Harness Engineering
介绍
2026 年初,AI 工程界达成了一个关键共识:
大模型能力的提升正遭遇边际效应递减,真正的瓶颈在于执行环境(Execution Environment)。
Harness 来自马具——缰绳、马鞍、嚼子——一套引导强大但不可预测的动物的完整装备。驾驭工程不是去削弱 AI 的能力,而是为它打造一套黄金缰绳,让它跑得又快又稳
Agent 的每一次失败,都是环境设计不完善的信号。正确的回应不是换一个更强的模型,而是重新设计运行环境。
Mitchell Hashimoto(Terraform 之父)将这一现象命名为 Harness Engineering(缰绳工程)。而 Nous Research 刚刚开源的 Hermes Agent 正是 Harness Engineering 概念的第一次完整产品化。
- 传统 AI “一次性对话” —— 每次从零开始,用完即走。
- Hermes “自我进化” —— 记住你,学习你,越用越懂你。
Harness 终将消亡
【2026-5-7】Claude Code之父:未来不靠 Harness,终将消亡
Boris Cherny 认为
- 随着模型能力持续跃迁, 现在围绕模型构建的外壳层(Harness),很多能力终将被模型原生吸收。
- 与其在接口层反复打补丁,不如思考下一个范式:让模型自己完成更多,让产品回归本质价值。
| 观点 | 说明 |
|---|---|
| Harness 会越来越薄 | 外壳层能力被原生吸收,接口复杂度持续下降。 |
| 产品形态会被模型重写 | 形态不是创新的结果,而是模型能力的必然产物。 |
| Domain 比 Coding 更值钱 | 价值在于深度的领域理解与数据,而非工具本身。 |
| AI-native 组织与 Loops 才是未来 | 从任务到持续循环,组织与流程才是护城河。 |
为什么非得套上 Harness?
因为大模型有 5 个改不掉的毛病:
无状态:聊完就忘,不记仇也不记账。上下文腐烂:塞超过窗口 40%,逻辑就开始混乱。工具调用幻觉:API 一多(几十个起),调错、传错参数。开环:每一步只管自己输出,不为下一步负责。过早停止:自己觉得差不多了,就宣布任务完成。
claude code 经验
- 长对话会降智:claude opus支持1m上下文,但依旧得到反直觉结论,上下文越长(超过60%),模型表现越差,拐点式下降,重复读文件、验证、忘记规则
- 跨session记忆:每次 /clear 或 开启新会话,claude就变成白纸。明确告诉读昨天历史时,依然读取了噪音,忽略了结论
- 规则会被绕过:CLAUDE.md 里加粗的“绝不做***”,但 claude在卡住、多次尝试失败、上下文将满的压力下,重复权衡“守规则”和“跳出困境交付结果”,选择后者
这几个问题的共同原因
- prompt 和 CLAUDE.md 里的规则最终都是 context 里的 token,每个token要跟其他token竞争注意力
怎么办?
- 换一个更好的 prompt,并不能有效解决
- 正确方向:把不相关内容拉出去,放在模型看不见的地方,做确定性约束 (即 harness)
所以要在外面搭一套工程系统兜底。
Agent 常见失败模式
- 失败模式 1:试图一步到位(One-shotting)
- Agent 倾向于在一个会话里把所有功能都做完。结果是上下文窗口耗尽,留下一堆没有文档的半成品代码,下一个会话启动时只能花大量时间猜测之前发生了什么。
- 失败模式 2:过早宣布胜利
- 项目后期,当部分功能已经完成后,Agent 会环顾四周,看到已有进展就直接宣布任务完成——即使还有大量功能未实现。
- 失败模式 3:过早标记功能完成
- 在没有明确提示的情况下,Agent 写完代码就标记为完成,却没有做端到端测试。单元测试或 curl 命令通过了不代表功能真正可用。
- 危险特性:非常擅长模式复制。
- 代码库里有什么模式,就忠实地复制并放大——包括坏模式和架构漂移。这意味着不加约束的 Agent 会以惊人的速度积累技术债务。
Agent 是否真厉害?只需问几个问题
- 上下文怎么管?
- 有没有独立工作区?子Agent 之间会不会互相污染上下文?
- 任务断了能不能续?
- 有没有Checkpoint?走错一步,能回滚到哪一版?
- 错误是它自己修,还是你帮它修?
- 报错日志会不会自动喂回模型?还是要人肉介入?
- “你这 Agent,Model用谁的,Harness是自己搓的还是用CMA?
答得上来再聊产品。答不上来,多半是Demo。
按 LangChain、Salesforce 的总结,Harness 工程关键有 6 件事:
- 持久化文件系统 —— 把没用上的上下文卸到文件里,窗口保持干净。
- 分层记忆 —— 短期上下文 / 中期文件 / 长期向量库,按需调度。
- 状态持久化与断点续跑 —— 每步打快照,断了能续,错了能回滚。
- 隔离沙箱 —— Docker 级强隔离,rm -rf 也烧不到宿主机。
- 错误自恢复 —— 报错日志喂回模型,自动改、自动重试。
- 全链路评估 —— 量化成功率、Token 成本、鲁棒性,把”玄学”变成”数据”。
一套生产级 Harness 大概要 1–2 个月。
2026年4月,Anthropic 把这套东西做成了PaaS服务:Claude Managed Agents(CMA),共内包含6 个 API 模块(Environments / Resources / Vaults & Memories / Sessions / Events / Agent Versions),对应上面 6 大能力,企业不再需要顶级基础设施团队,也能在短期内实现Claude Code级别的稳定性。
案例
LangChain
LangChain 案例尤其有说服力:
- 底层模型一个参数都没动,仅仅通过优化外部驾驭环境 “缰绳”(Harness)配置(上下文管理、工具权限、反馈机制),编码 Agent 在 Terminal Bench 2.0 的得分从 52.8% 飙升至 66.5%,全球排名从第 30 位跃升至第 5 位。
- 模型一行代码未改,仅凭”缰绳”的优化就实现了质的飞跃。
Forge
【2026-5-19】Antoine Zambelli 发布 Forge,开源可靠性层,通过领域无关的护栏大幅提升本地 LLM 在多步代理任务上的准确率
- 8B 模型从 53% 提升至 99.3%。
- Forge 将免费本地模型与昂贵前沿 API 之间的准确率差距缩小到 1 个百分点以内,使得无需云成本的实用自托管代理系统成为可能。
- 还揭示了基础设施因素(如服务后端选择)对性能的关键影响,这些因素在标准基准测试中常被忽略。
Forge 包含五个可独立开关的护栏层;消融研究显示,重试提示(retry nudges)和错误恢复(error recovery)影响最大。该系统引入新的 ToolResolutionError 异常类,用于区分工具返回数据和返回空结果,防止静默数据污染。
定义
Harness Engineering(驾驭工程)是 OpenAI 在 2026 年初正式提出的一套面向 AI 时代的新型软件工程方法论。
核心理念:「Humans steer, agents execute」(人类掌舵,智能体执行)。
- 传统软件开发模式中,工程师亲自编写每一行代码,就像自己骑马奔跑一样。
- 而在 Harness Engineering 范式下,人类工程师不再手动编写代码,而是转变为设计环境、明确意图和构建反馈回路的角色。
这种转变将工程速度提升数个数量级,最大化利用人类最稀缺的资源——时间和注意力。
- OpenAI 实践数据非常惊人:在五个月内,仅用 3-7 名工程师的小团队,就从空 Git 仓库起步,交付了约 100 万行代码的产品,打开了约 1500 个 Pull Request,平均每位工程师每日能完成 3.5 个 PR,开发效率提升约 10 倍。更重要的是,这个产品已经拥有了数百名内测用户。
Harness Engineering 把问题推到了更远的一层:不只是管理信息输入,而是设计整个工作环境——围栏在哪里,路怎么铺,什么时候需要兽医巡检,马走偏了谁来纠正。
Harness 工程 = 给 AI 搭建”自动纠错的基础设施”(测试+监控+安全边界),让从”需要 babysit 的实习生”变成”能独立交付的工程师”。
核心公式
“Agent = Model + Harness”
Harness 原义: 挽具, 套在马身上的那套皮带、缰绳和金属件,让人可以引导一匹强壮但不知道该往哪走的动物去做有用的工作。
烈马、马具与骑手”的生产力模型:
- 烈马(AI 模型):算力强大、速度极快,但容易偏离方向或产生幻觉。
- 马具(Harness):基础设施、代码检查工具(Linters)、自动化测试、系统沙盒和反馈循环。
- 骑手(人类工程师):提供方向、设定意图,并设计好这套“马具”。
PE vs CE vs HE
| 范式 | 类比 | 核心问题 | 优化对象 | 交互模式 |
|---|---|---|---|---|
| 提示词工程 | 对马喊话的技巧 | 怎么把话说清楚 | Prompt 的措辞、格式、示例 | 一问一答 |
| 上下文工程 | 给马看的地图 | 怎么给 AI 喂信息 | 文档、代码片段、历史对话 | 信息注入 → 生成 |
| 驾驭工程 | 给马造一条高速公路,配上护栏、限速牌和加油站 | 怎么让 Agent 可靠工作 | 约束、反馈回路、控制系统 | 人类掌舵,Agent 执行 |
详见站内专题:上下文工程
Agent 框架 vs Agent Harness
Agent 开发框架 与 AI Harness 运行框架
- Agent框架:LangChain、CrewAI、AutoGen、Vercel AI SDK
- AI Harness框架:AgentScope、OpenHarness、DeepAgents、Harbor
| 对比维度 | Agent框架 | AI Harness框架 |
|---|---|---|
| 核心定位 | 模块化开发SDK、代码组装工具库 | 受控完整运行时容器、生产驾驭底座 |
| 设计目标 | 提供Agent基础原子组件,让开发者自定义流程 | 约束模型行为、保障长任务稳定、安全可落地上线 |
| 核心内置能力 | LLM封装、基础Memory、Tool基类、Chain流程、多Agent通信抽象 | 沙箱隔离、细粒度权限、断点续跑、自动校验反思、人在回路、全链路观测、持久状态快照、故障回滚 |
| 安全体系 | 无原生安全防护,沙箱/权限需业务自行编码实现 | 原生多层安全围栏:操作白名单、高危指令拦截、资源配额、数据脱敏、审计日志 |
| 灵活自由度 | 极高,循环逻辑、记忆策略、调度方式完全自定义 | 中等,底层运行规则固化,仅支持配置化微调,无法推翻驾驭主循环 |
| 依赖层级 | 最底层组装零件,可被Harness封装在内 | 外层运行容器,可内嵌Agent框架作为内部组件 |
| 上手方式 | 手写代码拼装Agent每一环,脚手架模式 | 配置驱动为主,少量业务代码,开箱即用具备生产防护 |
| 任务适配 | 短流程Prompt任务、实验原型、轻量工具调用 | 长周期复杂任务、代码执行、运维操作、政企/金融高合规场景 |
| 多智能体模式 | 仅提供通信与调度抽象,协作规则自己写 | 内置分布式集群、A2A协议、任务委派、批量协同调度能力 |
| 迭代评估 | 无内置自动评估体系,需额外集成第三方工具 | 自带评估打分、错误回放、策略对比实验能力 |
| 典型产出 | 可二次改造的Agent代码片段、业务逻辑模块 | 可直接部署运行的独立Agent服务实例 |
演变
2026年2月,这个词几乎同时从三个地方冒了出来。
- 2025-11-26,Anthropic 发布《Effective harnesses for long-running agents》,首次在官方技术博客把外部运行系统命名为 Harness,将 Claude Agent SDK 定义为通用 Harness 载体,社区开始零散使用 Agent Harness 词汇,但无统一工程方法论。
- 2026年2月5日,Mitchell Hashimoto,HashiCorp创始人、Terraform作者,在博客里定义了 harness engineering 完整工程方法论,统一术语、三层架构 、迭代哲学,瞬间席卷硅谷与国内 AI 工程圈。
- 每当agent犯一次错,就把工作环境改造一次,让它不可能再犯同样的错。
- 2026年2月13日,OpenAI发表白皮书,使用
Harness engineering,公开 Codex 生产级 Harness 落地流程。- 白皮书 《Harness engineering: leveraging Codex in an agent-first world》
- 【2026-2-11】工程技术:在智能体优先的世界中利用 Codex
- Codex 团队花了五个月,用零行手写代码构建了一个百万行的生产系统。工程师做了什么?不写代码。他们设计约束、编写文档、构建检查机制、部署定期清理“垃圾”的后台agent——所有这些都是在打造一副让AI能够稳定工作的挽具。
- LangChain 创始人、Martin Fowler 等技术权威背书,Harness Engineering 取代 Prompt Engineering 成为生产 Agent 第一工程范式。
- 同一周,Martin Fowler 网站上发了一篇评论,把harness组成归纳为三块:
- context engineering(让agent看到该看的东西)
- architectural constraints(用确定性的规则卡住agent的行为边界)
- garbage collection(定期清扫agent制造的混乱)
进化路径: Prompt -> Context -> Harness
| 范式 | 时间 | 核心问题 | 主要手段 | 能解决什么 | 解决不了什么 |
|---|---|---|---|---|---|
Prompt Engineering |
2023–2024 | 优化输入措辞,怎么”说”得好 | 精心设计指令、少样本示例 | 单次调用质量 | 多步骤任务的一致性 |
Context Engineering |
2025 | 优化信息输入,”知道”什么 | RAG、MCP、Memory、AGENTS.md | 信息检索与注入 | 架构级的行为约束 |
Harness Engineering |
2026 | 优化运行环境,在什么”环境”里做事 | 约束、验证、反馈回路、状态管理 | 系统可靠性与长期维护性 | ——(当前最前沿) |
上下文工程见站内专题:上下文工程
更多内容:Harness Engineering:重塑Al Agent时代的软件工程
分类
三层体系:
- 执行 Harness:工具调用、任务拆解、子代理调度(负责干活)
- 评估 Harness:自动化校验、打分、结果比对(判断对错)
- 控制 Harness:沙箱隔离、权限、行为白黑名单(划定边界)
总结
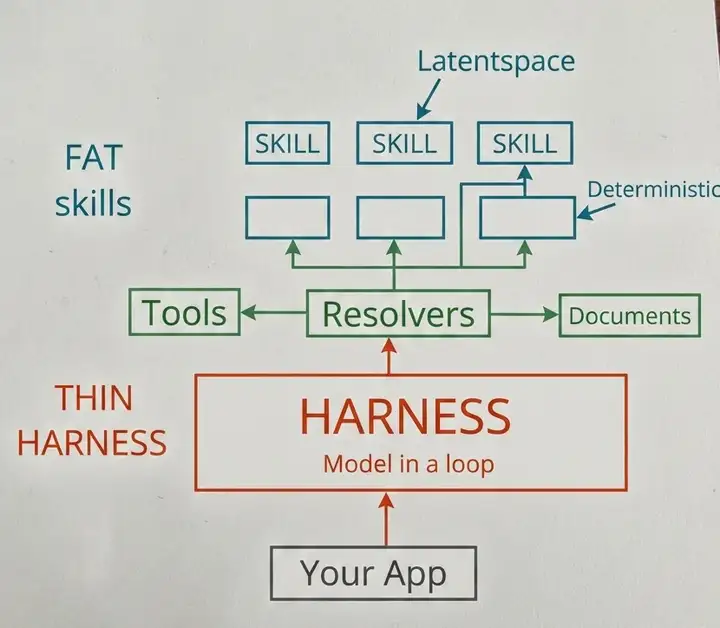
Thin Harness, Fat Skills
YC Combinator CEO Garry Tan 发布文章 Thin Harness, Fat Skills,不是“AI Agent 又要提效多少倍”,而是把 Agent 系统为什么会拉开差距讲清楚了。
- 同一个模型,有人只能用出 2 倍效率,有人能用出 10 倍、100 倍,差别不一定在模型本身,而在模型外面的架构。
- Thin Harness 指运行模型的外壳要薄:负责模型循环、文件读写、上下文管理和安全边界,不要把所有工具、规则、接口都塞进去。
- Fat Skills 指真正的能力要沉淀在可复用的 skill 里。一次调查、一次代码审查、一次资料整理,如果以后还会再做,就不该永远靠临场提示词,而应该写成可调用的流程。
记住:
- 需要理解、判断、综合、识别矛盾的事,交给模型。
- 需要查询、计算、排序、精确执行的事,交给确定性工具。
- 很多 Agent 不稳定,不是模型不够强,而是把工作放错了地方
Agent 设计准则 框架
- 最上层: 大量的Agent Skills。Garry 称
Fat Skills,Agent软件中开发量最大的主体部分。 - 每个SKILL就像一个函数,等待被Agent调用。其中既包括纯粹用英语描述的SKILL.md,也包括完成任务的程序脚本。
二者要严格区分开:
- 前者在 Latent Space 工作,用文字驱动LLM的智能去做事情;
- 后者是确定逻辑(Deterministic)的,用代码脚本完成工作。
论文
综述
总结
- CMU / Yale / Amazon 等 9 个机构论文 Agent Harness Engineering
LLM agent 真正的瓶颈,可能不在模型 🔥
CMU、Yale、Amazon 等 9 个机构联合发布的 agent 系统提出相当直接的观点:
决定一个 LLM agent 能否在生产环境可靠运行的,往往不是模型本身,而是包在模型外面那层基础设施。
这层基础设施定义为 agent harness。
同一个模型, 完全不动权重,只改 harness:
- coding benchmark 上 10× 提升
- Terminal-Bench 2.0 上 +13.7 个点
表现超过所有人工调过的 baseline
核心贡献:
- 1️⃣ 提出 ETCLOVG 七层 taxonomy,涵盖 Execution / Tool / Context / Lifecycle / Observability / Verification / Governance
- 2️⃣ 系统梳理 170+ 个开源 agent 项目,看清各层生态密度
- 3️⃣ 总结了 prompt → context → harness engineering 的三阶段演化
- 4️⃣ 指出当前最薄弱的层(governance、observability)及未来研究方向
🎯 适合谁看:
- 做 coding agent、browser agent、long-running research agent,或者任何想把 agent 跑进生产的从业者。
- 📄 论文 + project page + Awesome list
【2026-6-8】上海AI Lab Self-Harness
【2026-6-8】上海AI Lab 推出 Self-Harness,新的技术路径:未来的大语言模型智能体,不再只是被动受调度框架约束,还能够主动参与框架的迭代优化
LLM Agent 的综合表现,由基座模型以及负责衔接智能体与环境交互的调度框架共同决定。由于不同模型的行为特性存在明显差异,一套效果出色的调度框架必然要针对特定模型定制开发。
问题
- 但目前这类框架仍主要依靠人工设计,随着LLM品类日益丰富、迭代速度不断加快,该模式已难以规模化落地。
自调度(Self-Harness 全新范式:Agent 可自主优化自身运行调度框架,无需依赖人工工程师或能力更强的外部智能体。
自调度机制由三阶段迭代循环构成:
- 缺陷挖掘:从运行轨迹中定位该模型独有的问题模式;
- 框架优化提案:针对已发现的问题,生成多样且精简的框架修改方案;
- 方案验证:通过回归测试后,才采纳对应的修改建议。
基于 Terminal-Bench-2.0 基准测试实验,仅使用最简初始调度框架,并选取三款不同系列的基座模型:MiniMax M2.5、通义千问 Qwen3.5-35B-A3B、智谱 GLM-5。
实验结果显示,三款模型在应用自调度方案后性能均实现稳步提升,测试集通过率分别从 40.5% 提升至 61.9%、23.8% 提升至 38.1%、42.9% 提升至 57.1%。定性分析进一步表明,自调度并非简单添加通用指令,而是针对模型固有短板,落地为具体可执行的框架改动。
Harness 要点
行业共识
综合 OpenAI、Anthropic、LangChain、Stripe、HashiCorp 等多个独立信息源
当前AI Agent驾驭工程领域的行业统一认知,可归纳为三大方向:
- 底层基建优先:模型性能上限由基础设施、工具链、控制系统决定,而非单纯提升大模型本身;
- Agent运行机制:上下文按需供给、文档动态维护、思考执行分层,解决长任务、信息冗余问题;
- 工程师定位转型:人类从直接写代码,转向搭建可约束、可校验、可迭代的Agent运行环境。
| 编号 | 共识 | 核心观点 |
|---|---|---|
| 1 | 瓶颈在基础设施,不在模型智能 | 五个独立团队得出相同结论。仅改变 Harness 工具格式,就能让模型得分从 6.7% 跳到 68.3% |
| 2 | 文档必须是活的反馈循环 | 静态文档是坟场,动态文档才有价值。让后台 Agent 定期清理过时文档并提交 PR |
| 3 | 思考与执行分离 | 复杂任务不可能在单个上下文窗口内完成,需要 Orchestrator + Worker 分层架构,状态持久化到外部存储 |
| 4 | 上下文不是越多越好 | 上下文是稀缺资源。巨大的指令文件会挤掉任务空间,应按需检索、动态注入 |
| 5 | 约束必须自动化 | 人工 Review 是瓶颈。护栏要编码为 Linter、CI、类型系统,让机器来执行而非人 |
| 6 | 工程师角色在转变 | 从代码的编写者变成环境的建筑师。最大的工程挑战是设计让 Agent 可靠工作的控制系统 |
核心组件
有效 harness 的六大组件,协同系统
| 组件名称 | 核心作用 |
|---|---|
| System Prompts(系统提示词) | 用 AGENTS.md / CLAUDE.md 写清项目规范、边界和约定,明确 Agent 的行为规则。 |
| Tools & MCP(工具与MCP) | 让 Agent 真正拥有可调用的工具链,从只会“说话”升级为能实际执行操作。 |
| Skills(技能) | 按需加载能力,避免把所有上下文一次性塞给模型,减少冗余并提升效率。 |
| Sub-agents(子智能体) | 把复杂任务拆小,让上下文范围受控、职责更清晰,降低主 Agent 的复杂度。 |
| Hooks(钩子) | 在关键节点插入确定性控制流,强制触发检查或动作,确保流程按规则执行。 |
| Back-pressure(反压) | 把测试、审查、规则校验反馈给 Agent,形成反压纠错机制,避免错误持续放大。 |
本质上,Harness Engineering 的目标
- 把 Agent 从“自由发挥”的黑盒模型,变成一个可预期、可控制、可校验的可控执行系统,少了任何一个组件都可能导致可靠性断层。
Harness 三大支柱:上下文工程、架构约束、熵管理
- 目标:不是限制产出,而是降低系统熵,让agent运行更稳定
4大护栏
Harness 四个核心组件,”护栏”:
| 核心模块 | 英文名称 | 形象比喻 | 核心实现逻辑 | 关键实践要点 |
|---|---|---|---|---|
| 上下文工程 | Context Engineering | 新员工手册 | 提供精简稳定的信息入口,引导智能体按需检索上下文,文档随Agent失败案例动态迭代 | AGENTS.md为核心入口;拒绝静态冗长文档;文档是活的反馈循环,非静态制品 |
| 架构约束 | Architecture Constraints | 缰绳 | 构建严格层级依赖规则,将约束编码为Linter规则,违规直接阻断合并,错误信息引导智能体自主修正 | 层级依赖:Types→Config→Repo→Service→Runtime→UI;下层不可反向依赖上层;Linter报错附带规则解释与正确示例 |
| 反馈循环 | Feedback Loop | 智能体审智能体 | 智能体间互相完成代码审查,通过自动化测试、无效用例校验,循环迭代直至合规 | Codex本地自审;运行测试套件,错误信息回传模型;校验测试用例有效性,强迫模型修正边界问题 |
| 熵管理 | Entropy Management | 垃圾回收 | 以小额持续修复的方式对冲系统熵增,避免技术债务集中爆发,Agent间互相维护系统 | 后台Codex任务扫描偏差、发起重构;文档园丁Agent自动修复文档与代码不一致;持续小额偿还技术债 |
四根最关键的「护栏」:
- 结构化文档(上下文工程) —— 新员工手册
- 结构化文档(AGENTS.md)是 AI 智能体进入代码仓库时看到的第一份指南。这不是一本 1000 页的说明书,而是一张地图——智能体需要的是清晰的路径指引,而不是冗长的细节描述。情境是一种稀缺资源,巨大的指令文件反而会挤掉任务、代码和相关文档的展示空间。
- 架构约束 —— 把品味编码成规则
- 每个团队都有自己的代码「品味」和架构原则,但在传统开发中,这些原则往往依赖于人的自觉遵守。Harness Engineering 将这些「品味」编码成可机械执行的规则——通过自定义 linters 和结构测试来强制执行架构规则。例如,依赖方向必须经过严格验证,仅允许有限的一组边;横切关注点必须通过单一显式接口进入。这种做法就像是在赛道上设置固定的护栏,赛马只能在规定的路径内奔跑。
- 反馈循环 —— 智能体审智能体;
- Agent 审查、自动化测试
- 传统开发中,人类工程师负责代码审查(Code Review)。
- Harness Engineering 中,这个工作变成了「智能体对智能体」的方式:
- Codex 在本地审核自身更改,请求额外审查,循环往复直到通过。人类可以审核 Pull Request,但已经不是必须步骤。这种机制就像赛马有自动计分系统,不需要人工裁判也能判定成绩。
- 可观测性(熵管理) —— 让智能体也能看日志
- 传统开发中,日志和监控主要是给人看的。
- 但在 Harness Engineering 中,AI 智能体也必须具备查看和分析这些信息的能力。这样智能体就能在独立版本上运行任务,查询监控系统来诊断问题,复现 bug 并验证修复。
- OpenAI 为 Codex 提供了完整的可观察性堆栈,包括日志、指标、追踪,支持使用 LogQL、PromQL、TraceQL 进行查询。
- 熵管理:小步偿还技术债,定期扫描偏差,文档自动修复过时内容
Harness Engineering 有个独特的概念——「熵与垃圾回收」。
随着时间推移,软件系统会逐渐变得混乱(熵增),技术债务会累积。
- 传统开发中,人们往往等到问题严重时才集中处理。
- 但在 Harness Engineering 中,OpenAI 采取了一种更持续的策略:定期运行后台 Codex 任务扫描偏差,更新质量等级,发起针对性重构 Pull Request。他们把这种方法形象地称为「垃圾回收」,并认为技术债务就像高息贷款——持续小额偿还优于一次性痛苦解决。此外,还有一个专门的「Doc-gardening」智能体扫描过时文档并修复。
实现
总结
【2026-5-3】Harness 工程化框架拆解:OpenSpec、Superpowers、GSD、OMC、ECC、Trellis
逻辑分层:
- 上层(规范/结构层):OpenSpec、Trellis,偏向项目前期规划、长期协作治理;
- 中层(方法/执行层):Superpowers、Get Shit Done,聚焦个人开发习惯、复杂任务拆解;
- 下层(AI增强/编排层):Oh My ClaudeCode、Everything Claude Code,面向多代理并行开发、AI能力工程化落地。
| 框架 | 更接近哪一层 | 核心关注点 | 更适合谁 |
|---|---|---|---|
| OpenSpec | 规范层 | 先把需求、设计、任务写清楚 | 需要先对齐再开工的个人/团队 |
| Superpowers | 方法论与技能层 | 把 TDD、调试、review、worktree 等工程习惯变成默认动作 | 重视质量纪律和流程约束的开发者 |
| Get Shit Done | 上下文工程 + 阶段化执行层 | 解决 context rot,把复杂任务拆成原子计划 | 长任务、复杂仓库、重构场景 |
| Oh My ClaudeCode | 多代理编排层 | 围绕 Claude Code⁺ 做 team-first orchestration | Claude Code 重度用户、并行开发场景 |
| Everything Claude Code | 增强层 | 用 skills、instincts、memory、安全、验证补全 Harness 能力 | 想把 AI workflow 长期工程化的人 |
| Trellis | 结构层 | 用 specs / tasks / workspace 组织跨平台工作流和项目记忆 | 多工具团队、长期协作项目 |
总结
- OpenSpec 负责:先把“要做什么”说清楚
- Superpowers 负责:让 agent 默认按工程纪律工作
- GSD 负责:把复杂任务拆进干净上下文中执行
- OMC 负责:把 Claude Code 组织成团队式执行系统
- ECC 负责:给 Harness 补技能、记忆、安全、验证和学习能力
- Trellis 负责:把 specs、tasks、workspace 变成统一工作流骨架
差异:
- OpenSpec、Superpowers、GSD 则更偏向单层补位:分别聚焦规范、工程技能、上下文与阶段执行
- OMC、ECC、Trellis 更偏体系型方案,只是各自覆盖的主轴不同
- ECC 更像在补 skills、memory、安全、验证、学习等能力,覆盖面更广,也更偏体系型增强系统
- Trellis 在 specs / tasks / workspace / project memory 上更完整,更像长期工作流骨架
- OMC 在 Claude Code 的 team-first orchestration 上更像一套成体系的编排套件

主流harness框架
| 框架名称 | 开发主体 | 原生Harness实现 | 开发语言 | 核心定位 | Harness核心能力 | 模型兼容性 | 多智能体能力 | 开源协议 | 适用场景 |
|---|---|---|---|---|---|---|---|---|---|
| AgentScope | 阿里通义实验室 | 完整内置HarnessAgent九大子系统 | Python/Java/TS | 企业级分布式智能体驾驭运行底座 | Docker沙箱、Workspace工作区、双层记忆压缩、会话持久、细粒度权限、生命周期钩子、子Agent调度、故障断点续跑、人在回路审批 | 通义、GPT、Claude、DeepSeek、Ollama全兼容 | Actor分布式集群、超大批量多Agent协同、A2A/MCP协议 | Apache 2.0 | 政企大规模SRE、数据智能、业务多角色协作、国产化生产部署 |
| OpenHarness(HKU) | 香港大学数据系统实验室 | 原生轻量化纯Harness运行时 | Python | 极简透明学术/自研驾驭底座 | 43+内置工具、多级权限、MEMORY.md持久、流式工具循环、后台任务、基础沙箱隔离 | 所有OpenAI兼容本地/云端模型 | 轻量子Agent集群、任务委派 | MIT | 算法研究、自定义深度改造、个人本地代码Agent、轻量工具智能体 |
| DeepAgents | LangChain官方 | 基于LangGraph封装标准Harness层 | Python | LangChain生态专属生产驾驭壳 | 图状态快照、重试校验、HITL人工拦截、上下文自动裁剪、基础安全围栏、评估回调钩子 | 适配全部LangChain接入模型 | 子Agent嵌套、串行/并行任务编排 | MIT | 存量LangChain项目快速生产化改造、通用业务单/多Agent |
| Harbor Framework | 学术社区(Terminal-Bench配套) | 评测专用标准化Harness运行时 | Python | Agent批量基准评测驾驭平台 | 统一执行管道、变量约束控制、批量打分回放、策略对比实验环境、无业务侵入沙箱 | 通用LLM接口标准化接入 | 仅评测场景轻量化多Agent | MIT | Agent性能对比实验、Harness调参对照、学术基准测试 |
AgentScope
AgentScope 2.0
Python 版本
AgentScope Java 1.0
阿里推出 AgentScope Java,发展过程
| 时间 | 版本 | 节点 | 说明 |
|---|---|---|---|
| 2025年07月 | v0.2 预览版 | 代码仓库开源 | GitHub仓库公开,具备基础ReActAgent核心能力 |
| 2025年10月28日 | v1.0 GA | 首个正式大版本 | 生产可用,对齐Python版核心能力,内置HarnessAgent基础运行时 |
| 2026年03月15日 | v1.1.0 | Harness完整版本 | 补齐Workspace持久化、沙箱隔离、子Agent编排,完整落地Java Harness全框架 |
| 2026年05月 | v2.0.0-RC2 | 2.0 RC版本 | 企业级生产底座,完善权限管控、断点续跑、分布式多Agent集群能力 |
Harness Agent 是 ReActAgent 一层薄包装,把长期运行 Agent 必备的工程能力打包进单一 Builder。
原生ReAct Agent 只解决”一次请求 → 推理 → 工具 → 回复”
Harness 在此基础上回答:
- 下一轮怎么接着上一轮?
- 上下文如何保持有界?
- 多用户如何隔离?
- 危险操作如何先 review 再执行?
- 可复用能力如何沉淀?
架构
AgentScope Java 2.0
Java 版 AgentScope 2.0 引入核心抽象:HarnessAgent。
- ReActAgent 之上的工程化封装——核心 ReAct 推理循环原样保留,但围绕长期稳定运行所需的工作区、长期记忆、上下文压缩、子智能体编排、沙箱隔离、计划模式等工程能力,全部打包进单一 builder。
- 开发者从 ReActAgent 起步,需要长期稳定运行时无缝迁移到 HarnessAgent,业务代码无须改动。
设计目标很直接:
ReActAgent 提供 Agent loop 抽象与所有底层原子能力,Harness 提供保障效果、稳定、分布式部署、长期运行的一站式解决方案。
对应的不是某项新模型能力,而是真实生产场景里那些“上线前看不到、上线后绕不开”的工程问题——身份持续注入、上下文规模可控、状态可恢复、能力可沉淀。这些问题在原型阶段几乎不存在,但在企业部署里几乎是全部。Harness 在不改写推理循环的前提下,把这些问题各自的解法以 middleware 与 toolkit 的形式叠加到关键时机上,只叠加,不替换。
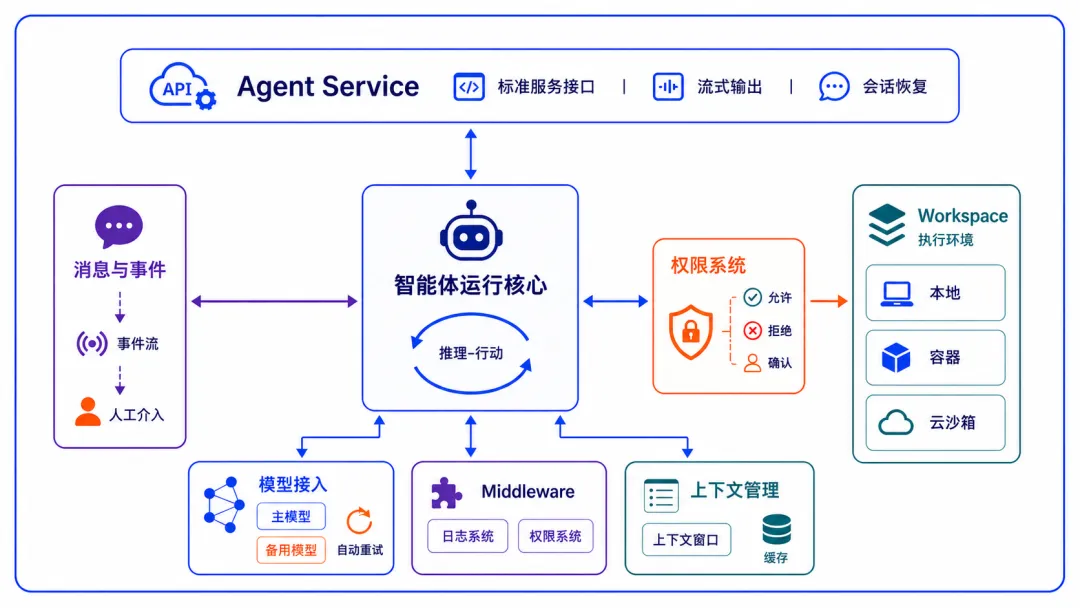
更多内容详见飞书笔记:Agent Scope Java
【2026-2-10】DeepMind AutoHarness
【2026-2-10】DeepMind 新论文解决了大语言模型做智能体的核心痛点,甚至让小模型直接吊打了大模型,思路简单又惊艳,非技术也能轻松看懂 AutoHarness。
AutoHarness 最打动人的地方,不是又刷了 benchmark,而是给 Agent 工程提供很清晰的方向:
- 不要把所有智能都塞进模型的一次输出里。让模型写代码,让代码守规则,让环境给反馈,让搜索来挑选可靠版本。
和做实际系统的经验非常一致。真正稳定的 Agent,往往不是“一个无所不能的大脑”,而是一个会把能力沉淀到工具、脚本、规则和测试里的系统。
AutoHarness 也许只是个开始,更有趣的问题:Agent 能不能不断把自己的失败经验固化成代码?能不能把这些代码迁移到新任务?能不能形成可审计、可复用、可演化的智能体操作层?
如果答案是肯定的,那么未来的 Agent 可能不只是会调用工具,而是会慢慢学会给自己建工具、写规则、做测试,并把一次次失败变成下一次成功的基础设施
harness 分成三类,从保守到激进依次:过滤、验证、直接生成
- 1 Harness-as-Action-Filter: 模型先生成多个候选动作,代码过滤出合法动作,再让 LLM 从合法动作里选。
- 好处是安全,坏处是仍然比较依赖 LLM 产生足够好的候选集合。
- 2 Harness-as-Action-Verifier 论文主要实验采用的形态。
- 1. LLM 根据当前 observation 生成一个动作;
-
- is_legal_action() 判断动作是否合法;
- 3.如果非法,就把“非法动作”反馈给LLM,让它重新生成;
-
- 直到得到合法动作或达到限制。这相当于给 Agent 加了一个行动前的守门员。
- 3 Harness-as-Policy 更激进的版本:不只是写校验器,而是让代码直接生成动作。
- 测试时甚至可以不再调用 LLM。LLM只在训练阶段作为代码合成器出现,推理阶段运行纯 Python 策略。
- 这就从“LLM+代码护栏”变成了“LLM 生成出来的代码策略”。
【2026-4-1】港大 OpenHarness
【2026-4-1】港大开源的 Harness 系统 OpenHarness 在GitHub上迅速收获万颗星。
这套万行代码构建的AI基础设施,如同给大模型装上了手脚和记忆
- 43个工具是灵巧的手指,54条指令是清晰的指令集,10个子智能体是默契的团队。
港大开源 Harness 系统,打造”一键启动”的AI代理基础设施,让开发者轻松构建个性化AI工作流。
- ① 系统规模:43+工具、54条指令、10个子智能体构成完整AI代理框架
- ② 核心功能:文件操作、联网搜索、多智能体协作、持久记忆、权限控制等全方位支持
- ③ 使用便捷性:单命令”o”启动全部系统,无需复杂配置,上手即用
- ④ 模型兼容性:无缝对接Claude、OpenAI、Copilot等主流AI模型,灵活切换
- ⑤ 实际应用:ohmo个人代理可在企业通讯软件中工作,直接处理编程任务
一键启动的AI代理框架,让每个开发者都能拥有自己的”AI驾驶舱”。
使用
- GitHub项目:OpenHarness
# 安装系统:
pip install openharness-ai
# 配置环境:
oh setup(Windows用openh setup)
# 启动系统:
oh(Windows用openh)
# 设置个人代理:
ohmo init → ohmo config → ohmo gateway start
【2026-4-28】复旦 AHE
复旦 Agentic Harness Engineering (AHE)
【2026-4-28】
- arXiv:Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
自动化框架工程面临三大难题
- 可编辑组件构成异构动作空间
- 海量运行轨迹掩盖有效信号
- 修改带来的效果难以归因。
智能体框架工程(Agentic Harness Engineering, AHE),通过闭环机制解决上述问题,依托三大配套可观测性支柱:
- 组件可观测性:为每一个可编辑框架组件提供文件级表示,让动作空间清晰可追溯、支持回滚;
- 经验可观测性:将数百万原始轨迹 Token 提炼为分层、可下钻的证据库,适配持续迭代的智能体直接使用;
- 决策可观测性:每一次修改都附带自我预测,后续通过下一轮任务级结果验证预测准确性。
三大支柱共同将每一次修改转化为可证伪契约,让框架实现自主迭代,而非陷入盲目的试错模式。
实验表明:
- 经过 10 轮 AHE 迭代后,Terminal‑Bench 2 数据集的一次通过率(pass@1)从 69.7% 提升至 77.0%,超越人工设计框架 Codex(71.9%)以及自迭代基线模型 ACE、无训练 GRPO
【2026-5-25】评测 Harness思路
【2026-5-25】关于Agent Harness,我整理了一个最小版
评测 Agent 不能只看最终答案,还要看用了什么工具、拿到什么结果、有没有按任务要求完成。
- 用户: “请判断这个项目是否支持插件系统”
- Agent: “当前 README 没有插件系统相关说明,不能确认支持”。
这句话看起来合理,但还要知道:
- 它有没有真的读取 README?
- 有没有读错文件?
- 有没有调用无关工具?
- 有没有把工具结果里没有的信息写进答案?
那这些信息怎么稳定记录?harness。
观点
Agent = model + harness
harness 理解:
- 把 Agentic model 放进可运行、可记录、可评分的小环境里。
- 不一定一开始就很复杂,只要能把任务、工具、执行过程和评分结果串起来,就已经很有价值。
Anthropic Agent Evals 文章把 eval harness 和 agent harness 分得很清楚:
- eval harness 负责跑评测、记录步骤、评分和汇总结果;
- agent harness 负责让模型作为 Agent 工作,比如处理输入、编排工具调用、返回结果。
- 强调: 评估 Agent 时,评到的是模型和 harness 一起工作的效果。
比如
- SWE-agent 重点是 Agent-Computer Interface。说明 coding agent 的表现不只取决于模型,也取决于外部接口怎么设计。比如怎么查看文件、怎么编辑代码、怎么运行测试、怎么把错误信息反馈给模型,这些都会影响最终效果。
- Terminal-Bench 任务结构也很适合参考。一个任务通常包含 instruction、隔离环境和测试脚本。harness 负责把模型接到终端环境里,让它执行命令、安装依赖、调试错误,最后用测试脚本验证任务是否完成。
- SWE-bench 则展示了 coding agent 的典型评测流程:给一个真实 issue,让模型生成 patch,再把 patch 放进环境里运行测试。这里的 harness 负责准备环境、应用 patch、执行测试、汇总结果。
mini harness 最少需要哪些模块
- Task:任务输入
- Environment:可操作环境
- Tools:工具接口
- Trace:执行记录
- Grader:评分器
评测case 基本点:任务目标明确,环境内容固定,工具范围清楚,评分规则也可检查。适合用来测试 Agent 是否会基于文件内容回答,而不是根据经验补结论。
{
"id": "case_001",
"task": "判断项目是否支持插件系统",
"environment": {
"files": {
"README.md": "本项目支持本地启动、基础登录和配置管理。",
"config.md": "配置项包括 port、theme、log_level。"
}
},
"tools": ["list_files", "read_file"],
"grader": {
"must_read": ["README.md"],
"answer_should_include": "不能确认支持插件系统",
"answer_should_not_include": "支持插件系统"
}
}
运行完毕后,harness 要记录的信息
{
"case_id": "case_001",
"trace": [
{
"tool": "list_files",
"arguments": {"path": "."},
"result": ["README.md", "config.md"]
},
{
"tool": "read_file",
"arguments": {"path": "README.md"},
"result": "本项目支持本地启动、基础登录和配置管理。"
}
],
"answer": "当前 README 没有插件系统相关说明,不能确认支持插件系统。",
"grade": {
"success": true,
"reason": "读取了 README,回答没有超出文件内容。"
}
}
 支付宝打赏
支付宝打赏  微信打赏
微信打赏 
