LLM/Agent 自我进化
观点
【2026-3-27】小米 MiMo 大模型负责人罗福莉:大模型的自进化,对科学研究带来的指数级加速
静态问题
Agent 与真实世界互动时,问题:
- 世界是动态:新知识、新事件、新梗层出不穷。一个知识停留在 2023 年的 AI,无法理解 2024 年的最新动态。
- 任务是开放:真实世界的任务千变万化,没有固定的「题库」。AI 需要具备处理未知问题的能力。
- 工具是变化:新的软件、API 和网站不断涌现。AI 需要学会使用新工具,甚至创造新工具。
- 用户是个性:每个人都有自己的偏好和习惯。AI 需要通过与用户的互动,不断适应和学习,提供个性化服务。
「静态」的 AI 在这样动态、开放的环境中,就像一个拿着旧地图的航海家,注定会迷航。
因此,AI 范式正在经历一场至关重要的转变:从追求模型的「规模」(Scale)转向追求智能体的「适应性」(Adaptivity)。
发展路径:
- 从
基础 LLM,到能执行任务的基础智能体(Foundation Agents),再到能够持续学习和适应的自进化智能体(Self-Evolving Agents),并最终指向理论上的人工超级智能(Artificial Super Intelligence, ASI)。 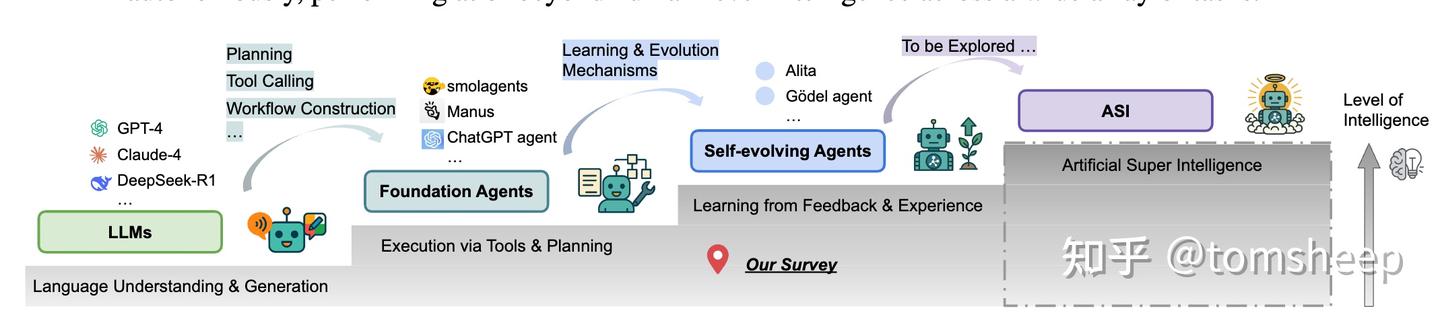
自学习,不断进化
综述
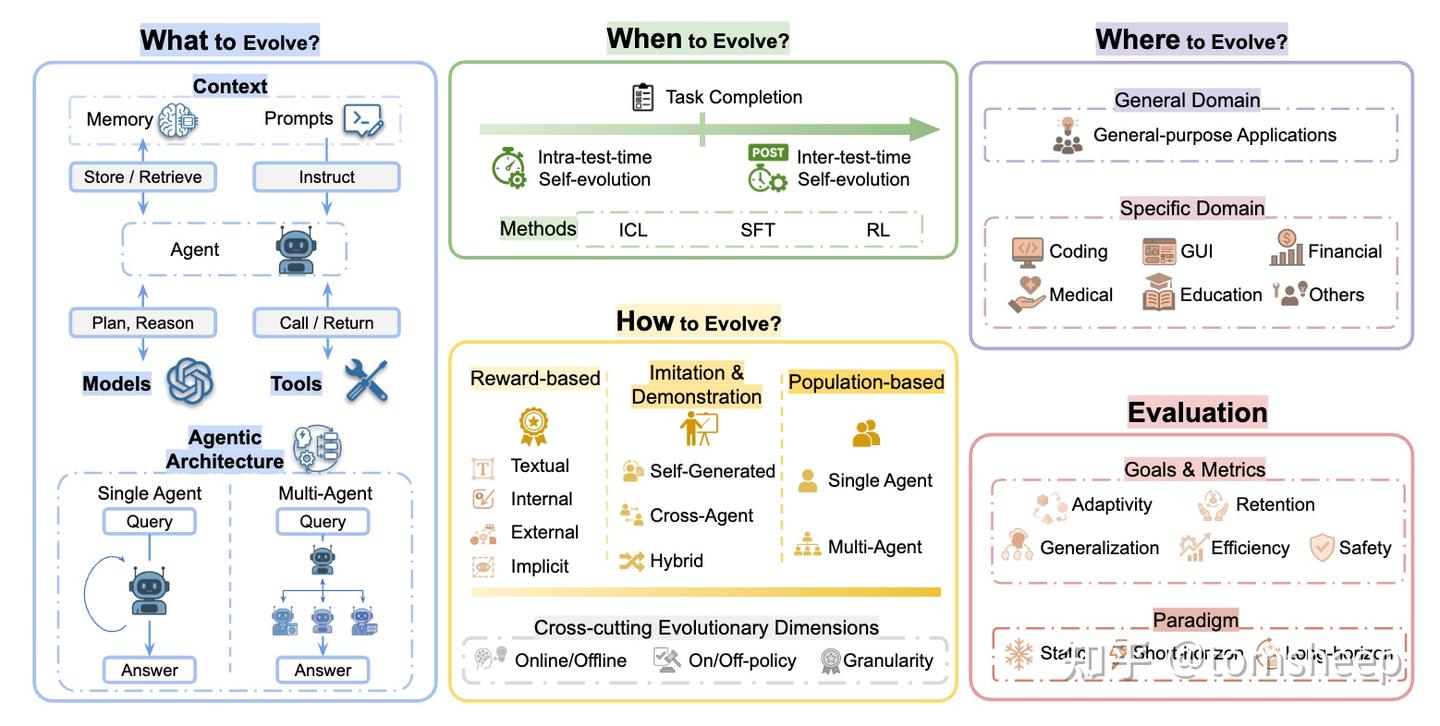
What-When-How 框架系统地解构和理解所有关于「自进化」的研究。三个维度分别是:
- 进化什么?(What to Evolve?):智能体作为一个系统,它的哪些部分可以被改进?模型、上下文、工具、架构
- 何时进化?(When to Evolve?):进化的过程发生在任务的哪个阶段?
- 「任务中进化」追求的是灵活性和即时响应
- 「任务间进化」追求的是系统性提升和长期成长。
- 一个优秀的自进化智能体,需要兼具这两种能力。
- 如何进化?(How to Evolve?):驱动进化的具体方法和信号是什么?
- 三大类进化引擎:奖励、模仿和演化
【2025-7-30】普林斯顿、清华、CMU等 综述:AI 如何实现自我进化?
截止2025年7月,「自进化智能体」(Self-Evolving Agents)领域的进展。
- 当前,尽管大语言模型(LLM)能力强大,但本质上「静态」,一旦训练完成,其内部参数就不会再改变。
- 这在需要实时适应新知识、新任务的动态世界中成了一个巨大的瓶颈。
与环境互动、从经验中学习并持续自我完善的智能体。
理论框架,围绕三个核心问题展开:进化什么(What)、何时进化(When) 以及 如何进化(How)。
- 论文: A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
- github Self-Evolving-Agents
进化案例
【2025-2-18】港大 AutoAgent
【2025-2-18】 港大开源全自动且高度自我进化的零代码AI Agent框架:AutoAgent
AutoAgent 是全自动且高度自我进化的框架,用户仅需自然语言即可创建并部署 LLM Agent。
核心特性
- 🏆 GAIA 基准测试冠军
- AutoAgent 在开源方法中排名 #1,性能媲美 OpenAI 的
Deep Research。
- AutoAgent 在开源方法中排名 #1,性能媲美 OpenAI 的
- 📚 Agentic-RAG,内置自管理向量数据库
- AutoAgent 配备原生自管理向量数据库,超越 LangChain 等行业领先方案。
- ✨ 轻松创建 Agent 和工作流
- AutoAgent 利用自然语言轻松构建可直接使用的工具、Agent 和工作流 —— 无需编码。
- 🌐 广泛兼容 LLM
- AutoAgent 无缝集成多种 LLM(如 OpenAI、Anthropic、DeepSeek、vLLM、Grok、Huggingface…)。
- 🔀 灵活交互模式
- 支持函数调用(Function-Calling) 和 ReAct 交互模式。
- 🤖 动态、可扩展、轻量级
- AutoAgent 是你的个人 AI 助手,具备动态、可扩展、可定制、轻量级的特性。
使用方法
- 用户模式(SOTA 🏆 对标 OpenAI Deep Research)
- AutoAgent 内置多智能体(Agent)系统,你可以在启动页面选择用户模式直接使用。这个多智能体系统是一个通用 AI 助手,具备与 OpenAI Deep Research 相同的功能,并在 GAIA 基准测试中实现了可媲美的性能。
- 🚀 高性能:基于 Claude 3.5 实现 Deep Research 级别的表现,而非 OpenAI 的 o3 模型。
- 🔄 模型灵活性:兼容任何 LLM(包括 DeepSeek-R1、Grok、Gemini 等)。
- 💰 高性价比:开源替代方案,无需支付 Deep Research $200/月 的订阅费用。
- 🎯 用户友好:提供易部署 CLI 界面,交互流畅无阻。
- 📁 文件支持:支持文件上传,实现更强的数据交互能力。
- 🎥 Deep Research(即用户模式)
- Agent 编辑器(无工作流的 Agent 创建)
- AutoAgent 最具特色的功能是自然语言定制能力。不同于其他 Agent 框架,AutoAgent 允许你仅通过自然语言创建工具、Agent 和工作流。只需选择 Agent 编辑器或工作流编辑器模式,即可开启对话式构建 Agent 之旅。
- 工作流编辑器(使用工作流创建 Agent)
- 通过工作流编辑器模式,使用自然语言描述创建代理工作流,如下图所示。(提示:此模式暂时不支持工具创建。)
【2025-3-8】AppAgentX 进化
【2025-3-8】西湖大学 推出自学习能力 Agent
进化框架,提高运营效率,同时保持智能和灵活性
每个步骤,Agent 都会
- 捕获设备的当前屏幕并分析,从预定义的作空间中选择合适的作。
- 执行所选作,与 GUI 交互。
- 任务执行轨迹被分解为多个重叠三元组。基于这些三元组,生成LLM页面和 UI 元素的功能描述。
- 将合并重复生成的页面描述。
- 整个交互历史记录使用节点链进行记录。
进化机制可识别重复序列并创建高级快捷方式,从而显著减少常见任务所需的步骤数和推理。
AppAgentX 在多个基准任务中的效率和成功率都明显优于现有方法。
- 与 GPT-4o 相比, AppAgentX 执行步数、耗时、token花销大幅降低,而准确率最高
【2025-8-5】CMU SQLM
大语言模型的训练很大程度上仍依赖人工整理数据集,堪称费时费力。
为了减轻这一负担,研究人员开发了用于强化学习的无监督奖励函数,然而,这些函数仍然依赖于预先提供的高质量输入提示。
因此,问题难点从“生成答案”转移到了“生成高质量问题”。
当前方法的关键不足:
- 缺乏可扩展且自我维持的流程,能够在无人干预的情况下自动生成有意义的问题和答案。
【2025-8-5】无需外部数据!AI自问自答实现推理能力进化
卡内基梅隆大学提出新框架SQLM——一种无需外部数据的自我提问模型。
- 论文 SELF-QUESTIONING LANGUAGE MODELS
- 该框架包含
提问者(proposer)和解答者(solver)两个角色,提问者生成与给定主题相关的问题,解答者旨在解决问题。 - SQLM框架,非对称的自我博弈框架
堪称:带 RL 的 GAN
实验结果显示
- SQLM 将 Qwen2.5-3B-Instruct 在算术任务上的准确率提高了14%,在代数任务上提高了16%;在编程任务上的准确率提高了7%。
此外,上表还显示出SQLM显著优于格式奖励基线(用于稳定训练和规范输出格式的参考值),表明推理能力的真正提升。
【2025-8-7】腾讯 R-Zero
【2025-8-7】腾讯AI Lab(西雅图),腾讯AI Lab推出「零数据自进化」推理LLM
- 论文标题:R-Zero: Self-Evolving Reasoning LLM from Zero Data
- 项目主页 R-Zero: Self-Evolving Reasoning LLM from Zero Data
- Code: R-Zero.
自我进化的大语言模型(LLM)通过自主生成、优化并从自身经验中学习,为实现超级智能提供了可扩展的途径。
然而,当前训练此类模型的现有方法仍高度依赖于海量的人工标注任务和标签,通常通过微调或强化学习实现,这构成了推动人工智能系统超越人类智能能力的根本瓶颈。
为克服这一限制,腾讯AI Lab 团队推出了一个完全自主、能够从零开始生成自我训练数据的框架——R-Zero。
从单个基础 LLM 出发,R-Zero 初始化两个具有不同角色且独立运行的模型:挑战者(Challenger)和解决者(Solver)。
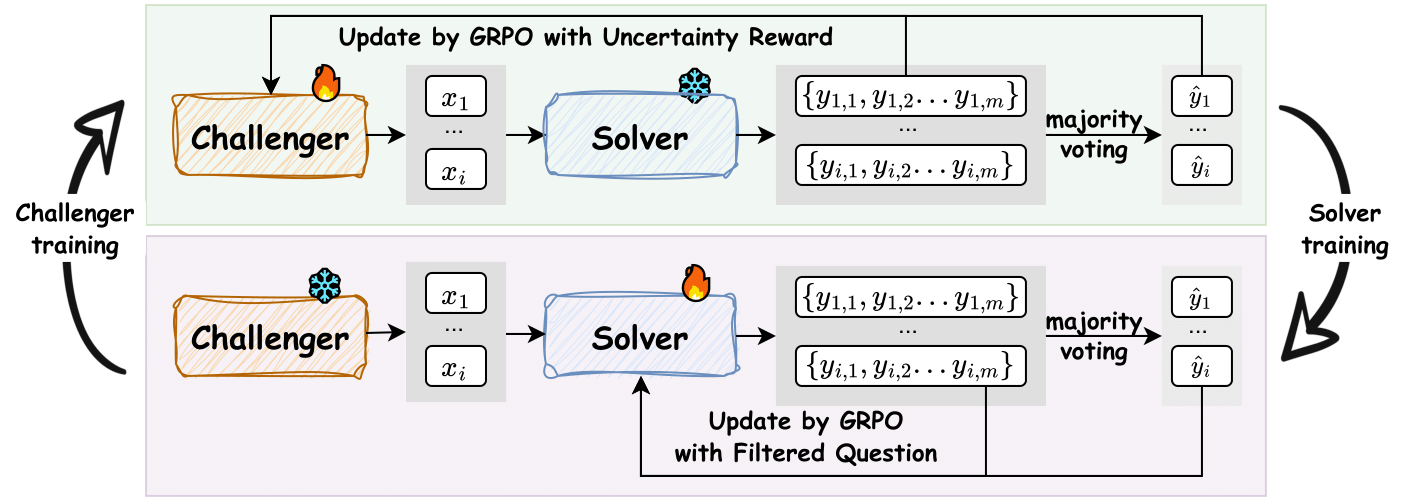
这两个模型分别进行优化,并通过相互作用实现协同进化:
挑战者因提出接近解决者能力边界的任务而获得奖励,而解决者则因解决挑战者提出的日益复杂的任务而获得奖励。
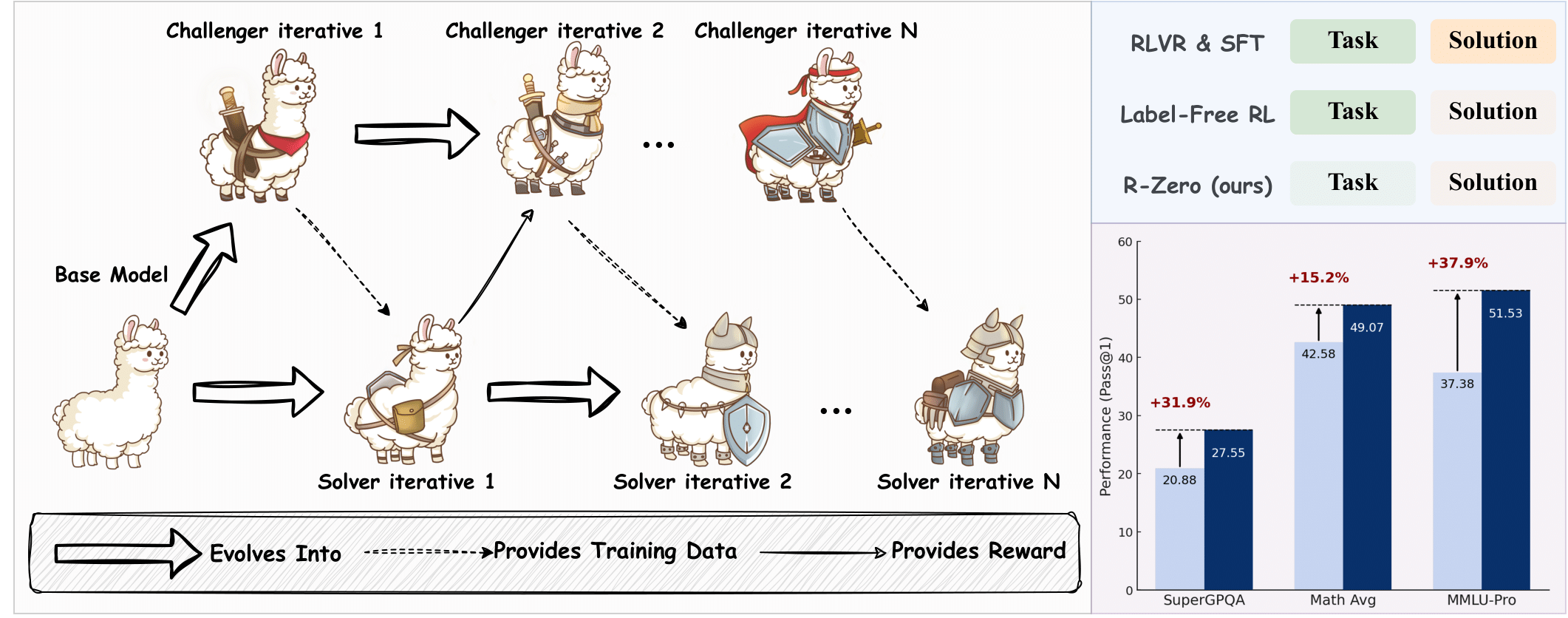
这一过程产生了无需预先存在的任务和标签的针对性、自我改进的课程。
实验结果表明
- R-Zero 显著提升了不同基础 LLM 的推理能力,例如在数学推理基准测试中使 Qwen3-4B-Base 的性能提升 6.49,在通用领域推理基准测试中提升 7.54。
【2025-11-20】斯坦福 agent0
【2025-11-20】斯坦福 agent0
已有自我进化框架:受限于模型能力和单轮交互,难以实现包含工具使用、动态推理的复杂模式进化
Agent0 全自主的智能体进化框架,通过多步协同进化、无缝工具集成,无需外部数据即可培育出高性能智能体
Agent0 让两个基于相同 LLM 初始化的智能体形成共生竞争关系:
- 一个是课程智能体,负责提出难度逐步提升的前沿任务;
- 另一个是执行智能体,专注于学习解决这些任务。
框架集成外部工具以增强执行智能体的问题解决能力,反过来促使课程智能体设计更复杂、且能适配工具使用的任务。
通过这一迭代过程,Agent0 构建起自我强化的循环,持续生成高质量的训练课程。
核心思想:
- Agent0 从同一个基础LLM创建两个智能体,并迫使它们进入竞争性的反馈循环。
- 一个发明任务,一个试图生存。这种持续的推拉产生的前沿难度问题是任何静态数据集都无法比拟的。
解决了自进化智能体的最大失败模式:停滞。
大多数智能体只生成比他们当前水平稍微难一点的问题。Agent0使用不确定性、采样答案之间的分歧和工具调用频率来检测执行智能体的弱点。
实证结果表明
- Agent0 显著提升了模型的推理能力:在数学推理基准测试中,Qwen3-8B-Base 模型性能提升 18%;在通用推理基准测试中,性能提升 24%。
【2025-11-13】AgentEvolver
【2025-11-13】通义实验室开源新框架 AgentEvolver,通过「自我提问」「自我导航」「自我归因」三大机制,系统性解决智能体强化学习中的任务稀缺、探索低效和样本利用率低等瓶颈。
大多数智能体系统仍停留在“按照指令完成任务”的层面——缺乏持续学习、适应变化的能力。
三大瓶颈:
- 任务构建成本高:新的环境往往需要重新定义任务与目标,人工成本高、覆盖面有限。
- 探索效率低:强化学习依赖大量交互采样,训练成本与时间消耗巨大。
- 样本利用不充分:奖励稀疏且模糊,模型难以判断哪些中间步骤真正起作用。
AgentEvolver 推动智能体从“被训练”迈向“自进化”的新范式
AgentEvolver 核心是由三大机制驱动的动态学习闭环。让智能体不再是被动执行任务的“工具”,而是一个能不断学习、总结、改进的动态系统
三大机制的协同作用,驱动智能体在复杂环境中持续优化和演化:
- 自我任务生成(Self-Questioning):自主生成探索任务,摆脱对人工数据集的依赖。
- 自我经验导航(Self-Navigating):高效复用历史经验,提升探索效率。
- 自我反思归因(Self-Attributing):精细评估步骤级奖励,提升样本利用率。
自我任务生成
【2026-3-17】MetaClaw
【2026-3-17】CMU、伯克利推出 MetaClaw 持续元学习框架
结合 OpenClaw,精准解决落地智能体静态固化、能力跟不上用户需求漂移的核心痛点。
🔑 关键方法
- 1️⃣ 技能驱动快速适配:从失败轨迹中蒸馏可复用的行为指令,无参数更新、零服务停机,prompt注入即刻生效
- 2️⃣ 机会主义策略优化:通过OMLS调度器捕捉用户空闲窗口,用云端LoRA+RL做梯度更新,全程不打扰正常使用
💡 核心创新
- 1️⃣ 双时间尺度互补闭环:秒级prompt技能进化+小时级梯度策略优化双向赋能,形成越用越强的良性学习循环
- 2️⃣ 技能版本隔离机制:严格拆分支撑数据与查询数据,彻底解决旧轨迹 stale reward 污染RL训练的行业痛点
- 3️⃣ 轻量化代理架构:无需本地GPU,兼容主流LLM厂商与智能体平台,可直接落地生产级大模型
📊 实验效果
- ✅ 纯技能适配让Kimi-K2.5准确率相对提升最高32.2%,全流程将其准确率从21.4%拉至40.6%,几乎追平GPT-5.2基线
- ✅ 端到端任务完成率提升8.25倍,文件校验完成率暴涨185%
- ✅ 跨域适配23步全自动科研管线,仅技能注入就将综合鲁棒性提升18.3%,阶段重试率降低24.8%
【2026-3-19】LSE
LLM 部署后遇到新任务时,最常见的做法是”自我反思”——让模型审视之前的失败并修改自己的 prompt。但问题:没人教过模型怎么做”自我进化”这件事。
- 所有现有方法(TextGrad、GEPA 等)都依赖模型天生的推理能力来做 prompt 优化,从未专门训练过这项技能。
问题
- 从未被专门训练
- 线性路径锁死
- 奖励信号含噪
Snowflake 团队提出 LSE(Learning to Self-Evolve)框架:用强化学习训练 4B 参数的”自进化策略”,专门学习如何改进上下文。
- 配合 UCB 树搜索防止进化路径塌缩,LSE 训练的 Qwen3-4B 在 Text-to-SQL(BIRD)上以 67.3% 超越 GPT-5 的 65.2%,在 MMLU-Redux 上以 73.3% 超过 GPT-5 的 72.5%。平均提升 +6.7 个百分点。 LSE 学到的不是针对特定模型的技巧,而是一种通用的”如何从反馈中改进上下文”的元能力
- 更关键: 训练好的自进化策略可以零样本迁移到完全不同的模型上,为其提供 +6.7% 的提升。
- 论文 Learning to Self-Evolve
- 解读 4B 小模型击败 GPT-5:Learning to Self-Evolve 用强化学习教会 LLM 在测试时自我进化
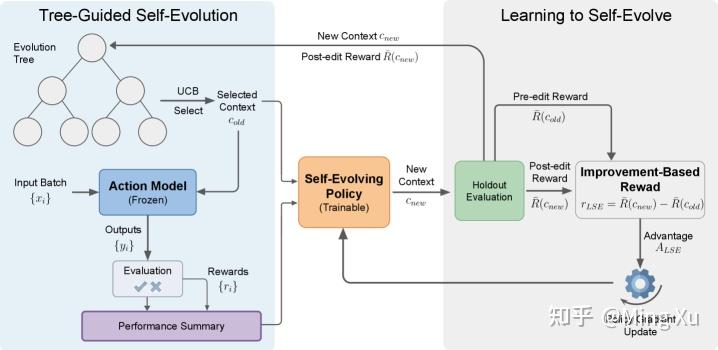
LSE 框架总览。
- 左侧为测试时的树引导自进化循环——UCB 算法从进化树中选择节点,Action Model 在新批次上执行后生成性能摘要,Self-Evolving Policy 据此提出新上下文。
- 右侧为训练流程——用改进量(编辑后性能 - 编辑前性能)作为 RL 奖励信号。
【2026-3-24】Hermes Agent
【2026-3-24】自主进化 Hermes Agent 适合自动化编程、浏览器操作等需持续学习的场景,能从任务中自动提炼复用技能。作为新兴开源项目,初期配置有一定技术门槛,复杂任务中的自主进化能力可能需要调优。
- 项目主页:Hermes Agent,GitHub hermes-agent
Nous Research 开发的开源自主 AI 智能体,2026年2月27日正式发布
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
source ~/.bashrc # reload shell (or: source ~/.zshrc)
hermes # start chatting!
# 命令
hermes # Interactive CLI — start a conversation
hermes model # Choose your LLM provider and model
hermes tools # Configure which tools are enabled
hermes config set # Set individual config values
hermes gateway # Start the messaging gateway (Telegram, Discord, etc.)
hermes setup # Run the full setup wizard (configures everything at once)
hermes claw migrate # Migrate from OpenClaw (if coming from OpenClaw)
hermes update # Update to the latest version
hermes doctor # Diagnose any issues
随你成长的 AI 智能体。
部署在自己服务器上,连接消息账号,成为持久个人智能体
- 学习你的项目、自动构建技能、随时随地触达你。不是聊天机器人,不是代码补全工具,而是一个住在你机器上、每天都在变聪明的智能体。
Hermes Agent 将持久记忆、自动技能创建和多平台接入整合在一个开源包中。
- 持久记忆:跨会话记住你的偏好、项目和环境。运行越久,越了解你——不再需要每次重新解释上下文。
- 自动技能创建:当 Hermes 解决了一个难题,它会写下可复用的技能文档,永远不会忘记解决方法。技能可搜索、可分享,兼容 agentskills.io 开放标准。
- 多平台消息网关:通过单一网关进程连接 Telegram、Discord、Slack、WhatsApp、Signal 和 CLI。支持语音备忘录转录,跨平台无缝切换。在 Telegram 开始对话,在终端继续。
- 定时自动化任务:内置 cron 调度器,可向任意平台推送。设置每日报告、夜间备份、每周审计和晨间简报——全部无人值守运行。
- 并行子智能体:为并行工作流生成隔离的子智能体,每个都有独立的对话和终端。通过 RPC 将多步骤流水线压缩为零上下文消耗的操作。
- 完整浏览器与网页控制:网页搜索、页面提取、完整浏览器自动化——导航、点击、输入、截图。还支持视觉分析、图像生成、文字转语音和多模型协作推理。
支持本地龙虾信息迁移: 导入人设、记忆、技能、命令、消息、api等信息
hermes claw migrate # Interactive migration (full preset)
hermes claw migrate --dry-run # Preview what would be migrated
hermes claw migrate --preset user-data # Migrate without secrets
hermes claw migrate --overwrite # Overwrite existing conflicts
【2026-3-19】 HyperAgents
【2026-4-15】AI学会左脚踩右脚自进化?Meta华人新研究改写Agent法则
【2026-3-19】华人学者 Jenny Zhang 在Meta实习期间,联合Meta AI、UBC、纽约大学等机构研究者,提出新智能体框架:HyperAgents(DGM-H)。
- 论文 Hyperagents
重点不是再造一个更能干活的Agent,而是瞄准更高层问题:
- 如果AI已经能够修改自己的任务解法,那能不能连「自己以后该怎么修改自己」这件事,也一并改掉?可以
HyperAgents 把「执行任务的 agent」和「负责改进 agent 的 meta agent」合并进同一个可编辑程序里,作者将之称为 hyperagent。
新框架下,系统不只会修改任务求解逻辑,还开始修改未来生成改进方案的机制本身,称为 metacognitive self-modification,元认知自我修改。
过去行业竞争的是:谁的Agent更会干活。而HyperAgents 指向的下一阶段则可能是:谁的Agent更会变强,而且会越来越会变强。
上一代自我进化路线的天花板。
去年 Darwin Gödel Machine(DGM)已经很惊艳。在coding任务中不断自改代码、自我验证、把成功版本存进archive,再从这些「垫脚石」里继续往前长。
但DGM 之所以能在coding里成立,是因为「评估」和「自我修改」本身也都是coding任务。一旦离开coding,这个对齐关系就断了。比如评审论文、设计机器人奖励函数、给IMO级数学解答打分,这些任务做得更好,不等于你就更会修改自己的元机制。
HyperAgents 最核心的一招:直接把这个假设砍掉:
既然任务能力和自我改进能力未必天然对齐,那就不要再把meta层写死。
表面上看,HyperAgents只是多了一个meta agent。
但真正值得注意的是,它把task agent和meta agent合成了同一个可编辑程序。HyperAgents 不是「再加一个Agent」,而是取消了「上层永远不变」这个默认前提。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
