OpenClaw 使用笔记
【2026-5-11】Agent 新发展趋势:Claw 化,从「对话聊天」向「工具助手」转变。
- 更多 Skill、更多 Tool、更深度系统交互和更好的上下文管理。
两种发展方向:个人 Agent 和 公共 Agent。
- 个人 Agent 高自由度、可成长,是个人能力的数字化延伸;
- 公共 Agent 开箱即用、领域专用,是领域知识的模型化封装。 本地化协同实践:通过共享 workspace,让 Agent 深度参与团队协作,从「工具」变为「协作者」,并展望 AI Native Workspace 的未来。
openclaw 介绍
时间线
- 首次发布(Clawdbot):2025-11-24(开源初版)
- 第一次更名(Moltbot):2026-01-27(因 Anthropic 商标投诉)
- 最终定名(OpenClaw):2026-01-30(社区投票确定)
详见飞书文档 OpenClaw笔记
原理
详见飞书文档 OpenClaw工作原理
Agent Loop
【2026-5-13】Agent Loop的实现方式(八):sub-agent/子agent的作用
为什么需要子代理?
当单次循环无法完成任务时,Agent 将工作分解。
子代理(Sub-agent)的核心价值:
- 并行化:多个子代理同时工作,缩短总耗时
- 上下文隔离:子代理不污染父级的上下文窗口
- 专注性:每个子代理只处理单一任务,减少指令冲突
- 安全性:子代理可被限制工具集和权限
📊 主流AI Agent框架子代理能力对比表
| 维度 | Claude Code | Codex CLI | OpenClaw | Hermes Agent |
|---|---|---|---|---|
| 子代理类型 | 6种内置 + 自定义 | Agent Tool + Symphony | 频道路由 + 运行时 spawn | delegate_task + Profile |
| 上下文策略 | Sidechain(仅摘要回传) | 独立 Thread | 独立 Workspace | 独立会话 |
| 并发能力 | ForkAgent 并行 | Async 驱动 | 独立 Runtime | ThreadPoolExecutor(3并发) |
| 最大深度 | 可变(按场景) | 未公开限制 | 1-5 可配置 | 默认 1,可至 3 |
| 性能优化 | Sidechain 摘要减负 | App Server 线程管理 | 独立进程 | 线程池复用 |
| 命名配置 | 代码级指定 | 未公开 | VISION.md | Agent Profiles |
| 安全性 | 权限继承 + 独立审批 | Thread 级隔离 | 独立 auth + 白名单 | 工具集限制 + 自动拒绝 |
🔍 关键差异解读
- 子代理模型与隔离
- Claude Code 和 OpenClaw 偏向“强隔离”:前者用 Sidechain 只回传摘要,后者直接用独立 Workspace/Runtime;
- Codex CLI 用 Thread 级隔离,Hermes 用独立会话+Profile,隔离粒度更轻,成本更低。
- 并发与深度控制
- Claude Code 和 OpenClaw 支持高灵活度的并发/深度配置,适合复杂任务;
- Hermes 限制了并发数(3)和默认深度(1),更适合稳定可控的场景,避免过度嵌套。
- 性能优化路径
- Claude Code 靠 Sidechain 摘要减少上下文压力;
- OpenClaw 用独立进程实现性能隔离;
- Hermes 采用线程池复用,资源占用更低,适合本地部署。
- 安全与权限
- OpenClaw 独立 auth + 白名单的安全策略最严格;
- Claude Code 权限继承+独立审批兼顾灵活性与可控性;
- Hermes 工具集限制+自动拒绝,适合对安全边界要求明确的场景。
Sub Agent 设计模式
【2026-5-9】subagent 的常用 4 种编排模式
主 agent 之外起 subagent 是搭复杂 AI 系统的常用做法。
按主 agent 对子 agent 生命周期的控制力从弱到强,4 种模式正在成形。
- Pattern 1
Inline Tool工具模式。subagent 当成普通 tool 调一次拿结果。call_agent 一个工具就够了。- Sync 模式 tool 阻塞返回结果,Async 模式立即返回 ID 结果稍后注入。
- 多数 subagent 用例从这里开始也停在这里 — research 查找、code review、文件分析、test 生成都能搞定。
- 局限:没法发 follow-up、没法查进度、没法提前 cancel。
- 任何支持 tool use 的模型都能跑,包括小模型。
- Pattern 2
Fan-Out。spawn_agent 立即返 ID,wait_agent 阻塞收集。模型自己决定何时 wait。好模型在 spawn 后做自己的活到节点再 wait,差模型 spawn 后立刻 wait 等于 Pattern 1 没拿到并发优势。- 适合多个独立任务可以并发跑,主 agent 不需要中间结果就能开下一个。仍然 fire-and-forget 没法中途纠偏。
- Pattern 3
Agent Pool。subagent 持久存在保留对话历史。主 agent 通过 spawn / send_message / wait / list / kill 五个工具协调。多回合对话,主 agent 在专家之间路由信息。适合多步工作流,agent 之间需要协作。局限是主 agent 要追踪多个 agent 状态,前沿模型勉强能管 2 至 4 个,更多就跟丢。 - Pattern 4
Teams。agent 之间直接对话,每个成员都有 cross-agent send_message。主 agent 搭好团队后退后只等汇报。适合大任务,协调逻辑超出单个 agent 能 step-by-step 管理。局限严重 — 每个 agent 都需要前沿级模型,还要解决循环检测、冲突解决、shutdown 协调、调试链追踪等基础设施挑战。
工程纪律:从 Pattern 1 起步。多数任务不需要复杂编排。只有真正需要并行 / 多步协作 / 复杂团队协调才往上走。模式越高,模型门槛越严,调试越痛。用便宜模型搭 Pattern 4 是最常见的失败方式。
应用
详见飞书文档 OpenClaw笔记
进化
基于 OpenClaw 改进论文
- 【2026-3-10】普林斯顿 OpenClaw-RL 实时回收利用这两类被浪费的信号,构建从任何交互流中持续学习的统一系统。
- 【2026-3-17】CMU+伯克利 推出持续元学习框架MetaClaw,联合维护基础 LLM 策略和不断演变的、包含可重用行为指令的技能库,实现 agent 自我进化
【2026-3-10】普林斯顿 OpenClaw-RL
解决什么问题?
现有 agent 强化学习系统大多依赖于预先收集的批量数据或最终结果奖励,忽视了真实交互中实时产生的、富含信息量的过程信号。
- 评价性信号:隐式地评价前一个动作的好坏。用户再次提问可能意味着不满意,通过的测试意味着成功,错误堆栈则意味着失败。这构成了一个天然的过程奖励,无需额外的人工标注。
- 指导性信号:指明动作应如何改进。用户说“你应该先检查文件”,不仅说明回答错了,更具体指出了改进方向。详细的软件错误追踪也常常暗示了具体的修正路径。
就像老师只根据期末考试成绩来评判学生,却完全忽略了日常作业、课堂提问和即时反馈的价值。
普林斯顿大学新研究——OpenClaw-RL,终结这种“数据浪费”,让AI智能体能够简单地通过被使用来学习与进化。无论是个人对话助手,还是执行终端、GUI、软件工程或工具调用任务的通用智能体,都能在同一套框架下,从实时交互信号中持续学习。
OpenClaw-RL 核心创新: 实时回收利用这两类被浪费的信号,构建从任何交互流中持续学习的统一系统。
2026-3-10】普林斯顿 OpenClaw-RL
- OpenClaw-RL: Train Any Agent Simply by Talking
- 代码 OpenClaw-RL
- 解读 OpenClaw-RL:让智能体在对话中自我进化,实现统一的智能体强化学习框架
OpenClaw-RL 框架: 完全解耦的异步架构。
- 下一状态信号是通用的,同一个策略可以同时从所有类型的信号中学习。
- 个人对话、终端执行、GUI交互、软件工程任务和工具调用轨迹,不再是各自独立的训练问题,而是可以用于在同一循环中训练同一策略的交互流。
完全解耦的异步架构
- 策略服务、环境交互、PRM(过程奖励模型)评判和策略训练作为四个独立的循环运行,彼此之间没有阻塞依赖。
- 模型在服务下一个用户请求的同时,PRM正在评判上一个响应,训练器则在应用梯度更新——三者互不等待。
- 正是这种设计,使得从实时、异构的交互流中进行连续训练变得可行。
OpenClaw-RL基础设施概览。
- 交互流来自两种智能体:部署在个人设备上的个人智能体(对话式、单用户),以及托管在云服务上的通用智能体(终端、GUI、SWE和工具调用智能体)。
- 收集的样本流入基于异步slime框架构建的RL服务器,该服务器由四个解耦的组件构成,支持优雅的权重更新,并能与任何智能体框架协同训练。
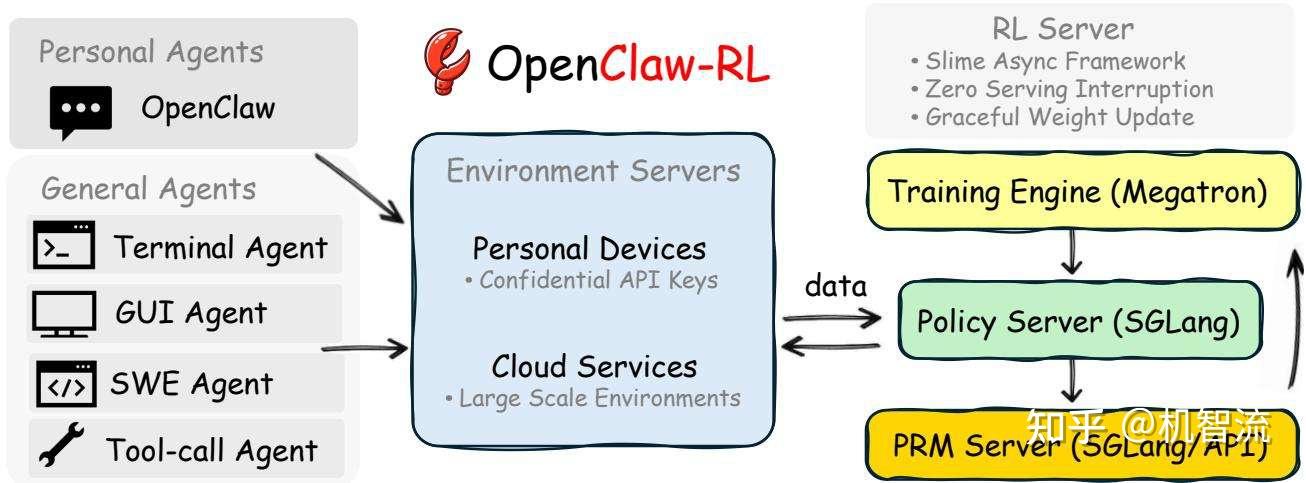
OpenClaw-RL 标志着智能体训练范式的重要转变。不再将训练和部署视为两个割裂的阶段,而是构建了实时交互中持续学习、自我演进的闭环系统。
【2026-3-17】CMU+伯克利 MetaClaw
解决什么问题?
- 现有agent部署后,保持静态,能力逐步过时
OpenClaw 平台上,单个智能体连接 20 多个消息渠道并处理多样化、不断变化的工作负载,现有方法
- 要么存储原始轨迹而不提炼可迁移的行为知识
- 要么维护与权重优化脱节的静态技能库
- 要么在重新训练期间导致服务中断。
【2026-3-17】CMU+伯克利
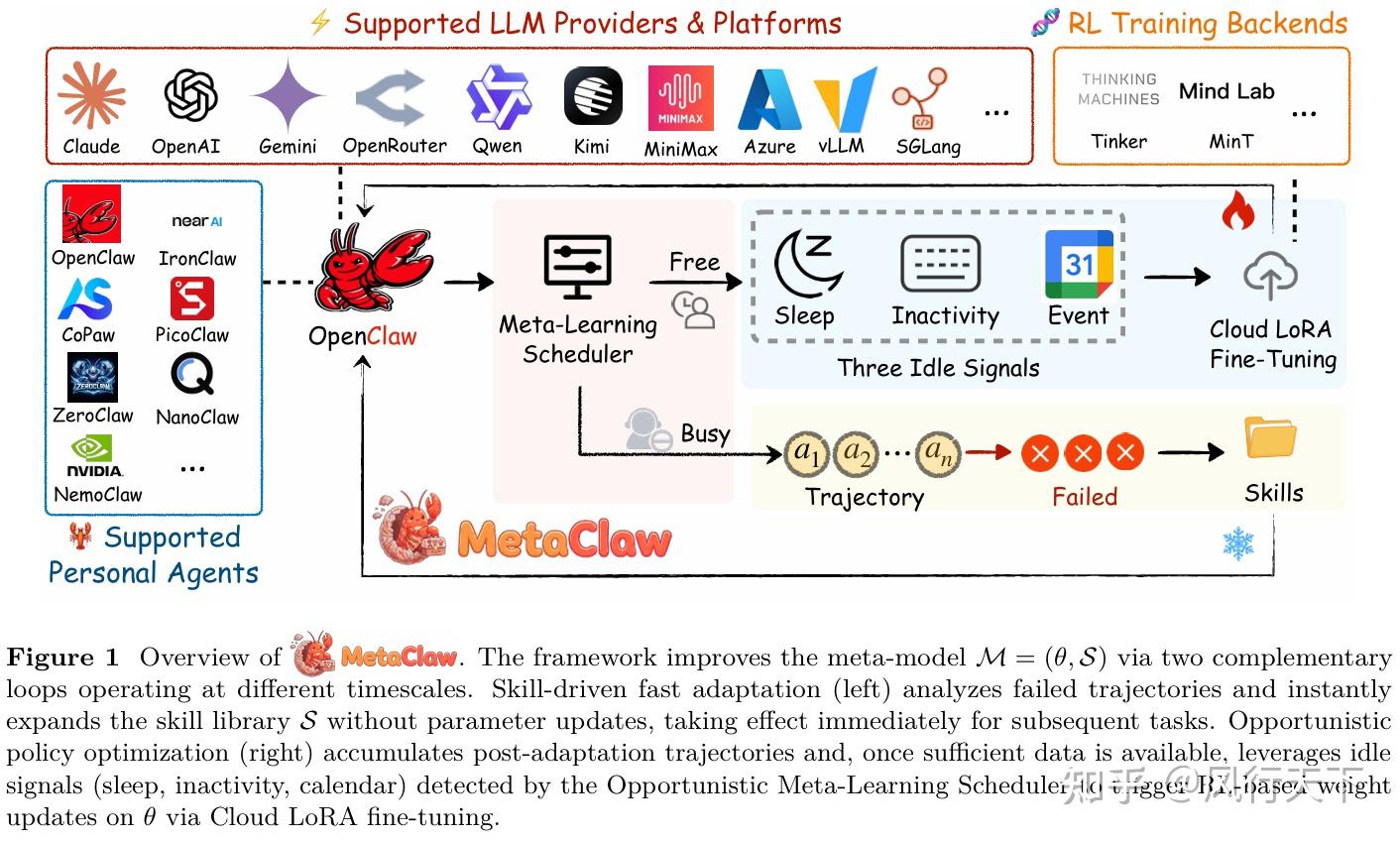
MetaClaw 持续元学习框架,联合维护基础 LLM 策略和不断演变的、包含可重用行为指令的技能库,并通过两种互补的机制对两者进行改进。
- 技能驱动的快速适应分析失败轨迹,并通过一个 LLM 进化器合成新技能,这些技能立即生效,实现零服务中断。
- 机会性策略优化通过机会性元学习调度器(OMLS)在用户非活动窗口期间被触发,利用带过程奖励模型(PRM)的强化学习(RL)在云端执行基于梯度的 LoRA 微调权重更新。
两种机制相互促进:更好的策略能为技能合成提供更多信息丰富的失败案例,而更丰富的技能则能为策略优化提供更高回报的轨迹。
MetaClaw 基于代理架构构建,无需本地 GPU 即可扩展到生产规模的 LLM。
MetaClaw-Bench(934 个问题,44 个模拟工作日)和 AutoResearchClaw(23 阶段自主研究流水线)上的实验显示出一致的改进:仅技能驱动适应就将准确率相对提升了高达 32%;完整流水线将 Kimi-K2.5 的准确率从 21.4% 提升至 40.6%(对比 GPT-5.2 基线 41.1%),端到端任务完成率提升了 8.25 倍;并且仅技能注入就将 AutoResearchClaw 的综合鲁棒性提升了 18.3%。
同类框架
【2026-4-11】OpenClaw、Hermes、Superagent:Agent 时代的三条路线,该怎么选?
三条完全不同的路线
- OpenClaw:怎么让 AI 真正变成常驻个人助手。
- Hermes:怎么让 Agent 在更低成本下持续学习、越用越顺手。
- Superagent:当 Agent 真要进生产环境时,怎么别把公司数据和合规底线一起送走。
这不是简单的“三个框架谁更强”。而是 Agent 时代分叉:有人抢生态,有人抢效率,有人抢安全入口。
Agent 下半场面临的工程问题:
- 要不要 24 小时常驻
- 要不要跨平台接入
- 成本会不会失控
- 技能怎么沉淀
- 上下文怎么管理
- 权限怎么收口
- 安全事故出了谁负责
大家争夺的不是“谁更像一个聪明聊天机器人”,而是:谁能成为下一代 AI 工作流里的基础设施。
| 产品 | 导向 | 特点 | 适合谁 |
|---|---|---|---|
| OpenClaw | 生态优先 | 通用助手中控层; 生态厚/产品强/扩展强; 但太重/成本高/上下文管理厚/安全问题 |
尽快跑起来 |
| Hermes | 学习效率优先 | 会进化的轻量agent | 重视效率和积累 |
| Superagent | 安全治理优先 | 安全与治理闸门 | 生产环境 |
更多比较
Claude Code / OpenClaw / Hermes Agent 对比表
| 维度 | Claude Code | OpenClaw | Hermes Agent |
|---|---|---|---|
| 核心隐喻 | 工匠 (Craftsman) | 宠物 (Pet) | 管家 (Manager) |
| 交互模式 | 实时结对编程 | 配置即行为 | 自主后台运行,跨平台汇报 |
| 擅长场景 | 写代码、重构、Debug | 个人助理、轻量任务 | 长周期任务、巡检、日报 |
| 模型支持 | 仅 Claude | 多模型 | 200+ 模型(含 Claude) |
| 部署形态 | 本地终端绑定 | 特定生态绑定 | Anywhere(VPS/Serverless) |
竞品
Hermes
详见站内地址:hermes
OpenHuman
详见站内专题:OpenHuman
Multica 团队协作管理
【2026-5-13】Multica 你的下一批员工不是人类。
- Multica 是一个开源平台,将编码 智能体 变成真正的队友。分配任务、跟踪进度、积累技能——在一个地方管理你的人类 + 智能体 团队。
【2026-5-13】Multica 开源 Managed Agents 平台让AI Agent成为真正的团队成员
一、Multica 是什么
Multica(全称 Multiplexed Information and Computing Agent)是2026年由中国四人团队(前TikTok工程师Jiayuan创立)推出的开源AI编程智能体协作平台,口号:Your next 10 hires won’t be human(你的下一批员工,不是人类)。 核心定位:把AI Agent变成可管理的“虚拟同事”,而非仅作为工具;提供类似Jira的看板,支持给Agent分配任务、跟踪进度、沉淀技能,实现“人类+AI混合团队”协同。
二、核心特点
- 团队原生设计:从看板/Issue/Inbox架构出发,天然支持多人+多Agent协作,非个人工具扩展。
- 厂商中立:不绑定特定AI,兼容Claude Code、OpenAI Codex、Gemini CLI、OpenClaw、Cursor Agent等主流编程Agent。
- 技能复利:Agent解决的问题自动沉淀为可复用“技能”,团队共享,越用越强。
- 自托管+开源:Apache 2.0协议,支持Docker/K8s部署,数据可控,适合企业合规场景。
- 架构分离:云端管理(Go+Next.js+PostgreSQL)、本地执行(Daemon守护进程),任务分布式运行。
三、参考/致敬对象
-
名字灵感:Multics操作系统(1960s) Multica名称直接致敬Multics(多路信息与计算系统)——首个实现多用户分时共享的操作系统,让多人共用一台大型机。 类比逻辑:Multics共享计算资源→Multica共享AI执行能力;Unix是Multics的简化(单用户单任务),Multica则反其道而行,回归“多智能体并行协作”。
- 产品形态参考:Jira + 开源替代对标
- Jira/看板工具:任务分配、状态流转、进度追踪的UI/UX直接参考Jira,降低团队学习成本。
- Claude Managed Agents(Anthropic):被称为“Anthropic Managed Agents的开源替代”,在Anthropic发布后迅速开源对标。
- OpenAI Symphony:OpenAI推出Codex任务编排器后,Multica强调“不绑定Codex,支持多Agent”,形成差异化。
- Devin(Cognition):商业闭源SWE Agent,Multica定位为开源、自托管、更灵活的低成本替代。
- 技术与理念参考
- Agent框架:底层兼容LangGraph、AutoGen、CrewAI等,但不自研Agent,专注协作层。
- 技能沉淀思路:借鉴Hermes Agent的“经验复用”,但聚焦团队共享而非个人专属。
四、关键时间线(2026年)
- 4月初:开源发布,对标Anthropic Managed Agents。
- 4月22日:OpenAI发布ChatGPT Workspace Agents,Multica称“开源版”。
- 4月28日:OpenAI开源Symphony,Multica强调“多Agent中立”。
- 5月初:GitHub Star超19k,成为AI协作赛道热门项目。
五、核心价值总结
Multica不是AI编程工具,而是AI团队协作的操作系统:把分散的Agent变成可管理、可协作、可沉淀能力的“虚拟员工”,让小团队(2-10人)通过AI放大产能,同时保持数据可控与成本灵活。
详见入门指南飞书笔记
【2026-5-21】腾讯 Marvis 多agent
2026年05月21日,腾讯旗下操作系统层级 AI 助手 马维斯 Marvis 正式上线。
很多 Agent 产品动辄让用户自己去搭工作流、安插件。Marvis 则是开箱即用,六个 Agent 零配置上手,对普通用户非常友好。刚进界面,里面已经有六个 Agent 在 7x24 小时待命了。
- 没接到任务的时候,有的在打盹,有的在办公室里闲逛,有的在健身,有的在喝咖啡,还有的直接去上厕所,一旦你发出指令,任务就会拆解分配给对应的成员。
分工明确的团队:
- PM 负责听懂你的需求,拆解任务往下派活;
- File Agent 处理文件的搜索、阅读和格式转换;
- Computer Agent 专门对付系统配置、查硬件、调夜间模式;
- APP Agent 负责在各种软件里代为操作,比如查个机票或者电商比价;
- Search Agent 负责快速从公开资源中定位答案并给出关键引用;
- 最后是个 Browser Agent,定位是网页交互专家,进行网页交互与数据抓取。

这些 Agent 可以并行工作。举例而言,我先抛出一个需求:「电脑开机太慢了,帮我看看哪些自启动程序没用,帮我关掉。」
Windows 端、Mac 端和安卓端同步上线。
腾讯对马维斯的定位不是普通聊天机器人,而是能够把整台电脑变成可对话对象的 AI 助手。
功能定位
- 马维斯更接近个人操作系统级 Agent。围绕本地文件、图片、文档、电脑设置和跨端任务进行处理,支持文件归类与解析、图片内容识别、系统设置修改、网络修复、手机远程操控电脑等能力。
- 腾讯 Marvis 官网也显示,马维斯支持本地文档与图片内容搜索、文件智能整理、文档深度理解与生成,以及一句话完成电脑设置等功能。
相比传统 AI 助手,马维斯核心特点
- 更深入地连接操作系统和本地文件环境。
- 马维斯提供“效率模式”和“隐私模式”两种使用方式:效率模式强调端云协同,以提升响应速度和准确性;
- 隐私模式则调用端侧大模型,支持文件 0 上传,适合对本地数据隐私更敏感的使用场景。
在跨端协同方面,马维斯支持通过手机连接电脑,用户可以在手机端实时查看电脑任务执行画面,并在需要时接管操作马维斯不只是桌面端 AI 助手,也在尝试成为随身携带的个人电脑控制入口。
硬件与平台方面,马维斯 Windows 版要求 6 核及以上 CPU、16GB 及以上内存、固态硬盘和 Win10 及以上 x64 系统;macOS 版要求 Apple Silicon M1 及以上芯片和 macOS 13 及以上系统;安卓端已开放下载,iOS 版本显示仍在送审,预计 6 月中旬上线。
从行业趋势来看,马维斯的正式上线说明个人 AI 助手正在从“聊天窗口”走向“系统入口”。过去很多 AI 产品主要围绕问答、写作、总结等单点能力展开,而马维斯这类产品更强调对文件、应用、系统设置和跨设备任务的持续操作能力。它代表了 AI Agent 产品从内容生成工具向操作系统级个人助理演进的方向。
【2026-5-26】阿里 AgentScope 2.0
AgentScope 是阿里于24年2月开源的多Agent开发平台,平台的架构、关键技术、容错机制、多模态应用支持,以及基于 actor 的分布式框架等
AgentScope 主要特点:
- 良好的易用性:AgentScope以基本的易用性为设计重点。通过实施面向过程的消息交换机制、广泛的语法实用工具,结合丰富的内置资源和集成的用户交互模块,AgentScope使构建多Agent应用更加轻松愉快。
- 强大的容错性:AgentScope集成了全面的服务级重试机制,并配备了一套基于规则的校正工具。此外,AgentScope提供了可定制的容错配置定制自己的容错机制。同时AgentScope也提出了一个具有自定义功能的日志系统作为系统保障。
- 多模态应用的广泛兼容性:AgentScope支持多模态数据作为消息呈现,并实现传输和存储。AgentScope通过消息中的统一基于URL的属性,将多模态数据传输与存储解耦。从而最大限度地减少了消息在每个Agent内存中的内存使用量。
- 优化的分布式操作效率:认识到分布式部署的至关重要性,AgentScope引入了基于actor的分布式机制,实现了复杂分布式工作流的集中编程和自动并行,AgentScope使开发人员能够专注于应用程序设计而不是实现细节。
AgentScope 1.0 以“透明开发”为核心,让开发者能清晰可见智能体的消息流转、工具调用和协作过程,从而降低理解与调试门槛。
阿里研发的AI Agent系统框架,支持事件流、多智能体协作、Workspace隔离与服务化Runtime,适用于企业级AI工作流与长期运行智能体系统
【2026-5-26】AgentScope 2.0 在延续透明理念的基础上,进一步聚焦真实场景下的稳定运行、安全控制与接入需求,带来一次更严肃、更完备、更整体的系统性升级。
- 核心目标是提升开发体验,让智能体在生产环境中更易构建和运行。
- 官方文档 AgentScope 2.0 是什么
- 【2026-5-28】AgentScope 2.0 发布:从”跑通 Demo”到”稳定落地”,构建可靠智能体的工程底座
- 深入浅出 AgentScope 2.0:打造你的 AI 智能体军团
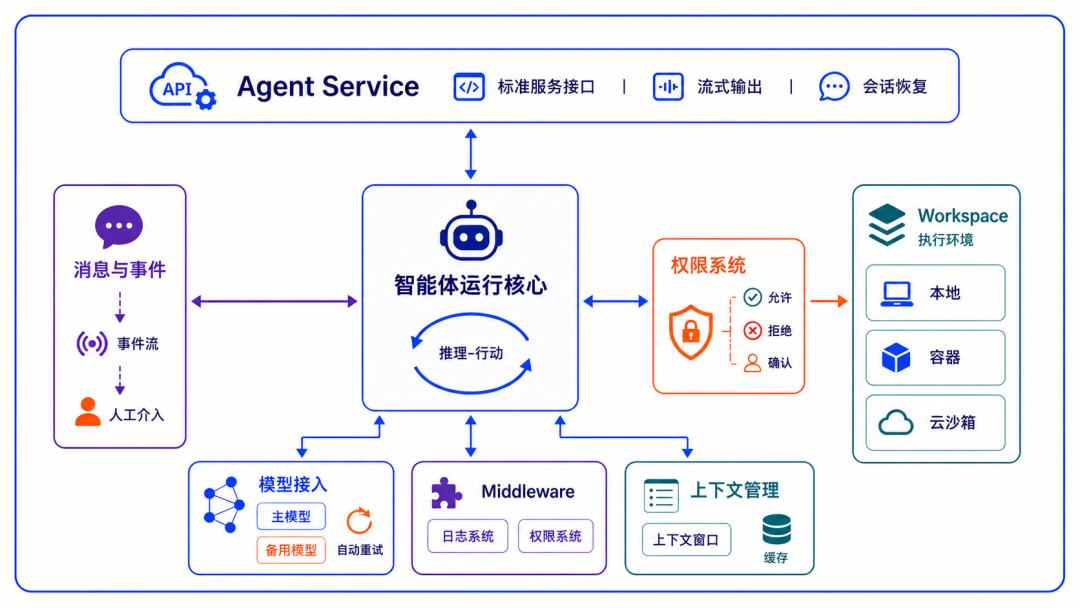
设计理念
- 为日益自主的大语言模型而设计。
- 方法:充分发挥模型的推理与工具调用能力,而不是用严格的提示词和固化的编排方式来束缚它们。
- 让模型自主决定何时调工具、规划任务、通过消息中心让agent自由协作
核心功能
- 多智能体协作:开发者可通过Supervisor Agent调度搜索、代码与总结Agent。
- 可恢复执行:系统支持Session日志恢复与长任务续传。当模型调用失败或服务中断后,Agent可从中断位置恢复执行,适合复杂工作流场景。
- 事件系统:一次Agent回复不再只是文本,而是模型调用、工具结果与用户审批等流式事件。前端可实时展示智能体完整执行过程。
- Middleware 扩展:开发者可在模型调用、工具执行与Prompt构造阶段插入自定义逻辑,例如日志追踪、安全审计与动态上下文注入。
- 上下文管理:AgentScope 2.0支持结构化上下文压缩、工具结果自动截断与文件缓存机制,可减少Token浪费并提高长期任务稳定性。
官方介绍
- 生产级在线 agent 骨架 —— agent 运行、后台任务、调度,以及 tool / MCP / skill / workspace 生命周期端到端纳管,会话事件流可扇出给多个订阅者,重连时还能从缓冲区中重放历史。
- Schema 驱动的前端 —— credential 公开 JSON schema,model 暴露声明式卡片(输入 / 输出类型、上下文长度、参数 schema),前端无需绑死特定 provider 的代码即可渲染表单与能力标签。
- 天然多租户 —— credential、agent、session、schedule、message 都归属于请求的 user_id,所有权在路由层强制;一份部署即可服务多用户,无需为每个租户单独编写代码路径。
- 模块化、可扩展 —— 鉴权、聊天协议、workspace 隔离策略、存储后端,以及 model provider 与 credential 类型集合,全部在边界处开放,可在不动框架代码的前提下替换。
AgentScope 不是实验性框架,从设计之初就考虑了生产环境的需求:
| 特性 | 说明 |
|---|---|
| 多租户支持 | 一个服务实例可以服务多个用户/组织 |
| 多会话管理 | 支持用户同时进行多个对话 |
| OpenTelemetry 集成 | 内置可观测性支持 |
| 多种部署方式 | 本地、云端 Serverless、Kubernetes 集群 |
| 权限控制 | 细粒度的工具调用权限管理 |
AgentScope 提供了丰富的内置组件:
- 内置工具:Bash、Grep、Glob、Read、Write、Edit 等
- 可以自定义工具(FunctionTool),工具函数的文档字符串(docstring) 非常重要,Agent 会通过阅读文档字符串来理解工具的用途和参数。
- 模型支持:OpenAI、Anthropic、DashScope(阿里云)、Gemini、DeepSeek、Ollama 等
- 协议支持:MCP(Model Context Protocol)、A2A(Agent-to-Agent)、Skill
- 中间件系统:可扩展的钩子机制
- Middleware(中间件) 扩展 Agent 行为,不修改 Agent 源代码的情况下添加自定义逻辑。
Message(消息) 是 Agent 与用户、Agent 与 Agent 之间通信的基本单位。
Event(事件) 是 AgentScope 实现流式响应的核心机制。当 Agent 执行任务时,会发出各种事件,让外部程序能够实时了解 Agent 的状态。
安装
uv pip install agentscope
# 或源码安装
git clone https://github.com/agentscope-ai/agentscope.git
# 进入目录
cd agentscope
# 安装
pip install -e .
核心要素
from agentscope.agent import Agent
from agentscope.model import OpenAIChatModel
# from agentscope.tool import Toolkit
from agentscope.tool import Toolkit, Bash, Read, Write, Edit
toolkit = Toolkit(
tools=[
Bash(),
Read(),
Write(),
Edit(),
]
)
agent = Agent(
name="Friday", # 名称:Agent 的标识
system_prompt="你是一个有帮助的助手", # 系统提示词:定义 Agent 的角色和行为
model=OpenAIChatModel(...), # 模型:Agent 的「大脑」
# toolkit=toolkit,
toolkit=Toolkit(tools=[...]), # 工具集:Agent 可以使用的工具
middlewares=[...], # 中间件:扩展 Agent 行为
state=AgentState(), # 状态:Agent 的记忆和上下文
)
# 同步回复
result = await agent.reply(UserMsg("Tony", "你好!"))
print(result.content)
# 流式回复
async for event in agent.reply_stream(UserMsg("Tony", "你好!")):
match event.type:
case EventType.TEXT_BLOCK_DELTA:
print(event.delta, end="", flush=True)
case EventType.TOOL_CALL_START:
print(f"\n[调用工具: {event.tool_name}]")
Agent Loop
Agent 的生命周期
- 当调用
agent.reply()或agent.reply_stream()时,Agent 会经历 接收→准备上下文→推理循环(ReAct)→生成回复→更新状态
ReActConfig 来配置 Agent 的推理-行动循环:
from agentscope.agent import Agent, ReActConfig
react_config = ReActConfig(
max_iters=10, # 最大迭代次数
verbose=True, # 是否输出详细日志
)
agent = Agent(
name="助手",
system_prompt="...",
model=model,
react_config=react_config,
)
【2026-5-28】清华 PilotDeck
OpenClaw 是极客浪漫主义的「大玩具」,PilotDeck 是真正面向纯粹生产力的「智能体协作舱」
【2026-5-28】清华THUNLP实验室、面壁智能、OpenBMB与AI9stars联合研发开源 Agent系统 PilotDeck 。项目独立建舱,记忆可视可改,Token还能省一大半。从此,一个人,就是一支AI军团
- 以「WorkSpace(工作舱)」为核心设计的开源智能体操作系统
- GitHub传送门:PilotDeck
- 官方网站:PilotDeck
- 解读 小龙虾彻底凉了?清华团队连夜开源Agent神器,Token成本狂降70%
核心亮点
- WorkSpace 级隔离与沉淀
- 每个项目拥有独立的专属文件系统、记忆库与技能集。多任务并行互不干扰,检索空间有边界,技能随任务自动沉淀,告别全局上下文污染。
- 可追溯的白盒记忆
- 记忆的生成、抽取、存储与使用全链路可见。AI 记错时可直接定位并手动修改。内置 Dream 模式,利用空闲时间自动归纳整理,并支持一键回滚。
- 智能路由与成本优化
- 内置任务难度识别,复杂任务调用强力模型(如 Claude 3.5 Sonnet / GPT-4o),简单任务降级至轻量模型。通过端云协同与精准匹配,大幅降低 Token 消耗。
- Always-on 常驻执行
- 突破”你问我答”的限制。用户离开后,Agent 仍能在后台主动发现潜在任务、执行长周期监控、并最终将成果落地为本地文件与摘要汇报。
PilotDeck 给每个项目建完整的「工作舱」,舱里有三层。
- 专属文件系统:哪些文件归这个项目、AI生成了什么,边界清楚。
- 专属记忆:Project Memory记项目定义和进度,Collaboration Feedback记你的偏好。全都看得见、改得了、追得到来源。
- 专属技能:Skill应用商店一键装到对应WorkSpace,给做游戏的舱装game-asset-finder,给写文档的舱装minimax-pdf。
区别
- 大部分WorkSpace是文件夹加静态规则。
- PilotDeck的WorkSpace是AI的完整生存环境
大部分路由方案是按request级别切,每次请求都单独判断走哪个模型。
- 问题:模型频繁切换会打断KV-cache,相当于每次换模型都要重新「读档」,推理效率反而下降。
PilotDeck 做了一套智能路由,在子Agent层面做的。
一个复杂任务拆成多个子任务后,整个子Agent分配给一个模型跑到底,这个子Agent内部的上下文缓存是连续的。
省的不只是token的钱,还有来回切换带来的性能损耗。
调度规则。
- 相比于写死的路由方案,比如「贵模型做难题、便宜模型做简单题」
- PilotDeck要灵活得多。支持用规则和prompt来调节路由策略,可以自己定义什么类型的任务走什么模型,甚至用自然语言告诉它「代码相关的子任务都走Claude Opus,文本处理走便宜模型」。
安装
curl -fsSL https://raw.githubusercontent.com/OpenBMB/PilotDeck/main/install.sh | bash
pilotdeck # starts the server at http://localhost:3001
pilotdeck status # check runtime status
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
