- 允许更大模型或批量大小适合设备,使一些非常大的模型的训练变得可行。
- 这是伴随着通信量增加的成本而来的。通过内部优化(例如重叠通信和计算)减少了通信开销。

FSDP 原理
FSDP 在不同阶段的基本处理过程,如下所示:
- 01
初始化阶段- 分片模型参数,每个 rank 只有自己的分片
- 02
forward阶段- 运行
all_gather,收集所有 rank 上的模型参数分片,生成恢复得到模型参数,以保证满足当前 FSDP Unit 的计算需要 - 运行 forward 计算过程
- 丢掉所有被收集过的其它 rank 上的模型参数分片
- 运行
- 03
backward阶段- 运行
all_gather, 收集所有 rank 上的模型参数分片,恢复全部的模型参数,以保证满足当前 FSDP Unit 的计算需要 - 运行 backward 计算过程
- 运行
reduce_scatter, 在所有 rank 之间同步梯度 - 丢掉所有从其它 rank 上收集过的模型参数分片
- 运行
查看 FSDP’s 分片方法
- 将 DDP 梯度全归约分解为
归约分散和全聚集。 - 向后传递过程中,FSDP 减少并分散梯度,确保每个等级都拥有梯度碎片。
- 在优化器步骤中更新参数的相应分片。
- 最后,后续前向传播中,执行全收集操作来收集并组合更新的参数分片
分片原理
FSDP 默认的分片策略(Sharding Strategy)是对模型参数、梯度、优化器状态都进行分片处理,即 Zero3 分片策略
- 编程中可以使用
ShardingStrategy.FULL_SHARD来指定。
对于 Zero2 分片策略,只对梯度、优化器状态进行分片处理
- 编程中可以使用
ShardingStrategy.SHARD_GRAD_OP来指定。 - 如果配置使用 Zero2 分片策略,那么所有模型参数都会全量加载到每个 rank 对应的 GPU 内,即每个 GPU 持有一个模型的副本。
- forward 阶段和 backward 阶段模型参数都在 GPU 内而不会被 offload 到 CPU,这样就不需要频繁地在多个 GPU 之间传输模型参数分片信息,能够在一定程度上降低 FSDP 集群的通信开销。
FSDP 处理模型分片的总体流程
- 论文《PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel》
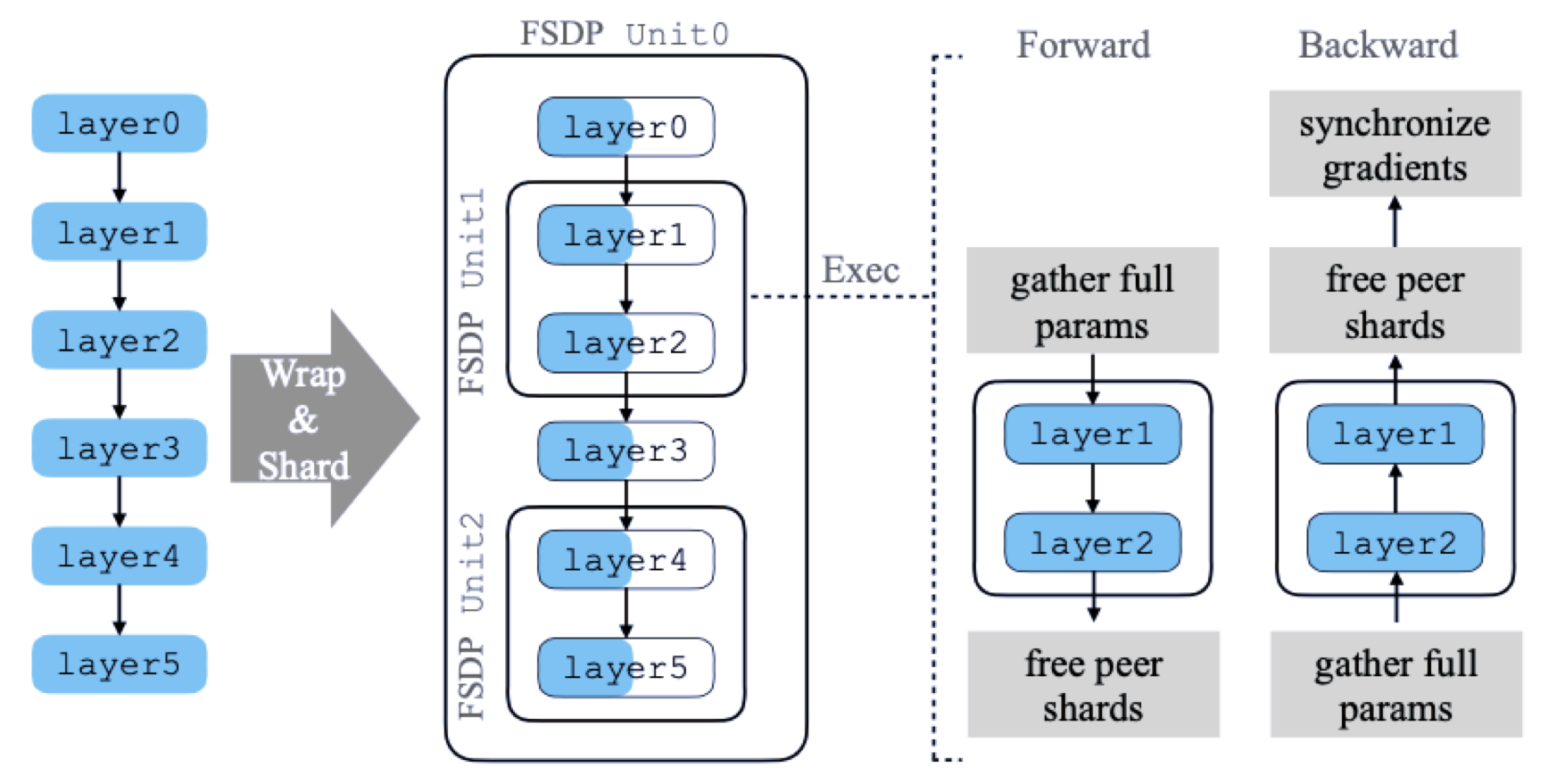
模型具有 6 个层,FSDP 将其分解为 3 个 FSDP Unit,分别为
- Unit0 = [layer0, layer3]
- Unit1 = [layer1, layer2]
- Unit2 = [layer4, layer5]
进行 forward 和 backward 计算之前需要从其它 rank 上收集对应的参数分片,从而保证计算是正确的。
以 Unit1 为例, 说明如何进行分片处理,该 FSDP Unit 包含了 layer1 和 layer2 两层。
- 进行 forward 计算之前,需要将这两层的参数对应于其它 rank 上的分片收集过来使 layer1 和 layer2 两层的参数是 Unsharded,即保证参数是完整的以便进行计算,然后在本地执行 forward 计算过程,完成 layer0 和 layer3 这两层的计算逻辑。当 forward 计算完成后,会释放掉刚刚从其它 rank 上收集到的参数分片,以降低内存空间的占用。每一轮 forward 计算,FSDP 一次只需要处理一个 Unit 的参数即可,而其它的 Unit 仍然保持其参数的分片状态。
- 对于 backward 计算的过程也是类似的,它会先计算 layer2,再计算 layer1,在开始计算 layer2 层之前,FSDP 会从其它 rank 上收集 layer2、layer1 层的分片参数,恢复得到这两层完整的参数后,Autograd 引擎会继续完成 layer2、layer1 这两层的计算,随后释放掉从其它 rank 上收集过来的参数分片。接着,FSDP 会进行 reduce-scatter 操作对梯度进行累加并分片。当 backward 计算结束后,每个 rank 都只保存了模型参数和梯度的分片部分。
FSDP 模型初始化
FSDP 模型初始化时,通过指定一个 device_id 参数来绑定到指定的 GPU 上
- 首先模型的 Module 会在 CPU 中初始化
- 然后加载到 GPU 内。
通过指定 device_id 能够保证当 GPU 无法容纳大的模型时,它能够 offload 到 CPU 中,而不至于出现 OOM 的问题。
创建 FSDP 模型
- 只要将模型(继承自 nn.Module) model,通过 FSDP 进行 wrap 即可
- 其中指定一些满足需要的配置选项
参数
auto_wrap_policy: 自动将模型分片处理,包括对模型参数、优化器状态、梯度进行分片,每个分片都放到一个不同的 FSDP Unit 中
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
model = DDP(model)
torch.cuda.set_device(local_rank)
model = FSDP(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=bfSixteen,
device_id=torch.cuda.current_device())
model = FSDP(model,
auto_wrap_policy=my_auto_wrap_policy,
cpu_offload=CPUOffload(offload_params=True))
注意
- Transformer Encoder-Decoder 架构模型包含一些被 Encoder 和 Decoder 共享部分,比如 embedding 表,如果直接使用上面的
auto_wrap_policy参数指定 Wrap Policy, 会使神经网络模型中这些共享的部分无法被共享 - 所以只能把共享部分移动到 FSDP Unit 外部去,以便 Encoder 和 Decoder 都能访问这部分。
- PyTorch 1.12 引入处理这种情况的特性,为 Transformer 注册一个 共享 Layer 实现类,使 FSDP 的分片计划(Sharding Plan)实现高效的通信处理。
t5_auto_wrap_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
T5Block, # T5 Transformer 层的实现类,封装了 MHSA 和 FFN 两层
},
)
torch.cuda.set_device(local_rank)
model = FSDP(model, fsdp_auto_wrap_policy=t5_auto_wrap_policy)
HSDP (FSDP改进)
【2024-12-02】结合 HSDP 及模型并行加速 Llama3 训练
全量分片(FSDP)的挑战
基于全量分片如 FSDP 或 DeepSpeed ZeRO 3 的训练范式,包括对于参数、梯度、优化器状态等的切分,能够带来明显的显存节省。但其所引入的额外通信开销,以及可能的 CPU 卸载所需的主机及 GPU 间内存拷贝开销等,所带来的挑战有:
- 额外通信开销:由于参数分片,在训练前向时,每个 GPU 都需要额外的通信操作(All-Gather)来从其他所有 GPU 汇集参数,并通过逐层汇集及用完丢弃的形式, 虽然保证了内存的节省,但引入了参数量规模的通信开销,叠加训练反向时的参数的逐层汇集及梯度分发汇总,导致累计 3 倍于参数量的通信,是标准的数据并行通信量的 1.5 倍,参考 ZeRO Ch5.3。
- 进程间通信时延瓶颈的累积:由于节点内和跨节点 GPU 进程通信时延的不对等,同时跨节点进程通信受集群拓扑的影响较大。由于全量分片涉及到集群中的所有 GPU 进程,因此当集群规模扩大时,通信路径上的时延瓶颈可能出现叠加及积累,导致其带来的影响更加显著,制约了集群规模及训练性能的进一步提升。
HSDP 混合分片并行
不同于 FSDP 中直接在全集群上进行训练状态的分片,HSDP(Hybrid Shard Data Parallel)使用混合分片策略,可以根据集群的拓扑形态进行分片,比如在节点内完全分片,并在节点之间使用不同模型副本进行数据并行。
使得较大开销的 AllGather 及 ReduceScatter 集合操作仅在节点内完成,因此可以更好的利用 GPU 间 NVLink 带宽,对于中等大小的模型训练,能够带来较显著的性能收益。
FSDP 和 HSDP 都依赖于进程组(Process Group)进行通信。进程组是用于模型分片的通信组,FSDP 默认自动构造进程组,来自动进行 AllGather 及 ReduceScatter 等集合通信操作。对于 HSDP,可以通过传入一个 ProcessGroup 的描述元组,来分别表征分片及模型副本所使用的组,用于描述模型状态分片、多副本间并行的组合形式。
较新的 DeviceMesh 是一种更高级别的抽象,用于管理多个进程组(ProcessGroup)。其简化了在节点内和节点间创建进程组的过程,无需手动设置子进程组的 Ranks。此外,DeviceMesh 也可以对多维并行场景下的底层进程组和设备进行管理。因此,在较新版本的 PyTorch 中,DeviceMesh 成为了进程组的互斥替代形式。比如,在混合分片(HSDP)训练时,可以通过指定一个2维的 DeviceMesh 来取代相对更复杂的 ProcessGroup 定义。
分布式训练高层封装
对 torch 几个流程进行一层封装【初始化、包装模型、优化器、数据加载】。
考虑几个因素
- 支持分布式训练模式丰富,如 CPU,单机单卡,单机多卡,多机多卡,FP16等
- 代码简单,不需要改动大量代码, 即可进行分布式训练
- 接口丰富,方便自定义。比如 能调用和访问底层分布式的一些变量如rank,worldsize,或实现或封装一些分布式函数,比如dist.gather/reduce等。
得到更加易用的框架:
- Accelerator
- Horovod
这两个都是非常易用的分布式框架。 还有一些其他的,比如 pytorch-lightning,deepspeed。
以bert情感分类为例子,介绍了如何使用原生DDP和上面2个框架来进行分布式训练
Accelerator
由大名鼎鼎的 huggingface 发布的 Accelerator,专门适用于Pytorch 分布式训练框架:
- GitHub: accelerate
- 官网教程:accelerate
将单进程代码改为多进程分布式:
import accelerate
accelerator = accelerate.Accelerator()
device = accelerator.device #获取当前进程的设备
...
# 进行封装
model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)
#训练时 loss.backward() 换为:
accelerator.backward(loss)
使用CLI命令行方式运行,先使用 accelerator config 配置一次分布式训练参数,之后就使用 acceleratoe launch 运行。
除此之外,accelerator 还提供了一些很便利的接口,基本覆盖了分布式训练中需要用到的方法,比如:
- accelerator.
print: 仅仅在主进程输出 - accelerator.
process_index: 当前进程ID,没有使用rank命名,而是用的process_index来表示 - accelerator.
is_local_main_process/is_main_processs: 是否local_rank 或则rank为0, 主进程 - accelerator.
wait_for_everyone(): 类似 dist.barrier() , 等所有进程到达这一步。 - accelerator.
save: 保存模型 - kwargs_handlers: 可以定义DDP初始化的一些参数,比如最常用的就是 find_unused_parameters,比如:
import accelerate
from accelerate import DistributedDataParallelKwargs as DDPK
kwargs = DDPK(find_unused_parameters=True)
accelerator = accelerate.Accelerator(kwargs_handlers=[kwargs])
accelerator 基本已经满足使用 Pytorch 进行分布训练的需求,而且十分符合 huggingface 风格,把某个小项目做到最好用,类似的还有 transformers, tokenizers, datasets 等等。
不足
- accelerate 支持的 collective function 比较少,目前只有 all_gather。
Horovod 第二个常用的分布式库Horovod是一个通用的深度学习分布式训练框架,支持Tensorflow,Pytorch,MXNet,Keras等等,因此比Accelerator要更加重些,但是功能也会更加丰富,这里以Pytorch为例来简单介绍。多说一下,Horovod的安装相对复杂一些,需要针对具体的环境参考readme进行安装。
GitHub:https://github.com/horovod/horovod 官网:https://horovod.ai/ Horovod的使用也很简单,基本也是那几个流程:
import horovod.torch as hvd
# 初始化
hvd.init()
# Samapler
# *此处num_replicas=hvd.size(), rank=hvd.rank()必须*
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
# 优化器包装
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
# 模型分发广播
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
# 模型训练不需要修改
horovod 支持的运行方式非常多,最常用的就是 horovodrun ,比如单机四卡运行:
horovodrun -np 4 -H localhost:4 python3 train.py
horovod 相比 accelerate 功能更加丰富,支持的接口,函数,框架都要多, 比如: hvd.all_reduce, hvd.all_gather等等。
Horovod
Horovod 是 Uber开源的跨平台的分布式训练工具,名字来自于俄国传统民间舞蹈,舞者手牵手围成一个圈跳舞,与Horovod设备之间的通信模式很像,有以下几个特点:
- 兼容TensorFlow、Keras和PyTorch机器学习框架。
- 使用Ring-AllReduce算法,对比Parameter Server算法,有着无需等待,负载均衡的优点。
- 实现简单,五分钟包教包会。
Horovod环境准备以及示例代码,可参考上一篇
Pytorch 1.x 多机多卡计算模型没有采用主流的 Parameter Server 结构,而是直接用了Uber Horovod 的形式,即百度开源的 RingAllReduce 算法
Uber 的 Horovod 采用 RingAllReduce 计算方案,特点:网络单次通信量不随着 worker(GPU) 的增加而增加,是一个恒定值。
与 TreeAllReduce 不同,RingAllreduce 算法的每次通信成本是恒定的,与系统中 gpu 的数量无关,完全由系统中 gpu 之间最慢的连接决定。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
