目标检测
资讯
【2023-10-27】大模型时代目标检测任务会走向何方?
经典目标检测一般指闭集固定类别检测。新类型
Open Set/Open World/OOD- 检测任何前景物体但有些不需要预测类别,unknown 标记

Open Vocabulary- 开放词汇目标检测:给定任意词汇都可以检测出来
- 开放集任务,相比 open set,识别训练集类别外的新类别
- 这类模型需要接入文本作为一个模态输入。训练集和测试集的类别不能重复,但图片重复可以重复
- OVD 任务更加贴合实际应用,文本的描述不会有很大限制,同一个物体你可以采用多种词汇描述都可以检测出来

Phrase Grounding, 也做phrase localization。- 给定名词短语,输出对应的单个或多个物体检测框。
- Phrase Grounding 任务包括 OVD 任务。
- 常见的评估数据集是 Flickr30k Entities
- 如果是输入一句话,那么就是定位这句话中包括的所有名词短语。在 GLIP 得到了深入的研究。


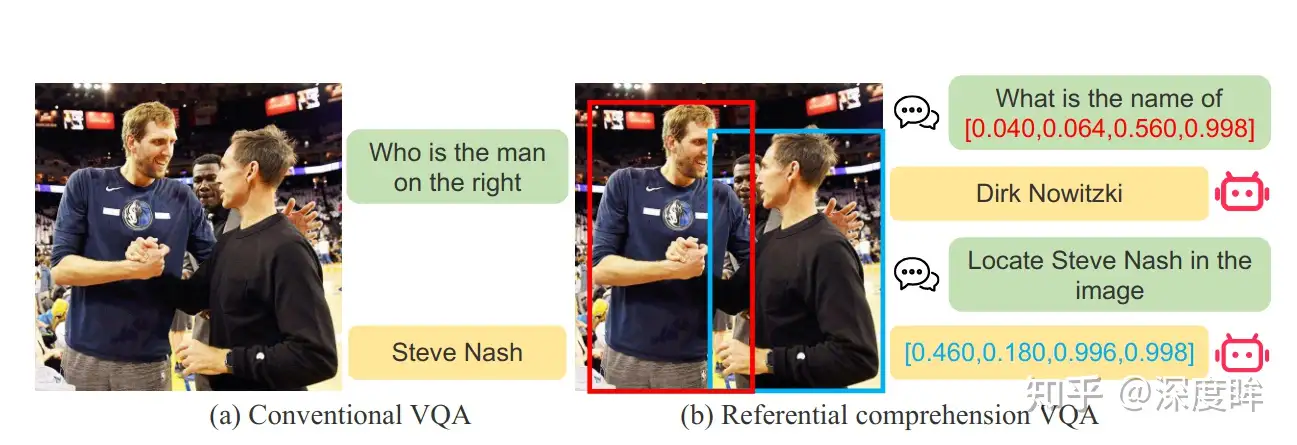
Referring Expression Comprehension简称REC, 也称为 visual grounding。- 给定图片和一句话,输出对应的物体坐标,通常就是单个检测框。
- 常用的是 RefCOCO/RefCOCO+/RefCOCOg 三个数据集。是相对比较简单的数据集。这个任务侧重理解。

Description Object Detection- 描述性目标检测也称 广义 Referring Expression Comprehension。
- 为何叫做广义,目前常用的 REC 问题:当前数据集只指代1个物体、没有负样本、正向描述
- Described Object Detection 论文提出新的数据集,命名为
DOD。类似还有 gRefCOCO 
Caption with Grounding- 给定图片,要求模型输出图片描述,同时对于其中的短语都要给出对应的 bbox
- 像 Phrase Grounding 的反向过程。
- 这个任务可以方便将输出的名称和 bbox 联系起来,方便后续任务的进行。

Reasoning Intention-Oriented Object Detection- 意图导向的目标检测,和之前的 DetGPT 提出的推理式检测非常类似。
- DetGPT 中的推理式检测含义是:给定文本描述,模型要能够进行推理,得到用户真实意图。
- 示例: 我想喝冷饮,LLM 会自动进行推理解析输出 冰箱 这个单词,从而可以通过 Grounding 目标检测算法把冰箱检测出来。模型具备推理功能。

- 论文 RIO: A Benchmark for Reasoning Intention-Oriented Objects in Open Environments
基于区域输入的理解和 Grounding- 非常宽泛的任务,表示不仅可以输入图文模态,还可以输入其他任意模态,然后进行理解或者定位相关任务。
- 最经典的任务是 Referring expression generation:给定图片和单个区域,对该区域进行描述。常用的评估数据集是 RefCOCOg
- 现在也有很多新的做法,典型的如 Shikra 里面提到的 Referential dialogue,包括 REC,REG,PointQA,Image Caption 以及 VQA 5 个任务
背景
计算机视觉领域的典型任务就是目标检测
- 目标检测最新趋势:deep_learning_object_detection
- 发展历史:


- 【2020-4-23】技术总结
类型
- 目标检测(Object Detection),在计算机视觉领域的任务就是给定一张图片,将图片中的物体识别并且框定出来。
- object detection的算法主要可以分为两大类:two-stage detector和one-stage detector。
- One-Stage检测算法是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。
- Two-Stage检测算法是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。
- PS:Multi-Stage检测算法的Selective Search、Feature extraction、Location regression、Class SVM等环节都是分开训练,操作繁杂而且效果不好,所以这里默认忽视。
- focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。
- 参考:目标检测算法综述
- One-Stage检测算法的初衷是提升速度,而Two-Stage中比较耗时就是proposal建议区域生成,所以索性One-Stage方法就是直接从图像建议区域提取特征进行分类和定位回归。
- 图像建议区域是直接从backbone的特征层中进行密集选取,所以一些one-stage算法也称为密集检测器。同时可以看出,one-stage主要处理的问题是:特征提取、分类和定位回归。即关键点全部在特征提取这一块上。
- 图像建议区域是直接从backbone的特征层中进行密集选取,所以一些one-stage算法也称为密集检测器。同时可以看出,one-stage主要处理的问题是:特征提取、分类和定位回归。即关键点全部在特征提取这一块上。
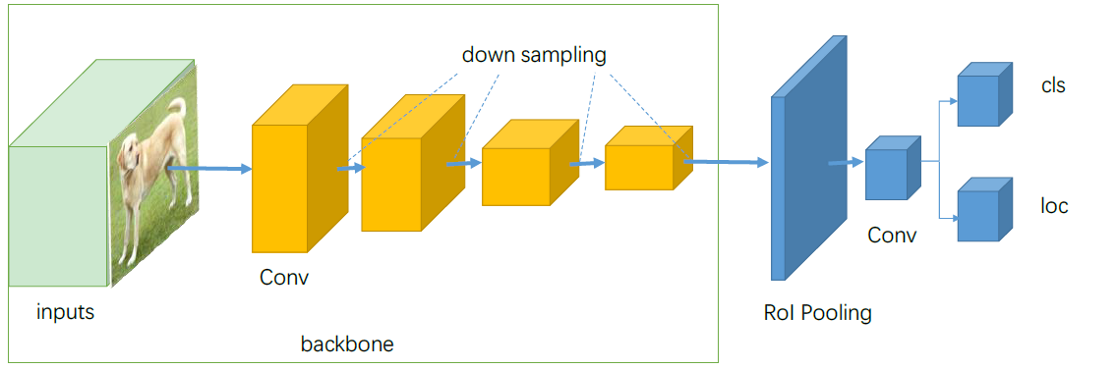
- Two-Stage检测算法可以通过ROI pooling layer(以Faster R-CNN为例)进行结构划分,前部分提出可能存在目标的区域,后部分即目标分类和定位回归。结构如下
- two-stage主要处理的几个问题是:backbone进行特征提取、proposal建议区域的生成、分类和定位回归。

- two-stage主要处理的几个问题是:backbone进行特征提取、proposal建议区域的生成、分类和定位回归。
算法综述
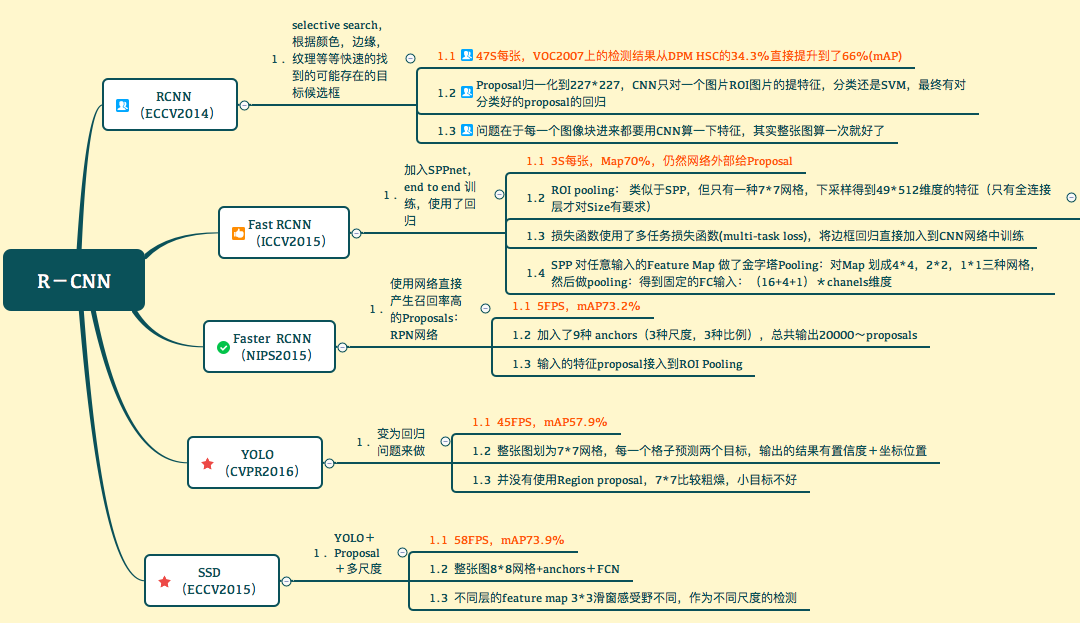
- 【2018-4-7】从RCNN到SSD,这应该是最全的一份目标检测算法盘点
目标检测进行了整体回顾
- 第一部分从 RCNN 开始介绍基于候选区域的目标检测器,包括 Fast R-CNN、Faster R-CNN 和 FPN 等。
- 第二部分则重点讨论了包括 YOLO、SSD 和 RetinaNet 等在内的单次检测器,它们都是目前最为优秀的方法。
排行榜
- huggingface 榜单:object_detection_leaderboard
数据集
大白智能数据集汇总
基于候选区域的目标检测器
滑动窗口检测器
自从 AlexNet 获得 ILSVRC 2012 挑战赛冠军后,用 CNN 进行分类成为主流。一种用于目标检测的暴力方法是从左到右、从上到下滑动窗口,利用分类识别目标。为了在不同观察距离处检测不同的目标类型,我们使用不同大小和宽高比的窗口。

滑动窗口(从右到左,从上到下)
我们根据滑动窗口从图像中剪切图像块。由于很多分类器只取固定大小的图像,因此这些图像块是经过变形转换的。但是,这不影响分类准确率,因为分类器可以处理变形后的图像。

将图像变形转换成固定大小的图像
变形图像块被输入 CNN 分类器中,提取出 4096 个特征。之后,我们使用 SVM 分类器识别类别和该边界框的另一个线性回归器。

滑动窗口检测器的系统工作流程图。
下面是伪代码。我们创建很多窗口来检测不同位置的不同目标。要提升性能,一个显而易见的办法就是减少窗口数量。
for window in windows
patch = get_patch(image, window)
results = detector(patch)
选择性搜索
我们不使用暴力方法,而是用候选区域方法(region proposal method)创建目标检测的感兴趣区域(ROI)。在选择性搜索(selective search,SS)中,我们首先将每个像素作为一组。然后,计算每一组的纹理,并将两个最接近的组结合起来。但是为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。我们继续合并区域,直到所有区域都结合在一起。下图第一行展示了如何使区域增长,第二行中的蓝色矩形代表合并过程中所有可能的 ROI。

图源:van de Sande et al. ICCV’11
R-CNN
R-CNN 利用候选区域方法创建了约 2000 个 ROI。这些区域被转换为固定大小的图像,并分别馈送到卷积神经网络中。该网络架构后面会跟几个全连接层,以实现目标分类并提炼边界框。

使用候选区域、CNN、仿射层来定位目标。
以下是 R-CNN 整个系统的流程图:

通过使用更少且更高质量的 ROI,R-CNN 要比滑动窗口方法更快速、更准确。
ROIs = region_proposal(image)
for ROI in ROIs
patch = get_patch(image, ROI)
results = detector(patch)
边界框回归器
候选区域方法有非常高的计算复杂度。为了加速这个过程,我们通常会使用计算量较少的候选区域选择方法构建 ROI,并在后面使用线性回归器(使用全连接层)进一步提炼边界框。

使用回归方法将蓝色的原始边界框提炼为红色的。
Fast R-CNN
R-CNN 需要非常多的候选区域以提升准确度,但其实有很多区域是彼此重叠的,因此 R-CNN 的训练和推断速度非常慢。如果我们有 2000 个候选区域,且每一个都需要独立地馈送到 CNN 中,那么对于不同的 ROI,我们需要重复提取 2000 次特征。
此外,CNN 中的特征图以一种密集的方式表征空间特征,那么我们能直接使用特征图代替原图来检测目标吗?


直接利用特征图计算 ROI。
Fast R-CNN 使用特征提取器(CNN)先提取整个图像的特征,而不是从头开始对每个图像块提取多次。然后,我们可以将创建候选区域的方法直接应用到提取到的特征图上。例如,Fast R-CNN 选择了 VGG16 中的卷积层 conv5 来生成 ROI,这些关注区域随后会结合对应的特征图以裁剪为特征图块,并用于目标检测任务中。我们使用 ROI 池化将特征图块转换为固定的大小,并馈送到全连接层进行分类和定位。因为 Fast-RCNN 不会重复提取特征,因此它能显著地减少处理时间。

将候选区域直接应用于特征图,并使用 ROI 池化将其转化为固定大小的特征图块。
以下是 Fast R-CNN 的流程图:

在下面的伪代码中,计算量巨大的特征提取过程从 For 循环中移出来了,因此速度得到显著提升。Fast R-CNN 的训练速度是 R-CNN 的 10 倍,推断速度是后者的 150 倍。
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
results = detector2(patch)
Fast R-CNN 最重要的一点就是包含特征提取器、分类器和边界框回归器在内的整个网络能通过多任务损失函数进行端到端的训练,这种多任务损失即结合了分类损失和定位损失的方法,大大提升了模型准确度。
ROI 池化
因为 Fast R-CNN 使用全连接层,所以我们应用 ROI 池化将不同大小的 ROI 转换为固定大小。
为简洁起见,我们先将 8×8 特征图转换为预定义的 2×2 大小。
- 下图左上角:特征图。
- 右上角:将 ROI(蓝色区域)与特征图重叠。
- 左下角:将 ROI 拆分为目标维度。例如,对于 2×2 目标,我们将 ROI 分割为 4 个大小相似或相等的部分。
- 右下角:找到每个部分的最大值,得到变换后的特征图。

输入特征图(左上),输出特征图(右下),ROI (右上,蓝色框)。
按上述步骤得到一个 2×2 的特征图块,可以馈送至分类器和边界框回归器中。
Faster R-CNN
Fast R-CNN 依赖于外部候选区域方法,如选择性搜索。但这些算法在 CPU 上运行且速度很慢。在测试中,Fast R-CNN 需要 2.3 秒来进行预测,其中 2 秒用于生成 2000 个 ROI。
feature_maps = process(image)
ROIs = region_proposal(feature_maps) # Expensive!
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
results = detector2(patch)
Faster R-CNN 采用与 Fast R-CNN 相同的设计,只是它用内部深层网络代替了候选区域方法。新的候选区域网络(RPN)在生成 ROI 时效率更高,并且以每幅图像 10 毫秒的速度运行。

Faster R-CNN 的流程图与 Fast R-CNN 相同。

外部候选区域方法代替了内部深层网络。
候选区域网络
候选区域网络(RPN)将第一个卷积网络的输出特征图作为输入。它在特征图上滑动一个 3×3 的卷积核,以使用卷积网络(如下所示的 ZF 网络)构建与类别无关的候选区域。其他深度网络(如 VGG 或 ResNet)可用于更全面的特征提取,但这需要以速度为代价。ZF 网络最后会输出 256 个值,它们将馈送到两个独立的全连接层,以预测边界框和两个 objectness 分数,这两个 objectness 分数度量了边界框是否包含目标。我们其实可以使用回归器计算单个 objectness 分数,但为简洁起见,Faster R-CNN 使用只有两个类别的分类器:即带有目标的类别和不带有目标的类别。

对于特征图中的每一个位置,RPN 会做 k 次预测。因此,RPN 将输出 4×k 个坐标和每个位置上 2×k 个得分。下图展示了 8×8 的特征图,且有一个 3×3 的卷积核执行运算,它最后输出 8×8×3 个 ROI(其中 k=3)。下图(右)展示了单个位置的 3 个候选区域。

此处有 3 种猜想,稍后我们将予以完善。由于只需要一个正确猜想,因此我们最初的猜想最好涵盖不同的形状和大小。因此,Faster R-CNN 不会创建随机边界框。相反,它会预测一些与左上角名为「锚点」的参考框相关的偏移量(如𝛿x、𝛿y)。我们限制这些偏移量的值,因此我们的猜想仍然类似于锚点。

要对每个位置进行 k 个预测,我们需要以每个位置为中心的 k 个锚点。每个预测与特定锚点相关联,但不同位置共享相同形状的锚点。

这些锚点是精心挑选的,因此它们是多样的,且覆盖具有不同比例和宽高比的现实目标。这使得我们可以以更好的猜想来指导初始训练,并允许每个预测专门用于特定的形状。该策略使早期训练更加稳定和简便。

Faster R-CNN 使用更多的锚点。它部署 9 个锚点框:3 个不同宽高比的 3 个不同大小的锚点框。每一个位置使用 9 个锚点,每个位置会生成 2×9 个 objectness 分数和 4×9 个坐标。

图源:https://arxiv.org/pdf/1506.01497.pdf
R-CNN 方法的性能
如下图所示,Faster R-CNN 的速度要快得多。

基于区域的全卷积神经网络(R-FCN)
假设我们只有一个特征图用来检测右眼。那么我们可以使用它定位人脸吗?应该可以。因为右眼应该在人脸图像的左上角,所以我们可以利用这一点定位整个人脸。

如果我们还有其他用来检测左眼、鼻子或嘴巴的特征图,那么我们可以将检测结果结合起来,更好地定位人脸。
现在我们回顾一下所有问题。在 Faster R-CNN 中,检测器使用了多个全连接层进行预测。如果有 2000 个 ROI,那么成本非常高。
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
class_scores, box = detector(patch) # Expensive!
class_probabilities = softmax(class_scores)
R-FCN 通过减少每个 ROI 所需的工作量实现加速。上面基于区域的特征图与 ROI 是独立的,可以在每个 ROI 之外单独计算。剩下的工作就比较简单了,因此 R-FCN 的速度比 Faster R-CNN 快。
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
score_maps = compute_score_map(feature_maps)
for ROI in ROIs
V = region_roi_pool(score_maps, ROI)
class_scores, box = average(V) # Much simpler!
class_probabilities = softmax(class_scores)
现在我们来看一下 5 × 5 的特征图 M,内部包含一个蓝色方块。我们将方块平均分成 3 × 3 个区域。现在,我们在 M 中创建了一个新的特征图,来检测方块的左上角(TL)。这个新的特征图如下图(右)所示。只有黄色的网格单元 [2, 2] 处于激活状态。

在左侧创建一个新的特征图,用于检测目标的左上角。
我们将方块分成 9 个部分,由此创建了 9 个特征图,每个用来检测对应的目标区域。这些特征图叫作位置敏感得分图(position-sensitive score map),因为每个图检测目标的子区域(计算其得分)。

生成 9 个得分图
下图中红色虚线矩形是建议的 ROI。我们将其分割成 3 × 3 个区域,并询问每个区域包含目标对应部分的概率是多少。例如,左上角 ROI 区域包含左眼的概率。我们将结果存储成 3 × 3 vote 数组,如下图(右)所示。例如,vote_array[0][0] 包含左上角区域是否包含目标对应部分的得分。

将 ROI 应用到特征图上,输出一个 3 x 3 数组。
将得分图和 ROI 映射到 vote 数组的过程叫作位置敏感 ROI 池化(position-sensitive ROI-pool)。该过程与前面讨论过的 ROI 池化非常接近。

将 ROI 的一部分叠加到对应的得分图上,计算 V[i][j]。
在计算出位置敏感 ROI 池化的所有值后,类别得分是其所有元素得分的平均值。

ROI 池化
假如我们有 C 个类别要检测。我们将其扩展为 C + 1 个类别,这样就为背景(非目标)增加了一个新的类别。每个类别有 3 × 3 个得分图,因此一共有 (C+1) × 3 × 3 个得分图。使用每个类别的得分图可以预测出该类别的类别得分。然后我们对这些得分应用 softmax 函数,计算出每个类别的概率。
以下是数据流图,在我们的案例中,k=3。

总结
基础的滑动窗口算法:
for window in windows
patch = get_patch(image, window)
results = detector(patch)
然后尝试减少窗口数量,尽可能减少 for 循环中的工作量。
ROIs = region_proposal(image)
for ROI in ROIs
patch = get_patch(image, ROI)
results = detector(patch)
单次目标检测器
第二部分,我们将对单次目标检测器(包括 SSD、YOLO、YOLOv2、YOLOv3)进行综述。我们将分析 FPN 以理解多尺度特征图如何提高准确率,特别是小目标的检测,其在单次检测器中的检测效果通常很差。然后我们将分析 Focal loss 和 RetinaNet,看看它们是如何解决训练过程中的类别不平衡问题的。
单次检测器
Faster R-CNN 中,在分类器之后有一个专用的候选区域网络。

Faster R-CNN 工作流
基于区域的检测器是很准确的,但需要付出代价。Faster R-CNN 在 PASCAL VOC 2007 测试集上每秒处理 7 帧的图像(7 FPS)。和 R-FCN 类似,研究者通过减少每个 ROI 的工作量来精简流程。
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
for ROI in ROIs
patch = roi_align(feature_maps, ROI)
results = detector2(patch) # Reduce the amount of work here!
作为替代,我们是否需要一个分离的候选区域步骤?我们可以直接在一个步骤内得到边界框和类别吗?
feature_maps = process(image)
results = detector3(feature_maps) # No more separate step for ROIs
让我们再看一下滑动窗口检测器。我们可以通过在特征图上滑动窗口来检测目标。对于不同的目标类型,我们使用不同的窗口类型。以前的滑动窗口方法的致命错误在于使用窗口作为最终的边界框,这就需要非常多的形状来覆盖大部分目标。更有效的方法是将窗口当做初始猜想,这样我们就得到了从当前滑动窗口同时预测类别和边界框的检测器。

基于滑动窗口进行预测
这个概念和 Faster R-CNN 中的锚点很相似。然而,单次检测器会同时预测边界框和类别。例如,我们有一个 8 × 8 特征图,并在每个位置做出 k 个预测,即总共有 8 × 8 × k 个预测结果。

64 个位置
在每个位置,我们有 k 个锚点(锚点是固定的初始边界框猜想),一个锚点对应一个特定位置。我们使用相同的 锚点形状仔细地选择锚点和每个位置。

使用 4 个锚点在每个位置做出 4 个预测。
以下是 4 个锚点(绿色)和 4 个对应预测(蓝色),每个预测对应一个特定锚点。

4 个预测,每个预测对应一个锚点。
在 Faster R-CNN 中,我们使用卷积核来做 5 个参数的预测:4 个参数对应某个锚点的预测边框,1 个参数对应 objectness 置信度得分。因此 3× 3× D × 5 卷积核将特征图从 8 × 8 × D 转换为 8 × 8 × 5。

使用 3x3 卷积核计算预测。
在单次检测器中,卷积核还预测 C 个类别概率以执行分类(每个概率对应一个类别)。因此我们应用一个 3× 3× D × 25 卷积核将特征图从 8 × 8 × D 转换为 8 × 8 × 25(C=20)。

每个位置做出 k 个预测,每个预测有 25 个参数。
单次检测器通常需要在准确率和实时处理速度之间进行权衡。它们在检测太近距离或太小的目标时容易出现问题。在下图中,左下角有 9 个圣诞老人,但某个单次检测器只检测出了 5 个。

大模型方案
【2025-11-12】RF-DETR 吊打 YOLO
【2206-5-26】YOLO 迎来最强宿敌:Roboflow 开源目标检测 RF-DETR
【2025-11-12】计算机视觉生态平台 Roboflow 开源最新实时目标检测与实例分割架构:RF-DETR(Roboflow Detection Transformer), AI 顶会 ICLR 2026。
不仅把 Transformer 的实时检测性能拉到了新高度,更是直接向统治了实时领域数年之久的 YOLO 系列发起了“降维打击”。

RF-DETR 到底强在哪里?它凭什么敢叫板 YOLO?
端到端 DETR(Detection Transformer)架构虽然精度高,但由于注意力的计算量巨大,往往贴着“非实时”的标签;
- 而 YOLO 系列则凭借轻量化主宰着实时领域,但精度在 55 AP 左右往往触及天花板。
这次,RF-DETR 直接打破了这道红线,在速度和精度上实现了双重跨越:
- 历史性突破:RF-DETR-2XL 在 COCO 数据集上斩获了 60.1 AP 的惊人成绩。这是人类视觉工业史上第一个突破 60 AP 大关的“实时”端到端检测模型!
- 同体量吊打 YOLOv11: 在同等甚至更低的延迟下,RF-DETR-L 仅需 6.8 毫秒,精度却比 YOLOv11x 高出接近 2 个百分点。
三大核心底层架构创新:
- DINOv2 视觉大模型的“降维打击”
- 引入了 Meta 的视觉基础大模型——DINOv2。
- 轻量化 Transformer 编码器(Hybrid Encoder): RF-DETR 采用了创新的混合编码器设计,在保持高阶语义信息提取的同时,大幅度裁剪了冗余的注意力和特征通道计算
- 解耦的目标查询(Decoupled Query)与 1-to-1 匹配
RF-DETR 标志着“大模型预训练 + Transformer 架构”正式攻陷实时工业落地的最后防线。
- 如果追求极致的轻量化,例如要把模型塞进资源极其受限的单片机、微控制器或老旧低端手机上运行,YOLO 的超小尺寸版本依然有其基建优势。
- 但如果是工业质检、自动驾驶、安防监控、无人机航拍,这些场景需要处理复杂的现实环境、对精度要求极苛刻,同时设备配备了主流边缘算力(如 NVIDIA Jetson 系列、T4、RTX 边缘显卡),RF-DETR 毫无疑问是目前综合性能最香、且没有任何开源法务风险的“王炸”选择!
【2026-5-7】应用:YOLO + 多模态大模型
【2026-5-7】资讯 融合 YOLO26 姿态评估与 Qwen-VL多模态大模型的跌倒检测系统。
- 采用“检测-分析-生成”的三段式架构:
- YOLO26负责实时捕捉人体关键点并判定跌倒事件
- Qwen-VL对检测到的跌倒画面进行深度语义理解
- 最终生成包含跌倒人数、性别、衣着等细节的标准化报告。
- 这一设计兼顾了实时性与语义丰富性,为智能安防与医疗监护领域提供了可行的技术方案。
| 层级 | 组件 | 职责 | 输出 |
|---|---|---|---|
| 感知层 | YOLO26-pose | 实时关键点检测与跌倒判定 | 跌倒事件列表(含边界框) |
| 理解层 | Qwen-VL | 语义分析与信息抽取 | 结构化属性数据 |
| 呈现层 | 报告生成模块 | 数据汇聚与格式化输出 | JSON/自然语言报告 |
【2026-5-26】LocateAnything
【2026-5-26】英伟达开源最强3B「目标检测」大模型 LocateAnything
- 论文 LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
- 解读 英伟达开源最强3B「目标检测」大模型LocateAnything
LocateAnything 是目前「最好」的目标检测大模型,相对于同级别的大模型,又「快」又「准」,没有之一
- 一、快:LocateAnything 速度快, 源于并行框解码 PBD 范式革新。
- 传统 VLM 把 2D 检测框拆成多个坐标 Token,采用逐 Token 自回归串行解码,需要十几步才能完成一个框预测,存在严重推理瓶颈;
- 而本文 PBD 将整个检测框视为一个原子单元,单步前向即可一次性输出全套坐标,把解码步数从十余步压缩至 2 步。
- 实测单 H100 上吞吐量达 12.7 BPS,比传统 Qwen3-VL 快 10 倍,且目标数量越多,并行加速优势越明显,在48G显存的vGPU上也是取得了不错的运行速度。
- 二、准:LocateAnything 精度高来自结构对齐解码 + 超大专业数据集两大支撑。
- 1,传统串行解码和通用 MTP 随意分块,破坏检测框四个坐标间天然几何耦合关系,易产生虚假关联与误差传播;
- 而 PBD 按检测框天然边界做块划分,训练时采用块内双向注意力、块间因果注意力,配合 NTP+MTP 双流联合训练,精准学习坐标内在关联,显著提升高 IoU 精细定位能力。
- 2,自建LocateAnything-Data 大规模数据集,一个庞大且多样化的训练语料库,包含 1.38 亿个语言查询和 7.85 亿个边界框,涵盖一般 OD、GUI 定位、指称理解、文本本地化和基于点的任务,还专门设计两阶段训练强化密集小目标检测,并加入海量负样本抑制幻觉。
如果场景是可以使用大模型来进行目标检测的,可以优先考虑「LocateAnything」。
SSD
SSD 是使用 VGG19 网络作为特征提取器(和 Faster R-CNN 中使用的 CNN 一样)的单次检测器。我们在该网络之后添加自定义卷积层(蓝色),并使用卷积核(绿色)执行预测。

同时对类别和位置执行单次预测。
然而,卷积层降低了空间维度和分辨率。因此上述模型仅可以检测较大的目标。为了解决该问题,我们从多个特征图上执行独立的目标检测。

使用多尺度特征图用于检测。
以下是特征图图示。

图源:https://arxiv.org/pdf/1512.02325.pdf
SSD 使用卷积网络中较深的层来检测目标。如果我们按接近真实的比例重绘上图,我们会发现图像的空间分辨率已经被显著降低,且可能已无法定位在低分辨率中难以检测的小目标。如果出现了这样的问题,我们需要增加输入图像的分辨率。

YOLO
YOLO 全称 You Only Look Once(你只需看一次)
- 从名称上也能看出这种算法速度快的优势,因此在许多边缘设备上,YOLO算法的使用十分广泛。
与另一种著名的目标检测算法 Fast R-CNN 不同的是,YOLO采用“一步”的策略,同时生成目标物体的类别和位置。
YOLO算法相比Fast R-CNN具有两大优势:
- 1、速度快:每秒45帧的检测速率,可用在实时视频检测中,在更小的模型上甚至达到155帧;
- 2、通用性好:在真实图像数据上训练的网络,可以用在虚构的绘画作品上。
但是YOLO也存在着一定的局限性:
- 正确率不如Fast R-CNN,每个方格中只能检测一个物体,对于边缘不规则的物体,将会影响到周围物体的识别。
作者Redmon后来又在原始的YOLO技术上,发展出了YOLO9000、YOLOv3等算法,扩展了检测物体的种类、提高了模型的准确率。
YOLO 资讯
【2020-2-22】YOLO之父退出CV界表达抗议,拒绝AI算法用于军事和隐私窥探
- Jeseph Redmon毕业于美国米德尔伯里学院计算机科学专业,辅修数学。2013年进入华盛顿大学计算机专业攻读硕士学位,继而攻读博士学位,直到2019年。
- 在此期间,他和导师Ali Farhadi共同提出并改进了YOLO算法。主要研究范围是目标检测、图像分类和模型压缩。
- Joseph Redmon曾凭借该算法获得过2016年CVPR群众选择奖(People’s Choice Award)、2017年CVPR最佳论文荣誉奖(Best Paper Honorable Mention)。
- YOLO及其改进算法在学术圈被广泛引用,Redmon三篇一作相关论文总引用量已经超过1万。
YOLO算法作者Joseph Redmon在个人Twitter上宣布,将停止一切CV研究,原因是自己的开源算法已经用在军事和隐私问题上。这对他的道德造成了巨大的考验。
YOLO 发展史
YOLO: A Brief History
【2023-11-14】ultralytics 官方文档
YOLO (You Only Look Once), a popular object detection and image segmentation model, was developed by Joseph Redmon and Ali Farhadi at the University of Washington.
- Launched in 2015, YOLO quickly gained popularity for its high speed and accuracy.
- YOLOv2, released in 2016, improved the original model by incorporating batch normalization, anchor boxes, and dimension clusters.
- YOLOv3, launched in 2018, further enhanced the model’s performance using a more efficient backbone network, multiple anchors and spatial pyramid pooling.
- YOLOv4 was released in 2020, introducing innovations like Mosaic data augmentation, a new anchor-free detection head, and a new loss function.
- YOLOv5 further improved the model’s performance and added new features such as hyperparameter optimization, integrated experiment tracking and automatic export to popular export formats.
- YOLOv6 was open-sourced by Meituan in 2022 and is in use in many of the company’s autonomous delivery robots.
- YOLOv7 added additional tasks such as pose estimation on the COCO keypoints dataset.
- YOLOv8 is the latest version of YOLO by Ultralytics. As a cutting-edge, state-of-the-art (SOTA) model, YOLOv8 builds on the success of previous versions, introducing new features and improvements for enhanced performance, flexibility, and efficiency. YOLOv8 supports a full range of vision AI tasks, including detection, segmentation, pose estimation, tracking, and classification. This versatility allows users to leverage YOLOv8’s capabilities across diverse applications and domains.
YOLO:简史
YOLO (You Only Look Once),由华盛顿大学的Joseph Redmon和Ali Farhadi开发的流行目标检测和图像分割模型,于2015年推出,由于其高速和准确性而迅速流行。
- YOLOv2 在2016年发布,通过引入批量归一化、锚框和维度聚类来改进了原始模型。
- YOLOv3 在2018年推出,进一步增强了模型的性能,使用了更高效的主干网络、多个锚点和空间金字塔池化。
- YOLOv4 在2020年发布,引入了Mosaic数据增强、新的无锚检测头和新的损失函数等创新功能。
- YOLOv5 进一步改进了模型的性能,并增加了新功能,如超参数优化、集成实验跟踪和自动导出到常用的导出格式。
- YOLOv6 在2022年由美团开源,现在正在该公司的许多自动送货机器人中使用。
- YOLOv7 在COCO关键点数据集上添加了额外的任务,如姿态估计。
- YOLOv8 是Ultralytics的YOLO的最新版本。作为一种前沿、最先进(SOTA)的模型,YOLOv8在之前版本的成功基础上引入了新功能和改进,以提高性能、灵活性和效率。YOLOv8支持全范围的视觉AI任务,包括检测, 分割, 姿态估计, 跟踪, 和分类。这种多功能性使用户能够利用YOLOv8的功能应对多种应用和领域的需求。
从v1到v8
【2023-1-16】YOLO家族系列模型的演变:从v1到v8
| 时间 | 版本 | 功能 | 备注 |
|---|---|---|---|
| 2015 | v1 | ||
| 2016 | v2 | ||
| 2018 | v3 | ||
| 2019 | v4 | ||
| 2020 | v5 | ||
| 2021.5 | R | 结合显性和隐性知识,多任务 检测精度和检出率高于竞争对手 |
You Only Learn One Representation: Unified Network for Multiple Tasks |
| 2022 | v6 | 美团,三个改进点: backbone 和 neck部分对硬件进行了优化设计 forked head 更准确 更有效的训练策略 与YOLOv6-nano模型相比,YOLOv6-nano模型的速度提高了21%,精度提高了3.6% |
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications 博客地址 |
| 2022.7 | v7 | sota,E-ELAN(扩展高效层聚合网络), pytorch 检测精度和检出率高于竞争对手 |
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors |
| 2023.1 | v8 | Ultralytics发布,无锚点模型 YOLOv8领先于YOLOv7和YOLOv6等 |
论文尚未发表 |
yolo迭代到了v8版本
- 2017年在mac上试过v2,实时目标检测,挺灵敏;
- 后面几个版本迭代到手机部署,v5在手机上识别速度几十ms,手机识别
-
- YOLOv3之前的所有YOLO对象检测模型都是用C语言编写的,并使用了Darknet框架,Ultralytics发布了第一个使用PyTorch框架实现的YOLO (YOLOv3),YOLOv3发布后不久,Joseph Redmon就离开了计算机视觉研究社区。
- Ultralytics发布了YOLOv5
- 在2023年1月,Ultralytics发布了YOLOv8。
- YOLOv8包含五个模型,用于检测、分割和分类。YOLOv8 Nano是其中最快和最小的,而YOLOv8 Extra Large (YOLOv8x)是其中最准确但最慢的,具体模型见后续的图。
YOLOv8附带以下预训练模型:
- 目标检测在图像分辨率为640的COCO检测数据集上进行训练。
- 实例分割在图像分辨率为640的COCO分割数据集上训练。
- 图像分类模型在ImageNet数据集上预训练,图像分辨率为224。
图解
YOLO 原理
YOLO 是另一种单次目标检测器。
YOLO 在卷积层之后使用了 DarkNet 来做特征检测。

然而,它并没有使用多尺度特征图来做独立的检测。相反,它将特征图部分平滑化,并将其和另一个较低分辨率的特征图拼接。例如,YOLO 将一个 28 × 28 × 512 的层重塑为 14 × 14 × 2048,然后将它和 14 × 14 ×1024 的特征图拼接。之后,YOLO 在新的 14 × 14 × 3072 层上应用卷积核进行预测。
YOLO(v2)做出了很多实现上的改进,将 mAP 值从第一次发布时的 63.4 提高到了 78.6。YOLO9000 可以检测 9000 种不同类别的目标。

以下是 YOLO 论文中不同检测器的 mAP 和 FPS 对比。YOLOv2 可以处理不同分辨率的输入图像。低分辨率的图像可以得到更高的 FPS,但 mAP 值更低。

YOLOv3
YOLOv3 使用了更加复杂的骨干网络来提取特征。DarkNet-53 主要由 3 × 3 和 1× 1 的卷积核以及类似 ResNet 中的跳过连接构成。相比 ResNet-152,DarkNet 有更低的 BFLOP(十亿次浮点数运算),但能以 2 倍的速度得到相同的分类准确率。

图源:https://pjreddie.com/media/files/papers/YOLOv3.pdf
YOLOv3 还添加了特征金字塔,以更好地检测小目标。以下是不同检测器的准确率和速度的权衡。

图源:https://pjreddie.com/media/files/papers/YOLOv3.pdf
特征金字塔网络(FPN)
检测不同尺度的目标很有挑战性,尤其是小目标的检测。特征金字塔网络(FPN)是一种旨在提高准确率和速度的特征提取器。它取代了检测器(如 Faster R-CNN)中的特征提取器,并生成更高质量的特征图金字塔。
数据流

FPN(图源:https://arxiv.org/pdf/1612.03144.pdf)
FPN 由自下而上和自上而下路径组成。其中自下而上的路径是用于特征提取的常用卷积网络。空间分辨率自下而上地下降。当检测到更高层的结构,每层的语义值增加。

FPN 中的特征提取(编辑自原论文)
SSD 通过多个特征图完成检测。但是,最底层不会被选择执行目标检测。它们的分辨率高但是语义值不够,导致速度显著下降而不能被使用。SSD 只使用较上层执行目标检测,因此对于小的物体的检测性能较差。

图像修改自论文 https://arxiv.org/pdf/1612.03144.pdf
FPN 提供了一条自上而下的路径,从语义丰富的层构建高分辨率的层。

自上而下重建空间分辨率(编辑自原论文)
虽然该重建层的语义较强,但在经过所有的上采样和下采样之后,目标的位置不精确。在重建层和相应的特征图之间添加横向连接可以使位置侦测更加准确。

增加跳过连接(引自原论文)
下图详细说明了自下而上和自上而下的路径。其中 P2、P3、P4 和 P5 是用于目标检测的特征图金字塔。

FPN 结合 RPN
FPN 不单纯是目标检测器,还是一个目标检测器和协同工作的特征检测器。分别传递到各个特征图(P2 到 P5)来完成目标检测。

FPN 结合 Fast R-CNN 或 Faster R-CNN
在 FPN 中,我们生成了一个特征图的金字塔。用 RPN(详见上文)来生成 ROI。基于 ROI 的大小,我们选择最合适尺寸的特征图层来提取特征块。

困难案例
对于如 SSD 和 YOLO 的大多数检测算法来说,我们做了比实际的目标数量要多得多的预测。所以错误的预测比正确的预测要更多。这产生了一个对训练不利的类别不平衡。训练更多的是在学习背景,而不是检测目标。但是,我们需要负采样来学习什么是较差的预测。所以,我们计算置信度损失来把训练样本分类。选取最好的那些来确保负样本和正样本的比例最多不超过 3:1。这使训练更加快速和稳定。
推断过程中的非极大值抑制
检测器对于同一个目标会做出重复的检测。我们利用非极大值抑制来移除置信度低的重复检测。将预测按照置信度从高到低排列。如果任何预测和当前预测的类别相同并且两者 IoU 大于 0.5,我们就把它从这个序列中剔除。
Focal Loss(RetinaNet)
类别不平衡会损害性能。SSD 在训练期间重新采样目标类和背景类的比率,这样它就不会被图像背景淹没。Focal loss(FL)采用另一种方法来减少训练良好的类的损失。因此,只要该模型能够很好地检测背景,就可以减少其损失并重新增强对目标类的训练。我们从交叉熵损失 CE 开始,并添加一个权重来降低高可信度类的 CE。

例如,令 γ = 0.5, 经良好分类的样本的 Focal loss 趋近于 0。

编辑自原论文
这是基于 FPN、ResNet 以及利用 Focal loss 构建的 RetianNet。

RetinaNet
YOLOX
【2021-10-8】2021年旷视科技推出yolox,YOLOX: Exceeding YOLO Series in 2021, 手把手教你使用YOLOX进行物体检测
YOLOX 是旷视开源的高性能检测器。旷视的研究者将解耦头、数据增强、无锚点以及标签分类等目标检测领域的优秀进展与 YOLO 进行了巧妙的集成组合,提出了 YOLOX,不仅实现了超越 YOLOv3、YOLOv4 和 YOLOv5 的 AP,而且取得了极具竞争力的推理速度。YOLOX-L版本以 68.9 FPS 的速度在 COCO 上实现了 50.0% AP,比 YOLOv5-L 高出 1.8% AP!还提供了支持 ONNX、TensorRT、NCNN 和 Openvino 的部署版本
部署实践
(1)环境准备
- 环境确认
- 先判断Windows系统是32位还是64位,再选择对应的工具包
- x86-64是64位版本,x86是32位版本
- 所有客户端软件都需要注意32还是64位
- 简洁方法: 右键 → 计算机 → 属性 → 系统类型
- 详细方法见微软官方文档
- 先判断Windows系统是32位还是64位,再选择对应的工具包
- Git工具安装
- windows安装git bash,参考地址
- 注意:
- Python环境安装
- windows安装Python3,下载地址
(2)yolox下载部署
- 使用git下载代码到本地计算机
- 进入目录 YOLOX,本地安装
git clone git@github.com:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -v -e . # or python3 setup.py develop
(3)数据准备
- 准备测试视频
- 可以从pixbay下载高速免费视频
(4)下载模型
从GitHub下载模型文件到本地model目录
- 以下是shell脚本,windows下需要手工下载、操作
mkdir model
cd model
wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_l.pth
(5)启动
# ==== image demo =====
#python tools/demo.py image -f exps/default/yolox_s.py -c /path/to/your/yolox_s.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device [cpu/gpu]
#python tools/demo.py image -n yolox-s -c $model_file --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device cpu # gpu
# 更换模型时,需要同步更新3个参数
model_name='yolox-l'
model_file='model/yolox_l.pth'
tsize=640
python tools/demo.py image -n $model_name -c $model_file --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize $tsize --save_result --device cpu
# ==== video demo =====
# python tools/demo.py video -n yolox-s -c /path/to/your/yolox_s.pth --path /path/to/your/video --conf 0.25 --nms 0.45 --tsize 640 --save_result --device [cpu/gpu]
python tools/demo.py video -n $model_name -c $model_file --path /path/to/your/video --conf 0.25 --nms 0.45 --tsize $tsize --save_result --device cpu
【2023-11-8】实践通过
cur_dir='YOLOX'
#python tools/demo.py image -n yolox-l -c model/yolox_l.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device cpu
model_name='yolox-l'
model_file="${cur_dir}/model/yolox_l.pth"
tsize=640
# ==== image demo =====
data_file="${cur_dir}/assets/dog.jpg"
cmd="python ${cur_dir}/tools/demo.py image -n $model_name -c $model_file --path $data_file --conf 0.25 --nms 0.45 --tsize $tsize --save_result --device cpu"
echo "$cmd" && eval $cmd
# ==== video demo =====
data_file='../data/road_human.mp4'
# python tools/demo.py video -n yolox-s -c /path/to/your/yolox_s.pth --path /path/to/your/video --conf 0.25 --nms 0.45 --tsize 640 --save_result --device [cpu/gpu]
cmd="python tools/demo.py video -n $model_name -c $model_file --path $data_file --conf 0.25 --nms 0.45 --tsize $tsize --save_result --device cpu"
echo "$cmd" && eval $cmd
YOLO V5
2020年5月发布YOLOv5,最大的特点就是模型小,速度快,所以能很好的应用在移动端。
【2021-12-7】用安卓手机解锁目标检测模型YOLOv5,识别速度不过几十毫秒
- YOLO最新:v5版本,可在手机上玩儿了!只需要区区几十毫秒,桌上的东西就全被检测出来了
- yolov5s_android

YOLO v8
【2023-9-12】用YOLOv8一站式解决图像分类、检测、分割,淡化YOLO版本,主打Ultralytics平台。YOLO原本是一种公开的目标检测算法。优势是速度快,准确率还高.
yolov8 功能
v8版本不局限于目标检测,更像是一个AI视觉处理平台,不但可以做检测,还可以做分类、分割、跟踪,甚至姿态估计。

功能
- Detection (COCO) 检测
- Detection (Open Image V7)
- Segmentation (COCO) 分割
- Pose (COCO) 姿态估计
- Classification (ImageNet) 分类
yolov8 模型
YOLOv8针对COCO数据集(一个很好的计算机视觉数据集)训练生成的。
- 可以自行使用labelImg进行图片标记,扩充数据集
| 名称 | 模型文件 | 家族 |
|---|---|---|
| 检测 | yolov8n.pt | 8n、8s、8m、8l、8x |
| 分割 | yolov8n-seg.pt | 8n、8s、8m、8l、8x |
| 分类 | yolov8n-cls.pt | 8n、8s、8m、8l、8x |
| 姿态 | yolov8n-pose.pt | 8n、8s、8m、8l、8x |
每一类模型包含一个家族。好比是同一款衣服的不同尺码
| 类型 | 准确度 | 耗时长 | 运算次数/秒 |
|---|---|---|---|
| YOLOv8n | 37.3 | 80.4 | 8.7 |
| YOLOv8s | 44.9 | 128.4 | 28.6 |
| YOLOv8m | 50.2 | 234.7 | 78.9 |
| YOLOv8l | 52.9 | 375.2 | 165.2 |
| YOLOv8x | 53.9 | 479.1 | 257.8 |
模型下载
- yolov8s.pt 下载地址:yolov8s.pt
- yolov8n.pt下载地址:yolov8n.pt
yolov8 实践
【2024-12-5】gradio+flask构建yolov8检测demo
安装
# 安装
pip install ultralytics
# 测试, 模型文件才 7m !
#yolo predict model=yolov8n.pt source=bus.jpg
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
目标检测
代码调用
# 从平台库导入YOLO类
from ultralytics import YOLO
# 从模型文件构建model
model = YOLO("xx.pt")
# 对某张图片进行预测
results = model("bus.jpg")
# 打印识别结果
print(results)
# -----------
from ultralytics import YOLO
from PIL import Image
model = YOLO('yolov8n-seg.pt')
image = Image.open("bus.jpg")
results = model.predict(source=image, save=True, save_txt=True)
# 识别来自文件夹的图像
results = model.predict(source="test/pics", ……)
# 识别来自摄像头的图像
results = model.predict(source="0", ……)
# 查看结果
results[0].boxes
results[0].masks
# -------------
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
model.train(data="coco128.yaml", epochs=3) # train the model
metrics = model.val() # evaluate model performance on the validation set
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
path = model.export(format="onnx") # export the model to ONNX format
results 类
- boxes: 检测出来物体的矩形框,就是目标检测的框。
- masks: 检测出来的遮罩层,调用图像分割时,这项有数据。
- keypoints: 检测出来的关键点,人体姿势估计时,身体的点就是这项。
- names: 分类数据的名称,比如{0: 人,1: 狗}这类索引。
目标跟踪
from ultralytics import YOLO
# Load an official or custom model
model = YOLO('yolov8n.pt') # Load an official Detect model
model = YOLO('yolov8n-seg.pt') # Load an official Segment model
model = YOLO('yolov8n-pose.pt') # Load an official Pose model
# model = YOLO('path/to/best.pt') # Load a custom trained model
# Perform tracking with the model
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True) # Tracking with default tracker
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml") # Tracking with ByteTrack tracker
端侧 目标检测
YOLO-NAS
YOLO-NAS 是一款基于YOLO系列的全新对象检测模型,采用NAS技术进行预训练,并在COCO、Objects365和Roboflow 100等数据集上进行了验证,实现了前所未有的精度-速度性能。
mediapipe
【2023-10-26】Google发布移动终端对象检测模型 —— mediapipe,无GPU依然飞快
而Google的mediapipe系列则成功将对象检测模型运行在移动终端上,实现了ms级别的延时。对于没有GPU的情况,可以使用MediaPipe对象检测模型,其int8模型只有29.31ms的延时,最大模型也只有198.77ms的延时
应用
Demo 体验
飞桨 PaddlePaddle AI Studio 里的目标检测体验
- 【2021-5-18】4种YOLO目标检测的C++和Python两种版本实现
- 2020年,新出了几个新版本的YOLO目标检测,最多的有YOLOv4,Yolo-Fastest,YOLObile以及百度提出的PP-YOLO。C++编写一套基于OpenCV的YOLO目标检测,这个程序里包含了经典的YOLOv3,YOLOv4,Yolo-Fastest和YOLObile这4种YOLO目标检测的实现
- Yolo-Fastest运行速度最快,YOLObile号称是实时的,但是从结果看并不如此。并且查看它们的模型文件,可以看到Yolo-Fastest的是最小的。
- opencv实现yolov5目标检测,程序依然是包含了C++和Python两种版本的实现,地址: python, C++
目标跟踪
详见站内专题: 目标跟踪
应用案例
无人机
大疆航拍巡查
无人机航空航拍技术应用,环境监测、水利巡检、交通巡查、线路巡检
河道巡查
全球领先的低空无人机遥感网运营商: 广州中科云图
- 公众号: GEOAI中科云图
无人机高效巡检河道违法捕捞和周围篷房违建
-
AI 识别船只、漂浮物和垃圾堆放
- 一巢三机
- 首创“一巢三机”智能化无人机飞行控制平台,机动性更强,作业能力覆盖更广。
- 5G+微波
- 超低延时图传,多重控制保障,飞行全程可控。
- 全局掌控
- 丰富感知负载,多源信息采集;低空飞行,提供720°全局视野。
- 机载AI
- 首创“无人机”智能负载,集成21T超强算力AI芯片,实现物体识别与目标跟踪。
实时检测
实时人物分割
- 【2019-04-11】浏览器上跑:TensorFlow发布实时人物分割模型,秒速25帧24个部位
- TensorFlow开源了一个实时人物分割模型,叫BodyPix。这个模型,在浏览器上用TensorFlow.js就能跑。而且,帧率还很可观,在默认设定下:
- 用2018版15吋MacBook Pro跑,每秒25帧。用iPhone X跑,每秒21帧。
- 如果不和其他模型搭配的话,BodyPix只适用于单人影像。
- TensorFlow开源了一个实时人物分割模型,叫BodyPix。这个模型,在浏览器上用TensorFlow.js就能跑。而且,帧率还很可观,在默认设定下:
OpenPose
【2024-1-12】实时多人关键点AI检测开源!
OpenPose 是一个开源的实时多人关键点检测库,由卡内基梅隆大学的感知计算实验室(Perceptual Computing Lab)开发。它旨在通过深度学习技术实现高效的人体姿态估计,并可以同时检测多个人的身体、面部、手部和脚部的关键点。
OpenPose 的出现为人体姿态估计领域带来了重要的突破,特别是在实时性和多人检测方面。img
核心特点
- 实时性:OpenPose 设计用于实时处理,可以在接近实时的时间内完成关键点检测。
- 多人检测:OpenPose 能够在单张图像中同时检测多个人的姿态,这对于多人交互场景尤为重要。
- 关键点检测:它可以识别和定位人体、面部、手部和脚部的关键点,总共超过 135 个关键点。
- 灵活性:OpenPose 支持多种编程语言和框架,包括 Python、C++ 和 MATLAB,以及 TensorFlow、Caffe 和 PyTorch 等。
- 开源:OpenPose 是开源的,这意味着任何人都可以自由使用和修改代码,以适应不同的应用需求。
应用场景
- 增强现实和虚拟现实:在 AR/VR 应用中,OpenPose 可以用来跟踪用户的身体和手部动作,提供更自然的交互体验。
- 人机交互:OpenPose 可以用于智能助手和机器人,帮助它们更好地理解和响应用户的需求。
- 体育分析:在体育比赛中,OpenPose 可以用来分析运动员的姿态和动作,提供战术和训练建议。
- 安全监控:在安全监控领域,OpenPose 可以用来识别异常行为或特定姿态,提高监控系统的有效性。
基于tensorflow.js的实时检测Demo

实时检测Demo
站内demo
代码
- detect.js内容
class App extends React.Component {
// reference to both the video and canvas
videoRef = React.createRef();
canvasRef = React.createRef();
// we are gonna use inline style
styles = {
position: 'fixed',
top: 150,
left: 150,
};
detectFromVideoFrame = (model, video) => {
model.detect(video).then(predictions => {
this.showDetections(predictions);
requestAnimationFrame(() => {
this.detectFromVideoFrame(model, video);
});
}, (error) => {
console.log("Couldn't start the webcam")
console.error(error)
});
};
showDetections = predictions => {
const ctx = this.canvasRef.current.getContext("2d");
ctx.clearRect(0, 0, ctx.canvas.width, ctx.canvas.height);
const font = "24px helvetica";
ctx.font = font;
ctx.textBaseline = "top";
predictions.forEach(prediction => {
const x = prediction.bbox[0];
const y = prediction.bbox[1];
const width = prediction.bbox[2];
const height = prediction.bbox[3];
// Draw the bounding box.
ctx.strokeStyle = "#2fff00";
ctx.lineWidth = 1;
ctx.strokeRect(x, y, width, height);
// Draw the label background.
ctx.fillStyle = "#2fff00";
const textWidth = ctx.measureText(prediction.class).width;
const textHeight = parseInt(font, 10);
// draw top left rectangle
ctx.fillRect(x, y, textWidth + 10, textHeight + 10);
// draw bottom left rectangle
ctx.fillRect(x, y + height - textHeight, textWidth + 15, textHeight + 10);
// Draw the text last to ensure it's on top.
ctx.fillStyle = "#000000";
ctx.fillText(prediction.class, x, y);
ctx.fillText(prediction.score.toFixed(2), x, y + height - textHeight);
});
};
componentDidMount() {
if (navigator.mediaDevices.getUserMedia || navigator.mediaDevices.webkitGetUserMedia) {
// define a Promise that'll be used to load the webcam and read its frames
const webcamPromise = navigator.mediaDevices
.getUserMedia({
video: true,
audio: false,
})
.then(stream => {
// pass the current frame to the window.stream
window.stream = stream;
// pass the stream to the videoRef
this.videoRef.current.srcObject = stream;
return new Promise(resolve => {
this.videoRef.current.onloadedmetadata = () => {
resolve();
};
});
}, (error) => {
console.log("Couldn't start the webcam")
console.error(error)
});
// define a Promise that'll be used to load the model
const loadlModelPromise = cocoSsd.load();
// resolve all the Promises
Promise.all([loadlModelPromise, webcamPromise])
.then(values => {
this.detectFromVideoFrame(values[0], this.videoRef.current);
})
.catch(error => {
console.error(error);
});
}
}
// here we are returning the video frame and canvas to draw,
// so we are in someway drawing our video "on the go"
render() {
return (
<div>
<video
style={this.styles}
autoPlay
muted
ref={this.videoRef}
width="720"
height="600"
/>
<canvas style={this.styles} ref={this.canvasRef} width="720" height="650" />
</div>
);
}
}
const domContainer = document.querySelector('#root');
ReactDOM.render(React.createElement(App), domContainer);
- 更多Demo地址
事件检测
视频事件检测
【2022-11-8】AI视频事件检测系统—JXVA8000系列
捷迅技术“JXVA”系列产品基于AI人工智能的深度学习算法以及GPU技术,对视频图像事件进行分析识别。利用视频大数据开展视频智能化应用服务实现对高速公路的交通事件和交通态势进行实时、精准检测

对交通道路正常交通秩序的事件进行实时检测,及时发现行人、车辆、物品等异常行为,并进行全客户端实时告警。实现对高速公路的交通事件和交通态势进行实时、精准检测,事件检测精准度达99%。对接高速公路车道监控摄像机的视频流,获取瞬间截面车流信息,为管理者提供实时的车流信息,为后续交通大数据的统计和预测做数据储备。
核心功能
- 交通事件分析
- 交通态势分析
- 路面智能养护
- 路网事件分析
优点
- ◆ 识别准确率高:识别准确率高达96%以上
- ◆ 自学习、自优化、越用越智能
- 具备在线自动学习能力,模型上线使用之后识别准确率不断提高
- ◆ 识别事件类型多
- 对道路行人、违停、拥堵、逆行、压线、超速、慢行、抛洒物等多种交通事件进行检测
交通事件检测功能点
- 停车
- 行人
- 遗留物
- 事故
- 拥堵
- 非机动车
- 变道检测
- 违规逆行
交通态势分析
- 交通流量检测
- 平均车速检测
- 排队长度检测
- 车道空间占有率
摄像头智能巡检
- 视频缺失
- 视频遮挡
- 视频卡顿
- 视频模糊
- 色彩失真
- 异常抖动
卡尔曼滤波
【2022-8-25】图说卡尔曼滤波,一份通俗易懂的教程
卡尔曼滤波(Kalman filter)是一种高效的自回归滤波器,它能在存在诸多不确定性情况的组合信息中估计动态系统的状态,是一种强大的、通用性极强的工具。它的提出者 鲁道夫.E.卡尔曼,在一次访问NASA埃姆斯研究中心时,发现这种方法能帮助解决阿波罗计划的轨道预测问题,后来NASA在阿波罗飞船的导航系统中确实也用到了这个滤波器。最终,飞船正确驶向月球,完成了人类历史上的第一次登月。
滤波器
【2022-8-25】滤波器(Filter)
- 对特定频率进行有效提取,并对提取部分进行特定的处理(增益,衰减,滤除)的动作被叫做滤波。
- 在混音领域中,最常用的滤波器类型有三种:
通过式(Pass),搁架式(Shelving)和参量式(Parametric)。滤波器都有一个叫参考频率(Reference Frequency)的东西,在不同类型的滤波器中,具体的叫法会有所不同。
通过式滤波器可以让参考频率一侧的频率成分完全通过该滤波器,同时对另一侧的频率成分做线性的衰减,用白话讲就是,一边让通过,一边逐渐被滤除。在信号学中,通过的区域被称为通带,滤除的区域被叫做阻带(图1)。另外,在通过式滤波器中,参考频率通常被称为截止频率。
- 高通滤波器(high-pass filters):顾名思义,让截止频率后的高频区域通过,另一侧滤除,通常被简称为HPF(参考图1)。
- 低通滤波器(low-pass filters):让截止频率前的低频区域通过,另一侧滤除,通常被简称为LPF(参考图1)。
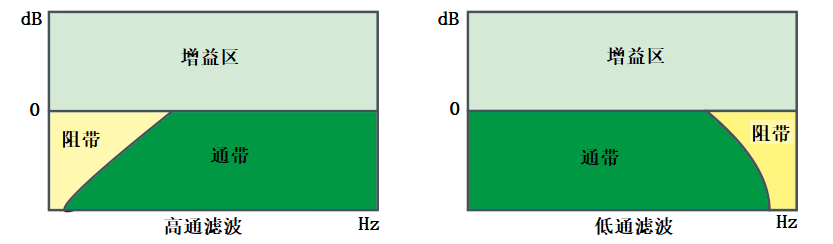
滤波器
- 只要是存在不确定信息的动态系统,卡尔曼滤波就可以对系统下一步要做什么做出有根据的推测。即便有噪声信息干扰,卡尔曼滤波通常也能很好的弄清楚究竟发生了什么,找出现象间不易察觉的相关性。
- 卡尔曼滤波非常适合不断变化的系统,它的优点还有内存占用较小(只需保留前一个状态)、速度快,是实时问题和嵌入式系统的理想选择。
示例:机器人导航
一个树林里四处溜达的小机器人,为了让它实现导航,机器人需要知道自己所处的位置。即机器人有一个包含位置信息和速度信息的状态
- 小机器人装有GPS传感器,定位精度10米
- 这个示例中的状态是位置和速度,其他问题里可以是水箱里的液体体积、汽车引擎温度、触摸板上指尖的位置,或者其他任何数据。
如何预测机器人移动?把指令发送给控制轮子的马达
- 如果这一刻它始终朝一个方向前进,没有遇到任何障碍物,那么下一刻它可能会继续坚持这个路线。
- 但是机器人对自己的状态不是全知的:可能会逆风行驶,轮子打滑,滚落颠簸地形…… 所以车轮转动次数并不能完全代表实际行驶距离,基于这个距离的预测也不完美。
这个问题下,GPS为提供了一些关于状态的信息是间接的、不准确的;预测提供了关于机器人轨迹的信息,但那也是间接的、不准确的。
但以上就是能够获得的全部信息,在此基础上能否给出一个完整预测,让它的准确度比机器人搜集的单次预测汇总更高?卡尔曼滤波,这个问题可以迎刃而解。
卡尔曼滤波假设两个变量(位置和速度)都是随机且符合高斯分布。每个变量都有一个均值 u,它是随机分布的中心;有一个方差 δ,它衡量组合的不确定性。
 |
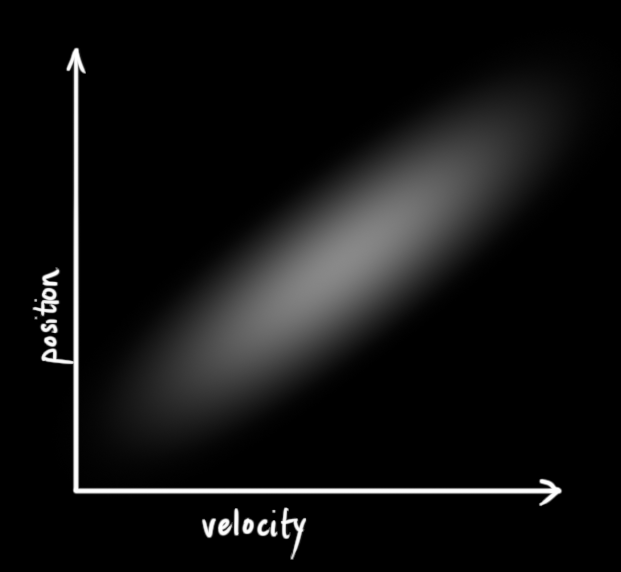 |
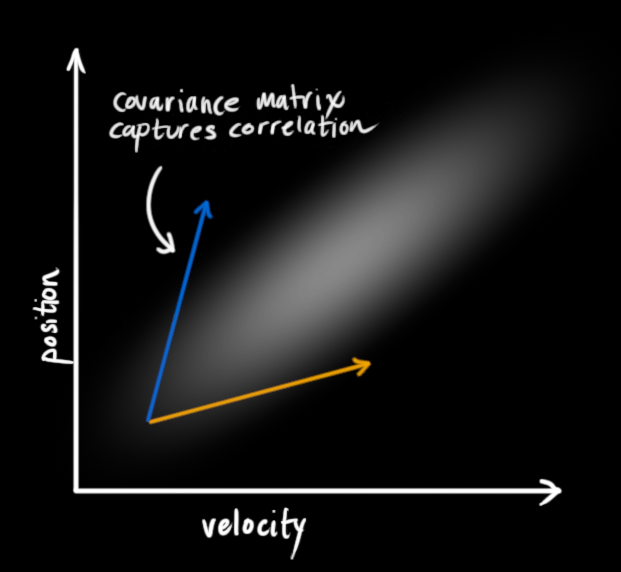
- 左图里,位置和速度是不相关的,这意味着不能从一个变量推测另一个变量
- 右图里,相关
如果基于旧位置估计新位置,会产生这两个结论:
- 如果速度很快,机器人可能移动得更远,所以得到的位置会更远;
- 如果速度很慢,机器人就走不了那么远。
这种关系对目标跟踪来说非常重要,因为它提供了更多信息:一个可以衡量可能性的标准。这就是卡尔曼滤波的目标:从不确定信息中挤出尽可能多的信息!
为了捕获这种相关性,用协方差矩阵。矩阵的每个值是第i个变量和第j个变量之间的相关程度(由于矩阵是对称的,i和j的位置可以随便交换)。用 Σ 表示协方差矩阵,在这个例子中,就是Σij。
YOLO + SAM
【2024-5-23】YOLO 和 SAM 强强联合能干什么大事
两种开创性模型之间的动态协同:YOLO(You Only Look Once)和 SAM(Segment Anything Model)
- YOLO 因其在目标检测方面的革命性进展而备受赞誉
- SAM(Segment Anything Model)是 Meta 在 2023 年推出,一种革命性的图像分割模型。以其卓越的性能而著称,SAM 已巩固了其作为最先进的分割模型之一的地位。
- SAM 在图像分割技术方面代表了一项突破性的进展,提供了前所未有的精确性和多功能性。与传统的受特定对象类型或环境限制的分割模型不同,SAM 凭借先进的神经网络架构和在大型数据集上进行的广泛训练,能够以无与伦比的准确性分割图像中的几乎任何对象。
- SAM 的架构采用多阶段的图像分割方法。其核心是一系列互联的神经网络模块,每个模块都针对分割过程的不同方面进行处理。
将 YOLO(You Only Look Once)与 SAM(Segment Anything Model)结合起来,提供了一个强大的协同效应,增强了两个模型的能力。 YOLO 在快速识别图像中的对象方面表现出色,而 SAM 在高精度分割对象方面具有优势。
- 通过将 YOLO 与 SAM 嵌入在一起,可以利用这两个模型的优势,实现更全面和准确的图像分析。
- 这种集成不仅可以检测对象,还可以精确地描绘它们的边界,为下游任务提供更丰富的上下文信息。
- 此外,将 YOLO 与 SAM 嵌入在一起,可以更稳健和高效地处理复杂的视觉数据,在自动驾驶、医学成像和监控系统等应用中具有不可估量的价值。
应用:
- 自动驾驶车辆:增强目标检测和分割能力,确保自动驾驶汽车的安全导航和决策。
- 医学成像:通过精确识别和分割医学图像中的异常,提高诊断准确性,如 X 光片、MRI 和 CT 扫描。
- 监控系统:通过精确检测和分割感兴趣的对象,提高公共场所的安全监控。
- 工业自动化:通过检测和分割装配线上制造产品中的缺陷,优化质量控制过程。
- 农业:通过精确识别和分割农业图像中的植物和害虫,协助作物监测和害虫检测。
- 环境监测:通过检测和分割卫星图像中的树木、水体和野生动物,帮助监测和分析环境变化。
- 增强现实:通过精确检测和分割现实世界中的物体,提升 AR 应用的沉浸式用户体验。
- 零售分析:通过精确检测和分割零售环境中的产品,改善客户分析和库存管理。
总之,SAM(Segment Anything Model)和 YOLO(You Only Look Once)的融合代表了图像分析领域的重大进步,在各个领域具有深远的影响。这一整合结合了 YOLO 在目标检测方面的敏锐性和 SAM 在分割方面的精确性,使我们能够从视觉数据中获得更深入的见解。从优化自动驾驶车辆的感知系统到帮助医学专家诊断疾病,SAM+YOLO 的协同潜力远远超越了传统边界。
代码实践见原文
姿态识别
数据集
【2024-4-22】人体姿态识别这9个数据集,
(1)HiEve数据集
数据集图片:原文
•在以人为中心的分析和了解复杂事件中,鼓励并加快新技术的开发。
•在“复杂事件中的大型以人为中心的视觉分析”方面培养新的思想和方向。
数据集内容:HiEve数据集,主要包括在各种人群和复杂事件(包括地铁上下车,碰撞,战斗
和地震逃生)中,以人为中心的非常具有挑战性和现实性的任务。
数据集数量:HiEve数据集包括当前最大的姿势数(> 1M),最大的复杂事件动作标签的数量(> 56k),并且是具有最长期限的轨迹的最大数量之一(平均轨迹长度> 480)。
数据集功能:人体检测、姿态识别、目标追踪、动作识别
下载链接:点击查看
(2)MPII Human Pose数据集
数据集图片:原文
数据集内容:MPII Human Pose数据集,是用于评估人体姿势识别的数据集。
数据集涵盖了410种人类活动,并且每个图像都带有活动标签。每个图像都是从YouTube视频中提取的,并提供了之前和之后的未注释帧。
此外,对于测试集,我们标注了丰富的注释,包括身体部位遮挡以及3D躯干和头部方向。
数据集数量:该数据集包含约 25K图像,其中对超过4万名人体进行关节标注。
数据集功能:姿态识别
下载链接:点击查看
(3)CrowdPose数据集
数据集图片:原文
数据集内容:CrowdPose数据集是一个用于拥挤场景姿势估计的新基准数据集,可用于拥挤场景下姿势估计问题。
数据集功能:姿态识别
下载链接:点击查看
(4)Human3.6M
数据集图片:原文
数据集内容:Human3.6M数据集是一个3D人体姿态识别的数据集,通过4个经过校准的摄像机拍摄获得,对于3D人体的24个部位位置和关节角度都有标注。
数据集数量:Human3.6M数据集包含360万个3D人体姿势图像,11名专业演员(男6名,女5名),17个场景(讨论,吸烟,拍照,通电话…)。
数据集功能:姿态识别、3维重建
下载链接:点击查看
(5)PedX数据集
数据集图片:原文
数据集内容:PedX 数据集是一个在复杂的城市交叉路口,对于行人进行采集的大规模多模式数据集。
该数据集提供高分辨率的立体图像,和具有手动2D和自动3D注释的LiDAR数据。此外,数据是使用两对立体相机和四个Velodyne LiDAR传感器进行的采集。
数据集功能:人体分割、姿态识别、人体检测
下载链接:点击查看
(6)SURREAL数据集
数据集图片:原文
数据集内容:SURREAL数据集是一个大规模人造姿态识别数据集,对于RGB视频,对多种状态进行标注:深度信息,身体部位,光流,2D / 3D姿势等。这些图像是在形状,纹理,视点和姿势有很大变化的情况下,对人物的真实渲染。
数据集数量:数据集包含600万帧合成人体数据
数据集功能:姿态识别、人体分割
下载链接:点击查看
(7)Mo2Cap2数据集
数据集图片:原文
数据集内容:硬件设置的移动性,在各种无限制的日常活动中,对3D人体姿势估计的稳定性会有影响。
因此,在Mo2Cap2数据集中,将头部的棒球帽,安装上一个鱼眼镜头类型的,高质量姿势估计设备。
除了新颖的硬件设置,该数据集主要贡献是:
(1)大型的自顶向下的鱼眼图像地面,实况训练数据集;
(2)一种新颖的3D姿态估计方法,该方法考虑了以自我为中心的独特属性。与现有算法基准相比,可以实现了更低的3D关节误差以及更好的2D覆盖。
数据集功能:姿态估计
下载链接:点击查看
(8)DensePose数据集
数据集图片:原文
数据集内容:DensePose数据集是户外的密集人体姿势估计数据集,目的在于建立从2D图像到人体表面的多关键点密集对应关系。标注过程主要分为两个阶段:
- 第一阶段:标注人员会标注出身体部位,可见的对应区域。当然对于后面的身体部位,标注人员会进行估算标注。
- 第二阶段:使用一组大致等距的关键点,对每个零件区域进行采样,并要求标注人员将这些点与表面相对应,从而得到最终的标注信息。
数据集数量:DensePose数据集,对5万个人进行了标注,超过500万个标注信息。
数据集功能:姿态识别、人体分割
下载链接:点击查看
(9)PoseTrack 数据集
数据集图片:原文
数据集内容:PoseTrack 数据集是用于人体姿势估计和视频中的关节跟踪的大型数据集,主要应用于两种挑战:“多人姿势估计”和“多人姿势跟踪”。
数据集数量:数据集中包含1356个视频序列,46000张标注的视频帧,276000个人体姿势标注信息。
数据集功能:姿态估计、姿态跟踪
下载链接:点击查看
ST-GCN
香港中大-商汤科技联合实验室的最新 AAAI 会议论文「Spatial Temporal Graph Convolution Networks for Skeleton Based Action Recognition」,提出新的 ST-GCN,即时空图卷积网络模型,用于解决基于人体骨架关键点的人类动作识别问题
STGCN 将 GCN 扩展到时空图模型上,用于实现动作识别。
主要工作就两点:
- 使用 OpenPose 处理了视频,提出了一个数据集
- 结合 GCN 和 TCN 提出了模型,在数据集上效果还不错
OpenPose 是一个标注人体的关节(颈部,肩膀,肘部等),连接成骨骼,进而估计人体姿态的算法。

STGCN结合了图卷积神经网络(GCN)和时间卷积网络(TCN)
STGCN 输入,即一系列骨架图。
- 每个节点对应于人体的一个关节,有两种类型的边
- ①符合节点自然连通性的空间边(图1中淡蓝色线条)
- ②跨越连续时间步长连接相同节点的时间边(淡绿色线条)
STGCN简单的网络结构如下所示

由三部分构成:
- 归一化:对输入数据归一化
- 时空变化:通过多个ST-GCN块,每个块中交替使用GCN和TCN
- 输出:使用平均池化和全连接层对特征进行分类
参考
骨骼化
poloclub 网站多种神经网络可视化
- 可视化 skeleton-vis
代码实现
# 只包含网络结构,“网络的输入(关节坐标)”和“邻接矩阵”都是随机生成的
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# ---------------------------------------------------------------------------------
# 空域图卷积
# ---------------------------------------------------------------------------------
class SpatialGraphConvolution(nn.Module):
"""
Args:
in_channels: 输入通道数,表示每个节点的特征维度(例如 3 对应 x, y, z 坐标)。
out_channels: 输出通道数,表示经过卷积后每个节点的特征维度。
s_kernel_size: 空间卷积核的大小,等于邻接矩阵的数量,表示多重图卷积的支持
"""
def __init__(self, in_channels, out_channels, s_kernel_size):
super().__init__()
self.s_kernel_size = s_kernel_size
self.conv = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels * s_kernel_size,
kernel_size=1)
def forward(self, x, A):
x = self.conv(x)
n, kc, t, v = x.size()
x = x.view(n, self.s_kernel_size, kc//self.s_kernel_size, t, v)
#对邻接矩阵进行GC,相加特征
x = torch.einsum('nkctv,kvw->nctw', (x, A))
return x.contiguous()
# ---------------------------------------------------------------------------------
# STGCN块
# ---------------------------------------------------------------------------------
class STGCN_block(nn.Module):
"""
Args:
in_channels:人体动作中的关节坐标维度,即in_channels=3
out_channels:经过这个块后每个节点的特征维度
stride:时间步长
t_kernel_size:时间卷积核大小为
A_size:图的邻接矩阵尺寸为
dropout=0.5: 随机失活的概率,用于防止过拟合
"""
def __init__(self, in_channels, out_channels, stride, t_kernel_size, A_size, dropout=0.5):
super().__init__()
# 空域图卷积
self.s_gcn = SpatialGraphConvolution(in_channels=in_channels,
out_channels=out_channels,
s_kernel_size=A_size[0])
# Learnable weight matrix M 给边缘赋予权重。学习哪个边是重要的。
self.M = nn.Parameter(torch.ones(A_size))
# 时域图卷积
self.t_gcn = nn.Sequential(nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Dropout(dropout),
nn.Conv2d(out_channels,
out_channels,
(t_kernel_size, 1), # kernel_size
(stride, 1), # stride
((t_kernel_size - 1) // 2, 0), # padding
),
nn.BatchNorm2d(out_channels),
nn.ReLU())
def forward(self, x, A):
x = self.t_gcn(self.s_gcn(x, A * self.M))
return x
# ---------------------------------------------------------------------------------
# STGCN网络模型
# ---------------------------------------------------------------------------------
class STGCN(nn.Module):
"""
Spatio-Temporal Graph Convolutional Network (ST-GCN) 模型。
Args:
A (torch.Tensor): 图的邻接矩阵。
num_classes (int): 分类的类别数。
in_channels (int): 输入通道数。
t_kernel_size (int): 时间卷积核的大小。
Attributes:
A (torch.Tensor): 图的邻接矩阵。
bn (nn.BatchNorm1d): 一维批量归一化层。
stgcn1, stgcn2, stgcn3, stgcn4, stgcn5, stgcn6 (STGCN_block): 时空图卷积块。
fc (nn.Conv2d): 用于分类的全连接层。
"""
def __init__(self, A, num_classes, in_channels, t_kernel_size):
super().__init__()
# 邻接矩阵
self.A = A
# 邻接矩阵的大小
A_size = A.size()
# 批量归一化
self.bn = nn.BatchNorm1d(in_channels * A_size[1]) # 75
# 空间-时间图卷积块
# 第一个时空卷积块
# 输入通道数:人体动作中的关节坐标维度,即in_channels=3
# 输出通道数:经过这个块后每个节点的特征维度
# 时间步长(stride)为 1(时间维度不缩减)
# 时间卷积核大小为 t_kernel_size(如 9)
# 图的邻接矩阵尺寸为 A_size
self.stgcn1 = STGCN_block(in_channels, 32, 1, t_kernel_size, A_size) # in_channels=3, t_kernel_size=9,步长为1
self.stgcn2 = STGCN_block(32, 32, 1, t_kernel_size, A_size)
self.stgcn3 = STGCN_block(32, 32, 1, t_kernel_size, A_size)
self.stgcn4 = STGCN_block(32, 64, 2, t_kernel_size, A_size) # 步长为2
self.stgcn5 = STGCN_block(64, 64, 1, t_kernel_size, A_size)
self.stgcn6 = STGCN_block(64, 64, 1, t_kernel_size, A_size)
# 分类层
self.fc = nn.Conv2d(64, num_classes, kernel_size=1)
def forward(self, x):
"""
前向传播函数
Args:
x (torch.Tensor): 输入张量,形状为 (N, C, T, V),其中 N 是批次大小,C 是通道数,T 是帧数,V 是节点数。
Returns:
torch.Tensor: 输出张量,形状为 (N, num_classes)。
"""
# 原始数据形状为 (N, C, T, V),即(batch size, 维度数,帧数,关节数)
N, C, T, V = x.size()
# 原始数据被重塑为 (N, V * C, T),N代表batch size;V*C表示关节数*维度数(3*25=75),即每一帧的所有特征作为一个整体;T表示帧数
x = x.permute(0, 3, 1, 2).contiguous().view(N, V * C, T)
# 在特征维度上,对每个时间帧的所有节点特征归一化
x = self.bn(x)
x = x.view(N, V, C, T).permute(0, 2, 3, 1).contiguous() # 重新排列张量
# 空间-时间图卷积块
x = self.stgcn1(x, self.A)
x = self.stgcn2(x, self.A)
x = self.stgcn3(x, self.A)
x = self.stgcn4(x, self.A)
x = self.stgcn5(x, self.A)
x = self.stgcn6(x, self.A)
# 分类
x = F.avg_pool2d(x, x.size()[2:]) # 全局平均池化
x = x.view(N, -1, 1, 1) # 重塑张量
x = self.fc(x) # 应用分类层
x = x.view(x.size(0), -1) # 重塑输出张量
return x
def random_adjacency_matrix(num_nodes):
# 生成一个随机的上三角矩阵
upper_triangle = np.triu(np.random.randint(0, 2, size=(num_nodes, num_nodes)), k=1)
# 生成对角线上的自环
diagonal = np.eye(num_nodes, dtype=int)
# 将上三角矩阵转为对称矩阵
adjacency_matrix = upper_triangle + upper_triangle.T + diagonal
return adjacency_matrix
if __name__ == "__main__":
# 一个图有25个节点,随机生成其邻接矩阵
num_nodes = 25
adjacency_matrix = random_adjacency_matrix(num_nodes)
adjacency_tensor_3d = torch.tensor(adjacency_matrix, dtype=torch.float32).unsqueeze(0)
# adjacency_tensor_3d: 三维邻接张量,用于定义图结构
# num_classes=10: 模型输出的类别数为10
# in_channels=3: 输入通道数为3
# t_kernel_size=9: 时间卷积核的大小为9
model = STGCN(adjacency_tensor_3d,
num_classes=10,
in_channels=3,
t_kernel_size=9,
)
# 数据集分为十个类别
# 0:喝
# 1:投掷
# 2:坐
# 3:站起来
# 4:掌声
# 5:挥手
# 6:踢
# 7:跳跃
# 8:敬礼
# 9:倒立
# 数据结构表示为(batch size, 维度数,帧数,关节数)
# 生成一个200, 3, 80, 25的张量
# 表示输入有200个数据,每个数据有80帧,一帧里有25个关节点,每个关节点有3个维度
input = torch.randn(200, 3, 80, 25)
# 经过网络模型,得到输出
# 输出为[batch,10]表示对应动作类别的概率
output = model(input)
print(output.shape)
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
